sivagao / blog Goto Github PK
View Code? Open in Web Editor NEWblog of sivagao,每天一篇好文章~
Home Page: https://sivagao.github.io/blog
blog of sivagao,每天一篇好文章~
Home Page: https://sivagao.github.io/blog



















































































































































































翻译自Making money takes practice like playing the piano takes practice,加入创业公司很不错,但是要学会怎么赚钱,而不是想很多人一样仅仅学会怎么花投资者的钱。
如何重构有问题的老代码
你是如何把一个渐渐失控的遗留代码仓库转变为高可维护性的。下面的文章是我这几年在一个大型老项目中摸爬滚打学的教训和经验的总结。
一些年后,当你沼泽湿地附近闲逛。在你视野所及内,你会发现公爵正在用啤酒的商业广告(庆祝!)替换之前的『危险,这里有恶龙』的标语。 他脸上洋溢着灿烂的笑容
http://marketing.intracto.com/paying-technical-debt-how-to-rescue-legacy-code-through-refactoring
Gopher China 今年是第三届了,这次在上海小南园花园酒店举行。下面是这两天的一些记录,主要是对我平时工作中涉及的如服务治理、微服务、高可用和分布式等话题有较为细致的关注,同时对于其中关联的 Golang 语言知识点进行较详细的记录。
PS:隔壁群组的同事使用了 Golang 开发行情云 V3 也在这次大会上进行分享了,涉及到不少海量并发情况下打造低延迟系统的系统的知识点。说起 Golang 早在14年还在北京前公司的时候,前同事(现在PingCAP的CXO们)就在公司小范围鼓动过。今年群组有计划打造一些稳定性和吞吐量要求较高的系统(微服务,全球结算交易系统),这次参会下来 Golang 的确没有让我们失望,相关的准备工作也可以开启了。
重点记录的话题整理如下:
PS:最近也在学习 Golang 语言,演讲中涉及到的一些知识点和之前看的 Go in Practice 的有呼应的,加了 reference,可以结合查看~
七牛的孙建波老师,介绍了七牛大数据产品 Pandora (潘多拉),它服务于:
▪ 将多样的大数据工具整合
▪ 将复杂的大数据管理简化
▪ 构建完整的大数据生命周期闭环
这样的理念下,引入的架构:
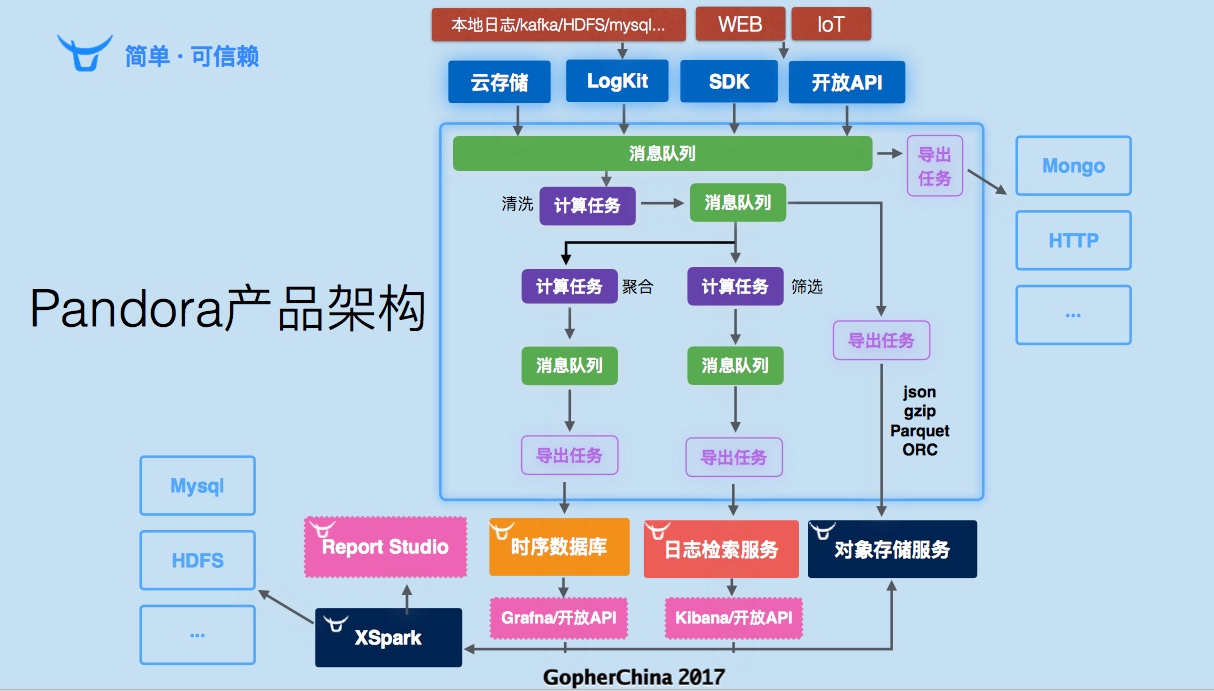 

海量数据的实时导出时存在的问题本质上是数据流动效率的问题。pull 和 push 的方式各有利弊。需要构建加速系统,这样的加速系统现在有 Logstash、Beat、Flume,但无法满足需求决定采用Go进行自研,下游的Sink代码由使用方编写为插件式,并利用 Go 的 Channel 实现快速响应与反压(入 Channel 的时候返回200,否则返回503)。
提到了分布式实践时的一些困难:维护困难、数据分散、资源浪费、负载不均等,这些都归结为一致性问题。七牛基于键值对实现了二级缓存的框架qconf,提供最终一致性。请求会先去本地缓存进行查找,如果没有再去memcache,如果还没有就去MongoDB进行查询了。
采用基于key hash的平衡调度算法,通过按需创建和资源回收提高资源利用率,同时使用protobuf代替json以缓解CPU开销,和变长的失败等待时间
由 PingCAP 的老师带来。TiDB 受到 Google Spanner 和F1的启发,采用Raft协议保证一致性。申老师为大家展示了TiDB的整个架构:
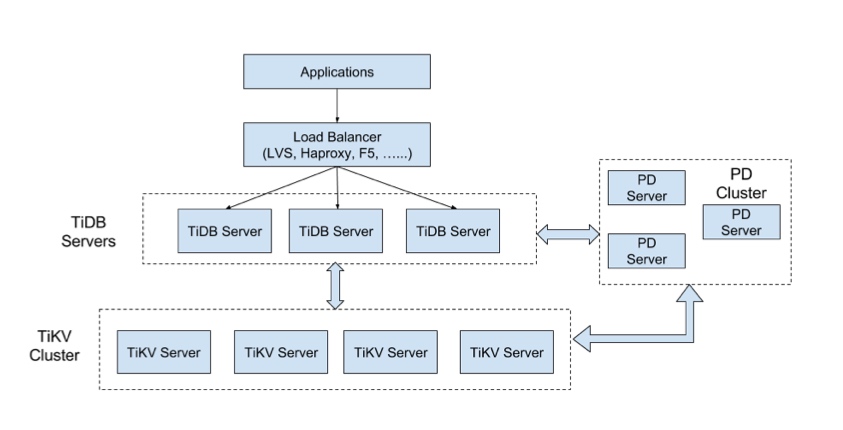 

讲了 SQL Layer 的架构和数据库内部实现细节。
分布式数据库的过程中有很多挑战,比如它是一个非常复杂的分布式系统,有很多RPC任务,需要在大量的数据压力下保证高性能,拥有大量的OLTP请求和非常复杂的OLAP请求。
如向一个没有 reader 的 channel 写入,向一个没有 writer 的channel 读取等。可以通过 Block profile(dump 下来分析看看哪些 goroutine 在阻塞),超时机制,利用context cancel 等
testleak: 查看前后两次调用,新多出来的goroutine 等
func (s testMiscSuite) TestRunWithRetry(c *C) {
defer testleak.AfterTest(c)()
…...
}
在 Query 时会使用大量内存读取数据,通过:
tonybai 老师结合 Go 团队的对外分享的话题、参考和提炼 Go 标准库以及主流 Go 开源项目的精华源码风格和惯用法,给出了地道 Golang 语言的写法。 作者自己有一篇 blog,把演讲的文稿也给出来了(http://tonybai.com/2017/04/20/go-coding-in-go-way)
首先高层次的提出:"语言影响/决定思维",提出实际问题素数筛。给出 C 和 Go 两个版本解法From divan's blog (http://divan.github.io/posts/go_concurrency_visualize/)
面对同一个问题,来自不同编程语言的程序员给出了思维方式截然不同的解决方法 一定程度上印证了前面的假说:编程语言影响编程思维 避免 Go coding in c way/in java way/in python way...
而编程语言思维的形成:
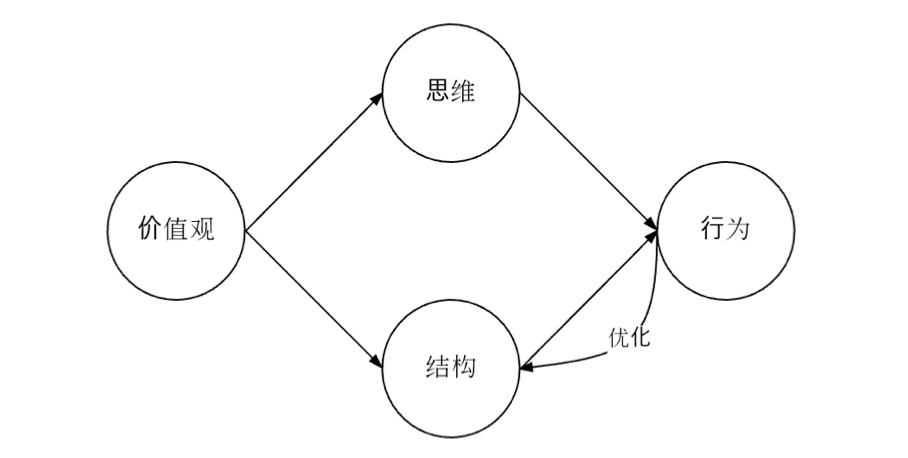 

而 Go 语言价值观的形成来自于背后的三位作者:Robert Griesemer, Rob Pike 和 Ken Thompson
 

那么Go语言的价值观就是:Go是在偏好并发的环境下的简单概念/事物的正交组合
简洁正规,仅仅25个keyword:主流编程语言中最简单的,没有之一(一个语言特性的加入需要得到三位作者的同意,这门语言是克制的,连三元符也没有~)
在gofmt的帮助下,Go语言一统coding style。(回看 JavaScript 社区各家特色和百花齐放的 Style Guide,目前也有类似于统一 coding style 的提出,不要为个人喜好而争论不休了)对于变量命名等在并不影响readablity的前提下,尽可能的用长度短小的标识符,于是我们经常看到用单个字母命名的变量(不同于 Java 语言“见名知义” ("index" vs. "i" "value" vs. "v")
Go is not a “TMTOWTDI — There’s More Than One Way To Do It”。这点与C++、Ruby有着很大不同。和 Python 是一致的
提倡显式代码(obvious),而不是聪明(clever)代码
短变量命名在 stdlib 中体现:

一种 for 循环
- 常规
for i := 0; i < count; i++ {}
- "while"
for condition { }
- "do-while"
for { // use "for-break" instead
doSomething()
if condition { break }
}
- iterator loop
for k, v := range f.Value {}
- dead loop
for {}另外Go语言的错误处理是基于比较的,没有针对exception的“try-catch"控制结构,这样的好处是让开发者聚焦于错误本身,能够显示地处理每一个error,同时保证了错误值和其他类型的值地位一样,并无特殊之处。关于错误处理的模式:
var ErrShortWrite = errors.New("short write"); if err := doSomeIO(); err == io.ErrShortWrite { ... }//net/net.go
type Error interface {
error
Timeout() bool // Is the error a timeout?
Temporary() bool // Is the error temporary?
}
//net/http/server.go中的使用举例:
rw, e := l.Accept()
if e != nil {
if ne, ok := e.(net.Error); ok && ne.Temporary() {其中 Go 关于 error type 和 variable 的命名方式
错误类型: xxxError
//net/net.go
type OpError struct { ... }
type ParseError struct { ... }
type timeoutError struct{}
导出的错误变量: ErrXxx
//io/io.go
var ErrShortWrite = errors.New("short write")
var ErrNoProgress = errors.New("multiple Read calls return no data or error")关于代码中大量重复着if err!= nil { return err} 这段snippet,可以使用将 error 作为一个内部状态解决(具体在 errors are values
关于错误处理的技巧还可以参见与 [Go in Practice Technique 16-18 - minimize the nils, custom error types, error variable]
需要注意的是Go语言无类型体系(type hierarchy),类型定义正交独立 (“If C++ and Java are about type hierarchies and the taxonomy(分类)of types, Go is about composition.”)
垂直组合(类型组合):Go通过 type embedding 类型嵌入机制提供;水平组合:Go通过interface语法进行“连接”。
垂直组合方式有:
// a) construct interface by embedding interface
type ReadWriter interface {
Reader
Writer
}
// b) construct struct by embedding interface
type MyReader struct {
io.Reader // underlying reader
N int64 // max bytes remaining
}
// c) construct struct by embedding struct
// sync/pool.go
type poolLocal struct {
private interface{} // Can be used only by the respective P.
shared []interface{} // Can be used by any P.
Mutex // Protects shared.
pad [128]byte // Prevents false sharing.
}其中在struct中嵌入interface type name和在struct嵌入struct,都是“委派模式(delegate)”的一种应用。需要注意的是:struct中嵌入struct,被嵌入的struct的method会被提升到外面的类型中,比如上述的poolLocal struct,对于外部来说它拥有了Lock和Unlock方法,但是实际调用时,method调用实际被传给poolLocal中的Mutex实例。
在Go语言中,你会发现小接口(方法数量在1~3)定义占据主流。无需显式的”implements”声明(但编译器会做静态检查); 很有意思的图体现了大量小接口用于在 stdlib, k8s,docker 等库中(背后是职责单一;易于实现和测试)
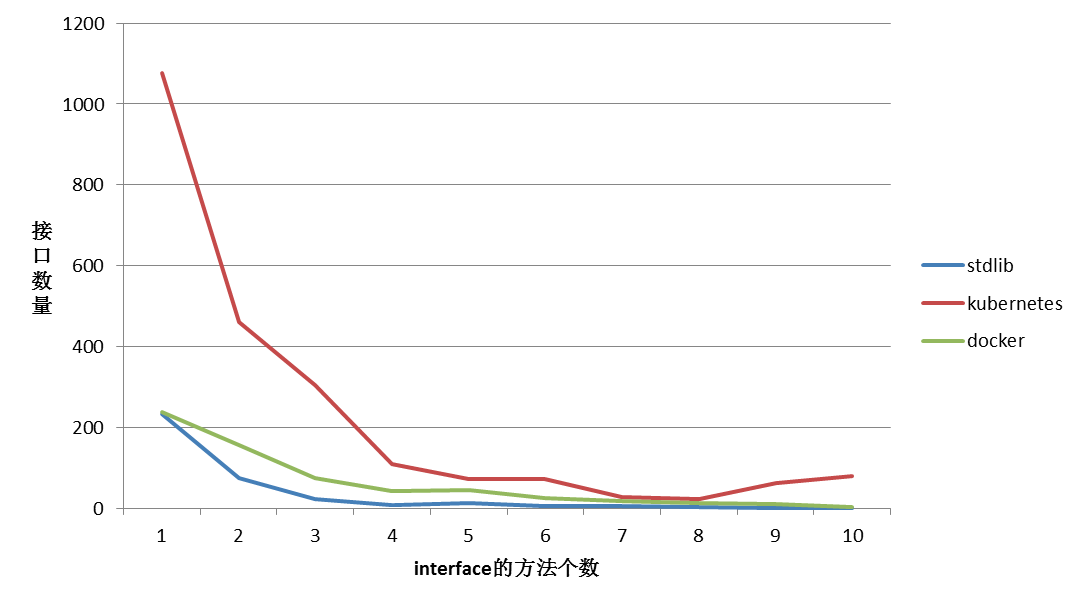 

最后讲到并发。Go语言通过goroutine提供并发执行,它是Go运行时调度的基本单元。channels用于goroutines之间的通信和同步。select可以让goroutine同时协调处理多个channel操作。
what is an interface?
"In object-oriented programming, a protocol or interface is a common means for unrelated objects to communicate with each other"
关注 unrelated objects, communication
老师首先援引了Wikipedia上对于Interface的定义:Interface是面向对象程序设计中用于不相关对象间通信用的一种协议或接口。这里面比较重要的两个关键一个是“communicate",另一个是“unrelated objects”。
接口一直符合约定就可以容器集装箱,乐高积木等
what is a go interface?
concrete types
abstract types
type Positiver interface {
Positive() bool
}
Abstract类型定义了方法集,用于描述行为。而Concrete类型定义了通过方法关联到数据的行为,用于描述内存布局。
concrete types 和 abstract types 关系
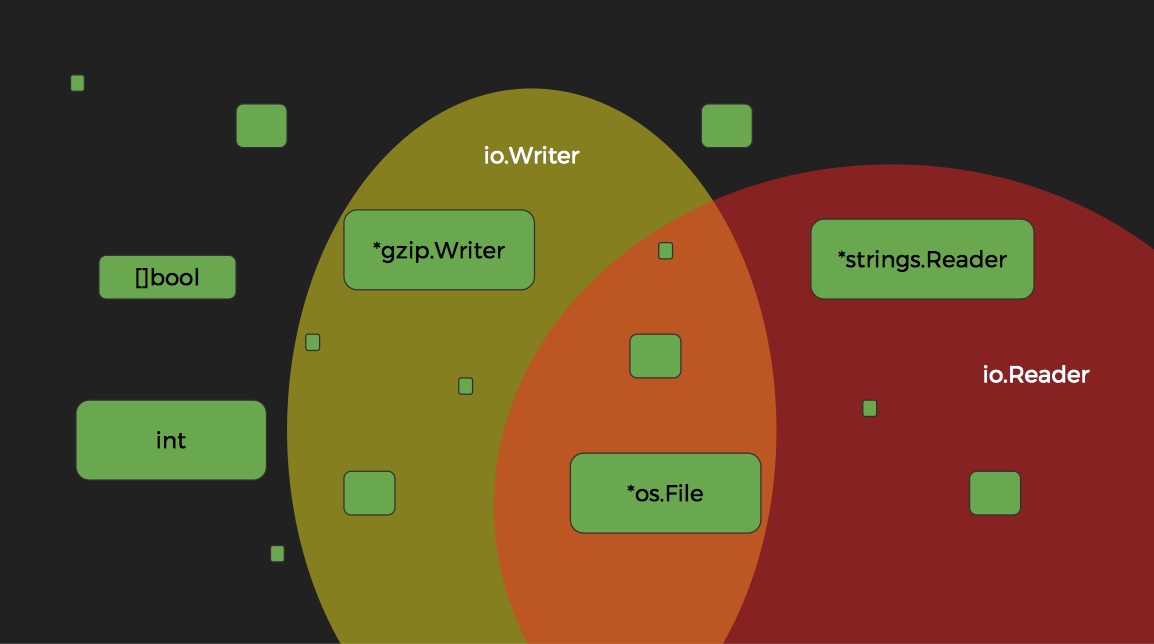 

union of interfaces
type ReadWriter interface {
Reader
Writer
}
type Reader interface {
Read(b []byte) (int, error)
}
interface{}, it ways nothing
为什么需要使用接口?
▪ 编写通用的代码
▪ 隐藏设计细节
▪ 检查监测点
“The bigger the the weaker the abstraction”
“Be conservative in what you do, be liberal in what you accept from others”
“Be conservative in what you send, be liberal in what you accept”
避免出现:
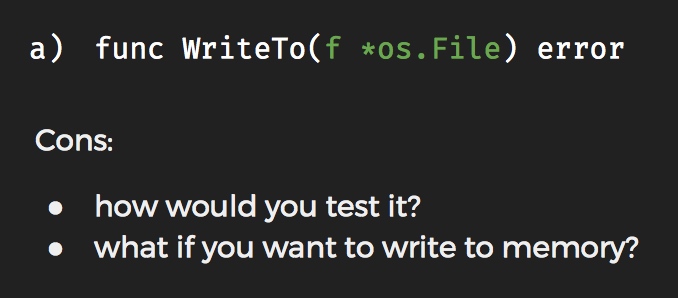 

 

a Stack interface
type Stack interface {
Push(v interface{}) Stack
Pop() Stack
Empty() bool
}write generic algorithms on interfaces
“Return concrete types, receive interfaces as parameters”
Hiding implementation details
Use interfaces to hide implementation details:
context.Context
满足 Context 接口的 emptyCtx, cancelCtx, timerCtx, valueCtx
 

interfaces: dynamic dispatch of calls
chaining interfaces
interfaces are interception points
Go 中的接口有什么特殊之处:
define interfaces where you use them
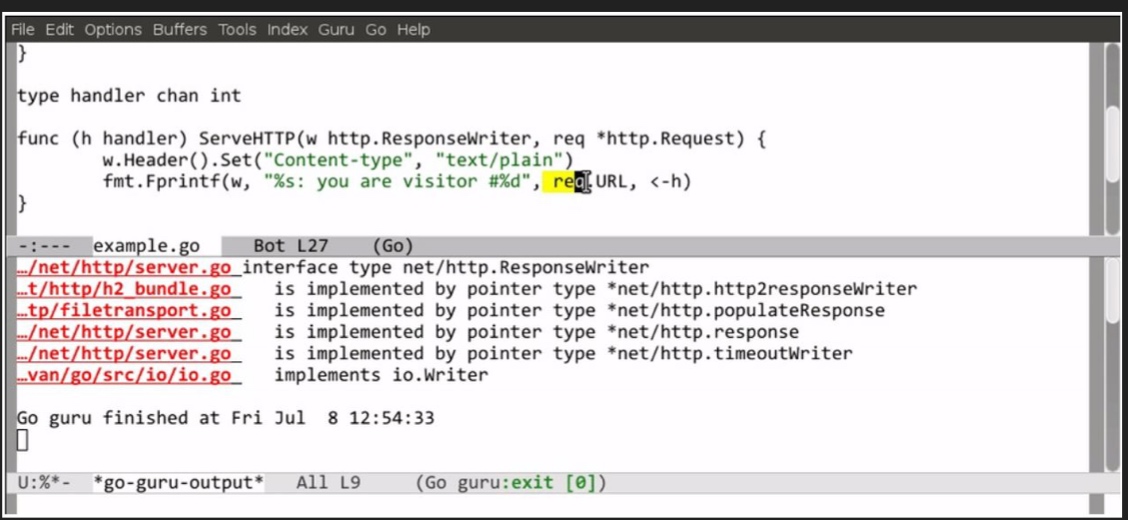
guru - a tool for answering questions about Go source code. (看一个interface在哪些地方被实现了

强大的 Go 接口
Don't just check errors, handle them gracefuly
Context interface
隐式满足:
类型断言:
由杭州有赞的李文带来。从原始架构开始,到给出重新设计的架构。在 NSQ 上的Jepsen 测试
有赞的应用场景里需要实现消息队列的高可用、自动平衡、有序发布和消费历史消息。现在存在的问题以及重新设计是:
▪ 从Topic Channel把所有的数据拷贝到Consume Channel
▪ 多份数据拷贝,浪费了很多磁盘
▪ 重新设计:使用Cursor用来指示要消费的数据。
有赞实现的自动平衡,包括如下方面:
▪ 负载因子:CPU负载、Topic PUB大小、Leaders
▪ 添加/移除节点平衡
▪ 手动迁移数据
以及实现了SmartClient。它可以周期性地刷新Topic Leader和分区,以及HA的重试(在非Leader上失败后的快速查询)以及发布策略(支持轮询和按照主键的sharding)。
还有按序发布,包括:在同一个分区里有序,在一个线程里向同一个节点发布相同的sharding键,以及按序一个接一个地向消费者发送消息。
来自于阿里云的聪心老师,以Spring开发者的视角进行了讲解。
该演讲主要从如下方面展开论述:
讲述的顺序是看目前云产品架构,其中新加的 Aliyun API 网关服务和天象全链路监控。其中阿里云内部大量使用的 Dubbo RPC 框架作为服务治理的重要手段,目前有一些瓶颈。如 big data payload 还有多语言的client 支持。所以引入了 gRPC,同时对比了用 go 开发(go-kit 微服务框架)对比目前的 Java/Spring 技术栈下的(Dubbo 和 Spring Cloud ),最后给出了一般微服务开发的实践总结。
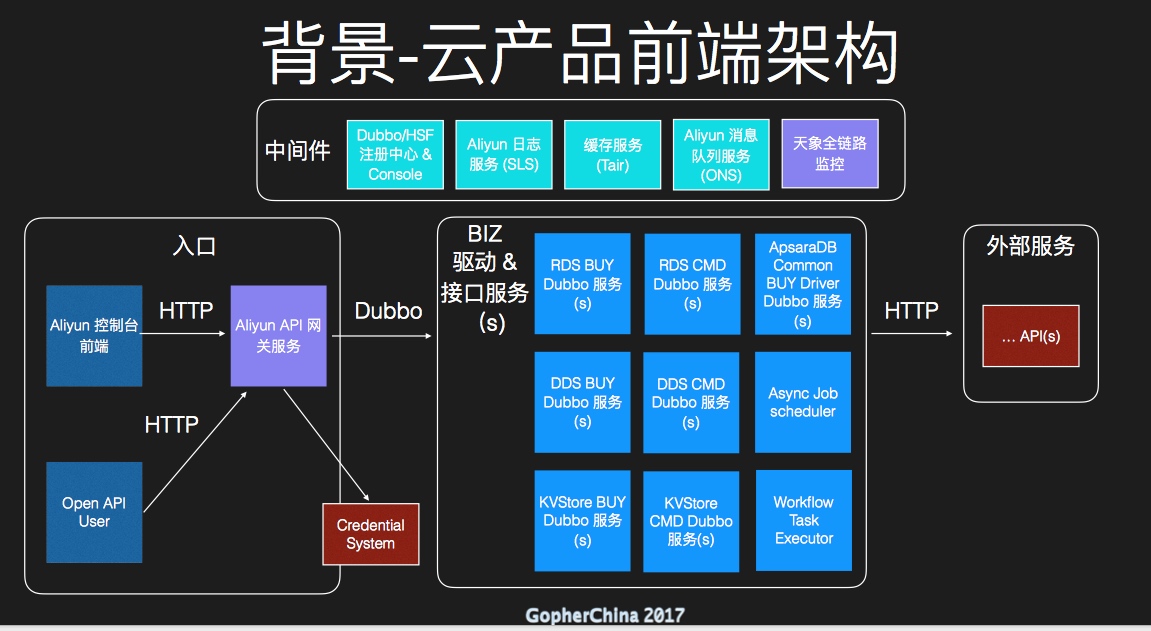 

Dubbo 背景介绍
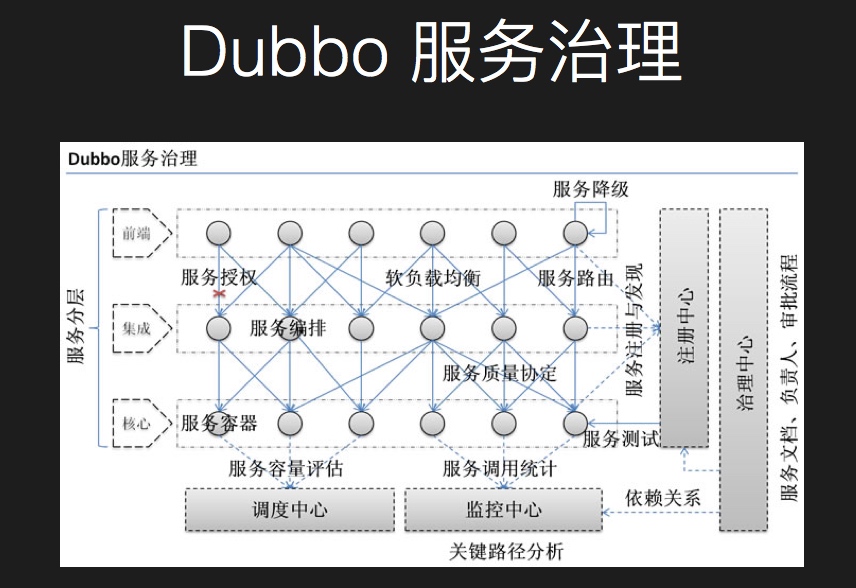 

但是微服务在阿里云这套仍然有问题:
目前团队服务端人员的技术分布:
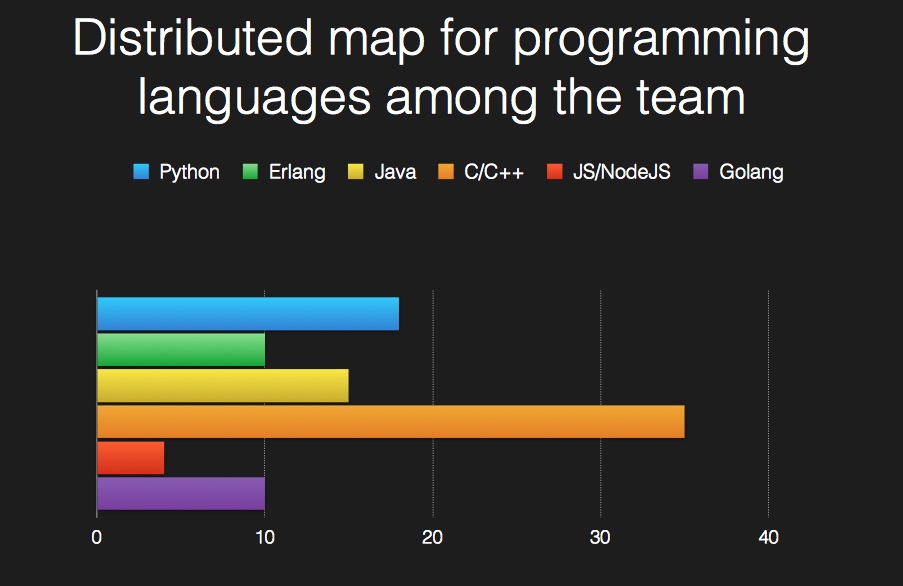 

Java is “SO DYNAMIC”! (Spring 框架 引入的一些动态。在 Spring Boot 中大量使用的 auto configuration 等)
Java is "MAGICAL" 一些annotaion 注解(@service,@autowire, @resource 。 AOP 切面 @aspect,@before 等)
 

介绍 gRPC - open sourced version of Google Stubby RPC
介绍 go kit - toolkit for micro-services.
PS:go-kit 我在之前也在 wiki 中给出过分享 go与微服务:使用 go-kit 开发
 

一些最佳实践的点:
部署应用可用通过容器进行,不管是Docker(或者OCI)都提供了标准的应用打包格式,Kubernetes或Swarm则提供了资源调度、集群管理的功能。
• Docker/OCI
• Standard app packaging format
• Kubernetes/Swarm
• Resource scheduling, cluster management
deploy stateful apps"
 

首先要解决复杂依赖的事情,如 Prometheus 中(alert manager, alerting rule)等。如etcd部署,每启动一个新 etcd 实例需要配置的initial-cluster要相同等。
perator是用来解决自动化应用运维的工具,而应用包括代码和配置两部分。Operator的原理是这样一个循环:首先观察集群的当前状态,然后分析之与期望配置之间的差异,最后以此为目标进行操作,并进入下个循环。
采用 self-updating kubernetes. 通过update strategy 描述需要什么
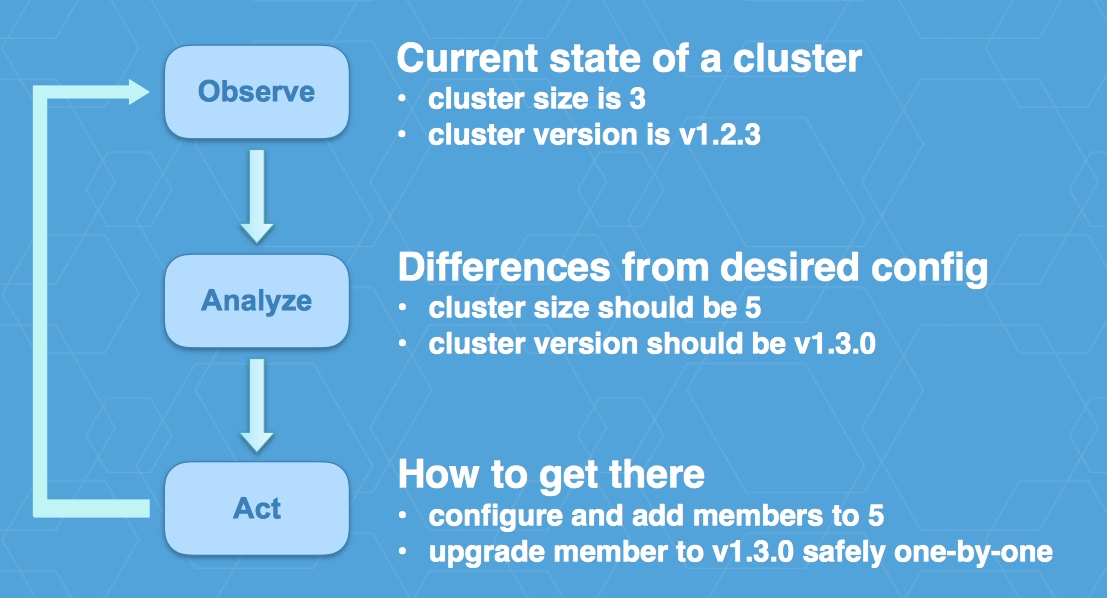 

kubectl create -f 根据yml中描述的服务信息(target service, resize, upgrade, backup, failover 等
由 B 站的毛剑老师分享,里面分享了不少 B 站改造的有趣故事,从一个一个人写的基于 php 某 cms 框架到一个高可用的 golang 系统的进程回顾。讲得思路非常清晰,重点突出。
演讲从下面的大纲进行讲述:
其中微服务的演进:
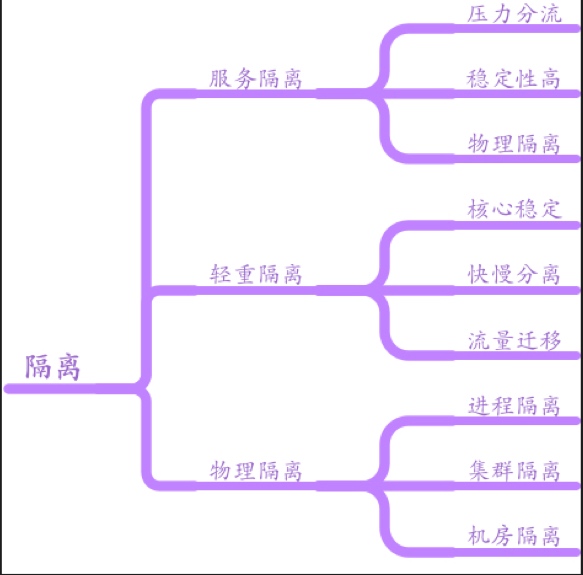
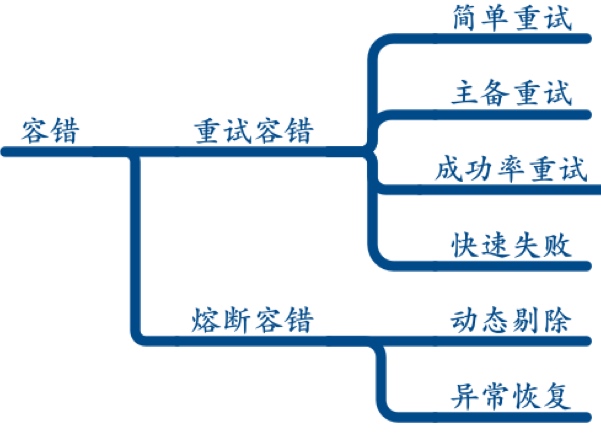
其中高可用部分包括了 隔离 ,超时 ,限流 ,降级 ,容错 几个部分。
微服务的架构可以很好的实现隔离。不同类型的微服务有不同的计算和内存资源的诉求,同时它们本身的稳定性和业务流量压力也是不一样的。同时新改造迁移的服务可以通过物理隔离和之前的legacy的系统分离开,避免被拖累~

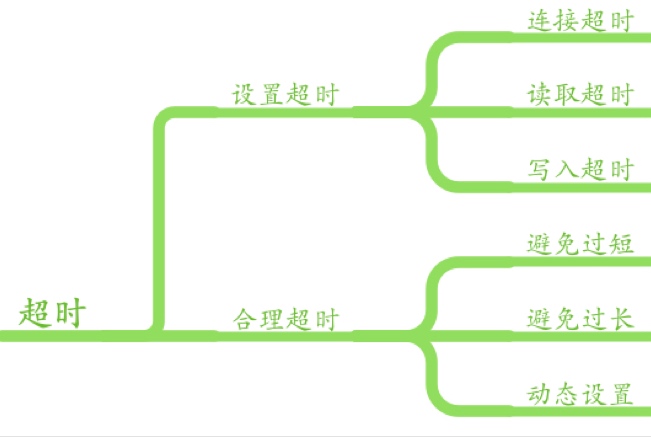
在 Web 系统中对于超时处理是很重要的,在微服务情况下,API 网关等聚合场景下也提出了一些新诉求(circuit breaker - 类 Hystrix),其他对外部系统和中间件也要处理好超时关系。
客户端实现服务器接口返回的ttl,在ttl时间内不要发请求,避免雪崩,聚合接口的降级(个别接口有问题就返回 default 值等,类 Hystrix ),熔断器,个别接慢就先踢掉,

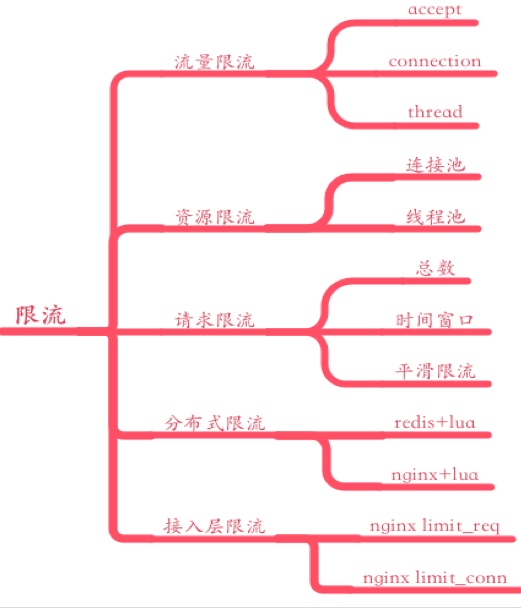
随着超时处理而来的是对限流的实施。不同系统有应对不同流量级别的能力,然后由于外部情况(如爆点事件,push 拉新,异常上游系统的不合理使用)都会引入无法处理的流量,所以合适的限流是系统防御性措施之一。

