![]()


KOMORAN은 KOrean MORphological ANalyzer의 약자로, Java로 구현한 한국어 형태소 분석기입니다.
- 순수한 Java로 구현
- 100% Java로만 개발되었기 때문에 자바가 설치된 환경이라면 어디서든지 사용 가능합니다.
- 외부 라이브러리 독립적
- 자체 제작한 Library들만을 사용하여 외부 Library와의 의존성 문제가 없습니다.
- 경량화
- 자소 단위 처리, TRIE 사전 등으로 약 50MB 메모리 상에서도 동작 가능합니다.
- 쉬운 사용법
- Library 적용 후 소스 코드 내 1줄만 추가하여 형태소 분석기를 사용할 수 있습니다.
- 사전 관리 용이
- 일반 텍스트 파일의 형태로 구성되어 가독성이 높으며 바로 편집이 가능합니다.
- 새로운 분석 결과
- 타 형태소 분석기와 달리 공백이 포함된 형태소 단위로 분석이 가능합니다.
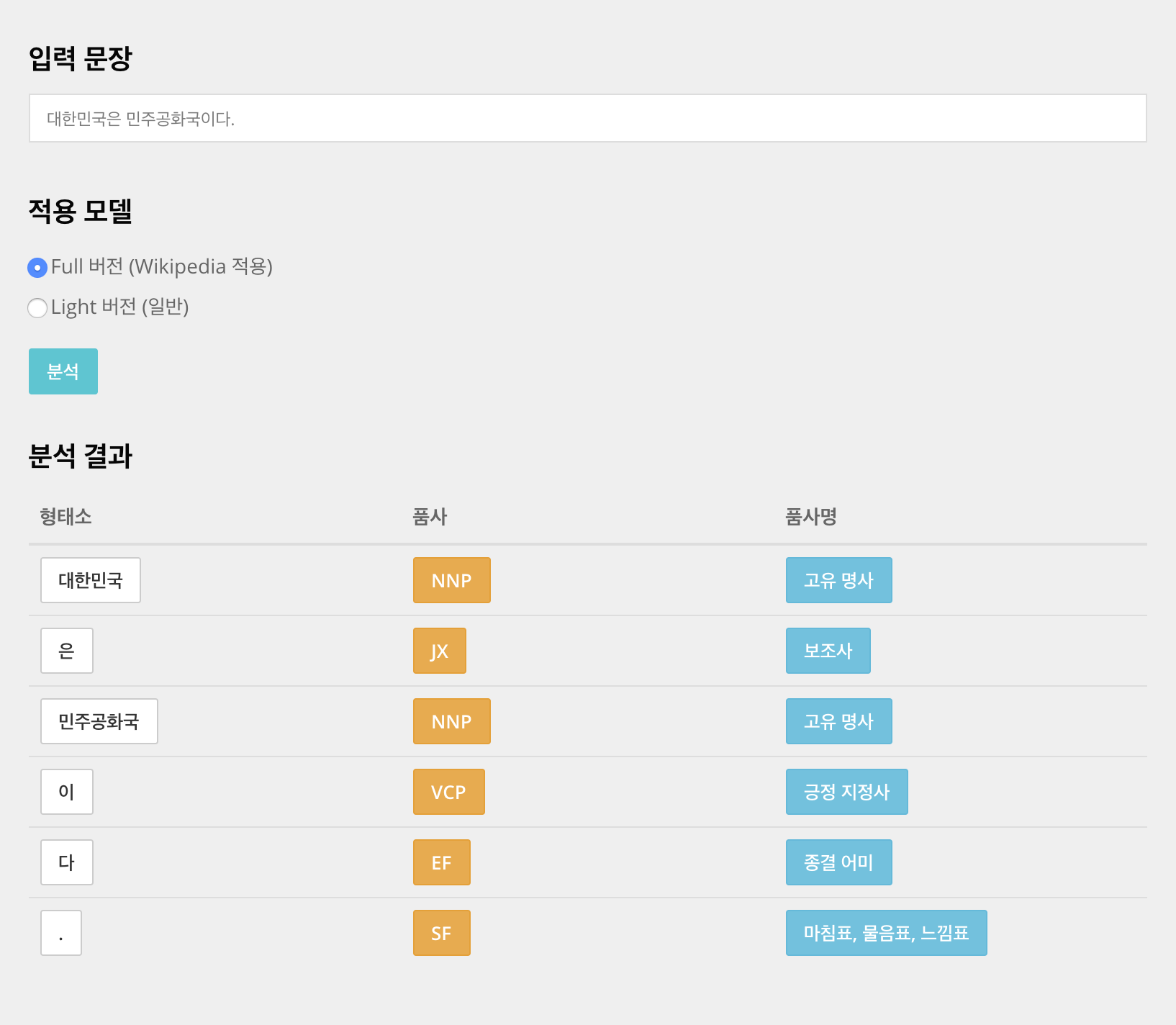
- KOMORAN 사이트에서 아래와 같이 분석 결과를 미리 확인해볼 수 있습니다.
