shidenggui / blog Goto Github PK
View Code? Open in Web Editor NEWReading makes thought sharper, writing makes thought clearer
Home Page: https://shidenggui.com
Reading makes thought sharper, writing makes thought clearer
Home Page: https://shidenggui.com

























































最近刷了一些 leetcode 的题目,发现里面经常需要检测整数相乘是否溢出的问题,而答案给出的检测方法都比较特定而且不够方便。这让我想起了之前看 CSAPP 的时候,在第二章 Representing and Manipulating Information中有一道课后题,提供了一种检测乘法溢出的方法,简洁明了。因此在这里介绍下。
题目来自于 CSAPP's Practice Problem 2.35:
int tmult_ok(int x, int y) {
int p = x * y;
return !x || p / x == y;
} 这里我们看到只要排除了 x 为 0 的情况后,如果 p / x != y 则溢出,否则即无溢出。这时候不禁要问一句
下面给出证明,在 CSAPP 答案的基础上按自己的理解稍做了一点修改:

判断的方法很简单,但是后面的论证却没那么容易。不过这便是不光知其然,还知其所以然的乐趣所在吧!
以前看过查理芒格写的《穷查理宝典》,里面谈到别人戏称他为只不过是本恰巧长了两条腿的书(They think I'm a book with couple of legs sticking out)。这自然也让我对查理芒格所看的书产生了兴趣。网上恰恰也流传着一份查理芒格的书单,大概有 30 多本,主要以人物传记、心理学、生物学、经济学、历史为主,而《Einstein》正是其中的一本。
之前我断断续续挑自己感兴趣的读了《枪炮、病菌与钢铁》、《影响力》、《国富国穷》、《寻找生命的意义》、《本杰明富兰克林自传》,所以慢慢的也到了《Einstein》。
每本书都有让人读它的理由。正如我以前看到的一句话“每个来到大都市的人都是抱着梦想而来”,每个翻开书本的人也是怀着求知而来。
爱因斯坦,继牛顿之后最伟大的物理学家,诺贝尔奖获得者。相对论里的光速不变让人感觉不可思议。以前高中老师用质能方程解释为什么核弹有如此之大的威力。德国犹太人,二战时受**逃亡美国。曾经在专利局上班的公务员,业余时间发表了相对论、光电效应的论文。
这样的人的一生难道不让人感到好奇吗?不值得我们探索一番,看能不能给予我们自己的人生以启迪吗?
草稿待续......
最近在准备尝试复活我很久前写的网文推荐系统,把 2 年前推送到 daocloud 的 Docker 镜像重现部署到了现在新的服务器,并暂时放到了这个域名。
这时候发现一个问题,里面的相似度计算是基于余弦算法,一般同作者的两本书 A、B 之间的相似度在 30% ~ 35% 左右,位于 35% 到 100% 间的极少,而 20% 左右已经不太像了。这时候就想找一个 mapping 算法,希望能满足以下特征:
结果值随着原始相似度的提高剧烈上升,在 30% 时候能映射到 90% 的相似度
结果值最大为 100%,因为最多就 100% 相似
在 20% 相似度左右的时候结果值较低
理想中应该是个 S 型的曲线。根据第一个特征想到了基于指数增长的函数:
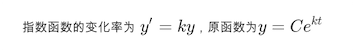
但是它不满足有极大值的限制,这时候就想到了常用于描述人口增长的 Logistic Differential Equation:
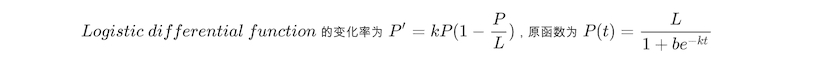
完美满足了前期指数级上升,又存在一个极限 L 的情况。但是它也有一个不太完美的地方,就是当相似度为 0 时它的值不能为 0 , 所以只能假设相似度为 0 时方程值为 1。
接下来就是解方程获取精确的公式了:

求解后就是试着画图和输入 0 到 100 之间的数值感觉符不符合预期了,结果如下 ,图中灰线交点为(30, 90):
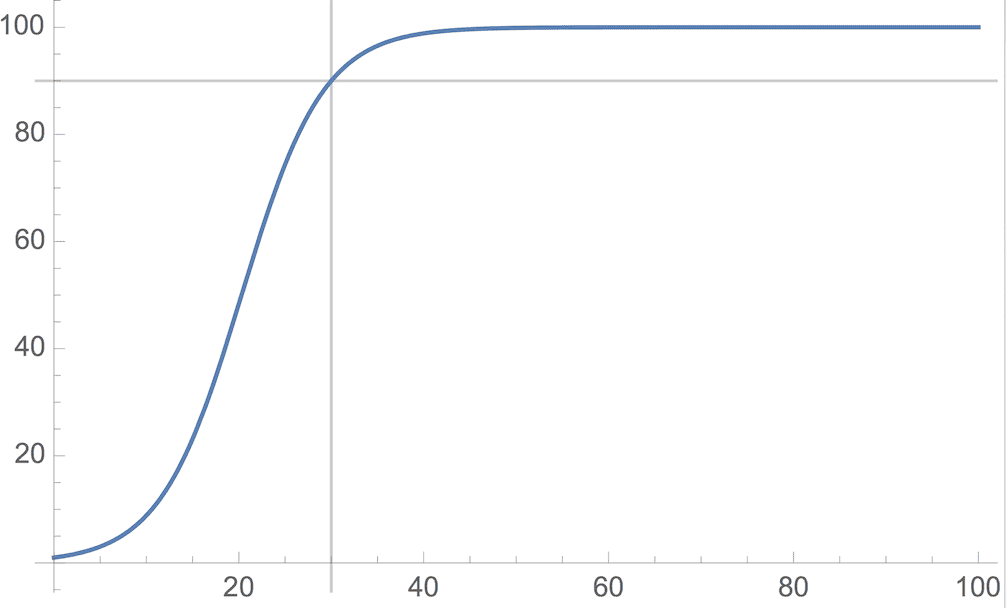
精确值如下:
0 1.00000
5 3.03817
10 8.85875
15 23.16620
20 48.32840
25 74.36770
30 90.00000
35 96.54200
40 98.85850
45 99.62910
50 99.88010
55 99.96130
60 99.98750
65 99.99600
70 99.99870
75 99.99960
80 99.99990
85 100.00000
90 100.00000
95 100.00000
100 100.00000
感觉还不错,参数可能还需要根据实际情况微调。如果有更好的 mapping 函数或者方法,欢迎大家留言。
在公司书架上随处翻阅,偶然看到一本书带着熟悉的装帧,封面是《雅典学院》,抽出来一看发现是属于《世纪人文系列》的一本小书。这套书是上海世纪出版社出版,我以前看过其中一本,整套书的质量非常不错。我手里的这本是《师从天才:一个科学王朝的崛起》,英文名是《APPRENTICE TO GENIUS: The Making of a Scientific Dynasty》,隶属于其中的“科学人文”系列。
随手翻了下,发现是介绍几个科学家生平的传记。内容挺有意思的,就花了几天看完了。发现确实是一本很不错的书,介绍了人类如何以理性为舵、激情为帆来探索广袤的知识海洋、深入展现了科学研究中理性、人性相交织的图景,而在作者的叙述中,读者仿佛也身临其境,心潮澎湃。
整本书主要围绕五个人按时间顺序讲述,分别是 美国国立卫生研究院(简称NIH)首任院长香农、香农召集的第一批部下中的药理学家布罗迪、曾作为布罗迪手下技师的阿克塞尔罗德、阿克塞尔罗德的弟子斯奈德以及斯奈德的弟子珀特,时间跨度从20世纪40年代初到80年代。其中一人获诺贝尔奖、三人获美国最高医学奖拉斯克奖。书中着重描写了布罗迪和阿克塞尔罗德的学术生涯以及他们之间的合作、冲突,还有之后阿克塞尔罗德跟斯奈德的师生情谊。
随着作者细腻的笔触,我们仿佛也回到了二战初期,看到了科学家们为了解决士兵中流行的疟疾苦思冥想,而随着战争结束他们又把目光投向了新兴的神经药理学领域,不断探索人类的知识边界。这既是一本科学家的群像史,也是美国医学逐渐崛起立于世界之巅的发展史。
下面主要谈谈书里面我感觉比较有意思的几个问题。
书中的科学家,跟现实中一样也有各种工作风格,书中以布罗迪、阿克塞尔罗德最为典型。布罗迪属于工作狂类型的人,不光在工作时间激情澎湃,下班后也照样在家继续工作,同时经常拉手下与他一起通宵达旦研究讨论。而阿克塞尔罗德属于严格区分工作生活,下班后基本就不再继续相关研究,同时注重私生活隐私。
他们日常的工作主要是承接各种相关课题或者对自己感兴趣的方向进行探索。比如书中前期布罗迪和阿克塞尔罗德就是为了解决美国二战时的疟疾问题而奋斗,而战争后他们基本都是研究神经领域的一些未解之谜。在他们的研究过程中,他们手下的博士生、技师起着非常重要的作用,通常都是导师确定研究某个方向,然后让相关的博士生继续深入研究,然后他们互相讨论推进,最后评判结果看是否需要继续投入或者放弃。书中的所提的师承链就是由此而来,每个学徒都是在导师的实验室里学习,因此受到导师精神、人格的影响,代代相传。
在决定具体的研究课题之后,就进入了真正的日常工作,书中人物都是神经药理学家,更加偏向实验。你可以看到他们每天在提出理论、设计实验、进行试验并收集数据中度过。其中以进行试验最为漫长,因为牵扯到很多细节的东西。由此最常接触的事物就是试管,书中常常描写道他们工作最重要的事之一就是清洗试管,这就像是他们手中的屠龙宝刀,尤为珍重。
总览全书,科学家的生活跟常人相比可能牵涉到更高强度的智力劳动,也由此得以享受智慧的果实。交际圈基本都是行业内的人,生活比较简单纯粹。
里面谈到了几项研究,可以一窥科学如何作用于现实。
首先是疟疾的研究,科学家在二战过程中通过优化已有药物的给药方式,极大的减轻了疟疾的影响,保证了美军的战斗力,而在二战后期发现的新药也对抗击疟疾做出了不少的贡献。
阿克塞尔罗德发现了新的神经递质,促进了人们对精神分裂症、抑郁症的生物学理解。
斯奈德跟他的学生珀特发现了阿片受体,促进了人们对毒品上瘾机制的理解。受体的概念在我后来读《自控力》的时候也被作者用来解释人大脑的奖励系统。
现有理论无法解答的问题的出现导致对应推测理论的诞生。而伴随理论而生的是可以通过试验验证的预测。通过设计精巧实验来验证理论的预测以证实或证伪,由此循环往复,不断导致新理论的推翻和建立,由此人也能从更科学的角度看待现实。
以书中药理学家而言,具体的实验过程往往让人感到不适。因为药物和神经、生理学相关的内容都需要在生物体上确认,所以可以经常看到书中的科学家磨碎猫脑、鼠脑、各种内脏之类的内容。
有好有坏。布罗迪和曾作为他手下的阿克塞尔罗德相处十几年却到最后决裂不再往来。斯奈德一直非常尊崇阿克塞尔罗德。珀特怀疑斯奈德霸占她的科研成果,发文引发学界争论。所谓有人的地方就有江湖,人性的复杂在科研领域也不例外。
举全国之力,集中当时最优秀的药理学家,提供全世界收集过来的各种天然、人工制物。有了医生、测试的药物之后还欠缺实验的病人,美国就发动全国监狱的囚犯自愿参与疟疾感染试药试验,至于是真的自愿还是威逼利诱就不得而知了。由此可见美国人还是以实用为主,很懂得变通的。
布罗迪,博士毕业后一直从事药理学研究,喜欢通宵达旦的工作,最后获美国医学界最高奖拉斯克奖,后期因为身体原因提早退休,最后死于心脏病,享年 82 (1907-1989)。
朱利叶斯·阿克塞尔罗德,普通本科,大学做实验意外不小心失去了一只眼睛。本科毕业后在一家普通的工业实验室当操作员,10 多年后 35 岁时被征调到布罗迪手下做技师从而接触科研领域。50岁考取博士后在 NIH 单独一人继续研究,随着发展慢慢扩招,后获拉斯克奖和 1970 年诺贝尔奖,他的弟子被亲切的称为“朱利叶斯的孩子”。享年 92 (1912-2004)。
斯奈德,天才科学家,指导研究生珀特发现阿片受体,由此获拉斯克奖。而同为合作者的珀特却落选,引发不满造成诸多争端,因此错失诺贝尔奖。1938年生。
珀特,研究生时在斯奈德指导下发现阿片受体,因为没有一同获拉斯克奖之故,指责导师从中作梗,引发争议。后逐渐退出科学界进入商业领域。享年 67 (1946–2013)。
良好的社会环境,美国本土基本没有受过外来战争的影响,书中人物基本上都是在和平的环境中度过一生,能顺利的追求其理想,实现其抱负,而其他国家则相对多灾多难。美国经济的发达,二战后美国作为世界第一强国,有足够的资源和耐心投入到长期的基础医学研究中。
本书内容极为丰富,读完后我深深为书中的人物的激情、坚毅、灵性所感染,心灵也随同他们的命运起伏和时间流转时而欢欣鼓舞,时而激情澎湃,时而黯然神伤。仿佛不是在读书,而是变成了书中的一个人物,与他们同呼吸共命运。人类充分发挥他们的智力、激情去探索知识的海洋是怎样的一番图景!
