学习记录
深度学习、计算机视觉学习过程。
写在前面
人工智能最新学术研究和技术实现追寻,可关注:
- 量子位 - 知乎 - 专栏
- 机器之心 - 知乎 - 专栏
- 新智元 - 知乎
- 计算机视觉论文速递 - 知乎 - 专栏
- PaperWeekly - 知乎 - 专栏
- 计算机视觉life - 知乎 - 专栏
- 相关网站:
学习经验参考:
AI Conference Deadlines:https://aideadlin.es/?sub=ML,CV,NLP,RO,SP,DM
一、基础学习
0. 数学基础
文章和博客:
- 标准差和方差 [荐]★★★
- 理解梯度下降 [荐]★★★
于是我们可以得出结论:函数在某点的梯度是这样一个向量,它的方向与取得方向导数最大值的方向一致,而它的模为方向导数的最大值。
总结:
概念 物理意义 导数 函数在该点的瞬时变化率 偏导数 函数在坐标轴方向上的变化率 方向导数 函数在某点沿某个特定方向的变化率 梯度 函数在该点沿所有方向变化率最大的那个方向 - one-hot 编码
- 数据标准化/归一化normalization [荐]
1. 深度学习★
1.1. 基础入门
入门:
- 神经网络入门 - 阮一峰的网络日志 [荐]
- 从入门到精通:卷积神经网络初学者指南 | 机器之心
- 能否对卷积神经网络工作原理做一个直观的解释? - YJango的回答 - 知乎
- 深度学习入门指南:25个初学者要知道的概念 - 知乎 [荐]
神经网络中的基础概念 1.神经元(Neuron) 2.加权/权重(Weights) 3.偏置/偏倚(Bias) 4.激活函数 5.神经网络 6.输入层/输出层/隐藏层 7.多层感知器(MLP-Multi Layer Perceptron) 8.正向传播(forward propagation) 9.成本函数(cost function) 10.梯度下降(gradient descent) 11.学习速率(learning rate) 12.反向传播(back propagation) 13.分批(Batches) 14.周期(epochs) 15.Dropout方法 16.分批标准化(Batch Normalization) 卷积神经网络 17.过滤器/滤波器(Filter) 18.CNN(卷积神经网络) 19.池化(pooling) 20.补白(padding) 21.数据增强(Data Augmentation) 递归神经网络 22.递归神经元(Recurrent Neural Network) 23.递归神经网络(RNN-Recurrent Neural Network) 24.梯度消失问题 25.梯度爆炸问题
基础:
- 李理:详解卷积神经网络 - qunnie_yi的博客 - CSDN博客
- 神经网络激励函数的作用是什么?有没有形象的解释? - 忆臻的回答 - 知乎 [荐]
- 为什么都说神经网络是个黑箱? - mileistone的回答 - 知乎
- 【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理 [荐]
- 一文弄懂神经网络中的反向传播法——BackPropagation [荐]
- 如何直观地解释 backpropagation 算法? - Anonymous的回答 - 知乎
1.2 迁移学习
以下几篇值得看看:
- 一文看懂迁移学习:怎样用预训练模型搞定深度神经网络? - 知乎 [荐]
- pytorch-handbook/chapter4/4.1-fine-tuning.ipynb [荐]
把别人现成的训练好了的模型拿过来,换成自己的数据,调整一下参数,再训练一遍,这就是微调(fine-tune)
。。。
其实 "Transfer Learning" 和 "Fine-tune" 并没有严格的区分,含义可以相互交换,只不过后者似乎更常用于形容迁移学习的后期微调中。 我个人的理解,微调应该是迁移学习中的一部分。微调只能说是一个trick。
下面只介绍下计算机视觉方向的微调,摘自 cs231
- ConvNet as fixed feature extractor
- Fine-tuning the ConvNet:固定前几层的参数,只对最后几层进行 fine-tuning ...
- Pretrained models:使用整个 pre-trained 的 model 作为初始化,然后 fine-tuning 整个网络而不是某些层,但是这个的计算量是非常大的,就只相当于做了一个初始化。
- 预训练模型Application - Keras中文文档
为什么预训练?
