mobei95 / blog Goto Github PK
View Code? Open in Web Editor NEW阿白smile的博客
阿白smile的博客







在真实的DOM环境中,一个DOM有非常多的属性,对DOM的操作会很容易引发重绘和回流,影响页面的性能;而虚拟DOM则是采用对象的方式对DOM进行描述,不直接操作DOM,从本质上来看,其实是用对象的方式对真实DOM的一种抽象;
使用虚拟DOM可以避免频繁的操作真实DOM引发的重绘和回流,页面的操作先全部反映到虚拟DOM上,等操作完成之后,再映射成真实的DOM,提升性能;虚拟DOM以JavaScript对象为基础,可以不依赖平台环境,从而实现跨平台的能力
先看一下Vue的渲染过程
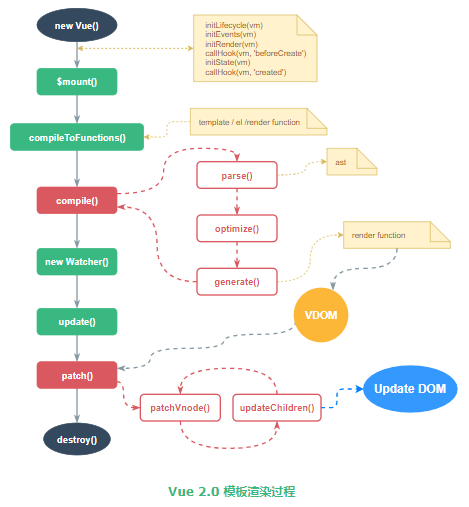
图片来自Vue2.0 源码阅读:模板渲染
从上图中可以看到,Vue模板在$mount方法之后使用compile方法进行编译并生成render function;通过render function生成虚拟DOM,虚拟DOM通过patch方法来更新DOM
在模拟虚拟DOM之前先模拟一个render function,运行render function之后得到与之相应的vNode
createElement('div',
{id: 'container', class: 'warp'},
[
createTextVnode('模拟实现'),
createElement('p', {style: {color: red}}, [createTextVnode('虚拟DOM')])
]
)
现在已经有了一段简单的render function字符串;接下来需要要实现createElement方法和createTextVnode方法,通过这两个方法的执行将上面的render function转换成vNode
/**
* element.js
*/
// 创建元素节点虚拟DOM
createElement(tag, props, children) {
let key
if (props.key) { // 如果节点存在key属性,则抽离出来,放入虚拟DOM对象中
key = props.key
delete props.key
}
return new Element(tag, props, key, children)
}
// 用于创建文本虚拟DOM
createTextVnode(str) {
// 文本节点没有标签, 属性, 子节点
return new Element(undefined, undefined, undefined, undefined, str)
}
// 用于描述虚拟DOM的类
class Element {
constructor(tag, props, key, children, text) {
this.tag = tag // 节点名称
this.props = props // 节点的属性集
this.key = key // 节点key
this.children = children // 节点下的子节点
ths.text = text // 文本节点的文本内容
}
}
现在使用element.js创建的方法来调用之前的render function
let vNode = createElement('div',
{id: 'container', class: 'warp'},
[
createTextVnode('模拟实现'),
createElement('p', {style: {color: red}}, [createTextVnode('虚拟DOM')])
]
)
console.log('vNode', vNode)
到浏览器中看一下运行的结果
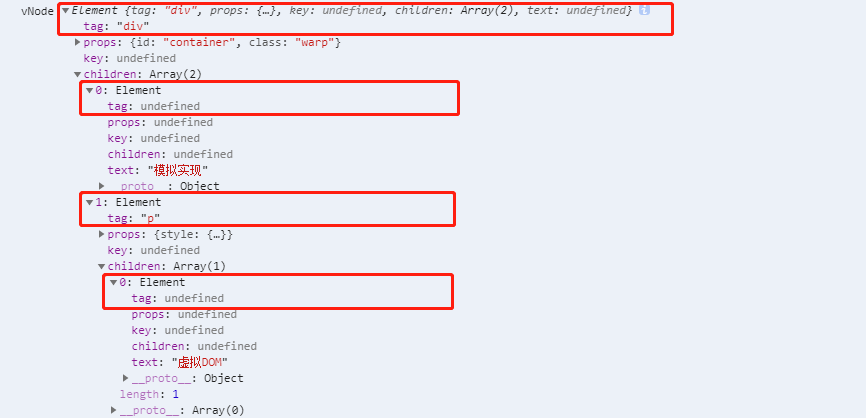
可以看到,函数执行后,各个节点都变成了vNode;因为vNode并不是真实DOM,所以页面上并不会有任何元素,接下来要做的就是将vNode转换成真实DOM并渲染到页面上
下面来实现一个render方法,将vNode转换成真实DOM然后渲染到节点上
/**
* render.js
*/
function render(vNode, container) {
let ele = createElementDom(vNode)
container.appendChild(ele)
}
// 使用vNode创建真实DOM,并返回这个DOM
function createElementDom(vNode) {
let { tag, props, key, children, text } = vNode
if (tag) {
vNode.domElement = document.createElement(tag)
updateProps(vNode)
children.forEach(child => {
render(child, vNode.domElement)
})
} else {
vNode.domElement = document.createTextNode(text)
}
return vNode.domElement
}
// 更新DOM属性
function updateProps(vNode) {
let { props, domElement } = vNode
for (let key in props) {
setDomAttribute(domElement, key, props[key])
}
}
// 设置DOM属性
setDomAttribute(element, key, value) {
switch(key) {
case 'style':
for (let style in value) {
element.style[style] = value
}
break;
default:
element.setAttribute(key, value)
}
}
上面的代码主要做了以下几件事情:
render方法,它接受一个vNode和一个DOM元素节点作为参数,主要作用是将vNode转换成真实DOM并渲染到指定的节点上createElementDom方法的主要作用是根据节点类型创建真实的DOM节点updateProps方法用于更新createElementDom方法创建的DOM节点的属性setDomAttribute方法用于不同属性的设置,在上面的代码中仅对style属性做了特殊处理,其他特殊属性(如事件绑定)也应该在这个方法中进行特殊处理接下来就在一个demo中调用以下上面封装的方法,看一下从render function到真实DOM渲染的过程
<!-- index.html -->
<div id="app"></div>
<!-- index.js -->
let vNode = createElement('div',
{id: 'container', class: 'warp'},
[
createTextVnode('模拟实现'),
createElement('p', {style: {color: 'red'}, class: 'content'}, [createTextVnode('虚拟DOM')])
]
)
console.log('vNode', vNode)
render(vNode, app)
到浏览器中看看效果

各个节点都渲染到了页面中,并且相关的属性也都正确的设置了;到这里就已经成功模拟了虚拟DOM从生成到渲染的全过程;
本文的源代码我已经提交到我的GitHub,欢迎大佬们拍砖
end
JavaScript 是一种弱类型语言,变量再在定义时并不会指定其类型,变量可以定义为任意类型的值;
除了日常的手动类型转换外,JavaScript 编译器在编译过程中会根据需要自动进行类型转换
一般将手动的类型转换叫做显示类型转换,而那些编译器自动进行的转换叫做隐式类型转换
Number 函数可以将任意类型的值转换为数值,Number 函数在转换过程中会根据不同的参数类型采用不同的转换规则
// Boolean转换换为number
Number(true) // 1
Number(false) // 0
// Null和Undefined转换为number
Number(null) // 0
Number(undefined) // NaN
// String转换为number
string转number的情况要相对复杂一些,总体规则如下:
1. 只包含数字(包含正负号和浮点数)的字符串,转出为十进制的数值
2. 对于包含其他字符(比如:英文)的字符串,则转换为NaN
3. 空字符串,制表符,空格,换行符统一转换为0
Number('000000.25') // 0.25
Number('0002523') // 2523
Number('-25') // -25
Number('25+25') // NaN
Number('12a') // NaN
Number('\n') // 0
// 对象转number
先调用对象的toString()方法,然后调用字符串转数字的规则
parseInt 函数接收两个参数,第一个参数是待转换的字符串,如果不是字符串,则会自动调用 toString 方法转为字符串,第二个参数为转换时使用的基数,即多少进制,默认为 10 进制
parseFloat 函数与 parseInt 函数的转换规则基本类似,不同的是可以解析浮点数,并且只有一个参数
Boolean 函数可以将任意类型的值转换为布尔值
Boolean 函数的转换规则相对简单,除了以下几个特定的值以外,其他的值转换后全部为 true
Boolean('') // 空字符串
Boolean(0) // 数字0
Boolean(null) // null
Boolean(undefined) // undefined
Boolean(NaN) // NaN
Boolean(false) // 布尔值false
包含空对象在内的所有对象转换为布尔值时都为 true,甚至连 false 对应的布尔对象都为 true
Boolean({}) // true
Boolean([]) // true
Boolean(new Boolean(false)) // true
String 函数可以将任意类型的值转换为字符串
数值类型则直接转换成相应的数字字符串
布尔类型,true 转换为‘true’,false 转换为‘false’
undefined 转换为‘undefined’
null 转换为 null
String(123) // '123'
String(true) // 'true'
String(false) // 'false'
String(undefined) // 'undefined'
String(null) // 'null'
先调用对象的 toString()方法,如果返回基本类型值,则对该值使用 String()方法;
如果 toString()方法返回的是对象类型的值,则调用原对象的 valueOf()方法;
如果 valueOf()方法返回基本类型的值,则对该值调用 String()方法;
如果 valueOf()方法返回对象,则报错
String([1,2,3]) // "1,2,3"
String({name: 'smile'}) // "[object Object]"
隐式类型的转换时相对于显示类型转换而言的,是指 JavaScript 编译器根据类型需要自动调用相应的转换函数
不同数据类型的运算
console.log(1 + '') // '1'
对非布尔值类型的数据求布尔值
if (123) {
console.log('smile')
}
对非数值类型的数据使用一元运算符
console.log(+'123') // 123
console.log(+[1, 2]) // NaN
if 语句的条件部分
if ('a') {
console.log('1111')
}
三目运算
'text' ? true : false
逻辑非操作符
!'a'
在这些情况下,编译器都会自动调用 Boolean 函数,因此,和显示类型转换一样,除了以下特定的几个值以外,其他的都为 true
null
undefined
0
''
NaN
字符串的自动转换主要发生在字符串的加法运算时,当一个值为字符串,另一个值为非字符串时,会自动将后一个值转换为字符串
字符串转换的规则为:先将对象类型的值转为基本类型的值,再将基本类型的值转为字符串
'' + true // 'true'
'' + false // 'false'
'' + 1 // '1'
'' + [] // ''
'' + {} // '[object Object]'
'' + function () {} // 'function () {}'
'' + undefined // 'undefined'
'' + null // 'null'
Number 值的自动转换主要发生在使用算术运算符进行运算的时候,除加号运算符(+)有可能将值转换成字符串外,其他的运算符都会将两侧的运算子自动转换为 Number 值
'6' - '3' // 3
'6' - 3 // 3
'6' * '3' // 18
'6' / '3' // 2
'6' % '3' // 0
true - 1 // 0
false - 1 // -1
6 * [] // 0
false / '5' // 0
null + 6 // 6
undefined + 6 // NaN
除上述算术运运算符外,一元运算符也会自动将运算子转换为 Number 值
+'abc' // NaN
+'11' // 11
-'55' // -55
-null // -0
-undefined // NaN
end
逻辑运算符可以将多个关系表达式组合起来形成一个更复杂的表达式;JavaScript 中常见的逻辑操作符主要为:逻辑与(&&),逻辑或(||),逻辑非(!)
