听闻用issue写博客省事又自带SEO,为了更关注内容本身,尝试迁移至此。
原博客地址:
- maxisacoder.github.io (技术blog,一锅炖)
- blog.sina.com.cn/u/2647396281 (大学时期遗址)
新博客,基于issue
听闻用issue写博客省事又自带SEO,为了更关注内容本身,尝试迁移至此。
原博客地址:












根据 Nadav Hollander(Dharma协议) 在白皮书中观点:
故Dharma对自己的定位是:
总结下来,Dharma的Scope包括:
包含四个角色,角色模型如下:
在0xProject的基础上加入了Underwritter这个角色,可以用来:
struct DebtOrder {
Issuance issuance;
uint underwriterFee;
uint relayerFee;
uint principalAmount;
address principalToken;
uint creditorFee;
uint debtorFee;
address relayer;
uint expirationTimestampInSec;
bytes32 debtOrderHash;
} struct Issuance {
address version;
address debtor;
address underwriter;
uint underwriterRiskRating;
address termsContract;
bytes32 termsContractParameters;
uint salt;
bytes32 agreementId;
}一个填完的订单应包含如下3个签名
agreementId + debtOrder的所有字段 function getDebtOrderHash(DebtOrder debtOrder)
internal
view
returns (bytes32 _debtorMessageHash)
{
return keccak256(
address(this),
debtOrder.issuance.agreementId,
debtOrder.underwriterFee,
debtOrder.principalAmount,
debtOrder.principalToken,
debtOrder.debtorFee,
debtOrder.creditorFee,
debtOrder.relayer,
debtOrder.relayerFee,
debtOrder.expirationTimestampInSec
);
}debtOderHash签名, 同debtor function getUnderwriterMessageHash(DebtOrder debtOrder)
internal
view
returns (bytes32 _underwriterMessageHash)
{
return keccak256(
address(this),
debtOrder.issuance.agreementId,
debtOrder.underwriterFee,
debtOrder.principalAmount,
debtOrder.principalToken,
debtOrder.expirationTimestampInSec
);
}注意到,underwriter在签名时不包含relayer和creditor的信息,这样设计的目的是:
同时注意到:
握手流程官方图示
整体流程官方图示
dharma主要维护的项目包括如下:
ganache --db导入已经部署的Dharma合约和状态生态中,有两个参考relayer实现:
Dharma.js现阶段只实现了抵押借贷分期还款的接口,儿无抵押分期还款只提供了contract。
下面我们先介绍其基类合约分期还款(SimpleInterestTermsContract),再详述 CollateralizedSimpleInterestTermsContract 流程。
在分期还款协议中,协议通过debtOder中的termsContractParameters封装了如下参数:
Location (bytes) Location (bits)
32 256
principalTokenIndex 31 248
principalAmount 19 152
interestRate 16 128
amortizationUnitType 15.5 124
termLengthInAmortizationUnits 13.5 108其完整参数为:
struct SimpleInterestParams {
address principalTokenAddress;
uint principalAmount;
uint termStartUnixTimestamp;
uint termEndUnixTimestamp;
AmortizationUnitType amortizationUnitType;
uint termLengthInAmortizationUnits;
// Given that Solidity does not support floating points, we encode
// interest rates as percentages scaled up by a factor of 10,000
// As such, interest rates can, at a maximum, have 4 decimal places
// of precision.
uint interestRate;
}
其中缺少的两个参数有下列逻辑得出. 其中debtRegisty()订单数据库中存储的 issuanceBlockTimestamp,为插入该条订单数据的时间, 也即债权人填单的时间。具体call stack路径是:
uint issuanceBlockTimestamp = contractRegistry.debtRegistry().getIssuanceBlockTimestamp(agreementId);
uint termEndUnixTimestamp = termLengthInSeconds.add(issuanceBlockTimestamp);分期抵押借贷是Dharma.js默认实现的借贷合约,值得我们完整研究。
从债务人发单到最后协议终止,完整流程简述如下:
dharma.js 的DebtOrder类静态方法create()完成订单创建。allowCollateralTransfer(), 同意抵押合约接受债务人的资产抵押。allowPrincipalTransfer(), 同意抵押合约接受债权人的本金抵押。Debtor.fill(), 债权人签名填单,将合约上链。makePayment(), 发起还款接下的内容详述每一个步骤:
dharma.js 订单创建CollateralizedSimpleInterestLoanOrder 订单CollateralizedSimpleInterestLoanAdapter, 将订单转化为标准的 DebtOrderDatadebtKernel和repaymentRouter, 并将其地址填入标准订单中。SignerAPI, 在下一章详述。(await debtOrder.signAsDebtor();)步骤3中,DebtOrderData的定义,也即白皮书中描述的标准订单格式:
export interface DebtOrderData {
kernelVersion?: string;
issuanceVersion?: string;
principalAmount?: BigNumber;
principalToken?: string;
debtor?: string;
debtorFee?: BigNumber;
creditor?: string;
creditorFee?: BigNumber;
relayer?: string;
relayerFee?: BigNumber;
underwriter?: string;
underwriterFee?: BigNumber;
underwriterRiskRating?: BigNumber;
termsContract?: string;
termsContractParameters?: string;
expirationTimestampInSec?: BigNumber;
salt?: BigNumber;
// Signatures
debtorSignature?: ECDSASignature;
creditorSignature?: ECDSASignature;
underwriterSignature?: ECDSASignature;
}注意到,此处创建 DebtOder还不会将订单发送到区块链。
调用栈及说明:
tokenAPI.setUnlimitedProxyAllowanceAsync(): 调用ERC20的approve()接口将代币抵押到tokenTransferProxydebtOder.enableTokenTransfers(address, tokenSymbol): 调用tokenRegisy合约获得ERC20代币的合约地址, 并调用setUnlimitedProxyAllowanceAsync.debtOder.allowCollateralTransfer(debtorAddress)流程与Debtor同意资产抵押基本相同
调用栈及说明:
debtKernel.fillDebtOrder(): 调用核心合约,完成合约确认的填单。OderAPI.fillAsync():先进行相关的订单校验,校验完毕后调用核心合约的填单逻辑。DebtOrder.fill()Dharma.js提交订单前,通过OrderAPI.assertFillableAsync()校验订单是否可以被填单:
OderAPI.assertValidityInvariantsAsync()
debtor和underwritter在订单fill之前都可以取消订单。debtTokenContract合约,判断该订单中对应的IssuranceCommitmentHash没有已被使用。assertConsensualityInvariants()
Debtor, Creditor, UnderWriter 三者的签名orderAPI.assertCreditorBalanceAndAllowanceInvariantsAsync()
validateAsync() 接口,校验是否creditor可以签单,在抵押借贷中:
dharma.js对各个合约提供的adpater中进行,故债权人如果直接操作合约,也可以成功签单。核心合约签单后
TermContract 的 registerTermStart,通知其合约开始Creditor的allowance作为本金转给 Debtor`Creditor的allowance作为手续费转给 Underwritter和Relyer fee注意到,如果做法币的抵押借贷,在上述流程中:
调用栈及说明:
RepaymentRouterContract.repay(): RepaymentRouter的作用是,帮助债务人得知还款地址,因为债务人在填单的时候不知道债券人的地址,同时,债券也有可能被转让。(转让债券只需要将NTF转让,并在DebtRgistry中调用modifyBeneficiary())ServicingAPI.makePayment():ServicingAPI中的makePayment(),支持的是对agreementId发起的还款。并不要求一定是是debtorOder中登记得Debtor发起还款,任何人都可以为agreementId发起还款。debtOder.makePayment()合同终止有两种情况,一种为债务人还清债务,赎回抵押物:
collateralizerContract.returnCollateral()CollateralizedSimpleInterestLoanAdapter.returnCollateralAsync()DdebtOder.returnCollateral()一种为债务人还清债务,赎回抵押物:
collateralizerContract.returnCollateral()CollateralizedSimpleInterestLoanAdapter.seizeCollateralAsync()DdebtOder.seizeCollateral()Dharmajs导出的顶层单例类,未按模块粒度导出。
public static Types = DharmaTypes 保存引用。([]为何要在此保存,而不直接将其各种type直接export?)DebtOrder类,见一下章。 public static Types = DharmaTypes;
public sign: SignerAPI;
public order: OrderAPI;
public contracts: ContractsAPI;
public adapters: AdaptersAPI;
public servicing: ServicingAPI;
public token: TokenAPI;
public blockchain: BlockchainAPI;
public logs: LogsAPI;
private readonly web3: Web3;该类提供了大部分的需要Debtor或者Creditor通过Dapp调用的顶层接口, 该顶层接口典型的调用路径为 DebtOder.someMethod()--> **API.someMethod() --> Contract.someFunction()
具有如下接口
export interface Adapter {
fromDebtOrder: (
debtOrder: DebtOrderData,
) => Promise<SimpleInterestLoanOrder | CollateralizedSimpleInterestLoanOrder>;
toDebtOrder: (params: object) => Promise<DebtOrderData>;
fromDebtRegistryEntry: (entry: DebtRegistryEntry) => Promise<object>;
getRepaymentSchedule: (entry: DebtRegistryEntry) => number[];
unpackParameters: (packedParams: string) => object;
validateAsync: (
order: SimpleInterestLoanOrder | CollateralizedSimpleInterestLoanOrder,
) => Promise<void>;
}SimpleInterestLoan和CollateralizedSimpleInterestLoan 两个具体的交易类型Oder 和 Term, 以及 TermsContractAdpter 负责 Oder格式的转化提供了如下合约的js封装,通过abi-gen生成,不对外部暴露。
- BaseContract,
- DebtOrderDataWrapper,
- DebtKernelContract,
- DebtRegistryContract,
- DebtTokenContract,
- DummyTokenContract,
- TokenRegistryContract,
- TokenTransferProxyContract,
- ERC20Contract,
- ERC721ReceiverContract,
- MockERC721ReceiverContract,
- TermsContract,
- SimpleInterestTermsContractContract,
- CollateralizedSimpleInterestTermsContractContract,
- RepaymentRouterContract,
- CollateralizerContract,
特别的,其中还包含了 DebtOrderDataWrapper的封装,是在DebtOrderData的基础上扩展了一些方法。
关于abi-gen, 是由Ox项目提供的工具:
deploy()和at()两个接口,主要用来获取已部署的合约Wrapper实例。提供了3中角色的签单逻辑,分别为:
asDebtor(DebtOrderData)asCreditorasUnderwriter以asDebtor为例,包含以下流程:
DebtOrderDataWrapper, 并获取getDebtorCommitmentHash.ECDSASignature.从链上加载达摩协议,返回wrapper中定义的如下协议实例。
export interface DharmaContracts {
debtKernel: DebtKernelContract;
debtRegistry: DebtRegistryContract;
debtToken: DebtTokenContract;
repaymentRouter: RepaymentRouterContract;
