ustccjw / blog Goto Github PK
View Code? Open in Web Editor NEWustccjw's blog base on github issues
ustccjw's blog base on github issues








































"引入 Falcor(async model)" 为原创,其余图皆为引用

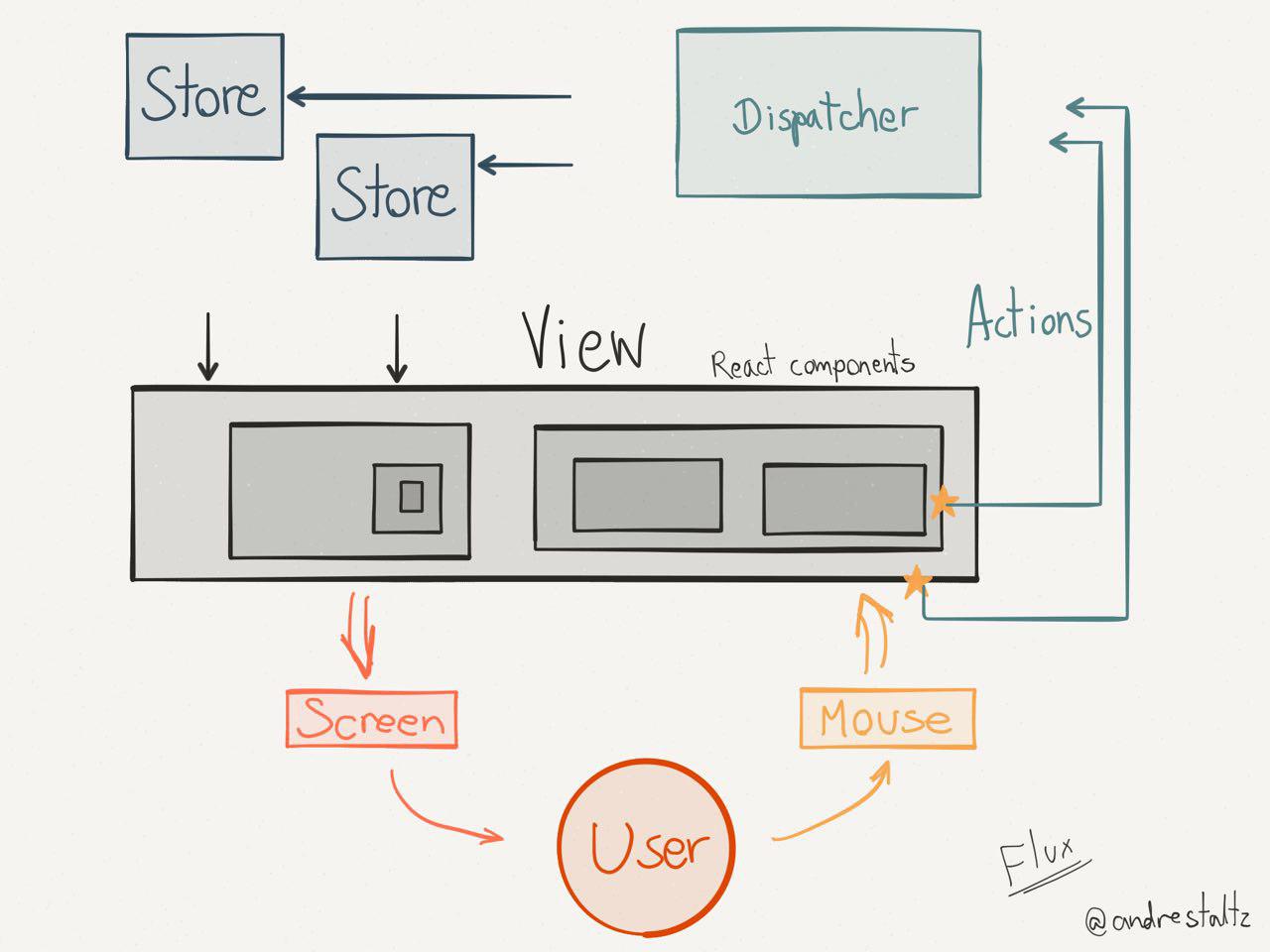
图来自 http://staltz.com/unidirectional-user-interface-architectures.html
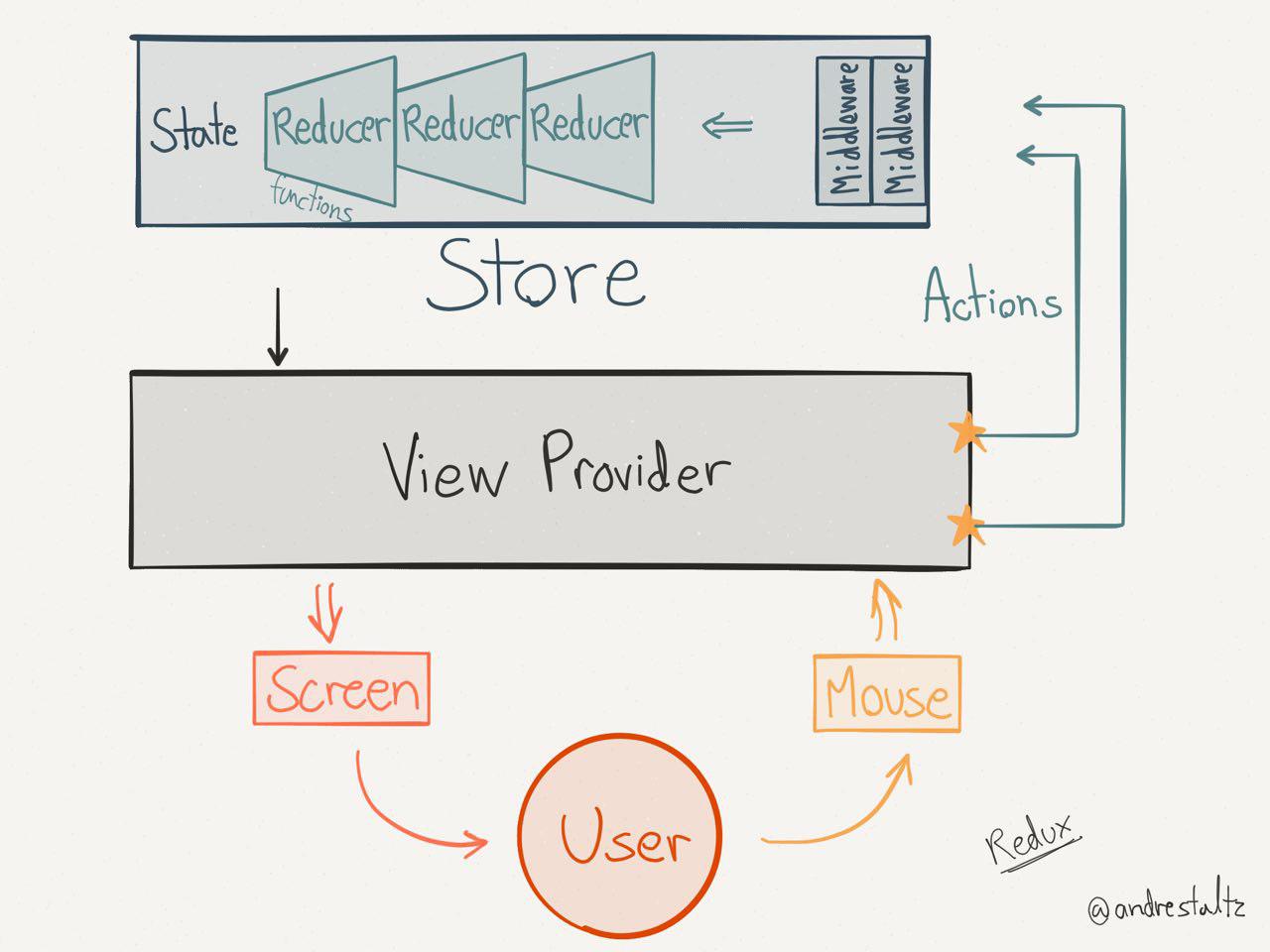
图来自 http://staltz.com/unidirectional-user-interface-architectures.html

HTML5中添加了getElementsByClassName方法,该方法只接收一个参数,即一个包含一或多个类名的字符串,返回带有指定类的所有元素的NodeList。
var allCurrentUserNames = document.getElementsByClassName('userName current');
IE9+以上和其他现代浏览器均支持。
var getElementsByClass = function(searchClass, node, tag) {
var classElements = new Array();
if (node == null) {
node = document;
}
if (tag == null) {
tag = '*';
}
var els = node.getElementsByTagName(tag);
var elsLen = els.length;
var pattern = new RegExp("(^|\\s)"+searchClass+"(\\s|$)");
for (i = 0, j = 0; i < elsLen; i++) {
if (pattern.test(els[i].className)) {
classElements[j] = els[i];
j++;
}
}
return classElements;
}
还有基于DOM Tree Walker和XPath的实现方法,在浏览器的兼容性方面可能存在差异。因此理想的方案是:优先使用原生方法 + 配合使用上述的基于DOM的实现方法(IE8以下)。
我们所说的web组件是一些在w3c约束下工作的标准集合,并且在浏览器中进行呈现。简而易之,它们允许我们在自定义的HTML元素中绑定标记和样式。更令人感到惊奇的是,它们对所有绑定的HTML和CSS实行完全封装。这意味着你写的样式总能够按照你的意图渲染(ps. 并且无副作用),无法通过外部的Javascript来窥探你的HTML。
如果你想玩下内置的Web组件,我建议你使用Chrome Canary,它能提供最好的支持。一定要在chrome://flags中确保下面的设置:
想想你如何来实现一个图像幻灯片,可能实现起来如下:
HTML:
<div id="slider">
<input checked="" type="radio" name="slider" id="slide1" selected="false">
<input type="radio" name="slider" id="slide2" selected="false">
<input type="radio" name="slider" id="slide3" selected="false">
<input type="radio" name="slider" id="slide4" selected="false">
<div id="slides">
<div id="overflow">
<div class="inner">
<article>
<img src="./rock.jpg" alt="an interesting rock">
</article>
<article>
<img src="./grooves.jpg" alt="some neat grooves">
</article>
<article>
<img src="./arch.jpg" alt="a rock arch">
</article>
<article>
<img src="./sunset.jpg" alt="a dramatic sunset">
</article>
</div>
</div>
</div>
<label for="slide1"></label>
<label for="slide2"></label>
<label for="slide3"></label>
<label for="slide4"></label>
</div>
这是一块还不错的HTML,我们甚至还没有包含CSS。但是想象一下如果我们可以删除所有额外的源码,将代码减少到只包括重要的部分。那看起来怎么样?
<img-slider>
<img src="./sunset.jpg" alt="a dramatic sunset">
<img src="./arch.jpg" alt="a rock arch">
<img src="./grooves.jpg" alt="some neat grooves">
<img src="./rock.jpg" alt="an interesting rock">
</img-slider>
不是太寒酸嘛!我们已经抛弃了样板文件,我们留下来的代码只包含我们所关心的东西。这是Web组件将允许我们的做的事。但在我深入细节之前我想告诉你另一个故事。
多年来,浏览器开发者都用一个卑鄙的伎俩来隐藏他们的袖子。来看一下
<video src="./foo.webm" controls></video>
这里有一个播放按钮,一个播放进度条,一个播放时间,一个音量调节器。这些东西都不需要你写任何标记,只要你用<video>标记,这些部件都会出现
但实际上,你看到的是一个错觉,浏览器开发者需要一种方法来保证无论我们在页面上添加任何古怪的HTML,CSS或Javascript,这些标签总能够渲染的一致。为此,他们创造了一个秘密通道的方式,可以对我们隐藏他们的代码。他们称之为:the Shadow DOM.
