liangzr / blog Goto Github PK
View Code? Open in Web Editor NEW北端的博客
Home Page: https://blog.liangzr.tech
北端的博客
Home Page: https://blog.liangzr.tech



































本系列文章预计有三篇:
Git 是日常开发时不可或缺的工具之一,可能你对 push、pull、commit、stash 这些操作早已信手拈来,但偶尔遇到一些复杂的情况,又会触及盲区,本文挑选了一些常见的场景来逐一突破,顺便带你探索 Git 背后的原理,揭开它的神秘面纱!
对于大多数人而言,更新远程分支随手就是一个 git pull ,但是你知道吗, git pull 其实是 git fetch 和 git merge FETCH_HEAD 两步操作的简写形式
$ git pull
# 等价于 git fetch && git merge FETCH_HEAD严格来说,以上也都是简写形式,不管是 pull 还是 fetch 都没有指明远程分支,这是因为当前分支已经配置了上游分支,在执行 pull 的过程中,默认取了配置好的上游分支。假如本地分支没有对应的上游分支呢,或者我们想合并任意的远程分支该如何操作?
在了解如何 pull 任意远程分支之前,我们先来看下 pull 的完整用例:
$ git pull [<options>] [<repository> [<refspec>...]]options 暂且不看,repository 即远程仓库的名字(比如常见的远程仓库名 origin),refspec 可以是任意的 refs 值,一般这里我们会用远程仓库的分支名,例如:
$ git pull origin feathre/other_branch对,直接指定远程仓库和远程分支,就可以合并任意远程分支到本地了,pull 的操作相对简单,下面再来看下 push 的场景
git push 的语法跟 pull 不太一样,先一看下 push 当前分支到远程
$ git push origin HEAD同理 origin 还是 repository,即远程仓库的名字(也可以任意支持的 Git URL),而后面的 HEAD 指代的即是当前分支,所以上面这行命令即推动当前分支(指定分支)到远程同名分支,默认情况下,都会推送到远程同名分支
如果你想指定到任意分支,也很简单:
$ git push origin branch_a:branch_b上述例子中,branch_a 即本地分支,branch_b 则指定了远程对应的分支,这样你就可以实现诸如将本地 develop 直接推送到 master 的神奇操作啦 :P
注意
这里要提醒下的是,千万不要随意尝试省略参数:
$ git push origin :branch_b这段代码将会删除 origin 对应远程仓库中的 branch_b 分支!不要想当然的认为不指定本地分支就是默认当前分支了……
上面两个 case 我们都手动指定了远程分支,但是大部分情况下我们使用 pull 或 push 都是没有特殊指定的,这是因为当前分支已经映射了远程仓库的上游分支了,如果没有配置上游分支,git 则会有相应的错误提示。
查看上游分支:
$ git branch -vv
branch_a 78a4aff [origin/branch_a] feat: xxxxx配置上游分支:
# 关联远程上游分支
$ git branch -u origin/branch_a
# 移除远程上游分支
$ git branch --unset-upstream虽然在日常使用中,我们本地分支都会映射同名的上游分支,但实际上它们之间是没有关联的,理论上可以给当前本地分支配置任意远程仓库的任意分支
考虑一下不同仓库之间 Pull Request 的操作是如何实现的呢?
查看远程分支详细信息
$ git remote show origin
* remote origin
Fetch URL: [email protected]:liangzr/Share-code-Anytime.git
Push URL: [email protected]:liangzr/Share-code-Anytime.git
HEAD branch: master
Remote branch:
