Ulož.to bohužel k 1. 12. 2023 přestalo nabízet stahování cizích souborů. Od teď funguje již jen jako Ulož.to Disk a programy typu ulozto-downloader ztrácejí význam a již nejsou použitelné.
Z tohoto důvodu je další rozvoj ulozto-downloaderu ukončen. Děkuji všem, kteří svoji troškou (ať už pull requestem, hlášením chyb nebo jenom tím, že ho používali a říkali o tom ostatním) přispěli k jeho rozšiřování, byl to hezký projekt.
Sbohem a díky za všechny ryby :)
Unfortunately, Ulož.to stopped offering downloads of shared files on December 1, 2023. Now it is only an Ulož.to Disk and programs like the ulozto-downloader lose their meaning and are no longer usable.
For this reason, further development of the ulozto-downloader is ceased. Thanks to everyone who added their bits for the ulozto-downloader (either by pull request, reporting errors or just by using it and spreading its popularity). It was a nice project.
So long and thanks for all the fish :)
This is a parallel downloader from Ulož.to with automatic
CAPTCHA solving. This README is in Czech but the program itself and its help are
in English (try to run it with --help option).
Paralelní stahovač z Ulož.to inspirovaný Vžum (credits to Popcorn) s automatickým louskáním CAPTCHA kódů pomocí TensorFlow modelu z projektu ulozto-captcha-breaker (credits to Jan Palasek).
Narozdíl od originálního Vžum je tato verze napsaná v Pythonu, dá se provozovat jednoduše i na Linuxu a zdrojový kód je veřejně dostupný, což umožňuje další forky a rozšíření do budoucna. Například by mohla vzniknout "serverová" verze s webovým rozhraním.
Nápady na další vylepšení (případně rovnou pull requesty) vítány :-)
- Sám pozná downloady, kde Ulož.to umožňuje stahovat bez CAPTCHA kódů
- Dokáže přečíst sám CAPTCHA kódy díky projektu
ulozto-captcha-breaker (thx Jan Palasek)
- Louská kódy pomocí natrénovaného TensorFlow modelu
- Download linky získává přes Tor, aby se vyhnul nové limitaci ze strany Uloz.to
- Umí opakovaně využít stejný stahovací link pro více částí
- Ulož.to nyní (podzim 2020) umožňuje získat jen dva stahovací linky za minutu, ale stejný link je možné používat po dostahování původní části opakovaně pro stahování dalších částí
- Umí navazovat přerušená stahování (pokud se zachová stejný počet částí)
- Umí stahovat zaheslované soubory (na straně Ulož.to)
- Stahuje přímo do finálního souboru, jednotlivá stahování zapisují na správné místo v souboru (než program ohlásí dostahováno, je soubor neúplný)
- Konzolový status panel se statistikou úspěšnosti při získávání linků
- Celkový průběh staženo / okamžitá rychlost stahování ve druhém řádku status panelu (save progress monitor)
- Cache soubor download linků pro pokračování nebo opětovné stažení, po restartu se bez nového
získávání download linků rovnou stahuje a nové download linky se získávají jen když jich není
v cache souboru dostatek. Vytváří malý textový soubor
.ucachejenž je možné použít znovu a stahovat maximální rychlostí ihned bez získávání linků. Tento soubor má malou velikost a lze ho např. sdílet. U velkých souborů (100ky MB) je platnost linku 48 hodin.
Ulož.to downloader je napsaný v Pythonu a je distribuovaný v podobě zdrojových kódů, které si každý může spustit, pokud má nainstalovaný Python. Předtím než s čímkoliv začnete, ujistěte se prosím, že máte:
- Nainstalovaný Python 3 – externí návod na instalaci
- Umíte instalovat Python balíky pomocí příkazu
pipnebopip3v příkazové řádce – malý externí návod na Pip
Protože Ulož.to downloader závisí na několika externích projektech, bude mimo instalace samotného ulozto-downloaderu potřeba zajistit ještě několik dalších věcí:
- TOR pro získávání download linků z různých IP adres a vyhnutí se limitaci
- Jeden z:
- TensorFlow Lite pro automatické louskání CAPTCHA kódů
- Tkinter když budete používat ruční opisování CAPTCHA kódů
Tor je program umožňující přistupovat na cílovou stránku přes jiné počítače a tím obejít limitaci na počet stahovacích linků z jedné IP adresy.
Ulož.to downloader vyžaduje spustitelný příkaz tor (vnitřně používá stem)
a očekává tento příkaz v $PATH.
Na Linuxu:
sudo apt install tor
# nebo...
yum install tor
# nebo podle vašeho balíčkovacího systémuNa Windows lze instalovat TorBrowser
a dostat tor.exe do %PATH%, tedy přidat do systémové proměnné %PATH
složku s tor.exe z instalace TorBrowseru (typicky C:\Program Files\Tor Browser\Browser\TorBrowser\Tor).
- Náhodný externí návod na přidání do
%PATH%.
TensorFlow Lite je balíček, který umožní spouštět na CAPTCHA obrázcích natrénovanou neuronovou síť a tím je automaticky louskat.
Dá se použít buď odlehčený Python balíček tflite-runtime, nebo plnotučný
Python balíčku tensorflow (vydávání tflite-runtime se často opožďuje, proto
je často potřeba s novým Pythonem sáhnout po plnotučné verzi).
Oba balíky se dají instalovat přes Python instalátor pip3. Správný balík pro
danou verzi Pythonu by se měl dát instalovat společně s celým Ulož.to
downloaderem, když použijete při instalaci ulozto-downloader[auto-captcha]
(viz níže), případně ručně takto:
pip3 install tflite-runtime
pip3 install tensorflowVerzi pro Windows (nebo pokud vám instalace hází chybu) stáhněte z repozitáře pycoral
Pokud vám tato metoda nefunguje (instalace vypisuje "Could not find a version
that satisfies the requirement"), je potřeba instalovat plnotučný tensorflow
(pozor, zabere po instalaci asi 1GB):
pip3 install tensorflowPokud vám žádná z metod výše nefunguje, postupujte podle instrukcí na stránce
TensorFlow Lite, kde si buď
instalujte balík do systému a nebo si stáhněte z odkazu správný Wheel soubor
podle své verze Pythonu (zjistíte zavoláním python3 -V).
