blog's People
Contributors

Stargazers
















Watchers



blog's Issues
高性能缓存库risterio
risterio code reading
risterio是一个基于内存的高性能KV存储,具有较高的读写性能和可靠性。它采用了多种技术来优化性能,分析代码可以看看具体的实现。
sync.Pool 实现BP-Wrapper
BP-Wrapper是一种无锁算法,BP代表的是batching和prefetching的缩写,在risterio中主要使用了batching的**。
Batching
batching比较容易理解,论文中为每个线程设置了一个FIFO队列,每个页面请求都会先进入队列,当队列满或符合特定条件后再获取锁进行后续操作。这样会有一定的延迟,是否需要使用batching也取决于业务场景是否能够接受。

Batching的**在很多场景中都有应用,比如TCP的缓冲区,以及一些数据处理任务中的批处理操作。将一些操作缓存下来,通过一定的时间或者数量的积累后再批量处理,可以有效地减少系统调用和网络传输的开销,提高系统的吞吐量和性能表现。在使用Redis或Kafka等系统时,通过缓冲一些操作再进行批量处理,也可以降低连接数,减轻系统负载,提高整体性能。
Prefetching
Prefetching在论文中没有详细描述,但通过图示可以比较清楚地了解其作用,简单来说就是为了避免在锁定并发访问的情况下发生cache miss并需要进行I/O操作。因此,Prefetching可以在进行计算之前提前获取数据,只有在实际进行计算时才需要对数据进行加锁。
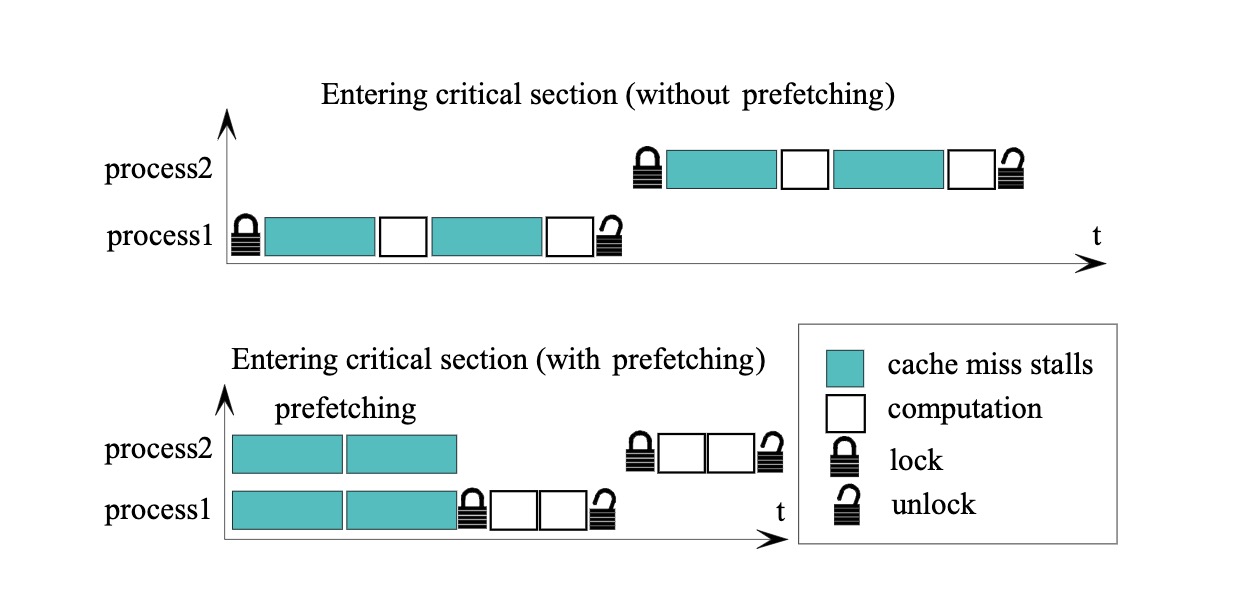
Sync.Pool 实现
他们的blog提到过实现批处理的功能,但也有提到使用channel的方式,不过通道的性能并没有sync.Pool表现得那么好。这是因为sync.Pool底层对于P做了一些优化,相当于实现了一层本地TLS(thread-local storage),将数据存储在poolLocal中,每个P都有自己的数据,可以大大减少竞争。
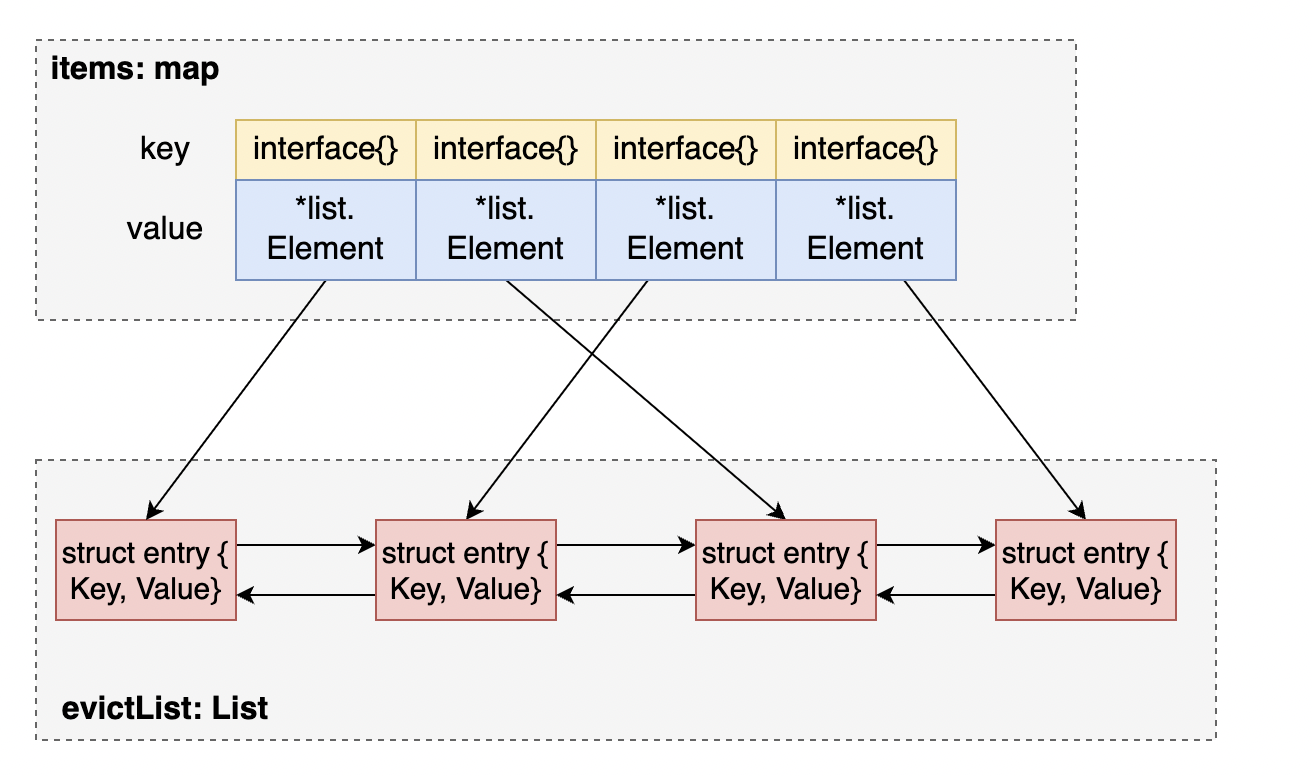
去看下risterio里面的代码实现,sync.Pool是在ringBuffer里定义的。其中核心**就是当ringbuffer满了之后再去统计LFU里面的一些metrics信息。
type ringBuffer struct {
pool *sync.Pool
}
// Push adds an element to one of the internal stripes and possibly drains if
// the stripe becomes full.
func (b *ringBuffer) Push(item uint64) {
// Reuse or create a new stripe.
stripe := b.pool.Get().(*ringStripe)
stripe.Push(item)
b.pool.Put(stripe)
}stripe会先把数据写入到s.data里面,这个操作是无锁的。当目前的data数据超过cap之后会让ringConsumer 去进行消费。
func (s *ringStripe) Push(item uint64) {
s.data = append(s.data, item)
// Decide if the ring buffer should be drained.
if len(s.data) >= s.capa {
// Send elements to consumer and create a new ring stripe.
if s.cons.Push(s.data) {
s.data = make([]uint64, 0, s.capa)
} else {
s.data = s.data[:0]
}
}
}上面的代码关键点就在于每次操作前都是从pool里面拿到的ringStripe对象,所以就无需进行加锁操作,在还回pool之前就不会有并发的一些问题,这也是比较巧妙的一点。
后续的操作因为已经没有pool来保证并发,所以在processItem的时候还是需要lock来进行并发保护的。
func (p *defaultPolicy) processItems() {
for {
select {
case items := <-p.itemsCh:
p.Lock()
p.admit.Push(items)
p.Unlock()
case <-p.stop:
return
}
}
}memory bouding
过期策略
risterio的内存管理方式不同于freecache等其他缓存库,它引入了一个"cost"概念。每次调用set函数时,会为每个key附加一个cost值,通过计算maxCost来控制整个缓存中存储的key数量。与其他库根据key的使用量来决定哪些key需要被删除不同,risterio使用cost作为标准来管理内存。
LRU(Least Recently Used), 算法根据数据的访问时间来决定其生命周期,最近访问的存活时间越长。然而,这种算法的缺点也很明显,即短时间内有大量的冷数据访问时,会刷掉热数据,导致缓存的命中率下降。以golang里面的LRU cache实现来讲的话,一般都是基于map以及linkedlist来实现的。这样GET和SET的时间复杂度都可以到O(1)。
LFU(Least Frequently Used)是根据数据访问的频率来决定key是否会被缓存在cache里面,访问频率越高的key生命周期越长。相比于LRU,LFU的缓存命中率一般情况下会更好,但是在突发流量的情况下表现不佳,因为它是根据访问频率来决定的。此外,LFU的实现相对复杂,需要考虑如何精确统计每个key的访问频率以及如何控制cache中的key数量。
risterio 里面使用tinyLFU还是受到了Caffeine的影响,TinyLFU是一种适用于大型数据库的高效缓存淘汰策略,它通过维护最近访问的项目的访问频率的近似表示来实现。相比之下,LRU和LFU是两种传统的缓存淘汰策略。LRU会优先淘汰最近最少使用的项目,而LFU会优先淘汰最不经常使用的项目。TinyLFU基于Count-Min Sketch策略并且可以在非常小的内存开销下实现高效率的统计,命中率也十分可观。
Count-Min sketch的**来自于bloomfilter,通过hash后的key来映射到位图上,在尽可能少的使用内存的情况下去进行过滤。但是在发生hash冲突的时候,可能不同的key会出现在位图的同一个位置,这就是为什么bloomfilter里面无法准确判断key是否存在(false postive)。
在Count-Min Sketch中,对于每一个值,写入时用n个独立的hash函数映射到每一行的一列中。每个位置上存储一个计数器,用于记录该位置上已经被映射到的元素的频率count。
查询时取最小的count作为element出现的次数,故名count-min。为了降低Count-Min Sketch表格的空间占用,TinyLFU会定期将Count-Min Sketch中的计数器减半。
+-----+-----+-----+-----+-----+-----+-----+
|key 0|key 1|key 2|key 3|key 4|key 5|key 6|
+---+-----+-----+-----+-----+-----+-----+-----+
| | | | | | | | |
|h0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| | | | | | | | |
+---+-----+-----+-----+-----+-----+-----+-----+
| | | | | | | | |
|h1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| | | | | | | | |
+---+-----+-----+-----+-----+-----+-----+-----+
| | | | | | | | |
|h2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| | | | | | | | |
+---+-----+-----+-----+-----+-----+-----+-----+
| | | | | | | | |
|h3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| | | | | | | | |
+---+-----+-----+-----+-----+-----+-----+-----+
除了上面的CM-Sketch, tinyLFU 前面还加了一层bloomFilter可以用来提高缓存命中率以及误判率。
type tinyLFU struct {
freq *cmSketch
door *z.Bloom
incrs int64
resetAt int64
}cmSketch以及Bloomfilter具体实现的代码就不展示,整个tinyLFU的实现还是比较好理解的。写入的时候由于是batch写,所以对外提供的接口是Push,另外查询的时候因为不是准确的频率,所以是p.freq.Estimate。
func (p *tinyLFU) Push(keys []uint64) {
for _, key := range keys {
p.Increment(key)
}
}
func (p *tinyLFU) Estimate(key uint64) int64 {
hits := p.freq.Estimate(key)
if p.door.Has(key) {
hits++
}
return hits
}还有个tinyLFU有意思的点就是当counter计数到一定的数量时,会去将counter里面的数目减半,进而减少记录访问频率的开支。
func (p *tinyLFU) Increment(key uint64) {
// Flip doorkeeper bit if not already done.
if added := p.door.AddIfNotHas(key); !added {
// Increment count-min counter if doorkeeper bit is already set.
p.freq.Increment(key)
}
p.incrs++
if p.incrs >= p.resetAt {
p.reset()
}
}
func (r cmRow) reset() {
// Halve each counter.
for i := range r {
r[i] = (r[i] >> 1) & 0x77
}
}时间片管理TTL
TTL的管理在risterio里的实现也比较简单,基于时间戳来划分不同的桶,定期回收过期的桶。
以5秒为一个时间片,数据结构是map[bucketNum]keys,每间隔2.5秒就会循环清理一次所有的桶。时间片的计算是基于Unix时间戳,使用time.Now()/5 + 1来定位到对应的时间片。
func storageBucket(t time.Time) int64 {
return (t.Unix() / bucketDurationSecs) + 1
}clean的tick到了后会去清除上一轮已经过期掉的的时间片, 新的写入操作只会写入当前5s的时间片。
这点设计跟kafka里的时间轮有点不一样,kafka的时间轮是一个环形的多层时间轮,这里的实现比较简单,就相当于是一个顺序展开的时间片。
其他的一些优化
Hash加速
通过go link直接调用底层的汇编函数,目前是比较快的。
//go:noescape
//go:linkname memhash runtime.memhash
func memhash(p unsafe.Pointer, h, s uintptr) uintptrMap分片,减少锁力度
这个优化手段比较常见了,通过声明多个map,每个map单独持有锁进而减少锁的粒度
type shardedMap struct {
shards []*lockedMap
expiryMap *expirationMap
}atomic padding
在高并发场景下,多个goroutine同时访问共享变量可能会导致false sharing的问题,即一个goroutine修改了共享变量的一部分,导致其他goroutine需要重新加载整个变量的情况,从而影响性能。
padding是在结构体中添加一些无用的字段,使得不同的字段位于不同的cache line中,从而避免了false sharing的问题。
atomic计数器在多核情况下的false sharing可通过padding解决。
valp := p.all[t]
// Avoid false sharing by padding at least 64 bytes of space between two
// atomic counters which would be incremented.
idx := (hash % 25) * 10
atomic.AddUint64(valp[idx], delta)Ref
分布式ID
分布式ID
BackGround
分布式ID在许多场景都是十分有用的,比如分布式数据库里面的MVCC实现(需要单调递增性), 比如支付场景的支付ID(需要唯一性)。一个高可用的分布式ID必须满足以下几个特征:
- 唯一性
- 单调递增
- 高可用
业内常见的解决方案可以参考如下几种解决方案:
UUID
UUID是一种比较常见的解决方案,全称Universally Unique Identifier,是由一组32位数的16进制数字所构成, 比如550e8400-e29b-41d4-a716-446655440000。大多数标准库都集成了UUID算法。常用的版本有以下5种:
- 版本1 - UUID 是根据时间和节点 ID(通常是MAC地址)生成;
- 版本2 - UUID是根据标识符(通常是组或用户ID)、时间和节点ID生成;
- 版本3、版本5 - 确定性UUID 通过散列(hashing)名字空间(namespace)标识符和名称生成;
- 版本4 - UUID 使用随机性或伪随机性生成。
通常情况下如果只是需要一个随机的ID,可以选择1或者4版本,1版本的可读性更强一点,4是完全基于随机数生成的,大多数情况下我们用到的都是基于版本1的实现。
如果需要指定名称每次生成相同的UUID则可以考虑版本3或者5,两者的不同是一个基于MD5 hash,一个基于SHA-1 hash。
使用也比较简单,用golang的satori/go.uuid这个库作为例子,可以很方便的得到一个UUID。
package main
import (
"fmt"
"github.com/satori/go.uuid"
)
func main() {
u1 := uuid.Must(uuid.NewV4())
fmt.Printf("UUIDv4: %s\n", u1)
}优点:
- 生成简单,大多数语言都有基础库集成,没有网络调用消耗
缺点;
- 字符串占据空间较大
- 无序字符串
雪花算法Snowflake
雪花算法将64bit的整数按位划分
+--------------------------------------------------------------------------+
| 1 Bit Unused | 41 Bit Timestamp | 10 Bit NodeID | 12 Bit Sequence ID |
+--------------------------------------------------------------------------+
- 1 Bit 保留位
- 41 Bit 时间戳,毫秒级别。
- 10 Bit 机器ID
- 12 Bit 序列号,用来记录同毫秒内产生的不同id。12位序列号表示每毫秒能产生4096个ID,如果超过此范围,需要等到下一个毫秒。
Golang中可以使用bwmarrin/snowflake来生成ID,整个代码也十分简单,指定唯一的机器ID即可。
package main
import (
"fmt"
"github.com/bwmarrin/snowflake"
)
func main() {
// Create a new Node with a Node number of 1
node, err := snowflake.NewNode(1)
if err != nil {
fmt.Println(err)
return
}
// Generate a snowflake ID.
id := node.Generate()
// Print out the ID in a few different ways.
fmt.Printf("Int64 ID: %d\n", id)
}优点:
- 序列自增
- 生成容易,不依赖外部存储,没有网络调用消耗
- Bit位调整灵活,可以适用于不同的场景
缺点:
- 强依赖系统时钟,可能会有时钟回拨的问题发生
数据库主键
Mysql
可以基于Mysql生成自增ID,每次需要相应ID的时候直接Insert一条语句即可。
CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
插入一条数据然后取出ID即可,需要额外注意的是Mysql并不能保证自增ID的连续性(事务失败或者回滚/自增锁的设置级别)。
insert into t values(null, 1);
SELECT LAST_INSERT_ID();
上面是一个典型的语句,每次生成之后需要再select取一下,有时候会对Mysql压力比较大。
idgo是一个基于Redis和Mysql的批号ID生成器, 每次取都是基于offset取出一批数据。具体可以参考实现
优点:
- 集成简单
- 数据递增
缺点:
- 引用了数据库依赖,需要一次调用
- 性能吞吐取决于Mysql
Etcd/Zookeeper
由于Etcd和Zookeeper是线性一致性的数据库,里面的ID不依赖同步时钟,没有时钟回拨的问题。
以Etcd举例,只考虑最简单的场景:每次从Etcd GET完之后在本地将value自增然后放回Etcd。
func generateID() uint64{
value, _ := etcdutil.GetValue(client, key)
current := util.BytesToUint64(value)
current += 1
_, err := etcdutil.PutValue(client, key, value)
if err != nil {
return 0
}
return value
}上面的代码跑跑demo可以用,但是在实际生产环境中会有几个问题:
1.每次Allocate都需要进行两次Etcd操作(Get/Put), 流量大了之后对Etcd的压力是十分恐怖的。
2.在高并发的情况下,我们无法保证我们Put进去的值是最新的,可能会出现ID覆盖的问题,这时候就需要用到Etcd原生的事务。
解决上面问题1的方法是每次Get时候使用号段模式,在提交的时候预分配1000个ID,使用完了再去Etcd里面Get和Put。问题2使用Etcd原生的Txn可以解决。
下面是简单的代码示例:
const (
step = 1000
)
var base, end uint64
func getID() uint64 {
// 号段用完,去generate一批
if base == end {
res := generateID()
// got error
if res == 0 {
return 0
}
end = res
base = end - step
}
base ++
return base
}
func generateID() uint64{
value, _ := etcdutil.GetValue(client, key)
current := util.BytesToUint64(value)
current += step
cmp = clientv3.Compare(clientv3.Value(key), "=", string(value))
client.Txn(context.Background()).If(cmp).Then(clientv3.OpPut(key, string(current))).Commit()
if err != nil {
return 0, err
}
if !resp.Succeeded {
return 0
}
return value
}优点:
- value格式支持自定义
- 数据有序
- 没有时钟拨回的隐患
缺点
- 引用了数据库依赖,需要一次调用
- 性能瓶颈以及可用性会依赖Etcd
主流开源方案
-
美团leaf
美团leaf支持两种模式:号段模式以及snowFlake模式。
在原生的号段模式上,leaf是采用双buffer优化去做的,相较于上面的实现,leaf每次在号段使用超过10%的时候就会去异步的申请一段号(异步更新)。 -
百度UidGenerator
UidGenerator 是 Java 实现的, 基于 Snowflake 算法的唯一 ID 生成器。Cache的实现是借用未来时间实现的RingBuffer。
时钟拨回问题
传统的snowFlake无法避免时钟回拨问题,常用的解决方案
- 服务端等待一段时间再比较时间
- 直接抛出异常,由客户端进行重试
- 消费未来时间位(利用cache)
- 使用 1~2台关闭NTP时钟的机器做backup
小结
在实际的生产环境中,需要使用哪种分布式ID方案都需要根据实际场景来决定。Snowflake算法可以满足大部分的场景,如果服务本身已经依赖了一些外部数据库不妨可以使用这些数据库来做分布式ID。如果要考虑做一个中间件的话,上面的开源方案都是一些很好的参考。
reference
- https://asktug.com/t/topic/1521
- https://zh.wikipedia.org/wiki/%E9%80%9A%E7%94%A8%E5%94%AF%E4%B8%80%E8%AF%86%E5%88%AB%E7%A0%81https://zh.wikipedia.org/wiki/%E9%80%9A%E7%94%A8%E5%94%AF%E4%B8%80%E8%AF%86%E5%88%AB%E7%A0%81
- https://tech.meituan.com/2017/04/21/mt-leaf.html
- https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
IOLoop分析
IOLoop
函数说明
__init__
- IOLoop.READ:Available for read
- IOLOOP.WRITE: Available for write
- IOLoop.ERROE: Error condition happened on the assoc. fd
IOLoop声明的时候有三种状态:READ, WRITE, ERROR。
_impl 根据操作系统有三种不同的支持方式,linux2.5.44以上支持epoll,free bsd和mac支持kqueue,windows支持select。__impl_在这里是对事件机制的一个封装,_register_注册事件,_modify_修改事件,_unregister_销毁事件,_poll_轮询事件.
初始化实例的时候添加一个__read_waker_,伪造一次IO事件,这样做的好处是以便事件循环阻塞而没有相应描述符出现,需要在最大timeout时间之前返回,就可以向这个管道发送一个字符,用来终止阻塞在监听阶段的事件循环监听函数。
instance
任意的一条线程共享IOLoop对象
add_handler
_self._handlers_是一个字典,其中fd作为键, handler作为值。对_self._impl_注册fd和events状态。
update_handler
对事件状态进行更新,调用_self.impl.modify
start
一个while循环,将_self._callbacks_里边的callback遍历执行,执行完callback再进行下一次的事件迭代。通过_self._impl.poll_取出事件和相应的handler,执行该事件。
stop
通过_self._read_waker_将_self._stopped_设置为False, 终止while循环。
通过test case 进行流程分析
#!/usr/bin/env python
import unittest
import time
from tornado import ioloop
class TestIOLoop(unittest.TestCase):
def setUp(self):
self.loop = ioloop.IOLoop()
def tearDown(self):
pass
def _callback(self):
self.called = True
self.loop.stop()
def _schedule_callback(self):
self.loop.add_callback(self._callback)
# Scroll away the time so we can check if we woke up immediately
self._start_time = time.time()
self.called = False
def test_add_callback(self):
self.loop.add_timeout(time.time(), self._schedule_callback)
self.loop.start() # Set some long poll timeout so we can check wakeup
self.assertAlmostEqual(time.time(), self._start_time, places=2)
self.assertTrue(self.called)
if __name__ == "__main__":
import logging
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s:%(msecs)03d %(levelname)-8s %(name)-8s %(message)s', datefmt='%H:%M:%S')
unittest.main()

Sync.Pool 源码分析及演进
Sync.Pool 源码分析
定义
A Pool is a set of temporary objects that may be individually saved and
retrieved.
sync.Pool 是一个临时的对象池,对外提供Get和Put的方法。
池化是优化的一种手段,新对象的连续创建和销毁都会给系统带来一定的压力,使用Pool可以有效的优化GC以及减少内存申请开销。
使用
下面写一个简单的例子:
func main() {
p := &sync.Pool{
New: func() interface{} {
// 默认对象,当pool里面没有则返回该默认值
return 0
},
}
// 没有可用对象,返回默认值
a := p.Get().(int)
// Put一个对象进去
p.Put(1)
// 返回值为1
b := p.Get().(int)
}上面的程序逻辑很简单,pool里面有可用对象的时候则返回,没有的话默认调用New方法,并返回。
An example of good use of a Pool is in the fmt package, which maintains a
dynamically-sized store of temporary output buffers. The store scales under
load (when many goroutines are actively printing) and shrinks when
quiescent.
官方的fmt也有在使用sync.Pool, 具体可以看下怎么在使用:
// 初始化pool
var ppFree = sync.Pool{
New: func() interface{} { return new(pp) },
}
type buffer []byte
// pp结构类型,只需关注里面bytes的使用
type pp struct {
buf buffer
arg interface{}
......
}
// newPrinter allocates a new pp struct or grabs a cached one.
func newPrinter() *pp {
// Get 操作
p := ppFree.Get().(*pp)
return p
}
// free saves used pp structs in ppFree; avoids an allocation per invocation.
func (p *pp) free() {
// Proper usage of a sync.Pool requires each entry to have approximately
// the same memory cost. To obtain this property when the stored type
// contains a variably-sized buffer, we add a hard limit on the maximum buffer
// to place back in the pool.
//
// See https://golang.org/issue/23199
if cap(p.buf) > 64<<10 {
return
}
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
ppFree.Put(p)
}这里比较有意思的一个地方是 23199 这个issue。
里面的例子 可以简单总结下,就是pool里面的一个Buffer在Get完之后对其进行一次Grow操作扩大其cap。虽然有很多的空间是没用到的,但是因为Get的操作可能导致之后需要很多个GC cycle才能完全把这部分内存释放掉。所以官方在这里很暴力的加了个64K的大小判断。本质上来说,pool里面的对象都需要差不多大小。
比较优雅的实现可以参考http库里面chunkPools的实现,不同大小的对象使用不同的pool
http2dataChunkPools = [...]sync.Pool{
{New: func() interface{} { return make([]byte, 1<<10) }},
{New: func() interface{} { return make([]byte, 2<<10) }},
{New: func() interface{} { return make([]byte, 4<<10) }},
{New: func() interface{} { return make([]byte, 8<<10) }},
{New: func() interface{} { return make([]byte, 16<<10) }},
}源码分析(基于1.12)
Pool 结构体
// A Pool must not be copied after first use.
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() interface{}
}- noCopy 这里表示的是该对象创建之后,理论上来说不能被其他对象复制,sync里的大多数包都不能被复制(避免指针污染)。这里的实现是实现一个空接口,通过govet来检测。
- local 实际上是一个[P]poolLocal的数组,数据类型为指针
- localSize local数组大小
- New 返回对应的数据类型
// Local per-P Pool appendix.
type poolLocalInternal struct {
private interface{} // Can be used only by the respective P.
shared []interface{} // Can be used by any P.
Mutex // Protects shared.
}- private 每个P的对象
- shared 可以给所有P共享的对象列表
- Mutex shared的读取和写入需要加锁(1.13实现了无锁版,后面介绍)
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}- pad 用来防止
false sharing, 大部分的CPU prefetch 的cache line都是64byte,使用128byte整除可以防止多核reload cache line。可以参考24
Get方法
func (p *Pool) Get() interface{} {
if race.Enabled {
race.Disable()
}
l := p.pin()
x := l.private
l.private = nil
runtime_procUnpin()
if x == nil {
l.Lock()
last := len(l.shared) - 1
if last >= 0 {
x = l.shared[last]
l.shared = l.shared[:last]
}
l.Unlock()
if x == nil {
x = p.getSlow()
}
}
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
if x == nil && p.New != nil {
x = p.New()
}
return x
}- 忽略race的噪音,分析整个流程,先开始调用pin函数绑定P,具体看下pin函数的执行过程。
- 调用完pin,拿到一个local对象之后,将
l.private赋值为空,解绑P。 - 如果x的对象为空,则会从shared里面去拿出最后一个,然后将shared的长度减一
- 如果shared里面数组也为空,则会去调用
getSlow方法,出现这个场景可能是pool刚初始化或者对象用尽。getSlow这个函数的作用就是从其他P的poolLocal里面拿一个出来。 - 如果上面的流程还是拿不到,会去从默认的New方法里面取出一个新的对象
pin函数流程
func (p *Pool) pin() *poolLocal {
pid := runtime_procPin()
s := atomic.LoadUintptr(&p.localSize) // load-acquire
l := p.local // load-consume
if uintptr(pid) < s {
return indexLocal(l, pid)
}
return p.pinSlow()
}func procPin() int {
_g_ := getg()
mp := _g_.m
mp.locks++
return int(mp.p.ptr().id)
}首先会调用runtime_procPin来将当前的G和一个P进行绑定,因为后续的一些像indexLocal等函数都需要P的ID来进行查找,所以这里需要禁止抢占(preemption)。
s := atomic.LoadUintptr(&p.localSize) 拿到localSize,赋值给s。然后判断pid(0-N), pid的取值范围跟runtime.Maxprocs有关,如果是在local的数组范围内,调用indexLocal 返回一个poolLocal对象。就是根据指针来从list里面下标取值的过程。
func indexLocal(l unsafe.Pointer, i int) *poolLocal {
lp := unsafe.Pointer(uintptr(l) + uintptr(i)*unsafe.Sizeof(poolLocal{}))
return (*poolLocal)(lp)
}当数组不够的时候,再看下最后一个pinSlow方法
func (p *Pool) pinSlow() *poolLocal {
// Retry under the mutex.
// Can not lock the mutex while pinned.
runtime_procUnpin()
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
s := p.localSize
l := p.local
if uintptr(pid) < s {
return indexLocal(l, pid)
}
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
atomic.StoreUintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid]
}pinSlow的流程看起来很有意思,先是unpin掉当前的P,然后对allPoolsMu进行一次加锁,再重新去local
的数组里面拿一次,没有的话就表示是第一次Get或者在GC期间GOMAXPROCS改变了local size,会把当前的p放到一个全局的allPools里面去。
这里加锁创建是因为在并发的环境里面可能会有不同的G去调用pinSlow函数,确保线程安全的情况下,如果一个G成功创建了一个pool,设置了正确的local,另外一个G就需要再去判断一次,然后返回。allPoolsMu是一个全局的大锁,在某些情况下可能会影响性能,在1.13里面已经实现了无锁版,下面会说到如何实现。
Put方法
// Put adds x to the pool.
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
if race.Enabled {
if fastrand()%4 == 0 {
// Randomly drop x on floor.
return
}
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
l := p.pin()
if l.private == nil {
l.private = x
x = nil
}
runtime_procUnpin()
if x != nil {
l.Lock()
l.shared = append(l.shared, x)
l.Unlock()
}
if race.Enabled {
race.Enable()
}
}忽略race噪音,看Put方法就比较轻松了
- 绑定一个P,拿到对应的poolLocal,给poolLocal的private赋值
- Unpin,然后append对象到shared里面
这里需要理解一下private和shared, 每次Put的时候都会覆盖private, 然后往shared里面追加一个对象。Get的时候会把private重置为nil, 然后shared里面移走一个元素。
clean
上面有Put和Get,另外需要关注的一点就是如何进行clean,可以看代码分析。
func init() {
runtime_registerPoolCleanup(poolCleanup)
}函数在init的时候会去注册一个poolCleanup函数,需要关注下runtime_registerPoolCleanup的实现。具体代码在runtime包里面搜索就可以看到:
func sync_runtime_registerPoolCleanup(f func()) {
poolcleanup = f
}gcStart会在函数里面调用poolcleanup,这就是说每次GC启动的时候都会去清空Pool。
poolCleanup函数很简单,清空allPool里面所有的相关元素,全部设置为nil。
func poolCleanup() {
// This function is called with the world stopped, at the beginning of a garbage collection.
// It must not allocate and probably should not call any runtime functions.
// Defensively zero out everything, 2 reasons:
// 1. To prevent false retention of whole Pools.
// 2. If GC happens while a goroutine works with l.shared in Put/Get,
// it will retain whole Pool. So next cycle memory consumption would be doubled.
for i, p := range allPools {
allPools[i] = nil
for i := 0; i < int(p.localSize); i++ {
l := indexLocal(p.local, i)
l.private = nil
for j := range l.shared {
l.shared[j] = nil
}
l.shared = nil
}
p.local = nil
p.localSize = 0
}
allPools = []*Pool{}
}1.13优化
1.13主要优化的有两个点:
victim cache
所谓受害者缓存(Victim Cache),是一个与直接匹配或低相联缓存并用的、容量很小的全相联缓存。当一个数据块被逐出缓存时,并不直接丢弃,而是暂先进入受害者缓存。如果受害者缓存已满,就替换掉其中一项。当进行缓存标签匹配时,在与索引指向标签匹配的同时,并行查看受害者缓存,如果在受害者缓存发现匹配,就将其此数据块与缓存中的不匹配数据块做交换,同时返回给处理器。 -- 维基百科
在sync.Pool里victim cache的可以定义为次级缓存,每次GC的时候只去删除victim的对象,减少两次GC间Pool冷启动导致的GC抖动,提高Get的命中率。
参照 cleanup的新实现
func poolCleanup() {
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
oldPools, allPools = allPools, nil
}每次GC前,都将oldPools重置,allPools里面的内容赋值给oldPools里面的victim(相当于old cache),然后再清空allPools。
Get操作里面会在getSlow里面使用victim cache,说简单点就是当一次GC后,如果Pool里面没有对象可以Get的时候,会从上一次的oldPool里面去拿对象,不会走New再去创建新的对象,如果一次GC后有大量的Get操作,但是Put跟不上,就可以利用oldPool相应的提高命中率,确保一个对象可以活过两个GC。具体可以参考22950这个issue。
locals = p.victim
l := indexLocal(locals, pid)poolChain lock-free structure
去掉了poolLocalInternal 里面的锁。之前锁的作用是在对poolLocal里面的shared进行操作的时候需要加上锁。之前shared字段是一个slice, 在1.13里面变成了poolChain,通过atomic的CompareAndSwapUint64操作来实现无锁。具体可以参考 这次的提交。之前的slice换成了poolDequeue, 里面用atomic实现了一个单生产者多消费者的双向队列,本质上就是利用CPU的CAS原子操作来替换锁。主要的实现代码popHead:
for {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if tail == head {
// Queue is empty.
return nil, false
}
// Confirm tail and decrement head. We do this before
// reading the value to take back ownership of this
// slot.
head--
ptrs2 := d.pack(head, tail)
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
// We successfully took back slot.
slot = &d.vals[head&uint32(len(d.vals)-1)]
break
}
}本质上就是一个For循环不停的去Get相应的Ptr,然后尝试修改d的指针地址,利用atomic.CompareAndSwapUint64实现CPU的原子操作,成功了就返回,失败了继续for循环,直到成功。
小结
其实从1.12到1.13的pool的优化我们就可以看到一次完整的性能优化,包括去锁和优化GC,多看看release note还是有好处的。几个需要注意的点:
- sync.Pool使用时最好可以根据大小划分不同的Pool
- 如果有优化Mutex的需求,可以考虑使用CAS
- victim cache延长对象的生命周期,提高命中率
- CPU false sharing在一些极度注重性能的地方还是能用就用
参考
Hystrix Go相关
微服务熔断与隔离
什么是微服务熔断与隔离
微服务熔断(circuit breaker) 可以理解为是一个保护自身服务以及其调用服务的开关。假设我们服务需要调用一个外部服务B,当B不可用的时候如果我们没有这个熔断器,请求本身还会一直打到B,相应自身系统的latency也会增加,从而造成整体服务的不可用,产生雪崩效应。如果加入了熔断机制,这时候有一个可靠的fallback,牺牲系统的部分准确性可以换来整体的可用性提高。
一些更加详细的介绍可以参考。
Hystrix
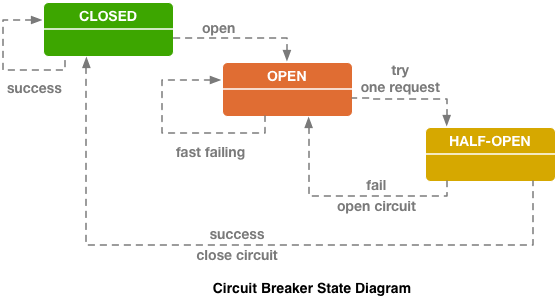
Circuit breaker的实现有很多种,主流的解决方案大多都是基于Netflix的 Hystrix 来做的。 下面是Hystrix的概念图