如果你用chrome,可以打开你的开发者工具,选中Show Shadow DOM,就可以看到
你会发现里面有大量的HTML隐藏代码。仔细看看,你会发现有播放按钮,播放进度条,播放时间,音量调节器等元素。
现在回想我们的幻灯片。假如我们能访问阴影DOM并且可以定义我们自己的标记类似video,那将会怎样?那么我们就可以真正意义上实现我们自定义的img-slider标记。
让我们来看看如何实现这一点,使用web组件的第一支柱:模板。
每个优秀的构建项目必须先得有一个蓝图,对于web组件,蓝图来自于template标记。模板标记允许你存储一些标记在页面上以供你稍后克隆和重用。如果你之前用过类似的模板库如mustache或者handlebars,那么对template会感到亲切。
<template>
<h1>Hello there!</h1>
<p>This content is top secret :)</p>
</template>
模板里的一切都被浏览器认为是滞后的。这意味着模板里的外部资源标签如,,
因此,创建我们自己的的第一步是将所有的HTML和CSS放进中。
<template>
<style>
* {
-webkit-box-sizing: border-box;
-moz-box-sizing: border-box;
-ms-box-sizing: border-box;
box-sizing: border-box;
}
#slider {
max-width: 600px;
text-align: center;
margin: 0 auto;
}
#overflow {
width: 100%;
overflow: hidden;
}
#slides .inner {
width: 400%;
}
#slides .inner {
-webkit-transform: translateZ(0);
-moz-transform: translateZ(0);
-o-transform: translateZ(0);
-ms-transform: translateZ(0);
transform: translateZ(0);
-webkit-transition: all 800ms cubic-bezier(0.770, 0.000, 0.175, 1.000);
-moz-transition: all 800ms cubic-bezier(0.770, 0.000, 0.175, 1.000);
-o-transition: all 800ms cubic-bezier(0.770, 0.000, 0.175, 1.000);
-ms-transition: all 800ms cubic-bezier(0.770, 0.000, 0.175, 1.000);
transition: all 800ms cubic-bezier(0.770, 0.000, 0.175, 1.000);
-webkit-transition-timing-function: cubic-bezier(0.770, 0.000, 0.175, 1.000);
-moz-transition-timing-function: cubic-bezier(0.770, 0.000, 0.175, 1.000);
-o-transition-timing-function: cubic-bezier(0.770, 0.000, 0.175, 1.000);
-ms-transition-timing-function: cubic-bezier(0.770, 0.000, 0.175, 1.000);
transition-timing-function: cubic-bezier(0.770, 0.000, 0.175, 1.000);
}
#slides article {
width: 25%;
float: left;
}
#slide1:checked ~ #slides .inner {
margin-left: 0;
}
#slide2:checked ~ #slides .inner {
margin-left: -100%;
}
#slide3:checked ~ #slides .inner {
margin-left: -200%;
}
#slide4:checked ~ #slides .inner {
margin-left: -300%;
}
input[type="radio"] {
display: none;
}
label {
background: #CCC;
display: inline-block;
cursor: pointer;
width: 10px;
height: 10px;
border-radius: 5px;
}
#slide1:checked ~ label[for="slide1"],
#slide2:checked ~ label[for="slide2"],
#slide3:checked ~ label[for="slide3"],
#slide4:checked ~ label[for="slide4"] {
background: #333;
}
</style>
<div id="slider">
<input checked="" type="radio" name="slider" id="slide1" selected="false">
<input type="radio" name="slider" id="slide2" selected="false">
<input type="radio" name="slider" id="slide3" selected="false">
<input type="radio" name="slider" id="slide4" selected="false">
<div id="slides">
<div id="overflow">
<div class="inner">
<article>
<img src="https://s3-us-west-2.amazonaws.com/s.cdpn.io/5689/rock.jpg">
</article>
<article>
<img src="https://s3-us-west-2.amazonaws.com/s.cdpn.io/5689/grooves.jpg">
</article>
<article>
<img src="https://s3-us-west-2.amazonaws.com/s.cdpn.io/5689/arch.jpg">
</article>
<article>
<img src="https://s3-us-west-2.amazonaws.com/s.cdpn.io/5689/sunset.jpg">
</article>
</div> <!-- .inner -->
</div> <!-- #overflow -->
</div>
<label for="slide1"></label>
<label for="slide2"></label>
<label for="slide3"></label>
<label for="slide4"></label>
</div>
</template>
接着,我们准备将template移进阴影DOM里。
阴影DOM给我们提供了iframes的最好特性,样式和标记的封装。
为了创建阴影DOM,选择一个元素然后调用其createShadowRoot方法。这将会返回一个文档碎片,你可以往里面填充内容。
<div class="container"></div>
<script>
var host = document.querySelector('.container');
var root = host.createShadowRoot();
root.innerHTML = '<p>How <em>you</em> doin?</p>'
</script>
在阴影DOM的术语里,你调用creatreShadowRoot的元素被称之为Shadow Host。这是唯一用户可见的片段,而且在这里要求用户提供组件相关的内容。
如果你之前考虑过
createShadow返回的文档碎片称之为Shadow Root。Shadow Root及其子孙就是对用户不可见的,但是当浏览器检测到我们的自定义标记时就会实际渲染Shadow Root及其子孙。
在
Shadow Root里的任何的HTML和CSS都被父文档的称之为Shadow Boundary的不可见障碍所保护。Shadow Boundary阻止父文档中CSS的渗入到Shadow DOM中,它也阻止外部的Javascript遍历Shadow Root。
也就是说假如你在shadow DOM中指定了所有h3的color: red。同时,在父文档中,你指定h3的color: blue。在这种情况下,在shadow DOM中的h3将会是红色,shadow DOM外面的h3将会是绿色。得益于Shadow Boundary,这两个样式完美地相互忽略。
相应的,当父文档用$('h3')来寻找h3元素,Shadow Boundary将会阻止任何对shadow root的探测,这个选择器将只返回shadow DOM外面的h3.
为了得到img-slider的Shadow DOM,我们需要创建Shadow host,并且用模板的内容来填充它。
<template>
<!-- Full of slider awesomeness -->
</template>
<div class="img-slider"></div>
<script>
// Add the template to the Shadow DOM
var tmpl = document.querySelector('template');
var host = document.querySelector('.img-slider');
var root = host.createShadowRoot();
root.appendChild(document.importNode(tmpl.content, true));
</script>
在这个例子中,我们创建了一个div,并且添加类名为img-silder,因此它可以用来充当shadow host。
我们选择模板,用document.importNode来对其进行深拷贝。然后添加到我们创建的shadow root内部('codepen效果')。
我们的img-slider在shadow DOM内部,但是图片的路径是硬编码的。就像
为了将这些内容插入shadow DOM中,我们用新的标签。标签用CSS选择器来从shadow host中选择元素,将它们在shadow DOM中构建。这些构建的元素称之为Insertion Points。
我们将简化问题,假设幻灯片只有4张图片,这样我们可以用nth-of-type来创建4个insertion points。
<template>
...
<div class="inner">
<article>
<content select="img:nth-of-type(1)"></content>
</article>
<article>
<content select="img:nth-of-type(2)"></content>
</article>
<article>
<content select="img:nth-of-type(3)"></content>
</article>
<article>
<content select="img:nth-of-type(4)"></content>
</article>
</div>
</template>
现在我们能够填充img-slider。
<div class="img-slider">
<img src="./rock.jpg" alt="an interesting rock">
<img src="./grooves.jpg" alt="some neat grooves">
<img src="./arch.jpg" alt="a rock arch">
<img src="./sunset.jpg" alt="a dramatic sunset">
</div>
这看起来很酷,我们还将更进一步,使用自定义标记img-slider。
创建你自己的HTML元素听说起来可能很吓人但实际上非常简单。在web组件上说,这样的新元素是一个自定义元素,仅有的两个条件是它的名字必须包含破折号,以及它的原型必须继承HTMLElement。
<template>
<!-- Full of image slider awesomeness -->
</template>
<script>
// Grab our template full of slider markup and styles
var tmpl = document.querySelector('template');
// Create a prototype for a new element that extends HTMLElement
var ImgSliderProto = Object.create(HTMLElement.prototype);
// Setup our Shadow DOM and clone the template
ImgSliderProto.createdCallback = function() {
var root = this.createShadowRoot();
root.appendChild(document.importNode(tmpl.content, true));
};
// Register our new element
var ImgSlider = document.registerElement('img-slider', {
prototype: ImgSliderProto
});
</script>
Object.create方法返回一个继承HTMLElement的原型对象。当解释器发现文档中的自定义标记时,它将会检查看是否其有一个createdCallback的方法。如果发现了这个方法它将会立即运行该方法。这是一个开始工作的好地方,因此我们创建Shadow DOM并且将我们的模板克隆并插进去。
我们用方法registerElement来注册自定义元素,第一个参数是标记的名字,第二个参数是元素的原型。
现在我们的元素已经被注册,我们可以有多种方法来使用它。一种是直接在HTML中用标记。另外一种是通过Javascript来调用document.createElement("img-slider")或者用document.registerElement返回的构造函数对象ImgSlider。
目前浏览器对web组件的支持参差不齐,尽管一直在提高。下图是目前的支持情况:
但是不要丧失使用它们的勇气!Mozilla 和 Google Chrome一直在努力构建的polyfill库在所有现代浏览器中支持web组件。这意味着你现在就可以开始使用这些技术并且提供反馈。
应用数据按照来源可分为远程数据和本地数据。远程数据一般是前端通过请求远程服务获得,本地数据一般是用来记录用户操作的状态。
数据层需要解决的问题一般是:远程数据的同步 和 组件间数据的同步。
远程数据需要同步的主要有两种情形:数据实时性比较高 和 用户操作导致了远程数据的更新。
远程数据的同步最简单的方法就是:不缓存远程数据,每次都向服务器请求新的数据。很显然,这样的做法能够保证数据的同步。这种方法对一些数据实时性比较高的情形是适用的,但是显然大部分情形下不需要这么实时,我们会缓存远程数据。
那么,我们更关注的是用户操作导致了远程数据更新应该如何同步。比较好的解决方案是:用户发起一些操作请求(POST)后,服务端能够返回需要同步的数据。
我们需要一个抽象层,能够对数据缓存进行设置(MAXSIZE, TTL 等等),自动完成远程数据同步。我们希望远程数据模型和本地数据模型接口完全一致,这里就需要提一下 Falcor 这个 JS 库。
Falcor 就是用来帮助你实现数据 Model 抽象的,它的主要特性是:
Falcor 的 Model 可以设置初始 cache 和 cache 的一些配置;可以设置数据源 source,数据源只要实现它的 DataSource 接口就好,可以是 HttpDataSource 或者是 WebSocketDataSource。
它的 Model 是 JSON Graph 形式,通过传递 JSON path 来实现对数据的 get/set/call 操作,这就是它的 The Data is the API。存储格式是 JSON Graph(引入了 $ref,可以实现数据引用),解析结果是通用的 JSON 数据格式。
远程数据实现缓存和同步后,远程数据和本地数据对我们来说没有区别,我们需要关心的是组件间数据的同步。这个很好解决,那就是组件共享一个 Model,数据更新后从 Model 重新获取数据再渲染。关于 Model 的结构类型,图形结构(ex: JSON Graph)要优于树形结构(ex: Redux reducer tree),图形结构可以很自然的定义实体,实现实体共享(引用)。
我们可以把 Model 分为:dataModel 和 uiModel。dataModel 关联远程服务数据源,uiModel 是用来存储本地 UI 操作的数据。用 Falcor 来创建和管理 dataModel 和 uiModel。需要注意:由于对远程数据源的抽象,我们对 Model 的操作(get/set/call)都是基于 Observable/Promise 的异步操作。
我们的 Model 数据操作现在是异步的了,可是 React 组件的渲染机制是同步的,为此,我们可以使用 react-router 的 async-props 扩展来实现异步 props。
我们不能把所有的组件都扩展成 async props,否则性能上肯定吃不消,也不利于优化,而且也容易导致数据流混乱。一种可能的方式是:以 route component 为数据获取入口,在 route component 处使用 async props 来获取数据。route component 的子组件使用的还是同步 props 数据。
执行数据更新操作后,如何刷新应用?那就是重新获取当前路径所有的 route components 的 async props ,然后再重新渲染(执行一次 reload 操作)。这样我们不需要知道需要更新哪些数据,这个由 set/call 操作的返回的 JSON Graph 来更新,我们只要在 set/call 操作(或者一组 set/call 操作)后执行 reload (更新当前路径所有的 route components 的 async props 再重新渲染)。
React 应用实现服务器端渲染很简单,我们可以把渲染完成后的 Model Cache 通过 js 注入传给前端用来作为前端初始化 Model 的 Chache。
const dataCache = safeScript(JSON.stringify(dataModel.getCache()))
scriptTag = `<script>
window.dataCache=${dataCache}
</script>`
export const dataModel = new falcor.Model({
source: new HttpDataSource(url),
})
export const uiModel = new falcor.Model({
cache: {
articleList: {
page: 1,
},
},
})
if (global.dataCache) {
dataModel.setCache(global.dataCache)
}
具体的实验可参考:https://github.com/ustccjw/tech-blog
李松峰老师翻译,Jeremy Keith 在 Fronteers 2010 上的主题演讲
今天我想跟大家谈一谈HTML5的设计。主要分两个方面:一方面,当然了,就是HTML5。我可以站在这儿只讲HTML5,但我并不打算这样做,因为如果你想了解HTML5的话,你可以Google,可以看书,甚至可以看规范。
实际上,确实有人会谈到规范的内容。史蒂夫·福克纳(Steve Faulkner)会讲HTML5与可访问性。而保罗·艾里什(Paul Irish)则会讲HTML5提供的各种API。因此,我今天站在这里,不会光讲一讲HTML5就算完事了。
说老实话,在正式开始之前,我想先交待清楚我所说的HTML5到底是什么意思。这话听起来有点搞笑:这会子你一直在说HTML5,难道我们还不知道什么是HTML5吗?大家知道,有一个规范,它的名字叫HTML5。我所说的HTML5,指的就是这个规范。但问题是,有些人所说的HTML5,指的不仅仅是这个规范,还有别的意思。比如说,用HTML5来代指CSS3就是一种常见的叫法。我可不是这样的。我所说的HTML5,不包含CSS3,就是HTML5。
类似的术语问题以前也有过。Ajax本来是一种含义明确的技术,但过了不久,它的含义就变成了“用JavaScript来做一切好玩的东西”。这就是Ajax,对不对?今天,HTML5也面临同样的问题,它本来指的是一个特定的规范,但如今含义却成了“在Web上做一切好玩的事。”我说的不是这种HTML5,不是这种涵盖了最近刚刚出现的各种新东东的HTML5。我说的仅仅是规范本身:HTML5。
刚才已经说了,我今天想要讲的内容不多,也没有打算介绍HTML5都包含什么。今天我要讲的是它的另一方面,即HTML5的设计。换句话说,我要讲的不是规范里都包含什么,而是规范里为什么会包含它们,以及在设计这个规范的时候,设计者们是怎么看待这些东西的。
设计原理本质上是一种信念、一种想法、一个概念,是你行动的支柱。不管你是制定规范,还是制造一种有形的物品,或者编写软件,甚至发明编程语言。你都能找到背后的一个或者多个设计原理,多人协作的任何成果都是例证。不仅仅Web开发领域是这样。纵观人类历史,像国家和社会这样大规模的构建活动背后,同样也有设计原理。
就拿美国为例吧,美国的设计原理都写在了《独立宣言》中了。
我们认为这些真理是不言而喻的,人人生而平等,造物主赋予了每个人不可剥夺的权利,包括生存、自由和追求幸福。
这里有一句口号:生存、自由和追求幸福。这是被写进宪法中的核心理念,它关系到我们所有人的一切,也就是我们构建自己社会的原则。
还有一个例子,就是卡尔·马克思(Karl Marx),他的著作在20世纪曾被奉为建设社会主义的圭臬。其基本**大致可以归结为下面这条设计原理:
各尽所能,各取所需。
这其实就是一种经济体系背后的设计原理。
还有一个例子,比前面两个的历史更久远一些,不过大同小异:
人人为我,我为人人。
这个极为简单的设计原理,是两千年前的拿撒勒犹太人耶稣基督提出来的。而这条原则成为了后来许多宗教的核心教义。原理与实践有时候并不是同步的。
下面是小说中的一个例子。英国小说家乔治·奥威尔(George Orwell)笔下的《动物庄园》,就是在一条设计原理的基础上构建起来的虚拟社会。这条设计原理是:
四条腿的都是好人,两条腿的都是坏蛋!
