


Auto PR is a GitHub Action designed to automatically generate pull request descriptions using Large Language Models (LLMs). By default, it utilizes OpenAI's models, but it also supports integration with a variety of other LLM providers such as fireworks.ai, together.xyz, anyscale, octoai, etc., allowing users to select their preferred provider and LLMs to best suit their needs. This action can be customized with system and user-provided prompts to tailor the PR description generation.
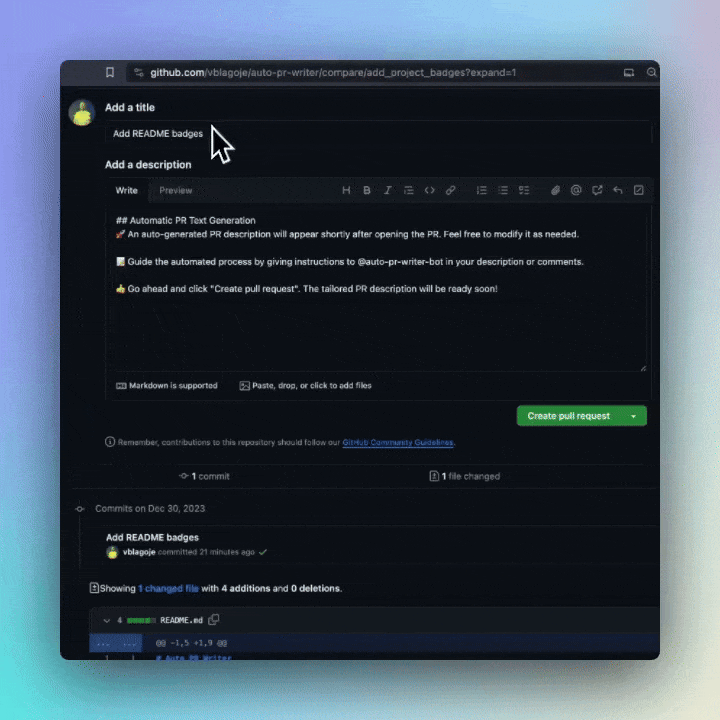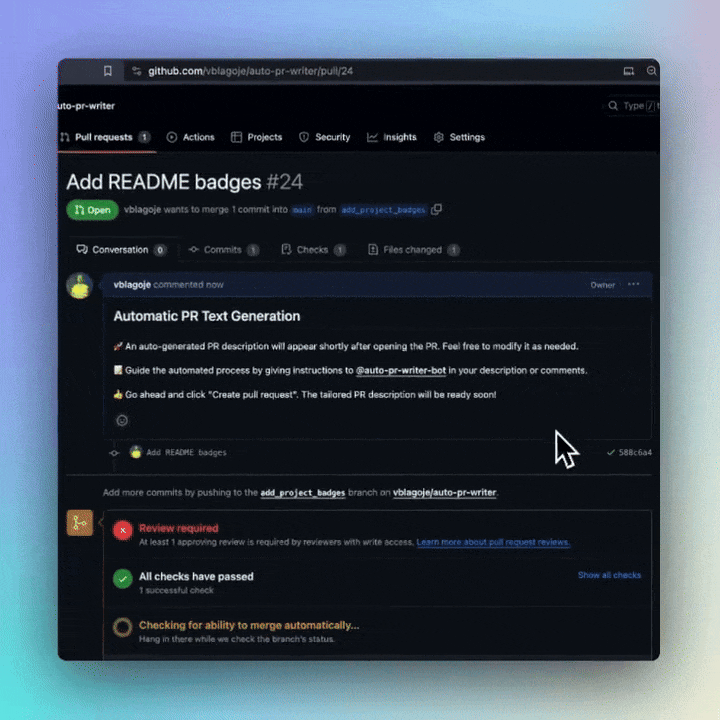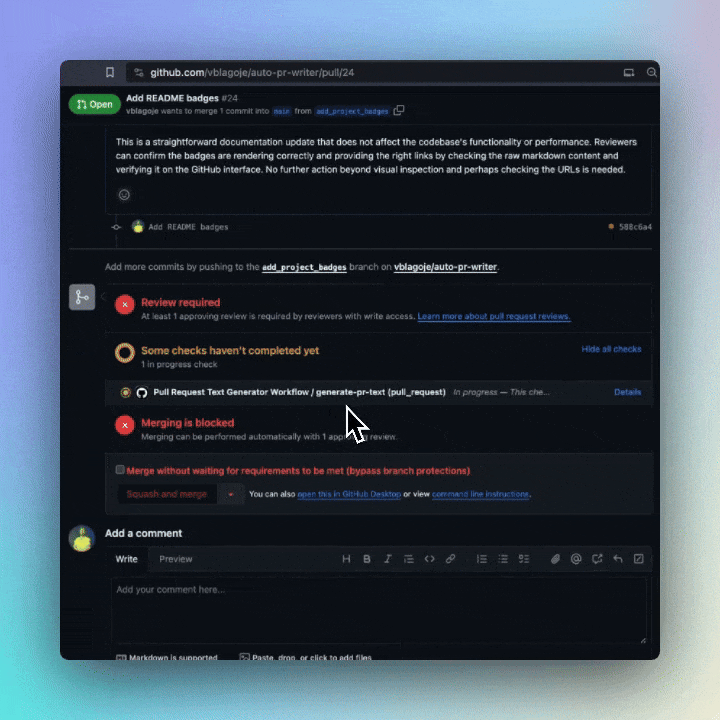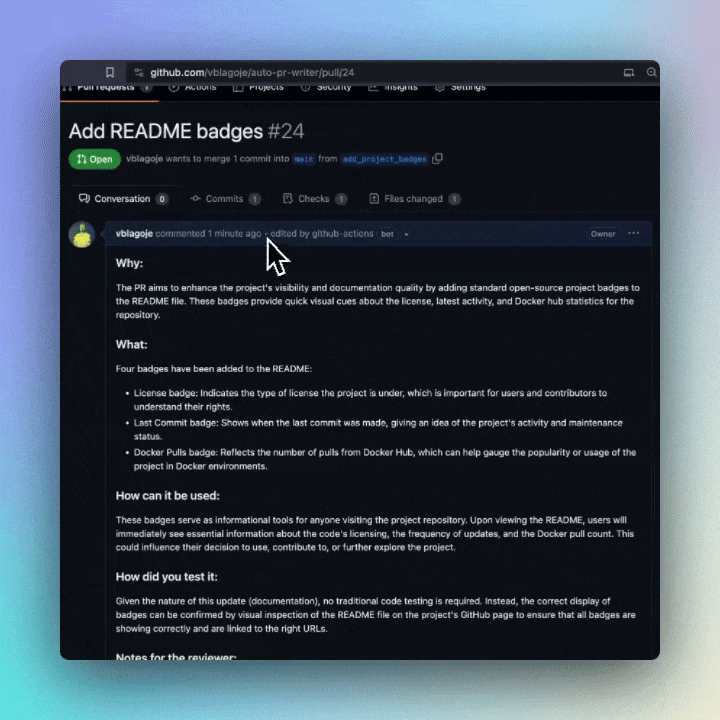
Ensure you have set the OPENAI_API_KEY in your repository's secrets. Add a default template for pull requests, clarifying that the pull request description will be automatically generated. Feel free to use our example. Lastly, incorporate a workflow trigger for this GitHub Action. Refer to the Minimal and Advanced example workflows provided below.
Here's a minimal example of how to use the Auto PR in a pull request workflow:
name: Pull Request Text Generator Workflow
on:
pull_request:
types: [opened]
jobs:
generate-pr-text-on-opened-pr:
runs-on: ubuntu-latest
steps:
- name: Run Auto PR on initial open PR
if: github.event_name == 'pull_request'
id: auto_pr_for_pr
uses: vblagoje/auto-pr@v1
with:
openai_api_key: ${{ secrets.OPENAI_API_KEY }}
openai_base_url: https://api.fireworks.ai/inference/v1
generation_model: accounts/fireworks/models/mixtral-8x7b-instruct
user_prompt: ${{ github.event.pull_request.body }}
- name: Update PR description
uses: vblagoje/update-pr@v1
with:
pr-body: ${{ steps.auto_pr_for_pr.outputs.generated_pr_text }}Here's an advanced example of how to use the Auto PR in a pull request workflow:
name: Pull Request Text Generator Workflow
on:
pull_request:
types: [opened, edited, reopened]
issue_comment:
types: [created]
jobs:
generate-pr-text-on-opened-pr:
runs-on: ubuntu-latest
if: github.event_name == 'pull_request'
steps:
- name: Run Auto PR on initial open PR
id: auto_pr_for_pr
uses: vblagoje/auto-pr@v1
with:
openai_api_key: ${{ secrets.OPENAI_API_KEY }}
openai_base_url: https://api.fireworks.ai/inference/v1
