A set of a misc tools to work with files and processes.
Various oldish helper binaries I wrote to help myself with day-to-day tasks.
License for all scripts is WTFPL (public domain-ish), feel free to just copy and use these in whatever way you like.
Mostly file/link/dir-entry manipulation tools.
A set of tools to bind a bunch of scattered files to a single path, with completely unrelated internal path structure. Intended usage is to link configuration files to scm-controlled path (repository).
Actually started as cfgit project, but then evolved away from git vcs into a more generic, not necessarily vcs-related, solution.
Adds a new link (symlink or catref) to a manifest (links-list), also moving file to scim-tree (repository) on fs-level.
Main tool to check binding and metadata of files under scim-tree. Basic operation boils down to two (optional) steps:
- Check files' metadata (uid, gid, mode, acl, posix capabilities) against metadata-list (
.scim_meta, by default), if any, updating the metadata/list if requested, except for exclusion-patterns (.scim_meta_exclude). - Check tree against links-list (
.scim_links), warning about any files / paths in the same root, which aren't on the list, yet not in exclusion patterns (.scim_links_exclude).
Tool to restore POSIX ACLs on paths, broken by chmod or similar stuff without actually changing them.
Tool to sync paths, based on berkley db and rsync.
Keeps b-tree of paths (files and dirs) and corresponding mtimes in berkdb, comparing state when ran and building a simple merge-filter for rsync (+ /path line for each changed file/dir, including their path components, ending with - *). Then it runs a single rsync with this filter to efficiently sync the paths.
Note that the only difference from "rsync -a src dst" here is that "dst" tree doesn't have to exist on fs, otherwise scanning "dst" should be pretty much the same (and probably more efficient, depending on fs implementation) b-tree traversal as with berkdb.
Wrote it before realizing that it's quite pointless for my mirroring use-case -I do have full source and destination trees, so rsync can be used to compare (if diff file-list is needed) or sync them.
Complex tool for high-level fs operations. Reference is built-in.
Copy files, setting mode and ownership for the destination:
fs -m600 -o root:wheel cp * /somepathTemporarily (1hr) change attributes (i.e. to edit file from user's editor):
fs -t3600 -m600 -o someuser expose /path/to/fileCopy ownership/mode from one file to another:
fs cps /file1 /file2fatrace-based script to read filesystem write events via linux fanotify system and match them against specific path and app name, sending matches to a FIFO pipe.
Use-case is to, for example, setup watcher for development project dir changes, sending instant "refresh" signals to something that renders the project or shows changes' results otherwise.
FIFO is there because fanotify requires root privileges, and running some potentially-rm-rf-/ ops as uid=0 is a damn bad idea. User's pid can read lines from the fifo and react to these safely instead.
Example - run "make" on any change to ~user/hatch/project files:
(root) ~# fatrace-pipe ~user/hatch/project
(user) project% xargs -in1 </tmp/fatrace.fifo makeScript to remove older kernel versions (as installed by /sbin/installkernel) from /boot or similar dir.
Always keeps version linked as "vmlinuz", and prioritizes removal of older patchset versions from each major one, and only then latest per-major patchset, until free space goal (specified percentage, 20% by default) is met.
Also keeps specified number of last-to-remove versions, can prioritize cleanup of ".old" verssion variants, keep config-* files... and other stuff (see --help).
Example:
# clean-boot --debug --dry-run -f 100
DEBUG:root:Preserved versions (linked version, its ".old" variant, --keep-min): 4
DEBUG:root: - 3.9.9.1 - System.map-3.9.9-fg.mf_master
DEBUG:root: - 3.9.9.1 - config-3.9.9-fg.mf_master
DEBUG:root: - 3.9.9.1 - vmlinuz-3.9.9-fg.mf_master
DEBUG:root: - 3.10.27.1 - vmlinuz-3.10.27-fg.mf_master
...
DEBUG:root: - 3.12.19.1 - System.map-3.12.19-fg.mf_master
DEBUG:root: - 3.12.20.1 - config-3.12.20-fg.mf_master
DEBUG:root: - 3.12.20.1 - System.map-3.12.20-fg.mf_master
DEBUG:root: - 3.12.20.1 - vmlinuz-3.12.20-fg.mf_master
DEBUG:root:Removing files for version (df: 58.9%): 3.2.0.1
DEBUG:root: - System.map-3.2.0-fg.mf_master
DEBUG:root: - config-3.2.0-fg.mf_master
DEBUG:root: - vmlinuz-3.2.0-fg.mf_master
DEBUG:root:Removing files for version (df: 58.9%): 3.2.1.0
... (removal of older patchsets for each major version, 3.2 - 3.12)
DEBUG:root:Removing files for version (df: 58.9%): 3.12.18.1
... (this was the last non-latest patchset-per-major)
DEBUG:root:Removing files for version (df: 58.9%): 3.2.16.1
... (removing latest patchset for each major version, starting from oldest - 3.2 here)
DEBUG:root:Removing files for version (df: 58.9%): 3.7.9.1
...
DEBUG:root:Removing files for version (df: 58.9%): 3.8.11.1
...
DEBUG:root:Finished (df: 58.9%, versions left: 4, versions removed: 66).("df" doesn't rise here because of --dry-run, -f 100 = "remove all non-preserved" - as df can't really get to 100%)
Note how 3.2.0.1 (non-.old 3.2.0) gets removed first, then 3.2.1, 3.2.2, and so on, but 3.2.16 (latest of 3.2.X) gets removed towards the very end, among other "latest patchset for major" versions, except those that are preserved unconditionally (listed at the top).
Wrapper around GNU find to accept paths at the end of argv if none are passed before query.
Makes it somewhat more consistent with most other commands that accept options and a lists of paths (almost always after opts), but still warns when/if reordering takes place.
No matter how many years I'm using that tool, still can't get used to typing paths before query there, so decided to patch around that frustrating issue one day.
Simple script to grab a file using wget and then validate checksum of the result, e.g.:
$ wgets -c http://os.archlinuxarm.org/os/ArchLinuxARM-sun4i-latest.tar.gz cea5d785df19151806aa5ac3a917e41c
Using hash: md5
Using output filename: ArchLinuxARM-sun4i-latest.tar.gz
--2014-09-27 00:04:45-- http://os.archlinuxarm.org/os/ArchLinuxARM-sun4i-latest.tar.gz
Resolving os.archlinuxarm.org (os.archlinuxarm.org)... 142.4.223.96, 67.23.118.182, 54.203.244.41, ...
Connecting to os.archlinuxarm.org (os.archlinuxarm.org)|142.4.223.96|:80... connected.
HTTP request sent, awaiting response... 416 Requested Range Not Satisfiable
The file is already fully retrieved; nothing to do.
Checksum matchedBasic invocation syntax is wgets [ wget_opts ] url checksum, checksum is hex-decoded and hash func is auto-detected from its length (md5, sha-1, all sha-2's are supported).
Idea is that - upon encountering an http link with either checksum on the page or in the file nearby - you can easily run the thing providing both link and checksum to fetch the file.
If checksum is available in e.g. *.sha1 file alongside the original one, it might be a good idea to fetch that checksum from any remote host (e.g. via "curl" from any open ssh session), making spoofing of both checksum and the original file a bit harder.
Things that manipulate whatever file contents.
Tool to process znc chat logs, produced by "log" module (global, per-user or per-network - looks everywhere) and store them using following schema:
<net>/chat/<channel>__<yy>-<mm>.log.xz
<net>/priv/<nick>__<yy>-<mm>.log.xzWhere "priv" differs from "chat" in latter being prefixed by "#" or "&". Values there are parsed according to any one of these (whichever matches first):
users/<net>/moddata/log/<chan>_<date>.logmoddata/log/<net>_default_<chan>_<date>.log(no "_" in<net>allowed)moddata/log/<user>_<net>_<chan>_<date>.log(no "_" in<user>or<net>allowed)
Each line gets processed by regexp to do [HH:MM:SS] <nick> some msg -> [yy-mm-dd HH:MM:SS] <nick> some msg.
Latest (current day) logs are skipped. New logs for each run are concatenated to the monthly .xz file.
Should be safe to stop at any time without any data loss - all the resulting .xz's get written to temporary files and renamed at the very end (followed only by unlinking of the source files).
All temp files are produced in the destination dir and should be cleaned-up on any abort/exit/finish.
Idea is to have more convenient hierarchy and less files for easier shell navigation/grepping (xzless/xzgrep), plus don't worry about the excessive space usage in the long run.
Same as znc-log-aggregator above, but seeks/reads specific tail ("last n lines") or time range (with additional filtering by channel/nick and network) from all the current and aggregated logs.
This one is for simple pcre-based text replacement, basically a sed's "s/from/to/" command with lookahead/lookbehind assertions.
Example, to replace all two-space indents with tabs and drop space-based inline alignment:
% pysed '(?<=\w)\s+(?=\w)' ' ' '^\s* ' '\t' -i10 -b somecode.pyUnlike tool from coreutils, can overwrite files with sorted results (e.g. pysort -b file_a file_b && diff file_a file_b) and has some options for splitting fields and sorting by one of these (example: pysort -d: -f2 -n /etc/passwd).
Outputs terminal color sequences, making important output more distinctive.
Also can be used to interleave "tail -f" of several logfiles in the same terminal:
% t -f /var/log/app1.log | color red - &
% t -f /var/log/app2.log | color green - &
% t -f /var/log/app2.log | color blue - &Script (py3) to find all specified (either directly, or by regexp) hostnames and replace these with corresponding IP addresses, resolved through getaddrinfo(3).
Examples:
% cat cjdroute.conf
... "fraggod.net:21987": { ... },
"localhost:21987": { ... },
"fraggod.net:12345": { ... }, ...
% resolve-hostnames fraggod.net localhost < cjdroute.conf
... "192.168.0.11:21987": { ... },
"127.0.0.1:21987": { ... },
"192.168.0.11:12345": { ... }, ...
% resolve-hostnames -m '"(?P<name>[\w.]+):\d+"' < cjdroute.conf
% resolve-hostnames fraggod.net:12345 < cjdroute.conf
% resolve-hostnames -a inet6 fraggod.net localhost < cjdroute.conf
...
% cat nftables.conf
define set.gw.ipv4 = { !ipv4.name1.local, !ipv4.name2.local }
define set.gw.ipv6 = { !ipv6.name1.local, !ipv6.name2.local }
...
