xufei / blog Goto Github PK
View Code? Open in Web Editor NEWmy personal blog
my personal blog










































































































































































































在广义的前端领域,模型驱动视图已经不是什么新鲜话题了,“低代码”和“搭建”也炙手可热,而这些概念都是以增强应用系统的可配置性为前提的。在这个大前提下,建立元数据驱动的前端架构就变得很重要了。
本次分享的目标是希望从零开始,初步建立一个小小的元数据驱动的原型系统(暂时只包括前端部分),并以此介绍这套系统与业务领域的可能结合方式。
从最简单的结构来看,一个模型驱动的视图体系包含以下要素:
这是很简单的一种渲染模式,可以适用于所有的场景(暂且忽略性能之类的情况)。
举例来说,我们尝试把状态与渲染分离:
type BooleanProps = {
value: boolean,
onChange: (v: boolean) => void
}
// 状态的持有者
const Boolean = (props: PropsWithChildren<BooleanProps>) => {
const { value, onChange, children } = props
const context: DataContextValue = {
value,
onChange
}
return <DataContext.Provider value={context}>{children}</DataContext.Provider>
}
// 仅渲染和触发变更
const Checkbox = () => {
const { value, onChange } = useContext(DataContext)
return (
<input
type="checkbox"
checked={value}
onChange={(e) => onChange(e.currentTarget.checked)}
/>
)
}
// 两者的组合
const Demo = () => {
const [value, onChange] = useState(false)
return (
<Boolean value={value} onChange={onChange}>
<Checkbox />
</Boolean>
)
}
在这个例子中,Boolean 组件持有状态,而下层的 Checkbox 只负责消费这个状态,或者触发上层传入的修改状态的动作。
进而,可以造出更加泛化的数据表达形态:
type DataProps<T> = {
value: T,
onChange: (v: T) => void
}
// 状态的持有者
const Data = <T>(props: PropsWithChildren<DataProps<T>>) => {
const { value, onChange, children } = props
const context: DataContextValue = {
value,
onChange
}
return <DataContext.Provider value={context}>{children}</DataContext.Provider>
}
const Demo2 = () => {
const [value1, onChange1] = useState(false)
const [value2, onChange2] = useState('hello')
return (
<>
<Data value={value1} onChange={onChange1}>
<Checkbox />
</Data>
<Data value={value2} onChange={onChange2}>
<Input />
</Data>
</>
)
}到这里,我们可以注意到,在同一个数据上下文之下,可以拥有若干个共享该数据的纯渲染组件,也有机会在不影响整体结构的情况下,把 Checkbox 换成与之等价的其他交互,比如 Switch,并不会影响业务的表达。甚至我们在 Data 下面添加任意的布局组件,也不会产生额外的改动。
之前的结构中,我们对于状态的操作方式还是非常简单的,只有读写两种操作,还可以使用 useReducer 进一步拓展,支持添加更多的自定义动作响应:
const Demo = () => {
// reducer 可以是外部注册的
const [state, dispatch] = useReducer(reducer, initialCount, init)
const context: DataContextValue = {
state,
dispatch
}
return <DataContext.Provider value={context}>{children}</DataContext.Provider>
}在这个时候,下层渲染组件的能力包括:
更极端一点,这里的各种动作都可以是在外部注册的,这样,可以把动作的实现外置,放在某些类似 serverless 的体系中去支撑。
并且,我们发现,渲染部分仍然是很轻量的,而且可以很容易有跨平台实现。
以上的例子仍然太过简单了,我们逐步去看一些更加复杂的,比如表格和表单的状态结构:
表格:
const Table = () => {
// 表头信息
// 行记录信息
}表单:
const Form = () => {
// 字段信息
// 字段值信息
}如果是按照之前的理念来实现,我们当然也可以把这些信息全部糅合到状态里,类似这样:
const Foo = () => {
const [state, setState] = useState({