master tracked
Local branch configured for 'git pull':
master merges with remote master
Local ref configured for 'git push':
master pushes to master (up to date)另一个很少用却很好用的实践是——推送或合并任意节点。
场景一:假设有一个 dev 分支,同学 A 合并了一些通用的修改之后,同学 B 又合并了一些其它 feature 的改动。而我们本地是一个比较古老的 feature 分支,我们想把 dev 分支上那些通用的修改合并过来,却不想合并同学 B 的改动。
$ git fetch origin
$ git merge <commit_id>
# commit_id 为同学 A 提交的最后一个节点 SHA-1 值由于 fetch 不支持 commit 维度的操作,自然 pull 也办不到,所以我们可以先拉取远程分支,然后直接 merge 指定节点即可
场景二:假设你想把某个节点以前的代码在远程仓库用一个单独的分支备份起来
$ git push origin ab8084:refs/heads/release/0.1.0ab8084 表示本地的节点 SHA-1 值,push 之后我们就会发现远程 origin 仓库多了一个 release/0.1.0 的分支啦
相信有不少人用过 pre-commit 或 husky 等插件在提交前对代码进行检测,但这可不是什么第三方库实现的黑魔法,这项特性正是由 git hooks 实现的。
初始化一个 git 仓库后,在 .git/hooks 目录即初始化了一些 hooks 示例:
├── applypatch-msg.sample
├── commit-msg.sample
├── fsmonitor-watchman.sample
├── post-update.sample
├── pre-applypatch.sample
├── pre-commit.sample
├── pre-push.sample
├── pre-rebase.sample
├── pre-receive.sample
├── prepare-commit-msg.sample
└── update.sample可以看到这里面有我们熟悉的 pre-commit 和 commit-msg ,下面我们从不同的角度来看下这些 hooks 的应用场景
hooks 最常见的应用场景就是我们一开始就提到过的提交工作流,在执行 commit 操作时,下面四个 hooks 会按顺序触发:
除了提交工作流之后,还有下面这些 hooks 也是存在的
这些 hooks 在执行前都能得到特定场景的一些入参,比如 pre-push 能够得到将要 push 的远程仓库和分支的名字等,结合这些入参我们可以在特定的场景下执行一系列自动化脚本
Tips:我们都知道 .git 是不会包含在代码版本库里的,所以一个正在使用的 git 仓库,如果同学 A 配置了 pre-commit 或 husky 并把相关的库的改动提交,同学 B 更新了
package.json之后,pre-commit hooks 并不会立即生效。因为 .git 里的 hooks 并没有同步过来。
正确的操作是如果增加了 hooks 相关的依赖库,更新代码后需要重新 install 一下相关的库,这些库会在 install 的时候更新 .git/hooks 中的配置
日常在使用 git 的过程中(比如 git log)经常会见到一长串字符串 id,比如:
ab808480be8a0340037693d47fa498ba11eb6e37这个字符串是 git 用存储的数据和一个特定头部信息一起做 SHA-1校验运算得到的一个 SHA-1 哈希值,换言之一个这样的 SHA-1 值代表了代码库的一个版本
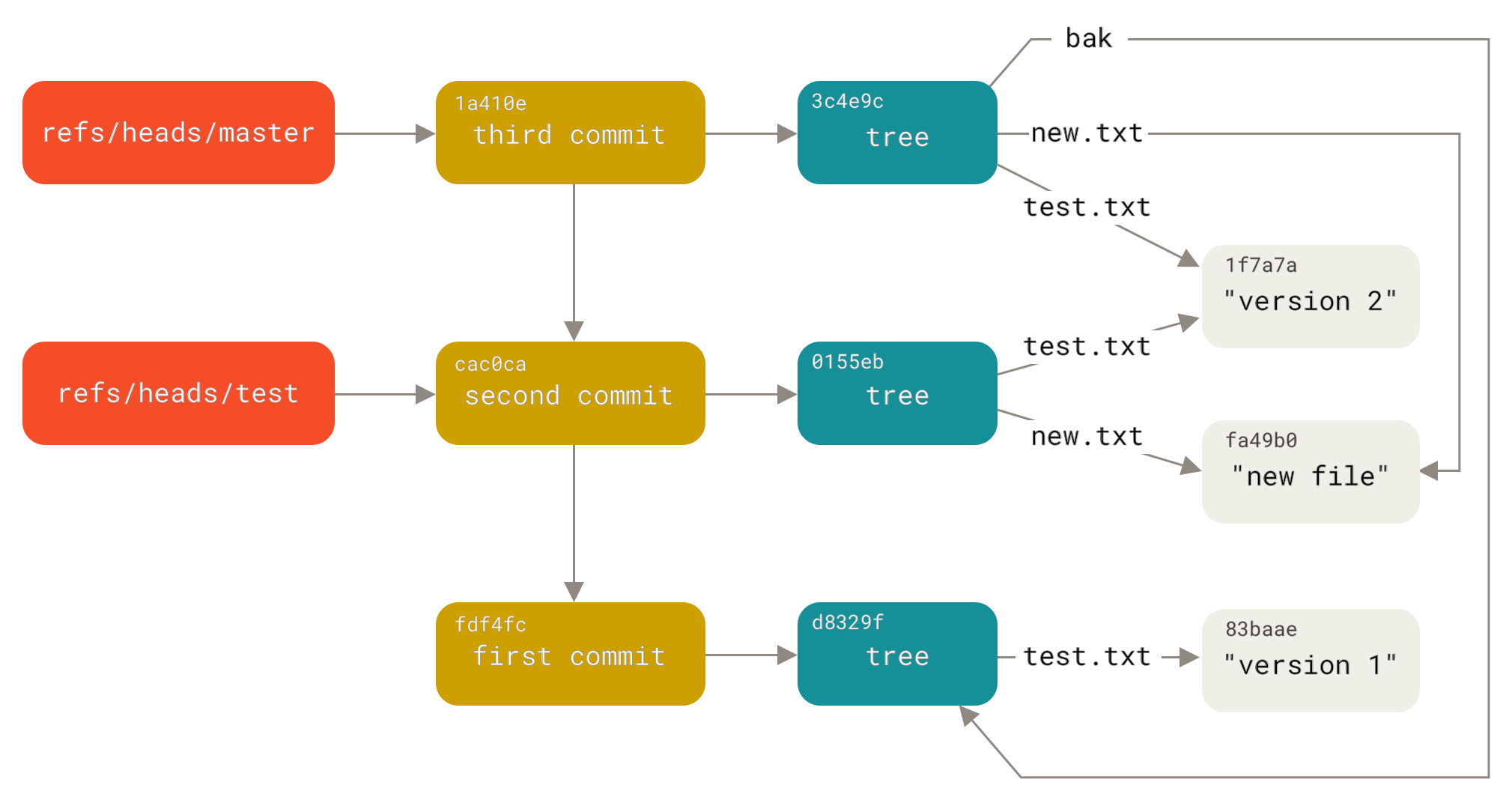
好在大部分情况下我们都不用直接操作这个 SHA-1 值,甚至可以用 ab8084 这样简短的标记来指代一个版本,但直接使用 SHA-1 依然是不太理想的用法,这个时候 git 引用(reference,以下简称 refs)的作用就体现出来了,一个存储了 SHA-1 值的文件就是 refs
你可以在 .git/refs 下找到 git 为我们生成的 refs:
.
