realxujiang / labs Goto Github PK
View Code? Open in Web Editor NEWResearch on distributed system
Home Page: http://www.itweet.cn
License: Apache License 2.0
Research on distributed system
Home Page: http://www.itweet.cn
License: Apache License 2.0
** The road ahaed. **
** 未来之路. **
关于 杂谈《编程之路职业指导》 我们从 BILL GATES 写的一本书《The road ahead》来开启话题,该书主要讲述了个人电脑的革命以及信息化对未来的巨大影响。
阐述一个职业发展与大势(行业发展、技术趋势)结合的最佳案例,主要阐述两个事实:
1 未来之路,编程之路的职业选择。
2 技术路线,保持持续学习的习惯。
我会以文字的方式娓娓道来,敬请期待。















欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。

原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
分布式搜索数据库产品,能满足很多企业高速检索的业务场景,海量的单表数据秒级搜索和全文检索,完全支持SQL语法,支持数据的增删改查,兼容MySQL/PostgreSQL协议,企业级分布式搜索数据库解决海量数据检索问题。
必须修改如下相关的配置文件,不然会无法正常启动集群。
vi /etc/sysctl.conf
vm.max_map_count=262144
sysctl -p
vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
vi /etc/profile
export CRATE_HEAP_SIZE=100g
创建数据存储目录,创建用户searchdb,cratedb集群安装在searchdb用户下。
wget https://cdn.crate.io/downloads/releases/crate-2.1.5.tar.gz -O /opt/
tar -zxvf crate-2.1.5.tar.gz
mkdir /disk0{1..4}/searchdb
useradd searchdb
chown searchdb:searchdb /disk0{1..4}/searchdb
chown searchdb:searchdb -R /opt/crate-2.1.5
rm -rf /disk0{1..4}/searchdb/*
注意:需要提前安装好JDK,配置JAVA_HOME信息,特别注意JDK版本需要jdk1.8.0_45以上。
三节点集群软件,需要注意的信息network.host为每个节点的主机名,node.name填写为主机名,my_cluster必须是唯一的,编辑crate.yml 文件。
cluster.name: my_cluster
node.name: node1
discovery.zen.ping.unicast.hosts:
- node1:4300
- node2:4300
- node3:4300
discovery.zen.minimum_master_nodes: 2
gateway:
recover_after_nodes: 2
recover_after_time: 5m
expected_nodes: 2
path.data: /disk01/searchdb,/disk02/searchdb,/disk03/searchdb/,/disk04/searchdb
network.host: node1
psql.enabled: true
psql.port: 5432
bin/crate -d
bin/crash
cr> \c node1:4200
+-------------------+-----------+---------+-----------+---------+
| server_url | node_name | version | connected | message |
+-------------------+-----------+---------+-----------+---------+
| http://node1:4200 | node1 | 2.1.5 | TRUE | OK |
+-------------------+-----------+---------+-----------+---------+
create table tweets (
created_at timestamp,
id string primary key,
retweeted boolean,
source string INDEX using fulltext,
text string INDEX using fulltext,
user_id string
);
insert into tweets values (1394182937, '1', true, 'web', 'Don''t panic', 'Douglas');
insert into tweets
values (
1394182938,
'2',
true,
'web',
'Time is an illusion. Lunchtime doubly so',
'Ford'
);
insert into tweets values (1394182937, '3', true, 'address', '**,北京', '北京');
select * from tweets where id = '2';
select user_id, _score from tweets where match(text, 'is') order by _score desc;
select user_id, _score from tweets where match(text, '北京') order by _score desc;
select user_id, _score from tweets where match(text, '京城') order by _score desc;
DELETE FROM tweets where id=3;
使用一些基础SQL语法测试,进行简单测试,包括带有的全文检索、分词能力,支持Update,Delete数据。
生成测试数据,生成books表数据,平均6.0K/条,100G大小,通过一个py脚本把文本数据转换为json数据。
nohup java -cp dbgen-1.0-jar.jar DBGen -p ./data -b 100 & --Total Time: 2610 seconds
cat books | python csv2json.py --columns id:integer isbn:string category:string publish_date:string publisher:string price:float > books.json
数据示例:
$ head data/books/books
0|6-20386-216-4|STUDY-AIDS|1998-05-31|Gakken|166.99
1|0-60558-466-8|JUVENILE-NONFICTION|1975-02-12|Holtzbrinck|128.99
2|3-16551-636-9|POETRY|1988-01-24|Oxford University Press|155.99
3|4-75505-741-2|COMICS-GRAPHIC-NOVELS|1992-02-24|Saraiva|101.99
4|3-32982-589-8|PERFORMING-ARTS|2011-03-09|Cambridge University Press|183.99
基础命令:
./crash --help
./crash --hosts node1 --sysinfo
./crash --hosts node1 -c "show tables"
创建表结构,导入数据。
CREATE TABLE books (
id integer,
isbn string,
category string,
publish_date string,
publisher string,
price float
);
COPY books FROM '/disk01/data/books/books.json';
通过如上命令,可以生成不同级别大小的测试数据,根据参数可以生成不同大小的表。
测试场景1
主要针对单表的查询测试。
select category,count(*) from books group by category limit 100; -- 3.137 s
select category,count(*) as num from books group by category order by num limit 100; --2.929 sec
select category,count(*) as num from books where category='SCIENCE' group by category order by num limit 100; --0.143 sec
select count(*) from books where category='SCIENCE' limit 100; -- 0.022 sec
select count(distinct category) from books limit 100; -- 2.990 sec
select distinct category from books limit 100; -- 3.032 sec
修改 number_of_shards 看是否提升性能
ALTER TABLE books SET (number_of_shards = 48)
OPTIMIZE table books; -- 这个参数比较有用,可以提升性能
SELECT count(*) as num_shards, sum(num_docs) as num_docs FROM sys.shards WHERE schema_name = 'doc' AND table_name = 'books';
测试场景2
创建表,导入数据。
CREATE TABLE books_t1 (
id integer,
isbn string,
category string INDEX using fulltext,
publish_date string,
publisher string INDEX using fulltext,
price float
) CLUSTERED BY (category) INTO 1024 SHARDS with (number_of_replicas = 2, refresh_interval=10000);
COPY books_t1 FROM '/disk01/data/books/books.json'; -- COPY OK, 235265838 rows affected (17285.888 sec)
测试性能。
OPTIMIZE table books_t1;
select category,count(*) from books_t1 group by category limit 100; -- 2.556 sec
select category,count(*) as num from books_t1 group by category order by num limit 100; -- 2.763 sec
问题:Error! SQLActionException[SQLParseException: Cannot GROUP BY 'category': grouping on analyzed/fulltext columns is not possible]
select count(*) from books_t1 where match(category, 'PERFORMING-ARTS'); -- limit 100; -- 0.256 sec
select * from books_t1 where match(category, 'ARTS'); -- limit 100; -- 0.256 sec; -- 0.928 sec
注意:fulltext字段的都无法做聚合分析操作,不带全文索引,只能做全文搜索match,重新导数据在测试.
测试场景3
创建表,插入数据。
CREATE TABLE books_t2 (
id integer,
isbn string,
category string,
publish_date string,
publisher string,
price float
) CLUSTERED BY (category) INTO 1024 SHARDS;
COPY books_t2 FROM '/disk01/data/books/books.json';
insert into books_t2 select * from books_t1; -- INSERT OK, 235265838 rows affected (5662.132 sec)
性能测试。
OPTIMIZE table books_t2;
select category,count(*) from books_t2 group by category limit 100; -- 3.994 sec
select category,count(*) as num from books_t2 group by category order by num limit 100; -- 4.159 sec
select category,count(*) as num from books_t2 where category='SCIENCE' group by category order by num limit 100; -- 1.731 sec
select count(*) from books_t2 where category='SCIENCE' limit 100; -- 0.001 sec
select count(distinct category) from books_t2 limit 100; -- 4.677 sec
select distinct category from books_t2 limit 100; -- 3.914 sec
select id,price,publisher from books_t2 where publish_date='1999-02-02' and category='SCIENCE' limit 100; -- 0.014 sec
注意:分片数量过多导致Heap Usage一直居高不下达到57%,表建立全局索引1024个分片,2个索引字段
测试场景4
生成的文本数据,转换为JSON格式。
nohup cat /disk01/searchdb/data/books/books | python csv2json.py --columns id:integer isbn:string category:string publish_date:string publisher:string price:float > /disk02/searchdb/books.json &
切割一个215g数据文件为22个10g大小的数据文件,并行入库。
split -b 10000m /disk02/searchdb/books.json -d -a 3 split_file
创建表。
CREATE TABLE books (
id integer,
isbn string,
category string,
publish_date string,
publisher string,
price float
) CLUSTERED BY (category) INTO 500 SHARDS;
批量入库数据。
/opt/crate-2.1.7/bin/crash --hosts node1 -c "COPY books FROM '/disk01/searchdb/split_file000'"
主要针对15亿单表的查询 - 性能测试。
OPTIMIZE table books;
select category,count(*) from books_t2 group by category limit 100; -- 3.994 sec
