jyzwf / blog Goto Github PK
View Code? Open in Web Editor NEW在Issues里记录技术得点滴
在Issues里记录技术得点滴





















队列是一种先入先出的数据结构,基本操作有如下几种:
#include <stdio.h>
#include <stdlib.h>
#define QueueSize 40
typedef char DataType;
//#include "seqQueue.h"
#include "scQueue.h"
int main()
{
SeqQueue Q;
DataType str[]="ABCDEFGH";
DataType e;
int i=0,length=8;
initQueue(&Q);
for(;i<length;i++)
pushQueue(&Q,str[i]);
printf("开始出栈操作:\n");
if(popQueue(&Q,&e)==1)
printf("出队元素:%4c\n",e);
printf("剩下顺序队列的元素:");
if(queueEmpty(Q)==1)
for(i=Q.front;i<Q.rear;i++)
printf("%c ",Q.queue[i]);
return 0;
}#ifndef SEQQUEUE_H_INCLUDED
#define SEQQUEUE_H_INCLUDED
// 定义一个队列的结构体
typedef struct Squeue
{
DataType queue[QueueSize];
int front,rear;
}SeqQueue;
// 初始化队列
void initQueue(SeqQueue *SQ)
{
SQ->front=SQ->rear=0;
}
// 判断队列是否为空
int queueEmpty(SeqQueue SQ)
{
if(SQ.front==SQ.rear)
return 0;
return 1;
}
// 入队
int pushQueue(SeqQueue *SQ,DataType *e)
{
if(SQ->rear==QueueSize-1){
printf("队列已满,不能插入");
return 0;
}
SQ->queue[SQ->rear++] = e;
return 1;
}
// 出队
int popQueue(SeqQueue *SQ,DataType *e)
{
if(SQ->front == SQ->rear){
printf("队列已空,不能出队");
return 0;
}
*e = SQ->queue[SQ->front++];
return 1;
}
#endif // SEQQUEUE_H_INCLUDED循环顺序队列节约了存储空间,利用一个标志位 flag 来标识当 队头指针等于对尾指针时是对满还是队空,出队时,flag 为0,此时如果 队头指针等于对尾指针,则表明队空,;入队时,flag 为1,此时如果 队头指针等于对尾指针,则表明队满;
#ifndef SCQUEUE_H_INCLUDED
#define SCQUEUE_H_INCLUDED
// 循环队列的操作
// 定义一个队列的结构体
typedef struct Scqueue
{
DataType queue[QueueSize];
int front,rear;
int flag; // 用来判断队头队尾指针相等时,是队满还是队空
}ScQueue;
// 初始化
void initQueue(ScQueue *SCQ)
{
SCQ->front=SCQ->rear=0;
SCQ->flag = 0;
}
// 判断是否为空
int queueEmpty(ScQueue SCQ)
{
if(SCQ.front==SCQ.rear &&SCQ.flag==0)
return 1;
return 0;
}
// 入队
int pushQueue(ScQueue *SCQ,DataType e)
{
if(SCQ->front == SCQ->rear && SCQ->flag == 1){
printf("顺序循环队列已满,不能入队");
return 0;
}
SCQ->queue[SCQ->rear] = e;
SCQ->rear=(SCQ->rear+1)%QueueSize;
SCQ->flag = 1;
return 1;
}
// 出队
int popQueue(Scqueue *SCQ,DataType *e)
{
if(queueEmpty(*SCQ))
{
printf("顺序循环队列已空,不能出队");
return 0;
}
*e = SCQ->queue[SCQ->front];
SCQ->front = (SCQ->front+1)%QueueSize;
SCQ->flag = 0;
return 1;
}
// 获取头元素
int get_top(Scqueue *SCQ,DataType *e)
{
if(queueEmpty(*SCQ))
{
printf("顺序循环队列已空,不能出队");
return 0;
}
*e = SCQ->queue[SCQ->front];
return 1;
}
// 清空队列
void clearQueue(Scqueue *SCQ)
{
SCQ->front=SCQ->rear=0;
SCQ->flag = 0;
}
#endif // SCQUEUE_H_INCLUDED书接上回,上回书说了 vuex 的安装、以及 store 构造函数,下面我们来讲后面部分

vuex 允许我们自定义多个模块,防止应用的所有状态会集中到一个比较大的对象,导致 store 就变的臃肿了。
const moduleA = {
state: { ... },
mutations: { ... },
actions: { ... },
getters: { ... }
}
const moduleB = {
state: { ... },
mutations: { ... },
actions: { ... }
}
const store = new Vuex.Store({
modules: {
a: moduleA,
b: moduleB
}
})
store.state.a // -> moduleA 的状态
store.state.b // -> moduleB 的状态这是如何实现的呢?

在store的构造函数里面有这样一段代码:this._modules = new ModuleCollection(options),他就是用来收集用户自定义的 modules,该函数位于 module/module-collection.js 下
现在假设我们的 modules 做如下设置:
store = {
modules: {
moduleA: {
state: {},
modules: {
moduleC: {
state: {},
actions: {}
}
}
},
modulesB: {
state: {},
mutations: {
// xxx
}
}
}
}模块关系图如下:

来到 ModuleCollection 的构造函数,很简单,调用其 register 方法,并传入三个参数
register(path, rawModule, runtime = true) {
if (process.env.NODE_ENV !== 'production') {
assertRawModule(path, rawModule)
}
const newModule = new Module(rawModule, runtime)
if (path.length === 0) {
// 整个传入store 里的 option 为一个大的 module ,
// 再对option 里的 modules 属性进行递归注册为 module
this.root = newModule
} else {
const parent = this.get(path.slice(0, -1))
parent.addChild(path[path.length - 1], newModule)
}
// register nested modules
if (rawModule.modules) {
forEachValue(rawModule.modules, (rawChildModule, key) => {
// 这里的 concat 并不改变原来的数组,所以如果是同级的 module ,那么他还是有着相同的父级
this.register(path.concat(key), rawChildModule, runtime)
})
}
}现在我们一步一步来分析。
先讲一下 register 里的对传入模块结构的断言,调用 assertRawModule(path, rawModule) 以确保 getters/mutations/actions 依次符合 函数/函数/(对象或者函数) 的结构,这部分代码并不难,但是作者的这种编码习惯非常值得学习,详见 assertRawModule

回到正题
this.register([], rawRootModule, false)此时传入 register 函数的 path 为 空数组,rawModule 为最外层的 store 对象,即可以理解为 根module,runtime 为 false

接着调用 new Module(rawModule, runtime) 实例化这个 根module
constructor (rawModule, runtime) {
this.runtime = runtime
// 存储子 modules
this._children = Object.create(null)
// Store the origin module object which passed by programmer
// 存储原始的这个传进来的 module
this._rawModule = rawModule
const rawState = rawModule.state // 获取模块的 state
// Store the origin module's state
this.state = (typeof rawState === 'function' ? rawState() : rawState) || {} // state 最终是一个对象
}回到 register 函数,如果此时的 path 为 空数组,那么就将此模块设置为 整个状态树的 根模块,即this.root= 根 module,这里我们的 path=[],所以它是 根 module,不走 else
来到后面,判断该模块是否有 modules属性,即有子模块,有则继续循环注册子模块,我们这里有 moduleA 和 moduleB ,所以继续注册
// util.js
function forEachValue (obj, fn) {
Object.keys(obj).forEach(key => fn(obj[key], key))
}this.register(path.concat(key), rawChildModule, runtime)此时传入 register 函数的 path 为 path.concat(key),即 path =['moduleA'] ,rawModule 为 moduleA 对象,runtime 为 false
注:
path.concat(key)并不改变原始的path,它返回一个新的数组,所以根module的path栈还是空,这一点很重要

继续重复第一步的步骤,不同的是,实例化完 moduleA 后,由于此时的 path =['moduleA'],所以它走 else
else {
const parent = this.get(path.slice(0, -1))
parent.addChild(path[path.length - 1], newModule)
}path.slice(0, -1) 返回 path 数组以外的其他元素,不改变原始数组,所以等价于 this.get([])
// 作用:获取当前的模块的父模块
// 传入的 path 是从根模块到父模块的一条链路
get(path) {
return path.reduce((module, key) => {
return module.getChild(key)
}, this.root)
}this.root为前面的 根 module,而 path 是空,所以 parent=根 module ,然后执行 parent.addChild(path[path.length - 1], newModule),此时获取 path 栈顶元素("moduleA")作为 key ,和 实例 moduleA 作为 value ,加入到 父模块(根 module)的子元素对象中
由于 moduleA 还有子模块,所以继续递归 子模块
this.register(path.concat(key), rawChildModule, runtime)此时传入 register 函数的 path 为 path.concat(key),即 path =['moduleA'] ,rawModule 为 moduleA 对象,runtime 为 false

继续上面步骤
来到 this.get,这是传入的参数是 ['moduleA'],即 moduleC 的父模块 moduleA。由于 根module 保存了 moduleA,所以通过这种类似于链的方式来获取 父模块,同理将 moduleC 加入 moduleA 的子模块对象中
至此,第一条链就讲完了,
返回到 根module 的 forEachValue 循环中,这里我们讲到,他的 path 还是空,这就体现了 使用 concat 方法的好处与机智。 所以与处理 moduleA 的过程一模一样
this.register(path.concat(key), rawChildModule, runtime)此时传入 register 函数的 path 为 path.concat(key),即 path =['moduleB'] ,rawModule 为 moduleB 对象,runtime 为 false

终于将 this._modules = new ModuleCollection(options) 的过程分析完毕了
最终的 this._modules.root(不包括方法) 如下图所示

总的看下来挺佩服作者的思维以及处理方式的

看着挺长的了,其实就是多了几个循环过程的讲解,所以要不要再翻篇呢?呢?呢?????


回到 store.js 的构造函数,
const state = this._modules.root.state // 将 "根模块对象的 state" (即最外层store的state对象)赋予 state ,初始化根模块,并且递归注册子模块,并且收集所有模块的 getters
function installModule(store, rootState, path, module, hot) {
// hot 当动态改变 modules 或者热更新的时候为 true.
const isRoot = !path.length // 判断是否是根模块
const namespace = store._modules.getNamespace(path) // 获取s使用的命名空间
// register in namespace map
if (module.namespaced) {
// 如果命名空间存在,就在store 对象中建立 namespace 到模块的映射
store._modulesNamespaceMap[namespace] = module
}
// set state
if (!isRoot && !hot) { // 如果不是根模块以及 hot = false,这里我们是根模块,所以我们先放一放,跳到下一步
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
store._withCommit(() => {
Vue.set(parentState, moduleName, module.state)
})
}
// 跳到下面先看看makeLocalContext,
// 又跳!!!放心,,不用跳多远,也就是下一个 issue,,,抠鼻.gif
const local = module.context = makeLocalContext(store, namespace, path)
// 注册各个模块的 mutaations 方法到 store._mutations 中,每个type对应一个数组
module.forEachMutation((mutation, key) => {
const namespacedType = namespace + key
registerMutation(store, namespacedType, mutation, local)
})
// 注册各个模块的 actions 到store._actions
module.forEachAction((action, key) => {
const type = action.root ? key : namespace + key
const handler = action.handler || action
registerAction(store, type, handler, local)
})
// 注册各个模块的 getters 到store._wrappedGetters
module.forEachGetter((getter, key) => {
const namespacedType = namespace + key
registerGetter(store, namespacedType, getter, local)
})
module.forEachChild((child, key) => { // 递归子模块
installModule(store, rootState, path.concat(key), child, hot)
})
}上面出现的有关函数由于排版以及篇幅原因,我放到了 我看Vue(三) 中。
总结下,installModule 都干了些神马:
dispatch/commit/getter/state 等属性或方法mutations/getters/actions 加入到全局的 _mutations /_wrappedGetters/_actions 里接下来我们简单讲讲 在组件里面调用 dispatch、commit 的过程
commit(_type, _payload, _options) {
// check object-style commit
// 这里就是获取正确的 type / payload /options
const {
type,
payload,
options
} = unifyObjectStyle(_type, _payload, _options)
const mutation = {
type,
payload
}
// 获取触发的type 对应的 mutation
const entry = this._mutations[type]
if (!entry) { // 如果不存在,给出警告
if (process.env.NODE_ENV !== 'production') {
console.error(`[vuex] unknown mutation type: ${type}`)
}
return
}
this._withCommit(() => { // 由于entry是一个数组,所以逐个执行,并传入负载
entry.forEach(function commitIterator(handler) {
handler(payload)
})
})
// 触发 订阅函数
this._subscribers.forEach(sub => sub(mutation, this.state))
if (
process.env.NODE_ENV !== 'production' &&
options && options.silent
) {
console.warn(
`[vuex] mutation type: ${type}. Silent option has been removed. ` +
'Use the filter functionality in the vue-devtools'
)
}
}
dispatch(_type, _payload) { // 基本和commit 一样
// xxx
}看完上面的代码,我有些疑问,这个 store.state 和 store.getter 是哪来的?

function resetStoreVM(store, state, hot) {
const oldVm = store._vm // 之前的 vue 实例
// bind store public getters
store.getters = {} // 终于找到你
const wrappedGetters = store._wrappedGetters // 前面说过的各个模块的 getters 集合
const computed = {}
forEachValue(wrappedGetters, (fn, key) => {
// use computed to leverage its lazy-caching mechanism
computed[key] = () => fn(store) // 收集各个 getter,等会传入 computed ,以此做到响应式
Object.defineProperty(store.getters, key, {
get: () => store._vm[key], // 因为利用了计算属性,所以各个 getter 就变成了 vue 实例的属性
enumerable: true // for local getters
})
})
// use a Vue instance to store the state tree
// suppress warnings just in case the user has added
// some funky global mixins
const silent = Vue.config.silent //// 是否取消Vue 所有的日志与警告
Vue.config.silent = true
// 重新 new
store._vm = new Vue({
data: {
$$state: state // 这里虽然是 $$state,但是利用store.state时获取的就是它
},
computed
})
/* get state() {
return this._vm._data.$$state
}*/
Vue.config.silent = silent
// enable strict mode for new vm
if (store.strict) {
enableStrictMode(store)
}
if (oldVm) {
if (hot) {
// 解除旧vm的state的引用,以及销毁旧的Vue对象
// dispatch changes in all subscribed watchers
// to force getter re-evaluation for hot reloading.
store._withCommit(() => {
oldVm._data.$$state = null
})
}
Vue.nextTick(() => oldVm.$destroy())
}
}解决了 store.getter了,那么 store.state是如何来的呢?
还记不记得第一次让你跳的地方,没错就是 installModule
if (!isRoot && !hot) { // 如果不是根模块以及 hot = false,这里我们是根模块,所以我们先放一放,跳到下一步
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
store._withCommit(() => {
Vue.set(parentState, moduleName, module.state)
})
}这里我们就来看 Vue.set(parentState, moduleName, module.state)。 它的作用是在父模块的state 属性上添加上本模块的state,还是按照一开始我们那种依赖关系来看:

这样我们就不难理解 getNestState 里面为什么可以如此获取 state 了
好了,vuex 核心大致的内容就是这些,后面在 我看Vuex(三)
中我会解释下其他一些函数的作用
如有不当,欢迎指出交流,谢谢 ^_^

var Person = function(name){
this.name = name;
}
Person.prototype.getName = function(){
return this.name;
}
var Bob = new Person('Bob'); // 这里 new Person('Bob') 发生了什么?下面我们来探探:
当代码 new Person('Bob') 执行时:
{ },这个对象的类型是 object;[[prototype]](i.e proto )属性为构造函数的原型对象;this 关键字指向这个新对象,执行构造函数; function New(func) {
var res = {};
if (func.prototype !== null) {
res.__proto__ = func.prototype;
}
var ret = func.apply(res, Array.prototype.slice.call(arguments, 1));
if ((typeof ret === "object" || typeof ret === "function") && ret !== null) { // typeof null === 'object'
return ret;
}
return res;
}最后附上一张原型链的图:

继续上文webpack打包后代码浅析1,现在我们对 show.js 作如下修改:
// 原来的:
/* function show(content) {
window.document.getElementById('app').innerHTML = content
};
export default */
export function show(content) {
window.document.getElementById('app').innerHTML = content
};
export function getAge(age) {
console.log(age)
}
export var fileName = 'show'现在我们是用 export直接暴露出两个方法和一个变量,我们来看看打包后的文件发生了啥变化:
(function (modules) {
// 这一部分没有变化
})([
// 数组的第一个元素也没有变
(function (module, exports, __webpack_require__) {
const show = __webpack_require__(1)
show('webpack hello 77')
}),
(function (module, __webpack_exports__, __webpack_require__) {
"use strict";
Object.defineProperty(__webpack_exports__, "__esModule", { value: true });
/* harmony export (immutable) */ __webpack_exports__["show"] = show;
/* harmony export (immutable) */ __webpack_exports__["getAge"] = getAge;
/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, "fileName", function() { return fileName; });
// 最终的 __webpack_exports__(也就是exports) 变为了如下:
/*
__webpack_exports__={
__esModule:true,
show,
getAge,
fileName
}
*/
function show(content) {
window.document.getElementById('app').innerHTML = content
};
function getAge() {
console.log(age)
}
var fileName = 'show'
})
])可以看到,变的是数组第二个元素,这里把原来传进来的第二个参数 exports 转为了 __webpack_exports__
这里我们注意到,对于暴露一个变量来说,他是直接调用 __webpack_require__.d 方法,并在 __webpack_exports__ 上定义属性,那么为什么不直接像定义方法一样定义 变量呢?
来到 __webpack_require__.d 函数,他是先做了一个 if 判断,!__webpack_require__.o(exports, name) ,判断该属性是否已经存在,,如果不存在就进行定义,这就有个问题,难道不能重复定义覆盖吗?我们做下测试:
// show.js 改为如下:
export function show(content) {
window.document.getElementById('app').innerHTML = content
};
export function getAge() {
console.log(age)
}
export var fileName = 'show1'
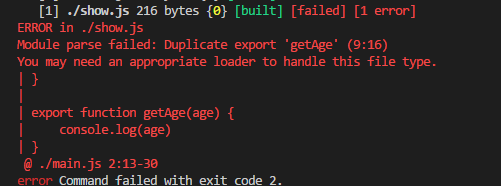
export var fileName = 'show2'果然,打包的时候出现了一个错误:

同理,重复暴露方法也会报错:
这里我还有一个疑问,就是为什么变量不能像方法一样,直接用 点的方式挂到 exports 上,而是使用defineProperty呢?
后面我又对 as 的作用做了测试:
// show.js
export function show(content) {
window.document.getElementById('app').innerHTML = content
};
function getAge(age) {
console.log(age)
}
var fileName1 = 'show1'
export {
fileName1 as f1,
getAge as age
}然后打包,发现基本没变,就只改了两行:

继续,我们试试 export default
// show.js
function getAge(age) {
console.log(age)
}
export default getAge
前面我们都是将 export 、 module.exports、 export default分开来用,现在我们把他们结合起来用试试
// show.js
function getAge(age) {
console.log(age)
}
export function show() {
console.log(55)
}
export var n = 'n'
export default {
getAge
}
这样子用没啥区别,如果既 export 有 export default 呢
// show.js
function getAge(age) {
console.log(age)
}
export function show() {
console.log(55)
}
export var n = 'n'
export default {
getAge,
n
}
好吧,他会两个地方都来一个,