├── heads
│ └── master
├── remotes
│ └── origin
│ └── master
└── tags
├── v0.2.0
└── v0.2.1其中 heads 和 tags 目录是初始化时就生成的, remote 是 git 在 fetch 远程仓库时自动生成的,跟其它目录不同的是, remote 下的文件是只读的
如果你想创建一个新的 refs 来帮助记忆某个 commit 版本,从技术上来讲只需如下操作:
$ echo "ab808480be8a0340037693d47fa498ba11eb6e37" > .git/refs/heads/spec_a然后,你就可以在 git 命令中使用这个引用代替 SHA-1 值了
$ git show spec_a但是一般来说不建议直接手动编辑 refs 文件,可以使用更加安全的 git update-ref 命令来创建:
$ git update-ref refs/heads/spec_a ab808480be8a0340037693d47fa498ba11eb6e37看到这里可能你也发现了,这就是 git 分支的本质——一个指向某一系列提交之首的指针或引用,如果想要在某个提交之上创建一个分支,可以这样操作:
$ git update-ref refs/heads/feature/new_feature 7c031a2可以参考下面这个图理解分支间的关系
实际上
git branch对分支的一系列操作都是通过git update-ref实现的
另一种常见的引用即远程引用(remote reference),远程仓库的分支信息同样会被保存到对应的 .git/refs/remote 中
$ cat .git/refs/remote/origin/master
1e83566de803a6dcd46a3e46e8f62ef35434e34e需要注意,remote 下的文件是只读的,虽然你可以直接 checkout 到某个远程引用,但 HEAD 指向并不会改变
认识到 refs 的本质之后,超威蓝猫又问了,git 是如何记录代码库当前的状态的呢?答案就是 HEAD 引用
HEAD 文件是一个符号引用(symbolic reference),指向目前所在的分支:
$ cat .git/HEAD
ref: refs/heads/master执行 git checkout feature/spec_a
$ cat .git/HEAD
ref: refs/heads/feature/spec_a由此可以 git 正是根据 HEAD 字段来标记当前所在分支的。
你当然也可以手动编辑此字段,然而同样有一个更安全的命令 git symbolic-ref 来完成这个操作
$ git symbolic-ref HEAD refs/heads/test
$ cat .git/HEAD
ref: refs/heads/test以前写过几个脚本需要获取当前 git 仓库所在的分支,作者写过很多黑魔法,比如
git status -bs来截取第一行的分支信息,但其实还有个更科学的办法。
现在你应该知道 HEAD 指向的即是当前分支了,但是cat .git/HEAD只能拿到 refs 指针,这个时候我们就可以用git symbolic-ref HEAD帮我们一键溯源,git symbolic-ref后面只跟一个参数,可以读出指定 refs 指针的值
类似的 HEAD 不止这一个,还有下面这些
$ tree .git
.
├── COMMIT_EDITMSG // 上一次中断的 commit 信息
├── FETCH_HEAD // 上一次 fetch 后的节点信息
├── HEAD // 当前分支
├── ORIG_HEAD // 上一次 HEAD 信息,用于备份假如你的分支名是由某些基础构建服务生成的,并且不能随便更改,这个时候你就可以创建一个别名,在本地用别名操作了
$ git symbolic-ref refs/heads/sprint_biz_S904935174_20190605 refs/heads/feature/add_somthing
$ git checkout feature/add_somthing
# git symbolic-ref refs/heads/daily/0.0.7 refs/heads/nightly
# git checkout nightly为了简化操作,可以用 shell 写一个简单的命令
$ echo 'git symbolic-ref refs/heads/$2 refs/heads/$1' > /usr/local/bin/gbalias
$ gbalias sprint_biz_S904935174_20190605 feature/add_somthing我们可以用上面的 git symbolic-ref 和 HEAD 一键获取当前分支
$ git symbolic-ref HEAD | cut -c 12-
feature/add_somthinggit log 在日常中的使用频次可能仅次于 git commit 了,但是大部分人的操作可能也仅仅停留在 git log 本身了,下面就先来看一下 log 命令的其它基本操作吧
直接 git log 我们可以看到的信息如下:
$ git log
commit 1afab788ab1d745159b0556a3f9d09eabe74cb9c
Author: Dustin L. Howett (MSFT) <[email protected]>
Date: Tue Jul 30 16:35:08 2019 -0700
Update the package version to v0.3
Acked-by: Pankaj Bhojwani <[email protected]>
Acked-by: Carlos Zamora <[email protected]>
commit 63df881f315fe70be70559252253c9fec80bcc55
Author: PankajBhojwani <[email protected]>
Date: Tue Jul 30 16:28:28 2019 -0700
VT sequence support for EraseInLine, EraseInDisplay, DeleteCharacter and InsertCharacter (#2144)
* We now support EraseInLine, EraseInDisplay, DeleteCharacter and InsertCharacter可以看到从最新到最早依次排序的每个 commit 的简要信息,比如 SHA-1 值,提交作者,提交日期,以及最重要的提交信息。
如果想看到改动了哪些文件,可以用 --stat 参数:
$ git log --stat
commit 1afab788ab1d745159b0556a3f9d09eabe74cb9c
Author: Dustin L. Howett (MSFT) <[email protected]>
Date: Tue Jul 30 16:35:08 2019 -0700
Update the package version to v0.3
Acked-by: Pankaj Bhojwani <[email protected]>
Acked-by: Carlos Zamora <[email protected]>
src/cascadia/CascadiaPackage/CascadiaPackage.wapproj | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
commit 63df881f315fe70be70559252253c9fec80bcc55
Author: PankajBhojwani <[email protected]>
Date: Tue Jul 30 16:28:28 2019 -0700
VT sequence support for EraseInLine, EraseInDisplay, DeleteCharacter and InsertCharacter (#2144)
* We now support EraseInLine, EraseInDisplay, DeleteCharacter and InsertCharacter
src/buffer/out/textBuffer.cpp | 25 +++++++++++++----
src/buffer/out/textBuffer.hpp | 1 +
src/cascadia/TerminalCore/ITerminalApi.hpp | 4 +++
src/cascadia/TerminalCore/Terminal.hpp | 4 +++
src/cascadia/TerminalCore/TerminalApi.cpp | 228 ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++-
src/cascadia/TerminalCore/TerminalDispatch.cpp | 58 +++++++++++++++++++++++++++++++++++---
src/cascadia/TerminalCore/TerminalDispatch.hpp | 7 ++++-
7 files changed, 316 insertions(+), 11 deletions(-)如上所示,可浏览的信息丰富了不少,现在我们能看到都有哪些文件被改动过,每个文件的增删改情况,以及最下面的变更统计。
如果想看到具体的变更内容,使用 -p 参数,它也可以跟 --stat 混用
$ git log -p
commit 1afab788ab1d745159b0556a3f9d09eabe74cb9c
Author: Dustin L. Howett (MSFT) <[email protected]>
Date: Tue Jul 30 16:35:08 2019 -0700
Update the package version to v0.3
Acked-by: Pankaj Bhojwani <[email protected]>
Acked-by: Carlos Zamora <[email protected]>
diff --git a/src/cascadia/CascadiaPackage/CascadiaPackage.wapproj b/src/cascadia/CascadiaPackage/CascadiaPackage.wapproj
index 665417e..c5be3f3 100644
--- a/src/cascadia/CascadiaPackage/CascadiaPackage.wapproj
+++ b/src/cascadia/CascadiaPackage/CascadiaPackage.wapproj
@@ -5,7 +5,7 @@
<PropertyGroup Label="Version">
<!-- These fields are picked up by PackageES -->
<VersionMajor>0</VersionMajor>
- <VersionMinor>2</VersionMinor>
+ <VersionMinor>3</VersionMinor>^M
</PropertyGroup>
<PropertyGroup Label="Configuration">
<TargetPlatformVersion>10.0.18362.0</TargetPlatformVersion>
@@ -305,4 +305,4 @@
</ItemGroup>
</Target>
-</Project>
\ No newline at end of file
+</Project>^Mgit log 的默认展示可以说并不算直观,某些可视化编辑器提供的简要图表比这要强的多,但其实 git log 中还有个强大的参数叫 --pretty ,光看这个名字估计你就已经猜出来它的用途了,我们先来看几个 on-my-zsh 为我们预置的几个 pretty 配置
彩色字体配置在这里无法体现,可以自行在命令行体验一下
glol :
* 6749ab0 - (HEAD -> master, origin/master, origin/HEAD) First draft of a spec for VT52 escape sequences (#2017) (4 weeks ago) <James Holderness>