select category,count(*) as num from books_t2 group by category order by num limit 100; -- 4.159 sec
select category,count(*) as num from books_t2 where category='SCIENCE' group by category order by num limit 100; -- 1.731 sec
select count(*) from books_t2 where category='SCIENCE' limit 100; -- 0.001 sec
select count(distinct category) from books_t2 limit 100; -- 4.677 sec
select distinct category from books_t2 limit 100; -- 3.914 sec
select id,price,publisher from books_t2 where publish_date='1999-02-02' and category='SCIENCE' limit 100; -- 0.014 sec
测试场景5
测试SQL如下,主要是针对单表的性能测试,无分区。
OPTIMIZE table books;
select category,count(*) from books group by category limit 100; -- 37.878 sec
select category,count(*) as num from books group by category order by num limit 100; -- 46.603 sec
select category,count(*) as num from books where category='SCIENCE' group by category order by num limit 100; -- 11.808 sec
select count(*) from books where category='SCIENCE' limit 100; -- 0.002 sec
select count(distinct category) from books limit 100; -- 44.924 sec
select distinct category from books limit 100; -- 44.335 sec
select id,price,publisher from books where publish_date='1999-02-02' and category='SCIENCE' limit 100; -- 0.347 sec
select price,count(publisher) from books where publish_date='1999-02-02' and category='SCIENCE' group by price order by price desc limit 100; -- 0.981 sec
select price,category from books where publisher='Kyowon' group by price,category order by price limit 100; --
3.602 sec
select price,category,count(*) from books where publisher='Kyowon' group by price,category order by price limit 100; -- 1.406 sec
场景1 数据量:496928035 4节点(mem:128g vcore: 24 storage: 4*250g) 大小:56.2g shards: 500 平均:6.0K/条 网络:千兆
场景2 数据量:993106194 4节点(mem:128g vcore: 24 storage: 4*250g) 大小:112g shards: 500 平均:6.0K/条 网络:千兆
场景3 数据量:1551303103 4节点(mem:128g vcore: 24 storage: 4*250g) 大小:174.4g shards: 500 平均:6.0K/条 网络:千兆

注意:如上测试并没有专业优化并发,除内存外,所有参数使用默认。
在单表15亿+,五分区,4台服务器,千兆网络,表现出来的性能还是非常强劲的,主要针对单表各种统计分析并且还带有全文检索的功能, 此数据库可以把它称为是分布式搜索数据库。底层用到了很多搜索引擎存储的技术,包括倒排索引,数据分片,利用大内存,细粒度索引,如果能支持多实例,目前CPU还没完全使用,磁盘IO和内存都满载。每一个字段都带索引,所以入库比较慢,在单机上入库是瓶颈,可以分开在多台机器入库,这样避免IO堵在一台机器;压力过大容易导致节点奔溃脱离集群;join性能没深入探索,不好评价。
一个分布式搜索数据库,支持标准SQL和JDBC,用来替代ES做一些全文检索并支持复杂统计分析能力,很有实际意义。
我目前参与过最大的ES集群,也就60节点300亿+doc(3个主节点,6T&2块SATA),数据量400TB,还有一个小集群20节点70亿+doc(3主节点,4T&2块SSD),性能基本能满足要求,存储近3年的数据,历史数据HDFS为Backup。
参考:
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
大家好,受学校老师的邀请,给即将毕业的同学们,讲述一下职业发展,对我个人来说也是一次职业总结的好机会。通过online的形式,给大家做个分享。今天以The road ahead为题。The road ahead表达的是“未来之路”。
内容结合作者多年的职业发展之路,介绍职业发展中的各种选择以及最前沿的技术发展路线,希望能对初入职场的同学有所帮助。
嗯,如何开启未来之路呢,我在网上查找资料的时候啊,发现这是比尔盖茨写的一本书,然后呢我就为了完成杂谈《编程之路职业指导》这个talk,对The road ahead未来之路啊,我就专门去看了一下这本书,这本书表达观点很有意思,讲述的是展望未来计算机的发展以及信息高速公路对世界的影响,可以看到很多想法目前已经成为现实,此书对未来之路的探索,充满无限的启迪,也很好的阐述了未来之路要表达的含义。我在接下来呀,所讲述的内容,也会大胆的去运用,我在未来之路里面看到的一些思考,包括我在学习和工作过程中的一些想法,然后来讲述我们今天的这个话题,关于,未来之路。
关于 杂谈《编程之路职业指导》 我们从 BILL GATES 写的一本书《The road ahead》来开启话题,该书主要讲述了个人电脑的革命以及信息化对未来的巨大影响。
阐述一个职业发展与大势(行业发展、技术趋势)结合的最佳案例,主要阐述两个事实:
1 未来之路,编程之路的职业选择。
2 技术路线,保持持续学习的习惯。
生成音频我尝试过百度、科大讯飞的文字转语音,但是效果没那么好,我就找时间重新录制了一下,在线分享过程随意扩展,啰嗦的东西较多,没有准备充足,所以逐字稿修饰,尽可能表达清晰,这是我做事的方式。
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
Ambari 2.5,我们的专注点是继续提高日常Hadoop集群的运维和管理工作,Ambari整个社区都在努力让Ambari更加智能化易用的提供Hadoop集群的运营。Ambari 2.5 做出的重点改进如下:
Service Management
Log Management
Configuration Management
Monitoring
Security
Upgrades
支持Service Auto Start(AMBARI-2330, 文档)能力,集群管理人员可以设置策略,以确保组件在运行失败后能自动重新启动,并确保在服务器重启后组件重启。
基于每个主机上的Ambari agent会主动检测托管组件是否异常退出,并且根据管理员设定的策略重启该组件。在启动时Agent会参考相关策略,并根据需要自动启动相关组件。
对于大型生产集群,我们增加了易于维护的功能特性,可以非常方便的添加或者删除JournalNodes(AMBARI-7748,文档)。此功能可以指导集群管理员通过可视化的方式对JournalNodes节点进行添加、删除和移动,对于大型集群来说启用HA功能保障集群高可靠,那么对JournalNodes节点的管理就显得非常重要。
Hadoop生产环境中往往会产生大量的日志数据,日志的管理通常需要管理员非常熟悉Log4j的工作原理。通过最新的日志轮询(AMBARI-16880,文档)功能简化配置。目前在最新的版本中管理员可以非常容易的配置应该保留多少个文件,以及在什么时候轮询日志(基于文件大小)。
LogSearch(技术预览)目前是最受欢迎的功能之一,在此版本中可以看到漂亮的UI,并可以根据用户操作进行后端刷新。日志的聚合搜索在下一个版本Ambari 3.0中UI将被简化,后端将会有更加强大的日志保留和扩展功能。
Ambari在进行单一配置更改时,在不同服务中由于有配置依赖共用参数,某些参数修改会导致多个配置更改?Ambari希望在配置发生更改时,Ambari能及时更新相关的从属配置。如果集群某些配置发生改变,而从属配置的修改没有让管理员能可视化的看到这样是非常不正确的。我们做了许多研究,通过配置更改通知功能,以确定目前集群最佳的配置建议。此外,我们还添加了可视化的弹出窗口和对话框通知,以确保管理员能看到配置建议,并根据经验选择保存修改或者修改部分配置。使得集群在修改部分配置的时候,及时出错了,也不会影响其他组件的正常工作。
一个大型的集群通常分工明确,有架构师、运维、开发、测试、管理,不同的人对集群的关注点不同,对于开发来说需要完整的集群客户端相关的配置信息,这个时候集群组件客户端配置导出功能就显得很重要。现在通过下载所有客户端配置功能,我们可以轻松的导出具有Ambari管理的每个服务的客户端配置gz文件包。
HDFS集群的监控非常重要,当你尝试找出NameNode为什么压力这么大,可能是那些原因导致的时候,缩小范围,通常直接排查像HDFS发送请求前10名用户,并且随着时间的推移,监控HDFS最常用的10个操作信息。使HDFS TopN用户和常用操作可视化,Grafana现在可以看到这些指标,使得故障排除更容易,并帮助您减少MTTB(mean time to blame),找出相关问题负责人。
Ambari相关的监控指标已经通过可以很好的帮助运营一个Hadoop集群,利用好集群资源。而服务于Ambari监控指标存储的相关组件一直以来都有单点问题,如果该数据收集存储节点AMS奔溃将会导致指标完全丢失,对于一个企业级的大数据软件来说是不可承受的灾难,所以在Ambari 2.5中我们引入了AMS Collector High Availability做为技术预览。这意味着此功能可用,但尚未推荐用于生产环境部署。此功能针对大型集群多维度收集数据、写入和聚合指标优化,保障大量监控指标实时入库和快速读取,添加相关监控指标项无需重启集群组件优点。这种高可靠对企业级用户来说,可以最大化保障AMS的价值。
对于集群安全性一直是我们重点关注的方向,在最新的版本中Hive,Oozie,Ranger和Log Search增加了Password Credential Store Management 功能。此功能使得Hadoop集群更加的安全。
此外还支持自动化的LDAP和Kerberos支持。
Ambari REST API在未来的版本中会支持基于Kerberos的身份认证能力。
没有人想要停机进行集群的升级,甚至为了不想数据丢失风险而进行数据备份升级。Ambari最新的滚动升级功能,可以避免在升级过程中停机时间太长,这里提供一种保守的方法,确保升级过程中不会有数据丢失风险。通过滚动升级总持续时间会比快速升级更长。在Ambari 2.5中,提供了滚动升级期间有能力暂停,以获得重新对集群的操作控制,防止出现的任务状况。一个常见的问题,如果滚动升级需要几天时间,如果我的HiveServer2实例有个问题,需要重启,会发生生么?这就是为什么要添加暂停功能。你只需要点击暂停按钮,最小化升级窗口,然后完全控制集群以重新启动HiveServer2。完成此操作之后,只需要点击Resume即可继续完成升级。
脚本报警:在于客户交流中,我们会经常被问到Ambari如何配置发送报警信息到HipChat或Slack或Pager Duty的问题。Ambari其实是有提供这样的功能的脚本报警。此功能允许您定义在Ambari中触发警报时应调用的脚本,以便您轻松地与外部系统集成。所以下次如果你想发送一个Ambari Alert到你的自定义接收系统,配置一个脚本报警即可。
下半年是项目季,好忙...研发告一段落,开始奔波各种项目
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。

原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
*** 数据仓库:过去、现在和未来 ***
欢迎来到我们全新的ITweet Talk系列视频和博客。我是作者,我将分享数百次咨询和部署数据平台的建议和最佳实践,这些咨询和部署是由企业客户围绕数据管理需求提出的,以支撑企业海量数据分析。下面我们深入探讨数据仓库的发展。
我经常接触数据仓库建设的需求,而现有的大数据系统也希望基于大数据建设数据仓库,然而Hadoop为核心发展起来的软件适用于OLAP的数据分析需求,OLTP这样的分布式数据库系统也如火如荼的发展。
在企业数据信息数据整合过程中,往往都是不同数据源放到不同的数据库系统中,没有数据仓库的规范化建设,跨部门进行数据协作,打破数据孤岛无法实现。
分布式系统,帮助解决这些问题,我们真正深入了解数据价值的人都知道,建设统一的数据中心,数据仓库,整合行业数据可以进行多种维度的数据分析,数据驱动决策,帮助企业创新。目前在金融、电商、广告等行业已经大规模利用新技术取得了不菲的成绩。
今天,企业级数据分析平台发生了很大的变化。

那么,对于传统的数据仓库,你有各种各样的数据来源。您正在收集、清洗和整合数据,以便您可以将其呈现在您的数据仓库中,进行统计分析、预测分析、商业智能和其他工作。
好吧,随着时间的推移,现在变得更加复杂了。

我们有云、有移动设备、社交媒体数据、机器数据、传感器数据。越来越多的数据来源,数据爆发式增长,非结构化数据、半结构化数据、结构化数据。
有大量的关于大数据介绍中,你会看到幻灯片谈论您必须处理PB级数据量,才能利用上这些新的数据分析技术。但是对我来说,这是没有抓住重点。
数据仓库真正的意义是什么?为什么企业对数据仓库支出不断增加。这是因为不是数据量和速度问题。随着发展,我们只需要增加硬件就能增加我们数据处理的规模,这才是分布式系统的强大之处。
万物互联的时代,随着数据的多样性和异质性从而增加数据分析的复杂性。我们的需求是关联和整合这些数据。但是,我们现有的数据分析工具,Hadoop或Spark并没有带来任何神器的解决方案。我们仍然在努力解决同样的问题:如何从不同的渠道获取数据、然后将他们关联起来,这样企业可以让数据说话,数据驱动决策。为了解决这些问题,我们需要依赖更多新的工具。
利用新技术,使我们能更好的解决实际业务问题。
那么,我们来看看不同的技术,是如何帮助我们解决与数据相关的需求,为业务提供数据支撑。
OLAP场景的Hadoop解决方案,OLTP场景的NewSQL解决方案。
我们看到一个有趣的现象,每个公司几乎都建立了一个数据流水线,随着新数据的进入,他们利用NoSQL数据库来存储文档数据。就像是一个无线容量的数据库,拥有很好的扩展性,并且还能进行大数据量的高速查询和搜索。
我们可以看到很多大规模使用MongoDB、Hbase、cassandra数据库,还有NewSQL的发展。
随着数据多样性的出现,出现了很多新型的数据库。
越来越高的数据分析需求和数据多样性的探索,导致了数据库系统的蓬勃发展,国产数据库也有了非常大的进步可以进入国际顶级的数据库会议发表论文,2017年腾讯的开源项目VLDB也发文了,而做为去IOE发起者的阿里在云端阿里云也如火如荼的发展数据库服务,比如:PolarDB、蚂蚁金服金融级数据库分布式数据库OceanBase都是黑科技级别的产品。为了在云端兼顾OLTP和OLAP的数据分析引擎,各大云厂商阿里云、腾讯云、XX云都使劲的推广各自的数据库技术,也采取与开源数据库厂商广泛合作的方式。
底层数据库系统,特别是NewSQL几大巨头也有有在长期招聘相关职位。可见目前分布式OLTP/OLAP数据库发展的势头,必然是与Cloud相结合,也只有云化才有机会大把捞金,不然开源数据库这样的生态下,底层基础软件出路在何方?

