

![]()

crowsetta provides a Pythonic way to work with annotation formats for animal vocalizations and bioacoustics data. These formats are used, for example, by applications that enable users to annotate audio and/or spectrograms. Such annotations typically include the times when sound events start and stop, and labels that assign each sound to some set of classes chosen by the annotator. crowsetta has built-in support for many widely used formats, such as Audacity label tracks, Praat .TextGrid files, and Raven .txt files.
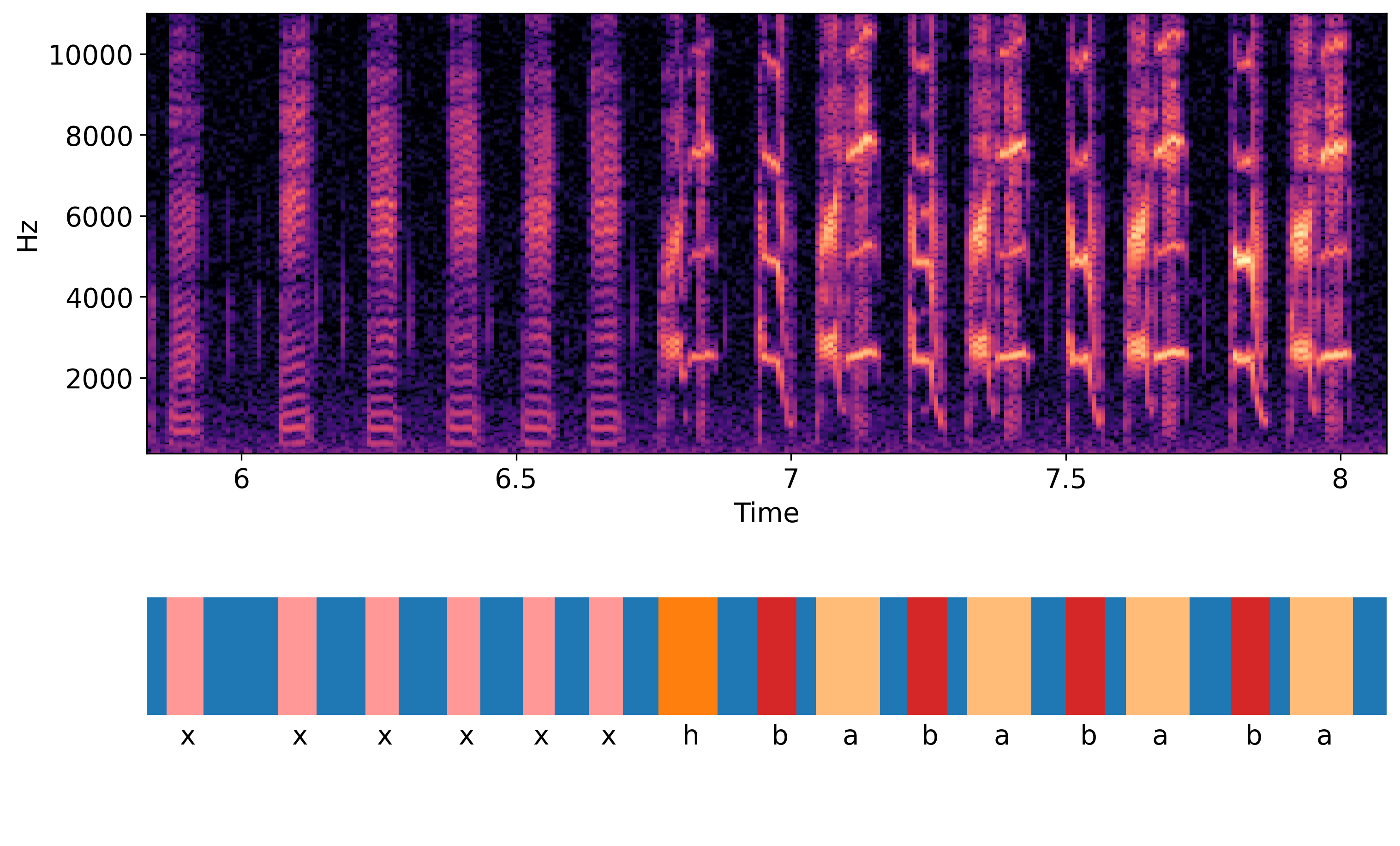
Spectrogram of the song of a Bengalese finch with syllables annotated as segments underneath. Annotations parsed by crowsetta from a file in the Praat .TextGrid format. Example song from Bengalese finch song dataset, Tachibana and Morita 2021, adapted under CC-By-4.0 License.