最后我们加上 module.exports,看看有啥刺激的
module.exports = function getAge(age) {
console.log(age)
}
export function show() {
console.log(55)
}
var n = 'n'
export default {
n
}

导出的结果:
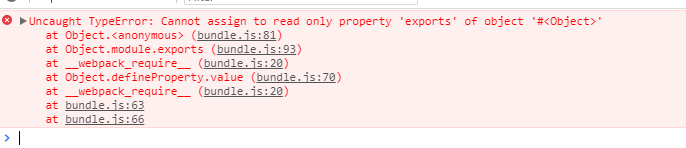
呦呵,确实我们不一样,不一样,还有,我的 getAge呢,来分析一波:
// __webpack_require__(1)
function (module, __webpack_exports__, __webpack_require__) {
"use strict";
Object.defineProperty(__webpack_exports__, "__esModule", {
value: true
});
/* WEBPACK VAR INJECTION */
(function (module) { /* harmony export (immutable) */
__webpack_exports__["show"] = show;
module.exports = function getAge(age) {
console.log(age)
}
function show() {
console.log(55)
}
var n = 'n'
__webpack_exports__["default"] = ({
n
});
}.call(__webpack_exports__, __webpack_require__(2)(module)))
}
// __webpack_require__(2)
function (module, exports) {
module.exports = function (originalModule) {
if (!originalModule.webpackPolyfill) {
// 以originalModule为原型创建一个新对象
var module = Object.create(originalModule);
// module.parent = undefined by default
if (!module.children) module.children = [];
Object.defineProperty(module, "loaded", {
enumerable: true,
get: function () {
return module.l; 这里是 originalModule 的 l
}
});
Object.defineProperty(module, "id", {
enumerable: true,
get: function () {
return module.i; // 这里是 originalModule 的 i
}
});
Object.defineProperty(module, "exports", {
enumerable: true,
});
module.webpackPolyfill = 1;
}
return module;
};
}上面,在 .call(__webpack_exports__, __webpack_require__(2)(module)) 时,先执行 __webpack_require__(2),执行后返回的 module.exports 是一个函数,接受一个参数,在这里就是 __webpack_require__(1)模块,并返回一个新模块对象:
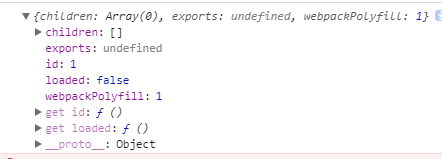
那为什么会报错呢?因为
writable 当且仅当该属性的writable为true时,value才能被赋值运算符改变。默认为 false。所以报错了,我们只要作如下改动:

结果就出来了,但是依旧没有 getAge 方法

所以尽量不要这么用
突然看了下上面的,还有一种单独使用 module.exports 的情形,我们看看:
function getAge(age) {
console.log(age)
}
function show() {
console.log(55)
}
var n = 'n'
module.exports = {
show,
getAge,
n
}

好嘛,,简洁明了。
今天就到这里,我们还没有解决 浅析1 中的一些疑问,我们明天继续 ^_^
之前阅读过 redux 的源码,vuex 同样也是一个状态管理工具,之前开发 vue 应用的时候,用到的 vuex 也比较多,所以自然对 vuex 颇有兴趣,最主要的原因是 我爱学习,(不好意思,脸掉地上了),,哈哈哈哈哈哈

(其实过年这几天也挺无聊的。。。
接下来我们来回归正题

我们都知道,在 Vue 中使用 Vuex 必须通过 Vue.use(Vuex) 方法来使用,所以先来瞄一瞄 Vue 对 Vuex 做了什么不可告人的事,惊恐.gif
来到 vue 源码下的 core/global-api/use.js
Vue.use = function (plugin: Function | Object) {
// 检测该插件是否已经被安装
if (plugin.installed) {
return
}
// use 支持传入一个选项对象,如
// Vue.use(MyPlugin, { someOption: true })
const args = toArray(arguments, 1) //获取可选对象
args.unshift(this) // 将Vue 构造器传入,当插件的第一个参数
if (typeof plugin.install === 'function') {
// install执行插件安装
plugin.install.apply(plugin, args)
} else if (typeof plugin === 'function') {
plugin.apply(null, args)
}
plugin.installed = true // 防止再次安装
return this
}所以,vue 对插件还是挺温柔的,只用了它的一个安装函数进行插件的安装。好,我们来看看 vuex 的 install 函数
在 store.js 的最下面,我们看到了它的身影
function install(_Vue) {
if (Vue && _Vue === Vue) {
// 给出警告:说明重复安装
return
}
Vue = _Vue
applyMixin(Vue)
}这里我们也可以看到 vuex 自己内部也做了一个限制,防止重复安装,最后该函数调用了 applyMixin(Vue)
咻一下,我们来到 mixin.js,该函数也很简单,先是获取 Vue 的版本号,如果版本是 2.0 以上版本,就使用 Vue.mixin 来在所有组件中混入 beforeCreate 生命钩子,对应的处理函数是 vuexInit,反之就向后兼容 1.x 版本
function vuexInit() {
// this -> vm
const options = this.$options
// store injection
if (options.store) { // 获取传入new Vue({store}) 里面的 store,并注册为 vm 的 $store 属性,这样我们就能在实例中使用 this.$store 访问 store 对象了
this.$store = typeof options.store === 'function' ?
options.store() :
options.store
} else if (options.parent && options.parent.$store) {
// 子组件从其父组件引用 $store 属性
this.$store = options.parent.$store
}
}至此,前菜已经上齐了

store.js,别看长长一窜,有500多行,其实看进去了,你会感觉,也没啥可怕嘛
该文件主要由一个 Store 类和一些辅助函数构成,我们先来看 这个构造类
该构造函数中首先是进行一些必要的判断,如浏览器环境下自动安装、是否已经安装了 Vue、是否支持 Promise,是否已经实例化了 Store 构造函数,其中用到了 assert 断言函数
// 构造函数
constructor(options = {}) {
// .......
}
// util.js
function assert (condition, msg) {
if (!condition) throw new Error(`[vuex] ${msg}`)
}然后是从传入的options 中提取出 plugins 和 strict,并做一些变量的初始化
// store internal state
// 表示提交状态,作用是保证对 Vuex 中 state 的修改只能在 mutation 的回调函数中,而不能在外部随意修改state
this._committing = false
// 用户定义的 actions
this._actions = Object.create(null)
// action 订阅者
this._actionSubscribers = []
// // 用户定义的 mutations
this._mutations = Object.create(null)
// 用户定义的 getters
this._wrappedGetters = Object.create(null)
// 收集用户定义的 modules
this._modules = new ModuleCollection(options)
// 模块命名空间map
this._modulesNamespaceMap = Object.create(null)
// 存储所有对 mutation 变化的订阅者,当执行commit时会执行队列中的函数
this._subscribers = []
// 创建一个 Vue 实例, 利用 $watch 监测 store 数据的变化
this._watcherVM = new Vue()接着后面是对 dispatch 和 commit 函数中的 this 的重新绑定
const store = this
const {
dispatch,
commit
} = this
this.dispatch = function boundDispatch(type, payload) {
return dispatch.call(store, type, payload)
}
this.commit = function boundCommit(type, payload, options) {
return commit.call(store, type, payload, options)
}这样做是因为在组件中通过 this.$store 直接调用 dispatch/commit 方法时, 能够使 dispatch/commit 方法中的 this 指向当前的 store 对象而不是当前组件的 this。
我们知道 new Vue 时会把传入的对象的中的 this 绑定为 vm,例如 computed 属性,里面我们写如下代码时,会把计算属性里面的 this 绑定为当前的 vm 实例
computed: {
// 计算属性的 getter
reversedMessage: function () {
// `this` 指向 vm 实例
return this.message.split('').reverse().join('')
}
}( 上面这段如有不妥,欢迎指出,谢谢 ^_^
接着就是 安装模块,vm 组件设置,传入插件以及 devtoolPlugin 插件的设置了
this.strict = strict
const state = this._modules.root.state
// init root module.
// this also recursively registers all sub-modules
// and collects all module getters inside this._wrappedGetters
installModule(this, state, [], this._modules.root)
// initialize the store vm, which is responsible for the reactivity
// (also registers _wrappedGetters as computed properties)
resetStoreVM(this, state)
// apply plugins
plugins.forEach(plugin => plugin(this))
if (Vue.config.devtools) {
devtoolPlugin(this)
}接下来我们先不讲 dispatch 和 commit 是怎么实现的,先来重点关注下 modules 这部分
由于现在的篇幅也算可以了,怕大家看到长篇大论头疼,所以我们转移阵地。

(如有不当,欢迎指出,谢谢 ^_^
递归算法在实际应用中很常见,递归的就是把一个大问题分割为几个相似的简单的小问题,在方法里调用自身,关键点有点:
递归结束条件,否则为无限循环使用递归能减少我们的代码量,但是递归的运行效率是较低的,在递归调用过程中,系统为每一层的返回点、局部变量等开辟栈来存储,递归次数过多容易导致栈溢出。
下面是一个使用递归进行进制转换的demo:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void convto(char *s,int n,int b)
{
char bit[] = ("0123456789ABCDEF");
int len;
if(n == 0)
{
strcpy(s,"");
return;
}
convto(s,n/b,b);
len = strlen(s);
s[len] = bit[n%b];
s[len+1]='\0';
}
int main()
{
char s[80];
int i,base,old;
printf("请输入十进制数:");
scanf("%d",&old);
printf("请输入转换的进制:");
scanf("%d",&base);
convto(s,old,base);
printf("%s\n",s);
getch();
return 0;
}
链队列即有一个头结点和一个尾结点,然后依次在队尾后面插入节点,形成链队列
基本操作:
#include <stdio.h>
#include <stdlib.h>
#include "linkQueue.h"
int main()
{
LinkQueue Q;
char str[] = "ABCDEFGH";
int i,length = 8;
char x;
initQueue(&Q);
for(i=0;i<length;i++)
{
enterQueue(&Q,str[i]);
}
displayQueue(Q);
deleteQueue(&Q,&x);
printf("出队元素的值为:%2c\n",x);
printf("当前队列中的元素:\n");
displayQueue(Q);
printf("\n");
return 0;
}#ifndef LINKQUEUE_H_INCLUDED
#define LINKQUEUE_H_INCLUDED
// 结点类型定义
struct QNode
{
char data;
struct QNode *next;
};
typedef struct QNode LQNode,*QueuePtr;
// 队列类型定义
typedef struct
{
QueuePtr front;
QueuePtr rear;
}LinkQueue;
// 初始化操作
void initQueue(LinkQueue *LQ)
{
LQ->front = (QueuePtr)malloc(sizeof(LQNode));
if(LQ->front==NULL)
exit(-1);
LQ->front->next = NULL;
LQ->rear=LQ->front;
}
// 判断队列是否为空
int queueEmpty(LinkQueue LQ)
{
if(LQ.rear->next==NULL)
return 1;
return 0;
}
// 入队
int enterQueue(LinkQueue *LQ,char e)
{
QueuePtr s;
s = (QueuePtr) malloc(sizeof(LQNode));
if(!s)
exit(-1);
s->data = e;
s->next = NULL;
LQ->rear->next = s;
LQ->rear = s;
return 1;
}
// 出队
int deleteQueue(LinkQueue *LQ,char *e)
{
QueuePtr s;
if(LQ->front == LQ->rear)
return 0;
s = LQ->front->next;
*e = s->data;
LQ->front->next=s->next;
if(LQ->rear == s)
LQ->rear = LQ->front;
free(s);
return 1;
}
// 取队头元素
int getHead(LinkQueue LQ,char *e)
{
QueuePtr s;
if(LQ.front==LQ.rear)
return 0;
s = LQ.front;
*e = s->data;
return 1;
}
// 清空队列
void clearQueue(LinkQueue *LQ)
{
while(LQ->front!=NULL)
{
LQ->rear = LQ->front->next;
free(LQ->front);
LQ->front = LQ->rear;
}
}
// 显示队列所有元素
void displayQueue(LinkQueue LQ)
{
QueuePtr p;
printf("队列的各个结点:\n");
p = LQ.front->next;
while(p)
{
printf("%2c ",p->data);
p = p->next;
}
}
#endif // LINKQUEUE_H_INCLUDED
// index.js
(function (window) {
let createTag = (tag, attrOpts) => { // 创建标签
let Tag = document.createElement(tag)
forEachValue(attrOpts, (key) => {
Tag[key] = attrOpts[key]
})
return Tag
}
let forEachValue = function (obj, fn) {
Object.keys(obj).forEach(key => fn(key))
}
// 注意,使用document.querySelector()获取 body元素 时,要传入 'body',而不是 document.body
let appendChild = (parent, child) => {
parent = document.querySelector(parent)
parent.appendChild(child)
return function () {
parent.removeChild(child)
}
}
let assert = (condition, msg) => { // 断言
if (!condition) throw new Error(`${msg}`)
}
let jsonp = req => {
let {
url,
data,
callback
} = req
let script,
removeChild,
params = [],
fnName = 'jsonpCb'
data['callback'] = fnName
assert(url, "url 不能为空")
assert(callback, "url 不能为空")
for (let key in data) {
params.push(`${encodeURIComponent(key)}=${encodeURIComponent(data[key])}`)
}
url = url.indexOf('?') > 0 ? `${url}&` : `${url}?`
url += params.join('&')
script = createTag('script', {
src: url,
type: "text/javascript"
})
removeChild = appendChild('body', script)
window[fnName] = res => {
callback(res)
removeChild()
delete window[fnName]
}
script.onerror = (error) => {
callback({
error
})
removeChild()
delete window[fnName]
}
}
jsonp({
url: 'http://localhost:8080/login',
data: {
name: 'echo666'
},
callback: function (res) {
console.log(JSON.stringify(res));
}
})
})(this);var qs = require('querystring');
var http = require('http');
var server = http.createServer();
server.on('request', function (req, res) {
var params = qs.parse(req.url.split('?')[1]);
console.log(params)
var fn = params.callback;
// jsonp返回设置
res.writeHead(200, {
'Content-Type': 'text/javascript'
});
res.end(fn + '(' + JSON.stringify(params) + ')');
});
server.listen('8080');
console.log('Server is running at port 8080...');原文翻译于 GET vs. POST
HTTP POST 请求在消息正文中将客户端(浏览器)中的附加数据提供给的服务器。相反,GET 请求在 URL 中包含所有的请求数据。HTML中的表单均可以使用两者,只要在 <form> 标签里指明 method="POST" 或者 method="GET" (默认值) 即可。指定的方法决定了表单数据如何提交给服务器。当请求方法是 GET 时,所有表单数据将被编码到 URL 中,作为查询字符串参数附加到 action 的 URL`中。当使用 POST 时,表单数据出现在 HTTP 请求的消息体中。
下面是两个方法的比较:
| GET | POST | |
|---|---|---|
| 历史记录 | 参数保留在浏览器的历史记录中,因为他们是 URL 的一部分 | 参数不保留在 URL 中 |
| 书签 | 可以加为书签 | 不能加为书签 |
| BACK按钮/重新提交行为(刷新) | GET 请求将重新执行,但是不一定重新提交到服务器,如果HTML存在浏览器的缓存中 | 浏览器经常弹出一个警告框,告诉用户数据将被重新提交 |
| 编码类型 | application/x-www-form-urlencoded | multipart/form-data 或者 application/x-www-form-urlencoded。为二进制数据使用多重编码 |
| 参数 | 能被发送,但是参数的长度不能超过 URL 的最大长度,最安全的是使用不到 2K 的参数,一些服务器能达到 64K | 能发送数据,包括文件给服务器 |
| 被攻击的可能性 | 很容易被黑客通过脚本攻击 | 比较难 |
| 数据类型的限制 | 只允许 ASCII 字符 | 没限制,二进制也可以 |
| 安全性 | GET 的安全性比 POST 低,因为,被发送的数据是 URL 的一部分。所以它将以明文的形式保存在浏览器的历史记录和服务器日志中 | POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。 |
| 表单数据长度的限制 | 当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(一个安全的URL 的最大长度是 2048 个字符)。不过因浏览器和 web 服务器会有些许区别 | 没限制 |
| 可用性 | GET 方法不应该被使用当发送密码或者其他敏感数据的时候 | POST 方法可以使用与发送密码或者敏感数据 |
| 可见性 | 数据在 URL 中对所有人都是可见的并且信息的长度被限制 | 数据不会显示在 URL 中 |
| 缓存 | 能被缓存 | 不能被缓存 |
基本的不同是 它们对应于不同的HTTP请求,如HTTP规范中所定义一样。两者在提交的过程中都以相同的方式开始---- 一个 表单数据集由浏览器构建,然后以 enctype 属性指定的编码方式进行编码。对于 METHOD="POST" ,enctype 属性可以是 multipart/form-data 或者 application/x-www-form-urlencoded 。 而对于METHOD ="GET",只允许 application/x-www-form-urlencoded。然后将该表单数据集发送到服务器。
对于使用 GET 的提交,浏览器通过获取 action 属性的值来构造一个 URL ,添加一个 ?在 URL 后面,然后添加 表单数据集在问号后面。接着,浏览器处理这个 URL,就好像跟随一个链接(或者就像用户自己直接输入了 URL一样)。浏览器将 URL 划分为不同部分,并识别主机,然后向该主机发送一个 GET 请求,其余的 URL 作为参数。注意:此过程意味着表单数据仅限于 ASCII 代码。
POST 请求将使用 action属性值和根据 enctype 属性指定的内容类型来创建发送消息以发送 POST 请求
来个视频解解闷Differences Between Get and Post - Web Development
由于数据以不同的方式编码,因此需要不同的解码机制。因此,一般来说,更改提交方法,可能需要更改处理提交的脚本。例如当使用 CGI 接口时,脚本会在使用 GET 时,在环境变量(QUERYSTRING)中接收数据,但是当使用POST时,表单数据在标准输入流(stdin)中传递,并且要读取的字节数由Content-length头指定。
在提交 "幂等" 表单时,建议使用 GET --仅涉及数据库查询的表单。另外一个观点是,几个 幂等的查询和单个查询有着相同的效果。如果数据库更新,或者其他操作例如触发了电子邮件等,建议使用 POST
幂等(idempotent、idempotence)是一个数学或计算机学概念,常见于抽象代数中。
幂等有一下几种定义:
对于单目运算,如果一个运算对于在范围内的所有的一个数多次进行该运算所得的结果和进行一次该运算所得的结果是一样的,那么我们就称该运算是幂等的。比如绝对值运算就是一个例子,在实数集中,有abs(a)=abs(abs(a))。
对于双目运算,则要求当参与运算的两个值是等值的情况下,如果满足运算结果与参与运算的两个值相等,则称该运算幂等,如求两个数的最大值的函数,有在在实数集中幂等,即max(x,x) = x。
浏览器不知道特定的 HTML 表单是什么,但是,如果表单通过 GET 发送,那么浏览器知道如果出现网络错误,可以重新尝试自动提交是安全的。而对于 POST 来说,重新提交可能不安全,所以浏览器会首先对用户进行确认。
GET 经常会缓存,而 POST 几乎不。对于查询系统来说,这可能产生相当大的效率影响,特别是如果查询字符串很简单,因为缓存可能会提供最常见的查询
在某些情况下,即使使用幂等查询也建议使用 POST:
POST 提供更高的安全性吗?这是一个有趣的问题。我们来看看一个 GET 请求
GET https://www.example.com/login.php?user=mickey&passwd=mini设想你的网络连接被监视,那么请求的哪些信息将提供给窥探者呢?如果使用 POST ,并且用户和密码数据包含在 POST 的变量中,那么在HTTPS连接的情况下会更安全吗?
答案是 no ,如果你使用 GET 请求,只有以下信息才能被攻击者知道:
URL的路径部分 -- 即请求的实际页面以及查询字符串 --- 是被保护的(加密的),而它们是 在线的,即在到达目的服务器的途中传输。POST 请求的情况也是完全一样
当然,web服务器往往会在访问日志中以纯文本的格式记录整个 URL;所以通过 GET 请求发送敏感信息也不是一个好主意。无论 HTTP 或 HTTPS 都适用