# Will crash nft-0.6 because it treats names in anonymous sets as AF_INET (ipv4 only)
% resolve-hostnames -rum '!(\S+\.local)\b' -f nftables.conf
define set.gw.ipv4 = { 10.12.34.1, 10.12.34.2 }
define set.gw.ipv6 = { fd04::1, fd04::2 }
...Useful a as conf-file pre-processor for tools that cannot handle names properly (e.g. introduce ambiguity, can't deal with ipv4/ipv6, use weird resolvers, do it dynamically, etc) or should not be allowed to handle these, convert lists of names (in some arbitrary format) to IP addresses, and such.
Has all sorts of failure-handling and getaddrinfo-control cli options, can resolve port/protocol names as well.
Python-3/Jinja2 script to produce a text file from a template, focused specifically on templating configuration files, somewhat similar to "resolve-hostnames" above or templating provided by ansible/saltstack.
Jinja2 env for template has following filters and values:
dns(host [, af, proto, sock, default, force_unique=True])filter/global.getaddrinfo(3) wrapper to resolve
host(name or address) with optional parameters to a single address, raising exception if it's non-unique by default.af/proto/sock values can be either enum value names (without AF/SOL/SOCK prefix) or integers.
hosts- /etc/hosts as a mapping.For example, hosts-file line
1.2.3.4 sub.host.example.orgwill produce following mapping (represented as yaml):sub.host.example.org: 1.2.3.4 host.example.org: sub: 1.2.3.4 org: example: host: sub: 1.2.3.4Can be used as a reliable dns/network-independent names.
--hosts-optscli option allows some tweaks wrt how that file is parsed.iface- current network interfaces and IPv4/IPv6 addresses assigned there (fetched from libc getifaddrs via ctypes).Example value structure (as yaml):
enp1s0: - 10.0.0.134 - fd00::134 - 2001:470:1f0b:11de::134 - fe80::c646:19ff:fe64:632f enp2s7: - 10.0.1.1 lo: - 127.0.0.1 - ::1 ip_vti0: []Probably a good idea to use this stuff only when IPs are static and get assigned strictly before templating.
{% comment_out_if value[, comment-prefix] %}...{% comment_out_end %}Custom template block to prefix each non-empty line within it with specified string (defaults to "#") if value is not false-y.
Can be used when format doesn't have block comments, but it's still desirable to keep disabled things in dst file (e.g. for manual tinkering) instead of using if-blocks around these, or to make specific lines easier to uncomment manually.
it- itertools,_v/v_/_v_- global funcs for adding spaces before/after/around non-empty strings.- Whatever is loaded from
--conf-file/--conf-dir(JSON/YAML files), if specified.
Use-case is a simple conf-file pre-processor for autonomous templating on service startup with a minimal toolbox on top of jinja2, without huge dep-tree or any other requirements and complexity, that is not scary to run from ExecStartPre= line as root.
Tool to temporarily modify (patch) a file - until reboot or for a specified amount of time. Uses bind-mounts from tmpfs to make sure file will be reverted to the original state eventually.
Useful to e.g. patch /etc/hosts with (pre-defined) stuff from LAN on a laptop (so this changes will be reverted on reboot), or a notification filter file for a short "busy!" time period (with a time limit, so it'll auto-revert after), or stuff like that.
Even though dst file is mounted with "-o ro" by default (there's "-w" option to disable that), linux doesn't seem to care about that option and mounts the thing as "rw" anyway, so "chmod a-w" gets run on temp file instead to prevent accidental modification (that can be lost).
There're also "-t" and "-m" flags to control timestamps during the whole process.
Disables terminal echo and outputs line-buffered stdin to stdout.
Use-case is grepping through huge multiline strings (e.g. webpage source) pasted into terminal, i.e.:
% term-pipe | g -o '\<http://[^"]\+'
[pasting page here via e.g. Shift+Insert won't cause any echo]
http://www.w3.org/TR/html4/loose.dtd
http://www.bugzilla.org/docs/3.4/en/html/bug_page.html
...There are better tools for that particular use-case, but this solution is universal wrt any possible input source.
Converts yaml files to an indented json, which is a bit more readable and editable by hand than the usual compact one-liner serialization.
Due to yaml itself being json superset, can be used to convert json to pretty-json as well.
Same thing as the common "head" tool, but works with \x00 (aka null character, null byte, NUL, ␀, \0, \z, \000, \u0000, %00, ^@) delimeters.
Can be done with putting "tr" in the pipeline before and after "head", but this one is probably less fugly.
Allows replacing input null-bytes with newlines in the output (--replace-with-newlines option) and vice-versa.
Common use-case is probably has something to do with filenames and xargs, e.g.:
% find -type f -print0 | shuf -z | hz -10 | xargs -0 some-cool-command
% ls -1 | hz -z | xargs -0 some-other-commandI have "h" as an alias for "head" in shells, so "head -z" (if there were such option) would be aliased neatly to "hz", hence the script name.
Defaults to reading ALL lines, not just arbitrary number (like 10, which is default for regular "head")!
"Log Interleaver And Colorizer" python script.
Reads lines from multiple files, ordering them by the specified field in the output (default - first field, e.g. ISO8601 timestamp) and outputs each with (optional) unique-filename-part prefix and unique (ansi-terminal, per-file) color.
Most useful for figuring out sequence of events from multiple timestamped logs.
To have safely-rotated logs with nice timestamps from any arbitrary command's output, something like stdbuf -oL <command-and-args> | svlogd -r _ -ttt <log-dir> can be used. Note "stdbuf" coreutils tool, used there to tweak output buffering, which usually breaks such timestamps, and "svlogd" from runit suite (no deps, can be built separately).
See blog post about liac tool for more info.
Script to create "fat" HTML files, embedding all linked images (as base64-encoded data-urls), stylesheets and js into them.
All src= and href= paths must be local (e.g. "js/script.js" or "/css/main.css"), and will simply be treated as path components (stripping slashes on the left) from html dir, nothing external (e.g. "//site.com/stuff.js") will be fetched.
Doesn't need anything but Python-3, based on stdlib html.parser module.
Not optimized for huge amounts of embedded data, storing all the substitutions in memory while it runs, and is unsafe to run on random html files, as it can embed something sensitive (e.g. <img src="../.ssh/id_rsa">) - no extra checks there.
Use-case is to easily produce single-file webapps or pages to pass around (or share somewhere), e.g. some d3-based interactive chart page or an html report with a few embedded images.
Python (2 or 3) script to feed /dev/random linux entropy pool, to e.g. stop dumb tools like gpg blocking forever on pacman --init in a throwaway chroot.
Basically haveged or rngd replacement for bare-bones chroots that don't have either, but do have python.
Probably a bad idea to use it for anything other than very brief workarounds for such tools on an isolated systems that don't run anything else crypto-related.
Shouldn't compromise deterministic stuff though, e.g. dm-crypt operation (except new key generation in cryptsetup or such).
My secret weapon in tabs-vs-spaces holywar.
In my emacs, tab key always inserts "", marking spaces as a bug with develock-mode. This script transparently converts all indent-tabs into spaces and back, designed to be used from git content filters, and occasionally by hand.
.git/config:
[filter "tabs"]
clean = tabs_filter clean %f
smudge = tabs_filter smudge %f.git/info/attributes or .gitattributes:
*.py filter=tabs
*.tac filter=tabsNot sure why people have such strong opinions on that trivial matter, but I find it easier never to mention that I use such script ;)
Same idea as in "tabs_filter", but on a larger scale - basically does to Go what coffee-script does to the syntax of javascript - drops all the unnecessary brace-cancer, with the ability to restore original perfectly ("diff -u reverse original" is checked upon transformation to make sure of that), as long as code intentation is correct.
.git/config:
[filter "golang"]
clean = golang_filter git-clean %f
smudge = golang_filter git-smudge %f.git/info/attributes or .gitattributes:
*.go filter=golangAgain, ideally no one should even notice that I actually don't have that crap in the editor, while repo and compiler will see the proper (bloated) code.
Tool to auto-update python package metadata in setup.py and README files.
Uses python ast module to parse setup.py to find "version" keyword there and update it (via simple regex replacement, not sure if ast can be converted back to code properly), based on date and current git revision number, producing something like "12.04.58" (year.month.revision-since-month-start).
Also generates (and checks with docutils afterwards) README.txt (ReST) from README.md (Markdown) with pandoc, if both are present and there's no README or README.rst.
Designed to be used from pre-commit hook, like ln -s /path/to/distribute_regen .git/hooks/pre-commit, to update version number before every commit.
Ad-hoc tool to dissect and convert darcs bundles into a sequence of unified diff hunks. Handles file creations and all sorts of updates, but probably not moves and removals, which were outside my use-case at the moment.
Was written for just one occasion (re-working old bundles attached to tahoe-lafs tickets, which crashed darcs on "darcs apply"), so might be incomplete and a bit out-of-date, but I imagine it shouldn't take much effort to make it work with any other bundles.
Script to read NYM env var and run git using that ssh id instead of whatever ssh-agent or e.g. ~/.ssh/id_rsa provides.
NYM var is checked for either full path to the key, basename in ~/.ssh, name like ~/.ssh/id_{rsa,ecdsa,ed25519}__${NYM} or unique (i.e. two matches will cause error, not random pick) match for one of ~/.ssh/id_* name part.
Can be used as NYM=project-x git-nym clone [email protected]:component-y to e.g. clone the specified repo using ~/.ssh/id_rsa__project-x key or as NYM=project-x git nym clone ....
Also to just test new keys with git, disregarding ssh-agent and lingering control sockets with NYM_CLEAN flag set.
Git-command replacement for git-diff to run meld instead of regular (git-provided) textual diff, but aggregating all the files into one invocation.
For instance, if diffs are in server.py and client.py files, running git meld will run something like:
meld \
--diff /tmp/.git-meld/server.py.hash1 /tmp/.git-meld/server.py.hash2 \
--diff /tmp/.git-meld/client.py.hash1 /tmp/.git-meld/client.py.hash2Point is to have all these diffs in meld tabs (with one window per git meld) instead of running separate meld window/tab on each pair of files as setting GIT_EXTERNAL_DIFF would do.
Should be installed as git-meld somewhere in PATH and symlinked as meld-git (git-meld runs GIT_EXTERNAL_DIFF=meld-git git diff "$@") to work.
