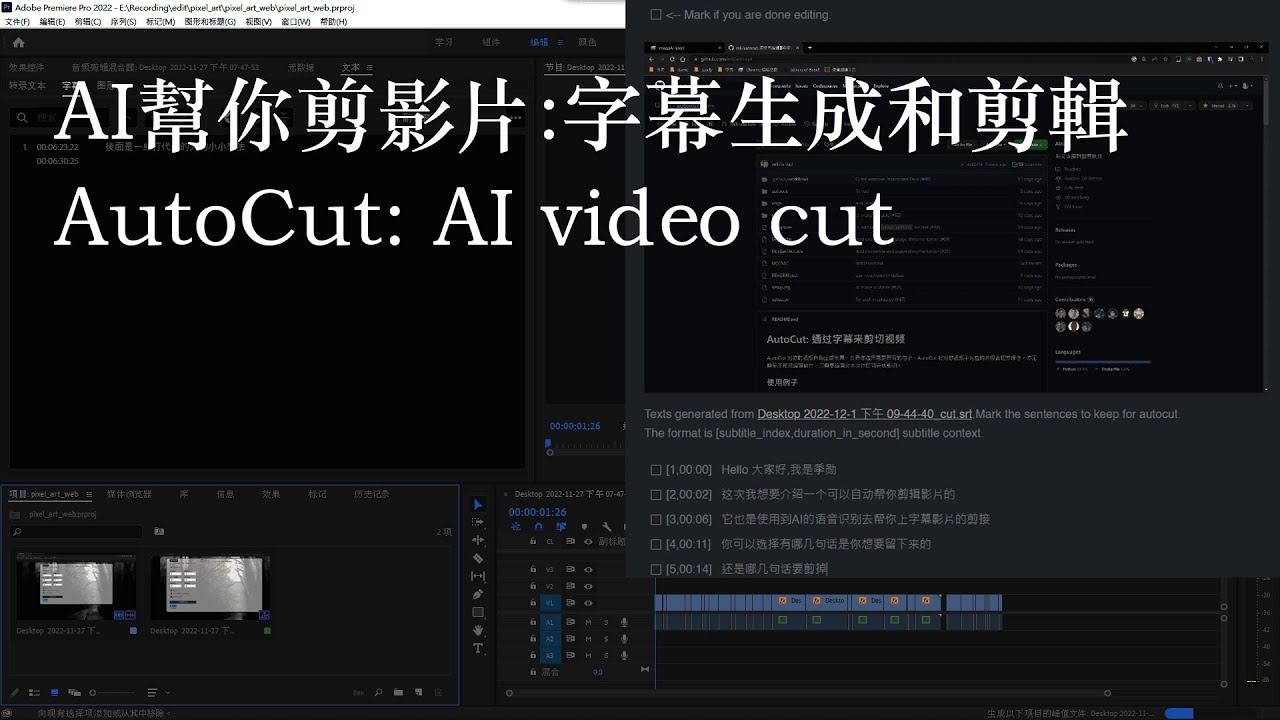
mli / autocut Goto Github PK
View Code? Open in Web Editor NEW用文本编辑器剪视频
License: Apache License 2.0
用文本编辑器剪视频
License: Apache License 2.0
































































































































































setup.py中11行的init_fn = os.path.join(os.path.dirname(__file__), 'autcut', '__init__.py') 应该是init_fn = os.path.join(os.path.dirname(__file__), 'autocut', '__init__.py')
如果不习惯Markdown文件,你也可以直接在srt文件里删除不要的句子,在剪切时不传入md文件名即可。就是 autocut -t 22-52-00.mp4 22-52-00.srt
autocut -t 22-52-00.mp4 22-52-00.srt
-c 吧D:\Miniconda3\envs\autocut\lib\site-packages\torchaudio\backend\utils.py:62: UserWarning: No audio backend is available.
warnings.warn("No audio backend is available.")
