This repository can be used to train deep neural networks for video classification. It also contains several Jupyter notebooks to transform data into the format required and to analyze model outputs.
These models were implemented for use in Ecology but can be used in any application. They were developed with the following applications in mind:
- Detect animals in camera trap videos.
- Classify animal actions in video captured using "first-person" animal-mounted cameras.


The following models are implemented (more information is given in the Training Models section):
Image-only Convolutional Neural Network (CNN)- input is a single frame. Baseline that ignores temporal information in the video. Best practice (implemented here) is to use "transfer learning" and fine-tune a CNN architecture that has already been trained on ImageNet.Concatenated Frames CNN- input is a concatenated clip of frames (sequence lengthnumber of frames) with a fully connected neural network mapping to output layersLong-term Recurrent Neural Network- input is a clip of frames which are first run through an ImageNet pre-trained CNN followed by a stacked RNN. Spatial-then-temporal model.3D-Convolutional Neural Network- input is clip of frames which are run through a spatio-temporal CNN.

This code is intended to be run on a machine with a GPU. It could be run locally or using a cloud provider such as Amazon Web Services or Google Cloud Platform.
The easiest way to get started is to create a virtual machine with a GPU on one of the cloud provider platforms using their deep learning image which will install and configure TensorFlow to be used with the GPU.
You may need to pip install some packages listed in requirements.txt. Check your package versions or submit an issue if you run into any errors.
Your dataset needs to be in the following format:
- A
datafolder containing one folder for each video with frame images named sequentially e.g.data/video_1/video_1_00001.jpg. Video frames can be extracted using FFMPEG or thehelper_extract_frames.ipynbhelper notebook. - A
labels.csvfile stored indatacontaining one row for each video frame with the following columns:video,frame,label,splitwhere video is the video folder name, frame is the frame filename, label is the ground-truth label for the frame and split is one of train/valid/test. There are helper notebooks for converting timestamp labels to frame-level labels and also to add train/valid/test splits to a labels file.
A single model can be trained using the train_single_model.ipynb notebook. Parameters are set in the experiment dictionary at the top of the notebook.
Here is an explanation of the parameters that can be used for an experiment:
model_idinteger identifier for this model e.g. 1234 - model will be saved in/models/model_idarchitecturearchitecture of model in [image_MLP_frozen, image_MLP_trainable, video_MLP_co video_LRCNN_frozen, video_LRCNN_trainable, C3D, C3Dsmall]sequence_lengthnumber of frames in sequence to be returned by Data objectframe_sizesize that frames are resized to (different models / architectures accept different input si will be inferred if pretrained_model_name is given since they have fixed sizes)pretrained_model_namename of pretrained model (or None if not using pretrained model e.g. for 3D-CNN)poolingname of pooling variant (or None if not using pretrained model e.g. for 3D-CNN or if fitting mor-dense layers on top of pretrained modelsequence_modelsequence model in [LSTM, SimpleRNN, GRU, Convolution1D] :sequence_model_layers` default to 1, can be stacked 2 or 3 (but less than 4) layer sequence model (always stacking the same sequence model, not mixing LSTM and GRU, for example)layer_1_sizenumber of neurons in layer 1layer_2_sizenumber of neurons in layer 2layer_3_sizenumber of neurons in layer 3dropoutamount of dropout to add (same applied throughout model - good default is 0.20)convolution_kernel_sizesize of 1-D convolutional kernel for 1-d conv sequence models (good default is 3)model_weights_pathpath to .h5 weights file to be loaded for pretrained CNN in LRCNN-trainbatch_sizebatch size used to fit model (default to 32)verbosewhether to log progress updates
A grid-search of models can be run using the train_grid_search.ipynb notebook which lets you specify experiment parameter ranges for the grid search.
The notebook model_analysis.ipynb can be used to load metrics about model training including loss curve statistics and other metadata produced during model training.
The results.json file located in the trained model directory contains data about the trained model. Other outputs including training loss curve data and a confusion matrix are stored in the model folder /models/*model_id*/.