逻辑与(&&)操作符主要包含三层含义
如果操作符的两边都是布尔值,只有当两个值都是 true 的时候,结果才为 true,否则为 false
true && true // true
false && false // false
true && false // false
如果某个操作数不为布尔值,则不一定返回布尔值;如果两个操作数均为真值,则返回后一个真值;如果其中一个为假值,则返回假值
'testString' && 'testString1' // 'testString1'
'testString' && '' // ''
null && 'testString' // null
0 && 'testString' // 0
undefined && 'testString' // undefined
逻辑与操作是一种短路操作,也就是说当第一个操作数就能决定结果的时候,将不会对第二个操作数求值;
if (a == b) {
fun()
}
// 等同于
(a == b) && func() // 如果a == b为false,则函数不会执行
逻辑或操作符与逻辑与操作符含义相似,但是功能却相反,它遵循以下规则:
如果操作数都是布尔值,只有当两个操作数都是false的时候才返回false
false || false // false
true || false // true
false || true // true
true || true // true
如果操作数中的某一个不为布尔值,则不一定返回布尔值;具体规则如下:
如果第一个操作数为真值,则返回第一个操作数;
如果第一个操作数为假值,则返回第二个操作数(此时,不论第二个操作是否是真值,都会被返回)
'test' || 'test1' // 'test'
'test' || null // 'test'
null || 'test' // 'test'
undefined || 'test' // 'test'
与逻辑与操作符一样,逻辑或操作符也是一种短路操作符;当第一个操作数的求职结果为true时,将不会对第二个操作数进行求值
逻辑非操作符只有一个操作数,适用于所有的JS数据类型;逻辑非操作符会先将操作数强制转换为布尔值(数据类型转换可以参考这篇文章),然后再对这个布尔值求反
!{} // false
!'' // true
!false // true
!NaN // true
!undefined // true
!'test' // false
!1 // false
end
基本数据类型:String,Number,Boolean,null,undefined,symbol
引用数据类型:Object
基本类型中的特殊类型:symbol,null,undefined
ES6新增的基本数据类型,表示独一无二的值,Symbol值需要调用Symbol函数生成;
let symbol = Symbol()
console.log(typeof symbol) // Symbol
因为生成的Symbol是一种基本类型数据,不是对象,所以不能使用new操作符并且不能添加属性
表示一个空值,指向一个空的对象指针,所以使用typeof来检测null时会得到object
表示一个值为空,变量声明但未赋值时默认为undefined
typeof操作符返回一个字符串,表示未经计算的操作数的类型;通过typeof操作符可以检测变量的数据类型
typeof 1 // number
typeof 'str' // string
typeof true // boolean
typeof Symbol() // symbol
typeof undefined // undefined
typeof null // object
typeof [1,2] // object
typeof {name: 'smile'} // object
typeof function (){} // function
typeof操作符只能检测基本数据类型,对于引用数据类型统一返回‘object’
instanceof运算符用于检测构造函数的prototype属性是否出现在实例对象的原型链上;通过instanceof运算符,可以检测一个对象是不是由某个指定的构造函数所创建的
语法
object instanceof constructor
// object 是待检测类型的对象
// constructor 是定义类的构造函数
如果object继承自constructor.prototype则返回true;
instanceof运算符的核心是检测对象的继承关系,举个例子:
function Foo(){}
Foo.prototype = new Bar()
let foo = new Foo()
console.log(foo instanceof Foo) // true
console.log(foo instanceof Bar) // true
在上面的代码中,变量foo直接继承自构造函数Foo,构造函数Foo又继承自构造函数Bar,因为变量foo和构造函数Bar形成了间接继承,所以第二条console语句也会得到true;
关于instanceof运算符的核心原理可以参考这篇文章:JS 系列四:深入剖析 instanceof 运算符
先看MDN中对这个方法的描述
每个对象都有一个 toString() 方法,当该对象被表示为一个文本值时,或者一个对象以预期的字符串方式引用时自动调用。默认情况下,toString() 方法被每个 Object 对象继承。如果此方法在自定义对象中未被覆盖,toString() 返回 "[object type]",其中 type 是对象的类型。
通过上面的描述可以知道,每个对象都会继承toString方法,这个方法会返回如"[object type]"格式的字符串,type就是对象的数据类型;看个例子
console.log(Object.prototype.toString.call(1)) // [object Number]
console.log(Object.prototype.toString.call('str')) // [object String]
console.log(Object.prototype.toString.call(true)) // [object Boolean]
console.log(Object.prototype.toString.call(undefined)) // [object Undefined]
console.log(Object.prototype.toString.call(null)) // [object Null]
console.log(Object.prototype.toString.call(Symbol())) // [object Symbol]
console.log(Object.prototype.toString.call({name: 'smile'})) // [object Object]
console.log(Object.prototype.toString.call([1,2])) // [object Array]
console.log(Object.prototype.toString.call(function (){})) // [object Function]
从上面的代码可以看到Object.prototype.toString返回的字符串中,type准确的表示了各个数据的类型;
这里与typeof不同的是null不再返回object,而是直接返回了null类型;同时type的首字母也采用了大写形式;
因为Object.prototype.toString方法返回的是格式统一的字符串,所以可以采用字符串的slice方法去除冗余的字符
let type = Object.prototype.toString.call(obj).slice(8, -1)
封装方法主要使用typeof和Object.prototype.toString来实现;typeof可以检测到null以外的基本类型和引用类型中的Function类型,Object.prototype.toString可以检测到所有的数据类型,将这两种方式结合起来就能封装出一个能检测到所有数据类型的方法
/**
* obj 需要检测的数据
*/
function checkType (obj) {
return typeof obj !== 'object' ? typeof obj : Object.prototype.toString.call(obj).slice(8, -1).toLowerCase()
}
方法解析:先通过typeof检测出除null以外的基本类型和引用类型function,对于null和其他引用类型则使用Object.prototype.toString方法,为了保证输出一致,使用slice方法取出类型字符串然后全部转换为小写
end
webpack是一个非常实用的静态模块打包工具,它通过递归的方式构建一个包含应用程序需要的所有模块的依赖图,然后将这些文件打包成一个或多个bundle输出
早期的开发中都是将各种静态文件(比如图片,CSS等)手动引入到html中,然后直接在浏览器中运行html文件;在这个时期,遇到大型项目时要么将所有的JS全部写在一个文件中,要么是引入多个脚本;前一种方式会导致代码混乱;后一种方式会导致HTTP请求过多;
随着前端技术的发展,开始使用模块化对代码进行分割,让代码能够复用且更方便维护,但浏览器对模块化的支持并不统一;
webpack最核心的功能就是解决模块之间的依赖问题,通过对webpack的简单配置即可完成代码转换,压缩,文件优化,模块加载及打包等功能
npm install webpack webpack-cli -D
entry用于告诉webpack应该使用哪个模块做为构建的开始;其默认值为./src/index.js
module.exports = {
entry: './src/main.js'
}
output指定了webpack构建完成后的文件输出位置以及输出后的文件名等信息;
const path = require('path') // nodeJs内置的path模块
module.exports = {
entry: './src/main.js',
output: {
filename: 'main.[hash].js', // 输出文件的文件名
path: path.resolve(__dirname, 'dist')
// path属性用于指定输出的文件路径,它必须接收绝对路径
// path.resolve()方法用于将相对路径转换成绝对路径
}
}
[hash]: [hash]用于解决静态文件缓存问题;静态文件内容更改而文件名不更改的情况下,可能会因为浏览器缓存问题而获取不到新的内容,通过hash可以让每一次打包的文件名不重复
webpack会根据配置模式自动调用相应的内置优化项; 可选的配置模式有development, production, none, 默认值为production
配置模式可以在webpack的配置文件中显式的指定
module.exports = {
mode: 'development'
}
在实际的项目开发中,更多的是通过脚本的方式执行CLI,通过CLI的参数传递
<!-- package.json -->
"scripts": {
"build": "webpack --mode=production",
"dev": "webpack-dev-server --mode=development"
}
loader用于对模块中的源代码进行转换,webpack本质上只能理解JavaScript和JSON文件,如果要解析其他代码就需要对代码进行转换,比如将typeScript代码转换成javascript代码;
test: 使用正则筛选出需要使用loader的文件use: 转换时需要使用的loader,可以同时使用多个loader;通过对象的方式可以对loader进行个性化的配置include: 指定loader必须要应用的文件夹exclude: 指定loader需要排除不处理的文件夹loader的执行顺序是从下往上,从右往左;也就是说,在代码中越靠后的loader越先执行;在下面的例子中,css-loader比style-loader先执行
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader', ''css-loader]
}
]
}
}
webpack的插件系统,通过插件可以扩展webpack的功能
webpack解析时默认从webpack.config.js文件提取配置,所以将webpack的相关配置都写到这个文件中
<!-- webpack.config.js -->
const path = require('path')
module.exports = {
entry: './main.js',
output: {
filename: 'index.js',
path: path.resolve(_dirname, 'dist')
}
}
以上就是一个最基础的webpack配置,以当前(webpack.config.js所在的目录)目录下的main.js为入口开始构建,输出到当前目录下的dist文件夹中;
在单页面应用开发中都需要使用一个html文件作为模板;html-webpack-plugin用于指定一个html文件作为模板,并以这个模板为基础引入打包后的js,css等文件,然后根据output的配置输出
安装
npm install html-webpack-plugin -D
配置
<!-- webpack.config.js -->
let HtmlWebpackPlugin = require('html-webpack-plugin')
module.exports = {
// 省略其他代码
plugins: [
template: './index.html', // 指定模板文件路径
filename: 'index.html', // 指定打包后输出的模板文件名
minify: { // 指定模板压缩的规则
removeAttributeQuotes: true, // 删除属性的双引号
collapseWhitespace: true, // 折叠空行
},
hash: true, // 添加hash戳,hash可以避免缓存问题
]
}
在上面的配置中,指定了模板的路径(template)以及打包完成后输出的文件名称(filename), 同时指定了模板文件的压缩规则(minify), 为解决缓存问题添加了hash戳,输出的模板文件都会带上hash值;更多html-webpack-plugin的配置可以参考官方文档
webpack-dev-server提供了一个本地的web开发服务和热更新的能力;通过这个本地server直接访问应用可以更好的开发和调试
安装
npm install webpack-dev-server -D
配置
module.exports = {
devServer: {
port: '8080', // 开发服务端口
host: 'localhost',
progress: true, // 配置打包进度条
contentBase: './dist', // 指定静态服务的启动文件夹
}
}
在package.json文件中配置一个脚本,
<!-- package.json -->
"scripts": {
"dev": "webpack-dev-server --mode=development"
}
此时通过npm run dev就可以启动一个本地开发服务了;更多关于webpack-dev-server的配置可以参考官方文档
webpack中css的解析主要依赖两个loader来完成:css-loader,style-loader
css-loader主要负责解析@import和url()
style-loader的主要作用是将css通过style标签的方式添加到模板文件中
安装
npm install style-loader css-loader -D
配置
<!-- webpack.config.js -->
module.exports = {
// 省略其他代码
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader', 'css-loader']
}
]
}
}
因为需要先解析css中的@import和url()语法,所以css-loader应该写style-loader之后
less和sass的解析依赖于less-loader和 sass-loader;
使用这两个loader之前需要安装less和sass模块
安装
npm install less less-loader node-sass sass-loader -D
配置
<!-- webpack.config.js -->
module.exports = {
// 省略其他代码
module: {
rules: [
{
test: /\.less/,
use: ['style-loader', 'css-loader', 'less-loader']
},
{
test: /\.scss/,
use: [
'style-loader',
'css-loader',
{
loader: 'sass-loader',
options: {}
}
]
}
]
}
}