* 66044ca - Try to turn audit mode back on without building test/utilities (#2179) (4 weeks ago) <Michael Niksa>
* a08666b - (origin/release-0.3) Accessibility: TermControl Automation Peer (#2083) (4 weeks ago) <Carlos Zamora>
* 1afab78 - Update the package version to v0.3 (4 weeks ago) <Dustin L. Howett (MSFT)>
* 63df881 - VT sequence support for EraseInLine, EraseInDisplay, DeleteCharacter and InsertCharacter (#2144) (4 weeks ago) <PankajBhojwani>
* 2d3e271 - Fix the terminal snapping across DPI boundaries strangely (4 weeks ago) <Mike Griese>
* 7abcc35 - Fix a crash on restore down (#2149) (4 weeks ago) <Mike Griese>
* c6c51fb - Change our manifest from depending on Windows.Universal to Windows.Desktop (#2155) (4 weeks ago) <Dustin L. Howett (MSFT)>gloga :
* 6749ab0 (HEAD -> master, origin/master, origin/HEAD) First draft of a spec for VT52 escape sequences (#2017)
* 66044ca Try to turn audit mode back on without building test/utilities (#2179)
| * dd2c4db (origin/dev/migrie/s/754-cascading-settings-spec) Add updates concerning dynamic profile generation (#1321)
| * 7aa0c42 Merge remote-tracking branch 'origin/release-0.3' into dev/migrie/s/754-cascading-settings-spec
| |\
| |/
|/|
| * c290461 Merge branch 'dev/migrie/s/754-cascading-settings-spec' of https://github.com/Microsoft/Terminal into dev/migrie/s/754-cascading-settings-spec
| |\
| | * ab2308a Apply suggestions from code review
| * | f100227 Lots of feedback from PR上面这些命令无需记忆,只需要知道 git log 也有非常强大的展示效果,下面这些 alias 配置可以自取:
glg='git log --stat'
glgg='git log --graph'
glgga='git log --graph --decorate --all'
glgm='git log --graph --max-count=10'
glgp='git log --stat -p'
glo='git log --oneline --decorate'
glod='git log --graph --pretty='\''%Cred%h%Creset -%C(auto)%d%Creset %s %Cgreen(%ad) %C(bold blue)<%an>%Creset'\'
glods='git log --graph --pretty='\''%Cred%h%Creset -%C(auto)%d%Creset %s %Cgreen(%ad) %C(bold blue)<%an>%Creset'\'' --date=short'
glog='git log --oneline --decorate --graph'
gloga='git log --oneline --decorate --graph --all'
glol='git log --graph --pretty='\''%Cred%h%Creset -%C(auto)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset'\'
glola='git log --graph --pretty='\''%Cred%h%Creset -%C(auto)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset'\'' --all'
glols='git log --graph --pretty='\''%Cred%h%Creset -%C(auto)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset'\'' --stat'pretty 的格式化语法可以查阅
git log --hlep手册中PRETTY FORMATS一节
git log 为我们提供了一系列的方式来限定范围,帮助我们尽快地找到想到的日志
如果你只想查找某个文件的改动记录,可以直接指定这个文件
$ git log index.jsgit log 默认提供的是所有时期的日志,如果已经大概定位到了问题的时间段,可以用 --after 和 --before 来指定时间区间,这两个命令也可以单独使用
$ git log --after="2019-8-29" --before="2019-10-10"有时你的改动只是一个版本号,或者你怀疑某个字符串被无意删掉了一个字符或一段,而 git log 提供的默认 diff 效果是按行对比的,这个时候按字 diff 就非常有用了,可以很直观的看到被增删的具体内容
$ git log -p --word-diff=color --word-diff-regex=.如果你想知道某行代码是谁最后编辑的,直接 git log 一段一段查变更可太难了,这个时候它的兄弟命令 git blame 就派上用场了
$ git blame NuGet.Config
^d4d59fa (Dustin Howett 2019-05-02 15:29:04 -0700 1) <?xml version="1.0" encoding="utf-8"?>
^d4d59fa (Dustin Howett 2019-05-02 15:29:04 -0700 2) <configuration>
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 3) <packageSources>
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 4) <add key="NuGet.org" value="https://api.nuget.org/v3/index.json" />
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 5) <!-- Add repositories here to the list of available repositories -->
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 6)
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 7) <!-- Dependencies that we must carry because they're not on public nuget feeds right now. -->
3377f06e (Michael Niksa 2019-07-12 15:22:03 -0700 8) <!--<add key="Static Package Dependencies" value="dep\packages" />-->
3377f06e (Michael Niksa 2019-07-12 15:22:03 -0700 9)
3377f06e (Michael Niksa 2019-07-12 15:22:03 -0700 10) <!-- Use our own NuGet Feed -->
3377f06e (Michael Niksa 2019-07-12 15:22:03 -0700 11) <add key="Windows Terminal NuGet Feed" value="https://terminalnuget.blob.core.windows.net/feed/index.json" />
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 12)
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 13) <!-- Internal NuGet feeds that may not be accessible outside Microsoft corporate network -->
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 14) <!--<add key="TAEF - internal" value="https://microsoft.pkgs.visualstudio.com/DefaultCollection/_packaging/Taef/nuget/v3/index.json" />
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 15) <add key="OpenConsole - Internal" value="https://microsoft.pkgs.visualstudio.com/_packaging/OpenConsole/nuget/v3/index.json" />-->
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 16) </packageSources>
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 17) <config>
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 18) <add key="repositorypath" value=".\packages" />
2c1ab620 (pythias 2019-05-14 09:06:36 +0800 19) </config>
^d4d59fa (Dustin Howett 2019-05-02 15:29:04 -0700 20) </configuration> 如上我们可以详细的看到都是哪个人在什么时间修改了某行代码,如果你的文件很长,你还可以用 -L 参数指定行数区间
如果你想继续溯源,找到这行代码上一个、再上一个版本都有谁做了改动,我们可以继续回到 git log 大法:
$ git log -L 10,10:NuGet.Config
commit 3377f06e52914fbe5b536f74b234c5e7173dfaf2
Author: Michael Niksa <[email protected]>
Date: Fri Jul 12 15:22:03 2019 -0700
Host our own NuGet feed for packages that we need that aren't elsewhere yet (#1951)
* Stop hosting packages inside of here. Put them on a blob storage account instead.