D:\Miniconda3\envs\autocut\lib\site-packages\torch\nn\modules\module.py:1190: UserWarning: operator () profile_node %668 : int[] = prim::profile_ivalue(%666)
does not have profile information (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\jit\codegen\cuda\graph_fuser.cpp:109.)
return forward_call(*input, **kwargs)
然后cpu占用率很高,显卡无占用率(不使用vad是可以使用cuda的)
我已经尝试了python3.7和3.9,pytorch也试过了GPU和CPU版本。但是每次安装到whisper,总会提示如下报错:“ERROR: Could not find a version that satisfies the requirement whisper (unavailable) (from autocut) (from versions: 0.9.5, 0.9.6, 0.9.7, 0.9.8, 0.9.9, 0.9.10, 0.9.11, 0.9.12, 0.9.13, 0.9.14, 0.9.15, 0.9.16, 1.0.0, 1.0.1, 1.0.2, 1.1.0, 1.1.1, 1.1.2, 1.1.3, 1.1.4, 1.1.5, 1.1.6, 1.1.7, 1.1.8, 1.1.9, 1.1.10)
ERROR: No matching distribution found for whisper (unavailable)"
请问该如何处理?
用的是autocut test目录下的测试视频,发现也无法正常剪辑视频


是在Windows上运行的,有兄弟也是碰到这个情况吗???
安装时出现以下错误,不论是直接用pip安装还是用docker
ERROR: Could not find a version that satisfies the requirement whisper (unavailable) (from autocut) (from versions: 0.9.5, 0.9.6, 0.9.7, 0.9.8, 0.9.9, 0.9.10, 0.9.11, 0.9.12, 0.9.13, 0.9.14, 0.9.15, 0.9.16, 1.0.0, 1.0.1, 1.0.2, 1.1.0, 1.1.1, 1.1.2, 1.1.3, 1.1.4, 1.1.5, 1.1.6, 1.1.7, 1.1.8, 1.1.9, 1.1.10)
ERROR: No matching distribution found for whisper (unavailable)
转录某个视频生成.srt和.md结果识别差不多是正确的。但我中间停顿比较少,使得字幕连成一片。能否有好的预处理方法,能合适的断句。
00:01:23,000 --> 00:01:51,000
好了,这就是我们创建出来的数据,还有包括它的一条预置线。然后我们拖动这个预置线的时候,就可以看到它对应的数据的位置就发生了,当我们拖动它的时候,就可以看到它的预置的位置,它就给你实时的显示出来了。
7
00:01:51,000 --> 00:02:12,000
好,这个我们怎样去查看这条具体的,在代码中获得具体的这个预置呢?然后我们可以看到我们创建的这个数据邮标对,数据预置对象呢,是叫DRAG9,然后我们也给一个show这样一个方法,就可以是表示它是实时的在图像中显示。
如图 这个视频六分钟,我转录一分钟的视频的时候就可以,这是什么原因?视频太大了吗

whisper.cpp may offer an efficient way for inference ?
今日在新电脑上部署 Docker GPU 版本,运行 autocut -t video.mp4 提示
RuntimeError: Detected that PyTorch and TorchAudio were compiled with different CUDA versions. PyTorch has CUDA version 11.6 whereas TorchAudio has CUDA version 11.7. Please install the TorchAudio version that matches your PyTorch version.
尝试使用 docker system prune --all 删除缓存,重新安装 无法解决。
应当如何修复这个问题呢?之前在旧电脑上安装是正常的。
whisper 默认为 none
https://github.com/openai/whisper/blob/9f70a352f9f8630ab3aa0d06af5cb9532bd8c21d/whisper/transcribe.py#L261
parser.add_argument("--language", type=str, default=None, choices=sorted(LANGUAGES.keys()) + sorted([k.title() for k in TO_LANGUAGE_CODE.keys()]), help="language spoken in the audio, specify None to perform language detection")
autocut这里被默认为zh并且可选项只有zh和en
https://github.com/chenqianhe/autocut/blob/d1d201c4940dfe0dd59ec90f0ab42b2b4f59e50a/autocut/main.py#L28
parser.add_argument('--lang', type=str, default='zh', choices=['zh', 'en'], help='The output language of transcription')
模型使用small时默认zh的话我出现了英文内容不会被识别出来的情况,不知道是不是共性问题。
zh 时,内容丢失,并且时间戳错误
1
00:00:00,000 --> 00:00:02,700
大家好,我的名字是AutoCut。2
00:00:02,700 --> 00:00:10,260
这是一条用于测试的视频。
en时是正常完整的
1
00:00:00,000 --> 00:00:05,000
大家好,我的名字是AutoCut.这是一条用于测试的视频。2
00:00:05,000 --> 00:00:10,260
Hello, my name is AutoCut. This is a video for testing.
