blog's People
blog's Issues
学习文档
Git的本地存储
探究 Git 原理
Git是个文件系统
首先我们需要有一个概念,Git亦是一个文件系统。
Git 和其它版本控制系统(包括 Subversion 和近似工具)的主要差别在于 Git 对待数据的方法。 概念上来区分,其它大部分系统以文件变更列表的方式存储信息。 这类系统(CVS、Subversion、Perforce、Bazaar 等等)将它们保存的信息看作是一组基本文件和每个文件随时间逐步累积的差异。
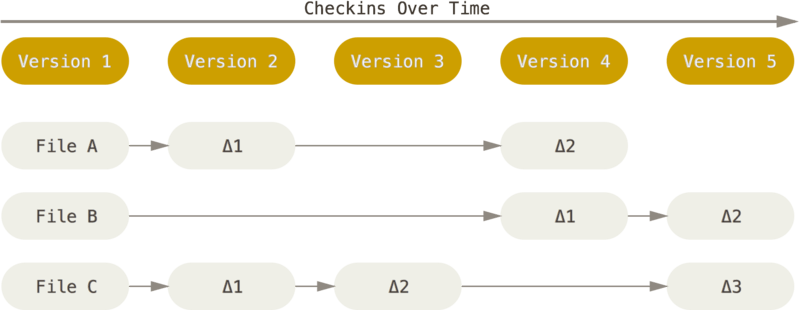
Git 不按照以上方式对待或保存数据。 反之,Git 更像是把数据看作是对小型文件系统的一组快照。 每次你提交更新,或在 Git 中保存项目状态时,它主要对当时的全部文件制作一个快照并保存这个快照的索引。 为了高效,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件。 Git 对待数据更像是一个 快照流。
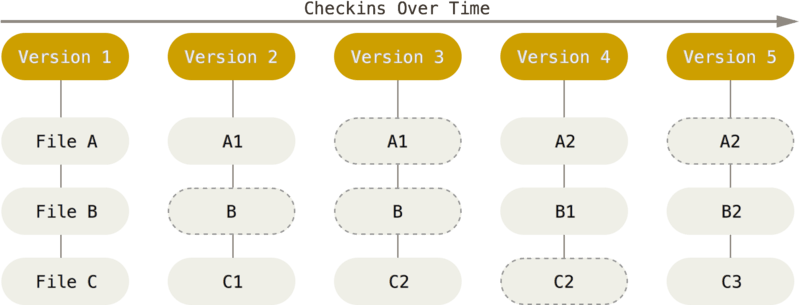
Git的本地存储
当在一个新目录或已有目录执行 git init 时,Git 会创建一个 .git 目录。 这个目录包含了几乎所有 Git 存储和操作的对象。 如若想备份或复制一个版本库,只需把这个目录拷贝至另一处即可。
$ ls -F1
HEAD
config*
description
hooks/
info/
objects/
refs/
先看对我们来说比较无关紧要的:
description文件仅供 GitWeb 程序使用,我们无需关心。config文件包含项目特有的配置选项。info目录包含一个全局性排除(global exclude)文件,用以放置那些不希望被记录在 .gitignore 文件中的忽略模式(ignored patterns)。hooks目录包含客户端或服务端的钩子脚本(hook scripts)。
剩下的四个条目很重要:HEAD 文件、(尚待创建的)index 文件,和 objects 目录、refs 目录。
objects目录存储所有数据内容;refs目录存储指向数据(分支)的提交对象的指针;HEAD文件指示目前被检出的分支;index文件保存暂存区信息。
objects
Git 的核心部分是一个简单的键值对数据库(key-value data store)。 你可以向该数据库插入任意类型的内容,它会返回一个键值,通过该键值可以在任意时刻再次检索(retrieve)该内容。
首先,我们需要初始化一个新的 Git 版本库,并确认 objects 目录为空:
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
可以看到 Git 对 objects 目录进行了初始化,并创建了 pack 和 info 子目录,但均为空。
通过底层命令 hash-object 来演示“将任意数据保存于 .git 目录,并返回相应的键值”:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
该命令输出一个长度为 40 个字符的校验和。 这是一个 SHA-1 哈希值——一个将待存储的数据外加一个头部信息(header)一起做 SHA-1 校验运算而得的校验和。现在我们可以查看 Git 是如何存储数据的:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
可以在 objects 目录下看到一个文件。 这就是开始时 Git 存储内容的方式——一个文件对应一条内容,以该内容加上特定头部信息一起的 SHA-1 校验和为文件命名。 校验和的前两个字符用于命名子目录,余下的 38 个字符则用作文件名。
可以通过 cat-file 命令从 Git 那里取回数据。
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
树对象