一些概念
-
HystrixCommand 和 HystrixObservableCommand:这是Java里面的函数,理解起来就是一个同步一个异步,对应, hystrix.Do 和 hystrix.Go 。
-
Circuit Open, Half Open 以及 close:一个正常的Hystrix 状态有三种,当服务正常运行的时候是close。当服务的错误率到达指定的时候就 Open。当Open之后过去一段时间,Hystrix 会让单独的request通过,测服务是否恢复,这个时候就叫做Half open。
-
Hystrix cache:hystrix 支持将命令的返回结果cache住,但是在Golang的Hystrix官方库并没有支持。
-
FallBack: 当circuit breaker Open之后,或者其他错误发生(queue或者Pool满了),这个时候就可以使用Fallback来兜底这些错误逻辑,fallback还是很有用的。
实现原理
这里以Golang的版本来作为参考,实现起来应该是有几个要点需要注意的: 最大并发的控制(queue实现),同步实现(hystrix.Do),异步实现(Hystrix.Go)。
代码实现并不复杂,先看 Hystrix.Go 的实现,简化的代码如下
go func() {
case cmd.ticket = <-circuit.executorPool.Tickets:
ticketChecked = true
ticketCond.Signal()
cmd.Unlock()
default:
ticketChecked = true
ticketCond.Signal()
cmd.Unlock()
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ErrMaxConcurrency)
reportAllEvent()
})
return
}
runStart := time.Now()
runErr := run(ctx)
returnOnce.Do(func() {
defer reportAllEvent()
cmd.runDuration = time.Since(runStart)
returnTicket()
if runErr != nil {
cmd.errorWithFallback(ctx, runErr)
return
}
cmd.reportEvent("success")
})
}()
go func() {
timer := time.NewTimer(getSettings(name).Timeout)
defer timer.Stop()
select {
case <-cmd.finished:
// returnOnce has been executed in another goroutine
case <-ctx.Done():
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ctx.Err())
reportAllEvent()
})
return
case <-timer.C:
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ErrTimeout)
reportAllEvent()
})
return
}
}()先判断cb状态是否允许请求,然后再尝试从ticketPool里面去拿一个ticket执行对应的命令,执行完就放回ticket。另外一个goroutine用来控制前一个goroutine的生命周期(判断是否超时,ctx结束等)。
Hystrix.Do 的方法较为简单,只有一些简单的逻辑判断就不贴代码了。
Pool的实现很简练,就是一个buffered channel,完整逻辑如下.
package hystrix
type executorPool struct {
Name string
Metrics *poolMetrics
Max int
Tickets chan *struct{}
}
func newExecutorPool(name string) *executorPool {
p := &executorPool{}
p.Name = name
p.Metrics = newPoolMetrics(name)
p.Max = getSettings(name).MaxConcurrentRequests
p.Tickets = make(chan *struct{}, p.Max)
for i := 0; i < p.Max; i++ {
p.Tickets <- &struct{}{}
}
return p
}
func (p *executorPool) Return(ticket *struct{}) {
if ticket == nil {
return
}
p.Metrics.Updates <- poolMetricsUpdate{
activeCount: p.ActiveCount(),
}
p.Tickets <- ticket
}
func (p *executorPool) ActiveCount() int {
return p.Max - len(p.Tickets)
}其他的像包括错误率统计以及allowSingleTest等逻辑,具体可以参考源代码,实现的都不复杂。
小结
基于Hystrix 的circuit breaker功能还是十分强大的,但是需要注意的是每一个请求都会额外产生两个goroutine, 统计错误率等一系列的方法也是比较吃CPU的,当服务对于性能要求较高的时候酌情使用。
在使用cb的时候也需要考虑到 goroutine的生命周期,合理利用Ctx去释放掉相应的资源,不然是会很容易造成goroutine leakd的。
Pyhton 装饰器和闭包
Pyhton 装饰器和闭包
闭包(closure)
了解闭包就先得了解nested function, 所谓嵌套函数从字面上就可以理解,一个简单例子。往简单了说就是返回一个函数,然后再去调用这个函数。
def print_msg(msg):
"""This is the outer enclosing function"""
def printer():
"""This is the nested function"""
print(msg)
return printer # this got changed
# Now let's try calling this function.
# Output: Hello
another = print_msg("Hello")
print another
another()
output
<function printer at 0x10bd9b758>
Hello
使用时有几个注意事项:
- 必须要有一个嵌套函数
- 嵌套函数里边必须要与其封闭函数中的一个变量相关联(否则闭包就没有意义了)
- 封闭函数需要返回嵌套函数
再来一个带参数的例子
def make_inc(x):
def inc(y):
# x is "closed" in the definition of inc
return y + x
return inc
make_3 = make_inc(3)
make_4 = make_inc(4)
print make_3(1)
print make_4(1)
output
4
5
装饰器(decorator)
装饰器说白了就是把一个函数当成参数传到嵌套函数里边去,举个简单的例子
def my_decorator(some_function):
def wrapper():
num = 10
if num == 10:
print("Yes!")
else:
print("No!")
some_function()
print("Something is happening after some_function() is called.")
return wrapper
def just_some_function():
print("Wheee!")
just_some_function = my_decorator(just_some_function)
just_some_function()
output
Yes!
Wheee!
Something is happening after some_function() is called.
当然,Pyhton里边有个语法糖,也可以这么写
def my_decorator(some_function):
def wrapper():
num = 10
if num == 10:
print("Yes!")
else:
print("No!")
some_function()
print("Something is happening after some_function() is called.")
return wrapper
@my_decorator
def just_some_function():
print("Wheee!")
just_some_function()
output
Yes!
Wheee!
Something is happening after some_function() is called.
可以看到输出的结果是一样的。
再来看一看常用的functools.wraps, 还是用上面的例子来测试
def my_decorator(some_function):
def wrapper():
num = 10
if num == 10:
print("Yes!")
else:
print("No!")
some_function()
print("Something is happening after some_function() is called.")
return wrapper
@my_decorator
def just_some_function():
print("Wheee!")
just_some_function()
print just_some_function.__name__
output
Yes!
Wheee!
Something is happening after some_function() is called.
wrapper
可以看到,当我门调用just_some_function时,其函数名称改变了,因为我门在调用时相当于做了这么个转换
just_some_function = my_decorator(just_some_function)
要想保留原始的函数信息需要用到functools.wraps
def my_decorator(some_function):
import functools
@functools.wraps(some_function)
def wrapper():
num = 10
if num == 10:
print("Yes!")
else:
print("No!")
some_function()
print("Something is happening after some_function() is called.")
return wrapper
@my_decorator
def just_some_function():
print("Wheee!")
just_some_function()
print just_some_function.__name__
output
Yes!
Wheee!
Something is happening after some_function() is called.
wrapper
functools.wraps具体信息可参考so
装饰器叠加:
def my_decorator(some_function):
@functools.wraps(some_function)
def wrapper(num):
print("calling my_decorator")
return some_function(num)
return wrapper
def another_decorator(some_function):
@functools.wraps(some_function)
def wrapper(num):
print("calling another_decorator")
return some_function(num)
return wrapper
@my_decorator
@another_decorator
def just_some_function(num):
return num * 2
print just_some_function(1)
output
calling my_decorator
calling another_decorator
2
分布式锁
分布式锁
Background
单机锁:
在单一的场景下,锁很好理解,用Golang里面的互斥锁举例:确保在同一时刻只有一个线程可以修改当前的资源。简单的代码示例可以查看 https://play.golang.org/p/7L8oJihNE1G
分布式锁:
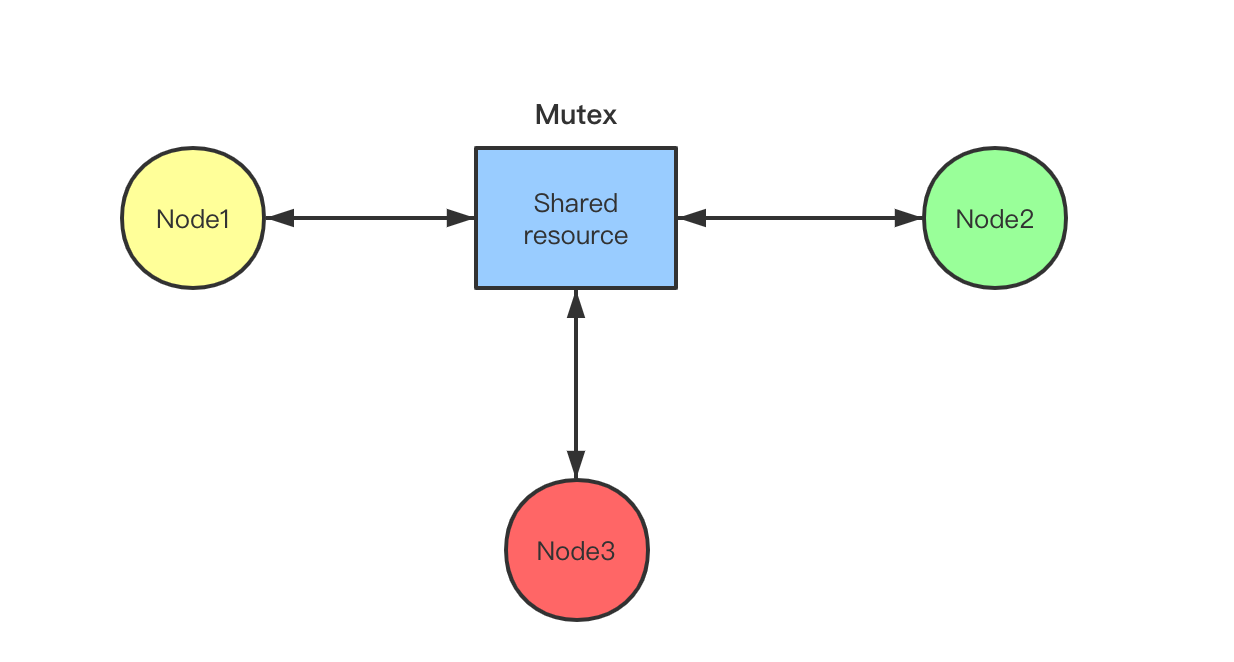
当在一个集群里面我们希望在任一时刻只有一台机器可以访问某个共享资源。与单机锁的最大区别就是锁的粒度已经不在一台机器上了,这个时候我们需要引入外部的资源来帮我们解决这个问题了。
CAP理论:
- Consistency: 一致性(强一致性,弱一致性......)
- Availability: 可用性表示服务在正常响应时间内一直可用。
- Partition tolerance: 但凡是分布式系统,则必须满足这点。表示的是分布式系统在某个节点挂点或网络分区之后仍然可以对外提供服务。
常用几种解决方案
基于数据库的单机锁
Mysql单机实现
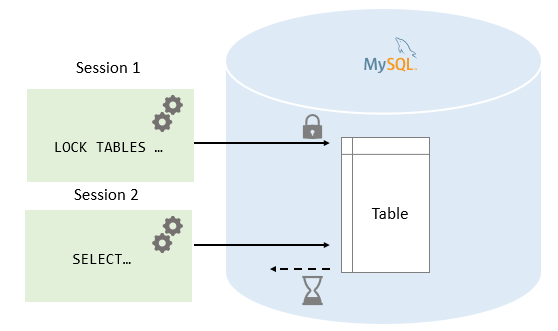
Mysql最简单的方法就是使用 select * for update 来操作某一个字段,使用innodb原生的悲观锁进行操作。这里只有一个简单的CAS操作,但是剩下的time-out可能还需要我们自己实现。
另外还可以考虑Mysql原生的函数 get_lock 与 release_lock 来实现。
mysql> SELECT GET_LOCK('abc', 10);
相较于for update的实现,lock原生支持超时设置
可以阅读详细的文档
基于Mysql实现起来的分布式锁十分方便快捷,但是性能可能不如redis,另外由于是单机版,所以当mysql挂掉之后服务将会变得不可用。
Redis单机实现
Redis自身提供了 setnx px 的命令供我们去使用,在拿锁的时候可以使用该命令。
简单的一条命令 SETNX resource value PX 30000
SETNX 表示的是只有这个Key不存在的时候才会去设置value, px表示的是过期时间。
释放锁的时候则可能需要配合lua脚本去使用来确保锁的原子性
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
Redis的单机锁的实现可以满足大部分场景,性能也是比较好的,唯一不足的就是当Redis节点挂掉之后服务也会变得不可用。
基于 Redis集群的解决方案
基于Redis集群的分布式锁方案官方其实给了一个Redlock 算法。大致的实现我简化下:
在 cluster模式下使用 setnx key val px 去拿到锁,key的方案基于 UUID的方式去生存,在集群中如果Quorum(大于一半的节点)同意,则返回该锁。
现在假设有5个Redis主节点(大于3的奇数个),这样基本保证他们不会同时都宕掉,获取锁和释放锁的过程中,客户端会执行以下操作:
- 获取当前Unix时间,以毫秒为单位
- 依次尝试从5个实例,使用相同的key和具有唯一性的value获取锁当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间,这样可以避免客户端死等
- 客户端使用当前时间减去开始获取锁时间就得到获取锁使用的时间。当且仅当从半数以上的Redis节点取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功
- 如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间,这个很重要
- 如果因为某些原因,获取锁失败(没有在半数以上实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁,无论Redis实例是否加锁成功,因为可能服务端响应消息丢失了但是实际成功了,毕竟多释放一次也不会有问题
关于redlock算法其实 Martin(DDIA作者)已经批判过了,事后redis的作者antirez也回应了
大致总结下:
- Redis本身是基于系统时钟生产的token(不可避免的会有时钟漂移),这个并不能完整的保障fencing token的线性一致性。
- Redlock太重了,本身的正确性也是无法保障的,大多数场景下,单节点的redis就可以满足大部分场景。
- 如果想使用分布式锁,最好使用线性一致性的系统(Zookeeper/Etcd)
基于Etcd的解决方案
Etcd是基于Raft实现的强一致的KV存储系统,其本身自带的一系列机制也可以很好的帮我们实现分布式锁:
- Lease 租约机制,
etcd本身的租约机制是根据单调时钟实现的,系统时间一直往前,不会出现分布式系统里面系统时钟的GAP。 - Revision 每个key 都有对应的revision,
etcd使用revision来实现的MVCC,本质上来说是一个乐观锁。 - Watch 监听机制,
etcd可以Watch某个key,当key产生变化的时候可以收到具体的消息通知
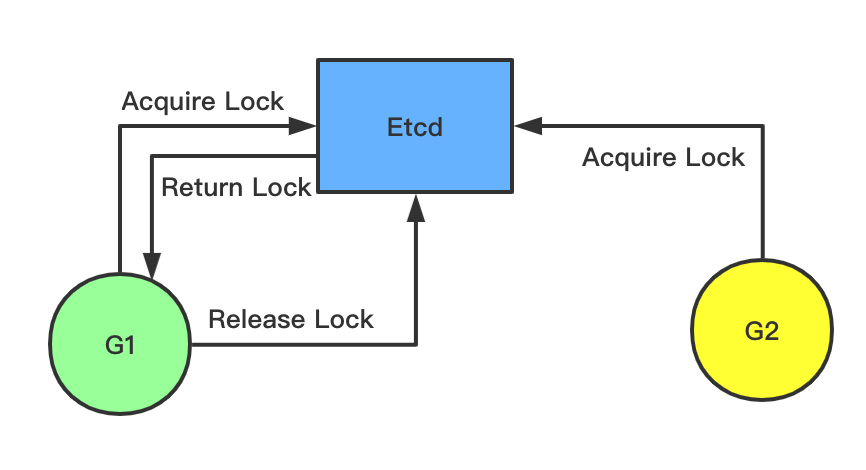
Etcd 本身提供了一个mutex包供我们使用,可以看个简单的例子
// goroutine 1
go func () {
session, err := concurrency.NewSession(cli)
m := concurrency.NewMutex(session, "test")
// Do something
m.Unlock(context.TODO())
}
// goroutine 2
go func () {
session, err := concurrency.NewSession(cli)
m := concurrency.NewMutex(session, "test")
// wait for lock
m.Unlock(context.TODO())
}上面的goroutine2会等待goroutine1执行完再去执行之后的代码。
具体看可以看实现的代码, etcd里面代码很简练,只看Lock和UnLock
func (m *Mutex) Lock(ctx context.Context) error {
s := m.s
client := m.s.Client()
m.myKey = fmt.Sprintf("%s%x", m.pfx, s.Lease())
cmp := v3.Compare(v3.CreateRevision(m.myKey), "=", 0)
// put self in lock waiters via myKey; oldest waiter holds lock
put := v3.OpPut(m.myKey, "", v3.WithLease(s.Lease()))
// reuse key in case this session already holds the lock
get := v3.OpGet(m.myKey)
// fetch current holder to complete uncontended path with only one RPC
getOwner := v3.OpGet(m.pfx, v3.WithFirstCreate()...)
resp, err := client.Txn(ctx).If(cmp).Then(put, getOwner).Else(get, getOwner).Commit()
if err != nil {
return err
}
m.myRev = resp.Header.Revision
if !resp.Succeeded {
m.myRev = resp.Responses[0].GetResponseRange().Kvs[0].CreateRevision
}
// if no key on prefix / the minimum rev is key, already hold the lock
ownerKey := resp.Responses[1].GetResponseRange().Kvs
if len(ownerKey) == 0 || ownerKey[0].CreateRevision == m.myRev {
m.hdr = resp.Header
return nil
}
// wait for deletion revisions prior to myKey
hdr, werr := waitDeletes(ctx, client, m.pfx, m.myRev-1)
// release lock key if wait failed
if werr != nil {
m.Unlock(client.Ctx())
} else {
m.hdr = hdr
}
return werr
}func (m *Mutex) Unlock(ctx context.Context) error {
client := m.s.Client()
if _, err := client.Delete(ctx, m.myKey); err != nil {
return err
}
m.myKey = "\x00"
m.myRev = -1
return nil
}
代码不复杂,Lock的时候会去通过Txn(etcd事务)尝试创建一个key, 并grant一个TTL。如果key存在的话,会去一直等待上一个Key删除,不存在就会返回,表示抢锁成功。删除的时候直接删除对应的Key就行。
小结
Redis lua单机锁可以满足大部分的使用场景,如果对于一致性和可用性有非常高的要求可以使用Etcd,不太推荐使用redis cluster分布式锁。
参考资料
redis相关
redis相关
数据库
redis默认情况下会创建16个db,并使用0号数据库,可以通过select语句切换数据库。是通过切换redisClient里面的redisDb指针来实现的
- expire key ttl,设置生存时间为ttl秒
- pexipre 同上,设置的粒度是ms
- expireat key timestamp 将key的过期时间设置为时间戳
- pexpireat 同上,粒度为ms
上面的4种都会转化成pexpireat
persist移除过期时间
过期算法有三种:
- 定时删除,根据timer来删除
- 被动删除,取key的时候删除
- 主动删除,每隔一段时间去检查
持久化
RDB
RDB是将数据库状态保存为文件,RDB可以手动执行,也可以在redis定期执行。有两个命令可以保存RDB文件,save和bgsave。save命令会阻塞redis服务进程,直到RDB文件创建完成,在这个期间服务器不能处理其它命令。bgsave会fork一个子进程,子进程负责RDB文件的写入,主线程负责处理请求。
- master执行save的时候不会保存过期的key到RDB文件里面
- slave执行save的时候会保存过期的key,在之后的replication去同步
AOF持久化
AOF持久化是通过保存redis的所执行的写命令来保存数据状态的,包括命令追加,文件写入,文件同步三个步骤
AOF的更新频率比RDB高,所以
- 服务器优先使用AOF
- 只有AOF关闭的时候,服务器才能使用RDB恢复数据库
AOF命令追加
当服务器执行完一个写命令后,会把协议追加到aof_buf的缓冲区里头
AOF写入和同步
redis在eventloop中执行完了写函数之后,都会调用flushAppendOnlyFile考虑是否将aof_buf的内容写到文件中,flushAppendOnlyFile由配置文件中的appendfsync来控制。appendfsync有三个选项
- always 每次都会写入并且同步到aof文件
- everysec 每次都会写入,距离上次写入的时间超过一秒就同步
- no 将aof_buf缓冲区写入文件,何时同步由系统决定
AOF的载入与还原:redis服务端创建一个不带网络连接的伪客户端,从aof文件读取命令,使用伪客户端执行命令
AOF文件写入
当数据库某个键已经过期,AOF不会因为这个过期键产生影响,当被删除之后,会向AOF文件apped一条del命令。在AOF重写的时候的过程中会去检查过期的键,已过期的键不会被写入AOF文件
AOF重写(BGREWRITEAOF)会去除一些冗余的写命令,重写后会用新的AOF文件去覆盖旧的。AOF重写是在子进程中进行的,在服务器处理完写操作后,会把命令同时追加到AOF缓冲区和AOF重写缓冲区。
复制
redis复制的步骤:
- 从服务器向主服务器发送psync命令
- 主服务器收到psync命令,执行bgsave生成RDB文件,并使用一个缓冲区记录从开始到结束所有的写命令
- 主服务器的bgsave执行完成后将RDB发送给从服务器,从服务器更新
- 主服务器发送缓冲区内容给从服务器,从服务器执行并更新
psync有完整同步和部分重同步,完整同步用于初次处理复制情况,部分重同步用来处理断线后的情况
集群
redis集群通过槽节点分片实现,集群的整个数据库被分为16384个槽节点,数据库中每个键都属于这些槽节点中。redis本身并不支持一致性hash,可以用twemproxy方案解决。
在集群中执行命令的时候如果键所在的槽正好指派给了该节点,则该节点执行命令。若不在该节点,节点返回一个moved错误,客户端指引到正确的节点,再次发送该命令。
发布与订阅
redis发布与订阅由publish,subscribe,psubcribe命令组成
psubcribe是用来订阅一个或者多个发布者的,用*作为匹配符
事务
redis通过multi,exec,watch实现事务功能,在事务执行期间,服务器不会中断事务去执行其他客户端的请求。事务由multi开始,exec提交给服务器。
事务执行
当一个客户端处于非事务状态时,发送的命令会被立即执行
当一个客户端处于事务状态时
- 如果客户端发送的是exec,discard,watch,multi命令中的一个,服务器立即执行
- 如果客户端发送的不是上面4个命令中的一个,服务端将命令放到一个事务队列里面,向客户端返回queued命令
当一个处于事务状态的客户端发送exec命令的时候,exec立即执行,服务器便利遍历客户端的事务队列,将执行结果全部返回给客户端。
watch是一个乐观锁,可以在exec执行之前监控任意数量的数据库键,并在exec执行的时候,检查被监控的键是否修改过,如果是的话则拒绝事务
redis的事务是不支持回滚的,事务只会因为语法的错误而失败
IOStream分析
IOStream
socket的非阻塞IO的读写操作封装
函数说明
__init__
初始化的时候将_self._handle_events_作为handler添加到IOLoop中,等待读事件
read_until
接收一个_delimiter_作为分隔符,当读取到_delimiter_的时候,调用_callback_。读取完后更新IOLoop事件,等待读事件。
read_bytes
接收一个_num_bytes_作为分隔符,当读取字节大于_num_bytes_的时候,调用_callback_。读取完后更新IOLoop事件,等待读事件。
write
将需要写的字符添加到_self.write_buffer, 调用__add_io_state_,更新IOLoop事件,等待写事件。
_handle_events
当fd状态发生改变的时候,对fd和相应事件进行处理。有读事件的时候,调用__handle_read_, 有写事件的时候调用__handle_write_。当_self._write_buffer_不为空时更新写事件,当_self._read_delimiter_或者_self._read_bytes_更新写事件。
_handle_read
将读取到的内容加载到_self._read_buffer_中,回调_self.read_bytes,清空_self.read_buffer
_handle_write
将_self._write_buffer_发送,回调_self.write_callback。
通过test case 进行流程分析
import socket
from tornado import ioloop, iostream
s = socket.socket()
s.connect(("baidu.com", 80))
stream = iostream.IOStream(s)
def on_headers(data):
headers = {}
for line in data.split("\r\n"):
parts = line.split(":")
if len(parts) == 2:
headers[parts[0].strip()] = parts[1].strip()
stream.read_bytes(int(headers["Content-Length"]), on_body)
def on_body(data):
print data
stream.close()
ioloop.IOLoop.instance().stop()
stream.write("GET / HTTP/1.0\r\n\r\n")
stream.read_until("\r\n\r\n", on_headers)
ioloop.IOLoop.instance().start()

cpu cache 相关
关于CPU cache
简要
一般来说x86 结构cpu cache line 的大小是64 byte, arm cacheline 是32 byte。
CPU 的 Cache 从上至下可以分为 L1(L1d 数据缓存, L1i指令缓存), L2, L3(多个 core 共享一个) 三层cache. 每层的访问速度由上至下依次递减, 可以使用lscpu命令查看.
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 39424K
CPU从Cache数据的最小单位是字节,Cache从Memory拿数据的最小单位是64Bytes,Memory从硬盘拿数据通常最小是4092Bytes。
CPU Cache 的 prefetch
CPU每次从地址空间拿地址的时候不是按照一个一个地址去拿的,而是有一个 prefetch 的操作,每次会拿一个 cache line(大部分 CPU 的 cache line 是 64 byte)的数据加载。
下面可以测试一下 prefetch 命中和没命中的情况:
本机测试环境 MBP
CPU: Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz
内存: 16 GB 2400 MHz DDR4
代码测试
func main() {
a := make([][]int, 1024)
r := 0
for i := 0; i < 1024; i++ {
a[i] = make([]int, 1024)
}
fmt.Printf("address of a[0][0] %p a[0][1] %p a[1][0] %p a[0][1023] %p \n", &a[0][0], &a[0][1], &a[1][0], &a[0][1023])
for i := 0; i < 1023; i++ {
for j := 0; j < 1023; j++ {
r += a[i][j]
//r += a[j][i]
}
}
fmt.Println(r)
}
a[i][j] 赋值的时间
➜ time go run slice.go
go run slice.go 0.34s user 0.29s system 54% cpu 1.166 total
a[j][i] 赋值的时间
go run slice.go 0.29s user 0.23s system 51% cpu 0.998 total
从上面的测试可以看到 a[i][j] 的花费时间为0.29s, 但是a[j][i]的花费时间为 0.34s. 因为我们在声明二维数组的时候可以发现其在内存里面连续分配的,代码输出地址a[0][0] 与 a[0][1] 相差一个int。但是a[0][0]与 a[1][0] 相差 1024 个int。 当我们从j开始从小到大依次便利的时候,CPU会一直从 cache line 里面去拿数据,如果是从i 开始的时候每次的cache line都会reload。从下面打印的数组地址也可以看出来:
address of a[0][0] 0xc000114000 a[0][1] 0xc000114008 a[1][0] 0xc000116000 a[0][1023] 0xc000115ff8
CPU Cache 的 false sharing
True sharing: 多核竞争的,是同一份将要访问的数据,比如全局变量的修改。
False sharing:
当一组相邻变量被多个核共享的时候(与true sharing不同的是访问的不是同一变量),其中一个core 改变了里面的值就会导致另外一个 core 里面的cache line reload,造成cache miss。
贴一下相关的代码以及本机的测试
type MyAtomic interface {
IncreaseAllEles()
GetEles() uint64
}
type NoPad struct {
a uint64
b uint64
c uint64
}
func (myatomic *NoPad) IncreaseAllEles() {
atomic.AddUint64(&myatomic.a, 1)
atomic.AddUint64(&myatomic.b, 1)
atomic.AddUint64(&myatomic.c, 1)
}
func (myatomic *NoPad) GetEles() uint64 {
return myatomic.a + myatomic.b + myatomic.c
}
type Pad struct {
a uint64
_p1 [8]uint64
b uint64
_p2 [8]uint64
c uint64
_p3 [8]uint64
}
func (myatomic *Pad) IncreaseAllEles() {
atomic.AddUint64(&myatomic.a, 1)
atomic.AddUint64(&myatomic.b, 1)
atomic.AddUint64(&myatomic.c, 1)
}
func (myatomic *Pad) GetEles() uint64 {
return myatomic.a + myatomic.b + myatomic.c
}
func testParallelAtomicIncrease(myatomic MyAtomic) {
paraNum := 1000
addTimes := 1000
var wg sync.WaitGroup
wg.Add(paraNum)
for i := 0; i < paraNum; i++ {
go func() {
for j := 0; j < addTimes; j++ {
myatomic.IncreaseAllEles()
}
wg.Done()
}()
}
wg.Wait()
}
测试结果
➜ test go test -bench=.
goos: darwin
goarch: amd64
BenchmarkNoPad-12 20 61637165 ns/op
BenchmarkPad-12 50 27061445 ns/op
PASS
解决false sharing的办法就是加padding,增加一些无意义的变量(64byte), 让原本相邻的变量不相邻,这样prefetch的时候就不会更改相应的 cache line , 产生cache reload 的现象。具体可以参考篇文章
TLB的影响
TLB是Translation Lookaside Buffer的简称, 为了避免CPU每次取页表的时候都访问MMU,所以引入了TLB这一层的cache。
所以在写程序的时候需要注意TLB的reload,Page的大小一般为4KB, 假设TLB的最大limit数是x, 当程序的内存使用超过 4xKb之后就会开始影响性能
由于手头上只有MAC,GCP上的虚拟机对perf的支持不是太友好,所以这边只贴一下perf的相关命令, 具体的测试结果可以参看下面的文章
perf stat -e dTLB-load,dTLB-load-misses,LLC-load,LLC-load-misses,LLC-prefetches,LLC-prefetch-misses,L1-dcache-loads,L1-dcache-misses,cycles:u,instructions:u -p PROCID sleep 10
相关测试可以参考
小结
在写代码的时候,同时注意到上面的东西很困难,但是我们也需要知道在代码里面发生了什么。
一般从cpu cache line reload -> cpu cache miss -> TLB miss -> page fault -> disk cache miss,这里面的每一层的miss其实都会带来损耗。所以实际上在写业务代码的时候需要根据各个方面去做trade-off.
Tornado之gen.engine
Tornado之gen.engine
这个模块是用来在Tornado里边写异步回调的,具体用法可以参考Tornado之gen.enegine
分析:
先看示例代码
class GenAsyncHandler(RequestHandler):
@asynchronous
@gen.engine
def get(self):
http_client = AsyncHTTPClient()
response = yield gen.Task(http_client.fetch, "http://example.com")
do_something_with_response(response)
self.render("template.html")
函数入口为gen.engine,是一个装饰器:
def engine(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
gen = func(*args, **kwargs)
if isinstance(gen, types.GeneratorType):
Runner(gen).run()
return
assert gen is None, gen
# no yield, so we're done
return wrapper
这里gen = func(*args, **kwargs)结合示例代码代码来看,返回一个可迭代对象。继续跟进Runner类的run方法。
def run(self):
"""Starts or resumes the generator, running until it reaches a
yield point that is not ready.
"""
if self.running or self.finished:
return
try:
self.running = True
while True:
if self.exc_info is None:
try:
if not self.yield_point.is_ready():
return
next = self.yield_point.get_result()
except Exception:
self.exc_info = sys.exc_info()
try:
if self.exc_info is not None:
exc_info = self.exc_info
self.exc_info = None
yielded = self.gen.throw(*exc_info)
else:
yielded = self.gen.send(next)
except StopIteration:
self.finished = True
if self.pending_callbacks:
raise LeakedCallbackError(
"finished without waiting for callbacks %r" %
self.pending_callbacks)
return
except Exception:
self.finished = True
raise
if isinstance(yielded, list):
yielded = Multi(yielded)
if isinstance(yielded, YieldPoint):
self.yield_point = yielded
self.yield_point.start(self)
else:
self.exc_info = (
BadYieldError(
"yielded unknown object %r" %
yielded),)
finally:
self.running = False
逐行进行分析,Runner类在__init__方法里边接收一个gen及迭代器作为参数,将self.yield_point设置为_NullYieldPoint。看一下_NullYieldPoint定义了三种方法:
class _NullYieldPoint(YieldPoint):
def start(self, runner):
pass
def is_ready(self):
return True
def get_result(self):
return None
主要看run方法, 先是进行一些列条件判断,然后进入while循环,self.exc_info里边存取系统报错信息。next = self.yield_point.get_result()这里的next为None,yielded = self.gen.send(next)开始迭代,这里结合示例代码,程序执行到第一个yield之前。即response = yield gen.Task(http_client.fetch, "http://example.com")。
class Task(YieldPoint):
def __init__(self, func, *args, **kwargs):
assert "callback" not in kwargs
self.args = args
self.kwargs = kwargs
self.func = func
def start(self, runner):
self.runner = runner
self.key = object()
runner.register_callback(self.key)
self.kwargs["callback"] = runner.result_callback(self.key)
self.func(*self.args, **self.kwargs)
def is_ready(self):
return self.runner.is_ready(self.key)
def get_result(self):
return self.runner.pop_result(self.key)
生成一个Task对象,回到Runner的run方法, self.yield_point = yielded这里的self.yield_point为Task对象,调用self.yield_point.start(self)。在start方法里边runner.register_callback(self.key)这里将当前的这个异步任务进行注册,添加到Runner的pending_callbacks中。self.kwargs["callback"] = runner.result_callback(self.key),这应该是整个回调的核心,将异步函数中的callback设置为result_callback。这就意味着我们在生成Task的时候,**kwargs中是不允许传callback进去的,并将异步函数中的回调设置为result_callback中的inner,当回调完成后调用set_result,继续进行迭代。
用简单的demo进行说明:
from tornado import gen
@gen.engine
def test():
print "start"
yield gen.Task(test_callback)
print "end"
def test_callback(callback=None):
print callback
print "start end!"
callback()
test()
其中test_callback必须要接受一个callback参数,当调用callback()后,设置Runner中self.results[key] = result,调用run进行下一次迭代,结束。
看另一个示例代码:
class GenAsyncHandler2(RequestHandler):
@asynchronous
@gen.engine
def get(self):
http_client = AsyncHTTPClient()
http_client.fetch("http://example.com",
callback=(yield gen.Callback("key"))
response = yield gen.Wait("key")
do_something_with_response(response)
这里的yield gen.Wait("key")为Runner.run(gen)第一次yield的值,并将gen.Callback("key")作为回调。当fetch完成后,再回调进行下一次yield。
烦人的线上TCP HOL
一次烦人的线上TCP 重传
Background
之前线上有段时间P99不太正常,于是跟同事开始排查原因。业务上的表现是每隔一段时间,线上的SLA就会出现一个毛刺,latency增加到800ms。发生的时间点不固定,可能出现在集群的任何机器上。
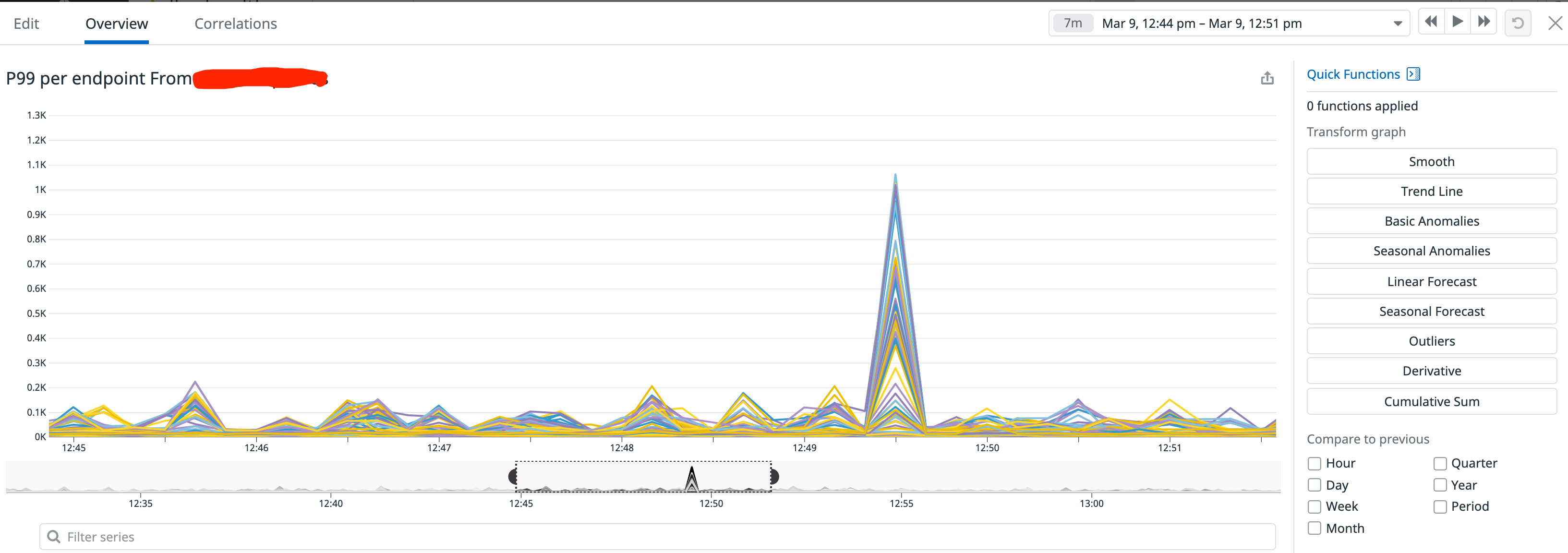
在对业务代码进行一一排除之后,发现可能出问题的只有grpc的调用链路了,于是我们打印了全量的grpc日志,但是发现并没有报错信息。于是最后只能在线上开启tcpdump抓取报文进行分析。
分析
抓到的报文有很多个case,不过大多都是类似的场景。我用其中一个进行举例:
时间点
- Client ip: 10.0.72.138
- Server ip: 10.0.79.240
业务侧日志时间点:
Client侧发送请求的时间点 04:07:14.28,Server侧收到请求的时间点 04:07:16.48,中间大概有两秒左右的时间差
tcpdump的时间点:
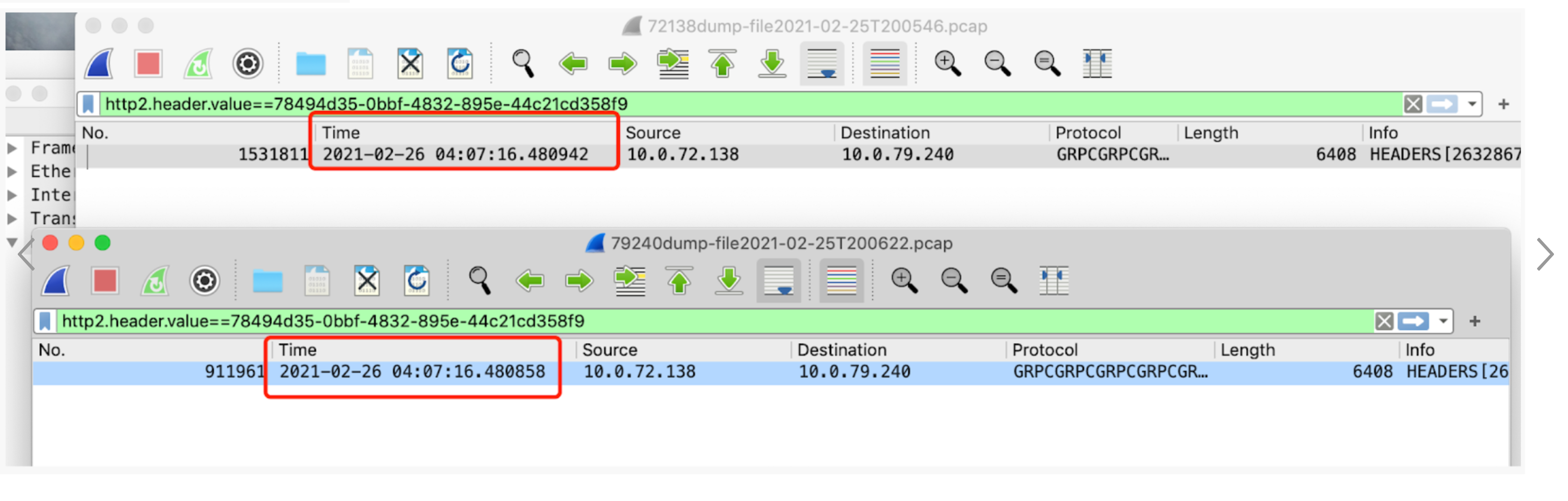
client侧发送的时间点 04:07:16.48, 基本与server侧业务代码收到的时间点吻合。server侧收到的时间点04:07:16.48,与发送的时间点几乎一致,于是可以断定是request阻塞在client侧。
TCP Stream分析
光看一个报文没有太多的有效信息,需要结合整个TCP的连接来进行分析,这里就用stream表示。
能够看到的现象是发生问题的时间点有TCP重传。但是整个tcp stream只有极少数的重传,占比很少。
先看Client侧的问题,length为1854的包在事故的时间点重传了三次,RTO时间指数增加,从200ms->400ms->1200ms,client侧的request全部block住了。
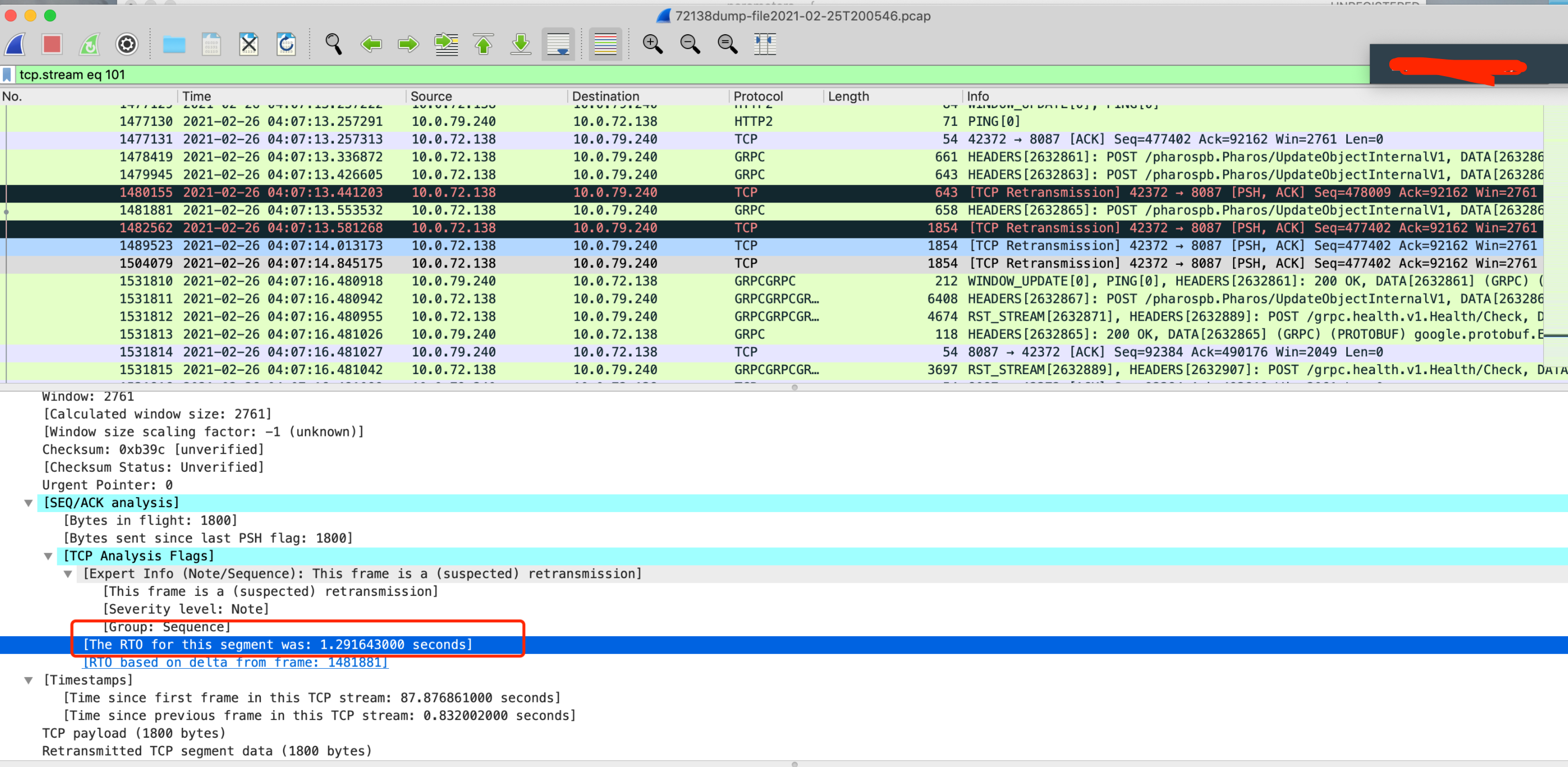
从下面的吞吐情况也可以看到当时的吞吐急剧下降。
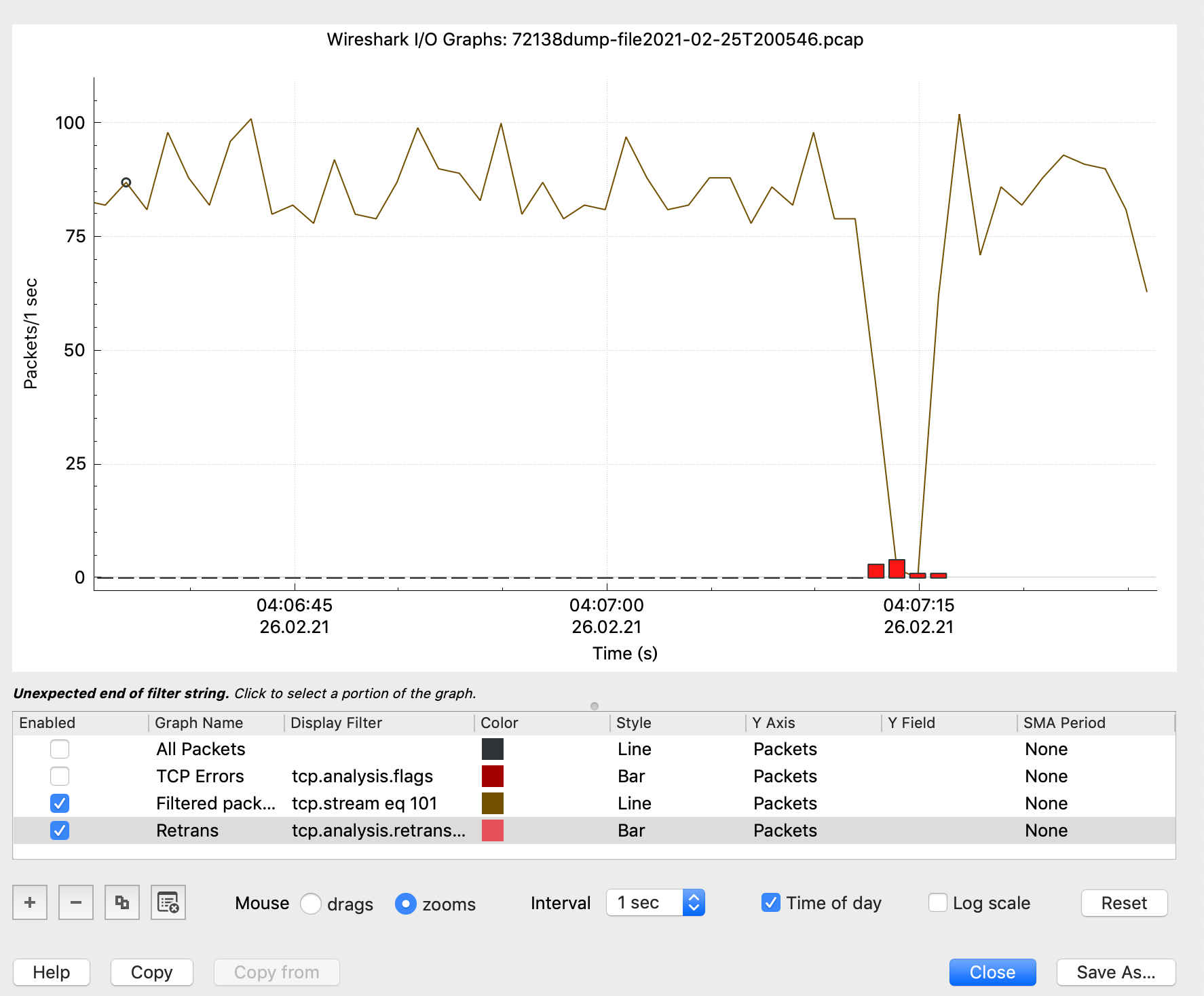
再看Server侧的,可以看到1854这个包Server是回复了ACK的,每次都很及时的回复了ACK。说明Server->client侧的连接出了问题,导致client侧收不到ACK, 于是触发超时重传,开始进行指数退避,所有的request都会被block在客户端。
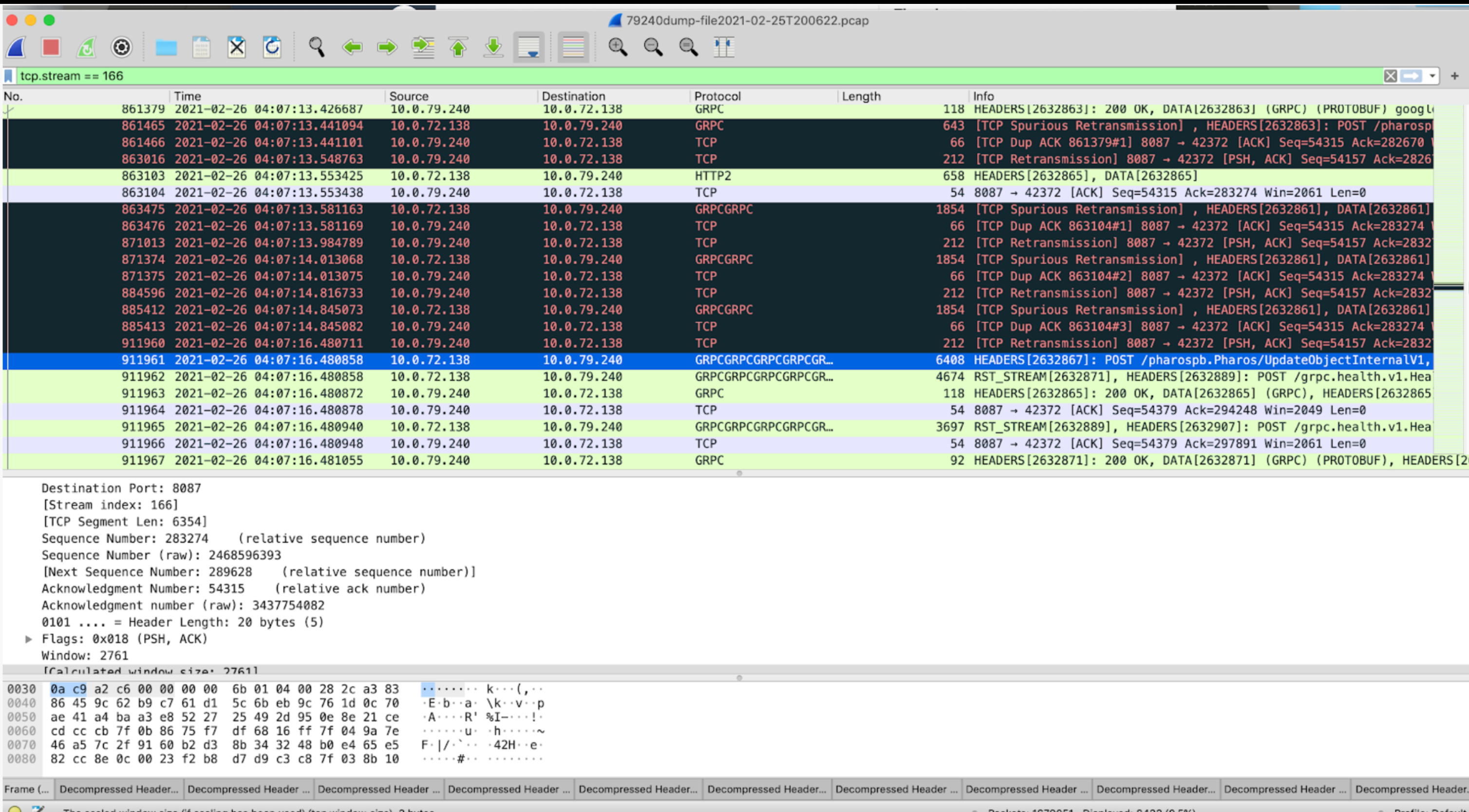
HOL
关于HOL的分析网上现在其实很多文章,这里就不再详细介绍了。关于TCP的这个HOL之前一直有个误解点,就是是否会阻塞整条链路,之前理解的是不会阻塞整条链路。只会在下次send的时候把缺失的包带上,结合实际拥塞控制算法来看,每当超时重传发生的时候,实际的CWND都会变成1开始进行传送,意味着只有一个发送窗口,如果对端不能及时返回,则会阻塞所有请求。
所以可以看到:如果能收到对端回复的ACK表示只是丢包,但是RTO超时就意味着网络情况及其糟糕,CWND重置为1开始进行发送。

