NanoDet是一个单阶段的anchor-free模型,其设计基于FCOS模型,并加入了动态标签分配策略/GFL loss和辅助训练模块。由于其轻量化的设计和非常小的参数量,在边缘设备和CPU设备上拥有可观的推理速度。其代码可读性强扩展性高,是目标检测实践进阶到深入的不二选择。作者在知乎上有一篇介绍的文章,指路:超简单辅助模块加速训练收敛,精度大幅提升!移动端实时的NanoDet升级版NanoDet-Plus来了!
笔者已经为nanodet增加了非常详细的注释,代码请戳此仓库:nanodet_detail_notes: detail every detail about nanodet 。
此仓库会跟着文章推送的节奏持续更新!
话不多说,从结构上我们直接分backbone、neck、head、assign module、dynamic label assigner五个模块进行超級详细的介绍。
surprise!首先当然要介绍一下整体的架构了。先看看整个模型的架构图:
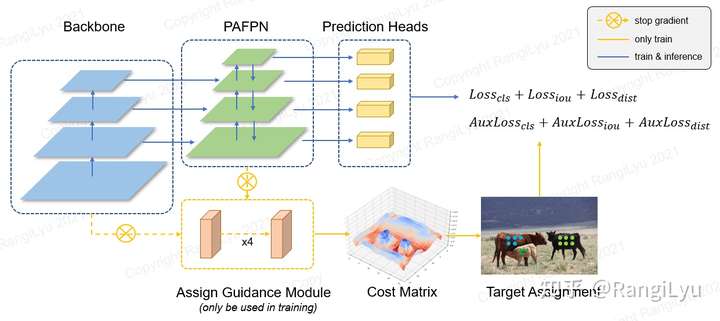
直观来看,最大的不同就是新增的Assign Guidance Module模块。检测框架还是FCOS式的一阶段网络,neck改为了GhostPAN,同时摒弃了FCOS的标签分配策略转向动态软标签分配并加入辅助训练模块也就是前述的AGM,它将作为教师模型帮助head获得更好的训练。头部的回归和标签预测仍然继承之前的Generalized Focal Loss。
以NanoDet-m (320x320)为例让我们先看一下config/下的配置文件中和网络架构有关的选项:
name: NanoDetPlus
detach_epoch: 10
backbone:
name: ShuffleNetV2 # 默认使用shuffleNetV2
model_size: 1.0x # 模型缩放系数,更大的模型就是相应扩大各层feature map的大小
out_stages: [2,3,4] # backbone中输出特征到FPN的stage
activation: LeakyReLU # 激活函数采用LeakyReLU
fpn:
name: GhostPAN # 用ghostNet的模块对不同特征层进行融合
in_channels: [116, 232, 464] # 输入fpn的feature map尺寸
out_channels: 96 #
kernel_size: 5 # 卷积核大小
num_extra_level: 1 # 输出额外一层,即在最底层的基础上再上采样得到更大的feature map
use_depthwise: True # 是否使用深度可分离卷积
activation: LeakyReLU # 激活函数
head:
name: NanoDetPlusHead # 检测头,还提供了之前的nanodet头和最简单的卷积头
num_classes: 80 # 类别数
input_channel: 96 # 输入通道数
feat_channels: 96 # 和输入通道数一致
stacked_convs: 2 # 头的卷积层数
kernel_size: 5 # nanodet-plus也换用了5x5的大核卷积
strides: [8, 16, 32, 64] # 有四个头,分别对应不同尺度特征的检测,这是不同head检测时的下采样倍数
activation: LeakyReLU
reg_max: 7 # 用于DFL的参数,head的回归分支会预测框的分布,即用回归reg_max+1个离散的几个值来表示一个分布
norm_cfg:
type: BN # head选用Batch Norm进行归一化操作
loss:
# loss仍然继承了nanodet,使用GFL,并且这些loss有不同的权重
loss_qfl:
name: QualityFocalLoss
use_sigmoid: True
beta: 2.0
loss_weight: 1.0
loss_dfl:
name: DistributionFocalLoss
loss_weight: 0.25
loss_bbox:
name: GIoULoss # 选取计算IOU loss的方法为GIoU
loss_weight: 2.0
# Auxiliary head, only use in training time.
# 新增的辅助训练模块,其实就是一个常规的检测头(上面的头是简化过的版本,表达能力显然不如标准头)
aux_head:
name: SimpleConvHead
num_classes: 80
input_channel: 192 # 可以看到输入通道数也比nanodet head多
feat_channels: 192
stacked_convs: 4 # 堆叠4层而不是上面的2层,反正是训练不是推理
strides: [8, 16, 32, 64] # 对应nanodet head的四个头
activation: LeakyReLU
reg_max: 7 # 同head中的参数下图是训练时feature的流图,backbone的输出进入两个Ghost PAN,其中一个是为AGM专门搭建的,另一个pan和head连接。AGM会将两个PAN的输出拼接在一起作为输入(猜想这样可以更好的获取当前Head的训练情况,同时也能获取更多特征),其有两个分支,分别负责生成用作标签分配的cls_pred和reg_pred。对于Ghost PAN中的不同层特征,AGM采用相同的参数(参数共享)进行运算,大大减小了训练时的参数数和运算量,提升精度的同时使得训练速度不会增加太多。AGM的输出在训练初期将会作为Head标签分配的参考,并且AGM的loss也会进行回传,帮助网络更快地收敛。经过数个epoch(默认是10个)的训练后Head的预测已经有较好的准确度,此时将AGM模块分离,直接由Head的输出自行完成标签分配的任务。
在训练完成进行推理时,直接去除AGM和aux_fpn,得到非常精简的网络结构。
作为一个着眼于边缘平台部署,尤其是针对CPU型设备的网络,NanoDet之前自然选择的是使用深度可分离卷积的轻量骨干网络。
这里我们主要介绍默认的Backbone:GhostNet,这是一个由华为提出的轻量骨干网络,关于GhostNet的详解请戳:占位符。此模块提供了预训练权重下载,并将结构封装成了一个类。
ghostnet.py这个文件被放在仓库中的nanodet/model/backbone下。
# _make_divisible()是一个用于取整的函数,确保ghost module的输入输出都可以被组卷积数整除
# 这是因为nn.Conv2d中要求groups参数必须能被输入输出整除,具体请参考深度可分离卷积相关的资料
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_vclass SqueezeExcite(nn.Module):
def __init__(
self,
in_chs,
se_ratio=0.25,
reduced_base_chs=None,
activation="ReLU",
gate_fn=hard_sigmoid,
divisor=4,
**_
):
super(SqueezeExcite, self).__init__()
self.gate_fn = gate_fn
reduced_chs = _make_divisible((reduced_base_chs or in_chs) * se_ratio, divisor)
# channel-wise的全局平均池化
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 1x1卷积,得到一个维度更小的一维向量
self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True)
# 送入激活层
self.act1 = act_layers(activation)
# 再加上一个1x1 conv,使得输出长度还原回通道数
self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True)
def forward(self, x):
x_se = self.avg_pool(x)
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
# 用刚得到的权重乘以原输入
x = x * self.gate_fn(x_se)
return x这个模块来自SENet,介绍请戳笔者之前介绍vision attention的博客:CV中的注意力机制_HNU跃鹿战队的博客-CSDN博客。利用额外的全局池化+FC+channel-wise multiply构建SE分支,这能够用来捕捉通道之间的相关性,给予重要的通道更大的权重。
class ConvBnAct(nn.Module):
def __init__(self, in_chs, out_chs, kernel_size, stride=1, activation="ReLU"):
super(ConvBnAct, self).__init__()
self.conv = nn.Conv2d(
in_chs, out_chs, kernel_size, stride, kernel_size // 2, bias=False
)
self.bn1 = nn.BatchNorm2d(out_chs)
self.act1 = act_layers(activation)
def forward(self, x):
x = self.conv(x)
x = self.bn1(x)
x = self.act1(x)
return x这其实就是卷积、批归一化和激活函数的叠加,这三个结构几乎是现在深度网络的构成单元的标准配置了,写成一个模块方便后面多次调用。
class GhostModule(nn.Module):
def __init__(
self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, activation="ReLU"
):
super(GhostModule, self).__init__()
self.oup = oup
# 确定特征层减少的比例,init_channels是标准卷积操作得到
init_channels = math.ceil(oup / ratio)
# new_channels是利用廉价操作得到的
new_channels = init_channels * (ratio - 1)
# 标准的conv BN activation层,注意conv是point-wise conv的1x1卷积
self.primary_conv = nn.Sequential(
nn.Conv2d(
inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False
),
nn.BatchNorm2d(init_channels),
act_layers(activation) if activation else nn.Sequential(),
)
# ghostNet的核心,用廉价的线性操作来生成相似特征图
# 关键在于groups数为init_channels,则说明每个init_channel都对应一层conv
# 输出的通道数是输入的ratio-1倍,输入的每一个channel会有ratio-1组参数
self.cheap_operation = nn.Sequential(
nn.Conv2d(
init_channels,
new_channels,
dw_size,
1,
dw_size // 2,
groups=init_channels,
bias=False,
),
# BN和AC操作
nn.BatchNorm2d(new_channels),
act_layers(activation) if activation else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
# new_channel和init_channel是并列的关系,拼接在一起形成新的输出
out = torch.cat([x1, x2], dim=1)
return out这个模块就是GhostNet的关键了,在了解GhostNet所谓的”廉价操作“即cheap_operation之前,你需要知道组卷积(group conv)和深度可分离卷积(depth-wise separable conv)的概念。首先对上一个特征层的输入进行标准卷积,生成init_channels的特征;随后将此特征进行分组卷积,并将groups数取得和输入的channel数相同(每一个channel都对应一个单独的卷积核),这样就可以尽可能的降低参数量和运算量,开销非常小.