《动物庄园》中有意思的是,随着社会的变迁——变得越来越坏,这条设计原理也跟着发生了改变,变成了“四条腿的都是好人,两条腿的就更好了。”最关键的是,即使是在虚构的作品里,设计原理都是存在的。
还有一套虚构的作品是以三条设计原理为基础构建起来的,那就是美国著名小说家艾萨克·阿西莫夫(Issac Asimov)的机器人经典系列。阿西莫夫发明了机器人学这个术语,并提出了机器人学三大法则,然后在这三个简单的设计原理基础上创作了一系列经典作品——大约有50本书。无论作品的情节如何变化,实际上都是从不同的角度来阐释这三大设计原理。我想,在座各位对机器人三大法则都不应该陌生。
机器人不得伤害人类,或袖手旁观人类受伤害。
机器人必须服从人类命令,除非命令违反第一法则。
机器人必须自卫,只要不违背第一和第二法则。
这些恐怕是第一次出现在小说中的针对软件的设计原理了。虽然基于这三个设计原理的软件运行在虚构的机器人的“正电子脑”中,但我想这应该是软件设计原理的事实开端。从此以后,我们才看到大量优秀软件背后的设计原理。
蒂姆·伯纳斯-李(Tim Berners-Lee),Web的发明者,在W3C的网站上发表过一份文档,其中有一个URL给出了他自己的一套设计原理。这些设计原理并不那么容易理解,不仅多,而且随着时时间推移,他还会不断补充、修改和删除。不过我还是觉得把自己认同的设计原理写出来放在某个地方真是个不错的主意。
实际上,CSS的发明人之一伯特·波斯(Bert Bos),也在W3C的网站上放着一份文档,其中讲的都是基本的设计原理,比如怎样设计并构建一种格式,无论是CSS还是其他格式。推荐大家看一看。
只要你在W3C的站点中随便找一找,就可以发现非常多的这种设计原理,包括蒂姆·伯纳斯-李个人的。当然,你还会看到他从软件工程学校里借用的一些口号:分权(decentalisation)、容忍(tolerance)、简易(simplicity)、模块化(modularity)。这些都是在他发明新格式的时候,头脑中无时无刻不在想的那些关键词。
在座各位对蒂姆·伯纳斯-李的贡献都是非常熟悉的,因为大家每天都在用。他发明了Web,与罗伯特·卡里奥(Robert Cailliau)共同发明了Web,而且在发明Web的同时,也发明了我们每天都在Web上使用的语言。当然,这门语言就是HTML:超文本标记语言。
HTML最早是从2.0版开始的。从来就没有1.0版。如果有人告诉你说,他最早是从HTML 1.0开始使用HTML的,那他绝对是在忽悠你。从前确实有一个名叫HTML Tags的文档,其中的部分标签一直用到现在,但那个文档并非官方的规范。
使用标签、尖括号、p或h1,等等,并不是蒂姆·伯纳斯-李首创的想法。当时的SGML里就有了这些概念,而且当时的CERN(Conseil Europeen pour la Recherche Nucleaire,欧洲核子研究委员会)也在使用SGML的一个特定的版本。也就是说,即便在那个时代,他也没有白手起家;这一点在HTML后来的发展过程中也体现了出来:继往开来、承前启后,而不是另立门户、从头开始。
换句话说,这篇名为HTML Tags的文档可以算作HTML的第一个版本,但它却不是一个正式的版本。第一个正式版本,HTML 2.0,也不是出自W3C之手。HTML 2.0是由IETF,因特网工程任务组(Internet Engineering Task Force)制定的。在W3C成立之前,IETF已经发布了不少标准。但从第三个版本开始往后,W3C,万维网联盟(World Wide Web Consortium)开始接手,并负责后续版本的制定工作。
20世纪九十年代HTML有过几次快速的发展。众所周知,在那个时代要想构建网站,可是一项十分复杂的工程。浏览器大战曾令人头疼不已。市场竞争的结果就是各家浏览器里都塞满了各种专有的特性,都试图在专有特性上胜人一筹。当时的混乱程度不堪回首,HTML到底还重不重要,或者它作为Web格式的前景如何,谁都说不清楚。
从1997年到1999年,HTML的版本从3.2到4.0到4.01,经历了非常快的发展。问题是到了4.01的时候,W3C的认识发生了倒退,他们说“好了,这个版本就这样了,HTML也就这样了;HTML 4.01是HTML的最后一个版本了,我们用不着HTML工作组了。”
W3C并没有停止开发这门语言,只不过他们对HTML不再感兴趣了。在HTML 4.01之后,他们提出了XHTML 1.0。虽然听起来完全不同,但XHTML 1.0与HTML 4.01其实是一样的。我的意思是说,从字面上看这两个规范的内容是一样的,词汇表是一样的,所有的元素是一样,所有的属性也都是一样的。唯一一点不同之处,就是XHTML 1.0要求使用XML语法。也就是说,所有属性都必须使用小写字母,所有元素也必须使用小写字母,所有属性值都必须加引号,你还得记着使用结束标签,记着对img和br要使用自结束标签。
从规范本身的内容来看,实际上是相同的,没有什么不同。不同之处就是编码风格,因为对浏览器来说,读取符合HTML 4.01、HTML 3.2,或者XHTML 1.0规范的网页都没有问题,对浏览器来说这些网页都是一样的,都会生成相同的DOM树。只不过人们会比较喜欢XHTML 1.0,因为不少人认同它比较严格的编码风格。
到了2000年,Web标准项目(Web Standards Project)的活动开展得如火如荼,开发人员对浏览器里包含的那些乱七八糟的专有特性已经忍无可忍了。大家都很生气,就骂那些浏览器厂商“遵守个规范就他妈的真有那么难吗?”当时CSS有了长足的发展,而且与XHTML 1.0结合得也很紧密,CSS加XHTML 1.0基本上就可以算是“最佳实践”了。虽然在我看来HTML 4.01与XHTML 1.0没有本质上的不同,但大家都接受了。专业的开发人员能做到元素全部小写,属性全部小写,属性值也全部加引号:由于专业人员起到了模范带头作用,越来越多的人也都开始支持这种语法。
我就是一个例子!过去的10年,我一直都使用XHTML 1.0文档类型,原因是这样一来验证器就能给我帮上很大的忙,对不对?只要我写的是XHTML 1.0,然后用验证器测试,它就能告诉我是不是忘了给属性值加引号,是不是没有结束某个标签,等等等等。而如果我写的是HTML 4.01,同样的问题就变成了有效的了,验证器就不一定会提醒我了。
这就是我一直使用XHTML 1.0的原因。我估计很多人都……使用XHTML 1.0的朋友,请把手举起来。好的。HTML 4.01呢?人少多了。一直没有举手的呢,大声点,你们用什么?HTML5,也很好!更早的呢,还有人使用更早的文档类型吗?没有了?
10年来我一直使用XHTML 1.0,就是因为验证器能够真正帮到我。有人用XHTML 1.1吗?你知道有人用吗?请举手,别放下。有人把网页标记为XML文档吗?有吗?那你们使用的就不是XHTML 1.1。
这就是个大问题。XHTML 1.0之后是XHTML 1.1,只是小数点后面的数字加了一个1,而且从词汇表的角度看,规范本身没有什么新东西,元素也都相同,属性也都相同。但对XHTML 1.1来说,唯一的变化是你必须把自己的文档标记为XML文档。在使用XHTML 1.0的时候,还可以把文档标记为HTML,而我们也正是这样做的,否则把文档标记为XML没准真会把人逼疯的。
为什么这么说呢?首先,把文档标记为XML后,Internet Explorer不能处理。当然,IE9是可以处理了。恐怕有人会讲“真是太可爱了”,他们到现在居然都没有忘了这件事。这艘船终于靠岸了!不过那时候,作为全球领先的浏览器,IE无法处理接收到的XML文档类型的文档,而规范又要求你以XML文档类型来发送文档,这不把人逼疯才怪呢。
所以说XHTML 1.1有点脱离现实,而你不想把文档以XML格式发送给那些能够理解XML的浏览器,则是因为XML的错误处理模型。XML的语法,无论是属性小写,元素小写,还是始终要给属性值加引号,这些都没有问题,都很好,事实上我也喜欢这样做,但XML的错误处理模型却是这样的:解析器如果遇到错误,停止解析。规范里就是这么写的。如果你把XHTML 1.1标记为XML文档类型,假设你用Firefox打开这个文档,而文档中有一个和号(&)没有正确编码,就算整个页面中就这一处错误,你看到的也将是黄屏,浏览器死掉了。Firefox会说:“没戏了,页面中有一个错误,你看不到这个网页了。”根据XML规范,这样处理是正确的,对Firefox而言,遇到错误就停止解析,并且不呈现其他任何内容是严格按照XML规范做的。因为它不是HTML,HTML根本就没有错误处理模型,但根据XML规范,这样做没错。
这就是为什么你不会把文档标记为XML的另一个原因。接下来,新的版本是XHTML 2,大家注意后面没有日期,因为这个规范并没有完成。
现在就说说XHTML 2,我很愿意把问题说清楚,XHTML 2实际上真是一个非常非常好的规范,确实非常好……从理论的角度来说。我的意思是说,制定这个规范的人都是非常非常有头脑的。直说吧,领导制定这个规范的家伙是斯蒂芬·彭伯顿(Stephen Pemberton),他应该是本地人,是一个聪明过人的家伙。规范本身也很了不起,如果所有人都同意使用的话,也一定是一个非常好的格式。只不过,还不够实际。
首先,XHTML 2仍然使用XML错误处理模型,你必须保证以XML文档类型发送文档;这一点不言自明:没人愿意这样做。其次,XHTML 2有意不再向后兼容已有的HTML的各个版本。他们甚至曾经讨论过废除img元素,这对每天都在做Web开发的人来说确实有点疯了的味道。但我们知道,他们之所以这样做,理论上确实有充足的理由——使用object元素可能会更好。
因此,无论XHTML 2在理论上是多么完美的一种格式,但却从未有机会付诸实践。而之所以难以将其付诸实践,就是因为像你我这样的开发人员永远不会支持它,它不向后兼容。同样,浏览器厂商也不会,浏览器厂商必须要保证向后兼容。
为什么XHTML 1.1没有像XML那样得到真正广泛地应用,为什么XHTML 2从未落到实处?因为它违反了一条设计原理,这条设计原理就是著名的伯斯塔尔法则(Postel’s Law)。大家都知道:
发送时要保守;接收时要开放。
没错,接收的时候要开放,而这也正是Web得以构建的基础。开发浏览器的人必须敞开胸怀,接收所有发送给浏览器的东西,因为它们过去一直都在接收那些不够标准的东西,对不对?Web上的很多文档都不规范,但那正是Web发展的动力。从某种角度讲,Web走的正是一条混沌发展之路,虽然混沌,但却非常美丽诱人。在Web上,格式不规范的文档随处可见,但那又怎样呢?如果所有人都能够写出精准的XML,所有文档的格式都十分正确,那当然好了。可是,那不现实。现实是伯斯塔尔法则。
作为专业人士,在发送文档的时候,我们会尽量保守一些,尽量采用最佳实践,尽量确保文档格式良好。但从浏览器的角度说,它们必须以开放的姿态去接收任何文档。
有人可能会说XML有错误处理模型,XHTML 1.1和XHTML 2都使用该模型,但那个错误处理模型太苛刻了。它绝对不符合接收时开放这个法则,遇到一个错误就停止解析怎么能叫开放呢?我们只能说它与健壮性法则(也就是伯斯塔尔法则)是对立的。
之后,就到了HTML5,但HTML5并不是由W3C直接制定的。故事的经过是这样的,到20世纪末的时候,还没有HTML工作组,W3C内部的一些人就开始琢磨了,“HTML也许还可以更长寿一点,只要我们对它稍加扩展就行了。只要把我们放在XHTML上的时间和精力拿出一部分来,就可以提升一下HTML中的表单,可以让HTML更接近编程语言,就可以让它更上一层楼。”
于是,在2004年W3C成员内部的一次研讨会上,当时Opera公司的代表伊恩·希克森(Ian Hickson)提出了一个扩展和改进HTML的建议。他建议新任务组可以跟XHTML 2并行,但是在已有HTML的基础上开展工作,目标是对HTML进行扩展。W3C投票表决的结果是——“反对”,因为HTML已经死了,XHTML 2才是未来的方向。然后,Opera、Apple等浏览器厂商,以及其他一些成员说:“那好吧,不指望他们了,我们自已一样可以做这件事,我们脱离W3C。”他们成立了Web Hypertext Applications Technology Working Group(Web超文本应用技术工作组,WHATWG)——可巧的是,他们自称工作组,而不是特别小组(task force),这就为HTML5将来的命运埋下了伏笔。
WHATWG决定完全脱离W3C,在HTML的基础上开展工作,向其中添加一些新东西。这个工作组的成员里有浏览器厂商,因此他们不仅可以说加就加,而且还能够一一实现。结果,大家不断提出一些好点子,并且逐一做到了浏览器中。
WHATWG的工作效率很高,不久就初见成效。在此期间,W3C的XHTML 2没有什么实质性的进展。特别是,如果从实现的角度来说,用原地踏步形容似乎也不为过。
结果,一件有意思的事情发生了。那是在2006年,蒂姆·伯纳斯-李写了一篇博客,说:“你们知道吗?我们错了。我们错在企图一夜之间就让Web跨入XML时代,我们的想法太不切实际了,是的,也许我们应该重新组建HTML工作组了。”善哉斯言,后来的故事情节果真就是这样发展的。W3C在2007年组建了HTML5工作组。这个工作组面临的第一个问题,毫无疑问就是“我们是从头开始做起呢,还是在2004年成立的那个叫WHATWG的工作组既有成果的基础上开始工作呢?”答案是显而易见的,他们当然希望从已经取得的成果着手,以之为基础展开工作。于是他们又投了一次票,同意“在WHATWG工作成果的基础上继续开展工作”。好了,这下他们要跟WHATWG并肩战斗了。
第二个问题就是如何理顺两个工作组之间的关系。W3C这个工作组的编辑应该由谁担任?是不是还让WHATWG的编辑,也就是现在Google的伊恩·希克森来兼任?于是他们又投了一次票,赞成“让伊恩·希克森担任W3C HTML5规范的编辑,同时兼任WHATWG的编辑,更有助于新工作组开展工作。”
这就是他们投票的结果,也就是我们今天看到的局面:一种格式,两个版本。WHATWG的网站上有这个规范,而W3C的站点上同样也有一份。
如果你不了解内情,很可能会产生这样的疑问:“哪个版本才是真正的规范?”当然,这两个版本内容是一样的……基本上相同。实际上,这两个版本将来还会分道扬镳。现在已经有了分道扬镳的迹象了。我的意思是说,W3C最终要制定一个具体的规范,这个规范会成为一个工作草案,定格在某个历史时刻。
而WHATWG呢,他们还在不断地迭代。即使目前我们说的HTML5,也不能完全涵盖WHATWG正在从事的工作。最准确的理解是他们正在开发一项简单的HTML或Web技术,因为这才是他们工作的核心目标。然而,同时存在两个这样的工作组,这两个工作组同时开发一个基本相同的规范,这无论如何也容易让人产生误解。误解就可能造成麻烦。
其实这两个工作组背后各自有各自的流程,因为它们的理念完全不同。在WHATWG,可以说是一种**的工作机制。我刚才说了,伊恩·希克森是编辑。他会听取各方意见,在所有成员各抒己见,充分陈述自己的观点之后,他批准自己认为正确的意见。
W3C则截然相反,可以说是一种**的工作机制。所有成员都可以发表意见,而且每个人都有投票表决的权利。这个流程的关键在于投票表决。从表面上看,WHATWG的工作机制让人不好接受。岂止是不好接受,简直是历史的倒退。相信谁都会认为“运作任何项目都不能采取这种方式!”
W3C的工作机制听起来让人很舒服。至少体现了人人平等嘛。但在实践中,WHATWG的工作机制运行得非常非常好。我认为之所以会这样,主要归功于伊恩·希克森。他的的确确是一个非常称职的编辑。他在听取各方意见时,始终可以做到丝毫不带个人感情色彩。
从原理上讲,W3C的工作机制很公平,而实际上却非常容易在某些流程或环节上卡壳,造成工作停滞不前,一件事情要达成决议往往需要花费很长时间。那到底哪种工作机制最好呢?我认为,最好的工作机制是将二者结合起来。而事实也是两个规范制定主体在共同制定一份相同的规范,我想,这倒是非常有利于两种工作机制相互取长补短。
两个工作组之所以能够同心同德,主要原因是HTML5的设计**。因为他们从一开始就确定了设计HTML5所要坚持的原则。结果,我们不仅看到了一份规范,也就是W3C站点上公布的那份文档,即HTML5语言规范,还在W3C站点上看到了另一份文档,也就是HTML设计原理。而这份文档的一位编辑今天也来到了我们大会的现场,他就是安妮·奇泰丝(Anne Van Kesteren)。如果大家对这份文档有问题,可以请教安妮。
这份文档非常好,真的非常出色。这份文档,可以说见证了W3C与WHATWG同心协力共谋发展的历程。难道你们不觉得他们像是一对欢喜冤家吗?那他们还怎么同心同德呢?这份文档忠实地记录了他们一道做了什么,他们共同拥护什么。
接下来,我想要讲的就是这份文档。因为,既然他们能就这份文档达成共识,那么我相信,HTML5必将是一个伟大的规范,而他们已经认可这就是他们的共同行动纲领。为此,你才会看到诸如兼容性、实用性、互用性之类的概念。即便W3C与WHATWG之间再有多大的分歧——确实相当多——至少他们还有这份文档中记录的共识。这一点才是至关重要的。正因为他们有了共识,才有了这份基于共识描述设计原理的文档。
下面我就给大家介绍一些这份文档中记载的设计原理。第一个,非常简单:避免不必要的复杂性。好像很简单吧。我用一个例子来说明。
假设我使用HTML 4.01规范,我打开文档,输入doctype。这里有人记得HTML 4.01的doctype吗?好,没有,我猜没有。除非……我的意思是说,你是傻冒。现场恐怕真有人背过,这就是HTML 4.01的doctype:
<!DOCTYPE html PUBLIC "-//W3C/DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
我不记这个两行代码,不然还要记事本、要Google、要模板有什么用呢?
要是我使用XHTML 1.0呢,这个规范我都已经用了10年了。有谁记得住这个doctype吗?没错,它的长度跟HTML 4.01的差不太多:
<!DOCTYPE html PUBLIC "-//W3C/DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
是不是,基本上相同。它要告诉浏览器的是:这个文档是XHTML 1.0的文档。那么在HTML 5中,省掉不必要的复杂性,doctype就简化成了:
<!DOCTYPE html>
仅此而已。好了,就连我也能过目不忘了。我用不着把这几个字符记在记事本里了。我得说,在我第一次看到这个doctype的时候——我当然以为这是一个HTML文档的doctype——被它吓了一跳:“是不是还少一个数字5啊?”我心里想:“这个doctype想告诉浏览器什么呢?就说这个文档是HTML吗?难道这是有史以来唯一一个HTML版本吗,这件事我得首先搞清楚,HTML今后永远不会再有新版本了吗?”好一副唯我独尊的架式!我错了,因为这个doctype并没有这个意思。为此,必须先搞清楚为什么文档一开头就要写doctype。它不是写给浏览器看的。Doctype是写给验证器看的。也就是说,我之所以要在文档一开头写那行XHTML 1.0的doctype,是为了告诉验证器,让验证器按照该doctype来验证我的文档。
浏览器反倒无所谓了。假设我写的是HTML 3.2文档,文档开头写的是HTML 3.2的doctype。而在文档中某个地方,我使用了HTML 4.01中才出现的一个元素。浏览器会怎么处理这种情况?它会因为这个元素出现在比doctype声明的HTML版本更晚的规范中,就不解释呈现该元素吗?不会,当然不会!它照样会解释呈现该元素,别忘了伯斯塔尔法则,别忘了健壮性。浏览器在接收的时候必须要开放。因此,它不会检查任何格式类型,而验证器会,验证器才关心格式类型。这才是存在doctype的真正原因。
而按照HTML5的另一个设计原理,它必须向前向后兼容,兼容未来的HTML版本——不管是HTML6、HTML7,还是其他什么——都要与当前的HTML版本,HTML5,兼容。因此,把一个版本号放在doctype里面没有多大的意义,即使对验器证也一样。
刚才,我说doctype不是为浏览器写的,这样说大多数情况下没有问题。在有一种情况下,你使用的doctype会影响到浏览器,相信在座诸位也都知道。但在这种情况下,Doctype并非真正用得其所,而只是为了达到某种特殊的目的才使用doctype。当初微软在引入CSS的时候,走在了标准的前头,他们率先在浏览器中支持CSS,也推出了自己的盒模型——后来标准发布了,但标准中使用了不一样的盒模型。他们怎么办?他们想支持标准,但也想向后兼容自己过去推出的编码方式。他们怎么知道网页作者想使用标准,还是想使用他们过去的方式?
于是,他们想出了一个非常巧妙的主意。那就是利用doctype,利用有效的doctype来触发标准模式,而不是兼容模型(quiks mode)。这个主意非常巧妙。我们今天也都是这样在做,在我们向文档中加入doctype时,就相当于声明了“我想使用标准模式”,但这并不是发明doctype的本意。这只是为了达到特殊的目的在利用doctype。
下面我出一道有奖抢答题,听好:“一分钟后开始,如果你手快的话,第一个在文档前面写完doctype html,然后我用Internet Explorer打开你的文档,会触发它的标准模式,还是会触发它的兼容模式?”
答案是,这是在Internet Explorer中触发标准模式的最少字符数目。我认为这也说明了HTML5规范的本质:它不追求理论上的完美。HTML5所体现的不是“噢,给作者一个简短好记的doctype不好吗?”,没错,简短好记是很好,但如果这个好记的doctype无法适应现有的浏览器,还不如把它忘了更好。因此,这个平衡把握得非常好,不仅理论上看是个好主意——简短好记的doctype,而且实践中同样也是个好主意——仍然可以触发标准模式。应该说,Doctype是一个非常典型的例子。
还有一个例子,同样可以说明规范是如何省略不必要的复杂性,避免不必要的复杂性的。如果前面的文档使用的是HTML 4.01,假设我要指定文档的字符编码。理想的方式,是通过服务器在头部信息中发送字符编码,不过也可以在文档这个级别上指定:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
同样,我也不会把这行代码背下来。我还想省下自己的脑细胞去记点别的更有价值的东西呢。不过,如果我想指定文档使用UTF-8编码,只能添加这行代码。这是在HTML 4.01中需要这样做。要是你在XHTML 1.0指定同样的编码,就得多敲一下键盘,因为你还得声明meta元素位于一个开始的XML标签中。
<?xml version="1.0" encoding="UTF-8" ?>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
在HTML5中,你要敲的字符只有:
<meta charset="utf-8">
简短好记。我能背下来。
同样,这样写也是有效的。它不仅适用于最新版本的浏览器,只要是今天还有人在用的浏览器都同样有效。为什么?因为在我们把这些meta元素输入浏览器时,浏览器会这样解释它:“元数据(meta)点点点点点,字符集(charset)utf-8。”这就是浏览器在解释那行字符串时真正看到的内容。它必须看到这些内容,根据就是伯斯塔尔法则,对不对?
我多次提到健壮性原理,但总有人不理解。我们换一种说法,浏览器会想“好,我觉得作者是想要指定一个字符集……看,没错,utf-8。”这些都是规范里明文规定的。如今,不仅那个斜杠可以省了,而且总共只要写meta charset=”utf-8″就行了。
关于省略不必要的复杂性,或者说避免不必要的复杂性的例子还有不少。但关键是既能避免不必要的复杂性,还不会妨碍在现有浏览器中使用。比如说,在HTML5中,如果我使用link元素链接到一个样式表,我说了rel=”stylesheet”,然后再说type=”text/css”,那就是重复自己了。对浏览器而言,我就是在重复自己。浏览器用不着同时看到这两个属性。浏览器只要看到rel=”stylesheet”就够了,因为它可以猜出来你要链接的是一个CSS样式表。所以就不用再指定type属性了。你不是已经说了这是一个样式表了嘛;不用再说第二次了。当然,愿意的话,你可以再说;如果你想包含type属性,请便。
同样地,如果你使用了script元素,你说type=”text/javascript”,浏览器差不多就知道是怎么回事了。对Web开发而言,你还使用其他的脚本语言吗?如果你真想用其他脚本语言,没人会阻拦你。但我要奉劝你一句,任何浏览器都不会支持你。
愿意的话,你可以添加一个type属性。不过,也可以什么都不写,浏览器自然会假设你在使用JavaScript。避免-不必要的-复杂性。
支持已有的内容。这一点非常重要,因为很多人都认为HTML5很新,很闪亮;它应该代表着未来发展的方向,应该把Web推向一个新的发展阶段。这就是HTML5,对吗?显然,我们都会考虑让Web的未来发展得更好,但他们则必须考虑过去。别忘了W3C这个工作组中有很多人代表的是浏览器厂商,他们肯定是要考虑支持已有内容的。只要你想构建一款浏览器,就必须记住这个原则:必须支持已有的内容。
下面我们就来看一个HTML5支持已有内容的例子。
这个例子展示了编写同样内容的四种不同方式。上面是一个img元素,下面是带一个属性的段落元素。四种写法唯一的不同点就是语法。把其中任何一段代码交给浏览器,浏览器都会生成相同的DOM树,没有任何问题。从浏览器的角度看,这四种写法没有区别。因而在HTML5中,你可以随意使用下列任何语法。
<img src="foo" alt="bar" />
<p class="foo">Hello world</p>
<img src="foo" alt="bar">
<p class="foo">Hello world
<IMG SRC="foo" ALT="bar">
<P CLASS="foo">Hello world</P>
<img src=foo alt=bar><p class=foo>Hello world</p>
好了,看到这几段代码,恐怕有人会说“不对不对不对。其中只有一个是对的,另外三个——说不好。”不对,应该给属性值加引号!拜托,我们可是一直都给属性值加引号的!元素名大写对吗?这种做法10年不是就被抛弃了吗?
看到HTML5同时允许这些写法,我心里忍不住一阵阵想吐。我写了10年的XHTML 1.0,已经非常适应严格的语法了。但你必须明白,站在浏览器的角度上,这些写法实际上都是一样的。确实没有什么问题。
还有谁也感到不舒服了吗?有谁看到这些之后想“噢,这不是乱写嘛,这样做不对”?只有我这样想吗?还有别人吗?
但是,HTML5必须支持已经存在的内容,而已有的内容就是这个样子的。不是吗?根据伯斯塔尔法则,浏览器没有别的选择。
有人可能会说“这样不行。我觉得语言本身应该提供一种开关,让作者能够表明自己想做什么。”比如说,想使用某种特定的语法,像XHTML,而不是使用其他语法。我理解这些人的想法。但我不赞成在语言里设置开关。因为我们讨论的只是编码风格或者写作风格,跟哪种语法正确无关。对于像我们这样的专业人士,我认为可以使用lint工具(一种软件质量保证工具,或者说是一种更加严格的编译器。它不仅可以象普通编译器那样检查出一般的语法错误,还可以检查出那些虽然完全合乎语法要求,但很可能是潜在的、不易发现的错误),对其他技术我们不是也在使用lint工具嘛。
比如说对JavaScript使用lint工具。JavaScript同样也是比较混乱、不严谨的例子,但它非常强大,原因恰恰是它混乱、不严谨,而且有很多不同的编码方式。在JavaScript,你可以在每条语句末尾加上分号,但不是必需的,因为JavaScript会自动插入分号……是不是听起来有点不好接受?
