Hi!
使用LOMO+LoRA时可以一切正常地运行。
但是!
我想将LOMO与QLoRA结合在一起,
于是:
我在您lomo_lora相关的源码中的模型代码加入了量化的功能:
train_lomo_lora.py:

并且在LoRA config后添加了:

因为deepspeed暂时不支持量化,我注释并修改了所有跟deepspeed相关的配置:
train_lomo_lora.py:


lomo_lora_trainer.py:


之后修改run.sh:
python src/train_lomo_lora.py config/args_lomo_lora.yaml
运行几次添加了需要的库后却报错如下:
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮ │ /root/model/utils/CustomLOMO/src/train_lomo_lora.py:181 in <module> │ │ │ │ 178 │ │ 179 │ │ 180 if __name__ == "__main__": │ │ ❱ 181 │ train() │ │ 182 │ │ │ │ /root/model/utils/CustomLOMO/src/train_lomo_lora.py:177 in train │ │ │ │ 174 │ │ compute_metrics=compute_metrics, │ │ 175 │ │ optimizers={'model_parameters': peft_params}, │ │ 176 │ ) │ │ ❱ 177 │ trainer.train() │ │ 178 │ │ 179 │ │ 180 if __name__ == "__main__": │ │ │ │ /root/model/utils/CustomLOMO/src/lomo_lora_trainer.py:197 in train │ │ │ │ 194 │ │ │ with tqdm.tqdm(self.train_dataloader, disable=not self.allow_print) as tqb: │ │ 195 │ │ │ │ for step, batch in enumerate(tqb, start=1): │ │ 196 │ │ │ │ │ self.model.train() │ │ ❱ 197 │ │ │ │ │ outs = self.model( │ │ 198 │ │ │ │ │ │ input_ids=batch['input_ids'].cuda(), │ │ 199 │ │ │ │ │ │ attention_mask=batch['attention_mask'].cuda(), │ │ 200 │ │ │ │ │ ) │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/torch/nn/modules/module.py:1501 in │ │ _call_impl │ │ │ │ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │ │ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │ │ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │ │ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │ │ 1502 │ │ # Do not call functions when jit is used │ │ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │ │ 1504 │ │ backward_pre_hooks = [] │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/peft/peft_model.py:678 in forward │ │ │ │ 675 │ ): │ │ 676 │ │ peft_config = self.active_peft_config │ │ 677 │ │ if not isinstance(peft_config, PromptLearningConfig): │ │ ❱ 678 │ │ │ return self.base_model( │ │ 679 │ │ │ │ input_ids=input_ids, │ │ 680 │ │ │ │ attention_mask=attention_mask, │ │ 681 │ │ │ │ inputs_embeds=inputs_embeds, │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/torch/nn/modules/module.py:1501 in │ │ _call_impl │ │ │ │ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │ │ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │ │ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │ │ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │ │ 1502 │ │ # Do not call functions when jit is used │ │ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │ │ 1504 │ │ backward_pre_hooks = [] │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/accelerate/hooks.py:165 in new_forward │ │ │ │ 162 │ │ │ with torch.no_grad(): │ │ 163 │ │ │ │ output = old_forward(*args, **kwargs) │ │ 164 │ │ else: │ │ ❱ 165 │ │ │ output = old_forward(*args, **kwargs) │ │ 166 │ │ return module._hf_hook.post_forward(module, output) │ │ 167 │ │ │ 168 │ module.forward = new_forward │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/transformers/models/llama/modeling_llam │ │ a.py:688 in forward │ │ │ │ 685 │ │ return_dict = return_dict if return_dict is not None else self.config.use_return │ │ 686 │ │ │ │ 687 │ │ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn) │ │ ❱ 688 │ │ outputs = self.model( │ │ 689 │ │ │ input_ids=input_ids, │ │ 690 │ │ │ attention_mask=attention_mask, │ │ 691 │ │ │ position_ids=position_ids, │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/torch/nn/modules/module.py:1501 in │ │ _call_impl │ │ │ │ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │ │ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │ │ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │ │ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │ │ 1502 │ │ # Do not call functions when jit is used │ │ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │ │ 1504 │ │ backward_pre_hooks = [] │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/accelerate/hooks.py:165 in new_forward │ │ │ │ 162 │ │ │ with torch.no_grad(): │ │ 163 │ │ │ │ output = old_forward(*args, **kwargs) │ │ 164 │ │ else: │ │ ❱ 165 │ │ │ output = old_forward(*args, **kwargs) │ │ 166 │ │ return module._hf_hook.post_forward(module, output) │ │ 167 │ │ │ 168 │ module.forward = new_forward │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/transformers/models/llama/modeling_llam │ │ a.py:570 in forward │ │ │ │ 567 │ │ │ │ │ │ │ 568 │ │ │ │ │ return custom_forward │ │ 569 │ │ │ │ │ │ ❱ 570 │ │ │ │ layer_outputs = torch.utils.checkpoint.checkpoint( │ │ 571 │ │ │ │ │ create_custom_forward(decoder_layer), │ │ 572 │ │ │ │ │ hidden_states, │ │ 573 │ │ │ │ │ attention_mask, │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/torch/utils/checkpoint.py:249 in │ │ checkpoint │ │ │ │ 246 │ │ raise ValueError("Unexpected keyword arguments: " + ",".join(arg for arg in kwar │ │ 247 │ │ │ 248 │ if use_reentrant: │ │ ❱ 249 │ │ return CheckpointFunction.apply(function, preserve, *args) │ │ 250 │ else: │ │ 251 │ │ return _checkpoint_without_reentrant( │ │ 252 │ │ │ function, │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/torch/autograd/function.py:506 in apply │ │ │ │ 503 │ │ if not torch._C._are_functorch_transforms_active(): │ │ 504 │ │ │ # See NOTE: [functorch vjp and autograd interaction] │ │ 505 │ │ │ args = _functorch.utils.unwrap_dead_wrappers(args) │ │ ❱ 506 │ │ │ return super().apply(*args, **kwargs) # type: ignore[misc] │ │ 507 │ │ │ │ 508 │ │ if cls.setup_context == _SingleLevelFunction.setup_context: │ │ 509 │ │ │ raise RuntimeError( │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/torch/utils/checkpoint.py:107 in │ │ forward │ │ │ │ 104 │ │ ctx.save_for_backward(*tensor_inputs) │ │ 105 │ │ │ │ 106 │ │ with torch.no_grad(): │ │ ❱ 107 │ │ │ outputs = run_function(*args) │ │ 108 │ │ return outputs │ │ 109 │ │ │ 110 │ @staticmethod │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/transformers/models/llama/modeling_llam │ │ a.py:566 in custom_forward │ │ │ │ 563 │ │ │ │ def create_custom_forward(module): │ │ 564 │ │ │ │ │ def custom_forward(*inputs): │ │ 565 │ │ │ │ │ │ # None for past_key_value │ │ ❱ 566 │ │ │ │ │ │ return module(*inputs, output_attentions, None) │ │ 567 │ │ │ │ │ │ │ 568 │ │ │ │ │ return custom_forward │ │ 569 │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/torch/nn/modules/module.py:1501 in │ │ _call_impl │ │ │ │ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │ │ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │ │ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │ │ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │ │ 1502 │ │ # Do not call functions when jit is used │ │ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │ │ 1504 │ │ backward_pre_hooks = [] │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/accelerate/hooks.py:165 in new_forward │ │ │ │ 162 │ │ │ with torch.no_grad(): │ │ 