深度网络存在以下缺点:
- 网络越深,需要的训练样本数越多。若用监督则需大量标注样本,不然小规模样本容易造成过拟合。(深层网络意味着特征比较多,机器学习里面临多特征:1、多样本 2、规则化 3、特征选择)
- 多层神经网络参数优化是个高阶非凸优化问题,常收敛较差的局部解。
- 梯度扩散问题。BP 算法计算出的梯度随着深度向前而显著下降,导致前面网络参数贡献很小,更新速度慢。
解决方法:逐层贪婪训练。无监督预训练(unsupervised pre-training)即训练网络的第一个隐藏层,再训练第二个…最后用这些训练好的网络参数值作为整体网络参数的初始值。无监督学习→参数初始值;监督学习→fine-tuning,即训练有标注样本。经过预训练最终能得到比较好的局部最优解。
参考:深度学习中的非线性激励函数以及unsupervised pre-training
1.3 强化学习/增强学习(Reinforce Learning)
强化学习(Reinforcement Learning)的输入数据作为对模型的反馈,强调如何基于环境而行动,以取得最大化的预期利益。与监督式学习之间的区别在于,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。——from:https://feisky.xyz/machine-learning/reinforcement.html
强化学习是一类算法, 是让计算机实现从一开始什么都不懂, 脑袋里没有一点想法, 通过不断地尝试, 从错误中学习, 最后找到规律, 学会了达到目的的方法. 这就是一个完整的强化学习过程. 实际中的强化学习例子有很多. 比如近期最有名的 Alpha go, 机器头一次在围棋场上战胜人类高手, 让计算机自己学着玩经典游戏 Atari, 这些都是让计算机在不断的尝试中更新自己的行为准则, 从而一步步学会如何下好围棋, 如何操控游戏得到高分。——from:什么是强化学习 - 知乎
1.4 生成式对抗网络(GAN)
GAN:一种概率生成模型。简单说, 概率生成模型的目的,就是找出给定观测数据内部的统计规律,并且能够基于所得到的概率分布模型,产生全新的,与观测数据类似的数据。
举个例子,概率生成模型可以用于自然图像的生成。假设给定1000万张图片之后,生成模型可以自动学习到其内部分布,能够解释给定的训练图片,并同时生成新的图片。
与庞大的真实数据相比,概率生成模型的参数个数要远远小于数据的数量。因此,在训练过程中,生成模型会被强迫去发现数据背后更为简单的统计规律,从而能够生成这些数据。——from:深度学习新星:GAN的基本原理、应用和走向 | 硬创公开课 | 雷锋网
1.x 新的研究方向和技术热点
自动机器学习(AutoML, Automated Machine Learning)
AutoML 基本分以下几个方向:(——from:https://zhuanlan.zhihu.com/p/75747814)
-
自动数据清理(Auto Clean)
-
自动特征工程(AutoFE)
-
超参数优化(HPO)
-
元学习(meta learning)
-
神经网络架构搜索(NAS) NAS 看作 AutoML 的子域,并且与 HPO 和元学习有重叠。根据三个维度,可以对 NAS 的现有方法进行分类:搜索空间,搜索策略和性能评估策略。
- 搜索空间(Search Space): 搜索空间原则上定义了可以代表哪些体系结构。结合适用于任务属性的先验知识可以减小搜索空间大小并简化搜索。然而,这也引入了人为偏见,可能会阻止找到超越当前人类知识的新颖架构构建块(building blocks)。 - 搜索策略(Search strategy):搜索策略说明了如何做空间搜索。它包含了经典的探索-开发(exploration-exploitation)之间的权衡。一方面,需要快速找到性能良好的架构,另一方面,避免过早收敛到次优架构(suboptimal architecture)区域。 - 性能评估策略(Performance estimation strategy):NAS的目标通常是找到在未知数据实现高预测性能的架构。性能评估是指评估此性能的过程:最简单的选择是对数据架构执行标准训练和验证,但遗憾的是,这种方法计算成本很高,限制了可以探索的体系结构量。因此,最近的研究大多集中在开发出方法去降低这些性能估计成本。
相关阅读:
2. Python基础
先学习掌握以下内容,包括 Python 基础、Anconada 安装等等:
- IDE之PyCharm的设置和Debug入门
- Python基础入门笔记(一)
- Python基础入门笔记(二)
- Python内置库和函数使用及常见功能实现记录
- 一键安装所有第三方库
- 关于 Python 的博文:
- Anaconda的介绍、安装和环境管理
- python包管理工具:Conda和pip比较 | Ubuntu下python选择pip install还是conda install更加合适? - 知乎
- Jupyter Notebook的介绍、安装及使用
3. 科学计数库
-
Python常用科学计算库快速入门(NumPy、SciPy、Pandas、Matplotlib、Scikit-learn) | 更详细的学习见:
-
