Implementation of the ChangeNet paper.
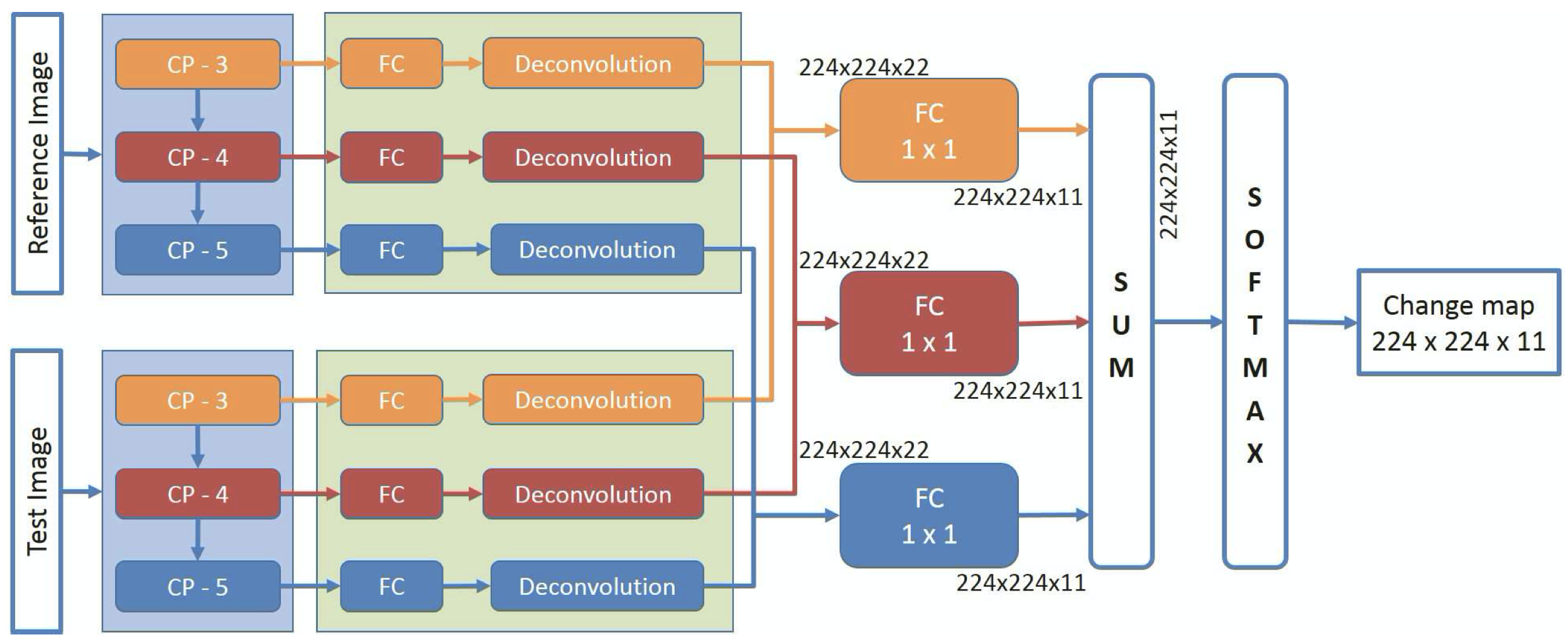
I did some few changes to squeeze some accuracy performance...
- Use of Focal Loss instead of CrossEntropy
