lornatang / srgan-pytorch Goto Github PK
View Code? Open in Web Editor NEWA simple and complete implementation of super-resolution paper.
License: Apache License 2.0
A simple and complete implementation of super-resolution paper.
License: Apache License 2.0
运行您的命令下载不了DIV2K训练集,如下图

请问训练集的目录文件格式应该是什么样的呢?
I was using an old version of your repo SRGAN-Pytorch (v0.2.2) and the model urls from the generator are:
model_urls = {
"srgan_2x2": "https://github.com/Lornatang/SRGAN-PyTorch/releases/download/v0.2.2/SRGAN_2x2_ImageNet2012-3f1d605edcbfb83dc836668731cd6135b00ff62ea6f8633559fbb5dffe8413ba.pth",
"srgan": "https://github.com/Lornatang/SRGAN-PyTorch/releases/download/v0.2.2/SRGAN_ImageNet2012-158a3f9e70f45aef607e4146e29cde745e8d9a35972cb067f1ee00cb92254e02.pth",
"srgan_8x8": "https://github.com/Lornatang/SRGAN-PyTorch/releases/download/v0.2.2/SRGAN_8x8_ImageNet2012-c8207fead3ec73cdf6772fb60fef759833bae4a535eb8d3287aba470696219c1.pth"
}
These links are down, as you have updated the repo, however, the generator network I am using fails on loading the newest weights from the google drive (https://drive.google.com/drive/folders/1jS4psAFj8WrnTS9U470RhGdp2OAlvILW).
The releases (v0.2.2) from SRGAN-Pytorch were erased.
I am wondering if you still have the SRGAN_2x2_ImageNet2012-3f1d605edcbfb83dc836668731cd6135b00ff62ea6f8633559fbb5dffe8413ba.pth, SRGAN_ImageNet2012-158a3f9e70f45aef607e4146e29cde745e8d9a35972cb067f1ee00cb92254e02.pth or SRGAN_8x8_ImageNet2012-c8207fead3ec73cdf6772fb60fef759833bae4a535eb8d3287aba470696219c1.pth checkpoints saved somewhere.
Hi Lornatang,
How can I train on 2 GPUs on my local device. For example, device 3 and 4 only ? When I use os.environ["CUDA_VISIBLE_DEVICES"]="3,4" it gives me an error.
"RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!"
Please help.
Thanks!
Hi,
Not much but there is a random comma at the end of the config.py, on line 113.
Weights link doesn't contain weights, it contains Set5 image dataset! Please upload the trained weights and provide the correct link. :)
Hi there, thank you for your dedicated work
However, I found that while training srgan, in discriminator, you said: # The real sample label is 1, and the generated sample label is 0. Then you used d_loss = (d_loss_real + d_loss_fake) / 2. Can you please kindly explain me this loss and the motivation behind setting real sample and generated sample? I may be blind but tbh I did not see it in the paper.
Thank you, best regards
Hi, I'm wondering if you experimented with different patch sizes besides the 96px one. This one works fine, but if I try anything else it will throw errors.
If the patch size is smaller than 96 (this example is 28) then I usually get:
** On entry to SGEMM parameter number 10 had an illegal value Traceback (most recent call last): File "train.py", line 283, in <module> main() File "train.py", line 175, in main train_gan(epoch) File "train.py", line 246, in train_gan d_loss_real = adv_criterion(netD(target), real_label) File "/home/calexand/env/srpy/lib/python3.8/site-packages/torch/nn/modules/module.py", li$ return forward_call(*input, **kwargs) File "/home/calexand/defTest/srpy/srgan_pytorch/model.py", line 124, in forward out = self.classifier(out) File "/home/calexand/env/srpy/lib/python3.8/site-packages/torch/nn/modules/module.py", li$ return forward_call(*input, **kwargs) File "/home/calexand/env/srpy/lib/python3.8/site-packages/torch/nn/modules/container.py",$ input = module(input) File "/home/calexand/env/srpy/lib/python3.8/site-packages/torch/nn/modules/module.py", li$ return forward_call(*input, **kwargs) File "/home/calexand/env/srpy/lib/python3.8/site-packages/torch/nn/modules/linear.py", li$ return F.linear(input, self.weight, self.bias) File "/home/calexand/env/srpy/lib/python3.8/site-packages/torch/nn/functional.py", line 1$ return torch._C._nn.linear(input, weight, bias) RuntimeError: CUDA error: CUBLAS_STATUS_INVALID_VALUE when calling cublasSgemm( handle, ople, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)
If the patch is bigger, for example 192:
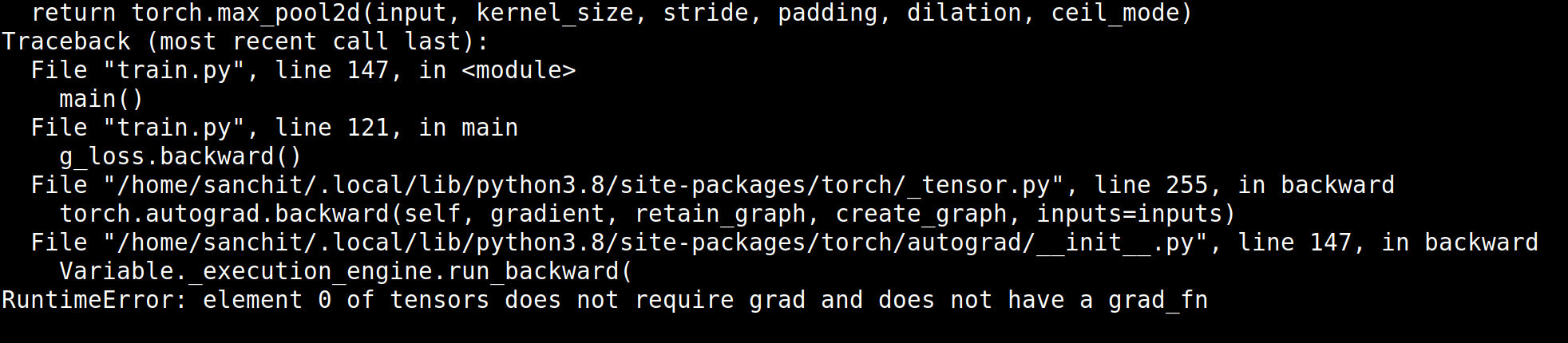
Traceback (most recent call last): File "train.py", line 418, in <module> main() File "train.py", line 215, in main allLossD,allLossG = train_gan(epoch) File "train.py", line 315, in train_gan d_loss.backward() File "/home/calexand/env/srpy/lib/python3.8/site-packages/torch/_tensor.py", line 255, in backward torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs) File "/home/calexand/env/srpy/lib/python3.8/site-packages/torch/autograd/__init__.py", line 147, in backward Variable._execution_engine.run_backward( RuntimeError: Function AddmmBackward returned an invalid gradient at index 1 - got [32, 18432] but expected shape compatible with [32, 73728]
I am trying to train data using one of the specified dataset (Div2k_valid_HR).
I have unzipped the Div2k dataset in the data folder as mentioned in the readme.md including train and val folders as it was mentioned i the training example. There were a number of errors including a error on non-extent test folder in data folder, so I created one.
I got his error.
Thanks for creating this.
I was trying this for the first time today.
I ran
cd data/
bash download_dataset.sh
then
cd ..
python3 test_benchmark.py -a srgan --pretrained --gpu 0 data
I get
FileNotFoundError: [Errno 2] No such file or directory: 'data/test'
I'm unsure on what should go into the test folder
Hi,sorry to bother you, but I find the RRDBNet weight is not in the weight set
I don't understand why using define optimizer in line 51 train_srgan.py. Can you help me, thank you!
Pre-trained Discriminator model cannot load when I try to continue training with my data.
Error:
Load dataset successfully.
Build SRGAN model successfully.
Downloading: "https://download.pytorch.org/models/vgg19-dcbb9e9d.pth" to /root/.cache/torch/hub/checkpoints/vgg19-dcbb9e9d.pth
100% 548M/548M [00:03<00:00, 156MB/s]
Define all loss functions successfully.
Define all optimizer functions successfully.
Define all optimizer scheduler functions successfully.
Loading SRResNet model weights
Loaded SRResNet model weights.
Check whether the pretrained discriminator model is restored...
Traceback (most recent call last):
File "train_srgan.py", line 512, in
main()
File "train_srgan.py", line 76, in main
d_optimizer.load_state_dict(checkpoint["optimizer"])
File "/usr/local/lib/python3.7/dist-packages/torch/optim/optimizer.py", line 146, in load_state_dict
raise ValueError("loaded state dict contains a parameter group "
ValueError: loaded state dict contains a parameter group that doesn't match the size of optimizer's group
Hi,
would you provide code for how to visualizing the network result in order to compare the images?