- 입력 문장: 대한민국은 민주공화국이다.
'설치하기' 문서를 참고해주세요.
'3분 만에 형태소 분석 따라하기' 문서를 참고해주세요.
KOMORAN을 개발한 shineware에서 제공하는 참고자료입니다.
- shineware 홈페이지에서 KOMORAN 소개 및 데모를 확인하실 수 있습니다.
- KOMORAN 공식 문서에서 KOMORAN 설치 및 사용 방법 등을 참고하실 수 있습니다
- KOMORAN Slack에 방문하셔서 사용법과 팁 등을 공유해주세요.
shineware에서 개발한 공식 wrapper 자료입니다.
- PyKOMORAN에서 Python용 KOMORAN을 사용하실 수 있습니다.
사용자 분들께서 만들어주신 참고자료입니다.
- Hyunjoong Kim님께서 Python 버전의 KOMORAN3Py(/lovit/komoran3py)를 공개해주셨습니다.
@misc{komoran,
author = {Junsoo Shin, Junghwan Park, Geunho Lee},
title = {komoran},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/shineware/KOMORAN}}
- 우윤희, and 김현희. "국민청원 주제 분석 및 딥러닝 기반 답변 가능 청원 예측." 정보처리학회논문지. 소프트웨어 및 데이터 공학 9.2 (2020): 45-52.
- 최병서, 이익훈, and 이상구. "신조어 및 띄어쓰기 오류에 강인한 시퀀스-투-시퀀스 기반 한국어 형태소 분석기." 정보과학회논문지 47.1 (2020): 70-77.
- 이현섭, and 김진덕. "빅데이터 클러스터에서의 추출된 형태소를 이용한 유사 동영상 추천 시스템 설계." 한국정보통신학회논문지 24.2 (2020): 172-178.
- 박종인, and 김남규. "복합 문서의 의미적 분해를 통한 다중 벡터 문서 임베딩 방법론." 지능정보연구 25.3 (2019): 19-41.
- 안정원, 강예미, and 김건동. "AI 스피커와 감성 대화 시 답변 유형에 따른 사용자 선호도 연구." 한국디자인학회 학술발표대회 논문집 (2019): 227-228.
- 우경진, and 정수현. "문장 유형에 따른 한글 형태소 분석기 비교." 한국정보과학회 학술발표논문집 (2019): 1388-1390.
- 김시은, and 김민수. "감정 상태를 파악하는 상담용 챗봇 설계." Proceedings of KIIT Conference. 2019.
- 이민정, and 김용현. "VoC 유형 자동분류." 대한산업공학회 추계학술대회 논문집 (2019): 2756-2780.
- 김현지, et al. "조현병과 정신분열병에 대한 뉴스 프레임 분석을 통해 본 사회적 인식의 변화." 한국문헌정보학회지 53.4 (2019): 285-307.
- 이새미, and 홍순구. "토픽모델링 기법을 활용한 블록체인 동향 분석." 한국정보통신학회 여성 ICT 학술대회 논문집 (2019): 44-47.
- 한정훈, 구소현, and 이한주. "남녀 운동선수 관련 언론보도의 성평등 정도 분석." 한국사회체육학회지 78 (2019): 217-229.
- 이현섭, et al. "키워드 분석을 위한 단어 및 형태소 추출 시스템 설계." 한국정보통신학회 종합학술대회 논문집 23.2 (2019): 538-539.
- 윤재연. 추가 정보를 고려한 상품 리뷰 요약 기법. 2019. PhD Thesis. 서울대학교 대학원.
- 신진섭, et al. "문서를 얼마 동안 보존해야 할까?-순환 신경망 기반의 문서 보존기간 자동 분류." 한국정보과학회 학술발표논문집 (2019): 850-852
- 허광호, 고영중, and 서정연. "저-자원 언어의 번역 향상을 위한 다중-언어 기계번역." 한국정보과학회 학술발표논문집 (2019): 649-651.
- 박찬민, et al. "한국어 ELMo 임베딩을 이용한 의미역 결정." 한국정보과학회 학술발표논문집 (2019): 608-610.
- 최민성, and 온병원. "형태소 자질에 따른 Bi-LSTM 모델의 감성분석 정확도 비교연구." Proceedings of KIIT Conference. 2019.
- 이인아, and 김혜진. "텍스트마이닝 기법을 활용한 국내외 장소성 관련 연구동향 분석." 한국비블리아학회지 30.2 (2019): 189-209.