前几天在公司书架上看到了《富足》这本书,英文名是 《ABUNDANCE: The Future Is Better Than You Think》。大概翻了下,主要是介绍一些可能改变人类未来的技术,感觉挺有意思的就抽了几天时间看完了。
整体书主要内容分为四部分。首先提出人类正在大步迈向富足,而我们时常悲观是源于远古形成的心理机制不适应现代社会所致。然后提出富足的三层金字塔概念,底层是水、食物,中间为能源、教育、信息流通,顶层则为健康和自由。第三部分是简析为了满足金字塔各个方面的需求,可以依赖哪些指数级发展的技术以及他们当前的发展情况。最后是介绍当前推动这些技术发展的中坚力量,包括底层的大多数、DIY爱好者、科技慈善家、大奖赛等等。
书出版于2012年,里面大部分都是一些介绍性的内容和数据罗列。我感觉比较有意思的是书里面提到的一些技术、项目在 6 年后的 2018 年发展的怎么样了,以及一些比较有意思的概念。
书中开篇以铝的价格变化作为技术改变资源稀缺的例子。在电解法制铝发明之前的中世纪,铝作为一种极轻的金属,享有比黄金还高贵的地位,但是在电解铝发明之后,廉价的铝随处可见。
铝因为电解法的发明而摆脱了资源稀缺的局面,那人类现在极度依赖的石油呢?作者认为马斯达尔城就是为了摆脱石油依赖而做出的一次尝试。这座城市投资200亿美元,于2008年开始建造,计划容纳4.5万人,使用 100% 的可再生能源。书中作者报以极其乐观的展望。那六年后的今天,马斯达尔城发展的怎么样了?
首先查看 wiki 的 Masdar City 条目,可知马斯达尔城的建成本来预定于2015年,但是目前仅建成5%的面积,预定完成时间已经推迟到2030年左右,目前可居住人口主要由一部分雇员和免费提供住宿和奖学金的马斯达尔理工学院的学生组成,大概2000人左右。
再通过 Google News 搜索相关的新闻,可以看到好几条质疑马斯达尔城已经沦为鬼城(green ghost town) 的报道。
马斯达尔城虽然暂时失败了,但是其他技术还在变革着石油领域。美国的页岩油革命越演越烈,据预估2018年美国石油日产量会超过1000万桶,超过1970的历史高点。石油价格很难再回到以前150美元的高位了。科技发展的美妙之处就在于你永远不知道是什么将会突然出现颠覆你的世界。
邓巴数是心理学家邓巴发现的一个数字,指一个人能维持紧密人际关系的人数,约为150人。
在原始部落中,每个人的人际关系都很重要,因此大脑逐渐进化出维护人际关系网络的能力。现代科技让世界变成了地球村,但是大家反而更孤独了,很少人在现实生活中能有150个关系还不错的朋友,这样的话什么东西会填充遗留的感情空隙呢,毕竟我们大脑进化出来的人际网络还嗷嗷待哺?作者认为是电视明星。由此衍生的追星一族的狂热崇拜也就可以理解了,虽然他们只是在电视上看到他们,但是已经不知不觉让明星在心中占了一个很重要的位置。
邓巴数的可怕之处在于它是潜意识、强制性的,只要别人一直在你眼前晃而又不招致你的反感,他可能慢慢就被你内化的大脑机制当成了你亲密的朋友之一。这跟心理学中的多看效应有异曲同工之妙,被广泛应用于现代广告之中。
书中只谈了明星,但是回想现实中的各种大V、直播的流行,是不是反应着日渐孤独的现代人需要填补的感情空隙越来越多了?
难道要坐等我们的大脑被现代科技所填满吗?这让我想起以前尼采曾说: "在被战胜的激情的土地上播下优秀的精神著作的种子,是这时候最直接的紧迫任务。...... 如果对它不是这样来看待,那么各种各样的杂草和可怕的东西就会迅速在这片变得空旷的肥沃土地上长出来,很快它就变得比以前任何时候都更加丰满、更加狂野不羁。“
现在技术的飞速发展毋庸置疑,智能手机、vr、人工智能、可回收火箭,层出不穷、眼花缭乱,有时不由感慨人类创造的才能。谈到技术进步,常常会听到汽车、高铁、飞机在速度上的提升,摩尔定律带来的信息革命,有没有一个统一的标准可以用来衡量历史发展中人类进步的程度呢?
书中提出了基于特定历史时间段,人类获取某样东西所花费的平均时间来衡量技术上的发展,因为时间对所有人都是公平的。
真正能够衡量一个东西价值的,是想得到它你所必需花费的时间。
获得一小时的人工照明:公元前1750年,使用芝麻油的话需工作超过 50 小时; 19 世纪 80 年代,使用蜡烛的话需要工作 6 个多小时,使用煤油灯,需要工作 15 分钟;现在,你只需工作不到半秒钟,不到公元前 1750 年的 35 万分之一,而且更加方便、安全。
从波士顿旅行到芝加哥:19世纪,乘坐公共马车需要两个星期时间加普通人一个月工资,现在飞机只需要两个小时以及一天的工资就足够了,综合成本只有以前的五千分之一。
通过相同的工作时间,我们比以前的人获得更多的水资源、卡路里、流明、里程、能源、信息,更不要说许多前所未有的新事物了。1000年前的人如果想上网一小时的话,他们要付出多少工作时间,而古时的君王又能支配多少劳力?从富足来讲,古时的君王不如现世的平民,而当下的巨富不如未来的贫民也是可以预期的了。
1977 年,Voyager 1 从地球出发,探索茫茫宇宙。1990 年,应天文学家和作家 Carl Sagan 之请,从 60 亿公里外拍摄了这张著名的照片。Carl Sagan 对此有一番精彩绝伦的演说。
如果真的有天外来客的话,会不会嘲笑人类在这小小的地球上,还有那么多恩怨纠葛、战争杀戮。
and all were not worth a passing glance
— "SIDDHARTHA"
1953年人类已经知道了生命密码 DNA 的组成,但是现在人类离自由操纵 DNA 还很远。2011 年左右我在环球科学上读到了人工生命合成成功的文章,科学家希望借此编码出能合成类石油化合物的藻类来解决能源问题,可惜此后就很少看到类似的进展。
直到最近在《富足》里又看到了相关的活动发展,里面介绍了《国际基因工程机器大赛》这项赛事。参加者利用 DNA 创造各种功能的生物积木来实现特定功能,并贡献到公开的数据库中。如果把基因工程比成编程的话,幸运的是编程语言只有一种,就是 DNA,但是不幸的是没有语法说明书,只能靠大家去摸索各种 DNA 序列的意义。
而且随着 2010 年后 CRISPR 技术的发明,这项简单、高效、便宜的技术也将由大型机构垄断的基因编辑技术开始普及到个人手中。已经有人尝试编辑自己的手臂相关部分的基因,使其肌肉变得更为发达,而相关工具的费用低于 $400 的。他们自称为 biohacker ,真像 20 世纪 80 年代,随着大型计算机小型化而来的 hacker 文化,我们是不是在黄金时代到来前的黎明呢?
肉作为人类蛋白质主要来源之一,有着非常重要的地位,但是自然养殖肉类需要耗费大量的水、土地、食物、时间,而且后续的屠杀、处理带来很多污染因素,总体效能低下。随着科技的发展,自然会想到直接养殖肉类细胞,让它们直接无限复制,由此得来的便是人造肉,英文称 clean meat。
谈到无限复制的细胞,我第一印象想到的就是因为突变失去控制的癌细胞,只是这里变成了科学家人工干预,但是由此而来的心理不适还是存在了一段时间。人造肉的效率毋庸置疑,只是因为技术限制,导致商业化一直受限,在作者所在的 2012 年还只是一种纸上谈兵。但是 6 年后的今天,关于人造肉的最新新闻是《美国牛肉协会要求区分人造肉和真实牛肉,人造肉不能称之为‘肉’》,而美国一些餐厅也已经开始销售人造肉汉堡。
随着人造肉技术的成熟,以其高效的能源利用率带来的低廉价格,占领市场也是预料之中的事,看来以后在“有机蔬菜”、“有机水果”之外又要多加一个“有机肉”了。
作者把此章冠名为《崛起的十亿人》,世界上每天生活费用不足 2 美元的人群达到 40 亿人之巨,以前人们认为在他们当中并没有什么机会存在,但是随着科技的发展,为底层的十亿人服务并实现双赢成了可能。
以智能手机为载体的科技浪潮极大的降低了人们获取服务的成本,只需要一部手机加电信网络,就可以加入全球互联网。而有志于此的服务商也只需要将服务构建在互联网的载体上,便对底层的 40 亿人触手可及。
Grameenphone 便是例证之一,这家创建于 1997 年的公司致力于在孟加拉国开展面向农民的电信小额贷款业务,至 2011 年 2 月用户数达 3000 万,同时在发展过程中又陆续投入 16 亿美元建设电信网络,不仅本身取得不菲的盈利,而且降低了全国的贫困率。据 wiki 的数据,截止 2016 年 8 月它的用户数达 5450 万。
而国内也有瞄准这一市场的公司。另类的非洲之王传音手机:出口8000万部 国内零销量,便是 BoP businnes 的绝好例证。
作者在书中提到一个很有意思的观念,叫“相邻可能”。技术的发展使人们犹如置身于一个有很多门的房间,随着人们打开一扇扇门,房间随之扩大,而越来越多的门也得以出现,指数级增长的门和几近无限的房间将带领人类走向无限的可能,而我们现在就处于这一梦幻般的历史进程之中。
The adjacent possible is a kind of shadow future, hovering on the edges of the present state of things, a map of all the ways in which the present can reinvent itself. As Steven [Weinberg] notes, the adjacent possible “captures both the limits and the creative potential of change and innovation.” — Eddie Smith (2010)
随着轮子的发明,手推车、自行车、汽车、溜冰鞋随着成为可能。随着晶体管的发明,电脑、智能手机、互联网成为可能。
自然界的所有蛋白质都由 20 种氨基酸组成,而如果 20 种氨基酸组成长度为 100 的蛋白质,有 20^100 可能,相比之下全宇宙的原子数约为 10^80。地球上所有现存的蛋白质只探索了可能存在的蛋白质样本空间的极小一部分就创造了我们现在的一切。令人惊奇生命到底还有多少未知的可能性,不由遥想所有可能性都得以展现的未来又将是什么样的一番景色?
Life has explored only an infinitesimal fraction of the possible proteins
... then there is plenty of room for human explorers to roam.
— Stuart A. Kauffman, “At Home in the Universe”
而我们自己,是不是也只探索了无限可能的一小部分,而未来又有什么在等待我们呢?
《富足》一书的阅读感想现在就告一段落了,希望人类真能如书中所说走向富足的未来。
好几年没有动笔写一篇正经的文章了,本来就想谈几个主题,没想到越写越多,加上查资料的一些时间,一下子就过去了 20 多天。不过发现写作跟阅读一样,都是一件很有乐趣的事情,以后应该会坚持写作,希望能给自己、也能给读者带来一些思考。
Life is such a poor business that the strictest economy must be exercised in its good things.
— Arthur Schopenhauer, “THE WISDOM OF LIFE”
有兴趣追更的可以 star & watch 这个 repo
R: How are you doing tonight?
I: I have been coding for a while.
R: That's typical.
R: Do you realize that you and your colleagues are in the cutting-edge of the technology explosion.
I: Yes.
R: Do you realize your generation is part of the technology explosion. I was born after WW2. When I was a child, we said poor China, no technology. Now, the last twenty years, BOOM. Do you feel it? Do you understand it?
I: The economic economy of China is growing rapidly.
