kcl-lang / kcl Goto Github PK
View Code? Open in Web Editor NEWKCL Programming Language (CNCF Sandbox Project). https://kcl-lang.io
Home Page: https://kcl-lang.io
License: Apache License 2.0
KCL Programming Language (CNCF Sandbox Project). https://kcl-lang.io
Home Page: https://kcl-lang.io
License: Apache License 2.0



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")





































































































































At present, KCL's attribute operators provide idempotent merge:, add +=, and override= three attribute operators (delete by using the Undefined override table) to modify the configuration, and it also defaults that all configuration values in the configuration block are variable. It does not provide semantics similar to Java final attributes, that is, the configuration is not allowed to be modified, and KCL is required to provide corresponding unique configuration semantics and stronger immutability
Extend immutable semantics to property operators in KCL (analogous to using different keywords in GPL to determine the variability of variables, see reference for details)
_, it is mutable._, its mutability depends on the property operator it uses
= operator are immutable.: and += operators are mutable.= assignment are not allowed for properties within the same configuration block.config = {
attr1 = "v1"
attr1 = "v2" # Error, attr1 is an immutable attribute
attr2.key1 = "v1" # Equivalent to attr2: {key1 = "v1"}, attr2 uses : declaration and is variable
attr2.key2 = "v2" # Since attr2 is mutable, different key-value pairs can be added multiple times and merged
}
= are also not allowed in different merge configuration blocks.import app
appConfig: app.Config { # appConfig uses : declaration and is a mutable variable
attr1 = "v1" # attr1 is declared with = and is an immutable attribute
attr2: "v2" # attr2 is declared with : and is a mutable attribute
}
appConfig: app.Config { # appConfig is a mutable variable that can be merged multiple times
attr1 = "new_v1" # Error, attr1 has been declared once with = and cannot be modified
attr2 = "new_v2" # Ok, attr2 is declared with : and can be modified with =
}
@chai2010
I run './run.sh -a build' in the KCLVM directory and can't get the result.
git clone 'XXX'
cd KCLVM
./run.sh -a build
KCLVM was successfully built.
configure:
By default, distutils will build C++ extension modules with "g++".
If this is not intended, then set CXX on the configure command line.
checking for the platform triplet based on compiler characteristics... darwin
configure: error: internal configure error for the platform triplet, please file a bug report
The current KCL repository has initially established simple development documents, ISSUE and PR templates, etc. However, there is a lack of detailed developer manuals to help all developers develop better collaboratively, such as https://github.com/rust-lang/rustc-dev-guide in rustc.
To sum up, KCL needs a corresponding developer manual to describe the following things clearly:
According to the content in the Roadmap #29 , use Rust to rewrite the KCL query tool
Attribute type checking information can be further enhanced. The information for attribute type checking can be further enhanced. For example, for the following KCL code, the following code will report a type error and a runtime error with unclear information respectively.
schema Data:
id: int = 1
dataList = [{data = 1} for data in [Data {}]]
dataMap = {data = 1 for data in [Data {}]}
KCL Compile Error[E2A31] : Illegal attribute
---> File test.k:4:14
4 |dataList = [{data = 1} for data in [Data {}]]
14 ^ -> Failure
type 'Data'
KCL Runtime Error[E3M38] : Evaluation failure
---> File test.k:5
5 |dataMap = {data = 1 for data in [Data {}]} -> Failure
unhashable type: 'dict'
Sometimes this is confusing to users, the error message can be improved. The improved error message is as follows:
KCL Compile Error[E2L23] : A complie error occurs during compiling
---> File test.k:4:14
4 |dataList = [{data = 1} for data in [Data {}]]
14 ^ -> Failure
illegal attribute type, expect str, got 'Data'
KCL Compile Error[E2L23] : A complie error occurs during compiling
---> File test.k:5:12
5 |dataMap = {data = 1 for data in [Data {}]}
12 ^ -> Failure
illegal attribute type, expect str, got 'Data'
https://github.com/KusionStack/KCLVM/blob/main/kclvm/ast/src/ast.rs#L265
pub struct TypeAliasStmt {
...