网络
我们的服务是跑在AWS虚拟机上的,所以后面的整个网络链路对于我们来说几乎都是黑盒。如果这种情况只发生一两次,我们可以理解为网络抖动,但是时常会发生的情况显得不太可接受。
小结
其实上面的场景就是一个典型的http2的 HOL(Head of line blocking),从业务侧的角度来看,一次重传是可以接受的。但是如果开始发生指数级别的多次退避,就会对这条链路带来一定的影响。从提高服务高可用的角度来看,有几个点可以优化:
- 业务侧开启retry,尽可能保证业务方不受影响
- 建立多条连接,提高容错性(grpc内部就是这么做的)
一次优化线上TIME_WAIT过多的connection leak案例
一次优化线上TIME_WAIT过多的connection leak案例
Background
一次观察系统指标的时候发现某个生产环境的TIME_WAIT连接状态异常,线上观察使用的指标是来自DataDog Agent收集的system.net.tcp4.time_wait,但是system.net.tcp4.established的连接数量并没有太大变化,可以观察到的现象大概就是图片所显示的。
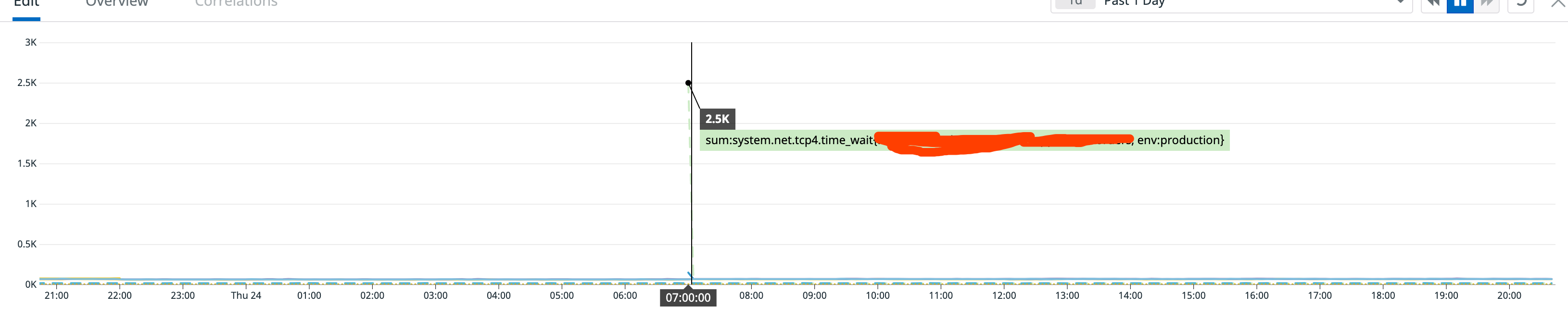
TIME_WAIT这一指标是主动关闭的一方进入的,理论上来说无论如何都需要先进行establish,这一现象太诡异了,于是开始查找原因。
Trace
网络状况
先进行复现,因为程序出现上面的现象是发生在程序启动的时候,所以先在测试环境跑下netstat看下现场:
~$ netstat -an | grep 6379 | awk '{print $1, $6}' | sort | uniq -c | sort -k 1
10 tcp ESTABLISHED
1794 tcp TIME_WAIT
可以 看到确实是ESTABLISHED比TIME_WAIT要少很多, 回忆下TCP的状态机, 能够进入TIME_WAIT的只有FIN_WAIT1, FIN_WAIT2以及CLOSING
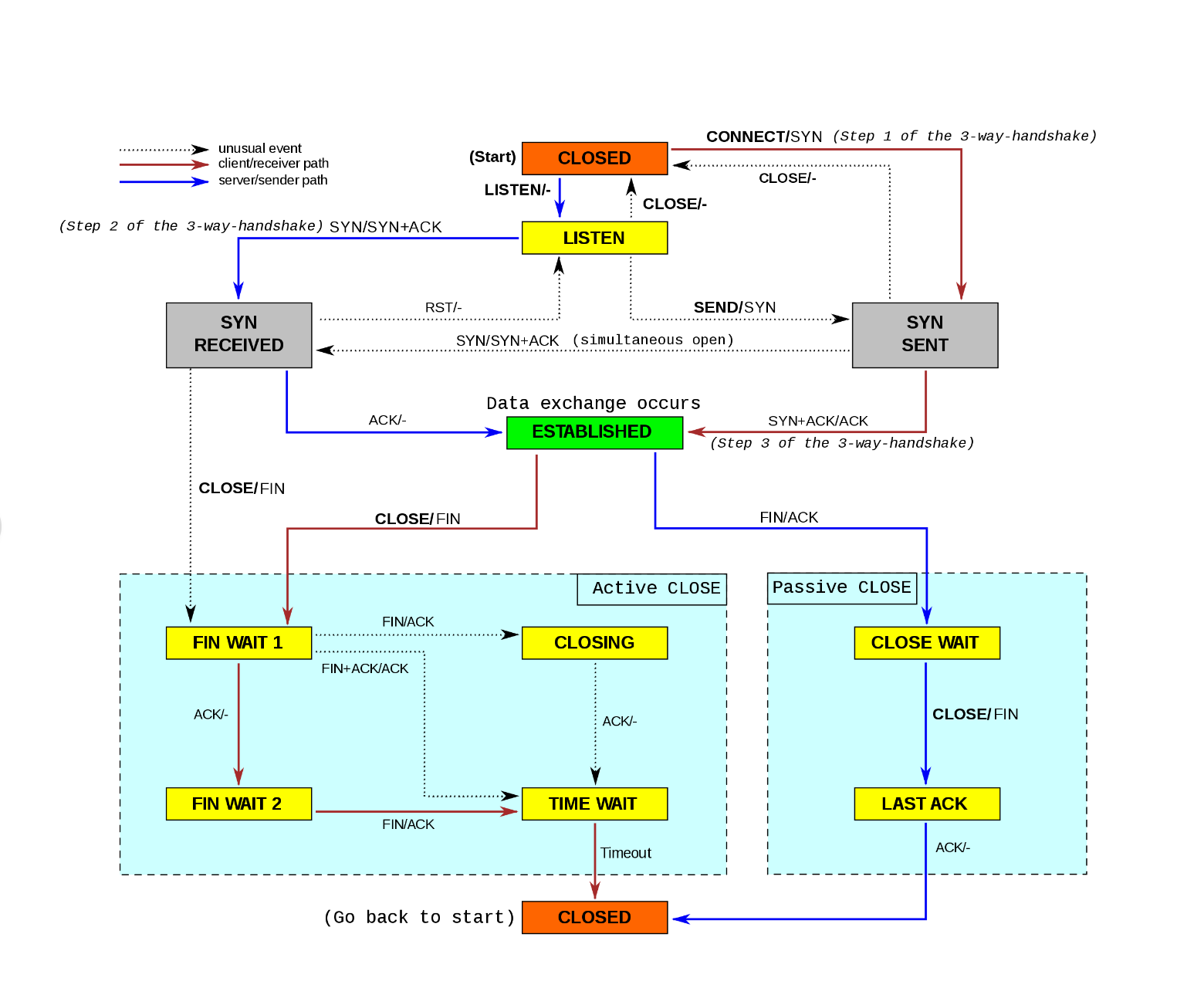
再去看下ESTABLISHED里面的四元组情况,发现里面的四元组一直在变化
➜ netstat -an | grep 6379 | grep 'ESTABLISHED' | awk '{print $4, $5, $6}' | sort | uniq -c | sort -k 1
1 ::1.62320 ::1.6379 ESTABLISHED
1 ::1.62346 ::1.6379 ESTABLISHED
1 ::1.62359 ::1.6379 ESTABLISHED
1 ::1.62360 ::1.6379 ESTABLISHED
1 ::1.62365 ::1.6379 ESTABLISHED
1 ::1.62373 ::1.6379 ESTABLISHED
1 ::1.62375 ::1.6379 ESTABLISHED
1 ::1.62376 ::1.6379 ESTABLISHED
所以上面那张图就可以解释了,因为TIME_WAIT状态需要2msl的等待,并且ESTABLISHED里面的连接是不断创建的新连接,所以TIME_WAIT就会大量堆积。
代码分析
上面的结论已经发现是redis的连接导致的,并且是在客户端的连接堆积,代码里面使用的是redigo的pool。
package main
var (
Pool *redis.Pool
)
import (
"fmt"
"time"
"github.com/garyburd/redigo/redis"
)
func init() {
redisHost := os.Getenv("REDIS_HOST")
if redisHost == "" {
redisHost = ":6379"
}
Pool = newPool(redisHost)
cleanupHook()
}
func newPool(server string) *redis.Pool {
return &redis.Pool{
MaxIdle: 10,
MaxActive: 80,
Wait: False,
IdleTimeout: 0,
Dial: func() (redis.Conn, error) {
c, err := redis.Dial("tcp", server)
if err != nil {
return nil, err
}
return c, err
},
TestOnBorrow: func(c redis.Conn, t time.Time) error {
_, err := c.Do("PING")
return err
},
}
}
func worker(id int, jobs <-chan int, results chan<- int) {
for j := range jobs {
conn := Pool.Get()
defer conn.Close()
// pool get
data, _ := redis.Bytes(conn.Do("GET", key))
// 简化下,输出一个长度,模拟redis操作
results <- len(data)
}
}
func main() {
const numJobs = 100000
jobs := make(chan int)
results := make(chan int)
// 30个goroutine并发去读大概14w条redis数据
for w := 1; w <= 30; w++ {
go worker(w, jobs, results)
}
for j := 1; j <= numJobs; j++ {
jobs <- j
}
close(jobs)
for a := 1; a <= numJobs; a++ {
<-results
}
}一般来说,使用了pool的话应该是不会出现connection leak额现象,但是netstat观察到的并发远远不止80,于是只能去读源码。
redigo的Pool几个参数的意义:
type Pool struct {
// 创建新连接的函数
Dial func() (Conn, error)
// TestOnBorrow is an optional application supplied function for checking
// the health of an idle connection before the connection is used again by
// the application. Argument t is the time that the connection was returned
// to the pool. If the function returns an error, then the connection is
// closed.
TestOnBorrow func(c Conn, t time.Time) error
// 最大空闲连接,我理解的是可复用的连接.
MaxIdle int
// 允许的最大的连接,这里需要与wait配合使用.
MaxActive int
// 超过这个时间的空闲连接会被系统回收.
IdleTimeout time.Duration
// 这里是个关键,如果设置为True,Get操作才会阻塞,MaxActive才有意义,如果是false,达到限制后就会一直创建新的连接.
Wait bool
chInitialized uint32 // set to 1 when field ch is initialized
mu sync.Mutex // mu protects the following fields
closed bool // set to true when the pool is closed.
active int // the number of open connections in the pool
ch chan struct{} // limits open connections when p.Wait is true
idle idleList // idle connections
}Get操作的
func (p *Pool) get(ctx interface {
Done() <-chan struct{}
Err() error
}) (Conn, error) {
// Wait 配合 MaxActive 使用, 来保证 Get() 将要等待一个连接放到 Pool中, 才会返回一个连接给使用方.
if p.Wait && p.MaxActive > 0 {
p.lazyInit()
if ctx == nil {
<-p.ch
} else {
select {
case <-p.ch:
case <-ctx.Done():
return nil, ctx.Err()
}
}
}
p.mu.Lock()
// 循环idleList, 关闭空闲队列中连接时长大于 IdleTimeout 的连接.
if p.IdleTimeout > 0 {
n := p.idle.count
for i := 0; i < n && p.idle.back != nil && p.idle.back.t.Add(p.IdleTimeout).Before(nowFunc()); i++ {
c := p.idle.back.c
p.idle.popBack()
p.mu.Unlock()
c.Close()
p.mu.Lock()
p.active--
}
}
// 从idle list里面获取连接.
for p.idle.front != nil {
ic := p.idle.front
p.idle.popFront()
p.mu.Unlock()
if p.TestOnBorrow == nil || p.TestOnBorrow(ic.c, ic.t) == nil {
return ic.c, nil
}
ic.c.Close()
p.mu.Lock()
p.active--
}
// 检查pool是否已经关闭.
if p.closed {
p.mu.Unlock()
return nil, errors.New("redigo: get on closed pool")
}
// 检查是否到达pool的极限,当active大于p.MaxActive时候会报错.
if !p.Wait && p.MaxActive > 0 && p.active >= p.MaxActive {
p.mu.Unlock()
return nil, ErrPoolExhausted
}
// 创建新的连接
p.active++
p.mu.Unlock()
c, err := p.Dial()
if err != nil {
c = nil
p.mu.Lock()
p.active--
if p.ch != nil && !p.closed {
p.ch <- struct{}{}
}
p.mu.Unlock()
}
return c, err
}整个代码流程有几个地方需要注意:
- 并发workNum为30
- rerdigo pool 的wait为false
- rerdigo pool 的MaxActive为80
- rerdigo pool 的MaxIdle 为10
因为线上的连接数超高,所以打了下p.activeLog,发现p.active的活跃数量一直是维持在10左右,并没有达到PoolExhausted, 说明整个流程还是符合预期的在work。那么重点就需要放在MaxIdle这个参数里面了,回忆了下抓包的现象:ESTABLISHED的连接是一直变化,只有10个左右是一直不变的,根据代码来看说明pool复用的是idle里面的连接,当idle满了之后就会一直create new connection。
验证:
调整MaxIdle以及MaxActive的连接数量进行再次测试,由于并发的goroutine为30,所以调整MaxIdle为40,MaxActive 为200.
func newPool(server string) *redis.Pool {
return &redis.Pool{
MaxIdle: 40,
MaxActive: 200,
Wait: False,
IdleTimeout: 0,
Dial: func() (redis.Conn, error) {
c, err := redis.Dial("tcp", server)
if err != nil {
return nil, err
}
return c, err
},
TestOnBorrow: func(c redis.Conn, t time.Time) error {
_, err := c.Do("PING")
return err
},
}
}测试完发现这次没有connection leak了,线上的TIME_WAIT 也是在一个正常的数量级。另外也可以选择设置Wait为true,这样就会强制要求pool等待idle 里面的conn,也不会产生connection leak的现象。
小结
其实一开始比较疑惑的是为什么TIME_WAIT会比ESTABLISHED多这么多,一开始进入了死胡同,没有考虑到TIME_WAIT是一个逐渐堆积的状态,而ESTABLISHED会很快就释放掉。
另外线上并发数量和连接池的设置也是一个需要考虑的点,刚好踩了redigo的一个坑,线上出于性能考虑设置的wait为false,但是并发量又比较高,所以就悲剧了。
Raft 实现(MIT6.824 Lab)
Raft 实现(MIT6.824 Lab)
Background
本篇是基于MIT6.824课后实践实现的一个简单Raft,包括三个部分:Leader选举,日志复制,持久化。整篇的核心在raft paper里面的figure2中,这张图可以直接理解为编程语言了,是整个raft的核心。
Leader选举
状态机
Leader选举的概念状态机再重新贴一下:
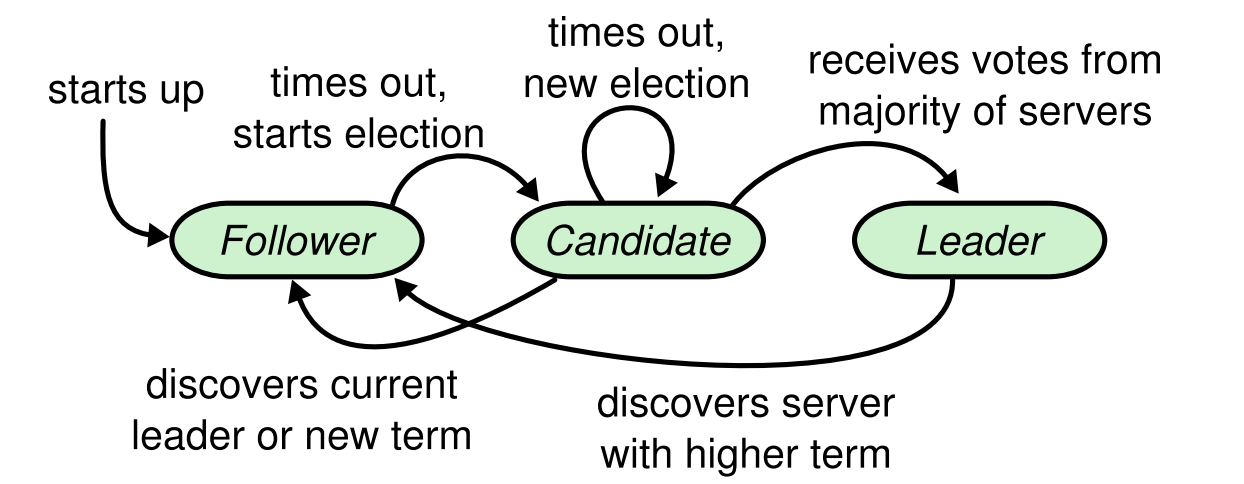
先理清楚两个timeout:electionTimeout以及heartbeatTimeout。
- 每个Follower节点初始化的时候都会随机设置一个electionTimeout,到达这个时间点就会变成Candidate发起投票请求。
- Leader需要维持心跳包,每隔一段时间即heartbeat timeout就会发送一个heart beat。
状态机的变化对照figure 2即可进行转化,这里我们只关注leader选举的部分。
Follower:
- 响应candidate的投票请求和leader的心跳请求
- 在electionTimeout时间内若没有收到心跳包或者投票请求则转化为candidate
Candidate:
- 变成Candidate后需要的操作
- 将自身的currentTerm自增
- 给自己投一票
- 重置electionTimeout
- 给其他节点发送投票请求
- 收到大多数响应就变成leader
- 如果收到心跳包就变成follower
- 如果electionTimeout超时,则再进行重试
Leader:
- 每间隔heartbeatTimeout则发送心跳包
Raft 结构体:
type Raft struct {
mu sync.RWMutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
currentTerm int
votedFor int
logs []LogEntry
// Volatile state on all servers
commitIndex int
lastApplied int
// Volatile state on leaders
nextIndex []int
matchIndex []int
voteCount int
state uint64
granted chan struct{}
AppendEntries chan struct{}
electWin chan struct{}
applyCh chan ApplyMsg
}状态机里面的electionTimout设置为随机值是为了避免选举 split vote 情况。
func (rf *Raft) run() {
for {
switch rf.state {
case StateCandidate:
// vote
select {
// 超时,再重试一遍
case <-time.After(time.Millisecond * time.Duration(rand.Intn(200)+300)):
rf.mu.Lock()
rf.becomeCandidate()
rf.mu.Unlock()
case <-rf.AppendEntries:
rf.mu.Lock()
rf.becomeFollower("candidate receive heart beat")
rf.mu.Unlock() case <-rf.electWin:
rf.mu.Lock()
rf.becomeLeader()
rf.mu.Unlock()
}
case StateFollower:
select {
// 收到投票请求
case <-rf.granted:
// 收到心跳请求
case <-rf.AppendEntries:
case <-time.After(time.Millisecond * time.Duration(rand.Intn(200)+300)):
rf.mu.Lock()
rf.becomeCandidate()
rf.mu.Unlock()
}
case StateLeader:
go rf.sendAppendEntries()
time.Sleep(time.Millisecond * 100)
}
}
}
func (rf *Raft) becomeLeader() {
rf.debug("changed to Leader, id %d , term %d, logs %v", rf.me, rf.currentTerm, rf.logs)
rf.state = StateLeader
rf.nextIndex = make([]int, len(rf.peers))
rf.matchIndex = make([]int, len(rf.peers))
for i := range rf.peers {
rf.nextIndex[i] = rf.getLastIndex() + 1
}
}
func (rf *Raft) becomeFollower(reason string) {
rf.debug("changed to Follower, id %d, term %d, reason %s", rf.me, rf.currentTerm, reason)
rf.state = StateFollower
}
func (rf *Raft) becomeCandidate() {
rf.debug("changed to Candidate, id %d, term %d, logs %v", rf.me, rf.currentTerm, rf.logs)
rf.state = StateCandidate
rf.currentTerm++
rf.votedFor = rf.me
rf.voteCount = 1
rf.persist()
go rf.sendAllVotesRequests()
}为了调式方便,写了一个带时间戳的Log,输出的日志看的比较方便
func (rf *Raft) debug(msg string, a ...interface{}) {
if debug < 1 {
return
}
selfMsg := fmt.Sprintf(" [me:%d term:%d, state: %d, log: %d] ", rf.me, rf.currentTerm, rf.state, len(rf.logs))
fmt.Println(strconv.Itoa(int(time.Now().UnixNano())/1000) + selfMsg + fmt.Sprintf(msg, a...))
}投票请求 RequestVote
RequestVote接口是发起投票用的RPC接口,只能由candidate发起。默认理解为每个Raft 集群的Node上都会这么一个接口用来接收candidate发起的投票请求。
Candidate给其他节点发送请求,处理response也在这个函数里面。
func (rf *Raft) sendAllVotesRequests() {
rf.mu.Lock()
// 投票的参数
args := &RequestVoteArgs{}
args.Term = rf.currentTerm
args.CandidateId = rf.me
// args.LastLogIndex = rf.getLastIndex()
// args.LastLogTerm = rf.getLastTerm()
rf.mu.Unlock()
var wg sync.WaitGroup
for p := range rf.peers {
if p != rf.me {
wg.Add(1)
go func(p int) {
defer wg.Done()
ok := rf.sendRequestVote(p, args, &RequestVoteReply{})
if !ok {
rf.debug("send request to p: %d, ok: %v", p, ok)
}
}(p)
}
}
wg.Wait()
rf.mu.Lock()
// 等待结果返回,如果符合quorum协议,则投票成功
win := rf.voteCount >= len(rf.peers)/2+1
// make sure the vote request is valid
if win && args.Term == rf.currentTerm {
rf.electWin <- struct{}{}
}
rf.debug("vote finished, voteCount: %d, win: %v", rf.voteCount, win)
rf.mu.Unlock()
}sendRequestVote里面加入了RPC的timeout,是因为测试用例里面会模拟网络不可达的情况,如果一个请求一直hang下去,系统会更加复杂。虽然paper上说的是可以无限重试,但是实际生产环境中外部RPC调用都是需要加上一个timeout来保护资源泄漏。
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
respCh := make(chan bool)
ok := false
go func() {
respCh <- rf.peers[server].Call("Raft.RequestVote", args, reply)
}()
select {
case <-time.After(time.Millisecond * 60): // 1s
return false
case ok = <-respCh:
}
if !ok {
return false
}
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
if rf.state != StateCandidate || args.Term != rf.currentTerm {
return ok
}
// 当前term较小了
if reply.Term > rf.currentTerm {
rf.becomeFollower("candidate received large term")
rf.currentTerm = args.Term
rf.votedFor = -1
}
if reply.VoteGranted {
rf.voteCount++
}
return ok
}心跳维持 AppendEntries
心跳包的维持是每隔一段时间(heartbeat timeout)去发送的,函数名为AppendEntries,因为log之后的数据每次同步也都是在这里面发送的。
func (rf *Raft) sendAppendEntries() {
var wg sync.WaitGroup
rf.mu.RLock()
for p := range rf.peers {
if p != rf.me {
args := &RequestAppendEntriesArgs{}
// 发送leader term
args.Term = rf.currentTerm
// leader ID
args.LeaderID = rf.me
// 日志同步需要用到的 leader 选举暂时用不到
args.PrevLogIndex = rf.nextIndex[p] - 1
args.LeaderCommit = rf.commitIndex
if args.PrevLogIndex >= 0 {
args.PrevLogTerm = rf.logs[args.PrevLogIndex].Term
}
// 发送空数据
if rf.nextIndex[p] <= rf.getLastIndex() {
args.Entries = rf.logs[rf.nextIndex[p]:]
}
//rf.debug("send Entries is: %v, index is: %d", args.Entries, p)
wg.Add(1)
go func(p int, args *RequestAppendEntriesArgs) {
defer wg.Done()
ok := rf.sendRequestAppendEntries(p, args, &RequestAppendEntriesReply{})
if !ok {
rf.debug("send %d AppendEntries result:%v", p, ok)
}
}(p, args)
}
}
rf.mu.RUnlock()
wg.Wait()
}Leader在发送RPC请求的时候也需要带上一个timeout,这样方便控制整个流程。
func (rf *Raft) sendRequestAppendEntries(server int, args *RequestAppendEntriesArgs, reply *RequestAppendEntriesReply) bool {
respCh := make(chan bool)
ok := false
go func() {
respCh <- rf.peers[server].Call("Raft.RequestAppendEntries", args, reply)
}()
select {
case <-time.After(time.Millisecond * 60): // 100ms
return false
case ok = <-respCh:
}
rf.mu.Lock()
defer rf.mu.Unlock()
if !ok || rf.state != StateLeader || args.Term != rf.currentTerm {
return ok
}
if reply.Term > rf.currentTerm {
rf.becomeFollower("leader expired")
rf.currentTerm = reply.Term
rf.persist()
return ok
}
return ok被调用方收到的请求处理流程
func (rf *Raft) RequestAppendEntries(args *RequestAppendEntriesArgs, reply *RequestAppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
return
}
// 发送channel表示收到心跳包,重置timeout
rf.AppendEntries <- struct{}{}
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
if rf.state != StateFollower {
rf.becomeFollower("request append receive large term")
rf.votedFor = -1
}
}
reply.Success = true日志复制
日志复制应该算是整个Lab里面最复杂的一部分,先简单回顾下paper内容。
当Leader被选出来后,就可以接受客户端发来的请求了,每个请求包含一条需要被replicated state machines执行的命令。leader会把它作为一个log entry append到日志中,然后给其它的server发AppendEntriesRPC请求。当Leader确定一个log entry被safely replicated了(大多数副本已经将该命令写入日志当中),就apply这条log entry到状态机中然后返回结果给客户端。如果某个Follower宕机了或者运行的很慢,或者网络丢包了,则会一直给这个Follower发AppendEntriesRPC直到日志一致。
当一条日志是commited时,Leader才可以将它应用到状态机中。Raft保证一条commited的log entry已经持久化了并且会被所有的节点执行。
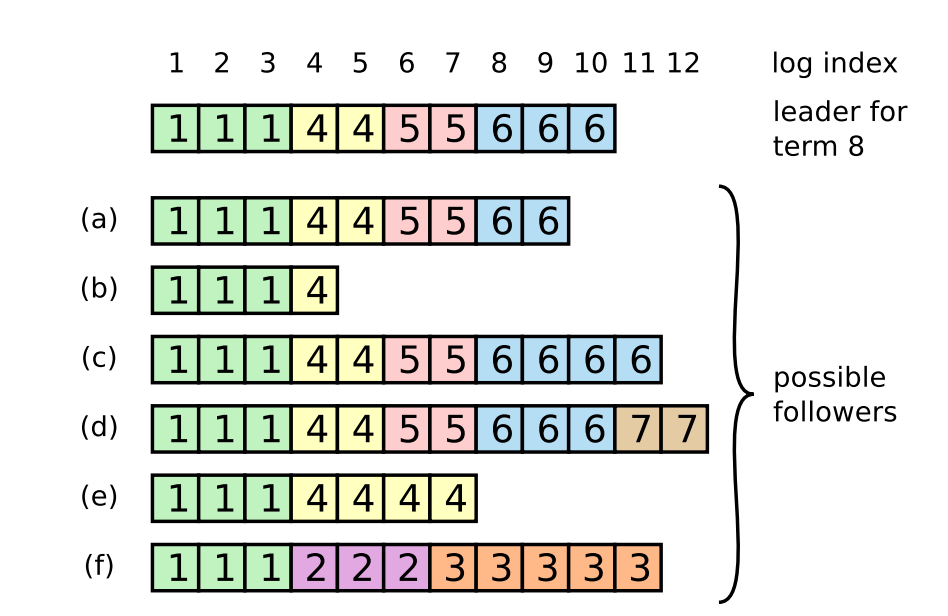
因此,需要有一种机制来让leader和follower对log达成一致,leader会为每个follower维护一个nextIndex,表示leader给各个follower发送的下一条log entry在log中的index,初始化为leader的最后一条log entry的下一个位置。leader给follower发送AppendEntriesRPC消息,带着(term_id, (nextIndex-1)), term_id即(nextIndex-1)这个槽位的log entry的term_id,follower接收到AppendEntriesRPC后,会从自己的log中找是不是存在这样的log entry,如果不存在,就给leader回复拒绝消息,然后leader则将nextIndex减1,再重复,知道AppendEntriesRPC消息被接收。
初始化,nextIndex为11,leader给b发送AppendEntriesRPC(6,10),b在自己log的10号槽位中没有找到term_id为6的log entry。则给leader回应一个拒绝消息。接着,leader将nextIndex减一,变成10,然后给b发送AppendEntriesRPC(6, 9),b在自己log的9号槽位中同样没有找到term_id为6的log entry。循环下去,直到leader发送了AppendEntriesRPC(4,4),b在自己log的槽位4中找到了term_id为4的log entry。接收了消息。随后,leader就可以从槽位5开始给b推送日志了。
相较于leader选举,根据figure2可以知道会增加几个变量,先解释几个参数的意义:
type raft struct {
logs []LogEntry
commitIndex int
lastApplied int
nextIndex []int
matchIndex []int
applyCh chan ApplyMsg
}- commitIndex 表示的是当前节点已经commit的位置
- lastApplied 表示的是上次apply的位置
- nextIndex 里面是一个数组,只有leader的nextIndex才有意义,表示的是希望与对应的peer下次同步日志的位置,初始化的时候是当前最长log的位置
- matchIndex 是用来表示已经同步过log的位置,初始化的时候位置为0,这个也是只有leader才有意义
- applyCh 在commit之后可以进行apply操作的channel
Log可以定义为[]LogEntry, 里面的command是Lab所需要的,这么一来Log的定义就完成了。
type LogEntry struct {
Term int
Command interface{}
}RequestVoteArgs 里面会新增LastLogIndex和LastLogTerm,用来判断当前leader是否是最新的。
type RequestVoteArgs struct {
LastLogIndex int
LastLogTerm int
}另外RequestAppendEntriesArgs里面也有所改变
type RequestAppendEntriesArgs struct {
// Your data here (2A, 2B).
PrevLogIndex int
PrevLogTerm int
Entries []LogEntry
}PrevLogIndex对应的Leader中的nextIndex数组减去一,PrevLogTerm同理。
接受写请求 Start
这里唯一需要注意的一点就是Lab与raft paper不同,每次是直接在append之后就返回,没有等待其他Leader的append。
func (rf *Raft) Start(command interface{}) (int, int, bool) {
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
if rf.state != StateLeader {
return 0, 0, false
}
index := rf.getLastIndex() + 1
term := rf.currentTerm
isLeader := true
// Your code here (2B).
// append to current logs
rf.logs = append(rf.logs, LogEntry{term, command})
rf.debug("receive start command, logs is :%v", rf.logs)
return index, term, isLeader
}Log发送 AppendEntries
相较于上次的Leader选举,新的AppendEntries会去同步日志,主要需要构建 PrevLogIndex以及Entries,Entries为空的话发送一个心跳包即可。
func (rf *Raft) sendAppendEntries() {
var wg sync.WaitGroup
rf.mu.RLock()
for p := range rf.peers {
if p != rf.me {
args := &RequestAppendEntriesArgs{}
args.Term = rf.currentTerm
args.LeaderID = rf.me
args.PrevLogIndex = rf.nextIndex[p] - 1
args.LeaderCommit = rf.commitIndex
if args.PrevLogIndex >= 0 {
args.PrevLogTerm = rf.logs[args.PrevLogIndex].Term
}
// send empty data if index are same
if rf.nextIndex[p] <= rf.getLastIndex() {
args.Entries = rf.logs[rf.nextIndex[p]:]
}
//rf.debug("send Entries is: %v, index is: %d", args.Entries, p)
wg.Add(1)
go func(p int, args *RequestAppendEntriesArgs) {
defer wg.Done()
ok := rf.sendRequestAppendEntries(p, args, &RequestAppendEntriesReply{})
if !ok {
rf.debug("send %d AppendEntries result:%v", p, ok)
}
}(p, args)
}
}
rf.mu.RUnlock()
wg.Wait()
}在看具体发送逻辑, 在每次成功响应后都会去提交日志, 更新Leader本地的rf.nextIndex以及rf.matchIndex。RetryIndex是用来优化的一个点,下个函数会讲到。
func (rf *Raft) sendRequestAppendEntries(server int, args *RequestAppendEntriesArgs, reply *RequestAppendEntriesReply) bool {
respCh := make(chan bool)
ok := false
go func() {
respCh <- rf.peers[server].Call("Raft.RequestAppendEntries", args, reply)
}()
select {
case <-time.After(time.Millisecond * 60): // 100ms
return false
case ok = <-respCh:
}
rf.mu.Lock()
defer rf.mu.Unlock()
if !ok || rf.state != StateLeader || args.Term != rf.currentTerm {
return ok
}
if reply.Term > rf.currentTerm {
rf.becomeFollower("leader expired")
rf.currentTerm = reply.Term
rf.persist()
return ok
}
//rf.debug("rf matchIndex is %v", rf.matchIndex)
if reply.Success {
rf.matchIndex[server] = args.PrevLogIndex + len(args.Entries)
//rf.debug("reply success, server is %d, matchIndex is %d", server, rf.matchIndex[server])
rf.nextIndex[server] = rf.matchIndex[server] + 1
go rf.commit()
} else {
rf.nextIndex[server] = reply.RetryIndex
}
return ok
}Commit的逻辑也很简单,遍历peers,如果超过半数以上的matchIndex都等于当前Leader Log的结尾,则认为这是一次有效的Append,进行提交。
func (rf *Raft) commit() {
majority := len(rf.peers)/2 + 1
for i := rf.getLastIndex(); i > rf.commitIndex; i-- {
count := 1
if rf.logs[i].Term == rf.currentTerm {
for j := range rf.peers {
if j == rf.me {
continue
}
// 当前的Leader的Log得到认可
if rf.matchIndex[j] >= i {
count++
}
}
}
if count >= majority {
rf.commitIndex = i
go rf.applyLog()
break
}
}
}
func (rf *Raft) applyLog() {
rf.mu.Lock()
defer rf.mu.Unlock()
// apply changes
for i := rf.lastApplied + 1; i <= rf.commitIndex; i++ {
msg := ApplyMsg{CommandIndex: i, Command: rf.logs[i].Command, CommandValid: true}
rf.debug("send msg is: %v, lastApplied is %d, commitIndex is %d", msg, rf.lastApplied, rf.commitIndex)
rf.applyCh <- msg
}
rf.lastApplied = rf.commitIndex
}接受方的逻辑,使用retry index进行优化,当收到的request是有效之后,覆盖有冲突的Logs,直接从rf.logs[:args.PrevLogIndex+1]开始,然后进行提交。
func (rf *Raft) RequestAppendEntries(args *RequestAppendEntriesArgs, reply *RequestAppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
return
}
rf.AppendEntries <- struct{}{}
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
if rf.state != StateFollower {
rf.becomeFollower("request append receive large term")
rf.votedFor = -1
}
}
// which means the request need to decrease the index and send request again
if args.PrevLogIndex > rf.getLastIndex() {
reply.RetryIndex = rf.getLastIndex() + 1
return
}
// 这里使用retry index 其实是一个优化点
// paper 里面是每次自减,回复一个false,这里直接找到下一个term的位置
// 减少了心跳包的发送次数
if args.PrevLogIndex > 0 && rf.logs[args.PrevLogIndex].Term != args.PrevLogTerm {
for reply.RetryIndex = args.PrevLogIndex - 1;
reply.RetryIndex > 0 && rf.logs[reply.RetryIndex].Term == rf.logs[args.PrevLogIndex].Term;
reply.RetryIndex-- {
}
return
}
rf.logs = append(rf.logs[:args.PrevLogIndex+1], args.Entries...)
//rf.debug("args.LeaderCommit is :%d, PrevLogIndex %d, commitIndex: %d", args.LeaderCommit, args.PrevLogIndex, rf.commitIndex)
if args.LeaderCommit > rf.commitIndex {
rf.commitIndex = min(rf.getLastIndex(), args.LeaderCommit)
go rf.applyLog()
}
reply.Success = true
}持久化
根据Paper的内容,需要持久化的内容有三个:currentterm, votedFor, log[]

这就意味着每次当raft结构体内上诉三个变量发生改变的时候我们都需要将其持久化。persisth和readPersist都很简单。
func (rf *Raft) persist() {
// Your code here (2C).
// Example:
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.logs)
data := w.Bytes()
rf.persister.SaveRaftState(data)
}
//
// restore previously persisted state.
//
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
d.Decode(&rf.currentTerm)
d.Decode(&rf.votedFor)
d.Decode(&rf.logs)
}至于Persist调用的地方只要完成了前面两个实现,添加也很简单,这里就不再贴代码了。
小结
在调测试的时候其实是很懵的,需要仔细看看测试代里面的内容,然后在调试的时候带上时间戳以及当前节点的信息,这样看起来就会容易许多。实现部分的代码其实没有多少,最精华的部分应该是这部分的测试代码,从模拟分区再到split over,再到节点的网络失效,有兴趣的可以仔细看下实现。
reference
TiDB HomeWork-1
TiDB HomeWork-1
目标
下载编译 TiDB/PD/TiKV 并修改源代码,使得事物启动时输出hello transaction的日志。
本机器环境MBP:
CPU: Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz
内存: 16 GB 2400 MHz DDR4
步骤
Clone 项目到本地
- Clone
TiDB项目git clone [email protected]:pingcap/tidb.git - Clone
TiKV项目git clone [email protected]:tikv/tikv.git - Clone
pd项目git clone [email protected]:pingcap/pd.git
修改代码
在 tidb 目录下全文search transaction 相关的内容,在tidb/store/tikv/txn里面可以找到startTS 函数,对其进行修改即可。
func (txn *tikvTxn) StartTS() uint64 {
logutil.Logger(context.Background()).Info("hello transaction.")
return txn.startTS
}编译
Clone完成项目后发现tidb里面 go.mod 最低的环境要求是1.13,小于1.13版本的请先升级本地的Go环境,每个项目里面都有Makefile,所以我们直接make进行编译就好:
➜ tidb git:(v4.0.4) ✗ make
CGO_ENABLED=1 GO111MODULE=on go build -tags codes -ldflags '-X "github.com/pingcap/parser/mysql.TiDBReleaseVersion=v4.0.4-dirty" -X "github.com/pingcap/tidb/util/versioninfo.TiDBBuildTS=2020-08-13 09:10:26" -X "github.com/pingcap/tidb/util/versioninfo.TiDBGitHash=c61fc7247e9f6bc773761946d5b5294d3f2699a5" -X "github.com/pingcap/tidb/util/versioninfo.TiDBGitBranch=heads/v4.0.4" -X "github.com/pingcap/tidb/util/versioninfo.TiDBEdition=Community" ' -o bin/tidb-server tidb-server/main.go
Build TiDB Server successfully!然后再以相同的命令依次编译tikv以及pd即可。编译的时候要等的时间比较长,rust的编译速度确实慢。
编译完成后,三个文件夹的二进制文件默认未知分别位于tidb/bin/tidb-server, pd/bin/pd-server, tikv/target/release/tikv-server。
这里需要注意如果都用线上master的编译可能不是稳定版本,出来的界面可能有一点问题,所以需要用一个统一的版本去编译。我这里统一checkout 到了 v4.0.4
启动
官方推荐用tiup进行管理集群,docker-compose 方式已废弃,直接看文章介绍即可
Flags:
--db int 设置集群中的 TiDB 数量(默认为1)
--db.binpath string 指定 TiDB 二进制文件的位置(开发调试用,可忽略)
--db.config string 指定 TiDB 的配置文件(开发调试用,可忽略)
--db.host host 指定 TiDB 的监听地址
--drainer int 设置集群中 Drainer 数据
--drainer.binpath string 指定 Drainer 二进制文件的位置(开发调试用,可忽略)
--drainer.config string 指定 Drainer 的配置文件
-h, --help 打印帮助信息
--host string 设置每个组件的监听地址(默认为 127.0.0.1),如果要提供给别的电脑访问,可设置为 0.0.0.0
--kv int 设置集群中的 TiKV 数量(默认为1)
--kv.binpath string 指定 TiKV 二进制文件的位置(开发调试用,可忽略)
--kv.config string 指定 TiKV 的配置文件(开发调试用,可忽略)
--monitor 是否启动监控
--pd int 设置集群中的 PD 数量(默认为1)
--pd.binpath string 指定 PD 二进制文件的位置(开发调试用,可忽略)
--pd.config string 指定 PD 的配置文件(开发调试用,可忽略)
--pump int 指定集群中 Pump 的数量(非 0 的时候 TiDB 会开启 TiDB Binlog)
--pump.binpath string 指定 Pump 二进制文件的位置(开发调试用,可忽略)
--pump.config string 指定 Pump 的配置文件(开发调试用,可忽略)
--tiflash int 设置集群中 TiFlash 数量(默认为0)
--tiflash.binpath string 指定 TiFlash 的二进制文件位置(开发调试用,可忽略)
--tiflash.config string 指定 TiFlash 的配置文件(开发调试用,可忽略)
所以最后我们的启动命令就是
➜ pingcap tiup playground --db.binpath ./tidb/bin/tidb-server --pd.binpath ./pd/bin/pd-server --kv.binpath ./tikv/target/release/tikv-server --db 1 --pd 1 --kv 3
Starting component `playground`: --db.binpath ./tidb/bin/tidb-server --pd.binpath ./pd/bin/pd-server --kv.binpath ./tikv/target/release/tikv-server --db 1 --pd 1 --kv 3
Use the latest stable version: v4.0.4
Specify version manually: tiup playground <version>
The stable version: tiup playground v4.0.0
The nightly version: tiup playground nightly
Playground Bootstrapping...
Start pd instance...
Start tikv instance...
Start tikv instance...
Start tikv instance...
Start tidb instance...
........
Waiting for tikv 127.0.0.1:20160 ready
Waiting for tikv 127.0.0.1:20161 ready
Waiting for tikv 127.0.0.1:20162 ready
Start tiflash instance...
Waiting for tiflash 127.0.0.1:3930 ready ...
CLUSTER START SUCCESSFULLY, Enjoy it ^-^
To connect TiDB: mysql --host 127.0.0.1 --port 4000 -u root
To view the dashboard: http://127.0.0.1:2379/dashboard
To view the Prometheus: http://127.0.0.1:9090
To view the Grafana: http://127.0.0.1:3000
然后登陆http://127.0.0.1:2379/dashboard 查看日志结果,正常输出hello, transaction.
《深入理解linux内核》笔记-内核同步
#《深入理解linux内核》笔记-内核同步
定义
在现代操作系统里,同一时间可能有多个内核执行流在执行,因此内核其实象多进程多线程编程一样也需要一些同步机制来同步各执行单元对共享数据的访问。尤其是在多处理器系统上,更需要一些同步机制来同步不同处理器上的执行单元对共享的数据的访问。
原子操作
原子操作可以保证指令以原子的方式执行一执行过程不被打断。 众所周知,原子原本指的是不可分割的微粒,所以原子操作也就是不能够被分割的指令。我们熟知的Atomic一系列操作就是原子操作。
内核提供了两组原子操作接口一-组针对整 数进行操作,另一组针对单独的位进行操作。在Linux支持的所有体系结构上都实现了这两组接口。大多数体系结构会提供支持原子操作的简
单算术指令。而有些体系结构确实缺少简单的原子操作指令,但是也为单步执行提供了锁内存总线的指令,这就确保了其他改变内存的操作不能同时发生。
原子整数操作
针对整数的原子操作只能对atomic_t 类型的数据进行处理。在这里之所以引入了一个特殊
数据类型,而没有直接使用C语言的int类型,主要是出于两个原因:
- 让原子函数只接收atomic_t类型的操作数,可以确保原子操作只与这种特殊类型数据一起使用。
- 同时,这也保证了该类型的数据不会被传递给任何非原子函数。
atomic等一系列操作都是通过Lock实现的
/**
* atomic_inc - increment atomic variable
* @v: pointer of type atomic_t
*
* Atomically increments @v by 1.
*/
static __inline__ void atomic_inc(atomic_t *v)
{
__asm__ __volatile__(
LOCK "incl %0"
:"=m" (v->counter)
:"m" (v->counter));
}
64位原子操作
随着64位体系结构越来越普及,内核开发者确实在考虑原子变量除32位atomic_t 类型外,也应引入64位的atomic64_t。
自旋锁
一种广泛应用的同步技术是加锁(locking)。当内核控制路径必须访问共享数据结构或进入临界区时,就需要为自己获取一把“锁”。由锁机制保护的资源非常类似于限制于房间内的资源,当某人进入房间时,就把门锁上。如果内核控制路径希望访问资源,就试图获取钥匙“打开门”。当且仅当资源空闲时,它才能成功。然后,只要它还想使用这个资源,门就依然锁着。当内核控制路径释放了锁时,门就打开,另一个内核控制路径就可以进入房间。
自旋锁(spinlock)是用来在多处理器环境中工作的一种特殊的锁。如果内核控制路径发现自旋锁“开着”,就获取锁并继续自己的执行。相反,如果内核控制路径发现锁由运行在另一个CPU.上的内核控制路径“锁着”,就在周围“旋转”,反复执行一条紧凑的循环指令,直到锁被释放。
自旋锁的循环指令表示“忙等”。即使等待的内核控制路径无事可做(除了浪费时间),它也在CPU上保持运行。不过,自旋锁通常非常方便,因为很多内核资源只锁1毫秒的时间片段;所以说,释放CPU和随后又获得CPU都不会消耗多少时间。
一般来说,由自旋锁所保护的每个临界区都是禁止内核抢占的。在单处理器系统上,这种锁本身并不起锁的作用,自旋锁原语仅仅是禁止或启用内核抢占。请注意,在自旋锁忙等期间,内核抢占还是有效的,因此,等待自旋锁释放的进程有可能被更高优先级的进程替代。
自旋锁与互斥锁有点类似,只是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,”自旋”一词就是因此而得名。
自旋锁与下半部
对于软中断,无论是否同种类型,如果数据被软中断共享,那么它必须得到锁的保护。这是因为,即使是同种类型的两个软中断也可以同时运行在一个系统的多个处理器上。但是,同一处理器上的一个软中断绝不会抢占另一个软中断,因此,根本没必要禁止下半部。
读/写 自旋锁
**读写自旋锁的引入是为了增加内核的并发能力。只要没有内核控制路径对数据结构进行修改,读/写自旋锁就允许多个内核控制路径同时读同一数据结构。**如果一个内核控制路径想对这个结构进写操作,那么它必须首先获取读/写锁的写锁,写锁授权独占访问这个资源。当然,允许对数据结构并发读可以提高系统性能。
自旋锁提供了一种快速简单的锁实现方法。如果加锁时间不长并且代码不会睡眠(比如中断处理程序),利用自旋锁是最佳选择。如果加锁时间可能很长或者代码在持有锁时有可能睡眠,那么最好使用信号量来完成加锁功能。
信号量
Linux中的信号量是一种睡眠锁。如果有-一个任务试图获得-一个不可用(已经被占用)的信号量时,信号量会将其推进一个等待队列,然后让其睡眠。这时处理器能重获自由,从而去执行
其他代码。当持有的信号量可用(被释放)后,处于等待队列中的那个任务将被唤醒,并获得该信号量。
- 由于争用信号量的进程在等待锁重新变为可用时会睡眠,所以信号量适用于锁会被长时间持有的情况。相反,锁被短时间持有时,使用信号量就不太适宜了。因为睡眠、维护等待队列以及唤醒所花费的开销可能比锁被占用的全部时间还要长。
- 由于执行线程在锁被争用时会睡眠,所以只能在进程上下文中才能获取信号量锁,因为在中断上下文中是不能进行调度的。
- 你可以在持有信号量时去睡眠(当然你也可能并不需要睡眠),因为当其他进程试图获得同一信号量时不会因此而死锁(因为该进程也只是去睡眠而已,而你最终会继续执行的)。
- 在你占用信号量的同时不能占用自旋锁。因为在你等待信号量时可能会睡眠,而在持有自旋锁时是不允许睡眠的。
信号量支持两个原子操作 P() 和 V(),前者叫做测试操作,后者叫做增加操作。后来的系统把两种操作分别叫做 down() 和 up()。
Linux也遵从这种叫法。down() 操作通过对信号量计数减1来请求获得一个信号量。如果结果是0或大于0,获得信号量锁,任务就可以进入临界区。如果结果是负数,任务会被放入等待队列,
处理器执行其他任务。该函数如同一个动词,降低(down)一个信号量就等于获取该信号量。相反,当临界区中的操作完成后,up(操作用来释放信号量,该操作也被称作是提升(upping)
信号量,因为它会增加信号量的计数值。如果在该信号量上的等待队列不为空,那么处于队列中等待的任务在被唤醒的同时会获得该信号量。
读写信号量
与自旋锁一样,信号量也有区分读-写访问的可能。与读-写自旋锁和普通自旋锁之间的关系差不多,读-写信号量也要比普通信号量更具优势。
所有的读一写信号量都是互斥信号量一也就是说, 它们的引用计数等于1,虽然它们只对写者互斥,不对读者。只要没有写者,并发持有读锁的读者数不限。相反,只有唯一的写者(在没有读者时)可以获得写锁。所有读-写锁的睡眠都不会被信号打断,所以它只有一一个版本的down()操作。
互斥体
mutex在内核中对应数据结构mutex,其行为和使用计数为1的信号量类似,但操作接口更简单,实现也更高效,而且使用限制更强。互斥体是一种互斥信号。
-
互斥体 VS 信号量
互斥体和信号量很相似,内核中两者共存会令人混淆。所幸,它们的标准使用方式都有简单的规范:
除非mutex的某个约束妨碍你使用,否则相比信号量要优先使用mutex。当你写新代码时,只有碰到特殊场合(一般是很底层代码)才会需要使用信号量。因此建议首选mutex。如果发现不能满足其约束条件,且没有其他别的选择时,再考虑选择信号量。 -
自旋锁 VS 互斥体
| 需求 | 建议的加锁方法|
| ---- | ---- |
| 低开销加锁 | 优先使用自旋锁 |
| 短期锁定 | 优先使用自旋锁|
| 长期加锁 | 优先使用互斥体|
| 中断上下文中加锁 | 使用自旋锁|
| 持有锁需要睡眠 | 使用互斥体|
完成变量
如果在内核中一个任务需要发出信号通知另一任务发生了某个特定事件,利用完成变量(completion variable) 是使两个任务得以同步的简单方法。如果一个任务要执行一些工作时,另一个任务就会在完成变量.上等待。当这个任务完成工作后,会使用完成变量去唤醒在等待的任务。事实上,完成变量仅仅提供了代替信号量的一个简单的解决方法。例如,当子进程执行或者退出时,vfork() 系统调用使用完成变量唤醒父进程。
顺序锁
Linux 2.6中引入了顺序锁(seqlock), 它与读1写自旋锁非常相似,只是它为写者赋予了较高的优先级:事实上,即使在读者正在读的时候也允许写者继续运行。这种策略的好处是写者永远不会等待(除非另外一个写者正在写),缺点是有些时候读者不得不反
复多次读相同的数据直到它获得有效的副本。
每个顺序锁都是包括两个字段的seqlock__t结构:一个类型为spinlock_t的lock字段和一个整型的sequence字段,第二个字段是一个顺序计数器。每个读者都必须在读数据前后两次读顺序计数器,并检查两次读到的值是否相同,如果不相同,说明新的写者已经开始写并增加了顺序计数器,因此暗示读者刚读到的数据是无效的。
Seq锁在你遇到如下需求时将是最理想的选择:
- 你的数据存在很多读者。
- 你的数据写者很少。
- 虽然写者很少,但是你希望写优先于读,而且不允许读者让写者饥饿。
- 你的数据很简单,如简单结构,甚至是简单的整型
- 在某些场合,你是不能使用原子量的。
顺序和屏障
内存屏障(memory barrier)原语确保,在原语之后的操作开始执行之前,原语之前的操作已经完成。因此,内存屏障类似于防火墙,让任何汇编语言指令都不能通过。
在80x86处理器中,下列种类的汇编语言指令是“串行的”,因为它们起内存屏障的作用:
-
对I/O端口进行操作的所有指令。
-
有lock前缀的所有指令(参见“原子操作”一节)。
-
写控制寄存器、系统寄存器或调试寄存器的所有指令(例如,cli和sti,用于修改eflags寄存器的IF标志的状态)。
-
在Pentium 4微处理器中引入的汇编语言指令lfence、sfence和mfence,它们分别有效地实现读内存屏障、写内存屏障和读一写内存屏障。
-
少数专门的汇编语言指令,终止中断处理程序或异常处理程序的iret指令就是其中之一。
《深入理解linux内核》笔记-内存寻址
《深入理解linux内核》笔记-内存寻址
地址类型
不同类型的地址类型:
- 逻辑地址: 每一个逻辑地址都由一个段(segment)和偏移量(offset或displacement)组成,偏移量指明了从段开始的地方到实际地址之间的距离。
- 线性地址(虚拟地址): 是一个32位无符号整数,可以用来表示高达4GB的地址。线性地址通常用十六进制数字表示,值的范围从0x00000000到0xffffffff。
- 物理地址: 用于内存芯片级内存单元寻址。它们与从微处理器的地址引脚发送到内存总线上的电信号相对应。物理地址由32位或36位无符号整数表示。
内存控制单元(MMU)通过一种称为分段单元(segmentation unit)的硬件电路把一个
逻辑地址转换成线性地址;接着,第二个称为分页单元(paging unit)的硬件电路把线性地址转换成一个物理地址
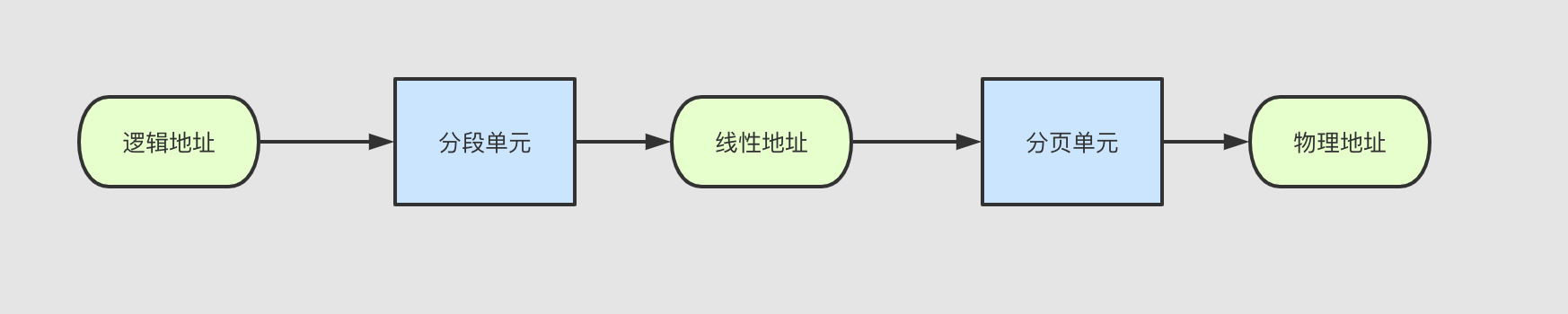
分段
从80286模型开始,Intel 微处理器以两种不同的方式执行地址转换,这两种方式分别称为实模式(real mode)和保护模式(protecied mode)。实模式存在的主要原因是要维持处理器与早期模型兼容,并让操
作系统自举。
- 实模式: 是 段地址+偏移量 的方式,得到物理地址,进而寻址。
- 保护模式: 不允许通过段寄存器取值得到段的起始地址,而是把虚拟地址转进一个 MMU 的硬件,经过额外的转换和检查,进而得到一个物理地址。其中的额外检查就可以起到例如保护某段数据的作用。
整个小节看下来还是比较疑惑的,所以网上翻了下分段为什会出现:
1976年开始设计,1978年中旬Intel 发布了8086。标志了x86王朝的开始。它是一款16位的微处理器,却被设计成可以访问1MB 的内存(即20位的地址空间)。问题就产生了,16位的 ALU怎么去取20位的地址呢?因此,段的概念 在8086身上被引入了。
段的引入是解决“ 地址总线的宽度一般要大于寄存器的宽度 ”这个问题。
8086的分段寻址,是指一个物理地址由段地址(segment selector)与偏移量(offset)两部分组成,长度各是16比特。其中段地址左移4位(即乘以16)与偏移量相加即为物理地址。例如,06EFh:1234h,表示段地址为06EFh,偏移量为1234h,物理地址为06EF0h + 1234h = 08124h。在计算物理地址时如果发生上溢出,8086处理器舍弃进位。例如,FFFFh:0010h所对应的物理地址为00000h.
这种分段寻址,即 段地址+偏移量 的做法,在以80286开始之后会被称为 实模式。
分段机制是IA32架构CPU的特色,并不是操作系统寻址方式的必然选择。Linux为了跨平台,巧妙的绕开段机制,主要使用分页机制来寻址。
详细的文章可以参考一下这篇
https://m.xp.cn/b.php/77856.html
硬件分页
分页单元(pagingunit)把线性地址转换成物理地址。其中的一个关键任务是把所请求的访问类型与线性地址的访问权限相比较,如果这次内存访问是无效的,就产生一个缺页异常。
页、页框、页表的概念:
-
页: 为了效率起见,线性地址被分成以固定长度为单位的组,称为页(page)。 页内部连续的线性地址被映射到连续的物理地址中。
-
页框: 分页单元把所有的RAM分成固定长度的页框(page frame) (有时叫做物理页)。每个页框包含一个页(page), 也就是说一个页框的长度与一个页的长度一致。页框是主存的一部分,因此也是一个存储区域。区分一页和一个页框是很重要的,前者只是一个数据块,可以存放在任何页框或磁盘中。
-
页表: 把线性地址映射到物理地址的数据结构称为页表(page table)。页表存放在主存中,并在启用分页单元之前必须由内核对页表进行适当的初始化。
从80386起,Intel处理器的分页单元处理4KB的页。(如果没有内存分页,那么就需要记录物理内存每字节到虚拟内存每字节的对应关系,在内存里面是放不下的。)
线性地址的转换分两步完成,每一步都基于一种转换表,第一种转换表称为页目录表(page directory), 第二种转换表称为页表(page table)。这也是我们常说的二级页表。
- Directory(目录) 最高10位
- Table(页表) 中间10位
- Offset(偏移量) 最低12位