First I used economic, but the teacher corrected me. I should use the word economy. But what's the difference between these words?
economy: 经济
economic: 经济的,形容词
economics: 经济学
economical: “not requiring too much of something” (such as money, space, time, etc.), e.g. 节省的,话费不多的
之前一段时间,easytrader 上用户报了很多 issues,基本都是关于客户端软件无法获取持仓的错误。所以最近就抽了段时间解决下,里面用到了策略模式,就想顺便复习下设计模式。
这里介绍下相关的上下文,easytrader 是一个模拟证券客户端操作的Python类库,基本就是一个定制版的按键精灵,支持银河、华泰等公司以及通用版客户端(支持多家券商),能进行的操作有买卖、获取持仓等。
issue 里面的错误是关于获取持仓 get_position 这个接口的,画成类图的话如下所示(省略了一些上下文无关的信息):
这边有问题的是获取持仓这一步。原来客户端的持仓保存在Grid 中,类似网页端的 table,然后 easytrader 通过Ctrl + C 的方式复制内容到剪切板,再解析剪切板的内容获取持仓:
示例代码:
class ClientTrader:
def get_position(self):
# ...
grid_data = self._get_grid_data()
# ...
return position这个逻辑是所有客户端通用的,因此 YHTrader 和 HTTrader 都是继承的父类 ClientTrader 中的默认方法。
但是前段时间银河和通用客户端的一部分券商通过更新封杀了通过剪切板获取 Grid 数据的方式,导致原有的 get_position 失效。这时在 issue 里有开发者提出可以通过在 Grid 上右键将对应内容保存为 xls 文件再解析保存的文件获取持仓,并给出了示例代码。
这时候的问题就是怎么将通过 xls 获取持仓的策略和原有的通过剪切板获取持仓的策略整合到代码里,修复银河客户端和一部分通用客户端无法获取持仓的 Bug。
在 ClientTrader 类中实现 get_position_by_copy 和 get_position_by_xls 的方法,并在 get_position 进行 hardcode,然后 YHTrader 通过继承的方式默认使用 xls 方式,示例代码如下:
class ClientTrader:
def get_position(self, strategy='copy'):
# ...
if strategy == 'copy':
grid_data = self._get_grid_data_by_copy()
elif strategy == 'xls':
grid_data = self._get_grid_data_by_xls()
else:
raise NotImplementedError(f'Stratege {strategy} not implenmented')
# ...
return position
def _get_grid_data_by_copy(self):
# ...
def _get_grid_data_by_xls(self):
# ...
class YHTrader(ClientTrader):
# 修改银河的方法默认为 xls 策略
def get_position(self, strategy='xls')
# ...api 的改动较小如果获取 position 的方式继续增多,get_position 中会有很多面条式的代码,不好维护。
修改持仓策略的话需要修改ClientTrader 类,而这个类作为父类,修改它影响范围较广,违背了对扩展开放,对修改关闭的开闭原则。
污染ClientTrader和 get_position 的代码结构,导致阅读代码时有很多无关的代码细节干扰思路
如果我们基于继承实现的话会怎么样,因为通用客户端从原有的仅支持一种策略变为支持两种,此时就需要基于 copy 策略的父类实现使用 Xls 策略的子类,而银河客户端从 Xls 策略子类继承,这里同时需要修改获取 Trader 的工厂方法,提供获取Xls类的方法。示例代码如下:
class ClientTrader:
def get_position(self):
# ...
grid_data = self._get_grid_data()
# ...
return position
def _get_grid_data(self):
# 默认实现基于 copy 的 grid_data 获取逻辑
class ClientTraderWithXls(ClientTrader):
def _get_grid_data(self):
# 实现基于 xls 的 grid_data 获取逻辑
# 银河改为从 ClientTraderWithXls 继承
class YHTrader(ClientTraderWithXls):
pass
class HTTrader(ClientTrader):
pass
### api.py
def get_trader(broker):
if broker == 'client_trader':
return ClienTrader()
if broker == 'client_trader_with_xls': # 新增获取 xls 策略子类的方法
return ClientTraderWithXls()
# ...xls 的策略逻辑抽取到了子类中,比较独立client_trader 类那有没有更好的方法呢?自然是有的,那就是设计模式中的策略模式。
根据《Design Pattern》,策略模式的目的是:
定义一组封装内部细节并可互换的算法,使得客户端跟它们使用的算法解耦。
而为什么不选择将对应的算法直接嵌入类中或通过继承实现呢?除了我们上面所讲的几点外,书中还列出了直接 hardcode 的带来的一些其他问题:
将算法细节包含在类内实现,会使得类本身复杂度上升和代码膨胀,导致维护困难,尤其需要支持多个算法的时候。
HardCode 的实现会导致类基本丧失了可维护性。可能需要在不同的时间使用不同的算法,而且有时不需要同时支持多种算法。
HardCode 本身允许通过参数调用不同的方法,但是也同时将所有算法的代码包含在内。
类继承的方式虽然只包含对应算法的代码,但是却不允许用户切换算法实现。
当类本身包含了大量算法实现的时候,修改或者变更已存在的算法都会非常困难。
而为了避免这些问题,我们可以定义一些将算法细节封装起来的类,它们具有统一的接口。而基于这样的选择封装的类,我们称它为一个Strategy。
这时就让我们按照策略模式的方式修改我们的代码如下 :
### grid_stragies.py
import abc
class IGridStrategy(abc.ABC):
"""获取 grid 策略接口定义"""
@abc.abstractmethod
def get(self):
"""返回 grid 数据"""
pass
class Copy(IGridStrategy):
def get(self):
"""实现基于 Copy 的逻辑"""
pass
class Xls(IGridStrategy):
def get(self):
"""实现基于 Xls 的逻辑"""
pass
### clienttraders.py
import grid_stragies
class ClientTrader:
# The strategy to use for getting grid data
grid_strategy = grid_stragies.Copy
def get_position(self):
# ...
grid_data = self.grid_strategy(self).get()
# ...
return position
# 银河改为使用 Xls strategy
class YHTrader(ClientTrader):
grid_strategy = grid_stragies.Xls
class HTTrader(ClientTrader):
pass
# 如果希望 ClientTrader 使用 Xls 方法,只需要
import grid_strategies
client_trader = ClientTrader()
client_trader.grid_strategy = grid_strategies.Xlsclient_trader 相关类grid_strategy 属性来动态切换策略,避免多种方法需要多种策略时组合爆炸的问题。mixin 的形式实现。策略模式适合于以下场景:
HardCode 的实现)。此时可以通过将相关条件分支移动到对应的策略类中消除条件语句。class Context:
strategy = ConcreteStrategy1
def do_something(self):
self.strategy.do_something(self)class Context:
strategy = ConcreteStrategy1
def do_something(self):
self.strategy.do_something(self.arg1, self.arg2)class Context:
def do_something(self, strategy):
strategy.do_something(self)
# usage
Context().do_something(ConcreteStrategy1)第一种方法更加灵活,但是暴露了 context 本身过多的信息给 strategy,使得策略和 context 紧耦合。
第二种方法如果需要新的参数,则需要变更 strategy 类的接口,这时候需要 strategy 类本身设计的较为合理。
第三种方法提供了 client 在运行时变更 strategy 的能力。
虽然策略模式有很多优点,但是不可避免的也会有一些缺陷,正如”没有银弹“所说的,掌握设计模式的关键便是理解它们对应的 tradeoff,如此才可以在正确的时间选择正确的模式。
如果 client 需要切换 strategy 的话,它必须理解对应的 strategy 的区别。
context 和 strategy 之间的交互带来的额外成本。如果 strategy 设计不合理的话,context 传递的一些参数可能在某些 strategy 中永远不会被用到。
类以及对象数量的膨胀。这在设计模式中是很难避免的,毕竟设计模式的第二原则就是 Favor object composition over class inheritance.
rest_framework.views.APIView 就大量使用了策略模式以使得用户在编写对应的 APIView 时可以获得最大的灵活性
class APIView(View):
# The following policies may be set at either globally, or per-view.
renderer_classes = api_settings.DEFAULT_RENDERER_CLASSES
parser_classes = api_settings.DEFAULT_PARSER_CLASSES
authentication_classes = api_settings.DEFAULT_AUTHENTICATION_CLASSES
throttle_classes = api_settings.DEFAULT_THROTTLE_CLASSES
permission_classes = api_settings.DEFAULT_PERMISSION_CLASSES
content_negotiation_class = api_settings.DEFAULT_CONTENT_NEGOTIATION_CLASS
metadata_class = api_settings.DEFAULT_METADATA_CLASS
versioning_class = api_settings.DEFAULT_VERSIONING_CLASS
https://shidenggui.com/articles/logistic-differential-equation
最近看了《自控力》,里面提到人的意志力可以分为三种力量,分别是“我不要”,“我要做”,“我想要”。作者认为意志力是类似肌肉一般的力量,可以通过科学合理的锻炼而得到增强,而我感兴趣的是里面提出的“每日实践法”,即对“我不要”和“我要做”各提出一个小要求,然后每日坚持执行来增强自己的意志力选择。针对“我要做”,我的要求是每日处理掉一件东西,而这也就是这篇文章的缘起。
在扔掉东西的过程中,会产生种种纠结,简单列举如下:
然后最近看到一篇博文,里面介绍了可以用公式法理清思路,比如 “天才等于百分之一的灵感加百分之九十九的汗水”,能直观的解释很多事情。因此也尝试用公式法分析下处理东西时内心的不舍到底来自哪里?
首先将相关可能的因子都罗列出来,假设如下
我们囤积物品是为了有朝一日能使用它,不过是出于物质目的的使用还是精神目的的回忆,则根据以上假设,如果我们未来用上这件闲置物品时获得的收益为:
未来使用时的购买价格 + 未来重新获得成本 + 投入的感情成本
而到不知何时我们能用上我们囤积的物品为止遭受的损失为
未来用到闲置物品时所经过的时间 * 物品的闲置成本
由此可以发现我们的收益是属于 O(1) 固定的,而损失却是 O(N) 随着时间增长的。而且与已经投入的 物品的购买价格 无关,这也是大家常说的 沉没成本,虽然理智上与当前的决定无关,但是在情感上却常常冒出来干扰我们的决定,留恋过去的人就是背负着这些无意义之物而活。
而且随着科技发展和生产力的发展, **未来使用时的购买价格 ** 和 未来重新获得成本 会随着时间衰减,而我们的损失却会日积月累,更不要说 物品的闲置成本 会随着我们人生所剩时间的减少而越来越昂贵。闲置物品每存在一天,它就在消耗你的精神力、记忆力和占用你的空间,而使用时获得的 感情投入 真的那么有意义吗?
丢东西有时候会出现一种很奇怪的现象,比如决定了第二天要丢一个食物秤,但是真正到了第二天要丢的时候却突然下不去手,过去种种使用的记忆涌上心头,感觉像幻灯片一样闪过,人一下子就呆住了,经不住问自己,真的要把凝聚了自己的记忆和情感的东西就这样丢掉吗?往往最后又犹豫了,换了其他东西丢。
很多东西只是简单的外物,而且跟我们纠缠的也不深在舍弃时就有了那么深的留恋之心,也怪不得人们常常谈到濒死体验,即人死前一生的回忆都会涌上心头。因为我们的身躯陪伴了我们太久太久了,凝聚了我们多少的记忆、情感,在不得不舍弃时,内心的眷恋不舍又会达到什么地步?
吾所以有患者,为吾有身。及吾无身,吾有何患。 --《老子》
我在丢东西时还发现一个奇怪的现象,丢旧手机我毫不犹疑,但是丢一个家庭秤,我却好久都没有下定决心。就价格来说,旧的手机买的时候要上千,一个秤不过五十元。为什么在丢有些东西的时候会有如此的区别呢?
想了想应该是人已经习惯于借助工具扩展自我。现代人类史就是一部工具史,原始人能利用的不过是四肢五官,借此却可以成为地球霸主,更不要说现代人所使用的手机、微波炉、空调等等东西。一旦要剥夺这种能力就相当于压缩了自我的能力范围自然会引起内心的反抗。
旧手机在我有新手机的情况下意义不大,它的功能完全可以被新手机替代。但是家庭秤就不一样了,虽然它的价格便宜,但是一旦我丢了它,我就丧失了称量物品重量的能力。人作为损失厌恶的动物,由此也可以解释内心那股莫名的拒绝感的来源。
如果从另一个方向理解,把人类社会视为一个整体,我们并不是丢了工具就减弱了自我的能力,因为社会作为一个我们生存其中的集体,总是可以以合适的代价提供我所需的事物,我并不需要将所有东西掌握在自己手中,毕竟个人的能力是有限的,而适度委托也是为了让自己可以更加专注的做自己想做的事情。
我是想生活在一个自己背负着无穷的杂物而活,还是像拥有机器猫的空间口袋一般,只是需要适当的媒介就可以拥有自己想用的东西,用完即丢,轻装上阵?
人是面向未来而活,还是背负着过去踽踽而行?每天丢东西只是一件很小的事情,但有时候会引发人对自我意识的思考。我们的存在有多少是依托于外物?如果一切外物都离我而去,我又是如何成为我呢?
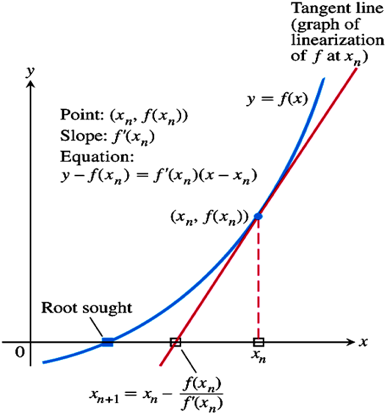
前几天看到一道题目,是关于“对整数 n 开平方,求其整数部分”,解法用到了 Newton's Method,因为之前刚刚学过,就顺便复习下什么是 Newton's Method,为什么可以用于求解这道题?
