sunweiguo / http Goto Github PK
View Code? Open in Web Editor NEW:watermelon:从头开始学HTTP
:watermelon:从头开始学HTTP



HTTP 是基于 TCP/IP 协议的应用层协议。它不涉及数据包(packet)传输,主要规定了客户端和服务器之间的通信格式,默认使用80端口。
这是第一个定稿的HTTP协议。
比如发起一个GET请求:
GET /index.html
上面命令表示,TCP 连接(connection)建立后,客户端向服务器请求(request)网页index.html。
协议规定,服务器只能回应HTML格式的字符串,不能回应别的格式。
<html>
<body>Hello World</body>
</html>服务器发送完毕,就关闭TCP连接。
跟现在比较普遍适用的1.1版本已经相差不多。
首先,任何格式的内容都可以发送。这使得互联网不仅可以传输文字,还能传输图像、视频、二进制文件。这为互联网的大发展奠定了基础。
其次,除了GET命令,还引入了POST命令和HEAD命令,丰富了浏览器与服务器的互动手段。
再次,HTTP请求和回应的格式也变了。除了数据部分,每次通信都必须包括头信息(HTTP header),用来描述一些元数据。
其他的新增功能还包括状态码(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等。
下面是一个1.0版的HTTP请求的例子。
GET / HTTP/1.0
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
Accept: */*
可以看到,这个格式与0.9版有很大变化。
第一行是请求命令,必须在尾部添加协议版本(HTTP/1.0)。后面就是多行头信息,描述客户端的情况。
客户端请求的时候,可以使用Accept字段声明自己可以接受哪些数据格式。上面代码中,客户端声明自己可以接受任何格式的数据。
服务器的回应如下:
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
<html>
<body>Hello World</body>
</html>
回应的格式是"头信息 + 一个空行(\r\n) + 数据"。其中,第一行是"协议版本 + 状态码(status code) + 状态描述"。
关于字符的编码,1.0版规定,头信息必须是 ASCII 码,后面的数据可以是任何格式。因此,服务器回应的时候,必须告诉客户端,数据是什么格式,这就是Content-Type字段的作用。
每个TCP连接只能发送一个请求。发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接。
为了解决这个问题,有些浏览器在请求时,用了一个非标准的Connection字段。
Connection: keep-alive
这个字段要求服务器不要关闭TCP连接,以便其他请求复用。服务器同样回应这个字段。
Connection: keep-alive
一个可以复用的TCP连接就建立了,直到客户端或服务器主动关闭连接。但是,这不是标准字段,不同实现的行为可能不一致,因此不是根本的解决办法。
在1.1版本以前,每次HTTP请求,都会重新建立一次TCP连接,服务器响应后,就立刻关闭。众所周知,建立TCP连接的新建成本很高,因为需要三次握手,并且有着慢启动的特性导致发送速度较慢。而1.1版本添加的持久连接功能可以让一次TCP连接中发送多条HTTP请求,值得一提的是默认是,控制持久连接的Connection字段默认值是keep-alive,也就是说是默认打开持久连接,如果想要关闭,只需将该字段的值改为close。
Connection: close
而管道化则赋予了客户端在一个TCP连接中连续发送多个请求的能力,而不需要等到前一个请求响应,这大大提高了效率。值得一提的是,虽然客户端可以连续发送多个请求,但是服务器返回依然是按照发送的顺序返回。(强调的是request不需要等待上一个request的response,其实发送的request还是有顺序的,服务端按照这个顺序接收,依次返回响应)
HTTP/1.1允许多个http请求通过一个套接字同时被输出 ,而不用等待相应的响应。然后请求者就会等待各自的响应,这些响应是按照之前请求的顺序依次到达。(me:所有请求保持一个FIFO的队列,一个请求发送完之后,不必等待这个请求的响应被接受到,下一个请求就可以被再次发出;同时,服务器端返回这些请求的响应时也是按照FIFO的顺序)。管道化的表现可以大大提高页面加载的速度,尤其是在高延迟连接中。
一个TCP连接现在可以传送多个回应,势必就要有一种机制,区分数据包是属于哪一个回应的。这就是Content-length字段的作用,声明本次回应的数据长度。
Content-Length: 3495
上面代码告诉浏览器,本次回应的长度是3495个字节,后面的字节就属于下一个回应了。
在1.0版中,Content-Length字段不是必需的,因为浏览器发现服务器关闭了TCP连接,就表明收到的数据包已经全了。
对于一些很耗时的动态操作来说,这意味着,服务器要等到所有操作完成,才能发送数据,显然这样的效率不高。更好的处理方法是,产生一块数据,就发送一块,采用"流模式"(stream)取代"缓存模式"(buffer)。
因此,1.1版规定可以不使用Content-Length字段,而使用"分块传输编码"(chunked transfer encoding)。只要请求或回应的头信息有Transfer-Encoding字段,就表明回应将由数量未定的数据块组成。
Transfer-Encoding: chunked
每个非空的数据块之前,会有一个16进制的数值,表示这个块的长度。最后是一个大小为0的块,就表示本次回应的数据发送完了。下面是一个例子。
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
25
This is the data in the first chunk
1C
and this is the second one
3
con
8
sequence
0
1.1版还新增了许多动词方法:PUT、PATCH、HEAD、 OPTIONS、DELETE。
另外,客户端请求的头信息新增了Host字段,用来指定服务器的域名。
Host: www.example.com
有了Host字段,就可以将请求发往同一台服务器上的不同网站,为虚拟主机的兴起打下了基础。
虽然1.1版允许复用TCP连接,但是同一个TCP连接里面,所有的数据通信是按次序进行的。服务器只有处理完一个回应,才会进行下一个回应。要是前面的回应特别慢,后面就会有许多请求排队等着。这称为"队头堵塞"(Head-of-line blocking)。
2009年,谷歌公开了自行研发的 SPDY 协议,主要解决 HTTP/1.1 效率不高的问题。
这个协议在Chrome浏览器上证明可行以后,就被当作 HTTP/2 的基础,主要特性都在 HTTP/2 之中得到继承。
HTTP/1.1 版的头信息肯定是文本(ASCII编码),数据体可以是文本,也可以是二进制。
HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为"帧"(frame):头信息帧和数据帧。
二进制协议的一个好处是,可以定义额外的帧。HTTP/2 定义了近十种帧,为将来的高级应用打好了基础。如果使用文本实现这种功能,解析数据将会变得非常麻烦,二进制解析则方便得多。
HTTP/2 复用TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应,这样就避免了"队头堵塞"。
举例来说,在一个TCP连接里面,服务器同时收到了A请求和B请求,于是先回应A请求,结果发现处理过程非常耗时,于是就发送A请求已经处理好的部分, 接着回应B请求,完成后,再发送A请求剩下的部分。
这样双向的、实时的通信,就叫做多工(Multiplexing)。
因为 HTTP/2 的数据包是不按顺序发送的,同一个连接里面连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。
HTTP/2 将每个请求或回应的所有数据包,称为一个数据流(stream)。每个数据流都有一个独一无二的编号。数据包发送的时候,都必须标记数据流ID,用来区分它属于哪个数据流。另外还规定,客户端发出的数据流,ID一律为奇数,服务器发出的,ID为偶数。
数据流发送到一半的时候,客户端和服务器都可以发送信号(RST_STREAM帧),取消这个数据流。1.1版取消数据流的唯一方法,就是关闭TCP连接。这就是说,HTTP/2 可以取消某一次请求,同时保证TCP连接还打开着,可以被其他请求使用。
客户端还可以指定数据流的优先级。优先级越高,服务器就会越早回应。
HTTP 协议不带有状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如Cookie和User Agent,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。
HTTP/2 对这一点做了优化,引入了头信息压缩机制(header compression)。一方面,头信息使用gzip或compress压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送(server push)。
常见场景是客户端请求一个网页,这个网页里面包含很多静态资源。正常情况下,客户端必须收到网页后,解析HTML源码,发现有静态资源,再发出静态资源请求。其实,服务器可以预期到客户端请求网页后,很可能会再请求静态资源,所以就主动把这些静态资源随着网页一起发给客户端了。
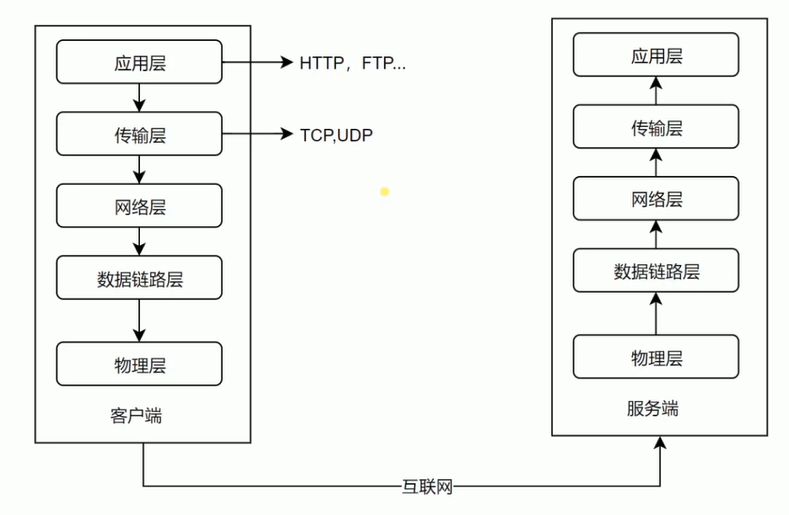
下面我们先来了解一下各层做的事情!
电脑要组网,第一件事要干什么?当然是先把电脑连起来,可以用光缆、电缆、双绞线、无线电波等方式。
这就叫做"物理层",它就是把电脑连接起来的物理手段。它主要规定了网络的一些电气特性,作用是负责传送0和1的电信号。
单纯的0和1没有任何意义,必须规定解读方式:多少个电信号算一组?每个信号位有何意义?