如果我们使用一级页表,总共就需要4GB/4KB个表项,就是2的20次方。使用上面的二级页表的话,整体的逻辑就跟电话簿类似,分成三本电话簿, 一本记录目录对应关系,最多2的10次方个项,一本记录页表对应关系,也是2的10次方个项,最后的offset是2的12次方。可以很大程度减少页表项占用的内存。

(图片来源 https://www.cnblogs.com/vamei/p/9329278.html)
从Pentium模型开始,80x86 微处理器引入了扩展分页(extended paging),它允许页框大小为4MB而不是4KB(见图2-8)。扩展分页用于把大段连续的线性地址转换成相应的物理地址,在这些情况下,内核可以不用中间页表进行地址转换,从而节省内存并保
留TLB项。
- Directory 最高10位
- Offset 其余22位
64位系统的分页
32位微处理器普遍采用两级分页。然而两级分页并不适用于采用64位系统的计算机。
首先假设一个大小为4KB的标准页。因为1KB覆盖210个地址的范围,4KB覆盖212个地址,所以offset字段是12位。这样线性地址就剩下52位分配给Table和Directory字段。如果我们现在决定仅仅使用64位中的48位来寻址(这个限制仍然使我们自在地拥
有256TB的寻址空间! ), 剩下的48-12 = 36位将被分配给Table和Directory字段。如果我们现在决定为两个字段各预留18位, 那么每个进程的页目录和页表都含有218个项,即超过256000个项。
所以在64位的操作系统一般采用的是3级及以上的分页技术。
硬件高速缓存(SRAM)以及TLB
SRAM就是我们理解的CPU Cache(L1/L2/L3)
Cache Line: 80x86体系结构中引入了一个叫行(line)的新单位。行由几十个连续的字节组成,它们以脉冲突发模式(burstmode)在慢速DRAM和快速的用来实现高速缓存的片上静态RAM (SRAM)之间传送,用来实现高速缓存。
读写策略:
- 读: 对于读操作,控制器从高速缓存行中选择数据并送到CPU寄存器;不需要访问RAM因而节约了CPU时间
- 写: 对于写操作,控制器可能采用以下两个基本策略之一,分别称之为直写(write-through) 和回写(write-back)。直写比较简单。当修改cache line时,处理器立即将它写入主存。这样可以保证主存与缓存的内容永远保持一致。当cache line被替代时,只需要简单地将它丢弃即可。这种策略很简单,但是速度比较慢。回写比较复杂。当修改cache line时,处理器不再马上将它写入主存,而是打上已弄脏(dirty)的标记。当以后某个时间点cache line被丢弃时,这个已弄脏标记会通知处理器把数据回写到主存中,而不是简单地扔掉。
TLB(Translation Lookaside Buffer):
当一个线性地址被第一次使用时,通过慢速访问RAM中的页表计算出相应的物理地址。同时,物理
地址被存放在一个TLB表项(TLBentry)中,以便以后对同一个线性地址的引用可以快速地得到转换。
Linux分页
Linux采用了一种同时适用于32位和64位系统的普通分页模型。正像前面“64位系统
中的分页”一节所解释的那样,两级页表对32位系统来说已经足够了,但64位系统需
要更多数量的分页级别。
4种页表分别为:
- 页全局目录 (Page Global Directory)
- 页上级目录 (Page Upper Directory )
- 页中间目录 (Page Middle Directory )
- 页表(Page Table)
对于没有启用物理地址扩展的32位系统,两级页表已经足够了。Linux通过使“页上级目录”位和“页中间目录”位全为0,从根本上取消了页上级目录和页中间目录字段。
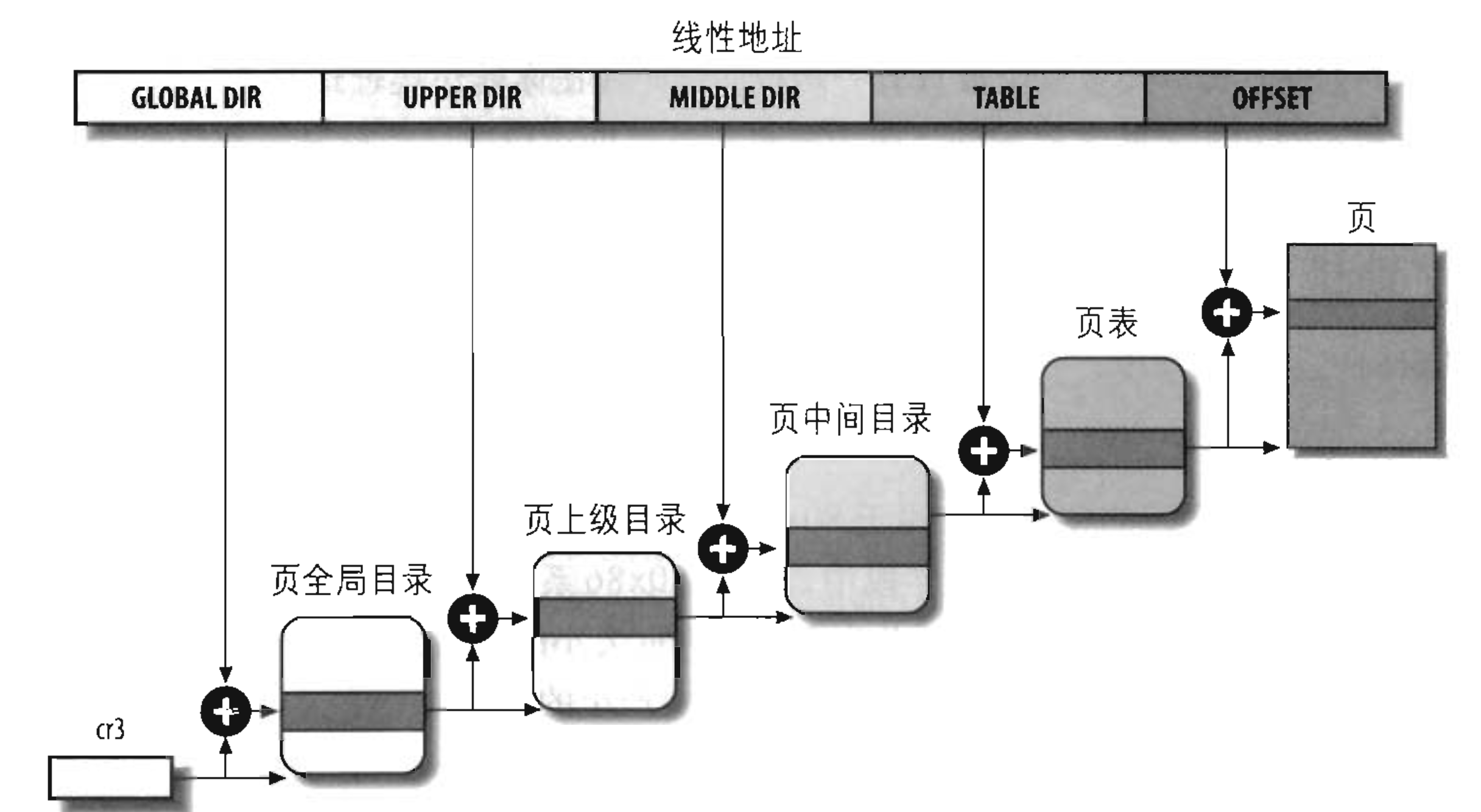
每一个进程有它自己的页全局目录和自己的页表集。当发生进程切换时(参见第三章“进程切换"一节),Linux把cr3控制寄存器的内容保存在前一个
执行进程的描述符中,然后把下一个要执行进程的描述符的值装入cr3寄存器中。因此,当新进程重新开始在CPU上执行时,分页单元指向一组正确的页表。
在初始化阶段,内核必须建立一个物理地址映射来指定哪些物理地址范围对内核可用而哪些不可用(或者因为它们映射硬件设备I/O的共享内存,或者因为相应的页框含有BIOS数据)。
进程的线性地址空间分成两部分:
- 从0x00000000到0xbfffffff的线性地址,无论进程运行在用户态还是内核态都可以寻址。
- 从0xc0000000到0xffffffff的线性地址,只有内核态的进程才能寻址。
当进程运行在用户态时,它产生的线性地址小于0xc0000000;当进程运行在内核态时,它执行内核代码,所产生的地址大于等于0xc0000000。但是,在某些情况下,内核为了检索或存放数据必须访问用户态线性地址空间。
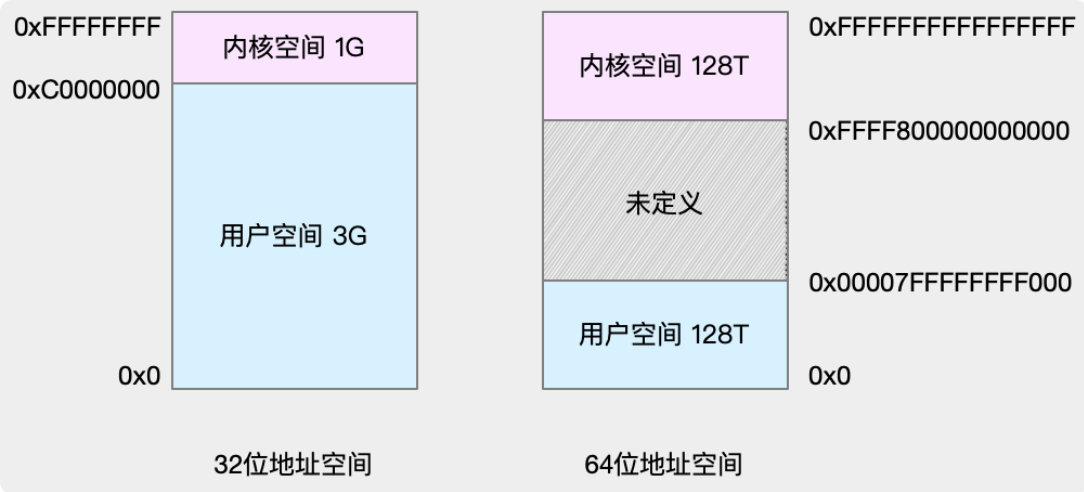
TLB 刷新:
一般来说,任何进程切换都会暗示着更换活动页表集。相对于过期页表。本地TLB表项必须被刷新:这个过程在内核把新的页全局目录的地址写入cr3控制寄在器时会自动完成。不过内核在下列情况下将避免TLB被刷新:
- 当两个使用相同页表集的普通进程之间执行进程切换时
- 当在一个普通进程和一个内核线程间执行进程切换时。事实上,内核线程并不拥有自己的页表集,更确切地说,它们使用刚在CPU上执行过的普通进程的页表集。
为了避免多处理器系统上无用的TLB刷新,内核使用一种叫做懒惰TLB (lazy TLB)模式的技术。其基本**是,如果几个CPU正在使用相同的页表,而且必须对这些CPU上的一个TLB表项刷新,那么,在某些情况下,正在运行内核线程的那些CPU上的刷新就可以延迟。
nsq消息投递
消息投递
nsqd创建topic
$ curl -d 'hello world 1' 'http://127.0.0.1:4151/pub?topic=test'
doPUB中会从http请求中去尝试拿到topic,这里的topicc从GetTopic中拿到,没有的话就去NewTopic新建一个,里面会加一个DeleteExistingTopic回调。每个NewTopic里面都会有起一个goroutine去调用messagePump。然后调用t.ctx.nsqd.Notify(t),这里的notify是将信息写到磁盘上。如果连接了nsqlookupd,之后会向其查询该topic的channel是否在client那边存在,如果存在的话就会去创建channel
if len(lookupdHTTPAddrs) > 0 {
channelNames, err := n.ci.GetLookupdTopicChannels(t.name, lookupdHTTPAddrs)
if err != nil {
n.logf(LOG_WARN, "failed to query nsqlookupd for channels to pre-create for topic %s - %s", t.name, err)
}
for _, channelName := range channelNames {
if strings.HasSuffix(channelName, "#ephemeral") {
// we don't want to pre-create ephemeral channels
// because there isn't a client connected
continue
}
t.getOrCreateChannel(channelName)
}
}
messagePump会将memoryMsgChan和backendChan里面的message发送给各个channelMap中的各个channel,channel维护的是nsqd到client之间的连接。
for {
select {
case msg = <-memoryMsgChan:
case buf = <-backendChan:
msg, err = decodeMessage(buf)
if err != nil {
t.ctx.nsqd.logf(LOG_ERROR, "failed to decode message - %s", err)
continue
}
case <-t.channelUpdateChan:
chans = chans[:0]
t.RLock()
for _, c := range t.channelMap {
chans = append(chans, c)
}
t.RUnlock()
if len(chans) == 0 || t.IsPaused() {
memoryMsgChan = nil
backendChan = nil
} else {
memoryMsgChan = t.memoryMsgChan
backendChan = t.backend.ReadChan()
}
continue
case pause := <-t.pauseChan:
if pause || len(chans) == 0 {
memoryMsgChan = nil
backendChan = nil
} else {
memoryMsgChan = t.memoryMsgChan
backendChan = t.backend.ReadChan()
}
continue
case <-t.exitChan:
goto exit
}
for i, channel := range chans {
chanMsg := msg
// copy the message because each channel
// needs a unique instance but...
// fastpath to avoid copy if its the first channel
// (the topic already created the first copy)
if i > 0 {
chanMsg = NewMessage(msg.ID, msg.Body)
chanMsg.Timestamp = msg.Timestamp
chanMsg.deferred = msg.deferred
}
if chanMsg.deferred != 0 {
channel.PutMessageDeferred(chanMsg, chanMsg.deferred)
continue
}
err := channel.PutMessage(chanMsg)
if err != nil {
t.ctx.nsqd.logf(LOG_ERROR,
"TOPIC(%s) ERROR: failed to put msg(%s) to channel(%s) - %s",
t.name, msg.ID, channel.name, err)
}
}
}
这里channel会调用PutMessage,将消息发送到channel的memoryMsgChan中。这里的memoryMsgChan是前面的nsqd启动的时在IOLoop里面新开的携程去处理,调用p.SendMessage去给客户端发送消息
case msg := <-memoryMsgChan:
if sampleRate > 0 && rand.Int31n(100) > sampleRate {
continue
}
msg.Attempts++
subChannel.StartInFlightTimeout(msg, client.ID, msgTimeout)
client.SendingMessage()
err = p.SendMessage(client, msg)
if err != nil {
goto exit
}
flushed = false
nsqd接收topic消息
curl -d 'hello world 1' 'http://127.0.0.1:4151/pub?topic=test'
这里先有一个reqParams, topic, err := s.getTopicFromQuery(req)操作,同上面的一样,拿到topic。后面会根据拿到的topic和body生成一条msgmsg := NewMessage(topic.GenerateID(), body), 然后再调用topic的PutMessage将消息发送到memoryMsgChan里面去。
如果memoryMsgChan写满了,会把msg写到磁盘里面去。
select {
case t.memoryMsgChan <- m:
default:
b := bufferPoolGet()
err := writeMessageToBackend(b, m, t.backend)
bufferPoolPut(b)
t.ctx.nsqd.SetHealth(err)
if err != nil {
t.ctx.nsqd.logf(LOG_ERROR,
"TOPIC(%s) ERROR: failed to write message to backend - %s",
t.name, err)
return err
}
}
client消费msg
这里用nsq_to_file作为例子来分析,main入口里面会有一个for循环去定时处理相关topic。
for {
select {
case <-ticker:
newTopics, err := t.ci.GetLookupdTopics(addrs)
if err != nil {
log.Printf("ERROR: could not retrieve topic list: %s", err)
continue
}
t.updateTopics(newTopics, pattern)
case <-t.termChan:
for _, cfl := range t.topics {
close(cfl.F.termChan)
}
break forloop
case <-t.hupChan:
for _, cfl := range t.topics {
cfl.F.hupChan <- true
}
}
}
每次在updateTopics时候都会创建newConsumerFileLogger,在这里面会去调用ConnectToNSQD。这里面有个关键的用法Subscribe会去订阅相应的topic和channel。
md := Subscribe(r.topic, r.channel)
err = conn.WriteCommand(cmd)
结合前面的nsqd里面protocol_v2来看,consumer对应的channel和topic是在这创建
var channel *Channel
for {
topic := p.ctx.nsqd.GetTopic(topicName)
channel = topic.GetChannel(channelName)
channel.AddClient(client.ID, client)
if (channel.ephemeral && channel.Exiting()) || (topic.ephemeral && topic.Exiting()) {
channel.RemoveClient(client.ID)
time.Sleep(1 * time.Millisecond)
continue
}
break
}
atomic.StoreInt32(&client.State, stateSubscribed)
client.Channel = channel
这里还有一个router方法在for循环中读取logChan,然后再去updateFile。这个就是用来往文件里面去写msg的。
case m := <-f.logChan:
if f.needsFileRotate() {
f.updateFile()
sync = true
}
_, err := f.writer.Write(m.Body)
if err != nil {
log.Fatalf("ERROR: writing message to disk - %s", err)
}
_, err = f.writer.Write([]byte("\n"))
if err != nil {
log.Fatalf("ERROR: writing newline to disk - %s", err)
}
output[pos] = m
pos++
if pos == cap(output) {
sync = true
}
}
回过头来再看newConsumerFileLogger里面的AddHandler方法,这里会去调用AddConcurrentHandlers并行的监听incomingMessages,这个消息是从readLoop里面取出来的。然后再调用HandleMessage发送给logChan。
func (f *FileLogger) HandleMessage(m *nsq.Message) error {
m.DisableAutoResponse()
f.logChan <- m
return nil
}
Python 中的Context Managers
Python 中的Context Managers
with语法
在Pyhton中最常见的with语法打开一个文件:
with open('context_managers.txt', 'r') as infile:
print infile
不使用with:
infile = open('context_managers.txt', 'r')
print infile
infile.close()
with的作用就是不需要你去调用close方法,它会自动帮你去调用close()。比如我们不使用with的时候去操作文件io时可能会碰到一些异常,我们就需要使用try...except...finally这种复杂的方式去处理异常:
try:
infile = open('context_managers.txt', 'r')
raise Exception("some unknown error occur")
except Exception, e:
pass
finally:
infile.close()
with就相当于是上下文管理器(context managers), 调用with的时候就相当于声明了一个函数。它包含两个方法__enter__()和__exit__(), 当我们调用with xxx as xxx的时候就相当于调用__enter__()打开了一个文件描述符,当整个with函数结束的时候,调用__exit__()方法去关闭文件描述符。
class file_open():
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
self.open_file = open(self.filename, self.mode)
return self.open_file
def __exit__(self, *args):
self.open_file.close()
with file_open('foo.txt', 'w') as infile:
pass
contextlib库
contextlib是用来操作上下文管理器的,可以使用一个简单的语法@contextmanager去声明一个上下文管理器,使用时必须要带有yield关键字。这里的yield就相当于上面提到的__enter__()和__exit__()分界线,在yield之前的部分都可以认为是__enter___()里边的代码,在其之后的都认为是__exit__()方法。
from contextlib import contextmanager
@contextmanager
def file_open(file_name, mode):
open_file = open(file_name, mode)
yield open_file
open_file.close()
with file_open('foo.txt', 'w') as infile:
pass
python的官方文档也有一个例子:
from contextlib import contextmanager
@contextmanager
def tag(name):
print("<%s>" % name)
yield
print("</%s>" % name)
with tag("test"):
print("foo")
output:
<test>
foo
</test>
mysql索引设计
mysql索引设计
索引类型
B-Tree
- 所有的值都是按照顺序来存储的
- 有效查询方式
- 全值匹配(对所有的列进行匹配)
- 匹配最左前缀(索引第一列)
- 匹配列前缀(比如第一列的开头部分)
- 匹配范围值(between查询)
- 精确匹配某一列并范围匹配另一列
- 只访问索引
- 限制
- 不是按照最左列开始匹配的
- 不能跳过索引的列
- 如果查询的索引有范围,该索引右边的列无法使用到索引
HASH索引
- 对每一行数据都会计算一个hash值
- 只有memory引擎支持
- 只包含哈希值和行指针,不存储字段值
- 无法排序
- 只支持等值比较
- 访问速度快
全文索引
用于查找文中关键字
索引策略
- 独立的列,不要将索引列放在函数中
- 善用前缀索引,计算前缀的长度使之接近完整的列的选择性
- 多列索引时,将选择性最高的列(对应条件的列更少,更有区分度)放在最左边
Golang锁的实现
Golang锁的实现
Why Lock
先从一个例子开始,思考下这个程序会输出什么?
var a, b int
func f() {
a = 1
b = 2
}
func g() {
print(b)
print(a)
}
func main() {
go f()
g()
}结果一共出现以下四种情况:
a = 0, b = 0
a = 1, b = 0
a = 1, b = 2
a = 0, b = 2
Mem Reordering
其实上述的场景就是一个典型的内存乱序的例子:在一些场景下,CPU访问代码的顺序并不是按照用户编写代码的顺序来的。一般内存乱序可以分为编译器乱序和CPU流水线乱序。
Compiler Reordering 可以参考这篇文章内容,GCC在开启编译优化的情况会打乱代码的执行顺序。
CPU的乱序执行可以看下面这个简单的例子:
ADD AX, BX; (1)
INC AX; (2)
MOV CX, DX; (3)
如果CPU按照上述汇编指令 1->2->3访问,在现代典型CPU流水线上的工作时间周期会如下所示

由于INC指令需要依赖ADD上一步的结果集,导致在WB(write back)阶段会有一个Buble, 三条指令的完成的时间点在T7。这就是典型的CPU流水线阻塞。
假如这时候把指令顺序优化成 1->3->2

可以看到3的指令被提前执行了,整体流水线的执行时间减少了一个cycle。这就是CPU 乱序执行。
乱序执行的目的其实很容易理解,无非就是:
1.减少CPU指令
2.加快CPU执行速度
但是,当我们需要保证代码执行顺序的时候需要怎么做呢,答案是内存屏障。
MEM barrier
内存屏障,也称为 membar、内存栅栏或栅栏指令,是一种屏障指令,主要是用来确保指令不会被重排。
x86 指令集:
- Lfence - read barrier
- Sfence - write barrier
- Mfence - read/write barrier
- Lock (implicit instruction prefix)
- Atomic.ADD -> LOCK ADD
- Atomic.CAS -> LOCK CMPXCHG
在大多数场景下,Lock前缀指令已经够用了,这也是锁的实现基础。
本质上Lock等一系列内存屏障的实现原理都是基于CPU cache line的MESI协议的一致性而来,感兴趣的可以具体去了解下。
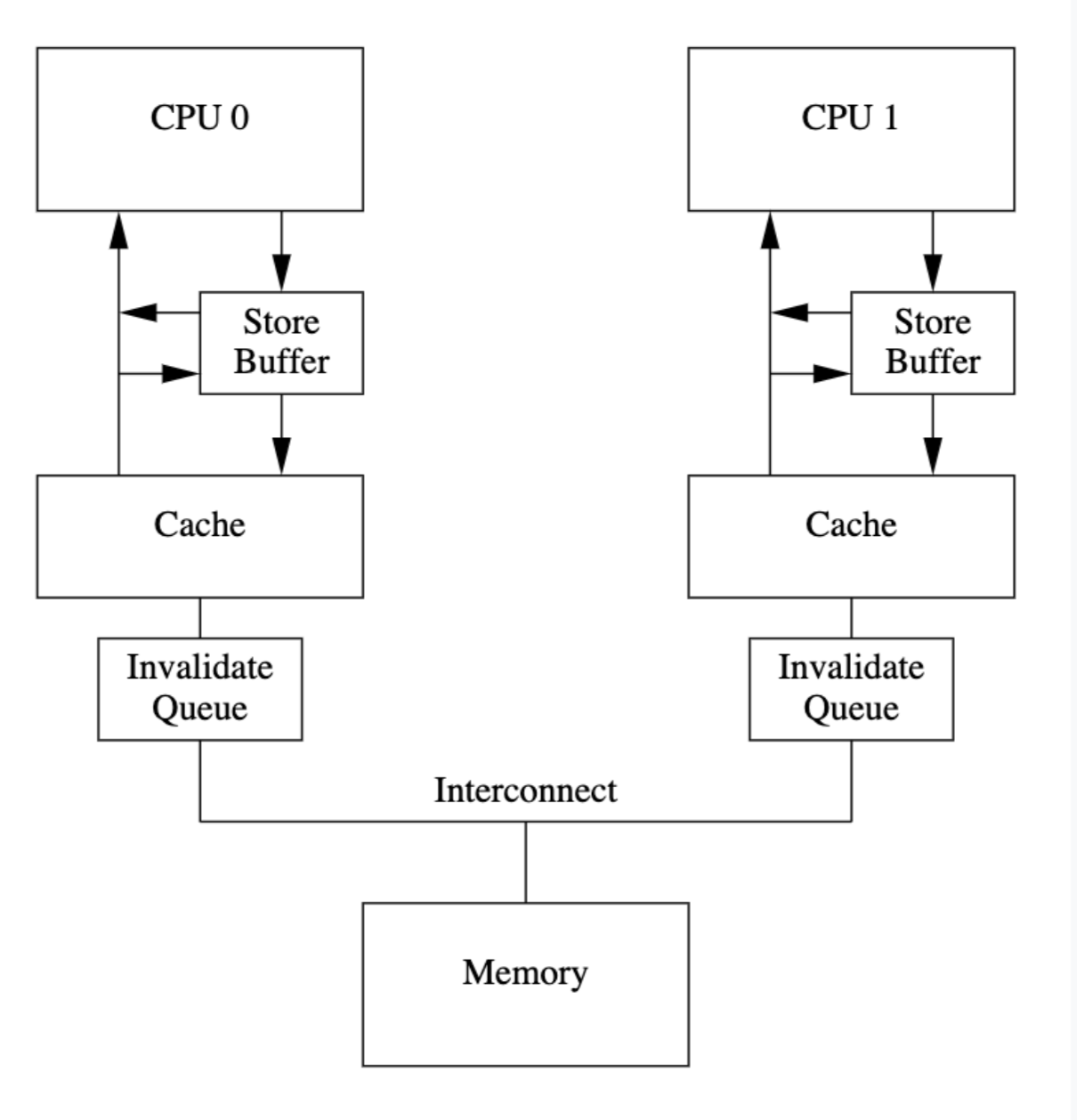
Linux下的Futex
Futex(Fast User Space Mutex)是在Linux 2.5.7 之后引入的一个概念。Futex的引入主要是为了解决内核-用户态切换带来的上下文消耗,在Futex出现之前,Linux下的同步机制分为用户态的同步机制 和 内核同步机制。
- 用户态的同步实际上就是利用
Atomic来实现的,可以看个简单的例子:在用户态里面使用Atomic熏黄尝试拿锁,本质上是一个自旋锁。这里的性能问题就比较显而易见了:忙等待造成的资源消耗
void lock(int lockval) {
//trylock是用户级的自旋锁
while(!trylock(lockval)) {
wait();//释放cpu,并将当期线程加入等待队列,是系统调用
}
}
boolean trylock(int lockval){
int i=0;
//localval=1代表上锁成功
while(!compareAndSet(lockval,0,1)){
if(++i>10){
return false;
}
}
return true;
}
- 内核提供的同步机制则是基于
semaphore,本质上也是基于原子指令实现的spinlock,但是额外的提供了唤醒休眠等操作。这也就意味着每次Lock与Unlock都会进入一次内核空间,带来的问题是用户态与内核态上下文切换带来的资源损耗。
Futex本身提供了两个操作:
int futex_wait(int *uaddr, int val);
int futex_wake(int *uaddr, int n);
程序进入内核态等待会直接调用上面的函数,如果发现这个时候有人释放或者解锁了资源就直接返回,不再进入内核态。内核实现同步机制,每次的操作都会在内核里面去比较,但是Futex的比较是在用户态完成的,提高了锁的获取效率。具体可以参考这篇文章。
Go中锁的实现
Go原生的包里面提供了两种锁:读写锁以及互斥锁。互斥锁的实现可以参考sync.Mutex, 读写锁的实现参考sync.RWMutex。Lock本身其实也是演进了很多个版本,核心离不开三个概念:
- 自旋锁
- 饥饿模式
- 信号量休眠
互斥锁
先看下定义的结构体:
type Mutex struct {
state int32 // 锁的状态
sema uint32 // 系统信号量,唤醒G
}Mutex 有两种工作模式:正常模式和饥饿模式
在正常模式中,等待者按照 FIFO 的顺序排队获取锁,但是一个被唤醒的等待者有时候并不能获取 mutex,它还需要和新到来的 goroutine 们竞争 mutex 的使用权。新到来的 goroutine 存在一个优势,它们已经在 CPU 上运行且它们数量很多,因此一个被唤醒的等待者有很大的概率获取不到锁,在这种情况下它处在等待队列的前面。如果一个 goroutine 等待 mutex 释放的时间超过1ms,它就会将 mutex 切换到饥饿模式
在饥饿模式中,mutex 的所有权直接从解锁的 goroutine 递交到等待队列中排在最前方的 goroutine。新到达的 goroutine 们不要尝试去获取 mutex,即使它看起来是在解锁状态,也不要试图自旋,而是排到等待队列的尾部。如果一个等待者获得 mutex 的所有权,并且看到以下两种情况中的任一种:1) 它是等待队列中的最后一个,或者 2) 它等待的时间少于1ms,它便将 mutex 切换回正常操作模式
Lock函数
Lock分为三种情况:
- 无冲突,直接CAS然后返回既可。
- 有冲突,开始自旋,等待锁释放。如果其他Goroutine释放了该锁,则直接获得。
- 有冲突,且已经过了自旋阶段 通过调用 semacquire 函数来让当前 goroutine 进入等待状态
正常模式和饥饿模式:
- 正常模式下,goroutine抢到了锁就执行,抢不到锁加到阻塞队列尾部,等待被唤醒
- 饥饿模式下,先来的goroutine只会被加到等待队列被唤醒,不可进行自旋操作
func (m *Mutex) Lock() {
// 无冲突,直接返回锁.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
}这里的语句很好理解,当Lock无冲突的时候直接返回锁即可。
for {
// 判断锁的状态,是否可以自旋
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state
continue
}
}判断自旋的条件在sync_runtime_canSpin这个函数里面:
func sync_runtime_canSpin(i int) bool {
// sync.Mutex is cooperative, so we are conservative with spinning.
// Spin only few times and only if running on a multicore machine and
// GOMAXPROCS>1 and there is at least one other running P and local runq is empty.
// As opposed to runtime mutex we don't do passive spinning here,
// because there can be work on global runq or on other Ps.
if i >= active_spin || ncpu <= 1 || gomaxprocs <= int32(sched.npidle+sched.nmspinning)+1 {
return false
}
if p := getg().m.p.ptr(); !runqempty(p) {
return false
}
return true
}
- 锁已被占用,并且锁不处于饥饿模式。
- 积累的自旋次数小于最大自旋次数(active_spin=4)。
- cpu核数大于1。
- 有空闲的P。
- 当前goroutine所挂载的P下,本地待运行队列为空。
runtime_doSpin这里调用的是sync_runtime_doSpin函数,最后调用 procyield,这里自旋的意义在于减少CPU内核态到用户态的切换。
TEXT runtime·procyield(SB),NOSPLIT,$0-0
MOVL cycles+0(FP), AX
again:
PAUSE
SUBL $1, AX
JNZ again
RET
接下来看自旋结束后的操作,就是给new赋值新的状态,在之后的CAS里面进行设置。
// 正常模式下,尝试去拿锁,把new设置为mutexLocked
if old&mutexStarving == 0 {
new |= mutexLocked
}
// 饥饿模式下直接加入到等待队列
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
// 设置当前状态为饥饿模式
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}CAS设置的一些逻辑:
// 调用 CAS 更新 state 状态
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// mutex 处于未加锁,正常模式下,当前 goroutine 获得锁
if old&(mutexLocked|mutexStarving) == 0 {
break
}
// queueLifo 为 true 代表当前 goroutine 是等待状态的 goroutine
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
// 记录开始等待时间
waitStartTime = runtime_nanotime()
}
// 将被唤醒却没得到锁的 goroutine 插入当前等待队列queueLifo的最前端,然后进行sleep。
runtime_SemacquireMutex(&m.sema, queueLifo)
// 如果当前 goroutine 等待时间超过starvationThresholdNs,mutex 进入饥饿模式
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
delta := int32(mutexLocked - 1<<mutexWaiterShift)
// 如果不是饥饿模式或者当前等待的只剩下一个,退出饥饿模式
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving
}
// 更新状态
atomic.AddInt32(&m.state, delta)
break
}
}Unlock函数
func (m *Mutex) Unlock() {
// mutex 的 state 减去1,从加锁状态 -> 未加锁
new := atomic.AddInt32(&m.state, -mutexLocked)
// 不可多次unlock
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
// mutex 正常模式
if new&mutexStarving == 0 {
old := new
for {
// 如果没有等待者,或者已经存在一个 goroutine 被唤醒或得到锁,或处于饥饿模式
// 无需唤醒任何处于等待状态的 goroutine
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 等待者数量减1,并将唤醒位改成1
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 唤醒一个阻塞的 goroutine,但不是唤醒第一个等待者
runtime_Semrelease(&m.sema, false)
return
}
old = m.state
}
} else {
// mutex 饥饿模式,直接将 mutex 拥有权移交给等待队列最前端的 goroutine
runtime_Semrelease(&m.sema, true)
}
}读写锁
Golang的读写锁适用于读多写少的场景,在RWMutex里面的Lock之后,读和写都会被Block住,如果只是Rlock则不会影响其他读的。
type RWMutex struct {
w Mutex // held if there are pending writers
writerSem uint32 // semaphore for writers to wait for completing readers
readerSem uint32 // semaphore for readers to wait for completing writers
readerCount int32 // number of pending readers
readerWait int32 // number of departing readers
}Lock
func (rw *RWMutex) Lock() {
// First, resolve competition with other writers.
rw.w.Lock()
// Announce to readers there is a pending writer.
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// Wait for active readers.
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false)
}
}先将互斥锁Lock住,阻塞后续的写操作,拿不到就会在这里Block住,进入自旋或者休眠。
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders 这段代码确保rw.readerCount小于0。r代表目前有多少个reader在等待,如果没有在等待的就会直接返回。atomic.AddInt32(&rw.readerWait, r)会在RUnlock里面进行操作。有在等待的reader的话,会调用runtime_SemacquireMutex进行休眠,一直等到没有writerSem收到消息(没有reader了)才返回。
Unlock
func (rw *RWMutex) Unlock() {
// Announce to readers there is no active writer.
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
race.Enable()
throw("sync: Unlock of unlocked RWMutex")
}
// Unblock blocked readers, if any.
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false)
}
// Allow other writers to proceed.
rw.w.Unlock()
}写锁的释放也比较简单,先将readerCount变为正数,再进行判断,如果当前的readerCount大于0,表示当前已经Unlock了(或者没有经过Lock),会抛出异常。这里很有意思的一个点就是rwmutexMaxReaders, Lock会减,Unlock会加。
然后再遍历reader里面lock的数量,去释放rw.readerSem,最后再释放互斥锁。
RLock
func (rw *RWMutex) RLock() {
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// A writer is pending, wait for it.
runtime_SemacquireMutex(&rw.readerSem, false)
}
}对当前的readerCount加1,如果小于0(表示写锁存在),写锁会进行atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders)这么一次操作,然后陷入休眠,等待readerSem释放。
RUnLock
func (rw *RWMutex) RUnlock() {
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
throw("sync: RUnlock of unlocked RWMutex")
}
// A writer is pending.
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// The last reader unblocks the writer.
runtime_Semrelease(&rw.writerSem, false)
}
}
}解锁时会将rw.readerCount减一,然后判断r的值,如果r为-1,表示已经Unlock过了。如果readerCount为负数,表示Lock过,但是没有Unlock过,这个时候执行RUnlock会出错。
接下来就是对readerWait进行减一,如果所有的reader都完成了,通知写锁可以Lock了。
如何优化
Mutex从来都是性能杀手,在进行业务代码开发的时候需要合理考虑怎么使用。
- Lock free
- 参考
Sync.Pool实现Lock free的数据结构 - cornelk/hashmap
- 参考
- Lock less
- 在读多写少的情况下,尽量使用
RWMutex - 把锁的粒度降低,可以有效的提高性能,比如把一个有锁的Map进行分片,mutex的压力会减少
- Contention-Aware Lock Scheduling
- 在读多写少的情况下,尽量使用
参考
TCMalloc
TCmalloc
TCMalloc 优势
Golang的内存分配是基于TCMalloc来实现的,TCMalloc相较于传统的Ptmalloc,性能提升了很多。根据文章来看,主要的优化有几点:
- 小对象无锁,每个
thread有自己的cache,分配更快 - 大对象使用自旋锁,每个
thread都可以重用这部分的空间。Ptmalloc为每个thread分配的arena对其他thread都是不可见的,会导致内存浪费。 - 占用更少的空间,
TCmalloc分配N个8字节对象可能要使用大约8N * 1.01字节的空间,Ptmalloc使用4byte的header来描述一个对象,一共需要16N字节。
TCMalloc介绍
TCMalloc的介绍可以参考
这里主要把TCMalloc分为了3个部分:
front-end让用户代码可以更快的分配和释放内存,这里可以理解为ThreadCachemiddle-end用来刷新front-endcache,这里可以理解为CentralCacheback-end从os获取内存,这里可以理解为PageHeap
几个概念先介绍下,方便后面更容易理解
- size-class 表示的是ThreadCache里面的不同大小的链表,里面存放的是object数组
- object size-class里面存储的对象
- page TCmalloc里面一个Page为自定义(比如4K),所有的分配操作都是基于page
- span 一个span包含多个page
Front-end
Front-end 是用来处理那些申请内存的请求的,里面的内存同一时间只能给一个线程使用,分配操作是无锁的。
申请内存的操作很简单,根据对象的大小判断,小对象的分配直接从ThreadCache里面获取,拿不到的话就从middle-end获取,middle-end也没有的话就直接从back-end获取。大对象的获取则是直接从back-end一侧获取,大对象不会在middle-end中去cache。
对象的释放也是根据大小来判断,小对象放回front-end, 大对象放回back-end。
ThreadCache 结构如下:
Threadcache维护的是一个free list链表的集合。不同的class的大小块不一样,分别为8byte、16byte、32byte、48byte...... 这样可以针对不同的size class将其取整分配到对应的free list的链表上,有效避免了内存碎片化。
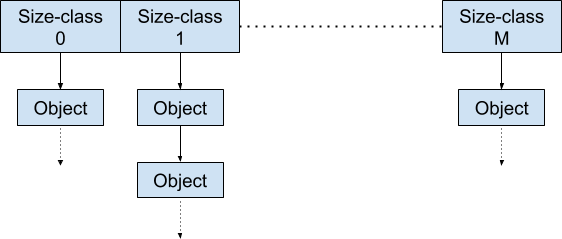
Middle-end
Middle-end有一个承上启下的作用,把不用的内存归还给OS以及提供内存给front-end。主要由两部分构成:Transfer Cache和Central Free List,通常我们把他理解为一个概念即CentralCache。所有的线程都会共享一个CentralCache,所以这里的操作是需要加锁的。
Transfer cache
这个概念比较有意思,是多个Thread公用的cache,当thread1不再使用的内存返回时,如果thread2正在申请相同的内存,这时候Transfer cache会把这部分内存直接给Thread2。如果Transfer cache无法命中才会去CentralFreeList里面查找。
Central Free List
Central Free List 里面管理的是一堆span,span里面映射的就是size class list。span 是由一组连续的page组成的。它可以用来管理大对象,同时也可以将其拆分为多个小对象,当管理的是小对象的时候,span里面记录的就是一系列的size-class。
每个回收回来的object都需要寻找自己所属的span,然后才能挂进freelist
TCMalloc Backend
back-end也可以理解为PageHeap, 它的主要工作有三个:
- 管理大块未使用的内存
- 当Memory不够的时候从OS去拿内存
- 把不需要的内存返回给OS
TCMalloc的backend工作模式有两种
-
Legacy Pageheap管理把Memory划分为对应size的chunk
比如一次请求三个page的话,会从3pages里面的free list查找合适的对象。如果当前的free list为空则从下一个free list里面去拿,再拿不到的话则从系统的mmap里面去拿。当内存返回给Pageheap的时候也会根据size插入到对应的free list里面去。图中的Other sizes里面包含的对象是大于255pages的free list。 -
Hugepage Aware Allocator 管理大页面的chunk,可以减少TLB的miss提升相应的性能。
在x86上一页为4KB,超过255pages就是2MB,这个时候就可以认为是huge size, 有三个cache用来实现这部分的功能。- filler cache 这部分里面存放的是小于huge size的cache,当请求的内存小于huge size的时候直接从这里拿,如果拿不到则再从huge page里面拿。
- region cache 处理的是大于 huge size的分配,它支持将跨页面的内存合并打包到一起变成连续的内存块,这对于稍微超过大页面大小的分配(例如2.1 MiB)特别有用。
- huge cache 处理的是至少大于一个huge page的分配,由于region cache是在runtime期间进行分配的,当只有系统认为region cache比较高效才会使用region cache,否则使用huge cache。
Small Object Allocation
通过size得到对应的class,先尝试在Threadcache里面的freelist分配,分配成功就会返回。为空的话再从central cache里面找,找不到再从pageheap申请一个span,拿到span之后将其拆分成N个object。pageheap没有的话则向kernel去申请。
Big Object Allocation
大块内存直接向PageHeap申请对应的的span,没有的话再去向kernel去申请。对于大于256k的内存申请,使用全局内存来分配。全局内存的组织也是单链表数组,数组长度为256,分别对用1 page大小, 2 page大小(1 page=4k)