本身是用于逼近函数零点的一种技巧。因为对没有求根公式的函数,求解它的零点是非常困难的,因此就发明了 Newton‘s Method 来逼近该函数的零点。具体方法如下图所示:
至于为什么用于逼近函数零点的 Newton's Method 会跟 “对整数 n 开平方” 有关

代码实现如下:
def int_sqrt(n):
"""
>>> int_sqrt(0)
0
>>> int_sqrt(1)
1
>>> int_sqrt(80)
8
>>> int_sqrt(81)
9
>>> int_sqrt(82)
9
"""
x_n = 1
x_n_plus_1 = (1 + n) / 2
#while int(x_n_plus_1) != int(x_n): 原来的错误做法,具体见评论
while abs(x_n_plus_1) != int(x_n):
x_n = x_n_plus_1
x_n_plus_1 = (x_n + n / x_n) / 2
return int(x_n_plus_1)
代码实现如下:
def int_sqrt_of(n, k=3):
"""
>>> int_sqrt_of(26, 3)
2
>>> int_sqrt_of(27, 3)
3
>>> int_sqrt_of(28, 3)
3
"""
x_n = 1
x_n_plus_1 = (k - 1 + n) / k
while abs(x_n_plus_1 - x_n) > 0.01:
x_n = x_n_plus_1
x_n_plus_1 = ((k - 1) * x_n + n / x_n ** (k - 1)) / k
return int(x_n_plus_1) 前几天偶然看到一道题:A、B 打赌互相扔硬币,先抛出正面的人胜利,假设 A 先抛的话他赢的概率是多少? 当时跟同事讨论了下,结果是 2/3。感觉这题挺有意思的,就想详细研究下,所以有了这篇文章。
从概率的角度看,第一个人可能赢在第 1、3、5、7 ..... 次,而每次赢必然是前几次抛硬币结果都为负,最后一次为正,因为抛硬币为独立事件,则可以知道赢的概率之和为:

如果是 3 个人打赌,则第一个人可能赢在第 1、4、7、11 ..... 次,则在级数中对应的项次由两个人时的 2n+1变为 3n+1(注:n 从零开始),同理可得如果是 k 个人,则为 kn+1,则可以知道 k 个人时赢的概率之和为:
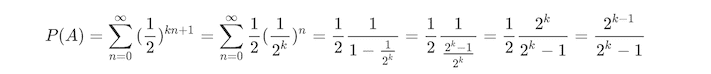
令 k=3,则 P(A) = 4 / 7。
同理可知,第一个人可能赢在第 1、3、5、7 ..... 2n+1 次,稍微不同是赢之前的那几次,他们只需要不掷出 6 即可:
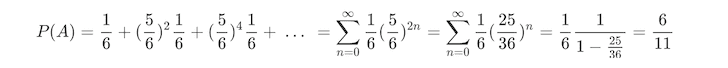
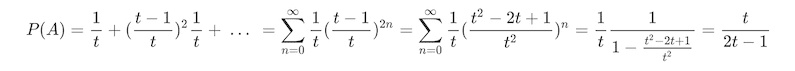
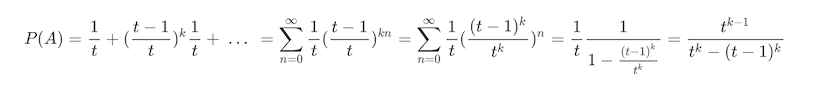
从上可以知道其实所有变化都只是 Geometric Series 的变种。这就是数学的魅力所在,从各种各样的形式中发现统一的模式,又将这统一的模式应用于无穷无尽的变化中。
枢始得其环中,以应无穷。 --《庄子·齐物论》
刷 leetcode 的时候碰到的这道题。LRUCache 在现实中也经常用到:
内存换页,需要淘汰掉不常用的 page。
缓存函数的结果,比如 Python 就自带的 lru_cache 的实现。
redis 在设置了 maxmemory 时,在内存占用达到最大值时会通过 LRU 淘汰掉对应的 key。
Leetcode 题目要求如下
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and put.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.
put(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.
Follow up:
Could you do both operations in O(1) time complexity?
Example:
LRUCache cache = new LRUCache( 2 /* capacity */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // returns 1
cache.put(3, 3); // evicts key 2
cache.get(2); // returns -1 (not found)
cache.put(4, 4); // evicts key 1
cache.get(1); // returns -1 (not found)
cache.get(3); // returns 3
cache.get(4); // returns 4 关键点在于 get 和 put 操作的时间复杂度都需为 O(1)。
为了实现 O(1) 的复杂度,使用哈希表来存储对应的元素。然后通过双向链表来实现 lru cache 相关的逻辑,
get 时,将命中的节点移动到头部put 时如果命中已存在的节点,参照 get 操作,如果为新节点
# 使用 双向链表和 hashmap 的组合来实现 get,put 都为 O(1) 的复杂度,空间复杂度为 O(N)
class Node:
def __init__(self, key, value, prev=None, next=None):
self.key = key
self.value = value
self.prev = prev
self.next = next
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self._map = {}
# linked list with head
self._list = Node(None, None)
# 使用 last 指针来加快删除最后一个节点的速度
# 在以下情况需要更新 last 指针
# 1. 第一次插入数据时,需要将 last 指针指向新插入的节点
# 2. 删除最后一个节点时,需要将 last 指针前移
# 3. 当 get 或者 put 命中节点需要移动到链表顶端时。
# 如果需要移动的节点正好是最后一个节点(这时候 last 指针才有可能发生变化)
# 而且 last 指针之前不是头结点(如果是的话,移动后该节点还是尾节点,不需要变动 last 指针)
self._last = self._list
self.size = 0
def get(self, key: int) -> int:
if key not in self._map:
return -1
node = self._map[key]
self._move_to_first(node)
return node.value
def _move_to_first(self, node):
# 当移动的节点为最后一个节点,且该节点之前不为头结点
# 将 last 指针前移
if node == self._last and node.prev != self._list:
self._last = node.prev
# 首先删除当前节点,要额外考虑该节点为最后一个节点,
# 此时不需要调整之后节点的 prev 指针
node.prev.next = node.next
if node.next is not None:
node.next.prev = node.prev
self._insert_to_first(node)
def _insert_to_first(self, node):
node.next = self._list.next
node.prev = self._list
self._list.next = node
# 插入到头结点之后,如果该节点不是最后一个节点
# 同样要调整之后节点的 prev 指针
if node.next:
node.next.prev = node
def put(self, key: int, value: int) -> None:
if key in self._map:
node = self._map[key]
node.value = value
self._move_to_first(node)
return
self.size += 1
node = Node(key, value)
self._map[key] = node
if self.size > self.capacity:
# 直接根据 last 指针删除最后一个节点,然后前移 last 指针
self._last.prev.next = None
del self._map[self._last.key]
self._last = self._last.prev
# 如果插入时为空链表,设置 last 指针
if self._list.next is None:
self._last = node
self._insert_to_first(node)
初版实现的方法,需要不断判断删除,移动的是不是尾部指针,引入了很多不必要的 if 判断。而 Leetcode 讨论区里面提出了一个更好的方法。
原本我们通过引入 Dummy Head 已经简化了头部相关的操作,这里额外再引入一个 Dummy tail ,这样的话在移动删除尾部节点的时候就不需要额外判断了。
# 使用 双向链表和 hashmap 的组合来实现 get,put 都为 O(1) 的复杂度,空间复杂度为 O(N)
class Node:
def __init__(self, key, value, prev=None, next=None):
self.key = key
self.value = value
self.prev = prev
self.next = next
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self._map = {}
# linked list with dummy head and tail
self._list = Node(None, None)
self._last = Node(None, None)
self._list.next = self._last
self.size = 0
def _delete_node(self, node):
node.prev.next = node.next
node.next.prev = node.prev
def get(self, key: int) -> int:
if key not in self._map:
return -1
node = self._map[key]
self._move_to_first(node)
return node.value
def _move_to_first(self, node):
self._delete_node(node)
self._insert_to_first(node)
def _insert_to_first(self, node):
node.next = self._list.next
node.prev = self._list
node.next.prev = node
self._list.next = node
def put(self, key: int, value: int) -> None:
if key in self._map:
node = self._map[key]
node.value = value
self._move_to_first(node)
return
self.size += 1
node = Node(key, value)
self._map[key] = node
if self.size > self.capacity:
del self._map[self._last.prev.key]
self._delete_node(self._last.prev)
self._insert_to_first(node)
# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value) 但是上面的方式还有一个问题,就是在 lru_cache 满了的时候,此时新增一个节点,会导致需要从链表中删除一个尾部的旧节点,然后同时在头部插入一个新节点。
有没有办法直接使用旧的删除的节点来代替新增的节点呢?这样在 LRUCache 满了的时候,put 新元素的性能会获得很大的提升。
而 Python 内部实现正是考虑了这一点,利用了带头结点root的循环双向链表,避免了该问题。
root 作为新节点,使用原来的尾部节点即 root.prev 作为新的 root 节点。list 代替 node 节省空间。下面是 Python 的 lru_cache 的实现,因为原实现是装饰器,这里略作修改为类的实现:
# 使用 双向链表和 hashmap 的组合来实现 get,put 都为 O(1) 的复杂度,空间复杂度为 O(N)
PREV, NEXT, KEY, RESULT = 0, 1, 2, 3
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self._cache = {}
# circular queue with root
self.root = []
self.root[:] = [self.root, self.root, None, None]
self.size = 0
def get(self, key: int) -> int:
if key not in self._cache:
return -1
node = self._cache[key]
self._move_to_front(node)
return node[RESULT]
def _delete_node(self, node):
node[PREV][NEXT] = node[NEXT]
node[NEXT][PREV] = node[PREV]
def _insert_to_front(self, node):
node[NEXT] = self.root
node[PREV] = self.root[PREV]
node[PREV][NEXT] = node[NEXT][PREV] = node
def _move_to_front(self, node):
self._delete_node(node)
self._insert_to_front(node)
def put(self, key: int, value: int) -> None:
if key in self._cache:
node = self._cache[key]
node[RESULT] = value
self._move_to_front(node)
return
self.size += 1
if self.size > self.capacity:
# 直接使用 root 节点作为新节点,然后通过将 root[NEXT] 的待删除节点设为新的 root 节点,避免了删除和分配新节点的消耗
self.root[KEY] = key
self.root[RESULT] = value
self._cache[key] = self.root
self.root = self.root[NEXT]
del self._cache[self.root[KEY]]
return
node = [None, None, key, value]
self._cache[key] = node
self._insert_to_front(node)
因为想到 redis 也实现了 lru cache,就抽空看了下源码,发现跟想象中非常不一样,并不是常规的实现方式。
当 redis 达到设置的 maxmemory,会从所有key 中随机抽样 5 个值,然后计算它们的 idle time,插入一个长度为 16 的待淘汰数组中,数组中的 entry 根据 idle time 升序排列,最右侧的就是接下来第一个被淘汰的。淘汰后如果内存还是不满足需要,则继续随机抽取 key 并循环以上过程。
因为是随机抽样,所以分为以下情况
抽样的 key idle 小于最左侧最小的 idle time,什么都不做,直接跳过
找到适合的插入位置 i
pool[i: end] pool[0: i + 1],这样的话 idle 时间最小的就被淘汰了关键实现逻辑如下:
while (mem_freed < mem_tofree) {
sds bestkey = NULL;
struct evictionPoolEntry *pool = EvictionPoolLRU;
while(bestkey == NULL) {
evictionPoolPopulate(i, dict, db->dict, pool);
/* Go backward from best to worst element to evict. */
for (k = EVPOOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
de = dictFind(server.db[pool[k].dbid].dict,
pool[k].key);
/* Remove the entry from the pool. */
if (pool[k].key != pool[k].cached)
sdsfree(pool[k].key);
bestkey = dictGetKey(de);
break;
}
}get、put 时间复杂度都为 O(1)locality ,即最近使用的数据很可能再次被使用long scan 的时候,会导致 lru 不断发生 evcit 行为。(数据库操作,从磁盘加载文件等,LFU 避免了该行为)
只利用了到了一部分的 locality,没有利用 最经常使用的数据很可能再次被使用(LFU 做到了,但是更慢,Log(N))
在这篇文章还没完稿的时候,看到了 B 站的 LRUCache 的源码实现,下面就顺便来分析一下。下面是对应的源码:
package lrucache
// 这里是 Node 节点的定义,中规中矩
// Element - node to store cache item
type Element struct {
prev, next *Element
Key interface{}
Value interface{}
}
// Next - fetch older element
func (e *Element) Next() *Element {
return e.next
}
// Prev - fetch newer element
func (e *Element) Prev() *Element {
return e.prev
}
// 通过这个结构体,猜测使用的是跟 Leetcode 经典实现类似的带头尾伪节点的链表实现。
// 后面发现实际上并不是
// LRUCache - a data structure that is efficient to insert/fetch/delete cache items [both O(1) time complexity]
type LRUCache struct {
cache map[interface{}]*Element
head *Element
tail *Element
capacity int
}
// New - create a new lru cache object
func New(capacity int) *LRUCache {
// 可以看到初始化 LRUCache 时,并没有初始化 Dummy head 和 Dummy tail
// 不过这样岂不是在操作过程中需要进行很多 if 判断,后面的代码也验证了这点。
return &LRUCache{make(map[interface{}]*Element), nil, nil, capacity}
}
// Put - put a cache item into lru cache
func (lc *LRUCache) Put(key interface{}, value interface{}) {
if e, ok := lc.cache[key]; ok {
e.Value = value
// 等同之前的 _insert_to_front
lc.refresh(e)
return
}
if lc.capacity == 0 {
return
} else if len(lc.cache) >= lc.capacity {
// evict the oldest item
delete(lc.cache, lc.tail.Key)
// 等同之前的 _delete_node
lc.remove(lc.tail)
}
e := &Element{nil, lc.head, key, value}
lc.cache[key] = e
// 因为没有 Dummy head 和 Dummy tail 而带来的不必要的 if 判断
if len(lc.cache) != 1 {
lc.head.prev = e
} else {
lc.tail = e
}
lc.head = e
}
// Get - get value of key from lru cache with result
func (lc *LRUCache) Get(key interface{}) (interface{}, bool) {
if e, ok := lc.cache[key]; ok {
lc.refresh(e)
return e.Value, ok
}
return nil, false
}
func (lc *LRUCache) refresh(e *Element) {
// 可以看到这里很多的 if 判断,严重干扰了代码的阅读逻辑。
if e.prev != nil {
e.prev.next = e.next
if e.next == nil {
lc.tail = e.prev
} else {
e.next.prev = e.prev
}
e.prev = nil
e.next = lc.head
lc.head.prev = e
lc.head = e
}
}
func (lc *LRUCache) remove(e *Element) {
// 可以看到这里很多的 if 判断,严重干扰了代码的阅读逻辑。
if e.prev == nil {
lc.head = e.next
} else {
e.prev.next = e.next
}
if e.next == nil {
lc.tail = e.prev
} else {
e.next.prev = e.prev
}
}怎么说呢,有点失望。一开始在看到结构定义了 head 、tail时以为是使用了 Dummy head 和 Dummy tail 的经典实现,但是在初始化时发现没有初始化对应的 head、tail,以为是使用了一种未知的新方法,但是一看 refresh 和 remove 的逻辑,发现是通过大量的 if、else 来判断 corner cases。
而大量使用 if 会严重干扰代码的可读性和可维护性,具体可见 Applying the Linus Torvalds “ Good Taste ” Coding Requirement 这篇文章。
跟网友的讨论中,有人又贴出了 google 的一版实现,在 Golang/groupcache 项目下。就顺便看了下对应的源码。
// Package lru implements an LRU cache.
