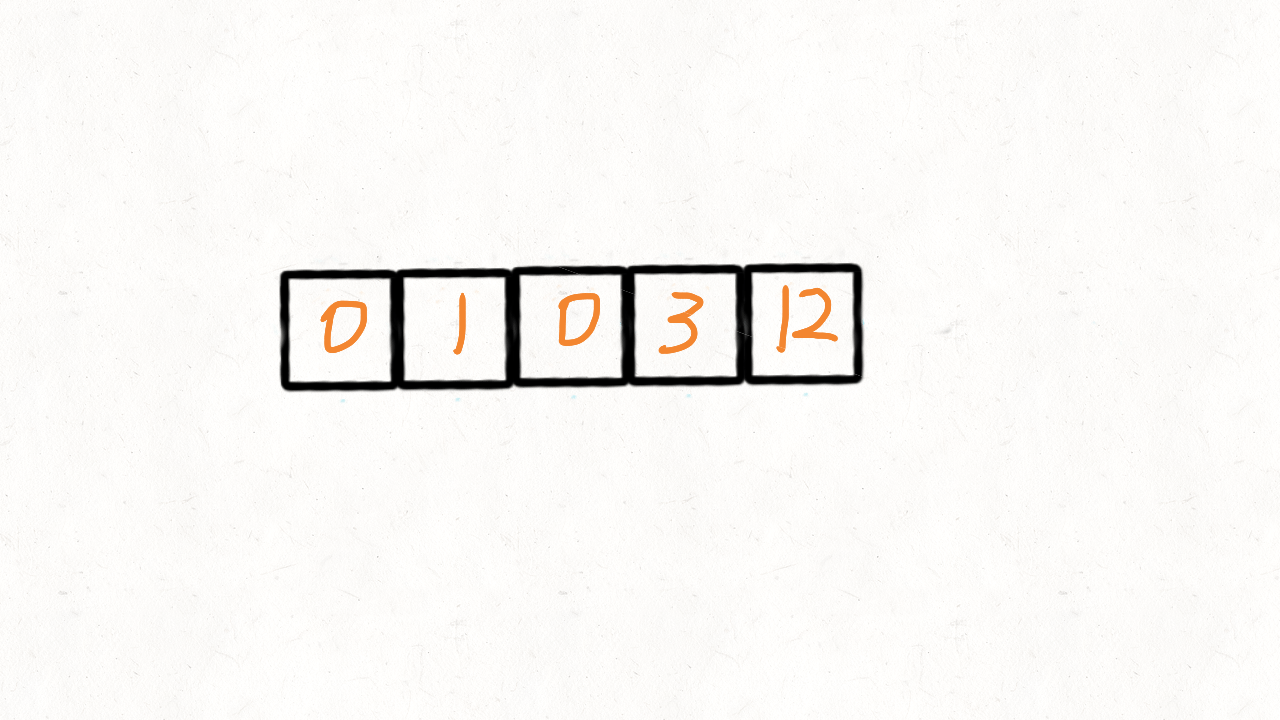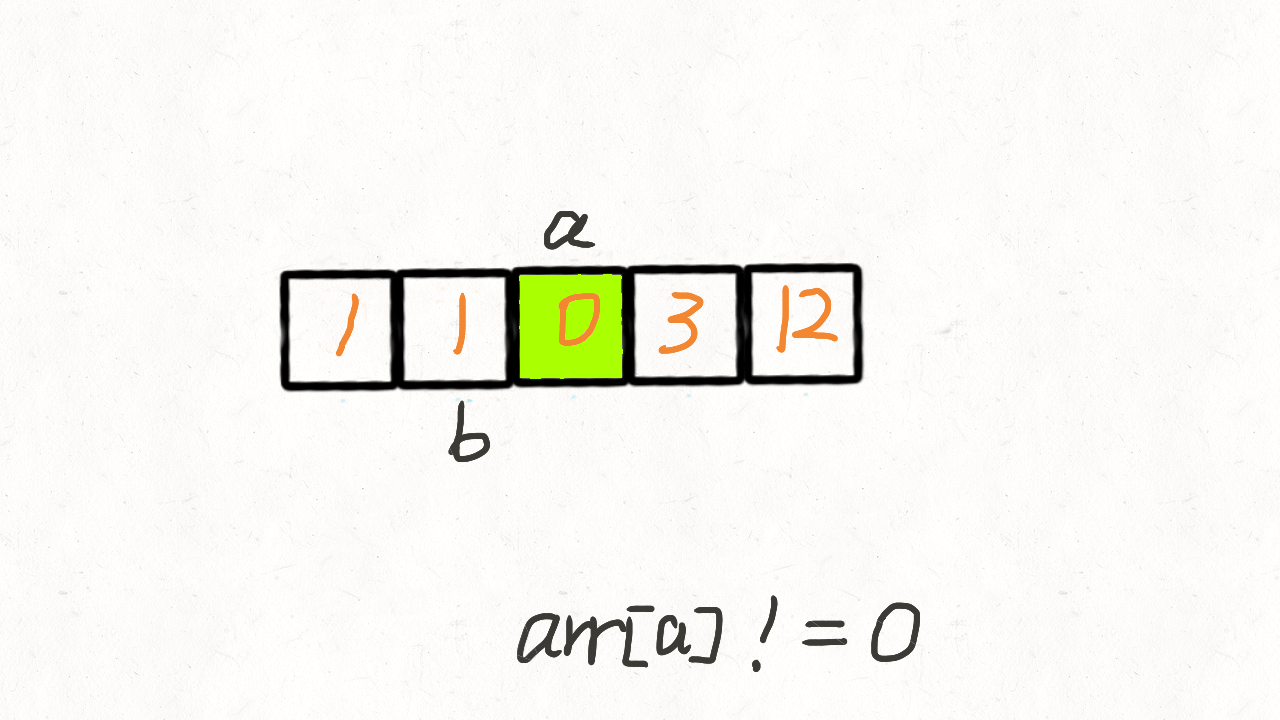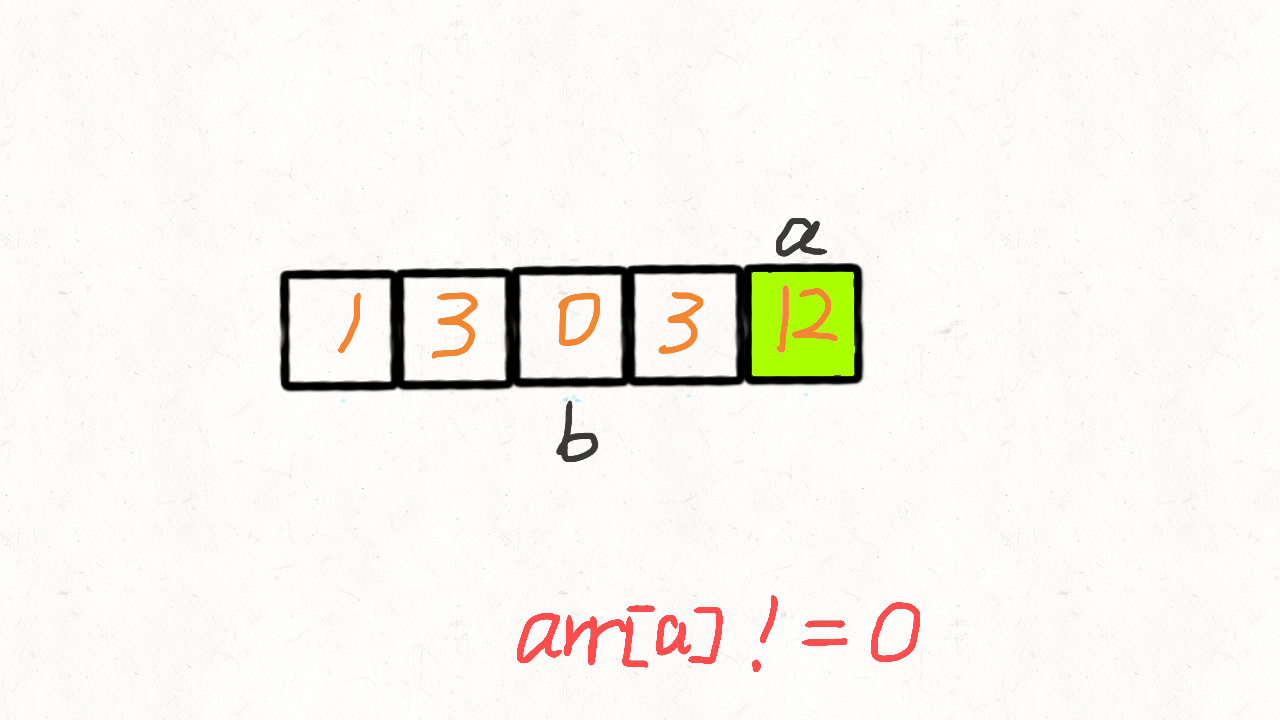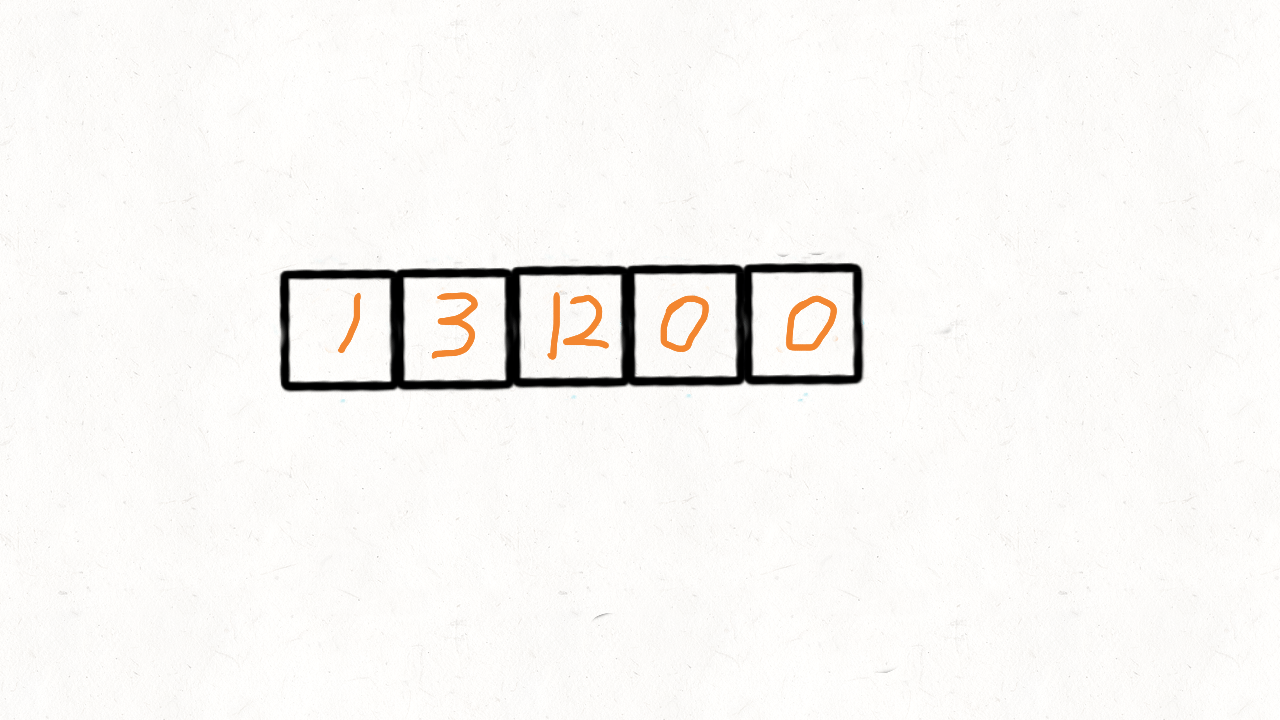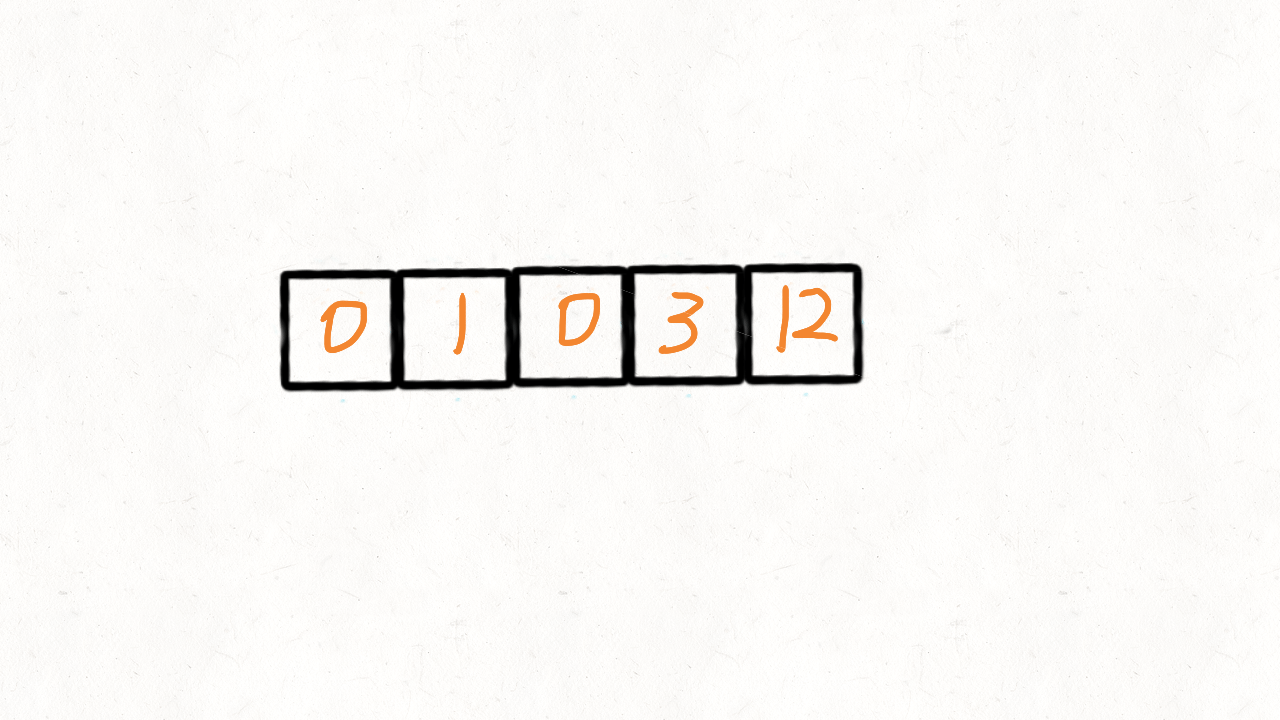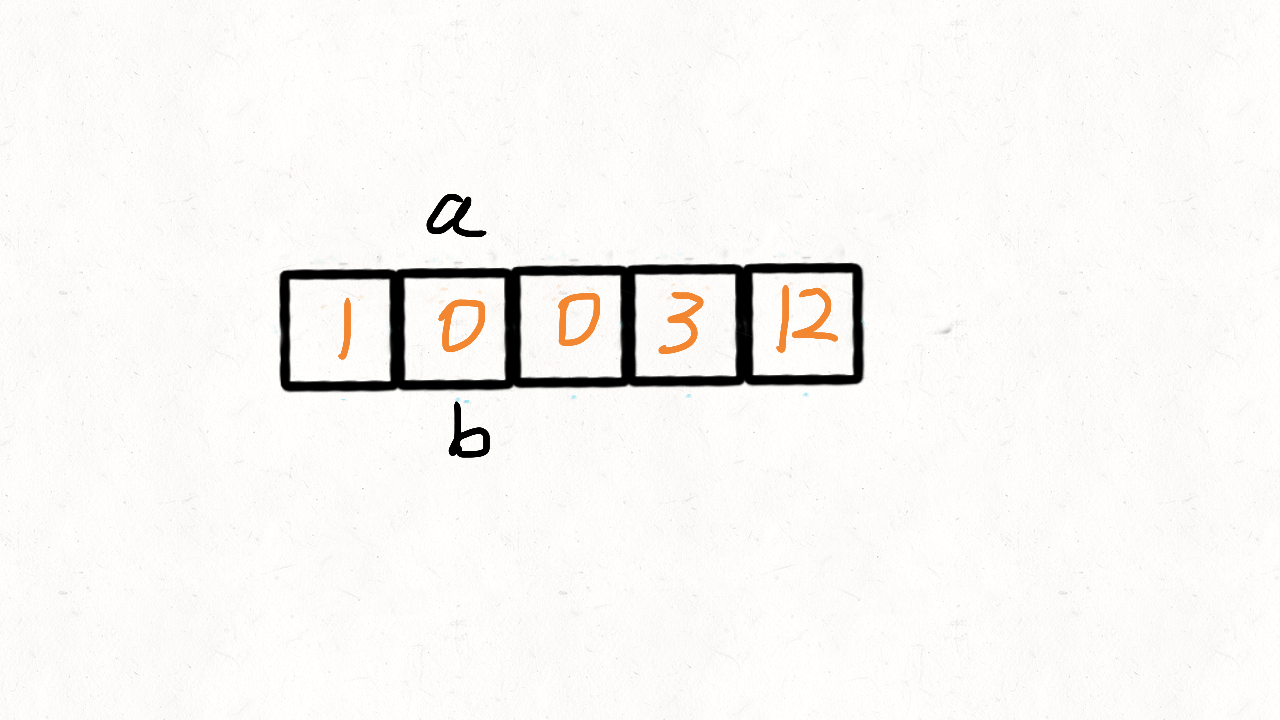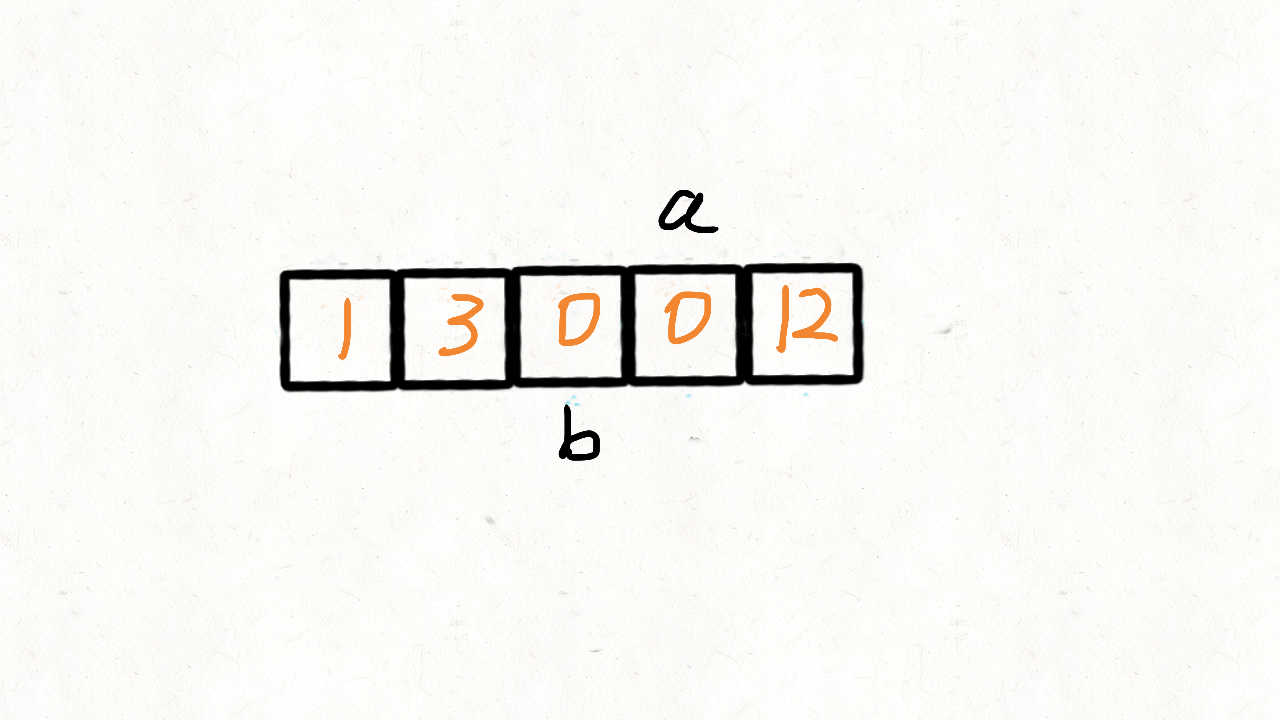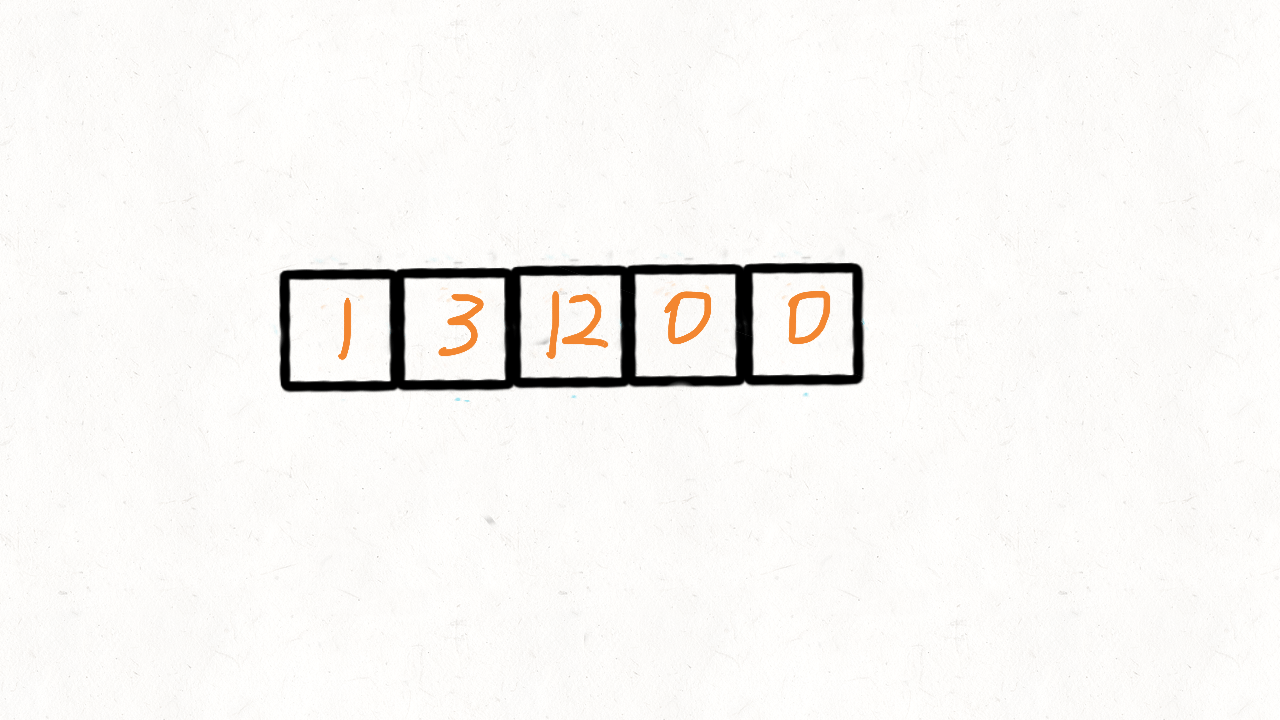sl1673495 / leetcode-javascript Goto Github PK
View Code? Open in Web Editor NEW:beers: 喝杯小酒,一起做题。前端攻城狮从零入门算法的宝藏题库,根据知名算法老师的经验总结了 100+ 道 LeetCode 力扣的经典题型 JavaScript 题解和思路。已按题目类型分 label,一起加油。
:beers: 喝杯小酒,一起做题。前端攻城狮从零入门算法的宝藏题库,根据知名算法老师的经验总结了 100+ 道 LeetCode 力扣的经典题型 JavaScript 题解和思路。已按题目类型分 label,一起加油。
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
注意:给定 n 是一个正整数。
示例 1:
输入: 2
输出: 2
解释: 有两种方法可以爬到楼顶。
示例 2:
输入: 3
输出: 3
解释: 有三种方法可以爬到楼顶。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/climbing-stairs
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题的思路是,对于到达任意一个阶梯 n,都可以分为「从前两个台阶跨两步到达」和「从前一个台阶跨一步到达」,而本题的目的是取「方式之和」,所以动态规划的状态转移方程是
dp[n] = dp[n - 1] + dp[n - 2]
然后把这两个方式的数量相加,就是到达第 n 阶的方式总数。
/**
* @param {number} n
* @return {number}
*/
var climbStairs = function (n) {
let dp = [];
dp[1] = 1;
dp[2] = 2;
for (let i = 3; i <= n; i++) {
// 到达第 n 阶的方式
// 1. 从上一阶的位置跨一步 取dp[i - 1]的到达方式数量
// 2. 从上两阶的位置跨两步 取dp[i - 2]的到达方式数量
// 把两种方式数量相加 即可得到到达第n阶方式数量
dp[i] = dp[i - 2] + dp[i - 1];
}
return dp[n];
};数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例:
输入:n = 3
输出:[
"((()))",
"(()())",
"(())()",
"()(())",
"()()()"
]
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/generate-parentheses
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题 DP 的思路比较难找,其实是这样的:
先建立一个数组 dp,假设 dp 中的每个下标存着「当前下标可以凑成的括号全部种类」。目前我们知道最小的状态,也就是只有一对括号的时候, dp[1] = ['()']。
对于之后的每一次状态,都先假设「拿出一个括号」包在最外面(所以后面的代码里会出现很多 i - 1,就是减去了已经使用的括号)。
然后分别去计算这个拿出来的括号「内部」分别使用 0 ~ n 时可以有几种排列方式,并且在这个括号的外部,用「剩余的括号对数」可以有几种排列方式,这几种方式的「笛卡尔积」就是结果。
dp[2]:我们假设有一对新加入的括号 ()包所有情况的最外面,因为我们默认用掉了 1 对括号包在最外面,那么此时还剩下的可使用的括号对数是 2 - 1 = 1,也就是 1 对。
那么我们思考一下, 被这对新括号所包括的内部(新加入的括号我会用空格分隔,便于观察):
包住「1 对括号时候的所有排列」,也就是 ( () ),此时正好用光两对括号。
包住「0 对括号时候的所有排列」,也就是 ( ),此时还剩一对括号,那么去找 dp[1],也就是剩余 1 对括号时的全部排列,放在( )的右边,也就拼成了( )()。
此时得出,dp[2] = ['(())', '()()']。
dp[3]:包住「2 对括号时候的所有排列」,从刚刚算出的 dp[2] 中分别取出所有情况,此时拼成了
(dp[2]的所有情况),也就是 ( (()) ), ( ()() )。
包住「1 对括号时的所有排列」,从 dp[1]取所有情况,此时拼成了
( () ),此时还剩下 1 对括号,再取 dp[1] 放在这个结果的右边, ( () )()。
包住「0 对括号时候的所有排列」,此时拼成了 ( ),此时还剩下 2 对括号,再取 dp[2]的所有情况拼在右边,( )(()), ( )()()。
以上所有情况,就是 dp[3]的结果,dp[3] = ['( (()) )', ' ( ()() )', '( () )()', '( )(())', ' ( )()()']。