scikit-learn 学习,网上资料:
-
Sklearn Universal Machine Learning Tutorial Series | 莫烦Python
-
混淆矩阵及confusion_matrix函数的使用 | 分类模型评判指标(一) - 混淆矩阵(Confusion Matrix) | 深度学习F2-Score及其他(F-Score) | Kappa系数 - 准确率 Accuracy、精确率 Precision、召回率 Recall、IoU 、f1_measure、kappa 系数等评价指标的计算。
注:要是碰到混淆矩阵中,某个类别的预测都是 0,precision=tp/(tp+fp),那除数为 0 呢,代码通不过啊,怎么办?通过和他人交流,有大佬说一般类似这么写:
xx / (xx+1e-10)加上 1e-10 。ok,mark 了。
-
3. Python图像处理(库)
Python 图像处理库学习:
- Python图像处理笔记(含opencv-python/PIL/scikit-image/libtiff/gdal库等等).md
- python+tifffile之tiff文件读写
- 可能用到 matlab,同时学习下:matlab的安装和学习.md
5. Python常用库
- Scikit-plot 画图神器 – Python量化投资
- python的Tqdm模块 - 可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器。
6. 其他知识点
机器学习中在线训练和离线训练?
-
请问在神经网络算法当中提到的在线训练和离线训练分别是什么意思? - 知乎 - 其中一个回答:
- online training:你有一个样本,你把第一条带入训练,调整权重,再把这一条带进去一次,重复多次,直至误差率很小,然后再带入下一条,直至跑完整个样本。
- offline training:你有一个样本,你把第一条带入训练,调整权重,然后带入下一条,直至跑完整个样本,这个时候的误差率可能不让你满意,于是你把整个样本又做了上述操作,直到误差很小。
offline 其实和 batch 更相似,假定这个样本有 m 条记录,offline 会训练 m 的整数倍次数,online 不知道会训练多少次 可能以一条记录训练了 10 次 第二条 8 次,第三条 1 次……
其他知识:
- 远程连接工具小结
- ……
二、框架学习
0. 框架比较
1. tensorflow1.x 学习
tensorflow 安装:深度学习硬件选购及tensorflow各系统下的环境搭建.md 【荐】
1.1 快速入门
参考「机器之心」编译文章:
1.2 学习笔记
《深度学习框架Tensorflow学习与应用》笔记索引(其中会有补充一些内容):
-
02-Tensorflow的基础使用,包括对图(graphs),会话(session),张量(tensor),变量(Variable)的一些解释和操作
-
- 开始以手写数字识别 MNIST 例子来讲解,关于 MNIST 的内容还可以看看该 README 下面的
-
04-softmax,交叉熵(cross-entropy),dropout以及Tensorflow中各种优化器的介绍 -
- softmax、损失函数、dropout - tensorflow 中各种优化器
注:在(三)节开始的代码
4-1交叉熵.py,发现 tf.nn.softmax_cross_entropy_with_logits 用法的小问题,详见-传送 -
05-使用Tensorboard进行结构可视化,以及网络运算过程可视化
- 用例子演示如何使结构的可视化 - 参数细节的可视化,绘制各个参数变化情况 - 补充内容:可视化工具 TensorBoard 更多使用和细节
-
06-卷积神经网络CNN的讲解,以及用CNN解决MNIST分类问题
- 卷积神经网络 CNN(包括局部感受野、权值共享、卷积、二维池化、多通道池化等) - 补充内容:参数数量的计算(以 LeNet-5 为例子) - 补充内容:TensorFlow 中的 Padding 到底是怎样的? - 补充内容:TensorFlow 中的卷积和池化 API 详解 - 补充内容:TensorFlow 中的 Summary 的用法
-
08-保存和载入模型,使用Google的图像识别网络inception-v3进行图像识别
- 保存模型、加载模型 - 使用 Inception-v3 网络模型进行图像识别 - 补充内容:加载预训练模型和保存模型以及 fine-tuning - 补充内容:迁移学习
-
09-Tensorflow的GPU版本安装。设计自己的网络模型,并训练自己的网络模型进行图像识别
- TensorFlow 的 GPU 版本安装 - 使用 inception-v3 模型进行训练预测 - 使用 tensorflow 已经训练好的模型进行微调 - 制作 `.tfrecord` 存储文件
笔记补充:
- 对 TensorFlow 的再次理解和总结:TensorFlow的理解和总结
- 对 TensorFlow 的 API 使用记录下来,方便查阅:🔎 TensorFlow的API详解和记录 ★★★ 【荐】,另外这里没记录和没记全的内容通过下面【相关阅读】找找看!!!
