tumimsaki / leetcode-recording Goto Github PK
View Code? Open in Web Editor NEWWhat just like the title says🙄️
What just like the title says🙄️


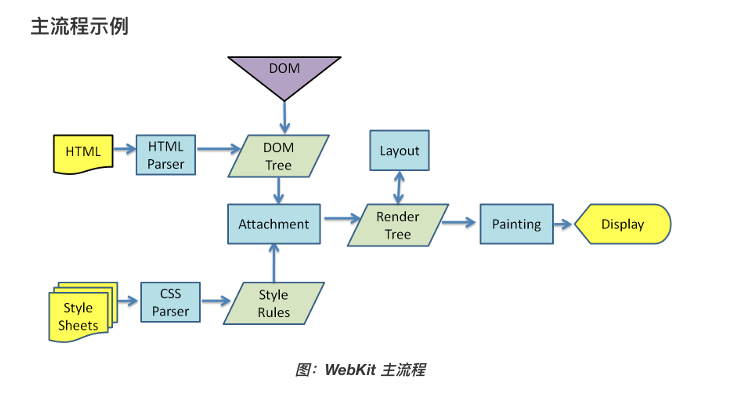
值得注意的是,和大多数浏览器不同,Chrome 浏览器的每个标签页都分别对应一个呈现引擎实例。每个标签页都是一个独立的进程。
浏览器会『从右往左』解析CSS选择器。
我们知道DOM Tree与Style Rules合成为 Render Tree,实际上是需要将Style Rules附着到DOM Tree上,因此需要根据选择器提供的信息对DOM Tree进行遍历,才能将样式附着到对应的DOM元素上。
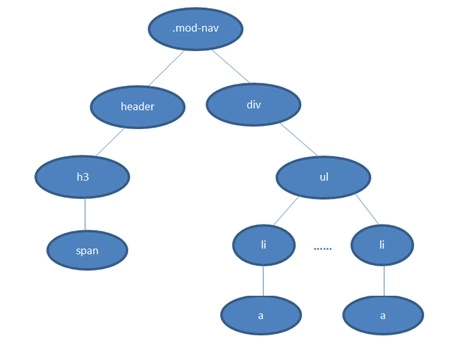
以下这段css为例
.mod-nav h3 span {font-size: 16px;}我们对应的DOM Tree 如下
若从左向右的匹配,过程是:
如果从右至左的匹配:
后者匹配性能更好,是因为从右向左的匹配在第一步就筛选掉了大量的不符合条件的最右节点(叶子节点);而从左向右的匹配规则的性能都浪费在了失败的查找上面。
单单改变元素的外观,肯定不会引起网页重新生成布局,但当浏览器完成重排之后,将会重新绘制受到此次重排影响的部分
重排和重绘代价是高昂的,它们会破坏用户体验,并且让UI展示非常迟缓,而相比之下重排的性能影响更大,在两者无法避免的情况下,一般我们宁可选择代价更小的重绘。
『重绘』不一定会出现『重排』,『重排』必然会出现『重绘』。
我们往往通过改变class的方式来集中改变样式
// 判断是否是黑色系样式
const theme = isDark ? 'dark' : 'light'
// 根据判断来设置不同的class
ele.setAttribute('className', theme)我们可以通过createDocumentFragment创建一个游离于DOM树之外的节点,然后在此节点上批量操作,最后插入DOM树中,因此只触发一次重排
var fragment = document.createDocumentFragment();
for (let i = 0;i<10;i++){
let node = document.createElement("p");
node.innerHTML = i;
fragment.appendChild(node);
}
document.body.appendChild(fragment);将元素提升为合成层有以下优点:
will-change:
短轮询的原理很简单,每隔一段时间客户端就发出一个请求,去获取服务器最新的数据,一定程度上模拟实现了即时通讯。
function polling() {
fetch(url).then(data => {
process(data);
return;
}).catch(err => {
return;
}).then(() => {
setTimeout(polling, 5000);
});
}comet有两种主要实现手段,一种是基于 AJAX 的长轮询(long-polling)方式,另一种是基于 Iframe 及 htmlfile 的流(streaming)方式,通常被叫做长连接。
长轮询是再此基础上的一种改进。客户端发起请求后,服务端会保持住该连接,直到后端有数据更新后,才会将数据返回给客户端;客户端在收到响应结果后再次发送请求,如此循环往复。
//client
function send() {
fetch('/xxxxxx')
.then(data => {
eventbus.emit('fetchEnd',{
data
})
})
}
eventbus.on('fetchEnd', (result) => {
exec(result)
send()
})// server
const servr = http.createServer((req, res) => {
const longPolling = date => {
res.end(data)
}
Event.addListener(MSG, longPolling)
req.socket.on('end', () => {
Event.removeListener(MSG, longPolling)
})
})当我们在页面中嵌入一个iframe并设置其src时,服务端就可以通过长连接“源源不断”地向客户端输出内容。
例如,我们可以向客户端返回一段script标签包裹的javascript代码,该代码就会在iframe中执行。因此,如果我们预先在iframe的父页面中定义一个处理函数process(),而在每次有新数据需要推送时,在该连接响应中写入parent.process(${your_data})。那么iframe中的这段代码就会调用父页面中预先定义的process()函数。(是不是有点像JSONP传输数据的方式?)
