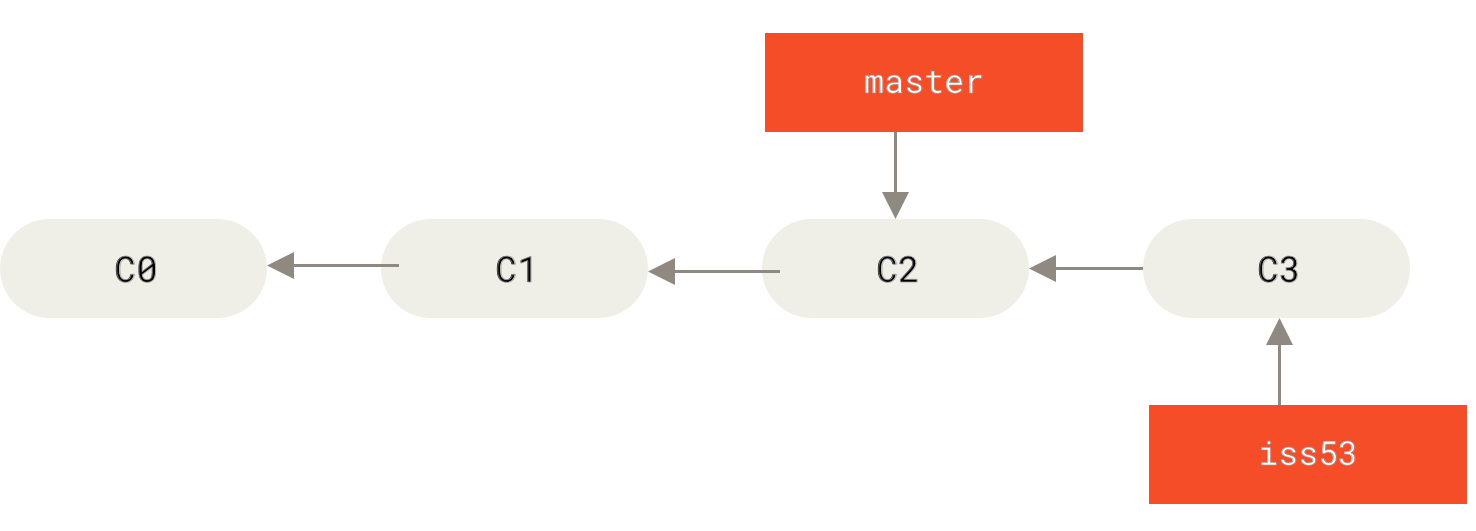
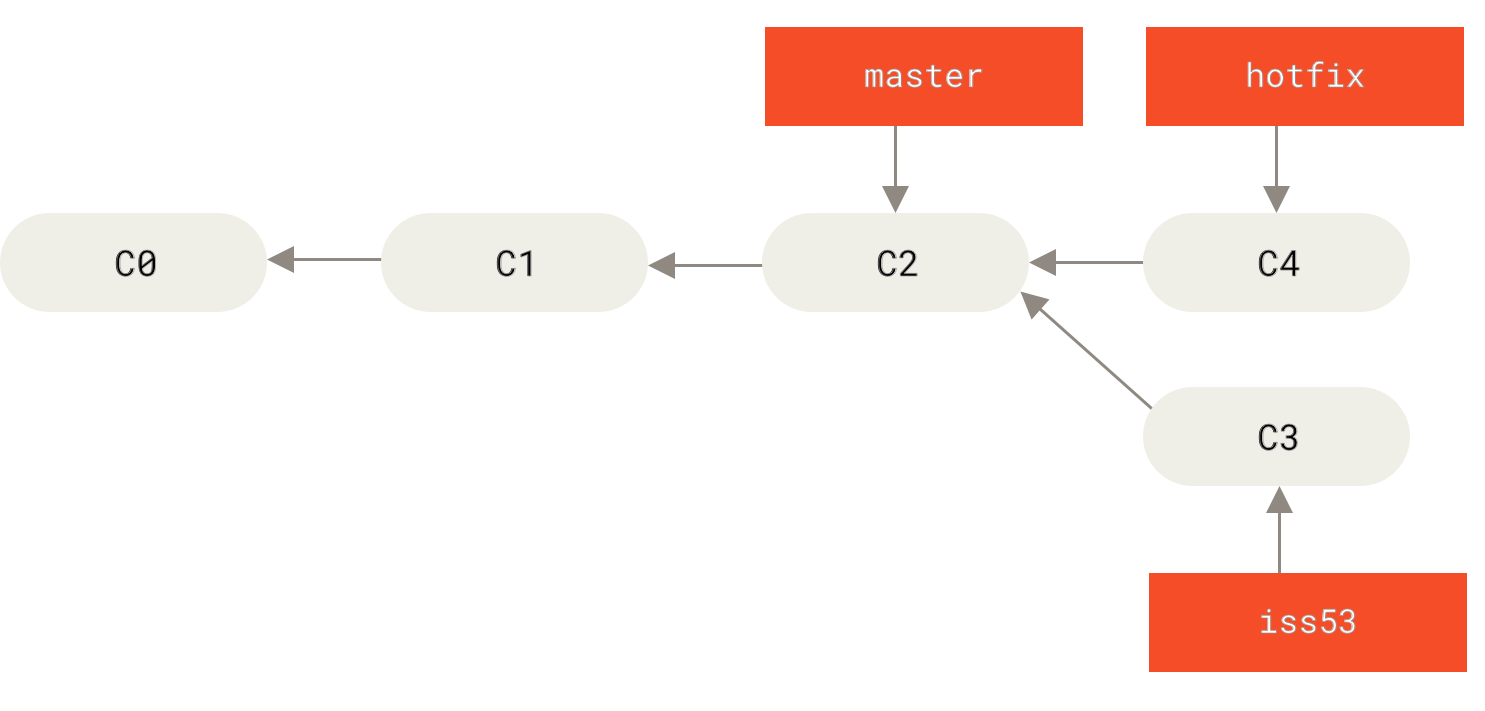
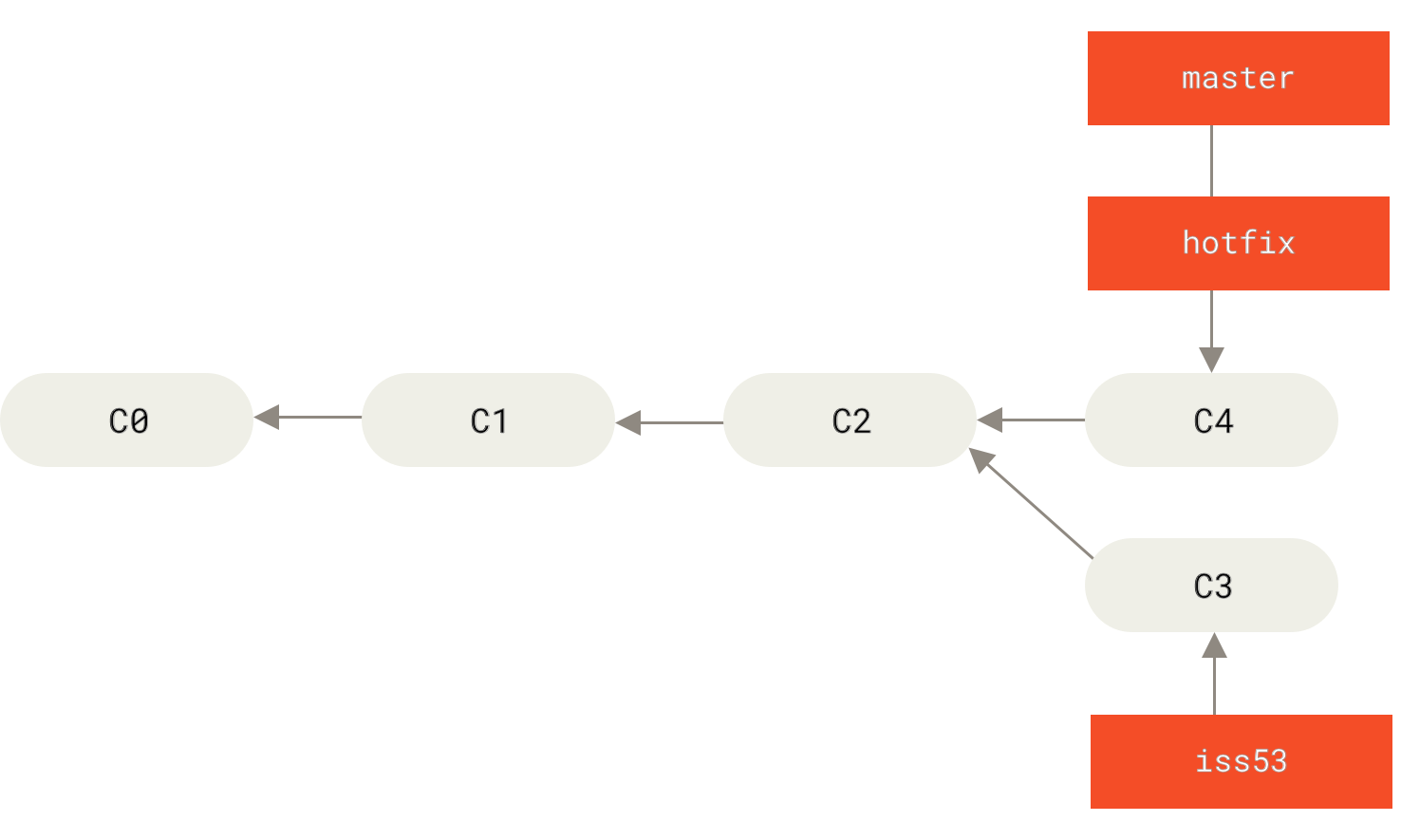
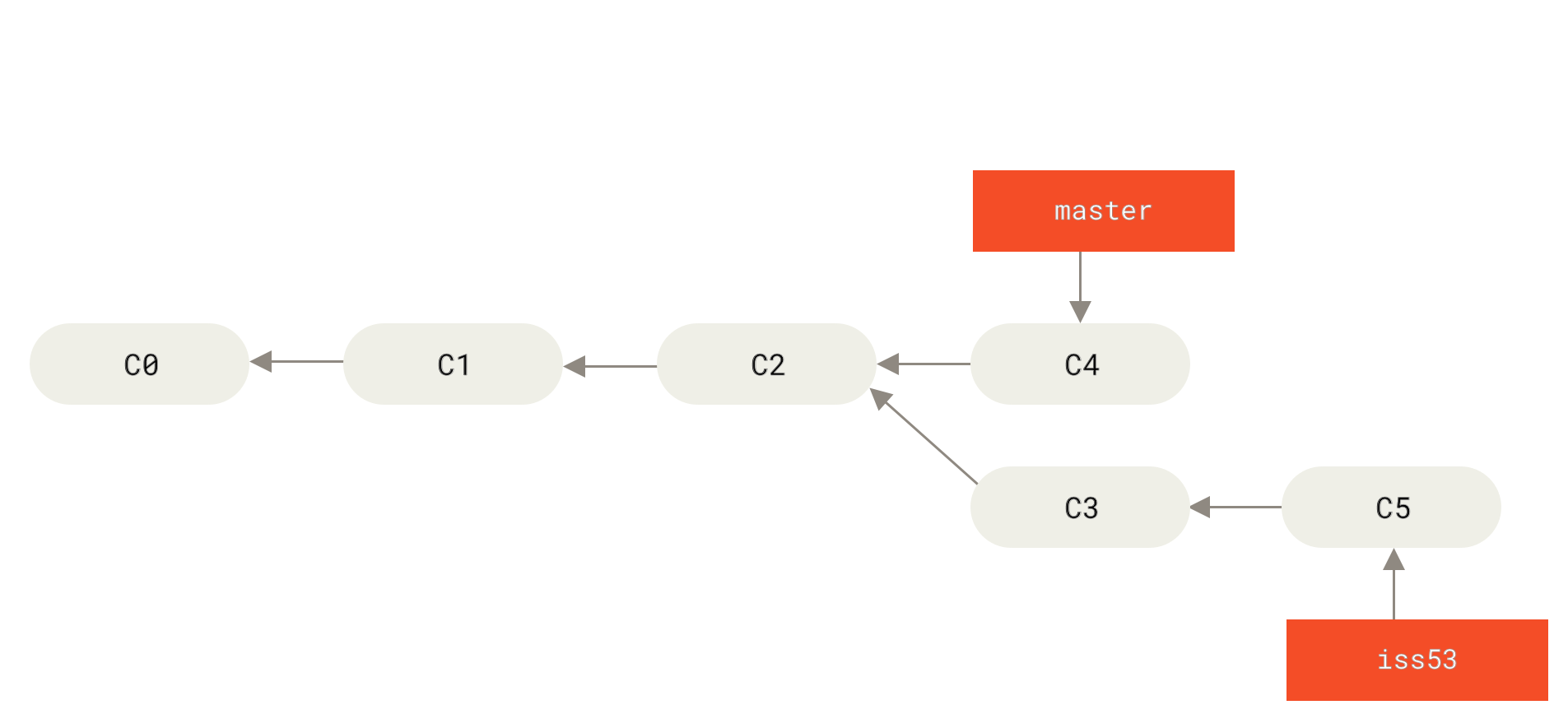
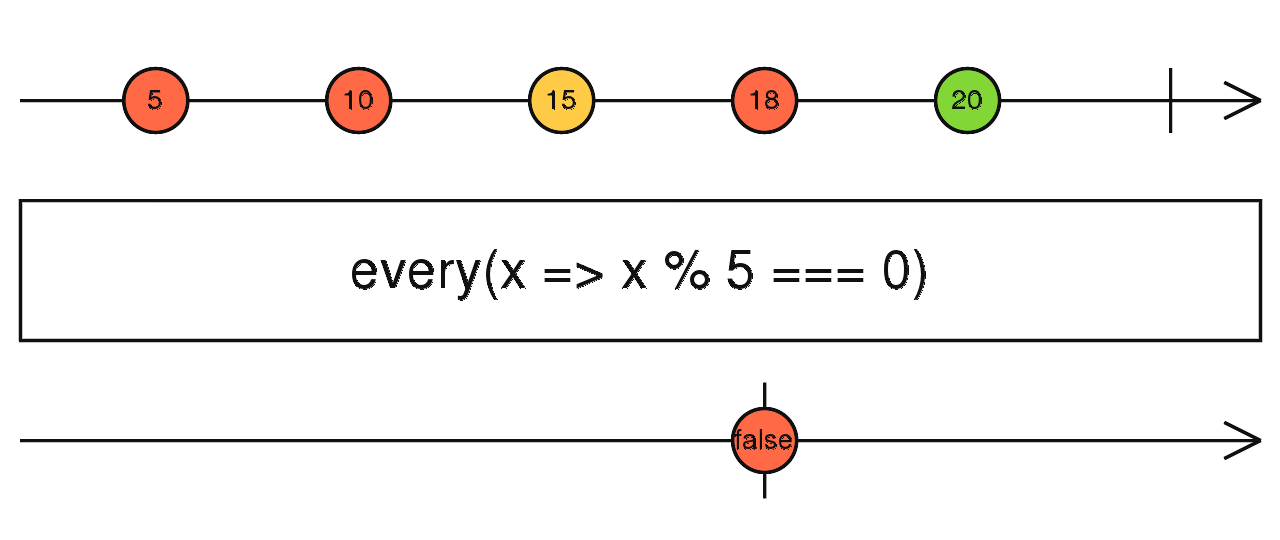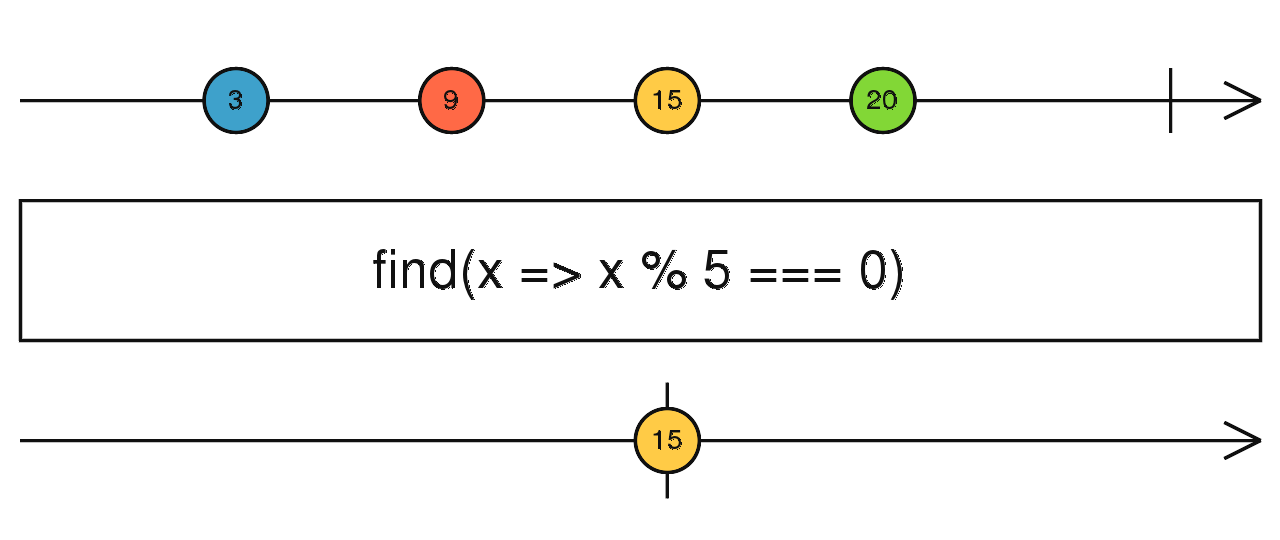lei4519 / blog Goto Github PK
View Code? Open in Web Editor NEW记录、分享
记录、分享
2024-04-21
Important
训练的收获隐藏在无聊的方法和充分锻炼的背后
你不需要新的训练科学,不需要任何新的策略,只需要进行更多已经有效的练习即可
想聊训练,必须要知道练的是什么,更重要的是要知道底层发生了什么
骨骼肌由两种肌纤维组成:
肌纤维收缩遵循顺序募集模式,其中 I 型肌纤维是最先募集的。随着运动强度的增加,肌肉收缩需求增加,I 型肌纤维无法维持必要的需求。IIa 型肌纤维开始发挥作用,最终,随着强度的不断增加,IIb 型肌纤维最终将被招募
简而言之,慢肌纤维用于较慢的速度,快肌纤维用于较快的速度
每种肌纤维具有不同的生物特性,因此在运动和比赛期间具有不同的行为
因此,每种运动强度意味着不同的代谢反应和肌纤维募集模式,这也对应于不同的训练区域,总结如下

肌肉运动(收缩)需要能量,汽车需要汽油,肌肉需要「三磷酸腺苷」(ATP, Adenosine Triphosphate)
我们摄入碳水化合物、脂肪、蛋白质都会分解成更小的能源底物,并且通过 不同的化学反应 提供运动时肌肉收缩所需的 ATP
不同的化学反应就是指三种产生能量的方式,即三大供能系统:
不同系统产生 ATP 的速度不同,产生 ATP 越快的系统,持续时间就越短
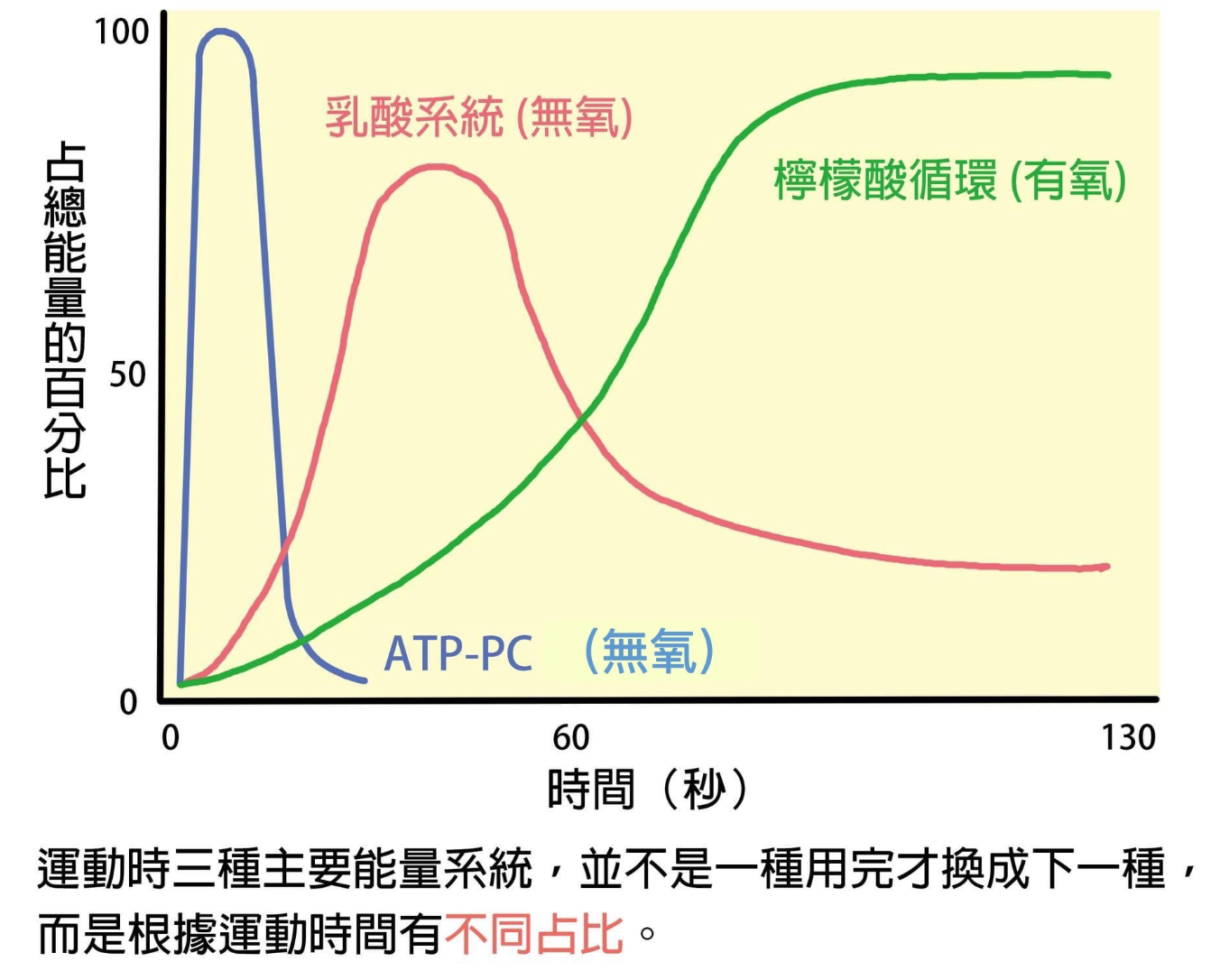
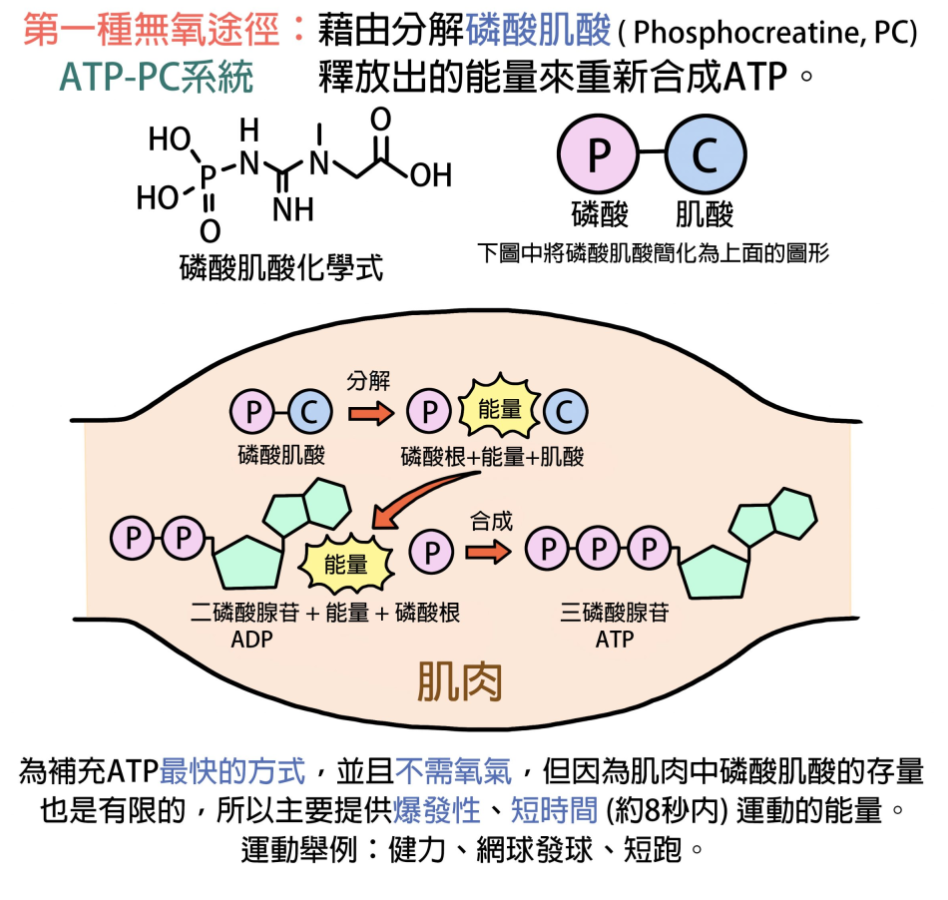
不需要氧气,是提供 ATP 最快的途径
磷酸原系统的反应机制是依靠磷酸肌酸(PCr,又记作 CP)与 ADP(ATP 高能磷酸键断裂后的产物)反应重新合成 ATP。因为中间只涉及到一步反应,因此这一机制可以完成 ATP 的快速补充
但由于肌肉中 PC 的含量是有限的,所以只能提供短时的爆发能量(冲刺、爆发)
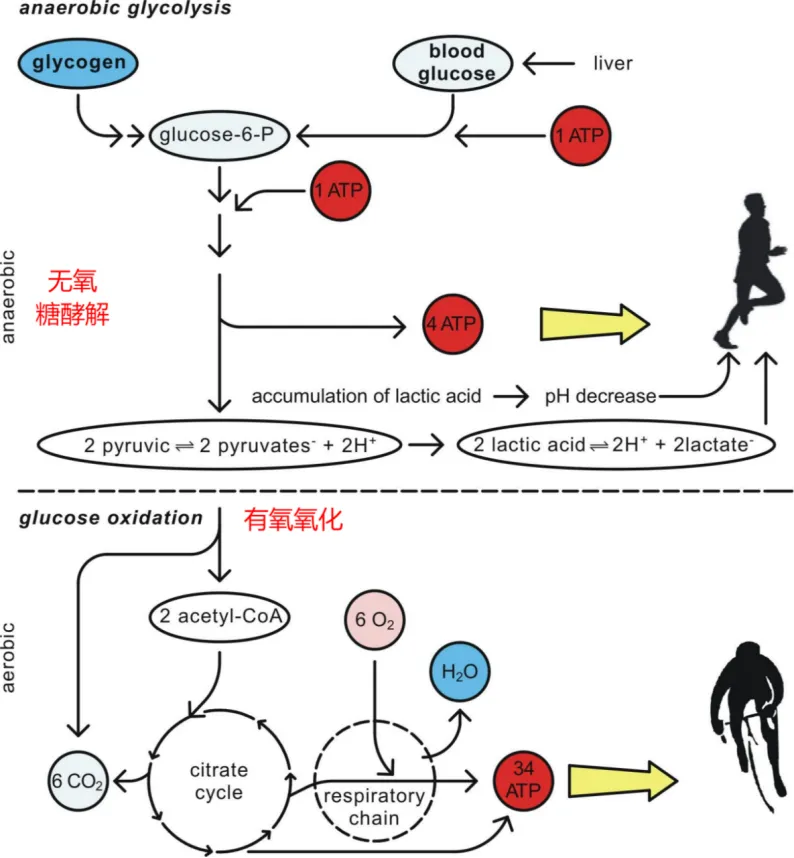
糖酵解过程(葡萄糖分解为丙酮酸)是糖类分解供能的第一步,糖酵解系统分为快速糖酵解和慢速糖酵解
快速糖酵解是无氧反应,慢速糖酵解是有氧反应,因此在反应机制和能源底物方面,糖酵解系统和有氧氧化系统是一致的,只不过在氧气不足的情况下,接下来的有氧氧化反应无法继续进行
糖酵解和有氧氧化的能源底物是储存在肌肉中的肌糖原,这部分糖原分解、氧化后直接就可以产生 ATP 供肌肉使用了
而肝糖原以及血糖主要是起到支持的作用,因为从毛细血管扩散到肌肉中需要一定的时间(变为肌糖原?),并不直接参与上面的反应
但这不意味着肝糖原和血糖不重要,当肌糖原不足时,需要血糖即时补充,否则运动员将「力竭」而无法继续运动
在相同的一分子糖原消耗下,糖酵解过程净产生 ATP 数量(4ATP-2ATP=2ATP)只有 2 分子;而如果继续有氧氧化过程,则可以继续产生 34 分子的 ATP!
因此,糖酵解过程的能量效率是很低的。同时这也意味着,相同的运动能量消耗,如果是由糖酵解过程提供,大概要比有氧过程多消耗约 17 倍的糖原!
这就是骑行时过多的无氧输出(糖酵解供能)容易「爆掉」的原因之一: 在糖酵解供能下,糖原消耗速率太快,很容易造成肌糖原的枯竭
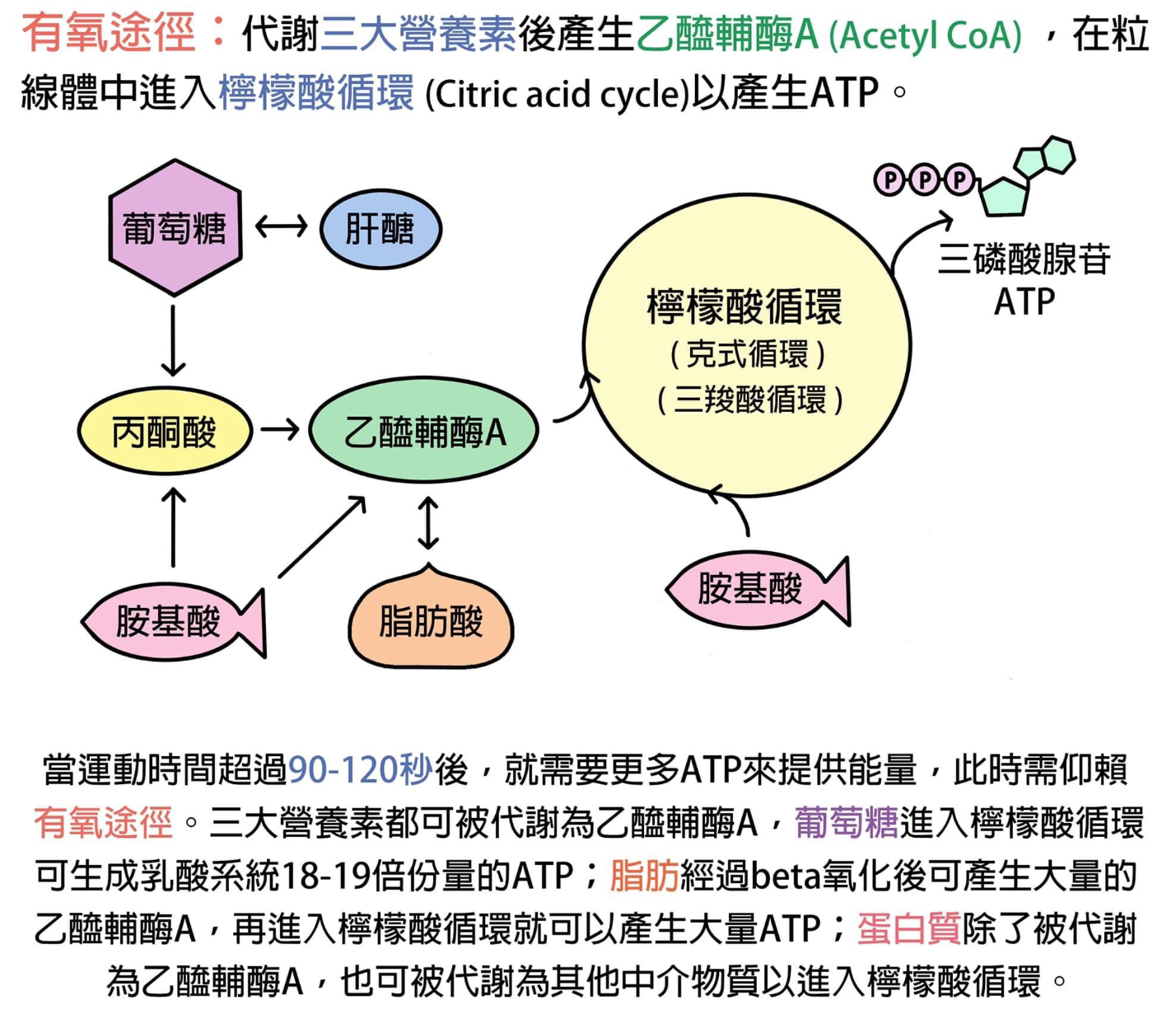
在有氧供能条件下,能量底物与氧气充分反应生成 ATP
尽管单位能量底物的氧化只能提供为数不多的 ATP,但有氧氧化可以在运动过程中源源不断进行,在底物消耗殆尽或电解质失衡之前,有氧运动可以一直持续下去
多年来,人们一直认为乳酸只是无氧运动产生的废物。甚至一度认为它会在运动后结晶,从而导致肌肉酸痛(现在我们知道这不是真的)
乳酸是骨骼肌细胞利用(消耗)葡萄糖的天然副产品(糖酵解系统),进入细胞的葡萄糖流量越高,乳酸的产量就越高(与氧气的可用性无关)
在高强度训练中,由于骨骼肌产生能量 (ATP) 的高收缩需求,II 型快肌纤维被充分募集,II 型肌纤维具有高度糖酵解能力(使用大量葡萄糖),所以会产生大量的乳酸
在剧烈运动期间,乳酸的产生量比静息水平高许多倍。与乳酸相关的氢离子 (H+) 的释放会导致收缩肌 pH 值显着降低,从而导致酸中毒(肌肉酸痛的原因)
但乳酸并不是废物,恰恰相反:乳酸是体内最重要的糖异生前体(新的葡萄糖生成剂)。我们在运动过程中消耗的所有葡萄糖中,约有 30% 来自乳酸「回收」(从乳酸重新变回葡萄糖,这是有氧氧化系统的能力)
而且不管你相信与否,乳酸对于大脑来说甚至至关重要,它是神经元使用的主要燃料。乳酸实际上对于长期记忆至关重要,甚至可能参与了解阿尔茨海默病。 (一些研究表明,当神经元对乳酸的摄取受到抑制时,长期记忆就会受到抑制)
在表 1 中可以清楚的观察到:运动员的竞技和训练水平越高,观察到的血乳酸积累就越少,功率输出和表现就越高
| Workload | Junior Cyclist 少年自行车手 | Top Amateurs 顶级业余爱好者 | Avg. Pro-Tour 平均。职业巡回赛 | World Class 世界一流 |
|---|---|---|---|---|
| w/kg 重量/千克 | Blood La (mmol/L) 血 La (mmol/L) | Blood La (mmol/L) 血 La (mmol/L) | Blood La (mmol/L) 血 La (mmol/L) | Blood La (mmol/L) 血 La (mmol/L) |
| 3 | 1.3 | 1.1 | 1.1 | 0.8 |
| 3.5 | 1.8 | 1.3 | 1.2 | 0.8 |
| 4 | 3 | 2.3 | 2 | 0.96 |
| 4.5 | 6.6 | 3.5 | 3.2 | 1.8 |
| 5 | 10 | 7.6 | 5.8 | 3.1 |
| 5.5 | 9.2 | 8.2 | 5.2 | |
| 6 | 8.9 |
表 1. 不同级别的自行车运动员血乳酸水平(mmol/L)差异。表由 San Millán 等人修改,2009 年
这是一个重要的观察结果,科罗拉多大学的运动生理学家圣米兰博士将其归因于某种能力:「顶级运动员观察到的较低血乳酸水平是由于 乳酸清除能力的增强」
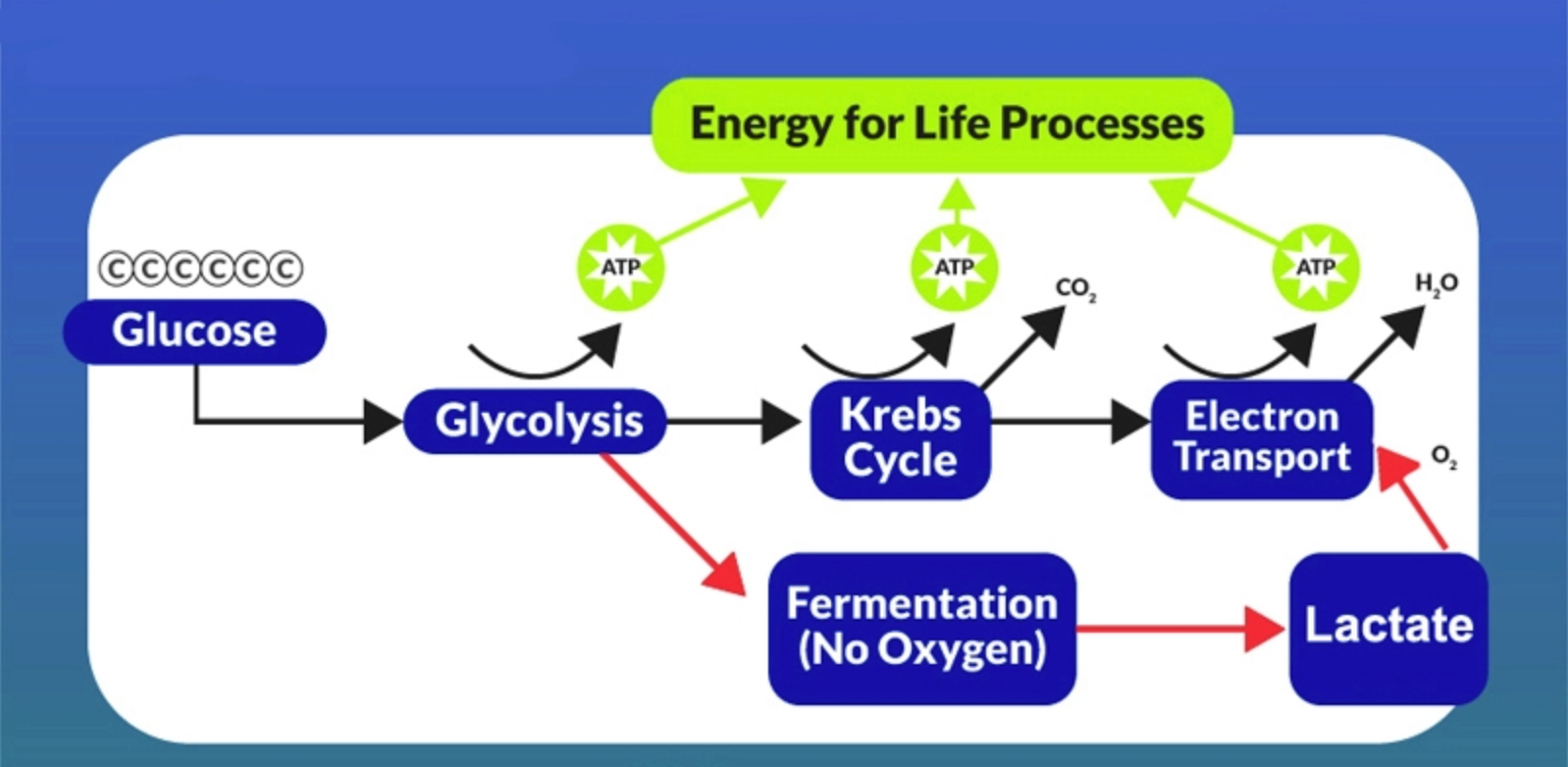
当氧气充足时(即在较低或中等强度的运动期间),肌肉通过有氧能量途径获取能量(上)
在剧烈运动期间(当糖酵解率非常高时),更多地依赖红色途径,导致乳酸积累(右下)
然而,这种乳酸可以通过「乳酸穿梭」途径(最右边的红色箭头)分解为能量,提供充足的氧气。身体通过将乳酸从工作肌肉输送到身体含氧量较高的区域来实现这一目标
乳酸穿梭理论描述了身体将乳酸从工作肌肉(乳酸水平升高的地方)通过血液运送到氧合更好的区域的能力,在那里乳酸可以用作燃料。这些地方就是你的肝脏或肾脏、心脏,然后是你的大脑
乳酸可以被供应到血液中,然后被运送到几乎每个需要利用的器官
但这里有一个问题:这个过程需要时间(分钟级),而乳酸在运动过程中会不断产生(当乳酸被成功转化成能量时,对决/比赛可能已经结束了)
训练有素的运动员血乳酸水平低的原因是他们清除乳酸(乳酸再利用)的效率很高,向血液输出的乳酸较少,因为他们在产生乳酸的肌肉中就清除了大量乳酸,这只需要几秒或几毫秒的时间
这是非常有利的,因为它可以使收缩肌肉更快地去除 H+,并更快地「回收」乳酸以获得额外的能量 (ATP)
因为乳酸主要在快肌纤维中产生(糖酵解系统),而在慢肌纤维中清除(有氧氧化系统)。这是一个复杂的过程,这个过程涉及不同的乳酸转运蛋白和酶
我们的训练目标似乎很明显:我们需要增加这些转运蛋白、酶和线粒体的数量,以提高我们的乳酸清除能力,从而大幅提高我们的整体运动表现
良好的训练从热身开始,这是一个大致 的热身流程,你可以根据自己的需要进行调整
根据过去 18 年的经验,2 区耐力训练已证明是提高乳酸清除能力效果最好的训练区
-- San Milan
如前所述,有氧训练(Zone 2)的目的主要是通过增加在慢肌纤维中清除乳酸的 线粒体数量,以及增加 MCT-1 和 mLDH 的数量来提高乳酸清除能力
高强度和耐力训练都会增加 MCT-4 的数量,从而增加乳酸从快肌纤维的转运
这里的关键不是仅仅去了解它,而是要做到这一点:2 区耐力训练应占训练的大部分。你需要掌握基础知识以在无聊的训练中找到安慰
通过刺激使生成更多的线粒体,增强慢肌纤维 (I 型) 周围的毛细血管化,训练身体更有效地使用脂肪作为主要燃料来源,减少碳水化合物作为燃料的使用,从而提高乳酸门槛,因为相比糖酵解产生的乳酸更少
最终,这些耐力运动有助于乳酸门槛、肌肉耐力、更大的有氧能力 (关于肌肉通过毛细血管向线粒体输送氧气的能力) 和降低 VLamax(最大乳酸生成速率)
为了减少无氧代谢的贡献,需要增加肌肉的有氧能力。有氧代谢在肌肉细胞内的线粒体中进行氧化脂肪和丙酮酸(或间接乳酸)以产生能量
因此,促进线粒体含量(肌肉内的数量/密度)和线粒体功能(参与氧化过程的酶的速度和效率)的训练将提高这种有氧能力,并相应地减少无氧代谢的贡献
最能刺激线粒体「含量」积极变化的训练方法似乎在很大程度上 与强度无关,而是与训练量和 训练持续时间 密切相关,线粒体「含量」已被证明是外周有氧能力(即肌肉内)的最大影响因素
因此,这些适应的关键刺激因素似乎是持续时间较长、强度较低、肌肉大量收缩的锻炼
此外,考虑到脂肪氧化不会产生任何乳酸,特别有利于与改善脂肪氧化而不是碳水化合物氧化相关的适应的训练将特别有利于减少乳酸的产生
同样,以脂肪氧化率最大化(通常约为 55-75% FTP)的强度进行长时间、低强度的骑行是实现这一目标的最佳选择
对于那些在训练中难以控制功率输出(即强度纪律不佳)的自行车手来说,重申这一点很重要:线粒体的这些适应并不会通过强度的增加而得到改善,即在锻炼中更加努力并不会增加适应性刺激或由此产生的适应的幅度
事实上,这样做会增加因疲劳而缩短锻炼时间的风险,并且不太重视脂肪氧化系统的工作,从而降低锻炼的质量
Warmup
- 1m 55%
- 2m 62%
- 2m 65%
7x
- 30m 68%
# 有氧锻炼的后期,增加几组低踏频的锻炼,增加肌肉力量
4x
- 2m 90%
- 2m 55%
- 10m 68%
Cooldown
- 2m 65%
- 2m 60%
W1m 55%
「甜蜜点」 是一种刚好低于乳酸门槛的强度,可以持续相当长的时间
Tip
与一些骑手和教练声称的相反,这不是一种神奇的锻炼,也不能提供「最物有所值」的效果
然而,当它被纳入一个更平衡的训练计划时,它仍然是一种有用的训练形式
特别是,甜区训练也显示出对乳酸清除能力的有益适应,有助于增加快肌纤维的有氧能力
因为低节奏和中等高功率会导致这些纤维被招募的比例更高,但在足够低的强度下,这种激活仍然主要是有氧的,所以这会使它们的有氧效率变得更好,因此线粒体密度增加、MCT-4、MCT-1 和 mLDH 增加
脂肪氧化也得到改善,并且随着肌肉毛细血管化的增强,可以提供更好的氧气供应,从而进一步改善乳酸清除率
除此之外还有如下益处:
甜区训练一般在 FTP 的 88-94% 下进行
逐浙热身,然后在大约 88-94% 的 FTP 之间进行 2-3 组 10-30m 的训练
最好使用 50-70 RPM 的踏频(除非你的膝盖有问题,在这种情况下使用你最自然的、舒服的踏频)
训练的 RPE 应该在 7/10 左右(即相当舒适,但并不「容易」)
你会注意到在这些努力过程中你的呼吸适度加快,但你仍然可以在呼吸之间说简短的句子,心率通常会上升到 75-85% Max HR
WU
- 1m 55%
- 1m 60%
- 2m 68%
- 1m 75%
- 1m 82%
- 1m 90%
- 2m 65%
3x
- 20m 89%
- 3m 50%
CD
- 2m 65%
- 2m 60%
- 2m 55%
在 2010 年,Tim Kerrison 接任了天空车队(现为英力士)的运动主管。他是整个车队转型的一部分,是边际收益大师,Kerrison 和天空队至今闻名的一件事是他们的上/下间歇训练
这种方式的训练包括多个「上/下」间歇块,主要目标是在「无氧阈值 (AT) 以上」部分积累乳酸,然后在「降至无氧阈值以下」部分恢复以清除乳酸
AT 通常称 为 FTP,尽管它们不是同一件事,但这是构建训练区的简单方法
如上所述,这种类型的训练就是教你的身体在持续的压力下有效地清除乳酸并重新获得葡萄糖作为燃料
Tip
在「上/超过」开始时保持保守,因为很容易过早地产生过多的乳酸,从而导致在「下/低于」部分很难进行良好的清除
功率和持续时间的正确组合应该允许每个区块持续至少 8-10m
很难给出具体的强度和持续时间的目标,因为这些可能是非常可变的,这取决于你的乳酸产生率和清除率
不过,总的来说,RPE 应该在 7/10 左右,心率应该大致在 80-90% Max HR 之间
这些锻炼不仅可以激发乳酸清除能力,还可以保持自行车训练的针对性:比赛节奏往往变化很大。进攻、爬坡、侧风、鹅卵石和狭窄的道路都塑造了一个动态的比赛结构,使用上/下块,您就已经为即将发生的事情做好了准备
这种训练有很多变种,你可以混合进行不同形式的训练,并根据自己的情况进行功率区间的微调(甚至可以自定义自己的训练)
Warmup
...
3x
- 2m 110%
- 2m 80%
- 5m 55%
3x
- 2m 110%
- 2m 80%
- 5m 55%
3x
- 2m 110%
- 2m 80%
- 5m 55%
Cooldown
...
Warmup
...
3x
- 1m 125%
- 4m 68%
- 5m 55%
3x
- 1m 125%
- 4m 68%
- 5m 55%
3x
- 1m 125%
- 4m 68%
- 5m 55%
1ooldown
...
Warmup
...
3x
- 45s 125%
- 2m15s 80%
- 5m 55%
3x
- 45s 125%
- 2m15s 80%
- 5m 55%
3x
- 45s 125%
- 2m15s 80%
- 5m 55%
Cooldown
...
值得注意的是,上面的「乳酸阈值」间隔不会直接提高乳酸清除率
阈值间隔几乎都在使用快肌纤维,清除是通过慢肌纤维完成的。这就是为什么我们需要在乳酸堆积后进行较低强度的配速变化
然而,在 FTP 上进行的间歇训练对于增加 MCT-4 转运蛋白、从肌纤维中提取乳酸并提高乳酸耐受性仍然非常有效
我们还希望能够在比赛中通过 FTP 产生动力,因此需要练习在 98-103% FTP 下进行 3x15m 或 2x20m 的锻炼
值得注意的是,即使间歇性最大摄氧量间隔也可以提高乳酸清除率。例如,Billat 30/30 间隔(30 秒开启,30 秒关闭),对于训练有素的运动员来说尤其如此。因为 30 秒的休息时间太长,无法保持足够高的摄氧量,因此作为乳酸清除锻炼效果更好
目标:保持最大心率的 90-95% 左右尽可能长的骑行
原因:通过以下方式促进每搏输出量的适应
本质上是想通过向心肌填充大量血液来「拉伸」心肌,这样它就可以增加容量并提高其收缩强度,从而在每次跳动时输送更多的血液
warm up
- 1m 55%
- 1m 63%
- 1m 70%
- 1m 78%
- 1m 85%
3x
- 1m 100%
- 1m 55%
- 1m 130%
- 2m 55%
6x
- 4m 120%
- 4m 55%
CD
- 5m 45%
目标:在高强度肌肉纤维内部和周围建立更大的毛细血管和线粒体密度
原因:
一组持续 3-8 分钟的间歇,从远高于阈值 (大约 120-130% FTP 或 8.5/10 的努力水平,持续 20 到 60 秒) 的硬起步开始,以迅速提高心率和耗氣量
然后根据间隔的长度调整到大约 100-115% FTP 之间的强度 (更短的间隔功率更高),这一部分应该保持在 90% Max HR 以上
使用 1:1 或 2:1 的恢复间隔,例如 5 次硬启动间隔,每次在 120-130% FTP 时开始 30 秒,然后在 100-108% FTP 骑行 4.5 分钟,在 45-55% 的 FTP 下每次间隔恢复 3 分钟
目的:这个训练的主要目的是提高最大摄氧量 (即你可以吸收和处理氧气以产生能量的最大速率)
这种训练被认为在帮助提高心输出量 (心脏每秒可以泵出的血量) 方面特别有效,因为心率非堂接近最大值
研究表明,像这样的硬启动间隔比恒定的功率间隔可以更快的启动心跳速率(接近最大值)
WU
- 1m 55%
- 1m 63%
- 1m 70%
- 1m 78%
- 1m 85%
- 1m 100%
- 1m 85%
- 1m 100%
- 3m 55%
7x
- 30s 130%
- 4m30s 110%
- 4m 45%
CD
- 5m 40%
这种间隔设计包括 2-4 个区块的「微爆发」间隔,或者换句话说,非常短、剧烈的努力,由同样短的恢复分开
每次微爆发通常持续 15 到 45 秒,在每个区块内,工作恢复比通常在 1:1 到 2:1 之间 (根据我们的经验,2:1 的间隔往往效果最好)
例如:3 个 9 分钟的方块,30 秒 「难」,15 秒「容易」
微爆通常在 120-130% FTP 左右,你可能需要增加或减少功率目标
微爆发的恢复间隔应该非常容易(45% FTP)
你应该看到心率至少达到 85% Max HR,总体来说,每一次努力的感觉应该是 8/10 的努力水平,你应该呼吸困难
每个块通常持续 9-15 分钟,中间大约有 3-5 分钟的轻松骑行
目的:和之前的训练一样,这次训练的目标是提高最大摄氧量
这些间歇训练的原理是,心率和耗氧量在每个区城向上漂移到最大水平。在每个区块中包含「微恢复」 允许实现合理的长时间区块,从而在最大心率和 VO2max 的高百分比下花费更长的总时间
warm up
- 1m 55%
- 1m 63%
- 1m 70%
- 1m 78%
- 1m 85%
- 1m 96%
- 1m 105%
- 1m 120%
- 1m 55%
15x
- 30s 130%
- 30s 45%
- 3m 40%
15x
- 30s 130%
- 30s 45%
- 3m 40%
15x
- 30s 130%
- 30s 45%
- 3m 40%
- 5m 110%
cold down
- 5m 40%
VO2max: Microbursts 2
warm up
- 1m 55%
- 1m 63%
- 1m 70%
- 1m 78%
- 1m 85%
- 1m 96%
- 1m 105%
- 1m 120%
- 1m 55%
12x
- 40s 130%
- 20s 40%
- 4m 40%
12x
- 40s 130%
- 20s 40%
- 4m 40%
12x
- 40s 130%
- 20s 40%
- 4m 40%
- 5m 110%
cold down
- 5m 40%
限制碳水化合物的可用性(RCA)可以让身体更有效的使用脂肪,延缓碳水化合物(「糖原」)储存的消耗,还可以通过减少给定功率输出下乳酸(以及相关的疲劳代谢物)的产生来帮助提高乳酸阈值(以及类似的阈值功率/FTP/临界功率)
RCA 主要有以下三种方法:
Important
备好碳水补充(能量胶/巧克力等),一旦发现情况不对立刻摄入!!!