fields: [],
records: []
})
return <Table fields={state.fields} state={state.records} />
}表单也是类似这样的:
const Foo = () => {
const [state, setState] = useState({
fields: [],
record: {}
})
// 假定我们有一个叫做 Form 的组件,内部展开这些字段和数据
return <Form fields={state.fields} state={state.record} />
}这里的 fields 就是一种没有经过抽象的元数据,我们可以考虑对这些代码进行一种初步抽象,把字段信息隔离出去:
type FieldsProviderProps = {
fields: Field[]
}
const FieldsProvider = (props: PropsWithChildren<FieldsProviderProps>) => {
const { fields } = props
const context: FieldContextValue = {
fields
}
return <FieldContext.Provider context={context}>{children}</FieldContext.Provider>
}
const Demo = () => {
const fields = [] // 字段定义
const [state, setState] = useState([])
return (
<FieldsProvider fields={fields} state={state}>
<Table />
<FormList />
</FieldsProvider>
)
}经过这样的抽象过程,我们把一些独立于数据状态的描述信息抽取出去,单独处理了。最下层的组件仍然职责很单一,只是与之前相比,多了使用一些配置信息的权利。
类似这种字段配置,就是一种元数据。它实际上是另外一个层面的类型信息,可以携带对业务模型的定义。
刚才的示例促使我们进行思考:在很多时候,我们需要运行时获取模型结构定义的详细信息。如果我们始终拥有这种信息,会导致编程过程变得不一样吗?
比如说,当我们试图表达一个任务实体的时候:
type Task = {
title: string,
completed: boolean
}它可以分解为最原子的数据类型的组合,而每种类型又可以使用一个描述数据来约束,据此,我们尝试描述各种常见数据类型的结构:
type BooleanSchema = {
type: 'boolean',
default?: boolean
}
type StringSchema = {
type: 'string',
default?: string
}
type NumberSchema = {
type: 'number',
default: number
}
type ObjectSchema = {
type: 'object',
properties: Record<string, Schema>,
default?: Object
}
type ArraySchema = {
type: 'array',
items: Schema,
default?: []
}
type Schema = BooleanSchema | NumberSchema | StringSchema | ObjectSchema | ArraySchema上面的这些类型定义很简陋,但是可以初步描述数据的基本形态。在此之上,可以更进一步,直接把业务的领域模型表达出来,比如,把前面示例中的 Task,可以换成这样的方式来描述:
const taskSchema = {
type: 'object',
properties: {
title: {
type: 'string'
},
completed: {
type: 'boolean'
}
}
}这样,我们可以重构刚才的代码结构,变成下面这种形状:
const Demo = () => {
return (
<SchemaProvider schema={schema}>
<Table />
<FormList />
</SchemaProvider>
)
}在 SchemaProvider 中,我们可以从定义中取出当前类型的初始值,甚至可以自动生成一个校验函数,以验证给定数据是否符合自身描述的规则。
至此,我们已经可以给一个承载状态的组件添加相应的 schema,但是,需要注意到,它对 TypeScript 的支持很不友好,schema 跟 value 没有建立比较好的关联。
设想有如下代码:
<Data schema={taskSchema} value={{}} />在这个地方,当我们填写了 schema,然后为 value 传入数据的时候,它们并未产生关联,简单来说,在 DataProps 定义的时候,如果不建立 schema 与 value 之间的关联,至少需要两个泛型参数:
type DataProps<T1 extends Schema, T2> = {
schema: T1,
value: T2
}在 T1 和 T2 之间,很明显 T1 的结构更可靠,那么,我们就考虑把类型定义变成下面这样,让 value 变成 schema 的一种类型运算:
type DataProps<T extends Schema> = {
schema: T,
value: ValueOf<T>
}这样,我们就得实现 ValueOf 这么一个类型操作了,不难得出类似以下的代码:
type ValueOfBoolean<T extends BooleanSchema> = boolean
type ValueOfNumber<T extends NumberSchema> = number
type ValueOfString<T extends StringSchema> = string
type ValueOfObject<T extends ObjectSchema> = {
[K in keyof T['properties']]: ValueOf<T['properties'][K]>