//client
function process(data) {
// do something
}
var iframe = document.createElement('iframe');
iframe.style = 'display: none';
iframe.src = './see';
document.body.appendChild(iframe);//server
const server = http.createServer((req, res) => {
const iframe = data => {
let script =
`<script type="text/javascript">
parent.process(${JSON.stringify(data)})
</script>`;
res.write(script);
};
res.setHeader('connection', 'keep-alive');
res.setHeader('content-type', 'text/html; charset=utf-8');
Event.addListener(MSG, iframe);
req.socket.on('close', () => {
Event.removeListener(MSG, iframeSend);
});
});长轮询优缺点:
长连接优缺点:
SSE(Server-Sent Event,服务端推送事件)是一种允许服务端向客户端推送新数据的HTML5技术,SSE规范比较简单,主要分为两个部分:浏览器中的EventSource对象,以及服务器端与浏览器端之间的通讯协议。
var source = new EventSource('./sse');// 默认的事件
source.addEventListener('message', function (e) {
console.log(e.data);
}, false);
// 用户自定义的事件名
source.addEventListener('my_msg', function (e) {
process(e.data);
}, false);
// 监听连接打开
source.addEventListener('open', function (e) {
console.log('open sse');
}, false);
// 监听错误
source.addEventListener('error', function (e) {
console.log('error');
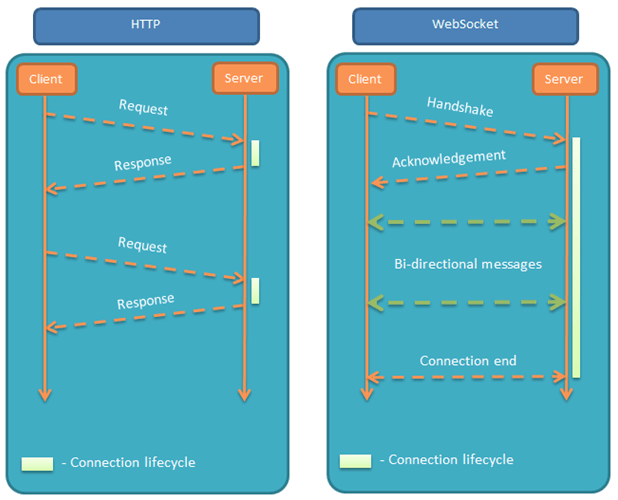
});Websocket是一个全新的、独立的协议,基于TCP协议,与http协议兼容、却不会融入http协议,仅仅作为html5的一部分,其作用就是在服务器和客户端之间建立实时的双向通信。
Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行
var worker = new Worker('work.js')然后,主线程调用worker.postMessage()方法,向 Worker 发消息。
worker.postMessage('Hello World')
worker.postMessage([first.value,second.value])主线程通过worker.onmessage指定监听函数,接收子线程发回来的消息。
worker.onmessage = function (event) {
console.log('Received message ' + event.data)
doSomething()
}
function doSomething() {
// 执行任务
worker.postMessage('Work done!')
}Worker 完成任务以后,主线程就可以把它关掉。
worker.terminate()Worker 线程内部需要有一个监听函数,监听message事件。
// 写法一
this.addEventListener('message', function (e) {
this.postMessage('You said: ' + e.data);
}, false);
// 写法二
addEventListener('message', function (e) {
postMessage('You said: ' + e.data);
}, false);根据主线程发来的数据,Worker 线程可以调用不同的方法,下面是一个例子。
self.addEventListener('message', function (e) {
var data = e.data
switch (data.cmd) {
case 'start':
self.postMessage('WORKER STARTED: ' + data.msg)
break
case 'stop':
self.postMessage('WORKER STOPPED: ' + data.msg)
self.close(); // Terminates the worker.
break
default:
self.postMessage('Unknown command: ' + data.msg)
}
}, false)service worker 是独立于当前页面的一段运行在浏览器后台进程里的脚本。
service worker不需要用户打开 web 页面,也不需要其他交互,异步地运行在一个完全独立的上下文环境,不会对主线程造成阻塞。基于service worker可以实现消息推送,静默更新以及地理围栏等服务。
service worker提供一种渐进增强的特性,使用特性检测来渐渐增强,不会在老旧的不支持 service workers 的浏览器中产生影响。可以通过service workers解决让应用程序能够离线工作,让存储数据在离线时使用的问题。
同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。
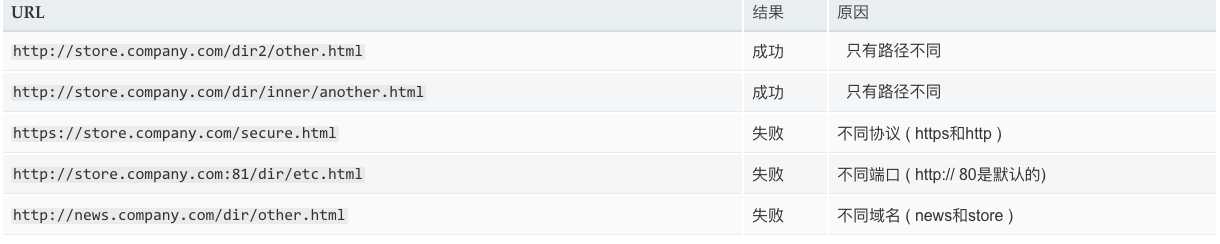
同源是指"协议+域名+端口"三者相同,即便两个不同的域名指向同一个ip地址,也非同源。
下表给出了相对http://store.company.com/dir/page.html同源检测的示例:
浏览器中的大部分内容都是受同源策略限制的,但是以下三个标签可以不受限制:
<img src=XXX><link href=XXX><script src=XXX>跨域是个比较古老的命题了,历史上跨域的实现手段有很多,我们现在主要介绍三种比较主流的跨域方案,其余的方案我们就不深入讨论了,因为使用场景很少,也没必要记这么多奇技淫巧。
jsonp本质上是一个Hack,它利用<script>标签不受同源策略限制的特性进行跨域操作。
jsonp优点:
jsonp的缺点:
<script>标签只能get)jsonp的实现:
function JSONP({
url,
params,
callbackKey,
callback
}) {
// 在参数里制定 callback 的名字
params = params || {}
params[callbackKey] = 'jsonpCallback'
// 预留 callback
window.jsonpCallback = callback
// 拼接参数字符串
const paramKeys = Object.keys(params)
const paramString = paramKeys
.map(key => `${key}=${params[key]}`)
.join('&')
// 插入 DOM 元素
const script = document.createElement('script')
script.setAttribute('src', `${url}?${paramString}`)
document.body.appendChild(script)
}
JSONP({
url: 'xxxx',
params: {
key: 'test',
},
callbackKey: '_cb',
callback(result) {
console.log(result.data)
}
})cors是目前主流的跨域解决方案,跨域资源共享(CORS) 是一种机制,它使用额外的 HTTP 头来告诉浏览器 让运行在一个 origin (domain) 上的Web应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求。
如果你用express,可以这样在后端设置
//CORS middleware
var allowCrossDomain = function(req, res, next) {
res.header('Access-Control-Allow-Origin', *);
res.header('Access-Control-Allow-Methods', 'GET,PUT,POST,DELETE');
res.header('Access-Control-Allow-Headers', 'Content-Type');
next();
}
//...
