uithen / blog Goto Github PK
View Code? Open in Web Editor NEWmy blog
my blog


在用户界面开发领域,它是一种面对用户的独立的可复用交互元素的封装
在前端开发中,一个完整的组件由三个单元组成:组件=html(结构) + css(样式) + js(逻辑)。或者也可以由这三个单元的任一个或两个组成。
像比较常见的组件: Mask、Slider、Datepicker、Modal、Pagination、Editor
既然已经有了这么多现成的组件库,还有没有必要自己开发组件?基本上大点的公司,都会构建自己的组件库,最大的原因在于,一个公司业务的发展不可能受限于技术框架,而一旦业务有所变化(产品驱动技术,而不是颠倒过来)如果不具备开发组件的能力,就会手足无措无法应对,所以就必定去设计适合公司业务场景与符合团队的组件。
组件的优点也是不言而喻的,通过组件化开发,我们可以把整个系统的复杂度封装到组件内,每个组件负责自己的逻辑,对外部来说,内部的复杂逻辑完全是一个黑盒,并不需要关心它是什么, 这样一来就降低了系统各个功能的耦合度,提高了功能内部的聚合度。
不仅如此使用组件开发还可以使我们避免冗余工作,在一个系统内会出现很多功能相同的单元,把其封装成组件之后就可以进行复用,从而提高开发效率和可维护性
如果我们使用组件化开发**,当我们看到一个页面时,就会很自然的把这个页面拆分成一个个组件,而此时的界面就是组件的有机结合
一个组件的完整流程应当是这样的:
下面,就以上的五步法来实现一个简易Modal组件
Modal(模态)又称弹窗,通过展示高聚焦性的窗口来直接捕获到用户的注意力。基本上是每一个网站必不可少的组件。
<!-- 2.静态结构 -->
<div class="m-modal">
<!-- 用于垂直水平居中 -->
<div class="modal_align"></div>
<div class="modal_wrap">
<div class="modal_head">标题</div>
<div class="modal_body">内容</div>
<div class="modal_foot">
<a href="" class="confirm">确认</a>
<a href="" class="cancel">取消</a>
</div>
</div>
</div>modal.show()、modal.hide()这一步骤,我们应当站在使用者的角度来设计
代码:
// 初始化Modal
var modal = new Modal({
// 1. 内容配置
content: '自定义内容', // 可传入节点和字符串
// 2. 确认与取消按钮回调,以便开发者对后续逻辑的处理
onConfirm() {
console.log('确认')
},
onCancel() {
console.log('取消')
}
})
// 接口调用
modal.show(/*可传入content,即自定义内容*/)
modal.hide()接口设计部分其实就是我们对前面分解需求映射到代码实现的一个体现,基本上就告诉了我们,具体的JS我们应当怎么去实现
非常重要的一点是,从抽象到细节。当对组件逻辑足够抽象之后,我们就可以针对每一个独立的逻辑去进行测试,一个正确的做法应当是这样的:
// 先写出Modal的骨架
function Modal(option) {
// 初始化逻辑
}
Modal.prototype.show = function() {
// 展示逻辑
}
Modal.prototype.hide = function() {
// 隐藏逻辑
}首先,我们的关注点应该在只对上面三个逻辑的细节进行实现,不过在此之前,先交代下两个辅助函数,它们分别是:
至此,贴出组件五步法前四步Modal逻辑的完整实现:
// 辅助函数
// -------
// 将HTML转换为节点
function html2node(str) {
var container = document.createElement('div')
container.innerHTML = str
return container.children[0] //将下列template字符串转换为node
}
// 拓展属性(用于往原型上添加属性)
// extend: {x:1},{a:1, b:2} ==> {x:1,a:1,b:2},注意不是覆盖,跟assign不一样!
function extend(o1, o2) {
for (var p in o2) if (typeof o1[p] === 'undefined') {
o1[p] = o2[p]
}
return o1
}
// 结构
var template = `
<div class="m-modal">
<div class="modal_align"></div>
<div class="modal_wrap">
<div class="modal_head">标题</div>
<div class="modal_body">内容</div>
<div class="modal_foot">
<a href="#" class="confirm">确认</a>
<a href="#" class="cancel">取消</a>
</div>
</div>
</div>
`
// Modal主逻辑
// -----
function Modal(options) {
options = options || {}
// 由于_layout设置在了原型上的,会导致所有实例共享,所以在这初始化的时候做了克隆处理,以保证每个实例拥有自己的container
this.container = this._layout.cloneNode(true)
this.body = this.container.querySelector('.modal_body')
this.wrap = this.container.querySelector('.modal_wrap')
console.log(this._layout)
// 拓展实例属性
extend(this, options)
this._initEvent()
}
// 拓展原型属性
extend(Modal.prototype, {
// modal结构渲染
_layout: html2node(template),
// modal内容区配置,支持传入字符串和DOM节点两种格式
setContent(content) {
if (!content) {
return
}
if (content.nodeType === 1) {
this.body.innerHTML = ''
this.body.appendChild(content)
} else {
this.body.innerHTML = content
}
},
// 显示弹窗
show(content) {
if (content) {
this.setContent(content)
}
document.body.appendChild(this.container)
},
// 隐藏弹窗
hide() {
document.body.removeChild(this.container)
},
// 初始化事件
_initEvent() {
this.container.querySelector('.confirm').addEventListener('click', this._onConfirm.bind(this))
this.container.querySelector('.cancel').addEventListener('click', this._onCancel.bind(this))
},
_onConfirm() {
this.onConfirm()
this.hide()
},
_onCancel() {
this.onCancel()
this.hide()
}
})不过,仔细review其实还是可以找出很多不足之处。比如:
现在,来到第五步,开始改进并完善。
就Modal来说,为窗体的动画,主要两个地方,窗体显示时和窗体关闭时。通过分析不难得出:
当窗体显示时,动画流程为:
当窗体关闭时,动画流程为:
可以发现有两步流程它们的逻辑是一样的,针对这样的共性就可以进行封装。
代码:
function animateClass(node, className, callback) {
function onAnimationEnd() {
// 2.移除类名
delClass(node, className)
node.removeEventListener('animationend', onAnimationEnd)
// 3.执行回调
callback && callback()
}
// 1.添加类名触发animation
addClass(node, className)
node.addEventListener('animationend', onAnimationEnd)
}使用事件Mixin
监听者模式:confirm为例,
// 逻辑解耦,不需要显式的传入
var modl = new Modal()
// 并且支持多回调逻辑
modal.on('confirm', function() {
console.log('confirm')
});
modal.on('confirm', function() {
console.log('confirm2')
});
// 还可动态绑定、解绑
modal.on('confirm', fn1)
modal.on('confirm', fn2)
modal.off('confirm', fn1)
_onConfirm: function() {
// this.onConfirm()
// Modal不在耦合于onConfirm参数
this.emit('confirm')
this.hide()
}实现思路:
var emitter = {
// 注册事件
on:function(event, fn){},
// 解绑事件
off:function(event, fn){},
// 触发事件
emit:function(event){}
}
// 使用混入Mixin的方式使得Modal具有事件发射器功能
extend(Modal.prototype, emitter)可以看到emitter并不是使用的原型继承,主要原因还是因为emitter本身是个独立的体系并不是Modal特有的一个功能,所以这里将其独立了出来,只需在用的时候使用mixin混入进去就可以了
GoF:设计模式是在面向对象软件设计过程中针对特定问题的简洁而优雅的解决方案。
也可以理解为,是对前人经验的一种总结,当我们封装一个函数时,是在复用代码;而当使用一个设计模式时,是在复用他人的经验
《设计模式》一书将设计模式分为三类:
此次学习目标为单例模式
保证一个类仅有一个实例,并提供一个访问它的全局访问点
文字定义总是晦涩难懂的,还是看代码:
// 皇帝,一国之主,有且只有一个
function Emperor() {
this.name = '皇帝';
this.id = Math.floor(Math.random() * 10);
}
Emperor.prototype.say = function() {
console.log(this.name + this.id + ' : 择日再议');
};
// 大臣,国之栋梁,多多益善
function Minister(name) {
this.name = name;
}
Minister.prototype.say = function() {
console.log(this.name + ': 陛下,臣附议!')
};
// 对某国事,三名大臣集体附议
var m1 = new Minister('张大人');
var e1 = new Emperor();
m1.say();
e1.say(); //每次皇帝的id都不一样
var m2 = new Minister('李大人');
var e2 = new Emperor();
m2.say();
e2.say(); //每次皇帝的id都不一样
var m3 = new Minister('王大人');
var e3 = new Emperor();
m3.say();
e3.say(); //每次皇帝的id都不一样以上,每次皇帝(Emperor实例)得到的都是不一样的id,这样显然是不行的,以单例模式定义来理解,一个类只能实例化出一个对象,不管你实例化多少次Emperor,最终所有实例应该都是同一个
如何保证Emperor实例的唯一性,有两种做法
// 皇帝,一国之主,有且只有一个
function Emperor() {
this.name = '皇帝';
this.id = Math.floor(Math.random() * 10);
// 保存着Emperor的实例
this.instance = null;
}
//注意这里,方法是定义在函数上而不是原型上
Emperor.getInstance = function() {
console.log(this) // --> Emperor {name: "king", id: 1, instance: null}
// 首次进入,实例化Emperor,并返回
if(!this.instance) {
this.instance = new Emperor();
}
return this.instance;
};
Emperor.prototype.say = function() {
console.log(this.name + this.id + ' : 择日再议');
};
// 大臣,国之栋梁,多多益善
function Minister(name) {
this.name = name;
}
Minister.prototype.say = function() {
console.log(this.name + ': 陛下,臣附议!');
};
// 对某国事,三名大臣集体附议
var m1 = new Minister('张大人');
var e1 = Emperor.getInstance();
m1.say();
e1.say(); // 每次输出一致,保存了第一次的id
var m2 = new Minister('李大人');
var e2 = Emperor.getInstance();
m2.say();
e2.say(); // 每次输出一致,保存了第一次的id
var m3 = new Minister('王大人');
var e3 = Emperor.getInstance();
m3.say();
e3.say(); // 每次输出一致,保存了第一次的id不难发现,以上代码中的instance并非私有成员,在外部是可以随意修改的,存在一定的安全隐患,所以私有化instance是个不错的选择:
// 皇帝,一国之主,有且只有一个
function Emperor() {
this.name = '皇帝';
this.id = Math.floor(Math.random() * 10);
}
Emperor.getInstance = (function() {
var instance = null;
return function() {
if(!instance) {
instance = new Emperor();
}
return instance;
};
})();
Emperor.prototype.say = function() {
console.log(this.name + this.id + ' : 择日再议');
};
// 大臣,国之栋梁,多多益善
function Minister(name) {
this.name = name;
}
Minister.prototype.say = function() {
console.log(this.name + ': 陛下,臣附议!');
};
// 对某国事,三名大臣集体附议
var m1 = new Minister('张大人');
var e1 = Emperor.getInstance();
m1.say();
e1.say(); // 每次输出一致,保存了第一次的id
var m2 = new Minister('李大人');
var e2 = Emperor.getInstance();
m2.say();
e2.say(); // 每次输出一致,保存了第一次的id
var m3 = new Minister('王大人');
var e3 = Emperor.getInstance();
m3.say();
e3.say(); // 每次输出一致,保存了第一次的id问题又来了,每次我们必须通过Emperor.getInstance()这样的静态访问获取对象而非使用new构造函数形式来获取,这就要求我们必须得知道Emperor是单例模式,同时还必须得知道通过.getInstance()方法才能获取到单例对象
那么如何通过new运算符正常获取对象?可以这样:
// 皇帝,一国之主,有且只有一个
var Emperor = (function() {
var instance = null;
// 与全局的Emperor没有任何关系
function Emperor() {
if(instance) {
return instance;
}
this.name = '皇帝';
this.id = Math.floor(Math.random() * 10);
return instance = this;
}
Emperor.prototype.say = function() {
console.log(this.name + this.id + ': 择日再议!');
};
return Emperor;
})();
// 大臣,国之栋梁,多多益善
function Minister(name) {
this.name = name;
}
Minister.prototype.say = function() {
console.log(this.name + ': 陛下,臣附议!');
};
// 对某国事,三名大臣集体附议
var m1 = new Minister('张大人');
var e1 = new Emperor();
m1.say();
e1.say(); // 每次输出一致
var m2 = new Minister('李大人');
var e2 = new Emperor();
m2.say();
e2.say(); // 每次输出一致
var m3 = new Minister('王大人');
var e3 = new Emperor();
m3.say();
e3.say(); // 每次输出一致以上,类似当想创建Emperor这样的只能实例化唯一对象的类的时候,就需要单例模式,而单例模式的原理其实就是,在每次创建之前需要判断一下是否存在,不存在就直接创建,存在的话,就把已经创建了的返回出去
JS与HTML之间的交互是通过事件来实现的。事件,就是文档或浏览器窗口发生的一些特定的交互瞬间。例如,点击一个DOM元素、键盘按下某个键、输入框输入内容或是当页面加载完成,以上这些都会触发DOM事件
当在网页中单击了某个按钮时,单击事件不仅仅发生在按钮上,也就是说在单击的同时,也单击了按钮的容器元素,甚至整个页面。事件流描述的就是一个这样的DOM事件处理的执行过程,也可以理解为从页面中接收事件的顺序。
DOM事件流主要分为三部分:
如果多个元素同时设置了capture和bubble,那么在 target phase,event handler 被调用的顺序不再遵循先捕获,后冒泡的原则,而是严格按照 event handler 注册的顺序
值的一提的是,在ie低版本中只有target和bubble过程,没有捕获过程.与此同时,也不是所有的事件都有这三个过程,有些事件时没有冒泡的,比如说load事件
target.addEventListener(type, listener, useCapture);
参数说明:
type:要处理的事件名的类型(string)
如click事件,type的参数为"click",并非"onclick",后者是事件处理程序的名字,前者才为事件的名字
listener:作为事件处理程序的函数(function)
useCapture:可选,是否是捕获过程,也就是说默认情况下DOM事件里它处理的是冒泡过程,只有把第三个参数设置为true时,才会处理捕获过程(boolean)
优点:可在某个dom节点上同时注册多个事件
elem.onclick = eventHandler;
事件注册的第二种方式,使用elem.onclick也能实现相同的逻辑
这种方式注册的事件被认为是元素的方法,所以程序中的this指向引用当前的元素(elem)
缺点:只能在某个dom节点上注册一个事件
target.removeEventListener(type, listener[, useCapture])elem.onclick = null事件触发有很多种方式,除了可以在点击元素或按下键盘时来触发,也可以用程序代码来触发
eventTarget.dispatchEvent(type)以上为W3C的官方定义,很不幸如果需要兼容低版本IE,则需要使用该浏览器的自身实现方法
在不同浏览器调用:
// 事件注册
var addEvent = document.addEventListener ?