个性化loader配置: 在上面的配置中,scss-loader使用了对象语法进行配置,这种方式可以通过options对象来对loader进行更多个性化的配置
由于浏览器对css新属性的兼容性不统一,所以一些新的css属性在使用的时候需要为不同的浏览器加上前缀
autoprefixer通过postcss配置后可以为自动为css添加不同浏览器的前缀
安装
npm install autoprefixer postcss-loader -D
配置
<!-- webpack.config.js -->
module.exports = {
// 省略其他代码
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader','postcss-loader' 'css-loader']
}
]
}
}
接下来还需要通过postCSS配置autoprefixer才能自动添加前缀
<!-- postcss.config.js -->
const autoprefixer = require('autoprefixer')
module.exports = {
plugins: [autoprefixer]
}
通过前面的配置,已经可以解析css并且将css通过style标签的形式插入到模板中; 但是如果css内容过多,则会让模板文件中的css显得臃肿,这个时候就需要将css单独抽离出一个文件,以link的方式引入模板
mini-css-extract-plugin插件用于将CSS提取到单独的文件中
安装
npm install mini-css-extract-plugin -D
配置
const MiniCssExtractPlugin = require('mini-css-extract-plugin')
module.exports = {
// 省略其他代码
plugin: [
new MiniCssExtractPlugin({
filename: 'css/index.css'
})
]
}
filename: 抽离之后的css文件名称,如果使用路径的方式则会将文件抽离到指定的路径下,以上面的代码为例,index.css会抽离到./dist/css/index.css
使用mini-css-extract-plugin插件之后,css将会抽离成单独的文件,所以需要使用MiniCssExtractPlugin.loader替换原有的style-loader
const MiniCssExtractPlugin = require('mini-css-extract-plugin')
module.exports = {
// 省略其他代码
plugin: [
new MiniCssExtractPlugin({
filename: 'index.css' // 抽离后的css文件名
})
],
module: {
rules: [
{
test: /\.css$/,
use: [MiniCssExtractPlugin.loader, 'css-loader']
}
]
}
}
由于浏览器对新的ES语法支持并不是一致,为了保证代码的兼容性,需要将新的ES语法(ES6,ES7,ES8等)转换为浏览器都支持ES5语法;在webpack中,这个转换的功能主要通过babel来完成
安装
npm install babel-loader @babel/core @babel/preset-env -D
配置
module.exports = {
// 省略其他代码
rules: [
{
test: '/\.js$/',
use: {
loader: 'babel-loader',
options: {
presets: [
'@babel/preset-env'
]
}
},
include: path.resolve(__dirname, 'src'), // 希望应用的文件夹
exclude: /node_modules/ // 需要排除的文件夹
}}
]
}
webpack中的文件压缩通过配置optimization来完成
module.exports = {
// 省略其他代码
optimization: [
]
}
optimize-css-assets-webpack-plugin插件可以用于css文件的压缩
安装
npm install optimize-css-assets-webpack-plugin -D
配置
const OptimizeCss = require('optimize-css-assets-webpack-plugin')
module.exports = {
// 省略其他代码
optimization: [
new OptimizeCss()
]
}
uglifyjs-webpack-plugin插件用于JS文件的压缩
安装
npm install uglifyjs-webpack-plugin -D
配置
const UglifyJsPlugin = require('uglifyjs-webpack-plugin')
module.exports = {
// 省略其他代码
optimization: [
new UglifyJsPlugin({
parallel: true
})
]
}
webpack中的图片配置可以使用url-loader来完成,url-loader与file-loader功能相似;但是它可以在图片大小低于指定的限制时,将图片转换为base64格式,以此减少HTTP请求
安装
npm install url-loader -D
配置
module.exports = {
// 省略其他代码
module: {
rules: [
{
test: /\.(png|jpg|gif)$/,
use: [
{
loader: 'url-loader',
options: {
limit: 10240, // 单位为字节
outputPath: 'img/'
}
}
]
}
]
}
}
outputPath: 指定图片输出路径,已上面的配置为例,图片文件将输出到./dist/img/目录下
当下前端开发的主流框架都是以数据驱动的,很少去操作DOM;但是如果项目业务特殊需要用到jQuery的话,为了避免每一次使用的时候都通过import去引入,可以使用webpack配置一个全局变量
webpack全局变量的配置主要使用webpack的内置模块(内置模块不需要通过npm安装,直接使用即可)ProvidePlugin来完成,详细内容可以参考官方文档
配置
npm install jquery
module.exports = {
// 省略其他代码
plugins: [
new webpack.ProvidePlugin({
$: "jquery"
})
]
}
为了避免多次打包后输出目录混乱(举例:每次打包都输出一个名称带hash的文件,多次打包后就会产生多个文件在同一个目录中,但是只有最后一次输出的文件才有用)的问题,可以通过clean-webpack-plugin插件,在每一次打包的时候都将输出目录清空,这样,每一次打包后的输出文件夹中都会比较干净
安装
npm install clean-webpack-plugin -D
配置
const CleanWebpackPlugin = require('clean-webpack-plugin')
module.exports = {
// 省略其他代码
plugins: [
new CleanWebpackPlugin()
]
}
本文主要了解了webpack中的一些核心概念并介绍了一些常用配置所需要的插件,loader等,通过这些配置就已经可以满足多数场景的基本开发需求了
本文所对应的配置源码已提交到我的github
end
自从网站,web等诞生开始,路由就一直存在;在前后端分离之前,一般提到的路由都是后端路由;路由通过一个请求,然后分发到指定的路径,匹配对应的处理程序;它的作用就是分发请求,把对应的请求分发到对应的位置
后端路由可以理解为服务器将浏览器请求的url解析之后映射成对应的函数,这个函数会根据资源类型的不同进行不同的操作,如果是静态资源,那么就进行文件读取,如果是动态数据,那么就会通过数据库进行一些增删查改的操作
后端路由的优点是利于SEO且安全性较高;缺点就是代码耦合度高,加大了服务器压力,且http请求受限于网络环境,影响用户体验
随着前端单页应用(SPA)的兴起,前端页面完全变成了组件化,不同的页面就是不同的组件,页面的切换就是组件的切换;页面切换的时候不需要再通过http请求,直接通过JS解析url地址,然后找到对应的组件进行渲染
前端路由与后端路由最大的不同就是不需要再经过服务器,直接在浏览器下通过JS解析页面之后就可以拿到相应的页面
前端路由的优点就是组件切换不需要发送http请求,切换跳转快,用户体验好;缺点就是没有合理的利用缓存且不利于SEO
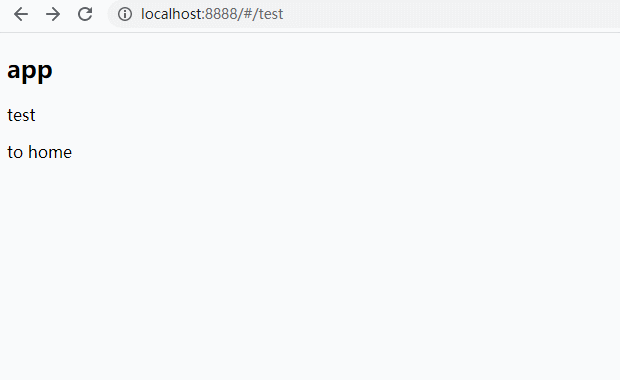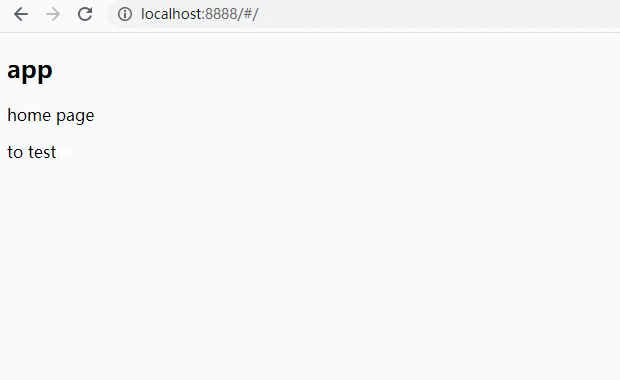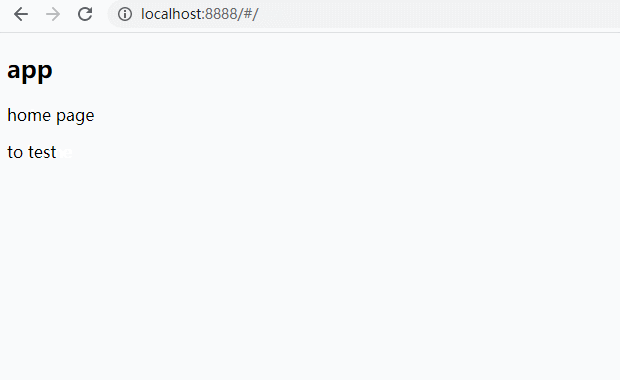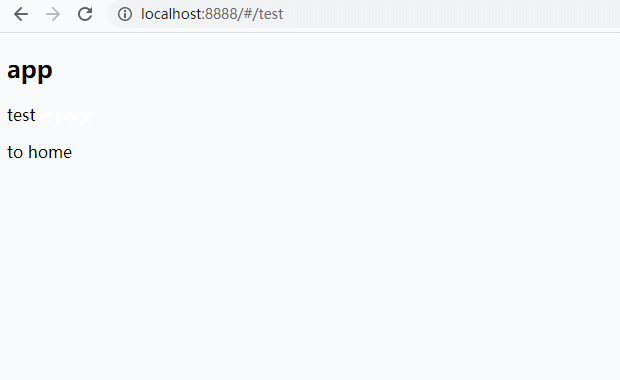
hash模式是vue-router的默认路由模式,它的标志是在域名之后带有一个#
http://localhost:8888/#/home
通过window.location.hash获取到当前url的hash;hash模式下通过hashchange方法可以监听url中hash的变化
window.addEventListener("hashchange", function(){}, false)
hash模式的特点是兼容性更好,并且hash的变化会在浏览器的history中增加一条记录,可以实现浏览器的前进和后退功能;
缺点由于多了一个#,所以url整体上不够美观
history模式是另一种前端路由模式,它基于HTML5的history对象
通过location.pathname获取到当前url的路由地址;history模式下,通过pushState和replaceState方法可以修改url地址,结合popstate方法监听url中路由的变化
history模式的特点是实现更加方便,可读性更强,同时因为没有了#,url也更加美观;
它的劣势也比较明显,当用户刷新或直接输入地址时会向服务器发送一个请求,所以history模式需要服务端同学进行支持,将路由都重定向到根路由
Vue.use()方法用于插件安装,通过它可以将一些功能或API入侵到Vue内部;
它接收一个参数,如果这个参数有install方法,那么Vue.use()会执行这个install方法,如果接收到的参数是一个函数,那么这个函数会作为install方法被执行
install方法在执行的时候也会接收到一个参数,这个参数就是当前Vue的实例
通过接收到的Vue实例,可以定义一些全局方法或属性,也可以通过prototype对Vue的实例方法进行扩展
class vueRouter {
constructor(){
}
}
vueRouter.install = function(Vue) {
}
Vue.mixin()方法用于注册全局混入,它接收一个对象作为参数,我们将这个对象称为混入对象;混入对象可以包含组件的任意选项;通过混入对象定义的属性和方法在每一个组件中都可以访问到
<!-- router.js -->
class vueRouter {
constructor(){
}
}
vueRouter.install = function(Vue) {
Vue.mixin({
data(){
return {
name: '阿白smile'
}
}
})
}
<!-- home.vue -->
// 省略代码
<script>
export default {
created(){
console.log(name) // '阿白smile'
}
}
</script>
通过前面的前置知识,已经对路由有了一些了解,接下来就开始实现一个routerJs
先来看一下vue-router的使用方法,然后再基于此进行一步一步的拆解分析
<!-- index.js -->
import vueRouter from './router'
import App from 'app.vue'
Vue.use(vueRouter)
const router = new vueRouter({
routes: []
})
new Vue({
router,
render: h => h(App)
})
在上面的使用示例中可以看出,通过Vue.use()方法将vueRouter安装为插件;通过插件的安装即可以在全局使用vueRouter的方法及相关组件;
首先需要先实现install方法,通过install向全局注入vueRouter
<!-- router.js -->
class vueRouter {
constructor(){}
}
vueRouter.install = function(Vue) {
Vue.mixin({
beforeCreate(){
// $options.router存在则表示是根组件
if (this.$options && this.$options.router) {
this._root = this
this._router = this.$options.router
Vue.util.defineReactive(this, 'current', this._router.history)
} else {
// 不是根组件则从父组件中获取
this._root = this.$parent._root
}
// 使用$router代理对this._root._router的访问
Object.defineProperty(this, '$router', {
get() {
return this._root._router
}
})
}
})
}
install方法接收一个Vue实例作为参数,通过Vue.mixin()全局混入beforeCreated生命周期钩子;通过Vue实例暴露的工具方法defineReactive将current属性变成一个监视者
为了避免在使用过程中对_router的修改,所以通过Object.defineProperty设置一个只读属性$router,并使用它代理对this._root._router的访问
vue-router在初始化的时候需要通过new操作符,所以需要提供一个vueRouter类并暴露给外部使用;同时还需要一个history类来保存当前的路由路径
class HistoryRoute {
constructor() {
this.current = null
}
}
class vueRouter {
// options 为初始化时的参数
constructor(options) {
this.mode = options.mode || 'hash'
this.routes = options.routes || []
this.history = new HistoryRoute
this.init()
}
init() {
if (this.mode === 'hash') {
// 初始化一个#
location.hash ? '' : location.hash = '/'
// 页面加载完成获取当前路由
window.addEventListener('load', () => {
this.history.current = location.hash.slice(1)
})
window.addEventListener('hashchange', () => {
this.history.current = location.hash.slice(1)
})
} else {
window.addEventListener('load', () => {
this.history.current = location.pathname
})
window.addEventListener('popstate', () => {
this.history.current = location.pathname
})
}
}
}
export default vueRouter
在上面的代码中,创建一个HistoryRoute类,HistoryRoute类current属性储存当前路由,在install方法会让这个值实现可响应并监视它的变化,并根据它的变化渲染不同的组件
vueRouter在实例化时接收到一个options对象作为初始化的参数,options中指定了路由模式(mode)和路由表(routes);如果options中没有指定mode和routes,则mode默认为hash模式,routes默认为[]
init方法会根据不同的路由模式在页面加载完成后设置current,同时还会为路由的变化添加事件监听,确保及时更新current属性然后渲染组件
router-view组件的实现依赖于Vue.component()方法,通过这个方法向全局注册一个组件,需要注意的是Vue的全局组件注册需要在Vue实例化之前进行;
Vue.component方法接收两个参数,第一个是组件的名称,另一个是组件的选项对象;
router-view组件的作用是根据路由的变化渲染出路由所对应的组件,所以在注册时候主要是使用到选项对象中的render函数
Vue.component('router-view', {
render(h) {
}
})
接下来就需要实现router-view组件最重要的功能,如何找到需要渲染的组件?