我们列表 RDBMS -> MPP -> HADOOP -> NOSQL -> NEWSQL 主流的系统,根据我接触过的公司或产品来列举,个人认知有限,如未能列表全面,欢迎补充。
| 数据库 | 公司 |
|---|---|
| Oracle | Oracle |
| SQLServer | Microsoft |
| DB2 | IBM |
| PostgreSQL | community |
| MySQL | Oracle & community |
| MariaDB | MariaDB & community |
| 数据库 | 公司 |
|---|---|
| Greenplum | Pivotal / DeepGreen |
| Teradata | Teradata |
| GBase 8a | 南大通用 |
| HAWQ | Pivotal(SQL on Hadoop) |
| Impala | Cloudera(SQL on Hadoop) |
| Vertica | HP |
| 大数据发行版 | 公司 |
|---|---|
| CDH | Cloudera |
| HDP | Hortonwork |
| MapR | MapR |
| TDH | Transwarp |
| CRH | Redoop |
| XXX | Unknown |
| NoSQL系统 | 公司 |
|---|---|
| MongoDB | MongoDB Company |
| Hbase | Community |
| Cassandra | DataStax |
| Hypertable | Zvents |
| Accumulo | Community |
| Elasticsearch | Elastic |
| NewSQL系统 | 公司 |
|---|---|
| Spanner | Google Cloud |
| CockroachDB | CockroachLabs & Community |
| TiDB | PingCAP & Community |
| OceanBase | 阿里巴巴 |
| CrateDB | CrateDB & Community |
虽然NoSQL因其性能、可伸缩性与可用性而广受赞誉,但其开发与数据重构的工作量要大于SQL存储。因此,有些人开始转向了NewSQL,它将NoSQL的优势与SQL的能力结合了起来。

各大云厂商也在大力发展支持OLTP的分布式金融级别的关系数据库,已解决MySQL分库分表难于管理的问题,底层直接提供分布式能力,而不用在业务层大动干戈,平滑迁移关系型单机数据库到分布式数据库集群,分布式以后提供弹性的伸缩能力,利用云端优势,发展基础软件即服务,帮助客户轻松应对海量数据多维度分析需求。
关于如今高速发展的数据引擎发展与详细设计细节,会通过ITweet Talk系列逐一介绍。
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
我为什么弃用OpenStack转向VMware Vsphere,一切皆为简单、高效。因为我们在工作过程中涉及到大量的测试工作,每天都有成百个虚拟机的创建和销毁工作。
工作任务非常繁重,我们的持续集成平台CI/CD也会大量和虚拟化平台进行交互。
早期,没有OpenStack的时候,我们用vmware workstation创建虚拟机编译和测试,这样效率是很低的,条件也比较艰苦,动不动磁盘就满了。要不就是虚拟机损坏导致很重要的基础环境出问题,很多时候其实是技术人员无法很好的掌握和运用这个技术,这时候就需要用到一个专业的工具完成大量虚拟机的管理和统一创建工作。Openstack是一个KVM的管理软件,提供存储,网络,操作系统虚拟化技术。
使用OpenStack完成几点需求:
当然,最重要的是可以申请服务器资源来进行产品研发了,目标是优化研发流程,提升整体研发效率。
研发效率的提升,通过优化整体流程,完成CI/CD的建设,整体效率提升50%,主要是目前研发流程更加成熟和稳定。我们的持续集成平台使用Docker、Openstack、Jenkins、gitlab、maven、nexus、Harbor等。
OpenStack M版本已经在线上跑2年左右,逐渐发现很多问题,坑很多,而且运维复杂,有些早期的目标没有很好的完成。
比如:
Cinder,支持的虽然很多,我们选择的是Glusterfs,容易挂载到虚拟机失败vxlan,支持多租户,底层是openvswitch,多层封包导致效率低linux bridge模式,稳定高效有个OpenStack系列内容可以参考:https://github.com/realxujiang/labs/tree/master/openstack-series
OpenStack定位大规模云主机管理系统,所以使用成本高,好处是规模,谨慎选择吧。
为了更易于维护和使用,我开始尝试新的方案。
调用发现vmware vsphere是个不错的技术,满足我们以上所有的需求,也能解决所有OpenStack的缺点,而且整个产品成熟度非常高,相关产品都融合得非常好。
目前保留原有的OpenStack集群,新增两个vmware vsphere集群,用于新的持续集成平台和测试资源服务。vmware vsphere资源利用率更高。更易于管理和使用,所以打算捣鼓一下VMware vsphere产品。
使用感受,觉得操作特别简单,企业级虚拟化产品肯定是首选,非常成熟,门槛低,很符合我们的需求。
让人感觉虚拟化产品就应该是这样的,安装极简,使用极简,设计哲学非常到位,真是非常好的产品。
美中不足,不支持混合盘,不同类型的盘不能做到一个大的存储卷中。
慢慢感受吧,有时间写进一步使用的感受。
群友提问,需求挺奇怪的。是否能使用OpenStack替代VMware Vsphere?
可以的他们做的事情都类似,只不过成熟度不一样,使用它可以学习现代云计算架构设计,OpenStack基本是AWS的一个copy开源作品。很多公有云使用方式和OpenStack高度一致,所以你会了OpenStack这样的私有云,公有云使用自然不在话下。
文末,推荐斯坦福大学:
云计算课程:《Cloud Computing Technology》
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
2016/05/08,也就是去年发了一篇<程序员必读的书>,很多我也没看过,我打算用几年的时间全都阅读一遍,在未来很长一段时间内都会边阅读边推荐。
人月神话
人件
大话数据结构
刻意练习
黑客与画家
霍华德.休斯
我心深处
由于工作的原因,没有那么多时间看书,只能是闲暇之余看一看,每次出差我基本都会看完1-2本书,很多书籍对我的影响很大,还记得最早期我在学校看很多黑客、TED、计算机类的传记,直接改变了我的整个人生。
自学编程,进入计算机领域,至今已经3年多时间,我热爱计算机技术,每个人工作3年以上都会遇到一些问题吧,我现在也在这个阶段,感觉进入一个低潮期,非常痛苦,技术进步比较缓慢,不知道怎么选择?很多人说选择大于努力?