function(elem, type, listener, useCapture) {
elem.addEventListener(type, listener, useCapture);
} :
function(elem, type, listener, useCapture) {
// 注意此处type(事件处理程序名)与参数(没有捕获阶段,因此只有两个参数)跟W3C标准的区别
elem.attachEvent('on' + type, listener);
};
// 取消事件注册
var delEvent = document.addEventListener ?
function(elem, type, listener, useCapture) {
elem.removeEventListener(type, listener, useCapture);
} :
function(elem, type, listener, useCapture) {
elem.detachEvent('on' + type, listener);
}; 当某个事件被触发会调用事件处理函数,此时会传入一个事件对象event,这个对象包含所有与事件有关的信息和状态
event = event || window.event,如果event没有找到,就把window的event赋给要处理的事件对象说明:在页面操作时都有一些默认行为,比如当点一个连接时,这个链接会被打开,双击一段文字,会选中该段文字等等这些都是浏览器定义的默认行为
根据上面所述,可以兼容一个包含事件注册与事件对象浏览器通用的方案:
var eventUtil = {
// 事件注册
addEvent: function(elem, type, listener, useCapture) {
if(elem.addEventListener) {
elem.addEventListener(type, listener, useCapture);
} else {
elem.attachEvent('on' + type, listener);
}
},
delEvent: function(elem, type, listener, useCapture) {
if(elem.removeEventListener) {
elem.removeEventListener(type, listener, useCapture);
} else {
elem.detachEvent('on' + type, listener);
}
},
// 事件对象
preventDefault: function(event) {
event = event || window.event;
if(event.preventDefault) {
event.preventDefault();
} else {
event.returnValue = false;
}
},
stopPropagation: function(event) {
event = event || window.event;
if(event.stopPropagation) {
event.stopPropagation();
} else {
event.cancelBubble = true;
}
},
getTarget: function(event) {
event = event || window.event;
return event.target || event.srcElement;
}
};对事件处理程序过多问题的解决方案就是事件委托.事件委托利用了事件冒泡,只指定一个事件处理程序(将事件注册到元素的父节点上),就可以管理某一类型的所有事件
HTML:
<ul id="ul">
<li id="i1">item1</li>
<li id="i2">item2</li>
<li id="i3">item3</li>
<li id="i4">item4</li>
<li id="i5">item5</li>
<li id="i6">item6</li>
<li id="i7">item7</li>
<li id="i8">item8</li>
<li id="i9">item9</li>
<li id="i10">item10</li>
</ul>JS:
document.querySelector('#ul').addEventListener('click', function(e) {
alert(e.target.id);
});尽管这里的每个li并没有注册事件,而是把事件注册到了它的父元素ul上,根据事件流的特性,这个事件会冒泡,li上的事件最终必定会冒泡到ul事件上
定义:
call/apply方法可以使用一个指定的this值来调用某个函数或方法,一句话概括:这俩就是改变this指向的,区别是它们的传参方式不同。
call方法,第二个参数像函数传参一样,一个一个传
apply方法第二个参数是个类数组
一个函数的调用,本质是调用其call方法(不修改call第一个默认参数情况下):
var name = 'window';
var obj = {
name: 'obj'
}
function foo() {
console.log(this.name);
}
// 下面两行代码对函数的调用,本质是没区别的
foo(); // 'window'
foo.call(); // 'window'
// 使用传入参数,改变this值
foo.call(obj); // 'obj'但当给call传入参数时,就又是一回事儿了,有这样一段代码:
function Person(name, age) {
this.name = name;
this.age =age;
}
// 新建一个空对象
var obj = {};
// 会让Person里的所有this全都指向obj
Person.call(obj,'J',18);
console.log(obj); // {name: "J", age: 18}
obj.hasOwnProperty('age'); // true
// 解析Person.call(obj,'J',18):
// 1. Person.call()调用的时候会把第一个参数(this)的作用域设置为指定的对象,这里为obj
// 2. Person函数里有this,此时Person作为构造函数他的this不再仅仅属于实例了,作为函数,他的this也不再仅仅属于全局了
// 3. 因为传入了obj作为其参数,Person.call()调用时,Person里的this更替为obj
// 4. 后面的参数即为实参,与形参一一对应
// 相当于:
// Person.call(obj,'J',18);Person执行时,Person内部有如下变化:
// Function Person(name, age) {
// var this = obj; // 但是Person本身和他的实例还是拥有此this,只不过obj可以借用
// obj.name = name;
// obj.age = age;
// }在现实开发协作中会有这样一种场景,同事A写了一个构造函数,同事B也需要写一个与A差不多但是功能可能还要更多的一个函数.就是在同事A原函数所有的功能上再添加一些功能,此时call/apply方法就派上用场了:
// A写的某个功能函数
function Person(name,sex) {
this.name = name;
this.sex = sex;
}
// B在A写的函数基础上(B函数涵盖A所有的功能)在新增一些功能(tel,grade)
// 此时就可以利用call来完成
function Stu(name, sex, tel, grade) {
this.tel = tel;
this.grade = grade;
// 由于new的缘故,此时this指向的就是Stu,而Stu又借用Person的方法来实现自己的功能
Person.call(this, name,sex);
}
var stu = new Stu('J', 'female', 26, 2020);
// Person.call(this, name,sex); 这条语句代表的是Person函数一定会执行,然后才是使用第一个参数改变this指向假设有个汽车厂,工厂分工协作都是模块化的,有专门生产轮子的车间,有专门生产座椅的车间等等:
// 轮胎车间
function Wheel(size, style) {
this.size = size;
this.style = style;
}
// 座椅车间
function Sit(color, comf) {
this.color = color;
this.comf = comf;
}
// 模型车间
function Model(len, width, height) {
this.len = len;
this.width = width;
this.height = height;
}
// 组装成成品车
function Car(len, width, height,color, comf,size, style) {
// 自己内部什么功能都没有,全是借由别人的
// 把Wheel填装进来
Wheel.apply(this, [size, style])
// 把Sit填装进来
Sit.apply(this, [color, comf])
// 把模型填装进来
Model.apply(this, [len, width, height])
}
// 借用别人的功能来实现自己的方法
var audi = new Car(3000, 1500, 1500, 'red', 'soft', 100, 'SUV');
// Car {size: 100, style: "SUV", color: "red", comf: "soft", len: 3000, …}call/apply方法在JS中虽然是一个特别小的知识点,甚至很少有教程对它们专门介绍。但是在实际开发中的它们的出镜率却是极为高频的。
起因源自一段代码:
function foo() {
var x = y = 1;
}
foo();
console.log(x); // 报错
console.log(y); // 由于JS语法错误会影响后续代码终止,所以不会执行到该行上面代码,在得知打印结果后的我是震惊的,通过网上搜寻相关资料,才知道JS在赋值操作时是从右至左的,也就是说,上面函数体里的代码执行过程分解下来实际上这样的:
function foo() {
// var x = y = 1;
var x;
y = 1;
x = 1;
}可以看到,变量y其实是一个没有经过var声明的全局变量
想要判断一个全局变量在非严格模式下是否是通过var声明的,可以这样:
var x =1; // var声明的全局x
y = 1; // 没有通过声明的y
delete x; // false,不能删除
delete y; // true 可以删除还可以这样:
var x;
Object.getOwnPropertyDescriptor(window,x);
// {value: undefined, writable: false, enumerable: false, configurable: false}经过声明了的变量,属性描述符对象就定义了configurable: false不能修改.
写到这里,只是了解了JS在赋值时的执行顺序,而让我疑惑的却是在搜寻上面资料时看到的另一段代码:
var a = {n: 1};
var b = a;
a.x = a = {n: 2};
console.log(a.x);
console.log(b.x);如果你也是JS初学者,我想你的解题思路可能是这样的:
// 1. 有一个对象`a`,将`a`复制给对象`b`,此时它们引用同一对象
var a = {n: 1};
var b = a;
// 2. 连等赋值,从右至左,发现`a`被重写了,指向另一个对象{n:2}
a = {n: 2};
// 3. 同时`a`有个属性`x`指向对象{n:2}
a.x = {n: 2};
// 4. 输出
console.log(a.x); // {n:2}
console.log(b.x); // undefined但正确的输出结果却是a.x为undefined,b.x为{n: 2}.
下面是该代码的解题思路:
a与b指向同一个对象n1a.x = a = {n: 2};这段代码时,它的实际执行过程是这样的:.运算符优先级高于=赋值运算符,所以不管这段代码是写成a.x = a = {n: 2};还是写成a = a.x = {n: 2};,其实都是先执行.运算符,也就是a.x = {n: 2}先被执行。此时,变量a与b指向的对象长这样{n :1, x: {n: 2}}a.x赋值后,继续为变量a赋值a = {n: 2},此时a被重写,指向一个新对象{n: 2}以下说明了对象的具体指向:
a --> {
n: 2
}
a.x --> undefined // 对象a里没有名为x的属性
b --> {
n: 1,
x: {n: 2}
}上一篇文章简单谈了下"预解析"的概念,文章末尾抛出了一个引子:
var x = 1;
function foo() {
if(!x) {
var x = 2;
}
console.log(x); // 2
}
foo();按照我们的惯性思维,它的代码执行思路应该是这样的:
if里的条件为假,语句里的代码不执行console.log(x)foo(),输出全局变量1可惜,事与愿违,这段代码最后的返回结果为2.是不是很惊讶,之所以这样,就不得不要说JS的变量作用域了。
1. 什么是变量作用域?
顾名思义,作用域就是变量的作用范围和变量的生命周期,生命周期即:变量是什么时候产生的,又是什么时候消亡的;作用范围即:在哪里我们可以访问到它
说的简单粗暴点,变量作用域就是变量起作用的范围,变量在哪里生,变量在哪里死.
2. 全局作用域&局部作用域
不仅如此,作用域还可以分为全局作用域和局部作用域.
所谓全局作用域就是指我们所定义的函数、变量在脚本的任何位置都可以访问,我们把在全局作用域内定义的变量叫作全局变量:
需要注意的是,如果一个变量没有用var声明,那么这个变量就是全局变量
与之相对应的就是局部作用域,而局部作用域也可以叫作函数作用域.我们把在局部作用域内定义的变量叫作局部变量,局部变量只能在定义它的函数体内才能访问得到:
需要注意的是,函数的参数其实也是一个局部变量
var a = 1; // 全局变量a
function foo() {
var a = 2; // 局部变量a,定义在了foo函数里,只能在该函数里访问
b = 1; // 全局变量,尽管定义在foo函数里,但是未使用var关键字声明
console.log(a);
console.log(b);
};
foo();
console.log(a); 上面代码分别返回2,1,1对应着局部变量a与全局变量b与全局变量a
3. 变量对象
先不用关心变量对象是什么,还是看代码:
定义了全局变量a和foo函数
var a = 1;
function foo(){alert(1)};
console.log(a); // 1
console.log(foo()); // 1除了以上访问方式,还可以:
console.log(window.a); // 1
console.log(window.foo()); // 1他们完全等价:
a === window.a // true
foo === window.foo // true这会儿,就可以引申出另一个概念执行环境了(其实在某种程度上执行环境等同于作用域),上面例子说明了在全局作用域下定义的变量和函数,其实都是window对象上的属性和方法.而window对象在浏览器中又处于全局全局环境,也就是最外层的环境,这个环境只有在关闭浏览器才会销毁.事实上,每个函数特都会有自己的执行环境,虽然这些环境我们看不见摸不着,但它确确实实存在,而每个执行环境又有自己对应的变量对象,也就是该环境中的变量和函数.
这段解释很拗口,还是来看代码:
var person = 'xiaoA';
function foo() {
var person = 'xiaoB';
var age = 18;
function bar() {
var person = 'xiaoC';
var sex = 'female';
console.log(person); // xiaoC
console.log(sex); // female
console.log(age); // 18
}
return bar();
}首先,上面例子包含三个环境:他们分别是:
window:person和foo()函数foo()的局部环境person(局部变量并非全局下的person)、变量age和bar()函数.如果在该环境没有定义person,就会在它的父环境找,如果有,就返回父环境的.bar()的局部环境person和变量sex.如果在该环境没有定义person,就会在它的父环境(foo的)找,如果foo也没定义,就继续往上到全局环境里找,此时全局已经是最外层了(假如此层不是最外层环境,如果上面还有很多嵌套的环境,就以此类推,按照这条链逐步往外追溯,直到找到为止),再往外就是null了,全局如果找到,就返回.
