wenmuzhou / pytorchocr Goto Github PK
View Code? Open in Web Editor NEW基于Pytorch的OCR工具库,支持常用的文字检测和识别算法
基于Pytorch的OCR工具库,支持常用的文字检测和识别算法
您好,非常感谢您提供的预训练模型,想了解下dbnet预训练模型 withconfig和普通的有什么区别呢?
我用楼主提供的预训练的模型调用det_infer做预测的时候,会报错,提示 如下错误:
KeyError:'cfg',
是不是预训练的模型里面没有cfg
Line 33 in 5028c9d
if __name__ == '__main__':
import torch
from torchsummary import summary
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = MobileNetV3(3, scale=0.5, model_name='small').to(device)
# print(net)
summary(net, input_size=(3, 32, 320))
会报错,我改成self.pool = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2), padding=0)可以运行

你好,
学习率调整默认是60epoh调整一次,
我训练中文数据集,前60的epoh loss一直降不下去,验证集准确率一直是30多,
请问学习率调整step=60是否合理,是有验证过所以选择这个数值吗?
Hi, interesting work.
Are there plans to implement CTPN?
我的task因为从头到尾预测阶段只有一个样本(只是为了判断一张发票上有没有印模糊或者印错的字,不需要考虑泛化性和鲁棒性), 您觉得这个方案可不可行。
2020-07-20 01:40:12,632 - torchocr - INFO - Training... 2020-07-20 01:40:12,632 - torchocr - INFO - train dataset has 10000 samples,1250 in dataloader 2020-07-20 01:40:12,632 - torchocr - INFO - eval dataset has 10000 samples,10000 in dataloader 2020-07-20 01:40:12,765 - torchocr - ERROR - Traceback (most recent call last): File "tools/det_train.py", line 205, in train for i, batch_data in enumerate(train_loader): # traverse each batch in the epoch File "/home/wqzhaha/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__ data = self._next_data() File "/home/wqzhaha/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 856, in _next_data return self._process_data(data) File "/home/wqzhaha/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 881, in _process_data data.reraise() File "/home/wqzhaha/anaconda3/lib/python3.6/site-packages/torch/_utils.py", line 395, in reraise raise self.exc_type(msg) cv2.error: Caught error in DataLoader worker process 0. Original Traceback (most recent call last): File "/home/wqzhaha/anaconda3/lib/python3.6/site-packages/torch/utils/data/_utils/worker.py", line 178, in _worker_loop data = fetcher.fetch(index) File "/home/wqzhaha/anaconda3/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch data = [self.dataset[idx] for idx in possibly_batched_index] File "/home/wqzhaha/anaconda3/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp> data = [self.dataset[idx] for idx in possibly_batched_index] File "/media/wqzhaha/TOSHIBA EXT/ocr/PytorchOCR/torchocr/datasets/DetDataSet.py", line 104, in __getitem__ im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) cv2.error: OpenCV(4.2.0) /io/opencv/modules/imgproc/src/color.cpp:182: error: (-215:Assertion failed) !_src.empty() in function 'cvtColor'
您可以试着跑一下训练,torch1.0.1 和 torch1.5.0都出现这个问题,数据集试了两个都出现这个问题。
我报了如下错误:OSError:[WinError 126]找不到指定的模块。
你好
运行det_train.py遇到位深度位8的图片会报错
遇到8位图时 im = cv2.imread(data['img_path'], 1 if self.img_mode != 'GRAY' else 0)
