Practical Deep Reinforcement Learning
This is a practical resource that makes it easier to learn about and apply deep reinforcement learning. For practitioners and researchers, Practical RL provides a set of practical implementations of reinforcement learning algorithms applied on different environments, enabling easy experimentations and comparisons.

Reinforcement Learning (RL) is a machine learning approach for teaching agents how to solve tasks by interaction with environments. Deep Reinforcement Learning refers to the combination of RL with deep learning.
Code for RL Algorithms:
- Simple RL algorithms from scratch, based on Numpy, such as Q-Learning, SARSA and REINFORCE applied on simple grid world environments.
- Advanced RL algorithms using the Stable Baselines that extends and improves the OpenAI Baselines.
1- Hello Environments!
Gym comes with a diverse suite of environments ranging from Classic control and toy text to Atari, 2D and 3D robots.
for t in range(1000):
action = env.action_space.sample()
env.render()
observation, reward, done, info = env.step(action)
rewards_list.append(reward)
if done:
break;


2- Hello RL!
Some RL methods must wait until the end of an episode to update the value function estimate. More practically, Temporal-difference (TD) methods update the value function after every time step. Two main algorithms are implemented:
- 2.1 SARSA: Updates Q after SARSA sequence (A is chosen from the e-greedy policy)
Q[s,a] = Q[s,a] + alpha * ((r + gama* Q[s1,a1]) - Q[s,a])
- 2.2 Q-Learning: Updates Q after SARS and use max A (A is chosen from the greedy policy)
Q[s,a] = Q[s,a] + alpha*(r + gama*np.max(Q[s1,:]) - Q[s,a])

Advanced Deep RL:
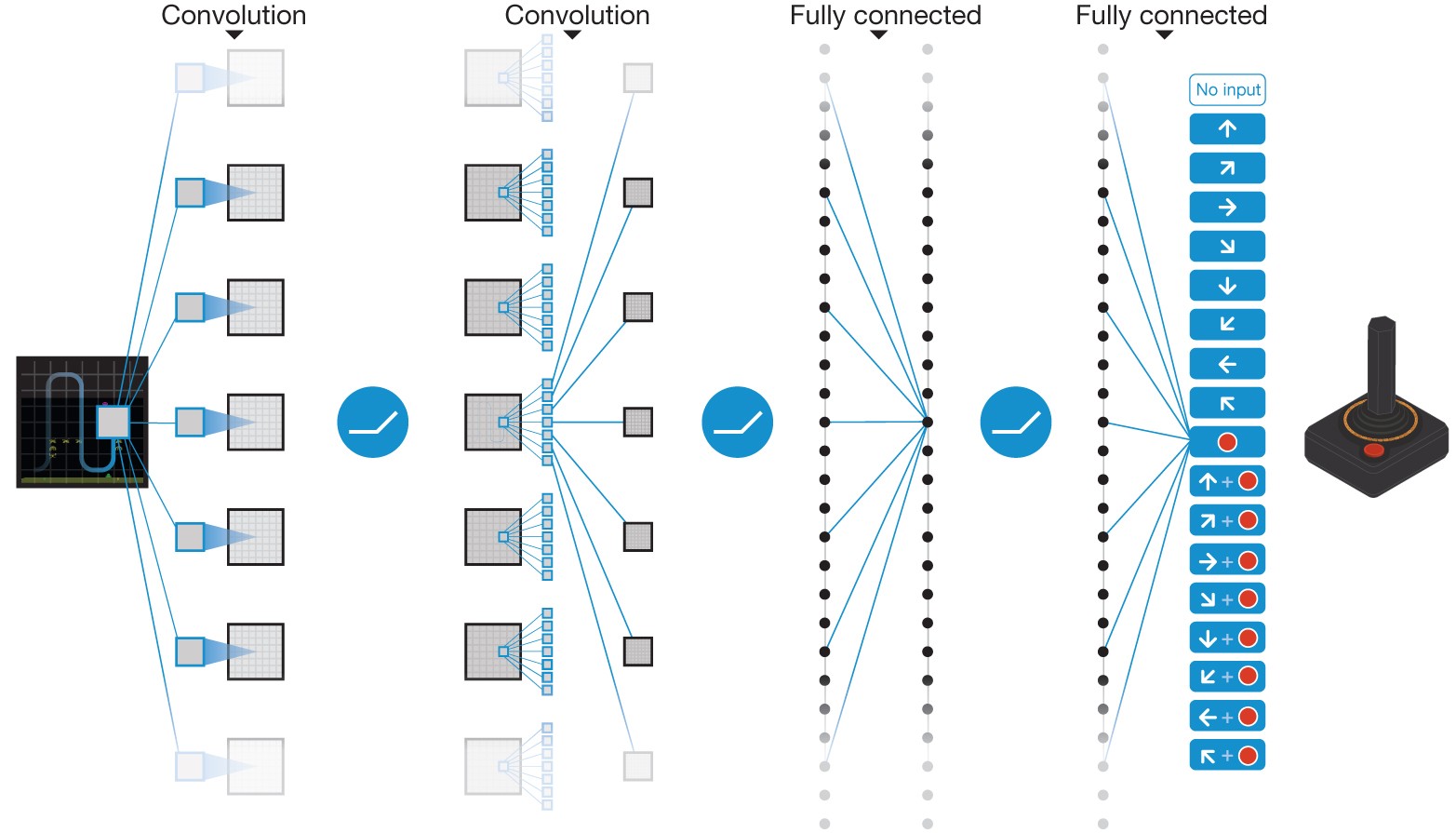
3- DQN Human-level control through deep reinforcement learning
A value based RL algorithm, where Deep Neural Network is used as a function approximator to estimate the action value function Q(s, a).

