Audio-Denoiser-CNN
When a noisy signal is present, we plan to extract only the clean signal and suppress the noise using supervised learning. This involves creation of dataset which consist of a large array of clean signal and a corresponding array of signals which have been augmented with common environment noises like wind, sirens, dog barks, thuds, breathing etc. This dataset will be used to train a deep autoencoder using GPU for faster training time The resultant model can be used on the client or the server side(depending upon the application) for denoising Dataset Traditionally, RNNs and LSTMs are used for speech/audio-based applications. However, in recent years, deep CNNs often outperform traditional neural networks. For this reason, we propose to solve the problem of audio denoising by building a deep CNN model which will extract the clean audio from the noisy source.
Dataset selection and preparation For this application, we choose the below datasets that are publicly available.
- Mozilla Common Voice Dataset: This is a large, free, and publicly available dataset of human speech that was organized by Mozilla and the voices have been crowdsourced. This will act as our clean audio[7]
- Vox Celeb Dataset: VoxCeleb1 contains over 100,000 utterances for 1,251 celebrities, extracted from videos uploaded to YouTube. We decided to augment this dataset with the Mozilla common voice dataset as the audio is of higher quality and has diverse speakers[9]
- Urbansound8K dataset: This dataset contains 8732 labeled sound excerpts (<=4s) of urban sounds from 10 classes[8]. This will act as our background noise.
Data preprocessing The audio samples in both the datasets need to be cleaned, mixed, and transformed to produce the desired samples. The following steps were performed:
- Data loading: Initially, the clean speech and the noise were loaded for transformation at the sampling rate of 8000 samples/sec. We observed poor voice quality and thus we increased the sampling rate of the audio to 22050 samples/sec. Each file was loaded into python as a numpy array using the Librosa audio library
- Data cleaning: After the data has been loaded, we will remove the silent frames from the clean human speech and noise samples as they will only increase the training time and will not contribute significantly to training. Also, clean audio samples larger than 10 seconds were discarded as they were not recorded properly and had a lot of noise.
- Data Mixing: The noise sample is then added to the clean speech sample to create the noisy audio sample. The length of the noise sample equated to the length of the clean sample be discarding or repeating the sample. Below is an example of a clean speech that is mixed with the noise of a barking dog. As seen below, the spikes of the dog barking can be seen.
- Data transformation/Feature Extraction: As CNN is primarily used on images (a 2d input) and our sound dataset has only a single dimension, we need to transform it. Most used feature extraction techniques are Mel-frequency Cepstral Coefficients (MFCCs) and Short Term Fourier transform (STFT). We decided to use STFT as for deep learning applications, MFCCs remove a lot of features and might not be usable.

Final Dataset specifications
- 2000 noisy and clean audio wav files
- 22179 samples of noisy and clean spectrograms each(128x128)
- Total size: 2.71 GB
UNet Autoencoder
U-Net was initially developed for biomedical applications.
The network consists of a contracting path and an expansive path, which gives it the u-shaped architecture. The contracting path is a typical convolutional network that consists of repeated application of convolutions, each followed by a rectified linear unit (ReLU) and a max pooling operation. During the contraction, the spatial information is reduced while feature information is increased. The expansive pathway combines the feature and spatial information through a sequence of up-convolutions and concatenations with high-resolution features from the contracting path[5].