generation_model: accounts/fireworks/models/mixtral-8x7b-instruct
user_prompt: ${{ github.event.pull_request.body }}
- name: Update PR description
uses: vblagoje/update-pr@v1
with:
pr-body: ${{ steps.auto_pr_for_pr.outputs.generated_pr_text }}
generate-pr-text-on-pr-comment:
runs-on: ubuntu-latest
if: github.event_name == 'issue_comment' && github.event.issue.pull_request && contains(github.event.comment.body, '@auto-pr-bot')
steps:
- name: Fetch PR details for comment event
id: pr_details
uses: octokit/[email protected]
with:
route: GET /repos/${{ github.repository }}/pulls/${{ github.event.issue.number }}
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- name: Run Auto PR on PR comment
uses: vblagoje/auto-pr@v1
id: auto_pr_for_comment
with:
openai_api_key: ${{ secrets.OPENAI_API_KEY }}
openai_base_url: https://api.fireworks.ai/inference/v1
user_prompt: ${{ github.event.comment.body }}
target_branch: ${{ fromJson(steps.pr_details.outputs.data).base.ref }}
source_branch: ${{ fromJson(steps.pr_details.outputs.data).head.ref }}
generation_model: accounts/fireworks/models/mixtral-8x7b-instruct
- name: Update Pull Request Description
uses: vblagoje/update-pr@v1
with:
pr-body: ${{ steps.auto_pr_for_comment.outputs.generated_pr_text }}
pr-number: ${{ github.event.issue.number }}This workflow triggers the action on pull request open, edit, and reopen events. Additionally, it activates the action on issue comment events in pull requests when the comment contains @auto-pr-bot.
If you change the bot_name input in your workflow, make sure to update the contains(github.event.comment.body, '@auto-pr-bot') condition accordingly in your workflow.
It's important to note that it utilizes fireworks.ai as an LLM provider, specifically the highly capable open-source LLM accounts/fireworks/models/mixtral-8x7b-instruct. This specific LLM has generated PR text descriptions comparable to those of gpt-4.
-
github_tokenRequired GITHUB_TOKEN or a repository-scoped Personal Access Token (PAT), defaulting to the GitHub token provided by the GitHub Actions runner. It is essential for invoking the GitHub API REST service to retrieve Pull Request details. Using GITHUB_TOKEN permits actions to access both public and private repositories, helping to bypass rate limits imposed by the GitHub API. -