total_timesteps = 150000
env = gym.make('LunarLander-v2')
model = DQN(MlpPolicy, env, verbose=0, prioritized_replay=True, tensorboard_log="./DQN_LunarLander_tensorboard/")
model.learn(total_timesteps=total_timesteps, tb_log_name="DQN_prioreplay")
model.save("dqn_LunarLander_prioreplay")

4- REINFORCE
A policy based RL algorithm that directly gets the optimal policy (direct mapping from states to actions) without estimating a value function. REINFORCE samples few trajectories using the current policy and uses them to estimate the gradient to increase / decrease the action probability based in the return.
5- PPO Proximal Policy Optimization
On policy algorithm that uses old trajectories, instead of just throwing them away, by modifying them so that they are representative of the new policy, using approximated re-weight factor.

# multiprocess environment
n_cpu = 4
env = SubprocVecEnv([lambda: gym.make('CartPole-v0') for i in range(n_cpu)])
model = PPO2(MlpPolicy, env, verbose=0, tensorboard_log="./ppo_cartpole_tensorboard/")
model.learn(total_timesteps=total_timesteps, tb_log_name = "PPO2_4")
model.save("ppo_cartpole_4")

6- A3C and A2C Asynchronous Methods for Deep Reinforcement Learning
Actor Critic (AC) methods are a hybrid of value based and policy based methods, where a Critic measures how good the action taken is by estimating a value function, and an Actor controls how the agent behaves (policy-based). Asynchronous Methods: multiple agents on different threads are used for parallel exploring the state spaces and make decorrelated updates to the actor and the critic. A3C Asynchronous Advantage Actor Critic where Each agent updates the network on its own, while A2C is the Synchronous variant where it waits for all agents and then update the network at once.
model = A2C(MlpPolicy, env, verbose=0, tensorboard_log="./a2c_cartpole_tensorboard/")
model.learn(total_timesteps=total_timesteps)

7- DDPG Deep Deterministic Policy Gradient
In DDPG, (DQN) is adapted to continuous action domains, where the Deterministic Policy (the Actor) gives the best believed action for any given state (no argmax over actions)

env = gym.make('Pendulum-v0')
env = DummyVecEnv([lambda: env])
action_noise = OrnsteinUhlenbeckActionNoise(mean=np.zeros(n_actions), sigma=float(0.5) * np.ones(n_actions))
model = DDPG(MlpPolicy, env, verbose=0, param_noise=param_noise, action_noise=action_noise)
model.learn(total_timesteps=total_timesteps, callback=callback)
8- TD3 Twin Delayed Deep Deterministic Policy Gradients
TD3 is an algorithm that addresses the overestimated Q-values issue of DDPG by introducing the Clipped Double-Q Learning. where TD3 learns two Q-functions instead of one.

env = gym.make('BipedalWalker-v2')
env = DummyVecEnv([lambda: env])
n_actions = env.action_space.shape[-1]
action_noise = NormalActionNoise(mean=np.zeros(n_actions), sigma=0.1 * np.ones(n_actions))
model = TD3(MlpPolicy, env, action_noise=action_noise, verbose=0, tensorboard_log="./td3_BipedalWalker_tensorboard/")
model.learn(total_timesteps=total_timesteps)

9- Behavior Cloning (BC)
BC uses expert demonstrations (observations-actions pairs), as a supervised learning problem. The policy network is trained to reproduce the expert behavior, then train the RL model for self-improvement.
Steps:
- Generate and save trajectories (ex: using a trained DQN agent)
- Load expert trajectories
- Pretrain the RL model in a supervised way
- Evaluate the pre-trained model
- Train the RL model for self improvement (RL)
- Evaluate the final RL model

10- GAIL Generative Adversarial Imitation Learning
In GANs Generative Adversarial Networks, we have two networks learning together:
- Generator network: try to fool the discriminator by generating real-looking images
- Discriminator network: try to distinguish between real and fake images
GAIL uses a discriminator that tries to separate expert trajectory from trajectories of the learned policy, which has the role of the generator here.
Steps:
- Generate and save expert dataset
- Load the expert dataset
- Train GAIL agent and evaluate