所以,此题的状态转移方程是 dp[i] = "(" + dp[j] + ")" + dp[i- j - 1] , j = 0, 1, ..., i - 1。
let generateParenthesis = function (n) {
let dp = []
// 这里放一个空字符串,不然遍历的时候会跳过
// dp[0]就是取出一个空的字符串拼接到括号的内部去
dp[0] = ['']
dp[1] = ['()']
for (let i = 2; i <= n; i++) {
let res = []
for (let j = 0; j <= i - 1; j++) {
let inners = dp[j]
let outers = dp[i - 1 - j]
for (let inner of inners) {
for (let outer of outers) {
res.push(`(${inner})${outer}`)
}
}
}
dp[i] = res
}
return dp[n]
}利用回溯法,不断的朝着前一个结果的尾部追加左括号或者右括号,即可枚举出全部结果。
注意条件限制,由于我们是只往尾部添加括号,所以右括号的使用数量不能大于左括号,否则无法形成结果,比如())这种就不可能在往尾部追加其他括号的情况下得到一个解。
利用变量 left、right 分别记录剩余的左右括号数量,利用 prev 记录上一轮递归中已经形成的中间结果,当 left 和 right 都为 0,就得到一个结果,记录进 res 中。
/**
* @param {number} n
* @return {string[]}
*/
let generateParenthesis = function (n) {
let res = []
let helper = (left, right, prev) => {
if (left < 0 || right < 0 || right < left) {
return
}
if (left === 0 && right === 0) {
res.push(prev)
return
}
helper(left - 1, right, prev + '(')
helper(left, right - 1, prev + ')')
}
helper(n, n, '')
return res
}https://leetcode-cn.com/problems/find-largest-value-in-each-tree-row
您需要在二叉树的每一行中找到最大的值。
输入:
1
/ \
3 2
/ \ \
5 3 9
输出: [1, 3, 9]
这是一道典型的 BFS 题目,BFS 的套路其实就是维护一个 queue 队列,在读取子节点的时候同时把发现的孙子节点 push 到队列中,但是先不处理,等到这一轮队列中的子节点处理完成以后,下一轮再继续处理的就是孙子节点了,这就实现了层序遍历,也就是一层层的去处理。
但是这里有一个问题卡住我了一会,就是如何知道当前处理的节点是哪个层级的,在最开始的时候我尝试写了一下二叉树求某个 index 所在层级的公式,但是发现这种公式只能处理「平衡二叉树」。
后面看题解发现他们都没有专门维护层级,再仔细一看才明白层级的思路:
其实就是在每一轮 while 循环里,再开一个 for 循环,这个 for 循环的终点是「提前缓存好的 length 快照」,也就是进入这轮 while 循环时,queue 的长度。其实这个长度就恰好代表了「一个层级的长度」。
缓存后,for 循环里可以安全的把子节点 push 到数组里而不影响缓存的当前层级长度。
另外有一个小 tips,在 for 循环处理完成后,应该要把 queue 的长度截取掉上述的缓存长度。一开始我使用的是 queue.splice(0, len),结果速度只击败了 33%的人。后面换成 for 循环中去一个一个shift来截取,速度就击败了 77%的人。
/**
* @param {TreeNode} root
* @return {number[]}
*/
let largestValues = function (root) {
if (!root) return [];
let queue = [root];
let maximums = [];
while (queue.length) {
let max = Number.MIN_SAFE_INTEGER;
// 这里需要先缓存length 这个length代表当前层级的所有节点
// 在循环开始后 会push新的节点 length就不稳定了
let len = queue.length;
for (let i = 0; i < len; i++) {
let node = queue[i];
max = Math.max(node.val, max);
if (node.left) {
queue.push(node.left);
}
if (node.right) {
queue.push(node.right);
}
}
// 本「层级」处理完毕,截取掉。
for (let i = 0; i < len; i++) {
queue.shift();
}
// 这个for循环结束后 代表当前层级的节点全部处理完毕
// 直接把计算出来的最大值push到数组里即可。
maximums.push(max);
}
return maximums;
};给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, ...)使得它们的和等于
n。你需要让组成和的完全平方数的个数最少。
示例 1:
输入: n = 12 输出: 3 解释: 12 = 4 + 4 + 4. 示例 2:
输入: n = 13 输出: 2 解释: 13 = 4 + 9.