小结
TCmalloc的整体流程图可以参考这个,总结的很好,可以参考
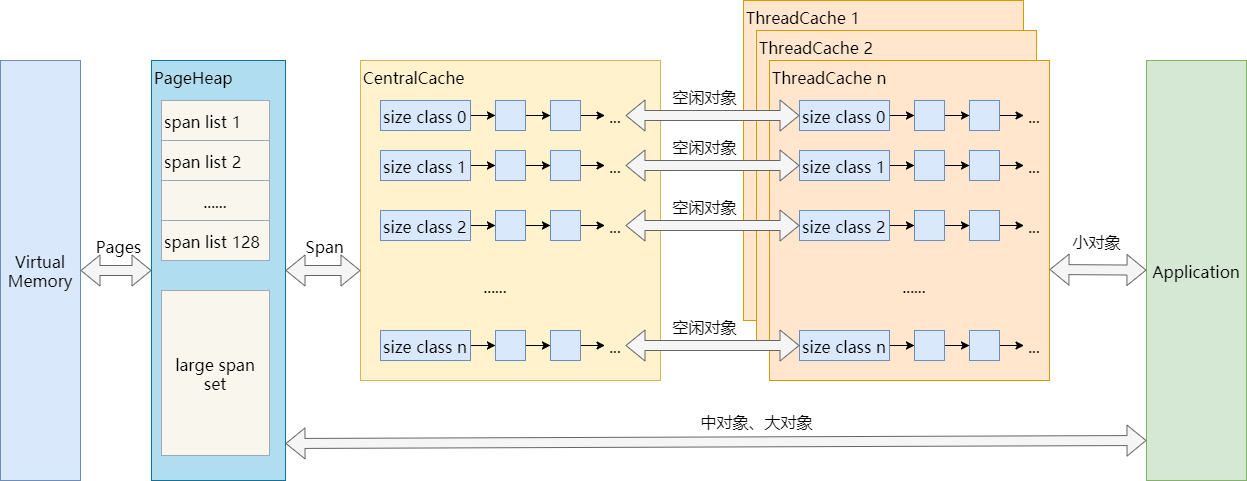
另外Tcmalloc的内存分配其实是一个懒加载的过程,在向OS申请了内存之后并不会马上使用,而是挂在内存池里,这里也是需要注意下的。
ref
nsqd入口分析
Main入口分析
nsqd的入口调用了go-svc的Run方法,这里的go-svc有点类似于watchdog监测用户signal的行为,可以很好的兼容Linux和Windows。svc_other里面声明的signalNotify是从signal.Notify这里拿到的,这个函数的主要作用是监听用户输入的signal。
Main还声明了一个tcpListener和一个httpListener,tcpListener是用来处理跟client的连接的。
tcpServer := &tcpServer{ctx: ctx}
n.waitGroup.Wrap(func() {
protocol.TCPServer(n.tcpListener, tcpServer, n.logf)
})
tcpServer有一个handle方法,用来处理tcp的连接的。里面只会接受" V2"的protocol,然后对每个连接进行IOLoop。
IOLoop会对每个client先进行messagePump
messagePumpStartedChan := make(chan bool)
go p.messagePump(client, messagePumpStartedChan)
<-messagePumpStartedChan
messagePump主要做的事:发送心跳包给客户端,获取channel中的消息,发送给客户端。
case <-heartbeatChan:
err = p.Send(client, frameTypeResponse, heartbeatBytes)
if err != nil {
goto exit
}
case b := <-backendMsgChan:
case msg := <-memoryMsgChan:
然后在IOLoop中,有新的for循环去监听客户端的消息并进行处理。这里大概理一下,后面详细分析
回到Main中,后面新开了两个goroutine,一个queueScanLoop处理消息,一个lookupLoop处理和nsqlookupd的连接的。
n.waitGroup.Wrap(func() { n.queueScanLoop() })
n.waitGroup.Wrap(func() { n.lookupLoop() })
queueScanLoop
- workTicker
workerTicker是一个主动去刷新queue的ticker - refreshTicker
refreshTicker是一个被动的ticker,每间隔5s去刷新一次,参照了redis的过期刷新算法。
随机挑选若干个key,删除所有过期的,如果过期的key的占比大于25%,则继续循环删除
在nsqd里面的定义是如果一个channel还有work在处理则认为是"dirty",判断dirty的占比如果大于QueueScanDirtyPercent就会继续循环给workCh发送channel。
resizePool
func (n *NSQD) resizePool(num int, workCh chan *Channel, responseCh chan bool, closeCh chan int) {
idealPoolSize := int(float64(num) * 0.25)
if idealPoolSize < 1 {
idealPoolSize = 1
} else if idealPoolSize > n.getOpts().QueueScanWorkerPoolMax {
idealPoolSize = n.getOpts().QueueScanWorkerPoolMax
}
for {
if idealPoolSize == n.poolSize {
break
} else if idealPoolSize < n.poolSize {
// contract
closeCh <- 1
n.poolSize--
} else {
// expand
n.waitGroup.Wrap(func() {
n.queueScanWorker(workCh, responseCh, closeCh)
})
n.poolSize++
}
}
}
resizePool是用来动态调整queueScanWorker的,idealPoolSize是当前的num(channels) / 4,会跟n.poolSize去做比较,这里表示的是queueScanWorker的数量。如果idealPoolSize要比当前的workpool小,再去新起一个queueScanWorker
queueScanWorker
在nsq中inFlight指的是正在投递但还没确认投递成功的消息,defferred指的是投递失败,等待重新投递的消息。 initPQ创建的字典和队列主要用于索引和存放这两类消息。其中两个字典使用消息ID作索引。
mysql数据类型优化
mysql数据类型优化
数据类型与优化
数据类型优化
- 选择更小的更好,占用更小的磁盘,内存和cpu
- 简单就好,e.g. 整型比字符要好,日期选择mysql的内建数据类型,而不是字符串,ip选择整型
- 避免使用NULL,查询包含NULL的列更难优化,索引统计也会更加复杂
整数类型
TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT分别使用8,16,24,32,64位存储空间,unsigned表示无符号,可以使上限提高一倍。
mysql可以为整数类型指定宽度,INT(11)只是在Mysql的一些交互工具中显示11位,对存储和计算来说INT(1)和INT(20)一样
实数类型
DECIMAL实数是带有小数部分的数字,不仅仅是为小数服务,也可以存储币bigint要大的数。DECIMAL(18, 9)表示存储18个数字,小数点后的占9个。需要尽量避免使用DECIMAL,需要额外的空间和计算
字符串类型
varchar
varchar是变长的,比char更节省空间,但是需要一个或者两个额外的字节记录字符串的长度,如果长度小于255字节,只需要一个字节。大于255字节则需要两个字节。varchar节省了空间对性能有帮助但是在UPDATE时时间会变得比char长
char
char类型是定长的,会用空格填充剩余的部分,如果char类型最后的字符为空格的话可能会被截断。
blob和text
blob和text分别采用二进制和字符串存储。blob一般存储图片等二进制内容,text存储超长字符串。与其他存储对象不一样,当blob和text特别大的时候,InnoDB会使用专门的外部区域存储。
优化字符串可以使用enum
使用enum的时候,mysql会将其保存为整数,在.frm文件中保存整数->字符串的映射关系
日期和时间类型
mysql提供两种选择,datetime和timestamp
- datetime保存很大的值,从1001年到9999年,精度为秒,把日期转化成YYYYMMDDHHMMSS的整数中,与时区无关
- timestamp 与unix时间戳子相同,只使用了4个字节的空间,只能表示1970到2038年,timestamp的值也依赖mysql服务器的时区设置
保存日期的时候尽量选择timestamp的类型
位数据
- bit,表示true/false。bit(1)定义一个单位字段,bit(2)存储2个位,bit的最大长度是64位。mysql在处理bit的时候是当成字符串进行处理的,如果存储的为b'00111001',检索得到的内容是字符码为57的字符串得到数字9,但是在数字场景下为57
- set,可以用来存储很多的 true/false值,可以使用一个整数包装一系列的位,例如可以把8个位包装到tinyint中
选择标识符
一般选择整数作为标识符,可以使用auto_increment
schema设计优化
- 避免使用太多的列
- 避免使用太多的关联
- 避免过度使用enum
范式和反范式
- 三范式
- 第一范式(1NF),即表的列的具有原子性,不可再分解,只要数据库是关系型数据库,就自动的满足1NF。
- 第二范式(2NF),要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要我们设计一个主键来实现
- 第三范式(3NF) 满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主键字段。就是说,表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放
- 反范式
没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,减少了查询时的关联,提高查询效率
范式的优点和缺点
范式
优点:
- 范式化的更新操作比反范式快,只需要更新小部分数据
- 范式化的表更小,执行速度比较快
缺点:
范式化的schema设计通常需要关联,代价昂贵,有事也可能导致索引策略无效
反范式
反范式的schema可以很好的避免关联, 如果没有关联表的话当数据比内存大的时候会比范式查询要快的多,因为这样避免了随机I/O,反范式也能使用更有效的索引策略。反范式的缺点就是表的结构比较混乱
混合使用范式化和反范式化
在真实的环境中,一般范式化和反范式化都是混合使用的
加快alter table速度
alter table有可能导致查询服务中断,有两种方法优化
- 在一台不提供服务的机器上alter
- 进行影子拷贝,首先创建一张和源表无关的新表,通过重命名和删表操作交换两张表,也可以通过修改.frm文件
nsqlookupd分析
nsqlookupd分析
tcpListener
nsqlookupd相较于nsqd就比较简单了,同样是在入口处声明了一个tcpListener,主要用来处理与nsqd的连接。里面的handler继承的逻辑是只接受“ V1”的protocol。后面对每个连接进行IOLoop。
client := NewClientV1(conn)
reader := bufio.NewReader(client)
params := strings.Split(line, " ")
response, err = p.Exec(client, reader, params)
IOLoop会对client、reader、params调用Exec方法。
case "PING":
return p.PING(client, params)
case "IDENTIFY":
return p.IDENTIFY(client, reader, params[1:])
case "REGISTER":
return p.REGISTER(client, reader, params[1:])
case "UNREGISTER":
return p.UNREGISTER(client, reader, params[1:])
}
exec做的事情主要是PING、IDENTIFY、REGISTER、UNREGISTER。
这里需要结合之前的nsqd里面的lookupLoop来分析看下, 先声明lookupPeer,再声明一个connectCallback。
connectCallback里面会把nsqd的相关信息注册注册一下,然后再发送给nsqlookupd。这个命令是连接完成后发送的第一个命令,会在每次Command里面判断下。
ci := make(map[string]interface{})
ci["version"] = version.Binary
ci["tcp_port"] = n.RealTCPAddr().Port
ci["http_port"] = n.RealHTTPAddr().Port
ci["hostname"] = hostname
ci["broadcast_address"] = n.getOpts().BroadcastAddress
cmd, err := nsq.Identify(ci)
发送完成后再把syncTopicChan塞到syncTopicChan里面去。
然后调用lookupPeer.Command(nil)开始连接nsqlookupd。
lookupPeer := newLookupPeer(host, n.getOpts().MaxBodySize, n.logf,
connectCallback(n, hostname, syncTopicChan))
lookupPeer.Command(nil) // start the connection
再后面会去接收ticker,发送心跳包保持连接。后面接收notifyChan,注册Channel或者是topic。
httpListener
httpListener主要是用来处理client与nsqlookupd的,包括topic查询,channel查询等。
- doLookup
curl "http://127.0.0.1:4161/lookup?topic=test",这里调用的是doLookup,给client返回一个producer。
registration := s.ctx.nsqlookupd.DB.FindRegistrations("topic", topicName, "")
if len(registration) == 0 {
return nil, http_api.Err{404, "TOPIC_NOT_FOUND"}
}
channels := s.ctx.nsqlookupd.DB.FindRegistrations("channel", topicName, "*").SubKeys()
producers := s.ctx.nsqlookupd.DB.FindProducers("topic", topicName, "")
producers = producers.FilterByActive(s.ctx.nsqlookupd.opts.InactiveProducerTimeout,
s.ctx.nsqlookupd.opts.TombstoneLifetime)
这里会把所有的channels找出来,再找到活跃的producers。
- doTopics
topics := s.ctx.nsqlookupd.DB.FindRegistrations("topic", "*", "").Keys()
return map[string]interface{}{
"topics": topics,
}, nil
这里会把所有的topic返回给client
- doChannels
topicName, err := reqParams.Get("topic")
if err != nil {
return nil, http_api.Err{400, "MISSING_ARG_TOPIC"}
}
channels := s.ctx.nsqlookupd.DB.FindRegistrations("channel", topicName, "*").SubKeys()
return map[string]interface{}{
"channels": channels,
}, nil
这里会返回所有的channel
HTTPClient分析
HTTPClient
Blocking and non-blocking HTTP client implementations using pycurl
Blocking client指的是HTTPClient,non-blocking HTTP client指的是AsyncHTTPClient
HTTPClient
函数说明
__init__
调用_curl_create初始化self._curl。
def _curl_create(max_simultaneous_connections=None):
curl = pycurl.Curl()
if logging.getLogger().isEnabledFor(logging.DEBUG):
curl.setopt(pycurl.VERBOSE, 1)
curl.setopt(pycurl.DEBUGFUNCTION, _curl_debug)
curl.setopt(pycurl.MAXCONNECTS, max_simultaneous_connections or 5)
return curl
fetch
将参数中的requets和kwargs封装成一个HTTPRequest对象,调用_curl_setup_request设置self.curl各种参数。将self.curl返回的buffer和反回的url以及请求信息封装成一个HTTPResponse对象.
AsyncHTTPClient
函数说明
__new__
这里初始化使用的是__new__而不是__init__, 可参照difference。还有_ASYNC_CLIENTS需要注意,源代码中的解释是There is one client per IOLoop since they share curl instances
_ASYNC_CLIENTS = weakref.WeakKeyDictionary()
cls._ASYNC_CLIENTS[io_loop] = instance
这段代码确保当AsyncHTTPClient被销毁的时候,ioloop也随之被销毁, 且每个AsyncHTTPClient只对应一个IOLoop。
fetch
接受一个httprequest和一个callback, 将request封装成一个HTTPRequest,将request和相应的callback存到self.request中。调用self._add_perform_callback()
_handle_socket
由libcurl回调更改文件描述符状态。声明一个event_map, 将libculr文件描述符封装成ioloop文件描素福状态,包括pycurl.POLL_IN,pycurl.POLL_OUT等。 将封装好的事件传入到ioloop中,设置handler为ioloop_event。
_handle_events
由ioloop回调更改文件描述符状态, 调用socket_action接口,调用self._finish_pending_requests。
_finish_pending_requests
调用info_read取出curl返回的信息。
num_q, ok_list, err_list = self._multi.info_read
调用self._finish处理curl, 调用_process_queue。
_process_queue
将self._free_list中的curl对象取出来,取出self._requests中的request和callback构造curl对象,将其加入到self._multi中。
_finish
读取curl的info,封装一个HTTPResponse对象,调用info中的callback。
通过代码分析流程图
from tornado import ioloop, httpclient
def handle_request(response):
if response.error:
print "Error:", response.error
else:
print response.body
ioloop.IOLoop.instance().stop()
http_client = httpclient.AsyncHTTPClient2()
http_client.fetch("http://www.baidu.com", handle_request)
ioloop.IOLoop.instance().start()

Linux 内核观测BPF
Linux 内核观测BPF
Linux BPF 全称是Berkeley Packet Filter,最早接触到这个概念是在《性能之巅》里面。是通过内核事件来动态跟踪内核网络行为。 eBPF则是基于内核JIT虚拟机的扩展BPF,实用性非常之强。用大白话来讲就是基于Linux内核的勾子,根据不同的事件类型,可以完成不同的功能。像tcpdump/iptales/perf等一系列的好用工具都是基于BPF技术实现。
iptables架构图:
从BCC开始
BCC is a toolkit for creating efficient kernel tracing and manipulation programs, and includes several useful tools and examples
0. Before bcc
Linux60秒性能分析里面介绍了一些常用的问题排查手段,囊括了Linux问题的一些基本知识。可以参考链接进行安装。
uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
iostat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top
1. General Performance
有了上面的背景,再来看一些常用的系统分析工具
- execsnoop 可以监控所有new process
- opensnoop 可以监控FD情况
- ext4slower ext4文件系统
- biolatency 磁盘 I/O 延迟
- biosnoop 磁盘 I/O 延迟以及吞吐等详细信息
- cachestat 文件系统cache
- tcpconnect TCP活跃链接
- tcpaccept passive TCP 链接
- tcpretrans tcp 重传
- runqlat CPU饱和度
- profile CPU 使用情况
2. Observatility with Generic Tools
主要有三种工具可以去做一些个性化的配置。就不一一展开了。
- trace
- argdist
- funccount
BPF 程序类型
第一类是跟踪,跟踪CPU,内存,文件描述符等。
第二类是网络,可以过滤,拒绝或者修改到达内核的网络数据包。
- BPF_PROG_TYPE_SOCKET_FILTER 是第一个添加Linux内核的BPF程序类型,主要用来filter socket。
- kprobe BPF_PROG_TYPE_KPROBE是动态附加到内核调用点的函数
- TRACEPOINT BPF_PROG_TYPE_TRACEPOINT是内核代码的静态标记,允许注入跟踪和调试相关的任意代码。因为跟踪点需要在内核中预先定义,所以它们的灵活性不如kprobe
- XDP BPF_PROG_TYPE_XDP 当网络包到达内核之后,XDP程序会被执行
- Perf BPF_PROG_TYPE_PERF_EVENT Perf是内核的内部分析器,可以产生硬件和软件的性能数据事件
- Cgroup BPF_PROG_TYPE_CGROUP_SKB 允许cgroup在其包含的进程中控制网络流量。与socket filter类似,是用来控制cgroup所有进程,不是单个进程
剩下的类型还有很多,就不再一一列举。
可视化之火焰图
数据可视化有很多表达方式,比如火焰图,直方图等。下面会结合Go程序完成CPU profile的火焰图分析。
火焰图一般分为on-CPU和off-CPU, 这里以on-CPU为例子。统计的是调用栈出现在CPU上的频率。从一个简单的go例子开始, 编写一个BPF程序去分析CPU使用情况。
package main
import "time"
func main() {
j := 3
for time.Since(time.Now()) < time.Second {
for i := 1; i < 1000000; i++ {
j *= i
}
}
}BCC
#!/usr/bin/python
import errno
import signal
import sys
from time import sleep
from bcc import BPF, PerfSWConfig, PerfType
def signal_ignore(signal, frame):
print()
bpf_source = """
#include <uapi/linux/ptrace.h>
#include <uapi/linux/bpf_perf_event.h>
#include <linux/sched.h>
struct trace_t {
int stack_id;
};
BPF_HASH(cache, struct trace_t);
BPF_STACK_TRACE(traces, 10000);
"""
bpf_source += """
int collect_stack_traces(struct bpf_perf_event_data *ctx) {
u32 pid = bpf_get_current_pid_tgid() >> 32;
if (pid != PROGRAM_PID)
return 0;
struct trace_t trace = {
.stack_id = traces.get_stackid(&ctx->regs, BPF_F_USER_STACK)
};
cache.increment(trace);
return 0;
}
"""
program_pid = int(sys.argv[1])
bpf_source = bpf_source.replace('PROGRAM_PID', str(program_pid))
bpf = BPF(text=bpf_source)
bpf.attach_perf_event(ev_type=PerfType.SOFTWARE,
ev_config=PerfSWConfig.CPU_CLOCK,
fn_name='collect_stack_traces',
sample_period=1)
exiting = 0
try:
sleep(300)
except KeyboardInterrupt:
exiting = 1
signal.signal(signal.SIGINT, signal_ignore)
print("dumping the results")
for trace, acc in sorted(bpf['cache'].items(), key=lambda cache: cache[1].value):
line = []
if trace.stack_id < 0 and trace.stack_id == -errno.EFAULT:
line = ['Unknown stack']
else:
stack_trace = list(bpf['traces'].walk(trace.stack_id))
for stack_address in reversed(stack_trace):
function_name = bpf.sym(stack_address, program_pid).decode('utf-8')
if function_name == '[unknown]':
continue
line.extend([function_name])
if len(line) < 1:
continue
frame = ";".join(line)
sys.stdout.write("%s %d\n" % (frame, acc.value))
if exiting:
exit()先看BCC相关的代码, BPF_HASH声明一个hash表,用来存储stack_id的。BPF_STACK_TRACE 初始化BPF栈跟踪映射,表示的是最大去跟踪10000个栈。
struct trace_t {
int stack_id;
};
BPF_HASH(cache, struct trace_t);
BPF_STACK_TRACE(traces, 10000);接下来看看collect_stack_traces这个函数,回去验证PROGRAM_PID是否为输入的pid。然后通过traces.get_stackid 去拿到userspace的stack。
最后再通过cache.increment收集到cache里。
bpf_source += """
int collect_stack_traces(struct bpf_perf_event_data *ctx) {
u32 pid = bpf_get_current_pid_tgid() >> 32;
if (pid != PROGRAM_PID)
return 0;
struct trace_t trace = {
.stack_id = traces.get_stackid(&ctx->regs, BPF_F_USER_STACK)
};
cache.increment(trace);
return 0;
}然后再回到pyhton部分的代码,相对就比较简单了。分为两部分来看,第一部分主要为attach的逻辑, 从参数里面拿到pid然后attach到PerfSWConfig.CPU_CLOCK里面。
program_pid = int(sys.argv[1])
bpf_source = bpf_source.replace('PROGRAM_PID', str(program_pid))
bpf = BPF(text=bpf_source)
bpf.attach_perf_event(ev_type=PerfType.SOFTWARE,
ev_config=PerfSWConfig.CPU_CLOCK,
fn_name='collect_stack_traces',
sample_period=1)第二部分其实就是一些数据的处理与收集,就不再具体介绍了,代码很简单。
可以简单看下代码输出
runtime.goexit.abi0;runtime.main;main.main;runtime.nanotime 678
runtime.goexit.abi0;runtime.main;main.main;time.Now;time.now 679
runtime.goexit.abi0;runtime.main;main.main 719
runtime.goexit.abi0;runtime.main;main.main;time.Now;time.now;time.now.abi0;__vdso_clock_gettime 755
runtime.goexit.abi0;runtime.main;main.main;time.Since;runtime.nanotime;runtime.nanotime1.abi0;__vdso_clock_gettime 762
runtime.goexit.abi0;runtime.main;runtime.sigreturn;runtime.sigtramp;runtime.sigtrampgo.abi0;runtime.sigtrampgo;runtime.sighandler;runtime.doSigPreempt;memeqbody 784
runtime.goexit.abi0;runtime.main;main.main;time.Now 785
然后我们基于上面的输出可以生成on-CPU的火焰图:
./bcc_example.py pid > /tmp/profile.out
./flamegraph.pl /tmp/profile.out > /tmp/flamegraph.svg
小结
本文基本上是对《Linux内核观测技术BPF》做的一些小结,里面还有很多的技术细节。之后有需要的话会慢慢完善。
Ref
Topic及Channle
nsq Topic及Channle
Topic
type Topic struct {
// 64bit atomic vars need to be first for proper alignment on 32bit platforms
messageCount uint64
sync.RWMutex
name string
channelMap map[string]*Channel // topic的channels
backend BackendQueue // 持久化
memoryMsgChan chan *Message // 消息管道
exitChan chan int
channelUpdateChan chan int
waitGroup util.WaitGroupWrapper
exitFlag int32
idFactory *guidFactory
ephemeral bool
deleteCallback func(*Topic)
deleter sync.Once
paused int32
pauseChan chan bool
ctx *context
}
Topic主要有三个goroutine:router、messagePump、DiskQueue
router只要是用来接收http接口的topic消息的,调用PutMessage将msg放入memoryMsgChan和DiskQueue中。
messagePump主要是将msg分发到该topic的channelMap中去。
DiskQueue主要是将内存中存放不下的msg,存入磁盘中去,稍后再处理
Channel
type Channel struct {
// 64bit atomic vars need to be first for proper alignment on 32bit platforms
requeueCount uint64
messageCount uint64
timeoutCount uint64
sync.RWMutex
topicName string
name string
ctx *context
backend BackendQueue // 磁盘持久化
memoryMsgChan chan *Message // 消息管道
exitFlag int32
exitMutex sync.RWMutex
// state tracking
clients map[int64]Consumer // 所有订阅改channel的消费者
paused int32
ephemeral bool
deleteCallback func(*Channel)
deleter sync.Once
// Stats tracking
e2eProcessingLatencyStream *quantile.Quantile
// TODO: these can be DRYd up
deferredMessages map[MessageID]*pqueue.Item
deferredPQ pqueue.PriorityQueue
deferredMutex sync.Mutex
inFlightMessages map[MessageID]*Message
inFlightPQ inFlightPqueue
inFlightMutex sync.Mutex
}
Channel比Topic更为复杂,设计的结构是single input and single output go-chan
设计的原理是input和output走的都是同一条Channel,不管有多少个client,一条msg确认只会被一个client消费掉。
另外在还会去维护一个inFlightPQ和deferredPQ,里面是按时间排序的,后续会有一个worker pool去维护这个两个queue。
NSQD在给client发送消息之后,会将该消息添加到该channel的一个叫inFlightPQ的优先级队列中。该优先级队列的个底层结构是数组,然后基于数组实现的小根堆。而权重则是发送消息时规定的timeOut的时长。
当NSQD在收到client发送过来的FIN确认消息之后,就会从inFlightPQ移除相应的消息。

nsqd中worker pool
nsqd中的worker pool模型,每隔一段时间会去动态的调整worker的数量,这部分代码是在queueScanLoop中实现的。
workCh := make(chan *Channel, n.getOpts().QueueScanSelectionCount)
responseCh := make(chan bool, n.getOpts().QueueScanSelectionCount)
closeCh := make(chan int)
workTicker := time.NewTicker(n.getOpts().QueueScanInterval)
refreshTicker := time.NewTicker(n.getOpts().QueueScanRefreshInterval)
channels := n.channels()
n.resizePool(len(channels), workCh, responseCh, closeCh)
声明workCh和responseCh,是用来决定是否需要继续去work的,closCh是用来减少worker的。然后进行第一次resizePool,resizepool是用来调整queueScanWorker goroutines数量的,同时需要确保 1 <= pool <= min(num * 0.25, QueueScanWorkerPoolMax)
func (n *NSQD) resizePool(num int, workCh chan *Channel, responseCh chan bool, closeCh chan int) {
idealPoolSize := int(float64(num) * 0.25)
if idealPoolSize < 1 {
idealPoolSize = 1
} else if idealPoolSize > n.getOpts().QueueScanWorkerPoolMax {
idealPoolSize = n.getOpts().QueueScanWorkerPoolMax
}
for {
if idealPoolSize == n.poolSize {
break
} else if idealPoolSize < n.poolSize {
// contract
closeCh <- 1
n.poolSize--
} else {
// expand
n.waitGroup.Wrap(func() {
n.queueScanWorker(workCh, responseCh, closeCh)
})
n.poolSize++
}
}
}
第一次resizePool后进入for循环开始处理worker,先看3个case
select {
// wait until ticker
case <-workTicker.C:
if len(channels) == 0 {
// continue means do select operation
continue
}
case <-refreshTicker.C:
// 这个是用来resize用的
channels = n.channels()
n.resizePool(len(channels), workCh, responseCh, closeCh)
continue
case <-n.exitChan:
goto exit
}
workTicker先判断channel是否为空,如果不为空的话则进入后面的loop,refreshTicker用来实时调整worker goroutine,exitChan用来推出程序。
loop:
for _, i := range util.UniqRands(num, len(channels)) {
// send work
workCh <- channels[i]
}
numDirty := 0
for i := 0; i < num; i++ {
// response chan is true
if <-responseCh {
numDirty++
}
}
if float64(numDirty)/float64(num) > n.getOpts().QueueScanDirtyPercent {
goto loop
}
}
loop里面的代码借鉴了redis的被动刷新过期key的算法,当超过一定比例的worker有工作的时候,则一直循环下去,直到worker工作部分的比例低于指定比例。这里会给workCh发送channel,用responseCh的返回值来判断一个worker是否有工作要做。
workCh的处理部分主要在queueScanWorker中。
func (n *NSQD) queueScanWorker(workCh chan *Channel, responseCh chan bool, closeCh chan int) {
for {
select {
// receive work chan
case c := <-workCh:
now := time.Now().UnixNano()
dirty := false
// process queue
if c.processInFlightQueue(now) {
dirty = true
}
if c.processDeferredQueue(now) {
dirty = true
}
responseCh <- dirty
case <-closeCh:
return
}
}
}
收到workCh后会去根据时间戳在InFlightQueue和DeferredQueue里面找到过期的msg,然后将消息重放。若收到closeCh,则关闭该goroutine。
# Raft 原理
Raft 原理
Background
要想了解熟悉分布式,Raft协议是绕不开的。相较于Paxos,raft的优点就是上手比较方便,容易理解。这篇文章主要是介绍下raft一些基本概念。
什么是Raft
基础
Raft is a protocol for implementing distributed consensus.
Raft是一个分布式的共识性协议,节点的状态分为Leader,Follower,以及Candidate三种状态。在集群中,节点的个数一般为大于3的基数,这是根据抽屉原理来的,每次选举都必须获得超过半数以上的同意。
- Follower:刚启动时所有节点为Follower状态,响应Leader的日志同步请求,响应Candidate的请求。
- Candidate:Follower状态服务器准备发起新的Leader选举前需要转换到的状态,是Follower和Leader的中间状态。
- Leader:集群中只有一个处于Leader状态的服务器,负责响应所有客户端的请求。
Raft会把运行时分为不同的term,一般来讲,其实就是根据Leader的任期来进行划分的,每个Term里面最多只包含一个Leader。
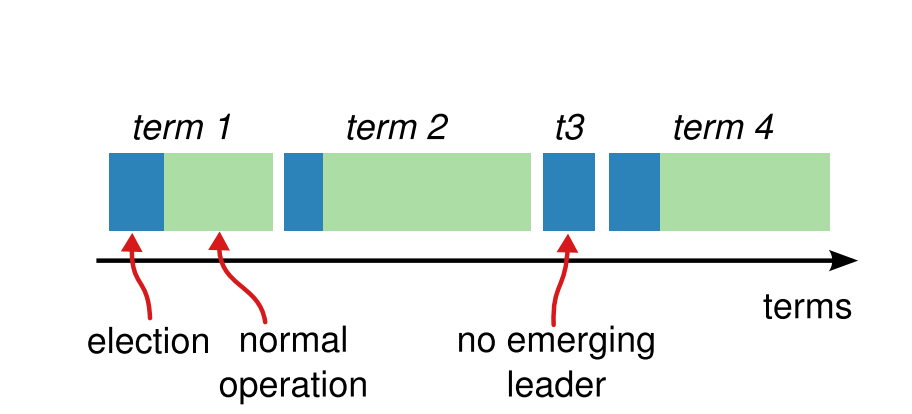
Term在Raft里面是用来替代逻辑时钟的,每个节点都会存储当前的Term ID,并且单调递增,通过RPC进行信息交换,Node根据不同的Term ID来进行当前的逻辑判断。
- 当前Term ID小于其他Node,则更新自己的Term ID。
- Leader 发现Term过期了,则将自身变为follower。
- 收到过期的Term,拒绝请求。
Leader选举
所有Node初始化的时候状态都是follower,如果一段时间后节点没有收到任何消息,就会认为当前没有Leader(election timeout),这个时候会重新开始选举一个新的leader。
开始之前,节点先把自己变为candidate状态,然后给其他节点发起投票请求,会出现三种情况:
- 赢得了选举,变成leader。在选举的过程中是根据Term的大小以及先来先服务的原则进行选举的。
- 其他节点成为了leader,在选举的过程中,candidate如果收到的Term大于等于自身的term,则把自身状态变为follower。
- 没有成功竞选出来的leader,这种情况可能是多个candidate出现,导致选举分流,解决方案是将election timeouts随机设置为(150-300ms)。
Leader选举里面的这个随机值的演变很有意思,之前Raft团队设计的是给每个Node一个rank,候选人根据rank的高低来选择将谁选举为leader,但是里面存在的一个可用性问题(如果高排名的服务器宕机了,那么低排名的服务器可能会超时并再次进入候选人状态。如果这个行为发生得足够快,则可能会导致整个选举过程都被重置掉)。最后选择了随机重试的方法显然更容易理解。
日志复制
leader选举出来之后就需要开始为客户端提供服务了,所有的请求都需要经过leader的处理,leader会把当前的请求转发给全部的follower。如果超过半数响应了本次请求,则leader就会响应户端
从上面的图片可以看到Log的结构,本身raft的**是基于WAL来实现的,先提交,然后再commit, 每次的日志都是在最尾端进行追加的。
如图所示,leader的日志和follower的日志是会出现不一致的状态的。Raft中是强制follower去同步leader的日志,同步的逻辑是找到最近一次两者达成一致的地方,然后从那个点删除之后的日志,leader将自身的日志再发送给follower。
安全性
前面的选举中可以看到,任何follower都有可能成为leader。Raft增加了一些限制来确保选出的leader包含之前大部分的log。
选举限制: Raft在投票的时候需要确保candidate上的log和大多数节点中都一样新才能变成leader,定义谁新的方法就是通过比较两份日志中最后一条日志条目的索引值和任期号。
提交约束: 只有leader才可以commit当前term的日志。考虑下面的corner case:
在时刻(a), s1是leader,在term2提交的日志只赋值到了s1 s2两个节点就crash了。在时刻(b), s5成为了term 3的leader,日志只赋值到了s5,然后crash。然后在(c)时刻,s1又成为了term 4的leader,开始赋值日志,于是把term2的日志复制到了s3,此刻,可以看出term2对应的日志已经被复制到了majority,因此是committed,可以被状态机应用。不幸的是,接下来(d)时刻,s1又crash了,s5重新当选,然后将term3的日志复制到所有节点,这就出现了一种奇怪的现象:被复制到大多数节点(或者说可能已经应用)的日志被回滚。
Raft在选举leader成功后,不会直接提交前任leader的日志,是通过发送当前的日志进而提交上一次的日志。两段提交在这里就很好的避免了上面的问题发生,如果发生上面的问题,第二段commit会直接rollback。
reference
Golang Graceful Shutdown解析
Golang Graceful Shutdown解析
BackGround
Graceful Shutdown顾名思义就是优雅退出,与之相对应的就是强制退出。强制退出指的的是不等待进程的连接结束,直接kill掉整个进程,中间可能会造成程序出现一些未知的错误(数据不一致等)。
Graceful Shutdown就是为了解决这类问题的,每次Graceful Shutdown都会等待连接处理完毕而退出,不会强制退出。
Http Graceful Shutdown
从1.8开始,Go标准库中的net/http支持了GracefulShutdown, 先看下简单的例子:
func main() {
var srv http.Server
idleConnsClosed := make(chan struct{})
go func() {
sigint := make(chan os.Signal, 1)
// interrupt signal sent from terminal
signal.Notify(sigint, os.Interrupt)
// sigterm signal sent from kubernetes
signal.Notify(sigint, syscall.SIGTERM)
<-sigint
// We received an interrupt signal, shut down.
if err := srv.Shutdown(context.Background()); err != nil {
// Error from closing listeners, or context timeout:
log.Printf("HTTP server Shutdown: %v", err)
}
close(idleConnsClosed)
}()
if err := srv.ListenAndServe(); err != http.ErrServerClosed {
// Error starting or closing listener:
log.Printf("HTTP server ListenAndServe: %v", err)
}
<-idleConnsClosed
}需要主要关注的就是Shutdown函数,graceful是集成在原生的server里面。
func (srv *Server) Shutdown(ctx context.Context) error {
// 标记关闭状态
atomic.StoreInt32(&srv.inShutdown, 1)
srv.mu.Lock()
// 关闭listen 的fd, 不能建立新连接了
lnerr := srv.closeListenersLocked()
// close done channel
srv.closeDoneChanLocked()
for _, f := range srv.onShutdown {
go f()
}
srv.mu.Unlock()
ticker := time.NewTicker(shutdownPollInterval)
defer ticker.Stop()
for {
// 判断当前的连接是否已经全部关闭
if srv.closeIdleConns() {
return lnerr
}
select {
case <-ctx.Done():
return ctx.Err()
case <-ticker.C:
}
}
}首先 srv.closeListenersLocked 关闭listener的fd,然后再去关闭所有的conn的fd。
上面的代码需要关注的点就是For循环中,不停的poll tikcer这个操作,每隔500ms去确认当前的Conns是否已经全部关闭了,如果全部关闭了,则返回。Ctx到期也会直接返回。
func (s *Server) closeIdleConns() bool {
s.mu.Lock()
defer s.mu.Unlock()
quiescent := true
for c := range s.activeConn {
st, unixSec := c.getState()
// Issue 22682: treat StateNew connections as if
// they're idle if we haven't read the first request's
// header in over 5 seconds.
if st == StateNew && unixSec < time.Now().Unix()-5 {
st = StateIdle
}
if st != StateIdle || unixSec == 0 {
// Assume unixSec == 0 means it's a very new
// connection, without state set yet.
quiescent = false
continue
}
c.rwc.Close()
delete(s.activeConn, c)
}
return quiescent
}closeIdleConns 会去s.activeConn里面拿到所有的活跃链接,然后判断state是不是idle了,并进行删除。如果不是idle则返回false。
State的状态有5种,状态的变化在setState里面
const (
// 一个初始化的新的连接状态,可变成 StateClosed或者StateActive
StateNew ConnState = iota
// 活跃的连接,正在读取数据
StateActive
// 连接中的请求已经完成,当前是一个keep-alive的状态,等待下一个连接
StateIdle
StateHijacked
// 连接已经关闭
StateClosed
)
func (c *conn) setState(nc net.Conn, state ConnState) {
srv := c.server
switch state {
case StateNew:
srv.trackConn(c, true)
case StateHijacked, StateClosed:
srv.trackConn(c, false)
}
}调用setState的地方分开来看:
func (srv *Server) Serve(l net.Listener) error {
// 在c.serve之前设置状态为StateNew
c := srv.newConn(rw)
c.setState(c.rwc, StateNew) // before Serve can return
go c.serve(ctx)
}
func (c *conn) serve(ctx context.Context) {
defer func() {
if !c.hijacked() {
// 在serve退出后设置为StateClosed
c.close()
c.setState(c.rwc, StateClosed)
}
}()
for {
w, err := c.readRequest(ctx)
if c.r.remain != c.server.initialReadLimitSize() {
// 新的request开始读写数据的时候设置为StateActive.
c.setState(c.rwc, StateActive)
}
...
w.finishRequest()
if !w.shouldReuseConnection() {
if w.requestBodyLimitHit || w.closedRequestBodyEarly() {
c.closeWriteAndWait()
}
return
}
// 在serve函数里面一个请求结束之后设置为StateIdle
c.setState(c.rwc, StateIdle)
if !w.conn.server.doKeepAlives() {
// We're in shutdown mode. We might've replied
// to the user without "Connection: close" and
// they might think they can send another
// request, but such is life with HTTP/1.1.
return
}
}
}所以从上面的代码来看,如果需要让连接全部退出,则需要等待活跃的连接读取完一个request之后变成idle之后方可退出。serve函数中的for循环退出则依赖于doKeepAlives这个函数,由于我们在shutdown的时候就将s.inShutdown设置为1,所以长连接在一次request完成之后就会立马退出了。
func (s *Server) doKeepAlives() bool {
return atomic.LoadInt32(&s.disableKeepAlives) == 0 && !s.shuttingDown()
}
func (s *Server) shuttingDown() bool {
// TODO: replace inShutdown with the existing atomicBool type;
// see https://github.com/golang/go/issues/20239#issuecomment-381434582
return atomic.LoadInt32(&s.inShutdown) != 0
}总结下来,关键地方就是in process的request需要等待conn变成idle之后才可以退出,实际的生产环境一般会加上一个timeout,如果shutdown超时则直接退出,不会永远等下去。简单的状态机如图所示 
Grpc Graceful Shutdown
grpc的通信协议是基于http2来实现,大致流程也与http类似,先关闭所有的fd,然后等待活跃连接退出。比http实现多出来一个流程: 会给客户端发送一个goaway帧信号,让客户端主动退出。
server端实现
func (s *Server) GracefulStop() {
s.quit.Fire()
...
s.mu.Lock()
if s.conns == nil {
s.mu.Unlock()
return
}
for lis := range s.lis {
lis.Close()
}
s.lis = nil
if !s.drain {
for st := range s.conns {
st.Drain()
}
s.drain = true
}
// Wait for serving threads to be ready to exit. Only then can we be sure no
// new conns will be created.
s.mu.Unlock()
s.serveWG.Wait()
s.mu.Lock()
for len(s.conns) != 0 {
s.cv.Wait()
}
s.conns = nil
if s.events != nil {
s.events.Finish()
s.events = nil
}
s.mu.Unlock()
}先把quit设置为true,在handle conn的时候发现quit之后会close掉conn。
然后再看listener的lis.Close,常规的close操作,关闭listener的套接字。需要注意的就是st.Drain 这个地方的函数,看下具体实现
func (t *http2Server) Drain() {
t.drain(http2.ErrCodeNo, []byte{})
}
func (t *http2Server) drain(code http2.ErrCode, debugData []byte) {
t.mu.Lock()
defer t.mu.Unlock()
if t.drainChan != nil {
return
}
t.drainChan = make(chan struct{})
t.controlBuf.put(&goAway{code: code, debugData: debugData, headsUp: true})
}发送goaway帧信号到t.controlBuf里面去,然后传给客户端进行关闭操作。
client端实现
当创建一个newHTTP2Client的时候,会起一个goroutine去后台监听收到的数据,代码在reader函数里面。当收到GoAwayFrame消息的时候,会进入t.handleGoAway逻辑里面,关闭client的连接。
func (t *http2Client) reader() {
...
for {
t.controlBuf.throttle()
switch frame := frame.(type) {
case *http2.GoAwayFrame:
t.handleGoAway(frame)
...
}
}再看handleGoAway里面的逻辑可以发现里面最终的调用就是close方法,回去关掉所有的FD。
func (t *http2Client) handleGoAway(f *http2.GoAwayFrame) {
t.mu.Lock()
if t.state == closing {
t.mu.Unlock()
return
}
if f.ErrCode == http2.ErrCodeEnhanceYourCalm {
infof("Client received GoAway with http2.ErrCodeEnhanceYourCalm.")
}
id := f.LastStreamID
if id > 0 && id%2 != 1 {
t.mu.Unlock()
t.Close()
return
}
....
}这样一来,在GRPC里面,server先关闭fd, 然后client也会去主动关闭fd,两者一先一后发送FIN
server处于FIN-WAIT-1状态收到 Client 发送的FIN 之后直接进入 TIME-WAIT 状态,等待 2MSL 超时结束。传统的四次握手变成了三次,期间省去了一段握手优化。
GRPC的fore close则简单粗暴许多,核心**是关闭listener,然后关闭conn。
小结
需要注意的是当关闭的时候有两个地方要注意,一个是listener的关闭,另外一个是所有conn的关闭。Listener的套接字是由listen方法创建出来的,而conn的套接字是由accept方法创建出来的。
graceful shutdown是线上服务必不可少的,可以看到HTTP和GRPC的实现都是内部维护自己的状态机,先关闭listener然后等待所有剩下的conn退出。
reference
mysql索引类型
mysql索引类型
B-Tree
- B-Tree类型索引,也叫平衡多路查找树,查找树上的一个节点就要进行一次i/o操作,所以为了尽量减少i/o操作,应尽可能降低树的高度,增加一个节点上的关键字数量,一颗度位d,包含n个key的树的查询的时间复杂度为O(logdN)
- B+Tree 与B-Tree相比,B+Tree有n棵子树的结点中含有n个关键字; (而B树是n棵子树有n-1个关键字)B+Tree上面只有叶子结点包含关键字信息,非叶子结点只包含索引信息
大多数Mysql引擎都支持B-Tree索引,InnoDB使用的是B+Tree索引
B-Tree友好的查询
- 全值匹配,即对索引中所有的列进行匹配
- 匹配最左前缀,只使用索引的第一列
- 匹配列前缀,只使用某一列的开头部分
- 匹配范围值
- 精确匹配某一列并范围匹配另一列
- 只访问索引的查询
B-Tree索引的限制
- 必须按照索引的最左列开始
- 不能跳过索引中的列,比如索引为三个列,只指定第一个和第三个,则只能使用第一列索引
- 如果查询中有某个列的范围查询,右边的列则无法使用索引
哈希索引
mysql中只有memory引擎显示支持hash索引
- hash索引只包含哈希值和行指针,不存储字段值
- hash索引无序
- hash索引不支持部分索引
- hash索引只支持等值比较查询
- 访问hash索引速度非常快
- 如果hash冲突很多的话,索引维护代价比价高
空间索引
MyISAM支持空间索引,可以从各个维度来进行查询
全文索引
用于查找文本中的关键字
Linux 零拷贝
零拷贝
什么是零拷贝(Zero-Copy)
拷贝的意思大家可能都知道,就是copy-paste。将需要的数据从src copy到dst即可。一般我们说的Linux零拷贝指的是没有经过用户空间与内核空间的转换,不用将内核里的buffer直接copy到用户态的buffer。
常见的read和write
以最常见的read和write函数来分析,下面是两个函数的定义:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
当你要操作文件时,势必会使用read和write这两个系统调用。当read的时候首先程序会由用户态切换进入内核态,然后再去pageCache里面进行一次拷贝,将里面的buffer copy到用户态。然后再切换回用户态,一来一去就是两次的上下文切换。
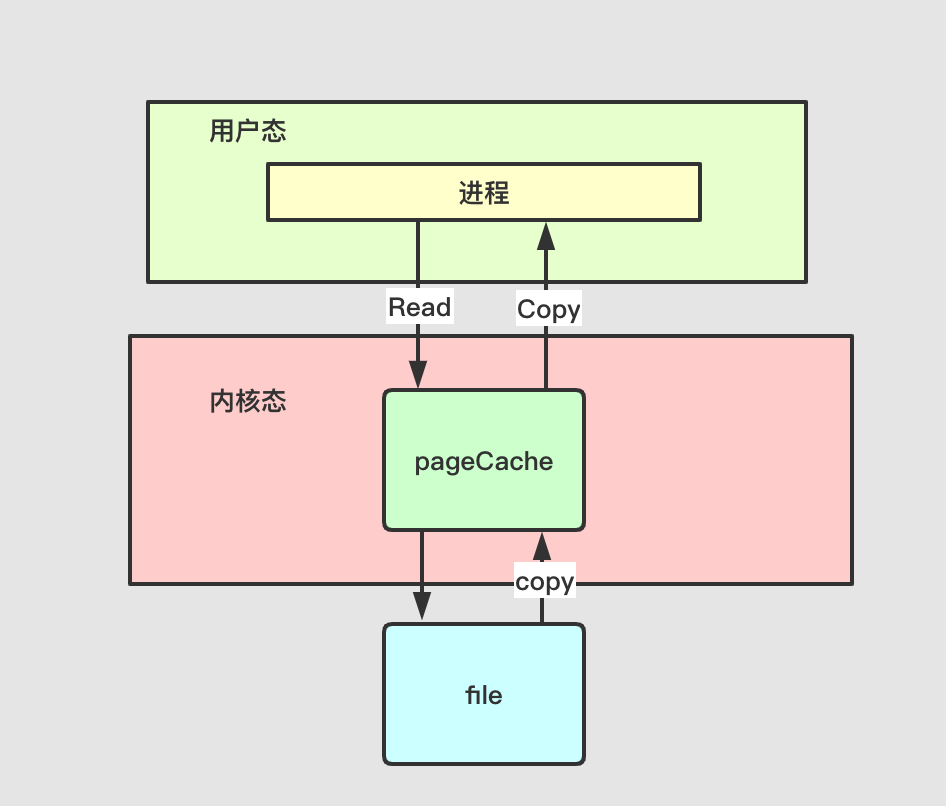
零拷贝技术分类
这里以文件发送为例子具体看下,假设有100MB的文件要发送,内存中缓冲区的大小为32KB,当我们需要把这100MB的文件发送给接收方,就需要将其分割成300多次进行操作。读取的逻辑 read(copy) -> 内核态pageCache(copy) -> 磁盘。发送的逻辑 write -> 内核态socket缓冲区(copy) -> 网卡。
可以看到每次的read到write都要经历4次的上下文切换,同时数据要在内核态以及用户态来回copy,一共也拷贝了4次。
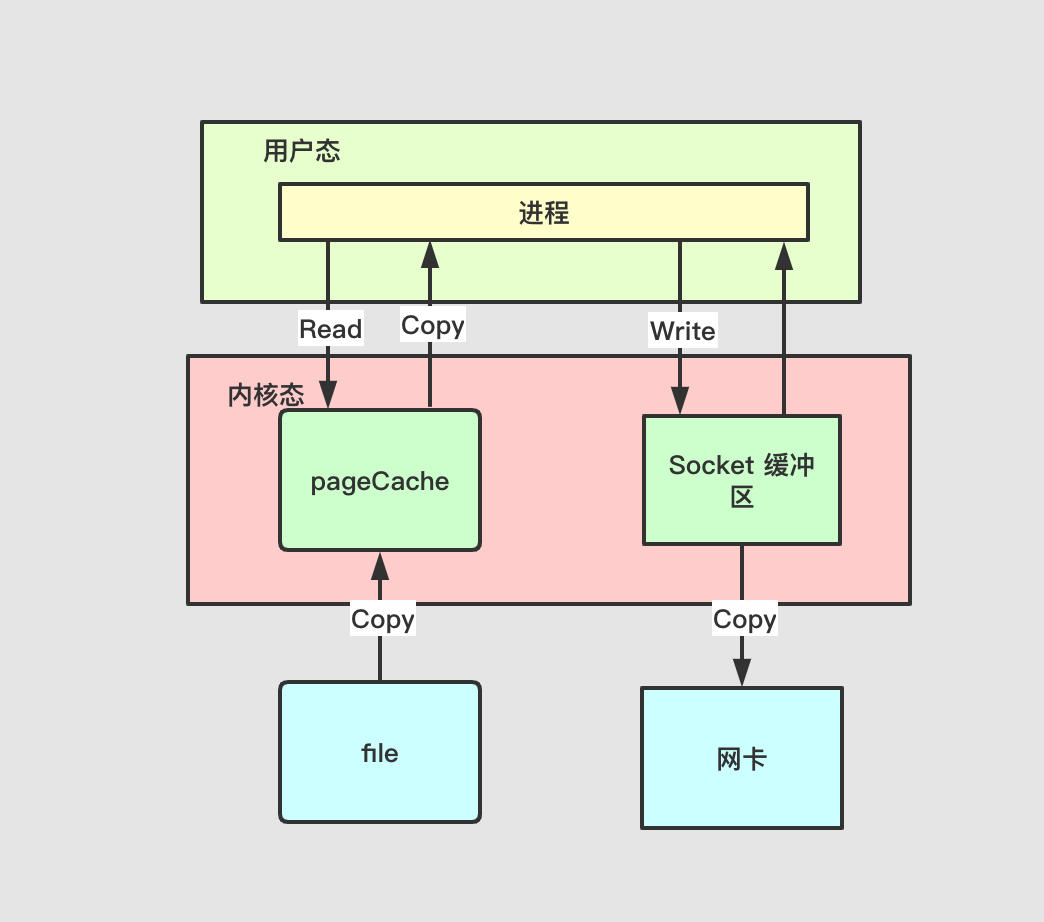
上面存在的性能问题:
- 上下文切换带来的CPU消耗
- 数据来回拷贝带来的性能损耗
零拷贝的技术就是为了解决以上两个问题,常见的方式有以下几种
直接I/O
使用直接I/O就不用经过内核缓冲区,数据不用再copy到page cahce
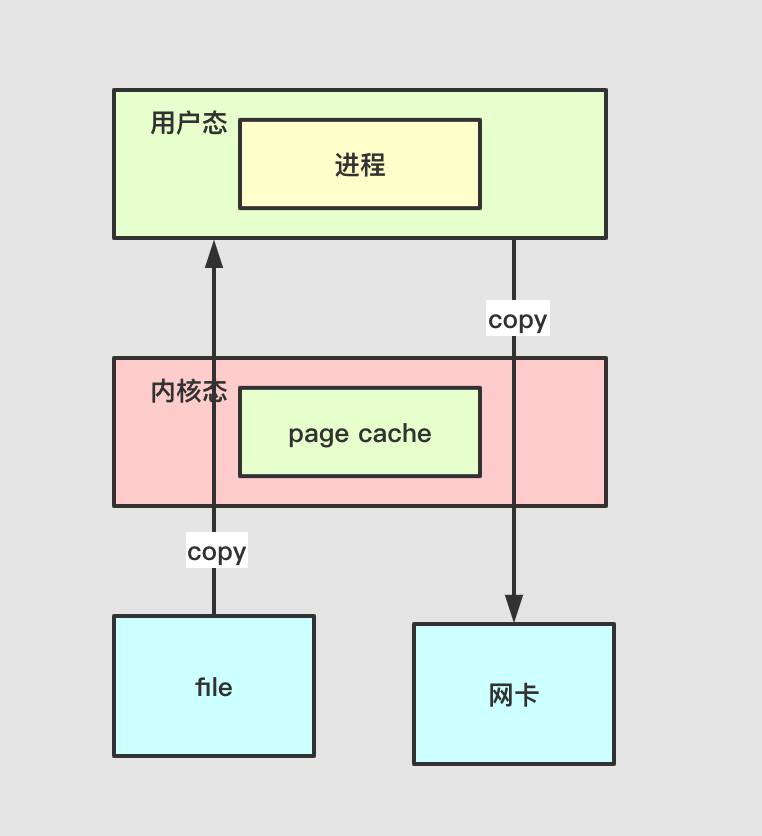
直接I/O也叫做标准I/O, 大多数文件系统的默认I/O 操作都是缓存I/O. 直接I/O与缓存I/O的区别在与直接I/O需要在数据完全被写会磁盘才能算完成,缓存I/O则是写回PageCache就算完成。
直接I/O的使用场景有两种:
- 应用程序实现了磁盘文件的缓存,这样就不需要PageCache导致额外的性能消耗。比如mysql里面实现了一套自己的buffer pool,每次落盘都是直接写磁盘。
- 大文件的传输,在大文件传输的场景下,PageCache 缓存的命中率会变得十分低,这个时候如果使用直接I/O就可以。
sendfile
这里的sendfile可以理解为一个系统调用,如图所示
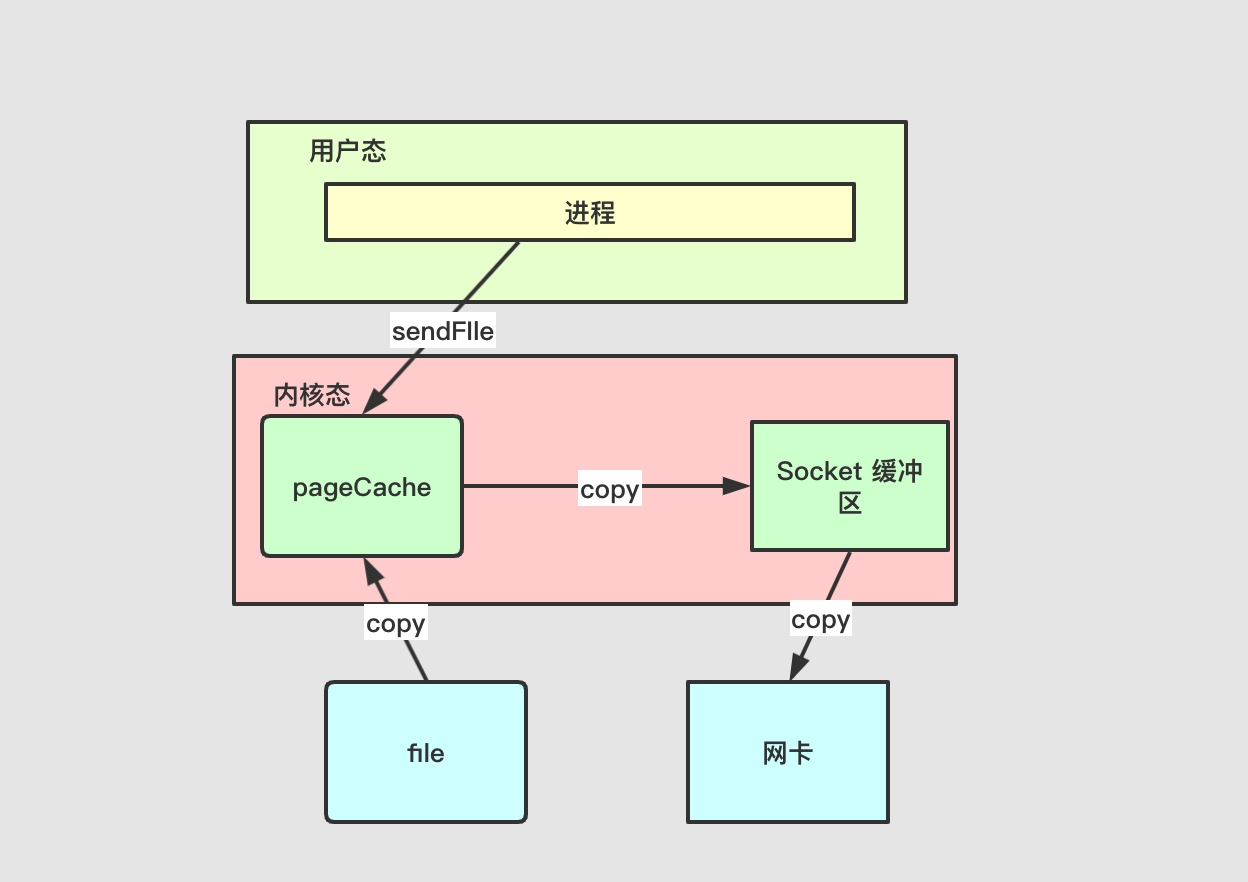
这里只需要一个系统调用,两次上下文切换,三次copy即可完成数据的读取以及发送,省略了pageCache到用户态代码的一次拷贝以及上下文切换。实际上,从pageCache到socket 缓冲区的这一次拷贝其实也是经历了CPU的一次拷贝,如果系统支持SG-DMA(The Scatter-Gather Direct Memory Access)技术,我们还可以优化掉这次拷贝,如下图
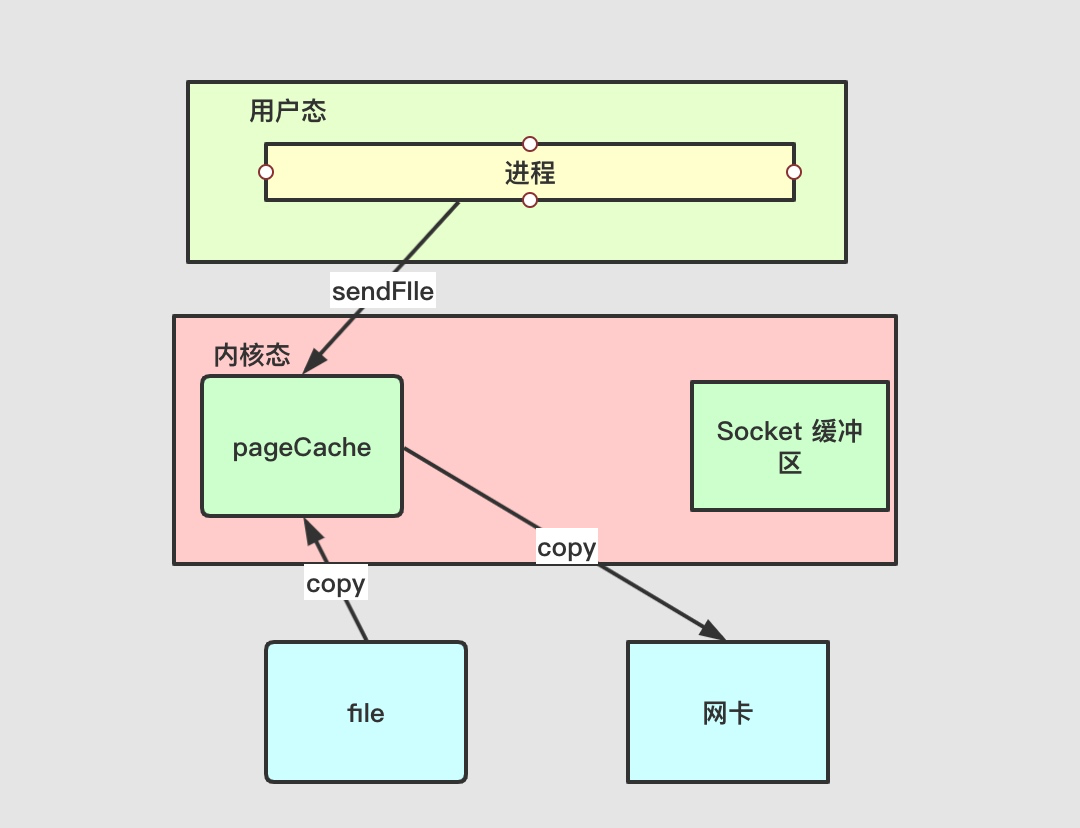
对sendFile感兴趣的可以看下其内部的实现源码
mmap
mmap相较于sendfile,多了两次的上下文切换。调用流程简述为以下:
tmp_buf = mmap(file, len);
write(socket, tmp_buf, len);
本质上显示mmap共享一部分内存buffer,mmap会有两次上下文切换,然后再去调用write函数,也会有两次上下文切换。buffer copy的次数可以理解为三次,在内核状态会直接使用tmp buffer进行copy。
相较于sendfile,mmap的使用多了两次的上下文切换。所以只在发送文件的场景下,sendfile还是比较优秀的。
splice
splice是基于管道的实现,用于在两个文件描述符之间传送数据。splice 提供了一种流控制的机制,通过预先定义的水印(watermark)来阻塞写请求,有实验表明,利用这种方法将数据从一个磁盘传输到另外一个磁盘会增加 30%-70% 的吞吐量,CPU负责也会减少一半。
看下splice的定义,将数据从fd_in移动到fd_out,移动len的长度。
ssize_t splice(int fd_in, loff_t *off_in, int fd_out,
loff_t *off_out, size_t len, unsigned int flags);
本质上来说,splice经历了两次上下文切换,三次copy。跟sendfile差不多,但是限制条件也比较明显,有一方必须是管道,并且没有对数据的修改。
零拷贝的一些思考
Go 里面string的转换
Go 里原生对于string以及byte的转化是一次数据的拷贝,性能本身会带来比较大的影响。
package main
import (
"fmt"
)
func main() {
s := "hello, world!"
b := []byte(s)
fmt.Println(s, b)
}在雨痕的这篇Blog中可以看到直接使用指针的移动完成的数据的转化极大的提高了性能(风险也比较大,string不可变类型变为可变)。
func str2bytes(s string) []byte {
x := (*[2]uintptr)(unsafe.Pointer(&s))
h := [3]uintptr{x[0], x[1], x[1]}
return *(*[]byte)(unsafe.Pointer(&h))
}
func bytes2str(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
小结
零拷贝的**本质上是减少数据间来回拷贝带来的性能影响,上面介绍了几种零拷贝的方法,在文件发送的情况下,直接调用sendfile还是最优秀的。
另外在写业务代码的时候,能尽量使用零拷贝的**也可以大大的提高性能。
reference
Golang 性能分析及优化
Golang 性能分析及优化
Background
想要调优,必须知道一个程序的瓶颈在哪,Golang本身自带的pprof和trace可以定位程序大部分的性能问题,这篇文章会介绍下pprof以及trace的使用。
pprof
pprof文件收集
pprof是一般用来收集CPU,内存,Goroutine等一系列的消耗工具。
针对HTTP server,直接导入一个包即可开启pprof。
import _ "net/http/pprof"
下载pprof也比较简单:
wget -O "/tmp/goroutine_10.10.3.214_${TIMESTAMP}.pb.gz" "http://127.0.0.1:3001/debug/pprof/goroutine?"
大部分生产环境应该都有对应的Jenkins去收集这些,不需要手动去跑。
pprof的种类分为profile、heap、threadcreate、block、mutex
- profile: CPU profile 里面可以看到哪些代码分别消耗了多少CPU的cycle
- heap: Heap profile 表示的是heap占用了多少内存,可以看不同对象的内存大小以及个数,用来debug memory leak的时候十分有用
- threadcreate: 用来观察创建了多少个OS thread。
- goroutine: 所有goroutine的栈,一般full-goroutine是可以直接用文本打开的
- block: goroutine同步阻塞的profile,不是默认开启的, 需要调用 runtime.SetBlockProfileRate 打开
- mutex: 互斥锁阻塞的profile,需要调用runtime.SetMutexProfileFraction打开
分析
pprof可以使用命令行或者是web UI进行分析,一般来说web UI比较方便的可以看火焰图等。
命令行
pprof -source_path ${GOPATH}/src:${GOROOT}/src ~/Downloads/profile_*.pb.gz
这里需要指定一下对应的gopath文件夹,不然打印出来的code可能有些无法显示,这里以profile为例子可以看下
File: v2.0.519843.sextant
Build ID: 9e3d4b710b641df08373e2944687150a0326432a
Type: cpu
Time: Dec 4, 2019 at 6:09pm (CST)
Duration: 5.11s, Total samples = 14.43s (282.58%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 6360ms, 44.07% of 14430ms total
Dropped 633 nodes (cum <= 72.15ms)
Showing top 10 nodes out of 270
flat flat% sum% cum cum%
1610ms 11.16% 11.16% 1610ms 11.16% runtime.procyield
860ms 5.96% 17.12% 860ms 5.96% runtime.futex
790ms 5.47% 22.59% 820ms 5.68% syscall.Syscall
650ms 4.50% 27.10% 650ms 4.50% runtime.epollwait
490ms 3.40% 30.49% 2440ms 16.91% runtime.lock
490ms 3.40% 33.89% 490ms 3.40% runtime.usleep
420ms 2.91% 36.80% 930ms 6.44% runtime.runqgrab
410ms 2.84% 39.64% 410ms 2.84% memeqbody
320ms 2.22% 41.86% 360ms 2.49% runtime.findObject
320ms 2.22% 44.07% 460ms 3.19% runtime.mapiternext
Top命令可以指定Flat、Cum或者Sum,三者的定义分别如下:
- Flat: 函数消耗的时间片
- Cum: Cum是当前函数所话费的时间总和
- Sum: Sum是所有函数逐渐累加,比如上面runtime.procyield+runtime.futex=17.12%
参考下面这个例子就可以很清晰的知道:
func foo(){
a() step1
b() step2
do something directly. step3
c() step4
}Flat的cost为step3,Cum的Cost为step1+ step2+ step3+ step4。
Peek命令可以追踪上一层函数,List命令可以展示指定函数消耗的时间片。
Web UI
Web UI的使用还是比较方便的,平时都是直接拿这个调试的,对应的命令
pprof -source_path ${GOPATH}/src:${GOROOT}/src -http "localhost:12346" ~/Downloads/profile_*.pb.gz
调用关系图可以参考
火焰图可以参考

