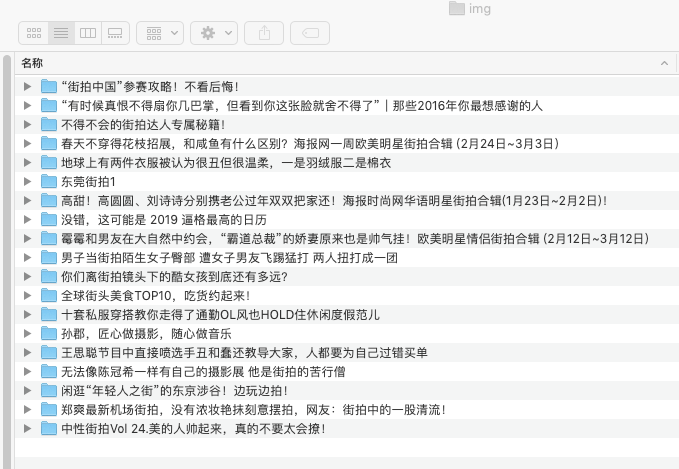
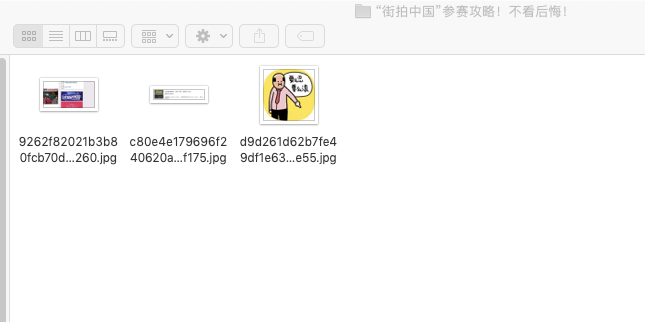
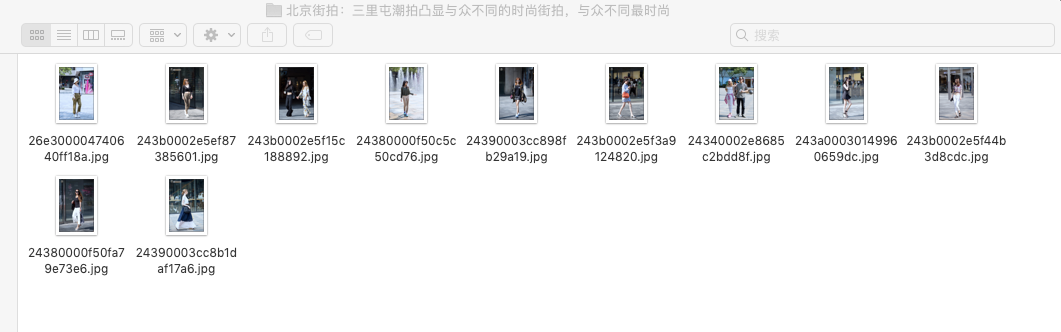
加了headers, 加了timestamp, 但是跑的时候偶尔出现OSError: [Errno 22] The filename, directory name, or volume label syntax is incorrect,我把这个名字直接自己创业却又是可以的,大神们帮忙看看
import requests
import os
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
from datetime import datetime
def get_page(offset):
timestamp = str(datetime.timestamp(datetime.today())).replace('.', '')[:-3]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'cookie': 'tt_webid=6705372327364445699; WEATHER_CITY=%E5%8C%97%E4%BA%AC; '
'UM_distinctid=16b7fbc4c5f2f3-055c8cad207e35-3e385b04-144000-16b7fbc4c601fb;'
' tt_webid=6705372327364445699; csrftoken=565955f383dfff6e64e1fcaf538414be;'
' CNZZDATA1259612802=429684378-1561215529-%7C1561296529; s_v_web_id=4b402c5aa53e24a17fca9d68bd6eb7ff',
'x-requested-with': 'XMLHttpRequest'
}
params = {
'aid': 24,
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'time': timestamp,
}
url = 'https://www.toutiao.com/api/search/content/?' + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
def get_images(json_data):
if json_data.get('data'):
for item in json_data.get('data'):
if item.get('cell_type') is not None:
continue
title = item.get('title')
images = item.get('image_list')
for image in images:
yield{
'image': image.get('url'),
'title': title
}
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'), md5(response.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to save image')
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 1
GROUP_END = 20
if name == 'main':
pool = Pool()
groups = ([x *20 for x in range(GROUP_START, GROUP_END + 1)])
pool.map(main, groups)
pool.close()
pool.join()