可以知道的是,当路由变化的时候可以获取到最新的路由地址,同时也可以访问到routes(路由表)的数据
所以只需要根据路由地址从路由表中拿到相应的组件然后交给render函数执行就可以了
根据路由从路由表中获取组件有两种方式:
一种是路由每次变化的时候都是用find方法从路由表中查询一次,获取到路由对象,这种方式虽然可行,但是每次路有变化都去查询一次性能消耗太大;
另一种方式则是将路由与它所对应的组件以键值对的方式进行储存,路由变化的时候只需要根据路由地址进行查询即可;这种方式只需要遍历一次,路由变化时直接使用键值对的方式获取组件,能够非常有效的提高渲染速度
class vueRouter {
constructor(options) {
// 省略其他代码
this.routes = options.routes || []
this.routeMap = this.createMap(this.routes)
}
// 省略其他代码
createMap(routes) {
return routes.reduce((memo, current) => {
memo[current.path] = current.component
return memo
}, {})
}
}
至此,所有的路由都已经使用键值对的方式存入routeMap中,接下来就可以使用render函数进行组件渲染了
vueRouter.install = function(_Vue) {
// 省略其他代码
Vue.component('router-view', {
render(h) {
let current = this._self._root._router.history.current // 当前路由
let routerMap = this._self._root._router.routeMap
return h(routerMap[current])
}
})
}
到这里,router-view组件就封装完成了,它可以在任何一个组件中使用,并根据路由的变化而渲染不同的组件
在vue-router中,无论是声明式的路由跳转还是编程式的路由跳转,都需要通过这两个方法参与来完成;
history模式下, 路由切换通过window.history.pushState方法完成;在hash模式下,路由的切换是直接通过hash值的变化来实现
pushState是H5引入的新方法,主要用于添加历史记录条目;
它接收三个参数,分别是状态对象,标题和URL;由于第二个参数(标题)在部分浏览器上会被忽略,所以在这里主要了解一下状态对象和URL
stateObj
状态对象,它会与历史记录条目相关联;popstate事件触发时,状态对象会传入回调函数;浏览器会将这个状态对象序列化以后保存在本地,重新载入这个页面的时候可以拿到这个对象
URL
新历史记录的URL,必须与当前页面处在同一个域;浏览器的地址栏会显示这个地址
class vueRouter {
constructor(options) {}
push(url) {
if (this.mode === 'hash') {
location.hash = url
} else {
pushState(url)
}
}
replace(url) {
if (this.mode === 'hash') {
location.hash = url
} else {
pushState(url, true)
}
}
}
function pushState(url, replace) {
const history = window.history
if (replace) {
history.replaceState({key: history.state.key}, '', url)
} else {
history.pushState({key: Date.now()}, '', url)
}
}
在上面的代码中,hash模式下直接通过location修改hash值,通过hash值的变化去改变视图组件,另外还封装了一个pushState方法统一负责history模式下的页面跳转,并通过一个replace参数判断使用哪种方式进行跳转;
router-link也是通过Vue.component()方法注册的一个全局组件
Vue.component('router-link', {
render(h) {
}
})
router-link接收一些props参数,这里列举几个常用的,全部参数可以查看官方文档
to: 目标路由地址
tag: 渲染的标签
replace: 使用replace方式进行路由跳转,不留下history记录
接下来开始实现一个简单router-link组件
Vue.component('router-link', {
props: {
to: {
type: [Object, String],
required: true
},
tag: {
type: String,
default: 'a'
},
replace: Boolean
},
render(h) {
let data = {}
if (this.tag === 'a') {
data.attrs = {href: this.to}
} else {
data.on = {click: () => {
if (this.replace) {
this._self._root._router.replace(this.to)
} else {
this._self._root._router.push(this.to)
}
}}
}
return h(this.tag, data, this.$slots.default)
}
})
router-link组件通过参数to设置目标路由,tag参数负责组件在页面上渲染的标签,默认为a标签,replace参数则负责控制在路由跳转时是否使用replace方法
在render函数中根据不同的tag进行不同的数据拼接,在改变路由时,默认的a标签可以直接设置href属性,而其他标签则需要监听事件,然后使用router的路由跳转方法进行路由切换
到此就已经实现了vue-router的核心的路由监听,跳转,切换,组件渲染等功能,先到浏览器中看一下效果
本文从路由的起源开始说起,到前后端路由的区别及优缺点,然后介绍了vue-router的工作流程并实现了vue-router中一些核心的方法及其原理
文章中涉及到的源码已提交到我的Github
End
JavaScript中的变量是松散的,他只是一个用来保存值的占位符,被保存的值可以是任意JavaScript类型
在JavaScript中,变量共有三种显示的声明方式:分别是:var,let,const(其中let和const为ES6新增)
var a = 0;
let b = 1;
const c = 2;
在ES6之前,使用一个变量之前通过var关键字来进行声明;他可以一次声明一个变量也可以一次声明多个变量,同时可以将变量的声明和赋值写在一起;如下:
var i; // 仅声明变量,不赋值
var sum = 5; // 声明变量的同时进行赋值
var j = 0, message = "hello"; // 同时声明多个变量并赋值
console.log(i) // undefined 变量赋值之前,他的值为undefined
如果在var的变量声明语句中没有给变量指定初始值,那么在给这个变量赋值之前,他的值都为undefined
var k;
console.lo(k); // undefined
k = 1;
console.log(k); // 1
如果使用var关键词重复声明了一个变量,则后声明变量会覆盖先声明的变量:如下
var num = 10;
console.log(num); // 10
var num = 20;
console.log(num); // 20
如果读取一个没有声明的变量,那么JavaScript会报错;
在严格模式中,给一个没有声明的变量赋值也会报错;但是在非严格模式中,如果给一个没有声明的变量赋值,实际上是创建了一个全局变量;
使用var关键词声明的变量存在变量提升,即在变量声明之前访问这个变量
upgrade = 2;
var upgrade;
console.log(upgrade); // 2
上面的这段代码,如果按照从上到下的执行顺序进行执行的话,那么这里的upgrade就应该为undefined,因为从顺序上看,他只是声明了,但是没有赋值;
但实际打印的结果是2,这里就牵扯到了变量提升,var语句被提升到了代码的顶部,所以实际的执行顺序应该是这样的:
var upgrade;
upgrade = 2;
console.log(upgrade);
这里的变量提升主要是因为JavaScript在编译阶段的时候搜集了所有的变量声明并且提前声明了变量;关于变量提升的具体细节,可以阅读这篇文章:JavaScript基础—变量提升与函数提升;
ES6中新增了let命令来声明变量,他与var的语法类似,不同的是let具有块级作用域,即let声明的变量仅在声明时所在的代码块内有效;
{
let text1 = '1',
var text2 = '2'
}
console.log(text2) // '2'
console.log(text1) // ReferenceError: text1 is not defined.