由于 .apply()是需要进行一系列的检查以及深拷贝,所以它比 .call()执行速度慢
插入排序 在少量元素的排序中很常见,插入排序 的工作方式就和我们玩扑克牌类似。
开始的时候,我们的左手为空并且桌子上的牌面向下。然后 每次从桌子上拿走一张牌,插入到左手的正确位置,我们从右到左将它与手中的牌进行比较。拿在手上的牌总是排列好的,原来这些牌是在桌子上的牌堆中的顶部的牌。
下面我们先来一个数组 A[1,......,n],它是一个无序数组,现在我们就来实现他的排序,伪代码如下:
SORT_ARRAY
for j = 2 to A.length
key = A[j]
i = j-1
while i > 0 and A[i] > key
A[i+1] = A[i]
i = i -1
A[i+1] = key
下标 j 指出正被插入到手中的 当前牌,在 for 循环的每次迭代开始的时候,包含元素 A[1...j-1] 的子数组就构成了当前在左手中排序好的牌,剩余的子数组的 A[j+1....n]仍对应于仍在桌上的牌堆。它的时间复杂度为 O(n)

(来自 wikipedia)
下面是 js 实现的一个排序:
let ary = [8, 5, 12, 2, 4, -6, 1, -3]
// 升序
let sortArrayByAscendingOrder1 = (ary) => {
for (var j = 1, l = ary.length; j < l; j++) {
let key = ary[j],
i = j - 1;
while (i > -1 && ary[i] > key) {
ary[i + 1] = ary[i]
--i;
}
ary[i + 1] = key;
}
return ary
}
let sortArrayByAscendingOrder2 = (ary)=>{
var i,j;
for(i = 1;i < ary.length; i++){
for(j = 0;j<i;j++){
if(ary[j]>ary[i]){
ary.splice(j,0,ary[i]);
ary.splice(i+1,1);
}
}
}
return ary;
};
// 降序
let sortArrayByDescendingOrder = (ary) => {
var l = ary.length,
j,
temp;
for(var i=1;i<l;i++){
if(ary[i]>ary[i-1]){
temp = ary[i]
for(j=i-1;j>-1&&ary[j]<temp;j--){
ary[j+1] = ary[j]
}
ary[j+1] = temp
}
}
return ary
}
sortArrayByAscendingOrder1 (ary) // [ -6, -3, 1, 2, 4, 5, 8, 12 ]
sortArrayByAscendingOrder2 (ary) // [ -6, -3, 1, 2, 4, 5, 8, 12 ]
sortArrayByDescendingOrder (ary) // [12, 8, 5, 4, 2, 1, -3, -6]var arr = [func1, func2, func3];
function func1(ctx, next) {
ctx.index++
next();
}
function func2(ctx, next) {
setTimeout(function () {
ctx.index++;
next();
});
}
function func3(ctx, next) {
console.log(ctx.index);
}
const compose = arr => arr.reverse().reduce((a, b) => obj => b(obj, () => a(obj)), () => { })
compose(arr)({ index: 0 }); // 输出:2
/*
function compose(arr) {
return arr.reverse().reduce((a, b) => {
return function (obj) {
b(obj, function () {
a(obj)
})
}
}, () => { })
}
*/U = max { f(x),g(x) },V = min { f(x),g(x) },求 U + V ,U - V,UV
U = max { f(x),g(x) } = ½ [ f(x) + g(x) + | f(x) - g(x) | ]
V = min { f(x),g(x) } = ½ [ f(x) + g(x) - | f(x) - g(x) | ]
U + V = f(x) + g(x)
U - V = | f(x) - g(x) |
UV = f(x) * g(x)
承接上文webpack打包后代码浅析2,今天我们来看看复杂一点的文件依赖情况
现在增加一个 getName.js 文件,然后各个 js 文件内容如下:
// main.js
var {
show
} = require('./show')
var {
getName
} = require('./getName')
// console.log(show)
show()
getName(666)
// show.js
var {
getName
} = require('./getName')
export function show() {
console.log(55)
}
// getName.js
export function getName(name) {
console.log(name)
}打包后文件:
// 立即执行函数体里面基本没变,只是最后return 的时候是从传进来的数组的第二个元素开始执行:
return __webpack_require__(__webpack_require__.s = 1);
// 传进来的参数为:
[
/* 0 */
(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
Object.defineProperty(__webpack_exports__, "__esModule", { value: true });
/* harmony export (immutable) */ __webpack_exports__["getName"] = getName;
function getName(name) {
console.log(name)
}
}),
/* 1 */
(function(module, exports, __webpack_require__) {
var {
show
} = __webpack_require__(2)
var {
getName
} = __webpack_require__(0)
// console.log(show)
show()
getName(666)
}),
/* 2 */
(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
Object.defineProperty(__webpack_exports__, "__esModule", { value: true });
/* harmony export (immutable) */ __webpack_exports__["show"] = show;
var {
getName
} = __webpack_require__(0)
function show() {
console.log(55)
}
})
]可以看到,入库文件被放在了第二个元素,且参数还是一样,所以我们就回答了浅析1中的问题,入口文件并不一定在第一个位置。那么这里又有一个疑问,就是为什么 getName模块被放在了第一,难道是因为他被引用的次数多吗?
我再来加一个文件 getAge.js,现在各个文件内容如下:
// main.js
var {
show
} = require('./show')
var {
getName
} = require('./getName')
import {
getAge
} from './getAge'
// console.log(show)
show()
getName(666)
getAge(777888)
// show.js
import {
getAge
} from './getAge'
export function show() {
console.log(55)
getAge(777888)
}
// getAge.js
export function getAge(age) {
console.log(age)
}
// getName.js
var {
show
} = require('./show')
import {
getAge
} from './getAge'
export function getName(name) {
console.log(name)
}这里我们的 getAge被引入了三次,show被引入了两次,那打包后的结果会不会是 getAge第一,show第二呢?
打包后结果:
return __webpack_require__(__webpack_require__.s = 2);
[
/* 0 */
(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
/* harmony export (immutable) */ __webpack_exports__["a"] = getAge;
function getAge(age) {
console.log(age)
}
}),
/* 1 */
(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
Object.defineProperty(__webpack_exports__, "__esModule", { value: true });
/* harmony export (immutable) */ __webpack_exports__["show"] = show;
/* harmony import */ var __WEBPACK_IMPORTED_MODULE_0__getAge__ = __webpack_require__(0);
function show() {
console.log(55)
Object(__WEBPACK_IMPORTED_MODULE_0__getAge__["a" /* getAge */])(777888)
}
}),
/* 2 */
(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
Object.defineProperty(__webpack_exports__, "__esModule", { value: true });
/* harmony import */ var __WEBPACK_IMPORTED_MODULE_0__getAge__ = __webpack_require__(0);
var {
show
} = __webpack_require__(1)
var {
getName
} = __webpack_require__(3)
// console.log(show)
show()
getName(666)
Object(__WEBPACK_IMPORTED_MODULE_0__getAge__["a" /* getAge */])(777888)
}),
/* 3 */
(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
Object.defineProperty(__webpack_exports__, "__esModule", { value: true });
/* harmony export (immutable) */ __webpack_exports__["getName"] = getName;
/* harmony import */ var __WEBPACK_IMPORTED_MODULE_0__getAge__ = __webpack_require__(0);
var {
show
} = __webpack_require__(1)
function getName(name) {
console.log(name)
}
})
]果然,是这样,那我就猜想传进去的数组是按引用次数排的。
到这里,简单的打包后的文件代码告一段落,但是,打包之路还很长,我们改日再叙 ^_^
快速排序由于排序效率在同为 O(n*logn) 的几种排序方法中效率较高,因此经常被采用
快速排序过程:
看上图,可以看将快排理解为找坑位,初始时,将 49 作为枢纽元素,把他挖出来,先放一边,就留下一个坑,然后第一次交换,从最右边寻找第一个小于49 的元素,然后将其放入之前49留下的坑中,自己留下一个坑位;第二次交换,从左边开始找第一个大于49 的元素去填补上一个元素留下的坑,如此循环,最后将 枢纽元素补入坑中,完成一趟排序。
js的实现:
let ary = [8, 5, 12, 2, 1, 4, -6, -3]
/**
*
* @param {Array} ary 数组
* @param {Number} l 排序的左边起始点
* @param {Number} r 排序的右边终点
*/
let quickSort = (ary, l, r) => {
if (l < r) {
let pivot; //枢轴元素
let i, j;
i = l;
j = r;
pivot = ary[i] // 以排序序列的第一个元素为枢轴元素
// 完成一趟排序
while (i < j) {
while (i < j && ary[j] > pivot) j--; // 从右向左找第一个小于pivot的数 前面 i<j 保证了 i ,j 不会有寻找的重合
if (i < j) { // 要加上这里的判断,不然会出现下面图片显示得最后一步 2和1 位置错误的问题
ary[i] = ary[j]
i++
}
while (i < j && ary[i] < pivot) i++;
if (i < j) { // 要加上这里的判断,不然会出现下面图片显示得最后一步 2和1 位置错误的问题
ary[j] = ary[i]
j--
}
}
ary[i] = pivot
// 递归地将pivot两边的序列进行按照上面的过程进行排序
quickSort(ary, l, i - 1) // 对左边进行排序
quickSort(ary, i + 1, r) // 对右边进行排序
}
return ary
}
quickSort(ary, 0, 7) // [ -6, -3, 1, 2, 4, 5, 8, 12 ]
// 不加判断的结果: [ -6, -3, 2, 1, 4, 5, 8, 12 ]不加判断出现的问题:
c语言:
#include <stdio.h>
#include <stdlib.h>
void QuickSort(int *s,int l,int r);
int main()
{
int i=0;
int k[] = {8, 5, 12, 2, 1, 4, -6, -3};
QuickSort(k,0,7);
for(;i<8;i++)
{
printf("%d ",k[i]); // -6 -3 1 2 4 5 8 12
}
return 0;
}
void QuickSort(int *s,int l,int r)
{
if(l<r)
{
int i,j,pivot;
i = l;
j = r;
pivot = s[i];
while(i<j)
{
while(i<j&&s[j]>pivot) j--; // 从右向左找第一个小于pivot的数
if(i<j)
{
s[i] = s[j];
i++;
}
while(i<j&&s[i]<pivot) i++; // 从左往右找第一个大于pivot的数
if(i<j)
{
s[j]=s[i];
j--;
}
}
s[i] = pivot;
QuickSort(s,l,i-1);
QuickSort(s,i+1,r);
}
} var eq, deepEq
eq = function (a, b, aStack, bStack) {
// 因为 0=== -0
// 所以,先判断 a !== 0 保证了,a和b 是不为0 的,
// 其次,判断,a 和b 与 0 和 -0 的关系
// 1/0 == Infinite
// 1/-0 == -Infinite
if (a === b) return a !== 0 || 1 / a === 1 / b
// a和b 中只要有一个是 undefined 或者 null ,就判为 false ,严格模式下
if (a == null || b == null) return false;
// NaN 情况
// 如果 a 是NaN ,则判断 b 是不是 NaN
if (a !== a) return b !== b
var type = typeof a
// 经过上面的if 语句,如果是基本类型,如果相等,那么前面就已经有了结论,不会跳到这里,
// 这里是排除 基本数据类型的判断,凡是数据基本类型,到了这一步,表明两者并不相等
// 以便下面的对象的深度比较
if (type !== 'function' && type !== 'object' && typeof b != 'object') return false;
// 接下来进行对象的深度比较
return deepEq(a, b, aStack, bStack);
}
deepEq = function (a, b, aStack, bStack) {
// 如果 a,b 是underscore 的子类,
// 那么就比较 _wrapped 属性值
// 也就是传进来的 obj
if (a instanceof _) a = a._wrapped;
if (b instanceof _) b = b._wrapped;
var className = toString.call(a)
// 先用Object.prototype.toString 方法判断是否属于同一类型
if (className !== toString.call(b)) return false
// 下面针对不同的情况进行讨论
switch (className) {
case '[object RegExp]':
case '[object String]':
// new String
// 正则和字符串的则转换为字符串来比较
return '' + a === '' + b;
case '[object Number]':
// 如果+a !== +a 那么a = NaN
// 此时判断 b 是否是 NaN
if (+a !== +a) return +b !== +b;
// 将 a 转换为 基本类型
// 如果 a 为 0,判断 1 / +a === 1 / b
// 否则判断 +a === +b
return +a === 0 ? 1 / +a === 1 / b : +a === +b;
// 直接将 Date 和 Boolean 转化为 数字比较
case '[object Date]':
case '[object Boolean]':
return +a === +b;
/**
* var a = Symbol(1)
var b = Symbol(1)
a === b -> false
所以此时比较 时应该就比较 传入 Symbol 的参数
var a = Symbol(1)
var b = Symbol(1)
Symbol.prototype.valueOf.call(b) === Symbol.prototype.valueOf.call(a) // false
Symbol.prototype.toString.call(b) === Symbol.prototype.toString.call(a) // true
// 这里好像判断失误了??????????????????????????????????????
*/
case '[object Symbol]':
return SymbolProto.valueOf.call(a) === SymbolProto.valueOf.call(b);
}
// 判断是否是数组
var areArrays = className === '[object Array]';
if (!areArrays) { // 如果不是数组
// 此时 typeof a| b 是函数。。这样两个函数不管如何直接 false
if (typeof a != 'object' || typeof b != 'object') return false;
// Objects with different constructors are not equivalent, but `Object`s or `Array`s
// from different frames are.
// 如果 a 和 b 有着不同的构造函数不一定是不等,如 Object 和 Array 如果在不同的 iframes 的时候
var aCtor = a.constructor,
bCtor = b.constructor;
// aCtor !== bCtor 说明 两者的构造函数不同
// _.isFunction(aCtor) 保证 能使用 instanceof 来进行判断
// ('constructor' in a && 'constructor' in b) 是防止如下情况:
/* var attrs = Object.create(null);
attrs.name = "Bob";
eq(attrs, {
name: "Bob"
});
// 这两个对象应该是相等的
*/
if (aCtor !== bCtor && !(_.isFunction(aCtor) && aCtor instanceof aCtor &&
_.isFunction(bCtor) && bCtor instanceof bCtor) &&
('constructor' in a && 'constructor' in b)) {
return false;
}
}
aStack = aStack || [];
bStack = bStack || [];
var length = aStack.length;
while (length--) { // 逐个比较其值 第一次时 length = 0 这里不会执行
if (aStack[length] === a) return bStack[length] === b
}
aStack.push(a)
bStack.push(b)
if (areArrays) { // 如果是数组
length = a.length
if (length !== b.length) return false // 数组长度不等,自然两者不相等
while (length--) { // 递归比较a和b 的一个个子元素,层层剥茧,只要有一个不同,就是false
if (!eq(a[length], b[length], aStack, bStack)) return false
}
} else { // 是纯对象情况
var keys = _.keys(a),
key // 获取a 的所有 键
length = keys.length
// 键值长度不等,自然不等
if (_.keys(b).length !== length) return false;
while (length--) {
// Deep compare each member
key = keys[length];
// 先看 b 中是否有这个键,有的话,再将a 和 b 对应这个键的键值进行递归比较
if (!(_.has(b, key) && eq(a[key], b[key], aStack, bStack))) return false;
}
}
aStack.pop();
bStack.pop();
return true;
}
_.isEqual = function (a, b) {
return eq(a, b);
};里面参考了JavaScript 中是如何比较两个元素是否 "相同" 的
不过其中也有些疑问,在上面的参考链接里面提出来了问题,可以移步到上面地址
总的来说就是利用 正则以及正则子项,将没有匹配到的字符串进行切割,并进行 实体编码转义,然后按照正则子项来拼接匹配到的字符串,接着在继续如上操作,最后传入 new Function() 的函数实体的参数中,返回一个函数,并可以指定参数,最后就是用户传入参数,并进行前面模板中的参数替换
// 三种模板的定义,并且是全局
// \s : Unicode 任何空白符
// \S : 任何非 Unicode 空白符之间外的字符
// 非贪婪匹配
_.templateSettings = {
evaluate: /<%([\s\S]+?)%>/g,
interpolate: /<%=([\s\S]+?)%>/g,
escape: /<%-([\s\S]+?)%>/g
};
// . :除换行符和其他Unicode 行终止符之外的任意字符
var noMatch = /(.)^/;
var escapes = {
"'": "'",
'\\': '\\',
'\r': 'r', // 回车
'\n': 'n', // 换行
'\u2028': 'u2028', // 行分隔符
'\u2029': 'u2029' // 段落分隔符
};
var escapeRegExp = /\\|'|\r|\n|\u2028|\u2029/g;
var escapeChar = function (match) {
return '\\' + escapes[match];
};
_.template = function (text, settings, oldSettings) {
// 如果没有新的 setting ,就将老的 setting 设置为 settings
if (!settings && oldSettings) settings = oldSettings
// 合并 setting 和 _.templateSettings,但不进行覆盖
settings = _.defaults({}, settings, _.templateSettings);
// 正则的属性:
// var escape = /<%-([\s\S]+?)%>/g
// escape.source ="d(b+)d" -> string
// escape.lastIndex :下一个匹配的索引值
var matcher = RegExp([
(settings.escape || noMatch).source,
(settings.interpolate || noMatch).source,
(settings.evaluate || noMatch).source
].join('|') + '|$', 'g'); // -> /<%-([\s\S]+?)%>|<%=([\s\S]+?)%>|<%([\s\S]+?)%>|$/g
var index = 0
var source = "__p+="
/**
* _.template("Using 'with': <%= data.answer %>", {variable: 'data'})({answer: 'no'});
以上述例子为例讲解
*/
text.replace(matcher, function (match, escape, interceptor, evaluate, offset) {
// \n ->\\n \->\\
// 此时 source ="__p+=Using \'with\': "
// match = <%= data.answer %>
// escape = ' data.answer '
source = += text.slice(index, offset).replace(escapeRegExp, escapeChar)
// 便于下次 slice
index = offset + match.length
if (escape) {
// 需要对变量进行编码
// source ="__p+=Using \'with\': '+\n((__t=( data.answer ))==null?'':_.escape(__t))+\n'"
source += "'+\n((__t=(" + escape + "))==null?'':_.escape(__t))+\n'";
} else if (interpolate) {
// 单纯地插入变量
source += "'+\n((__t=(" + interpolate + "))==null?'':__t)+\n'";
} else if (evaluate) {
// 可以直接执行的 JavaScript 语句
// 注意 "__p+=",__p 为渲染返回的字符串
source += "';\n" + evaluate + "\n__p+='";
}
// 将匹配到的内容原样返回(Adobe VMs 需要返回 match 来使得 offset 值正常)
return match;
})
// source ="__p+=Using \'with\': '+\n((__t=(' data.answer '))==null?'':_.escape(__t))+\n'';\n"
source += "';\n"
// 如果没有指定 settings.variable 直接用 with 指定作用域
// 关于 with
// https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Statements/with
if (!settings.variable) source = 'with(obj||{}){\n' + source + '}\n';
// 增设 print 函数,返回 所有参数 link 在一起的 字符串
source = "var __t,__p='',__j=Array.prototype.join," +
"print=function(){__p+=__j.call(arguments,'');};\n" +
source + 'return __p;\n';
/**
* source = (
* var __t,__p = '',__j = Array.prototype.join,
* print = function(){
* __p+=__j.call(arguments,"");
* }
*
* __p+=(Using \'with\':
* ((__t=(' data.answer '))==null?'':_.escape(__t))
* )
*
* return __p
* )
*/
var render;
try {
// obj 为传入的 JSON 对象,传入 _ 参数使得函数内部能用 Underscore 的函数
// source: 一个含有包括函数定义的JavaScript语句的字符串。
// {variable: 'data'}
/**
* render = function(data=obj,_){
* // 函数执行实体
* var __t,__p = '',__j = Array.prototype.join,
* print = function(){
* __p+=__j.call(arguments,"");
* }
*
* __p+=(Using \'with\':
* ((__t=(' data.answer '))==null?'':_.escape(__t))
* )
*
* return __p
* }
*/
render = new Function(settings.variable || 'obj', '_', source);
} catch (e) {
e.source = source;
throw e;
}
var template = function (data) {
// data = {answer: 'no'}
// 执行render
/**
* render = function(data=obj,_){
* // 函数执行实体
* var __t,
* __p = '',
* __j = Array.prototype.join,
* print = function(){
* __p+=__j.call(arguments,"");
* }
*
* __p+=(Using \'with\':
* // data.answer = 'no'
* ((__t=(' data.answer '))==null?'':_.escape(__t))
* )
* // __p = "Using \'with\':no"
* return __p
* }
*/
return render.call(this, data, _);
};
var argument = settings.variable || 'obj';
/* 预编译模板对调试不可重现的错误很有帮助. 这是因为预编译的模板可以提供错误的代码行号和堆栈跟踪,
有些模板在客户端(浏览器)上是不能通过编译的 在编译好的模板函数上, 有 source 属性可以提供简单的预编译功能. */
template.source = 'function(' + argument + '){\n' + source + '}';
return template
}上面如有不当,欢迎指正^_^
let _isPlainObj = (obj) => {
if (typeof obj !== 'object' || obj === null) return false
let proto = obj
while (Object.getPrototypeOf(proto) !== null) {
proto = Object.getPrototypeOf(proto)
}
return Object.getPrototypeOf(obj) === proto
}
let _execFn = function (fn) {
if (typeof fn === 'function') {
return fn()
}
return fn
}
let pickTrue = (isToStr, ...args) => {
let trueCollections = []
let len = args.length
for (let i = 0; i < len; i++) {
let arg = args[i]
if (!arg)
continue;
let type = typeof arg
if (type === 'string' || type === 'number') {
trueCollections.push(arg)
} else if (Array.isArray(arg) && arg.length) {
let arrayReturn = pickTrue.apply(null, [false, ...arg]) // 使用apply 保证了pickTrue 里面为一系列的参数
trueCollections.push(...arrayReturn)
} else if (_isPlainObj(arg)) {
for (let k in arg) {
if (arg.hasOwnProperty(k) && _execFn(arg[k])) {
trueCollections.push(k)
}
}
} else if (type == 'function') {
let fnReturn = arg()
let fnResult = pickTrue.apply(null, [true, fnReturn])
trueCollections.push(fnResult)
}
}
return isToStr ? trueCollections.join(' ') : trueCollections
}
module.exports = pickTrue
let assert = require('assert')
let pickTrue = require('../index')
describe('单输入基本类型', function () {
it('保留基本类型->字符串', function () {
assert.equal(pickTrue(
true,
1,
2,
's1',
's2'
), '1 2 s1 s2')
})
it('保留基本类型->数组', function () {
let p = pickTrue(
false,
1,
2,
's1',
's2'
)
let expect = [1, 2, 's1', 's2']
p.map((v, i) => {
assert.equal(v, expect[i])
})
})
})
describe('对象和基本类型', function () {
it('对象->字符串', function () {
assert.equal(pickTrue(true,
{
a: 1,
b: false,
c: true,
d: null
}
), 'a c')
})
it('对象->数组', function () {
let p = pickTrue(false,
{
a: 1,
b: false,
c: true,
d: null
}
)
let expect = ['a', 'c']
p.map((v, i) => {
assert.equal(v, expect[i])
})
})
it('数组、对象、函数、以及基本类型--> 字符串', function () {
assert.equal(pickTrue(true,
1,
's2',
undefined,
{
a: true,
b: null,
c: undefined
},
[
function () {
return 'fn'
},
[
2, {
d: true,
e: false,
f: function () {
return false
},
g: function () {
return true
}
}
]
]
), '1 s2 a fn 2 d g')
})
it('数组、对象、函数、以及基本类型--> 数组', function () {
let p = pickTrue(false,
1,
's2',
undefined,
{
a: true,
b: null,
c: undefined
},
[
function () {
return 'fn'
},
[
2, {
d: true,
e: false,
f: function () {
return false
},
g: function () {
return true
}
}
]
]
)
let expect = [1, 's2', 'a', 'fn', 2, 'd', 'g']
p.map((v, i) => {
assert.equal(v, expect[i])
})
})
})
链栈的即有一个头结点,然后依次在头结点后面插入节点,形成链栈
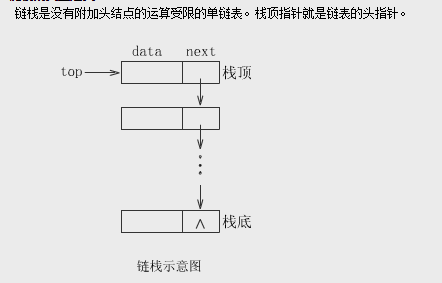
基本操作有:
#include <stdio.h>
#include <stdlib.h>
#include "linkStack.h"
int main()
{
LinkStack S;
LinkStack s;
char ch[50],e,*p;
initStack(&S);
printf("请输入进栈的字符;\n");
gets(ch);
p = &ch[0];
while(*p)
{
pushStack(S,*p);
p++;
}
printf("显示当前栈顶元素:\n");
getTop(S,&e);
printf("%4c\n",e);
printf("输出栈中元素的个数: %d \n",stackLength(S));
printf("元素出栈的序列:\n");
while(!stackEmpty(S))
{
popStack(S,&e);
printf("%4c\n",e);
}
printf("\n");
return 0;
}#ifndef LINKSTACK_H_INCLUDED
#define LINKSTACK_H_INCLUDED
struct node
{
char data;
struct node *next;
};
typedef struct node LStackNode,*LinkStack;
// 初始化链栈
void initStack(LinkStack *top)
{
if((*top = (LinkStack)malloc(sizeof(LStackNode)))==NULL)
exit(-1);
(*top)->next = NULL;
}
// 判断链栈是否为空
int stackEmpty(LinkStack top)
{
if(top->next==NULL)
return 1;
return 0;
}
// 进栈
int pushStack(LinkStack top,char e)
{
LinkStack p;
if((p=(LinkStack)malloc(sizeof(LStackNode)))==NULL) // 节点指针
{
printf("内存分配失败");
exit(-1);
}
p->data = e;
p->next = top->next;
top->next = p;
return 1;
}
// 退栈
int popStack(LinkStack top,char *e)
{
LinkStack p;
p=top->next;
if(!p)
{
printf("栈为空");
return 0;
}
top->next=p->next;
*e = p->data;
free(p);
return 1;
}
// 取栈顶元素
int getTop(LinkStack top,char *e)
{
LinkStack p;
p = top->next;
if(!p)
{
printf("栈为空");
return 0;
}
*e = p->data;
return 1;
}
// 获取栈中元素长度
int stackLength(LinkStack top)
{
LinkStack p;
int count=0;
p = top->next;
while(p!=NULL)
{
count+=1;
p = p->next;
}
return count;
}
// 销毁链栈
void destortStack(LinkStack top)
{
LinkStack p,q;
p = top;
while(p)
{
q=p;
p = p->next;
free(q);
}
}
#endif // LINKSTACK_H_INCLUDED