Similar to "cat" (specifically coreutils' cat -n file), but shows specific line in a file with a few "context" lines around it:
% catn js/main.js 188
185: projectionTween = function(projection0, projection1) {
186: return function(d) {
187: var project, projection, t;
>> 188: project = function(λ, φ) {
189: var p0, p1, _ref1;
190: λ *= 180 / Math.PI;
191: φ *= 180 / Math.PI;Above command is synonymous to catn js/main.js 188 3, catn js/main.js:188 and catn js/main.js:188:3, where "3" means "3 lines of context" (can be omitted as 3 is the default value there).
catn -q ... outputs line + context verbatim, so it'd be more useful for piping to another file/command or terminal copy-paste.
Script to permanently delete files/folders from repository and its history -including "dangling" objects where these might still exist.
Should be used from repo root with a list of paths to delete, e.g. git_terminate path1 path2.
WARNING: will do things like git reflog expire and git gc with agressive parameters on the whole repository, so any other possible history not stashed or linked to existing branches/remotes (e.g. stuff in git reflog) will be purged.
Checks if passed tree-ish (hash, trimmed hash, branch name, etc - see "SPECIFYING REVISIONS" in git-rev-parse(1)) object(s) exist (e.g. merged) in a specified git repo/tree-ish.
Essentially does git rev-list <tree-ish2> | grep $(git rev-parse <tree-ish1>).
% git_contains -C /var/src/linux-git ee0073a1e7b0ec172
[exit status=0, hash was found]
% git_contains -C /var/src/linux-git ee0073a1e7b0ec172 HEAD notarealthing
Missing:
notarealthing
[status=2 right when rev-parse fails before even starting rev-list]
% git_contains -C /var/src/linux-git -H v3.5 --quiet ee0073a1e7b0ec172
[status=2, this commit is in HEAD, but not in v3.5 (tag), --quiet doesn't produce stdout]
% git_contains -C /var/src/linux-git --any ee0073a1e7b0ec172 notarealthing
[status=0, ee0073a1e7b0ec172 was found, and it's enough with --any]
% git_contains -C /var/src/linux-git --strict notarealthing
fatal: ambiguous argument 'notarealting': unknown revision or path not in the working tree.
Use '--' to separate paths from revisions, like this:
'git <command> [<revision>...] -- [<file>...]'
git rev-parse failed for tree-ish 'notarealting' (command: ['git', 'rev-parse', 'notarealting'])Lines in square brackets above are comments, not actual output.
Renders gtk3 window with a slider widget and writes value (float or int) picked there either to stdout or to a specified file, with some rate-limiting delay.
Useful to mock/control values on a dev machine.
E.g. instead of hardware sensors (which might be hard to get/connect/use), just setup app to read value(s) that should be there from file(s), specify proper value range to the thing and play around with values all you want to see what happens.
There's a Dashboard-for-... blog post with more details.
root@damnation:~# systemd-dashboard -h
usage: systemd-dashboard [-h] [-s] [-u] [-n] [-x]
Tool to compare the set of enabled systemd services against currently running
ones. If started without parameters, it'll just show all the enabled services
that should be running (Type != oneshot) yet for some reason they aren't.
optional arguments:
-h, --help show this help message and exit
-s, --status Show status report on found services.
-u, --unknown Show enabled but unknown (not loaded) services.
-n, --not-enabled Show list of services that are running but are not
enabled directly.
-x, --systemd-internals
Dont exclude systemd internal services from the
output.
root@damnation:~# systemd-dashboard
smartd.service
systemd-readahead-replay.service
apache.serviceReplacement for standard unix'ish "atd" daemon in the form of a bash script.
It just forks out and waits for however long it needs before executing the given command. Unlike with atd, such tasks won't survive reboot, obviously.
Usage: ./at [ -h | -v ] when < sh_script
With -v flag ./at mails script output if it's not empty even if exit code is zero.Simple bash wrapper for sendmail command, generating From/Date headers and stuff, just like mailx would do, but also allowing to pass custom headers (useful for filtering error reports by-source), which some implementations of "mail" fail to do.
Uses adict english dictionaly to generate easy-to-remember passphrase. Should be weak if bruteforce attack picks words instead of individual lettters.
Script to keep persistent, unique and reasonably responsive ssh tunnel. Mostly just a wrapper with collection of options for such use-case.
Python 3.6+ (asyncio) scripts to establish multiple ssh reverse-port-forwarding ("ssh -R") connections to the same tunnel-server from mutliple hosts using same exact configuration on each.
Normally, first client host will bind the "ssh -R" listening port and all others will fail, but these two scripts negotiate unique port within specified range to each host, so there are no clashes and all tunnels work fine.
Tunnel server also stores allocated ports in a db file, so that each client gets more-or-less persistent listening port.
Each client negotiates port before exec'ing "ssh -R" command, identifying itself via --ident-* string (derived from /etc/machine-id by default), and both client/server need to use same -s/--auth-secret to create/validate MACs in each packet.
Python (3.6+) wrapper for mosh-server binary to do UDP hole punching through local NAT setup before starting it.
Comes with mosh-nat-bind.c source for LD_PRELOAD=./mnb.so lib to force mosh-client on the other side to use specific local port that was used in "mosh-nat".
Example usage (server at 84.217.173.225, client at 74.59.38.152):
server% ./mosh-nat 74.59.38.152
mosh-client command:
MNB_PORT=34730 LD_PRELOAD=./mnb.so
MOSH_KEY=rYt2QFJapgKN5GUqKJH2NQ mosh-client <server-addr> 34730
client% MNB_PORT=34730 LD_PRELOAD=./mnb.so \
MOSH_KEY=rYt2QFJapgKN5GUqKJH2NQ mosh-client 84.217.173.225 34730Notes:
- mnb.so is mosh-nat-bind.c lib. Check its header for command to build it.
- Both mnb.so and mosh-nat only work with IPv4, IPv6 shouldn't use NAT anyway.
- Should only work like that when NAT on either side doesn't rewrite src ports.
- 34730 is default for -c/--client-port and -s/--server-port opts.
- Started mosh-server waits for 60s (default) for mosh-client to connect.
- Continous operation relies on mosh keepalive packets without interruption.
- No roaming of any kind is possible here.
- New MOSH_KEY is generated by mosh-server on every run.
Useful for direct and fast connection when there's some other means of access available already, e.g. ssh through some slow/indirect tunnel or port forwarding setup.
See mobile-shell/mosh#623 for more info and links on such feature implemented in mosh directly.
Source for LD_PRELOAD lib is based on https://github.com/yongboy/bindp/
Simple script to parse long URL with lots of parameters, decode and print it out in an easily readable ordered YAML format or diff (that is, just using "diff" command on two outputs) with another URL.
No more squinting at some huge incomprehensible ecommerce URLs before scraping the hell out of them!
Do openssl s_client -connect somesite </dev/null | openssl x509 -fingerprint -noout -sha1 in a nicer way - openssl cli tool doesn't seem to have that.
Also can be passed socks proxy IP:PORT to use socat and pipe openssl connection through it - for example, to get fingerprint over Tor (with SocksAddress localhost:1080) link:
% openssl-fingerprint google.com localhost:1080
SHA1 Fingerprint=A8:7A:93:13:23:2E:97:4A:08:83:DD:09:C4:5F:37:D5:B7:4E:E2:D4Tool to load/dump stored graphite graphs through formats easily editable by hand.
For example, creating even one dashboard there is a lot of clicky-clicks, and 10 slightly different dashboards is mission impossible, but do graphite-scratchpad dash:top (loaded straight from graphite db) and you get:
name: top
defaultGraphParams:
from: -24hours
height: 250
until: -20minutes
width: 400
...
graphs:
- target:
- *.memory.allocation.reclaimable
- target:
- *.disk.load.sdb.utilization
- *.disk.load.sda.utilization
yMax: 100
yMin: 0
- target:
- *.cpu.all.idle
yMax: 100
yMin: 0
...That's all graph-building data in an easily readable, editable and parseable format (yaml, nicely-spaced with pyaml module).
Edit that and do graphite-scratchpad yaml dash:top < dash.yaml to replace the thing in graphite db with an updated thing. Much easier than doing anything with GUI.
Some minor tools for network configuration from console/scripts, which iproute2 seem to be lacking, in a py3 script.
For instance, if network interface on a remote machine was (mis-)configured in initramfs or wherever to not have link-local IPv6 address, there seem to be no tool to restore it without whole "ip link down && ip link up" dance, which can be a bad idea.
ipv6-lladdr subcommand handles that particular case, generating ipv6-lladdr from mac, as per RFC 4291 (as implemented in "netaddr" module) and can assign resulting address to the interface, if missing:
# ip-ext --debug ipv6-lladdr -i enp0s9 -x
DEBUG:root:Got lladdr from interface (enp0s9): 00:e0:4c:c2:78:86
DEBUG:root:Assigned ipv6_lladdr (fe80::2e0:4cff:fec2:7886) to interface: enp0s9ipv6-dns tool generates *.ip.arpa and djbdns records for specified IPv6.
ip-check subcommand allows to check if address (ipv4/ipv6) is assigned to any of the interfaces and/or run "ip add" (with specified parameters) to assign it, if not.
iptables-flush removes all iptables/ip6tables rules from all tables, including any custom chains, using iptables-save/restore command-line tools, and sets policy for default chains to ACCEPT.
Tools to work with cjdns and Hyperboria stuff.
Has lots of subcommands for cjdns admin interface interaction, various related data processing, manipulation (ipv6, public key, switchLabel, config file, etc) and obfuscation. Full list with descriptions and all possible options is in --help output.
Some of the functionality bits are described below.
Decode cjdns "Path" to a sequence of integer "peer indexes", one for each hop.
Relies on encoding schema described in NumberCompress.h of cjdns. Nodes are not required to use it in theory, and there are other encoding schemas implemented which should break this tool's operation, but in practice no one bothers to change that default.
Examples:
hype decode-path 0000.013c.bed9.5363 -> 3 54 42 54 15 5 30hype decode-path -x 0ff9.e22d.6cb5.19e3 -> 03 1e 03 6a 32 0b 16 62 03 0f 0f
Obfuscates cjdns config file (cjdroute.conf) in a secure and (optionally) deterministic way.
Should be useful to pastebin your config file without revealing most sensitive data (passwords and keys) in it. Might still reveal some peer info like IP endpoints, contacts, comments, general list of nodes you're peered with. Use with caution.
Sensitive bits are regexp-matched (by their key) and then value is processed through pbkdf2-sha256 and output is truncated to appear less massive. pbkdf2 parameters are configurable (see --help output), and at least --pbkdf2-salt should be passed for output to be deterministic, otherwise random salt value will be used.