GhostBottleneck就是GhostNet的基本架构了,GhostNet就由数个GhostBottleneck堆叠而成,对于Stride=2的bottleneck在两个Ghost module之间增加了一个深度可分离卷积作为连接。
class GhostBottleneck(nn.Module):
"""Ghost bottleneck w/ optional SE"""
def __init__(
self,
in_chs,
mid_chs,
out_chs,
dw_kernel_size=3,
stride=1,
activation="ReLU",
se_ratio=0.0,
):
super(GhostBottleneck, self).__init__()
# 可以选择是否加入SE module
has_se = se_ratio is not None and se_ratio > 0.0
self.stride = stride
# Point-wise expansion
# 第一个ghost将会有较大的mid_chs即输出通道数
self.ghost1 = GhostModule(in_chs, mid_chs, activation=activation)
# Depth-wise convolution
# 对于stride=2的版本(或者你自己选择添加更大的Stride),两个GhostModule中间增加DW卷积
if self.stride > 1:
self.conv_dw = nn.Conv2d(
mid_chs,
mid_chs,
dw_kernel_size,
stride=stride,
padding=(dw_kernel_size - 1) // 2,
groups=mid_chs,
bias=False,
)
self.bn_dw = nn.BatchNorm2d(mid_chs)
# Squeeze-and-excitation
if has_se:
self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)
else:
self.se = None
# Point-wise linear projection
# 最后的输出不添加激活函数层,并且会使用一个较小的out_chs以匹配short cut连接的通道数
self.ghost2 = GhostModule(mid_chs, out_chs, activation=None)
# shortcut
# 最后的跳连接,如果in_chs等于out_chs则直接执行element-wise add
if in_chs == out_chs and self.stride == 1:
self.shortcut = nn.Sequential()
# 如果不相等,则使用深度可分离卷积使得feature map的大小对齐
else:
self.shortcut = nn.Sequential(
nn.Conv2d(
in_chs,
in_chs,
dw_kernel_size,
stride=stride,
padding=(dw_kernel_size - 1) // 2,
groups=in_chs,
bias=False,
),
nn.BatchNorm2d(in_chs),
nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_chs),
)
def forward(self, x):
# 保留identity feature,稍后进行连接
residual = x
# 1st ghost bottleneck
x = self.ghost1(x)
# 如果stride>1则加入Depth-wise convolution
if self.stride > 1:
x = self.conv_dw(x)
x = self.bn_dw(x)
# Squeeze-and-excitation
if self.se is not None:
x = self.se(x)
# 2nd ghost bottleneck
x = self.ghost2(x)
x += self.shortcut(residual)
return xGhost module中用于生成复杂特征的卷积是1x1的point-wise conv,对于Stride=2的bottleneck来说又有一个stride=2的DW,那么就可以将前者就和后者看作是构成了一组深度可分离卷积,只不过Ghost module生成ghost feature的操作大大降低了参数量和运算量。若启用了has_se的选项,则会在两个ghost module之间加入一个SE分支。
讲解完了基本的模块之后,我们就可以利用上述的GhostBottleneck来构建GhostNet了:
#exp 代表了在经过bottleneck中的第一个Ghost module后通道扩展的倍数,通道数随后会在同一个bottleneck中的第二个ghost module被减少到和该bottleneck中最开始的输入相同,以便进行res连接。#out 是输出的通道数。可以发现,Stride=2的bottleneck被用在两个不同的stage之间以改变feature map的大小。
为了用作检测网络,删除最后用于分类的FC,并从stage4、6、9分别取出stage的输出作为FPN的输入。若需要追求速度,可以考虑进一步减少每个stage的层数或是直接砍掉几个stage也无妨。
前一个版本的NanoDet为了追求极致的推理速度使用了无卷积融合的PAN架构,即top-down和down-top路径都是直接通过双线性插值的上下采样+element-wise add实现的,随之而来的显然是性能的下降。在NanoDet-Plus中,作者将Ghost module用于特征融合中,打造了Ghost-PAN,在保证不增加过多参数和运算量的前提下增强了多尺度目标检测的性能。
Ghost PAN中用到了一些GhostNet中的模块,直接查看第一部分关于GhostNet的介绍即可。
作者在Ghost bottleneck的基础上,增加一个reduce_layer以减小通道数,构成Ghost Blocks。这就是用于top-down和bottom-up融合的操作。同时还可以选择是否使用残差连接。且Ghost Block中的ghost bottle neck选用了5x5的卷积核,可以扩大感受野,更好地融合不同尺度的特征。
class GhostBlocks(nn.Module):
"""Stack of GhostBottleneck used in GhostPAN.
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
expand (int): Expand ratio of GhostBottleneck. Default: 1.
kernel_size (int): Kernel size of depthwise convolution. Default: 5.
num_blocks (int): Number of GhostBottlecneck blocks. Default: 1.
use_res (bool): Whether to use residual connection. Default: False.
activation (str): Name of activation function. Default: LeakyReLU.