个人使用感觉还是web UI比较舒服。
trace
trace可以撑的上是大杀器,在分析整个程序的吞吐以及GC对应的相关瓶颈更加实用,他可以分析所有goroutine的生命周期,调度创建以及销毁时间(必须是在采样的时间内)。
启动也很简单,一行命令搞定即可,只可以在chrome上展示
go tool trace trace.out, 如果打开是空白,可以尝试用gotip打开。
-
View Trace:整个程序执行期间的生命周期,包括heap变化,GC时间,goroutine在哪些P上调用.
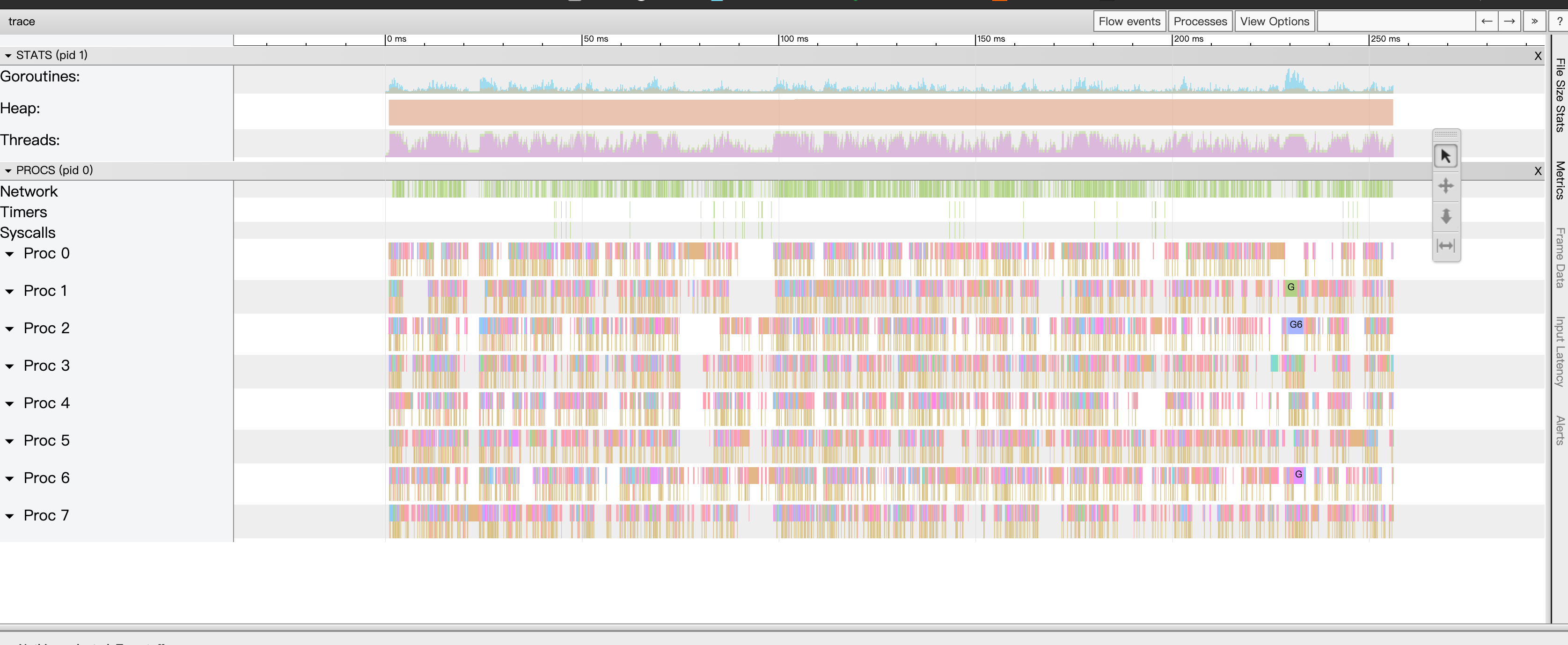
-
Goroutine analysis: 一共有多少个goroutine,每个goroutine分别占用了多少时间.
-
Network/Sync/Syscall blocking profile: Goroutine分别在网络/同步阻塞/系统调用上花费了多少时间

-
Scheduler latency profiler: 调度花费的时间,一般指的G从runnable到running中间花费了多久.
-
Minimum mutator utilization: 用来分析整个程序的性能吞吐,这个比较实用。
在trace里就重点聊下MMU这个东西吧,在GC的概念里面运行的程序就可以认为是一个mutator,这里能观察到不同的GC事件对于整个系统性能的影响。
x轴可以理解为采样的时间点,y轴则代表程序整体可以使用的吞吐,1.0表示整个系统可用率为100%,为0则表示当前的GC STW了,系统当前不可用。
一个简单的例子来看,对比上面的图,加上了Sweep之后可以打线,整个系统的吞吐变慢了,直道1ms左右才看到系统的吞吐恢复到90%左右,这里就是一个典型的sweep latency过长的情况。