在上面的代码中,分别使用let和var声明了两个变量;但是当执行之后发现,var声明的变量正常执行,而let声明的变量则报错;从这个案例可以看出,let声明的变量仅在他声明时所在的代码块中有效;
let与var的另一个不同点就在于没有变量提升,即在变量声明之前使用变量会导致报错
console.log(text4) // undefined
console.log(text3) // ReferenceError
let text3 = '3'
var text4 = '4'
通过上面的代码可以看到,使用var声明的变量发生了变量提升,在代码开始运行时,变量text4就已经存在;但是再看let声明的text3,因为没有发生变量提升,在代码运行时该变量还不存在,所以导致了一个报错;
let的特点之一就是暂时性死区;暂时性死区是指在一个块级作用域内如果存在let命令,那么let所声明的变量就会绑定这个块级作用域,不会再受到外部的影响;看个例子:
var text5 = '5';
if(1){
console.log(text5) // ReferenceError
let text5;
}
在上面的代码中,我们通过var声明了一个全局变量text5,同时在块级作用域中使用let也声明了一个text5,此时通过let声明的text5绑定了块级作用域;
代码中console语句报错,就是因为块级作用域被let所声明的text5绑定,形成暂时性死区,所以此时全局的的text5在块级作用域中是不可用的;
let的另一个特点是不允许重复声明,这一点和var也不一样;看个例子:
function () {
let text6 = 6;
var text6 = 6;
}
上面的代码在编译阶段就会报错;
ES6中新增了const关键词,用来声明常量;常量一旦声明,其值就不能再改变,这也意味着,常量在声明的时候就必须赋值初始化;
'use strict'
const test = 12345;
test = 2135; // 报错
上面这段代码运行在严格模式中,更改常量的值会导致报错
const test1 = 12345;
test1 = 54321;
console.log(test1); // 12345
这段代码运行在非严格模式中,虽然更改常量的值不会报错,但是更改并不会生效
const与let的特点基本一致:
另外一个特点是针对引用类型的数据,const声明的引用类型变量,其变量名并不是直接指向数据,而是指向数据所在的地址;因为这个特性,所以对于const声明的引用类型数据,只要保证其变量地址不变,就可以更改其中的数据;看个例子:
const foo = {};
foo.num = 123;
console.log(foo.num) // 123
foo = {} // 报错
上面的代码中,foo储存的是一个对象的地址,而不是这个对象本身;因为对象本身是可写的,所以可以给foo添加属性;但是后来的赋值操作是直接更改foo储存的地址了,所以导致报错;
对于引用类型,变量名储存的是数据的地址而不是数据本身,所以可以为引用类型添加或修改属性,但不可以直接重写数据本身;
end
这篇文章主要了解vue是如何实现数据的响应式以及这种方式的优缺点并探索更好的响应式方式
在vue中,实现响应式的主要方式就是Object.defineProperty,关于Object.defineProperty的更多内容,可以参考MDN
下面看一下这个方法具体如何使用
/**
* obj 需要操作的目标对象
* key 需要操作的属性名称
* descriptor 将被定义或修改的属性描述符
*/
Object.defineProperty(obj, key, descriptor)
descriptor中有几个常用的属性和方法,分别看一下
configurable: 是否可配置,默认为false;只有当属性的可配置性为true时,才能对该属性进行修改和删除
enumerable: 是否可枚举,默认为false;只有当属性的可枚举性为true时,才能使用for..in和Object.keys()对这个属性进行遍历
get: 获取属性时将触发这个方法
set: 设置属性时将触发这个方法,接收这个属性的新的参数值作为参数
通过Object.defineProperty方法,当一个属性获取和设置的时候都会触发相应的拦截方法,所以接下来就要实现一个Observer类,让所有属性都变成响应式
Observer类接收一个对象作为需要操作的数据;之后关于Observer的所有方法都将是这个类的方法
/**
* 观察者
*/
class Observer {
constructor (data) {
this.data = data
}
}
接下来实现Observer类最核心的方法defineReactive,这个方法通过Object.defineProperty来实现属性的响应化;
它需要接收三个参数,分别是当前操作的对象(obj),当前操作的属性(key)以及当前操作属性的值(value)
defineReactive(obj, key, value) {
Object.defineProperty(obj, key, {
configurable: true, // 属性可以修改和删除
enumerable: true, // 属性可以通过for...in和Object.keys()遍历
get() {
// 获取属性时触发
return value
},
set(newVal) {
// 设置属性时触发
if (newVal != value) { // 如果新的值和旧的值一致,则没有设置的必要
value = new Val
}
}
})
}
因为需要让每一个属性都是响应式的,所以还需要实现一个observer方法,这个方法需要将实例中的data接收过来作为参数;它的主要功能是判断接收到的参数是否是对象,然后遍历对象中的每一个参数并将他们设置为可响应的
observer(data) {
if (data && type data === 'object') {
for (let key in data) {
this.defineReactive(data, key, data[key])
}
}
}
考虑到observer循环的时候,当前的value可能也是一个对象,所以在defineReactive方法中需要使用当前的value参数再次调用observer方法进行递归遍历;同时设置属性的时候也可能设置一个对象,所以在设置属性的时候也需要调用observer方法
defineReactive(obj, key, value) {
this.observer(value) // 如果value为object,则会遍历该对象的所有属性
Object.defineProperty(obj, key, {
configurable: true, // 属性可以修改和删除
enumerable: true, // 属性可以通过for...in和Object.keys()遍历
get() {
// 获取属性时触发
return value
},
set: (newVal) => { // 方法内部使用了this,保证指向正确
// 设置属性时触发
if (newVal != value) { // 如果新的值和旧的值一致,则没有设置的必要
this.observer(value) // 如果newVal为object,则遍历改对象下的所有属性
value = new Val
}
}
})
}
到这里,一个简单的Observer类旧封装完成了;只需要在Vue进行实例化的时候,将data作为参数传递给Observer类并将它实例化,就会将data中的数据全部变为响应式的
Object.defineProperty方法对数据进行劫持,完成数据的响应化,但它还是有一些缺陷;先来看一段代码
class Vue {
constructor(options) {
this.$el = options.el
this.$data = options.data
// 实现响应化
new Observer(this.$data)
console.log('新增前' this.$data) // 查看响应化之后的数据
this.$data.test = 'test'
console.log('新增后', this.$data) // 查看新增属性之后的数据
}
}
new Vue({
data: {
user: {
name: '阿白Smile',
age: 24,
sex: `<p>性别:男</p>`
},
location: '北京'
}
})
在浏览器中运行一下上面的代码
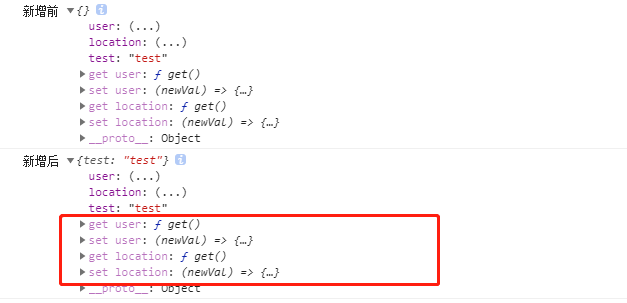
从上图中可以看到,在Vue实例化的时候作为参数传入的这些属性都是响应式的(都有get和set方法);但是我们可以发现,在实例化之后新增的属性却没有变成响应式
出现这个问题的主要原因是Object.defineProperty方法中的get和set只能拦截到属性的获取和设置操作,并不能拦截到属性的新增
所以,在vue3.0种,使用了ES6新增的构造函数Proxy进行数据响应化
Proxy是ES6原生提供的一个构造函数,用来生成proxy实例;先看一下MDN的描述:Proxy对象用于定义基本操作的自定义行为(如属性查找,赋值,枚举,函数调用等)
简单的来说,就是proxy在目标对象之前架设了一层拦截,外界对目标对象的访问都需要经过这层拦截
那么接下来就使用Proxy对Observer类进行一些改造
class Observer {
// 接收Vue实例作为参数,并Vue实例中的$data进行Proxy改造
constructor (data, vm) {
vm.$data = this.observer(data)
}
observer(data) {
if (data && typeof data === 'object') {
for (let key in data) {
data[key] = this.observer(data[key])
}
return this.defineReactive(data)
} else {
return data
}
}
defineReactive(obj) {
return new Proxy(obj, {
get(target, key) {
return target[key]
},
set: (target, key, value) => {
if (target[key] != value) {
console.log('set', key) // 设置属性时打印属性名
target[key] = this.observer(value) // 如果设置的属性是对象,则对其加上Proxy拦截
return true
}
}
})
}
}
通过上面的优化后,Vue实例中的data数据将变为使用data作为目标对象的Proxy实例,对data中数据的访问,修改和新增等都会经过Proxy实例的拦截,这样就是实现了一个非常简单的响应式,可以监听到所有数据的增删查改;现在把改造后的方法放到实例中去看一下
class Vue {
constructor(options) {
this.$el = options.el
this.$data = options.data
// 实现响应化
new Observer(this.$data, this)
this.$data.test = 'test' // 新增一个属性
}
}
new Vue({
data: {
user: {
name: '阿白Smile',
age: 24,
sex: `<p>性别:男</p>`
},
location: '北京'
}
})
在浏览器中运行查看一下

通过上图看到,经过Proxy改造后,Vue实例化之后新增的属性依然可以被拦截,解决了Object.defineProperty方法的缺陷
在上一篇文章中实现了简单的模板编译,本文主要了解了vue响应式系统的响应原理以及当前版本中响应式的缺陷,最后还探索了新的响应式方式;但是,数据的修改还不能让视图发生改变,所以在下一篇文章中将学习响应式系统的另一个重要部分——依赖收集
本文的源代码我已经提交到我的GitHub,欢迎大佬们拍砖
end
vue原生的模板编译功能的作用是将模板生成AST,然后通过AST生成渲染函数,再执行渲染函数生成vnode,最后根据vnode进行渲染
今天来实现一个简单版的模板编译功能,通过节点筛选和指令解析来完成渲染;
在实现模板编译功能之前首先得有一个模板,同时还得要一个Vue类作为基础
<!-- html -->
<div id="app">
<p>姓名</p>
<input type="text" v-model="user.name">
<p>年龄:{{user.age}}</p>
<p>位置:{{location}}</p>
<div v-html="user.sex"></div>
</div>
<!-- js -->
new Vue({
el: '#app',
data: {
user: {
name: '阿白Smile',
age: 24,
sex: `<p>性别:男</p>`
},
location: '北京'
}
})
class Vue {
constructor(options) {
this.$el = options.el
this.$data = options.data
}
}
有了这个模板和基础类就可以开始进行模板编译了,接下来都将在这段代码上进行操作
因为模板编译是一个独立的功能,所以将它单独封装一个Compiler类,在Vue实例创建的时候调用它,并且将Vue实例作为参数传递给Compiler
class Compiler {
constructor(vm) {}
}
现在有了一个提供模板编译功能的Compiler类,在Vue实例创建的时候调用它就可以开始对模板进行编译;
但是,我们还不能直接进行调用,因为Vue实例在创建的时候可能没有传递挂载元素,如果没有挂载元素也就不存在编译了,所以这里需要加一层判断,确保挂载元素存在
class Vue {
constructor(options) {
this.$el = options.el
this.$data = options.data
// 判断是否传递挂载元素
if (this.$el) {
new Compiler(this)
}
}
}
Vue实例创建的时候挂载元素可能传的是一个字符串同时也可能是一只元素节点,如果是字符串,还需要获取到相应的元素节点才能进行下一步的操作;为了方便在之后的代码中更好的使用挂在元素和Vue实例,所以将他们都设置到Compiler实例上
class Compiler {
constructor(vm) {
this.el = this.isElement(vm.$el) ? vm.$el : document.querySelector(vm.$el)
this.vm = vm
}
// 判断节点是否是元素节点
isElement(node) {
return node.nodeType === 1
}
}
到这里已经获取到挂载节点的DOM和Vue实例,下面要开始考虑匹配页面中的各个绑定数据并替换他们;但是如果直接在DOM节点中进行替换的话会导致页面多次重绘和回流;
为了解决这个问题,所以我们将挂载节点下的所有DOM都获取到然后放入文档碎片中,在文档碎片中执行替换操作,全部替换完成后再将文档碎片塞回到挂载节点中,这样就避免了页面多次回流重绘;现在先创建一个fragment,并将挂载节点中的DOM节点移进去
class Compiler {
constructor(vm) {
this.el = this.isElement(vm.$el) ? vm.$el : document.querySelector(vm.$el)
this.vm = vm
let fragment = this.nodeToFragment(this.el)
}
// 判断节点是否是元素节点
// 创建文档碎片
nodeToFragment(node) {
let fragment = document.createDocumentFragment()
let firstChild
while(firstChild = node.firstChild) {
// appedChild具有移植性,使用appendChild将DOM移入到fragment之后,挂载节点下这个DOM将会被移除
fragment.appendChild(firstChild)
}
}
}
接下来可以开始对fragment中的节点进行编译了;在编译的时候需要注意将元素节点和文本节点进行区分,因为元素节点采用的是指令进行数据绑定,并且还需要进一步向下遍历;而文本节点采用的是小胡子语法,两种语法的解析方式不一样,所以分成两个方法单独处理
class Compiler {
constructor(vm) {
this.el = this.isElement(vm.$el) ? vm.$el : document.querySelector(vm.$el)
this.vm = vm
let fragment = this.nodeToFragment(this.el)
// 用数据进行模板编译
this.compile(fragment)
}
// 判断节点是否是元素节点
// 创建文档碎片
// 模板编译
compile(node) {
let childNodes = [...node.childNodes]
childNodes.forEach(child => {
if (this.isElement(child)) {
this.compileElement(child)
// 进一下向下遍历编译
this.compile(child)
} else {
this.compileText(child)
}
})
}
// 元素节点编译
compileElement(node) {
}
// 文本节点编译
compileText(node) {
}
}
通过上面的代码,我们将元素节点和文本节点进行了区分(这里暂不考虑注释节点),针对不同的节点可以做不同的处理;
需要注意的是在模板中有一些节点是没有做任何数据绑定的,他们不需要替换数据,我们将这些节点称为静态节点,所以在具体的编译过程中需要跳过这些静态节点;
那么,接下来就是通过元素节点的指令属性和文本节点的小胡子语法对静态节点进行过滤
// 元素节点编译
compileElement(node) {
let attributs = [...node.attributes]
attributs.forEach(attr => {
let {name:attrName, value:attrVal} = attr
// 利用“v-”过滤指令
if (attrName.startsWith('v-')) {
}
})
}
// 文本节点编译
compileText(node) {
let content = textContent
// 利用正则过滤小胡子语法
if (/\{\{(.+?)\}\}/.test(content)) {
}
}
到这里已经将数据绑定的节点全部筛选出来了,并且拿到了指令的key,value和小胡子语法字符串;接下来需要进行指令解析,先来看一个完整的vue指令,以v-model为例
v-model
在这个指令中“v-”是指令的标识,model是指令的名称,我们需要通过名称找到相对应的方法来执行;
在指令解析之前我们还需要实现一个指令方法集directiveUtil,存入所有指令相对应的方法;并且指令方法应该接收当前操作的节点,绑定的字符串以及Vue实例作为参数
// 指令集
const directiveUtil = {
// v-model处理方法
model(node, expr, vm) {},
// v-html处理方法
html(node, expr, vm) {},
// 小胡子语法处理方法
text(node, expr, vm) {}
}
好了,现在有了指令集,可以开始指令解析了
// 元素节点编译
compileElement(node) {
let attributs = [...node.attributes]
attributs.forEach(attr => {
let {name:attrName, value:attrVal} = attr
// 利用“v-”过滤指令
if (attrName.startsWith('v-')) {
// 解析指令
let [,directive] = attrName.split('-')
// 执行指令方法
directiveUtil[directive](node, attrVal, this.vm)
}
})
}
// 文本节点编译
compileText(node) {
let content = textContent
// 利用正则过滤小胡子语法
if (/\{\{(.+?)\}\}/.test(content)) {
directiveUtil['text'](node, content, this.vm)
}
}
到这一步就已经找到相关指令的执行方法了,接下来就是要执行相关的指令方法,将绑定的参数替换为实例data中对应的值;
因为绑定参数的时候可能使用了对象语法(如:obj.key),所以需要添加一个获取value的方法
directiveUtil.getVal(expr, vm) {
let exprs = expr.spilt('.')