为了使得小显存的电脑也能运行large模型,可以增加cpu选项,速度也不错。在cpu i5 12500 6核心12线程上运行, 1小时的视频,生成字幕也是1小时。
在main.py中增加
parser.add_argument('--device', type=str, default='cuda',
choices=['cpu', 'cuda'],
help='cpu or cuda')
在transcribe.py中修改,模型导入的时候选择一下device【cpu或者cuda】
https://github.com/mli/autocut/blob/main/autocut/transcribe.py#L71
改为:
self.whisper_model = whisper.load_model(self.args.whisper_model, self.args.device)
这样运行的时候,默认是cuda;命令增加 --device cpu 即可在cpu上运行,不用担心显存不够。
以上共大家参考。large模型效果比其他的好太多了。
测试环境,windows miniconda
torch 1.11.0+cu113 pypi_0 pypi

(torch_env) C:\Users\User\Videos\nn>autocut -t visualization.mkv
[autocut:transcribe.py:L24] INFO Transcribing visualization.mkv
[autocut:transcribe.py:L81] INFO Done transcription in 8.5 sec
Traceback (most recent call last):
File "E:\miniconda\envs\torch_env\lib\runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "E:\miniconda\envs\torch_env\lib\runpy.py", line 87, in _run_code exec(code, run_globals)
File "E:\miniconda\envs\torch_env\Scripts\autocut.exe\__main__.py", line 7, in <module>
File "E:\miniconda\envs\torch_env\lib\site-packages\autocut\main.py",
line 41, in main
Transcribe(args).run()
File "E:\miniconda\envs\torch_env\lib\site-packages\autocut\transcribe.py", line 34, in run
self._save_srt(output, transcribe_results)
File "E:\miniconda\envs\torch_env\lib\site-packages\autocut\transcribe.py", line 110, in _save_srt
f.write(srt.compose(subs))
File "E:\miniconda\envs\torch_env\lib\encodings\cp1252.py", line 19, in encode
return codecs.charmap_encode(input,self.errors,encoding_table)[0]
UnicodeEncodeError: 'charmap' codec can't encode characters in position
37-47: character maps to <undefined>
autocut似乎只支持视频,不支持音频, 有的时候我将一些音频转换为文字, 同时可以自动同步, 类似与歌词一样的功能.
谢谢.
docker 安装 gpu版本
测试过 默认和 large, 都是一样的结果.
视频中一直在对话, 1-7 分钟都是正常的.之后就基本都错了,只有少量正确.
此处省略两百行,都是 我会发现
- [ ] [823,28:11] 我会发现
- [ ] [824,28:13] 我会发现
- [ ] [825,28:15] 我会发现
- [ ] [826,28:17] 我会发现
- [ ] [827,28:19] < No Speech >
- [ ] [828,28:47] 不好意思
- [ ] [829,28:49] < No Speech >
- [ ] [830,28:51] 我是回家的
- [ ] [831,28:53] 蔡阿嫂
- [ ] [832,28:55] 欢迎回家
- [ ] [833,28:57] 你喝醉了吗
- [ ] [834,28:59] 我喝醉了
- [ ] [835,29:01] 真厉害
- [ ] [836,29:03] 还有什么细胞
- [ ] [837,29:05] 还有什么细胞
- [ ] [838,29:07] 嗯
- [ ] [839,29:09] 嗯
- [ ] [840,29:11] 嗯
- [ ] [841,29:13] 嗯
- [ ] [842,29:15] 嗯
- [ ] [843,29:17] 嗯
- [ ] 此处省略 1988行,都是 嗯.
我安装时出现ERROR: Package 'autocut' requires a different Python: 3.8.13 not in '>=3.9',但我虚拟环境中的Python的确是3.8.13,是什么问题呢?

git clone --filter=blob:none --quiet https://github.com/mli/autocut.git /private/var/folders/vr/cr26bvtn2p766k8919j2hrb80000gn/T/pip-req-build-iish4v7y did not run successfully.