Thanks in advance.
I got these output,why?please help me! myGPU : 2080Ti driver 11.2
[ WARNING ] You have chosen a specific GPU. This will completely disable data parallelism.
[ INFO ] Use GPU: 0 for training.
[ INFO ] Creating model srgan_2x2.
[ INFO ] Losses function information:
Pixel: MSELoss
Content: VGG19_36th
Adversarial: BCELoss
[ INFO ] Optimizer information:
PSNR learning rate: 0.0001
Discriminator learning rate: 0.0001
Generator learning rate: 0.0001
PSNR optimizer: Adam, [betas=(0.9,0.999)]
Discriminator optimizer: Adam, [betas=(0.9,0.999)]
Generator optimizer: Adam, [betas=(0.9,0.999)]
PSNR scheduler: None
Discriminator scheduler: StepLR, [step_size=self.gan_epochs // 2, gamma=0.1]
Generator scheduler: StepLR, [step_size=self.gan_epochs // 2, gamma=0.1]
[ INFO ] Load training dataset
[ INFO ] Dataset information:
Train Path: /home/zhang/code-space/data/train
Test Path: /home/zhang/code-space/data/test
Number of train samples: 800
Number of test samples: 100
Number of train batches: 50
Number of test batches: 7
Shuffle of train: True
Shuffle of test: False
Sampler of train: False
Sampler of test: None
Workers of train: 4
Workers of test: 4
[ INFO ] Turn on mixed precision training.
[ INFO ] Train information:
PSNR-oral epochs: 500
GAN-oral epochs: 500
Epoch: [0][ 0/50] Time 4.5959 (4.5959) Loss 0.405921 (0.405921)
Epoch: [0][ 5/50] Time 0.0693 (1.0562) Loss 0.087571 (0.207982)
Epoch: [0][10/50] Time 0.0969 (0.8460) Loss 0.068509 (0.141885)
Epoch: [0][15/50] Time 0.0597 (0.7817) Loss 0.040221 (0.114032)
Epoch: [0][20/50] Time 2.5262 (0.8705) Loss 0.027806 (0.094019)
Epoch: [0][25/50] Time 0.0585 (0.7959) Loss 0.032152 (0.081912)
Epoch: [0][30/50] Time 0.0532 (0.7511) Loss 0.016601 (0.072890)
Epoch: [0][35/50] Time 0.0593 (0.7287) Loss 0.029243 (0.066070)
Epoch: [0][40/50] Time 3.0444 (0.7835) Loss 0.024154 (0.060616)
Epoch: [0][45/50] Time 0.0654 (0.7643) Loss 0.021094 (0.056146)
PSNR: nan SSIM: nan LPIPS: 0.5387 GMSD: nan: 100%|███████████████████████████████████████████| 7/7 [00:05<00:00, 1.33it/s]
[ WARNING ] NaN or Inf found in input tensor.
[ WARNING ] NaN or Inf found in input tensor.
[ WARNING ] NaN or Inf found in input tensor.
[ WARNING ] NaN or Inf found in input tensor.
Epoch: [1][ 0/50] Time 3.3172 (3.3172) Loss nan (nan)
[ WARNING ] NaN or Inf found in input tensor.
[ WARNING ] NaN or Inf found in input tensor.
Epoch: [1][ 5/50] Time 0.0581 (1.0160) Loss 0.020317 (nan)
[ WARNING ] NaN or Inf found in input tensor.
[ WARNING ] NaN or Inf found in input tensor.
[ WARNING ] NaN or Inf found in input tensor.
Epoch: [1][10/50] Time 0.5341 (0.9001) Loss nan (nan)
During the execution of GAN epochs:
Traceback (most recent call last):
File "/content/drive/MyDrive/SRGAN-PyTorch-master/train.py", line 590, in
main()
File "/content/drive/MyDrive/SRGAN-PyTorch-master/train.py", line 154, in main
main_worker(args.gpu, ngpus_per_node, args)
File "/content/drive/MyDrive/SRGAN-PyTorch-master/train.py", line 392, in main_worker
args=args)
File "/content/drive/MyDrive/SRGAN-PyTorch-master/train.py", line 544, in train_gan
content_loss = content_criterion(sr, hr.detach())
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/content/drive/MyDrive/SRGAN-PyTorch-master/srgan_pytorch/loss.py", line 156, in forward
source = (source - self.mean) / self.std
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
Any advice?