- TensorFlow 使用指定的 GPU 以及显存分析:tensorflow中使用指定的GPU及显存分析 【荐】
1.3 学习来源
学习来源:炼数成金的《深度学习框架TensorFlow学习与应用》视频 + 网上博客内容 。
视频目录:
第 1周 Tensorflow简介,Anaconda安装,Tensorflow的CPU版本安装
第 2周 Tensorflow的基础使用,包括对图(graphs),会话(session),张量(tensor),变量(Variable)的一些解释和操作
第 3周 Tensorflow线性回归以及分类的简单使用
第 4周 softmax,交叉熵(cross-entropy),dropout以及Tensorflow中各种优化器的介绍
第 5周 卷积神经网络CNN的讲解,以及用CNN解决MNIST分类问题
第 6周 使用Tensorboard进行结构可视化,以及网络运算过程可视化
第 7周 递归神经网络LSTM的讲解,以及LSTM网络的使用
第 8周 保存和载入模型,使用Google的图像识别网络inception-v3进行图像识别
第 9周 Tensorflow的GPU版本安装。设计自己的网络模型,并训练自己的网络模型进行图像识别
第10周 使用Tensorflow进行验证码识别
第11周 Tensorflow在NLP中的使用(一)
第12周 Tensorflow在NLP中的使用(二)说明:实际第 5 周讲的是 tensorborad 结构可视化,第 6 周讲的是 CNN,下面网盘该视频的文件夹顺序,我已修正。
在线观看:
- YouTube:tensorflow教程(十课)
- 或 B 站:《深度学习框架TensorFlow学习与应用》
视频下载:
- 《深度学习框架Tensorflow学习与应用》(含视频+代码+课件,视频总时长:13小时31分钟) 【百度网盘下载 密码: 1a8j】
- 《深度学习框架Tensorflow学习与应用[只有videos-720p]》(该份资料只有视频文件) 【 百度网盘下载 密码: i3e2】
1.4 其他资料
其他学习视频,觉得有必要可以看看:
- 油管视频:TF Girls 修炼指南 或 B 站观看: TF Girls 修炼指南
- 油管视频:51CTO视频 深度学习框架-Tensorflow案例实战视频课程、或 B 站观看:深度学习框架-Tensorflow案例实战视频课程
- Tensorflow 教程系列 | 莫烦Python
相关资料:
- 郑泽宇/顾思宇:《Tensorflow:实战Google深度学习框架》 出版时间 2017-2-10
- 官方维护的书中的 TensorFlow 不同版本的示例程序仓库:https://github.com/caicloud/tensorflow-tutorial;
- 有人在 GitHub 上写了笔记:TensorFlow_learning_notes
- 黄文坚/唐源:《TensorFlow实战》 出版时间 2017-2-1
- 掘金翻译:TensorFlow 最新官方文档中文版 V1.10
- 极客学院:TensorFlow 官方文档中文版
- TensorFlow 官方文档中文版
2. tensorflow2.x 学习
学习资料:
- czy36mengfei/tensorflow2_tutorials_chinese - tensorflow2中文教程,持续更新(当前版本:tensorflow2.0)
3. keras 学习
keras 学习
- Keras 学习笔记.md [荐]★★★
- 主页 - Keras 中文文档
- 详解keras的model.summary()输出参数Param计算过程 - 关于 console 台打印的参数数量的计算。
- tensorflow - What does 'non-trainable params' mean? - Stack Overflow - console 台打印的 non-trainable params 的理解。
keras - 模型可视化
keras - 迁移学习/预训练
keras - 导入模型测试
1、Keras加载预训练模型 - 豌豆ip代理 [荐]
比如训练模型的时候用到了自定义的模块AttentionLayer,那么在加载模型的时候需要在custom_objects的参数中声明对应的字典项,否则将会报模块未定义的错误。
model = load_model('./model1/GRUAttention( 0.8574).h5', custom_objects={'AttentionLayer': AttentionLayer})
在训练的过程中有时候也会用到自定义的损失函数,这时候如果你加载模型知识为了进行预测不再其基础上再进行训练,那么加载模型的时候就没有必要在custom_objects参数中声明对应的字典项,只需要将compile参数设为False即可:
model = load_model('./model1/GRUAttention(0.8574).h5', compile=False})
如果此时你好需要在加载后的模型上继续进行训练,那么声明损失函数对应的字典项就是必须的:
model = load_model('./model1/GRUAttention(0.8574).h5', compile=True, custom_objects={'focal_loss_fixed':focal_loss})
keras - 使用多 GPU
- 如何让keras训练深度网络时使用两张显卡? - 知乎
- keras 关于使用多个 gpu | Keras同时用多张显卡训练网络 - 简书
- Keras多GPU及分布式 - 有两种方法可以在多张 GPU 上运行一个模型:数据并行/设备并行。大多数情况下,你需要的很可能是“数据并行”。
keras - 相关文章
1、Keras中的多分类损失函数categorical_crossentropy
注意:当使用`categorical_crossentropy`损失函数时,你的标签应为多类模式,例如如果你有 10 个类别,每一个样本的标签应该是一个 10 维的向量,该向量在对应有值的索引位置为 1 其余为 0。
可以使用这个方法进行转换:
from keras.utils.np_utils import to_categorical
categorical_labels = to_categorical(int_labels, num_classes=None)
2、keras中的keras.utils.to_categorical方法 - to_categorical(y, num_classes=None, dtype='float32')
将整型标签转为 onehot。y 为 int 数组,num_classes 为标签类别总数,大于 max(y)(标签从0开始的)。
返回:如果 num_classes=None,返回 len(y)*[max(y)+1](维度,m*n表示m行n列矩阵,下同),否则为 len(y)*num_classes。说出来显得复杂,请看下面实例。
4、为何Keras中的CNN是有问题的,如何修复它们? - 知乎 - 关于参数初始化的问题。
我们证明,初始化是模型中特别重要的一件事情,这一点你可能经常忽略。此外,文章还证明,即便像 Keras 这种卓越的库中的默认设置,也不能想当然拿来就用。
4. “HelloWord”:MNIST
5. 相关阅读
损失函数(代价函数)
1)损失函数(代价函数)
2)自定义损失函数
- tensorflow内置的四个损失函数 [荐] | 自定义损失函数 | 二分类、多分类与多标签问题的区别,对应损失函数的选择,你知道吗? - 掘金 [荐]
- 损失函数loss大大总结 | 从loss处理图像分割中类别极度不均衡的状况---keras | 语义分割 各种loss实现 python | 语义分割中常用的损失函数2(进阶篇)
梯度下降优化算法(优化器)
1)优化器
- 第三章(1.5)关于tensorflow优化器 optimizer 的选择
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
2)学习率/权重衰减/动量/滑动平均等
炼丹技巧
1)批归一化(Batch Normalization):
2)批大小(Batch Size)
3)学习率(Learning Rate)
-
探索学习率设置技巧以提高Keras中模型性能 | 炼丹技巧 - GitHub 链接:https://github.com/gunchagarg/learning-rate-techniques-keras
- 差分学习(Differential learning) 2. 具有热启动的随机梯度下降(SGDR)
其他文章
- 一文总览CNN网络架构演进:从LeNet到DenseNet - CNN网络架构演进。[荐]
- 详解 TensorBoard-如何调参 | [干货|实践] TensorBoard可视化 - 知乎 - 学习使用 TensorBoard 可视化。
- TensorFlow学习笔记(8)--网络模型的保存和读取 - tensorflow 模型的保存和读取。
- tensorflow从已经训练好的模型中,恢复(指定)权重(构建新变量、网络)并继续训练(finetuning) - 微调 fine-tuning。
- 关于Padding实现的一些细节 - 知乎 - pytorch 采用的是第一种,即在卷积或池化时先确定 padding 数量,自动推导输出形状;tensorflow 和 caffe 采用的是更为人熟知的第二种,即先根据 Valid 还是 Same 确定输出大小,再自动确定 padding 的数量。
- ……
6. 一些问题
1、什么是基准测试?
基准测试是一种测量和评估软件性能指标的活动。你可以在某个时候通过基准测试建立一个已知的性能水平(称为基准线),当系统的软硬件环境发生变化之后再进行一次基准测试以确定那些变化对性能的影响。这是基准测试最常见的用途。其他用途包括测定某种负载水平下的性能极限、管理系统或环境的变化、发现可能导致性能问题的条件,等等。——from:http://www.blogjava.net/qileilove/archive/2012/07/05/382241.html
2、神经网络不收敛指的是什么?