app.configure(function() {
app.use(express.bodyParser());
app.use(express.cookieParser());
app.use(express.session({ secret: 'cool beans' }));
app.use(express.methodOverride());
app.use(allowCrossDomain);
app.use(app.router);
app.use(express.static(__dirname + '/public'));
});在生产环境中建议用成熟的开源中间件解决问题。
nginx是一款极其强大的web服务器,其优点就是轻量级、启动快、高并发。
现在的新项目中nginx几乎是首选,我们用node或者java开发的服务通常都需要经过nginx的反向代理。
反向代理的原理很简单,即所有客户端的请求都必须先经过nginx的处理,nginx作为代理服务器再讲请求转发给node或者java服务,这样就规避了同源策略。
#进程, 可更具cpu数量调整
worker_processes 1;
events {
#连接数
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
#连接超时时间,服务器会在这个时间过后关闭连接。
keepalive_timeout 10;
# gizp压缩
gzip on;
# 直接请求nginx也是会报跨域错误的这里设置允许跨域
# 如果代理地址已经允许跨域则不需要这些, 否则报错(虽然这样nginx跨域就没意义了)
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Headers X-Requested-With;
add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
# srever模块配置是http模块中的一个子模块,用来定义一个虚拟访问主机
server {
listen 80;
server_name localhost;
# 根路径指到index.html
location / {
root html;
index index.html index.htm;
}
# localhost/api 的请求会被转发到192.168.0.103:8080
location /api {
rewrite ^/b/(.*)$ /$1 break; # 去除本地接口/api前缀, 否则会出现404
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://192.168.0.103:8080; # 转发地址
}
# 重定向错误页面到/50x.html
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}具体而言你会搞清楚以下问题:
在了解JavaScript运行机制之前,我们需要搞清楚几个主要概念,这有助于我们接下来的理解。
赋予一段代码意义的正是JavaScript引擎,目前JavaScript引擎有许多种:
而最为大家熟知的无疑是V8引擎,他用于Chrome浏览器和Node中。
V8引擎由两个主要部件组成:
想让JavaScript真正运作起来,单单靠JavaScript Engine是不够的,JavaScript Engine的工作是编译并执行 JavaScript 代码,完成内存分配、垃圾回收等,但是缺乏与外部交互的能力。
比如单靠一个V8引擎是无法进行ajax请求、设置定时器、响应事件等操作的,这就需要JavaScript运行时(JavaScript Runtime)的帮助,它为 JavaScript 提供一些对象或机制,使它能够与外界交互。
比如,虽然Chrome和node都是用了V8引擎,但是他们的运行时却不同,比如process、fs浏览器都无法提供。
V8只能使用系统的一部分内存,具体来说,在64位系统下,V8最多只能分配1.4G, 在 32 位系统中,最多只能分配743M。
我们知道对于栈内存而言,当ESP指针下移,也就是上下文切换之后,栈顶的空间会自动被回收。但对于堆内存而言就比较复杂了,我们下面着重分析堆内存的垃圾回收。
首先JS是单线程运行的,这意味着一旦进入到垃圾回收,那么其它的各种运行逻辑都要暂停; 另一方面垃圾回收其实是非常耗时间的操作。
以 1.5GB 的垃圾回收堆内存为例,V8 做一次小的垃圾回收需要50ms 以上,做一次非增量式的垃圾回收甚至要 1s 以上。
v8将内存分为两个部分,新生代和老生代,新生代就是临时分配的内存,存活时间短, 老生代是常驻内存,存活的时间长。
一段JavaScript代码的运行我们可以分为两个阶段:
本文的重点在于执行阶段。
JavaScript并非简单的一行行解释执行,而是将JavaScript代码分为一块块的可执行代码块进行执行,那么如何划分代码块?
