Course - CPSC 531 Advanced Database Management
Developers -
- Sarita Joshi
- Hritika Phule
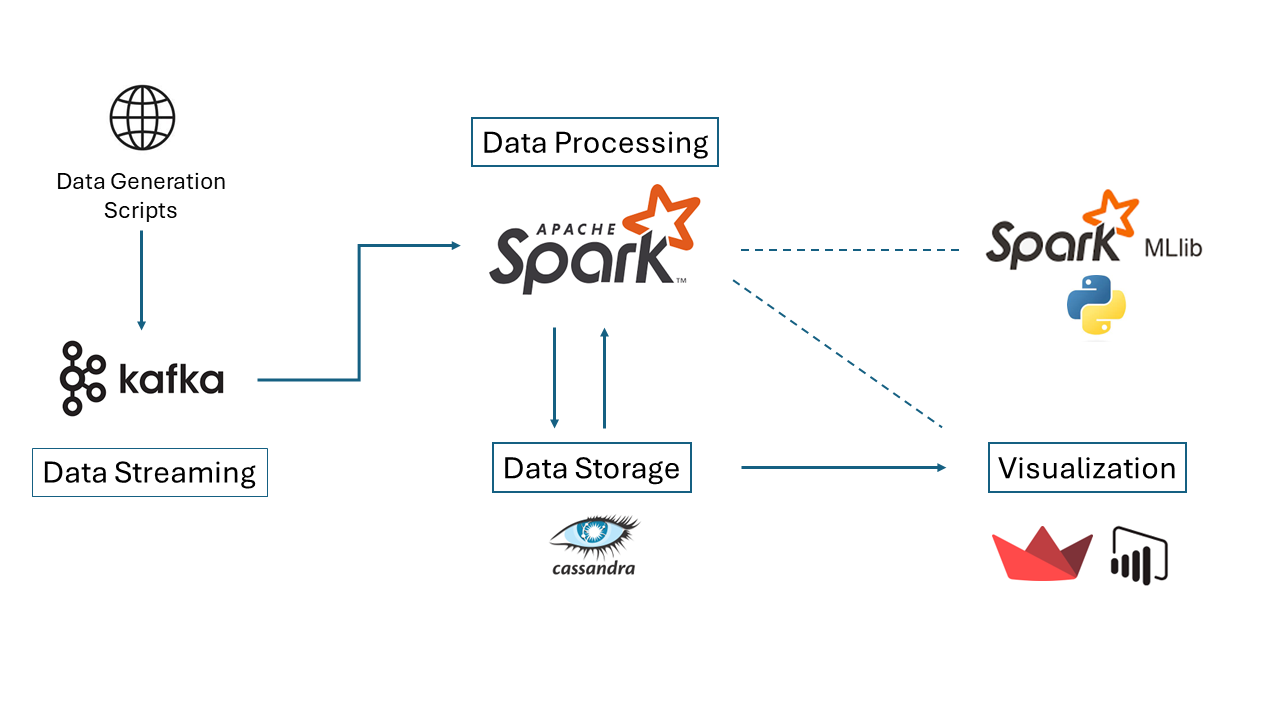
This project demonstrates a robust implementation of a real-time credit card fraud detection system using Apache Spark ML, integrated with Apache Kafka, Zookeeper, and Cassandra for data streaming, processing, and storage, respectively. A live dashboard for reporting and analytics is created using Python Streamlit.

Each component plays a crucial role in the system:
- Data Generation: Python Script
- Data Streaming: Apache Kafka + Zookeeper
- Model Training: PySpark
- Data Processing: Spark and Python Script
- Data Storage: Cassandra
- Data Reporting and Analytics: Streamlit Python Live Dashboard
Dataset link - https://www.kaggle.com/datasets/kartik2112/fraud-detection
Dataset generator - https://github.com/namebrandon/Sparkov_Data_Generation/
The dataset was generated using Sparkov Data Generation | Github tool created by Brandon Harris.
The simulator has certain pre-defined list of merchants, customers and transaction categories. And then using a python library called "faker", and with the number of customers, merchants that you mention during simulation, an intermediate list is created.