Shows peer stats, with some extra info, like ipv6'es derived from keys (--raw to disable all that).
Shows a list of peers (with pubkeys, ipv6'es, paths, etc) for any remote node, specified by its ipv6, path, pubkey or addr, resolving these via SearchRunner_search as necessary.
Misc pubkey/ipv6 representation/conversion helpers.
Picks first wireless dev from iw dev and runs hostapd + udhcpd (from busybox) on it.
Use-case is plugging wifi usb dongle and creating temporary AP on it - kinda like "tethering" functionality in Android and such.
Configuration for both is generated using reasonable defaults - distinctive (picked from ssid_list at the top of the script) AP name and random password (using passgen from this repo or falling back to tr -cd '[:alnum:]' </dev/urandom | head -c10).
Dev, ssid, password, ip range and such can also be specified on the command line (see --help).
If inet access thru local machine is needed, don't forget to also do something like this (with default ip range of 10.67.35.0/24 and "wlp0s18f2u2" interface name):
# sysctl -w net.ipv4.conf.all.forwarding=1
# iptables -t nat -A POSTROUTING -s 10.67.35.0/24 -j MASQUERADE
# iptables -A FORWARD -s 10.67.35.0/24 -i wlp0s18f2u2 -j ACCEPT
# iptables -A FORWARD -d 10.67.35.0/24 -o wlp0s18f2u2 -j ACCEPTThese rules are also echoed in the script, with IP and interface name that was used.
For consistent naming of network interfaces from usb devices (to e.g. have constant set of firewall rules for these), following udev rule can be used (all usb-wlan interfaces will be named according to NAME there):
SUBSYSTEM=="net", ACTION=="add", ENV{DEVTYPE}=="wlan",\
DEVPATH=="*/usb[0-9]/*", NAME="wlan_usb"Systemd wrapper for wpa_supplicant or hostapd, enabling either to work with Type=notify, support WatchdogSec=, different exit codes and all that goodness.
Starts the daemon as a subprocess, connecting to its management interface and watching state/wpa_state changes, only indicating "started" state for systemd when daemon actually starts scanning/connecting (for wpa_supplicant) or sets state=enabled for hostapd.
WatchdogSec= issues PING commands to underlying daemon, proxying responses back, as long as daemon state is somehting valid, and not INTERFACE-DISABLED, locally-generated disconnect or such, usually indicating hw failure, kernel module issue or whatever else.
Such thing is needed to have systemd unit state follow AP/STA state, failing when e.g. wifi dongle gets pulled out from USB port, as that doesn't actually cause these things to fail/exit otherwise, which might be desirable if that wifi link is critical to other services or as a reboot-workaround for driver bugs.
Example systemd unit (AP mode):
[Service]
ExecStart=/usr/local/bin/wpa-systemd-wrapper \
--exit-check '/run/wpa.wlan0.first-run:config' \
--ap-mode wlan0 /etc/hostapd.wlan0.conf
Type=notify
WatchdogSec=90
Restart=on-failure
RestartPreventExitStatus=78
RestartSec=3
# StartLimitInterval=8min
# StartLimitBurst=10
# StartLimitAction=rebootThis will run hostapd (due to -a/--ap-mode), and exit with special 78/CONFIG code if "first-run" file exists and hostapd never gets into ENABLED state on the first attempt - i.e. something likely wrong with the config and there's no point restarting it ad nauseum.
Python3/asyncio, requires python-systemd installed, use -h/--help and -d/--debug opts for more info.
Script to ssh into mikrotik router with specified ("--auth-file" option) user/password and get the backup, optionally compressing it.
Can determine address of the router on its own (using "ip route get").
Can be used more generally to get/store output of any command(s) to the router.
RouterOS allows using DSA (old, disabled on any modern sshds) keys, which should be used if accessible at the standard places (e.g. "~/.ssh/id_dsa"). That might be preferrable to using password auth.
Python script, uses "twisted.conch" for ssh.
Script to update sources in /usr/src/linux to some (specified) stable version. Reuires "patch-X.Y.Z.xz" files (as provided on kernel.org) to be available under /usr/src/distfiles (configurable at the top of the script).
Does update (or rollback) by grabbing current patchset version from Makefile and doing essentially patch -R < <patch-current> && patch < <patch-new> - i.e. rolling-back the current patchset, then applying new patch.
Always does patch --dry-run first to make sure there will be no mess left over by the tool and updates will be all-or-nothing.
When updates get to e.g. 3.14.21 -> 3.14.22, there's a good chance such update will mtime-bump a lot of files (because it'll be 3.14.21 -> 3.14.0 -> 3.14.22), so there's "-t" option to efficiently symlink the whole sources tree, do patch --follow-symlinks and rsync -c only actually-changed (between .21 and .22) stuff back.
In short, allows to run e.g. kernel-patch 3.14.22 to get 3.14.22 in /usr/src/linux from any other clean 3.14.* version there.
Ad-hoc python3 script to check any random snippet with linux kernel CONFIG_... values (e.g. "this is stuff you want to set" block on some wiki) against kernel config file, current config in /proc/config.gz or such.
Reports what matches and what doesn't to stdout, trivial regexp matching.
Script to blink gpio-connected leds via /sys/class/gpio interface.
Includes oneshot mode, countdown mode (with some interval scaling option), direct on-off phase delay control (see --pre, --post and --interval* options), cooperation between several instances using same gpio pin, "until" timestamp spec, and generally everything I can think of being useful (mostly for use from other scripts though).
Trivial script to ping systemd watchdog and do some trivial actions in-between to make sure os still works.
Wrote it after yet another silent non-crash, where linux kernel refuses to create new pids (with some backtraces) and seem to hang on some fs ops. In these cases network works, most running daemons kinda-work, while syslog/journal get totally jammed and backtraces (or any errors) never make it to remote logging sinks.
So this trivial script, tied into systemd-controlled watchdog timers, tries to create pids every once in a while, with either hang or crash bubbling-up to systemd (pid-1), which should reliably reboot/crash the system via hardware wdt.
Example watchdog.service:
[Service]
WatchdogSec=60s
Restart=on-failure
StartLimitInterval=10min
StartLimitBurst=10
StartLimitAction=reboot-force
Type=notify
ExecStart=/usr/local/bin/systemd-watchdog
[Install]
WantedBy=multi-user.targetUseless without systemd and requires systemd python module.
Note: you might want to look at "bneptest" tool that comes with bluez - might be a good replacement for this script, which I haven't seen at the moment of its writing (maybe wasn't there, maybe just missed it).
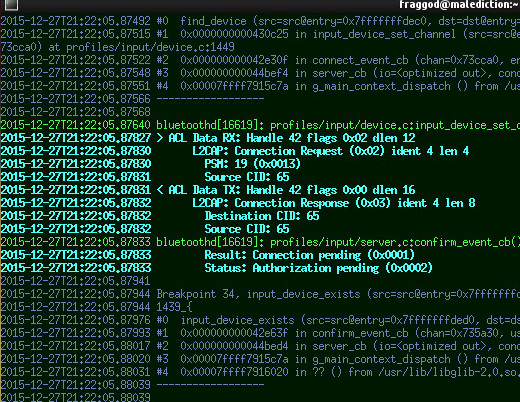
Bluetooth Personal Area Network (PAN) client/server setup script.
BlueZ does all the work here, script just sends it commands to enable/register appropriate services.
Can probably be done with one of the shipped tools, but I haven't found it, and there's just too many of them to remember anyway.
machine-1 # ./bt-pan --debug server bnep
machine-2 # ./bt-pan --debug client <machine-1-bdaddr>First line above will probably complain that "bnep" bridge is missing and list commands to bring it up (brctl, ip).
Default mode for both "server" and "client" is NAP (AP mode, like with WiFi).
Both commands make bluetoothd (that should be running) create "bnepX" network interfaces, connected to server/clients, and "server" also automatically (as clients are connecting) adds these to specified bridge.
Not sure how PANU and GN "ad-hoc" modes are supposed to work - both BlueZ "NetworkServer" and "Network" (client) interfaces support these, so I suppose one might need to run both or either of server/client commands (with e.g. "-u panu" option).
Couldn't get either one of ad-hoc modes to work myself, but didn't try particulary hard, and it might be hardware issue as well, I guess.
ssh-keyscan, but outputting each key in every possible format.
Imagine you have an incoming IM message "hey, someone haxxors me, it says 'ECDSA key fingerprint is f5:e5:f9:b6:a4:6b:fd:b3:07:15:f6:d9:0c:f5:47:54', what do?", this tool allows to dump any such fingerprint for a remote host, with:
% ssh-fingerprint congo.fg.nym
...
congo.fg.nym ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNo...zoU04g=
256 MD5:f5:e5:f9:b6:a4:6b:fd:b3:07:15:f6:d9:0c:f5:47:54 /tmp/.ssh_keyscan.key.kc3ur3C (ECDSA)
256 SHA256:lFLzFQR...2ZBmIgQi/w /tmp/.ssh_keyscan.key.kc3ur3C (ECDSA)
---- BEGIN SSH2 PUBLIC KEY ----
...Only way I know how to get that "f5:e5:f9:b6:a4:6b:fd:b3:07:15:f6:d9:0c:f5:47:54" secret-sauce is to either do your own md5 + hexdigest on ssh-keyscan output (and not mess-up due to some extra space or newline), or store one of the keys from there with first field cut off into a file and run ssh-keygen -l -E md5 -f key.pub.
Note how "intuitive" it is to confirm something that ssh prints (and it prints only that md5-fp thing!) for every new host you connect to with just openssh.
With this command, just running it on the remote host - presumably from diff location, or even localhost - should give (hopefully) any possible gibberish permutation that openssh (or something else) may decide to throw at you.
Tool to extract raw private key string from ed25519 ssh keys.
Main purpose is easy backup of ssh private keys and derivation of new secrets from these for other purposes.
For example:
% ssh-keygen -t ed25519 -f test-key
...