tokenTransferProxy: TokenTransferProxyContract;
collateralizer: CollateralizerContract;
}
包含对ERC20 token的如下操作:
tokenTransferProxy包含对订单操作API,不同于DebtOder实例上的API是,这些API较之更加底层,且会被DebtOder实例调用。而DebtOder上面的API基本上只会被Creditor和Debtor直接消费。
ERC721兼容的Token,tokenId为Issurance的hash。
TermsContract兼容的合约如 SimpleInterestTermsContract,通过该ContractRegistry调用所有已部署的达摩合约。DebtKernal和RepaymentRouter有权限转移用户抵押的代币。Charta中,继承TermsContract,实现接口并部署。Dharma.js中,实现协议的Adpater接口。wrapper和schema。Dharma.js最顶层的 DebtOrder与具体的termsContract有较大的耦合,故实现新的自定义合约在现有的状态下无法做到不修改 Dharma.js代码。dharma-turorial,进行已有的dharma API的调用。charta的目录,执行truffle console,其中自带合约的引用。dharmajs的sourceMap:前端用 yarn run eject 将webpack配置发射,然后在rule中加入以下配置,会加载dharmajs的sourceMap,但运行速度会相对变慢 {
test: /\.js$/,
use: ["source-map-loader"],
enforce: "pre"
},
dharma.js如何找到已部署的合约地址,如何发起调用?[x]"@dharmaprotocol/dharma.js": "0.1.10"中dharma-chain的data中,由ganache 的 --db 功能导入基于综上对达摩协议的调研,在 OTC, 法币,仲裁,双向挂单
初步想法:
dharma协议过程可以简述如下:
注意到,如果引入法币,只影响3和4步骤的转账逻辑。故拟转账双方可以走如下流程:
实际逻辑可能比上述逻辑稍复杂,但主体逻辑应该为上述步骤。故我们可以引入Fiat合约,代理法币转账逻辑。提供相应的方法同时发射相应的事件,供Dapp或者Relayer调用或监听。
在上述引入法币的基础上,法币抵押借贷流程可整理为:
dharma协议过程可以简述如下:
对比OTC和法币抵押借贷的逻辑,OTC交易可以看成满足一下要求的特殊抵押token借出法币的流程:
由于抵押逻辑发生在 collateral 合约中,我们可以实现另外一 OTC 合约来实现不同于collateral中的抵押物逻辑。
目前的仲裁,只涉及法币的到账确认问题。故仲裁合约可以设计在所有合约之外,只负责对法币支付是否到账做仲裁,如何处理仲裁结果,由上层合约处理。未来为了支持非智能合约的代币支付,我们可能通过仲裁机制为其提供支持。同时,详细的仲裁细节和vena代币在仲裁中的激励涉及,需要另外专题详述。
在dharma协议中,订单格式与协议流程只支持借贷者发起订单,债权人不能发起订单。而对应于OTC交易中,issurance只能由tokenSeller发起。
在达摩协议中,订单是以一下的步骤握手生成的:
在上述流程中,订单的发起有如下限制:
本文档基于go-etherum v1.9.13,亦是bsc节点fork的eth版本起点。 目标在于以可debug的方式启动geth节点
# Note: this config doesn't contain the genesis block.
[Eth]
NetworkId = 11133
SyncMode = "fast"
# DiscoveryURLs = ["enrtree://AKA3AM6LPBYEUDMVNU3BSVQJ5AD45Y7YPOHJLEF6W26QOE4VTUDPE@all.rinkeby.ethdisco.net"]
NoPruning = false
NoPrefetch = false
LightPeers = 100
UltraLightFraction = 75
DatabaseCache = 512
DatabaseFreezer = ""
TrieCleanCache = 256
TrieDirtyCache = 256
TrieTimeout = 3600000000000
EnablePreimageRecording = false
EWASMInterpreter = ""
EVMInterpreter = ""
[Eth.Miner]
GasFloor = 8000000
GasCeil = 8000000
GasPrice = 1000000000
Recommit = 3000000000
Noverify = false
[Eth.Ethash]
CacheDir = "ethash"
CachesInMem = 2
CachesOnDisk = 3
CachesLockMmap = false
DatasetDir = "/Users/lixianji/Documents/coding/play/go-ethereum/data/ethash"
DatasetsInMem = 1
DatasetsOnDisk = 2
DatasetsLockMmap = false
PowMode = 0
[Eth.TxPool]
Locals = []
NoLocals = false
Journal = "transactions.rlp"
Rejournal = 3600000000000
PriceLimit = 1
PriceBump = 10
AccountSlots = 16
GlobalSlots = 4096
AccountQueue = 64
GlobalQueue = 1024
Lifetime = 10800000000000
[Eth.GPO]
Blocks = 20
Percentile = 60
[Shh]
MaxMessageSize = 1048576
MinimumAcceptedPOW = 2e-01
RestrictConnectionBetweenLightClients = true
[Node]
DataDir = "/Users/lixianji/Documents/coding/play/go-ethereum/data/chain"
omitempty = ""
IPCPath = "geth.ipc"
HTTPPort = 18545
HTTPVirtualHosts = ["127.0.0.1"]
HTTPModules = ["net", "web3", "eth"]
WSPort = 18546
WSModules = ["net", "web3", "eth"]
GraphQLPort = 18547
GraphQLVirtualHosts = ["localhost"]
[Node.P2P]
MaxPeers = 50
NoDiscovery = false
# BootstrapNodes = ["enode://a24ac7c5484ef4ed0c5eb2d36620ba4e4aa13b8c84684e1b4aab0cebea2ae45cb4d375b77eab56516d34bfbd3c1a833fc51296ff084b770b94fb9028c4d25ccf@52.169.42.101:30303", "enode://343149e4feefa15d882d9fe4ac7d88f885bd05ebb735e547f12e12080a9fa07c8014ca6fd7f373123488102fe5e34111f8509cf0b7de3f5b44339c9f25e87cb8@52.3.158.184:30303", "enode://b6b28890b006743680c52e64e0d16db57f28124885595fa03a562be1d2bf0f3a1da297d56b13da25fb992888fd556d4c1a27b1f39d531bde7de1921c90061cc6@159.89.28.211:30303"]
# BootstrapNodesV5 = ["enode://a24ac7c5484ef4ed0c5eb2d36620ba4e4aa13b8c84684e1b4aab0cebea2ae45cb4d375b77eab56516d34bfbd3c1a833fc51296ff084b770b94fb9028c4d25ccf@52.169.42.101:30303", "enode://343149e4feefa15d882d9fe4ac7d88f885bd05ebb735e547f12e12080a9fa07c8014ca6fd7f373123488102fe5e34111f8509cf0b7de3f5b44339c9f25e87cb8@52.3.158.184:30303", "enode://b6b28890b006743680c52e64e0d16db57f28124885595fa03a562be1d2bf0f3a1da297d56b13da25fb992888fd556d4c1a27b1f39d531bde7de1921c90061cc6@159.89.28.211:30303"]
StaticNodes = []
TrustedNodes = []
ListenAddr = ":30303"
EnableMsgEvents = false
[Node.HTTPTimeouts]
ReadTimeout = 30000000000
WriteTimeout = 30000000000
IdleTimeout = 120000000000
替换alloc中的地址
{
"config": {
"chainId": 11133,
"homesteadBlock": 0,
"eip150Block": 0,
"eip155Block": 0,
"eip158Block": 0,
"byzantiumBlock": 0,
"constantinopleBlock": 0,
"petersburgBlock": 0,
"istanbulBlock": 0
},
"alloc": {
"xx": {
"balance": "111111111000000000000000000000"
},
"xxx": {
"balance": "22222111111111000000000000000000000"
}
},
"coinbase": "0x0000000000000000000000000000000000000000",
"difficulty": "0x20000",
"extraData": "",
"gasLimit": "0x2fefd8",
"nonce": "0x0000000000000042",
"mixhash": "0x0000000000000000000000000000000000000000000000000000000000000000",
"parentHash": "0x0000000000000000000000000000000000000000000000000000000000000000",
"timestamp": "0x00"
}
运行
geth init --datadir ./data/chain genesis.json在goland中配置启动参数
--rpc启动rpc端口--debug显示debug输出
cmd/main.go
func geth(ctx *cli.Context) error {
if args := ctx.Args(); len(args) > 0 {
return fmt.Errorf("invalid command: %q", args[0])
}
prepare(ctx) //1
node := makeFullNode(ctx) //2
defer node.Close()
startNode(ctx, node) //3
node.Wait()
return nil
}ctx.GlobalSet(utils.CacheFlag.Name, strconv.Itoa(4096))
gogc := math.Max(20, math.Min(100, 100/(float64(cache)/1024)))
godebug.SetGCPercent(int(gogc))
utils.SetupMetrics(ctx)
makeFullNode(ctx *cli.Context)
// 1. read config
stack, cfg := makeConfigNode(ctx)
// 2. eable eth service
utils.RegisterEthService(stack, &cfg.Eth)
// 3. enable whisper
// 涉及到 shh: whisper 协议
// 用作dapp间,借助eth的p2p层进行通信
// ref:https://eth.wiki/concepts/whisper/whisper
shhEnabled := enableWhisper(ctx)
// 4. config graphql service
utils.RegisterGraphQLService(stack, cfg.Node.GraphQLEndpoint(), cfg.Node.GraphQLCors, cfg.Node.GraphQLVirtualHosts, cfg.Node.HTTPTimeouts)
// 5. eth stats service
// 节点状态上报,通过websocket
// 配套使用 https://github.com/cubedro/eth-netstats
// https://github.com/cubedro/eth-net-intelligence-api
// https://github.com/ethereum/eth-net-intelligence-api
// https://eth.wiki/concepts/network-status
// 目前官方使用情况不佳,不过可以用作自己的节点监控
utils.RegisterEthStatsService(stack, cfg.Ethstats.URL)上述流程中,关键点在于RegisterEthService, 展开其流程,如下
func RegisterEthService(stack *node.Node, cfg *eth.Config) {
var err error
// light sync只支持启动les节点
if cfg.SyncMode == downloader.LightSync {
err = stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
return les.New(ctx, cfg)
})
} else {
err = stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
fullNode, err := eth.New(ctx, cfg)
if fullNode != nil && cfg.LightServ > 0 {
ls, _ := les.NewLesServer(fullNode, cfg)
// 如果开启light client,则在fullnode基础上加入les功能,以支持web3.les
// les 协议:https://github.com/ethereum/devp2p/blob/master/caps/les.md
// les 介绍:https://eth.wiki/concepts/light-client-protocol
fullNode.AddLesServer(ls)
}
return fullNode, err
})
}
if err != nil {
Fatalf("Failed to register the Ethereum service: %v", err)
}
}// 1. 启动节点
utils.StartNode(stack)
// 2. 启动wallet相关服务
events := make(chan accounts.WalletEvent, 16)
stack.AccountManager().Subscribe(events)
// 3. 启动geth client
rpcClient, err := stack.Attach()
ethClient := ethclient.NewClient(rpcClient)
// 4.注册lesservice,处理les请求
// 5. 处理POA共识最终具体的节点启动逻辑来到了node.go 中的start方法。在后续系列中详细解析
func (n *Node) Wait() {
n.lock.RLock()
if n.server == nil {
n.lock.RUnlock()
return
}
stop := n.stop
n.lock.RUnlock()
<-stop
}Node is a container on which services can be registered.