当真正的用户实际流量随着业务开展不可避免快速增长起来,或者线上部分节点出故障被隔离起来后。需要进行合理的降级来让整个系统基本可用,去掉那些 fancy 的增强点。整个需要前后各端系统的通力配合。
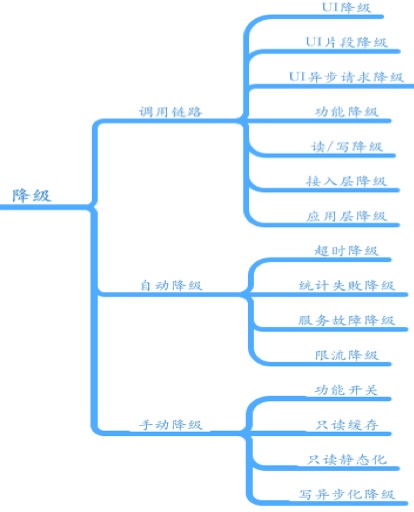 

一个响应式的系统还需要对故障保持灵敏。可回复性可以通过复制,围控,隔离和委派等方式实现。

微服务的打造,离不开以下的中间件:
databus(基于Kafka)
canal(MySQL Replication)
bilitw(基于 Twemproxy)
bfs(facebook haystack,opencv)
config-service
dapper(google dapper 分布式追踪)
运维体系。统一的 portal 去管控资源和服务运行环境进行回顾。


第二天的议题如下:
这个话题由Grab的高超带来。Grab 是东南亚最大的出行平台(类滴滴)
首先回顾之前的技术栈(Ruby on Rails, Nodejs, MySQL 等)随着快速增长的业务需求,老旧系统无法满足。开始改造,给出了目前最新的技术栈:
 

引入了常见的容器化和分布式技术(如 etcd, docker, kubernetes)外,显著特点是目前后台均采用Go实现。他们认为 Golang 语言:
▪ 简洁的语言规范
◦ 上手轻松
◦ 提升生产效率
▪ 完整的工具链
◦ go test,go build,go vet...
▪ 方便的部署流程
◦ 直接部署打包好的二进制文件
▪ 优秀的性能
◦ 弹性云机器数量骤减90% (啊... 之前 Rails / Node.js 系统是咋写的)
◦ 响应延迟骤降80%
其中用 Golang 打造的系统包括:流式数据采集系统(每天亿万事件处理)、API Gateway、RPC和RESTful框架、ORM(约束对数据库的访问模式,缓解后台扩展瓶颈,可以后续替换。也是 Rails 等成熟框架下的preference了)、CI系统(与Jenkins深度集成),还有机器学习平台和Serverless平台计划(弥补目前 AWS lambda 不支持等等。
Grab 的Golang 实践从下面展开:
▪ 单体代码库
▪ 分布式追踪
▪ 测试
▪ 代码质量控制
▪ Bugs
在代码管理方面, Grab采用了单体代码库,也就是说所有的Go代码都放置在同一个Repo里面。这样的好处是可以保证不同组件间版本的一致,简化了依赖管理,同时提供了良好的代码复用和分享基础。另外也保证原子化的代码更改,利于支撑大规模的重构和更新。
分布式追踪对于判断系统的运行状况、分析调用性能瓶颈、快速发现和诊断服务存在的问题等都非常重要。Grab通过在请求头里添加traceId和spanId来进行追踪。利用Go的Context进行实现,Context的生命周期等于Request的生命周期,在其中添加全局唯一的traceId刚好可以实现对整个Request流的追踪和观察。
测试中提到了“契约驱动的测试”,它的实现类似于这样:在测试代码里编写好一个结构体数组,其中每个元素都代表了一种特定的场景(输入和输出),最后借助于Go test这样的工具完成测试。同时Grab的实践还包括使用了Testify这个第三方的测试包、在Staging集群上进行端到端的测试以及将数据库从单例改写为接口,作为依赖进行注入。
代码的质量是非常重要的,好的工具能够提高Code Review的效率。在Grab使用了 Phabricator、Jenkins、Slackbot 帮助 Code Review 流程,值得一提的是:
最后分享了在实践中他们遇到的一些Bug,比如Nil Pointer(技巧是 make zero values useful),DNS Resolution(已经提交,在 Go 1.9 修复)
“支付系统用Go编写行么?”。张老师说对于很多金融企业来说,目前使用的系统可能是十年前甚至二十年前的系统,那么在这些系统仍然运行稳定的基础上,推动新技术的落地是非常挑战的事情。
除了常见的Golang的技术特点(上手容易,天生并发),下面特点
并且在自己电脑上对常见 case 进行了压测benchmark看吞吐量,对比 Java 和 Golang 效率
如 Http 接口 和 RSA 加解密

最终架构如下:
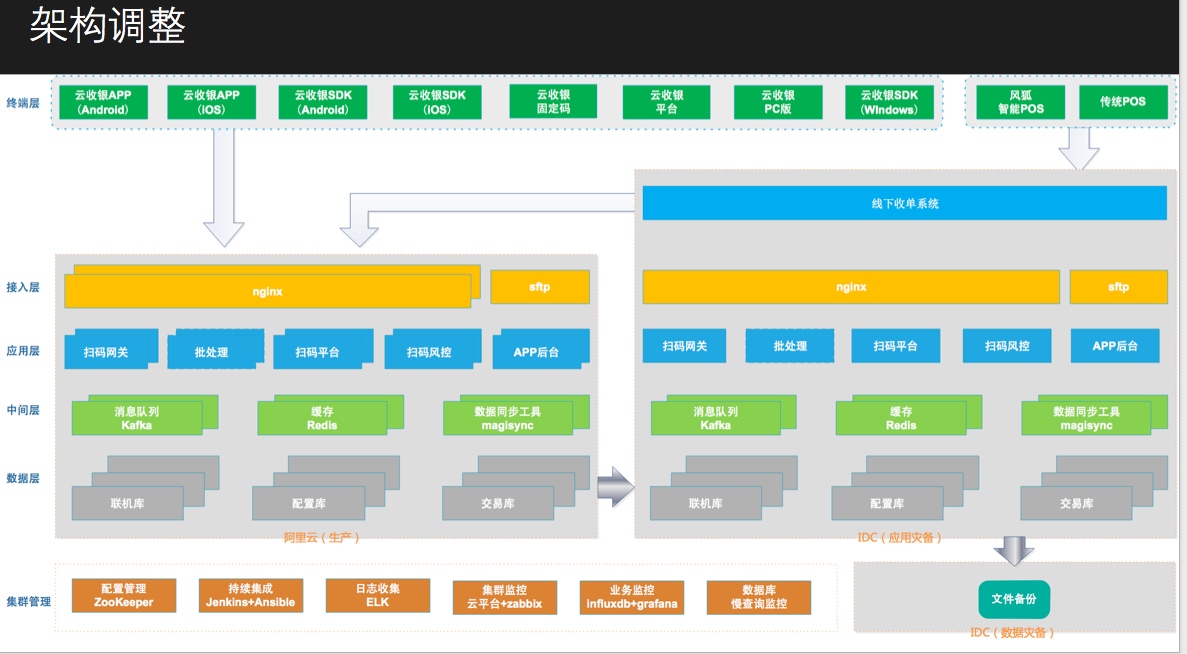 

其中实践中遇到的一些坑:
变量作用域(玩 JavaScript 应该会很熟悉。closure
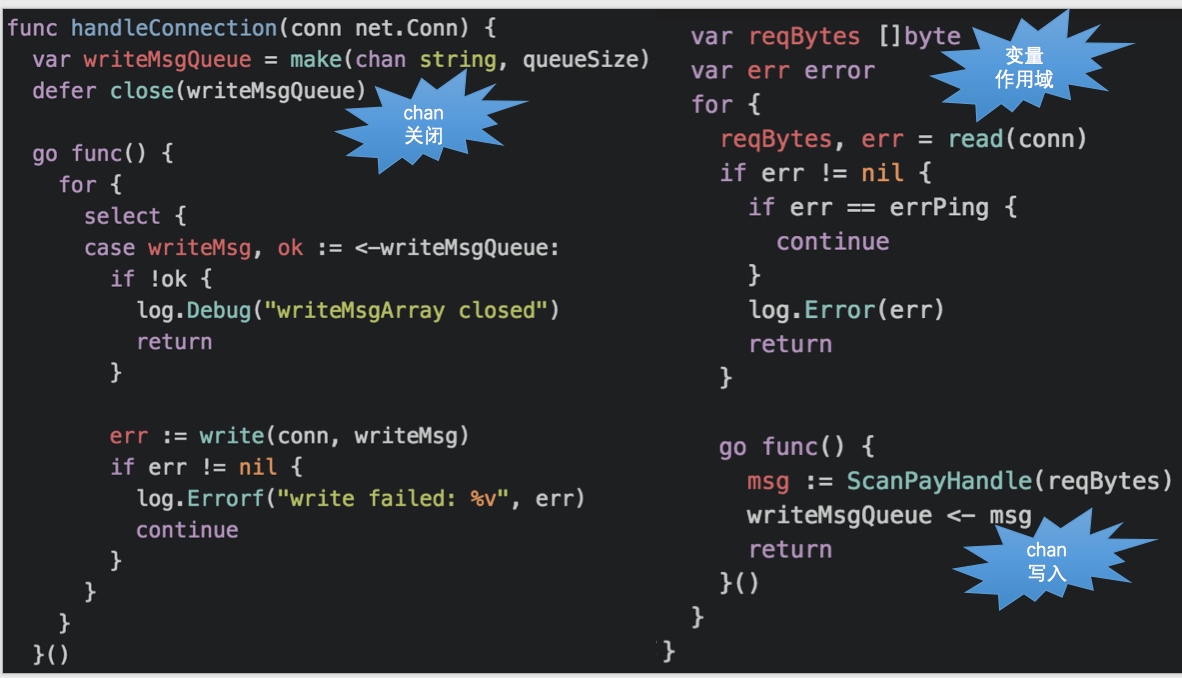
chan 操作和关闭的注意点(见 Go in Practice Tip 14)
问题代码:

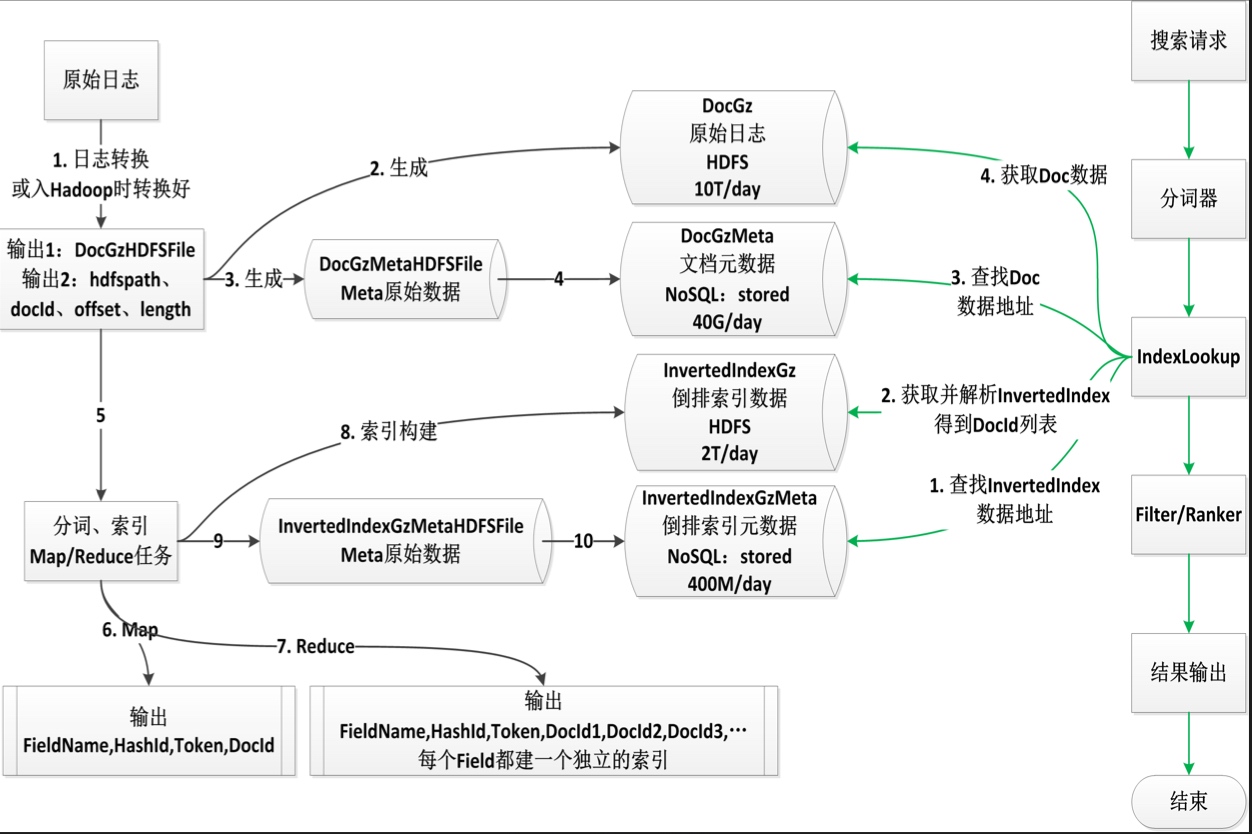
这个话题由的360的郭军老师带来。开源在 https://github.com/Qihoo360/poseidon A search engine which can hold 100 trillion lines of log data.
由于数据量级特别大(大小在100PB,每天还继续灌入约2000亿条的新数据。这么大的数据量需要实现秒级响应),无法使用目前的常用技术栈(如 ELK 等)
造轮子的目标是:对现有的Map-Reduce无侵入、自定义分词、实现故障转移、节点负载均衡、自动恢复,并且要支持单天/多天批量查询和下载。

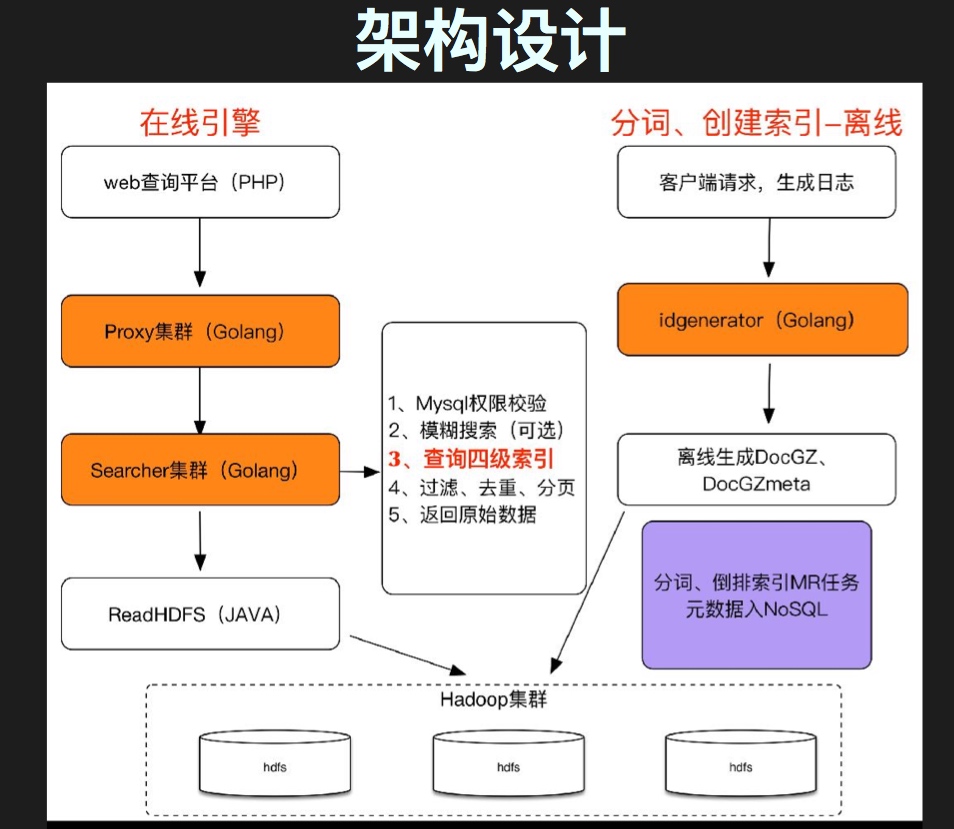 

Go 问题与瓶颈:
大量使用 goroutine,子 goroutine panic 在主 goroutine中不能被 recover (看 Go in Practice Technique 21. a panic on a goroutine can't jump to the call stack of the function that initiated the goroutine(no path for a panic to go from handle to listen). 可以通过通道传回给主 goroutine。该通道类型为struct,封装正常数据和error。从而便于在主 goroutine 取出数据统一处理)
参考NSQ,利利⽤用for+select的不不确定性来分流,随机流量量到 cache和hdfs做热测试,缺点:开发成本较⾼高
ReadHDFS (goroutine太多,底层readhdfs挂掉, 通过连接池和熔断机制。超过连接数量就直接返回 error)
演讲者是大胡子 Gopher sticker 的原型
不同于C,Go语言的pragma实现在注释里,由编译器识别并执行。老师介绍了下面几个Go的Pragma:
▪ //go: noinline
▪ //go: nosplit
▪ //go: noescape
▪ //go: norace
▪ //go: nolinkname
由于 Ezbuy 工程师带来。集中在讲解构建开发上,对群组有不少参考价值
▪ 背景&前言
▪ 开发环境构建
▪ 微服务选型
▪ 分布式追踪
▪ 跨数据中心
开发环境构建,通过 Goflow 统一开发环境。使得与个人开发环境共存同时保持独立。依赖管理要实现共享依赖、内网缓存、业务隔离、并且允许修改第三方包。使用官方的vendor方案进行实现,新建一个仓库存放所有的依赖包,第三方包通过subtree进行导入,这个库的名字就叫做vendor。
微服务选项:使用 gRPC 利用PB描述接口、扩展代码生成、使用Consul进行服务发现和负载均衡。
▪ 使用Internal来隔离资源/函数
▪ Consul深度结合
▪ 程序内维护地址列表
▪ Polling 获取更新
使用 option 定义接口特性;接口路径 === 代码路径;让远程调用看起来像是本地调用;
分布式追踪:
分布式追踪,比如要实现跨进程的错误跟踪时,错误可能会被覆盖掉,那么“懒人做法”是建立一个错误栈,类似于将每个调用的错误信息都收集在这个栈里,最后一并打印出来。“更进一步”的做法是利用Context完成。最终灌入到 Sentry 中,是比起 opentracing 比较另类的方案。同时不仅仅是 latency
跨数据中心:
DevOps,它的终极目标认为在开发的时候需要考虑到将来要部署到的生产环境(比如网络、存储等)
而通过 Docker 容器较好的统一了开发到生产的环境变化,尽可能自动化全部的流程。
ContainerOPS 就是代表:
defining -> Component
drawing -> Workflow
running -> Container Orchestration
其中 Components 封装一个DevOps任务,传递一些数据(环境变量等),利用phusion作为baseimage,启动多个进程,在ContainerOps系统中管理组件声明周期。
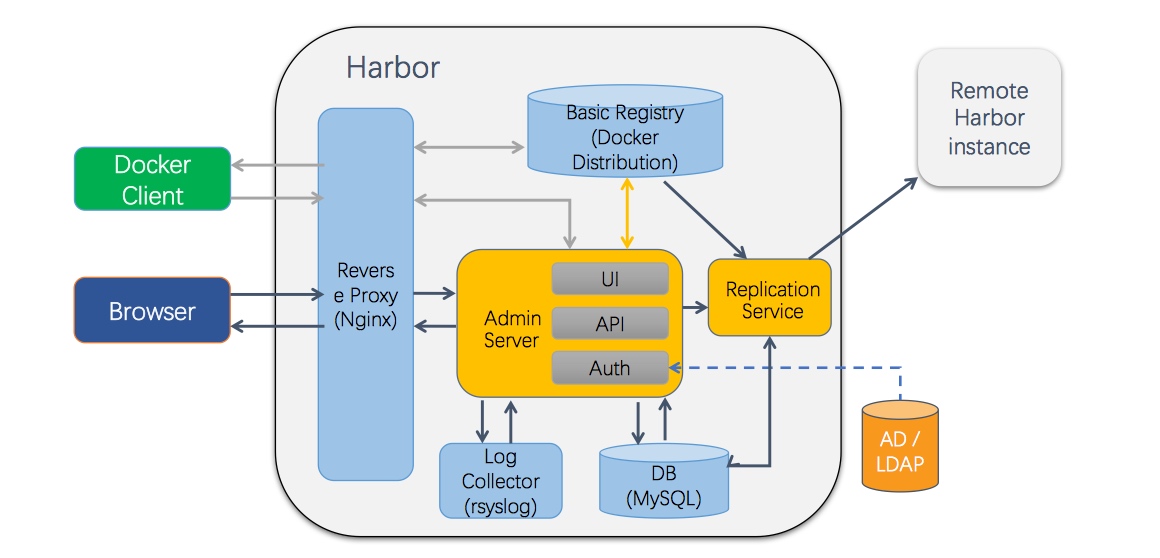
首先从为什么需要 Private registry 开始 (拉取和推送镜像的网络效率高,安全对私有镜像实施 ACL)
在以前传输镜像的方式要么是写shell脚本,将某镜像打包、传输、推送到指定仓库,或者利用rsync进行执行,这样会有很多的不可控因素。Harbor让镜像的管理变得简单和可靠。
而镜像复制的使用case。譬如总公司需要分发多个镜像到各个省市。可以先分发 replica 到各个省市的 registry 上。用于 geographically distributed teams,和备份
其中技术点包含:
type workerPool struct {
workerChan chan *WorkerPool // a channel for free workers
workerList []*Worker // a pool of available workers
}
var WorkerPool *workerPool
func Dispatch() {
for {
job := <-jobQueue
go func(jobID int64) {
worker := <-WorkerPool.workerChan
// Channel WorkerPool.workerChan is blocked if no worker is available
worker.RepJobs <- jobID
}(job)
}
}
type Worker struct {
ID int
RepJobs chan int64
SM *SM
quit chan bool
}
func (w *Worker) Start() {
go func() {
for {
WorkerPool.workerChan <- w
select {
case jobID := <-w.RepJobs:
w.handleRepJob(jobID)
case q := <-w.quit:
if q {
return
}
}
}
}
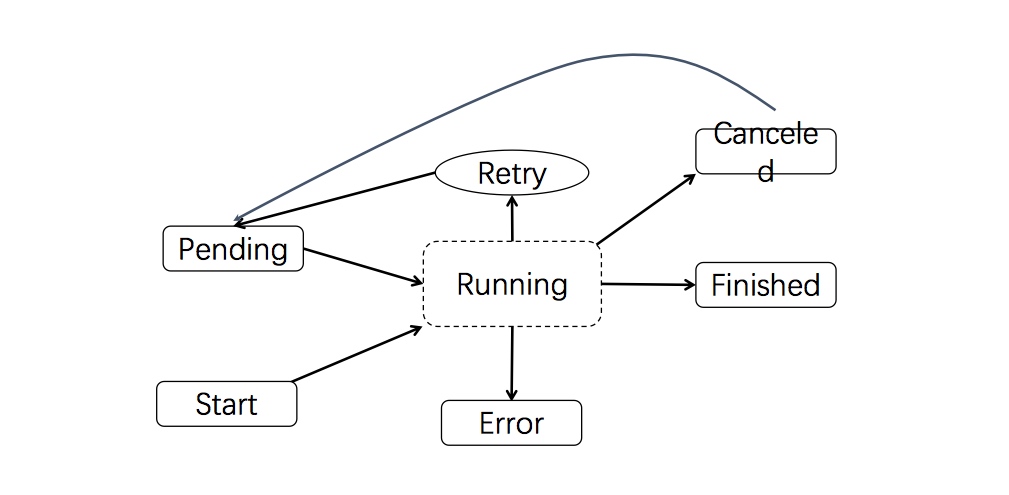
}(limited states, conditions of transition, handle logic for each state, separate concerns like error and retries)

 


行情开发遇到的挑战有:
▪ 开发语言的选择
▪ GC问题的困扰
▪ 面向并发的数据结构
▪ 融合替代方案
▪ 网络底层优化
首先是开发语言的选择。刘楠老师很形象地用AE86、99坦克和特斯拉Model X类比C/C++、Java和Golang。C/C++性能好,历史悠久,更适于“爱改装”的老司机。Jave大而全,被广泛使用,安全性高,但是太重而迟缓。Golang是为并发而生,集成了现代设计理念的系统级语言,代表了业界的发展方向。
GC的内存对象扫描标记会消耗大量的CPU,同时它的“Stop The World”特性还会造成毫秒级的延时
创建Goroutine固然很方便,但也要考虑到频繁创建销毁带来的麻烦。
▪ 并发量小于1000时,每个请求分配一个Goroutine,模型简单,类似于Apache的并发模型
▪ 并发量大于1000时,频繁创建销毁的Goroutine会产生大量的内存垃圾,GC拖慢系统响应速度,适宜采用Nginx的并发模型(异步io加状态机处理回调等)
尽量使用栈对象。因为堆上的对象需要GC才能释放,栈对象在函数结束时就释放了。另外在堆上创建对象需要先进过分配算法,回收的时候也可能产生碎片。在栈上就简单多了,只需移动栈指针即可。(逃逸的对象变量,是函数返回时会清除回收的局部变量)
对于大对象:goroutine一开始分配4k栈。默认是分段的当超过,链表连起来。所以大对象放在堆上,避免goroutine创建时的开销来栈创建回收
面向并发的数据结构:
cpu多核多socket 卡槽。cpu有三级缓存,goroutine多个跑在不同的cpu,要独占内存,其他cpu的内缓存要通知失效. 缓存失效,由于goroutine各种在cpu上跑,得到时间片就会造成其他cpu上的缓存失效,多次缓存就无效了。访问同一片的内存造成cpu缓存失效
pb使用产生垃圾,使用cgo常驻 . 如推送机器30w链接的goroutine,但是一边网络情况不好移动,导致大概3k的重连,就有频繁的goroutine销毁创建。使用常驻的不退出,告知执行等
 

mtu加大,协议栈中不segment,而在网卡中支持分片去减少cpu load . 线上问题,docker内网卡支持分片,host机器被vm虚拟化出来不支持 offload FALSE
docker issues 18776
最后的面向并发的数据结构、融合替代方案和网络底层优化内容比较偏细节
行情服务的特点:快,准,稳
系统设计的特性要求: 高并发要求系统在用户规模变大的时候具有弹性扩展的能力。高容错要求系统在出现故障时可以将错误的影响控制在一定范围,不影响整体的服务。
服务设计:
其中主要讲解了接入服务:



以上是对本次 Gopher China 2017 topics 的小结,比较少参与这种垂直会议。前者的一些于会前的准备如基础语言知识,相关工程实践等还是非常重要的~
两天的会议中,先后听了十几篇分享,议题涉及到如下层面:应用如何微服务,大数据结合,平台搭建和运维(devops,CI/CD持续集成和部署,容器编排(mesos,kubernetes,swarmkit等,应用场景:电商金融等。
整体感觉主会场的三篇,还有第二题早上的海外创业分会场中分享都是特别的棒!剩下的更多集中在DI/DC,运维视角下的还颇要慧眼识金去探寻~ 其中『docker化 - 容器应用基石』,『从SOA到微服务的技改之路』,『爱奇艺 - 日志容器』都是相对比较浅显易懂的,甚至其中讲到的一些做法和遇到问题也是我们当下有的并且解决的。
以下是我对重点分享的笔记和总结。
PS:后续的分享应该会随后带来。
PPS:梁总和烈波大神的ppt请自行取阅,吓尿指数飙升~
网飞家的微服务实践从来都是业界最前沿最开放的典范了,这次通过这次一瞥网飞家的微服务实践的现状还有开源技术方案大练兵还是收获不少的。之前还有一份分享非常有参考性( http://www.slideshare.net/aspyker/netflix-and-containers-titus 是AWS的Meetup 上分享的)
现状:online video streaming (最早是邮寄video),500+微服务,8kw的订阅用户,日播放1亿2500小时,双活的region,1/3北美互联网下载流量峰值
打造微服务和团队文化是离不开的:
这样背后的云生态体系是:
实现这些涉及的开发技术包括:
各个微服务间的链接

这次分享还是比较合胃口的,尤其是包含了目前我们也正在实践的SpringBoot,SpringCloud的一些,也包含了一些我们没有做到的高阶实践。
作者主要从12军规开始,加上Spring母公司Pivotal新提出的3条,组成了:

这样依次查看,要实现应用微服务化。必须要做到这些,这是容器甚至集群的前置工作基本功。
这一场是有docker官方的开源负责人东洛先生讲解的,除了ppt让我们看到官方的思路想法,也通过了简单的swarmkit demo给我们演示了具体的例子。
微服务带来部署的挑战 - 复杂化:
资源管理,任务调度,系统安全和网络通讯,运维开销等等,从而提出了集群管理的思路和社区实现(k8s,mesos等
为什么docker要做编排?
对于社区现有的mesos, k8s等(相互不兼容的,带着厂商vendor的业务特征)
官方要对『build, ship, run application』做的 battery included, but replacement and removable 可插拔
Docker在容器化的项目:
从engine,compose(container deploy多个机器), swarm(很多节点 group 到cluster) 【compose 把任务推送到swarm】, machine(准备运行环境,机器中有tls,有docker内置了), distribution, libnetwork, docker for mac/windows, swarmkit

容器编排需要考虑的问题:
• 编排:如何将任务匹配到对应的计算,网络,存储资源上来提供服务
• 集群管理:如何管理各种系统资源,包括计算,存储,网络;如何自劢的处理系统变化,如节点离线
• 任务调度:如何调度任务到对应节点并路由请求,如何管理任务的整个生命周期
• 用户接口:如何定义服务架构来进行编排
• 安全性:如何实现端到端安全保障 - 实现端到端的加密,密钥的安全,分发)
• 适用性:如何解决公有云,私有云和混合云的部署;如何协劣企业进行测试及生产环境部署
从compose+swarm到swarmkit
前者:(1.12前)
container api 去管理(用swarm知道把任务如何分发
服务管理,负载均衡,状态和网络都是由外部去
后者:
service api(定义service包含task【由容器去实现】)
服务生命周期内置,系统状态保存在内置的raft store上,直接对服务做负载均衡,集群内置ca进行,所有通讯加密,网络状态内置,通过gossip来传播
前后架构对比图:

Swarm Mode的架构
• Docker发布以来的一次重大架构变化,引入了集群管理和服务;同时向后兼容
• 多个管理者节点(manager)使用raft实现(coreos/etcd)组成高可用,强一致性Quorum以管理集群
• 内置分布式K/V仓库保存系统状态,支持批处理状态更新
• 多个管理者分担工人(worker)连接
• 管理者进行资源管理,调度任务,监测服务,通过gRPC进行任务分发和状态收集
• 工人节点执行任务,反馈任务状态
• 工人节点通过gossip协议实现分布式消息同步,消除overlay延时线性增长问题
• 内置CA进行秘钥分发和更新,所有节点通讯加密

然后又看了 Docker 1.12 下的网络(1.9 overlay. 1.11 内置dns, 1.12 内置集群(不需要外部的kv store和LB,dns服务发现),服务请求路由,安全性(manager节点有leader,内置CA,分发和定时更新
在最后,faq环节,因为有T恤送,所以我也提问了。☺
大数据和容器化集群管理现在是非常明显的一大趋势,解决计算资源分配问题
微服务(要多micro,足够小,让k8s能够见缝插针去), 程序要写的硬件配置无关的(譬如你的process不要假设要启动64G内存,不要写中断要kernel)
并行计算框架变得很容器(很多算法几千行go写的mapreduce,写一些新的framework并行开发技巧,而不是使用一种的hadoop等,节省大量的计算浪费) - researcher了解怎么写分布式系统,工程师了解AI潮流(不需要博士是本科)
会什么在一起?解决计算问题给AI,计算节点
计算级别: alpha go(4000 GPU), deep speech (32 GPU), siri (8GPU)
AI,互联网兴起:
(搜索引擎(图书管理员),推荐(服务推销员和报刊亭)和广告(而不是广告代理公司)三大业务。互联网金融(合作信用社))
用户行为数据log(有机会收集数十亿用户的行为数据)
互联网数据是长尾数据:
用户(绝大数用户少于5部),电影(绝大部分电影很少人评论)
产品运行一段时间后,数据就很稀疏了,稀疏矩阵的计算等
长尾才是真金:
去噪声(出现频率很低,不重要的),稀疏性,指数族分布,冷启动问题、
通过( 红酒木瓜汤【小众case】(出什么广告,应该是丰胸的 - 语义分析系统 - topic id,weight,keywords ), 苹果(大众case)- (苹果,手机,范冰冰)【巨量文本训练后的关联词】 苹果大尺度 (范冰冰)来具体case展示了长尾的价值
长尾数据引入了计算更大(不能去噪
之前的问题:
手工管理集【每个团队申请机器不愿归还,数据计算后放哪里,后续有task怎么办】,HPC集群,Mesos和Yarn
云之声的设计架构:

使用k8s遇到的一些问题:
单机操作系统:CoreOS -为什么因为包管理器各个语言版本等,通过自动安装和部署的sextant,
Ceph最早的时候(大的存储卷被join后切分逻辑卷,因为之前的虚拟化需要。但是现在在k8s中,不需要大的操作系统。所以ceph现在做的)
网络性能(k8s虚拟网络,不是网卡路由器。是软件开发,类似于Google GAE的网络方案)
这一篇,Timothy让我们见识到了Mesosphere家产品的无穷魅力(尤其是DC/OS使用起来尤其方便,第三方社区的插件非常多,web ui精美,在最后的demo环境(展示了部署twitter clone,然后如何扩缩容,如何数据分析-利用部署大数据计算节点和分发task等) https://github.com/mesosphere/time-series-demo
首先讲了 为什么是DC/OS:

为什么要DC/OS:
即使你有了mesos但是你还是需要做很多事情(去装framework,去装load balance等)- 最大不同和其他的集群方案(islolation隔离非常灵活)
DC/OS具体包含了哪些:

本文罗列JavaScript代码中常见的代码坏味道,如临时定时器,双向数据绑定的坑,复杂的分支语句,重复赋值等,对它们进行分析如现场还原,糟糕代码回顾,问题诊断和识别(通过ESlint或其他工具),代码重构方案,给出了怎么写好代码的一手经验~
如果单词以辅音开头(或辅音集),把它剩余的步伐移到前面,并且添加上『ay』如pig -> igpay
如果单词以元音开头,保持顺序但是在结尾加上『way』如,egg->eggway等
/* const */ var CONSONANTS = 'bcdfghjklmnpqrstvwxyz';
/* const */ var VOWELS = 'aeiou';
function englishToPigLatin(english) {
/* const */ var SYLLABLE = 'ay';
var pigLatin = '';
if (english !== null && english.length > 0 &&
(VOWELS.indexOf(english[0]) > -1 ||
CONSONANTS.indexOf(english[0]) > -1 )) {
if (VOWELS.indexOf(english[0]) > -1) {
pigLatin = english + SYLLABLE;
} else {
var preConsonants = '';
for (var i = 0; i < english.length; ++i) {
if (CONSONANTS.indexOf(english[i]) > -1) {
preConsonants += english[i];
if (preConsonants == 'q' &&
i+1 < english.length && english[i+1] == 'u') {
preConsonants += 'u';
i += 2;
break;
}
} else { break; }
}
pigLatin = english.substring(i) + preConsonants + SYLLABLE;
}
}
return pigLatin;
}关于Lint的配置项:如最大语句数,复杂度,最大嵌套数,最大长度,最多传参,最多嵌套回调
/*jshint maxstatements:15, maxdepth:2, maxcomplexity:5 */
/*eslint max-statements:[2, 15], max-depth:[1, 2], complexity:[2, 5] */7:0 - Function 'englishToPigLatin' has a complexity of 7.
7:0 - This function has too many statements (16). Maximum allowed is 15.
22:10 - Blocks are nested too deeply (5).describe('Pig Latin', function() {
describe('Invalid', function() {
it('should return blank if passed null', function() {
expect(englishToPigLatin(null)).toBe('');
});
it('should return blank if passed blank', function() {
expect(englishToPigLatin('')).toBe('');
});
it('should return blank if passed number', function() {
expect(englishToPigLatin('1234567890')).toBe('');
});
it('should return blank if passed symbol', function() {
expect(englishToPigLatin('~!@#$%^&*()_+')).toBe('');
});
});
describe('Consonants', function() {
it('should return eastbay from beast', function() {
expect(englishToPigLatin('beast')).toBe('eastbay');
});
it('should return estionquay from question', function() {
expect(englishToPigLatin('question')).toBe('estionquay');
});
it('should return eethray from three', function() {
expect(englishToPigLatin('three')).toBe('eethray');
});
});
describe('Vowels', function() {
it('should return appleay from apple', function() {
expect(englishToPigLatin('apple')).toBe('appleay');
});
});
});const CONSONANTS = ['th', 'qu', 'b', 'c', 'd', 'f', 'g', 'h', 'j', 'k',
'l', 'm', 'n', 'p', 'q', 'r', 's', 't', 'v', 'w', 'x', 'y', 'z'];
const VOWELS = ['a', 'e', 'i', 'o', 'u'];
const ENDING = 'ay';
let isValid = word => startsWithVowel(word) || startsWithConsonant(word);
let startsWithVowel = word => VOWELS.includes(word[0]);
let startsWithConsonant = word => CONSONANTS.includes(word[0]);
let getConsonants = word => CONSONANTS.reduce((memo, char) => {
if (word.startsWith(char)) {
memo += char;
word = word.substr(char.length);
}
return memo;
}, '');
function englishToPigLatin(english='') {
if (isValid(english)) {
if (startsWithVowel(english)) {
english += ENDING;
} else {
let letters = getConsonants(english);
english = `${english.substr(letters.length)}${letters}${ENDING}`;
}
}
return english;
}max-statements: 16 → 6
max-depth: 5 → 2
complexity: 7 → 3
max-len: 65 → 73
max-params: 1 → 2
max-nested-callbacks: 0 → 1
jshint - http://jshint.com/
eslint - http://eslint.org/
jscomplexity - http://jscomplexity.org/
escomplex - https://github.com/philbooth/escomplex
jasmine - http://jasmine.github.io/
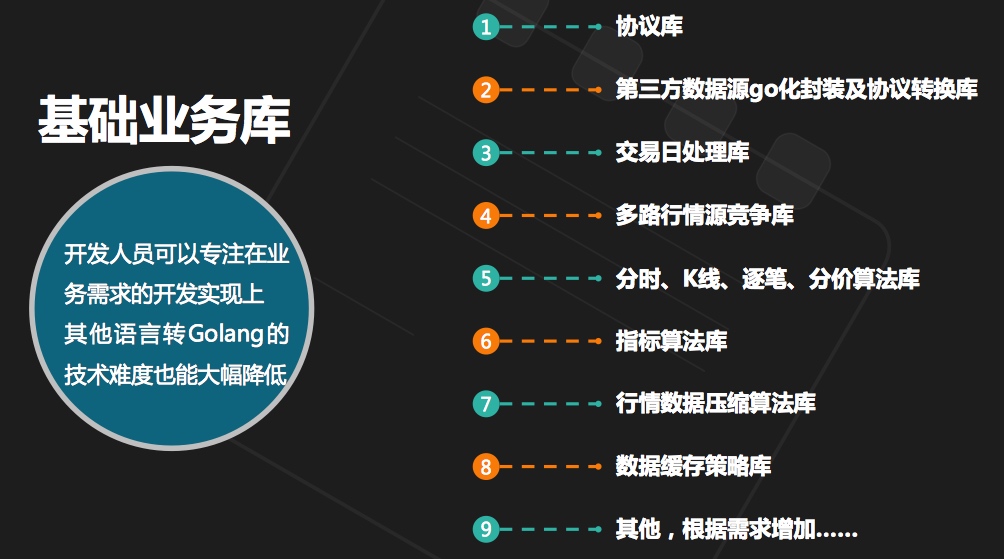
我们需要实现如下的效果

var boxes = document.querySelectorAll('.Box');
[].forEach.call(boxes, function(element, index) {
element.innerText = "Box: " + index;
element.style.backgroundColor =
'#' + (Math.random() * 0xFFFFFF << 0).toString(16);
});
var circles = document.querySelectorAll(".Circle");
[].forEach.call(circles, function(element, index) {
element.innerText = "Circle: " + index;
element.style.color =
'#' + (Math.random() * 0xFFFFFF << 0).toString(16);
});因为我们在粘贴复制!!
检查出粘贴复制和结构类似的代码片段 - jsinspect
https://github.com/danielstjules
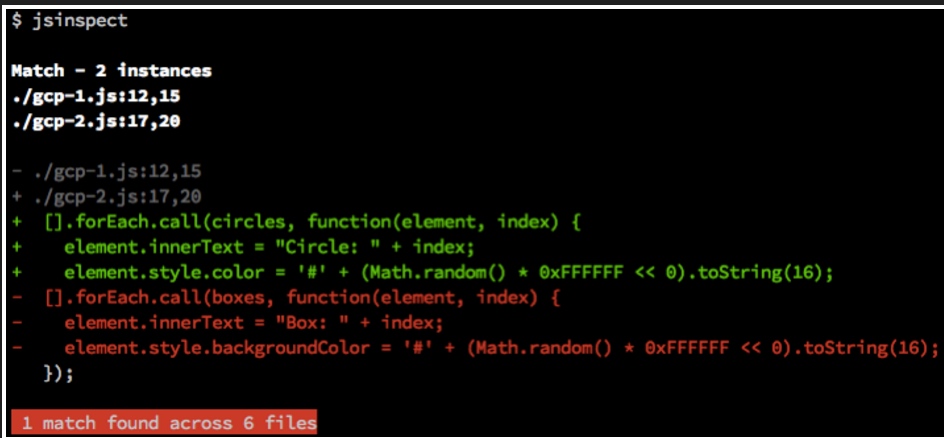 

