![]()
![]()
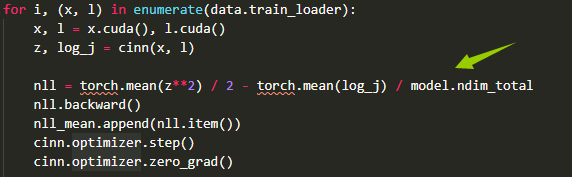
This is the Framework for Easily Invertible Architectures (FrEIA).
- Construct Invertible Neural Networks (INNs) from simple invertible building blocks.
- Quickly construct complex invertible computation graphs and INN topologies.
- Forward and inverse computation guaranteed to work automatically.
- Most common invertible transforms and operations are provided.
- Easily add your own invertible transforms.
Table of contents
Our following papers use FrEIA, with links to code given below.
"Generative Classifiers as a Basis for Trustworthy Image Classification" (CVPR 2021)
"Training Normalizing Flows with the Information Bottleneck for Competitive Generative Classification" (Neurips 2020)
- Paper: arxiv.org/abs/2001.06448
- Code: github.com/vislearn/IB-INN
"Disentanglement by Nonlinear ICA with General Incompressible-flow Networks (GIN)" (ICLR 2020)
- Paper: arxiv.org/abs/2001.04872
- Code: github.com/vislearn/GIN
"Guided Image Generation with Conditional Invertible Neural Networks" (2019)
- Paper: arxiv.org/abs/1907.02392
- Supplement: drive.google.com/file/d/1_OoiIGhLeVJGaZFeBt0OWOq8ZCtiI7li
- Code: github.com/vislearn/conditional_INNs
"Analyzing inverse problems with invertible neural networks." (ICLR 2019)
FrEIA has the following dependencies:
| Package | Version |
| Python | >= 3.7 |
| Pytorch | >= 1.0.0 |
| Numpy | >= 1.15.0 |
| Scipy | >= 1.5 |
pip install FrEIAFor development:
# first clone the repository
git clone https://github.com/vislearn/FrEIA.git
cd FrEIA
# install the dependencies
pip install -r requirements.txt
# install in development mode, so that changes don't require a reinstall
python setup.py developThe full manual can be found at https://vislearn.github.io/FrEIA including
If you used this repository in your work, please cite it as below:
@software{freia,
author = {Ardizzone, Lynton and Bungert, Till and Draxler, Felix and Köthe, Ullrich and Kruse, Jakob and Schmier, Robert and Sorrenson, Peter},
title = {{Framework for Easily Invertible Architectures (FrEIA)}},
year = {2018-2022},
url = {https://github.com/vislearn/FrEIA}
}





![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")