"""
def __init__(
self,
in_channels,
out_channels,
expand=1,
kernel_size=5,
num_blocks=1,
use_res=False,
activation="LeakyReLU",
):
super(GhostBlocks, self).__init__()
self.use_res = use_res
if use_res:
# 若选择添加残差连接,用一个point wise conv对齐通道数
self.reduce_conv = ConvModule(
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding=0,
activation=activation,
)
blocks = []
for _ in range(num_blocks):
blocks.append(
GhostBottleneck(
in_channels,
int(out_channels * expand), # 第一个ghost module选择不扩充通道数,保持和输入相同
out_channels,
dw_kernel_size=kernel_size,
activation=activation,
)
)
self.blocks = nn.Sequential(*blocks)
def forward(self, x):
out = self.blocks(x)
if self.use_res:
out = out + self.reduce_conv(x)
return out把Ghost Block对PAN中用于特征融合的卷积进行替换就得到了Ghost PAN。
-
初始化和参数部分
class GhostPAN(nn.Module): """Path Aggregation Network with Ghost block.用ghost block替代了简单的卷积用于特征融合 Args: in_channels (List[int]): Number of input channels per scale. out_channels (int): Number of output channels (used at each scale) 拥有相同的输出通道数,方便检测头有统一的输出 use_depthwise (bool): Whether to depthwise separable convolution in blocks. Default: False kernel_size (int): Kernel size of depthwise convolution. Default: 5. expand (int): Expand ratio of GhostBottleneck. Default: 1. num_blocks (int): Number of GhostBottlecneck blocks. Default: 1. use_res (bool): Whether to use residual connection. Default: False. num_extra_level (int): Number of extra conv layers for more feature levels. Default: 0. upsample_cfg (dict): Config dict for interpolate layer. Default: `dict(scale_factor=2, mode='nearest')` norm_cfg (dict): Config dict for normalization layer. Default: dict(type='BN') activation (str): Activation layer name. Default: LeakyReLU. """ def __init__( self, in_channels, out_channels, use_depthwise=False, kernel_size=5, expand=1, num_blocks=1, use_res=False, num_extra_level=0, upsample_cfg=dict(scale_factor=2, mode="bilinear"), norm_cfg=dict(type="BN"), activation="LeakyReLU", ): super(GhostPAN, self).__init__() assert num_extra_level >= 0 assert num_blocks >= 1 self.in_channels = in_channels self.out_channels = out_channels # DepthwiseConvModule和ConvModule都是MMdetection中的基础模块,分别对应深度可分离卷积和基本的conv+norm+act模块 conv = DepthwiseConvModule if use_depthwise else ConvModule
-
top-down连接
# build top-down blocks self.upsample = nn.Upsample(**upsample_cfg) # 在不同stage的特征输入FPN前先进行通道数衰减,降低计算量 self.reduce_layers = nn.ModuleList() for idx in range(len(in_channels)): self.reduce_layers.append( ConvModule( in_channels[idx], out_channels, 1, norm_cfg=norm_cfg, activation=activation, ) ) self.top_down_blocks = nn.ModuleList() # 注意索引方式,从最后一个元素向前开始索引到0个 for idx in range(len(in_channels) - 1, 0, -1): self.top_down_blocks.append( GhostBlocks( # input channel为out_channels*2是因为特征融合采用的cat而非add out_channels * 2, out_channels, expand, kernel_size=kernel_size, num_blocks=num_blocks, use_res=use_res, activation=activation, ) )
这是top-down连接的可视化图:
-
bottom-up连接
# build bottom-up blocks self.downsamples = nn.ModuleList() self.bottom_up_blocks = nn.ModuleList() for idx in range(len(in_channels) - 1): self.downsamples.append( conv( out_channels, out_channels, kernel_size, stride=2, padding=kernel_size // 2, norm_cfg=norm_cfg, activation=activation, ) ) self.bottom_up_blocks.append( GhostBlocks( out_channels * 2, # 同样是因为融合时使用cat out_channels, expand, kernel_size=kernel_size, num_blocks=num_blocks, use_res=use_res, activation=activation, ) )
bottom-up连接和top-down一样,只不过方向相反,稍后在 foward() 方法中可以很清楚的看到,这里不再作图(PPT画图真的太慢了累死我了)
-
extra layer
# extra layers,即PAN上额外的一层,由PAN的最顶层经过卷积得到. self.extra_lvl_in_conv = nn.ModuleList() self.extra_lvl_out_conv = nn.ModuleList() for i in range(num_extra_level): self.extra_lvl_in_conv.append( conv( out_channels, out_channels, kernel_size, stride=2, padding=kernel_size // 2, norm_cfg=norm_cfg, activation=activation, ) ) self.extra_lvl_out_conv.append( conv( out_channels, out_channels, kernel_size, stride=2, padding=kernel_size // 2, norm_cfg=norm_cfg, activation=activation, ) )
extra layer就是取reduce_layer后的最上层feature map经过extra_lvl_in_conv后的输出和bottom-up输出的最上层feature map经过extra_lvl_out_conv的输出进行element-wise相加得到的层,稍后将用于拥有过最大尺度 (最高的下采样率) 的检测头。
-
前向传播
def forward(self, inputs): """ Args: inputs (tuple[Tensor]): input features. Returns: tuple[Tensor]: multi level features. """ assert len(inputs) == len(self.in_channels) # 对于每一个stage的feature,分别送入对应的reduce_layers inputs = [ reduce(input_x) for input_x, reduce in zip(inputs, self.reduce_layers) ] # top-down path inner_outs = [inputs[-1]] # top-down连接中的最上层不用操作 for idx in range(len(self.in_channels) - 1, 0, -1): # 相邻两层的特征要进行融合 feat_heigh = inner_outs[0] feat_low = inputs[idx - 1] inner_outs[0] = feat_heigh # 对feat_high进行上采样扩充 upsample_feat = self.upsample(feat_heigh) # 拼接后投入对应的top_down_block层,得到稍后用于进一步融合的特征 inner_out = self.top_down_blocks[len(self.in_channels) - 1 - idx]( torch.cat([upsample_feat, feat_low], 1) ) # 把刚刚得到的特征插入inner_outs的第一个位置,进行下一轮融合 inner_outs.insert(0, inner_out) # bottom-up path,和top-down path类似的操作 outs = [inner_outs[0]] # inner_outs[0]是最底层的特征 for idx in range(len(self.in_channels) - 1): feat_low = outs[-1] # 从后往前索引,每轮迭代都会将新生成的特征append到list后方 feat_height = inner_outs[idx + 1] downsample_feat = self.downsamples[idx](feat_low) # 下采样 # 拼接后投入连接层得到输出 out = self.bottom_up_blocks[idx]( torch.cat([downsample_feat, feat_height], 1) ) outs.append(out) # extra layers # 把经过reduce_layer后的特征直接投入extra_in_layer # 再把经过GhostPAN后的特征输入extra_out_layer # 两者element-wise add后追加到PAN的输出后 for extra_in_layer, extra_out_layer in zip( self.extra_lvl_in_conv, self.extra_lvl_out_conv ): outs.append(extra_in_layer(inputs[-1]) + extra_out_layer(outs[-1])) return tuple(outs)
