If you like my work, do leave a star ✨. I'd more than happy if you give any receive suggestions to improve my work!!
In this project various techniques are used. The basic concepts such as data cleaning, data transformation are also explained very clearly.
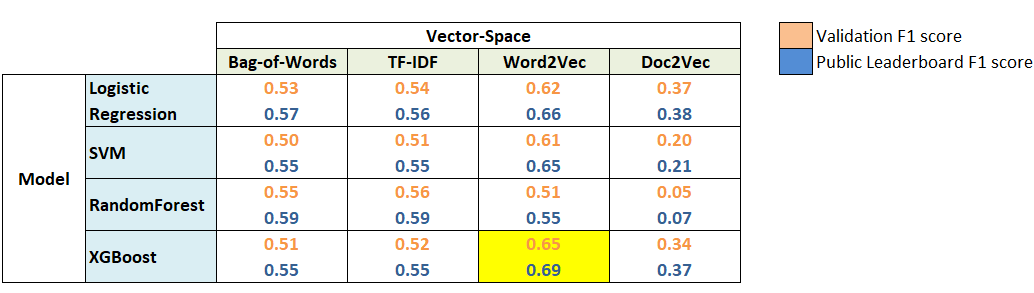
Word2Vec features turned out to be most useful. Whereas XGBoost with Word2Vec features was the best model for this problem. This clearly shows the power of word embeddings in dealing with NLP problems.
WHAT ELSE CAN BE TRIED? We have covered a lot in this Sentiment Analysis project, but still there is plenty of room for other things to try out. Given below is a list of tasks that you can try with this data.
1.We have built so many models in this, we can definitely try model ensembling. A simple ensemble of all the submission files (maximum voting) yielded an F1 score of 0.55 on the public leaderboard.
2.Use Parts-of-Speech tagging to create new features.
3.Use stemming and/or lemmatization. It might help in getting rid of unnecessary words.
4.Use bi-grams or tri-grams (tokens of 2 or 3 words respectively) for Bag-of-Words and TF-IDF.
5.We can give pretrained word-embeddings models a try.