进入 shell 命令行,执行如下命令即可:


PCB(PCB是有限的) 。若 PCB 申请失败则创建失败等待状态 ,或者为 阻塞状态 ,等待的是内存这个资源PCB ,主要包括初始化标志信息、初始化处理机状态信息、初始化处理机控制信息,以及设置进程的优先级等PCB ,从中读出该进程的状态PCB 信息PCB 移入相应的对列,如就绪队列、在某事件阻塞等对列PCB父进程创建子进程后,父进程与子进程同时执行(并发)。主程序调用子程序后,主程序暂停在调用点,子程序开始执行,直到子程序返回,主程序才开始执行
创建后就常驻内存,进程结束后删除
进程描述信息
- 用户标识符
- 进程标识符
进程控制和管理信息
- 进程当前状态
- 进程优先级
资源分配清单
处理机相关信息,主要指处理机中各寄存器值,当进程切换时,处理机的状态就必须保存在相应的 PCB
中,以便在该进程重新执行的时候,能再从断电处继续执行
在单处理器系统中,任何时刻只有一个进程处于运行状态
错 ---- 在系统发生死锁的时候,可能所有进程都处于阻塞状态
同一个程序经过多次创建,运行在不同的数据集上,形成了 不同 的进程
进程是程序在一个数据集合上运行的过程,不同的数据集,进程也不同
这里只是简单的窥探 webpack 的打包过程,能力有限,欢迎交流
webpack.config.js 文件里配置的参数,生产最后的配置结果webpack 构建生命周期的事件节点,以做出对应的反应entry 入口文件开始解析文件构建AST语法树,找出每个文件所依赖的文件,递归下去loader配置 找出合适的loader用来对 文件进行转换entry 配置生成代码块 chunkchunk 到文件系统webpack.config.js:
const path = require('path')
module.exports = {
entry: './main.js',
output: {
filename: 'bundlejs',
path: path.resolve(__dirname, './dist')
}
}main.js:
const show = require('./show')
show('webpack hello 77')show.js:
function show(content) {
window.document.getElementById('app').innerHTML = content
}
module.exports = show最后打包到 bundle.js,现在我们就看看他是长什么样子?
(function(modules){
// xxx
})([
// main.js
(function(module,exports,__webpack_require__){
const show = __webpack_require__(1)
show('webpack hello 77')
}),
// show.js
(function(module,exports){
function show(content) {
window.document.getElementById('app').innerHTML = content
}
module.exports = show
})
])我们可以看到,它是一个立即执行函数,该函数的参数是一个数组,并把 entry 所对应的文件作为该数组的第一个元素,那么是不是这是一个约定呢?(我们后面再谈),然后将 main 依赖的 show 作为后续元素,而且我们注意到,它不像 main 一样有 __webpack_require__ 这个参数,这个又是不是是一个约定呢?
好,现在我们来看看立即执行函数里面发生了什么
// 用于模块的缓存
var installedModules = {}
function __webpack_require__(moduleId) {
// 先检查该 id 对应的模块是否存在于缓存中
if (installedModules[moduldId]) {
// 我们看见,如果有,就直接暴露该模块的 `exports` 对象
return installedModules[moduleId].exports;
}
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
}
// 执行该模块,并把this 指向该模块的exports对象,
// 最后把该模块、该模块的 `exports` 方法,`__webpack_require__`方法传给该模块函数
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__)
// 这里我们知道,模块的 `l` 属性是用来说明该模块是否已经被加载
module.l = true
// 返回该模块暴露的接口
return module.exports;
}
// 暴露 modules 对象
__webpack_require__.m = modules
// 暴露模块的缓存
__webpack_require__.c = installedModules
// 为 `harmony exports` 定义 getter 方法
__webpack_require__.d = function (exports, name, getter) {
if (!__webpack_require__.o(exports, name)) {
Object.defineProperty(exports, name, {
configurable: false,
enumerable: true,
get: getter
})
}
}
// 获取默认的函数为了兼容性
__webpack_require__.n = function (module) {
var getter = module && module.__esModule ?
function getDefault() {
return module['default']
} :
function getModuleExports() {
return module
}
__webpack_require__.d(getter, 'a', getter)
return getter
}
// 调用对象的 `hasOwnProperty`
__webpack_require__.o = function (object, property) {
return Object.prototype.hasOwnProperty.call(object, property)
}
// Webpack 配置中的 publicPath,用于加载被分割出去的异步代码
__webpack_require__.p = ""
// 加载传进来的modules[0],并返回 `exports`
return __webpack_require__(__webpack_require__.s = 0)如上,我们看见,先是定义一个 __webpack_require__,然后在上面添加一些方法,最后开始模块的加载,我们来讲解加载的流程,
先是执行 数组的第一个元素,main,然后里面遇到 __webpack_require__(1),自动将 要加载的数值加一,然后去加载 show.js,并将 exports 返回,供 main 使用,这里我们看见模块加载和 SeaJs一样,是延迟加载的,show 里面的函数,就是 SeaJs 中 define函数的factory
参数,详见我写的 seajs 阅读感悟
至此,我们简单的分析了其中的加载原理,但这仅仅是两个模块的情况,那么更复杂的呢?还有里面的 __webpack_require__的一些方法在这里面都没有体现作用,它们又是干嘛的呢?
我们继续 ^_^
最近在看 Vue 源码的时候,发现有这样的一个代码片段:

之前一直以为,JSON.stringify只有一个参数。那么 他的另外两个参数是干嘛的呢?
JSON.stringify(value[, replacer [, space]])
value:需要序列化成一个JSON 字符串的值
replacer:
- 如果是 函数,被序列化的值的每个属性都会经过该函数的转换和处理
- 如果是 数组,则只有包含在这个数组中的属性名才会被序列化到最终的 JSON 字符串中
- 如果是 null 或 未提供,对象的所有属性都会被序列化
space:指定缩进用的空白字符串,用于美化输出
- 如果是 数字,代表有多少个空格,上限为 10
- 如果 小于 1,就没有空格
- 如果该参数为 字符串(字符串的前十个字母),该字符串将被作为空格
- 如果该参数没有提供(或者为null,将没有空格
// 1. 布尔值、数字、字符串的包装对象在序列化过程中会自动转换成对应的原始值
JSON.stringify([new Boolean(5),new Number(5),new String('5')]) // "[true,5,"5"]"
// 2. undefined、任意的函数以及 symbol 值,在序列化过程中会被忽略(出现在非数组对象的属性值中时)或者被转换成 null(出现在数组中时)
JSON.stringify({x: undefined, y: function(){}, z: Symbol("")}); // "{}"
JSON.stringify([{x: undefined}, {y: function(){}}, {z: Symbol("")}]); // "[{},{},{}]"
JSON.stringify([undefined, Object, Symbol("")]); // "[null,null,null]"
// 3. 所有以 symbol 为属性键的属性都会被完全忽略掉,即便 replacer 参数中强制指定包含了它们
JSON.stringify({[Symbol("foo")]: "foo"}); // "{}"
JSON.stringify(
{[Symbol.for("foo")]: "foo"},
function (k, v) {
if (typeof k === "symbol"){
return "a symbol";
}
}
); // undefined
// 4. 不可枚举的属性会被忽略
JSON.stringify(
Object.create(
null,
{
x: { value: 'x', enumerable: false },
y: { value: 'y', enumerable: true }
}
)
); // "{"y":"y"}"只有两个参数 replacer (key,value)
// 1. 如果返回一个 Number, 转换成相应的字符串被添加入JSON字符串。
function replacer(key, value) {
return 2
}
var time= {year:2018,month:1,day:3};
JSON.stringify(time,replacer) // "2"
// 2. 如果返回一个 String, 该字符串作为属性值被添加入JSON。
function replacer(key, value) {
return ''+value
}
var time= {year:2018,month:1,day:3};
JSON.stringify(time,replacer) // ""[object Object]""
// ==============================
function replacer(key, value) {
return '2'
}
var time= {year:2018,month:1,day:3};
JSON.stringify(time,replacer) // ""2""
// 3. 如果返回一个 Boolean, "true" 或者 "false"被作为属性值被添加入JSON字符串。
function replacer(key, value) {
return !!value
}
var time= {year:2018,month:1,day:3};
JSON.stringify(time,replacer) // "true"
// 4. 如果返回undefined,该属性值不会在JSON字符串中输出。
function replacer(key, value) {
if (typeof value === "string") {
return undefined;
}
return value;
}
var foo = {foundation: "Mozilla", model: "box", week: 45, transport: "car", month: 7};
var jsonString = JSON.stringify(foo, replacer); //"{"week":45,"month":7}" var time= {year:2018,month:1,day:3};
JSON.stringify(time,['year']) // "{"year":2018}" JSON.stringify({a:2 }, null, 2)
// "{
// "a": 2
// }"
JSON.stringify({a:2 }, null,' 2')
// "{
// 2"a": 2
// }"
JSON.stringify({a:2 ,b:3}, null,'\n')
/*
"{
"a": 2,
"b": 3
}"
*/如果一个被序列化的对象拥有 toJSON 方法,那么该 toJSON 方法就会覆盖该对象默认的序列化行为:不是那个对象被序列化,而是调用 toJSON 方法后的返回值会被序列化
var obj = {
foo: 'foo',
toJSON: function () {
return 'bar';
}
};
JSON.stringify(obj); // '"bar"'
JSON.stringify({x: obj}); // '{"x":"bar"}'枚举法就是从所有候选答案中搜索出正确的解,满足两个条件:
将数字带入下面式子,使等式成立:

#include <stdio.h>
#include <stdlib.h>
int main()
{
int a1,a2,a3,a4,a5;
long multi,result;
for(a1=1;a1<=9;a1++)
{
for(a2=0;a2<=9;a2++)
{
for(a3=0;a3<=9;a3++)
{
for(a4=0;a4<=9;a4++)
{
for(a5=0;a5<=9;a5++){
multi = a1*10000 + a2*1000 + a3*100 + a4*10 + a5;
result = a5*100000 + a5*10000 + a5*1000 + a5*100 + a5*10 + a5;
if(multi*a1 == result){
printf("\n%5d%2d%2d%2d%2d\n",a1,a2,a3,a4,a5);
printf("X%12d\n",a1);
printf("_____________\n");
printf("%3d%2d%2d%2d%2d%2d",a5,a5,a5,a5,a5,a5);
}
}
}
}
}
}
getch();
return 0;
}
computed 是 Vue 中常用的一个属性,具体见计算属性和侦听器
现在我们就以官网里的例子来进行源码探秘
var vm = new Vue({
el: '#example',
data: {
message: 'Hello'
},
computed: {
// 计算属性的 getter
reversedMessage: function () {
// `this` 指向 vm 实例
return this.message.split('').reverse().join('')
}
}
})首先 computed 的初始化是在 state.js 里的 initState方法中,该方法不仅初始化了 computed ,还初始化了 props、data、methods、watch等
/*初始化props、methods、data、computed与watch*/
export function initState(vm: Component) {
vm._watchers = []
const opts = vm.$options
/*初始化props*/
if (opts.props) initProps(vm, opts.props)
/*初始化方法*/
if (opts.methods) initMethods(vm, opts.methods)
/*初始化data*/
if (opts.data) {
initData(vm)
} else {
/*该组件没有data的时候绑定一个空对象*/
observe(vm._data = {}, true /* asRootData */ )
}
/*初始化computed*/
if (opts.computed) initComputed(vm, opts.computed)
/*初始化watchers*/
if (opts.watch) initWatch(vm, opts.watch)
}现在我们就来看看 initComputed方法
const computedWatcherOptions = {
lazy: true
}
function initComputed(vm: Component, computed: Object) {
const watchers = vm._computedWatchers = Object.create(null)
for (const key in computed) { // 遍历computed 对象里的元素
const userDef = computed[key]
/*
计算属性可以是 `function`,也可以是有 `get/set` 属性的对象。
*/
let getter = typeof userDef === 'function' ? userDef : userDef.get // 判断对应的计算属性值是否是函数还是设置了 `get/set` 属性的对象,并获取函数
if (process.env.NODE_ENV !== 'production') {
if (getter === undefined) {
warn(
`No getter function has been defined for computed property "${key}".`,
vm
)
getter = noop // function noop(){}
}
}
// create internal watcher for the computed property.
/*
为计算属性创建一个内部的监视器Watcher,保存在vm实例的_computedWatchers中
这里的computedWatcherOptions参数传递了一个lazy为true,会使得watch实例的dirty为true
*/
// 这里我们先跳到后面看看 new Watcher
watchers[key] = new Watcher(vm, getter, noop, computedWatcherOptions) // 这里返回了 watcher 实例,保存在 `watchers = vm._computedWatchers` 中
// component-defined computed properties are already defined on the
// component prototype. We only need to define computed properties defined
// at instantiation here.
// 组件正在定义的计算属性已经定义在现有组件的原型上则不会进行重复定义
if (!(key in vm)) { // 此时 key (`reversedMessage`) 不在 vm 实例上,所以就定义计算属性,来到下面的 `defineComputed`
// 定义计算属性
defineComputed(vm, key, userDef)
} else if (process.env.NODE_ENV !== 'production') {
// 如果计算属性与已定义的data或者props中的名称冲突则发出warning
if (key in vm.$data) {
warn(`The computed property "${key}" is already defined in data.`, vm)
} else if (vm.$options.props && key in vm.$options.props) {
warn(`The computed property "${key}" is already defined as a prop.`, vm)
}
}
}
}class Watcher {
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: Object
) {
this.vm = vm
/*_watchers存放订阅者实例*/
vm._watchers.push(this)
// options
if (options) {
this.deep = !!options.deep
this.user = !!options.user
this.lazy = !!options.lazy // true
this.sync = !!options.sync
} else {
this.deep = this.user = this.lazy = this.sync = false
}
this.cb = cb
this.id = ++uid // uid for batching
this.active = true
this.dirty = this.lazy // for lazy watchers => true
this.deps = []
this.newDeps = []
this.depIds = new Set()
this.newDepIds = new Set()
this.expression = process.env.NODE_ENV !== 'production'
? expOrFn.toString()
: ''
// parse expression for getter
/*把表达式expOrFn解析成getter*/
if (typeof expOrFn === 'function') {
this.getter = expOrFn // 这里就是开头的 `reversedMessage`对应的函数
} else {
this.getter = parsePath(expOrFn)
if (!this.getter) {
this.getter = function () {}
process.env.NODE_ENV !== 'production' && warn(
`Failed watching path: "${expOrFn}" ` +
'Watcher only accepts simple dot-delimited paths. ' +
'For full control, use a function instead.',
vm
)
}
}
this.value = this.lazy // true ,所以为undefined
? undefined
: this.get()
}
get () {
/*将自身watcher观察者实例设置给Dep.target,用以依赖收集。*/
/* Dep.target = null
const targetStack = []
// 将watcher观察者实例设置给Dep.target,用以依赖收集。同时将该实例存入target栈中
export function pushTarget(_target: Watcher) {
// 这里如果 Dep.target 已经存在,就先暂存在栈中,先将 Dep.target 赋值为 此时的 watcher,
// 到最后 popTarget 中再把之前的 Dep.target 给重新恢复
if (Dep.target) targetStack.push(Dep.target)
Dep.target = _target
}
// 将观察者实例从target栈中取出并设置给Dep.target
export function popTarget() {
Dep.target = targetStack.pop()
} */
pushTarget(this) // 现将全局的 Dep.target 设置为当前这个 计算属性对应的 watcher ,此时并不入栈
let value
const vm = this.vm
// 这里执行了 getter 方法,也就是 reversedMessage 对应的 函数
// 在执行的过程中会获取 this.message 的值,这里就会触发 this.message 的 `get` 方法,
// 因为 data 里的每个属性都已被 observe 了,重写了[get/set](https://github.com/vuejs/vue/blob/v2.3.0/src/core/observer/index.js#L152)
// 并且此时 Dep.target 是当前这个 计算属性对应的 watcher,所以 this.message 收集的依赖中就会有该 watcher 了,
// 从而当 this.message 发生改变时,执行 set ,触发 dep.notify() 通知所有的观察者,
// 然后执行 watcher 的 update 方法,这样 reversedMessage 就和 this.message 联系在了一起
// 这里似乎看上去即使你 this.message 改变了 notify -> update 的时候因为 lazy = true,仅仅改变了dirty = true
// 但是这里并没有联系上 compile 的时候,即 `<p>Reversed message: "{{ reversedMessage() }}"</p>` 的情况,
// 所以 当改变 this.message 的时候是会触发试图的更新的,即该计算属性不仅仅只有这一个 watcher
if (this.user) {
try {
value = this.getter.call(vm, vm)
} catch (e) {
handleError(e, vm, `getter for watcher "${this.expression}"`)
}
} else {
value = this.getter.call(vm, vm)
}
// "touch" every property so they are all tracked as
// dependencies for deep watching
//如果存在deep,则触发每个深层对象的依赖,追踪其变化
if (this.deep) { // 此时为 false ,所以不触发这里
//递归每一个对象或者数组,触发它们的getter,使得对象或数组的每一个成员都被依赖收集,形成一个“深(deep)”依赖关系
traverse(value)
}
//将观察者实例从target栈中取出并设置给Dep.target
popTarget() // 此时Dep.target为null
this.cleanupDeps()
return value
}
evaluate () { // 当使用计算属性时,就会执行 `this.get()` 方法,
this.value = this.get() // 执行函数,并获取返回值
this.dirty = false
}
update () {
/* istanbul ignore else */
// 在计算属性时,因为各个计算属性都是lazy= true
// 这里当重新访问计算属性时,createComputedGetter里面调用 watcher.evaluate() 会将 this.dirty = false
// 这样,再次获取计算属性的时候,就会取之前的值,只有当计算属性依赖的data 值发生改变通知watcher 时
// 才会将dirty 置为true,从而使再次访问计算属性时,会获取最新的值
if (this.lazy) { // 此时为 true
this.dirty = true
} else if (this.sync) {
/*同步则执行run直接渲染视图*/
this.run()
} else {
/*异步推送到观察者队列中,下一个tick时调用。*/
queueWatcher(this)
}
}
cleanupDeps () {
/*移除所有观察者对象*/
let i = this.deps.length
while (i--) {
const dep = this.deps[i]
if (!this.newDepIds.has(dep.id)) {
dep.removeSub(this)
}
}
let tmp = this.depIds
this.depIds = this.newDepIds
this.newDepIds = tmp
this.newDepIds.clear()
tmp = this.deps
this.deps = this.newDeps
this.newDeps = tmp
this.newDeps.length = 0
}定义计算属性
export function defineComputed(target: any, key: string, userDef: Object | Function) {
if (typeof userDef === 'function') { // 此时 userDef 对应的 reversedMessage 是一个函数,否则如果是对象就走下面的 else
/*创建计算属性的getter*/
sharedPropertyDefinition.get = createComputedGetter(key) // 返回 computedGetter 函数
/*
当userDef是一个function的时候是不需要setter的,所以这边给它设置成了空函数。
因为计算属性默认是一个function,只设置getter。
当需要设置setter的时候,会将计算属性设置成一个对象。参考:https://cn.vuejs.org/v2/guide/computed.html#计算-setter
*/
sharedPropertyDefinition.set = noop
} else {
/*get不存在则直接给空函数,如果存在则查看是否有缓存cache,没有依旧赋值get,有的话使用createComputedGetter创建*/
sharedPropertyDefinition.get = userDef.get ?
userDef.cache !== false ?
createComputedGetter(key) :
userDef.get :
noop
/*如果有设置set方法则直接使用,否则赋值空函数*/
sharedPropertyDefinition.set = userDef.set ?
userDef.set :
noop
}
/*defineProperty上getter与setter*/
// 将 计算属性绑定到 vm 实例上
Object.defineProperty(target, key, sharedPropertyDefinition)
}创建计算属性的getter
function createComputedGetter(key) {
return function computedGetter() {
// 获取到 该计算属性对应的 watcher 实例
const watcher = this._computedWatchers && this._computedWatchers[key]
if (watcher) {
/*实际是脏检查,在计算属性中的依赖发生改变的时候dirty会变成true,在get的时候重新计算计算属性的输出值*/
if (watcher.dirty) { // 此时为true
watcher.evaluate() // 来到上面的 watcher
}
/*依赖收集*/
if (Dep.target) {
watcher.depend()
}
// 返回 watcher.value 也就是 reversedMessage 执行的返回值
return watcher.value
}
}
}上面仅仅是浅析了一部分简单情况下的 computed 代码,如有不当,欢迎指出 ^_^
Vue 很精彩,我们继续 ^_^
/**
*
* @param {*Nunmer} year
* @param {*Number} week
*/
const findDaysInWeek = (year, week) => {
if (isOverYearWeeks(year, week)) {
throw new Error('输入的周数大于该年的总周数')
}
var daysInWeek = [], // 记录每周里面的日期集合
oneDayMs = 24 * 3600 * 1000
var firstDayWeekMs = firstDayWeek(year, true)
for (var i = (week - 1) * 7; i < 7 * week; i++) {
let d = firstDayWeekMs + i * oneDayMs
daysInWeek.push(new Date(d))
}
return daysInWeek
}
// 获取一年中有几周
/**
*
* @param {*Number} year
*/
const weeksOfYear = year => {
var yearDays = getDayCountOfYear(year, true)
var firstDayOfYear = new Date(year, 0, 1)
return Math.ceil((yearDays - firstDayOfYear.getDay()) / 7.0)
}
// 是否超过该年的总周数
/**
*
* @param {*Number} year
* @param {*Number} week
*/
const isOverYearWeeks = (year, week) => {
var totalWeeks = weeksOfYear(year)
return week > totalWeeks
}
// 判断是否是瑞年
/**
*
* @param {*Number} year
* @param {*Boolean} isDays
*/
const getDayCountOfYear = (year, isDays) => {
const isLeapYear = year % 400 === 0 || (year % 100 !== 0 && year % 4 === 0);
return isDays ?
(isLeapYear ? 366 : 365) :
isLeapYear
};
// 获取一年中第一周第一天(这里的第一天指周日)是几号或者该天距离 1970年1月1日00:00:00 (世界标准时间) 起经过的毫秒数。
/**
*
* @param {*Number} year
* @param {*Boolean} isMs
*/
const firstDayWeek = (year, isMs) => {
var oneDayMs = 24 * 3600 * 1000,
firstDayOfYear = new Date(year, 0, 1),
firstDayOfYear_day = firstDayOfYear.getDay(), // 获取一年中1月1号是星期几
preDaysInWeek = -firstDayOfYear_day, //1月1号该周前面还有几天
firstDayWeekMs = firstDayOfYear.getTime() + preDaysInWeek * oneDayMs // 第一周是几号
return isMs ? firstDayWeekMs : new Date(firstDayWeekMs)
}
findDaysInWeek(2018, 1)本文阅读收获于 Web图片资源的加载与渲染时机,感谢作者。
浏览器工作流程

图片加载和渲染时机:
<style>
.bg-img {
display: none;
background: url(../assets/imgs/process-of-browserlove.jpg)
}
</style>
<body>
<img src="../assets/imgs/process-of-browser.png" alt="">
<div class="bg-img"></div>
</body>
可渲染元素 上的所有属性(如:display:none / background-image)结合一起产出到渲染树。当解析渲染树时会加载 img 标签上的图片,发现元素上有 background-image 属性时会加载背景图片
当绘制时发现元素上有 display:none 时,不计算该元素的位置,也不会绘制该元素
<style>
.bg-img {
background: url(../assets/imgs/love.jpg)
}
</style>
<div style='display:none'>
<img src="../assets/imgs/process-of-browser.png" alt="">
<div class="bg-img"></div>
</div>
可渲染的元素产出到渲染树,这就是说,当匹配 DOM 树和样式规则树时,如果发现一个元素的属性上有 display:none,浏览器就会认为该元素是不可渲染的,所以不会把该元素的子元素产出到渲染树 <style>
.bg-img {
width: 400px;
height: 400px;
background-size: cover;
}
</style>
<body>
<div class="bg-img"></div>
<script>
var div = document.querySelector('div');
div.style.display = 'none';
div.style.background = 'url(../assets/imgs/love.jpg)';
</script>
</body>
<style>
.bg-img {
width: 400px;
height: 400px;
background-size: cover;
}
</style>
<div style="display:none">
<div class="bg-img"></div>
</div>
<script>
var div = document.querySelector('.bg-img');
div.style.background = 'url(../assets/imgs/love.jpg)';
</script>
浏览器请求资源时,先判断是否有缓存,如有,且未过期的,则会从缓存中读取,不再请求。反之,先加载的图片会存储到浏览器的缓存中,以便后期获取
<style>
.bg-img {
width: 400px;
height: 400px;
background: url(../assets/imgs/love.jpg)
}
.bg-img:hover {
background: url(../assets/imgs/process-of-browser.png)
}
</style>
<div class="bg-img"></div>hover 前:

hover 后:

当使用样式表中的背景图片作为占位符时,要把背景图片转为 base64 格式。这是因为背景图片加载的顺序在标签后面,背景图片可能会在 标签图片加载完成后才开始加载,达不到想要的效果。
很多场景里图片是在改变或触发状态后才显示出来的,例如点击一个Tab后,一个设置display:none隐藏的父元素变为显示,这个父元素里的子元素图片会在父元素显示后才开始加载;又如当鼠标hover到图标后,改变图标图片,图片会在hover上去后才开始加载,导致出现闪一下这种不友好的体验。
解决:
堆是一颗完全二叉树,分为大根堆和小根堆,大根堆(小根堆)的每个节点都大于或等于(小于或等于)其子节点(如果有子节点)的值
关于堆的操作有插入和删除,下面讲的是大根堆,小根堆与之类似
大根堆的 插入 就是从最后一个叶子节点到根节点的一趟 起泡过程,将最后一个节点与其父节点相比较,如果大于父节点,两个交换位置,反之啥都不做,时间复杂度就是每一层的高度,即 O(logn)
大根堆的 删除 就是删除根节点,然后将最后一个节点放到根节点的位置,再和子节点相比较,调整节点的位置,使其满足大根堆的性质,即删除策略是一条从根节点到一个叶子节点的路径,时间复杂度为 O(logn)
c代码如下:
#include <stdio.h>
#include <stdlib.h>
typedef struct
{
int *pnData; // 指向堆的数据的指针
int nSize; // 堆中当前元素的个数
}MyHeap;
// 函数声明
int Insert(MyHeap *pHeap,int nData);
int IncreaseKey(MyHeap *pHeap,int nPos);
int PopMaxHeap(MyHeap *pHeap);
int main()
{
int i,data;
int n; // 对元素的个数
MyHeap myHeap; // 声明一个大根堆
printf("请输入堆元素的个数:");
scanf("%d",&n);
myHeap.pnData = (int*)malloc(sizeof(int) * n); // 分配堆所需要的存储空间
myHeap.nSize = 0;
printf("请输入每个元素的值:");
for(i=0;i<n;i++)
{
scanf("%d",&data);
Insert(&myHeap,data);
}
printf("大根堆排序后的结果:");
while(myHeap.nSize >0)
{
printf("%d ",PopMaxHeap(&myHeap));
printf("\n");
}
return 0;
}
int Insert(MyHeap *pHeap,int nData)
{
++pHeap ->nSize; // 先给堆中的数据个数加一
pHeap -> pnData[pHeap->nSize] = nData; // 将堆中的最后一个数据元素赋值为新插入的数据
IncreaseKey(pHeap,pHeap->nSize);
return 1;
}
int IncreaseKey(MyHeap *pHeap,int nPos) // 调整新插入的值的位置,使其满足大根堆
{
while(nPos>1) // 循环和父节点进行比较调整位置
{
int nMax = pHeap->pnData[nPos];
int nParent = nPos / 2;
if(nMax>pHeap->pnData[nParent]) // 如果子节点大于父节点,调换两者的位置
{
pHeap->pnData[nPos] = pHeap->pnData[nParent];
pHeap->pnData[nParent] = nMax;
nPos=nParent;
}else // 否则跳出循环
{
break;
}
}
return 1;
}
int PopMaxHeap(MyHeap *pHeap) // 删除第一个元素,并调整堆的位置,使其满足大根堆
{
int nMax = pHeap->pnData[1]; // 一开始最大值为根元素
int nPos = 1;
int nChild = nPos*2; // 得到左孩子节点
int lastChild = pHeap->pnData[pHeap->nSize]; // 得到最后一个元素
while(nChild<=pHeap->nSize)
{
int temp = pHeap->pnData[nChild];
if(nChild+1<=pHeap->nSize && pHeap->pnData[nChild+1]>temp)
// 如果节点的右孩子存在并且左孩子小于右孩子节点,就得到要交换的是右孩子节点的位置
nChild++;
if(lastChild>pHeap->pnData[nChild])
// 如果最后一个元素大于两个孩子节点,就跳出循环
break;
pHeap->pnData[nPos] = pHeap->pnData[nChild]; // 调换位置
nPos = nChild; // 查找位置下移
nChild *=2;
}
pHeap->pnData[nPos] = pHeap->pnData[pHeap->nSize]; // 给最后一个元素找坑
-- pHeap->nSize; // 同时减少堆中元素的个数
return nMax;
}引用MDN上的解释:
块级元素占据其父元素(容器)的整个空间,因此创建了一个 “块“
行内元素只占据它对应标签的边框所包含的空间
width/height。行内元素设置宽高无效margin/padding;行内元素起边距作用的只有 margin-left/margin-right/padding-left/padding-right,其他的不起边距效果display
display : none 不显示该元素,且不保留该元素原来占有的文档流位置
display : block 转换为块级元素
display : inline 转换为行内元素
display : inline-block 转换为行内块级元素,拥有块级元素的性质
float
当把行内元素设置为 float:left/right时,该行内元素的 display 属性会变为 block,且有浮动特性
position
当为行内元素进行定位时,position:absolute/fixed 都会使得行内元素变为块级元素
栈是一种先入后出的数据结构,基本操作有如下几个:
c 的实现:
// 主文件:
#include <stdio.h>
#include <stdlib.h>
typedef char DataType;
#include "seqStack.h"
int main()
{
SeqStack S;
int i;
DataType a[]={'A','B','C','D','E'};
DataType e;
// 初始化栈
initStack(&S);
for(i=0;i<sizeof(a)/sizeof(a[0]);i++)
{
if(pushStack(&S,a[i])==0)
{
printf("栈已满,插入失败");
return 0;
}
}
printf("出栈的元素:");
if(popStack(&S,&e)==1)
printf("%4c",e);
if(popStack(&S,&e)==1)
printf("%4c\n",e);
printf("当前栈顶元素:");
if(getTop(S,&e)==1)
printf("%4c\n",e);
if(pushStack(&S,'F')==0)
{
printf("栈已满,不能进栈");
return 0;
}
if(pushStack(&S,'G')==0)
{
printf("栈已满,不能进栈");
return 0;
}
// 栈的个数
printf("当前栈中的元数个数:%d\n",stackLength(S));
// 元素出栈的顺序是:
while(stackEmpty(S))
{
popStack(&S,&e);
printf("%4c",e);
}
printf("\n");
return 0;
}// 头文件
#ifndef SEQSTACK_H_INCLUDED
#define SEQSTACK_H_INCLUDED
#define StackSize 100
typedef struct
{
DataType stack[StackSize]; // 存储栈中数据元素
int top; // 栈顶指针
}SeqStack;
void initStack(SeqStack *S) // 初始化栈
{
S->top = -1; // 把栈顶指针置为0
}
int stackEmpty(SeqStack S) // 判断栈是否为空
{
if(S.top == -1)
return 0;
return 1;
}
// 取栈顶元素
int getTop(SeqStack S,DataType *e)
{
if(S.top<=0)
{
printf("该栈为空");
return 0;
}
*e = S.stack[S.top];
return 1;
}
// 插入元素
int pushStack(SeqStack *S,DataType e)
{
if(S->top>=StackSize){
printf("该栈已满,不能进栈\n");
return 0;
}
S->stack[++S->top] = e;
return 1;
}
//出栈
int popStack(SeqStack *S,DataType *e)
{
if(S->top<0){
printf("该栈为空,不能出栈\n");
return 0;
}
*e = S->stack[S->top--];
return 1;
}
// 栈的长度
int stackLength(SeqStack S)
{
return S.top+1;
}
// 清空栈S
void clearStack(SeqStack *S)
{
S->top = -1;
}
#endif // SEQSTACK_H_INCLUDED