- 홍기혜, and 최민지. "텍스트 네트워크 분석을 활용한 학교사회복지와 교육복지 연구동향 비교 분석." 학교사회복지 46 (2019): 25-51.
- Kim, Soohyon, et al. "경제 분석을 위한 텍스트 마이닝 (Text Mining for Economic Analysis)." Available at SSRN 3405781 (2019).
- 배수진. "대학글쓰기의 과제와 빅데이터를 활용한 인문계 글쓰기 방안." 어문학 143 (2019): 395-421.
- 정지수, et al. "문서 유사도를 통한 관련 문서 분류 시스템 연구." 방송공학회논문지 24.1 (2019): 77-86.
- 고명현, et al. "효율적 대화 정보 예측을 위한 개체명 인식 연구." 방송공학회논문지 24.1 (2019): 58-66.
- Jee, H., M. Tamariz, and R. Shillcock. "The meaning-sound systematicity also found in the Korean language."
- Park, Seungsoo, and Manhee Lee. "ARTAS: automatic research trend analysis system for information security." Proceedings of the 35th Annual ACM Symposium on Applied Computing. 2020.
- Choi, Yong Suk, Hansung Kim, and Dongyoung Sohn. "Mapping Social Distress: A Computational Approach to Spatiotemporal Distribution of Anxiety." Social Science Computer Review (2020): 0894439320914505.
- Jin, Hoon, and Dong-Won Joo. "Method and Steps for Diagnosing the Possibility of Corporate Bankruptcy Using Massive News Articles." IEIE Transactions on Smart Processing & Computing 9.1 (2020): 13-21.
- Heo, Yoonseok, Sangwoo Kang, and Donghyun Yoo. "Multimodal neural machine translation with weakly labeled images." IEEE Access 7 (2019): 54042-54053.
- Nam, Chung-Hyeon, and Kyung-Sik Jang. "KNE: An Automatic Dictionary Expansion Method Using Use-cases for Morphological Analysis." Journal of information and communication convergence engineering 17.3 (2019): 191-197.
- Lee, Joohong, Dongyoung Sohn, and Yong Suk Choi. "A tool for spatio-temporal analysis of social anxiety with Twitter data." Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing. 2019.
- Ihm, Sun-Young, Ji-Hye Lee, and Young-Ho Park. "Skip-Gram-KR: Korean Word Embedding for Semantic Clustering." IEEE Access 7 (2019): 39948-39961.
- Kwon, Sunjae, Youngjoong Ko, and Jungyun Seo. "Effective vector representation for the Korean named-entity recognition." Pattern Recognition Letters 117 (2019): 52-57.
- Kim, Jayong, and Y. Yi Mun. "A hybrid modeling approach for an automated lyrics-rating system for adolescents." European Conference on Information Retrieval. Springer, Cham, 2019.
- Edmiston, Daniel, and Taeuk Kim. "Intrinsic Evaluation of Grammatical Information within Word Embeddings." (2019).
- Xu, Guanghao, Youngjoong Ko, and Jungyun Seo. "Improving Neural Machine Translation by Filtering Synthetic Parallel Data." Entropy 21.12 (2019): 1213.
- Kim, Tae-Ho, et al. "Emotional Voice Conversion using multitask learning with Text-to-speech." arXiv preprint arXiv:1911.06149 (2019).
- Yoo, Kang Min, Taeuk Kim, and Sang-goo Lee. "Don't Just Scratch the Surface: Enhancing Word Representations for Korean with Hanja." arXiv preprint arXiv:1908.09282 (2019).
- Lee, Sang Yup, and Min Ho Ryu. "Exploring characteristics of online news comments and commenters with machine learning approaches." Telematics and Informatics 43 (2019): 101249.
- JAE-YON, L. E. E., and KIM HYUNJOO. "The Text-Mining of Munhwa (Culture): The Case of a Popular Magazine in 1930s Korea." Acta Koreana 22.2 (2019).
- Kong, Hyesoo, and Wooju Kim. "Generating summary sentences using Adversarially Regularized Autoencoders with conditional context." Expert Systems with Applications 130 (2019): 1-11.
- Jo, Wonkwang, and Myoungsoon You. "News media’s framing of health policy and its implications for government communication: A text mining analysis of news coverage on a policy to expand health insurance coverage in South Korea." Health Policy 123.11 (2019): 1116-1124.
























































































































