



Luigi is a Python (3.6, 3.7, 3.8, 3.9, 3.10, 3.11 tested) package that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization, handling failures, command line integration, and much more.
Run pip install luigi to install the latest stable version from PyPI. Documentation for the latest release is hosted on readthedocs.
Run pip install luigi[toml] to install Luigi with TOML-based configs support.
For the bleeding edge code, pip install git+https://github.com/spotify/luigi.git. Bleeding edge documentation is also available.
The purpose of Luigi is to address all the plumbing typically associated with long-running batch processes. You want to chain many tasks, automate them, and failures will happen. These tasks can be anything, but are typically long running things like Hadoop jobs, dumping data to/from databases, running machine learning algorithms, or anything else.
There are other software packages that focus on lower level aspects of data processing, like Hive, Pig, or Cascading. Luigi is not a framework to replace these. Instead it helps you stitch many tasks together, where each task can be a Hive query, a Hadoop job in Java, a Spark job in Scala or Python, a Python snippet, dumping a table from a database, or anything else. It's easy to build up long-running pipelines that comprise thousands of tasks and take days or weeks to complete. Luigi takes care of a lot of the workflow management so that you can focus on the tasks themselves and their dependencies.
You can build pretty much any task you want, but Luigi also comes with a toolbox of several common task templates that you use. It includes support for running Python mapreduce jobs in Hadoop, as well as Hive, and Pig, jobs. It also comes with file system abstractions for HDFS, and local files that ensures all file system operations are atomic. This is important because it means your data pipeline will not crash in a state containing partial data.
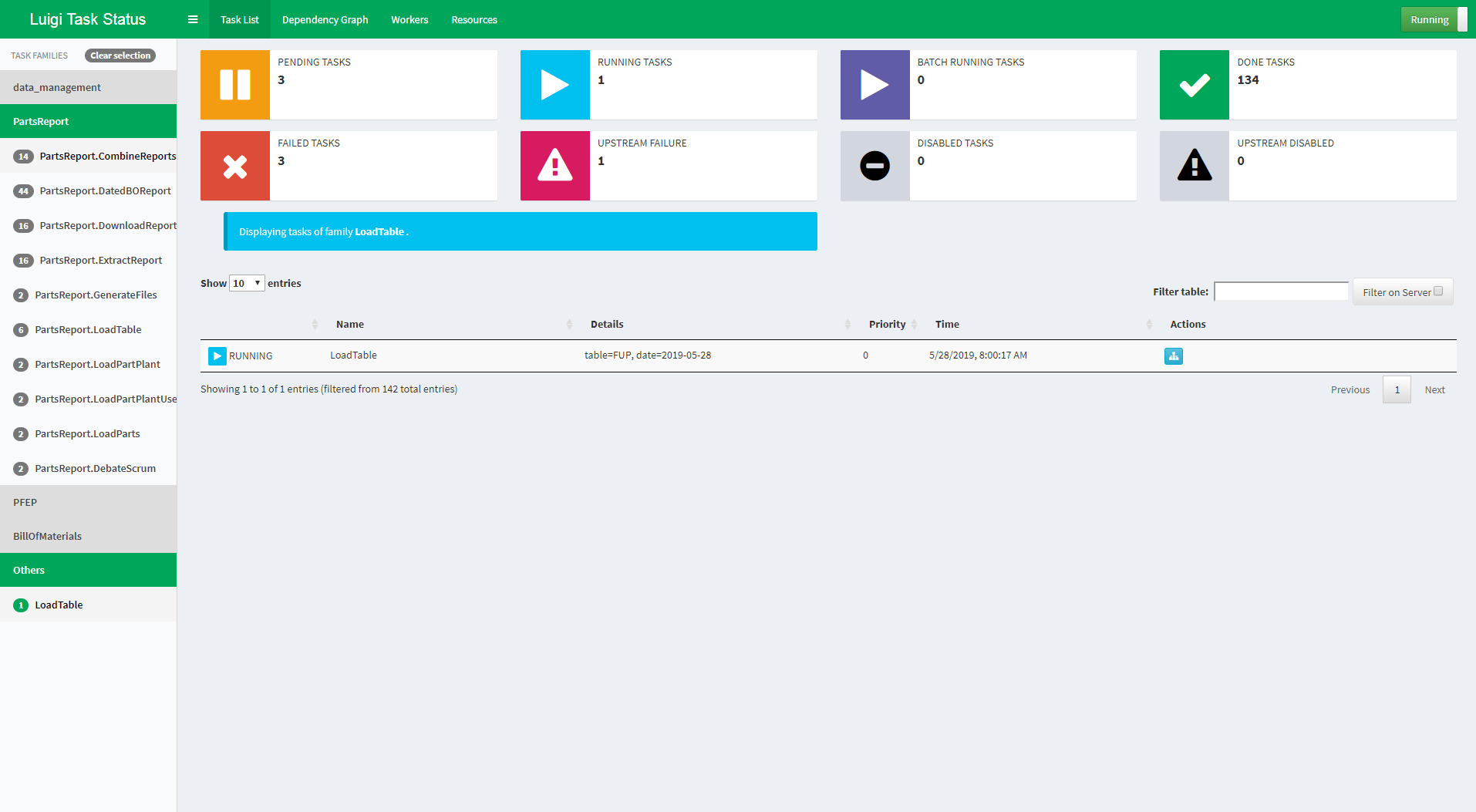
The Luigi server comes with a web interface too, so you can search and filter among all your tasks.
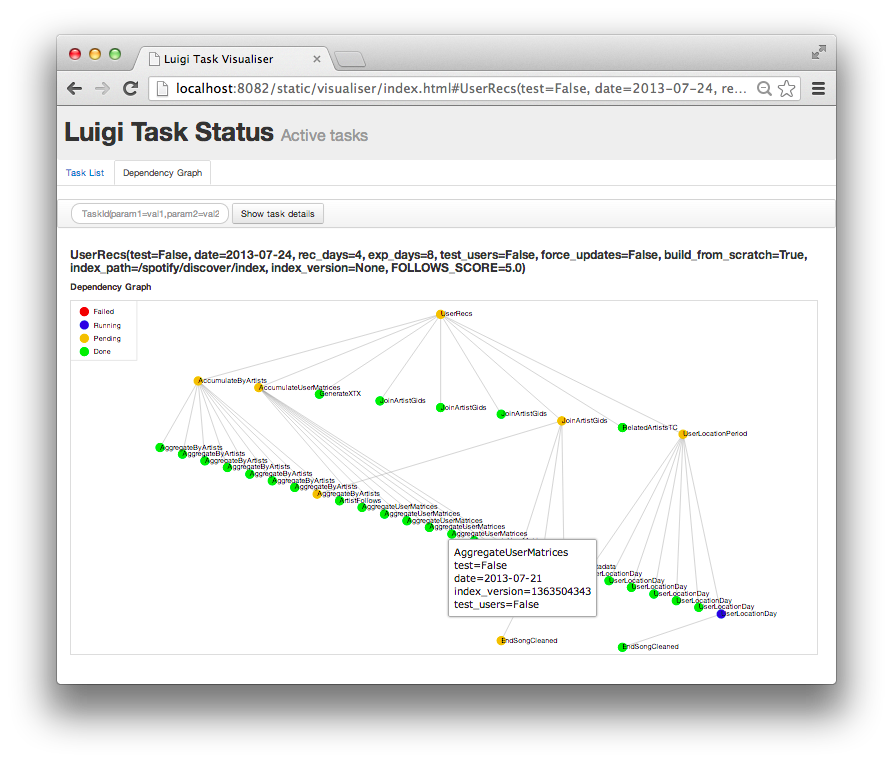
Just to give you an idea of what Luigi does, this is a screen shot from something we are running in production. Using Luigi's visualiser, we get a nice visual overview of the dependency graph of the workflow. Each node represents a task which has to be run. Green tasks are already completed whereas yellow tasks are yet to be run. Most of these tasks are Hadoop jobs, but there are also some things that run locally and build up data files.