目前有三类代码块:
我们先看一个简单的例子:
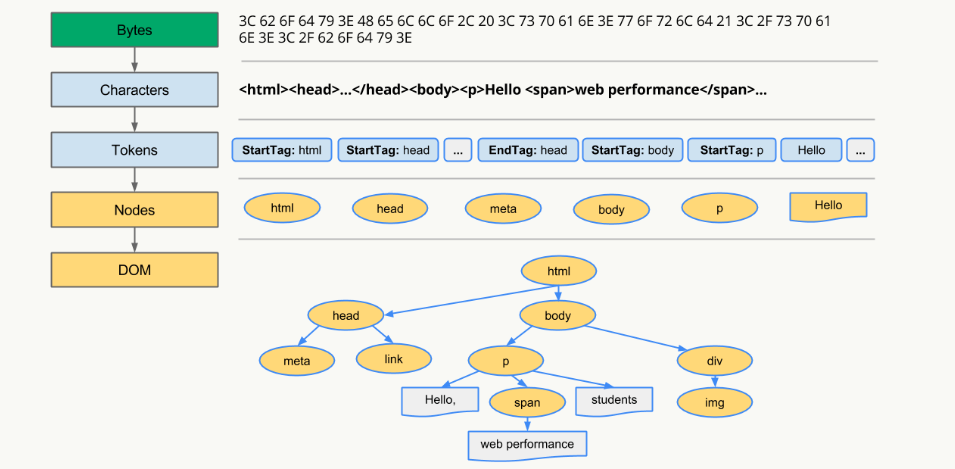
首先需要明白的是,机器是读不懂 JS 代码,机器只能理解特定的机器码,那如果要让 JS 的逻辑在机器上运行起来,就必须将 JS 的代码翻译成机器码,然后让机器识别。JS属于解释型语言,对于解释型的语言说,解释器会对源代码做如下分析:
然后解释器根据字节码来执行程序。但 JS 整个执行的过程其实会比这个更加复杂,接下来就来一一地拆解。
生成 AST 分为两步——词法分析和语法分析。
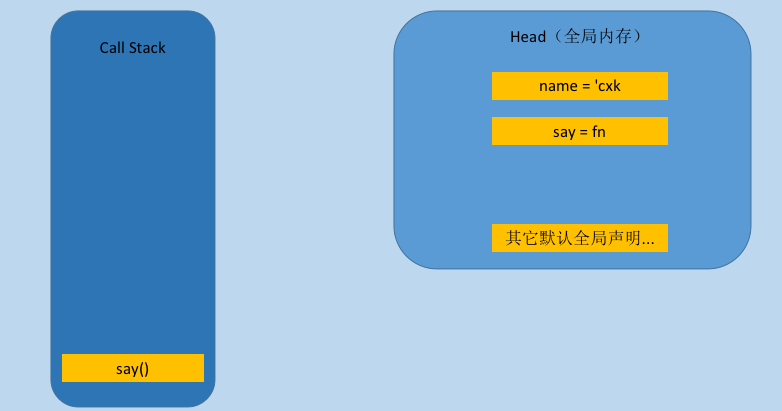
词法分析即分词,它的工作就是将一行行的代码分解成一个个token。 比如下面一行代码:
var name = 'cxk'关键字:var
变量名:name
赋值:=
字符串:'cxk'
即解析成了四个token,这就是词法分析的作用。
babel 的工作原理就是将 ES6 的代码解析生成ES6的AST,然后将 ES6 的 AST 转换为 ES5 的AST,最后才将 ES5 的 AST 转化为具体的 ES5 代码。
生成 AST 之后,直接通过 V8 的解释器来生成字节码。但是字节码并不能让机器直接运行,V8 的早期是将AST转换成机器码,但后来因为机器码的体积太大,引发了严重的内存占用问题。
子节码是介于AST 和 机器码之间的一种代码,但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码然后执行。
在执行字节码的过程中,如果发现某一部分代码重复出现,那么 V8 将它记做热点代码(HotSpot),然后将这么代码编译成机器码保存起来,这个用来编译的工具就是V8的编译器, 因此在这样的机制下,代码执行的时间越久,那么执行效率会越来越高,因为有越来越多的字节码被标记为热点代码,遇到它们时直接执行相应的机器码,不用再次将转换为机器码。
这种字节码跟编译器和解释器结合的技术,我们称之为即时编译, 也就是我们经常听到的JIT。
我们之前提到过JavaScript引擎两个重要部分:
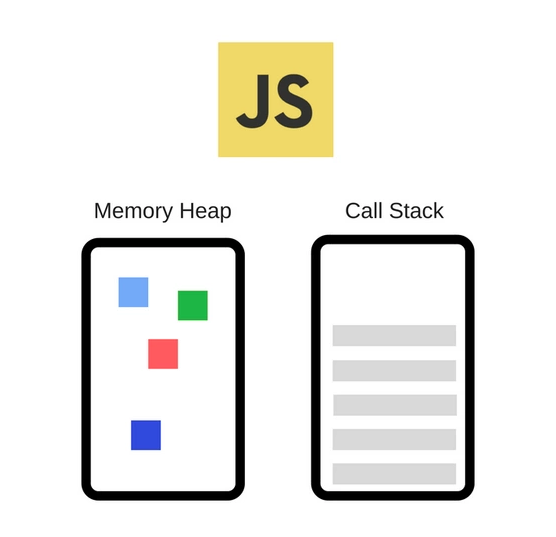
而上面的代码声明正是被存放在『堆』中。
此时虽然变量和函数都被声明了,但是函数还没有执行,我们现在执行say函数。
那么接下来又会发生什么呢?
调用栈(Call Stack)这个概念对于经常调试JavaScript代码的同学应该不陌生。
我们声明的函数与变量被储存在『内存堆』中,而当我们要执行的时候,就必须借助于『调用栈』来解决问题。
如果熟悉数据结构的同学应该知道,栈是一个基础的数据结构,它的特点就是先进后出。
我们仍然看这个例子,当say函数被调用的时候,他会被压入栈底。
那么是不是将函数压入栈内就结束了?肯定没有这么简单,这里需 要在引入一个概念,执行上下文(execution context)。
执行上下文在代码块执行前创建,作为代码块运行的基本执行环境,那么执行上下文分为几种?