}
type ValueOfArray<T extends ArraySchema> = Array<ValueOf<T['items']>>
type ValueOf<T extends Schema> = T extends BooleanSchema
? ValueOfBoolean<T>
: T extends NumberSchema
? ValueOfNumber<T>
: T extends StringSchema
? ValueOfString<T>
: T extends ObjectSchema
? ValueOfObject<T>
: T extends ArraySchema
? ValueOfArray<T>
: unknown这时候,再看看刚才的数据类型:
const Demo = () => {
return (
<Data
schema={{
type: 'object',
properties: {
title: {
type: 'string',
},
completed: {
type: 'boolean',
},
},
}}
value={{ title: '' }}
/>
)
}就能够实时校验出 value 结构的错误了。
建立了完整的 schema 结构之后,我们再回头去看表格和表单,就会发现比较简单了。
我们会发现,它们其实是两种迭代模式,一种是对象迭代为字段,一种是列表迭代为列表项。如果在迭代过程中拥有字段这类信息,那么,整个迭代过程都是可以抽象的。
比如这里是简单的字段迭代的过程:
type ObjectIteratorProps<T extends ObjectSchema> = {
schema: T,
value: ValueOf<T>,
onChange: (v: ValueOf<T>) => void
}
const ObjectIterator = <T extends ObjectSchema>(props: PropsWithChildren<ObjectIteratorProps<T>>) => {
const { schema, value, onChange, children } = props
return Object.keys(schema.properties).map((key) => {
const fieldSchema = schema.properties[key]
const fieldValue = value[key]
const fieldOnChange = (v) => {
onChange({
...value,
key: v,
})
}
return (
<Field key={key} value={fieldValue} onChange={fieldOnChange}>
{children}
</Field>
)
})
}在使用的时候,可以:
const Demo = () => {
const [value, onChange] = useState<ValueOf<taskSchema>()
return <ObjectIterator schema={taskSchema} value={value} onChange={onChange}></ObjectIterator>
}类似,ListIterator 也可以很容易表达出来。这样,我们之前碰到的表格表单,或者类似的形态,就有了比较统一的抽象方式了。
更夸张一些,我们还可以对常见的数据结构都实现一遍这样的组件,而且内部可以做很多优化,比如虚拟滚动之类的,这样,就减轻了渲染组件的负担。
在业务中,我们常常看到若干种交互形态,其内在的数据结构完全一致。在之前的示例中,已经简单看到一些了。
在软件架构中,一个很重要的过程是在抽象的基础上合并同类项。回到刚才的场景,我们会发现,对字段的描述,实际上是很通用的,这部分信息很大程度上并非来自前端,而是业务建模的一个体现。
这就是说,只要存在能够表达这种业务模型的最低交互,它在业务上就是可用的,只是不一定友好。然后,在不修改其他代码的情况下,替换为表达能力等价,但是交互更友好的渲染器,就可以提升这部分的体验。
举例来说,假设我们有一个下象棋的游戏,已知规则,但是暂时还没时间写棋盘和棋子,能不能在表单和表格里面下棋呢?
下面展示一个 demo,一个可以在表单中下的象棋游戏,篇幅所限,暂不放出代码,在现场有过演示。
从这里我们就可以认识到,棋盘和表单,尽管形态差异非常大,实际上是等价的。推而广之,我们甚至可以用表单表达一切业务。
理想状态下,应用架构可以划分以下两个部分:
在这种状态下,我们期望:
业务专家尽可能不需要去关注具体实现,而通过某种方式描述和表达业务细节,这就是业务建模。
比如说,当我们做业务建模的时候,并不需要去额外关心:
而是侧重于描述:
然后,尽可能把技术设施变成一个底层实现多样化的业务解释引擎,再去具体组合业务。
在以上的探讨中,我们已经努力去做了以下事项:
在此基础上,前端部分成为了对领域模型的解释引擎,视图的组合与布局都不再影响业务正确性。沿着这个角度思考,我们可以看到更多的可能性,比如:
<DataSource schema={model}>
<Query />
<Table />
</DataSource>更语义化地表达:数据源、查询、请求、异常 等概念,并且定义它们的组合方式。
而更大的体系,则是前后端一体化,整个都是业务领域的解释引擎,元数据从存储、到传输、再到呈现,一直伴随整个应用的生命周期。
这个时候,我们发现,一个完整的“配置化”的业务软件系统,就拥有了完整的表达链路了。
注:本文主要是为了说明基于元数据思考的方式,本身的实现很简陋,也并不代表需要这样完全从底层建立应用架构,在一些环节,社区早已存在很多相关库可以使用了。
本文是在厦门稿定的现场分享稿,感谢雪碧 @doodlewind 邀请。
搞前端时间比较长的同学都会知道一个东西,那就是HTC(HTML Components),这个东西名字很现在流行的Web Components很像,但却是不同的两个东西,它们的思路有很多相似点,但是前者已是昨日黄花,后者方兴未艾,是什么造成了它们的这种差距呢?