使用之前的方式我们仅保存了文件的内容,没有记录文件名称和相互之间的关联。接下来要探讨的对象类型是树对象(tree object),它能解决文件名保存的问题,也允许我们将多个文件组织到一起。某项目当前对应的最新树对象可能是这样的:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
master^{tree} 语法表示 master 分支上最新的提交所指向的树对象。 请注意,lib 子目录(所对应的那条树对象记录)并不是一个数据对象,而是一个指针,其指向的是另一个树对象:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
从概念上讲,Git 内部存储的数据有点像这样:
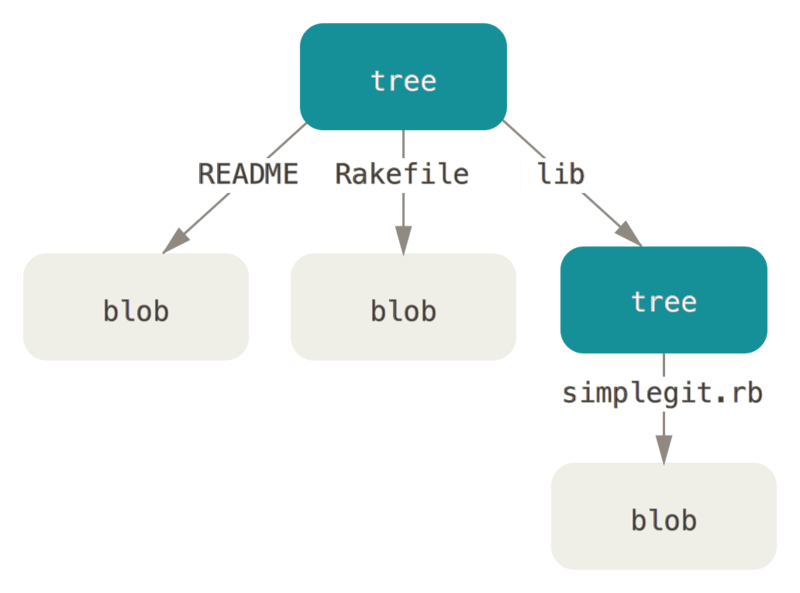
通常,Git 根据某一时刻暂存区(即 index 区域,下同)所表示的状态创建并记录一个对应的树对象,如此重复便可依次记录(某个时间段内)一系列的树对象。
为了简化演示,我们只做一次暂存区的提交,首先先把刚才创建的test.txt文件生成树对象。
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt
现在,可以通过 write-tree 命令将暂存区内容写入一个树对象。 此处无需指定 -w 选项——如果某个树对象此前并不存在的话,当调用 write-tree 命令时,它会根据当前暂存区状态自动创建一个新的树对象:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
接下来提交这个暂存区的记录
$ echo 'first commit' | git commit-tree d8329f
dc40a3036fcad0a1b8f34f11bcbc1fe23a95efa8
这时候我们同样可以通过find .git/objects -type f命令发现树对象、commit也是存在object目录下的
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # text.txt 'version 2'
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # text.txt 'version 1'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree
.git/objects/dc/40a3036fcad0a1b8f34f11bcbc1fe23a95efa8 # first commit
我们可以查看commit的内容,也就是git log的内容
$ git cat-file -p dc40
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author kasinooya <[email protected]> 1466577926 +0800
committer kasinooya <[email protected]> 1466577926 +0800
first commit
$ git log --stat dc40
commit dc40a3036fcad0a1b8f34f11bcbc1fe23a95efa8
Author: kasinooya <[email protected]>
Date: Wed Jun 22 14:45:26 2016 +0800
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)
复杂一些的三次提交对象关系图可能展示如此:
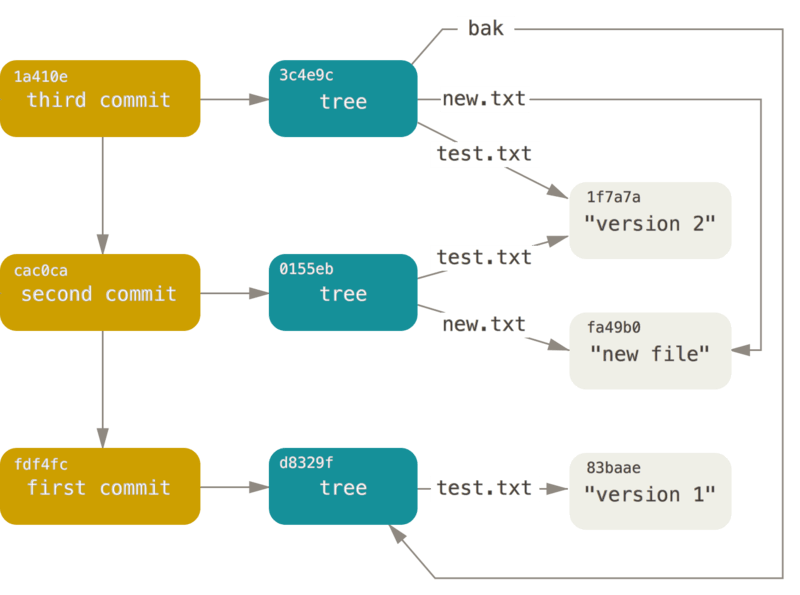
拓展:如果你好奇怎么git存储对象
refs
我们可以借助类似于 git log 1a410e 这样的命令来浏览完整的提交历史,但为了能遍历那段历史从而找到所有相关对象,你仍须记住 1a410e 是最后一个提交。 我们需要一个文件来保存 SHA-1 值,并给文件起一个简单的名字,然后用这个名字指针来替代原始的 SHA-1 值。