在 45-55% FTP 之间骑行 5 分钟
然后,尽可能地控制你的力量,以大约 2 - 3% 的 FTP 增量骑 5m,从 55% FTP 开始,到 85% FTP 结束
在每个阶段的最后一分钟,大声背诵字母表,并注意说话的舒适程度
对于每个阶段,将其分为「易说」、「难说」或「不确定」。请在活动后评论中记录你对每个阶段的分类
然后在 55-75% 的 FTP 之间稳定地骑行剩余的路程
你的 VT1 是呼吸感觉舒适的最高功率。如果你的呼吸感觉不舒服,或者你不确定,那么这个能力被归类为高于你的 VT1
目的: 本课程的目的是确定您的第一个通气阈值 (VT1) 位于何处。你的 VT1 是你的呼吸频率从舒适过渡到稍微升高的一个点,它与你开始从碳水化合物中获得大量能量的强度相关。这也是一个接近你的「脂肪最大值」的强度 (即你以最大速率氧化脂肪的强度)。VT1 的位置对于长距离耐力比赛非常重要,因为它标志着你可以持续数小时的强度上限
2021-03-01
好的程序员懂得如何从重复的工作中逃脱:
- 操作DOM时,发现了Jquery。
- 操作JS时,发现了lodash。
- 操作事件时,发现了Rx。
Rxjs 本身的 概念 并不复杂,简单点说就是对观察者模式的封装,观察者模式在前端领域大行其道,不管是使用框架还是原生 JS,你一定都体验过。
在我看来,Rxjs 的强大和难点主要体现对其近 120 个操作符的灵活运用。
可惜官网中对这些操作符的介绍晦涩难懂,这就导致了很多人明明理解 Rxjs 的概念,却苦于不懂的使用操作符而黯然离场。
本文总结自《深入浅出 Rxjs》一书,旨在于用最简洁、通俗易懂的方式来说明 Rxjs 常用操作符的作用。学习的同时,也可以做为平时快速查阅的索引列表。
subscribenextcomplete需要注意流的完成和订阅时间,某些操作符必须等待流完成之后才会触发。
其实根据操作符的功能我们也可以大致推断出结果:如果一个操作符需要拿到所有数据做操作、判断,那一定是需要等到流完成之后才能进行。
创建流操作符最为流的起点,不存在复杂难懂的地方,这里只做简单的归类,具体使用查阅官网即可,不再赘述。
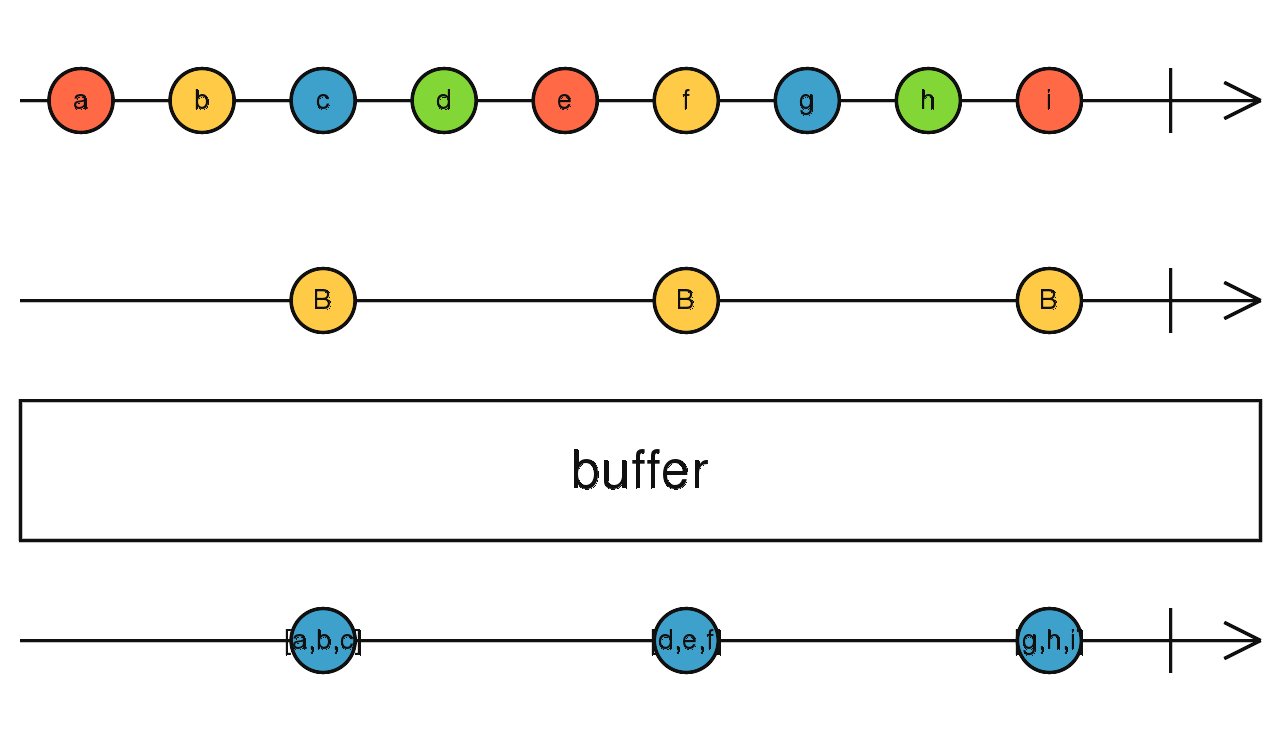
订阅多条流,将接收到的数据向下吐出。
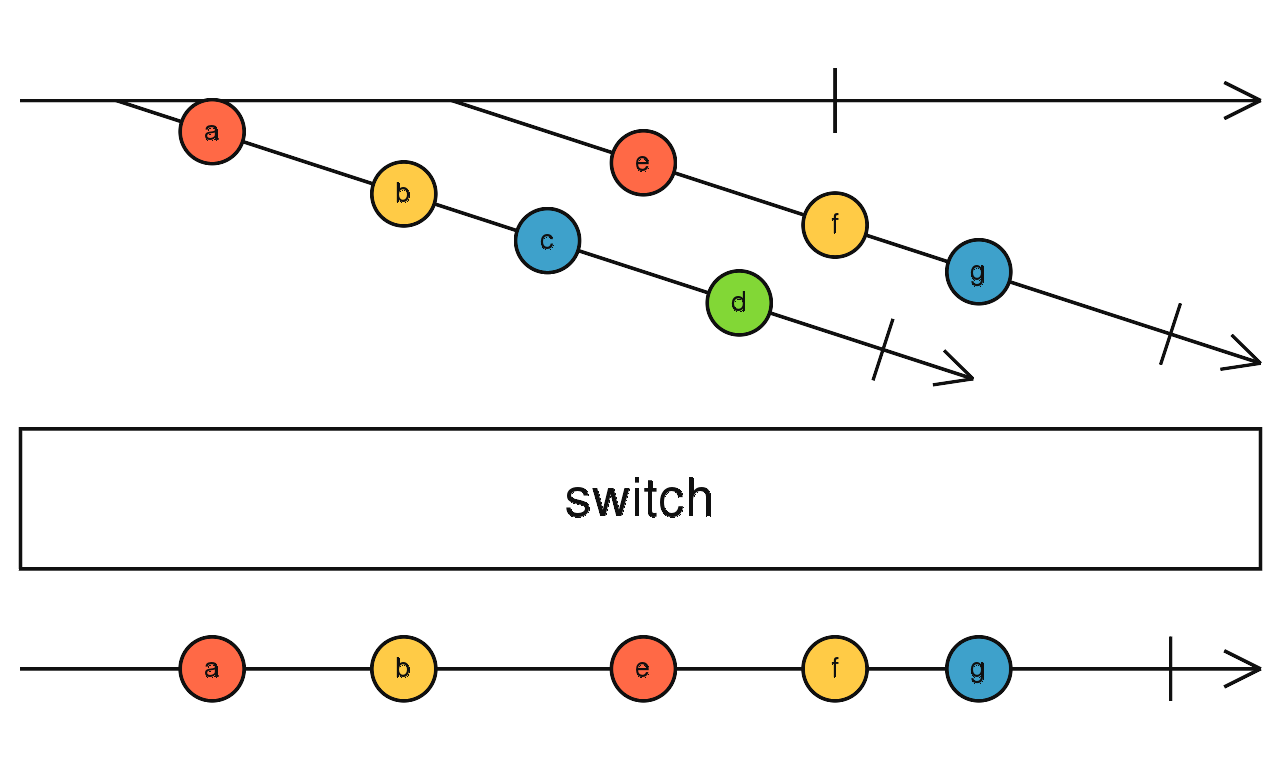
首尾连接
依次订阅:前一个流完成,再订阅之后的流。
当流全部完成时 concat 流结束。
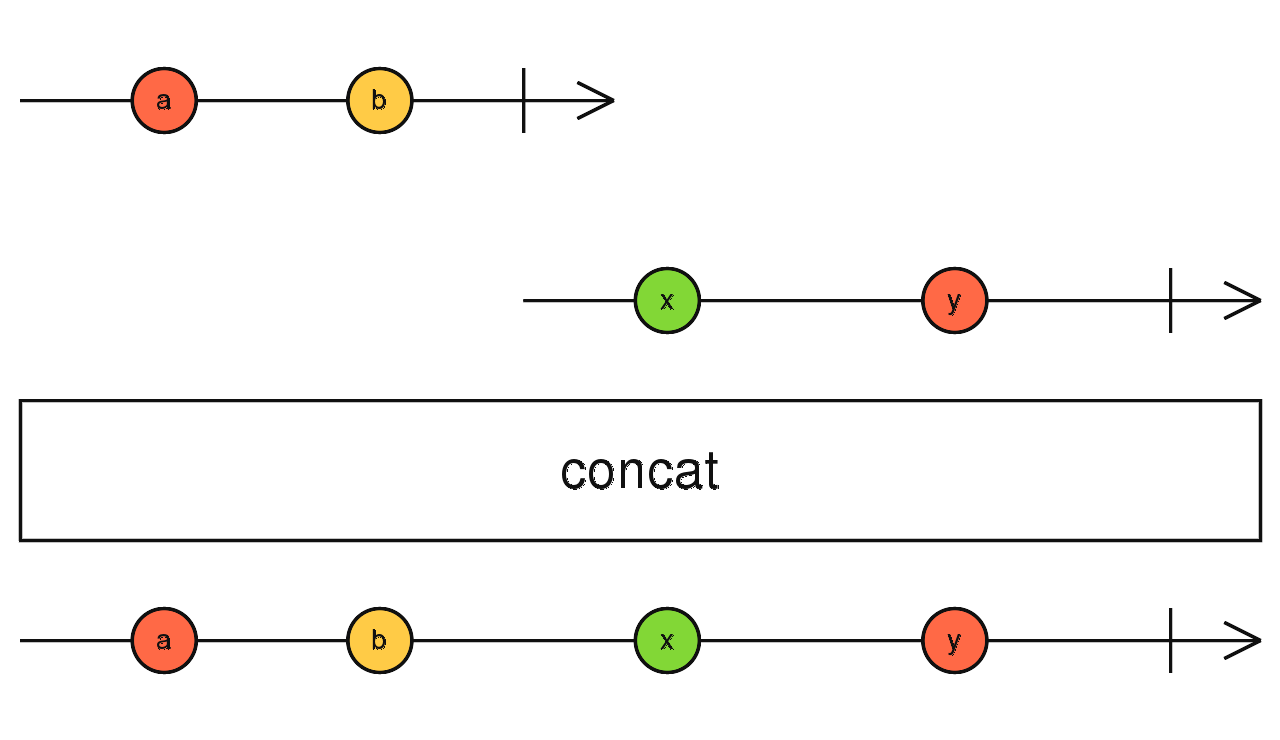
concat(source1$, source2$) 先到先得
订阅所有流,任意流吐出数据后,merge 流就会吐出数据。
对异步数据才有意义。
当流全部完成时 merge 流结束。
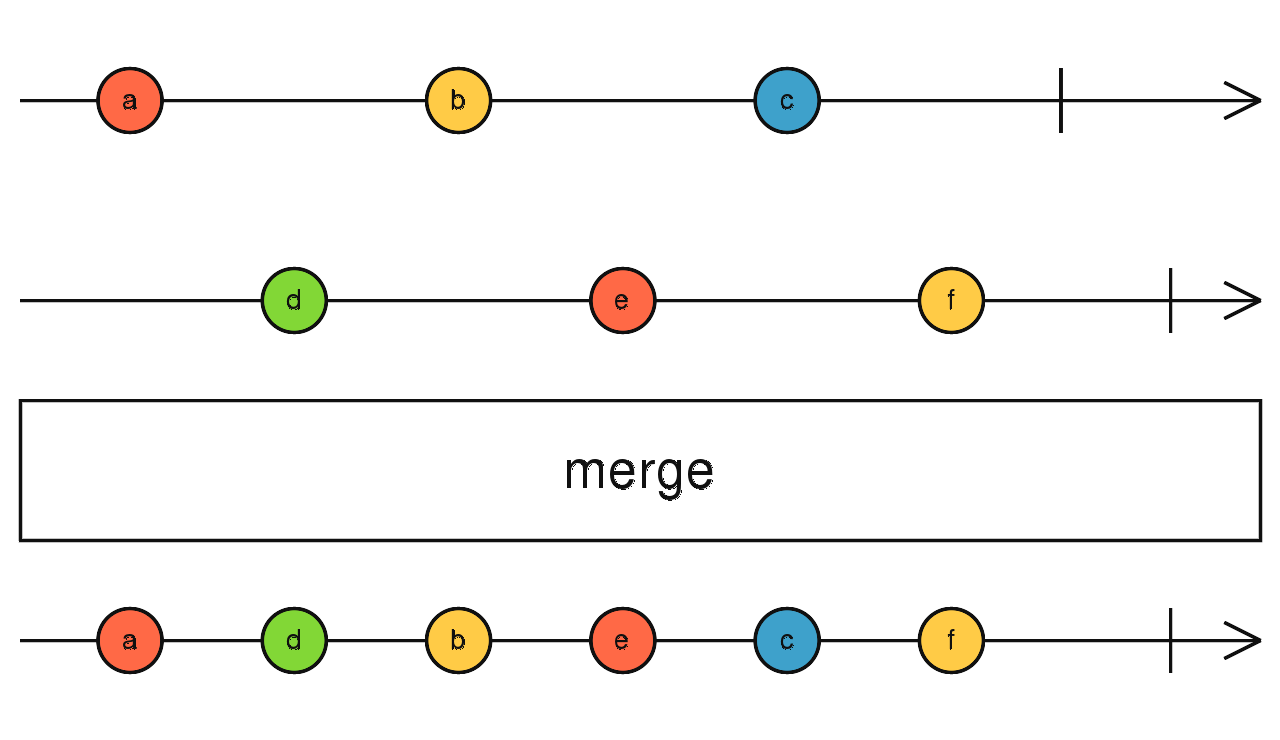
merge(source1$, source2$) 一对一合并(像拉链一样)
i 次,将第 i 次的数据合并成数组向下传递。zip(source1$, source2$) 合并所有流的最后一个数据
订阅所有流,任意流触发时,获取其他所有流的最后值合并发出。
因为要获取其他流的最后值,所以在刚开始时,必须等待所有流都吐出了值才能开始向下传递数据。
所有的流都完成后,combineLatest 流才会完成。
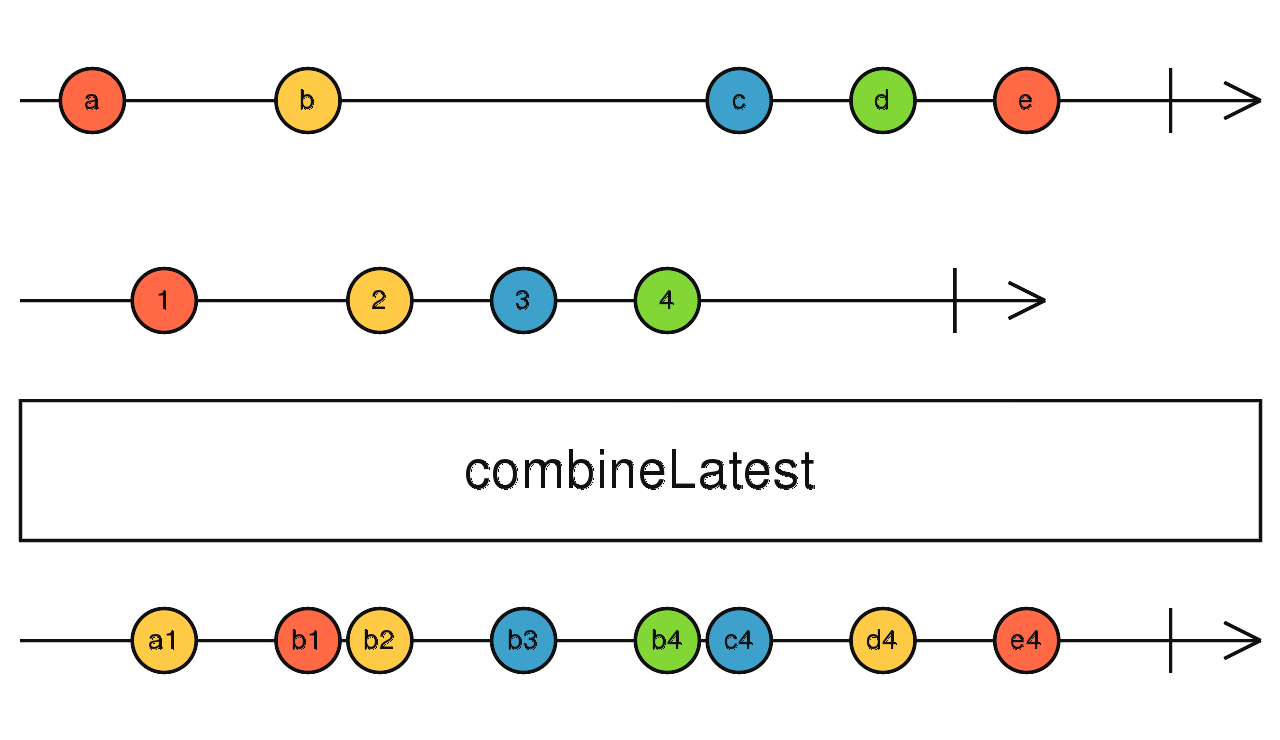
combineLatest(source1$, source2$) 合并所有流的最后一个数据,功能同 combineLatest,区别在于:
combineLatest:当所有流准备完毕后(都有了最后值),任意流触发数据都会导致向下吐出数据。
withLatestFrom:当所有流准备完毕后(都有了最后值),只有调用 withLatestFrom 的流吐出数据才会向下吐出数据,其他流触发时仅记录最后值。
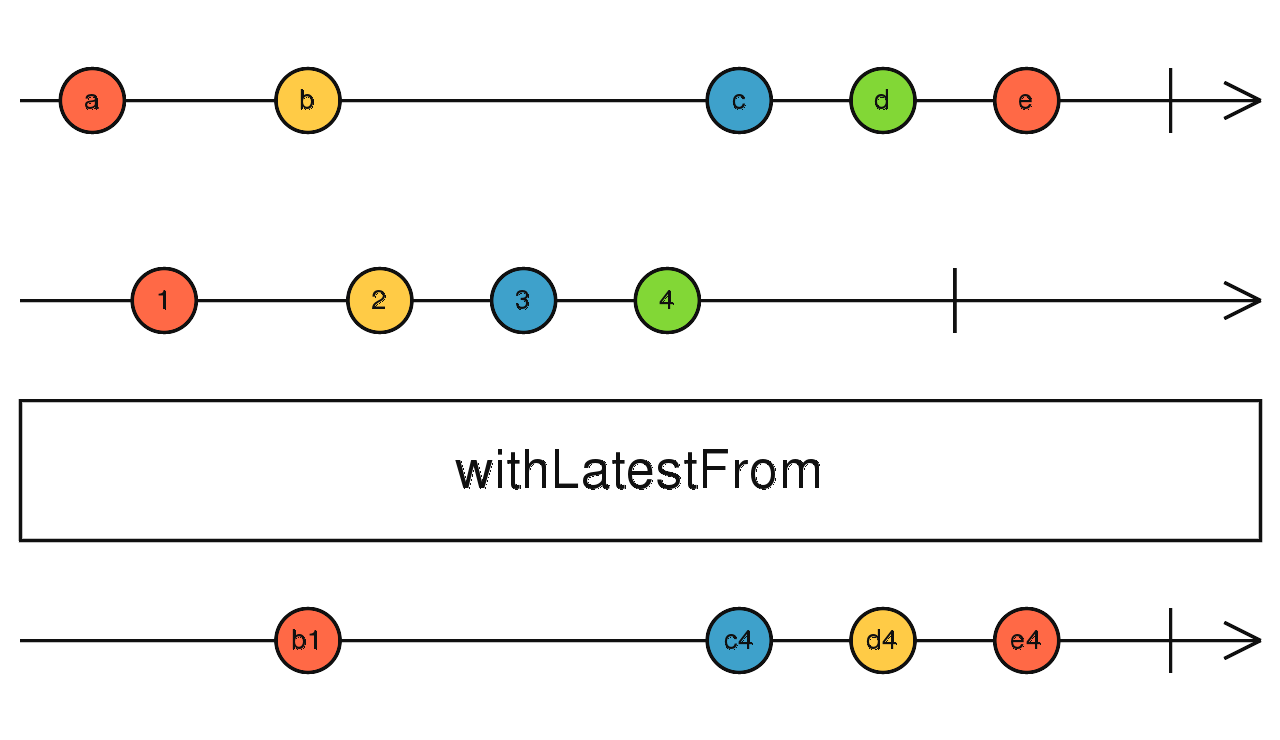
source1$.pipe(withLatesFrom(source2$, source3$)) 胜者通吃
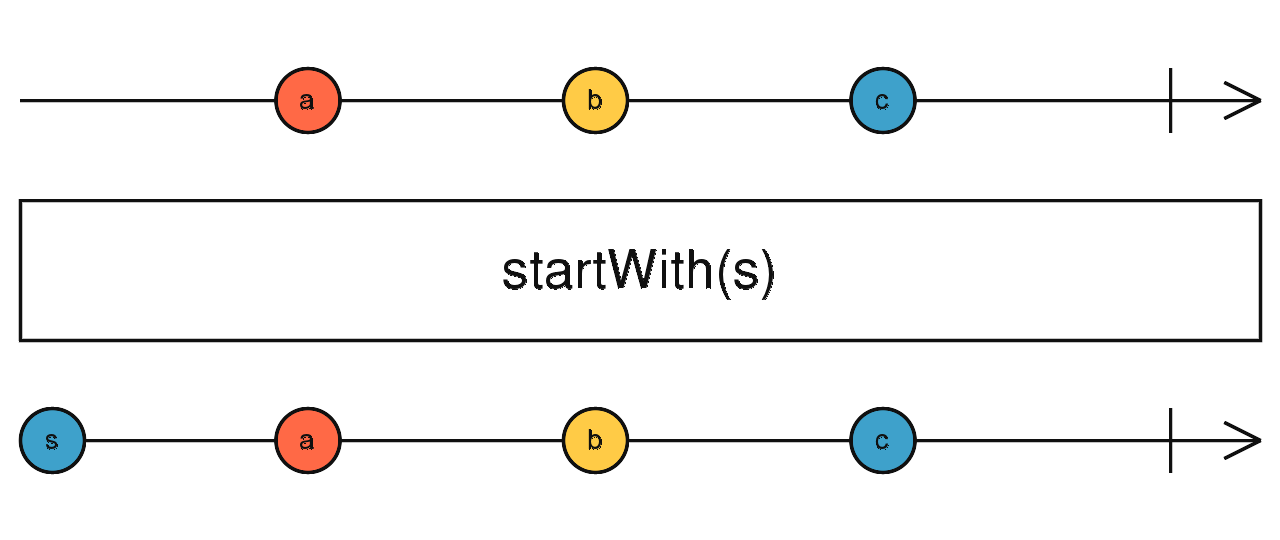
race(source1$, source2$) 在流的前面填充数据
source1$.pipe(startWith(1)) 合并所有流的最后一个数据
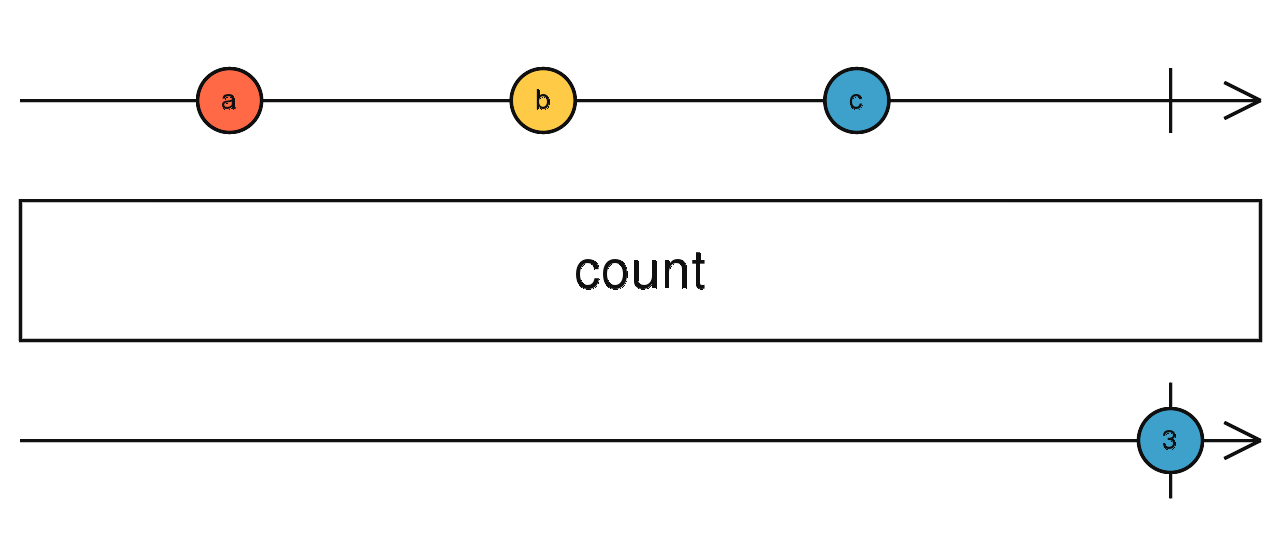
forkJoin(source1$, source2$) 当前流完成之后,统计流一共发出了多少个数据。
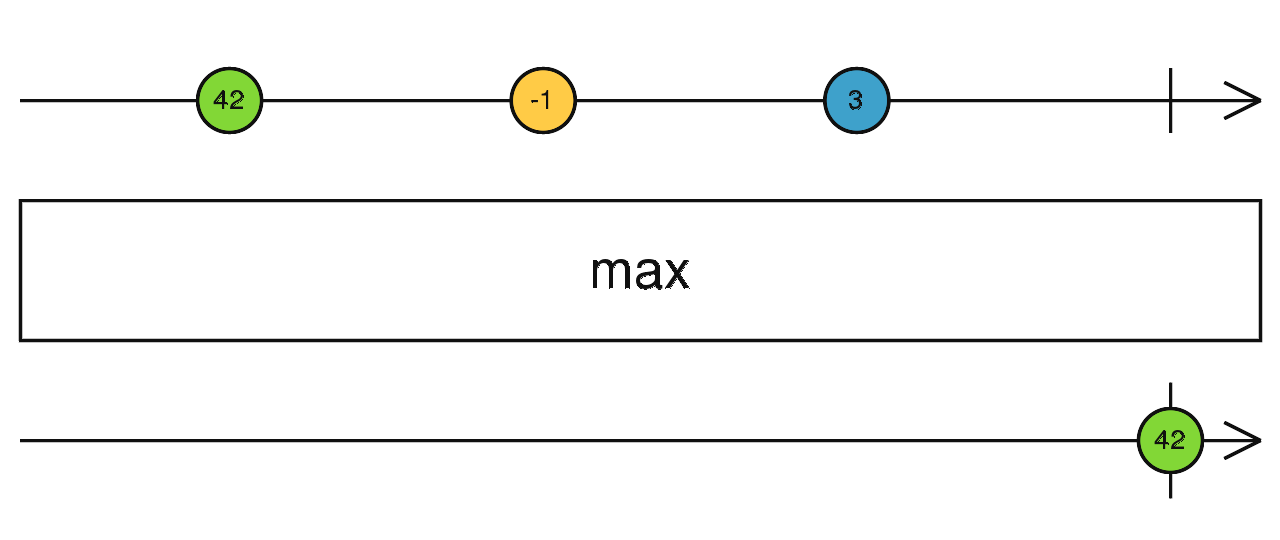
source$.pipe(count()) 当前流完成之后,计算 最小值/最大值。
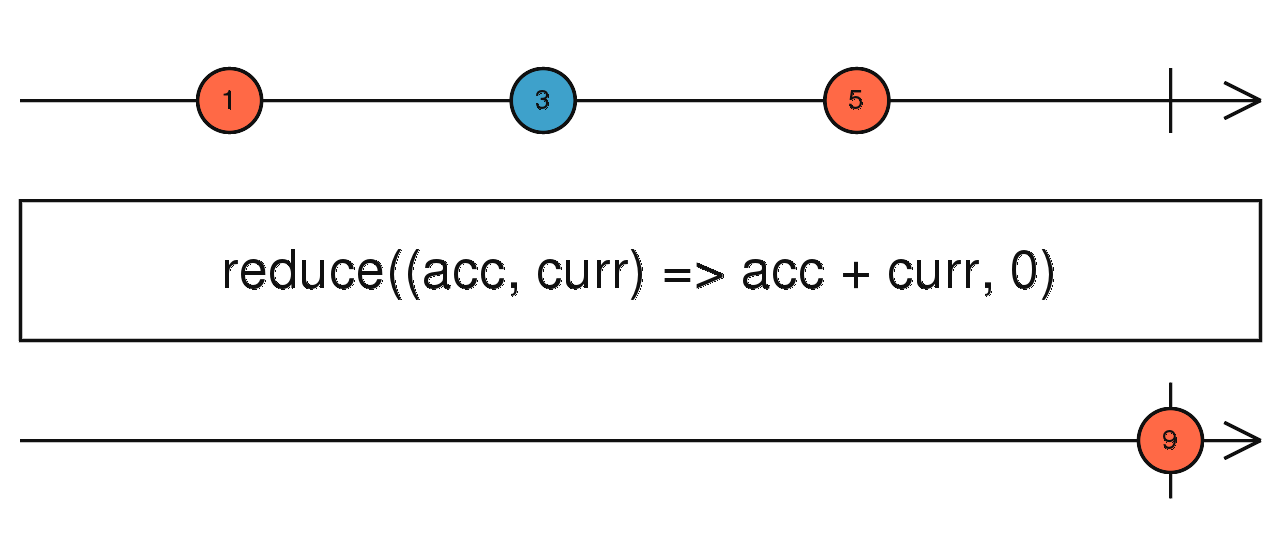
source$.pipe(max()) 同数组用法,当前流完成之后,将接受的所有数据依次传入计算。
source$.pipe(reduce(() => {}, 0)) 同数组,需要注意的是:如果条件都为 true,也要等到流完成才会吐出结果。
原因也很简单,如果流没有完成,那怎么保证后面的数据条件也为 true 呢。
source$.pipe(every(() => true / false)) 同数组,注意点同 every
source$.pipe(find(() => true / false)) 判断流是不是一个数据都没有吐出就完成了。
source$.pipe(isEmpty()) 如果流满足 isEmpty,吐出默认值。
source$.pipe(defaultIfEmpty(1)) 同数组
source$.pipe(filter(() => true / false)) 取第一个满足条件的数据,如果不传入条件,就取第一个
source$.pipe(first(() => true / false)) 取第一个满足条件的数据,如果不传入条件,就取最后一个,流完成才会触发。
source$.pipe(last(() => true / false)) 拿够前 N 个就完成
source$.pipe(take(N)) 拿够后 N 个就结束,因为是后几个所以只有流完成了才会将数据一次发出。
source$.pipe(takeLast(N)) 给我传判断函数,什么时候结束你来定
source$.pipe(takeWhile(() => true / false)) 给我一个流 (A),什么时候这个流 (A) 吐出数据了,我就完成
source$.pipe(takeUntil(timer(1000))) 跳过前 N 个数据
source$.pipe(skip(N)) 给我传函数,跳过前几个你来定
source$.pipe(skipWhile(() => true / false)) 给我一个流 (A),什么时候这个流 (A) 吐出数据了,我就不跳了
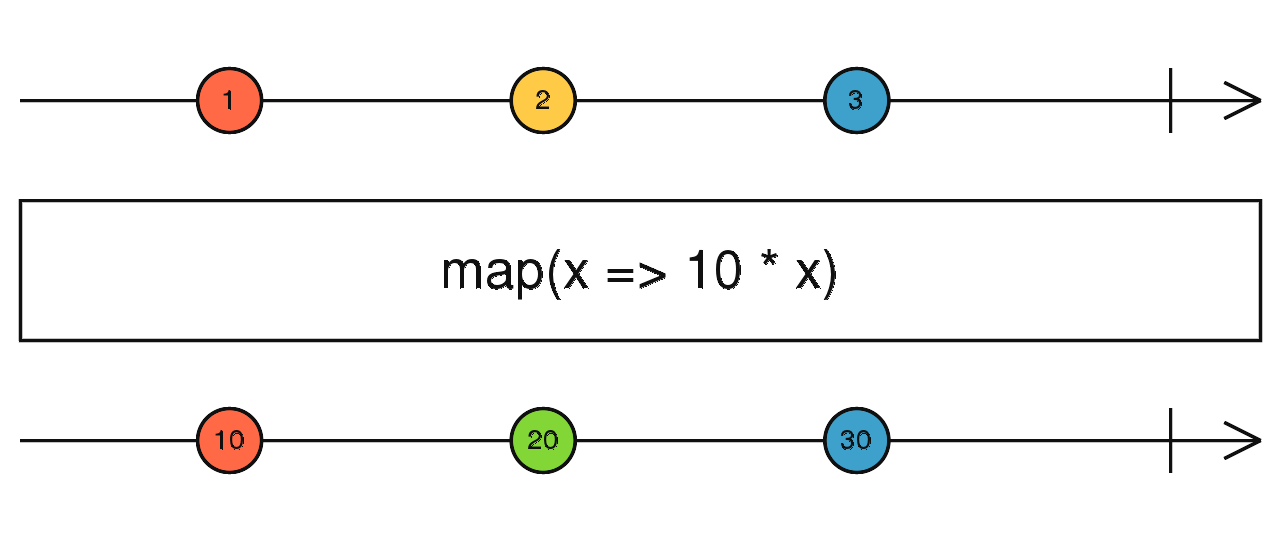
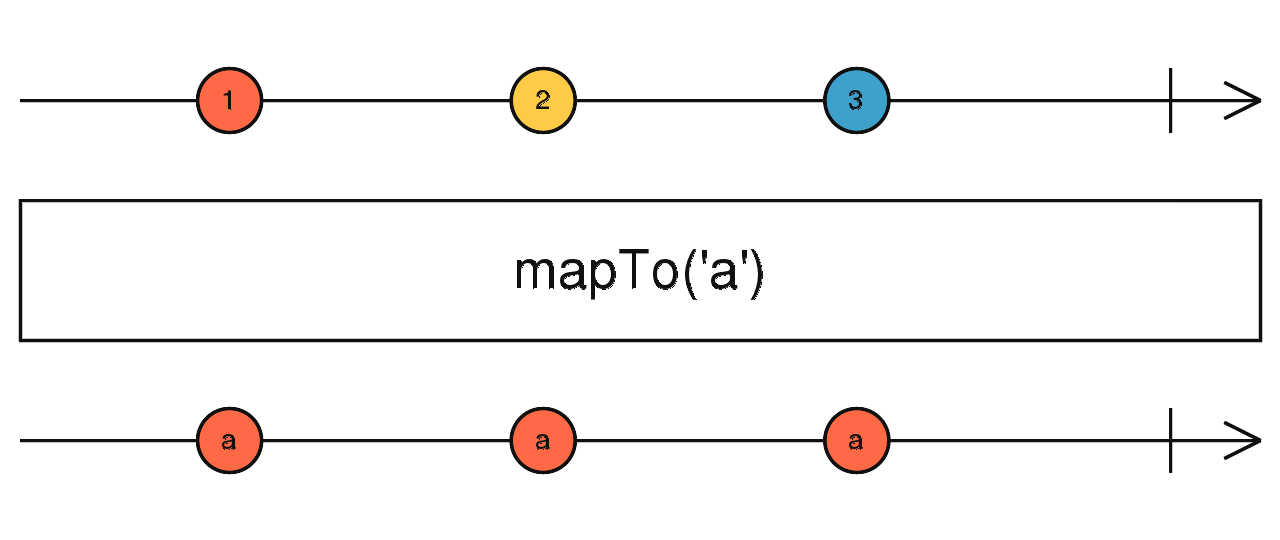
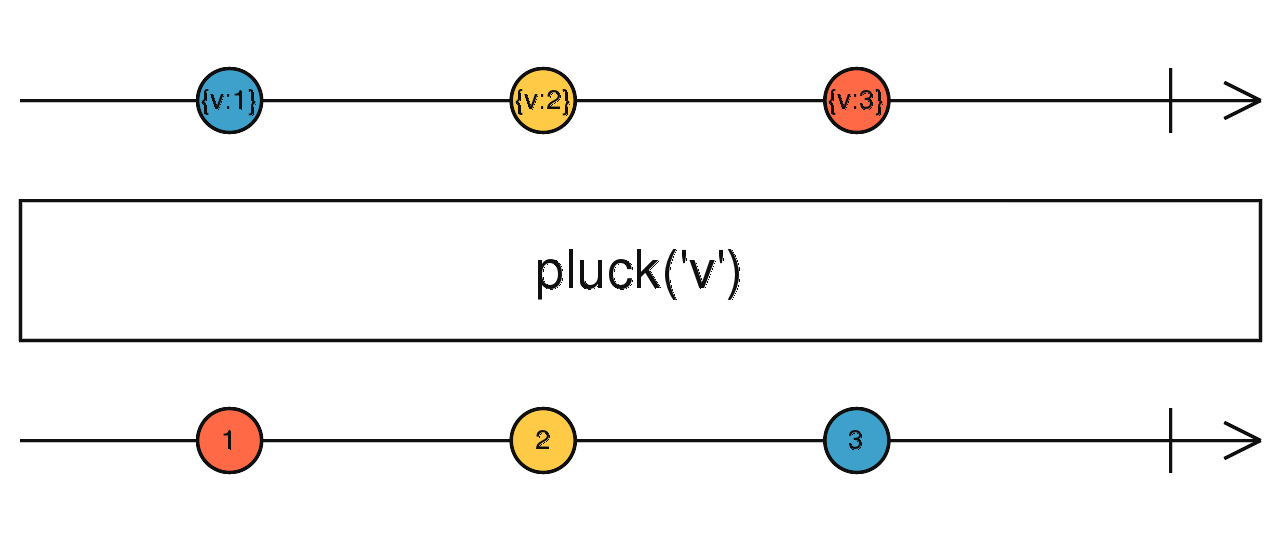
source$.pipe(skipUntil(timer(1000))) source$.pipe(map(() => {})) source$.pipe(mapTo("a")) source$.pipe(pluck("v")) 对防抖、节流不了解的请自行查阅相关说明。
传入一个流 (A),对上游数据进行节流,直到流 (A) 吐出数据时结束节流向下传递数据,然后重复此过程
source$.pipe(throttle(interval(1000))) 根据时间 (ms) 节流
source$.pipe(throttleTime(1000)) 传入一个流 (A),对上游数据进行防抖,直到流 (A) 吐出数据时结束防抖向下传递数据,然后重复此过程
source$.pipe(debounce(interval(1000))) 根据时间 (ms) 防抖
source$.pipe(debounceTime(1000)) audit 同 throttle,区别在于:
source$.pipe(audit(interval(1000))) 同上,不再赘述
source$.pipe(auditTime(1000)) 传入一个流 (A),对上游数据吐出的最新数据进行缓存,直到流 (A) 吐出数据时从缓存中取出数据向下传递,然后重复此过程
source$.pipe(sample(interval(1000))) 根据时间 (ms) 取数
source$.pipe(sampleTime(1000)) 所有元素去重,返回当前流中从来没有出现过的数据。
传入函数时,根据函数的返回值分配唯一 key。
source$.pipe(distinct())
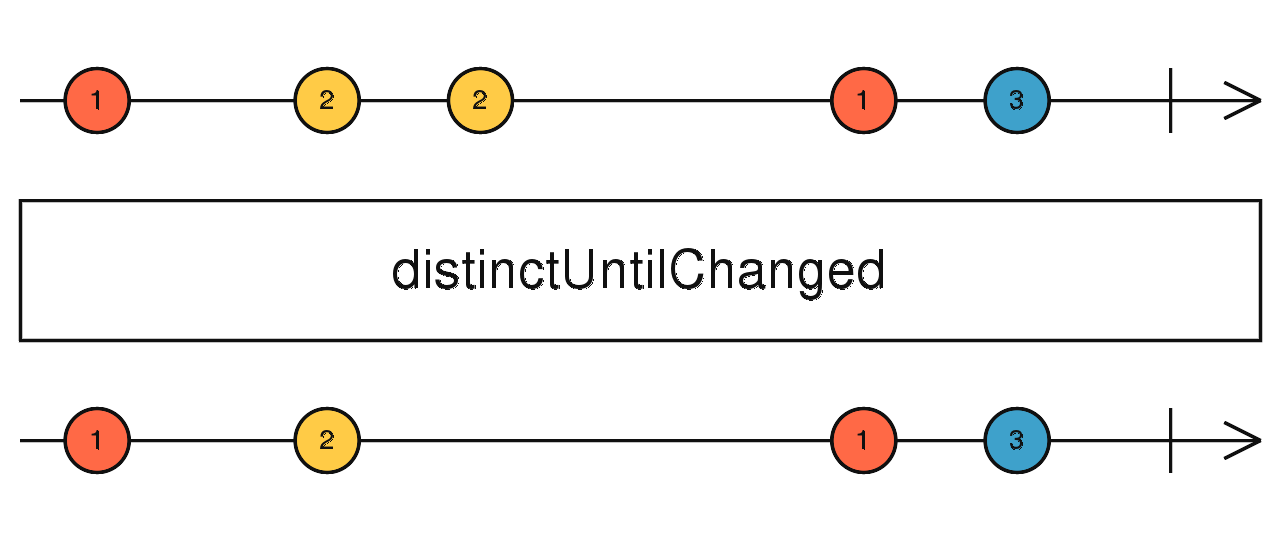
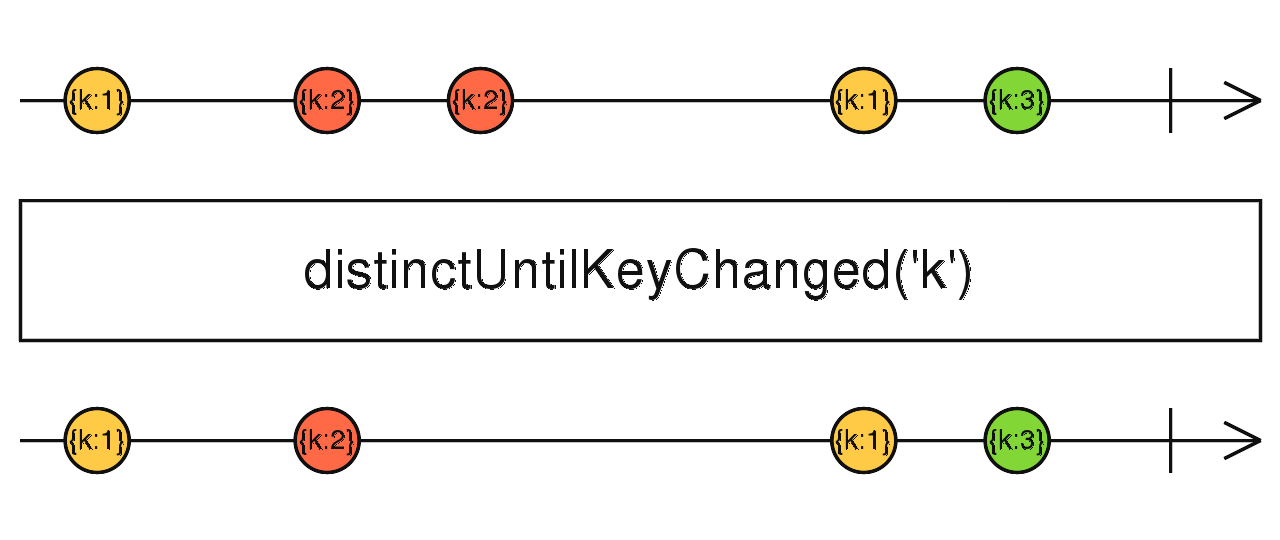
Observable.of({ age: 4, name: "Foo" }).pipe(distinct((p) => p.name)) 相邻元素去重,只返回与上一个数据不同的数据。
传入函数时,根据函数的返回值分配唯一 key。
source$.pipe(distinctUntilChanged()) source$.pipe(distinctUntilKeyChanged("id")) 忽略上游的所有数据,当上游完成时,ignoreElements 也会完成。(我不关心你做了什么,只要告诉我完没完成就行)
source$.pipe(ignoreElements()) 只获取上游数据发出的第 N 个数据。
第二个参数相当于默认值:当上游没发出第 N 个数据就结束时,发出这个参数给下游。
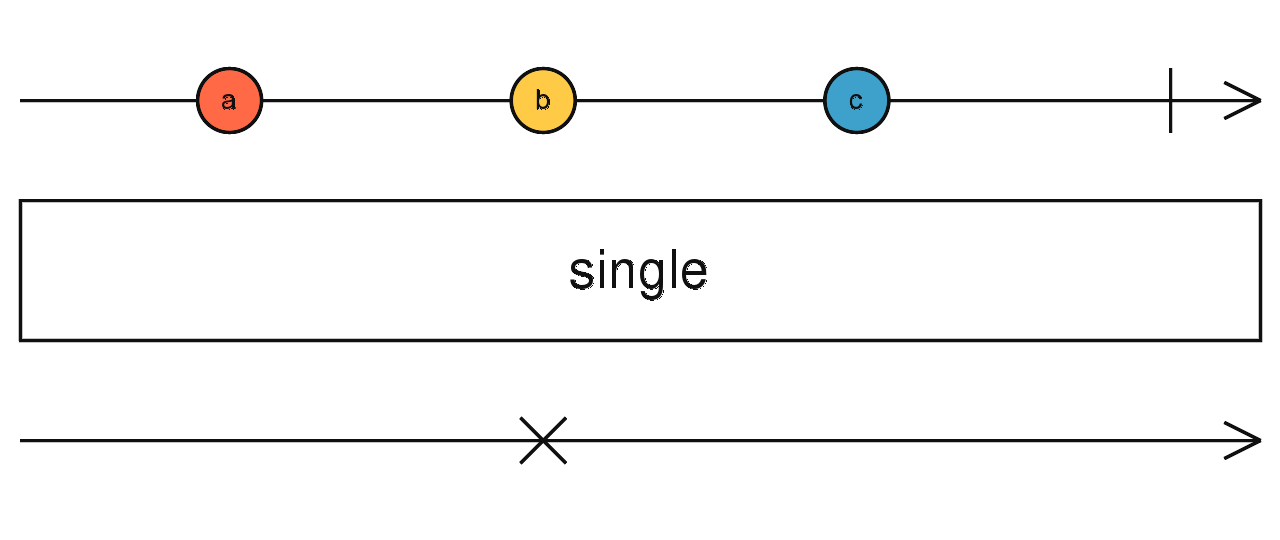
source$.pipe(elementAt(4, null)) source$.pipe(single(() => true / false)) 缓存上游吐出的数据,到指定时间后吐出,然后重复。
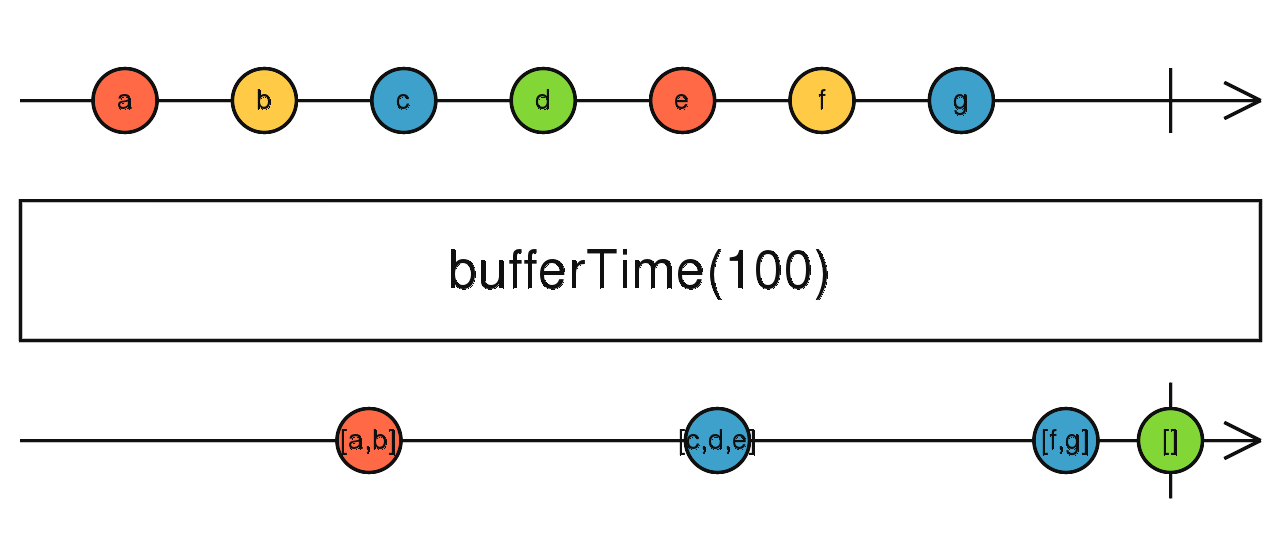
source$.pipe(bufferTime(1000)) 缓存上游吐出的数据,到指定个数后吐出,然后重复。
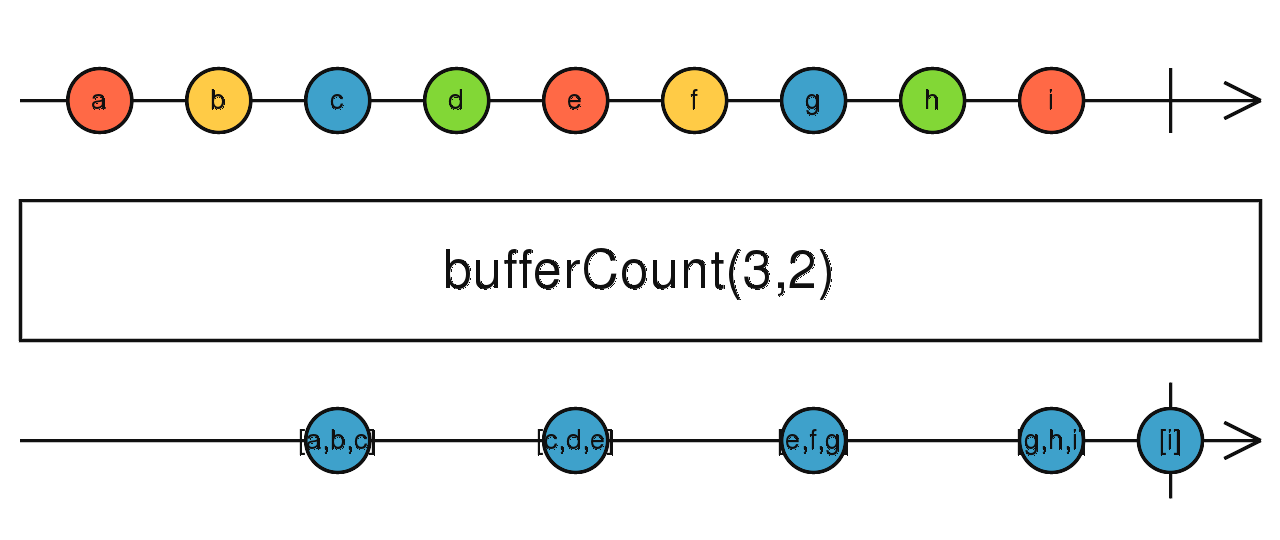
第二个参数用来控制每隔几个数据开启一次缓存区,不传时可能更符合我们的认知。
source$.pipe(bufferCount(10)) 传入一个返回流 (A) 的工厂函数
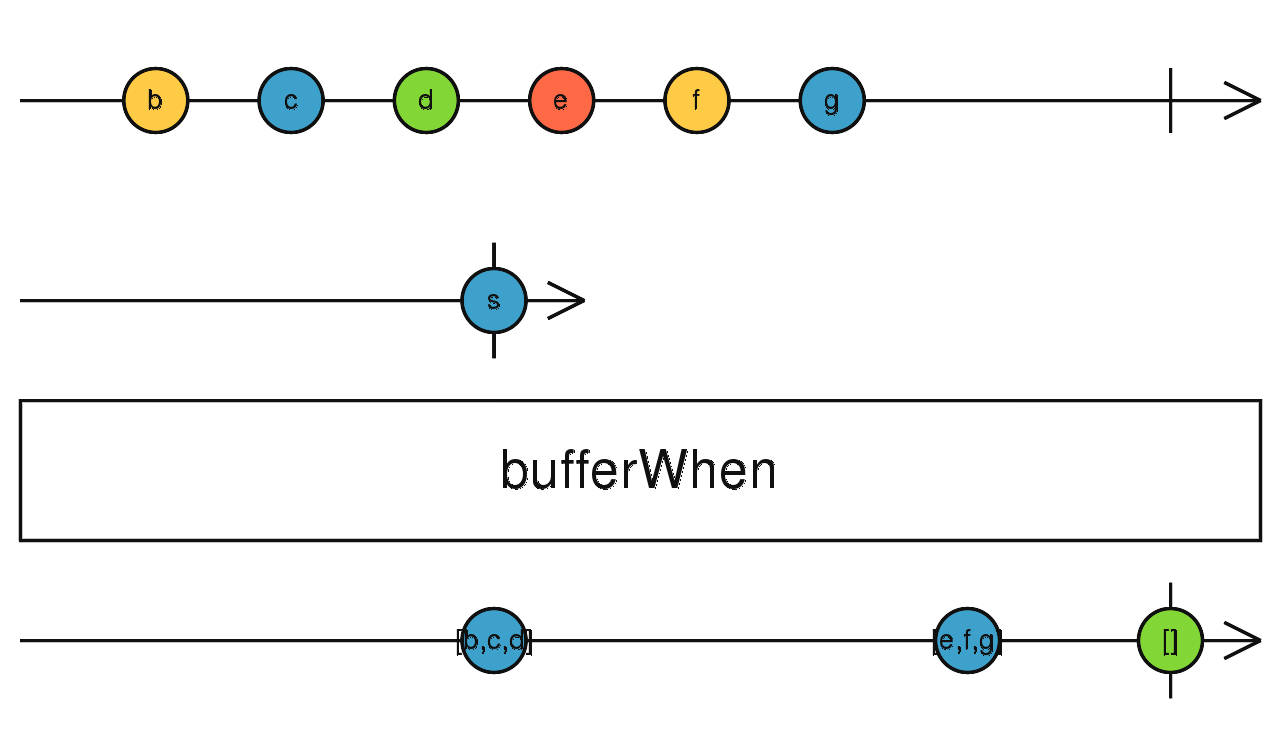
流程如下:
randomSeconds = () => timer((Math.random() * 10000) | 0)
source$.pipe(bufferWhen(randomSeconds)) 第一个参数为开启缓存流 (O),第二个参数为返回关闭缓存流 (C) 的工厂函数
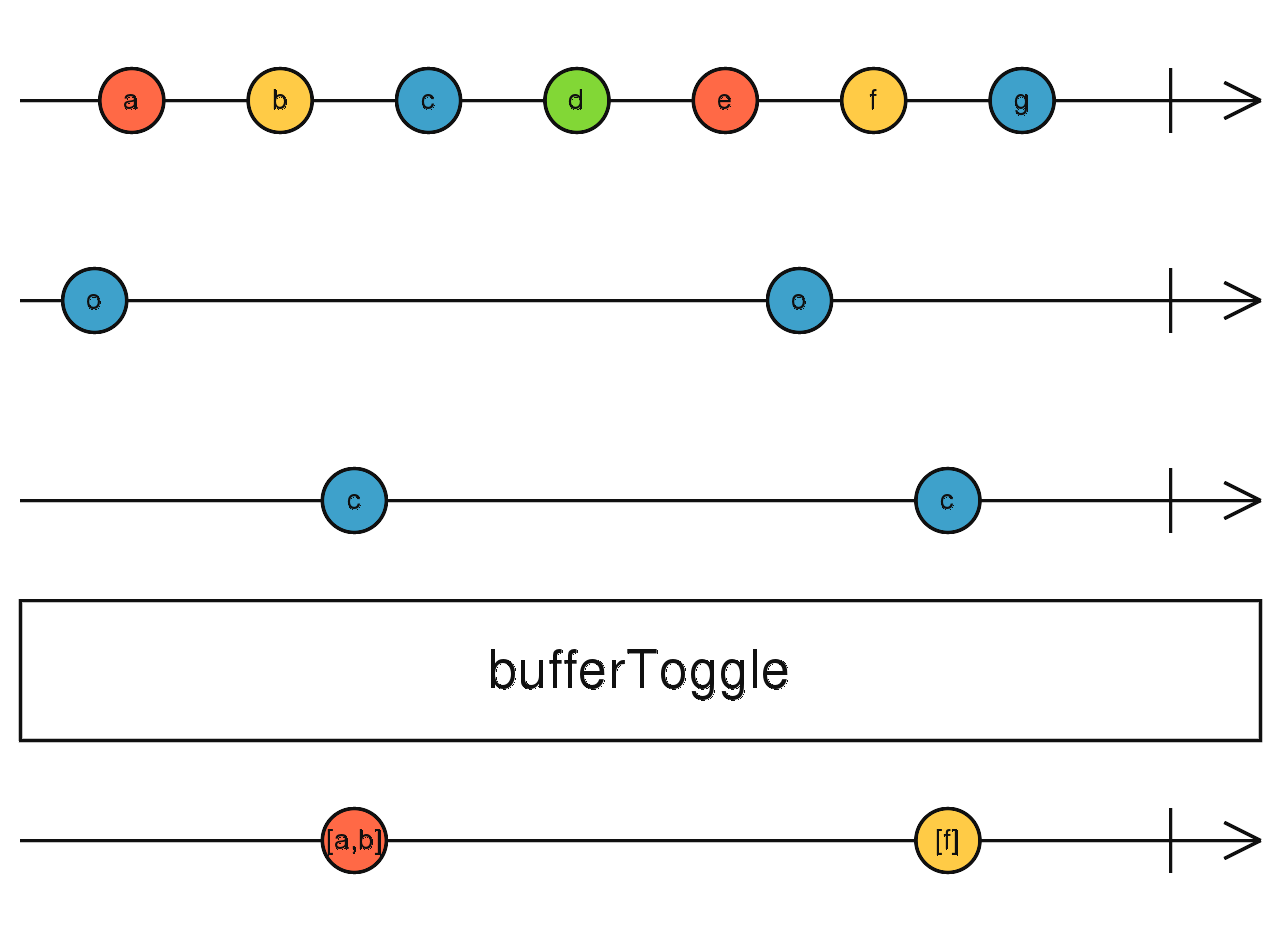
流程如下:
source$.pipe(bufferToggle(interval(1000), () => randomSeconds)) 传入一个关闭流 (C),区别与 bufferWhen:传入的是流,而不是返回流的工厂函数。
触发订阅时,开始缓存,当关闭流 (C) 吐出数据时,将缓存的值向下传递并重新开始缓存。
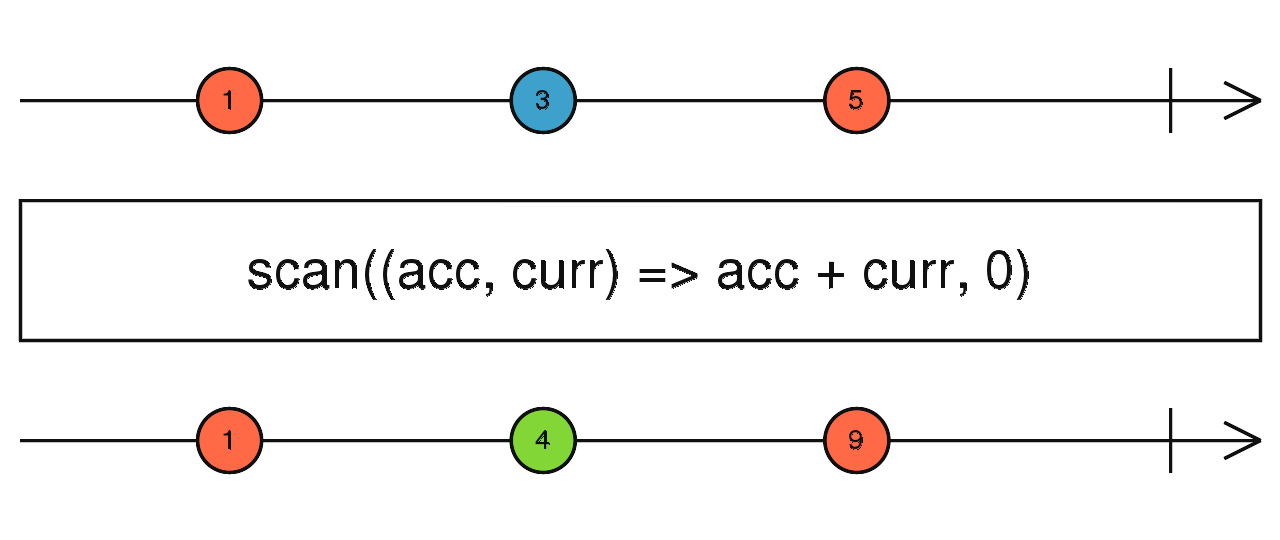
source$.pipe(buffer(interval(1000))) scan 和 reduce 的区别在于:
区别于其他流,scan 拥有了保存、记忆状态的能力。
source$.pipe(scan(() => {}, 0)) 同 scan,但是返回的不是数据而是一个流。
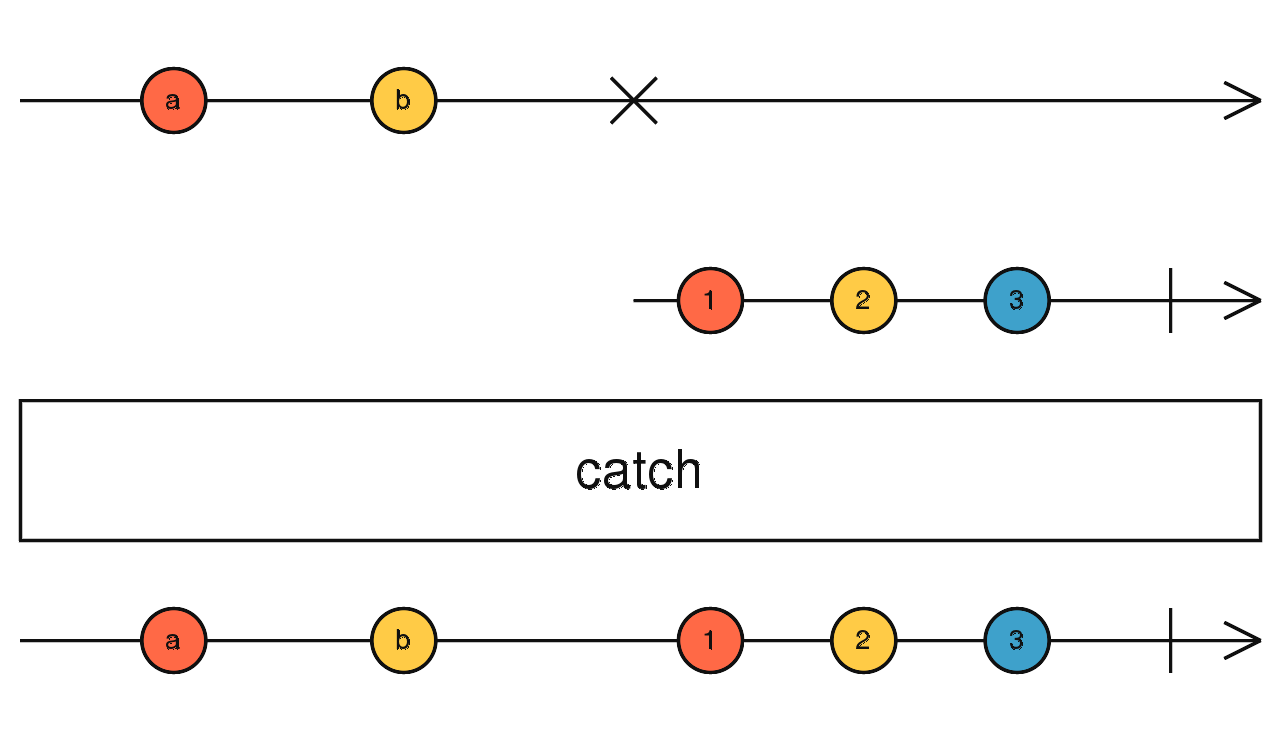
source$.pipe(mergeScan(() => interval(1000))) 捕获错误
source$.pipe(catch(err => of('I', 'II', 'III', 'IV', 'V'))) 传入数字 N,遇到错误时,重新订阅上游,重试 N 次结束。
source$.pipe(retry(3)) 传入流 (A),遇到错误时,订阅流 (A),流 (A) 每吐出一次数据,就重试一次。流完成,retrywfhen 也完成。
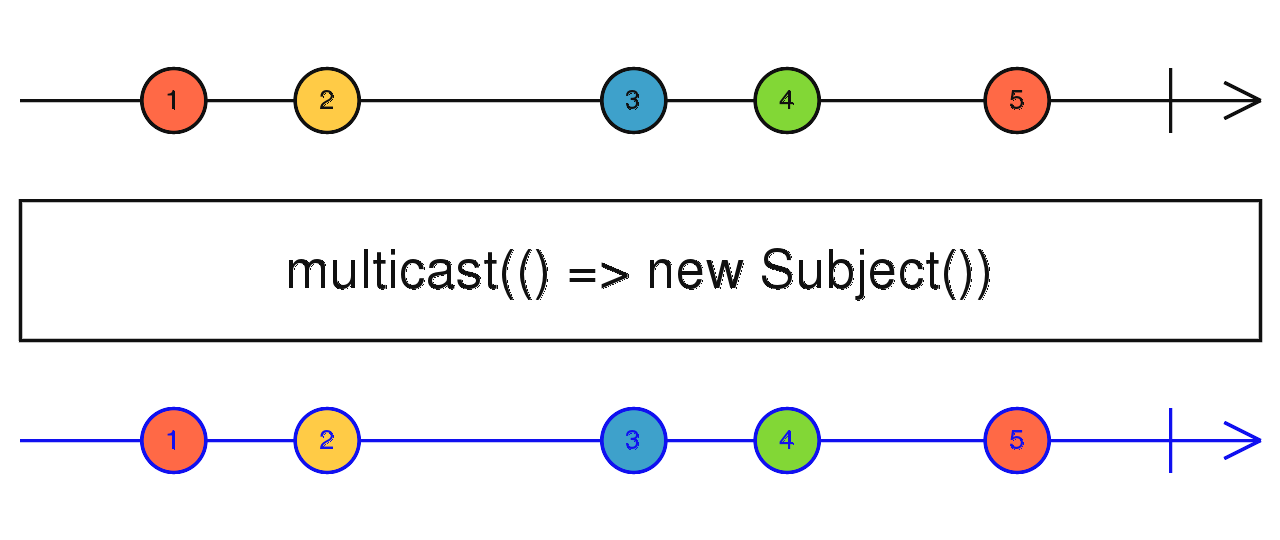
source$.pipe(retryWhen((err) => interval(1000))) source$.pipe(finally()) 接收返回 Subject 的工厂函数,返回一个 hot observable(HO)
当链接开始时,订阅上游获取数据,调用工厂函数拿到 Subject,上游吐出的数据通过 Subject 进行多播。
connect、refCount 方法。connect 才会真正开始订阅顶流并发出数据。refCount 则会根据 subscribe 数量自动进行 connect 和 unsubscribe 操作。source$.pipe(multicast(() => new Subject())) source$.pipe(publish()) 基于 publish 的封装,返回调用 refCount 后的结果(看代码)
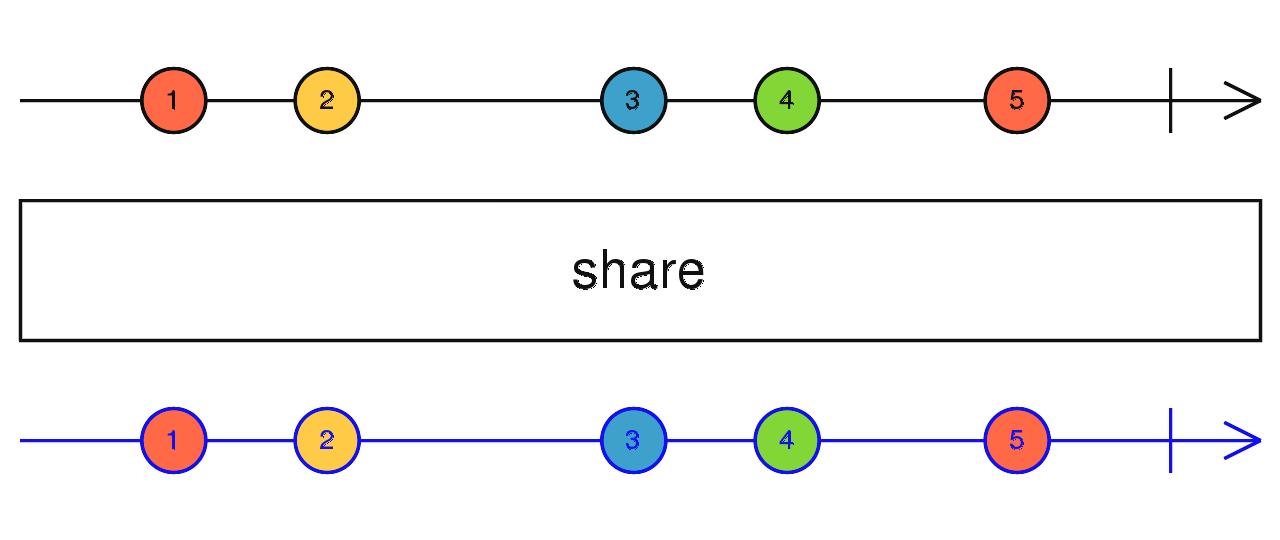
source$.pipe(share())
// 等同于
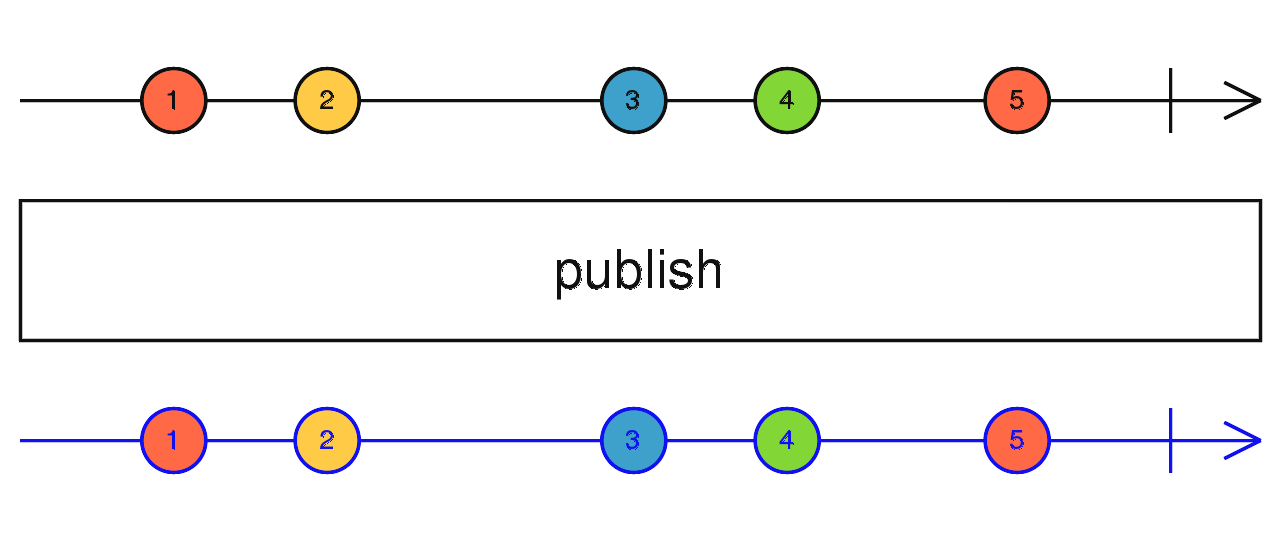
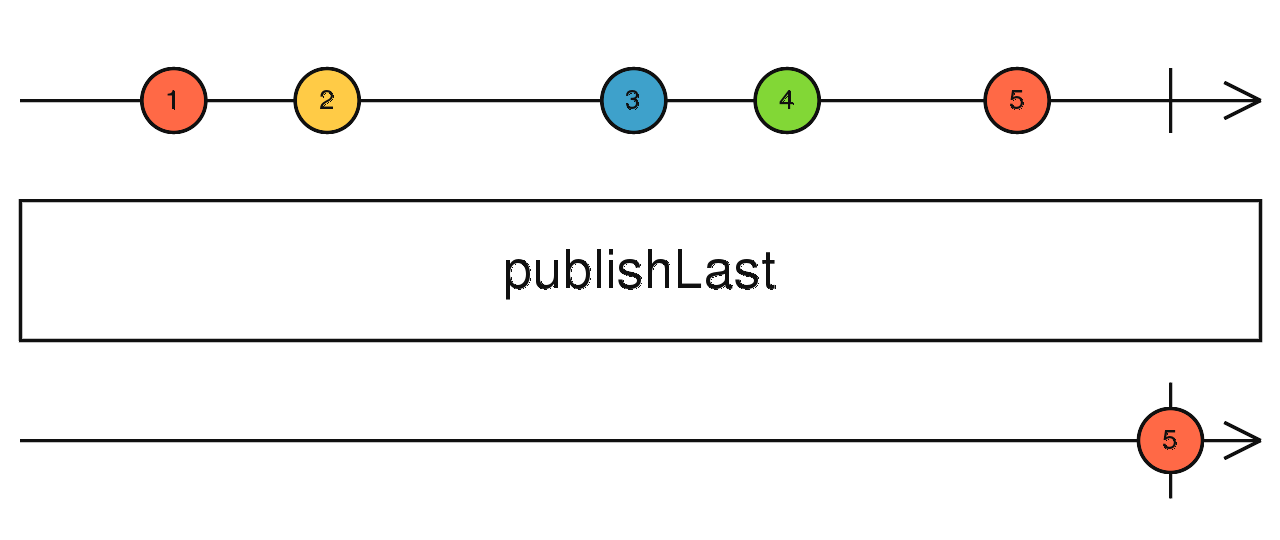
source$.pipe(publish().refCount()) 当上游完成后,多播上游的最后一个数据并完成当前流。
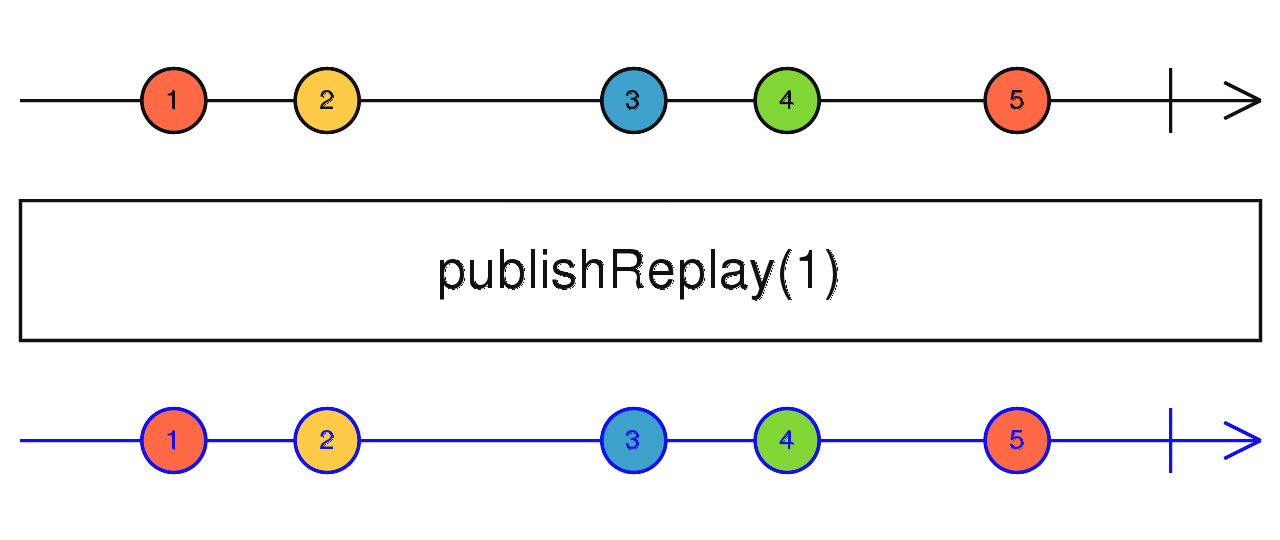
source$.pipe(publishLast()) 传入缓存数量 N,缓存上游最新的 N 个数据,当有新的订阅时,将缓存吐出。
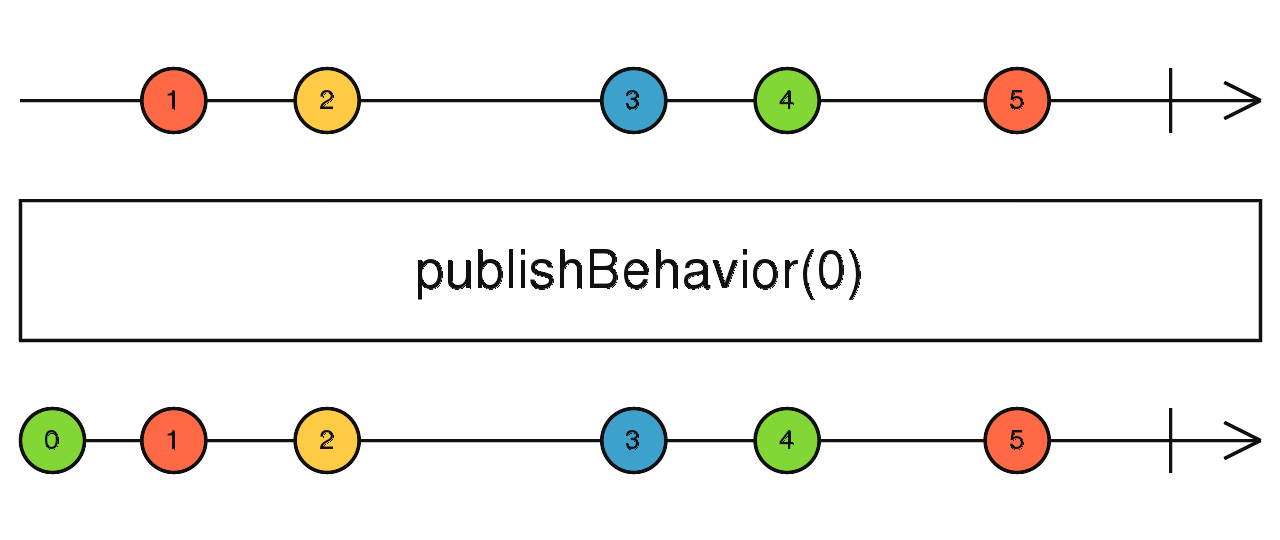
source$.pipe(publishReplay(1)) 缓存上游吐出的最新数据,当有新的订阅时,将最新值吐出。如果被订阅时上游从未吐出过数据,就吐出传入的默认值。
source$.pipe(publishBehavior(0)) 如下代码示例,顶层的流吐出的并不是普通的数据,而是两个会产生数据的流,那么此时下游在接受时,就需要对上游吐出的流进行订阅获取数据,如下:
of(of(1, 2, 3), of(4, 5, 6))
.subscribe(
ob => ob.subscribe((num) => {
console.log(num)
})
)
上面的代码只是简单的将数据从流中取出,如果我想对吐出的流运用前面讲的操作符应该怎么办?