来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/perfect-squares 著
作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这个问题完全可以转化成 DP 问题。
对于求 f(12)来说,可以转化为求 f(12 - 任意一个平方数) + 1。
这个 + 1 是由于我们选出了一个平方数,所以也会算作凑目标值的次数。
那么假设这个平方数是 n,就在求解 12 的这一次循环里,不断的从 1 开始递增这个平方
数 1、2、4、8 .... 直到 12 - n < 0 中断,在这个过程中去找到能凑成 12 的最小的次
数。由于动态规划是自底向上的,f(12 - n) 是已经求好的值,那么结果就很容易得出了。
/**
* @param {number} n
* @return {number}
*/
let numSquares = function(n) {
let dp = []
// 求0就假设为0次
dp[0] = 0
for (let i = 1; i <= n; i++) {
let j = 1
// 初始化为Infinity 这样后面任意一个小值都可以覆盖它
let min = Infinity
while (true) {
// 用 i 减去不断递增的平方数 j * j
let prev = i - j * j
if (prev < 0) {
break
}
// 假设i = 10、j = 1 实际上就是在求dp[10 - 1] + 1
// 也就是凑成 9 的最小次数 再加上 1(也就是 1 这个平方数的次数)
min = Math.min(min, dp[prev] + 1)
j++
}
dp[i] = min === Infinity ? 0 : min
}
return dp[n]
}给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题是比较典型的滑动窗口问题,定义一个左边界 left 和一个右边界 right,形成一个窗口,并且在这个窗口中保证不出现重复的字符串。
这需要用到一个新的变量 freqMap,用来记录窗口中的字母出现的频率数。在此基础上,先尝试取窗口的右边界再右边一个位置的值,也就是 str[right + 1],然后拿这个值去 freqMap 中查找:
right ++,扩大窗口右边界。left ++,缩进左边界,并且记得把 str[left] 位置的值在 freqMap 中减掉。循环条件是 left < str.length,允许左边界一直滑动到字符串的右界。
/**
* @param {string} s
* @return {number}
*/
let lengthOfLongestSubstring = function (str) {
let n = str.length
// 滑动窗口为s[left...right]
let left = 0
let right = -1
let freqMap = {} // 记录当前子串中下标对应的出现频率
let max = 0 // 找到的满足条件子串的最长长度
while (left < n) {
let nextLetter = str[right + 1]
if (!freqMap[nextLetter] && nextLetter !== undefined) {
freqMap[nextLetter] = 1
right++
} else {
freqMap[str[left]] = 0
left++
}
max = Math.max(max, right - left + 1)
}
return max
}给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
示例:
输入: [0,1,0,3,12]
输出: [1,3,12,0,0]
说明:
必须在原数组上操作,不能拷贝额外的数组。尽量减少操作次数。
https://leetcode-cn.com/problems/move-zeroes
先遍历一次,找出所有 0 的下标,然后删除掉所有 0 元素,再 push 相应的 0 的个数到
末尾。
var moveZeroes = function (nums) {
let zeros = []
for (let i = 0; i < nums.length; i++) {
if (nums[i] === 0) {
zeros.push(i)
}
}
for (let j = zeros.length - 1; j >= 0; j--) {
nums.splice(zeros[j], 1)
}
for (let j = 0; j < zeros.length; j++) {
nums.push(0)
}
return nums
}慢指针 j 从 0 开始,当快指针 i 遍历到非 0 元素的时候,i 和 j 位置的元素交换,然
后把 j + 1。
也就是说,快指针 i 遍历完毕后, [0, j) 区间就存放着所有非 0 元素,而剩余的[j,
n]区间再遍历一次,用 0 填充满即可。
var moveZeroes = function (nums) {
let j = 0
for (let i = 0; i < nums.length; i++) {
if (nums[i] !== 0) {
nums[j] = nums[i]
j++
}
}
while (j < nums.length) {
nums[j] = 0
j++
}
}在上面的算法里,快指针遍历完成后,还要遍历慢指针到末尾来填充 0。实际上这题只要遇
到非 0 元素,就把当前位置的值和慢指针位置 j 的值交换,然后只有此时 j 才 + 1,即
可完成。
var moveZeroes = function (nums) {
let j = 0
for (let i = 0; i < nums.length; i++) {
if (nums[i] !== 0) {
swap(nums, i, j)
j++
}
}
}
function swap(nums, i, j) {
let temp = nums[i]
nums[i] = nums[j]
nums[j] = temp
}给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回你可以获得的最大乘积。
示例 1:
输入: 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1。
示例 2:
输入: 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。
说明: 你可以假设 n 不小于 2 且不大于 58。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/integer-break
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题在求解每个子问题 i 的时候,都需要另外循环一个 j,这个 j 从 1 开始把 i 拆分成 i - j。
比如 3 需要拆分成 1,2 和 2,1,4需要拆分成 1,3、2,2、3,1。
以求 max(3) 的时候为例:
先考虑 1 * max(2)、 2 * max(1)
还需要考虑 1 * 2、2 * 1 也就是把右侧直接作为一个值相乘,而不是拿它拆分后的最大乘积(不然这里只能求出 1 * dp[2],也就是 1 * 1 * 1 = 1,其实是小于 1 * 2 = 2 的)。
也就是说,状态转移方程是: dp[i] = max(j * (i - j), j * dp[i - j])。
let integerBreak = function (n) {
let memo = [];
memo[1] = 1;
for (let i = 2; i <= n; i++) {
let max = 0;
// 对于每一个 i 来说,都要从 1 开始拆分成 j 和 i - j 两个正整数
// 比如 3 需要拆分成 1,2 和 2,1
// 4需要拆分成 1,3、2,2、3,1
// 然后再进一步决定最大值
for (let j = 1; j < i; j++) {
max = Math.max(
max,
// 不继续拆分 i - j,直接对比一次
// 比如 1 和 2,不光要对比 1 * (2 拆分后的结果)
// 也要直接对比 1 * 2
j * (i - j),
// 和拆分后的最大乘积相乘
j * memo[i - j]
);
}
memo[i] = max
}
return memo[n]
};给你 n 个非负整数 a1,a2,...,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内
画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,
使得它们与 x 轴共同构成的容器可以容纳最多的水。
说明:你不能倾斜容器,且 n 的值至少为 2。

这题利用双指针去做,i 指向最左边,j 指向最右边。当发现左边比较高的时候,保持左边
不动,右边左移。当发现右边比较高的时候,保持右边不动,左边右移。在这个过程中不断
更新最大值,最后 i === j 的时候,即可求得最大值。
let maxArea = function(height) {
let i = 0
let j = height.length - 1
let max = 0
while (i !== j) {
let leftHeight = height[i]
let rightHeight = height[j]
let x = j - i
let area
if (leftHeight > rightHeight) {
area = rightHeight * x
j--
} else {
area = leftHeight * x
i++
}
max = area > max ? area : max
}
return max
}给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
示例:
给定一个链表: 1->2->3->4->5, 和 n = 2.
当删除了倒数第二个节点后,链表变为 1->2->3->5.