因为主流浏览器里面只有IE支持过HTC,所以很多人潜意识都认为它不标准,但其实它也是有标准文档的,而且到现在还有链接,注意它的时间!
http://www.w3.org/TR/NOTE-HTMLComponents
我们来看看它主要能做什么呢?
它可以以两种方式被引入到HTML页面中,一种是作为“行为”被附加到元素,使用CSS引入,一种是作为“组件”,扩展HTML的标签体系。
行为(Behavior)是在IE5中引入的一个概念,主要是为了做文档结构和行为的分离,把行为通过类似样式的方式隔离出去,详细介绍在这里可以看:
http://msdn.microsoft.com/en-us/library/ms531079(v=vs.85).aspx
行为里可以引入HTC文件,刚才的HTC规范里就有,我们把它摘录出来,能看得清楚一些:
engine.htc
<HTML xmlns:PUBLIC="urn:HTMLComponent">
<PUBLIC:EVENT NAME="onResultChange" ID="eventOnResultChange" />
<SCRIPT LANGUAGE="JScript">
function doCalc()
{
:
oEvent = createEventObject();
oEvent.result = sResult;
eventOnResultChange.fire (oEvent);
}<HTML xmlns:LK="urn:com.microsoft.htc.samples.calc">
<HEAD>
<STYLE>
LK\:CALC { behavior:url(engine.htc); }
</STYLE>
</HEAD>
<LK:CALC ID="myCalc" onResultChange="resultWindow.innerText=window.event.result">
<TABLE>
<TR><DIV ID="resultWindow" STYLE="border: '.025cm solid gray'" ALIGN=RIGHT>0.</DIV></TR>
<TR><TD><INPUT TYPE=BUTTON VALUE=" 7 "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" 8 "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" 9 "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" / "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" C "></TD>
</TR>
<TR><TD><INPUT TYPE=BUTTON VALUE=" 4 "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" 5 "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" 6 "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" * "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" % " DISABLED></TD>
</TR>
<TR><TD><INPUT TYPE=BUTTON VALUE=" 1 "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" 2 "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" 3 "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" - "></TD>
<TD><INPUT TYPE=BUTTON VALUE="1/x" DISABLED></TD>
</TR>
<TR><TD><INPUT TYPE=BUTTON VALUE=" 0 "></TD>
<TD><INPUT TYPE=BUTTON VALUE="+/-"></TD>
<TD><INPUT TYPE=BUTTON VALUE=" . "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" + "></TD>
<TD><INPUT TYPE=BUTTON VALUE=" = "></TD>
</TR>
</TABLE>
</LK:CALC>
</HTML>这是一个计算器的例子,我们先大致看一下代码结构,是不是很清晰?再看看现在用jQuery,我们是怎么实现这种东西的:是用选择器选择这些按钮,然后添加事件处理函数。注意你多了一步选择的过程,而且,整个过程混杂了声明式和命令式两种代码风格。如果按照它这样,你所有的JS基本都丢在了隔离的不相关的文件中,整个是一个配置的过程,分离得很干净。
除了这种计算器,还有规范文档中举例的改变界面展示,或者添加动画之类,注意它们的切入点,都是相当于附加在特定选中元素上的行为,即使DOM不给JS暴露任何选择器,也毫无影响,因为它们直接就通过CSS的选择器挂到元素上了。
这种在现在看来,意义不算明显,现在广为使用的先选择元素再添加事件,也是不错的展现和行为分离方式。
但另外一种使用方式就不同了。
狭义的HTML5给我们带来了什么?是很多新增的元素标签,比如section,nav,acticle,那这些东西跟原先直接用div实现的,好处在哪里呢?在于语义化。
所谓语义化,就是一个元素能清晰表达自己是干什么的,不会让人有歧义,像div那种,可以类比成是一个Object,它不具体表示什么东西,但可以当成各种东西来用。而nav一写,就知道,它是导航,它就像有class定义的一个实体类,能表达具体含义。
那么,原有的HTML元素显然是不够的,因为实际开发过程中要表达的东西显然远远超出这些元素,比如日历,这种东西就没有一个元素用来描述它,更不用说在一些企业应用中可能会出现的树之类复杂控件了。
不提供原生元素,对开发造成的困扰是代码写起来麻烦,具体可以看之前我在知乎的一个回复,第三点:
http://www.zhihu.com/question/22426434/answer/21433867
所以,大家都想办法去提供自己的扩充元素的方式,现在我们是知道典型的有angularjs,polymer,但很早的时候也不是没有啊:
http://msdn.microsoft.com/en-us/library/ms531076(v=vs.85).aspx
看,这就是HTC的添加自定义元素的方式,每个元素可以定义自己对外提供的属性、方法,还有事件,自己内部可以像写一个新页面一样,专注于实现功能。而且你发现没有,它考虑得很长远,提供了命名空间,防止你在一个页面引入两个不同组织提供的同名自定义元素。
这个东西就可以称为组件了,它跟外界是完全隔离的,外界只要把它拿来就可以用,就像用原生元素一样,用选择器选择,设置属性,调用方法,添加事件处理等等,而且,注意到没有,它的属性是带get和set的,这是多么梦寐以求的东西!