163 │ │ │ │ output = old_forward(*args, **kwargs) │ │ 164 │ │ else: │ │ ❱ 165 │ │ │ output = old_forward(*args, **kwargs) │ │ 166 │ │ return module._hf_hook.post_forward(module, output) │ │ 167 │ │ │ 168 │ module.forward = new_forward │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/transformers/models/llama/modeling_llam │ │ a.py:292 in forward │ │ │ │ 289 │ │ hidden_states = self.input_layernorm(hidden_states) │ │ 290 │ │ │ │ 291 │ │ # Self Attention │ │ ❱ 292 │ │ hidden_states, self_attn_weights, present_key_value = self.self_attn( │ │ 293 │ │ │ hidden_states=hidden_states, │ │ 294 │ │ │ attention_mask=attention_mask, │ │ 295 │ │ │ position_ids=position_ids, │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/torch/nn/modules/module.py:1501 in │ │ _call_impl │ │ │ │ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │ │ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │ │ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │ │ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │ │ 1502 │ │ # Do not call functions when jit is used │ │ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │ │ 1504 │ │ backward_pre_hooks = [] │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/accelerate/hooks.py:165 in new_forward │ │ │ │ 162 │ │ │ with torch.no_grad(): │ │ 163 │ │ │ │ output = old_forward(*args, **kwargs) │ │ 164 │ │ else: │ │ ❱ 165 │ │ │ output = old_forward(*args, **kwargs) │ │ 166 │ │ return module._hf_hook.post_forward(module, output) │ │ 167 │ │ │ 168 │ module.forward = new_forward │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/transformers/models/llama/modeling_llam │ │ a.py:194 in forward │ │ │ │ 191 │ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]: │ │ 192 │ │ bsz, q_len, _ = hidden_states.size() │ │ 193 │ │ │ │ ❱ 194 │ │ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self. │ │ 195 │ │ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.he │ │ 196 │ │ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self. │ │ 197 │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/torch/nn/modules/module.py:1501 in │ │ _call_impl │ │ │ │ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │ │ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │ │ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │ │ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │ │ 1502 │ │ # Do not call functions when jit is used │ │ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │ │ 1504 │ │ backward_pre_hooks = [] │ │ │ │ /root/miniconda3/envs/train/lib/python3.10/site-packages/peft/tuners/lora.py:565 in forward │ │ │ │ 562 │ │ │ │ self.unmerge() │ │ 563 │ │ │ result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self. │ │ 564 │ │ elif self.r[self.active_adapter] > 0 and not self.merged: │ │ ❱ 565 │ │ │ result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self. │ │ 566 │ │ │ │ │ 567 │ │ │ x = x.to(self.lora_A[self.active_adapter].weight.dtype) │ │ 568 │ ╰──────────────────────────────────────────────────────────────────────────────────────────────────╯ RuntimeError: mat1 and mat2 shapes cannot be multiplied (327x4096 and 1x8388608)
返回再看源码感觉是lomo_lora_trainer里

的问题。
请问如果需要完全剔除deepspeed并想要成功运行LOMO+QLoRA,我应该做何修改?
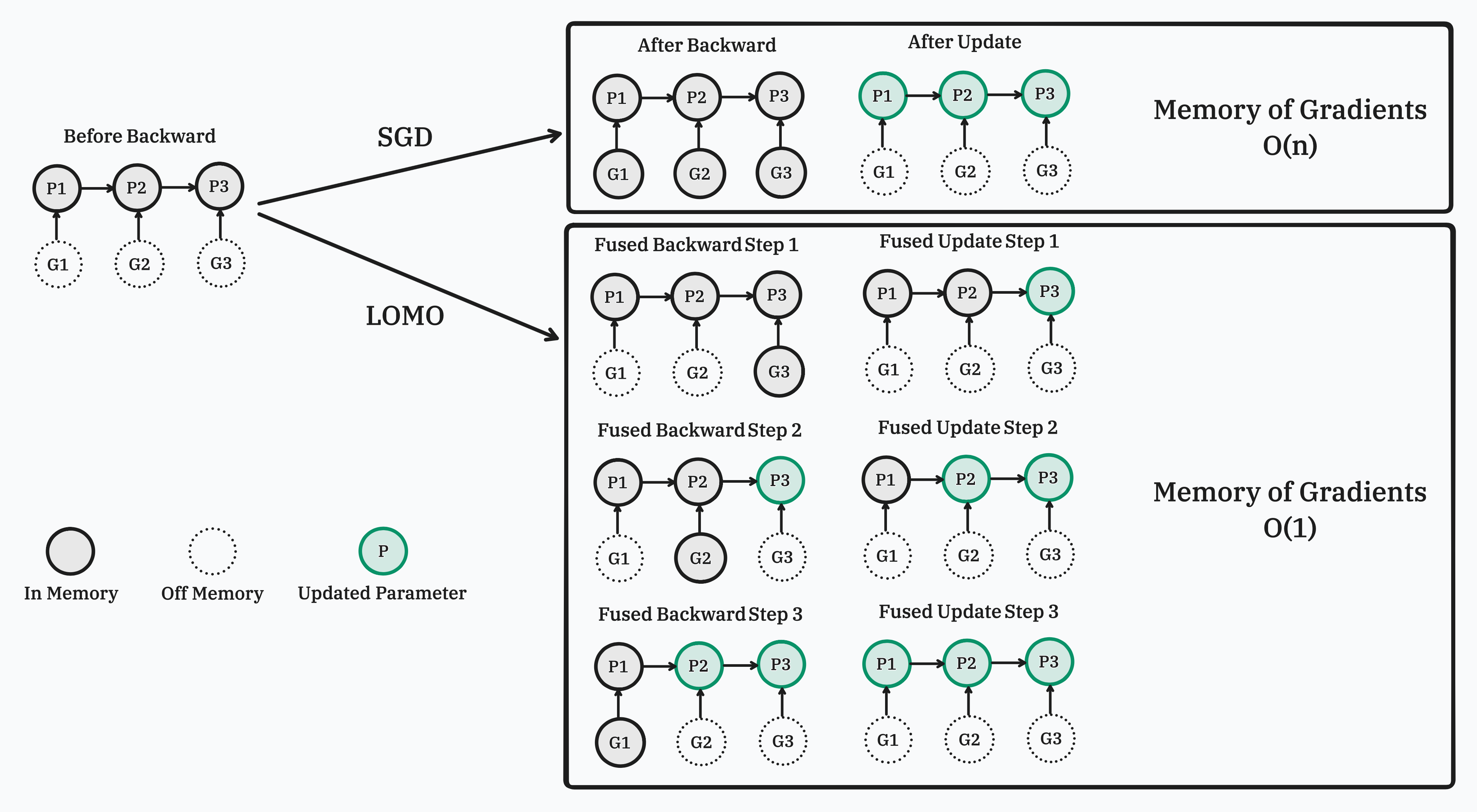
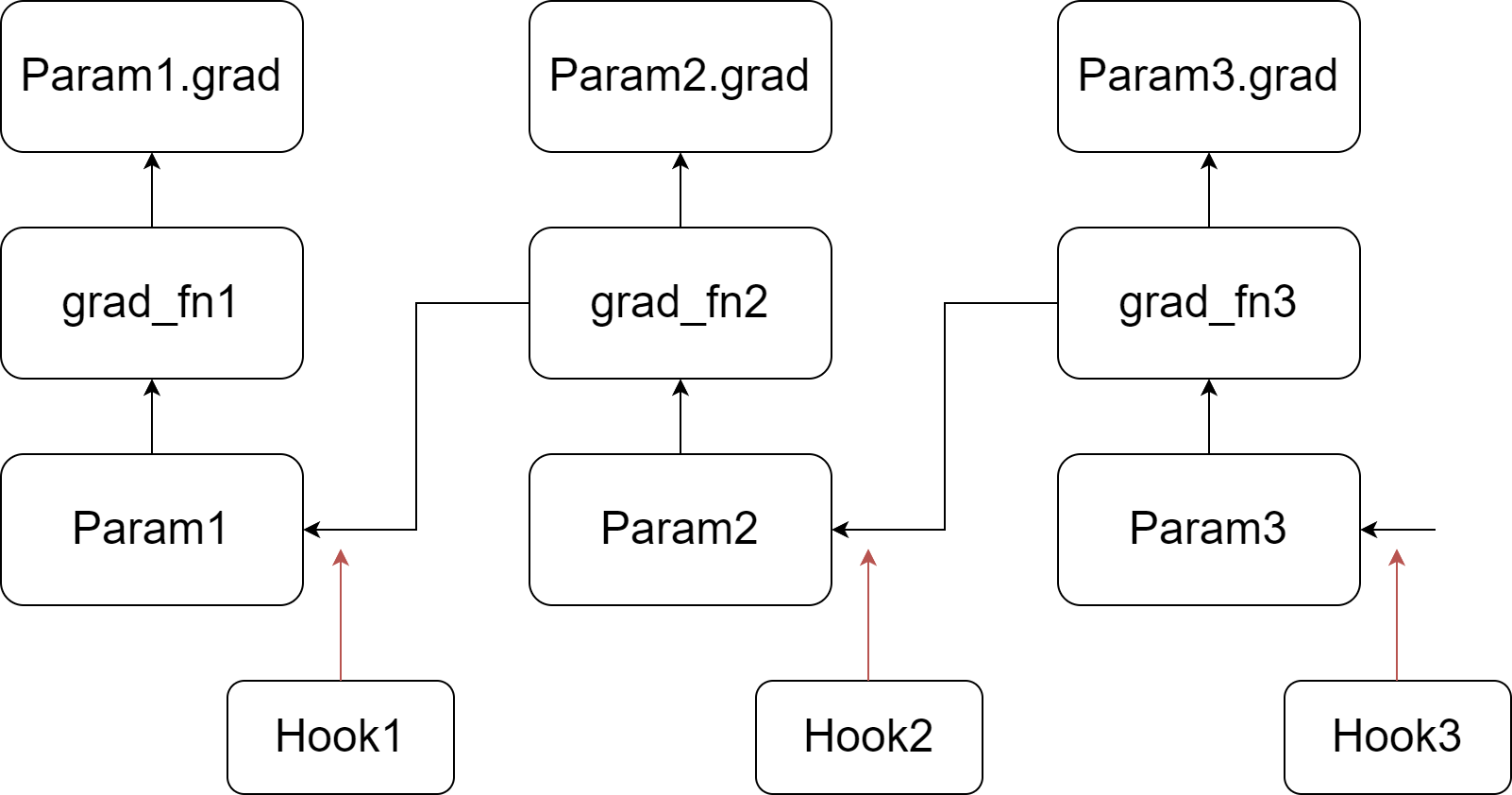 Our implementation relies on injecting hook functions into PyTorch's backward pass. As depicted in the figure, we register a customized hook function for each parameter. When the gradient of a parameter is computed (prior to writing it to the .grad attribute), its corresponding hook function is invoked. For more information about hook functions and the backward pass of the autograd graph, please refer to PyTorch's documentation. In summary, during the backward pass, we go through a tensor and its grad_fn, write the gradient into the .grad attribute, and then pass to the next tensor.
Our implementation relies on injecting hook functions into PyTorch's backward pass. As depicted in the figure, we register a customized hook function for each parameter. When the gradient of a parameter is computed (prior to writing it to the .grad attribute), its corresponding hook function is invoked. For more information about hook functions and the backward pass of the autograd graph, please refer to PyTorch's documentation. In summary, during the backward pass, we go through a tensor and its grad_fn, write the gradient into the .grad attribute, and then pass to the next tensor.
































































































