A Sample architecture of U-Net[4] :
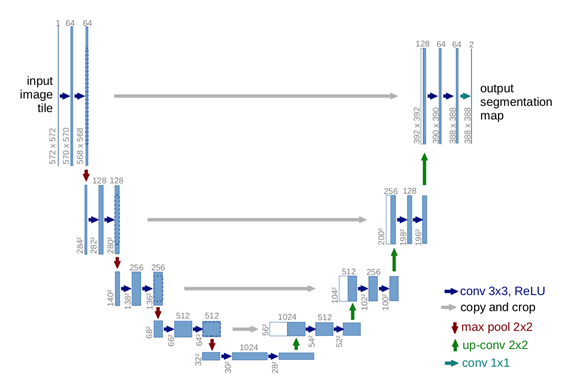
Decoder Network: Input the network is 128x128x1 There are 2, 3x3 Conv2D (16 layers) with valid padding followed by 2x2 max pooling layers in a set. The activation function used after each Conv layers is ‘LeakyReLU’. After each max pooling layer, the size of the 1st and the 2nd dimension is reduced by half and the convolutional layers are doubled. This is because the max pooling layer has a stride of 2. There are 4 such sets in the decoder network. In the last set, there is a dropout before the max pooling layer. 2 more 3x3 Con2D (256 layers) filters are present after the 4 sets followed by a 2nd dropout. The output of the encoder network is 8x8x256
Encoder Network: Input the network is 8x8x256(output of dropout_1) A single set consists of an up-sampling layer followed by a 2x2 Conv2D (128 layers) filter with valid padding. This followed by a concatenation layer which combines the weights of the preceding conv layer with the dropout from the last set of the decoder network. The output of the concatenate layer is followed by 2 3x3 Conv2D (128 layers) filters. These 5 layers make one set. The activation function used after each Conv layers is ‘LeakyReLU’. After each up-sampling, the size of the 1st and the 2nd dimension is doubled, and the convolutional layers are halved. There are 4 such sets in the decoder network. Finally, a 3x3 conv2D (2 layers) filter is applied followed by a 1x1 Conv2D(1layer) filter to get the desired array shape. The output of the encoder network is 128x128x1.
Training on Google Colaboratory
Google Colaboratory or ‘Colab’ is a free Jupyter notebook environment running on the cloud complete with RAM, Hard disk, and processing units like CPU/GPU/TPU. Availability of GPU/TPU can vastly reduce the training time. Colab has popularly used python libraries of data science, machine learning etc already installed. It has the feature to link a personal Google Drive. Thus, the dataset was uploaded to the drive so that it can be easily loaded on Colab and the trained model weights can also be saved easily.
The U-Net model took around 3 hours to train 60 epochs on the GPU on a dataset of 21000 training samples and 1179 validation samples.
Result
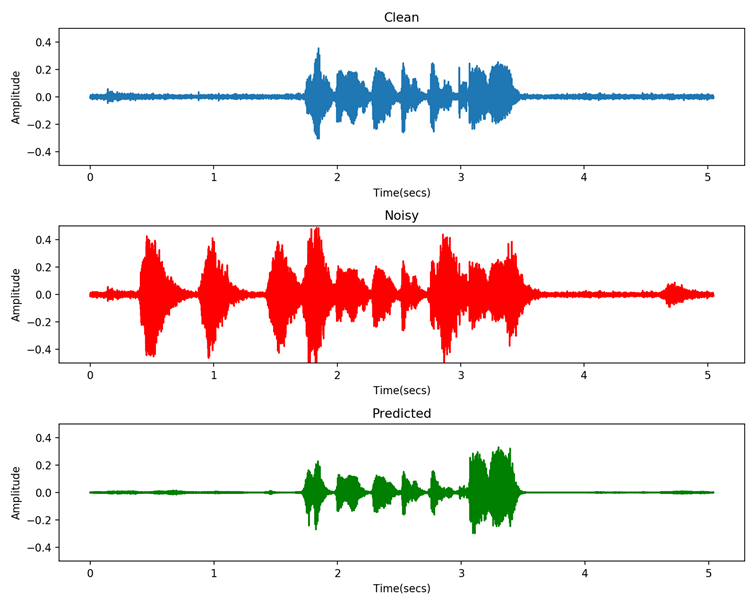
References/Sources for audio denoising:
- Web article for audio concepts: https://betterprogramming.pub/how-to-build-a-deep-audio-de-noiser-using-tensorflow-2-0-79c1c1aea299
- Paper used for inspiration of using CNN for audio denoising: https://arxiv.org/pdf/1609.07132.pdf
- RNNoise: https://arxiv.org/pdf/1709.08243.pdf%7D
- U-Net: https://arxiv.org/pdf/1505.04597.pdf
- U-Net Wikipedia: https://en.wikipedia.org/wiki/U-Net
- STFT Wikipedia: https://en.wikipedia.org/wiki/Short-time_Fourier_transform
- Mozilla common voice dataset: https://commonvoice.mozilla.org/en
- Urban Sound 8k dataset: https://urbansounddataset.weebly.com/urbansound8k.html
- VoxCeleb1 Dataset: https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html
- Dropout: A Simple Way to Prevent Neural Networks from Overfitting: https://jmlr.org/papers/v15/srivastava14a.html