Datset size- 1GB
| # | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | trans_date_trans_time | 14814000 non-null | object |
| 1 | cc_num | 14814000 non-null | int64 |
| 2 | merchant | 14814000 non-null | object |
| 3 | category | 14814000 non-null | object |
| 4 | amt | 14814000 non-null | float64 |
| 5 | first | 14814000 non-null | object |
| 6 | last | 14814000 non-null | object |
| 7 | gender | 14814000 non-null | object |
| 8 | street | 14814000 non-null | object |
| 9 | city | 14814000 non-null | object |
| 10 | state | 14814000 non-null | object |
| 11 | zip | 14814000 non-null | int64 |
| 12 | lat | 14814000 non-null | float64 |
| 13 | long | 14814000 non-null | float64 |
| 14 | city_pop | 14814000 non-null | int64 |
| 15 | job | 14814000 non-null | object |
| 16 | dob | 14814000 non-null | object |
| 17 | trans_num | 14814000 non-null | object |
| 18 | unix_time | 14814000 non-null | int64 |
| 19 | merch_lat | 14814000 non-null | float64 |
| 20 | merch_long | 14814000 non-null | float64 |
| 21 | is_fraud | 14814000 non-null | int64 |
Ensure all dependencies and required technologies are installed. Refer to official documentation for Apache Spark, Kafka, Cassandra, and Python for detailed installation instructions.
To get started with this project, you will need to set up your environment with Apache Spark, Apache Kafka, Zookeeper, and Cassandra. Below are detailed steps and links to resources for installing and configuring each component.
- Java 8
- Python 3.11
-
Download Apache Spark:
- Download the latest version of Apache Spark from Apache Spark Downloads.
- Choose a package type that supports Hadoop.
-
Installation:
- Unzip the downloaded Spark package to a directory of your choice, e.g.,
C:\spark.
- Unzip the downloaded Spark package to a directory of your choice, e.g.,
-
Environment Variables:
- Add
C:\spark\binto the PATH environment variable. - Set
SPARK_HOMEtoC:\spark.
- Add
Apache Kafka requires Zookeeper for coordination.
-
Download Apache Kafka:
- Kafka can be downloaded from Kafka Downloads. Select the binary files that include the Scala version you prefer.
-
Installation:
- Extract the Kafka binaries to your preferred location, e.g.,
C:\kafka.
- Extract the Kafka binaries to your preferred location, e.g.,
-
Configuration:
- Edit the Kafka configuration to set up data directories. Detailed configuration steps can be found in the Kafka documentation.
-
Environment Variables:
- Add
C:\kafka\binto the PATH environment variable.
- Add
-
Download Apache Cassandra:
- Download it from Apache Cassandra Downloads.
- Ensure that the installed version contains .bat files for windows.
-
Installation:
- Extract Cassandra into a directory, e.g.,
C:\cassandra.
- Extract Cassandra into a directory, e.g.,
-
Environment Setup:
- Set
CASSANDRA_HOMEtoC:\cassandra. - Add
C:\cassandra\binto the PATH environment variable.
- Set
The development and implementation of this project follow these steps:
Start zookeeper, kafka and cassandra using below commands.
-
Start zookeeper
C:/kafka/kafka_2.12-3.7.0/bin/windows/zookeeper-server-start.bat C:/kafka/kafka_2.12-3.7.0/config/zookeeper. -
Start kafka
C:/kafka/kafka_2.12-3.7.0/bin/windows/kafka-server-start.bat C:/kafka/kafka_2.12-3.7.0/config/server.properties -
Start cassandra First navingate to the bin directory in cassandra and write below commands.
cd C:/cassandra/bin
cassandra
Input data is cleaned and preprocessed to ensure quality and compatibility for model training, including feature encoding and normalization.
A Random Forest model is trained using Spark ML, evaluated for accuracy, and the model is saved locally.
A Python script generates random credit card transactions and publishes them to a Kafka topic.
The trained model processes transactions from the Kafka queue in real-time to predict fraud, and results are stored in Cassandra.
A Streamlit dashboard displays real-time data, graphs, and analytics, pulling data directly from Cassandra.
- System Compatibility issues
- Synthetic Data generation
- Cassandra setup - Memory allocation issues