node.go中,start方法实现了对节点的启动
// 1. create p2p server
running := &p2p.Server{Config: n.serverConfig}
// 2. start services p2p
// 其中、p2p协议会多个版本共存、该版本中eth service会同时启动63、64、65三个版本的p2p服务
// Gather the protocols and start the freshly assembled P2P server
for _, service := range services {
running.Protocols = append(running.Protocols, service.Protocols()...)
}
if err := running.Start(); err != nil {
return convertFileLockError(err)
}
// Start each of the services
var started []reflect.Type
for kind, service := range services {
// Start the next service, stopping all previous upon failure
if err := service.Start(running); err != nil {
for _, kind := range started {
services[kind].Stop()
}
running.Stop()
return err
}
// Mark the service started for potential cleanup
started = append(started, kind)
}
// 3. start services RPC
if err := n.startRPC(services); err != nil {
for _, service := range services {
service.Stop()
}
running.Stop()
return err
}对于定制化的节点,可以实现Service接口,注入node
service接口如下:
type Service interface {
// Protocols retrieves the P2P protocols the service wishes to start.
Protocols() []p2p.Protocol
// APIs retrieves the list of RPC descriptors the service provides
APIs() []rpc.API
// Start is called after all services have been constructed and the networking
// layer was also initialized to spawn any goroutines required by the service.
Start(server *p2p.Server) error
// Stop terminates all goroutines belonging to the service, blocking until they
// are all terminated.
Stop() error
}Package eth implements the Ethereum protocol.
ethereum struct
type Ethereum struct {
config *Config
// Handlers
txPool *core.TxPool
blockchain *core.BlockChain
protocolManager *ProtocolManager
lesServer LesServer
dialCandiates enode.Iterator
// DB interfaces
chainDb ethdb.Database // Block chain database
eventMux *event.TypeMux
engine consensus.Engine
accountManager *accounts.Manager
bloomRequests chan chan *bloombits.Retrieval // Channel receiving bloom data retrieval requests
bloomIndexer *core.ChainIndexer // Bloom indexer operating during block imports
closeBloomHandler chan struct{}
APIBackend *EthAPIBackend
miner *miner.Miner
gasPrice *big.Int
etherbase common.Address
networkID uint64
netRPCService *ethapi.PublicNetAPI
lock sync.RWMutex // Protects the variadic fields (e.g. gas price and etherbase)
}func (s *Ethereum) Start(srvr *p2p.Server) error {
// EIP778: Ethereum Node Records (ENR)
// https://eips.ethereum.org/EIPS/eip-778
// EIP778 提供了一套节点记录的编码规范、用于p2p以及其他类似DNS等协议之上的节点发现
// EIP-2124:用于识别p2p网络中的协议分叉,可能可以用于快速扫描网络中的节点
// https://github.com/ethereum/EIPs/blob/master/EIPS/eip-2124.md
// P2P 一节可以详细讨论一下这里
s.startEthEntryUpdate(srvr.LocalNode())
// Start the bloom bits servicing goroutines
s.startBloomHandlers(params.BloomBitsBlocks)
// Start the RPC service
// ?? 这个API为什么传入的是p2p的server
s.netRPCService = ethapi.NewPublicNetAPI(srvr, s.NetVersion())
// Figure out a max peers count based on the server limits
maxPeers := srvr.MaxPeers
if s.config.LightServ > 0 {
if s.config.LightPeers >= srvr.MaxPeers {
return fmt.Errorf("invalid peer config: light peer count (%d) >= total peer count (%d)", s.config.LightPeers, srvr.MaxPeers)
}
maxPeers -= s.config.LightPeers
}
// 协议层启动发生在这个方法
// Start the networking layer and the light server if requested
s.protocolManager.Start(maxPeers)
if s.lesServer != nil {
s.lesServer.Start(srvr)
}
return nil
}func (pm *ProtocolManager) Start(maxPeers int) {
pm.maxPeers = maxPeers
// broadcast transactions
pm.wg.Add(1)
//txChanSize默认4096
//** 这个比较关键、决定了txPool的大小,可以做一定的修改
pm.txsCh = make(chan core.NewTxsEvent, txChanSize)
// 订阅pending
pm.txsSub = pm.txpool.SubscribeNewTxsEvent(pm.txsCh)
// 广播pending给peer,** 可以只广播自己的交易
go pm.txBroadcastLoop()
// broadcast mined blocks
pm.wg.Add(1)
// ?? 不知道这个从哪儿订阅上的
pm.minedBlockSub = pm.eventMux.Subscribe(core.NewMinedBlockEvent{})
go pm.minedBroadcastLoop()
// start sync handlers
pm.wg.Add(2)
// 开始sync
go pm.chainSync.loop()
go pm.txsyncLoop64() // TODO(karalabe): Legacy initial tx echange, drop with eth/64.
}上一片儿失联了
然后可能要起两个节点了,通过两个节点,来figure out
我们从交易发送的线索开始挖,主要关注
以sendTx为例,流程如下
// 1. ethapi/backend.go 定义API接口,对接口的创建在 node 包实现
SendTx(ctx context.Context, signedTx *types.Transaction) error
// 2. eth/api_backend.go 实现了 SendTx
func (b *EthAPIBackend) SendTx(ctx context.Context, signedTx *types.Transaction) error {
return b.eth.txPool.AddLocal(signedTx)
}
// 3. 进入core/tx_pool.go
func (pool *TxPool) AddLocal(tx *types.Transaction) error {
...
pool.addTxs(txs, !pool.config.NoLocals, true)
}
// 4. 过滤已知交易、设置cache
pool.mu.Lock()
newErrs, dirtyAddrs := pool.addTxsLocked(news, local)
pool.mu.Unlock()
// 5. 加入池子 addTxsLocked
func (pool *TxPool) addTxsLocked(txs []*types.Transaction, local bool) ([]error, *accountSet) {
dirty := newAccountSet(pool.signer)
errs := make([]error, len(txs))
for i, tx := range txs {
// 把新交易加入池子
replaced, err := pool.add(tx, local)
errs[i] = err
if err == nil && !replaced {
dirty.addTx(tx)
}
}
// 6. pool.add 核心处理
// If a newly added transaction is marked as local, its sending account will be
// whitelisted, preventing any associated transaction from being dropped out of the pool
// due to pricing constraints. (*** local账户添加,防止因为价格原因drop)
func (pool *TxPool) add(tx *types.Transaction, local bool) (replaced bool, err error)
// a. If the transaction is already known, discard it
// b. If the transaction fails basic validation, discard it
// c. If the transaction pool is full, discard underpriced transactions
// d. pricing bump : Try to replace an existing transaction in the pending pool
// 对同nonce替换的处理,参数决定了交易替换的最小gas比例,本地可能可以逃过,但网络中不太好跳过,看出块节点的配置
// TxPoolPriceBumpFlag = cli.Uint64Flag{
// Name: "txpool.pricebump",
// Usage: "Price bump percentage to replace an already existing transaction",
// Value: eth.DefaultConfig.TxPool.PriceBump,
// }
// e. 送入交易队列
pool.enqueueTx(hash, tx)
func (pool *TxPool) enqueueTx(hash common.Hash, tx *types.Transaction) (bool, error) {
// Try to insert the transaction into the future queue
from, _ := types.Sender(pool.signer, tx) // already validated
if pool.queue[from] == nil {
pool.queue[from] = newTxList(false)
}
inserted, old := pool.queue[from].Add(tx, pool.config.PriceBump)
if !inserted {
// An older transaction was better, discard this
queuedDiscardMeter.Mark(1)
return false, ErrReplaceUnderpriced
}
// Discard any previous transaction and mark this
if old != nil {
pool.all.Remove(old.Hash())
pool.priced.Removed(1)
queuedReplaceMeter.Mark(1)
} else {
// Nothing was replaced, bump the queued counter
queuedGauge.Inc(1)
}
if pool.all.Get(hash) == nil {
pool.all.Add(tx)
pool.priced.Put(tx)
}
return old != nil, nil
}接收交易后,如果是miner,就需要进行交易打包了
如果作为普通的全节点,接下来主要是广播交易,
*** 广播交易和节点处理的链路,我们可以专门优化,此处可以测试一下典型的延时,应该链路上优化空间比较大
顶层从InsertChain开始track
// blockchain.go
func (bc *BlockChain) InsertChain(chain types.Blocks) (int, error)
-->
func (bc *BlockChain) insertChain(chain types.Blocks, verifySeals bool) (int, error)
// 处理区块
receipts, logs, usedGas, err := bc.processor.Process(block, statedb, bc.vmConfig)
// 写入区块
status, err := bc.writeBlockWithState(block, receipts, logs, statedb, false)
-->
func (p *StateProcessor) Process(block *types.Block, statedb *state.StateDB, cfg vm.Config) (types.Receipts, []*types.Log, uint64, error)An outline of the fast sync algorithm would be:
这是相对省资源的一种方式,fast sync 的模式会下载 Header, Body 和 Receipt,插入的过程不会执行交易,因此也不会产生 StateDB 的数据,然后在某一个区块高度(最高的区块高度 - 1024)的时候同步完成所有的 StateDB 中的数据,作为本节点上的初始 StateDB Root 信息,最后的 downloader.fsMinFullBlocks(当前为 64)个区块会采用 full mode 的方式来构建。这种模式会缩小区块的同步时间(不需要执行交易),同时不会产生大量的历史的 StateDB 信息(也就不会产生大量的磁盘空间),但是对于网络的消耗会更高(因为需要下载 Receipt 和 StateDB),与 full sync 相比较,fast sync 是用网络带宽换取 CPU 资源。
snap sync 是1.10.0引入的一个新的同步机制,旨在解决fast sync带来的带宽及disk io的浪费问题
fast sync可以工作在snap协议上,handler中的snapSync字段控制了这个选项的开关
协议详情:https://github.com/ethereum/devp2p/blob/master/caps/snap.md
snap 从geth 1.10.0加入
In the case of fast sync, the unforeseen bottleneck was latency, caused by Ethereum’s data model. Ethereum’s state trie is a Merkle tree, where the leaves contain the useful data and each node above is the hash of 16 children. Syncing from the root of the tree (the hash embedded in a block header), the only way to download everything is to request each node one-by-one. With 675 million nodes to download, even by batching 384 requests together, it ends up needing 1.75 million round-trips. Assuming an overly generous 50ms RTT to 10 serving peers, fast sync is essentially waiting for over 150 minutes for data to arrive. But network latency is only 1/3rd of the problem.