前面我们提到过,JavaScript中有三种可执行代码块,当然也对应着三种执行上下文。
肯定会有人好奇,这个执行上下文到底包含哪些东西呢,他是如何运行的呢?
执行上下文分为两个阶段:
我们主要讨论创建阶段,执行阶段的主要工作就是分配变量
执行上下文的创建阶段主要解决以下三点:
伪代码如下:
我们应该知道this的指向是在代码执行阶段确定的,所谓的『代码执行阶段』正是『执行上下文的创建阶段』。
默认情况下this指向全局对象,比如浏览器中的window.
此外可能存在隐式绑定的情况,比如通过对象调用函数:
这个时候this指向对象。
然后就是显示绑定对象(call apply bind)等,最后优先级最高的就是new调用构造函数生成一个对象。
词法环境分为三大类:
词法环境本身包括两个部分:
对于『环境记录器』而言,它又分为两个主要的环境记录器类型:
比如我们在全局声明一个函数:
那么他的词法环境可以这样表示(下图我们省略了this绑定、变量环境等信息,便于理解):
变量环境的定义在es5标准和es6标准是略有不同的,我们采用es6的标准
变量环境也是一个词法环境,但不同的是词法环境被用来存储函数声明和变量(let 和 const)绑定,而变量环境只用来存储 var 变量绑定。
在 JS 中,大部分的任务都是在主线程上执行,常见的任务有:
渲染事件
用户交互事件
js脚本执行
网络请求、文件读写完成事件等等。
微任务是为了解决异步回调的问题。
如果采用第一种方式,那么执行回调的时机应该是在前面所有的宏任务完成之后,倘若现在的任务队列非常长,那么回调迟迟得不到执行,造成应用卡顿。
为了规避这样的问题,V8 引入了第二种方式,这就是微任务的解决方式。在每一个宏任务中定义一个微任务队列,当该宏任务执行完成,会检查其中的微任务队列,如果为空则直接执行下一个宏任务,如果不为空,则依次执行微任务,执行完成才去执行下一个宏任务。
常见的微任务有:
console.log('start');
setTimeout(() => {
console.log('timeout');
});
Promise.resolve().then(() => {
console.log('resolve')
});
console.log('end');参考
栈一种计算受到限制的数据结构,通常所说的栈有两种含义,以下内容以JavaScript作为🌰
数据的存放方式
可以将栈想想成一个木桶,先放入的物品将被压在下面;因此,先放入的数据将被后取出,也就是经常说的LIFO(last in, first out)。
同时这种数据结构有几种方法:
isempty 查看栈是否为空
top 查看最栈顶的元素
push 将元素放到栈的顶部
pop 将栈顶的元素取出
class Stack {
stack: any[]
constructor(stack: any[]) {
this.stack= stack
}
push(element: any) {
this.stack.push(element)
}
pop(element: any) {
return this.stack.pop()
}
top() {
return this.stack[this.stack.length - 1]
}
isempty() {
return this.stack.length === 0
}
}代码的运行方式 (执行栈,或者说调用栈)
将函数压入执行上下文栈,每次取出最上面的一个函数执行并将其弹出
ECStack = []; //执行上下文栈 我们都知道在函数执行的过程中,在外层环境是全局环境,也就是global。因此这个执行栈的最先被压入的永远是global,最后被弹出的也是global。
当我们的函数执行在另一个函数内部时,js将会创建执行上下文栈,
例如下面这个函数
function fn1() {
fn2()
console.log('fn1执行完了')
}
function fn2() {
fn3()
console.log('fn2执行完了')
}
function fn3() {
console.log('fn3执行完了')
}
fn1()
//fn3执行完了
//fn2执行完了
//fn1执行完了而执行过程就是之前所说的,函数在执行时会创建执行上下文栈,并依次将fn1,fn2,fn3压入执行栈中,并从最顶部开始弹出执行
//压入栈中
ECStack.push(window)
ECStack.push(fn1)
ECStack.push(fn2)
ECStack.push(fn3)
//fn3执行完了
ECStack.pop(fn3)
//fn2执行完了
ECStack.pop(fn2)
//fn1执行完了
ECStack.pop(fn1)
ECStack.pop(window)
ECStack.isempty() //true一般请求都是有客户端发出的,而服务器回复的是响应。服务器相对来说是比较被动的。
客户端,请求方法 :GET 、地址: / 、协议版本 :HTTP1.1 、请求首部:Host:xxx等。服务器返回的信息:HTTP协议版本号,状态码以及结果短语、响应首部(响应时间之后的)和资源主体(html开始)。
前后分离之后,引入了token机制,为什么要这么做?本质上还是因为HTTP协议是无状态的。所谓无状态,就是通信的双方没有记住通信历史,协议本身是不保留一切请求和响应的信息。这也是确保HTTP协议有能够处理大量事务且具有可伸缩性的原因。
GET :获取资源。
POST :传输实体主体,主要目的是传输。
PUT : 传输文件,保存到指定的位置
HEAD : 获得报文首部
DELETE :删除文件
OPTIONS :查询支持的方法
TRACE :追踪路径
CONNECT :要求使用隧道协议连接代理
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
|---|---|
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
|---|---|---|