正因为如此,才有了像JSlint这样的工具,在道格拉斯·克劳克福德(Douglas Crockford)的网站jslint.org上面。有个网页上写着“JSlint可能会伤害你的感情。”但这确实是个非常棒的工具,它可以把JavaScript代码变得完美无瑕。如果你通过JSlint运行JavaScript,它会告诉你“好,你的JavaScript代码有效,但写法不妥。你这种编码风格啊,我不喜欢。不赞成你这样写。这样写不好。”特别是对团队,对于要使用统一的编码风格的团队,JSlint是非常方便的工具。
我个人认为,不仅对团队来说,就算是你自己写代码,也要坚持一种语法风格。从浏览器解析的角度讲,不存在哪种语法比另一种更好的问题,但我认为,作为专业人士,我们必须能够自信地讲“这就是我的编码风格。”然而,我不认为语言里应该内置这种开关。你可以使用lint工具来统一编码风格。现在就来说说lint工具。大家可以登录htmllint.com,在其中运行你的HTML5文档,它会帮你检查属性值是否加了引号,元素是否小写,你还可以通过勾选复选框来设置其他检查项。
但这不意味着拒绝粗心大意的标记,做不做清理完全取决于你自己。我说过,因为浏览器必须支持已有的内容,HTML5自然也不能例外。归根结底还是伯斯塔尔法则。我们始终离不开伯斯塔尔法则。
HTML5的另一个设计原理是解决现实的问题。显而易见的是,解决各种问题的格式和规范已经比比皆是了,但是在我看来,那些格式和规范要解决的都是理论问题,而非现实问题。这条设计原理才是真正要解决今天的人们所面临的现实问题、令人头疼的问题。
下面我来举个例子。相信这个例子有不少人都遇到过。假设我使用HTML 4或XHTML 1,页面中已经有了一块内容,我想给整块内容加个链接,怎么办?问题是这块内容里包含一个标题,一个段落,也许还有一张图片。如果我想给它们全部都可以点击,必须使用3个链接元素。于是,我得先把光标放在标题(比如说h2元素)中,写一个链接标签,然后再选中所有要包含到链接里面来的文本。接着,再把光标放在段落里,写一个链接标签,然后把段落中的文本放在链接里……
<h2><a href="/path/to/resource">Headline text</a></h2>
<p><a href="/path/to/resource">Paragraph text.</a></p>
在HTML5中,我只要简单地把所有内容都包装在一个链接元素中就行了。
<a href="/path/to/resource">
<h2>Headline text</h2>
<p>Paragraph text.</p>
</a>
没错,链接包含的都是块级元素,但现在我可以用一个元素包含它们。这样太好了。因为我碰到过类似的情形,必须给几个块级元素加上相同的链接,所有能这样写就太好了。为此,我就非常欢迎HTML5这个新标准。
它解决了一个现实的问题。我敢说在座不少朋友都曾遇到过这个问题。
那这到底解决的是什么问题呢?浏览器不必因此重新写代码来支持这种写法。这种写法其实早就已经存在于浏览器中了,因为早就有人这样写了,当然以前这样写是不合乎规范的。所以,说HTML5解决现实的问题,其本质还是“你都这样写了很多年了吧?现在我们把标准改了,允许你这样写了。”
在所有设计原理中,这一条恐怕是最响亮的了——求真务实。不知道大家有没有在公司里开会时听到过这种口号:“开拓进取,求真务实。”实际上,除了作为企业的口号,它还是一条非常重要的设计原理,因为求真务实对于HTML的含义是:在解决那些令人头痛的问题之前,先看看人们为应对这些问题都想出了哪些办法。集中精力去理解这些“民间的”解决方案才是当务之急。
HTML5中新的语义元素就是遵循求真务实原理的反映。新增的元素不算多,谈不上无限的扩展性,但却不失为一件好事。尽管数量屈指可数,但意义却非同一般。这些新元素涉及头部(header)、脚部(footer)、分区(section)、文章(article)……,相信大家都不会觉得陌生。我的意思是说,即便你不使用HTML5,也应该熟悉这些称呼,这些都是你曾经使用过的类名,比如class=”header”/“head”/“heading”,或class=”footer”/“foot”。当然,也可能是ID,id=”header”,id=”footer”。这些不都是我们已经司空见惯了的嘛。
好,举个例子吧,假设你今天写了下面这个文档。
<body>
<div id="header">...</div>
<div id="navigation">...</div>
<div id="main">...</div>
<div id="sidebar">...</div>
<div id="footer">...</div>
</body>
这里有一个div使用了id=”header”,另一个div使用了id=”navigation”,……。怎么样,都轻车熟路了吧?在HTML5中,这些元素都可以换掉。说起新增的语义元素,它们价值的一方面可以这样来体现:“嘿,看啊,这样多好,用HTML5新增的元素可以把这些div都替换掉。”
<body>
<header>...</header>
<nav>...</nav>
<div id="main">...</div>
<aside>...</aside>
<footer>...</footer>
</body>
当然了,你可以这样做。在文档级别上使用这些元素没有问题。但是,假如新增这些元素的目的仅仅是为了取代原来的div,那就真有点多此一举了。
虽然在这个文档中,我们用这些新元素来替换的是ID,但在我个人看来,将它们作为类的替代品更有价值。为什么这么说呢?因为这些元素在一个页面中不止可以使用一次,而是可以使用多次。没错,你可以为文档添加一个头部(header),再添加一个脚部(footer);但文档中的每个分区(section)照样也都可以有一个头部和一个脚部。而每个分区里还可以嵌套另一个分区,被嵌套的分区仍然可以有自己的头部和脚部,是这样吧?
这四个新元素:section、article、aside和nav,之所以说它们强大,原因在于它们代表了一种新的内容模型,一种HTML中前所未有的内容模型——给内容分区。迄今为止,我们一直都在用div来组织页面中的内容,但与其他类似的元素一样,div本身并没有语义。但section、article、aside和nav实际上是在明确地告诉你——这一块就像文档中的另一个文档一样。位于这些元素中的任何内容,都可以拥有自己的概要、标题,自己的脚部。
其中最为通用的section,可以说是与内容最相关的一个。而article则是一种特殊的section。Aside呢,是一种特殊的section。最后,Nav也是一种特殊的section。
好,即便是现在,你照样可以使用div和类来描述页面中不同的部分,就像下面这样:
<div class="item">
<h2>...</h2>
<div class="meta">...</div>
<div class="content">...</div>
<div class="links">...</div>
</div>
其中包含可能是有关内容作者的元数据,而下面会给出一些链接,差不多就这样。在HTML5中,我完全可以说这块内容就是一个文档,通过对内容分区,使用section或article或aside,我可以说“这一块完全是可以独立存在的。”因此,我当然可以使用header和footer。
<section class="item">
<header><h1>...</h1></header>
<footer class="meta">...</footer>
<div class="content">...</div>
<nav class="links">...</nav>
</section>
请注意,即便是footer,也不一定非要出现在下面,不是吗?这几个元素,header、footer、aside、nav,最重要的是它们的语义;跟位置没有关系。一想到footer这个词,我们总会不由自主地想,“噢,应该放在下面。”同样,我们把aside想象成一个侧边栏。可是,如果你看一看规范,就会发现这些元素只跟内容有关。因此,放在footer中的内容也可以是署名,文章作者之类的,它只是你使用的一个元素。这个元素并没有说“必须把我放在文档或者分区的下面。”
这里,请注意,最重要的还不是我用几个新元素替换了原来的div加类,而是我把原来的H2换成了H1——震撼吧,我看到有人发抖了。我碰到过不少职业的Web开发人员,多年来他们一直认为规范里说一个文档中只能有一个H1。还有一些自诩为万能的SEO秘诀同样说要这样。很多SEO的技巧其实是很教条的。所谓教条,意思就是不相信数据。过去,这种教条表现为“不行,页面中包含两个以上的H1,你就会死掉的。”在HTML5中,只要你建立一个新的内容块,不管用section、article、aside、nav,还是别的元素,都可以在其中使用H1,而不必担心这个块里的标题在整个页面中应该排在什么级别;H2、H3,都没有问题。
这个变化太厉害了。想一想吧,这个变化对内容管理是革命性的。因为现在,你可以把每个内容分区想象一个独立的、能够从页面中拿出来的部分。此时,根据上下文不同,这个独立部分中的H1,在整个页面中没准会扮演H2或H3的角色——取决于它在文档中出现的位置。面对这个突如其来的变化,也许有人的脑子会暂时转不过弯来。不要紧,但我可以告诉你,我认为这才是HTML5中这些新语义标记的真正价值所在。换句话说,我们现在有了独立的元素了,这些元素中的标题级别可以重新定义。
我的文档中可能会包含一个分区,这个分区中可能会嵌套另一个分区,或者一篇文章,然后文章再嵌套分区,分区再嵌套文章、嵌套分区,文章再嵌套文章。而且每个分区和文章都可以拥有自己的H1到H6。从这个意义上讲,H元素真可谓“子子孙孙,无穷匮也”了。但是,在你在编写内容或者内容管理系统的时候,它们又都是独立的,完全独立的内容块。这才是真正的价值所在。
实际上,这个点子并不HTML5工作组拍脑门想出来的,也不是W3C最近才提出来的。下面这几句话摘自蒂姆·伯纳斯-李1991年的一封邮件,邮件是发给丹·康纳利(Dan Connolly)的。他在邮件中解释了对HTML的理解,他说:“你知道……知道我的想法,我认为H1、H2这样单调地排下去不好,我希望它成为一种可以嵌套的元素,或者说一个通用的H元素,我们可以在其中嵌套不同的层次。”但后来,我们没有看到通用的H元素,而是一直在使用H1和H2——那是因为我们一直在支持已有的内容。20年后的今天,这个理想终于实现了。
下一条原理大家应该都很熟悉了,那就是平稳退化。毕竟,我们已经遵守这条规则好多年了。渐进增强的另一面就是平稳退化。
有关HTML5遵循这条原理的例子,就是使用type属性增强表单。下面列出了可以为type属性指定的新值,有number、search、range,等等。
input type="number"
input type="search"
input type="range"
input type="email"
input type="date"
input type="url"
最关键的问题在于浏览器在看到这些新type值时会如何处理。现有的浏览器,不是将来的浏览器,现有的浏览器是无法理解这些新type值的。但在它们看到自己不理解的type值时,会将type的值解释为text。
无论你写的是input type=”foo”还是input type=”bar”,现有的任何浏览器都会说:“嗯,也许作者的意思是text。”因而,你从现在开始就可以使用这些新值,而且你也可以放心,那些不理解它们的浏览器会把新值看成type=”text”,而这真是一个浏览器实践平稳退化原理的好例子。
比如说,你现在输入了type=”number”。假设你需要一个输入数值的文本框。那么你可以把这个input的type属性设置为number,然后理解它的浏览器就会呈现一个可爱的小控件,像带小箭头图标的微调控件之类的。对吧?而在不理解它的浏览器中,你会看到一个文本框,一个你再熟悉不过的文本框。既然如此,为什么不能说输入type=”number”就会得到一个带小箭头图标的微调控件呢?
当然,你还可以设置最小和最大值属性,它们同样可以平稳退化。这是问题的关键。
再看input type=”search”。你也可以考虑一下这种输入框,因为这种输入框在Safari中会被呈现为一个系统级的搜索控件,右边还有一个点击即可清除搜索关键词的X。而在其他浏览器中,你得到的则是一个文本框,就像你写的是input type=”text”一样,也就是你已经非常熟悉的文本框。那为什么还不使用input type=”search”呢?它不会有什么副作用,没有,对不对?
HTML5还为输入元素增加了新的属性,比如placeholder(占位符)。有人不知道这个属性的用处吗,没有吧?没错,就是用于在文本框中预先放一些文本。不对,不是标签(label)——占位符和标签完全不是一回事。占位符就是文本框可以接受的示例内容,一般颜色是灰色的。只要你一点击文本框,它就消失了。如果你把已经输入的内容全部删除,然后单击了文本框外部,它又会出现。
使用JavaScript编写一些代码当然也可以实现这个功能,但HTML5只用一个placeholder属性就帮我们解决了问题。
当然,对于不支持这个属性的浏览器,你还是可以使用JavaScript来实现占位符功能。通过JavaScript来测试浏览器支不支持该属性也非常简单。如果支持,后退一步,把路让开,乐享其成即可。如果不支持,可以再让你的JavaScript来模拟这个功能。
现在,我不得不提到另一个话题了:HTML5对Flash。也许你早听说过了,或者在哪里看到了这方面的讨论。说实话,我一点也不明白。我搞不懂人们怎么会仅仅凭自己的推测来展开争论。
首先,他们所说的HTML5对Flash,并不是指的HTML5,也不是指的Flash。而是指HTML5的一个子集和Flash的一个子集。具体来说,他们指的是视频。因此,不管你在哪里听到别人说“HTML5对Flash”,那很可能说的只是HTML5视频对Flash视频。
其次,一说HTML5对Flash,就好像你必须得作出选择一样:你站在哪一边?实际上不是这样的。HTML5规范的设计能够让你做到鱼和熊掌兼得。
好,下面就来看看这个新的video元素;真是非常贴心的一个元素,而且设计又简单,又实用。一个开始的video元素,加一个结束的video元素,中间可以放后备内容。注意,是后备内容,不是保证可访问性的内容,是后备内容。下面就是针对不支持video元素的浏览器写的代码:
<video src="movie.mp4">
<!-- 后备内容 -->
</video>
那么,在后备内容里面放些什么东西呢?好,你可以放Flash影片。这样,HTML5的视频与Flash的视频就可以协同起来了。你不用作出选择。
<video src="movie.mp4">
<object data="movie.swf">
<!-- 后备内容 -->
</object>
</video>
当然,你的代码实际上并没有这么简单。因为这里我使用了H264,部分浏览器支持这种视频格式。但有的浏览器不支持。
对不起,请不要跟我谈视频格式,我一听就心烦。不是因为技术。技术倒无所谓,关键是会牵扯到一大堆专利还有律师、知识产权等等,这些都是Web的天敌,对我建网站一点好处都没有。
可你实际上要做的,仅仅就是把后备内容放在那而已,后备内容可以包含多种视频格式。如果愿意的话,可以使用source元素而非src属性来指定不同的视频格式。
<video>
<source src="movie.mp4">
<source src="movie.ogv">
<object data="movie.swf">
<a href="movie.mp4">download</a>
</object>
</video>
上面的代码中包含了4个不同的层次。
不错,一开始就能考虑这么周到很难得啊。有了这几个层次,已经够完善了。
总之,我是建议你各种技术要兼顾,无论是HTML5,还是Flash,一个也不能少。如果只使用video元素提供视频,难免搬起石头砸自己的脚,我个人认为。而如果只提供Flash影片,情况也好不到哪去,性质是一样的。所以还是应该两者兼顾。
为什么要兼顾这两种技术呢?假设你需要面向某些不支持Flash的手持设备——只是举个例子——提供视频,你当然希望手持设备的用户能够看到视频了,不是吗?