package lru
import "container/list"
// Cache is an LRU cache. It is not safe for concurrent access.
type Cache struct {
// MaxEntries is the maximum number of cache entries before
// an item is evicted. Zero means no limit.
MaxEntries int
// OnEvicted optionally specifies a callback function to be
// executed when an entry is purged from the cache.
OnEvicted func(key Key, value interface{})
ll *list.List
cache map[interface{}]*list.Element
}
// Add adds a value to the cache.
func (c *Cache) Add(key Key, value interface{}) {
if c.cache == nil {
c.cache = make(map[interface{}]*list.Element)
c.ll = list.New()
}
if ee, ok := c.cache[key]; ok {
c.ll.MoveToFront(ee)
ee.Value.(*entry).value = value
return
}
ele := c.ll.PushFront(&entry{key, value})
c.cache[key] = ele
if c.MaxEntries != 0 && c.ll.Len() > c.MaxEntries {
c.RemoveOldest()
}
}
// Get looks up a key's value from the cache.
func (c *Cache) Get(key Key) (value interface{}, ok bool) {
if c.cache == nil {
return
}
if ele, hit := c.cache[key]; hit {
c.ll.MoveToFront(ele)
return ele.Value.(*entry).value, true
}
return
} 关键点在于 container/list ,这是一个带头结点的循环双向链表,但是并没有暴露 root 节点,所以 google 的实现同 Leetcode 经典实现是一致的。
我还发了一个 issue 去询问为什么不采用类似 Python 的实现。官方的回答是目前够用,如果需要变更的话,需要 benchmark 的支持。理论上 Python 的实现在不断读取新数值的时候性能会好很多。
综合下来 Python 内置库 functools.lru_cache 的带头结点的双向循环队列的实现是最优雅的
For programmer: Talk is cheap. Show me the code.
For math: Talk is cheap. Show me the proof.
For physics: Talk is cheap. Show me the prediction.
For life: Talk is cheap. Show me the action.
For meditation: Talk is cheap. Show me yourself.
For yoga: Talk is cheap. Show me the practice.
《自控力》是我很早以前买的一本书,但是在我最需要自控力的时候却没有意志力去阅读这本书,真是讽刺!之前把公司的书架都扫了下,感兴趣的基本都读了,然后就想到了这本买了大半年还尘封的书,花了几天看完了,感觉还不错,因此就写一篇读书笔记总结下。
《自控力》开篇就提出“自控力跟肌肉类似是一种生理力量,可以通过科学合理的方式得到锻炼和增强”。
如果有人问你“你觉得多久能练出一身肌肉?”,恐怕回答肯定不是几天、几周,至少也是几个月甚至好几年的时间,而且需要科学的方法、坚持不懈和以及付出艰苦的努力,而且在这个过程中,肯定会遇到不少的挫折、困难。但是我以前对“自控力”却有一种幻觉,总觉的只要我下定决心,我的内心就会发生神奇的变化,自此之后我就会充满“自控力”,但是实际上这只是一种幻觉,当这种幻觉在现实中破灭时人反而更加低落。
一旦人认识到“自控力”作为一种生理力量而存在,并不存在任何的神秘之处,自然就能从更加科学合理的角度来看待”自控力“不足的问题,无非是疏于使用而导致的力量不足。而如何理解、认识并增强”自控力“就是本书要阐述的话题了。
作者认为“自控力”有如下属性:
自控力本身是有三部分组成:“我要做”,“我不要”,“我想要”。
因为我有目标,而我的目标跟我当前的行动不匹配,我需要改变我目前的行动以使它能跟我的目标相契合。没有目标,自然也不需要自控,因为你都不知道你想成为什么样的人,自控什么呢?但是人没有目标真的好吗?
Where there is no vision, the people perish --《Proverbs 29:18》
自控力的来源是人类的大脑皮层,如果人类没有后天发展出来的大脑皮层,现在不过是跟动物一样随着自身的欲望而行动。当人类的欲望中心看到某些能引发人内心原始欲望的事物时,人的内心就会产生一种冲动,而此时人的大脑皮层就会介入,从理性的角度评估这种冲动的合理性,或允许或抑制。
在以下几种情况下,失控会发生:
盘点我个人的情况,可以发现一下几种情况
早上刚睡醒的时候自控力比晚上下班后强很多,基本上安排在早上的计划大部分都可以正常执行,而安排在晚上的计划就难说了。
某段时间想控制的事情太多,到最后耗尽自控力,完全无法控制自己的行为。
主要分为生理因素和心理因素:
当你做善事的时候,你内心感觉良好,然后放纵自己的内心冲动。大部分觉得自己品德高尚的人,都不会质疑自己内心的选择,他们会想“我已经那么好了,应该给自己一点奖励”,而忘记了他们真正的目标。书中例子:和那些不记得自己做过善事的人相比,有行善经历的人在慈善活动中捐的钱要少 60%。
关键不是我们以前做了什么,而是我们现在做的是否有助于我们真正想要实现的目标。“不要把支持目标实现的行为误认为是目标本身“。
应对方法:取消许可,牢记理由。
作出改变的决定,内心获得满足感,然后实践遇到挫折,引发内心的罪恶感、抑郁和自我怀疑,这时大部分人都会放弃努力。因为下决心是最容易的,但是往后的实践就越来越难了。
这时我最感兴趣的地方,毕竟不实践,终究都只是空想。书里提了好几种方法:
包括均衡的饮食、适当的运动、良好的睡眠,自控力是一种生理现象,自然也可以从一切有益于身体健康的行为中获益。额外比较有效的还有冥想,而且有时候冥想感觉糟糕,反而有助于自控力的养成。
核心**是任何事情都可以通过长期锻炼得到增强,可以说是 growth mindset 的一种变体。具体方法是针对“我想要”、“我不要”两个类别设置一个小任务,每天坚持。我针对“我想要”设置的是“每日扔一件闲置的东西”,具体执行情况可见"断舍离之公式法"这篇文章。个人感觉还是挺有用的。
A small time can make a big different.
很多人在自控失败后往往会陷入更深的绝望,而为了摆脱绝望往往又会去做一些令自己失望的事情从而进入恶性循环。书里提出为了摆脱这种“绝望之螺旋”,在最初自控失败时,不要对自己进行严苛的批评,而是要安慰自己。想象你的朋友遇到了一件很糟糕的事情,像你寻求安慰时,你会对他说“这是你应得的,你活该如此,你一辈子都不可能摆脱这种情况,你只配自暴自弃”吗?而很多时候人就是这样对待自己的,而后果也可想而知。人不要虐待自己。
至于降低对自我的要求和批评是否会导致自控力的滑坡,书里通过一些实验表明并不会发生这种事情。很多事情遇到挫折是很正常的,但是怎么处理挫折在某种程度上对结果却有绝对性的影响。
书中谈到众多研究表明,自我批评会降低积极性和自控力,不仅耗尽了“我要做”的力量,还会耗尽“我想要”的力量。相反,自我同情则会提升积极性和自控力。
未来的自己会跟现在的自己不同,这是很多人都会抱有的梦想。而一旦年华逝去而自己却没有改变时,失望也就不期而至了。这样想想“中年危机”也就可以理解了,中年的自己跟老年的自己不会有任何不同,这是怎样的一种情况呢?
当然凡事也有正面的一面,一旦认识到“现在即未来”,也表明你不再需要等待虚无缥缈的未来才能实现你想实现的事情。现在的你就是未来的你,而未来的你就是现在的你。现在你做的,未来的你也将不停的重复做,而现在的你停止做的,未来的你也将一直拒绝去做,你想成为哪个你呢?
或者说“延迟满足感”,“未来折现率”越高的人,自然也越能为了未来的收益而在当下努力。未来的健康 * 未来折现率 是否大于 当下吃零食的满足感 在某种程度下就觉得了你下面的行为。这边是一个很有趣的实验:“Don't eat the marshmallow!”,查看小孩对棉花糖的反应来测试他们的延迟满足感。
想像自己已经获得了自己期许的未来,而在眼前的诱惑面前,是否愿意放弃自己已经获得的期许中的未来,而交换现在的回报呢?这利用了人的“损失厌恶”的心里,失去比获得更加痛苦。
巴浦洛夫有个非常有名的实验:摇铃后给实验的狗分发食物,经过一段时间的训练后每当狗听到铃声,就会不由自主的流口水。人类的奖励中枢也是类似,在现代社会中,我们不知不觉已经养成了很多习惯,一听到“铃声”,就会引发内心的冲动,但是冲动毕竟只是冲动,人按自己的冲动行事往往不能带来真正的满足感,事后只会感到更加的空虚。这就像是从不可能获取满足感的事物中寻求满足感。
所以作者提出要识别自己的内心冲动,它会引导我们去做能真正带来内心满足感的事情吗?比如阅读、跑步、听英语、散步、学习等。只有内心真正得到满足后人才能摆脱无处不在的冲动、焦虑。
又称为“预先承诺”,限制自己的选择可能性,迫使自己只能从事有限的选项,因为如果受诱惑的自我能为所欲为的话,最终的结果只会伤及自己。
给自己未来的选择减少,提前做好准备,而对未来可能的改变预先设置好障碍,增加摩擦力,以使到时的变更更为困难。
每个人都有各种各样的想法,这是无法避免的,但是我们可以选择是否去执行。倾听内心的声音,但是拒绝行动。
如果上面的方法你尝试之后都失败了,这也是非常常见的情况,毕竟 “Everthing worth to do is hard to do(The wisedom of the life)"。这时候给自己十分钟的间隔期,如果十分钟后你还是想做,那就去做吧,堵不如疏。
在面对意志力抉择时,放慢呼吸 1 ~ 2 分钟,可以提高心率变异度,增加意志力储备。
这书改变了我对“自控力”很多不切实际的幻想,相比较泛滥的畅想书籍更像是一本精彩的科普书。将科学的方法应用于人的心理上而诞生的心理学,在某种程度上也具有科学那种改造自然的伟力,只不过这次的目标是我们自己。
最近有一天晨跑的时候,突然想到了刚学的微积分里面的 The Mean Value Theorm。因为记得书上说这是微积分中最重要的定理之一,就心血来潮想回忆下这个定理是怎么推导出来的?也因此有了一段很奇妙的体验。
The Mean Value Theorm 简述如下:

证明如下:

而此时我们可以回想起 Rolle's Theorem:

代入上式,则



这时候我没有疑问了,心满意足了,而跑步也临近结束,此时我内心的满足感无以复加,仿佛一个小孩终于得到了自己想要的东西。
那这些数学的推论跟跑步有什么关系呢?因为只有在跑步的时候才能放空自我,让思维漫无边际的漫游,飘荡在这世界中,欣赏人类纯粹的智慧成就。
我突然理解为什么那么多人醉心于数学的优雅和精致。在现实生活中,有很多问题你无法获得解答,但是在数学中,对于你感到疑惑的定理,只要你有好奇心,你总是可以问到你心满意足为止。
我想,这是不是所谓的苏格拉底式提问法呢?一直追问下去,直到你的好奇心满足或者回答不了发现自己的盲点为止。
最近我偶然看到了一个费曼关于 why 的视频,里面也谈到了类似的思考方式。我想用一句话总结我的感受:
Ask why! Ask why! Ask why until you're satisfied!