% cat test-key
-----BEGIN OPENSSH PRIVATE KEY-----
b3BlbnNzaC1rZXktdjEAAAAABG5vbmUAAAAEbm9uZQAAAAAAAAABAAAAMwAAAAtzc2gtZW
QyNTUxOQAAACDaKUyc/3dnDL+FS4/32JFsF88oQoYb2lU0QYtLgOx+yAAAAJi1Bt0atQbd
GgAAAAtzc2gtZWQyNTUxOQAAACDaKUyc/3dnDL+FS4/32JFsF88oQoYb2lU0QYtLgOx+yA
AAAEAc5IRaYYm2Ss4E65MYY4VewwiwyqWdBNYAZxEhZe9GpNopTJz/d2cMv4VLj/fYkWwX
zyhChhvaVTRBi0uA7H7IAAAAE2ZyYWdnb2RAbWFsZWRpY3Rpb24BAg==
-----END OPENSSH PRIVATE KEY-----
% ssh-keyparse test-key
HOSEWmGJtkrOBOuTGGOFXsMIsMqlnQTWAGcRIWXvRqQ=That one line at the end contains 32-byte ed25519 seed (with urlsafe-base64 encoding) - "secret key" - all the necessary info to restore the blob above, without extra openssh wrapping (as per PROTOCOL.key).
Original OpenSSH format (as produced by ssh-keygen) stores "magic string", ciphername ("none"), kdfname ("none"), kdfoptions (empty string), public key and index for that, two "checkint" numbers, seed + public key string, comment and a bunch of extra padding at the end. All string values there are length-prefixed, so take extra 4 bytes, even when empty.
Gist is that it's a ton of stuff that's not the actual key, which ssh-keyparse extracts.
To restore key from seed, use -d/--patch-key option on any existing ed25519 key, e.g. ssh-keygen -t ed25519 -N '' -f test-key && ssh-keyparse -d <seed> test-key
If key is encrypted with passphrase, ssh-keygen -p will be run on a temporary copy of it to decrypt, with a big warning in case it's not desirable.
There's also an option (--pbkdf2) to run the thing through PBKDF2 (tunable via --pbkdf2-opts) and various output encodings available:
% ssh-keyparse test-key # default is urlsafe-base64 encoding
HOSEWmGJtkrOBOuTGGOFXsMIsMqlnQTWAGcRIWXvRqQ=
% ssh-keyparse test-key --hex
1ce4845a6189b64ace04eb931863855ec308b0caa59d04d60067112165ef46a4
% ssh-keyparse test-key --base32
3KJ8-8PK1-H6V4-NKG4-XE9H-GRW5-BV1G-HC6A-MPEG-9NG0-CW8J-2SFF-8TJ0-e
% ssh-keyparse test-key --base32-nodashes
3KJ88PK1H6V4NKG4XE9HGRW5BV1GHC6AMPEG9NG0CW8J2SFF8TJ0e
% ssh-keyparse test-key --raw >test-key.binWith encoding like --base32 (Douglas Crockford's human-oriented Base32, last lowercase letter there is a checksum), it's easy to even read the thing over voice-comm link, if necessary.
Bash script to generate (init) ssh key (via ssh-keygen) without asking about various legacy and uninteresting options and safe against replacing existing keys.
I.e. don't ever want RSA, ECDSA or such nonsense (Ed25519 is the norm), don't need passwords for 99.999% of the keys, don't care about any of the ssh-keygen output, don't need any interactivity, but do care about silently overwriting existing key and want the thing to create parent dirs properly (which -f fails to do).
Has -m option to init key for an nspawn container under /var/lib/machines (e.g. ssh-key-init -m mymachine) and -r option to replace any existing keys. Sets uid/gid of the parent path for all new ones and -m700.
Daemon script to grab data from whatever sensors and log it all via rrdtool.
Self-contained, configurable, handles clock jumps and weirdness (for e.g. arm boards that lack battery-backed RTC), integrates with systemd (Type=notify, watchdog), has commands to easily produce graphs from this data (and can serve these via http), print last values.
Auto-generates rrd schema from config (and filename from that), inits db, checks for time jumps and aborts if necessary (rrdtool can't handle these, and they are common on arm boards), cleans up after itself.
Same things can be done by using rrdtool directly, but it requires a ton of typing for graph options and such, while this script generates it all for you, and is designed to be "hands-off" kind of easy.
Using it to keep track of SoC sensor readings on boards like RPi (to see if maybe it's time to cram a heatsink on top of one or something), for more serious systems something like collectd + graphite might be a better option.
Command-line usage:
% rrd-sensors-logger daemon --http-listen --http-opts-allow &
% rrd-sensors-logger print-conf-example
### rrd-sensors-logger configuration file (format: YAML)
### Place this file into ~/.rrd-sensors-logger.yaml or specify explicitly with --conf option.
...
% rrd-sensors-logger print-last
cpu.t: 30.22513627594576
gpu.t: 39.44316309653439
mb_1.t: 41.77566666851852
mb_2.t: 41.27842380952381
% curl -o graph.png http://localhost:8123/
% curl -o graph.png http://localhost:8123/t
% curl -o graph.png 'http://localhost:8123/t/width:+1900,height:+800'
% curl -o graph.png 'http://localhost:8123//start:+-2d,logarithmic:+true,title:+my+graph'
% feh $(rrd-sensors-logger graph t -o 'start: -3h')See top of the script for yaml config (also available via "print-conf-example") and systemd unit file example ("print-systemd-unit" command).
Uses: layered-yaml-attrdict-config (lya), rrdtool.
Bash script to "nsenter" into specified machine's (as can be seen in ps -eo machine or nsh when run without args) container namespaces and run login shell there.
Machine in question must run systemd as pid-1 (e.g. systemd-nspawn container), as it gets picked as --target pid for nsenter.
Very similar to machinectl login <machine>, but does not asks for user/password and does not start new "systemd --user" session, just runs su - to get root login shell.
Essentially same as machinectl shell <machine>, but doesn't require systemd-225 and machine being registered with systemd at all.
If running tty there says not a tty and e.g. screen bails out with Must be connected to a terminal., just run extra getty tty there - will ask to login (be mindful of /etc/securetty if login fails), and everything tty-related should work fine afterwards.
If run without argument or with -l/--list option, will list running machines.
See also: lsns(1), nsenter(1), unshare(1)
Bash script to list or kill users' sshd pids, created for "ssh -R" tunnels, that don't have a listening socket associated with them or don't show ssh protocol greeting (e.g. "SSH-2.0-OpenSSH_7.4") there.
These seem to occur when ssh client suddenly dies and reconnects to create new tunnel - old pid can still hog listening socket (even though there's nothing on the other end), but new pid won't exit and hang around uselessly.
Solution is to a) check for sshd pids that don't have listenings socket, and b) connect to sshd pids' sockets and see if anything responds there, killing both non-listening and unresponsive pids.
Only picks sshd pids for users with specific prefix, e.g. "tun-" by default, to be sure not to kill anything useful (i.e. anything that's not for "ssh -R").
Uses ps, ss, gawk and ncat (comes with nmap), only prints pids by default (without -k/--kill option).
Also has -s/--cleanup-sessions option to remove all "abandoned" login sessions (think loginctl) for user with specified prefix, i.e. any leftover stuff after killing those useless ssh pids.
See also: autossh and such.
Wrapper that opens specified PAM session (as per one of the configs in /etc/pam.d, e.g. "system-login"), switches to specified uid/gid and runs some command there.
My use-case is to emulate proper "login" session for systemd-logind, which neither "su" nor "sudo" can do (nor should do!) in default pam configurations for them, as they don't (and shouldn't) load pam_systemd.so.
This script can load any pam stack however, so e.g. running it as:
# pam-run -s system-login -u myuser -t :1 \
-- bash -c 'systemctl --user import-environment \
&& systemctl --user start xorg.target && sleep infinity'Should initiate proper systemd-logind session (and close it afterwards) and start "xorg.target" in "myuser"-specific "systemd --user" instance (started by logind with the session).
Can be used as a GDM-less way to start/keep such sessions (with proper display/tty and class/type from env) without much hassle or other weirdness like "agetty --autologin" or "login" in some pty (see also mk-fg/de-setup repo), or for whatever other pam-session wrapping, as script has nothing specific (or even related) to desktops.
Self-contained python-3 script, using libpam via ctypes.
machinectl shell myuser@ some-command seem to do very similar if not same exact thing, so maybe a good idea to use that instead, if possible. Didn't think it'd work for root container like that at the time of writing this script.
Warning: this script is no replacement for su/sudo wrt uid/gid-switching, and doesn't implement all the checks and sanitization these tools do, so only intended to be run from static, clean or trusted environment (e.g. started by systemd or manually).
Python-3 (asyncio) tool to try connecting to specified TCP port until connection can be established, then just exit, i.e. to wait until some remote port is accessible.
Can be used to wait for host to reboot before trying to ssh into it, e.g.:
% tping myhost && ssh root@myhost(default -p/--port is 22 - ssh)
Tries establishing new connection (forcing new SYN, IPv4/IPv6 should both work) every -r/--retry-delay seconds (default: 1), only discarding (closing) "in progress" connections after -t/--timeout seconds (default: 3), essentially keeping rotating pool of establishing connections until one of them succeeds.
This means that with e.g. -r1 -t5 there will be 5 establishing connections (to account for slow-to-respond remote hosts) rotating every second, so ratio of these delays shouldn't be too high to avoid spawning too many connections.
Host/port names specified on the command line are resolved synchronously on script startup (same as with e.g. "ping" tool), so it can't be used to wait until hostname resolves, only for connection itself.
Above example can also be shortened via -s/--ssh option, e.g.:
% tping -s myhost 1234
% tping -s root@myhost:1234 # same thing as above
% tping -s -p1234 myhost # same thing as aboveWill exec ssh -p1234 root@myhost immediately after successful tcp connection.
Uses python3 stdlib stuff, namely asyncio, to juggle multiple connections in an efficient manner.
bindfs wrapper script to setup id-mapping from uid of the mountpoint to uid/gid of the source directory.
I.e. after bindfs-idmap /var/lib/machines/home/src-user ~dst-user/tmp, ~dst-user/tmp will be accessible to dst-user as if they were src-user, with all operations proxied to src-user's dir.
Anything created under ~dst-user/tmp will have uid/gid of the src dir.
Useful to allow temporary access to some uid's files in a local container to user acc in a main namespace.
For long-term access (e.g. for some daemon), there probably are better options than such bindfs hack - e.g. bind-mounts, shared uids/gids, ACLs, etc.
Python3 script to "shift" or "patch" uid/gid values with new container-id according to systemd-nspawn schema, i.e. set upper 16-bit to specified container-id value and keep lower 16 bits to uid/gid inside the container.