cache = []
of(of(1, 2, 3), of(4, 5, 6))
.subscribe({
next: ob => cache.push(ob),
complete: {
concat(...cache).subscribe(console.log)
zip(...cache).subscribe(console.log)
}
})
先不管上述实现是否合理,我们已经可以对上游吐出的流运用操作符了,但是这样实现未免也太过麻烦,所以 Rxjs 为我们封装了相关的操作符来帮我们实现上述的功能。
总结一下:高阶操作符操作的是流,普通操作符操作的是数据。
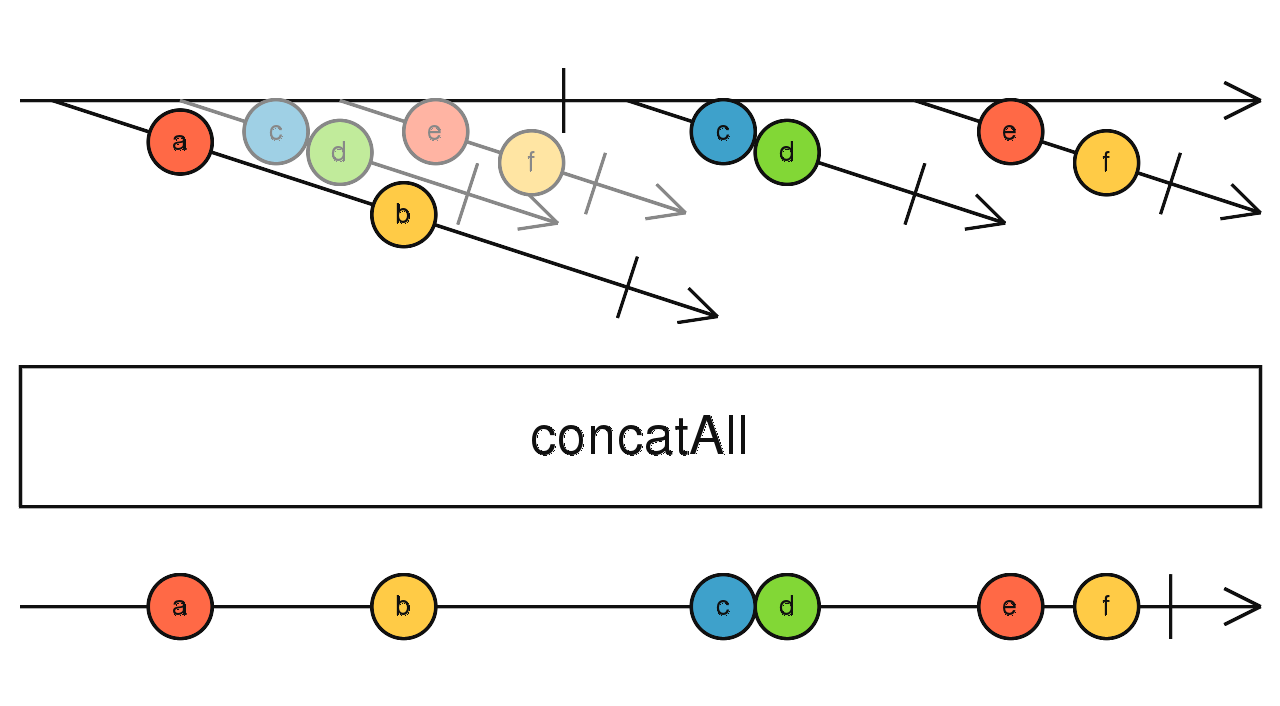
对应 concat,缓存高阶流吐出的每一个流,依次订阅,当所有流全部完成,concatAll 随之完成。
source$.pipe(concatAll()) 对应 merge,订阅高阶流吐出的每一个流,任意流吐出数据,mergeAll 随之吐出数据。
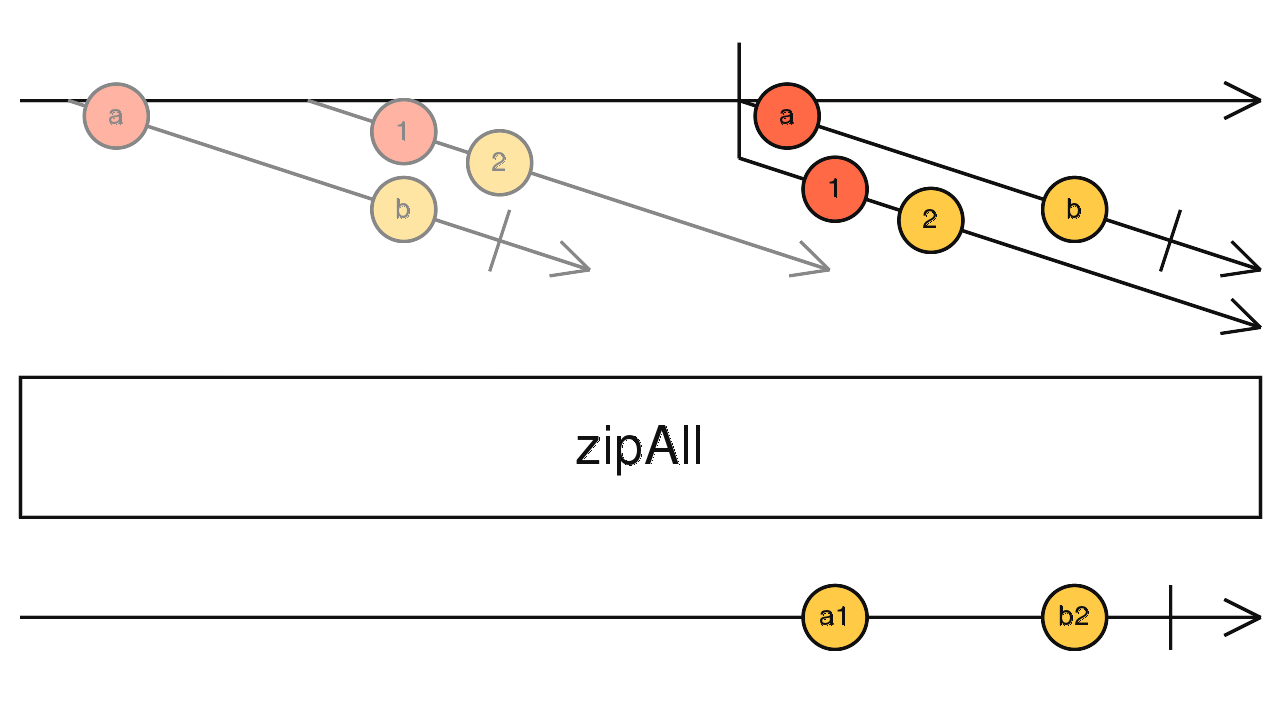
source$.pipe(mergeAll()) 对应 zip,订阅高阶流吐出的每一个流,合并这些流吐出的相同索引的数据向下传递。
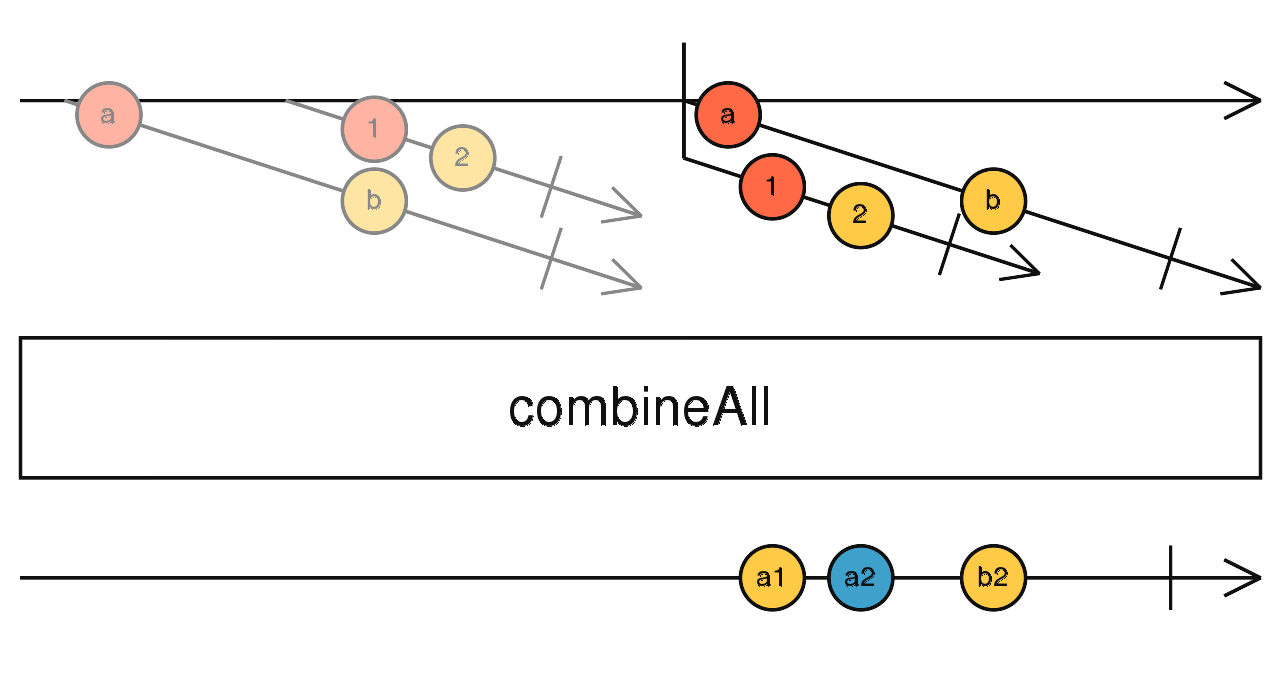
source$.pipe(zipAll()) 对应 combineLatest,订阅高阶流吐出的每一个流,合并所有流的最后值向下传递。
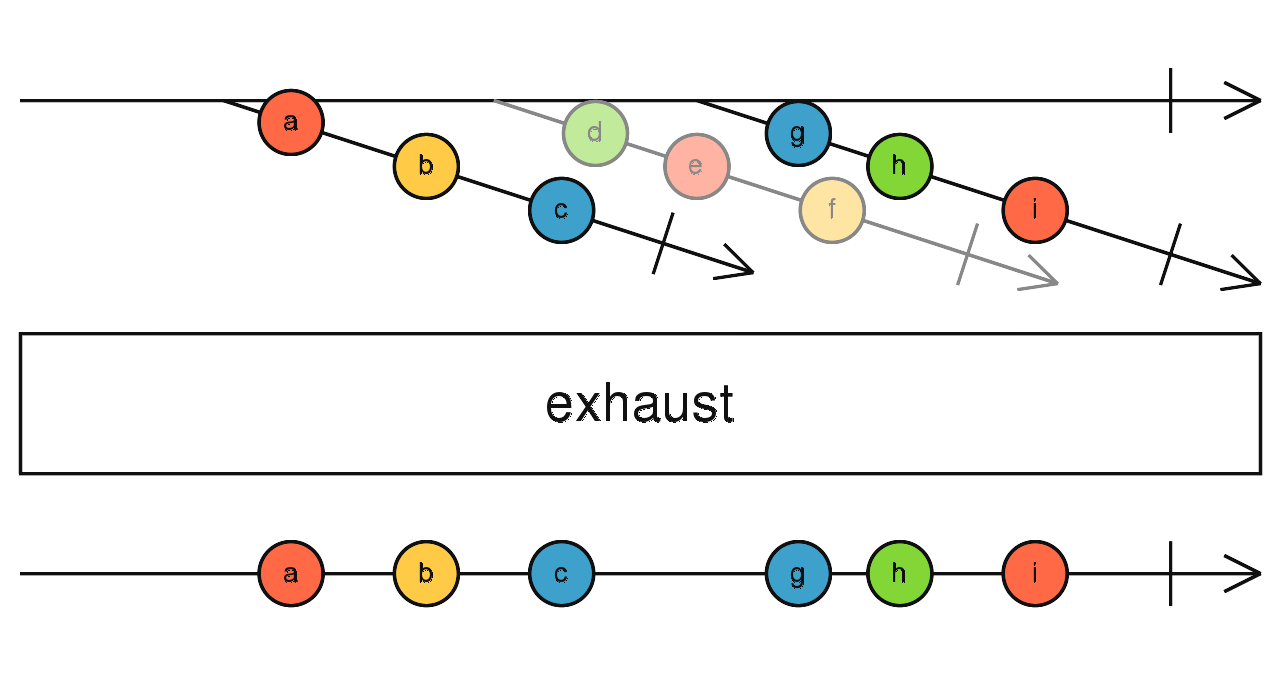
source$.pipe(combineAll()) 切换流 - 喜新厌旧
高阶流每吐出一个流时,就会退订上一个吐出的流,订阅最新吐出的流。
source$.pipe(switch()) 切换流 - 长相厮守
当高阶流吐出一个流时,订阅它。在这个流没有完成之前,忽略这期间高阶流吐出的所有的流。当这个流完成之后,等待订阅高阶流吐出的下一个流订阅,重复。
source$.pipe(exhaust()) 看完例子,即知定义。
实现如下功能:
mousedown 事件触发后,监听 mousemove 事件mousedown$ = formEvent(document, "mousedown")
mousemove$ = formEvent(document, "mousemove")
mousedown$.pipe(
map(() => mousemove$),
mergeAll()
) mousedown 事件触发后,使用 map 操作符,将向下吐出的数据转换成 mousemove 事件流。mergeAll 操作符帮我们将流中的数据展开。mousemove 的 event 事件对象了。注:由于只有一个事件流,所以使用上面介绍的任意高阶合并操作符都是一样的效果。
mousedown$.pipe(mergeMap(() => mousemove$)) 不难看出,所谓高阶 map,就是
concatMap = map + concatAll
mergeMap = map + mergeAll
switchMap = map + switch
exhaustMap = map + exhaust
concatMapTo = mapTo + concatAll
mergeMapTo = mapTo + mergeAll
switchMapTo = mapTo + switch
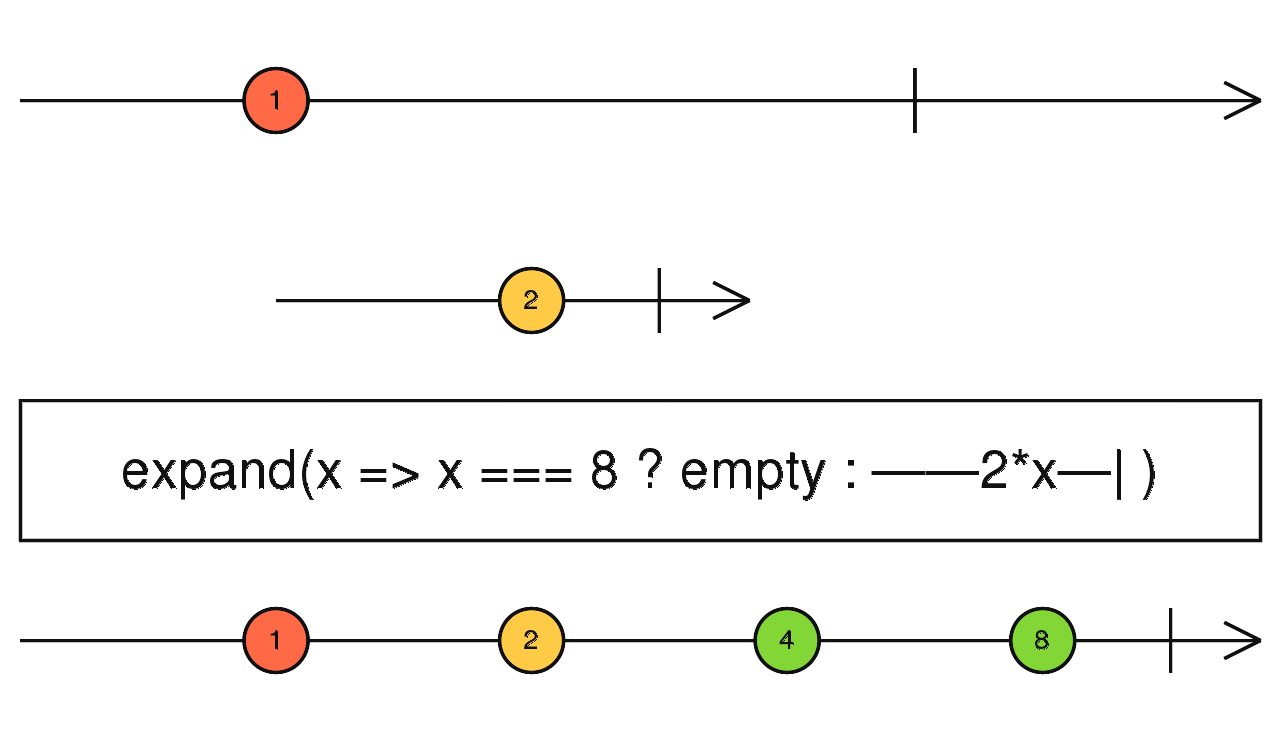
类似于 mergeMap,但是,所有传递给下游的数据,同时也会传递给自己,所以 expand 是一个递归操作符。
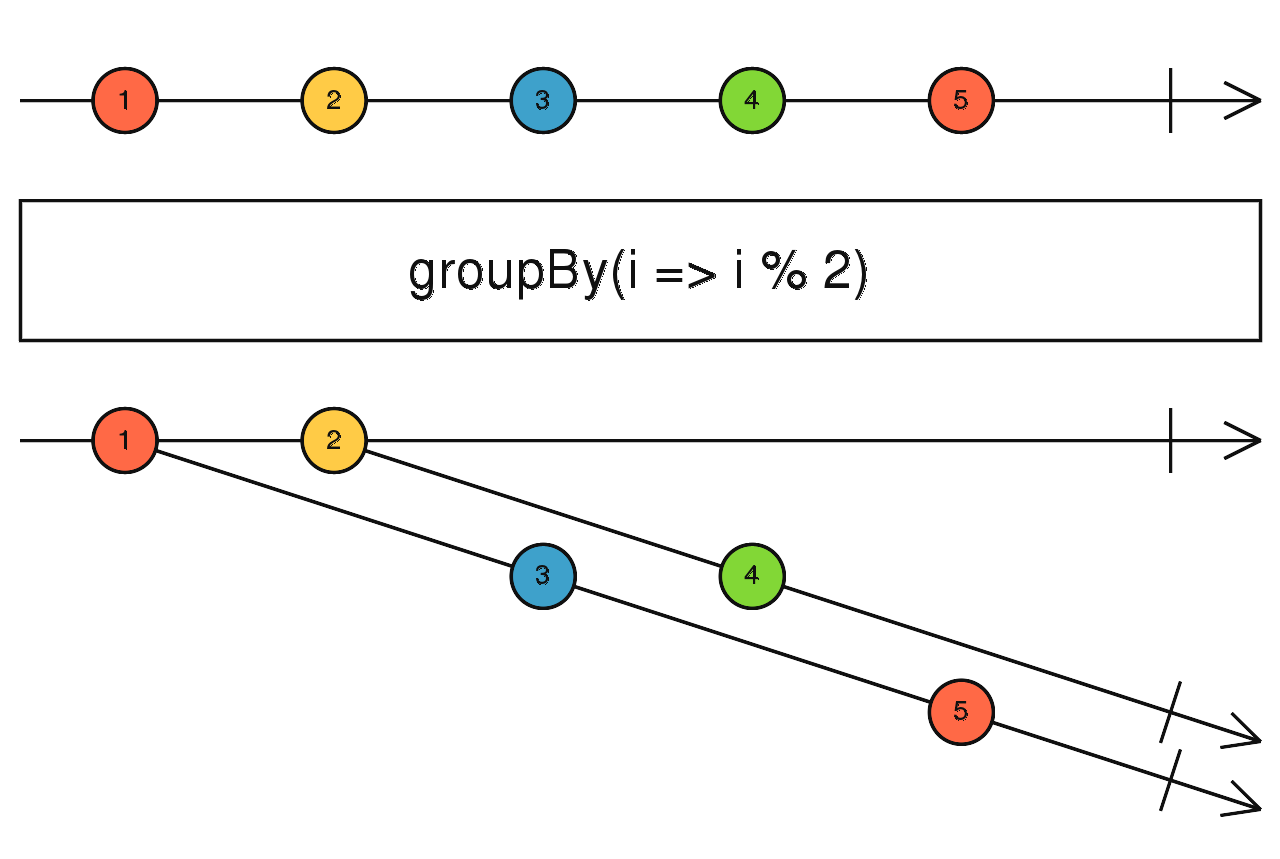
source$.pipe(expand((x) => (x === 8 ? EMPTY : x * 2))) 输出流,将上游传递进来的数据,根据 key 值分类,为每一个分类创建一个流传递给下游。
key 值由第一个函数参数来控制。
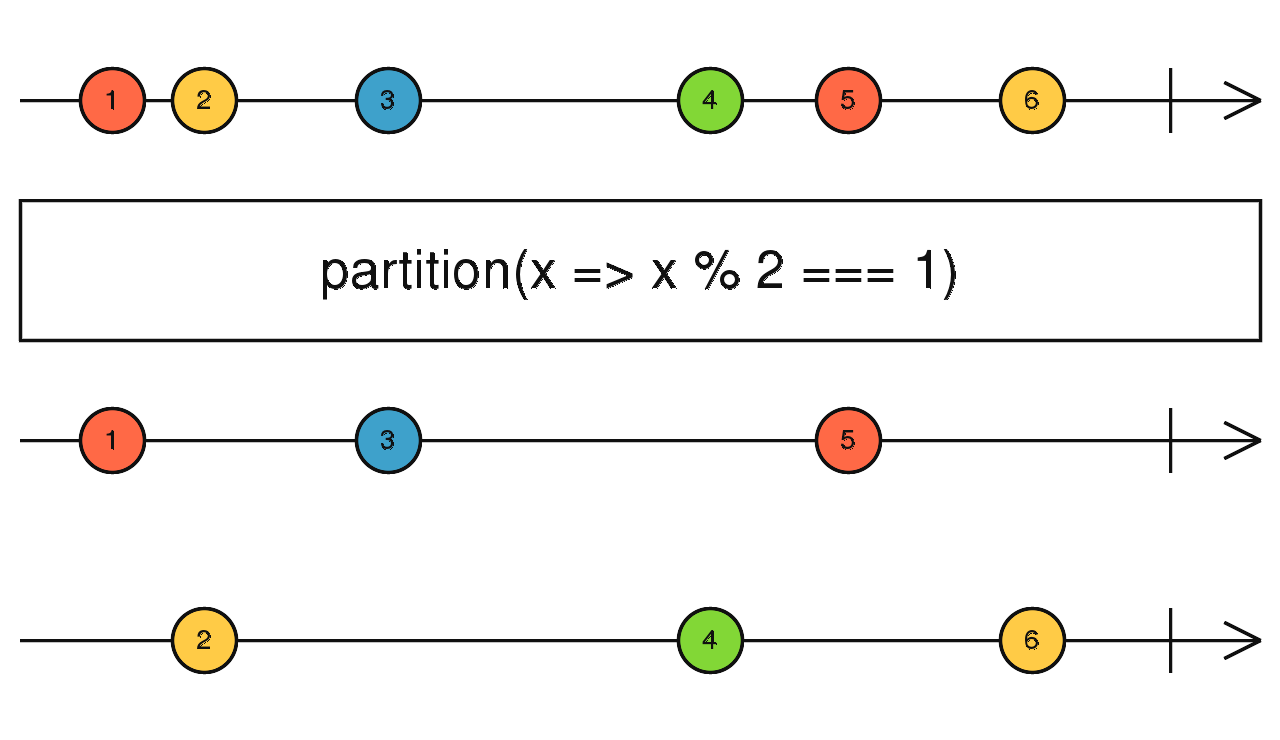
source$.pipe(groupBy((i) => i % 2)) groupBy 的简化版,传入判断条件,满足条件的放入第一个流中,不满足的放入第二个流中。
简单说:
source$.pipe(partition()) 以上就是本文的全部内容了,希望你看了会有收获。
如果有不理解的部分,可以在评论区提出,大家一起成长进步。
祝大家早日拿下 Rxjs 这块难啃的骨头。
2024-04-16
年前自己的 Mac 进水了,考虑良久(穷...)还是组了台台式机,作为一个终端重度使用者,Windows 用的真要发疯,果断切换到 Linux...
查了半天资料,对 Arch 比较感兴趣,主要想在使用的过程中实践一下操作系统相关的知识
本文记录一下折腾的过程(万一后面滚挂了...)
ArchWiki 在手,万事不愁
在 U 盘里制作一个微型系统,用于安装真正的系统
我用的 Mac,所以按照 U 盘安装介质 - Arch Linux Wiki
# 查看自己的 U 盘名称,一般是 /dev/disk2
diskutil list
# 先卸载 U 盘
diskutil unmountDisk /dev/diskXA
# 将镜像写入到 U 盘中
dd if=$path/$archlinux.iso of=/dev/rdiskX bs=1m Caution
这种方式会将 U 盘格式化,注意提前备份
Note
会 vim 的话体验会好很多(hahahah)
先通过 BIOS 进入 U 盘系统中
首先需要联网 WIFI
# 进入交互式提示符
iwctl
# 如果不知道你的网络设备名称,列出所有 WiFi 设备
device list
# 扫描网络,注意替换设备名(注意:这个命令不会输出任何内容)
station $device scan
# 列出所有可用的网络
station $device get-networks
# 连接到一个网络
station $device connect $SSID
# 退出 or Ctrl+d
quit ping baidu.com 试下网络是否连接成功
先看一下系统目前的引导模式,后面要用到
检查 UEFI 位数:
cat /sys/firmware/efi/fw_platform_size 如果命令结果为
64,则系统是以 UEFI 模式引导且使用 64 位 x64 UEFI
如果命令结果为32,则系统是以 UEFI 模式引导且使用 32 位 IA32 UEFI,虽然其受支持,但引导加载程序只能使用 systemd-boot
如果文件不存在,则系统可能是以 BIOS 模式(或 CSM 模式)引导。
Tip
注意!这里如果你的硬盘可以直接无脑格式化的话,就不需要在此操作
等下进到 archinstall 中直接使用推荐的分区方式即可
因为我已经有一个 Windows 系统了,并且还要接着使用,所以不能直接格式化
之前的 EFI 分区只有 300M 大小,需要扩大一点,这里我扩到了 1G,参考 Create EFI
对已有 EFI 分区的进行扩展,可以自行搜索教程
简单点说就是先把已存在的 ESP 分区中的内容 Copy 出来,分好新区之后把内容再放回去就行了
因为已经有 Windows 了,所以我直接在 Win 中用 DiskGenius 分好 Linux 所需要的区了:分别是一个主系统分区和一个同内存大小的 SWAP 分区(我还专门给系统备份分了一个区)
进入到 U 盘系统之后,通过命令找到自己的主系统分区和 SWAP 分区的设备名
# 列出所有的设备
fdisk -l 先通过如下命令更改一下主系统分区的文件系统的格式
Tip
我想要用 btrfs,但是 DG 中没有 btrfs 的选项,只能先选了 ext4
如果你想用的系统可以在 DG 中制作,就可以跳过这步
滚动升级发行版建议用 btrfs ,滚之前做个快照,滚挂了能立即恢复。
挂载系统盘到 U 盘系统
# 格式化
mkfs.btrfs $dev -f
mount $dev /mnt
# btrfs 系统的子卷,备份用(参考 timeshift, Ubuntu 的类型布局)
btrfs subvolume create /mnt/@
btrfs subvolume create /mnt/@home
umount $dev
mount $dev /mnt -o subvol=@
mount $dev /mnt/home -o subvol=@home --mkdir 挂载启动分区(Windows 已经有了,所以不用创建直接挂载即可,正常应该创建一个分区用来放引导)
# timeshift 需要是这个路径
mount $efi_dev /mnt/boot/efi --mkdir 制作 SWAP 分区
mkswap $dev
# 启用
swapon $dev Tip
linux 可以使用 fdisk|cfdisk 分区
使用 vim /etc/pacman.d/mirrorlist,在开头加上镜像源
Server = https://mirrors.ustc.edu.cn/archlinux/$repo/os/$arch
Server = https://mirrors.tuna.tsinghua.edu.cn/archlinux/$repo/os/$arch 更新一下 pacman -Syu
人生苦短,我用
archinstall
好处是根据配置项一个一个选择,一些相关的依赖会提示你选择 or 自动帮你选择
坏处自然就是帮你做了选择... 囧(对于想完全自定义的人来说是坏处吧
但对于新手来说,推荐的反而更省心
下面根据需要配置的选项顺序一个一个说
Tip
搜索统一是键入 / 后直接输入字符
上面已经配置了,所以这一步可以直接跳过
主要是这一步虽然可以通过选择 Mirror region 后选 Chind,但安装速度依然很慢(可能默认的地理位置离我都比较远
Tip
如果你的硬盘可以格式化,就选择推荐的方式
如果像我一样已经分好区了并挂载到 U 盘系统中了,这里就选择 Pre-mounted configuration,然后输入 /mnt 回车
正常的话会看到 /mnt 中已挂载的分区名称
根据上面 验证引导模式 的结果选择合适的引导,我的是 64,所以选了 Grub
设置一下主机名字,我直接用的 root
设置一下 root 密码
再创建一个普通用户,日常用的就是这个
选择桌面环境、驱动之类的,可以按照自己的需要选择
🔍 linux 桌面环境(
kde/gnome/xface)、窗口管理器 (dwm/i3/bspwm)
我选的是 Desktop -> Hyprland
Note
为什么选 Hyprland 呢?
因为本来我也是想用 i3wm 之类的窗口管理器的(现在 Mac 中就是用的 yabai)
结果看到 Hyprland 之后就被它吸引了,关键词大概是:漂亮、动画、流畅、轻量、新特性等等
以及我的电脑也没有 Nvidia GPU,并且也想试一些新的东西
Tip
Hyprland 需要访问您的硬件设备,例如键盘、鼠标和显卡,请选择访问方式?
硬件访问选了 polkit ,其实我也不知道应该选哪个,但是我在 Must have – Hyprland Wiki 上搜到了 polkit ,没有搜到 seatd
Graphics driver 显卡驱动默认所有 all open-source
Greeter 默认 sddm (如果有多个桌面环境/窗口管理器,可以在登录时进行选择切换
我选择了 pipewire ,简单说 pipewire 是更新的产物,兼容 PulseAudio
这里有一篇文章可以详细查看:PipeWire vs PulseAudio: What's the Difference?
默认了 linux
archinstall 已经默认安装了如 base base-devel linux linux-firmware efibootmgr 等包
如果有其他需要安装的包,可以在这里输入(使用空格分隔多个包)
我需要如下包:man git zsh neovim openssl btrfs-progs os-prober grub linux-headers
Tip
os-prober 是双系统引导要使用的
选择 Use NetworkManager
时区选 上海 (直接 / 搜 shanghai)
其他的根据自己的需要选择就好
都弄完后然后执行 Install 等待安装成功
全部安装成功之后,会提醒你是否使用 chroot 进入系统中配置后续的内容,点击否
回到 U 盘系统中执行
# 挂载配置
genfstab -U /mnt >> /mnt/etc/fstab 之后通过 arch-chroot /mnt 进入系统
Note
有些命令 archinstall 已经帮我们做了,具体的可以自己再 check 一下
nvim /etc/locale.conf 添加 LANG=en_US.UTF-8systemctl enable NetworkManagergrub-install --target=x86_64-efi --efi-directory=/boot后面说些还需要我们自己手动做的
nvim /etc/locale.gen
# 取消 zh_CN.UTF-8 前的注释(en_US.UTF-8 已经取消了
locale-gen # 在HOOKS中加入 btrfs
nvim /etc/mkinitcpio.conf
mkinitcpio -P nvim /etc/pacman.conf
# 取消 Color 和 ParallelDownloads 前的注释
# 加上一行 ILoveCandy 吃豆人彩蛋
pacman -Syu su <用户名>
# 查看 shell 位置
whereis zsh
chsh -s /usr/bin/zsh
# Ctrl+D 退出用户登陆 双系统需要设置一下引导
# 检查
sudo grub-install --recheck /dev/你的硬盘
# grub-install --target=x86_64-efi --efi-directory=/boot
sudo nvim /etc/default/grub
# 将最后一行的注释去掉,启用 os-prober 检测双系统
# 设置引导界面的分辨率
# 在文件内搜索 GRUB_GFXMODE 变量,如果没有的话就新加一个
# 将 `GRUB_GFXMODE` 的值设置为你希望的分辨率,例如 `GRUB_GFXMODE=1920x1080`
# 如果之前为 Arch 创建了单独的 EFI,那么现在将 windows 的EFI分区挂载到任意目录 例如(/mnt)
# 运行 sudo os-prober 看看能不能检测到windows
sudo os-prober
# 重新生成配置文件
sudo grub-mkconfig -o /boot/grub/grub.cfg Tip
如果这一步的 os-prober 没有成功也没关系,等下进入到系统中再做也一样
# Ctrl+D 退出登陆
umount -R /mnt #取消挂载
reboot #重启 配置完后重启电脑并拔掉 U 盘
之后就可以进入 arch 系统了,后面的继续参考 Arch Linux 系统配置篇
2023-06-18
声明一下,下文中提到极化训练,不是在谈 极化训练方法,只是指其提出的 三区间划分 方式,三个区间所对应的不同的生理反应。
跟极化训练 80%-20% 的训练方式是没有关系的,在我看来每个区间的生理反应都是独特的、不可代替的。
究竟要在哪个区间花费多少精力取决去你想要练什么,你想得到什么
国内关于训练的文章并不少,不管是极化训练还是金字塔训练大家都在说一个论点,多骑二区(有氧)。
那为什么要多骑二区呢?其他的运动向来都是想要提升什么就去练什么
在各篇文章里我都没有找到直观的答案,大家只是说这是在打基础,但是这个基础要打多久、打到什么程度呢?

我相信不少人,包括我自己都会有上述的疑惑
尤其是当你真正开始长达四个小时以上、枯燥的二期训练时,你难免会怀疑,它真的有用吗?
我们会在不同的训练计划中摇摆不定。
所以上述的答案是什么呢?当我在外网逛了一圈后,我找到了一些答案,希望这篇文章能为你揭开长有氧训练的面纱。
在此之前,必须要讲清楚功率训练划分七个区间的不足之处,如果只从七区间的视角去看待二区(有氧),的确会让我们很难理解二区(有氧)训练的作用。
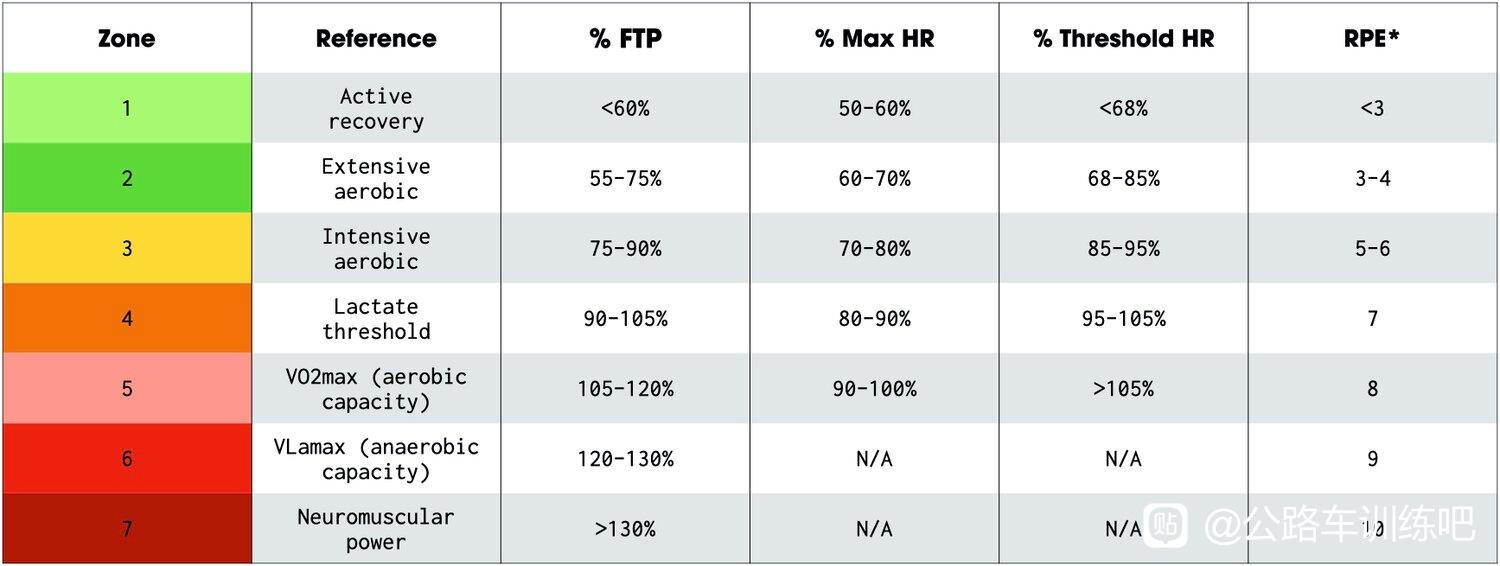
这张图片里有功率、最大心率、阈值心率、RPE 所对应的区间百分比
功率训练的七个区间,它使用了一个生理指标「乳酸阈值」(FTP)作为参照点划分百分比,其中 55% 到 75% 为有氧区间,也就是二区。
这会让我们进入一个思维误区:
这里面最大的问题就在于我们以乳酸阈值这个生理指标去估算有氧能力,它真的合理吗?
55%~75% 就是一个绝对的有氧区间吗?
对于不同能力的运动员这个数值是否不会变化?
答案是否定的。
有氧能力强的人,他的有氧区间是会变大的,有可能 55% 到 85%,甚至 90% 都是有氧区间,那对他而言,55% 到 90% 都算是二区。
我们谈二区时,其实真正想表达的是其对应的有氧区间,是指有氧能力。当我们专项的对有氧能力进行训练时,它变得越来越强是很符合逻辑思维的。
只不过是有氧能力的增强会影响到 FTP,所以我们误以为是 FTP 增长带动了有氧能力的变强,这是颠倒了因果关系
接下来我们要讲一下极化训练的区间划分,它的区间有三个,划分标准是血液内的「乳酸含量」,划分节点有两个:第一通气阈 和 第二通气阈。
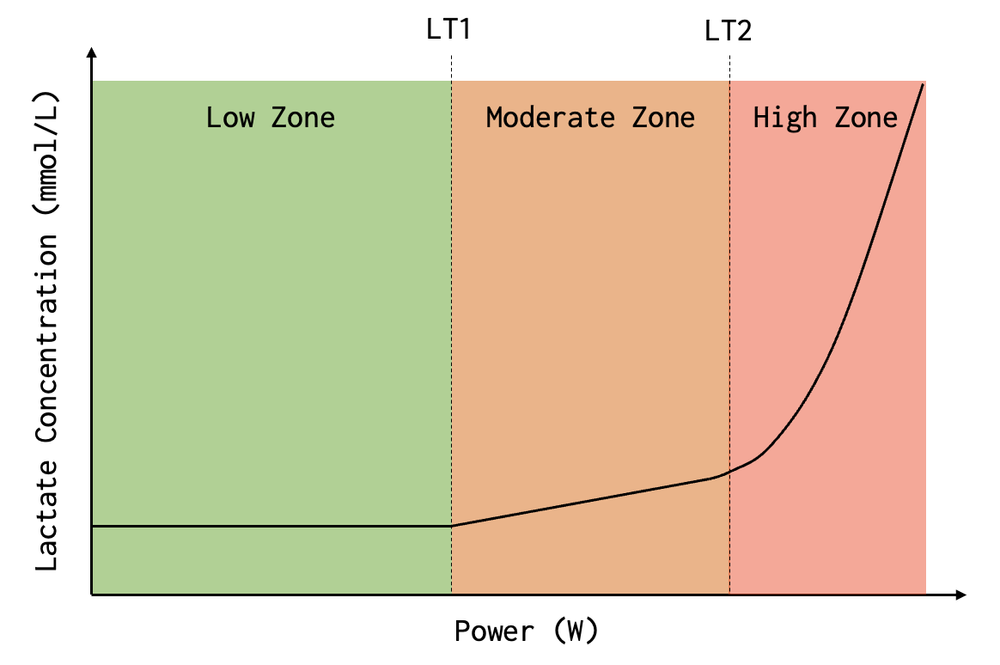
第一通气阈就是我们的有氧阈值
在这个区间以下骑行,我们的身体通过脂肪氧化进行供能,脂肪氧化并不会产生乳酸,所以血液中的乳酸含量是稳态的,并不会随着骑行时间的增加而增加。
在这个区间我们可以骑行很长的时间,即使是一个很瘦的人,他的脂肪供能也足以连续骑行两到三天。
在这个阶段,只需要水和氧气,理论上就可以无限制地骑行下去(当然这只是理论上的,实际即使我们躺着不动,身体依然会消耗能量)
第二通气阈,也就是乳酸阈值,熟悉的 FTP 强度。
在这个节点之下骑行,脂肪氧化来不及提供身体所需的能量,我们的身体转而使用糖酵解供能,也就是碳水氧化进行供能。
碳水氧化会使身体产生乳酸,在这个区间骑行,血液内的乳酸含量会随着骑行时间的增长而增长,但仍然是线性的。
一个普通人的碳水化合物能量,一般可以支持一到一个半小时的供能,如果没有及时补充能量就会出现“撞墙”的情况
高于乳酸阈值的区间就是我们的无氧区间(其实并不准确,依然是有氧气功能的)
在这个区间骑行身体会非线性的大量的产生乳酸,所以我们无法长时间在此区间骑行。
这与七区间的五区及之上是一样的,不再多说。
我们可以看到相比七区间使用一个生理指标 乳酸阈值 进行区间划分,极化训练的划分使用了两个生理指标 有氧阈值 和 乳酸阈值。
并且通过血液内乳酸含量来决定有氧区间的划分,相比七区间使用固定用百分比进行有氧划分,是更加合理和符合科学依据的。
回到训练黄金定律:想提高什么就去练什么,训练应该为目标去服务,想清楚你的目标是什么
值得一提的是,乳酸阈值和有氧阈值并不是独立的,它们是相互影响的,所以我们看到新手即使只骑二区 FTP 依然会快速增长;而很少骑二区的高 FTP 车手有氧能力也不会很差。
但当我们的 FTP 达到瓶颈时(增长缓慢),不同能力的车手差距就会显现出来
试想一下两个同样是 350 瓦的运动员
当他们同样以 90% 功率的强度骑行时
当骑行时间较短的时候,我们并不能很好地看出两者的差距,但当骑行时间变长两者的差距显而易见
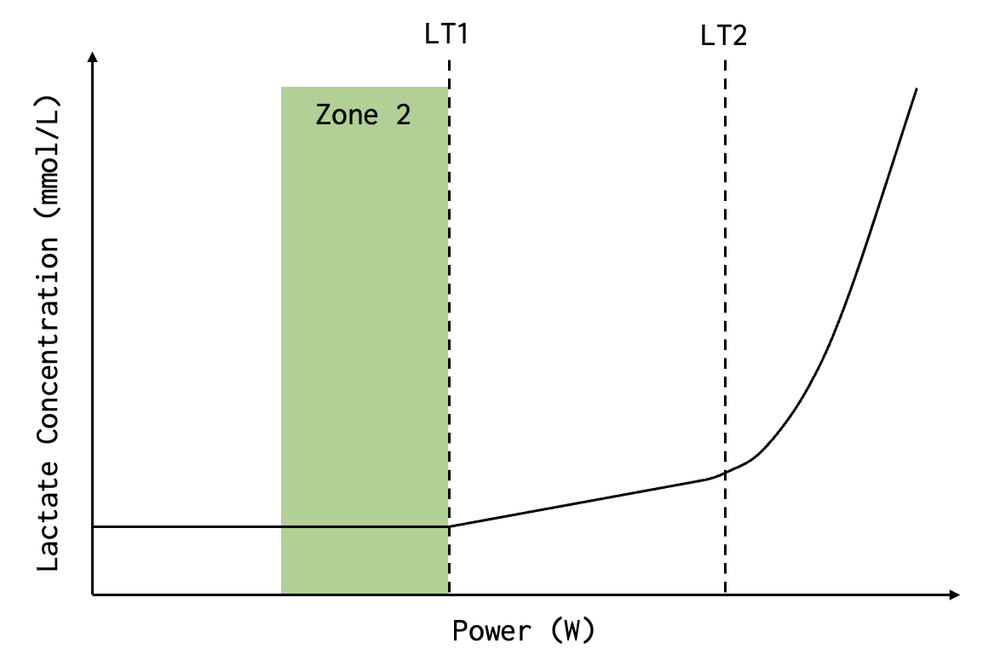
讲完原理我们来讲一下怎么确定二区的范围,显然我们不能方便的去测量血液乳酸含量(倒是有相应的仪器售卖)
波加查教练的二区视频中提到过这个问题,他建议使用 心率 + RPE
我们可以所有手段结合一下,起始依然用功率二区去练,比如 65%-68%。然后观察心率和本体感受,你应该可以轻松的说上几句话(谈话测试):
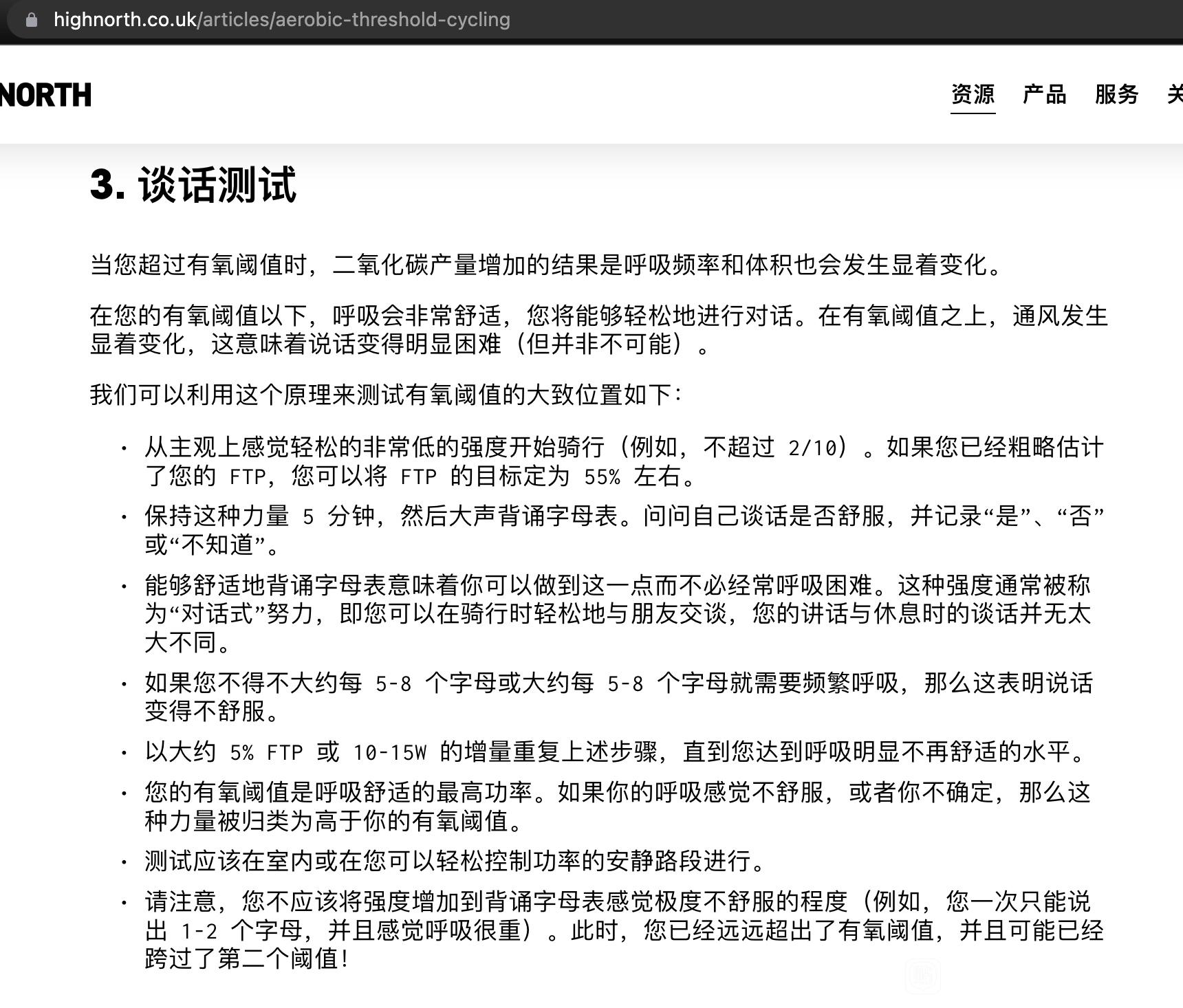
最后我们查看有氧解耦率,如果在 5%-10% 说明这个区间正合适你,如果超过了 10% 说明强度太高了。如果只有 0%-5% 说明强度需要增加了,你可以测 FTP 或提高百分比。
最后总结一下,如果你只是一个普通爱好者,如果你没有太多的时间,那就去练甜区,提高 FTP。
如果你有时间,那就多骑有氧,提高 FTP 的同时也在提高你的骑行下限,让你能以更低的心率骑出更高的功率
以上,是下午四小时二区骑行时写的,共勉
甜区指功率的 88% - 93%
不用太过纠结某个指标具体的数字,自身的感受(RPE)也是训练中很重要的一部分。不管是心率、功率、解耦率还是 RPE 都是在给我们提供一个观察自身状态的指标而已,结合越多的指标去观察,它的参考意义也就越大。
对 11 名挪威 XC 滑雪者奥运冠军一年训练的研究(下面的区间都是极化区间)
他们大部分训练时间都是在“1 区”低强度下度过的,其中乳酸水平低于 1.1 毫摩尔/升,然而,这项研究中的运动员已经拥有高度发达的 LT1(有氧阈值)。
平均而言,运动员的 Zone 1 的顶端位于最大心率的 73%。对于大多数普通人来说,73% 的最大心率将稳固地处于 2 区,甚至可能进入 3 区,乳酸水平通常约为 2-3 毫摩尔/升。
更重要值得考虑的是,虽然 XC 运动员测得的乳酸水平较低,但乳酸生成率和肌纤维募集程度可能相对较高,这些运动员能够在高乳酸生成率的情况下维持低乳酸水平的原因是因为他们接受过高度有氧训练,因此非常擅长清除产生的乳酸。
Inigo San Milan 在他关于有氧训练和执教 Tadej Pogačar 的经验讨论中提出的一个观点:训练有素的自行车运动员的乳酸通量非常高,在大部分训练时间里,这些运动员需要根据乳酸水平以低于“正常”的强度骑行,以避免积累太多很多代谢压力。
在实践中,这意味着训练有素的自行车手可能会以大约 50-65% 的 FTP 为目标进行长距离耐力骑行。
相比之下,相对新手的自行车手可能更适合 70-80% 的 FTP,因为他们的绝对功率输出较低,而且他们可以忍受以较高百分比的 FTP 骑行,同时代谢和肌肉紧张较少。
由于女性相对于男性产生的绝对功率也较低,因此有一种理论认为,出于同样的原因,她们也应该略微增加强度。
同样,这是我们在指导各种能力水平的运动员时注意到的事情;Zone 2 骑行的“传统”定义需要根据个人情况进行迭代
国家冠军级选手低强度骑行的原因可能是新陈代谢压力太高,这是由于持续的「绝对高功率/速度」(FTP 450w,70% 依然有 315w 的功率输出,速度在 40+ 以上),所以即使在 Zone 1 训练,乳酸生成率和肌纤维募集程度依然较高,而这些运动员能够在高乳酸生成率的情况下维持低乳酸水平的原因是因为他们接受过高度有氧训练,因此非常擅长清除乳酸
2024-04-23
书接上回 Arch Linux 系统安装篇
进入系统之后需要对新系统进行设置
Tip
里面有些软件是 wayland 下的,如果是其他的窗口系统需要寻找对应的安装配置
要先保证电脑的 wifi/键盘/鼠标 等可以正常使用,不然一切都是空谈
Tip
如果有网线跳过这一步
因为之前选的是 NetworkManager 管理网络,所以可以以下步骤任选其一
nmcli device wifi connect <网络名> password <密码>nmtuinm-connection-editor还可以安装 networkmanager-dmenu: Control NetworkManager via dmenu ,可以通过 dmenu 或 rofi 管理 NetworkManager
Tip
如果你是用 iwd 管理网络,可以安装
iwgtk: Lightweight wireless networking GUI (front-end for iwd)
有几种方式
bluetoothctl
bluetoothctl,交互就舒服多了bluetoothctl这里以最基础的 bluetoothctl 为例
pacman -Syu bluez bluez-utils
systemctl enable bluetooth.service
systemctl start bluetooth.service bluetoothctl
default-agent
power on
# 扫描
scan on
# 设备开启蓝牙,会看到 [NEW] Device MAC_address Name
# 找到自己的设备
# 配对
pair MAC_address 这位同学你也不想辛辛苦苦装好的系统又被玩崩了吧~
Important
升级前备份! 备份! 备份!
建议安装 informant: An Arch Linux News reader and pacman hook
这是一个 pacman hook,可以保证你在升级系统前必须先阅读 Arch Linux 的新闻,否则就会中断升级动作
升级之后 检查孤立包和丢弃的包,命令在下面 [ > [Pacman](https <//wiki.archlinux.org/title/Pacman>) 速览](Arch%2520Linux%2520%E7%B3%BB%E7%BB%9F%E9%85%8D%E7%BD%AE%E7%AF%87.md##%5BPacman%5D(https%2520%3C//wiki.archlinux.org/title/Pacman%3E)%2520%E9%80%9F%E8%A7%88)
sudo pacman -S timeshift
# 参考 https://github.com/linuxmint/timeshift/issues/147
# 它在 Wayland 中运行正常,只是它当前的启动方式(以 root 身份)正在丢失 Wayland 环境
# 并且会回退到 x11。通过运行 sudo -E ,它可以在启动时保留 OP 的环境(因此它作为 wayland 客户端运行)
sudo -E timeshift-launcher 启动之后选择 Wizard 根据自己的需要配置,我选择每天进行一次快照,保留 15 天的记录
与计划在一天中的固定时间进行备份的类似工具不同,Timeshift 设计为每小时运行一次,并且仅在快照到期时才拍摄快照。
这更适合每天打开笔记本电脑和台式机几个小时的台式机用户。
为此类用户安排固定时间的快照将导致备份丢失,因为在安排快照运行时系统可能尚未运行。
通过每小时运行一次并在到期时创建快照,Timeshift 可确保不会错过备份。
# 安装
pacman -S package_name
# 删除,保留依赖项
pacman -R package_name
# 删除,不保留依赖项(推荐)
pacman -Rs package_name
# 升级包/系统
pacman -Syu
# 查询
# queries the local package database with the `-Q` flags
pacman -Qs package_name
# the sync database with the `-S` flag
pacman -Ss package_name
# files database with the `-F` flag
pacman -F string
# 列出所有显示安装的包
pacman -Qqe
# query package information
pacman -Si package_name
pacman -Qi package_name
# 列出不再需要作为依赖项(孤立项)的所有包
pacman -Qdt
# 列出所有显式安装且不需要作为依赖项的包:
pacman -Qet
# 列出不再需要作为依赖项(孤立项)的所有包
pacman -Qdt
# 对于递归删除孤立包及其配置文件
pacman -Qdtq | pacman -Rns -
# 如果某些包不希望被当作孤立包,可以改为显示安装
pacman -D --asexplicit package
# 找到所有损坏的软链接
find / -xtype l -print sudo systemctl enable paccache.timer
sudo systemctl start paccache.timer # 安装 yay,ARU 助手 或者可以选择 paru
# 但是 hyprland 中推荐使用 yay
git clone https://aur.archlinux.org/yay.git
cd yay
makepkg -si
# 首次安装后配置
yay -Y --gendb
yay -Syu --devel
yay -Y --devel --save
yay -S google-chrome
yay -S rofi Arch Linux 系统安装篇 里已经选了 hyprland,所以这里基本的配置应该已经完成了
我们直接进行配置的安装即可,可以在 hyprland · GitHub Topics · GitHub 中挑选自己喜欢的配置,我选择的方案和配置参考 dotfiles#hyprland
Tip
热门的配置方案中,会把相关的系统配置、软件都安装好
建议再进行其他配置之前,先把 hyprland 配置安装好,这样就可以省去一些工作
基本上安装完这个之后,系统就已经完全可用了
我习惯把 ctrl 放在 alt (command)的位置,所以要改一下按键
对于这种无脑重映射,最好是从底层修改,以不需要用运行程序的方法以提高性能 Map scancodes to keycodes - ArchWiki
步骤如下
Tip
后面涉及到键盘配置的都需要先找到自己的设备号
先安装 pacman -S evtest 用来查看按键的 scancode,安装好后,执行 sudo evtest
先选择自己的键盘设备 /dev/input/event$,如果不确定就一个一个试,试对了按键后屏幕会有输出
输出内容格式如下:
Event: time 1628668903.193667, type 4 (EV_MSC), code 4 (MSC_SCAN), value 70039
Event: time 1628668903.193667, type 1 (EV_KEY), code 58 (KEY_CAPSLOCK), value 0 其中 KEY_CAPSLOCK 表示我按下的是 capslock 键,MSC_SCAN 后面的 value 70039 是 scancode ,code 58 是 keycode
有了按键信息之后还需要设备信息做匹配,上面我们已经找到了自己的设备号了,通过以下命令查看设备
把 event$ 中的 $ 换成具体的设备号
cat /sys/class/input/event$/device/modalias 在 /etc/udev/hwdb.d/ 中创建一个 90-remap-keyboard.hwdb 的文件
Tip
如果你想所有的键盘都交换,而不只是这一个键盘,可以写 evdev:input:b000*,而不具体指定到具体的设备上
evdev:input:b0003v05ACp0259*
# leftalt 和 leftctrl 交换
KEYBOARD_KEY_700e2=leftctrl
KEYBOARD_KEY_700e0=leftalt
# capslock 映射到 leftmeta
KEYBOARD_KEY_70039=leftmeta 保存退出,更新 hwdb 数据库:
systemd-hwdb update 激活配置
udevadm trigger 我喜欢把 ctrl 单击映射为 esc 按键,而与其他键组合时仍然是 ctrl 键,参考 Vim ESC 键的解决方案,这种功能就必须使用程序来实现了
最终选用了 kanata,因为我对 rust 比较熟。也可以看看 kmonad
kanata具体配置和使用参考 dotfiles
Tip
以下内容仅为参考使用
evremap参考 Input remap utilities - ArchWiki
这种方案的问题是,一旦换了键盘或者连接方式,就要重新修改配置文件
evremapyay -S evremap evremapcopy https://github.com/wez/evremap/blob/master/pixelbookgo.toml 内容至自己本地,命名为 evremap.toml,记住存放的路径,后面要用
修改 evremap.toml ,参考 GitHub - evremap 进行个人配置,主要是 device_name 要配置对,不然会报错无法启动
配置好之后先测试一下
sudo evremap remap evremap.toml 如果没有报错就可以正常使用了,可以去其他地方试一下按键有没有生效
udev
参考
这种方式可以在设备(蓝牙)触发相应事件时(自动连接后)执行命令
Tip
可以运行 udevadm monitor 后,把设备断开并重新链接,来查看具体的事件名称
查看设备信息,$device_name 就是上面 查找键盘设备 中的路径 eg: /dev/input/event18
udevadm info --attribute-walk --name=$device_name 然后找到可以唯一标识自己设备的一些信息,比如 id/product、id/vendor、phys 之类的,用于规则匹配使用
编写规则
sudo nvim /etc/udev/rules.d/90-evremap.rules 写入规则
ACTION=="add", SUBSYSTEM=="input", ATTRS{id/product}=="0220", ATTRS{is/vendor}=="05ac", ATTRS{phys}=="64:49:7d:a2:7d:34", RUN+="/usr/bin/evremap remap /evremap.toml" 根据自己的设备情况把匹配条件写好
Important
注意,这里的 evremap.toml 路径不能放到自己的家目录,不然会无法正常启动
😭 我卡在这里好久
放在根目录最省事,也可以软连接到根目录 ln -s /home/lay/dotfiles/linux/evremap.toml /evremap.toml
然后重启测试
也是 evremap Readme 中推荐的方式,但是!
Important
如果设备在开机的时候没有挂载的话(比如蓝牙还没有连上),通过这种方式 evremap 会启动失败,还需要手动重启
所以这种方法对于蓝牙键盘来说完全不能用,因为系统没启动前蓝牙肯定没有连上啊,但如果你是有线键盘,这种还是比较省事
使用如下命令创建 systemd service
sudo nvim /etc/systemd/system/evremap.service 把 https://github.com/wez/evremap/blob/master/evremap.service 中的内容写入,并把 evremap.toml 的绝对路径替换成你自己的本地路径
然后使用 systemctl 控制开机自启动
sudo systemctl daemon-reload
sudo systemctl enable evremap.service
sudo systemctl start evremap.service TUI、shell、输入法、nvim、terminal 等安装和配置,可以参考 GitHub - lei4519/dotfiles: vim、linux、mac 配置,这里不再赘述
我平时喜欢用终端,所以比较钟意 TUI
awesome-tuis
awesome-shell
awesome-zsh-plugins
awesome-cli-apps
sudo systemctl enable fstrim.timer
sudo systemctl start fstrim.timer 完善的 dots 配置应该会自动配置好睡眠和休眠
Power management/Suspend and hibernate - ArchWiki
Tip
建议先安装 Hyprland 配置 ,如果你选择的配置没有自动帮你配置字体,再进行如下操作
参考:
# 安装中文字体
sudo pacman -S ttf-roboto noto-fonts noto-fonts-cjk adobe-source-han-sans-cn-fonts adobe-source-han-serif-cn-fonts ttf-dejavu
# 配置字体
nvim ~/.config/fontconfig/fonts.conf 复制以下内容,然后重启电脑即可
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<its:rules xmlns:its="http://www.w3.org/2005/11/its" version="1.0">
<its:translateRule
translate="no"
selector="/fontconfig/*[not(self::description)]"
/>
</its:rules>
<description>Android Font Config</description>
<!-- Font directory list -->
<dir>/usr/share/fonts</dir>
<dir>/usr/local/share/fonts</dir>
<dir prefix="xdg">fonts</dir>
<!-- the following element will be removed in the future -->
<dir>~/.fonts</dir>
<!-- Disable embedded bitmap fonts -->
<match target="font">
<edit name="embeddedbitmap" mode="assign">
<bool>false</bool>
</edit>
</match>
<!-- English uses Roboto and Noto Serif by default, terminals use DejaVu Sans Mono. -->
<match>
<test qual="any" name="family">
<string>serif</string>
</test>
<edit name="family" mode="prepend" binding="strong">
<string>Noto Serif</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>sans-serif</string>
</test>
<edit name="family" mode="prepend" binding="strong">
<string>Roboto</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>monospace</string>
</test>
<edit name="family" mode="prepend" binding="strong">
<string>DejaVu Sans Mono</string>
</edit>
</match>
<!-- Chinese uses Source Han Sans and Source Han Serif by default, not Noto Sans CJK SC, since it will show Japanese Kanji in some cases. -->
<match>
<test name="lang" compare="contains">
<string>zh</string>
</test>
<test name="family">
<string>serif</string>
</test>
<edit name="family" mode="prepend">
<string>Source Han Serif CN</string>
</edit>
</match>
<match>
<test name="lang" compare="contains">
<string>zh</string>
</test>
<test name="family">
<string>sans-serif</string>
</test>
<edit name="family" mode="prepend">
<string>Source Han Sans CN</string>
</edit>
</match>
<match>
<test name="lang" compare="contains">
<string>zh</string>
</test>
<test name="family">
<string>monospace</string>
</test>
<edit name="family" mode="prepend">
<string>Noto Sans Mono CJK SC</string>
</edit>
</match>
<!-- Windows & Linux Chinese fonts. -->
<!-- Map all the common fonts onto Source Han Sans/Serif, so that they will be used when Source Han Sans/Serif are not installed. This solves a situation where some programs asked for a font, and under the non-existance of the font, it will not use the fallback font, which caused abnormal display of Chinese characters. -->
<match target="pattern">
<test qual="any" name="family">
<string>WenQuanYi Zen Hei</string>
</test>
<edit name="family" mode="assign" binding="same">
<string>Source Han Sans CN</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>WenQuanYi Micro Hei</string>
</test>
<edit name="family" mode="assign" binding="same">
<string>Source Han Sans CN</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>WenQuanYi Micro Hei Light</string>
</test>
<edit name="family" mode="assign" binding="same">
<string>Source Han Sans CN</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>Microsoft YaHei</string>
</test>
<edit name="family" mode="assign" binding="same">
<string>Source Han Sans CN</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>SimHei</string>
</test>
<edit name="family" mode="assign" binding="same">
<string>Source Han Sans CN</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>SimSun</string>
</test>
<edit name="family" mode="assign" binding="same">
<string>Source Han Serif CN</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>SimSun-18030</string>
</test>
<edit name="family" mode="assign" binding="same">
<string>Source Han Serif CN</string>
</edit>
</match>
<!-- Load local system customization file -->
<include ignore_missing="yes">conf.d</include>
<!-- Font cache directory list -->
<cachedir>/var/cache/fontconfig</cachedir>
<cachedir prefix="xdg">fontconfig</cachedir>
<!-- the following element will be removed in the future -->
<cachedir>~/.fontconfig</cachedir>
<config>
<!-- Rescan configurations every 30 seconds when FcFontSetList is called -->
<rescan>
<int>30</int>
</rescan>
</config>
</fontconfig> 2020-12-18
Taro 1、2 可以让我们使用类 react 语法开发小程序,之所以说是类 react 语法,是因为这些“react”代码在编译完成之后,会被全部编程小程序的原生语法,里面是没有 react 参与的。
这也导致在 Taro 1、2 中写 JSX 时,需要遵照官方文档中的规范,否则运行时就会出现问题。
并且由于 JSX 的灵活性,将 JSX 转换成小程序模板时,是一件工作量非常大的事情。
Taro 就是用穷举法硬生生的将 JSX 全部转换成了模板。但即使这样,依然会有问题,比如无法实时的享受 react 的新语法、新特性,大多数 react 生态都无法直接使用。即使用了穷举法,转换过程中还是会出现各种问题,Taro 的大多数 commit 提交都是有关于模板转换的。
小程序的设计很明显是借鉴了 vue,不管是模板的写法还是逻辑层的写法。所以相比起 JSX 转换的困难,vue 代码在转换时就轻松很多了。
所以像 mpvue、uni-app 就是利用这一特性,将 vue 的模板转换成了小程序的 wxml,这是其编译型的特性。
在编译时,并没有将逻辑层的代码转换成小程序原生的语法,而是完全的保留了 vue 的能力,这是其运行时的特性。
由于完全保留了 vue 的能力,也使得上述纯编译型框架的痛点得以解决。我们可以享受最新的语法特性,不用担心由于写法问题导致转换错误,可以方便的复用 vue 生态。
那现在留下的疑问就是:vue 是浏览器中的运行时框架,它是怎么去操作改变小程序视图的呢?
首先,vue 在浏览器中的运行流程如下:
new Vue() -> render() -> patch() -> 浏览器视图 观察上述流程,发现只在第三步中涉及到了浏览器相关的东西。所以 1、2 步是完全可以在小程序中运行的。
所以只需要对第三步做适配,就可以将 vue 运行在小程序中了。
那如何做适配呢?当 patch 函数 diff 出需要更新渲染的 vnode,就会去调用更新视图的 API,在浏览器中那是 DOM 系列的 API。而在小程序中,其只为我们提供了 setData 这个用来更改视图的方法,所以很明显,我们只需要在 diff 结束后,调用 setData 来更新视图就可以了。
这就又引出了另一个问题,patch 出来的是 vnode,而我们在模板中用的是 data 中的数据,所以肯定不能直接将 vnode 传到 setData 中,应该给 setData 传入 data 中改变的数据才对,那我们怎么才能拿到 data 中改变的数据呢?
说起改变的数据,可能第一反应是 diff,我们将老的数据保存一份,当数据改变之后。对新旧数据进行 diff,然后拿到差异数据,传入 setData 更新视图。
这样当然是可行的,我们只需要将 patch 中对比 vnode 的代码干掉,换成 diff 新旧数据的代码,这样 diff 结束后将结果传入 setData 即可。
但是这么做会有一个性能问题,如果 data 中有很多的数据,而在视图中我们只用到了一个简单的变量,这时对 data 数据进行全量 diff 就是一个很浪费时间的工作了。
所以我们可以用另一个方案来更高效的实现,让我们回到上一个问题,patch 出来的是 vnode,而传入 setData 的是 data 数据。那我们可不可以通过 vnode 来获取到 data 中改变的数据呢?
答案是可以的,因为我们会编译模板层的代码,所以在编译时,我们完全可以将相关的信息记录下来。
不废话,上代码:
<!-- vue template -->
<view>
<view>{{ text }}</view>
<view v-for="item in list">{{ item }}</view>
</view>
<!-- 编译后的wxml -->
<view>
<view>{{ text }}</view>
<view wx:for="list" wx:for-item="item" wx:for-index="i">{{ list[i] }}</view>
</view>
<!-- template编译的render函数 -->
render(h) { return h('view', null, [ h('view', {path: 'text'}, text),
list.map((_, i) => { return h('view', {path: 'list[i]'}, list[i]) }) ]) } 通过观察上面的三段代码,我们可以看到,在编译时,我们是可以感知到模板中使用的响应式数据,相对于 data 的访问路径。所以我们就可以将这些路径记录在 vnode 中,这样通过 patch 之后的 vnode,我们就可以获取到对应数据的路径了。
并且通过这种方式,我们也可以避免给视图层传递无用的数据,每次 diff 之后,只会将视图层中用的数据传入 setData。
上面的半编译、半运行时框架只能用于 vue,对 react 而言,其灵活的语法特性和底层架构注定与之无缘。难道说 react 就不能再小程序中运行了吗?
我们来回顾一下上一节中提到的
vue 的 patch 函数 diff 之后的结果是 vnode,而模板中用的是 data 数据,所以我们不能将 vnode 传给 setData,而应该找到对应的数据传给 setData。
再来回顾一下第一节中所说的
JSX 的灵活性导致转换成 wxml 时的工作量巨大,并且要严格遵守规范,否则就会出问题。
放飞你的大脑,我们来刚一下
vue 的 patch 函数 diff 之后的结果是 vnode,而模板中用的是 data 数据,所以我们不能将 vnode 传给 setData
那就是说,如果模板中没有使用 data 数据,那我就可以将 vnode 传入 setData 喽。
JSX 的灵活性导致转换成 wxml 时的工作量巨大,并且要严格遵守规范,否则就会出问题
转换起来那么难,那我干脆不转了。JSX 最后生成的是什么?vnode 啊,我直接把 vnode 传给 setData 喽。
所以现在的问题变成了,小程序模板可以根据 vnode 对象来渲染视图吗?
答案是可以,方案就是小程序的 template 语法可以动态递归的调用渲染。
<template name="tpl_view">
<view class="{{ className }}">
<block wx:for="{{children}}">
<template is="tpl_view" data="{{ item }}"></template>
</block>
</view>
</template> 以上为伪代码,只为方便理解,实际上微信小程序不允许模板调用自身。
上面定义了一个模板,我们只需要构建如下的数据结构,将其传入模板内,这个模板就可以根据数据生成对应结构的 view 元素
const data = {
className: '1',
children: [
{
className: '1-1'
children: [
{
className: '1-1-1',
children: []
}
]
}
]
} 也就是说,如果我们将小程序的所有基础组件,全部都使用模板的形式定义一遍。那我们就可以传入一个描述对象(vnode,注意这个 vnode 不是 vue 或者 react 的),让 wxml 根据这个对象生成视图。
这也是目前 Taro next、Remax 在视图层的实现方式,如果打开 Taro next 编写的小程序代码就会发现里面有一个 base.wxml,其中就是实现了所有的小程序基础组件的模板。
到此为止,视图层我们已经解决了,但是这个解决方案好像和 react 没有什么关系,理论了只要能产生 wxml 渲染模板的 vnode,任何框架都可以这样实现。
事实上也是,用这种方案,可以很轻松的同时支持 Vue 和 React 这两种框架。Taro next 就是如此。
接下来就说一说 react 的事
react 的源码相比 vue 更加复杂,但整体的**并无太多差距,可以简单总结为
React.render() -> reconciler() -> renderer() -> 浏览器视图 看过 vue 的实现之后,我们不难猜到,这里要动刀的肯定是 renderer 这一步了。
那如何做呢?别忘了我们的核心点是什么:构建出 wxml 用来遍历渲染的 vnode。
我们重新翻译一下上面的第三步:
renderer 负责将需要更新的虚拟 vnode,通过 DOM API 转换成真实的 dom。
然后想想我们怎么实现呢?
renderer 负责将需要更新的虚拟 vnode,通过【自定义 API】转换成 wxml 用来遍历渲染的 vnode。
是的,就是这么“简单”,我们只需要将原本操作生成 DOM 的那套 API,更改成操作生成 vnode 的 API 就可以啦~~~ 完结!撒花 ❀❀❀❀❀❀❀❀❀❀❀
开玩笑,当然没那么“简单”,但是**就是这样,不管是 vue 还是 react,其实我们需要做的就是将更改 DOM 的 API,换成更改 vnode 的 API。
举个例子:
// DOM API
function createElement(type) {
return document.createElement(type)
}
// vnode API
function createElement(type) {
return {
template_name: "tpl_" + type,
}
} 还有一个好消息就是,不管是 React 还是 Vue,当需要操作 DOM 时,都不会直接在代码中调用 DOM API,而是将操作统一封装到了工具函数中,这样我们就可以很方便的对这些 API 进行改写了。
更具体的实现,这里就不在赘述,可以看下面的参考链接去详细了解。
2024-03-25
咬文嚼字
如今的前端已经不局限在语言(JS)、环境(Browser)中了,我们几乎可以做任何与用户进行交互的界面或工具
我们想要表达:所有服务于设计和开发用户可以直接看到和交互的部分这件事情
其实「前端」这个词本身的含义已经足够好了,但是因为时代的原因被绑上了固有的标签
所以不得不用一些新词/概念来区别时代的变化
开始之前先说一下 TUI,就是运行在终端里的用户界面,不知道有多少人了解/使用过这个
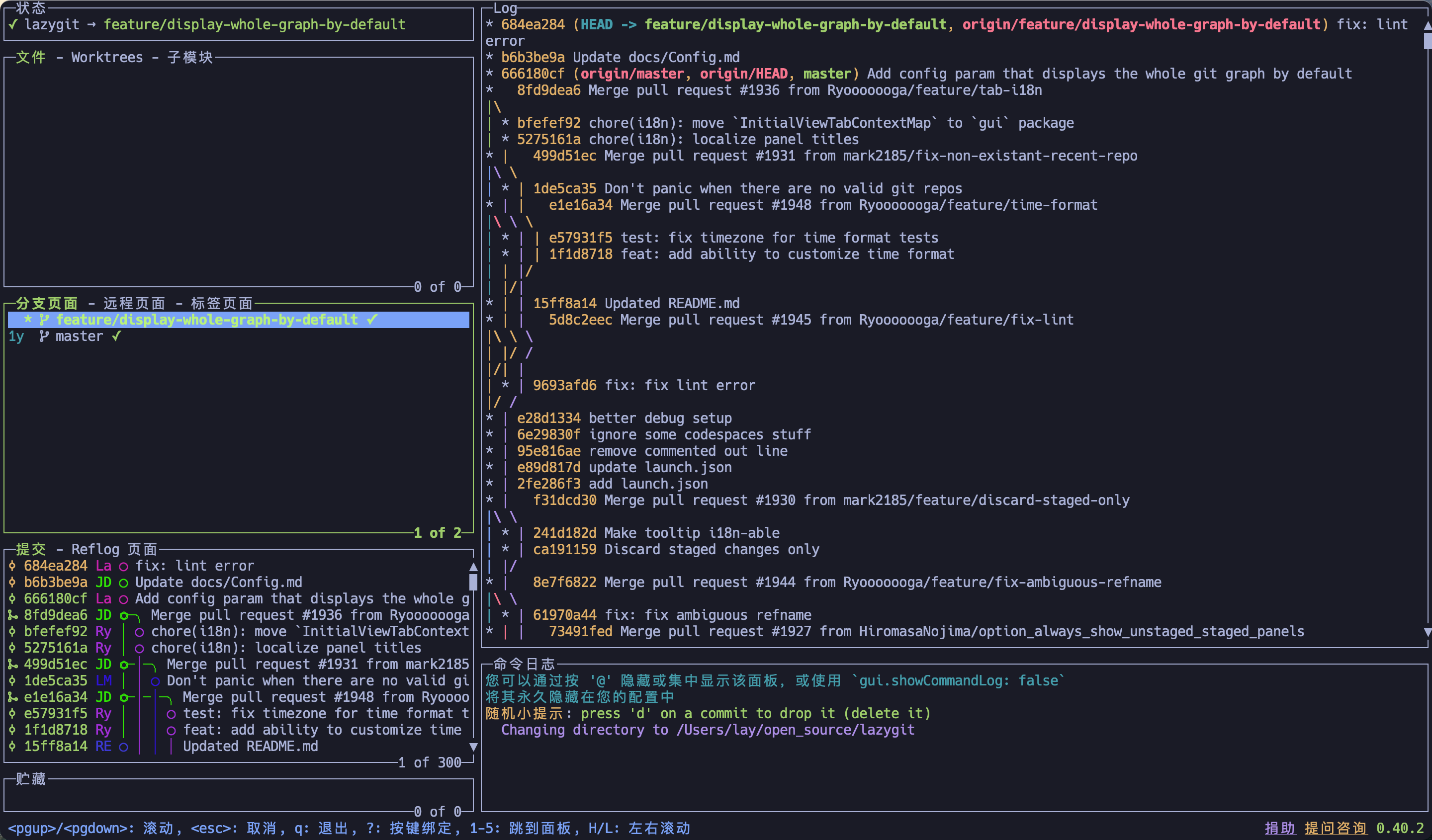
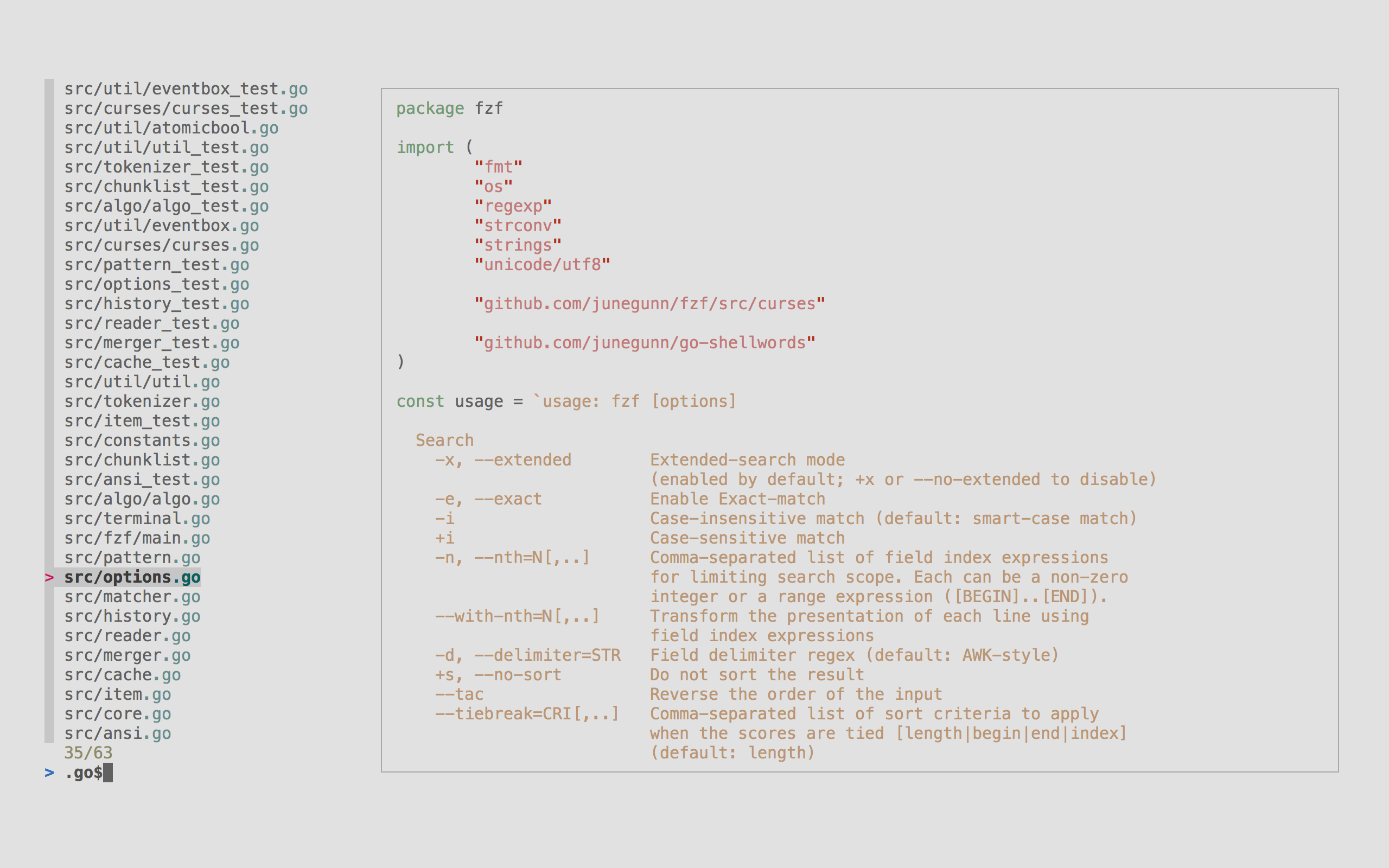
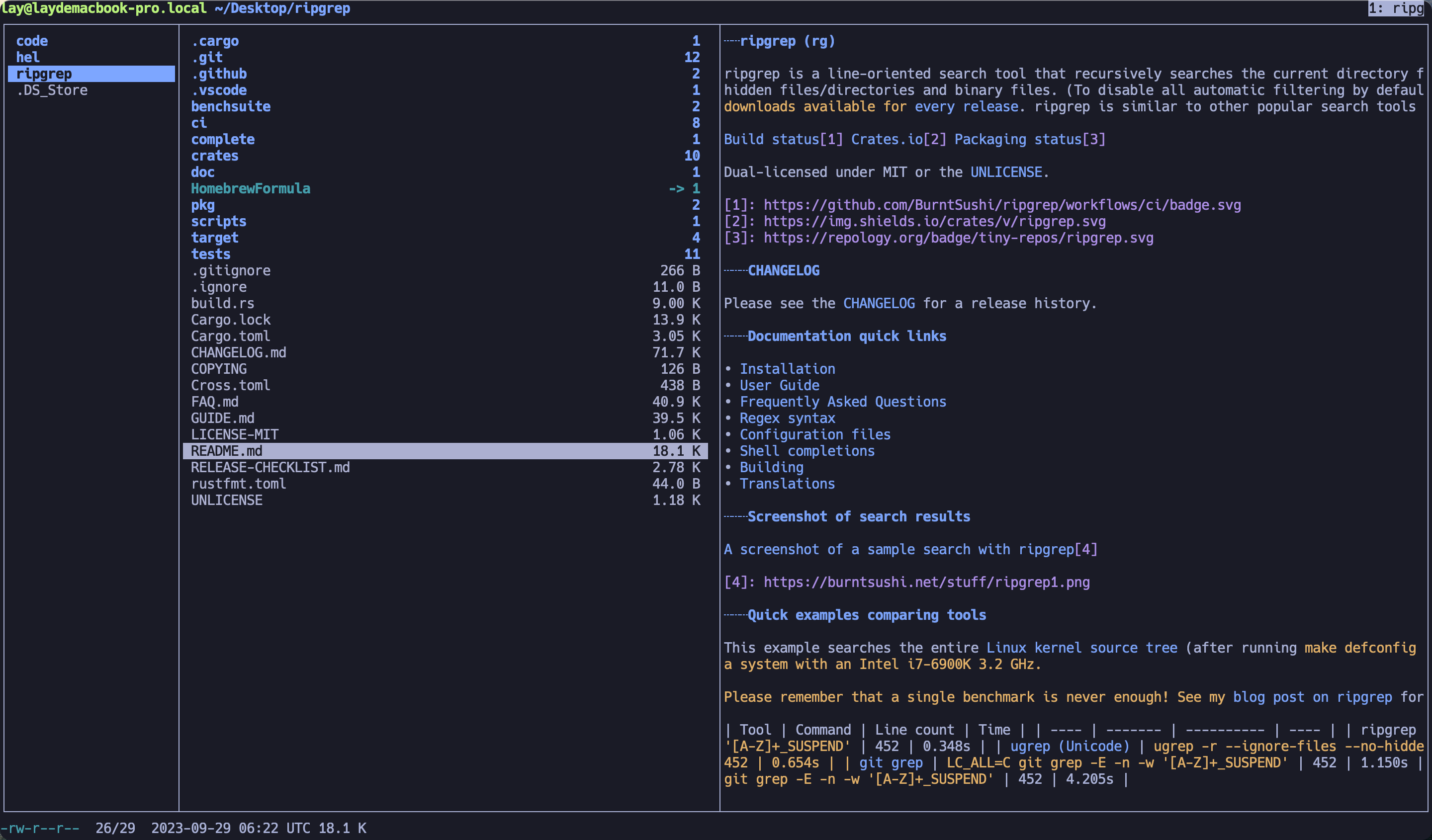
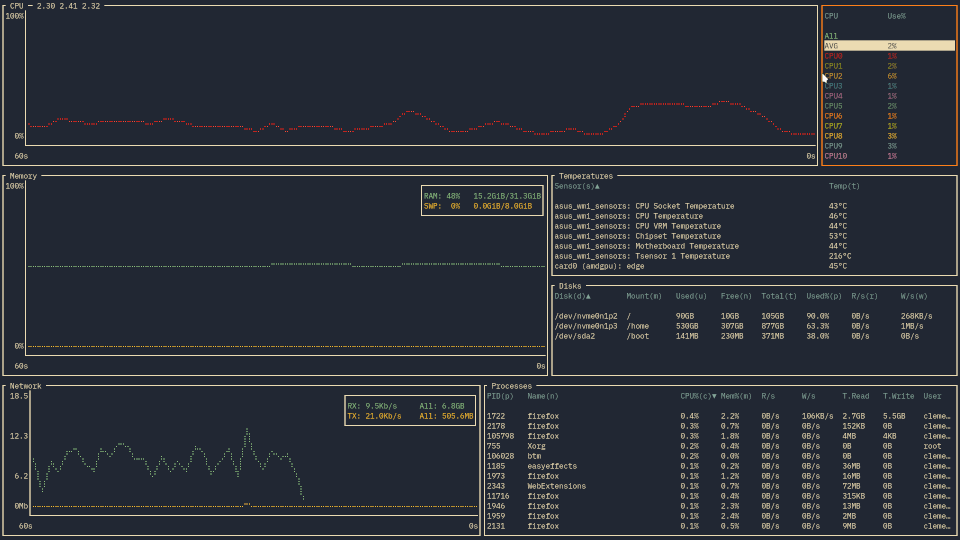
简单列一些比较常用的:
| lazygit | fzf | ranger/ yazi | bottom | wtf |
|---|---|---|---|---|
 |
 |
 |
 |
 |
除此之外还有诸如音乐播放器、邮箱、游戏(口袋妖怪)等等等,感兴趣可以访问 awesome-tuis
开发 TUI 的技术栈各种各样:Go / Python / Rust...