这就是"链接层"的功能,它在"实体层"的上方,确定了0和1的分组方式。
早期的时候,每家公司都有自己的电信号分组方式。逐渐地,一种叫做"以太网"(Ethernet)的协议,占据了主导地位。
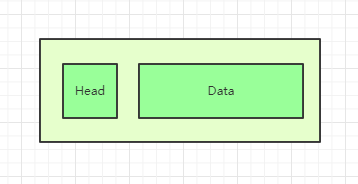
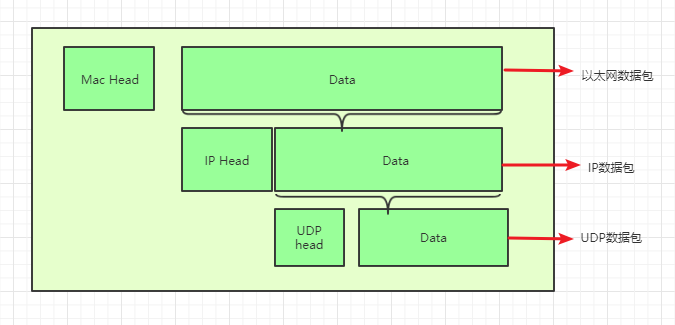
以太网规定,一组电信号构成一个数据包,叫做"帧"(Frame)。每一帧分成两个部分:标头(Head)和数据(Data)。
"标头"包含数据包的一些说明项,比如发送者、接受者、数据类型等等;"数据"则是数据包的具体内容。
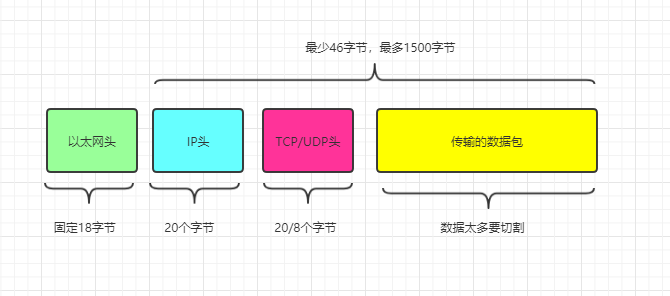
"标头"的长度,固定为18字节。"数据"的长度,最短为46字节,最长为1500字节。因此,整个"帧"最短为64字节,最长为1518字节。如果数据很长,就必须分割成多个帧进行发送。
上面提到,以太网数据包的"标头",包含了发送者和接受者的信息。那么,发送者和接受者是如何标识呢?
以太网规定,连入网络的所有设备,都必须具有"网卡"接口。数据包必须是从一块网卡,传送到另一块网卡。网卡的地址,就是数据包的发送地址和接收地址,这叫做MAC地址。
每块网卡出厂的时候,都有一个全世界独一无二的MAC地址,长度是48个二进制位,通常用12个十六进制数表示。
前6个十六进制数是厂商编号,后6个是该厂商的网卡流水号。有了MAC地址,就可以定位网卡和数据包的路径了。
定义地址只是第一步,后面还有更多的步骤。
首先,一块网卡怎么会知道另一块网卡的MAC地址?
回答是有一种ARP协议,可以解决这个问题。下面介绍ARP。
其次,就算有了MAC地址,系统怎样才能把数据包准确送到接收方?
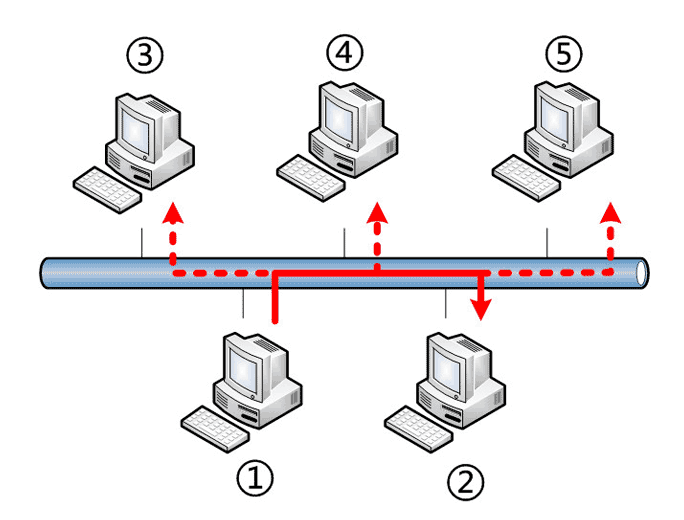
回答是以太网采用了一种很"原始"的方式,它不是把数据包准确送到接收方,而是向本网络内所有计算机发送,让每台计算机自己判断,是否为接收方。
上图中,1号计算机向2号计算机发送一个数据包,同一个子网络的3号、4号、5号计算机都会收到这个包。它们读取这个包的"标头",找到接收方的MAC地址,然后与自身的MAC地址相比较,如果两者相同,就接受这个包,做进一步处理,否则就丢弃这个包。这种发送方式就叫做"广播"(broadcasting)。
有了数据包的定义、网卡的MAC地址、广播的发送方式,"链接层"就可以在多台计算机之间传送数据了。
以太网协议,依靠MAC地址发送数据。理论上,单单依靠MAC地址,上海的网卡就可以找到洛杉矶的网卡了,技术上是可以实现的。
但是,这样做有一个重大的缺点。以太网采用广播方式发送数据包,所有成员人手一"包",不仅效率低,而且局限在发送者所在的子网络。也就是说,如果两台计算机不在同一个子网络,广播是传不过去的。这种设计是合理的,否则互联网上每一台计算机都会收到所有包,那会引起灾难。
互联网是无数子网络共同组成的一个巨型网络,很像想象上海和洛杉矶的电脑会在同一个子网络,这几乎是不可能的。
因此,必须找到一种方法,能够区分哪些MAC地址属于同一个子网络,哪些不是。如果是同一个子网络,就采用广播方式发送,否则就采用"路由"方式发送。("路由"的意思,就是指如何向不同的子网络分发数据包,这是一个很大的主题,本文不涉及。)遗憾的是,MAC地址本身无法做到这一点。它只与厂商有关,与所处网络无关。
这就导致了"网络层"的诞生。它的作用是引进一套新的地址,使得我们能够区分不同的计算机是否属于同一个子网络。这套地址就叫做"网络地址",简称"网址"。
于是,"网络层"出现以后,每台计算机有了两种地址,一种是MAC地址,另一种是网络地址。两种地址之间没有任何联系,MAC地址是绑定在网卡上的,网络地址则是管理员分配的,它们只是随机组合在一起。
网络地址帮助我们确定计算机所在的子网络,MAC地址则将数据包送到该子网络中的目标网卡。因此,从逻辑上可以推断,必定是先处理网络地址,然后再处理MAC地址。
规定网络地址的协议,叫做IP协议。它所定义的地址,就被称为IP地址。
目前,广泛采用的是IP协议第四版,简称IPv4。这个版本规定,网络地址由32个二进制位组成。
习惯上,我们用分成四段的十进制数表示IP地址,从0.0.0.0一直到255.255.255.255。
互联网上的每一台计算机,都会分配到一个IP地址。这个地址分成两个部分,前一部分代表网络,后一部分代表主机。比如,IP地址172.16.254.1,这是一个32位的地址,假定它的网络部分是前24位(172.16.254),那么主机部分就是后8位(最后的那个1)。处于同一个子网络的电脑,它们IP地址的网络部分必定是相同的,也就是说172.16.254.2应该与172.16.254.1处在同一个子网络。
但是,问题在于单单从IP地址,我们无法判断网络部分。还是以172.16.254.1为例,它的网络部分,到底是前24位,还是前16位,甚至前28位,从IP地址上是看不出来的。
那么,怎样才能从IP地址,判断两台计算机是否属于同一个子网络呢?这就要用到另一个参数"子网掩码"(subnet mask)。
所谓"子网掩码",就是表示子网络特征的一个参数。它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0。比如,IP地址172.16.254.1,如果已知网络部分是前24位,主机部分是后8位,那么子网络掩码就是11111111.11111111.11111111.00000000,写成十进制就是255.255.255.0。
知道"子网掩码",我们就能判断,任意两个IP地址是否处在同一个子网络。方法是将两个IP地址与子网掩码分别进行AND运算(两个数位都为1,运算结果为1,否则为0),然后比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是。
比如,已知IP地址172.16.254.1和172.16.254.233的子网掩码都是255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码分别进行AND运算,结果都是172.16.254.0,因此它们在同一个子网络。
总结一下,IP协议的作用主要有两个,一个是为每一台计算机分配IP地址,另一个是确定哪些地址在同一个子网络。
根据IP协议发送的数据,就叫做IP数据包。不难想象,其中必定包括IP地址信息。
但是前面说过,以太网数据包只包含MAC地址,并没有IP地址的栏位。那么是否需要修改数据定义,再添加一个栏位呢?
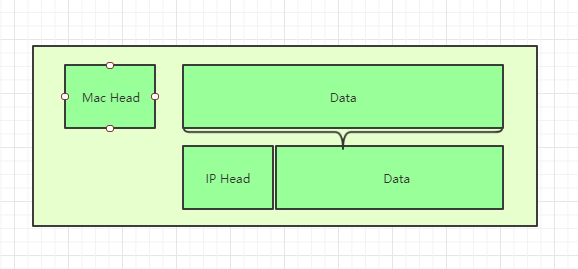
回答是不需要,我们可以把IP数据包直接放进以太网数据包的"数据"部分,因此完全不用修改以太网的规格。这就是互联网分层结构的好处:上层的变动完全不涉及下层的结构。
具体来说,IP数据包也分为"标头"和"数据"两个部分。"标头"部分主要包括版本、长度、IP地址等信息,"数据"部分则是IP数据包的具体内容。它放进以太网数据包后,以太网数据包就变成了下面这样。
IP数据包的"标头"部分的长度为20个字节,整个数据包的总长度最大为65,535字节。因此,理论上,一个IP数据包的"数据"部分,最长为65,515字节。前面说过,以太网数据包的"数据"部分,最长只有1500字节。因此,如果IP数据包超过了1500字节,它就需要分割成几个以太网数据包,分开发送了。
关于"网络层",还有最后一点需要说明。
因为IP数据包是放在以太网数据包里发送的,所以我们必须同时知道两个地址,一个是对方的MAC地址,另一个是对方的IP地址。通常情况下,对方的IP地址是已知的,但是我们不知道它的MAC地址。
所以,我们需要一种机制,能够从IP地址得到MAC地址。
这里又可以分成两种情况。第一种情况,如果两台主机不在同一个子网络,那么事实上没有办法得到对方的MAC地址,只能把数据包传送到两个子网络连接处的"网关"(gateway),让网关去处理。
第二种情况,如果两台主机在同一个子网络,那么我们可以用ARP协议,得到对方的MAC地址。ARP协议也是发出一个数据包(包含在以太网数据包中),其中包含它所要查询主机的IP地址,在对方的MAC地址这一栏,填的是FF:FF:FF:FF:FF:FF,表示这是一个"广播"地址。它所在子网络的每一台主机,都会收到这个数据包,从中取出IP地址,与自身的IP地址进行比较。如果两者相同,都做出回复,向对方报告自己的MAC地址,否则就丢弃这个包。
总之,有了ARP协议之后,我们就可以得到同一个子网络内的主机MAC地址,可以把数据包发送到任意一台主机之上了。
有了MAC地址和IP地址,我们已经可以在互联网上任意两台主机上建立通信。
接下来的问题是,同一台主机上有许多程序都需要用到网络,比如,你一边浏览网页,一边与朋友在线聊天。当一个数据包从互联网上发来的时候,你怎么知道,它是表示网页的内容,还是表示在线聊天的内容?