看完了《富足》之后继续在公司的书架上淘书,偶然看到了一本薄薄的小书《软件测试的艺术》,英文名是 《The Art of Software Testing》。本书出版于 1979 年,距今已经快 40 年了,我手里拿的是第三版。粗粗翻了下,虽然书很久远,但还是有一些挺有意思的观点,所以花了几天时间把它读完了。
我一开始编程完全不知道有测试的概念,后面了解到 TDD,在项目中实践了下,但是有感于测试用例编写的繁琐,最后又废弛了。后面慢慢的又开始写测试了,因为高效的编程离不开测试。测试可以解放我们的大脑,专注于面向接口编程而不需要记住所有接口的内部逻辑,更不要说随之而来的减少 Bug,方便重构等好处了。
整体书主要内容分为二部分。首先是软件测试的心理学,如果你不是从心底认为测试是一个好东西,又怎么能真正重视测试呢。然后是测试的方法论,讲解如何高效的编写测试用例。
因为对测试我本身就怀有很多的疑惑,所以这里以问答的形式总结本书的内容和给我已启发的地方
什么是测试?
我:为了保证我们编写的代码正常运行而实行的校验措施,提高我对程序能实现预期功能并在生产环境正常运行的信心。
作者:软件测试是为了发现程序错误而执行程序的过程,是为了增强软件的可靠性。
评论:我以前对测试的态度是消极的,对我编写的代码块来说,我一般认为它是能正常运行的,或者说它大概率能实现我的所思所想,而我写测试只是为了对这个大概率正常的代码进行进一步的验证,可能我多花了一半的时间,但是只剔除了小概率会失败的情况。而作者正好相反,他预期我们的代码大概率蕴含错误,而我们多花一半的时间,剔除了大概率会失败的情况,由此测试的价值大大增加。自然我们内心也有了更强的动力去写测试,毕竟谁不喜欢投入低,产出高的事情呢?
以简单的数学论的话:
假设正常完成的代码块的价值为 1,我投入 10 个单位时间完成功能代码的编写,如果有 90% 的概率能正常运行,此时代码价值为 10 * 0.9 = 9,编码单位时间价值为 0.9 / 10 = 0.09,此时投入 5 个单位时间编写测试,确保剩下的 0.1 个单位的软件价值,则测试单位时间的价值为 0.1 / 5 = 0.02,如果投入 2 个单位时间进行测试,则价值为 0.1 / 2 = 0.05,编程效率分别是之前的 22.22% 、 55.55%。我想任何一个对效率有所的追求的人都很难满意,更不要说跟创造带来的愉悦感相比,测试的编写是个相对无聊的过程。
而作者假设投入 10 个单位时间完成编写过程后,编写的代码只有 50 % 的概率能正常运行,此时代码价值为 10 * 0.5 = 5,单位时间价值为 0.5 / 10 = 0.05。如果我投入 5 个单位时间编写测试,确保了剩下的 0.5 个单位的软件价值,则编写测试单位时间的价值为 0.5 / 5 = 0.1,如果投入 2 个单位时间进行测试,则测试单位时间价值为 0.5 / 2 = 0.25,编程效率为之前的 100% 、 250%。
总结成公式的话,假设 p 为先验代码正确率,Vt / Vc 为测试/编码价值之比,t / c 为测试时间/编码时间, 则公式如下
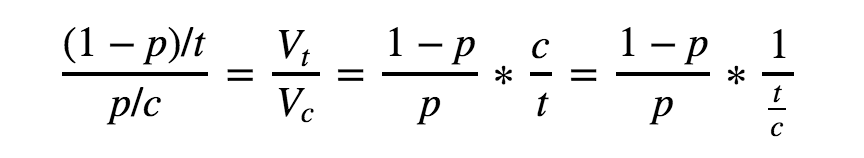
转化成图表如下:
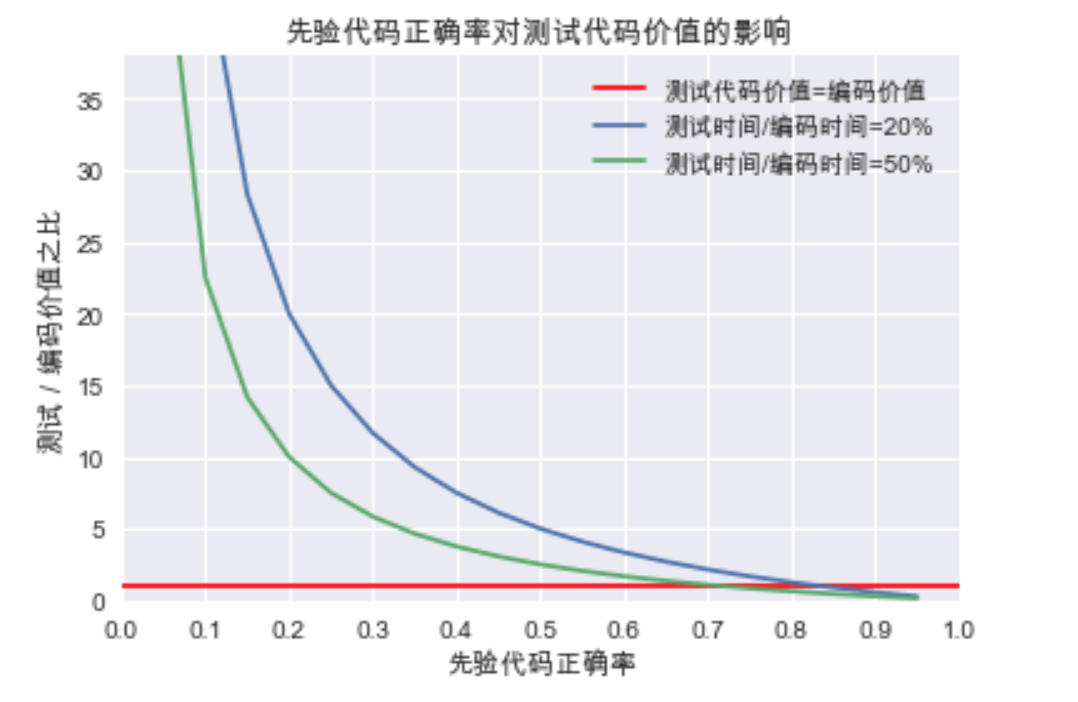
可见测试的代码价值随着我们对代码正确率信心的下降而指数级上升。在这个复杂的现实世界中,懒惰而又讲究效率的程序员反而会成为测试的坚定拥护者。
为什么我们要写测试?
我:
主要有三方面:
一、编写测试可以保证代码实现了我们需要的逻辑,不至于到线上才出现一些低级 Bug。
二、测试可以快速重复多次运行,节省我们每次修改完代码后花费无聊、痛苦的手动测试时间。
三、写测试的过程可以理清我们代码的逻辑,毕竟你不能对一个你自己都不了解要做什么的代码块编写测试。
作者: 软件的运行应当是可预期、稳定的,符合最小惊异原则,软件测试是实现这一目标的手段。据统计分析,每千行代码一般蕴含 1-25 个错误,而测试的目的就是为了找出相关错误。
什么是成功的测试?
我: 没有发现错误的测试就是成功的测试
作者: 发现错误的测试才是成功的测试。类比于对病人做检查,正确查出病因的检查才可称为成功或者有效,测试同样如此。
这里作者提到一个挺有意思的心理学原理,当人知道自己的目标无法达成或者自认为无法实现时,表现会非常糟糕。
为什么测试往往难以落实到实践中
我:
一、测试用例编写编写不当,很多时候对的逻辑可能只有一条,但是错的逻辑有千千条,一开始投入编写测试用例的时间会降低增加软件开发的效率,而无法高效的编写测试用例也会导致对测试心生厌烦。
二、一开始没考虑到模块化、测试的需求,导致后期无法高效的 mock 数据,测试成本过高。
三、测试没有集成到开发流程中,导致有时候测试被破坏没有修复,根据破窗效应,后面的废弛也是预料之中了。
作者:在复杂的现实中,对软件进行完全的测试貌似是不可能的任务,但是我们可以通过相关的方法和技巧提高测试的效率,以达到可以享有测试的大部分好处而不至于投入过多的时间。
而如何高效的测试也是我最有兴趣把本书看完的动力
以下是我感觉比较有意思的
书里面提到的覆盖条件计算比较复杂,可以用《代码大全》里面提到的简化版来决定测试用例数
尽量将输入范围划分为几个等价类,使得对某个等价类元素的测试等同于对整个集合的测试。同时区分有效等价类和无效等价类。如果可能的话对输出范围也进行等价类划分。
测试用例的选取尽量选择边界值。边界值一般为上边界、上边界 + 1、下边界、下边界 - 1
尽量选取一些容易导致出错的特殊值,比如 0、None、空数组等等。这个更加依赖于程序员的经验和对编写代码的理解。
这个方法我没看懂,有理解的欢迎在下面回复。具体好像是利用了一些数理逻辑的方式进行了非常复杂的逻辑推断最后得出如何编写对应的测试用例。
以下面这个小函数为例
def double_if_less_than_ten(num):
if num < 10:
return num * 2
return num(num < 10) 以及 (num >= 10),无效等价类为 (num 不为数字)9, 100综合以上的条件,便可选取尽量少的测试用例覆盖尽量大的测试范围。
| num | expected_value | 满足条件 |
|---|---|---|
| 9 | 18 | if 为 True、(num < 10)、边界值为 9 |
| 10 | 20 | if 为 False、(num >= 10)、边界值为 10 |
| 0 | 0 | 错误猜测 0 |
| None | raise TypeError | 无效等价类 (num 不为数字) |
《代码大全》里面提到,越好的程序员越是谦虚,因为他们明白编程是为了弥补人有限的智力,因此愿意通过学习来弥补。而编程糟糕的程序员往往自负,为此失去了提升自我的机会。对测试而言,我觉得下面这句话总结的很好,以此自勉。
Form is liberating
R: What's the difference between secretary and receptionist?
I: Secretary is someone who assists somebody.
R: A secretary is usually a woman who does paperwork, making the calls, checking the email.
R: who is a receptionist?
I: A receptionist is someone who says hello to visitors.
R: A receptionist is someone who greets the customers or visitors.
R: Does your company have a receptionist or a secretary or both?
I: Both.
R: Full sentence.
I: Our company has both receptionists and secretaries.
R: One secretary or one receptionist or several?
I: Our company has one secretary and one receptionist.
R: Is the website updated every day?
I: Yes, the website is updated every day.
R: Was the website updated yesterday?
I: Yes, the website was already updated.
I: No, the website wasn't updated yet.
R: Has the website been updated today?
I: Yes, the website has already been updated.
I: No, the website hasn't been updated yet.
R: Showing the 7:15 picture. What time is this?
I: It's seven-fifteen. Also, it's a quarter past seven.
R: Showing the 7:30 picture. What time is this?
I: It's seven-thirty. Also, it's half of seven.
R: Showing the 7:45 picture. What time is this?
I: It's seven forty-five. Also, it's a quarter to eight.
R: Did you swim today?
I: I swam with my leader and another colleague.
R: I want you to use both.
I: I swam with both my leader and another colleague.
R: It sounds like you got a good environment.
The Teacher talked about his cough.
R: I have a couple of questions. I have a persistent cough. What will you do if you are sick? Do you buy antibiotics in the drug store?
I: We need a prescription to buy antibiotics in the drug store.
...
R: OTC means over the counter. (counter 是柜台的意思,第一次知道 OTC 原来是这个意思)
R: There are many big-box stores in American, like Walmart. The big-box store means a very large store.