│ exit code: 128
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
本身编辑器做基础调整的话,是可以满足绝大部分需求的。但是由于最终生成的是一个完整视频。如果可以将 autocut 粗剪的视频,导出为 XML 然后导入到具体视频软件的话流程上会更加方便。
初步浏览下来 Finalcut Pro 导出的XML格式,是被 premier* / Davinci* 有限支持的(需要做一点点额外处理,但是能用)
所以,建议沐神考虑要不要增加一个导出 XML 的能力。
目前发现两个似乎满足要求的项目:
(工程能力不太好,我先自己实验一下,争取后面提PR)
另外,AAF 其实几个剪辑软件都支持,但是相关资料很少,感觉不太好弄。
达芬奇的时间码不一样,需要在设置里面做一些调整 sony a7s2 拍摄的视频,final cut剪辑导出xml文件进达芬奇为什么不能显示呢? - 知乎
premiere 从 Final Cut Pro 导入 XML 文件
我看一下为什么现在 CI 不太稳定
现在怀疑是 windows 可能测试不太稳定。
对现在来说是好事情,我先看看是代码问题还是 CI 的问题。
我来试试
我按要求成功安装了ffmpeg和autocut,并且通过 autocut -t 成功生成了 .md 和 .srt 文件,当我在 .md 文件中完成选择了相应片段,并尝试使用 autocut -c 命令时,脚本在没有任何输出(文件和log)的情况下结束了。于是我尝试将刚生成的 .md 和 .srt 文件使用 autocut -c ,结果仍然是一样的。我在 Windows 和 Linux 机器上都尝试了,结果是一样的,如下两个图所示:


有趣的是,我使用 autocut -t test_gbk.mp4 --encoding gbk 生成 test_gbk.srt 后,'autocut -s test_gbk.srt' 可以成功生成剪辑后的视频,这也是我唯一能成功运行的命令。
可能需要加一个模型区分不同人的声音。
原始:
1080x1920,H.264
剪辑后:
1920x1080,H.264
我在WSL 22.04 上安装,使用了pip install . 但是提示如下:
ERROR: Could not find a version that satisfies the requirement whisper (unavailable) (from autocut) (from versions: 0.9.5, 0.9.6, 0.9.7, 0.9.8, 0.9.9, 0.9.10, 0.9.11, 0.9.12, 0.9.13, 0.9.14, 0.9.15, 0.9.16, 1.0.0, 1.0.1, 1.0.2, 1.1.0, 1.1.1, 1.1.2, 1.1.3, 1.1.4, 1.1.5, 1.1.6, 1.1.7, 1.1.8, 1.1.9, 1.1.10)
ERROR: No matching distribution found for whisper (unavailable)
看上去是安装不了whisper,但我直接在whisper官网安装 pip install -U openai-whisper 也没出现任何问题,但接着pip install . 还是提示相同的错误。
于是我把setup.py中的 whisper删去后进行了 安装,测试后发现还是可以使用的(纯cpu环境)



whisper使用ffmpeg读取视频文件拿到audio代码如下
try:
# This launches a subprocess to decode audio while down-mixing and resampling as necessary.
# Requires the ffmpeg CLI and `ffmpeg-python` package to be installed.
out, _ = (
ffmpeg.input(file, threads=0)
.output("-", format="s16le", acodec="pcm_s16le", ac=1, ar=sr)
.run(cmd=["ffmpeg", "-nostdin"], capture_stdout=True, capture_stderr=True)
)
except ffmpeg.Error as e:
raise RuntimeError(f"Failed to load audio: {e.stderr.decode()}") from e
return np.frombuffer(out, np.int16).flatten().astype(np.float32) / 32768.0目前我是在做将输入修改为bytes并使用pipe进行输入输出,但是目前遇到问题了,不知道怎么拿到audio了。
视频上传目前是需要支持['.mp4', '.mov', '.mkv', '.flv']四种格式。我在ffmpeg处理之前可以拿到视频格式和视频宽高等信息。
out, _ = Popen(shlex.split('ffprobe -v error -i pipe: -select_streams v -print_format json -show_streams'),
stdin=PIPE, stdout=PIPE, bufsize=-1)\
.communicate(input=bytes_data)
video_info = json.loads(out)
width = (video_info['streams'][0])['width']
height = (video_info['streams'][0])['height']
out, _ = (
ffmpeg.input('pipe:', threads=0, format='rawvideo', s='{}x{}'.format(width, height))
.output('pipe:', format="s16le", acodec="pcm_s16le", ac=1, ar=self.args.sampling_rate)
.run(input=bytes_data, capture_stdout=True, capture_stderr=True)
)目前这么做会有如下信息输出
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x14f704be0] stream 0, offset 0x30: partial file
[rawvideo @ 0x153f04080] Packet corrupt (stream = 0, dts = 0).