说明:
给定的 n 保证是有效的。
进阶:
你能尝试使用一趟扫描实现吗?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/remove-nth-node-from-end-of-list
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
由于不知道链表有几个节点,所以先建立一个数组,用来记录节点对应的下标顺序。
求倒数第 n 个,可以转化成求 正数的数组长度 - n 个,而通过数组又可以很容易的拿到待删除节点的前一个节点,那么就把前一个节点 prevNode.next = targetNode.next 这样更换指向即可。
/**
* @param {ListNode} head
* @param {number} n
* @return {ListNode}
*/
let removeNthFromEnd = function (head, n) {
let node = head
let nodes = []
do {
nodes.push(node)
node = node.next
} while (node)
const l = nodes.length
const index = l - n
const targetNode = nodes[index]
const prevNode = nodes[index - 1]
if (prevNode) {
prevNode.next = targetNode.next
}
const tempNext = targetNode.next
targetNode.next = null
if (targetNode === head) {
return tempNext
}
return head
}最初的版本,对于 partition 这一步中的取基准值,我们直接取最左边的值,然后把小于这个值的划分在它的左边,把大于等于这个值的划分在它右边,然后分别对左和右再进一步做递归的快速排序。
它的问题在于,如果数组是个近似有序的数组的话,它的时间复杂度会退化到接近 On² 的级别。排序分治形成的二叉树会非常不平衡,退化成接近链表。
function partition(arr, left, right) {
// 取一个基准值 取第一项
let pivot = arr[left]
// arr[left+1...index] < pivot, arr[index+1...i) > pivot
let index = left
for (let i = left + 1; i <= right; i++) {
let num = arr[i]
if (num < pivot) {
swap(arr, index + 1, i)
index++
}
}
swap(arr, left, index)
return index
}对于上述的近似有序数组的问题,我们可以选择每次的基准值选取一个随机值,这样退化成 On² 的可能性就趋近于零了。
function partition(arr, left, right) {
// 取一个基准值 取随机值
let rand = random(left, right)
swap(arr, left, rand)
let pivot = arr[left]
// arr[left+1...index] < pivot, arr[index+1...i) > pivot
let index = left
for (let i = left + 1; i <= right; i++) {
let num = arr[i]
if (num < pivot) {
// 如果当前值小于基准值的话,就交换到index + 1的位置去。
// 扩充了index的范围 [index...], pivot, [...right]
swap(arr, index + 1, i)
index++
}
}
swap(arr, left, index)
return index
}但是这样还是会有问题,对于重复元素很多的数组,只会简单的把大于等于基准值的元素简单粗暴的划分到右侧范围里,然后继续递归的快排,浪费了大量时间。
比如 [8, 9, 9, 9, 9, 9, 9, 10],下一步只会拿掉左边的 [8],进一步的去排 [9, 9, 9, 9, 9, 9, 10],然后很有可能又只是拿出了一个 9,继续递归… 排序树依然很不平衡。

最终优化版就是三路快排了,顾名思义这种快排就是把数组区分成 < v, ===v, >v 三个区间,然后把等于 v 的区间排除掉,继续对剩余的两个区间进行递归的快速排序。

function sortArray(arr) {
_quickSort(arr, 0, arr.length - 1)
return arr
}
/**
* 对 arr[l...r] 部分进行快速排序
* @param {number[]} arr
* @param {number} l 左边界
* @param {number} r 右边界
*/
function _quickSort(arr, l, r) {
if (l >= r) {
return
}
let [p, q] = partition(arr, l, r)
_quickSort(arr, l, p)
_quickSort(arr, q, r)
}
function random(low, high) {
return Math.round(Math.random() * (high - low)) + low
}
function swap(arr, i, j) {
let temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
}
/**
* 对 arr[l...r] 部分进行快速排序
* @param {number[]} arr
* @param {number} l 左边界
* @param {number} r 右边界
* @returns {number} 返回索引值p,使得arr[l...p-1] < arr[p] < arr[p+1...r]
*/
function partition(arr, left, right) {
// 取一个基准值 取随机值
let rand = random(left, right)
swap(arr, left, rand)
let pivot = arr[left]
// 三路 注意看注释里的区间
let lt = left // arr[left + 1...lt] < v
let gt = right + 1 // arr[gt...r] > v
let index = left + 1 // arr[lt + 1...index) === v
while (index < gt) {
let num = arr[index]
if (num < pivot) {
swap(arr, index, lt + 1)
lt++
index++
} else if (num > pivot) {
swap(arr, index, gt - 1)
gt--
} else if (num === pivot) {
index++
}
}
swap(arr, left, lt)
return [lt - 1, gt]
}20.有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
示例 1:
输入: "()"
输出: true
示例 2:
输入: "()[]{}"
输出: true
示例 3:
输入: "(]"
输出: false
示例 4:
输入: "([)]"
输出: false
示例 5:
输入: "{[]}"
输出: true
https://leetcode-cn.com/problems/valid-parentheses
提前记录好左括号类型 (, {, [和右括号类型), }, ]的映射表,当遍历中遇到左括号的时候,就放入栈 stack 中(其实就是数组),当遇到右括号时,就把 stack 顶的元素 pop 出来,看一下是否是这个右括号所匹配的左括号(比如 ( 和 ) 是一对匹配的括号)。
当遍历结束后,栈中不应该剩下任何元素,返回成功,否则就是失败。
/**
* @param {string} s
* @return {boolean}
*/
let isValid = function (s) {
let sl = s.length
if (sl % 2 !== 0) return false
let leftToRight = {
"{": "}",
"[": "]",
"(": ")",
}
// 建立一个反向的 value -> key 映射表
let rightToLeft = createReversedMap(leftToRight)
// 用来匹配左右括号的栈
let stack = []
for (let i = 0; i < s.length; i++) {
let bracket = s[i]
// 左括号 放进栈中
if (leftToRight[bracket]) {
stack.push(bracket)
} else {
let needLeftBracket = rightToLeft[bracket]
// 左右括号都不是 直接失败
if (!needLeftBracket) {
return false
}
// 栈中取出最后一个括号 如果不是需要的那个左括号 就失败
let lastBracket = stack.pop()
if (needLeftBracket !== lastBracket) {
return false
}
}
}
if (stack.length) {
return false
}
return true
}
function createReversedMap(map) {
return Object.keys(map).reduce((prev, key) => {
const value = map[key]
prev[value] = key
return prev
}, {})
}给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1
返回:
[
[5,4,11,2],
[5,8,4,5]
]
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/path-sum-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
典型的可以用 DFS 来解决的问题,定义一个 search 方法并且参数里带一个用来收集路径的 paths 数组,每当到达叶子节点(没有 left 也没有 right),就计算一把路径的总和,如果等于目标值就 push 到结果数组里。(注意这里要浅拷贝一下,防止下面的计算污染这个数组)
任何一个节点处理完成时,都要把当前节点 pop 出 paths 数组。
let pathSum = function (root, sum) {
let res = [];
let search = function (node, paths) {
if (isInvalid(node)) return;
paths.push(node.val);
if (node.left) {
search(node.left, paths);
}
if (node.right) {
search(node.right, paths);
}
if (!node.left && !node.right) {
if (sumVals(paths) === sum) {
res.push(paths.slice());
}
}
paths.pop();
};
search(root, []);
return res;
};
function sumVals(nodes) {
return nodes.reduce((prev, val) => {
prev += val;
return prev;
}, 0);
}
function isInvalid(node) {
return !node || node.val === undefined || node.val === null;
}数组的每个索引做为一个阶梯,第 i 个阶梯对应着一个非负数的体力花费值 costi。
每当你爬上一个阶梯你都要花费对应的体力花费值,然后你可以选择继续爬一个阶梯或者爬两个阶梯。
您需要找到达到楼层顶部的最低花费。在开始时,你可以选择从索引为 0 或 1 的元素作为初始阶梯。
示例 1:
输入: cost = [10, 15, 20]
输出: 15
解释: 最低花费是从 cost[1]开始,然后走两步即可到阶梯顶,一共花费 15。
示例 2:
输入: cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1]
输出: 6
解释: 最低花费方式是从 cost[0]开始,逐个经过那些 1,跳过 cost[3],一共花费 6。
注意:
cost 的长度将会在 [2, 1000]。
每一个 cost[i] 将会是一个 Integer 类型,范围为 [0, 999]。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/min-cost-climbing-stairs
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
经典的 DP 问题,先从最后的台阶开始求最小花费值,每一层可以选择走一步或走两步,
状态转移方程是:dp[i] = Math.min(oneStep, twoStep)。
/**
* @param {number[]} cost
* @return {number}
*/
let minCostClimbingStairs = function (cost) {
let dp = [];
for (let i = cost.length - 1; i >= 0; i--) {
let oneStep = cost[i] + (dp[i + 1] || 0);
let twoStep = cost[i] + (dp[i + 2] || 0);
dp[i] = Math.min(oneStep, twoStep);
}
return Math.min(dp[0], dp[1]);
};92.反转链表 II
反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。
说明:
1 ≤ m ≤ n ≤ 链表长度。
示例:
输入: 1->2->3->4->5->NULL, m = 2, n = 4
输出: 1->4->3->2->5->NULL
这题相对于反转链表的第一题,就比较有难度了,所以说它是 medium 难度。
需要考虑的点很多:
首先需要找出需要反转的链表的起点 node,终点 node。
并且还需要记录下来需要反转的起点的前一个点 sliceStartPrev。
需要反转的终点的后一个节点 sliceEndNext。
在反转完成后要把起点的前一个节点的 sliceStartPrev 的 next 设为反转链表后的 head 头部。
并且把反转后链表的 tail 尾部的 next 设置成 sliceEndNext。
当然,反转链表的部分还是可以沿用第一题的代码啦。
/**
* Definition for singly-linked list.
* function ListNode(val) {
* this.val = val;
* this.next = null;
* }
*/
/**
* @param {ListNode} head
* @param {number} m
* @param {number} n
* @return {ListNode}
*/
let reverseBetween = function (head, m, n) {
let i = 1
let sliceStartPrev = null
let sliceStart = null
let sliceEnd = null
let cur = head
// 记录切分起点的前一个节点,和切分终点的后一个节点
while (i <= n) {
if (i === m - 1) {
sliceStartPrev = cur
}
if (i === m) {
sliceStart = cur
}
if (i === n) {
sliceEnd = cur
}
cur = cur.next
i++
}
let sliceEndNext = sliceEnd.next
// 切断切分终点的next 防止反转的时候反转过头
sliceEnd.next = null
const { head: slicedHead, tail: slicedTail } = reverse(sliceStart)
if (sliceStartPrev) {
// 如果需要反转的部分有前一个节点 那么只需要在中间动手脚 原样返回head节点即可
sliceStartPrev.next = slicedHead
} else {
// 这里需要注意的是 如果没有sliceStartPrev 说明是从第一个节点就开始反转的
// 那么我们需要手动调整head为反转后的head
head = slicedHead
}
slicedTail.next = sliceEndNext
return head
}
function reverse(head) {
let prev = null
let cur = head
while (cur) {
let next = cur.next
cur.next = prev
prev = cur
cur = next
}
// 返回反转后的头尾节点
return { head: prev, tail: head }
}实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
示例 1:
输入: 4
输出: 2
示例 2:
输入: 8
输出: 2
说明: 8 的平方根是 2.82842...,
由于返回类型是整数,小数部分将被舍去。
本题利用二分查找来求解,一开始把右边界粗略的设定为目标值 x,左右边界的中间值设为 mid,然后在二分过程中每次发现 mid * mid < x 的情况,就把这个 mid 值记录为 ans。
如果计算出的乘积正好等于 x,就直接返回这个 mid 值。
如果二分查找超出边界了,无论最后的边界是停留在小于 x 的位置还是大于 x 的位置,都返回 ans 即可,因为它是最后一个乘积小于 x 的值,一定是正确答案。
/**
* @param {number} x
* @return {number}
*/
let mySqrt = function (x) {
let left = 0;
let right = x;
let ans = -1;
while (left <= right) {
let mid = Math.round((left + right) / 2);
let product = mid * mid;
if (product <= x) {
ans = mid;
left = mid + 1;
} else if (product > x) {
right = mid - 1;
} else {
return mid;
}
}
return ans;
};面试题 18.删除链表的节点
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。
返回删除后的链表的头节点。
注意:此题对比原题有改动
示例 1:
输入: head = [4,5,1,9], val = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
示例 2:
输入: head = [4,5,1,9], val = 1
输出: [4,5,9]
解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.
说明:
题目保证链表中节点的值互不相同
若使用 C 或 C++ 语言,你不需要 free 或 delete 被删除的节点
这题循环体里的代码还是很好定义的,不断的判断 cur.next.val 是否等于目标值 val,如果等于的话,就把 cur.next 直接赋值为 cur.next.next 即可。
但是问题就在于,这个逻辑对于头部节点是不适用的,因为是直接判断 next,所以这种题目有个通用的思路就是建立一个虚拟节点 virtual node 来替换头部位置,这样就可以轻松解决此题。
/**
* Definition for singly-linked list.
* function ListNode(val) {
* this.val = val;
* this.next = null;
* }
*/
/**
* @param {ListNode} head
* @param {number} val
* @return {ListNode}
*/
var deleteNode = function (head, val) {
let virtual = {
next: head,
}
let cur = virtual
while (cur) {
if (cur.next) {
if (cur.next.val === val) {
cur.next = cur.next.next
}
}
cur = cur.next
}
return virtual.next
}给定一个只包含正整数的非空数组。是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
注意:
每个数组中的元素不会超过 100
数组的大小不会超过 200
示例 1:
输入: [1, 5, 11, 5]
输出: true
解释: 数组可以分割成 [1, 5, 5] 和 [11].
示例 2:
输入: [1, 2, 3, 5]
输出: false
解释: 数组不能分割成两个元素和相等的子集.
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/partition-equal-subset-sum
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题的难点在于如何转化为 01 背包问题,要想清楚如果数组可以分割成两个相等的数组,那么我们的目标其实是求有没有子数组的和为「整个数组的和的一半」(下文称为 target)。而由于这个和是「整个数组」的值加起来的一半求得的,所以其中的一半我们找到了,此时另外的子数组相加的值一定也是一半,也就是 target。
只要想清楚这个问题,题目就迎刃而解了。
这里的二维 DP 表:
纵坐标 i 代表数组中覆盖到的元素,从第一个元素开始( i = 2 是包含了 i = 1 和 i = 0 的情况的。)。
横坐标 j 代表 [0...target] 中的值 j 是否可以由 i 覆盖到的数值凑得,它是 true 或 false。
每一步也分为「拿当前的元素」和「不拿当前的元素」。
只要这三项中有任意一项为 true,那么结果就为 true。
另外有几个注意点:
说实话这篇题解讲的更好:
/**
* @param {number[]} nums
* @return {boolean}
*/
let canPartition = function (nums) {
let n = nums.length
let sum = nums.reduce((a, b) => a + b);
let target = sum / 2;
// 数据不是整数 直接return
if (Math.ceil(target) !== target) {
return false;
}
let dp = new Array(n);
for (let i = 0; i < dp.length; i++) {
dp[i] = new Array(target + 1).fill(false);
}
// 列代表可以选择去凑数的数值
for (let i = 0; i < dp.length; i++) {
// 行代表是否可以凑到这个数字j
for (let j = 0; j <= target; j++) {
// 不用当前数,直接选择前一行的结果
let pickPrev = (dp[i - 1] ? dp[i - 1][j]: false) || false
// 拿出当前数,并且从前一行里找其他的值能否凑成剩下的值
let pickCurrentAndPrev = (dp[i - 1] ? dp[i - 1][j - nums[i]]: false) || false
// 只拿的值直接去凑目标值
let pickCurrent = j === nums[i]
// 任意一者满足 即可理解成 「i下标的值」配合「i下标之前的数值」 可以一起凑成目标值
let can = (
pickPrev ||
pickCurrent||
pickCurrentAndPrev
)
dp[i][j] = can
// 只要任意一行的 target 列满足条件 即可认为有「子数组」可以凑成目标值 直接返回 true
if ((j === target) && can) {
return true
}
}
}
return dp[n - 1][target]
};给定一个已按照升序排列 的有序数组,找到两个数使得它们相加之和等于目标数。
函数应该返回这两个下标值 index1 和 index2,其中 index1 必须小于 index2。
说明:
返回的下标值(index1 和 index2)不是从零开始的。
你可以假设每个输入只对应唯一的答案,而且你不可以重复使用相同的元素。
示例:
输入: numbers = [2, 7, 11, 15], target = 9
输出: [1,2]
解释: 2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。
因为是有序数组,所以可以建立两个指针,i指向数组的头部,j指向数组的尾部。
此时开始遍历,如果左右指针指向的值,相加大于目标值,说明右指针需要左移指向稍小的值再尝试,反之左指针右移,如果相加的值相等,那么答案就是两个指针的值 [i, j]。
直到 i === j 循环终止。
/**
* @param {number[]} numbers
* @param {number} target
* @return {number[]}
*/
let twoSum = function(numbers, target) {
let i = 0;
let j = numbers.length - 1;
while (i !== j) {
let sum = numbers[i] + numbers[j];
if (sum > target) {
j--;
} else if (sum < target) {
i++;
} else {
return [i + 1, j + 1];
}
}
};71.简化路径
以 Unix 风格给出一个文件的绝对路径,你需要简化它。或者换句话说,将其转换为规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。更多信息请参阅:Linux / Unix 中的绝对路径 vs 相对路径
请注意,返回的规范路径必须始终以斜杠 / 开头,并且两个目录名之间必须只有一个斜杠 /。最后一个目录名(如果存在)不能以 / 结尾。此外,规范路径必须是表示绝对路径的最短字符串。
示例 1:
输入:"/home/"
输出:"/home"
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:"/../"
输出:"/"
解释:从根目录向上一级是不可行的,因为根是你可以到达的最高级。
示例 3:
输入:"/home//foo/"
输出:"/home/foo"
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:"/a/./b/../../c/"
输出:"/c"
示例 5:
输入:"/a/../../b/../c//.//"
输出:"/c"
示例 6:
输入:"/a//b////c/d//././/.."