当然也少不了 JS:React TUI - Ink:
npx mnswpr
能用 JS 写的终将会用 JS 写
能用 Rust 写的终将会用 Rust 写
提到前端很容易会联想到这些标签:HTML + CSS + JS / Browser / Web / React / Vue
但现在 (2024) 的前端已经完全不限于上述的标签里了
国内把这种拥有更全面能力的前端称为「大前端」,但我觉得这个词不好的地方是:会让人自以为了解其含义
并且由于里面存在「前端」的字眼,所以大概率还是会局限在固有标签里
把 终端的异步状态管理 这篇文章的「终端」换为「大前端」,我觉得就不能很好的表达其意思了
终端(Terminal)固有印象:黑窗口/命令行窗口
-- Terminal

鸿蒙 HarmonyOS 系统是面向万物互联的全场景分布式操作系统,支持手机、平板、智能穿戴、智慧屏等多种终端设备运行
更接近我们要表达的意思:人机交互入口、链路的终点,而不是局限在 Web/Native/Terminal,又或是手机、电脑、电视等
而且终端这个词的“好处”是人们的第一反应是疑惑与好奇:这跟前端有什么关系?这会驱使其进一步了解,而不是自以为了解
黄玄视频中提到的词


其实我觉得前端(Front-end)这个词本身是挺好的:设计和开发用户可以直接看到和交互的部分
单看这一句完全可以把 end device 相关的都算到前端里,但由于时代的固有印象,不得不用一些新词/概念来进行区分
2024-03-28
Important
各区间训练是会相互影响的,并不是完全割裂的
有氧和无氧都会提升 乳酸穿梭能力,进而提高阈值水平
所以各区间都是要练的,只是侧重点会根据目标略有不同
最近刷到了一个讲跑步训练的视频,发现里面讲的训练方法和骑行的侧重点并不相同,明明两者都是有氧运动,不免让人产生疑惑 🤔
但细思之下又发现其底层逻辑和之前讲的 极化训练,为什么要多骑二区(有氧)? 不谋而合
文中跑步特指长跑、马拉松,骑车特指公路车
以三区模型为例
从上到下依次为
骑行训练中目前流行的是极化训练,基本**是把训练的总时间 80% 分给 Zone1 训练,20% 分给 Zone3 的训练,在临近赛期的时候才会去 Zone2 训练
而跑步训练中,则更多是阈值或金字塔型,会发现相比之下 Zone2 训练时间变长了
训练是有目的性的,是为目标所服务的。从这个点出发,可以看一下跑步比赛和自行车比赛的差别
跑步我们都知道马拉松就是 42 公里,顶尖的运动员的时间大概是在两小时到两个半小时之间
那骑车呢?我们需要去对比单日赛,五大古典赛的里程数是 240KM 到 300KM 之间,完赛时间五小时到六小时之间
然后可以再看一下比赛过程中的差异
跑步的话,过程中并没有太多战术性的东西,大家的对手只是自己,所以都在顶着自己的阈值去完成比赛,尽可能多的提高自己的成绩
而公路车就复杂的多了,里面充斥着各种心机战术
由于速度和空气动力的原因,车手跟车骑行时会极大的节省体力,尤其当车手处于大集团中,他们的功率是相当低的
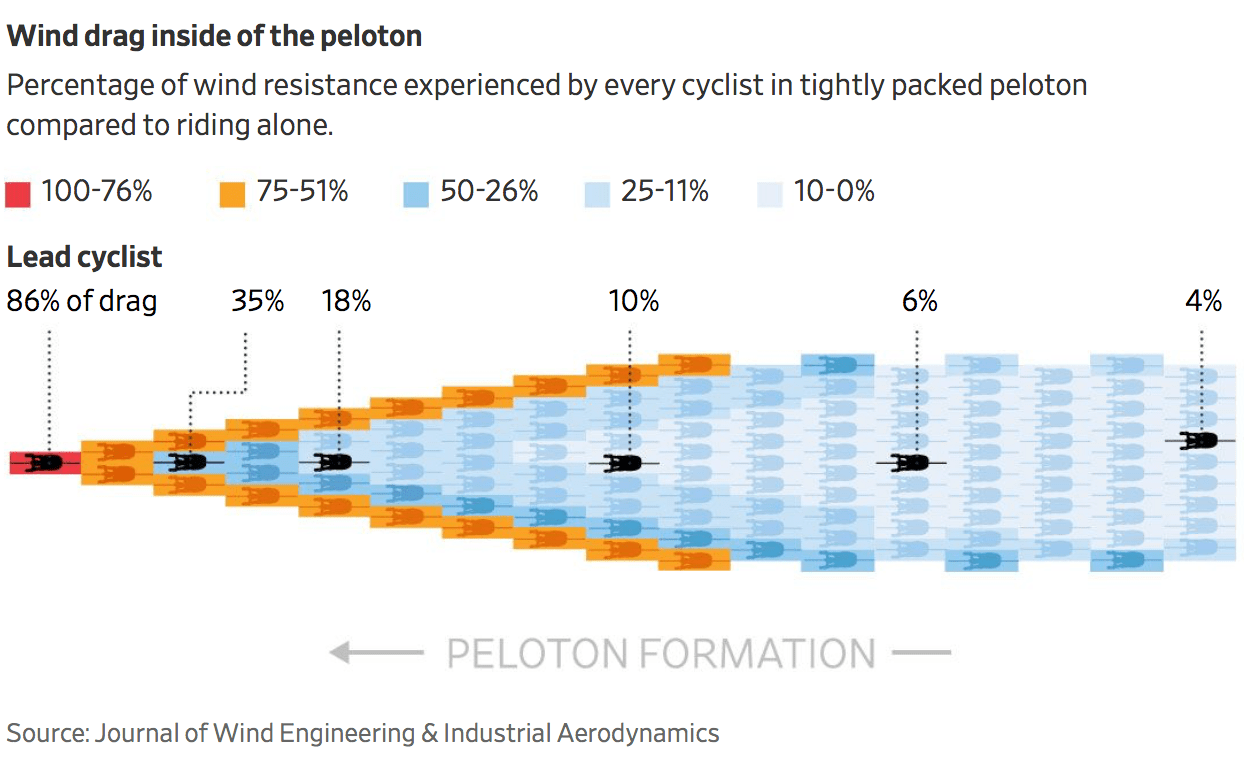
所以比赛的基本原则是
同时也可以从供能系统去看,由于骑车完赛时间过长,我们无法全程依靠糖原供能去进行比赛
非常粗略/不严谨的说,糖原大概会在 90 分钟左右消耗完毕
所以不得不想办法提高有氧供能的能力,让自己二区的速度越来越快
在可以跟住主集团的同时保留糖原,以在关键时刻发起进攻决定胜负
所以结论也不言自明,对跑步来说,更像是公路车的计时赛,我们没有太多的对手,更多是对自己的比拼,所以要全力完成比赛(全程阈值输出),所以要尽可能多的提高自己的阈值的能力
而公路车整个赛程中大多数都是以有氧的强度进行的,只在关键时刻才会发起进攻以阈值以上的强度输出,所以会尽量提高自己的有氧和无氧能力
2021-01-05
公司要开发一个 Chrome 扩展,用来模拟人为操作,爬取目标网站的数据。
通过这篇文章来记录和分享一下开发过程中的经验与心得。
此扩展开发时,Chrome 扩展 v3 版本的文档已经发布。但是只有最新的 Chrome 才支持,考虑兼容性问题,扩展使用的仍然是 v2 版本,本篇文章中的相关介绍,也都是以 v2 版本为主。
虽然标题是使用 Umi 开发 Chrome 扩展,但是本篇 95% 都是在讲扩展本身,最后会简单说一下开发扩展时 Umi 的配置。
扩展程序是可以定制浏览体验的小型软件程序。它使用户可以根据个人需要或偏好来定制 Chrome 功能和行为。它们是基于 Web 技术(例如 HTML,JavaScript 和 CSS)构建的。
扩展由相互联系的各种组件组成,组件可以包括 后台脚本,内容脚本,选项页,UI 元素 和各种逻辑文件。
本节介绍一下常用的扩展组件和功能,带你了解扩展在浏览器中能做什么事情。
浏览器右上角(工具栏)展示的小图标,每一个图标就代表一个扩展程序。

action 有三种操作方式:
toopli:鼠标 hover 后的文字提示badge:徽标popup:点击后弹窗其中弹出窗口是 action 的主要交互区域。

顾名思义,可以增加和修改浏览器的键盘快捷键操作。
说起这个功能,就不得不提一个非常热门的扩展:Vimium
这个扩展可以让你用 vim 的快捷键操作浏览器,让你完全脱离鼠标操作。
向右键菜单中加入自定义项。

使用 override 可以将 Chrome 默认的一些特定页面替换掉,改为使用扩展提供的页面。
可以替代的页面如下:
Chrome://history 历史记录页Chrome://newtab 新标签页Chrome://bookmarks 书签页一个扩展只能替代一个页面,不能替代无痕模式窗口的新标签页。
新标签页扩展:掘金、Infinity

在地址栏中注册关键字,用户输入指定关键字后按下 tab 键即可输入内容,每次用户按下回车键,地址栏中输入的内容都会被发送到扩展中。
百度、必应、Github 等网站在 Chrome 中都有对应的关键字搜索功能,相信不少人都用过。在地址栏中输入 github.com 或者 baidu.com,然后按下 tab 键,地址栏就会变成下面的样子。在这种状态下我们输入的内容都会在相应网站中进行搜索执行。

向开发者工具中的增加功能,如 Vue devtools、React devtools,前端一定不会陌生,本文不会重点讲解,建议查阅官网。
对着 action 图标右键,菜单中就会显示 选项 菜单,如果菜单是亮起的,说明此扩展开启了选项功能。

选项页一般情况下,都会作为扩展的配置页面,如下

当然,所谓的选项页其实就是加载了一个指定的 HTML,至于 HTML 中是展示扩展的配置还是别的东西,这个完全取决于你自己。
上面讲的都是使用者可以直观感受的功能,接下来这两个脚本功能是使用者无法直接感知但又在扩展中无比重要的功能。
后台脚本就是指伴随扩展的整个生命周期进而运行的 JS 文件,在这个 JS 中可以使用 Chrome 提供的 API 来监听浏览器、扩展的各种事件,通过对这些事件的监听,进而对扩展其他功能进行协调和处理。
content-script 可以把指定的 JS、CSS 文件放在当前正在浏览的网页上下文中执行。
CSS 可以修改的网页的样式,JS 可以访问和更改当前页面的 BOM、DOM,进而对网页的样式、行为进行控制和更改。
以上就是插件中比较常用的一些功能,除了这些常用的功能 Chrome 还给我们提供了很多强大的 API,下面我们罗列一些常用的。
Management: 管理已安装和运行的扩展
Message Passing: 各个扩展之间、扩展与 content-script 之间的通信Storage:提供本地存储与账号同步存储功能Tabs:在浏览器中创建、修改和重新排列标签
oneTabWindows:在浏览器中创建、修改和重新排列窗口Cookies:浏览和修改浏览器的 cookie 系统
cookiesCross-Origin:扩展中的 XMLHttpRequest 和 fetchAPI 是不受同源策略影响的。webRequest:拦截,阻止或修改请求网络请求Bookmarks:书签创建、组织和操作书签行为Downloads:以编程方式启动、监视、操作和搜索下载History:历史记录 与浏览器访问页面的记录交互Devtools: 向开发者工具中添加功能Accessibility(a11y):可访问性Internationalization(i18n):国际化identity: OAuth2 访问令牌Proxy:管理 Chrome 的代理设置
VPN在开始之前,我们需要再了解一个东西:
mainfest.json。
上一小节,我们讲了关于扩展的很多功能。再回顾开头,官方介绍中提到了这些组件都是由 Web 技术构建出来的,也就是说我们只需要给 Chrome 提供 HTML、CSS、JS,Chrome 就可以将它们作为扩展进而运行。
那这里就有了一个问题,Chrome 怎么知道这些文件就是扩展要运行的文件呢?它又如何知道哪些文件对应哪个功能呢?
所以这里就需要一个配置文件,来 告诉 Chrome 这个扩展应该如何构建,如何运行。这就是 mainfest.json 的作用。
详细的 mainfest.json 配置后面再说,这里了解完其概念之后我们接着往下讲。
先说后台脚本,因为有些扩展的运行依赖于它。
配置方式:
// manifest.json
{
"background": {
// 两种方式选其一
"page": "background.html",
"scripts": ["background.js"],
// 关闭持久连接
"persistent": false
}
} 在 manifest.json 中的 background 属性中,可以指定一个 JS 数组,或者一个 HTML。
HTML 作用就是加载执行其中的 JS,HTML 本身的内容是不会被展示出来的。
persistent 属性代表后台脚本的运行方式,默认为 true,表示会一直运行。如果指定为 false,则只会在一些重要的事件中运行。
runtime.getBackgroundPage。官方推荐将其设置为 false,并且在 v3 中,persistent 属性被取消,取而代之的是使用 service script 指定后台脚本,其中的脚本将以 service worker 的方式运行。
persistent 怎么设置,还是要取决于扩展的功能。如果你还不知道怎么配置,那就指定为 false,因为多数情况下后台脚本都应该是由事件进而驱动运行的。
后台脚本可以访问 Chrome 提供的除 devtools 外的所有 API。
配置方式:
{
"content_scripts": [
{
"matches": ["<all_urls>"],
"js": ["js/content-script.js"],
"css": ["css/custom.css"],
"run_at": "document_start",
// "exclude_matches": "",
// "include_globs": ""
// "exclude_globs": ""
// "match_about_blank": false
},
{
"matches": ["*://*.baidu.com/*"],
"js": ["bd-content.js"],
"run_at": "document_start"
}
]
}
content_scripts 属性是个数组,其中可以配置多个匹配规则,当匹配成功,就会将配置的文件进行注入执行。
matches:指定 匹配模式,"<all_urls>" 表示所有网址。js/css: 要注入的文件。match_about_blank: 脚本是否应注入到 about:blank 页面,默认 false。exclude_matches/include_globs/exclude_globs: 配置额外的匹配模式。run_at:代码注入的时机
document_start:在 CSS 注入之后,在构建 DOM 和运行脚本文件之前被注入。document_end:在 DOM 加载完成之后,可以理解为 DOMContentLoaded 事件。document_idle:默认值,在 window.onload 事件调用的前后执行。具体时机取决于文档的复杂程度和加载所需的时间,并针对页面加载速度进行了优化。这个注入方式中不需要监听 onload 事件,因为可以确保 DOM 已经加载完成。如果必须要知道 onload 有没有触发,可以使用 document.readyState 进行判断。出于安全性的考虑,content-script 的 JS 是在沙箱环境中执行的,它访问不到网页本身加载的 JS 定义的属性、方法,比如说网页本身加载了 jquery,那在 content-script 中是访问不到的,如果想要使用,只能在配置项中配置,在 content-script 的执行环境中注入一个 jquery。
content-script 可以对页面中的 DOM 进行随意的修改、删除、新增,可以给已有的 DOM 元素绑定事件,也可以创建一个新的 DOM 并给其添加事件后插入页面中。正常来说呢,已经可以满足大多数的需求了。
在参考文章 【干货】Chrome 插件(扩展)开发全攻略 中,提到 content-script 无法给 DOM 绑定事件,经测试是可以的,不知是不是扩展的功能更新了。
如果真的有需求,需要 JS 在当前网页的执行环境中进行执行,那也是可以实现的,既然我们可以操作 DOM,就可以很轻松的写出如下代码:
const script = document.createElement("script")
script.innerHTML = "console.log(window.$)"
document.body.append(script) 这样通过操作 DOM 注入的 JS 就是在网页自身的执行环境运行的了。
当然,正常情况下我们不会通过 innerHTML 来实现,而是使用 script 的 src 属性直接加载一个 JS 文件。
代码如下:
const script = document.createElement('script')
script.src = chrome.extension.getURL('js/inject.js')
document.head.appendChild(script)
需要注意的是加载的路径是扩展目录的文件(当然也可以加载网络资源),这个目录地址我们需要通过 chrome.extension.getURLAPI 来获得。
还需要注意,如果你加载的是扩展目录的文件,那就需要在 web_accessible_resources 明确的配置文件名才行(网络资源不需要)。
{
"web_accessible_resources": [
"inject.js"
]
}
内容脚本中只能访问如下的 Chrome API
其中的 runtime 中的前四个 API 提供了与扩展的其他部分进行通信的能力。

上节说到 action 点击后会弹出一个窗口,这个窗口其实就是一个小型的 tab 页面,里面加载了一个我们指定的 HTML 文件。
配置方式:
// manifest.json
{
// "page_action"
"browser_action": {
// 图标
"default_icon": "img/icon.png",
// tooltip
"default_title": "标题",
// 弹窗页面
"default_popup": "popup.html"
}
} 可以看到我们在 default_popup 字段中指定了一个 HTML,这个 HTML 会在弹窗打开时加载,弹窗关闭后销毁。
也就是说,弹窗的每次的出现和消失,都是一个完整的生命周期。就像你在浏览器中打开一个 tab 页加载页面,随后又把这个 tab 页关闭了一样。
browserAction 的图标是常亮的,它的功能在任何网页中都可以使用。pageAction 只会在指定的网站中亮起,它的功能也只限于这些指定网站使用。
octotree 扩展只会在 github 的项目页面亮起。
在 background.js 中使用 declarativeContent 对页面的变化进行匹配,然后来决定 pageAction 的点亮和置灰。
// manifest.json
{
"permissions": ["declarativeContent"]
}
// background.js
chrome.runtime.onInstalled.addListener(function(details) {
chrome.declarativeContent.onPageChanged.removeRules(undefined, function() {
chrome.declarativeContent.onPageChanged.addRules([{
conditions: [
new chrome.declarativeContent.PageStateMatcher({
pageUrl: { hostEquals: 'www.google.com', schemes: ['https'] },
css: ["input[type='password']"]
})
],
actions: [ new chrome.declarativeContent.ShowPageAction() ]
}]);
});
});
在 Chrome ext v3 版本中,browserAction 与 pageAction 这两个区别并不大的功能被统一合并成了 action 功能。
action 和 background 一样,可以访问 Chrome 提供的除 devtools 外的所有 API。
在 action 中可以通过 chrome.extension.getBackgroundPage 或者 chrome.runtime.getBackgroundPage 直接获取到 background 脚本的 window 对象,进而访问其中的方法和属性。
这两个 API 的区别在于 background 的 persistent 属性,如果值为 false,空闲时后台脚本就是关闭的,需要使用 runtime.getBackgroundPage 通过事件机制将其唤醒,然后才能交互。
const bgs = chrome.extension.getBackgroundPage()
// or
chrome.runtime.getBackgroundPage((bgs) => {
bgs.backgroundFunction()
})
在权限配置中声明我们需要 contextMenus 权限,然后为其制定一个图标。
{
"permissions": [
"contextMenus"
],
"icons": {
"16": "icon-bitty.png",
"48": "icon-small.png",
"128": "icon-large.png"
}
}
在 background.js 中可以使用 chrome.contextMenus API 对菜单项进行增删改查。
chrome.contextMenus.create({
type: 'normal', // 类型,可选:["normal", "checkbox", "radio", "separator"],默认 normal
title: '菜单的名字', // 显示的文字,除非为“separator”类型否则此参数必需,如果类型为“selection”,可以使用%s显示选定的文本
contexts: ['page'], // 上下文环境,可选:["all", "page", "frame", "selection", "link", "editable", "image", "video", "audio"],默认page
onclick: function(){}, // 单击时触发的方法
parentId: 1, // 右键菜单项的父菜单项ID。指定父菜单项将会使此菜单项成为父菜单项的子菜单
documentUrlPatterns: 'https://*.baidu.com/*' // 只在某些页面显示此右键菜单
});
// 删除某一个菜单项
chrome.contextMenus.remove(menuItemId);
// 删除所有自定义右键菜单
chrome.contextMenus.removeAll();
// 更新某一个菜单项
chrome.contextMenus.update(menuItemId, updateProperties);
"chrome_url_overrides":
{
// 选其一覆盖
"newtab": "newtab.html",
"history": "history.html",
"bookmarks": "bookmarks.html"
}
通过上节罗列的扩展 API,我们可以拿到自己需要的数据并加以渲染。
这个功能没有去深究,这里把官网的介绍复制一下。
每次打开 Devtools 窗口时,都会创建扩展的 Devtools 页面的实例。DevTools 页面在 DevTools 窗口的生命周期内一直存在。DevTools 页面可以访问 DevTools API 和一组有限的扩展 API。具体来说,DevTools 页面可以:
devtools.panels API 创建面板并与面板进行交互。devtools.inspectedWindow API 在检查窗口中评估代码。devtools.network API 获取有关网络请求的信息。DevTools 页面和 content-script 类似,只能使用有限的 Chrome API。DevTools 页面与后台页面通信同样是使用 runtime 的相关 API。
{
// 只能指向一个 HTML 文件,不能是 JS 文件
"devtools_page": "devtools.html"
}
Devtools 的开发场景并不多,如果想了解可以看文末的参考资料进行学习。
先在 manifest.json 中指定一个关键字以提供搜索建议(只能设置一个关键字)
{
"omnibox": { "keyword" : "go" },
}
在 background.js 中监听相关事件
// 输入框内容变化时触发,suggest用以提示做输入建议
chrome.omnibox.onInputChanged.addListener((text, suggest) => {
if(!text) return;
if(text == '美女') {
suggest([
{content: '**' + text, description: '你要找“**美女”吗?'}
])
}
})
// 当用户接收关键字建议时触发
chrome.omnibox.onInputEntered.addListener((text) => { });
在 manifest.json 中指定渲染 HTML 即可
{
"options_ui": {
"page": "options.html",
"chrome_style": true
}
}
{
// 清单文件的版本,值固定为2,现在已经有3了
"manifest_version": 2,
// 插件的名称
"name": "demo",
// 插件的版本
"version": "1.0.0",
// 插件描述
"description": "简单的Chrome扩展demo",
// 图标,一般偷懒全部用一个尺寸的也没问题
"icons": {
"16": "img/icon.png",
"48": "img/icon.png",
"128": "img/icon.png"
},
// 会一直常驻的后台JS或后台页面
"background": {
// 2种指定方式,如果指定JS,那么会自动生成一个背景页
"page": "background.html"
//"scripts": ["js/background.js"]
},
// 浏览器右上角图标设置,browser_action、page_action、app必须三选一
"browser_action": {
"default_icon": "img/icon.png",
// 图标悬停时的标题,可选
"default_title": "这是一个示例Chrome插件",
"default_popup": "popup.html"
},
// 当某些特定页面打开才显示的图标
"page_action": {
"default_icon": "img/icon.png",
"default_title": "我是pageAction",
"default_popup": "popup.html"
},
// 需要直接注入页面的JS
"content_scripts": [
{
//"matches": ["http://*/*", "https://*/*"],
// "<all_urls>" 表示匹配所有地址
"matches": ["<all_urls>"],
// 多个JS按顺序注入
"js": ["js/jquery-1.8.3.js", "js/content-script.js"],
// JS的注入可以随便一点,但是CSS的注意就要千万小心了,因为一不小心就可能影响全局样式
"css": ["css/custom.css"],
// 代码注入的时间,可选值: "document_start", "document_end", or "document_idle",最后一个表示页面空闲时,默认document_idle
"run_at": "document_start"
},
// 这里仅仅是为了演示content-script可以配置多个规则
{
"matches": ["*://*/*.png", "*://*/*.jpg", "*://*/*.gif", "*://*/*.bmp"],
"js": ["js/show-image-content-size.js"]
}
],
// 权限申请
"permissions": [
"contextMenus", // 右键菜单
"tabs", // 标签
"notifications", // 通知
"webRequest", // web请求
"webRequestBlocking",
"storage", // 插件本地存储
"http://*/*", // 可以通过executeScript或者insertCSS访问的网站
"https://*/*" // 可以通过executeScript或者insertCSS访问的网站
],
// 普通页面能够直接访问的插件资源列表,如果不设置是无法直接访问的
"web_accessible_resources": ["js/inject.js"],
// 插件主页,这个很重要,不要浪费了这个免费广告位
"homepage_url": "https://www.baidu.com",
// 覆盖浏览器默认页面
"chrome_url_overrides": {
// 覆盖浏览器默认的新标签页
"newtab": "newtab.html"
},
// Chrome40以前的插件配置页写法
"options_page": "options.html",
// Chrome40以后的插件配置页写法,如果2个都写,新版Chrome只认后面这一个
"options_ui": {
"page": "options.html",
// 添加一些默认的样式,推荐使用
"chrome_style": true
},
// 向地址栏注册一个关键字以提供搜索建议,只能设置一个关键字
"omnibox": { "keyword": "go" },
// 默认语言
"default_locale": "zh_CN",
// devtools页面入口,注意只能指向一个HTML文件,不能是JS文件
"devtools_page": "devtools.html"
} 开发时主要会用到 content-script 与 popup 和 background 之间的通信,通信分为短链接和长链接。
两者的通信其实就是进程间的通信,通信内容必须可以被序列化,可以理解消息体会被 JSON.stringify 后进行传递。所以消息体中不能发送 function、symbol、Map 等数据。
background 中可以通过 chrome.extension.getViews({type:'popup'}) 来获取已打开的 popup,进而访问其中的属性、方法。
popup 可以通过 chrome.extension.getBackgroundPage 或者 chrome.runtime.getBackgroundPage 获取到 background 的 window,进而访问其属性和方法。
popup 和 background 给 content-script 发送消息
接收方 content-script 需要先完成消息事件的监听
const handleMessage = (message, sender, sendResponse) => { }
chrome.runtime.onMessage.addListener(handleMessage)
message: 消息内容sender: 发送者信息sendResponse: 回复消息的方法发送方 popup | background 调用 API 发送消息
// 封装获取当前选中的tab标签方法
const getCurrentTab = () => new Promise((resolve, reject) => {
chrome.tabs.query({active: true, currentWindow: true}, ([tab]) => {
tab?.id ? resolve(tab) : reject('not found active tab')
})
})
const tab = await getCurrentTab()
// 发送消息
chrome.tabs.sendMessage(tab.id, {greeting: "hello"}, (response) => { })
tabs.sendMessage 的三个参数分别是
tab 标签页的 idsendResponse 函数短链接注意事项:
sendResponse 只能使用一次,不能多次使用。handleMessage 函数执行结束,消息通道就会关闭,此时的 sendResponse 已经无效。也就是说 sendResponse 不能异步使用。sendResponse,需要在 handleMessage 中明确的写下 return true,这样消息通道会一直保持,直到 sendResponse 被调用。接收方 content-script 需要先完成消息事件的监听
// 监听长链接 链接事件
chrome.runtime.onConnect.addListener(port => {
// 可以根据 name 来区分不同的长链接逻辑
if (port.name === 'knockknock') {
// 给另一端发送消息
port.postMessage()
// 监听另一端的消息
port.onMessage.addListener(message => {})
}
})
发送方 popup | background 调用 API 发送消息
const tab = await getCurrentTab()
// 建立链接
const port = chrome.tabs.connect(tab.id, {name: "knockknock"})
// 给另一端发送消息
port.postMessage()
// 监听另一端的消息
port.onMessage.addListener(message => {})
port 端口对象
name: 端口名称disconnect: 关闭端口postMessage: 发送消息onDisconnect: 监听端口关闭事件onMessage: 监听端口消息事件sender: 发送者的信息content-script 给 popup 和 background 发送消息
两者的逻辑其实是一样的,只不过 popup | background 给 content-script 发送消息时,使用的是 chrome.tabs API,需要指定一个 tab 的 id。
而 content-script 给 popup | background 发送消息时,使用的时 chrome.runtime API,不需要 id。
接收方 popup | background 需要先完成消息事件的监听
const handleMessage = (message, sender, sendResponse) => { }
chrome.runtime.onMessage.addListener(handleMessage)
发送方 content-script 调用 API 发送消息
// tabs 改为了 runtime
chrome.runtime.sendMessage({greeting: "hello"}, (response) => { })
如果 popup 和 background 都使用了 runtime.onMessage 监听了事件,那么当 content-script 发送了消息,两者都会接到。
但是 sendResponse 只有一个,一个先用了后者就无法使用了。
这里还存在一个坑,我们下节再说。
接收方 popup | background 需要先完成消息事件的监听
// 和上面一模一样
chrome.runtime.onConnect.addListener(port => {
if (port.name === 'knockknock') {
port.postMessage()
port.onMessage.addListener(message => {})
}
})
发送方 content-script 调用 API 发送消息
// tabs 改为了 runtime
const port = chrome.runtime.connect({name: "knockknock"})
port.postMessage()
port.onMessage.addListener(message => {})
可以看到两者出了 API 的调用之外几乎没有区别,具体由谁主动发送消息,由谁来监听,需要根据实际需求来决定。
说一下在短链接中,popup | background 回复 content-script 时的坑。
问题的前置条件:
sendResponse 需要异步发送。popup 和 background 都使用 runtime.onMessage 监听了 content-script 发来的消息。当遇到上述场景时,会发现调用 sendResponse 后无法回复消息。
原因也很简单,我们在上面已经说过了,当 sendResponse 需要异步发送时,需要明确的在 runtime.onMessage 监听事件中返回 true,但是由于有两者都监听了,那么其中一个可能就会事先返回 undefined,这就导致了消息通道的提前关闭。
解决办法呢也很简单,我们需要将发送给 popup 和 background 的消息区分并封装,并将是否是异步消息发送给接收方。
代码如下
// 消息格式
interface RuntimeMessage<T = string> {
type: T
payload: any
receiver?: 'bgs' | 'popup'
isAsync?: boolean
}
// 封装发送消息
const sendMessageToRuntime = (
msg: RuntimeMessage,
cb?: LooseFunction,
) => {
// 当传入callback时,默认这是一个异步消息
if (msg.isAsync === void 0 && isFunction(cb)) {
msg.isAsync = true
}
chrome.runtime.sendMessage(msg, cb)
}
// 使用
sendMessageToRuntime({
type: 'crossFetch',
payload: {...},
receiver: 'bgs',
}, (response) => {})
// background.js
chrome.runtime.onMessage.addListener(
(
{
type,
payload,
receiver,
isAsync,
},
sender,
sendResponse,
) => {
if (receiver === 'bgs') {...}
return isAsync
},
)
// popup.js
chrome.runtime.onMessage.addListener(
(
{
type,
payload,
receiver,
isAsync,
},
sender,
sendResponse,
) => {
if (receiver === 'popup') {...}
return isAsync
},
)
由于本次开发过程中有这样的需求,而常规的 JS 手段无法与另一个 tab 页面建立通信(新 tab 页面地址是多次重定向的结果)。
这里主要演示一下由 background 作为消息通道,为两个 tab 签建立通信。
// tab页面1 content-script
const port = chrome.runtime.connect({
name: 'createTabAndConnect',
})
// 创建目标tab
port.postMessage({
type: 'createTab',
// tab 信息
payload: {...},
})
// 监听消息
port.onMessage.addListener(handleMessage)
// 发送消息
port.postMessage({
type: 'message',
payload: {...}
})
// tab页面2 content-script
chrome.runtime.onConnect.addListener(port => {
if (port.name === 'createTabAndConnect') {
// 监听消息
port.onMessage.addListener(handleMessage)
// 发送消息
port.postMessage({
type: 'message',
payload: {...}
})
}
})
// background.js
port.onMessage.addListener(async ({ type, payload }) => {
switch (type) {
case 'createTab':
{
// 创建tab
const tab = await new Promise(resolve => {
chrome.tabs.create(payload, resolve)
})
// 监听tab 页面的状态
chrome.tabs.onUpdated.addListener((id, info) => {
if (id === tab.id) {
// 加载完成
if (info.status === 'complete') {
// 建立链接
tabPort = chrome.tabs.connect(id, {
name: port.name,
})
// 监听消息
tabPort.onMessage.addListener(msg => {
// 中转tabPort的消息给port
port.postMessage({
type: 'message',
payload: msg,
})
})
}
}
})
}
return
case 'message':
// 中转port的消息给tabPort
tabPort?.postMessage(payload)
return
}
})
最后简单说一下 Umi 开发扩展的配置。
思路是将脚本文件加入入口文件单独打包,HTML 页面使用路由的方式,通过 hash 访问。
所以像 popup、options 这些需要视图的页面,直接在 pages 文件夹中写就行了。Umi 默认会将其作为路由进行打包。
// manifest.json
{
"browser_action": {
"default_popup": "index.html#/popup"
},
"options_ui": {
"page": "index.html#/options",
}
}
在 scripts 文件夹中编写 content-script 和 background 文件,在 Umi 的配置文件中添加入口文件。
最终的 .umirc.ts 如下:
// .umirc.ts
import { defineConfig } from "Umi"
export default defineConfig({
nodeModulesTransform: {
type: "none",
},
cssLoader: {
localsConvention: "camelCase",
},
dynamicImport: {},
history: {
type: "hash",
},
targets: {
Chrome: 73,
firefox: false,
safari: false,
edge: false,
ios: false,
},
ignoreMomentLocale: true,
devServer: {
writeToDisk: true,
},
copy: ["manifest.json", "index.html", "hot-reload.js"] as any,
chainWebpack(memo, { env }) {
memo.devServer.hot = false as any
memo.plugins.delete("hmr")
memo
.entry("background")
.add("./src/scripts/background.ts")
.end()
.entry("content-script")
.add("./src/scripts/content-script.ts")
.end()
},
}) targets 配置决定了代码如何被 polyfill,很明显作为 Chrome 的插件,我们不需要其他浏览器的 polyfill。devServer 将开发模式存在内存中的文件写到磁盘中,webpack 关闭热更新。
copy 将 manifest.json 拷贝到根目录。copy index.html 是因为 Umi 默认会向 index.html 中注入两段 script 脚本,而扩展的 html 中是不允许存在内联脚本的。如果有的话就会有两个报错,当然这两个报错除了不好看之外也没有别的影响。所以这里不做处理也一样。2020-12-08
child_process.spawn()方法使用给定的 command 衍生新的进程,并传入 args 中的命令行参数。
interface SpawnOptions {
cwd: string
env: Object
argv0: string[]
stdio: string[] | string
detached: boolean
uid: number
gid: number
serialization: string
shell: boolean
windowsVerbatimArguments: boolean
windowsHide: boolean
}
function spawn(command: string, options: SpawnOptions): ChildProcess
function spawn(
command: string,
args: ReadonlyArray<string>,
options: SpawnOptions
): ChildProcess spawn 模块会创建一个子进程,并在这个进程中调用传入的系统命令。
这里的系统命令 command 就是指你可以在终端中输入的命令,比如 npm、node、bash、ls、pwd、mongod 等等等等,你可以在终端中输入,就可以在这里传入
比如我们可以这样调用 ls 命令
const { spawn } = require("child_process")
spawn("ls") 如果需要给命令传递参数,可以传入 args 属性,此属性默认为空数组
spawn("ls", ["-a"]) 常用这两个:shell stdio
shell: boolean | string = false
stdio: string[] | string = 'pipe'
默认情况下,子进程的输入输出流都会在子进程中处理,我们可以将其设置为 inherit,来把子进程的输入输出放到副进程中处理。详见 options_stdio
举个例子
// index.js 文件
require('child_process').spawn('ls')
node index.js
// 如果我们直接这样执行代码,那么在终端中我们是看不到任何输出的
// 这是因为输出信息都传递给了子进程,而子进程并没有打印处理
// 我们加上下面的代码进行打印
require('child_process').spawn('ls').stdout.on('data', console.log)
// 此时再执行就可以在终端中看到输出的信息了
// 而如果我们将 stdio 设置为 inherit,则会将输入输出交由父进程处理,子进程不需要监听事件也可以在终端中看到输出的信息了 cwd: string
env: object
argv0: string
command 参数的值,如果没有传入,则会被设置为传入的 command 值detached: boolean
serialization: string = json
windowsVerbatimArguments: boolean
windowsHide: boolean
在 unix 系统中,我们可以这样使用 spawn('npm'),这场可以正常运行的。但在 windows 系统中则会报错,这是因为在 windows 中我们实际执行的是 npm.cmd 批处理,而在 windows 上,.cmd .bat 批处理需要使用 cmd.exe 来运行。
所以我们需要显示的调用 cmd:spawn('cmd', ['/c', 'npm']),或者我们可以设置 shell 参数来隐式调用 cmd spawn('npm', {shell: true})
虽然在 unix 中,我们设置 shell 为 true 也不妨碍命令的执行,但是这样就会额外产生一个不必要的 shell 进程。
所以我们可以这么来写,如果系统是 windows 则打开 shell
spawn("npm", {
shell: process.platform === "win32",
}) 从上面的文章我们可以了解到, 默认情况下,spawn 并不会创建一个 shell 来执行我们传入的命令。
这个行为使得它比 exec 函数效率更高,但是有时我们又确实需要执行 shell 命令,那这个时候我们怎么使用 spawn 来执行呢?要知道 exec 函数会缓存输出结果一次性返回给我们,而 spawn 则是使用流的形式。如果我们的命令数据数据规模较小,那使用 exec 的确是个不错的选择,但在大多数情况下,使用 spawn 将会是更合理、更安全的方式
那么如果使用 spawn 来执行 shell 命令呢?
// 设置为true
spawn("npm run dev", { shell: true })
// 指定终端
spawn("npm run dev", { shell: "bash" }) // 直接传入shell命令
spawn("bash", ["npm", "run", "dev"])
// 通过stdin.write写入命令
const bash = spawn("bash")
bash.stdin.write("npm run dev")
bash.stdin.end() 2020-01-31
Intersection Observer 可以异步的监听元素是否进入了可视区域内,当元素进入可视区域后,会触发相应的回调函数。
const callback = () => {}
// 实例化一个交叉观察者,并传入回调函数
const intersectionObserver = new IntersectionObserver(callback)
// 调用observe方法,监听需要观察的dom元素
intersectionObserver.observe(document.querySelector(".scrollerFooter")) 图片懒加载的实现原理都是一样的,通过 data-src 属性保存真正的 src 地址,等到了触发条件时(即将进入视口),将 data-src 的值赋予 src 属性,开始加载图片。
有了 IntersectionObserver 我们可以很轻松的知道图片进入视口的时机,只需要再 callback 回调函数中替换 src 属性就可以了。
这里值得注意的一点是,一般情况下,我们并不希望图片在完全进入视口后才开始加载图片,我们需要让用户尽可能的感知不到图片的加载替换。所以我们将加载时机提前一点,比如说一屏的高度,那如果来设置这个高度呢。IntersectionObserver 在初始化时允许传入一个配置项,其中的 rootMargin 选项是用来标注额外的 margin 带来的位置信息判断错误问题,我们可以利用这一点,比如我们将 margin-bottom 设为 200px,IntersectionObserver 就会在视口距离监听元素 200px 时去触发回调函数,这就给了我们可以控制距离底部的距离的方法。
<img src="loading.jpg" data-src="realSrc.jpg">
const intersectionObserver = new IntersectionObserver(function(entries) {
// entries是一个数组,我们会观察多个元素,所以会有多个元素同时进入视口这种情况
// intersectionRatio代表了元素进入视口的比例,当元素完全进入视口时值为1,当元素没有进入视口时值为0
// intersectionObserver在监听dom元素后就会执行一次callback,所以这里需要判断一下
if (entries[0].intersectionRatio <= 0) return;
// 开始替换src
entries.forEach(e => {
e.target.src = e.target.dataset.src
})
}, {rootMargin: '0px 0px 200px 0px'})
// 监听所有data-src属性的元素
document.querySelectorAll('[data-src]').forEach(element => intersectionObserver.observe(element)) 2024-05-13
借助 lua_processor,自行实现 vim_mode 的中英文切换逻辑,使其支持:
insert mode 时自动切换回中文模式(如果离开时是处于中文模式的话)这并不是一个完美的解决方案,可能达不到 100% 的使用效果,但是在普通的情况下已经足以使用
可以参考此 feat: vim_modeI
vim_mode.lua 文件首先将 vim_mode.lua 文件放入自己的 lua 文件夹中,并在 rime.lua 中进行导出
vim_mode = require("vim_mode") lua_processor在自己的中文输入方案中,加入 lua_processor
比如我使用的是小鹤双拼,所以我修改 double_pinyin_flypy.custom.yaml,加入如下逻辑
patch:
# 加入 lua_processor
engine/processors/@before 0: lua_processor@vim_mode
# 默认关闭 vmode,只在对应的 app 中打开
switches/+:
- name: vmode
reset: 0 app_options在对应平台的 .custom.yaml 中配置在什么应用下启用 vmode
比如 macOS 的 squirrel.custom.yaml
patch:
app_options:
org.alacritty:
ascii_mode: true
vmode: true
net.kovidgoyal.kitty:
ascii_mode: true
vmode: true 我觉得 vim_mode 的确是一个非常好的功能,尤其是我这种既要用 Obsidian,又要用 Terminal,偶尔还要用 VSCode 的人
虽然这些软件中都有类似 im-select 之类的切换插件,但是每个软件中都需要单独安装,且不同的操作系统,配置还可能不一样(比如我自己就在 macOS 和 Linux 下频繁切换)
所以如果能有一个 IM 级别的 vim_mode 切换解决方案,那真是再好不过了
可是目前的 vim_mode 有两个问题:
normal mode,再进入 insert mode,会保持 ascii mode,而不会自动切换会中文模式
im-select 就会自动切换回中文模式搜索之后发现并没有一个现成的解决方案,但是却有大佬写过类似的逻辑,比如
稍微组合一下,就有了本文的解决方案
通过 switches 配置 vmode,再通过 app_options 配置在相应应用下打开 vmode ,即可实现原生的 vim_mode 在指定应用下开启的效果
利用 lua_processor 对按键输入进行处理,如果当前应用处于 vmode 下,就进行相关的逻辑处理
如 有考虑加入win端和macos端的vim mode · Issue #84 · fcitx/fcitx5-rime · GitHub 中所说,rime 是无法感知应用处于什么模式的(vim)
同样我们也无法知道应用处于什么模式,只能是根据 vim 的常规操作逻辑去大致的处理一下
思路如下:
在开启了 vmode 的应用中
esc 键,就认为要切换到 normal mode
normal mode,并且按下了 i/a/o/c 等会进入插入模式的按键
2021-10-21
❌ 使函数式组件拥有状态,从而实现 Class 组件的功能
function App() {
// this.state this.setState
const [state, setState] = useState()
// componentDidMount()
useEffect(() => {
// componentWillUnmount()
return () => {}
}, [])
// componentDidUpdate()
useEffect(() => {})
// render()
return <div></div>
} ✅ 👇
class XXX extends Component {
state = { bool: false }
handleTrue() {}
handleFalse() {}
render() {}
} function useBoolean() {
const [bool, setBool] = useState(false)
const handleTrue = () => {}
const handleFalse = () => {}
} ##「视图」「逻辑」分离
如何更好的适应无休止的需求变化
分层架构、设计模式、领域驱动、SOLID、KISS、YAGNI、DRY、迪米特法则 ...
「每次」需求变化时,都将代码「重构」成最适合当前的
##「分离」让下一个程序员更易「重构」
###「分离」为主,「复用」是顺其自然的
如若下次需求需要复用,分离的代码可以让下个人很容易的「重构」,反之则不行。
好的代码不是告诉计算机怎么做,
而是告诉另一个程序员你想要计算机怎么做。
--《趣学设计模式》
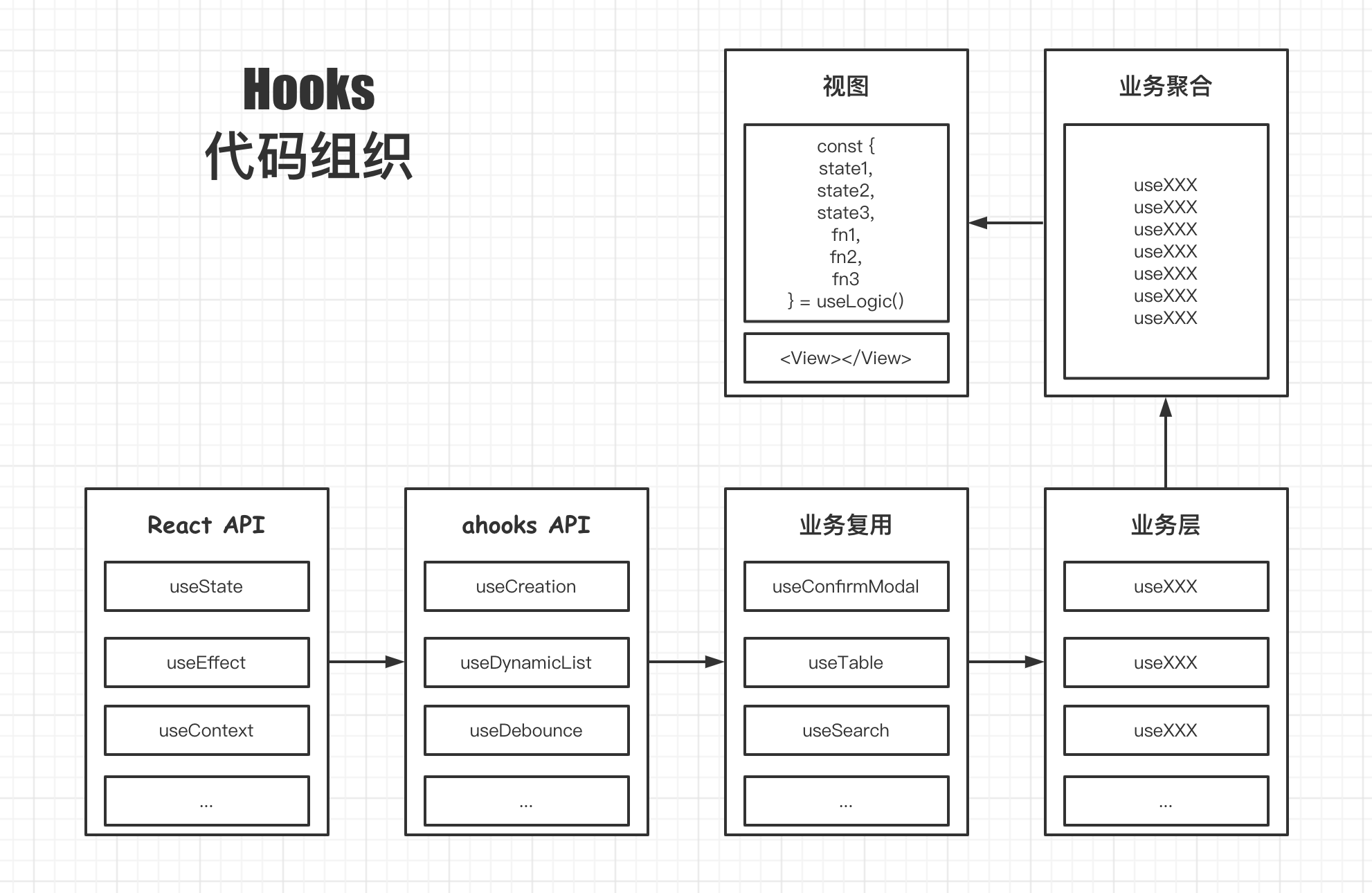
以下均为概念性的思考和理解,不等于最佳实践 & 不等于源码实现
React 的运行机制是每次更新时,函数都会重新运行,这意味着作用域重建,函数内的状态丢失
所以需要将状态存在函数作用域之外,且要与组件的生命周期挂钩(申请和释放)
useRef 就提供了这样的能力,这很重要,因为一旦有了状态,我们自己就可以做很多事情
需要框架层提供能力
const root = document.getElementById("root")
function App() {
// let i = 0 ❌
const i = useRef(0)
return <h1>{i.current++}</h1>
}
setInterval(() => {
ReactDOM.render(<App />, root)
}, 1000) useState 的核心在于 setter 函数,它会触发视图更新
实际上,我们完全可以使用 useRef + setter 来完成状态更新
只是说明有了持久化状态后我们可以这样做,实际工作中不要这么做(会被打
const root = document.getElementById("root")
const { useState } = React
function App() {
const i = useRef(0)
let [, reRender] = useState(0)
setInterval(() => {
i.current++
reRender()
}, 1000)
return <h1>{i.current}</h1>
}
ReactDOM.render(<App />, root) 如果你尝试了上面的代码,很快就会页面更新出现了问题
这是因为每次 reRender,组件函数都会重新运行,导致 setInterval 被重复多次的注册
所以我们需要某种方式,来控制函数的调用逻辑,同样的有了状态之后,这并不是一个困难的事情
const root = document.getElementById("root")
const { useState, useRef } = React
const isEq = (value, other) => {
if (Object.is(value, other)) return true
if (Array.isArray(value) && Array.isArray(other)) {
if (value.length === 0 && other.length === 0) return true
return value.every((item, i) => Object.is(item, other[i]))
}
return false
}
function useCtlCall(fn, deps) {
const prevDeps = useRef(undefined)
if (isEq(prevDeps.current, deps)) return
fn()
prevDeps.current = deps
}
function App() {
let [i, setState] = useState(0)
useCtlCall(() => {
setInterval(() => {
setState(i++)
}, 1000)
}, [])
return <h1>{i++}</h1>
}
ReactDOM.render(<App />, root) 是的,轻松就可以实现 useMemo 和 useCallback
不等于实际源码
function useMemo(fn, deps) {
const cacheValue = useRef()
useCtlCall(() => {
cacheValue.current = fn()
}, deps)
return cacheValue.current
}
function useCallback(fn, deps) {
return useMemo(() => fn, deps)
} 同上是用来控制函数调用时机,但是需要集成进框架中,以在适当的时机触发函数调用
不等于实际源码
export const createContext = (defaultValue) => {
const context = {
value: defaultValue,
subs: new Set(),
Provider: ({ value, children = "" }) => {
useEffect(() => {
context.subs.forEach((fn: any) => fn(value))
context.value = value
})
return children
},
}
return context
}
export const useContext = (context, selector?) => {
const subs = context.subs
const [, forceUpdate] = useReducer((c) => c + 1, 0)
const selected = selector ? selector(context.value) : context.value
const ref = useRef(null)
useEffect(() => {
ref.current = selected
})
useEffect(() => {
const fn = (nextValue: unknown) => {
if (selector && ref.current === selector(nextValue)) return
forceUpdate(nextValue)
}
subs.add(fn)
return () => subs.delete(fn)
}, [subs])
return selected
} 如 redux 或其他框架也是一样的
观察下面的代码中有多少是重复的,可封装的
const m: IReuseTaskDetailModel = {
namespace: "reuseTaskDetail",
state: {
detail: {},
auditRecord: {},
list: {},
},
effects: {
*getTaskDetail({ payload: id }, { call, put }) {
const { data } = yield call(() => axios.get("xxx"), id)
return yield put({
type: "mergeModel",
payload: {
detail: data,
},
})
},
*getAuditRecord({ payload: params }, { call, put }) {
const { data, paging } = yield call(() => axios.get("xxx"), params)
return yield put({
type: "mergeModel",
payload: {
auditRecord: {
data,
paging,
},
},
})
},
*getList({ payload: params }, { call, put }) {
const { data, paging } = yield call(() => axios.get("xxx"), params)
return yield put({
type: "mergeModel",
payload: {
list: {
data,
paging,
},
},
})
},
},
} 事实上我们可以把所有请求全放入一个 namespace,使用 api 地址做 state[key] 即可
const mergeState = ({ put, key, data, isLoading, isError }) =>
put({
type: "mergeModel",
payload: {
[key]: {
data,
isLoading,
isError,
},
},
})
interface State {
// 接⼝地址
[key: string]: {
data: any
isLoading: boolean
isError: boolean
}
}
const serverModel = {
namespace: "serverModel",
state: {},
effects: {
*fetch({ payload: { key, fn } }, { call, put }) {
try {
yield mergeState({
put,
key,
data: undefined,
isLoading: true,
isError: false,
})
const data = yield call(fn)
yield mergeState({ put, key, data, isLoading: false, isError: false })
return data
} catch (e) {
yield mergeState({
put,
key,
data: undefined,
isLoading: false,
isError: true,
})
return Promise.reject(e)
}
},
},
} function useTaskList() {
const key = "/api/tasklist"
const dispatch = useDispatch()
useEffect(() => {
dispatch({
type: "serverModel/fetch",
payload: {
key,
fn: fetchTaskList,
},
})
}, [])
return useSelector(({ serveState }) => serveState[key])
}
function TaskList() {
const { data, isLoading } = useTaskList()
return <div>{data}</div>
} 细看会发现取值逻辑也是重复的,依然可以简化
function useQuery(key, fn) {
const dispatch = useDispatch()
useEffect(() => {
dispatch({
type: "serverModel/fetch",
payload: {
key,
fn,
},
})
}, [])
return useSelector(({ serveState }) => serveState[key])
}
function useTaskList() {
return useQuery("/api/tasklist", fetchTaskList)
} 查询逻辑是挂载时自动请求的,写入逻辑则需要手动触发,所以可以再简单封装下
function useMutation(key, fn) {
const dispatch = useDispatch()
return {
...useSelector(({ serveState }) => serveState[key]),
mutate() {
dispatch({
type: "serverModel/fetch",
payload: {
key,
fn,
},
})
},
}
}
function useDelTask() {
return useMutation("/api/del/tasklist", fetchTaskList)
} 是不是干净整洁无异味,
const useTaskList = () => useQuery("/api/xxx", fetchXXX)
const useTaskDetail = () => useQuery("/api/xxx", fetchXXX)
const useAuditTask = () => useQuery("/api/xxx", fetchXXX)
const useAuditInfo = () => useQuery("/api/xxx", fetchXXX)
const useDelTask = () => useMutation("/api/xxx", fetchXXX)
const usePostTask = () => useMutation("/api/xxx", fetchXXX) 
上述代码只是想说明 hooks 的封装、简化能力,真实的场景中还会有更多的挑战:
实际上工作中我们可以直接使用 react-query 来帮助我们管理服务端状态
而对于服务端状态管理的话题,终端的异步状态管理 中有更深入的探讨,感兴趣可以继续阅读
2023-02-03
现如今 TS 已经完全走进了前端社区,纵观流行的前端框架/库,都有 TS 类型支持,不少框架/库更是对于源码是使用 TypeScript 开发,完美支持 TypeScript 类型提示当作一大亮点去宣传。
在业务中用 TS 写写页面、表格等上层逻辑,基本就是把后端数据定义/转换成 interface,往后一把梭就完了,不需要对 TS 的类型系统有深入的了解。
但当封装公用组件/函数时,如果想封装的代码能够支持 TS 类型,就需要了解类型编程的一些技巧,本文就分享一些常用的类型编程技巧。
良好的类型推断,避免重复的类型定义
// string[]
const result = [1, 2, 3]
.map((item) => () => item)
.map((fn) => ({ value: fn() }))
.map((item) => ({ label: `${item.value}` }))
.map((item) => item.label)
// ---
interface ResponseData {
is_success: boolean
data: {
id: number
pu_info: Record<string, string>
service_price: number
order_price: number
}[]
}
const fetchListData = async () => {
let data = await request<ResponseData>("/api/list") // ResponseData
data = transformKeys(data) // ResponseData1: isSuccess puInfo orderPrice
return transformMoney(data, ["orderPrice"]) // ResponseData2: orderPrice: string
}
const { data, isLoading, isError } = useSWR(fetchListData) // data: ResponseData2
const id = get(data, "data.id") // number 常见套路:提取 → 转换 → 重组 → 递归(循环)
// 类型
type T = string | number | boolean | class | interface // ...
// 类型推断
{
let A = 1 // number
let B = "hello" // string
let C = [1, 2, 3] // number[]
}
// 常量类型推断
{
const A = 1 // 1
const B = "hello" // 'hello'
const C = [1, 2, 3] as const // readonly [1, 2, 3]
}
// 联合类型:|
type Union = { hello: string } | { world: number }
// 交叉类型: &
type Intersect = { hello: string } & { world: number }
// ..... // 返回对象 key 的常量联合类型
keyof T // hello | world
// 返回对象值的联合类型
T[keyof T] // string | number
T['hello'] // string
T['world'] // number
// in 操作符遍历联合类型
interface A {
[K in string | number]: never
[K in 'hello' | 'world']: never
[K in keyof T]: T[K]
}
// ------ 源码 ------
/**
* Make all properties in T required
*/
type Required<T> = {
[P in keyof T]-?: T[P];
};
/**
* From T, pick a set of properties whose keys are in the union K
*/
type Pick<T, K extends keyof T> = {
[P in K]: T[P];
};
/**
* Construct a type with a set of properties K of type T
*/
type Record<K extends keyof any, T> = {
[P in K]: T;
} // 泛型参数约束
type T<P extends string> = {}
// 条件类型
type IsString<T> = T extends string ? true : false
type A = IsString<"1"> // true
type B = IsString<2> // false // 条件类型推断
type Example<T> = T extends infer R ? R : never
type A = Example<"1"> // '1'
type B = Example<2> // 2 type A = [1, 2, 3]
type ExampleA = A extends [infer First, ...infer Rest] ? First : never // 1
type B = "123"
type ExampleB = B extends `${infer FirstChar}${infer Rest}` ? FirstChar : never // '1'
type C = (p: number) => string
type ExampleB = C extends (p: infer R) => any ? R : never // number
// ------ 源码(删减了类型约束) ------
/**
* Obtain the parameters of a function type in a tuple
*/
type Parameters<T> = T extends (...args: infer P) => any ? P : never
/**
* Obtain the return type of a function type
*/
type ReturnType<T> = T extends (...args: any) => infer R ? R : any
/**
* Obtain the parameters of a constructor function type in a tuple
*/
type ConstructorParameters<T> = T extends abstract new (...args: infer P) => any
? P
: never
/**
* Obtain the return type of a constructor function type
*/
type InstanceType<T> = T extends abstract new (...args: any) => infer R
? R
: any function f<A, B, C extends string>(a: A, b: B, c: C) {}
f("a", "b" as const, "c") // function f<string, "b", "c">(): void
interface Api {
"/api/phone": { phone: string }
"/api/email": { email: string }
}
function request<T extends keyof Api>(url: T): Api[T] {
return "" as any
}
request("/api/phone") // { phone: string }
request("/api/email") // { email: string } type Get<T, Paths extends string> = Paths extends keyof T // 递归出口
? T[Paths]
: Paths extends `${infer K}.${infer R}` // 匹配 . 语法
? K extends keyof T
? Get<T[K], R> // 递归
: unknown
: unknown
// _.get(obj, 'a.b.c')
type R = Get<{ a: { b: { c: { d: number } } } }, "a.b.c"> // @ts-nocheck
// Define a service using a base URL and expected endpoints
export const pokemonApi = createApi({
endpoints: (builder) => ({
getPokemonByName: builder.query<Pokemon[], string>({
query: (name) => `pokemon/${name}`,
}),
getPokemonById: builder.query<Pokemon, string>({
query: (id) => `pokemon/${id}`,
}),
}),
})
// Export hooks for usage in functional components, which are
// auto-generated based on the defined endpoints
export const { useGetPokemonByNameQuery, useGetPokemonByIdQuery } = pokemonApi
const { data, isLoading, isError } = useGetPokemonByNameQuery() interface Endpoints {
getPokemonByName: string
getPokemonById: number
}
// 转化 key 字符串
// 问题:无法取出准确的值类型
type _B = {
[K in `use${Capitalize<keyof Endpoints>}Query`]: Endpoints[keyof Endpoints]
}
// 准确的值类型:双重遍历
// 问题:结构不是我们想要的
type B = {
[P in keyof Endpoints]: {
[K in `use${Capitalize<P>}Query`]: Endpoints[P]
}
}
// 取出值类型
// 问题:联合类型,无法使用
type C = B[keyof B]
// 联合类型转交叉类型
type UnionToIntersect<T> = (T extends any ? (k: T) => any : never) extends (
k: infer P
) => any
? P
: never
type E = UnionToIntersect<C>
const e = {} as E
e.useGetPokemonByNameQuery // ✅ import { configureStore, createSlice, PayloadAction } from "@reduxjs/toolkit"
export const counterSlice = createSlice({
name: "counter",
initialState: {
value: 0,
},
reducers: {
increment: (state) => {
state.value += 1
},
incrementByAmount: (state, action: PayloadAction<number>) => {
state.value += action.payload
},
},
})
export default configureStore({
reducer: {
counter: counterSlice.reducer,
},
})
// @ts-ignore
dispatch({ type: "counter/incrementByAmount", payload: 1 }) 实现:略
interface ResponseData {
is_success: boolean
data: {
id: number
pu_info: Record<string, string>
service_price: number
order_price: number
}[]
}
// 下划线转驼峰
type Camelize<
S extends string,
V extends string = ""
> = S extends `${infer A}_${infer B}${infer C}`
? Camelize<C, `${V}${A}${Capitalize<B>}`>
: `${V}${S}`
type A = Camelize<"hello_java_script">
// 工具函数:取出 Value 的类型
type ValueType<T> = T[keyof T]
// 联合转交叉
type UnionToIntersect<T> = (T extends any ? (k: T) => any : never) extends (
k: infer P
) => any
? P
: never
// 转换 keys
type TransformKeys<T> = UnionToIntersect<
ValueType<{
[K in keyof T]: K extends string
? {
[P in `${Camelize<K>}`]: T[K] extends any[]
? Array<TransformKeys<T[K][0]>>
: T[K] extends Record<string, any>
? TransformKeys<T[K]>
: T[K]
}
: never
}>
>
type R1 = TransformKeys<ResponseData>
const a = {} as R1
a.data[0].id transformMoney(data, ["orderPrice"]) // ResponseData2: orderPrice: string
// 元祖转联合
type A = ["A", "B"]
type B = A[number] // A | B
// ---
interface Data {
id: number
servicePrice: number
orderPrice: number
}
// 转换 keys
type Transform<T, Keys> = {
[K in keyof T]: K extends Keys ? string : T[K]
}
type R = Transform<Data, "orderPrice"> /**
* Convert string literal type to uppercase
*/
type Uppercase<S extends string> = intrinsic
/**
* Convert string literal type to lowercase
*/
type Lowercase<S extends string> = intrinsic
/**
* Convert first character of string literal type to uppercase
*/
type Capitalize<S extends string> = intrinsic
/**
* Convert first character of string literal type to lowercase
*/
type Uncapitalize<S extends string> = intrinsic 函数参数逆变 + 分配条件类型
// 类型推断时,在逆变位置的同一类型变量中的多个候选会被推断成交叉类型(函数签名重载的参数位置类型会被推断为交叉类型)
// https://github.com/Microsoft/TypeScript/pull/21496
type Func = ((arg: { a: string }) => void) | ((arg: { b: number }) => void)
type U = Func extends (arg: infer A) => any ? A : never // { a: string } & { b: number }
// {a: string} | {b: number} 如何变为函数签名重载?
// 分配条件类型
// 官网:当泛型类型是联合类型时,条件判断会变得具有分配性
// 人话:extends 左边的范型联合类型,会拆开分别处理
type ToArray<Type> = Type extends any ? Type[] : never
type StrArrOrNumArr = ToArray<string | number> // string[] | number[] 而非是 (string | number)[] 类型系统中的概念,表达父子类型关系
TS 中参数位置是逆变的,返回值是协变的

https://jkchao.github.io/typescript-book-chinese/tips/covarianceAndContravariance.html
type A = ["A", "B"]
type B = A[number] T extends string ? T : never2024-05-01
啊,性能优化的味道
利用 JS 读取配置文件,懒加载启动插件
卡片笔记法 里面提到笔记的的启动速度很重要
但随着 obsidian 安装的插件越来越多,也越来越不满足我们的要求了,尤其是在手机上!
简单搜索之后发现早已有人发现并解决了问题:Improve Obsidian Startup Time on Older Devices with the FastStart Script
看完之后发现实现原理就是利用 templater 插件可以执行 JS 的能力,初始情况下仅保留必要插件启用,等启动之后再使用 JS 延时启动插件
创建一个模板,设置 templater 的 StartUp templates 选项为此模板,模板内容如下:
<%*
fastStart = async (filename, delayInSecond) => {
if (tp.file.exists(filename)) {
const f = tp.file.find_tfile(filename);
let plugins = (await app.vault.read(f)).split(/\r?\n/).map(l => l.trim()).filter(l => !l.startsWith('//')).filter(l => tp.obsidian.Platform.isMobile ? !l.startsWith('onlyDesktop') : true).map(l => l.replace(/^onlyDesktop\s*&&\s*/, ''));
setTimeout(async () => {
plugins.forEach(async (p) => await app.plugins.enablePlugin(p))
}, delayInSecond * 1000)
}
}
await fastStart("FastStart-Plugins-FastDelay", 2)
await fastStart("FastStart-Plugins-ShortDelay", 10)
await fastStart("FastStart-Plugins-LongDelay", 30)
%> 如果你会编程,不难发现逻辑是很简单的,就是读取配置文件中的插件列表进行启用
原始源码 再此,我稍微做了些修改,增加了如下功能
// 表示禁止启用此插件onlyDesktop && 表示插件仅在桌面端启用其中最下面的三行代码是可以根据自己的需求改动的,括号内的参数:
await fastStart("FastStart-Plugins-FastDelay", 2)
await fastStart("FastStart-Plugins-ShortDelay", 10)
await fastStart("FastStart-Plugins-LongDelay", 30) 逻辑是这样的,把插件分为 N 类
你可以根据自己的插件情况增加或减少分类,调整不同分类的延迟时间
一旦你确定了自己的分类,就可以建立相应的配置文件了
就是普通的 markdown,只不过内容是插件名称
那怎么知道插件名称呢?