Input #0, rawvideo, from 'pipe:':
Duration: N/A, start: 0.000000, bitrate: 1119955 kb/s
Stream #0:0: Video: rawvideo (I420 / 0x30323449), yuv420p, 2564x1456, 1119955 kb/s, 25 tbr, 25 tbn
Output #0, s16le, to 'pipe:':
Output file #0 does not contain any stream
不知道怎么处理视频bytes才能达到和whisper中load_audio一样的效果
安装后, 我选了一个很小的视频(大小13MB, 时长10s)进行测试。
autocut -d .\10-20\
[autocut:transcribe.py:L24] INFO Transcribing .\10-20\10月20日.mp4
100%|████████████████████████████████████████| 461M/461M [27:26<00:00, 294kiB/s]
[autocut:warnings.py:L109] WARNING C:\f_code\pyProject\autocut\venv\lib\site-packages\whisper\transcribe.py:78: UserWarning: FP16 is not supported on CPU; using FP32 instead
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
[autocut:transcribe.py:L81] INFO Done transcription in 1679.6 sec
[autocut:transcribe.py:L35] INFO Transcribed .\10-20\10月20日.mp4 to .\10-20\10月20日.srt
[autocut:transcribe.py:L37] INFO Saved texts to .\10-20\10月20日.md to mark sentences
[autocut:transcribe.py:L24] INFO Transcribing IMG_8103.MOV
100%|█████████████████████████████████████| 72.1M/72.1M [00:12<00:00, 6.07MiB/s]
/Users/@/Library/Python/3.9/lib/python/site-packages/whisper/transcribe.py:78: UserWarning: FP16 is not supported on CPU; using FP32 instead
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
[autocut:transcribe.py:L81] INFO Done transcription in 15.4 sec
[autocut:transcribe.py:L35] INFO Transcribed IMG_8103.MOV to IMG_8103.srt
Traceback (most recent call last):
File "/Users/@/Library/Python/3.9/bin/autocut", line 8, in
sys.exit(main())
File "/Users/@/Library/Python/3.9/lib/python/site-packages/autocut/main.py", line 51, in main
Transcribe(args).run()
File "/Users/@/Library/Python/3.9/lib/python/site-packages/autocut/transcribe.py", line 36, in run
self._save_md(name + '.md', output, input)
File "/Users/@/Library/Python/3.9/lib/python/site-packages/autocut/transcribe.py", line 118, in _save_md
md.add_done_edditing(False)
AttributeError: 'MD' object has no attribute 'add_done_edditing'
最终可以获得SRT字幕文件,但没有MD文件。
根据安装步骤到了本地测试,终端输入pip install .
Processing /Users/xxxxx/autocut
Preparing metadata (setup.py) ... done
Collecting whisper@ git+https://github.com/openai/whisper.git
Cloning https://github.com/openai/whisper.git to /private/var/folders/by/czbk451x27x5ksmtrsrl8jzm0000gn/T/pip-install-voxu3n35/whisper_137b9cf0e94b47aa8bc1c2055b37bf9e
Running command git clone --filter=blob:none --quiet https://github.com/openai/whisper.git /private/var/folders/by/czbk451x27x5ksmtrsrl8jzm0000gn/T/pip-install-voxu3n35/whisper_137b9cf0e94b47aa8bc1c2055b37bf9e
Resolved https://github.com/openai/whisper.git to commit 7858aa9c08d98f75575035ecd6481f462d66ca27
Preparing metadata (setup.py) ... done
WARNING: Generating metadata for package whisper produced metadata for project name openai-whisper. Fix your #egg=whisper fragments.