When a serving peer receives a request for trie nodes, it needs to retrieve them from disk. Ethereum’s Merkle trie doesn’t help here either. Since trie nodes are keyed by hash, there’s no meaningful way to store/retrieve them batched, each requiring it’s own database read. To make matters worse, LevelDB (used by Geth) stores data in 7 levels, so a random read will generally touch as many files. Multiplying it all up, a single network request of 384 nodes - at 7 reads a pop - amounts to 2.7 thousand disk reads. With the fastest SATA SSDs’ speed of 100.000 IOPS, that’s 37ms extra latency. With the same 10 serving peer assumption as above, fast sync just added an extra 108 minutes waiting time. But serving latency is only 1/3 of the problem.
Requesting that many trie nodes individually means actually uploading that many hashes to remote peers to serve. With 675 million nodes to download, that’s 675 million hashes to upload, or 675 * 32 bytes = 21GB. At a global average of 51Mbps upload speed (X Doubt), fast sync just added an extra 56 minutes waiting time. Downloads are a bit more than twice as large, so with global averages of 97Mbps, fast sync popped on a further 63 minutes. Bandwidth delays are the last 1/3 of the problem.


eth/backend.go
1. node start
err := n.openEndpoints()
--> server.Start() // server start 即为p2p模块的server
2. p2p server
- setupLocalNode
- create rplx handshake obj
- init or load node db: level db
- initial NAT // ref NAT 网络类型 https://juejin.cn/post/6984996578587050021
- setupListening
- tcp listen
- update enr
- server.listenLoop()
- set max pending peers
- accept and check inbound
- 这里有一个"too many attempts"的控制,逻辑为同一个peer每30秒只能尝试一次handshake
- 这里使用ip控制,使用代理池可以解决这个限制
- `srv.inboundHistory.add(remoteIP.String(), now.Add(inboundThrottleTime))`
- 记录metric
- SetupConn
- doEncHandshake // 秘钥协商
- srv.checkpoint(c, srv.checkpointPostHandshake) --> 检查max peer
// 是否能在未建立连接的情况下获取到hello返回,不能
- doProtoHandshake // rplx hello mesg,包含client id,即name,客户端版本
- srv.checkpoint(c, srv.checkpointAddPeer) // 检查协议的兼容性
细节见文档 p2p.md
1. cmd/geth
threads := ctx.GlobalInt(utils.MinerThreadsFlag.Name)
if err := ethBackend.StartMining(threads); err != nil {
utils.Fatalf("Failed to start mining: %v", err)
}
2. eth/backend
// get miner account
eb, err := s.Etherbase()
if parlia, ok := s.engine.(*parlia.Parlia); ok {
wallet, err := s.accountManager.Find(accounts.Account{Address: eb})
if wallet == nil || err != nil {
log.Error("Etherbase account unavailable locally", "err", err)
return fmt.Errorf("signer missing: %v", err)
}
// sign dat func & sign tx func
parlia.Authorize(eb, wallet.SignData, wallet.SignTx)
}
// start miner
go s.miner.Start(eb)
3. miner/miner
// save start signal
func (miner *Miner) Start(coinbase common.Address) {
miner.startCh <- coinbase
}
// start signal fire
case addr := <-miner.startCh:
miner.SetEtherbase(addr)
if canStart {
// start worker
miner.worker.start()
}
shouldStart = true
4. commit to engine
// worker.go/commit: commit seal to task channal
case w.taskCh <- &task{receipts: receipts, state: s, block: block, createdAt: time.Now()}:
// worker.go/taskLoop: commit to engine
w.engine.Seal(w.chain, task.block, w.resultCh, stopCh);
5. seal in engine
parlia/Seal:
func (p *Parlia) Seal(chain consensus.ChainHeaderReader, block *types.Block, results chan<- *types.Block, stop <-chan struct{})
val, signFn := p.val, p.signFn // val 是出块的签名地址
snap, err := p.snapshot(chain, number-1, header.ParentHash, nil)
// Bail out if we're unauthorized to sign a block
if _, authorized := snap.Validators[val]; !authorized {
return errUnauthorizedValidator
}
// Sweet, the protocol permits us to sign the block, wait for our time
delay := p.delayForRamanujanFork(snap, header)
// Sign all the things!
sig, err := signFn(accounts.Account{Address: val}, accounts.MimetypeParlia, ParliaRLP(header, p.chainConfig.ChainID))
// send result
results <- block.WithSeal(header):
6. validators set 中的逻辑
这几日team里要来几个新同学,对区块链暂时没太多了解。故有了此篇blog,收集一些我看过的高质量的入门资料。这些资料收录的原则是,宁缺毋滥,尽量精简。
| dip | title | author |
|---|---|---|
| 3 | Partial Fills | Max Li <max> |
For debtor order with a big value of principleAmount, the debtor may want only fill part of it instead of the whole of it. This feature allows more agility and convenience for both parties of debt. The efficiency of the whole market will also increase.
This proposal introduces a straightforward design for this feature with the overhead of none-backward compatible NFT token. Whether there are more clever solutions for better compatibility is still remained to be explored by our communities.
Splitting out this issue, we need to deal with the following questions:
Inspired by 0x Protocol, which do partial fill when call fillOder with a fillTakerTokenAmount for partial-fill-value for contract caller. A similar method can be considered by adding this parameter to fillOder. For supporting partial fills, DebtOrder struct need a minor revision by adding a minPrincipalAmount field.
struct Issuance {
address version;
address debtor;
address underwriter;
uint underwriterRiskRating;
address termsContract;
bytes32 termsContractParameters;
uint salt;
bytes32 agreementId;
}
struct DebtOrder {
Issuance issuance;
uint underwriterFee;
uint relayerFee;
uint principalAmount;
+ uint minPrincipalAmount; // value equal to principalAmount means no-partial-fill allowed
address principalToken;
uint creditorFee;
uint debtorFee;
address relayer;
uint expirationTimestampInSec;
bytes32 debtOrderHash;
}
In original charta design, DebtRegistry contract records every occurred debt behavior on-chain. DebtToken contract get the hash of every record and mint token by the record hash. This proposal will follow this pattern for minimal changes. In DebtKernel contract, we save an orderRemain, which maps debtOder hash to current remaining for every order. This map can determine whether the remaining value is big enough for a fillDebtOder call.
mapping (byte32 => Remainning) orderRemain;
struct Remainning {
uint total;
uint min;
uint remain;
}
function fillDebtOrder(
address creditor,
address[6] orderAddresses,
uint[8] orderValues,
+ uint partialFillAmount, // for partial fill
bytes32[1] orderBytes32,
uint8[3] signaturesV,
bytes32[3] signaturesR,
bytes32[3] signaturesS
)
public
whenNotPaused
returns (bytes32 _agreementId)
{
+ // check the exisitence of order for given order hash
DebtOrder memory debtOrder = getDebtOrder(orderAddresses, orderValues, orderBytes32);
if (!orderRemain[orderBytes32]) {
orderRemain[orderBytes32] = Remainning (
debtOrder.principalAmount,
debtOrder.minPrincipalAmount,
debtOrder.principalAmount,
}
}
+ // Assert remain is enough for this fill
require(orderRemain[orderBytes32].remain > partialFillAmount);
// Assert order's validity & consensuality (some checking allowance value need also change)
+ // Mint debt token and finalize debt agreement
issueDebtAgreement(creditor, debtOrder.issuance, partialFillAmount);
orderRemain[orderBytes32].remain = orderRemain[orderBytes32].principalAmount - partialFillAmount;
// Register debt agreement's start with terms contract
// Transfer principal to debtor
// Transfer underwriter fee to underwriter
// Transfer relayer fee to relayer
}
In the current design of NFT, the ERC-721 tokenId is set to agreementId(Issuance Id). In the context of partial fills, one order is corresponding to one issuance, but possibly multiple fills. Every occured fill event need a NTF for tokenlizing the creditor's right. So, there are avoidless breaking changes in DebtToken contract for minting this new NTF for every fill.
function create(
address _version,
address _beneficiary,
address _debtor,
address _underwriter,
uint _underwriterRiskRating,
address _termsContract,
bytes32 _termsContractParameters,
uint _salt,
uint _amount;
)
public
whenNotPaused
returns (uint _tokenId)
{
require(tokenCreationPermissions.isAuthorized(msg.sender));
bytes32 entryHash = registry.insert(
_version,
_debtor,
_underwriter,
_underwriterRiskRating,
_termsContract,
_termsContractParameters,
_salt
);
+ // record the fill to registry
// Fill struct record the related order, beneficiary, and partial-filled amount
bytes32 fillHash = registry.insertFill(
entryHash, (issurance hash)
_beneficiary,
_amount,
_salt
);
+ // mint by fillHash
super._mint(_beneficiary, uint(fillHash));
return uint(fillHash);
}
The meaning of agreementId is the unique key for all off-chain Order or on-chain Entry. Replacing this agreementId with fillHash for NFT minting, the NFT issued and the on-chain Entry can no long keep an one-to-one relationship. In this proposal, Fill is a structure looks like:
strtuct Fill {
btyte32 agreementId;
uint amount;
uint salt;
btyte32 fillHash;
}
TermsContract will retrieve order paraments from DebtRegisty by fillHash now. For example, querying _termsContractParameters by fillHash, DebtRegisty will get agreementId form Fill, than get _termsContractParameters from Entry.
