I have posted a new repo on creating and using a fine tuned transformer model to detect state-troll tweets. Detailed notebooks, data and a web app can be found here if you'd like to explore an alternative approach to this.
Social media companies like Twitter and Facebook have been exposing the activities of state-backed operators on their platforms. But little is known about how Twitter, FB and other companies uncover these shadowy operations and their politically motivated content.
As part of my capstone project at General Assembly, I'm proposing a 3-step approach to uncovering the work of these state operators. This involves using data science techniques to establish a troll's digital fingerprint, followed by the building and training of a machine learning model to detect the troll's work in large numbers. The third step involves using a relatively new tool called SHAP to better understand how the model made individual predictions, particularly where the model classified a tweet wrongly.
These three steps are mutually reinforcing, and create a virtuous cycle that reinforces the accuracy of future predictions.
I've also written a lengthier Medium post outlining my approach to this problem.
The notebooks for this project are split into three sections - data collection/creation, EDA and visualisation, followed by model building and evaluation
Overall, there are 4 main sets of tweets in this project - 3 sets of troll tweets from Russia, Iran and Venezuela, and 1 set of real tweets from 35 verified users. The troll tweets were officially released by Twitter, while I used Tweepy to scrape over 85,000 tweets from real users.
To build my first classifier, I trained it on a dataset comprising 50,000 tweets with an equal mix of Russian troll and real tweets.
The second model was built on a dataset comprising 50,000 tweets with an equal mix of Iranian troll and real tweets.
To test the two models, I created and kept aside three unseen test sets from the Russian, Iranian and Venezuelan troll tweets.
Here are the detailed file names:
1.0_real_tweets_collect_cch.ipynb: Use of Tweepy to scrape tweets from real users
1.1_real_tweets_format_cch.ipynb: Formatting of tweets collected in 1.0
1.2_bot_tweets_collect_cch.ipynb: Filtering out non-English troll tweets plus formatting of Russian troll tweets
1.3_tweets_cleaning_cch.ipynb: Feature engineering plus text "cleaning" for NLP
1.4_create_test_sets_cch.ipynb: Create 3 unseen test sets for model evaluation
1.5_iranian_tweets_cch.ipynb: Filtering out non-English troll tweets plus formatting of Iranian troll tweets
State trolls may operate behind the scenes, but their end-goals force them to leave a clear digital trail on social media. The key is to discern key structural patterns in an operator's modus operandi in terms of time, activity, and mode-of-disguise.
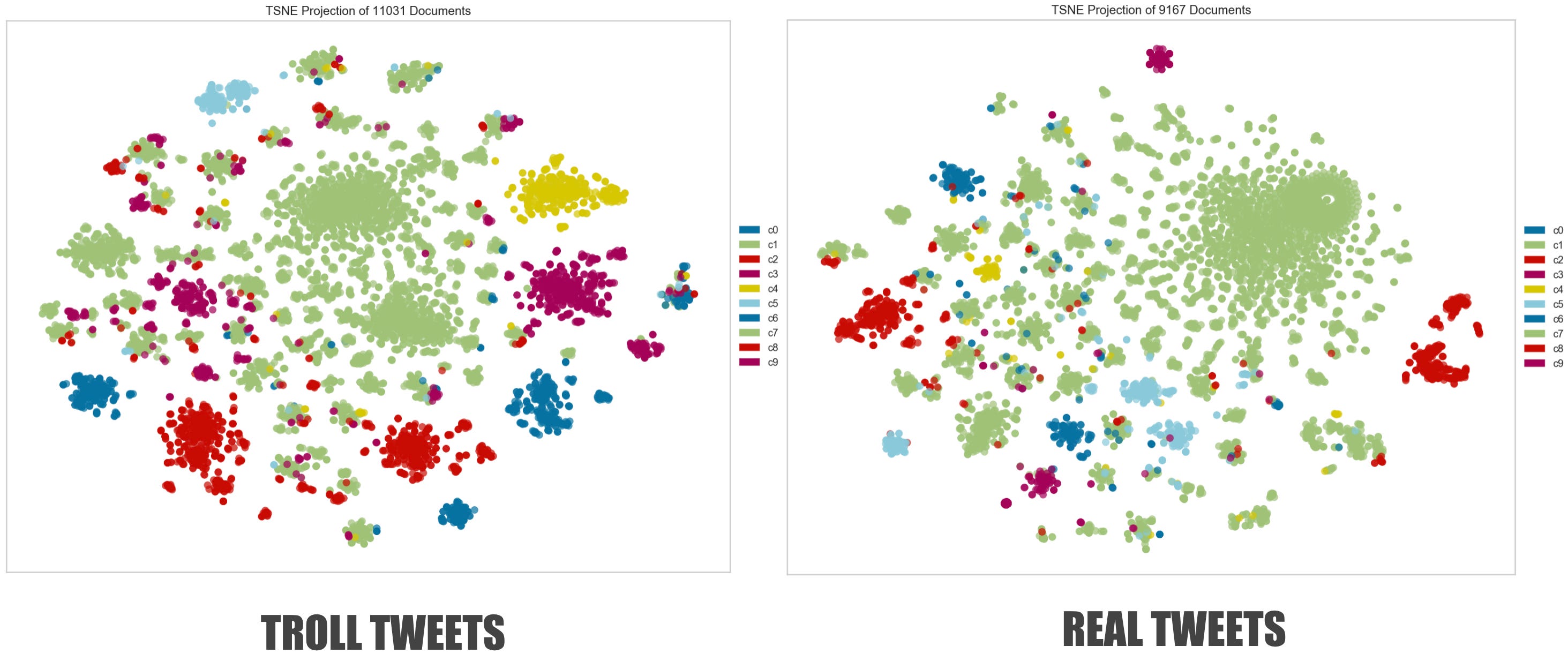
In notebook 2.0, I use a range of visualisation techniques to illustrate the structural and content-based differences(as well as similarities) between the troll and real tweets.
File name: 2.0_EDA_visualisation_cch.ipynb
The training and evaluation of the models are split across three notebooks. The file sizes of these notebooks are huge due to the use of SHAP force plots in the analysis.
Here are the detailed file names:
3.0_Russian_model_cch.ipynb: Train and test a classifier using Russian troll/American real tweets. SHAP is then used to analyse and explain where the predictions went right or wrong.
3.1_unseen_tests_cch.ipynb: Model built in 3.0 is tested against unseen Iranian and Venezuelan troll tweets to see if the model can generalise well. SHAP is then used to figure out where the model's predictions failed.
3.2_Iranian_model_cch.ipynb: New classifier built using Iranian troll/American real tweets, in order to contrast with poor predictions in 3.1