未来,我计划重新来过。
数据结构与算法
操作系统原理 & 编译原理
编程语言
数据库设计与实现
计算机网络
以上,够折腾很久了,计算机知识太多,慢慢学习吧。
未来一段时间,打算写一写有关团队、大数据创业的小故事吧。
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
10G 的Hadoop有什么意义呢?你会怎么设计集群呢?我们一起讨论一下适合或者不适合10G Hadoop的案例,然后看看怎么对10G集群进行网络的设计。如果你想快速开启10G Hadoop或升级, 基于Hadoop集群和网络请认真阅读这篇文章然后再回过头来思考。
Hadoop是被一个网络公司设计的(雅虎)出于必要的有效存储和分析网络扩展应用本身存在的大量数据设置,这里假设你能创造利润的是办法是设置大量的数据, 那么不管你喜不喜欢,目标都很简单:通过以最低的成本和最好的用户体验构建基础设施去处理大量数据设置来提高底线。那它应该可以扩展,需要更大的数据容量和更大的带宽,你只需要增加更多的机架和降低机器成本,添加水平集群置入到数据中心仓库。同样,网络扩展Hadoop集群可能会变得很大(数以千计的机器)因此每个机器的变量成本会快速增加,真的非常的快。所以这里的设计理念是让每个机器和机架的开关尽可能的便宜,尽可能的利用组件,例如内置1GE NICs (LOM),和1GB 的机架交换机。由于这些原因,10GE Hadoop也没有什么意义, 也很难确保成本(但是也不总是这样)
但是Hadoop再也不是只是针对网络公司或者数据中心仓库。其他产业例如零售,银行,保险,电信,政府等产业现在都在利用大数据从曾经被他们遗弃的数据中获取更多的价值,这里可能需要设置大量的数据, 但是我敢说是可选择性的和具有主动权的(那就是核心商业)很多IT底线工作模式和以前是有区别的,也不需要数据中心仓库,对于这些企业来说。 10GE 的Hadoop不值得多考虑点的吗? 我想是的, 但是一如既往的标准免责声明的应用, 得看情况。
你不是雅虎公司, 你只是一个运用有限的Hadoop部署的普通企业,你已经部署了10GE在IT基础设施上的其他区域(可能是私有云)而保持操作一致性和资源替代是具有非常重要的意义的。10GE的增量没能和规模形成正比,但它确实是一个有上千个节点的巨大的集群
空间是很珍贵的, 你没有数据中心仓库, 那么你就要想办法扩展Hadoop部署且不用耗光所有的机架在你的有限的数据中心。
你的Hadoop集群运行了大量ETL类型的工作负载,因此在集群中从映射器到减速器环绕了很多中型数据,还有在数据节点中间有很多HDFS复制的数据流,这样子在10GE的机器中运行的集群就更流畅了。
当你在部署存储密集的2RU机器时(例如,Dell PowerEdge C2100, or R720xd,可能是每个节点24TB, 这些节点之一有12-16个核可能比典型的8核1RU 4TB 需要更多的网络 I/O,当节点崩溃时(或者更糟糕的是整个机架)那么庞大的数据量需要从整个集群进行再复制。
如果你是雅虎尽管你有数据中心仓库但仍然远远不够,你要在集群300米之内连接这么多的互联交换机还是很困难的因为横向扩展已经到极限了你只能选择扩展节点的深度。
在一个有限的集群中10GE的增量成本可能和1Gig相差不大,并且日益便宜。10G交换机和NIC的价格迅速的下滑,特别是基层交换机和NIC,你不需要花哨的CNAs 或者 DCB。
10GE NICs仍未广泛提供LOM,所以你需要花费额外的成本去购买配备了10GE存储的机器。
端口接端口的10 GE ToR 交换机所需成本是一个标准的1GE交换机成本的三倍,
你的工作负载没有网络压力, 你的工作也没有移动或者更改数据,你正在所以机器间的数据传输(中间数据)是光纤数据因此1GE也可以很好的实现
还没有公开的数据可以显示10GE Hadoop的明确成本/效益(如果你在一些博文中看到有讨论记录或链接)据我所知这种结论还是有大量理论依据的。另一方面,成本/效益的标准线还是很明确的。
花费在装备每个节点和10GE的钱另一方面还可以用来添加更多的节点在你的集群上。如果你的工作负载中CPU和存储限制比网络多那么添加节点和磁盘到集群上比添加网络更有意义
集群的性能其实也不是最重要的你可以利用Hadoop离线量处理,没有人非要计较工作量是在一个小时,或者20分钟完成的。
其实一个很小的10G集群(只有一个或者两个机架)操作起来和有40个节点 10G顶级换机一样简单,你可以用向交换机LAG技术把两个交换机链接在一起(此处所示的是VLT)每个节点通过LAG连接到两个交换机上,然后链接10GE交换机到剩下的外部访问网络(如果有需要, 最好能是L3)操作非常的简单直接,对于这项操作不错的交换机有Dell Force10 S4810 线率 L2/L3 10G/40G交换机,当然你也可以使用相对便宜的L2交换机,但是你要想想ToR 交换机有什么性能可以让你轻松自如的扩展超越前两个机架(例如, 3层换自动资源配置和Perl/Python 操作)
要超过两个机架以上, 你可以用一个性价比高的10GE 交换机提供机架间集群的互联(Spine).为此你不用买一个既昂贵, 又庞大,还需要充电的高阶的机架式交换机。其实低成本, 低能耗, 固定的交换机也可以很好的完成工作,再次推荐,我们可以用S4810来完成。如下图所示
用一对1UR的交换机来互相连接10GE Hadoop集群 你可以结合实际规模连接160个节点,假设在机架之间的超额认购率为2.5:1(在机架内部的线率)考虑到你的2RU节点有24TB或者更多,可以用一个超过了1PB可用内存的集群(三倍复制之后)也挺好的。
因为Hadoop没有要求2层邻接在集群中的节点间, 所以我们将在机架间采用比较优质经典的L3交换机, 既简单易懂还可以扩展, 你可以选择你最喜欢的路由协议,OSPF, IS-IS, BGP, 无论哪一个都可以
如果160个节点不够,你可以把同样的架构通过添加更多同样的1RU交换机在Spine层里来扩展到1280个节点,随着需求增加集群也将增加到16Spine。每个交换机有16个上行链路并对应连接1x10GE到每个Spine交换机上,因为我们选择3层交换机作为集群互联,所以我们不受典型的两层topology的约束,见下文
像这种具有较大的Hadoop集群, 你可能要考虑到用单链接连接每个节点到单交换机上降低成本扩大集群大小,毕竟是用64个机架,即使全部机架崩溃了你也只损失了集群资源的一小部分,可能都不值得为了冗余加倍连接到主机上。
如果你一开始想要创建一个150-300个节点 相当大的一个10GE Hadoop集群,你肯定会考虑一并创建一个40G互联集群,为什么呢?可以减少Spine交换机的个数, 减少从ToR到Spine的电缆,减少网络配置端口。另一大优势是40G的光纤比10G的贵1.8倍,所以即便你要扩展集群也可以省一大笔钱。
用40G光纤省65%的成本优势,根据我的经验来看,任何一个用40G spine交换机 320-640个节点的集群都比创建10G spine交换机的性价比高,即使用相同参数的机架到机架间2.5:1过载比和机架内部的线路速率一起工作都具有优势的。
再次强调,你不需要一个庞大的电源和昂贵的40G线卡给高阶的机架式交换机充电, 取而代之可以采用相对成本低,功耗低的2RU固定交换机, 例如40G的32个端口的Dell Force10 Z9000,如下所示
这儿也适用40G互联横向扩展到spine层同样的规则,利用S4810 ToR (Leaf)切换4 x 40G上行链路,你可以把40Gspine从2个交换机增加到4个交换机,把集群大小从320个节点加一倍到640个节点。
如果你需要把你的集群连接到外面,最好的位置是在Leaf层ToR交换机。利用spine交换机上的端口连接就不会影响集群大小,因为每个端口都代表了机架上的节点。只需要少量的端口在ToR交换机上并且用3层链路连接交换机的核心就可以给你的集群提供很好的隔离和安全性了。你可以在这里使用BGP或者甚至是静态路由保证您的内部路由安全的和外部隔离。
你可能觉得疯了吧,10G Hadoop和640个节点,一个集群完全不够用,没问题的,把这些Z9000交换机放在spine里面用作128x 10G的交换机取代32 x 40G。然后把S4810 ToR
交换机上行链路到16 x 10G. 务必注意,使用越狱的10G链路可以减少电缆100米的距离
你可以在spine里面横向扩展到(16)Z9000交换机,因为每个ToR有16个上行链路。而一个集群里面有128个ToR交换机-每个Z9000里面有128个端口。另外, 横向扩展是有可能的因为我们是用的优质经典的的3层交换机从ToR到集群交互连接,如果用2层交换机是不可能完成设置的,除非你有TRILL那也不可能真正的完全实现,反正都毫无意义,因为Hadoop节点根本不在乎是2层或者3层还是来自其它层。
你甚至可以通过添加第三步到fabric中创建比这更大的集群,在第三步中ToR连接Leaf,Leaf再连接到spine。在这种情况下集群大小超过20,000 10GE 的主机也可以用相同的低成本, 低能耗, 1RU 和2RU 的固定交换机。
对于很大的集群就像这种,或甚至小一点的,都可以很方便的自动部署交换机,有点类似服务器引导本身从网上下载OS,从CMDB中自动检索配置文件,网络交换机也应该可以自动安装。这儿讨论了交换机, 同样你还可以用 Perl和Python 脚本和熟悉的脚本语言自定义操作.
对于要建设一个10 GE 的Hadoo集群来说他不是一件容易的事情, 例如密集虚拟服务器和IP存储。对于一些人来说,没有经济意义, 对于其他人来说,10GE Hadoop 具有非常重大的意义。例如支持密集的节点,扩展有限的数据中心,现存的基础设施和围绕10GE的操作,以及强烈的网络作业对集群的压力。
就像你用1GE的集群你可以创建一些令人映像深刻的小集群,随着不断发展你可以用低成本,低能耗,固定10G 或者40G的互联网交换机,创建一个具有3层交换配置的网络,你不需要一个2层 在机架间,也不需要一个又贵又庞大的机箱交换机来完成工作。
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
由于资源紧张,为了完成CI/CD的自动化,所以打算把一台128g、24c、10T存储的一台独立GitLab服务器虚拟化为多台服务器。完成持续集成平台的迁移,减少资源浪费,现在记录一下操作过程。
gitlab-rake gitlab:backup:create RAILS_ENV=production
注:默认备份后文件一般位于/var/opt/gitlab/backups/,文件名:1513578325_2017_12_18_gitlab_backup.tar
这里说明下为什么要一样,原因应该是由于Gitlab自身的兼容性问题,高版本的Gitlab无法恢复低版本备份的数据.
原Gitlab安装版本: gitlab-ce-8.7.0-ce.0.el6.x86_64.
wget https://packages.gitlab.com/gitlab/gitlab-ce/packages/el/6/gitlab-ce-8.7.0-ce.0.el6.x86_64.rpm
通过rpm命令安装GitLab服务,配置并启动GitLab
rpm -i gitlab-ce-8.7.0-ce.0.el6.x86_64.rpm
sudo gitlab-ctl reconfigure
3.将步骤1生成的tar文件拷贝到新服务器上相应的backups目录下
可以利用scp进行直接拷贝。
scp /var/opt/gitlab/backups/1513578325_2017_12_18_gitlab_backup.tar username@src_ip:/var/opt/gitlab/backups
注: username为新服务器的用户名,src_ip新服务器IP地址
4.新GitLab服务数据恢复
# This command will overwrite the contents of your GitLab database!
gitlab-rake gitlab:backup:restore RAILS_ENV=production BACKUP=1513578325_2017_12_18
注:BACKUP的时间点必须与原服务器备份后的文件名一致
版本不匹配问题
GitLab version mismatch:
Your current GitLab version (8.7.0) differs from the GitLab version in the backup!