diff --git a/NuGet.Config b/NuGet.Config
--- a/NuGet.Config
+++ b/NuGet.Config
@@ -8,1 +10,1 @@
- <add key="Static Package Dependencies" value="dep\packages" />^M
+ <!-- Use our own NuGet Feed -->^M
commit 2c1ab620bf6ccf8eab29f821749e7e88c349526f
Author: pythias <[email protected]>
Date: Tue May 14 09:06:36 2019 +0800
Tab to spaces (#578)
* tab to spaces
* change tab size to 4.
diff --git a/NuGet.Config b/NuGet.Config
--- a/NuGet.Config
+++ b/NuGet.Config
@@ -3,14 +8,1 @@
- <packageSources>^M
- <add key="NuGet.org" value="https://api.nuget.org/v3/index.json" />^M
- <!-- Add repositories here to the list of available repositories -->^M
- ^M
- <!-- Dependencies that we must carry because they're not on public nuget feeds right now. -->^M
- <add key="Static Package Dependencies" value="dep\packages" />^M
- ^M
- <!-- Internal NuGet feeds that may not be accessible outside Microsoft corporate network -->^M
- <!--<add key="TAEF - internal" value="https://microsoft.pkgs.visualstudio.com/DefaultCollection/_packaging/Taef/nuget/v3/index.json" />^M
- <add key="OpenConsole - Internal" value="https://microsoft.pkgs.visualstudio.com/_packaging/OpenConsole/nuget/v3/index.json" />-->^M
- </packageSources>^M
- <config>^M
- <add key="repositorypath" value=".\packages" />^M
- </config>^M
+ <add key="Static Package Dependencies" value="dep\packages" />^Mgit log 可以查找指定行区间(10,10 表示第 10 行)的全部改动记录,但很遗憾每次代码变更之后行数可能会变化,所以这个命令在实践中意义不大,可以期待下篇我们将要讲到的搜索代码变更一章。
不过话说回来都 9102 年了,现代编辑器/IDE 早就支持查看单行 log 的能力了,在 VSCode 上还有更好用的 GitLens 插件帮助我们一键溯源+Diff,但了解下功能背后的实现可以抹去对未知能力的盲目依赖,卸下神秘的光环,更可以在特殊情况下应急不是吗~
上面这些命令的用法不再赘述,这里只是抛砖引玉带你认识到 log 的诸多能力,更强大的代码搜索请关注下节,或查询手册
git diff 命令其实才是在排查问题中,最常用到的一个命令,但我们上文并没有提到它,实际上每当我们执行 git log -p 时,每个 commit 的变更内容,都等价于 git diff commit_a commit_b ,所以使用 diff 我们可以灵活的比较不同的 commit,不同的分支,当前分支相比于代码库的改动等。
一直以来,Virtual DOM 都是 React 的一大特色,Facebook 宣称 React 借其能很大程度提高 SPA 的性能表现。但这就意味着 React 的性能一定优秀吗,可能并不是,在某些情况下,React 慢的令人抓狂,这时你可能就需要用一些正确的手段来优化它了。
我们不妨先简单了解下 React 的更新机制,如果能降低它的更新频率,自然能大大提高整体渲染速度。
props 和 state 的基本概念不再赘述,组件的 props 是只读的,只能通过上层 JSX 声明时的属性传递进来,state 则完全受组件自身控制,并且只存在于 class 语法声明的组件。
无论是 props 还是 state 发生变化都可以触发组件更新,下面这些生命周期方法会在组件重新渲染时被依次调用:
*号标注的生命周期方法将会在 React 17 移除,一旦调用了新的生命周期方法,这些方法将不会被调用。
从上面的生命周期中我们可以看到,shouldComponentUpdate 方法将在组件接收到新的 props 或者 state 时被调用。然而在默认情况下, 每次更新,React 都会去调用 render 方法重新生成 Virtual DOM 并通过 diff 算法计算出需要变动的部分,然后操作 DOM 完成这部分更新。
对于一些简单的 React 应用来说,每次 render 带来的消耗不会特别大,不过一旦你的应用有了一定规模,尤其是复杂的树形结构时,每次更新都会消耗不少的系统资源。
我们先来看下官方文档里的示意图。
从图中可以看到,在这个简单的树形结构中,仅仅是 c7 的状态发生了改变,所有的组件都要进行一次 render,那如果我这个树下有 10 个组件呢,50 个呢?尤其当这个 c7 的状态变化与鼠标移动这种高频操作相关时,所有的组件不停的重新生成 Virtual DOM,这样能有多卡顿你能想象的到吗?不要问我是怎么知道的,某天 Leader 叫我写了个表单设计器……
如果不用 SCU 对 React 的更新进行限制,你可能像我之前一样,对着 Chrome 的 Perfomance 工具里锯齿般的火焰图束手无策。那假如 SCU 可以正确的感知数据变化并返回你期待的结果,实际情况又会如何呢?