正是因为它这么好用,所以在那个时代,我们用它干了很多东西,封装了各种基础控件,比如树,数据表格,日期选择,等等,甚至当时也有人嫌弃浏览器原生select和radio不好看,用这么个东西,里面封装了图片来模拟功能,替换原生的来用。
当时也有人,比如我在04年就想过,能不能把这些扩大化,扩展到除了基础控件之外的地方,把业务的组件也这么搞一下,一切皆组件,多好?
但有些事情我直到后来很久以后才想明白,基于业务的端到端组件虽然写起来很方便,却是有致命缺陷的。
到这里为止,对HTML Components的回顾告一段落,也不讨论它为什么就没了之类,这里面争议太大,我只想谈谈从这里面,能看到Web Components这么个大家寄予厚望的新标准需要面对一些什么问题。
以下逐条列出,挨个说明,有的已经有了,有的差一些,有的没有,不管这么多,总之谈谈我心目中的这个东西应当是怎样的。
原因我前面已经说了,可能会有不同组织实现同类功能的组件,存在于同一个页面内,引起命名歧义,所以我想了很久,还是觉得有前缀比较好:
<yours:ComponentA></yours:ComponentA>
<his:ComponentA></his:ComponentA>甚至,这里的前缀还可以是个简称别名,比如yours=com.aaa.productA,这可能只有复杂到一定程度才会出现,大家不要以为这太夸张,但总有一天Web体系能构建超大型软件,到那时候你就知道是不是可能了。
这个前一段时间有的浏览器实现过,在组件内部,style上加一个scoped属性,这是正确的方向。为什么要这么干呢,所谓组件,引入成本越小越好,在无约定的情况下都能引入,不造成问题,那是最佳的结果。
如果你一个组件的样式不是局部的,很可能就跟主界面的冲突了,就算你不跟主界面的冲突,怎么保证不跟主界面中包含的其他组件的样式冲突?靠命名约定是不现实的,看长远一些,等你的系统够大,这就是大问题了。
一个自定义组件,应当能够跟主文档进行通讯,这个过程包括两个方向,分别可以有多种不同的方式。
除了事件,真没有什么好办法可以做这个方向的通讯,但事件也可以有两种定义方式,一种是类似onclick那种,主文档应当能够在它上面直接添加对应的事件监听函数,就像对原生元素那样,每个事件都能单独使用。另一种是像postMessage那样,只提供一个通道,具体怎么处理,自己去定义消息格式和处理方式。
这两种实现方式都可行,后者比较偷懒,但也够用了,前者也没有明显优势。
这个也可以有两种方式,一种是组件对外暴露属性或者方法,让主文档调用,一种是外部也通过postMessage往里传。前者用起来会比较方便,后者也能凑合用用。
所以,如果特别偷懒,这个组件就变得像一个iframe那样,跟外部基本都通过postMessage交互。
写到这里我是很纠结的,因为终于来到争议最大的地方了。按照很多人的思路,我这里应该也写隔离成局部作用域的JavaScript才对,但真不行,我们可以先假设组件内部的所有JavaScript都跑在局部作用域,它不能访问主文档中的对象。
我这里解释一下之前那个坑,为什么端到端组件是有缺陷的。
先解释什么叫端到端组件。比如说,我有这么一个组件,它封装了对后端某接口的调用,还有自身的一些展示处理,跟外界通过事件通信。它整个是不需要依赖别人的,初始加载数据都是自己内部做,别人要用它也很简单,直接拿来放在页面里就可以了。
照理说,这东西应当非常好才对,使用起来这么方便,到底哪里不对?我来举个场景。
在页面上同时存在这个组件的多个实例,每个组件都去加载了初始数据,假设它们是不带参数的,每个组件加载的数据都一样,这里是不是就有浪费的请求了?有人可能觉得一点点浪费不算问题,那么继续。
假设这个组件就是一个很普通的下拉列表,用于选取人员的职业,初始可能有医生,教师,警察等等,我把这个组件直接放在界面上,它一出现,就自己去加载了所需的列表信息并且展示了。有另外一个配置界面,用于配置这些职业信息,这时候我在里面添加了一个护士,并且提交了。假设为了数据一致性,我们把这个变更推回到页面,麻烦就出现了。
界面只有一个职业下拉列表的时候可能还好办,有多个的时候,这个更新的策略就有问题了。
如果在组件的内部做这个推送的对接,就会出现要推送多份一致的数据给组件的不同实例的问题。如果把这个放在外面,那我们也有两种方式:
这两种很类似,不管哪种,都面临一个问题:
数据源放在哪?