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
AJAX即“Asynchronous Javascript And XML”(异步JavaScript和XML),是指一种创建交互式网页应用的网页开发技术。Ajax不是一种新的编程语言,而是使用现有标准的新方法。**AJAX可以在不重新加载整个页面的情况下,与服务器交换数据。**这种异步交互的方式,使用户单击后,不必刷新页面也能获取新数据。使用Ajax,用户可以创建接近本地桌面应用的直接、高可用、更丰富、更动态的Web用户界面。
利用AJAX可以做:
说起异步,就要先说说JavaScript运行机制。我们知道,JavaScript是单线程执行的,意味着同一个时间点,只有一个任务在运行。单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。
从诞生起,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
单线程的好处是实现起来比较简单,执行环境相对单纯;坏处是只要有一个任务耗时很长,后面的任务都必须排队等着,会拖延整个程序的执行。常见的浏览器无响应(假死),往往就是因为某一段Javascript代码长时间运行(比如死循环),导致整个页面卡在这个地方,其他任务无法执行。
为了解决这个问题,Javascript语言将任务的执行模式分成两种:同步(Synchronous)和异步(Asynchronous)。
在谈异步之前,先来说说JavaScript的执行机制,看下面这段代码
function foo () {
return foo();
}
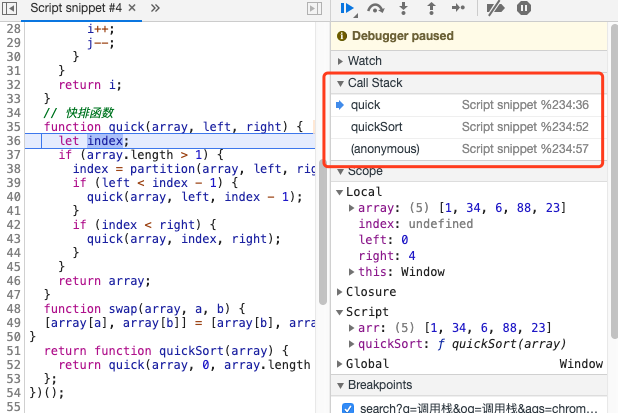
foo();stack是一种数据结构,数据先入后出,后入先出。执行JavaScript的call stack,也是如此。
var i = 0;
function inc() {
i++;
inc();
}
inc();webApi,任务队列,event loop
DOM0级事件
element.onclick=function(){
console.log("clicked");
}
window.onload=function(){
console.log("loaded");
}DOM2级事件
element.addEventListener("click",function(){
console.log("clicked");
});定时器
console.log(1);
setTimeout(() => {console.log('after 0ms')} ,0);
console.log(2);
console.log(3);
iframe就是我们常用的iframe标签:<iframe>。iframe标签是框架的一种形式,也比较常用到,iframe一般用来包含别的页面,例如我们可以在我们自己的网站页面加载别人网站或者本站其他页面的内容。iframe标签的最大作用就是让页面变得美观。iframe标签的用法有很多,主要区别在于对iframe标签定义的形式不同,例如定义iframe的长宽高。
因此,iframe标签具有局部加载内容的特性,所以可以使用其来伪造Ajax请求。
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>伪造AJAX</title>
</head>
<body>
<div>
<p>请输入要加载的地址:<span id="currentTime"></span></p>
<p>
<input id="url" type="text" />
<input type="button" value="提交" onclick="LoadPage();">
</p>
</div>
<div>
<h3>加载页面位置:</h3>
<iframe id="iframePosition" style="width: 100%;height: 500px;"></iframe>
</div>
<script type="text/javascript">
window.onload= function(){
var myDate = new Date();
document.getElementById('currentTime').innerText = myDate.getSeconds();
};
function LoadPage(){
var targetUrl = document.getElementById('url').value;
document.getElementById("iframePosition").src = targetUrl;
}
</script>
</body>
</html>Ajax的核心是XMLHttpRequest对象(XHR)。XHR为向服务器发送请求和解析服务器响应提供了接口。能够以异步方式从服务器获取新数据。
一、XMLHttpRequest对象
Ajax的核心是XMLHttpRequest对象(XHR)。XHR为向服务器发送请求和解析服务器响应提供了接口。能够以异步方式从服务器获取新数据。
XHR的主要方法有:
XHR的主要属性有:
Number readyState状态值(整数),可以确定请求/响应过程的当前活动阶段
0:未初始化。未调用open()方法1:启动。已经调用open()方法,未调用send()方法2:发送。已经调用send()方法,未接收到响应3:接收。已经接收到部分数据4:完成。已经接收到全部数据,可以在客户端使用
Function onreadystatechange 当readyState的值改变时自动触发执行其对应的函数(回调函数)
String responseText 作为响应主体被返回的文本(字符串类型)
XmlDocument responseXML 服务器返回的数据(Xml对象)
Number states 状态码(整数),如:200、404...
String statesText 状态文本(字符串),如:OK、NotFound...