如上所示,如果 SCU 正常工作,只会发生 3 次 Virtual DOM 的比较,换言之,只有发生改变的 c7 以及它的父级组件会进入 render 方法,生成 Virtual DOM。那这次如果我们有 100 个子组件,但 c7 的深度还是 3 呢?没错,它依然是只会调用 3 次 render 方法,在大型树形结构里,这样的渲染效率无疑是成几何倍提升。
那么问题又来了,SCU 是一定要实现的,但在每个组件中都手写 SCU,手动地比较复杂的对象中每个键的值,难度非同一般,那么如何轻松地让 SCU 返回你期待的结果?
虽然完全手写 SCU 不现实,但这里依然有一些组合方案可以助我们实现目标。
PureComponent 是 React 提供的另一个组件,它默认帮你实现了 SCU 方法,其实在它出现之前,它的前身是 React 的 addons 提供的 PureRenderMixin,它的源码如下:
var shallowEqual = require('fbjs/lib/shallowEqual');
module.exports = {
shouldComponentUpdate: function(nextProps, nextState) {
return (
!shallowEqual(this.props, nextProps) ||
!shallowEqual(this.state, nextState)
);
}
};我们可以看到它帮我们实现了 SCU 方法,实现的机制是浅比较(Shallow Compare),也就是说,它只简单的比较了 this.props 和 nextProps 两个变量(以及他们的第一层子属性)引用的是否为同一个地址,如果是则返回 false,否则返回 true。
shallowEqual的具体实现请查阅源码
同样的我们也来看下使用 PureComponent 时的具体实现:
function checkShouldComponentUpdate(
...
) {
const instance = workInProgress.stateNode;
const ctor = workInProgress.type;
// 用户自己实现
if (typeof instance.shouldComponentUpdate === 'function') {
const shouldUpdate = instance.shouldComponentUpdate(
newProps,
newState,
newContext,
);
return shouldUpdate;
}
if (ctor.prototype && ctor.prototype.isPureReactComponent) {
return (
!shallowEqual(oldProps, newProps) || !shallowEqual(oldState, newState)
);
}
return true;
}可以看到,如果用户不定义 SCU 方法,并且当前组件为 PureComponent 时,最终依然会对新旧 Props 和 State 进行一个浅比较。
虽然 PureComponent 帮我们实现了 SCU 方法,但这并不意味着我们已经达到目标了,别忘了它只是实现了浅比较,在 JavaScript 中,Primitive 数据能直接的用 = 号简单的浅比较,而 Object 数据仅仅表示两个变量引用的堆地址相同,但这块儿内存中的数据有没有改动过,就无从得知了,看个简单的例子:
oldState = { expand: true };
oldState.expand = false;
newState = oldState;
shallowEqual(newState, oldState) // true如上我们更新了 state 的 expand 的值,但 PureComponent 在比较时会认为 state 并没有更新返回 SCU 返回 false,这样我们的组件就得不到正确的更新了。
可能比较有经验的童鞋会说,只要用深拷贝就行了,那我们来看下几种常见的深拷贝实现
这个原理比较简单,序列化之后,对象变成了一个字符串,JSON.parse 会从字符串重新生成对象,很明显这已经不是之前那个对象了,实现了完全的深拷贝。但是别忘了,JSON 只有 6 种基本数据类型,这样转换很显然不少对象会出现问题,比如 Function 对象,Date 对象等等,都无法正常转换。可见这种方案的适用场景也是比较少的。
const o = {
a: 1,
b: false,
c: 'react',
d: null,
e: [1, 2],
f: function () { console.log('Forget me!') },
g: new Date(),
h: /forget me/g,
i: [1, new Date()],
j: Symbol('Forget me'),
}
console.log(JSON.stringify(JSON.parse(o)));Output:
相较于用 JSON 粗暴的转换,lodash 的处理更为细致,Primitive 数据直接返回,Object 数据则逐一处理。
还是上面的例子,lodash 的输出结果:
类似的还有 jQuery 的 extend 方法(第一个参数为 true 时为深拷贝)。虽然深拷贝帮我们重新处理了浅比较的问题,但当你使用的时候可能会发现,每次修改树形结构的里的一个值,所有的组件依然会全部渲染。这是因为树形结构中所有的对象引用地址都被改变了,PureComponent 在浅比较时,自然所有的 SCU 都会返回 ture,我们似乎又回到了起点,那如何只让变动的部分改变引用呢?
Immutable 即不可变的,意思是对象创建后,无法通过简单的赋值更改值或引用。Facebook 推出了 ImmutableJS 来实现这套机制,它有自己的一套 API 来对已有的 Immutable 对象进行修改并返回一个全新的对象,但与深拷贝不同,这个对象只修改了变动的部分,示意如下:
Facebook 推荐使用 ImmutableJS 来优化 React 应用,但使用它的同时也意味需要重新学习大量的 API
Immutability-helper 原来是 React 的 addons 里面的 update 模块,独立出来后又新增了拓展模块,它提供了一种语法糖,你可以直接描述需要修改的对象,并且用预置命令对这部分进行修改,最后返回一个修改后的对象,以此来模拟 Immutable 数据的行为
extend 的行为与 Object.assign 一致:
const newData = extend(myData, {
x: extend(myData.x, {
y: extend(myData.x.y, {z: 7}),
}),
a: extend(myData.a, {b: myData.a.b.concat(9)})
});使用 immutability-helper:
import update from 'immutability-helper';
const newData = update(myData, {
x: {y: {z: {$set: 7}}},
a: {b: {$push: [9]}}
});可以看到通过这个库提供的语法糖,我们可以更快速清晰便捷的修改对象,而不用一层一层地用 Object.assign 之类的包起来。这种方式相较于 ImmutableJS 比较没有侵入性,性能也不比 Immutable 差多少(有待测试),没有学习成本,比较推荐!
