



ML4Floods is an end-to-end ML pipeline for flood extent estimation: from data preprocessing, model training, model deployment to visualization. Here you can find the WorldFloodsV2🌊 dataset and trained models 🤗 for flood extent estimation in Sentinel-2 and Landsat.
Install from pip:
pip install ml4floodsInstall the latest version from GitHub:
pip install git+https://github.com/spaceml-org/ml4floods#egg=ml4floodsThese tutorials may help you explore the datasets and models:
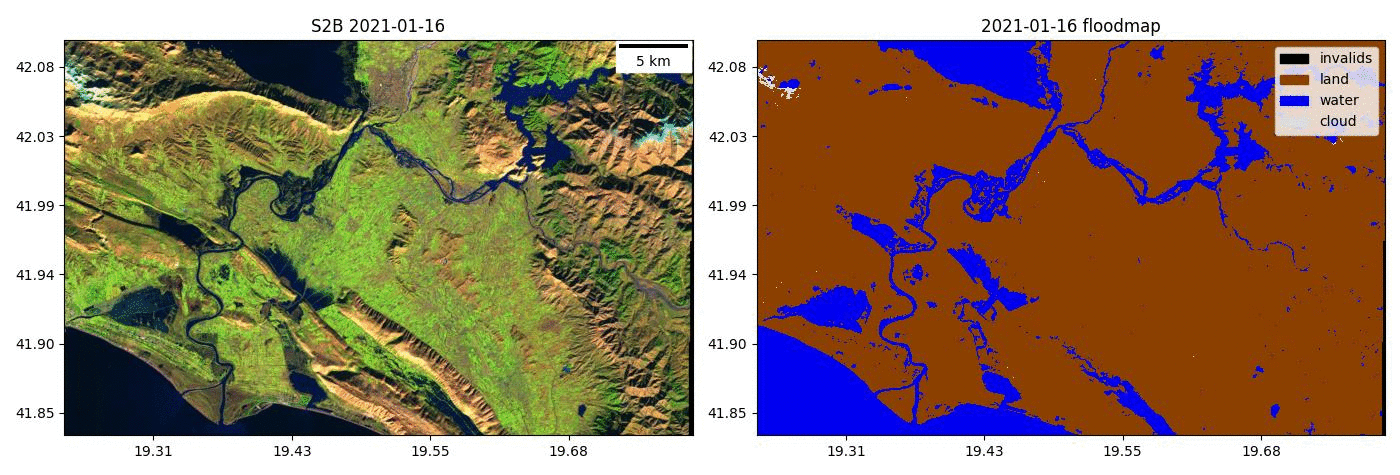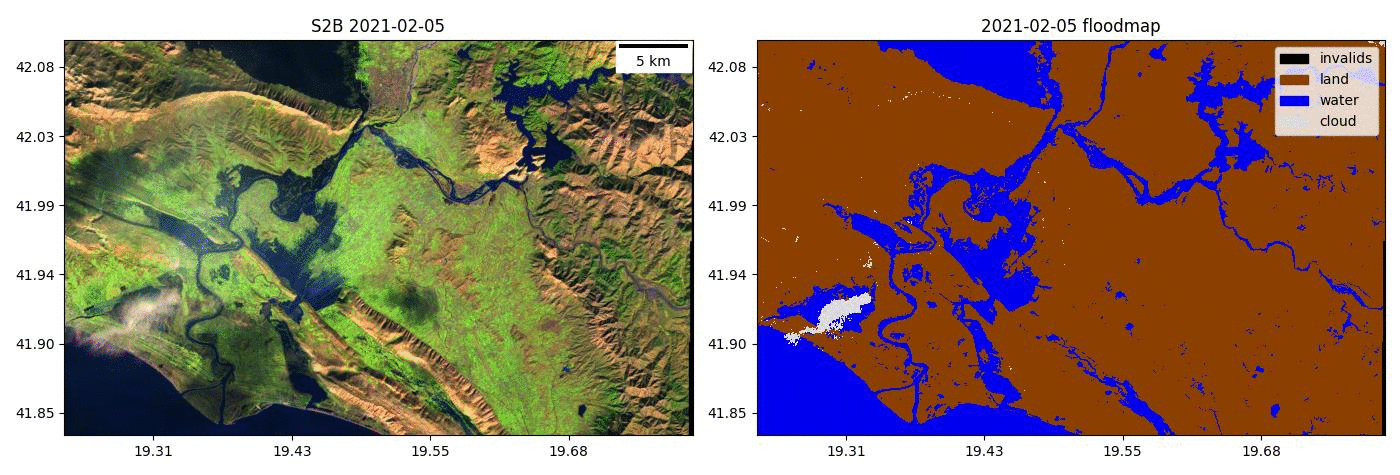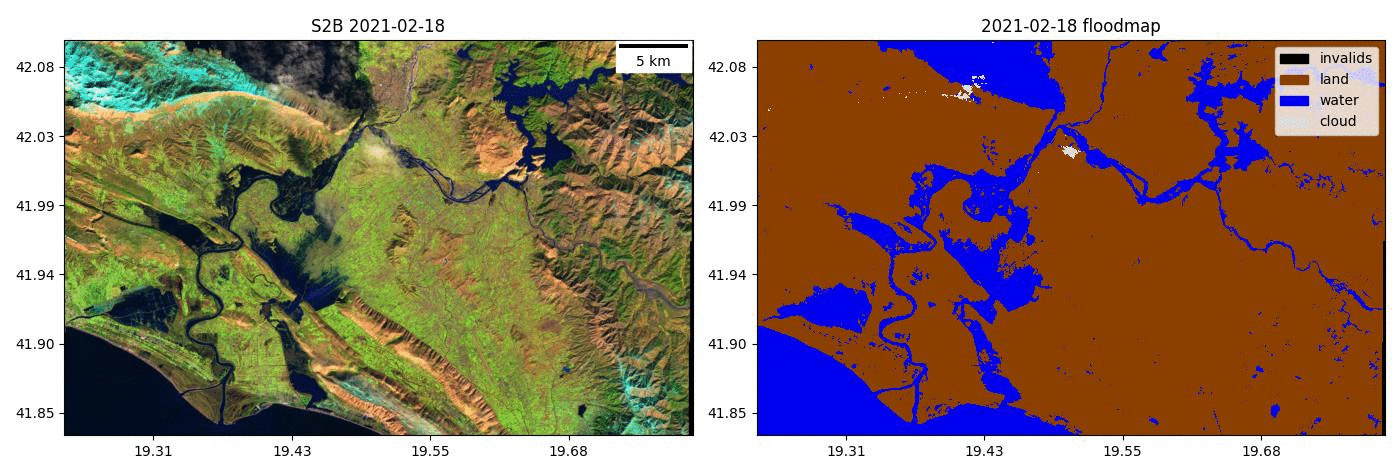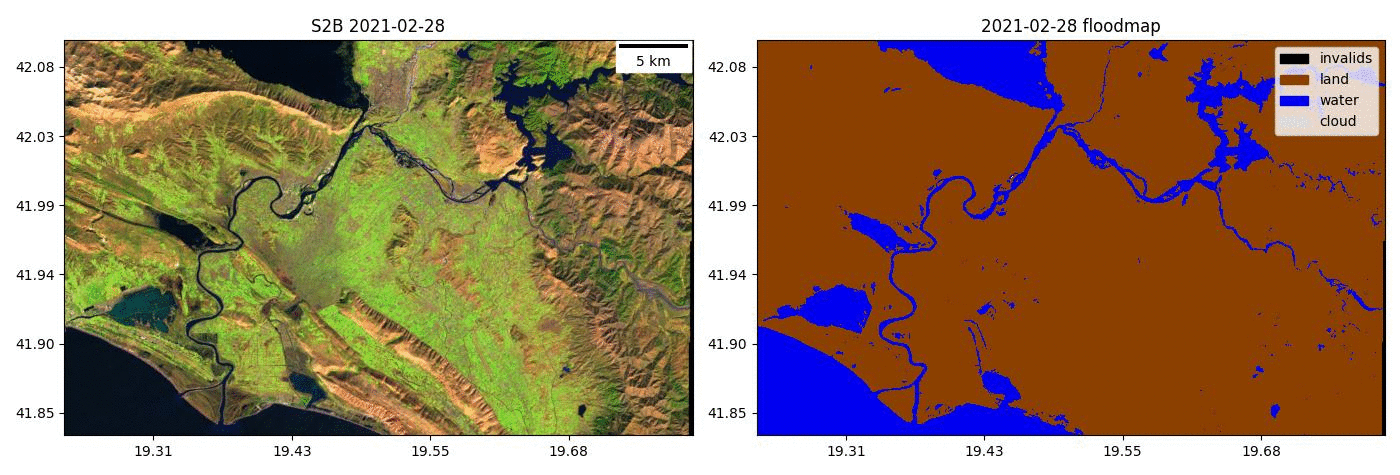
- Kherson Dam Break end-to-end flood extent map
- Run the model on time series of Sentinel-2 images
- Ingest data from Copernicus EMS
- ML-models step by step
- Training
- Inference on new data (a Sentinel-2 image)
- Perf metrics
- Training
The WorldFloods database contains 509 pairs of Sentinel-2 images and flood segmentation masks. It requires approximately 76GB of hard-disk storage.
The WorldFloods database and all pre-trained models are released under a Creative Commons non-commercial licence

To download the WorldFloods database or the pretrained flood segmentation models see the instructions to download the database.
If you find this work useful please cite:
@article{portales-julia_global_2023,