至于为什么要使用不同的格式,为什么Flash视频和音频如此成功,我想可以归结为另一个设计原理,即梅特卡夫定律(Metcalfe’s Law):
网络价值同网络用户数量的平方成正比。
梅特卡夫的这个定律虽然是针对电话网提出来的,但在很多领域里也是适用的。使用网络的用户越多,网络的价值也就越大。人人都上Facebook,还不是因为人人都上Facebook嘛。虽然Facebook真正的价值不在于此,但只有人人都上才会让它的变得如此有价值。
梅特卡夫定律也适用于传真机。如果只有一个人购买了传真机,当然没有什么用处。但如果其他人也陆续购买了传真机,那么他的投资会就得到回报。
当然,面对竞争性的视频格式和不同的编码方式,你感觉不到梅特卡夫定律的作用,我也很讨厌以不同的方式来编码视频,但只向浏览器发送用一种方式编码的视频是行不通的。而这也正是Flash在视频/音频领域如此成功的原因。你只要把Flash影片发送给浏览器就好了,然后安装了插件的浏览器都能正常播放。本质上讲,Flash利用了梅特卡夫定律。
今天我要讲的最后一个设计原理,也是我个人最推崇的一个,但没有要展示的代码示例。这个原理更有哲学的味道,即最终用户优先。
这个设计原理本质上是一种解决冲突的机制。换句话说,当你面临一个要解决的问题时,如果W3C给出了一种解决方案,而WHATWG给出了另一种解决方案,一个人这么想,另一个人那么想……这时候,有人站出来说:“对这个问题我们这样来解决。”
一旦遇到冲突,最终用户优先,其次是作者,其次是实现者,其次标准制定者,最后才是理论上的完满。
理论上的完满,大致是指尽可能创建出最完美的格式。标准制定者,指的是工作组、W3C,等等。实现者,指的是浏览器厂商。作者,就是我们这些开发人员,对吧?看看我们在这个链条里面的位置多靠上啊!我们的地位仅次于最终用户——事情本来就该这个样子。用户是第一位的。而我们的声音在标准制定过程中也同样非常非常重要。
Hixie(即Ian Hickson, Acid2、Acid3的作者及维护者,HTML5、CSS 2.1规范的制定者)经常说,在有人建议了某个特性,而HTML5工作组为此争论不下时,如果有浏览器厂商说“我们不会支持这个特性,不会在我们的浏览器中实现这个特性”,那么这个特性就不会写进规范。因为即使是把特性写进规范,如果没有厂商实现,规范不过是一纸空文,对不对?实现者可以拒绝实现规范。
而根据最终用户优先的原理,我们在链条中的位置高于实现者,假如我们发现了规范中的某些地方有问题,我们想“这样规定我们不能同意,我们不支持实现这个特性”,那么就等于把相应的特性给否定了,规范里就得删除,因为我们的声音具有更高的权重。我觉得这样挺好!本质上是我们拥有了更大的发言权,对吧?我认为开发人员就应该拥有更多的发言权。
我觉得这应该是最重要的一条设计原理了,因为它承认了你的权利,无论是设计一种格式,还是设计软件,这条原理保证了你的发言权。而这条原理也正道出了事物运行的本质。难道还不够明显吗?用户的权利大于作者,作者的权利大于实现者,实现者的权利大于标准制定者。然而,反观其他规范,比如XHTML2,你就会发现完全相反的做法。把追求理论的完满放在第一位,而把用户——需要忍受严格错误处理带来的各种麻烦的用户——放在了链条的最底端。我并没有说这种做法就是错误的,但我认为这是一种完全不同的思维方式。
因此,我认为无论你做什么,不管是构建像HTML5这样的格式,还是构建一个网站,亦或一个内容管理系统,明确你的设计原理都至关重要。
软件,就像所有技术一样,具有天然的政治性。代码必然会反映作者的选择、偏见和期望。
下面我们讲一个例子。Drupal社区曾联系马克·博尔顿(Mark Boulton)和丽莎·雷贺特(Leisa Reichilt)设计Drupal的界面。他们计划遵循一些设计原理。为此,他们并没有纸上谈兵,而是经过了一段时间的思考和酝酿,提出指导将来工作的4个设计原理:
简化最常见的任务,让不常见的任务不至于太麻烦。
只为80%设计。
给内容创建者最大的权利。
默认设置智能化。
实际上,我在跟马克谈到这个问题时,马克说主要还是那两个,即“只为80%设计。给内容创建者最大的权利。”这就很不错了,至少它表明了立场,“我们认为内容创建者比这个项目中的任何人都重要。”在制定设计原理时,很多人花了很多时间都抓不住重点,因为他们想取悦所有人。关键在于我们不是要取悦所有人,而是要明确哪些人最重要。他们认为内容创建者是最重要的。
另一条设计原理,只为80%设计,其实是一条常见的设计原理,也是一种通用模式,即帕累托原理(Pareto principle)。
帕累托是意大利经济学家,他提出这个比例,80/20,说的是世界上20%的人口拥有80%的财富。这个比例又暗合了自然界各个领域的幂律分布现象。总之,无论你是编写软件,还是制造什么东西,都是一样的,即20%的努力可以触及80%的用例。最后20%的用例则需要付出80%甚至更多的努力。因此,有时候据此确定只为80%设计是很合理的,因为我们知道为此只要付出20%的努力即可。
再比如,微格式同样也利用了帕累托原理,只处理常见用例,而没有考虑少数情形。他们知道自己不会让所有人都满意;而他们的目标也不是让所有人都满意。他们遵循的设计原理很多,也都非常有价值,但最吸引人的莫过于下面这条了:
首先为人类设计,其次为机器设计。
同样,你我都会觉得这是一条再明显不过的道理,但现实中仍然有不少例子违反了这条原理:容易让机器理解(解析)比容易让用户理解更重要。
所以,我认为平常多看一看别人推崇的设计原理,有助于做好自己手头的工作。你可以把自己认为有道理的设计原理贴在墙上。当然,你可以维护一个URL,把自己认为有价值的设计原理分享出来,就像Mozilla基金会那样,对不对,以下是Mozilla的设计原理:
Internet作为一种公共资源,其运作效率取决于互通性(协议、数据格式、内容)、变革及全球范围内的协作。
基于透明社区的流程有助于增进协作、义务和信任。
我觉得像这样的设计原理都非常好。而有了设计原理,我认为才更有希望设计出真正有价值的产品。设计原理是Web发展背后的驱动力,也是通过HTML5反映出来的某种思维方式。我想,下面这条原理你绝对不会陌生:
大多数人的意见和运行的代码。
对不对?这句话经常在我脑际回响,它囊括了Web的真谛,触及了HTML5的灵魂。
也许我该把这条原理打印出来贴到办公室的墙上,让它时刻提醒我,这就是Web的设计原理:大多数人的意见和运行的代码。
我想,今天的演讲就到这里了。如果大家有什么想法可以在twitter上通过@adactio找到我。有时候我也会在自己的博客,adactio.com上写写有关这个主题的文章。最后,可能还要顺便给我自己做个广告,我刚出了一本书,希望大家关注。
非常感谢大家。
[全文完]
面试中经常会被问到,这个问题并不是很难,只是容易忘记,所以写篇blog记录下。
其实主要分为寄生式继承和寄生组合式继承。
function object(o) {
function F () {}
F.prototype = o;
return new F();
}
function getChild(parent) {
var child = object(parent);
child.sayHi = function () {
console.log(this.name);
}
return child;
}
var parent = {
name: 'ustccjw',
friends: ['Alice', 'Bob']
}
var child = getChild(parent);
child.sayHi();
原型式继承要求必须有一个对象(比如parent)作为另一个对象的基础。如果有这么一个对象的话,可以把他传递给object()函数,然后再根据具体需求对返回的对象加以修改即可。
ECMA中的Object.create()方法规范了原型式继承。Object.create()方法有两个参数,第一个参数是基础原型对象,第二个参数是一个属性描述符对象,其中描述的每一个属性都会覆盖原型对象上的同名属性。
function inheritPrototype(subType, superType) {
var prototype = object(superType.prototype);
prototype.constructor = subType;
subType.prototype = prototype;
}
function SuperType(name) {
this.name = name;
this.friends = ['Alice', 'Bob']
}
SuperType.prototype.sayName = function () {
console.log(this.name);
}
function SubType(name, age) {
SuperType.call(this, name);
this.age = age;
}
inheritPrototype(SubType, SuperType);
寄生组合式继承是实现类继承的最有效的方式,模拟OO中的类继承的概念。
auto-ellipsis 是一个用于解决文本超长溢出截断并加 ... 的 React 组件。
随着 React 的火热,随之而来的负面消息也变得更多。之前网上就有人批评说 React 的鼓吹者很多,甚至被定性为『无脑』,这就如同当年批评 jQuery 一样。
React 对我而言,不仅仅是一个前端 View 库,它对我的影响主要有以下几方面:
下面开始介绍 auto-ellipsis 的开发过程。
.truncate {
width: 250px;
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
}
老实说,我所遇到的需求,CSS 中的 ellipsis 基本很少能够满足:
目前,auto-ellipsis 基本无法优雅地通过 CSS 来实现。但是,仔细想想这个需求原本就不是纯样式上的问题。我们不仅仅希望自适应截断(不管尾部加 ...),还希望有提示信息(tooltip or title),这是一个功能需求,可以封装成一个组件。
既然 CSS 无法实现,那就只有依靠 JS 来实现。最简单的想法就是:从后向前不断的裁剪文本,检查文本是否溢出,一旦不溢出,我们就终止这个过程。考虑
<div>content</div> => <div>conten</div>
显然上面的方法是有效的,但也极其暴力的。首先多套一个 div 就会让人很不爽,于是我们注意到 text 节点也是 dom,可以比较 div 节点和 text 节点吗?可惜 text 节点没办法获得其高度和位置信息。
这时,也许你记得《JavaScript 高级程序设计》中有介绍 Range 这个概念。老实说,我当时看的时候没多大感觉。是的,Range 派上用场了。
Range 属于 dom 对象,通过 Range 可以选择文档中的一个区域,而不必考虑节点的界限。我们可以通过 Range 实现文本的裁剪(比暴力替换文本节点要高效)。 Range 的高度和位置信息可以获取,我们可以通过 getBoundingClientRect() 来获取 div 节点和 Range 相对于视口的 bottom,进行位置比较。而且, Range 的创建对用户透明,这意味着整个裁剪检查的过程 UI 不会有变化。
我们还可以做一些优化:考虑 div 元素的 padding-buttom 和 border-bottom-width;匹配文本减去三个字符用于存放 ...;考虑 word-break ,最终文本截取到空格处(考虑到中文等其他语言,不好实现...)。
首先,组件的属性 props 就是组件的对外接口。对于 auto-ellipsis,我们的对外接口包括:tag(组件的标签),content(文本信息),addTitle(截断时是否加 title 属性),styles(自定义样式)。
其次,组件的状态 state 是随着时间而变化的,一般来说基础组件(dumb component)最好是状态无关的,由上层业务组件(smart component)来管理状态。通常,组件状态的改变是由用户交互造成的,所以组件只需要暴露用户交互结束后相应的处理接口(比如:handleClick)就好。
对于 auto-ellipsis,我们基本没有与用户交互(如果元素宽高不是定值,如百分比,那么视口大小变化是会造成影响的,我们这里不考虑这种情形)。实际上我们更多的是对 DOM 的直接操作,那么我们何时重新渲染组件,何时需要重新剪裁文本?