其实说到这里,本篇基本已经结束了,在 PureComponent 和 Immutable Data 的搭配使用下,SCU 能很大程度提高 React 应用的性能,不过这也只是从组件更新的角度来优化 React,实际上我们能做的事还有很多。
上文只是作者本人在 React 优化中的实践,翻阅网上的资料与源码总结而出的一篇分享,如有谬误欢迎指正!
昨天在群里看到有人问:
网友:“Object.keys会给值排序,那用哪个方法取对象属性能不排序的?”
我:“对象的属性有顺序吗?”
网友:“这个就会按照从小到大排序,我只是想保持原样~~” (如下)
我:"for...in 应该不会"
......
结果我试了下发现 for..in 也会,最终我试了六种方法:
const obj = { 100: 'a', 2: 'b', 7: 'c' }
Object.keys(obj) // ["2", "7", "100"]
Object.values(obj) // ["b", "c", "a"]
Object.entries(obj) // "2,b,7,c,100,a", toString() 之后
for (key in obj) { console.log(key) } // 2, 7, 10
Object.getOwnPropertyNames(obj) // ["2", "7", "100"]
Reflect.ownKeys(obj) // ["2", "7", "100"]可以看到,以上方法都无一例外地以 { 2: 'b', 7: 'c', 100: 'a' } 的方式打印出了相关值,那这个问题的影响在哪里呢?
假如你从接口中获取一段 JSON 数据如下:
{
"100": { ... },
"2": { ... },
"7": { ... }
}上面个数据可能是经过后端排序的,并且数据中并没有带有可供排序的信息,毫无疑问经过 JS 的重新排序后,它的排序信息就丢失了,假如我就是不想丢失呢?
欲知其然,先知其所以然。在了解它如果遍历属性之前,首先我们需要知道的是,在 V8 中对象是如何存储属性的呢?
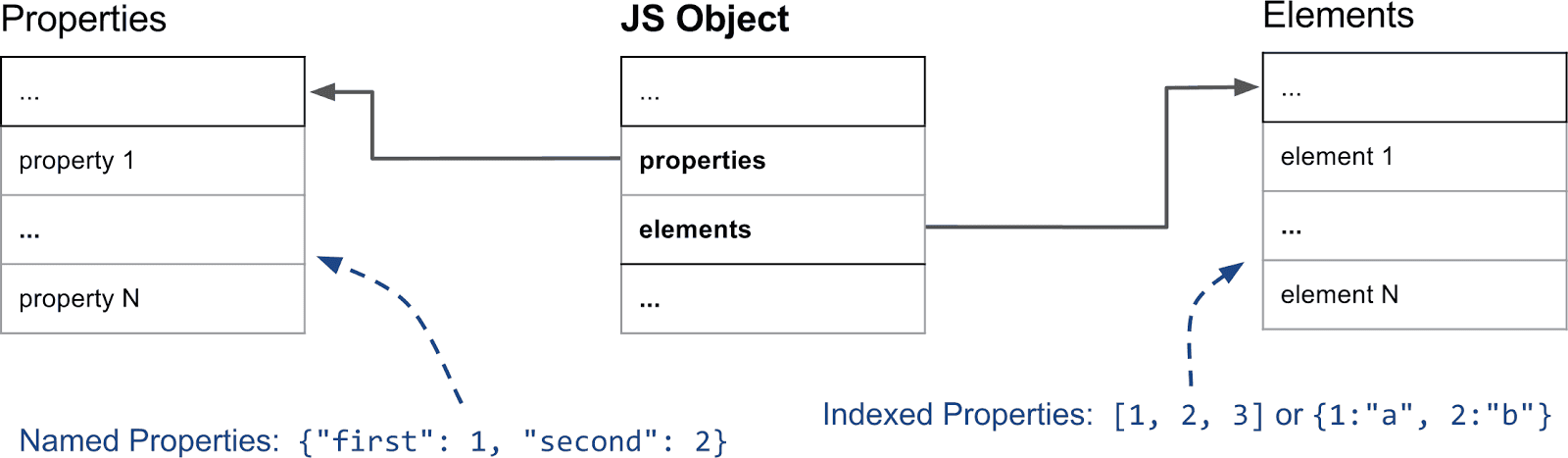
在 JavaScript 中,大部分时候对象的行为类似一个字典,它以字符串做为键名,以任意对象作为值。虽然在迭代的时候,规范约定了以不同的方式处理整数索引属性和其他属性。
下面我们先来解释下整数索引属性和命名属性的区别。
先来假设一个简单的对象 {a: 'foo', b: 'bar'}。该对象有两个命名属性,a 和 b,它没有整数索引。整数索引属性(通常叫做元素element)在数组中比较常见,如 ['foo', 'bar'] 有两个整数索引,分别为 0 和 1。这是 V8 处理属性的第一个主要区别。
元素和属性存储在两个独立的数据结构中,这使得添加和访问属性或元素,在不同的场景下都更有效率。
元素主要用于 Array.prototype 的各种方法,鉴于这些函数访问的是连范围内的属性,V8 在内部也将他们表示为简单数组(在大多数情况下是这样的,有时会切换到基于稀疏字典的形式来节省内存)
命名属性以类似的方式存储在单独的数组中。但是与元素不同的是,我们不能使用简单的键来推断他们在属性数组中的位置,我们需要一些额外的元数据。在 V8 中,每个 JavaScript 对象都有一个关联的 HiddenClass,它用来存储对象的结构信息,以及从属性名到属性数组的索引的一个映射关系。对于复杂的情况,通常会使用一个字典来存储属性信息,而不是一个简单的数组。
更详细的内容请阅读 V8 博客的文章 Fast properties in V8
通过查询 ECMA 262 规范我们可以看到,第一节中我们使用的六种遍历属性的方法,在类似的情况下,最终都会返回 Obj.[[OwnPropertyKeys]] 的结果。
按照 ECMA 262 中对 [[OwnPropertyKeys]] 的定义:
When the
[[OwnPropertyKeys]]internal method of O is called, the following steps are taken:
- Return ! OrdinaryOwnPropertyKeys(O).