title = {Global flood extent segmentation in optical satellite images},
volume = {13},
issn = {2045-2322},
doi = {10.1038/s41598-023-47595-7},
number = {1},
urldate = {2023-11-30},
journal = {Scientific Reports},
author = {Portalés-Julià, Enrique and Mateo-García, Gonzalo and Purcell, Cormac and Gómez-Chova, Luis},
month = nov,
year = {2023},
pages = {20316},
}
@article{mateo-garcia_towards_2021,
title = {Towards global flood mapping onboard low cost satellites with machine learning},
volume = {11},
issn = {2045-2322},
doi = {10.1038/s41598-021-86650-z},
number = {1},
urldate = {2021-04-01},
journal = {Scientific Reports},
author = {Mateo-Garcia, Gonzalo and Veitch-Michaelis, Joshua and Smith, Lewis and Oprea, Silviu Vlad and Schumann, Guy and Gal, Yarin and Baydin, Atılım Güneş and Backes, Dietmar},
month = mar,
year = {2021},
pages = {7249},
}
ML4Floods has been funded by the United Kingdom Space Agency (UKSA) and led by Trillium Technologies. In addition, this research has been partially supported by the DEEPCLOUD project (PID2019-109026RB-I00) funded by the Spanish Ministry of Science and Innovation (MCIN/AEI/10.13039/501100011033) and the European Union (NextGenerationEU).






















































































