很明显不能放在组件内部了,只能放在某个“全局”的地方,但刚才我们假设的是,组件内部的JavaScript代码不能访问外界的对象,所以……
但要是让它能访问,组件的隔离机制等于白搭。最好的方式,也许是两种都支持,默认是局部作用域,另外专门有一个作用域放给JS框架之类的东西用,但浏览器实现的难度可能就大了不少。
可能有人会说,你怎么把问题搞这么复杂,用这么BT的场景来给我们美好的未来出难题。我觉得问题总是要面对的,能在做出来之前就面对问题,结果应该会好一些。
我注意观察了很多朋友对Web Components的态度,大部分都是完全叫好,但其中有一部分,主要是搞前端MV*的同学对它的态度很保守,主要原因应该是我说的这几点。因为这个群体主要都在做单页型的应用,这个里面会遇到的问题是跟传统前端不同的。
那么,比如Angular,或者React,它们跟Web Components的协作点在哪里呢?我个人觉得是把引擎保留下来,上层部分逐步跟Web Components融合,所以它们不是谁吃掉谁的问题,而是怎样去融合。最终就是在前端有两层,一层是数据和业务逻辑层,一层是偏UI的,在那个层里面,可以存在像Web Components那样的垂直切分,这样会很适宜。
最后说说自己对Polymer的意见,我的看法没有@司徒正美 那么粗暴,但我是认同他的观点的,因为Polymer的根本理念就是在做端到端组件,它会面临很多的挑战。虽然它是一个组件化框架,组件化最适宜于解决大规模协作问题,但是如果是以走向大型单页应用这条路来看,它比Angular和React离目标的距离还远很多。
这几年来,各类前端组件化框架层出不穷,江山代有框架出,各领风*几个月。
回头看两三年前(2014年初)的情况,大致是这样的:
现在来看,他们的状况分别是这样:
这里面,最大的冷门莫过于Polymer的衰落。Polymer的衰落意味着Web Components的受重视程度下滑。
原先,人们需要Web Components,是因为觉得在大型应用做组件化方案的时候,缺少一些东西,主要是一些逻辑和样式隔离,但这些事情,被用工程手段解决了,主要的贡献方是React和Webpack,它们用构建的方式,让逻辑和样式在构建之后,互相不影响,从而变通解决了这个问题。
在此之前,人们很少会觉得前端的编译、构建是这么必要,但现在,大部分人都觉得这么做理所当然,所以前端开始配置环境,编写实际上在浏览器中还未必能直接运行的ES新特性,给它们添加函数式编程的特性,添加基于类的面向对象模式等等。
如果一个3年前的前端穿越过来,他很可能会像清朝末年内地的人到了1920年的上海,瞠目结舌,不知所措,而从传统软件开发者(桌面端或者移动端)角度来看,Web前端开发终于走上正规道路了。
另外两个冷门,莫过于Angular1的停止增长,React的如日中天。
3年前,Angular1击败Backbone和Knockout的原因,是它的开发效率。无论是Backbone,还是Knockout,他们的数据模型都需要层层包裹,更新数据不能使用原生方法,而是必须使用包装过的方法。而Angular使用POJO,可以不必对数据进行包装,所以代码会简洁很多。这个时代,人们的主要关注点是数据驱动的界面。
Angular1虽然当时很火,但还是存在不少缺陷的,主要在于组件化理念的不强势,复杂数据变化的难于追踪等,还有一些前端领域不特别必要的理念,而React在这些方面是有所作为的,所以吸引了不少的用户。但在我看来,React能这么火的最大原因还是其工程化配套设施非常强大,而其他相比Angular的亮点,往深了看,仍然有很大改进余地。
此外,Vue也取得了很大的增长,能取得这么大增长的原因包括:在Angular1停止增长的同时,有很多人对React那套东西不完全认同,而Vue在很多方面,能满足这个群体的要求;Vue自身充分拥抱工程体系,也从React吸收了很多优点。
