cuxfilter ( ku-cross-filter ) is a RAPIDS framework to connect web visualizations to GPU accelerated crossfiltering. Inspired by the javascript version of the original, it enables interactive and super fast multi-dimensional filtering of 100 million+ row tabular datasets via cuDF.
cuxfilter is one of the core projects of the “RAPIDS viz” team. Taking the axiom that “a slider is worth a thousand queries” from @lmeyerov to heart, we want to enable fast exploratory data analytics through an easier-to-use pythonic notebook interface.
As there are many fantastic visualization libraries available for the web, our general principle is not to create our own viz library, but to enhance others with faster acceleration, larger datasets, and better dev UX. Basically, we want to take the headache out of interconnecting multiple charts to a GPU backend, so you can get to visually exploring data faster.
By the way, cuxfilter is best used to interact with large (1 million+) tabular datasets. GPU’s are fast, but accessing that speedup requires some architecture overhead that isn’t worthwhile for small datasets.
For more detailed requirements, see below.
The current version of cuxfilter leverages jupyter notebook and bokeh server to reduce architecture and installation complexity.

cuxfilter wouldn’t be possible without using these great open source projects:
The original version (0.2) of cuxfilter, most known for the backend powering the Mortgage Viz Demo, has been moved into the GTC-2018-mortgage-visualization branch branch. As it has a much more complicated backend and javascript API, we’ve decided to focus more on the streamlined notebook focused version here.

import cuxfilter
#update data_dir if you have downloaded datasets elsewhere
DATA_DIR = './data'
from cuxfilter.sampledata import datasets_check
datasets_check('auto_accidents', base_dir=DATA_DIR)
cux_df = cuxfilter.DataFrame.from_arrow(DATA_DIR+'/auto_accidents.arrow')
cux_df.data['ST_CASE'] = cux_df.data['ST_CASE'].astype('float64')
label_map = {1: 'Sunday', 2: 'Monday', 3: 'Tuesday', 4: 'Wednesday', 5: 'Thursday', 6: 'Friday', 7: 'Saturday', 9: 'Unknown'}
cux_df.data['DAY_WEEK_STR'] = cux_df.data.DAY_WEEK.map(label_map)
gtc_demo_red_blue_palette = [ "#3182bd", "#6baed6", "#7b8ed8", "#e26798", "#ff0068" , "#323232" ]
#declare charts
chart1 = cuxfilter.charts.scatter(x='dropoff_x', y='dropoff_y', aggregate_col='DAY_WEEK', aggregate_fn='mean',
color_palette=gtc_demo_red_blue_palette, tile_provider='CartoLight', unselected_alpha=0.2,
pixel_shade_type='linear')
chart2 = cuxfilter.charts.multi_select('YEAR')
chart3 = cuxfilter.charts.bar('DAY_WEEK_STR')
chart4 = cuxfilter.charts.bar('MONTH')
#declare dashboard
d = cux_df.dashboard([chart1, chart3, chart4], sidebar=[chart2], layout=cuxfilter.layouts.feature_and_double_base, title='Auto Accident Dataset')
# run the dashboard as a webapp:
# Bokeh and Datashader based charts also have a `save` tool on the side toolbar, which can download and save the individual chart when interacting with the dashboard.