Conceptually, Luigi is similar to GNU Make where you have certain tasks and these tasks in turn may have dependencies on other tasks. There are also some similarities to Oozie and Azkaban. One major difference is that Luigi is not just built specifically for Hadoop, and it's easy to extend it with other kinds of tasks.
Everything in Luigi is in Python. Instead of XML configuration or similar external data files, the dependency graph is specified within Python. This makes it easy to build up complex dependency graphs of tasks, where the dependencies can involve date algebra or recursive references to other versions of the same task. However, the workflow can trigger things not in Python, such as running Pig scripts or scp'ing files.
We use Luigi internally at Spotify to run thousands of tasks every day, organized in complex dependency graphs. Most of these tasks are Hadoop jobs. Luigi provides an infrastructure that powers all kinds of stuff including recommendations, toplists, A/B test analysis, external reports, internal dashboards, etc.
Since Luigi is open source and without any registration walls, the exact number of Luigi users is unknown. But based on the number of unique contributors, we expect hundreds of enterprises to use it. Some users have written blog posts or held presentations about Luigi:
- Spotify (presentation, 2014)
- Foursquare (presentation, 2013)
- Mortar Data (Datadog) (documentation / tutorial)
- Stripe (presentation, 2014)
- Buffer (blog, 2014)
- SeatGeek (blog, 2015)
- Treasure Data (blog, 2015)
- Growth Intelligence (presentation, 2015)
- AdRoll (blog, 2015)
- 17zuoye (presentation, 2015)
- Custobar (presentation, 2016)
- Blendle (presentation)
- TrustYou (presentation, 2015)
- Groupon / OrderUp (alternative implementation)
- Red Hat - Marketing Operations (blog, 2017)
- GetNinjas (blog, 2017)
- voyages-sncf.com (presentation, 2017)
- Open Targets (blog, 2017)
- Leipzig University Library (presentation, 2016) / (project)
- Synetiq (presentation, 2017)
- Glossier (blog, 2018)
- Data Revenue (blog, 2018)
- Uppsala University (tutorial) / (presentation, 2015) / (slides, 2015) / (poster, 2015) / (paper, 2016) / (project)
- GIPHY (blog, 2019)
- xtream (blog, 2019)
- CIAN (presentation, 2019)
Some more companies are using Luigi but haven't had a chance yet to write about it:
- Schibsted
- enbrite.ly
- Dow Jones / The Wall Street Journal
- Hotels.com
- Newsela
- Squarespace
- OAO
- Grovo
- Weebly
- Deloitte
- Stacktome
- LINX+Neemu+Chaordic
- Foxberry
- Okko
- ISVWorld
- Big Data
- Movio
- Bonnier News
- Starsky Robotics
- BaseTIS
- Hopper
- VOYAGE GROUP/Zucks
- Textpert
- Tracktics
- Whizar
- xtream
- Skyscanner
- Jodel
- Mekar
- M3
- Assist Digital
- Meltwater
- DevSamurai
- Veridas
We're more than happy to have your company added here. Just send a PR on GitHub.
- Mailing List for discussions and asking questions. (Google Groups)
- Releases (PyPI)
- Source code (GitHub)
- Hubot Integration plugin for Slack, Hipchat, etc (GitHub)
Luigi was built at Spotify, mainly by Erik Bernhardsson and Elias Freider. Many other people have contributed since open sourcing in late 2012. Arash Rouhani was the chief maintainer from 2015 to 2019, and now Spotify's Data Team maintains Luigi.






































































































































































































