这句结果是None
cv2.error: OpenCV(4.4.0) /tmp/pip-req-build-kne9u3r2/opencv/modules/imgproc/src/color.cpp:182: error: (-215:Assertion failed) !_src.empty() in function 'cvtColor'
错误code位置:
def __getitem__(self, index):
# try:
data = copy.deepcopy(self.data_list[index])
print(data['img_path'])
im = cv2.imread(data['img_path'], 1 if self.img_mode != 'GRAY' else 0)
if self.img_mode == 'RGB':
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) #报错
data['img'] = im
data['shape'] = [im.shape[0], im.shape[1]]
data = self.apply_pre_processes(data)
请问如何解决
作者您好,感谢您优秀的工作,似乎目前repo中的crnn处于不可用的状态,我进行了一个简单的中文识别的尝试,但是输出中acc一直为0,loss跳变, 请问是否有比较稳定的识别的分支可供参考,用以寻找bug,或者是否有什么建议可以提示我需要注意的信息
2020-07-14 09:45:39,163 - torchocr - INFO - [80/200] - [1300/1587] - lr:8.271806125530277e-28 - loss:4.5751 - acc:0.0312 - norm_edit_dis:0.2261 - time:51.0078
2020-07-14 09:46:29,372 - torchocr - INFO - [80/200] - [1400/1587] - lr:8.271806125530277e-28 - loss:4.9632 - acc:0.0000 - norm_edit_dis:0.1499 - time:50.2079
2020-07-14 09:47:19,655 - torchocr - INFO - [80/200] - [1500/1587] - lr:8.271806125530277e-28 - loss:5.0862 - acc:0.0000 - norm_edit_dis:0.1370 - time:50.2833
2020-07-14 09:48:54,075 - torchocr - INFO - [81/200] - [100/1587] - lr:4.1359030627651385e-28 - loss:4.6698 - acc:0.0000 - norm_edit_dis:0.2278 - time:50.8783
2020-07-14 09:49:43,349 - torchocr - INFO - [81/200] - [200/1587] - lr:4.1359030627651385e-28 - loss:4.7732 - acc:0.0000 - norm_edit_dis:0.1903 - time:49.2733
2020-07-14 09:50:32,552 - torchocr - INFO - [81/200] - [300/1587] - lr:4.1359030627651385e-28 - loss:4.7276 - acc:0.0156 - norm_edit_dis:0.2363 - time:49.2031
2020-07-14 09:51:22,197 - torchocr - INFO - [81/200] - [400/1587] - lr:4.1359030627651385e-28 - loss:5.2084 - acc:0.0156 - norm_edit_dis:0.1432 - time:49.6451
2020-07-14 09:52:12,403 - torchocr - INFO - [81/200] - [500/1587] - lr:4.1359030627651385e-28 - loss:4.4954 - acc:0.0469 - norm_edit_dis:0.2290 - time:50.2050
2020-07-14 09:53:04,682 - torchocr - INFO - [81/200] - [600/1587] - lr:4.1359030627651385e-28 - loss:4.8725 - acc:0.0000 - norm_edit_dis:0.1751 - time:52.2787
2020-07-14 09:53:54,543 - torchocr - INFO - [81/200] - [700/1587] - lr:4.1359030627651385e-28 - loss:4.5594 - acc:0.0000 - norm_edit_dis:0.2187 - time:49.8607

召回率有点偏低,请问是不是跟数据集过少有关。
不懂就问 有什么提升召回率的思路?

When loading data, the length of the data and the characters not in the character set should be filtered, some complex mistakes can be made in the course of the experiment.
Line 234 in 866651e
PytorchOCR/torchocr/metrics/RecMetric.py
Lines 22 to 24 in 866651e
PytorchOCR/torchocr/datasets/RecDataSet.py
Lines 90 to 95 in 5028c9d
PytorchOCR/config/rec_train_lmdb_config.py
Lines 73 to 80 in 866651e
详细请见图

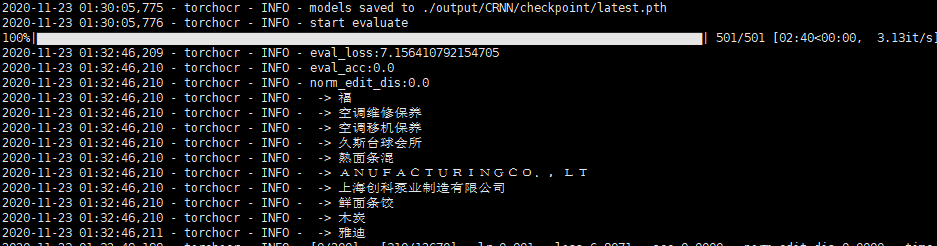
预测结果和概率值都为空,感觉是model没有读出来?