在文件中写入
注意去掉
%\>中的\,我如果不写转义符号,内容就会被替换
<% Object.values(app.plugins.manifests).map(p=>p.id).sort((a,b)=>a.localeCompare(b)).join('\n') %\>
然后执行 Templater: replace templates in active file
模板代码就会被转换为你所安装的所有插件的插件名了
然后你只需要将不同的插件名划分到不同分类的文件中即可,写好之后可以重启 obsidian 测试一下
🚀 然后就继续享受本地笔记软件带来的速度体验了 🥰
2021-05-06
想要知道 React 的内部运行机制,实际上就是要探索 React 如何将组件映射屏幕,以及组件中的状态发生了变化之后 React 如何将这些「变化」更新到屏幕上。

对于首次渲染,React 的主要工作就是将 React.render 接收到的 VNode 转化 Fiber 树,并根据 Fiber 树的层级关系,构建生成出 DOM 树并渲染至屏幕中。
而对于更新渲染时,Fiber 树已经存在于内存中了,所以 React 更关心的是计算出 Fiber 树中的各个节点的差异,并将变化更新到屏幕中。
在进行流程解读之前,有一些关于 React 源码中的概念需要先了解一下。
为了实现 concurrent 模式,React 将渲染更新的过程分为了两个阶段:
render 阶段,利用双缓冲技术,在内存中构造另一颗 Fiber 树,在其上进行协调计算,找到需要更新的节点并记录,这个过程会被重复中断恢复执行。commit 阶段,根据 render 阶段的计算结果,执行更新操作,这个过程是同步执行的。JSX 会被编译转换成 React.createElement 函数的调用,其返回值就是 VNode,虚拟DOM 节点的描述对象。
在 React 源码中称之为 element,为了避免和 DOM元素 的冲突,这里我就用大家比较熟悉的 虚拟DOM 来称呼了。
{
// DOM节点名称或类组件、函数组件
type: 'div' | App,
ref: null,
key: null,
props: null
} Fiber 有两层含义:程序架构、数据结构
从程序架构的角度来看,为了实现 concurrent 模式,需要程序具备的可中断、可恢复的特性,而之前 VNode 的树型结构很难完成这些操作,所以 Fiber 就应运而生了。
那 Fiber 究竟是如何实现可中断、可恢复的呢?这就要说说 Fiber 的具体数据结构了。
Fiber 是一个链表结构,通过 child、sibling、return 三个属性记录了树型结构中的子节点、兄弟节点、父节点的关系信息,从而可以实现从任一节点出发,都可以访问其他节点的特性。
除了作为链表的结构之外,程序运行时还需要记录组件的各种状态、实例、真实 DOM 元素映射等等信息,这些都会被记录在 Fiber 这个对象身上。
function FiberNode() {
this.tag = tag
this.key = key
this.elementType = null
this.type = null
this.stateNode = null
this.return = null
this.child = null
this.sibling = null
this.index = 0
this.ref = null
this.pendingProps = pendingProps
this.memoizedProps = null
this.updateQueue = null
this.memoizedState = null
this.dependencies = null
this.mode = mode
this.effectTag = NoEffect
this.nextEffect = null
this.firstEffect = null
this.lastEffect = null
this.expirationTime = NoWork
this.childExpirationTime = NoWork
this.alternate = null
} 这三个属性主要用途是将每个 Fiber 节点连接起来,用链表的结构来描述树型结构的关系。
副作用标记,标识了此 Fiber 节点需要进行哪些操作,默认为 NoEffect。
标记了 NoEffect、PerformedWork 的节点在更新过程中会被跳过。
// 源码位置:packages/shared/ReactSideEffectTags.js
// 作为 EffectTag 的初始值,或者用于 EffectTag 的比较判断,其值为 0 表示没有副作用,也就是不涉 及更新
export const NoEffect = 0b000000000000
// 由 React devtools 读取, NoEffect 和 PerformedWork 都不会被 commit,当创建 Effect List时,会跳过NoEffect 和 PerformedWork
export const PerformedWork = 0b000000000001
// 表示向树中插入新的子节点,对应的状态为 MOUNTING,当执行 commitPlacement 函数完成插入后, 清除该标志位
export const Placement = 0b000000000010
// 表示当 props、state、context 发生变化或者 forceUpdate 时,会标记为 Update ,检查到标记后,执行 mmitUpdate 函数进行属性更新,与其相关的生命周期函数为 componentDidMount 和 componentDidUpdate
export const Update = 0b000000000100
export const PlacementAndUpdate = 0b000000000110
// 标记将要卸载的结点,检查到标记后,执行 commitDeletion 函数对组件进行卸载,在节点树中删除对应对 节点,与其相关的生命周期函数为 componentWillUnmount
export const Deletion = 0b000000001000
export const ContentReset = 0b000000010000
export const Callback = 0b000000100000
export const DidCapture = 0b000001000000
export const Ref = 0b000010000000
export const Snapshot = 0b000100000000
export const Passive = 0b001000000000
export const LifecycleEffectMask = 0b001110100100
export const HostEffectMask = 0b001111111111 链表结构,保存了需要更新的后代节点,每个 Fiber 节点处理完自身后都会根据相应逻辑与父节点的 lastEffect 进行连接。
这样在 commit 阶段,只需要从根节点的 firstEffect 向下遍历,就可以将所有需要更新的节点进行相应处理了。
保存了同一事件循环中对组件的多次更新操作(多次调用 setState)
tag 描述了 Fiber 节点的类型
// 源码位置:packages/shared/ReactWorkTags.js
export const FunctionComponent = 0 // 函数组件元素对应的 Fiber 结点
export const ClassComponent = 1 // Class组件元素对应的 Fiber 结点
export const IndeterminateComponent = 2 // 在不确定是 Class 组件元素还是函数组件元素时的取值 export const HostRoot = 3; // 对应 Fiber 树的根结点
export const HostPortal = 4 // 对应一颗子树,可以另一个渲染器的入口
export const HostComponent = 5 // 宿主组件元素(如div,button等)对应的 Fiber 结点
export const HostText = 6 // 文本元素(如div,button等)对应的 Fiber 结点
export const Fragment = 7 Fiber 节点的 stateNode 属性存储的当前节点的最终产物
ClassComponent 类型的节点则该属性指向的是当前 Class 组件的实例HostComponent 类型的节点则该属性指向的是当前节点的 DOM 实例HostRoot 类型的节点则该属性指向的是 fiberRoot 对象fiberRoot 对象是整个 Fiber架构 的入口对象,其上记录了应用程序运行过程中需要保存的关键信息。
function FiberRootNode(containerInfo, tag, hydrate) {
this.tag = tag
// current树
this.current = null
// 包含容器
this.containerInfo = containerInfo
this.pendingChildren = null
this.pingCache = null
this.finishedExpirationTime = NoWork
// 存储工作循环(workLoop)结束后的副作用列表,用于commit阶段
this.finishedWork = null
this.timeoutHandle = noTimeout
this.context = null
this.pendingContext = null
this.hydrate = hydrate
this.firstBatch = null
} containerInfo 保存了 React.render 函数第二个参数,也就是程序的真实 DOM 容器。
current 属性既是应用程序中 Fiber树 的入口。
current 的值是一个 HostRoot 类型的 Fiber 节点,这个 HostRoot 的子节点就是程序的根组件(App)对应的 Fiber 节点。
在首次渲染调用 React.render 时,应用程序中其实只有一个 HostRoot 的 Fiber 节点,而在 render 过程中,才会将我们传入的 App 组件构建成 HostRoot 的子 Fiber 节点。
双缓冲是指将需要变化的部分,先在内存中计算改变,计算完成后一次性展示给用户,这样用户就不会感知到明显的计算变化。离屏 Canvas 就是双缓冲的**。
对于 Concurrent 模式来说,更新计算的过程会被频繁中断,如果不使用缓冲技术,那用户就会感知到明显的中断变化。
每个 Fiber 节点的 alternate 属性会指向另一个 Fiber 节点,这个 Fiber 节点就是「草稿」节点,当需要进行计算时,就会在这个节点上进行。计算完成后将两个节点进行互换,展示给用户。
作为已经计算完成并展示到视图中的 Fiber 树,在源码中称为 current 树。
而 current 树的 alternate 指向的另一棵树,就是用来计算变化的,称为 WorkInProgress 树(WIP)。
函数或者是类,最终产出 VNode 和定义生命周期钩子。
类组件实例化后的对象,其上记录了生命周期函数、组件自身状态、响应事件等。对于函数组件来说,没有实例对象,所以在 hooks 出现之前函数组件不能拥有自己的状态,而在 hooks 之后,函数组件通过调用 hooks 的产生状态被记录在组件对应的 Fiber 对象中。
包含过期时间、更新内容的对象。
update 的集合,链表结构。React 的更新操作都是异步执行的,在同一个宏任务中执行的更新操作都会被记录在此处,统一在下一个队列中执行。
不管是首次渲染还是更新渲染,都一定会经过以下步骤:
所以我们先来了解一下什么是更新对象和队列。
主要是对同步的多次调用 setState 进行缓冲,避免冗余的渲染调用。
触发更新操作时,React 会从 this(类组件)或 hooks 返回的 setter 函数中找到对应的 Fiber 节点,然后根据传入 setState 的参数创建更新对象,并将更新对象保存在 Fiber 节点的 updateQueue 中。
这样我们在同一个事件循环中对组件的多次修改操作就可以记录下来,在下一个事件循环中统一进行处理。处理时就会遍历 updateQueue 中的修改,依次合并获取最终的 state 进行渲染。
function createUpdate(expirationTime, suspenseConfig) {
var update = {
// 过期时间与任务优先级相关联
expirationTime: expirationTime,
suspenseConfig: suspenseConfig,
// tag用于标识更新的类型如UpdateState,ReplaceState,ForceUpdate等
tag: UpdateState,
// 更新内容
payload: null,
// 更新完成后的回调
callback: null,
// 下一个更新(任务)
next: null,
// 下一个副作用
nextEffect: null,
}
{
// 优先级会根据任务体系中当前任务队列的执行情况而定
update.priority = getCurrentPriorityLevel()
}
return update
} 为了防止某个 update 因为优先级的问题一直被打断,React 给每个 update 都设置了过期时间(expirationTime),当时间到了就会强制执行改 update。
expirationTime 会根据任务的优先级计算得来
// 源码位置:packages/scheduler/src/Scheduler.js
// 立即执行(可由饥饿任务转换),最高优先级
var ImmediatePriority = 1
// 用户阻塞级别(如外部事件),次高优先级
var UserBlockingPriority = 2
// 普通优先级
var NormalPriority = 3
// 低优先级
var LowPriority = 4
// 最低优先级,空闲时去执行
var IdlePriority = 5 简单点说,具有 UserBlockingPriority 级别的多个更新,如果它们的时间间隔小于 10ms,那么它们拥有相同的过期时间。
同样的方式可以推到出具有 LowPriority 级别的多个更新(一般为异步更新),如果它们的时间间隔小于 25ms,那么它们也拥有相同的过期时间。
React 的过期时间机制保证了短时间内同一个 Fiber 节点的多个更新拥有相同的过期时间,最终会合并在一起执行。
// 源码位置:packages/react-reconciler/src/ReactUpdateQueue.js
function createUpdateQueue(baseState) {
var queue = {
// 当前的state
baseState: baseState,
// 队列中第一个更新
firstUpdate: null,
// 队列中的最后一个更新 lastUpdate: null,
// 队列中第一个捕获类型的update firstCapturedUpdate: null,
// 队列中第一个捕获类型的update lastCapturedUpdate: null,
// 第一个副作用
firstEffect: null,
// 最后一个副作用
lastEffect: null,
firstCapturedEffect: null,
lastCapturedEffect: null,
}
return queue
} JSX 定义会被 babel 转换为 React.createElement 的调用,其返回值为 VNode树。React.render 调用,实例化 FiberRootNode,并创建 根Fiber 节点 HostRoot 赋值给 FiberRoot 的 current 属性React.render 接受到的第一个参数 VNode树,将更新对象添加到 HostRoot 节点的 updateQueue 中HostRoot 节点开始遍历,在其 alternate 属性中构建 WIP 树,在构建 Fiber 树的过程中会根据 VNode 的类型进行组件实例化、生命周期调用等工作,对需要操作视图的动作将其保存到 Fiber 节点的 effectTag 上面,将需要更新在 DOM 上的属性保存至 updateQueue 中,并将其与父节点的 lastEffect 连接。commit 阶段,此阶段就是将 effectList 收集的 DOM 操作应用到屏幕上。commit 完成将 current 替换为 WIP 树。React 会先以 current 这个 Fiber 节点为基础,创建一个新的 Fiber 节点并赋值给 current.alternate 属性,然后在这个 alternate 节点上进行协调计算,这就是之前所说的 WIP 树。
协调时会在全局记录一个 workInProgress 指针,用来保存当前正在处理的节点,这样中断之后就可以在下一个事件循环中接着进行协调。
此时整个更新队列中只有 HostRoot 这一个 Fiber 节点,对当前节点处理完成之后,会调用 reconcileChildren 方法来获取子节点,并对子节点做同样的处理流程。
workInProgress 指针,作为下一个处理的节点。这里主要说一下三种主要节点:HostRoot、ClassComponent、HostComponent
HostRoot 主要是处理其身上的更新队列,获取根组件的元素。HostRoot 后会返回其 child 节点,一般来说就是 ClassComponent 了。Fiber 节点是需要进行组件实例化的,实例会被保存在 Fiber 的 stateNode 属性上。render 拿到其 VNode 再次进行构建过程。VNode,会使用 sibling 属性将其相连。HostComponent 就是原生的 DOM 类型了,会创建 DOM 对象并保存到 stateNode 属性上。简单思考一下,叶子节点必然是一个 DOM 类型的节点,也就是 HostComponent,所以对叶子节点的处理可以理解为将 Fiber 节点映射为 DOM 节点的过程。
当碰到叶子节点时,会创建相应的 DOM 元素,然后将其记录在 Fiber 的 stateNode 属性中,然后调用 appendAllChildren 将子节点创建好的的 DOM 添加到 DOM 结构中。
叶子节点处理完毕后
workInProgress 指针指向其兄弟节点。workInProgress 指向其父节点。收集副作用的过程中主要有两种情况
returnFiber.lastEffect.nextEffect = workInProgress.firstEffectreturnFiber.lastEffect.nextEffect = workInProgress从根节点的 firstEffect 开始向下遍历
before mutation:遍历 effectList,执行生命周期函数 getSnapshotBeforeUpdate,使用 scheduleCallback 异步调度 flushPassiveEffects 方法(useEffect 逻辑)mutation:第二次遍历,根据 Fiber 节点的 effectTag 对 DOM 进行插入、删除、更新等操作;将 effectList 赋值给 rootWithPendingPassiveEffectslayout:从头再次遍历,执行生命周期函数,如 componentDidMount、DidUpdate 等,同时会将 current 替换为 WIP 树,置空 WIP 树;scheduleCallback 触发 flushPassiveEffects,flushPassiveEffects 内部遍历 rootWithPendingPassiveEffects至此整个 DOM 树就被创建并插入到了 DOM 容器中,整个应用程序也展示到了屏幕上,初次渲染流程结束。
setState 触发更新,React 通过 this 找到组件对应的 Fiber 对象,使用 setState 的参数创建更新对象,并将其添加进 Fiber 的更新队列中,然后开启调度流程。Fiber 节点开始构建 WIP 树,此时会重点处理新旧节点的差异点,并尽可能复用旧的 Fiber 节点。Fiber 节点,检查 Fiber 节点的更新队列是否有值,context 是否有变化,如果没有则跳过。
state,调用 shouldComponentUpdate 判断是否需要更新。render 方法获取 VNode,进行 diff 算法,标记 effectTag,收集到 effectList 中。
PlacementDOM 元素,判断属性是否发生变化,标记 UpdateDeletioneffectList,调用生命周期并更新 DOM。当 key 和 type 都相同时,会复用之前的 Fiber 节点,否则则会新建并将旧节点标记删除。
在 Concurrent 模式下,任务以 Fiber 为单位进行执行,当 Fiber 处理完成,或者 shouldYield 返回值为 true 时,就会暂停执行,让出线程。
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress)
} 在 shouldYield 中会判断当前时间与当前切片的过期时间,如果过期了,就会返回 true,而当前时间的过期时间则是根据不同的优先级进行计算得来。
对于浏览器而言,如果我们想要让出 js 线程,那就是只能把当前的宏任务执行完成。等到下一个宏任务中再接着执行。当浏览器执行完一个宏任务后就会切换只渲染进程进行视图的渲染工作。MessageChannel 可以创建一个宏任务,其优先级比 setTimeout(0) 高。
2020-10-02
如果上面这个问题你都知道了,那你对事件循环的理解在日常工作中就够用了,但还是建议看一下文章,因为会讲一些原理性的知识。
想把事件循环讲明白,就绕不过浏览器的进程和线程。
异步代码是什么?从哪里来的?
浏览器的主进程(负责协调、主控)
负责渲染工作
渲染线程的工作流程
GUI 渲染线程与 JS 执行线程是互斥的,一个执行的时候另一个就会被挂起。
常说的 JS 脚本加载和执行会阻塞 DOM 树的解析,指的就是互斥现象。
在 JS 执行过程中,对 GUI 线程的写操作,并不会被立即执行,而是被保存到一个队列中,等到 JS 引擎空闲时(当前宏任务执行完,下面会详细讲)被执行。
document.body.style.color = "#000"
document.body.style.color = "#001" document.body.style.color = '#2'
```
- 如果JS线程的当前宏任务执行时间过长,就会导致页面渲染不连贯,给用户的感觉就是页面卡顿。
- `1000毫秒 / 60帧 = 16.6毫秒`
负责执行 Javascript 代码,V8 引擎指的就是这个。
JS 引擎在执行代码时,会将需要执行的代码块当成一个个任务,放入任务队列中执行,JS 引擎会不停的检查并运行任务队列中任务。
// html
<script>
console.log(1)
console.log(2)
console.log(3)
</script>
// 将需要执行的代码包装成一个任务 const task = () => { console.log(1)
console.log(2) console.log(3) } // 放入任务队列 pushTask(task) JS 引擎执行逻辑:伪代码(所有的伪代码都是为了理解写的,并不是浏览器的真实实现):
// 任务队列
const queueTask = []
// 将任务加入任务队列
export const pushTask = (task) => queueTask.push(task)
while (true) {
// 不停的去检查队列中是否有任务
if (queueTask.length) {
// 队列:先进先出
const task = queueTask.shift()
task()
}
} 事件监听触发
document.body.addEventListener('click', () => {})
伪代码:
// JS线程 -> 监听事件
function addEventListener(eventName, callback) {
sendMessage("eventTriggerThread", this, eventName, callback)
}
// 事件触发线程 -> 监听元素对应事件
// 事件触发线程 -> 元素触发事件
function trigger(callback) {
pushTask(callback)
} 定时器 setInterval 与 setTimeout 所在线程
伪代码:
// JS线程 -> 开始计时
function setTimeout(callback, timeout) {
sendMessage("timerThread", callback, timeout)
}
// 定时器线程 -> 设定定时器开始计时
// 定时器线程 -> 计时器结束
function trigger(callback) {
pushTask(callback)
} Ajax、fetch 请求
伪代码:
// JS线程 -> 开始请求
XMLHttpRequest.send()
sendMessage("netWorkThread", options, callback)
// 网络线程 -> 开始请求
// 网络线程 -> 请求响应成功
function trigger(callback) {
pushTask(callback)
} 在地址栏输入 URL,请求 HTML,浏览器接受到响应结果,将 HTML 文本交给渲染线程,渲染线程开始解析 HTML 文本。
...
</div>
<script>
document.body.style.color = '#f40'
document.body.addEventListener('click', () => {})
setTimeout(() => {}, 100)
ajax('/api/url', () => {})
</script>
</body> 渲染线程解析过程中遇到 <script> 标签时,会把 <script> 中的代码包装成一个任务,放入 JS 引擎中的任务队列中,并挂起当前线程,开始运行 JS 线程。
pushTask(<script>) JS 线程检查到任务队列中有任务,就开始执行任务。
第一个宏任务执行完成,执行写操作队列(渲染页面)
while (true) {
if (queueTask.length) {
const task = queueTask.shift()
task()
requestAnimationFrame()
// 执行写操作队列后进行渲染
render()
// 检查空闲时间是否还够
requestIdleCallback()
}
} 第一个任务就完全结束了,任务队列回到空的状态,第一个任务中注册了 3 个异步任务,但是这对 JS 引擎不会关心这些,它要做的就是接着不停的循环检查任务队列。
为了简化流程,假设三个异步任务同时完成了,此时任务队列中就有了 3 个任务
// 任务队列
const queueTask = [addEventListener, setTimeout, ajax] 但是不管有多少任务,都会按照上面的流程进行循环重复的执行,这整个流程被称为事件循环。
上面说的是 ES6 之前的事件循环,只有一个任务队列,很好理解。
在 ES6 标准中,ECMA 要求 JS 引擎在事件循环中加入了一个新的队列:微任务队列
实际功能:Vue 为了性能优化,对响应式数据的修改并不会立即触发视图渲染,而是会放到一个队列中统一异步执行。(JS 引擎对 GUI 线程写操作的**)
那怎么实现这个功能呢?想要异步执行,就需要创建一个异步任务,setTimeout 是最合适的。
// 响应式数据修改
this.showModal = true
// 记录需要重新渲染的视图
const queue = []
const flag = false
// 触发setter
function setter() {
// 记录需要渲染的组件
queue.push(this.render)
if (flag) return
flag = true
setTimeout(() => {
queue.forEach((render) => render())
flag = false
})
} 这样实现有什么问题呢?
// 任务队列
const queueTask = [addEventListener, setTimeout, ajax] 用上面的例子,现在任务队列里有三个任务,在第一个任务 addEventListener 中进行了 Vue 响应式修改。
假设 setTimeout 立即就完成了,那么现在的任务队列如下:
// 任务队列
const queueTask = [addEventListener, setTimeout, ajax, vueRender] 这个结果符合任务队列的运行逻辑,但却不是我们想要的。
因为视图更新的代码太靠后了,要知道每次任务执行之后并不是立即执行下一个任务,而是会执行 requestAnimationFrame、渲染视图、检查剩余时间执行 requestIdleCallback 等等一系列的事情。
按这个执行顺序,vueRender 的代码会在页面渲染两次之后才执行。
我们想要实现的效果是这个异步代码最好是在当前任务执行完就执行,理想的任务队列是下面这样。
// 任务队列
const queueTask = [addEventListener, vueRender, setTimeout, ajax] 相当于要给宏任务队列加入插入队列的功能,但是如果这么改,那就整个乱套了。之前的异步任务还有个先来后到的顺序,先加入先执行,这么一改,异步任务的顺序就完全无法控制了。
上面的问题总结来说
既然之前的任务队列逻辑不能动,那不如就加个新队列:微任务队列。
JS 引擎自己创建的异步任务,就往这个微任务队列里放。通过别的线程创建的异步任务,还是按老样子放入之前的队列中(宏任务队列)。
微任务队列,会在宏任务执行之后被清空执行。
加入了微任务队列之后,JS 引擎的代码实现:
// 宏任务队列
const macroTask = []
// 微任务队列
const microTask = []
while (true) {
if (macroTask.length) {
const task = macroTask.shift()
task()
// 宏任务执行之后,清空微任务队列
while (microTask.length) {
const micro = microTask.shift()
micro()
}
requestAnimationFrame()
render()
requestIdleCallback()
}
} 注意 while 循环的实现,只要微任务队列中有任务,就会一直执行直到队列为空。也就是说如果在微任务执行过程中又产生了微任务(向微任务队列中 push 了新值),这个新的微任务也会在这个 while 循环中被执行
// 微任务队列 = []
Promise.resolve().then(() => {
console.log(1)
Promise.resolve().then(() => {
console.log(2)
})
})
// 微任务队列 = [log1函数体]
// log1函数体 = 微任务队列.shift()
// 微任务队列 = []
// log1函数体()
// 微任务队列 = [log2函数体]
// log2函数体 = 微任务队列.shift()
// 微任务队列 = []
// 渲染视图 以上就是为什么要有微任务队列,以及微任务队列的运行逻辑。
浏览器中可以产生微任务异步代码的 API:Promise.prototype.then、MutationObserver、setImmediate(IE、nodejs)、MessagePort.onmessage
Vue 渲染视图的异步代码就是放在微任务队列中的。
Vue2 的 nextTick 实现为:Promise -> setImmediate -> MessagePort.onmessage -> setTimeout
API 介绍:使用 nextTick 注册的代码会在 DOM 更新之后被调用。
nextTick 的实现比我们想的要简单的多,尤其是我们已经了解了微任务的执行逻辑。
// 记录需要重新渲染的视图
const queue = []
const flag = false
// 触发setter
function setter() {
// 记录需要渲染的组件
queue.push(this.render)
if (flag) return
flag = true
// setTimeout 换成了 Promise, 将异步任务注册进微任务队列中
Promise.resolve().then(() => {
queue.forEach((render) => render())
flag = false
})
}
// 微任务队列:[]
this.showModal = true
// 微任务队列:[vueRender]
this.$nextTick(() => {})
// 微任务队列:[vueRender, nextTickCallback] Vue3 的 nextTick(支持 Proxy 的浏览器不可能不支持 Promise)
const resolvedPromise = Promise.resolve()
export function nextTick(fn) {
return fn ? resolvedPromise.then(fn) : p
} 2024-03-05
精力是有限的,多花费一分在某个点上,就注定会减少在另一个点上
好用 + 好看 = 时间长
时间短 + 好看 = 不好用
时间短 + 好用 = 不好看

制定更多基础的 UI 规范(字号、间距、圆角...),提高设计、开发的交付效率
规范 = 约束= 效率
假设左边是精心设计的完美视觉效果页面,右边是根据「死板」规范无脑堆出来的页面
| 100% 视觉效果 & 100% 成本(心智负担) | 80% 视觉效果 & 50% 成本(心智负担) |
|---|---|
 |
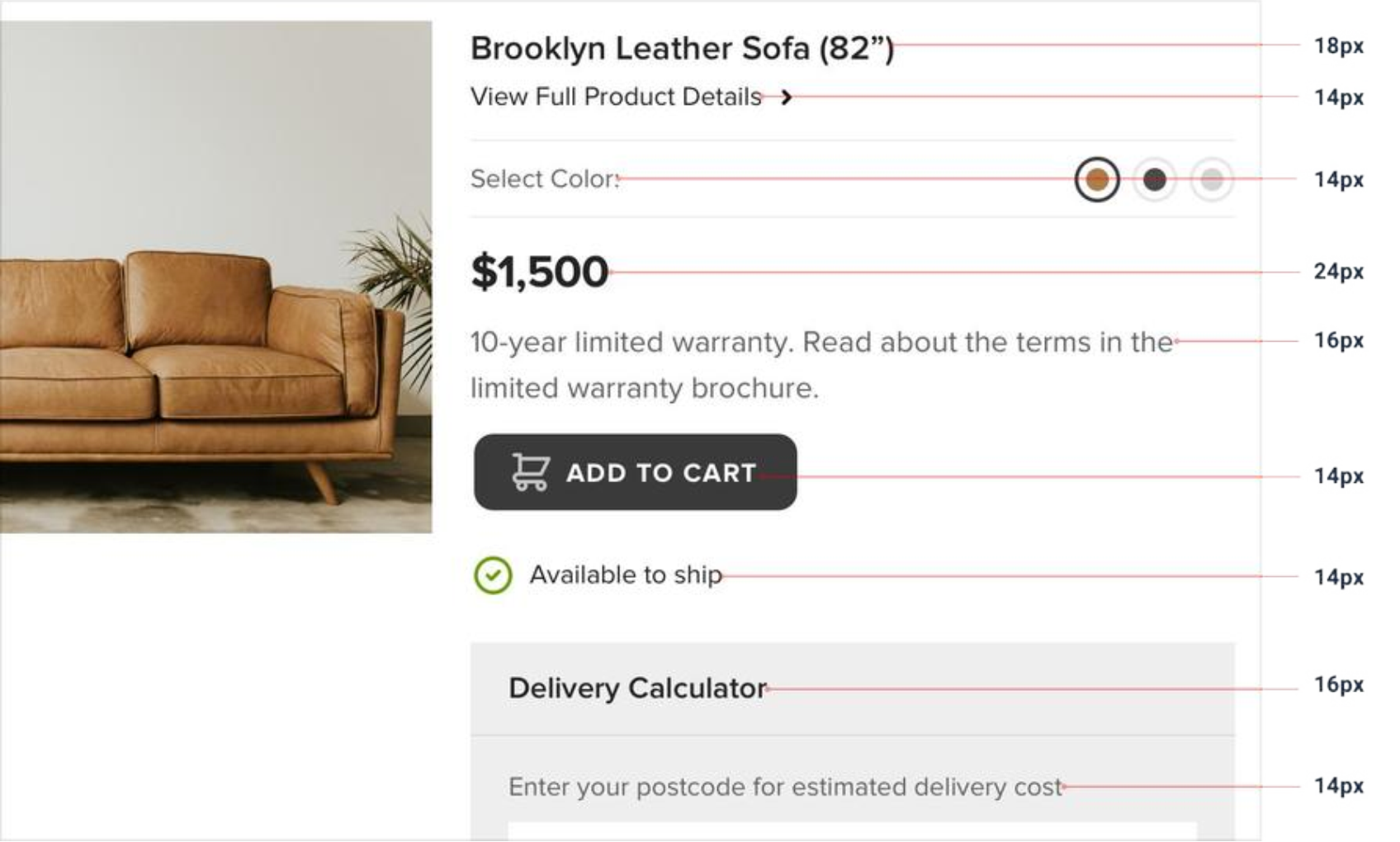 |
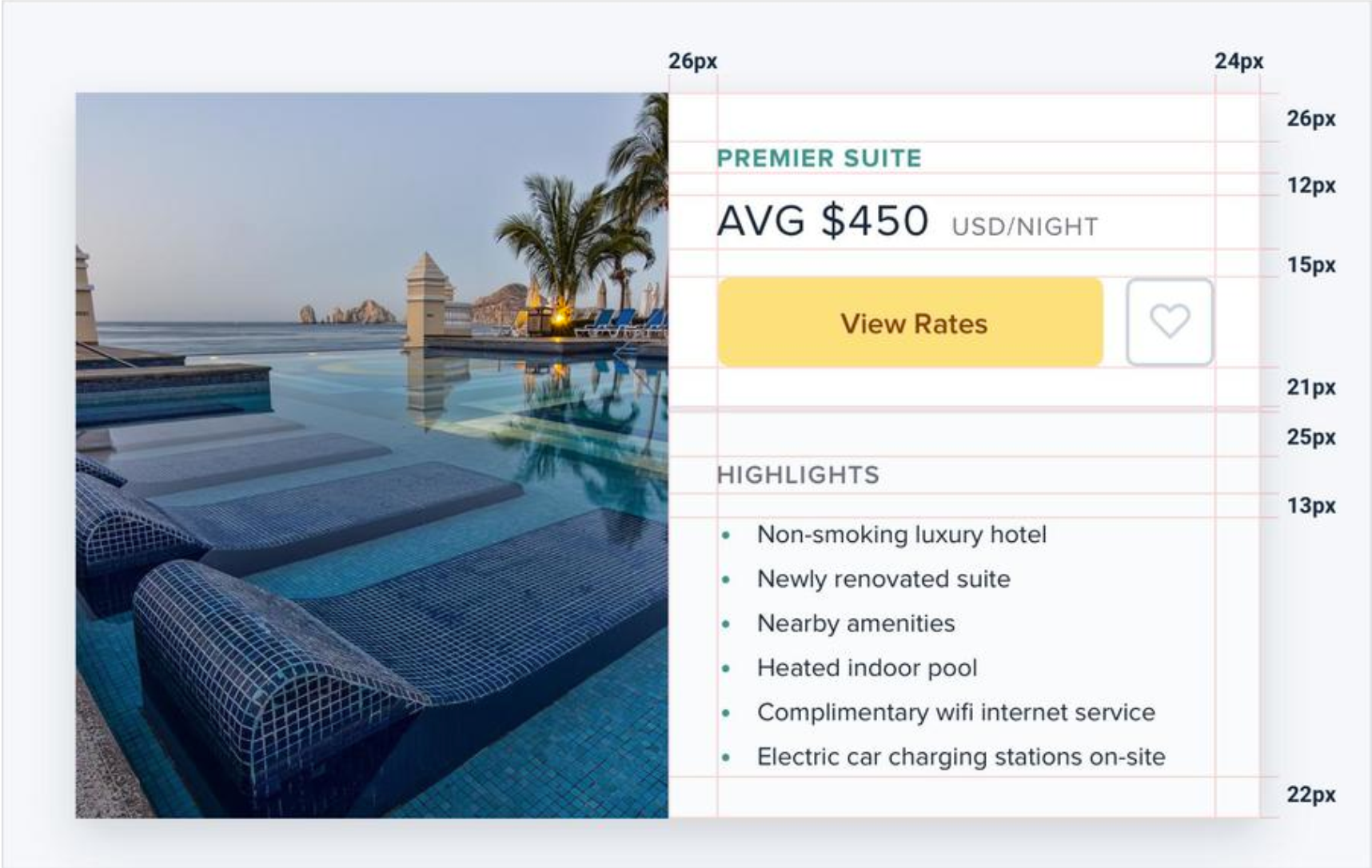 |
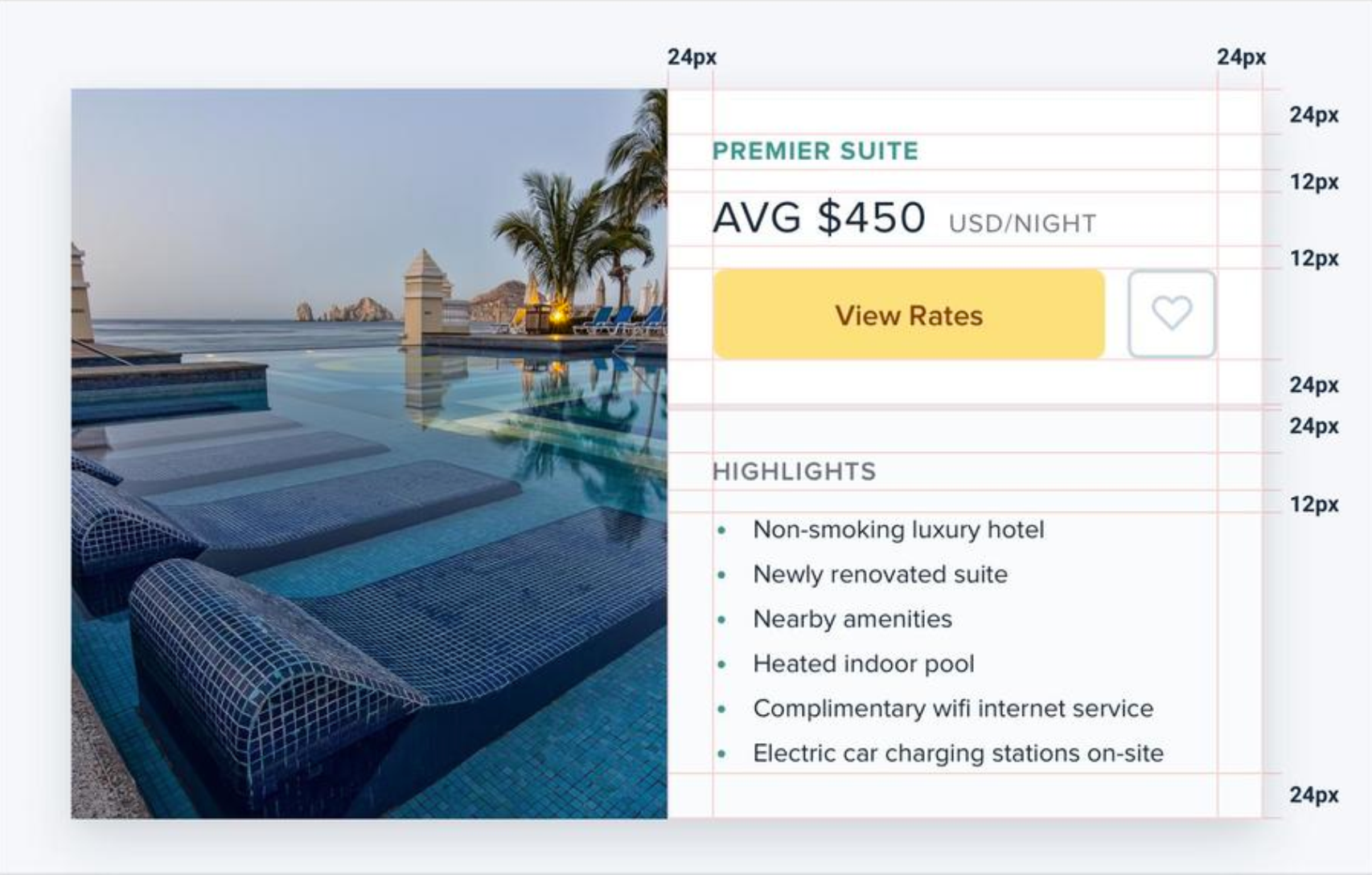 |
没有标准答案,需要考虑具体的应用场景、定位
但不可否认的是,如果去掉标注,仅凭肉眼是很难分辨两者的差 |
没有标准答案,需要考虑具体的应用场景、定位
但不可否认的是,如果去掉标注,仅凭肉眼是很难分辨两者的差异的,所以右边的性价比高无疑是更高的
长期持续的系统组件化 + 芝士组件迁移之后,现在已经大幅减少了设计和研发在 UI 上的成本
需求很多,但真正需要设计的模块很少,绝大多数都是直接复用现有组件
在商业经常 battle 颜色问题,比如按钮组件封装后,后续需求发现颜色变了
(用提示文案举例可能更合适,八百种灰

「颜色」只是举例,间距、字号、行高、圆角等等都有同样的问题

转社区后,就再也没有过这样的问题了,因为有了颜色规范
上次的组件迁移时,就聊到能不能规范一下圆角,统一一下,最后的结果就是做不到
要么都改,要么都不改。怕的就是每处都单独改,每处都不一样,系统就失控了
◦ 纠结字体大小是 12px 还是用 13px ?
◦ 边框阴影应具有 10% 的不透明度还是 15% 的不透明度?
◦ 头像高度应该是 24px 还是 25px?
成本降低:
限制设计发挥,达不到完美效果
◦ 字体大小(Font size)
◦ 字体粗细(Font weight)
◦ 行高(Line height)
◦ 颜色(Color)
◦ 外边距(Margin)
◦ 内边距(Padding)
◦ 宽度(Width)
◦ 高度(Height)
◦ 边框阴影(Box shadows)
◦ 边框半径(Border radius)
◦ 边框宽度(Border weight)
◦ 不透明度(Opacity)
◦ …
| text | gap |
|---|---|
 |
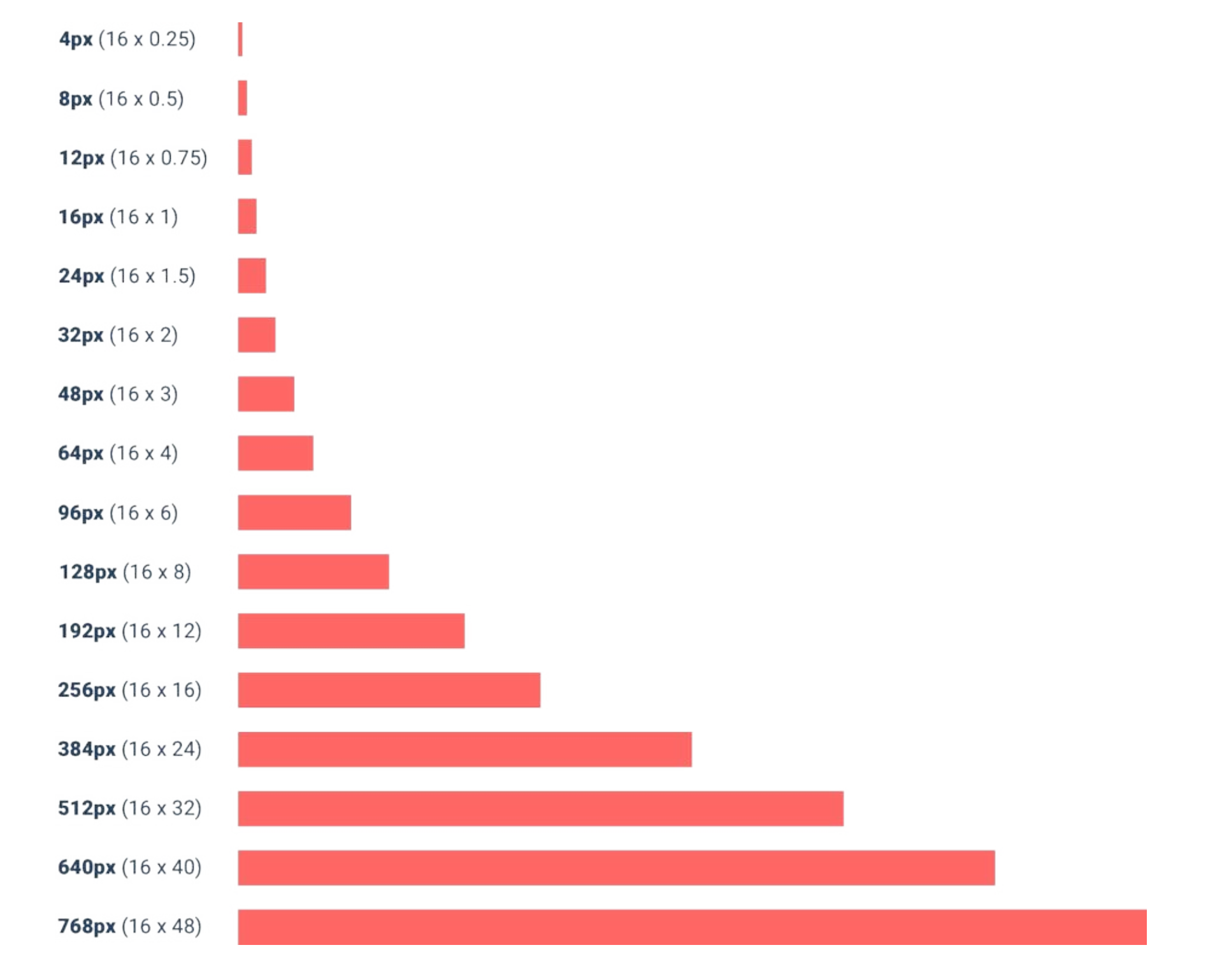 |
举例:间距规范下的按钮设计,更加具有辨识度
| before | after |
|---|---|
 |
 |
所有 CSS 属性都被符号化了



2021-11-25
浏览器中的流式操作可以节省内存,扩大 JS 的应用边界,比如我们可以在浏览器里进行视频剪辑,而不用担心视频文件将内存撑爆。
浏览器虽然有流式处理数据的 API,并没有直接提供给 JS 进行流式下载的能力,也就是说即使我们可以流式的处理数据,但想将其下载到磁盘上时,依然会对内存提出挑战。
这也是我们讨论的前提:
本篇文章分析了如何在 JS 中流式的处理数据,流式的进行下载,主要参考了 StreamSaver.js 的实现方案。
分为如下部分:
JS 下载文件的方式JS 持有数据并下载文件的场景APIJS 流式的实现方案JS 读取本地文件并打包下载流这个概念在前端领域中提及的并不多,但是在计算机领域中,流式一个非常常见且重要的概念。
当流这个字出现在 IO 的上下文中,常指的得就是分段的读取和处理文件,这样在处理文件时(转换、传输),就不必把整个文件加载到内存中,大大的节省了内存空间的占用。
在实际点说就是,当你用着 4G 内存的 iPhone 13 看电影时,并不需要担心视频文件数据把你的手机搞爆掉。

在谈下载之前,先提一下流式响应。
如上可知,当我们从服务器下载一个文件时,服务器也不可能把整个文件读取到内存中再进行响应,而是会边读边响应。
那如何进行流式响应呢?
只需要设置一个响应头 Transfer-Encoding: chunked,表明我们的响应体是分块传输的就可以了。
以下是一个 nodejs 的极简示例,这个服务每隔一秒就会向浏览器进行一次响应,永不停歇。
require("http")
.createServer((request, response) => {
response.writeHead(200, {
"Content-Type": "text/html",
"Transfer-Encoding": "chunked",
})
setInterval(() => {
response.write("chunked\r\n")
}, 1000)
})
.listen(8000) 启动后访问 http://localhost:8000 可以看到效果
JS 下载文件的方式在 js 中下载文件的方式,有如下两类:
// 第一类:页面跳转、打开
location.href
window.open
iframe.src
a[download].click()
// 第二类:Ajax
fetch("/api/download")
.then((res) => res.blob())
.then((blob) => {
// FileReader.readAsDataURL()
const url = URL.createObjectURL(blob)
// 借助第一类方式:location.href、iframe.src、a[download].click()
window.open(url)
}) 不难看出,使用 Ajax 下载文件,最终还是要借助第一类方法才可以实现下载。
而第一类的操作都会导致一个行为:页面级导航跳转
所以我们可以总结得出浏览器的下载行为:
Content-Disposition: attachment。对于 a[download] 和 createObjectURL 的 url 跳转,可以理解为浏览器帮忙加上了这个响应头。Ajax 发出的请求并不是页面级跳转请求,所以即使拥有下载响应头也不会触发下载行为。这两种下载文件的方式有何区别呢?
第一类请求的响应数据直接由下载线程接管,可以进行流式下载,一边接收数据一边往本地写文件。

第二类由 JS 线程接管响应数据,使用 API 将文件数据创建成 url 触发下载。

但是相应的 API createObjectURL、readAsDataURL必须传入整个文件数据才能进行下载,是不支持流的。也就是说一旦文件数据到了 JS 手中,想要下载,就必须把数据堆在内存中,直到拿到完整数据才能开始下载。
所以当我们从服务器下载文件时,应该尽量避免使用 Ajax,直接使用 页面跳转类 的 API 让下载线程进行流式下载。
但是有些场景下,我们需要在 JS 中处理数据,此时数据在 JS 线程中,就不得不面对内存的问题。
JS 持有数据并下载文件的场景以下场景,我们需要在 JS 中处理数据并进行文件下载。
纯前端处理文件流:在线格式转换、解压缩等
接口鉴权:鉴权方案导致请求必须由 JS 发起,如 cookie + csrfToken、JWT
ajax:简单但是数据都在内存中iframe + form 实现:麻烦但是可以由下载线程流式下载服务端返回文件数据,前端转换处理后下载

可以看到第一种情况是必须用 JS 处理的,我们来看一下如果不使用流式处理的话,会有什么问题。
去网上搜索「前端打包」,99% 的内容都会告诉你使用 JSZip,谈起文件下载也都会提起一个 file-saver 的库(JSZip 官网也推荐使用这个库下载文件)。
那我们就看一下这些流行库的的问题。
<script setup lang="ts">
import { onMounted, ref } from "@vue/runtime-core";
import JSZip from 'jszip'
import { saveAs } from 'file-saver'
const inputRef = ref<HTMLInputElement | null>(null);
onMounted(() => {
inputRef.value?.addEventListener("change", async (e: any) => {
const file = e.target!.files[0]!
const zip = new JSZip();
zip.file(file.name, file);
const blob = await zip.generateAsync({type:"blob"})
saveAs(blob, "example.zip");
});
});
</script>
<template>
<button @click="inputRef?.click()">JSZip 文件打包下载</button>
<input ref="inputRef" type="file" hidden />
</template> 以上是一个用 JSZip 的官方实例构建的 Vue 应用,功能很简单,从本地上传一个文件,通过 JSZip 打包,然后使用 file-saver 将其下载到本地。
我们来直接试一下,上传一个 1G+ 的文件会怎么样?

通过 Chrome 的任务管理器可以看到,当前的页面内存直接跳到了 1G+。
当然不排除有人的电脑内存比我们硬盘的都大的情况,豪不在乎内存消耗。

OK,即使你的电脑足以支撑在内存中进行随意的数据转换,但浏览器对 Blob 对象是有大小限制的。
下面是 file-saver 的 github:

官网的第一句话就是
If you need to save really large files bigger than the blob's size limitation or don't have enough RAM, then have a look at the more advanced StreamSaver.js
如果您需要保存比 blob 的大小限制更大的文件,或者没有足够的内存,那么可以查看更高级的 StreamSaver.js
然后给出了不同浏览器所支持的 Max Blob Size,可以看到 Chrome 是 2G。
所以不管是出于内存考虑,还是 Max Blob Size 的限制,我们都有必要去探究一下流式的处理方案。
顺便说一下这个库并没有什么黑科技,它的下载方式和我们上面写的是一样的,只不过处理了一些兼容性问题。
下面是源码:

APIStreams API 是浏览器提供给 JS 的流式操作数据的接口。
 、
、
其中包含有两个主要的接口:可读流、可写流
创建一个可写流对象,这个对象带有内置的背压和排队。
// 创建
const writableStream = new WritableStream({
write(chunk) {
console.log(chunk)
},
})
// 使用
const writer = writableStream.getWriter()
writer.write(1).then(() => {
// 应当在 then 再写入下一个数据
writer.write(2)
}) write 函数,在其中处理具体的写入逻辑(写入可读流)。getWriter() 获取流的写入器,之后调用 write 方法进行数据写入。write 方法是被包装后的,其会返回 Promise 用来控制背压,当允许写入数据时才会 resolve。CountQueuingStrategy,这里不细说。创建一个可读的二进制操作,controller.enqueue 向流中放入数据,controller.close 表明数据发送完毕。
下面的流每隔一秒就会产生一次数据:
const readableStream = new ReadableStream({
start(controller) {
setInterval(() => {
// 向流中放入数据
controller.enqueue(value)
// controller.close(); 表明数据已发完
}, 1000)
},
}) 从可读流中读取数据:
const reader = readableStream.getReader()
while (true) {
const { value, done } = await reader.read()
console.log(value)
if (done) break
} 调用 getReader() 可以获取流的读取器,之后调用 read() 便会开始读取数据,返回 Promise
Promise penging)。controller.enqueue 或 controller.close 后,Promise 就会 resolve。done:数据发送完毕,表示调用了 controller.close。value:数据本身,表示调用了 controller.enqueue。while (true) 的写法在其他语言中是非常常见的,如果数据没有读完,我们就重复调用 read(),直到 done 为 true。
fetch 请求的响应体和 Blob 都已经实现了 ReadableStream。
流式的读取服务端响应数据:
const response = await fetch("/api/download")
// response.body === ReadableStream
const reader = response.body.getReader()
while (true) {
const { done, value } = await reader.read()
console.log(value)
if (done) break
} Blob 对象的 stream 方法,会返回一个 ReadableStream。
当我们从本地上传文件时,文件对象 File 就是继承自 Blob
流式的读取本地文件:
<input type="file" id="file">
document.getElementById("file")
.addEventListener("change", async (e) => {
const file: File = e.target.files[0];
const reader = file.stream().getReader();
while (true) {
const { done, value } = await reader.read();
console.log(value);
if (done) break;
}
}); 有了可读、可写流,我们就可以组合实现一个转换流,一端转换写入数据、一端读取数据。
我们利用 MessageChannel 在两方进行通信
const { port1, port2 } = new MessageChannel()
const writableStream = new WritableStream({
write(chunk) {
port1.postMessage(chunk)
},
})
const readableStream = new ReadableStream({
start(controller) {
port2.onmessage = ({ data }) => {
controller.enqueue(data)
}
},
})
const writer = writableStream.getWriter()
const reader = readableStream.getReader()
writer.write(123) // 写入数据
reader.read() // 读出数据 123 在很多场景下我们都会这么去使用读写流,所以浏览器帮我们实现了一个标准的转换流:TransformStream
使用如下:
const { readable, writable } = new TransformStream()
writable.getWriter().write(123) // 写入数据
readable.getReader().read() // 读出数据 123 以上就是我们需要知道的流式 API 的知识,接下来进入正题。
ok,终于到了流式下载的部分。
这里我并不会推翻自己前面所说:
只有页面级跳转会触发下载。
createObjectURL、readAsDataURL 只能接收整个文件数据。
所以应该怎么做呢?
是的,黑科技主角 Service worker,熟悉 PWA 的人对它一定不陌生,它可以拦截浏览器的请求并提供离线缓存。
Service workers 本质上充当 Web 应用程序、浏览器与网络(可用时)之间的代理服务器。这个 API 旨在创建有效的离线体验,它会拦截网络请求并根据网络是否可用来采取适当的动作、更新来自服务器的的资源。
——MDN
这里有两个关键点:
也就是说,通过 Service worker 前端完全可以自己充当服务器给下载线程传输数据。
让我们看看这是如何工作的。
请求的拦截非常简单,在 Service worker 中注册 onfetch 事件,所有的请求发送都会触发其回调。
通过 event.request 对象拿到 Request 对象,进而检查 url 决定是否要拦截。
如果确定要拦截,就调用 event.respondWith 并传入 Response 对象,既可完成拦截。
self.onfetch = (event) => {
const url = event.request.url
if (url === "拦截") {
event.respondWith(new Response())
}
} Response 就是 fetch() 返回的 response 的构造函数。
直接看函数签名:
interface Response: {
new(body?: BodyInit | null, init?: ResponseInit): Response
}
type BodyInit = ReadableStream | Blob | BufferSource | FormData | URLSearchParams | string
interface ResponseInit {
headers?: HeadersInit
status?: number
statusText?: string
} 可以看到,Response 接收两个参数
Body,其类型可以是 Blob、string 等等,其中可以看到熟悉的 ReadableStream 可读流这意味着:
Content-Disposition:attachment,浏览器就会让下载线程接管响应。Body 构建成 ReadableStream,就可以流式的向下载线程传输数据。也意味着前端自己就可以进行流式下载!
我们构建一个最简的例子来将所有知识点串起来:从本地上传文件,流式的读取,流式的下载到本地。
是的这看似毫无意义,但这可以跑通流程,对学习来说足够了。

通知 service worker 准备下载文件,等待 worker 返回 url 和 writable
const createDownloadStrean = async (filename) => {
// 通过 channel 接受数据
const { port1, port2 } = new MessageChannel()
// 传递 channel,这样 worker 就可以往回发送消息了
serviceworker.postMessage({ filename }, [port2])
return new Promise((resolve) => {
port1.onmessage = ({ data }) => {
// 拿到url, 发起请求
iframe.src = data.url
document.body.appendChild(iframe)
// 返回可写流
resolve(data.writable)
}
})
} Service worker 接受到消息,创建 url、ReadableStream、WritableStream,将 url、WritableStream 通过 channel 发送回去。
self.onmessage = (event) => {
const filename = event.data.filename
// 拿到 channel
const port2 = event.ports[0]
// 随机一个 url
const downloadUrl =
self.registration.scope + Math.random() + "/" + filename
// 创建转换流
const { readable, writable } = new TransformStream()
// 记录 url 和可读流,用于后续拦截和响应构建
map.set(downloadUrl, readable)
// 传回 url 和可写流
port2.postMessage({ download: downloadUrl, writable }, [writable])
} 主线程拿到 url 发起请求(第 1 步 onmessage 中),Service worker 拦截请求,使用上一步的 ReadableStream 创建 Response 并响应。
self.onfetch = (event) => {
const url = event.request.url
// 从 map 中取出流,存在表示这个请求是需要拦截的
const readableStream = map.get(url)
if (!readableStream) return null
map.delete(url)
const headers = new Headers({
"Content-Type": "application/octet-stream; charset=utf-8",
"Content-Disposition": "attachment",
"Transfer-Encoding": "chunked",
})
// 构建返回响应
event.respondWith(new Response(readableStream, { headers }))
} 下载线程拿到响应,开启流式下载(但是此时根本没有数据写入,所以在此就阻塞了)
主线程拿到上传的 File 对象,获取其 ReadableStream 并读取,将读取到的数据通过 WritableStream(第 1 步中返回的)发送出去。
input.addEventListener("change", async (e: any) => {
const file = e.target!.files[0];
const reader = file.stream().getReader();
const writableStream = createDownloadStrean()
const writable = writableStream.getWriter()
const pump = async () => {
const { done, value } = await reader.read();
if (done) return writable.close()
await writable.write(value)
// 递归调用,直到读取完成
return pump()
};
pump();
}) 当 WritableStream 写入数据时,下载线程中的 ReadableStream 就会接收到数据,文件就会开始下载直到完成。
// index.vue
<script setup lang="ts">
import { onMounted, ref } from "@vue/runtime-core"
import { createDownloadStream } from "../utils/common"
const inputRef = ref<HTMLInputElement | null>(null)
// 注册 service worker
async function register() {
const registed = await navigator.serviceWorker.getRegistration("./")
if (registed?.active) return registed.active
const swRegistration = await navigator.serviceWorker.register("sw.js", {
scope: "./",
})
const sw = swRegistration.installing! || swRegistration.waiting!
let listen: any
return new Promise<ServiceWorker>((resolve) => {
sw.addEventListener(
"statechange",
(listen = () => {
if (sw.state === "activated") {
sw.removeEventListener("statechange", listen)
resolve(swRegistration.active!)
}
})
)
})
}
// 向 service worker 申请下载资源
async function createDownloadStream(filename: string) {
const { port1, port2 } = new MessageChannel()
const sw = await register()
sw.postMessage({ filename }, [port2])
return new Promise<WritableStream>((r) => {
port1.onmessage = (e) => {
const iframe = document.createElement("iframe")
iframe.hidden = true
iframe.src = e.data.download
iframe.name = "iframe"
document.body.appendChild(iframe)
r(e.data.writable)
}
})
}
onMounted(async () => {
// 监听文件上传
inputRef.value?.addEventListener("change", async (e: any) => {
const files: FileList = e.target!.files
const file = files.item(0)!
const reader = file.stream().getReader()
const writableStream = await createDownloadStream(file.name)
const writable = writableStream.getWriter()
const pump = async () => {
const { done, value } = await reader.read()
if (done) return writable.close()
await writable.write(value)
pump()
}
pump()
})
})
</script>
<template>
<button @click="inputRef?.click()">本地流式文件下载</button>
<input ref="inputRef" type="file" hidden />
</template> // service-worker.js
self.addEventListener("install", () => {
self.skipWaiting()
})
self.addEventListener("activate", (event) => {
event.waitUntil(self.clients.claim())
})
const map = new Map()
self.onmessage = (event) => {
const data = event.data
const filename = encodeURIComponent(data.filename.replace(/\//g, ":"))
.replace(/['()]/g, escape)
.replace(/\*/g, "%2A")
const downloadUrl = self.registration.scope + Math.random() + "/" + filename
const port2 = event.ports[0]
// [stream, data]
const { readable, writable } = new TransformStream()
const metadata = [readable, data]
map.set(downloadUrl, metadata)
port2.postMessage({ download: downloadUrl, writable }, [writable])
}
self.onfetch = (event) => {
const url = event.request.url
const hijacke = map.get(url)
if (!hijacke) return null
map.delete(url)
const [stream, data] = hijacke
// Make filename RFC5987 compatible
const fileName = encodeURIComponent(data.filename)
.replace(/['()]/g, escape)
.replace(/\*/g, "%2A")
const headers = new Headers({
"Content-Type": "application/octet-stream; charset=utf-8",
"Transfer-Encoding": "chunked",
"response-content-disposition": "attachment",
"Content-Disposition": "attachment; filename*=UTF-8''" + fileName,
})
event.respondWith(new Response(stream, { headers }))
} 跑通了流程之后,压缩也只不过是在传输流之前进行一层转换的事情。
首先我们寻找一个可以流式处理数据的压缩库(你肯定不会想自己写一遍压缩算法),fflate 就很符合我们的需求。
然后我们只需要在写入数据前,让 fflate 先处理一遍数据就可以了。
onMounted(async () => {
const input = document.querySelector("#file")!;
input.addEventListener("change", async (e: any) => {
const stream = createDownloadStrean()
const file = e.target!.files[0];
const reader = file.stream().getReader();
const zip = new fflate.Zip((err, dat, final) => {
if (!err) {
fileStream.write(dat);
if (final) {
fileStream.close();
}
} else {
fileStream.close();
}
});
const helloTxt = new fflate.ZipDeflate("hello.txt", { level: 9 });
zip.add(helloTxt);
while (true) {
const { done, value } = await reader.read();
if (done) {
zip.end();
break
};
helloTxt.push(value)
}
});
});
是的,就是这么简单。
这里有一份 完整的代码,感兴趣的可以克隆跑起来看看。
2024-01-03
React Server Component - RFC |suspense-in-react-18
也许忘掉 React 相关的知识会更好理解
| JSX | HTML |
|---|---|
 |
 |
React 一直以来都面临两个挑战:
一开始 React 寻找相应问题的有针对性的解决方案 (Fiber / stream SSR),但结果都不满意。核心问题是 React 应用以客户端为主,没有充分利用服务器

如果能够让开发人员更轻松的利用他们的服务器,就可以解决所有这些挑战,并提供更强大的方法来构建应用程序
服务端组件:仅在服务端运行的组件(性能取决于服务器硬件,而不是客户端硬件)
在文件中加入相应指令(最早是以文件命名区分:.server.js / .client.js)
服务端:'use server'(所有组件默认为服务端)
客户端:'use client'

Tips:
区别只在于一个直接使用 renderToStirng 将组件渲染为 HTML 返回,由浏览器直接解析渲染
一个使用 resolveModelToJSON 将组件渲染为可序列化传输的数据返回,由客户端的 JS 负责解析渲染


首次页面加载时可以选择 SSR 模式,这与现在的 React SSR 没有什么差别,所以就直接讲 RSC 的流程了
bootstrap.js,用于处理客户端逻辑bootstrap.js 正常使用 React render 渲染 <Router /> 组件RSC data,这个请求会被加上标识(?jsx)以区分正常的网页路由请求?jsx 的请求,同样根据路由匹配到相应组件,并使用 resolveModelToJSON 将组件转换为 RSC data
ReactElementTree 的可被序列化版本,目前在 JS 中的 Tree 虽然改一改也可以变成 JSON,但是一个是数据冗余不方便解析,一个是无法很好的流式传输promise 会交给 createFromFetch,它会流式的读取响应并通过 use 做渲染工作
handle-form-submission-with-a-server-action
在客户端就可以直接调用服务端的方法,本质是一个 RPC 调用
这个 API 出来之后的调侃...
 |
 |
 |
|---|
 |
 |
|---|
还是一个网络请求,相当于用编译器把我们本要做的事给做了
所以根本不会出现那些所谓的 SQL 注入、密钥不安全之类的问题

2024-03-25
esc 键的便利性直接决定了 vim 的使用体验,多数的解决方案是将 caps lock 映射为 esc,或者使用 jj / jk 等方案
我的方案是将 command(Mac) 单击时映射为 esc 键,组合时仍然是原始功能
思路是:ctrl / alt / command / shift 正常情况下都是组合使用的,单独点击是无意义的,所以通过映射将单击行为利用起来
使用 karabiner-elements 的 complex_modifications 功能进行如下配置
{
"profiles": [
{
"complex_modifications": {
"rules": [
{
"description": "Alone Command to Esc",
"manipulators": [
{
"from": {
"key_code": "left_gui",
"modifiers": {
"optional": ["any"]
}
},
"to": [
{
"key_code": "left_gui",
"lazy": true
}
],
"to_if_alone": [
{
"key_code": "escape"
}
],
"type": "basic"
}
]
}
]
}
}
]
} 参考 Arch Linux 系统配置篇 > 按键映射,或者使用 xcape
可以使用 Capsicain 实现,但是我用了这个之后老是出现按键延迟、粘连的现象
这也是弃用 Windows 的一大原因
AHK 也可以实现,但是我自己没玩明白
2024-04-10
通过 link.preload 在渲染 HTML 的时候就开始加载必要的接口请求,这样等 JS 执行请求的时候就可以直接使用响应了,减少请求的等待时间
关键内容绘制(First Meaningful Paint,简称 FMP)是网页性能分析中的一个指标,用于衡量网页加载过程中首次呈现对用户有意义的内容所花费的时间。
与首次内容绘制(First Contentful Paint,FCP)不同,FMP 更加关注页面加载的实用性和用户体验。
FCP 只关注页面上任何内容(如文本或图片)首次出现在屏幕上的时间点,而 FMP 则进一步考虑这些内容是否对用户有实际意义。
例如,一个页面可能很快就显示了一个加载动画或者一个背景图像,但这些内容对用户来说并没有提供有价值的信息。
相比之下,FMP 可能会等到页面的主要内容(如文章标题、导航菜单或者重要图像)加载并渲染到屏幕上时才被触发。
FMP 是一个更为综合的性能指标,它结合了页面的视觉变化和页面内容的实用性。
一个良好的 FMP 体验意味着用户在较短的时间内就能看到并与之交互的页面核心内容,这通常会导致更高的用户满意度和更低的跳出率。
大多数中后台系统中,必须要先请求类似 me/user 之类的接口数据之后才能开始真正渲染页面(多是因为角色、权限等需要拿到数据后才知道如何渲染)
而在接口请求成功之前只能给页面一个大大的 loading 或者骨架屏
请求瀑布流如下(无缓存):
me 接口
emmm....5s 之后才开始请求 me 接口,这还是线上的环境
不过大多数中后台并不(特别)在意性能,所以一般也不会去做优化
但如果仅需要一行代码就可以轻松提高 N 倍的性能呢,你会去做吗?


说了半天终于到了重点,利用 link.preload.fetch 的功能,可以在渲染 HTML 时就预加载接口请求,这样等 JS 执行请求的时候就可以直接拿到接口响应了,减少请求的等待时间
<link rel="preload" href="/api/data" as="fetch" crossorigin="use-credentials" /> 2022-11-11

React
X.Y.Z (16.1.0)
X:做了不兼容的 API 修改Y:做了向下兼容的功能性新增Z:做了向下兼容的问题修正X.Y.Z: 指定版本,严格匹配(16.1.0)~X.Y.Z: 接受 Z 的最新版本(16.1.0、16.1.9、16.1.99)^X.Y.Z: 接受 Y.Z 的最新版本(16.1.0、16.9.9、16.99.99)*: 接受最新版本模块联邦实现了运行时的语义化版本管理,在指定的范围内尽量用高的版本

模块联邦
资源复用 & 资源隔离
模块联邦 &(iframe、qiankun、MicroApp..)
独立运行 | 独立开发 | 独立升级 | 独立部署
尽量避免各个模块间的耦合关系,保持独立。

Q: 你所了解的微前端子模块一般都是如何划分的?有什么建议?
A: 我的 PPT 里有一页其实提到了,微前端拆分其实需要有明确的服务边界划分。如果你的微应用之间存在了过多的交互或者耦合,那你可能就要考虑是不是拆分的粒度过细了。
有一个简单的判断方式,就是看你的 微应用在独立打开的情况下,是否能完成一个独立 功能/服务 的提交,如果不是的,那可能就要看看了。
模块联邦完全相反,其功能就是模块间共享依赖,让模块与模块之间可以相互调用。
会有什么问题?
简单说:耦合越多,独立运行、独立开发、独立升级、独立部署 就越难完成()
模块联邦:依赖共享,跨模块调用,会有什么问题?
依赖版本冲突风险示例


远程模块冲突风险示例

模块提供方,不能假设使用方是完全按照规矩去使用模块的。
具有调用关系(输入输出)的多项目共享模块,必须进行版本控制(npm 包)
调用

资源(css/js)加载、组合 (共享)、执行


公用类名、tailwind
clearfix、mt-8、ellipsis/* A */
.inactive {
color: #ddd;
}
/* B */
.inactive {
display: none;
}
:global {
.ant-menu .ant-menu-item-selected {
border-right: none;
border-left: 3px solid;
}
.ant-menu-inline .ant-menu-item::after {
border-right: none;
}
} 如果事情有变坏的可能,不管这种可能性有多小,它总会发生 - 墨菲定律


React
X.Y.Z (16.1.1)
X:做了不兼容的 API 修改Y:做了向下兼容的功能性新增Z:做了向下兼容的问题修正~: 接受 Z 的最新版本
^: 接受 Y.Z 的最新版本
模块联邦实现了运行时的语义化版本管理,在指定的范围内尽量用高的版本

经过测试的版本,受其他模块影响,在线上运行时被动态升级。
new ModuleFederationPlugin({
shared: {
...dependencies,
react: { singleton: true },
"react-dom": { singleton: true },
},
}) 


import React, { useState } from "react"
import ReactDOM from "react-dom"
function App() {
useState()
}
ReactDOM.render(React.createElement(App)) module.exports = {
plugins: [
new ModuleFederationPlugin({
shared: {
react: {
/**
* 一些库使用全局内部状态(例如 react、react-dom)。
* 因此,一次只运行一个库的实例至关重要。
*/
singleton: true,
},
},
}),
],
} 
进行模块拆分、复用,模块相互之间具备调用关系
进行模块组合、引入



表格对比:
| n/n | 标准 Lazyload | 构建时集成 | 构建后集成 | 应用独立 |
|---|---|---|---|---|
| 开发流程 | 多个团队在同一个代码库里开发 | 多个团队在不同的代码库里开发 | 多个团队在不同的代码库里开发 | 多个团队在不同的代码库里开发 |
| 构建与发布 | 构建时只需要拿这一份代码去构建、部署 | 将不同代码库的代码整合到一起,再构建应用 | 将直接编译成各个项目模块,运行时通过懒加载合并 | 将直接编译成不同的几个应用,运行时通过主工程加载 |
| 适用场景 | 单一团队,依赖库少、业务单一 | 多团队,依赖库少、业务单一 | 多团队,依赖库少、业务单一 | 多团队,依赖库多、业务复杂 |
| 表现方式 | 开发、构建、运行一体 | 开发分离,构建时集成,运行一体 | 开发分离,构建分离,运行一体 | 开发、构建、运行分离 |
详细的介绍如下:
开发流程:多个团队在同一个代码库里开发,构建时只需要拿这一份代码去部署。
行为:开发、构建、运行一体
适用场景:单一团队,依赖库少、业务单一
开发流程:多个团队在不同的代码库里开发,在构建时将不同代码库的代码整合到一起,再去构建这个应用。
适用场景:多团队,依赖库少、业务单一
变体 - 构建时集成:开发分离,构建时集成,运行一体
开发流程:多个团队在不同的代码库里开发,在构建时将编译成不同的几份代码,运行时会通过懒加载合并到一起。
适用场景:多团队,依赖库少、业务单一
变体 - 构建后集成:开发分离,构建分离,运行一体
开发流程:多个团队在不同的代码库里开发,在构建时将编译成不同的几个应用,运行时通过主工程加载。
适用场景:多团队,依赖库多、业务复杂
前端微服务化:开发、构建、运行分离
总体的对比如下表所示:
| n/n | 标准 Lazyload | 构建时集成 | 构建后集成 | 应用独立 |
|---|---|---|---|---|
| 依赖管理 | 统一管理 | 统一管理 | 统一管理 | 各应用独立管理 |
| 部署方式 | 统一部署 | 统一部署 | 可单独部署。更新依赖时,需要全量部署 | 可完全独立部署 |
| 首屏加载 | 依赖在同一个文件,加载速度慢 | 依赖在同一个文件,加载速度慢 | 依赖在同一个文件,加载速度慢 | 依赖各自管理,首页加载快 |
| 首次加载应用、模块 | 只加载模块,速度快 | 只加载模块,速度快 | 只加载模块,速度快 | 单独加载,加载略慢 |
| 前期构建成本 | 低 | 设计构建流程 | 设计构建流程 | 设计通讯机制与加载方式 |
| 维护成本 | 一个代码库不好管理 | 多个代码库不好统一 | 后期需要维护组件依赖 | 后期维护成本低 |
| 打包优化 | 可进行摇树优化、AoT 编译、删除无用代码 | 可进行摇树优化、AoT 编译、删除无用代码 | 应用依赖的组件无法确定,不能删除无用代码 | 可进行摇树优化、AoT 编译、删除无用代码 |
2020-12-19
对于一直面对电脑的程序员,眼睛的休息是很重要的。但是我们程序员又太过于勤勤恳恳、聚精会神、专心致志、任劳任怨!难免会忽略了时间的流逝。
所以我们迫切的需要一个定时提醒软件,来帮助我们管理时间!~
秉承着钻研技术的理念,这次我们就自己来动手做一个定时提醒软件。
本文将会从项目搭建 -> 代码实现 -> 应用打包,手把手一行行代码的带你完成这个项目。
看完本文你将学会什么知识呢?
让我们开始吧~!