Similar operation to what systemd-nspawn's --private-users-chown option does (described in nspawn-patch-uid.c), but standalone, doesn't bother with ACLs or checks on filesystem boundaries.
Main purpose is to update uids when migrating systemd-nspawn containers or adding paths/filesystems to these without clobbering ownership info there.
Should be safe to use anywhere, as in most non-nspawn cases upper bits of uid/gid are always zero, hence any changes can be easily reverted by running this tool again with -c0.
Helpers for more interactive (client) machine, DE and apps there.
Scripts to delegate downloads from firefox to a more sensible download managers.
Mostly I use remote mldonkey for ed2k and regular http downloads and rtorrent / transmission for bittorrent (with some processing of .torrent files to drop long-dead trackers from there and flatten tracker tiers, for reasons I blogged about in some distant past).
Scripts - mostly wrappers around ffmpeg and pulseaudio - to work with (or process) various media files and streams.
Creates null-sink in pulseaudio and redirects browser flash plugin audio output stream to it, also starting "parec" and oggenc to record/encode whatever happens there.
Can be useful to convert video to podcast if downloading flv is tricky for whatever reason.
Queries pa sinks for specific pid (which it can start) and writes "media.name" (usually track name) history, which can be used to record played track names from e.g. online radio stream in player-independent fashion.
Simple script to toggle mute for all pluseaudio streams from a specified pid.
Script to toggle - load or unload - pulseaudio module.
For example, to enable/disable forwarding sound over network (e.g. to be played in vlc as rtp://224.0.0.56:9875):
% pa_modtoggle module-rtp-send \
source=alsa-speakers.monitor destination=224.0.0.56 port=9875
Loaded: [31] module-rtp-send source=alsa-speakers.monitor destination=224.0.0.56 port=9875Same exact command will unload the module (matching it by module name only), if necessary.
Optional -s/--status flag can be used to print whether module is currently loaded.
Uses/requires pulsectl module, Python-3.
Same as pa_track_history above, but gets tracks when mpv dumps icy-* tags (passed in shoutcast streams) to stdout, which should be at the start of every next track.
More efficient and reliable than pa_track_history, but obviously mpv-specific.
Simple script to dump "online radio" kind of streams to a bunch of separate files, split when stream title (as passed in icy StreamTitle metadata) changes.
By default, filenames will include timestamp of recording start, sequence number, timestamp of a track start and a stream title (in a filename-friendly form).
Sample usage: icy_record --debug -x http://pub5.di.fm/di_vocaltrance
Note that by default dumped streams will be in some raw adts format (as streamed over the net), so maybe should be converted (with e.g. ffmpeg) afterwards.
This doesn't seem to be an issue for at least mp3 streams though, which work fine as "MPEG ADTS, layer III, v1" even in dumb hardware players.
Wrapper around mpv_icy_track_history to pick and play hard-coded radio streams with appropriate settings, generally simplified ui, logging and echoing what's being played, with a mute button (on SIGQUIT button from terminal).
Any-media-to-ogg convertor, using ffmpeg and - optionally (with -l/--loudnorm) -its loudnorm filter (EBU R128 loudness normalization) in double-pass mode.
Main purpose is to turn anything that has audio track in it into podcast for an audio player.
Can process several source files or URLs (either audio content-type or URL for youtube-dl) in parallel, displays progress (from ffmpeg -progress pipe), python3/asyncio.
loudnorm filter and libebur128 are fairly recent additions to ffmpeg (3.1 release, 2016-06-27), and might not be enabled/available in distros by default (e.g. not enabled on Arch as of 2016-09-27).
Needs youtube-dl installed if URLs are specified instead of regular files.
Wrapper around awesome img2xterm tool to display images in a color-capable terminal (e.g. xterm, not necessarily terminology).
Useful to query "which image is it" right from tty. Quality of the resulting images is kinda amazing, given tty limitations.
Simple bash script to split media files into chunks of specified length (in minutes), e.g.: split some-long-audiobook.mp3 sla 20 will produce 20-min-long sla-001.mp3, sla-002.mp3, sla-003.mp3, etc. Last length arg can be omitted, and defaults to 15 min.
Uses ffprobe (ffmpeg) to get duration and ffmpeg with "-acodec copy -vn" (default, changed by passing these after duration arg) to grab only audio chunks from the source file.
Splits m4b audiobook files on chapters (list of which are encoded into m4b as metadata) with ffprobe/ffmpeg.
Chapter offsets and titles are detected via ffprobe -v 0 -show_chapters, and then each gets extracted with ffmpeg -i ... -acodec copy -ss ... -to ..., producing aac files with names corresponding to metadata titles (by default, can be controlled with --name-format, default is {n:03d}__{title}.aac).
Doesn't do any transcoding, which can easily be performed later to e.g. convert resulting aac files to mp3 or ogg, if necessary.
Script to download any time slice of a twitch.tv VoD (video-on-demand).
This is a unix-ish OS version, though it might work on windows as well, otherwise check out Choonster's fork of this repo for a tested and working windows version.
youtube-dl - the usual tool for the job - doesn't support neither seeking to time nor length limits, but does a good job of getting a VoD m3u8 playlist with chunks of the video (--get-url option).
Also, some chunks getting stuck here at ~10-20 KiB/s download rates, making "sequentially download each one" approach of mpv/youtube-dl/ffmpeg/etc highly inpractical, and there are occasional errors too.
So this wrapper grabs that playlist, skips chunks according to EXTINF tags (specifying exact time length of each) to satisfy --start-pos / --length, and then passes all these URLs to aria2 for parallel downloading with stuff like --max-concurrent-downloads=5, --max-connection-per-server=5, --lowest-speed-limit=100K, etc (see TVFConfig at the start of the script), also scheduling retries for any failed chunks a few times with delays.
In the end, chunks get concatenated (literally, think "cat") together into one resulting mp4 file.
Process is designed to tolerate Ctrl+C (or SIGKILL) and resume from any point, keeping some temporary files around for that until file is fully downloaded.
Includes "--scatter" ("-x") mode to download every-X-out-of-Y timespans instead of full video, and has source timestamps on seeking in concatenated result (e.g. for -x 2:00/15:00, minute 3 in the video should display as "16:00", making it easier to pick timespan to download properly).
Video chunks get concatenated into partial file as they get downloaded, allowing to start playback before whole process ends.
General usage examples (wrapped):
% twitch_vod_fetch \
http://www.twitch.tv/starcraft/v/15655862 sc2_wcs_ro8 \
http://www.twitch.tv/starcraft/v/15831152 sc2_wcs_ro4 \
http://www.twitch.tv/starcraft/v/15842540 sc2_wcs_finals \
http://www.twitch.tv/starcraft/v/15867047 sc2_wcs_lotv
% twitch_vod_fetch -x 120/15:00 \
http://www.twitch.tv/redbullesports/v/13263504 sc2_rb_p01_preview
% twitch_vod_fetch -s 4:22:00 -l 2:00:00 \
http://www.twitch.tv/redbullesports/v/13263504 sc2_rb_p01_picked_2h_chunk
% twitch_vod_fetch -p \
http://www.twitch.tv/starcraft/v/24523048 sc2_blizzcon_finals \
&>sc2_blizzcon_finals.log &
% mpv sc2_blizzcon_finals.mp4 # starts playback before download endsA bit more info (on its previous py2 version) can be found in this twitchtv-vods-... blog post.
Bash wrapper script around youtube-dl tool to download numbered range of videos (from n_first to n_last) for youtube channel in reverse order to how they're listed in the metadata cache file (usually latest-to-oldest, hence reverse order).
Basically a thing to binge-watch everything from some channel, in order, without instantly running out of disk space.
Usage is simply ytdl-chan 1 10 to e.g. download 10 (1st to 10th) oldest videos (numbers are inclusive, 1-indexed) on the channel to the current dir, numbering them accordingly (001__sometitle.mp4, 002__..., etc).
Run in an empty dir with any numbers to get more info on how to get metadata cache file (list of yt json manifests, one per line).
Be sure to use ~/.config/youtube-dl/config for any ytdl opts, as necessary, or override these via env / within a script.
Requires youtube-dl and jq (to parse URLs from json).
Bash wrapper for streamlink to make dumping stream to a file more reliable, auto-restarting the process with new filename after any "stream ended" events or streamlink app exits.
Example use:
% streamdump --retry-streams 60 --retry-open 99999 \
--twitch-disable-hosting --twitch-oauth-token ... \
twitch.tv/user 720p -fo dump.mp4Will create "dump.000.mp4", "dump.001.mp4" and so on for each stream restart.
Intended use is for unreliable streams which go down and back up again in a minute or few, or working around streamlink quirks and fatal errors.
A bunch of tools to issue various desktop notifications.
Wrapper to run specified command and notify (via desktop-notifications only atm) if it fails (including "no such binary" errors) or produces any stderr.
Optionally produces notification in any case.
Useful mainly for wrapping hooks in desktop apps like firefox, to know if click on some "magnet:..." link was successfully processed or discarded.
% notify.exec -h --
usage: notify.exec [ options... -- ] command [ arguments... ]
Wrapper for command execution results notification.
optional arguments:
-h, --help show this help message and exit
-e, --exit-code-only Issue notification only if exit code not equals zero,
despite stderr.
-v, --notify-on-success
Issue notification upon successful execution as well.
-d, --dump Include stdou/stderr for all notifications.Script to spam sounds and desktop-notifications upon detecting low battery level. Not the only one to do somethng like that on my system, but saved me some work on many occasions.
Script to watch log files (as many as necessary) for changes with inotify and report any new lines appearing there via desktop notifications, handling file rotation (via truncation or rename/unlink) and such.
Can remember last position in file either by recording it in file's xattrs or in a shelve db (specified via -x/--xattr-db option). Doesn't do much with it by default though, starting to read files from the end, but that can be fixed by passing --keep-pos.
Has --tb-rate-filter option to rate-limit occasional log-spam (reporting only "skipped N msgs" as soon as filter allows) via simple token-bucket filter, see -h/--help output for more info.
Somewhat advanced usage example:
% logtail \
--keep-pos --tb-rate-filter 1:5 \
--icon ~/media/appz/icons/biohazard_48x.png \
--xattr-db "$XDG_RUNTIME_DIR"/logtail.db \
/var/log/messages /var/log/important/*Python-3, needs python-gobject ("gi" module, for notifications), uses inotify via ctypes.
Daemon script to monitor dovecot delivery logs (either generic ones, or produced via "mail_log" plugin), efficiently find delivered messages by their message-id and issue desktop notification to a remote host with parsed message details (path it was filed under, decoded from and subject headers).