前几天,Angular2也发布了正式版,细节不评论了,在上次的回答里已经写得比较多。https://www.zhihu.com/question/50666914/answer/122280198
除此之外,还有几个值得关注的东西:
以上叙及,都是侧重视图层,当视图层的组件化做大、做深以后,除了其中少数框架,都需要额外借助某些数据层方案,以达到让数据流转方向单一,容易收敛的目的,比如React的Redux,Mobx,Vue的Vuex,Angular2中的RxJS等,另外一些框架比如CycleJS,从底往上彻底依赖RxJS这样的东西,有自己独特的一种方式去实现整个应用,所以无需借助额外的库和理念。
如何使用一个框架,很大程度上取决于我们的业务场景,常见的场景中,数据层并不会很复杂,例如各类控制台,所以在这类情况下,不引入数据层辅助机制也可以做得很好,使用Redux之类反而有自找麻烦的嫌疑。https://medium.com/@dan_abramov/you-might-not-need-redux-be46360cf367#.ww12q7y31
当组件层级较多的时候,可能会需要在组件通信的时候引入一些东西做转发,在这个方面,大家争议并不多,有不少React阵营的人会在单个组件内部也使用Redux,在这个点上,我有些保留。
这段时间我在RxJS上面作了不少思考,在数据层比较重的场景下,使用它会是一个很好的选择,然而,也会面临一个问题,这样构建的数据层,它与组件结合的那个位置应当怎么写代码?
如果参阅CycleJS的那套理念,它的上层也是完全使用Observable去处理DOM事件,界面更新之类,对此我也不能完全认同,这样开发效率还是偏低。在我的理想中,由RxJS构建的下层数据层,加上轻量MVVM视图层组件可以比较平衡地达到理想状态。
越是函数式,或者Reactive的东西,在数据层能起到的作用越大,但是在视图层则未必,因为视图层是最讲开发效率的地方,如果在这个层面也大量应用函数式的理念,实际上是加大了思考负担,因为这里可能导致函数不纯的东西太多了,而实际上大多数都不会影响结果,反而会让一直使用函数式编程的开发者面对很多干扰,陷入不必要的纠结:“我这里不纯,是不是不对,要不要想办法改成无副作用?”
而如果把这块放心地交给MVVM框架,就可以免去很多这种麻烦。我们可以尽可能地去把数据处理过程剥离到函数式的管道中,而仅仅是最后一步与视图的关联交给框架去自动处理,当框架触发一些事件的时候,它再反过来调用到这些函数式管道,就可以在数据正确性和开发效率之间达到一种取舍平衡。
实践的时候,有不少地方要考虑的。
上半年,我写过一篇《2015前端组件化框架之路》,现在大半年过去了,这段时间一直在思考,未来的东西是怎样的。
目前我主导着苏宁的云计算相关的所有前端项目,这些项目以控制台为主,几乎都广泛使用了Angular 1.x,一方面因为个人技能之前有积累,一方面因为产品的开发人员基本都是Java方向转岗,对Angular的接受度较高,上手非常快,开发效率也非常高。
但2015年,前端的世界发生了很多变化,这些变化快得超出我想象。在这个巨变的时代,产品的技术选型是个麻烦的事情,具体来说,有几个方面:
我之前没有预料到的,是ES6的普及之快。在此之前,对于新的语言特性,人们一般会等到支持的浏览器普及之后,才会大量使用,比如ES5,但由于Babel这样转译的工具出现,我们可以渐进使用,所以,开发过程中可以完全使用ES6甚至ES7的特性编写代码,然后通过构建去达到兼容的结果。
有鉴于此,在未来的项目中,使用ES语言新特性进行开发,是一个必然要做的事情。但,这并不能算是整体方案。整体的方案应当包括但不限于:
所以,我们面临的,还是基础框架选型这么一个重大问题。照理说,使用Angular 1.x,后续应当选择往2.0版本过渡,但现在这个阶段,乱花迷人眼,谁也不知道未来的事情怎样,在这一层上,我个人觉得还是要再看看。
于是就卡在这里了,这个选不了,后面的事情都没法考虑做了吗?