至此,我们回到文章开头的那段代码来分析下:
var x = 1;
function foo() {
if(!x) {
var x = 2;
}
console.log(x); // 2
}
foo();实际的执行过程是这样的:
预解析(在代码执行前JS引擎在后台就已经处理完了),
1. 初始化全局环境:
var x;
function foo(){};
x=10;
2. 执行foo(),初始化foo()的局部环境:
function foo() {
var x;
//JS中只有函数作用域,不存在块级作用域,所以这里面的x其实是个局部变量
if(!x) { // !x ==>!undefined ==> true
var x = 2; // x = 2
}
console.log(x); // 2
}
3. 执行完毕,打印2趁热打铁,把上面的代码再稍稍修改下,变成这样:
var x = 1;
function fn() {
if(x) { // undefined ==> false
var x = 2; // 条件不成立,所以根本就不会执行到if语句的代码块里,也就是说这段代码不会执行
}
console.log(x);
}
fn(); // undefined这里简单说下这段代码的执行过程,预解析完成后,执行fn函数,由于JS没有块级作用域,所以说在fn函数内部,JS解析器在进入函数的时候,就把变量x的声明提升到函数顶部了(仿佛没有if存在一样),理所应当的此时x为undefined,然后才是执行if语句,第一步判断condition,此时x为undefined,condition为false,所以根本就不会执行if语句块里的代码,所以最后打印出了undefined
通过上面例子的返回值,知道为什么局部作用域也叫函数作用域了吧,因为JS根本没有块级作用域:
// JS没有块级作用域,在JS里,函数里的{}是叫作函数体,而if,else,while这些{}才叫作block(代码块)
var a = true;
if(a) {
var b = 1;
}
// 如果有块级作用域这里b会报错,实际上
console.log(b); // 1
function foo() {
var d = 1;
}
console.log(d); // 报错,未定义下面来几个例子,加深下预解析和作用域的理解:
var x = 1;
function foo() {
console.log(x);
x = 2; // 没有用var声明,即x为外部那个全局x
}
foo(); // 1
console.log(x); // 2在上面例子的基础上稍微修改下:
var x = 1;
function foo(x) {
console.log(x); // 函数的参数x,尽管foo()调用的时候没有传参,但是之前我们说过函数的参数也是局部变量,在函数体里也就是相当于var声明的,需要预解析(初始化为undefined)所以此条其实是undefined
x = 2; // 修改局部x为2
}
foo(); // undefined
console.log(x); // 1返回结果说明了不仅函数的参数是局部变量,并且函数作用域内部的修改不会反映到全局上
继续在它们的基础上变下型:
var x = 1;
function foo(x) {
console.log(x); // 全局x,foo调用的时候传了进来
x = 2; // 执行到这句时,这个x其实是参数x,为局部变量
}
foo(x); // 1
console.log(x); // 1调用函数传入了参数(全局上有)与函数内部参数(函数内部也有一个同名的)同名时,会先执行全局的(在函数内部预解析之前就已经有值了),此时预解析(初始化)函数内部的x,然后修改x的值
继续变型:
var x = 1;
function foo() {
console.log(x);
var x = 2;
}
foo(); // undefined
console.log(x); // 1foo()的局部环境中,根据作用域链的机制,虽然有同名的x变量,但它始终会找离本环境最近的x,由于x在函数内部是var声明的,所以后台做了预解析,把变量提升到了该环境顶部.
首先从一段代码开始:
demo 1:
console.log(a); // undefined
var a = 1;不禁疑惑,变量a的值为什么不是1。说到这里,就不得不提到JS的"Hoisting"了,所谓hoisting,有人把它叫作"预解析",有人把它叫作"声明提升",其实叫什么没关系,看个人理解,不过要记住是,得知道这是什么,能干什么。
我们知道,JavaScript有两个特点:单线程和解释型语言;
所谓解释型语言即JS引擎运行代码时会读到一句翻译一句执行一句,其实这种说法并不严谨,因为在这个步骤之前后台已经悄蔫儿的进行了以下三步操作:
undefined,其实这段代码在打印输出之前,js引擎已经在后台初始化了如下操作:// console.log(a); // undefined
// var a = 1;
以上两行代码的预解析过程:
var a; // 把用var声明的变量,提升到该作用域顶部(此行代码我们是看不见摸不着的,js在后台处理。只作提升,不作赋值)
console.log(a); // undefined
a = 1; 可以看出,当访问到第二行时,a=1的那段代码还未读取到,我们知道凡是用var声明不赋值的操作,js都会返回undefined,结果当然就是undefined
2. 函数声明提升
不仅如此,js引擎不仅会提升变量的声明,还会对函数声明进行提升:
demo 2:
// console.log(a);
// function a() {}
以上两行代码的预解析过程:
function a() {} // 1. function a() {} 只提升声明,不会调用
console.log(a); // 2. 按正常流执行代码,输出结果同样地,上面代码在读取到console.log(a)之前,已经把函数a的声明提升到了该作用域的顶部,然后才是正常的逐步读取js代码。
接下来我们对demo1和demo2进行个比较,问题来了:
3. 当变量名与函数名冲突,背后发生了什么?
demo 3:
console.log(a); // function a() {}
var a = 1;
function a() {}没错,a返回的正是函数的引用,这说明标识符同名情况下,不仅函数声明与变量声明都会提升,并且函数声明提升的优先级是高于变量声明提升的,也就是说函数的覆盖了变量的提升
继续扩展上面代码:
console.log(a); // function a() {}
var a = 1;
function a() {}
console.log(a); // 1与上面demo3中的例子比较,在最后添加了一条输出语句,第一个a的返回值从一个函数引用变成了全局变量a,最后一个a为1,很奇怪,都是a为什么是两个值?
别着急我们把代码一步一步拆开来看:
js预解析过程:
1. var a; // 变量声明提升,此时为undefined
2. function a() {}; // 函数声明提升
预解析完成,按顺序逐步执行原代码:
3. console.log(a); // 标识符相同,由于函数声明高于变量声明,此时a为function a() {}
4. a =1; // 赋值操作,a为1
5. console.log(a); //14. 对于非var声明的变量(全局变量),js不作预解析处理
console.log(a); // 报错,a未定义
a = 1;经过之前的了解,来分析一道经典面试题:
f1();
console.log(c);
console.log(b);
console.log(a);
function f1() {
var a = b = c =9; // 这段相当于 var a = 9; b = 9; c = 9; b与c为全局变量
console.log(a);
console.log(b);
console.log(c);
}
// 输出 :9 9 9 9 9 报错
// 执行前,JS引擎解析如下:
function f1() {
var a;
a =b =c = 9;
var a = b = c =9;
console.log(a);
console.log(b);
console.log(c);
}
f1();
console.log(c);
console.log(b);
console.log(a);最后,抛一个问题:
var x = 1;
function foo() {
if(!x) {
var x = 2;
}
console.log(x);
}
foo(); // 此时x的值为?当你测试了这段代码,结果是不是很惊讶,这里不仅要涉及预解析,还涉及到了作用域,下一篇文章将近一步来讨论javascript的作用域。
而具有JS特色的单例模式,只要保证它是单一实例就好,而不用在意是否是通过类(JS没有类)来创建的
其实在JS中对象就是天生的单例
var obj1 = {};
var obj2 = {};
obj1 == obj2; // false可以利用这样唯一性的对象单例来做命名空间,最常用到的就是防止变量冲突和规范代码,特别在多人协作上,这两个优点就越发突出
以获取dom元素为例,在不使用jQuery类库的前提下,我们使用原生获取dom元素,一般会这样做:
// 便于使用,把类似获取id,标签名的方法封装成函数
function getId(id) {
return document.getElementById(id);
}
function getTag(tag) {
return document.getElementsByTagName(tag);
}但是随着代码越来越多,可能这样的函数就越来越多,就意味着在全局作用域中增加了非常多的全局变量,时间一长,你的同事如果要修改你的代码,他可能不知道你使用了什么变量,如果此时他命名了一个与全局同名的变量,也就意味着你之前的函数就失效了.怎么解决?使用单例模式(命名空间):
// 我的命名空间
var Zayne = {};
Zayne.getId = function() {};
...
...
...
// 对方的命名空间
var You = {};
You.getId = function() {};像上面这样,每个人都有自己的命名空间,无论是否使用了相同的函数,也是该命名空间下的函数,双方互不干扰
还是延续上面的,一旦代码量上来了,我们应该更细化我们的代码,也就是说,一个命名空间下,应包含多个子命名空间,把dom相关的放在一个子空间里,把正则相关的放在一个子空间里等等...类似这样的,让它们各司其职:
// 我的命名空间
var Zayne = {};
// dom相关的子命名空间
Zayne.dom = {};
Zayne.dom.getId = function() {};
// 字符换相关的子命名空间
Zayne.string = {};
Zayne.string.trim = function() {}
// 正则相关的子命名空间
Zayne.reg = {};
Zayne.reg.tel = ...//..这样的好处是代码不容易造成冲突,代码也变得井井有条,就可以在相应的子命名空间下找到我们需要的东西.再说下去就要跑偏了,还是拉回到本文的主题
现在,我们有一个这样的需求.点击页面一个按钮,相应弹出一个弹窗,为了捕捉到用户的注意力,我们还应该要设置一个遮罩层,以更好地告知用户点击了按钮.这样一个简单又常用的功能,经验欠缺的开发人员可能不假思索的就会这样做:
<!-- 直接把登录窗口和遮罩的HTML结构写死: -->
<button id="loginBtn">登录</button>
<div id="loginLayer">弹窗区域</div>
<div id="maskLayer"></div>或者等页面加载完成后动态地用JS来创建:
// 创建弹窗
var loginLayer = (function () {
var loginLayer = document.createElement('div');
loginLayer.id = 'loginLayer';
loginLayer.innerHTML = '登录窗口';
loginLayer.style.display = 'none';
document.body.appendChild(loginLayer);
return loginLayer;
})();
// 创建遮罩层
var maskLayer = (function () {
var maskLayer = document.createElement('div');
maskLayer.id = 'maskLayer';
maskLayer.style.display = 'none';
document.body.appendChild(maskLayer);
return maskLayer;
})();
// 点击按钮显示弹窗和遮罩
document.getElementById('loginBtn').addEventListener('click', function () {
loginLayer.style.display = 'block';
maskLayer.style.display = 'block';
});上面这种实现方式,当页面加载完成后就会立即创建结构,并且只会执行一次,优点是不管点击多少次登录按钮,都只会创建一次.但它的缺点也是很致命的
弊端:就是不管我们是否点击了登录按钮,这些结构都会加载,这样一来就会白白的浪费了资源和性能
所以摒弃以上的创建方式吧,让我们用更优雅的方式来完成它!
所谓惰性单例,可以理解为按需创建的单例模式
// 创建弹窗
function createLoginLayer() {
var loginLayer = document.createElement('div');
loginLayer.id = 'loginLayer';
loginLayer.innerHTML = '登录窗口';
loginLayer.style.display = 'none';
document.body.appendChild(loginLayer);
return loginLayer;
}
// 创建遮罩层
function createMaskLayer() {
var maskLayer = document.createElement('div');
maskLayer.id = 'maskLayer';
maskLayer.style.display = 'none';
document.body.appendChild(maskLayer);
return maskLayer;
}
// 显示弹窗和遮罩
document.getElementById('loginBtn').addEventListener('click', function (e) {
// 当我们点击登录按钮时,才会创建结构
var loginLayer = createLoginLayer();
var maskLayer = createMaskLayer();
loginLayer.style.display = 'block';
maskLayer.style.display = 'block';
});以上,只有在需要的时候才会去创建弹窗和遮罩的结构,换句话说,如果我们不点击登录按钮,是不会去创建弹窗和遮罩的结构的.不过新的问题又来了,如果此时我们打开控制台,我们会发现,当我们连续点击登录按钮时,页面中弹窗和遮罩的结构也会被连续的创建,对于这种频繁的操作dom,对性能也是有着很大的消耗
弊端:当多次点击登录按钮时,相应的也会重复创建结构,因为创建和点击的动作是绑定的
单例模式的**:每次点击登录时,判断是否创建了弹窗和遮罩的结构,如果是则返回,如果不是,则创建
// 创建弹窗
var createLoginLayer = (function () {
// 保持单一实例的变量
var loginLayer = null;
return function () {
if (!loginLayer) {
loginLayer = document.createElement('div');
loginLayer.id = 'loginLayer';
loginLayer.innerHTML = '登录窗口';
loginLayer.style.display = 'none';
document.body.appendChild(loginLayer);
}
return loginLayer;
};
})();
// 创建遮罩层
var createMaskLayer = (function () {
var maskLayer = null;
return function () {
if (!maskLayer) {
maskLayer = document.createElement('div');
maskLayer.id = 'maskLayer';
maskLayer.style.display = 'none';
document.body.appendChild(maskLayer);
}
return maskLayer;
}
})();
// 显示弹窗和遮罩
document.getElementById('loginBtn').addEventListener('click', function (e) {
// 第一次进入创建结构,第一次之后,结构都存在直接返回,不会重复创建结构
var loginLayer = createLoginLayer();
var maskLayer = createMaskLayer();
loginLayer.style.display = 'block';
maskLayer.style.display = 'block';
});至此很完美,不过别着急,仔细看看其实还存在一些小瑕疵,不难发现createLoginLayer函数做了两件事,创建登录节点与验证单例,很显然,一个函数做两件事不符合单一职责原则,即一个函数只应做一件事.再细心点,还会发现createLoginLayer与createMaskLayer函数,其实它们做的都是类似的功能,一想到这里,我们就知道还应该把它们抽象出来
把createLoginLayer与createMaskLayer函数的控制单例和创建结构这两功能的逻辑抽象出来,使其变为更通用
// 专门负责创建结构的函数
function createLoginLayer() {
var loginLayer = document.createElement('div');
loginLayer.id = 'loginLayer';
loginLayer.innerHTML = '登录窗口';
loginLayer.style.display = 'none';
document.body.appendChild(loginLayer);
return loginLayer;
}
function createMaskLayer() {
var maskLayer = document.createElement('div');
maskLayer.id = 'maskLayer';
maskLayer.style.display = 'none';
document.body.appendChild(maskLayer);
return maskLayer;
}
// 保证单例的函数
function getSingleton(fn) {
var instance = null;
return function() {
// return instance || (instance = fn());
// 如果在功能上有更多需求,希望调用getSingleton()之后返回的函数可以传递参数,可以向下面这样写,也就是说这样fn也可以接收参数了
return instance || (instance = fn.apply(null, arguments));
};
}
// 生成单一节点
var createSingletonLoginLayer = getSingleton(createLoginLayer);
var createSingletonMaskLayer = getSingleton(createMaskLayer);
document.querySelector('#loginBtn').addEventListener('click', function(e) {
var loginLayer = createSingletonLoginLayer();
loginLayer.style.display = 'block';
var maskLayer = createSingletonMaskLayer();
maskLayer.style.display = 'block';
});通用的惰性单例把各函数的职责划分的更明确,假若日后单例出现问题,直接去getSingleton里面修改,而不用去修改创建节点的函数.换句话说,如果把创建节点和保证单例都混合写进一个函数,目前只有两个创建节点的函数,可以很轻松地修改,那么成百上千个将会变成一场灾难
通过之前对原型和原型链的了解,知道了原型是构造函数构造出来的对象(实例)的公共祖先,实例会沿着原型链继承原型的属性和方法.也正是由于这种特性,实例会继承所有原型链上的属性,而有些属性对实例来说没有用.