请问这个Demo的DIV2K训练集只需用到HR图像吗?因为您给的下载链接里只有HR
Link on overview page for downloading weights is broken
When the code run at 'scaler.scale(d_loss).backward()' , I got an error:"one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [512]] is at version 3; expected version 2 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True)."
It has been bothering me for many days, can someone help me?
Hi,
Would you please provide code for SSIM calculation error during the training?
Thanks in advance.
Facing this issue while running the following command- python3 test_benchmark.py -a srgan --pretrained --gpu 0 DIR
FileNotFoundError: [Errno 2] No such file or directory: 'DIR/test'
I changed upscale_factor = 2 in config.py
I run inferernce.py and results are upscaled by 4.
How can I pass in an upscale_factor of 2 in inference.py?
Hey!
I was playing around with your solution and was positively surprised that there is a pre-trained model included. I set everything up and tried to verify your results for Set5. I used the test.py. Sadly the results are rather mediocre:
0.png:
MSE 0.0209
RMSE 0.1445
PSNR 16.80
SSIM 0.6989
LPIPS 0.3019
GMSD 0.1458
2.png:
MSE 0.0020
RMSE 0.0444
PSNR 27.05
SSIM 0.7365
LPIPS 0.1433
GMSD 0.0778
3.png
MSE 0.0058
RMSE 0.0765
PSNR 22.33
SSIM 0.8100
LPIPS 0.1888
GMSD 0.0901
4.png:
MSE 0.0058
RMSE 0.0763
PSNR 22.35
SSIM 0.4969
LPIPS 0.2875
GMSD 0.0887
Image 1 gave an error.
What dataset is the pre-trained model trained with? Do you have any idea why I got so bad results?
Anyway, cool model and thanks for your work:)
I am trying to do inference on one of the default dataset images suggested in the Readme.md
`user#:/home/ubuntu/SRGAN-PyTorch# python test_image.py --arch srgan --lr /home/ubuntu/SRGAN-PyTorch/data/train/0001.png --hr /home/ubuntu/SRGAN-PyTorch/data/0001_HR.png --model-path /home/ubuntu/SRGAN-PyTorch/weights/lpips_vgg.pth --pretrained --gpu 0
[ WARNING ] Directory `/home/ubuntu/SRGAN-PyTorch/tests` already exists!
[ INFO ] TestEngine:
[ INFO ] API version .......... 0.3.0
[ INFO ] Build ................ 2021.06.13
[ INFO ] Using pre-trained model `srgan`.
Traceback (most recent call last):
File "test_image.py", line 150, in <module>
main(args)
File "test_image.py", line 59, in main
model = configure(args)
File "/home/ubuntu/SRGAN-PyTorch/srgan_pytorch/utils/common.py", line 46, in configure
model = models.__dict__[args.arch](pretrained=True)
File "/home/ubuntu/SRGAN-PyTorch/srgan_pytorch/models/generator.py", line 104, in srgan
return _gan("srgan", pretrained, progress)
File "/home/ubuntu/SRGAN-PyTorch/srgan_pytorch/models/generator.py", line 92, in _gan
state_dict = load_state_dict_from_url(model_urls[arch], progress=progress, map_location=torch.device("cpu"))
File "/opt/conda/lib/python3.8/site-packages/torch/hub.py", line 517, in load_state_dict_from_url
cached_file = os.path.join(model_dir, filename)
File "/opt/conda/lib/python3.8/posixpath.py", line 90, in join
genericpath._check_arg_types('join', a, *p)
File "/opt/conda/lib/python3.8/genericpath.py", line 155, in _check_arg_types
raise TypeError("Can't mix strings and bytes in path components") from None
TypeError: Can't mix strings and bytes in path components
`
facing similar problem while test_benchmark as well.
When I tried to run the test_image.py with --upscale-factor 2, I got an error pointing
images = torch.cat([bicubic, sr], dim=-1)
RuntimeError: Sizes of tensors must match except in dimension 3. Got 256 and 512 in dimension 2 (The offending index is 1)
Could you please suggest a solution to solve this.
Hello!
I noticed that you have recently removed the gradient clipping from the Automatic Mixed Precision, I would really like to ask you why you made this change, is it because the gradient clipping is not suitable for this case?
Thank you very much!
Hi!
How should I structure my training dataset in order for this implementation to work?
Also, what does IMAGE_SIZE refer to? Why the default is 96?