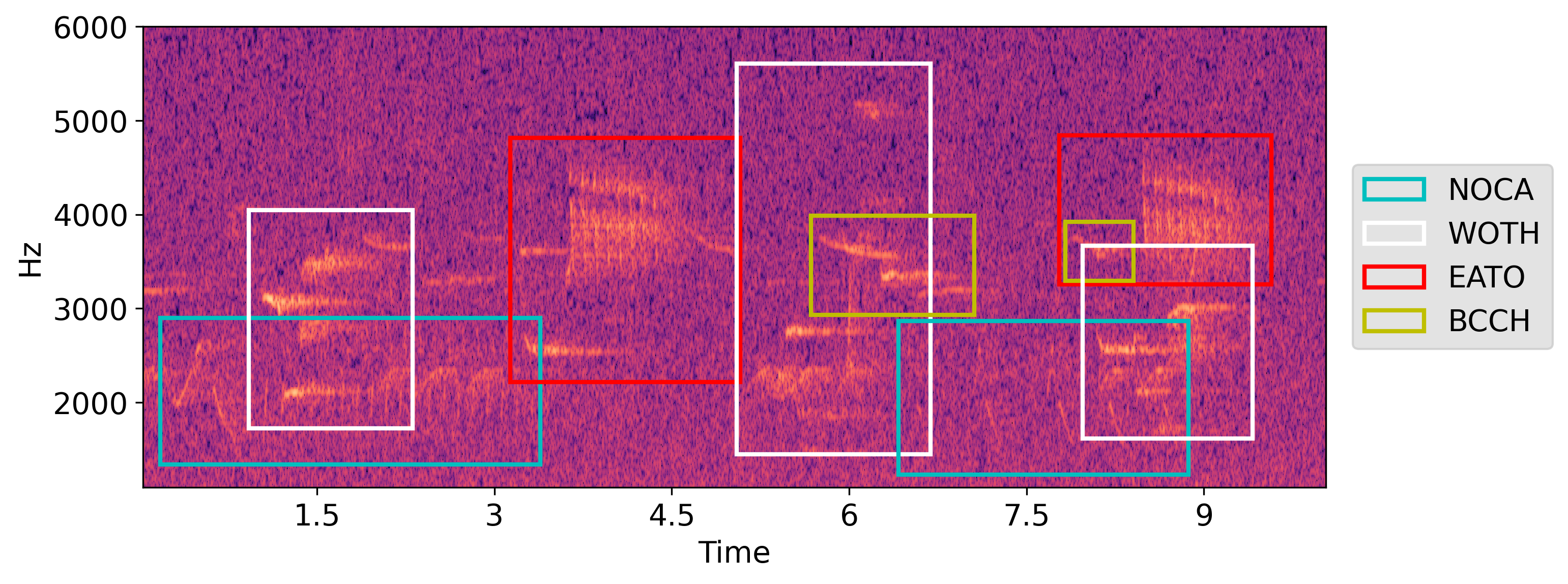
Spectrogram of a field recording with annotations of songs of different bird species indicated as bounding boxes. Annotations parsed by crowsetta from a file in the Raven Selection Table format. Example song from "An annotated set of audio recordings of Eastern North American birds containing frequency, time, and species information", Chronister et al., 2021, adapted under CC0 1.0 License.
Who would want to use crowsetta? Anyone that works with animal vocalizations or other bioacoustics data that is annotated in some way. Maybe you are a neuroscientist trying to figure out how songbirds learn their song, or why mice emit ultrasonic calls. Or maybe you're an ecologist studying dialects of finches distributed across Asia, or maybe you are a linguist studying accents in the Caribbean, or a speech pathologist looking for phonetic changes that indicate early onset Alzheimer's disease. crowsetta makes it easier for you to work with your annotations in Python, regardless of the format.
- take advantage of built-in support for many widely used formats, such as Audacity label tracks, Praat .TextGrid files, and Raven .txt files.
- work with any format by remembering just one class:
annot = crowsetta.Transcriber(format='format').from_file('annotations.ext')- no need to remember different functions for different formats
- when needed, use classes that represent the formats to write readable scripts and libraries
- convert annotations to common file formats like
.csvthat anyone can work with - work with custom formats that are not built in to
crowsettaby writing simple classes, leveraging abstractions that can represent a wide array of annotation formats
For examples of these features, please see: https://crowsetta.readthedocs.io/en/latest/index.html#features
$ pip install crowsetta$ conda install crowsetta -c conda-forgeIf you are new to crowsetta, start with tutorial.
For vignettes showing how to use crowsetta for various tasks, such as working with your own annotation format, please see the how-to section.
crowsetta was developed for two libraries:
hybrid-vocal-classifierhttps://github.com/vocalpy/hybrid-vocal-classifiervakhttps://github.com/vocalpy/vak
To report a bug or request a feature (such as a new annotation format),
please use the issue tracker on GitHub:
https://github.com/vocalpy/crowsetta/issues
To ask a question about crowsetta, discuss its development,
or share how you are using it,
please start a new topic on the VocalPy forum
with the crowsetta tag:
https://forum.vocalpy.org/
Please note that this project is released with a Contributor Code of Conduct. By participating in this project you agree to abide by its terms.
Below we provide some quick links,
but you can learn more about how you can help and give feedback
by reading our Contributing Guide.
To ask a question about crowsetta, discuss its development,
or share how you are using it,
please start a new "Q&A" topic on the VocalPy forum
with the crowsetta tag:
https://forum.vocalpy.org/
To report a bug, or to request a feature,
please use the issue tracker on GitHub:
https://github.com/vocalpy/crowsetta/issues
You can see project history and work in progress in the CHANGELOG
The project is licensed under the BSD license.
If you use crowsetta, please cite the DOI:
Thanks goes to these wonderful people (emoji key):
 Tessa Rhinehart 📖 🐛 📓 🤔 |
 Sylvain HAUPERT 💻 🤔 📓 |
 Yannick Jadoul 🤔 🐛 📖 📓 |
 sammlapp 🤔 |
This project follows the all-contributors specification. Contributions of any kind welcome!
![allcontributors[bot] avatar](https://avatars.githubusercontent.com/in/23186?v=4 "allcontributors[bot]")
















