除了上面说的以原型链这种传统的继承方式之外还有以下几种继承
// Person实现了Stu函数的部分功能,Stu就没必要重新再写,直接用Person已写的就好
function Person(name,age,sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
function Stu(grade,sex,name,age) {
// 只是借Person的方法来用,却不能继承Person的原型
Person.call(this, name, age,sex);
this.grade = grade;
}
// 所以这种借用继承必须要new才会有意义,不然this指向谁?!
var stu = new Stu(2020,'male', "J", 18);优点:代码结构简晰(只是视觉上代码量少了,但程序实际执行了至少多一次的函数调用,没有效率一说)
缺点:只能借用构造函数的方法,却不能继承人家的原型,并且每调用一次构造函数都要多走一个函数
但是实际开发中,两个人写的两个构造函数,一个人写的方法涵盖了另一个人的方法时还是需要这种写法的.但是从继承的角度讲,实现X继承Y,还是得从原型本身上着手
A.prototype.name = 'AAA';
function A() {
}
function B() {
}
// B的原型继承了A的原型
B.prototype = A.prototype;
// 两个实例都共享了A的原型
var a = new A();
console.log(a.name); // AAA
var b = new B();
console.log(b.name); // AAA
// 也可以封装成一个函数以便使用
// function extend(Target, Origin) {
// Target.prototype = Origin.prototype;
// }
// extend(B, A);
// var c = new B();
// // !!注意上面两行代码的顺序一定不能写反
// // 首先是先修改原型指向,然后才是new,不然先new使用的是自己的原型(未等到原型指向更变)
// console.log(c.name); // AAA虽然实现了公有原型的继承,像上面代码中表现的一样.但问题来了,由于A和B共享A的原型,如果我想给B原型添加新的功能,那么势必A的原型中也会反应出来(本来就是用的A嘛)
function extend(Target, Origin) {
Target.prototype = Origin.prototype;
}
A.prototype.name = 'AAA';
function A() {
}
function B() {
}
// B的原型继承了A的原型
extend(B, A);
// 如果想给B单独设置一个原型属性
B.prototype.unique = 'shared';
var b = new B();
// 成功设置
console.log(b.unique); //shared
// 问题是A上面也相应的对了这条属性
A.prototype.unique === 'shared'; //true那么如何能做到我既继承自你的同时而给我自己添加新功能时又不影响到你(自定义和公共的分别独立),可以使用圣杯模式
圣杯模式并不是什么新的知识,而是可以利用原型链的特性,建立一个中间层来实现继承对象之间的耦合性
理解中间层:
// 场景: 实现B继承A的同时,B又能给自己单独设置原型属性而不影响A的原型
A.prototype.name = 'AAA';
function A() {
}
function B() {
}
// 1. B继承A,原型指向原型(AB共享A的原型)
// B.prototype = A.prototype;
// 2. B继承A的同时,把B的原型对象指向new A(),而非具体某个实例
// 由于每new一次产生一个新的对象,所以A的任何一个实例对象对于B原型的变化是感觉不到的
B.prototype = new A();
// unique只能在B原型上找到,因为我们永远无法访问上面的那个new A()所在
B.prototype.unique = 'unique';
console.log(new B().unique); // unique
// 使用new调用,相当于一个新的实例对象,而该实例并非B原型的指向所在
console.log(new A().unique); // undefined
// 即便用实例来调用也是如此
var a = new A();
console.log(a.unique); // undefined
console.log(a); // 空对象
// 3. 如果这样来写就大不相同了
var a = new A();
// 把B的原型指向为一个具体的实例
B.prototype = a;
// 当给B原型添加属性时也就相当于给实例给自己添加属性a='xyz'一样
B.prototype.xyz = 'xyz';
var b = new B();
console.log(a.xyz); // xyz
console.log(a); // {xyz: "xyz"}
console.log(A.prototype.xyz); // undefined 并未映射到A原型
// 总结:
// 1. 两个对象共享一个原型,通过这种继承变其一即都变
// 2. 把原型指向new Fn(),通过这种继承在对被继承对象修改原型时,只体现在被继承对象原型上
// 3. 把原型指向某个具体实例上时,通过这种继承在对被继承对象修改原型时,实例本身也会体现,但是不会影响实例的原型像B.prototype = new A()或 B.prototype = a;这种就类似中间层的作用,就是将原型对象(B.prototype)赋值给另一个类型的实例(new A()),此时的原型对象将包含一个指向另一个原型的指针(B.prototype.__proto__ ==> new A().__proto__),相应地,另一个原型对象中也包含着一个指向另一个构造函数的指针(A.prototype.__proto__ ==> Object.prototype),如此层层递进,以__proto__为链子来实现继承.
现在我们结合共享原型以及这个中间层的特性,来包装为一个中间函数:
// 利用中间层封装一个继承函数
function inherit(Target, Origin) {
function F() {} //中间层函数F
// F.prototype (new F().__proto__) = A.prototype AF共享原型A
F.prototype = Origin.prototype;
// B.prototype = new F() B原型对象赋给函数F的实例,达到中间层的作用
Target.prototype = new F();
}
A.prototype.name = 'AAA';
function A() {
}
function B() {
}
inherit(B, A);
// unique属性除了在B.prototype上面能找到,其他任何地方都不会存在
B.prototype.unique = 'unique';
var a = new A();
var b = new B();
console.log(a.unique); // undefined
console.log(b.unique); // unique不过到这里还没有结束,我们会发现,此时被继承的对象的constructor属性指向的是继承函数,讲道理虽然我想继承自你,但我应该还是我自己.将constructor属性归位自己,在inherit函数里增加一条:
// 将constructor属性重新指向自己
Target.prototype.constructor = Target;由于我们使用了一个函数F作为中间层,但其实我们真正继承的是A.还能优化一点的是,要是有一个能知道被继承对象的超类,即他究竟继承自谁的这么一个信息就更好了,继续再inherit函数下面添加这样一条代码作为信息的储存,以便我们日后想知道继承信息时来调用这条属性:
// 由于super是个关键字,超类的名字这里用uber代替
Target.prototype.uber = Origin.prototype;现在,一个几近完美的继承-圣杯继承模式就写好了:
function inherit(Target, Origin) {
function F() {}
// 以下两行代码顺序一定不要搞反了,否则Origin会使用重写后的prototype对象,Target将无法继承Origin
F.prototype = Origin.prototype;
Target.prototype = new F();
Target.prototype.constructor = Target;
Target.prototype.uber = Origin.prototype;
}
A.prototype.name = 'AAA';
function A() {
}
function B() {
}
inherit(B, A);
B.prototype.unique = 'unique';
var a = new A();
var b = new B();
console.log(a.unique); // undefined 一个实例对象自然无法访问另一个实例对象的属性
console.log(b.unique); // unique
console.log(b.constructor); // function B
console.log(b.uber); // A.prototype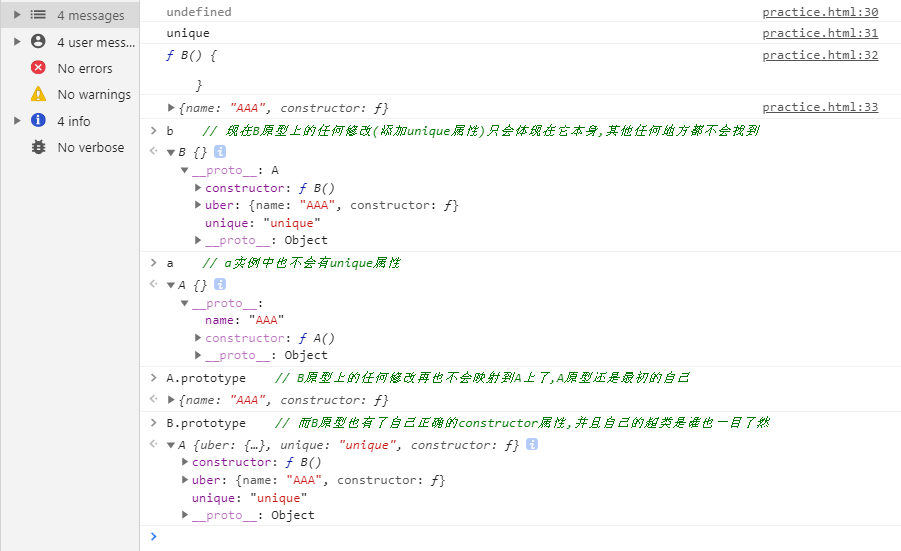
再吹毛求疵一点,其实YUI3库有个更优雅的inherit函数写法(建议使用这种):
由于中间层函数F的本质就是用来过渡的没有什么实际性的用途,类似这种隐式的功能性质的变量或函数,我们可以利用闭包的特性把它变为一个私有化的变量,这会使我们代码的写法看起来更好也更具语义化
var inherit = (function() {
var F = function() {};
return function(Target, Origin) {
F.prototype = Origin.prototype;
Target.prototype = new F();
Target.prototype.constructor = Target;
Target.prototype.uber = Origin.prototype;
}
}());通过上一篇的了解,至此可以对之前的原型做个这样的总结:
每个函数都有一个原型(prototype)属性,它指向该函数的原型对象,该对象里有个默认的constructor属性,是为当前函数本身(Fn.prototype.constructor === Fn),如果该函数是个构造函数,那么该构造函数的原型对象(构造函数.prototype ==> {constructor: 构造函数})上的属性和方法都会被它的实例对象所继承.