输出:"/a/b/c"
https://leetcode-cn.com/problems/simplify-path
这题看似很复杂,但是其实用栈来做还是蛮简单的,先用 / 来分割路径字符串,然后不停的把分割后的有效值 push 到栈中即可,
注意的点:
'..'、'.'、'' 这些特殊值以外的值。.. 字符,说明要回退一级目录,把栈中弹出一个值即可。/**
* @param {string} path
* @return {string}
*/
let simplifyPath = function (path) {
let tokens = path.split("/")
let stack = []
for (let index = 0; index < tokens.length; index++) {
let token = tokens[index]
if (token === "..") {
if (stack.length > 0) {
stack.pop()
}
} else if (!(token === "") && !(token === ".")) {
stack.push(token)
}
}
let res = "/"
for (let token of stack) {
res += `${token}/`
}
if (res !== "/") {
res = res.substr(0, res.length - 1)
}
return res
}350.两个数组的交集 II
给定两个数组,编写一个函数来计算它们的交集。
示例 1:
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2,2]
示例 2:
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [4,9]
说明:
输出结果中每个元素出现的次数,应与元素在两个数组中出现的次数一致。
我们可以不考虑输出结果的顺序。
进阶:
如果给定的数组已经排好序呢?你将如何优化你的算法?
如果 nums1 的大小比 nums2 小很多,哪种方法更优?
如果 nums2 的元素存储在磁盘上,磁盘内存是有限的,并且你不能一次加载所有的元素到内存中,你该怎么办?
为两个数组分别建立 map,用来存储 num -> count 的键值对,统计每个数字出现的数量。
然后对其中一个 map 进行遍历,查看这个数字在两个数组中分别出现的数量,取出现的最小的那个数量(比如数组 1 中出现了 1 次,数组 2 中出现了 2 次,那么交集应该取 1 次),push 到结果数组中即可。
/**
* @param {number[]} nums1
* @param {number[]} nums2
* @return {number[]}
*/
let intersect = function (nums1, nums2) {
let map1 = makeCountMap(nums1)
let map2 = makeCountMap(nums2)
let res = []
for (let num of map1.keys()) {
const count1 = map1.get(num)
const count2 = map2.get(num)
if (count2) {
const pushCount = Math.min(count1, count2)
for (let i = 0; i < pushCount; i++) {
res.push(num)
}
}
}
return res
}
function makeCountMap(nums) {
let map = new Map()
for (let i = 0; i < nums.length; i++) {
let num = nums[i]
let count = map.get(num)
if (count) {
map.set(num, count + 1)
} else {
map.set(num, 1)
}
}
return map
}排好序的数组。
对于排好序的数组,用双指针的方法会更优。
两个数组数量差距很大。
优先遍历容量小的数组,提前结束循环。
64.最小路径和
给定一个包含非负整数的 m x n 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
示例:
输入:
[
[1,3,1],
[1,5,1],
[4,2,1]
]
输出: 7
解释: 因为路径 1→3→1→1→1 的总和最小。
https://leetcode-cn.com/problems/minimum-path-sum
首先这题要想清楚的一点是,到达了一个格子只有两种可能:
有了这个思路,状态转移方程其实就可以定义出来了:dp[i] = min(dp[left], dp[top])
其实第一行和第一列都是基础状态,第一行的格子只有可能从左边过来,而第一列的格子只可能从上面过来。
/**
* @param {number[][]} grid
* @return {number}
*/
let minPathSum = function (grid) {
let y = grid.length
if (!y) {
return 0
}
let x = grid[0].length
let dp = []
for (let i = 0; i < y; i++) {
dp[i] = []
}
dp[0][0] = grid[0][0]
// 第一行的基础状态 记得加上左边格子的值
for (let j = 1; j < x; j++) {
dp[0][j] = grid[0][j] + dp[0][j - 1]
}
// 第一列的基础状态 加上上方格子的最优解即可
for (let i = 1; i < y; i++) {
dp[i][0] = grid[i][0] + dp[i - 1][0]
}
// 开始求左上往右下求解
for (let i = 1; i < grid.length; i++) {
for (let j = 1; j < grid[i].length; j++) {
let cur = grid[i][j]
let fromUp = cur + (dp[i - 1][j] !== undefined ? dp[i - 1][j]: Infinity)
let fromLeft = cur + (dp[i][j - 1] !== undefined ? dp[i][j - 1]: Infinity)
dp[i][j] = Math.min(
fromUp,
fromLeft
)
}
}
return dp[y - 1][x - 1]
};146.LRU 缓存机制
https://leetcode-cn.com/problems/lru-cache
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果密钥已经存在,则变更其数据值;如果密钥不存在,则插入该组「密钥/数据值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
这篇小姐姐的算法文章,很优雅的代码思路。
https://juejin.im/post/5ec1c3a76fb9a0435749da1d
维护一个「双向链表」node :
class DoubleNode {
constructor(key, val) {
this.key = key
this.val = val
this.prev = null
this.next = null
}
}和一个「哈希表」map,map 的目的是通过 key 去查找对应的 node:
// key -> DoubleNode
this.map = new Map()并且维护 LRUCache 实例中的 head 头结点和 tail 尾结点。
从 map 中获取节点,并且把节点的头部更新为本次获取的节点。
分为几种情况:
class DoubleNode {
constructor(key, val) {
this.key = key
this.val = val
this.prev = null
this.next = null
}
}
class LRUCache {
constructor(max) {
this.max = max
this.map = new Map()
this.head = null
this.tail = null
}
get(key) {
const node = this.map.get(key)
if (!node) {
return -1
} else {
const res = node.val
this.remove(node)
this.appendHead(node)
return res
}
}
put(key, value) {
let node = this.map.get(key)
// 有这个缓存
if (node) {
node.val = value
// 新加入的 放在最前面
this.remove(node)
this.appendHead(node)
} else {
// 没有这个缓存
node = new DoubleNode(key, value)
// 如果超出容量了 删除最后一个 再放到头部
if (this.map.size >= this.max) {
this.map.delete(this.tail.key)
this.remove(this.tail)
this.appendHead(node)
this.map.set(key, node)
} else {
// 未超出容量 就直接放到头部
this.appendHead(node)
this.map.set(key, node)
}
}
}
/**
* 把头部指针的改变成新的node
* @param {DoubleNode} node
*/
appendHead(node) {
if (this.head === null) {
this.head = this.tail = node
} else {
node.next = this.head
this.head.prev = node
this.head = node
}
}
/**
* 删除某个节点
* @param {DoubleNode} node
*/
remove(node) {
if (this.head === this.tail) {
this.head = this.tail = null
} else {
// 删除头部
if (this.head === node) {
this.head = this.head.next
node.next = null
} else if (this.tail === node) {
this.tail = this.tail.prev
this.tail.next = null
node.prev = null
} else {
node.prev.next = node.next
node.next.prev = node.prev
node.prev = node.next = null
}
}
}
}给定一个排序数组,你需要在 原地 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
示例 1:
给定数组 nums = [1,1,2],
函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。
你不需要考虑数组中超出新长度后面的元素。
示例 2:
给定 nums = [0,0,1,1,1,2,2,3,3,4],
函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。
你不需要考虑数组中超出新长度后面的元素。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
维护快慢指针,慢指针只有在遇到「和当前慢指针位置的值」不一样的值的时候,才向前进一位,并且把这个位置的值替换成新值。
说的口语化一点,就是慢指针乖乖的留在原地,只有当快指针遇到的值发生变化的时候(这个变化的界定,是通过对比「当前慢指针位置的值」来决定的),才会把慢指针前进一位,并且替换成快指针此时指向的「新变化值」。
更直观的话,直接看这个视频吧:
https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array/solution/shi-ping-dong-hua-jie-xi-bao-ni-dong-by-novice2mas
/**
* @param {number[]} nums
* @return {number}
*/
let removeDuplicates = function (nums) {
// 快指针
let i = 0;
// 慢指针
let j = 0;
while (i < nums.length) {
let fast = nums[i];
let slot = nums[j];
// 快慢不相等,说明找到了一个新的值
// 把慢指针的位置更新,并且赋值成新的值,继续等待下一个新值。
if (fast !== slot) {
j++;
nums[j] = num;
}
i++;
}
return j + 1;
};125.验证回文串
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
说明:本题中,我们将空字符串定义为有效的回文串。
示例 1:
输入: "A man, a plan, a canal: Panama"
输出: true
示例 2:
输入: "race a car"
输出: false
https://leetcode-cn.com/problems/valid-palindrome
先根据题目给出的条件,通过正则把不匹配字符去掉,然后转小写。
建立双指针 i, j 分别指向头和尾,然后两个指针不断的向中间靠近,每前进一步就对比两端的字符串是否相等,如果不相等则直接返回 false。
如果直到 i >= j 也就是指针对撞了,都没有返回 false,那就说明符合「回文」的定义,返回 true。
/**
* @param {string} s
* @return {boolean}
*/
let isPalindrome = function(s) {
s = s.replace(/[^0-9a-zA-Z]/g, '').toLowerCase()
let i = 0
let j = s.length - 1
while(i < j) {
let head = s[i]
let tail = s[j]
if (head !== tail) {
return false
}else {
i++
j--
}
}
return true
};斐波那契数列是一个很经典的问题,虽然它很简单,但是在优化求解它的时候可以延伸出很多实用的优化算法。
它的概念很简单,来看一下 LeetCode 真题里对他的定义:
斐波那契数,通常用 F(n) 表示,形成的序列称为斐波那契数列。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
给定 N,计算 F(N)。
先大概预览一下斐波那契数列的样子:
1、1、2、3、5、8、13、21、34
在本文中,下面出现的 fib(n) 代表对于 n 的求解。
有了定义以后,对于这个问题我们第一直觉就是可以用「递归」来解,思路也很简单,只需要定义好初始状态,也就是 fib(1) = 1,fib(2) = 1,那么假设要求 fib(3) 只需要去求 fib(2) + fib(1) 即可,以此类推。
大概在 fib(50) 的时候,在我的笔记本上跑了 123.167 秒,再往后就更加不敢想象了。由于大量的递归调用加上不断的重复计算,导致这个算法的速度慢到不可接受。
青铜的解法由于有大量的重复计算,
比如 fib(3) 会计算 fib(2) + fib(1),
而 fib(2) 又会计算 fib(1) + fib(0)。
这个 fib(1) 就是完全重复的计算,不应该为它再递归调用一次,而是应该在第一次求解除它了以后,就把他“记忆”下来。
把已经求得的解放在 Map 里,下次直接取,而不去重复结算。
这里用 iife 函数形成一个闭包,保留了 memo 这个私有变量,这是一个小技巧。
此时对于 fib(50) 的计算速度来到了 0.096 秒,在 50 这个小数量级的情况下就比青铜解法快了 1200 倍。
有一部分说算法无用论的人,持有的观点是随着硬件的进步这些差异都会被抹平,那我期待着硬件进步 1000 倍的那一天吧。
看似上面的备忘录解法已经很完美了,实际上不是,虽然备忘录解法把无用的重复求解都优化了,在速度上达到了比较优的程度。
但是对于第一次求解,未被记忆化的值来说,还是会进入递归调用逻辑。
比如 f(10000),那么必然会递归调用 f(9999)、f(9998) ...... f(0),而在递归的过程中,这些调用栈是不断叠加的,当函数调用的深处,栈已经达到了成千上万层。
此时它就会报出一个我们熟悉的错误:
RangeError: Maximum call stack size exceeded
at c:\codes\leetcode-javascript\动态规划\斐波那契数列-509.js:20:19
at c:\codes\leetcode-javascript\动态规划\斐波那契数列-509.js:32:14
我们回过头来思考一下,备忘录的思路下我们的解法路径是「自顶向下」的,如果我们把思路倒置一下,变成「自底向上」的求解呢?
也就是说,对于 fib(10000),我们从 fib(1), fib(2), fib(3) ...... fib(10000),
从最小的值开始求解,并且把每次求解的值保存在“记忆”(可以是一个数组,下标正好用来对应 n 的解答值)里,下面的值都由记忆中的值直接得出。
这样等到算到 10000 的时候,我们想要求解的值自然也就得到了,直接从 记忆[10000] 里取到值返回即可。
那么这种解法其实只需要一个 for 循环,而不需要任何递归的逻辑。
其实这就是「动态规划」的一种比较经典的解法啦,那么这种算法强力吗?
