local-first-web / state Goto Github PK
View Code? Open in Web Editor NEWA Redux-based state container for local-first software, offering seamless synchronization using Automerge CRDTs. (Formerly known as 🐟 Cevitxe).
A Redux-based state container for local-first software, offering seamless synchronization using Automerge CRDTs. (Formerly known as 🐟 Cevitxe).

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")
















































































































Possibilities:
I'm thinking of the grid data generator, which completes pretty quickly but then still has a lot of work to do in the background. In general, keep track of a queue of tasks to complete - whether they're changes that have been dispatched, or messages to process from peers; and add information to state about whether we're busy or not, and how much is left to do.
This is obviously the right thing to do, but it breaks tests. For some reason RepoSync
continues to respond to messages from the peer after the repo is closed, and then tries to
access the closed database.
We've manually gotten our signal server up and running on Heroku. We'd like to script this and/or include configuration files to make it possible to deploy instances of the signal server to multiple providers such as Heroku, Zeit Now, and Netlify.
I observed this with the known document IDs dropdown on the grid example.

Run yarn dev:grid
Generate 10 rows
Notice the order of the rows

Reload
Notice that the order has changed
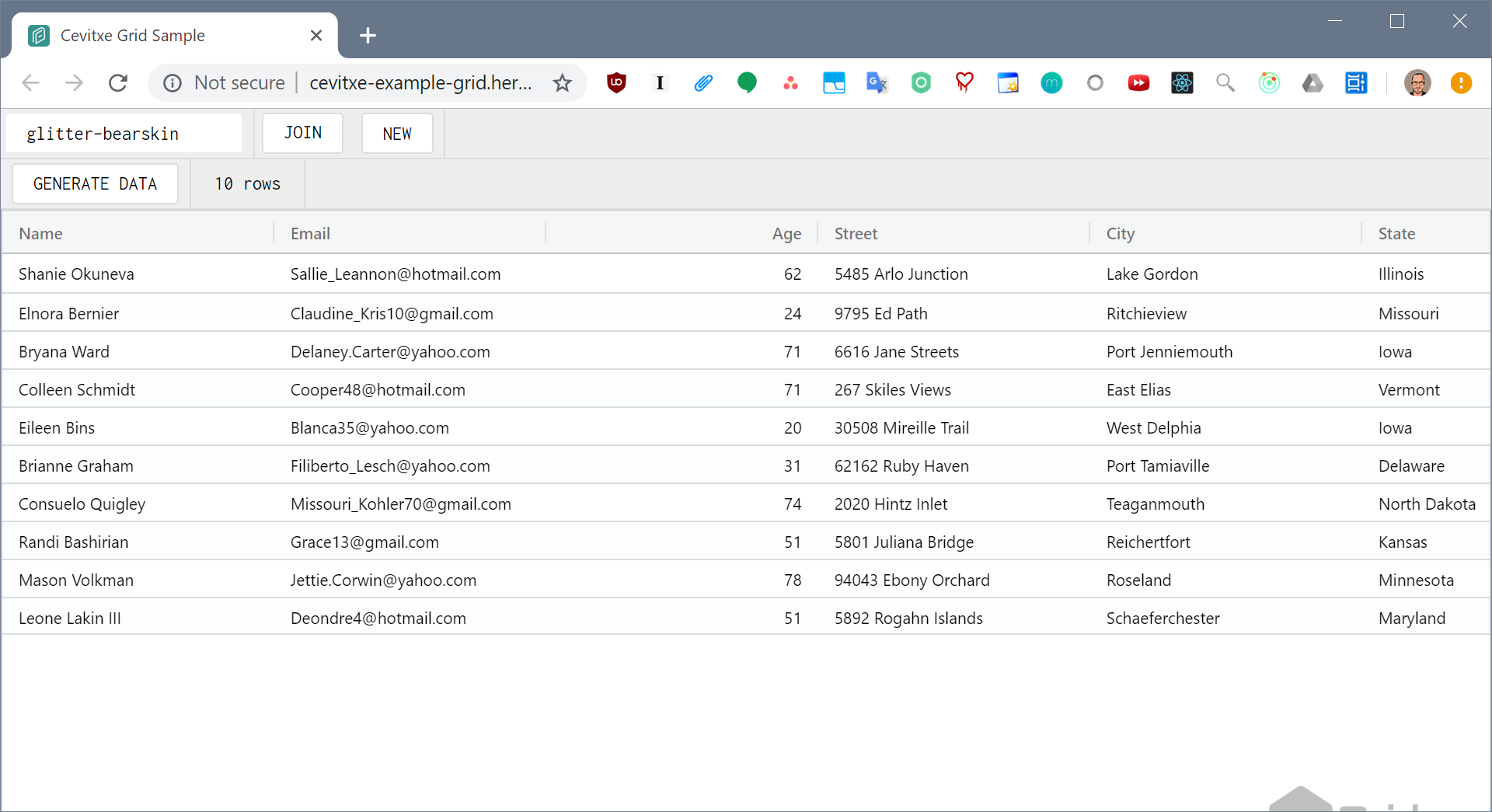
On subsequent reloads, the sort order won't change any further. I'm guessing the initial sort order reflects the order in which items were added, whereas the subsequent sort order is maybe the lexical order of the UUIDs?
Probably the same issue:
Generate 10 rows
Add 5 rows at the bottom containing the numbers 1 through 5. The rows are where you put them.