This proposal introduce main changes including:
partialFillAmount in DebtOrder definition. When this field is ignored, contract can treat the order with no-partial-fill supporting and keep compatibility.Copyright and related rights waived via CC0.
JavaScript异步从最初的callback,到promise,到Observable(RFP,reactive functional programming), 可谓各种范式不断演进,es6提出的Generator是什么玩法?和async/await有什么关系?和现在唱的很火的协程(coroutine) 之间的关系是什么?暂且跟随本文的思路一探究竟。
Generator是一组可以暂停和继续的process
function* genFunc() {
// (A)
console.log('First');
yield;
console.log('Second');
} function* genFunc() { ··· }
const genObj = genFunc(); const genFunc = function* () { ··· };
const genObj = genFunc(); const obj = {
* generatorMethod() {
···
}
};
const genObj = obj.generatorMethod();4 在类定义中的generator:
class MyClass {
* generatorMethod() {
···
}
}
const myInst = new MyClass();
const genObj = myInst.generatorMethod();ES6 中 Iterator有如下的接口:
interface Iterator { // data producer
next() : IteratorResult;
return?(value? : any) : IteratorResult;
}事实上,Generator函数实现了ES6 Iterable接口,故可以用Generator函数实现可迭代的对象
function* objectEntries(obj) {
const propKeys = Reflect.ownKeys(obj);
for (const propKey of propKeys) {
// `yield` returns a value and then pauses
// the generator. Later, execution continues
// where it was previously paused.
yield [propKey, obj[propKey]];
}
}
objectEntries() is used like this:
const jane = { first: 'Jane', last: 'Doe' };
for (const [key,value] of objectEntries(jane)) {
console.log(`${key}: ${value}`);
}
// Output:
// first: Jane
// last: Doe这里需要注意的是,我们用(...)操作符,亦可以用来迭代这个Genrator生成的迭代器。事实上,spread
操作符的实际作用便是将可迭代的序列转化成数组。
function* genFunc() {
yield 'a';
yield 'b';
}
const arr = [...genFunc()]; // ['a', 'b']广义的Observerr具有如下接口
interface Observer { // data consumer
next(value? : any) : void;
return(value? : any) : void;
throw(error) : void;
}接下来我们将列举分别用promise, Generator, 和es6 2017的async方法实现相同的异步逻辑:
function fetchJson(url) {
return fetch(url)
.then(request => request.text())
.then(text => {
return JSON.parse(text);
})
.catch(error => {
console.log(`ERROR: ${error.stack}`);
});
}const fetchJson = co.wrap(function* (url) {
try {
let request = yield fetch(url);
let text = yield request.text();
return JSON.parse(text);
}
catch (error) {
console.log(`ERROR: ${error.stack}`);
}
});async function fetchJson(url) {
try {
let request = await fetch(url);
let text = await request.text();
return JSON.parse(text);
}
catch (error) {
console.log(`ERROR: ${error.stack}`);
}
}根据维基百科,协程有如下定义:
Coroutines are computer-program components that generalize subroutines for non-preemptive multitasking, by allowing multiple entry points for suspending and resuming execution at certain locations.
我们可以粗略得到以下总结:
具体而言, ES6的结合了Iterator和Observer,具有如下接口:
interface Observer { // data consumer
next(value? : any) : void;
return(value? : any) : void;
throw(error) : void;
}为了更好地理解协程,我们先回顾一下JavaScript的并行哲学。运行时,js只会run一个process,但我们有一下两种方式用来处理并行程序逻辑:
利用co库,我们可以实现自执行的generator,也即coroutine
co(function* () {
try {
const [croftStr, bondStr] = yield Promise.all([ // (A)
getFile('http://localhost:8000/croft.json'),
getFile('http://localhost:8000/bond.json'),
]);
const croftJson = JSON.parse(croftStr);
const bondJson = JSON.parse(bondStr);
console.log(croftJson);
console.log(bondJson);
} catch (e) {
console.log('Failure to read: ' + e);
}
});利用generator实现coroutine,有以下的局限性:
coroutine 本来要求在一个coroutine中的任何函数都可以挂起整个coroutine(这个函数本身,或者这个函数的调用者,甚至函数调用者的调用者),但用generator实现的coroutine只能挂起generator内的的函数,即这个函数本身。故这种coroutine被称为shadow coroutine。
但同时,伴随局限性,带来的好处是:
有如下要求:
/^[A-Za-z0-9]+$//^[0-9]+$/如题所属,分享给立志成为Blockchain Researcher的要求
Write high quality and secure solidity contracts
Fluent in Python, GOlang, Java, or Node.js
Experience analyzing data structures and algorithms and issues related to scale, security and availability
Proficient with Merkle Trees, Fraud Proofs, RLP, UTXO, Priority Queues
Understanding of crypto-economic incentivisation
Database experience: preferably SQL, but noSQL is fine too
Familiarity with Ethereum/blockchains
Understanding we are a globally distributed, remote-first team; Comfortable with handling uncertainty and ambiguity
'Oracle', not that database 'Oracle', is a term come from complexity theory and computability theory. According to Wikipedia [8], an oracle machine is an abstract machine used to study decision problems. It can be visualized as a Turing machine with a black box, called an oracle, which is able to solve certain decision problems in a single operation. The problem can be of any complexity class, which means that the problem does not have to be computable. Even undecidable problems, such as the halting problem, can be used.
In the context of blockchain technology, blockchain is defined by all the information that is publically available on the decentralized network. However, there come certain situations where the blockchain does not have access to information that is off of the chain.
Oracles provide the data that is required for these smart contracts to execute. These are external data feeds that are provided by third-party services and are designed to be used with these smart contracts. They will provide information to the smart contract such as whether a payment has succeeded, a price has reached some limit or even other external factors like the weather.
Oracles are essential to the functioning of the smart contracts. They provide essential inputs for all of these smart contracts and allow for the legitimate interaction of these contracts with real world and external factors.
There are centralized oracles, which pipe Internet information into Ethereum. For example, Oraclize and Real Keys. These oracles substantially suffer from central failure points. Shapeshift built a custom centralized price feed for their exchange Prism. MakerDAO implemented an Oracle controlled by the team’s multisig for their first stable coin Sai. The oracle is often the only centralized unit of such systems.
Prediction markets, such as Augur and Gnosis, can theoretically be used as price feed providers. In practice, however, it’s unlikely to be feasible soon due to the overhead added by the generic nature of these projects.
We will review the following oracle project in this chapter:
SchellingCoin is posted by Vitalik, a mechanism that allows you to create a decentralized data feed.
This mechanism is how SchellingCoin works. The basic protocol is as follows:
During an even-numbered block, all users can submit a hash of the ETH/USD price together with their Ethereum address
During the block after, users can submit the value whose hash they provided in the previous block.
Define the “correctly submitted values” as all values N where H(N+ADDR) was submitted in the first block and N was submitted in the second block, both messages were signed/sent by the account with address ADDR and ADDR is one of the allowed participants in the system.
Sort the correctly submitted values (if many values are the same, have a secondary sort by H(N+PREVHASH+ADDR) wherePREVHASH is the hash of the last block)
Every user who submitted a correctly submitted value between the 25th and 75th percentile gains a reward of N tokens (which we’ll call “schells”)
Potential attack for this SchellingCoin system are: 1. 49% coalition. 2. Micro-cheating. The interesting part about SchellingCoin is that it can be used for more than just price feeds. SchellingCoin can tell you the temperature in Berlin, the world’s GDP or, most interestingly of all, the result of a computation. Some computations can be efficiently verified; for example, if I wanted a number N such that the last twelve digits of 3N are 737543007707, that’s hard to compute, but if you submit the value then it’s very easy for a contract or mining algorithm to verify it and automatically provide a reward. Other computations, however, cannot be efficiently verified, and most useful computation falls into the latter category. SchellingCoin provides a way of using the network as an actual distributed cloud computing system by copying the work among N parties instead of every computer in the network and rewarding only those who provide the most common result.
One solution is to accept data inputs from more than one untrusted or partially trusted party and then execute the data-dependent action only after a number of them have provided the same answer or an answer within some constrains. This type of system can be considered a decentralized oracle system. Unfortunately, this approach has severe limitations:
The solution developed by Oraclize is instead to demonstrate that the data fetched from the original data-source is genuine and untampered. This is accomplished by accompanying the returned data together with a document called authenticity proof. The authenticity proofs can build upon different technologies such as auditable virtual machines and Trusted Execution Environments.

The following authenticity proof is supported by oraclize:
Note that, the TLSNotary is an open-source technology, developed and used by the PageSigner project. TLSNotary allows a client to provide evidence to a third party auditor that certain web traffic occurred between himself and a server. The evidence is irrefutable as long as the auditor trusts the server’s public key.
The full detail of this protocol is out of scope of this review, we put the flow chart of TLSNatory for reference here:
ethfinex
dydx
ethlend
The TRFM is prominently described in their current white paper, but it is now no longer meant to be part of the Dai protocol.