点击上面的线,可以具体看到具体的调用栈。sweep一般有两个地方会调用:1.background sweep在后台定期的去扫 2.allocate的时候会从已经mark为不用的对象里面重新拿
优化
STW latency
Go在1.14之前是没有抢占调度的,在STW的时候需要所有的goroutine park下来,抢占点位一般有两个:要么进入系统调用或者扩栈。如果当前有一个G一直在tight loopli里面跑着,就会导致STW的时间无限拉长。
package main
import (
"runtime"
"time"
)
func main() {
runtime.GOMAXPROCS(1)
go func() {
for {
}
}()
time.Sleep(time.Millisecond)
println("OK")
}上面这段代码就永远不会输出OK,同理也永远进入不了GC。
所以在进行问题排查的时候,需要我们自己去注意看函数里面是否有一些超级大的循环导致STW latency过长。
Go 1.14使用信号量去抢占,已经fix了这个问题,在M启动的时候会去注册信号量,有需要的时候直接进行抢占。
Mark assist
在Heap里面的活对象越多,Mark的latency就会越长。
所以优化可以从几个角度考虑
-
对于比较大的slice,尽量避免使用指针,使用数组可以有效的优化GC(GC认为数组是一个对象,使用数组相当于减少了扫描个数)。
-
更少的goroutine意味着更好的性能,Mark assist 会去扫面goroutine的栈,如果栈太长, latency也会越高。
Sweep latency
具体可以参考这个issue,当heap里面没有垃圾,不停的allocate导致sweep latency过长。根本原因是span list太长,要扫的对象太多。具体分为两种情况:
- mcache的span list满了,扫了一圈发现几乎没有可以reclaimed出来的span,中间扫描的时间太长
- allocate新的对象,也会去尝试找空的span,如果发现扫list太长,也会导致latency
Go在1.15修复了这个问题,扫描一定长度的span就不继续往下扫了。tidb之前也有个热修复将对象不分配在mcache上,2048byte变成40K, 直接将对象变大用mheap去管理也是十分trick,
for i := range tbl {
tbl[i] = make([]uint32, w)
}
// Background: The Go's memory allocator will ask caller to sweep spans in some scenarios.
// This can cause memory allocation request latency unpredictable, if the list of spans which need sweep is too long.
// For memory allocation large than 32K, the allocator will never allocate memory from spans list.
//
// The memory referenced by the CMSketch will never be freed.
// If the number of table or index is extremely large, there will be a large amount of spans in global list.
// The default value of `d` is 5 and `w` is 2048, if we use a single slice for them the size will be 40K.
// This allocation will be handled by mheap and will never have impact on normal allocations.
arena := make([]uint32, d*w)
for i := range tbl {
tbl[i] = arena[i*int(w) : (i+1)*int(w)]
}
要优化的话可以考虑:
- 尽量分散对应的size class span(或者放到mheap)
- sync.Pool 对象重用
小结
一般pprof更方便用来定位程序代码的瓶颈,trace可以更加方便的定位GC导致的一些latency,针对不同的latency可以做不同的优化,具体场景需要具体的分析。
Channel 实现原理
Channel 实现原理
Background
从内存的角度来看,并行计算的方式有两种:
- 共享内存: 多线程或多进程共享一块区域的内存,每次要操作时候先拿锁
- 消息通信(CSP模型): 基于内存拷贝的原理,管道集中管理内存,每次线程发送相应的变量给管道,管道拷贝再发送给接收方。
Golang里面的channel实现就是基于上面描述的CSP模型,同时sync和atomic也提供了基于共享内存的通信方式。
使用
Channel有两种:带缓冲的以及不带缓存的, 具体的使用可以参考下面的简单例子。
// buffered channel
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
v, ok := <- ch // v=1, ok=true
close(ch)
v, ok := <- ch // close之后读到的v为默认值 v=0, ok=false
// unbuffered channel
ch1 := make(chan int)
// 一直Block住,直到有其他的goroutine接收 ch
ch1 <- 1
// block
go func(){ <- ch}有兴趣的同学还可以参考一下官方写的一个pipeline
例子,可以加深对于channel的理解。
源码分析
结构体
Channel的源码在src/runtime/chan里面,先看下最主要的结构体hchan
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}- qcount 队列里面的元素数量
- dataqsiz 环形队列里面的数量
- buf 环形队列,用指针表示
- elemsize 元素大小
- closed 是否关闭,0表示未关闭,1表示关闭。
- elemtype 元素类型
- sendx ring buffer的send index
- recvx ring buffer的recvieve index
- recvq 阻塞在recv上的sudog,里面的结构是双向链表
- sendq 阻塞在send上的goroutine
- lock 互斥锁,多线程操作buf要加锁
引用一张图片就可以很好的理解 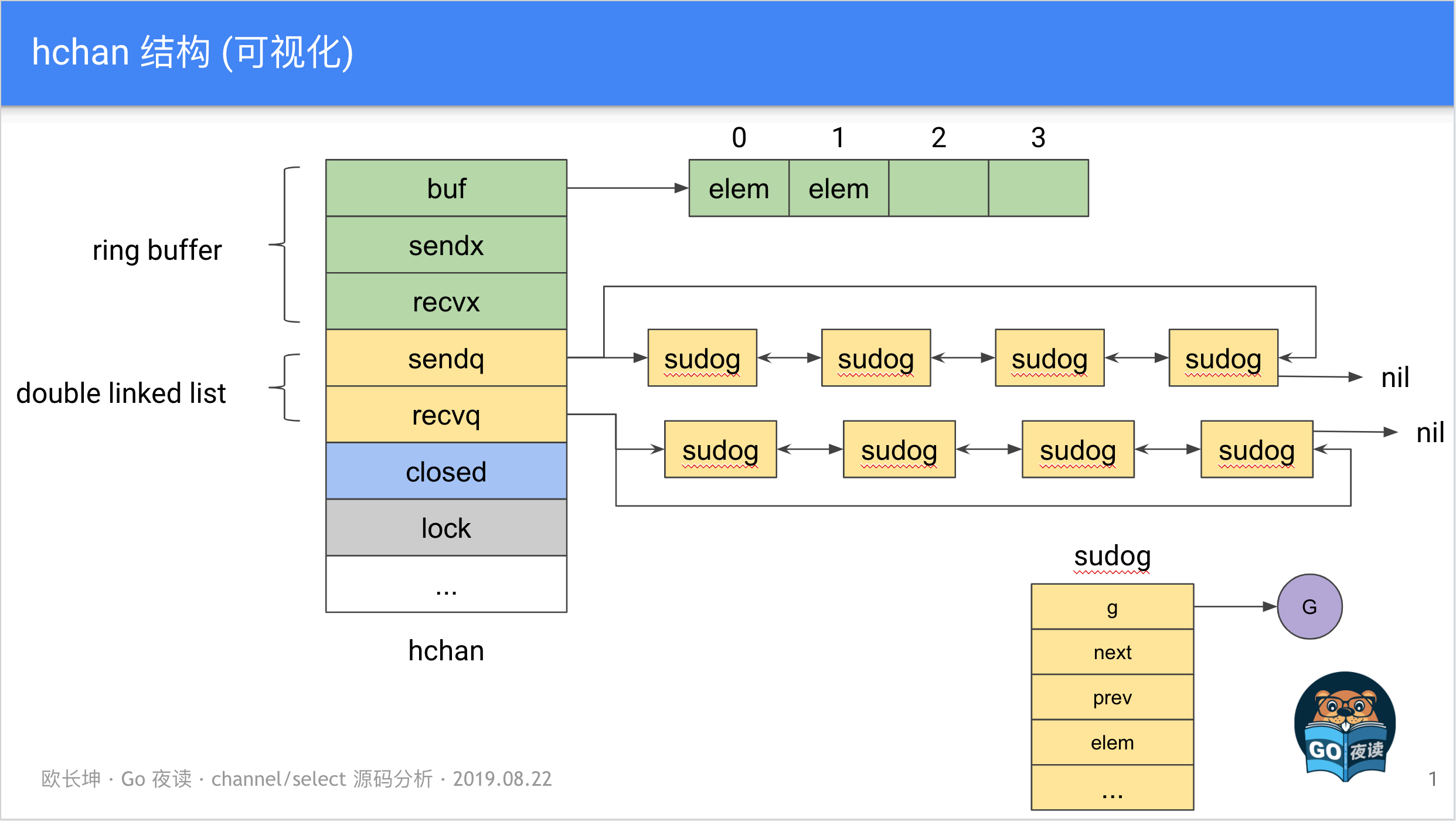 ,图片出处
,图片出处
创建
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// compiler checks this but be safe.
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// Hchan does not contain pointers interesting for GC when elements stored in buf do not contain pointers.
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
var c *hchan
switch {
case mem == 0:
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case elem.kind&kindNoPointers != 0:
// Elements do not contain pointers.
// Allocate hchan and buf in one call.
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// Elements contain pointers.
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; elemalg=", elem.alg, "; dataqsiz=", size, "\n")
}
return c
}先是一大波判断:判断elem.size的大小,在判断hchanSize是否与maxAlign对齐,内存是否会溢出。
判断完之后就进入主干逻辑,如果是不带缓存的channel(mem=0),就不会给分配额外的内存。带了buffer的话就会使用(*hchan)(mallocgc(hchanSize+mem, nil, true))把mem那部分的内存加上。如果是指针类型,直接调用mallocgc(mem, elem, true)分配内存。这里的mallocgc可以看到channel是分配在堆上的。
最后给c.elemsize等赋值,然后退出。
chansend
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 首先如果向空的channel发送,则调用gopark,引发deadlock
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// 加锁
lock(&c.lock)
// 已经关闭则直接panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// 当recvq里有数据一定表示buf空了,有消费者在阻塞等待,向头部的第一个直接发送。
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// 没有消费者等待,buf里面还有空间
if c.qcount < c.dataqsiz {
// Space is available in the channel buffer. Enqueue the element to send.
qp := chanbuf(c, c.sendx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
// 拷贝数据
typedmemmove(c.elemtype, qp, ep)
// ring buffer index自增
c.sendx++
// index满了重置
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
if !block {
unlock(&c.lock)
return false
}
// 阻塞在channel上,等待唤醒
gp := getg() // 获取当前G
mysg := acquireSudog() // 拿到一个sudog
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
// 给sudog赋值
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
// 往sendq里面放入一个sudog
c.sendq.enqueue(mysg)
// 当前的G执行gopark,由running->waiting,等待被唤醒
goparkunlock(&c.lock, waitReasonChanSend, traceEvGoBlockSend, 3)
// Ensure the value being sent is kept alive until the
// receiver copies it out. The sudog has a pointer to the
// stack object, but sudogs aren't considered as roots of the
// stack tracer.
KeepAlive(ep)
// G的状态不是waiting了,直接退出
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
// 正常状态下的param应该有数据,也不应该是关闭的
if gp.param == nil {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
// 释放sudog
releaseSudog(mysg)
return true
}send函数里面也比较简单,直接看下。
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func()) {
...
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf() // 解锁c.Lock
gp.param = unsafe.Pointer(sg)
...
// 恢复goroutine,放入调度队列等待被后续调度
goready(gp) // 将 gp 作为下一个立即被执行的 Goroutine
}简单总结下就是有三种情况:
- buffer为空,有消费者阻塞,直接发送给消费者
- buffer还有空间,没有消费者阻塞,直接copy到buffer里面
- buffer满了,则直接copy到sendq里面,调用gopark,等待唤醒。
chanrecv
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
// nil channel,会导致死锁,跟上面发送里的逻辑一样
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
...
// 开始加锁,进入接收逻辑
lock(&c.lock)
// 如果channel已经关闭并且element数量为0,
// 直接解锁,返回
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// 如果sendq里面有生产者阻塞,有两种情况考虑:
// buffer为0则直接发送
// buffer 满了,也会直接dequeue,具体等会分析recv函数
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
// buffer里面还没满,直接从buf里面get数据
if c.qcount > 0 {
// Receive directly from queue
qp := chanbuf(c, c.recvx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
// 内存拷贝
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
// 没有发送着,阻塞在消费者,流程基本跟send一样,阻塞G,等待唤醒
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
goparkunlock(&c.lock, waitReasonChanReceive, traceEvGoBlockRecv, 3)
// someone woke us up
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
closed := gp.param == nil
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, !closed
}具体分析recv函数
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// no buffer channel
if c.dataqsiz == 0 {
if raceenabled {
racesync(c, sg)
}
if ep != nil {
// copy data from sender
// 直接从sender拷贝数据
recvDirect(c.elemtype, sg, ep)
}
} else {
// 这里的逻辑有点绕
// 先把buf里面对应的c.recvx数据拿出来,返回给receiver
// 然后再把sg(就是阻塞队列里的数据copy出来)放到c.recvx
// c.recvxz自增,确保整个channel都是FIFO的
qp := chanbuf(c, c.recvx)
...
// copy data from queue to receiver
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// copy data from sender to queue
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}整体看下来,recv的逻辑跟send其实差不多
- 如果是已经关闭的channel并且里面没数据,则直接返回
- 如果有阻塞的消费者:
- 如果是没有buffer的则直接接收
- 如果是有buffer的,则直接copy出buffer第一个数据,然后将sendq里的数据放到buffer里
- 如果没有sender,调用gopark阻塞住,等待goready唤醒
close
func closechan(c *hchan) {
// 不能close一个空的channel,会panic
if c == nil { panic(plainError("close of nil channel"))
}
// 加锁
lock(&c.lock)
// close一个已经close掉的也会panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
...
c.closed = 1
var glist gList
// 释放所有的接收方
for {
sg := c.recvq.dequeue()
if sg == nil { // 队列已空
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem) // 清零
sg.elem = nil
}
...
gp := sg.g
gp.param = nil
...
glist.push(gp)
}
// 释放所有的发送方
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
...
gp := sg.g
gp.param = nil
...
glist.push(gp)
}
// 解锁
unlock(&c.lock)
// 就绪所有的 G
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}小结
channel是Go语言的核心之一,基于CSP实现的通信模式实现的也是比较简单优雅的。另外在实际开发中,我们在大部分场合可能需要考虑清楚什么时候需要使用buffered channel和unbuffered channel。buffered channel可能会带来额外的goroutine生命周期管理成本。
reference
mysql初识
mysql架构
基本架构: 客户端->(缓存or解析器)->优化器->存储引擎
客户端
客户端一个连接为一个线程
优化与执行(mysql服务器)
mysql会解析查询,构建内部数据结构(查询树),然后对其进行优化。进行select查询会优先进行缓存查找,没有的话再进行优化等一系列后续的行为。
并发
读写锁
读锁是共享的,互不阻塞。写锁具有排他性,在给定时间只能有一个写入动作。
锁粒度
表锁(table lock)
开销最小的锁,锁定整张表
行级锁(row lock)
可以较大程度的支持并发,只在最底层就是存储引擎实现
事务
一组原子性的sql查询,或者说是独立的工作单元,acid,原子性(atomicity),一致性(consistency),隔离性(isolation),持久性(durability)
隔离级别
- read uncommitted(未提交读)也叫做脏读,可以读取其他未提交事务的数据,事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
- read committed(提交读),一个事务从开始到提交前对其他事务都是不可见的,大多数默认的数据库都是这个。也叫不可重复读,两次执行相同的查询,可能会得到不一样的结果,事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
- repeatable read(可重复读)解决了脏读的问题,保证同一事务多次读取结果一致,是mysql默认的事务隔离级别,容易产生幻读。系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
- SERIALIZABLE (可串行化)是最高的隔离级别,强制事务顺序执行,可以解决幻读。会在读取的每一行数据都加锁。开销比较大。
死锁
两个事务或者多个事务在同一资源互相暂用,发生后只能回滚其中一个事务。
事务
mysql采用自动提交的模式(autocommit)如果不显示的开启一个事务,每个查询都会被当成事务, 事务型的表InnoDB和非事务型的表MyISAM也可混合使用。InnoDB采用两端锁定,在事务执行的过程中随时都可以执行锁定,只有在commit或者roolback后才会释放,这个叫做隐式锁定。另外显示锁定可以通过特殊的语句锁定。
多版本并发控制
mvcc可以认为是行级锁的一个变种,但是避免了加锁操作,mvcc的实现是通过某个时间点快照实现的,不管需要执行多久,事务看到的数据都是一样的。InnoDB的mvcc是保存两个隐藏的列实现的,一个保留的行的创建时间,一个是行的过期时间。每开始一个事务后,系统的版本号自动递增,事务开始时刻的版本号作为事务的版本号
存储引擎
在文件系统中,mysql将数据库保存为数据目录下的子目录,在数据库的子目录下保存和表同名的frm文件
InnoDB引擎
InnoDB是mysql的默认事务型引擎
MyISAM引擎
MyISAM是Mysql5.1版本之前的默认版本,不支持事务和行级锁
ETCD 源码分析
ETCD 源码分析
Etcd作为业界强一致性KV的主流解决方案,满足了CAP理论中的CP,实现了最终的强一致我司在实际生产环境也在大量使用,下面会分为几部分去介绍一下ETCD的几个模块的实现。
Raft
之前的这篇文章介绍了简单的Raft实现,Etcd封装了一个raft的library, 下面我们具体分析下Etcd在实际生产环境下的raft是如何具体实现的。
leader选举
startNode
raft启动是在raft.StartNode里面的,结点启动时候默认全部都是Follower, 状态机的处理在go n.run(r)里面。
func StartNode(c *Config, peers []Peer) Node {
r := newRaft(c)
r.becomeFollower(1, None)
for _, peer := range peers {
cc := pb.ConfChange{Type: pb.ConfChangeAddNode, NodeID: peer.ID, Context: peer.Context}
d, err := cc.Marshal()
if err != nil {
panic("unexpected marshal error")
}
e := pb.Entry{Type: pb.EntryConfChange, Term: 1, Index: r.raftLog.lastIndex() + 1, Data: d}
r.raftLog.append(e)
}
for _, peer := range peers {
r.addNode(peer.ID)
}
n := newNode()
n.logger = c.Logger
go n.run(r)
return &n
}这里初始化还有一个逻辑就是会将pb.ConfChange这个消息apply到log里面。
func (n *node) run(r *raft) {
...
for {
if lead != r.lead {
if r.hasLeader() {
propc = n.propc
} else {
propc = nil
}
lead = r.lead
}
select {
case m := <-propc:
m.From = r.id
r.Step(m)
case m := <-n.recvc:
// filter out response message from unknown From.
if pr := r.getProgress(m.From); pr != nil || !IsResponseMsg(m.Type) {
r.Step(m) // raft never returns an error
}
case cc := <-n.confc:
..
case <-n.tickc:
r.tick()
...
case c := <-n.status:
c <- getStatus(r)
case <-n.stop:
close(n.done)
return
}
}
}- propc 这个channel是将自身升级为leader的channel,下面介绍
stepLeader会详细介绍 - recvc 这个channel用来接收其他节点的所有类型的消息
- tickc 这个channel主要控制节点状态机变化不同的timeout设置,主要有
tickElection和tickHeartbeat,tickHeartbeat是leader状态下ticker,tickElection则是其他状态的tikcer。
step状态机
先看下Step这个函数,主要是处理各个状态间的变化,etcd里的节点状态分别有Follower,Candidate,Leader,PreCandidate这几个状态。PreCandidate这个状态是来自于Prevote算法。
当集群发生分区时,某一台follower处于分区网络下,会不断将自身的term自增,当其重新加入集群中时会导致leader进行重选,etcd采用Prevote来避免这种情况发生。
PreVote算法解决了网络分区节点在重新加入时,会中断集群的问题。在PreVote算法中,网络分区节点由于无法获得大部分节点的许可,因此无法增加其Term。然后当它重新加入集群时,它仍然无法递增其Term,因为其他服务器将一直收到来自Leader节点的定期心跳信息。一旦该服务器从领导者接收到心跳,它将返回到Follower状态,Term和Leader一致。
func (r *raft) Step(m pb.Message) error {
// Handle the message term, which may result in our stepping down to a follower.
switch {
case m.Term == 0:
// local message
case m.Term > r.Term:
if m.Type == pb.MsgVote || m.Type == pb.MsgPreVote {
force := bytes.Equal(m.Context, []byte(campaignTransfer))
inLease := r.checkQuorum && r.lead != None && r.electionElapsed < r.electionTimeout
if !force && inLease {
return nil
}
}
switch {
case m.Type == pb.MsgPreVote:
// Never change our term in response to a PreVote
case m.Type == pb.MsgPreVoteResp && !m.Reject:
default:
r.logger.Infof("%x [term: %d] received a %s message with higher term from %x [term: %d]",
r.id, r.Term, m.Type, m.From, m.Term)
if m.Type == pb.MsgApp || m.Type == pb.MsgHeartbeat || m.Type == pb.MsgSnap {
r.becomeFollower(m.Term, m.From)
} else {
r.becomeFollower(m.Term, None)
}
}
case m.Term < r.Term:
if r.checkQuorum && (m.Type == pb.MsgHeartbeat || m.Type == pb.MsgApp) {
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp})
} else {
// ignore other cases
r.logger.Infof("%x [term: %d] ignored a %s message with lower term from %x [term: %d]",
r.id, r.Term, m.Type, m.From, m.Term)
}
return nil
}
switch m.Type {
case pb.MsgHup:
if r.state != StateLeader {
ents, err := r.raftLog.slice(r.raftLog.applied+1, r.raftLog.committed+1, noLimit)
if err != nil {
r.logger.Panicf("unexpected error getting unapplied entries (%v)", err)
}
if n := numOfPendingConf(ents); n != 0 && r.raftLog.committed > r.raftLog.applied {
r.logger.Warningf("%x cannot campaign at term %d since there are still %d pending configuration changes to apply", r.id, r.Term, n)
return nil
}
r.logger.Infof("%x is starting a new election at term %d", r.id, r.Term)
if r.preVote {
r.campaign(campaignPreElection)
} else {
r.campaign(campaignElection)
}
} else {
r.logger.Debugf("%x ignoring MsgHup because already leader", r.id)
}
case pb.MsgVote, pb.MsgPreVote:
if r.isLearner {
// TODO: learner may need to vote, in case of node down when confchange.
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] ignored %s from %x [logterm: %d, index: %d] at term %d: learner can not vote",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
return nil
}
// The m.Term > r.Term clause is for MsgPreVote. For MsgVote m.Term should
// always equal r.Term.
if (r.Vote == None || m.Term > r.Term || r.Vote == m.From) && r.raftLog.isUpToDate(m.Index, m.LogTerm) {
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] cast %s for %x [logterm: %d, index: %d] at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
r.send(pb.Message{To: m.From, Term: m.Term, Type: voteRespMsgType(m.Type)})
if m.Type == pb.MsgVote {
// Only record real votes.
r.electionElapsed = 0
r.Vote = m.From
}
} else {
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] rejected %s from %x [logterm: %d, index: %d] at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
r.send(pb.Message{To: m.From, Term: r.Term, Type: voteRespMsgType(m.Type), Reject: true})
}
default:
r.step(r, m)
}
return nil
}-
inLease 这里的作用是防止网络分区后leader
进行重选的,每次leader当选之后都会有一段时间的当选期,在这期间结点不会给其他结点投票,配合prevote算法解决网络分区中的问题。prevote中的check quorum是leader自身保证,inLease是从follower角度考虑 -
m.Term > r.Term在这个逻辑分支下,如果收到的不是投票请求,都会调用becomeFollower将自身变为follower -
在
m.Term < r.Term情况下,一般都会忽略掉消息,然后return -
接下来判断m的类型,如果是
MsgHup,表示结点election timeout到,发起一个投票请求,进入campaignPreElection或者campaignElection -
如果收到的M是投票请求
MsgVote或者MsgPreVote, 则会判断term大小以及日志位置是否给该结点投上一票r.raftLog.isUpToDate(m.Index, m.LogTerm) -
default方法是执行
stepFunc,这是在becomeFollower等结点状态变更时设置的
tick变化
// tickElection is run by followers and candidates after r.electionTimeout.
func (r *raft) tickElection() {
r.electionElapsed++
if r.promotable() && r.pastElectionTimeout() {
r.electionElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgHup})
}
}
// tickHeartbeat is run by leaders to send a MsgBeat after r.heartbeatTimeout.
func (r *raft) tickHeartbeat() {
r.heartbeatElapsed++
r.electionElapsed++
if r.electionElapsed >= r.electionTimeout {
r.electionElapsed = 0
if r.checkQuorum {
r.Step(pb.Message{From: r.id, Type: pb.MsgCheckQuorum})
}
// If current leader cannot transfer leadership in electionTimeout, it becomes leader again.
if r.state == StateLeader && r.leadTransferee != None {
r.abortLeaderTransfer()
}
}
if r.state != StateLeader {
return
}
if r.heartbeatElapsed >= r.heartbeatTimeout {
r.heartbeatElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgBeat})
}
}- tickElection 发起投票请求
- tickHeartbeat 是结点变为leader之后定期给follower同步心跳包用的,注意
r.checkQuorum这里是每次会去判断是否能得到大多数结点的支持再发送心跳包,主要是为了解决网络分区时leader 重选的问题。
campaign 竞选
func (r *raft) campaign(t CampaignType) {
var term uint64
var voteMsg pb.MessageType
if t == campaignPreElection {
r.becomePreCandidate()
voteMsg = pb.MsgPreVote
// PreVote RPCs are sent for the next term before we've incremented r.Term.
term = r.Term + 1
} else {
r.becomeCandidate()
voteMsg = pb.MsgVote
term = r.Term
}
if r.quorum() == r.poll(r.id, voteRespMsgType(voteMsg), true) {
// We won the election after voting for ourselves (which must mean that
// this is a single-node cluster). Advance to the next state.
if t == campaignPreElection {
r.campaign(campaignElection)
} else {
r.becomeLeader()
}
return
}
for id := range r.prs {
if id == r.id {
continue
}
r.logger.Infof("%x [logterm: %d, index: %d] sent %s request to %x at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), voteMsg, id, r.Term)
var ctx []byte
if t == campaignTransfer {
ctx = []byte(t)
}
r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})
}
}- PreCandidate -> Candidate这个过程上面已经说了,使用prevote来解决网络分区中的一些问题
r.quorum() == r.poll(r.id, voteRespMsgType(voteMsg), true)是判断当前是否获取大多数结点的投票,然后成为leader,这种一般是单节点的情况,所以不用给r.peers其他结点发消息,直接返回- 给其他所有节点发送
MsgPreVote或者MsgVote投票消息
日志复制
TODO
MVCC
MVCC(Multi Version Concurrency Control的简称),代表多版本并发控制。MVCC主要用来减少锁冲突,提高并发度。大多数的MVCC实现都是通过版本链来实现,比如Mysql就是通过版本链 + 快照读来实现。
从KV结构体开始看,MVCC里面KV对外暴露的几个接口
type KV interface {
ReadView
WriteView
// Read creates a read transaction.
Read() TxnRead
// Write creates a write transaction.
Write() TxnWrite
// Hash computes the hash of the KV's backend.
Hash() (hash uint32, revision int64, err error)
// HashByRev computes the hash of all MVCC revisions up to a given revision.
HashByRev(rev int64) (hash uint32, revision int64, compactRev int64, err error)
// Compact frees all superseded keys with revisions less than rev.
Compact(rev int64) (<-chan struct{}, error)
// Commit commits outstanding txns into the underlying backend.
Commit()
// Restore restores the KV store from a backend.
Restore(b backend.Backend) error
Close() error
}Read和Write分别返回一个事务,ReadView以及WriteView是两个接口, 分别实现了增删改查的功能。
type WriteView interface {
DeleteRange(key, end []byte) (n, rev int64)
Put(key, value []byte, lease lease.LeaseID) (rev int64)
}
type ReadView interface {
FirstRev() int64
Rev() int64
Range(key, end []byte, ro RangeOptions) (r *RangeResult, err error)
}索引
在etcd里面,版本的概念是revision,每个key修改之后,对应的revision都会自增。先看看revision的定义:
type revision struct {
// main is the main revision of a set of changes that happen atomically.
main int64
// sub is the the sub revision of a change in a set of changes that happen
// atomically. Each change has different increasing sub revision in that
// set.
sub int64
}main对应事务ID,全局单调递增。sub代表在一次事务中操作的子序号。
KeyIndex里面存储一个key的各个生命周期所设计的revision变化,里面还有一个generation的概念。一个generation代表了一个key从创建到被删除的过程,generation里面主要存储的是revision数组。
type keyIndex struct {
key []byte
modified revision // the main rev of the last modification
generations []generation
}
type generation struct {
ver int64
created revision // when the generation is created (put in first revision).
revs []revision
}再看看内存中的树状结构treeIndex,本质上实现的是Btree,所以范围查询什么的都会很快
type treeIndex struct {
sync.RWMutex
tree *btree.BTree
}存储
底层存储封装了一层Backend, 主要是通过boltDB来实现的,boltDB本质上也是基于Btree实现的读友好数据库。
type Backend interface {
ReadTx() ReadTx
BatchTx() BatchTx
Snapshot() Snapshot
Hash(ignores map[IgnoreKey]struct{}) (uint32, error)
Size() int64
SizeInUse() int64
Defrag() error
ForceCommit()
Close() error
}读写
读操作的入口在applier里面,先看下具体操作。
func (a *applierV3backend) Range(txn mvcc.TxnRead, r *pb.RangeRequest) (*pb.RangeResponse, error) {
if txn == nil {
txn = a.s.kv.Read()
defer txn.End()
}
rr, err := txn.Range(r.Key, mkGteRange(r.RangeEnd), ro)
if err != nil {
return nil, err
}
}
func (s *store) Read(trace *traceutil.Trace) TxnRead {
s.mu.RLock()
s.revMu.RLock()
tx := s.b.ConcurrentReadTx()
tx.RLock()
firstRev, rev := s.compactMainRev, s.currentRev
s.revMu.RUnlock()
return newMetricsTxnRead(&storeTxnRead{s, tx, firstRev, rev, trace})
}先生产一个txn, 默认获取当前最新的revision,使用读写锁来控制并发, 每次默认拿到的rev都是当前事务开始时间节点的最新值。
Range最终会落到rangeKeys这个函数里面
func (tr *storeTxnRead) rangeKeys(key, end []byte, curRev int64, ro RangeOptions) (*RangeResult, error) {
rev := ro.Rev
...
revpairs := tr.s.kvindex.Revisions(key, end, rev)
limit := int(ro.Limit)
kvs := make([]mvccpb.KeyValue, limit)
revBytes := newRevBytes()
for i, revpair := range revpairs[:len(kvs)] {
revToBytes(revpair, revBytes)
_, vs := tr.tx.UnsafeRange(keyBucketName, revBytes, nil, 0)
kvs[i].Unmarshal(vs[0])
}
return &RangeResult{KVs: kvs, Count: len(revpairs), Rev: curRev}, nil
}整个流程的核心是调用kvindex.Revisions从Btree里面找到符合条件的revision,然后根据revision去Bolt里面拿到具体存储的KV。
写操作的实现类似,也是先生成一个txn, 然后调用Put方法。
func (a *applierV3backend) Put(ctx context.Context, txn mvcc.TxnWrite, p *pb.PutRequest) (resp *pb.PutResponse, trace *traceutil.Trace, err error) {
if txn == nil {
if leaseID != lease.NoLease {
if l := a.s.lessor.Lookup(leaseID); l == nil {
return nil, nil, lease.ErrLeaseNotFound
}
}
txn = a.s.KV().Write(trace)
defer txn.End()
}
resp.Header.Revision = txn.Put(p.Key, val, leaseID)
trace.AddField(traceutil.Field{Key: "response_revision", Value: resp.Header.Revision})
return resp, trace, nil
}
func (s *store) Write(trace *traceutil.Trace) TxnWrite {
s.mu.RLock()
tx := s.b.BatchTx()
tx.Lock()
tw := &storeTxnWrite{
storeTxnRead: storeTxnRead{s, tx, 0, 0, trace},
tx: tx,
beginRev: s.currentRev,
changes: make([]mvccpb.KeyValue, 0, 4),
}
return newMetricsTxnWrite(tw)
}从上面可以看到同样是需要使用锁去RLock,获取当前的currentRev,生成storeTxnWrite然后再调用put方法进行写入操作。
func (tw *storeTxnWrite) put(key, value []byte, leaseID lease.LeaseID) {
rev := tw.beginRev + 1
...
ibytes := newRevBytes()
idxRev := revision{main: rev, sub: int64(len(tw.changes))}
revToBytes(idxRev, ibytes)
kv := mvccpb.KeyValue{
Key: key,
Value: value,
CreateRevision: c,
ModRevision: rev,
Version: ver,
Lease: int64(leaseID),
}
d, err := kv.Marshal()
tw.tx.UnsafeSeqPut(keyBucketName, ibytes, d)
tw.s.kvindex.Put(key, idxRev)
tw.changes = append(tw.changes, kv)
}Put 主要是构造新的revision,将value写入后端bolt中并更新内存中索引。
Watch
Background
etcd内部使用GRPC stream多路复用来处理Watch, 主要是为了节省连接资源。
多路复用的概念:
多路复用GRPC使用HTTP/2作为应用层的传输协议,HTTP/2会复用底层的TCP连接。每一次RPC调用会产生一个新的Stream,每个Stream包含多个Frame,Frame是HTTP/2里面最小的数据传输单位。同时每个Stream有唯一的ID标识,如果是客户端创建的则ID是奇数,服务端创建的ID则是偶数。如果一条连接上的ID使用完了,Client会新建一条连接,Server也会给Client发送一个GOAWAY Frame强制让Client新建一条连接。一条GRPC连接允许并发的发送和接收多个Stream,而控制的参数便是MaxConcurrentStreams,Golang的服务端默认是100。
The etcd3 API multiplexes watches on a single connection. Instead of opening a new connection, a client registers
a watcher on a bidirectional gRPC stream. The stream delivers events tagged with a watcher’s registered ID. Multiple
watch streams can even share the same TCP connection. Multiplexing and stream connection sharing reduce etcd3’s
memory footprint by at least an order of magnitude.
代码分析
先明确几个概念,避免之后看源码会混淆
- watchableStore: 从store继承,实现了Watch功能mvcc的具体实现
- watchStream: 对watchableStore的封装,暴露出和Watch有关方法
- serverWatchStream: 接收Watch请求的入口,将服务端从mvcc.WatchStream产生的events转发给客户端,可以认为是一个中转的地方
serverWatchStream
func (ws *watchServer) Watch(stream pb.Watch_WatchServer) (err error) {
sws := serverWatchStream{
...
}
sws.wg.Add(1)
go func() {
sws.sendLoop()
sws.wg.Done()
}()
errc := make(chan error, 1)
// Ideally recvLoop would also use sws.wg to signal its completion
// but when stream.Context().Done() is closed, the stream's recv
// may continue to block since it uses a different context, leading to
// deadlock when calling sws.close().
go func() {
if rerr := sws.recvLoop(); rerr != nil {
if isClientCtxErr(stream.Context().Err(), rerr) {
sws.lg.Debug("failed to receive watch request from gRPC stream", zap.Error(rerr))
} else {
sws.lg.Warn("failed to receive watch request from gRPC stream", zap.Error(rerr))
streamFailures.WithLabelValues("receive", "watch").Inc()
}
errc <- rerr
}
}()
select {
case err = <-errc:
close(sws.ctrlStream)
case <-stream.Context().Done():
err = stream.Context().Err()
// the only server-side cancellation is noleader for now.
if err == context.Canceled {
err = rpctypes.ErrGRPCNoLeader
}
}
sws.close()
return err
}sendLoop 以及recvLoop
针对每一个Watch请求,都需要创建一个对应的serverWatchStream去进行sendLoop以及recvLoop操作,sendLoop具体可以理解为接收MVCC的events然后将其发送给客户端,recvLoop可以理解为接收GRPC的请求。
func (sws *serverWatchStream) recvLoop() error {
for {
req, err := sws.gRPCStream.Recv()
...
switch uv := req.RequestUnion.(type) {
case *pb.WatchRequest_CreateRequest:
...
id := sws.watchStream.Watch(creq.Key, creq.RangeEnd, rev, filters...)
if id != -1 {
sws.mu.Lock()
if creq.ProgressNotify {
sws.progress[id] = true
}
if creq.PrevKv {
sws.prevKV[id] = true
}
if creq.Fragment {
sws.fragment[id] = true
}
sws.mu.Unlock()
}
wr := &pb.WatchResponse{
Header: sws.newResponseHeader(wsrev),
WatchId: int64(id),
Created: true,
Canceled: id == -1,
}
select {
case sws.ctrlStream <- wr:
case <-sws.closec:
return nil
}
case *pb.WatchRequest_CancelRequest:
if uv.CancelRequest != nil {
id := uv.CancelRequest.WatchId
err := sws.watchStream.Cancel(mvcc.WatchID(id))
if err == nil {
sws.ctrlStream <- &pb.WatchResponse{
Header: sws.newResponseHeader(sws.watchStream.Rev()),
WatchId: id,
Canceled: true,
}
sws.mu.Lock()
delete(sws.progress, mvcc.WatchID(id))
delete(sws.prevKV, mvcc.WatchID(id))
delete(sws.fragment, mvcc.WatchID(id))
sws.mu.Unlock()
}
}
case *pb.WatchRequest_ProgressRequest:
if uv.ProgressRequest != nil {
sws.ctrlStream <- &pb.WatchResponse{
Header: sws.newResponseHeader(sws.watchStream.Rev()),
WatchId: -1, // response is not associated with any WatchId and will be broadcast to all watch channels
}
}
default:
// we probably should not shutdown the entire stream when
// receive an valid command.
// so just do nothing instead.
continue
}
}
}recvLoop主要接收的请求有三种:
- WatchRequest_CreateRequest: 创建watch请求
- WatchRequest_CancelRequest: sws.watchStream调用cancle,退出watch流程
- WatchRequest_ProgressRequest: 将当前的
sws.watchStream.Rev通过ctrlStream发送给客户端,是客户端watcher发送过来的RequestProgress请求。
这里需要注意的就是ctrlStream这个channel,主要是用来转发客户端与MVCC端之间的消息。
下面看下sendLoop的源码
func (sws *serverWatchStream) sendLoop() {
for {
select {
case wresp, ok := <-sws.watchStream.Chan():
evs := wresp.Events
events := make([]*mvccpb.Event, len(evs))
for i := range evs {
events[i] = &evs[i] }
canceled := wresp.CompactRevision != 0
wr := &pb.WatchResponse{
Header: sws.newResponseHeader(wresp.Revision),
WatchId: int64(wresp.WatchID),
Events: events,
CompactRevision: wresp.CompactRevision,
Canceled: canceled,
}
sws.gRPCStream.Send(wr)
case c, ok := <-sws.ctrlStream: // ...
case <-progressTicker.C: // ...
case <-sws.closec:
return
}
}
}主要是有两个channel需要监听:
- sws.watchStream.Chan主要是监听
[]mvccpb.Event, 然后封装WatchResponse并通过grpc发送给客户端 - ctrlStream 转发消息到客户端
总的来说serverWatchStream就是封装在MVCC实现上的一层,主要跟客户端交互。sendLoop以及recvLoop分别接受客户端的请求和发送MVCC events到客户端。
watchableStore
watchableStore可以认为是MVCC对外暴露的Watch的具体实现,先看结构体
type watchableStore struct {
*store
// mu protects watcher groups and batches. It should never be locked
// before locking store.mu to avoid deadlock.
mu sync.RWMutex
// victims are watcher batches that were blocked on the watch channel
victims []watcherBatch
victimc chan struct{}
// contains all unsynced watchers that needs to sync with events that have happened
unsynced watcherGroup
// contains all synced watchers that are in sync with the progress of the store.
// The key of the map is the key that the watcher watches on.
synced watcherGroup
stopc chan struct{}
wg sync.WaitGroup
}
type watcherGroup struct {
// keyWatchers has the watchers that watch on a single key
keyWatchers watcherSetByKey
// ranges has the watchers that watch a range; it is sorted by interval
ranges adt.IntervalTree
// watchers is the set of all watchers
watchers watcherSet
}有四个结构体需要看下:
- victims 当watch的channel满了之后,后续进来的events会保存到 victims
- victimc 用来通知
syncVictimsLoop去处理victim - unsynced 存储未完成同步的
watcherGroup - synced 存储已经完成同步的
watcherGroup - watcherGroup 一个watcherGroup结构体管理多个watcher,使用map和adt(红黑树)对key进行增删改查
在创建一个新的watchableStore之后,后台会有两个goroutine在执行,分别是syncWatchersLoop和syncVictimsLoop. syncWatchersLoop里面会每间隔100ms去调用syncWatchers同步watcher,syncVictimsLoop里面会每间隔10ms调用moveVictims。
watchableStore里面的watch方法会返回一个watcher结构体:
type watcher struct {
// the watcher key
key []byte
end []byte
victim bool
compacted bool
restore bool
minRev int64
id WatchID
fcs []FilterFunc
ch chan<- WatchResponse
}Watcher里面会去往ch里面发送一系列的events消息。events事件就是mvcc底层发生变动后产生的事件Events []mvccpb.Event.
events产生是在watchableStoreTxnWrite里面
func (tw *watchableStoreTxnWrite) End() {
changes := tw.Changes()
if len(changes) == 0 {
tw.TxnWrite.End()
return
}
rev := tw.Rev() + 1
evs := make([]mvccpb.Event, len(changes))
for i, change := range changes {
evs[i].Kv = &changes[i]
if change.CreateRevision == 0 {
evs[i].Type = mvccpb.DELETE
evs[i].Kv.ModRevision = rev
} else {
evs[i].Type = mvccpb.PUT
}
}
// end write txn under watchable store lock so the updates are visible
// when asynchronous event posting checks the current store revision
tw.s.mu.Lock()
tw.s.notify(rev, evs)
tw.TxnWrite.End()
tw.s.mu.Unlock()
}
type watchableStoreTxnWrite struct {
TxnWrite
s *watchableStore
}
func (s *watchableStore) Write() TxnWrite { return &watchableStoreTxnWrite{s.store.Write(), s} }MVCC外层的写操作都会调用Write生成一个TxnWrite,然后经历End->tw.s.notify的调用栈去通知上层对events进行处理。
func (s *watchableStore) notify(rev int64, evs []mvccpb.Event) {
var victim watcherBatch
for w, eb := range newWatcherBatch(&s.synced, evs) {
if eb.revs != 1 {
plog.Panicf("unexpected multiple revisions in notification")
}
if w.send(WatchResponse{WatchID: w.id, Events: eb.evs, Revision: rev}) {
pendingEventsGauge.Add(float64(len(eb.evs)))
} else {
// move slow watcher to victims
w.minRev = rev + 1
if victim == nil {
victim = make(watcherBatch)
}
w.victim = true
victim[w] = eb
s.synced.delete(w)
slowWatcherGauge.Inc()
}
}
s.addVictim(victim)
}整个逻辑不复杂,send方法就是尝试往w.ch里面发送消息,如果消息满就返回false,然后将这些events加入到victim中去。等待后台的syncVictimsLoop去发送消息。
func (w *watcher) send(wr WatchResponse) bool {
progressEvent := len(wr.Events) == 0
if len(w.fcs) != 0 {
ne := make([]mvccpb.Event, 0, len(wr.Events))
for i := range wr.Events {
filtered := false
for _, filter := range w.fcs {
if filter(wr.Events[i]) {
filtered = true
break
}
}
if !filtered {
ne = append(ne, wr.Events[i])
}
}
wr.Events = ne
}
// if all events are filtered out, we should send nothing.
if !progressEvent && len(wr.Events) == 0 {
return true
}
select {
case w.ch <- wr:
return true
default:
return false
}
}除了notify会调用send外,还有另外几个地方会调用,还有moreVictims以及syncWatchers这两个地方。moreVictims是在syncVictimsLoop里面去调用的,逻辑比较简单。需要关注的是syncWatchers这个函数,看看里面究竟干了哪些事情:
func (s *watchableStore) syncWatchers() int {
s.mu.Lock()
defer s.mu.Unlock()
if s.unsynced.size() == 0 {
return 0
}
s.store.revMu.RLock()
defer s.store.revMu.RUnlock()
// in order to find key-value pairs from unsynced watchers, we need to
// find min revision index, and these revisions can be used to
// query the backend store of key-value pairs
curRev := s.store.currentRev
compactionRev := s.store.compactMainRev
wg, minRev := s.unsynced.choose(maxWatchersPerSync, curRev, compactionRev)
minBytes, maxBytes := newRevBytes(), newRevBytes()
revToBytes(revision{main: minRev}, minBytes)
revToBytes(revision{main: curRev + 1}, maxBytes)
// UnsafeRange returns keys and values. And in boltdb, keys are revisions.
// values are actual key-value pairs in backend.
tx := s.store.b.ReadTx()
tx.Lock()
revs, vs := tx.UnsafeRange(keyBucketName, minBytes, maxBytes, 0)
evs := kvsToEvents(wg, revs, vs)
tx.Unlock()
var victims watcherBatch
wb := newWatcherBatch(wg, evs)
for w := range wg.watchers {
w.minRev = curRev + 1
eb, ok := wb[w]
if !ok {
// bring un-notified watcher to synced
s.synced.add(w)
s.unsynced.delete(w)
continue
}
if eb.moreRev != 0 {
w.minRev = eb.moreRev
}
if w.send(WatchResponse{WatchID: w.id, Events: eb.evs, Revision: curRev}) {
pendingEventsGauge.Add(float64(len(eb.evs)))
} else {
if victims == nil {
victims = make(watcherBatch)
}
w.victim = true
}
if w.victim {
victims[w] = eb
} else {
if eb.moreRev != 0 {
// stay unsynced; more to read
continue
}
s.synced.add(w)
}
s.unsynced.delete(w)
}
s.addVictim(victims)
vsz := 0
for _, v := range s.victims {
vsz += len(v)
}
slowWatcherGauge.Set(float64(s.unsynced.size() + vsz))
return s.unsynced.size()
}- 根据curRev选出一组待处理的watcherGroup
- 去store里面根据当前版本取出一组events
- 尝试发送这些events,如果发送出去了,则从unsynced里面移除,加到synced里面,发送不出去则将这些events放到victim里面
小结
Watch整体实现的流程还是挺长,这里只是介绍了一些主要的部分,理清了消息传递在各个chan传递的流程以及chan满了之后的一些逻辑。如果想深入了解,可以继续阅读源码。
Ref
- https://mp.weixin.qq.com/s?__biz=MzIyMzM5OTc2NA==&mid=2247483788&idx=1&sn=0eef59a0398be16cf4bd0e6c414354db&chksm=e81f9bb7df6812a1463e6d0c3c3d5a705d95444d8c551800411df8a333742dd93aa772a7b9eb&scene=178&cur_album_id=1341064230149373953#rd
- https://www.jianshu.com/p/1496228df9a9
- https://draveness.me/etcd-introduction/
- https://youjiali1995.github.io/raft/etcd-raft-leader-election/
nsq其它组件分析
nsq其它组件分析
消息持久化
nsq里面不管是topic或者是channel都会有一个memoryMsgChan,当这个chan里面达到预设的值的时候会进行刷盘。
for msg := range c.incomingMsgChan {
select {
case c.memoryMsgChan <- msg:
default:
err := WriteMessageToBackend(&msgBuf, msg, c.backend)
if err != nil {
// ... handle errors ...
}
}
}
可以具体看下writeMessageToBackend这个方法里头的实现
func writeMessageToBackend(buf *bytes.Buffer, msg *Message, bq BackendQueue) error {
buf.Reset()
_, err := msg.WriteTo(buf)
if err != nil {
return err
}
return bq.Put(buf.Bytes())
}
这里会从buf pool里面去申请buf,重用pool的目的是为了减少GC的压力,bufPool的代码也很简单,实现主要是靠sync.Pool。BackendQueue这里是一个interface,可以具体看diskqueue里面是如何实现这些方法的。
func (d *diskQueue) Put(data []byte) error {
d.RLock()
defer d.RUnlock()
if d.exitFlag == 1 {
return errors.New("exiting")
}
d.writeChan <- data
return <-d.writeResponseChan
}
diskqueue在New的时候会去开启一个ioLoop,在ioLoop里面有一个writeChan去监听,然后再去调用writeOne将消息写进文件里面。
磁盘文件里的信息是通过readChan发送给topic里头的channel的,当有消息可读的时候会把buf发送给backendChan。
if (d.readFileNum < d.writeFileNum) || (d.readPos < d.writePos) {
if d.nextReadPos == d.readPos {
dataRead, err = d.readOne()
if err != nil {
d.logf(ERROR, "DISKQUEUE(%s) reading at %d of %s - %s",
d.name, d.readPos, d.fileName(d.readFileNum), err)
d.handleReadError()
continue
}
}
r = d.readChan
} else {
r = nil
}
然后topic里面的messagePump会把buf decode成为msg,再发送给各个channel。
case buf = <-backendChan:
msg, err = decodeMessage(buf)
if err != nil {
t.ctx.nsqd.logf(LOG_ERROR, "failed to decode message - %s", err)
continue
}
goroutine管理
新起一个goroutine很容易,但是清理goroutine却比较费劲。通常我们在起一个goroutine之后需要明确知道该goroutine的生命周期,不然就可能会造成memory leak。nsq是使用WaitGroupWrapper去管理所有的goroutine的,可以看看具体实现。
type WaitGroupWrapper struct {
sync.WaitGroup
}
func (w *WaitGroupWrapper) Wrap(cb func()) {
w.Add(1)
go func() {
cb()
w.Done()
}()
}
// can be used as follows:
wg := WaitGroupWrapper{}
wg.Wrap(func() { n.idPump() })
...
wg.Wait()
正确的goroutine关闭时应该做以下几件事情:
- 关闭所有连接 (close listeners)
- 将exit chan发送给所有的子携程
- 等待子携程结束
- 恢复缓冲数据
- 刷盘操作
func (n *NSQD) Exit() {
if n.tcpListener != nil {
n.tcpListener.Close()
}
if n.httpListener != nil {
n.httpListener.Close()
}
if n.httpsListener != nil {
n.httpsListener.Close()
}
n.Lock()
err := n.PersistMetadata()
if err != nil {
n.logf(LOG_ERROR, "failed to persist metadata - %s", err)
}
n.logf(LOG_INFO, "NSQ: closing topics")
for _, topic := range n.topicMap {
topic.Close()
}
n.Unlock()
close(n.exitChan)
n.waitGroup.Wait()
n.dl.Unlock()
}
在nsq的Exit函数中可以看到上面的操作,其中close(n.exitChan)会在三个子grroutine中去关闭当前的goroutine,所有的topic和channel信息将会被写进磁盘中,如果channel中还有未发送的msg,channel会调用flush方法将其写进磁盘中。
GC优化
golang的gc原理这里就不展开了,减少gc压力最重要的一条原则是the less garbage you create the less time you’ll collect.。在nsqadmin中可以查看gc的一些具体数值。
对一些hotcode做benchmark test总结出来几条经验
- 避免[]byte到string的转换,这种操作需要重新分配内存
- 尽可能重用buffers或者对象,可参考buff pool
- 创建slice的时候需要知道slice的大小,避免append操作
- 给连接发送消息的时候尽量做一些限制,比如mesage的size大小
- 避免使用一些无意义的结构体,类似interface{}或是一些有多个值的go chan
- 避免使用defer,defer会分配额外的内存,所有的逻辑尽量在预期的逻辑里写好
《深入理解linux内核》笔记-进程
《深入理解linux内核》笔记-进程
定义
从内核观点看,进程的目的就是担当分配系统资源(CPU 时间、内存等)的实体。
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
执行线程,简称线程(thread),是在进程中活动的对象。每个线程都拥有-一个独立的程序计数器、进程栈和一组进程寄存器。内核调度的对象是线程,而不是程。在传统的Unix系统中,一个进程只包含一个线程,但现在的系统中,包含多个线程的多线程程序司空见惯。
进程描述符
为了管理进程,内核必须对每个进程所做的事情进行清楚的描述。例如,内核必须知道进程的优先级,它是正在CPU.上运行还是因某些事件而被阻塞,给它分配了什么样的地址空间,允许它访问哪个文件等等。这正是进程描述符(process descriptor) 的作用。
进程状态
- 可运行状态(TASK_RUNNING)进程要么在CPU上执行,要么准备执行。
- 可中断的等待状态(TASK_INTERRUPTIBLE)进程被挂起(睡眠),直到某个条件变为真。产生一个硬件中断,释放进程正等待的系统资源,或传递一个信号都是可以唤醒进程的条件(把进程的状态放回到TASK_RUNNING) 。
- 不可中断的等待状态(TASK_UNINTERRUPTIBLE)与可中断的等待状态类似,但有一个例外,把信号传递到睡眠进程不能改变它的状态。这种状态很少用到,但在一些特定的情况下(进程必须等待,直到-一个不能被中断的事件发生),这种状态是很有用的。例如,当进程打开一个设备文件,其相应的设备驱动程序开始探测相应的硬件设备时会用到这种状态。探测完成以前,设备驱动程序不能被中断,否则,硬件设备会处于不可预知的状态。
- 暂停状态(TASK_STOPPED)进程的执行被暂停。当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU信号后,进入暂停状态。
- 跟踪状态(TASK_TRACED) 进程的执行已由debugger程序暂停。当一个进程被另一个进程监控时(例如debugger执行ptrace()系统调用监控- -个测试程序),任何信号都可以把这个进程置于TASK_ TRACED 状态。
- 僵死状态(EXIT_ZOMBIE)进程的执行被终止,但是,父进程还没有发布wait4()或waitpid()系统调用来返回有关死亡进程的信息。发布wait()类系统调用前,内核不能丟弃
- 僵死撤消状态(EXIT_DEAD)最终状态:由于父进程刚发出wait4 ()或waitpid()系统调用,因而进程由系统删除。为了防止其他执行线程在同一个进程上也执行wait()类系统调用(这是一种竞争条件),而把进程的状态由僵死(EXIT_ZOMBIE)状态改为僵死撤消状态(EXIT_DEAD)。
对应在Top命令的输出中:
- R -> RUNNING
- D 是 Disk Sleep 的缩写,也就是不可中断状态睡眠 TASK_UNINTERRUPTIBLE
- Z -> EXIT_ZOMBIE
- S -> Interruptible Sleep也就是TASK_INTERRUPTIBLE
- T -> Stop
- S -> EXIT_DEAD
- I -> TASK_IDLE(Linux 4.14 kernel之后引入),表示空闲
一般来说,能被独立调度的每个执行上下文都必须拥有它自己的进程描述符;因此,即使共享内核大部分数据结构的轻量级进程,也有它们自己的task_struct结构。
在 Linux 中每一个进程都由 task_struct 数据结构来定义。task_struct 就是我们通常所说的 PCB。
进程链表把所有进程的描述符链接起来。每个task_struct 结构都包含一个list_head 类型的tasks字段,这个类型的prev和next字段分别指向前面和后面的task_struct元素。
**进程链表的头是init_task 描述符,它是所谓的0进程(process 0)**或swapper进程的进程描述符。init_task的tasks.prev字段指向链表中.最后插入的进程描述符的tasks字段。
程序创建的进程具有父1子关系。如果一个进程创建多个子进程时,则子进程之间具有兄弟关系。
等待队列惊群效应
在Linux内核中等待队列有很多用途,可用于中断处理、进程同步及定时。
要唤醒等待队列中所有睡眠的进程有时并不方便。例如,如果两个或多个进程正在等待互斥访问某一要释放的资源,仅唤醒等待队列中的一个进程才有意义。这个进程占有资源,而其他进程继续睡眠。(惊群问题)
因此,有两种睡眠进程:互斥进程(等待队列元素的flags字段为1)由内核有选择地唤醒,而非互斥进程(falgs值为0)总是由内核在事件发生时唤醒。等待访问临界资源的进程就是互斥进程的典型例子。等待相关事件的进程是非互斥的。例如,我们考虑等待磁盘传输结束的一组进程: 一但磁盘传输完成,所有等待的进程都会被唤醒。
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换(process switch)、任务切换(task switch)或上下文切换(contextswitch)。
进程切换只发生在内核态。在执行进程切换之前,用户态进程使用的所有寄存器内容都已保存在内核态堆栈上。
从本质上说,每个进程切换由两步组成:
- 切换页全局目录以安装一个新的地址空间;
- 切换内核态堆栈和硬件上下文,因为硬件上下文提供了内核执行新进程所需要的所有信息,包含CPU寄存器。
进程切换的关键操作无非就是切换地址空间、切换内核堆栈、切换内核控制流程以及必要寄存器的现场保护与还原。
进程创建
传统的Unix操作系统以统--的方式对待所有的进程:子进程复制父进程所拥有的资源。这种方法使进程的创建非常慢且效率低,因为子进程需要拷贝父进程的整个地址空间。实际上,子进程几乎不必读或修改父进程拥有的所有资源,在很多情况下,子进程立即调用execve(),并清除父进程仔细拷贝过来的地址空间。
现代Unix内核通过引入三种不同的机制解决了这个问题:
- **写时复制技术(COW)**允许父子进程读相同的物理页。只要两者中有一个试图写一个物理页,内核就把这个页的内容拷贝到一个新的物理页,并把这个新的物理页分配给正在写的进程。
- 轻量级进程允许父子进程共享每进程在内核的很多数据结构,如页表(也就是整个用户态地址空间)、打开文件表及信号处理。
- vfork()系统调用创建的进程能共享其父进程的内存地址空间。为了防止父进程重写子进程需要的数据,阻塞父进程的执行,一直到子进程退出或执行一个新的程序为止。
clone()、fork()及vfork()系统调用
clone的完整函数如下:
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);- fn 指定一个由新进程执行的函数。当这个函数返回时,子进程终止。函数返回一个整数,表示子进程的退出代码。
- arg 指向传递给fn()函数的数据。
- flags 各种各样的信息。低字节指定子进程结束时发送到父进程的信号代码,通常选择SIGCHLD信号。剩余的3个字节给一clone标志组用于编码,如表3-8所示。
- child_stack 表示把用户态堆栈指针赋给子进程的esp寄存器。调用进程(指调用clone()的父进程)应该总是为子进程分配新的堆栈。
传统的fork()系统调用在Linux中是用clone()实现的,其中clone()的flags参数指定为SIGCHLD信号及所有清0的clone标志,而它的child_stack参数是父进程当前的堆栈指针。因此,父进程和子进程暂时共享同一个用户态堆栈。但是,要感谢写时复制机制,通常只要父子进程中有一个试图去改变栈,则立即各自得到用户态堆栈的一份拷贝。
vfork创建的子进程与父进程共享数据段,而且由vfork()创建的子进程将先于父进程运行
-
由vfork创造出来的子进程还会导致父进程挂起,除非子进程exit或者execve才会唤起父进程
-
由vfok创建出来的子进程共享了父进程的所有内存,包括栈地址,直至子进程使用execve启动新的应用程序为止
-
由vfork创建出来得子进程不应该使用return返回调用者,或者使用exit()退出,但是它可以使用_exit()函数来退出
内核线程
线程定义:
Linux实现线程的机制非常独特。从内核的角度来说,它并没有线程这个概念。Linux 把所有的线程都当做进程来实现。内核并没有准备特别的调度算法或是定义特别的数据结构来表征线程。相反,线程仅仅被视为一个与其他进程共享某些资源的进程。每个线程都拥有唯一隶属于自己的task_struct, 所以在内核中,它看起来就像是一个普通的进程(只是线程和其他一些进程共享某些资源,如地址空间)。
在 Linux 的实现中,task_struct 结构体中除了存在一个 pid 字段之外还存在一个 tgid 字段,也就是线程组的概念。从上一小节的第三点中我们知道,当一个进程创建为 普通的进程的时候,pid 和 tgid 属于同一个值,也就是说它属于一个只包含它自己的 线程组。但是从一个进程派生一个线程(比如通过 pthread_create() 函数)的时候, 新产生的 task_struct 会分配到一个新的 pid,但是它的 tgid 和它的父进程保持 一致,这样一来子进程(线程)就加入到了父进程的线程组中
传统的Unix系统把一些重要的任务委托给周期性执行的进程,这些任务包括刷新磁盘高速缓存,交换出不用的页框,维护网络连接等等。事实上,以严格线性的方式执行这些任务的确效率不高,如果把它们放在后台调度,不管是对它们的函数还是对终端用户进程都能得到较好的响应。因为一些系统进程只运行在内核态,所以现代操作系统把它们的函数委托给内核线程(kernel thread),内核线程不受不必要的用户态上下文的拖累。
进程0
所有进程的祖先叫做进程0,idle进程或因为历史的原因叫做swapper进程,它是在Linux的初始化阶段从无到有创建的一个内核线程。
在多处理器系统中,每个CPU都有一个进程0。只要打开机器电源,计算机的BIOS就启动某一个CPU,同时禁用其他CPU。运行在CPU0上的swapper进程初始化内核数据结构,然后激活其他的CPU,并通过copy_process()函数创建另外的swapper进程,
把0传递给新创建的swapper进程作为它们的新PID。此外,内核把适当的CPU索引赋给内核所创建的每个进程的thread_info描述符的cpu字段。
进程1
由进程0创建的内核线程执行init()函数,init()依次完成内核初始化。init()调用execve()系统调用装入可执行程序init。 结果,init内核线程变为一个普通进程,且拥有自己的每进程(per-process) 内核数据结构(参见第二十章)。在系统关闭之前,init进程一直存活,因为它创建和监控在操作系统外层执行的所有进程的活动。
撤销进程
进程终止的一般方式是调用exit()库函数,该函数释放C函数库所分配的资源,执行编程者所注册的每个函数,并结束从系统回收进程的那个系统调用。exit ()函数可能由编程者显式地插入。另外,C编译程序总是把exit ()函数插人到main()函数的最后一条语句之后。
在Linux2.6中有两个终止用户态应用的系统调用:
- exit_group() 系统调用,它终止整个线程组,即整个基于多线程的应用。do_group exit()是实现这个系统调用的主要内核函数。这是C库函数exit ()应该调用的系统调用。
- exit()系统调用,它终止某一个线程,而不管该线程所属线程组中的所有其他进程。do_exit() 是实现这个系统调用的主要内核函数。这是被诸如pthread_exit()的Linux线程库的函数所调用的系统调用。
孤儿进程:
如果父进程在子进程之前退出,必须有机制来保证子进程能找到-一个新的父亲,否则这些成为孤儿的进程就会在退出时永远处于僵死状态,白白地耗费内存。前面的部分已经有所暗示,对于这个问题,解决方法是给子进程在当前线程组内找-一个线程作为父亲,如果不行,就让init做它们的父进程。
暂时没有太多危害
僵尸进程
当一个子进程结束运行(一般是调用exit、运行时发生致命错误或收到终止信号所导致)时,子进程的退出状态(返回值)会回报给操作系统,系统则以SIGCHLD信号将子进程被结束的事件告知父进程,此时子进程的进程控制块(PCB)仍驻留在内存中。一般来说,收到SIGCHLD后,父进程会使用wait系统调用以获取子进程的退出状态,然后内核就可以从内存中释放已结束的子进程的PCB;而如若父进程没有这么做的话,子进程的PCB就会一直驻留在内存中,也即成为僵尸进程
解决方案:
- 父进程调用wait或waitpid
- SIGCHLD处理函数
HTTP Client & Server 的Keep Alive 策略
HTTP Client & Server 的Keep Alive 策略
Background
由于线上存在网络问题,会导致GRPC HOL blocking, 于是决定把GRPC client改写成HTTP client。
改写HTTP client的过程还算顺利,但是搜索日志里面会发现有极少数的EOF错误。
call xxx failed: Post "http://localhost:8080": EOF
EOF这个东西一般是跟 IO 关闭有关系的,Google了下相关的错误,在stackoverflow找到相关的参考
Go by default will send requests with the header Connection: Keep-Alive and persist connections for re-use. The problem that I ran into is that the server is responding with Connection: Keep-Alive in the response header and then immediately closing the connection.
粗略看了下,问题很清晰,就是server和client的Keep-Alive机制的问题,去看下client和serve的设置参数再去调下应该就可以解决问题。
Keep-Alive parameter
HTTP Client
线上在使用的http.Client的参数如下:
func main() {
c := &http.Client{
Transport: &http.Transport{
MaxIdleConnsPerHost: 1,
DialContext: (&net.Dialer{
Timeout: time.Second * 2,
KeepAlive: time.Second * 60,
}).DialContext,
DisableKeepAlives: false,
IdleConnTimeout: 90 * time.Second,
},
Timeout: time.Second * 2,
}
// c := &http.Client{}
// sendRequest(c)
}-
Dial中的
DisableKeepAlives为开启状态 -
KeepAlive: 官方文档介绍是一个用于
TCP Keep-Alive的probe指针,间隔一定的时间发送心跳包。每间隔60S进行一次Keep-Alive
type Dialer struct {
...
// KeepAlive specifies the interval between keep-alive
// probes for an active network connection.
// If zero, keep-alive probes are sent with a default value
// (currently 15 seconds), if supported by the protocol and operating
// system. Network protocols or operating systems that do
// not support keep-alives ignore this field.
// If negative, keep-alive probes are disabled.
KeepAlive time.Duration
...
}HTTP Server
线上在使用的http server的参数
func main() {
s := http.Server{
Addr: ":8080",
Handler: http.HandlerFunc(Index),
ReadTimeout: 10 * time.Second,
// IdleTimeout: 10 * time.Second,
}
s.SetKeepAlivesEnabled(true)
s.ListenAndServe()
}- Server的
KeepAlive主要是通过IdleTimeout来进行控制的,IdleTimeout如果为空则使用ReadTimeout
type Server struct {
...
// IdleTimeout is the maximum amount of time to wait for the
// next request when keep-alives are enabled. If IdleTimeout
// is zero, the value of ReadTimeout is used. If both are
// zero, there is no timeout.
IdleTimeout time.Duration
...
}Debug again
可以看到,client侧的Keep-Alive是60s,但是server侧的时间是间隔10s就去关掉空闲的连接。所以这里很容易就认为是:client侧的Keep-Alive心跳间隔时间太长了,server侧提前关闭了连接。
于是作出更改:调整client Keep-Alive为1s,这个时候感觉就不会出现EOF的错误了。
于是修改参数,重新上线,持续观察一段时间发现还是有EOF错误。看来只有进行本地复现看看究竟发生了什么。
Reproduce
Mock EOF
在尝试复现EOF错误的时候,看到有Hijack这种东西,还是挺好用的。可以看到直接在server侧关掉连接, client侧感知不到连接关闭确实是会有EOF错误发生的。
func test(w http.ResponseWriter, r *http.Request) {
log.Println("receive request from:", r.RemoteAddr, r.Header)
if count%2 == 1 {
conn, _, err := w.(http.Hijacker).Hijack()
if err != nil {
return
}
conn.Close()
count++
return
}
w.Write([]byte("ok"))
count++
}
func main() {
s := http.Server{
Addr: ":8080",
Handler: http.HandlerFunc(test),
ReadTimeout: 10 * time.Second,
}
// s.SetKeepAlivesEnabled(false)
s.ListenAndServe()
}EOF的原因知道了,在这里应该就是Server侧主动关闭了连接,至于为什么关闭连接,可以再继续往下看
Mock Keep-Alive
然后先在本地开始尝试复现Keep-Alive的问题,client侧使用KeepAlive: time.Second,每间隔一秒钟的keep-alive, server侧同样使用两秒IdleTimeout: time.Second 。
Client侧代码的Keep-Alive
func sendRequest(c *http.Client) {
req, err := http.NewRequest("POST", "http://localhost:8080", nil)
if err != nil {
panic(err)
}
resp, err := c.Do(req)
if err != nil {
panic(err)
}
defer resp.Body.Close()
buf := &bytes.Buffer{}
buf.ReadFrom(resp.Body)
}
func main() {
c := &http.Client{
Transport: &http.Transport{
MaxIdleConnsPerHost: 1,
DialContext: (&net.Dialer{
Timeout: time.Second * 2,
KeepAlive: time.Second,
}).DialContext,
DisableKeepAlives: false,
IdleConnTimeout: 90 * time.Second,
},
Timeout: time.Second * 2,
}
// c := &http.Client{}
sendRequest(c)
time.Sleep(time.Second * 3)
sendRequest(c)
}Server侧的代码:
func echo(w http.ResponseWriter, r *http.Request) {
log.Println("receive a request from:", r.RemoteAddr, r.Header)
w.Write([]byte("ok"))
}
func main() {
var s = http.Server{
Addr: ":8080",
Handler: http.HandlerFunc(echo),
IdleTimeout: time.Second * 2,
}
s.ListenAndServe()
}理论上来讲,client间隔一秒发送probe,server的idle为两秒是不会关闭连接的,但是实际却是关闭了旧的连接,重新创建了新的连接。
Server侧输出:
➜ http-client-server go run http-server-simple.go
2021/08/07 19:46:47 receive a request from: [::1]:53196 map[Accept-Encoding:[gzip] Content-Length:[0] User-Agent:[Go-http-client/1.1]]
2021/08/07 19:46:50 receive a request from: [::1]:53197 map[Accept-Encoding:[gzip] Content-Length:[0] User-Agent:[Go-http-client/1.1]]
抓包分析
结果有些出乎意料,因为是在本地进行代码复现的,所以去看下抓包分析结果。
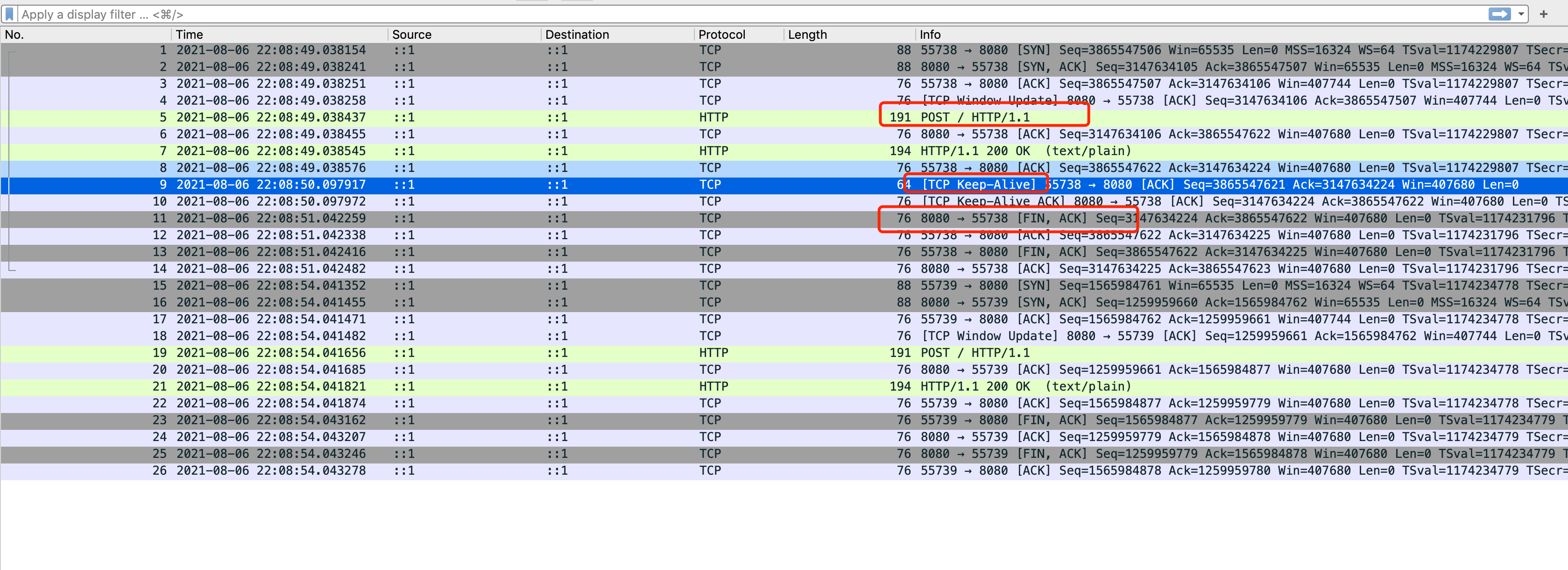
Client使用的基于TCP层面的Keep-alive协议,针对的是整条TCP连接Server侧明显是基于应用层协议做的判断
所以初步的结论就是两者的Keep-Alive是工作在不同层面,让人产生了误解。
源码分析
Client
Client侧的代码在net/dial.go里面,主要进行Keep-Alive 的逻辑如下
func (d *Dialer) DialContext(ctx context.Context, network, address string) (Conn, error) {
...
if tc, ok := c.(*TCPConn); ok && d.KeepAlive >= 0 {
setKeepAlive(tc.fd, true)
ka := d.KeepAlive
if d.KeepAlive == 0 {
ka = defaultTCPKeepAlive
}
setKeepAlivePeriod(tc.fd, ka)
testHookSetKeepAlive(ka)
}
...
}
func setKeepAlivePeriod(fd *netFD, d time.Duration) error {
// The kernel expects seconds so round to next highest second.
secs := int(roundDurationUp(d, time.Second))
if err := fd.pfd.SetsockoptInt(syscall.IPPROTO_TCP, syscall.TCP_KEEPINTVL, secs); err != nil {
return wrapSyscallError("setsockopt", err)
}
err := fd.pfd.SetsockoptInt(syscall.IPPROTO_TCP, syscall.TCP_KEEPIDLE, secs)
runtime.KeepAlive(fd)
return wrapSyscallError("setsockopt", err)
}上面的代码可以看到,最后调用的是SetsockoptInt,这个函数就不在这具体的展开了,本质上来讲Client侧是在TCP 4层让OS来帮忙进行的Keep-Alive。
因为网络的环境是比较复杂的,有很多的请求是跨LB进行的,比如AWS的ELB之类的,所以这个keep-alive在这里也显得合理。
Server
Server侧的代码在 net/http/server.go里:
func (c *conn) serve(ctx context.Context) {
...
defer func() {
if !c.hijacked() {
c.close()
c.setState(c.rwc, StateClosed, runHooks)
}
}
for {
w, err := c.readRequest(ctx)
...
serverHandler{c.server}.ServeHTTP(w, w.req)
...
if d := c.server.idleTimeout(); d != 0 {
c.rwc.SetReadDeadline(time.Now().Add(d))
if _, err := c.bufr.Peek(4); err != nil {
return
}
}
}
...
}简单的说明下, defer 就是关闭连接用的,当函数退出的时候server会关闭连接。
for循坏是处理连接请求用的,可以看出来HTTP server本身其实是不支持处理多个请求的,并没有实现HTTP 1.1协议中的Pipeline。
然后再看keep-alive的操作,先设置ReadDeadline,然后调用c.bufr.Peek这里的调用流程比较长,其实最后会落到conn.Read,本质上是一个阻塞操作。然后开始等待bufr里面的数据,如果client在这个时间段没有发送数据过来,则会退出for循环然后关闭连接。
conclusion
所以在上述的场景下想要reuse一个conn主要还是取决于server 侧的idleTimeout。如果没收到client发送的请求是会主动发送fin包进行close的。
Fix
Retry
其实解决方案有很多种,在这里线上采用的是客户端进行重试。这里引申一下,像上面这种错误,如果是GET,HEAD等一些幂等操作的话,client代码库会自动进行重试。我们线上使用的是POST, 所以直接在业务侧进行重试。
Increase IdleTimeout
另外一个解决方案就是增加server的IdleTimeout,但是这样一来会消耗更多的server资源。
Short-lived conn
还有一种方法就是短连接,这样对server的资源浪费就减轻了,但是不能重用连接。整体latency会受到影响。
GIL初识
Python之GIL
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython's memory management is not thread-safe.
GIL就是全局解释锁,确保只有一条线程在Python虚拟机中的解释器中执行。
Python Thread
线程是内核调度的最小单位。
On a multiprocessor or multi-core system, multiple threads can execute in parallel, with every processor or core executing a separate thread simultaneously
- 多线程并发与并行:
- 并发是在同一个处理器中进行上下文切换,时间线上并不会进行重叠
- 并行指的是在不同的处理器中两条或及以上的线程在时间性上重叠的进行
- Python的线程是kernel level的线程(pthread, windows thread),由操作系统调度
- Python解释器执行的单位是线程级的
GIL初识
- GIL不允许线程并行
- GIL确保只有一条线程在解释器中执行
- 使用GIL不用关注许多底层的系统操作
- 一条线程运行的时候获得GIL锁,进行IO等待的时候释放GIL锁,切换到另一条线程
GIL锁
GIL锁由三个部分组成
- locked表示锁定状态
- mutex表示pthread锁
- cond表示pthread状态,或者等待
IO多线程切换
release() {
mutex.acquire()
locked = 0 mutex.release() cond.signal()
}
acquire() {
mutex.acquire()
while (locked) {
cond.wait(mutex)
}
locked = 1
mutex.release()
}
线程切换,当一个线程进行io读写等待时向内核发送一个信号量,释放GIL。内核接到通知后进行上下文切换到下一条线程。
CPU多线程切换
上面简单的示例适用于单核IO操作较为密集的场景,当我们需要用到CPU较为密集的计算时。GIL会十分影响性能
在多核操作系统上,线程的调度在不同的核心上是可以同时进行的,同时去竞争GIL锁,这就表示了多线程此时是不可能在多核上并行的。