也就是说,我们还需要一个参数,表示这个数据包到底供哪个程序(进程)使用。这个参数就叫做"端口"(port),它其实是每一个使用网卡的程序的编号。每个数据包都发到主机的特定端口,所以不同的程序就能取到自己所需要的数据。
"端口"是0到65535之间的一个整数,正好16个二进制位。0到1023的端口被系统占用,用户只能选用大于1023的端口。不管是浏览网页还是在线聊天,应用程序会随机选用一个端口,然后与服务器的相应端口联系。
"传输层"的功能,就是建立"端口到端口"的通信。相比之下,"网络层"的功能是建立"主机到主机"的通信。只要确定主机和端口,我们就能实现程序之间的交流。因此,Unix系统就把主机+端口,叫做"套接字"(socket)。有了它,就可以进行网络应用程序开发了。
现在,我们必须在数据包中加入端口信息,这就需要新的协议。最简单的实现叫做UDP协议,它的格式几乎就是在数据前面,加上端口号。
UDP数据包,也是由"标头"和"数据"两部分组成。
"标头"部分主要定义了发出端口和接收端口,"数据"部分就是具体的内容。然后,把整个UDP数据包放入IP数据包的"数据"部分,而前面说过,IP数据包又是放在以太网数据包之中的,所以整个以太网数据包现在变成了下面这样:
UDP数据包非常简单,"标头"部分一共只有8个字节,总长度不超过65,535字节,正好放进一个IP数据包。
UDP协议的优点是比较简单,容易实现,但是缺点是可靠性较差,一旦数据包发出,无法知道对方是否收到。
为了解决这个问题,提高网络可靠性,TCP协议就诞生了。这个协议非常复杂,但可以近似认为,它就是有确认机制的UDP协议,每发出一个数据包都要求确认。如果有一个数据包遗失,就收不到确认,发出方就知道有必要重发这个数据包了。
因此,TCP协议能够确保数据不会遗失。它的缺点是过程复杂、实现困难、消耗较多的资源。
TCP数据包和UDP数据包一样,都是内嵌在IP数据包的"数据"部分。TCP数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常TCP数据包的长度不会超过IP数据包的长度,以确保单个TCP数据包不必再分割。
关于TCP细节以后再探讨。
应用程序收到"传输层"的数据,接下来就要进行解读。由于互联网是开放架构,数据来源五花八门,必须事先规定好格式,否则根本无法解读。
"应用层"的作用,就是规定应用程序的数据格式。
举例来说,TCP协议可以为各种各样的程序传递数据,比如Email、WWW、FTP等等。那么,必须有不同协议规定电子邮件、网页、FTP数据的格式,这些应用程序协议就构成了"应用层"。
这是最高的一层,直接面对用户。它的数据就放在TCP数据包的"数据"部分。因此,现在的以太网的数据包就变成下面这样。
*注:UDP头为8个字节,TCP头为20个字节
整理于:http://www.ruanyifeng.com/blog/2012/05/internet_protocol_suite_part_i.html
这个过程看的就是用户从浏览器输入一条url之后,是如何发送过去的。
我们已经知道,网络通信就是交换数据包。电脑A向电脑B发送一个数据包,后者收到了,回复一个数据包,从而实现两台电脑之间的通信。数据包的结构,基本上是下面这样:
发送这个包,需要知道两个地址:
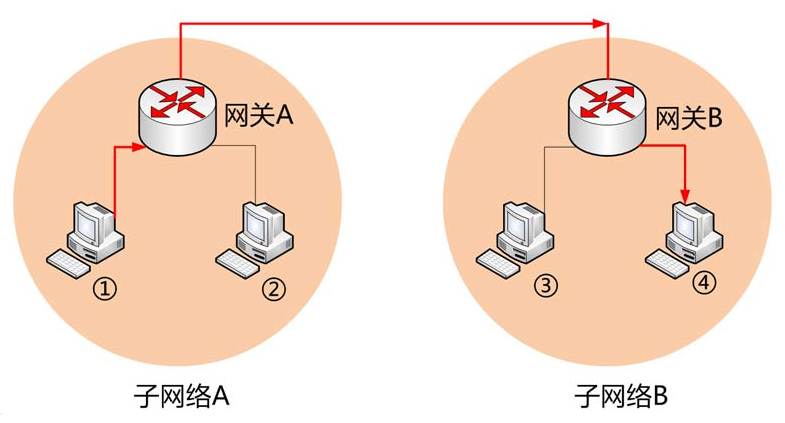
有了这两个地址,数据包才能准确送到接收者手中。但是,前面说过,MAC地址有局限性,如果两台电脑不在同一个子网络,就无法知道对方的MAC地址,必须通过网关(gateway)转发。
上图中,1号电脑要向4号电脑发送一个数据包。它先判断4号电脑是否在同一个子网络,结果发现不是(后文介绍判断方法),于是就把这个数据包发到网关A。网关A通过路由协议,发现4号电脑位于子网络B,又把数据包发给网关B,网关B再转发到4号电脑。
1号电脑把数据包发到网关A,必须知道网关A的MAC地址。
发送数据包之前,电脑必须判断对方是否在同一个子网络,然后选择相应的MAC地址。
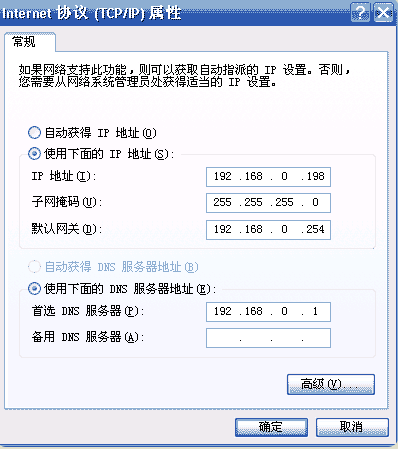
有了一台新电脑之后,要想上网,一种方式是自己配置静态IP:
很多人都没有进行过这个配置,因为一般情况下我们根本不需要这样。但是有的时候也会用到,比如我在电信实习的时候,他们每一个网口旁边都贴着这四个参数,你联网必须要适用他提供的一系列地址才行。其实经过上面的学习,我们已经知道,通信的时候,需要知道对方的IP(ARP知道对方的MAC地址)、子网掩码(确定所在的子网)、默认网关(不在一个子网,要通过网关取转发、路由)、DNS服务器(解析域名为IP地址)。
但是,这样的设置很专业,普通用户望而生畏,而且如果一台电脑的IP地址保持不变,其他电脑就不能使用这个地址,不够灵活。出于这两个原因,大多数用户使用"动态IP地址上网"。
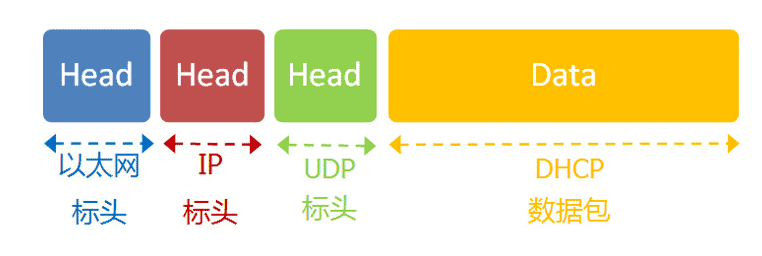
所谓"动态IP地址",指计算机开机后,会自动分配到一个IP地址,不用人为设定。它使用的协议叫做DHCP协议。
这个协议规定,每一个子网络中,有一台计算机负责管理本网络的所有IP地址,它叫做"DHCP服务器"。新的计算机加入网络,必须向"DHCP服务器"发送一个"DHCP请求"数据包,申请IP地址和相关的网络参数。
前面说过,如果两台计算机在同一个子网络,必须知道对方的MAC地址和IP地址,才能发送数据包。但是,新加入的计算机不知道DHCP服务器的两个地址,怎么发送数据包呢?
DHCP协议做了一些巧妙的规定。
首先,它是一种应用层协议,建立在UDP协议之上,所以整个数据包是这样的:
(1)最前面的"以太网标头",设置发出方(本机)的MAC地址和接收方(DHCP服务器)的MAC地址。前者就是本机网卡的MAC地址,后者这时不知道,就填入一个广播地址:FF-FF-FF-FF-FF-FF。
(2)后面的"IP标头",设置发出方的IP地址和接收方的IP地址。这时,对于这两者,本机都不知道。于是,发出方的IP地址就设为0.0.0.0,接收方的IP地址设为255.255.255.255。
(3)最后的"UDP标头",设置发出方的端口和接收方的端口。这一部分是DHCP协议规定好的,发出方是68端口,接收方是67端口。
这个数据包构造完成后,就可以发出了。以太网是广播发送,同一个子网络的每台计算机都收到了这个包。
因为接收方的MAC地址是FF-FF-FF-FF-FF-FF,看不出是发给谁的,所以每台收到这个包的计算机,还必须分析这个包的IP地址,才能确定是不是发给自己的。
当看到发出方IP地址是0.0.0.0,接收方是255.255.255.255,于是DHCP服务器知道"这个包是发给我的",而其他计算机就可以丢弃这个包。
接下来,DHCP服务器读出这个包的数据内容,分配好IP地址,发送回去一个"DHCP响应"数据包。
这个响应包的结构也是类似的,以太网标头的MAC地址是双方的网卡地址,IP标头的IP地址是DHCP服务器的IP地址(发出方)和255.255.255.255(接收方),UDP标头的端口是67(发出方)和68(接收方),分配给请求端的IP地址和本网络的具体参数则包含在Data部分。
新加入的计算机收到这个响应包,于是就知道了自己的IP地址、子网掩码、网关地址、DNS服务器等等参数。
动态拿到最核心的四个参数:自己的IP地址、子网掩码、网关地址、DNS服务器,就可以联网了。
我们假定,经过上一节的步骤,用户设置好了自己的网络参数:
然后他打开浏览器,想要访问Google,在地址栏输入了网址:www.google.com。
这意味着,浏览器要向Google发送一个网页请求的数据包。
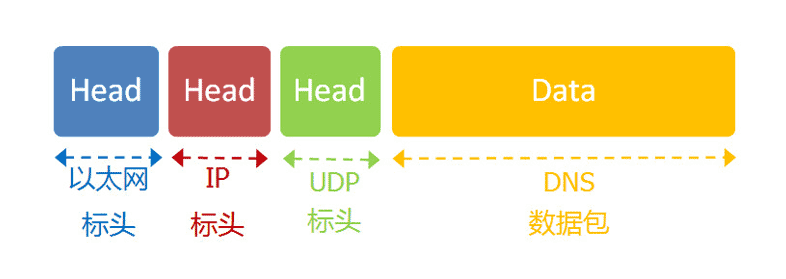
我们知道,发送数据包,必须要知道对方的IP地址。但是,现在,我们只知道网址www.google.com,不知道它的IP地址。
DNS协议可以帮助我们,将这个网址转换成IP地址。已知DNS服务器为8.8.8.8,于是我们向这个地址发送一个DNS数据包(53端口)。
然后,DNS服务器做出响应,告诉我们Google的IP地址是172.194.72.105。于是,我们知道了对方的IP地址。
接下来,我们要判断,这个IP地址是不是在同一个子网络,这就要用到子网掩码。
已知子网掩码是255.255.255.0,本机用它对自己的IP地址192.168.1.100,做一个二进制的AND运算(两个数位都为1,结果为1,否则为0),计算结果为192.168.1.0;然后对Google的IP地址172.194.72.105也做一个AND运算,计算结果为172.194.72.0。这两个结果不相等,所以结论是,Google与本机不在同一个子网络。
因此,我们要向Google发送数据包,必须通过网关192.168.1.1转发,也就是说,接收方的MAC地址将是网关的MAC地址。
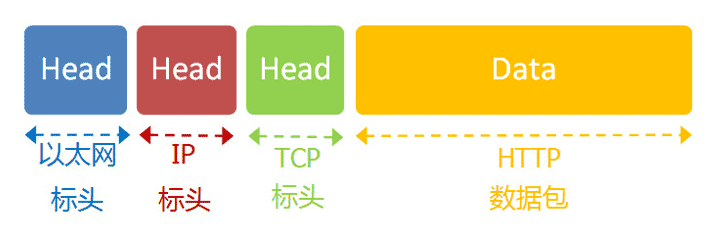
浏览网页用的是HTTP协议,它的整个数据包构造是这样的:
HTTP部分的内容,类似于下面这样:
GET / HTTP/1.1
Host: www.google.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1) ......
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh-CN,zh;q=0.8
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.3
Cookie: ... ...
我们假定这个部分的长度为4960字节,它会被嵌在TCP数据包之中。
TCP数据包需要设置端口,接收方(Google)的HTTP端口默认是80,发送方(本机)的端口是一个随机生成的1024-65535之间的整数,假定为51775。
TCP数据包的标头长度为20字节,加上嵌入HTTP的数据包,总长度变为4980字节。
然后,TCP数据包再嵌入IP数据包。IP数据包需要设置双方的IP地址,这是已知的,发送方是192.168.1.100(本机),接收方是172.194.72.105(Google)。
IP数据包的标头长度为20字节,加上嵌入的TCP数据包,总长度变为5000字节。
最后,IP数据包嵌入以太网数据包。以太网数据包需要设置双方的MAC地址,发送方为本机的网卡MAC地址,接收方为网关192.168.1.1的MAC地址(通过ARP协议得到)。
以太网数据包的数据部分,最大长度为1500字节,而现在的IP数据包长度为5000字节。因此,IP数据包必须分割成四个包。因为每个包都有自己的IP标头(20字节),所以四个包的IP数据包的长度分别为1500、1500、1500、560。
经过多个网关的转发,Google的服务器172.194.72.105,收到了这四个以太网数据包。
根据IP标头的序号,Google将四个包拼起来,取出完整的TCP数据包,然后读出里面的"HTTP请求",接着做出"HTTP响应",再用TCP协议发回来。
本机收到HTTP响应以后,就可以将网页显示出来,完成一次网络通信。
整理自:http://www.ruanyifeng.com/blog/2012/06/internet_protocol_suite_part_ii.html
这是计算机网络相关的第七篇文章。HTTPS(SSL/TLS)的加密机制是前端后端ios安卓等都应了解的基本问题。也是面试经常问的点。
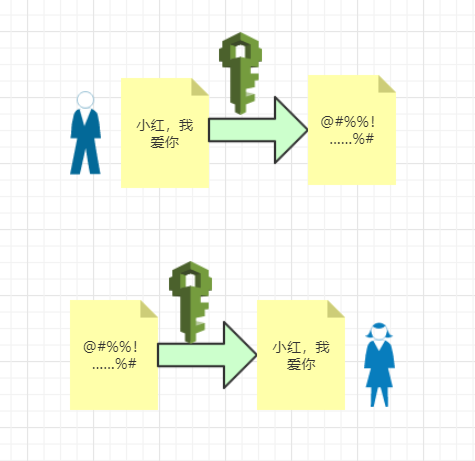
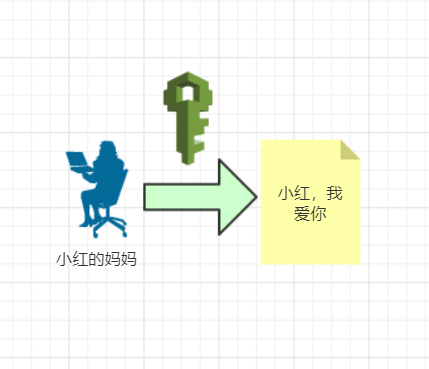
小时候看谍战片,情报发过来了之后,用一个小本本进行翻译,然后解密出情报。加密就是防止明文被别人看到甚至篡改嘛!
回到互联网,因为http的内容是明文传输的,明文数据会经过中间代理服务器、路由器、wifi热点、通信服务运营商等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了,他还可以篡改传输的信息且不被双方察觉,这就是中间人攻击。所以我们才需要对信息进行加密。最简单容易理解的就是对称加密 。
小明写个求爱信给小红,小明担心小红的妈妈看到这封信的内容,他灵机一动,对信加个密,并确定好我用这个密钥加密的,小红收到之后也用这个密钥解密才行。
但是呢,这里有个麻烦的地方就是,小明和小红不在一个学校,这个钥匙呢,不方便直接送到手里。所以呢,小明得想办法把这个钥匙寄一个送给小红,好吧,就用最贵的顺丰吧!
就是有一个密钥,它可以对一段内容加密,加密后只能用它才能解密看到原本的内容,和我们日常生活中用的钥匙作用差不多。
顺丰快递到了,结果小红不在家,小红的妈妈收到了,一看是个男同学寄的,怎么能忍住,赶紧打开,以看是一把钥匙,作为程序猿,妈妈得意一笑:哼哼,还能逃过我的眼睛?我赶紧复制一把藏着,我倒要看看他后面要寄啥来,还要加密?!
果然小红的妈妈等到了来自小明寄过来的情书,解密一看,实锤早恋。
同样地,小明这边也非常危险,快递员刚出发,就被小明的妈妈拦截了,拿到了这个钥匙,那小明还没寄出的信已经被妈妈看光了。
所以问题的根本就是,这把钥匙要传输,传输就可能被截取。
回到互联网,如果通信双方都各自持有同一个密钥,且没有别人知道,这两方的通信安全当然是可以被保证的(除非密钥被破解)。
然而最大的问题就是这个密钥怎么让传输的双方知晓,同时不被别人知道。
如果由服务器生成一个密钥并传输给浏览器,那这个传输过程中密钥被别人劫持弄到手了怎么办?
换种思路?试想一下,如果浏览器内部就预存了网站A的密钥,且可以确保除了浏览器和网站A,不会有任何外人知道该密钥,那理论上用对称加密是可以的,这样浏览器只要预存好世界上所有HTTPS网站的密钥就行啦!这么做显然不现实。
怎么办?所以我们就需要神奇的非对称加密。
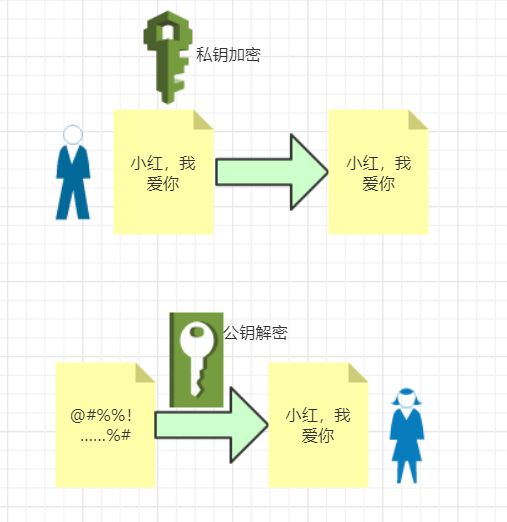
有两把密钥,通常一把叫做公钥、一把叫做私钥。
用公钥加密的内容必须用私钥才能解开,同样,私钥加密的内容只有公钥能解开。
公钥呢,还是要通过快递员送给小红的。OK,假设小红要回信,写好了用公钥加密,小红的妈妈因为拿不到私钥,看不到信的内容。
OK,但是反过来呢?小明用私钥加密传给小红,那么小红的妈妈可就能解密了(因为公钥可能会被小红的妈妈拿到)。
回到互联网,服务器先把公钥直接明文传输给浏览器,之后浏览器向服务器传数据前都先用这个公钥加密好再传,这条数据的安全似乎可以保障了!因为只有服务器有相应的私钥能解开这条数据。
然而由服务器到浏览器的这条路怎么保障安全?
如果服务器用它的的私钥加密数据传给浏览器,那么浏览器用公钥可以解密它,而这个公钥是一开始通过明文传输给浏览器的,这个公钥被谁劫持到的话,他也能用该公钥解密服务器传来的信息了。
所以目前似乎只能保证由浏览器向服务器传输数据时的安全性(其实仍有漏洞,下文会说)。
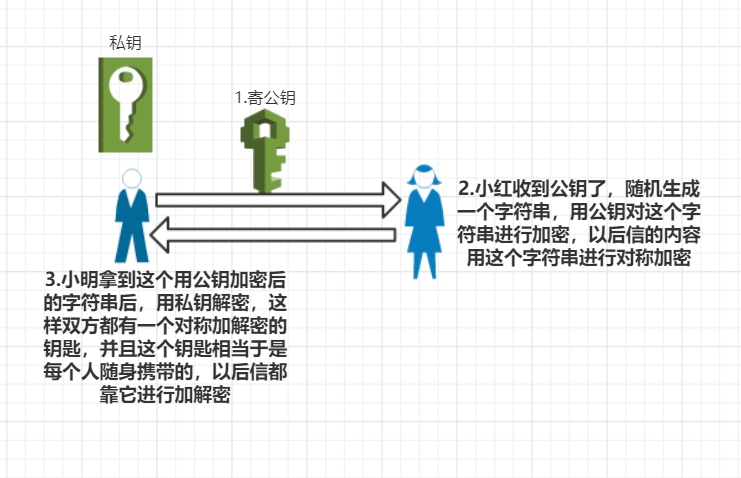
小明和小红年纪不大,但是很聪明,针对这个情况,还是迅速升级加密方法。他们想到既然一组公钥私钥不够,那两组呢?
OK,小明和小红各造了一对。下面就是互相交换公钥。那么就变成:
下面就好办啦,小明写信用公钥B加密,那么信的内容只有小红能破解,因为小红是随身携带私钥B。相反,小红用公钥A对信加密,这样只有小明能破解,因为小明也是随身携带私钥A。好像很安全啦!除了下面提到的漏洞,唯一的缺点可能是:小红得花半天时间才能解密完这封信,有点受不了。
回到互联网。请看下面的过程:
的确可以!抛开这里面仍有的漏洞不谈(下文会讲),HTTPS的加密却没使用这种方案,为什么?最主要的原因是非对称加密算法非常耗时,特别是加密解密一些较大数据的时候有些力不从心。
小明也知道,这个信很长,用非对称加密,太慢!办法也有,没有必要对那么长的信加密,我只要保证这个真正解密的钥匙不被别人拿到就行,那么他灵机一动想到这个方法:
小明和小红利用非对称加密对钥匙加密,姑且认为是这个钥匙被放在了一个盒子里,这个盒子也被锁起来了,只有小红或者小明才能打开盒子,再用钥匙去解密。
这个真正用于对称加密解密的钥匙别人就拿不到啦!
自从用了这个方案,感觉又安全,解密又快,感情又深温了呢!
回到互联网,步骤如下:
HTTPS的基本**就是基于这个。但是这个方案也存在上面一直在说的漏洞。
像妈妈这样级别的程序猿可能是那他们两没办法啦,但是呢,校区有个看门的大爷,以前是个黑客,也不知道咋回事,明明才50岁,但是看起来像80岁,头上光溜溜的,冬天冷呢。整天在那胡言乱语:docker牛逼啊,spring cloud牛逼啊,这个开源软件XXX写的真好,跟周围的老大爷老大妈根本谈不到一起去。
他也是闲的蛋疼,非要掺和,因为据说他以前单身30年,苦逼敲代码,不知道谈恋爱是啥滋味,姑且认为他好奇心重吧。
在小明第一次寄公钥A的时候,大爷出手了,截取下来。换成自己做的公钥B。然后送给小红。
小红哪里会知道这公钥被掉包了呢,所以直接就用了,按照正常步骤,小红想了一个随机字符串,这次就叫xiaomingwoxuanni吧,OK,用这个公钥B对这个字符串加个密,这个字符串就被锁进了用大爷公钥B锁的盒子里。
老大爷在门口守着呢,一看到小红寄东西了,又偷偷地截取下来,用自己的私钥B来解密这个盒子。轻易地拿到了里面的字符串,OK,怕小明察觉,再用小明寄来的公钥A加密传给小明,这样双方都不知道他们的钥匙已经被大爷给获取了。
小明和小红之间的信就用xiaomingwoxuanni这个钥匙进行对称加密和对称解密,完全不知道有个大爷就天天拿着这个字符串去解密信件,看的不亦乐乎,甚至还偷偷改几个字呢。
回到互联网。中间人的确无法得到浏览器生成的密钥B,这个密钥本身被公钥A加密了,只有服务器才有私钥A解开拿到它呀!然而中间人却完全不需要拿到密钥A就能干坏事了。请看:
这样在双方都不会发现异常的情况下,中间人得到了密钥B。根本原因是浏览器无法确认自己收到的公钥是不是网站自己的。只要解决了这个公钥一定是这个网站发来的,那么基本就OK了
现实生活中,如果想证明某身份证号一定是小明的,怎么办?看身份证。这里政府机构起到了“公信”的作用,身份证是由它颁发的,它本身的权威可以对一个人的身份信息作出证明。互联网中能不能搞这么个公信机构呢?给网站颁发一个“身份证”?
网站在使用HTTPS前,需要向“CA机构”申请颁发一份数字证书,即SSL证书,数字证书里有证书持有者、证书持有者的公钥等信息,服务器把证书传输给浏览器,浏览器从证书里取公钥就行了,证书就如身份证一样,可以证明“该公钥对应该网站”。然而这里又有一个显而易见的问题了,证书本身的传输过程中,如何防止被篡改?即如何证明证书本身的真实性?身份证有一些防伪技术,数字证书怎么防伪呢?解决这个问题我们就基本接近胜利了!
SSL证书内容:
我们把证书内容生成一份“签名”,比对证书内容和签名是否一致就能察觉是否被篡改。这种技术就叫数字签名。
提到数字签名,其实原理很简单啦,就是比如我要传输一句话叫:“你给我转100块钱,我的账号是123456,转完了告诉我一声。”,如果不做任何处理,被刚才的老大爷截取了,他偷偷地改一下内容“你给我转200块钱,我的账号是654321,不要告诉任何人,尤其是你嫂子。”
是不是太坏了,弄不好被抓,大爷可不敢做大的,只敢骗个喝酒钱。
那么怎么防止大爷这种猥琐技术又高的人篡改呢?数字签名排上用场啦!
以后再传消息就是“你给我转100块钱,我的账号是123456,转完了告诉我一声。”+“!……@&@%#……!¥@¥!@%……#¥!%……”,后面那一串东西就是数字签名,简单来说,就是想办法对前面的内容进行非对称加密(这样别人根本不知道你加密的私钥是什么,也就伪装不了签名了)。传过去之后,我要对其进行解密,与传过来的明文一一对比参数,看有没有被改动过。一旦发现哪里不对应,说明已经被篡改了。
“CA机构”制作签名的过程:
明文和数字签名共同组成了数字证书,这样一份数字证书就可以颁发给网站了。网站把这个数字证书传给浏览器。
那浏览器拿到服务器传来的数字证书后,如何验证它是不是真的?(有没有被篡改、掉包)
浏览器验证过程:
为什么这样可以证明证书可信呢?我们来仔细想一下。
老大爷就算有天大的能耐,也拿不到加密的私钥,那么只是单纯地篡改明文,只会造成校验不通过。
回到互联网,假设中间人篡改了证书的原文,由于他没有CA机构的私钥,所以无法得到此时加密后签名,无法相应地篡改签名。
浏览器收到该证书后会发现原文和签名解密后的值不一致,则说明证书已被篡改,证书不可信,从而终止向服务器传输信息,防止信息泄露给中间人。
假设有另一个网站B也拿到了CA机构认证的证书,它想搞垮网站A,想劫持网站A的信息。于是它成为中间人拦截到了A传给浏览器的证书,然后替换成自己的证书,传给浏览器,之后浏览器就会错误地拿到B的证书里的公钥了,会导致上文提到的漏洞。
其实这并不会发生,因为证书里包含了网站A的信息,包括域名,浏览器把证书里的域名与自己请求的域名比对一下就知道有没有被掉包了。
总结:因为一个网站域名对应一个证书,你的证书根其他人的证书肯定是不一样的,那么你就算拿到了其他人的证书再掉包成自己的,也没用,毕竟浏览器那边只要看一下是不是我要查看的域名。
最显然的是性能问题,前面我们已经说了非对称加密效率较差,证书信息一般较长,比较耗时。而hash后得到的是固定长度的信息(比如用md5算法hash后可以得到固定的128位的值),这样加密解密就会快很多。
让我们回想一下数字证书到底是干啥的?没错,为了证明某公钥是可信的,即“该公钥是否对应该网站/机构等”,那这个CA机构的公钥是不是也可以用数字证书来证明?没错,操作系统、浏览器本身会预装一些它们信任的根证书,如果其中有该CA机构的根证书,那就可以拿到它对应的可信公钥了。
实际上证书之间的认证也可以不止一层,可以A信任B,B信任C,以此类推,我们把它叫做信任链或数字证书链,也就是一连串的数字证书,由根证书为起点,透过层层信任,使终端实体证书的持有者可以获得转授的信任,以证明身份。
另外,不知你们是否遇到过网站访问不了、提示要安装证书的情况?这里安装的就是根证书。说明浏览器不认给这个网站颁发证书的机构,那么没有该机构的根证书,你就得手动下载安装(风险自己承担XD)。安装该机构的根证书后,你就有了它的公钥,就可以用它验证服务器发来的证书是否可信了。
也就是说,公钥是从证书中获取的。证书是网站从机构那边申请来的,证书+签名传给浏览器。只要校验通过,那么公钥必然没有被篡改过,并且一定是这个网站传来的,那么解决了我们最核心的问题:确定公钥是我们指定的网站传来的。
既然公钥是正确的,那么小红就会用正确的公钥对随机字符串加密,中间不会出现篡改。
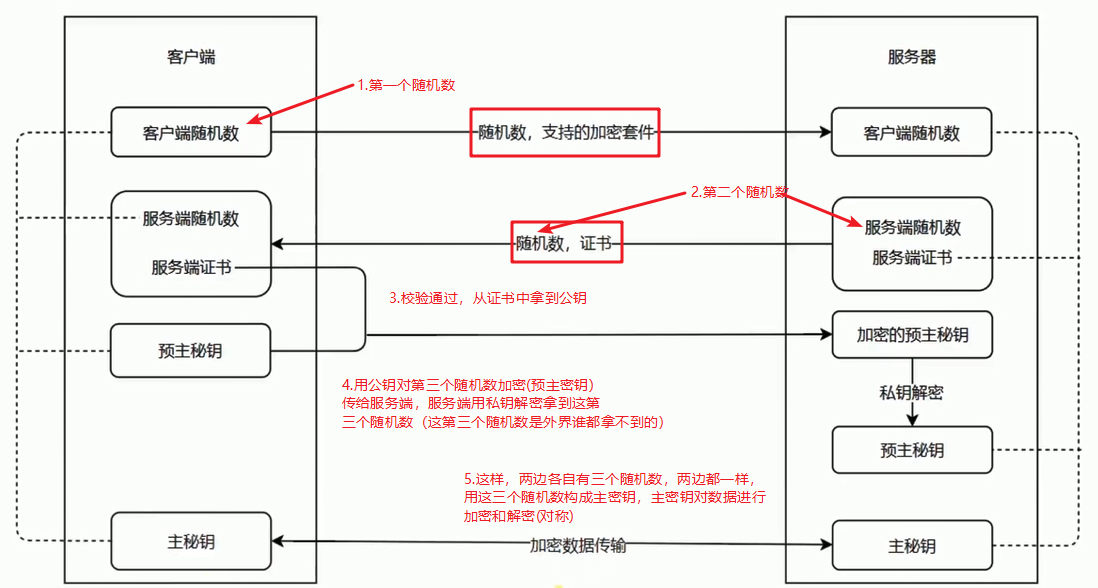
这也是我当时的困惑之一,显然每次请求都经历一次密钥传输过程非常耗时,那怎么达到只传输一次呢?用session就行。
服务器会为每个浏览器(或客户端软件)维护一个session ID,在TSL握手阶段传给浏览器,浏览器生成好密钥传给服务器后,服务器会把该密钥存到相应的session ID下,之后浏览器每次请求都会携带session ID,服务器会根据session ID找到相应的密钥并进行解密加密操作,这样就不必要每次重新制作、传输密钥了!
下面再来看看HTTPS原理就特别简单啦!
HTTPS 协议(HyperText Transfer Protocol over Secure Socket Layer):可以理解为HTTP+SSL/TLS, 即 HTTP 下加入 SSL 层,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL,用于安全的 HTTP 数据传输。
HTTP
SSL/TLS
TCP
IP
我们只要知道,在SSL层里面可以完成校验和密钥的传输。
理解了上面,这个图也就没啥好解释的了。
这是计算机网络相关的第四篇文章。首先要明确:信道本身不可靠(丢包、重复包、出错、乱序),不安全。所以引出了七层或五层模型来保证。因此,任何一个东西的提出都是为了解决某个问题的。学习计算机,从他的历史出发,理解为什么会有不断低迭代,因为是为了解决某个痛点问题。比如HTTP的发展,为什么在HTTP1.0基础上还要提出HTTP1.1,为什么还要提出HTTP2.0,我们学习了他的发展历史之后就会明白了。同样,下面再说一说为什么要有TCP协议,TCP到底解决了什么问题。
首先简单回顾一下。
物理层是相当于物理连接,将0101以电信号的形式传输出去。
数据链路层,有一个叫做以太网协议,规定了电子信号是如何组成数据包的,这个协议的头里面,包含了自身的网卡信息,还有目的地的网卡信息(一般我们可以知道对方的IP,IP可以通过DNS解析到,然后根据ARP协议将IP转换为MAC地址)。那么,如果在同一个局域网内,我们就可以通过广播的方式找到对应MAC地址的主机。---即以太网协议解决了子网内部的点对点通信。
但是呢,以太网协议不能解决多个局域网通信,每个局域网之间不是互通的,那么以太网这种广播的方式不可用,就算可用,网络那么大,通过广播进行找,是一个可怕的场景。那么,IP协议可以连接多个局域网,简单来说,IP 协议定义了一套自己的地址规则,称为 IP 地址。物理器件,比如说路由器,就是基于IP协议,里面保存一套地址指路牌,想去哪个局域网,可以通过这个牌子来找,然后逐步路由到目标局域网,最后就可以找到那台主机了。IP层就是对应了网络层。
那么,此时解决了多个局域网路由问题,也解决了局域网内寻址问题,即我这台主机已经可以找到那台主机了,下面还有什么事情需要做呢?显然,找到主机还不行啊,比如我用微信发一条消息,我发到你主机了,但是你主机上的微信不知道这条消息发给他了,这里说的就是端口,信息要发到这个端口上,监听这个端口的程序才会收到消息。
OK,最上层的应用层,就是最贴近用户的,他的一系列协议只是为了让两台主机会互相都理解而已。
在明白了计算机网络为什么要这几层模型之后,我们再回到一开始,如何保证安全、可靠、完整地传输信息呢?
很显然,上面提到的,只是保证信息能找到对方主机和端口,但是这个信息中途被拦截了、甚至被篡改了、信息延迟了(几分钟或者几个小时,或者几个世纪)、网络不通或者挂了,信息自己可不会告诉你他挂了或者要迟到一会,如果没有一个协议来保障可靠性,那么我这条消息发出去,能不能到、能不能及时到、能不能完整到、能不能不被篡改到等这些问题将会造成灾难,网络传输也就没有了意义。
计算机的前辈们,为我们提供了一系列的措施来尽可能保证信息能正确送达。
首先在数据链路层,可以通过各种校验,比如奇偶校验等手段来判断数据包传的是否正确。
好了,解决了数据是否正确之后,但是还不能保证线路是可靠的,加入某个包没发出去或者发错了,应该有一个出错重传机制,保证信息传输的可靠性。这就引出了TCP协议。
TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。
下面来看看TCP是如何解决丢包、重复包、出错、乱序等不可靠的一些问题的。
这就引出了TCP中最终的一个东西:滑动窗口协议。
先从简单的角度出发,自己想一下,如何保证不丢包、不乱序。
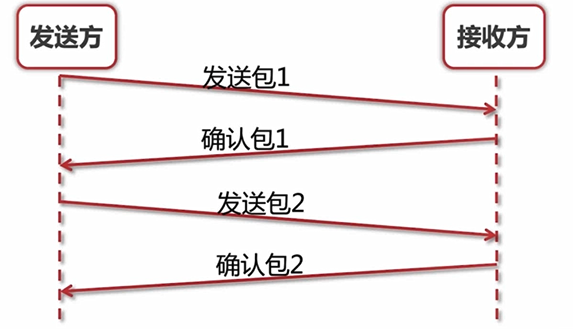
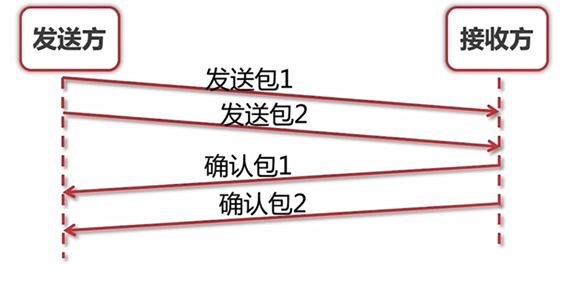
按照顺序,发送一个确认一个,显然,吞吐量非常低。那么,一次性发几个包,然后一起确认呢?
那么就引出第二个问题,我一次性发几个包合适呢?就这引出了滑动窗口。
在说明滑动窗口原理之前,必须要说一下TCP数据包的编号SEQ。
我们知道,由于以太网数据包大小限制,所以每个包承载的数据是有限的,如果发一个很大的包,必然是要拆分的。
发送的时候,TCP 协议为每个包编号(sequence number,简称 SEQ),以便接收的一方按照顺序还原。万一发生丢包,也可以知道丢失的是哪一个包。
第一个包的编号是一个随机数。为了便于理解,这里就把它称为1号包。假定这个包的负载长度是100字节,那么可以推算出下一个包的编号应该是101。这就是说,每个数据包都可以得到两个编号:自身的编号,以及下一个包的编号。接收方由此知道,应该按照什么顺序将它们还原成原始文件。
TCP协议就是根据这些编号来重新还原文件的。并且接收端保证顺序性返回ACK确认,比如有两个包发过去,为1号和2号,2号接收成功,但是发现1号包还没接收到,所以2号的ACK是不会发回去的,这个时候,如果在重传时间内收到1号了,那么就把这两个包的ACK都返回回去,如果超时了,就重传1号包。知道1号包接收成功,后续的才会返回ACK。
具体是如何做到的呢?