AGM的代码位于nanodet/model/head下的simple_conv_head.py中。
class SimpleConvHead(nn.Module):
def __init__(
self,
num_classes,
input_channel, # 输入的特征通道数
feat_channels=256, # AGM内部的特征通道数
stacked_convs=4, # 使用四层卷积
# 默认三个尺度,但是PAN中添加了额外层,配置文件可以看到是[8,16,32,64]
strides=[8, 16, 32],
conv_cfg=None,
# 使用group norm作为归一化层,效果优于BN
norm_cfg=dict(type="GN", num_groups=32, requires_grad=True),
activation="LeakyReLU",
# 配置文件中的默认参数是7
reg_max=16,
**kwargs
):
super(SimpleConvHead, self).__init__()
self.num_classes = num_classes
self.in_channels = input_channel
self.feat_channels = feat_channels
self.stacked_convs = stacked_convs
self.strides = strides
self.reg_max = reg_max
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.activation = activation
self.cls_out_channels = num_classes
self._init_layers()
self.init_weights()使用了GFL的检测头在输出位置时将会输出**4*(reg_max+1)**个值,每条边都有reg_max+1个输出用于建模其分布,即用reg_max+1个离散值的积分来得到最终的位置预测。至于为什么是reg_max➕1而不是reg_max,请看下图:
因此reg_max=7实际上是根据用于检测的feature map相对于原图的上采样率计算得到的。
这部分对于稍后要介绍的 NanoDet-plus head的回归分支也是同理。
def _init_layers(self):
self.relu = nn.ReLU(inplace=True)
self.cls_convs = nn.ModuleList()
self.reg_convs = nn.ModuleList()
# range从0开始索引到stacked_convs-1
for i in range(self.stacked_convs):
# 第一层需要和输入对齐通道数,之后始终保持为feat_channels
chn = self.in_channels if i == 0 else self.feat_channels
# 分类分支
self.cls_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
activation=self.activation,
)
)
# 回归分支
self.reg_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
activation=self.activation,
)
)
# 最后加上分类头
self.gfl_cls = nn.Conv2d(
self.feat_channels, self.cls_out_channels, 3, padding=1
)
# 回归头的输出为4*(reg_max+1),解释见 3.1
self.gfl_reg = nn.Conv2d(
self.feat_channels, 4 * (self.reg_max + 1), 3, padding=1
)
# 用于缩放回归出的bbox的系数,这是一个可学习的参数
self.scales = nn.ModuleList([Scale(1.0) for _ in self.strides])Scale的构成非常简单,就是乘上一个数值,使得回归出的框更加精确:
class Scale(nn.Module):
"""
A learnable scale parameter
"""
def __init__(self, scale=1.0):
super(Scale, self).__init__()
self.scale = nn.Parameter(torch.tensor(scale, dtype=torch.float))
def forward(self, x):
return x * self.scale# 全部采用normal init,没什么好说的
def init_weights(self):
for m in self.cls_convs:
normal_init(m.conv, std=0.01)
for m in self.reg_convs:
normal_init(m.conv, std=0.01)
bias_cls = -4.595
normal_init(self.gfl_cls, std=0.01, bias=bias_cls)
normal_init(self.gfl_reg, std=0.01)
def forward(self, feats):
outputs = []
for x, scale in zip(feats, self.scales):
cls_feat = x
reg_feat = x
# 对于来自PAN的每一层输入,计算class分支
for cls_conv in self.cls_convs:
cls_feat = cls_conv(cls_feat)
# 计算regression分支
for reg_conv in self.reg_convs:
reg_feat = reg_conv(reg_feat)
# 得到类别分数
cls_score = self.gfl_cls(cls_feat)
# 得到回归分布并进行缩放
bbox_pred = scale(self.gfl_reg(reg_feat)).float()
# 拼接得到输出
output = torch.cat([cls_score, bbox_pred], dim=1)
# 追加到aux_pred后面
outputs.append(output.flatten(start_dim=2))
# 整理对齐维度,在之后的dsl_assigner中我们会详细介绍如何处理来自AGM和head的输出
outputs = torch.cat(outputs, dim=2).permute(0, 2, 1)
return outputs了解了AGM的输出后,第四部分会介绍本文最重要的Dynamic soft label assigner这个模块了。
随着目标检测网络的发展,大家发现anchor-free和anchor-based、one-stage和two-stage的界限已经十分模糊,而ATSS的发布也指出是否使用anchor和回归效果的好坏并没有太大差别,最关键的是如何为每个prior(可以看作anchor,或者说参考点、回归起点)分配最合适的标签。关于ATSS更详细的内容请参考笔者的这篇博客:anchor-free 模型概览。
ATSS就是一种动态的标签分配方法,它会根据当前预测的结果选出最优的prior对ground truth进行匹配,而不是像之前一样使用先验的固定规则如iou最大、最接近anchor中点、根据尺寸比例等方法进行匹配。由旷视提出的OTA就是将标签分配视作最优传输问题,将ground truth和background当作provider,anchor当作receiver,很好地解决了标签分配中cost计算的问题。再如DETR中的二分图一对一匹配问题,也是一种动态的标签分配方法,需要在训练过程中实时计算cost(关于DETR的介绍请戳:目标检测终章:Vision Transformer
作者在介绍nanodet-plus的文章中也指出:
既然标签匹配需要依赖预测输出,但预测输出又是依赖标签匹配去训练的,但我的模型一开始是随机初始化的,啥也没有呀?那这不就成了一个鸡生蛋,蛋生鸡的问题了吗?由于小模型的检测头非常轻量,在NanoDet中只使用两个深度可分离卷积模块去同时预测分类和回归,和大模型中对分类和回归分别使用4组256channel的3x3卷积来说简直是天壤之别!让这样的检测头从随机初始化的状态去计算Matching Cost做匹配,这是不是有点太难为它了 。
之前的nanodet使用FCOS的方法进行标签分配,但是显然小模型的检测头在训练初期对于位置特征的提取有些力不从心。因此,为了解决小模型初期无法获取较好的预测的问题,作者借鉴了KD(knowledge distillation,关于知识蒸馏的介绍可以看占位符,讲得非常好)的**,增加了一个AGM模块(已经在第三部分介绍过)并利用AGM的输出进行动态标签分配。
dsl_assigner.py这个模块位于nanodet/model/head/assigner下。
'''
dynamic soft label assigner,根据pred和GT的IOU进行软标签分配
某个pred与GT的IOU越大,最终分配给它的标签值会越接近一,反之会变小
'''
class DynamicSoftLabelAssigner(BaseAssigner):
"""Computes matching between predictions and ground truth with
dynamic soft label assignment.
Args:
topk (int): Select top-k predictions to calculate dynamic k
best matchs for each gt. Default 13.
iou_factor (float): The scale factor of iou cost. Default 3.0.
"""
def __init__(self, topk=13, iou_factor=3.0):
self.topk = topk
self.iou_factor = iou_factor
def assign(
self,
pred_scores,
priors,
decoded_bboxes,
gt_bboxes,
gt_labels,
):
"""Assign gt to priors with dynamic soft label assignment.
Args:
pred_scores (Tensor): Classification scores of one image,
a 2D-Tensor with shape [num_priors, num_classes]
priors (Tensor): All priors of one image, a 2D-Tensor with shape
[num_priors, 4] in [cx, cy, stride_w, stride_y] format.
decoded_bboxes (Tensor): Predicted bboxes, a 2D-Tensor with shape
[num_priors, 4] in [tl_x, tl_y, br_x, br_y] format.
gt_bboxes (Tensor): Ground truth bboxes of one image, a 2D-Tensor
with shape [num_gts, 4] in [tl_x, tl_y, br_x, br_y] format.
gt_labels (Tensor): Ground truth labels of one image, a Tensor
with shape [num_gts].
Returns:
:obj:`AssignResult`: The assigned result.
"""
INF = 100000000
num_gt = gt_bboxes.size(0)
num_bboxes = decoded_bboxes.size(0)
# assign 0 by default
assigned_gt_inds = decoded_bboxes.new_full((num_bboxes,), 0, dtype=torch.long)这里主要是label assign需要的参数,请特别注意几个tensor的维度和长度,之后非常重要!如果读者对于python的切片和索引操作不熟悉的,可能需要去复习一下,AGM这里为了提高速度,使用了大量的tensor索引tensor的操作。下面让我们开始吧!
