This is the project I carried out during the seven-week Insight Data Engineering Fellows Program which helps recent grads and experienced software engineers learn the latest open source technologies by building a data platform to handle large, real-time datasets.
RedditR is a real time content engagement platform that helps maximize your content engagement on reddit. The platform gives you real time trend tracking so you never miss out on anything. You can find the app at <a href="http://www.redditr.space> www.redditr.space
The Functional motivation for this project was to create a real-time trending feature
very similar to the one you can find on twitter. With so much interactions happening on reddit, it may be useful for a user
to be able to gauge traction received on a subreddit.
With so much information out there, it may also be overwhelming for users to navigate across reddit to find the
contents they like and for this particular reason, i've built in some
features in the app namely "Engagement" and "Snapshot" that lets users track historical stats about a particular subreddit
with dynamic recommendations of subreddits they may like.
The Engineering movitation behind building such a product is to demonstrate the ability to create a scalable real-time big data
pipleline using open source technologies.
 Thanks to /r/Stuck_In_the_Matrix for providing the historical dataset from October 2007- December 2015 for this project. The entire repo is here. The data is a monthly dump that is in the bz2 file format. The file dump was then downloaded to s3 bucket on Amazon AWS and uncompressed using a
Thanks to /r/Stuck_In_the_Matrix for providing the historical dataset from October 2007- December 2015 for this project. The entire repo is here. The data is a monthly dump that is in the bz2 file format. The file dump was then downloaded to s3 bucket on Amazon AWS and uncompressed using a wget request in python. ( This was automated using a bash script)
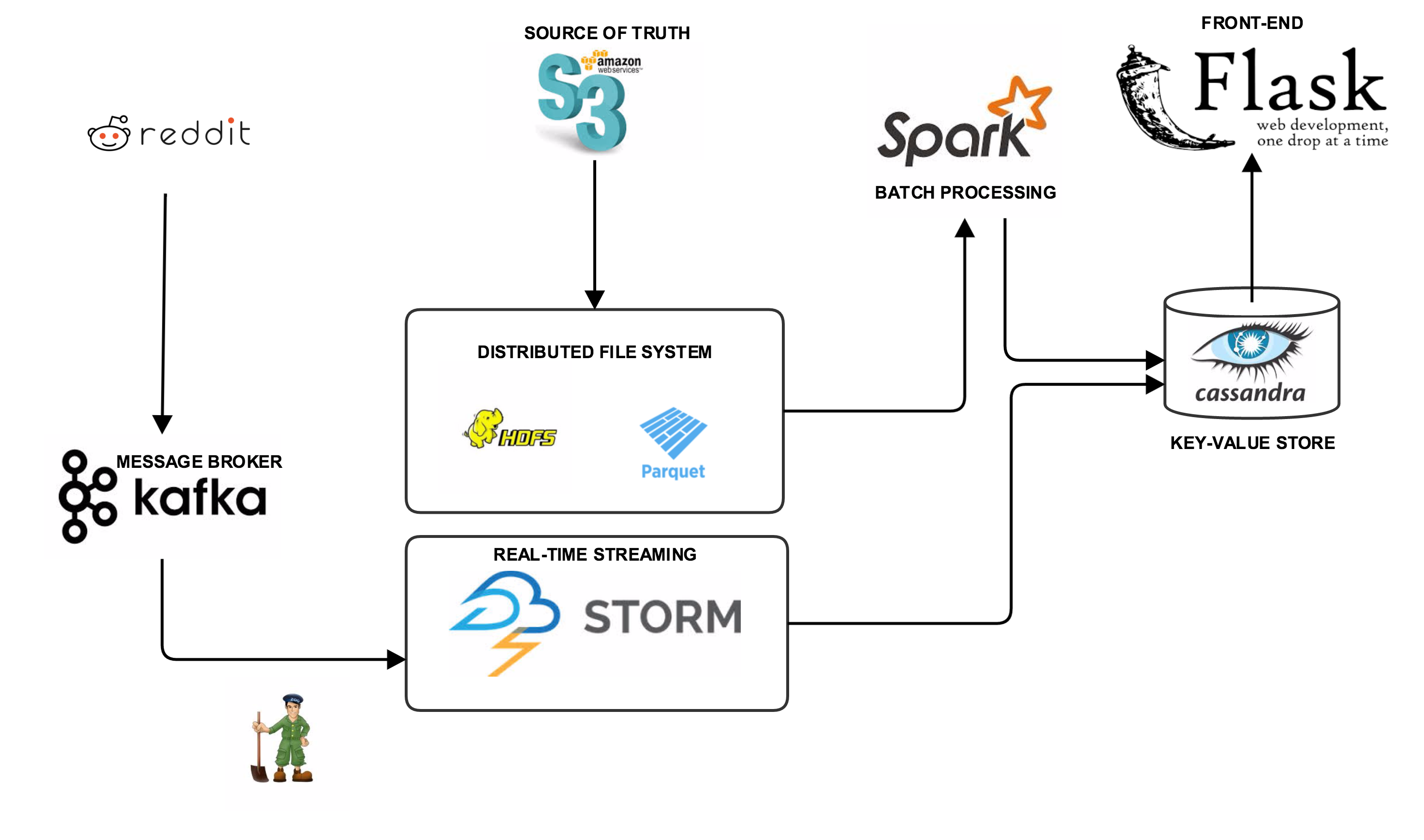
In Order to ensure fast processing on Spark, the file from s3 was processed and compressed into Parquet. Parquet is a columnar store that helps us store the data(JSONs) with its schema on HDFS there by leveraging the fault tolerance and distributed nature of the Hadoop Distributed File System. The original dataset, roughly about 1084.5 GB when compressed into Parquet was a mere 187.8 GB which gave us a lot of space savings with queries running 3x faster on Spark as compared to text data. Checkout the Ingest folder for implementation details.
Spark is used for Batch Processing. Check out the Batch folder for implementation and code in python. The feature implemented is called "Flashback" that lets user input their username and the system shows the first ever post of that particular user. There is also support to download all the posts of a user as a json file which may then be used to carry out user profiling. The next feature implemeted in pyspark was the recommendation and user interaction which can be found in the SimpleGraph folder. The idea is to connect users who have interacted with each other by a directed graph and grouping them by the subreddits. Once this is done, we then compute the indegree and outdegree of everynode in the clusters of subreddits. This gives us an idea as so to who the most influential and active users in a particular subreddits are. This helps us maximize content engagement as it would make more sense to interact often with these influential users to elicit maximum viewability and interaction on your posts. The recommendation is implemented by looking up at the subreddits that the influential users of a subreddit of your liking are active on and then suggesting these subreddits as recommendations. Recommendation folder contains implementation of a collaborative filter algorithm (ALS) in python. This was done to validate the user graph approach that I came up with. The results were very intuitive and promising. The user graph model also scored much higher in terms of compute time as it took 4.6 mins for computing recommendations as compared to the ALS approach with 20 iterations which took approximately 13 hours
Real time processing was done using Storm and Kafka was used as the publish-subscribe broker. Implementation can be found in the storm folder.
real-time reddit api can be found in the Stream folder Cassandra was chosen as the key-value store for this project.