I: We also have Walmart in China.
最近一直在 Cambly 上课,目前是一周五节课。这里把老师简称为 R 老师,是一个风趣的美国退休老头,我已经跟着老师上了一个多月的课。
开头我们提到了 Puffin,因为 Cambly 会默认为用户生成一个唯一的 ID,以 puffin_xxx 开头,老师以为是我自己起的。
puffin 是指海雀。
R: Why do you use puffin in your cambly nickname?
I: The name was automatically generated by Cambly when I registered by mobile phone.
R: I think because Cambly's symbol is a bird.
R: Is five days a week still good for you or is it too much?
I: I think it's good, not too much.
R 这次提到要开始教一些简单的 phrasal verbs 即动词短语。
R: Today, I want to concentrate on phrasal verb.
R: What's the meaning of tolerate?
I: To allow something to happen.
R: The idiom in phrasal verb is put up with. Put up with means tolerate.
R: For instance, I could not tolerate traffic noise, so I closed the windows. Say the same thing with put up with.
R: I could not put up with traffic noise, so I closed the window.
R: Let's try another one. I could not tolerate the loud music, so I left the party.
I: I could not tolerate the loud music, so I left the party.
待续...
R: Why did you leave the party?
I: Because I could not put up with the loud music.
而刚刚学习 Python 的人常常会遇到一个问题,如下
# 意图是获取包含 10 个空 list 的列表
>>> li = [[]] * 10
# print 出来感觉没问题
>>> li
[[], [], [], [], [], [], [], [], [], []]
# 尝试往第一个 list 添加一个元素,并打印
>>> li[0].append(1)
>>> li
[[1], [1], [1], [1], [1], [1], [1], [1], [1], [1]]
# 结果发现每个 list 里面都包含了新添加的元素,而预期中应该是
>>> li[0].append(1)
>>> li
[[1], [], [], [], [], [], [], [], [], []]
# 原因是当 Python 执行 [obj] * count 时,新的 list 中的 item 拷贝的是原 obj 的引用,而不会进行复制。
# 如果想要初始化全新的 list 的话,则需要按如下方式初始化
>>> li = [[] for _ in range(10)]
>>> li[0].append(1)
>>> li
[[1], [], [], [], [], [], [], [], [], []] 最近在看 《Python源码剖析》,让我们看看 [obj] * count 在 Python 底层是如何实现的。
Python 所有的代码都会编译成字节码之后执行,而类似 [obj] * count 的表达式,编译成字节码之后为
>>> import dis
>>> def test(): return [obj] * count
>>> dis.dis(test)
# 构建 [obj]
1 0 LOAD_GLOBAL 0 (obj)
2 BUILD_LIST 1
# 读取 count
4 LOAD_GLOBAL 1 (count)
# 实现 [obj] * count
6 BINARY_MULTIPLY
# 函数返回值
8 RETURN_VALUE而 BINARY_MULTIPLY 指令在源码中的实现为
TARGET(BINARY_MULTIPLY) {
# 获取 count
PyObject *right = POP();
# 获取 [obj]
PyObject *left = TOP();
# 重点来了,在这里获取相乘的结果
PyObject *res = PyNumber_Multiply(left, right);
Py_DECREF(left);
Py_DECREF(right);
SET_TOP(res);
if (res == NULL)
goto error;
DISPATCH();
}指令的核心便是 PyNumber_Multiply,Python 源码中对该函数的注解
/* This is the equivalent of the Python expression: o1 * o2. */
PyAPI_FUNC(PyObject *) PyNumber_Multiply(PyObject *o1, PyObject *o2);原来 Python 中所有 o1 * o2 的操作最后都是通过该函数实现,而 [obj] * count 也不例外。
PyNumber_Multiply 的实现如下:
PyObject *
PyNumber_Multiply(PyObject *v, PyObject *w)
{
// ......
// v 为 [obj],w 为 count
// v->ob_type 就是 [obj] 的类型 list, 而 tp_as_sequence 是其实现的一组与 sequence 相关的函数集合。
PySequenceMethods *mv = v->ob_type->tp_as_sequence;
PySequenceMethods *mw = w->ob_type->tp_as_sequence;
Py_DECREF(result);
if (mv && mv->sq_repeat) {
// 因为 [obj] 定义了 tp_as_sequence->sq_repeat 所以最后会进入这里
return sequence_repeat(mv->sq_repeat, v, w);
}
else if (mw && mw->sq_repeat) {
return sequence_repeat(mw->sq_repeat, w, v);
}
return result;
}而 sequence_repeat 仅仅是简单进行了一些类型检查,最后直接 call repeatfunc,也即外界传入的 sq_repeat
static PyObject *
sequence_repeat(ssizeargfunc repeatfunc, PyObject *seq, PyObject *n)
{
// 略过
return (*repeatfunc)(seq, count);
}该函数在 list 类型的实现为
// list_as_sequence 实现了一组与 list 相关的操作
static PySequenceMethods list_as_sequence = {
// 比如 list 的长度
(lenfunc)list_length, /* sq_length */
// 这就是最终调用的函数
(ssizeargfunc)list_repeat, /* sq_repeat */
...
};经过寻找,我们最后终于找到了最终实现 [obj] * count 的代码。
下面是 list_repeat 简化后的代码:
static PyObject *
list_repeat(PyListObject *a, Py_ssize_t n)
{
...
PyObject *elem;
# np 指向新分配的 count 大小的 list 对象
np = (PyListObject *) PyList_New(size);
items = np->ob_item;
# 如果 [obj] 的对象大小为 1 的话,我们这里就是如此
if (Py_SIZE(a) == 1) {
# 获取 obj,即这里的 elem
elem = a->ob_item[0];
for (i = 0; i < n; i++) {
# 因为 elem 是指针,所以这里新的 list 的 items 里面包含的是原有的 obj 的引用,而不是复制
items[i] = elem;
Py_INCREF(elem);
}
return (PyObject *) np;
}
...
}所以 [obj] * count 最后获得是包含 count 个 obj 引用的新 list
最后我们可以看到实际上最后实现该功能的函数是
obj->ob_type->tp_as_sequence->sq_repeat = list_repeat Python 为什么经过那么多层的抽象呢?因为 C 本身并不支持 class,而 Python 本身却是万物皆对象,而基于 C 实现的 Python 自然就需要通过大量的抽象来模拟实现面向对象的功能。
结尾安利下 《Python源码剖析》,虽然书有点老了,而且基于 Python 2.5 ,但是 Python 整体的大框架并没有改变很多,还是非常值得一看。
最近在看《编程之美》,里面有一小节是探讨 N! 的阶乘的尾部零的数量的问题。里面提出来一个规律即对于 N! 的二进制表示,则尾部的零的数量为 N - one_bits(N),即 N 减去 N 的二进制表示里 1 的数量,只需要 O(1) 的时间即可求解该问题。然后书里面举了一个例子,但是没有给出证明为什么这个规律成立。这么优雅的规律怎么能没有证明呢,它真的成立吗?
首先书里面指出 binary(N!) 尾部零的数量 = N / 2 + N / 4 + N / 8 .... 直到 N / (2^k) 为 0 为止,这个很容易理解,接下来比较关键的就是证明 N / 2 + N / 4 + N / 8 .... 直到 N / (2^k) 为 0 为什么等于 N - one_bits(N)。(这里的 / 是 C 里面的 / )
下面给出证明,如有错误欢迎指出:
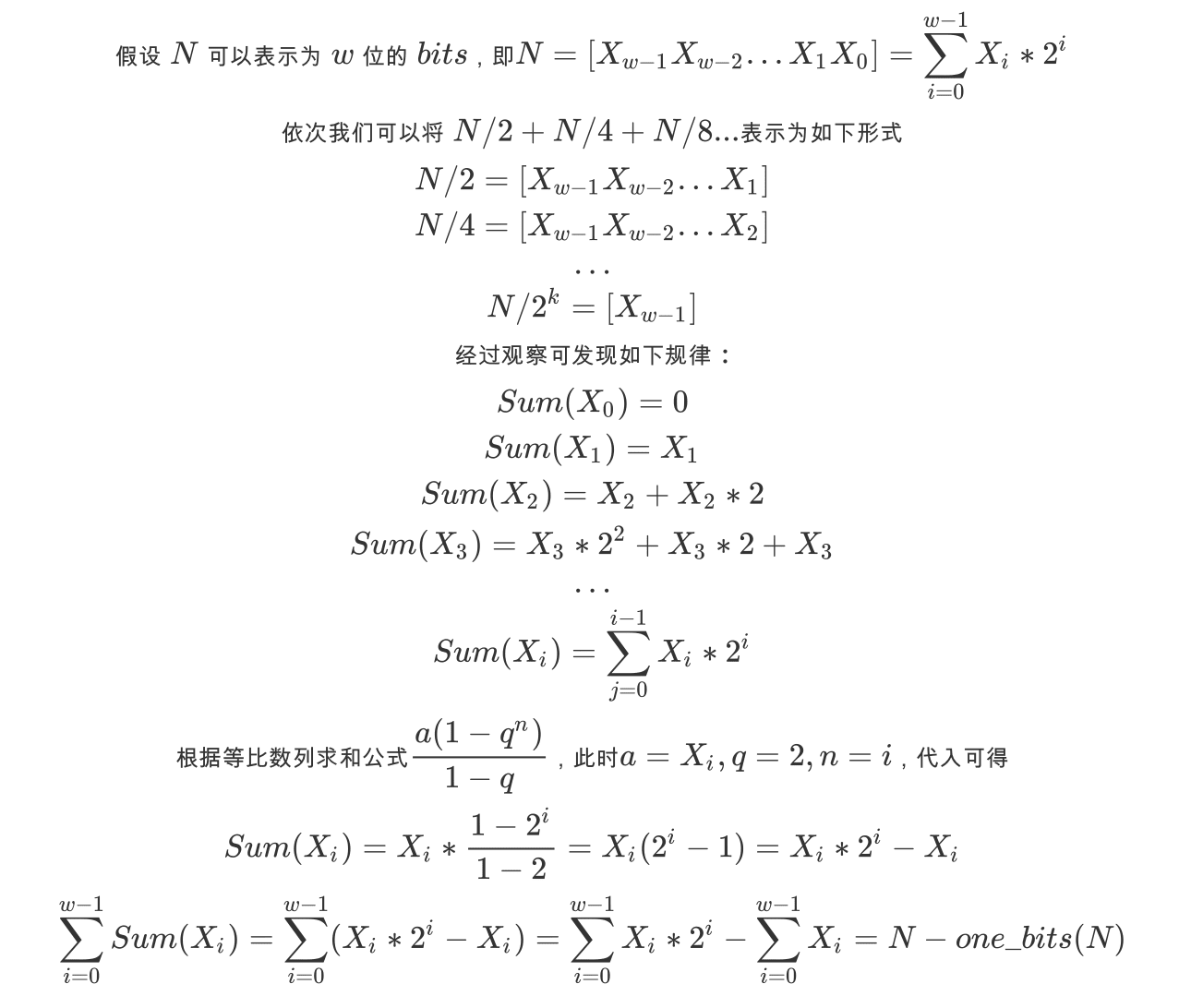
优雅的结论背后一定隐藏着优雅的证明,我想这就是数学猜想的魅力所在吧!