从你的JS,TypeScript,C#,Ruby,CSS,HTML等源代码中找到粘贴复制的部分 - JSCPD
https://github.com/kucherenko/jscpd
 

let randomColor = () => `#${(Math.random() * 0xFFFFFF << 0).toString(16)}`;
let $$ = selector => [].slice.call(document.querySelectorAll(selector || '*'));
let updateElement = (selector, textPrefix, styleProperty) => {
$$(selector).forEach((element, index) => {
element.innerText = textPrefix + ': ' + index;
element.style[styleProperty] = randomColor();
});
}
updateElement('.Box', 'Box', 'backgroundColor'); // 12: Refactored
updateElement('.Circle', 'Circle', 'color'); // 14: Refactoredfunction getArea(shape, options) {
var area = 0;
switch (shape) {
case 'Triangle':
area = .5 * options.width * options.height;
break;
case 'Square':
area = Math.pow(options.width, 2);
break;
case 'Rectangle':
area = options.width * options.height;
break;
default:
throw new Error('Invalid shape: ' + shape);
}
return area;
}
getArea('Triangle', { width: 100, height: 100 });
getArea('Square', { width: 100 });
getArea('Rectangle', { width: 100, height: 100 });
getArea('Bogus');违反了 open/close 原则:
软件元素(类,模块和方法等)应该易于被打开扩展,但是除了本身不要多于的修改。既代码本身可以允许它的行为被扩展,但是不要修改源代码
可以使用诸如检查:
no-switch - disallow the use of the switch statement
no-complex-switch-case - disallow use of complex switch statements
这时候添加一个代码就不像之前那样该原先的switch,直到它又长又臭,还容易把之前的代码逻辑broken掉。
(function(shapes) { // triangle.js
var Triangle = shapes.Triangle = function(options) {
this.width = options.width;
this.height = options.height;
};
Triangle.prototype.getArea = function() {
return 0.5 * this.width * this.height;
};
}(window.shapes = window.shapes || {}));
function getArea(shape, options) {
var Shape = window.shapes[shape], area = 0;
if (Shape && typeof Shape === 'function') {
area = new Shape(options).getArea();
} else {
throw new Error('Invalid shape: ' + shape);
}
return area;
}
getArea('Triangle', { width: 100, height: 100 });
getArea('Square', { width: 100 });
getArea('Rectangle', { width: 100, height: 100 });
getArea('Bogus');
// circle.js
(function(shapes) {
var Circle = shapes.Circle = function(options) {
this.radius = options.radius;
};
Circle.prototype.getArea = function() {
return Math.PI * Math.pow(this.radius, 2);
};
Circle.prototype.getCircumference = function() {
return 2 * Math.PI * this.radius;
};
}(window.shapes = window.shapes || {}));如上面看到的,如Magic Strings,对于诸如Triangle,Square这些就是特殊字符串。
这些魔法数字和字符串是直接写死在代码中,不容易修改和阅读。注入password.length > 9,这里面的9是指 MAX_PASSWORD_SIZE ,这样先定义后使用更清晰。同时如果多个地方需要这个判断规则,也可以避免多次修改类似9这样的数字
https://en.wikipedia.org/wiki/Magic_number_(programming)
http://stackoverflow.com/questions/47882/what-is-a-magic-number-and-why-is-it-bad
1 通过对象
var shapeType = {
triangle: 'Triangle' // 2: Object Type
};
function getArea(shape, options) {
var area = 0;
switch (shape) {
case shapeType.triangle: // 8: Object Type
area = .5 * options.width * options.height;
break;
}
return area;
}
getArea(shapeType.triangle, { width: 100, height: 100 }); // 15: 2 通过 const 和 symbols
const shapeType = {
triangle: Symbol() // 2: Enum-ish
};
function getArea(shape, options) {
var area = 0;
switch (shape) {
case shapeType.triangle: // 8: Enum-ishPerson.prototype.brush = function() {
var that = this;
this.teeth.forEach(function(tooth) {
that.clean(tooth);
});
console.log('brushed');
};奇奇怪怪的 self /that/_this 等
使用一下的eslint:
利用Function.bind, 2nd parameter of forEach, es6
Person.prototype.brush = function() {
this.teeth.forEach(function(tooth) {
this.clean(tooth);
}.bind(this)); // 4: Use .bind() to change context
console.log('brushed');
};
Person.prototype.brush = function() {
this.teeth.forEach(function(tooth) {
this.clean(tooth);
}, this); // 4: Use 2nd parameter of .forEach to change context
console.log('brushed');
};
Person.prototype.brush = function() {
this.teeth.forEach(tooth => { // 2: Use ES6 Arrow Function to bind `this`
this.clean(tooth);
});
console.log('brushed');
};var build = function(id, href, text) {
return $( "<div id='tab'><a href='" + href + "' id='" + id + "'>" +
text + "</a></div>" );
}代码很丑陋,也很啰嗦,不直观。
使用 ES6的模板字符串(字符串插值和多行)
很多工具和框架也都提供了响应的支持,如lodash/underscore,angular,react 等
var build = (id, href, text) =>
`<div id="tab"><a href="${href}" id="${id}">${text}</a></div>`;
var build = (id, href, text) => `<div id="tab">
<a href="${href}" id="${id}">${text}</a>
</div>`;$(document).ready(function() {
$('.Component')
.find('button')
.addClass('Component-button--action')
.click(function() { alert('HEY!'); })
.end()
.mouseenter(function() { $(this).addClass('Component--over'); })
.mouseleave(function() { $(this).removeClass('Component--over'); })
.addClass('initialized');
});太多的链式调用
// Event Delegation before DOM Ready
$(document).on('mouseenter mouseleave', '.Component', function(e) {
$(this).toggleClass('Component--over', e.type === 'mouseenter');
});
$(document).on('click', '.Component button', function(e) {
alert('HEY!');
});
$(document).ready(function() {
$('.Component button').addClass('Component-button--action');
});setInterval(function() {
console.log('start setInterval');
someLongProcess(getRandomInt(2000, 4000));
}, 3000);
function someLongProcess(duration) {
setTimeout(
function() { console.log('long process: ' + duration); },
duration
);
}
function getRandomInt(min, max) {
return Math.floor(Math.random() * (max - min + 1)) + min;
}out of sync timer 不能确认时序和执行
等 3s 去执行timer(setTimeout),然后调用 someLongProcess (long process: random time ),接着在循环
使用setInterval fn(其中在进行 long process),还是通过callback传递来反复setTimeout(timer, )
setTimeout(function timer() {
console.log('start setTimeout')
someLongProcess(getRandomInt(2000, 4000), function() {
setTimeout(timer, 3000);
});
}, 3000);
function someLongProcess(duration, callback) {
setTimeout(function() {
console.log('long process: ' + duration);
callback();
}, duration);
}
/* getRandomInt(min, max) {} */data = this.appendAnalyticsData(data);
data = this.appendSubmissionData(data);
data = this.appendAdditionalInputs(data);
data = this.pruneObject(data);有些重复和啰嗦
eslint-plugin-smells
1 嵌套的函数调用
2 forEach
3 reduce
4 flow
// 1
data = this.pruneObject(
this.appendAdditionalInputs(
this.appendSubmissionData(
this.appendAnalyticsData(data)
)
)
);
// 2
var funcs = [
this.appendAnalyticsData,
this.appendSubmissionData,
this.appendAdditionalInputs,
this.pruneObject
];
funcs.forEach(function(func) {
data = func(data);
});
// 3
// funcs 定义如上
data = funcs.reduce(function(memo, func) {
return func(memo);
}, data);
// 4
data = _.flow(
this.appendAnalyticsData,
this.appendSubmissionData,
this.appendAdditionalInputs,
this.pruneObject
)(data);function ShoppingCart() { this.items = []; }
ShoppingCart.prototype.addItem = function(item) {
this.items.push(item);
};
function Product(name) { this.name = name; }
Product.prototype.addToCart = function() {
shoppingCart.addItem(this);
};
var shoppingCart = new ShoppingCart();
var product = new Product('Socks');
product.addToCart();
console.log(shoppingCart.items);依赖被紧紧的耦合了
相互调用,耦合!如 product 和 shoppingCart 关系
1 dependency injection 依赖注入
2 消息经纪人broker
function Product(name, shoppingCart) { // 6: Accept Dependency
this.name = name;
this.shoppingCart = shoppingCart; // 8: Save off Dependency
}
Product.prototype.addToCart = function() {
this.shoppingCart.addItem(this);
};
var shoppingCart = new ShoppingCart();
var product = new Product('Socks', shoppingCart); // 15: Pass in Dependency
product.addToCart();
console.log(shoppingCart.items);var channel = postal.channel(); // 1: Broker
function ShoppingCart() {
this.items = [];
channel.subscribe('shoppingcart.add', this.addItem); // 5: Listen to Message
}
ShoppingCart.prototype.addItem = function(item) {
this.items.push(item);
};
function Product(name) { this.name = name; }
Product.prototype.addToCart = function() {
channel.publish('shoppingcart.add', this); // 13: Publish Message
};
var shoppingCart = new ShoppingCart();
var product = new Product('Socks');
product.addToCart();
console.log(shoppingCart.items);var search = document.querySelector('.Autocomplete');
search.addEventListener('input', function(e) {
// Make Ajax call for autocomplete
console.log(e.target.value);
});会造成卡顿,多余的计算等
throttle 和 debounce
var search = document.querySelector('.Autocomplete');
search.addEventListener('input', _.throttle(function(e) {
// Make Ajax call for autocomplete
console.log(e.target.value);
}, 500));
var search = document.querySelector('.Autocomplete');
search.addEventListener('input', _.debounce(function(e) {
// Make Ajax call for autocomplete
console.log(e.target.value);
}, 500));var search = document.querySelector('.Autocomplete');
search.addEventListener('input', _.debounce(function(e) {
// Make Ajax call for autocomplete
console.log(e.target.value);
}, 500));匿名函数是个好东西,但是给函数命名可以帮助我们:
var search = document.querySelector('.Autocomplete');
search.addEventListener('input', _.debounce(function matches(e) {
console.log(e.target.value);
}, 500));明确触发时机而不是,写在 domready
$(document).ready(function() {
// wire up event handlers
// declare all the things
// etc...
});很难做单元测试
利用单例模块,加上构建器函数
单例模式(单例有个init 方法,来Kick off) & 构造函数(new Application() -> 在原来的构造函数中Kick off your code!)
(function(myApp) {
myApp.init = function() {
// kick off your code
};
myApp.handleClick = function() {}; // etc...
}(window.myApp = window.myApp || {}));
// Only include at end of main application...
$(document).ready(function() {
window.myApp.init();
});
var Application = (function() {
function Application() {
// kick off your code
}
Application.prototype.handleClick = function() {};
return Application;
}());
// Only include at end of main application...
$(document).ready(function() {
new Application();
});随便看看你们手头的MVVM项目(如Angular的等)
很难定位执行顺序和数据流(Hard to track execution & data flow )
(也是Angular1.x被大力吐槽的地方,被React的Flux)
方案: flux(action, dispatcher, store->view)
React Flux
An Angular2 Todo App: First look at App Development in Angular2
更多的lint规则,在npm上搜索 eslint-plugin 查找
翻译自Facebook工程团队的官方博客,React Native: A year in review,本文分别从 RN 起源,项目过去一年在FB内部的发展,在业界的广泛使用和生态圈的快速建立,在 Github 上的开源协作,核心团队对 RN 的未来展望等进行一一讲述,来吧看看 RN 的传奇之路
自从我们开源 React Native 已经有一年的时间了。这个最早仅仅是一小撮工程师『异想天开』的项目现在已经作为应用开发框架被广泛使用在 Facebook 的产品团队甚至其他公司中。在今天的 F8 大会上,我们宣布了微软正在把 React Native 技术带到Windows的生态系统这消息,让开发者可以在 Windows PC,Phone,Xbox 上构建 RN 的应用,同时也提供了开源工具和服务(譬如Visual Studio Code的RN扩展和CodePush相关的RN服务)来帮助开发者在 Windows 平台构建 RN 应用。同时,三星正在用 RN 技术构建它的混合应用平台,来辅助三星的开发者在数以百万级的SmartTV,手机和可穿戴设备上开发应用。我们Facebook 也发布了 RN 的 Facebook 开发者套件,使得开发者更加容易集成 Facebook 的社交特性(例如登录,分享,应用分析和 Graph API 等功能)到他们的应用中。就这一年,React Native 显著的改变开发者在主流手机客户端上开发应用的方式。
史诗般的旅程不是吗,不过我们才刚刚开始。接下来我们往回看自从开源后这一年,RN 是如何一步步流行和不断完善的,看这一路来我们面对的挑战,并且我们是怎么看待 RN 未来的发展的。
作为Facebook 黑客文化的精髓,React Native 于2013年也是作为编程马拉松 hackathon 的项目开始。类似于 React,React Native一开始也是看起来很大胆的异类想法。一开始我们并不确定这是否能行。譬如 JS 和原生滚动间的交互怎么做,性能怎么样,如调试等。不过这些挑战都没有阻止我们的工程师进一步的推进这个项目。
当我们把这个想法做出原型后,我意识到这个项目在 Facebook 中可能会大有用途。在几年前,我们从Web H5 开发转变到目前的原生客户端开发上。不过,每次修改代码都需要漫长的重新编译,开发不同的客户端(iOS、Android)需要不同的配套技能等都让我们头疼,这些都导致了产品开发的进展缓慢。React Native 这样的构想就能把之前我们热衷的Web开发的一些优点借鉴到原生应用开发上,譬如足够快的开发迭代速度,只需要精简的 JS 工程团队就能交付整个移动端产品。
所以,我们开始在这个项目继续投资时间和精力。我们也知道证明一项新技术是否真的有效好用就是用它来尝试解决生产环境下的复杂问题。所以我们决定做 FB 的消息流主页的原型,这就是我们用 RN 开发的第一个产品项目,同时也在不断丰富优化 RN 这个基础框架本身。这些代码最后成为现在 FB 群组应用代码的基础部分。
在2014年7月,还在 RN 上持续下功夫的我们小群团队第一次接了一项大活:广告管理大师团队希望构建单独的 iOS 应用,但是他们没有直接的iOS工程师也没相关的开发经验。这是个非常不错的机会,接下来几个月广告管理大师的产品团队和 RN 工程团队紧密工作相互配合。产品工程师不断挑战提升着RN平台的功能和性能边界。我们的目标就是要发布一款用户体验不差于 Objective-C 构建的 iOS 应用。
在对此任务非常有信心实现后,我们决定尽早让 RN 能够跨平台,在伦敦组建了 RN 的 Android 团队。这团队在14年下半年开始写了最早的 Android 核心运行时和第一个组件。此后我们决定要让 Android 能顺利运行之前的 iOS 广告管理大师的JS代码。到2014年底,我们有个最基础版本,尽管它还缺了不少的界面,在低端Android手机上性能也不行,不过你还是可以看到如下图展示的一列广告和可以用它来创建新的广告。我们当时非常自信能把这项工作推进下去,获得更棒的性能,更强大的功能。
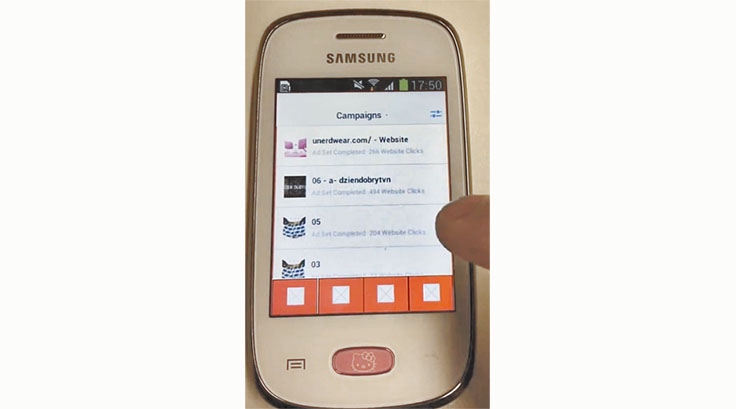 

Facebook的广告管理大师运行在Android低端机上。2015/01
FB 广告管理大师这款应用在2015年2月在iOS在苹果 AppStore 发布,离我们正式在全职搞 RN 不过才6个月。同时,关注 JS 或 iOS 的同事开始考虑开源这套 iOS RN的实现。在2015年1月的 React.js 开发者大会,我们发布了初次的公开预览版。在2015年3月的 F8 开发者大会,我们正式开源所有代码~
在此之后,广告管理大师的工程团队开始把他们的 JavaScript 代码移植到 Android 应用上。和伦敦的RN团队紧密配合,一开始我们并没寄希望能在这两个平台很复用很多代码(我们只是把它当做 RN 方案的加分点),不过当 Android 版的广告管理大师准备发布上线后,我们惊喜发现这两个应用的85%的代码都是可共用的。
在2015年的6月,经过三个月的开发和一个月左右的内部 dogfooding 使用,第一个 Android 版本的广告管理大师发布了,考虑到 RN 的 iOS 部分大受欢迎的情况,我们立即开始把工作重心转移到开源 RN 的 Android 部分。我们对此热情高涨。毕竟,需要给不同平台构建同一款应用是业界都有的大难题,我们从开发广告管理大师项目的经验来看,RN 正是解决这样难题的好方案。
类似于 iOS 部分的发布,我们希望 Android 部分也能尽早发布,从而尽快获得反馈。因此,我们从核心运行时开始,加上一小部分的视图和模块(如文本,图片,ScrollView,Network,AsyncStorage等)的支持。在9月14号,我们把 Android 核心运行时和初始部分的 Android 模块发布到 Github 和 npm 上。在 React Native 的0.11版本上,我们第一次发布了 Android 部分的支持。从开源 Android 部分后,我们也陆续加入这些模块的支持:Alert,APPState,CameraRoll,Clipboard,Date和time pickers,Geolocation,Intent,Modal,NetInfo,Pull to refresh view,Picker,Slider,View pager,WebView等(它们和 iOS 部分的 API 非常类似)
 

从最早 React Native 设想,到我们开源 RN的 Android 部分的时间轴
不得不说,在开源后,外界对 RN 的接受程度和热情让我们 RN 团队感到非常惊喜。
React Native 的流行程度和它的开发者社区都在快速发展,远超我们的预期。
超过650个人给 RN 的代码仓库贡献过代码。在代码仓库的5800个提交,有30%左右都是被不在 FB 工作的贡献者提交的。在2016年2月,第一次超过50%的代码提交来源于这些外部贡献者。随着这么多来着于社区对RN的贡献,我们发现每个月都将近266新的 PR(每天多大10个PR)被要求合入。这些 PR 很多都是高质量的,提供着后续被广泛使用的功能特性。
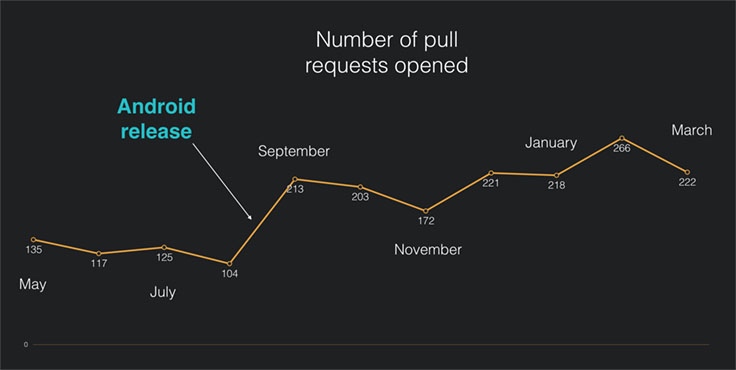 

这是RN的Github代码仓库每个月被提交PR数量趋势图
在一开始,这些暴涨的 PR 数量导致我们很难快速高效的审核合入。每天为这些 PR 找到合适的审核人员都消耗着很多人力成本。为了解决这个问题,我们通过开发两个 Github 机器人来自动化分发 PR 到合适的reviewer头上~
第一个机器人是提醒机器人,为每个PR找出合适的 Reviewer 审核人。
 

这个提醒机器人现在被开源了,他的确帮助了我们在一天中更高效的审核这些PR。有趣的是:在上个月(2月份)超过50%的提交来自于社区,提醒机器人总能在社区中找到合适的reviewer来审核(工作原理大概是通过在 Github issues 中定位到提出的人,和 PR 要解决的 issues 关联起来)
很难Merge这些PR是我们遇到的第二个难题。FB 工程师们用的同一个代码仓库(就想你在 Github React Native Repo 上看到的一样),我没有对这个做任何 fork 没有其他的内部 commit 之类的。因此,每次要合入 PR 的代码到我们内部的大型叫做 fbsource 的Mercurial 仓库后我们都会自动执行测试脚本来回归我们类似于 Facebook Ads Manager(广告管理大师?)等应用功能。
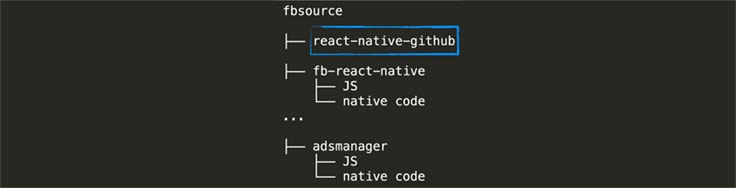 

简化版的单例Mercurial代码仓库fbsource。这个仓库包含所有的移动端和服务端端代码
之前合入一个 PR 涉及多个手动操作。我们现在把这些简化为仅仅需要在 Github 回复一句评论。
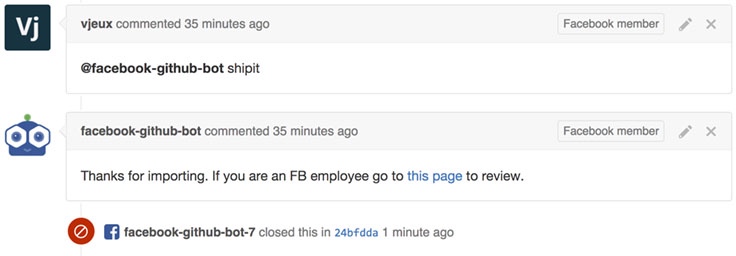 

@facebook-github-bot-shipit: 如果所有的内部测试运行通过,PR的那些代码会被自动合入到 fbsource 主分支和 Github 主分支中
感谢这些工具,我们这个项目才能和这么多社区持续贡献的 PR 保持上同一进度。在过去一年,我们总共关闭了2351个 PR!!
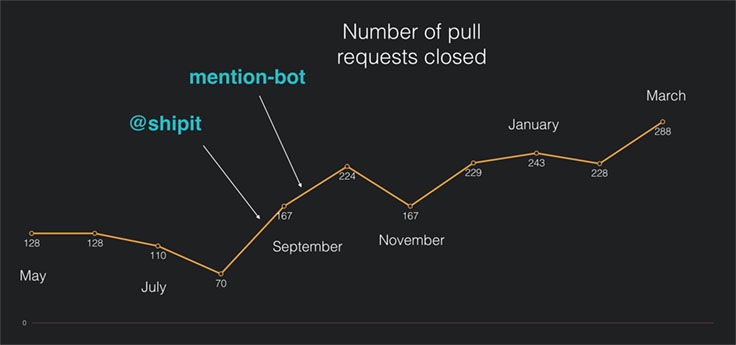 

Github的RN项目上每个月被关闭的PR数量趋势图
随着项目的流行,我们要构建和引导一种机制环境:让社区中有心的人来帮忙一起管理日益增多的 issues。
我们实施了另外一个机器人来使得社区中的任何人都能来帮助管理 Github issues。它可以让任何人(无需push权限)都可以关闭重复的 issues,回答后关闭 issues,给 issues 添加标签等等。你可以参考这篇指南参与进来 guide to managing Github issues

React Native 涉及的 API 面非常广泛。它暴露了构建 iOS 和 Android 应用的绝大部分 JavaScript 调用,同时提供了跨平台的抽象。很难有一个对这些所有APIs都很熟悉的人,即使 FB 中有很多产品团队在使用 RN,我们还是不能保证覆盖到所有的边缘情况。RN 适合我们,但是我们不能保证它绝对完美。这就是需要社区中了解这些代码仓库的人参与进来,这对于我们和更宽泛社区的其他人(那些把自己的应用押宝在 RN 上,在 RN 上构建自己的服务,为 RN 开发第三方类库工具的)都非常重要。
React Native 开源贡献者组织是由社区中那些提供非常高质量的代码补丁,非常积极帮助其他遇到使用问题用户的人构成的。我们创建这个组织感谢他们为RN项目的推进表示感谢,也给我们代码仓库的提交权限。
下面是我们 RN 开源贡献者组织的大合照,依次是这些人:省略
 

开源贡献者组织的不少人,在2016/02/22的旧金山的React.js Conf开发者大会的合照
每两周RN就会有新的发布。意味着在主分支中发布后,你就能在你的应用中立即使用上这些功能特性。仅仅在2016年3月,RN 的代码在 NPM 上的下载次数就达到7w次。在 Github 有着近3w的加星,RN 是 Github 上最受关注的21项目之一。
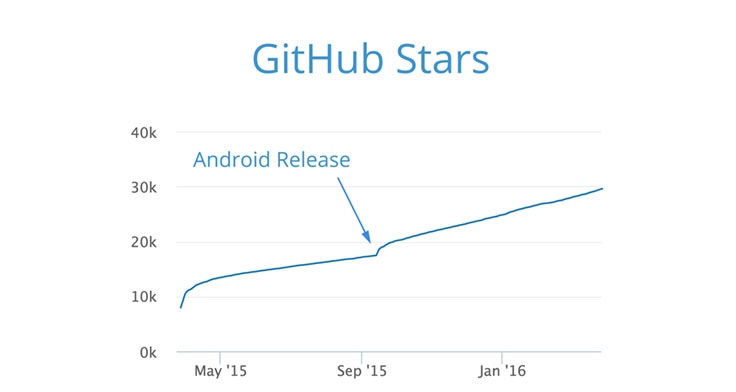 

在过去一年,RN在Github的代码仓库的加星数从0到30000之多
自从 iOS 版的 RN 发布后的这一年,有非常多用RN开发的应用被上架到苹果的AppStore,高质量的RN写的的Android应用也慢慢出现了。在展示页面罗列了107个用 RN 构建的优秀应用,通过提交 PR 把你的 RN 应用也加入其中。
 

我们尝试使用这些,发现了不少被精细打磨的RN应用。所以确保你也下载一些来试一试,看看 React Native 能用来干什么。
这样高质量的RN还有很多,在这里就不一一陈诉了。去showcase展示页去一探究竟吧。
除了这些应用外,现在还有不少辅助RN或构建于RN之上的服务:Exponent 让你无需编译任何东西就能开发和分享 RN 应用。React Native Playground 让你在浏览器中编辑和运行RN应用。AppHub和微软的CodePush让你避开应用市场快速部署新代码。JS.coach提供着索引大量第三方模块的数据库,Deco 是用于构建 React Native 的 IDE 集成开发环境。
随之还有快速发展的第三方模块的生态,你可以很方便的把这些功能/插件集成到你的应用中。借助于JS.coach,这些模块非常容易查找。借助于 rnpm 安装他们也变得非常容易。
网上现在也有非常多的关于 RN 的优秀技术博客和入门提升的教程。感谢社区,继续保持!我们在这里特别推荐下 Brent Vatne的 React Native Newsletter,它提供了对 RN 社区发生的所有好玩有趣值得关注的事的不错的概述,同时提供了不少指向优秀 RN 技术博客的链接。
对了,我们现在还有三本关于 RN 的书籍呢~
所有的这些都是在这一年诞生的,成果不少!
Facebook 中越来越多的产品团队用 RN 来开发新功能和应用。它即被应用在其他业务的单例App中也被集成在大Facebook的iOS/Android App中。

Facebook群组应用就是个混合应用,消息流就是用RN实现的
在去年,RN团队中的工程师人数从过去的10名快速增长到20名,成员分布在加州的Menlo Park, 伦敦和纽约。自从 Ads Manager(广告管理大师)发布RN后,RN 团队的主要聚焦在:
这个项目在去年发展很快取得了长足的进展,不过就像我们在Facebook内部说的『我们才完成了1/100的进度』!我们内部会持续大力开发RN项目。在去年,我们团队规模扩大了一倍。我们也会继续在开源工具链上投入。我们希望 React Native 项目在公司内外都能取得成功~
下面是大家可以参与到这个项目中的一些我们推荐的方式:
如果你刚开始接触 RN,那我推荐你看看我们为RN设计的一系列的教程来介绍这个框架和它的开源生态圈。就拿今年的F8应用作为例子,我们展示了我们在开发时是如何为多平台做设计的,如何整合数据,通过测试应用来提高代码质量等。
感谢每一位用 React Native 技术来开发他们优秀应用的开发者,感谢那些在 RN 之上构建工具和服务,开发开源第三方模块,帮助回答问题,提交PR,帮忙组织会议分享,给RN写技术博客等社区中的每一位成员。 继续保持吧!
让我们期待来年的 RN 的大发展吧~
来听年入40的老开发者讲讲故事,听听教诲。
今年4月25号,我在 App Builders 大会做了 年迈40的开发者 (Being A Developer After 40)的演讲。该份ppt可以在 SpeakerDeck 上看到,传送门
 

Examples of galaxies are, for example, .NET, Cocoa, Node.js, PHP, Emacs, SAP, etc. Each of these features evangelists, developers, bloggers, podcasts, conferences, books, training courses, consulting services, and inclusion problems. Galaxies are built on the assumption that their underlying technology is the answer to all problems. Each galaxy, thus, is based in a wrong assumption.
不要期望软件公司会为你职业发展路线出谋划策。You are solely responsible for the success of your career.
It is your duty to send the elevator down.
Do not critisize or make fun of the technology choices of your peers; for other people will have their own reasons to choose them, and they must be respected. Be prepared to change your mind at any time through learning.
Everybody is raving about Swift, but in reality what I pay more attention to these days is LLVM itself.
I think LLVM is the most important software project today, as measured in its long-term impact. Objective-C blocks, Rust & Swift (the two most loved strongly typed and compiled programming languages in the 2016 StackOverflow developer survey,) Dropbox Pyston, the Clang Static Analyser, ARC, Google Souper, Emscripten, LLVMSharp, Microsoft LLILC, Rubymotion, cheerp, watchOS apps, the Android NDK, Metal, all of these things were born out or powered by LLVM. There are compilers using LLVM as a backend for pretty much all the most important languages of today. The .NET CLR will eventually interoperate with it, and Mono already uses it. Facebook has tried to integrate LLVM with HHVM, and WebKit recently switched from LLVM to the new B3 JIT JavaScript compiler.
Great APIs enable great apps. If the API sucks, the app will suck, too, no matter how beautiful the design.
Remember that chunky is better than chatty, and that clients should be dumb; push as much logic as you can down to the API.
Do not invent your own security protocols.
Learn a couple of server-side technologies, and make sure Node is one of those.
Leave REST aside and embrace Socket.io, ZeroMQ, RabbitMQ, Erlang, XMPP; explore realtime as the next step in app development. Realtime is not only for chat apps. Remove polling from the equation forever.
Oh, and start building bots around those APIs. Just saying.
 