除此之外,原型对象里除了天生自带的constructor属性外,还有个隐式属性__proto__
function Person() {
}
Person.prototype.lastName = 'He';
var p1 = new Person();最直接简明的方式就是通过浏览器的控制台来查看:

上图除了自定义的属性lastName和自带属性constructor外,还有个__proto__属性
可以通过p1.__proto__实例对象访问这个属性:
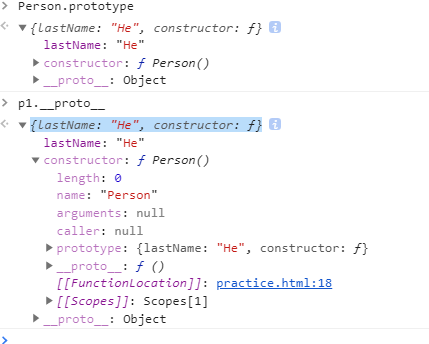
返回的正是原型对象Person.prototype
p1.__proto__ === Person.prototype // true
这也解释了为什么实例可以访问自己没有的属性和方法,正是因为实例通过系统内部设置的隐式属性__proto__来实现的.实现过程如下:
function Person() {
// 1. 使用new操作符时,其实函数内部创建并非是一个空对象
var this = {
// 当访问一个对象的属性时,如果该对象没有该属性,会沿着__proto__这个属性的
// 指向去查找,即Person.prototype
__proto__: Person.prototype
}
}
Person.prototype.lastName = 'He';
var p1 = new Person();既然如此,当我们手动更改这个属性的指向时,自然就沿着新给定的指向:
function Person() {
}
Person.prototype.lastName = 'He';
// 创建一个新对象
var obj = {
lastName: 'X'
}
var p1 = new Person();
console.log(p1.lastName); // He
// 原型指向给一个新的对象obj
p1.__proto__ = obj; // 相当于以下操作
// p1 {
// __proto__ : obj
// }
// 实例自己没有lastName属性的情况下,搜寻__proto__指向所在对象里的lastName
console.log(p1.lastName); // X再次说明,用实例对象访问一个属性和方法时,在自身没有的情况下(如果有,肯定返回自己的),是通过自己内部的隐式属性__proto__来查找的,通过修改__proto__的指向,使其切断与原本Person.prototype之间的关联(Person.prototype还是Person.prototype,而p1.__proto__已经不再属于他了)
需要注意的是,当我们这样操作原型时:
function Person() {
}
Person.prototype.lastName = 'He';
var p1 = new Person();
console.log(p1.lastName); // He
// 修改原型上lastName属性为X
Person.prototype.lastName = 'X';
// 输出正常
console.log(p1.lastName); // X但是,当使用"代码块"的方式来修改原型属性时,有一些变化:
function Person() {
}
Person.prototype.lastName = 'He';
var p1 = new Person();
console.log(p1.lastName); // He
//
Person.prototype = {
lastName: 'X'
}
console.log(p1.lastName); // He究其原因在于第一种使用.操作修改原型时,是在原型的基础上作修改(操作自己的空间),而第二种则是完完全全重写了一个新的对象(地址换成了一个新的空间).但是由于new操作符的缘故,我实例上对象的p1.__proto__指向的可是重写之前的Person.prototype空间
上面代码模拟过程:
// 1. Person本来的空间 --> 空间1
Person.prototype = {
lastName: 'He'
};
// 2. new操作符实例对象后指向空间1
p1.__proto__ = Person.prototype;
// 3. 重写Person.prototype --> 空间2
Person.prototype = {
lastName: 'X'
}
// 4. 就像引用类型赋值一样,我p1.__proto__的指向并未改变,还是最开始的空间1
p1.__proto__ = {
lastName: 'He'
}因此,当把实例化语句置于修改后的原型空间语句后面时,这时,实例就用的是修改后的空间里的属性了:
function Person() {
}
// 1. 原空间上添加一个属性
Person.prototype.lastName = 'He';
// 2. 重写(覆盖)原型,变为一个新的空间
Person.prototype = {
lastName: 'X'
}
// 3. 实例化语句置在了重写后的原型下面,函数内部new时,p1.__proto__ --> Person.prototype
var p1 = new Person();
// 4. 而Person.prototype此时已经变为 --> lastName:X
console.log(p1.lastName); // X有了以上了解,我们知道对象访问属性是通过__proto__指针找到原型
为了更清晰直观的表述这层关系,来写这样一段代码:
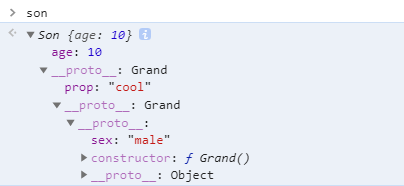
function Grand() {
}
Grand.prototype.sex = 'male';
var grand = new Grand();
function Dad() {
this.prop = 'cool';
}
// 将构造函数Dad的原型设置为grand
Dad.prototype = grand;
var dad = new Dad();
function Son() {
this.age = 10;
}
// 将构造函数Son的原型设置为dad
Son.prototype = dad;
var son = new Son();
console.log(son.age); // 10
console.log(son.sex); //male首先打印son.age,由于实例本身有该属性则直接返回.然后打印son.sex,实例自身没有,则沿着son.__proto__所指向的dad上找(由于dad赋给了Son.prototype),实例对象dad也没有,继续沿着dad.__proto__所指向的grand上找(由于grand赋给了Dad.prototype),至此实例对象grand的__proto__所指向的Grand.prototype原型上有,则最后返回原型上的结果.如此层层递进,就构成了实例与原型的链条,即所谓的原型链,原型链的链接点就是通过__proto__来实现的
上面代码在控制台查看会更明了:
可以通过上图发现,在自定义的对象中,最外层的对象是Grand原型对象,而Grand原型对象下面的竟然还有一个并非我们自己定义的__proto__指针,这是否意味着原型对象也有自己的__proto__?答案是肯定的
在控制台查看下Grand.prototype.__proto__:
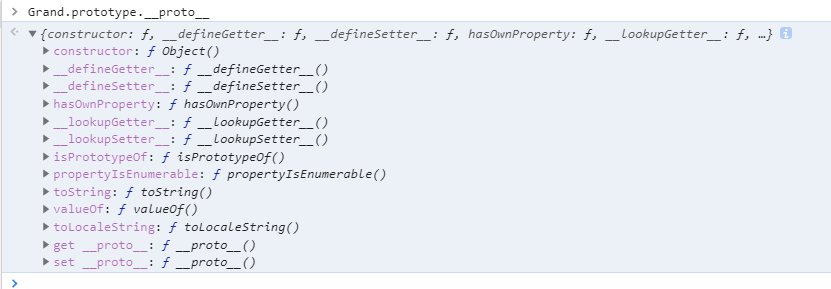
会发现,该对象最下方已经没有__proto__属性了,正是因为该对象为"JS中所有对象的最终原型" ==> Object.prototype,因为:
Grand.prototype.__proto__ === Object.prototype // true
Object.prototype.__proto__ === null // true不仅如此,我们看到它里面还定义了很多我们未了解原型之前所经常使用的一些方法,toString(),valueOf()等等...也正是因为原型链机制,当我们才能调用某个对象身上并不存在的toString方法
son.toString(); // "[object Object]"对于原型以及原型相关的还需知道以下一些知识点:
function Dad() {
this.prop = 'cool';
this.card = {
c1 : 'Visa',
c2: 'Master'
}
}
var dad = new Dad();
function Son() {
this.age = 10;
}
Son.prototype = dad;
var son = new Son();
// 不是修改原型链上的prop,而是自身增加一个prop属性并为其赋值
son.prop = 'good';
console.log(son.prop); // good {age: 10, prop: "good"} // 可以修改原型链上引用类型里的属性
son.card.c1 = 'JCB';
console.log(son.card.c1); // JCB
delete son.card.c1; // true
console.log(son.card); // {c2: "Master"}
// 但不能对其地址进行变更(其实这一步删除的是自身的card属性,而自身并没有该属性)
delete son.card;
console.log(son.card); // {c2: "Master"}
// 实例对象自身增加card属性,而非修改原型链上的
son.card = [1,2,3];
console.log(son.card); // [1, 2, 3] {age: 10, prop: "good", card: Array(3)} // 在传入null创建对象时
var obj = Object.create(null);
// 空对象,并且没有__proto__属性!
console.log(obj); // {}
// 创建一个对象
var obj1 = {
name:'a'
}
// 手动给obj加一个指针指向obj1
obj.__proto__ = obj1;
// 在控制台输出,指针确实是有了(为自定义的深色字体.而系统的是浅色)
console.log(obj);
// 但是无法访问
console.log(obj.name); // undefined这就说明__proto__是内部一个隐式属性,尽管我们可以修改其指针指向,但我们是无法手动添加该属性的
之前说过,我们平时会经常用到在Object.prototype上定义的一些方法和属性,例如toString方法,不过该方法对于不同类型的返回结果却大相径庭:
// 使用数字调用(必须加括号或者赋给一个变量然后再调用,否则会把'.'运算符当成浮点小数的'·')
(123).toString(); // '123'
var obj = {};
obj.toString(); // "[object Object]"为什么数字调用的结果是123而不是"[object Number]",又或者说为什么obj不是'{}'而是"[object Object]"?
我们知道在对数字等基本类型进行属性方法调用的时候,程序后台会首先将其包装成对象,变成对象后自然可以使用属性和方法,而恰好数字的包装类Number的原型里正好有个与Object.prototype里重名的toString方法(可以在控制台console.dir(Number)查看),根据原型链的继承机制,就像作用域链一样,自己有的不会再沿着链条继续查找.所以当使用一个数字调用toString方法时,其实是调用自己包装类原型上经过重写后的toString方法(同名不同功能),执行过程如下:
// 基本类型值123 --> 转换为包装类new Number(123) --> 包装类有该方法new Number(123).toString()
// 重写的过程大概长这样
var num = 123;
Number.prototype.toString = function() {
return this + '';
}
num.toString(); // '123'不仅是Number对象的toString方法,重写了该方法的还有Array Boolean String等等.
如果一个数字类型的不想用自己的toString方法而想调用Object上的toString方法也是可行的:
var num = 123;
// 借助call来完成
Object.prototype.toString.call(num); // "[object Number]"需要注意的是undefined和null没有任何方法,因为它们没有包装类,也就没有原型指向.
关于toString还有一点比较有意思的是,在使用document.write()时,其实每次都会隐式调用Object.prototype.toString:
var obj = {};
document.write(obj); // [object Object]
// 为了佐证会每次调用toString,创建一个空对象(没有原型指针)
// var obj1 = Object.create(null);
// // 下行代码相当于执行的是document.write(obj1.toString())
// document.write(obj1); // 报错,因为obj1没有toString方法
// 甚至更明显些,手动给obj加个toString方法
obj.toString = function() {
return 'hehe';
}
document.write(obj); // heheJavaScript 是一种弱类型或者说动态语言。即便不提前声明变量的类型,在程序运行过程中,类型也会被自动确定。这也意味着可以使用同一个变量保存不同类型的数据。
ECMAScirpt 变量有两种不同的数据类型:基本类型,引用类型。
简述:按值访问的变量都称之为基本类型
简述:使用{},[]及new+关键字定义的变量都是引用类型
除了以上ECMA规范定义的对象外,前端栈还可以细分为在浏览器运行环境所提供的宿主对象(DOM、BOM)和各个浏览器厂商为各自浏览器所提供的浏览器扩展的对象
注:此篇仅讨论原生对象
var obj = {name:'obj'};这段代码变量obj中的name属性的值,就必须通过obj.name或者obj['name']。可以理解为,这里的变量obj就是那个地址,而obj.name就是那个地址的指向所在区域。在垃圾收集那篇文章讲到过,由于JS中的内存管理,包括内存分配回收等等都是由JS引擎后在后台完成,所以初学者不必纠结于栈内存和堆内存本身是什么作深入了解,有些知识点不到实际开发中很难理解,否则很可能打击学习的积极性。
var a = '{}';
var b = '{}';
console.log(a==b); // true由于两个变量都是同值的字符串,基本类型的值只要是"长得一模一样",那么它们就相等。
你可能会说,不对,我有两个值不一样的变量他们也相等,不信你看:
var c = 0;
var d = false;
console.log(c == d); // true哎哟,对啊。为什么呢?这是JS数据类型的隐式转换,等到后面我们再来讲。
var obj1 = {a:1};
var obj2 = {a:1};
console.log(obj1==obj2); // false它们明明长得一样,为什么不相等?前面说了引用类型保存的是对象的地址,obj1与obj2它俩的地址就不相同,就算长得一模一样也是两个独立的对象。
复制变量的值时的表现:
var a = 1;
var b = a; // 复制a到b
b++;
console.log(a); // 1
console.log(b); // 2b只是a的一个副本,它们任何操作都不会影响到对方
var obj1 = {
name:'a'
}
var obj2 = obj1;
obj2.age = 18;
console.log(obj2.age); // 18
console.log(obj1.age); // 18
console.log(obj2.name); // 'a'将obj1的引用复制给了obj2,此时它们引用了同一个对象,所以当我们为obj2添加一个age属性时,也会反映到obj1里,同时,obj2也会有obj1的name属性,它们完全等价!
var str = 'string';
str.toUpperCase();
console.log(str) // "string"可以看到变量str的值并没有改变。可能你会说,能修改,不信你看:
var num = 1;
num = 2;
console.log(num); // 2确实变量num的值由1变成2了,但是,请注意这里的2是num的值,我们说的不可变是指,这个Number类型的值1不可能被改变,而不是num这个变量不可变,这一点不要混淆了。
如果你对字符串比较熟悉,会发现所有的字符串方法都可不能改变原有的值,而都是返回一个新的字符串
还有一点需要注意的是基本类型不能添加属性:
var person = 'person';
person.name = 'Xiaoming';
console.log(person.name); // undefined可能你会问,那在刚才上面的str它只是个字符串,属于基本类型又不是对象,为什么还能拥有方法呢?其实这里涉及到了JS的基本包装类型,不仅字符串有,布尔类型与数字类型也有,它们与其他引用类型相似,最主要的的区别就是对象的生存周期不同,使用new操作符创建的引用类型实例,在执行流离开当前作用域之前都一直保存在内存中,而自动创建的基本包装类型对象,则只存在于一行代码的执行瞬间。
也就是说上面代码中第二行给person加一个name属性,但是第三行访问时该属性不见了,其原因就在于第二行创建的String对象在执行到第三行时就已经被销毁了。此时,第三行代码又创建了自己的String对象,而该对象没有name属性,对于不存在的属性,我们访问时,都是返回undefined(并不是报错)。
其代码表述为:
// 后台在读取到行字符串时
var person = 'person';
// 1. 创建字符串String包装对象,使其像其他引用类型一样拥有属性和方法
var person = new String('person');
// 2. 给这个包装类添加属性 new String('person').name
person.name = 'Xiaoming';
// 3. 接着立马销毁这个属性
person.name = undefined;
// 4. 此时,又会创建一个 new String(),但该对象里并没有name这个属性,返回undefined
console.log(person.name); // undefined如果我们想让这个字符串包装对象拥有这个的属性,可以把person.name = undefined;去掉,这样就可以访问到了这个属性了,不过实在没这个必要。
还有一点容易让人产生疑惑的点,同为基本类型的数字和字符串,字符串可以访问length属性,数字却不可以:
var str = 'abc';
console.log(str.length); // 3
var num = 123;
console.log(num.length); // undefined究其原因是Number和String对象除了共有的私有值[[PrimitiveValue]]外,String对象里还内置了一个length的属性。
现在回到之前那个例子,同样地,其实在读取字符串时,后台就已经自动完成了以下操作:
(1) 创建String的实例
(2) 在实例上调用指定的方法
(3) 销毁这个实例
用代码来表述其过程就是:
var str = new String('string');
str.toUpperCase();
str = null;经过此番处理,基本类型就变得跟对象一样了。但我们还是要清楚的知道一点,基本类型本身是没有属性和方法的。
需要特别注意点的是,通过显式的调用Boolean、String和Number来创建基本包装类型对象(尽管我们基本没有必要这么做),在类型比较的时候会有很大出入。这个放到下一篇类型识别时说。
var person = {};
console.log(person); //{}
person.name = 'A';
person.age = 18;
delete person.name;
person.age = 19;
console.log(person); // {age:19}person从一个空对象改变成了带有一个age属性的对象,在这期间我们还给它添加、删除和修改了属性。
其实我们不难发现,尽管基本类型有很多叫法,原始类型啊,值类型啊。还是引用类型又叫作对象类型。它们的命名跟该类型的类型特点很有关联。
之前在上面谈到复制变量的值的表现时说过
var obj1 = {
name:'a'
}
var obj2 = obj1;
obj2.age = 18;
console.log(obj2.age); // 18
console.log(obj1.age); // 18如此,这两个对象完全等价了,现在来想一想,如果我想要搞出一个他们长的"一模一样"但又各自独立的对象来该怎么做呢?