GET用于向服务器查询某些信息:
向url后添加需要访问的数据
如:
https://a.com/student?a=1&b=2
这里的?后面的是要发送的数据,用&连接
xmlhttp.open("GET","xxx",true);
xmlhttp.send();
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<h1>Ajax请求</h1>
<input type="button" onclick="XmlGetRequest();" value="Get发送请求" />
<script type="text/javascript">
function GetXHR(){
var xhr = null;
if(XMLHttpRequest){
xhr = new XMLHttpRequest();
}else{
xhr = new ActiveXObject("Microsoft.XMLHTTP");
}
return xhr;
}
function XmlGetRequest(){
var xhr = GetXHR();
// 定义回调函数
xhr.onreadystatechange = function(){
if(xhr.readyState == 4){
// 已经接收到全部响应数据,执行以下操作
var data = xhr.responseText;
console.log(data);
}
};
xhr.open('get', "xxx", true);
xhr.send();
}
</script>
</body>
</html>xmlhttp.open("POST","xxx",true);
xmlhttp.setRequestHeader("Content-type","application/x-www-form-urlencoded");
xmlhttp.send("a=1;b=2");
post在send中发送请求数据,和get中的?a=1&b=2对应
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>POST</title>
</head>
<body>
<h1>Ajax请求</h1>
<input type="button" onclick="XmlPostRequest();" value="Post发送请求" />
<script type="text/javascript">
function GetXHR(){
var xhr = null;
if(XMLHttpRequest){
xhr = new XMLHttpRequest();
}else{
xhr = new ActiveXObject("Microsoft.XMLHTTP");
}
return xhr;
}
function XmlPostRequest(){
var xhr = GetXHR();
// 定义回调函数
xhr.onreadystatechange = function(){
if(xhr.readyState == 4){
// 已经接收到全部响应数据,执行以下操作
var data = xhr.responseText;
console.log(data);
}
};
// 指定连接方式和地址
xhr.open('POST', "xxx", true);
// 设置请求头
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded; charset-UTF-8');
// 发送请求
xhr.send('n1=1;n2=2;');
}
</script>
</body>
</html>
postFailed to load file:///C:/Users/admin/Desktop/work/test.json: Cross origin requests are only supported for protocol schemes: http, data, chrome, chrome-extension, https.为什么会跨域
协议,域名,端口相同,视为同一个域,一个域内的脚本仅仅具有本域内的权限,可以理解为本域脚本只能读写本域内的资源,而无法访问其它域的资源。这种安全限制称为同源策略。 同源策略保证了资源的隔离。一个网站的脚本只能访问自己的资源,就像操作系统里进程不能访问另一个进程的资源一样,如果没有同源策略,你在网站浏览,跳转其他网页,然后这个网页就可以跨域读取你网站中的信息,这样整个Web世界就无隐私可言了。这就是同源策略的重要性,它限制了这些行为。当然,在同一个域内,客户端脚本可以任意读写同源内的资源,前提是这个资源本身是可读可写的。
通俗的讲,浏览器有一个很重要的安全机制,即为同源策略:不用域的客户端脚本在无明确授权的情况下不能读取对方资源,跨域也就是不同源。
这里要提一点,访问本地计算机中的文件,使用的是file协议
怎么解决跨域问题
前端人员使用的一般是JSONP进行跨域。
项目中使用nginx反向代理。
proxy_pass
修改谷歌浏览器的配置。
本地服务器(canvas)
CORS
使用jsonp解决跨域
实现原理:<script> 标签是不受同源策略的限制的,它可以载入任意地方的 JavaScript 文件,而并不要求同源。所以 JSONP 的理念就是,我和服务端约定好一个函数名,当我请求文件的时候,服务端返回一段 JavaScript。这段 JavaScript 调用了我们约定好的函数,并且将数据当做参数传入。非常巧合的一点(其实并不是),JSON 的数据格式和 JavaScript 语言里对象的格式正好相同。所以在我们约定的函数里面可以直接使用这个对象
<script type="text/javascript">
var localHandler = function(data){
alert('我是:' + data.result);
};
</script>
<script type="text/javascript" src="./test2.js"></script>
localHandler({"result":"我是远程js带来的数据"});
//PHP jsonp -> 字符拼接,了解即可
$jsonp = $_GET['callback']
$result = $jsonp . '({"xxx":"xx"})'
在正式进入我们主题之前,先给大家讲个故事,从前有个叫某马的人,在他的下面有很多很多的工人,在全国不同的地方做着同样的工作---搬砖,每个人都搬着自己那块地盘的砖,干的津津有味;突然有一天,搬砖工A想要给搬砖工B写一封信,又由于他们在不同的城市,而且他不能脱离自己的岗位,这让搬砖工A很苦恼,于是他找到他的上司,把他的信给了当地的包工头,这个包工头不想跑着么远帮他送信,于是把这封信给了某马,某马想了想,就帮一帮他把,于是把信带到了另一个城市,但是由于不熟悉每个员工,就把信交给了当地工地的包工头,这个包工头顺利的把信给了搬砖工B,这个搬砖工B将自己收藏了很久的网图放在了信封里让某马带了回去,交给了搬砖工A,这一看不得了,我靠,是个PLMM,于是他们两个开始了愉快的通”信“。A所在工地的工人当然不服了,凭什么就你有PLMM聊天,于是也开始写信,交给包工头,交给某马。这一年,某马因为机票破产了,完结。当然不是,某马可是很聪明的,他想啊想啊,突然,想出了一个办法,他叫了自己麾下的一批搬砖工,让他们很快做出了一个叫秋秋的东西,当然由于经费问题,这个秋秋做的事情很简单,每个人都可以将自己的信交给秋秋,然后向秋秋发出要求,将信发给B,当然,秋秋很笨,你需要提前把所有要发的所有信交给它,比如“你好”、“NMSL”、“CXK”,然后对他提出要求,“把’NMSL‘发出去”,这样它就会从所有消息里选择你要求的那个,并把消息发过去了。但是要收到这个信的复制品的前提是你要先去预约这个消息,这样🐦就能找到你的地方,然后将信送过来。从此以后,某马蒸蒸日上...慢慢的,秋秋有了语言功能,A发现了,B是个男的,完结。
在很多萌新(当然包括我)在刚刚开始接触Redux的时候,都有一总感觉,我*,这东西怎么这么绕,好烦啊。然后,就开是麻烦某马了...