对于 fib(10000) 这个上面两种解法都无能为力的情况来说,它花了 0.114 秒就得出了结果。
对于 fib(100000) 它花了 0.827 秒。
对了,在 JavaScript 中这个数字由于超出最大值,会被展示成 Infinity,其实解决方法也很简单,用 BigInt 的数据类型即可。
来看一下 fib(100000) 求出的天文数字吧:
当然求解斐波那契数列还有更多的优化方式,比如 尾递归优化、通项公式 解法等等,但是本文的目的在于由浅入深的入门 动态规划 这个算法,所以也就不再提及。
顺带一提,这个解法在 LeetCode 上击败了 94% 的 JavaScript 解法,所以不用担心它不够优秀啦。
本文用一个简单的斐波那契数列的例子来体会了动态规划算法的美感,以及它的强大能力。相信看完这篇文章的你,能够知道算法并不是用来炫技的,而是真切的可以解决效率问题的。
笔者最近正在学习算法,会把 LeetCode 的一些题解代码和思路放在这个仓库里,欢迎 star 一波给我点动力哦。
150.逆波兰表达式求值
根据逆波兰表示法,求表达式的值。
有效的运算符包括 +, -, *, / 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
整数除法只保留整数部分。
给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
示例 1:
输入: ["2", "1", "+", "3", "*"]
输出: 9
解释: ((2 + 1) * 3) = 9
示例 2:
输入: ["4", "13", "5", "/", "+"]
输出: 6
解释: (4 + (13 / 5)) = 6
https://leetcode-cn.com/problems/evaluate-reverse-polish-notation
提前声明好运算符对应的运算函数,当遇到数字时就放进栈中,遇到运算符,就 pop 出栈中的两个数据,对它们使用运算函数,把结果继续放入栈中即可。
运算到最后,栈中剩下的唯一元素就是最后的结果。
/**
* @param {string[]} tokens
* @return {number}
*/
let opMap = {
"+": (a, b) => b + a,
"-": (a, b) => b - a,
"*": (a, b) => b * a,
"/": (a, b) => parseInt(b / a, 10),
}
let evalRPN = function (tokens) {
let stack = []
for (let token of tokens) {
let op = opMap[token]
if (op) {
let a = parseInt(stack.pop())
let b = parseInt(stack.pop())
let res = op(a, b)
stack.push(res)
} else {
stack.push(token)
}
}
return stack[0]
}给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
示例 2:
输入: [1,2,3,4,5]
输出: 4
解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
贪心算法,只要第二天的价格比第一天高,就选择今天买入明天卖出。
let maxProfit = function(prices) {
let max = 0;
for (let i = 0; i < prices.length - 1; i++) {
let current = prices[i];
let next = prices[i + 1];
if (current < next) {
max += next - current;
}
}
return max;
};144.二叉树的前序遍历
给定一个二叉树,返回它的 前序 遍历。
示例:
输入: [1,null,2,3]
1
\
2
/
3
输出: [1,2,3]
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
https://leetcode-cn.com/problems/binary-tree-preorder-traversal
注意题目中的进阶部分,需要用迭代算法完成。
本题用递归真的很简单,不是题目的考点,这个题目的考点应该是如何用栈去模拟递归。
先声明一个栈 stack,然后定义一个数据结构 type Command = { type: 'go' | 'print', node: Node } 来方便后续的递归操作。如果类型是 go 的话,就进一步的把左右子树的节点推入栈中,如果类型是 print 的话,就把这个节点的值放进结果数组 res 中。
由于栈是后入先出的,对于 go 类型的节点,需要和写递归代码时的顺序相反,按照 处理右节点、处理左节点、打印 的顺序推入栈中,这样在取出栈顶元素的过程中,才能按照 打印 -> 处理左节点 -> 处理右节点 的顺序去操作。
假设现在的栈中有 [right, left, print] 这样的 Command 操作符,在循环中:
print,把 node.val 放入结果数组中。left节点类型为 go 的操作符,又把 left 左子节点的左右节点和打印操作分别转化为操作符推入栈中,此时的栈内是 [right, left.right, left.left, print(left)]left 的值放入结果数组中,然后再进一步的去处理 left.left 节点。这样,就完美模拟了递归的前序遍历过程,一定是等到左子节点全部访问完了,才会去访问右子节点。
/**
* @param {TreeNode} root
* @return {number[]}
*/
let preorderTraversal = function (root) {
let res = []
let stack = [
{
type: "go",
node: root,
},
]
while (stack.length) {
let { type, node } = stack.pop()
if (!node) continue
if (type === "print") {
res.push(node.val)
}
if (type === "go") {
// 先右
if (node.right) {
stack.push({ type: "go", node: node.right })
}
// 再左
if (node.left) {
stack.push({ type: "go", node: node.left })
}
// 最后打印
stack.push({ type: "print", node })
}
}
return res
}也可以进一步的把栈中的元素直接换成函数,每次出栈其实都执行一个函数。
let preorderTraversal = function (root) {
let res = []
let stack = [() => { visit(root) }]
const visit = (node) => {
if (!node) return
stack.push(() => {
if (node.right) {
visit(node.right)
}
})
stack.push(() => {
if (node.left) {
visit(node.left)
}
})
stack.push(() => res.push(node.val))
}
while (stack.length) {
stack.pop()()
}
return res
};中序遍历和后序遍历,只需要调换 go 流程中推入栈的顺序即可。
右 -> 打印 -> 左打印 -> 右 -> 左实现一个 Trie (前缀树),包含 insert, search, 和 startsWith 这三个操作。
示例:
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 true
trie.search("app"); // 返回 false
trie.startsWith("app"); // 返回 true
trie.insert("app");
trie.search("app"); // 返回 true
说明:
你可以假设所有的输入都是由小写字母 a-z 构成的。
保证所有输入均为非空字符串。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/implement-trie-prefix-tree
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
Trie (也叫前缀树、字典树),是一种可以实现快速查找字符串前缀的数据结构。它为单词中的每一个字母开辟一个新的 TrieNode,这个 TrieNode 的结构如下:
let TrieNode = function () {
this.next = new Map();
this.isEnd = false;
};这里的 next 代表这个字母后面可以继续追加的组合,比如 apple和ad 它们共用 a 这个 TrieNode,而 a 的 next 表里又保存了 p和d 的 TrieNode。
在插入的时候,会循环构建这个 TrieNode 树,而在单词的末尾字母的 TrieNode 节点上,会把 isEnd 属性置为 true,用以标识这可以作为一个单词的结尾(注意,是可以作为,并不一定到此为止,因为可能有 ad和adc 这种两个单词的情况)
而查询某种前缀的单词也就变得很简单,利用前缀中的每个字母不断的循环下去,找到前缀中最后一个单词的 TrieNode,再看它的next 表里有哪些组合,即可找出某个前缀下排列组合的所有可能性。

单词 "leet" 在 Trie 树中的表示

let TrieNode = function () {
this.next = new Map();
this.isEnd = false;
};
/**
* Initialize your data structure here.
*/
let Trie = function () {
this.root = new TrieNode();
};
/**
* Inserts a word into the trie.
* @param {string} word
* @return {void}
*/
Trie.prototype.insert = function (word) {
let node = this.root;
for (let i = 0; i < word.length; i++) {
let { next } = node;
let trieNode = next.get(word[i]);
if (!trieNode) {
trieNode = new TrieNode();
next.set(word[i], trieNode);
}
node = trieNode;
if (i === word.length - 1) {
node.isEnd = true;
}
}
};
/**
* Returns if the word is in the trie.
* @param {string} word
* @return {boolean}
*/
Trie.prototype.search = function (word) {
let node = this.root;
for (let i = 0; i < word.length; i++) {
let { next } = node;
let trieNode = next.get(word[i]);
if (!trieNode) {
return false;
}
node = trieNode;
}
return node.isEnd;
};
/**
* Returns if there is any word in the trie that starts with the given prefix.
* @param {string} prefix
* @return {boolean}
*/
Trie.prototype.startsWith = function (prefix) {
let node = this.root;
for (let i = 0; i < prefix.length; i++) {
let { next } = node;
let trieNode = next.get(prefix[i]);
if (!trieNode) {
return false;
}
node = trieNode;
}
return true;
};
/**
* Your Trie object will be instantiated and called as such:
* let obj = new Trie()
* obj.insert(word)
* let param_2 = obj.search(word)
* let param_3 = obj.startsWith(prefix)
*/实现 pow(x, n) ,即计算 x 的 n 次幂函数。
https://leetcode-cn.com/problems/powx-n
这题的第一反应是一步步去用x * x暴力计算,但是这种解法会超时。
所以用一种快速幂计算的方式,也就是把 x 的 n 次方转化为 x * x 的 n / 2 次方。
比如求 2 的 10 次方可以转为 4 的 5 次方,这时候遇到奇数次方了,就转化为 4* (4 的 4 次方)。
然后对于 4 的 4 次方,再进一步转化为 16 的 2 次方,最后转为 256 的 1 次方 * 4,就得出最终解 1024。
/**
* @param {number} x
* @param {number} n
* @return {number}
*/
var myPow = function (x, n) {
if (n === 0) return 1;
if (n === 1) return x;
let abs = Math.abs(n);
let isMinus = abs !== n;
let res = abs % 2 === 0 ? myPow(x * x, abs / 2) : x * myPow(x, abs - 1);
return isMinus ? 1 / res : res;
};给你一个整数数组 nums ,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字)。
示例 1:
输入: [2,3,-2,4]
输出: 6
解释: 子数组 [2,3] 有最大乘积 6。
示例 2:
输入: [-2,0,-1]
输出: 0
解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/maximum-product-subarray
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题和 53. 最大子序和 的思路是类似的,都是从后往前来通过动态规划划分子数组。
对于每一个下标的规划,分别有两种选择:
比如对于 [2, -1],来说,从后往前规划,dp[1] 后面没有值了,所以只能选择 -1,而 dp[0] 则可以选择只取 2(构成子数组 [2]),也可以选择 2 * -1(构成子数组 [2, -1]),显然前者比较大,因此 dp[0] = 2。
这题比较特殊的是,后面的最小值(负数)也有可能和前面的负数凑成最大值。比如[-2, 2, -3],其实他们的最大值是三个数的乘积,而如果单纯的判断大小的话,到 dp[1]也就是以 2 为起点的位置,就会选择把 2 保留,而把 2 * -3 = -6 丢弃掉了。但这样会导致前面的-2 没办法和 -6 相乘,得到真正的最大值 12。
所以我选择在每次 dp 填表的时候,会去从「只选择当前值」和「选择当前值 * 后一项开始的最大值」和「选择当前值 * 后一项开始的最小值」找出最大和最小值,分别记录下来。这样即使是负数乘负数(负数会被记录为最小值)的情况也可以 cover 到了。
运行到最后,只需要在 dp 数组中挑出所有值中的最大值即可。这是因为子数组的起点是不固定的。
let maxProduct = function (nums) {
let dp = [];
let n = nums.length;
let last = nums[n - 1];
dp[n - 1] = {
max: last,
min: last,
};
for (i = nums.length - 2; i >= 0; i--) {
let num = nums[i];
let withNextMin = num * dp[i + 1].min;
let withNextMax = num * dp[i + 1].max;
let withoutNext = num;
dp[i] = {
max: Math.max(withoutNext, withNextMin, withNextMax),
min: Math.min(withoutNext, withNextMin, withNextMax),
};
}
return Math.max(...dp.map(({ max }) => max));
};
maxProduct([2, 3, -2, 4]);空间复杂度优化为 O(1),在运行的过程中不断去记录上一个最大最小值以及全局最大最小值即可。
let maxProduct = function (nums) {
let n = nums.length
let last = nums[n - 1]
let prevMax = last
let prevMin = last
let allMax = last
let allMin = last
for (i = nums.length - 2; i >= 0; i--) {
let num = nums[i]
let withNextMin = (num * prevMin)
let withNextMax = (num * prevMax)
let withoutNext = num
prevMax = Math.max(withoutNext, withNextMin, withNextMax)
prevMin = Math.min(withoutNext, withNextMin, withNextMax)
allMax = Math.max(allMax, prevMax)
allMin = Math.min(allMin, prevMin)
}
return allMax
};438.找到字符串中所有字母异位词
给定一个字符串 s 和一个非空字符串 p,找到 s 中所有是 p 的字母异位词的子串,返回这些子串的起始索引。
字符串只包含小写英文字母,并且字符串 s 和 p 的长度都不超过 20100。
说明:
字母异位词指字母相同,但排列不同的字符串。
不考虑答案输出的顺序。
示例 1:
输入:
s: "cbaebabacd" p: "abc"
输出:
[0, 6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的字母异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的字母异位词。
示例 2:
输入:
s: "abab" p: "ab"
输出:
[0, 1, 2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的字母异位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的字母异位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的字母异位词。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-all-anagrams-in-a-string
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
还是典型的滑动窗口去解决的问题,由于字母异位词一定是长度相等的,所以我们需要把窗口的长度始终维持在目标字符的长度,也就是说,每次循环结束后 left 和 right 是同步前进的。
由于字母异位词不需要考虑顺序,所以只需要运用一个辅助函数 isAnagrams 去判断两个 map 中记录的字母次数,即可判断出当前位置开始的子串是否和目标字符串形成字母异位词。
/**
* @param {string} s
* @param {string} p
* @return {number[]}
*/
let findAnagrams = function (s, p) {
let targetMap = makeCountMap(p)
let sl = s.length
let pl = p.length
// [left,...right] 滑动窗口
let left = 0
let right = pl - 1
let windowMap = makeCountMap(s.substring(left, right + 1))
let res = []
while (left <= sl - pl && right < sl) {
if (isAnagrams(windowMap, targetMap)) {
res.push(left)
}
windowMap[s[left]]--
right++
left++
addCountToMap(windowMap, s[right])
}
return res
}
let isAnagrams = function (windowMap, targetMap) {
let targetKeys = Object.keys(targetMap)
for (let targetKey of targetKeys) {
if (
!windowMap[targetKey] ||
windowMap[targetKey] !== targetMap[targetKey]
) {
return false
}
}
return true
}
function addCountToMap(map, str) {
if (!map[str]) {
map[str] = 1
} else {
map[str]++
}
}
function makeCountMap(strs) {
let map = {}
for (let i = 0; i < strs.length; i++) {
let letter = strs[i]
addCountToMap(map, letter)
}
return map
}给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值。
示例:
输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
输出: [3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
提示:
你可以假设 k 总是有效的,在输入数组不为空的情况下,1 ≤ k ≤ 输入数组的大小。
注意:本题与主站 239 题相同:https://leetcode-cn.com/problems/sliding-window-maximum/
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/hua-dong-chuang-kou-de-zui-da-zhi-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
滑动窗口,每次左右各滑动一位,并且求窗口中的最大值记录即可,这题坑的地方在于边界情况比较多。
let maxSlidingWindow = function (nums, k) {
if (k === 0 || !nums.length) {
return []
}
let left = 0
let right = k - 1
let res = [findMax(nums, left, right)]
while (right < nums.length - 1) {
right++
left++
res.push(findMax(nums, left, right))
}
return res
}
function findMax(nums, left, right) {
let max = -Infinity
for (let i = left; i <= right; i++) {
max = Math.max(max, nums[i])
}
return max
}在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为“根”。 除了“根”之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。
计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
示例 1:
输入: [3,2,3,null,3,null,1]
3
/ \
2 3
\ \
3 1
输出: 7
解释: 小偷一晚能够盗取的最高金额 = 3 + 3 + 1 = 7.