Discarding git+https://github.com/openai/whisper.git: Requested openai-whisper from git+https://github.com/openai/whisper.git (from autocut==0.0.3) has inconsistent name: expected 'whisper', but metadata has 'openai-whisper'
Collecting srt
Using cached srt-3.5.2.tar.gz (24 kB)
Preparing metadata (setup.py) ... done
Collecting moviepy
Using cached moviepy-1.0.3.tar.gz (388 kB)
Preparing metadata (setup.py) ... done
Collecting opencc-python-reimplemented
Using cached opencc_python_reimplemented-0.1.7-py2.py3-none-any.whl (481 kB)
Collecting torchaudio
Using cached torchaudio-0.13.1-cp310-cp310-macosx_12_0_arm64.whl (3.4 MB)
Collecting parameterized
Using cached parameterized-0.8.1-py2.py3-none-any.whl (26 kB)
ERROR: Could not find a version that satisfies the requirement whisper (unavailable) (from autocut) (from versions: 0.9.5, 0.9.6, 0.9.7, 0.9.8, 0.9.9, 0.9.10, 0.9.11, 0.9.12, 0.9.13, 0.9.14, 0.9.15, 0.9.16, 1.0.0, 1.0.1, 1.0.2, 1.1.0, 1.1.1, 1.1.2, 1.1.3, 1.1.4, 1.1.5, 1.1.6, 1.1.7, 1.1.8, 1.1.9, 1.1.10)
ERROR: No matching distribution found for whisper (unavailable)
小白请教安装方法。谢谢。
mac:
3.1 GHz Quad-Core Intel Core i7
16 GB 2133 MHz LPDDR3
https://github.com/zcf0508/autocut
新增了一个 pyinstaller 打包需要的 spec 文件,并且 release 中提供了一个 x86_64 的 .zip 压缩包。主要为了方便对代码不是很了解,又想体验一下的同学,可以下载压缩包解压之后直接运行。
https://github.com/da-tubi/pants-minimal
可以让项目更加reproducible
win10系统,autocut和whisper均已完整安装,在anaconda的python38环境下运行时报错如下:

(python38) C:\Windows\System32\2022-11-08>autocut -t 20221108_195852.mp4
Traceback (most recent call last):
File "D:\anacoda\envs\python38\lib\runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "D:\anacoda\envs\python38\lib\runpy.py", line 87, in run_code
exec(code, run_globals)
File "D:\anacoda\envs\python38\Scripts\autocut.exe_main.py", line 7, in
File "D:\anacoda\envs\python38\lib\site-packages\autocut\main.py", line 17, in main
action=argparse.BooleanOptionalAction)
AttributeError: module 'argparse' has no attribute 'BooleanOptionalAction'
求大佬指点!感激不尽~!
这是 TODO 列表。欢迎有兴趣的同学来报名贡献:
如下我给了绝对地址还是依旧报错,是为什么呢?
(deep_learning) D:\all_codes\deep_learning\autocut\video>autocut -t D:\all_codes\deep_learning\autocut\video
[autocut:transcribe.py:L24] INFO Transcribing D:\all_codes\deep_learning\autocut\video
Traceback (most recent call last):
File "C:\Users\songHat\miniconda3\envs\deep_learning\lib\runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\songHat\miniconda3\envs\deep_learning\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\Users\songHat\miniconda3\envs\deep_learning\Scripts\autocut.exe\__main__.py", line 7, in <module>
File "C:\Users\songHat\miniconda3\envs\deep_learning\lib\site-packages\autocut\main.py", line 96, in main
Transcribe(args).run()
File "C:\Users\songHat\miniconda3\envs\deep_learning\lib\site-packages\autocut\transcribe.py", line 29, in run
audio = whisper.load_audio(input, sr=self.sampling_rate)
File "C:\Users\songHat\miniconda3\envs\deep_learning\lib\site-packages\whisper\audio.py", line 42, in load_audio
ffmpeg.input(file, threads=0)
File "C:\Users\songHat\miniconda3\envs\deep_learning\lib\site-packages\ffmpeg\_run.py", line 313, in run
process = run_async(
File "C:\Users\songHat\miniconda3\envs\deep_learning\lib\site-packages\ffmpeg\_run.py", line 284, in run_async
return subprocess.Popen(
File "C:\Users\songHat\miniconda3\envs\deep_learning\lib\subprocess.py", line 951, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "C:\Users\songHat\miniconda3\envs\deep_learning\lib\subprocess.py", line 1420, in _execute_child
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
I can do this.
https://openai.com/blog/introducing-chatgpt-and-whisper-apis
I will take it
工具很不错,谢谢分享。
我在运行命令时报错
autocut -t 0046_video.mp4

请教,怎么修复?
os: debian
python: 3.10
autocut install by the following cmd:
python steup.py install
使用环境:win10,i5 10210u +mx350
使用过程:首先使用autocut -t对视频字幕进行转录,gpu占用率90%以上,速度在预期范围内;autocut -c对视频进行剪辑时,核显和mx350占用率基本为零,cpu占用率为60%左右,跑不满。
疑问:视频剪辑的话是不是只能换一个性能很强的CPU了?