循环等待条件:存在一种进程资源的循环等待链,链中的每一个进程已获得资源的同时,被链中的下一个进程所请求。即存在一个处于等待状态的进程集合 {P1,P2,....,Pn} ,其中 Pi 等待的资源被 P(i+1) 占有,Pn 等待的资源被 P0 占有,如下:

而死锁构成等待环的要求更加严格,他要求 Pi 等待的资源必须由 P(i+1) 来满足,而循环等待则无此限制。
例如,系统有两台打印机,P0 占有一台,Pk 占有一台,且 k 不属于集合 {0,1,2,3,......,n},Pn等待一台输出设备可以由 P0 获得,也可以由 Pk 获得,但 Pk 不在环中,如果 Pk 释放了设备,则可以打破等待,所以循环等待只是死锁的 必要条件

可利用资源矢量 Avaliable :含有 m 个元素的数组,其中每一个元素代表一类可用的资源数目。Avaliable[i] = K 表示系统中现有 Rj类资源 K 个
最大需求矩阵 Max :为 n*m 矩阵,定义系统中 n 个进程中的每一个进程对 m 类资源的最大需求量。Max[i,j] = K,则表示进程 i 需要 Rj 类资源的最大数目是 K
分配矩阵 Allocation :为 n*m 矩阵,定义系统中每一类资源分配当前给每一个进程的资源数目。Allocation[i,j] = K,则表示进程 i 当前已分得 Rj 类资源的数目是 K
需求矩阵 Need :为 n*m 矩阵,表示每一个进程还需要各类资源数。Need[i,j] = K,则表示进程 i 还需要 Rj 类资源的数目是 K
Need = Max - Allocation
设 Request(i) 是进程 Pi的请求矢量,Request(i) = K 表示需要 j 类资源数目为 K,发出资源请求后,系统按照下面步骤进行检查:
Available = Available - Request
Allocation[i,j] = Allocation[i,j] + Request(i)[j]
Need[i,j] = Need[i,j] - Request(i)[j]
安全性算法,检查此次分配后,系统是否处于安全状态,若安全,则把资源分配,否则,本次试探作废,回复原来的资源分配,让进程等待这是对 我看Vuex(二) 里面的一些函数的介绍,感觉放在二里面,层次显得不清楚
// module/module-collection.js
getNamespace(path) {
// 当根模块到前模块的路径
let module = this.root
return path.reduce((namespace, key) => {
module = module.getChild(key)
// 如果模块设置了命名空间,就取从根模块到该模块的key值作为命名空间
// 上面 moduleC 如果设置了命名空间,那么 moduleC 的 namespace 为 “moduleA/moduleC”
// 这里为什么不直接调用模块的 _rawModule.namespaced 呢????
return namespace + (module.namespaced ? key + '/' : '')
}, '')
}这里注意一下,这个module 是一个模块实例,所以当他获取 namespace 属性时是调用下面的代码,还有一点就是 根模块的 namespace 是
空字符串
// module.js
get namespaced () { // _rawModule 保存了模块的对象描述
return !!this._rawModule.namespaced
}function makeLocalContext(store, namespace, path) {
const noNamespace = namespace === '' // 判断是否有命名空间
// 这里是在本地dispatch / commit
// 如下面例子:
/* actions: {
actionA(){},
actionB({
dispatch,
commit
}) {
return dispatch('actionA').then(() => {
commit('someOtherMutation')
})
} */
// 所以说,如果在组件实例中 dispatch ,就要加上模块名
const local = {
// 如果没有命名空间,就直接获取 store的dispatch
dispatch: noNamespace ? store.dispatch : (_type, _payload, _options) => {
// unifyObjectStyle :获取正确的 type / payload /options
// Actions 支持同样的载荷方式和对象方式进行分发:
const args = unifyObjectStyle(_type, _payload, _options)
const {
payload,
options
} = args
let {
type
} = args
// options 不存在,或者其root 属性不存在
// 因为vuex 支持下面功能:
// 需要在全局命名空间内分发 action 或提交 mutation,
// 将 { root: true } 作为第三参数传给 dispatch 或 commit 即可
// 这里是不需要分发的情况
if (!options || !options.root) {
type = namespace + type // 获取命名空间下的 action
// 使用命名空间
if (process.env.NODE_ENV !== 'production' && !store._actions[type]) { // 确保 dispatch 的 action存在
console.error(`[vuex] unknown local action type: ${args.type}, global type: ${type}`)
return
}
}
// 这里已经对type 做了命名空间的处理,
// 如果传入了 { root: true } ,这里的 type 就是没有加上 namespace 的,
// 如果没有传入 { root: true },这里的 type 经过上面的 if 处理,也就可以正确触发了
return store.dispatch(type, payload)
},
commit: noNamespace ? store.commit : (_type, _payload, _options) => {
// 和上面差不多,,不讲了,,
}
}
// getters and state object must be gotten lazily
// because they will be changed by vm update
Object.defineProperties(local, {
getters: {
get: noNamespace ?
() => store.getters : // 没有,直接获取getters
() => makeLocalGetters(store, namespace) // 有,获取自己本模块的 getters
},
state: {
// 获取嵌套的state
get: () => getNestedState(store.state, path)
}
})
return local
}function makeLocalGetters(store, namespace) {
const gettersProxy = {}
// 获取命名空间长度
const splitPos = namespace.length
// 循环每个 getters
Object.keys(store.getters).forEach(type => {
// skip if the target getter is not match this namespace
// 跳过没有匹配与命名空间不匹配的 getter
if (type.slice(0, splitPos) !== namespace) return
// extract local getter type
// 提出 getter 类型
// 有 namespace 如:namespace 为 moduleA/moduleC/,type 为 moduleA/moduleC/cGetter,则 localType 为 cGetter
// 没有 namespace , 或者说那么spacename ='' ,type 为 cGetter,则 localType 为 cGetter
// slice 不改变原字符串
const localType = type.slice(splitPos)
// Add a port to the getters proxy.
// Define as getter property because
// we do not want to evaluate the getters in this time.
Object.defineProperty(gettersProxy, localType, {
get: () => store.getters[type], // 获取原字符串所对应的 getter
enumerable: true
})
})
return gettersProxy
}// 注册各个模块的 mutaations 方法到 store._mutations 中,每个type对应一个数组
function registerMutation(store, type, handler, local) {
// 将相同的type放入到同一个数组中,这是因为在没有命名空间的情况下,各个模块会有相同的 mutation
// 这样把这些 mutations 注册到全局,commit(type) 时候,就全部触发
const entry = store._mutations[type] || (store._mutations[type] = [])
entry.push(function wrappedMutationHandler(payload) { // 获取负载,只有它是需要用户传进来的
handler.call(store, local.state, payload)
})
}// 注册各个模块的 actions 到store._actions
function registerAction(store, type, handler, local) {
const entry = store._actions[type] || (store._actions[type] = [])
// 这里要说明下,由于 action 里是执行异步的地方,所以,如果没有命名空间的情况下
// 多个相同 type 的action 加入到 store._actions[type],dispatch(type) 的时候,
// 就要等这几个 action 都完成后才能 返回结果,所以这里用来 Promise 来处理,于此同时,
// 在dispatch(type) 里面,也会使用 Promise.all(),来等待所有结果返回
entry.push(function wrappedActionHandler(payload, cb) {
let res = handler.call(store, {
dispatch: local.dispatch,
commit: local.commit,
getters: local.getters,
state: local.state,
rootGetters: store.getters,
rootState: store.state
}, payload, cb)
if (!isPromise(res)) {
res = Promise.resolve(res)
}
// 调用开发者工具,并在错误的时候触发 vuex:error
if (store._devtoolHook) {
return res.catch(err => {
store._devtoolHook.emit('vuex:error', err)
throw err
})
} else {
return res
}
})
}// 注册各个模块的 getters 到store._wrappedGetters
function registerGetter(store, type, rawGetter, local) {
// getter 不能重复,因为他是依靠 vue 的computed 属性,computed 属性不能重复,这个也就不能重复
if (store._wrappedGetters[type]) {
if (process.env.NODE_ENV !== 'production') {
console.error(`[vuex] duplicate getter key: ${type}`)
}
return
}
store._wrappedGetters[type] = function wrappedGetter(store) {
return rawGetter(
local.state, // local state
local.getters, // local getters
store.state, // root state
store.getters // root getters
)
}
}在上面和前面有不少地方调用了 _withCommit 函数,,这个函数他有啥妙用呢?
他就是防止 state 被除了 mutation 以外的函数或者直接被修改,这个函数在 store 类里面,要结合 enableStrictMode 函数来看
_withCommit(fn) {
const committing = this._committing
this._committing = true
fn()
this._committing = committing
}
function enableStrictMode(store) {
store._vm.$watch(function () {
return this._data.$$state
}, () => {
if (process.env.NODE_ENV !== 'production') {
assert(store._committing, `Do not mutate vuex store state outside mutation handlers.`)
}
}, {
deep: true,
sync: true
})
}从上面函数知道,它只是改变 this._commiting 的状态,在 enableStrictMode 里监听 state。我们知道 vuex 规定只有在 mutation 函数才能修改 state,这里当 _withCommit 执行时,会执行 传入的 fn 函数,然后 fn 修改了 state ,导致 enableStrictMode 里的 watch 检测到了变化,执行后面的函数,在里面先进行判断 this._commiting 是否是 true,否则就会抛出错误,这样就做到了很好的保证
注:enableStrictMode 函数只有在
strict = true,才会执行,所以开发环境下,最好开启
总的来说就是把所有的 getter,mutation,action 放到 store 上,然后做相应的操作
单链表是数据结构里的常用结构,操作有:
#include <stdio.h>
#include <stdlib.h>
#include "linkList.h"
void delEle(LinkList A,LinkList B);
int main()
{
int i;
int a[] = {2,3,6,7,9,14,56,45,65,67};
int b[] = {3,4,7,11,34,54,45,67};
LinkList A,B;
ListNode *p;
/*
initList(A);这样就传对应于linkList.h中注释的那个部分结果就会崩溃,,为什么?
*/
initList(&A);
initList(&B);
//
for(i=1;i<=sizeof(a)/sizeof(a[0]);i++)
{
if(insertList(A,i,a[i-1])==0){
printf("插入失败");
return 0;
}
}
for(i=1;i<=sizeof(b)/sizeof(b[0]);i++)
{
if(insertList(B,i,b[i-1])==0){
printf("插入失败");
return 0;
}
}
printf("单链表A中的元素有%d个:\n",ListLength(A));
for(i=1;i<=ListLength(A);i++)
{
p= Get(A,i);
if(p)
printf("%4d",p->data);
}
printf("\n");
printf("单链表B中的元素有%d个:\n",ListLength(B));
for(i=1;i<=ListLength(B);i++)
{
p= Get(B,i);
if(p)
printf("%4d",p->data);
}
printf("\n");
delEle(A,B);
printf("将在A中出现的B元素删除后长度是%d:\n",ListLength(A));
for(i=1;i<=ListLength(A);i++)
{
p= Get(A,i);
if(p)
printf("%4d",p->data);
}
return 0;
}
void delEle(LinkList A,LinkList B)
{
int i ,pos;
int e;
ListNode *p;
for(i=0;i<ListLength(B);i++)
{
p=Get(B,i);
if(p){
pos = LocatePos(A,p->data);
if(pos>0)
deleteList(A,pos,e);
}
}
}#ifndef LINKLIST_H_INCLUDED
#define LINKLIST_H_INCLUDED
struct Node
{
int data;
struct Node *next;
};
typedef struct Node ListNode,*LinkList;
// 初始化链表
void initList (LinkList *head)
// head是指向指针变量A的指针变量,所以head里面存的是A的地址,*head 就是main 里面的 A
{
if((*head = (LinkList)malloc(sizeof(ListNode)))==NULL)
{
exit(-1);
}
(*head)->next = NULL;
}
/*
void initList (LinkList head) // 这样就会报错
{
if((head = (LinkList)malloc(sizeof(ListNode)))==NULL)
{
exit(-1);
}
head->next = NULL;
}*/
// 判断链表是否为空
int ListEmpty(LinkList head)
{
if(head->next==NULL)
return 1;
return 0;
}
// 按序号查找操作
ListNode *Get(LinkList head,int i)
{
ListNode *p;
int j=0;
if(ListEmpty(head))
return NULL;
if(i<1)
return NULL;
p = head;
while(p->next!=NULL&& j<i)
{
p = p->next;
j++;
}
if(j==i)
return p;
else
return NULL;
}
// 按内容查找
ListNode *LocateEle(LinkList head,int i)
{
ListNode *p;
p = head->next;
while(p)
{
if(p->data !=i){
p = p->next;
}else
{
break;
}
}
return p ;
}
// 定位操作
int LocatePos(LinkList head,int i)
{
int j=1;
ListNode *p;
p = head->next;
while(p)
if(p->data==i){
return j;
}else{
p = p->next;
j++;
}
if(!p)
return 0;
}
// 插入操作
int insertList(LinkList head,int i,int e)
{
ListNode *p,*pre; // p 是新生成的节点,pre 是要插入位置的前一个节点
int j=0;
pre = head;
while(pre->next!=NULL && j<i-1){
pre = pre->next;
j++;
}
if(j!=i-1){
printf("插入位置错误");
return 0;
}
p = (LinkList) malloc(sizeof(ListNode));
p->data = e;
p->next = pre->next;
pre->next = p;
return 1;
}
// 删除操作
int deleteList(LinkList head,int i,int e)
{
LinkList p ,pre;
int j=0;
pre = head;
while(pre->next!=NULL&&pre->next->next!=NULL&&j<i-1)
{
pre= pre->next;
j++;
}
if(j!=i-1){
printf("删除位置错误");
return 0;
}
p = pre->next;
e = p->data;
pre->next=p->next;
free(p);
return 1;
}
// 求表长度
int ListLength(LinkList head)
{
LinkList p;
int counter=0;
p = head;
while(p!=NULL)
{
p=p->next;
counter++;
}
return counter;
}
// 销毁链表
void destoryList(LinkList head)
{
LinkList p,q;
p=head;
while(p!=NULL)
{
q=p;
p=p->next;
free(q);
}
}
#endif // LINKLIST_H_INCLUDED
这里面一开始不理解为什么 initList 的时候传的是 A 的地址,而后面的 insertList之类的操作传的就是 A,特地还去问了下:

后面也明白了,一开始 main 里面声明 linkList A的时候,还只是一个指针变量,里面没有存任何东西,后面再 initList 的时候如果不传入 A的地址,那么,由于c语言是 按值 传的,即使在函数里面改变了值,外面的A还是没有改变,这样 A 还是什么都没有存。如果传递了 A的地址,函数里面通过 malloc函数分配内存空间给 head,由于传递的是 A的地址,A这时候就存了一个地址了。而后面的插入操作,直接把A传给函数,就是把 A 结构体首地址传给函数的形参,然后形参是一个指针,他通过链表的首地址来找到结构体,进行插入操作后面,改变了A这个地址所指向的结构体的后续节点,形成链表。
后面的 ListLength 函数传入的是 A,也就是链表的首地址,这样,函数的形参也是地址,它就能通过首地址找到后面的一系列几点,获取长度。
所以后面 A 的值一直都是 首地址,没有改变
参考:
类似于树的层次遍历,必须借助一个队列来记忆正在访问的顶点的下一层代码
当各边权值相等时可以解决单源最短路径问题
bool visited[MAX_VERTEX_NUM]; // 访问标记数组
void BFSTraverse(Graph G){
// 对图进行广度优先遍历,设访问函数为 visit()
for (i = 0; i < G.vexnum; ++i){
visited[i] = false; //访问标记数组
}
InitQueue(Q); // 初始化辅助队列
for (i = 0; i < G.vexnum; ++i){
if (!visited[i]) // 对每个连通分量进行一次 BFS
BFS(G, i);
}
}
void BFS(Graph G, int v){
visit(v); // 访问初始顶点
visited[v] = true;
Enqueue(Q, v); // 顶点 v 入队列
while (!isEmpty(Q)){
Dequeue(Q, v); // 顶点 v 出队列
for (w = FirstNeighbor(G, v); w > = 0; w = NextNeighbor(G, v, w)){
if (!visited[w]){ // w 为没有被访问的 v 的邻接顶点
visit(w);
visited[w] = true;
Enqueue(Q, w) // 顶点 w 入列
}// if
}// for
}// while
}由于他要借助一个辅助队列 Q,所以他的空间复杂度为 O(|V|) ,其中 V 为顶点个数
如果采用 邻接表 存储,则时间复杂度为 O(|E|),总的为 O(|V| + |E|)
如果采用 邻接矩阵存储,总的复杂度为 O( |V| * |V|)
bool visited[MAX_VERTEX_NUM]; // 访问标记数组
void DFSTraverse(Graph G){
// 对图进行深度优先遍历,设访问函数为 visit()
for (i = 0; i < G.vexnum; ++i){
visited[i] = false; //访问标记数组
}
for (i = 0; i < G.vexnum; ++i){
if (!visited[i]) // 对每个连通分量进行一次 DFS
DFS(G, i);
}
}
void DFS(Graph G, int v){
// 使用递归
visit(v); // 访问初始顶点
visited[i] = true
for (w = FirstNeighbor(G, v); w > = 0; w = NextNeighbor(G, v, w)){
if (!visited[w]){ // w 为没有被访问的 v 的邻接顶点
DFS(G,w)
}// if
}// for
}由于他要借助一个递归栈,所以他的空间复杂度为 O(|V|) ,其中 V 为顶点个数
如果采用 邻接表 存储,则时间复杂度为 O(|E|),总的为 O(|V| + |E|)
如果采用 邻接矩阵存储,总的复杂度为 O( |V| * |V|)