Thank you
Hi,
I have a question regarding the training of the GAN and namely I wonder why you don't call the optimizer from the generator as well as from the discriminator with zero_grad() at the beginning of the for loop and only call discriminator.zero_grad() and generator.zero_grad() respectively ? Unfortunately I'm still quite new to Pytorch and have always used Tensorflow before and could imagine that it amounts to the same thing ?
Further, I also wonder why, for example, you don't do something like G.train(False) and D.train(True) when updating the discriminator and vice versa ?
I hope you can answer my questions and I remain with kind regards
Niklas
Hi,
Correct me if I am wrong, but I needed to install tensorboard version 2.8.0 and setuptools 59.5.0
Not a big deal, but it was not in the requirements.txt.
I might be wrong with that, just wanted to ask
HI,thanks for you job ! When i train SRGAN Generator model in my environment(pytorch 1.7 torchvision 0.8 ),and it work,but got a big size model weights about 18.7M.But I found your SRGAN Generator model weights Download in https://drive.google.com/drive/folders/1A6lzGeQrFMxPqJehK9s37ce-tPDj20mD which name is "SRGAN_x4-ImageNet-c71a4860.pth.tar" only got 5.98M.i found those two mode weights get the same backbone . How can i got the same size of model weights?
Another: file train_srgan.py line 51
"d_scheduler, g_scheduler = define_scheduler(discriminator, generator)"
should be "d_scheduler, g_scheduler = define_scheduler(d_optimizer, g_optimizer)"??
look forward to your answer !!
Hi, when I was trying to train grayscale tiff images I get RuntimeError: Given groups=1, weight of size [64, 1, 9, 9], expected input[16, 3, 48, 48] to have 1 channels, but got 3 channels instead.
I changed first Conv2d input channel 3 to 1 but still the same. Can you help?
Hello everyone :)
thanks a lot for the repo! Training the PSNR part worked well. However, when training the GAN I had problems, because of a missing lpips_vgg.pth file. Maybe I oversee something, but I can't find it.
Would be nice if you could help me out here!
Best,
Jenny
While training SRGAN model, learning rate scheduler is used in train.py with parameters step_size=epochs // 2 and gamma=0.1.
From this I suppose schedulerD.step() and schedulerG.step() to be called at each epoch.
However, they are called at each training step which means that learning rate is quickly becoming zero after a few training steps.
The SRGAN does not seem to train.
But when I put schedulerD.step() and schedulerG.step() after the epoch end, it started showing nice results.
When following the documentation in https://github.com/Lornatang/SRGAN-PyTorch/tree/master/data the command
"create_dataset_for_kernelGAN.py" throws an error:
File "create_dataset_for_kernelGAN.py", line 46
lr_dir = f"./{args.upscale_factor}x/input"
^
The PSNR improves during generator training, but drops drastically during adversarial training.
Train Epoch[0045/0046](00010/00015) Loss: 0.007902.
Train Epoch[0045/0046](00015/00015) Loss: 0.006159.
Valid stage: generator Epoch[0045] avg PSNR: 19.95.
Train Epoch[0046/0046](00010/00015) Loss: 0.006377.
Train Epoch[0046/0046](00015/00015) Loss: 0.008251.
Valid stage: generator Epoch[0046] avg PSNR: 19.99.
Train stage: adversarial Epoch[0001/0010](00010/00015) D Loss: 0.139652 G Loss: 0.598175 D(HR): 0.990013 D(SR1)/D(SR2): 0.112813/0.022210.
Train stage: adversarial Epoch[0001/0010](00015/00015) D Loss: 0.002624 G Loss: 0.810450 D(HR): 0.998733 D(SR1)/D(SR2): 0.001354/0.000455.
Valid stage: adversarial Epoch[0001] avg PSNR: 9.15.
Train stage: adversarial Epoch[0002/0010](00010/00015) D Loss: 0.002039 G Loss: 0.589604 D(HR): 0.998040 D(SR1)/D(SR2): 0.000008/0.000007.
Train stage: adversarial Epoch[0002/0010](00015/00015) D Loss: 0.001770 G Loss: 0.579492 D(HR): 0.998254 D(SR1)/D(SR2): 0.000018/0.000017.
Valid stage: adversarial Epoch[0002] avg PSNR: 8.84.
Train stage: adversarial Epoch[0003/0010](00010/00015) D Loss: 0.001410 G Loss: 0.456838 D(HR): 0.999054 D(SR1)/D(SR2): 0.000449/0.000344.
Train stage: adversarial Epoch[0003/0010](00015/00015) D Loss: 0.000123 G Loss: 0.389203 D(HR): 0.999966 D(SR1)/D(SR2): 0.000089/0.000067.