# assign 0 by default
assigned_gt_inds = decoded_bboxes.new_full((num_bboxes,), 0, dtype=torch.long)
# 切片得到prior位置(可以看作anchor point的中心点)
prior_center = priors[:, :2]
# 计算prior center到GT左上角和右下角的距离,从而判断prior是否在GT框内
lt_ = prior_center[:, None] - gt_bboxes[:, :2]
rb_ = gt_bboxes[:, 2:] - prior_center[:, None]
deltas = torch.cat([lt_, rb_], dim=-1)
# is_in_gts通过判断deltas全部大于零筛选处在gt中的prior
# [dxlt,dylt,dxrb,dyrb]四个值都需要大于零,则它们中最小的值也要大于零
# tensor.min会返回一个 namedtuple (values, indices),-1代表最后一个维度
# 其中 values 是给定维度 dim 中输入张量的每一行的最小值,并且索引是找到的每个最小值的索引位置
# 这里判断赋值bool,若prior落在gt中对应的[prior_i,gt_j]会变为true
# [i,j]代表第i个prior是否落在第j个ground truth中
is_in_gts = deltas.min(dim=-1).values > 0
# 这一步生成有效prior的索引,这里请注意之所以用sum是因为一个prior可能落在多个GT中
# 因此上一步生成的is_in_gts确定的是某个prior是否落在每一个GT中,只要落在一个GT范围内,便是有效的
valid_mask = is_in_gts.sum(dim=1) > 0
# 利用得到的mask确定由哪些prior生成的pred_box和它们对应的scores是有效的,注意它们的长度
# 注意valid_decoded_bbox和valid_pred_scores的长度是落在gt中prior的个数
# 稍后在dynamic_k_matching()我们会再提到这一点
valid_decoded_bbox = decoded_bboxes[valid_mask]
valid_pred_scores = pred_scores[valid_mask]
num_valid = valid_decoded_bbox.size(0)
# 出现没有预测框或者训练样本中没有GT的情况
if num_gt == 0 or num_bboxes == 0 or num_valid == 0:
# No ground truth or boxes, return empty assignment
max_overlaps = decoded_bboxes.new_zeros((num_bboxes,))
if num_gt == 0:
# No truth, assign everything to background
# 通过这种方式,可以直接在数据集中放置没有标签的图像作为负样本
assigned_gt_inds[:] = 0
if gt_labels is None:
assigned_labels = None
else:
assigned_labels = decoded_bboxes.new_full(
(num_bboxes,), -1, dtype=torch.long
)
return AssignResult(
num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels
)FCOS式的网络把feature map上的每个格点当作参考点(回归起点),预测得到的数值是距离该参考点的四个数值(上下左右),其做法是将每个落在GT范围内的prior都当作正样本,这同样是一种先验的固定的规则。显然将那些处于ground truth和background边缘的prior直接作为正样本是不太合适的,这里我们先将在gt范围内的priors筛选出来,稍后根据这些priors输出的预测类别和位置算出cost matrix,进一步确定是否要将其当作正样本(并且即使是作为正样本,也会有soft label的衰减),比起原来的方法会合理不少。
把落在gt范围内的prior筛选出来之后就可以计算IOU loss、class loss和distance loss了。
最终的cost为$C_{total}=C_{cls}+\lambda C_{reg}+C_{dis}$ ,
其中$ C_{reg}=-log(IOU)$ ,
这部分比较难懂的就是tensor的reshape和索引,相信你配着注释看一定能理解。
# 计算有效bbox和gt的iou损失
pairwise_ious = bbox_overlaps(valid_decoded_bbox, gt_bboxes)
# clamp,加上一个很小的数防止出现NaN
iou_cost = -torch.log(pairwise_ious + 1e-7)
# 根据num_valid的数量(有效bbox)生成对应长度的one-hot label,之后用于计算soft lable
# 每个匹配到gt的prior都会有一个[0,0,...,1,0]的tensor,即label位置的元素为一其余为零
gt_onehot_label = (
F.one_hot(gt_labels.to(torch.int64), pred_scores.shape[-1])
.float()
.unsqueeze(0)
.repeat(num_valid, 1, 1)
)
valid_pred_scores = valid_pred_scores.unsqueeze(1).repeat(1, num_gt, 1)
# IOU*onehot得到软标签,直觉上非常好理解,预测框和gt越接近,说明预测的越好
# 那么,稍后计算交叉熵的时候,标签值也会更大
soft_label = gt_onehot_label * pairwise_ious[..., None]
# 计算缩放权重因子,为软标签减去该prior预测的bbox的score
# 可以想象,差距越大说明当前的预测效果越差,稍后的cost计算就应该给一个更大的惩罚
scale_factor = soft_label - valid_pred_scores
# 计算分类交叉熵损失
cls_cost = F.binary_cross_entropy(
valid_pred_scores, soft_label, reduction="none"
) * scale_factor.abs().pow(2.0)
cls_cost = cls_cost.sum(dim=-1)
# 最后得到的匹配开销矩阵,数值为分类损失和IOU损失,这里利用iou_factor作为调制系数
cost_matrix = cls_cost + iou_cost * self.iou_factor接下来就是根据上一部分得到的cost矩阵,进行动态匹配,决定哪些prior最终会得到正样本的监督训练。
def dynamic_k_matching(self, cost, pairwise_ious, num_gt, valid_mask):
"""Use sum of topk pred iou as dynamic k. Refer from OTA and YOLOX.
Args:
cost (Tensor): Cost matrix.
pairwise_ious (Tensor): Pairwise iou matrix.
num_gt (int): Number of gt.
valid_mask (Tensor): Mask for valid bboxes.
"""
matching_matrix = torch.zeros_like(cost)
# select candidate topk ious for dynamic-k calculation
# pairwise_ious匹配成功的组数可能会小于默认的topk,这里取两者最小值防止越界
candidate_topk = min(self.topk, pairwise_ious.size(0))
# 从IOU矩阵中选出IOU最大的topk个匹配
# topk函数返回一个namedtuple(value,indices),indices没用,python里无用变量一般约定用"_"接收
topk_ious, _ = torch.topk(pairwise_ious, candidate_topk, dim=0)
# calculate dynamic k for each gt
# 用topk个预测IOU值之和作为一个GT要分配给prior的个数
# 这个想法很直观,可以把IOU为1看作一个完整目标,那么这些预测框和GT的IOU总和就是最终分配的个数
# clamp规约,最小值为一,因为不可能一个都不给分配,dynmaic_ks的大小和GT个数相同
dynamic_ks = torch.clamp(topk_ious.sum(0).int(), min=1)
# 对每一个GT,挑选出上面计算出的dymamic_ks个拥有最小cost的预测
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(
cost[:, gt_idx], k=dynamic_ks[gt_idx].item(), largest=False # False则返回最小值
)
matching_matrix[:, gt_idx][pos_idx] = 1.0 # 被匹配的(prior,gt)位置上被置1
del topk_ious, dynamic_ks, pos_idx
# 第二个维度是prior,大于1说明一个prior匹配到了多个GT,这里要选出匹配cost最小的GT
prior_match_gt_mask = matching_matrix.sum(1) > 1
if prior_match_gt_mask.sum() > 0:
cost_min, cost_argmin = torch.min(cost[prior_match_gt_mask, :], dim=1)
# 匹配到多个GT的prior的行全部清零
matching_matrix[prior_match_gt_mask, :] *= 0.0
# 把这些prior和gt有最小cost的位置置1
matching_matrix[prior_match_gt_mask, cost_argmin] = 1.0
# get foreground mask inside box and center prior
# 统计matching_matrix中被分配了标签的priors
fg_mask_inboxes = matching_matrix.sum(1) > 0.0
'''
假设priors长度是n,并且有m个prior落在gt中,那么valid_mask长度也是n,并且有m个true,n-m个false;
在这m个落在gt中的prior里,又有k个被匹配到了,故fg_mask_inboxes的维度是m,其中有k个位置为true;
因此valid_mask中有m-k个位置的true也需要被置为false.