你唯一需要记住的就是,在这个行业中, your age does not matter.
Of course I do not know what will happen 19 years from now, but I can tell you three things that will happen for sure:
And maybe you will remember this talk with a smile.
翻译于Why I left Wall Street for FinTech,后续会更多选择相关的题材进行关注,来吧,加入Fintech Storm~
做出这个大的职业转变的决定主要是因为一推一拉的原因。当它们同时作用,你就会做出这个决定。
在2008年,在监管者意识到系统杠杆和复杂度不可能在短期内得到解决,美国银行业迎来了高度的监管。在这样背景下,像摩根斯坦利和高盛这样的投资银行被迫转变为银行控股公司从而获得流动性和融资发债券的可能。银行控股下就限制了类似于会计审计,高风险高获利的机会也少了,导致之前投资银行可以开展的业务都不好开展了
我工作的摩根斯坦利公司也被迫在这样的环境下转型。它把主要资源投入到财富管理业务(通过从花旗银行收购美邦这样的零售经纪公司)。这清晰的标志着它的重心从之前交易回报转变为获取顾客业务。
当时在圈子里,一般有两个选择。要么还是待在着不景气的银行业,要么去对冲基金大业中。大部分交易员选择了后者。
而我,选择了第三个:Fintech 金融科技公司。
比特币
谷歌,脸书,苹果,微软,亚马逊。这些顶级的技术公司每天会收到数以百万计的简历。所以几乎不用怀疑,它们有一套筛选好简历的优秀流程,不是吗。问题是,它们怎么做到的?
要澄清下,这不是一份可以在 Google 中搜索到关于 Google 流行面试题列表。实际上,它们精细调整的招聘流程不仅仅是一些对算法或量化物理这些关键词的基础查询。
如果,你和它们一样,也想招聘到世界上最优秀的技术天才,那么试试下面这些绝密的招聘策略。
每个人都能在精心准备后在合适面试时间上,回答好一系列的刨根问底的问题。但是想想看,如果你在他们还在睡觉时,在健身课上,甚至在上厕所时,给他们打电话面试。这就是那些顶级技术公司怎么找到哪些永远让自己专业让自己随时准备好应对挑战的方法。
如果在面试中,面试官和面试者在面试都不知道接下来该做什么。这是一个非常好观察时机,来看看谁会在这个沉默的时刻保持主动和发表观点。

故意把考察候选人需要做展示的房间中的投影设备『搞坏』。看看候选人逆来顺受和不介意调整,看看他是否足够好相处和合作。如果候选人对展示还有 B 计划,C 计划甚至 D 计划,这就是加分项了,因为这在技术领域非常常见。
如果候选人上家公司是滴滴,试着这样问,『你在快的工作呢多长时间?』注意看候选人改正你时的语调语气,他是保持冷静还是会显得很不舒服。技术公司常常会不可避免的被误解和被背黑锅,通过这个测试可以预测到他那时会怎么处理。

技术公司经常让候选人解决它们当前遇到的真实问题。这是一个很好获得免费帮助的方式
永远不要让你的职位申请人一直舒服的面试。通过那样的方法,找到那些在自己不舒服时仍然能保持专注,同时真的解决你公司一整天都没有空余会议室的难题。

在技术领域,可预测性是一件好事。 在面试时,不要担心一直问同一个问题多次。这是一个很好用于测试候选人一致性的工具。只有在面试高级职位时,候选人才会对他们的回答变得非常不一致。
ps: 这一段不是很理解,附上原文
『In the tech world, predictability is a good thing. During the interview, don’t worry about asking the same question over and over again because you keep blanking out. This is a great tool for testing the candidate’s consistency. Candidates should only be wildly inconsistent with their answers when interviewing for senior roles.』
把候选人安排在会议室中间,两端各有面试官。看看候选人能否同时能取得两位面试官的关注和同时能无压力的回答他们两人提出的各种有跳跃的问题。这是一个很好的机会看看他能否在困难时期把事做成。
问候选人问题,然后等他开始回答,就大声敲击键盘,并且向她解释说你在听他回答但是在记录笔记。你可以真的在记录或者仅仅是给朋友写邮件。看看他是否能够专注回答问题还是被打乱思路了。这样可以筛除那些被一些小事就干扰到无法顺利完成工作的人。
这是非常好的用于筛出那些并不是非常看重这份工作的人。看候选人是否为了这个想要 offer 而做出牺牲和努力。他是否认为该份 offer 就是他面前最好的选择。还是拒绝了因为上个月拿到的其他 offer。这就是帮你搞清这些问题的策略。
微架构:微服务的设计模式
We’ve had a lot of questions about the micro architecture and design patterns for microservices over the past few months. So today we’ll try cover both.
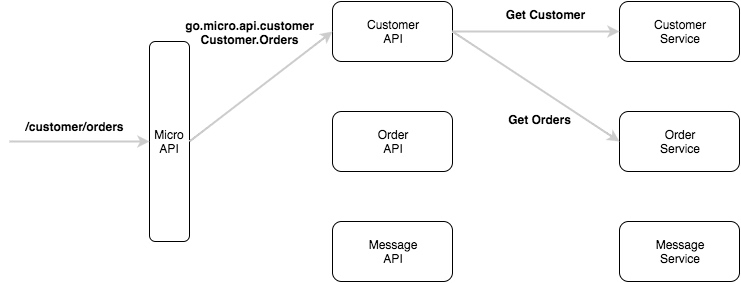 

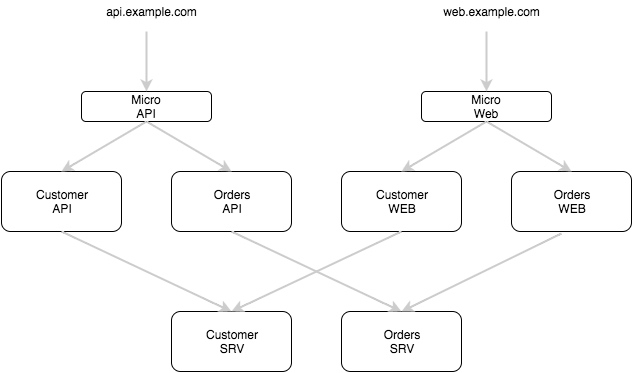 

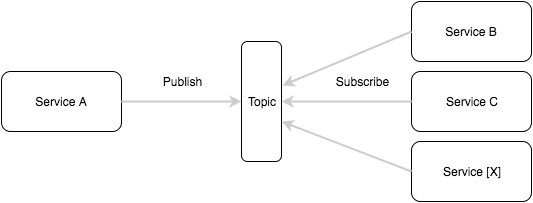 



 


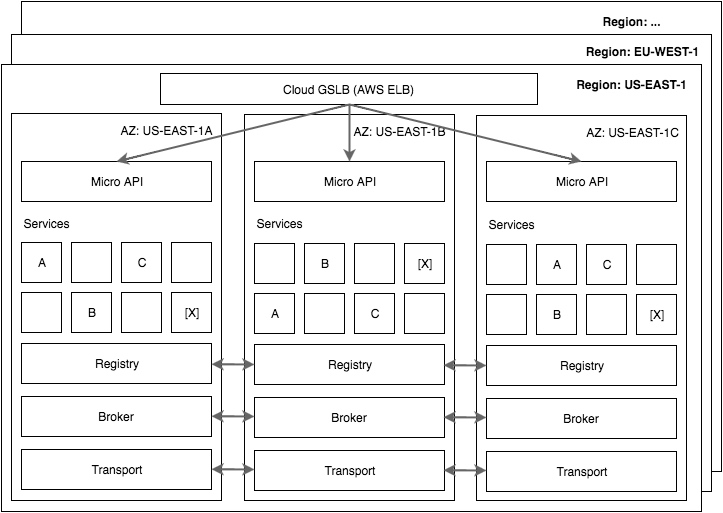 

Hopefully this blog post provides clarity on the architecture of Micro and how it enables scalable design patterns for microservices.
Microservices is first and foremost about software design patterns. We can enable certain foundational patterns through tooling while providing flexibility for other patterns to emerge or be used.
Because Micro is a pluggable architecture it’s a powerful enabler of a variety of design patterns and can be appropriately used in many scenarios. For example if you’re building video streaming infrastructure you may opt for the HTTP transport for point to point communication. If you are not latency sensitive then you may choose a transport plugin such as NATS or RabbitMQ instead.
The future of software development with a tool such as Micro is very exciting.
If you want to learn more about the services we offer or microservices, check out the blog, the website micro.mu or the github repo.
翻译自Working at Netflix 2016。每个人都想优秀的公司里工作,和优秀的同事合作,这样才不辜负你的大好年华,那我们看看在Netflix这样一个超一流的科技公司(PS:它家的微服务实践业界一流哈)是什么体验,你还差多少?
该文章翻译自Facebook官方博客,传送门
React Native 允许我们运用 React 和 Relay 提供的声明式的编程模型,写JavaScript来构建我们的 iOS 和 Android 的应用。这样的做法使得我们的代码更精简,更容易理解和阅读,这些代码还可以在多个平台共享。我们也可以加快迭代速度(因为在开发时不用等待漫长的编译。使用React Native,我们可以发布更快,打磨更多细节,让应用运行的更流畅。这其中优化性能是我们工作的一大重要部分,接下来讲述 Facebook 如何使应用性能足足提升两倍的故事~
当应用运行的更快,内容加载的更迅速,就意味着用户可以有更多时间来使用应用,流畅的动画让用户更加享受的使用应用。在新型市场中,2G网络和几年前的机型还是主力。这时那些性能良好的和那些运行卡顿就有很大差别了。
自从发布了 iOS 和 Android 版本的 React Native 后,我们团队一直在诸如 提升列表视图的滚动性能,优化内存占有,让 UI 界面更具响应性和加快应用启动速度 上做了不少工作。这其中应用启动关乎初次印象和是框架其他部分的压力源头,所以它是要解决的头等难题。
我们把Facebook的iOS版中的事件主页用RN重新实现(在更多标签页下点击事件进入查看)。这是个非常好的用于测试性能的例子,因为原生版已经做了大量的优化工作,而且该页面也是非常好的典型列表交互的例子。
接下来,我们自动化的 CT-Scan 性能测试来帮助我们自动定位到我们需要到的标签页。然后反复打开和关闭事件主页50次。在每次交互中,我们能够记录下从点击事件按钮到事件主页能够被完整显示的时间,我们也添加更多详细的性能埋点来告诉我们启动过程哪些步骤是缓慢或消耗CPU的
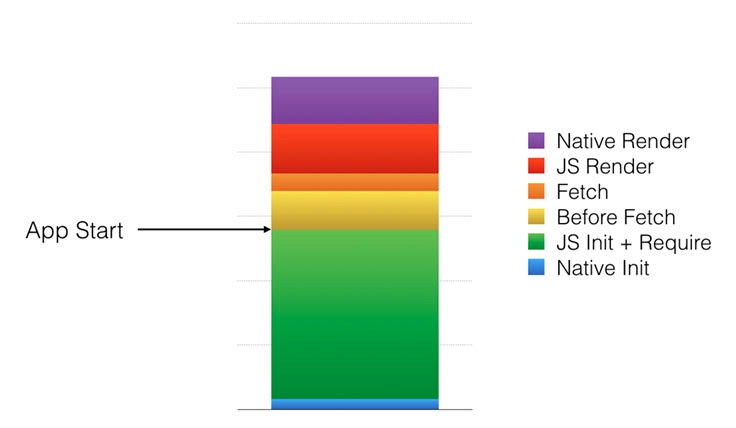
下面是我们记录和测量的一些步骤的大致描述:
1 原生启动:初始化JavaScript虚拟机和其他一些原生模块(如磁盘缓存,网络,UI管理器等)
2 JS初始化和依赖加载:从手机存储中读取被压缩的JS代码,加载到JavaScript虚拟机,从而解析和产生字节码,加载相关的依赖
3 取数据前:加载和执行事件主页的应用代码,构建Relay的查询语句,然后触发取数据。
4 取数据:从手机磁盘缓存读取数据
5 JS渲染:初始化所有相关的React组件,把它们发送到原生的UI管理器模块来显示。
6 原生渲染:在shadow线程中先通过根据 FlexBox 布局计算视图大小。然后在主线程中创建和定位这些视图。
我们根据于此的黄金法则是:永远不要忘了回归测试。我们持续的运行它来追踪性能提升和功能回归。开发者在提交改动的代码之前用它对特定的提交做运行和详细的性能分析。其他的一些测试也需要被同样的方式建立来衡量诸如功能性能和内存使用等
当我们设置好自动性能追踪,我们需要一个工具来给我们更多细节来决定启动过程中的那些部分需要优化。我们在我们框架里添加详细的启动/暂停的性能锚点,收集数据,使用 catapult 查看器来定位热点和阻塞线程间交互的。也可以从开发者菜单下触发开始对我们应用的性能分析。
在RN中,代码是在JavaScript线程中执行的。每次你要写数据到磁盘,在一次网络请求,或者取一些其他原生的资源(如摄像机),你的代码都需要调用原生模块。当你要渲染力你的 React 组件,它们会被转发到界面管理器的原生模块中,它在主线程中来执行布局和创建相应的视图。桥协议来转发请求到原生模块和被回调到你的JS代码(如果需要)。在RN中,所有原生的调用必须是异步的来避免阻塞主线程和JS线程。
在下面的事件组件的启动可视化图中,我们可以看到应用在 JS 队列中运行,为了显示事件列表,触发了相关的缓存读取(在本地存储队列中被异步触发)。一旦它取得了缓存数据,应用在 JS 队列用 React 渲染事件单元格,接着又传给栅格队列来布局和最终传给主队列来创建视图显示。这个例子展示了多个缓存读取(组合成单个常用读取操作可以做到更快)和一些React在JS线程上的渲染操作可以被统一合并。
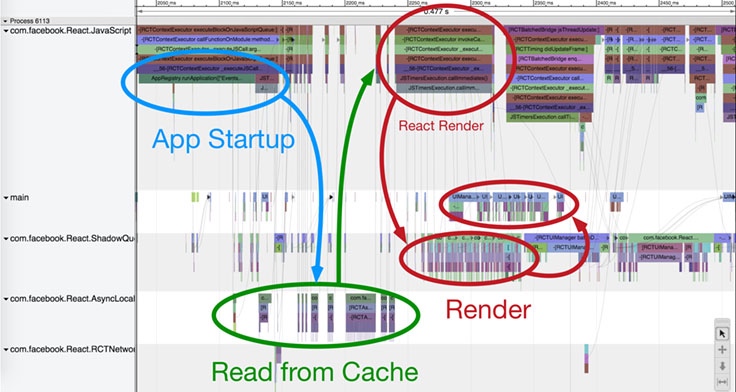
下面是那些我们在实施过程中最重要的性能和时序安排的提升做法,同时配有对应代码提交的链接。
几个月前,事件主页的启动在 iPhone5 上需要2秒。经过我们在RN上的大量性能优化工作,在伦敦,门洛帕克和纽约的RN,React和Relay团队,事件主页的启动被加快了一倍。而且大部分我们实施的优化是在RN的框架层的,这就意味着开发者们的RN应用也会自动得益于这些工作(当他们把应用迁移到最新版本的RN下
这些优化才仅仅是个开始:我们会继续在整个栈的各个部分都开展工作,从JavaScript代码解析时间到数据拉取性能。同时,你们也可以给社区贡献,学习如何让应用更快,在社区论坛提出你可能遇到的任何问题。
Picking the right architecture = Picking the right battles + Managing trade-offs
选对架构就等于选对合适的战场和权衡管理好各种的选项。
一些链接:
How to rock a systems design interview
System Design Interviewing
Scalability for Dummies
Introduction to Architecting Systems for Scale
Scalable System Design Patterns
Scalable Web Architecture and Distributed Systems
What is the best way to design a web site to be highly scalable?
How web works?
本文是16年4月9号 深圳 Node Party 的讲稿修改而成。活动总结
前几位的分享都特别棒,最后我给大家带来的topic是讲述我们广发证券这样一个传统券商在新技术如nodejs,微服务,koa上的一些尝试和使用经验吧。
先做个简单的自我介绍:我13年毕业,之前在百度实习做前端开发的一些工作,临近毕业去了豌豆荚这家创业公司做WebApp开发(主要集中在Angular使用上)。接下来从去年5月到目前所在的广发证券,先是做混合应用ionic相关开发,而现在主要是focus在Node.js在团队内部的使用和推广上。
私下我对技术还是非常感兴趣,结合自己思考和理解,会翻译和写一些文章在自己的github的博客上。

这是今天我要分享的大纲大致是:
// 如果时间允许会看下我们在开源的贡献和参与。
那我们是谁呢,广发证券,国内的TOP3的券商的信息技术部门。
从13年开始,我们已经重视相关技术的积累,我们标榜自己是一只fintech范的团队。
我们希望和国际投行对肩,『目前证券行业创新高涨尤其现在的互联网金融。
在国际化进程中,IT人员会占到 1/3的比例,国内远远不到,我们在这人员配置方面还在努力。
我们的技术选型时非常前言的,可以看到我们在13年就开始使用类似于angular, node.js等,算是非常早的运用这些技术框架开发复杂运用的公司了(金融领域
为什么这么做了,激进的采用这样的方式,首先这些新的基于互联网的新业务上允许了而且需要迭代快开发效率高的技术。然后最主要还是人员上的思考。
我们需要这样的技术态度:
那么就不难理解我们目前技术栈选项的背后,那么究竟 Node.js 在我们公司技术栈到底是什么定位呢?
// 去看我们的一些技术选项前,先看看我们是什么样的组织,再看看我们对开源技术的态度,这样才能得出一些背后的原因,也给你们一些技术参考。
//(我是较高复杂度的譬如购买一个理财产品很多逻辑的判断和,流量上的倒不是很大,但业务上流动的钱到时候百千万到亿的~,其次我们推崇的微服务就允许让我们xxx(因为它xxx
这是我们的技术体系全景图,对它感兴趣的会后可以详细在看)。
我们先要看第二列云端/edge部分,就这里就是我们nodejs发光发热的部分(它在接入层非常灵活的对接前面各种终端入口请求,做他合适做的事情)
然后在后面与第三列的微服务结合,打通和连接背后的更后端的东西(譬如大数据,金融柜台,交易总线等等)。

并且从去年开始,我们推崇从接入层之后到柜台之前的服务和业务都变微服务的形式来提供,在保证接口服务的健壮性的同时,提供接入层聚合原子化到具体用户场景下的接口和灵活性。 对微服务不熟悉的听众们/同行们没关系,在分享的最后我们会回到微服务,看看它和node.js的结合。

• 原子化服务 – 细粒度、独立部署、独立维护升级、独立扩容
• 所有服务内置平台层、应用层监控(Google Dapper类技术)
• 金管家、金钥匙、易淘金、开户系统。。。功能拆分、微服务容器、云化
• 应用层“聚合” – 不同应用场景聚合不同的微服务
可以看到我们的架构中
(性能速度损耗,但是用户不care,可能被传统的金融银行等『惯坏』了,关于钱财的还是别轻飘的好
好,现在我们知道了我们要在edge层实施一个强大的API 服务器来对接各种微服务,那在正式动手撩开袖子搞之前,有必要看下在更广的视野下理解它的历史和现状。因为在过于一段时间它们改变了不少。
最早的后端渲染页面,通过ajax来满足部分简单的前台交互(这时候后端MVC模型已经开始成熟 譬如rails, php,django 都是此中好手。
然后随着移动客户端iOS/Android快速发展和前端webapp化,越来越多的应用逻辑前移,富应用要求动态页面从而把渲染前移,所以此时接口要前后数据分离,所以restful这种基于资源为中心,加之http方法对应CRUD行动动作的,以status code 状态吗对应操作结果的接口框架和规范就流行起来。
但是问题还是有的:如资源接口的聚合上,接口数据的适用性上,要知道现在复杂的页面上不会那么傻傻的仅仅对应单个资源,它通常会依赖于多个相关资源的信息和部分信息。
所以有些基于RESTful扩展的接口约定协议来尝试解决。同时在新时代的,如GraphQL, Falcor,Meteor等来解决这些问题。
那么什么是基于RESTful扩展呢。我们知道RESTful有它3层的成熟度模型,业界也有如Github, Heroku Platform API 提供的指南。对于 JSON API 我们需要在类似于opt-field筛选特定字段,嵌入关联资源等进行统一抽象的接口理解,来满足业务上的一些需要,最好是在http request 中间件层面就处理好,不需要业务的controller在parse这些urlparams和body。
// 看起来每个开发者最后都会疑问那么关于API接口呢?很多人会直接想到RESTful API(因为太流行了),同时SOAP真的成为过去式了。同时现在也有不少其他标准如:HATEOAS, JSON API,HAL,GraphQL 等
// 第 2 级服务:使用多个 URI,不同的 URI 代表不同的资源,同时使用多个 HTTP 方法操作这些资源,例如使用 POST/GET/PUT/DELET 分别进行 CRUD 操作。这时候 HTTP 头和有效载荷都包含业务逻辑,例如 HTTP 方法对应 CRUD 操作,HTTP 状态码对应操作结果的状态。第3级服务: 使用超媒体hypermedia 作为应用状体引擎。
15年Facebook开源自己的relay,也引入了graphql(它是早在12年就被开始使用在它们的ios/andriod项目上)一种依赖于类型系统的数据查询拉取的描述语言。GraphQL 赋予客户端强大的能力(也是职责),允许它来实施几乎任意的查询接口。结合Relay,它能为你处理客户端状态和缓存,统一完成多个component的接口拉取。在服务器端实施GraphQL看起来比较困难。
网飞(NetFlix)的Falcor 看起来它也能提供那些Relay和GraphQL提供的功能,但是对于服务器端的实现要求很低。但现在它仅仅是开发者预览版没有正式发布。
这是现在流行的react技术栈(react+relay+graphql),我们发现之前ad-hoc query要多个复杂业务相关的接口需要后端实施,用graphql就简单多了,让client描述自己需要什么就行了。


// Servers publish a type system specific to their application, and GraphQL provides a unified language to query data within the constraints of that type system. That language allows product developers to express data requirements in a form natural to them: a declarative and hierarchal one.
需要值得一提的是,Meteor,算是异类但是通过类似DDP,Remote Method,pub/sub等非常高效的完成了前后端的数据同步。想想看:
前端说模板绑定时需要绑定最新的用户feed,那么通过live query,每次数据库的内容变化,变化的内容会自动同步到前端,模板就会重新render。
通过remote method,你向后端调用数据就像是一个方法调用只不过不是进程间的是跨网络的。但是它太异类的,我们没法在现有的架构下使用它。
所以我觉得现在有什么方案完美的),所以我们还是需要结合我们的场景实现自己的API Server。这里我们就引进了koa2。

那么为什么会选择它呢,主要是三个原因
应付异步IO我们有类似于callback,promise,node-fiber,generator/yeid的。
我们看下代码:这是读取目录下所有路径和markdown文件内容,然后拼接成字符串的操作。怎么样是不是非常直观不需要callback了,但是不用担心我们的操作仍然是异步的,不会阻塞和等待
await关键词必须在async function有有效,await通常等待一个promise的值。
const fsp = require('fs-promise');
async function readDirContent(doc) {
let paths = await fs.readdir('docs');
let files = await paths.map(function(path){
return fs.readFile('docs/' + path, 'utf8');
});
this.type = 'markdown';
this.body = files.join('');
};那错误处理呢,如果promise 抛异常可以被try catch住()
之前express的错误处理相信大家也都知道同步错误可以在app.use的next error-handling middleware,但是对于异步代码中却无能无力因为在你进入回调中已经丢掉调用栈了。除非要在每个node.js惯例的error-first的callback中,手动处理或者把他next出去往上推。
统一的错误处理意味着,就是说如同步代码的异常如json.parse对一个非法字符串进行转意时可以try catch,对于异步的类似于等待promise时被reject也能被try catch,但是如果你不去(否着会被吞掉这一点要除以)。所以我们一般需要类似这样的错误处理中间件放在全局的包下
// error handler to JSON stringify errors
const errorRes = require('./middleware/error-res');
app.use(errorRes);
module.exports = async function(ctx, next) {
try {
await next();
} catch (err) {
if (err == null) {
err = new Error('Null or undefined error');
}
// some errors will have .status
// however this is not a guarantee
ctx.status = err.status || 500;
ctx.type = 'application/json';
ctx.body = {
success: false,
message: err.stack
};
ctx.app.emit('error', err, this);
}
};
// 用于关闭前的一些处理如保存数据,记录错误,发送邮件等等
process.on('uncaught', ()={});中间件的写法也更直观了,这个是koa也都用的优势。看这个response-time的,在进入中间件时记住开始时间,然后await 等待后续中间件的执行,然后在结束后被交回执行权限后,计算diff
要知道得益于koa的回形针的写法,而不用像之前express那样,曲折
function responseTime() {
return async(ctx, next) => {
var start = Date.now();
await next();
var delta = Math.ceil(Date.now() - start);
ctx.set('X-Response-Time', delta + 'ms');
}
}中间件是非常重要的概念。要知道,一个Koa的应用就是包含一组async函数写的中间件的对象,然后按照一定顺序对请求操作返回响应。
那么我们看多个中间件是怎么运行的。我们发现请求先后从上往下进入进入response-time, logger, content-length, body 函数中,在body函数中我们执行yield后面的设置我们body内容后因为是最后一个中间件,所以执行又继续从下往上执行之前中间件yield后面的部分如设置header头如content-length,response-time, 打log等。整个执行顺序非常像右侧图表现的回形针的样子。

那么具体是怎么实现的呢?koa-compose 就是内部实现。下面这是它具体的代码(感兴趣的可以看下,可以发现就这十几行的代码就把这些中间件串联起来的逻辑

这些是比较常见的中间件,官方wiki上有详细的成熟的列表。如cookie的,body parse的,等等

把es6的generator和yield的变成es7的async/await写法
既然我们用上来koa2,那之前的koa1的中间件怎么办呢,官方推荐做法是在代码仓库提供next分支,来host新的async版本的中间件。当然可以通过koa adapter 这样的中间件来替我们转换。
// use Koa 1.0 middleware
app.use(function*(next) {
const start = Date.now()
yield next
const ms = Date.now() - start
console.log(`${this.method} ${this.url} - ${ms}ms`)
})
// koa-logger@1 only support koa@1
const logger = require("koa-logger")
// use legacy middlewares with adapt(...)
app.use(adapt(logger))// 内部实现co.wrap。 If you want to convert a co-generator-function into a regular function that returns a promise, you now use co.wrap(fn*).
关于验证我们有两个,请求入参如query,params,body的检查如是否存在,格式如email,字符长度等
关于数据模型的验证,mongodb 本身是schema-less,但这并不意味着我们容忍脏数据的随意插入(只是方便我们修改和扩展数据Schema,方便业务发展)。hapi的joi提供了很好的API,mongoose也有自己的plugin机制来实现validate,社区也有插件来统一把两套schema统一如从joi的生成mongoose的schema。
// 关于请求的入参验证
ctx.checkQuery('query', 'Invalid query').notEmpty();
ctx.checkQuery('type', 'Invalid type').
isIn(baseSearchTypes.concat(['all', 'stock']));
function assertPagintionQuery(ctx) {
ctx.checkQuery('page', 'Invalid page').notEmpty().isInt();
ctx.checkQuery('size', 'Invalid size').notEmpty().isInt();
}
var joiUserSchema = Joi.object({
name: Joi.object({
first: Joi.string().required(),
last: Joi.string().required()
}),
email: Joi.string().email().required(),
bestFriend: Joi.string().meta({ type: 'ObjectId', ref: 'User' }),
metaInfo: Joi.any()
});以上是koa web相关的,当然我们日常开发也少不了其他部分。譬如现在代码ES6化,构建npm scripts化(它会集中在持续集成,代码质量上),上线前准备(如性能调优,安全),web开发上下游等
很多旧代码用es5写起来比较verbose,可以使用最新的es6语法来改造,精简轻量很多。如解析构,模板字符串等等都不错。如之前从req.query中去数据。现在xxx
// before
var page = req.query.page,
, size = req.query.size;
// after
let {pgae, size} = req.query;
rp({
uri, params: {page, size}
});之前有些人吐槽说babel改过后,代码xxx,反正我们是没有遇到,代码不够复杂?!
首先确保你的基础node版本不小于5.6,Tip: 使用node 5确保我们的babel transpile 可以尽量让产出的代码精简 。因为大部分新的es6的语法在Node5中已经被实现了不需要babel再去transpile(听说有转错的风险还有性能也不好)
你会发现使用 similiairty 去跑没啥差别,我们看下 .babelrc 中的preset为 es2015-node5,然后就有两个babel的插件用于转换2a的代码
部署es6代码用于线上生产(先构建好 es5-compatible,加入到docker镜像中 )
eslint
{
"presets": ["es2015-node5"],
"plugins": [
"transform-async-to-generator",
"syntax-async-functions"
]
}现在的一大趋势,是把多余的Gulp也好,Grunt也好,去除掉。
为什么?因为npm本身提供很好的脚本支持,它不需要都与的gulp wrap(因为你还需要依赖于它去包少了或者它出bug都是问题),直接引入了你需要的工具如(uglifyjs, cssmin, babel等),通过灵活的hook来做一些构建task的设置
那我们看看用它可以具体做什么事情和我们又是怎么做到的
想必大家对前不久的left-padding的事件都有耳闻。一位开发者下架了自己的仅仅用于格式化字符串的一个函数就导致了很多开源项目构建失败。所以我们给出的建议是通过shrinkwrap锁定住要上线的版本,同时定期的通过npm check来检查依赖组件的更新情况。

这个特性在前端开发中已经习以为常了(如livereload, browsersync)。我们当然也可以通过pm2来设置,看个人喜好。为他配置一些需要ignore的目录,然后自由编码去吧。
运行 npm run dev就可以了, 可以看到ns中的一些特殊变量如 $npm_package_main来指定babel-node这个解释器来运行我们的入口文件(这样在开发时不需要编译代码
{
"main": "index.js",
"scripts": {
"dev": "nodemon --exec babel-node -- $npm_package_main"
}
}nodemon Simple monitor script for use during development of a node.js app.
使用 hurky 可以修改你的git命令,提供hook点在commit/push/merge 前执行检查。
譬如我们利用npm的hook(pre)在提交commit前运行下我们的单元测试等(在那些),在推送代码仓库前,执行我们的lint检查是否良好的代码格式等等。
甚至我们可以运行inspect,看看我们是否有存在代码的copy&paste这种情况。
说到测试,很多人说项目很赶没时间啊。还有人有些测试用例写起来还naive,不想写。其实我们并不需要对所有代码做测试。尤其在迭代速度很块的情况下很多需求没理清楚,说不定一些前天的在明天就要remove掉。
那么我们会集中在如下部分:
对这些进行测试:
我们真的应该非常关注我们的代码质量,想想看对于关键代码如基础组件,核心业务功能如果维护性不好,后续的需求和代码的更改都很困难等。
因为我们也接手过(相信大家也是),我们能不能避免这些呢,不要给自己挖坑(事实上我们也乐于给自己挖坑哈 - 啪啪啪打脸程序员的九本指南)以不符合设计原理 / 不易维护 / 不易调整 / 不够健壮 / 不够美观的方式解决问题
我们可以通过plato,从 代码复杂度, 代码行数(维持在100一下),lint出的错误数等,去关注它。
它也提供的基于日期对关键指标的统计看看代码改进的趋势,是不是朝着好的方向还是走想可怕的不好维护急需重构的深渊。

确保自己不要变成一下说的情况:

我之前也从国外的slide整理过一篇文章,对于代码坏味道进行了回顾。感兴趣的可以多看看,看看那些有问题的代码是不是和我们的很像,o(╯□╰)o。
我们当然可以通过 eslint rule 来发现:
如不允许复杂的switch语句,不允许重复reassign等,代码复杂度(if/else等嵌套不超过5等)
哈哈,希望我们尽量不写出这种糟糕的代码:

当然咯,我们代码通过层层考验,最终准备上线了,最好还是需要一些确保如对性能进行调优,具体koa上线设置,安全上有哪些考虑等。
我强烈推荐你们看strongloop(他从TJ手中取得Express的项目权限,接着被IBM收购专注于Node.js企业开发)出品的系列博文,看看如何优化。
如果你的应用很轻不需要前置的nginx,那么需要在引入诸如gzip, static service 这些中间件来高效处理。或者如果你的应用如果有前面的反向代理的nginx,那么开启它们。
正如之前提到的,不要使用复杂的同步代码阻塞你的event loop。要打好全量的log来监控你应用发生的一切即包括了operation error也要含有system error等。还可以用类似debug模块调整log显示的级别如在线上问题诊断开启verbose,没问题后再把环境变量改成info,warning之类来通过发送进程信号量给应用调整。
PS在我们一些关键的金融理财业务很多log都是不允许的删除的为了审核和合规,所以做好rotate等
这方面很多公司都非常了积累了,最后又一些链接
我们之前也分享过16年新node项目有哪些注意点的文章,这里也简单提下。
版本管理刚才有提到,需要特别重要npm install要加上--save, save-dep的选项不然会漏掉,或者你可以通过npmrc来设置默认就保存等
web应用开发的十二条军规是来自于rails社区关于web开发的一些通用型原则很有名很值得一读。
还有诸如代码风格结合eslint的统一等等
Web开发不仅仅包括了应用Server逻辑本身的书写,我们还需要关注上下游的组件。
那么最终还是要回到我们应用的运行环境, docker容器和k8s中,看看微服务到底是。
这种架构方式并没有非常准确的定义,但是在业务能力、自动部署、端对端的整合、对语言及数据的分散控制上,却有着显著特征。
微服务架构风格,就像是把小的服务开发成单一应用的形式,每个应用运行在单一的进程中,并使用如HTTP这样子的轻量级的API。这些服务满足某需求,并使用自动化部署工具进行独立发布。这些服务可以使用不同的开发语言以及不同数据存储技术,并保持最低限制的集中式管理。

这是它的大概组成,在左下角是入口的api gateway也是我们node重点关注的地方,在具体微服务实现后专门被路由到需要服务发现的机制,单独的微服务需要怎么被部署要借助于容器等新的运维devops的支持。具体文章
需要在一些节点加上agent,实现动态扩容等(mind shift from 机器性能到集群扩展容,随时挂掉预设)
公司整理的一些规范:docker化,无状态。从而方便Kubernets扩缩容或调整机器资源(重启等),或者有状态恢复机制,环境变量配置优先(配置项通过env传入,如数据库,redis等,不要使用卷映射(如logs文件通常打到console中,然后fluentd传入大数据(走kafka; node_modules ADD file 到docker中,提供健康检查脚本
那么我们想实践微服务,node.js web上需要做哪些工作了?
Docker, 用来打包,分发和在容器中运行应用的好用工具。它和虚拟机是类似的,独立应用和它的依赖到独立自包含的直到你可以在其他地方运行、允许我们更有有效地使用计算资源、他们的主要差别体现在它们的架构实现方案上
这是它主要部分和命令的图片,感兴趣的又可以看我的翻译的文章容器,Dokcer,虚拟化 - 写给开发者的入门指南

这是关于docker操作相关的命令,我们集成在npm scripts 中了
{
"rsync:gftest": "rsync --cvs-exclude -cauvz -e \"ssh -A gf@<relay-ip> ssh\" .es5 ubuntu@<dest-ip>:/opt/gf/gfwealth-composite/",
"docker:prebuild": "rsync -avz --exclude .es5 --exclude .idea . ./.es5 && babel . --out-dir ./.es5 --ignore ./.es5,./node_modules",
"docker:build": "cd .. && docker build -t <private-docker-host>/gfwealth-composite:koa-2016-03-17 .",
"docker:run": "sudo docker run -d --name gfwealth-composite -p 8000:9321 -v /opt/gf/gfwealth-composite/logs:/opt/gf/gfwealth-composite/logs -v /etc/localtime:/etc/localtime:ro --env-file=\"config/env/product\" docker.gf.com.cn/gfwealth-composite:koa-2016-03-17",
"docker:restart": "npm run docker:run && npm run docker:rm"
"docker:rm": "sudo docker rm -f gfwealth-composite",
"docker:push": "docker login docker.gf.com.cn && docker push <private-docker-host>/gfwealth-composite:koa-2016-03-17"
}我们的web应用接受请求,也发送请求。 我们需要对这些请求进行记录和追踪,这样才能对一些用户的具体操作进行trakc甚至replay来辅助我们debug用户的线上问题。
尤其在我们微服务下,对于大量原子化的外部微服务的请求返回数据进行审视和使用杜绝可能存在的外部broken或者不符合预期的返回搞挂我们的应用,辅助和对口同事撕逼。
这是我们的代码,request本身支持debug模式,我们通过request-debug来对请求响应生命周期中的关键点进行监听,记录log。如状态码,响应时间,用户id,返回的部分结果等等。
require('request-debug')(rp, function(type, data, r) {
// put your request or response handling logic here
// Todo: request-post data lost? response json.stringify broken?
if(type === 'request') {
var {debugId, uri, method, body} = data;
var userId = data.headers.userId;
var more = body ? '' : ('-'+body) + userId ? '' : ('userId:'+userId);
debug(`${debugId}-${method}-${uri}` + more);
}
if(type === 'response') {
var {debugId, statusCode, body} = data;
debug(`${debugId}-response-${statusCode}-`+JSON.stringify(body).slice(0, 155));
}
});我们当然可以通过一些工具来可视化这些,如下面RisingStack的strack和Google开源的zipkin,这个分布式的追踪系统来帮忙做这事情,如清晰看到整个请求链路中依赖的接口个别耗时等。


我们使用paypal的confit,来加载默认的配置,还会根据通过环境变量env来自动加载环境相关配置文件(做到差异化配置,还有很多增强协议如从环境变量中读取,从yaml文件,从特定文件读取内容,读取相对目录路径到绝对路径等等。
从环境变量读取你的外部依赖非常重要在微服务下面,我们依赖于此
社区还有nconf,选一个你顺手的使用起来吧。
// envfile - 可以在 docker run 的时候以env-file 参数带入
GFWC_storeExShopList=http://shopdev.gf.com.cn/api/store/shop/excellentshop/{id}/{page}/{size}
// 配置:
{
"env": "dev",
"api": {
"articleSearch": "env:GFWC_articleSearch"
}
}我们非常重视开源技术,去IOE化。
所以从去年开始,开源上的做了一些工作,回馈社区:
可以看到正是我们在技术上的尝试,使得我们在 Node 及其相关的技术选型形成来今天的风格
今天很大而全的跟朋友们过了下广发在一些技术上的实践,思考和观点。每个知识点一般都会有外链给感兴趣的同学会后继续学习和了解。
后端的纵深很多,前端的涉及面很宽,这就是我们折腾的现状。
谢谢大家,可能今天的内容比较多,不管怎么样希望今天的分享能让大家有些收获。
我个人的联系方式是:ghlndsl,微博,Twitter),邮箱:[email protected]
我们现在还持续长期的招人,准备好FinTech Storm了,来撩开袖子一起和我们 玩到想玩的技术,赚到想赚的钱 ~
没过瘾,来深圳海岸城约饭交流,SCC 8 楼16年中我们会有分享会,更深的技术交流还有金融业务知识
今天的纽约时报关于职员有时候会破产的文章很值得阅读。不过作为职员应该也会喜欢上周Hunter关于如何在创业公司致富的文章,下面是我在这方面的一些想法。
一个我被变着法子,反复问到的问题就是:『加入创业公司X后,我会赚到大钱吗?』
待补充
If you want to get rich, your best bet on a risk-adjusted basis is to join a profitable and growing public company. Google for short. Make $200-500k all-in a year, work hard and move up a level every 3-5 years, sell options as they vest (in case you joined Enron), and retire at 60, rich. This plan works every time.
但是有一点要记住:永远不要仅仅因为钱才加入一家创业公司!
明确自己想要什么。你希望在产品市场打开前加入,还是希望有清晰商业模式后在加入。你需要薪酬吗,要多少,你介意工作内容是否和自我定位匹配,介意工作地点,是否出差等。大部分人会发现最终发现自己的这份工作并不适合自己(因为他在找之前并没有想清楚想要的完美职位是什么样的)。主动积极的推进。很多人并没有做到。创业团队在面试你,实际上你也在面试创业团队。选择是双向的,写出你的评价标准。放眼200个创业团队,联系其中50家,再和20家进行初次的面试,只和挑选的5家进行下一轮,最后在2-3个好的机会中选择。如果你是被动的,你只和很小一部分的创业公司联系,那么你的选择也是受限的。通过这个你可以在短短几个小时内选到还不错的创业公司。押宝在好的同事和团队文化上。除去其他的,我观察到找到优秀的同事(聪明,勤奋,自我驱动的等)和相匹配适应的团队文化,你会工作的很快乐即使公司可能最后黄掉。如果你只是看重要做的产品是否足够吸引人,薪酬回报是否高,那么你可能最后对这段经历不会很开心。接受薪酬。靠实力说话。不少创业团队招聘开发者把他们叫做CTO架构师之类的。这没什么意义,你没法帮他变成CTO。如果你想成为CXO,那么就靠实力说话。进入创业团队,就意味着发展不受限,和创始人约好,你想在这里学到成长到什么样,然后给这个目标设立对应的里程碑,在各个阶段配备你需要的资源,然后就努力把这创业公司做大,然后自然而然你就是CXO了。Discount the vertical去学点商业知识。关于透明和开放。公司不可能对员工公开所有的信息和细节,尤其是关于招聘薪酬期权等。但是,通常意义上需要给到足够的信息来帮助员工做出明智的决定(译者:之前待的豌豆荚在这方面就做的非常,Google Docs总能找到你想要的需要了解的)。例如说,你的期权占比。信任就像条双向街道,如果公司对员工隐瞒起欺骗,那么之间的信任也很难维持。人生在世不要为这些事烦恼担心咯~你们中很多人可能注意到了:在职位列表中,最近有个新类别在不断的如雨后春笋般冒出。
你们可能也注意到了有些工作看起来非常有趣,可能比你能接受上下班通勤范围内发现的工作机会都有趣。我认为每个人都应该有机会做他自己真正感兴趣的工作。如果我创办个公司,我找人的第一考察要素就是候选人是否对我们要做的足够有热情,其他的指标都没有这个重要!
那么现在的问题是你该如何面试哪些你们梦寐以求的远程工作机会。接下来我们看看一些指导意见和一些你会向可能的远程工作的老板问的问题。
大部分我为之工作和支持过的公司都允许某种程度的远程工作。很明显一些比另一些好,因为远程工作对员工和老板都有一条较为陡峭的学习曲线。
一般而已在职位列表中出现标为远程的工作是指彻底的远程工作。这意味着你可以完全可以飞刀另外的国家去间一个朋友,在一个季度(甚至更少)才见上同事们一面(很显然是除了视频聊天的方式)。有时候你也不一定非要现场见他们。通过类似于Slack/Hipchat,像Skype或Google环聊这样的视频聊天工具,项目灌流工具等,交流沟通工作很容易被完成,对,别忘了还有电话和电子邮件。
我相信有很多重要的事要注意,我建议你们在下面回复评论~
好的回答:『我们员工大概有25%在远程工作』
不好的回答:『事实上你会是第一个,我听说把职位设成远程可以吸引更多人。对了,你考虑换城市到我们这吗?』
好的回答:『我们通常在网聊,但是通常在站立式早会上会接视频会议。除了小明(Fred)他在船房上网速带宽不高』
不好的回答:『我们使用 XXX 项目管理软件和电邮,大概就这样』
好的回答:『几乎一整天都在用。他们经常坐在旁边不转头聊却在聊天室中发消息~』
不好的回答:『既然他们都在办公室那就没必要用网上聊天了』
好的回答:『我们有个大画板,每个人都有个APP可以在在上面图画,其他人都能看到。我们也会让每个人参加项目的视频会议,如果有需要会定期对一些难题进行探讨』
不好的回答:『我们通常不会把人都叫上。在办公室的人会在白板上图画,然后就开始实施项目』
好的回答:『一般会在5,6点,也看他们什么时候开始上班。6点半以后的工作一般会非常低效率。但是偶尔也是需要发一些紧急的消息和文章等』
不好的回答:『通过IM聊天,我们随时随地交流,让团队在24/7/365都是可联络到的』
好的回答:『我们用特定的工具解决特定的问题。我们用Github作为仙姑管理,Slack作为异步沟通工具,Skype来做视频会议。』
不好的回答:『我们使用邮件,还有不少项目管理软件,bitbucket,github还有一些内部的gitlab项目仓库,一些人在AIM一些人在IRC,其他人用Slack,有个小组用邮件沟通的特别多~』
以上各种问题和回答的评判标准,主要是看看管理是否足够好,来利用好远程工作提供的那些好处优势。如果管理层不能100%支持远程员工,那么你可能会有个理想的工作机会,做着自己理想的产品但是事情很快会变得糟糕,让你想要逃离~
你可以试着在多个提供远程工作机会的公司面试,看看他们是怎么回答这些问题的。通过这些不同的回答你可以分辨出哪些在文化骨子中就支持和提倡远程工作的,和那些刚开始转型并没有十分认同这概念的公司~
这篇文章是为了帮助那些开始面试一份远程工作的人。所以请把你的想法和点子评论回复出来,很可能因为你的贡献就能让那些原本很可能进入远程工作的坑的候选人找到份可以和之成长为之奋斗的好远程工作机会!
16 Apps That Will Help You Travel The World
 

 

It can sometimes be a pain to book a trip when you want to visit multiple cities in between your first and last stop. QuestOrganizer makes the multi-destination trip easier to plan by helping you find free stopovers, build a custom flight using a number of one-way flights, and hack your trip to find the cheapest total rate possible. We love the simplicity of this app.
 