openai_api_keyRequired The OpenAI API key for authentication. Note that this key could be from other LLM providers as well. -
openai_base_urlOptional The base URL for the OpenAI API. Using this input one can use different LLM providers (e.g. fireworks.ai, together.xyz, anyscale, octoai etc.) Defaults to https://api.openai.com/v1 -
github_repositoryOptional The GitHub repository where the pull request is made. Defaults to the current repository. -
base_branchOptional The base (target) branch in the pull request. Defaults to the base branch of the current PR. -
head_branchOptional The head (source) branch in the pull request. Defaults to the head branch of the current PR. -
generation_modelOptional The generation_model specifies the model to use for PR text generation. While it defaults to gpt-4-1106-preview from OpenAI, users have the flexibility to select from a range of models available from various LLM providers, including but not limited to fireworks.ai, together.xyz, anyscale, octoai, etc. This allows for more tailored and varied text generation capabilities to meet diverse needs and preferences. -
function_calling_modelOptional LLM to use for function calling (service parameter resolution, output formatting etc). Defaults to gpt-3.5-turbo-0613 from OpenAI. -
system_promptOptional System message/prompt to help the model generate the PR description. -
user_promptOptional Additional user prompt to help the model generate the PR description. -
bot_nameOptional The name of the bot so users can guide LLM generation with @bot_name from PR comments. Defaults to auto-pr-bot
If you have ideas for enhancing Auto PR, or if you encounter a bug, we encourage you to contribute by opening an issue or a pull request.
The core of this GitHub Action is built on top of Docker image of the vblagoje/openapi-rag-service project.
Therefore, for contributions beyond minor edits to the action.yml or README.md, please direct your pull requests to
the vblagoje/openapi-rag-service GitHub repository.
To confirm the correct operation of the Docker image, perform a smoke test locally using the following steps:
-
Prepare Your OpenAI API Key: Ensure your OpenAI API key is ready for use.