在这里valid_mask[valid_mask]会把原来所有为true的位置索引返回,让他们等于fg_mask_inboxes
维度对照表:
n为priors长度即所有prior个数,m为落在gt中的prior个数,k为匹配到gt的prior的个数,g为gt个数
valid_mask:[n] 其中m个为true
matching_matrix:[gt,m] 每一列至多只有一个为1
fg_mask_inboxes:[m] 其中k个为true
最终得到的valid_mask中只有k个为true剩余为false
'''
# 注意这个索引方式,valid_mask是一个bool类型tensor,以自己为索引会返回所有为True的位置
valid_mask[valid_mask.clone()] = fg_mask_inboxes
# 找到已被分配标签的prior对应的gt index,argmax返回最大值所在的索引,每一个prior只会对应一个GT
matched_gt_inds = matching_matrix[fg_mask_inboxes, :].argmax(1)
# 同上,把它们的IOU提取出来
matched_pred_ious = (matching_matrix * pairwise_ious).sum(1)[fg_mask_inboxes]
return matched_pred_ious, matched_gt_inds需要特别注意的有两个地方,因为一个prior可能会匹配到多个GT,当出现这种情况的时候要选择匹配cost最小的那个gt。
第二处是在最后增加了长注释的这一段,务必要清楚,因为valid_mask的长度和cost matrix的长度是不一样的,cost matrix中代表priors的那一维的长度是落在gt中priors的数量,而valid_mask的长度是priors的总数。这里巧妙的利用了valid_mask[valid_mask.clone()]对那些有效的prior进行索引。
这部分代码还是在 assign() 函数里,就是调用完 dynamic_k_matching() ,紧接着 4.3。
# 返回值为分配到标签的prior与它们对应的gt的iou和这些prior匹配到的gt索引
matched_pred_ious, matched_gt_inds = self.dynamic_k_matching(
cost_matrix, pairwise_ious, num_gt, valid_mask
)
# convert to AssignResult format
# 把结果还原为priors的长度
assigned_gt_inds[valid_mask] = matched_gt_inds + 1
assigned_labels = assigned_gt_inds.new_full((num_bboxes,), -1)
assigned_labels[valid_mask] = gt_labels[matched_gt_inds].long()
max_overlaps = assigned_gt_inds.new_full(
(num_bboxes,), -INF, dtype=torch.float32
)
max_overlaps[valid_mask] = matched_pred_ious
return AssignResult(
num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels
)AssignResult 是分配的结果,也被构造成了一个类方便调用和调试。其成员变量和构造请自行参看源码,存储了此次分配中gt的数量 num_gt、分配了prior的gt的索引 assigned_gt_inds和这些gt与prior的iou max_overlaps ,还有标签 labels。
head部分总共有五百多行代码,将分为
- 初始化、构造、前向传播
- priors获取、标签分配、loss计算
- 检测框转换、后处理
这三个部分进行讲解。中间会穿插一下来自其他module的函数或class的介绍,如QFL、DFL、用于从框分布得到框位置的Integral,还有GIoU loss。
class NanoDetPlusHead(nn.Module):
"""Detection head used in NanoDet-Plus.
Args:
num_classes (int): Number of categories excluding the background
category.不包括背景类,可以认为全部类的输出低于某个阈值视为背景
loss (dict): Loss config.
input_channel (int): Number of channels of the input feature.
刚送入检测头的通道数量,需要和PAN的输出通道数量保持一致
feat_channels (int): Number of channels of the feature. 经过检测头卷积后的通道数
Default: 96.
stacked_convs (int): Number of conv layers in the stacked convs. 堆叠的卷积层数
Default: 2.
kernel_size (int): Size of the convolving kernel. Default: 5.
strides (list[int]): Strides of input multi-level feature maps. 下采样步长
Default: [8, 16, 32].
conv_type (str): Type of the convolution.
Default: "DWConv".
norm_cfg (dict): Dictionary to construct and config norm layer.
Default: dict(type='BN').
AGM中使用GN,但是GN对于CPU型设备不友好,BN可以直接和卷积一同参数化而不需要额外计算
reg_max (int): The maximal value of the discrete set. Default: 7.
参见GFL的论文,用于建模框的任意分布,而不是得到一个Dirac分布
在第四部分的AGM中也介绍过,请查看往期博客
activation (str): Type of activation function. Default: "LeakyReLU".
assigner_cfg (dict): Config dict of the assigner. Default: dict(topk=13).
"""
def __init__(
self,
num_classes,
loss,
input_channel,
feat_channels=96,
stacked_convs=2,
# 选择5x5的卷积大核
kernel_size=5,
# 输入特征相对原图像的下采样率,因为PAN中采用了extra_layer-
# 从配置文件也可以看到这里实际有四层:[8,16,32,64]
strides=[8, 16, 32],
conv_type="DWConv",
norm_cfg=dict(type="BN"),
reg_max=7,
activation="LeakyReLU",
assigner_cfg=dict(topk=13),
**kwargs
):
super(NanoDetPlusHead, self).__init__()
self.num_classes = num_classes
self.in_channels = input_channel
self.feat_channels = feat_channels
self.stacked_convs = stacked_convs
self.kernel_size = kernel_size
self.strides = strides
self.reg_max = reg_max
self.activation = activation
# 必然是使用深度可分离卷积了,DepthwiseConvModule来自MMDetection,请直接看源码
self.ConvModule = ConvModule if conv_type == "Conv" else DepthwiseConvModule
self.loss_cfg = loss
self.norm_cfg = norm_cfg
# 第四部分介绍的动态分配器,稍后计算loss会使用到
self.assigner = DynamicSoftLabelAssigner(**assigner_cfg)
# 根据输出的框分布进行积分,得到最终的位置值
self.distribution_project = Integral(self.reg_max)
# 联合了分类和框的质量估计表示
self.loss_qfl = QualityFocalLoss(
beta=self.loss_cfg.loss_qfl.beta,
loss_weight=self.loss_cfg.loss_qfl.loss_weight,
)
# 初始化参数中reg_max的由来,在对应模块中进行了详细的介绍
self.loss_dfl = DistributionFocalLoss(
loss_weight=self.loss_cfg.loss_dfl.loss_weight
)
# IoU loss的一种改进,IoU loss家族还有CIoU/DIoU等
self.loss_bbox = GIoULoss(loss_weight=self.loss_cfg.loss_bbox.loss_weight)
self._init_layers()
self.init_weights()下面是_buid_not_shared_head、_init_layers()和init_weights():
def _buid_not_shared_head(self):
cls_convs = nn.ModuleList()
# stacked_convs是参数中设定的卷积层数
for i in range(self.stacked_convs):
# 第一层要和PAN的输出对齐通道
chn = self.in_channels if i == 0 else self.feat_channels
cls_convs.append(
self.ConvModule(
chn,
self.feat_channels,
self.kernel_size,
stride=1,
# 加大小为卷积核一般的padding使得输入输出feat有相同尺寸
padding=self.kernel_size // 2,
norm_cfg=self.norm_cfg,
bias=self.norm_cfg is None,
activation=self.activation,
)
)
return cls_convsdef _init_layers(self):
self.cls_convs = nn.ModuleList()
for _ in self.strides:
# 为每个stride的创建一个head,cls和reg共享这些参数
cls_convs = self._buid_not_shared_head()
self.cls_convs.append(cls_convs)
# 同样,为每个头增加gfl卷积
self.gfl_cls = nn.ModuleList(
[
nn.Conv2d(
self.feat_channels,
# 每个位置需要num_classes个通道用于预测类别分数,还有4*(reg_max+1)来回归位置
# 用同一组卷积来获得,输出结果时再split成两份即可
self.num_classes + 4 * (self.reg_max + 1),
1,
padding=0,
)
for _ in self.strides
]
)还有平平无奇的权重初始化:
# 采用norm初始化
def init_weights(self):