①误差一直来回波动,进入不到容忍度内。②跟迭代不收敛或者系统不稳定差不多,上下波动不能趋近一个定值。
3、深度学习中的端对端?
端到端指的是输入是原始数据, 输出是最后的结果。
4、Global Average Pooling 全局平均池化?
[1] global average pooling 与 average pooling 的差别就在 "global" 这一个字眼上。global 与 local 在字面上都是用来形容 pooling 窗口区域的。 local 是取 feature map 的一个子区域求平均值,然后滑动这个子区域; global 显然就是对整个 feature map 求平均值了。
[2] 说白了,“global pooling”就是pooling的 滑窗size 和整张feature map的size一样大。每个 W×H×C 的feature map输入就会被转化为 1×1×C 输出。因此,其实也等同于每个位置权重都为 1/(W×H) 的 FC 层操作。
三、计算机视觉
1. 数据预处理
1)网上博文
★★★CS231n课程笔记翻译:神经网络笔记 2,内容如下:
- 设置数据和模型
- 数据预处理
- 权重初始化
- 批量归一化(Batch Normalization)
- 正则化(L2/L1/Maxnorm/Dropout)
- 损失函数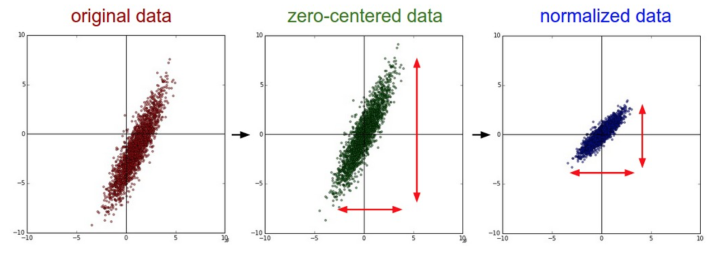
一般数据预处理流程:左边: 原始的2维输入数据。中间: 在每个维度上都减去平均值后得到零中心化数据,现在数据云是以原点为中心的。右边: 每个维度都除以其标准差来调整其数值范围。红色的线指出了数据各维度的数值范围,在中间的零中心化数据的数值范围不同,但在右边归一化数据中数值范围相同。
▶我的补充:常在代码中看到,如下:
img = cv2.resize(cv2.imread('../../Downloads/cat2.jpg'), (224, 224))
mean_pixel = [103.939, 116.779, 123.68]
img = img.astype(np.float32, copy=False)
for c in range(3):
img[:, :, c] = img[:, :, c] - mean_pixel[c]
img = img.transpose((2,0,1))
img = np.expand_dims(img, axis=0)可以看这里这个回答:https://gist.github.com/baraldilorenzo/07d7802847aaad0a35d3#gistcomment-1616734,解释是:The mean pixel values are taken from the VGG authors, which are the values computed from the training dataset.
另外也常看到代码是 X = X /255.0 这样处理。
PCA 和白化(Whitening) 是另一种预处理形式。在这种处理中,先对数据进行零中心化处理,然后计算协方差矩阵,它展示了数据中的相关性结构。
(余下内容略...
2)Data Augmentation - Python 代码
image——Data Augmentation的代码 - CSDN博客
- 切片(crop)
- 左右上下翻转
- 图像旋转
- 图像归一化处理
- 图像平移
- 调整光照2. 图像的处理
图像处理:
网上博文:
优质专栏:
3. 存在的问题
1)样本不均衡
4. 注意力机制
- 【AI不惑境】计算机视觉中注意力机制原理及其模型发展和应用 - 有三AI - 1. 空间注意力模型(spatial attention);2. 通道注意力机制;3. 空间和通道注意力机制的融合。还有,残差注意力机制,多尺度注意力机制,递归注意力机制等。
5. 模型评价
方向:图像分割(Image Segmentation)
学习:
- 语义分割相关资料总结 - 知乎 [荐]
- 2019年最新基于深度学习的语义分割技术讲解 - 知乎 [荐]
- 史上最全语义分割综述(FCN,UNet,SegNet,Deeplab,ASPP...)
- 语义分割入门的一点总结 - 知乎
其他:
方向:目标检测(Object Detection)
方向:光学字符识别(OCR)
优质专栏:





