sunshowerc / blog Goto Github PK
View Code? Open in Web Editor NEW个人博客,如对你有帮助是我的荣幸,你的 star 是对我最大的支持!
个人博客,如对你有帮助是我的荣幸,你的 star 是对我最大的支持!






























































































































大家使用 typescript 总会使用到 interface 和 type,官方规范 稍微说了下两者的区别
- An interface can be named in an extends or implements clause, but a type alias for an object type literal cannot.
- An interface can have multiple merged declarations, but a type alias for an object type literal cannot.
但是没有太具体的例子。
明人不说暗话,直接上区别。
interface User {
name: string
age: number
}
interface SetUser {
(name: string, age: number): void;
}
type User = {
name: string
age: number
};
type SetUser = (name: string, age: number): void;
interface 可以 extends, 但 type 是不允许 extends 和 implement 的,但是 type 缺可以通过交叉类型 实现 interface 的 extend 行为,并且两者并不是相互独立的,也就是说 interface 可以 extends type, type 也可以 与 interface 类型 交叉 。
虽然效果差不多,但是两者语法不同。
interface Name {
name: string;
}
interface User extends Name {
age: number;
}
type Name = {
name: string;
}
type User = Name & { age: number };
type Name = {
name: string;
}
interface User extends Name {
age: number;
}
interface Name {
name: string;
}
type User = Name & {
age: number;
}
// 基本类型别名
type Name = string
// 联合类型
interface Dog {
wong();
}
interface Cat {
miao();
}
type Pet = Dog | Cat
// 具体定义数组每个位置的类型
type PetList = [Dog, Pet]// 当你想获取一个变量的类型时,使用 typeof
let div = document.createElement('div');
type B = typeof div
type StringOrNumber = string | number;
type Text = string | { text: string };
type NameLookup = Dictionary<string, Person>;
type Callback<T> = (data: T) => void;
type Pair<T> = [T, T];
type Coordinates = Pair<number>;
type Tree<T> = T | { left: Tree<T>, right: Tree<T> };
interface 能够声明合并
interface User {
name: string
age: number
}
interface User {
sex: string
}
/*
User 接口为 {
name: string
age: number
sex: string
}
*/
一般来说,如果不清楚什么时候用interface/type,能用 interface 实现,就用 interface , 如果不能就用 type 。其他更多详情参看 官方规范文档
技术不只是用于工作,也用于生活。
------- 沃兹基 · 梭德
去年,我开始了基金定投理财。
没错,就我这兜里的几个铜崩也敢叫嚣着也"搏一搏,单车变摩托"了。
结果今年年初疫情来袭,全球股市大跌,恐慌中我疯狂低位抛售美基,裤兜里本来就不多的铜崩就更孤影形单了。
又过了几个月……
卧槽!美国这疫情爆发力他娘的美股这都能涨回来?这不科学!
那些个日子,我都这种心情:
后来仔细想想,投资肯定有涨有跌跌跌跌跌跌跌,这都是浮亏,只要我不撒手,我就永远不亏,最重要的还是理性,有自己的投资决策树,不为外物所动。
大涨行情的我:好的,我懂了,要理性。
大跌行情的我:你懂个屁!!
说起来容易,做起来难,毕竟投资交易都是反人性的。坚持自己的投资策略谈何容易。然而,投资理财不就是一堆数字游戏,低买高卖嘛。
恰好,作为一只程序员,对数据从来不陌生。
那么整一个基金回测网站,模拟下投资策略收益应该不难吧?
要是不小心发现了”财富密码“,不用多久,我就会财富指数增长、一夜暴富、完成一个小目标、迎娶白富美、走上人生巅峰,想想还有点小激动。
那么,要开发一个基金回测网站,需要几步呢?
要搞网站,还要很多数据图表,因为经常用支付宝投资基金,那就直接用蚂蚁家的东西 antd + g2 数据可视化 ,搞定啦!
这是难住大家的一道坎。一般大家会想到以下几个方案:
那我的方法是啥呢?白嫖!
偶然发现某基金网站用的是 jsonp 来处理跨域问题,用了 js script + cache 来存储大量的基金历史数据,而且有意无意地没有限制 referrer。于是就轻松解决了数据源的问题啦(需要注意的是,网站不能用 https 哦,不然数据请求就会被同源策略block 掉)。
白嫖大发,真香~
业务代码的核心是记录每天的基金、资产快照,包括但不限于:基金净值,相对涨幅,基金资产,可用资金,仓位,收益率等等信息。
然后前端图表库 G2,将时间区间内的所有数据渲染出来,就可以啦。
数据全白嫖,我们这就是一个静态前端网站。那就好办了,都不用 服务器,直接上 GitHub Pages。
再增加一些细节,
我们的基金定投回测网站就完成啦,此处为访问地址[目前仅支持 PC 端访问]
最近基金投资的话题越来越多,尤其是基金定投,也发现突然多出很多想要割韭菜的营销号,分辨能力差点的很容易被带到坑里去,我想说:
别弄那么多花里胡哨的了,想要知道定投靠不靠谱?能不能赚钱?有多少收益率?空口物品,直接模拟一下历史数据的定投策略,回测一下不就可以了么?
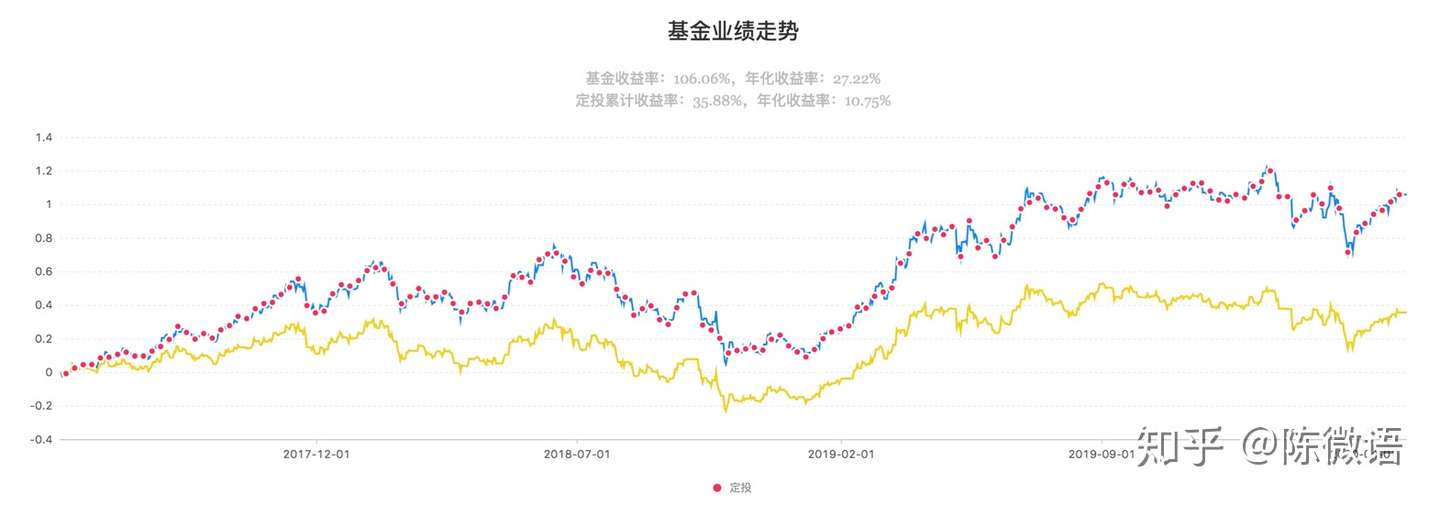
招商中证白酒定投三年收益
上面是模拟 招商中证白酒分级指数基金 定投三年的收益情况,投了多久,赚了多少,最亏的时候回撤了多少,收益率多少,一目了然。
有人质疑你,就直接把数据砸对方脸上。
PS: 提前说明下可能有异议的地方
- 收益率算法参考了支付宝基金和天天基金网的定投计算器,数据误差范围内基本一致。
- 下文的收益率都是泛指累计收益率,不是内部收益率,没有考虑资金的时间占用成本。
3. 过往收益率不等于未来收益率,过往可知,未来叵测,仅供参考。
4. 所举基金例子不作为投资建议。投资需谨慎。
近一年老听说人推荐理财,尤其是推荐定投指数基金。什么股神巴菲特强力推荐,微笑定投,轻轻松松年化收益率 15%,吹的花里胡哨的。
但是大部分人也就说说定投的原理,很少有人能实实在在提供数据来证明,定投指数基金到底能给你提供多少收益。
那么作为一个程序员,和数据打交道比较多,所以习惯用数据说话,于是写了个程序来模拟历史时间的定投收益率到底能达到多少?
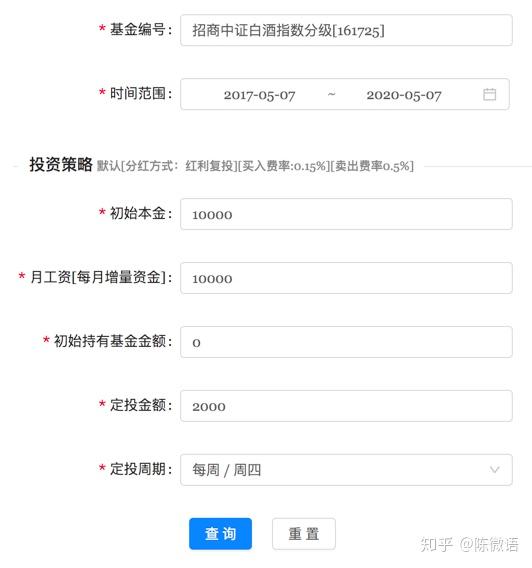
首先,定投的基本操作是:
耐心,定投时间够长
笑脸指数曲线
所以,我们选择过去 3 年作为历史测试数据,过去三年刚好通过了一个小熊市和小牛市,符合微笑特征,时间也够长。
我们打开过去 3 年【2017/01/29 ~ 2020/01/29】的指数基金排行榜。
第一名,招商中证白酒指数分级[161725],过去三年累计收益率高达 135%,够牛逼吧,这指数基金。
那么我们回到过去,对这个基金定投 3 年看看效果:

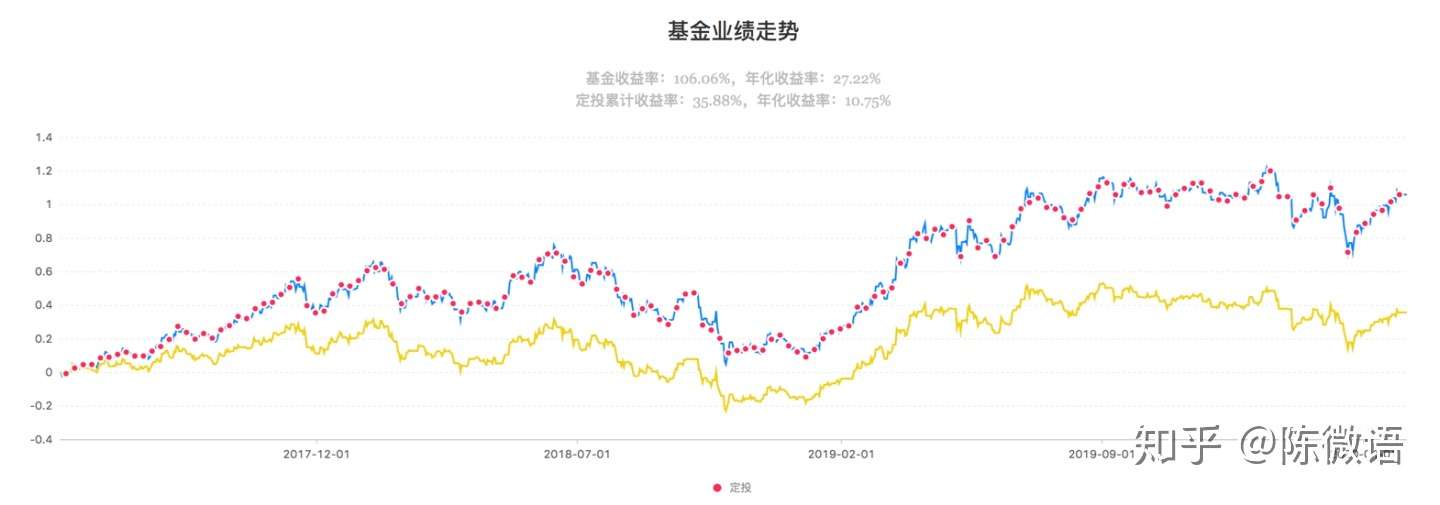
【2017/01/29 ~ 2020/01/29】定投招商中证白酒
定投3年累计收益率 44.19%,折算年化收益率是 12.97%
看起来是挺不错接近 15% 了是吧,但是要知道这是指数基金收益排行第一名,定投都达不到 15%。
那么我们再看看很多人推荐的宽基指数,如 上证50,沪深300 之类的。
通过排行榜,宽基指数表现最好的是 易方达上证 50指数[110003],定投结果:

哦豁,平均年化收益率 8%,别说 15%,10% 都不到哦。
那是不是这说明定投宽基指数的收益率还不如 P2P 呢?
并非如此。假如累计定投指数基金 10w 和投资 P2P 累计 10w,最后收益虽然都一样是 1w,但两者的资金占用时间成本是不一样的。P2P 是 10w 被占用了一年,定投是有 1w 被占用 1 年,有 1w 被占用 11 个月,......,上个月才定投的 1w 才被占用了 1 个月。收益差不多定投基金是明显优于 P2P 的。
那么,是不是定投就没有能达到 15% 收益率的呢?
也不能这么说,这次,我们打开下定投排行榜。 选择第一名,银河创新成长混合[519674]

【2017/01/29 ~ 2020/01/29】定投 银河创新成长混合
很牛逼,定投年化收益率高达 24%。
高是高了,但是通过基金曲线发现没,这个基金是在 一年前表现平平无奇,在最近一年才一飞冲天。
也就是说,这个基金是在不被看好的时候,开始定投,在低价位积攒了很多筹码,然后在最近一年厚积薄发,才有了如此之高的定投收益率。
这毫无疑问存在一个悖论。
如果我有这个实力,有这个眼光,能看到目前低估值将来牛逼的基金,那完全没必要定投,直接择时分批建仓就行。
定投指数基金,本身就是对市场缺乏深刻的理解,只能通过佛系定投来分摊风险,要让人判断一只基金的未来趋势,就太强人所难了。
换句话说,就 银河创新成长混合 3 年前的平平无奇的业绩,你敢坚持定投3年不放手?
结论: 那些吹嘘定投指数基金就能轻轻松松年化收益率 15% 的人,纯属吹牛逼,不是蠢就是坏。定投指数基金,甚至年化收益率上 10% 都不容易。
那么是不是说定投就是错的呢?
并非如此,上面只是说明定投没有你想象中那么美好而已。
该定投还是得定投的。
定投的根本原因是,咱目前没那么多小钱钱,只好每个月拿工资的一部分来投资。
要是咱有好几百万要投基金,那还定投个啥,逢低买入,逐渐建仓就好了。
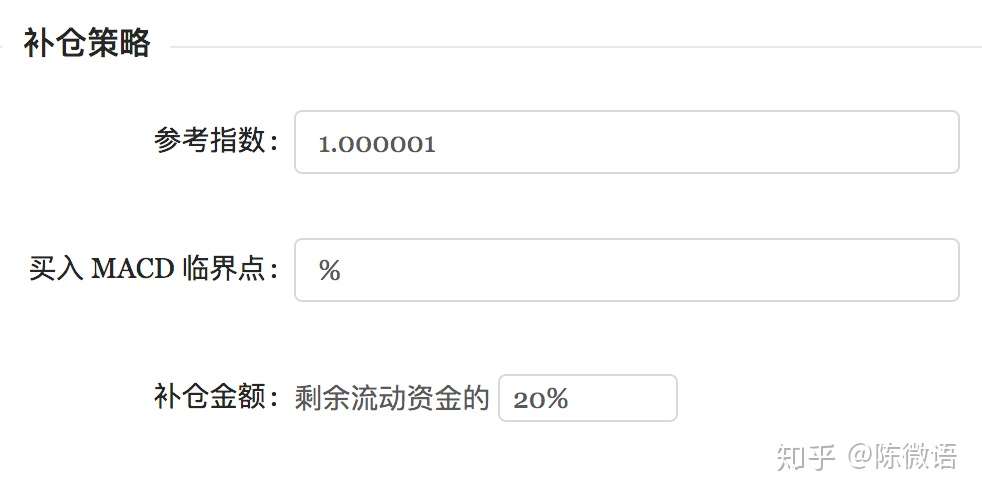
那么定投也要有定投的学问,不能瞎几把定投,每个人其实开始准备定投时,都会有一大堆疑问 :
上面的这些问题,开始我也没有一个明确答案
所以我写了一个 网页程序 来分析,不同策略下的定投,对最终收益率的影响。
首先是基本操作,选基金,和选定投时间:
然后,制定定投策略选项:
定投策略选择项
通过这些参数,我们就能得到区间时间内基金定投的各种曲线了:
会买的是徒弟,会卖的才是师傅。
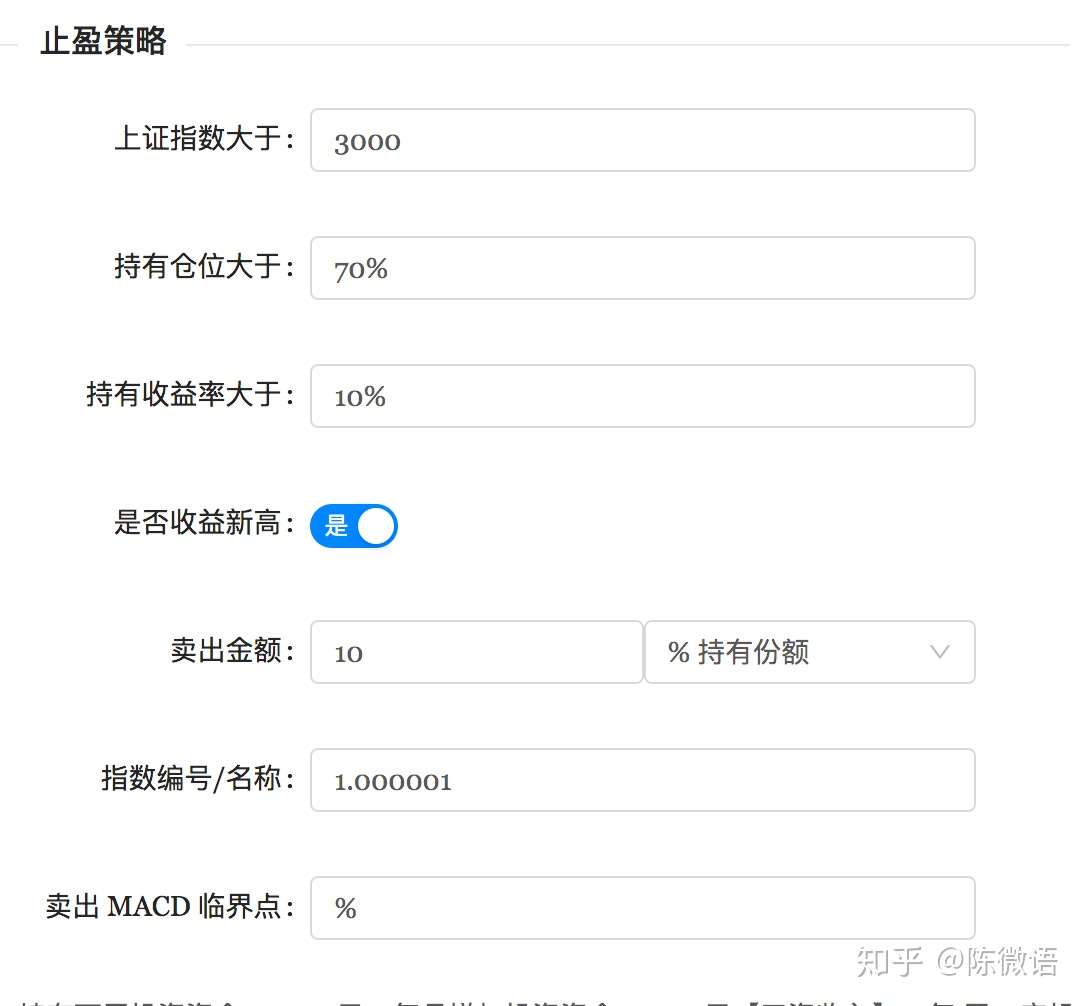
很多人基金定投最大的一个问题是:什么时候止盈?止盈多少?
很多大佬也给出成熟的意见了,
都挺有道理的,问题是哪个策略最优呢?
咱可以将这些策略参数化,选择不同的止盈策略,不同策略下的收益:
止盈策略
除了单调地定投之外,想要提高收益率,那么就应该逢低买入,按需补仓。
问题是什么时候补仓?大跌补仓?低估值补仓?这里简单地列出了 macd 位置补仓策略,其他的策略我还没写,懒。有人看再说吧。
综合止盈和补仓策略,很多人总结出来了 macd 金叉死叉交易法,网格交易法等等之类的投资策略,但是很少能准确说出收益数据比正常定投高多少了的。
所以我也实现了多个策略的收益数据比较功能 。
能比较什么东西呢?不同策略下的不同基金投资效果曲线比较图。
能看哪些数据曲线呢?目前暂定有以下这些数据可选:
基金策略比较选项
通过对比定投策略,大家很快地就能得出这种投资策略的盈亏,仓位,收益率等数据曲线图。从而找到更合适自己的投资策略了。
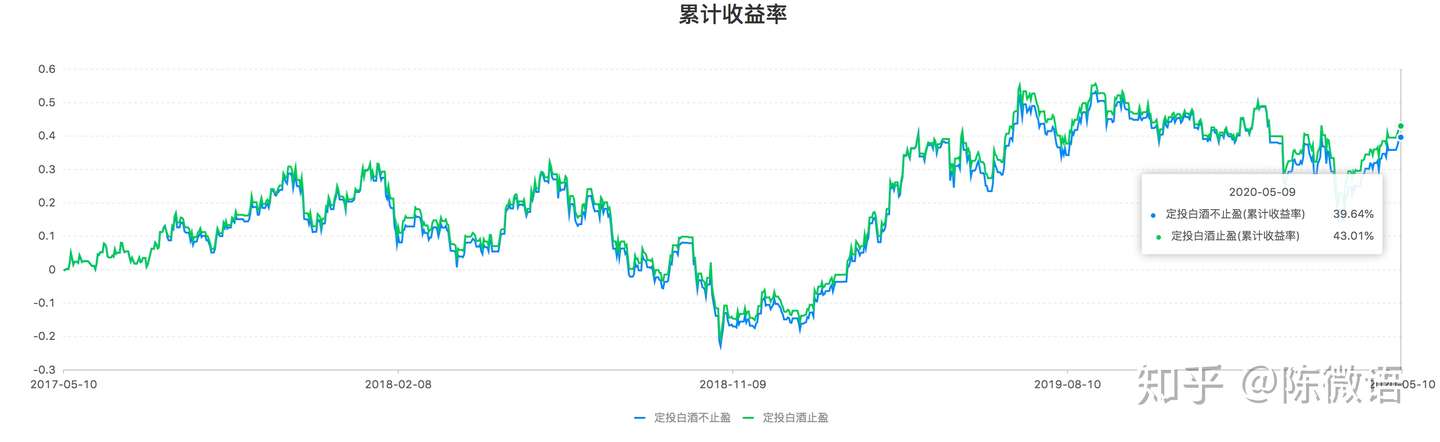
举个栗子,定投招商中证白酒3年,止盈和不止盈的差别是什么?请看数据:
累计收益率 = 总收益/总投入(止盈VS不止盈)
明显看出,止盈策略比不止盈高 3.4%
不高嘛,是不是觉得止盈和不止盈没啥区别?
错!
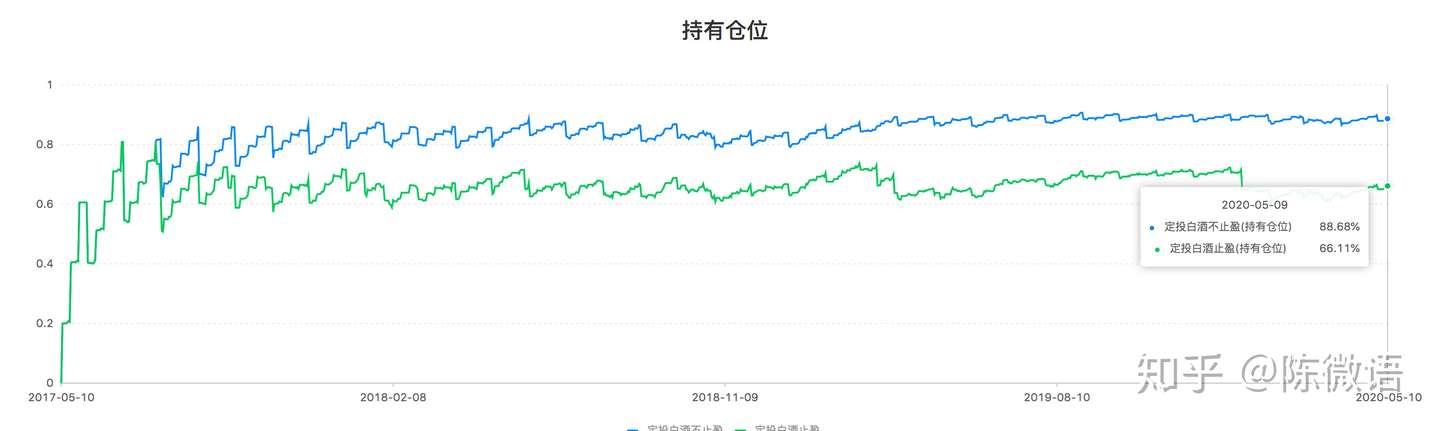
我们再看看定投期间的仓位比较:
持有仓位 = 在投基金资产/当前总资产
大概 止盈策略比不止盈仓位低 15%,投资要控制仓位这是基本投资素养,仓位太高一波动你就心态崩。
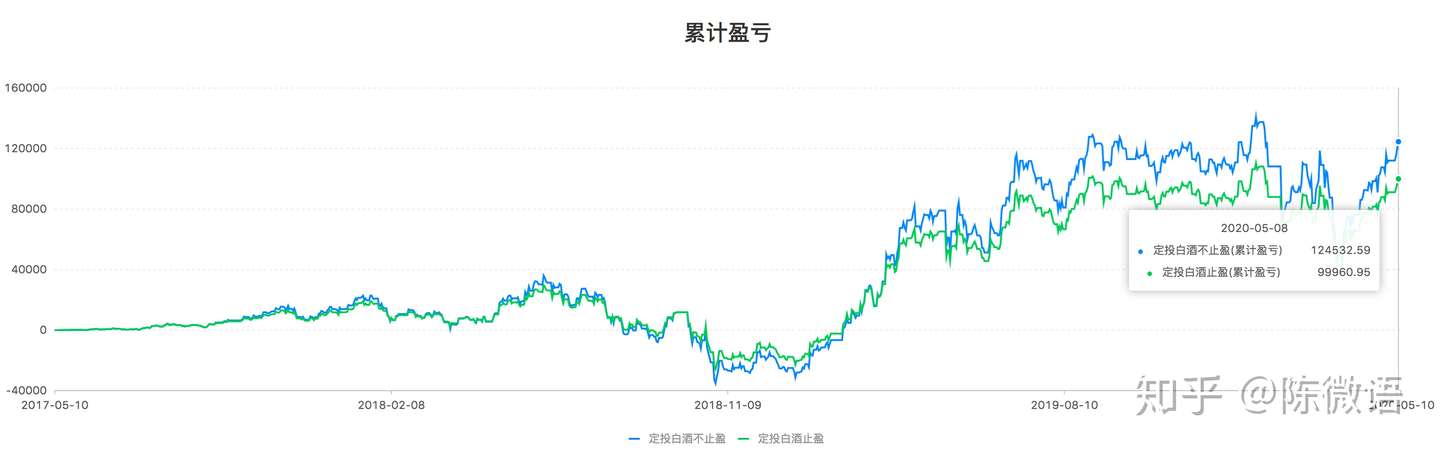
累计盈亏
仓位高是不是不好呢?也不是,看个人可承受风险能力。累计收益率虽然止盈比不止盈高,但是实际上的 累计收益是”不止盈策略“高出一筹的。
这是因为高仓位,高风险高收益,近三年整体白酒都是在涨的。要是换一个整体下行的基金,那高仓位收益就崩咯。有兴趣的可以自行在网站上测下相关基金,这里就不再赘述了。
以上投资策略的模拟,来自于我个人依靠兴趣写的网页:http://sunshowerc.github.io/fund/,仅支持 PC 端,没兼容移动端访问,懒。
后面可能会更新更全的止盈策略和补仓策略
github 开源地址:
https://github.com/SunshowerC/fund-strategy
佛系求 star
.
.
"慢着,你给我站住!"
"财富密码呢?标题说的财富密码呢?把财富密码交出来!"

大家都知道 babel 是兼容对 ES6 支持不完善的低版本浏览器的转换编译器。
而 babel 其实主要做的只有两件事情:
那么废话少说,我们直接点,直接说说常见几个场景下兼容旧版浏览器的方案。
如果你的工程是用的语法是 ES5,但是用了一些 ES6+ 的API特性,那么可以直接引入:
<script src="https://cdn.polyfill.io/v2/polyfill.min.js"></script>
来兼容 Web 应用不支持的 API。
原理大概是 polyfill.io 会读取每个请求的User-Agent标头,并返回适合请求浏览器的polyfill。具体的还可以自己指定加载哪些 特性的 polyfill,具体想了解更多的大家可以看看 官方文档。
优点:每个浏览器的设备加载的 polyfill 都不一样,最新的完全兼容ES6栋浏览器基本加载的 polyfill 大小为0。
缺点:
es6.array.from 特性,polyfill.io 依然可能会把该浏览器所有不支持的特性(如:es6.promise,es6.string.includes等特性)全部加载进来。上面提到了 polyfill.io 的一个缺点是无法按需引入,那么现在就介绍下 babel7 @babel/preset-env
@babel/preset-env 默认根据 .browserslist 所填写的需要兼容的浏览器,进行必要的代码语法转换和 polyfill
// .babelrc.js
module.exports = {
presets: [
[
"@babel/preset-env",
{
"modules": false, // 模块使用 es modules ,不使用 commonJS 规范,具体看文末附录
"useBuiltIns": 'usage', // 默认 false, 可选 entry , usage
}
]
]
}此处重点介绍一下其新推出的 useBuiltIns 选项:
import '@babel/polyfill', 会无视 .browserslist 将所有的 polyfill 加载进来。
import '@babel/polyfill' 才生效(否则会抛出错误:regeneratorRuntime undefined), 根据 .browserslist 过滤出 需要的 polyfill (类似 polyfill.io 方案)
import '@babel/polyfill'(加上也无妨,编译时会自动去掉), 且会根据 .browserslist + 业务代码使用到的新 API 按需进行 polyfill。
usage 风险项:由于我们通常会使用很多 npm 的 dependencies 包来进行业务开发,babel 默认是不会检测 依赖包的代码的。
也就是说,如果某个 依赖包使用了
Array.from, 但是自己的业务代码没有使用到该API,构建出来的 polyfill 也不会有 Array.from, 如此一来,可能会在某些使用低版本浏览器的用户出现 BUG。所以避免这种情况发生,一般开源的第三方库发布上线的时候都是转换成 ES5 的。
上面提到的 useBuiltIns:'usage' 似乎已经很完美解决我们的需要了,但是我们构建的时候发现:
// es6+ 源码:
const asyncFun = async ()=>{
await new Promise(setTimeout, 2000)
return '2s 延时后返回字符串'
}
export default asyncFun根据上述的 useBuiltIns:'usage' 配置编译后:
import "core-js/modules/es6.promise";
import "regenerator-runtime/runtime";
function asyncGeneratorStep(gen, resolve, reject, _next, _throw, key, arg) { try { var info = gen[key](arg); var value = info.value; } catch (error) { reject(error); return; } if (info.done) { resolve(value); } else { Promise.resolve(value).then(_next, _throw); } }
function _asyncToGenerator(fn) { return function () { var self = this, args = arguments; return new Promise(function (resolve, reject) { var gen = fn.apply(self, args); function _next(value) { asyncGeneratorStep(gen, resolve, reject, _next, _throw, "next", value); } function _throw(err) { asyncGeneratorStep(gen, resolve, reject, _next, _throw, "throw", err); } _next(undefined); }); }; }
var asyncFun =
/*#__PURE__*/
function () {
var _ref = _asyncToGenerator(
/*#__PURE__*/
regeneratorRuntime.mark(function _callee() {
return regeneratorRuntime.wrap(function _callee$(_context) {
while (1) {
switch (_context.prev = _context.next) {
case 0:
_context.next = 2;
return new Promise(setTimeout, 2000);
case 2:
return _context.abrupt("return", '2s 延时后返回字符串');
case 3:
case "end":
return _context.stop();
}
}
}, _callee, this);
}));
return function asyncFun() {
return _ref.apply(this, arguments);
};
}();
export default asyncFun;上述代码中,我们看到,asyncGeneratorStep, _asyncToGenerator 这两个函数是被内联进来,而不是 import 进来的。
也就是说,如果你有多个文件都用到了 async,那么每个文件都会内联一遍 asyncGeneratorStep, _asyncToGenerator 函数。
这代码明显是重复了,那么有什么方法可以进行优化呢? 答案是 @babel/plugin-transform-runtime
babel 在每个需要的文件的顶部都会插入一些 helpers 代码,这可能会导致多个文件都会有重复的 helpers 代码。 @babel/plugin-transform-runtime 的 helpers 选项就可以把这些模块抽离出来
// .babelrc.js
module.exports = {
"plugins": [
[
"@babel/plugin-transform-runtime",
{
"corejs": false, // 默认值,可以不写
"helpers": true, // 默认,可以不写
"regenerator": false, // 通过 preset-env 已经使用了全局的 regeneratorRuntime, 不再需要 transform-runtime 提供的 不污染全局的 regeneratorRuntime
"useESModules": true, // 使用 es modules helpers, 减少 commonJS 语法代码
}
]
],
presets: [
[
"@babel/preset-env",
{
"modules": false, // 模块使用 es modules ,不使用 commonJS 规范
"useBuiltIns": 'usage', // 默认 false, 可选 entry , usage
}
]
]
}// 添加新配置后编译出来的代码
import "core-js/modules/es6.promise";
import "regenerator-runtime/runtime";
import _asyncToGenerator from "@babel/runtime/helpers/esm/asyncToGenerator";
var asyncFun =
/*#__PURE__*/
function () {
var _ref = _asyncToGenerator(
/*#__PURE__*/
regeneratorRuntime.mark(function _callee() {
return regeneratorRuntime.wrap(function _callee$(_context) {
while (1) {
switch (_context.prev = _context.next) {
case 0:
_context.next = 2;
return new Promise(setTimeout, 2000);
case 2:
return _context.abrupt("return", '2s 延时后返回字符串');
case 3:
case "end":
return _context.stop();
}
}
}, _callee, this);
}));
return function asyncFun() {
return _ref.apply(this, arguments);
};
}();
export default asyncFun;
可以看到,已经没有了内联的 helpers 代码,大功告成。
如果没有什么特殊的需求,使用 babel 7 的最佳配置是:
首先安装依赖包: npm i -S @babel/polyfill @babel/runtime && npm i -D @babel/preset-env @babel/plugin-transform-runtime
配置 .babelrc.js
// .babelrc.js
module.exports = {
"plugins": [
[
"@babel/plugin-transform-runtime",
{
"corejs": false, // 默认值,可以不写
"helpers": true, // 默认,可以不写
"regenerator": false, // 通过 preset-env 已经使用了全局的 regeneratorRuntime, 不再需要 transform-runtime 提供的 不污染全局的 regeneratorRuntime
"useESModules": true, // 使用 es modules helpers, 减少 commonJS 语法代码
}
]
],
presets: [
[
"@babel/preset-env",
{
"modules": false, // 模块使用 es modules ,不使用 commonJS 规范
"useBuiltIns": 'usage', // 默认 false, 可选 entry , usage
}
]
]
}PS: 如果想要了解更多有关 @babel/preset-env 和 @babel/plugin-transform-runtime 的选项配置用途,可以参考我的个人总结
上述的方案,其实还一直隐藏着一个不算问题的问题,那就是如果使用最新的浏览器,其实不需要任何的语法转换和polyfill。
那么参考下上述的 polyfill 方案,能不能实现如果低版本浏览器,就使用usage方案按需 transform + polyfill 的代码,如果是较新浏览器,就不进行任何的语法转换和 polyfill 呢?
必须能!
参考这篇文章 deploying es2015 code in production today,其中提出了基于 script 标签的 type="module" 和 nomodule 属性 区分出当前浏览器对 ES6 的支持程度。
具体原理体现在,对于以下代码:
<script type="module" src="main.js"></script>
<script nomodule src="main.legacy.js"></script>
支持 ES Module 的浏览器能够识别 type="module" 和 nomodule,会加载 main.js 忽略 main.legacy.js,
还未支持 ES module 的浏览器则恰恰相反,只会加载main.legacy.js。
那么怎么实现优化就很清晰了:
nomodule 属性@babel/preset-env 的选项 target.esmodules = true,不转换所有的语法也不添加 polyfill,生成 ES6+ 的能被现代浏览器识别解析的代码,并给这类代码文件的 script 标签加上 type="module"vue-cli 3.0 官方提供 modern build 功能
create-react-app 预计在下一个版本3.0的迭代中才实现。 现阶段实现需要自己写 webpack 插件来实现 module/nomodule 插入。此处可以推荐使用 create-react-app 模板: react-scripts-modern ,来实现 Modern Build
常规webpack打包流程图

Modern Build 打包构建流程

<link href="app.css" rel="stylesheet" onload="this.media='all'" media="nope!"> 动态加载,不然也会下载两份代码只执行一份都下载的情况:
<script type="module" src="./ddds/dd.js"></script>
<script src="./dd.js"></script>
<script nomodule src="./js/es/5.js?v2"></script>
<script type="module" src="./js/e/s6.js?v2"></script>
只下载一份的情况
<body>
<script type="module" src="./js/e/s6.js?v2"></script>
<script nomodule src="./js/es/5.js?v2"></script>
<script src="./dd.js"></script>
</body>
参考文献: type module 执行顺序
不想看爬虫过程只想看职位钱途数据分析请看这里:
前端招聘岗位分析
C++招聘岗位分析
JAVA招聘岗位分析
PHP招聘岗位分析
Python招聘岗位分析
想看源码或想自己爬一个请看这里:本文github源码
早在一年前大学校招期间,为了充实下简历,就写了个node爬虫,可惜当时能力有限,工程存在一定的局限性,不好意思拿出来装逼分享。
一年过去了,现在能力依然有限,但是脸皮却练厚了,于是就有了这篇文章。
关于爬虫,主流技术是用python,然而随着node的出现,对于对python了解有限的前端同学,用node来实现一个爬虫也不失为一个不错的选择。
当然无论是python爬虫还是node爬虫或者其他品种的爬虫,其实除了语言特性之外,其思路基本大同小异。下面我就为大家详细介绍下node爬虫的具体思路与实现,内容大概如下:
JSON数据HTML文档,提取有用信息既然要写爬虫,当然要爬一些利益相关的数据比较好玩啦。爬取招聘网站的招聘信息,来看看互联网圈子里各个工种的目前薪酬状况及其发展前景,想来是不错的选择。
经我夜观天下,掐指一算,就选拉勾网吧。
一个职位招聘信息,一般来说,我们关注的重点信息会是:
带着想要收集的信息,首先,进入拉勾官网,搜索web前端岗位,能看到
很好,我们想要的信息基本都有了。
F12 分析请求资源,可得https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0
post 请求体
{
first:false,
pn:1,
kd:`web前端`
}
响应JSON数据
完美!!! 数据格式都已经帮我们整理好了,直接爬就行了。
但,完美的数据总不会这么轻易让你得到,经我用 node 和 python,还有postman 携带浏览器全部header信息一一测试,均发现:
好吧,此路不通。(此接口反爬虫机制不明,有研究的大神请留言=_=)
所谓条条大路通罗马,此路不通,咱绕路走。
经过一番探索,发现 拉勾移动端站点 空门大开!
提示: 一般有点技术含量的网站都可能会存在不同强度的反爬虫机制,而一般其移动端站点的反爬虫机制相对于PC站点较弱,是一个不错的着手点。再不行的话,还可以去其app端抓包分析是否存在想要的请求哦。
GET请求: https://m.lagou.com/search.json?city=全国&positionName=web前端&pageNo=1&pageSize=15
响应信息:
很好,虽然数据信息有点少,但是总算是一个能爬的接口了。
好了,分析也分析完了,现在正式设计爬虫程序。
首先,把请求的路径与参数单独抽离。
let spider = {
requestUrl : "http://m.lagou.com/search.json",
query: {
city: '',
pageNum: '',
job: '',
},
...
}发出请求,此处的服务端构造请求使用 superagent,当然,用 request 等类似的包也可以,并无限定。
let spider = {
....
/**
* 发起单个请求
* @return {<Promise<Array>> | <Promise<String>>} 请求成功resolve原始数据,否则reject
**/
request() {
return new Promise((resolve,reject)=>{
superagent
.get(this.requestUrl)
.query({
city: this.query.city,
pageNo: this.query.pageNum,
positionName: this.query.job
}).end((err, res)=>{
let dataList = [];
if (err || !res || !res.ok) {
console.error(err);
reject('request failed!')
} else {
dataList = res.body.content.data.page.result
if (dataList.length === 0) {
// 当请求结果数组长度为0,即认为已经到末页,结束爬虫
reject('finish');
} else {
resolve(dataList)
}
}
})
})
},
处理数据
let spider = {
....
/**
* 处理爬取到的原始数据,提取出所需的数据
* @param {<Array>} - companyList : 原始数据
* @return {<Promise<Array>>} resolve处理过的数据
**/
handleCallbackData(companyList) {
//处理数据
let arr = companyList.map((item) => {
let salary = item.salary.split('-');
//工资两种情况:”10k以上“ or "10k-15k", 平均工资取中位数
aveSalary = salary.length == 1 ? parseInt(salary[0])*1000 : (parseInt(salary[0]) + parseInt( salary[1] ) )*500;
//过滤出所需数据
return {
companyFullName: item.companyFullName,
positionId : item.positionId ,
salary:aveSalary ,
city:item.city ,
field: '',
companySize:'',
workYear:'' ,
qualification: '',
}
});
return Promise.resolve(arr)
}
保存数据,此处数据库使用mongodb,ORM使用 moogoose。
save2db(jobList) {
return new Promise((resolve, reject)=>{
Job.create(jobList,function (err,product) {
if (err) {
console.error(err.errmsg)
err.code == 11000 && resolve('丢弃重复数据')
reject(err);
} else {
resolve("save data to database successfully")
}
})
})
},
从上述的json数据其实我们可以看到,JSON返回的信息十分有限,那么我们需要爬取更多的信息,就需要在招聘详情页解析 html 后提取出所需的信息
随便打开一个移动端的招聘详情页https://m.lagou.com/jobs/3638173.html,目测出url结构很简单,就是jobs/{{positionId}}.html
从详情页中可以找出 JSON 数据中缺少的数据项:工作年限要求,学历要求,雇主公司领域,雇主公司融资情况,雇主公司规模大小。
爬取方法和上述爬取 JSON 数据相差无几,主要差别就是数据解析部分,这里需要用到cherrio来解析 爬取到的HTML,从而更简单地提取必要信息。
handleCallbackData({res, jobId}) {
var $ = cheerio.load(res.text);
let workYear = $('#content > div.detail > div.items > span.item.workyear > span').text(),
qualification = $('#content > div.detail > div.items > span.item.education').text().trim(),
field = $('#content > div.company.activeable > div > div > p').text().trim().split(/\s*\/\s*/)[0]
companySize = $('#content > div.company.activeable > div > div > p').text().trim().split(/\s*\/\s*/)[2];
/* 如果这四项数据都没有提取到,很有可能是被拉勾的反爬虫机制拦截了 */
if ( !(workYear || qualification || field || companySize) ) {
console.log(res.text)
return Promise.reject({code:-1, msg:'wrong response!', jobId});
}
return {
id: jobId,
jobInfo: {
workYear,
qualification,
field,
// financeStage,
companySize,
}
}
},
做过爬虫的都知道,爬虫的请求并发量是必须要做的,为什么要控制并发?
实现并发控制可以使用npm包 async.mapLimit,这里为了自由度更大我使用了自己实现的 15 行代码实现并发控制。
具体代码如下:
let ids = [2213545,5332233, ...], // 招聘岗位详情id列表
limit = 10, // 并发数
runningRequestNum = 0 , // 当前并发数
count = 0; // 累计爬取数据项计数
mapLimit(ids, limit, async (jobId)=>{
let requestUrl = `http://m.lagou.com/jobs/${jobId}.html?source=home_hot&i=home_hot-6` ;
let delay = parseInt(Math.random() * 2000);
let currentIndex = count++;
runningRequestNum++
await sleep( delay ); // 避免爬太快被封ip,休眠一两秒
let result = await spiderHTML.run({
requestUrl,
jobId,
proxyIp
})
console.log(`当前并发数`, runningRequestNum)
runningRequestNum--
return result;
}).then(mapResult => {
// 并发控制下将 ids 全部迭代完毕
// do something
})
对于反爬虫措施比较暴躁的网站来说,一个IP爬取太过频繁,被识别成机器爬虫几乎是不可避免的。
一般来讲,我们最简单直接的方法就是:换IP。这个IP访问频率太高了被反爬拦截到,换个IP就行了嘛。
单个IP爬虫对于反爬较为严厉的网站是走不通的。那么我们需要用到动态IP池,每次爬取时从IP池中拉取一个IP出来爬数据。
道理很简单,
1秒内1个IP访问了100个页面,即便是单身20多年的手速也无法企及。只能是机器爬虫无疑。
但1秒内100个IP访问100个页面,平均每个IP一秒内访问了1个页面,那基本不会被反爬干掉
**怎么搭建动态IP池? **
动态IP池工作流程:

具体实现代码其实和上面的爬虫差不多,无非就是爬岗位变成了爬IP而已,具体实现源码在这,就不在这写了。
我们最终折腾爬虫,无非就是想要看爬到的数据到底说明了什么。
成功爬取了拉钩网上多个招聘岗位的具体信息后,数据可视化并得出分析结果如下:
从整体看,北上广深杭这五个城市前端工程师招聘岗位,北京是遥遥领先,是深圳的两倍,是广州的三倍,其次到上海,深圳,杭州,广州居末。
从需求量大概可以看出,整体互联网产业发达程度是 北 > 上 > 深 > 杭 > 广
由平均工资曲线图可以看到,每隔2K算一档的话,北京一档,上海一档,杭州深圳一档,空一档,广州吊车尾,杭州竟然比深圳高了300,这就代表着深圳虽然招聘需求比杭州大,但两者薪酬待遇其实差不多。
从不同薪酬的招聘数量也能看出一些很大的区别,招聘提供薪资水平中,普遍数量最多的是10k-20k这个水平,但,北京牛逼,招聘岗位60%以上都是20K以上的。我们具体来看看,各个城市对高端人才(提供薪酬20k以上)的招聘比例,那就可以看出明显区别了:
基本可以看到一个明显的趋势,公司规模越大,能提供的薪酬越高,不差钱。
另外,从不同规模的公司的前端招聘数量来看,北京又一枝独秀,大公司招聘需求很高。
但从全国来看,不同规模的公司(除了15人以下的)招聘数量基本在同一水平,基本说明:大公司少,但是每个公司招聘的人多;小公司多,但是每个公司招聘的人少。好像这是句废话。
从图上看,工作经历在1-5年的现在需求最旺盛,并且理所当然地,工作资历越高,薪资越高。
其中3-5年的最吃香,广州有点奇怪,1-3年的最吃香?综合上面的多项数据,感觉像是1-3年工资比3-5年低所以广州互联网公司多招1-3年
当然,这里存在这一个幸存者偏差,拉勾上大部分的都是社招性质的招聘,而应届生和1年经验的大部分都跑校招去了吧,所以数量低也不出奇。
移动互联网占据了大半壁江山,剩下之中,金融,电子商务,企业服务,数据服务在同一层次。另外,物联网,智能硬件各有一招聘岗位,薪酬都是5K...嗯虽说node现在也可以做物联网了(还别说,我还真的用node搞过硬件串口通信Orz),但是终究不是主流技术,数据展示表明,前端基本与硬件绝缘。
薪酬待遇倒是都在同一水平上,“大数据”工资倒是一枝独秀,但是数据量太少,参考价值不大。
总结:北京钱多机会多当之无愧第一档;上海稍逊一筹;杭州深圳又低一筹;广州真的是差了两个身位。 而对于前端来说,北京 移动互联网 大公司,钱多!坑多!速来!

本文面向的前端小伙伴:
- 有前端 BFF 开发经验或对此有兴趣的
- 对 gRPC 和 protobuf 协议有一定理解的
首先简单谈一下
BFF (Back-end for Front-end), BFF的概念大家可能都听滥了,这里就不复制粘贴一些陈词滥调了,不了解的可以推荐看这篇文章了解下。
那么简单来说,BFF 就是做一个进行接口聚合裁剪的 http server。
随着后端 go 语言的流行,很多大公司的都转向了用 go 开发微服务。而总所周知,go 是 谷歌家的,那么自然,同样是谷歌家开发的 rpc 框架 gRPC 就被 go 语言广泛用了起来。
如果前端 BFF 层需要对接 go 后端提供的 gRPC + protobuf 接口,而不是前端所熟悉的 RESTful API,那么咱们就需要使用 grpc-node 来发起 gRPC 的接口调用了。
本文就是来和大家一起理解下 grpc-node 中的 client interceptor(拦截器) 到底该怎么用?
grpc 拦截器和我们所知道的 axios 拦截器类似,都是在请求发出前,或者请求响应前,在请求的各个阶段进行我们的一些处理。
例如:给每个请求加上 token 参数,给每个请求响应都校验下 errMsg 字段是否有值。
这些统一的逻辑,每个请求都写一遍就太扯了,一般我们都会在拦截器里统一处理这些逻辑。
在讲 grpc-node 拦截器之前,我们先假定一个 pb 协议文件,方便后面大家理解案例。
下面所有的案例都以这个简单的 pb 协议为基准:
package "hello"
service HelloService {
rpc SayHello(HelloReq) returns (HelloResp) {}
}
message HelloReq {
string name = 1;
}
message HelloResp {
string msg = 1;
}
那么最简单的一个 client 拦截器怎么写呢?
// 没有干任何事情,透传所有操作的拦截器
const interceptor = (options, nextCall: Function) => {
return new InterceptingCall(nextCall(options));
}没错,根据规范:
express 中间件的 nextoptions 参数,描述了当前 gRPC 请求的一些属性
options.method_descriptor.path: 等于 /<package名>.<service名>/<rpc名> 例如,这里就是 /hello.HelloService/SayHellooptions.method_descriptor.requestSerialize: 序列化请求参数对象成为 buffer 的函数,同时会对请求参数中非必要数据裁剪掉options.method_descriptor.responseDeserialize: 对响应 buffer 数据反序列化成 json 对象options.method_descriptor.requestStream: boolean, 请求是不是 流式传输options.method_descriptor.responseStream: boolean, 响应是不是 流式传输一般情况下,我们对 options 不会做任何修改,因为如果后面还有其他拦截器,这就会影响到下游的拦截器的 options 值了。
以上的 interceptor demo 只是简单说下 拦截器的规范,demo 没有干任何实质性的事情。
那么如果我们要在请求出站前做一些*操作时,我们应该怎么做呢?
这就要用到 Requester 了
在 InterceptingCall 的第二个参数中,我们可以传入一个 request 对象,来处理请求发出前的操作。
const interceptor = (options, nextCall: Function) => {
const requester = {
start(){},
sendMessage(){},
halfClose(){},
cancel(){},
}
return new InterceptingCall(nextCall(options), requester);
}requester 其实就是个俱备指定参数的对象, 结构如下:
// ts 定义如下
interface Requester {
start?: (metadata: Metadata, listener: Listener, next: Function) => void;
sendMessage?: (message: any, next: Function) => void;
halfClose?: (next: Function) => void;
cancel?: (next: Function) => void;
}
在启动出站调用之前调用的拦截方法。
start?: (metadata: Metadata, listener: Listener, next: Function) => void;
参数
const requester = {
start(metadata, listener, next) {
next(metadata, listener)
}
}
在每个出站消息之前调用的拦截方法。
sendMessage?: (message: any, next: Function) => void;
const requester = {
sendMessage(message, next) {
// 对于当前 pb 协议
// message === { name: 'xxxx' }
next(message)
}
}
当出站流关闭时(在消息发送后)调用的拦截方法。
halfClose?: (next: Function) => void;
从客户端取消请求时调用的拦截方法。比较少用到
cancel?: (next: Function) => void;
既然出站拦截操作,自然有入站拦截操作。
入站拦截方法在前面提到的 Requester.start 方法中的 listener 进行定义
interface Listener {
onReceiveMetadata?: (metadata: Metadata, next: Function) => void;
onReceiveMessage?: (message: any, next: Function) => void;
onReceiveStatus?: (status: StatusObject, next: Function) => void;
}
接收响应元数据时触发的入站拦截方法。
const requester = {
start(metadata, listener) {
const newListener = {
onReceiveMetadata(metadata, next) {
next(metadata)
}
}
}
}
接收到响应消息时触发的入站拦截方法。
const newListener = {
onReceiveMessage(message, next) {
// 对于当前 pb 协议
// message === {msg: 'hello xxx'}
next(message)
}
}接收到状态时触发的入站拦截方法
const newListener = {
onReceiveStatus(status, next) {
// 成功调用时, status 为 {code:0, details:"OK"}
next(status)
}
}
那么上面描述了那么多个拦截器入站出站的拦截相关方法,那么具体他们的执行顺序是怎么样的呢,下面简单说下, 单个拦截器:
那么问题来了,如果我们配置了多个拦截器,假设配置顺序是 [interceptorA, interceptorB, interceptorC],那么拦截器的执行顺序会是:
interceptorA 出站 ->
interceptorB 出站 ->
interceptorC 出站 ->
grpc.Call ->
interceptorC 入站 ->
interceptorB 入站 ->
interceptorA 入站
可以看到,执行顺序是类似栈,先进后出,后进先出。
那么看这流程图,大家可能会下意识觉得多个拦截器的执行顺序会是:
拦截器A:
1. start
2. sendMessage
3. halfClost
拦截器B:
4. start
5. sendMessage
6. halfClost
拦截器C:
......
但是实际上并非如此。
前面提到,每个拦截器都会有一个 next 方法,next 方法的执行,其实就是执行下一个拦截器的同一个阶段的拦截方法,例如:
// 拦截器A
start(metadata, listener, next) {
// 此处执行的next 其实是执行拦截器 B
// 的 start 方法
next(metadata, listener)
}
// 拦截器 B
start(metadata, listener, next) {
// 此处的 metadata, listener 就是上一个拦截器传递的值
next(metadata, listener)
}
所以,最后多个拦截器的具体方法执行顺序会是:
出站阶段:
start(拦截器A) ->
start(拦截器B) ->
sendMessage(拦截器A) ->
sendMessage(拦截器B) ->
halfClost(拦截器A) ->
halfClost(拦截器B) ->
grpc.Call ->
入站阶段:
onReceiveMetadata(拦截器B) ->
onReceiveMetadata(拦截器A) ->
onReceiveMessage(拦截器B) ->
onReceiveMessage(拦截器A) ->
onReceiveStatus(拦截器B) ->
onReceiveStatus(拦截器A)
看了那么多定义,估计人都懵了,大家可能对拦截器的作用没有太大的概念,下面看下 拦截器的实际应用场景。
可以在请求与响应拦截器中,记录日志
const logInterceptor = (options, nextCall) => {
return new grpc.InterceptingCall(nextCall(options), {
start(metadata, listener, next) {
next(metadata, {
onReceiveMessage(resp, next) {
logger.info(`请求:${options.method_descriptor.path} 响应体:${JSON.stringify(resp)}`)
next(resp);
}
});
},
sendMessage(message, next) {
logger.info(`发起请求:${options.method_descriptor.path};请求参数:${JSON.stringify(message)}`)
next(message);
}
});
};
const client = new hello_proto.HelloService('localhost:50051', grpc.credentials.createInsecure(), {
interceptors: [logInterceptor]
});微服务场景最大的好处是业务分割,但是在 BFF 层,如果微服务接口还未完成,就很容易被微服务那边阻塞,就类似前端被后端接口阻塞一样。
那么,我们就可以用同样的思路,来在拦截器层面实现 grpc 接口的数据 mock
const interceptor = (options, nextCall) => {
let savedListener
// 通过环境变量,或其他判断逻辑,判断当前是否需要 mock 接口
const isMockEnv = true
return new grpc.InterceptingCall(nextCall(options), {
start: function (metadata, listener, next) {
// 保存 listener, 以便后续调用响应入站的 method
savedListener = listener
// 如果是 mock 环境,就不需要 调用 next 方法,避免请求出站到 server
if(!isMockEnv) {
next(metadata, listener);
}
},
sendMessage(message, next) {
if(isMockEnv) {
// 根据需要, 构造自己的 mock 数据
const mockData = {
hello: 'hello interceptor'
}
// 调用前面保存了的 listener 响应方法,onReceiveMessage, onReceiveStatus必须都调用
savedListener.onReceiveMetadata(new grpc.Metadata());
savedListener.onReceiveMessage(mockData);
savedListener.onReceiveStatus({code: grpc.status.OK});
} else {
next(message);
}
}
});
};原理很简单,其实就是让请求不出站,直接在出站准备阶段,调用入站响应的方法。
有时候可能 server 端异常,导致接口异常,可以在拦截器响应入站阶段,判断状态,避免应用异常。
const fallbackInterceptor = (options, nextCall) => {
let savedMessage
let savedMessageNext
return new grpc.InterceptingCall(nextCall(options), {
start: function (metadata, listener, next) {
next(metadata, {
onReceiveMessage(message, next) {
// 暂且保存 message 和 next,等到 接口响应状态 确定后,再响应
savedMessage = message;
savedMessageNext = next;
},
onReceiveStatus(status, next) {
if (status.code !== grpc.status.OK) {
// 如果 接口响应异常,响应预设数据,避免 xxx undefined
savedMessageNext({
errCode: status.code,
errMsg: status.details,
result: []
});
// 设定当前接口为正常
next({
code: grpc.status.OK,
details: 'OK'
});
} else {
savedMessageNext(savedMessage);
next(status);
}
}
});
}
});
};原理也不复杂,大概就是捕获异常状态,响应正常状态以及预设数据。
可以看到, grpc 的拦截器概念并没有什么特殊或者难以理解的地方,和我们常用的拦截器,例如 axios 拦截器理念基本一致,都是提供方法来对请求阶段与响应阶段做一些自定义的统一逻辑处理。
本文主要是对 grpc-node 的拦截器做简单的解读,希望本文能给正在用 grpc-node 做 BFF 层的同学一些帮助。
browser VS module VS main前端开发中使用到 npm 包那可算是家常便饭,而使用到 npm 包总免不了接触到 package.json 包配置文件。
那么这里就有一个问题,当我们在不同环境下 import 一个 npm 包时,到底加载的是 npm 包的哪个文件?
老司机们很快地给出答案:main 字段中指定的文件。
然而我们清楚 npm 包其实又分为:只允许在客户端使用的,只允许造服务端使用的,浏览器/服务端都可以使用。
如果我们需要开发一个 npm 包同时兼容支持 web端 和 server 端,需要在不同环境下加载npm包不同的入口文件,显然一个 main 字段已经不能够满足我们的需求,这就衍生出来了 module 与 browser 字段。
本文就来说下 这几个字段的使用场景,以及同时存在这几个字段时,他们之间的优先级。
在说 package.json 之前,先说下文件优先级
由于我们使用的模块规范有 ESM 和 commonJS 两种,为了能在 node 环境下原生执行 ESM 规范的脚本文件,.mjs 文件就应运而生。
当存在 index.mjs 和 index.js 这种同名不同后缀的文件时,import './index' 或者 require('./index') 是会优先加载 index.mjs 文件的。
也就是说,优先级 mjs > js
browser,module 和 main 字段main : 定义了 npm 包的入口文件,browser 环境和 node 环境均可使用module : 定义 npm 包的 ESM 规范的入口文件,browser 环境和 node 环境均可使用browser : 定义 npm 包在 browser 环境下的入口文件首先,我们假定 npm 包 test 有以下目录结构
----- lib
|-- index.browser.js
|-- index.browser.mjs
|-- index.js
|-- index.mjs
其中 *.js 文件是使用 commonJS 规范的语法(require('xxx')),*.mjs 是用 ESM 规范的语法(import 'xxx')
其 package.json 文件:
"main": "lib/index.js", // main
"module": "lib/index.mjs", // module
// browser 可定义成和 main/module 字段一一对应的映射对象,也可以直接定义为字符串
"browser": {
"./lib/index.js": "./lib/index.browser.js", // browser+cjs
"./lib/index.mjs": "./lib/index.browser.mjs" // browser+mjs
},
// "browser": "./lib/index.browser.js" // browser根据上述配置,那么其实我们的 package.json 指定的入口可以有
mainmodulebrowserbrowser+cjsbrowser+mjs下面说下具体使用场景。
这是我们最常见的使用场景,通过 webpack 打包构建我们的 web 应用,模块语法使用 ESM
当我们加载
import test from 'test'
实际上的加载优先级是 browser = browser+mjs > module > browser+cjs > main
也就是说 webpack 会根据这个顺序去寻找字段指定的文件,直到找到为止。
然而实际上的情况可能比这个更加复杂,具体可以参考流程图

const test = require('test')
事实上,构建 web 应用时,使用 ESM 或者 commonJS 模块规范对于加载优先级并没有任何影响
优先级依然是 browser = browser+mjs > module > browser+cjs > main
我们清楚,使用 webpack 构建项目的时候,有一个 target 选项,默认为 web,即进行 web 应用构建。
当我们需要进行一些 同构项目,或者其他 node 项目的构建的时候,我们需要将 webpack.config.js 的 target 选项设置为 node 进行构建。
import test from 'test'
// 或者 const test = require('test')
优先级是: module > main
通过 node test.js 直接执行脚本
const test = require('test')
只有 main 字段有效。
通过 --experimental-modules 可以让 node 执行 ESM 规范的脚本(必须是 mjs 文件后缀)
`node --experimental-modules test.mjs
import test from 'test'
只有 main 字段有效。
npm 包导出的是 ESM 规范的包,使用 modulenpm 包只在 web 端使用,并且严禁在 server 端使用,使用 browser。npm 包只在 server 端使用,使用 mainnpm 包在 web 端和 server 端都允许使用,使用 browser 和 mainnpm 包需要提供 commonJS 与 ESM 等多个规范的代码文件,请参考上述使用场景或流程图很多人可能看完 babel 的官方文档 ,依然不是很了解其中的一些特性,这里我详细解读一下,供大家参考参考。
@babel/preset-env 会根据 browserlist 配置进行转换,如果需要兼容比较旧的浏览器,需要手动引入 @babel/polyfill
targets.esmodules:boolean = false
请注意:在指定 esmodules 目标时,将忽略 browserlists, 即 useBuiltIn 会失效,不转化 es6 语法也不 polyfill
如果 想用 esmodules 又需要 polyfill ,请组合使用 modules = false , useBuiltIn
useBuiltIns = false
根据 browserlist 是否转换新语法与 polyfill 新 API
import '@babel/polyfill', 会无视 browserlist 将所有的 polyfill 加载进来import '@babel/polyfill', 这样会根据 browserlist 过滤出 需要的 polyfillimport '@babel/polyfill'(加上也无妨,构造时会去掉), 且会根据 browserlist + 业务代码使用到的新 API 按需进行 polyfillmodules = 'commonjs'
"amd" | "umd" | "systemjs" | "commonjs" | "cjs" | false, defaults to "commonjs".
转换 es6 模块语法到其他 模块规范, false不会转换
include:Array<string|RegExp> = []
如果你 使用了某个新特性(如es6.array.from),无论browserslist 如何你都想 转化它, 则 include: ['es6.array.from']
exclude:Array<string|RegExp> = []
同理
loose = false(推荐)
loose mode
优势:代码更加简洁,更容易看懂,可能被老浏览器引擎执行得更快,兼容性更好。
缺点:当从 编译后的 es6 代码转换成 原生 es6 代码,有可能出现问题。这不值得冒险启用 loose
多数的 babel plugin 有两种模式,普通模式会将代码编译成尽可能接近 es6 语义,loose 模式则会将代码编译成 es5 风格。如:
// 源码
class Point {
constructor(x, y) {
this.x = x;
this.y = y;
}
toString() {
return `(${this.x}, ${this.y})`;
}
}
// 普通模式 更接近 es6
function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } }
function _defineProperties(target, props) { for (var i = 0; i < props.length; i++) { var descriptor = props[i]; descriptor.enumerable = descriptor.enumerable || false; descriptor.configurable = true; if ("value" in descriptor) descriptor.writable = true; Object.defineProperty(target, descriptor.key, descriptor); } }
function _createClass(Constructor, protoProps, staticProps) { if (protoProps) _defineProperties(Constructor.prototype, protoProps); if (staticProps) _defineProperties(Constructor, staticProps); return Constructor; }
var Point =
/*#__PURE__*/
function () {
function Point(x, y) {
_classCallCheck(this, Point);
this.x = x;
this.y = y;
}
_createClass(Point, [{
key: "toString",
value: function toString() {
return "(".concat(this.x, ", ").concat(this.y, ")");
}
}]);
return Point;
}();
// loose = true编译模式 更接近 es5
var Point =
/*#__PURE__*/
function () {
function Point(x, y) {
this.x = x;
this.y = y;
}
var _proto = Point.prototype;
_proto.toString = function toString() {
return "(" + this.x + ", " + this.y + ")";
};
return Point;
}();
forceAllTransforms = false
默认情况下, preset-env 会把根据 browserslist 进行有必要的 transform, 但是你可以强制所有 es6 语法都转换,通常用于 应用只支持 es5 的情况下。 此属性不影响 polyfill。
configPath = process.cwd()
.browserslist(或 package.json->browserslist) 配置所在文件夹,根据此文件夹一直向父文件夹查找,直到找到配置文件
ignoreBrowserslistConfig = false
忽略 .browserslist 配置
shippedProposals = false
是否启用 还在提案中但已经被浏览器正式使用的新特性。如果你要支持的浏览器很新,已经支持了某些提案,可以启用这个选项,避免语法转换。 这个属性和 @babel/preset-stage-3 有所区别,stage-3 新特性在还未正式上线浏览器仍然有可能被修改变更的哦
@babel/plugin-transform-runtime不能单独使用,它需要指定 preset 为 es2015,env, typescript 还是 其他,才知道要转换的特性有哪些
babel 在每个需要的文件的顶部都会插入一些 helpers 代码,这可能会导致多个文件都会有重复的 helpers 代码。
@babel/plugin-transform-runtime + @babel/runtime 可以避免编译构建时重复的 helper 代码
此转换器的另一个目的是为您的代码创建沙盒环境。如果您使用@ babel / polyfill及其提供的内置函数(例如Promise,Set和Map),那些将污染全局范围。虽然这可能适用于应用程序或命令行工具,但如果您的代码是您打算发布供其他人使用的库,或者如果您无法准确控制代码运行的环境,则会出现问题。
适用于不需要修改 全局变量的工具/库,同时,适用这种方法也不会转换实例的方法(如:Array.prototype.includes)
PS: 为什么 transform-runtime 不会转换实例的方法呢?这是因为,前面讲到的transform-runtime是为代码创建沙盒环境,并不会污染全局,假如要转换
'abc'.includes(xxx),势必会重写includes,和transform-runtime的初衷相悖。有人又说了,通过自定义函数
transformedIncludes('abc', xxx)不就行咯?要知道,js 是门动态语言,如果存在foo.includes('a'),你根本无法知道这里的 includes 到底是String.prototype.includes, 还是Array.prototype.includes,亦或是 自定义对象上的 includes 方法,自然无法 转换那么,同样的限制,为啥子
@babel/preset-env就能 polyfill includes 实例方法的呢?其实很简单粗暴,只要有变量出现 includes 方法,@babel/preset-env会有杀错没放过,把 es6.string.include 和 es7.array.includes 都加载进来。
@babel/preset-env -> ignoreBrowserslistConfig = true 则都转换 generator 和 async 语法。exports.__esModule = true;
exports.default = function(instance, Constructor) {
if (!(instance instanceof Constructor)) {
throw new TypeError("Cannot call a class as a function");
}
};
export default function(instance, Constructor) {
if (!(instance instanceof Constructor)) {
throw new TypeError("Cannot call a class as a function");
}
}
关于前端性能优化,其实网上也有很多文章已经讲了很多,但是随着 webpack 4, babel 7 等工具的发布以及一些前沿技术的挖掘,很多以前的优化手段,例如雅虎34军规等已经不足以满足我们的需求了。刚好最近项目做了很多优化工作,所以来跟大家一起分享一下前端性能优化这个话题,以及个人做的一些优化工作。
首先,要知道如何优化一个网站,那么就得清楚,从输入网址,到看到页面视图,这个过程到底发生了什么。
那么,我大概将这个过程分为三大模块,分别是:
接下来我们将从这三方面探索前端优化技术
首先,输入网址,通过 chrome devtools 的 timeline 板块 我们可以看到这个过程到底发生了什么:
要清楚怎么优化,那么就得知道,这些过程代表什么,其瓶颈又是什么。
根据HTTP1.0/1.1协议规定,一个域名的并发请求量存在限制 :
一般情况下,我们的 web 应用有可能会有多个资源,一旦请求资源过多,请求就会被阻塞掉。导致耗时长,影响用户体验。
小图片资源 base64 编码内联。
css sprite : 雪碧图
JS 文件合并
上线时我们会把所有的代码进行压缩合并,合并成一个文件,这样不管多少模块,都请求一个文件,减少了HTTP的请求数。
缺点:文件的缓存。当我们有100个模块时,有一个模块改了东西,按照之前的方式,整个文件浏览器都需要重新下载,不能被缓存。
一个域名存在请求量限制,为什么不把资源放在多个域名下呢? 比如 github 上就是用了 avatars.githubusercontent.com 等域名 存放头像图片资源,一定程度上提升了响应速度和用户体验。
缺点:多域名,每个新域名都需要重新进行DNS解析(只需解析一次),DNS的解析时间会变长。
Multiplexed support(one single TCP connection for all requests) : 多路复用
在同一个 TCP 连接之中并行执行多个请求,不再有 浏览器请求并发限制。
我们知道,当我们访问一个网站如 www.amazon.com 时,需要将这个域名先转化为对应的 IP 地址,这是一个非常耗时的过程,当然浏览器有DNS缓存,一旦访问过,再次访问从缓存中读取就会快很多。

一个从未访问过的域名解析耗时长达 1 秒
要优化 DNS 解析时间,我们用到一种 DNS prefetch 的技术。
DNS prefetch 会分析这个页面需要的资源所在的域名,浏览器空闲时提前将这些域名转化为 IP 地址,真正请求资源时就避免了上述这个过程的时间。
<meta http-equiv='x-dns-prefetch-control' content='on'>
<link rel='dns-prefetch' href='http://g-ecx.images-amazon.com'>
<link rel='dns-prefetch' href='http://z-ecx.images-amazon.com'>
当我们的资源存放在不同的域名下,那么提前声明好域名,就可以节省域名解析的时间
用户拿到资源的耗时, 一般来说这个性能瓶颈是后端负责的。一般优化方法有,异地机房,CDN,提高带宽,提高 CPU 运算速度 等方式来来提高用户体验
CDN(内容分发网络),其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。
通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。
CDN目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络“边缘”,使用户可以就近取得所需的内容,解决 Internet 网络拥塞状况,提高用户访问网站的响应速度。
通过了一系列的网络请求过程,资源到了 Content Download 的过程。
资源下载的耗时 = 资源大小 / 用户网速。
用户网速我们无法控制,那么资源的瓶颈其实很显而易见:资源大小。
减少资源文件大小,就能降低资源下载耗时。
在此进行资源优化之前,我们先将web 应用的资源文件按类型分为以下三种:
我们就分别从这几个方面了来说下资源优化方案。
首先是常规优化操作,即对上述所有资源都通用的优化方法。
体现为 from disk/memory cache, 具体是 from disk cache 还是 from memory cache 由浏览器自身控制
协商缓存由服务端控制,体现为 304 not Modified
具体缓存策略流程图如下:

开源的第三方库,如 vue , react, 之类的,一般是指 package.json -> dependencies 的包。
第三方库一般比较稳定,一般比较很少会变更,而业务代码可能会频繁变更。
所以,如果不抽离打包,业务变动后,用户需要重新下载全部的代码:

修改代码部署后需要重新下载100KB
而抽离第三方库进行打包则只需要下载变更的业务代码

修改代码部署只需要重新下载20KB
tree shaking 是基于 es modules 的静态结构 筛除没有用到的代码(dead code)
- Use ES2015 module syntax (i.e. import and export).
- Ensure no compilers transform your ES2015 module syntax into CommonJS modules (this is the default behavior of popular Babel preset @babel/preset-env - see documentation for more details).
- Add a "sideEffects" property to your project's package.json file.
- Use production mode configuration option to enable various optimizations including minification and tree shaking.
注意事项:
webpack 2.0 开始原生支持 ES Module,也就是说不需要 babel 把 ES Module 转换成曾经的 commonjs 模块了,想用上 Tree Shaking,请务必关闭 @babel/preset-env 默认的模块转义 (modules: false)。
Webpack 4.0 开始,Tree Shaking 对于那些无副作用的模块 (package.json -> sideEffects = false ) 也会生效,无副作用的模块是指执行该模块的代码不会对环境造成影响(如 lodash 只 export 一些辅助函数)。
也就是说对于有副作用的模块,尽量不要在没有使用它的情况下引入该模块,不然 webpack 依然会将该模块打包构建。
如果是自己的 ES 代码import {say} from 'hello' 和 import hello from 'hello'; hello.say() 都能够被 tree shaking
自 ES2015/ES6 发布以来,现在已经到了 ES2018 了,但是依然有许多老旧浏览器依然占有一定的市场份额,所以我们依然需要对这部分浏览器作兼容性处理。
具体优化请参考:Show me the code,babel 7 最佳实践!
现在 SPA 已经是一个常见的场景了,而一般情况下,单页面应有一般都会存在多路由。而我们每次访问其实只访问一个路由,将代码按路由拆分并按需加载,对于首屏资源加载优化,是一个不错的选择。

不进行拆包需要下载 100Kb

进行拆包后只需要下载 20Kb
前面提到是按路由拆分模块包,其实存在一个问题是,如果存在公共模块,那么在每一个拆分出来的路由模块都会加载这个公共模块。

路由分割后
我们可以将公共模块抽离出来,避免重复的代码。

抽离公共代码后
可以明显看出减少了重复的 common01.js 和 common02.js 的代码
缺点:路由动态按需加载 + 抽离公共代码可能会加载路由不必要的公共代码。例如: 访问 home 会加载 home.js + common.js(包含common01.js + common02.js),但其中的 common02.js 是没有用到的。
Webpack 4 的 splitChunksPlugin 可以根据模块之间的依赖关系,自动打包出很多很多(而不是单个)通用模块,可以保证加载进来的代码一定是会被依赖到的。

当然,打包出了多个通用模块的同时也会增加资源请求数,对前面所说的网络性能造成影响。
要优化渲染性能,根本目的就是尽快让用户看到页面内容,那么我们来看看到底用户从一片空白,到看到内容到底发生了哪些事情。
ReactDOM.render(<App />, document.getElementById('root')) 触发后,界面显示出大体外框(侧边栏/头部导航栏/底部菜单栏等信息)。好了,了解完了整个过程,我们就可以分析其中的瓶颈以及得出优化方案了。
首先,我们从上述过程可以看到,js 资源会阻塞 HTML 的解析,那么其实以前我们的常规操作就是把 JS 资源从 head 标签移动到 body 标签的末尾,避免阻塞。
但是随着技术发展,我们已经有更好解决的方案了。
从上图中我们可以看到, 不同情况下的脚本处理机制。
得出的优化选择是:
<script defer src="script.js"></script>其实以上两者从效果差不多,因为放在 body 内末尾基本上 HTML Parser 也已经结束。
前面说到大多数基于标记语言的资源能被浏览器的预加载器(Preloader)尽早发现,推测出页面需要下载哪些资源,但不是所有的资源都是基于标记语言的,比如一些隐藏在 CSS 和 Javascript 中的资源。当浏览器发现自己需要这些资源时已经为时已晚,所以大多数情况,这些资源的加载都会对页面渲染造成延迟(如用作字体图标 font 字体资源,CSS 内的背景图片资源等)。
现在可以通过 preload 来提前声明当前页面会需要哪些资源(preload 资源请求优先级为 highest):
<link rel="preload" href="late_discovered_thing.js" as="script">
当 SPA 使用了路由分割动态加载的时候,我们从一个页面跳转到另外一个页面的时候,浏览器会动态加载新页面所需要的 js 资源,然后再执行渲染。
使用预加载技术(prefetch) 技术能提前下载即将需要的资源。
它的原理是:
利用浏览器的空闲时间去先下载用户指定需要的内容,然后缓存起来,这样用户下次加载时,就直接从缓存中取出来,效率就快了。
<!-- 提前下载好 user 模块的 js 资源,用户访问 /user 时就可以直接读缓存 -->
<link href="/static/js/user.479d709b.js" rel="prefetch">总结:
preload (资源优先级 highest)prefetch (资源优先级 lowest)PS: prefetch 可能存在的风险:http 1.1 存在请求并发限制,如果 prefetch 数量太多,有可能阻塞异步加载的 script 资源
前面提到,HTML 文件下载下来后,因为要等待文件加载,JS 解析等过程,而这些过程比较耗时,导致用户会长时间出于不可交互的首屏白屏状态。
在这个白屏阶段,可以用 预渲染 提前展示一部分内容,让用户感知到网站正在正常加载,而非糟糕的白屏体验。
预渲染原理:在 index.html 的 <div id="app">...</div> 填充自定义的内容,在 JS 资源下载之前展示必要的内容。让页面看起来很快,实际的加载速度并没有变化
我们清楚了预渲染的原理,下面介绍下预渲染有哪几种类型。
首先,很简单,也很常见,在 index.html 页面内联一个 loading 动画。
loading 动画可以很简单,一个菊花图即可。
也可以很复杂,如 Google Mail 的加载动画。

这其实只是一个CSS动画,进度条也是假的,并不是真实的加载进度,动画目的是让用户知道网页正在加载中,而不是看到一片不知道是不是挂了的白屏。
加载动画,依然会让用户知道自己在等待,那我们何不直接给 index.html 添加我们真实页面的 HTML 呢?
Prerender SPA Plugin 就是能帮我们实现这个功能的 webpack 插件。
其原理是: 在构建的时候启动模拟的浏览器环境(headless chrome),并通过预渲染的事件钩子获取当前的页面内容,生成最终的 HTML 文件。

上述gif 图中,左边用了静态预渲染,右边是常规的单页面,可以明显看到,虽然最终表现一样,但明显使用了预渲染优化的页面,会看起来快很多。
优点:这样就能让用户感受不到 loading, “误以为”自己的页面已经成功打开了,给用户很快打开页面的错觉。但页面实质上还在加载 JS 内容。
缺点:
上面那种方案提到了一个缺点是,基于动态数据的UI不能展示完全,例如一个账单列表,使用 Prerender SPA Plugin 预渲染的话,账单列表将会是空列表。 那么,这种情况有什么合适的方案解决呢?
骨架屏!
骨架屏是根据构建出来的页面结构,构造出页面的基本骨架内容。
自动生成骨架屏和 预渲染静态DOM 原理差不多,都是 在构建的时候启动模拟的浏览器环境(headless chrome), 获取到 HTML,但是骨架屏在此 HTML 基础上,根据一定的规则,将 HTML 中的 UI 用 灰色块替代。
优点:可以预渲染基于动态数据渲染出来的内容。
缺点:目前开源社区暂时没有一个高稳定性,高可用性的骨架屏自动生成插件。可能需要在业务代码上插入 骨架屏组件,侵入性比较强。
从网络请求,到资源下载,最后到页面渲染,整体个人探索出来的优化到此为止,其实基本上都是基于构建角度来实现的优化,当然还有更颗粒到代码层级的优化,入用 Web Worker处理长耗时的JS任务避免阻塞之类的,这里不再细说。
另外,有不同意见的,或者还有哪些重要的优化操作我没有提及的,欢迎留言,互相学习。
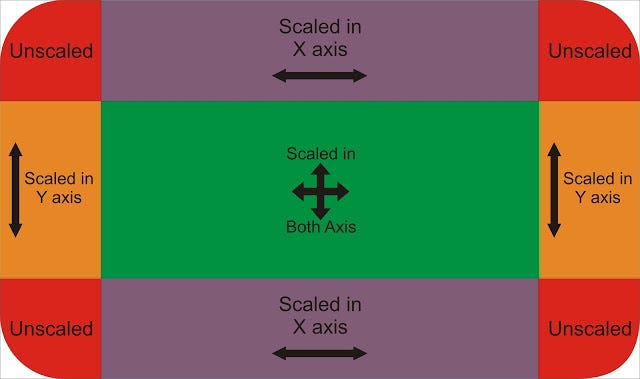
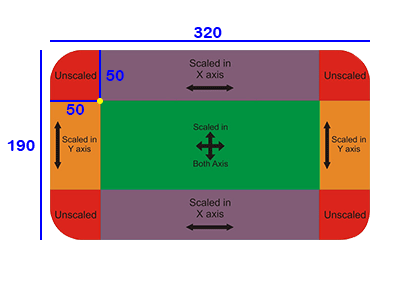
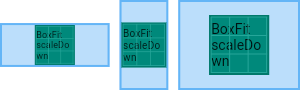
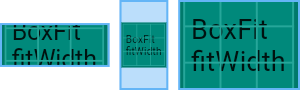
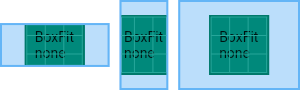
Container部件用于包含子部件,可以应用某些样式属性。,具备了常见的绘画,定位和大小调整等功能。(相当于 HTML 中的 div)
如果Container小部件没有子节点,它将尽可能大地自动填充屏幕上的给定区域。
由于Container结合了许多其他小部件,每个小部件都有自己的布局行为,因此Container的布局行为有点复杂。
Container尽可能大
Center(
child: Container(
color: Colors.green,
),
);
Container 适应子组件的大小
Center(
child: Container(
color: Colors.green,
child: Text("Flutter CheatSheet."),
),
);
alignment: Alignment(x, y) 属性接受两个参数:x 和 y。
x, y 坐标轴如下
注意:默认情况下,alignment 中 x 值可以大于 1 或者 小于 -1,但除非设置了 constraints 限制, 否则 y 值设置只在 -1 <= y <= 1 范围内有效
Center(
child: Container(
color: Color.fromARGB(255, 66, 165, 245),
child: new Text("Flutter Cheatsheet",
style: TextStyle(
fontSize: 10.0
),
),
// `Container` 的中心。
alignment: Alignment(0.0, 0.0),
),
);
alignment: Alignment(1.0, 1.0),
Alignment.bottomCenter == Alignment(0.0, 1.0)
Alignment.bottomLeft == Alignment(-1.0, 1.0)
Alignment.bottomRight == Alignment(1.0, 1.0)
Alignment.center == Alignment(0.0, 0.0)
Alignment.centerLeft == Alignment(-1.0, 0.0)
Alignment.centerRight == Alignment(1.0, 0.0)
Alignment.topCenter == Alignment(0.0, -1.0)
Alignment.topLeft == Alignment(-1.0, -1.0)
Alignment.topRight == Alignment(1.0, -1.0)
FractionalOffset 和 Alignment 类似,都能表达位置。
两个方式之间的区别在于它们用于表示位置的坐标系。
不同于 Alignment 以 中心为原点, FractionalOffset 是以左上角为原点的,如下图:
constraints 属性用于指定容器可以占据的大小和空间。一般值为 BoxConstraint 类
基本可以使用简单的 BoxConstraint 构建大多数的部件和UI。
BoxConstraint 只有 4 个属性
注意:
当没有 child 时,选择 max 的值
当有 child 时,选择 min 值
当设置了 alignment 时,无论有没有 child 值,都选择 max 值。
因为有 child,所以会渲染 min 值的容器。
Center(
child: Container(
color: Color.fromARGB(255, 66, 165, 245),
alignment: AlignmentDirectional(0.0, 0.0),
child: Container(
color: Colors.green,
child: Text("Flutter"),
constraints: BoxConstraints(
maxHeight: 300.0,
maxWidth: 200.0,
minWidth: 150.0,
minHeight: 150.0
),
),
),
);
Center(
child: Container(
color: Color.fromARGB(255, 66, 165, 245),
alignment: AlignmentDirectional(0.0, 0.0),
child: Container(
color: Colors.green,
child: Text("Flutter Cheatsheet Flutter Cheatsheet"),
constraints: BoxConstraints(
maxHeight: 300.0,
maxWidth: 200.0,
minWidth: 150.0,
minHeight: 150.0
),
),
),
);
子部件长文本,会撑开容器,最大能够撑开到 max-width 和 max-height。再大就会溢出。
上面说过,如果存在 child 子部件,容器就会限制在 min 值,
那么要让存在 child 子部件的情况下让容器扩展到最大,也是有办法的。
Center(
child: Container(
color: Color.fromARGB(255, 66, 165, 245),
alignment: AlignmentDirectional(0.0, 0.0),
child: Container(
color: Colors.green,
child: Text("Flutter"),
constraints: BoxConstraints.expand(),
// 等价于
/*
constraints: BoxConstraints(
minWidth: double.infinity,
minHeight: double.infinity
),
*/
),
),
);
上面提到的都是 弹性容器,下面介绍下,通过BoxConstraints.expand(width, height) 可以设置定宽容器:
Center(
child: Container(
color: Color.fromARGB(255, 66, 165, 245),
alignment: AlignmentDirectional(0.0, 0.0),
child: Container(
color: Colors.green,
child: Text("Flutter"),
constraints: BoxConstraints.expand(
width: 350.0,
height: 400.0
),
),
),
);
margin 是外边距,和 CSS 的一样。
Center(
child: Container(
color: Color.fromARGB(255, 66, 165, 245),
alignment: AlignmentDirectional(0.0, 0.0),
child: Container(
color: Colors.green,
margin: new EdgeInsets.all(20.0),
// 相当于 CSS 的 margin: 20px;
),
),
);
EdgeInsets.symmetric)margin : EdgeInsets.symmetric(
vertical: 20,
horizontal: 50
)
// 相当于 CSS 的 margin: 20px 50px;
EdgeInsets.fromLTRB)EdgeInsets.fromLTRB(left, top, right, bottom)
margin: new EdgeInsets.fromLTRB(20.0, 30.0, 40.0, 50.0),
// 相当于 CSS 的 margin: 30px 40px 50px 20px;
注意,CSS 的 margin 的顺序是上右下左,而EdgeInsets.fromLTRB 的顺序是 左上右下,千万不要弄混
EdgeInsets.only({double left: 0.0, double top: 0.0, double right: 0.0, double bottom: 0.0})
margin: new EdgeInsets.only(
left: 20.0,
top: 50.0
),
// 相当于 margin-left: 20px; margin-top: 50px;
Center(
child: Container(
color: Color.fromARGB(255, 66, 165, 245),
alignment: AlignmentDirectional(0.0, 0.0),
child: Container(
color: Colors.green,
padding: EdgeInsets.all(20.0),
// 相当于 CSS 的 margin: 20px;
),
),
);
使用方式同 margin,不再多说
修饰背景。
值可以是:
原作者将在另外的文章中讨论上述类
PS: 前面提到了 margin, padding,但是 Container 是 没有 border 属性的哦,要实现 border,需要在 decoration 属性中进行设置。
Center(
child: Container(
color: Color.fromARGB(255, 66, 165, 245),
alignment: AlignmentDirectional(0.0, 0.0),
child: Container(
color: Colors.green,
decoration: BoxDecoration(
border: Border.all(width: 2, color: Color(0xffaaaaaa))
)
// 相当于 CSS 的 border: 2px solid #aaaaaa;
),
),
);
修饰前景
同上。
值为 Matrix 类
Center(
child: Container(
color: Color.fromARGB(255, 66, 165, 245),
alignment: AlignmentDirectional(0.0, 0.0),
child: Container(
padding: new EdgeInsets.all(40.0),
color: Colors.green,
child: Text("Flutter Cheatsheet"),
transform: new Matrix4.rotationZ(0.5)
),
),
);
原作者将在另外的文章中讨论 Matrix
大家用过 Typescript 都清楚,很多时候我们需要提前声明一个类型,再将类型赋予变量。
例如在业务中,我们需要渲染一个表格,往往需要定义:
interface Row {
user: string
email: string
id: number
vip: boolean
// ...
}
const tableDatas: Row[] = []
// ...
有时候我们也需要表格对应的搜索表单,需要其中一两个搜索项,如果刚接触 typescript 的同学可能会立刻这样写:
interface SearchModel {
user?: string
id?: number
}
const model: SearchModel = {
user: '',
id: undefined
}
这样写会出现一个问题,如果后面id 类型要改成 string,我们需要改 2 处地方,不小心的话可能就会忘了改另外一处。所以,有些人会这样写:
interface SearchModel {
user?: Row['user']
id?: Row['id']
}
这固然是一个解决方法,但事实上,我们前面已经定义了 Row 类型,这其实是可以更优雅地复用的:
const model: Partial<Row> = {
user: '',
id: undefined
}
// 或者需要明确指定 key 的,可以
const model2: Partial<Pick<Row, 'user'|'id'>>
这样一来,很多情况下,我们可以尽量少地写重复的类型,复用已有类型,让代码更加优雅容易维护。
上面使用到的 Partial 和 Pick 都是 typescript 内置的类型别名。下面给大家介绍一下 typescript 常用的内置类型,以及自行拓展的类型。
将类型 T 的所有属性标记为可选属性
type Partial<T> = {
[P in keyof T]?: T[P];
};
使用场景:
// 账号属性
interface AccountInfo {
name: string
email: string
age: number
vip: 0|1 // 1 是vip ,0 是非vip
}
// 当我们需要渲染一个账号表格时,我们需要定义
const accountList: AccountInfo[] = []
// 但当我们需要查询过滤账号信息,需要通过表单,
// 但明显我们可能并不一定需要用到所有属性进行搜索,此时可以定义
const model: Partial<AccountInfo> = {
name: '',
vip: undefind
}
与 Partial 相反,Required 将类型 T 的所有属性标记为必选属性
type Required<T> = {
[P in keyof T]-?: T[P];
};
将所有属性标记为 readonly, 即不能修改
type Readonly<T> = {
readonly [P in keyof T]: T[P];
};
从 T 中过滤出属性 K
type Pick<T, K extends keyof T> = {
[P in K]: T[P];
};
使用场景:
interface AccountInfo {
name: string
email: string
age: number
vip?: 0|1 // 1 是vip ,0 是非vip
}
type CoreInfo = Pick<AccountInfo, 'name' | 'email'>
/*
{
name: string
email: stirng
}
*/
标记对象的 key value类型
type Record<K extends keyof any, T> = {
[P in K]: T;
};
使用场景:
// 定义 学号(key)-账号信息(value) 的对象
const accountMap: Record<number, AccountInfo> = {
10001: {
name: 'xx',
email: 'xxxxx',
// ...
}
}
const user: Record<'name'|'email', string> = {
name: '',
email: ''
}
// 复杂点的类型推断
function mapObject<K extends string | number, T, U>(obj: Record<K, T>, f: (x: T) => U): Record<K, U>
const names = { foo: "hello", bar: "world", baz: "bye" };
// 此处推断 K, T 值为 string , U 为 number
const lengths = mapObject(names, s => s.length); // { foo: number, bar: number, baz: number }
移除 T 中的 U 属性
type Exclude<T, U> = T extends U ? never : T;
使用场景:
// 'a' | 'd'
type A = Exclude<'a'|'b'|'c'|'d' ,'b'|'c'|'e' > 乍一看好像这个没啥卵用,但是,我们通过一番操作,之后就可以得到 Pick 的反操作:
type Omit<T, K extends keyof T> = Pick<T, Exclude<keyof T, K>>
type NonCoreInfo = Omit<AccountInfo, 'name' | 'email'>
/*
{
age: number
vip: 0|1,
}
*/
Exclude 的反操作,取 T,U两者的交集属性
type Extract<T, U> = T extends U ? T : never;
使用 demo:
// 'b'|'c'
type A = Extract<'a'|'b'|'c'|'d' ,'b'|'c'|'e' >
这个看起来没啥用,实际上还真没啥卵用,应该是我才疏学浅,还没发掘到其用途。
排除类型 T 的 null | undefined 属性
type NonNullable<T> = T extends null | undefined ? never : T;
使用 demo
type A = string | number | undefined
type B = NonNullable<A> // string | number
function f2<T extends string | undefined>(x: T, y: NonNullable<T>) {
let s1: string = x; // Error, x 可能为 undefined
let s2: string = y; // Ok
}
获取一个函数的所有参数类型
// 此处使用 infer P 将参数定为待推断类型
// T 符合函数特征时,返回参数类型,否则返回 never
type Parameters<T extends (...args: any) => any> = T extends (...args: infer P) => any ? P : never;
使用demo:
interface IFunc {
(person: IPerson, count: number): boolean
}
type P = Parameters<IFunc> // [IPerson, number]
const person01: P[0] = {
// ...
}
另一种使用场景是,快速获取未知函数的参数类型
import {somefun} from 'somelib'
// 从其他库导入的一个函数,获取其参数类型
type SomeFuncParams = Parameters<typeof somefun>
// 内置函数
// [any, number?, number?]
type FillParams = Parameters<typeof Array.prototype.fill>
类似于 Parameters<T>, ConstructorParameters 获取一个类的构造函数参数
type ConstructorParameters<T extends new (...args: any) => any> = T extends new (...args: infer P) => any ? P : never;
使用 demo:
// string | number | Date
type DateConstrParams = ConstructorParameters<typeof Date>
获取函数类型 T 的返回类型
type ReturnType<T extends (...args: any) => any> = T extends (...args: any) => infer R ? R : any;
使用方式和 Parameters<T> 类似,不再赘述
获取一个类的返回类型
type InstanceType<T extends new (...args: any) => any> = T extends new (...args: any) => infer R ? R : any;
使用方式和 ConstructorParameters<T> 类似,不再赘述
使用 typescript 有时候需要重写一个库提供的 interface 的某个属性,但是重写 interface 有可能会导致冲突:
interface Test {
name: string
say(word: string): string
}
interface Test2 extends Test{
name: Test['name'] | number
}
// error: Type 'string | number' is not assignable to type 'string'.
那么可以通过一些 type 来曲线救国实现我们的需求:
// 原理是,将 类型 T 的所有 K 属性置为 any,
// 然后自定义 K 属性的类型,
// 由于任何类型都可以赋予 any,所以不会产生冲突
type Weaken<T, K extends keyof T> = {
[P in keyof T]: P extends K ? any : T[P];
};
interface Test2 extends Weaken<Test, 'name'>{
name: Test['name'] | number
}
// ok
有时候需要
const ALL_SUITS = ['hearts', 'diamonds', 'spades', 'clubs'] as const; // TS 3.4
type SuitTuple = typeof ALL_SUITS; // readonly ['hearts', 'diamonds', 'spades', 'clubs']
type Suit = SuitTuple[number]; // union type : 'hearts' | 'diamonds' | 'spades' | 'clubs'
enum 的 key 值 union
enum Weekday {
Mon = 1
Tue = 2
Wed = 3
}
type WeekdayName = keyof typeof Weekday // 'Mon' | 'Tue' | 'Wed'
enum 无法实现value-union , 但可以 object 的 value 值 union
const lit = <V extends keyof any>(v: V) => v;
const Weekday = {
MONDAY: lit(1),
TUESDAY: lit(2),
WEDNESDAY: lit(3)
}
type Weekday = (typeof Weekday)[keyof typeof Weekday] // 1|2|3
前面我们讲到了 Record 类型,我们会常用到
interface Model {
name: string
email: string
id: number
age: number
}
// 定义表单的校验规则
const validateRules: Record<keyof Model, Validator> = {
name: {required: true, trigger: `blur`},
id: {required: true, trigger: `blur`},
email: {required: true, message: `...`},
// error: Property age is missing in type...
}
这里出现了一个问题,validateRules 的 key 值必须和 Model 全部匹配,缺一不可,但实际上我们的表单可能只有其中的一两项,这时候我们就需要:
type PartialRecord<K extends keyof any, T> = Partial<Record<K, T>>
const validateRules: PartialRecord<keyof Model, Validator> = {
name: {required: true, trigger: `blur`}
}
这个例子组合使用了 typescript 内置的 类型别名 Partial 和 Partial。
解压抽离关键类型
type Unpacked<T> =
T extends (infer U)[] ? U :
T extends (...args: any[]) => infer U ? U :
T extends Promise<infer U> ? U :
T;
type T0 = Unpacked<string>; // string
type T1 = Unpacked<string[]>; // string
type T2 = Unpacked<() => string>; // string
type T3 = Unpacked<Promise<string>>; // string
type T4 = Unpacked<Promise<string>[]>; // Promise<string>
type T5 = Unpacked<Unpacked<Promise<string>[]>>; // string
递归 Partial
type RecursivePartial<T> = {
[P in keyof T]?:
T[P] extends (infer U)[] ? RecursivePartial<U>[] :
T[P] extends object ? RecursivePartial<T[P]> :
T[P];
};
递归 Required
type DeepRequired<T> = {
[P in keyof T]-?: // 给最顶层的 key 去除 `?:`
T[P] extends ((infer U)[]|undefined) ? DeepRequired<U>[] : // 如果 value 值是数组,那么递归数组内每一项的类型值
T[P] extends (object|undefined) ? DeepRequired<T[P]> : // 如果 value 还是object,递归值类型
T[P] // 其他类型,不进行操作
}
事实上,基于已有的类型别名,还有新推出的 infer 待推断类型,可以探索出各种各样的复杂组合玩法,这里不再多说,大家可以慢慢探索。
感谢阅读!
都 9012 年了,Flutter 有多火,就不需要我多说了,之前掘金首页顶着好长一段时间的 Flutter 视频教程推广足以证明。
那么正如必须要先 ”入门“ 才能 ”出门“,那么前端劝退 Flutter 前也必须得先了解 Flutter。
本文就以前端的角度来给大家捋一捋:在前端眼中,Flutter 的开发到底有何不同?
......然后劝退=_=。【想直接被劝退请滑到最后】
首先,什么是 Flutter?
官网解释:
Flutter是一款 Google 开源的 SDK,可跨平台地为移动端,Web 端,桌面端构建高性能的应用。
当然,当然,虽说是Web端桌面端都能开发,但是我们更多地会着重于 flutter 的移动端跨平台开发功能。
那么,在 flutter之前,其实就有很多跨平台开发的框架了,知名的有 C# 的 Xamarin, 用 js 的有 nativescript ,阿里的 weex 以及大家都比较熟悉的 react native,那么名气不大的就更多了

所以,flutter 在一堆跨平台开发框架中凭什么脱颖而出呢?

前面的这些都是其次,最关键的是什么呢?
Flutter 有个好“爹”!
大家琢磨一下,当下的主流的三大前端框架,react、react native 是 facebook 的,angular 又是 google 的,只有 vue 是没有大公司背景。事实上社区的很多开源框架,其实都是大企业内部孵化出来的。
有个好爹,背靠 Google 爸爸,含着金钥匙出生,一看就前途不可估量。框架的稳定性和成长性就能得到一定保证,给开源社区信心。
这就是,拼爹一时爽,一直拼一直爽。
言归正传,这里提到 flutter 能不局限于系统 OEM,以及相比其他跨平台框架提供更优秀的性能,那么凭啥就 flutter 那么秀呢?我们可以从 flutter 框架结构上去探索一下。
flutter 的框架结构图如下:

好了,相信大家不只一次看到这一张图了。 懂的可能已经了然于胸,不懂的可能还是一脸懵逼。
这里还是简单说下
从上往下看,
首先是 Framework,Framework 是用 dart 语言写的,从上往下,
Framework 往下是 Engine, Framework 中的 UI 交互都是有 Engine 来进行绘制渲染的。Engine 层内部会通过 Skia 图形引擎画出 UI 组件,Skia 是 Google 开源的 2D 图形引擎,适用于多个平台系统,这也是 flutter 能跨平台的核心元素之一。这也是为什么前面说 flutter 能不局限系统 OEM 组件的限制。
也就是说,如果你想要自己封装一个 ant-design 画风的 flutter UI 框架,你可以直接通过基础的 Widget 搭建出自己的 UI 框架。如果底层基础 UI 满足不了你的需求。你可以直接用 dart 调用 Skia 图像引擎的 API,画出自己的 UI,没有任何的限制。
最后是 embedded,嵌入层,这一块是处理平台差异性的事情,从而能够把 flutter 应用嵌入到各个系统平台。
可以看到 Flutter 没有用原生系统上的 OEM,而是用 2D 渲染引擎 skia 直接渲染绘制 UI, 这使得其平台相关层很低,平台只是提供一个画布,剩余的所有渲染相关的逻辑都在Flutter内部,这就使得它具有了很好的跨端一致性。
以上就是 flutter 跨平台开发的结构了, 那么这样设计的优越性在哪呢?我们可以对比下其他应用开发的架构。
首先我们来看下原生APP开发的架构设计,一般一个 App,会分为两大块,分别是 UI 渲染和系统服务调用,我们常说的跨平台开发,其实就是跨的这两块。

原生 App 的 UI ,会通过平台提供的原生 OEM 控件实现,
而系统服务调用,如相机,蓝牙等传感器的使用,也会通过平台系统提供的 API 来实现
那么这就会粗线一个问题,不同平台的 OEM 控件和 系统服务调用规范,以及编程语言不统一,Android 使用 Java / Kotlin,而 iOS 使用 Objective-C / Swift,这就产生了平台差异性。
一个 app 要开发几套代码,UI 效果还不一定能保持一致,费时费力。
于是,就产生了跨平台开发的需求。
我们来看下常见的跨平台架构

首先最常见的跨平台方案,是直接用 webview ,这其实就是我们常说的 hybrid app 了。
虽说不同平台的 webview 内核不一定一样,但是总归会遵循 w3c 规范, 那么我们的前端的代码可以运行在平台的 Webview 上,实现 UI 上的跨平台开发
而系统服务调用这一块呢,就通过 bridge 来通过协议来调用原生的方法。
那么 hybrid app 的方案缺点也是很明显的, webview 性能比不上原生。
为了解决这个 webview 的性能问题,社区又推出了另外一种方案

如图所示,React native ,Weex 等框架,是用前端语言描述系统 OEM 之类 实现跨平台,简单的来说,是通过写 js 配置页面布局,然后通过 react native 解析成原生的控件。
这样的做法,就明显提高了性能,因为实质上渲染出来的,还是原生的控件。
但是,即便性能提高了,但是依然达不到原生的层次,因为 RN 是通过 Jscore 解析 jsbunder 文件布局,和原生直接布局还是有那么一丁点差距的。
另外,使用 react native 并不能避免写原生的代码,如果遇到一些平台相关的复杂问题,还是不得不深入到原生库中进行必要的调整。去年 Airbnb 就因为类似的原因放弃了 rn。
那么,用 flutter 就能避免这个问题了么?我们来看下 flutter 的架构

前面其实也说过了,flutter 的 UI 渲染是基于 skia 图像引擎完成的,不依赖任何一个系统平台,平台仅仅提供一个画布,让 图像渲染在画布上。
那么直接越过原生的渲染机制,从自身的渲染引擎去渲染视图,这就和原生一模一样,没有了中间商赚差价。
两者的渲染性能也提升为了 两者的渲染引擎之间的比较。
至此,我们比较了几种跨平台架构的 UI 渲染实现,
那么关于系统服务的调用呢?Flutter 并没有消除 跨平台 系统服务调用的问题,因为硬件设计层面以及编程语言的差异性是客观存在的,基本无法避免。
但是不同于之前几种用 bridge 的方式来调用系统服务,flutter 用 Platform channel 的形式去调用系统服务,这里先跳过,下面的章节会详细讲一下这里的通信机制

不同于 Web 把页面分成了 HTML,CSS,JS, 在 Flutter 中,所有东西都是 widgets
具体 widgets 类型分为:
所有的 widget 嵌套组合在一起,就构成了一个 flutter app。
关于样式语法,前端的代码我们很熟悉了,用 HTML 和CSS 能快速实现一个简单的 UI。
我们来看看一个最基本的盒子模型:
<div class="greybox">
Lorem ipsum
</div>
<style>
.greybox {
background-color: #e0e0e0; /* grey 300 */
width: 320px;
height: 240px;
font: 900 24px Georgia;
}
</style>var container = Container( // grey box
child: Text(
"Lorem ipsum",
style: TextStyle(
fontSize: 24.0,
fontWeight: FontWeight.w900,
fontFamily: "Georgia",
),
),
width: 320.0,
height: 240.0,
color: Colors.grey[300],
);在 flutter ,由于 Flutter 没有标记语言,我们需要嵌套一个个 Widget 类来实现我们的 UI,这里的 Container Widget类,其实就相当于 div 标签。
那么看到这个代码风格,如果有写过 非 jsx 的 react 的话,你会发现代码风格有点像是 React.createElement 的画风。
React.createElement("div", {
class: "test-c",
style: "width: 10px;"
}, "Hello", React.createElement("span", null, "world!"));实现一个 UI ,第二个比较重要的点是布局,
在 Web 前端,实现布局的核心要点是 CSS 的属性:
<div class="greybox">
<div class="redbox">
Lorem ipsum
</div>
</div>
<style>
.greybox {
background-color: #e0e0e0; /* grey 300 */
width: 320px;
height: 240px;
font: 900 24px Roboto;
display: flex;
align-items: center;
justify-content: center;
}
.redbox {
background-color: #ef5350; /* red 400 */
padding: 16px;
color: #ffffff;
}
</style>而在 flutter,则需要一些官方提供的样式类来实现,例如这里的 BoxDecoration 类来修饰整个盒子,Alignment 确定文本对齐方式等等
var container = Container( // gray box
child: Center(
child: Container( // red box
child: Text(
"Lorem ipsum",
style: bold24Roboto,
textAlign: TextAlign.center,
),
decoration: BoxDecoration(
color: Colors.red[400],
),
padding: EdgeInsets.all(16.0),
),
alignment: Alignment.center,
),
width: 320.0,
height: 240.0,
color: Colors.grey[300],
);Web:
<input name="account" />
<div onclick="handleSubmit()">Submit</div>
最后一点是交互,类似于大部分的前端 UI 框架,每个组件其实都会暴露出一些事件钩子,
通过这些钩子,我们就可以捕获到用户的行为,从而实现对应的逻辑,
这里的 demo 就简单实现了 输入校验, 按钮的点击提交等基本的交互。
Flutter:
// ...
children: <Widget>[
TextFormField(
decoration: InputDecoration(
hintText: 'Email/Name/Telephone',
labelText: 'Account *',
),
onSaved: (String value) {
loginForm.account = value;
},
validator: (String value) {
if (value.isEmpty) return 'Name is required.';
}
),
RaisedButton(
child: Text(
'Login'
),
onPressed: () {
// print('提交操作');
// dosomething with loginForm
handleSubmit()
},
),
]其余的还有 路由,动画,手势等交互,这里不再多说,基本上能用 Web 技术实现的,大都能够在 flutter 实现
可以看到,flutter 的 UI 部分除了没有 jsx 之外,其余部分的设计**与 react 大同小异。
那么简单介绍完语法,我们来实际操作看看,怎么写一个 APP
首先怎么安装 flutter 开发环境这个就不多说了,官网教程教程已经很完善了
简单说下目录结构,通过 flutter 创建出一个工程后,会自动生成这样的目录结构,
.
├── android # Android 平台配置,flutter 自动生成
├── ios # iOS 平台配置,flutter 自动生成
├── assets # 静态资源目录
├── build # 存放构建出的 release 相关文件
├── lib # 业务代码
├── └── main.dart # app 入口
└── pubspec.yaml # 包管理文件
上手一个框架,当然要来一个经典的 Hello World。
要实现一个 flutter app,
我们需要 加载 flutter 的基本组件 import 'package:flutter/widgets.dart';,
然后执行基本的 runApp , 那么一个基本的 hello world 就完成了。
// main.dart 文件
import 'package:flutter/widgets.dart';
void main() {
runApp(
Center(
child: Text(
'Hello, world!'
),
),
);
}效果如下:

可以看到,如果没有样式的话,应用就是一坨黑....
就像在前端开发时我们喜欢使用的 ant design 或者 iview 之类的 UI 框架,开发 flutter 一般也会用 UI 框架
Flutter 内置两套 UI 组件,分别是 Material UI 和 Cupertino UI,
现在简单看下一个 material 风格的APP是怎么实现的,
首先 import material 组件
new 一个 MaterialApp 组件,配置 title, app bar 等信息,就简单地生成了个 material 画风的 app 了。
import 'package:flutter/material.dart';
void main() {
runApp(
MaterialApp(
title: 'Hello App',
home: Scaffold(
appBar: AppBar(
title: Text('Hello'),
),
body: Center(
child: Text(
'Hello Flutter',
style: TextStyle(
fontSize: 30
),
)
),
),
)
);
}
更复杂的还可以在这里配置路由相关信息,这里就不再多说。
通过这些我们知道怎么实现一个 flutter app,那么看到所有有实体的元素,都是称为 Widgets, 这里为了方便理解,我们统称为组件。

而组件又细分为 Stateless Widget 和 Stateful Widget,这里可以很容易联想到 react 的 无状态组件和 有状态组件
事实上 flutter 的这两种组件确实和 react 的差不多
我们首先看下 无状态组件(StatelessWidget)
void main() {
runApp(MyApp());
}
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Hello App',
home: Scaffold(
appBar: AppBar(
title: Text('Hello'),
),
body: Center(
child: Text(
'Hello Flutter',
style: TextStyle(fontSize: 30),
)),
),
);
}
}
StatelessWidget 对应 react 的函数组件 Functional Component build 方法对应 react 的 render 方法再来看看 状态组件(StatefulWidget)
Flutter 的状态由两个类组成: 分别是 StatefulWidget 和 State 类。
写法虽然不同,但是概念都大同小异:
StatefulWidget 对应 React.ComponentStatefulWidget 类管理父组件传递的 PropState 类中管理自身的 StatesetState 更新状态class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Counter App',
home: Scaffold(
appBar: AppBar(
title: Text('Counter'),
),
body: Center(
child: Counter(10) ),
),
);
}
}
class Counter extends StatefulWidget {
// 这个类是 state 的配置,可以在此定义父组件传递下来的 prop
final int increaseNum;
// 构造函数
Counter(this.increaseNum);
@override
_CounterState createState() => _CounterState();
}
class _CounterState extends State<Counter> {
int _counter = 0;
void _increment() {
print('count: $_counter');
setState(() {
// setState 的回调告诉 flutter 去变更 当前 State, 并且 setState() 的调用会触发 build() 从而更新视图
_counter += widget.increaseNum;
});
}
@override
Widget build(BuildContext context) {
// 每次调用 setState 都会触发 build 方法,同时,类似于 react 的 render 方法,
// flutter 框架为了让 重新 build 更加快,也已经对此做了优化
return Row(
crossAxisAlignment: CrossAxisAlignment.center,
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
RaisedButton(
onPressed: _increment,
child: Text('Increment'),
),
Text('Count: $_counter'),
],
);
}
}学过 React 的同学,是不是对此有种似曾相识的感觉呢?
组件出来了,生命周期还远么?
类似 React ,Flutter 也有自己的组件生命周期:

到此我们的 UI 组件部分就告一段落。
跨平台开发,“跨” 的除了平台 UI 部分外,还有跨了前面提到的平台系统服务调用。
不管是哪一个跨平台开发的解决方案,基本上都是在UI层面去完成跨平台,一次开发运行多处,但是当你需要完成特定的功能时,比如:打开相册获取照片,这在这一层面上就无法撼动了,你依然需要使用 Native 的方式来完成。
例如 h5 本身是无法调用系统底层 API 的,在 h5 我们就会用到 jsbridge 来给 native 发送命令,从而让 native 调用系统 API。
而在 flutter, 官方提供了一些插件(plugins packages)来实现常用的功能,例如:本地图片选择,相机功能等,让我们能够简单直接地使用到不同平台的系统接口。
这里也提供了一个唤起相机的 demo :
import 'package:image_picker/image_picker.dart';
class MyHomePage extends StatefulWidget {
@override
_MyHomePageState createState() => _MyHomePageState();
}
class _MyHomePageState extends State<MyHomePage> {
File _image;
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text('Image Picker Example'),
),
body: Center(
child: _image == null
? Text('No image selected.')
: Image.file(_image),
),
// 点击按钮进行拍照
floatingActionButton: FloatingActionButton(
onPressed: getImage,
tooltip: 'Pick Image',
child: Icon(Icons.add_a_photo),
),
);
}
Future getImage() async {
// 打开相机拍摄,并获得图片资源
var image = await ImagePicker.pickImage(source: ImageSource.camera);
setState(() {
_image = image;
});
}
}那么 插件是怎么调用 系统服务的呢?这里就需要用到 flutter 的 methodchannel / platform channel 通信机制。

如图所示,flutter 通过 methodchannel 机制来调用不同平台 native 层的 api。由于代码最终会被编译成机器码,所以这个调用过程基本上和原生调用差不多,都是无损的,不像通过 bridge 方式调用,需要协议转化。
要自己实现一个 底层服务调用的 FlutterPlugin,可以参考官方文档,简单来说步骤如下:
看了那么多,是不是感觉这不像劝退,而是一篇 Flutter 吹文?
别急,这就劝退了。
Flutter 虽然看起来很强大,但是实际上深入琢磨一下,其实也有不少局限性。
大家都知道,国内的流量几乎都被几个大公司垄断, 而 App 的推广下载成本也很高。
所以各大公司才推出了五花八门的小程序,到目前为止,已知的有:
微信/百度/支付宝/字节跳动/ QQ 小程序以及快应用等......
为了快速引流,考虑投入产出比,小公司更愿意会用 小程序/快应用/H5 方案,而不是用获客成本更高的 App 方案。
例如京东的 taro 框架或类似的跨端小程序开发框架,就比 Flutter 更加符合**特色。
taro 是一个多端统一开发框架,支持用 React 的开发方式编写一次代码,生成能运行在微信/百度/支付宝/字节跳动/ QQ 小程序、快应用、H5、React Native 等的应用。
大家可以看到,整篇下来,除了 react-style 的设计**之外,flutter 和前端其实关系不大。
江湖传言道:一切能用js实现的应用,都将用js实现。
但是很可惜的是,基于各方面的考虑,google 选择了 dart 这门并不算热门的语言作为 flutter 的开发语言,而不是 JavaScript / Typescript。给前端开发接触 flutter 设置了一定的门槛。
但是,flutter 也不是只给我们前端用的,站在前端角度,我们当然希望用 js/ts咯。
但这对于 Android/ios 等终端开发来说,其实也是同样需要一定的成本,可以算是一视同仁了。
那么又由于 dart 语言这两年才被 flutter 带起来的缘故,之前一直火不起来,直到 flutter 出来后才强行续命。至此 dart 的社区生态,开源库等等都比较欠缺,不像前端社区,有丰富的 npm 包。
那么,大家可以想下,在 flutter 之前,你有听过 dart 语言么?
google 为什么用 dart 作为 flutter 的开发语言呢?
其实是因为……
dart 也有个好爹 Orz,他的爹也是Google。
看到没有,有个好爹多么重要,三线语言 dart 这不就被捧得大红大紫了么[滑稽]
flutter 用自绘引擎彻底解决了 UI 层面的平台差异性,但是前面也提到了,系统硬件服务(如相机蓝牙等服务)的差异性是无可避免的。
作为一个纯前端来说,理想情况下,用 flutter 可以完成所有原生能实现的功能。
但现实往往是不理想的,跨端开发往往会遇到一些平台相关的问题,如 flutter plugin的相机拍照 ,在某个型号的安卓设备上有点小bug。如果你是个纯前端,运气好的话能在开源社区找到解决方案,运气不好,只能向终端(iOS/Android)开发寻求技术支持。
那么,还需要 iOS/Android 开发来兜底的跨端开发框架,还是一个跨端开发框架么?
要开发一个成熟的 App,你敢放心交给纯前端用 flutter 负责么?
当然,这并非是 flutter 弊端,而是所有跨平台方案共同的问题。要是没这问题,react native 早就一统江湖了,airbnb 也不至于弃坑 react native了。
只要跨平台框架还存在需要程序员自行解决的平台差异bug,那么 纯前端程序员全盘负责移动端开发 就是个伪命题。

那么,是不是 flutter 就与前端绝缘了呢?
也并非如此。
如果你要开发一个重 UI 展示 ,调用系统服务比较少的简单应用,那么 flutter 是个不错的选择。
事实上,可以看出,最适合用 flutter 的是哪些程序员呢?
既会 iOS 开发,又懂一些 Android 开发,这不需要太精通, 能搜索解决常见终端问题即可的程序员。那么学 flutter 就是如虎添翼了。
如果真的有前端有志于做一名 flutter 开发工程师,那么不妨简单学习下 Android 和 iOS 开发。
互联网寒冬什么人才最吃香?
多面手,综合性人才,爆栈工程师...
劝退完毕。
大家出来写 Bug 代码的,难免会出 Bug。
文章背景就发生在一个 Bug 身上,
有一天,测试慌张中带着点兴奋冲过来:
测试:"xxx系统前端线上出 Bug 了,点进xx页面一片空白啊"。
我:"纳尼?我写的Bug怎么会出现代码呢?"。

虽然大脑一片空白,但是锅还是要背的。
进入页面一看,哦豁,完蛋,cannot read the property 'xx' of undefined。确实是前端常见的报错呀。
背锅王,我当定了?未必。
我眉头一皱,发现事情并不是那么简单,经过一番猛如虎的操作之后,最终定位到问题是:后端接口响应的 JSON 数据中,一个嵌套比较深的字段没有返回,即前端只读到了 undefined。
咱按章程办事,后端提供的接口文档指定了数据结构,那你没有返回正确数据结构,这就是你后端的锅,虽然严谨点前端也能捕获到错误进行处理,但归根到底,是你后端数据接口处理有问题,这锅,我不背。
甩锅又是一门扯皮的事情,杀敌一千自伤八百,锅已经扣下来了,想甩出去就难咯,。
唉,要是在接口出错的时候,能立刻知道接口数据出问题,先发制人,马上把锅甩出去那就好咯。
这就是本文即将要讲述的 "Typescript 运行时数据校验"。
众所周知,Typescript 是 JavaScript 超集,可以给我们的项目代码提供静态类型检查,避免因为各种原因而未及时发现的代码错误,在编译时就能发现隐藏的代码隐患,从而提高代码质量。
但是,TypeScript 项目的一个常见问题是: 如何验证来自外部源的数据并将验证的数据与TypeScript类型联系起来。 即,如何避免后端 API 返回的数据与 Typescript 类型定义不一致导致的运行时错误。
Typescript 能用于运行时校验数据类型,那么有没有一种方法,能让我们在 运行时 也进行 Typescript 数据类型校验呢?
业界开源了一个运行时校验的工具库:io-ts。
// io-ts 例子
import * as t from 'io-ts'
// ts 定义
interface Category {
name: string
categories: Array<Category>
}
// 对应上述ts定义的 io-ts 实现
const Category: t.Type<Category> = t.recursion('Category', () =>
t.type({
name: t.string,
categories: t.array(Category)
})
)但是,如上面的代码所示,这工具看起来就有点啰嗦有点难用,对代码的侵入性非常强,要全盘依据它的语法来重写代码。这对于一个团队来说,存在一定的迁移成本。
而我们更希望做到的理想方案是:
写好接口的数据结构 typescript 定义,不需要做太多的额外变动,直接就能校验后端接口响应的数据结构是否符合 typescript 接口定义
首先,我们了解到,后端响应的数据接口一般为 JSON,那么,抛开 Typescript,如果要校验一个 JSON 的数据结构,我们可以怎么做到呢?
答案是JSON schema。
JSON schema 是一种描述 JSON 数据格式的模式。
例如 typescript 数据结构:
type TypeSex = 1 | 2 | 3
interface UserInfo {
name: string
age?: number
sex: TypeSex
}等价于以下的 json schema :
{
"$id": "api",
"$schema": "http://json-schema.org/draft-07/schema#",
"definitions": {
"UserInfo": {
"properties": {
"age": {
"type": "number"
},
"name": {
"type": "string"
},
"sex": {
"enum": [
1,
2,
3
],
"type": "number"
}
},
"required": [
"name",
"sex"
],
"type": "object"
}
}
}根据已有 json-schema 校验库,即可校验数据对象
someValidateFunc(jsonSchema, apiResData)这里大家可能就又会困惑:这json-schema写起来也太费劲了?还不一样要学习成本,那和 io-ts 有什么区别。
但是,既然我们同时知道 typescript 和 json-schema 的语法定义规则,那么就两者必然能够互相转换。
也就是说,即便我们不懂 json-schema 的规范与语法,我们也能通过typescript 转化生成 json-schema。
那么,在以上的前提下,我们的思路就是:既然 typescript 本身不支持运行时数据校验,那么我们可以将 typescript 先转化成 json schema, 然后用 json-schema 校验数据结构
要将 typescript 声明转换成 json-schema ,这里推荐使用 typescript-json-schema。
我们可以直接使用它的命令行工具,这里就不仔细展开说明了,感兴趣的可以看下官方文档:
Usage: typescript-json-schema <path-to-typescript-files-or-tsconfig> <type>
Options:
--refs Create shared ref definitions. [boolean] [default: true]
--aliasRefs Create shared ref definitions for the type aliases. [boolean] [default: false]
--topRef Create a top-level ref definition. [boolean] [default: false]
--titles Creates titles in the output schema. [boolean] [default: false]
--defaultProps Create default properties definitions. [boolean] [default: false]
--noExtraProps Disable additional properties in objects by default. [boolean] [default: false]
--propOrder Create property order definitions. [boolean] [default: false]
--required Create required array for non-optional properties. [boolean] [default: false]
--strictNullChecks Make values non-nullable by default. [boolean] [default: false]
--useTypeOfKeyword Use `typeOf` keyword (https://goo.gl/DC6sni) for functions. [boolean] [default: false]
--out, -o The output file, defaults to using stdout
--validationKeywords Provide additional validation keywords to include [array] [default: []]
--include Further limit tsconfig to include only matching files [array] [default: []]
--ignoreErrors Generate even if the program has errors. [boolean] [default: false]
--excludePrivate Exclude private members from the schema [boolean] [default: false]
--uniqueNames Use unique names for type symbols. [boolean] [default: false]
--rejectDateType Rejects Date fields in type definitions. [boolean] [default: false]
--id Set schema id. [string] [default: ""]
github 上也有所有类型转换的 测试用例,可以对比看看 typescript 和 转换出的 json-schema 结果
利用 typescript-json-schema 工具生成了 json-schema 文件后,我们需要根据该文件进行数据校验。
json-schema 数据校验的库很多,ajv,jsonschema 之类的,这里用 jsonschema 作为示例。
import { Validator } from 'jsonschema'
import schema from './json-schema.json'
const v = new Validator()
// 绑定schema,这里的 `api` 对应 json-schema.json 的 `$id`
v.addSchema(schema, '/api')
const validateResponseData = (data: any) => {
// 校验响应数据
const result = v.validate(data, {
// SomeInterface 为 ts 定义的接口
$ref: `api#/definitions/SomeInterface`
})
// 校验失败,数据不符合预期
if (!result.valid) {
console.log('data is ', data)
console.log('errors', result.errors.map((item) => item.toString()))
}
return data
}当我们校验以下数据时:
// 声明文件
interface UserInfo {
name: string
sex: string
age: number
phone?: number
}
// 校验结果
validateResponseData({
name: 'xxxx',
age: 'age应该是数字'
})
// 得出结果
// data is { name: 'xxxx', age: 'age应该是数字' }
// errors [ 'instance.age is not of a type(s) number',
// 'instance requires property "sex"' ]配合上前端上报系统,当线上系统接口返回了非预料的数据,导致出 bug,就可以实时知道到底错在哪了,并且及时甩锅给后端啦。
前面提到,我们需要执行 typescript-json-schema <path-to-typescript-files-or-tsconfig> <type> 命令来声明 typescript 对应的 json-schema 文件。
那么,这里就有个问题,接口数量有可能增加,接口数据也有可能变动,那也就代表着,我们每次变更接口数据结构,都要重新跑一下 typescript-json-schema ,时刻保持 json-schema 和 typescript一一对应。
这我们就可以用 husky 的 precommit , 加上 lint-staged 来实现每次更新提交代码时,自动执行 typescript-json-schema,无需时刻关注 typescript 接口定义的变更。
综上,我们实现了
typescript 声明文件 转换生成 json-schema 文件husky + lint-staged 每次提交代码自动执行 步骤1,保持git 仓库的代码 typescript 声明 和 json-schema 时刻保持一致。那么,当 Bug 出现的时候,你甚至可以在测试都还没发现这个 Bug之前,就已经把锅甩了出去。
只要你跑得足够快,Bug 就会追不上你。

BoxDecoration 类提供了几种方式来绘制一个容器,主要用于绘制更加复杂的样式。
容器有 border(边框),body(主体),可能还有 boxShadow(阴影)
容器的形状可以是圆形或者矩形,如果是矩形,可以设置 borderRadius 控制角的弧度。
容器主体背景分为多个层级,最底层是填充满容器的背景颜色,再上一层是填充容器的渐变色,最后是图像,由 DecorationImage 类控制,
也就是说背景优先级: 图像 > 渐变色 > 纯色
new Center(
child: new Container(
decoration: new BoxDecoration(
color: Colors.purple,
),
child: new FlutterLogo(
size: 200.0,
)
),
);PS: Container 部件的 color 属性不能和 decoration 属性同时使用
事实上,
Container(
color: Colors.purple
)
是以下 decoration 的简写:
Container(
decoration: new BoxDecoration(color: Colors.purple)
)
线性渐变颜色列表
线性渐变的起始点
线性渐变的终止点
Center(
child: new Container(
decoration: new BoxDecoration(
color: Colors.purple,
gradient: new LinearGradient(
colors: [Colors.red, Colors.cyan],
begin: Alignment.centerRight,
end: Alignment.centerLeft
),
),
child: new FlutterLogo(
size: 200.0,
)
),
);

由于是线性渐变,所以
begin: Alignment.centerRight,
end: Alignment.centerLeft
begin: Alignment.topRight,
end: Alignment.topLeft
begin: Alignment.bottomRight,
end: Alignment.bottomLeft
这几种都是等价的
定义了在 指定的 begin 和 end 之外的区域,渐变色应该如何渲染
TileMode.clamp 表明在 begin - end 区域外,渐变色应该保持 colors 列表内指定的颜色。
new Center(
child: new Container(
decoration: new BoxDecoration(
color: Colors.purple,
gradient: new LinearGradient(
colors: [Colors.red, Colors.cyan],
begin: Alignment.centerRight,
end: new Alignment(0.8, 0.0),
tileMode: TileMode.clamp
),
),
child: new FlutterLogo(
size: 200.0,
)
),
);
在 begin - end 区域外,应该保持镜像的渐变色。
new Center(
child: new Container(
decoration: new BoxDecoration(
color: Colors.purple,
gradient: new LinearGradient(
colors: [Colors.red, Colors.cyan],
begin: Alignment.centerRight,
end: new Alignment(0.8, 0.0),
tileMode: TileMode.mirror
),
),
child: new FlutterLogo(
size: 200.0,
)
),
);
在区域外重复进行渐变色的渲染
new Center(
child: new Container(
decoration: new BoxDecoration(
color: Colors.purple,
gradient: new LinearGradient(
colors: [Colors.red, Colors.cyan],
begin: Alignment.centerRight,
end: new Alignment(0.8, 0.0),
tileMode: TileMode.repeated
),
),
child: new FlutterLogo(
size: 200.0,
)
),
);
如果没有给 stops 赋值, 渐变色区域将会根据颜色数量均匀分割。
即:
gradient: new LinearGradient(
colors: [Colors.red, Colors.cyan, Colors.yellow ],
begin: Alignment.centerRight,
end: Alignment.centerLeft,
// stops 默认值为
// stops: [0, 0.5, 1]
),
new Center(
child: new Container(
decoration: new BoxDecoration(
color: Colors.purple,
gradient: new LinearGradient(
colors: [Colors.red, Colors.cyan, Colors.purple, Colors.lightGreenAccent],
begin: Alignment.centerRight,
end: Alignment.centerLeft,
tileMode: TileMode.clamp,
stops: [0.3, 0.5, 0.6, 0.7]
),
),
child: new FlutterLogo(
size: 200.0,
)
),
);
这里表示:假定宽度长 100%,从右往左进行 Colors.red(红), Colors.cyan(青), Colors.purple(紫), Colors.lightGreenAccent(绿) 这 4 种颜色的渐变。
RadialGradient 有 5 个主要属性:
new Center(
child: new Container(
decoration: new BoxDecoration(
color: Colors.purple,
gradient: new RadialGradient(
colors: [Colors.red, Colors.cyan, Colors.purple, Colors.lightGreenAccent],
center: Alignment(-0.7, -0.6),
radius: 0.2,
tileMode: TileMode.clamp,
stops: [0.3, 0.5, 0.6, 0.7]
),
),
child: new FlutterLogo(
size: 200.0,
)
),
);
绘制图片背景,图片通常是 AssetImage (应用配置的图片资源),或者是 NetworkImage (网络图片资源)
new Center(
child: new Container(
decoration: new BoxDecoration(
color: Colors.purple,
gradient: new RadialGradient(
colors: [Colors.red, Colors.cyan, Colors.purple, Colors.lightGreenAccent],
center: Alignment(0.0, 0.0),
radius: 0.5,
tileMode: TileMode.clamp,
stops: [0.3, 0.5, 0.9, 1.0]
),
image: new DecorationImage(
image: new NetworkImage("http://jlouage.com/images/author.jpg")
)
),
child: new FlutterLogo(
size: 200.0,
)
),
);
可以看到,由于图片优先级比较高,渲染在最上层,图片背景绘制覆盖了渐变背景和 纯色背景。
同 Container 部件的 alignment,不再赘述
centerSlice 决定以哪一种方式,按区域对图像进行缩放处理。
例如,我们有一张图片,可以设置其四个角的区域不进行缩放,其他区域进行缩放(这么说可能有点抽象,以下实例再详细说明)
centerSlice 属性的值为 Rect 类,也就是一个矩形。
假如我们有一张这样尺寸的图片
当我们的 centerSlice 值为 Rect.fromLTWH(50.0, 50.0, 220.0, 90.0) 时,即
new Center(
child: new Container(
decoration: new BoxDecoration(
image: new DecorationImage(
image: new AssetImage('assets/images/9_patch_scaled_320x190.png'),
centerSlice: new Rect.fromLTWH(50.0, 50.0, 220.0, 90.0),
fit: BoxFit.fill,
)
),
child: new Container(
//color: Colors.yellow,
width: 110.0,
height: 110.0,
)
),
);
得到的效果如下(将 320 x 190 尺寸大小的图片拉伸在 110 x 110 的容器中,其中图片四个角 50 x 50 的区域不进行拉伸,其他区域进行拉伸):
扩大容器的大小后:
new Center(
child: new Container(
decoration: new BoxDecoration(
image: new DecorationImage(
image: new AssetImage('assets/images/9_patch_scaled_320x190.png'),
centerSlice: new Rect.fromLTWH(50.0, 50.0, 220.0, 90.0),
fit: BoxFit.fill,
)
),
child: new Container(
//color: Colors.yellow,
width: 350.0,
height: 450.0,
)
),
);
得到的效果如下(将 320 x 190 尺寸大小的图片拉伸在 350 x 450 的容器中,其中图片四个角 50 x 50 的区域不进行拉伸,其他区域进行拉伸):
这个属性的效果一般比较少用,其中的值大家可以随便测试看看效果。
给背景图片加上颜色滤镜。值一般为 ColorFilter.mode(颜色, 混合模式)。
我们将给以下图片
加上粉色滤镜colorFilter: new ColorFilter.mode(Colors.red.withOpacity(0.5), BlendMode.color), 并以不同的模式进行混合。
new Center(
child: new Container(
width: double.infinity,
height: double.infinity,
color: Colors.white,
child: new Container(
decoration: new BoxDecoration(
image: new DecorationImage(
image: new AssetImage('assets/images/JL-Logo-empty.png'),
colorFilter: new ColorFilter.mode(Colors.red.withOpacity(0.5), BlendMode.color),
)
),
),
),
);


滤镜的混合模式很多,这里就不一一解读了,有兴趣的可以看原文详细解读
如何渲染图像到盒子中,(PS: 不同于 DecorationImage.centerSlice 作用于图片本身,DecorationImage.fit 是作用于画布的)
值为 BoxFit 的枚举值
Center(
child: new Container(
width: double.infinity,
height: double.infinity,
color: Colors.white,
child: new Container(
decoration: new BoxDecoration(
image: new DecorationImage(
image: new NetworkImage('http://jlouage.com/images/author.jpg'),
fit: BoxFit.contain
)
),
),
),
);
图片尽可能大,并且容器依然包含整个图片资源
以下图片为同一图片资源在不同尺寸的容器中的展示方式。
图片尽可能小,且必须覆盖满整个容器。
通过拉伸图片来覆盖满整个容器
确保图片资源的全部高度都可见,无论图片资源的宽度是不是溢出容器
类似上,确保图片资源的全部宽度都可见,无论图片资源的高度是不是溢出容器
居中对齐图片资源,不缩放大小,丢弃容器之外的部分。
类似于 BoxFit.contain,居中对齐图片资源,并在必要的时候,缩小图片资源以确保整个资源都在容器啊,
渲染图片到图片大小之外的容器其他区域。
值为 ImageRepeat 枚举值
其他区域保持透明
Center(
child: new Container(
width: double.infinity,
height: double.infinity,
color: Colors.white,
child: new Container(
decoration: new BoxDecoration(
image: new DecorationImage(
image: new AssetImage('assets/images/JL-Logo-150.png'),
repeat: ImageRepeat.noRepeat
)
),
),
),
);
在x和y方向上重复图像,直到填充满容器。
在x轴上重复图像,直到水平填充满容器。
在y轴上重复图像,直到垂直填充满容器。
是否以 TextDirection 的方向渲染图片,值为 true/false;
如果是 true。 那么在 TextDirection.ltr 的环境下,图片将会以左上角为原点开始绘制(一般情况下的绘制方向),如果是在TextDirection.rtl 的环境下, 图片将会以右上角为原点开始绘制。
在背景颜色(color),渐变色背景(gradient)或图像背景(image)上方绘制的边框。
值为 Border 类,Border.all 和 BorderDirectional 类
设置4边的边框:
参数如下:
new Center(
child: new Container(
width: 200.0,
height: 200.0,
color: Colors.white,
child: new Container(
decoration: new BoxDecoration(
border: new Border.all(
color: Colors.green,
width: 5.0,
style: BorderStyle.solid
),
image: new DecorationImage(
image: new AssetImage('assets/images/JL-Logo-150.png'),
)
),
),
),
);
指定边的边框, 参数分别为 top, bottom, right, left; 值为 BorderSide 类(参数同Border.all).
border: new Border(
top: new BorderSide(
color: Colors.green,
width: 5.0,
style: BorderStyle.solid
),
),
BorderDirectional 类似 Border , 同样有 4 个参数(top, bottom, start, end),其中的 start/end 对应Border 的 left/right。
border: new BorderDirectional(
top: new BorderSide(
color: Colors.green,
width: 5.0,
style: BorderStyle.solid
),
start: new BorderSide(
color: Colors.green,
width: 5.0,
style: BorderStyle.solid
),
),
ima
设置圆角。(仅在 shape: BoxShape.rectangle 时有效)。
值可以为: BorderRadius.all, BorderRadius.only, BorderRadius.circular, BorderRadius.horizontal, BorderRadius.vertical.
new Center(
child: new Container(
width: 200.0,
height: 200.0,
color: Colors.white,
child: new Container(
decoration: new BoxDecoration(
border: new Border.all(
color: Colors.green,
width: 5.0,
style: BorderStyle.solid
),
borderRadius: new BorderRadius.all(new Radius.circular(20.0)),
image: new DecorationImage(
image: new AssetImage('assets/images/JL-Logo-150.png'),
)
),
),
),
);
BorderRadius.circular(20) 等价于 BorderRadius.all(new Radius.circular(20.0))
设置水平方向一边的边框
borderRadius: new BorderRadius.horizontal(
left: new Radius.circular(20.0),
//right: new Radius.circular(20.0),
),
设置垂直方向一边的边框
borderRadius: new BorderRadius.vertical(
top: new Radius.circular(20.0),
//bottom: new Radius.circular(20.0),
),
指定角的圆角弧度
borderRadius: new BorderRadius.only(
// 设置椭圆
topLeft: new Radius.elliptical(40.0, 10.0),,
//topRight: new Radius.circular(20.0),
//bottomRight: new Radius.circular(20.0),
bottomLeft: new Radius.circular(20.0),
),
在容器后设置阴影。
值是一个 list , 也就是说可以设置多个阴影的值
值为 BoxShadow 类, 参数为:
仅设置偏移值
new Center(
child: new Container(
width: 200.0,
height: 200.0,
color: Colors.white,
child: new Container(
decoration: new BoxDecoration(
color: Colors.white,
border: new Border.all(
color: Colors.green,
width: 5.0,
style: BorderStyle.solid
),
borderRadius: new BorderRadius.only(
topLeft: new Radius.elliptical(40.0, 10.0),
bottomLeft: new Radius.circular(20.0),
),
boxShadow: [
new BoxShadow(
color: Colors.red,
offset: new Offset(20.0, 10.0),
)
],
image: new DecorationImage(
image: new AssetImage('assets/images/JL-Logo-150.png'),
)
),
),
),
);
设置高斯模糊值
boxShadow: [
new BoxShadow(
color: Colors.red,
offset: new Offset(20.0, 10.0),
blurRadius: 20.0,
)
],
高斯模糊的扩散范围 spreadRadius
boxShadow: [
new BoxShadow(
color: Colors.red,
offset: new Offset(20.0, 10.0),
blurRadius: 20.0,
spreadRadius: 40.0
)
],
多个阴影值(由外向内)
boxShadow: [
new BoxShadow(
color: Colors.red,
offset: new Offset(20.0, 10.0),
blurRadius: 20.0,
spreadRadius: 40.0
),
new BoxShadow(
color: Colors.yellow,
offset: new Offset(20.0, 10.0),
blurRadius: 20.0,
spreadRadius: 20.0
),
new BoxShadow(
color: Colors.green,
offset: new Offset(10.0, 5.0),
blurRadius: 20.0,
spreadRadius: 5.0
)
],
形状,只有矩形和圆形两种
new Center(
child: new Container(
width: 200.0,
height: 200.0,
child: new Container(
decoration: new BoxDecoration(
color: Colors.white,
border: new Border.all(
color: Colors.green,
width: 5.0,
style: BorderStyle.solid
),
boxShadow: [
new BoxShadow(
color: Colors.red,
offset: new Offset(20.0, 10.0),
blurRadius: 20.0,
spreadRadius: 40.0
)
],
shape: BoxShape.circle,
image: new DecorationImage(
image: new AssetImage('assets/images/JL-Logo-150.png'),
)
),
),
),
);
同 Container 中的 padding 值,参考 Flutter: 图解 Container 部件
做过爬虫的都知道,要控制爬虫的请求并发量,其实也就是控制其爬取频率,以免被封IP,还有的就是以此来控制爬虫应用运行内存,否则一下子处理N个请求,内存分分钟会爆。
而 python爬虫一般用多线程来控制并发,
然而如果是node.js爬虫,由于其单线程无阻塞性质以及事件循环机制,一般不用多线程来控制并发(当然node.js也可以实现多线程,此处非重点不再多讲),而是更加简便地直接在代码层级上实现并发。
为图方便,开发者在开发node爬虫一般会找一个并发控制的npm包,然而第三方的模块有时候也并不能完全满足我们的特殊需求,这时候我们可能就需要一个自己定制版的并发控制函数。
下面我们用15行代码实现一个并发控制的函数。
首先,一个基本的并发控制函数,基本要有以下3个参数:
list {Array} - 要迭代的数组limit {number} - 控制的并发数量asyncHandle {function} - 对list的每一个项的处理函数以下以爬虫为实例进行讲解
设计思路其实很简单,假如并发量控制是 5
// limit = 5
while(limit--) {
handleFunction(list)
}
list项
let recursion = (arr) => {
return asyncHandle(arr.shift())
.then(()=>{
// 迭代数组长度不为0, 递归执行自身
if (arr.length!==0) return recursion(arr)
// 迭代数组长度为0,结束
else return 'finish';
})
}
list所有的项迭代完之后的回调
return Promise.all(allHandle)
上述步骤组合起来,就是
/**
* @params list {Array} - 要迭代的数组
* @params limit {Number} - 并发数量控制数
* @params asyncHandle {Function} - 对`list`的每一个项的处理函数,参数为当前处理项,必须 return 一个Promise来确定是否继续进行迭代
* @return {Promise} - 返回一个 Promise 值来确认所有数据是否迭代完成
*/
let mapLimit = (list, limit, asyncHandle) => {
let recursion = (arr) => {
return asyncHandle(arr.shift())
.then(()=>{
if (arr.length!==0) return recursion(arr) // 数组还未迭代完,递归继续进行迭代
else return 'finish';
})
};
let listCopy = [].concat(list);
let asyncList = []; // 正在进行的所有并发异步操作
while(limit--) {
asyncList.push( recursion(listCopy) );
}
return Promise.all(asyncList); // 所有并发异步操作都完成后,本次并发控制迭代完成
}
模拟一下异步的并发情况
var dataLists = [1,2,3,4,5,6,7,8,9,11,100,123];
var count = 0;
mapLimit(dataLists, 3, (curItem)=>{
return new Promise(resolve => {
count++
setTimeout(()=>{
console.log(curItem, '当前并发量:', count--)
resolve();
}, Math.random() * 5000)
});
}).then(response => {
console.log('finish', response)
})
结果如下:

手动抛出异常中断并发函数测试:
var dataLists = [1,2,3,4,5,6,7,8,9,11,100,123];
var count = 0;
mapLimit(dataLists, 3, (curItem)=>{
return new Promise((resolve, reject) => {
count++
setTimeout(()=>{
console.log(curItem, '当前并发量:', count--)
if(curItem > 4) reject('error happen')
resolve();
}, Math.random() * 5000)
});
}).then(response => {
console.log('finish', response)
})
并发控制情况下,迭代到5,6,7 手动抛出异常,停止后续迭代:

对总结表示不赞同。
interface是接口,type是类型,本身就是两个概念。只是碰巧表现上比较相似。
希望定义一个变量类型,就用type,如果希望是能够继承并约束的,就用interface。
如果你不知道该用哪个,说明你只是想定义一个类型而非接口,所以应该用type。
Originally posted by @trlanfeng in #7 (comment)
前端工程化的概念在近些年来逐渐成为主流构建大型web应用不可或缺的一部分,在此我通过以下这三方面总结一下自己的理解。
随着近些年来前端技术的不断发展,越来越多复杂的业务放在了前端,前端不再是以前几个HTML + CSS + javascript就能解决的了。业务复杂了,需要维护的代码量就自然多了,如此一来,前端代码的可靠性,可维护性,可拓展性,以及前端web应用的性能,开发效率等等各方面就成了不得不考虑的问题。
于是我们就产生了前端工程化这个概念,来解决这些问题。现阶段的前端工程化,需要考虑到各个方面,包括但不限于以下这几点:
webpack-dev-server 热加载
以前,我们的日常前端开发的流程是这样的: 修改代码 -> 切换IDE到浏览器 -> 刷新浏览器查看效果(有时候还需要清除缓存) -> 修改代码 ....。
这套流程,尤其是刷新浏览器这个过程,无疑是相当低效繁琐枯燥的。 而webpack-dev-server 替我们解决了这个问题,它有两种模式,两种模式,一种是 watch 模式,功能是你修改代码,自动帮你刷新页面,无需手动刷新;另一种更加强大,基于 websocket 全双工通信技术,直接无刷新帮你把修改的代码替换掉。 从而极大程度上提高了开发效率。
数据mock
在后端接口还没提供的时候,前后端制定好共同的接口协议,开发时前端可以使用mock模拟数据,与后端彻底分离,并行开发。面向接口编程,尽可能减少前后端沟通成本。
loader: 'url-loader?limit=8192',使得小于8kb的图片使用data:image base64 编码内联,减少图片请求量模块化
主要指 js 代码的模块化。以前的前端开发并没有模块化这个概念,这给维护大型项目带来了极大的困难。发展到现在的前端有很多模块化的方法可供选择,如seajs ,requirejs, webpack 等。 模块化能很大程度上提高了代码的可维护性。
CSS 预处理
通过sass,less 等css 预处理器,可以实现 css 文件的拆分,颗粒化,实现css可复用。而且通过autoprefixer或postcss 还可以让 css 样式对老旧浏览器向下兼容。
此外,通过使用 css-modules 能够避免css全局污染的问题,极大提高css代码的可控性,不需要设定一堆命名空间与命名规范来限制。
ES6 + babel 编译
javascript本身设计存在一定程度上的缺陷,例如“没有模块化”,“没有块级作用域”,“全局变量污染”,“回调地狱”等等之类的问题,为了改善这些缺陷,计算机协会在2015年推出了ECMAScript 6 标准(今年已经ES8 已经发布了),使用ES6的语法除了能有效减少代码量之外,还引入了块级作用域,模块化,类的语法糖,promise以及一些新的API,很大程度上填了以前javascript的遗留下的坑,以及提高了代码质量。
不过即便过了两年,ES6也并没有被市面的主流浏览器完全支持,所以我们还需用 babel 将ES6 编译成ES5,再将一些不支持的API polyfill 处理。
eslint 代码检查
一直一来,代码风格都是一场无休止的争论,每个人都有自己的代码风格习惯,而这些习惯无非就是tab还是空格,换不换行,加不加空格等等之类的琐事,与其通过制定规范去强行限制开发者的编写习惯,不如从工具层面彻底解决代码风格的问题。eslint可以自动处理一些代码风格的问题,直接将代码通过指定的规则格式化,使代码整体风格统一。
更进一步,eslint 还可以禁止代码的一些可能造成不良影响的行为(例如eval,未定义变量),使其抛出错误。降低代码产生bug的可能性。
单元测试
集成单元测试,提高代码可靠性。前端较为流行的单元测试 mocha,qunit 等
UI 自动化测试
UI 自动化测试是 软件通过模拟浏览器,对页面进行UI操作,判断是否产生预想的UI效果。目前较为流行的UI自动化测试套件主要是 基于phantomjs的 nightmare
web组件化
web组件化是通过自定义标签,从UI层面对代码的拆分,提高前端代码的可复用性。尽管w3c已经初步对web组件化制定了规范, 但目前浏览器对web 组件化的支持惨不忍睹,无法通过原生的方法来实现web组件,但目前流行的前端框架,如vue,angular,react都有提供自己的web组件化,从而提高代码可复用性。
<script> 直接引入加载在没有引入模块化的概念之前,前端往往需要手动处理js文件的依赖关系,例如;bootstartp 依赖 jquery,就需要在引入bootstrap之前引入jquery
<script src="src/jquery.min.js" ></script>
<script src="src/bootstrap.min.js" ></script>
如果引入js文件顺序错了则会报错。 乍一看似乎没什么难度呀,是人都能分清是吧。那么请看下面这种情况:
有 a.js, b.js, c.js, d.js, e.js 五个文件,其中
那么根据以上关系,请按正确顺序引入js文件(黑人问号???)。当然,事实上也并不难区分其优先级,逐级递推就很快可以推断出引入顺序为 e,d,b,a,c。
毫无疑问,对于稍微复杂点的web工程,存在复杂依赖情况是极有可能发生的,并且把时间耗费在管理依赖关系上也不值当。
所以就诞生了前端模块化
经历了混乱加载的黑历史,我们终于迎来了js的模块化,忽如一夜春风来,一夜之间冒出一堆模块化标准。
其中具有代表性的模块加载器分别是是遵循AMD(Asynchronous Module Definition)规范的RequireJS ,还有淘宝玉伯开源的 遵循CMD(Common Module Definition)规范的 SeaJS。 两者除了遵循规范不一样之外,封装模块有差别之外,都各有所长,而且对旧版本浏览器的支持都相当完美。
当然除了这两个,还有各类其他开发者开发的模块加载器,当真是一番群魔乱舞百家争鸣的盛世呀。在此就不一一细述了。
下面有请我们的主角出厂: ES6 Module。
ES6 Module 是新一代javascript标准 ECMAScript 6 的新增特性,其语法和Python相似,比较简洁易用。另外,相比于其他模块加载器,ES6 Module 是语法级别的实现,其静态代码分析相比于其他框架会更快更高效,方便做代码检测。
// import 基本语法
import React from 'react'; //等价于 var React = require("react");
import { stat, exists, readFile } from 'fs';
// 等价于
// var fs = require('fs');
// var stat = fs.stat, exists = fs.exists, readFile = fs.readFile;
而且,且不论其API优劣,其语法与前面说的模块化有什么区别的,ES6 Module最大优点是显而易见的: 它是官方标准,而不是其他妖艳贱货第三方开发的框架/库。跟着有名分的原配混,毫无疑问是有前途更稳定的吧。
当然,缺点也是很明显的,不同于RequireJS,SeaJS 向下兼容到极致(ie6+),ES6 Module 的兼容性还未覆盖绝大部分浏览器,支持ES6 Module的浏览器寥寥无几,虽然可以通过babel进行语法转译,不过兼容性毕竟是硬伤,唯有时间能治愈。
从描述可知,前端工程化需要做的事情,单凭人力一个一个去处理基本没有可能完成,那么,我们就需要学会使用工具,毕竟程序猿和猿之间最大的区别就是会不会使用工具。
grunt 和 gulp 就是自动化构建工具。我们通过安装对应的node_module,根据gulp/grunt 的API编写相对应的任务(如:css预处理,代码合并压缩,代码校验检查等任务,js代码转译),那么就可以生成我们想要的结果,完成前端工作流管理,极大程度地提高效率。其作用其实就相当于makefile 的make 操作,将手工操作自动化,其任务编写格式如下。
// gulp scss预处理任务
gulp.task('styles', function() {
return gulp.src('src/styles/main.scss')
.pipe(sass({ style: 'expanded' }))
.pipe(autoprefixer('last 2 version', 'safari 5', 'ie 8', 'ie 9', 'opera 12.1', 'ios 6', 'android 4'))
.pipe(gulp.dest('dist/assets/css'))
.pipe(rename({suffix: '.min'}))
.pipe(minifycss())
.pipe(gulp.dest('dist/assets/css'))
.pipe(notify({ message: 'Styles task complete' }));
});
前面说了那么多SeaJS,RequireJS的模块化 ,又有gulp ,grunt的自动化处理,想必都有点觉得这前端工程化的技术栈也太繁琐了吧。
那么现在,你可以统统不用管啦,让我们推出终极解决方案:Webpack。
相比于seajs / requirejs 需要在浏览器引入 sea.js 、require.js 的模块解析器文件,浏览器才能识别其定义的模块。 webpack不需要在浏览器中加载解释器,而是直接在本地将模块化文件(无论是AMD,CMD规范还是ES6 Module)编译成浏览器可识别的js文件。
另外,相对于gulp/grunt 的批处理工作流功能,webpack 也可以通过 loader、plugin的形式对所有文件进行处理,来实现类似的功能。
其主要工作方式是: 整个项目存在一个或多个入口js文件,通过这个入口找到项目的所有依赖文件,通过loader,plugin进行处理后,打包生成对应的文件,输出到指定的output目录中。可以说是集模块化与工作流于一身的工具。
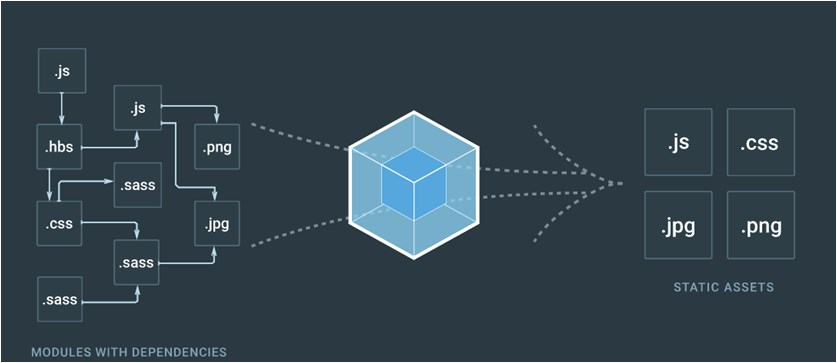
当然,webpack也并非银弹。工具没有好坏,只有适合与否。即便是webpack也并非适用于所有场合。
webpack 的最大特点是一切皆为模块,一切全包,最适和应用在SPA一站式应用场景。只有简单几个页面的情况下使用 webpack 反而可能会增加不必要的配置成本,反而直接用gulp或者其他工具处理代码压缩,css 预处理之类的工作会更加快捷易用。
另外,除了最主流的 webpack 之外,同性质的模块化打包器还有 browserIfy,以及百度的 fis ,由于对这两者了解不多,就不一一比较了。
废话少说,talk is easy , show me the code,我们来看看webpack是怎么工作的。以下是一个配置了webpack-dev-server的本地开发webpack配置文件。 具体可访问 github 地址 查看完整信息
// webpack.dev.config.js
let path = require('path'),
webpack = require('webpack');
let resolve = path.resolve;
let webRootDir = resolve(__dirname, '../');
module.exports = {
entry: { // 入口文件,打包通过入口,找到所有依赖的模块,打包输出
main: resolve(webRootDir, './src/main.js'),
},
output: {
path: resolve(webRootDir, './build'), // 输出路径
publicPath: '/build/', // 公共资源路径
filename: '[name].js' // 输出文件名字,此处输出main.js, babel-polyfill.js , 视情况可以配置[name].[chunkhash].js添加文件hash, 管理缓存
},
module: {
rules: [ //模块化的loader,有对应的loader,该文件才能作为模块被webpack识别
{
test: /\.js$/,
loader: 'babel-loader',
exclude: /node_modules/
},
{
test: /\.(png|jpg|gif|svg|ico)$/,
loader: 'file-loader',
options: {
name: '[name].[ext]?[hash]'
}
},
{
test: /\.(eot|svg|ttf|woff|woff2)(\?\S*)?$/,
loader: 'file-loader'
},
{
test: /\.css$/,
loader: 'style-loader!css-loader'
},
{
test: /\.scss$/,
loader: 'style-loader!css-loader!autoprefixer-loader?{browsers:["last 5 version", "Firefox' +
' 15"]}!sass-loader?sourceMap&outputStyle=compressed'
}
]
},
resolve: {
extensions: ['.js'], // 定义后缀名 ,import时可以省略“.js”后缀
alias: { // 别名。 如 import "./src/style/common.css" ==> import "style/common.css"
'components': resolve(webRootDir, './src/components'),
'page': resolve(webRootDir, './src/page'),
'style': resolve(webRootDir, './src/style'),
'script': resolve(webRootDir, './src/script'),
'static': resolve(webRootDir, './static')
}
},
devServer: { // webpack-dev-server 热加载的配置
host: '127.0.0.1', //本地ip, 如需局域网内其他及其通过ip访问,配置"0.0.0.0"即可
port: 8080,
disableHostCheck: true,
historyApiFallback: true,
noInfo: true
},
performance: {
hints: false
},
}
module.exports.devtool = '#source-map'
/*插件*/
module.exports.plugins = (module.exports.plugins || []).concat([
// webpack 变量定义,,可在其他模块访问到该变量值,以便根据不同环境来进行不同情况的打包操作。
// 例如,在main.js 下 console.log( process.env.Node_ENV ) 输出 development字符串
new webpack.DefinePlugin({
'process.env': {
NODE_ENV: `"development"`
}
}),
])
@SunshowerC 请问博主有考虑webpack resolve.mainFields配置吗。
按照文档,浏览器环境下,解析顺序是 browser > module > main。但是看上面的图,会首先看module 是否有值,如果没有值的话,就算browser 有值,也会用main。这似乎有些出入?
其次,不知道图中的顺序是基于webpack resolve.mainFields什么顺序得出的结论?
@colgin 流程图确实有点问题,实际上不存在 module 时会再判断有没有 browser 的,解析顺序是 browser > module > main,所以有 browser 无 module 的场景下是用 browser 的,图中基于 mainFields 的默认配置得出的结论,可以通过自行配置 mainFields 改变其优先级
Originally posted by @SunshowerC in #8 (comment)
用过 vue-cli 3.0 的人可能会知道,vue-cli 提供了一个 modern 模式,可以在一个工程同时构建打包 ES5 和 ES6 两份代码:
Vue CLI 会产生两个应用的版本:一个现代版的包,面向支持 ES modules 的现代浏览器,另一个旧版的包,面向不支持的旧浏览器。
最酷的是这里没有特殊的部署要求。其生成的 HTML 文件会自动使用 Phillip Walton 精彩的博文(译文)中讨论到的技术:
现代版的包会通过
<script type="module">在被支持的浏览器中加载;它们还会使用<link rel="modulepreload">进行预加载。旧版的包会通过
<script nomodule>加载,并会被支持 ES modules 的浏览器忽略。一个针对 Safari 10 中
<script nomodule>的修复会被自动注入。对于一个 Hello World 应用来说,现代版的包已经小了 16%。在生产环境下,现代版的包通常都会表现出显著的解析速度和运算速度,从而改善应用的加载性能。
简单来说,通过这种技术能够
这么棒的技术已经在 vue-cli 上集成了,可惜在 create-react-app 上有过一阵讨论,却依旧没什么进展。
所以我个人根据 create-react-app 2.x 的 react-scripts 做了些自己的改造,在 react 上实现了这个现代模式的构建。具体可以访问 github 仓库 : react-scripts-modern
接下来我们来看看基本实现思路。
上面说过,我们需要用 webpack 构建编译出 ES5 和 ES6 两份代码。
首先是编译出 ES5 的代码,大家应该很熟悉 babel 7 那一套了,这里不再多说,这里直接给出 babel 配置代码。还对 babel 7
// .babelrc.js
module.exports = {
"plugins": [
[
"@babel/plugin-transform-runtime",
{
"corejs": false, // 默认值,可以不写
"helpers": true, // 默认,可以不写
"regenerator": false, // 通过 preset-env 已经使用了全局的 regeneratorRuntime, 不再需要 transform-runtime 提供的 不污染全局的 regeneratorRuntime
"useESModules": true, // 使用 es modules helpers, 减少 commonJS 语法代码
}
]
],
presets: [
[
"@babel/preset-env",
{
"modules": false, // 模块使用 es modules ,不使用 commonJS 规范
"useBuiltIns": 'usage', // 默认 false, 可选 entry , usage
}
]
]
}
对babel 7不是很了解的同学,可以看下官方文档或者我之前写的文章: Show me the code,babel 7 最佳实践!
要编译 ES6 是不是说就可以直接不用 babel 了呢?
然鹅并不是,因为还有一些 ES7/ES8 特性是 浏览器尚未正式支持但我们确实需要的,例如:异步加载,JSX 语法等等,我们一般需要找到对应的 babel plugin 来实现,所以还是需要 babel。
module.exports = {
// ... 其他可能需要的 plugin
presets: [
[
"@babel/preset-env",
{
"modules": false, // 模块使用 es modules ,不使用 commonJS 规范
"targets": {
"esmodules": true, // 忽略 browserslist 配置,不转换 ES6 语法也不 polyfill ES6 的 API
},
}
]
]
}正常的构建过程,我们一般使用 HtmlWebpackPlugin 来将 webpack 构建出来的 JS/CSS 资源嵌入到 我们的 HTML 模板中。
那么,若要将我们的 HTML 的 script 标签加上 module 和 nomodule 属性,我们就需要额外写一个 webpack 插件,在 HtmlWebpackPlugin 的钩子中,做一些我们的处理。
// 在 htmlWebpackPlugin 拿到资源的钩子函数中,
// 给 script 标签加上 type=module 或者 nomodule 属性
this.htmlWebpackPlugin
.getHooks(compilation)
.alterAssetTags
.tapAsync(
id,
(data, cb) => {
data.assetTags.scripts.forEach(tag => {
// 遍历下资源,把 script 中的 ES2015+ 和 legacy 的处理开
if (tag.tagName === 'script') {
// 给 legacy 的资源加上 nomodule 属性,反之加上 type="module" 的属性
if (/-legacy\./.test(tag.attributes.src)) {
delete tag.attributes.type
tag.attributes.nomodule = true
} else {
tag.attributes.type = 'module'
}
}
})
}
)
完全的插件代码可直接访问 html-webpack-esmodules-plugin.js
上面说到,我们其实是分别进行了 两次 webpack 编译打包构建:
(async ()=>{
await buildByConfig(es6WebpackConfig)
await buildByConfig(es5WebpackConfig)
})()那么其实存在一个问题,打包一次,生成一份 js 代码,一个 index.html
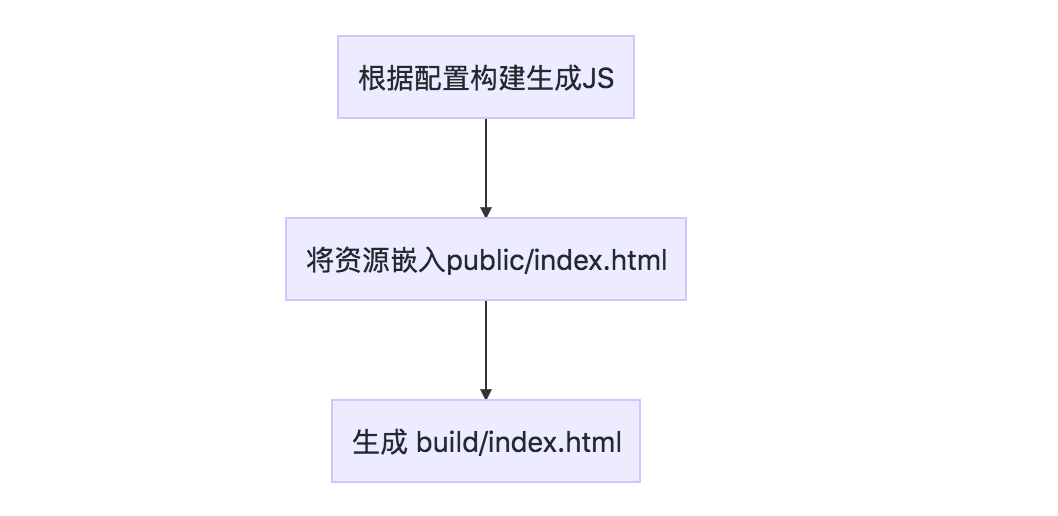
那如果 webpack 打包了两次,构建出了两份 JS 代码, 那岂不是也会出现 两份 index.html ?
当然事实上虽然不会构建出两份 index.html,但是这个问题明显会导致第二次构建出来 index.html 覆盖掉 第一次构建出来的 index.html。**导致只有 ES5 或者 ES6 的资源被 外链进 index.html **,不符合我们的预期。
解决方案其实很简单,第一次构建是用 public/index.html 为模板,构建出来 build/index.html;那么,第二次构建,就明显不能用 public/index.html 为模板,而是用第一次构建生成的 build/index.html 为模板,进行第二次构建,那么即便生成的 build/index.html 模板覆盖掉了原有的 build/index.html,但仍然是包含 es5 和 es6 的代码。