Things like rsyslog make it fairly easy to create a separate log with such notifications for just one user, e.g.:
if (
$programname == 'dovecot'
and $syslogfacility-text == 'mail'
and $syslogseverity-text == 'info'
and re_match($msg, '^lda\\(someuser\\): sieve: msgid=[^:]+: stored mail into mailbox .*') )
then action(
type="omfile" FileCreateMode="0660"
FileOwner="root" FileGroup="someuser"
File="/var/log/processing/mail.deliver.someuser.log" )Remote notifications are delivered to desktop machines via robust zeromq pub/sub sockets as implemented in notification-thing daemon I have for that purpose.
Even idle-imap doesn't seem to provide proper push notifications with multiple folders yet, and this simple hack doesn't even require running a mail client.
Script to display specified xdg icon or image in a transparent popup window, with specified size (proportional scaling) and offset.
Supposed to be used with compositing WMs to display an icon (e.g. png with transparency) on top of everything else as a very crude and "in your face" means of notification.
For example, icon -o=-10%:-10% -s=300 ~/battery-critical.png will display specified png scaled proportionately to 300x300 px box with 10% (of screen width/height) offset from bottom-right screen corner.
icon call-start will dislay "call-start" icon from the theme (with -s/--size specifying icon size to pick, e.g. 32, 64, 128).
If file/icon cannot be found, Error: {icon-name} replacement text will be displayed in a semi-transparent box instead.
Stuff gets displayed until process is terminated. Uses gtk3/pygobject.
A simple tool to randomly pick and copy files (intended usage is music tracks) from source to destination.
Difference from "cp" is that it will stop when destination will be filled (to the configurable --min-df threshold) and will pick files in arbitrary order from arbitrary path hierarchy.
Use-case is simple - insert an SD card from a player and do:
% mount /mnt/sd_card
% rm -rf /mnt/sd_card/music
% pick_tracks -s 200 /mnt/music/OverClocked_Remix /mnt/sd_card/music
INFO:root:Done: 1673.1 MiB, rate: 1.29 MiB/s"--debug" also keeps track of what's being done and calculates how much time is left based on df-goal and median rate.
Source dir has like 3k files in many dirs, and cp/rsync will do the dumb "we'll copy same first things every time", while this tool will create the dst path for you, copy always-new selection there and - due to "-s 200" - leave 200 MiB there for podcasts you might want to also upload.
As with "cp", pick_tracks /path1 /path2 /dst is perfectly valid.
And there are neat cleaup flags for cases when I need to cram something new to the destination, preserving as much of the stuff that's already there as possible (and removing least important stuff).
Cleanup (if requested) also picks stuff at random up to necessary df.
"--shuffle" option allows to shuffle paths on fat by temporarily copying them off the media to some staging area and back in random order.
Use-case is dumb mp3 players that don't have that option (see also vfat_shuffler script for these, which is way more efficient).
Uses plumbum to call "rsync --inplace" (faster than "cp" in most cases) and "find" to do the actual copy/listing.
ssh wrapper to save time on typing something like exec ssh -X -A -p3542 [email protected] 'screen -DR', especially for N remote hosts.
Also has the ability to "keep trying to connect", useful (to me, at least) for crappy shared-hosting servers, where botnets flood ssh with slowloris-like attacks on it's authentication, exceeding limit on unauthorized connections in sshd.
Yapps2-based (grammar as-is in *.g file) parser script for Enlightenment (E17) config file (doing eet-decoding beforehand) for the purposes of it's backup in de-setup git repo alongside other DE-related configuration.
Whole purpose of decoding/encoding dance is to sort the sections (which E orders at random) and detect/filter-out irrelevant changes like remembered window positions or current (auto-rotated) wallpaper path.
Tool to shuffle entries inside a vfat (filesystem) directory (and do some other things) without actually mounting filesystem.
Some crappy cheap mp3 players don't have shuffle functionality and play files strictly in the same order as their dentries appear on the device blocks.
Easy way to "shuffle" stuff for them in quick-and-efficient manner is to swap dentries' places, which unfortunately requires re-implementing a bit of vfat driver code, which (fortunately) isn't that complex.
Tool takes path to device and directory to operate on as arguments (see --help) and has -s/--shuffle (actual shuffle operation), -l/--list (simply list files, default), -r/--rename action-flags, and --debug --dry-run can be useful to check what thing will do without making any changes.
One limitation is that it works only with FAT32 "vfat" fs type, which can be created with "mkfs.vfat" tool, not the types that "mkdosfs" tool creates, not FAT16 or whatever other variations are out there. Only reason is that I didn't bother to learn the differences between these, just checked and saw parser bug out on mkdosfs-created fs format.
Might be useful baseline to hack some fat32-related tool, as it has everything necessary for full r/w implementation - e.g. a tool to hardlink files on fat32, create infinite dir loops, undelete tool, etc.
Script to control speed of dying laptop fan on Acer S3 using direct reads/writes from/to /dev/ports to not run it too fast (causing loud screech and vibrating plastic) yet trying to keep cpu cool enough.
Or, failing that, use cpupower tool to drop frequency (making it run cooler in general) and issue dire warnings to desktop.
Script to query beets music database (possibly on a remote host) with specified parameters and add found tracks to EMMS playlist (via emacsclient).
Also allows to just dump resulting paths or enqueue a list of them from stdin.
Script to backup various firefox settings in a diff/scm-friendly manner (i.e. decoded from horrible one-liner json into pyaml, so that they can be tracked in e.g. git.
Written out of frustration about how YouTube Center seem to loose its shit and resets config sometimes.
Can/should be extended to all sorts of other ff/ext settings in the future - and probably is already, see its yaml config for details.
Simple py3 script to decompress .mozlz4 files, which can be found in FF profile directory (e.g. search.json.mozlz4), and are "mozLz40\0" || lz4-compressed-data, which lz4 cli tool can't handle due to that mozLz40 header.
Same cli interface as with gzip/xz/lz4 and such, uses lz4 module (pip3 install --user lz4).
Usage example (jq tool is for pretty json):
% ff_mozlz4 < search.json.mozlz4 | jq . > search.json
% nano search.json
% ff_mozlz4 search.jsonBlueZ bluetooth authorization agent script/daemon.
Usually included into DE-specific bluetooth applet or can be used from "bluetoothctl" client (agent on), but I don't have former (plus just don't want to rely on any DE much) and latter isn't suitable to run daemonized.
When run interactively (-i/--interactive option), will ask permission (y/n) to authorize new pairings and enter PINs for these.
With -a/--authorize-services [whitelist-file] option (and optional list of bdaddrs), will allow any paired device to (re-)connect without asking, allowing to run it in the background to only authorize trusted (and/or whitelisted) devices.
Does device power-on by default, has -p/--pairable [seconds], -d/--discoverable [seconds] and -t/--set-trusted options to cover usual initialization routines.
Python-3.x, needs dbus-python module with glib loop support.
Script to issue notification(s) after some specified period of time.
Mostly to simplify combining "sleep" with "date" and whatever notification means in the shell.
Parses timestamps as relative short times (e.g. "30s", "10min", "1h 20m", etc), iso8601-ish times/dates or falls back to just using "date" binary (which parses a lot of stuff).
Checks that specified time was parsed as a timestamp in the future and outputs how it was interpreted (by default).
Examples:
% alarm -q now
% alarm -c timedatectl now
Parsed time_spec 'now' as 2015-04-26 14:23:54.658134 (delta: just now)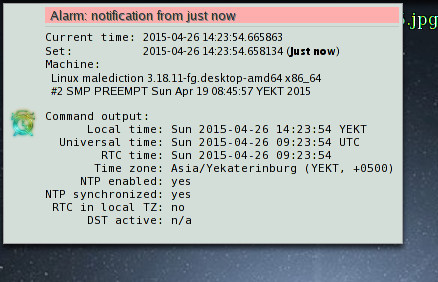
% alarm -t 3600 -i my-alarm-icon -s my-alarm-sound -f 'tomorrow 9am' \
'hey, wake up!!!' "It's time to do some stuff... here's the schedule:" \
-c 'curl -s http://my-site.com/schedule/today'
Parsed time_spec 'tomorrow 9am' as 2015-04-27 09:00:00 (delta: 18h 25m)Currently only uses desktop notifications, libcanberra sounds (optional), mail/wall (optional fallbacks) and/or runs whatever commands (use e.g. "zenity" to create modal windows or "wall" for terminal broadcasts).
Can keep track of pending alarms if -p/--pid-file option is used (see also -l/-list and -k/--kill opts), for persistent notifications (between reboots and such), there's an --at option to use at(1p) daemon.
Python-3, needs python-gobject ("gi" module) for desktop notifications.
Bash script to statelessly enable/disable (and not toggle) events in /proc/acpi/wakeup (wakeup events from various system sleep states).
E.g. acpi-wakeup-config -LID0 to disable "opening lid wakes up laptop" regardless of its current setting.
Usual echo LID0 > /proc/acpi/wakeup toggles the knob, which is inconvenient when one wants to set it to a specific value.
Also has special +all and -all switches to enable/disable all events and prints the whole wakeup-table if ran without arguments.
"one-letter-at-a-time" script to display (via gtk3/gi) a semi-transparent overlay with lines from stdin, which one can navigate up/down and left/right wrt highlighted characters.
Useful to do any kind of letter-by-letter checks and stuff manually.
Can also be an example code / stub for composited screen overlays with input grab.
Py3/Gtk3 script to draw an empty colored/transparent window with custom hints (default: undecorated) and size/position just to cover some screen area.
Useful as a hack to cover windows that grab input or do something stupid on mouseover, but still be able to see their contents, or maybe just cover something on the screen entirely.
For example, to cover left half (960px-wide) of screen with greenish-tinted half-transparent pane: blinds --pos=960xS+0 --color=0227107f
With custom wm hints/opacity:
blinds -o 0.2 -x 'stick keep_above skip_taskbar skip_pager -accept_focus -resizable'(see -h/--help output for a full list of these)
Simple tool to bind events (and specific values passed with these) from arbitrary evdev device(s) to keyboard button presses (through uinput).
"evdev -> keyboard" mappings are specified in a YAML file, as well as some other minor parameters (e.g. how long to press keys for, intervals, delays, etc).
For example, to bind rightmost-ish joystick position to press "right" key, yaml mapping can have this line: ABS_X >30_000: right (absolute right is ~32768, so anything >30k is "close enough", "30_000" is valid YAML integer spec).