for m in self.cls_convs.modules():
if isinstance(m, nn.Conv2d):
normal_init(m, std=0.01)
# init cls head with confidence = 0.01
bias_cls = -4.595
for i in range(len(self.strides)):
normal_init(self.gfl_cls[i], std=0.01, bias=bias_cls)
print("Finish initialize NanoDet-Plus Head.")# head的推理方法
def forward(self, feats):
# 有一个为了兼容onnx的方法
if torch.onnx.is_in_onnx_export():
return self._forward_onnx(feats)
# 输出默认有4份,是一个list
outputs = []
# feats来自fpn,有多组,且组数和self.cls_cons/self.gfl_cls的数量需保持一致
# 默认的参数设置是4组
for feat, cls_convs, gfl_cls in zip(
feats,
self.cls_convs,
self.gfl_cls,
):
# 对每组feat进行前向推理操作
for conv in cls_convs:
feat = conv(feat)
output = gfl_cls(feat)
# 所有head的输出会在展平后拼接成一个tensor,方便后处理
# output是一个四维tensor,第一维长度为1
# 长为W宽为H(其实长宽相等)即feat的大小,高为80 + 4 * (reg_max+1)即cls和reg
# 按照第三个维度展平,就是排成一个长度为W*H的tensor,另一个维度是输出的cls和reg
outputs.append(output.flatten(start_dim=2)) # 变成1x112x(W*H)维了,80+4*8=112
# 把不同head的输出交换一下维度排列顺序,全部拼在一起
# 按照第三维拼接,就是1x112x2125(对于nanodet-m)
outputs = torch.cat(outputs, dim=2).permute(0, 2, 1)
return outputs因为第一个维度长度为1的维度没有消除掉,所以很多读者初看认为这是一个三维的向量,这造成了一些困惑。**对于训练或者批量推理的时候,第一个向量的长度就不会为1了!**我们直接看看NanoDet-m转成onnx后的可视化:
split操作不需要理会,这是在推理的时候拆分分类输出和位置输出使用到的算子。我们会在介绍完训练后介绍部署和推理。
loss的运算流程如下,当aux_head即AGM启用的时候,aux_head从fpn和aux_fpn获取featmap随后输出预测,在detach_epoch(需要自己设置的参数,在训练了detach_epoch后标签分配将由检测头自己进行)内,使用AGM的输出来对head的预测值进行标签分配。
先根据输入的大小获取priors的网格,然后将AGM预测的分数和检测框根据prior进行标签分配,把分配结果提交给head,再使用head的输出和gt计算loss最后反向传播完成一步迭代。
这里我们先“假装”已经知道封装好的函数在做什么,先关注整体的计算流程:
def loss(self, preds, gt_meta, aux_preds=None):
"""Compute losses.
Args:
preds (Tensor): Prediction output. head的输出
gt_meta (dict): Ground truth information. 包含gt位置和标签的字典,还有原图像的数据
aux_preds (tuple[Tensor], optional): Auxiliary head prediction output.
如果AGM还没有detach,会用AGM的输出进行标签分配
Returns:
loss (Tensor): Loss tensor.
loss_states (dict): State dict of each loss.
"""
# 把gt相关的数据分离出来,这两个数据都是list,长度为batchsize的大小
# 每个list中都包含了它们各自对应的图像上的gt和label
gt_bboxes = gt_meta["gt_bboxes"]
gt_labels = gt_meta["gt_labels"]
# 一会要传送到GPU上
device = preds.device
# 得到本次loss计算的batch数,pred是3维tensor,可以参见第一部分关于推理的介绍
batch_size = preds.shape[0]
# 对"img"信息取shape就可以得到图像的长宽,这里请看DataSet和DataLoader了解训练数据的详细格式
# 所有图片都会在前处理中被resize成网络的输入大小,不足的则直接加zero padding
input_height, input_width = gt_meta["img"].shape[2:]
# 因为稍后要布置priors,这里要计算出feature map的大小
# 如果修改了输入或者采样率,输入无法被stride整除,要取整
# 默认是对齐的,应该为[40,40],[20,20],[10,10],[5,5]
featmap_sizes = [
(math.ceil(input_height / stride), math.ceil(input_width) / stride)
for stride in self.strides
]
# get grid cells of one image
# 在不同大小的stride上放置一组priors,默认四个检测头也就是四个不同尺寸的stride
# 最后返回的是tensor维度是[batchsize,strideW*strideH,4]
# 其中每一个都是[x,y,strideH,strideW]的结构,当featmap不是正方形的时候两个stride不相等
mlvl_center_priors = [
self.get_single_level_center_priors(
batch_size,
featmap_sizes[i],
stride,
dtype=torch.float32,
device=device,
)
for i, stride in enumerate(self.strides)
]
# 按照第二个维度拼接后的prior的维度是[batchsize,40x40+20x20+10x10+5x5=2125,4]
# 其中四个值为[cx,cy,strideW,stridH]
center_priors = torch.cat(mlvl_center_priors, dim=1)
# 把预测值拆分成分类和框回归
# cls_preds的维度是[batchsize,2125*class_num],reg_pred是[batchsize,2125*4*(reg_max+1)]
cls_preds, reg_preds = preds.split(
[self.num_classes, 4 * (self.reg_max + 1)], dim=-1
)
# 对reg_preds进行积分得到位置预测,reg_reds表示的是一条边的离散分布,
# 积分就得到位置(对于离散来说就是加权求和),distribution_project()是Integral函数,稍后讲解
# 乘以stride(在center_priors的最后两个位置)后,就得到[dl,dr,dt,db]在原图的长度了
# dis_preds是[batchsize,2125,4],其中4为上述的中心到检测框四条边的距离
dis_preds = self.distribution_project(reg_preds) * center_priors[..., 2, None]
# 把[dl,dr,dt,db]根据prior的位置转化成框的左上角点和右下角点方便计算iou
decoded_bboxes = distance2bbox(center_priors[..., :2], dis_preds)
# 如果启用了辅助训练模块,将用其结果进行标签分配
if aux_preds is not None:
# use auxiliary head to assign
aux_cls_preds, aux_reg_preds = aux_preds.split(
[self.num_classes, 4 * (self.reg_max + 1)], dim=-1
)
aux_dis_preds = (
self.distribution_project(aux_reg_preds) * center_priors[..., 2, None]
)
aux_decoded_bboxes = distance2bbox(center_priors[..., :2], aux_dis_preds)
# 可以去看multi_apply的实现,是一个稍微有点复杂的map()方法
# 每次给一张图片进行分配,应该是为了避免显存溢出,代码写起来可读性也更高
# 应该有并行优化,因此不用太担心效率问题
batch_assign_res = multi_apply(
self.target_assign_single_img,
aux_cls_preds.detach(),
center_priors,
aux_decoded_bboxes.detach(),
gt_bboxes,
gt_labels,
)
else:
# use self prediction to assign
# multi_apply将参数中的函数作用在后面的每一个可迭代对象上,一次处理批量数据
# 因为target_assign_single_img一次只能分配一张图片
# 并且由于显存限制,有时候无法一次处理整个batch
batch_assign_res = multi_apply(
self.target_assign_single_img,
cls_preds.detach(),
center_priors,
decoded_bboxes.detach(),
gt_bboxes,
gt_labels,
)
# 根据分配结果计算loss,这个函数稍后会介绍
loss, loss_states = self._get_loss_from_assign(
cls_preds, reg_preds, decoded_bboxes, batch_assign_res
)
# 加入辅助训练模块的loss,这可以让网络在初期收敛的更快
if aux_preds is not None:
aux_loss, aux_loss_states = self._get_loss_from_assign(
aux_cls_preds, aux_reg_preds, aux_decoded_bboxes, batch_assign_res
)
loss = loss + aux_loss
for k, v in aux_loss_states.items():
loss_states["aux_" + k] = v
return loss, loss_states获取每个priors坐标的函数get_single_level_center_priors()如下,注意一定要先学习FCOS式检测器的原理,否则理解loss计算和推理将会有很大的阻碍。
# 在feature map上布置一组prior
# prior就是框分布的回归起点,将以prior的位置作为目标中心,预测四个值形成检测框
def get_single_level_center_priors(
self, batch_size, featmap_size, stride, dtype, device
):
"""Generate centers of a single stage feature map.