var p1 = {
name1:'A',
age:20,
sex:'male',
family:['dad','son']
}
function copyObj(obj) {
// 跟构造函数返回对象差不多,有木有?
var newObj = {};
for(var prop in obj) {
newObj[prop] = obj[prop];
}
return newObj;
}
var p2 = copyObj(p1);这里封装了一个函数,在函数里用for...in遍历了传入对象的各个属性,测试p2后,会发现它们"长得一样"了,可是当我们对p2的family属性进行修改的时候,怪事儿出现了:
p2.family[0] = 'mom'; //"mom"
p1.family[0] //"mom"
p1.age = 18; // 18
p2.age; // 20对对象里的基本类型进行修改时它们各不影响,可是对含有引用类型的值进行修改时,另一个对象的值也会随之改变。这是为何?其实对于引用类型的复制,for...in把p1.family与p2.family指向了同一个地址,地址一样,修改它们任何一个,另一个都会反映出来,这种拷贝又称作浅拷贝。
反之,消除指向同一对象的复制,叫作深拷贝,下面给出两种常用的深拷贝方法:
var newObj = JSON.parse(JSON.stringify(p1))
p1.family[0] = 1; // 1
newObj.family[0]; // 'dad'利用JSON实现对象拷贝的方法局限性在于无法复制函数并且会切断原型链
var obj = {
a: 1,
b: 2,
c: {
card1: 'visa',
card2: ['XX', 'XXX', 'XXXX']
},
d: ['r', 'g', 'b']
}
function deepClone(origin, target) {
var target = target || {},
toStr = Object.prototype.toString,
arrStr = '[object Array]';
for(var prop in origin) {
if(origin.hasOwnProperty(prop)) {
if(origin[prop] !== 'null' && typeof origin[prop] == 'object') {
target[prop] = toStr.call(origin[prop]) == arrStr ? [] : {};
deepClone(origin[prop], target[prop]);
} else {
target[prop] = origin[prop];
}
}
}
return target;
}
var newObj = deepClone(obj);
console.log(newObj);简单总结下浅拷贝与深拷贝:
MDN对闭包的定义:
函数和对其周围状态(lexical environment,词法环境)的引用捆绑在一起构成闭包(closure)。闭包可以让你从内部函数访问外部函数作用域。
其实这段话不像看上去的那么难理解,如果熟悉JS的执行上下文(环境)和作用域机制,对于闭包的理解自然也水到渠成。对于闭包的定义我更认为是没有定义,因为从广义的角度来讲,所有的函数都是闭包。
var a = 1;
function test() { // test访问的正是外层作用域(全局上)的a
return a; // a并非test创建的局部变量
}上面代码它看起来好像跟我们想要学习的“闭包”有点不一样,但确确实实test与变量a形成了闭包。正是由于输出结果很按常理出牌,我们平时反而没有特别留意。
毕竟在现实中,不按常理出牌,让我们犯迷糊的闭包,应该是长这样的:
function test() {
var arr = [];
for(var i = 0; i < 5; i++) {
arr[i] = function() {
console.log(i);
}
}
return arr;
}
var newArr = test();
for(var j = 0; j < newArr.length; j++) {
newArr[j](); // 5 5 5 5 5
}我们预期的输出结果应该是0,1,2,3,4,为了对文章后续的理解,先分析下上面例子中代码的执行过程:
过程分解:
1. 调用test之前,全局上下文为:
test 定义时 test.[[scopes]]:
0: GO
// GO(GlobalObject全局对象,又或者说全局上下文)
GO: {
test: function(){},
newArr: undefined
}
2. 调用test
// AO(ActivationObject活动对象又或者叫VO变量对象VariableObject)
test 执行时 test.[[scopes]]:
0: test的AO
1: GO
test的AO: {
arr: [...],
i: 5
}
3. test内部,执行for语句,arr[i]函数的上下文为:
arr[i] 定义时 arr[i].[[scopes]]:
0: test的AO
1: GO
4. test执行完毕,结果返回给newArr,此时全局对象AO更新为:
GO: {
test: function(){},
newArr: [...]
}
5. 由于返回的数组每项是个函数的引用,调用时,即内部函数的AO更新为:
arr[i] 定义时 arr[i].[[scopes]]:
0: arr[i]的AO
1: test的AO
2: GO
arr[i]的AO: {
// 并没有变量i
}
6. 最后一步,调用newArr[j]()访问数组里的每一项,可以看到arr[i]的AO里没有自己的局部变
量i从上面的过程分解可以看出,当进入for循环,执行到arr[0]时,arr[0]执行上下文的AO并没有i,所以它会沿着作用域链的顶端搜寻,在外层test上下文的AO里找到i,i为5。arr[1-4]同理,都是引用的test函数执行完毕最后未进入循环的i值5。
话说回来,这两个例子本质并没有什么区别。只是第一个例子是我们预期的结果,没问题。而第二个例子没有按照我们的预期输出,实则是我们对JS内部执行原理的不完全掌握所带来的困惑。如果非要给闭包一个定义,那么类似这种不符合预期输出的特性,又或者说当我们在一个函数中使用一个既不是该函数参数又不是它局部定义的变量时,此时就已经形成了闭包。
至此,现在应该思考的是如何使上面的例子“按常理出牌”(返回预期的0,1,2,3,4),其实也很简单,既然内部函数(arr[i])没有自己的变量i,那我们使其拥有自己的i不就解决了吗!
改进上面的例子:
function test() {
var arr = [];
for(var i = 0; i < 5; i++) {
(function(i) {
arr[i] = function() {
console.log(i);
}
}(i))
}
return arr;
}
var newArr = test();
for(var j = 0; j < newArr.length; j++) {
newArr[j](); // 0 1 2 3 4
}改进后的代码使用了一个带有参数立即执行函数将其包裹了起来,就是利用作用域链的机制,保存变量i的值,使内部函数访问,而不是使用test执行上下文AO里的变量i值。
改进后的代码,当进入for语句时,有一个立即执行函数的AO:
立即执行函数的AO: {
arguments: {
0: 0,
length: 1
},
i : 0
}此时,执行到arr[0]时,arr[0]执行上下文的AO同样没有i,所以它也会沿着作用域链的顶端搜寻,在外层立即执行函数上下文的AO里找到i,i为0,既然在这里找到了i自然不会继续往下找test执行上下文里AO的i值了。for继续下一轮循环,i变为1,当执行到arr[1]时,此时又会重新创建一个新的立即执行函数的AO(立即执行函数执行完就会销毁),同样它的作用域链上保存着test的AO,test的AO里i的值此时为1,最后内部函数使用离自己最近的立即执行函数AO里保存的i值(1)。arr[2-4]同理也是如此,每次创建新的立即执行函数AO供内部函数调用i值。
可以看出来,至始至终都是通过函数的执行上下文和作用域链的相关知识来达到我们想要的效果,这也正是我之前所说的关于闭包的定义就是没有定义的理解,所以我更愿意把闭包当作与JS其他普通代码一样看待。
eg:函数累加器
正常情况下,想实现重复调用一个函数,实现数字累加的效果是这样做的:
var num = 0; // 依赖于这个变量才实现的累加
function test() {
console.log(num++);
}
test(); // 0
test(); // 1
test(); // 2如果能做到不依赖外部变量并且能反复执行的函数累加器?
使用闭包:
function foo() {
var num = 0;
function bar() {
console.log(num++);
}
return bar;
}
var a = foo();
a(); // 0
a(); // 1
a(); // 2eg:eater
这个例子严格来讲并不是缓存,只是类似
对象被返回出来,两个函数共用的都是test AO里的变量food,即在obj任何一个函数里做了修改food都会同步(food类似一个保存东西 的仓库,存储什么东西都在里面)
function eater() {
var food = 'apple';
var obj = {
eat: function() {
if(food != '') {
console.log(food);
food = '';
}else {
console.log('xxx');
}
},
push: function(myFood) {
food = myFood;
}
}
return obj;
}
var a = eater();
a.eat(); //apple
a.eat(); //xxx
a.push('樱桃');
a.eat(); // 樱桃eg:Person();
function Person(name, status) {
// 私有变量,只能通过使用方法来访问它
var mood = 'sad'
this.name = name;
this.status = status;
this.trans = function() {
this.status = mood;
}
this.sayStatus = function() {
console.log(this.status);
}
}
var p1 = new Person('J', 'happy');
p1.trans();
p1.sayStatus(); // sad
// 尽管显式访问,在外部还是无法访问到
console.log(p1.mood); // undefined上面代码中, 生成对象p1后,由于对象内有函数且也被返回到了外部,对象内的函数与Person形成闭包,尽管Person函数已经执行完并销毁了,但对象内部函数却一直储存了Person的执行上下文,因此Person活动对象里的变量mood会被返回的函数所共享.我们可以利用闭包的这个特性实现对属性的封装和私有化
多人协作开发时,难免出现变量冲突等因素,此时就可以闭包里变量的私有化特性,防止全局变量污染
// 全局有个name变量
var name = 'XXX';
// 同事A写的
var initA = (function() {
var name = 'Z';
function demo() {
console.log(name);
}
return function() {
demo();
}
}());
initA(); // Z
// 同事B写的
var initB = (function() {
var name = 'J';
function demo() {
console.log(name);
}
return function() {
demo();
}
}());
initB(); // J写在最后:本文对于闭包的概念带有严重的个人理解因素,不保证其严谨性,而是作为自己学习路上起到一个标尺的目的,日后对JS有了更深入的了解更会不断重新颠覆之前的理解,所以如果有幸得到您的阅读,请务必保留自己的思考。
上一篇文章简述了什么是基本类型与引用类型以及它们的区别.
其中在讲基本类型时,留坑了这样一段代码
var c = 0;
var d = false;
console.log(c == d); // true为什么0可以与false相等,其实是JS在比较==(相等操作符)时在背后做了类型的隐式转换
那么JS会在什么时候为我们做类型的隐式转换呢?