$ find .git/refs
.git/refs
.git/refs/heads
.git/refs/tags
$ find .git/refs -type f
若要创建一个新引用来帮助记忆最新提交所在的位置,从技术上讲我们只需简单地做如下操作。
$ echo "1a410efbd13591db07496601ebc7a059dd55cfe9" > .git/refs/heads/master
$ git update-ref refs/heads/master 1a410efbd13591db07496601ebc7a059dd55cfe9 # 后一种更推荐
现在,你就可以在 Git 命令中使用这个刚创建的新引用来代替 SHA-1 值了:
$ git log --pretty=oneline master
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
或者建一个分支:
$ git update-ref refs/heads/test cac0ca

HEAD
当运行类似于 git branch (branchname) 这样的命令时,Git 实际上会运行 update-ref 命令,取得当前所在分支最新提交对应的 SHA-1 值,并将其加入你想要创建的任何新引用中。Git 如何知道最新提交的 SHA-1 值呢? 答案是 HEAD 文件。
HEAD 文件是一个符号引用(symbolic reference),指向目前所在的分支。 所谓符号引用,意味着它并不像普通引用那样包含一个 SHA-1 值——它是一个指向其他引用的指针。 如果查看 HEAD 文件的内容,一般而言我们看到的类似这样:
$ cat .git/HEAD
ref: refs/heads/master
如果执行 git checkout test,Git 会像这样更新 HEAD 文件:
$ cat .git/HEAD
ref: refs/heads/test
当我们执行 git commit 时,该命令会创建一个提交对象,并用 HEAD 文件中那个引用所指向的 SHA-1 值设置其父提交字段。
tags
标签对象(tag object)非常类似于一个提交对象——它包含一个标签创建者信息、一个日期、一段注释信息,以及一个指针。 主要的区别在于,标签对象通常指向一个提交对象,而不是一个树对象。 它像是一个永不移动的分支引用——永远指向同一个提交对象,只不过给这个提交对象加上一个更友好的名字罢了。
可以像这样创建一个轻量标签:
$ git update-ref refs/tags/v1.0 cac0cab538b970a37ea1e769cbbde608743bc96d
远程引用
如果你添加了一个远程版本库并对其执行过推送操作,Git 会记录下最近一次推送操作时每一个分支所对应的值,并保存在 refs/remotes 目录下。例如,你可以添加一个叫做 origin 的远程版本库,然后把 master 分支推送上去。如果查看 refs/remotes/origin/master 文件,可以发现 origin 远程版本库的 master 分支所对应的 SHA-1 值,就是最近一次与服务器通信时本地 master 分支所对应的 SHA-1 值:
$ cat .git/refs/remotes/origin/master
ca82a6dff817ec66f44342007202690a93763949
远程引用和分支(位于 refs/heads 目录下的引用)之间最主要的区别在于,远程引用是只读的。 虽然可以 git checkout 到某个远程引用,但是 Git 并不会将 HEAD 引用指向该远程引用。因此,你永远不能通过 commit 命令来更新远程引用。 Git 将这些远程引用作为记录远程服务器上各分支最后已知位置状态的书签来管理。
其他
好用的数据恢复辅助命令
git reflog
参考文档
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.