This library is used as a proof-of-concept to determine the best way to create a library of SYCL kernels that can run and be offloaded to various devices. In this description, I'll highlight the issue and provide a way to solve it.
First of all, let's settle the common misunderstanding. SYCL is a specification for a heterogeneous C++-based programming model that uses a single-source paradigm, meaning that both host and device parts are located in a single set of source files.
Then we have a set of SYCL implementations, the most famous are DPC++, ComputeCpp, and Open SYCL (formerly hipSYCL). Those implementations can be called languages and often implement some extensions in addition to the original specification. There used to be some confusion about DPC++ since Intel called their new oneAPI compiler DPC++ as well (dpcpp), but they have deprecated it since in favour of ipcx -fsycl.
Speaking of the extensions, DPC++ has an ESIMD extension set, which is short for Explicit SIMD. This is a way for kernel developers to express their intent to disable compiler auto-vectorization and use intrinsics.
One of the biggest selling points for SYCL-based programs is the ease of use and integration: you have one set of source files (most examples contain a single main.cpp file) which contains both the host code with all the necessary preparation, I/O, etc., as well as device-specific information, wrapped in a functor that is passed to the execution queue.
To make this work, the following approach is taken (more details can be found here):
All of the source code is treated as a whole during preprocessor and frontend (where all the templates are resolved and constexpr magic is happening). Then the device part is prepared as a SPIR-V intermediate representation format and stored as a resource inside the host application/library. That allows using JIT-like compilation in runtime where the exact SPIR-V can be compiled to target-specific binary.
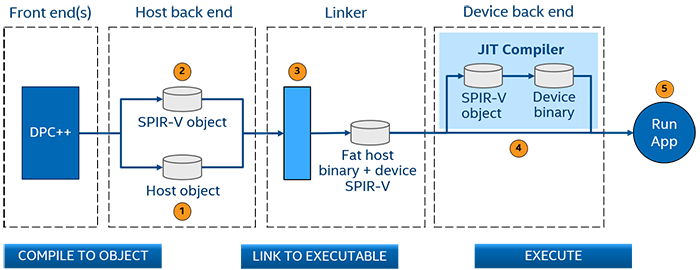
This approach works ok in the case of specific applications when you know all the information in advance like data types and dimensions. However, this is not the case for frameworks or library developers. Since, as I mentioned, the device object is stored in an IR form, there's no possible way to inject type dependency into there and if the library user will request kernel for integers instead of floats it will fail.
This leads us to the fact that we need to somehow generate multiple kernel versions for various data types and other parameters. There are two approaches:
- Pre-generate multiple source files based on CMake template capabilities, as Codeplay does with their SYCL-DNN library;
- Use
std::variantwithstd::visitto leverage standard C++ for this capabilities. Let me describe this idea in detail in the following sections.
To make this library more user-friendly I've decided to make it in the form of a shared library that contains all the SYCL-related stuff, so the users can call it from their applications built with various compilers and programming languages.
Inside this repository you'll find the following sections:
benchmark— (WIP) used to measure performance, currently under heavy developmentexamples— separate subproject that is intended to build with a regular C++ compiler and calls functions that pass the data to kernelsexternal— various dependencies, currently only my other project calledtype_mapto reduce the number of boilerplate codeinclude— header file for the shared librarysrc— folder with all the utility source and header filestest— (WIP) tests to confirm that everything works as intended
Apart from the kernel pre-generation approach, this library is pretty straightforward, so let's focus on the device part. According to SYCL specification, each program or library has three parts:
- Application scope — regular host part responsible for preparing the data, I/O and other non-device-related stuff
- Command group scope — still a host code, but tightly coupled with kernel. We can interpret it as a glue code with various helpers to improve interaction with a kernel
- Kernel scope — a function that is designed to work on a device.
A simplified snipped of code will look like this:
// application scope
queue my_queue;
// ...
my_queue.submit([&](sycl::handler& cgh) {
// command group scope
// ...
cgh.parallel_for(1024, [=](id<1> idx) {
// kernel scope
writeResult[idx] = idx;
}); // End of the kernel function
}); // End of our commands for this queueSimply put, if we have a function template for kernel scope, we need to pre-instantiate multiple template function versions for kernel scope. To achieve this we can utilize the fact that command group scope is a functor and can be represented with a class with overloaded operator(). Such a class will have a templated constructor and each of its' parameters stored as std::variant with all the types it might require.
To pre-generate kernels we'll use std::visit, which accepts a function (which will be a lambda function with auto parameters) and multiple variants. You can find detailed code in binary/unary.hpp files for now. The simplified version will look like this:
struct Kernel {
std::variant<float, double, int> data;
template <typename T>
Kernel(T val) : data(val) {}
void operator(sycl::handler& cgh) {
std::visit([&](auto input) { Process(h, input); }, data);
}
private:
template <typename T>
void Process(sycl::handler& h, T input) {
h.parallel_for(1024, [=](id<1> idx) {
writeResult[idx] = input;
});
}
};
queue my_queue;
auto kernel = Kernel(0.1);
my_queue.submit(kernel);With that approach we'll pre-instantiate all the required templated and then the runtime will select the appropriate one depending on the arguments that were passed. The downside of this approach (as well as the CMake source generation one) if the amount of over-compilation, leading to enormous compilation and (more importantly) linking times.
Below are the milestones I'd like to reach eventually, any help is highly appreciated:
- Enable GitHub Actions CI
- Enable oneMKL and add an interface for FFT/matmul/other operations
- Expand the number of functions
- Add full support for complex data types

