Docker containers for running big data platform. Containers for Hadoop NameNode, Hadoop DataNodes, Hive, Impala, Zookeeper and Postgres.
All containers are build from docker-compose files, but docker-compose does not support building containers from a base image. A Makefile has been included to build the containers.
Build all Containers
make build
Build Individual Container
make build-hive
All containers can be run using docker-compose The -p option is used to specify the docker network for the containers.
docker-compose -p bigdata-net up
Individual containers can be run by referencing the container name. This is typically not recommended however as there are dependencies between a number of the containers.
docker-compose -p bigdata-net up postgres
Use docker-compose to access containers by name.
docker-compose -p bigdata-net exec impala bash
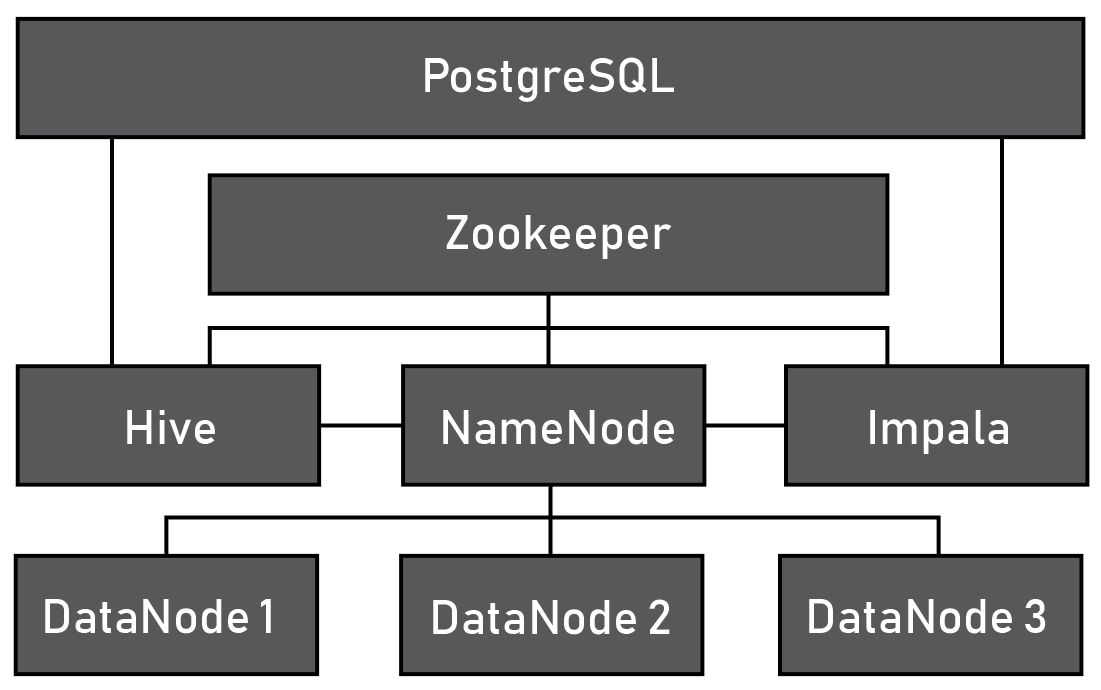
- Copy files to the NameNode container.
docker cp <data-file> <hadoop-container-id>:/
- Enter the NameNode Container
docker-compose -p bigdata-net exec namenode bash
- Create a directory in the HDFS for the files
hdfs dfs -mkdir -p /user/data/
- Add the files to the HDFS directory
hdfs dfs -put <data-file> /user/data/
Using beeline
- From the Hive container, run the beeline CLI
beeline
- Connect to HiveServer2
!connect jdbc:hive2://localhost:10000
- Run Queries
show databases;
Using JDBC with Maven
- From the Hive container, navigate to the directory containing the pom.xml file and project file
cd jdbc
- Run the Maven package command
mvn package
- Run the Java Project
cd target/
java -jar hive-jdbc-example-1.0-jar-with-dependencies.jar
Using Impala Shell
- Start the Impala Shell
impala-shell -i localhost
- Run Queries
show databases;