Valid stage: adversarial Epoch[0003] avg PSNR: 8.22.
Train stage: adversarial Epoch[0004/0010](00010/00015) D Loss: 0.023198 G Loss: 0.501722 D(HR): 0.999708 D(SR1)/D(SR2): 0.016052/0.000103.
Train stage: adversarial Epoch[0004/0010](00015/00015) D Loss: 0.006275 G Loss: 0.574956 D(HR): 0.993783 D(SR1)/D(SR2): 0.000000/0.000000.
Valid stage: adversarial Epoch[0004] avg PSNR: 8.21.
Hi. I got this error message while validating on Colab:
RuntimeError: Error(s) in loading state_dict for Generator:
Missing key(s) in state_dict: "conv_block1.0.weight", "conv_block1.0.bias", "conv_block1.1.weight", "trunk.0.rcb.0.weight", "trunk.0.rcb.1.weight", "trunk.0.rcb.1.bias",
...
"upsampling.1.upsample_block.0.bias", "upsampling.1.upsample_block.2.weight", "conv_block3.weight", "conv_block3.bias".
Unexpected key(s) in state_dict: "epoch", "best_psnr", "state_dict", "optimizer", "scheduler".
Tries to use this weight file: SRGAN_x4-ImageNet-2204c839.pth.tar as provided in the link
To overcome the error, updated the code;
model.load_state_dict(checkpoint["state_dict"])
to
model.load_state_dict(checkpoint["state_dict"],False)
in validate.py on line 34.
After changing, validation works but PSNR is only 8.89dB. I tried also all weight files of SRGAN in the link but all 3 of them have the same PSNR result: 8.89

Which point have I missed?
hello,
I've tried to run inference using the test_image.py script but am receiving the following:
$SRGAN-PyTorch$ python test_image.py --lr lr.png --hr hr.png -a srgan_4x4_16 --upscale-factor 4 --pretrained --device 0
Receive the following error:
usage: test_image.py [-h] --lr LR --hr HR [-a ARCH] [--upscale-factor {4}] [--model-path PATH] [--pretrained] [--detail] [--outf PATH] [--device DEVICE] test_image.py: error: argument -a/--arch: invalid choice: 'srgan_4x4_16' (choose from 'discriminator', 'load_state_dict_from_url', 'srgan', 'srresnet')
I then attempted:
$SRGAN-PyTorch$ python test_image.py --lr lr.png --hr hr.png -a srgan --upscale-factor 4 --pretrained --device 0
Receive the following error:
Traceback (most recent call last): File "test_image.py", line 65, in <module> estimate = Estimate(args) File "/home/user/SRGAN-PyTorch/tester.py", line 138, in __init__ self.model, self.device = configure(args) File "/home/user/SRGAN-PyTorch/srgan_pytorch/utils/common.py", line 56, in configure model = models.__dict__[args.arch](pretrained=True, upscale_factor=args.upscale_factor).to(device) TypeError: srgan() got an unexpected keyword argument 'upscale_factor'
Steps to reproduce on debian box:
$ git clone https://github.com/Lornatang/SRGAN-PyTorch.git
$ cd SRGAN-PyTorch/
$ pip3 install -r requirements.txt
Hello! While running the test.py I am not getting the results, instead, the process is getting killed. Can you tell if I am doing something wrong?
pankhuri@pankhuri-G5-5500:~/academics/sem2/hlcv/project/baseline-setup/SRGAN-PyTorch$ python3 test.py --pretrained
[ WARNING ] Directory `/home/pankhuri/academics/sem2/hlcv/project/baseline-setup/SRGAN-PyTorch/tests` already exists!
[ WARNING ] Directory `/home/pankhuri/academics/sem2/hlcv/project/baseline-setup/SRGAN-PyTorch/tests/Set5` already exists!
[ INFO ] TrainEngine:
[ INFO ] API version .......... 0.4.0
[ INFO ] Build ................ 2021.07.09
Killed
why when i want to calculate psnr during training i get this error even though the batch_size config is very small?
Load all datasets successfully.
Build SRResNet model successfully.
Define all loss functions successfully.
Define all optimizer functions successfully.
Check whether the pretrained model is restored...
