This repository is the source code for the paper named Attentive Visual Semantic Specialized Network for Video Captioning. In this paper, we present a new architecture that we call Attentive Visual Semantic Specialized Network (AVSSN), which is an encoder-decoder model based on our Adaptive Attention Gate and Specialized LSTM layers. This architecture can selectively decide when to use visual or semantic information into the text generation process. The adaptive gate makes the decoder to automatically select the relevant information for providing a better temporal state representation than the existing decoders. We evaluate the effectiveness of the proposed approach on the Microsoft Video Description (MSVD) and the Microsoft Research Video-to-Text (MSR-VTT) datasets, achieving state-of-the-art performance with several popular evaluation metrics: BLEU-4, METEOR, CIDEr, and ROUGE_L.
 |
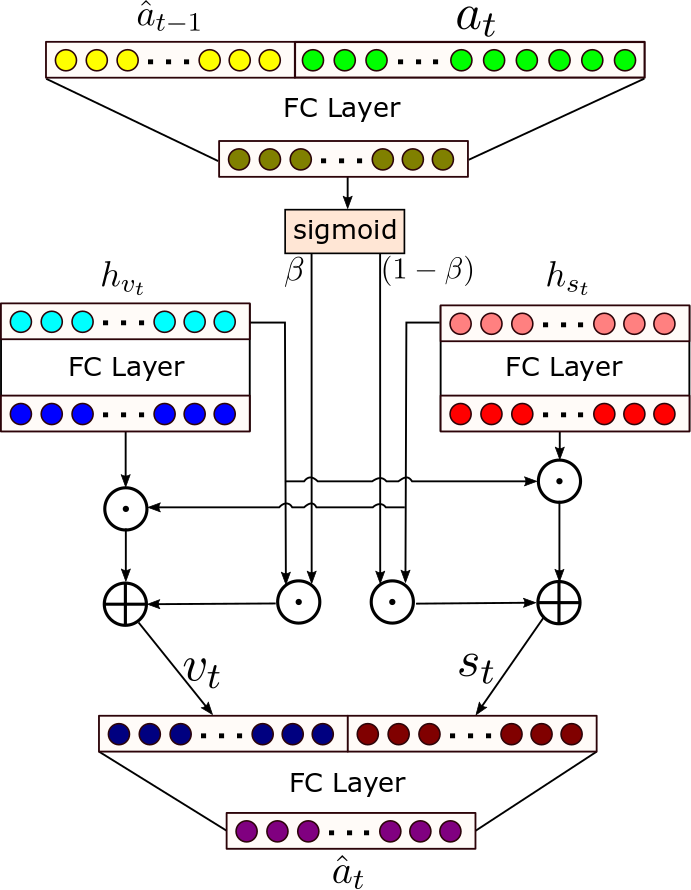 |
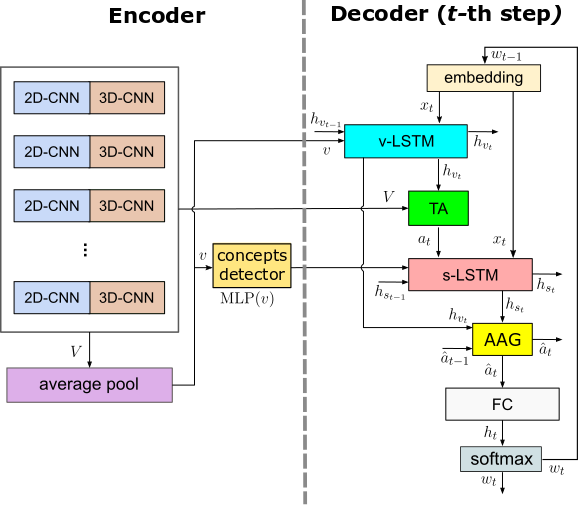
| Proposed Adaptive Visual Semantic Specialized Network (AVSSN) | Adaptive Attention Gate |
- Python 3.6
- PyTorch 1.2.0
- NumPy
git clone --recursive https://github.com/jssprz/attentive_specialized_network_video_captioning.git
mkdir -p data/MSVD && wget -i msvd_data.txt -P data/MSVD
mkdir -p data/MSR-VTT && wget -i msrvtt_data.txt -P data/MSR-VTT
For extracting your own visual features representations we provide the visual-feature-extracotr package.
If you want to train your own models, you can reutilize the datasets' information stored and tokenized in the corpus.pkl files.
For constructing these files you can use the scripts we provide in video_captioning_dataset module.
The content of these files is organized as follow:
0: train_data: captions and idxs of training videos in format [corpus_widxs, vidxs], where:
corpus_widxsis a list of lists with the index of words in the vocabularyvidxsis a list of indexes of video features in the features file
1: val_data: same format of train_data.
2: test_data: same format of train_data.
3: vocabulary: in format {'word': count}.
4: idx2word: is the vocabulary in format {idx: 'word'}.
5: word_embeddings: are the vectors of each word. The i-th row is the word vector of the i-th word in the vocabulary.
We use the val_references.txt and test_references.txt files for computing the evaluation metrics only.
wget https://s06.imfd.cl/04/github-data/AVSSN/MSVD/captioning_chkpt_15.pt -P pretrain/MSVD
wget https://s06.imfd.cl/04/github-data/AVSSN/MSR-VTT/captioning_chkpt_15.pt -P pretrain/MSR-VTT
python test.py -chckpt pretrain/MSVD/captioning_chkpt_15.pt -data data/MSVD/ -out results/MSVD/
python test.py -chckpt pretrain/MSR-VTT/captioning_chkpt_15.pt -data data/MSR-VTT/ -out results/MSR-VTT/
python evaluate.py -gen results/MSVD/predictions.txt -ref data/MSVD/test_references.txt
python evaluate.py -gen results/MSR-VTT/predictions.txt -ref data/MSR-VTT/test_references.txt

| Dataset | epoch | B-4 | M | C | R |
|---|---|---|---|---|---|
| MSVD | 100 | 62.3 | 39.2 | 107.7 | 78.3 |
| MSR-VTT | 60 | 45.5 | 31.4 | 50.6 | 64.3 |
@article{PerezMartin2020AttentiveCaptioning,
title={Attentive Visual Semantic Specialized Network for Video Captioning},
author={Jesus Perez-Martin and Benjamin Bustos and Jorge Pérez},
booktitle={25th International Conference on Pattern Recognition},
year={2020}
}
