首先搭建一个 vue3 的项目,我们将使用随着 vue3 的到来同样大火的 vite 来搭建。
$ yarn create vite-app remind-rest
$ cd remind-rest
$ yarn
$ yarn dev 执行完上面的命令,打开 http://localhost:3000/ 就可以看到启动的 vue 项目了。
接下来我们将 vue 项目放入 electron 中运行
首先安装 electron + typescript(注意设置淘宝源或者使用 cnpm 下载)
$ yarn add dev electron typescript 使用 npx tsc --init 初始化我们的 tsconfig.json,vue 中的 ts 文件会被 vite 进行处理,所以这里的 tsconfig 配置只处理我们的 electron 文件即可,我们增加 include 属性 include: ["main/"]。
我们会把打包后的代码都放到 dist 目录中,所以配置一下 outDir 属性,将 ts 编译后的文件放入 dist/main 目录中
修改如下
{
"compilerOptions": {
"outDir": "./dist/main"
},
"include": ["main/"]
} 在根目录创建 main 文件夹,用来存放 electron 主进程中的代码
在 main 目录中新建 index.ts
const { app, BrowserWindow } = require("electron")
// Electron会在初始化完成并且准备好创建浏览器窗口时调用这个方法
app.whenReady().then(createWindow)
// 创建一个窗口
function createWindow() {
const win = new BrowserWindow()
win.loadURL("http://localhost:3000")
} 嗯,so easy!加上注释换行才 9 行代码,启动一下试试看~
我们在 package.json 中加一个脚本 main-dev,然后执行
"scripts": {
"dev": "vite",
"build": "vite build",
"main-dev": "electron ./main/index.ts"
} 不出意外你应该已经可以看到启动的桌面应用了,而里面显示的正是我们的 vue 项目。
至此,开发环境已经搭建完毕,接下来我们梳理一下需求,看一下我们要做的究竟有哪些功能。然后开始实现代码。
设置页面
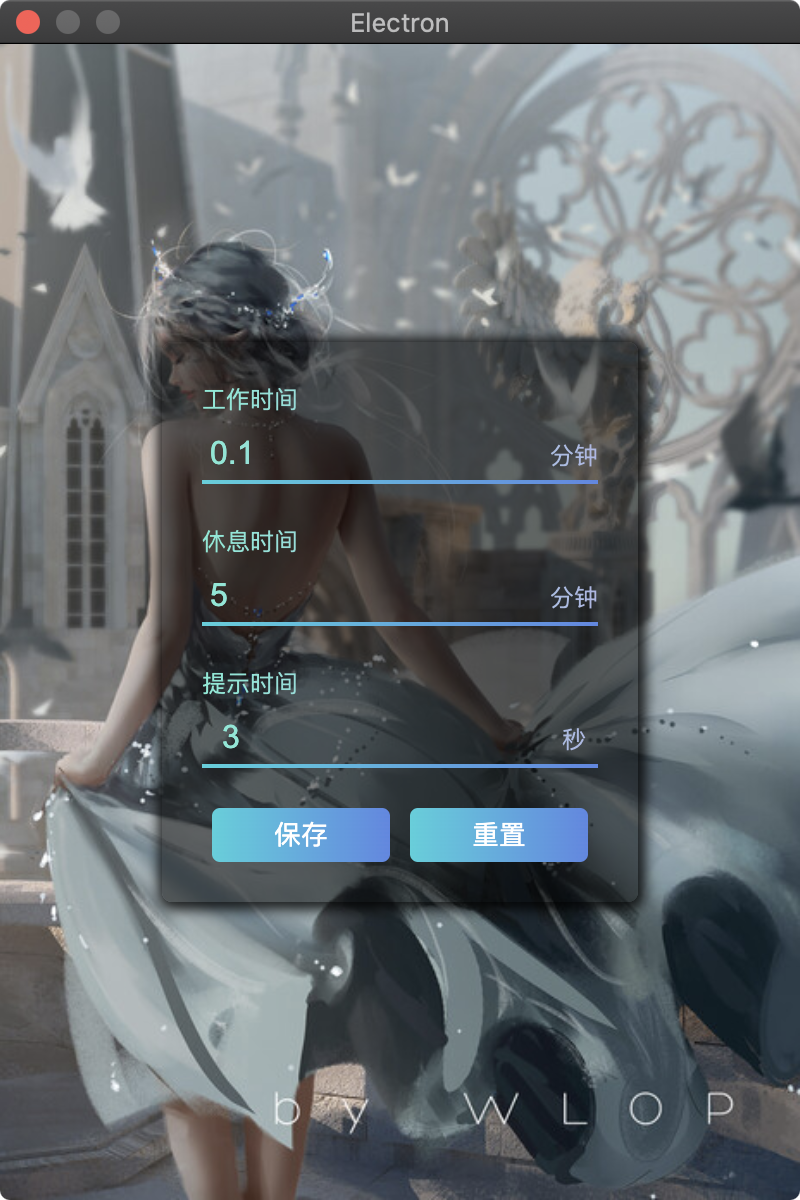
倒计时提示框
锁屏页面

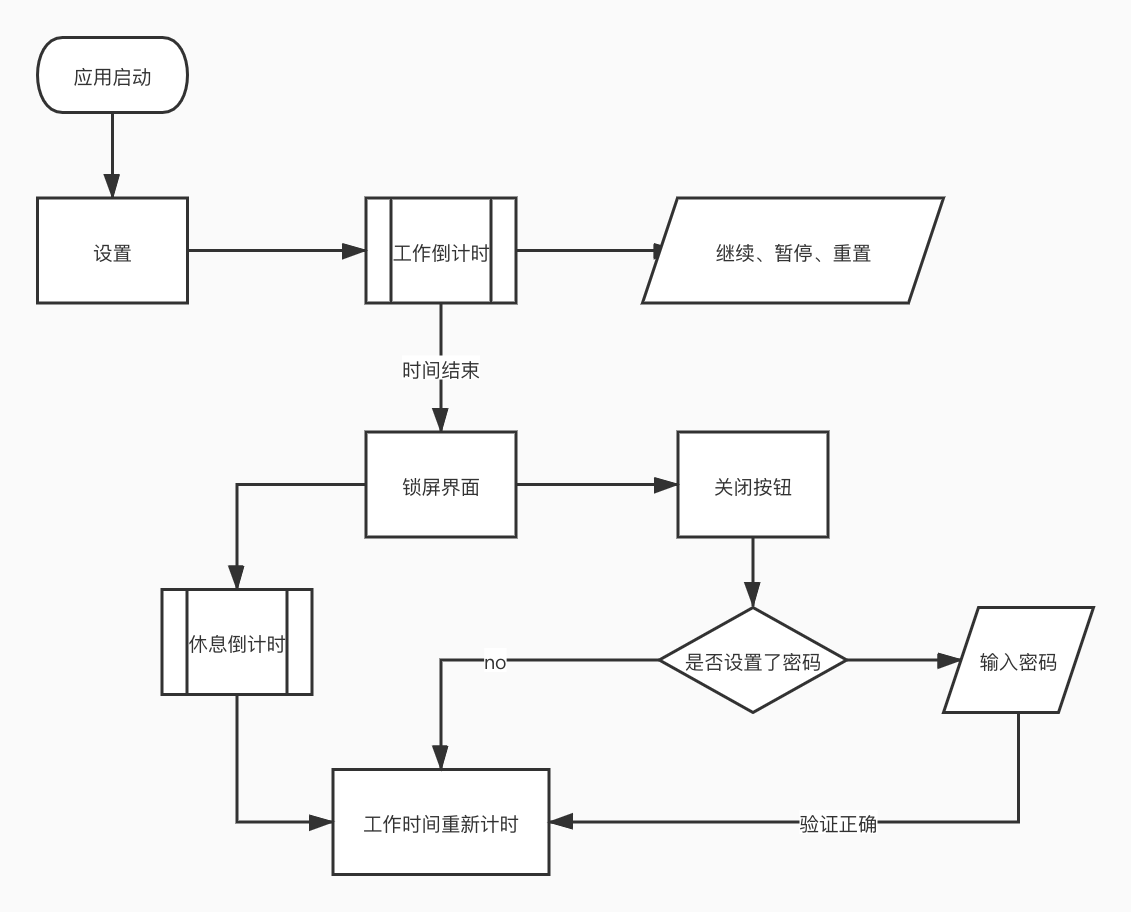
设置 暂停 继续 重置 退出暂停 和 重置 按钮,对倒计时进行操作关闭 按钮提前退出锁屏界面,其他所有常规操作都无法退出锁屏界面(如切换屏幕、切换软件、cmd + Q)好了,需求梳理完毕,让我们开始快乐的 coding 吧 👌 ~
在 vue 项目中创建如下文件
- src
- main.js // 入口文件
- route.js // 路由配置
- App.vue
- views
- LockPage.vue // 锁屏界面
- Tips.vue // 提示气泡界面
- Setting.vue // 设置界面
安装 vue-router
yarn add vue-router@^4.0.0-alpha.4 其中 main.js route.js 都是 vue3 的新写法,和老版本没有太大区别,就不详细说明了,直接看代码吧
views 文件夹中的文件我们后面再具体实现
main.js
import { createApp } from "vue"
import App from "./App.vue"
import router from "./route"
const app = createApp(App)
app.use(router)
router.isReady().then(() => app.mount("#app")) route.js
import { createRouter, createWebHashHistory } from "vue-router"
import LockPage from "./views/LockPage.vue"
import Tips from "./views/Tips.vue"
import Setting from "./views/Setting.vue"
export default createRouter({
history: createWebHashHistory(),
routes: [
{
path: "/LockPage",
name: "LockPage",
component: LockPage,
},
{
path: "/Tips",
name: "Tips",
component: Tips,
},
{
path: "/Setting",
name: "Setting",
component: Setting,
},
],
}) App.vue
<template>
<router-view></router-view>
</template>
<script>
export default {
name: "App",
}
</script> ;-main -
index.ts - // 入口
tary.ts - // 托盘模块
browserWindow.ts - // 创建渲染进程窗口
countDown.ts - // 倒计时模块
setting.ts - // 设置模块
utils.ts - // 工具代码
store.json // 本地存储 渲染进程的代码,每次我们修改之后都会进行热更新。而主进程的代码却没有这样的功能(社区中未找到相关实现),这就导致在主进程的开发过程中我们需要频繁的手动重启终端以去查看效果,这显然是一件很不效率的事情。这里我们通过 node 的 api 来简单实现一个主进程代码的自动重启的功能。
思路其实也很简单,就是监听到文件变更后,自动重启终端
首先我们需要使用 node 来运行终端命令,这样才能去进行控制。node 怎么运行终端命令呢?使用 child_process 中的 spawn 模块就可以了,不熟悉的同学可以看一下这片文章 child_process spawn 模块详解
在根目录新建一个 scripts 文件夹,用来存放我们的脚本文件
然后在 scripts 目录中创建 createShell.js dev.js 这两个文件
mkdir scripts
cd scripts
touch createShell.js dev.js 在 createShell.js 文件中,创建一个工厂函数,传入终端命令,返回执行此命令的终端实例,代码如下:
const { spawn } = require("child_process")
module.exports = function createShell(command) {
return spawn(command, {
shell: true,
})
} 接下来我们实现 dev.js 的内容,先来捋一下思路,当我们执行 dev.js 的时候,我们需要执行如下命令:
::: tip 小提示
&& 代表串行命令,前一个执行完才会执行后一个
& 代表并行命令,前后两个命令同时执行
:::
// 引入我们刚才写的工厂函数
const createShell = require("./createShell")
// 运行vite 和 tsc
const runViteAndTsc = () =>
new Promise((reslove) => {
// 运行终端命令 下面会解释
createShell(
"npx vite & rm -rf ./dist/main && mkdir dist/main && cp -r main/store.json dist/main/store.json && tsc -w"
).stdout.on("data", (buffer) => {
// 输出子进程信息到控制台
console.log(buffer.toString())
// tsc在每次编译生成后,会输出Watching for file changes
// 这里利用Promise状态只会改变一次的特性,来保证后续的代码逻辑只执行一次
if (buffer.toString().includes("Watching for file changes")) {
reslove()
}
})
})
// 运行electron
const runElectron = () => {
// 定义环境变量,启动electron
createShell("cross-env NODE_ENV=development electron ./dist/main/index.js")
//监听到子进程的退出事件
.on("exit", (code) => {
// 约定信号100为重启命令,重新执行终端
if (code === 100) runElectron()
// 使用kill而不是exit,不然会导致子进程无法全部退出
if (code === 0) process.kill(0)
})
}
// 串起流程,执行命令
runViteAndTsc().then(runElectron) 在这里解释一下上面的终端命令,我们格式化一下
npx vite & rm -rf ./dist/main &&
mkdir dist/main &&
cp -r main/store.json dist/main/store.json &&
tsc -w
1. 运行vite,同时删除掉上一次编译产生的main目录
2. 删除目录后,重新建一个空的main目录
3. 重建的目的是为了这行的copy命令,ts不会编译非.ts文件,我们需要手动拷贝store.json文件
4. 拷贝完成后,开始编译ts 这里补充一下,自己来写启动命令除了实现自动刷新之外,还有下面的原因:
以上只完成了第一步,接下来我们要监听文件变化并退出 electron 进程,退出时我们传入 code:100,来通知外部这是一次重启
先写一个辅助函数, 递归遍历指定目录下的所有文件,并执行传入的回调函数,向回调函数中传入当前文件的路径
main/utils.ts
import fs from "fs"
type callback = (name: string) => void
export function readDeepDir(path: string, fn: callback) {
const _reader = (path: string) => {
fs.readdirSync(path).forEach((name) => {
if (!fs.statSync(path + "/" + name).isDirectory()) {
return fn(path + "/" + name)
}
return _reader(path + "/" + name)
})
}
return _reader(path)
} 在 main/index.ts 中监听当前的主进程目录,只要有文件变化,我们就执行 app.exit(100) 退出当前进程
import { readDeepDir } from "./utils"
function watchFile() {
let debounce: NodeJS.Timeout
const reload = () => {
clearTimeout(debounce)
debounce = setTimeout(() => {
// 当前应用退出,外部进程接收到之后重启应用
app.exit(100)
}, 300)
}
// fs.watch并不稳定,使用watchFile进行监听
const watcher = (path: string) => {
fs.watchFile(path, reload)
}
readDeepDir(__dirname, watcher)
} 说明一下
fs.watch 是因为这个 api 并不稳定,会导致刷新结果不符合预期。watchFile 是监听不到新增文件的,这个解决方案其实是借助 tsc -w 的能力,当有已监听的文件去引用新增文件的时候,就会导致 tsc 重新编译,然后触发自动刷新,当第二次启动 electron 的时候,就会把新的文件进行监听了app.relaunch()api 的,调用这个 api 就会重启应用,那我们为什么不使用这个而要自己去写呢?是因为 app.relaunch 其实是另起了一个进程来运行新的 electron,当前这个进程我们需要执行 app.exit() 来退出才可以,这是在官网说明的。但是如果我们这么做的话,app.relaunch 启动的这个进程就会脱离了我们 node scripts/dev.js 这个进程的管控,导致我们中断 node scripts/dev.js 这个进程的时候,app.relaunch 启动的这个进程还在运行的问题。到此自动刷新就完成了,让我们真正的来实现代码逻辑吧!
import { app } from "electron"
import fs from "fs"
import { inittary } from "./tary"
export const isDev = process.env.NODE_ENV === "development"
// 自动刷新
isDev && watchFile()
// 隐藏dock
app.dock.hide()
// Electron会在初始化完成并且准备好创建浏览器窗口时调用这个方法
app.whenReady().then(() => {
inittary()
}) index.js 代码很简单,这里的 inittary 我们还没实现,在实现它之前,让我们先把倒计时模块写好
首先定义些关于时间的常量
export const BASE_UNIT = 60
export const SECONDS = 1000
export const MINUTES = SECONDS * BASE_UNIT
export const HOURS = MINUTES * BASE_UNIT 将倒计时模块写成一个类,方便管理
这个类有三个私有属性
class CountDown {
// 用来计算当前的时间
private time = 0
// 保存传入的时间,重置时会用到
private _time = 0
// 清除定时器,暂停时会用到
private timer?: NodeJS.Timeout
} 接下来实现相关方法,我们需要有设置时间、暂停时间、重置时间,启动倒计时这几个功能
setTime(ms: number) {
// 如果之前有一个定时器在运行,就中断掉
this.stop()
this.time = this._time = ms
return this
}
stop() {
this.timer && clearInterval(this.timer)
}
resetTime() {
this.time = this._time
return this
}
run() {
this.timer = setInterval(() => {
this.time -= SECONDS
}, SECONDS)
} easy ~再定义一个静态方法,用于将时间戳转换为我们的需要的时间格式
static formatTimeByMs(ms: number) {
return {
h: String((ms / HOURS) | 0).padStart(2, '0'),
m: String((ms / MINUTES) % BASE_UNIT | 0).padStart(2, '0'),
s: String((ms / SECONDS) % BASE_UNIT | 0).padStart(2, '0'),
}
} ok,大体功能写好了,接下来我们需要把时间的变化发送出去
为了时间的精确性,再使用时我们将为倒计时模块单独开一个进程,所以这里也使用进程通信的方式来发送消息
先定义发送消息的接口
export interface SendMsg {
// 格式化后的时间
time: {
h: string
m: string
s: string
}
// 原始时间戳
ms: number
// 时间是否归零
done: boolean
} 写一个发送消息的方法
private send(msg: SendMsg) {
process.send!(msg)
} 然后在重置时间和启动时间时给父进程发送消息
resetTime() {
this.time = this._time
this.send({
time: CountDown.formatTimeByMs(this.time),
ms: this.time,
done: this.time <= 0
})
return this
}
run() {
this.send({
time: CountDown.formatTimeByMs(this.time),
ms: this.time,
done: this.time <= 0
})
this.timer = setInterval(() => {
let done: boolean
if (done = this.time <= 0) this.stop()
this.send({
time: CountDown.formatTimeByMs(this.time -= SECONDS),
ms: this.time,
done
})
}, SECONDS)
} OK,发送消息的逻辑我们处理完成了,接下来处理一下接收消息的流程
首先定义接口,这会比较复杂,因为我们的这些方法中,setTime 是需要传入参数的,而其他的方法并不需要,如果想准确进行提示,那我们就需要这么做
首先我们将需要接收参数的方法名定义一个 type,这里是将类型当成了变量来使用
type hasDataType = "setTime" 然后我们定义不接受参数的接口,这里使用了两个技巧
这样操作之后,这里的 type 其实就是 resetTime | run | stop
interface ReceiveMsgNoData {
type: Exclude<keyof CountDown, hasDataType>
} 接收参数的接口就很简单了
interface ReceiveMsgHasData {
type: hasDataType
data: number
} 最终定义一个联合类型供外部使用,这里之所以要定义数组类型,是为了方便外部使用,之后的代码中我们可以看到用法了
export type ReceiveMsg =
| ReceiveMsgNoData
| ReceiveMsgHasData
| Array<ReceiveMsgNoData | ReceiveMsgHasData> 接口定义完了,来实现一下代码
const c = new CountDown()
process.on("message", (message: ReceiveMsg) => {
if (!Array.isArray(message)) {
message = [message]
}
message.forEach((msg) => {
if (msg.type === "setTime") {
c[msg.type](msg.data)
} else {
c[msg.type]()
}
})
}) 接收消息的功能也实现了,至此倒计时模块就写完了,快让我们去 tary.js 中把它使用起来吧!~
同样的,tary 也将使用类来实现
在代码实现之前,我们先来捋一下逻辑
先定义要使用的私有属性
import { Tray as ElectronTary } from 'electron'
type TimeType = 'REST' | 'WORK'
class Tary {
// 初始化托盘栏,并传入托盘图标
private tray: ElectronTary = new ElectronTary(
path.resolve(__dirname, '../icon/img.png')
)
// 标示当前时间为工作时间或休息时间
private timeType: TimeType = 'WORK'
// 菜单实例
private menu: Menu | null = null
// 锁屏窗口实例
private restWindows: BrowserWindow[] | null = null
// 提示框口实例
private tipsWindow: BrowserWindow | null = null
// 倒计时模块 使用 child_process.fork 创建一个子进程
private countDown: ChildProcess = fork(path.resolve(__dirname, './countDown'))
} 定义向子进程发送消息的方法
send(message: ReceiveMsg | ReceiveMsg[]) {
this.countDown.send(message)
} 设置菜单项,这里其实就是调用 electron 的 api,详细的可以看官方文档。
当用户点击暂停、继续、重置时,给倒计时模块发送消息。偏好设置的功能我们后面再实现
private setContextMenu() {
this.menu = Menu.buildFromTemplate([
{
label: '偏好设置',
accelerator: 'CmdOrCtrl+,',
click: () => {},
},
{
type: 'separator',
},
{
id: 'play',
label: '继续',
accelerator: 'CmdOrCtrl+p',
visible: false,
click: (menuItem) => {
this.send({
type: 'run'
})
// 暂停和继续 只显示其中一个
menuItem.menu.getMenuItemById('pause').visible = true
menuItem.visible = false
},
},
{
id: 'pause',
label: '暂停',
accelerator: 'CmdOrCtrl+s',
visible: true,
click: (menuItem) => {
this.send({
type: 'stop'
})
// 暂停和继续 只显示其中一个
menuItem.menu.getMenuItemById('play').visible = true
menuItem.visible = false
},
},
{
label: '重置',
accelerator: 'CmdOrCtrl+r',
click: (menuItem) => {
menuItem.menu.getMenuItemById('play').visible = false
menuItem.menu.getMenuItemById('pause').visible = true
this.startWorkTime()
},
},
{
type: 'separator',
},
{ label: '退出', role: 'quit' },
])
this.tray.setContextMenu(this.menu)
} 监听倒计时模块消息
handleTimeChange() {
this.countDown.on('message', (data: SendMsg) => {
if (this.timeType === 'WORK') {
this.handleWorkTimeChange(data)
} else {
this.handleRestTimeChange(data)
}
})
} 开始工作时间倒计时
private startWorkTime() {
this.send([
{
type: 'setTime',
data: workTime,
},
{
type: 'run',
},
])
} 实例化时调用上面的方法
constructor() {
this.setContextMenu()
this.handleTimeChange()
this.startWorkTime()
} 上面代码执行完成后,倒计时就启动了,接下来就要处理时间变化的逻辑了
先来处理工作时间的变化
handleWorkTimeChange({ time: {h, m, s}, ms, done }: SendMsg) {
this.tary.setTitle(`${h}:${m}:${s}`) // 1
if (ms <= tipsTime) {
this.handleTipsTime(s, done) // 2
} else if (this.tipsWindow) {
this.closeTipsWindow() // 3
}
if (done) {
this.toggleRest() // 4
}
} export const TIPS_MESSAGE = 'TIPS_MESSAGE'
handleTipsTime(s: string, done: boolean) {
if (!this.tipsWindow) { // 初始化
ipcMain.on(TIPS_MESSAGE, this.handleTipsMsg)
this.tipsWindow = createTipsWindow(this.tary.getBounds(), s)
} else { // 发送消息
this.tipsWindow.webContents.send(TIPS_MESSAGE, {
s,
done
})
}
} 监听提示框渲染进程的消息
interface TipsMsgData {
type: 'CLOSE' | 'RESET' | 'STOP'
}
handleTipsMsg = (event: IpcMainEvent, {type}: TipsMsgData) => {
if (type === 'CLOSE') {
this.closeTipsWindow()
} else if (type === 'RESET') {
this.closeTipsWindow()
this.send({
type: 'resetTime'
})
} else if (type === 'STOP'){
this.closeTipsWindow()
this.send({
type: 'stop'
})
this.menu.getMenuItemById('play').visible = true
this.menu.getMenuItemById('pause').visible = false
}
}
closeTipsWindow() {
if (this.tipsWindow) {
ipcMain.removeListener(TIPS_MESSAGE, this.handleTipsMsg)
this.tipsWindow.close()
this.tipsWindow = null
}
} 在 browserWindow.ts 中添加如下代码
const resolveUrl = (address: string) => `http://localhost:3000/#${address}`
export function createTipsWindow(rect: Rectangle, s: string): BrowserWindow {
const win = new BrowserWindow({
x: rect.x, // 窗口x坐标
y: rect.y, // 窗口y坐标
width: 300, // 窗口宽度
height: 80, // 窗口高度
alwaysOnTop: true, // 一直显示在最上面
frame: false, // 无边框窗口
resizable: false, // 不可以resize
transparent: true, // 窗口透明
webPreferences: {
webSecurity: false, // 忽略web安全协议
devTools: false, // 不开启 DevTools
nodeIntegration: true, // 将node注入到渲染进程
},
})
// 加载Tips页面,传入消息通信的事件名称和时间
win.loadURL(resolveUrl(`/Tips?type=${TIPS_MESSAGE}&s=${s}`))
return win
} 页面结构很简单,提示用户还有几秒开始休息,然后提供暂停和关闭的按钮
<template>
<div class="wrap">
<div class="title">还剩{{ time }}s开始休息~</div>
<div class="progress"></div>
<div class="btns">
<button @click="stop">暂停</button>
<button @click="reset">重置</button>
</div>
</div>
</template> 主要看一下逻辑代码
<script>
import { ref } from "vue"
import { useRoute } from "vue-router"
const { ipcRenderer } = require("electron")
export default {
setup() {
// 取到当前页面的query参数
const { query } = useRoute()
// 使用传入的s作为时间
const time = ref(query.s)
// 向主进程发送消息
const close = () => {
ipcRenderer.send(query.type, { type: "CLOSE" })
}
const stop = () => {
ipcRenderer.send(query.type, { type: "STOP" })
}
const reset = () => {
ipcRenderer.send(query.type, { type: "RESET" })
}
// 监听时间变化,修改时间
ipcRenderer.on(query.type, (ipc, { s, done }) => {
time.value = s
if (done) close()
})
return {
time,
stop,
reset,
}
},
}
</script> 为了节省篇幅,样式代码就不贴上来了,各位可以自行发挥,或者看下面的完整代码
到此,气泡提示的代码已经被我们完成了。接下来我们继续处理工作时间结束时,切换至休息时间的逻辑
handleWorkTimeChange({ time: {h, m, s}, ms, done }: SendMsg) {
// ...
if (done) {
this.toggleRest()
}
}
toggleRest() {
this.timeType = 'REST'
this.closeTipsWindow()
ipcMain.on(REST_MESSAGE, this.handleRestMsg)
this.restWindows = createRestWindow()
} interface RestMsgData {
type: 'CLOSE' | 'READY'
data?: any
}
handleRestMsg = (event: IpcMainEvent, data: RestMsgData) => {
if (data.type === 'READY') {
this.startRestTime()
} else if (data.type === 'CLOSE') {
this.toggleWork()
}
}
startRestTime = () => {
this.send([
{
type: 'setTime',
data: restTime
},
{
type: 'run'
}
])
}
toggleWork() {
this.timeType = 'WORK'
ipcMain.removeListener(REST_MESSAGE, this.handleRestMsg)
this.restWindows?.forEach(win => {
win.close()
})
this.restWindows = null
this.startWorkTime()
} 代码很简单,当渲染进程初始化成功后(vue create 时机)会向我们发送 READY 事件,此时我们开始休息事件的倒计时。
当渲染进程的倒计时结束或者点击了关闭按钮时,会触发关闭事件,此时我们将切换回工作时间
再说一下切换回工作时间的逻辑
喝口水接着来!创建休息时间的窗口(锁屏界面)
main/browserWindow.ts
export function createRestWindow(): BrowserWindow[] {
return screen.getAllDisplays().map((display, i) => {
// 创建浏览器窗口
const win = new BrowserWindow({
x: display.bounds.x + 50,
y: display.bounds.y + 50,
fullscreen: true, // 全屏
alwaysOnTop: true, // 窗口是否应始终位于其他窗口的顶部
closable: false, // 窗口是否可关闭
kiosk: true, // kiosk模式
vibrancy: "fullscreen-ui", // 动画效果
webPreferences: {
devTools: false,
webSecurity: false,
nodeIntegration: true,
},
})
// 并且为你的应用加载index.html
win.loadURL(
resolveUrl(
`/LockPage?type=${REST_MESSAGE}${
i === 0 ? "&isMainScreen=1" : ""
}&password=${password}`
)
)
return win
})
} 这个有几点需要特殊处理,因为我们希望出现锁屏界面时,用户就不可以进行别的操作了。
这里我们需要启用 kiosk 模式来达到效果
windows 中的 kiosk 模式介绍如下(取自百度):
什么是 Windows 自助终端模式?
Windows Kiosk 模式只是 Windows 操作系统(OS)的一项功能,它将系统的可用性或访问权限仅限于某些应用程序。意思是,当我们在 Windows 上打开 Kiosk 模式时,它只允许一个应用程序运行,就像机场上的 kiosk 系统那样设置为仅运行 Web 浏览器,某些应用程序如 PNR 状态检查一个。
Kiosk 模式的好处是,它允许企业仅在办公室,餐馆等运行特定的销售点(POS)应用程序,以阻止客户使用机器上的任何其他应用程序,除了他们已分配的应用程序。它不仅可以在 windows 10 上使用,而且还可以在 Windows XP,Windows Vista,Windows 7 和 Windows 8.1 中启用。
简单点说就是让你的电脑只运行当前这个应用程序,阻止你使用别的应用程序。
主要的配置如下
fullscreen: true, // 窗口全屏
alwaysOnTop: true, // 窗口一直显示在最上面
closable: false, // 窗口不可关闭
kiosk: true, // 窗口为kiosk模式 那代码中的 screen.getAllDisplays() 是干什么用的呢?这是为了防止外接显示器(程序员大多数都会外接的),如果我们只创建一个窗口,那只能让当前屏幕无法操作,而别的显示器还是可以正常工作的。所以我们使用这个 api 来获取到所有的显示器,然后为每一个显示器都创建一个窗口。
同时我们只让第一个窗口中出现提示信息和关闭按钮。所以我们给渲染进程传入一个主屏幕的标志。
vue 渲染进程代码 views/LockPage.vue
<template>
<div v-if="isMainScreen" class="wrap">
<div class="time">{{ time }}</div>
<div class="btn" @click="close">X</div>
</div>
</template>
<script>
export default {
setup() {
const { query } = useRoute()
const time = ref("")
const close = () => {
ipcRenderer.send(query.type, { type: "CLOSE" })
}
const isMainScreen = ref(!!query.isMainScreen)
if (isMainScreen) {
ipcRenderer.send(query.type, { type: "READY" })
ipcRenderer.on(query.type, (ipc, { time: { h, m, s }, done }) => {
time.value = `${h}:${m}:${s}`
if (done) close()
})
}
return {
isMainScreen,
time,
close,
}
},
}
</script> 逻辑很简单,如果是主屏幕,那初始化的时候我们就发送一个 ready 事件,然后监听时间变化。如果时间结束就发送关闭的事件。
至此,就只剩设置相关的逻辑没有写
import fs from "fs"
import path from "path"
const storePath = path.resolve(__dirname, "./store.json")
function get() {
const store = fs.readFileSync(storePath, "utf-8")
return JSON.parse(store)
}
export let { restTime, tipsTime, workTime } = get()
export function setTime(rest: number, work: number, tips: number) {
restTime = rest
tipsTime = tips
workTime = work
fs.writeFileSync(
storePath,
JSON.stringify({ restTime, tipsTime, workTime }, null, 2)
)
} 逻辑:从本地文件中获取工作、休息、提示时间,当设置新的时间时再改写本地文件
完善托盘栏菜单项的代码
interface SettingMsgData {
rest: number
work: number
tips: number
}
Menu.buildFromTemplate([
{
label: '偏好设置',
accelerator: 'CmdOrCtrl+,',
click: () => {
const win = createSettingWindows(restTime, tipsTime, workTime)
const handleSettingMsg = (event: IpcMainEvent, {rest, work, tips}: SettingMsgData) => {
setTime(rest, work, tips)
win.close()
}
win.on('close', () => {
ipcMain.removeListener(SETTING_MESSAGE, handleSettingMsg)
})
ipcMain.on(SETTING_MESSAGE, handleSettingMsg)
},
}
]) 当我们点击设置菜单项时
而设置窗口发消息的时机就是当用户点击保存的时候,此时会把设置之后的工作时间、休息时间、提示时间传过来。我们设置到本地即可
下面我们看一下创建窗口和渲染进程的逻辑
main/browserWindow.ts
export function createSettingWindows(
restTime: number,
tipsTime: number,
workTime: number
) {
const win = new BrowserWindow({
maximizable: false,
minimizable: false,
resizable: false,
webPreferences: {
webSecurity: false,
nodeIntegration: true, // 将node注入到渲染进程
},
})
win.loadURL(
resolveUrl(
`/Setting?type=${SETTING_MESSAGE}&rest=${restTime}&tips=${tipsTime}&work=${workTime}`
)
)
return win
} vue: views/setting.vue
export default {
setup() {
const { query } = useRoute()
const rest = ref(+query.rest / MINUTES)
const work = ref(+query.work / MINUTES)
const tips = ref(+query.tips / SECONDS)
const save = () => {
ipcRenderer.send(query.type, {
rest: rest.value * MINUTES,
work: work.value * MINUTES,
tips: tips.value * SECONDS,
})
}
const reset = () => {
rest.value = +query.rest / MINUTES
work.value = +query.work / MINUTES
tips.value = +query.tips / SECONDS
}
return {
rest,
work,
tips,
save,
reset,
}
},
} 好了,至此我们的代码已经完全实现了。
但是现在还有一个点需要解决,那就是电脑休眠时,我们应该让计时功能暂停。
我们在 main/index.ts 中修改如下代码
app.whenReady().then(() => {
const tray = initTray()
// 系统挂起
powerMonitor.on("suspend", () => {
tray.send({
type: "stop",
})
})
// 系统恢复
powerMonitor.on("resume", () => {
tray.send({
type: "run",
})
})
}) 好了,就是监听两个事件的事~都是些 api,就不多说了。
接下来我们打包一下 electorn,让我们的代码可以在电脑上安装。
项目打包主流的方式有两种:electron-builder 和 electron-packager
electron-builder 会把项目打成安装包,就是我们平时安装软件的那种形式。
electron-packager 会把项目打包成可执行文件,你可以理解为上面 👆 的安装包安装之后的软件目录。
下面我们分别介绍一下这两种的打包步骤(这里只打包了 mac 版本,win 版本可自行查阅官网,差别不大)
electron-builder 打包安装
cnpm i electron-builder --save-dev package.json 新增 build 项
"build": {
// 软件的唯一id
"appId": "rest.time.lay4519",
// 软件的名称
"productName": "Lay",
// 要打包的文件
"files": [
"node_modules/",
"dist/",
"package.json"
],
// 打包成mac 安装包
"dmg": {
"contents": [
{
"x": 130,
"y": 220
},
{
"x": 410,
"y": 220,
"type": "link",
"path": "/Applications"
}
]
},
// 设置打包目录
"directories": {
"output": "release"
}
} 增加脚本
"scripts": {
// ...
"buildMac": "cp -r icon dist/icon && npx electron-builder --mac --arm64"
} electron-packager 打包增加脚本
"scripts": {
// ...
"packageMac": "rm -rf ./dist && npx vite build && tsc && cp -r icon dist/icon & cp main/store.json dist/main/store.json && electron-packager . --overwrite"
} 这个大概解释一下
好了,打包已经完成了。但是你以为到此就结束了吗?
点开 vite 打包后的 index.html,你会发现 script 标签上有一个 type="module",这意味着 vite 默认打包后,还是使用了 es6 的模块机制,这个机制依赖了 http,所以我们无法使用 file 协议来加载文件。
也就是说,这个 html 我们双击打开是无法运行的,所以你在 electron 里直接 loadFile 也是无法运行的。
怎么解决呢?也许 vite 可以配置 CMD、AMD 的模块机制,但是我也懒得再去翻阅文档了。反正是用的 electron,我们直接在本地起一个 http 服务就是
main/browserWindow.ts
const productPort = 0
const resolveUrl = (address: string) => `http://localhost:${isDev ? 3000 : productPort}/#${address}`
if (!isDev) {
// 检测端口是否被占用
const portIsOccupied = (port: number): Promise<number> => {
return new Promise(r => {
const validate = (p: number) => {
const server: http.Server = http
.createServer()
.listen(p)
.on('listening', () => {
server.close()
r(p)
})
.on('error', (err: any) => {
if (err.code === 'EADDRINUSE') {
server.close()
validate(p += 1)
}
})
}
validate(port)
})
}
// 执行
portIsOccupied(8981)
.then((p) => {
productPort = p
http.createServer((req, res) => {
if (req.url === '/') {
// content-type: application/javascript
return fs.readFile(path.resolve(__dirname, '..', 'renderer/index.html'), (err, data) => {
if (err) return
res.setHeader('content-type', 'text/html; charset=utf-8')
res.end(data)
})
} else {
return fs.readFile(path.resolve(__dirname, '..', 'renderer' + req.url), (err, data) => {
if (err) return
if (req.url!.endsWith('.js')) {
res.setHeader('content-type', 'application/javascript')
} else if (req.url!.endsWith('.css')) {
res.setHeader('content-type', 'text/css')
}
// 缓存7天
res.setHeader('cache-control', 'max-age=604800')
res.end(data)
})
}
})
.listen(p)
})
} 好啦,这下我们就真正的把代码完成了~
完整代码点此,觉得文章还可以的欢迎 star、following。
如果有什么问题欢迎在评论区提出讨论。感谢观看 🙏
2020-03-01
UI 这边要求 pc 端也进行 rem 布局进行适配,包括字号也需要使用 rem,这就导致了在小屏幕下 rem 计算值小于 12px,对于 chrome 浏览器而言小于 12px 则会显示为 12px,而其他的浏览器则会正常显示。这种显示差异自然是通不过 UI 的走查要求的,并且小于 12px 的字体在 pc 端已经很难看清楚,所以需要将别的浏览器行为统一成 chrome 的行为。即小于 12px 也显示为 12px 字体。
因为 rem 的计算是浏览器计算的,不同宽度下的计算值也不尽相同,所以无法提前进行 css 适配。
使用 js 来控制 css 当然是可以的,但是我们不可能对每个元素单独进行判断来改变其样式。我们希望的是 js 改变了字号,所有使用这个字号的元素都会发生改变,所幸的是我们有 css 变量技术(ie 不支持),而 js 也刚好可以操控它。
我们可以将每一个字号都设置为变量,例如 --font-size-12: 0.12rem 代表 12px 的字号,当我们写 css 时统一写 css 变量 font-size: var(--font-size-12),然后在页面运行时使用 js 来计算哪些字号小于了 12px,改变这些变量的值为 12px。
function adaptiveFS() {
var rootValue = 100 // 同postcss-pxtorem 的rootValue
var rt = document.documentElement
var rootFS = parseFloat(getComputedStyle(rt).fontSize)
var minFontsize = 12
var fs = 12
var styleText = ""
while ((fs / rootValue) * rootFS < minFontsize) {
styleText += "--font-size-" + fs + ":12px;"
fs++
}
rt.style = styleText
} 虽然上述方案可行,但是作为开发人员,我们不希望每次写字号的时候都去写变量,而且我们也不需要将所有的字号都设置为变量。
对于 pc 端的 rem 布局,一般来说我们是不会让屏幕无限进行缩小和放大的,所以我们会设置屏幕最大宽度和最小宽度,有了最小宽度也就有了最小的 html font-size。我们只需要将 font-size / rootValue * minHTMLFontSize < 12 的字号设置为变量就可以了。
可是这样就更加大了开发的心智负担,我们不仅要写 css 变量,还要记忆哪些字号写 css 变量,哪些字号写正常的 px。
还好我们有各种构建工具可以帮助我们避免这种情况,我们可以使用 postcss-loader 来自动替换字号为 css 变量,使用 nodejs 自动生成 css 变量文件,使用 webpack plugin 自动注入在 html 中注入 js。
这些已经都被我写好了,大家直接拿去用就可以了,详见 adaptive-fontsize,好用的话记得 star ~~
2020-06-28
http2.0 是一种安全高效的下一代 http 传输协议。安全是因为 http2.0 建立在 https 协议的基础上,高效是因为它是通过二进制分帧来进行数据传输。
在 http 1.0 中,每此消息传输(请求/响应)都需要建立一次 TCP 链接。为了减少 TCP 链接的时间消耗,http 1.1 中加入了 connection: keep-alive,来持久化 TCP 链接,进而使一个 TCP 链接可以重复使用。
但是 TCP 链接中的 HTTP 请求只能串行执行,一个 TCP 链接同一时间内只能处理一个 HTTP 请求。为了解决串行的阻塞问题,浏览器(chrome)会为同一个 host 建立多个(6 个)TCP 链接,如果 6 个 TCP 链接依然不够用,那就要在不同的 host 中分布资源,以尽可能多的并行请求资源。
突破 http1.X 标准的性能限制,改进传输性能,实现低延迟和高吞吐量
帧 (frame) 包含部分:类型 Type, 长度 Length, 标记 Flags, 流标识 Stream 和 frame payload 有效载荷。
消息 (message):一个完整的请求或者响应,比如请求、响应等,由一个或多个 Frame 组成。
流是连接中的一个虚拟信道,可以承载双向消息传输。每个流有唯一整数标识符。为了防止两端流 ID 冲突,客户端发起的流具有奇数 ID,服务器端发起的流具有偶数 ID。
流标识是描述二进制 frame 的格式,使得每个 frame 能够基于 http2 发送,与流标识联系的是一个流,每个流是一个逻辑联系,一个独立的双向的 frame 存在于客户端和服务器端之间的 http2 连接中。一个 http2 连接上可包含多个并发打开的流,这个并发流的数量能够由客户端设置。
多路复用允许同时通过单一的 http/2 连接发起多重的请求 - 响应消息。有了新的分帧机制后,http/2 不再依赖多个 TCP 连接去实现多流并行了。每个数据流都拆分成很多互不依赖的帧,而这些帧可以交错(乱序发送),还可以分优先级,最后再在另一端把它们重新组合起来。
http 2.0 连接都是持久化的,而且客户端与服务器之间也只需要一个连接(每个域名一个连接)即可。http2 连接可以承载数十或数百个流的复用,多路复用意味着来自很多流的数据包能够混合在一起通过同样连接传输。当到达终点时,再根据不同帧首部的流标识符重新连接将不同的数据流进行组装。
http/2 使用 encoder 来减少需要传输的 header 大小,通讯双方各自缓存一份头部字段表,对于相同的数据,通信期间只需发送一次,如果首部发生了变化,则只需将变化的部分加入到 header 帧中,改变的部分会加入到头部字段表中,首部表在 http 2.0 的连接存续期内始终存在,由客户端和服务器共同渐进地更新。
用 header 字段表里的索引代替实际的 header。
http/2 的 HPACK 算法使用一份索引表来定义常用的 http Header,把常用的 http Header 存放在表里,请求的时候便只需要发送在表里的索引位置即可。
例如 :method=GET 使用索引值 2 表示,:path=/index.html 使用索引值 5 表示
只要给服务端发送一个 Frame,该 Frame 的 Payload 部分存储 0x8285,Frame 的 Type 设置为 Header 类型,便可表示这个 Frame 属于 http Header,请求的内容是:
GET /index.html
为什么是 0x8285,而不是 0x0205?这是因为高位设置为 1 表示这个字节是一个完全索引值(key 和 value 都在索引中)。
类似的,通过高位的标志位可以区分出这个字节是属于一个完全索引值,还是仅索引了 key,还是 key 和 value 都没有索引 (参见:HTTP/2 首部压缩的 OkHttp3 实现 ④)。
因为索引表的大小的是有限的,它仅保存了一些常用的 http Header,同时每次请求还可以在表的末尾动态追加新的 http Header 缓存,动态部分称之为 Dynamic Table。Static Table 和 Dynamic Table 在一起组合成了索引表
HPACK 不仅仅通过索引键值对来降低数据量,同时还会将字符串进行霍夫曼编码来压缩字符串大小。
以常用的 User-Agent 为例,它在静态表中的索引值是 58,它的值是不存在表中的,因为它的值是多变的。第一次请求的时候它的 key 用 58 表示,表示这是一个 User-Agent,它的值部分会进行霍夫曼编码(如果编码后的字符串变更长了,则不采用霍夫曼编码)。
服务端收到请求后,会将这个 User-Agent 添加到 Dynamic Table 缓存起来,分配一个新的索引值。客户端下一次请求时,假设上次请求 User-Agent 的在表中的索引位置是 62,此时只需要发送 0xBE(同样的,高位置 1),便可以代表:User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36。
最终,相同的 Header 只需要发送索引值,新的 Header 会重新加入 Dynamic Table。
通过流的形式进行数据传输时,每个流都可以携带 31 比特的优先值:0 表示最高优先级;2 的 31 次方 -1 表示最低优先级。
服务器可以根据流的优先级,控制资源分配(CPU、内存、带宽),但这不是绝对的,也会根据实际的情况进行处理,否则又会出现阻塞的问题:高优先级请求慢阻塞低优先级资源。
服务器可以对一个客户端请求发送多个响应,服务器向客户端推送资源无需客户端明确地请求。
2020-06-07
技术的沉淀免不了分享和记录,用本文记录了一下自己搭建博客的过程。
本文将一步步带你实现:
vuepress + gitPage 搭建并部署你的博客网站nodejs fs api 根据项目目录自动配置博客侧边栏nodejs child_process 一键部署你的博客网站让赶快我们开始吧~
Warning
vuepress v1.5.0 存在热更新不生效的问题,请注意升级版本
本项目使用 yarn,如使用 npm 请自行替换
首先让我们新建一个文件夹作为项目的根目录, 然后进入此目录
mkdir blog
cd blog 接着来进行 git 和 npm 的初始化工作,并创建 .gitignore 文件,在 .gitignore 中忽略 node_modules 文件夹
npm init -y
git init
echo node_modules >> .gitignore 我们使用 src 目录作为项目的入口目录,创建一下它
mkdir src 至此,项目目录已经搭建完毕,接下来开始配置一下 vuepress
安装 vuepress 依赖
yarn add vuepress 在 src 目录中创建 .vuepress目录,并在 .vuepress 中创建 config.js
cd src
mkdir .vuepress
touch config.js 在 config.js 中写入以下代码
module.exports = {
// 项目的基础路径,可以理解为github的仓库名称
base: "/blog/",
// 打包的输出目录,这里使用docs是为了配合gitpage部署,下面会讲
dest: "./docs",
// 博客的标题
title: "Lay",
// 描述
description: "lay的博客",
// 主题配置
themeConfig: {
// 侧边栏
sidebar: ["/"],
// 开启滚动效果
smoothScroll: true,
// 仓库地址,用于编辑跳转使用
repo: "https://github.com/lei4519/blog",
// 开发目录
docsDir: "src",
// 开启页面编辑功能
editLinks: true,
editLinkText: "在 GitHub 上编辑此页",
// 更新时间文字
lastUpdated: "最后更新时间",
},
} 在 src目录 中新建 README.md 文件,用作博客的首页,并增加如下内容
touch README.md ---
home: true
heroText: 博客
tagline: 前端技术分享
actionText: 开始阅读 →
---
配置 package.json script 字段
"scripts": {
"dev": "vuepress dev src",
"build": "vuepress build src"
} 运行 yarn dev,我们可以在浏览器中看到搭建好的博客首页
接着我们在 src 中新建 hello.md, 在里面随便写点内容,然后在 README.md 中新增 actionLink 属性,值为我们的路径(/blog/应保持和 config.js 中的 base 属性一直)
---
home: true
heroText: 博客
tagline: 前端技术分享
actionText: 开始阅读 →
actionLink: /blog/hello
---
接着我们点击首页的开始阅读按钮,就会跳转至 hello 页面了
ok,到此我们的项目配置已经完成,接下来让我们配合 gitpage 来部署我们的博客。
首页执行 yarn build 来打包代码
然后在 github 创建一个新的仓库,上传我们刚才写的代码(这个步骤就不写了,不会的可以自行百度)
上传成功之后,进入刚才创建的仓库中,点击 Settings 进入仓库配置
进入之后直接向下滚动找到 GitHub Pages 选项,在 Source 选项中选择 master barnch /docs folder
这样就可以直接使用我们仓库的 docs 目录作为我们网站的根目录,并且我们每次需要部署线上网站时,只需要 yarn build 之后推送代码到 git 仓库,线上博客就会自动更新,完全不需要额外的操作,十分方便。
刚才我们提到,每次更新部署,只需要 yarn build 之后推送代码到 git 仓库即可,虽然很简单,但是也要以下命令一顿操作才可以
yarn build
git add .
git commit -m '这次的更新信息'
git push 每次这样执行显然不符合程序员的 don't repeat 原则,我们很容易就会发现上面的命令中只有提交信息是每次变化的,那我们可不可以将不变的部分提取出来呢?
当然是可以的,既然是前端开发,那我们就是用原生的 nodejs 来简单实现一个命令行交互的功能
在项目根目录新建 release.js,并将 package.json script 字段调整如下
"scripts": {
"dev": "vuepress dev src",
"release": "node release.js"
} 接着我们来完善 release.js,代码如下
// 封装一个命令行执行函数
function sh(commitMsg) {
const { spawn } = require("child_process")
// 创建一个运行bash的进程
const bash = spawn("bash")
// 错误事件监听
bash.on("error", function () {
console.log("error")
console.log(arguments)
})
// 输出信息监听
bash.stdout.on("data", onData)
bash.stderr.on("data", onData)
function onData(data) {
process.stdout.write(data)
}
// 运行结束事件
bash.on("close", (code) => {
console.log(`打包完成:${code}`)
process.exit(code)
})
// 像bash中写入以下命令
bash.stdin.write(`vuepress build src
git add .
git commit -m ${commitMsg}
git push`)
// 开始执行
bash.stdin.end()
}
// 检测执行此文件时是否传入了提交信息
// process.argv: ['node', 'release.js', '提交信息']
if (!process.argv[2]) {
// 如果没有传入提醒输入git信息
process.stdin.on("data", (data) => {
data = data.toString()
if (!data.toString().trim()) {
console.log("请输入git提交信息:")
} else {
sh(data)
}
})
console.log("请输入git提交信息:")
} else {
// 如果传入了直接执行命令行
sh(process.argv[2])
} 接下来我们只需要运行 node release.js 提交信息 就可以直接将代码推送到 github 上了。
以上的配置还有一些问题,如果你看了 vuepress 文档,就会发现 slider 的配置虽然有 auto 选项,但是实际效果并不如人意,而自己去配置又太过繁琐,那有没有什么办法可以不使用官方的 auto 属性又可以自动配置侧边栏呢?
当然是可以的,前端的朋友一定不会陌生 webpack 中的 require.context 函数,我们经常使用这个来自动生成路由配置等信息,在这里我们也可以用这个思路来根据项目目录来生成侧边栏配置。
这里我们使用 nodejs fs 模块来实现目录读取,并根据文件的更新时间,使用归并排序来对同一个目录中的文件进行排序
我们将这个工具方法建立在 /src/.vuepress/utils/index.js 中
具体实现如下
const path = require("path")
const fs = require("fs")
// 生成侧边栏配置信息
function genSliderBar() {
// 项目根目录
const basePath = path.resolve(__dirname, "..", "..")
// 需要排除的目录和文件
const excludes = ["README.md", "img"]
// 目录读取函数
// path是当前目录的父目录路径
// arr 用来存放读取到的目录和文件
// depth 用来记录目录的深度,也是用作slide配置中的sidebarDepth值
const _readdir = (path, arr, depth) => {
// 读取目录
const dirsOrFiles = fs.readdirSync(basePath + path)
// 遍历目录中的每一项
dirsOrFiles.forEach((name) => {
// 以.开头和excludes中的文件都不做处理
if (name.indexOf(".") === 0) return
if (excludes.includes(name)) return
// 拿到当前项的信息
const stat = fs.statSync(basePath + path + name)
// 如果是目录
if (stat.isDirectory()) {
// 读取这个目录中的信息
const rawChildren = _readdir(path + name + "/", [], depth + 1)
// 对目录中的文件,根据更新时间进行排序
const sortChildren = mergeSort(rawChildren, (a, b) => {
// 没有更新时间代表当前项是目录,目录都放在文件的上方
if (!b.mtime) return true
return a.mtime < b.mtime
})
// 将当前目录的配置信息放入arr中
// children的操作是提取文件的path信息,真正的sidebar配置中是不需要mtime属性的
arr.push({
title: name,
sidebarDepth: depth,
children: sortChildren.map((item) => (item.path ? item.path : item)),
})
} else {
// 如果不是目录,则放入arr中
arr.push({
path: path + name,
mtime: stat.mtime,
})
}
})
return arr
}
return _readdir("/", [], 1)
}
// 归并排序
function mergeSort(array, fn) {
// 函数安全检测
if (!fn || typeof fn !== "function") fn = (a, b) => a > b
// 分
const divide = (arr) => {
const len = arr.length
if (len < 2) return arr
const mid = (len / 2) | 0
return merge(divide(arr.slice(0, mid)), divide(arr.slice(mid)))
}
// 合
const merge = (a1, a2) => {
const a = []
while (a1.length && a2.length) {
a.push(fn(a1[0], a2[0]) ? a2.shift() : a1.shift())
}
return a.concat(a1, a2)
}
return divide(array)
}
module.exports = {
genSliderBar,
} 接着在我们的 config.js 中配置即可
themeConfig: {
sidebar: utils.genSliderBar()
} 接下来我们新增一下导航栏,将博客进行分类
好的,到此我们的博客搭建就算告一段落了。
如果遇到问题,可以去 github 中问我。
如果觉得我写的还不错,欢迎去 github 中给个 star ~谢谢观看 🙏
2020-09-14
svn checkout http://...git clone http://....git,这个就是 Git 的版本库。Linus 用来管理 Linux 源码。(Linus 自己用 C 语言花了两周时间写的)
Linux 系统:开源项目,由全世界的热心志愿者共同完成的。
Git 对每一次提交直接记录文件快照,而非差异比较
$ touch README test.rb LICENSE
$ git add README test.rb LICENSE
$ git commit -m 'The initial commit of my project' git cz git add 暂存操作:为工作区中已修改的文件创建快照
git commit 提交版本库
创建树对象,记录着目录结构和文件快照索引(可以理解为整个项目的快照)
创建提交对象,保存树对象和所有的提交信息(作者姓名、邮箱、提交信息)
.git/refs/headsmaster,.git/refs/heads/master$ git branch testing .git/refs/heads 中创建了 testing 文件HEAD 的指针区分所在分支,HEAD 总是指向当前所在的分支git branch 命令仅仅 创建 一个新分支,并不会自动切换到新分支中去$ git checkout testing HEAD 就指向 testing 分支开发 2.0 版本,并进行一些功能提交,线上版本依旧指向发版时的提交对象
线上版本紧急 BUG
切换回 master 分支
git stash 或者提交操作 git commitmaster 分支中进行代码开发,master 分支的代码都是合并的别的分支,以此保证 master 分支的稳定性(线上版本的稳定性)新建紧急修复 hotfix 分支,在该分支上工作直到问题解决,并提交修改。
master 合并 hotfix 分支,测试部署上线
$ git checkout master
$ git merge hotfix
Fast-forward 删除 hotfix 分支,因为我们已经不再需要它了——master 分支已经指向了同一个位置
$ git branch -d hotfix 回到开发分支继续工作
hotfix 分支所做的修改,并没有合并到开发分支上git merge master 命令将 master 分支合并入 开发分支(推荐)master 分支2.0 开发测试完成,将开发分支的代码合并到主分支上,部署上线
$ git checkout master
$ git merge iss53
Merge made by the 'recursive' strategy. 通过“递归”策略进行合并。 master 分支所在提交对象并不是 iss53 分支所在提交对象的直接祖先,Git 会使用两个分支的末端所指的快照(C4 和 C5)以及这两个分支的公共祖先(C2),做一个三方合并Git 会将合并的结果做了一个新的快照并且自动创建一个新的提交指向它。
这种提交被称为合并提交,因为他不止有一个父提交对象。
如果我们在两个不同的分支中,对同一个文件的同一个部分进行了不同的修改,Git 就没法干净的合并它们。
此时 Git 做了合并,但是没有自动地创建一个新的合并提交。Git 会暂停下来,等待你去解决合并产生的冲突。
确定之前有冲突的的文件都已经暂存了,输入 git commit 来完成合并提交。默认情况下提交信息看起来像下面这个样子:
Merge branch 'iss53'
Conflicts:
index.html
#
# It looks like you may be committing a merge.
# If this is not correct, please remove the file
# .git/MERGE_HEAD
# and try again.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# All conflicts fixed but you are still merging.
#
# Changes to be committed:
# modified: index.html
# 如果你觉得上述的信息不够充分,不能完全体现分支合并的过程,你可以修改上述信息,添加一些细节给未来检视这个合并的读者一些帮助,告诉他们你是如何解决合并冲突的,以及理由是什么。
我们可能不想处理冲突这种情况,可以通过 git merge --abort 来简单地退出合并
$ git merge --abort git merge --abort 选项会尝试恢复到运行合并前的状态。-Xignore-all-space whitespace:在比较行时 完全忽略 空白修改-Xignore-space-change whitespace:将一个空白符与多个连续的空白字符视作等价的merge 一样,用来合并分支merge 合并时会产生很多无用的 Merge 信息,尤其是多分支开发合并时,时间长了之后整个项目提交信息会非常杂乱。下载远程仓库
git clone 仓库地址$ git init
$ git add .
$ git commit -m 'initial project version'
$ git remote add origin [email protected]
$ git push -u origin master git pull 拉取远程仓库代码
git push 推送本地仓库至远程仓库
master 线上分支:绝对稳定,此版本代码可以随时发布线上,总是合并 test 测试分支或紧急修复分支代码。
test 测试分支:提交测试线的代码,总是合并 develop 测试分支代码。
develop 开发分支:共享分支,总是合并本地分支代码。
临时、修复、功能分支:本地分支,各功能开发,开发完成合并入开发分支。
git tag <tagname> 给当前分支打标签,也可以在后面指定一个 commit id,给对应的提交对象打标签。git tag -a <tagname> -m "blablabla..." 可以指定标签信息。git tag 可以查看所有标签。git push origin <tagname> 可以推送一个本地标签。git push origin --tags 可以推送全部未推送过的本地标签。git tag -d <tagname> 可以删除一个本地标签。git push origin :refs/tags/<tagname> 可以删除一个远程标签。git clone 下载仓库develop 分支创建本地分支,开发过程中针对每个功能点进行提交记录。git pull,拉取开发分支最新代码。git rebase develop 合并开发分支的代码,如有代码冲突,解决后需要重新提交合并对象。git merge 合并本地分支,使用 git push 推送远程仓库。git pull 拉取最新代码。git merge develop 合并开发分支代码,使用 git push 推送远程仓库,部署测试。master 分支,使用 git pull 拉取最新代码。git merge test 合并测试分支代码,使用 git push 推送远程仓库,部署上线。master 分支新建紧急修复分支,修复问题直到完成。master 分支合并紧急修复分支,推送远程仓库并部署。以上操作只会在
git rebase时有可能会遇到代码冲突。所以上述所有merge操作都是快进操作。
git rebase -i 可以修改提交记录,具体可以查看官网教程 - 重写历史。应该只对本地分支进行操作。
Commit message 一般包括三部分:Header、Body 和 Footer。
type(scope):subject
feat(表格): 增加表格下载功能
对本次 commit 的详细描述,可分多行
首先,全局安装工具:
cnpm install commitizen cz-conventional-changelog-chinese -g
生成配置文件:
echo '{ "path": "cz-conventional-changelog-chinese" }' > ~/.czrc
提交时使用 git cz 代替 git commit
git commit)
每次提交版本时自动检查提交信息是否符合规范
cnpm install --save-dev @commitlint/config-conventional @commitlint/cli husky
在项目根目录执行,生成配置文件
echo 'module.exports = {
extends: ["@commitlint/config-conventional"],
rules: {
"type-enum": [
2,
"always",
[
"feat",
"fix",
"docs",
"refactor",
"build",
"style",
"perf",
"chore",
"deps",
"test",
"ci",
"revert"
]
]
}
}' > commitlint.config.js
echo '{
"hooks": {
"commit-msg": "commitlint -E HUSKY_GIT_PARAMS"
}
}' > .huskyrc
npx eslint --fix --ext .js,.jsx,.ts,.tsx,.vue src
cnpm i lint-staged --save-dev .lintstagedrcecho '{
"src/**/*.{js,jsx,txs,ts,vue}": "eslint --fix"
}' > .lintstagedrc 配置 .huskyrc,增加预提交钩子
"hooks": {
"pre-commit": "lint-staged --no-stash"
} 配置完成后,提交代码时会自动做 Eslint 检查和修复,此步骤如果无法通过则需要重新提交代码。
2023-10-27
本篇文章不会去过多的讨论技术细节,只是从核心概念上去说明 GraphQL 解决了什么问题,是如何怎么做到的
现在只需要知道,对于前端来说,它是一种资源请求方式,可以用来代替 RESTful 风格的 API 请求。
那为什么要去代替 RESTful 的 API 请求呢?因为遇到了一些问题
前端的多个功能可能会依赖一份数据源的不同部分
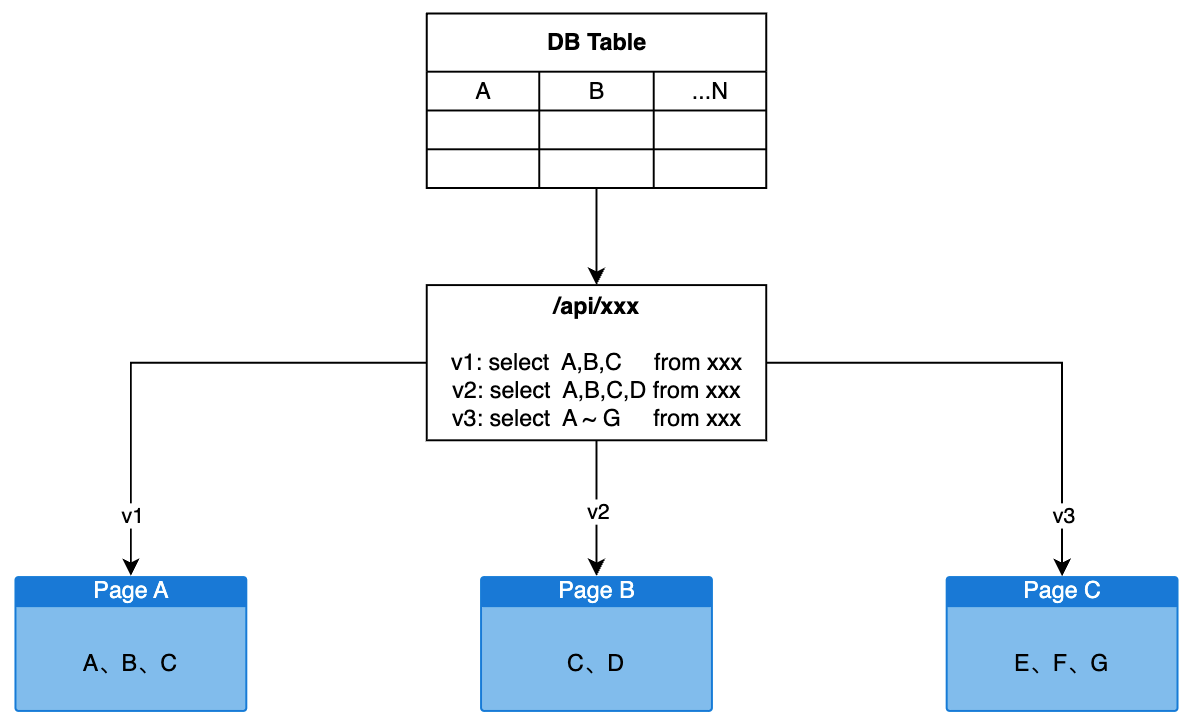
把需要的字段传进去
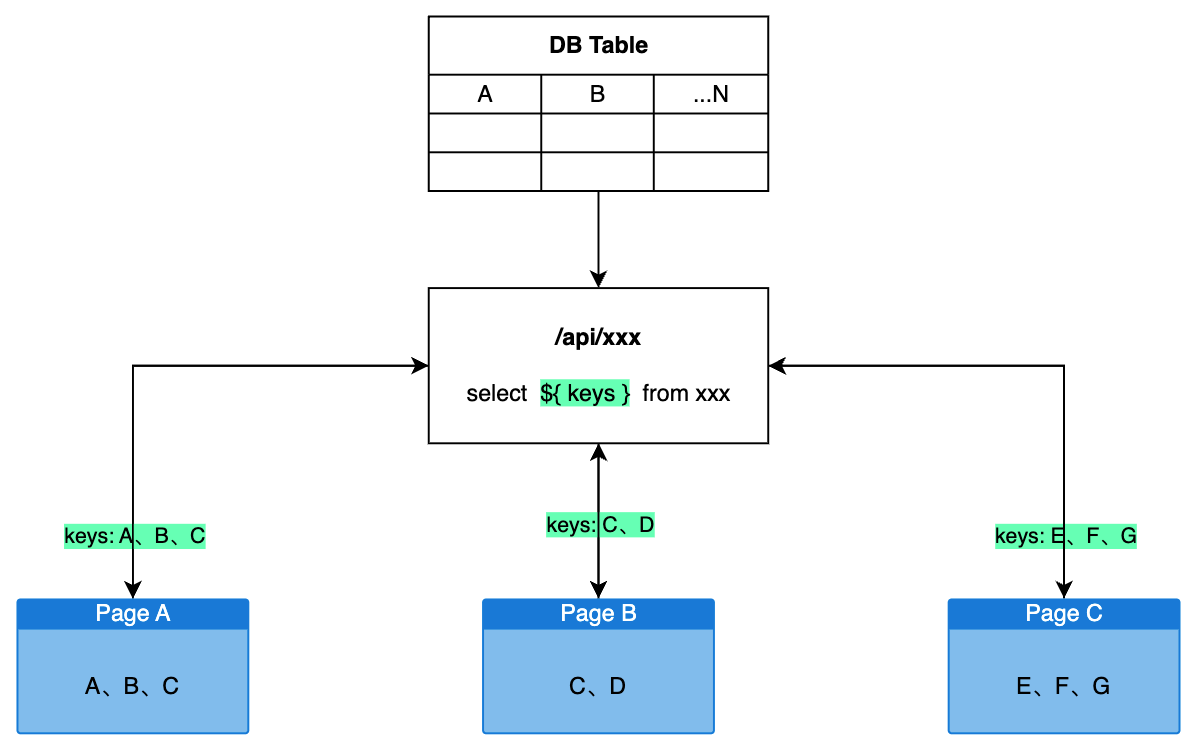
把表名传进去
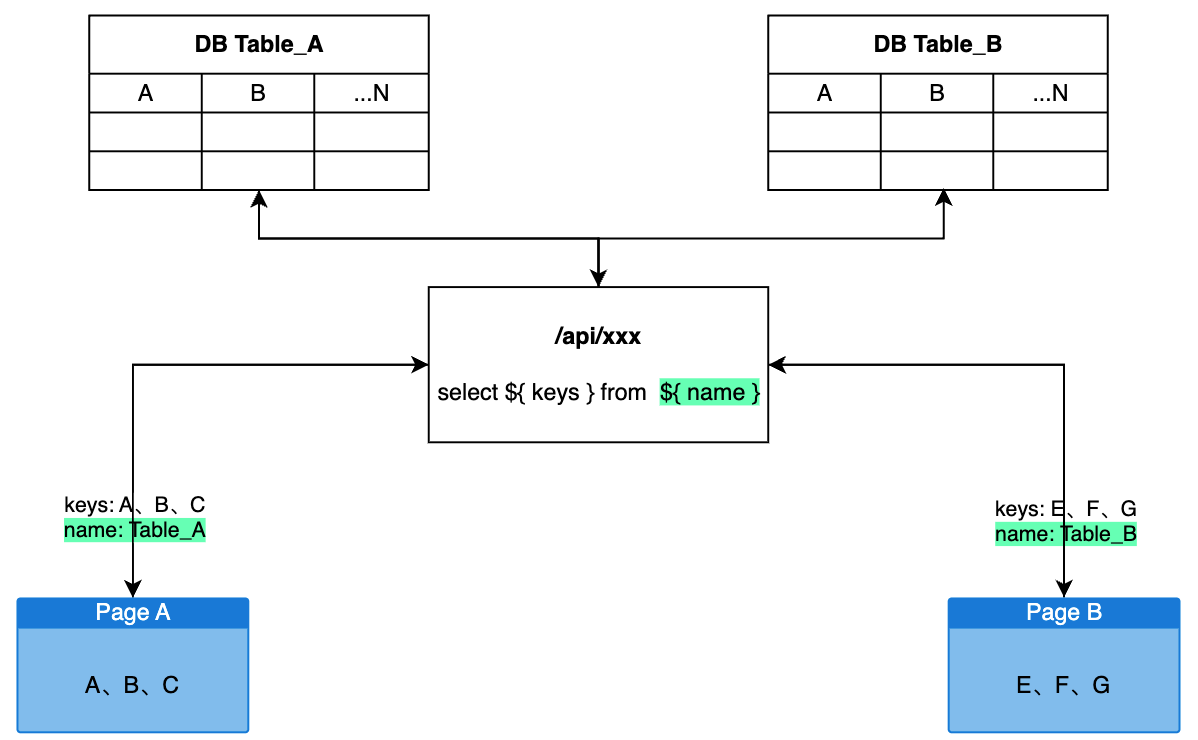
重构传输结构
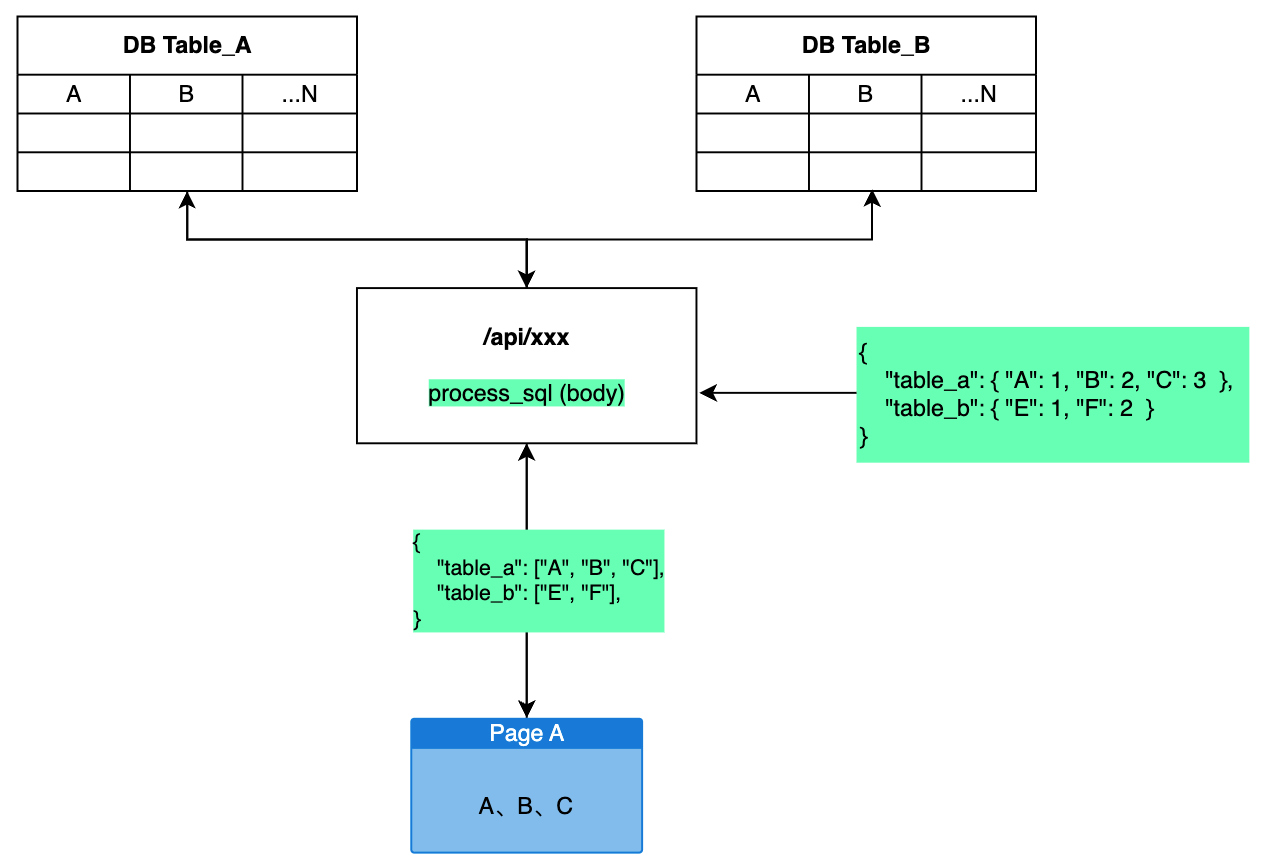
数据源:数据库、redis、ES、RPC 等等
数据处理:多数情况从数据源拿到的数据,还需要进行逻辑处理才会返回
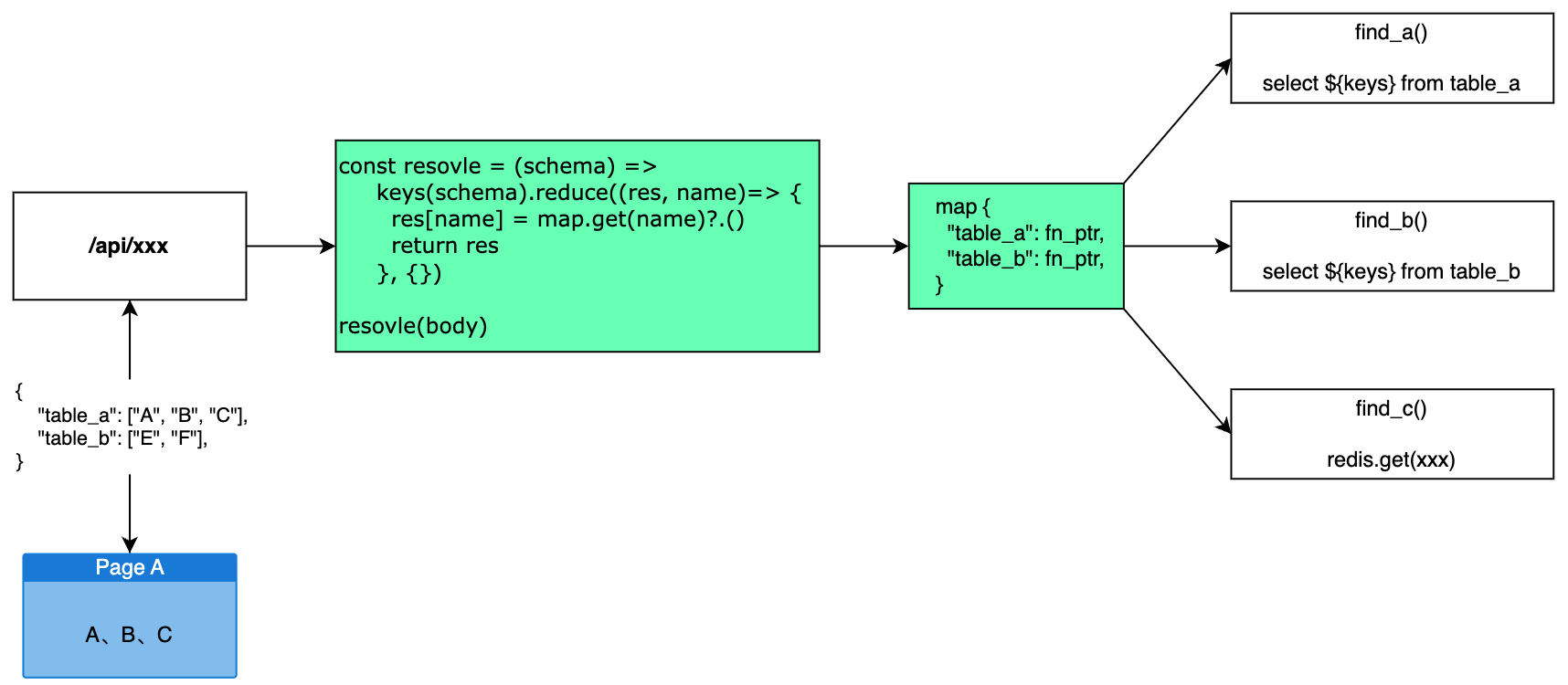
子查询:先执行父级的查询,再用父级的信息查找子级
重构传输结构
封装、分层
拿到的数据和 API 文档不一致
可不可以如果返回的和需要的不一致,就直接报错,接口 500,这样可以更快的定位问题(更好的甩锅)
问题:
GraphQL | A query language for your API

| Query 类型定义 | Query 查询 |
|---|---|
 |
 |
从 resolves 中找到对应 type 的各字段解析方法,如果字段的类型不是标量类型(基础类型),就递归对 type 进行解析
内置标量类型:Int、Float、String、Boolean、ID
考虑上述代码示例,如果 1 条回答中,有 20 条评论,各 fetch 方法分别会被调用多少次?
fetchAnswer: 1
fetchReviews: 1
fetchUser: 21 如果我们查询的是 1 个回答列表,列表中有 20 条回答,每个回答有 20 条评论,上述方法有会被调用多少次?
fetchAnswer: 1
fetchReviews: 20
fetchUser: 420 遇事不决加抽象
简单实现
const arr = new Set()
let flag = true
const fetchUser = (user_id) => {
arr.add(user_id)
if (flag) {
flag = false
setTimeout(() => {
batch_fetch_user([...arr])
arr.clear()
flag = true
})
}
} 封装
class Loader {
constructor(callback) {
this.arr = new Set()
this.flag = true
this.callback = callback
}
load(key) {
this.arr.add(key)
if (this.flag) {
this.flag = false
setTimeout(() => {
this.callback([...this.arr])
this.arr.clear()
this.flag = true
})
}
}
} const DataLoader = require("dataloader")
const userLoader = new DataLoader((ids) => {
console.log(ids)
// `SELECT * FROM user WHERE id IN (${ids.join(',')})`
// rpc.client.fetchUsers(ids)
return Promise.resolve(["123"])
})
Array(20)
.fill(1)
.map((_, i) => userLoader.load(i))
Array(20)
.fill(1)
.map((_, i) => userLoader.load(0)) | DataLoader | Vue |
|---|---|
 |
 |
重复的写 schema 和 类型(结构)定义,并且两者又是很像的
GraphQL Schema
type Answer {
id: Int
content: String
} Go
type Answer struct {
id int
content string
} Rust
struct Answer {
id: i32
content: string
} TS
class Answer {
id: Number
content: string
} 先写 schema,生成类型(结构)
先写类型(结构),生成 schema
| lib | star | modal |
|---|---|---|
| graphql-js | 19.7k | 两种都支持:code first(调用式) |
| apollo-server | 13.5k | schema first |
| type-graphql | 7.9k | code first(结构式) |
| graphql-yoga | 7.8k | schema first |
| nestjs | 60.4k / 1.3k | 两种都支持:code first(结构式) |
| lib | star | modal |
|---|---|---|
| graphql-go | 9.5k | code first(调用式) |
| gqlgen | 9.3k | schema first |
| lib | star | modal |
|---|---|---|
| juniper | 5.3k | code first(结构式) |
| async-graphql | 3k | code first(结构式) |
2020-01-31
横向模糊匹配
匹配的字符串长度不是固定的,使用量词实现
纵向模糊匹配
匹配的字符不是确定的,使用字符组实现
[abc],表示匹配一个字符,它可以是 "a"、"b"、"c" 之一
范围表示法
[a-z0-9]: 匹配 a 到 z,0 到 9 的字符
排除字符组
使用
^表示求反,[^a-z]匹配除了 a 到 z 的字符
简写形式
| 字符组 | 具体含义 |
|---|---|
| \d | 表示 [0-9]。表示是一位数字。记忆方式: 其英文是 digit(数字)。 |
| \D | 表示 [^0-9]。表示除数字外的任意字符。 |
| \w | 表示 [0-9a-zA-Z_]。表示数字、大小写字母和下划线。记忆方式:w 是 word 的简写,也称单词字符。 |
| \W | 表示 [^0-9a-zA-Z_]。非单词字符。 |
| \s | 表示 [ \t\v\n\r\f]。表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页 符。记忆方式:s 是 space 的首字母,空白符的单词是 white space。 |
| \S | 表示 [^ \t\v\n\r\f]。非空白符。 |
| . | 表示 [^\n\r\u2028\u2029]。通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符 除外。记忆方式: 想想省略号 ... 中的每个点,都可以理解成占位符,表示任何类似的东西。 |
量词也称为重复
| 量词 | 具体含义 |
|---|---|
| {m,} | 表示至少出现 m 次。 |
| {m} | 等价于 {m,m},表示出现 m 次。 |
| ? | 等价于 {0,1},表示出现或者不出现。记忆方式: 问号的意思表示,有吗? |
| + | 等价于 {1,},表示出现至少一次。记忆方式: 加号是追加的意思,得先有一个,然后才考虑追加。 |
| * | 等价于 {0,},表示出现任意次,有可能不出现。记忆方式: 看看天上的星星,可能一颗没有,可能零散有几颗,可能数也数不过来。 |
量词默认匹配模式是贪婪匹配,尽可能多的匹配。在量词后面加上
?可以关闭贪婪匹配模式,尽可能少的匹配
一个模式可以实现横向和纵向模糊匹配。而多选分支可以支持多个子模式任选其一
/good|nice/,此正则用来匹配 "good" 或 "nice" 字符。使用管道符 | 分割模式,匹配其中之一
分支结构是惰性的,当前面的匹配上了,后面的就不再尝试了
/good|goodbye/ 当我们用这个正则匹配 "goodbye" 时,只会匹配到 "good"
掌握字符组和量词就能解决大部分常见的情形
位置 (锚) 是相邻字符之间的位置,对于位置的理解,我们可以理解成空字符 ""
比如 "hello" 字符串等价于如下的形式:
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "" + "o" + "" 也等价于:
"hello" == "" + "" + "hello"
因此,把 /^hello$/ 写成 /^^hello$$$/,是没有任何问题的:
var result = /^^hello$$$/.test("hello")
console.log(result)
// => true 甚至可以写成更复杂的:
var result = /(?=he)^^he(?=\w)llo$\b\b$/.test("hello")
console.log(result)
// => true 也就是说字符之间的位置,可以写成多个。
| 锚 | 具体含义 |
|---|---|
| ^ | 匹配行的开头 |
| $ | 匹配行的结尾(从结尾开始匹配) |
| \b | 匹配单词的边界(就是\w 和\W 之间的位置,包括 \w 与 ^ 之间的位置,和 \w 与 $ 之间的位置) |
| \B | 匹配非单词的边界 |
| (?=模式) | 匹配模式之前的位置 |
| (?!模式) | 匹配不是这个模式之前的位置 |
/a+/ 匹配连续出现的 "a",而要匹配连续出现的 "ab" 时,需要使用 /(ab)+/
其中括号是提供分组功能,使量词 + 作用于 "ab" 这个整体
在多选分支结构 (p1|p2) 中,此处括号的作用也是不言而喻的,提供了分支表达式的所有可能
当模式被放入括号内,匹配的到结果会被捕获,我们可以使用环境提供的 API 来引用它们
可以使用构造函数的静态属性来引用,
RegExp.$1至$9,$num,代表最近匹配上的第几个捕获组
在正则本身里也可以引用分组。引用之前的分组中匹配到的结果。使用
\1至\9
\10 代表什么呢?