基数排序是桶排序的一种,可分为最低位优先(LSD)和最高位优先(MSD),时间复杂度为
O (nlog(r)m),其中 r 为所采取的基数,而 m 为堆数,下面介绍的是 LSD
过程如下:
js 代码:
var ary = [18, 225, 412, 2, 11, 34, 69, 3]
var radixSort = (ary, maxDigit) => {
let dev = 1,
len = ary.length,
counter = []
for (let i = 0; i < maxDigit; i++ , dev *= 10) {
for (let j = 0; j < len; j++) {
let bucket = parseInt(ary[j] / dev) % 10 // 获取每个桶的索引
if (!counter[bucket])
counter[bucket] = []
counter[bucket].push(ary[j])
}
let pos = 0
for (let j = 0, l = counter.length; j < l; j++) { // 对每个桶进行处理,从而对数组进行从新排序
let val = null;
if (counter[j]) {
while (val = counter[j].shift()) {
ary[pos++] = val
}
}
}
}
return ary
}
radixSort(ary, 3) // [ 2, 3, 11, 18, 34, 69, 225, 412 ]c语言:
#include <stdio.h>
#include <stdlib.h>
#define LEN 7
int get_index(int num,int dec,int order);
void redixSort(int ary[],int dec,int order);
/**
* @param num : 输入的数字
* @param dec : 输入数字的位数
* @param order : 指定要获取的数字的哪一位
*/
int get_index(int num,int dec,int order)
{
int i ,j, n;
int index;
int div;
// 根据位数循环减去不需要的高位数
for(i=dec;i>order-1;i--)
{
n=1;
for(j=0;j<dec-1;j++)
n*=10;
div = num/n;
num-=div * n;
dec--;
}
return div;
}
void redixSort(int ary[],int dec,int order)
{
int i,j;
int index; // 要排序的索引值
int tmp[LEN]={0}; // 临时数组,保存等待排序的中间结果
int num[10] = {0}; // 保存索引值的数组
for(i=0;i<LEN;i++)
{
index = get_index(ary[i],dec,order); // 获取索引值
num[index]++; // 对应位加一
}
for(i=1;i<10;i++)
num[i] += num[i-1]; // 调整索引数组
for(i=LEN-1;i>=0;i--)
{
index = get_index(ary[i],dec,order);
j =--num[index]; // 根据索引来计算该数字在按位排序之后在数组中的位置
tmp[j] = ary[i]; // 数字放入到临时数组
}
for(i=0;i<LEN;i++)
ary[i] = tmp[i]; // 从临时数组赋值到原数组
for(i=0;i<LEN;i++)
printf("%d ",ary[i]); // 2 3 11 18 34 69 225 412
printf("\n");
}
int main()
{
int array[LEN] = {179,208,306,888,946,55,9};
int i;
for(i=1;i<=3;i++)
redixSort(array,3,i);
}var hasEnumBug = !{ toString: null }.propertyIsEnumerable('toString')
var nonEnumerableProps = ['valueOf', 'isPrototypeOf', 'toString',
'propertyIsEnumerable', 'hasOwnProperty', 'toLocaleString']; // 不能用for... in 遍历的 key 集合
var collectNonEnumProps = function (obj, keys) {
var nonEnumIdx = nonEnumerableProps.length;
var constructor = obj.constructor;
// 对象的原型如果被重写,则 proto 为 Object.prototype
// 反之,则为 obj.constructor.prototype
var proto = _.isFunction(constructor) && constructor.prototype || ObjProto
// 如果obj 有 constructor 这个key
// 并且没有存在数组中,就存入数组
var prop = 'constructor'
if (_.has(obj, prop) && !_.contains(keys, prop)) keys.push(prop)
while (nonEnumIdx--) {
prop = nonEnumerableProps[nonEnumIdx]
// prop 在对象里面,并且与Object原型上的不是同一个引用,且不包含在keys 中
if (prop in obj && obj[prop] !== proto[prop] && !_.contains(keys, prop)) {
keys.push(prop)
}
}
}
// 取出对象的所有属性名
_.allKeys = function (obj) {
if (!_.isObject(obj)) return [] // 不是对象,直接返回空数组
var keys = []
for (var key in obj) keys.push(key)
// 处理 ie < 9 以下的情况
if (hasEnumBug) collectNonEnumProps(obj, keys)
return keys
}上面这段代码中,除了一般的使用 for...in 来取出属性名,后面还有一步判断是否有 可枚举的bug 情况,主要针对,ie<9下,for...in 的问题。不过我在 mdn 上查到 for...in在 ie6 下都支持,所以可能之前编写这个库时 for...in 在ie<9下都不支持

不过阅读这段代码还是能收获不少
首先
var hasEnumBug = !{ toString: null }.propertyIsEnumerable('toString')
在 ie<9 下,{ toString: null }.propertyIsEnumerable('toString') 会返回 false,因此可以用此来判断是否是 ie<9 的浏览器
注:现在ie 下的情况:

var nonEnumerableProps = ['valueOf', 'isPrototypeOf', 'toString', 'propertyIsEnumerable', 'hasOwnProperty', 'toLocaleString'];
这是一些不可枚举的属性,除了 constructor:

var proto = _.isFunction(constructor) && constructor.prototype || ObjProto
这里上面代码里面注释了一些,不过还要说的一点是, _.isFunction(constructor) && constructor.prototype 排除了 对象的 constrcutor 是直接量的问题,并且排除了 var a = {}; a.__proto__ = null 的情况,如果 constrcutor 是上述两种情况 (a.__proto__ = null 时 a.constructor = undefined),则返回 ObjProto 。
后来又想了下,如果 constructor 是函数,那么它 的原型一定存在:

那么后面何必再判断 constructor.prototype 呢?有一点可以肯定的是如果 自己手动将 constructor.prototype = null 的时候这个判断是有效的,其他的确实想不到为什么要这个来判断,如果有谁懂,望告知
接着是 将 constructor 这个属性单独拿出来判断(但是为什么要这么做呢??不能也放入上述数组中??求告知)
其中 _.has() 使用 hasOwnProperty来判断,保证了不包含 原型上的 constructor
最后就是循环判断那6个不可枚举属性
其中 prop in obj很重要,那为啥要加这句呢?
var a = {},
keys = [];
a.__proto__ = null
collectNonEnumProps(a, keys);
// 如果没有 `prop in obj`,那么返回的是 ` keys=['valueOf', 'isPrototypeOf', 'toString', 'propertyIsEnumerable', 'hasOwnProperty', 'toLocaleString']`
// 如果有,keys = []最后,大家尽量少改写原生对象的属性,避免不必要的错误
/**
* 这一部分参考了https://github.com/hanzichi/underscore-analysis/issues/22
* 这里如设置了 leading === false 那么这个函数一开始就不会执行,一直延迟到 wait 时间后再执行
* 1. 立马执行和延迟执行
* 2. 只有立马执行 ->trailing === false
* 3. 只有延迟执行 -> leading === false
*/
_.throttle = function (func, wait, options) {
var timeout, context, args, result;
var previous = 0; // 上一次执行回调的时间戳
if (!options) options = {};
var later = function () {
// 如果 options.leading === false
// 则每次触发回调后将 previous 置为 0,确保 下一次执行的时候,依旧延迟 wait 时间
previous = options.leading === false ? 0 : _.now();
timeout = null;
result = func.apply(context, args);
// 防止 func 里面对 timeout 的修改
if (!timeout) context = args = null;
};
var throttled = function () {
// 记录当前的时间戳
var now = _.now();
// 第一次调用,此时,previous 为0,如果 leading 为 false,就将previous 置为 now ,
// 表示上一次已经执行过了
if (!previous && options.leading === false) previous = now;
var remaining = wait - (now - previous);
context = this;
args = arguments;
// <=0 表示过了指定的 wait 时间,立马执行
// remaining > wait,表示客户端系统时间被调整过
if (remaining <= 0 || remaining > wait) {
if (timeout) { // 解除引用
clearTimeout(timeout);
timeout = null;
}
// 重置时间戳
previous = now;
// 并执行函数
result = func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
// trailing === false 时,这时候,如果window.onscroll 时,只会立马执行一次函数,而不会再有延迟执行
// 在wait 时间间隔里面,如果定时器已经存在,不管你怎么在调用这个函数,仍为上一次的值 并且 trailing !== false
timeout = setTimeout(later, remaining);
}
return result;
};
throttled.cancel = function () {
clearTimeout(timeout);
previous = 0;
timeout = context = args = null;
};
return throttled;
};// immediate:函数一开始就执行还是延迟 wait 后执行
_.debounce = function (func, wait, immediate) {
var timeout, result;
// wait 间隔之后执行的函数
var later = function (context, args) {
timeout = null;
// 这里通过设置 args 是否存在来阻止 func 的再次执行,当 immediate 是真的时候,
if (args) result = func.apply(context, args);
};
var debounced = restArgs(function (args) {
// 如果再次调用,就重置之前的前面的时间
if (timeout) clearTimeout(timeout);
if (immediate) {
// 如果立即触发,则需要 定时器没有设置
// 这里注意,timeout 第一次是 null 后面会变成定时器Id ,
// 以 window.onscroll = _.debounce(log, 1000,true); 为例
// 就是说 func 在此次快速滚动中只会执行一次,后面的不停滚动, timeout 为定时器的 id , 因而 callNow 为 false ,不在执行,直到此次滚动停下后,并且执行定时器函数
var callNow = !timeout;
// 这里虽然又设置了 timeout ,但是在later 中会置为 null ,如果不置为 null ,那么在后面的执行中,不会再执行函数, 并且由于未给 later 传参数,所以 func 不会执行
timeout = setTimeout(later, wait);
if (callNow) result = func.apply(this, args);
} else {
timeout = _.delay(later, wait, this, args);
}
return result;
});
debounced.cancel = function () {
clearTimeout(timeout);
timeout = null;
};
return debounced;
};现在的函数,原型上就有 bind 方法,但是如果我们在不支持该方法的浏览器上,要怎么来实现呢?

简单的bind无非就是使用 call或者apply,然后返回一个函数
要点:是绑定后的函数与被绑定的函数在同一条原型链上
// 1
Function.prototype.bind = function (context) {
let self = this;
return function () {
return self.apply(context, arguments)
}
}
// 2
Function.prototype.bind = function (cxt) {
var args = Array.prototype.slice.call(arguments, 1),
self = this;
return function () {
let innerArgs = Array.prototype.slice.call(arguments)
let finalArgs = args.concat(innerArgs)
return self.apply(cxt, finalArgs)
}
}
// 3
Function.prototype.bind = function (cxt) {
let args = Array.prototype.slice(arguments, 1),
F = function () { },
self = this,
bound = function () {
let innerArgs = Array.prototype.slice.call(arguments),
finalArgs = args.concat(innerArgs)
return self.apply((this instanceof F ? this : cxt), finalArgs)
}
// // 维护原型关系
F.prototype = this.prototype;
bound.prototype = new F();
return bound
}
// 4
Function.prototype.bind = Function.prototype.bind || function (oThis) { // 偏函数
if (typeof this !== "function") {
// closest thing possible to the ECMAScript 5
// internal IsCallable function
throw new TypeError("Function.prototype.bind - what is trying to be bound is not callable");
}
var aArgs = Array.prototype.slice.call(arguments, 1),
fToBind = this,
fNOP = function () { }, //用于原型继承,防止直接引用被修改原型
fBound = function () {
/**
* this instanceof fNOP 为了防止以下的情况,例如 Bloomer 是调用 bind 函数返回的函数的实例
* 和setTimeout一起使用
* 一般情况下setTimeout()的this指向window或global对象。
* 当使用类的方法时需要this指向类实例,就可以使用bind()将this绑定到回调函数来管理实例。
* function Bloomer() {
* this.petalCount = Math.ceil(Math.random() * 12) + 1;
* }
*
* Bloomer.prototype.bloom = function() {
* window.setTimeout(this.declare.bind(this), 1000);
* }
*
* Bloomer.prototype.declare = function() {
* console.log('我有 ' + this.petalCount + ' 朵花瓣!');
* }
*/
return fToBind.apply(this instanceof fNOP // 这里的判断为 true 的情况见下面,这时候的 this 就是 fBound 函数
? this
: oThis || this, // 为false 的情况就是上面所讲的 setTimeout 情况,这时调整 this 指向,没有指定的就直接为 this
aArgs.concat(Array.prototype.slice.call(arguments)));
};
fNOP.prototype = this.prototype;
fBound.prototype = new fNOP();
return fBound;
}
function Point(x, y) {
this.x = x;
this.y = y;
}
Point.prototype.toString = function () {
return this.x + ',' + this.y;
};
var p = new Point(1, 2);
p.toString(); // '1,2'
var emptyObj = {};
var YAxisPoint = Point.bind(emptyObj, 0 /*x*/ );
YAxisPoint.prototype.aaa = 66666666
console.log(YAxisPoint.prototype)
console.log(Point.prototype)
// this instanceof fNOP
var YAxisPoint = Point.bind(null, 0/*x*/);
var axisPoint = new YAxisPoint(5);
axisPoint.toString(); // '0,5'
axisPoint instanceof Point; // true
axisPoint instanceof YAxisPoint; // true 
那么underscore 里面是怎么实现的呢?
// 决定一个函数是作为构造函数还是接受参数的普通函数
var executeBound = function (sourceFunc, boundFunc, context, callingContext, args) {
// 这里的和上文的 this instanceof fNOP == false 一样
if (!(callingContext instanceof boundFunc)) return sourceFunc.apply(context, args)
// 下面的几步骤,基本和 new 一个构造函数的过程一样,详见如下:
// https://github.com/jyzwf/blog/issues/27
// 获取继承sourceFun原型的一个对象
var self = baseCreate(sourceFunc.prototype) // 类似上文的 fNOP
// 执行构造函数,并将里面的 this 指向 self ,返回结果
var result = sourceFunc.apply(self, args)
// 如果 返回的结果是一个对象,就直接返回该对象
if (_.isObject(result)) return result
// 否则返回之前 new 出来的对象
return self
}
_.bind = restArgs(function (func, context, args) {
/**
* startIndex = 2
* 返回如下函数
* function () {
var length = Math.max(arguments.length - startIndex, 0), // 防止startIndex 过大
rest = Array(length),
index = 0;
for (; index < length; index++) { // 将从startIndex开始的后面参数放入数组
rest[index] = arguments[index + startIndex] // 从args 开始收集参数
}
switch (startIndex) {
case 0:
return func.call(this, rest);
case 1:
return func.call(this, arguments[0], rest);
// 在_.invoke()使用
case 2: // 调用这个 case
return func.call(this, arguments[0], arguments[1], rest);
}
}
*/
if (!_.isFunction(func)) throw new TypeError('Bind must be called on a function')
var bound = restArgs(function (callArgs) { // 收集剩余函数
/**
* startIndex = 0
*
* function () {
var length = Math.max(arguments.length - startIndex, 0), // 防止startIndex 过大
rest = Array(length),
index = 0;
for (; index < length; index++) { // 将从startIndex开始的后面参数放入数组
rest[index] = arguments[index + startIndex] // 从args 开始收集参数
}
switch (startIndex) {
case 0: // 调用这个 case
return func.call(this, rest);
case 1:
return func.call(this, arguments[0], rest);
// 在_.invoke()使用
case 2:
return func.call(this, arguments[0], arguments[1], rest);
}
}
*/
return executeBound(func, bound, context, this, args.concat(callArgs))
})
return bound
})这里我们看到出现了两个 restArgs函数,这个函数在 underscore里面很重要,我们看看他长什么样 ?
// 类似es6的剩余参数集合
var restArgs = function (func, startIndex) {
startIndex = startIndex == null ? func.length - 1 : +startIndex
return function () {
var length = Math.max(arguments.length - startIndex, 0), // 防止startIndex 过大
rest = Array(length),
index = 0;
for (; index < length; index++) { // 将从startIndex开始的后面参数放入数组
rest[index] = arguments[index + startIndex]
}
// switch 干嘛的?????????????
switch (startIndex) {
case 0:
return func.call(this, rest);
case 1:
return func.call(this, arguments[0], rest);
// 在_.invoke()使用
case 2:
return func.call(this, arguments[0], arguments[1], rest);
}
// 收集startIndex 之前的参数,并将 startIndex 开始的后面的参数包装为一个数组使用
var args = Array(startIndex + 1);
for (index = 0; index < startIndex; index++) {
args[index] = arguments[index]
}
// 将args的最后一个参数设置为之前的 rest
args[startIndex] = rest;
return func.apply(this, args)
}
}洗牌算法可以将一组数据变得随机无序,具体的过程如下:

时间复杂度是 O(n)
注:Math.random() 函数返回一个浮点, 伪随机数在范围
[0,1)
js 的实现:
var shuffle = function (array) {
let length = array.length,
randomIdx,
tempVal;
for (var i = length - 1; i >= 0; i--) {
randomIdx = Math.floor(Math.random() * (i + 1));
tempVal = array[randomIdx]
array[randomIdx] = array[i]
array[i] = tempVal
}
length = randomIdx = tempVal = null
return array
}
shuffle([1,2,3,4,5,6,7,8]) // [4, 1, 2, 7, 8, 3, 6, 5]
shuffle([1,2,3,4,5,6,7,8]) // [8, 3, 7, 2, 5, 1, 6, 4]译文自:Composing Software: An Introduction
在我高中的编程课上,我就被告知:
编程是将复杂的问题化简为一个个小问题,并将各个小问题的解决方法组合成这个复杂问题的完整解决方案的行为
我生命中最大的遗憾之一就是没有过早的领会那节课的意义。我学会软件设计的本质的时候太晚了。
我采访了很多开发者,我发现并不是只有我一个人有这种想法,几乎或者很少有软件开发者能很好的掌握软件开发的本质。他们没有意识到我们开发中的最重要的工具,或者说怎么把它们使用的更好。他们所有人都在努力回答下面的一个或者两个问题:
问题是你不能避免在开发中使用组合,只是你还没有意识到。你使用了复合--但是你使用的很差。你写了很多有 bug 的代码,并且让其他开发者难以理解。这是一个巨大的问题。这个代价是十分昂贵的。我们花了很多时间来维护代码而不是重写它,另外我们的 bug 正在影响着世界上成千上万的人。
软件充斥着我们世界的每一处,每一辆车都是一台迷你超级计算机,软件设计上的问题会导致真正的交通事故并且夺去人的生命。
黑客和政府利用漏洞来窥探人们,窃取信用卡,进行DDoS攻击,破解密码,甚至是操纵选举结果
所以我们必须做的更好
如果你是一个开发者,你每天将函数和数据结构组合在一起,不管你有没有注意到。你可以有意识的(或者更好)地做到这一点,或者你可以不经意地做到它。
软件开发过程是将大的问题分解成小的,建立组件来解决这些小问题,然后将这些组件复合起来来形成最后的完整应用
复合函数是将一个函数应用于另一个函数输出的过程。在代数中,给出两个函数,f 和 g,(f ∘ g)(x) = f(g(x))。中间的圆圈是复合操作符。
很多时候你这样写代码,你正在复合函数:
const g = n => n+1;
const f = n =>n * 2;
const doStuff = x => {
const afterG = g(x);
const afterF = f(afterG);
return afterF;
};
doStuff(20); // 42每次你写一个 Promise ,你也是在使用复合函数:
const g = n => n + 1;
const f = n => n * 2;
const wait = time => new Promise(
(resolve, reject) => setTimeout(
resolve,
time
)
);
wait(300)
.then(() => 20)
.then(g)
.then(f)
.then(value => console.log(value)) // 42
;同样,每当你组复合函数的时候,都会连接数组方法调用,lodash 方法,observables(RxJS 等)。如果你正在连接,那么你就是在复合操作。如果你将一个返回值传递给另一个函数,你也是在复合操作。如果你在一个序列中调用两种方法,则使用 this 作为输入数据。
If you’re chaining, you’re composing.
当你有意复合函数的时候,你将做的更好
复合的组合函数,我们能将上面的 doStuff() 函数变成简单的一行
const g = n => n + 1;
const f = n => n * 2;
const doStuffBetter = x => f ( g (x) )
doStuffBetter( 20 ); // 42但是,对于反对这种形式的一个共同点是,它难以调试。例如,我们要怎样使用函数组合来写下面的代码
const doStuff = x => {
const afterG = g(x);
console.log(`after g: ${ afterG }`);
const afterF = f(afterG);
console.log(`after f: ${ afterF }`);
return afterF;
};
doStuff(20); // =>
/*
"after g: 21"
"after f: 42"
*/首先,让我们抽象出 after f , after g 到一个名为 trace() 函数中
const trace = label => value =>{
console.log(`${ label }: ${ value }`);
return value;
};现在我们可以这样使用了:
const doStuff = x => {
const afterG = g(x);
trace('after g')(afterG);
const afterF = f(afterG);
trace('after f')(afterF);
return afterF;
};
doStuff(20); // =>
/*
"after g: 21"
"after f: 42"
*/当下受欢迎的函数式编程库,例如:Lodash 和 Ramda ,可以让函数复合更加容易。你可以重写上面代码:
import pipe from 'lodash/fp/flow';
const doStuffBetter = pipe(
g,
trace('after g'),
f,
trace('after f')
);
doStuffBetter(20); // =>
/*
"after g: 21"
"after f: 42"
*/如果你不想引入其他库,可以自己定义 pipe()
// pipe(...fns: [...Function]) => x => y
const pipe = (...fns) => x => fns.reduce((y, f) => f(y), x);如果你没有理解他是怎么工作的,不要担心。后面我们将详细的探讨复合函数。事实上,它是很重要的,
你将在本文中看见它定义和演示多次。关键是帮助你更加熟悉它的定义和让你更加自如地使用。成为使用复合的开发者。
pipe() 创建了一个函数管道,将一个函数的输出作为另一个函数的输入。当你使用 pipe() 时 ( 或者它的孪生兄弟 compose() ),你不需要中间变量,写函数时没有提及到参数的函数成为 point-free style。做到它,你将调用一个能返回一个新函数的函数,而不是显式声明这个函数。这意味着,你不在需要 function 关键字或者 箭头函数。
Point-free style 可以举例很多,这里只是一点点,它是不错的,因为这些中间变量增加了函数不必要的复杂性
减少复杂性的好处有:
平均每个人的大脑在 工作记忆 中只有少量的共享资源用于离散量子,并且每个变量都在潜在地消耗这些量子。如果你增加更多的变量,我们准确回忆这些变量的意思的能力就会减弱。工作记忆模型通常涉及4-7个离散量子。超过这些数量,错误率将会显著增加。
使用管道形式,我们消除了3个变量 ——释放了我们可用的工作记忆的几乎一半用于其他工作。这显着降低了我们的认知负荷。软件开发者往往比普通人更好地将数据分组到工作记忆中,但不是削弱保护的重要性(wtf??)
简洁的代码提高了代码的信噪比。这就好比你听收音机——当你的收音机没有调到合适的频道,你就会感觉到很多杂音干扰,以至于很难清晰的听到音乐。当你调节到合适的频道,杂音没了,你获得了更强的音乐信号。
代码同样如此。更加简洁的表达能增强理解能力。一些代码给我们有用的信息,但一些代码只是占用空间。如果你能减少使用的代码量,而不减少要表达的意思,你将使代码更加容易解析和理解,对于其他阅读你的代码的人来说。
对比前后的代码,它们看起来就像是一个是减肥前,一个是减肥后,哈哈。这是很重要的,因为额外的代码意味着额外的隐藏的 bugs 。
Less code = less surface area for bugs = fewer bugs.
“赞成对象复合而不是类继承” the Gang of Four, “Design Patterns: Elements of Reusable Object Oriented Software”
“In computer science, a composite data type or compound data type is any data type which can be constructed in a program using the programming language’s primitive data types and other composite types. […] The act of constructing a composite type is known as composition.” ~ Wikipedia
原始的:
const firstName = 'Claude';
const lastName = 'Debussy';复合形式:
const fullName = {
firstName,
lastName
};同样,所有数组、Sets、 Maps、 WeakMaps、TypedArrays 等都是复合数据类型。任何时候,你在构建任何非原始数据结构,您正在执行某种对象组合。
Gang of Four 定义了一种设计模式叫 复合模式 ,这是一种将容器组件的每个独立的子组件复合在一起的模式。一些开发者会迷惑,认为 复合模式 只是对象组合的一种形式。不要感到迷惑!
类继承可以用于构造复合对象,但是这是一种有限制和脆弱的方法。当 Gang of Four 表示 赞成对象复合而不是类继承 时,他们建议你使用灵活的方法来复合构建对象,而不是强制类型继承的方法。
Gang of Four 同样也定义了其他的复合设计模式,包括 飞行模式(flyweight pattern),委托模式(the delegate pattern), 聚合模式(the aggregate pattern )等
我们将使用更一般的对象复合定义 “Categorical Methods in Computer Science: With Aspects from Topology”
复合对象通过将对象放在一起的形式,使得后者是前者的一部分
类继承只是对象复合结构形式之一。所有的类产生复合对象,但是并不是所有的复合对象通过类或者类继承来产生。赞成对象复合而不是类继承 意味着你应该从小的组件来构建复合对象,而不是在类的层次结构中从祖先对象继承所有的属性。后者将造成很多著名的问题在面向对象设计中:
紧耦合问题:因为子类依赖父类的实现,类继承是面向对象设计中最紧密的耦合。
脆弱的基类问题:因为紧耦合,改变基类会潜在破坏大量的子孙类——在第三方管理的代码中。作者可能会破坏他们不知道的代码
不灵活的层次问题:With single ancestor taxonomies, given enough time and evolution, all class taxonomies are eventually wrong for new use-cases.
重复的必要性问题:因为不灵活的层次结构,新的用例往往通过复制来实现,而不是扩展,导致类似的类不同。Once duplication sets in, it’s not obvious which class new classes should descend from, or why.
大猩猩 / 香蕉问题:面向对象语言的问题是他们拥有所有这些隐含的环境。你想要一个香蕉,但是你获得的确实一个拿着香蕉的大猩猩以及整个丛林 ~ Joe Armstrong “Coders at Work”
最常见的对象复合形式是所谓的混合复合。它工作得像冰淇淋。你从一个对象开始,然后在其中添加你想要的属性。
通过类继承:
class Foo {
constructor () {
this.a = 'a'
}
}
class Bar extends Foo {
constructor (options) {
super(options);
this.b = 'b'
}
}
const myBar = new Bar(); // {a: 'a', b: 'b'}通过混合模式:
const a = {
a: 'a'
};
const b = {
b: 'b'
};
const c = {...a, ...b}; // {a: 'a', b: 'b'}你将更加深层次的发现对象复合的其他形式。现在,你的理解应该是:
这不是 函数式编程 与 面向对象编程的 较量,或者一种语言对于另一种语言。组件可以采取函数、数据结构、类等形式。不同的编程语言为组件提供不同的原子元素。Java 提供类,Haskell 提供 函数等。不管你支持哪种语言或范例,你都不能逃避函数组合和数据结构。
The essence of software development is composition.
给定一个数组和一个目标值,求数组中的两个值相加等于目标值,假定目标值在数组中只有一种组合方式,求出这两个值的下标
一开始我自然而然想到通过双重 for 循环,后来又去找了其他算法,下面这种通过hash的方法让我眼前一亮,下面显示两种算法:
// 普通 双重 for 循环
var twoSum = function (nums, target) {
for (let i = 0, len = nums.length; i < len; i++) {
for (let j = i + 1; j < len; j++) {
if (nums[i] + nums[j] === target) {
return [i, j]
}
}
}
};
// hash 方法的算法
var twoSum = function (nums, target) {
var len = nums.length;
var hash = {};
var i = 0;
do {
var a = nums[i];
var j = hash[a];
if (j !== undefined) {
return [j, i];
} else {
hash[target - a] = i;
}
} while (++i < len);
};第二种方法先将数组的值 a 与 target 的差值存在一个对象中,而这个值就是 a 的下标,这样就建立了两个和值之间的联系,后面通过遍历数组,看看hash对象中是否有这个键值,有就是找到了这两个和值。时间复杂度 O(n)
之前讲了单链表,双向循环链表,链表的每个结点中较单链表多一个指针域。所以总共有两个指针域,一个指向直接后继,一个指向直接前趋,还有一个数据域。链表的最后一个结点的右指针指向第一个结点,头节点的左指针指向最后一个结点。
链表的基本操作有:

#include <stdio.h>
#include <stdlib.h>
#include "DuLinkList.h"
int main()
{
DuLinkList h;
int n,pos;
char e;
initDuList(&h);
printf("输入元素的个数: ");
scanf("%d",&n);
getchar();
createDuList(h,n);
printf("链表中的元素: ");
printDuList(h);
printf("\n");
printf("请输入插入的元素和位置:");
scanf("%c",&e);
getchar();
scanf("%d",&pos);
insertDuList(h,pos,e);
printf("插入新元素后的链表中的元素: ");
printDuList(h);
return 0;
}#ifndef DULINKLIST_H_INCLUDED
#define DULINKLIST_H_INCLUDED
struct Node
{
char data;
struct Node *left;
struct Node *right;
};
typedef struct Node DuListNode,*DuLinkList;
// 初始化双向循环列表
int initDuList(DuLinkList *head)
{
*head = (DuLinkList)malloc(sizeof(DuListNode)); // 分配存储空间
(*head)->right = *head;
(*head)->left = *head;
return 1;
}
// 创建双向循环列表
int createDuList(DuLinkList head,int n)
{
DuListNode *p,*q; // q指向最后一个结点
int i;
char e;
q = head;
for(i=1;i<=n;i++)
{
printf("输入第%d个结点的值:",i);
e = getchar();
p = (DuLinkList)malloc(sizeof(DuListNode));
p->data = e;
p->right = q->right;
q->right = p;
p->left = q;
head->left = p;
q=p;
getchar();
}
return 1;
}
void printDuList(DuLinkList head) // 输出双向循环链表的每一个结点
{
DuListNode *p;
p=head->right;
while(p!=head)
{
printf("%c ",p->data);
p=p->right;
}
printf("\n");
}
DuLinkList getEle(DuLinkList head,int i) // 查找插入的位置,返回结点的指针,否则返回NULL
{
DuLinkList p;
int j=1;
p=head->right;
while(p!=head && j<i){
p=p->right;
j++;
}
if(p==head || j>i){
return NULL;
}
return p;
}
int insertDuList(DuLinkList head,int i,char e) // 在双向循环链表的第i个位置插入元素 e
{
DuLinkList p,s;
p = getEle(head,i);
if(!p){
return -1;
}
s = (DuLinkList) malloc(sizeof(DuListNode));
s->data = e;
s->left = p->left;
p->left->right = s;
s->right = p;
p->left = s;
return 1;
}
#endif // DULINKLIST_H_INCLUDED
要点如下:
时间复杂度为:O(n*n)
js得实现:
let ary = [8, 5, -3, 12, 2, 4, -6, 1, -3]
let swap = (ary, i1, i2) => {
let temp
temp = ary[i2]
ary[i2] = ary[i1]
ary[i1] = temp
}
let selectionSort = (ary) => {
let len = ary.length,
i = 0,
j,
min
while (i < len - 1) {
min = i
for (j = i + 1; j < len; j++) {
if (ary[min] > ary[j]) {
min = j
}
}
swap(ary, i, min)
i++
}
return ary
}
selectionSort(ary)c得实现:
#include <stdio.h>
#include <stdlib.h>
void SelectSort(int *a,int n)
{
int i,j,t;
int min;
for(i=0;i<n-1;i++)
{
min = i;
for(j=i+1;j<n;j++)
{
if(a[min]>a[j])
min = j;
}
t = a[i];
a[i] = a[min];
a[min] = t;
}
}
void SelectSort(int *a,int n);
int main()
{
int a[9] = {8, 5, -3, 12, 2, 4, -6, 1, -3},i;
SelectSort(a,9);
for(i=0;i<9;i++)
{
printf("%d ",a[i]);
}
}与 冒泡排序得比较:
简单选择排序和冒泡排序很相似,他们得排序次数是一样的,不过冒泡排序每一趟排序中,每比较一组数据就进行交换一次,而简单选择排序则一趟排序中先暂存 最小值得编号,最后来一次交换,所以每趟只有一次交换
先将待排序表分割成若干个形如 L [i, i + d, i + 2d,...,i + kd] 的 特殊 子表,分别进行直接插入排序,当整个表中元素已经呈 基本有序 时,再对全体记录进行一次直接的插入排序
d1 = 元素个数的一半var shellSort = ary => {
var l = ary.length,
dk = l / 2,
i, j, temp;
for (; dk >= 1; dk = dk / 2) { // 定步长
for (i = dk; i < l; i++) { //对步长之后的元素进行比较
if (ary[i] < ary[i - dk]) {
temp = ary[i]
for (j = i - dk; j >= 0 && ary[j] > temp; j -= dk) { // 直接插入排序
ary[j + dk] = ary[j]
}
ary[j + dk] = temp
}
}
}
}
var ary = [8, 5, 12, 2, 4, -6, 1, -3]
shellSort(ary)
console.log(ary) // [-6, -3, 1, 2, 4, 5, 8, 12]var ary = [50, 30, 60, 15, 20, 70]
var createSearchSortTree = (ary) => {
let l = ary.length,
Rootobj = {},
i = 0;
var SearchSortTree = (ary, obj) => {
if (!obj.data) {
obj.data = ary[i];
if (++i < l) {
SearchSortTree(ary, Rootobj)
}
} else if (obj.data < ary[i]) {
obj.rchild ? obj.rchild : obj.rchild = {}
SearchSortTree(ary, obj.rchild)
} else if (obj.data > ary[i]) {
obj.lchild ? obj.lchild : obj.lchild = {}
SearchSortTree(ary, obj.lchild)
}
}
SearchSortTree(ary, Rootobj)
return Rootobj
}
var result = createSearchSortTree(ary)
var searchSortTreeArray = obj => {
var ary = []
var sortProcess = (obj) => {
if (obj) {
sortProcess(obj.lchild)
ary.push(obj.data)
sortProcess(obj.rchild)
}
}
sortProcess(obj)
return ary
}
console.log(searchSortTreeArray(result)) // [ 15, 20, 30, 50, 60, 70 ]

浅显的记录下 指令系统 的一些知识点
指令系统是计算机硬件的语言系统,也叫机器语言,指计算机所具有的全部指令集合,是软硬件的主要界面,反映了计算机所拥有的基本功能
指令通常包括操作码和地址码字段,还可以包括寻址方式(后面会讲)
操作码:支指出指令中该指令应该执行什么性质的操作和具有何种操作
地址码:给出被操作的信息的地址或操作数本身,可以有多个地址码
指令字长取决于操作码的长度、操作数地址码的长度和操作数地址的个数,因为主存一般按字节编址,所以指令字长多为字节的整数倍
| OP |
|---|
该指令有两种情况:
堆栈计算机 中,参与操作的两个操作数直接隐含的从栈顶和次栈顶弹出参与计算冒泡排序是常见的一种排序,,过程很easy,首先将第一个元素与第二个元素相比较,如果第一个大于第二个,则交换两个数的位置,然后比较第二个和第三个元素的大小,以此类推,直到第 n-1 个元素与第 n 个元素比较。这样就完成了一次排序,这时候最大的元素值就被排到了最后。这只是第一趟排序,所以接下来要对前 n-1个元素进行和上面一样的操作。
通常 第 i 趟排序 是从第 1 个元素到 第n-i+1 个元素之间比较排序
下面是 js 的两种实现:
let ary = [8, 5, 12, 2, 4, -6, 1, -3]
let swap = (ary, i1, i2) => {
let temp
temp = ary[i2]
ary[i2] = ary[i1]
ary[i1] = temp
}
let bubbleSort1 = (ary) => {
let i = 1,
len = ary.length;
while (i < len) {
for (let j = 0; j < len - i; j++) {
if (ary[j] > ary[j + 1]) {
swap(ary, j, j + 1)
}
}
i++
}
return ary
}
let bubbleSort2 = (ary) => {
let l = ary.length,
temp;
while (l > 1) {
for (let j = 0; j < l - 1; j++) {
if (ary[j] > ary[j + 1]) {
swap(ary, j, j + 1)
}
}
l--
}
return ary
}
bubbleSort1(ary) // [ -6, -3, 1, 2, 4, 5, 8, 12 ]
bubbleSort2(ary) // [ -6, -3, 1, 2, 4, 5, 8, 12 ]c的实现
#include <stdio.h>
#include <stdlib.h>
void swap(int *a,int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
int main()
{
void swap(int *a,int *b);
int ary[8] = {8, 5, 12, 2, 4, -6, 1, -3};
int i=8,j;
while(i>1)
{
for(j=0;j<i-1;j++)
{
if(ary[j]>ary[j+1])
{
swap(&ary[j],&ary[j+1]);
}
}
i--;
}
for(i=0;i<8;i++)
{
printf("%d ",ary[i]);
}
return 0;
};冒泡排序的最坏情况的时间复杂度是 O(n²)
1) 找出算法中的基本语句
算法中执行次数最多的那条语句就是基本语句,通常是最内层循环的循环体
2)计算基本语句的执行次数的数量级
只需计算基本语句执行次数的数量级,这就意味着只要保证基本语句执行次数的函数中的最高次幂正确即可,可以忽略所有低次幂和最高次幂的系数。这样能够简化算法分析,并且使注意力集中在最重要的一点上:增长率
3)用大Ο记号表示算法的时间性能
将基本语句执行次数的数量级放入大Ο记号中
如果算法中包含嵌套的循环,则基本语句通常是最内层的循环体,如果算法中包含并列的循环,则将并列循环的时间复杂度相加
当我们在浏览器输入URL按回车或者点击一个链接的时候发生了啥?
以访问 http://jyzwf.github.io/page/index.html 为例:
DNS 请求解析 jyzwf.github.io/的 IP地址TCP 连接(默认端口号 80,三次握手 )四次挥手)关于为什么是三次握手而不是两次或者其他,可以参考知乎上的回答:
TCP 为什么是三次握手,为什么不是两次或四次?
下面摘取一个不错的回答
三次握手:
“喂,你听得到吗?”
“我听得到呀,你听得到我吗?”
“我能听到你,今天balabala……”
两次握手:
“喂,你听得到吗?”
“我听得到呀”
“喂喂,你听得到吗?”
“草,我听得到呀!!!!”
“你TM能不能听到我讲话啊!!喂!”
“……”
四次握手:
“喂,你听得到吗?”
“我听得到呀,你听得到我吗?”
“我能听到你,你能听到我吗?”
“……不想跟**说话”



A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.