 

 

 

 

 

 

 

 

 

 

 

 

 

翻译自Growth is a system, not a bag of tricks PS:译者也是上过增长黑客这本书作为案例的人呢~。 本文是 Manifesto 大会上通过Q&A和视频编辑而来
最近我被Tim Chang(他是这次 Manifesto 大会的总组织人)采访了,我们对增长这个话题进行探讨,再尝试了多种策略,成功验证过不少增长的试验。
下面是这次分享和Q&A环节的关键点总结。
 

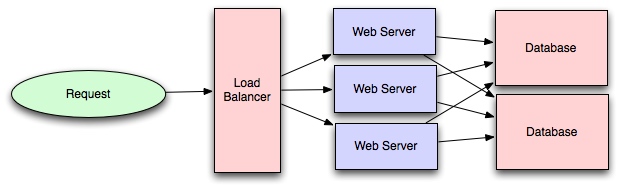
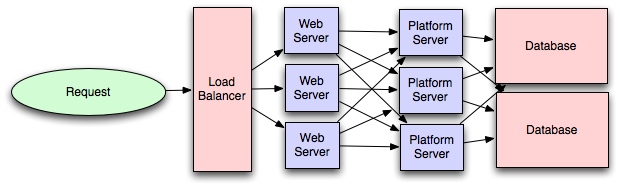
如果你是位程序员或技术爱好者,你可有可能已经听说过 Docker:用来打包,分发和在容器中运行应用的好用工具。这段时间获得巨大的用户关注,从普通开发者到系统管理员之类的。对于那些像Google,VMware和亚马逊这样的大公司都在开发支持它的服务。
不管你是否在脑袋中立即对Docker有了使用场景,我仍然认为去理解诸如什么是容器和它和之前虚拟机是什么关系等这些基本概念都是非常重要的。虽然网上有大量的优秀的Docker使用指南等资源,但我还没发现一些针对入门者的概念性指南,尤其是容器是有什么组成等概念上。希望,这篇博客能解决目前这问题。
让我们从理解什么是虚拟机和容器开始吧。
在各自的目标上看,容器和虚拟机是类似的 - 就是独立应用和它的依赖到独立自包含的直到你可以在其他地方运行。
进一步,容器和虚拟机消除了实体机的需求,允许我们更有有效地使用计算资源(在能源消耗和成本花费上)
容器和虚拟机的主要差别体现在它们的架构实现方案上。让我们细细看来:
一个虚拟机通常就是对一台真实电脑的虚拟,就像真机那样用来执行软件。
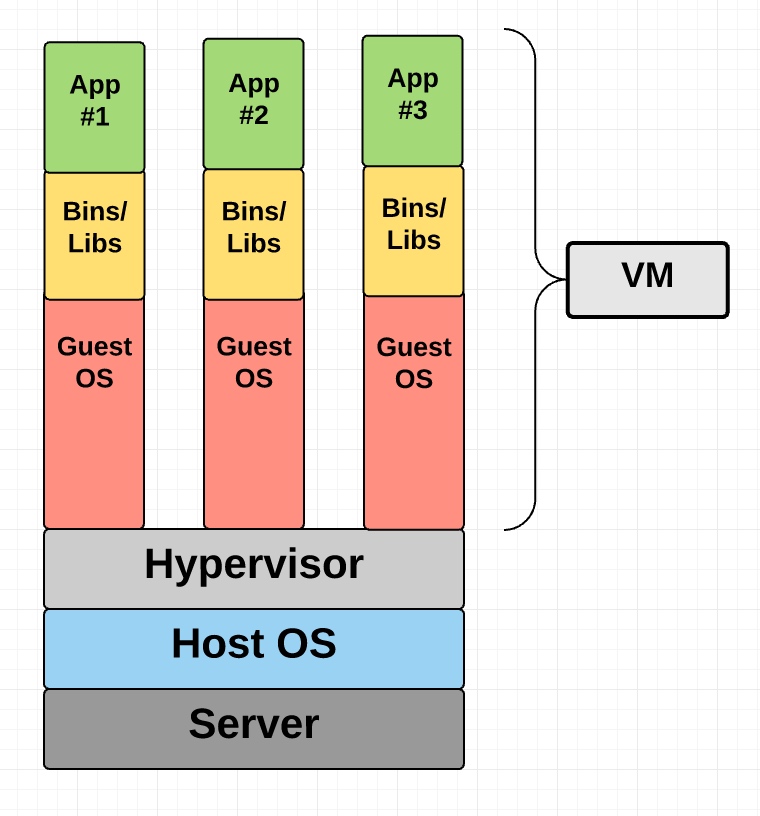 

不像虚拟机技术提供硬件虚拟化,容器通过抽象用户空间(用户态)提供操作系统级别的虚拟化。随着我一步步解包容器这个术语,你就会理解我所说的。
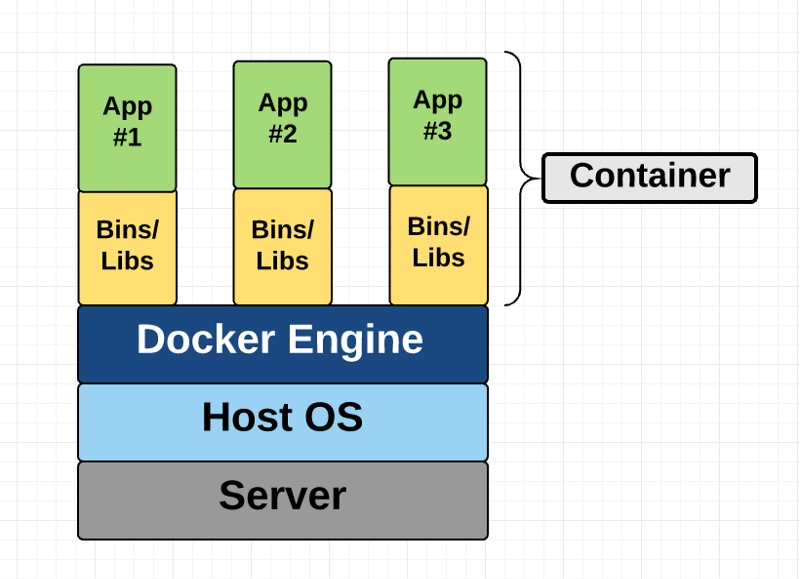 

Docker是基于Linux容器之上的开源项目。它使用了Linux内核特性如命名空间和控制组在操作系统之上来创建容器。
容器从不是个新东西。Google已经使用自家的容器技术数年之久了,其他的Linux容器技术包括如:Solaris Zones, BSD jails, and LXC也面世了好几年了。
那为什么Docker突然一下子流行起来了呢?
最后也同样重要的是:谁能不喜欢这么可爱的 Docker 鲸呢
 

现在我们先全局看下,然后一步步过下Docker的主要部分
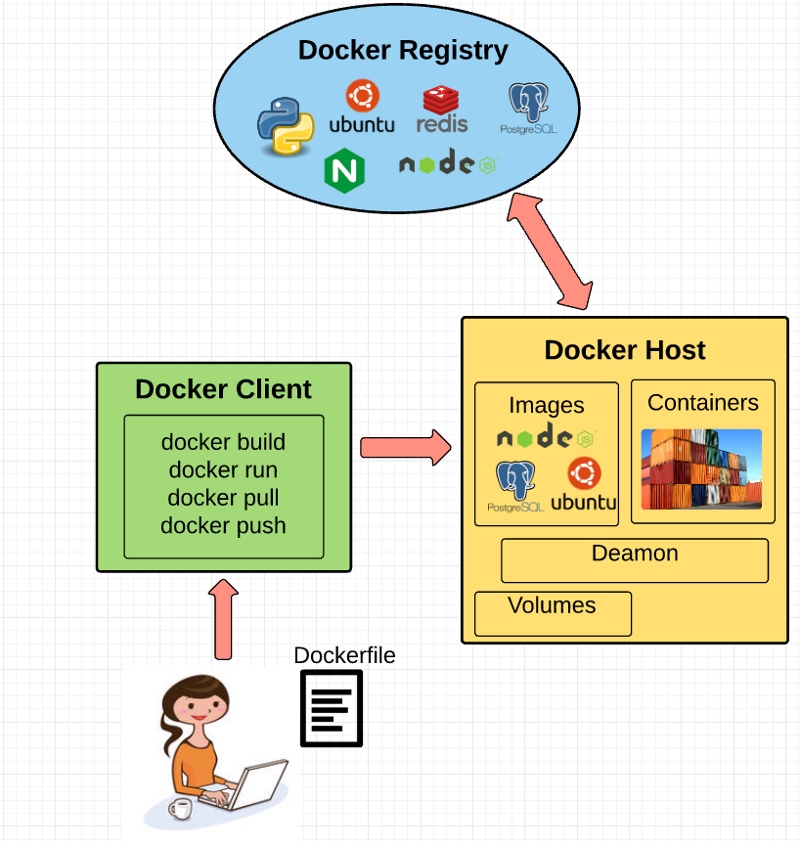 

docker引擎是docker运行在的那层。它是轻量级的运行时和诸如管理容器,镜像,构建和其他等系列工具。它原生运行子Linux系统上,有下面部分组成:
Docker客户端,是我们作为Docker的终端用户需要打交道的。把它想成Docker的界面UI。
你和Docker客户端沟通,而它会最终把你的指令送给Docker守护进程去执行。
Docker守护进程是真正执行那些先被送给Docker客户端命令的地方,如构建,运行和分发你的容器。Docker守护进程在你的宿主机器上运行,但是做为用户你从不用直接和它打交道。Docker Client也可以在宿主机器上运行(但不是强制必须的)。它可以在不同机器上和宿主机器上的Docker守护进程进行通信。
Dockerfile正是你把如何构建Docker镜像的一步步指令记录的地方。这些指令可以是:
迄今一旦一设置好了 Dockfile,你就可以用 docker build 命令来依据它来构建镜像了。下面是一个 Dockerfile 的例子:
# Start with ubuntu 14.04
FROM ubuntu:14.04
MAINTAINER preethi kasireddy [email protected]
# For SSH access and port redirection
ENV ROOTPASSWORD sample
# Turn off prompts during installations
ENV DEBIAN_FRONTEND noninteractive
RUN echo "debconf shared/accepted-oracle-license-v1-1 select true" | debconf-set-selections
RUN echo "debconf shared/accepted-oracle-license-v1-1 seen true" | debconf-set-selections
# Update packages
RUN apt-get -y update
# Install system tools / libraries
RUN apt-get -y install python3-software-properties \
software-properties-common \
bzip2 \
ssh \
net-tools \
vim \
curl \
expect \
git \
nano \
wget \
build-essential \
dialog \
make \
build-essential \
checkinstall \
bridge-utils \
virt-viewer \
python-pip \
python-setuptools \
python-dev
# Install Node, npm
RUN curl -sL https://deb.nodesource.com/setup_4.x | sudo -E bash -
RUN apt-get install -y nodejs
# Add oracle-jdk7 to repositories
RUN add-apt-repository ppa:webupd8team/java
# Make sure the package repository is up to date
RUN echo "deb http://archive.ubuntu.com/ubuntu precise main universe" > /etc/apt/sources.list
# Update apt
RUN apt-get -y update
# Install oracle-jdk7
RUN apt-get -y install oracle-java7-installer
# Export JAVA_HOME variable
ENV JAVA_HOME /usr/lib/jvm/java-7-oracle
# Run sshd
RUN apt-get install -y openssh-server
RUN mkdir /var/run/sshd
RUN echo "root:$ROOTPASSWORD" | chpasswd
RUN sed -i 's/PermitRootLogin without-password/PermitRootLogin yes/' /etc/ssh/sshd_config
# SSH login fix. Otherwise user is kicked off after login
RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
# Expose Node.js app port
EXPOSE 8000
# Create tap-to-android app directory
RUN mkdir -p /usr/src/my-app
WORKDIR /usr/src/my-app
# Install app dependencies
COPY . /usr/src/my-app
RUN npm install
# Add entrypoint
ADD entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
ENTRYPOINT ["/entrypoint.sh"]
CMD ["npm", "start"]
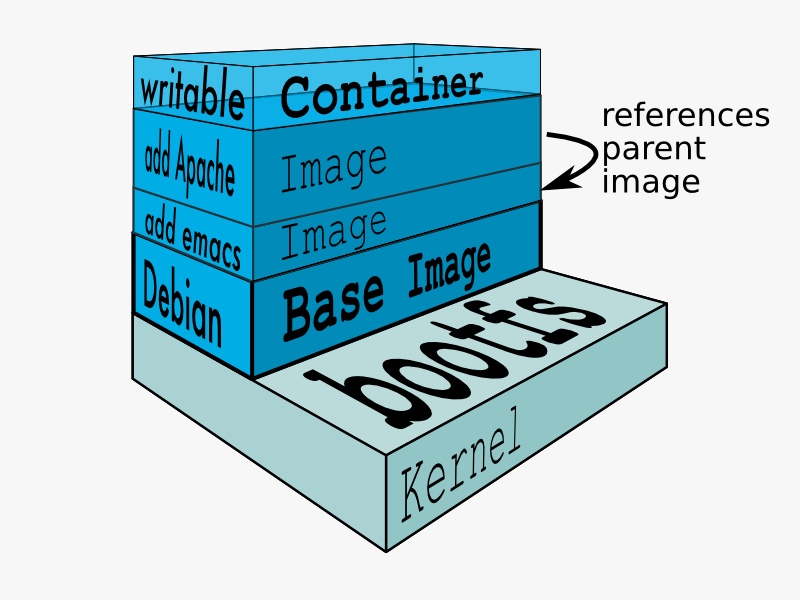
镜像是从你在Dockerfile写的指令中构建生成的只读模板。镜像既定义了你需要什么软件和它的依赖同时定义了在它启动时需要运行的进程。
Docker镜像是用Dockerfile构建的,每个在Dockerfile中的指令都给该镜像添加了新的一层,通过layer层这概念代表镜像中的文件系统被添加或被替换的那部分文件。Layers层是Docker能够足够轻量但能有强大结构的关键点。Docker使用联合文件系统实现了它:
Docker使用联合文件洗通过你来构建镜像。你可以把联合文件系统看作是可堆栈的文件系统,意味着不同文件系统(内部叫做分支branches)的文件和目录可以透明的层叠来形成单一的文件系统。
那些目录中内容如果和它所要层叠的分支中有相同的路径,那么会被看做单一被合并的目录。这样就避免为每一层单独创建拷贝的需要了。实际上,它们可是都是对相同资源的指针。当特定层的内容需要被改变,它会先创建拷贝然后在修改本地的拷贝,不去动原来的。这就是看起来可以写却没有写权限的文件系统是如何实现的(换句话就是,一个先copy后write的系统)
分层的系统提供了下面两大好处:
卷是容器的数据部分。当容器被创建时候被初始化。卷允许你持久化和分享容器的数据。数据卷和默认的联合文件系统是独立的,作为宿主系统中的正常文件和目录的形式存在。所以,如果你删除,更新或重新构建你的容器,你的数据卷不会被影响。当你想要更新容器时,你可以直接去更改他(作为奖励,数据卷可以在多个容器见分享和复用,这一点很赞~)
Docker容器,正如上面讨论的,把应用软件和它运行所需要的一切都打包到一个看不见的盒子中。它包含了操作系统,应用代码,运行时(如.NET或JVM),系统工具,系统类库等等。Docker容器是从Docker镜像中创建而来的,既然镜像是只读的,Docker在这个只读文件系统镜像之上加了可读写的文件系统来创建一个容器
同时,在创建容器时,Docker也为其创建了网络接口从而容器可以和本地网络『对话』通信,把尚有的IP地址绑定到容器上,接着运行你在定义镜像时声明的进程。
一旦你成功创建了容器,你可以在任何环境下不做修改的运行它。

唷,Docker还包含了不少东西。一件始终让我感到好奇的事情:容器是如何实现的,尤其是既然这其中没有抽象的基础设施边界在容器周围。经过大量的阅读,我大概了解了现在准备尝试解释给你们听听。
容器这个词事实上是用来描述一些不同特性如何在一起配合工作,可视化的像个容器。让我们快速过下它们:
1) 命名空间
命名空间提供给容器对底层的Linux系统它们特殊视图,控制容器能看看到和访问它们什么什么。当你运行一个容器,Docker为要被运行的那个容器创建命名空间。
在Docker利用的内核中,有好几种不同类型的命名空间,如:
ps aux来查看你系统中运行中哪些进程,那么你肯定对PID这列有印象。PID命名空间让容器对它们的查看和交互的进程有自己特定范围的视图,包括独立的init初始进程 PID 1(它是所有其他进程的祖先。Docker 使用这些命名空间一起从而隔离和开始了容器的创建。下面我要聊的特性是控制组
2) 控制组
控制组(通常也被称为 cgroups)是Linux内核特性用来对一系列进程的进行隔离,优先和为资源(如CPU,memory,磁盘 I/O,网络等)使用负责。在这个层面上,一个cgrou确保了Docker容器只使用它们需要的资源 - 同时,如果要需要,对容器所能使用的资源进行约束。cgroups也确保单一的容器不会消耗完所有的资源,使得整个系统挂掉。
最后,联合文件系统是另外Docker使用的特性。
3)联合的文件系统
在上面 Docker 镜像章节描述过。
这实际上就Docker容器中有的所有了(当然,魔鬼都在实现的细节中 - 如何管理不同组件之间的交互调用等)
我希望你现在已经拥有一些关于容器Docker等基本知识,用于下一步的继续学习或有一天在项目中的使用。
按惯例,如果我说错什么或有什么好建议,不要吝啬留下你的评论。
16年程序员最需要看的9本小书 - 啪啪啪打脸指南
本文罗列的这些书籍封面其实是各种典型的反模式,不过它们真的是非常常见以至于大家都习以为常了~
你最需阅读的一本编程书籍(其实编程书留下这本就够了!)
搞笑的是,在 Gitbook 上真有这样的小书(https://tra38.gitbooks.io/essential-copying-and-pasting-from-stack-overflow/content/code_licensing.html) 从 code licensing issues, code attribution, code selection 上来论述
 

唯一正确写 JavaScript 的方式就是每周换个花样重写一遍!
事实上拥有一个不断进化和自我革命的社区是一件很不错的事情,但前提是要你要接受这样的现实。不断学习和充实自己,并且透过变动改变的这些抓住真正永恒和持久的东西。
关于JavaScript社区为什么这么生机勃勃,折腾不止,请看文章永不停步(折腾死人)的JavaScript 生态
 

不写单元测试你还有千般理由!!
单测其实有很多好处,譬如尽早发现问题,为重构代码和更新代码逻辑提供保障,简化集成(因为单测从细节底层入手),可以起到文档作用(详细完善单测用例完全可以),导向设计(测试驱动的更容易让你设计出优雅低耦合的代码)
你要对如下的代码准备好足够的单元测试用例
 

你说你下周会开始重构这坨意大利面条似的恶心回调嵌回调代码?! - 你TM在跟我开玩笑?
交付的确很重要,但是这绝不是让你写出烂代码的接口。
以不符合设计原理 / 不易维护 / 不易调整 / 不够健壮 / 不够美观的方式解决问题。
比如水管连接处生了锈开始漏——
• 把水管系统整个重新布置成没有接头的管线,叫做 refactor
• 按原样把锈掉的水管换新的,叫做 proper fix
• 把水管拆下来用防渗胶带缠住螺丝纹再装回去,叫做 patch
• 叫你女朋友先把漏水的地方捂住然后下面放个脸盆接漏水,叫做 monkey patch
• 用电焊把接头焊起来,叫做 hack
• 用口香糖塞住漏缝然后用水泥把接头浇筑起来,结果因为那一大坨太重,下面不得不放一根木棍撑着,叫做 dirty hack
Dirty hack 不一定总是坏事,如果你没有脸盆、电焊、管钳、女朋友、新水管和防渗胶带,而这套水管系统反正就快整个报废了的话。
 

你还在花时间修复那些挠人的bug?
你是10X工程师,怎么可能出错,肯定是别人的问题。是他们的手机,浏览器的问题,一定是!!很多工程师的确是这样解决问题,一些特殊case,一些在设计代码没有考虑的情况,就这样被他忽悠过去了。
 

要做『温赵轮』式程序员?那么感觉拿起这本书开读吧。
表现型选手就是这样,他们常常需要挑活做,去做那些看起来很高大上的事情,却不愿撩开袖子去处理细节去干脏活累活。
他们也经常在简历上写着 XXX 项目的主要负责任(实际上很可能就是参与了一部分,做了边缘系统的部分功能)。或者在简历毫不谦虚的写着精通XX编程语言(实际上很可能就是用它写过helloworld而已)。或者在简历大大方方的写着熟练使用XX消息队列(实际上可能也就仅仅是看了篇肤浅的博客而已)
 

如果连你自己都看不懂,那就更棒了!
他们对系统代码的要求很低,『它不是能跑吗,你管那么多干什么』
这样的态度,让后来的同事很难推动后续的工作。譬如总是有莫名其妙的错误像是被它黑洞似的吞掉了,让周边模块的开发者背黑锅,一旦定位进去就像是在漆黑伸手不见五指的下水道走路,胆战心惊瑟瑟冷风还有弥漫空中的坏味道(代码逻辑很绕,变量名称很奇葩看不懂,几乎没有log日志打印出等等)
 

在网上总能找到让这些问题消失的方法!

如果你项目的依赖少于72个npm的包,那么你的代码是那么的孤独,赶快拿起这本书开始阅读吧。那些网上陌生人写的代码总是打包票的好是吧?
这些人真是把不重新发明轮子的优良传统发挥到极致,可能就是为了用某个函数方法就把一个巨大的依赖库加入到代码仓库中(后续花费在安装依赖上的时间,很可能超过了那个简单函数方法编写上),更有甚至不把依赖下载类似于 packages.json,bundler,requirements.txt等中,居然让后续协作人去生产机器上把依赖直接copy回来(orz...)PS:要用好类似于 pip freeze, npm shrinkwrap 等功能啊
 

title: 【Review】 成为高效工程师
首先,作者有本书The Effective Engineer。主要亮点是一手的最新的故事和技巧从硅谷创业公司,很多技巧非常实用和有帮助。譬如顶级的软件技术公司,如 Google, Facebook, Twitter, 和 LinkedIn 这些家喻户晓的; 快速成长的中型独角兽公司,如 Dropbox, Square, Box, Airbnb, 和 Etsy; 还有那些酷炫的初创公司,如 Reddit, Stripe, Instagram, 和 Lyft。
作者的书其实是从他两三年前的博客中抽取的:
| 书籍截图 | 作者博客 |
|---|---|
 |
 |
这篇文章主要是针对作者在谷歌内部的 Google Talk做的分享,进行总结和整理。传送门
那些牛逼的工程师,哪些被提拔为高级工程师或公司里团队leader的哪些,能产出比起其他程序员的10x的影响力,不是通过工作10倍的时间达成的。而是因为他们做了高杠杆的事情。那么有哪些高杠杆的事情呢?
把那些优先级高的项目和任务完成,来产出影响力
学习效率成倍提升,像个复利指数曲线。
你学的越多,以后学到越快。
这一块也是老生常谈来,不清楚的可以结合阅读李笑来的文章
在日常工具上的投资来提升加快迭代速度。我发现那些成功的工程师们,绝大多数都是会花时间为自己写工具的人。作者建议花日常工作1/3的时间去写工具,那些用于监控,用于让调试更容易的,用于把多个系统粘合在一起的工具。譬如你需要调一个 Android 特定页面 activity 下的具体按钮的逻辑,你可以写个启动命令来直接进入改页面而不是APP 启动后通过多个 也买呢跳转才能进入。
每隔一段时间就回顾开发过程中哪些事或瓶颈需要通过工具和改善流程(workflow)来优化的
如果验证一个功能特性是否有效,你不一定要真正先开发完它们。
作者然后介绍之前做的电商页无限滚动加载的 case,事实上费了大量功夫开发的这个功能并没有提升预期的用户购买率,反而降低了(可能是因为选择更多,导致选择困难症?)
所以通过实施很多的 AB 测试的这种以试验驱动的产品设计方法(experiment-driven product design)是非常有效的工具。把一个很大的猜想切分成很多小的可以单独测试的假设,从而验证要不要一步步继续实施和执行。
开发那些最小可用产品。Google 也通过很多 AB 测试来优化关于速度,性能,可扩展性上。
工程师在无用功上花了不少时间。所以在撩开袖子大搞之前,花10%的时间验证下你的假设是否成立。
很多工程师被(糟糕的)老项目的维护拖累的无法去开发新项目新功能。
更少时间来维护项目和fix bugs更多时间来构建发布新的特性和功能
instagram(被 Facebook 高价收购时才5个人技术团队服务亿万用户)的内部信条 - 这是不是我们目前能做的最简单的事情!
复杂度后面是长期的维护成本,很多工程师的方案被产品挑战后,往往会选择一个看起来复杂度就很高的方案来显示自己的高水平。
譬如系统复杂度导致很多技术债,不要乱用各种存储方案和组件,简单的加机器很多时候看来上成本最低的。
时刻问自己『这是不是解决这个问题最简单的方案』
想想看你喜欢在什么氛围的团队和组织内工作,你为什么离开上一家公司?
我们喜欢在那些高产出的事情上花时间,而不是一个没有远景非常低效的项目,这样没有成就感。
所以在团队内部形成那样的氛围:
在主要观点讲诉完后,作者开始 Q&A 环节
翻译自The career advice no one tells you。这篇真不是传统的鸡汤文,有一些观点新颖,建议可操,那么我们喝下这碗浓汤吧。
选自于The (Near) Future of Technology
对 VR虚拟现实,AR现实增强,AI人工智能,IoT物联网,Bitcoin比特币,3D Printing3D打印,Drones 无人机,Wearables可穿戴设备 和 Self-Driving Cars无人驾驶汽车等这些热门也慢慢走进人们日常生活的技术进行盘点
 

 

http://thefullstack.xyz/history-express-javascript-framework/
如果你在过去5年什么时间点里用过 Node.js,那么你很有可能也用过 Express。
它是在github上被加星最多的nodejs相关的项目,每周平均大概100w的下载量。
这就是最近项目进展中发生的冲击破迅速引起了我的注意。
『I am closing down Express5.0. I'm quitting the Express TC now. I cannot trust anyone any more.』
我要关掉 Express5.0项目了,我现在要退出Express技术委员会了。我再也不会相信任何人!!
谁是 Doug Wilson?他凭什么可以关掉Express的未来版本?!
接下来我的一些发现让我真是大吃一惊
如果你和我一样,认为过去两年Express核心项目被Strongloop公司积极维护着。那我准备告诉你一些新消息了,Express并没有被他们维护着!
那些像我们一样在过去两年用着的Express,其实是要靠着Doug Wilson的辛苦工作支持的。
『谁说Doug Wilson』你可能会问,如果你之前没有听说过他,你绝不是少数。我也是知道最近才了解他的。
为了更加全景化了解这个问题,我们最好先从Express框架的全能创建者 TJ Holowaychuk 聊起~
TJ已经对他把Express卖出的决定感到后悔。把开源项目卖掉是你能做的最混账的事!
很多人也对此很生气。
但让我真正生气的是,TJ并没有卖到什么钱。
『你弄得看起来卖完后,我突然好有钱的样子,但实际上连我半个月的工资都不到。。。』
这才是真正让我无语的地方。如果你真要做什么坏事,好歹是为了什么非常吸引人的诱惑如大量钱财等
如果读者中有任何想过把自己开源项目卖掉给最高的开价者,那么我的建议是:
 

StrongLoop 收购了Express项目在Github的所有权。这是个明智的决定,毫无疑问让它到了社区的前沿和中心。
虽然说这不是什么道德优越的好事,但是这意味着Strongloop就要影响Express项目的进展?
这还很有可能StrongLoop是对Express是出于好心,同时会给社区分配除足够的资源和支持。甚至精心的找了个全职的开发者来帮助开发这个项目。
『那些不那么多地道的行为会持续产生,沿着不地道的方式』
在 2014年的 7月29 号,StrongLoop 发表了臭名昭著的声明:
TJ HolowayChuk 把Express的赞助方转让给了StrongLoop。
在同年的8月,Express 在github的项目被移StrongLoop org下。同年10月,Express官方网站在显著位置加了一条指向LoopBack的链接(StrongLoop自己的构建在Express之上的开源框架)
在2014年那个命运般的日子和知道2016年3月到这个月这篇文章写的日子下,你猜StrongLoop给Express项目的主分支提交了几次代码?
一次都没!!
或者说几乎为0.反正绝对少于5个,就如下图所示:

该项目的最高提交数的6位贡献者都不是StrongLoop的员工。
你可能已经听到了,IBM最近收购了Strongloop。我敢肯定Strongloop对Express项目的慷慨赞助对IBM收购这个决定起了不小的作用。
IBM最近还把Express也加入了Node基金(head off xx to 阻止?)
据传言,IBM分配了两个全职工程师在这个项目上。
Doug 和他的朋友们目前在全力以赴在类似于Express的崭新项目上。我相信你不久后就会有所耳闻。
按我目前理解的,Express需要彻底的重写来支持HTTP/2。希望这能顺利进展但是谁知道呢现在
说实话,如果你只能从这件JavaScript历史的风暴轶事中记住一件的话:
『在互联网的某个角落有个名叫 Doug Wilson(@blipsofadoug)的人,在过去的三年里,它就是为了我们默默支持和照顾Express的人!』
在过去的三年中,Doug 很可能解决了影响你生产环境下的应用的一个真实bug,而同时你可能都没有用意识到这一点就提升了服务器的运行性能~
翻译自[Techies](A study of Silicon Valley),本文作者陈述了他为什么想关注不同背景的人怎么开始从事这个行业(如年过半百高龄的,换了行业的,身有残疾的,移民的,LGBT同性恋的,没有学位的,作为父母的,通过自学的,贫穷的,作为研究员的,设计师开发者企业家,做管理的,投资人的,变性者等等)
在今年一月份我宣布我想做一个聚焦硅谷人物的肖像项目。三个月过去了,下面是我的成果:
我开始做这个项目主要是因为如下两个原因:我希望给外界展示更为具体真实的硅谷的那些技术人的面貌。我也希望讲述这个行业中那帮默默无闻的人物的故事。
从一月份开始我开始和技术圈来自各种背景的,大概100人左右进行交流。从事这份行业对他们来说并不容易,即使现在他们也遇到各种难题。但是他们坚持下来了,因为他们天赋异禀,他们热情工作,他们迫切希望改善技术生态~
这个项目设计的初衷是让你主导怎么使用它。你可以使用过滤器来确保你来排序和探索你感兴趣的内容。也许你想借此机会看看和你工作生活背景迥异的人是怎么进去这个圈子的,或者你也可以看看和你背景相似的人的那些故事。他们和你来自于同一个地方或前行业,或者和你经历过一样的困难~

我希望感兴趣的人利用好这些内容基于它们做自己想做的东西。他们可以深入追寻,逐个击破和构建新的故事。我希望它让部分人感到不愉快,愤怒和获有灵感。我希望它能激发出更多新的,难以应对的问题,不断想要回答的尝试。
我希望大家尽自己所能分享这个项目(网站),和那些认为技术圈是一个完美的英才聚集的地方的人分享,和那些想要多元化员工,演讲者和顾问的人分享,和那些在这技术圈感到孤独的人分享。
我以我的一位受访者Victor Roman的一句话结尾:
我认为去思考理解人们是从哪里起步非常关键。因为很多时候我们衡量一个人是否成功却忽略了他们是从哪里开始旅程,他们是否在同一起跑线上。一些人可能在起跑线的一两公里外开始,最终没有获得第一名,人们会说『哈,他们做的不是不好』。单实际上他们比第一名跑的更快,跑的更远的路,他们只是在不一样的起点出发。所以,我觉得去思考和关注那些起跑线外的一两公里,那些具体导致不同距离的背后原因和努力。
Function Template
Object Template
By now, we learned how to expose C++ methods\structures to JavaScript. We will now learn how to run JavaScript code in those modified contexts. It’s simple. Just compile and run principle.
Modularity
Let’s start with NativeModule first.
Another thing is Module loader implementation.
在 Airbnb,数据团队的一大指责就是让让我们基于数据的决策的系统更容易扩展。我们**化数据读取权限来让所有同事都能借助数据做出好决策,让他们使用实验来正确衡量他们决定的影响力,把从用户倾向数据中得到的洞见加入到数据产品中从而提升我们产品的用户体验。最近,我们开始处理另一类型的难题。随着组织的不断的发展,我们要怎么确保一个人的精彩见解如何有效的传递给需要的人。在内部,我们成这个叫做知识规模化
一开始我们团队成员还不多,在团队内部分享各自发现的调研结果和技巧都很方便。但是随着团队不断扩展,之前的小问题变得越来越严重起来。就拿 小琳(Jennifer)的故事来说,新来的数据科学家想要把一个同事在Airbnb的房东退订这个话题的工作进一步拓展,我们来看看现在是怎么做的:
和和其他公司在这个问题上沟通后,这样的例子太常见了。随着组织不断增长扩大,在团队内或跨团队的知识分享消耗呢大量的时间。这样的无效率的无政府的研发环境导致了成本飙高,分析和决策速度也随着降下来。因此,一个更加流式的解决方案可以加开决策的速度,让公司在快速增长的知识库上更加敏捷智能。
随着我们眼看上述有问题的流程被一遍遍重复,我们意识到我们能够做的更好。作为一个组织,我们聚集在一起,形成了以下5个关键的原则性信条:
把这些信条牢记心中,我们独立评估现在来解决这些问题的工具集。我们发现 R Markdowns 和 iPython notebooks 通过附带代码和结果解决再现性问题。Github 提供了不错的 review 流程的框架,但是对于诸如图片这些不同代码和文章的内容不适应于。好定位一般通过文件夹目录组织,但注入 Quora 的文章通过标签组织出多对单的层级结构。可学习通过关注哪些代码被提交上线或人际之间的交流。
从而,我们整合这些想法成为统一系统。我们的解决方案结合贡献和 review,借助工具来展示和分发。在内部我们称之为知识仓库(Knowledge Repo)
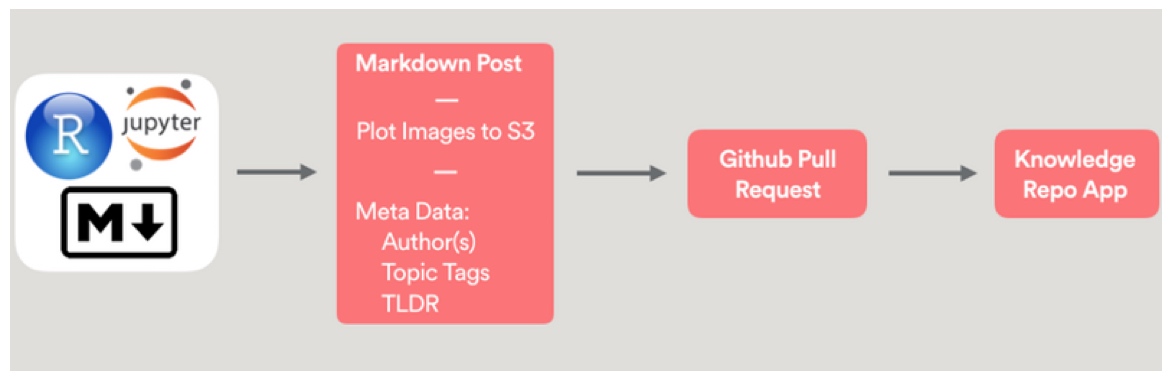 

在中心位置是我们用来提交工作的 Git 仓库。文章帖子用 Jupyter 笔记本,Rmardown 文件,或纯 markdown 文件的方式被撰写,同时所有其他文件(包括查询文件和其他脚本)也要提交。每个文件都要附上一些部分结构化的元数据(如作者,标签和内容概要)。有个 Python 脚本来验证内容同时把帖子文章转化为 Markdown 语法的纯文本。然后我们使用 Github 的 Pull/request 系统来实施我们的 review 审核流程。最终,有个 Flask 写的 webapp 来渲染仓库的内容成为我们内部的博客,根据内容,话题和时间被良好的组织着。
在这些工具之上,我们有个流程专注于确保让这些调研是高质量和好理解的。不像工程代码,低质量的调研成果不会造成运行指标的下降或系统崩溃报告。相反,它只是宣告了知识无效劣质的环境,从而同事只相信那些它们自己撰写的调研。
为了防止这种情况的发生,我们流程中结合了工程师的代码review和来自于学术同事的互查。在代码review中,我们检查代码的正确性,最佳时间和工具。在同事互查中,我们检查方法上的提升,和优先工作的关联上,说明性主张的准确性上。
我们的工具包括来内部的R包和Python类库来维护有统一调性,美感,一致性,和现有数据仓库整合的方法,来处理文件从而适配R和Python Notebook的格式来提交Github PR。
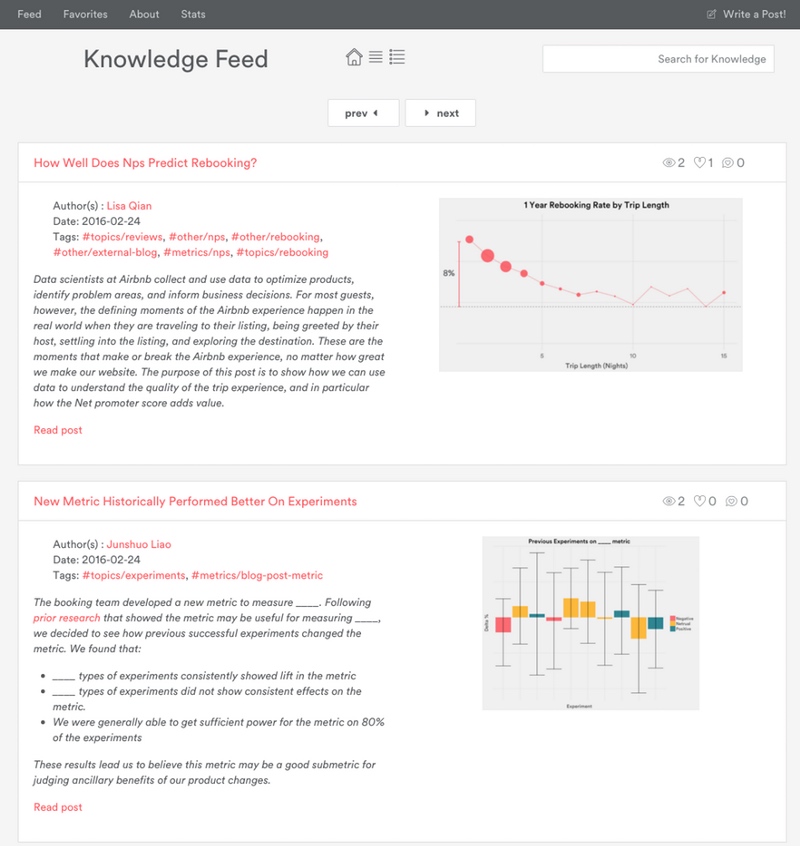 

