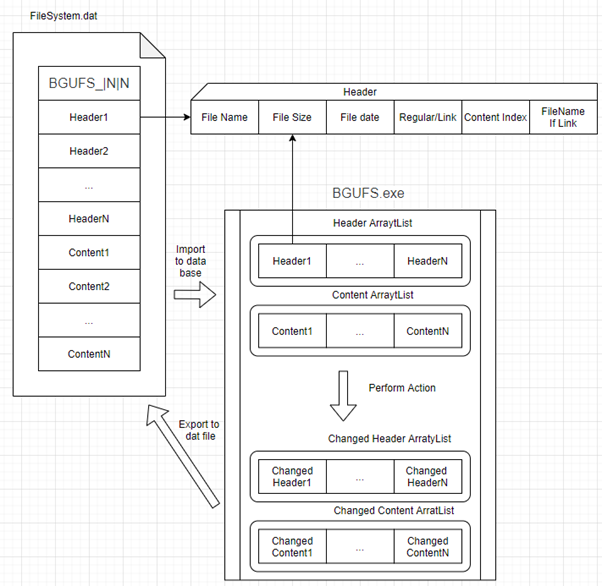
The dat file itself, contain a system header, beginning with the prefix to show that it is a BGUFS file type.
That header also contains the number of headers we have, and the amount of content in that saved file
(There can be multiple links to the same content, so those numbers are not necessarily equal).
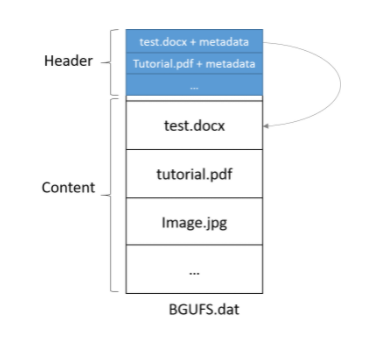

Are based on the concept guidelines from the dir function, where the printed output is in the following format:
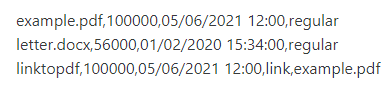
With an addition of a content index to show us in which place the content of the header is held in the content section (Which is hidden from the user in the print function because it is irrelevant).
In our dat file, we use “|” to separate the fields instead of “,” since “,” can appear as part of the name of the file (Windows allows you to use “,” in naming files, but not “|” hence it was chosen).
We can see an example of a test file below:
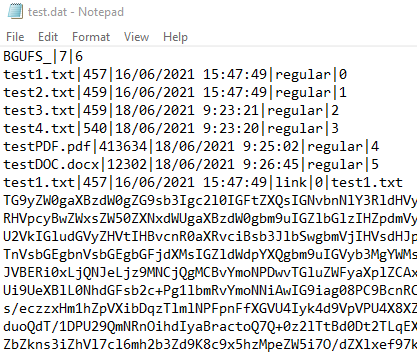

Whenever we need to do a action on the file system, since you can’t write in the middle of a file, only add to the end or rewrite it.
We have to load the entire file into our system, using the 2 counts in the file header to know how many lines to read of headers and how many of content.
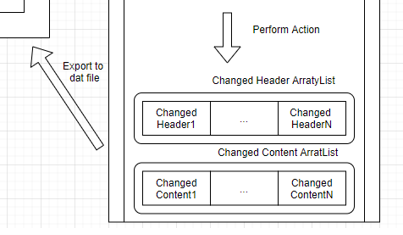
We separate the headers and content into two separate arrays so we could manipulate them easily, just as show in the diagram:

After having the data in the system, we can do the various actions like adding, removing, making links or sorting, which results in different arrays of headers and content,
which are then being wrote back into the file and overwrite the previous one, just as shown in the diagram:
We make sure to load the files only if needed, we do not load the dat file if we need to create a new one.
We also only save if needed, we do not save the dat file if we did actions that did not change anything, as showing the hash value, extracting a file, or printing the dir.
When removing content, an empty place is left in its place, which can be handled by optimizing the system or through various sorting operations, when we always make sure to properly update the regular headers when we make changes in the content and update the link headers when we make changes in the regular headers to ensure all headers always correctly point on their respective content.
While regular headers index points to the place of the content in the content array, we use the header index for the links as an index to the place of the header that the link is referring in the header array, instead of making a separate value field for content/reference we use the same spot for multiple purposes.