Please switch to the following version and try again:
version: 9.0.5
5.重启GitLab服务并检测恢复数据情况
sudo gitlab-ctl restart
sudo gitlab-rake gitlab:check SANITIZE=true
如果check命令出现错误,说明备份的GitLab服务和新的GitLab服务版本不匹配,请安装正确的版本。
6.总结
GitLab是一款企业级私有Git服务最佳选择。可以完成企业持续集成平台代码库管理的工作。也可以和很多持续集成工具进行无缝结合,让开发人员专注开发,部署、打包、测试、上线的工作自动化完成。关键是它免费的,linus真年神人也。GIT也是他的作品。
膜拜大神,进一步了解,最近在看《只是为了好玩:Linux之父林纳斯自传》Linux之父Linus`写的一本书,关于开源软件做了很好的阐述。
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
简介
结合作者多年的职业发展之路,介绍职业发展中的各种选择以及最前沿的技术发展路线,希望能对初入职场的同学有所帮助。
学习目标
适用人群
主线
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/

今天我们聊NFSGateway,近期真的是忙得不可开交,在构建100个节点集群的时,由于一些特殊的业务需求需要使用NFS-Gateway或者HDFS-fuse功能,把HDFS分布式文件系统挂在到某些机器上,可以通过访问Linux本地文件系统操纵HDFS中的数据,这就是类似传统的NFS文件系统的功能。通过把HDFS整个分布式文件系统,挂载到某些Linux机器,通过往挂载的目录中传递数据,即可直接上传到HDFS,让HDFS的使用方式非常的方便。
目前开源世界有很多分布式文件系统的优秀软件,比如:Ceph,Glusterfs,Alluxio等都提供了类似nfs,fuse挂载分布式文件系统到Linux主机的能力,也都大量复用了Linux本身已经有的软件,所以都是兼容NFS,FUSE的接口的。HDFS也不例外,也都通过类似的技术来支持这样的功能。
在HDFS中目前提供了两种方式:
HDFS-NFSGateway 在HDP版本中原生支持此方式
HDFS-Fuse
$ hdp-select versions
2.6.1.0-129
$ cat /etc/redhat-release
CentOS Linux release 7.2.1511 (Core)
通过ambari界面自动化去安装NFSGateway的方法,在Ambari管理的最新的Hadoop2.x以上的版本都是支持这种方式的,并且在界面上可以自动化安装NFSGateway。
首先,登录ambari-server的可视化界面,点击“Hosts”,任意选择一个主机单机。
其次,点击+Add按钮,选择NFSGateway,点击Confirm Add进行安装NFSGateway。
最后,点击Start按钮,启动NFSGateway。
手动教程参考:http://itweet.cn/blog/2014/02/04/HDFS_NFS_Gateway
首次挂载遇到如下问题,环境是Centos 7.2我亲自安装的,采用的是最小化的安装Linux系统模式,而集群的版本HDP 2.6.1.0-129。
# mount -t nfs -o vers=3,proto=tcp,nolock localhost:/ /hdfs
mount: wrong fs type, bad option, bad superblock on localhost:/,
missing codepage or helper program, or other error
(for several filesystems (e.g. nfs, cifs) you might
need a /sbin/mount.<type> helper program)
In some cases useful info is found in syslog - try
dmesg | tail or so.
根据提示,并且进一步排除/sbin/mount.<type>目录发现,根本没有mount.<type>的文件,进而断定为缺少nfs-utils软件包,安装即解决问题。
# yum install nfs-utils
NFSGateway挂载,HDFS分布式文件系统挂载到本地系统挂载点为/hdfs,如下:
# mkdir /hdfs
# mount -t nfs -o vers=3,proto=tcp,nolock localhost:/ /hdfs
# df -h|grep hdfs
localhost:/ 4.8T 3.2G 4.8T 1% /hdfs
NFSGateway挂载成功之后,我们对他进行一些基本的读写测试,看是否满足我们的要求,让HDFS分布式文件系统的访问,就像访问Linux本地目录一样简单。

例如:
[root@bigdata-server-1 ~]# su - hdfs
[hdfs@bigdata-server-1 ~]$ echo aaa > test.txt
测试cp文件到挂载点(/hdfs)的属于分布式文件系统的/hdfs/tmp,出现错误,表现的现象为无法正常cp数据到此目录,并且在hdfs看到生成此相关文件大小为0
$ cp test.txt /hdfs/tmp/
cp: cannot create regular file ‘/hdfs/tmp/test.txt’: Input/output error
既然是NFS的问题,首先排查NFS服务相关日志,定位问题,发现如下警告信息。
# tail -300 /var/log/hadoop/root/hadoop-hdfs-nfs3-bigdata-server-1.log
cannot create regular file ‘/hdfs/tmp/test.txt’: Input/output error关键错误信息如下:
2017-07-20 22:01:52,737 WARN oncrpc.RpcProgram (RpcProgram.java:messageReceived(172)) - Invalid RPC call program 100227
2017-07-20 22:04:08,184 WARN nfs3.RpcProgramNfs3 (RpcProgramNfs3.java:setattr(471)) - Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException):Access time for hdfs is not configured. Please set dfs.namenode.accesstime.precision configuration parameter.
at org.apache.hadoop.hdfs.server.namenode.FSDirAttrOp.setTimes(FSDirAttrOp.java:105)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.setTimes(FSNamesystem.java:2081)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.setTimes(NameNodeRpcServer.java:1361)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.setTimes(ClientNamenodeProtocolServerSideTranslatorPB.java:926)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:640)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2351)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2347)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1866)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2345)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1554)
at org.apache.hadoop.ipc.Client.call(Client.java:1498)
at org.apache.hadoop.ipc.Client.call(Client.java:1398)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:233)
at com.sun.proxy.$Proxy14.setTimes(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.setTimes(ClientNamenodeProtocolTranslatorPB.java:901)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:291)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:203)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:185)
at com.sun.proxy.$Proxy15.setTimes(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.setTimes(DFSClient.java:3211)
at org.apache.hadoop.hdfs.nfs.nfs3.RpcProgramNfs3.setattrInternal(RpcProgramNfs3.java:401)
at org.apache.hadoop.hdfs.nfs.nfs3.RpcProgramNfs3.setattr(RpcProgramNfs3.java:465)
at org.apache.hadoop.hdfs.nfs.nfs3.RpcProgramNfs3.setattr(RpcProgramNfs3.java:407)
at org.apache.hadoop.hdfs.nfs.nfs3.RpcProgramNfs3.handleInternal(RpcProgramNfs3.java:2193)
at org.apache.hadoop.oncrpc.RpcProgram.messageReceived(RpcProgram.java:184)
at org.jboss.netty.channel.SimpleChannelUpstreamHandler.handleUpstream(SimpleChannelUpstreamHandler.java:70)
at org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:560)
at org.jboss.netty.channel.DefaultChannelPipeline$DefaultChannelHandlerContext.sendUpstream(DefaultChannelPipeline.java:787)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:281)
at org.apache.hadoop.oncrpc.RpcUtil$RpcMessageParserStage.messageReceived(RpcUtil.java:132)
at org.jboss.netty.channel.SimpleChannelUpstreamHandler.handleUpstream(SimpleChannelUpstreamHandler.java:70)
at org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:560)
at org.jboss.netty.channel.DefaultChannelPipeline$DefaultChannelHandlerContext.sendUpstream(DefaultChannelPipeline.java:787)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:296)
at org.jboss.netty.handler.codec.frame.FrameDecoder.unfoldAndFireMessageReceived(FrameDecoder.java:462)
at org.jboss.netty.handler.codec.frame.FrameDecoder.callDecode(FrameDecoder.java:443)
at org.jboss.netty.handler.codec.frame.FrameDecoder.messageReceived(FrameDecoder.java:303)
at org.jboss.netty.channel.SimpleChannelUpstreamHandler.handleUpstream(SimpleChannelUpstreamHandler.java:70)
at org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:560)
at org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:555)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:268)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:255)
at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:88)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.process(AbstractNioWorker.java:107)
at org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:312)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:88)
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:178)
at org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108)
at org.jboss.netty.util.internal.DeadLockProofWorker$1.run(DeadLockProofWorker.java:42)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
根据日志定位问题,发现日志中有相关提示dfs.namenode.accesstime.precision需要进行配置,在去查看相关配置的含义。
The access time for HDFS file is precise upto this value. The default value is 1 hour. Setting a value of 0 disables access times for HDFS.