它返回了一个 OrdinaryOwnPropertyKeys(O) 的处理结果,而 OrdinaryOwnPropertyKeys(O) 的执行过程则是:
When the abstract operation OrdinaryOwnPropertyKeys is called with Object O, the following steps are taken:
- Let
keysbe a new empty List.- For each own property key
PofOthat is an array index, in ascending numeric index order, do
a. AddPas the last element ofkeys.- For each own property key
PofOthat is a String but is not an array index, in ascending chronological order of property creation, do
a. AddPas the last element ofkeys.- For each own property key
PofOthat is a Symbol, in ascending chronological order of property creation, do
b. Add P as the last element ofkeys.- Return
keys.
我们来简单描述下上述过程就是:首先创建一个名为 keys 的空数组,然后先遍历对象中的数组索引的属性,结果以升序排列,并逐个放入 keys 中;再遍历字符串属性(但不是数组索引),以属性创建时间升序排列,并逐个放入 keys 中去;然后再遍历 Symbol 类型的属性名,同样以属性创建时间升序排列,放入 keys 中,最后返回 keys 数组。
下来我们来验证一下:
var a = {
b: 1,
a: 2,
c: 3,
7: 4,
1: 5,
10: 6,
[Symbol('a')]: 7
}
a.d = 8
a[Symbol('b')] = 9
Reflect.ownKeys(a)output(devtools):
(9) ["1", "7", "10", "b", "a", "c", "d", Symbol(a), Symbol(b)]
0: "1"
1: "7"
2: "10"
3: "b"
4: "a"
5: "c"
6: "d"
7: Symbol(a)
8: Symbol(b)
length: 9Chrome 的实现与规范的约定完全一致😕,所以至此我们知道它为什么打印出来是升序的了。
另外引用 Chromium 社区上� Issue 164: Wrong order in Object properties interation 的讨论所述:
There seems to be a widespread feeling that this used to work the way people expected it, but then the V8 team broke it in order to be mean.
What actually happened was that originally the order was completely arbitrary in V8. At a later point it was changed so that non-numeric indices were in insertion order, and numeric indices were sometimes in insertion order. Whether or not the numeric indices were in in insertion order was dependent on internal V8 heuristics that decide whether to use an array or a hash map implementation for the numeric indices. Making heuristics in the V8 implementation visible in this way was felt to be undesirable so it was normalized so that numeric indices were always iterated in numeric order regardless of the internal representation. Numeric iteration order was always a possibility, but with the last change it was made predictable.
There has never been any difference between the internal representation or iteration order of arrays vs. other objects in V8.
Here is an independent test of the way arrays and objects perform in various engines (a little out of date now): http://news.qooxdoo.org/javascript-array-performance-oddities-characteristics If this bug ever gets 'fixed' you can wave goodbye to some of the nice performance results in that graph.
结合前面介绍的 V8 属性一节我们知道,数组属性总是存储在一个单独的空间(可能是数组,也可能是字典)。在这种情况下,始终以有序数组的状态输出键值,这样的结果是可预测的(始终一致)。并且在 V8 内部,数组的内部表示和迭代方式,和其它对象没有任何不同。
综上所讲,这样的内部实现,有性能的因素,也有历史原因。
讲了那么多,我就是想按原顺序打印怎么办?
首先如果目标结构已经是 JavaScript 对象,应该是没有办法了。我们回到最终的问题,如果我们有一串 JSON 数组,想把它按原序获得键值,可以怎么做?假如我们有串数据:
{"100":"foo","2":"bar","7":"baz"}首先能想到的一个简单的方法就是,自己写一个简单的 json-parser。
下面是一个简单的实现:
const jsonString = '{"100":"foo","2":"bar","7":"baz"}'
const parseKeys = str => {
const out = []
const tokens = str.slice(1, -1).split(',')
for (let i = 0; i < tokens.length; i += 1) {
out.push(tokens[i].split(':')[0].slice(1, -1))
}
return out
}
// try
console.log(parseKeys(jsonString)) // ✅ ["100", "2", "7"]看起来我们得到了想要的结果(yeah),但是如果 json 数组稍微复杂点儿呢?
{"100":{"b":"foo"},"2":[1,2],"7":200}我们再来重构下这个解析器:
var parseKeys = (str, lvl = 1) => {
let out = []
let level = 0
let matching = false
let pair = []
for (let i = 0; i < str.length; i += 1) {
if (str.charAt(i) === '"' && level === lvl) {
if (!matching) {
pair[0] = i
} else {
pair[1] = i
out.push([...pair])
}
matching = ~matching
} else if (['{', '['].indexOf(str.charAt(i) > 0)) {
level += 1
} else if (['}', ']'].indexOf(str.charAt(i) > 0)) {
level -= 1
}
}
return out.map(pair => str.slice(pair[0], pair[1]))
}output(devtools):
["100", "2", "7"]上面这个方法执行效率并不高,只是提出一种思路,当然我们的目标还是解析出 key,而不是完整的引入一个 json 解释器,那样可能得不偿失。
更高效的解决方法,我们之后再补充...
V8 在内部将命名属性和数组索引属性分开存储,并且数组和其它对象的内部实现和迭代机制是完全一致的。
由规范定义,对象在迭代的时候,总是以升序输出数组索引的属性。如果要解决这个问题,目前可能自己去解析 JSON 字符串。
更多问题的延伸讨论,请参考 Chromium 社区的 Issue: 164 讨论。
对于 V8 内对象属性的存储,本人也理解尚浅,如有谬误欢迎指正!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.