截图:展示了两篇文章的总结性卡片的知识流。
 

图2:一篇解释房东接客决定的间隔天数的文章帖子
一起,这些一起提供了我们知识信条下的很多功能:
我们的知识仓库存储了大量的文章。这其中包括了回答一些重要问题深入见解和研究,这些对试验结果的说明并没有完全在experiment reporter(内部其他方式)中提到。还有很多其他的文章被撰写仅仅来扩展做数据分析同事的视野,如对新方法论的讲诉,对个工具或代码包的示例,在SQL或Spark上的教程。我们很多公开的数据博客都在Knowledge仓库,也包括这篇。通常,如果你写的能够对其他人产生作用,那么就开始写吧,分享他,和别人讨论,接受同事们的review~
知识仓库仍然是在不断进展中的项目。一个攻克小组在处理不断的功能性需求。我们在朝着让全公司的有研究的团队都能适应使用的目标努力着。如那些不使用Github的质量研究团队。最终,我们已经开始测试一个内部构建的在内置浏览器的markdown编辑应用的review流程。它很可能包括如一票否决的审查者,在待调研话题的投票。我们也在想办法让复制现有的帖子后继续再此之上的新帖子流程更方便。
尤其在新生尚不成熟的数据科学领域,不同的数据团队很有可能在不断的重新发明轮子。我们通过分享我们的实践做法希望给你们组织在处理我们也在处理的这类问题一些启发,后续通过你们的一些分享和学习借鉴,通过协作出最佳实践。
https://medium.com/airbnb-engineering/data-infrastructure-at-airbnb-8adfb34f169c
在airbnb,我们推崇数据导向的文化,利用数据作为我们市场决定的关键依据。跟踪指标,验证假设通过实验,构建机器学习模型,深挖商业价值,这些都让我们变得更快更明智。
经过许多次的进化步骤,我们现在感到我们的数据基础架构栈变得稳定,可依赖和可以扩展的。所以这看起来是个好机会,来和社区分享我们的经验。在最近几个星期,我们发布了不少博客文章来讲述我们的分发/分布式架构和我们的工具集。因为开源贡献者提供了许多我们现在在用的基础系统,这些让我们也非常乐意于通过开源有用的项目在github来回馈社区,也记录我们这一路学到的东西~
在我们实施数据基础架构时,一些非正式哲学慢慢形成了:
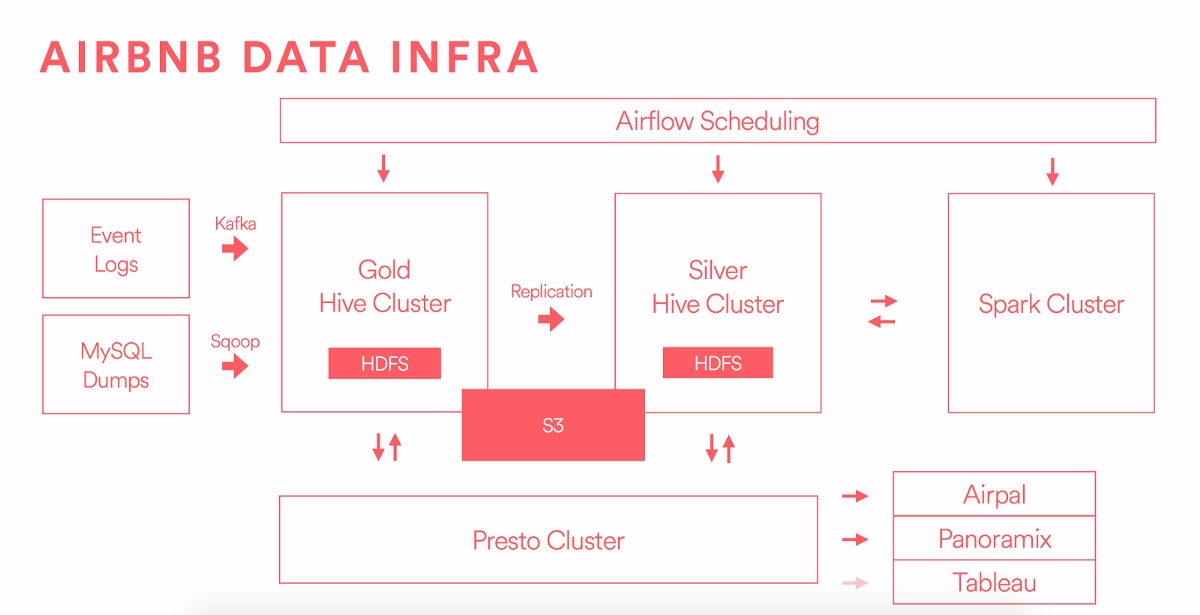 

上图是简化的图表来展示我们基础架构中的主要组件
我们系统的原数据主要来自于两个主要的渠道:那些代码中的指令通过kafka来发送书剑 和 生成数据库dump出然后通过Sqoop导入(通过AWS的RDS(类MySQL)在时间恢复点导出)
这些源头数据包含了用户活动事件数据和多维的快照被接着发送到黄金集群(Gold)中(我们用于存储数据和开始跑我们的ETL任务(抽取,转换和加载)在这一步,我们实施业务逻辑,构建汇总表,和实施数据质量检查。
在上图中,有两个分离开的集群代表Gold金和Silver银,它们会在下一博文中详细讲解。抽象解释下这样分离是为了确保计算和存储资源的隔离,这样在遇到灾难等情况可以提供确保恢复的机制。这样的架构让Gold环境下,大部分重要的任务可以在严格确保下运行,SLA服务级别得意确保,从而避免受到资源密集型的热查询的干扰。我们也把Silver环境作为生产环境,但是不那么严格要求和容忍突发的资源密集的查询
要意识到通过设置两个集群我们拥有了隔离的能力,但是它的代价是大数据量的数据复制和复杂动态系统间的数据同步的管理。Gold是我们数据源头,我们从它那边到Silver做全量的复制。在Silver产生的数据不会被复制到Gold下,你可以这样认为这样的单向复制的设计方式让Silver免于成为其他任何东西的父集。 因为我们很多的分析和报告在Silver集群上实施,所以确保新数据被尽快加载到Silver中使用户的任务执行的没有延期是至关重要的。更重要的是,如果我们在Gold集群更新现有的数据,我们必须通知更新事件和同时把更新的变化同步到Silver。这复制优化问题在开源社区目前木有什么好方案,所以我们在接下来的博客中会详细描述为解决这问题构建新的一套工具。
我们在调优HDFS上付出了巨大的努力,对我们的中间源和数据池 - Hive管理的数据表提供更精确的调优。数据仓库的质量和稳健依赖于数据要不可修改和所有的延生可以被重现 - 使用分区Hive表对实现这个目标是很重要的。进一步,我不鼓励不同数据系统的延续和我们也不想维护在数据源头和最终用户表报间的中间数据基础架构。在我们的经验中,这些中间系统会混淆唯一数据事实,给ETL任务的管理添加负担,让展现在Dashboard仪表盘上的指标的线性最终变得困难,从而不明确它是怎么从源数据一步步来的。我们不需要跑 Oracle, Teradata,Vertica和Redshift等,相反我们使用Presto对于据大部分热查询在Hive维护管理的数据表。我们喜欢在不久将来把Presto直接连接到我们的Tableau的按照上。
图上需要单独说明的点,包括Airpal,我们开发和开源的web界面的查询执行工具(背后是presto)
<Todo - 省略部分>
在经历过旧集群按照配置时遇到的各种错误和低效能,我们决心来系统性的解决这些难题。它是个长期的工程来迁移PT级别的数据,和数以百计的用户任务(但不干扰同事们的任务)。我们会新写一篇在此主题上的博客,和发布一系列的工具到开源社区中。
非常感谢对原先实现Airbnb的数据基础架构的工程团队和对那些持续工作让系统不断稳定和提升的同事们。我很高兴能写这篇文字,但是真正的工作和荣耀属于这项目背后的人员:Nick Barrow-Williams, Greg Brandt, Dan Davydov, Wensheng Hua, Swaroop Jagadish, Andy Kramolisch, Kevin Long, Jingwei Lu, Will Moss, Krishna Puttaswamy, Liyin Tang, Paul Yang, Hongbo Zeng, and Jason Zhang。
整理摘抄于 FinTech 100
The financial services industry is facing a wave of digital disruption that is starting to reshape the sector. The Fintech 100 celebrates the top companies this bold new space: the 50 leading established players creating change within financial services, and 50 of the emerging fintech stars of tomorrow.
The Fintech 100 offers an in-depth view of the most exciting startups and organisations taking advantage of technology to revolutionise the industry. The report is a collaborative effort between H2 Ventures and KPMG.
ZhongAn is an innovative online property insurance company. They utilize big data technology to assist with product design, automatic underwriting, auto claims, precision marketing and risk management. Founded in 2013 in Shanghai, ZhongAn Insurance is the first company in China to be issued an internet (online) insurance license. The company is a joint venture between: Alibaba Group Holding (an e–commerce company), Tencent Holdings (an online gaming and social networking company) and Ping An Insurance. ZhongAn offers wide range of online insurance services to the Chinese market, catering to all socio economic groups, with a major focus on travel, accident and health.
“Beijing–based Qufenqi.com, recently completed US$ 9–digit Series E funding round and will soon announce investors and specific funding amounts. We also rolled out a new product, “Quzu,” which allows users to pay their apartment rent in installments” - Min Luo, CEO
Qufenqi is an electronics retailer that offers monthly installment payment solutions to the students and professionals in China. The company primarily offers smart phones, laptops and other consumer electronics online, allowing customers to choose their own down payment option and the time period for making regular monthly installments. Customers have to close the installments within two years of the purchase. The business model is tailored for students and young white collar workers, with the final price and monthly required payments shown transparently on the product page.
Shanghai Lujiazui International Financial Asset Exchange (“Lufax”) is an online marketplace for the origination and trading of financial assets. Lufax has grown into China’s largest internet finance company in less than four years. Lufax takes advantage of the latest big data and IT technologies, and leverages the most advanced risk assessment models and risk control systems.
Wecash is China’s first Internet credit assessment company that provides solutions for technology companies. The development of Wecash is currently the most advanced big data platform credit assessment, using machine learning algorithms to provide credit assessments in under fifteen minutes. Their singular commitment to eliminate information asymmetry with big data, provides faster, more accurate credit decisions. By relying on data mining analysis and machine learning technology, the information submitted by
the applicant is used to identify and combine personal, social behavior and massive internet information on the personal credit score online.
FangDD offers an online platform through which home buyers and home sellers can directly connect to each other, working on a “”pay-for-performance”” business model. The goal is to provide accurate information about properties, services and transactions to create an open, cooperative, coexistent and mutually beneficial industrial pattern. In the first 6 months of 2015, more than US$8b worth of real estate transactions took place using this platform. The company’s O2O internet real estate marketing platform is based on big data technology. It integrates online and offline property businesses and buyers on
a single platform, allowing user friendly property transaction services. FangDD follows a business model of pay–for–performance, catering to customers across 50 cities in China, including Beijing, Shanghai and Shenzhen.
Jimubox is a Beijing-based marketplace lending platform that provides small and medium enterprise loans and individual consumption loans to under banked Chinese borrowers. Jimubox delivers safe and attractive investment opportunities to RMB investors through an innovative online marketplace which leverages transparency and technology to ensure investor safety.
Rong360 is China’s leading financial vertical search platform. They are committed to providing financial searches of financial products to consumers and small businesses, giving recommendation and application services, business scope cover loans, credit cards and financial management. Rong360 is free for the user, which provides convenient, cost-effective, secure financial information services, and is currently the most extensive coverage in Beijing, as well as the largest financial service users search platform.
The Oscar team is focused on utilizing technology to simplify the entire healthcare experience. A team of technology and healthcare experts looked at the current state of the US healthcare system, and were frustrated by the horrible consumer experience. In response, they decided to reinvent how healthcare is delivered. They are reinventing how to manage care, process medical claims, control healthcare costs, and provide transparency. With all the complexity hidden behind an easy experience for members. Oscar is making the healthcare system simple, smart and friendly.
Wealthfront is an automated investment service which combines world-class financial expertise and leading edge technology to provide sophisticated investment management at prices that are affordable for everyone. Wealthfront makes it easy for anyone to get access to world-class, long-term investment management without the high fees or steep account minimums. Their mission is to provide access to the same high quality financial advice offered by major financial institutions and private wealth managers, like tax-loss harvesting, without the high account minimums or costs.
“Our vision is to help millions of businesses across the world sidestep the outdated and inefficient banking system and borrow from investors.” - Samir Desai, Co-Founder & CEO
Funding Circle was created with one big idea; to revolutionise the outdated banking system and secure a better deal for everyone; with offices in the UK, US, Germany, Spain and the Netherlands. Funding Circle is the world’s leading marketplace exclusively focused on small businesses, providing a platform where investors can browse businesses that Funding Circle has credit assessed and approved for lending. Once approved, businesses post their loan request on the Funding Circle marketplace. It is here that investors choose which type of business to lend to, the amount of money they wish to lend, and the interest rate they want to earn.
“In three years, Alexander and I have built Kreditech into an industry leader tackling a serious mission in a very innovative way — and it works.” - Sebastian Diemer, Co-Founder
Kreditech Group is a technology company that delivers a range of custom- tailored financial services with a focus on under banked consumers across the globe. Kreditech uses big data, proprietary algorithms and automated workflows to acquire, identify and underwrite customers within seconds. Automated processes combined with self-learning algorithms ensure fast and convenient customer service, minimizing cost and human error while continually improving by incorporating new customer data.
Avant is a fast-growing marketplace lending platform that is lowering the
costs and barriers of borrowing for consumers. Through the use of big data
and machine-learning algorithms, the company offers a unique and highly customized approach to streamlined credit options. At its core, Avant is a tech company that is dedicated to creating innovative and practical financial products for all consumers.
Atom Bank is a new digital banking system, authorised by the Prudential Regulation Authority (PRA) and regulated by the Financial Conduct Authority (FCA). They offer an app-based experience, using leading technology. The digital world is constantly changing and Atom will be changing banking too. Atom Bank is based in the UK and doesn’t have any branches, instead you can do all your banking on your phone, 24/7. Their aim is to breathe new life into banking.
Klarna is one of Europe’s leading providers of payment solutions for e-commerce. Klarna separates buying from paying by allowing buyers to
pay for ordered goods after receiving them, providing them with a safe after delivery payment solution. At the same time, Klarna assumes all credit and fraud risk for e-stores so that sellers can rest assured that they will always receive their money. Klarna’s vision is to enable trust and to offer a frictionless buying experience to buyers and sellers across the world.
OurCrowd is the world’s leading equity crowdfunding platform for accredited investors to invest in Israeli and global companies. Managed by a team of seasoned investment professionals and led by serial entrepreneur Jon Medved, OurCrowd vets and selects opportunities, invests its own capital and brings startups to its accredited membership of 10,000 global investors. OurCrowd provides post-investment support to its portfolio companies, assigning industry experts as mentors and taking board seats.
Robinhood is a new way to invest in the stock market. They believe that everyone should have access to the financial markets and are on a mission to inspire a new generation of investors. Robinhood is a stock brokerage that allows customers to buy and sell US stocks and ETFs with zero commission. They cut out the fat that makes other brokerages costly — hundreds of storefront locations and manual account management.
Square helps anyone take care of their business. Their service supports your entire business, from a register in your pocket to reports on your laptop. Square’s register service is a full point of sale with tools for every part of running a business, from accepting credit cards and tracking sales and inventory to small-business financing. Customers also use Square Cash, the easiest way to send and receive money, and Square Order, a new way to pre-order food and drinks for pickup.
Motif Investing is a concept-driven trading platform that allows you to act on your investing desires—whether it’s a hot trend like “robotics revolution,” a trading strategy like “buy the dip,” or an investment style like “Ivy League endowment.” They make it easy to act on these concepts by turning them into motifs— intelligently weighted baskets of up to 30 stocks or ETFs. Based in Silicon Valley they are changing the face of online investing. Their social platform is transparent and allows individuals and investment advisors to invest in stock and bond portfolios built around everyday ideas and broad economic trends, as well as creating brand-new motifs from scratch.
Xero is changing the game for small businesses with easy-to-use online accounting software. The cloud-based software connects people with the right numbers anytime, anywhere, on any device. For accountants and bookkeepers, Xero helps build a trusted relationship with small business clients through online collaboration. It includes a full accrual accounting system with a cashbook, automated daily bank feeds, invoicing, debtors, creditors, sales tax and reporting. Xero is designed to be the accounting engine for your small business, giving you real time access to your financial data and access for your accountant or bookkeeper for quicker, easier collaboration at any point.
Stripe provides a developer-friendly way to accept payments online and in mobile apps direct to your bank accounts from a range of local and international cards. Processing billions of dollars a year for thousands of companies of all sizes. The Stripe platform is designed for businesses of all sizes: from public launch to public company, and handles billions of dollars a year for forward- thinking businesses around the world. Stripe is built for developers, makers and creators. They believe that enabling frictionless transactions is a problem rooted in code and design, not finance. Their robust, clean Application Programming Interface lets users focus on building great products.
Collective Health was founded to fix what was broken about the healthcare experience. They work as a technology company to improve health insurance by taking better care of their people; bringing together the best medical, pharmacy, dental and vision networks. Collective Health is combining intelligence, empathy and common sense to the health insurance experience.
Lending Club is the world’s largest online credit marketplace, facilitating personal loans, business loans, and financing for elective medical procedures and K-12 education and tutoring. Borrowers access lower interest rate loans through a fast and easy online or mobile interface. Investors provide the capital to enable many of the loans in exchange for earning interest. They operate fully online with no branch infrastructure, and use technology to lower cost and deliver an improved customer experience. Cost savings are passed onto borrowers in the form of lower rates and investors in the form of attractive returns. Lending Club is transforming the banking system into a frictionless, transparent and highly efficient online marketplace, helping people achieve their financial goals every day.
SoFi is reinventing consumer finance for the better. They are a leader in marketplace lending, with over $5 billion in loans issued to date. SoFi helps
early stage professionals accelerate their success with student loan refinancing, mortgages, mortgage refinancing, and personal loans. Their non-traditional underwriting approach takes into account merit and employment history among other factors, therefore offering products that can’t be found elsewhere. They offer individual and institutional investors the ability to create positive social impact on the communities they care about while earning compelling rates of return.
AngelList is a platform for startups to raise money online, recruit and apply to incubators. They connect startups to angel investors whom they would not otherwise be able to find, and facilitate angel investment through features such as the formation of syndicates. AngelList startups connect to angel investors by creating a profile for their business on AngelList which will then show in
the feeds of angel investors. Angel investors are also able to form syndicates, whereby they pledge money to mirror the investment backing of prominent angel investors.
http://fintechinnovators.com/about-list
The Fintech 100 is a collaborative effort between H2 Ventures and KPMG and analyses the fintech space globally. The report highlights those companies globally that are taking advantage of technology and driving disruption within the financial services industry.
The benefits of being included on the list go beyond profile. This year, 10 of the top emerging fintech startups will be invited to attend a Fintech Summit in London to pitch their ideas to some of the world’s leading financial institutions, venture capital funds and investors. In addition they will receive professional services support from KPMG, plus membership and discounted deal-success rates with Matchi, the online fintech matchmaking platform.
The Fintech 100 consists of two separate lists: Top 50 Established Fintech List, and the 50 Emerging Stars.
The process for selecting the Top 50 Established Fintech List involves a universal search for the most innovative fintech companies. A comprehensive list is then created, with companies ranked based on four groups of factors: total capital raised, rate of capital raising, location and degree of sub industry disruption and the judging panel's subjective rating of the degree of product, service, customer experience and business model innovation.
The process for selecting the 50 Emerging Stars is necessarily subjective, and involves a search for largely ‘undiscovered’ fintech companies. The judges are looking for the players of the future – a diversity of companies from all over the world with fresh, new, disruptive ideas and industry solutions. The evaluation is far less about size and capital raisings than it is about having an “X factor”.
两天的会议中,先后听了十几篇分享,参加的议题主要集中在“高可用架构”,“云服务架构探索”,“架构演进从0到100”等专场,也参加了诸如“证券极速交易系统关键技术分析以及架构实践”,“QQ Hybrid的演进”,“Twitter从支撑千万到万亿级索引的搜索引擎架构演化” 等其他专场的感兴趣话题。同时,最后一晚参加了“架构师之路夜谈”,收获颇丰。这次和以往不同的事,除了务实的业务细节和技术干货外,也包含了设计妥协和一步步演进推进的过程(算是实施的艺术)这的确是架构师的日常关键工作,而不仅仅是技术点的最优。
PS:由于冲突,没有听到58沈剑的分享(之前已经关注他的公众号,系统易读的文章分享 - 微信号名称:架构师之路)
2016年12月02日
1-《Lessons in Internet scale stream processing @linkedln》-Kartik Paramasivam
2-《Architecting for the Cloud in Creating One Engineering System at Microsoft》-Sam Guckenheimer
3-《天猫双11容量规划演进》-蒋江伟
4-《京东数据中心网络的高可用架构》-王大泳
5-《大规模下的存储解决方案和迁移实例分析》
6-《滴滴的高可用建设之路》-许令波
7-《证券极速交易系统关键技术分析以及架构实践》-刘鑫
2016年12月03日
1-《构建高效的私有云平台:今日头条私有云架构设计》-夏绪宏
2-《利用 Apache Helix 构建高可用和易伸缩的大规模分布式数据云系统》
3-《QQ Hybrid的演进》-涂强
4-《Twitter从支撑千万到万亿级索引的搜索引擎架构演化》-庄易
5-《云数据库架构演进和实践》-余锋
6-《Go微服务架构的基石
7-《外卖的背后:饿了么基础构架从0到1的演进》-兰建刚
2016年12月03日 - 夜谈
《系统架构师的修炼》白山合伙人兼工程副总裁 丛磊
《从草根到优秀架构师的奋斗》同程旅游首席架构师 EGO会员 王晓波
《代码之外,架构师在做什么》环信首席架构师&IM事业部技术总监 梁宇鹏(一乐)
《圆桌活动问答》 崔宝秋
架构模式,允许我们使用Apache Kafka,Apache Samza,Brooklin,Databus和其他一些数据系统进行大规模流处理。
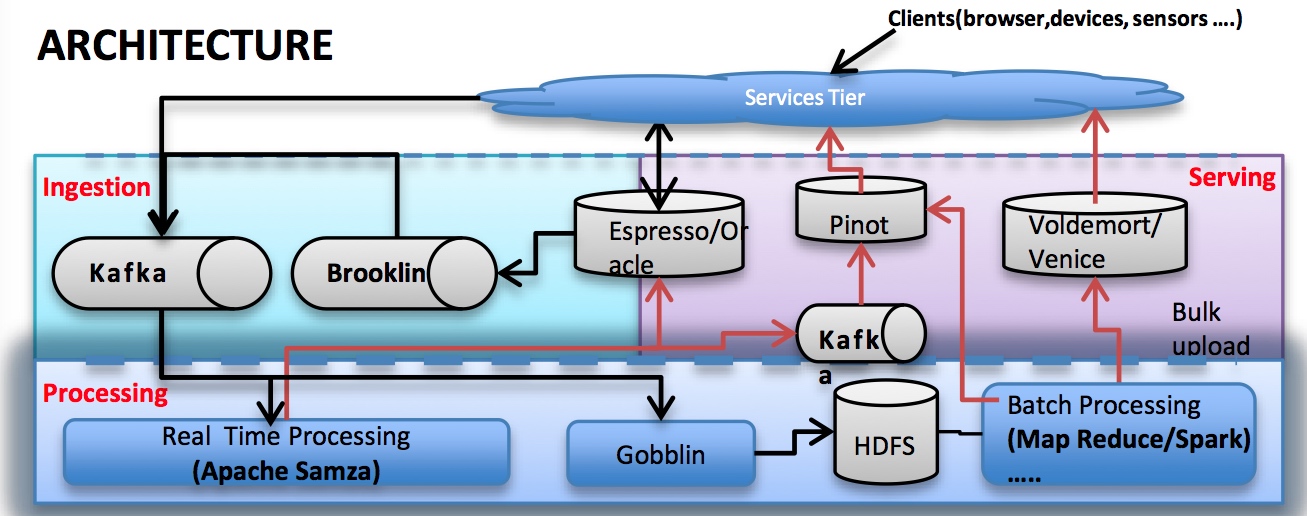 

数据采集,其中分析了现有采集中间件的优劣(Kafka,EventHub,Kinesis, Pub-Sub 等),给出了 cost based comparison(对于1TB a day、100 Billion messages/day 和 5000 partitions 截点使用云服务提供的还是自己搭建),最后给出了自家的数据采集和消费量(1.2 Trillion Messages, 350TB, 峰值 16 million messages/second,data consumed/day: 1.3PB)
lessons from running kafka @ scale
流式计算领域:

流式计算要解决的问题:
对于性能,引入 embedded database(RocksDB,来 reading adjunct data 「使用 Brooklin 从 db load/sync 到 RocksDB」,lazily flushed for durability 中间临时数据到 Kafka compacted topic


SAMZA 支持 Async I/O, incremental checkpoints

stability,backpressure
support for variety of souces,通过 Brokolnn 引入
reprocessing,为什么重新消费(因为业务逻辑更改和软件bug
case study: title standardizer
更新你的title,到 member databases(espresso) - profile updates(brooklin) - > Samaza(title-standardizer) -< machine learning model - kafka
offline processing
Batch processing in SAMZA
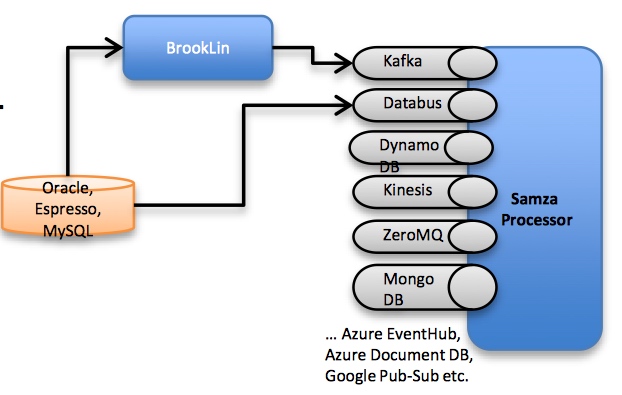 

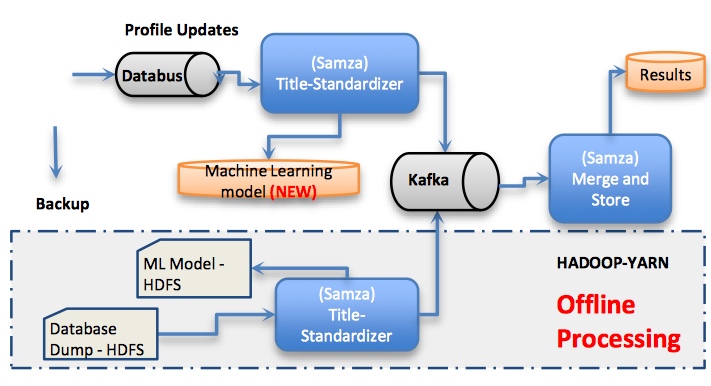 

讲微软全球研发团队在构建统一工程体系过程中云端架构设计转型的一些实践。
如全面支持DevOps的开发方法,以更好的支持Azure与其他云平台产品的开发节奏,基本上是老树新花

 

容量规划,当业务发展飞快,新促销活动不断上线,对你的服务容量提出了挑战。什么系统,什么时候,需要多少服务器:系统预估容量 / 系统单机能力 = 服务器数量
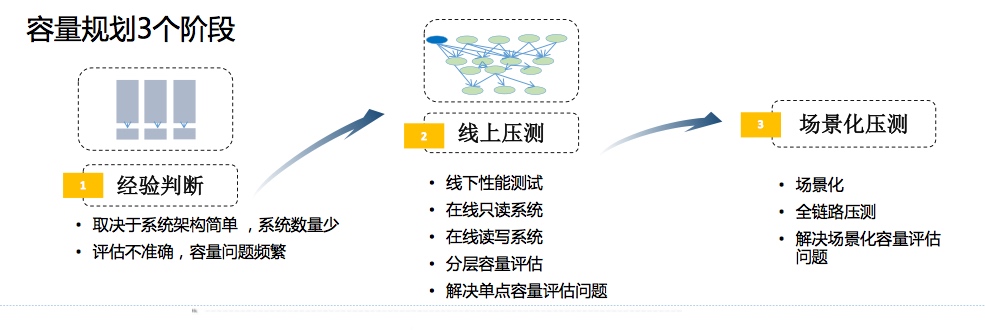 

传统思路:以点到面覆盖所有系统(系统的木桶原理-短板,分层评估-如应用层,服务层,存储层。每层都有各自的特点)
搭建压测平台(使用线上流量压测线上应用,通过压测模型去模拟复制流量,同时要监控和采集)

PS:之前阿里有自己的压测团队,然后这套平台开发完后他们就被解散了
场景化的容量评估(不同的场景活动会触发不同的业务流程,它们背后对应的服务也是不一样的,所以需要场景化评估才准确,全链路压测工具来更加精确的进行容量评估(通过工具不断弥补
PS:阿里在整个技术架构上保持了一定的统一性,使得容量规划(不只是容量规划等技术)可以被很快进行平台化,各个业务都可以使用(受益于Java 体系的
通过资源隔离拉平各个系统所需的最小资源。



回答一个问题“现在你们的网络有没有问题”

• 需求和策略
◦ application arcitect (每个产品组有infra的小组去做优化,桥接基础优化组)
◦ cost, data recovery, agile to change
• storage system
◦ tao(mysql+memcache) - the power of the graph (tao, mysql 的分布式和一致性的- region, cluster, 加上memcache 去加速) - 问题(贵,短时间对object建connection-锁住shard使得其他人没法用)
◦ memory based system(不同大陆region的问题)
◦ RocksDB(对SSD做了很多优化,k-v的,单机版的)
◦ HIVE(类似BigTable Google, data warehouse, 数据压缩比高columns不像其他基于行压缩如特定列性别male这种就压缩很高,没real time read/write,bridge for backup->存分析的每天db的snapshot)
◦ Scribe(aggregate logging system, high fan in/throughput, put data on aggregated hdfs), 写本地的daemon,)
• designs
◦ Laser(based RocksDB+Hive) - optimized for read (write daily new data in Hive with Scribe, hive pipeline 导出新数据到RocksDB with repl)
◦ ZippyDB
◦ 结合两者设计(分离不同的组件,通过不同场景下的需求区分来需求)
• compare+lessons
一.关于我
二.难点与挑战
滴滴的乘客、司机模型是一个动态匹配的过程。订单的流转也比较复杂。业务模型复杂导致了稳定性建设的难度。
业务开发的快速迭代,导致滴滴的技术栈一直没有统一掉,所以导致系统开发语言非常多样

高速公路上换轮子(技术栈不统一,基础设施建设如机房网络网关DNS等。业务耦合不敢删代码越加越多
三. 高可用体系化建设思路
• 压测体系、管控体系、监控体系、恢复体系和度量体系建设
规范建设:

工具建设:

组织建设:

四.全链路压测、服务治理等在滴滴场景下技术方案设计实践介绍
又黑了下Php(之前的老系统,现在慢慢迁移到Go,长连接需要inrouter去实现,RPC框架DiSF)
思路(通过trace传递标识识别流量,中间件等通过标记将流量导入到影子表中隔离测试数据。通过发压工具,状态流转等
 

管控体系:开关平台

监控体系:数据链路监控: trace,metrics

五.踩过的坑以及经验教训和总结
一些教训:
1.介绍量化交易特点、策略、交易需求以及市场状态;
#### 特点
量化交易是指借助现代统计学和数学的方法,利用计算机技术来进行 交易的证券投资方式。从庞大的历史数据中海选能带来超额收益的多种“大概率” 事件以制定策略,用数量模型验证及固化这些规律和策略,然后严格 执行已固化的策略来指导投资。
(概率 - 把小概率频繁交易放大概念(目前最赚钱的),定量套利,策略固化-避免情绪化除非是bugs,交易期间不要改动但是后面可以review自己策略
#### 方式
- 择股:以股票基本面因子为主,选取投资股票池,替代公墓基金
- 择时:选取合适的时间买入或卖出,以市场状态因子、技术分析因子为主,市场博弈行为,具备冲击性极高收益的能力
- 市场中性:对冲,现货股指市场,未来期权将是市场中性的利器(
- 套利交易:在市场的非理性波 动中寻找存在的价差,并利用价差获取收益、甚至是无风 险收益。比拼技术系统能力,而数学模型固定(ETF套利、期权套利、期现 套利、分级基金套利、可转债套利 - 分级B溢价机会等
PS:国内绝大部分的量化交易都是赚钱的,因为韭菜太多了。。。海外不是,因为各个机构间的博弈
量化交易市场基础环境日益改善
2.介绍证券市场整体交易架构和拓扑,以及市场各个参与者的交易系统 ;

投资者交易系统
券商交易系统
券商柜台
交易所交易系统
交易主机系统
分Set交易,多个交易主机,分别对应不同Set的交易,股票代码区分
Cluster模式,同一个Set双主机构成集群
同城主备实时同步交易模式
3.量化交易对证券公司交易系统技术需求的理解和分析;

 

4.极速交易系统关键技术和架构设计;
 

系统指标
 

1
随着今日头条业务的高速发展,对基础设施的要求越来越高,已有的研发模式和效率越来越不能满足业务快速发展的需要,TCE私有云PaaS平台应运而生。平台基于Kubernetes构建,结合今日头条的研发模式,融合微服务的理念,构建一套高效的研发、运维计算平台。本演讲分享今日头条在私有云PaaS的架构设计,技术选型等方面的的思路和经验。
演讲提纲:
1.公有云vs私有云,符合自己需要的云;
2.头条私有云的构架设计;
3.遇到的问题及未来的规划;
听众收益:
1.私有云平台的设计和实现思路;
2.私有云构建相关技术进展分析。
2
Apache Helix是一个通用的分布式集群资源管理和调度框架,它能被用作构建各种高可用和易伸缩的分布式数据存储和服务系统。 夏磊博士将与大家分享Helix的设计和工作原理,并实例分析Helix如何帮助构建LinkedIn的各类大数据系统, 如LinkedIn的分布式NoSQL数据库Espresso,以及LinkedIn开发的高性能的数据抓取系统Databus等。
演讲提纲:
1. Helix的设计**和工作原理;
2. 快速构建高可用的分布式大数据存储和支持系统;
3. 构建用户友好和易伸缩的大数据服务云。
听众受益:
1.分布式大数据系统设计;
2.弹性大数据云构建案例分析。
优化1: 点击将要进入网页前,launch WebView同时,发起页面请求 - 而不是等到WebView发起(客户端改造)
优化2:offlineCache 客户端的,页面暂存(通过OfflineServer)
优化3:可能数据版本多(导致页面打开后闪动被更新),引入diff推送
引入类似于 YouTube spfjs(fast navigation and page updates),来提示页面刷新体验(页面内容分框体,小块小块更新数据块
同时结合一些自定义的头 Cache-Offline,template-tag, template-change 等
PS:是否可以复用QQ原有的消息推送聊天的 socket package,结论是不可以



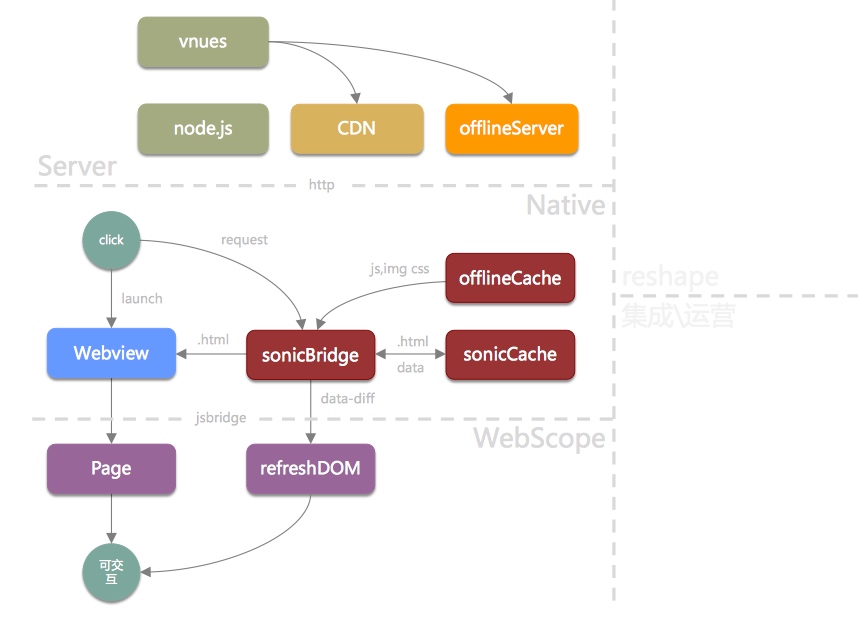 

他们自研了新的 SharpP格式 (对比jpg,webP,在大小上有优势,但是解码速度妥协),有一些应用成本(client要把自己的能力-是否能解码sharpP待在header上,然后走cdn逻辑根据不同的header返回不同格式的image
同理,响应式图片(针对不同手机屏幕大小的图片裁剪返回,reshape
User-Agent: Android QQ NetType/WIFI Pixel/750
Accept: image/sharpP, image/webp, image/*, /; q=0.8
PS:分享了他们的坑,因为中间运营商会针对GET URL缓存资源(图片url一致),所以需要通过 Vary header 告诉 中间层的服务器区别对待的头: Vary: Accept,User-Agent
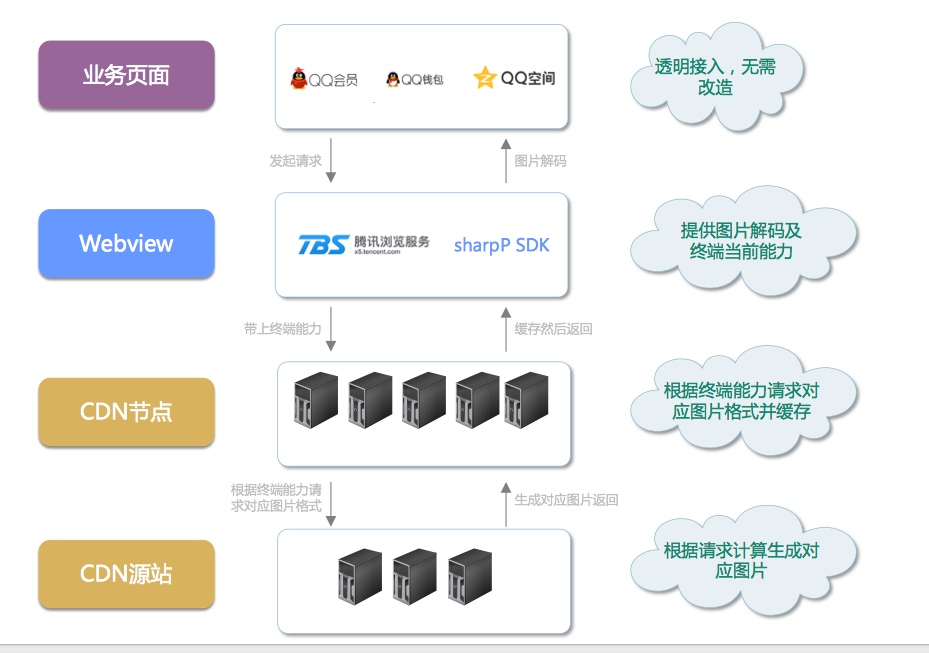 