Or, to type stuff on gamepad button press: BTN_SOUTH 1: [t,e,s,t,enter]
Can work with multiple evdev inputs (uses asyncio to poll stuff).
Requires python3, python-evdev, standard "uinput" kernel module enabled/loaded, read access to specified evdev(s) and rw to /dev/uinput.
Scripts to start and manage qemu/kvm based VMs I use for various dev purposes.
These include starting simple vde-based networking, syncing kernels and initramfs images out of vms (where needed), doing suspend/resume for running vms easily, etc.
Don't really need abstractions libvirt (and stuff using it) provide on top of qemu/kvm, as latter already have decent enough interfaces to work with.
Cheatsheet for qemu-img commands:
% qemu-img create -f qcow2 stuff.qcow2 10G
% qemu-img create -b stuff.qcow2 -f qcow2 stuff.qcow2.inc
% qemu-img commit stuff.qcow2.inc && rm stuff.qcow2.inc \
&& qemu-img create -b stuff.qcow2 -f qcow2 stuff.qcow2.incLua "chisels" for sysdig tool.
Basically simple scripts to filter and format data that sysdig reads or collects in real-time for various common tasks.
A few tools to work with a layered aufs filesystem on arm boards.
Modified script from aufs2-util.git, but standalone (with stuff from aufs.shlib baked-in) and not failing on ro-remounts, which seem to be a common thing for some places like /var or /home.
Convenience wrapper around aubrsync for mounts like none /var -o br:/aufs/rw/var=rw:/aufs/ro/var=ro.
Can also just list what's there to be synced with "check" command.
Usage: aufs_sync { copy | move | check } module
Example (flushes /var): aufs_sync move varTools for automating various Arch Linux tasks.
Shows shared-lib dependencies for specified binary/so even if it's for different arch (objdump-deps option), packages they might belong to (objdump-pkgs) and deps-of-deps recursively (ldd-deep / ldd-deep-pkgs).
For instance, when one wants to figure out which .so files ELF32 binary might want to use:
% elf-deps objdump-deps ~player/gog/SRHK/game/SRHK
/usr/lib/libGL.so.1
/usr/lib/libGL.so.1.2.0
/usr/lib/libGLU.so.1
...If one then wants to grab all these from some 32-bit packages (on a vm or maybe some chroot, see also tar-strap tool), objdump-pkgs might help:
% elf-deps objdump-pkgs ~player/gog/SRHK/game/SRHK
gcc-libs
glibc
...And to list all deps of a binary or a lib and their deps recursively, there's ldd-deep and ldd-deep-pkgs:
% elf-deps ldd-deep /usr/lib/libGL.so
/usr/lib/ld-linux-x86-64.so.2
/usr/lib/libX11-xcb.so.1
...
% elf-deps ldd-deep-pkgs /usr/lib/libGL.so
expat
glibc
libdrm
...Can be useful for providing necessary stuff to run proprietary 32-bit binaries (like games or crapware) on amd64.
Creates text manifests for Arch setup in /var/lib/pacman/:
- db.explict - explicitly installed packages, names only.
- db.leaf - packages without anything depending on them, names only.
- db.extras - packages not in any pacman repos, names only.
- db.all - all installed packages, names and versions.
- db.diffs - list of
\.pac(new|orig|save)$files on the system (found via mlocate). - db.local - list of stuff in
/usr/local.
Taken together, these represent some kind of "current os state".
Useful to pull them all into some git to keep track what gets installed or updated in the system over time, including makepkg'ed things and ad-hoc stuff in /usr/local.
Lists files that don't belong to any of the packages in either in default /etc /opt /usr dirs or whichever ones are specified.
My version of utility to merge .pacnew files with originals, using convenient and familiar (at least to me) git add -p interface and git diffs in general.
Can build list of files to process from last update in pacman.log (-a/--auto option), locate (e.g. mlocate, -l/--locate opt) or these can be specified manually as args.
Copies all original and associated pacnew files to tmp dir, and runs git add -p to apply/rebase original files on top of pacnew ones, showing resulting git diff original merged and prompting for whether to apply all the changes there.
Has misc options to skip parts of that process (-y/--yes, -o/--old, -n/--new), should be relatively safe against whatever accidents, breaks and typos - only changes stuff at the very end, if all commands worked, all checks pass and confirmation received.
Bash script, requires git and perl (as "git-add--interactive" is a perl script). Shorter and simplier than most scripts for same purpose, as git does most of the work in this case, less wheels re-invented, less interfaces to learn/remember.
Wrapper to quickly download and setup archlinux chroot (for e.g. systemd-nspawn container) using bootstrap tarball from https://mirrors.kernel.org/archlinux/iso/latest/
Checks gpg sig on the tarball with pacman-key, copies basic stuff like locale.gen, resolv.conf, mirrorlist, pacman gnupg setup, etc from the current root into the new one and runs arch-chroot into that.
Should be way faster than pacstrap, but kinda similar otherwise.
Either URL or path to source tarball should be specified on the command line.
Wrapper to bootstrap ready-to-use Arch container ("can") in /var/lib/machines, which (at the moment of writing) boils down to these steps:
- mkdir && pacstrap
- Copy layout files: localtime, profile, locale.conf, locale.gen.
Copy basic tools' configuration files, such as: zsh, screenrc, nanorc, gitconfig, etc.
But only copy each if it exists on the host machine (hence likely to be useful in a container as well).
- systemd-nspawn into container and run locale-gen and do chsh to zsh, if it's set as $SHELL on the host.
pacstrap installs not just any specified packages, but intentionally prefixes each with "can-" - these are meta-packages that I use to pull in package groups suitable for containers.
They all should be in my archlinux-pkgbuilds repo, see e.g. can-base PKGBUILD for example of such metapackage.
Running can-strap -c pacman.i686.conf buildbot-32 tools -- -i (intentionally complicated example) will produce "buildbot-32" container, suitable to boot and log into with e.g. systemd-nspawn -bn -M buildbot-32.
Misc prefabs and really ad-hoc scripts.
Rolling plot of "free" output via gnuplot.
Mostly a reminder of how to use the thing and what one can do with it.
There's more info on it in gnuplot-for-live-last-30-seconds blog post.
Processor for tshark's xml (pdml) output, for cases when wireshark's filtering/ui is not enough or it should be automated.
Script (or a template of one) designed to be run periodically to process latest log entries.
Handles log rotation/truncation and multiple changing logs cases.
Only reads actually last lines, storing last position and hash of "N bytes after that" (incl. N itself) in files' "user." xattrs, to reliably detect if file was rotated/truncated on the next run (i.e. if offset doesn't exist or there's diff data there).
Also stores state of the actual processing there, which is just "check occurence of regexp 'name' group within timeout, print line if there isn't" in the script.
Standard template for a trivial bash + coreutils "df" checker to put into crontab on any random linux box, just in case.
Script to resize RPi's boot FAT32 partition and filesystem to conver as much of the SD card as possible, from RPi itself, while booted from the same card.
Needs python-2.7, modern util-linux tools (lsblk and sfdisk with -J option for json output), sleuthkit (to query size of FAT fs), and parted.
More info on this script can be found in the resizing-first-fat32-partition-... blog post.
D3-based ES6 graphing app for time-series data from rather common temperature (t) and relative humidity (rh) sensors (DHT22, sht1x, etc) in tsv (tab-separated-values) files with [iso8601-ts, t, rh] fields.
Can be used directly via gh-pages: d3-temp-rh-sensor-tsv-series-chart.html
Bunch of real-world sample tsv files for it can be found alongside the html in d3-temp-rh-sensor-tsv-series-chart.zip.
Assembled (from simple html, d3.v4.js and main js) via html-embed script from this repo, doesn't have any external links, can be easily used as a local file.
More info can be found in the d3-chart-for-common-temperaturerh-time-series-data blog post.
D3-based xdiskusage implementation - app to parse du -b output and display directory hierarchy as d3 "partition" layout, with node size proportional to directory size from du output.
Can be used directly via gh-pages (d3-du-disk-space-usage-layout.html) or as a local file, doesn't have any external links.
Allows uploading multiple files to display in the same hierarchy, if paths in them are absolute (otherwise each one will be prefixed by "root-X" pseudo-node).
Py3 script to parse output of asciitree.LeftAligned tree, as produced by asciitree module (see module docs for format examples).
Can be embedded into python code as a parser for easily-readable trees of strings, without need to abuse YAML or something less-readable for those.
Script (python3) to copy trusted.* xattrs to user.* and/or wipe out either one of these.
Useful when running patched glusterd in a container, as described in running-glusterfs-in-a-user-namespace blog post here, and probably not much else.
Py3 script to blink bit-pattern from a passed argument using linux led subsystem (i.e. one of the leds in /sys/class/leds).
Useful to make e.g. RPi boards booted from identical OS img distinguishable by blinking last bits of their IP address, MAC, serial number or stuff like that.
Py3 script to blink any arbitrary on/off sequence or numbers (using bits) on an LED, using sysfs interface (/sys/class/leds or /sys/class/gpio).
Sequence is expressed using simple embedded language, for example:
+1s r:5 [ -100 +100 ] -1.5s 237 -5s <Where:
{ '+' | '-' }{ ms:int | s:float 's' }(e.g. "+100", "+1s", "-1.5s") is a simple on/off state for specified number of seconds or ms.r[epeat]:{N}(e.g. "r:5") instructs to repeat next command N times.[ ... ]is used to group commands for repeating.- Simple number (or more complex
n[/bits][-dec]form) will be blinked in big-endian bit order with 150ms for 0, 1.3s for 1 and 700ms in-between these (see BlinkConfig, also adjustable viabit-repr:{bit1_ms),{bit0_ms),{interval_ms)command). <repeats whole thing from the start forever.
Somewhat easier than writing one-off "set(0), sleep(100), set(1), ..." scripts with mostly boilerplate or extra deps for this simple purpose.
Bash script to setup/destroy GRE tunnel with Generic UDP Encapsulation (GUE).
One command instead of bunch of them, with some built-in templating to make it easier to use on identical remote hosts.
DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
Version 2, December 2004Copyright (C) 2010-2038 Mike Kazantsev
Everyone is permitted to copy and distribute verbatim or modified copies of this license document, and changing it is allowed as long as the name is changed.
DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
- You just DO WHAT THE FUCK YOU WANT TO.




