nvlabs / step Goto Github PK
View Code? Open in Web Editor NEWSTEP: Spatio-Temporal Progressive Learning for Video Action Detection. CVPR'19 (Oral)
STEP: Spatio-Temporal Progressive Learning for Video Action Detection. CVPR'19 (Oral)
How can i draw MIUT , Comparison of the per-class breakdown frame-AP at IoU threshold 0.5 on AV and other graphs like mention here. for this repo?
http://xiaodongyang.org/publications/papers/step-supp-cvpr19.pdf
Building I3D model...
Building I3D head for global branch...
Building I3D head for global branch...
Building I3D head for global branch...
Building I3D head for context branch...
Datalist len: 0
Hi,
Thanks for these wonderful works. I can launch the demo.
As I mentioned, I would like to know if this model is suitable for online detection application or there will be latency.
Hello,i want to konw how to generate pre-defined proposals?
I don't find some codes in generating the pre-defined proposals through the whole project.So,the pre-trained proposals are trained independently,and then feed them into the two-branch network?
Hi there,
First of all I would like to congratulate you for this great work and thank you for saharing the this awsome content publicly.
I am trying to run the demo.py after following all the steps described in the demo paragraph but unfortunately I am encountering problems and no visual results are generated in results folder except an empty results.txt file. Following is the terminal output that I am getting. The "Datalist len" is 0. I don't know why it is so. I have provided a total of 778 frames but I am not getting any output. Is there a minimum nunber of frames to be provided for detection?
Please help, Thanks.
python3 demo.py
Warning: If you want to use fp16, please apex with cuda support (https://github.com/NVIDIA/apex) and update pytorch to 1.0
Warning: If you want to use fp16, please apex with cuda support (https://github.com/NVIDIA/apex) and update pytorch to 1.0
Warning: If you want to use fp16, please apex with cuda support (https://github.com/NVIDIA/apex) and update pytorch to 1.0
Loading pretrain model from pretrained/ava_step.pth
Building I3D model...
Building I3D head for global branch...
Building I3D head for global branch...
Building I3D head for global branch...
Building I3D head for context branch...
Datalist len: 0
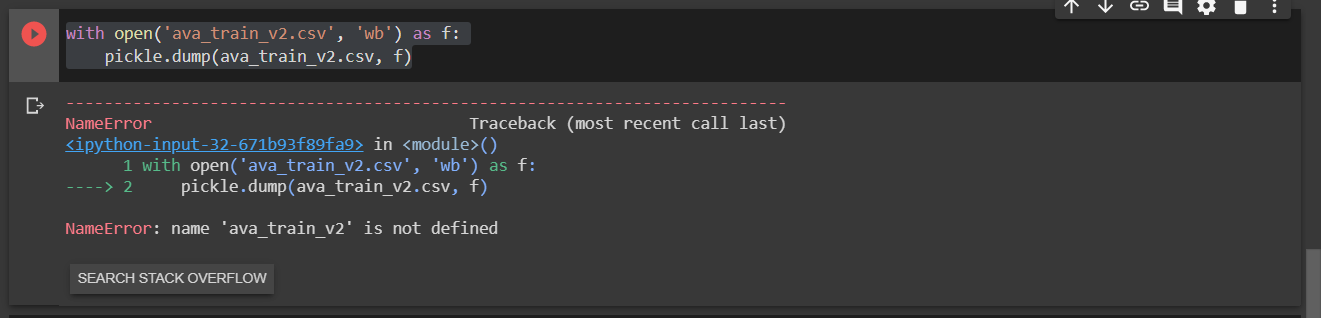
Hi , I am really new here, I have this issue where i am not able to convert csv file to pickle file, please correct my code if I am wrong.
Should it be this :
with open('ava_train_v2.csv', 'wb') as f:
pickle.dump(ava_train_v2.csv, f)
or this ?
with open('ava_train_v2.pkl', 'wb') as f:
pickle.dump(ava_train_v2.pkl, f)
(https://user-images.githubusercontent.com/23328577/80235678-9b768280-868c-11ea-8e73-fcaaac3f851e.PNG)
RuntimeError: A tensor was not on the same device as the first tensor
When i run the train.py ,i face up with this problem
when I train my datasets,it always reports errors like:
ValueError: Image path /STEP/datasets/ava/frames/D01/00922/ not Found
because my datasets' each video only has 20 clips,which from 00902 to 00921,and fps equals 8.