Reload. The numbered rows are now randomly scattered among the other rows.
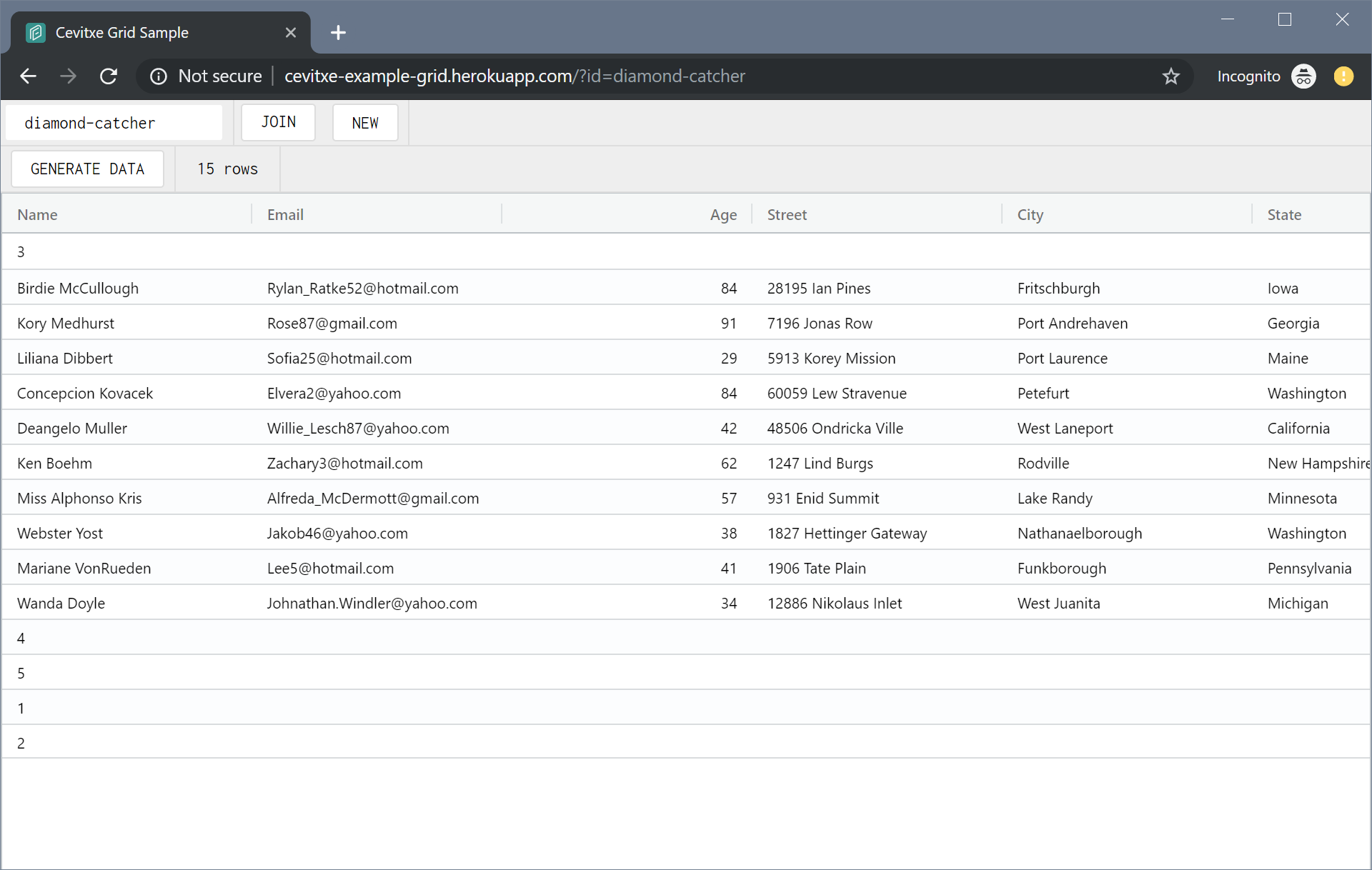
so we don't have to iterate each document when returning to a large repo
We currently only provide browser-based persistent storage using IndexedDb. A superpeer running in a serverless function would need access to a third-party hosted datastore like Redis, MongoDB or DynamoDB. An installable Electron app might prefer to work with self-contained, portable documents in the file system; or with a database like Sqlite.
Hypercore provided this for us, needs to be reimplemented in Repo. We already have the infrastructure in place for storing keypairs associated with a discovery key:
so should just be a matter of encrypting/decrypting just before & after db write/read, respectively.
Store collections as multiple Automerge documents: One per item, plus one for an index.
I'm really interested in this one, because I think the idea of having a local file - that you could email to someone, or put on a USB drive, or whatever - will be comforting to some potential users.
e.g.
Possible behaviors:
Just go down, add row if needed (kinda-default, current)
Go to the first column (in addition to the above)
Guess the right column to go to (true Excel-like behavior)
TODO comment in c8f9e8c in #26. cc @DevResults.Originally posted by @todo in #26 (comment)
From #49 (comment) :
we need some additional markers on the provided state to indicate which things should be persisted/synced to the remote instances. For instance, you might want to exclude the ui section of the state in this example from the redux docs.
A potential solution could look like the whitelist/blacklist config used in redux-persist.
Something to think about, I think we'll want to allow the flexibility of consumers putting things in their redux store but not being transmitted to all replicas (e.g. UI filter selections, etc.).
waiting on #26
Would be nice to have some indication in the toolbar of whether or not we're connected to a signal server.
Add core.js import
TODO comment in c8f9e8c in #26. cc @DevResults.Originally posted by @todo in #26 (comment)
In a peer-to-peer network where clients are only online intermittently and updates can only happen when two peers happen to be online at the same time, it can take a while for updates to propagate. One solution would be to leave a client running on a computer that's never turned off. We'd like to provide a "superpeer" (don't call it a server!!) that can be inexpensively deployed using the command line to cloud hosting providers.
Currently the StoreManager constructor takes an array of middlewares.
export const storeManager = new StoreManager({
databaseName: 'todo',
proxyReducer,
initialState,
urls,
middlewares: [logger],
})To maintain consistency with the Redux createStore interface, this should accept a StoreEnhacer:
export const storeManager = new StoreManager({
databaseName: 'todo',
proxyReducer,
initialState,
urls,
middlewares: applyMiddleware([logger]),
})I think the difficulty had to do with composing an existing enhancer with the Redux Dev Tools browser extension here:
We haven't really used the Redux Dev Tools, so we could just not wire it up. Or we could figure out how to make it work. See http://github.com/zalmoxisus/redux-devtools-extension#1-with-redux
yarn dev:todo