# d.show('jupyter-notebook/lab-url')
#run the dashboard within the notebook cell
d.app()
import cuxfilter
#update data_dir if you have downloaded datasets elsewhere
DATA_DIR = './data'
from cuxfilter.sampledata import datasets_check
datasets_check('mortgage', base_dir=DATA_DIR)
cux_df = cuxfilter.DataFrame.from_arrow(DATA_DIR + '/146M_predictions_v2.arrow')
geoJSONSource='https://raw.githubusercontent.com/rapidsai/cuxfilter/GTC-2018-mortgage-visualization/javascript/demos/GTC%20demo/src/data/zip3-ms-rhs-lessprops.json'
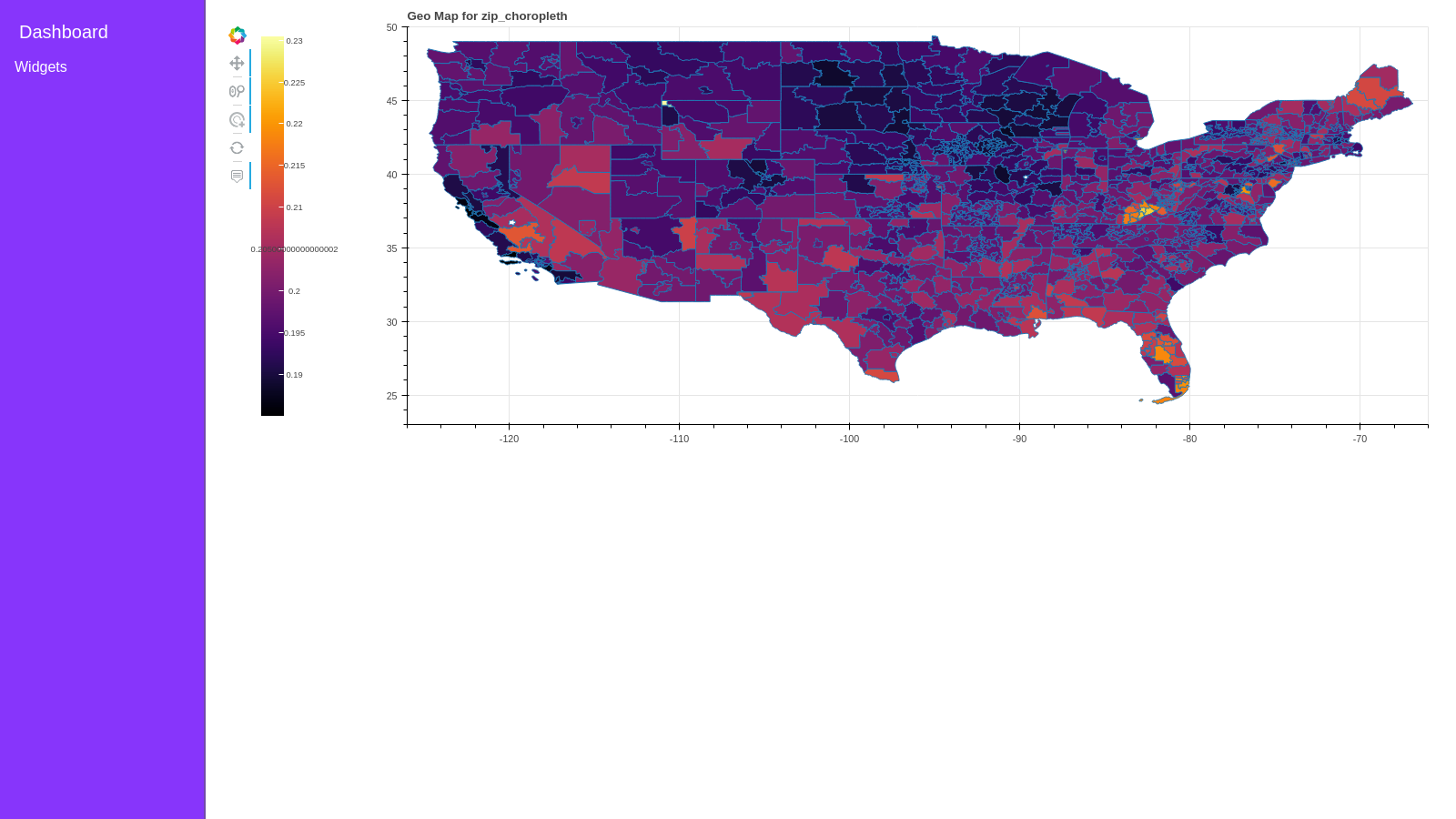
chart0 = cuxfilter.charts.choropleth( x='zip', color_column='delinquency_12_prediction', color_aggregate_fn='mean',
elevation_column='current_actual_upb', elevation_factor=0.00001, elevation_aggregate_fn='sum',
geoJSONSource=geoJSONSource
)
chart2 = cuxfilter.charts.bar('delinquency_12_prediction',data_points=50)
chart3 = cuxfilter.charts.range_slider('borrower_credit_score',data_points=50)
chart1 = cuxfilter.charts.drop_down('dti')
#declare dashboard
d = cux_df.dashboard([chart0, chart2],sidebar=[chart3, chart1], layout=cuxfilter.layouts.feature_and_double_base,theme = cuxfilter.themes.dark, title='Mortgage Dashboard')
# run the dashboard within the notebook cell
# Bokeh and Datashader based charts also have a `save` tool on the side toolbar, which can download and save the individual chart when interacting with the dashboard.