理解之后,通过调整,在Ambari-Web中查看发现默认值 dfs.namenode.accesstime.precision = 0 改为 dfs.namenode.accesstime.precision = 3600000,根据提示重启集群相关受影响的足迹,即解决问题。
再次进行测试,发现此报错消失。
$ echo aaa > text.2
$ cp text.2 /hdfs/tmp/
$ cat /hdfs/tmp/text.2
aaa
到此,通过touch、echo、cp、cat、mv等命令测试,依然正常使用,基本的nfs功能测试完成。
NFSGateway的功能相对来说是非常不错的,降低使用HDFS成本的特性,如上我总结的在配置NFSGateway遇到的一些小问题,因为对于几百个节点的HDFS集群来说,有NFS这样的特性,可以让很多Gateway服务器通过FTP-Server接收海量数据,只要进入FTP就进入HDFS集群,这样HDFS入库就变得特别简单,可以节省时间。后续集内容会提供数据对比深度剖析HDFS提供的类似NFSGateway功能的软件性能情况和原理。
事物都是两面性的,带来便利的同时也会带来一定的代价,使用此软件会导致数据传输性能降低很多。在使用dd命令测试结果如下:
我通过dd命令生成一个10G的大文件,让后通过hdfs fs put这样的命令,对比三者的上传性能。
如上,Hadoop原生提供的put命令上传效率最高,其次是Fuse,最差的是NFSGateway,这是在5台服务器万兆网络(9.84 Gbits/sec)测试的结果,仅作为参考。
综上所述,我仅仅提供了一些基础的测试数据和结论,使用非原生提供的API进行数据接入,虽然方便了很多,但是性能有很大损耗,这个就是权衡的结果,看是否在你的业务忍耐限度以内,选择哪种方案,得通过数据和相关业务经验结合选择最合适的。
写到这里,内容相对浅显,后续我会对多方测试结果进行整理汇总,发布一版更加有力的测试数据对比情况。最近我也在做一些MPP数据库的测试优化,后续会有更多精彩的生产环境经验积累,原创文章发布,敬请关注。
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
参考:
在2017年11月28日,上午,apache宣布Impala晋升为apache顶级项目,这一令人振奋的消息。

五年前,cloudera计划开发一个全新的SQL引擎Apache Impala(这是第一个最快的Hadoop开源MPP SQL引擎),Impala融入了几十年来关系型数据库研究的经验教训和优势。Impala使用完全开放的形式融入Hadoop生态,允许用户使用SQL操作Hadoop中的海量数据,目前已经支持更多存储选择,比如:Apache Kudu、Amazon S3、Microsoft ADLS、本地存储等。
最初impala仅支持HDFS海量数据的交互式分析,其灵活性和领先的分析型数据库性能推动了Impala在全球企业中的大量部署。为企业业务提供BI和交互式SQL高效率分析支持,让支持impala的第三方生态系统快速增长。
三年前,cloudera将Impala捐赠给Apache Software Foundation以及最近宣布的Apache Kudu项目,进一步巩固了其在开源SQL领域的地位。自从捐赠Impala以来,社区一直保持高度活跃,希望引入更多的社区力量来繁荣社区,一直致力于创建一个积极创新的社区生态。现在impala从孵化项目晋升为一个Top-Level Apache Software Foundation Project。
Cloudera的Jim Apple是Apache Impala的重要导师,并且即将担任副总裁,他将持续以Apache way的方式指导和发展开源社区。
这是impala项目及社区非常重要的时刻,未来Impala将拥有更大规模的运行,为在云端持续优化减轻工作负载而努力。期待更多人参与推动impala的发展。
Apache Impala是一个开源的,原生的Apache Hadoops数据库分析引擎,Apache Impala支持者Cloudera, MapR, Oracle, and Amazon.
Impala解决Hadoop生态圈无法支持交互式查询的数据分析痛点,早期出现语法完全兼容Hive,现在逐渐支持更多语法,在底层数据库分析join中的优化是有很多创新之处的,特别是针对分布式数据库执行器的优化,利用Bloom Filter让join性能有很大的提升,目前impala建议使用的文件格式是Parquet。
Impala是一个分布式并行MPP SQL引擎在大数据上的实现,底层调度算法非常灵活,可支持HDFS多副本本地化计算在合并,效率非常高,而且是一个C++实现引擎能高效率使用硬件资源,融入了很多传统关系数据库的设计优势,在分布式查询有很多创新点,融合LLVM优化提升性能,它是一个OLAP引擎。
Impala和HDFS结合做海量数据的交互式分析ad-hoc查询,OLAP场景,BI报表可视化的最佳选择。
Impala和Kudu结合做海量数据的交互式查询,可支持CRUD操作,对强一致性事物要求不高的场景可以使用。
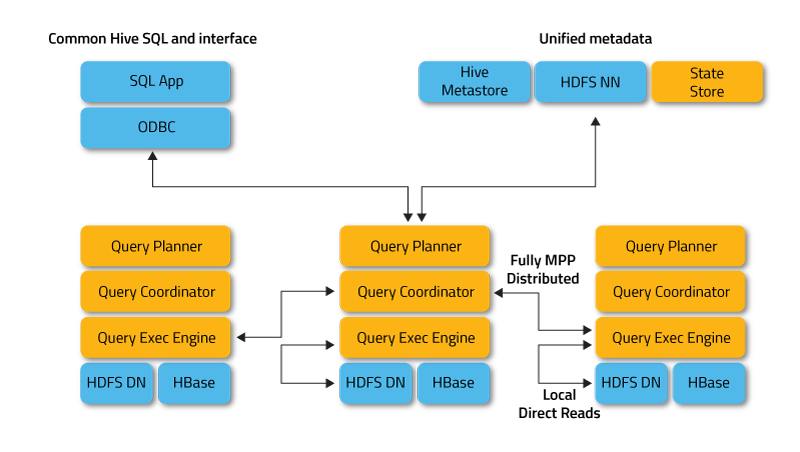
Impala可以无缝融入现有Hadoop集群,支持直接hive中的数据,完全兼容hive语法。直接可读取Hbase中数据,目前还支持Kudu,为了本地化计算符合Hadoop架构设计,impala部署需要遵守一定的原则。Impalad必须和DataNode、Hbase region server部署在一个节点上,StateStore、catalogd和NameNode部署在同一个节点上。

Impala Daemon: 与 DataNode 运行在同一节点上,由 Impalad 进程表示,它接收客户端的查询请求(接收查询请求的 Impalad 为 Coordinator,Coordinator 通过 JNI 调用 java 前端解释 SQL 查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它 Impalad 进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给 Coordinator,由 Coordinator 返回给客户端。同时 Impalad 也与 State Store 保持连接,用于确定哪个 Impalad 是健康和可以接受新的工作。
Impala State Store: 跟踪集群中的 Impalad 的健康状态及位置信息,由 statestored 进程表示,它通过创建多个线程来处理 Impalad 的注册订阅和与各 Impalad 保持心跳连接,各 Impalad 都会缓存一份 State Store 中的信息,当 State Store 离线后(Impalad 发现 State Store 处于离线时,会进入 recovery 模式,反复注册,当 State Store 重新加入集群后,自动恢复正常,更新缓存数据)因为 Impalad 有 State Store 的缓存仍然可以工作,但会因为有些 Impalad 失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
Impala Catalog service: 被称为catalog service的Impala组件中继SQL 语句导致的元数据更改到集群中的所有节点。通常由物理进程catalogd 表示。集群中只需要一个这样的节点。由于请求通过statestored,因此statestored和catalogd 可以运行在同一节点。
CLI: 提供给用户查询使用的命令行工具(Impala Shell 使用 python 实现),同时 Impala 还提供了 Hue,JDBC, ODBC 使用接口。
这里说一个Impala坑,由于他没有直接存储元数据信息,而是靠从Hive Metastore定期同步,因为impalad任何一个节点都有可能充当协调者和执行者的角色,所以元数据信息需要所有节点存储最新的数据,这是为了兼容Hive而导致的一些遗留问题。Statestored模块的作用是实现一个业务无关的订阅(Subscribe)发布(Publish)系统,元数据的更改需要它去进行通知各个节点,这解决了一个MPP无法大规模扩展的问题,大大增加了系统的可扩展性,降低了catalogd的实现和运维复杂度。但是,带来一个问题,由于impalad可以直接提供jdbc服务,如果连接的任意impalad创建表,那么其他节点短期内是不知道这个表已经存在并且提供服务的,这个时候,如何解决,需要你每次只需SQL的时候都去执行INVALIDATE METADATA Statement,否则无法及时查询到最新的数据。
如果出现,底层HDFS抽取大量分区数据入库,不执行INVALIDATE METADATA Statement则无法查询到最新的数据,这个时候,我们客户就通过ETL Server每隔30秒就执行全局的metadata更新,导致impalad底层疯狂的去ScanHDFS上的数据,日志在后台一直疯狂刷新block信息。导致impala急剧下降,甚至一个SQL很久都无法返回结果的情况。只有简单查询才能有结果。所以一定要慎用、合理的用INVALIDATE METADATA。
我是在2013年9月,开始接触Impala了,当时就是利用impala做hive结果数据的bi报告对接查询,效果非常不错,甚至在很长一段时间,Hadoop生态都没有出现和impala进行pk的类似软件,它是SQL on Hadoop领域唯一原生的交互式SQL查询引擎。现在出现的竞争对手有Hive on Tez(0.8+ LLAP)、GreenPlum on Hadoop、Drill、PrestoDB等。
Impala on Hbase一般不建议使用,效率太低下,甚至还没有Hive效率高。可参考我做的性能测试相关文章。
Impala on Kudu已经可以使用在生产,面对那种事务性要求不高,但是需要CURD的场景很合适。
总体看来,impala未来在云端SQL on Cloud场景也会非常有前景,底层同时支持OLAP/OLTP,非常值得期待,所以现在更多投资在Impala中吧。
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
GitLab是利用 Ruby on Rails 一个开源的版本管理系统,实现一个自托管的Git项目仓库,可通过Web界面进行访问公开的或者私人项目。它拥有与Github类似的功能,能够浏览源代码,管理缺陷和注释。可以管理团队对仓库的访问,它非常易于浏览提交过的版本并提供一个文件历史库。团队成员可以利用内置的简单聊天程序(Wall)进行交流。它还提供一个代码片段收集功能可以轻松实现代码复用,便于日后有需要的时候进行查找。
官网写的安装已经很全面,后面基本都是web可视化操作,考验Git能力,我这里就照抄下来啦。
[root@gitlab-machine ~]# git config --global user.name "whoami"
[root@gitlab-machine ~]# git config --global user.email "[email protected]"
[root@gitlab-machine ~]# git config --global color.ui true
[root@gitlab-machine ~]# git config --list
user.name=whoami
[email protected]
color.ui=true
If you install Postfix to send email please select 'Internet Site' during setup. Instead of using Postfix you can also use Sendmail or configure a custom SMTP server and configure it as an SMTP server.
On Centos 6 and 7, the commands below will also open HTTP and SSH access in the system firewall.