您好,我使用您的crnn.pytorch仓库中的代码进行训练,却发生了keyerror的问题。训练日志如下:

数据集是我自己准备的,数据标签文件格式如下:
img/word_20347.png 中國國際航空公司
img/word_20351.png 头等舱
img/word_20363.png 北京市科普教育基地
按照您的readme,我使用gen_key.py通过上面的数据标签生了字典文件:
迫
迹
追
送
适
选
透
递
途
通
速
造
逸
逻
使用的yaml文件如下(其实用的是您仓库里的imagedataset_None_VGG_RNN_CTC.yaml文件):
{'name': 'crnn', 'base': ['config/image_dataset.yaml'], 'arch': {'type': 'Model', 'trans': {'type': 'None', 'input_size': [32, 320], 'num_fiducial': 20}, 'backbone': {'type': 'VGG', 'conv_type': 'BasicConv'}, 'neck': {'type': 'RNNDecoder', 'hidden_size': 256}, 'head': {'type': 'CTC'}}, 'loss': {'type': 'CTCLoss', 'blank': 0}, 'optimizer': {'type': 'Adam', 'args': {'lr': 0.001}}, 'lr_scheduler': {'type': 'StepLR', 'args': {'step_size': 30, 'gamma': 0.1}}, 'trainer': {'seed': 2, 'gpus': [0], 'epochs': 10, 'log_iter': 10, 'resume_checkpoint': '', 'finetune_checkpoint': '', 'output_dir': 'output', 'tensorboard': True}, 'dataset': {'alphabet': 'digit.txt', 'train': {'dataset': {'type': 'ImageDataset', 'args': {'data_path': [['path/train.txt']], 'data_ratio': [1.0], 'pre_processes': [{'type': 'Resize', 'args': {'img_h': 32, 'img_w': 120, 'pad': True, 'random_crop': False}}], 'transforms': [{'type': 'ToTensor', 'args': {}}], 'img_mode': 'RGB', 'ignore_chinese_punctuation': True, 'remove_blank': True}}, 'loader': {'batch_size': 16, 'shuffle': True, 'pin_memory': False, 'num_workers': 6}}, 'validate': {'dataset': {'type': 'ImageDataset', 'args': {'data_path': ['path/val.txt'], 'pre_processes': [{'type': 'Resize', 'args': {'img_h': 32, 'img_w': 120, 'pad': True, 'random_crop': False}}], 'transforms': [{'type': 'ToTensor', 'args': {}}], 'img_mode': 'RGB', 'ignore_chinese_punctuation': True, 'remove_blank': True}}, 'loader': {'batch_size': 4, 'shuffle': True, 'pin_memory': False, 'num_workers': 6}}}}
此外,我用的是国外的操作系统,文字编码问题会不会成为报错原因?
希望能得到您的答复,谢谢!
你好,请问是否可以提供一下您训练的预训练模型
您好,出现了新的错误:
模型虽然跑了起来,但是第一个saving point之后就出现了错误。
而且accuracy的值一直是0.


望解答!由衷感谢!
模型权重下载百度云密码错误
大佬您好:请问为什么我使用预训练模型 MobileNetV3_large_x0_5.pth 训练 icdar2015 得到的 MobileNetV3 模型有21M多?去除梯度信息后还有7M多,大约是您百度网盘里模型的两倍,您是如何训练得到这么小的模型?谢谢!

如图
decode结构中加了如下的判断条件会不会使拥有相同字母的单词无法被打印出来(比如'Hello'中的'l')
难道CTC算法默认每个字符中存在blank?
不太了解,望解答。

大佬,我按照文档配置自己的路径之类,
训练准确率一直为0,,,,
eval阶段准确率也是0.。。。。


如题,怎么修改GPUID? 现在是默认‘cuda:0’,我修改为其他的id都会报错。。。
请教下各位学霸,为什么我尝试训练识别模型时显存好像在不停的增长,然后就RuntimeError: CUDA out of memory,这个要怎么解决?