# d.app()
#run the dashboard as a webapp:
# if running on a port other than localhost:8888, run d.show(jupyter-notebook-lab-url:port)
d.show()
Full documentation can be found on the RAPIDS docs page.
Troubleshooting help can be found on our troubleshooting page.
- python
- cudf
- datashader
- cupy
- panel
- bokeh
- pyproj
- geopandas
- pyppeteer
- jupyter-server-proxy
Please see the Demo Docker Repository, choosing a tag based on the NVIDIA CUDA version you’re running. This provides a ready to run Docker container with example notebooks and data, showcasing how you can utilize cuxfilter, cuDF and other RAPIDS libraries.
- CUDA 11.2+
- NVIDIA driver 450.80.02+
- Pascal architecture or better (Compute Capability >=6.0)
cuxfilter can be installed with conda (miniconda, or the full Anaconda distribution) from the rapidsai channel:
For nightly version cuxfilter version == 24.06 :
# for CUDA 12.0
conda install -c rapidsai-nightly -c conda-forge -c nvidia \
cuxfilter=24.06 python=3.11 cuda-version=12.0
# for CUDA 11.8
conda install -c rapidsai-nightly -c conda-forge -c nvidia \
cuxfilter=24.06 python=3.11 cuda-version=11.8For the stable version of cuxfilter :
# for CUDA 12.0
conda install -c rapidsai -c conda-forge -c nvidia \
cuxfilter python=3.11 cuda-version=12.0
# for CUDA 11.8
conda install -c rapidsai -c conda-forge -c nvidia \
cuxfilter python=3.11 cuda-version=11.8Note: cuxfilter is supported only on Linux, and with Python versions 3.8 and later.
Install cuxfilter from PyPI using pip:
# for CUDA 12.0
pip install cuxfilter-cu12 -extra-index-url=https://pypi.nvidia.com
# for CUDA 11.8
pip install cuxfilter-cu11 -extra-index-url=https://pypi.nvidia.comSee the Get RAPIDS version picker for more OS and version info.
See build instructions.
bokeh server in jupyter lab
To run the bokeh server in a jupyter lab, install jupyterlab dependencies
conda install -c conda-forge jupyterlab
jupyter labextension install @pyviz/jupyterlab_pyviz
jupyter labextension install jupyterlab_bokeh- Auto download datasets
The notebooks inside python/notebooks already have a check function which verifies whether the example dataset is downloaded, and downloads it if it's not.
- Download manually
While in the directory you want the datasets to be saved, execute the following
Note: Auto Accidents dataset has corrupted coordinate data from the years 2012-2014
#go the the environment where cuxfilter is installed. Skip if in a docker container
source activate test_env
#download and extract the datasets
curl https://s3.amazonaws.com/nyc-tlc/trip+data/yellow_tripdata_2015-01.csv --create-dirs -o ./nyc_taxi.csv
curl https://data.rapids.ai/viz-data/146M_predictions_v2.arrow.gz --create-dirs -o ./146M_predictions_v2.arrow.gz
curl https://data.rapids.ai/viz-data/auto_accidents.arrow.gz --create-dirs -o ./auto_accidents.arrow.gz
python -c "from cuxfilter.sampledata import datasets_check; datasets_check(base_dir='./')"Currently supported layout templates and example code can be found on the layouts page.
| Library | Chart type |
|---|---|
| bokeh | bar |
| datashader | scatter, scatter_geo, line, stacked_lines, heatmap, graph |
| panel_widgets | range_slider, date_range_slider, float_slider, int_slider, drop_down, multi_select, card, number |
| custom | view_dataframe |
| deckgl | choropleth(3d and 2d) |
cuxfilter acts like a connector library and it is easy to add support for new libraries. The python/cuxfilter/charts/core directory has all the core chart classes which can be inherited and used to implement a few (viz related) functions and support dashboarding in cuxfilter directly.
You can see the examples to implement viz libraries in the bokeh and cudatashader directories. Let us know if you would like to add a chart by opening a feature request issue or submitting a PR.
For more details, check out the contributing guide.
cuxfilter development is in early stages and on going. See what we are planning next on the projects page.





![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")