- Use bigger Deconvolutio Network (Instead of FC-->Upsample)
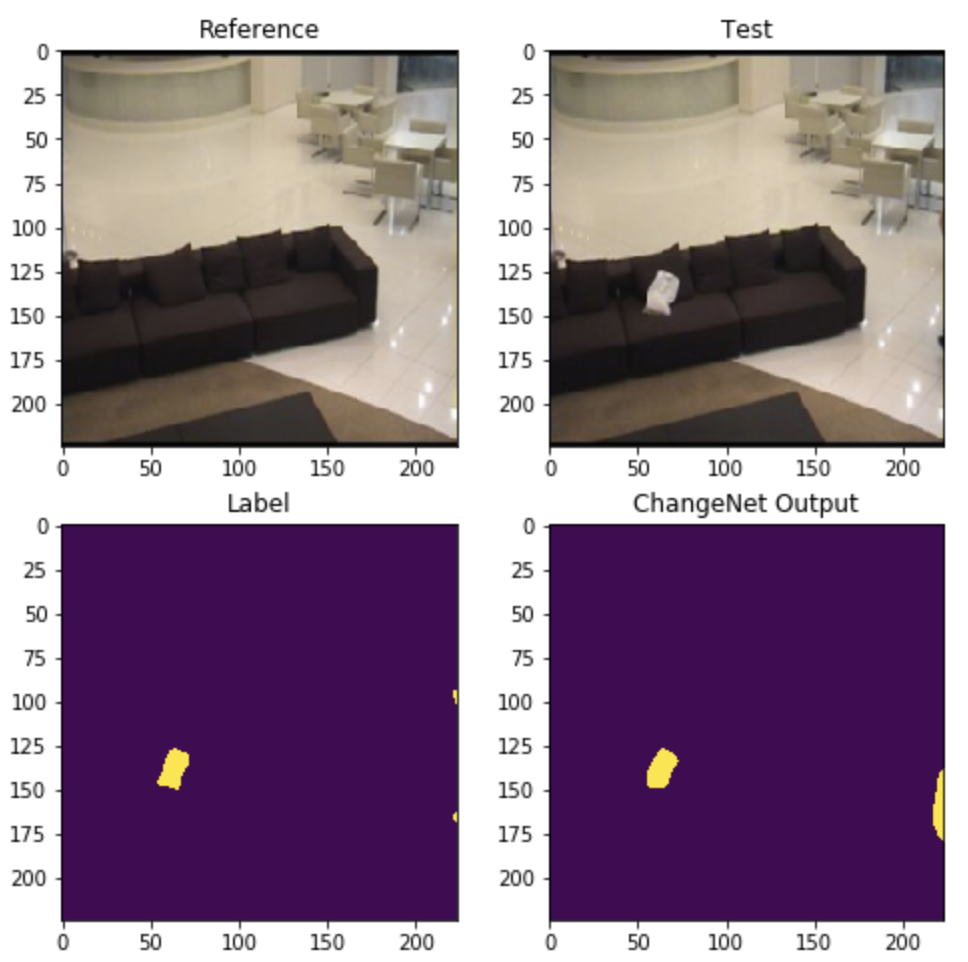
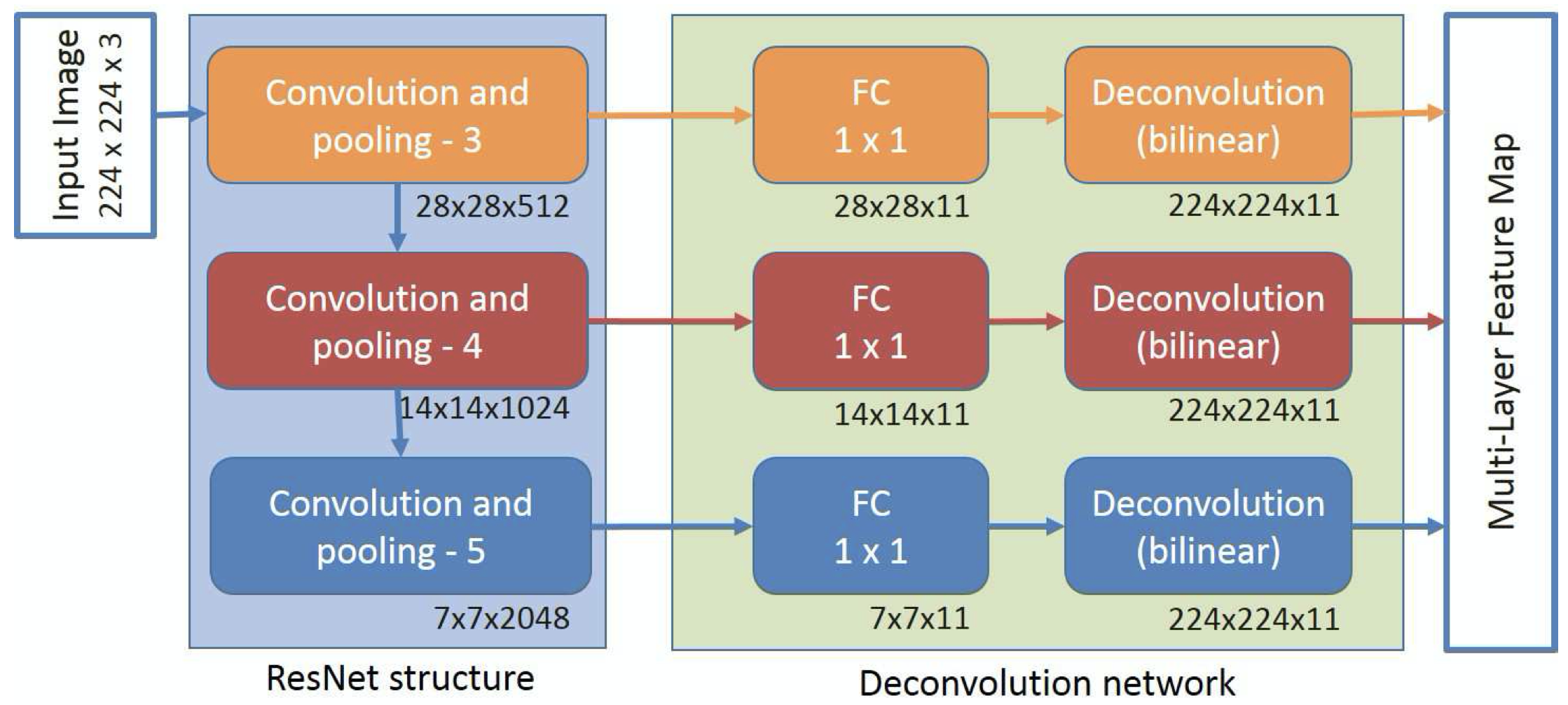
Implementation of the ChangeNet paper
Implementation of the ChangeNet paper.