终端输入autocut -d 文件夹地址后,生成了autocut.md、文件名.md、文件名.srt 三个新文件。
按照教程编辑文件名.md 文件,选定需要的内容后,勾选第一行「Mark if you are done editing.」,但终端一直没有任何变化,不会按照选择自动剪辑。
查看autocut.md 文件,里面只显示音视频前2句内容,并非全部内容。
终端一直停留在以下状态:
autocut -d /Users/xxxxxx/Desktop/test
[autocut:transcribe.py:L37] INFO Transcribing /Users/xxxxxx/Desktop/test/test1.mp3
Using cache found in /Users/xxxxx/.cache/torch/hub/snakers4_silero-vad_master
[autocut:transcribe.py:L86] INFO Done voice activity detection in 92.0 sec
0%| | 0/60 [00:00<?, ?it/s][autocut:warnings.py:L109] WARNING /opt/homebrew/lib/python3.10/site-packages/whisper/transcribe.py:79: UserWarning: FP16 is not supported on CPU; using FP32 instead
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
100%|███████████████████████████████████████████| 60/60 [03:45<00:00, 3.75s/it]
[autocut:transcribe.py:L138] INFO Done transcription in 227.1 sec
[autocut:transcribe.py:L55] INFO Transcribed /Users/xxxxxx/Desktop/test/test1.mp3 to /Users/xxxxxx/test/test1.srt
[autocut:transcribe.py:L57] INFO Saved texts to /Users/xxxxxx/Desktop/test/test1.md to mark sentences
是安装哪里出了问题?还是使用方法出了问题?完全的新手小白,盼指点迷津
老师,中文识别出来都是乱码可能是什么原因呢?


我的命令
pip install . --user
我的错误
copying autocut/daemon.py -> build/lib/autocut
error: [Errno 1] Operation not permitted
ubuntu2204
After trying the input autocut -d 2023-03-06, I received the following message:
[autocut:transcribe.py:L37] INFO Transcribing 2023-03-06/230115.mp4
Using cache found in /Users/.cache/torch/hub/snakers4_silero-vad_master
[W NNPACK.cpp:53] Could not initialize NNPACK! Reason: Unsupported hardware.
zsh: segmentation fault autocut -d 2023-03-06
Is the failure happening because of the M2 chip since the message mentioned Unsupported hardware?
Thanks!
在vscode里面,如果打开了jupyter-notebook,再打开md文件,直接打钩的话,markdown中标记用的是大写X ,而不是小写x,导致后续无法运行。可以用快捷键 “alt + c” 快捷标记,这时候是小写x,没有问题。
对于腾讯会议录制的视频,剪辑过程中,会出现导出时长非常长,原因是cut.py中
# an alterantive to birate is use crf, e.g. ffmpeg_params=['-crf', '18']
final_clip.write_videofile(output_fn, audio_codec='aac', bitrate=self.args.bitrate)
这个里面保存的时候,fps其实是等于90000的,可以在前面加上print(final_clip.fps) 来看到。
我们可以参考网页https://www.ab62.cn/article/9901.html
在前面加上
import cv2
source_video = cv2.VideoCapture(fns['video'])
fps = source_video.get(cv2.CAP_PROP_FPS)
print("fps=",fps)
# an alterantive to birate is use crf, e.g. ffmpeg_params=['-crf', '18']
final_clip.write_videofile(output_fn, audio_codec='aac', bitrate=self.args.bitrate,fps=fps)
logging.info(f'Saved video to {output_fn}')
我在开头尝试删除了一些字幕,然后根据删除后的字幕直接-c 裁剪得到剪切后的视频,但发现没有剪切的字幕段对应的视频段落也受到了一定的影像 ,请问能怎么避免这个问题?或者说这个问题是什么造成的呢,谢谢
谢谢
1.在使用GPU时,使用例如-d参数,首先是仅50%的cpu资源被占用,看到docker里面只有半数于cpu逻辑核心数的python进程,随后当GPU计算过程,则只有约50%的cuda核心负载。
2.在进行.MD文件的编辑后,随后是生成cut后的音频文件,这部分在Moviepy - Building video阶段单个逻辑核在负载,Moviepy - Writing video阶段则能正确使用所有的CPU逻辑核。
3.,其后则是进行了第二轮的Transcribing过程,对于为什么进行第二轮的Transcribing觉得不是太合理,不是应该对第一轮产生的SRT文件等进行裁剪编辑就可以了么?再次调用whisper做一次有什么意义呢,尤其是对于超大音频文件来说,相当于付出了2倍的等待时间。
英文视频能保留两份字幕吗?一份英文和中文,现在是直接翻译中文了
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.