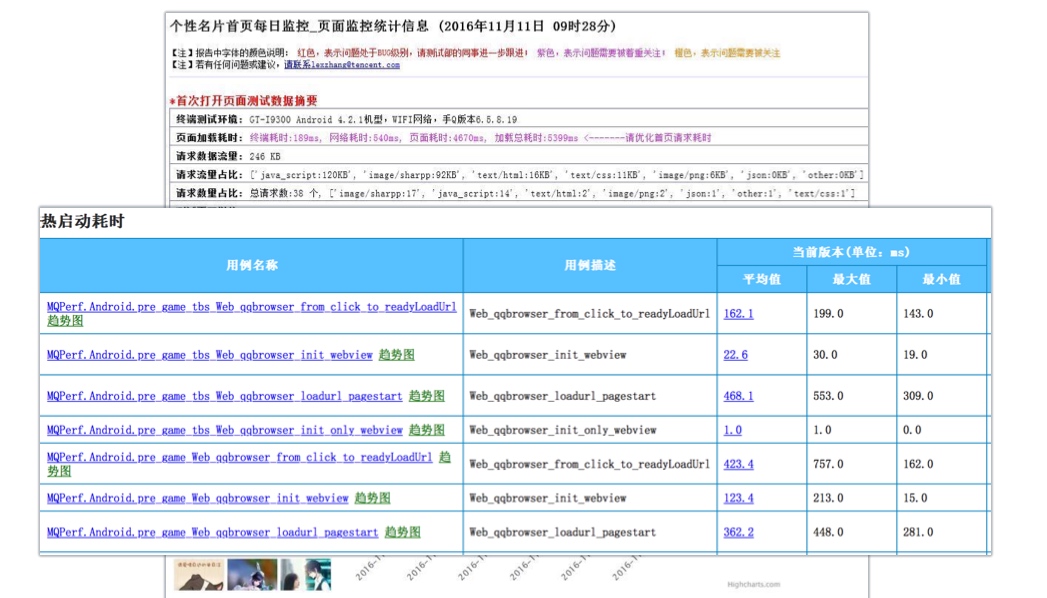 

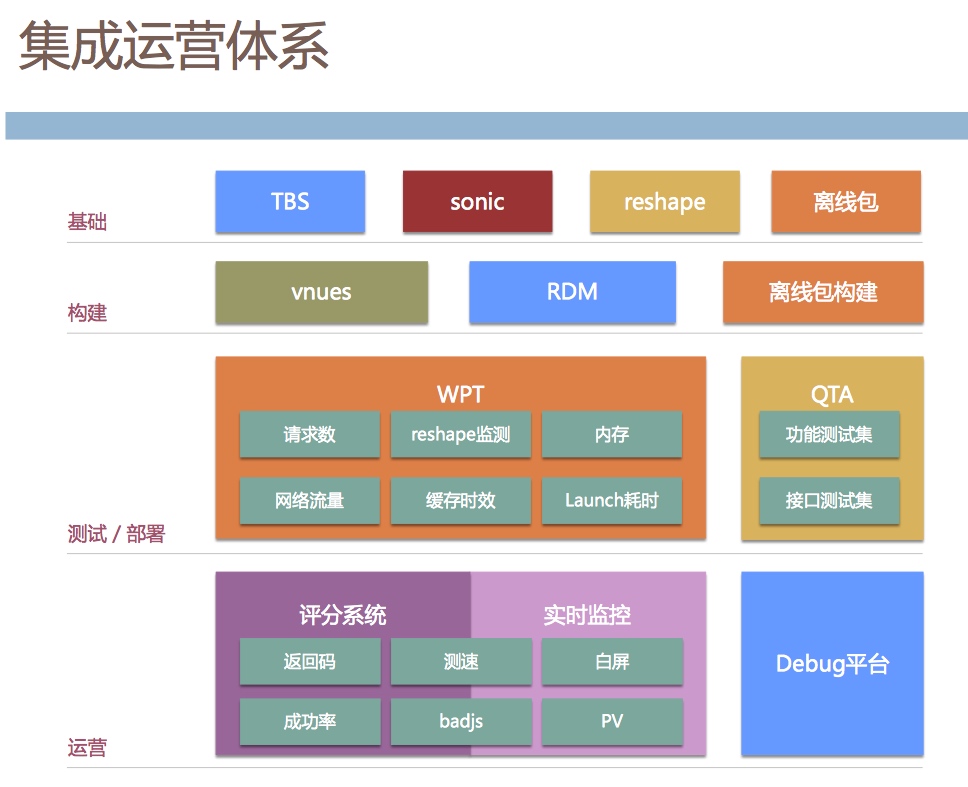 

Twitter的搜索引擎起初只能检索最近7天的推文,只能满足基本的实时搜索需求。现在的完整推文集索引 (Complete Tweet Index) 可以检索有史以来10多年的所有推文。从架构上的演进完成从千万推文规模到万亿条推文的规模。同时介绍了围绕搜索的应用:如 Ranked Timeliness 等
Current Scale of Twitter Search
”Our Complete Tweet Index is served by thousands of instances, each with 256GB RAM and 2TB SSD“ 超大规模的机器集群和存储实例 - 10名工程师(包括1名SRE)
The History of Twitter Search Infra
 

论文:http://www.umiacs.umd.edu/~jimmylin/publications/Busch_etal_ICDE2012.pdf
一些精彩时刻(如奥巴马再次总统,奥斯卡经典等推文)居然搜索不到(因为7天的realtime search)
一些挑战(scaling - 推文会越来越多!架构要调整-之前realtime是把7天内的所有推文放到RAM中去搜索)
设计目标:
主要组件:
背后的一些难点:
https://blog.twitter.com/2016/superroot-launching-a-high-sla-production-service-at-twitter
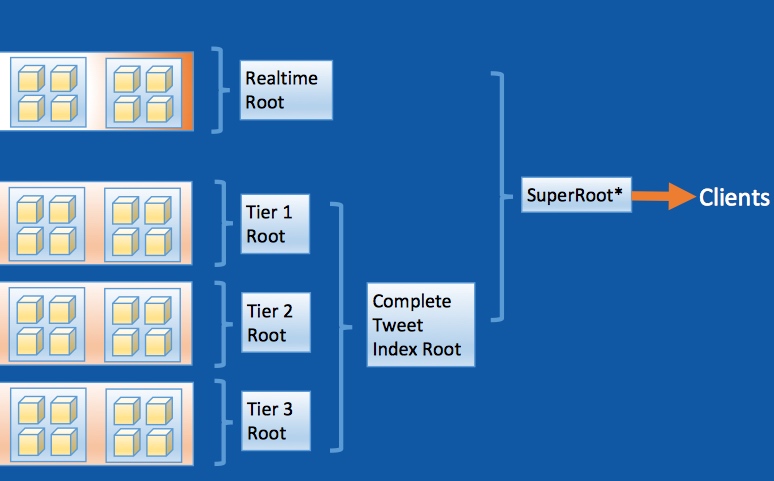 

基于搜索的玩法(ranked timelines -> 用户不会看光所有timeline找出用户关心的那些-> 基于搜索用户following的并且sort -> search it)
其他还有(antispam, ads and sales[企业广告主关注被推文中提到多少次基于时间轴上],Gnip(买数据给企业-基于关键词搜索))

未来更好的支持 scoring 打分和ranking 排序(基于 search engine)
OmniSearch
5
阿里云数据库从最初的只支持MySQL,到现在支持关系数据库、NoSQL、HTAP、EMR产品体系,在管控系统和数据链路上做了好几次重大架构迭代,云产品很长的生命周期里面会遇到新老架构共存,如何做到架构连续和系统无缝迁移是个很大的挑战, 本次报告为你分享实践。
本人挺喜欢这个分享的,孟军在Go社区第一人哈,演讲也是很有激情(《Go Web编程》作者,开源框架 beego 作者)

然后给出了各个部分下,Golang的一些实现:
负载均衡: seesaw, caddy
服务网关:tyk,fabio,vulcand
进程间通信:RESTful(beego,gin,go-kit,goa,micro,lris),RPC(grpc,thrift,hprose)
服务注册发现:etcd,consul,serf
分布式调度:k8s, swarm
异步消息队列:NSQ,Nats
APM:appdash,Cloudinsight,opentracing
分布式配置管理:etcd, consul, mgmt
日志分析:Beats,Heka
服务监控/告警:open-falcon, prometheus
CI/CD:Drone
熔断器:gateway,Hystrix-go
Go是Google开发,09年发布,12年正式版本的作为系统性语言
 

背后的人:
 

Russ Cox,Ian Lance Taylor,Brad Fitzpatrick
“Go is not meant to innovate programming theory. It’s meant to innovate programming practice.”
1 出身名门,血统纯正
2 开发效率,运行效率
3 学习曲线(类C语法,内置GC,编译快速,调试方便
4 天生并发(多核支持,轻量并发,简易同步
5 Unix精髓(组合无对象,无侵入接口
6 标准库(网络编程必备库,系统编程必备库
7 部署方便(交叉编译,无依赖部署
8 稳定(编译检查,编码规范,工程工具
中间件系统
服务器编程
分布式系统
网络编程
云平台应用
数据库系统
运维系统
云存储系统
容器类系统
7
随着互联网网民数的爆发式增加以及人们对随时随地接入互联网诉求的加强,互联网产品需要面对的并发请求量越来越大,云计算的诞生和普及为海量并发请求的应用提供了弹性的硬件支撑。本案例分享基于微服务的应用架构设计,内容涉及如何构建一个微服务应用,服务注册与发现,微服务测试和典型的微服务架构设计模式,以及微服务架构在七牛的实践案例。
演讲提纲:
1. 构建一个微服务应用;
2. 服务注册与发现;
3. 微服务测试;
4. 典型微服务架构设计模式;
5. 七牛微服务架构实践。
听众受益:
1. 学习如何构建、测试和部署一个高可用应用;
2. 了解常见微服务架构设计模式。
创业老板企业家每天都做什么?
翻译自The Daily Routines of 15 Successful Entrepreneurs
该文章是从 Product Hunt Live 整理而来。
what their typical day looks like. 各自有各自的不同。
Some wake up by 4am; others don’t start the day until closer to 11am. Some exercise every single day; others write or meditate. Some have their routine planned down to (what seems like) the minute; others keep more of a loose schedule.
但是有一点是明确的,routines help us get into a flow state that unlokcs our ability to be happy and effective every day.
一般会冥想对要做的事情进行可视化。同时每天晚上会把第二天会做的事情罗列出来,还会进行必要的营养补充(那些缺少的维生素和矿物质)
每天会跳到冰水中(毛主席吗....)as a discipline to make my mind know that when I say I'm going to do something, I do it now - no matter how difficult it may seem. 对身体也不错(every cell, nerve, and muscle in your body pumps like crazy when you make that radical of a temperature change. it moves your lymph and makes you ready for anything. completely invigorating.)
『try to do the things that i think are important, and be ruthless about not doing things that i don't think are important』. 通常给自己当天确定3个大目标和20个小的待办事项
目前为止我已经有五个流行项目(登上Github的Trending页),所以想分享我的一些经验和方法。
如果你开源过代码,就会知道让别人对你的感兴趣是多么困难。这很奇怪,不是吗? 我们花了至少数百小时在这上,把它免费提供给别人却没人感兴趣!!经过几次较为幸运经历,我慢慢发现如何让其他人对我的开源工作感兴趣。如下图展示的:
 

最终你希望得到那些使用你Repo(Github上开源的项目)的开发者的点赞加星。但第一步你需要先获得一些加星,你就是这篇文章的目的。
首先,我介绍下我自己。我目前主要是一名iOS开发者,我在六个月前开始发布自己的开源作品。目前为止,我应该算是能在Github的世界范围顶级iOS开发者榜单上出现了。
 

事实上我没有Github上显示的那么厉害(谢天谢地,不要鄙视我~)我觉得我能够在开源社区有些影响力,是因为我同时能做些设计工作(你接下来会见识到),下面是我的流行项目:
这上面的5个项目都上过Github流行的页面,我把如何做到如此分为6个步骤。
六步骤(主要秘诀在第四到第六步)
为了行文简短,一到三步骤会简单论诉下,四到六步骤会详细讲解。
Repo就是你作为开发者在构建的产品。
那既然是产品,它就要解决用户的难题。你估计听见过不少那些著名的产品都是创始人正好碰到一些难题需要解决而产生。同样的思路,大部分开源出来的代码也是要解决开发者的一些难题。所以,你不一直的创造新东西你怎么会遇到那些待解决的难题呢~
Twindr(Twitter+Tinder)就是我为了逗乐我朋友和自己这个简单原因做的傻傻的业务项目。不过最后它带来了 RKCardView(500+个加星)
所以做业务项目,参加编程马拉松吧,周末和同事瞎搞搞。找到你在重复什么样的代码,从而你可以构建别人也会需要的模块化的东西~
大部分问题已经被解决过成百上千万次了,并且它还会被继续重新解决。
每次你想到某些可以开源做成Repo的,先看看是否其他人已经做过类似的了。如果真的已经存在,很多人已经在用了,说明它还不错,那么拿起来用别自己搞了。
如果它还没有被解决,或者没有被优雅的解决,那开始你的调研。看看现有的方案,找出不喜欢它们的原因。我喜欢浏览现有项目的Githu Issues来为如何构建自己类似方案找灵感。如果我有足够时间,我会亲自使用这些项目记录下我遇到的一些问题(或文档上不好的地方),虽然我自己没这么做过,我只是听说过这个方案而且觉得真的不错。
最后,开始真正过下它们现有的代码。譬如我喜欢 SVProgressHUB 这个项目。特别的,我喜欢它仅仅通过一行代码就能调用而不需要创建和维护对象才能实现。最终我以类似的方式实现了 RKDropdwonAlert。
先快速说5次这句话:『简单,直白,可用』!
我意识到我最近的项目比之前的老项目更快的获得一些关注和加星。可能是因为越来越多人认识我了(我觉得自己非常有名哈哈哈),但我觉得是因为我越来越懒了。一开始我写开源项目时,我会写很多很多代码就为了些不那么明显优化,我因为那些很重要很吸引人。不过现在我会构建优雅好用的东西,却花不少时间来清理接口/界面。

RKNotificationHub 汉堡菜单按钮的左上角。
我们拿RKNotificationHub(RKNH)来举个例子。
一开始我设想RKNN是当我希望在我项目的菜单按钮上加上一些东西,因为我认为是非常好的懂事吸引用户来检查下新功能。这的确工作的很好,我持续在其他项目中也陆续使用。
一开始我设想这个Repo可以支持大量的后端的全能型通知系统。譬如链接到类似 set,array,dictionary,API hit,APN等上,每次值改变了就更新它。
不过最终,我就实现了简单的UI逻辑,把具体业务逻辑交还给用户自己去实施,使它们有更多精细控制。为什么?因为我变懒了,但是我认为它也有它的优势:足够简单,轻量和直白,非常易于使用。
一句话总结就是:如果没人知道怎么使用你的代码,那么就没有会使用它。
Readme(Github允许你创建该文件,通过markdown等语法来在项目主页显示你项目相关内容)是你整个项目中最重要的内容。
如果你最后只能从该文章学到一样的话,我觉得就应该是:
你在代码上花多长时间,那么就花同样的时间来写你的 README 吧。
我是认真的!事实上,我认为我在Github上的成功很大部分来自于我认真设计我的 README 让它更具美感(也证明了我就是一般程序员而已)。
下面是我是怎么布局我的 README 文件的:

一些关键点是:
图片效果是好于文字的。
Repo 中确实需要好代码。不过我敢打赌如果我画一些好看的图片不放代码依然能获得现在60%的加星。有了好的科技,然后好的设计就随之而来 (wherever tech goes, design eventually follow)。消费硬件,应用,网站,着陆页等都说明了这个趋势。技术我们定位的是Github的浏览用户,而仅仅是开发者。
下面有些当你在做图需要考虑的一些关键点。我还是使用 RKNK 中图作为例子。
思考怎么把你的Repo的目的传达出来。
你想要他们能理解为什么这个Repo能有用。RKNK 就是创建出简单的通知图标,所以我决定使用 Facebook 的通知中心作为中心图片。
留意空间
 

在顶部的title部分有个特定的短链接,在结尾有我的Twitter。然后把中间部分且为两块。
左边的图来展示如何使用RKNH的使用。它被居中排放(有不少的留白),人们大多都是从左读到右的,所以左面承载了更主要的概念。
右边的图通用被居中并且留有空白。如果说左边是为了说明这是个什么产品,那右边就是来说明你为什么需要使用它。动画很具有吸引力,所以我想用它来展示。
最终效果:
 

这个图不仅仅是开始一份不错 README 的简单有效的方式,也同样是_适合分享_。
快速说下目前的工具。我绝大部分的设计工作通过 Sketch3 来完成(它是个非常简单的图片设计软件),GIFs 通过 LICEcap 录制,并且在 GIMP 中被编辑。它们有些不太好用,不过也是我目前能发现最好的免费方案了
迭代!开动!可执行的指标!
现在我们有了图片和不错被加了文档的代码。我要向你展示如何玩转整个洗通过你。我首先介绍下 Github 的 Trending 流行页的机制。

这就是你要努力登上的页面。

数据是 Github 提供的,时间窗口不明确,我觉得应该是一周。
这就是原因。大于90%的页面流量和跳转来自于 Github 本身,很可能是来自于 trending 流行榜单页。
成千上万的开发者到 Github 的流行页面来看看开发社区中又有哪些流行的东西。更棒的是这些人都有Github帐号并且都登录着。如果你喜欢获得Github加星,这些人就是最好的来源。
流行页的算法也很简单:就是看在特定时间内被加星的次数。当天和一周都是这样。
反馈回路(feedback loop)是我用来让更多观众参与进来的方法(对他们的建议尽快的回复和迭代)。这是从 the lean startup 中获得的启发和也是我第一次获得30个加星的方法。
反馈回路看起来像:
因为之前的不愉快的事,我现在不太喜欢也很警惕在我个人的社交网络中王婆卖瓜似推广自己的东西。所以除了这篇文章,你很少能在Facebook上看我的状态。对我来说, Reddit 就是个不错的地方,我能够获得匿名的反馈(因为那些人也喜欢学习和接受新东西)。它确实是一个积极和提升自信的好环境。
当然你不一定就要选Reddit作为主要平台。我只是觉得它适合我。你可以更倾向于 Product Hunt,Twitter,Facebook,同事间,本地的计算机科学的用户组类似于编程马拉松的群组等。确保记住一下的原则:
我们再看看上面的来源网站的截图,可以发现Reddit给我带来了58个人,那我需要从这个58人中取得最初的30个加星。这就是显示出之前我们的工作(如项目文档README和配图)的作用了,所以要加倍努力去取得这最初的加星。
如果我遇到一些举棋不定的时刻,我总会求助于我的部分开发者朋友。他们都会帮我解决难题,所以密切关注他们。
感谢那些读到现在的朋友,我希望你们马上就能够获得你想要的效果,但是要记住这不是一个一撮而就的魔法。你还是需要做你该做的工作,也许需要花上上百个小时。我并没有夸大(当我说编码和写文档的时间应该1:1的对应),越是复杂的大型项目越需要越清晰易懂的文档。
你也许会从你写的小东西上获得好几百的加星,但是如果你真的搞出影响力,你需要做出大型项目。我个人在接下来几个月会继续花时间来维护现有的开源项目,试着理解开发者上什么使用我的Repo的。构建创造是快乐的,不过修复问题也是同样重要的。
不管何时,你对你的代码仓库进行的任何修改,都会有可能搞砸线上的某些服务。
没人喜欢那样(服务downtime),没人喜欢惹怒用户,更没人喜欢惹怒他的经理。所以说每次发布迭代的新代码到线上都是充满压力的事。
不过,事实上不必每次都那么紧张的。在这篇文章我会反复说明这样的观点:
『你的部署应该变得非常无聊,非常直白,从而毫无压力』
部署产品服务新的主要功能到生产环境:
这是一篇非常长的(抱歉,但不得已不如此)的关于部署的较高层次的观点文章:协作,安全和节奏。不过文中还是有不少较为底层细节的部分,因为那些很难在语言层面上去抽象,所以不得不撩开袖子去单独解决和说明。我喜欢讨论团队间是如何配合协同,而部署恰恰是最需要和别人(团队)打交道的一件事,我认为你们要时不时花时间去验证下目前团队的一些做法,这很有价值。
这篇文章的内容大部分来自于我在Github长达五年的工作经历和最近一年为大大小小的很多创业公司的建议和咨询的经历(主要集中在提升它们部署流程方面,而它们之前的状况既有『目前还不错的』又有『要紧急救火的』)。特别值得说的是,其中一家叫 Dockbit 的创业公司,它们的产品正是为了在部署时更好协同。所以本文不少来自于我和他们团队城成员的交谈中,这其中有不少我认为是关于部署这个话题很有价值要记录下来与大家分享的。
我非常感谢来自于把不同公司的朋友对此篇文章的不断评审检查和建议(来源于他们自身在部署方面的深刻见解和经验): Corey Donohoe (Heroku), Jesse Toth (GitHub), Aman Gupta (GitHub), and Paul Betts (Slack)。我发现非常有趣的是不同公司在部署这件事上的做法非常不同,但是大家都基于类似的目标和关注点:协作,风险和注意事项。我认为这正是共通东西。
为这么长的开头道歉。不过考虑到这篇是那么的长,也值得如此。
目录:
目标
部署不是要解决一些问题吗
准备
开始部署前的热身,让我们关注测试,功能标志位/开关(flag),和你们常用的代码协作方式
分支
为代码建立分支对于部署非常重要。你要尽量隔离新代码可能导致的一些未知后果。所以我们会讨论分支部署上的一些不同做法:如主分支自动部署和蓝绿部署等
控制
部署的主要工作。你们控制那些需要发布的代码?需要围绕部署和合并代码设置不同的权限结构,开发和审查你所有部署有迹可循,通过部署锁和部署队列来让一些变得有序。
监控
酷,我们的代码终于能上线了。接下来你可以关注部署相关的多样监控指标,为部署收集足够的数据,来最终确定部署是否符合预期还是要回滚代码。
结论
朋友们,你学到了什么?
好像有没什么,大概是不要再犯愚蠢错误了
本篇文章初发宇2016年3月1号。
当你讨论如何把一行行代码把它们从代码仓库移动到不同的服务器的过程。的确有不少把这个解决的很好很傻瓜方案:Ruby下的Capistrano,Python下的Fabric,Node的Shipit,还有AWS,最差的还有FTP这个几个世纪前的方案。所以说目前工具还不是部署的问题所在。
那既然我们有这多好用的工具,为什么我们的部署还会出错呢?为什么线上还有那多bug呢?为什么服务还会有宕机呢?我们都是完美的程序员交付完美的代码。呵呵!
显然事情不总会按照我们预期的方式进行。所以我才认为部署对于小或中型公司是非常值得集中投入的有趣领域。很少有这么具有高收益的领域了。你能否在你的流程中加入提前预测问题的机制,你能否使用不同工具来帮助使你的部署更容易?
『根本不是工具的问题,是流程问题!』
过去几年我聊过的有大量大量的创业公司,并没有在公司层面上对一个好的部署流程应该是什么样子这件事做上的很好。
你不需要发行(部署)经理。不需要要预留特定某天做部署。你不需要每次部署都xin'sh
兴师动众。你只需要选择一个明知的部署方案。
跑之前我们要学会走。我发现现在所有创业公司的都会使用上最新的部署相关的工具链,当他们开始尝试使用却发现在这个过程需要花80%的时间去处理一些基础问题。一旦把一些基础事项准备好,剩下的就很容易按部就班的实施了
测试是最容易开始的部分了。它不是正常部署迭代中的一部分,但却对部署有巨大影响。
根据不同的语言,框架和平台,关于测试有不少技巧。但通用建议是:测试你的代码,然后加速你的测试运行。
我一直喜欢引用Ryan Tomayko 在Github内部测试文档写的一句话来说明这个问题:
『我们让好的测试运行的足够快,但不能让那些草率的测试变得足够好而有用』
所以打好基础:写好测试。不要对它敷衍了事,因为它影响你接下来流程的所有其他事。
一旦你有了可以依赖的测试集后,接下来就要花钱处理这个问题。如果你们团队有部分预算和收入,几乎最值得投入的就是优化下你测试运行的机器。如果你运行测试在类似于 Travis CI 或 CircleCI上,并行运行它们,花目前两倍的钱在这上。如果你的测试运行在某些机器上,那么多买些机器。
通过让测试集运行的更快,我觉得是公司能够在效率提升上取得最大成效的不二做法了。因为它毫无意外的影响这反馈迭代速度,部署时间,开发者心情和惯性。在这个问题上花足够的预算吧:服务器很便宜,工程师很贵。
你的测试应该要快到什么程度?我还在Github时,它的测试一般在两三分钟内运行玩。我们并没有太多的整合测试,从而允许相对快的测试运行。
现在有非常多的项目来帮助并行加快你的构建。如 Ruby社区就有 parallel_tests 和 test_queue。
从另外的角度看这个问题:开始关注下你们的代码,让它现在就开始支持多部署代码路径?(multiple deployed codepaths)
记住,我们的目标是『你的部署应该变得非常无聊,非常直白,从而毫无压力』。而一般压力来源于你新部署的代码会导致你之前没有预测到的问题。从而最终影响了用户的使用(如它们遇到服务宕机或bug了)即使你有全宇宙最好的工程师但是你还有有可能把糟糕错误的代码部署上线,不过这错误代码影响了100%的用户还是就影响了一个用户区别很大!
一种处理这个问题的好方法是功能开关位feature flags,功能开关位早就存在了,从if语句被发明时估计就存在了。不过我记得第一次听到有公司使用功能开关位是在Flickr在2009年的一篇博客中:失控(Flipping out)
These allow us to turn on features that we are actively developing without being affected by the changes other developers are making. It also lets us turn individual features on and off for testing.
在生产环境中使用功能开关位,从而使的一些功能只有你看见,或只有你的团队,你们公司员工才能看到。这提供了两个好处:
它带了的巨大好处,就意味着当你准备好真正上线你的新功能时候只需要设置之前的开关位置成true就行了,然后所有用户都能使用这些了。这样就让很吓人的发行新版本『变得非常无聊,非常直白,从而毫无压力』。
译者注:好像在Facebook通过WIFI等公司网络的调整,使得类似*.facebook.com等访问自动被切换到最新的UAT环境,使得 eat oneself's dogfood,也是不失为一种好方案。
功能开关位跟进一步提供了一种非常好的方式,来证明你要部署的代码不会导致对性能和稳定性上反面效果。最近几年有不苏澳工具来帮助你实现它。
我过去写过类似的(Move Fast and Break Nothing)。这个做法就是在线上同时运行包含开启和关闭功能开关位的代码,从这两个运行环境下收集数据,从而可以产出图表和统计数据来知道你带到线上的新代码是否匹配你准备替换掉代码的功能。一旦有了类似的数据,你就能确保你是否搞糟某些。『部署变得非常无聊,非常直白,从而毫无压力』

Github开源的叫 Scientist 的Ruby类库来帮助在这方面抽象。这个类库已经被移植到很多流行语言上。如果你感兴趣它们值得你花些时间去研究使用下。
关于此的另一个法子是:逐步发布/灰度发布(percentage rollout)。即使你非常确信你要部署的代码是准确无疑的,明知的做法还是先把代码分发出一部分比例的用户,来再三确认没有什么未预料到的不好后果。因为再不济,影响100%的全部用户肯定比影响5%的用户严重的多。
这也有不少工具类库来帮我们实施,从Ruby社区的Rollout,Java社区的Togglz,Javascript社区的fflip 等等还有很多。还有一些创业团队来攻克这个难题如LauchDarkly。
这不是仅仅Web上能做的,手机客户端软件也可以得益于此。看看GroundControl 这个类库是怎么在iOS上实现类似行为的。
在通过网络部署上云之前,我们网飞是如何编译代码?考虑到之前部分内容已经被讲诉过,这次我们准备分享更多细节。在这篇文章中,我们描述工具和技术用来从源代码到最总部署为线上服务来给全球超过7500w的用户提供电影和电视节目的服务
上述图标对之前博客讲的Spinnaker做了扩展,我们全球的持续交付的平台。如果一行代码需要进入Spinnaker中,这之间还有一系列的步骤用来执行。
这篇文章接下来就探索用在上述每个步骤中的工具和流程,也解释了我们为什么这么做的原因。最后通过分享我们现在正在面临的难题结尾。你可以认为这是我们准备详细讲诉在网飞我们如何构建和发布代码的如工具和挑战等方方面面系列文章的第一篇。
title: 【Guide】 写给那些还不想走向技术管理程序员的职业建议
做一辈子程序员是否是一个好的职业选择?或者如果在工程师这个职业阶梯上进一步发展是否必须要走向管理?这是不少工程师在知乎 Quora 表示疑惑的。这是个需要来陈述解决的重要问题,尤其对那些心理上不愿意去管人的工程师们。
好消息是,一直做个好的软件工程师,请求免除做管理的安排,仍然是一个较好的职业选择。但不管怎么样,如果你想要突破那层天花板,你不能仅仅是期望持续多年的技术开发经验就能让你走上职业阶梯顶层。一个关于你职业的大致模型是:你的成就和成长是跟你创造的价值成正比的。
那些在 Google 呆了10年以上拥有深厚经验的工程师们,常常质疑自己为什么仍然是位高级软件工程师的title。那些职业初期快速职位提升的事情看来已经远去,为什么其他同事可以比自己提升的更高更快?
工程师,尤其是那些不想做管理的,会犯的一个大错误是:认为技术能力加上工作经历就会提升自己的影响力。他们甚至常常幻想:如果继续做好工作,他们最终将会获得提升。这个想法是错误,下面是两个原因:
首先,你写代码和构建软件的技术能力随着时间趋于稳定。在你职业初期的那些尝试,你会经常犯一些错误。每个小项目都是打磨你编程技能的好机会。但随着时间流逝,你在软件设计上变得熟练,几乎更少的犯错。你早期在职业阶梯上的一次次提升来源于你早期的技术学习。10年后,你可以仍然保持学习 - 你可以选一门新的编程语言,去学习新的酷炫的框架,但是你的进步和提升肯定不会像你职业生涯第一年那样的快。
其次,经历不会简单而直接的变成影响力。如果十年后二十年后,你仍然解决这目前这样规模和这个领域的问题,实际上你并没有在提升能力来创造影响力。如果你没有创造新的价值,为什么会有老板愿意非给同样没有经验的人付更多的薪水?这个事实在任何其他行业和职业也是存在的。
继续保持做目前做的事情(编程)是简单的,容易的,让人舒服的。如果你想把精力花在其他地方,这个选择也是非常合理的,但是就不要期望你的职业也能随着年限而发展。真正重要的不是你工作了多长时间,而是你创造了多少价值。如果想保持在职业上的继续发展,那么就持续找到新的提升你影响力的方法吧。
拥有良好的职业生涯,转向到管理是一条途径,但不仅仅只有这条。许多工程师成为管理者是因为管理提供了显而易见又真实有效用于提升影响力的杠杆支点。随着团队的成长需要管理者,多年的技术经历对于发展技术管理技能来说是很有用的资产。作为管理者,你影响和改变着你负责的产品和工作。如果你是好的管理者,你就能提升你们团队所有人产出的新价值。如果这新价值超过你作为独立开发者能提供的,那么你的管理就是有价值的。
管理,只是一种职业发展途径。不是每个厉害的工程师都会成为或适合成为一个好的管理者。只要你能找到那些提升你影响力的杠杆支点,你的职业就能继续发展。在很多技术起重要作用的大型公司里,如Google, Facebook, Amazon, Microsoft等,除了管理路线外,都有一条明确的技术发展路线。攀登职业阶梯成为首席工程师,也是要面临不好挑战和竞争的。那些不同于管理的路线越是不常规越是需要更多的创造力。
重要的是意识到:你的技术水平可能会进入稳定的平台期,但是你的技术贡献不一定要。你用来决定在哪些方面下功夫来提升影响力的能力,写什么样的代码,去构建什么样的软件,解决什么业务难题,是没有限制的。这就是区分优秀和普通工程师的重要能力。
具体怎么做呢?你要找到和解决哪些对业务至关重要的技术难题,或者你要你身边的同事更有效率的解决哪些对业务重要的难题。正是这种把自己的技术努力和业务价值相对应结合让你的职业能有进一步发展。随着你付出时间直接带来有意义和可衡量的结果,或你的努力直接提升来业务增长和收入指标的增长,你的老板就会更多的物质奖励你,给你更多的资源和灵活性从而让你更快取得更大的成就。
根据我认识的一些优秀工程师,这些是你可以做的,在不用做管理外:
这些仅仅是一些你能提高影响力的例子,但是可能的路径和方式是无止境的。但是要意识到,在这些方法中没有一项是把构建软件作为最终目的的。它只是帮助团队和业务成功的途径。
在那些能创造最大价值的事情保持专注。你的职场成功和成长会随之而来。
要注意的是,如果你的工作,你的团队或你的公司不再增长,你很难获得进步成长因为你能创造的价值被限制了。这就是脸书的COO Sheyl Sandberg 说当有机会登上一艘火箭时就赶紧上去不管是坐在哪。
Reference: the effective engineer
本文翻译自State of the Art JavaScript in 2016,加上了部分译者的观点。就像是隧道终点前的光明,JS生态的最佳实践不再剧烈变更着,现在关于需要学什么越来越明确了。本文就关于核心类库,状态管理,语言特性,构建工具,CSS预处理,API & HTTP 类库,测试工具,依赖管理等等前端开发的方方面面进行了展望和梳理,为你挑出这些最佳实践和面向未来的设计~
那么,你要开始一个崭新的Javascript前端项目了,或者被之前老项目折腾半死,你也许并没有和改变进化步伐极快的社区生态保持技术实践的同步,或者你开始了,但是有大量的可选项不知道怎么选。React,Flux,Angular,Aurelia,Mocha,Jasmine,Jasmine,Babel,TypeScript,Flow。哦我的天呐这么多~ 为了让事件变得更简单,我们很多人正陷入一个陷阱:被我喜欢的XKCD漫画描述的很好:
 

是的,好消息是现在JS生态开始慢下来了,好项目开始冒出。最佳实践慢慢开始变得清晰了。工程师开始在现有项目上构建自己的工程还是重新创造轮子。
作为起点,下面是我对现代化Web应用各个部分的个人选择。一些选择看起来会有些争议,我会在每个选择后附上我的基本推理判断。要注意的是,这些选择通常是我建立在我目前对社区的观察和我个人的经历。你的看法当然会有不同~
 

目前胜者很显然就是React(译者:你确定?!)
现在不少全能的大型框架如Ember,Angular,它们承诺说帮你处理所有的事。但是在React生态中,尽管需要对组件做一些决定(哈这就是你为什么要阅读本文的原因啦),但是这方案更强壮。很多其他框架,譬如Angular2.0正在快速追赶React。
『选择React不仅是个技术上的选择,更多是个商业决定!』
(很牵强哈,Angular社区的Ionic也是PC Web向移动端迁移的好选择。各自的2.0版本也相辅相成推进上)
 

PS: 以上不是它最终的logo
现在我们有了我们的视图和组件层,应用程序还需要管理数据状态和应用的生命周期。Redux也是毋容置疑的优胜者。
除了React,Facebook展示了名叫Flux的单向数据流的设计模式。Flux最早用来解决和简化应用的状态管理,但是随之而来,很多开发者提出了不少新的问题如如何存储数据状态和从哪发送Ajax请求。
为了解决这些问题,不少基于Flux模式之上的框架诞生了:Fluxible, Reflux, Alt, Flummox, Lux, Nuclear, Fluxxor 还有很多。
不过,这其中的类Flux的优雅实现最终赢得了社区的关注,它就是Redux。
最重要的是,学习Redux小菜一碟。它的作者,Dan Abranmov是一位非常棒的老师(他的教学视频非常易懂好学)。通过那些视频你很容易成为Redux的专家。我见见识到一组几乎没有任何React开发经验的工程师通过学习他的视频,在几周内就开发好能上线的React项目(代码质量也是顶级的)
Redux的生态系统和Redux本身一样优秀。从神乎其神的开发者工具到令人记忆深刻的reselect,Redux的社区是你最好的后盾。
不过有一点需要注意的是不要轻易的去尝试抽象Redux的项目模板。那些模板背后都是有意义有原因的。所以你尝试盲目修改前确保你已经使用过它和理解这样组织代码背后的原因。
 

不用再用CoffeeScript了(译者哭了出来,公司13年大规模的使用它,至今后端JS项目80%都是它的身影)。因为它的大部分好的特性在ES6都有了(它是JavaScript的标准语言规范),而且CoffeeScript的工具很弱(如CoffeeLint),它的社区也在快速的衰落。
ES6是语言的标准。它的大部分特性在最新的主流浏览器中已经被实现,Babel是个可插拔ES6编译器。把它配置到使用合适的预设目标(preset target,如es2015浏览器,es2015-node5),就可以开动了。
那么关于类型呢,TypeScript和Flow都给JavaScript提供了加上静态类型的功能,来配合编辑器提供更好的IDE支持和不需要测试就能捕获一些bug。不过我还是建议,先等等看,看看社区的进展和动向。
TypeScript做了很多工作让JavaScript写起来看起来非常像Java/C#,但它缺乏完善的现代化的类型系统特性如代数数据类型(它对你真正开始实操静态类型时是很重要的)。它也不像Flow那样很好的处理 nulls。
更新:TypeScript有union types也能覆盖很多用户开发场景。
Flow比起来似乎更强大,能捕获到更大范围的bug异常,但是比较难设置。在语言特性上,它比起Babel落后不少,在Windows上的支持也不好。
我要说些有争议性的话了:类型在前端开发中并没有我们想的那么重要(可能需要写一篇长文来讲述了)。所以就先等着类型系统变得更强健,目前先只使用Babel,同时关注下Flow~
 

关于ESLint异议也不大。使用它的React插件和良好的es6的支持,几乎非常完美完成lint的工作。JSLint是过时了,ESLint这个软件可以单独完成原本需要 JSHint 和 JSCS 联合起来做的事。
你需要配置他用你的风格约定。我强烈建议你使用 Airbnb的风格指南,大部分可以被 ESLint airbnb config 来严格约束实现。如果你们团队会在代码风格上产生分歧和争超,那么拿出这份指南来终结所有的不服!它也不是完美的(因为完美的风格不存在),但保持统一一致的代码风格是要高度推荐的。
一旦你开始熟悉它,我建议你开启更多的规则。在编辑撰写代码时候越多的捕获不规范(配置你的编辑器IDE使用上这个ESLint插件),就会避免分歧和在决定费神,从而让你和团队更加高效!
 