之前有段时间睡眠不太好,就想找本睡眠相关的科普书看下。毕竟想改善某些事物的话,最好能多了解它一点。在查看了豆瓣、Amazon、Goodreads 上面的评分后,选择了《Why We Sleep》。主要有以下几点:
评分不错
作者是哈佛专门研究睡眠的教授,几十年的科学研究经验
年份较近,对于快速发展的生物医学来说,越近说明知识靠谱的概率会高一点。
看了之后虽然感觉作者文笔一般而且比较啰嗦,不过在科普方面还是挺不错的。
书的内容按照以下几章分布
古时候的人们以为是太阳控制着睡眠节律,毕竟在没有人造光源的时代,大家都过着日出而作、日落而栖的生活,而随着科学时代的到来,人们的观念也逐渐发生了改变。
欧洲中世纪的人发现有些植物的枝叶会随着跟随太阳的轨迹而移动,他们以为是受到太阳光照的影响。直到 1729 有位法国科学家 Jean-Jacques d’Ortous de Mairan 针对 Mimosa pudica(含羞草)做了一个精妙的实验。因为含羞草本身不止枝叶会有向阳性,而且晚上会把叶子收起直到太阳升起时再展开,也因此被达尔文戏称为“sleeping leaves"。当时的人们以为是受太阳光照的影响,而他将含羞草密闭在一个黑盒中 24 小时,在中间打开小盒窥视发现植物的行为还是跟它在受光照时一样,因此猜测植物内部有独立的生物钟,而不仅仅是太阳光照的奴隶。而其后过了 200 年,才证实人类也存在着类似独立的昼夜节律。200 年,现在的我们是真正站在巨人的肩膀上,沐浴着智慧的光芒。
人类昼夜节律的发现要归功于两位勇敢的科学家。1938 年芝加哥大学的两个科学家 Nathaniel Kleitman 和 Bruce Richardson 准备进行一个疯狂的实验,带满六周的口粮和两张高脚床在世界上最深的洞穴之一的 Mammoth Cave 中居住并记录人类的睡眠周期。因为洞穴深处完全隔绝了阳光,是一个非常理想的实验地点。他们想要回答的是这样一个问题:当人类脱离自然光照后,他们的体温、睡眠周期同正常情况下有什么区别?他们最后在洞穴中居住了 32 天。在此间还有一件趣事,他们为了防止被洞穴中的生物侵袭,将床的四只脚都放在水桶里,因为大部分动物都不会涉水,也就避免了在伸手不见五指的深处床上爬满各种古怪的生物。32 天的付出带来的是人们对睡眠的全新认知:
现在的科学家通过大量实验,已经确认了成年人的昼夜节律大概是 24 小时 15 分钟,也就是说在没有外界参照的情况下,人类本身就会每天睡的越来越迟。这也解决了我很久以前的一个疑惑,为什么我以前经常每天会迟睡一点,然后不知不觉就熬夜到很迟了,原来人本身的昼夜节律就倾向推迟人本身的睡眠时间。
而我们之所以能维持 24 小时的生活节律是因为外部环境的影响。其主要作用的是太阳光照,但是定时摄入食物,温度的周期性变化,定时运动甚至人际之间的交往都有一定的作用,大脑会据此轻微的修改我们的昼夜节律。
昼夜节律的发现到现在己经有70多年的历史了,科学家也对它有了越深入的理解。昼夜节律本身由大脑内部命名为 suprachiasmatic(“supra, meaning above, and chiasm, meaning a crossing point of the optic nerves”. ) 的神经细胞控制。这群细胞的数量只有 2w 个,在大脑 1000 亿左右的神经元中占比微不足道,但却对我们的生理系统有着重要的影响。昼夜节律本声是由一系列的生理反应组成,包括体温周期性的变化、人类周期行的苏醒和睡眠等。人类的体温在凌晨 4 点左右逐渐升温,到下午 3 时左右达到顶峰,然后逐渐下降。所以一般下午 3 点作用是人体能的巅峰期。然后到了晚上脱离了光照后会逐渐分泌褪黑素,褪黑素作为吹响入睡的号角声,会导致一系列诱发睡眠的生理反应产生,伴随夜晚体温降低人就入睡了。这时到了早上受到阳光照射使褪黑素停止分泌加上体温的逐渐上升,人就从睡眠状态醒来。这就是昼夜节律在人的睡眠中所起的作用。
每个人都有自己的昼夜节律。据统计有 30% 的人为 “morning types”,即早起型,30% 为 “evening types”,即夜猫子型,剩下的人介于其中之间。
为什么人们都说一年之际在于晨,白天刚起床的时候人会比较清醒呢?为什么我们熬夜到后面会越来越困,而如果你通宵到快天亮时反而没那么困,而到了第二天下午又很想睡觉?为什么喝了咖啡后会很精神,但是效力过去后又会非常困?这些现象的背后是什么生理机制在其作用呢?
随着现代医学的发展,人们发现人类大脑中有一个腺体,叫做 suprachiasmatic, 会分泌一种 adenosine(中文名腺苷,下面简称为睡意激素) 的物质,而这种激素正是人类产生睡意的来源。你感到困倦、昏昏欲睡都是这种激素在起作用,科学家把这种机制称为 sleep presure。而它跟昼夜节律一起正是决定人类睡眠的两大因素。
睡意激素在人醒着时开始分泌并积累在人的血液中,通过跟大脑中特定的受体结合而起作用,不断的对人施加睡眠的压力,而只有在睡眠时这种激素才会被从身体里清除。
而咖啡提神的原因也是因为它比睡眠激素有着更强的跟大脑中受体结合的能力。当人摄入咖啡因时,它会将睡眠激素从受体上挤开而自己跟受体结合,但咖啡因却不会使你产生睡意,因此人会感觉精神起来。你精神并不是咖啡提神,它只是将你原有的睡意暂时消除了。但是此时睡眠激素并没有被从身体里清除,还不断堆积在身体中,而更糟糕的是它的受体被咖啡因霸占了,导致它在身体里的浓度比平常更高,而一旦咖啡因的效力过去,高浓度的睡眠激素又会跟受体结合,人会感觉到比之前更困,这种现象被称为 ““caffeine crash”。
而咖啡因不只在存在于咖啡中,在茶、运动饮料、巧克力、冰淇淋中都广泛分布。而且咖啡因的在血液中的代谢半衰期在 5 到 7 小时左右,很可能你早上喝的一杯咖啡,到晚上还在你的血液中残留着 25% 的咖啡因,此时你很难将你晚上的难以入眠跟白天的一杯咖啡关联起来,咖啡因成了一个隐藏的黑手。
而早晨人会比较清醒是因为此时人体内的睡眠激素浓度随着昨晚的睡眠浓度不断下降,而刚起床时受昼夜节律的影响体温处在逐渐上升中,因此整个人都比较精神。
而熬夜到早晨没有那么困也是因为虽然睡眠激素还在积累中,但是到早上受昼夜节律的影响人的体温也处在逐渐上升中,所以抵消了一部分睡眠激素的影响,而到了下午体温下降加上高浓度的睡眠激素积累,便遇到了睡意的大爆发。
具体可以参照下图
睡眠本身由两个阶段组成,分为快速眼动期(Rapid eye movement sleep: REM)和非快速眼动期(Not rapid eye movement sleep: NREM)。
人类以前并不知道由快速眼动期的存在,直到有一个科学家偶然发现为止。
快速眼动期人的脑电波比清醒时还活跃,而在非快速眼动期人的脑电波则比较和缓。人类做梦的阶段通常就发生在快速眼动期阶段。通常快速眼动期和非快速眼动期会交替出现,它们一起会组成大概90分钟的一个周期,通常在睡眠早期以 NREM 为主,在睡眠晚期,临近起床时以 REM 为主。
所以如果早起导致睡眠不足的话会损失一大部分的 REM。
具体参上,很多人睡眠不好其实是受到很久之前摄入的咖啡因到了晚上睡觉时还残留在身体里的影响,并不是真正的失眠。
人们认为喝酒助眠。作者在书里面驳斥了这个理论,喝了很多酒的人看起来是睡着了,但是通过监测他们的脑电波可以发现,说他们处于睡眠状态,不如说是“麻醉”状态。而“麻醉”状态本身并不能像真正的睡眠一样带来种种益处,只是一种自我欺骗。
科学家曾做过实验,研制了一种可以控制温度的衣服给受试者穿着,然后通过调控衣服的问题来观察受试者的入睡时间,发现 18 度左右是比较适宜的入睡温度。低于 13 度或者过高的温度都会导致入睡时间延长。科学家提出的理论是人类起源于非洲,古时没有衣服都是裸睡,因此比较适宜非洲夜间 18 摄氏度左右的温度。
这边也解释了为什么晚上洗澡会比较助眠,洗完澡后身上残留的水珠蒸发时会带走热量,导致平均体温的降低,因此人也更容易入睡。
人的昼夜节律会受到一部分光照的影响。科学家发现晚上只要经过灯光几分钟的光照就可以将褪黑素的分泌推迟 1 小时左右。而褪黑素正是人类睡眠过程开始的发令枪,由此也会干扰到人类睡眠。而且现代 led 灯中富含对人的干扰更严重的蓝光,不像以前的白炽灯接近太阳光,因此现代无处不在的光污染也会干扰人类正常的睡眠过程。推荐有条件的换用白织灯。
这个我觉得没什么好说的。不过科学家发现睡眠时播放一些特定的音乐可以对人的睡眠产生一定的影响,比如增强或者减弱对某些事的记忆里。
我以前只是觉得睡眠是为了恢复人类白天的劳累所丧失的精力,并不清楚睡眠本身到底有什么具体的意义,因此自然也不知道睡眠不足到底有什么坏处。
作者首先探讨了为什么会有睡眠这种现象。睡眠占了人类一生中 1/3 的时间,而且在睡眠时人失去了对外界的感知,基本上丧失了自卫能力。在残酷的自然法则下,为什么人或者说大部分的动物都进化出了睡眠这个机制呢?睡眠本身一定有着极为重要的理由才能导致它能在那么多年的生物演化史中经受达尔文进化论的冲刷而屹立不动。
那睡眠本身到底有什么作用呢?虽然现代科学还没有揭开睡眠的全部秘密,但也产生了不少的收获,而这也是作者着力阐述的重点。
有些人得了一种特殊的病症,导致难以入睡,而且现代的一切药物都对他们不起效。在医学史上少数几个患有这个病症的人都在几个月的睡眠缺失后走向了死亡。
人在白天接受了很多信息,而睡眠就是大脑在晚上深加工这些信息的时候。哪些信息是没有意义需要丢弃的?哪些信息是最近可能用到的需要暂存起来的?哪些记忆非常重要需要长期记忆的?哪些记忆跟以前的记忆有关联可以联系起来的?这便是睡眠所做的事情。
睡眠不足会导致记忆力下降相信都可以理解,而睡眠充足会导致记忆力上升却是很少听到的理论。科学家找了一些受试者进行实验,一部分人在记忆一定量的单词后休息一段时间,但是不能睡觉,而另一部分人在记忆单词后进行几小时的短暂睡眠,然后测试他们对单词的记忆程度,有睡眠过的人对单词的记忆力远超过不休息的人。而重复这个实验,只是受试者变成晚上睡眠 6 小时和睡眠 8 小时两组,也可以得出同样的结论。
我常常背单词的,因此有更深的体会。有些单词你但是怎么都背不住,但是睡了一觉,在看到它时你自己还没意识到,单词的意思就自然而然出现了,就像魔法一样。
在 REM 阶段,人会做梦。而这也是大脑在不断对记忆进行深加工的阶段,大脑会将过去的储存的知识跟当前保存的记忆进行联想,看能不能找出深层次的关系。如果背过单词的应该可以理解,如果一个单词能跟一幅画或者一个动作、声音、感觉关联起来,那这个单词想忘记都比较困难。
大脑的机制也是类似,如果能找到记忆之间的关联性,则保存记忆的成本就会大大下降。而许多科学家也有对一个问题百思不得其解,但是某天做梦却突然梦到了解决方案。比如元素周期表的发明和 DNA 双螺旋结构的发现。而发现、建立、创造事物之间的联系,是创新和理解力的源泉之一。大脑作为一个网状结构,如果你能在其中建立更多关联,你的整个网络会更健壮,而当你遇到问题的时候也因此能激发大脑更多部分参与思考、联想、推理、理解。
在清醒的时候,人体内会产生大量的代谢废物和相关的压力激素。毕竟谁能在有意识的时候毫无压力、忧虑呢?而科学家观察到这些累积的废物大部分都会在睡眠时得到清除。睡眠不好的人相对脾气暴躁也更加容易抑郁,因为之前的压力激素和其他废物都没有得到合适的处理,不断在他身体里累积。
人们常说时间会抹去一切伤痛,而这又是怎么实现的呢?正是通过一次又一次的睡眠,大脑对过往痛苦的记忆进行重加工,减轻了人每次回忆旧事时的心理创伤。而患有 PTSD 的人往往睡眠不好,因为他们这一机制受到了破坏,因此每次他们想到旧事就仿佛真的是旧事重现,而不是像大多数人一样一笑了之。
书里面举了一个美国夏令时和冬令时切换的时候人们会少睡或者多睡一个小时,导致当日全美交通事故发生波动的例子。
同时反对现在学校上学时间越来越早的变化,因为早起会干扰到深度 REM 的相关的睡眠质量,导致记忆力和理解力的下降。
同时建议公司上班时间更加的弹性化以便个人能根据自己的生物钟合理安排最高效的时间用于工作。
书的结尾谈到了一些改善睡眠的办法,以下逐条列举:
书里面还谈到对一些有睡眠障碍的人,比如很迟才能睡着,或者很早就醒了睡不着的,可以尝试使用 "Cognitive Behevier Theropy",做法也非常简单:
可以看到更上面的建议非常类似,但是有一点重要的区别,就是“不到非常困不要上床”,书里面谈到这是为了积累足够的睡眠压力,在刚开始受试者的睡眠时间会缩短,但逐渐会慢慢恢复正常时间,并且他们的睡眠质量也得到了提高
所以作者在一开始就感叹,睡眠是大自然赐给人类最宝贵的礼物之一,是真正的“灵丹妙药”,更美妙的是你每天都有机会享受。可惜很多人不懂得珍惜,他们不知道他们失去了什么?
书中的建议我实行之后确实改善了我的睡眠质量,入睡时间变短而且睡眠质量得到提升。更重要的是它让我理解了睡眠到底是怎么一回事,而我们又怎么看待这占我们生命三分之一的睡眠?毕竟“知行合一”,真知方能真行。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.