其实Redux真的不难,正如上面我们故事所讲的,React的跨组件通信在Hooks出来之前急需一种能在全局监听和订阅状态的工具,这个时候,Reudx出现了,不过在这里申明,Redux并不是因为React产生的,不要因为自己不想学React就不去接触Redux,我觉得这个真的很有必要了解熟悉。
为了更好的上手,我们来自己实现一下吧!在上面的秋秋是什么?也就是一个叫做store的东西,他要把所有信息搜集起来,在这里有些什么东西呢,发布你要让他执行的行为是吧,也就是Action,还有呢,它要得到所有的信,让后把信统一管理,就是一个Reducer,然后通过dispatch将指定的Action行为告诉秋秋,它就能将消息发出去。对方要收到这个消息需要怎么样,当然是订阅这个消息了,subscribe是吧,这样当State改变的时候,你就可以获取改变消息了。
首先,我们要定一个createStore的东西,来产生store吧,这个东西也要搜集所有的信息吧,也就是Reducer
const createStore = (reducer) => {}在这里面有什么呢,我们的秋秋store
const createStore = (reducer) => {
const store = {}
}当然还有一些方法和订阅的人
const createStore = (reducer) => {
const store = {}
store.listener = []
store.state = reducer(undefined, {})
store.subscribe = (listener) => {}
store.dispatch = (action) => {}
return store
}当然,还需要有人来订阅这个消息。
store.subscribe = listener => {
store.listener.push(listener)
}最后,我们要需要根据Action去改变我们要发出消息,然后通知所有的订阅者是吧。
store.dispatch = action => {
store.state = reducer(store.state, action)
store.listener.forEach(listener => listener())
}然后,我们就完成了一个Redux,什么!完了?没错,其实Redux真的就这么简单,最后,我们加上获取所有state的方法。把代码放在一起来看看
const createStore = reducer => {
const store = {}
store.state = reducer(undefined, {})
store.listener = []
store.subscribe = listener => {
store.listener.push(listener)
}
store.dispatch = action => {
store.state = reducer(store.state, action)
store.listener.forEach(listener => listener())
}
store.getState = () => store.state
return store
}我们来试试怎么样
const initialState = {
count: 0
}
const reducer = (state = initialState, action) => {
switch (action.type) {
case "ADD":
return {
count: state.count + 1
}
case "REDUCE":
return {
count: state.count - 1
}
default:
return {
...state
}
}
}
const action = {
add: {
type: "ADD"
},
reduce: {
type: "REDUCE"
}
}
const store = createStore(reducer)
store.subscribe(() => {
console.log(store.getState())
})
store.dispatch(action.add)
store.dispatch(action.add)
//{ count: 1 }
//{ count: 2 }完美!
以上是本人自己的理解,Reducer其实不能理解为所有的信息,我也想不出来到底该怎么来说这个能更好的插入这个故事里面了😭,如有意见欢迎提出了,我一定接受!
参考文章
[Redux中文官方文档][https://www.redux.org.cn/]
[【React系列】从零开始实现Redux][https://juejin.im/post/5d88200bf265da03c721dfb2]
队列和栈一样,是一种计算受到限制的结构,对拿和取有着严格的要求,与栈不同的是队列采取的存取方式是FIFO(first in first out),通常,我们称数据进入的一端为**“队尾”,而数据弹出的一端为“队头”,整个过程叫做“入队”和“出队”**。
通常,队列储存结构的实现有两种方式:
顺序队列是最简单的队列实现方式,我们只需要使用顺序表并按照队列的定义原则操作数据,就可以实现顺序队列。
class Queue {
items: any[]
constructor(items) {
this.items = items || []
}
enqueue(element: any){
this.items.push(element)
}
dequeue(){
return this.items.shift()
}
front(){
return this.items[0]
}
clear(){
this.items = []
}
get size(){
return this.items.length
}
get isEmpty(){
return !this.items.length
}
print() {
console.log(this.items.toString())
}
}以来我们就实现了一个队列的类
但是顺序队列适用会对整体内存优化并不友好,比如在之前使用的内存在数据弹出之后会导致内存的浪费,在内存需要自己申请内存空间的语言中不断的入队还会导致益处。
因此我们还可以对我们的队列进行扩展,使其有更多的适用环境,循环队列
而实现的原理很简单,我们只需要将队列的首位相连,就实现了我们的循环队列
class LoopQueue extends Queue {
constructor(items) {
super(items)
}
getIndex(index: number) {
const length = this.items.length
return index > length ? (index % length) : index
}
find(index: number) {
return !this.isEmpty ? this.items[this.getIndex(index)] : null
}
}而队列实现的另一种方式是链表队列,链表队列的**基本和顺序队列相同,只是只用了链表的方式。
class QNode {
element: string | number
next: object
constructor(element) {
this.element = element
this.next = null
}
}
class LinkedList {
head: object
length: number
constructor() {
this.head = null
this.length = 0
}
enqueue(element: string | number) {
const node = new QNode(element)
let current = null
while(current.next) {
current = current.next
}
current.next = node
this.length++
}
dequeue() {
let current = null
while(current.next) {
current = current.next
}
current.next = null
this.length--
}
front(){
return this.head
}
get isEmpty() {
return !this.length
}
get size() {
return this.length
}
}还有一种名为队列却常常使用堆来实现的结构,优先队列
class PriorityQueue {
items: any[]
constructor() {
this.items = []
}
enqueue(element: any, priority: number) {
const queueElement = { element, priority }
if (this.isEmpty) {
this.items.push(queueElement)
} else {
const preIndex = this.items.findIndex(
item => queueElement.priority < item.priority
)
if (preIndex > -1) {
this.items.splice(preIndex, 0, queueElement)
} else {
this.items.push(queueElement)
}
}
}
dequeue() {
return this.items.shift()
}
front() {
return this.items[0]
}
clear() {
this.items = []
}
get size() {
return this.items.length
}
get isEmpty() {
return !this.items.length
}
print() {
console.log(this.items)
}
}A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.