Stability Mechanisms (Dai is not redeemable)
MakerDao目前有两个版本的Oracle。一种为直接的喂价加中位数机制,另外一种利用signed message进行链下的计算并上链。
该方案的代码在一下3个repo,同时也是现行方案
Independent price feed operators constanly monitor the reference price across a number of external sources and will submit updates to the blockchain when:
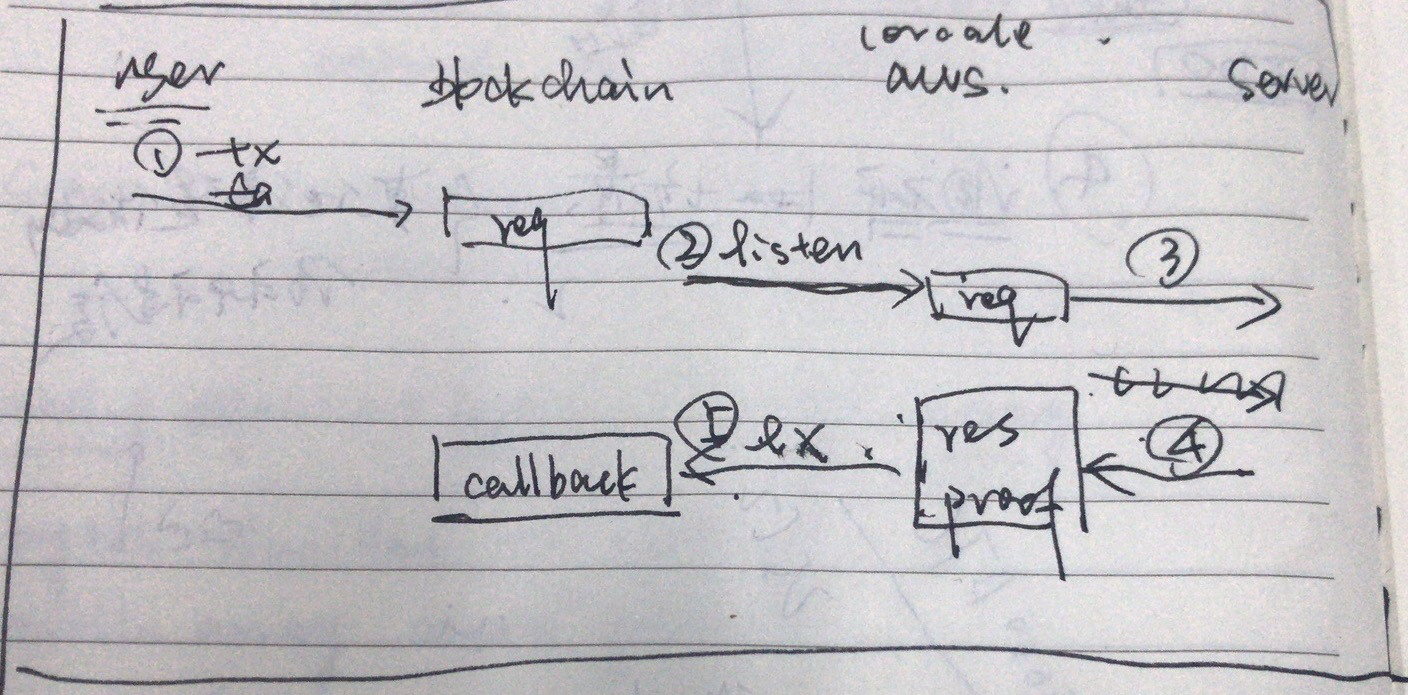
简单画了流程图如下:

可以看到,上图中的operator是服务器上的中心化程序,实时监控币价波动,在满足上述时间或者波动幅度条件的情况下,调用合约的poke方法,以更新medianizer合约中的最新价格中位数。上述的预言机设计和代码对我们的参考价值很大,初步我们可以直接借鉴这种设计来实现我们的预言机机制。
该方案的代码在一下2个repo,是未来的makerdao的预言机系统,主要使用了链下的签名消息来节约手续费,目前还没有上线主网,安全性有待检验。时间所限,只把repo列出,详细的原理和代码视makerdao上线后的实际效果后续跟进。
MakerDao的平仓机制,只支持一种抵押物的Sai中,和在支持多种抵押物的Dss中,是完全不同的。由于dss现在系统还处于不成熟阶段,我们主要介绍Sai的liquadation流程。
在MakerDao中,keeper这个角色会对所有链上CDP的抵押率做实时的监控。当发现某个CDP的抵押率低于150%的时候,调用tub合约的bite(cup)方法,其中tub合约的作用是 CDP record store, cup的参数是指某一个cdp的编号。 激励keeper角色去主动监控抵押率并调用bite方法的动力有以下两点:
在Maker的术语体系中,bite()方法完成了下面的事情。

其中涉及到的术语如下:
SIN: token DAI 的镜像,表示CDP中待偿还的token数目。
Tub: CDP record store
Tap: The Liquidator
woe: SIN balance, bad debt transferred from bite
fog: PETH balance, collateral pending liquidation
air: PETH backing CDPs
ice: SIN locked up with CDPs
代码如下
function bite(bytes32 cup) public note {
require(!safe(cup) || off); // 判断是否真的抵押率低于150%
// Take on all of the debt, except unpaid fees
// // 计算当前这个CDP中有多少未还的DAI,
// 将这一部分用SIN表示的债转到tap合约中, 并清空CDP中的债务
var rue = tab(cup);
sin.mint(tap, rue);
rum = sub(rum, cups[cup].art);
cups[cup].art = 0;
cups[cup].ire = 0;
// Amount owed in SKR, including liquidation penalty
// owe表示可以拍卖的peth数目,并将这部分peth转到tap合约中,
// 计算后剩余的peth可以留给cdp的开单者提取
var owe = rdiv(rmul(rmul(rue, axe), vox.par()), tag());
if (owe > cups[cup].ink) {
owe = cups[cup].ink;
}
skr.push(tap, owe);
cups[cup].ink = sub(cups[cup].ink, owe);
}如上述代码,在bite方法被调用之后,tap合约中的 Sin 表示需要换上的DAI的数目,而SKR 表示可以卖的PETH数量,这两者的比例就可以算出一个拍卖池子中PETH的价格。当SIN归零的时候,表示整个系统中所有处于liquadation阶段的CDP欠下的债务都已经还清,也就完成了CDP的清算。
MakerDao是一个非常吸引我的项目,他在以下的几点都是有非常独特的价值:
话说有信仰的基督信徒,在每餐之前,都会双手合十,说一句:感谢上帝赐予我食物。上次,我和某位币圈大佬请我们吃饭,高朋满座,玉盘珍馐,米其林三星。饭前呢,这位币圈大佬酒杯一举,说:干杯干杯,感谢中本聪赐予我食物。
上面只是一个故事哈,有一点演绎的成分,但确是我亲身经历。那中本聪是谁?为什么能养活这么多币圈的人?比特币又如何从艰难中前行,一步一步走到今天的呢?作为系列课程的第一节,我今天会从区块链的创始人讲起,扒一扒比特币的历史。
在比特币成功之前,已经存在了下图这些数不清的电子支付方式。比特币的成功,是踩着失败者的尸体过来的。这些失败的项目往往不被人们重视和提起。我相信,对于历史的认知会让我们对区块链技术有一个更加全面的理解。我们可以认识到,比特币从这些失败的项目身上,汲取了哪些营养。这个复杂的技术落地的过程中,经历了哪些问题。

电子现金的初步尝试,来源于1982年的David Chaum[1]。从1982年 Chaum发表第一篇探索电子文献,到1998年到eCash技术的主体公司DigiCash破产,这个技术经历了大起大落,但无疑是人类社会探索电子现金支付系统的第一步。
Ecash对于电子现金最大的贡献,在于他对双花问题提出了第一个解决方案。所谓的双花问题,double-spend,顾名思义,即1块钱花两次,甚至更多次。在现实世界中,这当然很难发生,你拿着1块钱,造一枚假币来花,或者是给别人1块钱花出去之后,再偷回来,都是一种“双花”。而你这样做,多半是要蹲局子的。但是在电子世界中,money,是一串数据。对于ecash来讲,就是一个编号,一个面值,加一个签名组成的数据。这串数据如果可以代表money,那无疑是可以轻易的被复制的,所以单纯的靠这串数据,是无法避免双花问题的。
在Ecash中:

可以看到,eCash是由一个中心化的服务器,来保证每一比电子现金只能被花费一次。从其核心原理上讲,eCash无疑是一个真正具有支付功能的电子现金系统。随着核心原理的提出,其商业化的尝试“DigiCash”也印证了这一点,同时也对其核心技术做了一些专利。但是,eCash面临以下的局限性:
中心化:依赖中心化的服务器,单节点故障将导致整个系统故障。
适用性不足:系统区分普通用户和商家,只支持普通用户和商家之间的交易,不支持普通用户之间的交易。
不可找零:最初版本的eCash系统不支持找零。后期引入了找零机制,增加了整个系统复杂度的同时,牺牲了用户的可匿名性。
虽然eCash面临上述局限性,但其对money电子化的尝试,和一些密码学技术包括blind signature, 零知识证明等运用。无疑启发了后人,同时也促使后人对其系统中的缺陷加以探索和改进。
Hashcash,是中本聪在bitcoin白皮书中直接参考的8篇文献之一。其背景却完全跟电子支付没有关系。那为什么我们要在比特币的发展历史上提到他。因为这个系统,是第一个提出工作量证明也即PoW(后面章节会专门讲解PoW)的系统!
HashCash由Adam Back[2]在1997年第一次提出,其目的是为了防止垃圾邮件。比如Alice想发给Bob一封邮件,Bob为了防止Alice产生大量的垃圾邮件对其产生*扰。Bob要求Alice在邮件的末尾,附上一个“可计算性难题”和其答案。Alice为了得到这个难题的答案,往往需要用其电脑进行几秒的演算时间,从而限制住了Alice发送邮件的频率。
那么,究竟“可计算性难题”是个什么玩意。我们可能都玩儿过数独,一个数独,解出他的答案,非常非常难,但是我们拿着答案,验证他,那是非常容易知道这个答案的对错。具体对于这个系统而言,这个数独问题要满足以下的三点性质:
对于不同的,发件人,收件人,邮件内容和发送时间,这个题目和答案都是不一样的。这样做可以防止Alice提前准备好问题和答案。
验证Alice提供的题目和答案,可以在很短的时间内完成验证。
不同的题目之间,是完全独立的。也即,不管Alice之前解过多少题目,每一次解一道新题的难度,都不会因此而变化。
HashCash就是一个基于上述“可计算性难题”的反垃圾邮件系统。比特币的很大一部分设计灵感,直接源于hashCash。Adam曾经声称 “Bitcoin is Hashcash extended with inflation control.” 但是这么说肯定是有失偏颇的,比特币相比hashCash,是一个更加复杂且精巧的系统,与其这么说,还不如说 “Tesla只不过是加了四个轮子的电池”。哈哈哈哈!