\10代表引用第十个分组匹配结果,而不是\1 和 0,如果想匹配\1 和 0,可以使用(?:\1)0或者\1(?:0)
从外向里,开始匹配分组,最外面的括号为
$1,最里面的括号为$maxNum。例如:
var regex = /^((\d)(\d(\d)))\1\2\3\4$/
var string = "1231231233"
console.log(regex.test(string)) // true
console.log(RegExp.$1) // 123
console.log(RegExp.$2) // 1
console.log(RegExp.$3) // 23
console.log(RegExp.$4) // 3 如果引用不存在的分组,正则不会报错,只是匹配反向引用的字符本身。
例如 \2,就匹配 "\2"。注意 "\2" 表示对 "2" 进行了转义
分组后面有量词的话,分组最终捕获到的数据是最后一次的匹配
var regex = /(\d)+ \1/
console.log(regex.test("12345 1"))
// => false
console.log(regex.test("12345 5"))
// => true 括号中匹配到的内容都会被捕获,如果只是想要括号最原始的功能,而不需要去引用它。可以使用非捕获括号:
(?: 模式)
2020-12-10
进程间的通信主要涉及一下四个模块
上面这些方法,其实都是 node 的事件机制,都是 EventEmitter 的实例。
主进程发送
const { BrowserWindow } = require("electron")
const win = new BrowserWindow()
win.webContents.send("eventType", "message") 渲染进程接收
const { ipcRenderer } = require("electron")
ipcRenderer.on("eventType", (IpcRendererEvent, msg) => {}) 使用 ipcRenderer.send 发送异步消息
使用 ipcRenderer.sendSync 发送同步消息
渲染进程发送
ipcRenderer.send("eventType", "msg") 主进程接收
ipcMain.on("eventType", (IpcMainEvent, msg) => {}) 上面两个例子的 on 方法,接受的回调函数都有一个 event 对象,可以使用这个 event 对象进行消息回复
先看一下这两个 event 对象有什么属性
主进程中定义全局对象
global.share = {
id: 1,
} 渲染进程中通过 remote 模块控制全局对象
const share = remote.getGlobal("share")
console.log(share.id) // get
share.id = 2 // set 只能实现数据共享,并非真正的通信
这个就不写代码了,就是 渲染进程A 发送消息至 主进程, 主进程 转发消息至 渲染进程B。
ipcRender.sendTo(ID, eventType, msg)remote.BrowserWindow.fromId(ID).webContents.send(eventType, msg)2020-12-18
通过对逻辑层的封装,让原生小程序使用 Vue3 的 Composotion API
index.wxml
<view>
<view>{{count}}</view>
<button bindtap="add">数字 +1</button>
</view> index.js
import { Epage, ref, onShowHooks } from "enhance-weapp"
function useCount() {
const count = ref(0)
const add = () => {
count.value++
}
onShowHooks(() => {
console.log("我是useCount")
})
return {
count,
add,
}
}
Epage({
setup() {
onShowHooks(() => {
console.log("我是setup")
})
return useCount()
},
}) 流程图先走一波

options 对象属性进行遍历,对所有的生命周期方法进行装饰,将生命周期改造成数组结构,并提供相关的 hooks 方式以调用注册。setup 函数,拿到其返回值 setupData。options.data 对象副本(如果有的话),使用 reactive 将其响应式后保存到 this.data$ 属性上。setupData,将其值直接赋值给 this.data$,响应式解包赋值给 this.data。this.setData(this.data),同步数据至渲染层。this.data 副本至 this.__oldData__。watch 监听 this.data$,响应式触发后 diff this.data$ 与 this.__oldData__。this.setData(diffData),同步数据至渲染层。以上是核心的实现思路,除此之外还有全局 mixins、生命周期阻塞执行、全局生命周期控制等逻辑,具体可以去 enhance-weapp,看下介绍和源码。
如果本篇内容对你有帮助,欢迎点赞 star👍。
2024-03-25
2024-03-25
标题经历了三次变化
*UI?开发与用户进行交互的界面或工具时,面对异步状态需要等、慢、数据过时这些不可避免的事实下,怎么尽可能的提高 UX
具体到前端
TanStack Query/SWR/RTK Query,它们与同步状态管理 redux/jotai/zustand 有什么区别redux-thunk 实现一个异步状态管理(React Query API)TanStack Query(FKA React Query)
代码立即执行并完成,不需要等待其他任何操作
a = 0
printf(a)
a = 1
printf(a) 需要 等待 某些操作的完成:锁、文件、网络 IO 等等
read(fd, buffer, BUFFER_SIZE) 聚焦到前端最常见、常用的就是 fetch -- 网络请求,所以就前端来说 异步状态 ≈ 服务端状态
当然还有诸如
IndexedDB、Web Worker以及各种授权请求(蓝牙、摄像头、地理位置)等等,本质是一样的
同理,同步状态 ≈ 客户端状态

从四个方面去看:


所有程序员都会关心异步的写法(async/await)和组织(rxjs),但也许只有 end device 会(必须)去关心异步耗时、状态更新这些事情

因为我们已经是链路的终点了,我们不关心,那就只能用户去关心,用户会去关心吗?(≈ 用户流失)
异步 == 等待 == 慢 == 体验不好
核心问题:用户体验
主题:在异步需要等、慢、数据过时这些不可避免的事实下,怎么尽可能的提高 UX

要想提高异步的体验(UX、DX),我们大概要面对如下挑战:
开始之前有一点要明确
Tip
异步状态应该是本地的还是全局的?
是应该这样?
const [state, setState] = useState()
useEffect(() => {
fetch(API.list).then((data) => setState(data))
}, []) 还是这样?
const state = useSelector(listSelector)
useEffect(() => {
dispatch(getList)
}, []) 听到过的回答:
如果这个状态只有组件自己用的就放本地,如果大家都用的就放全局
这个回答是经不起推敲的,产品是在不断迭代的,我们的判断仅限于当下这个时刻而已
V1: 自己 -- 放在本地
V2: 兄弟节点 -- 提升到父级
V3:跨节点 -- 提升到全局(root)
V4:需求全砍了,变回 V1 版本了 -- 再降下来?
单从开发维护角度来看,应该是全局的
跳出前端视角事情就更简单了,因为上面已经说过异步状态是共享所有权的,我们拥有的只是某个时刻的快照而已
从一致性角度看,快照可以是过时的,但不能是多版本的
可以接受这两个数字是相同但是过时了,但不能接受两个数字不一样
也就是说同一份异步状态不管多少地方在用,都需要一种方式使其保持一致,答案很明显也是全局状态管理
数据获取很简单,异步状态管理不是
所以接下来使用 redux-thunk 来封装实现异步状态管理,看下为什么说异步状态会有如上的挑战,以及如何解决
下面应该是使用 redux-thunk 请求异步数据的最简代码,有两点值得注意:
ASM,与其他同步状态区分开queryKey 和具体要执行的请求函数 queryFn
modal 单独写一遍请求逻辑,key 随 modal 的定义在对应的文件中export const fetchAsyncState = (props) => (dispatch) => {
const { queryKey, queryFn } = props
return queryFn(props).then((data) =>
dispatch({ ASM: { [queryKey]: { data } } })
)
} Tip
本文所有代码目的均为说明作用
完整的 dispatch 应该是 dispath({ type, payload }),为了简化代码就都省略了
使用代码如下
const dispatch = useDispatch()
const queryKey = "taskList"
useEffect(() => {
dispatch(
fetchAsyncState({
queryKey,
queryFn: () => fetch("/api/list").then((res) => res.json()),
})
)
}, [])
const { data } = useSelector((state) => state.ASM[queryKey]) 上面的代码还是太啰嗦了,实际使用中只有 queryKey & queryFn 会变化,其他都是模版代码,所以再封装一个 useQuery
export const useQuery = (props) => {
const dispatch = useDispatch()
useEffect(() => {
dispatch(fetchAsyncState(props))
}, [])
return useSelector((state) => state.ASM[props.queryKey])
} 这下用起来舒服多了
const { data } = useQuery({
queryKey: "taskList",
queryFn: () => fetch("/api/list").then((res) => res.json()),
}) 假如 N 个组件都在用这个数据,我们不想 queryKey 和 queryFn 分散在各组件中,为了统一管理还需要再封一层(数据层),比如放在 service/*.ts
export const useTaskList = () =>
useQuery({
queryKey: "taskList",
queryFn: () => fetch("/api/list").then((res) => res.json()),
}) 最终组件里(视图层)直接调用
const { data } = useTaskList() 这也是最终的代码结构,后面会持续的修改 useQuery 的实现,但业务层要做的只有最后这两步
异步状态需要等、慢是不可避免的,但人机交互需要及时响应,我们需要从交互上告诉用户:你的操作我受理了,只是现在需要等待
也就是所有视图中发生异步状态的地方,要在视觉上反馈用户
Note
有些时候设计是不会出 loading 效果的,但作为前端一定要提出/直接自己加上去
这里就要夸一夸 antd 了,它可能是内置 loading 属性组件最多的库了:input/select/button/dropdown/table/modal/tree/card...
作为状态管理要做的事情就是把异步过程状态暴露出来,方便视图层渲染:loading/error/success
回到代码实现,这一步是很简单的,而且相信大家自己一定也都写过:请求过程中使用 status 记录状态
export const fetchAsyncState = (props) => (dispatch) => {
const { queryKey, queryFn } = props
dispatch({ ASM: { [queryKey]: { status: "loading" } } })
return queryFn(props)
.then((data) =>
dispatch({ ASM: { [queryKey]: { status: "success", data } } })
)
.catch((error) =>
dispatch({ ASM: { [queryKey]: { status: "error", error } } })
)
} 在 useQuery 中派生出具体的变量方便外部使用:
export const useQuery = (props) => {
// ...
const state = useSelector((state) => state.ASM[props.queryKey])
return {
...state,
isLoading: state.status === "loading",
isError: state.status === "error",
isSuccess: state.status === "success",
}
} Tip
为什么不直接在 fetchAsyncState 写 isLoading/isError/isSuccess 呢?
会有很多重复的代码
dispatch({
ASM: { [queryKey]: { isLoading: true, isError: false, isSuccess: false } },
})
return queryFn(props)
.then((data) =>
dispatch({
ASM: {
[queryKey]: { isLoading: false, isError: false, isSuccess: true, data },
},
})
)
.catch((error) =>
dispatch({
ASM: {
[queryKey]: {
isLoading: false,
isError: true,
isSuccess: false,
error,
},
},
})
) 这可能是异步状态管理与同步状态管理最大的差异点了
Important
要聊缓存,必须先要明确 queryKey 的含义,这很重要
queryKey: "taskList" 的问题如果大家在用同步状态管理异步数据,这应该就是正在使用的方式了,我们用一个 key 去承载一个接口返回的数据
Tip
这有什么问题吗,有遇到过 BUG 吗?

Tip
/api/list?page=1 和 /api/list?page=2 和 /api/list?name=s
算是同一种状态吗?
queryKey: "taskList" 是它们的唯一标识吗?
page=1 的数据渲染在了第二页里,算 BUG 吗?type=1|2,对其中一个翻页,结果两个同时进行了 loading 和结果更新,算 BUG 吗?
数据竞争:网络请求是没有时序性保证的,先发的请求不一定是先响应的)
这些问题大家多少应该都碰到过,解决方案也有很多,比如:
key/api/list?page=1 和 /api/list?page=2 和 /api/list?name=s 根本就不是同一种状态,但在代码开发上却用一个字段承接了 N 种不同的数据
把 N 种状态抽象成了 1 种,抽象的代价就是会遇到各种问题
换句话说,如果不做抽象,就不会有这些问题
还是列表场景,操作路径:
?page=1 -> ?page=2 -> ?page=1(往返翻页)?page=1 -> ?page=1&s="React" -> ?page=1(搜索后清空)Tip
Q:频繁重复的获取 page=1 的数据,是否有必要?
可能的回答:
要看具体场景,看对数据实时性的要求;还要看请求数据的代价(请求耗时)
Tip
但使用抽象 key 的方式,其实是没有选择的
因为每次请求成功后,之前的数据就已经被丢弃了,下次只能重新请求获取数据
而且针对这个问题还有更好的回答:SWR: stale-while-revalidate
SWR 是指在请求数据时,如果之前已经有缓存了
原则是「有」总比「空」强(体验好),就算数据是过时的,也比没有数据强(更何况会在几百毫秒内(可能的)新数据就会到来
key 结论所以不管是从代码开发考虑,还是从数据缓存考虑
都应该具象 queryKey,保证每一个 key 对应一份数据
具体来说就是对于 get 请求,我们应该把 url + [query] + [body] 作为 queryKey,这样就可以标识唯一的数据源了
const queryKey = ["/api/list", { page: 1, name: "s" } /* something... */] 解决 key 的问题
key 序列化现在的 key 变成了一个非基本类型,不能直接用作对象的 key,所以需要序列化(stringify)操作
也不能用 Map,因为每次 rerender 引用都会变
多数情况 key 的组成都是传给后端的,所以可以直接用 JSON.stringify 来序列化(React Query)
/**
* Hashes the value into a stable hash.
*/
export function hashKey(queryKey: QueryKey | MutationKey): string {
return JSON.stringify(queryKey, (_, val) =>
isPlainObject(val)
? Object.keys(val)
.sort()
.reduce((result, key) => ({ ...result, [key]: val[key] }), {} as any)
: val
)
} 键值对的顺序不同,序列化后的字符串也是不同的(但含义相同),所以需要排序
JSON.stringify({ a: 1, b: 1 })
// '{"a":1,"b":1}'
JSON.stringify({ b: 1, a: 1 })
// '{"b":1,"a":1}' 也可以直接使用 stable-hash 库(useSWR),它可以稳定序列化任意类型的值(Function/RegExp/BigInt/Symbol..),包括循环引用(JSON.stringify 会直接报错)
// https://github.com/shuding/stable-hash#readme
import hash from "stable-hash"
const foo = []
foo.push(foo)
hash({ a: { b: 2n, c: () => {}, d: [/1/g, Symbol(), foo] } })
// #a:#d:@/1/g,Symbol(),@4~,,,c:5~,b:2,, 应用到代码中就是存 key 的时候调用一下 hash 函数:
export const fetchAsyncState = (props) => (dispatch) => {
// ...
payload: { ASM: { [hash(queryKey)]: { /* */ } } },
// ...
} key 变化时请求数据利用 useEffect 可以轻易做到(记得 hash key)
export const useQuery = (props) => {
// ...
useEffect(() => {
// ...
}, [hash(props.queryKey)])
// ...
} React Query/useSWR 都建议使用这种方式监听 key 变化以重新发起请求,而不是手动调用请求函数
有人希望 useQuery 提供一个类似 manualFetch 的返回值,以在事件发生的时候手动传入参数进行请求:
// ❌ 示例:不存在这样的 API,也不建议
const { manualFetch } = useQuery({
key: {
/**/
},
})
const onPageChange = (page) => {
manualFetch({ page })
} 单从封装的角度是不能提供手动函数的
后面会讲自动缓存更新,如果使用手动查询更改 key,会产生更多的心智负担
useQuery 里已经传入了一个 key(外部状态manualFetch 也会传入 key(内部状态manualFetch 数据源的状态被封装在了 useQuery 内部React 官网 Sending a POST request - You Might Not Need an Effect 中:
当您选择是否将某些逻辑放入事件处理程序或 useEffect 中时,您需要回答的主要问题是从用户的角度来看它是什么样的逻辑
- 如果此逻辑是由特定交互引起的,请将其保留在事件处理程序中
- 如果是由于用户看到屏幕上的组件引起的,请将其保留在 useEffect 中
论点:尽可能让事情发生在它产生的地方
内存野指针难以排查,因为它们往往是由一系列复杂的交互和操作引起的,而且出现问题的症状可能不会立即显现,或者不在引起问题的实际代码位置出现
但实际上这只是针对 变更 操作,对于 查询 操作官方紧跟着就给出了说法:
Fetching data - You Might Not Need an Effect
您不需要将此 获取 移至事件处理程序
这可能看起来与前面的示例相矛盾,在前面的示例中您需要将逻辑放入事件处理程序中!
但是,请考虑到 input 事件并不是获取数据的主要原因,搜索输入通常是从 URL 预先填充的,用户可以在不输入的情况下导航后退和前进。
page 和 query 来自哪里并不重要。虽然此组件可见,但您希望使 results 与当前 page 和 query 的网络数据保持同步。这就是为什么它是一个 useEffect
key 可能不是单一来源(url)这也是为什么 React Query/useSWR 都给我们提供了用以变更的方法 useMutation/useSWRMutation,以使得查询和变更分开
key 的问题解决之后,其实已经实现了 SWR 的功能,回顾下目前的代码
export const fetchAsyncState = (props) => (dispatch) => {
const { queryKey, queryFn } = props
dispatch({ ASM: { [queryKey]: { status: "loading" } } })
return queryFn(props)
.then((data) =>
dispatch({ ASM: { [queryKey]: { status: "success", data } } })
)
.catch((error) =>
dispatch({ ASM: { [queryKey]: { status: "error", error } } })
)
}
export const useQuery = (props) => {
const hashKey = hash(props.queryKey)
useEffect(() => {
dispatch(fetchAsyncState({ ...props, queryKey: hashKey }))
}, [hashKey])
const state = useSelector((state) => state.ASM[hashKey])
// ...
} 再看分页场景:?page=1 -> ?page=2 -> ?page=1
key 都被单独保存了一份数据data 的动作,所以如果 data 之前已经有值了,那么 useSelector 很自然的就会获取到已有的值data回顾下 SWR 的定义:
SWR是指在请求数据时,如果之前已经有缓存了
- 缓存没有过时,直接返回缓存
- 缓存已经过时,仍然返回缓存,同时在后台重新获取数据并更新缓存
但目前的代码里根本就没有过不过时的概念,不会出现「缓存没有过时」的情况
我们可以加入一个 staleTime 的配置,来控制异步数据的过期时间,如果数据还是新鲜的,就不会发起请求,直接返回缓存
staleTime:数据从新鲜(fresh)转变为陈旧(stale)的持续时间只要查询是新鲜的,数据将始终只从缓存中读取 - 不会发生网络请求!
如果查询已过时(默认情况下是:
0立即过时),您仍将从缓存中获取数据,但在某些条件下可能会发生后台重新获取(如果过时的时候并没有任何使用此数据的组件挂载,则不会发起请求)-- React Query
代码中,当数据请求成功后,记录一个时间
export const fetchAsyncState = (props) => (dispatch) => {
// ...
dispatch({ ASM: { [queryKey]: { status: "success", data, dataUpdatedAt: Date.now() } } }),
//...
}; 触发请求时,判断数据是否过期
export const useQuery = (props) => {
// ...
const staleTime = props.options?.staleTime || 0
const state = useSelector((state) => state.ASM[hashKey])
useEffect(() => {
if (state.dataUpdatedAt + staleTime < Date.now()) return
dispatch(fetchAsyncState({ ...props, queryKey: hashKey }))
}, [hashKey])
// ...
} 默认情况下 staleTime 为 0,即立即过时
从库的设计角度,0 是最安全的
让使用者根据自己的应用场景去思考决定数据的新鲜度。即使不思考,程序也不会因此出错
如果希望数据在程序的运行期间都不过期,可以设置 staleTime: Infinity
比如登录用户的信息(
/user、/me...
useSWRuseSWR 中并没有 staleTime 的概念,只有 revalidateIfStale & dedupingInterval
revalidateIfStale = true: 即使存在陈旧数据,也自动重新验证
revalidateIfStale: true === staleTime: 0revalidateIfStale: false === staleTime: InfinitydedupingInterval = 2000: 删除一段时间内相同 key 的重复请求
staleTime其实 HTTP SWR 中也是有 staleTime 的概念的
Cache-Control: max-age=604800, stale-while-revalidate=86400
后面会讲到请求去重、自动更新和手动缓存失效
staleTime 的概念可以轻松的与这些概念结合,没有什么心智负担
staleTime = Infinity 的情况下,手动缓存失效,会重新发起请求吗?revalidateIfStale & dedupingInterval 就不是这样了
dedupingInterval = Infinity 的情况下,手动缓存失效,会重新发起请求吗?
dedupingInterval配置的主要作用是防止在指定时间间隔内重复发送相同的请求。它不会影响使用mutate函数来更新数据或者触发重新请求
所有的异步状态管理都会提供这些能力,使用得当可以让用户体验上升一个层级
React Query 选择了一些触发重新获取的策略点
这些点似乎是一个很好的指标,可以表达:「是的,现在是获取一些数据的好时机」
refetchOnMount每当安装调用
useQuery的新组件时,React Query 都会进行重新验证
目前的实现就是这样
refetchOnWindowFocus每当您聚焦浏览器选项卡时,就会重新获取
这是我最喜欢进行重新验证的时间点
但它经常被误解,在开发过程中,我们经常切换浏览器选项卡,因此我们可能会认为这「太多」
然而在生产中,它很可能表明在选项卡中打开我们的应用程序的用户现在从检查邮件或阅读 Twitter 回来
在这种情况下,向他们展示最新的更新是非常有意义的
功能的代码实现就是监听 focus visibilitychange 重新发起请求
目前只会在 queryKey 变化时,才会重新发起请求,现在我们需要加入另一个状态: isInvalidated,true 表示需要重新请求
为什么要通过加一个状态来实现呢?手动更新中会看到它的巧妙之处
export const useQuery = (props) => {
// ...
const state = useSelector((state) => state.ASM[hashKey]);
useEffect(() => {
const fn = () => visible && dispatch({ ASM: { [hashKey]: { /**/, isInvalidated: true } } })
window.addEventListener('visibilitychange', fn)
return () => window.removeEventListener('visibilitychange', fn)
}, [hashKey])
useEffect(() => {
if (!state.isInvalidated && state.dataUpdatedAt + staleTime < Date.now()) return;
// dispatch(fetchAsyncState(/**/));
}, [hashKey, state.isInvalidated]);
};
// 请求成功后要重置状态
export const fetchAsyncState = (props) => (dispatch) => {
// ...
dispatch({ ASM: { [queryKey]: { status: "success", /**/, isInvalidated: false } } }),
// ...
}; refetchOnReconnect如果您失去网络连接并重新获得它,这也是重新验证您在屏幕上看到的内容的一个很好的指示
同上,监听 online/offline,不再赘述
refetchInterval定时轮询,窗口不可见时会停止轮询
refetchIntervalInBackground:窗口不可见时依然轮询
useSWR:refreshInterval + refreshWhenHidden
!== 数据删除/无效 的场景不要使用(eg. 推荐流loading(后面说进行 变更 操作之后,明确知道数据源发生变化了,数据已经过时了
Q: 需要重新发起请求(吗?)
A: 取决于当前页面中有没有组件在使用这个数据源
大家现在是怎么做的,在哪做的(视图层 or 数据层)?或者说是在组件里,还是在 redux 里
应该都是在组件里:
const onClick = () => {
dispatch({ type: "task/delete" }).then(() => {
dispatch({ type: "task/getList", payload: searchParams })
})
} 如果放在 redux 里会有以下问题
key 的问题,重新请求参数应该传什么?(要把参数也记到 redux 中)dispatch({type: 'task/getList'}) 会直接触发网络请求,无法判断是否有组件正在使用数据switch (type) {
case "task/delete":
fetch("/api/delete").then(() => dispatch({ type: "task/getList" }))
} 就是说因为代码原因,无法(不能简单的)把它抽象到数据层中,所以不得不在视图层做
期望数据层的事尽可能放在 uu ju c g 数据层做,而不是散落在视图里
在我们目前的实现中,可以轻松的解决这个问题,把逻辑都放在数据层中
只需要提供如下代码:
export const invalidateQueries = (key) => {
const ASM = useSelector((state) => state.ASM);
Object.keys(ASM).forEach((hashKey) => {
const { queryKey } = ASM[hashKey]
// 部分匹配
if (partialMatchKey(queryKey, key)) {
dispatch({ ASM: { [key]: { /**/, isInvalidated: true } } }),
}
})
}
function partialMatchKey(a: any, b: any): boolean {
if (a === b) return true
if (typeof a !== typeof b) return false
if (a && b && typeof a === 'object' && typeof b === 'object') {
return !Object.keys(b).some((key) => !partialMatchKey(a[key], b[key]))
}
return false
} queryKey 是会被存下来的(为了避免干扰前面没写filters 精确控制具体的失效逻辑业务代码中如下使用:
export const useDeleteTask = () => {
return useMutation({
mutationFn: () => fetch("/api/delete"),
onSuccess() {
invalidateQueries(["/api/list"])
},
})
} 这就是增加一个
isInvalidated的巧妙之处
使用了 useEffect 天然的订阅机制:通过 useEffect 监听了状态的变化发送请求
如果没有任何相关的 useEffect 存在,单纯的修改状态是没有意义的,什么都不会发生
TanStack Query 被设计的不局限于框架,所以抽象了这一部分(
observer)
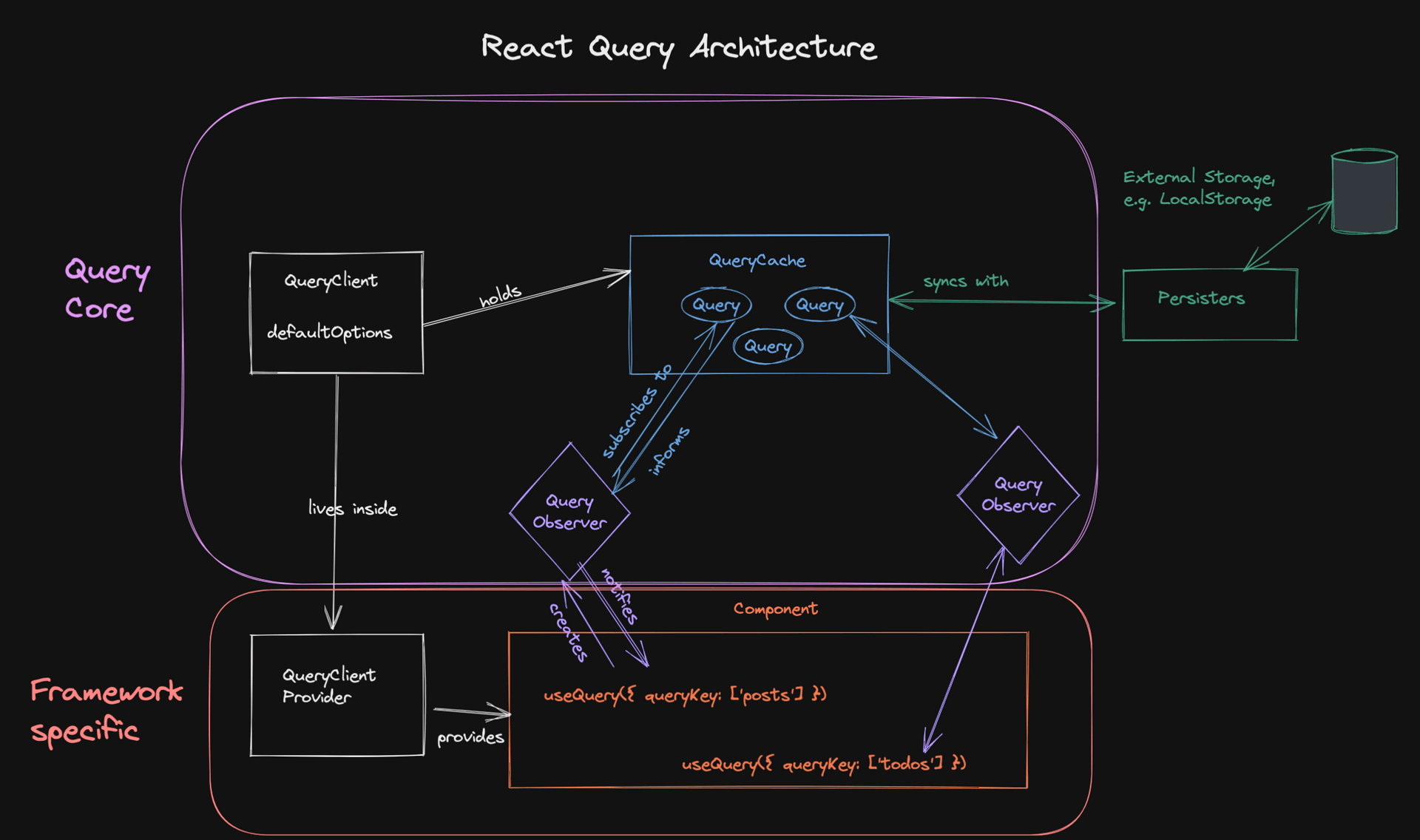
实际的业务场景中,很少在页面上同时存在接口路径相同,参数不同的视图(eg. /api/list?type=1、/api/list?type=2)
基于这样的提前:
invalidateQueries(['/api/list']) 效果等同于 invalidateQueries(['/api/list', {page: 1}])invalidateQueries(['/api/detail']) 效果等同于 invalidateQueries(['/api/detail', {id: 1}])而且如果真遇到这种场景,你就把参数传进去呗
有些后端接口实现中,会在 post/patch 的接口响应里就把最新的数据返回过来,而不用再去发起 get 请求
针对这种场景可以提供 setQueryData 手动更新缓存数据
export const setQueryData = (key, data) => {
dispatch({ ASM: { [key]: { data } } }),
} 业务使用如下:
export const useEditTask = () => {
return useMutation({
mutationFn: (params) =>
fetch(`/api/task${params.id}`, { method: "PATCH" }).then((data) => {
setQueryData(["/api/task", { id: params.id }], data)
}),
})
} useSWR 中
mutate(key) 等同于 invalidateQueries(默认精确匹配,可以传入函数来实现部分匹配mutate(key, data, options) 等同于 setQueryData事情都是两面的,抽象和具象各有优劣
把每一个 key 的数据都存下来,体验好了,内存也上去了
抽象
key是不需要考虑GC的,因为每次请求完,就已经把旧数据释放了,内存中每个抽象key只有一份数据就算用户把所有的页面都点一遍,也只会有代码中
modal数量的数据存在内存中而已
直接看 React Query 是如何解决的
gcTime:从缓存中删除非活动查询之前的持续时间,默认为 5 分钟一旦没有注册观察者,即当使用该查询的所有组件都已卸载时,查询就会转换为非活动状态(
inactive)
如果一份数据已经没有任何组件在使用了,gcTime 后回收它
频繁触发请求的场景可以设置的短一点,比如搜索场景
代码实现上,就是订阅模式配合定时器
依然是利用 useEffect 的特性,配合全局状态管理实现:「是否还在组件在使用数据」
export const useQuery = (props) => {
// ...
useEffect(() => {
dispatch({ type: "gc/add", payload: hashKey })
return () => dispatch({ type: "gc/remove", payload: hashKey })
}, [hashKey])
// ...
} redux 中:
case 'gc/add':
const {count = 0, timer} = state.GC[hashKey] || {}
clearTimeout(timer)
return { GC: { [hashKey]: { count: count + 1 } } }
case 'gc/remove': {
const count = state.GC[hashKey] - 1
let timer
if (count === 0 && state.ASM[hashKey]) {
timer = setTimeout(() => {
state.ASM[hashKey] = null
}, crime)
}
return { GC: { [hashKey]: { count, timer } } }
} useSWR 中并没有提供清理缓存的相关配置,但是它允许你完全 自定义缓存行为,所以可以自行实现相关功能
目前的同步全局状态管理中,如果大家要取一个全局的数据(比如 userInfo),是用哪种方式取的?
useSelector 取到后,利用 props 向下不同的透传(props drilling)useSelector 取我觉得在问废话,当时是 2 啊(不会真的有人用 1 吧 😱
我们知道 useQuery 的实现其实也只是一个有副作用的 useSelector 而已
export const useQuery = (props) => {
// ...
const state = useSelector(/**/)
useEffect(/**/)
// ...
} 我们希望对于使用者(视图层)来说,就把它当成 useSelector,只管取数据、用数据就好了
这些都是数据层的事情,视图层管好渲染就可以了
当然这是理想状态,只能尽可能去做
目前的实现如果多个组件同时挂载,是会同时发出多个请求的
只需要加入 loading 态的判断即可完成去重
export const fetchAsyncState = (props) => (dispatch, getState) => {
const { status } = getState().ASM[queryKey] || {}
if (status === "loading") return
dispatch({ ASM: { [queryKey]: { status: "loading" } } })
// ...
} Tip
抽象 key 这样写就会有问题,因为可能会有不同参数的请求进来
上面的代码控制了接口 loading 过程中的重复请求(取决于接口的速度,也许是几百毫秒)
对于同步的组件树挂载,这已经足够了(面试题:useEffect 的调用时机和顺序
但如果遇到异步组件(lazy load),就还有可能发生重复请求,那应该怎么办呢?
staleTime 是你的好朋友
staleTime也没有「正确」值。在许多情况下,默认设置(0)效果非常好就个人而言,我喜欢将其设置为至少 20 秒,以便在该时间范围内删除重复请求,但这完全取决于您
-- React Query
有些场景请求的数据已经不可能再被使用了,此时需要忽略/丢弃/取消请求的结果
相信这些问题大家多少也遇到过
key:前两种情况必须要去解决,不然就会有 BUG(弱网必现key:可以不解决,是不会有 BUG 的。但考虑到缓存、GC 的原因,最好还是解决一下可以用 AbortController 优雅的实现相关逻辑
fetch,以实现请求取消( promise rejectaborted 属性实现丢弃逻辑const ac = new AbortController()
console.log(ac.signal.aborted) // false
ac.abort()
console.log(ac.signal.aborted) // true 具体到代码中,在每次请求时创建一个 AbortController 实例,并将其 signal 传递给实际的执行者:queryFn
export const fetchAsyncState = (props) => (dispatch) => {
// ...
const ac = new AbortController()
dispatch({ ASM: { [queryKey]: { status: "loading", ac } } })
return queryFn({...props, signal: ac.signal })
.then((data) =>
dispatch({ ASM: { [queryKey]: { status: "success", data } } })
)
}
// GC
case 'gc/remove': {
if (count === 0 && state.ASM[hashKey]) {
state.ASM[hashKey]?.ac?.abort()
// timer = setTimeout(() => {
}
} 而使用者只需要在 queryFn 中使用 signal 就可以了(绝大多数情况也是直接透传给 fetch
export const useTaskList = () =>
useQuery({
queryKey: "taskList",
queryFn: ({ signal }) =>
fetch("/api/list", { signal }).then((res) => res.json()),
}) loading大多数时候,我们(和我们的用户)不喜欢讨厌的加载旋转器。
有时它们是必需的,但我们仍然希望尽可能避免它们
这就是为什么 React Query/SWR 会为我们提供两个 loading 变量:
isLoading: 请求中且没有数据可用isFetching/isValidating: 请求中已有数据可用为了良好的用户体验,要准备两个 loading 效果
loading:首次请求时,没有数据可用于渲染

loading:数据更新(手动/自动)时,页面中已有数据渲染

配合组件化
处理错误是处理异步数据(尤其是数据获取)不可或缺的一部分
我们必须面对现实:并不是所有的请求都会成功,也不是所有的 Promise 都会得到履行
对于初始请求(没有数据),没有什么可以值得讨论的,我们需要展示降级的视图或提示
一般使用全局处理 or 组件封装的方式来解决
对于数据更新的场景,如果你用的是 toast 错误提示,也还好
但如果用的是渲染错误视图的方式,就要多考虑一下了,尤其是自动更新的场景: refetchOnWindowFocus/refetchOnReconnect ,如果此类自动更新获取失败,可能会导致用户体验混乱
比如用户在浏览列表的时候来了个微信消息,等回完消息从微信切回浏览器后,发现列表变成了一个错误提示视图
优先展示错误还是陈旧的数据?这个问题没有明确的答案,取决于具体场景
对于一个库来说,要做的就是「同时将收到的错误和过时的数据返回给用户」(目前的代码实现就是这样)
现在,由你来决定显示什么:
const { data, error } = useTodos()
// 错误优先
if (error) return "An error has occurred: " + todos.error.message
if (data) return todos.data.map(renderTodo)
// 数据优先
if (data) return todos.data.map(renderTodo)
if (error) return "An error has occurred: " + todos.error.message
// 同时展示
return (
<>
{error && "An error has occurred: " + todos.error.message}
{data && todos.data.map(renderTodo)}
</>
) 在合适的场景里又是一个提升体验的大杀器
这种策略的核心**是在数据实际写入服务器之前,就假设写入操作会成功,并且立即在前端应用中更新数据
这样做的目的是为了提升用户体验,减少等待时间,并给予用户一种快速响应的感觉
目前我们对 变更 操作的处理应该都是阻塞 UI:给用户一个 loading/disable,在此期间无法进行其他操作,直到接口响应(成功/失败
在有业务校验的场景(eg 购物),这是合理的,因为会有很多因素导致失败(余额、商品数量、地址…),有些来自于用户输入,这是无法控制的
但有些场景(eg 聊天、评论),接口的成功/失败只取决于服务可用性,我们知道所有公司都对服务可用性有要求
高可用性指标通常用“几个 9”来表示,即系统在一年中的正常运行时间所占的百分比。例如:
- 99.9%(三个 9):在一年中最多允许 8.76 小时的停机时间。
- 99.99%(四个 9):在一年中最多允许 52.56 分钟的停机时间。
- 99.999%(五个 9):在一年中最多允许 5.26 分钟的停机时间。
既然很多时候(> 99.9%),我们非常确定更新将会完成,为什么还要用户多等待几秒钟,直到从后端获得许可才能在 UI 中显示结果?
乐观更新的想法是在我们将
mutate发送到服务器之前就 伪造 成功,一旦我们收到成功的响应,所要做的就是使缓存失效以获取真实的服务端数据如果请求失败,我们将把 UI 回滚到
mutate之前的状态(并在接下来回退到阻塞模式)
交互流程大概如下,以列表新增为例:
用户点击新增按钮后,同时进行以下操作
unshift 新数据请求过程中,列表已经展示了本地数据行,但最好在视觉上提醒用户这不是终态,比如可以:
loadingopacity: 0.5
请求成功,什么都不需要做
请求失败,可以做如下操作
toast 错误提示一旦发生乐观更新失败的场景,就关闭乐观更新模式,回退到阻塞模式
配合组件化
React Query 提供了两种乐观更新的方式,先来看标准的:通过修改缓存数据实现
const queryClient = useQueryClient()
useMutation({
mutationFn: updateTodo,
// 每次 mutate 被调用时触发:
onMutate: async (newTodo) => {
// 1. 取消所有正在进行的列表获取请求
// 因为它们会覆盖我们的乐观更新
await queryClient.cancelQueries({ queryKey: ["todos"] })
// 2. 获取目前的数据快照,以便我们可以回滚
const previousTodos = queryClient.getQueryData(["todos"])
// 3. 乐观更新,直接修改数据
// 加入了 isOptimistic 字段,方便视图中的展示判断
queryClient.setQueryData(["todos"], (old) => [
{ isOptimistic: true, ...newTodo },
...old,
])
// 4. 将快照存入 context,以便在失败时回滚
return { previousTodos }
},
// 如果失败,使用 onMutate 返回的 context 回滚
onError: (err, newTodo, context) => {
queryClient.setQueryData(["todos"], context.previousTodos)
},
// 无论成功还是失败,这个函数都会被调用,在此重新获取列表数据
// 成功时获取最新的服务端数据以同步乐观更新的状态
// 失败时获取是因为我们为了防止乐观更新被覆盖,在第一步取消了正在进行中的请求,此时要让它们继续
onSettled: () => {
queryClient.invalidateQueries({ queryKey: ["todos"] })
},
}) 很取巧但是更简单的方式,不会去修改缓存数据,利用 mutate + query 配合 loading 直接在 UI 层做乐观更新
首先数据层代码是这样的:
useMutation({
mutationFn: updateTodo,
// make sure to _return_ the Promise from the query invalidation
// so that the mutation stays in `pending` state until the refetch is finished
onSettled: async () => {
return queryClient.invalidateQueries({ queryKey: ["todos"] })
},
}) 看起来好像什么都没有做:我们发起请求,并在完成后触发缓存失效更新数据,这是最常规的写法
诀窍在 onSettled 的 return,它返回了 queryClient.invalidateQueries
我们知道 invalidateQueries 的作用是使缓存失效,但实际上它会返回一个 promise,缓存失效时如果触发了网络请求,promise 会在请求成功之后 resolve
也就是说上面的代码等同于:
return fetch("/api/update", { method: "POST" }).then(() => fetch("/api/todos")) 它把 mutate 和 query 链接在了一起,变成了一个 promise 链,当整个链条没有 resolve 时,useMutation 也不会结束
所以视图层我们可以直接访问 isPending 来展示乐观更新的状态
const { isPending, variables } = useMutation()
<ul>
{todoQuery.items.map((todo) => (
<li key={todo.id}>{todo.text}</li>
))}
{isPending && <li style={{ opacity: 0.5 }}>{variables}</li>}
</ul> 非常的巧妙,如果请求成功了,isPending 就会变成 false,这样就不会展示乐观更新的数据了,但同时最新的列表数据也已经请求回来并更新在了 UI 上
如果请求失败了,isPending 同样变为 false,相当于自动执行了回滚操作
这是一个取巧且简单的方法,所以有着一些局限性:
isPending 只有一个
考虑如下场景:
const result = useTaskList()
const { isLoading, data } = result 我们知道 result 里的数据是会频繁变化的,比如当 isFetching/error/isInvalidated... 变化时
但这个组件只使用了 isLoading & data,如果其他数据的变化导致了 result 变化,进而导致组件重新渲染,这有必要吗?
因为我们只使用了 isLoading & data,所以其他数据的变化并不会导致重新渲染的组件有什么变化,所以这是没有必要的
React Query 通过监听数据的 get,实现了只会在使用的数据变化时,重新渲染组件
目前 redux 的代码,没法简单的实现这个功能,所以就直接看 ReactQuery 的源码吧
trackResult(
result: QueryObserverResult<TData, TError>,
): QueryObserverResult<TData, TError> {
const trackedResult = {} as QueryObserverResult<TData, TError>
// 只监听了第一层
Object.keys(result).forEach((key) => {
Object.defineProperty(trackedResult, key, {
configurable: false,
enumerable: true,
get: () => {
this.#trackedProps.add(key as keyof QueryObserverResult)
return result[key as keyof QueryObserverResult]
},
})
})
return trackedResult
}
const shouldNotifyListeners =() => {
const includedProps = new Set(this.#trackedProps)
return Object.keys(this.#currentResult).some((key) => {
const typedKey = key as keyof QueryObserverResult
const changed = this.#currentResult[typedKey] !== prevResult[typedKey]
// 发生更新并且数据被访问过
return changed && includedProps.has(typedKey)
})
} 每次从后台请求回来的数据,即使数据完全没有变化,引用也全部都是新的了
考虑如下响应,新获取的数据中只 id=1 发生了变化,id=2 数据是没有变的
[
- { "id": 1, "name": "Learn React", "status": "active" },
+ { "id": 1, "name": "Learn React", "status": "done" },
{ "id": 2, "name": "Learn React Query", "status": "todo" }
] React Query 会深度比较数据,并尽可能多地保留以前的状态(引用)
对于上面的响应,id=1 会是一个新的引用,而 id=2 则仍然是之前的引用
虚拟 DOM diff -> 减少 DOM 的操作
数据 diff -> 减少 虚拟 DOM 的操作
Suspense还可以接着列,但是没有必要了,详细的可以直接去看对应库的官网
就目前说的这些,已经完全可以说明同步、异步状态管理的不同了
回过头来再看:「数据获取很简单,异步状态管理不是」,也可以说「代码开发很简单,用户体验不是」
2024-04-16
在 卡片笔记法 中提到我是如何开始、进行个人知识管理,与自己对话
其中的知识体(永久笔记)是可以分享出来,所以就有了这篇文章,记录下自己是如何使用 Obsidian 来方便的将文章进行发布、分享
利用 obsidian-github-publisher 插件对内链和附件进行转换处理,自动提交合并 MR
然后在 github actions 中利用代码对内容做二次处理(这是因为插件功能太少,不够灵活)
github actions 内容处理完成,进行发布动作(issue/Blog/知乎/公众号...)
具体代码参考 blog 仓库
先说一下为什么要把文章(主要)发到 issue
star/watch发到其他地方纯粹是为了 SEO
Tip
踩坑:publisher 的链接转换必须是 [[]] 风格的才行
所以要先关闭 ob 本身的链接格式转换,避免自转换成 []() 格式
Github 仓库配置根据教程来就行,不赘述
根据 property - issue 生成目录
发布前先在 Github issue 创建一个对应的 issue,记录下 issue id 放在文章的 metadata 中
这一步其实也可以自动化,但是我个人觉得没有必要,就没有做
因为发布的整个流程中我一定会打开 GitHub 的,所以多做一步新建也无所谓
而且这个主动的操作可以防止误发(比如内链了未发布的文章)
将 Convert internal links pointing to unpublished notes 打开
因为我觉得链接了内链,说明其是有承上启下的作用的,所以不能直接删除或不做处理
但其实我还留了个后门,对于某些文章我可能先写了「上篇」,想先发布,此时可以给内链前加上 TODO 的标记
- [ ]也可以跳过检查
插件只负责内容的转换,校验相关的事情放在 github actions 中做
选择 transform link 内容填空
将内嵌的链接从 ![[]] 变成 [[]],这样发布之后就是一个正常的内链了
其他配置根据自己的需要配置
metadata 中最好记录上文章的创建/发布时间,方便后续排序/展示使用,可以使用 Update time on edit 插件
文章写完通过 obsidian-github-publisher 发布,其会创建 、自动合并 PR(需要配置)
触发 github actions 后,流程如下
代码合并之后会触发主分支的 github action 构建流程
综上所述在发布文章时一定会先获得并填入一个 issue id,所以如果内链的地址没有 issue id,说明这篇文章还没有准备好发布
此时就校验失败,阻断 Workflow 就好
首先通过 git diff 找出本次提交中变更的文件列表,筛选出文章路径后,依次进行处理
主要是内链和 metadata 的处理,Blog 与 issue 之间并不相同,所以要存两份数据单独处理
以及处理过程中收集每一篇文章的 metadata 信息,后面要用
首先是本地图片路径,直接转换成 git 仓库的绝对路径,示例如下
https://github.com/$username/$blogname/blob/main/$assets_path.png
然后是文章的内链,对于 Blog 可以直接转换成 ./issue_id 的相对路径
而对于 issue 来说则必须是绝对路径,否则无法触发 hover 预览
https://github.com/$username/$blogname /issues/$issue_id
issue 不需要 metadata,所以直接丢弃掉即可
而对 Blog 则根据情况自动补充一些冗余的属性
比如我用的 jekyll blog,其可以配置 permalink 来生成固定的文章地址,所以我就会把 issue 映射到 permalink 上
每篇内容处理完后,把 blog 的内容写入到仓库的对应 md 文件中,后续 jekyll 会根据这些文件生成博文
此时可以通过 API 把 issue 内容发布到 issue 上,这样 issue 的部分就处理完毕了
当所有内容处理结束后,将收集的 metadata 信息写入到仓库中,以方便下次更新时使用
通过 metadata 生成博客首页数据(index.md),其实就是根据时间排序的文章链接列表
然后把修改后的 Blog 文件内容写入到 docs/ 文件夹下,后面合并到主分支后会自动触发部署动作
同样再通过 metadata 生成 Github 首页数据(README.md),将跳转链接指向 issue 中
此时 Github issue 上的工作就已经全部完成了
之后通过 job 开始部署 Jekyll Blog 就完成了所有部分
由于我不熟悉 ruby 的语法,以及 github-pages 中有很多插件的限制,所以有些不重要(SEO)的功能就直接用 JS 去实现了
Tip
最主要是 ruby 的依赖问题搞得心累,装上个插件就各种崩…
上面说到所有文章的 Metadata 信息都被收集并保存在了本地,这个会被 jekyll 发布到网站中,进而可以通过 JS 直接获取
能拿到所有文章的信息,再和当前文章做对比,自然就可以渲染出「上一篇」「下一篇」了
同上,创建一个单独的 tags 页面,其中用 JS 做分类渲染、筛选功能
从 tags 页进入的文章,URL 上会携带 tag query,进而调整分页的渲染逻辑
actions 中是可以使用无头浏览器的,所以理论上都可以做,但我目前还没时间搞,后面搞了再补充
2024-01-03
原文:JavaScript engine fundamentals: Shapes and Inline Caches · Mathias Bynens
JavaScript 引擎解析 source code 并将其转换为 AST(抽象语法树)
基于该 AST,解释器可以开始执行并生成 bytecode(字节码)
为了使其运行得更快,字节码与分析数据一起发送到优化编译器
优化编译器根据其拥有的分析数据做出某些假设,然后生成高度优化的机器代码
如果在某个时刻,其中一个假设被证明是不正确的,优化编译器就会取消优化并返回到解释器
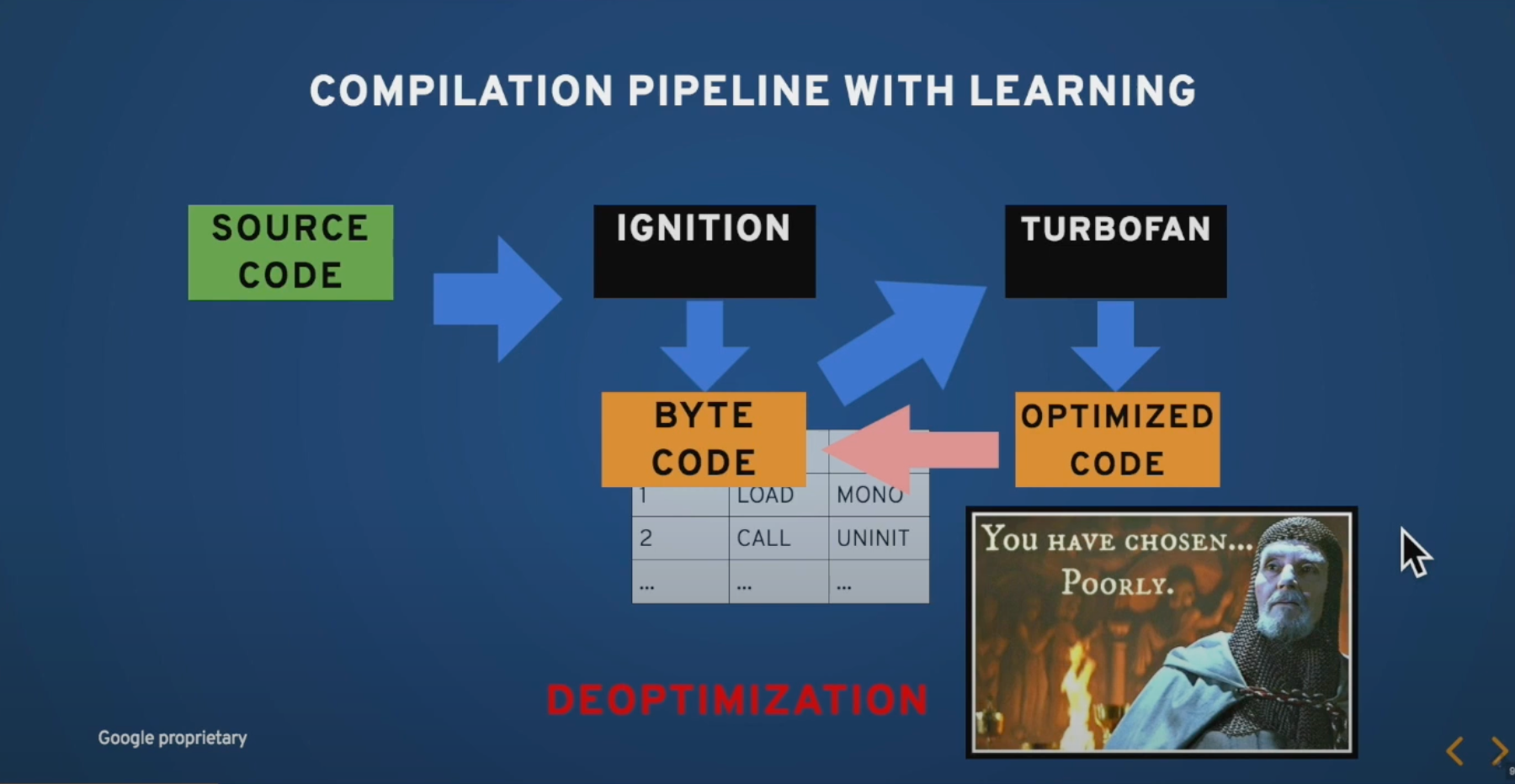
主要是黄色部分
早期的 V8 只有一个解释器 Ignition 和一个 优化编译器 TurboFan(21 年加入了 Sparkplug 编译器,23 年引入了 Maglev 优化编译器,在 Sparkplug 和 TurboFan 之间)
而 SpiderMonkey(在 Firefox 和 SpiderNode 中使用的 Mozilla JavaScript 引擎)拥有两个优化编译器
解释器优化为基线编译器,生成某种程度优化的代码。结合运行代码时收集的分析数据,IonMonkey 编译器可以生成高度优化的代码。如果推测性优化失败,IonMonkey 将回退到基线代码
JSC(JavaScriptCore)是苹果公司在 Safari 和 React Native 中使用的 JavaScript 引擎,通过三种不同的优化编译器将其发挥到了极致
虽然差异存在,但是整体上都是相同的架构:有一个解析器和某种解释器/编译器管道
为什么引擎之间会有这些差异呢?核心都是 trade-off
在快速运行(启动)代码(解释器)或花费更多时间但最终以最佳性能运行代码(优化编译器)之间存在权衡
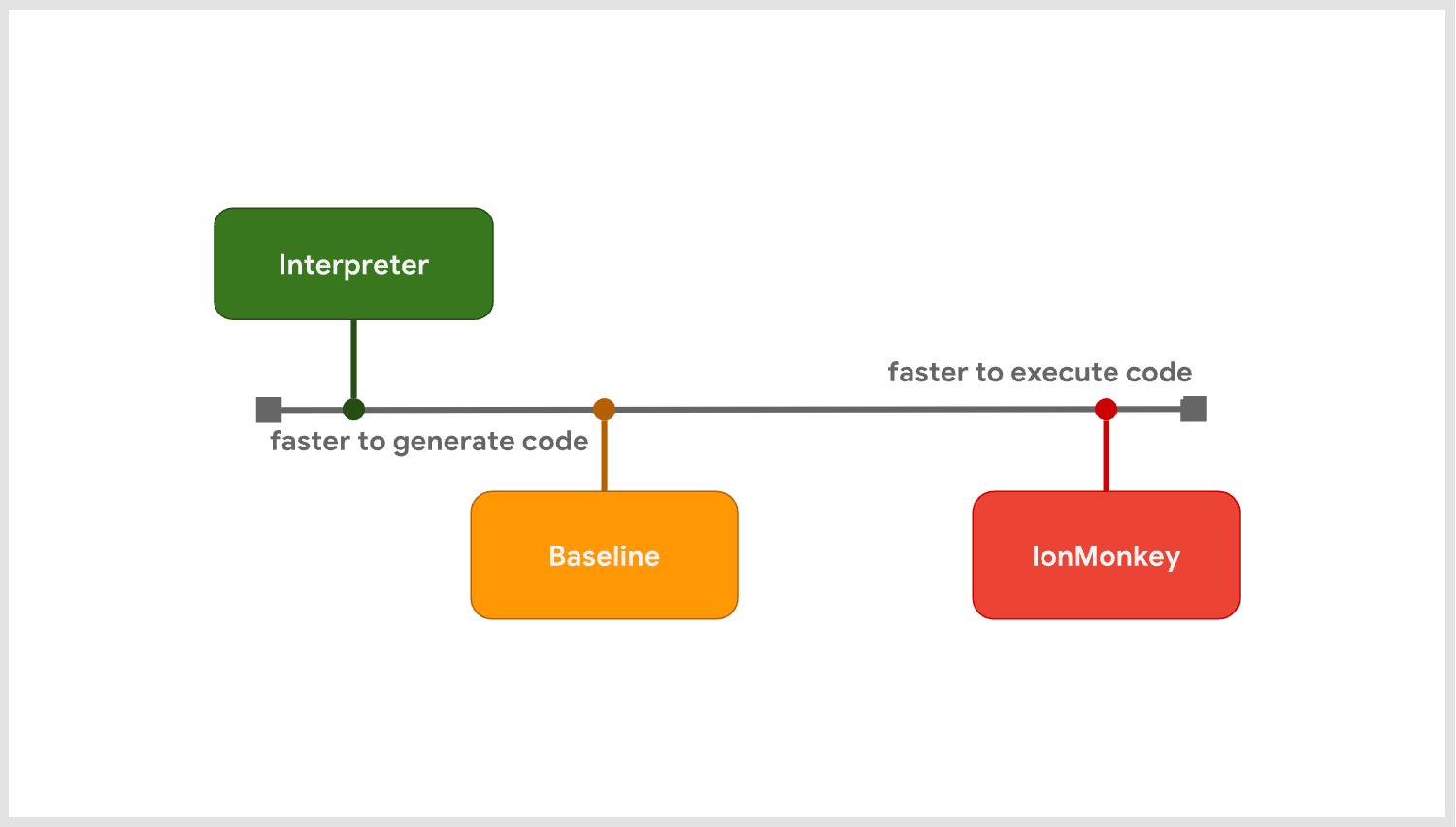
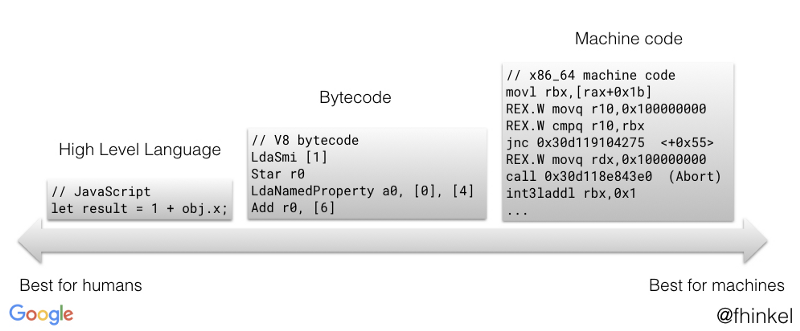
启动延迟和执行速度之间的权衡是 JavaScript 引擎选择在两者之间添加优化层的原因
还有一个原因就是内存使用
这里有一个简单的 JavaScript 程序,它将两个数字相加
function add(x, y) {
return x + y;
}
add(1, 2); 这是我们使用 V8 中的 Ignition 解释器为 add 函数生成的字节码:
StackCheck
Ldar a1
Add a0, [0]
Return
不用关注确切的字节码——你只需要知道这只是四个指令
当代码变热(hot)时,TurboFan 会生成以下高度优化的机器代码:
leaq rcx,[rip+0x0]
movq rcx,[rcx-0x37]
testb [rcx+0xf],0x1
jnz CompileLazyDeoptimizedCode
push rbp
movq rbp,rsp
push rsi
push rdi
cmpq rsp,[r13+0xe88]
jna StackOverflow
movq rax,[rbp+0x18]
test al,0x1
jnz Deoptimize
movq rbx,[rbp+0x10]
testb rbx,0x1
jnz Deoptimize
movq rdx,rbx
shrq rdx, 32
movq rcx,rax
shrq rcx, 32
addl rdx,rcx
jo Deoptimize
shlq rdx, 32
movq rax,rdx
movq rsp,rbp
pop rbp
ret 0x18
与四个字节码指令相比,机器码无疑会有更多的内存占用
但字节码需要解释器才能运行,而优化后的代码可以直接由处理器执行
这也是引擎选择优化时所要考虑的主要原因,生成优化的机器代码需要很长时间,还需要更多的内存
基于上述问题,不同引擎间选择添加多个具有不同时间/效率特征的优化编译器,允许对进行更细粒度的控制,但代价是增加了复杂性和开销
虽然引擎在架构上都有所不同,但有些优化手段是共有的
JavaScript 引擎如何实现 JavaScript 对象模型,以及它们使用哪些技巧来加速访问 JavaScript 对象的属性
ECMAScript 规范本质上将所有对象定义为字典,其中字符串键映射到属性属性,纵观 JavaScript 程序,访问属性是最常见的操作
对于 JavaScript 引擎来说,快速访问属性至关重要
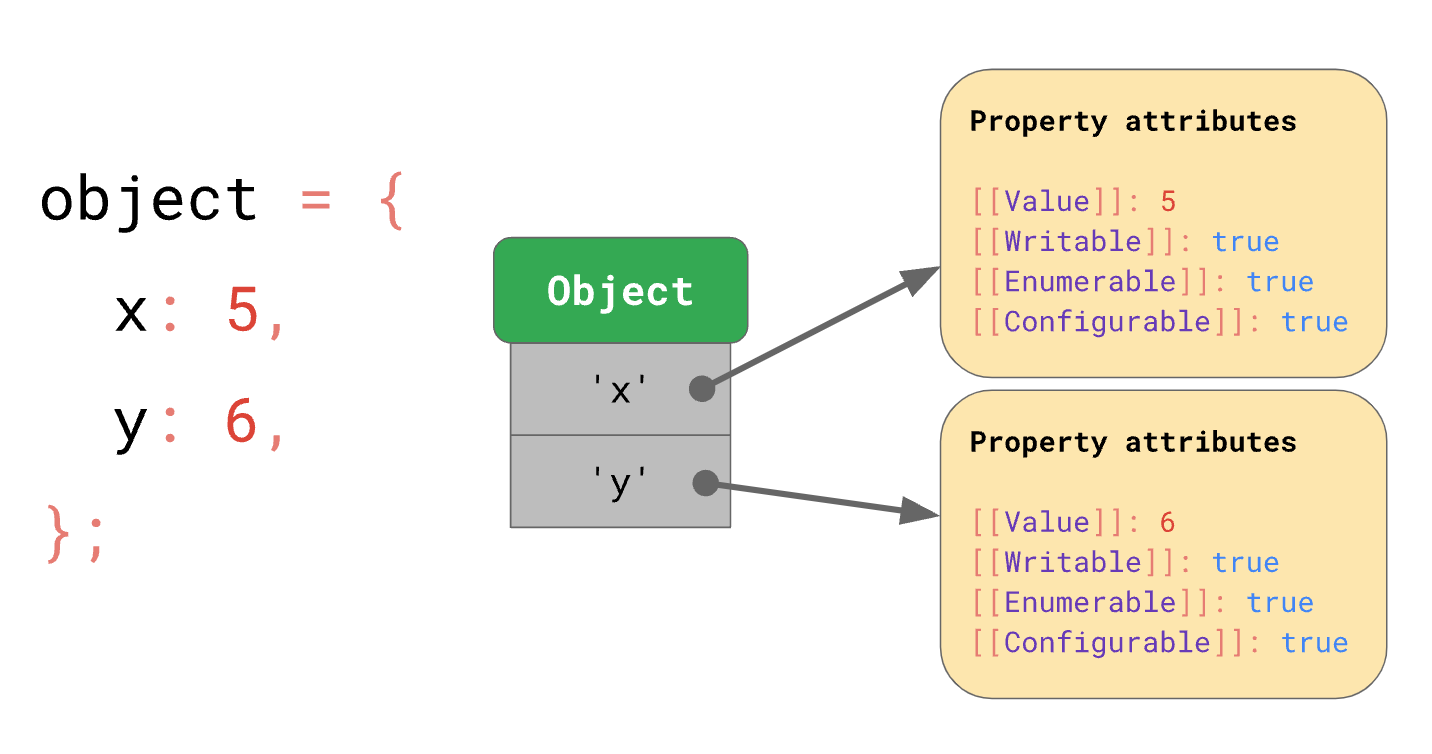
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
// `object1` and `object2` have the same shape. 在 JavaScript 程序中,多个对象具有相同的属性键是很常见的,我们称这些物体具有相同的形状(shapes)
function logX(object) {
console.log(object.x)
}
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2); 访问具有相同形状的对象的相同属性也很常见
考虑到这一点,JavaScript 引擎会根据对象的形状优化对象属性访问
考虑下面这个结构,当访问 object.y 时,会在 Object 上查找 y,并返回其中存储的 [[Value]] 属性
但如果现在有 N 个形状相同的 Object 呢?在每一个 Object 上都存储完整、重复的属性表显然是不必要和浪费的
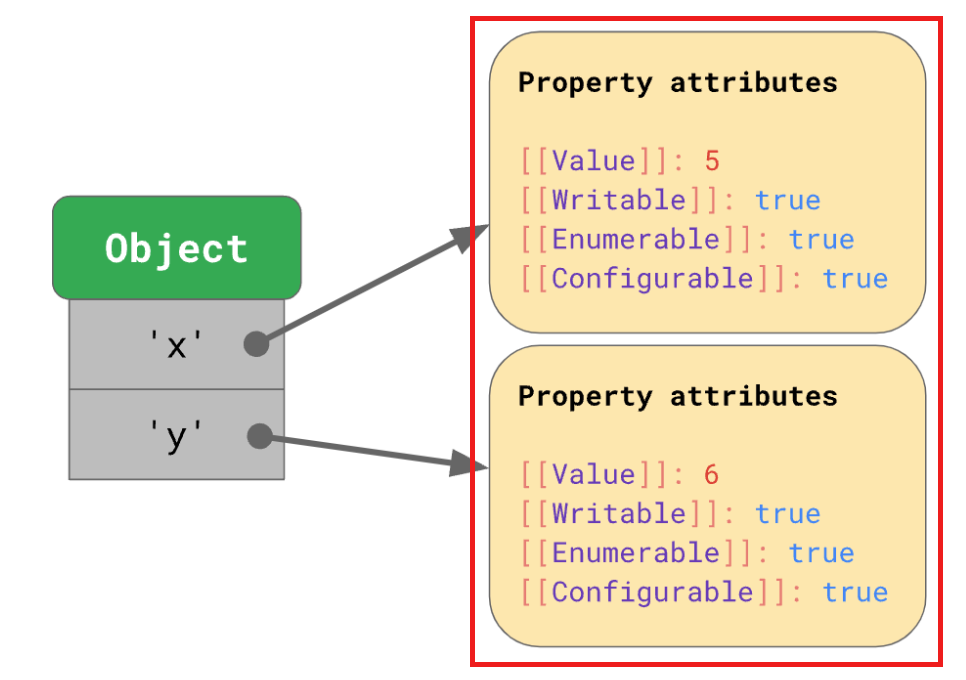
所以我们可以单独存储对象的 Shape,并将所有形状相同的对象与这个 Shape 进行关联,这样每个 JSObject 只需存储该对象唯一的值
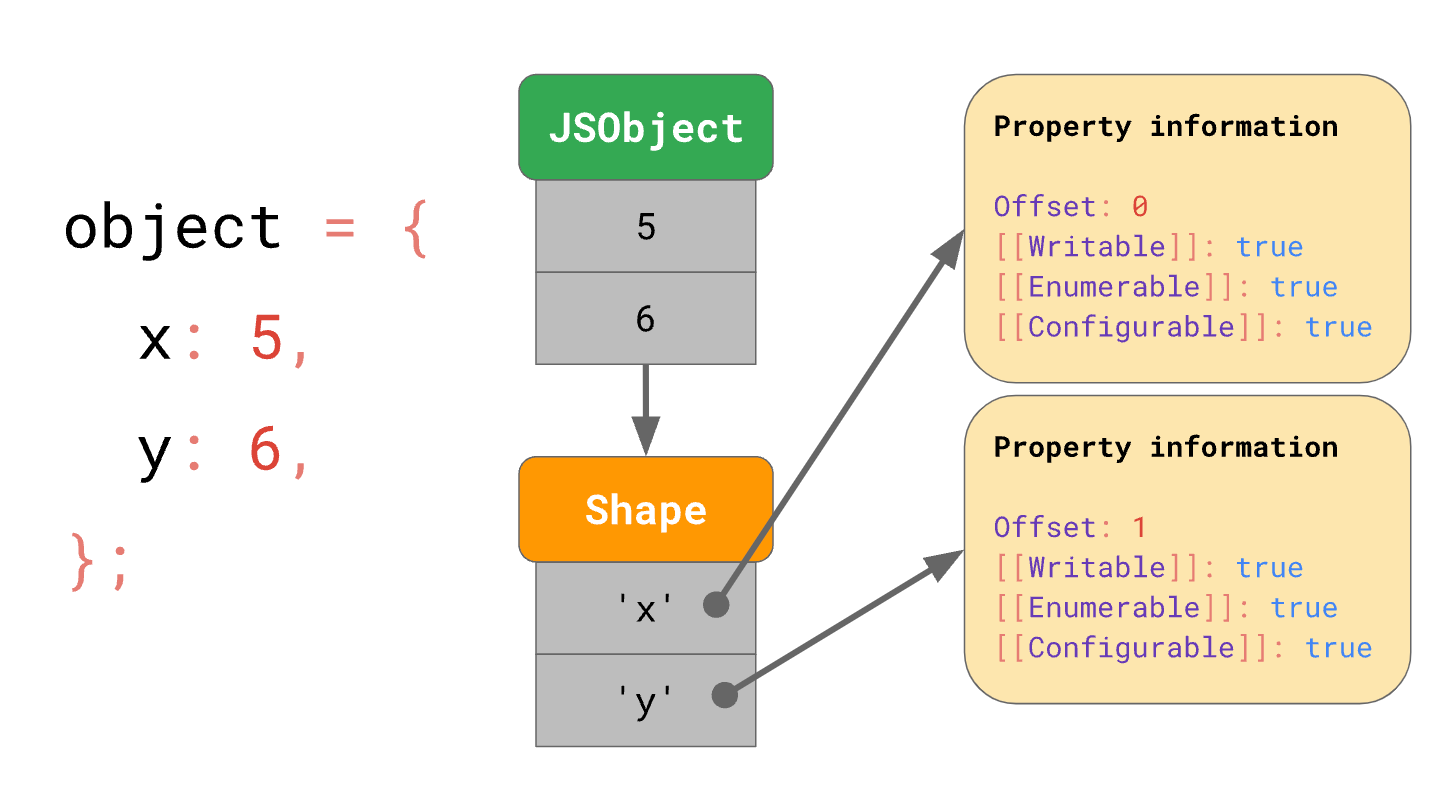
Shape 包含所有属性名称和属性,除了 [[Value]],它包含了 JSObject 内部值的偏移量,以便找到 [[Value]]
所有 JavaScript 引擎都使用 Shape 作为优化,但不一定都称其为 Shape:
如果向一个具有特定形状的对象添加了属性,会发生什么情况,JavaScript 引擎如何对新属性进行查找呢?