#[serde(skip_serializing)]
pub ty: Option<NodeRef<Type>>, // remove Option
}use kclvm_parser::parse_expr;
parse_expr("", Some("".to_string()))parse_expr should return a Result<Expr> or Option<Expr> instead of panic directly.
parse_expr raises a panic
All KCLVM Rust code needs to be formatted using the rustfmt tool and pinned to the rustfmt style file. This is done for two purposes:
rustfmt.toml.Please answer these questions before submitting your issue. Thanks!
cd scripts/docker/kclvm-builder-centos8
make
Error: Failed to download metadata for repo 'appstream': Cannot prepare internal mirrorlist: No URLs in mirrorlist
The KCL language is currently in a stage of rapid development. Therefore, in the future, KCL will continue to iteratively evolve around the goals of stability, ease of use, and ecological expansion. At the same time, the KCL language will be used in more field scenarios for continuous iteration and development. The following are some of the contents of the route planning, welcome to discuss and exchange.

Growth and developer experience
We have a core dynamic library at the KCLVM Rust level, which has an API that can execute KCL code and return JSON/YAML results. When other languages call the API, they need the ability to release the memory allocated by the KCL code. Because at this stage KCL does not have the ability to automatically manage memory.
The kcl code (test.k) is:
schema Base(Sub):
schema Sub(Base):
The error message is
KCL Compile Error[E2D33] : Cycle Inheritance is illegal
---> File test.k:3:1
3 |schema Sub(Base):
1 ^ -> Failure
Sub and Base
The improved error message is
KCL Compile Error[E2D33] : Cycle Inheritance is illegal
---> File test.k:3:1
3 |schema Sub(Base):
1 ^ -> Failure: There is a circular reference between schema Sub and Base
Cycle Inheritance is illegal
Please answer these questions before submitting your issue. Thanks!
Restore the "kclvm/runner/test.rs/fn test_kclvm_runner_execute()" method that has been commented out.
In the KCLVM
make sh-in-docker
cd kclvm/runner
cargo test -- --nocapture
running 1 test
test tests::test_kclvm_runner_execute ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 7.10s
running 1 test
thread '<unnamed>' panicked at 'called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }', src/command.rs:391:66
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
src/command.rs:391:66
let txt_path = std::path::Path::new(&executable_root)
.join(if Self::is_windows() { "libs" } else { "lib" })
.join("rust-libstd-name.txt");
391 ------> let rust_libstd_name = std::fs::read_to_string(txt_path).unwrap();
^ 66Cannot found the file "rust-libstd-name.txt".
kclvm version is 0.4.2; checksum: e07ed7af0d9bd1e86a3131714e4bd20c
kusionstack/kclvm-builder docker image is missing python pip and llvm lld components.
Please answer these questions before submitting your issue. Thanks!
Write the following KCL code (test.k) and run:
data: [int] = [
if False:
*[0]
else:
*[1]
]
test.kThe YAML output:
data:
- 1The compile error:
KCL Compile Error[E2G22] : The type got is inconsistent with the type expected
---> File test.k:1:1
1 |data: [int] = [
1 ^ -> got [int(0)|[int(1)]]
expect [int], got [int(0)|[int(1)]]
v0.4.2-alpha.4
Please answer these questions before submitting your issue. Thanks!
take str "8_________i" as the input parameter of method "kclvm-parser.parse_expr".
parse_expr("8_________i");
kclvm output syntax error message.
the rust panic message.
thread '...' panicked at '{"__kcl_PanicInfo__":true,"rust_file":"","rust_line":0,"rust_col":0,"kcl_pkgpath":"","kcl_file":"","kcl_line":1,"kcl_col":0,"kcl_arg_msg":"","kcl_config_meta_file":"","kcl_config_meta_line":0,"kcl_config_meta_col":0,"kcl_config_meta_arg_msg":"","message":"UnexpectedToken { expected: [\"int\"], got: \"8_________i\" }","err_type_code":5,"is_warning":false}', src/session/mod.rs:48:9
stack backtrace:
...