(1080的老卡,bs=16,开始运行时只要3G多显存,逐渐上升。)
2020-09-10 06:55:41,145 - torchocr - INFO - [0/200] - [7650/85482] - lr:0.001 - loss:0.8423 - acc:0.2500 - norm_edit_dis:0.8858 - time:3.2507
2020-09-10 06:55:44,284 - torchocr - INFO - [0/200] - [7660/85482] - lr:0.001 - loss:0.8961 - acc:0.1875 - norm_edit_dis:0.8449 - time:3.1395
2020-09-10 06:55:47,402 - torchocr - INFO - [0/200] - [7670/85482] - lr:0.001 - loss:0.5101 - acc:0.5625 - norm_edit_dis:0.9381 - time:3.1169
2020-09-10 06:55:49,011 - torchocr - ERROR - Traceback (most recent call last):
File "tools/rec_train.py", line 237, in train
loss_dict['loss'].backward()
File "/opt/conda/lib/python3.7/site-packages/torch/tensor.py", line 185, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/opt/conda/lib/python3.7/site-packages/torch/autograd/init.py", line 127, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: CUDA out of memory. Tried to allocate 232.00 MiB (GPU 0; 7.93 GiB total capacity; 6.42 GiB already allocated; 110.19 MiB free; 7.22 GiB reserved in total by PyTorch)
Exception raised from malloc at /pytorch/c10/cuda/CUDACachingAllocator.cpp:272 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x42 (0x7f19c980e1e2 in /opt/conda/lib/python3.7/site-packages/torch/lib/libc10.so)
frame #1: + 0x1e64b (0x7f19c9a6464b in /opt/conda/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
frame #2: + 0x1f464 (0x7f19c9a65464 in /opt/conda/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
frame #3: + 0x1faa1 (0x7f19c9a65aa1 in /opt/conda/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
frame #4: at::native::empty_cuda(c10::ArrayRef, c10::TensorOptions const&, c10::optionalc10::MemoryFormat) + 0x11e (0x7f19cc78c52e in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cuda.so)
frame #5: + 0xf51329 (0x7f19cabc8329 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cuda.so)
frame #6: + 0xf6b157 (0x7f19cabe2157 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cuda.so)
frame #7: + 0x10e9c7d (0x7f1a0194cc7d in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #8: + 0x10e9f97 (0x7f1a0194cf97 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #9: at::empty(c10::ArrayRef, c10::TensorOptions const&, c10::optionalc10::MemoryFormat) + 0xfa (0x7f1a01a57a1a in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #10: at::native::empty_like(at::Tensor const&, c10::TensorOptions const&, c10::optionalc10::MemoryFormat) + 0x49e (0x7f1a016d5c3e in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #11: + 0x12880c1 (0x7f1a01aeb0c1 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #12: + 0x12c3863 (0x7f1a01b26863 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #13: at::empty_like(at::Tensor const&, c10::TensorOptions const&, c10::optionalc10::MemoryFormat) + 0x101 (0x7f1a01a3ab31 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #14: at::native::contiguous(at::Tensor const&, c10::MemoryFormat) + 0x89 (0x7f1a016f2469 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #15: + 0x1290470 (0x7f1a01af3470 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #16: + 0x12c351f (0x7f1a01b2651f in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #17: at::Tensor::contiguous(c10::MemoryFormat) const + 0xe8 (0x7f1a01b912e8 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #18: at::Tensor at::native::(anonymous namespace)::host_softmax_backward<at::native::(anonymous namespace)::LogSoftMaxBackwardEpilogue, true>(at::Tensor const&, at::Tensor const&, long, bool) + 0x14b (0x7f19cc01826b in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cuda.so)
frame #19: at::native::log_softmax_backward_cuda(at::Tensor const&, at::Tensor const&, long, at::Tensor const&) + 0x65a (0x7f19cc0026da in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cuda.so)
frame #20: + 0xf3efa0 (0x7f19cabb5fa0 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cuda.so)
frame #21: + 0x11141d6 (0x7f1a019771d6 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #22: at::_log_softmax_backward_data(at::Tensor const&, at::Tensor const&, long, at::Tensor const&) + 0x119 (0x7f1a01a05649 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #23: + 0x2ec639f (0x7f1a0372939f in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #24: + 0x11141d6 (0x7f1a019771d6 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #25: at::_log_softmax_backward_data(at::Tensor const&, at::Tensor const&, long, at::Tensor const&) + 0x119 (0x7f1a01a05649 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #26: torch::autograd::generated::LogSoftmaxBackward::apply(std::vector<at::Tensor, std::allocatorat::Tensor >&&) + 0x1d7 (0x7f1a035a5057 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #27: + 0x3375bb7 (0x7f1a03bd8bb7 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #28: torch::autograd::Engine::evaluate_function(std::shared_ptrtorch::autograd::GraphTask&, torch::autograd::Node*, torch::autograd::InputBuffer&, std::shared_ptrtorch::autograd::ReadyQueue const&) + 0x1400 (0x7f1a03bd4400 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #29: torch::autograd::Engine::thread_main(std::shared_ptrtorch::autograd::GraphTask const&) + 0x451 (0x7f1a03bd4fa1 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #30: torch::autograd::Engine::thread_init(int, std::shared_ptrtorch::autograd::ReadyQueue const&, bool) + 0x89 (0x7f1a03bcd119 in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #31: torch::autograd::python::PythonEngine::thread_init(int, std::shared_ptrtorch::autograd::ReadyQueue const&, bool) + 0x4a (0x7f1a1136dc8a in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
frame #32: + 0xc70f (0x7f1a10a3070f in /opt/conda/lib/python3.7/site-packages/torch/lib/libtorch.so)
frame #33: + 0x76ba (0x7f1a1454a6ba in /lib/x86_64-linux-gnu/libpthread.so.0)
frame #34: clone + 0x6d (0x7f1a1428041d in /lib/x86_64-linux-gnu/libc.so.6)
2020-07-16 09:45:12,213 - torchocr - ERROR - Traceback (most recent call last):
File "tools/det_train.py", line 205, in train
for i, batch_data in enumerate(train_loader): # traverse each batch in the epoch
File "/home/mlp/python/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 336, in next
return self._process_next_batch(batch)
File "/home/mlp/python/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 357, in _process_next_batch
raise batch.exc_type(batch.exc_msg)
TypeError: Traceback (most recent call last):
File "/home/mlp/python/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 106, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
TypeError: 'NoneType' object is not callable
您好!
我完全按照教程的步骤,出现net.module 不错,模型里没有module 吧 ?
还有logging一直报错./weights/resnet50_vd.pth not exists, 真的只要把resnet50放入weights就可以吗 ?
我总觉得你们的说明缺少了什么。
谢谢,期待回答!
用了lmdb和textline两个格式的数据集训练出来的accuracy都为0. 崩溃了。
比如下图:

是不是linux环境下textline前面的img_path都要是绝对路径?
比如改成/home/user/Pytorch-master/imageset.*.png之类的?
望解答,谢谢!
训练的时候可以设置成多卡,但是验证的时候就会报错~大佬解决了这个问题了吗?
我使用讯飞的数据集训练,用了作者的数据转换脚本,
下载使用的resnet50预训练模型,
模型其他的配置都没有改,
在训练的时候,发现loss从头到尾都是1.000, loss_shrink和loss_threshold一直是0.
我想问一下这种情况是怎么回事。
在预测的时候我我用了很多张图片发现每张图都没有点,预测出来的全为空。
希望大佬能指点一下,谢谢谢谢!
training setting:
icdar2015
resnet-50(pre-trained)
result:
the best model on icdar2015 validation set achieves recall=75.9%, precision=~88.xx%, hmean=~81.xx%
question:
recall = 75.9% vs 79.9%(reported in this repo) vs 82.7%(reported in official paper)
recall is a little lower than both in this repo and official paper. Is this normal?
作者,您好!我对您们所做的这个代码一直都有在关注,现在我遇到的情况是,det_infer/det_train和rec_infer/rec_train都在自己的电脑上跑通了,但是minimum_2stage_inference.py这个没办法去跑通它,如何在这个代码中放入图片后,出检测框和文字识别的结果一直困扰着我,希望您可以给出2stage_inference的readme文件,非常感谢!希望能得到您的回复,谢谢!