1991年,Haber和Stornetta两位学者,在论文中第一次提出了Linked timestamping,即链式时间戳技术。这个技术通过将内容,时间戳,和签名作为一份文档,并对没份文档加上对上一份文档的一个链接的引用,实现了非常重要的特性:文档有序性,和文档历史的不可篡改性。通过对过去文档历史的引用,每当一份新的文档被附加在这个文档链条的末尾,都是对之前整个文档历史的肯定和确认。在链式结构生成后任何对文档历史的改变,都可以被第三方发现。
Linked timestamping是比特币另一个重要的灵感源泉。可以说,HashCash启发了比特币的共识体系设计,而Linked timestamping启发了比特币的去中心化账本设计,也即“区块链”这个词本身。Linked timestamping的文档概念可以直接对应于比特币中的区块概念,每个文档可以看成一个区块,而每一笔交易组成了文档内容。

Wei Dai, 1998, 第一次提出了b-money的想法。b-money系统,结合了上述HashCash和Linked timepstamping,用HashCash的可计算性难题来产出具有稀缺性的电子money,同时,用Linked timepstamping来实现账本的记账。b-money无疑是在比特币之前,设计上与比特币最接近的尝试。同时,b-money也是中本聪提出比特币白皮书中的第一篇参考文献,可见其思路对Bitcoin的启发和影响。但是,下面三个问题,是b-money与Bitcoin体系的不同之处:
B-money中,可计算性难题用来直接产出money。
B-money依赖中心化的timepstamping服务。
B-money对于多个节点发生不一致时,没有给出明确的算法来解决。
上述三个问题,让b-money仅仅停留在学术研究阶段。中心化和缺乏一致性算法,是其最大漏洞。
中本聪,从2007年五月份,开始写第一行Bitcoin代码。2008年十月份,他发表了大名鼎鼎的比特币白皮书。从此,中本聪老爷子赐饭的时代,就此拉开序幕。
此后的两年间,他成立了Botcoin talk,并各种论坛中传播Bitcoin,一面持续维护Bitcoin的项目代码。直到2010年12月份,中本聪这个名字,从论坛和开源项目中消失,除了世人对其真实身份的各种猜测,不带走一片云彩。
关于中本聪的真实身份,众说纷纭,没有定论。有人因姓名,猜测中本聪是日本人。有人因为其在论坛中的英式英语表达方式如”bloody hard“,猜测他是英国人。甚至有人猜测他是一个团体而非一个个人。同时中本聪在密码邮件组中是一个年轻后辈(可能30岁出头),地位十分显赫。(在这个邮件组中,有菲利普·希默曼(PGP技术的开发者)、约翰·吉尔摩(太阳微系统公司的明星员工)、斯蒂文·贝洛文(美国贝尔实验室研究员,哥伦比亚大学计算机科学教授)、布拉姆·科恩(BT下载的作者)、蒂姆希·C·梅(英特尔公司前首席科学家)、阿桑奇(维基解密创始人)这样的大牛)
比特币的理论总量为2100万,中本聪持有100万个,但从未使用过一个。有人说,正是中本聪的消失,才使比特币成为今天的比特币。中本聪是谁,其实并不重要。时代和技术的进步,往往是靠巨人的推动,产生了跨越式的发展。我们做不到像中本聪一样开创整个时代的发展,但是我们可以紧随他的脚步,学习区块链的**和技术,站在巨人的肩膀上,通过不断地学习完善我们对这个领域的认知,探索更多的机会,甚至推动技术的进步和变革。

参考文献:
近年来,区块链技术风靡全球。得益于区块链技术的发展,我们正在全球构建起一个数字化的,去中心化的网络世界。在区块链技术繁荣发展的同时,也会有越来越多的去中心化组织(DAO),去中心化交易出现在区块链平台之上。正如现实生活中所发生的一样,有交易往来,就会有争议发生。比如去中心化的eBay上的顾客可能对买到的产品不满意,去中心化的airbnb上的顾客也可能会抱怨房子跟照片中的不一致,这个时候我们就得思考,如何在去中心化的网络中解决这些争议? 这已经成为当下区块链技术发展一个急需解决的问题。
区块链平台上有一大技术特点,就是智能合约。智能合约一旦部署,就能自动运行。但是,智能合约无法自动处理上面所说的争议,因为这些争议的解决涉及到主观意愿的判断,而这些是智能合约不擅长且无法解决的。鉴于此,我们需要思考一下,如何在去中心化网络,尤其是区块链平台上,设定一种机制,公平,高效地解决区块链平台上所出现的争议。目前已有针对这个问题所提出的解决方案,是一种叫做陪审员网络的制度。
在探索如何解决区块链平台上的争议这一领域,已经有了一些优秀开拓者。OpenBazaar是一个结合了ebay和BitTorrent特点的去中心化商品交易市场,使用Bitcoin,Zcash等数字货币进行交易。用户在该平台上交易,既不用被平台收取高额交易费,也不用担心受到审查。在该平台上,有一个类似于“调解员”的角色,用户可以在进行交易的时候,选取一个“调解员”参与交易。当有争议发生的时候,就由该“调解员”来判断争议谁对谁错,以此来决定资金该流向何处,同时“调解员”获得相应的报酬。“调解员”参与过的案例也会公布在平台上,并伴随有客户的评价。这样的一套评价系统,可以更好地帮助用户选择“调解员”。作为前期的开拓者,OpenBazaar可以说是很优秀的,但是它的局限性也比较明显:a. 只适用于电商交易这一特定领域的交易,通用性不高;b.“调解员”由用户选取,且仅有一位,安全性和公平性不高。
Kleros是以太坊上的一个应用,它作为一个去中心化的第三方团体,致力于解决智能合约上的任何争议。它有一个分层的法院系统,最底层的法院会解决具体领域的一些“案件”,如有的法院会专门处理有关汽车保险的案件。如果用户对于法院做出的结果不满意,则可以提起上诉,由更高一级的法院来审理案件,比如,由专门管理交通保险的法院来重新处理该案件。上一级的法院可以驳回下一级的法院做出的决定。逐级往上,直到最上面一层的法院,案件无法再提起上诉。每一级法院中的陪审员,都是通过抵押代币来成为陪审员的候选人,且是根据抵押的代币数量多少而随机选取,一旦有陪审员做出和绝大多数陪审员相反的决定,那么该陪审员不但不能获得奖励,还会受到惩罚,其抵押的代币会被部分收走。
Aragon也有类似的陪审员制度。相比于Kleros,Aragon做出了以下几点改进:a. 增加了一个reputation system(名声系统),陪审员的选择不单单根据抵押代币的多少,还根据过去的表现。b. 不仅仅是用户可以上诉,陪审员对于结果不满也可以上诉。
针对以上三个Projects的分析,我们可以总结出在去中心化网络解决争议的一般步骤:
(1)用户发起争议解决的请求,触发相应的陪审员网络制度
(2)选取相应的法院和陪审员
(3)陪审员投票
(4)陪审员获得结果,不服可上诉
(5)用户获得结果,不服可上诉
(6)争议解决,分配奖励
首先,让我们来根据以上步骤的核心要素来对OpenBazaar,Kleros,Aragon来做一个对比。

从上面来看,我们可以总结出这三个项目的优缺点:
OpenBazaar的争议处理机制简单易行,同时还有评价系统,提供陪审员的过往案例,让用户可以更好地根据自己的需要而选择陪审员。但同时它的缺点也是很明显的,主要有以下几点:
其机制只适用于电商交易纠纷等少数案例,并没有普遍性。主要的原因是其只使用数字货币的多签交易来作为纠纷的解决机制,没有利用智能合约来进一步地拓宽适用范围。
单个案例的陪审员数量太少,只有一个,公平性和安全性不高
用户对结果不满,无法提起上诉
Kleros可以说在OpenBazaar的基础上进一步地完善了这个陪审员网络机制。Kleros是以太坊上的一个应用,它利用智能合约来完善陪审员网络机制,让其可以适用于区块链平台上的所有应用,同时也可以让更多的陪审员参与进来。Kleros还提出了分层级的陪审员网络,每一层级都有对应领域的法院处理相应的案件。用户可以决定选择哪个法院及多少名陪审员来审理这个案件。一般会是3个。当然了,越多的陪审员参与进来,需要付出的手续费就会越高。每一名陪审员都是根据抵押资金的多少随机选取出来的。在此基础上,用户如果对于法院审查的结果不满意,可以提起上诉,让更高一级的法院来审理案件。这种制度,可以更进一步地防止陪审员被贿赂而作恶的情况发生。Kleros已经做得挺好的了,但是还有以下几点需要改进:
陪审员是通过自愿抵押代币来成为某一个案例的陪审员候选人的,那么就可能出现有一些案例没有陪审员来审查(原因可能有手续费太低,或在线的陪审员人数不够)。同时,陪审员过往的案例并没有积累效应,以前做的好与不好并不影响其被选择成为某一案例的陪审员的概率。这有点不合理。
陪审员无法对不满意的结果进行上诉,只有争议双方可以上诉
Aragon的陪审员网络机制,很多一部分是借鉴Kleros的,所以说Kleros有的优点,Aragon也有。Aragon在Kleros的基础上,增加了一个reputation system,陪审员过往的表现会体现在其reputation上,其表现的好,reputation越高,反之则越低。而陪审员被选为某一个案例的陪审员的概率是跟其reputation有关的。其次,Aragon还增加了一个流程,即陪审员也可以对结果进行上诉。要求一个叫做review court的法院来审查处理该案件的陪审员是否有作恶。当然,Aragon也有可以改进的地方:
在Aragon中,无论陪审员做的好与不好,都是能够获得奖励的,同时其对于陪审员没有一个准入机制。这样会导致一旦某一陪审员做错了,就可以选择重新换一个账号继续作恶。
陪审员提起上诉并不需要额外付费,这样会导致该机制被滥用,影响整个陪审员网络的效率。
Aragon同样没解决陪审员不在线的情况。
综合上述三个Projects的分析,我们可以扬长避短,来设计一个更好的陪审员网络机制。我觉得我们可以借鉴以下几点:
利用智能合约,设计出一套适用性更广的陪审员网络机制。
引入层级结构的陪审员网络,用户和陪审员都可以对结果进行上诉,且提起上诉需要再额外付费
引入“评价系统”,让陪审员过往的表现可以积累。
对陪审员进行KYC或设计一套良好的奖惩,准入机制,让陪审员作恶成本极大。
针对陪审员不在线或人数不够的情况,我认为可以有以下方法:a. 针对长期在线的陪审员进行奖励,同时对于长期不在线的陪审员进行惩罚或取消其陪审员的身份;b. 社区和项目方共同拿出一部分代币,来雇佣一些全职的,经过专门培训的陪审员来长期在线应对各种案例。
casper ffg basics
validator vote on checkpoints
⟨ν, s, t, h(s), h(t)⟩
FOLLOW THE CHAIN CONTAINING THE JUSTIFIED CHECKPOINT OF THE GREATEST HEIGHT.
reward
panelty
economics
In bitcoin context
PeerCoin argue to this attack
We went deep in tree projects previously, namely MakerDao, Dharma, dydx. They all have some design choice of Risk Management. The following Chapter will grasp some key desisn rationale of them.
Dharma provides only seizable collateral if and only if the creditor fails to repay. 这种方式无疑只提供了最低程度的风险控制,对于真实的抵押借贷业务,没有基于抵押物价格波动的风控方案无疑是无法对接真实业务的。当然,社区现在也在探索风控方案,详见讨论 https://github.com/dharmaprotocol/DIPs/issues/2
dydx 的风控机制在于,将全部的风险给到creditor,creditor需要自己在链下实时监测币价,同时creditor可以在任何时间要求debtor加仓任何金额的抵押物,所以creditor需要一个reputation系统来保证其最大程度的自由带来的最大程度作恶的可能性。这种设计哲学无疑是粗放的且奇怪的,因为他极大程度的增加了creditor的操作成本,同时由于reputation系统的引入,并没有减小整个系统的复杂度。
在上一篇MakerDao Deep Dive文章中,我们事无巨细的探讨了MakerDao的平仓系统,这套系统为我们提供了很多的参考,但同时也面临着很多的问题。在下面的讨论中,在预言机和平仓机制中,我们都阐释了其可取之处和局限性,并采用了十分不同于MakerDao方案的路径来考虑整个系统的设计。
首先,我们进行拆分,按照不同的功能需求,这个问题可以拆分成以下几个问题:
三者个系统之间有一定的调用关系,1. 喂价系统要被加仓提醒,和强平机制调用。喂价系统的主要指标是安全性,及时性,准确性。2.加仓提醒由加仓警戒线触发,强平机制由强制平仓线来触发。考虑到债务人的利益,在强平之前,一定要有充足的时间去提醒债务人加仓。这个问题非常关键,下面我们将分别讨论这三个系统的设计。
币价feed是一个经典的oracle问题,oracle在很多系统中例如makerdao和oraclize已经有了基本的解决方案。但在设计这个oracle系统的时候,我们首先考的的问题是。链下的价格,何时,何地上链。
该种方案,根据makerdao的经验,在满足条件1. 交易对币价波动超过某个百分比。2.一段时间内未更新币价的两种下,触发币价的上链。参考上一篇文档,在币价上链后,结合多个交易所最后更新的币价,取中位数得到某个交易对当前的币价。下面的图阐释了这种完全的链上喂价的基本流程:

这一种方案,在makerdao中已经安全的运行了半个多年头,可以说安全性,稳定性,去中心化程度都是非常不错的。但面临的最大问题是:随着交易对的增多,需要部署的合约和需要触发的交易手续费快速增加。假设每个交易对需要对接5个交易所,那么一共就是6个合约,平均每个合约至少6个小时调用一次,每次调用平均需要 0.001个以太坊。那么如果我们有n种支持的抵押物,就需要至少1个稳定币USDT和其的交易对的币价,至少需要6n个合约部署,和每天至少4*5*0.001*n = 0.02n ether的合约手续费。假设n=10, 那么每天花在预言机上面的手续费就是至少0.2个以太,一个月的成本至少在 15个以太。这样的成本是否对于一个节点来说是可控的,现在看起来是非常危险的。makerdao之所以可以这么玩儿,是因为其交易对偏少,同时对进入强平阶段的CDP惩罚较高,故可以用这种方式来实现。
这里面的一个关键问题在于,谁来call这个喂价合约,在makerdao中是DAO选取的server,和foundation运营的server在提供服务。因为maker只有4个交易对,估算其所有的server加起来一个月的开销可能就在十个以太以内。而我们如果这个费用让节点来出,在支持的抵押物越来越多的情况下,gas开销可能会非常的难以接受。 同时,我们研究了目前处在实验阶段的新的makerdao的喂价合约terra,其使用了签名消息来减少交易手续费的使用。调研后发现terra的代码还处在非常不成熟的阶段,基本上没有实际的实现。无法获得太多参考信息。
如果我们想规避手续费过高的问题,我们可以将喂价逻辑与平仓逻辑整合,也即在 liquadation 的 transaction call 中进行喂价。这是一个非常机智的idea,但是面临的最大question就是,caller即控制了喂价也控制了平仓的触发,如何保证合约caller喂价的准确性和客观性。可以强制要求caller在链上喂价时,也附带除自己之外的一定数量的喂价者签名的喂价值,换句话说,就是设计一个基于链下签名消息的喂价协议,不同的节点和喂价人(这些喂价者是注册在喂价合约白名单中的)之间可以交换其喂价值,在喂价时进行链上的真实喂价值计算(目前采取的算法是基于中位数)。这样做的好处是,在理论上保证了和链上喂价一样的安全性,甚至可以做到更加实时。(我们可以在平仓的时候直接链下请求喂价人暴露的接口,实时请求当前的价格)同时,这种方案节省下来的gas开销可以作为喂价者的激励返还给他一部分,激励大家去run一个喂价服务。同时,这个系统中可以设计一些惩罚去治理错误的喂价者。
margin call 的定义是在抵押率危险的时候,提前提醒用户加仓,以为强制平仓提供一定程度的缓冲时间。作为debt servicing 的一部分。这样的时间对于债务人是必要的,否则可能会发生一些纠纷。在Dharma的DIP-2 中提到了一种链上触发预警transaction,同时触发margin call事件以供dapp来监听的一种模式。我个人非常不欣赏这种方式的预警系统设计,原因有二:1. dapp一定不是永远在线,靠dapp去监听margin call 面临及时性的危险。 2. 在没有集成DID系统的情况下,dapp无法掌握用户的真实联系方式,这对提醒加仓是十分不利的。3. 同时,对于ETH为抵押物的债权人,由于不涉及催收,技术上可以不需要其kyc信息。
因此,基于上述的考虑,我认为Margin Call的系统可以完全做成一个链下的系统,因为margin call不会实际的引起抵押物的transfer,故其对交易对价格源的安全性有较高的容忍,节点可以自行决定是否对一笔订单发起margin call,如果错误的发起了margin call,只是某个节点的单独错误行为,受到的影响是可控的。同时因为签单的节点可以对用户进行链下的kyc,在做margin call的时候就有可能联系到真实用户,甚至可以线下去接触用户。这样无疑才是预警系统的意义之所在。
平仓系统可以拆分为3个步骤:
(collateralUnitPrice * collateralAmount) / (principalUnitPrice * principalAmount) < minimumCollateralRatio在上次讨论中,我们的提出了在以下几点上的优化空间或者需要跟进的点。
按照上一次的讨论,每一个server对接了一家交易所,上链时仅代表某一家交易所的价格。但其实对于中心化的服务器资源,我们完全可以在每一个server都对接所有交易所,对所有交易所的币价取中位数后,再将该中位数作为自己的喂价,在平仓线判断和平仓出发时,都使用该喂价。在有效市场的前提下,多个交易所之间的价差应该不会太大,但实际去将抵押物平仓的平仓者,可能在交易所中平仓的价格与其喂价不同。这个价差导致的亏损或者盈利都应该由节点自己来承担。在市场不会剧烈波动的大部分情况下,节点应该都是有盈利空间的,因为我们再计算中使用的是价格的中位数,而真正liquadate抵押物时,可以使用价格最优的某个交易所的价格。
喂价源是一个非常重要的系统,不准确的喂价将导致不必要的平仓发生,使债务人蒙受损失。在vitalik 2014年就畅想过一篇trust-free的喂价源系统,使用了博弈论中的schelling point作为理论支持。这个理论强调,要无偏向性的选择喂价人,同时尽量保证在喂价人中间有不同的价格趋向性以应对micro-cheating。在我们的系统中,节点方由于有平仓激励,所有有将价格喂低来提早触发平仓的倾向。同时,债务人由于将抵押物抵押到了智能合约中,故有倾向将价格喂得偏高。在健康的喂价源选择中,两方的人都需要,同时要无偏见的选取这两方参与系统。
直接在链上设计价格的审查机制可能比较困难同时不够经济(类似casper这种智能合约,设计一定是非常复杂的且没有通用性),我们可以通过仲裁网络,对由喂价不准确的平仓发生的订单寓意仲裁。我们只要在链下喂价的系统中提交上链时,附带每一个提交价格者的价格数据结构的commitment,在发生纠纷时可以reveal这一部分信息,以为仲裁者提供仲裁依据。
如果上面的章节关注的是各种设计的可能性,和不同可能性的优缺点。这一章更加关注在短时间比较容易落地的方案,所以简洁性,可拓展性是一个主要的trade-off因素。
对于三个不同的系统,我们分别采取以下路径
这三个系统的优先级是 喂价 = 平仓 > 预警, 实现难度是 平仓>喂价>预警。同时,这三个系统都是可以完全开源的系统。
下面做出调用时序图,以阐释不同系统之间的关联和平仓整体的业务流程:

其中特别值得注意的有两点:
在现有的设计中,我们的平仓机制仍然局限于ETH及ERC-20代币的抵押。对于BTC,目前我们走的方式还是多签地址用来抵押的模式,在产品设计中,对于BTC的抵押和ERC20的抵押,我们希望获得较为一致的产品体验和统一的dapp包装,对于BTC而言,可能面临一些技术挑战如下:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.