示例 2:
输入: [3,4,5,1,3,null,1]
3
/ \
4 5
/ \ \
1 3 1
输出: 9
解释: 小偷一晚能够盗取的最高金额 = 4 + 5 = 9.
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/house-robber-iii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题的题目上存在误导,并不是简单的跳一级去找最大值就可以,注意考虑这种情况:
2
/ \
1 3
/ \
n 4
这种情况下并不要跳级,而是第二层的 3 和第三层的 4 是去凑成打劫的最优解。
所以此题的解法是从顶层节点开始
这两者对比求出的最大值,就是最优结果。
let memo = new WeakMap()
let rob = function (root) {
if (!root) {
return 0
}
let memorized = memo.get(root)
if (memorized) {
return memorized
}
let notRob = rob(root.left) + rob(root.right)
let robNow =
(root.val || 0) +
(root.left ? rob(root.left.left) + rob(root.left.right) : 0) +
(root.right ? rob(root.right.left) + rob(root.right.right) : 0)
let max = Math.max(notRob, robNow)
memo.set(root, max)
return max
}上面的解法是自顶向下的,那么动态规划的自底向上解法应该怎么做呢?我们上一层的打劫最优解是依赖下一层的,所以显然我们应该先从最下层的求解。思考提取关键字「层序」、「自底向上」。
灵机一动,用递归回溯法配合BFS:
递归版的 BFS 先求出当前队列里所有的子节点,放入一个新的队列 subs 中,然后进一步 BFS 这个子节点队列 subs。
那么这个递归 subs 之后的一行,就代表递归后回溯的时机,我们把「动态规划」求解的部分放在递归函数的后面, 当 BFS 到达了最后一层后,发现没有节点可以继续 BFS 了,这个时候最底层的函数调用慢慢弹出栈,从最底层慢慢往上回溯,
那么 「动态规划」求解的部分就是「自底向上」的了,我们在上层中求最优解的时候,一定能取到下面层的最优解。
/**
* @param {TreeNode} root
* @return {number}
*/
let rob = function (root) {
if (!root) return 0
let dp = new Map()
dp.set(null, 0)
let bfs = (nodes) => {
if (!nodes.length) {
return
}
let subs = []
for (let node of nodes) {
if (node.left) {
subs.push(node.left)
}
if (node.right) {
subs.push(node.right)
}
}
bfs(subs)
// 到达最底层后 最底层先开始 dp
// 再一层层回溯
for (let node of nodes) {
// 打劫这个节点
let robNow = node.val
if (node.left) {
robNow += dp.get(node.left.left)
robNow += dp.get(node.left.right)
}
if (node.right) {
robNow += dp.get(node.right.left)
robNow += dp.get(node.right.right)
}
// 不打劫这个节点 打劫下一层
let robNext = dp.get(node.left) + dp.get(node.right)
dp.set(node, Math.max(robNow, robNext))
}
}
bfs([root])
return dp.get(root)
}其实这题本身是我想复杂了,我是一个个格子去遍历,然后再上下左右去扩展延伸。
但是其实只需要遍历四个边界上的节点,遇到 O 的边界点才开始蔓延遍历,并且把遍历到的节点都标记为 M(防止重复遍历)
最后再一次性遍历整个二维数组,遇到 W 标记的格子都转为 O(因为是从边界蔓延的,一定是不符合 X 的条件的)。
这样遍历所走的路就会少很多。
var solve = function (board) {
if (board.length == 0) return null;
for (var y = 0; y < board.length; y++) {
for (var x = 0; x < board[0].length; x++) {
if (board[y][x] == "O" && (y == 0 || y == board.length - 1 || x == 0 || x == board[0].length - 1)) {
dfs(board, y, x);
}
}
}
for (var y = 0; y < board.length; y++) {
for (var x = 0; x < board[0].length; x++) {
if (board[y][x] == "W") {
board[y][x] = "O";
} else {
board[y][x] = "X";
}
}
}
return board;
};
function dfs(board, y, x) {
if (y < 0 || x < 0 || y >= board.length || x >= board[0].length || board[y][x] == "X" || board[y][x] == "W") {
return;
}
board[y][x] = "W";
dfs(board, y + 1, x);
dfs(board, y - 1, x);
dfs(board, y, x + 1);
dfs(board, y, x - 1);
return;
}给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
注意:
不能使用代码库中的排序函数来解决这道题。
示例:
输入: [2,0,2,1,1,0]
输出: [0,0,1,1,2,2]
进阶:
一个直观的解决方案是使用计数排序的两趟扫描算法。
首先,迭代计算出0、1 和 2 元素的个数,然后按照0、1、2的排序,重写当前数组。
你能想出一个仅使用常数空间的一趟扫描算法吗?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/sort-colors
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
最简单的思路就是遍历一遍整个数组,统计出其中各个颜色的数量,最后把这个数组重新填充即可。
let sortColors = function(nums) {
let colors = [0, 0, 0]
for (let i = 0; i < nums.length; i++) {
colors[nums[i]] ++
}
nums.length = 0
for (let i = 0; i < colors.length; i++) {
for(let j = 0; j < colors[i]; j++) {
nums.push(i)
}
}
};88.合并两个有序数组
给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为一个有序数组。
说明:
初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。
你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n)来保存 nums2 中的元素。
示例:
输入:
nums1 = [1,2,3,0,0,0], m = 3
nums2 = [2,5,6], n = 3
输出: [1,2,2,3,5,6]
https://leetcode-cn.com/problems/merge-sorted-array
从后往前的双指针思路,先定义指针 i 和 j 分别指向数组中有值的位置的末尾,再定义指针 k 指向待填充的数组 1 的末尾。
然后不断的迭代 i 和 j 指针,如果 i 位置的值比 j 大,就移动 i 位置的值到 k 位置,反之亦然。
如果 i 指针循环完了,j 指针的数组里还有值未处理的话,直接从 k 位置开始向前填充 j 指针数组即可。因为此时数组 1 原本的值一定全部被填充到了数组 1 的后面位置,且这些值一定全部大于此时 j 指针数组里的值。
/**
* @param {number[]} nums1
* @param {number} m
* @param {number[]} nums2
* @param {number} n
* @return {void} Do not return anything, modify nums1 in-place instead.
*/
let merge = function (arr1, m, arr2, n) {
// 两个指针指向数组非空位置的末尾
let i = m - 1;
let j = n - 1;
// 第三个指针指向第一个数组的末尾 填充数据
let k = arr1.length - 1;
while (i >= 0 && j >= 0) {
let num1 = arr1[i];
let num2 = arr2[j];
if (num1 > num2) {
arr1[k] = num1;
i--;
} else {
arr1[k] = num2;
j--;
}
k--;
}
while (j >= 0) {
arr1[k] = arr2[j];
j--;
k--;
}
};反转一个单链表。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
进阶:
你可以迭代或递归地反转链表。你能否用两种方法解决这道题?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/reverse-linked-list
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
记录一个 next 表示下一个节点, cur 表示当前节点,prev 表示上一个节点, 在循环中不断的把 cur.next 赋值为 prev,然后 cur 前进为刚刚保存的 next 节点,直到 cur 为 null。
/**
* Definition for singly-linked list.
* function ListNode(val) {
* this.val = val;
* this.next = null;
* }
*/
/**
* @param {ListNode} head
* @return {ListNode}
*/
let reverseList = function (head) {
let prev = null
let cur = head
while (cur) {
let next = cur.next
cur.next = prev
prev = cur
cur = next
}
return prev
}给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
如果你最多只允许完成一笔交易(即买入和卖出一支股票一次),设计一个算法来计算你所能获取的最大利润。
注意:你不能在买入股票前卖出股票。
示例 1:
输入: [7,1,5,3,6,4]
输出: 5
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
暴力循环,i 为卖出的天数,j 为买入的天数。
i 从 1 开始,因为第 0 天不可能卖出。
j 从 0 开始到 i 结束,因为买入的天数一定小于卖出的天数。
然后在这两者间的差价中找最大值。
/**
* 循环版
* @param {number[]} prices
* @return {number}
*/
let maxProfit = function (prices) {
let max = 0;
for (let i = 1; i < prices.length; i++) {
for (let j = 0; j < i; j++) {
let price = prices[j];
let sale = prices[i] - price;
max = Math.max(max, sale);
}
}
return max;
};状态转移方程是
当天的最大收益 = max(
当天卖出:当天的价格 - 过去几天最低的价格,
当天不卖:过去几天的最大收益
)
/**
* DP版
*/
let maxProfit = function (prices) {
let n = prices.length;
if (!n || n === 1) return 0;
// 最大收益
let prevMax = 0;
// 最小价格
let prevMin = prices[0];
for (let i = 1; i < n; i++) {
let price = prices[i];
prevMax = Math.max(price - prevMin, prevMax);
prevMin = Math.min(price, prevMin);
}
return prevMax;
};209.长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的连续子数组,并返回其长度。如果不存在符合条件的连续子数组,返回 0。
示例:
输入: s = 7, nums = [2,3,1,2,4,3]
输出: 2
解释: 子数组 [4,3] 是该条件下的长度最小的连续子数组。
进阶:
如果你已经完成了 O(n) 时间复杂度的解法, 请尝试 O(n log n) 时间复杂度的解法。
https://leetcode-cn.com/problems/minimum-size-subarray-sum/submissions
纯暴力的循环也就是穷举每种子数组并求和,当然是会超时的,这里就不做讲解了。下面这种解法会在暴力法的基础上稍作优化,具体的思路如下:
/**
* @param {number} s
* @param {number[]} nums
* @return {number}
*/
let minSubArrayLen = function (s, nums) {
let min = Infinity
for (let i = 0; i < nums.length; i++) {
let sum = 0
for (let j = i; j < nums.length; j++) {
sum += nums[j]
if (sum >= s) {
min = Math.min(min, j - i + 1)
if (min === 1) {
return min
}
break
}
}
}
return min === Infinity ? 0 : min
}定义两个下标 i、j 为左右边界,中间的子数组为滑动窗口。在更新窗口的过程中不断的更新窗口之间的值的和 sum。
当 i 超出了数组的右边界,循环终止。
/**
* @param {number} s
* @param {number[]} nums
* @return {number}
*/
let minSubArrayLen = function (s, nums) {
let n = nums.length
// 定义[i,...j]滑动窗口 取这个窗口里的和
let i = 0
let j = -1
let sum = 0
let res = Infinity
while (i < n) {
if (sum < s) {
sum += nums[++j]
} else {
sum -= nums[i]
i++
}
if (sum >= s) {
res = Math.min(res, j - i + 1)
}
}
return res === Infinity ? 0 : res
}给定不同面额的硬币和一个总金额。写出函数来计算可以凑成总金额的硬币组合数。假设每一种面额的硬币有无限个。
示例 1:
输入: amount = 5, coins = [1, 2, 5]
输出: 4
解释: 有四种方式可以凑成总金额:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
示例 2:
输入: amount = 3, coins = [2]
输出: 0
解释: 只用面额 2 的硬币不能凑成总金额 3。
示例 3:
输入: amount = 10, coins = [10]
输出: 1
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/coin-change-2
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题比较特殊的点在于,如果你用普通的 DP 思路去做,外层循环是 amount,内层循环是 coins 的话,会掉进陷阱里。
比如在凑 3 的时候,会拿出 1 然后去凑 2,然后拿出 2 去凑 1,但是这两种其实是算作一种凑法。
所以把 coins 的循环放在外层,
以 amount = 5, coins = [1, 2, 5] 为例,
这样问题就变成了先求用 1 硬币凑 1-5 面值的方式数,再用 2 硬币和 1 硬币去配合求 1-5 面值的方式数,最后用 5 硬币和之前 2、1 硬币求得的方式数再去组合,这样就不会出现重复组合的情况了。
/**
* @param {number} amount
* @param {number[]} coins
* @return {number}
*/
let change = function (amount, coins) {
let dp = new Array(amount + 1).fill(0);
dp[0] = 1;
for (let coin of coins) {
for (let i = 1; i <= amount; i++) {
if (i >= coin) {
dp[i] += dp[i - coin];
}
}
}
return dp[amount];
};给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4],
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/maximum-subarray
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这题评论区普遍反应不应该是 easy 难度,实际上确实是比较有难度的。这题有 DP 来做的话,状态转移方程和打劫问题类似。找两种情况中的最大值:
如果选项 1 比选项 2 要大,那么说明后面的都抛弃掉,从当前数字开始作为子数组的起点。
比如 [2, -2, 1] 来说,先从最右边开始,dp[2]的最大值是 1。
然后求 dp[1],选出两种情况,分别是只选择 -2, 和选择 -2 + 1 = -1,明显是后者更大,所以 dp[1]的值更新为 -1。此时可以想象一下,dp[1] 记录的值其实就是 [-2, 1] 这个连续子数组的和。
然后再往左到了 dp[0],分别是只选择 2,和选择 2 + -1 = 1,当然是只选择 2 更大,此时右边的子数组中断,dp[0] 上记录的其实是子数组 [2]
最后需要返回 dp 数组中的最大值,因为子数组的起点是不确定的。这样就找到了 dp[0] 上保留的 [2] 这个最大子数组。
这不是一个简单的自底向上求解,然后返回最顶部的值的 DP 问题。
/**
* @param {number[]} nums
* @return {number}
*/
let maxSubArray = function(nums) {
let n = nums.length;
let dp = [];
dp[n - 1] = nums[n - 1];
for (let i = n - 2; i >= 0; i--) {
let pickSelf = nums[i];
let pickWithNext = pickSelf + dp[i + 1];
dp[i] = Math.max(pickSelf, pickWithNext);
}
return Math.max(...dp);
};给定一个数组 w 代表物品的重量,v 数组代表物品的价值,C 代表背包的总容量。求背包最多能装下价值多少的物品。每个物品只能装一次。
物品的重量是 [1, 2, 3],物品的价值是 [6, 10, 12],背包重量是 5。
这种情况下最优解是 22。
这题递归的思路就是对于以每一个物品为起点,分为两种情况。装当前物品和不装当前物品,求它们之间最大值作为结果。
选择装,最大值 = 当前物品的价值 + 递归去找减去当前物品重量后的可以装的最大价值。