<!-- ES6 的代码,只会被 现代浏览器下载执行 -->
<script type="module" src="/js/main.min.js" ></script>
<!-- ES5 的代码,只会被老版浏览器下载执行 -->
<script nomodule src="/js/main-legacy.min.js" ></script>safari 10.3 不支持 nomodule, 需要进行简单的 polyfill。
在 safari 浏览器或者 IOS webview 的场景下, 如果同时使用了 module/nomodule 和 常规的 script 外链。例如:
<script src="https://www.google.com/some-script.js" ></script>
<script type="module" src="/js/main.min.js" ></script>
<script nomodule src="/js/main-legacy.min.js" ></script>由于<script src="https://www.google.com/some-script.js" ></script> 的存在, **safari 会同时下载 main.min.js(ES6的代码), main-legacy.min.js(ES5的代码),但只会执行其中一份代码(所以不会影响代码逻辑),但是下载了 ES5 + ES6 的代码,有一份代码却没有用到,终究是造成了负面影响。
解决方案是将所有带有 type=module/nomodule 的 script 标签放到没有 type=module/nomodule 的 script 标签之前:
<script type="module" src="/js/main.min.js" ></script>
<script nomodule src="/js/main-legacy.min.js" ></script>
<script src="https://www.google.com/some-script.js" ></script>在更低的浏览器版本(例如 Chrome 43),会出现和 2 类似的问题,同样会下载两份代码,却执行其中一份,同时2 的解决方案对此无效。这种情况,很大程度上只能用动态插入 script 标签取代 type=module/nomodule 来解决。
<!-- 将代码内联在 HTML -->
<head>
<script>
(function(){
var insertScript = function(option, elem) {
if(!option) return false;
var s = document.createElement("script");
elem = elem || document.head
for(var name in option) {
s.defer = true
s.setAttribute(name, option[name])
}
elem.appendChild(s)
}
var script = document.createElement("script");
var supportEsModule = 'noModule' in script;
var modernList = [{src: '/main.min.js'}];
var legacyList = [{src: '/main-legacy.min.js'}];
var scriptList = supportEsModule ? modernList : legacyList
scriptList.forEach(function(item){
insertScript(item)
})
})()
</script>
</head>但这种方法明显延缓 资源的下载时机(大概十几毫秒),虽然 现代浏览器通过 preload 还是能够实现提前下载资源避免这种方案的缺陷,但是 不支持nomodule 也不支持 preload 的老版浏览器依然会有这种缺陷。
所以除非你的用户里老版浏览器占据了相当一部分份额,否则个人不建议这种做法。
以上全部实现,我都已经封装到了 react-scripts-modern
习惯用 create-react-app 生成项目的同学 可以快速通过 create-react-app 工程名 --scripts-version react-scripts-modern (加上 --typescript 属性 生成 react + ts 工程) 命令生成支持 modern build 的工程,开箱即用
Row 是用于展示水平方向的子部件的部件。
基本使用:
MaterialApp(
title: 'Flutter Demo',
home: Row(
children: [
Container(
color: Colors.orange,
child: FlutterLogo(
size: 60.0,
),
),
Container(
color: Colors.blue,
child: FlutterLogo(
size: 60.0,
),
),
Container(
color: Colors.purple,
child: FlutterLogo(
size: 60.0,
),
),
],
)
);
}
Row 部件本身不会水平滚动,如果您有很多子部件并希望它们能够在没有足够空间的情况下滚动,请考虑使用ListView类。
Column是用于展示垂直方向的子部件的部件。
Column(
children: [
Container(
color: Colors.orange,
child: FlutterLogo(
size: 60.0,
),
),
Container(
color: Colors.blue,
child: FlutterLogo(
size: 60.0,
),
),
Container(
color: Colors.purple,
child: FlutterLogo(
size: 60.0,
),
),
],
)
同样,Column部件不会垂直滚动。如果您有一系列小部件并希望它们能够在没有足够空间时滚动,请考虑使用ListView。
Column 和 Row 部件拥有同样的属性,所以在以下的例子中我们将会同时使用这两个部件。
将子部件将子部件尽可能接近主轴起点
Row(
mainAxisAlignment: MainAxisAlignment.start,
children: [
Container(
color: Colors.blue,
height: 50.0,
width: 50.0,
),
Icon(Icons.adjust, size: 50.0, color: Colors.pink),
Icon(Icons.adjust, size: 50.0, color: Colors.purple,),
Icon(Icons.adjust, size: 50.0, color: Colors.greenAccent,),
Container(
color: Colors.orange,
height: 50.0,
width: 50.0,
),
Icon(Icons.adjust, size: 50.0, color: Colors.cyan,),
],
);
相当于 CSS 的
.row {
display: flex;
justify-content: flex-start;
/* 竖直排列时 flex-direction: column; */
}子部件居中
相当于 CSS 的
.row {
display: flex;
justify-content: center;
/* 竖直排列时 flex-direction: column; */
}子部件尽可能靠近主轴尾部
相当于 CSS 的
.row {
display: flex;
justify-content: flex-end;
}将可用空间均匀地放置在子部件之间,且头尾两个部件离边缘的空间只有子部件之间空间的一半
相当于 CSS 的
.row {
display: flex;
justify-content: space-around;
}将可用空间均匀地放置在子部件之间
相当于 CSS 的
.row {
display: flex;
justify-content: space-between;
}将可用空间均匀地放置在子部件之间,包括首尾部件的边缘。
相当于 CSS 的
.row {
display: flex;
justify-content: space-evenly;
}和主轴垂直相交方向的轴。
与交叉轴起始边对齐
Row(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Container(
color: Colors.blue,
height: 50.0,
width: 50.0,
),
Icon(Icons.adjust, size: 50.0, color: Colors.pink),
Icon(Icons.adjust, size: 50.0, color: Colors.purple,),
Icon(Icons.adjust, size: 50.0, color: Colors.greenAccent,),
Container(
color: Colors.orange,
height: 50.0,
width: 50.0,
),
Icon(Icons.adjust, size: 50.0, color: Colors.cyan,),
],
);
相当于 CSS 的:
.row {
display: flex;
align-items: flex-start;
}Row 部件:
Column 部件
交叉轴居中对齐
相当于 CSS 的:
.row {
display: flex;
align-items: center;
}交叉轴末端对齐
相当于 CSS 的:
.row {
display: flex;
align-items: flex-end;
}子部件填充满交叉轴
相当于 CSS 的:
.row {
display: flex;
align-items: stretch;
}子部件 基线对齐
值为 CrossAxisAlignment.baseline时 必须同时使用 textBaseline, 否则会报错
Row(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Text(
'Flutter',
style: TextStyle(
color: Colors.yellow,
fontSize: 30.0
),
),
Text(
'Flutter',
style: TextStyle(
color: Colors.blue,
fontSize: 20.0
),
),
],
);
Row(
crossAxisAlignment: CrossAxisAlignment.baseline,
textBaseline: TextBaseline.alphabetic,
children: [...]
)相当于 CSS 的:
.row {
display: flex;
align-items: baseline;
}文字从右到左排列,主轴(水平)方向 start->end 是 从右到左
Row(
mainAxisAlignment: MainAxisAlignment.start,
crossAxisAlignment: CrossAxisAlignment.center,
textDirection: TextDirection.rtl,
children: [
Text(
'Flutter',
style: TextStyle(
color: Colors.yellow,
fontSize: 30.0
),
),
Text(
'Flutter',
style: TextStyle(
color: Colors.blue,
fontSize: 20.0
),
),
],
);
从左往右排列,主轴(水平)方向 start->end 是 从左到右
交叉轴(水平)方向 start->end 是 从左到右
Column(
mainAxisAlignment: MainAxisAlignment.start,
crossAxisAlignment: CrossAxisAlignment.start,
textDirection: TextDirection.rtl,
children: [
Text(
'Flutter',
style: TextStyle(
color: Colors.yellow,
fontSize: 30.0
),
),
Text(
'Flutter',
style: TextStyle(
color: Colors.blue,
fontSize: 20.0
),
),
],
);
默认情况不必多说
和 textDirection 类似
从上往下摆放组件,竖直方向 start->end 是 从上到下
对于 Column 部件的子部件从下往上摆放组件,竖直方向 start->end 是 从下到上
Column(
mainAxisAlignment: MainAxisAlignment.start,
crossAxisAlignment: CrossAxisAlignment.end,
verticalDirection: VerticalDirection.up,
children: [
Text(
'Flutter',
style: TextStyle(color: Colors.yellow, fontSize: 30.0),
),
Text(
'Flutter',
style: TextStyle(color: Colors.blue, fontSize: 20.0),
),
],
);
所有子部件占据主轴的空间大小
Center(
child: Container(
color: Colors.yellow,
child: Row(
mainAxisSize: MainAxisSize.max,
mainAxisAlignment: MainAxisAlignment.center,
children: [
Container(
color: Colors.blue,
height: 50.0,
width: 50.0,
),
Icon(Icons.adjust, size: 50.0, color: Colors.pink),
Icon(Icons.adjust, size: 50.0, color: Colors.purple,),
Icon(Icons.adjust, size: 50.0, color: Colors.greenAccent,),
Container(
color: Colors.orange,
height: 50.0,
width: 50.0,
),
Icon(Icons.adjust, size: 50.0, color: Colors.cyan,),
],
),
),
);
加上黄色背景可以看到 Row 部件占据了一整行空间
Column 同理,不再赘述。
使子部件占据空间尽可能小。
Center(
child: Container(
color: Colors.yellow,
child: Column(
mainAxisSize: MainAxisSize.min,
children: [
Container(
color: Colors.blue,
height: 50.0,
width: 50.0,
),
Icon(Icons.adjust, size: 50.0, color: Colors.pink),
Icon(Icons.adjust, size: 50.0, color: Colors.purple,),
Icon(Icons.adjust, size: 50.0, color: Colors.greenAccent,),
Container(
color: Colors.orange,
height: 50.0,
width: 50.0,
),
Icon(Icons.adjust, size: 50.0, color: Colors.cyan,),
],
),
),
);
Row 部件同理,不再赘述。
一个复杂的应用,往往由很多个模块组成,而且往往会存在各种各样奇奇怪怪的使用场景,谁也不能保证自己维护的服务永远不会出问题,等用户投诉才发现问题再去处理问题就为时已晚,损失已无法挽回。
所以,通过数据指标来衡量一个服务的稳定性和处理效率,是否正常运作,监控指标曲线的状态,指标出现异常时及时主动告警,这一套工具就十分重要。
常见的一些指标,包括但不限于:
举个例子,假如一个服务:
又或者一个前端单页面应用:
这到底是人性的扭曲还是道德的沦丧
一旦应用存在某些缺陷导致这些问题,通过服务日志,很难直观快速地察觉到这些指标的变化波动。
而对于前端,则很可能根本无法感知到用户的行为,只能通过埋点进行一定程度地监控。
通过监控和告警手段可以有效地覆盖了「发现」和「定位」问题,从而更有效率地排查和解决问题。
Prometheus 是一个开源的服务监控系统和时间序列数据库。
工作流可以简化为:
具体的架构设计如下:
Prometheus 用的是自己设计的时序数据库(TSDB),那么为什么不用我们更加熟悉,更加常用的 mysql, 或者其他关系型数据库呢?
假设需要监控 WebServerA 每个API的请求量为例,需要监控的维度包括:服务名(job)、实例IP(instance)、API名(handler)、方法(method)、返回码(code)、请求量(value)。

如果以SQL为例,演示常见的查询操作:
# 查询 method=put 且 code=200 的请求量
SELECT * from http_requests_total WHERE code=”200” AND method=”put” AND created_at BETWEEN 1495435700 AND 1495435710;
# 查询 handler=prometheus 且 method=post 的请求量
SELECT * from http_requests_total WHERE handler=”prometheus” AND method=”post” AND created_at BETWEEN 1495435700 AND 1495435710;
# 查询 instance=10.59.8.110 且 handler 以 query 开头 的请求量
SELECT * from http_requests_total WHERE handler=”query” AND instance=”10.59.8.110” AND created_at BETWEEN 1495435700 AND 1495435710;通过以上示例可以看出,在常用查询和统计方面,日常监控多用于根据监控的维度进行查询与时间进行组合查询。如果监控100个服务,平均每个服务部署10个实例,每个服务有20个API,4个方法,30秒收集一次数据,保留60天。那么总数据条数为:100(服务)* 10(实例)* 20(API)* 4(方法)* 86400(1天秒数)* 60(天) / 30(秒)= 138.24 亿条数据,写入、存储、查询如此量级的数据是不可能在Mysql类的关系数据库上完成的。 因此 Prometheus 使用 TSDB 作为 存储引擎。
时序数据库主要用于指处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时序数据。
对于 prometheus 来说,每个时序点结构如下:
每个指标,有多个时序图;多个时序数据点连接起来,构成一个时序图

假如用传统的关系型数据库来表示时序数据,就是以下结构:
| create_time | __metric_name__ |
path | value |
|---|---|---|---|
| 2020-10-01 00:00:00 | http_request_total | /home | 100 |
| 2020-10-01 00:00:00 | http_request_total | /error | 0 |
| 2020-10-01 00:00:15 | http_request_total | /home | 120 |
| 2020-10-01 00:01:00 | http_request_total | /home | 160 |
| 2020-10-01 00:01:00 | http_request_total | /error | 1 |
指标 request_total{path="/home"} 在 2020-10-01 00:01:00 时的 qps = (160 - 100)/60 = 1 , 同理,
指标 request_total{path="/error"} 在 2020-10-01 00:01:00 时的 qps = 1/60
相比于 MySQL,时序数据库核心在于时序,其查询时间相关的数据消耗的资源相对较低,效率相对较高,而恰好指标监控数据带有明显的时序特性,所以采用时序数据库作为存储层
const reqCounter = new Counter({
name: `credit_insight_spl_id_all_pv`,
help: 'request count',
labelNames: ['deviceBrand','systemType', 'appVersion', 'channel']
})
reqCounter.inc({
deviceBrand: 'Apple',
systemType: 'iOS',
appVersion: '26014',
channel: 'mepage'
},1)/metrics 的controller @Get('metrics')
getMetrics(@Res() res) {
res.set('Content-Type', register.contentType)
res.send(register.metrics())
}
/metrics 接口,获得
promQL 是 prometheus 的查询语言,语法十分简单
查询指标最新的值:
{__name__="http_request_total", handler="/home"}
# 语法糖:
http_request_total{handler="/home"}
# 等价于 mysql:
select * from http_request_total
where
handler="/home" AND
create_time=《now()》
查询过去一分钟内的数据
# promQL
http_request_total[1m]
# 等价于
SELECT * from http_requests_total
WHERE create_time BETWEEN 《now() - 1min》 AND 《now()》;
PS: promQL 不支持指定时间点进行查询,只能通过 offset 来查询历史某个点的数据
查询一个小时前的数据。
# promQL
http_request_total offset 1h
# 等价于
SELECT * from http_requests_total
WHERE create_time=《now() - 1 hour》;
根据以上的查询语法,我们可以简单组合出一些指标数据:
例如,查询最近一天内的 /home 页请求数
http_request_total{handler="/home"} - http_request_total{handler="/home"} offset 1d
那么实际上面这个写法很明显比较不简洁,我们可使用内置 increase 函数来替换:
# 和上述写法等价
increase(http_request_total{handler="/home"}[1d])
除了 increase 外,还有很多其他好用的函数,例如,
rate 函数计算 QPS
// 过去的 2 分钟内平均每秒请求数
rate(http_request_total{code="400"}[2m])
// 等价于
increase(http_request_total{code="400"}[2m]) / 120
除了上述基础查询外,我们可能还需要聚合查询
假如我们有以下数据指标:
credit_insight_spl_id_all_pv{url="/home",channel="none"}
credit_insight_spl_id_all_pv{url="/home",channel="mepage"}
credit_insight_spl_id_all_pv{url="/error",channel="none"}
credit_insight_spl_id_all_pv{url="/error",channel="mepage"}
将所有指标数据以某个维度进行聚合查询时,例如:查询 url="/home" 最近一天的访问量,channel 是 none还是mepage 的 /home 访问量都包括在内。
我们理所当然地会写出:
increase(credit_insight_spl_id_all_pv{url="/home"}[1d])
但实际上我们会得出这样的两条指标结果:
credit_insight_spl_id_all_pv{url="/home",channel="none"} 233
credit_insight_spl_id_all_pv{url="/home",channel="mepage"} 666

并非我们预期中的:
credit_insight_spl_id_all_pv{url="/home"} 899
而要是我们想要得到这样的聚合查询结果,就需要用到 sum by
# 聚合 url="/home" 的数据
sum(increase(credit_insight_spl_id_all_pv{url="/home"}[1d])) by (url)
# 得出结果:
credit_insight_spl_id_all_pv{url="/home"} 899 # 所有 channel 中 /home 页访问量累加值
# 聚合所有的 url 则可以这样写:
sum(increase(credit_insight_spl_id_all_pv{}[1d])) by (url)
# 得出结果:
credit_insight_spl_id_all_pv{url="/home"} 899
credit_insight_spl_id_all_pv{url="/error"} 7
# 等价于 mysql
SELECT url, COUNT(*) AS total FROM credit_insight_spl_id_all_pv
WHERE create_time between <now() - 1d> and <now()>
GROUP BY url;
以上的所有例子的查询数值,其实都是最近时间点的数值,
而我们更关注的是一个时间段的数值变化。
要实现这个原理也很简单,只需要在历史的每个时间点都执行一次指标查询,
# 假如今天7号
# 6号到7号的一天访问量
sum(increase(credit_insight_spl_id_all_pv{}[1d] )) by (url)
# 5号到6号的一天访问量 offset 1d
sum(increase(credit_insight_spl_id_all_pv{}[1d] offset 1d)) by (url)
# 4号到5号的一天访问量
sum(increase(credit_insight_spl_id_all_pv{}[1d] offset 2d)) by (url)
而 Prometheus 已经内置了时间段查询功能,并对此优化处理。
可通过 /api/v1/query_range 接口进行查询,获的 grpah:

数据存储:
指标数据有 “Writes are vertical,reads are horizontal” 的(垂直写,水平读)模式:
“Writes are vertical,reads are horizontal” 的意思是 tsdb 通常按固定的时间间隔收集指标并写入,会 “垂直” 地写入最近所有时间序列的数据,而读取操作往往面向一定时间范围的一个或多个时间序列,“横向” 地跨越时间进行查询
而 Prometheus 的默认查询 sample 上限是 5000w

所以,如果指标的时序图数量过大,允许查询的时间区间相对就会较小了。
一个图表查询时序数量的影响因素有 3 个,分别是:
以 credit_insight_spl_id_all_pv 指标为例,该指标总共大约有 n = 163698 种时序,

假如 step = 15s,如果搜索该指标过去 time = 60m 的全部时序图,那么,需要搜索的例子要
163698 * 60 * (60/15) = 39287520,将近 4kw,是可以搜出来的。
但如果搜的是过去 90m 的数据,163698 * 90 * 4 = 58931280,超过了 5000w,你就发现数据请求异常:
Error executing query: query processing would load too many samples into memory in query execution

所以,目测可得一个图的查询时序点数量公式是:total = n * time / step, time 和 step 的时间单位必须一致,total 必须不超过 5000w。
反推一下得出,time < 5000w / n * step 。要扩大搜索时间范围,增大 step ,或者降低 n 即可做到。
step 不变, 降低 n 【指定label值可减少搜索条件的结果数】 : credit_insight_spl_id_all_pv{systemType="Android", systemVersion="10"},n = 18955

增大 step 到 30s, n 不变:

当然,一般情况下,我们的 n 值只有几百,而 step 基本是大于 60s 的,所以一般情况下都能查询 2 个多月以上的数据图。
grafana 是一个开源的,高度可配置的数据图表分析,监控,告警的平台,也是一款前端可视化的产品。

grafana 内置提供多种图表模板,具体是以下类型:

Prometheus 作为数据源的情况下,一般用的 graph 类型画时序图比较多。
对于一些基础的数据大盘监控,这些图表类型已经足够满足我们的需求。
但对于复杂的需求,这些类型无法满足我们的需要时,我们安装 pannel 插件,来更新可用的图表类型,也可以根据官方文档 build a panel plugin 开发自己的前端图表 panel。

在时序图表配置场景下,我们需要核心关注配置的有:

从上图可以看到,
为了实现一些常用的筛选过滤场景,grafana 提供了变量功能
变量配置:变量配置有多种方式(Type),可以自定义选项,也可以根据prometheus 指标的 label 动态拉取。

变量使用:变量通过 $xxx 形式去引用。

除了 Prometheus 本身可以配置告警表达式之外:

grafana 也可以配置告警:

Prometheus 通常用于后端应用的指标数据实时上报,主要用于异常告警,问题排查,所以数据存在时效性,我们不会关注几个月前的一个已经被排查并 fixed 的指标异常波动告警。
但是,要是我们将 Prometheus 用于业务指标监控,那么我们可能会关注更久远的数据。
例如我们可能想要看过去一个季度的环比同比增长,用 Prometheus 作为数据源就不合适,因为 Prometheus 是时序数据库,更多关注实时数据,数据量大,当前数据保存的时效设定只有 3 个月。
那么这个时候可能我们要维护一个长期的统计数据,可能就需要存储在 mysql 或者其他存储方式。
grafana 不是 Prometheus 的专属产品,还支持多种数据源,包括但不限于:
如果没有自己需要的数据源配置,还可以安装 REST API Datasource Plugin, 通过 http 接口查询作为数据源
了解 grafana 的高度可配置性设计后,有值得思考的几点:
等等这些,其实都是值得我们去思考的。
此外,Prometheus 和 grafana 都有些进阶的玩法,大家有兴趣也可以去探索下。
还没毕业时在其他平台写的博客,搬运到这吧,一家人就是要齐齐整整!
随着 CSS3 的推出与普及,其各种属性开始被广泛使用。尤其是其动画功能,对于一些简单的动画实现,实在没必要用 Javascript 去实现,这是 @Keyframes 动画就派上了用场。今天来讲一下@Keyframes的一些基本的用法和常见坑。
【本文志于向前端新手普及一些常见错误,如有任何错误,请指正。】
W3School 有更详细的介绍,这里就不再展开了,还不清楚的同学可以先去了解一下CSS3 @keyframes 规则再往下看。并且需要注意一下@Keyframes 和 animation的兼容性问题。对于各种浏览器的兼容情况可以参考下图:
可以看见当前大部分主流浏览器都支持@Keyframes和animation( 就剩下IE9及之前的版本"一枝独秀" 了);另外,IOS safari 8.4和安卓浏览器4.4.4及之前的版本需要加 -webkit- 前缀兼容
@Keyframes 的原理是把样式的从一个状态,慢慢转变为另一个状态。例如:
/*
* div 在2s内下移200px
*/
div {
position:absolute;
animation: move 2s;
}
@keyframes move {
from { top:0; }
to { top:200px;}
}
上述div的移动,不是一步完成的,而是中间有很多个状态,从top:1px , 到top :2px , top: 3px ……最终到 top:200px; 这样一系列状态组成而构成的动画。
所以,如果不存在渐变的状态,是无法用@Keyframes构成动画的,例如:
div {
animation: apear 2s;
}
@keyframes appear {
from { display:none; }
to { display:block;}
}
我们知道,display:none;是将div消失并且不占空间,display:block;则是将div展现存在并占据空间。但上述代码是无法使div拥有 2秒内从消失到展现 的渐变动画的,因为display:none;和display:block;是突变的,是从display:none;一下子到display:block;状态的。所以@Keyframes无法实现。
同理其他种类的突变属性也无法拥有@Keyframes的动画效果,@Keyframes 只存在于渐变属性当中,例如各种width, height, opacity等属性值为数值的属性。
/*
* div 在2s内下移200px
*/
div {
position:absolute;
top:0px;
animation: move 2s;
}
@keyframes move {
from { top:20px; }
to { top:200px;}
}
覆盖属性:如上述情况,div初始状态是top:0; @Keyframes首先用top:20px覆盖原属性(top:0;),然后再启动@Keyframes功能。 所以我们看到的效果是:div突然瞬间下降20px,然后在2秒内下降至指定位置(top:200px;)。
/*
* div 在2s内下移200px
*/
div {
position:absolute;
top:0px;
animation: move 2s;
}
@keyframes move {
from { top:0px; }
to { bottom:0px;}
}
添加属性:上述代码初始状态是div在顶部,最后状态是div 在底部,但像上面这样写 并不会出现div 从顶部慢慢下滑至底部的动画,而是div突然就出现在了底部。这是因为初始状态为div{ top:0px ;},但最终状态却不会是 div { bottom:0px; } , 而是 div { top:0px; bottom: 0px; } ,这样就会出现明显的错误,达不到我们预想的效果。
小结: @Keyframes 中的属性,如果div本身存在该属性,就被@Keyframes 中的属性给覆盖掉。 如果div本身不存在该属性,则为div增添该属性。
当你在使用@Keyframes 动画时,如果做的动画比较复杂的话,就会发现一个问题,那就是不流畅,掉帧,可能在PC端还不是很明显,但在移动端你就会发现严重地掉帧。这是因为,如果@Keyframes 改变的属性是与layout相关的话,就会触发重新布局,导致渲染和绘制的时间会更加地长。 所以,我们应该尽可能地使用不会触发重新布局的属性完成我们的动画。
1,Can I use animation
2,CSS3 @keyframes 规则
3,css属性的选择对动画性能的影响
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.