[root@gitlab-machine ~]# sudo yum install curl openssh-server openssh-clients postfix cronie
[root@gitlab-machine ~]# sudo service postfix start
[root@gitlab-machine ~]# sudo chkconfig postfix on
[root@gitlab-machine ~]# sudo lokkit -s http -s ssh
curl -sS https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/script.rpm.sh | sudo bash
sudo yum install gitlab-ce
If you are not comfortable installing the repository through a piped script, you can find the entire script here and select and download the package manually and install using
Download RPM Package:
https://packages.gitlab.com/gitlab/gitlab-ce
curl -LJO https://packages.gitlab.com/gitlab/gitlab-ce/packages/el/6/gitlab-ce-XXX.rpm/download
rpm -i gitlab-ce-XXX.rpm
[root@gitlab-machine ~]# lsof -i :80|wc -l
0
[root@gitlab-machine ~]# netstat -lntp|grep 80|wc -l
0
[root@gitlab-machine ~]# ls -l gitlab-ce-8.7.0-ce.0.el6.x86_64.rpm
-rwxr-xr-x 1 root root 261779557 May 2 14:06 gitlab-ce-8.7.0-ce.0.el6.x86_64.rpm
[root@gitlab-machine ~]# rpm -ivh gitlab-ce-8.7.0-ce.0.el6.x86_64.rpm
Preparing... ########################################### [100%]
1:gitlab-ce ########################################### [100%]
hostname: Host name lookup failure
gitlab: Thank you for installing GitLab!
gitlab: To configure and start GitLab, RUN THE FOLLOWING COMMAND:
sudo gitlab-ctl reconfigure
gitlab: GitLab should be reachable at http://gitlab.example.com
gitlab: Otherwise configure GitLab for your system by editing /etc/gitlab/gitlab.rb file
gitlab: And running reconfigure again.
gitlab:
gitlab: For a comprehensive list of configuration options please see the Omnibus GitLab readme
gitlab: https://gitlab.com/gitlab-org/omnibus-gitlab/blob/master/README.md
gitlab:
It looks like GitLab has not been configured yet; skipping the upgrade script.
[root@gitlab-machine ~]# sudo gitlab-ctl reconfigure
Starting Chef Client, version 12.6.0
...omit...
Running handlers:
Running handlers complete
Chef Client finished, 221/300 resources updated in 01 minutes 24 seconds
gitlab Reconfigured!
[root@gitlab-machine ~]# lsof -i :80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 2392 root 6u IPv4 83966 0t0 TCP *:http (LISTEN)
nginx 2394 gitlab-www 6u IPv4 83966 0t0 TCP *:http (LISTEN)
[root@gitlab-machine ~]# netstat -lnop|grep 80|wc -l
3
[root@gitlab-server data]# cat /etc/gitlab/gitlab.rb |grep git_data
# git_data_dir "/var/opt/gitlab/git-data"
git_data_dir "/data/gitlab/git-data"
[root@gitlab-server data]# sudo gitlab-ctl reconfigure
[root@gitlab-server data]# sudo gitlab-ctl restart
On your first visit, you'll be redirected to a password reset screen to provide the password for the initial administrator account. Enter your desired password and you'll be redirected back to the login screen.
The default account's username is root. Provide the password you created earlier and login. After login you can change the username if you wish.
For configuration and troubleshooting options please see the Omnibus GitLab documentation
If you are located in China, try using https://mirror.tuna.tsinghua.edu.cn/help/gitlab-ce/
访问地址http://gitlab.itweet.cn:80 (需要提前映射好域名和ip地址到hosts文件),第一次访问,提示’Change your password‘页面,你可以输入密码,此密码即为root密码;然后可用此密码登录root用户,比如我这里设置为root/admin123。
基本都是web可视化操作。这里我简单减少几个概念吧。
6.1 Project 可以发起一个项目,查询当前用户所拥有或者能管理的项目列表
6.2 Users 用户管理模块,管理员可见。
6.3 Groups 组织机构,公司管理;比如一个公司可以开启一个groups下面有很多开发人员。
6.4 Deploy keys 免密码ssh验证,git提交或者拉去代码,可以免密码验证。
6.5 SSH keys
当我们从GitHub或者GitLab上clone项目或者参与项目时,我们需要证明我们的身份。一种可能的解决方法是我们在每次访问的时候都带上账户名、密码,另外一种办法是在本地保存一个唯一key,在你的账户中也保存一份该key,在你访问时带上你的key即可。GitHub、GitLab就是采用key来验证你的身份的,并且利用RSA算法来生成这个密钥。
[root@gitlab-machine ~]# git config --list
user.name=whoami
[email protected]
color.ui=true
[root@gitlab-machine ~]# ssh-keygen -t rsa -C "[email protected]"
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
05:07:1c:92:ec:ec:79:cd:09:96:a3:8e:a3:13:bf:e2 [email protected]
The key's randomart image is:
+--[ RSA 2048]----+
| ..o+o. |
| o..o |
| o .. |
| o =. |
| . +S= . |
| . + . + |
| o o . |
| o + . |
| .E+.o |
+-----------------+
[root@gitlab-machine ~]# cat .ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAtWly2W39tM88fNrPHDoutQUe/iZZonOs/Qf8ZVxF+Kyivj8PrvlR83MmPoBbGwF/YOn5EHROEBy2EAFCHk+zQZ9uHJlsRF4EU6Aq5yZBfOTA8erdllDIy25BLITAhNe4AXmcGKJMl/TmNBWmN5+GjmTyL5l85+hMTUM3cUT8WVhPDFGlm+3UPh1AwptlDOe+t0XX6dl39BZ3i1CTmh+X38Q1K7RHkIjSSeUZQANGzJlfENQqse/zhENvUftk4EwRXL6+RIPwdk+ijAvnKGIwIfSx75u51E29jvvnP8FidU0HnBsbbedFg6cWlnMj/6AgXxnP22skmEBRAlRb7qO/zQ== [email protected]
添加,id_rsa.pub到ssh keys 页面,即可完成认证。如下验证:
[root@gitlab-machine data]# git clone [email protected]:xujiang/test.git
Initialized empty Git repository in /data/test/.git/
The authenticity of host 'gitlab.itweet.cn (192.168.1.125)' can't be established.
RSA key fingerprint is d4:2d:bb:87:cf:41:ff:fd:64:b7:66:56:45:f2:d1:64.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'gitlab.itweet.cn,192.168.1.125' (RSA) to the list of known hosts.
remote: Counting objects: 6, done.
remote: Compressing objects: 100% (4/4), done.
Receiving objects: 100% (6/6), 4.30 KiB, done.
remote: Total 6 (delta 0), reused 0 (delta 0)
[root@gitlab-machine data]# pwd
/data
[root@gitlab-machine data]# tree
.
└── test
├── LICENSE
└── README.md
2 directories, 2 files
For Examples
[root@gitlab-machine data]# cd test/
[root@gitlab-machine test]# cat hello.py
#!/usr/bin/python
print("hello itweet.cn!")
[root@gitlab-machine test]# git add hello.py
[root@gitlab-machine test]# git commit -m 'first python script...'
[master 25bddfa] first python script...
1 files changed, 2 insertions(+), 0 deletions(-)
create mode 100644 hello.py
[root@gitlab-machine test]# git push origin master
Counting objects: 4, done.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 351 bytes, done.
Total 3 (delta 0), reused 0 (delta 0)
To [email protected]:whoami/test.git
f0eb0f6..25bddfa master -> master
6.6 导入项目可以支持来自多个主流代码托管地,可以是本地初始化项目。
导入成功后,基本上可以看到,所有的github相关的代码,版本都会获取过来。包括社区全部完整的信息。更多功能参考:https://about.gitlab.com/gitlab-ce-features/
Git-scm: https://git-scm.com/downloads
SourceTree: https://www.sourcetreeapp.com/
For windows:
For Mac:
I. 如果提示:“You won't be able to pull or push project code via SSH until you add an SSH key to your profile Don't show again | Remind later”
解决:需要本地配置.ssh免密码登录,可以通过ssh隧道git clone项目,效率会高得多。
II. Gitlab 项目地址不对,希望是自己的域名地址,如:“[email protected]:itweet.cn/hadoop.git”,希望是:“[email protected]:itweet.cn/hadoop.git”
解决:
[root@gitlab-machine ~]# sudo vim /etc/gitlab/gitlab.rb
## external_url 'http://gitlab.example.com'
external_url 'http://gitlab.itweet.cn'
[root@gitlab-machine gitlab]# sudo gitlab-ctl reconfigure
[root@gitlab-machine ~]# sudo gitlab-ctl restart
需要发送邮件的用户,比如使用qq发送,需要SMTP settings,并且发邮件用户开启smtp/impi功能。
For examples
gitlab_rails['smtp_enable'] = true
gitlab_rails['smtp_address'] = "smtp.exmail.qq.com"
gitlab_rails['smtp_port'] = 465
gitlab_rails['smtp_user_name'] = "[email protected]"
gitlab_rails['smtp_password'] = "password"
gitlab_rails['smtp_authentication'] = "login"
gitlab_rails['smtp_ssl'] = true
gitlab_rails['smtp_enable_starttls_auto'] = true
gitlab_rails['smtp_tls'] = false
参考:https://gitlab.com/gitlab-org/omnibus-gitlab/blob/master/doc/settings/configuration.md#configuring-the-external-url-for-gitlab
https://gitlab.com/gitlab-org/omnibus-gitlab/blob/master/doc/settings/smtp.md#smtp-on-localhost
http://itweet.github.io/2015/07/12/git-manual/
https://help.github.com/desktop/guides/getting-started/
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
本测试硬件环境是在比较老旧的Dell R710机器上测试的,具体配置参考下面内容,我们在这里主要测试和探讨的是对Spark2、Hive2、Spark1、Hive1进行跑同样的TPCDS测试用例、比较它们的性能有多大差别,其中也会测一组最早期的Hive on MR的性能。
注:数据通过TPC-DS提供的数据生成程序生成1TB的TextFile,再通过这1TB文件生成ORC文件格式同样的表。