Pokud se vám nepovede rozchodit TensorFlow Lite pro automatické louskání (nebo chcete poměřit síly s natrénovaným modelem a louskat ručně), potřebujete na systému instalovaný Tkinter na zobrazení okénka s obrázkem.
Bohužel není na PyPI, takže je potřeba instalovat ručně. Často už je instalovaný,
ale pokud by náhodou nebyl, tak bývá v balíčku python3-tk (případně následujte
instrukce na webu Tk).
Teď už byste měli mít vše připraveno. Stačí jen instalovat samotný Ulož.to downloader.
Nejjednodušší je využít verzi uveřejněnou na PyPI.
Pokud máte platformu, pro který existuje na PyPI validní balíček
tflite-runtime, můžete rovnou
instalovat speciální target s [auto-captcha] a ulehčit si tak instalaci
TensorFlow Lite.
pip3 install --upgrade ulozto-downloader
pip3 install --upgrade ulozto-downloader[auto-captcha] # <-- doporučenoPři zavolání s -h nebo --help vypíše Ulož.to downloader popis všech svých
přepínačů a nastavítek. Zde jsou vyjmenována základní nastavení, ale výčet není
rozhodně kompletní.
Od verze 3.1 je v defaultu aktivovaná autodetekce TensorFlow a pokud je instalované, tak se použije pro automatické louskání louskání CAPTCHA kódů, jinak se vypisuje ruční opisování. Pro vynucení chování můžete použít přepínače:
--auto-captchavynutí použití TensorFlow Lite--manual-captchavynutí použití manuálního opisování
Pokud není dostupný žádný solver, lze stahovat jen soubory bez CAPTCHA.
Pro volbu počtu částí slouží přepínač --parts N, default je 20 částí. Ve
výchozím nastavení Ulož.to downloader zobrazuje pouze sumární stav. Pokud chcete
zobrazit stav stahování jednotlivých částí, použijte přepínač
--parts-progress.
ulozto-downloader --parts 30 --parts-progress "https://ulozto.cz/file/TKvQVDFBEhtL/debian-9-6-0-amd64-netinst-iso"Lze specifikovat i více URL ke stažení, v takovém případě probíhá stahování sekvenčně (po dostahování prvního se začne stahovat druhý atd.):
ulozto-downloader --parts 30 "https://ulozto.cz/file/TKvQVDFBEhtL/debian-9-6-0-amd64-netinst-iso" "https://ulozto.cz/file/YPivhc3Jyn9r/debian-live-11-1-0-amd64-mate-iso"Pro zadání hesla slouží přepínač --password <heslo>:
ulozto-downloader --parts 30 --password akcniset "https://uloz.to/file/FFwsQeBeMdcY/debian-9-6-0-amd64-netinst-iso"Pokud chcete ukládat log do souboru, použijte přepínač --log <název souboru>
(v defaultním nastavení se log neukládá).
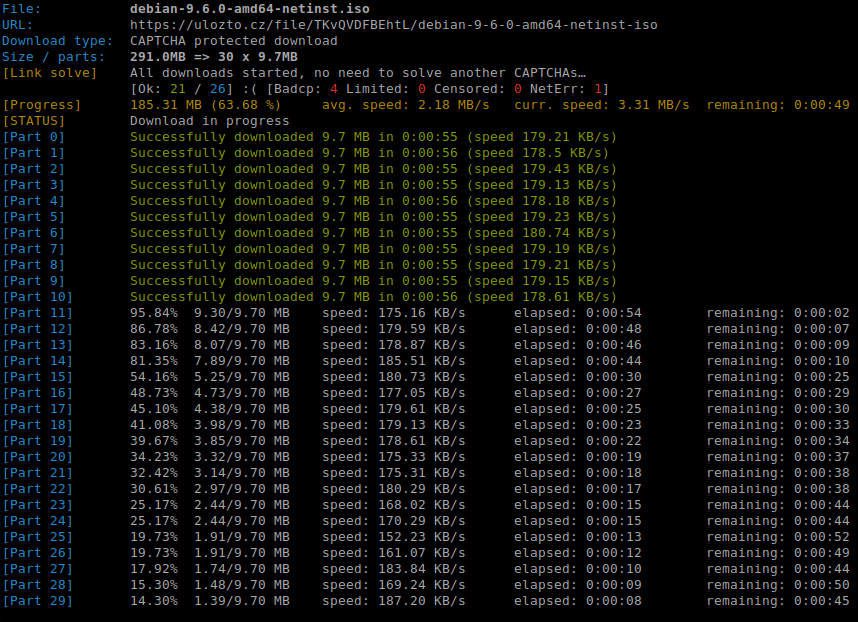
Při využití automatického louskání doporučuji využít velký počet částí, klidně
50 (spustíte ulozto-downloader a necháte ho pracovat, on si postupně louskne
další stahovací linky a postupně navyšuje počet najednou stahovaných částí).
When contributing to this project, please use English in the code. Issues and pull request comments could be in Czech or English, I will discuss them according to the thread language :)






































































































