return exprs.reduce((current, item) => {
return current[item]
},vm.$data)
}
通过getVal方法已经可以获取到绑定参数的value了,所以接下来只需要进行替换就可以了;需要注意的是关于文本节点需要去除小胡子,并且还要考虑节点中绑定多个参数的可能
// v-model处理方法
model(node, expr, vm) {
let val = this.getVal(expr, vm)
node.value = val
},
// v-html处理方法
html(node, expr, vm) {
let val = this.getVal(expr, vm)
node.innerHTML = val
},
// 小胡子语法处理方法
text(node, expr, vm) {
let content = expr.replace(/\{\{(.+?)\}\}/g, (...args) => {
return this.getVal(args[1], vm)
})
node.textContent = content
}
现在,fragment中所有绑定数据的节点都已经完成了相应内容的替换,所以,此时需要将fragment塞回到挂载节点中
class Compiler {
constructor(vm) {
this.el = this.isElement(vm.$el) ? vm.$el : document.querySelector(vm.$el)
this.vm = vm
let fragment = this.nodeToFragment(this.el)
// 用数据进行模板编译
this.compile(fragment)
// 将fragment塞回到挂载节点中
this.el.appendChild(fragment)
}
}
到这里,一个简单的模板编译机制就实现成功了,打开页面看一看

各个数据都已经成功渲染了,但是由于还没有做响应式系统和依赖收集,所以数据还不能正常更新;并且当前的实现过程中只是阐明功能逻辑,所以很多容错机制,以及修饰符,事件等都没有进行处理;
源代码我已经提交到我的GitHub,欢迎大佬们拍砖
end
在前两篇文章中主要了解了模板编译机制和响应式的基本原理,实现了简单的模板编译和数据响应,但是数据的改变还不能触发视图的更新
本文将主要探索vue中的依赖收集与追踪的原理,实现数据与视图的绑定关系;
首先来实现一个订阅者Dep,它的主要作用是存放Watcher的实例
class Dep {
constructor() {
// 存放watcher
this.subs = []
}
// 新增watcher
addSub(watcher) {
this.subs.push(watcher)
}
// 通知所有的watcher更新
notify() {
this.subs.forEach(watcher => {
watcher.update()
})
}
}
在上面实现的Dep类中,主要做了两件事情:
addSub方法用于向Dep类中添加watchernotify方法用于遍历所有的watcher,并调用watcher的update方法,通知视图更新接下来实现一个Watcher类,它的主要作用是监听属性的更改并通知视图更新
class Watcher {
constructor(vm, expr, cb) {
this.vm = vm
this.expr = expr
this.cb = cb
// 获取一个旧的值
this.oldVal = this.getOldValue()
}
// 获取旧的值
getOldValue() {
// 将当前的watcher实例作为Dep.target属性的值
Dep.target = this
let oldValue = directiveUtil.getVal(this.expr, this.vm)
Dep.target = null
return oldValue
}
// 通知视图更新
update() {
let newVal = directiveUtil.getVal(this.expr, this.vm)
if (newVal != this.oldVal) {
this.cb(newVal)
}
}
}
在上面实现Watcher中,主要做了这几件时间
getOldValue方法用于获取当前的属性值oldVal,这个值的主要作用是在update中判断更新的值与当前的值是否相等,如果相等则不更新视图directiveUtil.getVal方法是在之前的代码中实现的一个通过绑定字符串获取属性值的方法update方法用于在数据更新的时候通知视图更新cb是数据更新后的回调函数,并且将新的值作为参数返回Dep.target设置为当前实例,并在取值完成后将它清空到这里,已经实现了依赖收集与追踪的两个非常重要的类;
那么接下来就是收集数据的依赖;因为依赖收集和追踪的主要目的是通知视图更新,所以只需要对模板中绑定的数据进行依赖收集
模板中绑定的数据都会通过指令集中的指令方法去改变视图,所以下面对指令集directiveUtil做一些改造
directiveUtil = {
// 获取属性的value值,eg:data.key
getVal(expr, vm) {
let exprs = expr.split('.')
// console.log('exprs', exprs, vm.$data)
return exprs.reduce((current, item) => {
return current[item]
}, vm.$data)
},
// 获取内容,eg:{{a}}{{b}}{{c}}
getContent(expr, vm) {
return expr.replace(/\{\{(.+?)\}\}/g, (...args) => {
return this.getVal(args[1], vm)
})
},
// 设置属性的value值
setVal(expr, vm, value) {
let exprs = expr.split('.')
exprs.reduce((current, item, index, arr) => {
if (index == arr.length - 1) {
current[item] = value
}
return current[item]
}, vm.$data)
},
// v-model指令的处理方法
model(node, expr, vm) {
let fn = this.uploadVlue.uploadModel
new Watcher(vm, expr, (newVal) => {
fn(node, newVal)
})
// 绑定事件
addEventListener('change', (e) => {
this.setVal(expr, vm, e.target.value)
}, false)
fn(node, this.getVal(expr,vm))
},
// v-html指令的处理方法
html(node, expr, vm) {
let fn = this.uploadVlue.uploadHtml
new Watcher(vm, expr, (newVal) => {
fn(node, newVal)
})
fn(node, this.getVal(expr,vm))
},
// 小胡子语法的处理方法
text(node, expr, vm) {
let fn = this.uploadVlue.uploadText
let content = expr.replace(/\{\{(.+?)\}\}/g, (...args) => {
new Watcher(vm, args[1], () => {
fn(node, this.getContent(expr, vm))
})
return this.getVal(args[1], vm)
})
fn(node, content)
}
}
在上面的代码中,主要做了几个改造
Watcher实例进行依赖追踪,当属性值发生改变时就会触发Watcher实例创建时的的回调函数,通过回调函数去改变视图getContent方法用于重新解析小胡子语法中的内容model方法添加了事件绑定setVal方法的功能是通过表达式设置属性值到这里已经找到了需要进行收集的数据,那么接下来就需要对defineReactive方法进行改造,完成依赖的收集
defineReactive(obj, key, value) {
let dep = new Dep()
Object.defineProperty(obj, key, {
configurable: true, // 属性可以修改和删除
enumerable: true, // 属性可以通过for...in和Object.keys()遍历
get() {
// 获取属性时触发
Dep.target && dep.addSub(Dep.target)
return value
},
set(newVal) {
// 设置属性时触发
if (newVal != value) { // 如果新的值和旧的值一致,则没有设置的必要
value = new Val
dep.notify()
}
}
})
}
在上面的代码改造中,每一个属性都会创建一个独立的Dep实例,然后通过这个实例来收集watcher;在读取属性的时候,get方法会将当前watcher收集到闭包中Dep实例的subs中,在写属性值的时候,set方法则会通过闭包中的Dep实例调用notify方法来触发实例中所有watcher对象的update方法更新相应的视图
为了便于理解,下面将按照代码的执行顺序来总结一下属性依赖收集与追踪的整个过程
directiveUtil中对应的方法进行视图更新Watcher实例Watcher内部,调用getOldValue方法获取到当前表达式的值,同时会将Dep.target的值设置为当前Watcher实例getOldValue的时候会触发属性的get方法,在get方法中,会将第3步中创建的Watcher实例push到闭包中Dep实例的subs中set方法,set方法会调用闭包中Dep实例的notify方法,notify方法会遍历当前实例所有的watcher,并调用watcher的update方法update方法调用的时候会判断新的属性值与旧的属性值(oldVal)是否相同,如果不相同,则会将新的属性值作为第3步中实例创建的时候传入的回调函数的参数,并且调用该函数directiveUtil中对应的指令方法中,在这里将调用视图更新的方法进行视图更新到这里,就已经完成了依赖收集与追踪的整个过程;配合之前的两篇文章,就已经完成了整个响应式系统的原理分析;其主要就是通过Observer类实现数据的可响应,通过Compiler类进行模板编译,通过Watcher和Dep进行依赖收集;
本文的源代码我已经提交到我的GitHub,欢迎大佬们拍砖
end
vuex的本质是一个vue插件,它是为了更好的实现多个组件间状态共享的状态管理工具

vuex工作流程图
在日常的开发工作中,特别是大型项目的开发中,常常会遇到以下两个问题:
vuex将公共状态抽离出来形成公共状态库,让组件能够共享这些状态;同时,通过new Vue的方式将状态进行响应式化,状态的改变会触发其视图的更新,让状态的维护变得简单高效
要理解Vuex的底层实现原理,首先需要了解两个Vue的API,他们是Vuex能够与Vue高度契合的基石
Vue.use()用于安装Vue插件,它需要提供一个install方法用于插件安装;install方法在执行的时候,Vue会作为第一个参数被传入;官方文档对这个API做了更加详细的解释,有需要的同学可以查看
Vue.mixin()会在全局注册一个混入对象,全局混入对象会影响到在它之后创建的每一个Vue实例;
混入对象可以包含任意组件选项,它通过一个比较灵活的方式来分发Vue组件中的可复用功能;当组件使用混入对象时,所有混入对象的选项将被“混合”进入该组件本身的选项;更多信息可以查看官方文档
Vuex是一个Vue的插件,所以需要调用Vue.use()进行安装,它会调用一个install方法,所以接下来先提供这个install方法
<!-- vuex.js -->
let Vue // 后面的代码中还会使用到这个Vue,所以放在了函数之外
const install = function(_Vue) {
Vue = _Vue
Vue.mixin({
beforeCreate() {
let options = this.$options
if (options.store) {
this.$store = options.store
} else {
this.$store = options.parent && options.parent.$store
}
}
})
}
// 导出方法
export default { install }
<!-- store.js -->
// 引入vuex并以插件的形式安装
import Vuex from './vuex.js'
Vue.use(Vuex)
<!-- main.js -->
import store from './store'
new Vue({
store,
render: h => h(App)
})
上面的代码主要做了几件事情:
this.$store,所以使用Vue.mixin混入全局的beforeCreate钩子函数,每一个组件都将调用这个钩子函数设置$store$options.store存在,说明当前节点为根节点,根节点的$store可以直接设置为$options.store;否则就要从父级节点中获取$store在日常使用vuex的时候都会创建一个Store实例,并将各种状态存放在该实例中;所以还需要提供一个Store类
<!-- vuex.js -->
let Vue
const install = function(_Vue){/********/}
class Store {
constructor(options) {
}
}
// 导出
export default { install, Store }
<!-- store.js -->
// 引入vuex并以插件的形式安装
import Vuex from './vuex.js'
Vue.use(Vuex)
export default new Vuex.Store({})
项目的共享状态状态都会存在Store实例的state中,并且为了确保状态的改变可以触发视图的更新,还需要将state进行[响应式化]处理
class Store {
constructor(options) {
this._s = new Vue({
data () {
return {
state: options.state
}
}
})
}
// Store类的getter
get state() {
return this._s.state
}
}
上面的代码中,Store实例在创建的时候将接收到一个state对象(即options.state),这个对象中保存了项目的共享状态;为了让这些状态可响应,所以重新构造了一个Vue实例,并将state作为Vue实例中data的一个属性,Vue在实例化的过程中会对state进行可[响应式化];
将新构造的Vue实例赋值给Store实例的_s属性,此时,通过this._s.state即可实现对[响应式化]后的state的访问;
通过类的getter,将Store实例中state属性的访问进行拦截,并返回_s属性中的state属性;此时对Store实例的state属性访问的实质是对_s属性的state的访问