Epoch: [1][ 0/1989] Time 15.878 (15.878) Data 0.000 ( 0.000) Loss 0.267222 (0.267222)
Traceback (most recent call last):
File "train_srresnet.py", line 463, in
main()
File "train_srresnet.py", line 98, in main
train_loss = train(model, train_prefetcher, pixel_criterion, optimizer, epoch, scaler, writer, psnr_model, ssim_model)
File "train_srresnet.py", line 249, in train
scaler.scale(loss).backward()
File "/usr/local/lib/python3.7/dist-packages/torch/_tensor.py", line 363, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/usr/local/lib/python3.7/dist-packages/torch/autograd/init.py", line 175, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
RuntimeError: CUDA out of memory. Tried to allocate 288.00 MiB (GPU 0; 14.76 GiB total capacity; 11.70 GiB already allocated; 123.75 MiB free; 13.22 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
python3 test_video.py --file /Users/admin/Work/Python/SRGAN-PyTorch/C.mp4 --pretrained --view
[ WARNING ] Directory /Users/admin/Work/Python/SRGAN-PyTorch/videos already exists!
[ INFO ] TestEngine:
[ INFO ] API version .......... 0.4.0
[ INFO ] Build ................ 2021.07.09
[ INFO ] show fps:15.0
[processing video and saving/view result videos]: 0%| | 0/4486 [00:28<?, ?it/s]
Traceback (most recent call last):
File "test_video.py", line 144, in
main()
File "test_video.py", line 106, in main
compare_image = Resize(compare_image_size, Mode.BICUBIC)(raw_frame)
File "/Users/admin/.conda/envs/P38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/Users/admin/.conda/envs/P38/lib/python3.8/site-packages/torchvision/transforms/transforms.py", line 297, in forward
return F.resize(img, self.size, self.interpolation, self.max_size, self.antialias)
File "/Users/admin/.conda/envs/P38/lib/python3.8/site-packages/torchvision/transforms/functional.py", line 401, in resize
return F_pil.resize(img, size=size, interpolation=pil_interpolation, max_size=max_size)
File "/Users/admin/.conda/envs/P38/lib/python3.8/site-packages/torchvision/transforms/functional_pil.py", line 209, in resize
raise TypeError('img should be PIL Image. Got {}'.format(type(img)))
TypeError: img should be PIL Image. Got <class 'numpy.ndarray'>
Thanks for the code,
when I use CPU inference time is less compared to GPU while testing the model.
Could you help me understand why such a thing is happening?
Code for reference,
Just change in line 109,
with torch.no_grad():
c_time = time.time()
sr = model(lr)
print('Total time is %f sec.'%(time.time()- c_time))
Hi,
I successfully have run train.py, but there is no .pth "weights file" generated at all. How may we generate the weights file?
Mike
[ WARNING ] Directory /glb/hou/pt.sgs/data/ml_ai_us/4d/usadh7/github_repos/SRGAN-PyTorch/benchmarks already exists!
[ INFO ] TestingEngine:
[ INFO ] Use GPU: 0 for testing.
[ INFO ] Using pre-trained model srgan.
[ INFO ] Load testing dataset.
/glb/hou/pt.sgs/data/ml_ai_us/4d/csoftware/miniconda3/envs/py36/lib/python3.6/site-packages/torch/utils/data/dataloader.py:477: UserWarning: This DataLoader will create 8 worker processes in total. Our suggested max number of worker in current system is 1, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