React 对组件生命周期的管理非常强大,我们只需要考虑怎么做比较合适就好。首先,我们需要在组件初始化挂载结束时(componentDidMount,可操作 DOM)尝试裁剪文本;其次,组件更新时,我们需要在组件更新完毕后(componentDidUpdate,可操作 DOM)尝试裁剪文本;最后,我们需要考虑是否要使用 shouldComponentUpdate,这主要是基于性能考虑。我觉得,对于基础组件,考虑到这三点就足够了,任何更复杂的设计只会让你的组件变得不那么通用,甚至引入一些潜藏的 bug。实际大多数情况下,基础组件连 shouldComponentUpdate 都不该使用,因为虚拟 DOM 已经很快了。但是 auto-ellipsis 比较特殊,它的每次更新需要重新操作 DOM,所以还是可以考虑进行优化的。
shouldComponentUpdate(nextProps, nextState) {
return JSON.stringify(this.props) !== JSON.stringify(nextProps)
}
CSS 模块化一直是组件封装的难题。webpack(style-loader, css-loader) 提供了使用 JS module loader 来加载 CSS 的功能。但这只更多的只是对资源的声明依赖和加载,并不是 CSS 模块化。解决 CSS 模块化要解决:CSS 局部作用域的问题;CSS 模块的输入和输出。
css-modules 通过生成唯一的 className,从工程角度上解决了 CSS 局部作用域的问题。css-modules 的输入和输出都是 JS 对象,这个对象是一系列 local-className: global-className 的映射(注意:输入输出不包含全局样式,可以通过 css-loader?modules 来开启默认局部样式,:global 开头是全局样式)。CSS 模块之间通过 composes 来组合。
React-css-modules 通过 high-order component 的方式将 css-modules 自然地应用于 React component,并且使用 styleName 和 className 来区分 local CSS 和 global CSS。我给 react-css-modules 提了一个 PR,用于解决自定义组件的样式,通过样式的声明顺序(先 import 组件,再 import 自定义 CSS 模块)来确保相同选择器下自定义样式具有更高的优先级(可以使用 css-loader?modules&localIdentName=[local]-[hash:base64:5],这样可以通过 [local] 标识 local-className,方便自定义样式)。注:PR 未通过,作者认为有些 hack,最终实现是可以给组件传递 styles 属性,不过是直接替换默认 styles。那么,如果我想在默认 styles 基础上修改一些样式,则需要在 css-modules 中处理,这部分讨论参见 讨论。
import React from 'react'
import ReactDOM from 'react-dom'
import CSSModules from 'react-css-modules'
import styles from './auto-ellipsis.css'
@CSSModules(styles)
export default class AutoEllipsis extends React.Component {
static propTypes = {
tag: React.PropTypes.string,
content: React.PropTypes.string.isRequired,
addTitle: React.PropTypes.bool,
styles: React.PropTypes.object,
}
render() {
const props = {
styleName: 'root',
}
const {tag, content} = this.props
return React.createElement(tag, props, content)
}
}
关于 CSS 模块化 和 CSS 局域化可具体参考 hax 的 关于前端开发中“模块”和“组件”概念的思考。
前端组件的测试,按照宿主一般可分为浏览器环境 和 Node.js 环境。测试框架的话,我推荐 mocha。
浏览器环境可以实际生成 DOM,测试真实有效。可以使用 webpack 配合 mocha-loader,使得测试和开发统一。但是,不方便使用 travis-ci 等一些集成工具。
Node.js 环境下需要模拟 DOM(jsdom),React 组件下可以和 react-addons-test-utils 配合使用。再者,一些涉及到 dom 位置的组件,无法使用模拟测试(比如:jsdom 中的 getBoundingClientRect 返回的都是 0)。
auto-ellipsis 显然依赖于 dom 位置信息,所以采用了浏览器环境测试。
浏览器自身提供了默认的缓存机制,也就是说在不指定expires和cache-control的情况下,浏览器也会对资源进行缓存。那么缓存多久呢,实际上是infinite。因为浏览器的缓存替换算法依赖于后续缓存资源,而不是取决于自身。
cache-control和expires是服务器端指明资源的缓存时间。也就是资源的缓存时间不再依赖于后续缓存资源,而是取决于自身的设置时间(其实还是受限于浏览器缓存的大小)。可以理解为,在指定的cache-control和expires有效期内,资源缓存的优先级最高。
值得思考的是:当cache-control和expires过期时,资源并没有立刻从缓存里移除,可以猜测此时浏览器应该把该资源的缓存优先级降低。只有cache-control:no-cache时,浏览器才不缓存该资源。
也就是服务器设置cache-control和expires会影响资源的缓存优先级,影响浏览器自身的缓存策略。
Etag和Last-Modified是服务器端对资源的唯一性标识。唯一性标识当然是用作验证的。(先不考虑cache-control和expires)浏览器加载一个资源时,当浏览器缓存有该资源,那么浏览器会发起一个Conditional GET Request(含有If-None-Match或If-Modified-Since字段,分别对应Etag和Last-Modified)。服务器端确定资源没修改时就返回304 Not Modified,浏览器可以使用缓存资源。
ok,现在开始有意思了!cache-control和expires是设置资源缓存的时间,Etag和Last-Modified是标识资源唯一性用于验证的,所以两者实际上是协同作用的,两者应该用AND而不是VS连接。
cache-control和expires带来的副作用是浏览器端可以不需要发送Conditional GET Request,直接使用缓存资源。(update:发现即便没设置 cache-control和expires,被缓存的资源也可能不发送 Conditional GET Request,比如:有 Last-Modified 时浏览器会自己生成一个 expires)
但是注意这仅仅是副作用,在以下场合生效:
在以下场合,浏览器会发送Conditional GET Request(前提是缓存中有该资源):
这个讨论的是浏览器发送cache-control的情形: max-age=0会导致资源被本地缓存时,总是向服务器端发送Conditional GET Request(类似刷新效果); no-cache会导致浏览器总是向服务器发送一个“无条件请求”(类似强刷新的效果)。
response cache-control:max-age=0 也会导致资源被本地缓存时,总是向服务器端发送Conditional GET Request。
对于cache-control,后续再浅析下。
优点就不多说了,文档上全是... 说几点应用中遇到的问题吧:
Falcor 存在的问题是和传统 REST API 的不兼容,不过我们可以做一些调整:在前端定义 Data Model,在 Model router 中执行 REST API;关于数据自同步,则需要 Model 严格遵循 JSON Graph $ref **(引用实体),退化方案可能是手动使得"需要更新的数据"缓存失效。
本文主要是对 Redux 官方文档 的梳理以及自身对 Redux 的理解。
对于复杂的单页面应用,状态(state)管理非常重要。state 可能包括:服务端的响应数据、本地对响应数据的缓存、本地创建的数据(比如,表单数据)以及一些 UI 的状态信息(比如,路由、选中的 tab、是否显示下拉列表、页码控制等等)。如果 state 变化不可预测,就会难于调试(state 不易重现,很难复现一些 bug)和不易于扩展(比如,优化更新渲染、服务端渲染、路由切换时获取数据等等)。
Redux 就是用来确保 state 变化的可预测性,主要的约束有:
state 为单一对象,使得 Redux 只需要维护一棵状态树,服务端很容易初始化状态,易于服务器渲染。state 只能通过 dispatch(action) 来触发更新,更新逻辑由 reducer 来执行。
action 可以理解为应用向 store 传递的数据信息(一般为用户交互信息)。在实际应用中,传递的信息可以约定一个固定的数据格式,比如: Flux Standard Action。
为了便于测试和易于扩展,Redux 引入了 Action Creator:
function addTodo(text) {
return {
type: ADD_TODO,
text,
}
}
store.dispatch(addTodo(text))
dispatch(action) 是一个同步的过程:执行 reducer 更新 state -> 调用 store 的监听处理函数。如果需要在 dispatch 时执行一些异步操作(fetch action data),可以通过引入 Middleware 解决。
reducer 实际上就是一个函数:(previousState, action) => newState。用来执行根据指定 action 来更新 state 的逻辑。通过 combineReducers(reducers) 可以把多个 reducer 合并成一个 root reducer。
reducer 不存储 state, reducer 函数逻辑中不应该直接改变 state 对象, 而是返回新的 state 对象(可以考虑使用 immutable-js)。
store 是一个单一对象:
在 Redux 应用中,只允许有一个 store 对象,可以通过 combineReducers(reducers) 来实现对 state 管理的逻辑划分(多个 reducer)。
middleware 其实就是高阶函数,作用于 dispatch 返回一个新的 dispatch(附加了该中间件功能)。可以形式化为:newDispatch = middleware1(middleware2(...(dispatch)...))。
// thunk-middleware
export default function thunkMiddleware({ dispatch, getState }) {
return next => action =>
typeof action === 'function' ? action(dispatch, getState) : next(action)
}
通过 thunk-middleware 我们可以看出中间件的一般形式:中间件函数接受两个参数参数: dispatch 和 getState(也就是说中间件可以获取 state 以及 dispatch new action)。中间件一般返回 next(action)(thunk-middleware 比较特殊,它用于 dispatch 执行异步回调的 action)。store 的创建过程如下:
const reducer = combineReducers(reducers)
const finalCreateStore = applyMiddleware(promiseMiddleware, warningMiddleware,
loggerMiddleWare)(createStore)
const store = finalCreateStore(reducer)
单页面应用中充斥着大量的异步请求(ajax)。dispatch(action) 是同步的,如果要处理异步 action,需要使用一些中间件。
redux-thunks 和 redux-promise 分别是使用异步回调和 Promise 来解决异步 action 问题的。
图来自 UNIDIRECTIONAL USER INTERFACE ARCHITECTURES
Redux 和 React 是没有必然关系的,Redux 用于管理 state,与具体的 View 框架无关。不过,Redux 特别适合那些 state => UI 的框架(比如:React, Deku)。
可以使用 react-redux 来绑定 React,react-redux 绑定的组件我们一般称之为 smart components,Smart and Dumb Components 在 react-redux 中区分如下:
| Location | Use React-Redux | To read data, they | To change data, they | |
|---|---|---|---|---|
| “Smart” Components | Top level, route handlers | Yes | Subscribe to Redux state | Dispatch Redux actions |
| “Dumb” Components | Middle and leaf components | No | Read data from props | Invoke callbacks from props |
简单来看:Smart component 是连接 Redux 的组件(@connect),一般不可复用。Dumb component 是纯粹的组件,一般可复用。
两者的共同点是:无状态,或者说状态提取到上层,统一由 redux 的 store 来管理。redux state -> Smart component -> Dumb component -> Dumb component(通过 props 传递)。在实践中,少量 Dumb component 允许自带 UI 状态信息(组件 unmount 后,不需要保留 UI 状态)。
值得注意的是,Smart component 是应用更新状态的最小单元。实践中,可以将 route handlers 作为 Smart component,一个 Smart component 对应一个 reducer。
初步的想法主要是引入 observable 数据推送的概念。
reactmvc 专注于构建 React App。
model 使用 observable 封装: uiModel observable(UI 操作),dataModel observable(服务端数据推送如:websocket 等)。uiModel 和 dataModel 是可序列化对象,在绝大多数情况下只有 uiModel。
任何 action 都生成新的 uiModel,从而 model observable 产生新的 model 推送。
每个路由对应一个 observable,提供这个路由页面整个生命周期的数据(从 root 更新)。这个 observable 接受 model observable 推送的 model,来生成页面所需要的数据,注意是 observable,所以可以灵活的推送数据,非常有利于性能优化。
废弃服务端数据模型(非服务端推送数据)。一般应用的数据接口大多是 restful 接口,服务端数据层接口需要提供:数据缓存和数据清空。
同源:如果两个页面拥有相同的协议,端口和主机,那么这两个页面就属于同一个源。
同源策略:浏览器的一套安全机制(沙箱机制),这些安全机制都以同源为限制条件。
同源策略的出发点很简单:浏览器存储着用户数据,比如认证令牌、cookie及其他私有元数据,这些数据不能泄露给其他应用。
SOP中,源A有以下权限限制:
拒绝读:
写操作包括以下情形:
由于XSS,CSRF等,浏览器开发人员和标准制定者禁止了一些跨域写操作,或者需要附加一些限制
http://stackoverflow.com/questions/3076414/ways-to-circumvent-the-same-origin-policy
http://www.nczonline.net/blog/2010/05/25/cross-domain-ajax-with-cross-origin-resource-sharing/
http://security.stackexchange.com/questions/8264/why-is-the-same-origin-policy-so-important
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Same_origin_policy_for_JavaScript
http://blogs.msdn.com/b/ieinternals/archive/2009/08/28/explaining-same-origin-policy-part-1-deny-read.aspx
http://usamadar.com/2012/06/24/getting-around-browsers-same-origin-policy-sop-with-proxies-script-injection-jsonp-and-cors/
对网站设计和开发人员来说,_float_属性是强大的武器。另一方面,如果你不完全了解它的工作机制,那么它将会让你觉得困惑和沮丧。
也许在过去,由于一些低级浏览器实现上的bugs让你对使用float产生恐惧。那么,现在你应该放松点。我将向你展示,一旦你掌握float,它将会变得非常有用。
在纸质世界,我们经常能看到杂志文章上的图片是浮动的,图片被周围的文字所包围。在HTML/CSS世界,我们可以对image元素设置float属性,使它产生类似杂志上浮动的效果。对图片产生浮动效果只是float属性其中一个应用,我们可以通过它来实现流行的两列布局。事实上,你可以对任何HTML元素设置float属性。通过学习和理解float属性和position属性,你将可以应付任何布局。
我们来看看W3C对float的定义:
float使“box”在当前行上移动到左边或者右边。float最有趣的特点是文本内容将流动在“float box”的另一侧(或者通过“clear”属性禁止)。_float:left_将会使内容流动在“float box”的右边,反之亦然。
float属性有四个取值:left,right,inherit,none。_float: left_将会让元素移动到其父元素的最左边,_float: right_将会让元素移动到其父元素的最右边,_float: inherit_将会让元素继承其父元素的float值,_float: none_是默认不浮动。
下面是一个简单的例子,Example A对应的CSS:
img {
float: right;
margin: 10px;
}
没有什么复杂的,现在一切还很美好是不是?好的,现在让我们进入float引导的精彩世界,让我们回头看看都发生了什么。在web世界,我们的HTML被一些规则所约束:常规流。在常规流里,每一个块级元素(div,p,h1_等)在垂直方向上相互堆积,从视口的顶端到底端。浮动元素初始是按照常规流来布局,然后跳出常规流,移动到父元素的最左边或最右边(取决于float的值)。换句话说,只要父元素有足够的空间让浮动元素放置,它们将从_垂直方向上相互堆积_转换为_水平方向上相互邻接。这个行为对构建你的网站至关重要。
让我们看看一些例子,Example B,有三个块级元素没有设置float属性:
.block {
width: 200px;
height: 200px;
}
注意到它们在垂直方向上相互堆积,这是常规流的基本概念。Example C,这一次所有的块级元素都是浮动的:
.block {
float: left;
width: 200px;
}
现在块级元素在水平方向上相互邻接。当前的父级元素是文档的body,我们调整浏览器窗口的大小,让父级元素没有足够的空间容纳浮动元素,可以看到有的浮动元素将移动到下一行。
_float_属性有一个对应的属性,clear。这两个互补的属性一起配合可以让你快乐的编码。前面提到过,浮动的元素首先按照常规流布局,然后从常规流中移除。这意味着每个在浮动元素后面的元素的布局将和你期待的有出入。这就是开始让我们陷入迷茫的情况。Example E,我们将两个块级元素设置成浮动,其后面两个块级元素不浮动。其HTML和CSS如下:
<div class="block pink float"></div>
<div class="block blue float"></div>
<div class="block green"></div>
<div class="block orange"></div>
.block {
width: 200px;
height: 200px;
}
.float { float: left; }
.pink { background: #ee3e64; }
.blue { background: #44accf; }
.green { background: #b7d84b; }
.orange { backgound: #e2a741; }
绿色块到哪里去了?跑到粉色块的底下了,被粉色块遮住了。这是因为浮动块从常规流中移除了,绿色块和橙色块就好像认为浮动块不存在一样。这就是绿色块在粉色块底下原因。那么我们怎么让绿色块显示出来呢?添加_clear_属性。
_clear_属性有五个取值:left,right,both,inherit,none。设置成_left_意味着该元素的上边缘必须位于任何_float: left_元素的下方(ps. 指的是位于其前面的浮动元素)。_right_意味着该元素的上边缘必须位于任何_float: right_元素的下方。_float: both_意味着元素的上边缘必须位于任何浮动元素的下方。_inherit_将继承父元素的_clear_属性值。_clear: none_是默认不清楚浮动。Example E2对绿色块设置_clear_属性,其HTML和CSS如下:
<div class="block pink float"></div>
<div class="block blue float"></div>
<div class="block green clear"></div>
<div class="block orange"></div>
.block {
width: 200px;
height: 200px;
}
.float { float: left; }
.clear { clear: left; }
.pink { background: #ee3e64; }
.blue { background: #44accf; }
.green { background: #b7d84b; }
.orange { backgound: #e2a741; }
通过对绿色块设置_clear: left_,就好像粉色块在常规流中一样。_clear_是一个很强大的属性,就像你所看到的的,它能让我们的非浮动元素按照我们的本意回归常规流。可见,熟悉理解_float_和_clear_属性将会对你书写HTML和CSS十分有益。
_float_属性在布局上可以发挥难以置信的作用。我们可以使用多种方式来实现两列布局,通常使用一到两个浮动元素。让我们来看一个简单的例子:两列布局,文本内容位于左列,导航位于右列,上下分别是页眉和页脚。这里我们只考虑用浮动来实现,Example F的CSS如下:
#container {
width: 960px;
margin: 0 auto;
}
#content {
float: left;
width: 660px;
background: #fff;
}
#navigation {
float: right;
width: 300px;
background: #eee;
}
#footer {
clear: both;
background: #aaa;
padding: 10px;
}
其中,父元素为_#container_,#content_和#navigation_是其浮动的子元素,#footer_位于它们之后。我们设置#content_左浮动,#navigation_右浮动,并且它们的宽度之和恰好等于父元素#container_的宽度。最后,我们设置_#footer_元素_clear: both_,这样会是的_#footer_元素位于_#content_和_#navigation_的下方。
当我们移除_#footer_元素的_clear_属性,将会如所Example G所示。
#footer_将位于#navigation_的底层。这是因为_#navigation_不在常规流中,#footer_位置进而得到提升。
ps. 这里值得注意的是#footer_元素的高度变高,直到保证_#footer_中的文本不在浮动元素的底层。这其实是_float_设计的初衷:即让文本围绕着浮动图片Example A。
如果你有强迫症,可能会注意到_#content_和_#navigation_不一样高,有很多解决这个问题的方法,这里推荐Faux Columns,这里介绍了如何使多列等高,而与文本无关。
到目前为止,我们看到的例子还没有令我们太头疼。然而,在用float属性时,我们要时刻小心。其中一个非常值得注意的是HTML自身而不是CSS。当浮动元素的位置不同时,产生的结果差异很大。Example H的CSS和HTML:
#container {
width: 280px;
margin: 0 auto;
padding: 10px;
background: #aaa;
border: 1px solid #999;
}
img {
float: right;
}
<div id="container">
<img src="image.gif" />
<p>This is some text contained within a small-ish box. I'm using it as an example of how placing your floated elements in different orders in your HTML can affect your layouts. For example, take a look at this great photo placeholder that should be sitting on the right.</p>
</div>
这是我们希望的结果,但是当我们把_img_元素放到最后时,如Example I所示。img_元素现在位于文本的下方,更糟糕的是,它撑破了父元素#container_的底部。首先,我发现布局上应该遵循_浮动优先_。其次,img_撑破了父元素#container_的原因我们称作折叠(collapsing)。
当父元素包含一些浮动元素,并且浮动元素没有完全围绕着其他的非浮动元素,超出的部分不会使父元素高度变大,这就是折叠。简单理解就是由于浮动元素从常规流移除,父元素认为其不存在。这里推荐Eric Meyer的Containing Floats,它更加深入的讲解了折叠。好消息是,我们可以有多种解决这个问题的方法,比如像你正在想的_clear_属性。
ps. 究其原因则是_BFC(Block formatting context)_的作用。
其中一个最常见的解决折叠问题的方法是在浮动元素后面添加一个具有_clear_属性的元素。Example J和Example I的区别在于在_img_元素后增加了一个具有_clear_属性的元素:
<div id="container">
<p>This is some text contained within a small-ish box. I'm using it as an example of how placing your floated elements in different orders in your HTML can affect your layouts. For example, take a look at this great photo placeholder that should be sitting on the right.</p>
<img src="image.gif" />
<div style="clear: right;"></div>
</div>
我们尝试从CSS来解决折叠问题,而不是添加额外的HTML标记。存在这么一个方法能够清除其自身的所有浮动子元素。它使用CSS中_overflow: hidden_。注意_overflow_并不是为了清除浮动而生的,它会引起一些如隐藏文本,出现不必要的滚动条的问题。这里我们应用_overflow: hidden_来设置父元素_#container_:
#container {
overflow: hidden;
width: 260px;
margin: 0 auto;
padding: 10px 0 10px 10px;
background: #aaa;
border: 1px solid #999;
}
结果如Example L所示,还不赖吧!另一种方法是使用伪元素选择器_:after_。代码如下:
#container:after {
content: ".";
display: block;
height: 0;
clear: both;
visibility: hidden;
}
对于这种方法更详细的介绍可以参照Position is Everything。
最后一种方法来自Eric Meyer的Containing Floats:
a floated element will expand to contain any floated elements that descend from it.