After generating or uploading data, adjust column widths to fit data
We don't have any way for DocSetSync to communicate to peers that DocSet.removeDoc has been called. For now we're just removing the removed doc's ID from the collection index so it's effectively ignored but this doesn't help reduce the size of the state and it probably doesn't work at all for non-collection documents.
I suspect we might need to update DocSet.removeDoc to call the handlers with undefined as the new doc so they can appropriately handle the removal of the document. We might get more clarity on this if we hear anything back on my automerge PR: #210
It should keep the alignment and font (and hopefully not move things by a pixel or so)
In the Todo example, our entire state fits easily in a single document, and the Repo API feels really cumbersome.
You have to put your state in a root-level document: instead of https://github.com/DevResults/cevitxe/blob/b34789110b10bcc1c83d4952b9a9a360550a64df/packages/examples/todo/src/redux/store.ts#L6-L10 you have to do this https://github.com/DevResults/cevitxe/blob/117ca3b0161dfcbe1a55849242afcac20b7ea1f0/packages/examples/todo/src/redux/store.ts#L6-L12
Reducers have to return a dictionary of change functions that work on individual documents, instead of a single function that works on the entire repo state: this https://github.com/DevResults/cevitxe/blob/117ca3b0161dfcbe1a55849242afcac20b7ea1f0/packages/examples/todo/src/redux/reducers.ts#L11-L19 instead of this https://github.com/DevResults/cevitxe/blob/b34789110b10bcc1c83d4952b9a9a360550a64df/packages/examples/todo/src/redux/reducers.ts#L18-L24
Same deal with selectors and anything else that cares about the shape of the overall state: You have to file everything inside this bogus root property.
Do we care? If so, I wonder how we can simplify this use case?
One idea I had was to accept reducers that return a single function instead of a dictionary of functions. When initializing the StoreManager, we could then check the shape of the proxyreducer we're passed, and if it returns single functions then go into "single-document mode" where we take care of putting things in the root document, and just exposing that document as the store's state, so the developer can deal with this as if there was just one document.
To reproduce:
yarn dev:gridlocalhost:3000NEWFor now, besides introducing two peers to each other, the signal server also serves as a relay, piping their two WebSocket connections together. In the future, Cevitxe will establish a direct connection between the two peers, using browser-to-browser communication technologies like WebRTC. For now, we've found WebRTC too unreliable to be worth the trouble.
Loading from storage currently ties up the UI while it's reading and rehydrating; this should be done asynchronously.
To reproduce:
dev:gridThe window remains blank until the stored feed entries have been read, parsed, and applied. I think at some point we're awaiting when we should just be firing an async action?
Enable running Cevitxe's StoreManager entirely in a web worker process. See HerbCaudill/react-redux-worker for a starting point.
All the Automerge, local storage and sync components would live in the worker, thus freeing the UI context of all the expensive overhead of the system.
We'll need a coarse-grained query API to query and retrieve a view of a set of rows, aggregate information, etc. In order of priority:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.