cpuset_checked))
[ INFO ] Dataset information:
Path: /glb/hou/pt.sgs/data/ml_ai_us/4d/usadh7/github_repos/SRGAN-PyTorch/./data/test
Number of samples: 0
Number of batches: 0
Shuffle: False
Sampler: None
Workers: 8
0it [00:00, ?it/s]
Traceback (most recent call last):
File "test_benchmark.py", line 167, in
main()
File "test_benchmark.py", line 82, in main
main_worker(args.gpu, args)
File "test_benchmark.py", line 149, in main_worker
print(f"MSE {total_mse_value / len(dataloader):6.4f}\n"
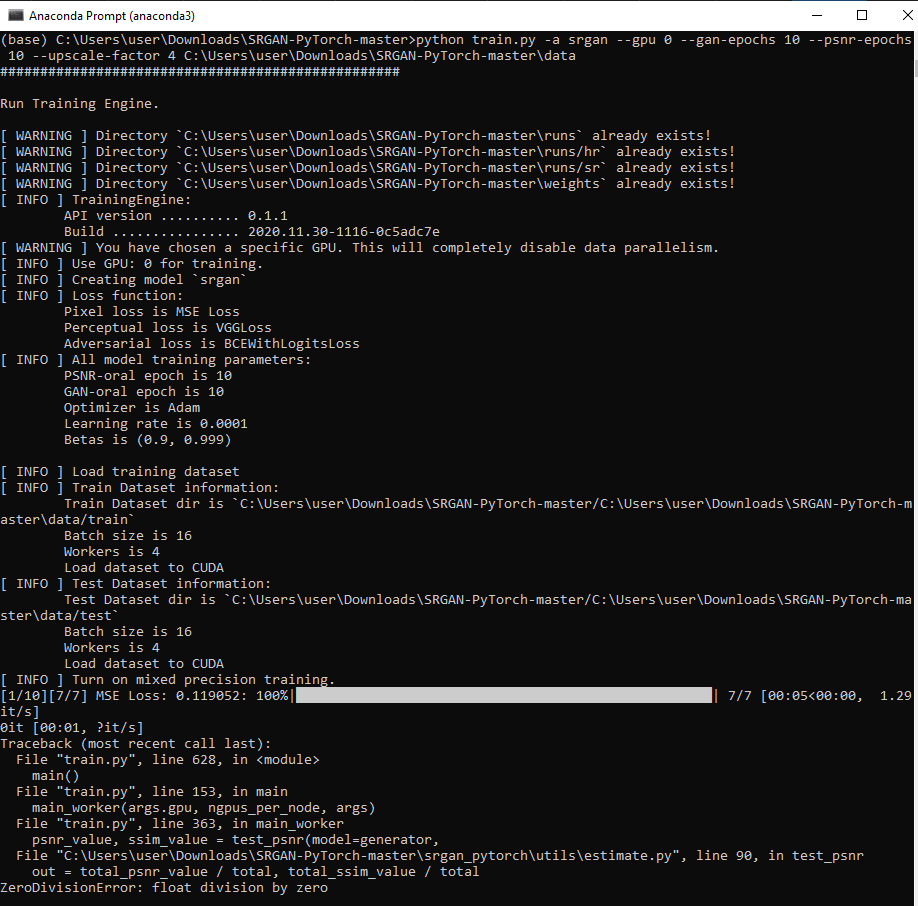
ZeroDivisionError: float division by zero
Hello,
I've applied your model to images containing white and yellow sections. The SR results shows green instead of yellow but the strangest is the white color is replaced by a patron I suspect is provoked by storing NaN or something like that. I attach two examples.
With the provided weights:


After fine tuning with images from the same dataset:


Any ideas how to fix it?
Hi, I have some incompatibility problems, would you mind sharing what python version and tensorboard version you were using while you made the latest release (few days ago)?
谢谢
when I reduce the upscale_factor value to 2 or 3, I had the problem at classifier layer. I used the DIV2K dataset. Can you help me to fix it?
Thank you!

Hello, I'm interested in the field of super resolution, so I'm looking your code.
My GPU is not good, so I want to get pre-trained weight.
Can I install the weight file?
Hi,
I have been training the SRGAN model from the repo and I have got the following losses :

I do not understand why D(SR) = 0 over the epochs and D(HR) = 1.
The dataset that I used is the ImageNet dataset provided in the readme. Is the generator unable to trick the discriminator ?
Thank you very much
ssh://[email protected]:22/data/tianhao.lu/software/anaconda3/envs/GAN/bin/python -u /home/tianhao.lu/.pycharm_helpers/pydev/pydevd.py --multiproc --qt-support=auto --client 0.0.0.0 --port 40739 --file /data/tianhao.lu/code/ProjectArchitecture/complete/SRGAN_demo.py
已连接到 pydev 调试器(内部版本 211.6693.115)# generator parameters: 734219
0%| | 0/5 [00:06<?, ?it/s]
Traceback (most recent call last):
File "/home/tianhao.lu/.pycharm_helpers/pydev/pydevd.py", line 1483, in _exec
pydev_imports.execfile(file, globals, locals) # execute the script
File "/home/tianhao.lu/.pycharm_helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "/data/tianhao.lu/code/ProjectArchitecture/complete/SRGAN_demo.py", line 98, in
g_loss.backward()
File "/data/tianhao.lu/software/anaconda3/envs/GAN/lib/python3.7/site-packages/torch/tensor.py", line 198, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/data/tianhao.lu/software/anaconda3/envs/GAN/lib/python3.7/site-packages/torch/autograd/init.py", line 100, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [1, 1024, 1, 1]] is at version 2; expected version 1 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
python-BaseException
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.