1. 所有直接量(字符串,数值)用.号去调用某个方法时
3.1415926.toFixed(2); // 3.14我们知道基本类型是没有属性和方法的,之所以这个数值型却能调用方法,是因为JS在后台为我们自动创建了该数值所属的基本包装对象,然后"借用"了new Number上的toFixed()上的原型方法,怎么确定这个方法是Number上的?请打开chrome浏览器,在控制台输出console.dir(new Number)就一目了然啦.同理,字符串也一样,快看看字符串类型能使用它对应的String类型上有什么方法吧
2. if,while这些循环语句的判断条件时
var age = 18;
if(age) {
alert('age转换为Boolean为true,所以这条就弹出来了');
}if语句的条件判断部分,可以写任何表达式,不过最终都会将这个表达式隐式的转换成对应的布尔类型来判断,JS引擎在后台自动调用了转型函数Boolean(age)
3. 作算术操作时
Number()'10' - 24; // -14
10 / '24'; //0.4166666666666667
'10' * '24'; // 240
'10'%24; // 10
// 注意:
10 + 24; // 34
10 + '24'; // '1024'String()转换成了字符串类型4. 使用==相等操作符时
在使用相等操作符做判断时,最终结果只会返回对或错,也就是Boolean的true与false,下面表格展示了各数据类型之间隐式转换的结果:
| 初始值 | String | Number | Boolean | Object | |
|---|---|---|---|---|---|
| String | 'abc' | 'abc' | NaN | true | new String('abc') |
| '123' | '123' | 123 | true | new String('123') | |
| '' | '' | 0 | false | new String('') | |
| ' '(非空) | ' ' | 0 | true | new String(' ') | |
| Number | 0 | '0' | 0 | false | new Number(0) |
| 1 | '1' | 1 | true | new Number(1) | |
| +/-Infinity | '+/-Infinity' | +/-Infinity | true | new Number(+/-Infinity) | |
| NaN | 'NaN' | NaN | false | new Number(NaN) | |
| Null | null | 'null' | 0 | false | 无 |
| Undefined | undefined | 'undefined' | NaN | false | 无 |
| Boolean | true | 'true' | 1 | true | new Boolean(true) |
| false | 'false' | 0 | false | new Boolean(false) | |
| Object | {} | "[object Object]" | NaN | true |
当隐式类型转换满足不了我们的需求时,就必须通过显式的来进行转换了:
例如上面说到的字符串与数值型进行加号运算时:
// 隐式转换的结果显然不是我们想要的
10 + '24'; // '1024'
// 需要显式的转换,除了Number,还可以使用parseInt(),parseFloat()
10 + Number('24'); // 34
// 同理对于一个变量,我们相对其取对应的布尔值
var a = 1;
// 可以这样
!!a; // 返回true. 先对变a取反,然后在一个!操作符对其转换成相应的布尔类型接下来说一说类型识别相关方面的.我们都知道JS原生带的两种类型识别方法分别是typeof与instanceof,下面来讲讲它们实现过程中的具体差异,以及如何扩展封装一个可以识别"所有"类型的函数
1. typeof
需要注意的是,typeof是一个操作符,而不是函数或者方法:
// 既可以这样
typeof('1'); // string
// 还可以把括号去掉
typeof '1'; // string下面使用typeof测试下数据类型:
// 返回结果均为字符串
// 1.测试标准类型
typeof 1; // number
typeof '1'; // string
typeof undefined; // undefined
typeof true; // Boolean
typeof null; // object
typeof {}; // object
// 2.测试具体的对象类型
typeof []; // object
typeof new Date; // object
typeof /\s/; // object
function Fn() {};
typeof new Fn; // object
typeof function() {}; // 'function'typeof-结论:
Null除外的标准类型Function除外的具体的对象类型2. instanceof
// instanceof返回true或false
// 1. 基本类型
1 instanceof Number; // false
'1' instanceof String; // false
true instanceof Boolean; // false
null instanceof Object; //false
undefined instanceof Object; // false
// 2.内置对象类型
[] instanceof Array; // true
/\s/ instanceof RegExp; // true
// 3. 自定义对象类型
function A() {}
function B() {}
B.prototype = new A();
B.prototype.constructor = B;
var c = new B();
c instanceof A; // true
c instanceof B; // true结论:
关于typeof与instanceof还有一点需要注意的是,如果显式的使用new调用基本包装类型的构造函数,跟直接使用对应的转型函数调用有巨大差别
// String
var str = String('str');
var consStr = new String('str');
console.log(typeof str); // string
console.log(typeof consStr); // object
console.log(str instanceof String); // false
console.log(consStr instanceof String); // true
// Number
var num = Number(1);
var consNum = new Number(1);
console.log(typeof num); // number
console.log(typeof consNum); // object
console.log(num instanceof Number); // false
console.log(consNum instanceof Number); // true
// Boolean
var bl = Boolean(true);
var consBl = new Boolean(true);
console.log(typeof bl); // boolean
console.log(typeof consBl); // object
console.log(bl instanceof Boolean); // false
console.log(consBl instanceof Boolean); // true3. 借用对象原型链上的方法
可以封装这样一个函数:
function nonDefined(obj) {
return Object.prototype.toString.call(obj).slice(8, -1).toLowerCase();
}
nonDefined(null); // null
nonDefined(undefined); // undefined
nonDefined(1); // number
nonDefined('1'); // string
nonDefined({}); // object
nonDefined([]); // array
nonDefined(/\s/); // regexp
nonDefined([]); // array
nonDefined(new Date); // number
function Person(age) {
this.age = age;
}
nonDefined(new Person(18)); // object封装了一个使用call借用Object原型上方法的函数来实现类型识别
结论:
4. constructor
除了null和undefined,js中的任何对象都有其对应的构造函数,可以利用这一特性去封装一个"全类型"识别的函数:
(1).constructor === Number; // true
'1'.constructor === String; // true
[].constructor === Array; // true
function Person() {};
function getConsName(obj) {
return (obj === undefined || obj === null) ? obj : (obj.constructor && obj.constructor.toString().match(/function\s*([^(]*)/)[1]).toLowerCase();
}
getConsName(0); // 'number'
getConsName(NaN); // 'number'
getConsName(''); // 'string'
getConsName(false); // 'boolean'
getConsName([]); // 'array'
getConsName(new Date); // 'date'
getConsName(new Person()); // 'person'结论:
所有函数都有一个prototype属性,该属性指向了一个对象,这个对象正是调用该构造函数而创建出来的实例的原型.它定义了构造函数制造出来的对象的公共祖先,通过该构造函数产生的对象,可以继承prototype属性指向的原型对象上的属性和方法
// Person.prototype --> 原型
// Person.prototype = {} Person所有实例的祖先,在这个对象里定义的任何属性和方法,实例都可以继承
// 在原型上添加一个属性和方法
Person.prototype.lastName = 'hehe';
Person.prototype.say = function() {
console.log(this.lastName);
}
function Person() {
}
// 实例继承了原型上的方法和属性,可以访问和调用
var p1 = new Person();
console.log(p1.lastName); // hehe
console.log(p2.say()); // hehe
var p2 = new Person();
console.log(p1.lastName); // hehe
console.log(p2.say()); // hehePerson.prototype为所有实例的祖先,在Person.prototype对象里定义的任何属性和方法,实例都可以继承
可以看到构造函数Person目前是个"空对象",也就是说现在实例上并没有属于自己的方法和属性.此时如果给自己添加一个和原型同名的属性时,实例访问同名属性会访问自己的(同理,如果实例要访问一个自身没有的属性,而原型上有,则访问原型上的):
Person.prototype.lastName = 'hehe';
Person.prototype.say = function() {
console.log(this.lastName);
}
function Person(name) {
this.lastName = name;
}
// 同名时,使用的都是自己身上的属性,除非自己身上没有才会去原型上找
// (构造函数如果带有同原型同名的属性,则以构造函数为准,传参了就正确返回,不传参返回undefined)
var p1 = new Person('He');
console.log(p1.lastName); // He
// 实例没传参,而构造函数带有参数,故p2.lastName === undefined
var p2 = new Person();
console.log(p2.lastName); // undefined
// 把原型上的传进去
var p3 = new Person(Person.prototype.lastName);
console.log(p3.lastName); // hehe新建一个构造函数Car,Car有流程化的属性也有一些可选配的属性
function Car(color, owner) {
this.color = color;
this.owner = owner;
this.brand = 'BMW';
this.wheel = 4;
this.engine = 'V8';
}
var car1 = new Car('black', 'Ze');
var car2 = new Car('pink', 'Jiao');对于流程化的一些属性(写死了的,不会变的),就意味着每创建一个实例都要重复执行brand.wheel.engine这三条语句,代码严重耦合,应该把它们提取出来.
可以利用原型的特性来继承他们:
Car.prototype.brand = 'BMW';
Car.prototype.wheel = 4;
Car.prototype.engine = 'V8';
function Car(color, owner) {
this.color = color;
this.owner = owner;
}
var car1 = new Car('black', 'Ze');
var car2 = new Car('pink', 'Jiao');既然prototype也是一个对象,那么当然可以也像对象字面量一样来创建它们(会产生一个小坑,后面会说),这样一来不仅风格上简约了代码,更提高了代码的可读性:
// 但是按照以对象字面量这种给`prototype`对象添加属性时,会切断实例与原型之间
// 的constructor属性(因为给一个属性赋引用类型的值本质就是重写对象),此时实例的constructor属性指向Object.
Car.prototype = {
// 可以显式的将其指向适当的值
// 但是这种情况又会出现它的enumerable会变成true(系统默认是false,我们自定义的则一律是true)
// 如果此时想把其与系统设置同步,可以使用数据属性Object.defineProperty(xxxxx)方法重置
// constructor: Car,
brand : 'BMW',
wheel : 4,
engine : 'V8'
}
function Car(color, owner) {
this.color = color;
this.owner = owner;
}
var car1 = new Car('black', 'Ze');
var car2 = new Car('pink', 'Jiao');实例是无法修改原型上的属性的,实例修改原型的属性本质是相当于给实例自己新建一个与原型同名的属性,并且实例上的增删查改都是实例对实例本身的操作,不会影响原型,尽管增删查改的属性名跟原型上的属性名同名
Car.prototype = {
brand : 'BMW',
wheel : 4,
engine : 'V8'
}
function Car(color, owner) {
this.color = color;
this.owner = owner;
}
var car1 = new Car('black', 'Ze');
console.log(car1); // 自身属性,Car {color: "black", owner: "Ze"}
console.log(car1.brand); // 原型里的 brand BMW
// 修改car1原型上的bran属性 ×
// 这里需要特别注意!!!car1.brand = 'audi';其实并不是在修改原型上的brand,
// 而是car1给自身新加了一个brand为audi的属性 √
car1.brand = 'audi';
// 返回的audi也并非是真的把原型上的改成了audi,而car1是自己的
console.log(car1.brand); // 实例car1自己的 brand audi
console.log(car1); // 自身多了个brand属性, Car {color: "black", owner: "Ze", brand: "audi"}
// 同理下面也不是删除原型上的属性,而是删除自身的(无论car1有没有这个属性)
delete car1.brand; // 删除自身的brand audi
console.log(car1.brand); // 访问原型上的brand BMW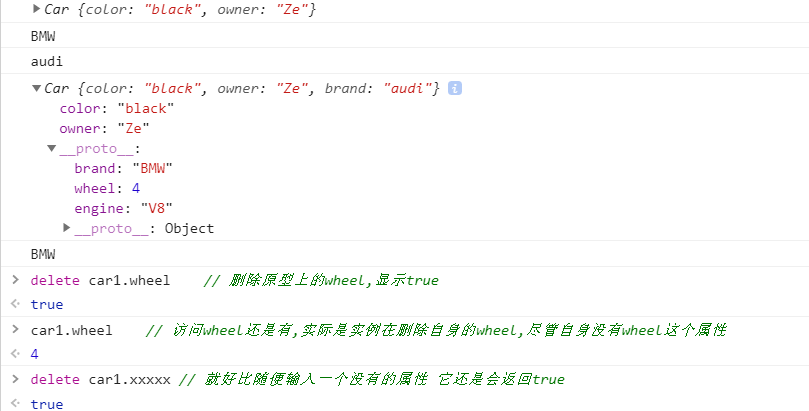
每个原型对象上都天生带有一个constructor属性,该属性指向创建该实例的构造函数
function Car() {
}
var car1 = new Car();
// 每个原型对象上都有一个constructor属性,大致长这样
/* Car.prototype {
constructor: Car
} */
Car.prototype.constructor === Car; // true
// car1的构造器为构造函数Car
car1.constructor === Car; // true
// 通过以上两行代码返回true,可得出
Car.prototype.constructor === car1.constructor // true不仅如此,我们还可以手动的更改constructor属性的指向,使其实例可以访问另外一个构造函数原型上的属性和方法:
function Car() {
}
Car.prototype.color = 'pink';
// 新建一个Person构造函数
function Person() {
}
Person.prototype.weight = 100;
var car1 = new Car();
car1.constructor === Car; // true
car1.constructor === Person; // false
// 把car1的constructor属性指向Person
Car.prototype.constructor = Person;
console.log(car1.constructor); // Person
// 既然Car原型对象的constructor属性已经指向Person了,是否意味着可以它的实例使用Person原型上的属性和方法了?
console.log(car1.weight); // undefined 显而易见,不能(除非Car.prototype = Person.prototype才能直接访问)
// 因为weight是Person构造函数原型上的属性,所以得这样访问
console.log(car1.constructor.prototype.weight); // 100
// 只是更改constructor的指向,并非修改原型,而constructor又属于原型里的属性.自然也能到原型中的color
console.log(car1.color); // pink
这里尤其要注意的是,想要修改constructor的指引,必须去原型对象里面修改.使用实例是修改不了的,比如car1.constructor = Person;.constructor是原型上的属性,之前说过,类似这样的操作,相当于是在给实例本身新加了一个叫constructor的属性,并把构造函数Person作为它的属性值.要始终牢记实例的任何操作都是针对自己的,都不会影响原型对象.
拜读《高程三》的过程中,看到书中有一个阶乘函数的代码,贴代码前,先看看什么是阶乘以及对它的定义:
一个正整数的阶乘(factorial)是所有小于及等于该数的正整数的积,并且0的阶乘为1。自然数n的阶乘写作n!
举个栗子说明:
5的阶乘为:
5! ==> 5* 4 * 3 * 2 * 1 = 120
4的阶乘为:
4! ==> 4 * 3 * 2 * 1 = 24
对比以上两个数的规律,可以总结出5的阶乘可以这样写:
5! ==> 5 * 4! = 120
也就是说一个正整数n的阶乘为:
n! ==> n * (n - 1)!
至此,了解了阶乘,回到文章开头说的代码:
function factorial(num) {
if(num <= 1) return 1;
return num * factorial(num - 1);
}
factorial(5); // 120讲道理,对于初学一门语言又没有计算机基础的人来说,我真是抓破了耳挠红了腮也没想出来具体的实现过程,不禁对自己的智商产生了极大的质疑,好在之前在逛论坛时,看到过一个编程前辈对初学者学习编程的一个建议:"不要钻牛角尖,对于不懂的,可以选择先搁置,等代码量上来了或者做过实际项目后再回来理解,不然很可能打击你学习的积极性和产生挫败感"....简直真真的感同身受不是?
废话到这里,也就是想说,如果你也是初学者,我倒是可以也以一个初学者的角度,讲下大致思路.
对于该代码,我想大部分都能想出来它的实现过程大概是这样的:
factorial(5); // 5* 4 * 3 * 2 * 1 = 120但就是不知道,比如:
return num * factorial(num-1); 这里开始执行应该是return 5 * factorial(4),但是factorial(4)是怎么变成4的呢?很捉急啊,有木有!放心,绝对不是你一个人这样想,没错,这也是我当时的疑惑点之一,其实造成疑惑的最主要的原因是因为我们不知道有个栈的概念,如果你在学习规划上的时间很紧凑,那你先不必对栈是什么作了解,只要记住栈有个特点就是数据先进后出,你可以想象成子弹匣.