I guess this error may be caught by the code:
if self.input_type == "rgb": images = read_images(self.imgpath_rgb, videoname, fid, num=TEM_REDUCE*self.T*self.chunks, fps=self.fps)
I want to know what is the meaning of "num=TEM_REDUCEself.Tself.chunks", is "num" related to "fps"?do you have some suggestions for my training?Thanks!
Thanks for your nice github!
I want to run the evaluation for the AVA dataset.
But I don't know the format of the result.csv .
Could you give me the example of the result.csv which your codes want?
I just want to know the format of the result.csv of prediction. Ex: video name, scores, label and so on.
Thank you!
when running python test.py it expects
val.pkl
and frames of data
I have downloaded test videos (from ava_test.txt)
But How can I generate pkl file?
Generate_label.py code generates it it expects a csv with video name, box details, etc which is not available for test data.
So ho to run it??
@tmbdev
@bkhailany @mjgarland @dumerrill @sdalton1
will you open the code of training on the ucf101 dataset?
hi,thank you for your work about action detection.i want to try this code.but the pre-trained mode is not found in Baidudisk.if you have time.Can you submit it once more?
wish your reply.
Mr.zhang
hi, thanks for you great works. When I add --fp16 flag, I meet a CUDA error: an illegal memory access was encountered error. However, when I remove the --fp16 flag, it works well. I have two gpus, one is GTX 1070 and another one is 980Ti.
pytorch version 1.1.0
cuda 9.0
thanks again..
Thank you for sharing the code of your wonderful work.
After setting up the environment, I tried the demo.py program on my own video clip having 64 frames.
I am getting the above mentioned error in following line:
for _, (images, tubes, infos) in enumerate(dataloader):
Have you ever faced this error? What could be possible solution.
Thanks.
I use my own image datas with demo.py and got this error, no any other infos display.
I have located the postion causing this error, its roi layer calling. However, I tested the ROIAlign_cuda.cu not using PyTorch Tensor as parameters but use float * instead and no errors raise.
my gcc version is 4.8.5, is the gcc version critical ? any advices? thanks
hi, thanks for you great works.
I train my dataset, which has ten classes, fps =1, and I don't add --fp16 flag.
max_iter=2
batch_size=2
But when I start training, there will be the error. This error happens during the third itertator. That means it is ok during the first and the second iterator. The model can forward,backforward and the function of optimizer.step is ok during the first and the second iterator. When the third itertator starts, there throw the error:
Traceback (most recent call last):
File "train.py", line 602, in
main()
File "train.py", line 235, in main
train(args, nets, optimizer, scheduler, train_dataloader, val_dataloader, log_file)
File "train.py", line 362, in train
optimizer.step()
File "/usr/local/lib/python3.6/dist-packages/torch/optim/lr_scheduler.py", line 51, in wrapper
return wrapped(*args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torch/optim/adam.py", line 103, in step
denom = (exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])
RuntimeError: CUDA error: an illegal memory access was encountered
Can you tell me the code which is used in UCF
Thanks for sharing such a nice work . I want to train a model using your given code . Is it necessary to make my dataset as in the "AVA-Data set Format". If it is yes then what is the way or tools can be used.What are pre-processing steps I need to do to complete the AVA Dataset Format. Is there any way which I can use to train my dataset.
I have dataset now as follow
Dataset/
├── Class-A
│ └── insp.mp4
├── Class-B
│ └── kep.mp4
└── Class-C
└── tak.mp4
I prepared the dataset folder in respect to the information listed in the Demo paragraph. But the demo is not working. This is what I got:
python demo.py
Warning: If you want to use fp16, please apex with cuda support (https://github.com/NVIDIA/apex) and update pytorch to 1.0
Warning: If you want to use fp16, please apex with cuda support (https://github.com/NVIDIA/apex) and update pytorch to 1.0
Warning: If you want to use fp16, please apex with cuda support (https://github.com/NVIDIA/apex) and update pytorch to 1.0
Loading pretrain model from pretrained/ava_step.pth
Building I3D model...
Building I3D head for global branch...
Building I3D head for global branch...
Building I3D head for global branch...
Building I3D head for context branch...