-
Execute the Image: Run the following command in your terminal, replacing
<YOUR_OPENAI_API_KEY>with your actual API key and<YOUR_GITHUB_TOKEN>with your actual GitHub token:docker run -e OPENAI_API_KEY=<YOUR_OPENAI_API_KEY> -e OPENAPI_SERVICE_TOKEN=<YOUR_GITHUB_TOKEN> -e SYSTEM_PROMPT=https://bit.ly/auto_pr_writer_system_prompt -e OPENAPI_SERVICE_SPEC=https://bit.ly/github_compare -e FUNCTION_CALLING_PROMPT="Compare branches main (BASE) and test/benchmarks2.0 (HEAD), in Github repository deepset-ai/haystack (owner/repo)" vblagoje/openapi-rag-service
Modify the parameters
deepset-ai/haystack main test/benchmarks2.0according to the specific repository main and pr branches, relevant to your use case. -
Check the Output: After execution, verify the output to ensure the image functions as expected.
This test will help you verify the basic functionality of the Docker image. Remember to adjust the command with the appropriate project, repository, and branches you wish to compare etc.
When choosing LLMs for generating PR text, it's essential to consider the model's capability to handle long contexts, as it's required to process all the PR diffs. As of January 2024, we've tested models like mixtral-8x7b-instruct, yi-34b-200k-capybara, and gpt-4 variants. Both mixtral-8x7b-instruct and gpt-4 have demonstrated consistent excellence in producing PR descriptions. Therefore, we recommend either of these LLMs for consistent quality, but also encourage experimentation to identify the most suitable option for your specific requirements.
Custom prompts are a powerful way to guide the LLM in generating PR text according to your specific needs. To use them
directly on the GitHub website, mention @auto-pr-bot followed by your instructions in the PR description or
comments. These instructions act as additional context or directives for the LLM, helping it understand how you want
the PR text to be structured or focused. For instance, if you want the PR description to be concise, you might
comment: @auto-pr-bot, please be brief and limit each section to one sentence. Remember to replace
@auto-pr-bot with the customized bot name if you've set one. This way, you can effectively communicate your
requirements to the LLM, resulting in more tailored and useful PR descriptions.
Yes, you can customize the bot name. In your action.yml specify the bot_name input. The bot_name is typically
set to a recognizable contributor on your project, so users can get name completion when they start typing @ in
comments. Customizing the bot name allows you to tailor the interaction to your project's or organization's branding
and user expectations.
Absolutely, to skip PR text generation, simply include the word "skip" in a comment tagged to your bot. For example,
you can comment @auto-pr-bot skip in the main PR description text area. This feature allows you to bypass the
automatic generation when you already have a specific description in mind or when it's not needed.
Yes, the Auto PR is designed to be flexible with various LLM providers such as fireworks.ai, together.xyz,
anyscale, octoai, etc. You can specify different LLMs and providers by setting the openai_base_url and
generation_model inputs in your workflow. This allows you to experiment with different language models and
platforms to find the one that best fits your needs and preferences for PR text generation.
To effectively test a new LLM and system prompt, refer to the Smoke Test for Docker Image section of this document.
Initiate a series of approximately a dozen PR generations, specifying your repository, base branch, and head branch
as parameters for the Docker run command. Feel free to modify the SYSTEM_PROMPT and FUNCTION_CALLING_PROMPT.
Ensure the following environment variables are set correctly in your Docker run command:
OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>: This should be your OpenAI or other LLM provider's API key.GITHUB_TOKEN=<YOUR_GITHUB_TOKEN>: Your GitHub token for accessing repository data and making changes.
Additionally, if you're using a specific LLM provider or model, set the corresponding environment variables
for OPENAI_BASE_URL and GENERATION_MODEL as needed. These variables will allow you to direct the script to use
the correct API endpoints and models for PR text generation. Refer back to the Smoke Test for Docker Image section
for the detailed procedure and adapt the instructions to fit your specific setup and testing needs.
Managing costs is a critical aspect of using LLMs for PR text generation. As of January 2024, depending on the size of
the PR diff, a typical cost per PR using gpt-4 model is approximately a few cents, whereas using the
mixtral-8x7b-instruct on fireworks.ai is less than a cent per PR. To precisely monitor and manage your costs,
especially if you are using platforms like OpenAI, you can set the OPENAI_ORG_ID environment variable to track costs
accurately. This will help you keep a close eye on your usage and optimize accordingly to minimize expenses. Keep in
mind that selecting the right model for your needs and monitoring the market for the best rates among various LLM
platforms are effective strategies to control costs.
This project is licensed under Apache 2.0 License.