v[i] + best(i - 1, c - w[i])
选择不装,最大值 = 背包重量不变,递归去找以上一件物品为起点可以装的最大价值。(在这个流程里又可会继续发展出装与不装的选择)
best(i - 1, c)
/**
*
* @param {number[]} w 物品的重量集合
* @param {number[]} v 物品的价值集合
* @param {number} C 背包容量
*/
function knapsack01(w, v, C) {
let n = w.length - 1;
return bestValue(w, v, n, C);
}
// 用 [0...index] 的物品
// 填充容积为c的背包的最大价值
function bestValue(w, v, index, c) {
if (index < 0 || c <= 0) return 0;
let max = bestValue(w, v, index - 1, c);
// 装背包之前需要先判断这个当前背包还可以容纳下这个物品
if (c >= w[index]) {
max = Math.max(
// 不装进背包
max,
// 装进背包
v[index] + bestValue(w, v, index - 1, c - w[index])
);
}
return max;
}这是 DP 问题的例题中第一个出现二维 dp 数组的问题,因此标为例题详解。
在这个问题中,子问题可以从递归版中总结出来,就是「装进背包」 or 「不装进背包」的选择。二维数组大致是这个结构:
1 2 3 4 5 <- 这一层代表背包的容量
物品1
物品2
物品3
↑ 这一层代表可选的物品。
注意可选物品也就是纵轴,它下面的层级是上面层级最优解的叠加值,也就是物品3的层级是包含了可以选择物品2和物品1的情况下的最大价值的。
所以这题的子问题就是可选物品由少增多的情况下,不断求解每个背包容量情况下的最优解。当双层循环遍历完毕后,最右下角的值也就代表了「包含了所有物品的情况下,并且容量为C时」的最优解。
/**
*
* @param {number[]} w 物品的重量集合
* @param {number[]} v 物品的价值集合
* @param {number} C 背包容量
*/
let knapsack01 = function (w, v, C) {
let n = w.length;
if (n === 0) return 0;
// 构建二维数组dp表
// x轴代表背包容量 y轴代表考虑的物品情况
// 第一行只考虑一种物品(基准情况)
// 第二行考虑一和二两种(通过拿取二和不拿二,再去组合第一行的最佳情况来求最大值)
// 第三行以此类推
let memo = new Array(n);
for (let i = 0; i < memo.length; i++) {
memo[i] = new Array(C + 1).fill(0);
}
// 基础情况 背包在各个容量的情况下 只考虑第一个物品时的最优解
for (let j = 0; j <= C; j++) {
memo[0][j] = j >= w[0] ? v[0] : 0;
}
for (let i = 1; i < n; i++) {
for (let j = 0; j <= C; j++) {
let weight = w[i];
let restWeight = j - weight;
// 有足够容量的情况下 选择当前的的物品 并且用剩余的重量去找前面几个物品组合的最优解
let pickNow = j >= weight ? v[i] + memo[i - 1][restWeight] : 0;
// 另一种选择 这个物品不放进背包了 直接求用这个背包容量组合前面几种物品的最优解
let pickPrev = memo[i - 1][j];
memo[i][j] = Math.max(pickNow, pickPrev);
}
}
return memo[n - 1][C];
};
console.log(knapsack01([1, 2, 3], [6, 10, 12], 5));由于纵轴的每一层的最优解都只需要参考上一层节点的最优解,因此可以只保留两行。通过判断除 2 取余来决定“上一行”的位置。此时空间复杂度是 O(2n)
由于每次参考值都只需要取上一行和当前位置左边位置的值(因为剩余重量的最优解一定在左边),因此可以把问题转为从右向左求解,并且在求解的过程中不断覆盖当前列的值,而不会影响下一次求解。此时空间复杂度是 O(n)。
并且在这种情况下对于时间复杂度也可以做优化,由于背包所装的容量,也就是 j,它是倒序遍历的,那么当发现它小于当前物品的重量时,说明不可能装下当前物品了,此时直接结束本层循环即可,因为左边的值一定是「不选当前物品时的最大价值」,也就是在上一轮循环中已经求得的值。
https://leetcode-cn.com/problems/max-area-of-island/
给定一个包含了一些 0 和 1 的非空二维数组 grid 。
一个 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为 0 。)
示例 1:
[[0,0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,1,1,0,1,0,0,0,0,0,0,0,0],
[0,1,0,0,1,1,0,0,1,0,1,0,0],
[0,1,0,0,1,1,0,0,1,1,1,0,0],
[0,0,0,0,0,0,0,0,0,0,1,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,0,0,0,0,0,0,1,1,0,0,0,0]]
对于上面这个给定矩阵应返回 6。注意答案不应该是 11 ,因为岛屿只能包含水平或垂直的四个方向的 1 。
示例 2:
[[0,0,0,0,0,0,0,0]]
对于上面这个给定的矩阵, 返回 0。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/max-area-of-island
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
在之前探索过「被包围的岛屿」问题后,这个问题显得格外简单了。希望这个分类的题刷完,能让我对DFS有进一步的掌握。
/**
* @param {number[][]} grid
* @return {number}
*/
var maxAreaOfIsland = function (grid) {
let yLen = grid.length;
if (!yLen) return grid;
let xLen = grid[0].length;
let max = 0;
for (let y = 0; y < yLen; y++) {
for (let x = 0; x < xLen; x++) {
if (grid[y][x] === 1) {
let countRef = { current: 0 };
dfs(grid, y, x, countRef);
if (countRef.current > max) {
max = countRef.current;
}
}
}
}
return max;
};
function dfs(grid, y, x, countRef) {
if (!grid[y] || !grid[y][x] || grid[y][x] === 0 || grid[y][x] === "COMPLETE") {
return;
}
if (grid[y][x] === 1) {
grid[y][x] = "COMPLETE";
countRef.current++;
}
dfs(grid, y - 1, x, countRef);
dfs(grid, y + 1, x, countRef);
dfs(grid, y, x - 1, countRef);
dfs(grid, y, x + 1, countRef);
}给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
示例:
二叉树:[3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/binary-tree-level-order-traversal
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
经典模板题,DFS 和 BFS 都可以。
遍历的时候记录一下 level,每次递归都把 level+1,即可获得正确的层级,push 到对应的数组中即可:
let levelOrder = function (root) {
let res = [];
let dfs = (node, level = 0) => {
if (!node) return;
if (!res[level]) {
res[level] = [];
}
res[level].push(node.val);
dfs(node.left, level + 1);
dfs(node.right, level + 1);
};
dfs(root);
return res;
};利用队列,while 中对于每轮的节点开一个 for 循环加入到数组的一层中即可。
/**
* @param {TreeNode} root
* @return {number[][]}
*/
let levelOrder = function (root) {
if (!root) return [];
let ret = [];
let queue = [root];
while (queue.length) {
let len = queue.length;
let level = [];
ret.push(level);
for (let i = 0; i < len; i++) {
let node = queue.shift();
level.push(node.val);
if (node.left) {
queue.push(node.left);
}
if (node.right) {
queue.push(node.right);
}
}
}
return ret;
};给定两个二叉树,编写一个函数来检验它们是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
示例 1:
输入: 1 1
/ \ / \
2 3 2 3
[1,2,3], [1,2,3]
输出: true
示例 2:
输入: 1 1
/ \
2 2
[1,2], [1,null,2]
输出: false
示例 3:
输入: 1 1
/ \ / \
2 1 1 2
[1,2,1], [1,1,2]
输出: false
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/same-tree
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
深度优先遍历就是直接递归比较,把 left 和 right 节点也视为一棵树。继续调用 isSameTree 方法。
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} p
* @param {TreeNode} q
* @return {boolean}
*/
var isSameTree = function(p, q) {
if (!p && !q) return true;
if ((p && !q) || (!p && q)) return false;
if (isSameTree(p.left, q.left) && isSameTree(p.right, q.right)) {
return p.val === q.val;
} else {
return false;
}
};BFS 也是标准的思路,就是把节点放进一个队列里,然后在处理节点的时候遇到有 left 或 right 子节点,就继续放进队列里,下一轮循环继续处理。
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} p
* @param {TreeNode} q
* @return {boolean}
*/
var isSameTree = function(p, q) {
let queue1 = [p];
let queue2 = [q];
while (queue1.length) {
let node1 = queue1.shift();
let node2 = queue2.shift();
if (!node1 || !node2) {
if (node1 !== node2) {
return false;
}
continue;
}
if (node1.val !== node2.val) {
return false;
}
queue1.push(node1.left);
queue1.push(node1.right);
queue2.push(node2.left);
queue2.push(node2.right);
}
return true;
};给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/binary-search
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
二分查找是个很经典的算法了,它的一个典型的特点就是“思路容易,细节非常易错”。
这里就主要讲讲代码里的细节吧:
首先,为什么是 while (left <= right) 而不是 while (left < right)?
这是因为要考虑到 left 和 right 相等的情况,也就是查找区间里只有一个值。
为什么 left = mid + 1,这个 +1 是什么?
这是因为 mid 位置的值已经查找过了,可以往右边跳一位。
什么情况 left 会超出 right?如果二分查找到的值一直小于目标值,left会不断右移,直到最后数组区间里只有一个值,如果此时这个目标值还是大于这个值,left 会继续加一,此时 left 会超过 right。
反之,则 right 会超出 left。
function search(arr, target) {
let left = 0;
let right = arr.length - 1;
while (left <= right) {
let mid = Math.round((right + left) / 2);
if (arr[mid] === target) {
return mid;
}
if (arr[mid] < target) {
left = mid + 1;
}
if (arr[mid] > target) {
right = mid - 1;
}
}
return -1;
}你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你在不触动警报装置的情况下,能够偷窃到的最高金额。
示例 1:
输入: [1,2,3,1]
输出: 4
解释: 偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入: [2,7,9,3,1]
输出: 12
解释: 偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12 。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/house-robber
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
动态规划的一个很重要的过程就是找到「状态」和「状态转移方程」,在这个问题里,设 i 是当前屋子的下标,状态就是 以 i 为起点偷窃的最大价值
在某一个房子面前,盗贼只有两种选择:偷或者不偷。
在这两个值中,选择最大值记录在 dp[i]中,就得到了以 i 为起点所能偷窃的最大价值。。
动态规划的起手式,找基础状态,在这题中,以终点为起点的最大价值一定是最好找的,因为终点不可能再继续往后偷窃了,所以设 n 为房子的总数量, dp[n - 1] 就是 nums[n - 1],小偷只能选择偷窃这个房子,而不能跳过去选择下一个不存在的房子。
那么就找到了动态规划的状态转移方程:
// 抢劫当前房子
robNow = nums[i] + dp[i + 2] // 「当前房子的价值」 + 「i + 2 下标房子为起点的最大价值」
// 不抢当前房子,抢下一个房子
robNext = dp[i + 1] //「i + 1 下标房子为起点的最大价值」
// 两者选择最大值
dp[i] = Math.max(robNow, robNext),并且从后往前求解。
function (nums) {
if (!nums.length) {
return 0;
}
let dp = [];
for (let i = nums.length - 1; i >= 0; i--) {
let robNow = nums[i] + (dp[i + 2] || 0)
let robNext = dp[i + 1] || 0
dp[i] = Math.max(robNow, robNext)
}
return dp[0];
};最后返回 以 0 为起点开始打劫的最大价值 即可。
76.最小覆盖子串
给你一个字符串 S、一个字符串 T,请在字符串 S 里面找出:包含 T 所有字符的最小子串。
示例:
输入: S = "ADOBECODEBANC", T = "ABC"
输出: "BANC"
说明:
如果 S 中不存这样的子串,则返回空字符串 ""。
如果 S 中存在这样的子串,我们保证它是唯一的答案。
https://leetcode-cn.com/problems/minimum-window-substring
根据目标字符串 t生成一个目标 map,记录每个字符的目标值出现的次数。
然后就是维护一个滑动窗口,并且针对这个滑动窗口中的字符也生成一个 map 去记录字符出现次数。
每次循环都去对比窗口的 map 里的字符是否能覆盖目标 map 里的字符。
覆盖的意思就是,目标 map 里的每个字符在窗口 map 中出现,并且出现的次数要 >= 目标 map 中此字符出现的次数。
窗口滑动逻辑:
两种情况下停止循环,返回结果:
给定字符长度 - 目标字符的长度,此时不管匹配与否,都是最短能满足的了。
/**
* @param {string} s
* @param {string} t
* @return {string}
*/
let minWindow = function (s, t) {
// 先制定目标 根据t字符串统计出每个字符应该出现的个数
let targetMap = makeCountMap(t)
let sl = s.length
let tl = t.length
let left = 0 // 左边界
let right = -1 // 右边界
let countMap = {} // 当前窗口子串中 每个字符出现的次数
let min = "" // 当前计算出的最小子串
// 循环终止条件是两者有一者超出边界
while (left <= sl - tl && right <= sl) {
// 和 targetMap 对比出现次数 确定是否满足条件
let isValid = true
Object.keys(targetMap).forEach((key) => {
let targetCount = targetMap[key]
let count = countMap[key]
if (!count || count < targetCount) {
isValid = false
}
})
if (isValid) {
// 如果满足 记录当前的子串 并且左边界右移
let currentValidLength = right - left + 1
if (currentValidLength < min.length || min === "") {
min = s.substring(left, right + 1)
}
// 也要把map里对应的项去掉
countMap[s[left]]--
left++
} else {
// 否则右边界右移
addCountToMap(countMap, s[right + 1])
right++
}
}
return min
}
function addCountToMap(map, str) {
if (!map[str]) {
map[str] = 1
} else {
map[str]++
}
}
function makeCountMap(strs) {
let map = {}
for (let i = 0; i < strs.length; i++) {
let letter = strs[i]
addCountToMap(map, letter)
}
return map
}
console.log(minWindow("aa", "a"))A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.