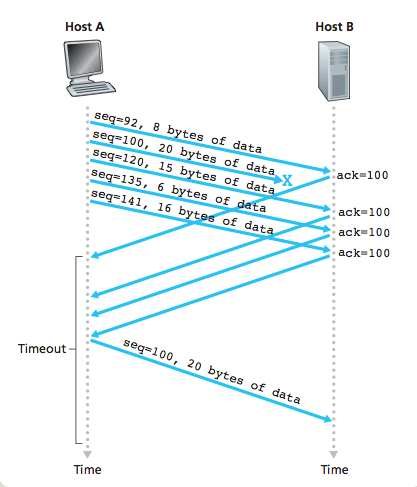
前面说过,每一个数据包都带有下一个数据包的编号。如果下一个数据包没有收到,那么 ACK 的编号就不会发生变化。
举例来说,现在收到了4号包,但是没有收到5号包。ACK 就会记录,期待收到5号包。过了一段时间,5号包收到了,那么下一轮 ACK 会更新编号。如果5号包还是没收到,但是收到了6号包或7号包,那么 ACK 里面的编号不会变化,总是显示5号包。这会导致大量重复内容的 ACK。
如果发送方发现收到三个连续的重复 ACK,或者超时了还没有收到任何 ACK,就会确认丢包,即5号包遗失了,从而再次发送这个包。通过这种机制,TCP 保证了不会有数据包丢失。
(图片说明:Host B 没有收到100号数据包,会连续发出相同的 ACK,触发 Host A 重发100号数据包。)
下面再来说说慢启动。
服务器发送数据包,当然越快越好,最好一次性全发出去。但是,发得太快,就有可能丢包。带宽小、路由器过热、缓存溢出等许多因素都会导致丢包。线路不好的话,发得越快,丢得越多。
最理想的状态是,在线路允许的情况下,达到最高速率。但是我们怎么知道,对方线路的理想速率是多少呢?答案就是慢慢试。
TCP 协议为了做到效率与可靠性的统一,设计了一个慢启动(slow start)机制。开始的时候,发送得较慢,然后根据丢包的情况,调整速率:如果不丢包,就加快发送速度;如果丢包,就降低发送速度。
Linux 内核里面设定了(常量TCP_INIT_CWND),刚开始通信的时候,发送方一次性发送10个数据包,即"发送窗口"的大小为10。然后停下来,等待接收方的确认,再继续发送。
默认情况下,接收方每收到两个 TCP 数据包,就要发送一个确认消息。"确认"的英语是 acknowledgement,所以这个确认消息就简称 ACK。
ACK 携带两个信息:
发送方有了这两个信息,再加上自己已经发出的数据包的最新编号,就会推测出接收方大概的接收速度,从而降低或增加发送速率。这被称为"发送窗口",这个窗口的大小是可变的。
我们可以知道,发送发和接收方都维护了一个缓冲区,可以理解为窗口。根据接收速度可以调整发送速度,逐渐达到这条线路最高的传输速率。
ok,下面就可以研究一下滑动窗口了。
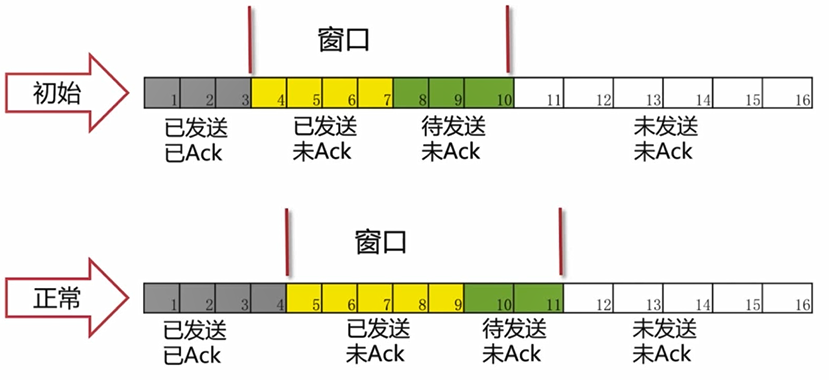
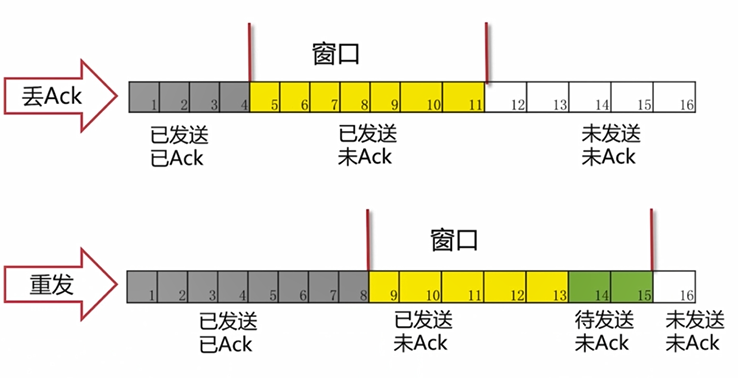
正常情况下:
(如图,123表示已经正常发送并且收到了ACK确认。4567属于已发送但是还没有收到ACK。8910表示待发送。这个窗口当前长度为7.正常情况下,4号包收到ACK,那么窗口就会右移一格。)
但是往往会出现一些问题,比如5号包迟迟收不到ACK,在接收端可能是没有收到5号包,但是可能会收到6号包甚至是7、8号包,那么此时只能等待5号包,如果5号包顺利到达了,那么就把5678号包的ACK都发给发送端,那么发送端滑动窗口向右右移四格。如果迟迟收不到5号包,只能重传。
以上就是关于TCP中比较重要的出错重传、编号、慢启动以及滑动窗口。这些保证了数据传输的可靠性。
整理自:http://www.ruanyifeng.com/blog/2017/06/tcp-protocol.html
这是计算机网络相关的第五篇文章。面试讲到TCP,那么基本都会问三次握手和四次挥手的过程,以及比如对于握手,为什么是三次,而不是两次或者四次,本章详细探讨其中的门道。
首先针对http协议,我们有必要复习一下最重要的东西。
HTTP协议即超文本传送协议(Hypertext Transfer Protocol ),是Web联网的基础,也是手机联网常用的协议之一,HTTP协议是建立在TCP协议之上的一种应用。
在HTTP 1.0以0.9版本中,客户端的每次请求都要求建立一次单独的连接,在处理完本次请求后,就自动释放连接。
在HTTP 1.1中则可以在一次连接中处理多个请求,并且多个请求可以重叠进行,不需要等待一个请求结束后再发送下一个请求。
由于HTTP在每次请求结束后都会主动释放连接,因此HTTP连接是一种“短连接”,要保持客户端程序的在线状态,需要不断地向服务器发起连接请求。
通常的做法是即使不需要获得任何数据,客户端也保持每隔一段固定的时间向服务器发送一次“保持连接”的请求,服务器在收到该请求后对客户端进行回复,表明知道 客户端“在线”。
若服务器长时间无法收到客户端的请求,则认为客户端“下线”,若客户端长时间无法收到服务器的回复,则认为网络已经断开。
初次接触这个名词:“套接字”,说实话,心里是蒙蔽的,这是啥玩意,但是可以去搜索一下什么是套接管:
我们可以看出来,两个管子可能直接连的话连不起来,那么可以通过中间一个东西连接起来。
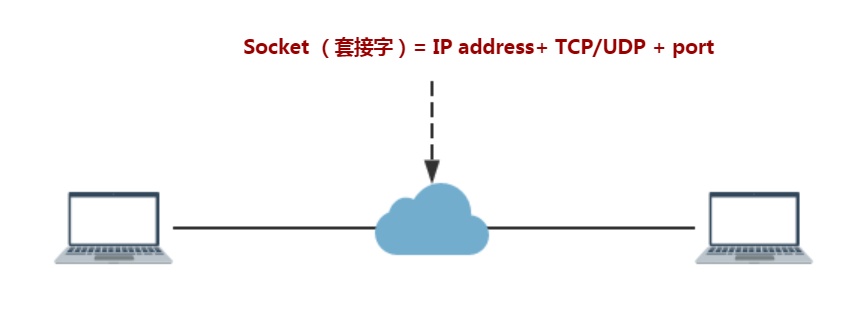
那么,现在就好理解了,两个程序要通信,需要知道对方的一些信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
它是什么呢?它是网络通信过程中端点的抽象表示,这个抽象里面就包含了网络通信必须的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
那为什么一定要用它呢?
在同一台计算机上,TCP协议与UDP协议可以同时使用相同的port而互不干扰。 操作系统根据套接字地址,可以决定应该将数据送达特定的进程或线程。这就像是电话系统中,以电话号码加上分机号码,来决定通话对象一般。
因为我们电脑上可能会跑很多的应用程序,TCP协议端口需要为这些同时运行的程序提供并发服务,或者说,传输层需要为应用层的多个进程提供通信服务,每个进程起一个TCP连接,那么这多个TCP连接可能是通过同一个 TCP协议端口传输数据。
如何区别哪个进程对应哪个TCP连接呢?
许多计算机操作系统为应用程序与TCP/IP协议交互提供了套接字(Socket)接口。应 用层可以和传输层通过Socket接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。
建立Socket连接至少需要一对套接字,其中一个运行于客户端,称为ClientSocket ,另一个运行于服务器端,称为ServerSocket 。
套接字之间的连接过程分为三个步骤:服务器监听,客户端请求,连接确认。
服务器监听:服务器端套接字并不定位具体的客户端套接字,而是处于等待连接的状态,实时监控网络状态,等待客户端的连接请求。
客户端请求:指客户端的套接字提出连接请求,要连接的目标是服务器端的套接字。为此,客户端的套接字必须首先描述它要连接的服务器的套接字,指出服务器端套接字的地址和端口号,然后就向服务器端套接字提出连接请求。
连接确认:当服务器端套接字监听到或者说接收到客户端套接字的连接请求时,就响应客户端套接字的请求,建立一个新的线程,把服务器端套接字的描述发 给客户端,一旦客户端确认了此描述,双方就正式建立连接。而服务器端套接字继续处于监听状态,继续接收其他客户端套接字的连接请求。
创建Socket连接时,可以指定使用的传输层协议,Socket可以支持不同的传输层协议(TCP或UDP),当使用TCP协议进行连接时,该Socket连接就是一个TCP连接。
TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。
针对协议中的字段,我们只需要了解一下:ACK、SYN、序号这三个部分。
ACK : 确认
SYN : 在连接建立时用来同步序号。
FIN 即终结的意思, 用来释放一个连接。
首先,TCP作为一种可靠传输控制协议,其核心**:既要保证数据可靠传输,又要提高传输的效率,而用三次恰恰可以满足以上两方面的需求!
然后,要明确TCP连接握手,握的是啥?
答案:通信双方数据原点的序列号!
我们在上面一篇文章知道,消息的完整是靠给每个消息包搞一个编号,依次地ACK确认。确认机制是累计的,意味着 X 序列号之前(不包括 X) 包都是被确认接收到的。
TCP可靠传输的精髓:TCP连接的一方A,由操作系统动态随机选取一个32位长的序列号(Initial Sequence Number)。
假设A的初始序列号为1000,以该序列号为原点,对自己将要发送的每个字节的数据进行编号,1001,1002,1003…,并把自己的初始序列号ISN告诉B。
让B有一个**准备,什么样编号的数据是合法的,什么编号是非法的,比如编号900就是非法的,同时B还可以对A每一个编号的字节数据进行确认。
如果A收到B确认编号为2001,则意味着字节编号为1001-2000,共1000个字节已经安全到达。
同理B也是类似的操作,假设B的初始序列号ISN为2000,以该序列号为原点,对自己将要发送的每个字节的数据进行编号,2001,2002,2003…,并把自己的初始序列号ISN告诉A,以便A可以确认B发送的每一个字节。如果B收到A确认编号为4001,则意味着字节编号为2001-4000,共2000个字节已经安全到达。
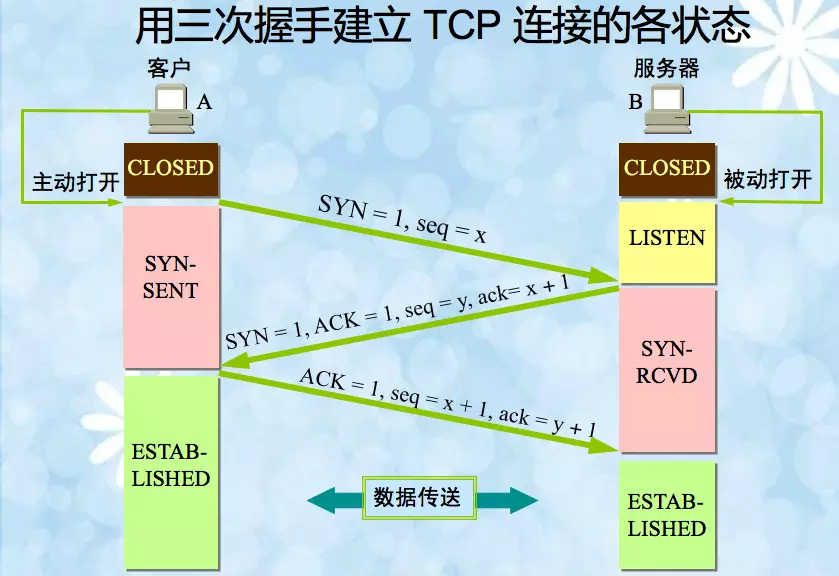
好了,在理解了握手的本质之后,下面就可以总结上面图的握手过程了。
对于A与B的握手过程,可以总结为:
SYN + A's Initial sequence number(丢失会A会重传)A's ISN 到本地,命名 B's ACK sequence numberSYN + B's Initial sequence number (丢失B会周期性超时重传,直到收到A的确认)B's ISN 到本地,命名 A's ACK sequence number很显然2和3 这两个步骤可以合并,只需要三次握手,可以提高连接的速度与效率。
这里就会引出一个问题,两次不行吗?