下面我们慢慢来阐述下这段代码的具体执行过程:
看到这里我相信你一定理解了,只不过可能就是对栈的概念模棱两可,不过没关系,**最重要,就是把栈说上天了,它也只是个名词,我们理解这段代码的实现过程就好了(不是说以后就不学栈了,如果想要在编程这条路走的更远,计算机底层的东西一定都要去学)
如果以上代码你还不理解,可以先看看这段代码,在重新回到上面理解:
function foo(a) {
if(a !== 1) {
console.log('在下行函数调用后,出现的都是我减1,我的值分别是:', a);
foo(a - 1); // 反复调用该函数,逐步压栈
// 当if条件不成立,开始出栈,即从压在最下面的foo(2)往上逐步出栈
console.log('在if条件成立时,这时我将逐步加1,我的值分别是:', a);
} else {
console.log('在if条件不成立时,这时我出来露一次脸', a);
}
}
foo(5);前言:
The secret to building large apps is never build large apps. Break your applications into small pieces. Then, assemble those testable,bite-sized pieces into your big application.
这是摘自Twitter上的一句非名人语录,它的大致意思是:构建一个大型项目不是去写很多代码,而是将你的应用程序分解成很小的模块,然后再组装它们
这段话很有道理,对于理解模块化我觉得很有帮助.
从一个简单的index.html页面说起:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<script src="a.js"></script>
<script src="b.js"></script>
<script src="c.js"></script>
</body>
</html>以上代码在文档中引入了三个js文件,并且它们存在依赖关系,其中b.js依赖于a.js与c.js,这好办置换下位置就好了,像这样:
<script src="a.js"></script>
<script src="c.js"></script>
<script src="b.js"></script>乍一看可能觉得很正常,不就引入文件嘛,就算有依赖关系,我手动调下顺序就好了,根本不用思考,太简单了!可是你想过没,在一个大型项目中,我们可能有几百几千甚至上万个js文件,先不说要手动敲几千行这样的重复代码,最重要的是,这种数量文件的依赖关系你能理的清吗?还有一点就是,这些js文件都是共享作用域的,那些数不清的全局变量你不担心命名冲突造成全局污染?
发现问题很容易,目的是要解决问题,我们可以把上面的问题简单归纳为:
答案是:模块化
解决上述问题的做法我们就称之为模块化,不仅js文件,对于css、图片等文件我们也可以视为一个模块(这种非js文件的模块化,需要用到打包工具,例如webpack),模块内部有自己的作用域,不会影响全局,并且约定一些关键词来进行依赖声明和API暴露
简述:以calculator模块依赖于math模块,来进行运算操作的示例
// HTML:
<body>
<script src="math.js"></script>
<script src="calculator.js"></script>
</body>
// JS
// math.js
function add(a, b) {
return a + b;
}
function sub(a, b) {
return a - b;
}
// calculator.js
var action = 'add';
function compute(a, b) {
switch(action) {
case 'add' : return add(a, b);
case 'sub' : return sub(a, b);
}
}
// math模块缺点:
// 1. 没有封装性:变量散落在全局
// 2. 接口结构不明显
// calculator模块缺点:
// 1. 没有依赖声明:依赖于math.js
// 2. 使用全局状态: 如action,在js里要尽量避免
// HTML:
<body>
<script src="math.js"></script>
<script src="calculator.js"></script>
</body>
// JS
// math.js
var math = {
add: function(a, b) {
return a + b;
},
sub: function(a, b) {
return a - b;
}
}
// calculator.js
var calculator = {
action: 'add',
compute: function(a, b) {
switch(this.action) {
case 'add': return math.add(a, b);
case 'sub': return math.sub(a, b);
}
}
}
// 说明:calculator模块依赖于math模块,来作运算操作
// math模块:
// 优点:
// 1. 结构性好:改进后的math,我们一眼就可以看出输出了什么,对象字面量为我们做了很好的结构化
// 缺点:
// 1. 依然没有进行"访问控制"
// calculator模块:
// 缺点:
// 1. 依然没有依赖声明:虽然action变为了其成员属性,但是我们在外部仍然能控制到它,即我们无法标明一个属性是私有的// HTML:
<body>
<script src="math.js"></script>
<script src="calculator.js"></script>
</body>
// JS
// math.js
var math = {
add: function(a, b) {
return a + b;
},
sub: function(a, b) {
return a - b;
}
}
// calculator-1.js
var calculator = (function() {
// 私有成员
var action = 'add';
// 输出接口
return {
// compute方法可以读取到action的同时action又不会暴露出来
compute: function(a, b) {
switch(action) {
case 'add': return math.add(a, b);
case 'sub': return math.sub(a, b);
}
}
}
})()
// calculator-1模板
// 优点:
// 1."访问控制"
// 缺点:
// 无依赖声明
// calculator-2.js
// 把math模块作为形参传入
var calculator = (function(m) {
var action = 'add';
function compute(a, b) {
switch(action) {
case 'add' : return m.add(a,b);
case 'sub' : return m.sub(a,b);
}
}
return {
compute: compute
}
})(math)
// calculator-2模块
// 优点:
// 1. 显示依赖声明
// 缺点:
// 1. 仍然污染了全局
// 2. 必须手动进行依赖管理
namespace的全局变量,实现所有模块的声明.// namespace
var namespace = (function() {
// 缓存所有模块
var cache = {};
// 模块名,依赖列表,定义
function createModule(name, deps, definition) {
// 如果只有模块名,直接输出
if(arguments.length === 1) return cache[name];
// 取得所有依赖的模块
deps = deps.map(function(depName) {
return namespace(depName);
})
// 初始化模块,并返回
cache[name] = definition.apply(null, deps);
return cache[name];
}
return createModule;
})()
// math.js
// 没有依赖
namespace('math', [], function() {
function add(a, b) {return a + b}
function sub(a, b) {return a - b}
return {
add: add,
sub: sub
}
})
// calculator.js
// 参数二:依赖声明,依赖于math模块
// 参数三:依赖"注入,传入math模块
namespace('calculator', ['math'], function(m) {
var action = 'add';
function compute(a, b) {
return m[action](a, b);
}
return {
compute: compute
}
})至此,通过几种示例,不难看出namespace这种方式其实还是没有解决依赖关系的问题,也就是说,如果这些模块分散在不同的文件里面,就需要对这些模块的脚本文件进行手动的排序.一旦项目体型变大,其包含的模块可能达到成千上万个,使用人脑分析这些依赖关系,可能会崩溃.所以请不要做这种尝试,这不应该是人工所需要解决的问题,而是使用模块系统来为我们分担
比较有名的模块系统有CMD、AMD、CommonJS 和 ES6 Module,而 ES6 Module则是未来最主要的模块系统。由于此文只是针对理解模块化**,所以对模块系统就不进行探讨了。
Tips:
我们会用变量来保存对象,数组,字符串等等,以便写程序时用到它们,可这些内容又都是些数据,是数据就会占用内存.当我们不需要这些数据时,它们就成了"垃圾"驻留在内存空间中成为隐患,如果不给出好的策略来处理这些"垃圾",我们可用的空间就会越来越少,直至空间耗尽,系统崩溃.
为了避免这种情况,所以就有了垃圾收集机制.
垃圾收集分为自动(JS),手动(C、C++)收集.
在JS中,执行环境会负责管理代码执行过程中使用的内存,也就是说JS具有自动垃圾收集机制,数据所需内存的分配以及无用内存的回收完全实现了自动化管理,开发人员无需关心内存使用问题,但是了解其内部运行机制还是非常有必要的.
主流浏览器实现垃圾收集机制原理:"垃圾收集器"会在后台找出那些不再继续使用的变量(例如函数的局部变量)周期性的释放器内存(时间间隔各浏览器互有不同),以便回收内存.
用一句话概括就是找到没用的数据,打上标记,释放内存,然后周期性的执行这一过程
这种用于标识无用数据的策略具体到到浏览器中实现,分为两种:标记清除与引用计数
标记清除的原理:
垃圾收集器在运行时,会给存储在内存中的所有变量都加上标记,然后去掉环境中的变量以及被环境中的变量所引用的变量(执行流在进入环境后需要用到它们,垃圾收集器会标记为"进入环境")它们身上的标记,而在此之后(周期性的,第二轮收集)再被加上标记(不在环境中的了)的变量(被标记了"离开环境"的变量,因为出了函数无法访问到了)将视为准备删除的变量,完成内存清除工作.
环境中的变量: 可以理解为变量还未离开的执行环境.例如对于局部变量来讲,它所对应的那个函数,在该函数执行完毕后,那么就可以认为这个变量离开了这个环境了(此时垃圾器标记为"离开环境"),因为这个环境执行完了就已经销毁了,而这个变量也就没有存在的必要了.
上面的思路整理一下就是:
引用计数垃圾清理策略实现方式的原理就比较明朗了,《高程三》是这样定义的:
当声明了一个变量并将引用类型值赋给该变量时,我们可以说这个值的引用次数是1,如果该值又被赋给了另一个变量,那么该值的引用次数加1,反之,如果对这个值引用的变量又取得了另一个值,那么该值引用次数减1,直到这个值引用次数变为0,说明没办法再访问它了,这会儿就可以将其占用的内存空间回收,待下次垃圾收集器再运行时,它就会释放那些引用次数为0的值所占用的空间
文字总是晦涩的,还是来看代码,比如我们有这样一个引用类型的值:
{
name:'person1',
age:20
}把该值赋值给一个变量:
var person1 = {
// 现在我们就可以说有一个变量引用了一次这个值,该值引用次数+1
name:'person1',
age:20
}
// 此时把person1的引用赋值给另一个变量person2
var person2 = person1; // 此时该值的引用次数再加1,变为+2
// 现在我把person2的引用指向另一个对象
person2 = {}; // 此时最初的那个引用类型值只有person1在引用了,引用次数减1,变成+1
// 如果我此时又让person1的引用指向再换成一个别的其他对象,像这样:
person1 = {}; // 此时最初的那个值已经没有任何变量引用它了,那么引用次数再减1,变成0现在最初的原始引用类型值的被引用次数为0,没有变量能访问到它了,就可以被回收了.
这么一看,引用计数策略也还可以嘛,为什么各大浏览器没有采用这么策略呢?实际上这个策略会造成一个非常严重的问题:循环引用
什么是循环引用?就是有两个对象,对象1包含一个指向对象2的指针的同时对象2中也包含一个指向对象A的引用,也就是说你中有我,我中有你.这就意味着它们的引用次数永远不可能为0,也就无法实现垃圾收集,导致大量内存驻留.
还是来看代码,正常情况下:
function foo() {
var person1 = {}; // 此时引用次数都为1
var person2 = {}; // 此时引用次数都为1
}
// 当我们调用函数后,由于函数里的是局部变量,那么它里面的变量都会被销毁,也就是相当于这样:
// var person1 = null; 对应的该变量对{}的引用变为0
// var person2 = null; 对应的该变量对{}的引用变为0
foo();像上面这样显然没有任何问题,但是:
function foo() {
var p1 = {}; // 此时引用次数都为1
var p2 = {}; // 此时引用次数都为1
p1.dad = p2;
p2.son = p1;
// 1. 现在p1有个dad属性指向p2,也就意味着p1.dad引用了一次p2的指针,此时p1对象值引用此时+1
// 2. p2有个son属性指向p1,也就意味着p2.son引用了一次p1的指针,此时p2对象值引用此时+1
// 3. 目前p1与p2所对应的值引用分别是:
// var p1 = {}; // 此时引用次数都为2
// var p2 = {}; // 此时引用次数都为2
}
// 4. 当我们执行foo()函数后,局部变量就要解除这个引用了,变成:
// var p1 = null; 对应的p1的引用次数减1 ==> 2 -1 = 1;
// var p2 = null; 对应的p2的引用次数减1 ==> 2 -1 = 1;
foo();最后他们的各自引用次数分别是1,这也就意味着它们的引用次数永远不可能为0,如果这个函数被重复多次调用,就会导致大量的内存得不到回收.这也正是各大浏览器摒弃引用计数,采用标记清除策略的主要原因.
既然JS是具备自动垃圾清理机制的,按理说我们不应该关心内存管理的才对.其实不然,最主要的原因就是在于,对Web浏览器的可用内存数量要比分配给桌面应用程序的少.不过想想也有道理,要是内存分配没有限制,运行JS的网页要是耗尽了全部系统内存,那么系统不就崩溃了吗!正是因为这个问题,其实我们在浏览器中可用的内存其实还是挺少的,该节省用就节省点用,这样一来,就引申出一个话题,怎么确保利用最少的内存占用来获得网页更好的性能,而优化内存的最佳方式为只保存有用的数据,对于没用的就释放呗,释放的方式也很简单,那就是把没用的变量设置为null,这个方式也叫作解除引用
// 在全局定义一个数组
var arr = [非常多项的一个数组];
...
...
... // 比如执行到这一步,我们不再需要用到arr,但是后面还有很多程序没有执行完毕,在这个过程里,这个arr会一直驻留在内存中,如果像arr这样全局变量特别多,这无疑给浏览器造成一定负担
arr = null; // 所以就需要手动解除引用,就相当于告诉JS引擎,这个arr已经脱离执行环境,我不再用到它,请下一轮回收它
...
...
...具体到一个闭包的例子:
function foo() {
var arr = new Array(99999);
function bar() {
console.log(arr.length);
}
return bar;
}
// bar函数引用着foo函数的局部变量arr,导致变量arr不会被释放(尽管foo已经执行完毕)
var res = foo();
res(); // 99999
// 解除引用,及时释放
res = null;
res(); // 报错注:手动解除引用并不意味着自动回收该值所占用的内存,其目的在于让它脱离执行环境,好让垃圾收集器下次运行时将其回收
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.