I did some few changes to squeeze some accuracy performance...

















































































Hello @leonardoaraujosantos !
We found some interest in your GitHub repository "ChangeNet", but we think something is missing there. We couldn't find the directory "ChangeDataset" and the files "train.txt" and "val.txt" (or any code that creates them).
We would like to get your help with this issue.
By the way, if you already have the trained model and are willing to share it with us, we will be thankful!
Hi @leonardoaraujosantos , seems like you did a great work.
I would like to ask if you can share the model (best_model.pkl), so I'll be able to run it.
Thanks.
hi, nice work, but where can i download the dataset
I want to train chang net with 3 classes, so i set num_classes to 4 (value of 4 class is 0, 1, 2, 3) and fix:
line 38 - utils_train.py to labels = sample['label'].squeeze(0).type(torch.LongTensor).to(device)
but it raise error:
RuntimeErrorTraceback (most recent call last)
in
1 num_epochs = 5
2 best_model, _ = utils_train.train_model(change_net, dataloaders_dict,
----> 3 criterion, optimizer, sc_plt, writer, device, num_epochs=num_epochs)
4 torch.save(best_model.state_dict(), 'best_model.pkl')
~/AFS/changenet/utils_train.py in train_model(model, dataloaders, criterion, optimizer, sc_plt, writer, device, num_epochs)
63 # backward + optimize only if in training phase
64 if phase == 'train':
---> 65 loss.backward()
66 optimizer.step()
67
/usr/local/lib/python3.6/dist-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph)
105 products. Defaults to False.
106 """
--> 107 torch.autograd.backward(self, gradient, retain_graph, create_graph)
108
109 def register_hook(self, hook):
/usr/local/lib/python3.6/dist-packages/torch/autograd/init.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables)
91 Variable._execution_engine.run_backward(
92 tensors, grad_tensors, retain_graph, create_graph,
---> 93 allow_unreachable=True) # allow_unreachable flag
94
95
RuntimeError: cuDNN error: CUDNN_STATUS_ALLOC_FAILED
Please help me to train with 3 classes. Thanks!
Hi.
From where can I download the data?
Also, can you upload a sample of the file you used as the input?
I have downloaded the VL-CMU-CD dataset, however, the dataset folder contains all bi-temporal .png images and GTs. Then,
how to generate the 'change_dataset_train.pkl' and 'change_dataset_train.pkl' using the downloaded VL-CMU-CD dataset? thus I can run the Train.py in this project.
I have tried running your code and stuck into the issue with RunTimeError:
Traceback (most recent call last):
File "train_changenet.py", line 90, in
best_model, _ = utils_train.train_model(change_net, dataloaders_dict, criterion, optimizer, sc_plt, None, device, num_epochs=num_epochs)
File "/home/files/ChangeNet/utils_train.py", line 34, in train_model
for sample in dataloaders[phase]:
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in next
data = self._next_data()
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 856, in _next_data
return self._process_data(data)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 881, in _process_data
data.reraise()
File "/opt/conda/lib/python3.6/site-packages/torch/_utils.py", line 395, in reraise
raise self.exc_type(msg)
RuntimeError: Caught RuntimeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/_utils/worker.py", line 178, in _worker_loop
data = fetcher.fetch(index)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 47, in fetch
return self.collate_fn(data)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/_utils/collate.py", line 74, in default_collate
return {key: default_collate([d[key] for d in batch]) for key in elem}
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/_utils/collate.py", line 74, in
return {key: default_collate([d[key] for d in batch]) for key in elem}
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/_utils/collate.py", line 55, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: stack expects each tensor to be equal size, but got [3, 224, 224] at entry 0 and [4, 224, 224] at entry 9
It seems that then generating the dataset, there is a problem with the tensor dimension.
Did you have this issue?
I can't understand about this part of the article. Would you please tell me the 'force the network to work in constrained space' means?

Hello, I think your work is quite amazing and I'm very interested in your job, but when I tested your code on VL_CMU_CD, I got a bad result. Could you please share your file lists of this dataset? Thanks a lot!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.