{
"architecture": "video_lrcnn_frozen",
"batch_size": 32,
"convolution_kernel_size": 3,
"data_total_rows_test": 265,
"data_total_rows_train": 10034,
"data_total_rows_valid": 1285,
"dropout": 0.2,
"fit_best_round": 3,
"fit_dt_test_duration_seconds": "0",
"fit_dt_test_end": "2020-04-07 10:50:30",
"fit_dt_test_start": "2020-04-07 10:50:29",
"fit_dt_train_duration_seconds": "925",
"fit_dt_train_end": "2020-04-07 10:50:28",
"fit_dt_train_start": "2020-04-07 10:35:02",
"fit_num_epochs": 24,
"fit_stopped_epoch1": 12,
"fit_stopped_epoch2": 4,
"fit_stopped_epoch3": 5,
"fit_test_acc": 0.7962264150943397,
"fit_train_acc": 0.8900737492763025,
"fit_train_loss": 0.2812534705062822,
"fit_val_acc": 0.9097276265055289,
"fit_val_loss": 0.252977742005415,
"frame_size": [
224,
224
],
"layer_1_size": 256,
"layer_2_size": 512,
"layer_3_size": 256,
"model_id": 1,
"model_param_count": 4984578,
"model_weights_path": null,
"num_features": 512,
"path_model": "/mnt/seals/models/1/",
"pooling": "max",
"pretrained_model_name": "vgg16",
"sequence_length": 20,
"sequence_model": "LSTM",
"sequence_model_layers": 2,
"verbose": true
}
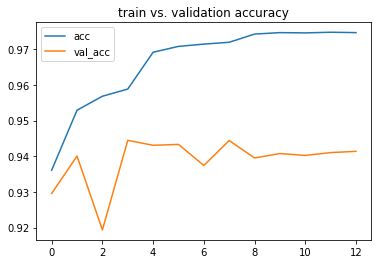
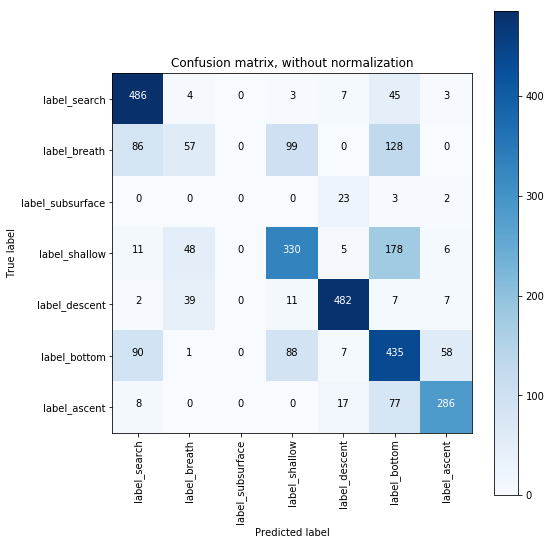
The load_model_and_predict_frames.ipynb notebook can be used to load a trained model and use it to output predictions for each frame in the dataset.
It produces a file in the model directory called frame_predictions.csv with the following columns:
class 1- predicted probability for class 1class 2- predicted probability for class 2...class n- predicted probability for class nprediction- class with max probabilityvideo- video nameframe- frame filenamelabel- label for given framesplit- train/valid/test spliterror- whether an error was made
If labels are unknown, a dummy label equal to one of the labels used by the model should be given in labels.csv.
There are several helper notebooks included in the /notebooks/ directory.
This notebook can be used to extract video frame images from a given video.
This notebook can be used to convert labels in timestamp format e.g. 01:20:05 - 01:20:34 into the required frame-level format.
This notebook can be used to check that there is a label corresponding to each video frame as is required.
This notebook can be used to add train/valid/test splits to your labels file once it is in the right format.
This notebook can be used to visualize some frames from each video.
- Alex Conway (UCT, www.NumberBoost.com)
- Dr. Ian Durbach (UCT, AIMS)

