![]()
This library implements:
- The BLS signature scheme (Boneh-Lynn-Shacham)
- over the BLS12-381 (Barreto-Lynn-Scott) pairing-friendly curve
Cipher suite ID: BLS_SIG_BLS12381G2_XMD:SHA-256_SSWU_RO_POP_
You can install the developement version of the library through nimble with the following command
nimble install https://github.com/status-im/nim-blscurve
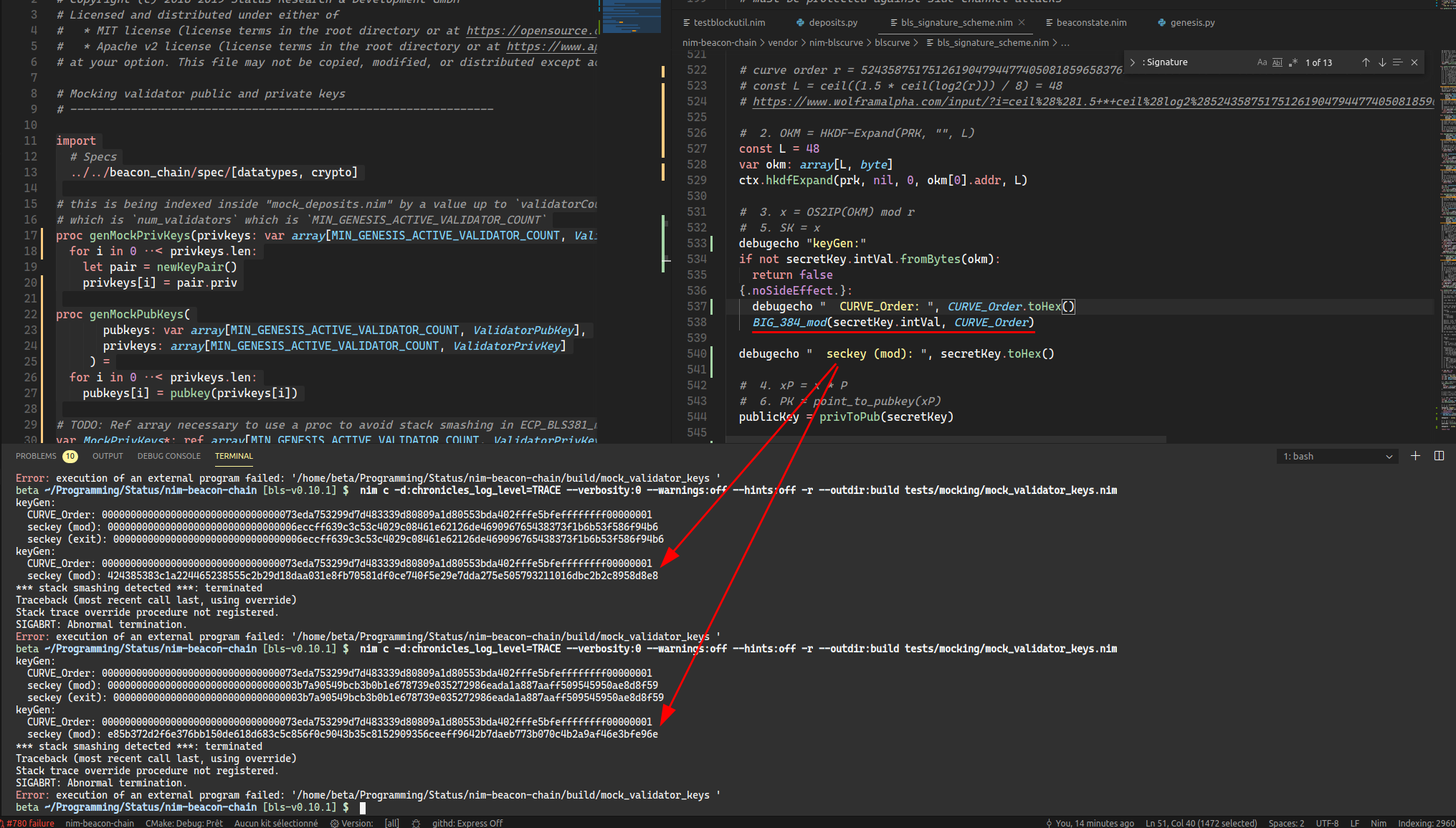
This repo follows Ethereum 2.0 requirements.
Besides the standardization work described below, no changes are planned upstream for the foreseeable future.
Currently (Jun 2019) a cross-blockchain working group is working to standardize BLS signatures for the following blockchains:
- Algorand
- Chia Network
- Dfinity
- Ethereum 2.0
- Filecoin
- Zcash Sapling
- IETF draft submission v2: https://tools.ietf.org/html/draft-boneh-bls-signature-02
- Repo for collaboration on the draft: https://github.com/cfrg/draft-irtf-cfrg-bls-signature
- https://tools.ietf.org/html/draft-irtf-cfrg-hash-to-curve-09
- https://github.com/cfrg/draft-irtf-cfrg-hash-to-curve
Note: the implementation was done following Hash-to-curve v7 v9 and v7 are protocol compatible but have cosmetic changes (naming variables, precomputing constants, ...)
This library uses:
- SupraNational BLST on all platforms.
BLST uses SSSE3 by default, if supported on the host. To disable that, when building
binaries destined for older CPUs, pass -d:BLSTuseSSSE3=0 to the Nim compiler.
We recommend working within the nimbus build environment described here: https://github.com/status-im/nim-beacon-chain/
To execute the test suite, just navigate to the root of this repo and execute:
nimble test
Please note that within the nimbus build environment, the repository will be located in
nim-beacon-chain/vendor/nim-blscurve.
Before you start, please make sure that the regular test suite executes successfully (see the instructions above). To start a particular fuzzing test, navigate to the root of this repo and execute:
nim tests/fuzzing/run_fuzzing_test.nims <test-name>
You can specify the fuzzing engine being used by passing an additional
--fuzzer parameter. The currently supported engines are libFuzzer
(used by default) and afl.
All fuzzing tests are located in tests/fuzzing and use the following
naming convention:
fuzz_<test-name>.nim
Licensed and distributed under either of
- MIT license: LICENSE-MIT or http://opensource.org/licenses/MIT
- Apache License, Version 2.0, (LICENSE-APACHEv2 or http://www.apache.org/licenses/LICENSE-2.0)
at your option. These files may not be copied, modified, or distributed except according to those terms.
- SupraNational BLST is distributed under the Apache License, Version 2.0