线程2会一直的尝试去获取GIL,但是当其被唤醒时,GIL已经重新被线程一获取了,将永远获取不到
线上GC优化
线上GC优化
Background
之前由于一些业务需要,导致我们需要上线一些endpoint,并逐步开始放量。在放量的过程中发现随着这个endpoint流量的逐渐增加,整个系统的延迟开始增高并伴随着吞吐的下降。于是开始着手一一系列性能分析以及系统调优的工作。
Debug
排除Mutex问题
之前由于整个系统里面读写锁十分密集,所以第一反应是一些资源竞争导致整个系统表现变差。这也是导致系统变慢的常见因素之一。于是抓取了线上的profile以及trace开始进行分析。
线上的block以及mutex并没有太大的变化,只有trace里面可以看到这些groutine的时间片看起来不太正常。
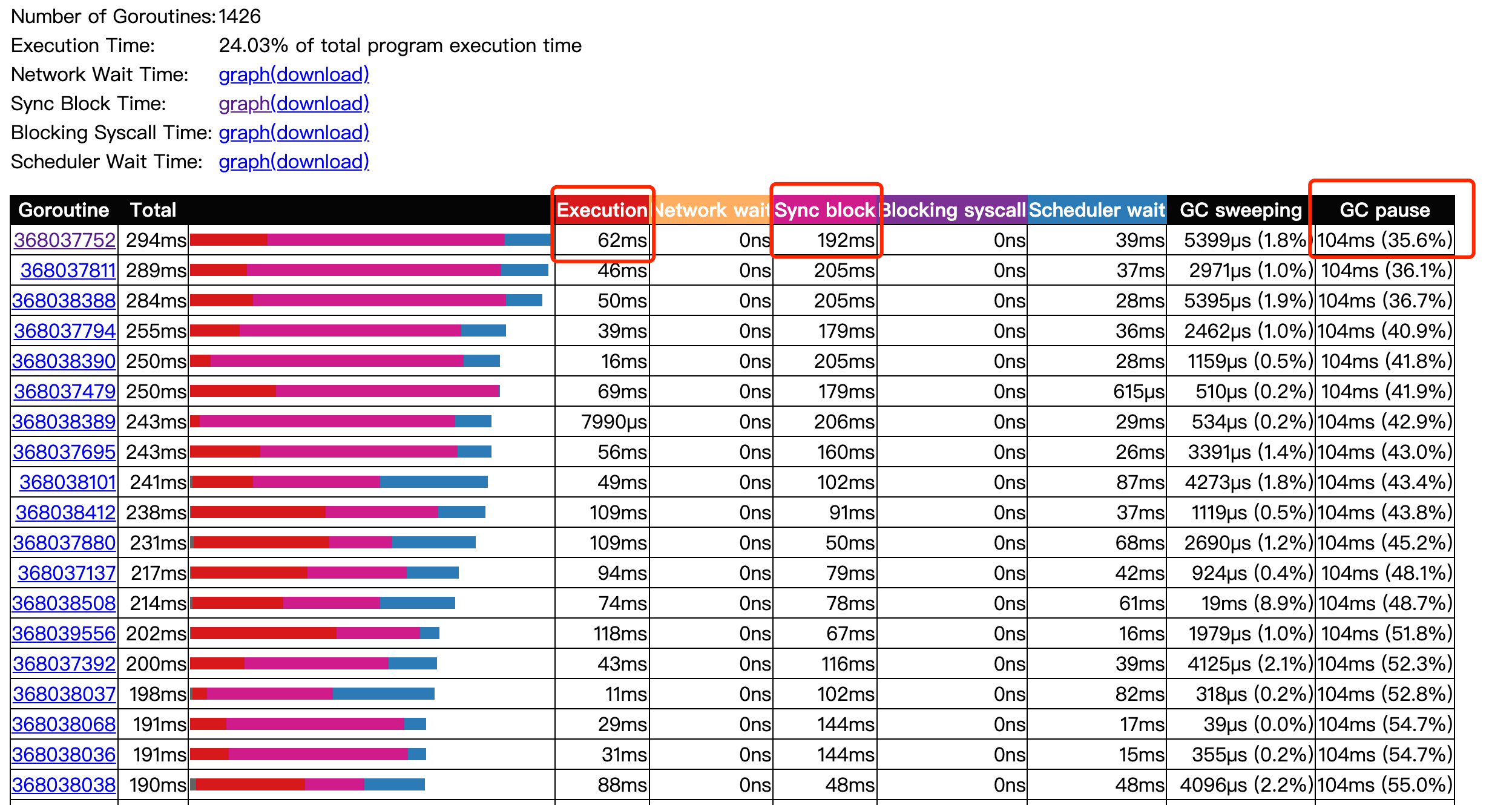
从图中很容易看到368037752这个groutine各个时间片的使用情况
- Total 294ms: 整个goroutine从开始到结束一共花费了294ms
- Execution 62ms: goroutine实际执行时间只有62ms
- Sync block 192ms: 同步阻塞的时间长达192ms(怀疑跟锁有关系,其实并不是)
- Scheduler wait 39ms: 这个goroutine从可执行到真正运行花费了39ms
- GC pause 104ms: 这个goroutine是受GC影响的,整个GC执行了104ms。这里显示的也是104ms。
先看sync block的graph长什么样子。runtime.gcStart也会被认为是一个sync block的事件。所以这里大概率是GC的问题。
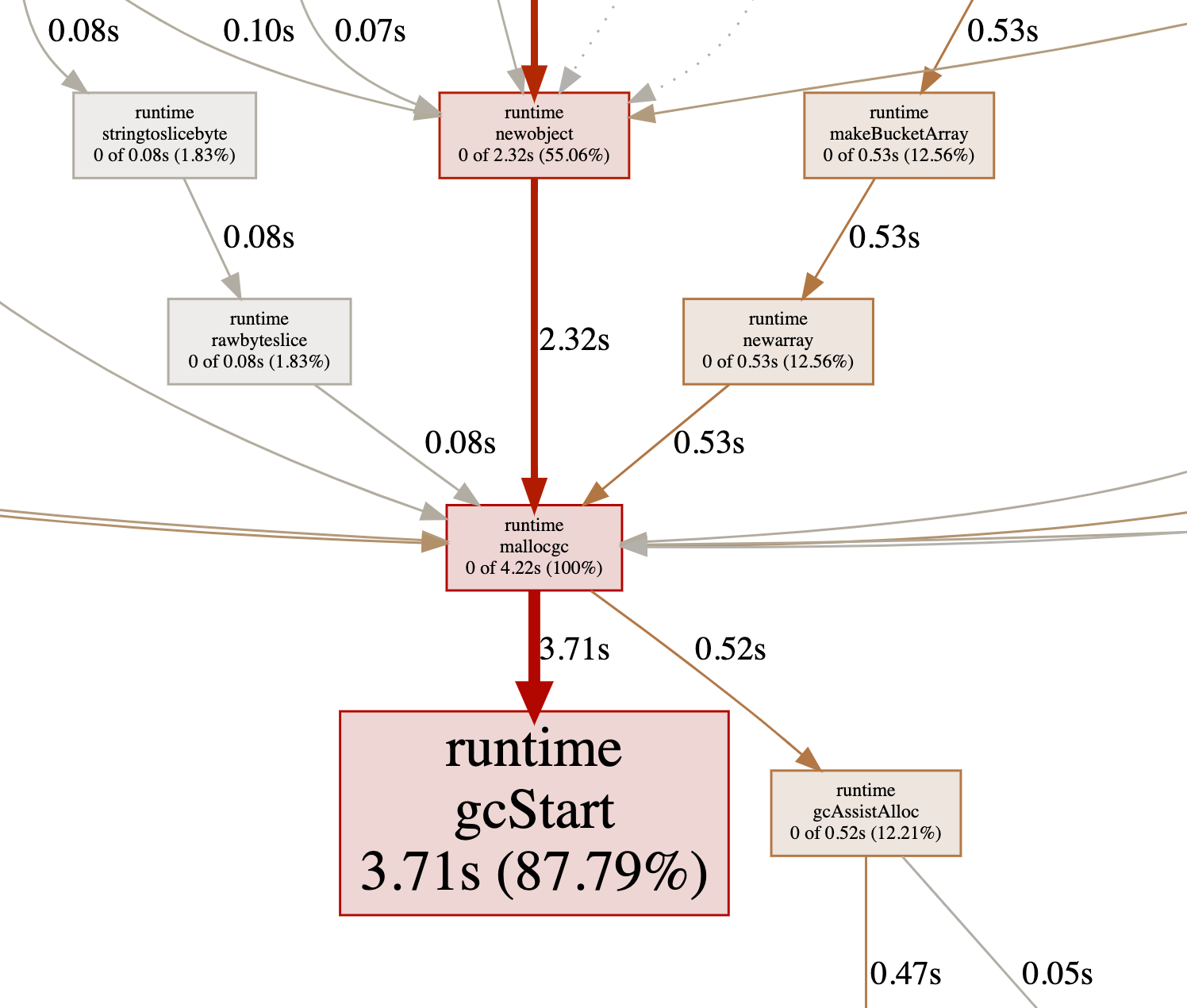
再回过头确认GC pause的问题。点击这个goroutine查看其完整的生命周期。发现104ms其实就是因为GC发生了,导致其没有被调度到,所以pause时间等于整个GC时间。
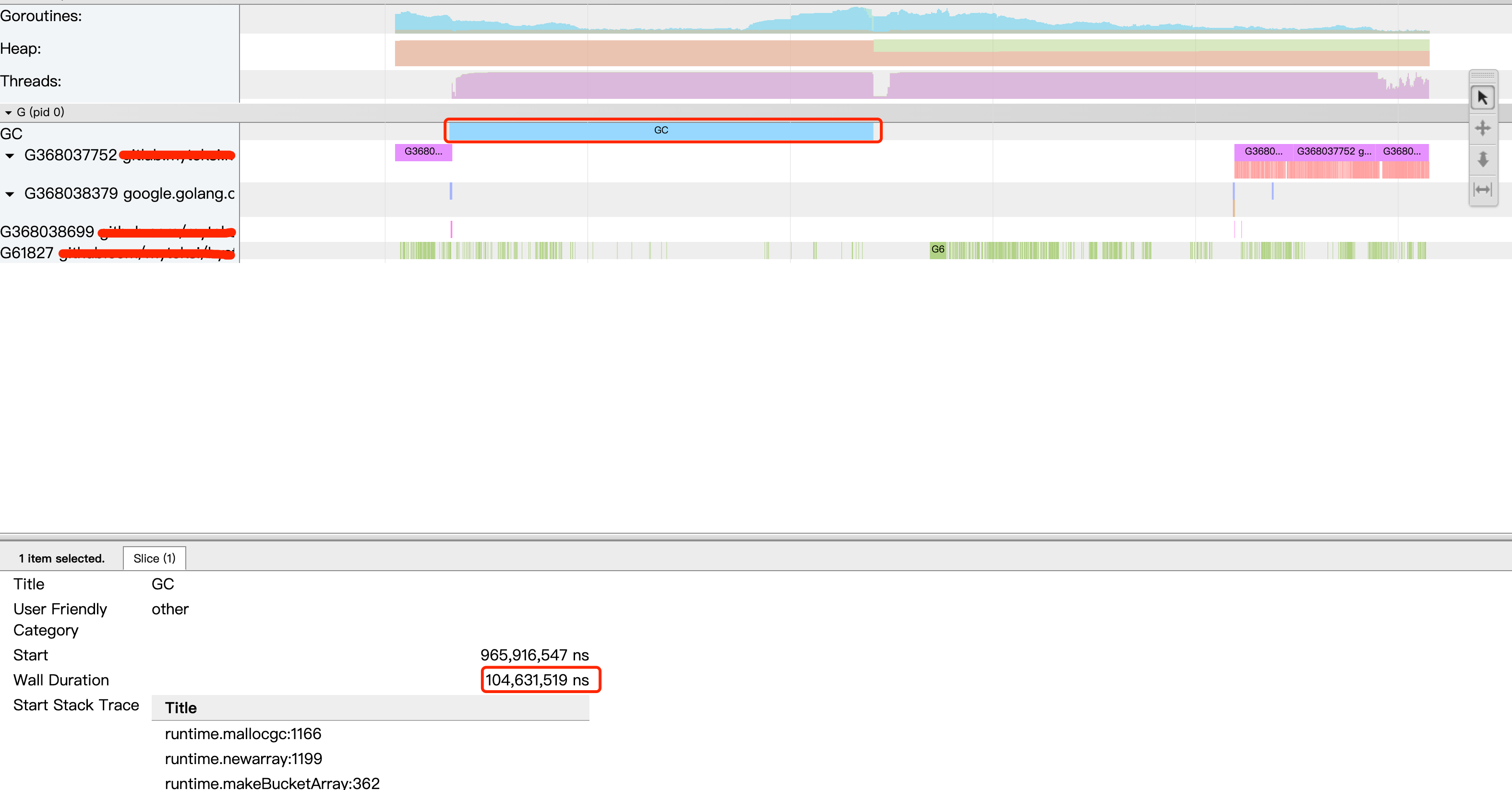
查看当时时间点的负载情况也确实如此,GC的压力比较大,系统可用的时间片不多。
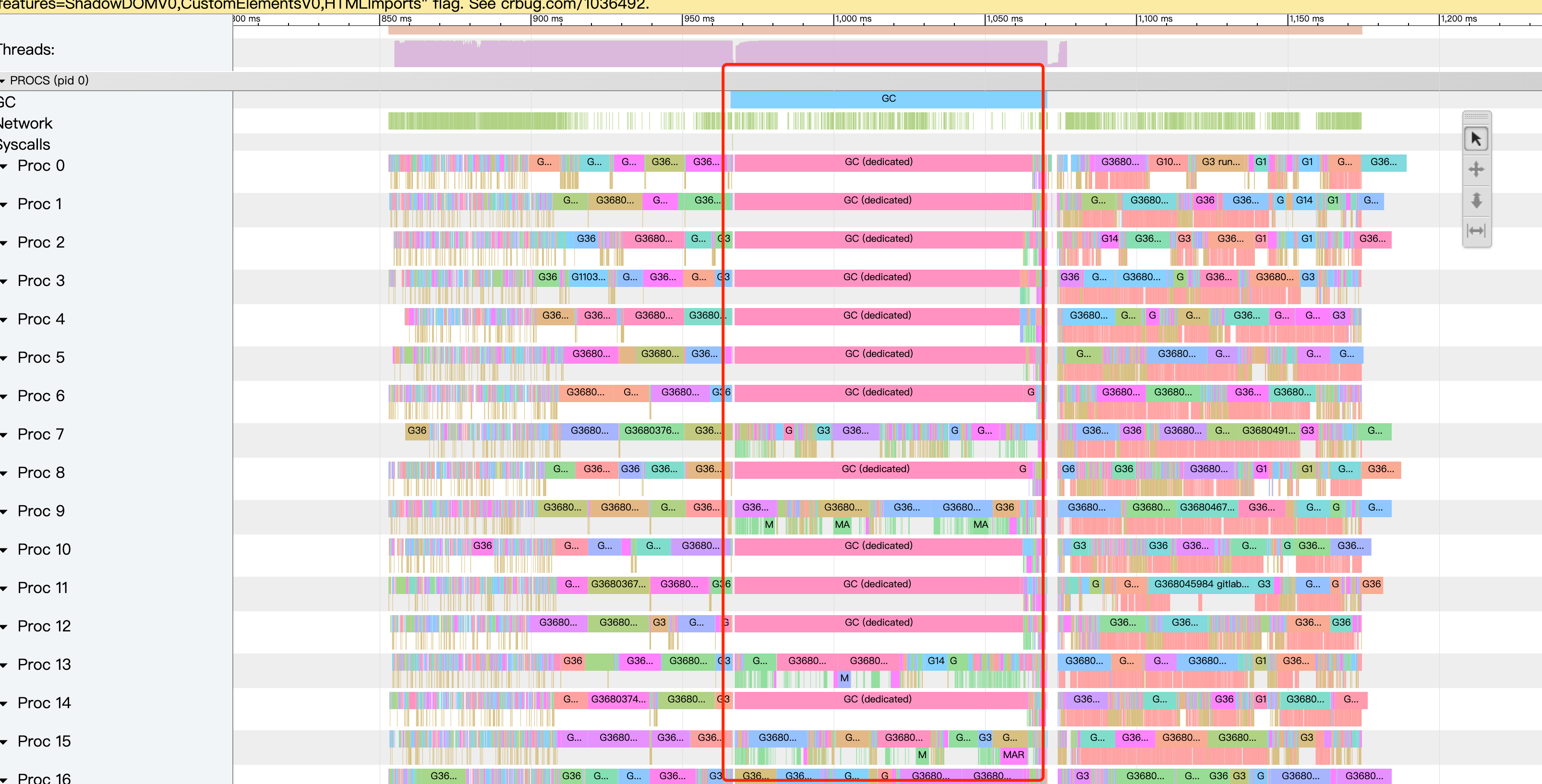
MMU的输出也很明显,当时的系统CPU可用率只有45%,所以会导致很多的goroutine分不到CPU进而造成的长尾问题。
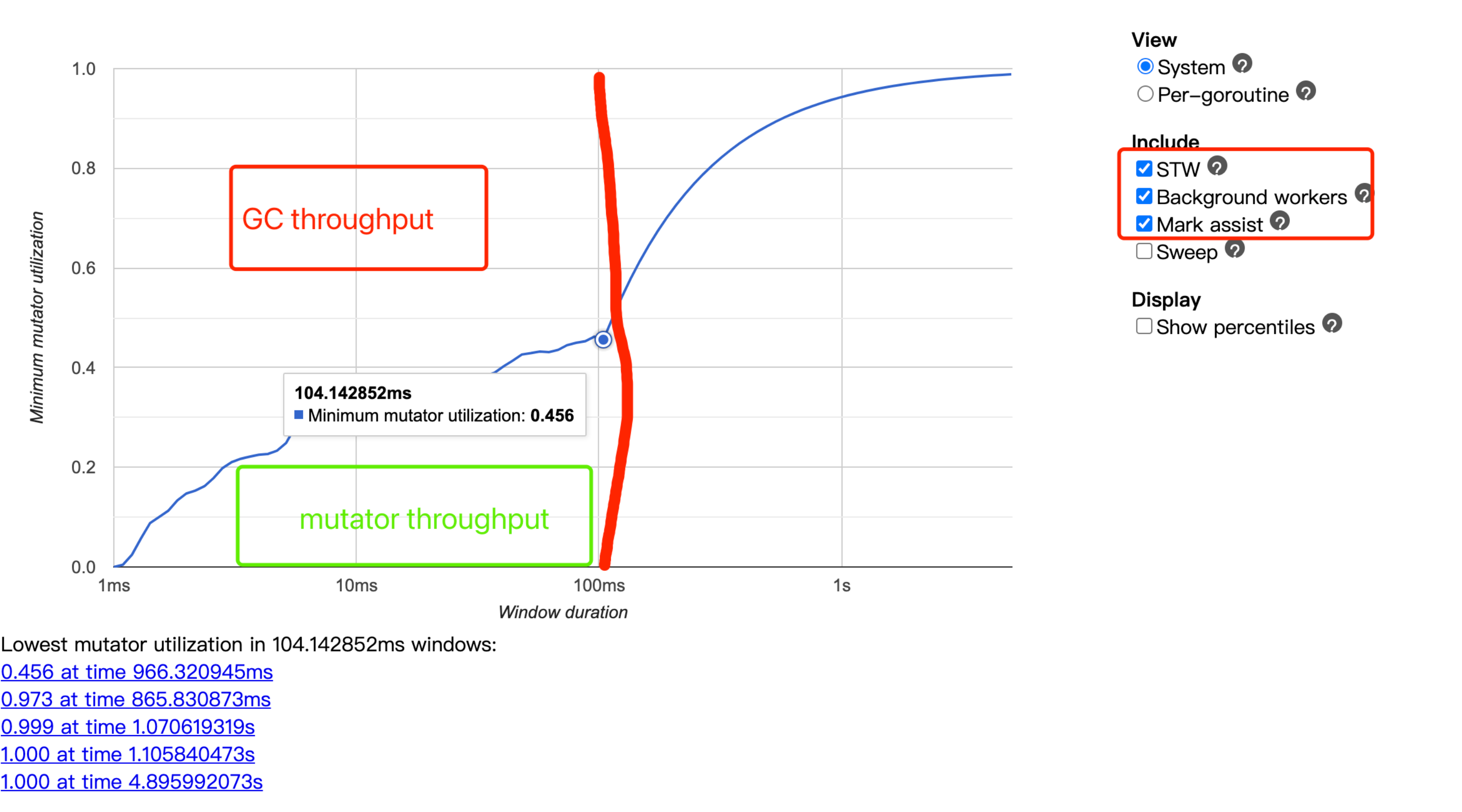
上面的一切信息都说明这是一个因为GC导致的延迟调度的长尾问题。所以接下来就是比较简单,得去分析heap的信息。
Analysis the heap profile
在开始分析profile之前先简单介绍GC的一些概
- GC的mark 时间是只跟活对象(从GCROOT开始扫,有被引用的对象)相关的,所有的死对象是不会引起mark时间增长的。
- GC 触发的三个时间点:
- 到了NextGC的阈值(这里我们只需要考虑这个)
- 2min到了
- 手动触发
有了以上的一些概念,我们再去分析heap。一般的操作基本就是先看inuse objects。 常驻对象其实就是1000w左右,跟我们新加endpoint有关联的对象也就84w左右,整体10%都不到。表现的十分正常。

再看alloc space,起初是没有往这个指标上想的,因为这部分里面大多都应该是被回收的垃圾。但是有个地方明显需要注意的是我们所有的alloc space的大概57%左右,也就是说大约57%的系统垃圾是由这个endpoint制造的。
再观察下GCTRACEE的输出看看这个
gc 12972 @15827.944s 2%: 1.1+67+0.023 ms clock, 54+967/789/1.4+1.1 ms cpu, 6377->6454->3359 MB, 6534 MB goal, 48 P
gc 12973 @15828.949s 2%: 0.20+58+0.086 ms clock, 9.6+980/684/3.6+4.1 ms cpu, 6551->6621->3308 MB, 6718 MB goal, 48 P
gc 12974 @15829.933s 2%: 0.22+74+0.035 ms clock, 10+641/867/94+1.7 ms cpu, 6454->6524->3251 MB, 6616 MB goal, 48 P
上面的输出可以看到,STW的时间不受影响,concurrent mark的时间也比较短。说明整体系统的latency是由于频繁GC造成的。基本上是一秒一次,所以先尝试从减少GC开始。
Zero alloc optimization
其实优化的思路比较简单清晰。从火焰图来看的话无非就是三点
- 减少制造的垃圾(alloc space)速度, 进而减少GC的次数
- 减少制造垃圾(alloc objects)的对象,尽量减少内存分配的开销(如果能将alloc 次数减少,CPU和程序延迟都会随之减少,alloc是由开销的)
- 减少活对象(inuse objects)的数量,使GC的时间尽可能的短
整体优化的核心**很简单,尽量在这个endpoint上做到less alloc或者是zero alloc,减少内存分配带来的压力(包括CPU压力和GC压力)。整体优化完我们线上的CPU(48核 2.5Ghz)优化了10%,这个接口的平均P99延迟由120ms降低到了40ms,效果还是不错的。
我写了个example,模拟了线上的逻辑。
type entry struct {
val int32
}
type pq struct {
// elemIDToIndex record key to array index
elemIDToIndex map[int32]int32
// elements array
elements []int32
cap int32
len int32
}
func newPQ() *pq {
return &pq{
elemIDToIndex: map[int32]int32{},
elements: make([]int32, 16),
cap: 16,
len: 0,
}
}
func (pq *pq) InsertWithData(key, val int32) {
serial := pq.len
pq.elemIDToIndex[key] = serial
if serial == pq.cap {
pq.expand()
}
pq.elements[serial] = val
pq.len++
}
// expand array
func (pq *pq) expand() {
newCap := pq.cap * 2
newElements := make([]int32, newCap, newCap)
copy(newElements, pq.elements)
pq.cap = newCap
pq.elements = newElements
}
type foo struct {}
func callback(key int32, fn func(e *entry) bool) bool {
return fn(&entry{key})
}
func test(pq2 *pq) func(e *entry) bool{
return func(e *entry) bool {
// do something with key
pq2.InsertWithData(e.val, e.val)
return true
}
}
// bar mock endpoint
func (f *foo) bar(i int32) {
// every request insert about 20k elements
pq1 := newPQ()
pq2 := newPQ()
for j := 0; j < 20000; j ++ {
pq1.InsertWithData(i, i + 1)
callback(int32(j), test(pq2))
}
}- pq struct: 模拟的是线上的一个PriorityQueue,elemIDToIndex存储的是key到数组的映射,elements是一个数组,存储所有的数据。
- callback 就是为了模拟匿名函数,会在每个pq insert后执行一下,在匿名函数里面对pq2进行一次插入操作
- bar用来模拟我们线上的endpoint。每个请求会有20000个左右pq的insert操作
Bench的结果如下,每次调用的内存开销还是不少的。
func BenchmarkFoo(b *testing.B) {
b.ReportAllocs()
f := &foo{}
for i := 0; i < b.N; i ++ {
f.bar(int32(i))
}
}
goarch: amd64
cpu: Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz
BenchmarkFoo-12 537 2113537 ns/op 1694561 B/op 40517 allocs/opOptimize case by case
Reuse pq
1694561 B/op 这个数字其实已经可以说是非常大了,这个指标主要会影响GC的次数,所以先看看如何减少这个指标。从最上面的火焰图来看,alloc space最大贡献者是pq expand。正常的操作可能是使用sync.pool来复用对象,但是我们这里的foo struct由于一些历史原因,本身是并发安全的。
func (pq *pq) Reset() {
pq.elemIDToIndex = map[int32]int32{}
pq.len = 0
}
type foo struct {
// reuse pq to reduce alloc
pq1 *pq
pq2 *pq
}
func (f *foo) barWithReusePQ(i int32) {
// every request insert about 20k elements
for j := 0; j < 20000; j ++ {
f.pq1.InsertWithData(i, i + 1)
callback(int32(j), test(f.pq2))
}
f.pq1.Reset()
f.pq2.Reset()
}与上面不一样的是pq成为了foo的成员变量,可以被复用了,每次endpoint返回后我们reset一下就可以了。
然后再对比看看bench的结果, 每次调用的mem alloc space是有明显减少的:1694561 B/op -> 1171486 B/op
// BenchmarkFooReuse mock endpoint
func BenchmarkFooReuse(b *testing.B) {
b.ReportAllocs()
f := &foo{
pq1:newPQ(),
pq2: newPQ(),
}
for i := 0; i < b.N; i ++ {
f.barWithReusePQ(int32(i))
}
}
BenchmarkFoo-12 537 2113537 ns/op 1694561 B/op 40517 allocs/op
BenchmarkFooReuse-12 583 2037790 ns/op 1171486 B/op 40497 allocs/op经过优化完,线上的表现也得到了一些提升:
- CPU减少了3%
- GC nums减少了50%(20/min->10/min)
- Avg P99 Latency减少了30%(120ms->80ms)
Reduce pointer on closure func
其实这里最主要容易忽略的是匿名函数上的指针是会逃逸到堆上的,虽然只逃逸了一个对象,但是整体的影响还是比较大的。
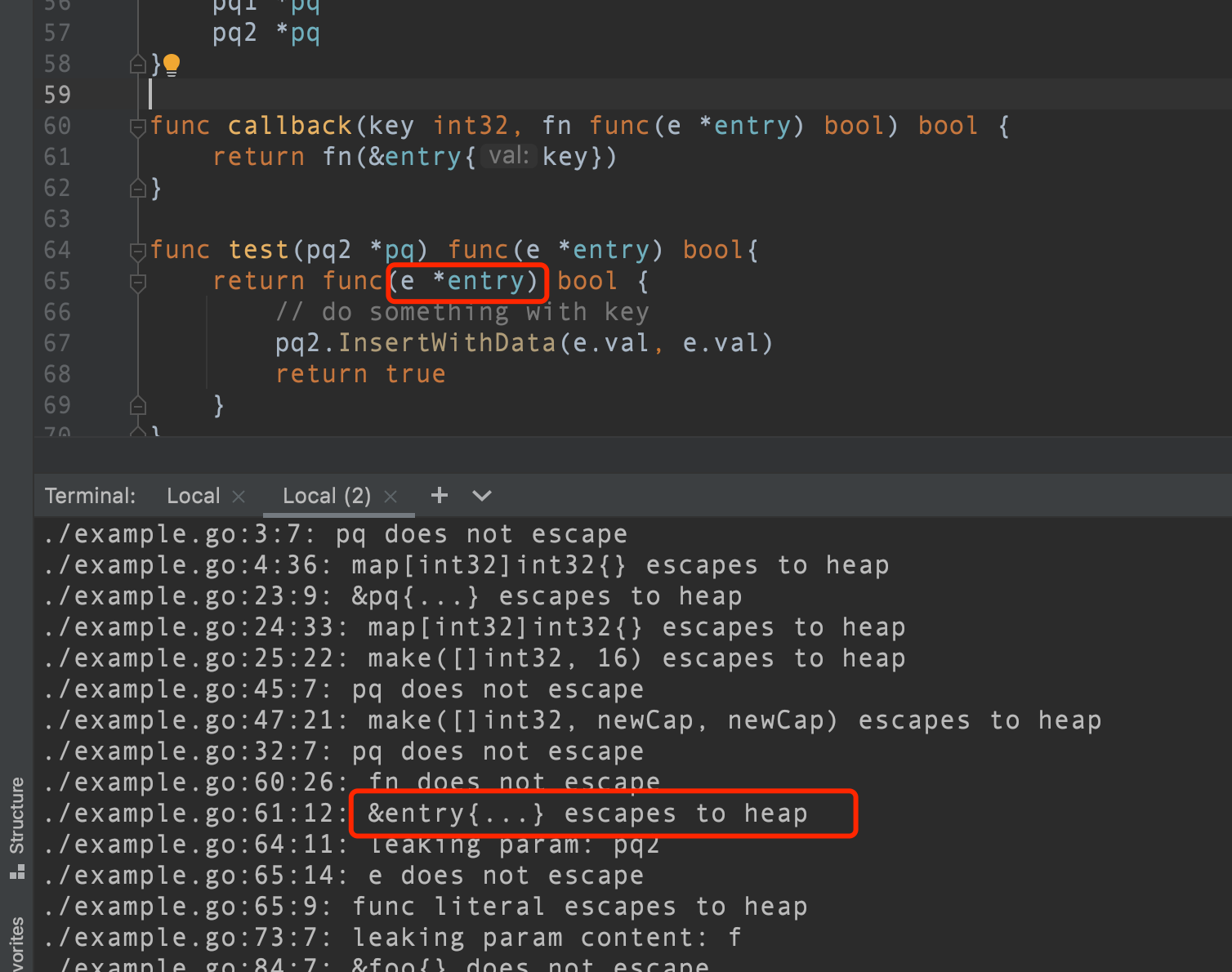
func callback(key int32, fn func(e *entry) bool) bool {
return fn(&entry{key})
}
func test(pq2 *pq) func(e *entry) bool{
return func(e *entry) bool {
// do something with key
pq2.InsertWithData(e.val, e.val)
return true
}
}冗余在匿名函数里面的代码其实都是一些简单的操作,所以我们其实是可直接将其去掉的,直接执行里面的逻辑即可。这里算的上是历史的一些包袱在里面吧。
func (f *foo) barWithoutCallback(i int32) {
// every request insert about 20k elements
for j := 0; j < 20000; j ++ {
f.pq1.InsertWithData(i, i + 1)
f.pq2.InsertWithData(i, i + 1)
}
f.pq1.Reset()
f.pq2.Reset()
}
func (f *foo) barWithoutCallback(i int32) {
// every request insert about 20k elements
for j := 0; j < 20000; j ++ {
f.pq1.InsertWithData(i, i + 1)
f.pq2.InsertWithData(i, i + 1)
}
f.pq1.Reset()
f.pq2.Reset()
}
BenchmarkFoo-12 537 2113537 ns/op 1694561 B/op 40517 allocs/op
BenchmarkFooReuse-12 583 2037790 ns/op 1171486 B/op 40497 allocs/op
BenchmarkFooWithoutCallback-12 3891 300708 ns/op 390 B/op 4 allocs/opbenchmark可以看到基本是提升巨大的(这里的bench结果并不能准确描述线上结果,因为这里涉及到许多的业务代码,所以只能这么简单比较)
实际我们生产环境的指标如下:
- CPU减少了5-7%
- GC nums减少了75%(20/min->5/min)
- Avg P99 Latency减少了50%(120ms->60ms)
Reuse map
在经历了上述的一些优化之后,唯一还能在heap profile里看到关于新加的endpoint的代码就是下面这个地方,在alloc space里面占了4TB。
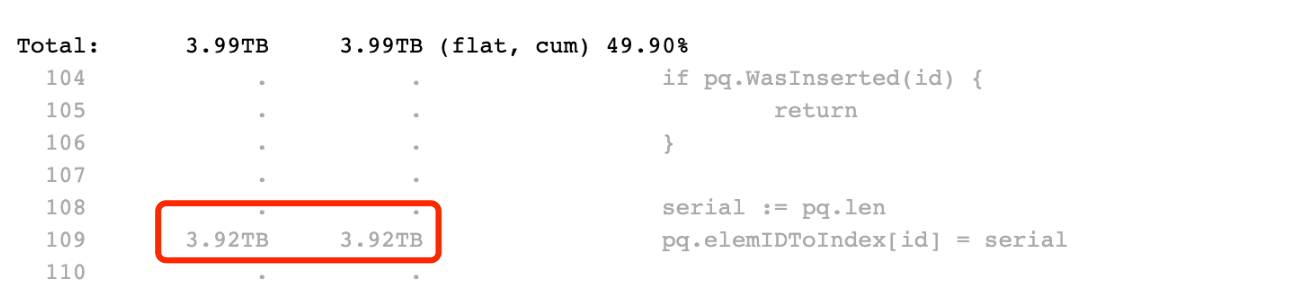
对应到我们上面的example代码就是这一行。
pq.elements[serial] = val。关于这个map其实一开始有点迟疑,要不要进行复用,因为复用就意味着需要每次都清空map。直觉上来说这样会更慢,但在实际跑完benchmark发现复用map的性能要更好。
// BenchmarkMapNew-12 975 1169423 ns/op 770402 B/op 494 allocs/op
// BenchmarkMapClean-12 2312 524583 ns/op 5515 B/op 10 allocs/op
// BenchmarkMapWithoutClean-12 1995 567611 ns/op 357956 B/op 13 allocs/op
func BenchmarkMapNew(b *testing.B){
m := make(map[int32]int32)
for i := 0; i < b.N; i ++ {
for j := 0; j < 20000; j ++ {
m[int32(j)] = int32(j)
}
m = make(map[int32]int32)
}
}
func BenchmarkMapClean(b *testing.B){
m := make(map[int32]int32)
for i := 0; i < b.N; i ++ {
for j := 0; j < 20000; j ++ {
m[int32(j)] = int32(j)
}
for k := range m {
delete(m, k)
}
}
}
func BenchmarkMapWithoutClean(b *testing.B){
m := make(map[int32]int32)
for i := 0; i < b.N; i ++ {
for j := 0; j < 20000; j ++ {
m[int32(j)] = int32(j)
}
m = make(map[int32]int32, 20000)
}
}然后再修改我们的代码,使用resetV2来进行map复用和重置
func (f *foo) barWithoutCallbackV2(i int32) {
// every request insert about 20k elements
for j := 0; j < 20000; j ++ {
f.pq1.InsertWithData(i, i + 1)
f.pq2.InsertWithData(i, i + 1)
}
f.pq1.ResetV2()
f.pq2.ResetV2()
}
func (pq *pq) ResetV2() {
for key := range pq.elemIDToIndex {
delete(pq.elemIDToIndex, key)
}
pq.len = 0
}
func BenchmarkFooWithoutCallbackV2(b *testing.B) {
b.ReportAllocs()
f := &foo{
pq1:newPQ(),
pq2: newPQ(),
}
for i := 0; i < b.N; i ++ {
f.barWithoutCallbackV2(int32(i))
}
}
BenchmarkFoo-12 544 2095126 ns/op 1694499 B/op 40517 allocs/op
BenchmarkFooReuse-12 583 2043699 ns/op 1171383 B/op 40497 allocs/op
BenchmarkFooWithoutCallback-12 3892 302843 ns/op 390 B/op 4 allocs/op
BenchmarkFooWithoutCallbackV2-12 3975 293163 ns/op 131 B/op 0 allocs/op可以看到,经过几轮的代码改动,这个endpoint上终于变成了 zero alloc. 最后的指标表现
- CPU减少了10-12%
- GC nums减少了85%(20/min->3/min)
- Avg P99 Latency减少了70%(120ms->40ms)
Summary
个人觉得这个性能问题比较有收获的是在于如何定位这是一个GC问题,尽管现在Go是concurrent mark,但是当GC发生时,一些goroutine得不到调度,导致长尾问题还是需要留意的。
剩下的关于GC优化其实就可从两个大方向去着手进行一些优化:
- 减少GC次数
- 减少堆上对象(包括死对象以及活对象)
具体问题对照火焰图进行具体分析,最后能做到less alloc或者zero alloc当然是很好的。
Tornado源码分析
前言
老早之前研究过shadowsocks源代码,发现里边的I/O多路复用写的挺好的,直到最近看Tornado源代码才发现是借鉴Tornado的。于是心血来潮,写下博客记录下自己的源代码分析过程吧。
Tornado之web.py
web.py
Tornado的web框架核心文件
Application
A collection of request handlers that make up a web application
主要是用来定义URI路由和对应的处理的Handler.
函数说明
init:
接受一个setting字典参数,里边包括gzip,ui_modules,ui_methods,static_path等一系列参数。并调用_load_ui_modules和_load_ui_methods去加载一些ui资源。此外还会调用self.add_handlers去加载handlers.
add_handlers:
self.handlers.append((re.compile(host_pattern), handlers))
这里的host_pattern为.*?.
spec = URLSpec(pattern, handler, kwargs)
handlers.append(spec)
将regex和相应的handler_class封装URLSpec对象,将其添加到handlers中.
call:
Called by HTTPServer to execute the request
当有新的请求传进来的时候,调用这个方法.
handlers = self._get_host_handlers(request)
获取请求host的handlers list.
handler = spec.handler_class(self, request, **spec.kwargs)
将handler初始化为RequestHandler
handler._execute(transforms, *args, **kwargs)
RequestHandler调用_execute.
RequestHandler
Subclass this class and define get() or post() to make a handler
支持的http方法有"GET", "HEAD", "POST", "DELETE", "PUT"这几种
函数说明
init:
声明self.application和self.request,调用self.clear方法
_execute:
if self.request.method not in self.SUPPORTED_METHODS:
return HTTPError(405)
如果请求方法不在定义之内,返回405错误。调用self.prepare()方法,这个方法是在handler之前调用的。
getattr(self, self.request.method.lower())(*args, **kwargs)
调用handler中复写的http方法,最后调用finish方法。
write
如果传入的是字典,encode为json对象
chunk = escape.json_encode(chunk)
将需要返回的chunk内容加入到self._write_buffer中。
finish
判断status_code和etag以及其他一些列参数。如果http request中带有connection,将绑定在IOStream上的callback清除即可
self.request.connection.stream.set_close_callback(None)
调用self.flush方法,调用self.request.finish()。
flush
将self._write_buffer拼接成字符串
chunk = "".join(self._write_buffer)
判断reuqest请求方法, 调用requests的write方法:
self.request.write(headers)
通过代码分析
#!/usr/bin/env python
# -*- encoding:utf-8 -*-
from tornado import web, httpserver, ioloop
class MainHandler(web.RequestHandler):
def get(self):
self.write("hello, world")
if __name__ == "__main__":
application = web.Application([
(r"/", MainHandler),
])
http_server = httpserver.HTTPServer(application)
http_server.listen(8888)
ioloop.IOLoop.instance().start()
流程图

异步模块asynchronous
代码很简短,直接贴上来
def asynchronous(method):
"""Wrap request handler methods with this if they are asynchronous.
If this decorator is given, the response is not finished when the
method returns. It is up to the request handler to call self.finish()
to finish the HTTP request. Without this decorator, the request is
automatically finished when the get() or post() method returns.
class MyRequestHandler(web.RequestHandler):
@web.asynchronous
def get(self):
http = httpclient.AsyncHTTPClient()
http.fetch("http://friendfeed.com/", self._on_download)
def _on_download(self, response):
self.write("Downloaded!")
self.finish()
"""
@functools.wraps(method)
def wrapper(self, *args, **kwargs):
if self.application._wsgi:
raise Exception("@asynchronous is not supported for WSGI apps")
self._auto_finish = False
return method(self, *args, **kwargs)
return wrapper
这里文档也说的很清楚,如果没有加装饰器,当get或者post方法返回时,http requests就直接执行并返回。当加上装饰器后,就需要结合上面的_execute方法来进行判断了,这里关键就是加上了一行self._auto_finish = False。
if not self._finished:
getattr(self, self.request.method.lower())(*args, **kwargs)
if self._auto_finish and not self._finished:
self.finish()
这里有一个判断,当self._auto_finish为False的时候,是不执行self.finish()的,所以这里的这个连接会一直打开,除非我们自己去调用self.finish()这个方法。
这里的finish方法前面没有细写,这里剖析一下。finish方法调用self.request.finish(), 跟进到request里面看,requests调用self._finish_request(), 最后执行
self.stream.read_until("\r\n\r\n", self._on_headers)
这里就是将这个socket的文件描述符重新设置为读事件, 就是初始化到一开始的状态。
用例子说明一下这里支持异步的真正含义。
假设我们要去请求十个url,并将其结果返回给客户端,同步的写法是这样:
sync mode
class MainHandler(web.RequestHandler):
def get(self):
client = httpclient.HTTPClient()
for _ in xrange(10):
response = client.fetch("http://example.com")
self.write(response.body)
self.finish()
如果我们不加这个asynchronous装饰器的话,直接用AsyncHTTPClient去请求的话,代码如下:
eror async mode
class MainHandler(web.RequestHandler):
def get(self):
done_list = []
client = httpclient.AsyncHTTPClient()
for i in xrange(10):
response = client.fetch("http://example.com", complete)
def complete(response):
self.write(response.body)
done_list.append(response)
if len(done_list == 10):
self.finish()
这里会报错assert not self._finished,如果不加装饰器,使用异步lib的进行write的话,当回调完成后,连接却关闭了,无法继续write。
正确的写法应该是:
correct async mode
@web.asynchronous
class MainHandler(web.RequestHandler):
def get(self):
done_list = []
client = httpclient.AsyncHTTPClient()
for i in xrange(10):
response = client.fetch("http://example.com", complete)
def complete(response):
self.write(response.body)
done_list.append(response)
if len(done_list == 10):
self.finish()
由于这里的代码是异步的,不会直接返回,所以http method不会阻塞整个ioloop,不影响其他的连接。
高性能索引策略
高性能索引策略
- 索引需要是独立的列,不能是函数的参数,如TO_DAYS(date)里面的date就无法使用索引
- 前缀索引和索引选择性,当需要索引的列是一个很长的字符串的时候,可以考虑前缀索引,sql语句
ALTER TABLE table_name ADD KEY(column_name(prefix_length))。 - 多列索引
- 当服务器需要对多个索引进行相交操作(and)的时候需要一个包含相关列的多列索引,而不是多个的单独索引
- 当服务器需要对多个索引做联合操作(or)的时候通常耗费大量的cpu和内存资源在算法的缓存、排序、合并操作上。优化器不会把这些成本计算到“查询成本中”
- 选择合适的索引列顺序,在B-Tree索引中,索引列的顺序按照最左列排序,所以一般情况下,将区分度最高的列放在索引的最左边
聚簇索引
不是一种索引类型,而是一种数据存储方式。InnoDB的聚簇索引在同一结构中保存了索引和数据行,当表又聚簇索引时,数据行存放在索引的叶子页中,数据行和相邻的健值紧凑的存储在一起。
优点:
- 局促索引可以把相关的数据保存在一起,例如实现电子邮箱,根据用户ID来聚集,要获取某个用户的全部邮件时,可以减少磁盘I/O次数
- 数据访问更快,聚簇索引的数据行也保存在B-Tree中,所以速度更快
- 使用覆盖索引扫描的查询可以直接使用页节点中的主键值
缺点:
- 聚簇索引数据大限度提高I/O密集型应用的性能,但如果数据全部放入内存中,访问的顺序就不太重要了
- 插入速度依赖于插入顺序。如果按照主键的顺序插入会很快,但是反过来就不太乐观了。
- 更新聚簇索引的代价高
- 基于聚簇索引的插入,或者主键被移动的时候需要面临"页分裂"的问题
- 聚簇索引可能导致全表扫描变慢,尤其是当行比较稀疏,或者由于页分裂导致存储不连续的时候
- 二级索引可能比想象的更大,因为二级索引的叶子包含了引用行的主键列
- 二级索引访问需要两次索引查找,因为二级索引的叶子结点保存的是对应的主键值,然后根据这个值去聚簇索引查找对应的行
索引覆盖
如果一个索引包含所有需要查询的值,就叫做覆盖索引,当发起一个被索引覆盖的查询时,在explain的extra中可以看到“using index”
- 索引的条目大小往往小于数据行,所以如果只读区索引,mysql可以极大的减少数据访问量
- 索引是按照顺序存储的(至少在单个页面如此),对I/O密集型的范围查询会比随机从磁盘读取数据I/O要少得多
- 对InnoDB的聚簇索引,InnoDB的二级索引在叶子结点保存了行的主键值,如果二级主键可以覆盖查询,则不用对主键索引进行二次查询
使用索引扫描来做排序
在使用order by查询语句的时候,索引的列顺序必须喝order by顺序完全一致,并且所有列的排序方向都一样时,mysql才能使用索引来对结果做排序
冗余和重复索引
mysql允许在相同列上创建多个索引,重复索引是指在相同的列上按照相同的顺序创建的相同的类型的索引。如果创建了索引(a, b),再创建索引(a)就是冗余索引,但是创建索引(b)则不是。解决冗余索引的办法很简单,删除这些索引就可以。
未使用的索引
除了冗余索引和重复索引,可能还会有一些服务器永远不用的索引,这类索引建议删除
索引和锁
InnoDB只有在访问行的时候才会对其加锁,而索引可以减少InnoDB访问的行数,从而减少锁的数量。
Tornado之stack_context
Tornado之stack_context
stack_context是Tornado1.1.0新增的一个类, 主要是用来处理异步函数的异常的,主要有这么几个部分:
- _State
- StackContext
- NullContext
- wrap
_State
Torndo是单线程的,这里的_State用来保存Tornado的上下文内容。
class _State(threading.local):
def __init__(self):
self.contexts = ()
_state = _State()
StackContext
先看代码:
@contextlib.contextmanager
def StackContext(context_factory):
old_contexts = _state.contexts
try:
_state.contexts = old_contexts + (context_factory,)
with context_factory():
yield
finally:
_state.contexts = old_contexts
结合之前提到的contextmanager,这里的context_factory必须是一个上下文管理器。_state.contexts存储的是主线程中其他还没有异步回调的事件管理器。当回调完成后则将其从主线程中删除。
NullContext
@contextlib.contextmanager
def NullContext():
'''Resets the StackContext.
Useful when creating a shared resource on demand (e.g. an AsyncHTTPClient)
where the stack that caused the creating is not relevant to future
operations.
'''
old_contexts = _state.contexts
try:
_state.contexts = ()
yield
finally:
_state.contexts = old_contexts
当我们写异步回调共享同一个资源的时候,比如说一个连接池,当我们其中一个回调的时候,我们需要对资源进行加锁,用with stack_context.NullContext():防止连接泄漏。
wrap
def wrap(fn):
'''Returns a callable object that will resore the current StackContext
when executed.
Use this whenever saving a callback to be executed later in a
different execution context (either in a different thread or
asynchronously in the same thread).
'''
# functools.wraps doesn't appear to work on functools.partial objects
#@functools.wraps(fn)
def wrapped(callback, contexts, *args, **kwargs):
# _state.contexts and contexts may share a common prefix.
# For each element of contexts not in that prefix, create a new
# StackContext object.
# TODO(bdarnell): do we want to be strict about the order,
# or is what we really want just set(contexts) - set(_state.contexts)?
# I think we do want to be strict about using identity comparison,
# so a set may not be quite right. Conversely, it's not very stack-like
# to have new contexts pop up in the middle, so would we want to
# ensure there are no existing contexts not in the stack being restored?
# That feels right, but given the difficulty of handling errors at this
# level I'm not going to check for it now.
pairs = itertools.izip(itertools.chain(_state.contexts,
itertools.repeat(None)),
contexts)
new_contexts = []
for old, new in itertools.dropwhile(lambda x: x[0] is x[1], pairs):
new_contexts.append(StackContext(new))
if new_contexts:
with contextlib.nested(*new_contexts):
callback(*args, **kwargs)
else:
callback(*args, **kwargs)
if getattr(fn, 'stack_context_wrapped', False):
return fn
contexts = _state.contexts
result = functools.partial(wrapped, fn, contexts)
result.stack_context_wrapped = True
return result
分析一下代码, wrap接受一个函数,获取当前线程的上下文(contexts),将wrapped和fn还有contexts封装成一个函数并返回。
再看一下wrapped里边的内容
先是将旧的context和新传进来的context打包,然后再解包,取出新的context。类似于set(contexts) - set(_state.contexts), 但是我们需要明确的对比不同之处,因为我们存放context的时候是有顺序的,所以不能用set去区分。例如我们要比较a:123与b:1234的不同,需要将b中新增加元素dump出来,则可以用上面的方法。取出新的context后,完成回调。
HTTPServer分析
httpserver
httpserve里边主要有三个类:HTTPServer, HTTPConnection, HTTPRequest。
HTTPServer
HTTPServer是基于IOStream对http进行的封装
函数说明
__init__
接受一个requet_callback, 和若干http headers。当http request完成后回调request_callback。
listen
相当于
server.bind(port, address)
server.start(1)
bind
调用socket的bind方法,调用
fcntl.fcntl(self._socket.fileno(), fcntl.F_SETFD, flags)
当程序执行完exec后,自动关闭socket文件描述符
start
接受一个num_procss参数,fork出num_procss条子进程对socket文件描述符进行监听。
stop
关闭socket,移除IOLoop中的该文件描述符的handler
_handle_events
当有新的读事件发生(即有新的连接时候),将新的连接的文件描述符封装成IOStream,生成一个HTTPConnection实例。
HTTPConnection
将接受的connection当作一个http client来进行处理,对http headers或http body进行解析。
函数说明
__init__
声明一些http headers,调用IOStream里边的read_until,当http headers读完后调用self._on_headers
_finish_request
判断http headers中是否存在Keep-Alive,如果不存在,则关闭IOStream, 存在的话就调用IOStream的read_until方法,回调self._on_headers。
_on_headers
解析http headers里边的内容, 封装一个HTTPRequest实例,如果Content-Length存在,则调用_on_request_body。将self._request作为参数,回调self.request_callback。
HTTPRequest
将http headers封装成一个HTTPRequest。
函数说明
__init__
接受一些列请求头和一个http connection,这里的http connection是由上面的HTTPConnection封装而来的。
write
self.connection调用write方法
finish
self.connection调用finish方法
__repr__
将各个请求头封装好,输出相应字符串。
通过代码进行流程分析
from tornado import httpserver, ioloop
def handle_request(request):
message = "You requested %s\n" % request.uri
request.write("HTTP/1.1 200 OK\r\nContent-Length: %d\r\n\r\n%s" % (
len(message), message))
request.finish()
http_server = httpserver.HTTPServer(handle_request)
http_server.listen(8888)
ioloop.IOLoop.instance().start()

Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.