资源分配主要涉及Yarn和HDFS的资源分配,因为Hive1和Hive2、SparkSQL都是基于Yarn分配资源运行,本身并不占用资源、安装之后以客户端的形式存在集群中,只有在需要的时候才会启动运行任务。
Yarn
HDFS
由于集群提供多种连接方式,不同的连接方式对集群性能会有所影响,所以统一使用一种方式连接集群也是所测试的框架都支持的方式beeline。
SQL on Hadoop框架中,和这个生态融合度高的基本都有beeline方式,他其实就是JDBC的命令行版本。
平台提供Hive1和Hive2的访问接口,分别如下方式,通过beeline方式连接Hive集群。
Hive1 Examples
beeline --hiveconf hive.execution.engine=tez -u 'jdbc:hive2://bigdata-server-3:2181,bigdata-server-1:2181,bigdata-server-2:2181/tpcds_bin_partitioned_orcfile_1000;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2' -n hive
Hive2 Examples
beeline --hiveconf hive.execution.engine=tez -u 'jdbc:hive2://bigdata-server-3:2181,bigdata-server-1:2181,bigdata-server-2:2181/tpcds_bin_partitioned_orcfile_1000;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-hive2' -n hive
平台提供Spark 1.6.3和Spark 2.2的beeline访问接口,可以通过如下方式直接访问spark集群。
由于默认启动的Jdbc Server没有提供动态资源分配的能力,如果通过beeline方式连接,不能完全把集群资源利用起来,导致查询性能还能有很大的优化空间。
所以针对sparkSQL集群的测试,使用的是spark-sql加了动态资源分配之后执行测试。
beeline -u 'jdbc:hive2://bigdata-server-1:10016/tpcds_bin_partitioned_orcfile_1000' -n spark
SparkSQL动态资源分配、预申请资源11个Executors、spark会在这个基础上在运行tpcds不同SQL的时候动态的去轮询申请资源,进行数据计算,具体参考如下:
/usr/crh/current/spark2-client/bin/spark-sql --master yarn-client --conf spark.driver.memory=10G --conf spark.driver.cores=1 --conf spark.executor.memory=8G --conf spark.driver.cores=1 --conf spark.executor.cores=2 --conf spark.shuffle.service.enabled=true --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.minExecutors=10 --conf spark.dynamicAllocation.maxExecutors=114 --database tpcds_bin_partitioned_orcfile_1000 -f sample-queries-tpcds/query98.sql
我自己通过Python封装了一下查询命令,可以通过直接通过变换命令行参数自动化测试整个tpcds过程,最后记录执行日志和时间到相应Log中。
python Hadoopdb-tpcds-test.py Hive2 tpcds_bin_partitioned_orcfile_1000
执行的TPCDS相关Log日志,我已经上传到百度云:
链接: https://pan.baidu.com/s/1nvE55fN 密码: 999r
里面有几个压缩文件,解压后对应有执行SQL的时间情况、执行SQL过程记录情况。
有关HAWQ的测试,是有段时间接触了一些做HAWQ的人,所以我就深度研究了一下这个东西,相对来说性能还是不错的,不过就是有很多莫名其妙的错误,社区也很不活跃,简单我自己修复了几个小问题。不过改造难度挺大的,跟Hadoop生态融合得也比较差,可以当做一个MPP DB来看比较直观,使用方式完全于GPDB一致。不过需要考虑很多HDFS参数改动和Linux系统本身的内核参数调整,不然很容易崩,相对来说稳定性没那么高。
我打算单独写一篇HAWQ相关的测试,这里就不多介绍了,下面是我遇到的几个莫名其妙的问题,Pivotal官方文档做的真心不错,使用之后,简单些几点感受,比较肤浅的看法,具体如下:
Hawq Load Data Error
这里使用到了PXF插件直接读取Hive 、Hbase、HDFS数据,发现通过他们提供的可视化工具部署安装,依然无法正常直接进入使用阶段,各种报错。
通过HAWQ CLI登录之后, 能查询到元数据信息,无法查询到具体的数据是什么鬼。底层看了下PXF实现,跑在一个Tomcat里面的JAVA程序算是咋回事,这个性能不用想,也很低下。只能Load数据到HAWQ。
drop external table pxf_sales_info;
CREATE EXTERNAL TABLE pxf_sales_info(
location TEXT,
month TEXT,
number_of_orders INTEGER,
total_sales FLOAT8
)
LOCATION ('pxf://bigdata-server-1:51200/sales_info?Profile=Hive')
FORMAT 'custom' (FORMATTER='pxfwritable_import');
SELECT * FROM pxf_sales_info;
gpfdist: error while loading shared libraries: libapr-1.so.0: cannot open shared object file: No such file or directory
解决:yum install -y apr
gpfdist: error while loading shared libraries: libevent-1.4.so.2: cannot open shared object file: No such file or directory
解决:yum install -y libevent
gpfdist: error while loading shared libraries: libyaml-0.so.2: cannot open shared object file: No such file or directory
解决:yum install libyaml -y
HAWQ Standby Master初始化的时候报错,原因是系统缺少net-tools导致。20170721:12:58:38:029877 hawq_init:bigdata-server-2:gpadmin-[INFO]:-Check: hawq_segment_temp_directory is set
20170721:12:58:39:029877 hawq_init:bigdata-server-2:gpadmin-[ERROR]:-bash: /sbin/ifconfig: No such file or directory
20170721:12:58:39:029877 hawq_init:bigdata-server-2:gpadmin-[INFO]:-Start to init standby master: 'bigdata-server-2'
20170721:12:58:39:029877 hawq_init:bigdata-server-2:gpadmin-[INFO]:-This might take a couple of minutes, please wait...
20170721:12:58:43:030205 hawqinit.sh:bigdata-server-2:gpadmin-[ERROR]:-Stop master failed
解决:yum -y install net-tools
Requires: libgsaslresource_management.core.exceptions.ExecutionFailed: Execution of '/usr/bin/yum -d 0 -e 0 -y install hawq' returned 1. Error: Package: hawq_2_2_0_0-2.2.0.0-4141.el7.x86_64 (hdb-2.2.0.0)
Requires: thrift >= 0.9.1
Error: Package: hawq_2_2_0_0-2.2.0.0-4141.el7.x86_64 (hdb-2.2.0.0)
Requires: libgsasl
解决:yum install epel-release,ambari-web界面重试解决。
HAWQ Standby Master初始化失败,导致HAWQ Standby Master服务一直无法启动,查看日志也看不出所以然来。20170721:12:13:53:041104 hawq_stop:bigdata-server-3:gpadmin-[INFO]:-Stop hawq with args: ['stop', 'master']
20170721:12:13:54:041104 hawq_stop:bigdata-server-3:gpadmin-[ERROR]:-Failed to connect to the running database, please check master status
20170721:12:13:54:041104 hawq_stop:bigdata-server-3:gpadmin-[ERROR]:-Or you can check hawq stop --help for other stop options
20170721:13:13:51:039854 hawqinit.sh:bigdata-server-2:gpadmin-[ERROR]:-Stop master failed
环境是在CentOS Linux release 7.2.1511 (Core)最小化安装操作系统,依赖多个第三方包,标准操作系统中都木有。
待我一一解决相关软件依赖后,再去重启集群,好桑心,集群再也无法启动了,我XXX。
---- xxxxx - xxxxx
/pivotalguru_{i},因为做测试前需要先创建这些目录。Error: cannot access directory '/pivotalguru_6'
Please specify a valid directory for -d switch
这些目录会创建大量数据,所以建议这些目录放到比较大的盘,避免跑测试把根目录跑满,导致系统异常,无法正常运行。
psql -v ON_ERROR_STOP=ON -f /pivotalguru/TPC-DS/04_load/051.insert.call_center.sql | grep INSERT | awk -F ' ' '{print $3}'
psql:/pivotalguru/TPC-DS/04_load/051.insert.call_center.sql:1: ERROR: failed to acquire resource from resource manager, 3 of 5 segments are unavailable, exceeds 25.0% defined in GUC hawq_rm_rejectrequest_nseg_limit. The allocation request is rejected. (pquery.c:804)
首先,排查集群状态是否可用。
postgres=# select * from gp_segment_configuration;
registration_order | role | status | port | hostname | address | description
--------------------+------+--------+-------+------------------+------------------+------------------------------------------
0 | m | u | 5432 | bigdata-server-3 | bigdata-server-3 |
2 | p | u | 40000 | bigdata-server-2 | 192.168.0.82 |
3 | p | u | 40000 | bigdata-server-3 | 192.168.0.83 |
1 | p | d | 40000 | bigdata-server-1 | 192.168.0.81 | heartbeat timeout;failed probing segment
4 | p | d | 40000 | bigdata-server-4 | 192.168.0.84 | heartbeat timeout;failed probing segment
5 | p | d | 40000 | bigdata-server-5 | 192.168.0.85 | heartbeat timeout;failed probing segment
(6 rows)
Time: 1.080 ms
[gpadmin@bigdata-server-3 ~]$ hawq state
Failed to connect to database, this script can only be run when the database is up.
简单测试
[gpadmin@bigdata-server-3 ~]$ source /usr/local/hawq/greenplum_path.sh
[gpadmin@bigdata-server-3 ~]$ psql -d postgres
psql (8.2.15)
Type "help" for help.
postgres=# create database test;
CREATE DATABASE
postgres=# \c test
You are now connected to database "test" as user "gpadmin".
test=# create table t (i int);
CREATE TABLE
test=# insert into t select generate_series(1,100);
INSERT 0 100
test=# \timing
Timing is on.
test=# select count(*) from t;
count
-------
100
(1 row)
Time: 75.539 ms
test-# \q
通过Ambari自动化安装HAWQ集群感受,这哪是安装啊,没有安,全程只有装,装完这个装那个,还报错~ 囧。
待全方位测试之后,我在发一篇完整的吧,HAWQ论文我是读完了,个人没感到有什么创新点,感兴趣的可以看看。
https://github.com/changleicn/publications
在测试跑全系CRH产品组件的时候,本想把Impala也放进来一起测试一下,没想到,依赖特定的Hive版本,有些兼容性问题,待解决。
NoSuchMethodError: org.apache.hadoop.hive.metastore.MetaStoreUtils.updatePartitionStatsFast(Lorg/apache/hadoop/hive/metastore/api/Partition;Lorg/apache/hadoop/hive/metastore/Warehouse;)Z

上图,可以看出,Hive2在性能上有了很大的提升,至于为什么,关注微信的可能又看到过有关Hive with LLAP优化的文章,剖析了很多篇,由于个人时间问题,导致博客和微信有些文章没时间同步。
相对来说Hive,SparkSQL在跑TPCDS的时候,在稳定性上都有了长足的进步,不在会出现各种莫名其妙崩溃的问题,甚至查询几个小时都没结果的情况,但是易用性和细粒度资源控制上还有很长的路要走,要达到企业级产品级别,各种做大数据发现版的公司得花费大的精力去完善产品,达到企业级可用的程度。
SQL on Hadoop产品五花八门,目前还没有一个相对完整和全面一点的软件产品,满足客户大部分需求,导致选择困难,POC的时间太长,都是成本。
SQL on Hadoop的框架,目前Hive、Spark、Impala都是可选对象,其他框架社区不活跃,用户少很难继续走下去。一直在吃老本的Hive2也憋了个大招,Impala也在不断优化,都在性能这条路上越走越远,我们敬请期待吧。
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive/
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.