因此,设置父元素为浮动可以同样解决折叠的问题。
实际上以上每种解决方法都是做了同一件事:使得父元素注意到其浮动的子元素。每中方法都存在其局限性,你可以针对具体场景选择使用合适的方法。
由于一些浏览器bugs会导致浮动产生更多的问题,如双倍外边距和三像素文本偏移。这些超出了本文的范畴,但是请记住,如果你想兼容一些老浏览器,你需要注意这些问题。
使用_float_属性可以为你的布局技术箱增加一种非常酷的技术。理解它们如何让工作和它们工作的原理将是你有效使用浮动的坚实基础。
理清CSS的优先级还是很有必要的
选择器的特异性由 CSS2 规范定义如下:
特异性高的样式优先级高
这部分主要参照 hax 的 关于前端开发中“模块”和“组件”概念的思考 一文。
在 React 开发中,webpack 是模块加载和打包的利器,基于 webpack 的工作流已经非常完善 。Webpack 使用 JS Module Loader 来加载其他 JS 模块,CSS 依赖以及图片等其他资源。但是,这里只是指明了组件中相关的 CSS 依赖,并没有解决组件化与 CSS 样式全局有效的冲突。
以前在组件化的讨论中,@fouber 和 @xufei 不止一次的说,Web 组件化的价值在于分治而不在于复用。我认为这个需要对组件做更细致的区分才能做出论断。对于基础组件,在于复用;对于业务组件,在于分治。由于基础组件复用性更强,我们可能需要更细致的去设计和实现。常见的 React 基础组件库有:material-ui, ant-design, react-toolbox。从实现来看,最大的区别就是如何组织组件的 CSS,以实现组件 CSS 局域化:
CSS in JS 通过 DOM 的 style 属性来实现 CSS 在组件上的挂载,并且保证了组件的封装性和隔离性。不过,这尼玛是内联样式,不是花了很长时间才把着玩意干掉的吗?这样做是不是违背了结构与样式分离的最佳实践(实际上,JSX 好像也违背了结构与行为的分离)?
Web 发展初期,为什么我们没有分离结构,样式和行为?为什么当时想不到耦合的问题?因为初期 web 页面是局限于很简单的结构,你甚至可以理解为一个页面就是一个组件。由于结构简单,样式和行为基本很容易控制,分离结构,样式和行为显得没有必要,因为实际运行的页面是结构,样式和行为的叠加。
随着 web 页面结构开始变得庞大,样式变得酷炫,交互变得复杂,我们发现内联样式和行为使得代码的可维护性变得很差,于是我们通过『选择器』来进行解耦,样式和行为都通过选择器来和结构挂钩。
Web 发展到现在,早已不局限于简单的 web 页面。Web 应用正大行其道,各种 MV* 框架应接不暇, JS 模块化和 web 组件化早已不是新鲜事。Web 应用一般都是一个 SPA,SPA 的一个典型特征就是部分加载,组件化也就显得很自然。组件蕴含着封装和自治:JS 的模块化已经非常成熟,CSS 并没有类似的模块化机制,我们需要 CSS 模块化或者局域化。实际上我们将解耦的目标从结构、样式和行为(通过选择器)转变为组件间(通过组件属性 props)。组件化开发下,由于层层组合嵌套,单个组件内部实现就会比较简单,组件内聚合反而更好。这样就不难理解 React 在 HTML 中直接绑定事件处理器了,甚至提出了 CSS in JS。
Css-modules 是通过工程化的方法自动生成唯一的 className,以实现 CSS 局域化的初衷,但是这样实现的侵入性太大,而且会造成 class dirty,而且自动生成的 className 与 HTML class 语义相违背。
类似方案如:ant-design 是手动给组件内所有的 className 加一个唯一的组件前缀来实现局域化。
CSS in JS 的主要缺点有:内联样式不支持一些伪类/伪元素/media query 等;内联样式书写起来比较困难。
Css-modules 和给组件内部 className 添加前缀主要的缺点在于:class dirty;不能保证 CSS 绝对局域化。
理想的方案是:使用 style 元素的 scoped 属性(很遗憾,目前只是 LS 阶段)。我们可以使用预处理器(sass/postcss)来实现一些模块化抽象(函数,mixin 等),使用 scoped style 来实现 CSS 局域化(可以利用 webpack 将依赖的的 CSS 插入到组件的根节点,并添加 scoped 属性,比如叫 scoped-style-loader)。
考虑到兼容未来的 scoped style,现阶段,我们可以这样组织组件 CSS:
组件的根节点使用 custom tag(唯一标识组件),内部样式使用标签结构选择器来定制(不使用 className),外面包一层根节点 tag(用来保证 CSS 局域化)。
这样看起来和 ant-design 的做法类似,但是我们『使用 custom tag 而不是 className 来唯一标识组件』,并添加了『内部样式使用标签结构选择器』这一限制:
解决办法:使得absolute相对定位的祖先元素hasLayout,_zoom:1
解决办法:
解决办法:将float元素的diaplay设置为inline,不用担心,浮动元素展现仍为block的
解决办法:
.bfc() {
&:after {
content: ".";
display: block;
height: 0;
font-size: 0;
clear: both;
visibility: hidden;
}
*zoom: 1;
}
都会让元素以display:inline-block的方式显示,可以设置长宽,默认宽度并不占满父元素,就算是显示的设置display:inline或display:block,仍然无效。
使用float使span元素浮动,这样就可以使得元素在行尾不够长时会另起一行
注意IE6/7 需要使用white-space: nowrap;来实现,理论上还应该在设置其父元素overflow;hidden;实际中发现可以对span元素同时使用float和white-space: nowrap;来实现
span {
float: left;
white-space: nowrap;
}
格式化上下文(Formatting contexts)是内容放置的区域。每个上下文持有其包含的元素,并且定义了一定的规则来约束其包含的元素如何放置。
最明显的格式化上下文就是整个页面。一个HTML页面定义了块级元素如何一个接一个的流动放置。在页面上,每个静态定位块级元素在下一个静态定位块级元素的上方。
块级格式化上下文是我们在web设计中考虑最多的部分。一个块级格式化上下文定义了其包含的块级元素如何放置。如果你有两个段落,一个接一个,那么在格式化上下文中,第一个段落将会出现在第二个段落的上方。如果没有定义宽度,那么这两个段落将会拉伸涵盖到整个块级格式化上下文的内容宽度。
再看一下常见的没有附加样式的页面。在这样的页面中,_标签为整个页面定义了块级格式化上下文。大部分浏览器会给设置些内间距,因此内容不会碰到窗口的边缘。在_标签里,所有的段落,表格,列表等等一个接一个的在其内容区域排列。
在一个页面里一般有许多块级格式化上下文。这是因为下面这些项可以触发创建块级格式化上下文:
如果你看到HTML页面里含有这些元素,那么很明显这些元素将会创建它们自己的上下文。浮动元素,绝对定位元素和表格单元格元素内的段落都放置在这些容器里。
上面这些元素(可创建上下文的元素)内的静态(和相对)定位元素将被放置在其创建的上下文中,就像与外界隔离开来。当上下文的高度属性是_auto_,其内的浮动元素也会被创建放置在上下文中。
在某种程度上,每个块级格式化上下文有点像微型的文档,以_overflow: auto_创建上下文时最明显。_overflow: auto_的元素和iframe的行为相似,其中元素的内容类似于iframe的源文档。
多个块级格式化上下文对浮动很有用。前面提到过,如果上下文的高度属性是_auto_,它将会拉伸以适应任何其所包含的浮动元素。基于这一事实,我们可以创建“自我清除”的元素,比如:
<style type="text/css">
#container {
overflow: auto;
padding: 1em;
border: 1px;
}
#floater {
float: right;
}
</style>
<div id="container">
<div id="floater">This is text on the right side.</div>
</div>
在这个示例中,外层元素的边框和内边距将包围着整个浮动元素。
块级格式化上下文能够有效地创建块级元素,并且不会被浮动元素覆盖。
<style type="text/css">
#floater {
float: left;
width: 40%;
border: 1px solid red;
margin-right: 2em;
}
#clearer {
display: table-cell;
padding: 1em;
border: 1px solid blue;
}
</style>
<div id="floater">
<p>This is floating content.</p>
</div>
<div id="clearer">
<p>This content is in a box that starts 2em's to the right of the floater.</p>
</div>
在这个示例中,红色边框的盒子浮动,蓝色边框的盒子不浮动。蓝色盒子不会被浮动的红色盒子所覆盖。相反的,两个边框之间有_2em_的空隙。
每个块级元素包含的行内元素还将包含一个行级格式化上下文,在块级格式化上下文中,每个块级元素在页面上下一个元素的上方。在行级格式化上下文中是从左向右的,每个行内元素从左到右沿着一条线放置,直到它因为容器边界限制而需要换行。
基本上,行级格式化上下文就是一个段落,表格单元格或者任何其他文本布局。
行内元素和块级元素的定位规则是不同的。
当人们说起“盒模型”时,他们通常描述的是在块级格式化上下文中的尺寸,内间距,边框和外间距。其中,许多概念不适用于行级。尽管水平的内间距,边框和外间距对行内元素也有影响,但是垂直内间距,边框和外间距对文本行间距却没有影响。(注意它们仍然对可替换元素有效,可替代元素代表的是外部资源,比如说表单按钮或者图片,而不是文本或者改变文本格式的元素。)
只有一件事会影响行内元素的垂直间距:行高。通常情况下,行高是基于同一行中文本的高度,或者是任意可替换元素的高度/内间距/边框/外间距。同一行中最大行高(或者可替代高度)的元素将决定这一行的垂直间距。
文本的高度/内间距/边框/外边距对行的高度(或者容器的高度)没有影响。相反,行间的边框、内间距、外间距会相互重叠。如果你想给行内文本设置内间距和边框,确保你有足够的行高。
当对行内元素设置水平边框,内间距或者外边距时,它们只作用于内联元素的两端。如果元素因为边界限制而断开换行,那么边框,内间距或者外边距
边框,内间距或者外边距并不适用于断开位置,只对元素的两端有效。
行内元素内容不会影响包含它的块级元素的宽度。如果行内内容片断大于容器(比如一个大的图片放置在一个小的浮动元素里),它将会溢出。(IE中容器则会被拉伸以适应行内元素)
A slide about React: http://slides.com/ustccjw/react
Related repo: https://github.com/ustccjw/admin
React 是一个用于构建前端界面的 Javascript 库。可以从下面三个方面来描述 React,
React may target the underlying browser’s Box Tree, the Graphics Layer, WebGL, and also mobile platforms like Android’s View system or iOS’s UIKit. Sebastian made it clear DOM diffing is just a necessary hack for the time being.


一个用于 React app 的 MVC 解决方案
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.