const object = {};
object.x = 5;
object.y = 6; 上面的代码中每一行都会创建一个独立的 Shape,这就形成了 transition chains (转换链)
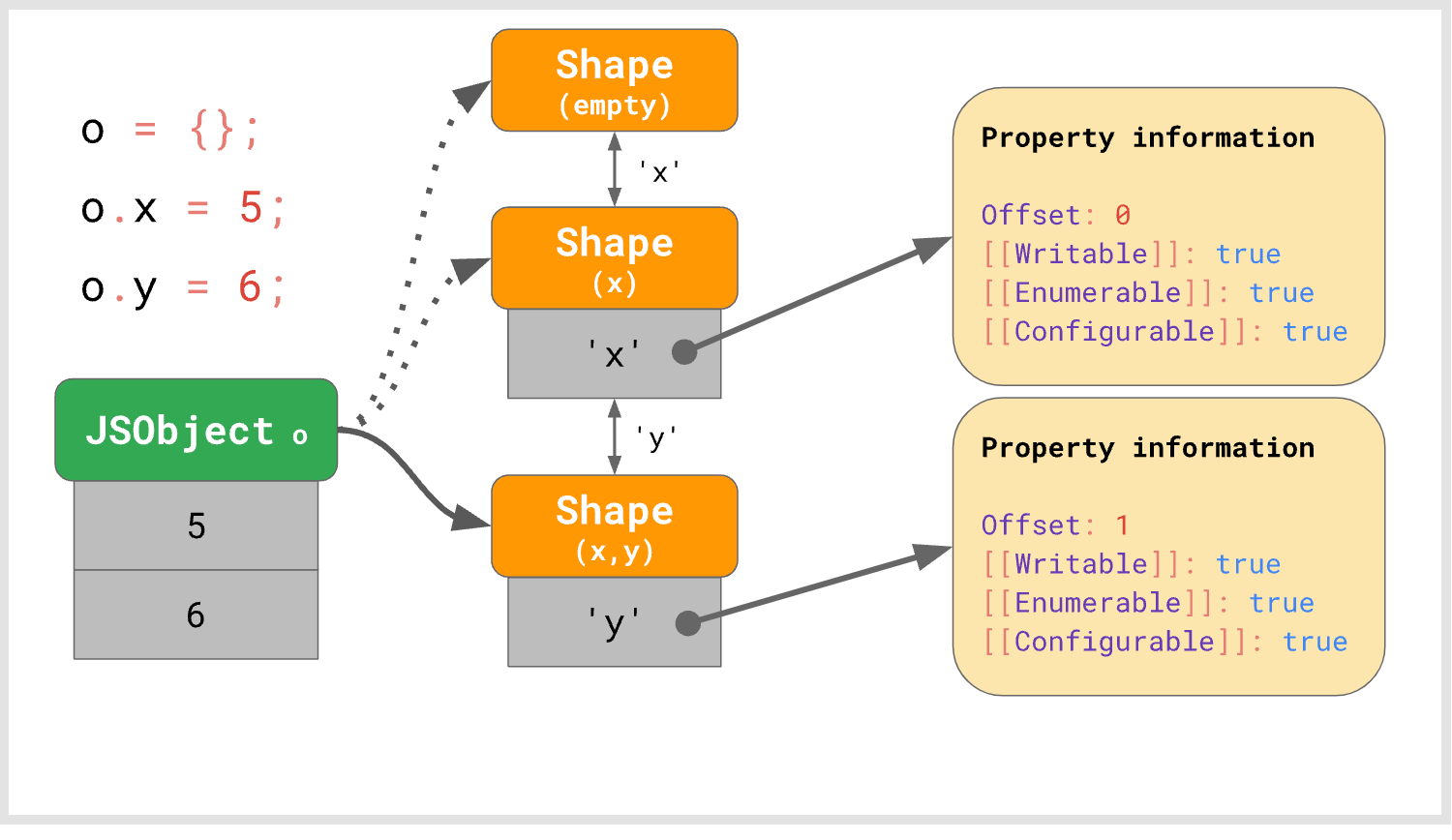
每个 Shape 只需要知道它引入的新属性,并通过链表进行链接,当进行属性查找时会从底部向上查找(这是一个问题,见下)
Warning
所以添加属性的顺序会影响形状。例如 { x: 4, y: 5 } 会产生与 { y: 5, x: 4 } 不同的形状
如果无法创建转换链,我们必须进行分支,最终会得到一个 transition tree (转换树)
例如,对两个空对象分别添加不同的属性
const object1 = {};
object1.x = 5;
const object2 = {};
object2.y = 6; 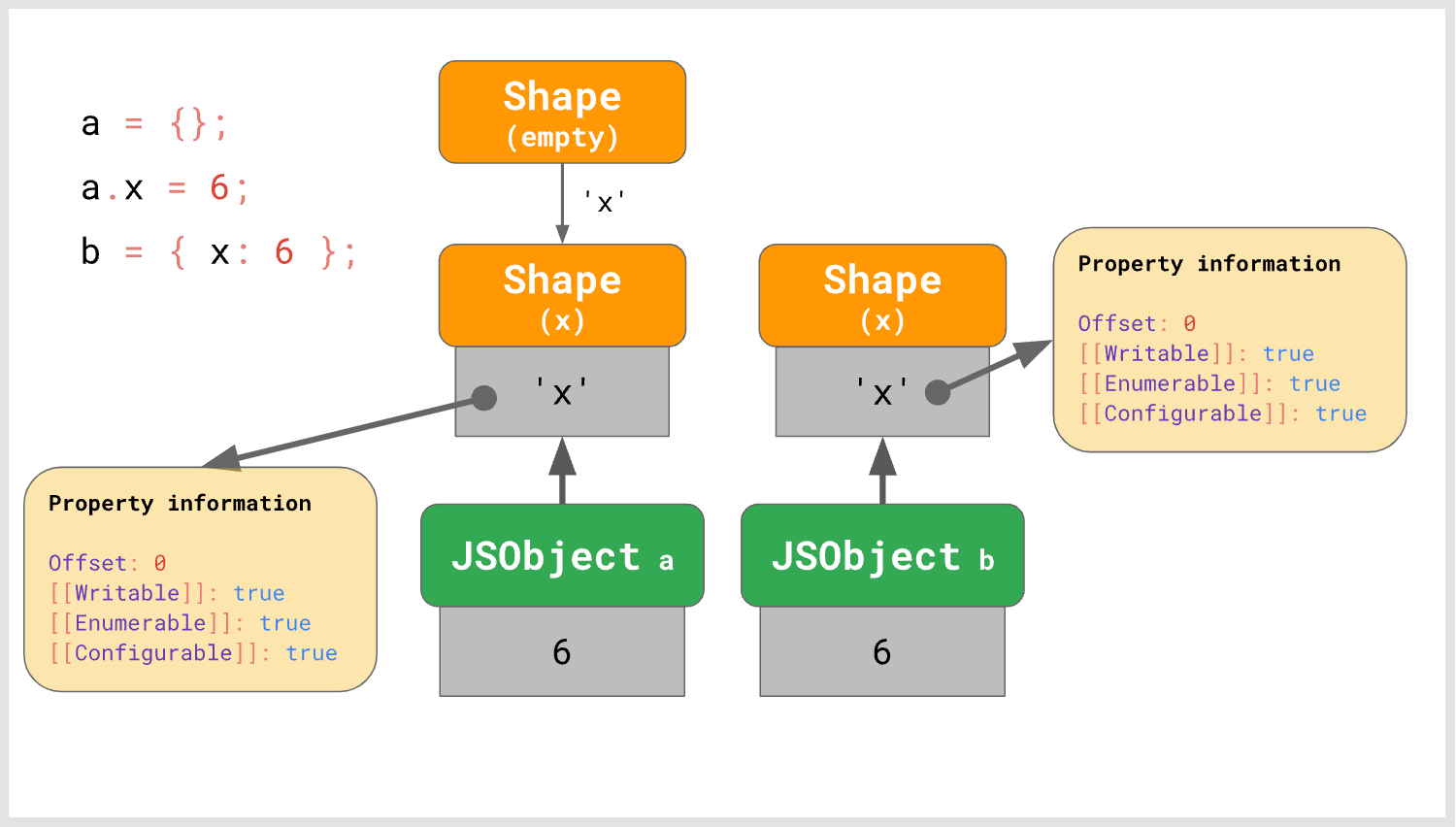
const point = {};
point.x = 4;
point.y = 5;
point.z = 6; 上述代码会产生如下 transition chain
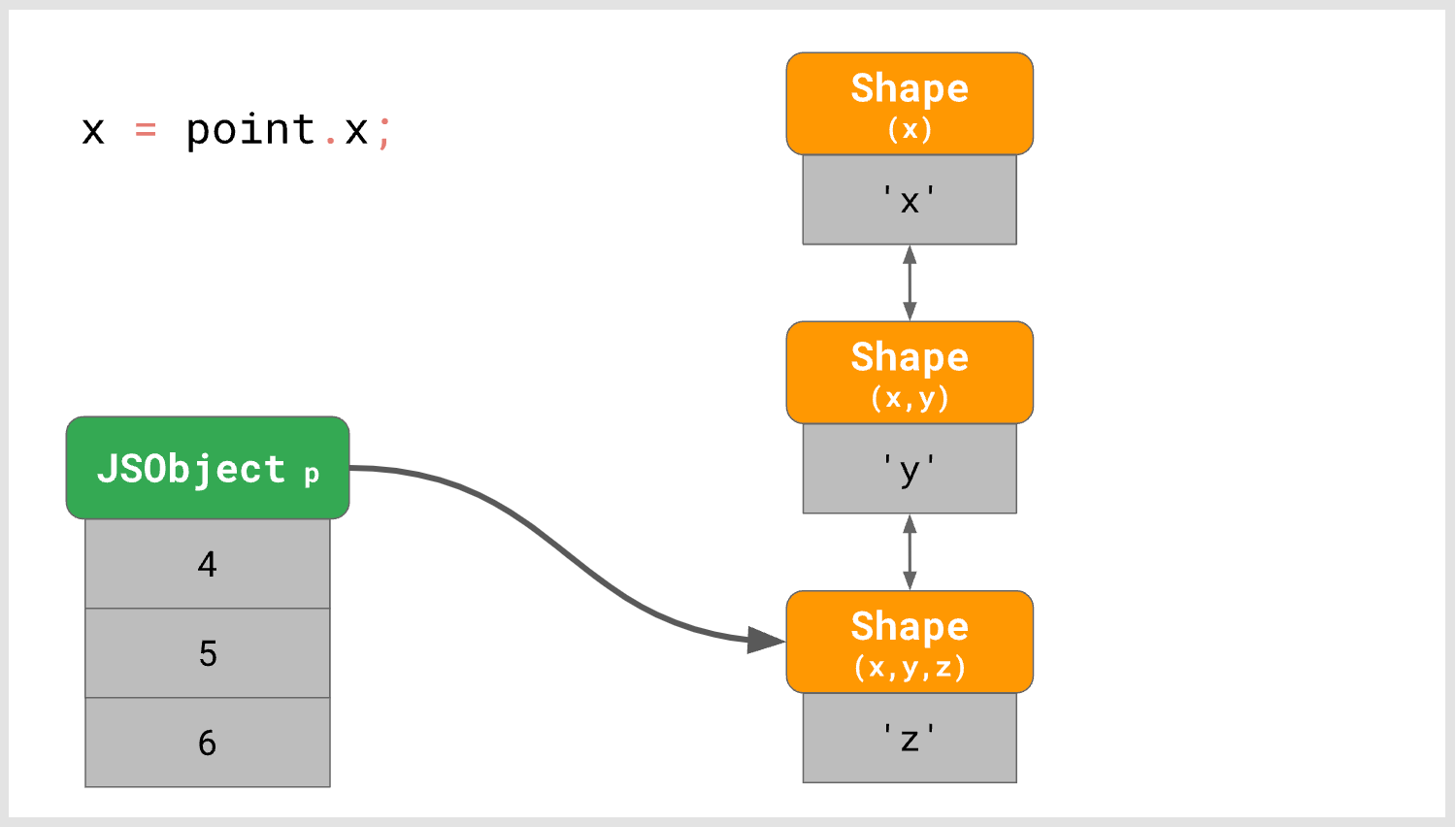
可以想到,如果我们访问 x(顶部的值),就需要从底部向上查找。找到属性的时间是 O(n) ,即与对象的属性数量成线性关系
为了加快属性搜索速度,JavaScript 引擎添加了 ShapeTable 数据结构。这个 ShapeTable 是一个字典,将属性键映射到引入给定属性的相应 Shape
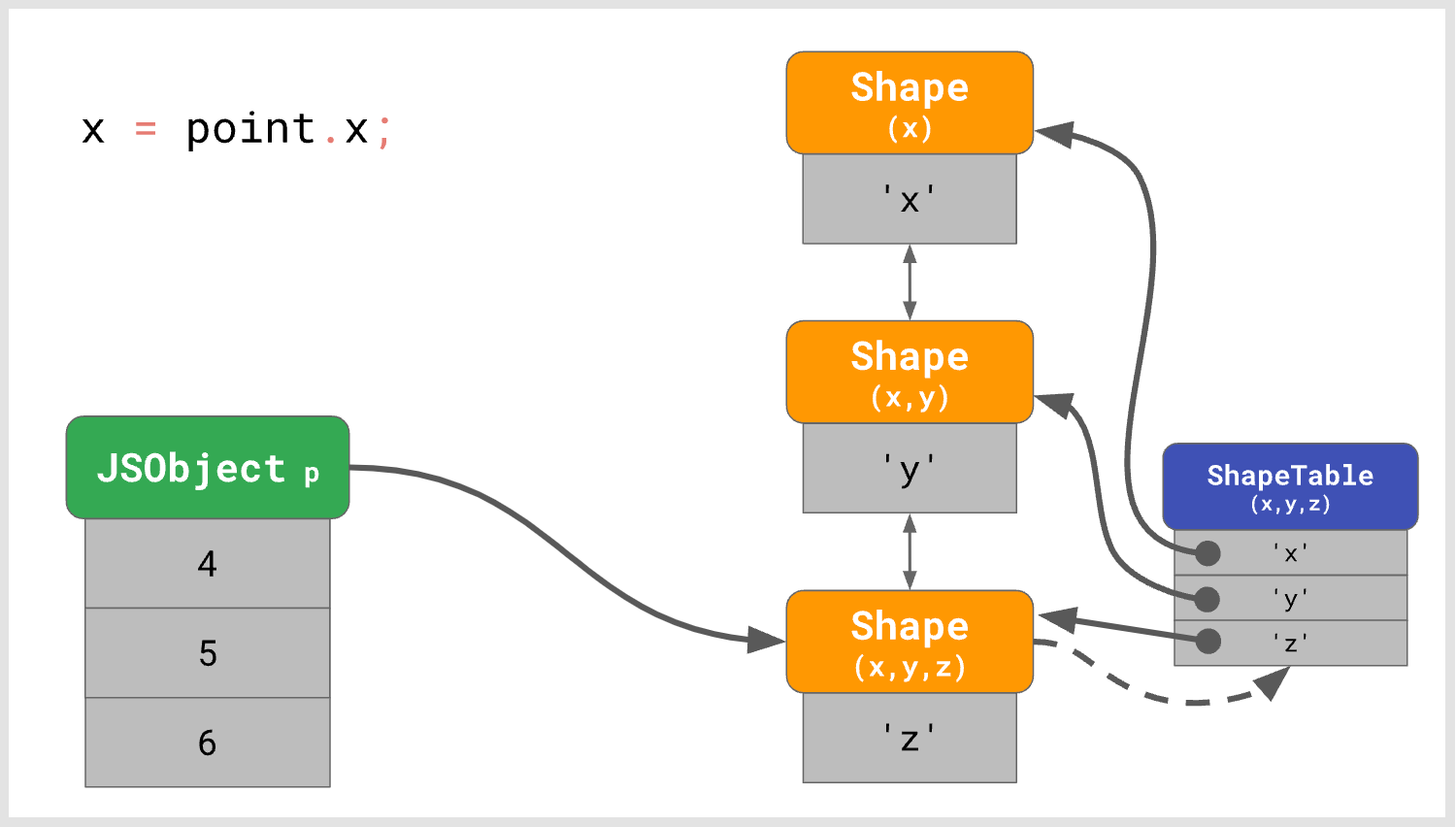
等等,我们似乎回到了原点 Object Model,这不就是添加 Shape 之前的内存结构吗?
所以为什么还要引入 Shape 呢?
原因是 Shape 可以实现一种称为 Inline Caches (内联高速缓存)的优化,这是 JavaScript 快速运行的关键因素
引擎使用 IC 来缓存查找对象属性的信息,以减少昂贵的查找次数
考虑 getX 函数,它会被编译成字节码(绿色部分),其中两个红色的 N/A 就是缓存信息所使用的 slots (槽)

每次函数运行时,都会记录传入对象的 Shape 和 offset
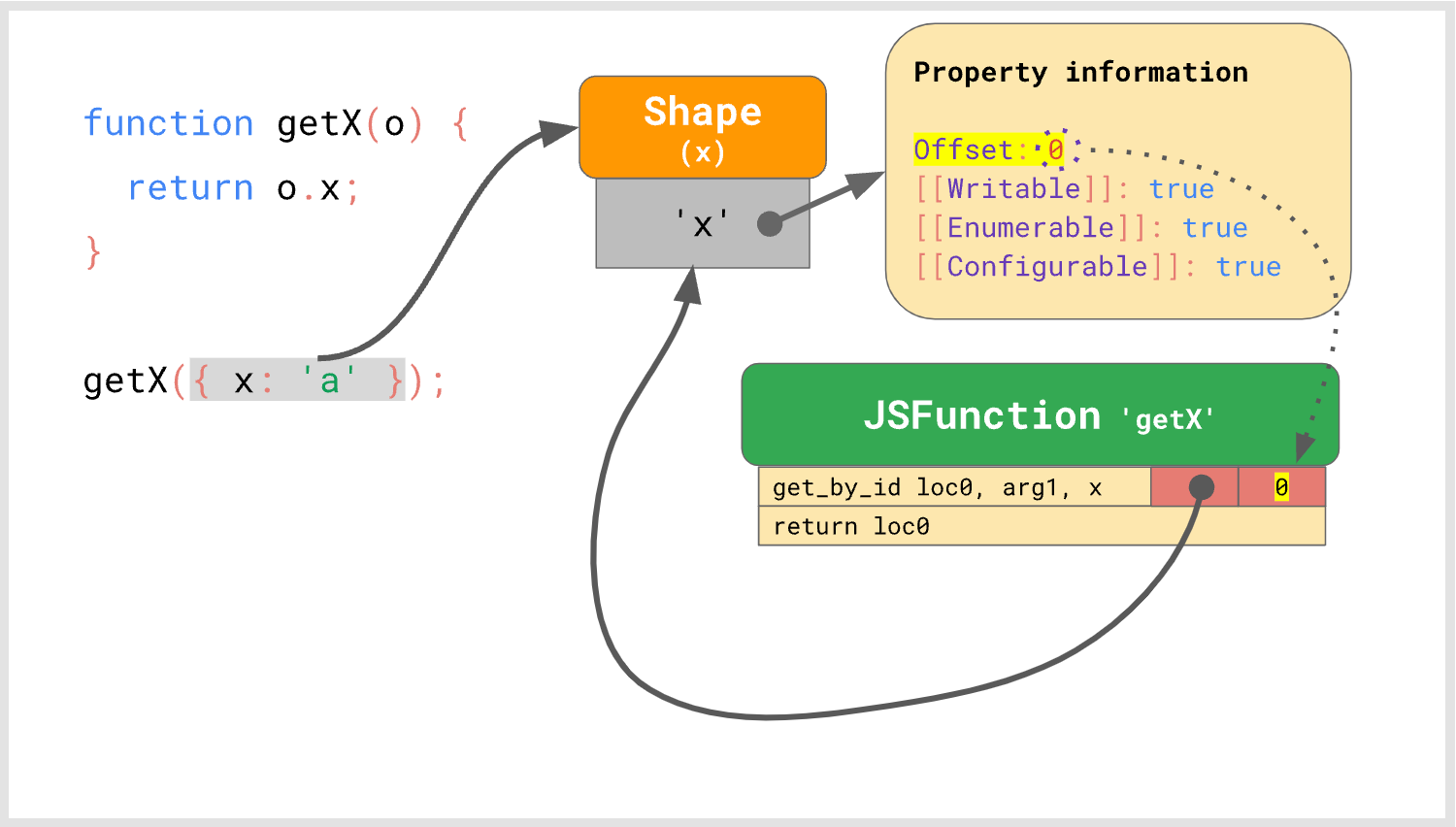
当函数再次运行时,会比较当前传入的 Shape 和之前的 Shape,如果它们是一致的,就可以直接使用缓存的 offset 读取值,省去查找的过程
Note
所以固定的 Shape 是会提高运行效率的,尽量在对象初始化的时候就将所有字段添加完整,避免后续的动态添加和删除(可以置为 null or undefined)
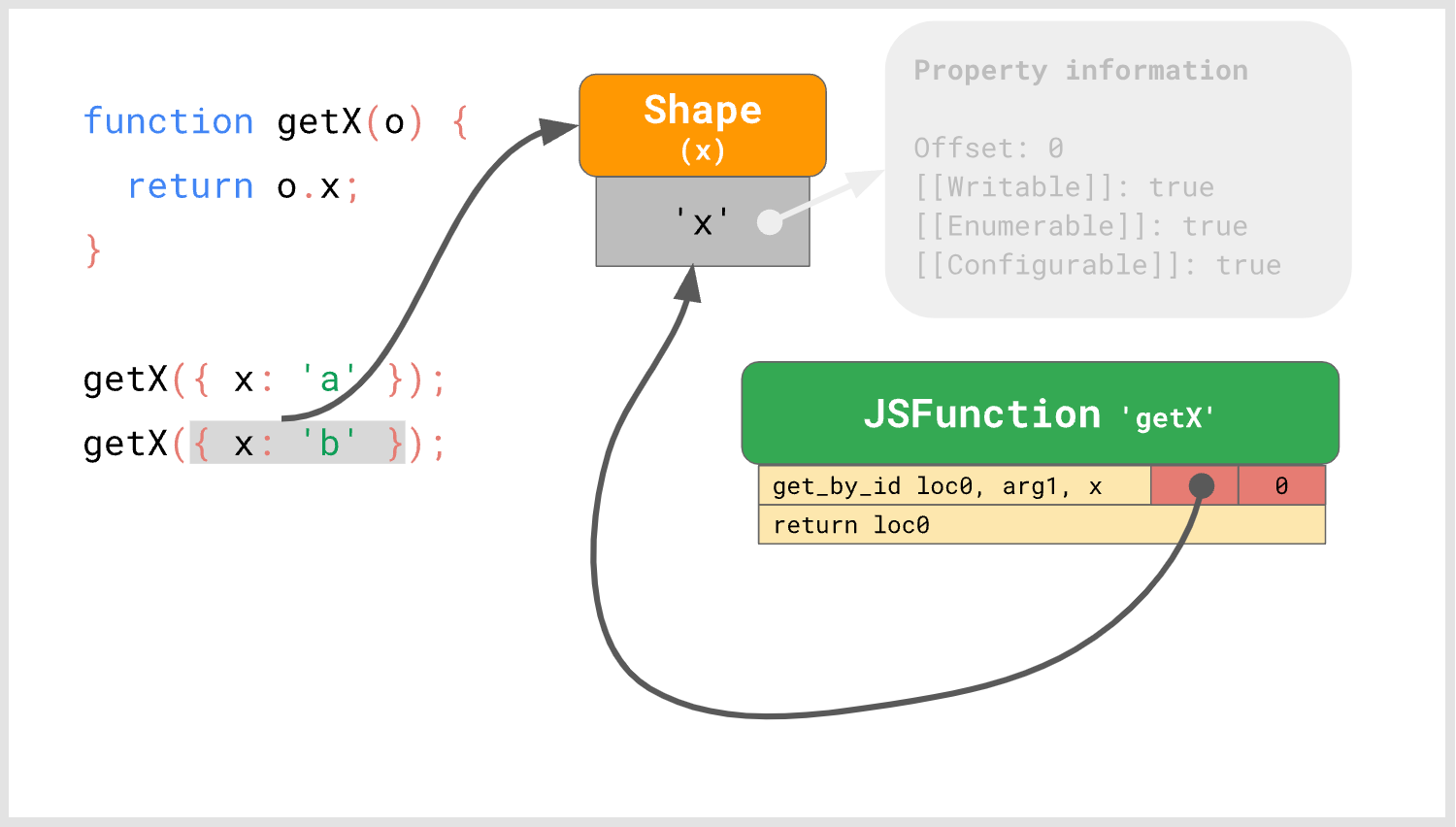
一个原始的数组,会有一个具有 length 属性的 Shape,并有一个单独的 Elements 用来存储其中的值
数组天然就是使用 offset 访问的,所以不需要额外记录 offset
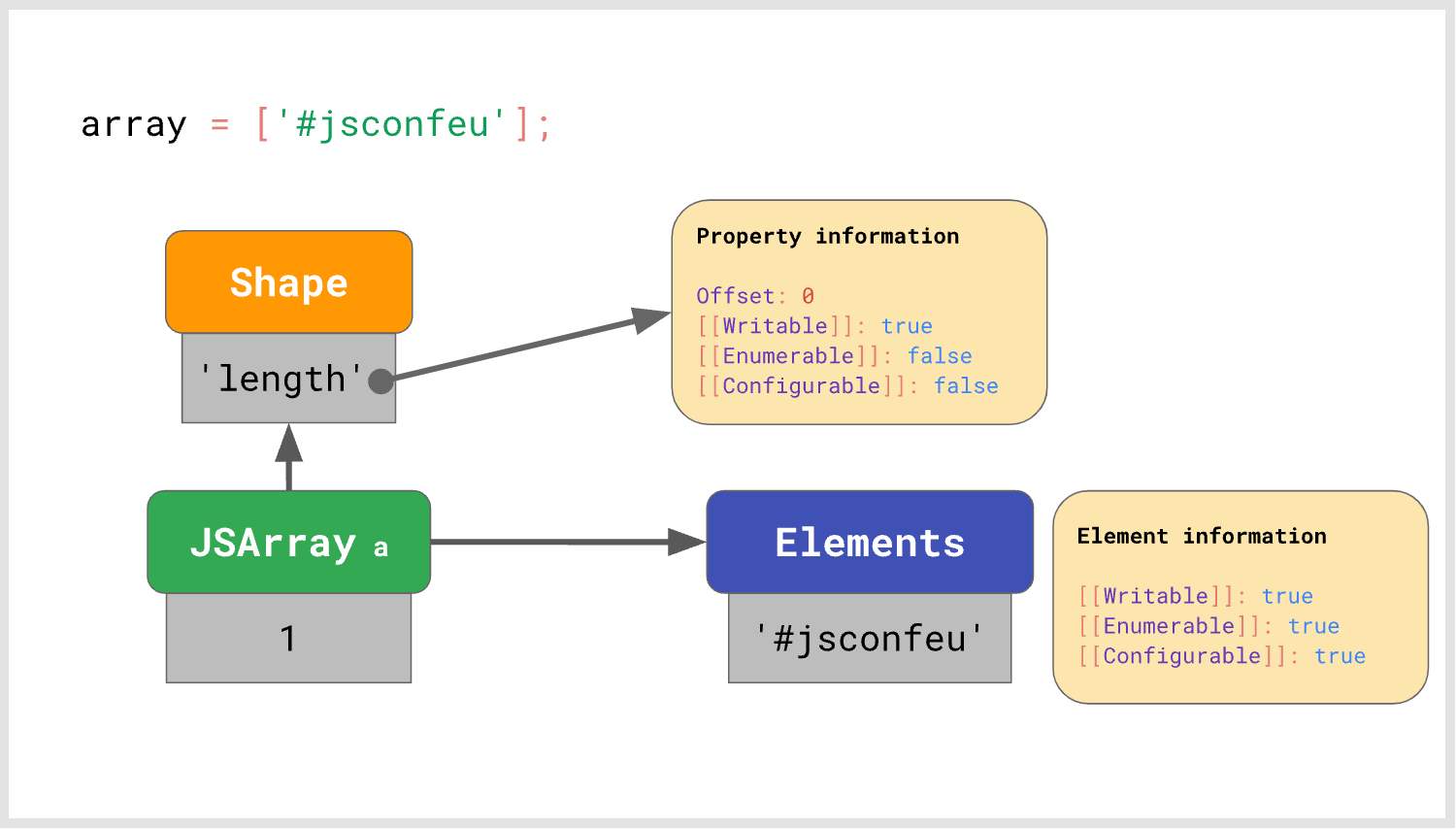
注意到我们并没有为 Elements 中的每一个值单独记录其属性 [[Writable]]/[[Enumerable]]/[[Configurable]],而是将其与整个 Elements 做了关联,这是因为数组索引属性默认情况下可写、可枚举和可配置的事实
但如果我们故意给某个索引的值修改了默认配置,会怎么样呢?
引擎会将整个 Elements 替换为以索引为键的字典结构,分别记录每一个索引的属性
即使只有一个数组元素具有非默认属性,整个 Elements 就会进入这种缓慢低效的模式
Important
所以不要!不要!不要去修改数据索引的默认属性
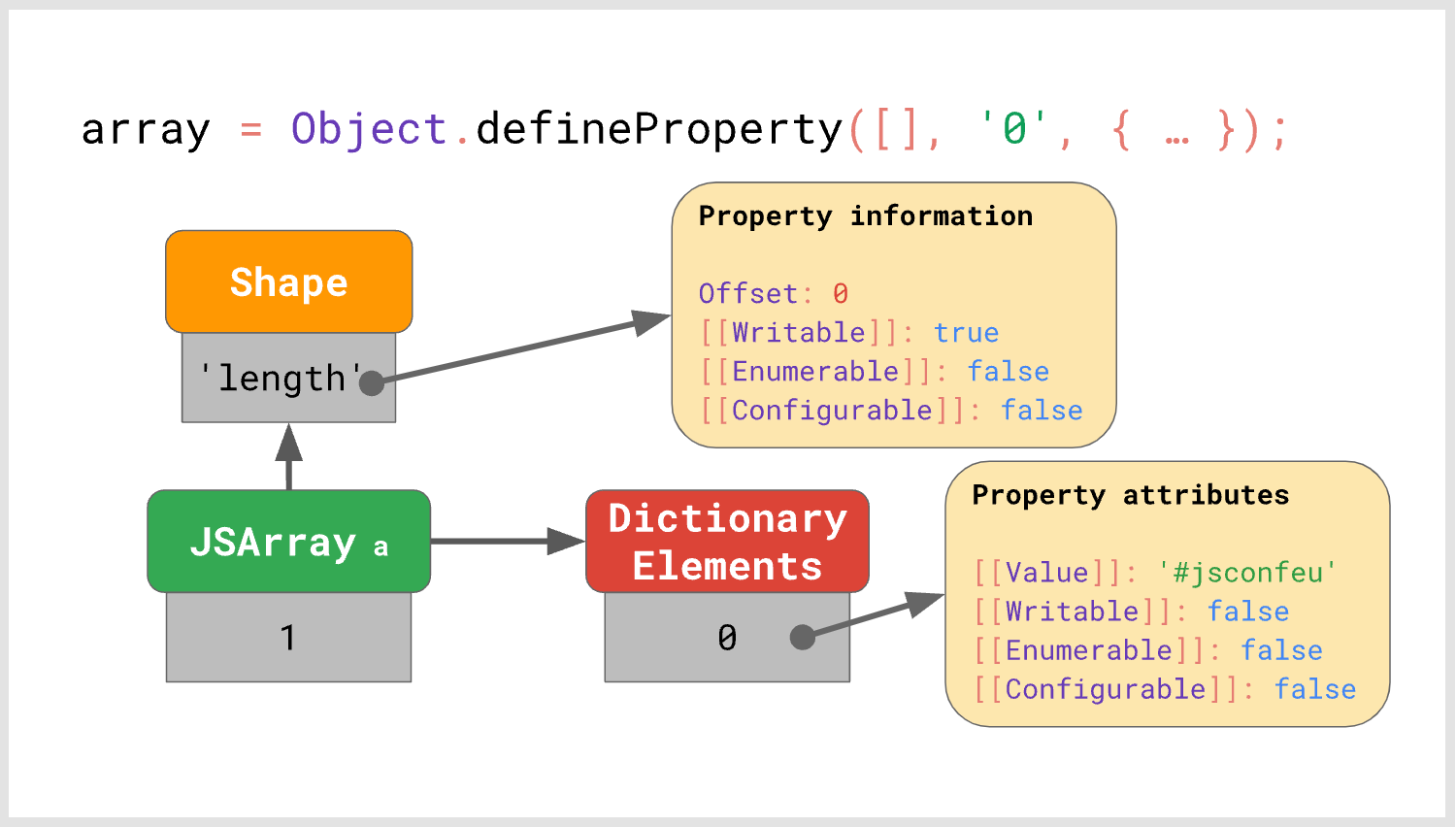
上面讲了使用 Shape 和 IC 优化对象属性加载,下面来看原型属性访问是如何进行优化的
我们都知道 ES6 中的 Class 只是 ES5 构造函数 & 原型链的语法糖而已,所以我们直接来看脱糖后的示例:
function Bar(x) {
this.x = x;
}
Bar.prototype.getX = function getX() {
return this.x;
} 当我们创建实例时,结构图如下
const foo = new Bar(true); 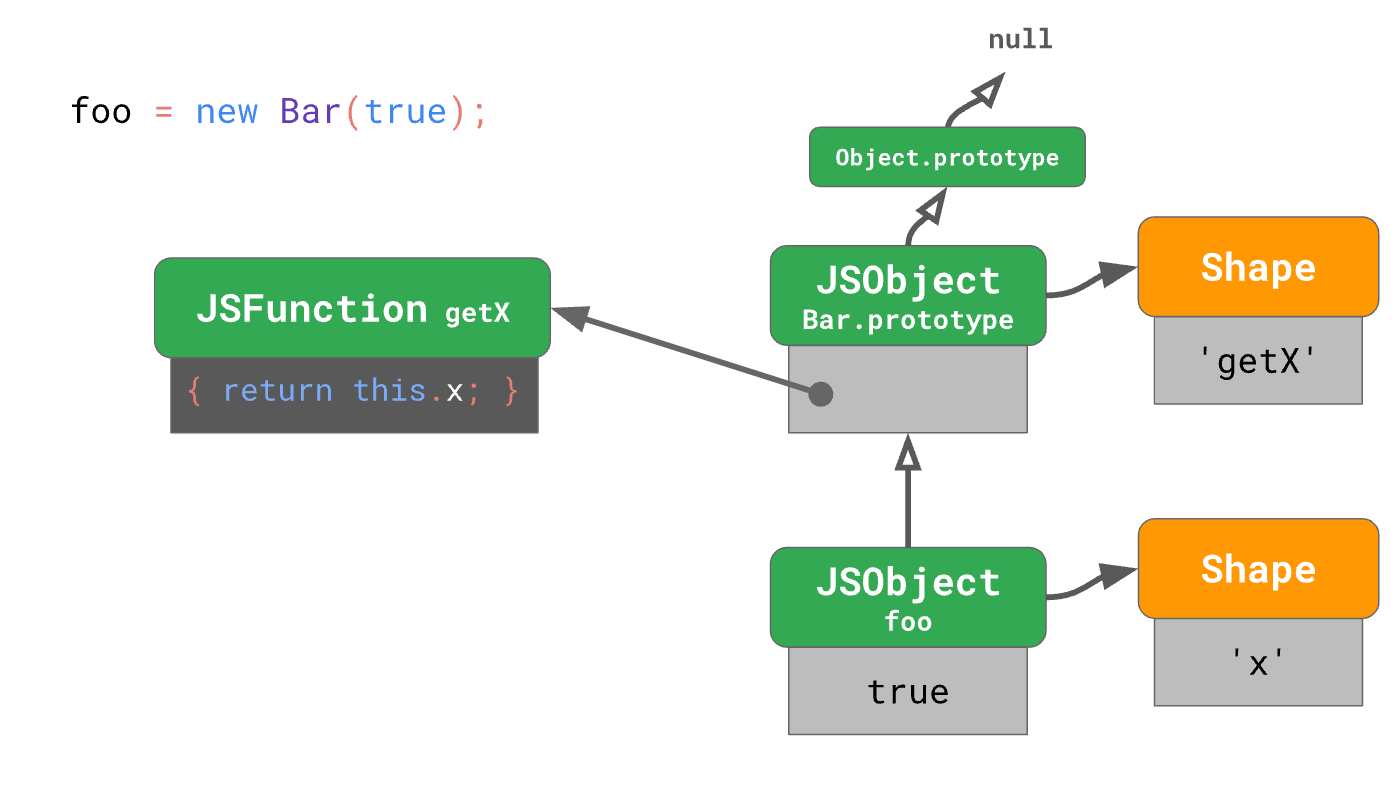
foo 本身具有 Shape-x,Bar.prototype 具有 Shape-getX,当我们创建另一个实例时,其会共享已存在的 Shape
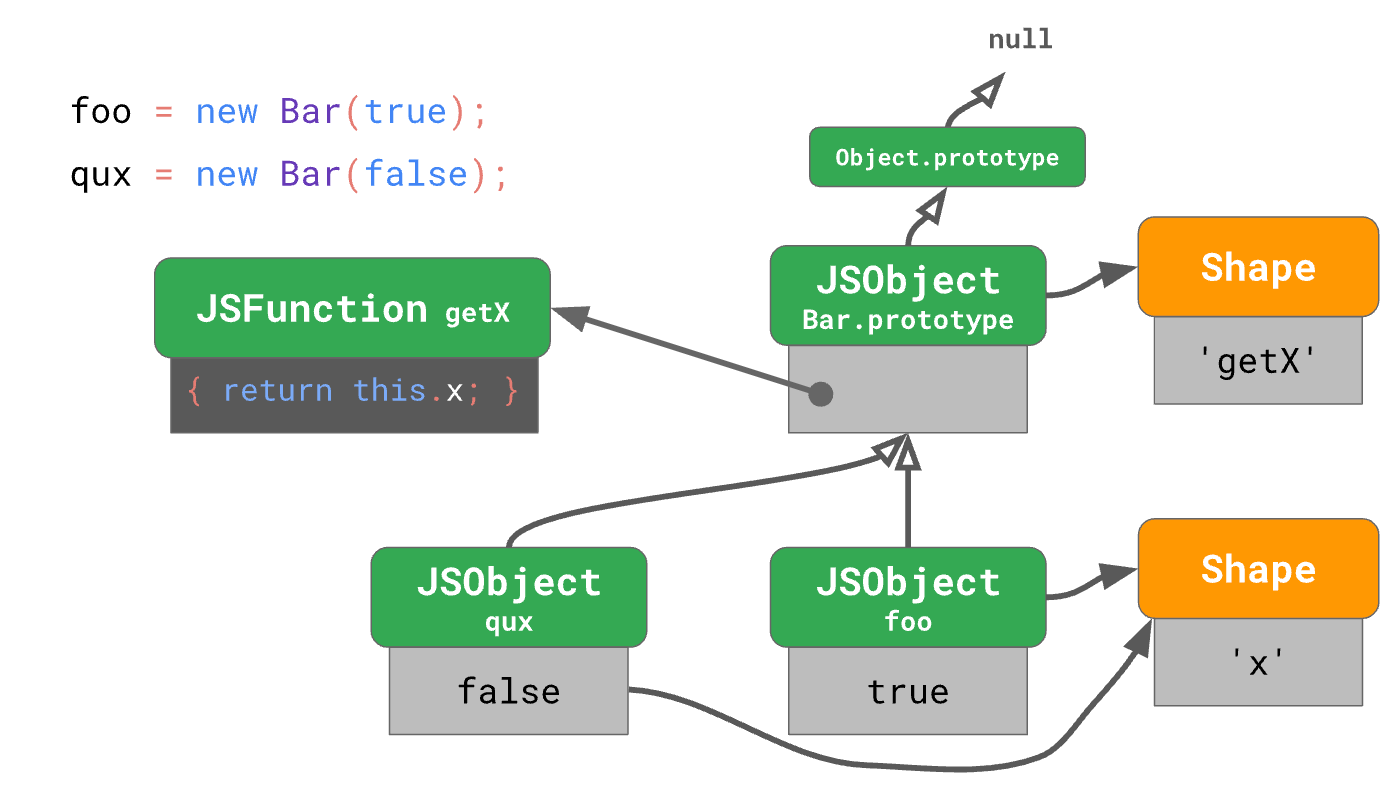
JS 中属性的访问规则是先从自身查找,如果没有则顺着原型链向上逐级查找
原型
Class.prototype也只是一个普通的对象,只是上述的查找规则赋予其共享的能力
当我们访问原型属性时
const $getX = foo.getX 引擎会从 foo 开始查找,并意识到 foo 的 Shape 上没有 'getX' 属性
因此它沿着原型链向上走,最终在 Bar.prototype 的 Shape 中发现了 'getX' 属性
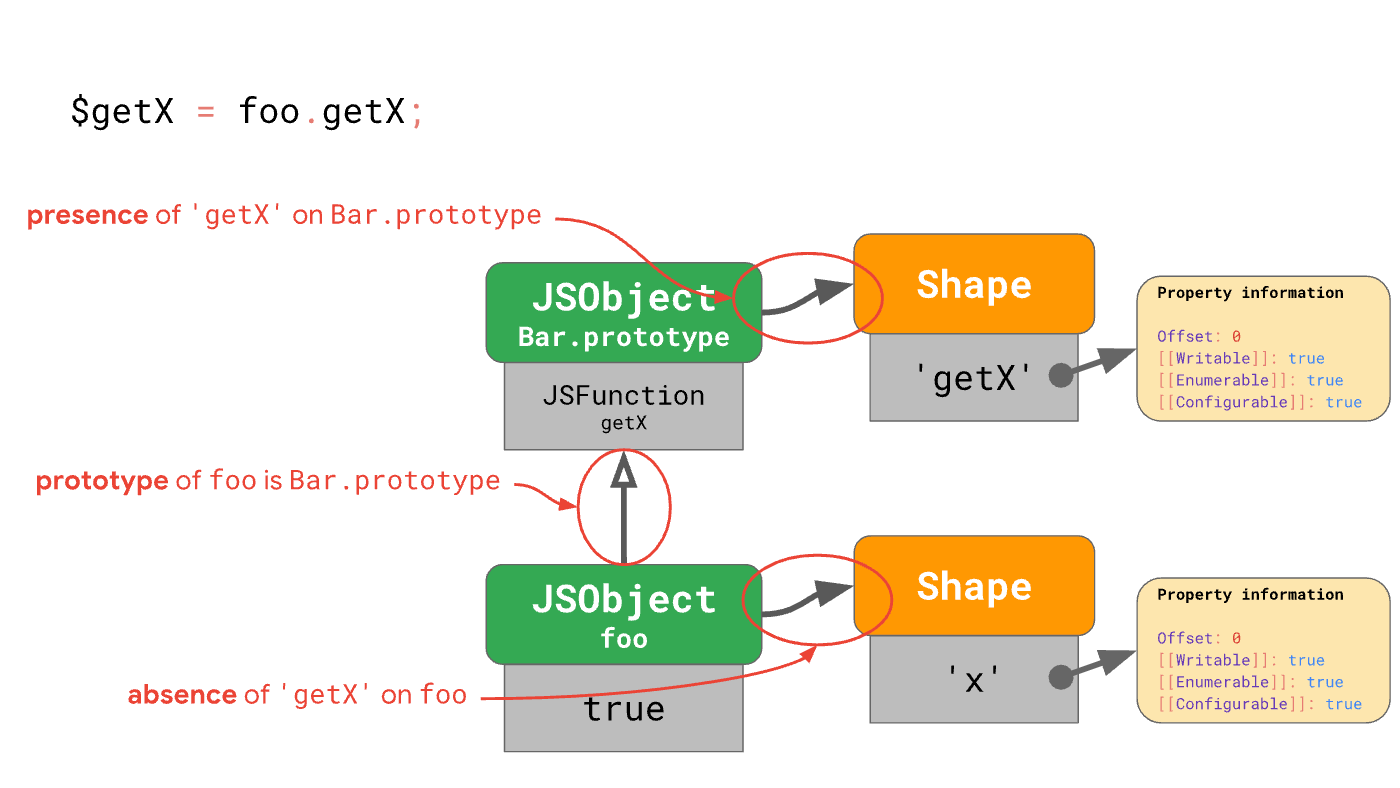
setPrototypeOfJavaScript 提供了 setPrototypeOf 用以改变原型链
const foo = new Bar(true);
foo.getX();
// → true
Object.setPrototypeOf(foo, null);
foo.getX();
// → Uncaught TypeError: foo.getX is not a function 这也导致了,虽然 prototype 只是 JavaScript 中的普通对象,但与常规对象的自身属性访问相比, 加速原型属性访问需要考虑更多的事情
为了在可能修改原型链的情况下进行访问缓存,必须需要知道以下三件事:
foo 的 Shape 不包含 getX,并且没有被修改过:这意味着没有人通过添加、删除、更改属性来变更对象 foo foo 的原型仍然是最初的 Bar.prototype 。这意味着没有人通过使用 Object.setPrototypeOf() 或分配给特殊的 __proto__ 属性来更改 foo 的原型Bar.prototype 的 Shape 包含 getX ,并且没有被修改过:这意味着没有人通过添加、删除、更改属性来变更 Bar.prototype 这意味着我们必须对实例本身执行 1 次检查,再加上对每个原型执行 2 次检查(原型是否还是最初的,以及是否还包含属性)
这意味着 1+2N 的检查次数(其中 N 是涉及的原型数量)
为了优化这种情况,引擎使用一个简单技巧:不是将原型链接存储在实例上,而是将其存储在 Shape 上,这意味着将(实例上的)原型检查合并到(Shape 上的)属性检查来减少检查数量
每个 Shape 都链接至其原型,这也意味着每次 foo 的原型发生变化时,引擎都会将 foo 的 Shape 转变为新的
对于查找链中的每个(原型)对象,我们只需要进行 Shape 检查就可以了,而无需关心其原型是否被修改过
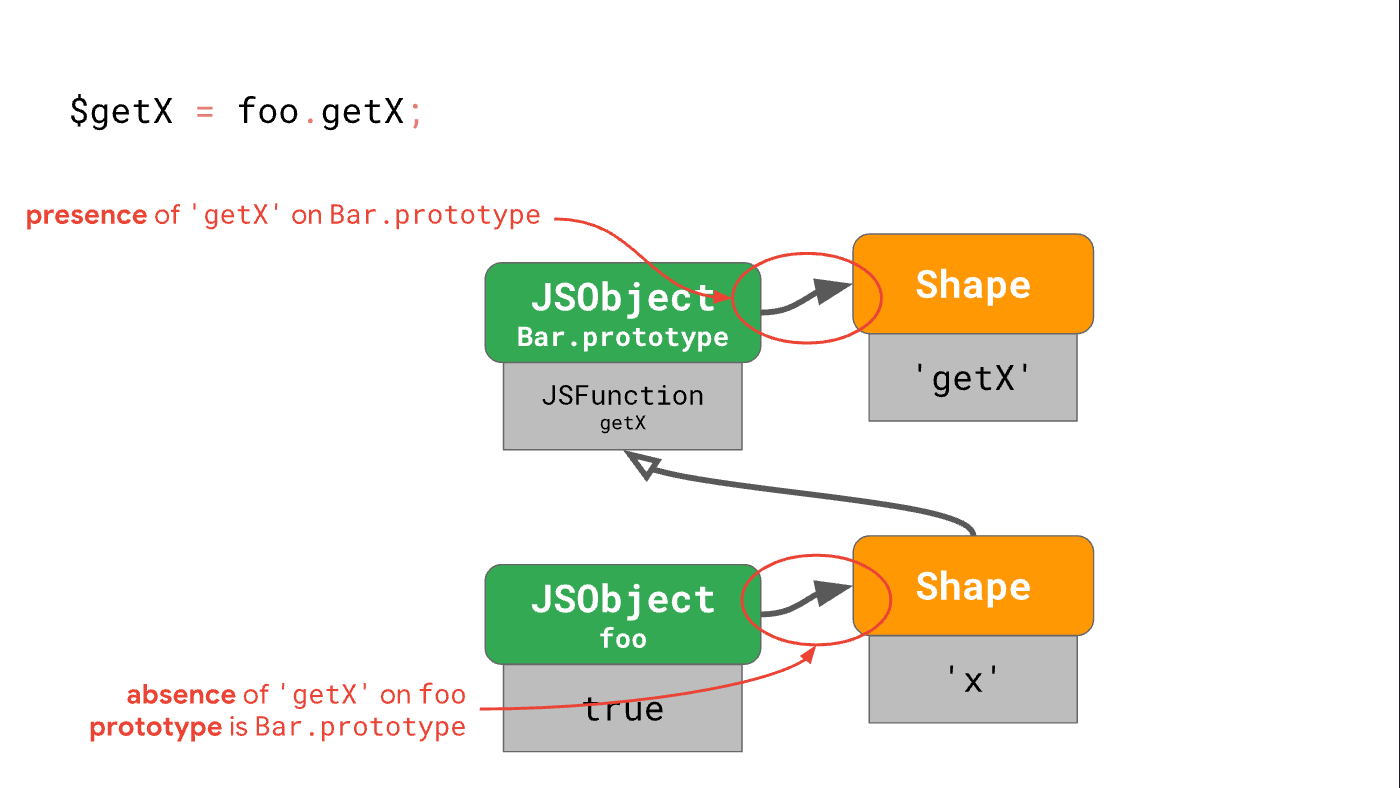
通过这种方法,我们可以将所需的检查次数从 1+2N 减少到 1+N ,以便更快地访问原型的属性
但这仍然相当昂贵,因为它仍然与原型链的长度呈线性关系
所以引擎继续实现其他的技巧,以进一步将其减少到常数级检查,特别是对于相同属性的访问
V8 为此专门处理原型的 Shape ,每个原型都有一个独特的 Shape,不与任何其他对象共享(尤其是不与其他原型共享)
并且每个原型形状都有一个与其关联的 ValidityCell(有效单元格),每当更改关联的原型或其之上的任何原型时, ValidityCell 就会失效
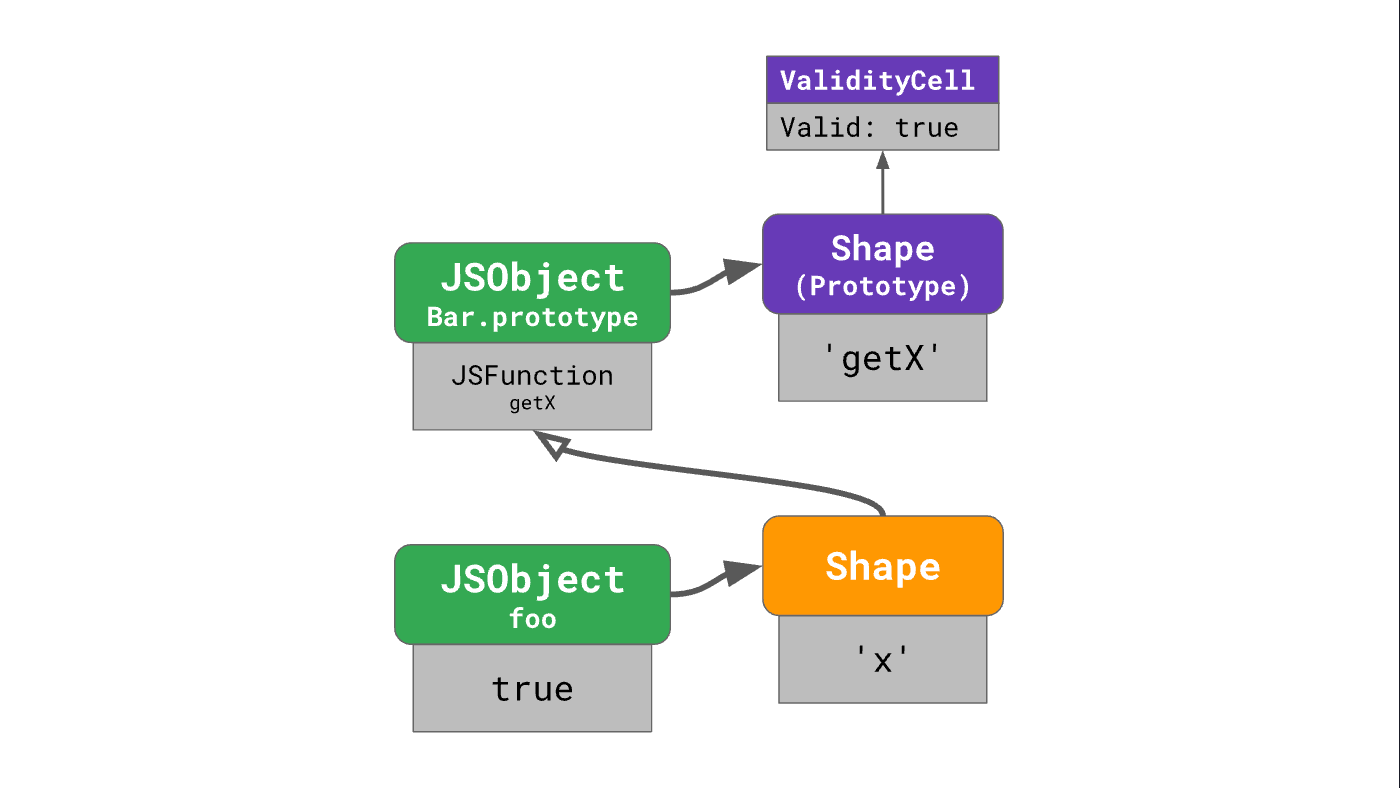
让我们看一下它到底是如何工作的
为了加速原型属性的访问,V8 给会给查找对象的 Shape 放置了一个内联缓存,其中包含四个字段:
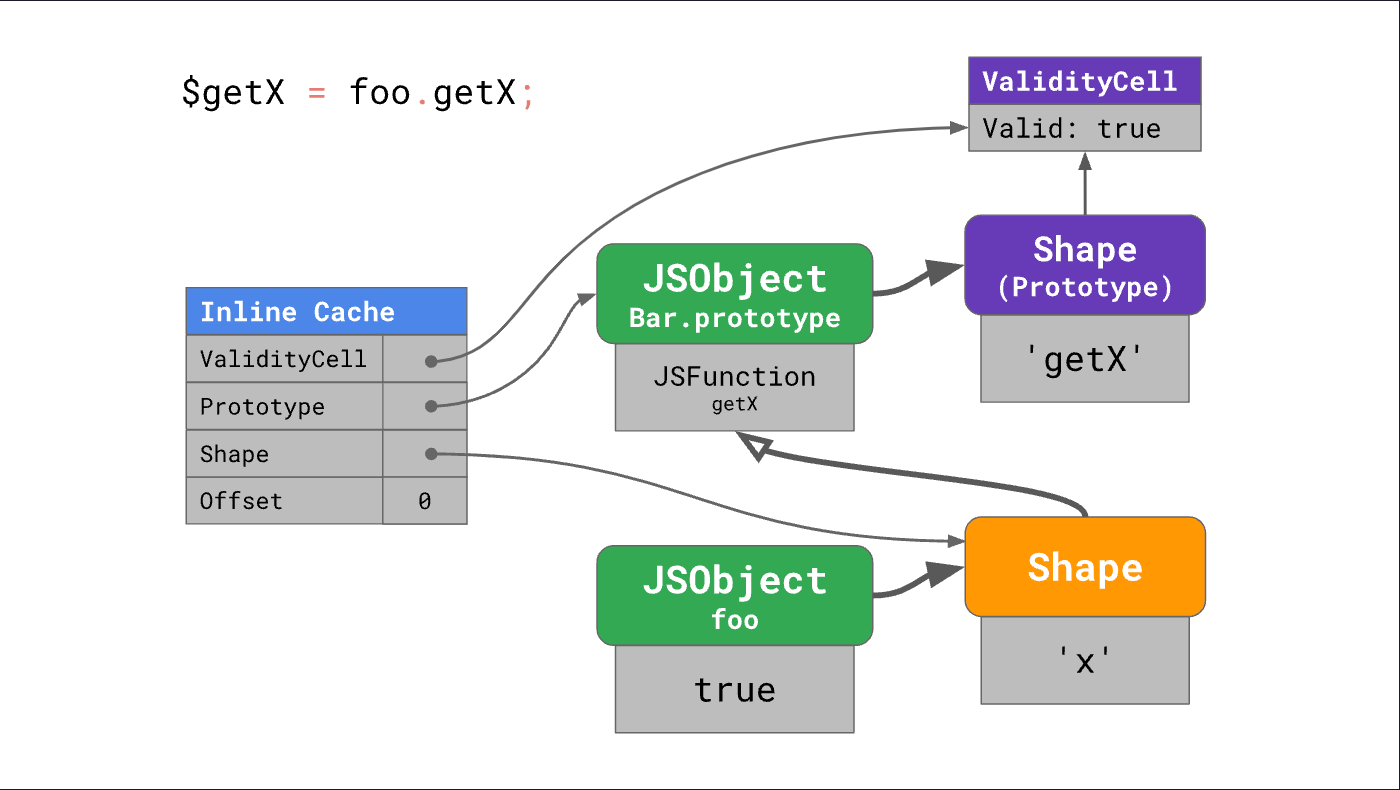
当第一次查找 foo.getX 时,V8 会记住找到 getX 时:
Bar.prototype)offsetfoo 的 Shape)ValidityCell下次查找时,引擎会通过内联缓存检查 ValidityCell,如果它仍然有效,就可以直接访问 Prototype 上的 Offset ,跳过额外的查找
当原型改变时,会为其分配一个新的 Shape,并将之前的 ValidityCell 失效。
因此下次查找时,内联缓存会失效,并重新从底部开始向上查找,导致性能变差
Important
需要注意的是,当我们更改原型时,会将其之下所有原型的 ValidityCell 失效需要注意的是,当我们更改原型时,会将其之下所有原型的 ValidityCell 失效
以 DOM 元素示例,Object.prototype 的任何更改,不仅会使 Object.prototype 本身的内联缓存失效,还会使以下任何原型失效,包括 EventTarget.prototype 、 Node.prototype 、 Element.prototype 等等
Important
在运行代码时修改 Object.prototype 意味着性能会被抛到九霄云外,不要这样做!
让我们通过一个具体的例子来进一步探讨这一点
假设我们有 Class Bar ,并且有一个函数 loadX ,它调用 Bar 对象上的方法
class Bar { /* … */ }
function loadX(bar) {
return bar.getX(); // IC for 'getX' on `Bar` instances.
} 我们使用同一类的实例多次调用此 loadX 函数
loadX(new Bar(true));
loadX(new Bar(false));
// IC in `loadX` now links the `ValidityCell` for `Bar.prototype`. loadX 中的内联缓存现在指向 Bar.prototype 的 ValidityCell
如果现在我们执行诸如改变 Object.prototype (JavaScript 中所有原型的根)之类的操作,则所有原型的 ValidityCell 都将变得无效,并且现有的内联缓存在下次命中时会丢失,导致性能更差
Object.prototype.newMethod = y => y;
// The `ValidityCell` in the `loadX` IC is invalid
// now, because `Object.prototype` changed. 改变 Object.prototype 总是一个坏主意,因为它会使引擎在此之前的任何原型内联缓存失效
这是应该避免的另一个例子:
Object.prototype.foo = function() { /* … */ };
// Run critical code:
someObject.foo();
// End of critical code.
delete Object.prototype.foo; Object.prototype ,这将使引擎在此之前放置的任何原型内联缓存失效虽然原型只是对象,但它们被 JavaScript 引擎特殊对待,以优化原型上方法查找的性能。
尽量不要修改原型,如果必须要这么做,请在所有代码开始之前,这样至少不会在代码运行时使引擎中的所有优化失效
2021-06-08
在 TypeScript 4.1 来临之前,对于像 dva、vuex 这种需要在触发时写入命名空间的函数,我们无奈的只能使用 any 对其进行类型定义。
dispatch({
type: "users/getUser",
payload: "...", // any
}) 这使得项目中本应良好的 TS 类型推导出现了断层,社区中也有相关的解决方案,但都是通过更加复杂类型、函数封装进而实现的,与官方写法大相径庭。
好在,TypeScript 4.1 带来了 Template Literal Types 特性,是我们可以对类型进行字符串拼接操作,从而使得此类函数的类型推导称为现实。
本文将带你一一讲解具体的推导过程,希望看完之后会有收获。
同时,本文的最终实现已经发布了 npm 包:dva-type,可以在项目中直接安装使用。
写代码之前先让我们回顾一下 dva 的基本使用,也好让我们知道自己最终要实现什么。
dva 中通过定义 model 来声明各模块的状态,其中 reducers 就是 redux 的 reducers,effects 就是用来执行异步操作的地方,在 effect 中最终也会通过 reducers 将状态更新到 state 中。
cosnt model = {
state: {},
effects: {
getList() {}
}
reducers: {
merge() {}
}
} 使用方法同 redux
connect 高阶函数或者 useSelector 来获取 stateconnect 或者 useDispatch 拿到 dispatch 函数connect((state) => ({
userInfo: state.users.info,
}))
// 类型断层
dispatch({
type: "users/getUser",
payload: false,
}) 类型断层主要在于 dispatch 时的 action 类型无法推导,state 的类型提示则没有问题,而 action 之所以会失效主要在于参数 type 需要拼接命名空间。
所以我们要解决的其实就是拼接命名空间之后的类型提示和推导,而这在 Template Literal Types 特性出现之后,就使得解决方案变得异常简单与自然。
开始 dva-type 的源码解析之前,先看一下它是如何使用的
定义单个 Model 类型(注意 Model、Effect 不是从 dva 中导入的)
import { Effect, Model } from "dva-type"
interface ListModel extends Model {
state: {
list: any[]
}
effects: {
// 定义effect 传入 payload 类型
getList: Effect<number>
// 不需要 payload 的 effect
getInfo: Effect
}
} 定义项目中所有 Model 的集合(使用 type 而不是 interface)
// 使用 type 定义 models,将项目中的所有 model 进行收集
type Models = {
list: ListModel
info: InfoModel
// ...
} 将 Models 传入 ResolverModels 获取 state 和 actions 的类型
import { ResolverModels } from "dva-type"
type State = ResolverModels<Models>["state"]
type Actions = ResolverModels<Models>["actions"] 使用
// hooks
useSelector<State>()
const dispatch = useDispatch<(action: Actions) => any>()
// class
const mapStateToProps = (state: State) => {}
interface Props {
dispatch: (action: Actions) => any
} 从上面的使用中可以看到,一切的秘密都在 ResolverModels 这个类型中,下面我们就看看其实现
interface ResolverModels<T extends Record<string, Model>> {
state: ResolverState<T> & Loading<T>
actions: ResolverReducers<T> | ResolverEffects<T>
} state 的解析很简单,使用 keyof 遍历 models 的 state 定义即可。
type ResolverState<T extends Record<string, Model>> = UnionToIntersection<{
[k in keyof T]: T[k]["state"]
}> 这是基本操作,让我们大致过一下这个过程发生了什么
T 是我们传入的 Models 类型定义[k in keyof T] 相当于遍历了 T 的键:list、infoT[k]['state'] 相当于:T['list']['state’]、T['info']['state’]这样就把 state 的类型给推导出来了,但是推导出来的类型是联合类型,我们还需要将其转换为交叉类型才能正确进行类型提示。
而将联合转换为交叉类型则是网上找到的黑魔法:
type UnionToIntersection<U> =
(U extends any ? (k: U) => void : never)
extends (k: infer I) => void
? I
: never 具体的深层原理我也没有搞懂,但是可以看一下具体做了那些事情:
U extends any ? (k: U) => void : never
extends any 这个条件永远是 true,所以这里就是把传入的类型 U 变为了 函数类型:(k: U) => voidextends (k: infer I) => void
(k: U) => void,所以这里的 extends 的判断结果肯定也是 true。infer I,这将类型 U 重新做了推断,就是这一步使联合类型变为了交叉类型。? I : never
I。dva 提供的 Effect 类型不能传入 payload 的类型定义,所以这里我们需要封装一个 Effect 出来:
type Effect<P = undefined> = (
action: { type: any; payload?: P },
effect: EffectsCommandMap
) => void effects 类型type ResolverEffects<T extends Record<string, Model>> = ValueType<{
[t in keyof T]: ValueType<{
[k in keyof T[t]["effects"]]: T[t]["effects"][k] extends (
action: { type: any; payload?: infer A },
effect: EffectsCommandMap
) => void
? A extends undefined
? {
type: `${t}/${k}`
[k: string]: any
}
: {
type: `${t}/${k}`
payload: A
[k: string]: any
}
: never
}>
}> 代码一大坨,按流程走一遍:
T 依然是传入的 Models 类型
[t in keyof T] 同 state,不再赘述。
[k in keyof T[t]['effects']],这一步就是将每个 model 中定义的 effect 进行了遍历,相当于:Models['list']['effects']['getList’]、Models['info']['effects']['getInfo’]
T[t]['effects'][k] extends (action: { type: any; payload?: infer A },effect: EffectsCommandMap) => void
extends 后面的函数类型与我们定义的 Effect 类型一致extends ... payload?: infer A …,这里将 payload 的类型提取了出来A extends undefined,这一步是为了判断 effect 是否需要传入 payload,如果不需要则不需要在类型中体现
{
type: `${t}/${k}`
payload: A
}
payload: A 这个就是将推导出来的类型又赋值回去了t 表示了命名空间,k 表示了 effect 的名称:type: 'list/getList'
至此,类型已经推导出来了,但是格式却不是我们想要的:
{
list: {
getList: {
type: 'list/getList',
payload: number
}
}
}
我们只想要最里面的 {type: .. payload ..} 部分,所以这里要做的就是将 value 的类型提取出来,做法也非常简单:T[keyof T],遍历并访问类型的键就可以将值类型全部取出。
将其简单封装,就是最外层的 ValueType 的作用了。
effects 的类型提取出来了,reducers 也是同样的做法,就不赘述了。
dva-loading 中可以根据 effects 提供 loading 变量,我们解析了 effects 之后,loading 的变量提示也是顺其自然了
interface Loading<T extends Record<string, Model>> {
loading: {
global: boolean
models: {
[k in keyof T]: boolean
}
effects: {
[k in ResolverEffects<T>["type"]]: boolean
}
}
} OK,感谢看到这里,希望看完之后对你有所提升,
2024-04-07
Important
再好用、重要的笔记法,也没有笔记本身重要
笔记,跟自己对话
19 年就想着开始写博客,后面博客也建了,文章也断断续续写了几篇,再之后就不了了之了
现在回看主要有两点原因:
功利是说太想写出「好的」文章,想要发出去分享给别人。但好的文章是需要知识积累的,知识不是一蹴而就的
所以结果就是基于当时的底蕴写出几篇后就写不动了
而一旦中断,放弃就是自然而然的事情了
重新开始写笔记的契机是开始学操作系统,想要记下重点。就开始接触笔记软件,也开始了解这些笔记软件所推崇的各种笔记法
其中让我最有感触的就是自下而上的写作法,自下而上是指笔记应该从小块开始构建,每篇笔记是一个小的、独立的知识点或感悟
自下而上的写作可以让写作难度降低到最低,我们不需要要求自己去写出一篇完整的、好的文章,只需要要求自己记录好这一小段的东西就可以了
等到时机来临,我们只需要把这些所有的小块组合在一起,重新编排一下,就可以自然的形成一篇文章
与之相对的就是前面说的自上而下的写作法,我们先去找一个主题,再往主题中加入各种小块
正如前面所说,知识不是一蹴而就的,对于你不熟悉的领域,你可能很久都组不出这些小块而自下而上的写作,则更符合知识学习的路径:学习某个知识的某个章节 -> 吸收记录笔记 ->重复重复 -> 到达时机组合出文章
其中最重要的是我不再有功利目的了,不再强求必须要产出文章,而更专注于记录的过程
至于什么时候可以把这些小块组成大块,已经不重要了,最重要的部分「写作」已经完成了
除了更多的写作之外,还有一个点是之前所没有的,那就是「与自己对话」
之前写东西,都是为了给别人看的,所以很多不适合、没必要、没到时机给别人看的文字,都不会记录下来
这就导致很多的想法、灵感、思考被丢弃了,而且随着心境的变化,大概率后面也不会再有了
这倒有点像现在去翻十年前的 QQ 空间一样
Important
想法的正确性不重要,没有人生下来的论点就全是正确的,思考的过程才重要
Important
再强调一遍,工具不重要,记录最重要
生活总是被各种意外所包裹,对于这些「意外」的事情,我们没有足够的时间去做记录、分类、标记等等,此时最需要的就是快,快速的记录下来,不要让记录这件事打断你正在进行的事情
做好一件事的第一步,就是降低完成它的难度,如果记录这样事让你感觉到困难、阻力,那就很难持续下去了
此时的要点就是快,我们的工具最好不要受网络、登陆、广告等等乱七八糟的事情干扰,本地的备忘录就是一个不错的选择,如果可以语音转文字那就更好了
同时也要记录上相关的链接、情景等,方便后续自己可以回溯起记录下这个瞬间的场景
等我们空了下来,有时间的时候就可以把这些碎片记录进行整理,进行更详细的了解和记录,变成一个真正的小块知识
此时也要为知识进行目录划分、打标签、引用相关链接等操作,方便后续的查找和扩展
以上持续的做下去,就可以构造我们自己的知识库了
随着知识块越来越多,我们可以在恰当的时机自然的根据相关性组合成一个个的知识体(文章)
这一步会面临如下问题:
这步也是比较依赖工具的地方,一个好的工具可以帮助我们更好的解决如上(以及更多)的问题
Important
所以你发现了吗?
对工具的依赖会随着知识块的增加而增加,我们是遇到问题才需要用工具解决问题
而不是在什么问题都没有的时候,一味的去挑选所谓的「好工具」
上面几个问题都是很基础的,基本上市面上流行的工具都可以解决(可能还有更好的方法)
以及更多的功能比如与浏览器交互、PDF 笔记、其他软件同步等等
这些功能都很好,但也都需要在你真正觉得它们是痛点的时候才有必要去折腾(有时间当然也可以去尝试,但不要把精力全放在折腾工具上)
如果你看过费曼笔记法的话,可能会发现我们上面说的三个步骤好像就是里面的闪念笔记、文献笔记、永久笔记
是的,没有错。但是我又不想太去关联两者,以免你会发出「奥,原来还是费曼笔记法」
如果用第一性原则,那笔记的第一性就应该是「写作」
所以跟工具一样,对于方法这种事情,我的看法仍然是「不要过于去折腾方法」,了解一个大概的流程和思路就可以了,然后结合自己的实际情况去发展出你自己的笔记法
如果我能坚持写下去,我相信十年后我的写作方法和今天一定不一样
所以不一定非要去严格的遵循所谓的方法,不要去问下面这些问题:
最重要的是里面的思维方式:
最后就是觉得这个思路和组件化、封装抽象等编程概念异曲同工
在开发组件时,我们并不会刻意的追求系统整体的组件化,也不会去思考过多未来的事情
我们只是根据一些基本的开发原则(SOLID)去做好当前这个组件自己的事情,然后做到极致
当系统中每个组件都是以这种形式进行的时候,我们会发现系统自然而然的就变成了组件化的系统,以及我们可以很好的应付未来的变化和挑战
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.