Datalist len: 1439
Traceback (most recent call last):
File "/home/bilel/anaconda3/envs/env_pytorch/lib/python3.6/queue.py", line 173, in get
self.not_empty.wait(remaining)
File "/home/bilel/anaconda3/envs/env_pytorch/lib/python3.6/threading.py", line 304, in wait
self._acquire_restore(saved_state)
File "/home/bilel/anaconda3/envs/env_pytorch/lib/python3.6/threading.py", line 251, in _acquire_restore
def _acquire_restore(self, x):
File "/home/bilel/anaconda3/envs/env_pytorch/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 12383) is killed by signal: Killed.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/bilel/anaconda3/envs/env_pytorch/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 724, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/bilel/anaconda3/envs/env_pytorch/lib/python3.6/queue.py", line 176, in get
return item
File "/home/bilel/anaconda3/envs/env_pytorch/lib/python3.6/threading.py", line 243, in __exit__
return self._lock.__exit__(*args)
RuntimeError: release unlocked lock
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "demo.py", line 228, in <module>
main()
File "demo.py", line 110, in main
for _, (images, tubes, infos) in enumerate(dataloader):
File "/home/bilel/anaconda3/envs/env_pytorch/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 804, in __next__
idx, data = self._get_data()
File "/home/bilel/anaconda3/envs/env_pytorch/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _get_data
success, data = self._try_get_data()
File "/home/bilel/anaconda3/envs/env_pytorch/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 737, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str))
RuntimeError: DataLoader worker (pid(s) 12383) exited unexpectedly
Hello,
I'm currently attempting to run The demo script of STEP on a CPU instead of a GPU. I made some modifications to the code accordingly, but unfortunately, I encountered an error. After replacing the GPU instructions, I received the following error message:
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for BaseNet:
Missing key(s) in state_dict: "base_model.0.conv3d.weight", "base_model.0.batch3d.weight", "base_model.0.batch3d.bias", "base_model.0.batch3d.running_mean", ....
I would greatly appreciate any assistance in resolving this issue. If anyone could help me understand and correct the problem, it would be very helpful.
Thank you in advance.
thank U for sharing first! I try to understand the meaning of "chunks"?is it related to "T"? Look foraward to your reply!
for i in range(1, exec_iter+1): # index from 1 # adaptively get the start chunk chunks = args.NUM_CHUNKS[i] T_start = int((args.NUM_CHUNKS[args.max_iter] - chunks) / 2) * args.T T_length = chunks * args.T chunk_idx = [j*args.T + int(args.T/2) for j in range(chunks)] # used to index the middel frame of each chunk half_T = int(args.T/2)
I run demo 1st time in google colab and it's working, but when i try 2th time the demo is not working. This is what I got:
Warning: If you want to use fp16, please apex with cuda support (https://github.com/NVIDIA/apex) and update pytorch to 1.0 Warning: If you want to use fp16, please apex with cuda support (https://github.com/NVIDIA/apex) and update pytorch to 1.0 Warning: If you want to use fp16, please apex with cuda support (https://github.com/NVIDIA/apex) and update pytorch to 1.0 Loading pretrain model from /content/drive/MyDrive/STEP/pretrained/ava_step.pth
Building I3D model... Building I3D head for global branch... Building I3D head for global branch... Building I3D head for global branch... Building I3D head for context branch... Datalist len: 978
THCudaCheck FAIL file=/content/drive/My Drive/STEP/external/maskrcnn_benchmark/csrc/cuda/ROIAlign_cuda.cu line=321 error=209 : no kernel image is available for execution on the device Traceback (most recent call last): File "demo.py", line 229, in <module> main() File "demo.py", line 122, in main history, _ = inference(args, conv_feat, context_feat, nets, args.max_iter, tubes) File "/content/drive/My Drive/STEP/utils/utils.py", line 48, in inference pooled_feat = nets['roi_net'](conv_feat[:, T_start:T_start+T_length].contiguous(), flat_tubes) File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 727, in _call_impl result = self.forward(*input, **kwargs) File "/content/drive/My Drive/STEP/models/networks.py", line 45, in forward tubes.view(-1, 5).detach()) File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 727, in _call_impl result = self.forward(*input, **kwargs) File "/content/drive/My Drive/STEP/external/maskrcnn_benchmark/roi_layers/roi_align.py", line 92, in forward input, rois, self.output_size, self.spatial_scale, self.sampling_ratio File "/content/drive/My Drive/STEP/external/maskrcnn_benchmark/roi_layers/roi_align.py", line 53, in forward output = _C.roi_align_forward(input, roi, spatial_scale, output_size[0], output_size[1], sampling_ratio) RuntimeError: cuda runtime error (209) : no kernel image is available for execution on the device at /content/drive/My Drive/STEP/external/maskrcnn_benchmark/csrc/cuda/ROIAlign_cuda.cu:321
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}