store数据流向图
Vuex中store的状态只能通过Mutation进行更改,而Mutation需要通过commit方法进行调用
class Store {
constructor(options) {
let mutations = options.mutations
this.mutations = {}
mutations && this.setMutations(mutations)
}
// 设置mutations
setMutations = (mutations) => {
Object.keys(mutations).forEach(name => {
this.mutations[name] = (payload) => {
return mutations(this.state, payload)
}
})
}
commit = (mutationName, payload) => {
return this.mutations[mutationName] = payload
}
}
上面的代码主要是增加了两个方法setMutations和commit;
setMutations方法的主要目的是将options中的mutations挂载到实例上,并且将mutations中每一个mutation的第一个参数设置为实例的state
commit则是用于调用mutation的方法,它的第一个参数是需要调用的mutation名称,payload将作为被调用的mutation的payload参数
Vuex中,Mutation的作用是同步的更改状态;如果需要异步的更改状态则需要使用Action;
Action与Mutation类似,但是也有不同,不同之处在于:
dispatch方法触发class Store {
constructor(options) {
let actions = options.actions
this.actions = {}
actions && this.setActions(mutations)
}
// 设置actions
setActions = (actions) => {
Object.keys(actions).forEach(actionName => {
this.actions[actionName] = (payload) => {
actions[actionName](this, payload)
}
})
}
dispatch = (actionName, payload) => {
this.actions[actionName](payload)
}
}
dispatch的实现与commit基本相似,不同的在于action的第一个参数是接收一个与Store实例具有相同方法和属性的content对象(代码中为了便于理解直接使用了Store实例)
到这里就实现了一个简单的vuex,通过这个简易版的vuex的实现,可以更好的理解Vuex的核心以及它是如何与Vue进行结合;、
本文的源代码我已经提交到我的GitHub,希望大家多提意见多点赞
end
在上一篇文章(变量声明)中提到了变量提升,但是并没有详细的探讨什么是变量提升,为什么会变量提升等问题,今天这篇文章就主要探讨这两个问题
先引用MDN的解释
变量提升(Hoisting)被认为是, Javascript中执行上下文 (特别是创建和执行阶段)工作方式的一种认识。
通俗一点的解释就是:函数及变量的声明都将被提升到当前作用域的最顶部也就是变量可以先使用再声明
看一段代码
num = 10
console.log(num) // 10
var num
foo() // 'foo'
function foo(){
console.log('foo')
}
运行上面的代码可以看到,变量num和函数foo都是在代码定义之前调用的,按照顺序执行的原则,在定义之前调用应该报错才对,但是这里却是正常执行,这就说明JavaScript并不是严格的顺序执行,而是存在变量提升
JavaScript先把变量和函数定义提升到代码顶部,所以上面例子中的代码其实际的执行顺序应该是这样的:
var num
function foo() {
console.log('foo')
}
num = 10
console.log(num)
foo()
要深入了解变量提升的原因需要引入一个新的概念:执行上下文(关于什么是执行上下文,可以参考这篇文章:JavaScript深入之执行上下文栈)
执行上下文是JavaScript引擎在执行一段代码之前(编译阶段)的准备工作,也就是常说的编译内容;执行上下文中主要包含了三个非常重要的属性,分别是变量对象,作用域链,this;
执行上下文的调用可以分为两个阶段
a. 创建作用域链
b. 创建变量,函数及参数(创建变量对象)
c. 求‘this’的值
指派变量的值和函数的引用,执行代码
因为这里主要探索变量提升的原因,所以了解变量对象的创建过程,变量对象的创建过程大概分为这几个阶段:
看一个例子:
function fun(i) {
var a = 'hello'
var b = function privateB() {
}
function c() {
}
}
fun(1)
// 当调用函数fun的时候,将创建一个执行对象,执行对象的内容如下:
funExecutionContext = {
// 创建作用域链
scopeChain: {},
// 创建变量对象
variableObject: {
// 创建arguments对象并初始化
arguments: {
0: 1,
length: 1
},
i: 1,
// 扫描执行上下文中的函数声明
c: pointer to function c(),
// 扫描上下文中的变量声明
a: undefined,
b: undefined
},
// 计算this
this: {}
}
在ES6中新增了let和const两个关键词可以声明变量,这两个关键词声明的变量不存在变量提升,必须先定义后使用
end

操作符在进行运算的过程中往往会涉及到一些数据类型转换,关于数据类型转换的类容可以参考《JavaScript基础-数据类型转换》
基本算数运算主要为普通的四则运算(加,减,乘,除)和取模(%),除加法运算外(加法运算比较特殊,单独讲解),其他四个操作符主要遵循以下规则
- 如果有一个操作数为NaN,则运算结果为NaN;
- 如果操作数不是数值,则会将操作数转换为数值;
console.log(NaN - 1) // NaN
console.log(1 - false) // 1
console.log(NaN * 1) // NaN
console.log(1 * false) // 0
console.log(NaN / 1) // NaN
console.log(1 / false) // Infinity
console.log(NaN % 1) // NaN
console.log(1 % false) // NaN
加号操作符的特殊之处在于除了运算功能外,它还有字符串连接功能。加法操作符主要遵循以下规则:
- 如果两个操作数都为数值,则执行常规的加法运算;
- 如果有一个操作数为NaN,则结果为NaN;
- 如果操作数中存在字符串
1. 两个操作数都是字符串,则直接将两个操作数拼接起来;
2. 如果只有一个操作数为字符串,则将另一个操作数转换为字符串,然后将两个操作数拼接起来;- 如果操作数中存在对象,则先调用对象的toString()方法,得到一个字符串,然后应用字符串的规则;
- 如果其中一个操作数是字符串,null和undefined则直接调用String()函数得到字符串
console.log(1 + 1) // 2
console.log(1 + '1') // 11
console.log('1' + '2') // 12
console.log(1 + [0]) // 10
console.log(1 + {}) // 1[object Object]
console.log('1' + null) // 1null
console.log('1' + undefined) // 1undefined
递增和递减操作符分为前置和后置两种类型,前置型即操作符位于操作数之前,后置型则是操作符位于操作数之后
let test = 1
// 前置型递增
++test
// 后置型递增
test++
// 前置型递减
--test
// 后置型递减
test--
后置型操作与前置型操作相比,最大的不同在于,后置型操作返回的是操作之前的值,也就是说,后置型操作是当前所在语句被求职之后才执行的
let num1 = 5
let num2 = num1++
console.log(num2) // 5 num2得到的是num1执行递增操作前的值
console.log(num1) // 6 第二条语句返回值之后开始执行递增操作,所以num1的值为6
一元加操作符在使用时,如果操作数为数值,则不会对操作数产生任何影响;如果操作数不是数值时,则会进行类型转换,如果不能转换为数值,返回NaN
let test = 1
let test1 = 1.1
let test2 = '1.2'
let test3 = false
let test4 = 'test'
let test5 = {}
console.log(+test) // 1
console.log(+test1) // 1.1
console.log(+test2) // 1.2
console.log(+test3) // 1
console.log(+test4) // NaN
console.log(+test5) // NaN
一元减操作符与一元加操作符基本一致,不同的地方在于,当操作数为数值时,会将负数变为正数,正数变为负数
基本的赋值操作符使用等号(=)表示,其作用是将等号右侧的值赋给等号左侧的变量
var num
console.log(num) // undefined
num = 10 // 使用赋值操作符,将10赋值给变量num
console.log(num)
除常规的赋值操作符外,还有一些将赋值运算和其他运算结合起来的赋值运算符,比较常见的有:+=,-=,*=,/=,%=
a += b
// 等价于
a = a + b
通过上面的例子可以看出,这种符合的赋值运算符的结构为:
a op= b
// op代表一个运算符
// 上面的语句等价于
a = a op b
// 注意:这里的a不能包含具有副作用的表达式
严格相等和相等操作符都是用于比较两个值是否相等,并且都返回布尔值;不同的地方在于严格相等操作符不存在任何形式的类型转换
console.log('1' == 1) // true 发生了数据类型转换
console.log('1' === 1) // false 数据类型不同
严格相等操作符在比较的过程中会首先计算两边操作数的值,然后再比较这两个值,它的具体规则如下:
- 两个操作数的类型不同,则返回false;
- null与undefined返回false;
- 其中一个操作数为NaN,则返回false;
- 如果字符串的长度和内容不同,则返回false;
- 0与-0严格相等,返回true;
- 两个操作数都为布尔值true或false时严格相等,返回true;
- 两个值都为数值且数值相等,则严格相等,返回true;
- 两个对象指向同一个引用时严格相等,返回true
相等操作符与严格相等操作符类似,相对严格相等操作符来讲没有那么严谨,当两个操作数类型不同时,会先进行类型转换,然后再进行比较;它的具体规则如下:
- 如果两个操作数的类型不同,则进行类型转换:
1. null和undefined相等,返回true;
2. 如果一个操作数时数字,另一个操作数时字符串,会将字符串转换为数字,然后进行比较;
3. 如果操作数是布尔值,则将布尔值转换为数字,然后进行比较
4. 如果某个操作数是对象,则将对象转换为原始值再进行比较
比较运算符用来检测两个操作数的大小关系,常见的比较运算符有大于(>),小于(<),大于等于(>=),小于等于(<=)
比较运算符的返回值为布尔值;纯数值的比较和数学上的比较规则是一样的,需要注意的是非数字的比较:
- 如果两个操作数都是字符串,则比较两个字符串对应的字符编码值;
- 如果其中一个操作数是数值,则将另一个操作数也转换为数值,然后执行数值比较
- 如果操作数含有布尔值,则将布尔值转换为数字
- 如果操作数是对象,则先将对象转换为原始值,再进行比较
条件运算符是JS中唯一的三元运算符,也称为三元运算符,语法格式如下:
let variable = boolean_expression ? true_value : false_value
三元运算符的含义为:根据boolean_expression的求职结果,决定给variable赋什么值;如果求职结果为true,则将true_value的求职结果赋给variable,否则将false_value的求职结果赋值给variable
let max = (num1 > num2) ? num1 : num2
// 等同于
let max = null
if (num1 > num2) {
max = num1
} else {
max = num2
}
end
在前一篇文章中介绍了一些webpack配置常用的loader和插件,并且完成了一个适合大多数场景的基础配置文件;本文将继续介绍webpack的配置,相对于上一篇文章,本文更加着重开发效率和个性化需求的配置
前一篇文章中配置都只适用于单页应用的打包,但是在实际的工作也还会涉及到多页应用的项目开发;
webpack中多页应用与单页应用打包的不同之处主要体现在以下几点:
配置
<!-- webpack.config.js -->
const path = require('path')
const HtmlWebpackPlugin = require('html-webpack-plugin')
module.exports = {
entry: {
main: './main.js',
miniApp: './miniApp.js'
},
output: {
filename: [name].[hsah].js,
path: path.resolve(__dirname, 'dist')
},
plugin: [
new HtmlWebpackPlugin({
template: './index.html',
filename: 'main.html',
chunks: ['main']
}),
new HtmlWebpackPlugin({
template: './index.html',
filename: 'miniApp.html',
chunks: ['miniApp']
})
]
// 省略其他代码
}
[name]: 构建包的名称,它来源于entry中的key值,在单页应用中默认为main
chunks: 用于指定需要引入到html中的js文件;与它相反,还有一个excludeChunks参数,它用于指定不需要引入的js文件
日常的开发中会遇到一些直接使用的文件,这些文件可能是js,也可能是css或者是图片,它们不需要经过打包,可以直接将他们拷贝到webpack构建目录;但是手动拷贝不仅麻烦并且容易出错(比如,修改之后忘记拷贝)
copy-webpack-plugin插件用于将指定文件/文件夹复制到构建目录;通过这个插件可以将静态文件直接复制到输出目录中
安装
npm install copy-webpack-plugin -D
配置
<!-- webpack.config.js -->
const path = require('path')