请发布mega.nz或GoogleDrive
这是第一阶段复现paddle ocr的任务认领,对哪个模块有兴趣的小伙伴可以at我,然后添加任务
backbone:
neck:
head:
rec:
paddle 里面的dynamic lstm无法在pytorch中有对应的,这块会有差异
det:
utils:
train:
data:
demo:
其他资源:
以下代码报错
make_order_map.py
padded_polygon = np.array(padding.Execute(distance)[0])
File "/data2/deliancen/workpace/OCR/PytorchOCR/torchocr/datasets/det_modules/make_border_map.py", line 54, in draw_border_map
padded_polygon = np.array(padding.Execute(distance)[0])
IndexError: list index out of range
请问为何采用预设的参数初始化而不用其他的? 例如He initialization
Does there any training support on both Chinese charactors detection and recognition?
mnt/ramdisk/max/90kDICT32px/2697/6/466_MONIKER_49537.jpg MONIKER mnt/ramdisk/max/90kDICT32px/2697/6/465_Ecclesiastics_24500.jpg Ecclesiastics
python ./tools/rec_train.py --config ./config/rec_train_config_self.py
`
config.loss = {
'type': 'CTCLoss',
'blank_idx': 0,
}
config.dataset = {
# 'alphabet': r'path/dic.txt',
'alphabet': r'torchocr/datasets/alphabets/enAlphaNumPunc90.txt',
# 'alphabet': r'torchocr/datasets/alphabets/digit.txt',
'train': {
'dataset': {
'type': 'RecTextLineDataset',
'file': r'path/mnt/ramdisk/max/90kDICT32px/annotation_train_other.txt',
'input_h': 32,
'mean': 0.5,
'std': 0.5,
'augmentation': False,
},
'loader': {
'type': 'DataLoader', # 使用torch dataloader只需要改为 DataLoader
'batch_size': 4,
'shuffle': True,
'num_workers': 1,
'collate_fn': {
'type': 'RecCollateFn',
'img_w': 120
}
}
},
'eval': {
'dataset': {
'type': 'RecTextLineDataset',
'file': r'path/mnt/ramdisk/max/90kDICT32px/annotation_val_other.txt',
'input_h': 32,
'mean': 0.5,
'std': 0.5,
'augmentation': False,
},
'loader': {
'type': 'RecDataLoader',
'batch_size': 4,
'shuffle': False,
'num_workers': 1,
'collate_fn': {
'type': 'RecCollateFn',
'img_w': 120
}
}
}
}
`
` train loop: 1
0
[INFO] end zero_grad
[INFO] end forward
[INFO] loss: tensor(6.5425, grad_fn=)
[INFO] end loss
[INFO] end backward
[INFO] end clip_grad_norm_
[INFO] end optimizer step
1
[INFO] end zero_grad
[INFO] end forward
[INFO] loss: tensor(nan, grad_fn=)
[INFO] end loss
[INFO] end backward
[INFO] end clip_grad_norm_
[INFO] end optimizer step
2
[INFO] end zero_grad
[INFO] end forward
[INFO] loss: tensor(nan, grad_fn=)
[INFO] end loss
[INFO] end backward
[INFO] end clip_grad_norm_
[INFO] end optimizer step
3
[INFO] end zero_grad
[INFO] end forward
[INFO] loss: tensor(nan, grad_fn=)
[INFO] end loss
[INFO] end backward
[INFO] end clip_grad_norm_
[INFO] end optimizer step
4
[INFO] end zero_grad
[INFO] end forward
[INFO] loss: tensor(nan, grad_fn=)
[INFO] end loss
[INFO] end backward
[INFO] end clip_grad_norm_
[INFO] end optimizer step
5
[INFO] end zero_grad
[INFO] end forward
[INFO] loss: tensor(nan, grad_fn=)
[INFO] end loss
Segmentation fault (core dumped)`
大佬,请问下怎么生成自己的训练数据集对应的字典文件
你好,我这里使用icdar 2017数据集训练,发现准确率一直为0,使用的配置项为rec_train_config.py,没有做什么太大的修改,只是修改了batch_size,alphabet的路径,dataset的路径,训练时log的打印如下:

期间进入到RecMetric.py中查看模型的输出值predictions,发现里面预测的结果都为0,0,0...0的tensor
训练数据的标注如下(图片路径与文字内容中间以\t进行分割):
E:\DataSets\icdar2017rctw\icdar2017rctw\recognition\train\image_0_0.jpg 金氏眼镜
E:\DataSets\icdar2017rctw\icdar2017rctw\recognition\train\image_0_1.jpg 创于1989
E:\DataSets\icdar2017rctw\icdar2017rctw\recognition\train\image_0_2.jpg 城建店
alphabet中的信息如下,一共5529个字符,加上blank的话那么最后的类别数n_class设置为5530:

另外config中的设置项:
2020-11-05 15:10:33,337 - torchocr - INFO - {'exp_name': 'CRNN', 'train_options': {'resume_from': '', 'third_party_name': '', 'checkpoint_save_dir': './output/CRNN/checkpoint', 'device': 'cuda:0', 'epochs': 200, 'fine_tune_stage': ['backbone', 'neck', 'head'], 'print_interval': 20, 'val_interval': 3000, 'ckpt_save_type': 'HighestAcc', 'ckpt_save_epoch': 4}, 'SEED': 927, 'optimizer': {'type': 'Adam', 'lr': 0.001, 'weight_decay': 0.0001}, 'lr_scheduler': {'type': 'StepLR', 'step_size': 60, 'gamma': 0.1}, 'model': {'type': 'RecModel', 'backbone': {'type': 'ResNet', 'layers': 18}, 'neck': {'type': 'PPaddleRNN'}, 'head': {'type': 'CTC', 'n_class': 5530}, 'in_channels': 3}, 'loss': {'type': 'CTCLoss', 'blank_idx': 0}, 'dataset': {'alphabet': 'E:/pro/ncnn_ocr/models/keys.txt', 'train': {'dataset': {'type': 'RecTextLineDataset', 'file': 'E:/pro/chineseocr-master/train/ocr/txt/icdar2017Backup.txt', 'input_h': 32, 'mean': 0.5, 'std': 0.5, 'augmentation': False}, 'loader': {'type': 'DataLoader', 'batch_size': 4, 'shuffle': True, 'num_workers': 1, 'collate_fn': {'type': 'RecCollateFn', 'img_w': 120}}}, 'eval': {'dataset': {'type': 'RecTextLineDataset', 'file': 'E:/pro/chineseocr-master/train/ocr/txt/2017valBackup.txt', 'input_h': 32, 'mean': 0.5, 'std': 0.5, 'augmentation': False}, 'loader': {'type': 'RecDataLoader', 'batch_size': 4, 'shuffle': False, 'num_workers': 1, 'collate_fn': {'type': 'RecCollateFn', 'img_w': 120}}}}}
希望得到回复,谢谢!
大佬你好
请问你尝试将crnn转过mnn吗?
目前发现crnn转mnn有一些问题,主要是在lstm部分,貌似lstm转mnn是不对的。。。导致mnn模型输出有错
poly [[1533.5558 3912.3967]
[1289.3611 3954.4272]
[1296.0596 3993.3525]
[1540.2543 3951.322 ]]2020-09-23 15:54:25,165 - torchocr - ERROR - Traceback (most recent call last):
File "tools/det_train.py", line 211, in train
for i, batch_data in enumerate(train_loader): # traverse each batch in the epoch
File "/usr/local/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 363, in next
data = self._next_data()
File "/usr/local/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 989, in _next_data
return self._process_data(data)
File "/usr/local/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 1014, in _process_data
data.reraise()
File "/usr/local/anaconda3/lib/python3.6/site-packages/torch/_utils.py", line 395, in reraise
raise self.exc_type(msg)
TypeError: Caught TypeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/usr/local/anaconda3/lib/python3.6/site-packages/torch/utils/data/_utils/worker.py", line 185, in _worker_loop
data = fetcher.fetch(index)
File "/usr/local/anaconda3/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/usr/local/anaconda3/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/nlp/lmy/PytorchOCR/torchocr/datasets/DetDataSet.py", line 103, in getitem
data = self.apply_pre_processes(data)
File "/home/nlp/lmy/PytorchOCR/torchocr/datasets/DetDataSet.py", line 92, in apply_pre_processes
data = aug(data)
File "/home/nlp/lmy/PytorchOCR/torchocr/datasets/det_modules/random_crop_data.py", line 54, in call
poly = ((poly - (crop_x, crop_y)) * scale).tolist()
TypeError: unsupported operand type(s) for -: 'list' and 'tuple'
crop_x,crop_y (0, 0)
楼主,你好。我用resnet18作为backbone训练crnn,训练过程很正常,infer的过程也政策。但是我用res50和res34作为backbone,loss一直降不下去,acc一直为0,是不是训练代码有bug呢?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.