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
UnexpectedToken { expected: ["int"], got: "8_________i" }
kclvm version is 0.4.2; checksum: e07ed7af0d9bd1e86a3131714e4bd20c
At present, several compilation stages in the KCL compiler code, such as parser, resolver, and code generation, lack the complete benchmark test set of e2e, which leads to the need to add new benchmarks when modifying the KCL compiler code. There is no good unity, and cannot reflect the e2e performance comparison.
In short, the KCL compiler needs a benchmark test set that can cover most of the syntactic and semantic e2e tests.
On ubuntu 20.04, run kcl examples/hello.k --target native
The right YAML output
__main__.so no such file or directory
CompilerBase-Error is an error handling kit, whose goal is to help compiler developers build the error handling of their own compiler during the development.
google docs:
[WIP] https://docs.google.com/document/d/1oXZr_T76DkL9tkU2RT5anNr615xpLperOghKWdG79NE/edit?usp=sharing
[WIP] https://docs.google.com/document/d/1xFwBOkwD2cJYdb6L-JLKgRMYCy_xfLKgU9-kdPZtqas/edit?usp=sharing
yuque docs:
[WIP] https://www.yuque.com/docs/share/64c4e739-9cbf-4946-8659-5b35b86f5956?# 《CompilerBase-Error》
The script builds KCLVM python package and publishs it to PyPI
The python version of KCL Lint follows the design of pylint and is a compiler-independent tool. The Lint has indepent command line parsing. In main fuction, Linter calls the parse_program() function to obtain the AST, and then checks the AST, generates Lint messages and output them. Therefore, the python version of KCL Lint needs to deal with many problems by itself, such as parameter parsing, path processing, file traversal, etc. In fact, these work has already been handled once in KCLVM. At the same time, the Lint tool also maintains another error messages and error output system, which is somewhat separated from the main body of KCLVM, and also required cost to maintain. Moreover, for some Warning level information, the user will not be prompted during the compilation process. They need to run the lint command separately to see it.
/kcllint_py.jpg?raw=true)
The KCL Lint rust version is based on the design of Rustc's Resolver and Lint, and executes lint checking during the semantic phase of compilation. Lint shares a common error handling system with the rest of the KCLVM. Lint tool checks AST, generates diagnostics and inserts them into handler.diagnostics, which are handled by the KCLVM. This avoids the need to maintain an additional set of error messages, and also throws the Lint-checked problems at compile time without the need to perform additional lint checks. If a separate lint check is required, the diagnostics are thrown after the lint check and the program exits. This avoids maintaining an additional set of error messages, and also emit the problems detected by Lint at compile time. If only lint checking is required, KCLVM will emit diagnostics after lint checking and exits the main program.
/kcllint_rust.jpg?raw=true)
When checking, the python ver. Lint divides different checks into multiple checkers by AST type, such as ImportCheck, BaseChecker etc. Each checker needs to traverse AST at least once. The Rust version is no longer divided into multiple checkers, but collects all lint checks by AST type in a CombinedLintPass structure. When traversing the AST node, Lint calls the check method of CombinedLintPass, which run all lint checks in one traversal.
Lint is executed during the semantic analysis phase, and the main structure consists of Lint, LintPass, CombinedLintPass and Linter, which implements the walker methods for traversing AST. When traversing AST node, the corresponding check method in CombinedLintPass is called. Static information and check methods for each lint are defined in Lint and LintPass respectively. CombinedLintPass aggregates the checks in these LintPasses according to the type of AST node.
/KCL_Lint.jpg?raw=true)
Lint is a struct type that defines a lint. It is a global identifier and a description of the lint, which contains some stastic information about the lint (name, level, error message, error code, examples, etc.).
pub struct Lint {
/// A string identifier for the lint.
pub name: &'static str,
/// Level for the lint.
pub level: Level,
/// Description of the lint or the issue it detects.
/// e.g., "imports that are never used"
pub desc: &'static str,
// Error/Warning code
pub code: DiagnosticId,
}The LintPass is an implementation of the specific check logic for Lint, containing the check methods that need to be called when traversing the AST tree. LintPass is defined as a trait, which needs to be implemented for each definition of lintpass. Not every Lint needs to check all ASTs, but only the check methods required by the Lint need to be overridden. So when defining trait LintPass, we give all methods a default implementation, i.e. a null check, and when defining LintPass, just override the partial check function.
Every LintPass needs to implement the get_lint() method to generate the corresponding Lint structure.
pub trait LintPass{
fn name(&self);
fn get_lint();
fn check_ident(&mut self, a: ast::Ident, diags: &mut IndexSet<diagnostics>){}
fn check_module(&mut self, a: ast::Module, diags: &mut IndexSet<diagnostics>){}
fn check_stmt(&mut self, a: ast::Stmt, diags: &mut IndexSet<diagnostics>){}
...
}
pub struct LintPassA{
name: str
}
pub struct LintPassB{
name: str
}
impl LintPass for LintPassA{
fn name(){..}
fn get_lint(){...}
fn check_ident(&mut self, a: ast::Ident, diags: &mut IndexSet<diagnostics>){
...
}
}
impl LintPass for LintPassB{
fn name(){..}
fn get_lint(){...}
fn check_stmt(&mut self, a: ast::Stmt, diags: &mut IndexSet<diagnostics>){
...
}
}Each LintPass defined separate check function for AST node. Traversing the AST once for each Lint individually would cause a relatively large performance overhead. Therefore, the CombinedLintPass structure is defined to aggregate the check methods of all defined LintPasses. By calling the check method of CombinedLintPass when traversing the AST, all Lint checks can be done in one traversal.
pub struct CombinedLintPass {
LintPassA: LintPassA;
LintPassB: LintPassB;
...
}
impl CombinedLintPass{
pub fn new() -> CombinedLintPass {
CombinedLintPass {
LintPassA: LintPassA::new(),
LintPassB: LintPassB::new(),
...
}
}
}
impl LintPass for CombinedLintPass {
fn check_ident(&mut self, a: Ident, diags:&mut IndexSet<diagnostics>){
self.LintPassA.check_ident(a, diags);
self.LintPassB.check_ident(a, diags);
...
}
fn check_stmt(&mut self, a: &ast::Stmt, diags: &mut IndexSet<diagnostics>){
self.LintPassA.check_stmt(a, diags);
self.LintPassB.check_stmt(a, diags);
...
}
}Linter is a structure that traverses the AST and required to implement mothods of Walker. Linter calls the check method of CombinedLintPass when traversing the AST.
pub struct Linter<T: LintPass> {
pass: T,
diags: diagnostics
}
impl Checker{
fn new() -> Checker{
Checker{
pass: CombinedLintPass::new()
diags: Default::default()
}
}
}
impl ast_walker::Walker for Linter{
fn walk_ident(&self, a: ast::Ident, diags: &mut IndexSet<diagnostics>){
pass.check_ident(a, diags);
walk_subAST();
}
fn walk_stmt(&self, a: ast::Ident, diags: &mut IndexSet<diagnostics>){
pass.check_stmt(a, diags);
walk_subAST();
}
}Lint errors are consistent with KCLVM error and are stored as diagnostics types, which are handled by the error handling module.
There are some lint checks that support custom parameters, such as naming convention, code length, etc., and the lint tool itself requires some configuration, such as allowing the user to ignore some checks. Lint configuration is set according to the following priorities.
.kcllint file in the directory of the file or folder being checked.The configuration file is written in yaml format, e.g.
ignore: ["E0501"]
max_line_length: 120
The definitions of Lint, LintPass and CombinedLintPass have a lot of repetitive code that can be generated using macro definitions. For example, declare_lint! and declare_lint_pass! are used in rustc to define Lint (WHILE_TRUE) and LintPass (WHILE_TRUE).
declare_lint! {
/// The `while_true` lint detects `while true { }`.
///
/// ### Example
///
/// ```rust,no_run
/// while true {
///
/// }
/// ```
///
/// {{produces}}
///
/// ### Explanation
///
/// `while true` should be replaced with `loop`. A `loop` expression is
/// the preferred way to write an infinite loop because it more directly
/// expresses the intent of the loop.
WHILE_TRUE,
Warn,
"suggest using `loop { }` instead of `while true { }`"
}
declare_lint_pass!(WhileTrue => [WHILE_TRUE]);
impl EarlyLintPass for WhileTrue{
...
}And the definition of BuiltinCombinedEarlyLintPass
early_lint_passes!(declare_combined_early_pass, [BuiltinCombinedEarlyLintPass]);
// Expand all macros
pub struct BuiltinCombinedEarlyLintPass {
UnusedParens: UnusedParens;
UnusedBraces: UnusedBraces;
...
}
impl BuiltinCombinedEarlyLintPass{
pub fn new() -> Self {
UnusedParens: UnusedParens,
UnusedBraces: UnusedBraces
...
}
pub fn get_lints() -> LintArray {
let mut lints = Vec::new();
lints.extend_from_slice(&UnusedParens::get_lints());
lints.extend_from_slice(&$UnusedBraces::get_lints());
...
lints
}
}
impl EarlyLintPass for BuiltinCombinedEarlyLintPass {
fn check_ident(&mut self, context: &EarlyContext<'_>, a: Ident){
self.UnusedParens.check_ident (context, a: Ident);
self.UnusedBraces.check_ident (context, a: Ident);
...
}
fn check_crats(&mut self, context: &EarlyContext<'_>, a: &ast::Crate){
self.UnusedParens.check_crats (context, a: Crate);
self.UnusedBraces.check_crats (context, a: Crate);
...
}
}Please answer these questions before submitting your issue. Thanks!
test.ka: int = {a = 1}
kcl test.k --target nativeThe error message
expect int, got {str:int(1)}
The yaml output
a:
a: 1
kclvm version is 0.4.2; checksum: e07ed7af0d9bd1e86a3131714e4bd20c
Code structure refactoring: sema::eval and sema::ty::parser modules are currently placed in kclvm_sema crate, which is not very suitable, they need to be moved to kclvm_parser for unified management. Files Involving modifications:
Deps.
Please answer these questions before submitting your issue. Thanks!
take str "fs1_i1re1~s" as the input parameter of method "kclvm-parser.parse_expr".
parse_expr("fs1_i1re1~s");
kclvm output syntax error message.
the rust panic message.
thread 'main' panicked at 'invalid binary expr: missing binary operation: ()', parser/src/parser/expr.rs:132:22
stack backtrace:
...
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
kclvm version is 0.4.2; checksum: e07ed7af0d9bd1e86a3131714e4bd20c
Good CONTRIBUTING documentation, but there's an outdated introduction in Code Structure chapter: I can't find a spec file or directory anywhere in this repo.
Please answer these questions before submitting your issue. Thanks!
Take “fh==-h==-” as input to “parse_expr”.
parse_expr("fh==-h==-");
kclvm output syntax error message.
Rust array out of bounds error
kclvm version is 0.4.2; checksum: e07ed7af0d9bd1e86a3131714e4bd20c
when use override_file API, it needs to support import deduplication for different aliased packages.
override_file call with the parameter import_paths = ["pkg.to.path", "pkg.to.path as alias"]schema Person:
name: str
override_file callimport pkg.to.path
import pkg.to.path as alias
schema Person:
name: str
KCLVM needs to be fully tested on different platforms in Github actions including macos, ubuntu and windows. Just like follows:

Write the following code (test.k) and run:
schema Data:
[
a for a in [0, 1, 2]
]
kcl test.k --target native
I got the internal parse error
Got a correct output
Got the internal parse error
The latest main branch. (2022.05.24)
container.envs = [{"name1": "value1"}, {"name2": "value2"}]
container.envs = [
{"name1": "value1"}
{"name2": "value2"}
]
Please answer these questions before submitting your issue. Thanks!
KCL code structure
├── hello.k
└── pkg
└── pkg.k
import pkg
person = pkg.Person {}
schema Name:
name?: str
schema Person:
name?: Name = Name {name = "Alice"}
run:
kcl hello.k --target native
The YAML output
person:
name: AliceThe panic info:
Symbol not found: _$pkg.$Name.11\n Referenced from: /.kclvm/cache/0.4.2-e07ed7af0d9bd1e86a3131714e4bd20c/pkg.dylib
kclvm version is 0.4.2; checksum: e07ed7af0d9bd1e86a3131714e4bd20c
Many errors in the current KCLVM Rust Parser stage are directly panicked, the location information of some AST nodes is not completed, and there is no good error handling and error disclosure. It is necessary to further collect and reveal errors. Such as the following places:
panic call in the parser::ty modulepanic call in the parser::stmt moduleKCLVM Resolver checking for import statements should be enhance. Need to check for user-defined but unused , and duplicate defined import statements. Prompting users to remove useless importstmt to improve compilation speed.
import a
import a
schema Data:
id: int = 1
KCL Warning [ReimportWarning]
---> File /path_to_file/main.k:2:1
1 |import a
a is reimported multiple times.
KCL Warning [UnusedImportWarning]
---> File /path_to_file/main.k:2:1
1 |import a
a imported but unused.
Since Ubuntu 20.10 comes with libff8 instead of libffi7, libffi7 used by KCLVM Python Plugin built on ubuntu20 may not work on ubuntu22.
:.The KCL code is
schema Person:
mixin [FullNameMixin]
firstName: str
lastName: str
age: int
id?: int
# protocol specifies what properties the host of the mixin must have
protocol FullNameProtocol:
firstName: str
lastName: str
mixin FullNameMixin for FullNameProtocol:
fullName: str = "{} {}".format(firstName, lastName)
alice = Person {
firstName = "Alice"
lastName = "Green"
age = 10
id = 1
}
The output YAML is
alice:
firstName: Alice
lastName: Green
age: 10
id: 1
fullName: Alice GreenAccording to the content in the Roadmap #29 , use Rust to rewrite the KCL validation tool.
KCL code meta information needs to have a specification.
The current KCL packet error information is based on 1-based column number, such as the following code, but the code writing allows setting the column number to 0, there is no good specification and verification, so what needs to be done is:
Note: These specifications need to be placed in the compiler_base Implementation.
A sample kcl error message is
KCL Compile Error[E2L23] : A complie error occurs during compiling
---> test.k:1:1
1 |import not_found_pkg
1 ^ -> Failure
Cannot find the module not_found_pkgKCLVM Rust Github CI has not added corresponding unit test coverage card points and statistical tools, and CI need to be used to further add code stability.
In addition to rust unit tests, some rust code related tests are not added to github actions, such as kclvm runtime lib test and grammar test.
Is your feature request related to a problem? Please describe:
Describe the feature you'd like:
Users can call kclvm's cli api through the C language dynamic link library to more efficiently support kcl cross-language calls
Describe alternatives you've considered:
The dynamic link library will be responsible for two aspects, one of which is to perform cross-language memory management, and the other to call functions inside rust according to user parameters
Teachability, Documentation, Adoption, Migration Strategy:
At present, the generation and execution of dynamic link libraries are all in the main function, and they need to be refactored and encapsulated separately.
the "extended attributes" stored in appledouble file, that causes the kclvm-Go/scripte create many .filename file, some time will causes the python start failed.
the kclvm build script should remove "extended attributes", and the kclvm-Go/script.untargz function should skip the appledouble file.
What and Why:
At present, when the kcl handler does semantic analysis, it will generate struct diagnostic, which contains the string type error message and the position of the error. But diagnostic is missing the necessary parameter information to describe the error, such as the name of token. For example, for import error, we get an error message like "pkgpath xx not found in the program" and the location of xx. However, in continue (lint, or other) analysis, the name of xx may be needed for concatenation other error messages, or continue to output as parameters (sarif report).
How:
new Dagnostic{...}Please answer these questions before submitting your issue. Thanks!
Parallel multi-file compilation code looks like follows:
1. let pool = ThreadPool::new(self.thread_count);
2. let (tx, rx) = channel();
3. for .... {
4. let tx = tx.clone();
5. pool.execute(move || {
6. ...
7. tx.send(dylib_path).expect("channel will be there waiting for the pool");
8. });
9. }
10. rx.iter().take(prog_count).collect::<Vec<String>>()If panic occurs when executing lines 5 to 8, the corresponding thread will be killed immediately, then "tx" in line 7 will not send the result, and "rx" in line 10 will wait for the result from "tx" and the main thread will never stop .
The program outputs a normal error message and stops.
The program cannot stop after outputting panic information.
kclvm version is 0.4.2; checksum: e07ed7af0d9bd1e86a3131714e4bd20c
Please answer these questions before submitting your issue. Thanks!
The kcl code is
a: str
A syntax error.
KCL Syntax Error[E1001] : Invalid syntax
---> File /Users/_Code/KusionOpenSource/KCLVM/a.k:1:7
1 |a: str
7 ^ -> Expected one of ['=']
Invalid syntax
thread 'main' panicked at 'called Option::unwrap() on a None value', sema/src/resolver/node.rs:280:47
kclvm version is 0.4.2; checksum: e07ed7af0d9bd1e86a3131714e4bd20c
Enhancement
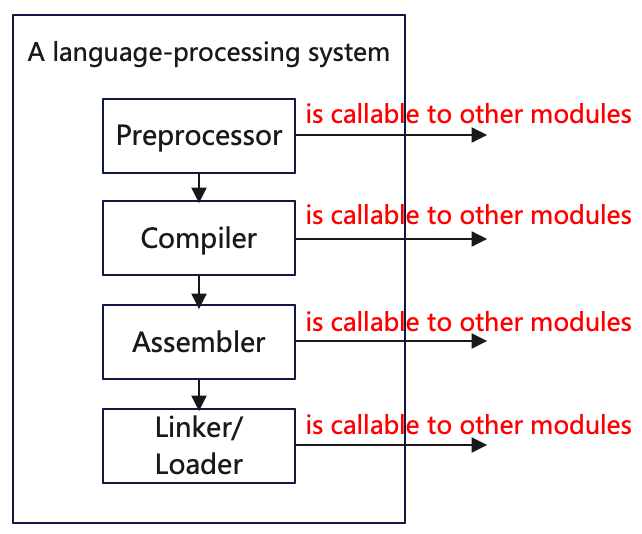
Assembler and Linker/Loader in the above figure are not individually encapsulated.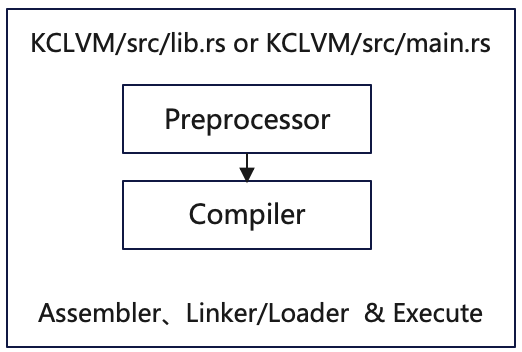
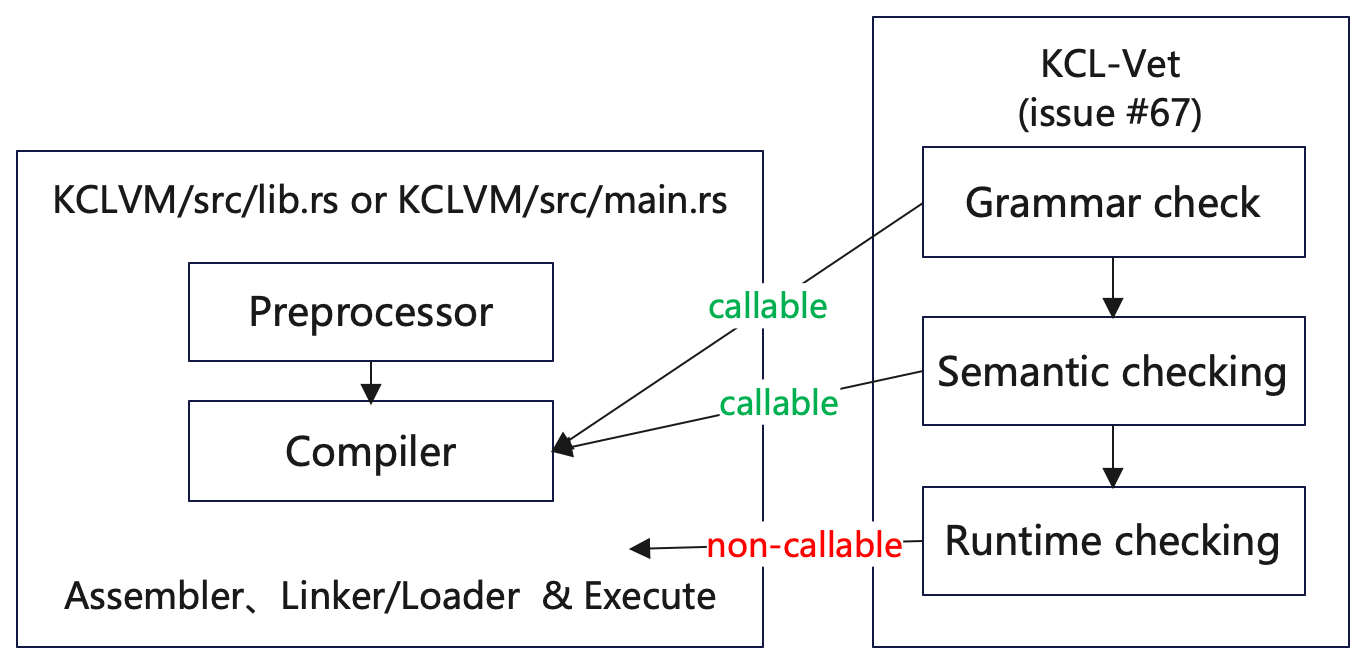
Therefore, the Assembler, Linker/Loader and Executor need to be encapsulated separately.
Please answer these questions before submitting your issue. Thanks!
Take "-" combine with an unicode char as input for the method parse_expr.
parse_expr("-\u{feff}sjda");
The KCLVM should tell me the exception information such as “illegal characters”.
The panic info:
running 1 test
thread 'tests::test_parse_expr_invalid' panicked at 'byte index 2 is not a char boundary; it is inside '\u{feff}' (bytes 1..4) of `-sjda`', library/core/src/str/mod.rs:127:5
stack backtrace:
...
failures:
tests::test_parse_expr_invalid
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 92 filtered out; finished in 0.03s
error: test failed, to rerun pass '-p kclvm-parser --lib'
The terminal process "cargo 'test', '--package', 'kclvm-parser', '--lib', '--', 'tests::test_parse_expr_invalid', '--exact', '--nocapture'" terminated with exit code: 101.
kclvm version is 0.4.2; checksum: e07ed7af0d9bd1e86a3131714e4bd20c
All versions of kclvm release larger than 150MB, smaller binaries are always welcome.
KCL provides the schema settings meta attribute for planning YAML. In addition, you can also write KCL code to customize the way of outputting YAML, so the settings meta attribute function can be removed, reducing the burden of understanding.
schema ManifestsYamlStreamOptions:
sort_keys: bool = False
ignore_private: bool = True
ignore_none: bool = False
separator: str = "\n---\n"
manifests.yaml_stream(values: [any], * , opts: ManifestsYamlStreamOptions = ManifestsYamlStreamOptions {})
The function is to serialize a list of KCL objects to YAML and output using the style with the --- delimiter, and add it to the existing YAML output stream.
Note: When the yaml.manifest_stream function is called, the output result of plan inside KCLVM is subject to this function, and global variables are not output by default.
import manifests
# resources.k
schema Deployment:
apiVersion: str = "v1"
kind: str = "Deployment"
metadata: {str:} = {
name = "deploy"
}
spec: {str:} = {
replica = 2
}
schema Service:
apiVersion: str = "v1"
kind: str = "Service"
metadata: {str:} = {
name = "svc"
}
spec: {str:} = {}
deployments = [Deployment {}, Deployment {}]
services = [Service {}, Service {}]
manifests.yaml_stream(deployments + services)
The output YAML is
apiVersion: v1
kind: Deployment
metadata:
name: deploy
spec:
replica: 2
---
apiVersion: v1
kind: Deployment
metadata:
name: deploy
spec:
replica: 2
---
apiVersion: v1
kind: Service
metadata:
name: svc
spec: {}
--
apiVersion: v1
kind: Service
metadata:
name: svc
spec: {}std.manifestYamlStream(
['a', 1, []],
indent_array_in_object=false,
c_document_end=true)
{
a: 1,
b: 2
}The output is
"---\n\"a\"\n---\n1\n---\n[]\n...\n{\"a\": 1, \"b\": 2}"
package kube
objects: [ for v in objectSets for x in v {x}]
objectSets: [
service,
deployment,
statefulSet,
daemonSet,
configMap,
]package kube
import (
"encoding/yaml"
"tool/cli"
)
command: dump: {
task: print: cli.Print & {
text: yaml.MarshalStream(objects)
}
}
schema __settingss__ attrtibute will be removed in KCLVM v0.4.6
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.