这一点很明确 - 就用NPM。所有东西,忘记之前的bower。类似与 Browserify 和 Webpack 的构建工具把npm的强大功能引到了web上。版本处理变得很简单,你也获得了node生态的大部分模块提供的功能。不过CSS的相关处理还是不够完美。
你可能会考虑的一件事:如何在开发服务器构建应用。不想Ruby社区的Bundler,npm 常使用通配符来指定版本号,导致你开始书写代码到最后部署时候版本号很可能已经变化了。使用 shrinkwrap 文件来锁定你的依赖(我建议使用 Uber的 shrinkwrap 来获得更见一致性的输入)。同时考虑使用利用类似于 Sinopia 来构建自己的私有npm服务器。
Babel可以把 ES6 模块语法编译到CommonJS。意味着你可面向未来的语法,和在使用构建工具(如Webpack 2.0)时获得它支持的一些静态代码分析工具如 tree shaking 的优势
 

不想在你的页面文件中加入非常多的外链Script引用,那你就需要一个构建工具来打包你的依赖。如果你也需要允许npm包在浏览器运行工作的工具,那么Webpack就是你需要的。
一年前,关于这块还有不少选择。根据你的开发环境,你可以利用Rails的sprockets来解决类似问题。RequireJS,Browserify和Webpack都是以JavaScript基础的工具,现在RollupJS声称自己在ES6模块上处理的更好。
在一个个尝试使用后,我最终还是高度推荐Webpack:
Webpack目前也是处理大型SPA应用项目的最好方案,利用它的代码切割(code splitting)和懒加载特性。
不过它的学习曲线很陡峭,但是一点你掌握了,你还是会认为非常值得因为它的强大功能。
那么Gulp或Grunt呢? Webpack比起来最适合处理静态资源。所以他们开始可以用来跑一些其他的任务(但是也不推荐),现在更简单的方法是直接用上 npm scripts
 

目前在 JavaScript 单元测试上,我们有众多选择,你选择任何一个都不会错太多。因为你开始做单元测试,你就走对一大步了。
一些选择包括了 Jasmine,Mocha,Tape,AVA 和 Jest。我知道我漏掉来一些,它们都有一些比其他做的好的地方。
我对一个测试框架的的选择标准是:
第一个指标让AVA脱颖而出(因为它的确做的非常棒)和Jest(自动Mocking并不像它说的那么好,因为它太慢了)
选择Jasmine,Mocha或Tape都不会差太多。我倾向于 Chai 断言因为它拥有很多插件,Sinon's mocks to Jasmine's built in construct。Mocha的异步测试支持很棒(你不用在写类似于 done callback之类的)。Chai as Promised 也是很屌。我强烈建议你使用 Dirty Chai 来避免一些让人头疼的问题。Webpack的 mocha loader 让你编码时自动执行测试。
对于React而言,Airbnb的Enzyme和Teaspoon(不是Rails那个!)是不错的相关工具选择。
我非常喜欢Mocha的特性和支持情况。如果你喜欢一些最小主义的,读读这篇关于tape的文章
PS:
Facebook在最近的文章中说,它们是如何扩展Jest的。可能对大部分人来说过于复杂了,如果你有那些资源,不关心是否在浏览器中跑测试,那么它就很适合你。
另外,很多人认为我对AVA太武断了。不要误会我,AVA的确很棒。但我有个标准:全浏览器支持。这样我们可以直接从任何浏览器去执行(来测试跨浏览器兼容性)同时要方便调试。如果你不介意那些,你可以使用非常棒的iron-node来debugging。
JavaScript不像Java或.NET上有很多强大的内置工具集。所以你可能需要引入一个。
Lodash,目前来说应该是杂七杂八都有的首选。同时它类似注入懒求值这样的特性让它成为性能最高的选择之一。如果你不想用你就不要把它全部都导入,同时:lodash能让你仅仅引入哪些你需要的函数(这点尤其重要考虑到它现在变得越来越大)。随着4.x版本带来,它原生支持可选的函数式模式给那些函数式编程的极客们使用。来看看怎么使用它
如果你真的很喜欢函数式编程,那么不管怎么样,留意下优秀的Ramda。如果你决定用它,你可能还是需要引入一些lodash函数(Ramda目前专注于数据处理和函数式构建),但这样你能在JavaScript中以非常友好方式获得函数式编程的强大功能
许多React应用再也不需要jQuery了。除非你需要使用一些遗留的老旧的第三方组件(它依赖于jQuery),因为根本没必要。同时,意味着你需要一个类似于$.ajax的替代品。
为了保持简单,仅仅使用fetch,它在Firefox和Chrome中内建支持。对于其他浏览器,你可能需要引入polyfill。我推荐使用isomorphic-fetch 来在服务器端在内覆盖了基础组件选择。
还有一些其他好的类库选择如Axios,但目前在fetch之上没有多余需求。
为了更多关于为什么Promise是重要的讨论,请看我们博客异步代码
这是个我觉得相对发展较慢的领域。Sass就是目前的选择,使用node-sass是你JavaScript项目的不错开始、。我仍然觉得离最终最好的方案还是有很多不足。缺乏引用导入(如仅仅是从文件导入变量和mixin,而不用重新定义选择器和它的样式规则)和原生的URL重写(使它在保持线上代码足够精简就很困难)。node-sass是一个C写的类库,所以要对应好你的Node版本。
LESS并不受此影响,不过它缺了很多Sass的特性功能。
PostCSS 看起来更有生命力,它允许你构建自己的CSS预处理器。我推荐你使用它,即使你已经有了你喜欢的预处理器如SASS,它类似于AutoPrefixer使得你不需要要导入类似于Bourbon这样的大型依赖。
有一点需要特殊注意的是,CSS Modules。它限制了CSS的层叠部分,使得我们可以定义更加明确的依赖,来避免冲突。你再也不用担心Class名称一致导致的覆盖,也不用特意为了避免它而添加额外的前缀。它和React也配合的很好。有个不足:css-loader和css modules一起使用会导致非常缓慢,如果你的样式数量不少,那么在它优化之前还是避免使用它吧。
如果要我现在从头开始一个新项目,那么我大概会使用PostCSS配合一些我喜欢的预编译的CSS类库。
不管你选择什么,我还是推荐你看下我这篇文章CSS performance with Webpack,尤其你也在配套使用SASS。
Universal或Isometric的JavaScript代表着JavaScript写的代码可以被同时运行在客户端和服务器上。这需要用来在服务器端预先渲染页面来提升性能或SEO友好。感谢React,之前只有类似于Ebay或Facebook这样的巨型科技公司才能实施的方案,现在很多小的开发团队都能做到。不过它并不那么容易,它显著的加大了复杂性,限制了你类库和工具选择。
如果你在构建B2C的网站,类似于电商网站,那么你可能必须使用这个方案。但如果你是在做内部网站或者是B2B应用站点,那么这样的性能提升和SEO其实并不需要。所以和你的项目经理讨论下,看看是否有必要~
看起来每个开发者最后都会疑问那么关于API接口呢?很多人会直接想到RESTful API(因为太流行了),同时SOAP真的成为过去式了。同时现在也有不少其他标准如:HATEOAS, JSON API,HAL,GraphQL 等
GraphQL 赋予客户端强大的能力(也是职责),允许它来实施任意的查询接口。结合Relay,它能为你处理客户端状态和缓存。在服务器端实施GraphQL看起来比较困难而且现有的文档大部分是针对Node.js的
网飞(NetFlix)的Falcor 看起来它也能提供那些Relay和GraphQL提供的功能,但是对于服务器端的实现要求很低。但现在它仅仅是开发者预览版没有正式发布。
所有这些有名的标准规范有他们各种的奇怪之处。一些是过于复杂,一些只能处理读取没有覆盖到更新接口。一些又严重和REST走失。许多人选择构建它们自己的,但是最终也要解决它们设计上带来的问题。
我不认为现在有什么方案是个大满贯(完美的),但是下面是我对API应该有的功能的一些思考:
我没有找到能覆盖这些需求的方案。如果有,务必让我知道。
同事考虑,如果你实施一个标准化的RESTful资源路径时,使用Swagger来文档化我们的API。
Electron 是Atom这个优秀编辑器的背后基石。你可以用它来构建自己的应用程序。它的核心,就是一个特殊版本的Node可以来打开Chrome窗口来渲染GUI页面,并且能够获取到操作系统底层的API(不用借助浏览器的安全沙箱等措施)。你可以打包你的应用程序像其他的桌面客户端软件那样分发安装包,并且辅以自动更新机制。
这就是用来构建横跨OSX,WIndows和Linux这多个桌面环境的应用软件的最简单的方式,利用起上面提到的所有好用的工具。它也有不错的文档和活跃的社区支持。
你也许也听过nw.js(之前叫node-webkit)它年事已高,Electron比它更稳健,更容易上手使用。
来使用这个模板项目来开搞自己的Electron,React和热更新项目吧,你可以看看这些东西是怎么相互配合工作的~
社区有一些大牛,你可以在Twitter,Weibo,掘金上关注他们。
还有不少好的文章和链接。
如 Removing user interface complexity, or why React is awesome 就是对了解React背后实现原理和原因的不错讲述。
JavaScript生态区发展很快,欣欣向荣,在快速前进着。但是就像是隧道终点前的光明,最佳实践不在剧烈变更着。现在关于需要学什么越来越明确了。
最重要的是记住要保持简单,如无必要,勿增实体。
如果你的应用就是两三个页面,那你不需要用到 Router。如果就一个页面,那么你也不用Redux,只需要用React自己管理状态就好。你的应用就是简单的 CRUD 程序,那么不需要用到 Relay。你在学习 ES6 的语法,那么先别急着弄 Async/Await 或者装饰器。你准备开始学习 React 了,你不必要立马就去了解 Hot Reload 热更新和服务器端渲染。如果你刚刚使用上 Webpack,那么也别急着就来用代码切割(code splitting)和多代码块(multiple chunks)。如果你才开始 Redux,那么也不用匆忙用 Redux-Form 或 Redux-Sagas。
保持简单,一次学一样,你就不会像其他人一样抱怨JavaScript的破碎(Fatigue
这就是我对目前JavaScript生态现状的看法和观点。如果你觉得我遗漏了那些类别的讨论,或者你认为我在一些选型上的决定不正确,你有更好的可以推荐。那么留言吧~
未完待续
翻译于Effective Code Reviews,本文对代码审查会遇到的问题(变成审查者炫技,开发者依赖审查找出代码问题对自己的代码不管不顾,总是等代码ready后才审查等),从管理者,开发者和审查者都提出了不少实用有效的建议(如建立合适的团队文化,讲点人情味,对事不对人,谦虚点~)
代码审查就是开发者写的代码被其他开发者来审视看是否有缺陷和可提升点的过程。换句话说,开发者先独立完成他们的编码工作,然后召集一次代码审查。
代码审查是一种被证明可以推升软件质量的编程方法。在Google,所有的代码都需要被同事进行审查才能入库。从《代码大全2》中列举两个例子:
不过,现在还是有很多团队在代码审查上做的并不好甚至还没有全完意识到它的好处。在这样『功能紊乱』的组织或团队中,很快会所有参与其中的人感到痛苦难过。
在这篇文章中,我们聊聊组织团队通过实施哪些规则和方法,让每个参与代码审查的人都能感到满意和愉快。
同事间的代码审查是相互交流沟通的过程,这其中的低效也是源自于社交层面的。不过不少管理者花了不少时间去考虑工具是否好用,是否酷炫。工具当然会有提升,不过仅仅通过它不会带来最终的好结果。从建立正确的文化开始,然后剩下的人与人之间配合和沟通~
PS:经过大半年的野蛮发展,我们交付了不错的软件应用给业务部门,随着团队的增大和后续人员的加入,新的功能点也需要在原有项目上迭代,我们广发团队们也开始了陆陆续续的Code Review的进展工作,你有什么好建议?
由于项目需要我最近几个月需要重试前端开发的旧业,我立即被一个悲催事实吓到:所有东西都变了!!
当我还在JavaScript或前端社区仅仅参与时,这种改变看起来很小。我们会时不时转换打包工具(从RequireJS 到 Browserify),或者改变框架(从Backbone 到 Web Component),有时候我也会玩玩最新的V8引擎的新特性。大部分时间,这种更迭是增量的。
我只是短暂离开了一会,回来后突然发现JavaScript社区的永不止步(折腾死人)的这种情况。
一些年前,我和朋友还在讨论怎么选择一款合适有正确的模块系统。那时他想要用上RequireJS,我却推荐他参考和选择 Browserify或Component(因为我们刚刚抛弃RequireJS替换为Component)。
昨天晚上和他又聊了会,他说他当时选择了RequireJS。到目前为止,他们公司在此之上构建了大量的代码 - 『我想我押错赛马了』
这让我思考,在JavaScript这个不断更迭的混沌下,没有所谓的正确的赛马可押。你要么要持续的更新你的技术栈来与时俱进,要么就要对你目前所押的技术知足。作为开发者我们为别人构建产品,很难知道什么时候需要投资到新技术栈中。
不管你喜欢不喜欢,JavaScript比现有计算机历史上的所有语言都以更快的速度更迭着。
我们现在用的大部分技术之前都不存在。如:React,Flux,JSX,Redux,ES6,Babel等。甚至为了新建个符合目前选型的项目就需要安装一大帮依赖,构建工具也几乎全是新的。没有其他语言会有这种糟糕的事情发生。顺便做个推荐篇文章16年JavaScript生态发展趋势和选型,这样你能确保目前的选择是大致正确的。
所以,为什么JavaScript这么能折腾?
这篇文章主要从一位研究员的视角,对『从学术界向工业界的转化,在Google项目的选择上和一些通用的建议』进行论述
最近我在庆祝在Google待满的10年,准备借此机会来分享下我对过去十年的一些思考。在加入Google前,我华盛顿大学的计算机科学工程学院工作,在那时我创建了数据库研究小组(目前仍然一派欣欣向荣蒸蒸日上)。在我在学校任职的几年,我创建过两个创业公司,Nimble科技和Transformic企业。在Google的最近8年,我领导Google研究院的结构化数据研究小组。所以我的一些思考集中在从学术界向工业界的转化,我在Google项目的选择上和一些通用的建议。需要我特别指出的是:我的这些观察是建立在Google在研究和工程紧密结合这样的模型上的(所以观点会有些偏颇~)
不管怎么样, 我这里还是想把那些指导我在Google工作的一些原则
在Google,我的优势就是,我们各种类型的海量数据和我们乐于尝试接受我们新产品的用户。 我用会两个例子来说明。
不管你的角色怎么转变提升,始终要坚持写些代码(如果你不会编程,也要让自己参与到代码审查中)。你用不着写的很多很好很重要,但是确保你能时常写些代码。受我两个好朋友(两位都是在他们各自领域毋庸置疑的领袖)的感染(他们就经常参与到日常编码活动中),我现在也开始编码了。在Google,
我的一些编码活动总是很有产出。他们要么被作为新产品发行出要么在现有项目转型上起了大作用。编码也能让我和团队成员对于一些技术细节进行详尽的探讨。要知道现在编码实践和工具在快速变动着,写些代码让我能够与时俱进。最重要的是,我非常享受这一过程,让我想起了很多年前吸引我进入这个领域的那种快乐一样~
已经有很多文章探讨过工作生活的平衡这个话题了。我的建议很简单:你的平衡不是通过强制削减工作达成的。你要通过找到那些你生活中的乐趣和激情来让你离开办公桌!当然,家庭永远是第一选择,但通常我们还需要一些其他的。那我自身说,我通常在写那本关于咖啡书籍时体验最快乐(我不是为了工作生活平衡而特意去奖励自己去做那个,经常是后知后觉)。除了那些配孩子的时间,我发现那些花了很长时间研究和撰写关于咖啡(更不用说在这学习过程中各种新的听闻见识)给了我长时间的放松,不用去思考工作中的烦事。
申明:
不管你在哪里和你做什么,最重要是确保和那些优秀的人一起共事。
翻译自What is Reactive Programming。 先后阐述了为什么Reactive编程范式应运而生下的背景,然后对它的四个主要原则进行梳理。响应性,弹性,可扩展性和消息驱动等进行讲解~
PS:本文会加工为PPT,在腾讯 AlloyTeam 2016 前端大会,作为 lightning talk(10min)快速分享下~ 感谢稀土
大家好,今天给大家带来的分享是JavaScript生态的新趋势。ppt1(cover)
我个人的经历是百度/豌豆荚/广发证券。算是全栈工程师,大概半年前也在这里分享过广发 Node.js的实践,平时会把自己喜欢的技术文章分享到稀土掘金上,所以这次掘金的朋友让这里做下这个闪电演讲。ppt2(about me & xitu)
由于项目开发需求我离开过前端一阵子,当我回来重操旧业,立即被一个悲催事实吓到:所有东西都变了!相信大家对最近火热的2016学习JavaScript是什么体验这篇文章还印象深刻,的确各式各样的新东西。ppt3(js 多元)
PS: 尽管大部分时间,这种更迭是增量的。(ppt3-b 盖住前面的)
社区中有些人感到fatigue!!就是 我们认识速度跟不上社区创新更迭的速度,慢慢就疲劳麻痹了。


为什么呢?我们在构建复杂的应用。它在数十种浏览器中数以百计的设备上要良好的运行,不同的屏幕尺寸不同操作系统不同的WebView),要应对糟糕的网络环境如电梯地铁,甚至是要对盲人等,都能deliver良好的体验。
有许多可行的方法来实现所有这些目标。新的平台能力(v8, chrome, web components, Progressive Web Apps),来自于其他社区的新思路(mvvm, virtual dom, immudate data的等),
我们新实践新潮流会引入新问题,从而循环往复,推着整个技术圈往前波浪式螺旋的发展。
而一个大型的工具生态系统已经出现 - 每一个从不同的角度攻击不同的问题。
接下来的趋势来自于 state-of-javascript调查问卷的开放数据:
一页ppt展示『
javascript flavors
front-end frameworks
css tools
build tools
』 目前的不同选择。相信大家都有所耳闻
当谈论“JavaScript”时,我们不只是在谈论单一的语言:它实际上更像是一个密切相关的表兄弟家庭。
ES6是新的标准。CoffeeScript已经过去了。新的JavaScript风格即将到来。
ES6与React,TypeScript与Angular 2,两大框架的站位让趋势更加明朗。
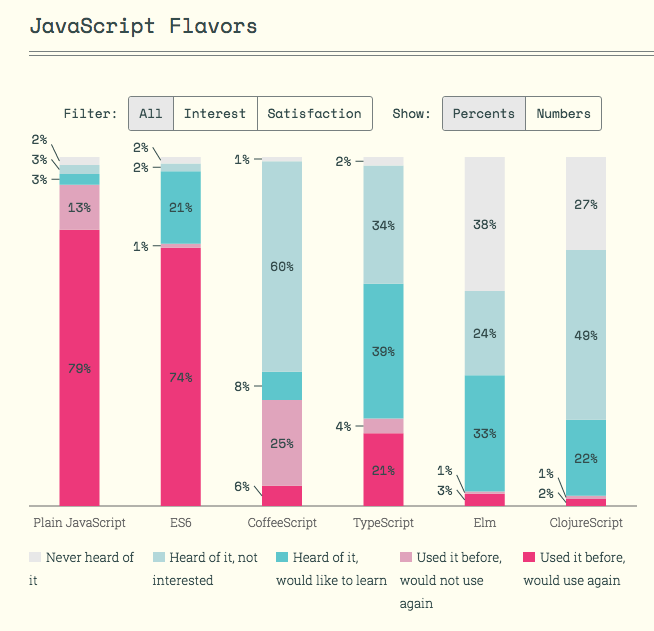 

不能错过 React.
Vue 越来越流行(因为国人?)
Angular 2 > Angular. 吸引着大量的关注
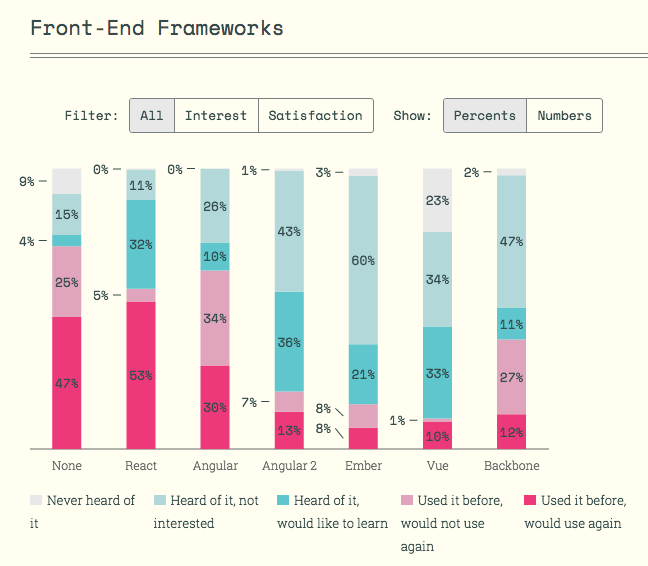 

SASS / SCSS是目前主流。
CSS Modules 也许值得研究。
在React中的CSS: - 如果你想构建可以在其他React应用中可使用的可移植React组件,CSS in JavaScript 是你的最佳选择。 除了CSS Modules,还有 Aphrodite。
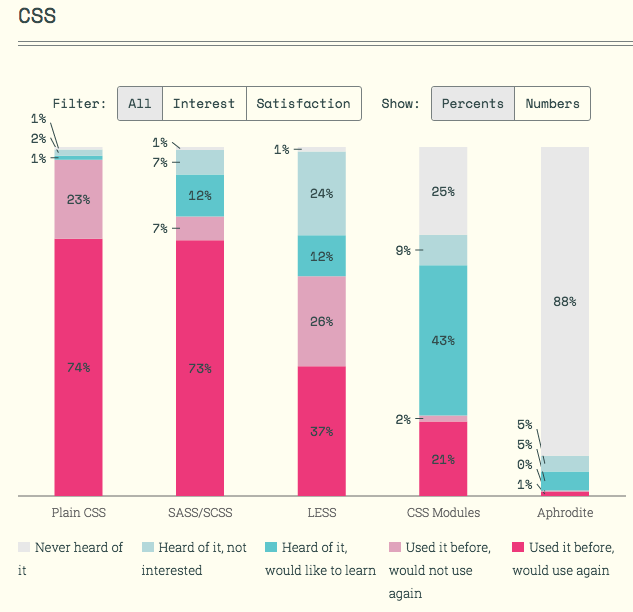 

Webpack和Gulp是闪亮的未来。
Grunt可能成为过去的东西
Webpack用户与ES6,React,React Native和Redux重叠 - happy family
Rollup - 声称生成比Browserify或Webpack更小的包,值得关注。 (成为ionic2的default,声称在 es6 module 使用更好,webpack2 开始集成 tree-shaking)
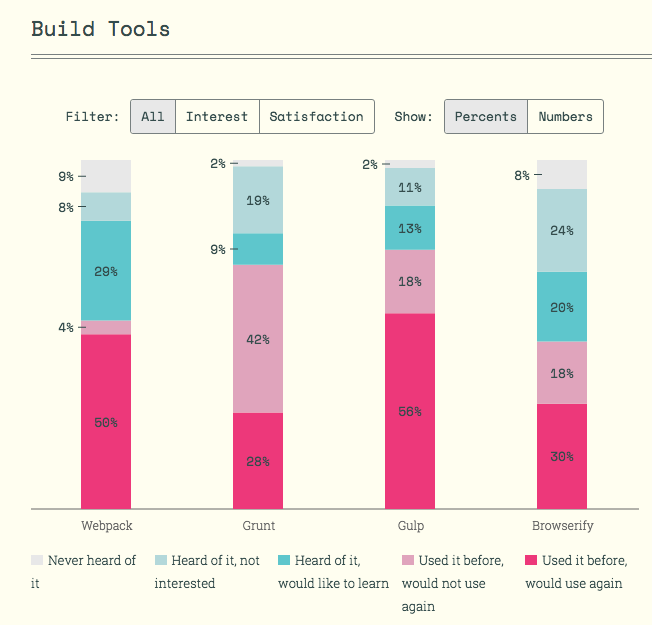 

ppt6
哇,这和我几年前刚入门前端的时候已经完全不一样、
极限编程的创造者肯特贝克 说过:
“让它工作,使它正确,使它快速。”
“Make it work, make it right, make it fast.” — Kent Beck
就是快速迭代,快速试错嘛。 在过去的20年,我们专注于使 Web能 Works~
工具正在被爆炸式的发展, 如果你想知道 JavaScript 社区生态朝着什么方向发展,你可能会去关注现在什么特性和工具正在快速流行被高度评价。
PS:社区中每个人都在拼了命的去做的更好,而且这个不是被大公司所夹持的,而是社区力量决定它的。。。
下面是这些特性:3代表Nice-to-have的,越高越代表是主要feature,越低代表没那么需要。
The Cambrian explosion of tools you see around you is what rapid progress looks like when it’s not controlled by an Apple or a Microsoft.
Everyone’s scrambling to make it right, and to make it fast, all at once.
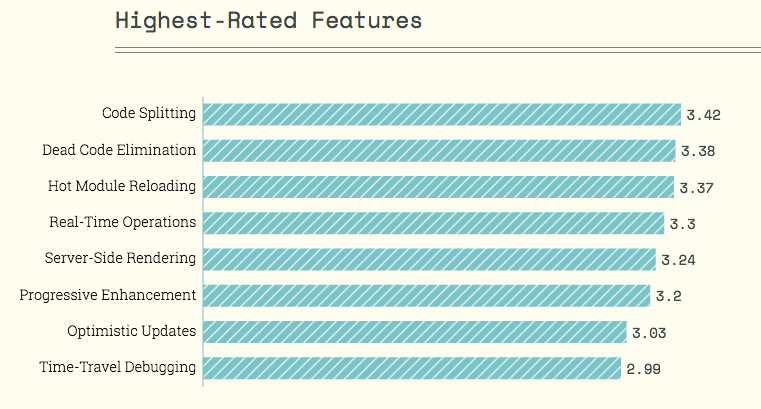 

接下来我们分别看看看那这些技术点。
来解决代码越来越复杂臃肿后的切分压缩传输问题
专注于提升复杂应用编码效率。
PS:『当您更改文件时,服务器将仅向客户端发送更改(以及可能是其依赖关系)。 “热感知”的模块(导入/要求彼此的文件)然后可以在新代码到达时采取动作来使用新代码。』HMR works by watching changes to files, and signaling the browser to replace specific modules, or functions, but not reload the entire page.
The major benefit of hot module replacement is that state is not lost – if you’ve had to perform a number of actions to get to a specific state, you won’t perform a full page refresh and lose the history of those actions.
数据交互是单页应用的核心功能点。
事实上上面特性不仅仅是体验上的,结合刚才提到的状态管理工具和新应用开发框架的特性,这些实施起来会变得相对容易并逐渐变成应用开发的标配。
PS:新框架新的工具库正在让这件事变得容易,从而
不得不说,JavaScript 变得不再是我们熟悉的犀牛书(第五版)中样子了。
1.5+2+1.5*4min
哇,我们应该感到高兴,蓬蓬勃勃发展的社区解决各种各样的问题,让整个圈子都往前一大步。
不要疲于追赶新技术,你完全不需要知道所有,因为两个月后它就过时了。不要因为某些东西看起来很酷就引入,像Redux(在小项目中为什么我加个小功能需要改三个文件?!!Why do I have to touch three files to get a simple feature working?)
但是 The myth of the “Real JavaScript Developer”
最后值得庆幸大部分人还是认为JavaScript正在向着一个好的方向去发展。我今天的分享就是这样,谢谢大家~
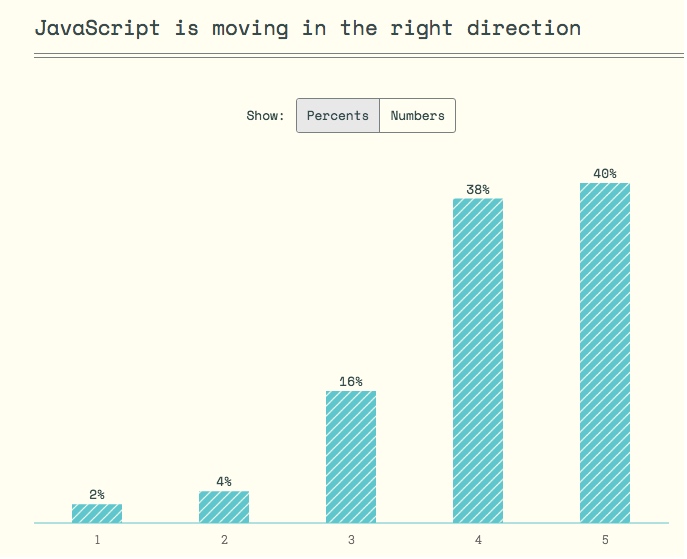 

2016/04/12 永不停步(折腾死人)的JavaScript 生态
2016/04/07 展望 Javascript 2016年的趋势和生态发展
The State of JavaScript in 2016
The myth of the “Real JavaScript Developer”
JavaScript Fatigue Fatigue
找到新工作最简单的方式通过你的个人职场网络。那些认识你的人和你一起共事过的同事,最有资格为你的杰出技术才能和迷人个性背书,通过这些人直接和有HeadCount的HR经理直接联系上是最有效找到新工作机会的方法。不过,你的网络始终是你目前所能看到的一切(从而也限制了你)。如果暂时还不认识你想要的工作机会公司的人,或者你的人际关系不够强。这时候你还是要依赖于你的简历来撬开那家公司的大门。
我不止一次听到过这样的观点:简历对程序员来说根本不重要。这些人认为简历是过去的产物现在我们只需要关注候选人的Github简历就足够了。不过,在我看来,大部分应聘者除了一些简单尝试的小项目或fork别人的项目外,很少在Github上有太多工作。除非你的工作就是围绕开源项目的,所以你的简历是筛选简历的人唯一有的关于你所有信息的一切,通常也是决定你是否能进入下一轮的关键印象。
 

大部分我见过的简历都没有把能进入我们团队的个人潜在价值沟通好。相反的,这些简历都多多少少了暴露来一些反模式:
模糊的说明着项目,夹杂着一系列的技术点,流行词汇和所谓的最佳实践。有资格的候选人被拒绝是因为离我的标准还有距离,还有不少候选人根本在简历山筛选上都没有通过。
你的简历上应该把你能够给公司和团队带来的价值阐述表达好(通过你给之前或现在雇主提供的价值说起)。下面我罗列来一些不好的反模式,也给出了相应的改进方案。
作为软件开发者,和潜在的老板聊聊你熟悉的各种编程语言和技术是很有价值的。对于不少职位,熟练掌握(甚至要精通)某项技术是职业必须项。不过,简单罗列技术名词,而对你掌握如何只字不提就不好了。尽管你的简历不必要成为详细的技术评审。你描述对一项技术的掌握可以给筛选简历的人积极的好感,也为将来的面试官看你简历时提供话题。
就像是购物列表似的罗列语言,技术和工具,没有任何上下文来说明你是如何使用的,或者它们根本与你要申请的职位风马牛不相及。
例子:
工具:Ruby,JavaScript,jQuery,React,Git,Jira等
提升:
给我们的Ruby on Rails 项目体检一系列的移动客户端的API,如来记录各个国家地区的爆米花热狗的价格。通过etags实现缓存,来减少移动设备在消费 API时 60%的API响应时间。领导团队升级到 Rails5。在此之前,实施和验证几个 Rails4 的安全补丁。
提升:
实施聚合各个国家的爆米花热狗价格数据并且通过JSON API的方式提供结果给客户端(符合 Ruby on Rails 的 JSONAPI 标准)。使用 Sidekip 来加速定时任务的执行,它们从第三方的JSON APIs中爬去数据然后把结果存储在MongoDB中。
提升:
领导和评估迁移到新的JavaScript UI类库的工作。最终在决定使用 Angular 还是 React时。根据 更低实施的成本(不是所有团队成员之前都使用过两个框架),容易实现组件化(我们的UI组件是通过许多小且易于复用的部分组成),方便实现Flux类似的单向数据流 选择了React。
提升:
由于缺乏明确专职的产品经理,我们的工程团队被分管市场的VP副总监领导着,但是我还是缺乏每天的项目管理指引。我提议和成功的在团队实施JIRA,并且被当做是默认的项目管理角色。除了日常开发工作外,我也和市场VP一起,把产品需求细化和分解到 JIRA 任务中作为每周迭代。
开发者,就想其他职员一样,能够有给团队和组织贡献不止他们专业技能本身的潜能。表达你个人的软实力不仅仅是来展示你价值的好机会,也代表你知道你比你目前的中高阶技术能力外的自信。
听起来不错。在简历上仅仅写出『拥有优秀的沟通技巧』恰恰体现了你不咋地的沟通能力。
例子:
优秀的沟通技巧
提升:
主导和对齐一个正在进展中的平台优化的例会(用来定期偿还我们之前留下的技术债)。我给例会中引入了一套代码准则来避免直接指责同事和确保所有团队成员都能有机会说出和提议对目前技术债的解决方案。
没有进一步解释你是如何或为什么指导同事的
例子:
指导实习生
提升:
把我们团队的实习工程师招聘项目扩展到我的母校去开展,找到那些合适的候选人
提升:
每周会花费5个小时左右去指导我手下计算机科学的本科实习生加速学习JavaScript相关最佳实践在他最后一个学期里。最终让他在毕业后能够以全职正式员工身份入职。
提升:
在得知其他组的同事对学习Ruby很感兴趣后,组织了每周的工程师读书俱乐部,定期指导阅读,布置课后练习和审核他们的相关答案
和软技能一样,表达你对工作的态度和对其他同事如何协同的观点会给你潜在老板很有价值的信息:看你和目前团队的文化是否契合。好的管理者一直都知道一个成功的团队是由很多迥然不同性格和能力的人组成的,在表达你的偏爱和工作风格后,他会知道你是否可以在目前这个团队和在的什么位置什么方面上发光发热。
大部分简历上都对应聘者本身的对于团队结构和组织里同事性格的偏好上缄口不语。
提升:
我喜欢高度配合协同的工作环境,任何时候都希望能够结对编程。我也喜欢参与在经过完善企划围绕着软件架构和系统设计的例会。我乐于和产品经理一起,把需求一起梳理清楚。但对花大量时间在项目一开始去脑暴和开发不怎么认同。
提升:
我特别喜欢在早期的创业公司工作,因为有机会去承担产品工程师的角色。我也喜欢在编码实现需求前,和产品,设计团队的成员一起去调研,头脑风暴,和功能原型。
提升:
我在独立开发时效率最高。我在和同事一起协作做功能设计和定位没有问题,不过作为天生的内向者,我在个人独自编码时效率最高。
https://medium.com/@mhriess/software-developer-resume-anti-patterns-4e906f2314cd#.ytcyvzpzu
翻译自How to Use Math Words to Sound Smart
你想过为什么每次和工程师们讲话沟通起来都感觉他们好聪gu明guai的样子。很多什么时候会用上不少数学术业来『装逼』。不过又不仅仅是他们才会用这些,快来学起来~
接下来我们来逐一看看这些词,并且学学怎么使用它~
这两份Snapchat的市场提议听起来都不错,但是他们之间区别是啥?
what’s the delta here?

our hands-free hand washing app is experiencing massive growth
we’ve got exponential growth 指数级增长
Vegan lunches have nothing to do with getting more expresso machines
That's an orthogonal issue
Either you're going to give us a million dollars or you're not.
I have binary expectations here
我们应该在那放上申明(不承诺),不过现在最重要的是我们被起诉了
The high order bit is we're being sued.
There's nothing positive about this review we got on Bloomberg.
This review is pretty 3rd quadrant.
I know the app doesn't really work but is it good enough to launch?
Is it good enough for t0?
We should a/b test calling it "the best app" or "the bestest app"
Let's do a multivaraiate test.
If no one clicks on this giant red button then we drop the whole project.
This is our forcing function.
It's like we keep almost keeping money but then we never do.
We've got asymptotic profit.
We can't afford to pay this quarter.
Your salary is null.

你今天用了什么数学术语吗?
Facebook 是怎么看待开源这件事的?
翻译自Inside Facebook's Open Source Machine. 福布斯专栏对Facebook开源负责人的采访整理。正直F8大会闭幕~
A:
A:
Q: Has there been an evolution in how you develop code in the first place based on the expectation that you could open source it?
Q: You mean to think modularly?
Q: So essentially, they’re not doing code in their pajamas.
Q: I would think one challenge might be that you can get efficiencies inside a company from intertwining systems, so how do you persuade engineers not to opt for that kind of advantage?
Q: Any less obvious benefits of open source for Facebook and other companies?
Q: What companies don’t understand this yet?
如果哪个时间段我没带上降噪耳机工作,那我的效率肯定不高,因为我没有进入到属于我自己的由音乐营造的氛围空间中~
编译自How Music Affects Your Productivity
Since music has increasingly become a part the modern-day workplace.
『Music has a strange temporal permanence; as art decorates space; so does music decorate time』
With so much of our time being spent at work, and so much of our work being done at computers, music has become inseparable from our day-to-day tasks — a way to “optimize the boring” while looking at screens.

为什么有效
听哪些
例子
为什么有效
听哪些
例子
为什么有效
听哪些
例子
为什么有效
听哪些
例子
the environment you create impacts the behavior you get.
test and tweak until you find the perfect harmony.
clear~~
翻译自What Technology will look like in five years。PS:这篇文章出来好几个月了,好像也有人翻译过,但是还是觉得想要自己再复述下
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.



{kind=link}