const copyWebpackPlugin = require('copy-webpack-plugin')
module.exports = {
plugin: [
new copyWebpackPlugin([
{
from: path.resolve(__dirname, './public'),
to: './dist'
}
])
]
}
from: 指定需要复制的文件夹
to: 指定复制后的文件夹
更多copyWebpackPlugin配置,可以参考官方文档
在开发的过程中经常会通过控制台查看错误信息;但是打包之后的错误信息位置将会以构建后的js为基准,这样的错误信息因为没有定位到源码的错误位置,对调试很不友好
这个问题可以通过对devTool配置sourceMap来解决;sourceMap是一个源码映射文件,有多种格式可选,这里只列举几个有代表性的,更多sourceMap格式可以查看官方文档
source-map: 原始源代码,会单独生成源码文件,可以提示错误信息的列和行eval-source-map: 原始源代码,不会产生单独的文件,但是可以显示行和列cheap-module-source-map: 转换后的代码,生成单独的文件,可以提示行但不能提示列cheap-module-eval-source-map: 原始源代码,集成在打包后的文件中,不会生成独立的文件,可以提示行,但不能提示列综合实际使用情况和构建速度考虑,开发环境中一般使用cheap-module-eval-source-map
<!-- webpack.config.js -->
module.exports = {
// 省略其他代码
devtool: 'cheap-module-eval-source-map'
}
跨域是前后端接口交互时一个很常见的问题,解决跨域发方式也有很多,这里主要介绍如何通过webpack的配置来解决跨域问题;
先通过server.js在本地创建一个node服务, 启动本地的3000端口作为后端服务
<!-- server.js -->
const express = require('express')
const app = express()
app.get('/api/user', (req, res) => {
res.json({name: '阿白Smile'})
})
app.listen(3000)
使用命令行工具执行node server.js命令启动node服务,然后使用client.js向后端服务发送请求
<!-- client.js -->
const xhr = new XMLHtttpRequest()
xhr.open('GET', '/api/user', true)
xhr.onload = function() {
console.log(xhr.response)
}
xhr.send()
接下来就通过webpack为前端服务配置一个代理,将前端的服务代理到后端的服务上,这样可以让前端和服务端在同一个服务下,以此来解决跨域问题
<!-- webpack.config.js -->
module.exports = {
devServer: {
prot: 3000,
host: 'localhost'
proxy: {
'/api': 'http://localhost:3000'
}
}
}
通过以上的配置,当client.js访问/api/user时,请求会被代理到http://localhost:3000/api/user
如果不想每次都在接口路径前加/api,或者后端的接口没有/api这一层路径,那么可以通过pathRewrite重写路径,将/api重写为空
<!-- webpack.config.js -->
module.exports = {
devServer: {
prot: 3000,
host: 'localhost'
proxy: {
'/api': {
target: 'http://localhost:3000',
pathRewrite: {'/api': ''}
}
}
}
}
通过服务端启动webpack,可以将前端和服务端启动在同一个服务上;当前后端都在同一个服务的时候自然就不存在跨域问题了
服务端启动webpack需要使用到webpack-dev-middleware中间件
安装
npm install webpack-dev-middleware -D
配置
<!-- server.js -->
const express = require('express')
const webpack = require('webpack')
const middle = require('webpack-dev-middleware')
const app = express()
let config = require('./webpack.config.js')
let compiler = webpack(config)
app.use(middle(compiler))
app.get('/user', (req, res) => {
res.json({name: '阿白Smile'})
})
app.listen(3000)
使用这种方式的前提是能够操作服务器,不过既然都可以操作服务器了,那么还可以通过设置header来实现跨域
webpack-dev-server提供了一个before钩子;它的第一个参数暴露了webpack-dev-server内部的express服务,通过这个服务,可以完成一些数据的mock
<!-- webpack.config.js -->
module.exports = {
devServer: {
before(app) {
app.get('/name', (req, res) => {
res.json('阿白Smile')
})
}
}
}
mocker-api是一个为 REST API 创建mock的webpack-dev-server中间件。在后端服务还没有完成的时候,可以通过这个中间件进行mock数据
安装
npm install mocker-api -D
配置
创建一个mock.js进行接口和数据mock
<!-- mock.js -->
module.exports = {
'GET /userInfo/:id': (req, res) => {
const { id } = req.params;
// 省略查询
return res.json({
id,
name: '阿白smile'
});
}
}
配置到devServer的before钩子中
<!-- webpack.config.js -->
const path = require('path')
const apiMocker = require('mocker-api');
const mockApi = path.resolve('./mock.js')
module.exports = {
devServer: {
before(app) {
mockApi(app, mockApi)
}
}
}
修改client.js文件,访问/userInfo接口
<!-- client.js -->
const xhr = new XMLHtttpRequest()
xhr.open('GET', '/userInfo/1', true)
xhr.onload = function() {
console.log(xhr.response)
}
xhr.send()
使用npm run dev命令执行脚本之后,在浏览器中打开,此时浏览器会打印出{"id":"1","name":"阿白smile"}
webpack启动后会从入口文件开始找出所有依赖的模块;resolve的作用就是告诉webpack如何寻找这些模块所对应的文件
resolve.alias用于配置别名,通过别名可以把原来的导入路径映射到一个新的路径, 它可以让模块的引入更加简单;vue中常常为src文件夹设置一个别名为@
文件结构
|--src
|--|--assets
|--|--|--main.css
配置
<!-- webpack.config.js -->
module.exports = {
// 省略其他代码
resolve: {
alias: {
'@': './src'
}
}
}
使用
import '@/assets/main.css'
使用别名之后,别名会直接映射到别名所指定的路径;在使用相关模块时,可以使用更加简单的方式书写模块路径
resolve.modules用于指定webpack解析模块时从哪些目录下搜索模块,默认情况下,webpack只从node_modules中搜索;
如果有一个模块是自己编写的文件,那么它就不需要到node_modules中取查找;比如, 我们经常会在src/components中编写一些组件,为了避免每次引用组件都写很长的路径,就可以通过modules配置来简化以下路径
文件结构
|--src
|--|--components
|--|--|--navMenu.vue
配置
<!-- webpack.config.js -->
module.exports = {
// 省略其他代码
resolve: {
modules: ['./src/components', 'node_modules']
}
}
使用
import navMenu from 'navMenu'
webpack在搜索模块时,会根据modules的配置从左到右开始搜索;所以,在使用navMenu时,会先从./src/components中查找,如果没有找到,则会去node_modules中查找;
在模块导入语句中没有带文件后缀时,webpack会自动带上尝试后缀去访问(默认带.js); resolve.extensions用于配置尝试访问的后缀列表,列表的优先级为从左到右
配置
<!-- webpack.config.js -->
module.exports = {
// 省略其他代码
resolve: {
extensions: ['.js', '.vue', '.json']
}
}
使用
import index from './index'
上面的代码结合配置之后,会先尝试使用.js作为后缀去访问index,如果不存在则尝试使用.vue作为后缀去访问;以此类推,如果配置的后缀都尝试了还没有找到文件,则会报错,文件未找到
在实际开发中,开发环境和线上生产环境往往会使用不同的服务和域名,并且不同的环境应该是可以自动切换的,这就需要在代码中使用环境变量来区分不同的环境,然后自动切换相应的服务和域名
webpack通过内置的DefinePlugin插件可以提供了一个区分环境的全局变量
DefinePlugin的键值都是一个标志符或者多个用 . 连接起来的标志符
如果value是一个字符串,它会被当作一个代码片段来使用
如果value不是字符串,它会被转化为字符串(包括函数)
如果value是一个对象,它所有的 key 会被同样的方式定义(即全局可以直接访问对象的key,value则会应用DefinePlugin的键值规则)
如果在一个 key 前面加了 typeof,它会被定义为 typeof 调用
module.exports = {
plugin: {
new webpack.DefinePlugin({
DEV: JSON.stringify('dev')
})
}
}
if (DEV) {
// 开发
BASE_URL: '' // 开发服务
} else {
// 生产
BASE_URL: '' // 生产服务
}
通过环境变量可以进行环境的区分,但是代码中如果涉及到多处需要区分且每次都需要手动去配置,这不仅加大了工作量而且还容易出错;
一般的解决方案是将不同环境的配置分开到不同的文件,然后使用webpack-merge将其与基础配置进行合并
webpack.base.config.js: 基础配置文件
webpack.pro.config.js: 线上生产环境配置文件
webpack.dev.config.js: 开发环境配置文件
webpack-merge是一个函数,它提供了合并功能,接收一个或多个对象/数组,用于对象的合并与数组的连接,返回合并后的对象;在合并对象时,如果同一个key出现多次,则后面的覆盖前面的
安装
npm install webpack-merge
配置
const merge = require('webpack-merge')
let result = merge({name: '阿白smile', age: 18}, {age: 24, location: '北京'})
// 合并后的结果
// {name: '阿白smile', age: 24, location: '北京'}
webpack.base.config.js是基础的webpack配置,各个环境可以通用,所以webpack.base.config.js需要作为merge的第一个参数
开发环境的配置
<!-- webpack.dev.config.js -->
const baseWebpackConfig = require('./webpack.base.config')
const merge = require('webpack-merge')
let devWebpackConfig = merge(baseWebpackConfig, {
mode: 'development',
devServer: {
// 省略其他代码
}
})
moudle.export = devWebpackConfig
生产环境的配置
<!-- webpack.pro.config.js -->
const baseWebpackConfig = require('./webpack.base.config')
const merge = require('webpack-merge')
let proWebpackConfig = merge(baseWebpackConfig, {
mode: 'production',
// 省略其他代码
})
moudle.export = proWebpackConfig
配置命令脚本
<!-- package.json -->
"scripts": {
"dev": "webpack-dev-server --config=webpack.dev.config.js"
"build": "webpack --config=webpack.pro.config.js"
}
热更新主要应用在开发环境,当代码更改之后页面上只更新被修改的部分,不需要刷新页面,对开发和调试非常有利;
webpack中的热更新的配置主要依赖devServer.hot以及webpack的内置插件HotModuleReplacementPlugin
<!-- webpack.config.js -->
module.exports = {
devServer: {
hot: true // 启用热更新
},
plugin: [
new webpack.HotModuleReplacementPlugin() // 热更新插件
]
}
以上的代码配置之后在浏览器查看,会发现还是会刷新整个页面;这个时候还需要在入口文件中做以下配置
if (module.hot) {
module.hot.accept()
}
module.hot用于通知webpack此模块可以用于热更新,更多信息可以参考官方文档
通过本篇文章中介绍的webpack配置,可以满足更加个性化的开发需求以及更高效率的开发
本文所对应的配置源码已提交到我的github
END
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.