Args:
batch_size (int): Number of images in one batch.
featmap_size (tuple[int]): height and width of the feature map
stride (int): down sample stride of the feature map
dtype (obj:`torch.dtype`): data type of the tensors
device (obj:`torch.device`): device of the tensors
Return:
priors (Tensor): center priors of a single level feature map.
"""
h, w = featmap_size
# arange()会生成一个一维tensor,和range()差不多,步长默认为1
# 乘上stride后,就得到了划分的网格宽度和长度
x_range = (torch.arange(w, dtype=dtype, device=device)) * stride
y_range = (torch.arange(h, dtype=dtype, device=device)) * stride
# 根据网格长宽生成一组二维坐标
y, x = torch.meshgrid(y_range, x_range)
# 展平成一维
y = y.flatten()
x = x.flatten()
# 扩充出一个strides的tensor,稍后给每一个prior都加上其对应的下采样倍数
strides = x.new_full((x.shape[0],), stride)
# 把得到的prior按照以下顺序叠成二维tensor,即原图上的坐标,采样倍数
proiors = torch.stack([x, y, strides, strides], dim=-1)
# 一次处理一个batch,所以unsqueeze增加一个batch的维度
# 然后把得到的prior复制到同个batch的其他位置上
return proiors.unsqueeze(0).repeat(batch_size, 1, 1)这里有两部分,分别是target_assign_single_img() 和sample()(被前者调用,生成正负样本)。刚刚已经看到,target_assign_single_img()被_get_loss_from_assign()调用。
# 标签分配时的运算不会被记录,我们只是在计算cost并进行匹配
# 需要特别注意,这个函数只为一张图片,即一个样本进行标签分配!
@torch.no_grad()
def target_assign_single_img(
self, cls_preds, center_priors, decoded_bboxes, gt_bboxes, gt_labels
):
"""Compute classification, regression, and objectness targets for
priors in a single image.
这些参数和第四部分介绍的label assigner差不多,稍后也会调用assign
主要是为能够进行批处理而增加了一些代码
Args:
cls_preds (Tensor): Classification predictions of one image,
a 2D-Tensor with shape [num_priors, num_classes]
center_priors (Tensor): All priors of one image, a 2D-Tensor with
shape [num_priors, 4] in [cx, xy, stride_w, stride_y] format.
decoded_bboxes (Tensor): Decoded bboxes predictions of one image,
a 2D-Tensor with shape [num_priors, 4] in [tl_x, tl_y,
br_x, br_y] format.
gt_bboxes (Tensor): Ground truth bboxes of one image, a 2D-Tensor
with shape [num_gts, 4] in [tl_x, tl_y, br_x, br_y] format.
gt_labels (Tensor): Ground truth labels of one image, a Tensor
with shape [num_gts].
"""
num_priors = center_priors.size(0)
device = center_priors.device
# 一些前处理,把数据都移到gpu里面
gt_bboxes = torch.from_numpy(gt_bboxes).to(device)
gt_labels = torch.from_numpy(gt_labels).to(device)
num_gts = gt_labels.size(0)
gt_bboxes = gt_bboxes.to(decoded_bboxes.dtype)
# dist_targets是最终用来计算回归损失的tensor,具体过程看后面
bbox_targets = torch.zeros_like(center_priors)
dist_targets = torch.zeros_like(center_priors)
# 把label扩充成one-hot向量
labels = center_priors.new_full(
(num_priors,), self.num_classes, dtype=torch.long
)
label_scores = center_priors.new_zeros(labels.shape, dtype=torch.float)
# No target,啥也不用管,全都是负样本,返回回去就行
if num_gts == 0:
return labels, label_scores, bbox_targets, dist_targets, 0
# class的输出要映射到0-1之间,看之前对head构建conv layer就可以发现最后的分类输出后面没带激活函数
# assign参见第四部分关于dsl_assigner的介绍
assign_result = self.assigner.assign(
cls_preds.sigmoid(), center_priors, decoded_bboxes, gt_bboxes, gt_labels
)
# 调用采样函数,获得正负样本,这个函数在下面马上介绍
pos_inds, neg_inds, pos_gt_bboxes, pos_assigned_gt_inds = self.sample(
assign_result, gt_bboxes
)
# 当前进行分配的这个图片上正样本的数目
num_pos_per_img = pos_inds.size(0)
# 把分配到了gt的那些prior预测的检测框和gt的iou算出来,稍后用于QFL的计算
pos_ious = assign_result.max_overlaps[pos_inds]
if len(pos_inds) > 0:
# bbox_targets就是最终用来和gt计算回归损失的东西了(reg分支),维度为[2125,4]
# 不过这里还需要一步转化,因为bbox_target是检测框四条边和他对应的prior的偏移量
# 因此要转换成原图上的框(绝对位置),和gt进行回归损失计算
bbox_targets[pos_inds, :] = pos_gt_bboxes
#
dist_targets[pos_inds, :] = (
bbox2distance(center_priors[pos_inds, :2], pos_gt_bboxes)
/ center_priors[pos_inds, None, 2]
)
dist_targets = dist_targets.clamp(min=0, max=self.reg_max - 0.1)
# 上面计算回归,这里就是得到用于计算类别损失的,把那些匹配到的prior利用pos_inds索引筛出来
labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
label_scores[pos_inds] = pos_ious
return (
labels,
label_scores,
bbox_targets,
dist_targets,
num_pos_per_img,
)sample()的实现很简单,没分配到标签的priors都是负样本,这也是动态标签分配的优点所在:
def sample(self, assign_result, gt_bboxes):
"""Sample positive and negative bboxes."""
# 分配到标签的priors索引,注意正样本和负样本的大小总和应该为prior的数目
# 对于320x320,是2125
pos_inds = (
torch.nonzero(assign_result.gt_inds > 0, as_tuple=False)
.squeeze(-1)
.unique()
)
# 没分配到标签的priors索引
neg_inds = (
torch.nonzero(assign_result.gt_inds == 0, as_tuple=False)
.squeeze(-1)
.unique()
)
# -----------------------------------------------------------------------
# @TODO:
# 这里有疑问,不知道为什么之前在dsl_assigner里面要将分配到标签的prior索引变成2
# 其实不是直接设置成1就可以了吗?然后这里又重新把index-1,有点不太明白
# 如果有看懂了的或者知道为什么,请联系我!
pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
#------------------------------------------------------------------------
if gt_bboxes.numel() == 0:
# hack for index error case
assert pos_assigned_gt_inds.numel() == 0
pos_gt_bboxes = torch.empty_like(gt_bboxes).view(-1, 4)
else:
if len(gt_bboxes.shape) < 2:
gt_bboxes = gt_bboxes.view(-1, 4)
# pos_gt_bboxes大小为[正样本数,4],4就是框的位置了
pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds, :]
return pos_inds, neg_inds, pos_gt_bboxes, pos_assigned_gt_inds根据 5.2.3 的分配结果,现在可以计算Loss了。
计算loss是整个检测头的重中之重,因此也采用了非常多封装好的函数。这里重点讲解QualityFocalLoss(),DistributionFocalLoss(),Integral(),GIoULoss(),还有理解起来难度比较大的weighted_loss()装饰器。
在介绍完结构后,我们再来看看如何进行训练,以及部署中的推理过程。同时我们还会顺着PolarMask的思路,修改处一个基于NanoDet-Plus的特征点检测网络。