这里有一个问题,A与B就A的初始序列号达成了一致,但是B无法知道A是否已经接收到自己的同步信号,如果这个同步信号丢失了,A和B就B的初始序列号将无法达成一致。
所以A必须再给B一个确认,以确认A已经接收到B的同步信号。
如果A发给B的确认丢了,该如何?
A会超时重传这个ACK吗?不会!TCP不会为没有数据的ACK超时重传。
那该如何是好?B如果没有收到A的ACK,会超时重传自己的SYN同步信号,一直到收到A的ACK为止。
写到这里,其实我们已经明白了,握手其实就是各自确认对方的序列号。因为后面的数据编号就会以此为基础,从而保证后续数据的可靠性。
谢希仁版《计算机网络》中的例子是这样的,“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”
但是有的人指出,其实这只是表象,或者说并不是三次握手的设计初衷,我表示认同,这个防止已失效的连接请求报文段应该只是附加的一些好处,而不应该是解释为什么是三次握手的原因。
TCP初始阶段为什么是三次握手,原因总结如下:
为了实现可靠数据传输, TCP 协议的通信双方, 都必须维护一个序列号, 以标识发送出去的数据包中, 哪些是已经被对方收到的。
三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值的必经步骤,如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认。
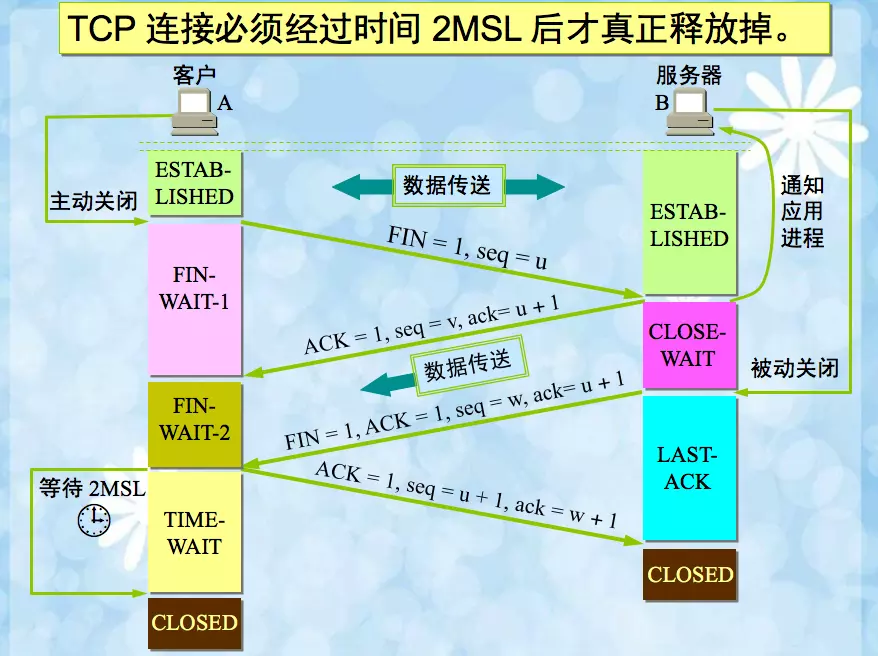
当主机1发出FIN报文段时,只是表示主机1已经没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕了;
但是,这个时候主机1还是可以接受来自主机2的数据;
当主机2返回ACK报文段时,表示它已经知道主机1没有数据发送了,但是主机2还是可以发送数据到主机1的;
当主机2也发送了FIN报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了;
主机1告诉主机2知道了,主机2收到这个确认之后就立马关闭自己。
主机1等待2MSL之后也关闭了自己。
针对最后一条消息,即主机1发送ack后,主机2接收到此消息,即认为双方达成了同步:双方都知道连接可以释放了,此时B可以安全地释放此TCP连接所占用的内存资源、端口号。
所以被动关闭的B无需任何wait time,直接释放资源。
但是主机1并不知道主机2是否接到自己的ACK,主机1是这么想的:
无论是情况1还是2,A都需要等待,要取这两种情况等待时间的最大值,以应对最坏的情况发生,这个最坏情况是:
主机2没有收到主机1的ACK,那么超时之后主机2会重传FIN,也就是说,要浪费一个主机1发出ACK的最大存活时间(MSL)+FIN消息的最大存活时间(MSL)
不可能时间再多了,这个已经针对最糟糕的状况。
等待2MSL时间,A就可以放心地释放TCP占用的资源、端口号,此时可以使用该端口号连接任何服务器。
在等待的时间内,主机2可以重试多次,因为2MSL时间为240秒,超时重传只有0.5秒,1秒,2秒,,16秒。
当主机2重试次数达到上限,主机2会reset连接。
那么为什么是2MSL我们已经了解了,但是为什么要等这个时间呢?
如果不等,释放的端口可能会重连刚断开的服务器端口,这样依然存活在网络里的老的TCP报文可能与新TCP连接报文冲突,造成数据冲突,为避免此种情况,需要耐心等待网络老的TCP连接的活跃报文全部死翘翘,2MSL时间可以满足这个需求。
整理自:
这是计算机网络相关的第六篇文章。这里简单记录一些关于HTTP的基本概念,比较基础。下面的内容是对《图解HTTP》提炼的再提炼,主要原因是很多重要的东西前面已经详细说过了,还有一些东西知道即可,用到再去查,作为一个后端攻城狮,也没有必要了解那么琐碎。
HTTP是无状态协议。自身不对请求和响应之间通信状态进行保存(即不做持久化处理)。 HTTP之所以设计得如此简单,是为了更快地处理大量事物,确保协议的可伸缩性。 HTTP/1.1 随时无状态协议,但可通过 Cookie 技术保存状态。
官方解释都是什么乱起八糟的东西。各种博客也是跟着抄,这两者到底是什么关系和意义?
统一资源标志符URI就是在某一规则下能把一个资源独一无二地标识出来。
对应于实际例子就是:每个人都有身份证,这个身份证号码就对应这个人。比如张三的身份证号码为123456,那么我只要知道123456就可以找到这个人。
那什么是URL呢?从名字看是:统一资源定位器。
如果做类比,URL就是:动物住址协议://地球/**/浙江省/杭州市/西湖区/某大学/14号宿舍楼/525号寝/张三.人
我们通过这个详细的地址也可以找到张三这个人。
那么他们俩到底是什么关系呢?
URI是以某种规则唯一地标识资源,手段不限,比如身份证号。当然了,地址可以唯一标识,那么也属于URI的一种手段。所以说URL是URI的子集。
回到Web上,假设所有的Html文档都有唯一的编号,记作html:xxxxx,xxxxx是一串数字,即Html文档的身份证号码,这个能唯一标识一个Html文档,那么这个号码就是一个URI。
而URL则通过描述是哪个主机上哪个路径上的文件来唯一确定一个资源,也就是定位的方式来实现的URI。
对于现在网址我更倾向于叫它URL,毕竟它提供了资源的位置信息,如果有一天网址通过号码来标识变成了http://741236985.html,那感觉叫成URI更为合适。
状态码的职责是当客户端向服务器端发送请求时,描述返回的请求结果。 状态码如200 OK,以3为数字和原因短语组成。 数字中的第一位定义了响应类别,后两位无分类。响应类别有以下五种:
| 类别 | 原因短语
---|---|---
1XX | Informational(信息性状态码) | 接收的请求正在处理
2XX | Success(成功状态码) | 请求正常处理完毕
3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求
4XX | Client Error(客户端错误状态码)| 服务器无法处理请求
5XX | Server Error(服务器错误状态码)| 服务器处理请求出错
4XX的响应结果表明客户端是发生错误的原因所在。
5XX的响应结果表明服务器本身发生错误。
SPDY以会话层的形式加入,控制对数据的流动,但还是采用HTTP建立通信连接。因此,可照常使用HTTP的GET和POST等方法、Cookie以及HTTP报文等。
使用 SPDY后,HTTP协议额外获得以下功能。
利用Ajax和Comet技术进行通信可以提升Web的浏览速度。但问题在于通信若使用HTTP协议,就无法彻底解决瓶颈问题。
WebSocket技术主要是为了解决Ajax和Comet里XMLHttpRequst附带的缺陷所引起的问题。
一旦Web服务器与客户端之间建立起WebSocket协议的通信连接,之后所有的通信都依靠这个专用协议进行。通信过程中可互相发送JSON、XML、HTML或图片等任意格式的数据。
WebSocket的主要特点:
HTTP相比,不但每次连接时的总开销减少,而且由于WebSocket的首部信息很小,通信量也相应较少。为了实现WebSocket通信,在HTTP连接建立之后,需要完成一次“握手”的步骤。
WebSocket通信,需要用到HTTP的Upgrade首部字段,告知服务器通信协议发生改变,以达到握手的目的。101 Switching Protocols 的响应。WebSocket连接后,通信时不再使用HTTP的数据帧,而采用WebSocket独立的数据帧。由于是建立在HTTP基础上的协议,因此连接的发起方仍是客户端,而一旦确立WebSocket通信连接,不论服务器端还是客户端,任意一方都可直接向对方发送报文。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.