也不尽然,我考虑了一段时间,觉得虽然每个层面都比较麻烦,但至少可以分层隔离一下。比如说,我们选了某个UI层的组件化框架,并不意味着对下层的数据模型和业务逻辑就有很强约束,至少说,这层还是有很多可选方案。
通常我们在前端,可以对一个Web应用这样分层:
UI层(View) -- 业务逻辑层(ViewModel / Controller) -- 数据层(Model)
比如说,数据层,有Relay,有GraphQL,有Falcor,但我们还可以继续使用原先的RESTful API啊。我们可以不使用某框架自带的请求库,比如$.get,比如$http,但我们还可以使用super agent这样独立的,框架无关的辅助请求库啊。甚至说,我们不想使用XHR了,还可以使用Fetch啊。
所以,把Web应用的前端先分层一看,发现每个层里面,都有很多独立的可选方案,而这些方案是可以组合的,比如说:
上层用React,下层用Falcor或者RESTful,然后把上层换成Vue,好像也没有什么不对啊?下层完全可以不动,也不需要就把每层代码都改一遍啊?
这样一来,我们可以先不管UI层,直接先把下面两层全部构建出来,这个部分不对DOM产生任何依赖,所以,跟上层框架没有关系,也无需按照上层框架的约定。
我们引入一个框架,对整个系统来说,最大的影响是会产生一些约定。有时候我们需要这些约定来帮我们规范代码,但在现在这种形势下,会尽可能希望框架本身不要产生约定,由我们自己,按照ES自身的一些机制来形成代码规范。
比如说,我们使用module,class之类的语法特性,基于传统的OO方法论进行一些规划,利用各种设计模式。或者,我们也可以基于函数式的理念,进行另外一个方向的规划。总之,这个层面的东西是纯业务的,可测试的,可独立运行的。
在构建模型层和业务逻辑层的过程中,我们可以使用ES6,也可以使用TypeScript。之前我曾经有个断言:如果ES6普及得快,TS的形势就会不太好。这主要是因为考虑到如果一个开发者已经在使用ES6,他去使用TS的可能性并不会很大,而如果他到ES6流行的时候尚未接触TS,后面接触TS的可能性就比较小,直接用ES6的可能性比较多。
不过,当业务逻辑比较复杂的时候,使用TS会有一些优势。即使不使用TS,我也建议把数据模型预先定义出来,在实体类里面做一些事情,尽可能使用实体类来构建数据,而不是直接用字面量来定义。当应用规模变大的时候,“严谨性”变得更加重要。
另外一个角度,如果我们要尽可能构建框架中立的业务逻辑层代码,最好是脱离上层框架的绑定监控机制,自己通过比如getter,setter这样的方式,实现数据模型的内部联动,所以从这个角度,预定义数据模型也是必要的。
在这个基础上,再回到我们的现实来,在文章开头,我提出了几个要考虑的可能,现在可以逐一回答了:
1. 如果2-3年后新开始一个业务项目,可能会有什么样的技术方案?
底层如上所述,上层根据当时情况判断选择
2. 如果现在立刻开始一个新业务项目,可能会有什么样的技术方案?
底层如上所述,上层使用Angular 1.4或者Vue之类的成熟框架,同时,使用ES6开发
3. 如果持续维护老的项目,后面可能会对它们有怎样的迁移方案?是逐步迁移,还是推倒重做?
先逐步重构,维持UI层框架不变,把底层重构成上述那样,然后引入ES6,先搞成方案2这样,后续再考虑迁移上层。
4. 在PC端项目为主体的业务体系里,如果将来某个时机出现了移动端项目,该如何去选型,并且利用之前的业务代码?
先把PC端重构如方案3,然后,PC端可继续使用Angular,移动端上层选用Vue之类性能较好的轻量库,PC端与移动端共用业务逻辑层。
以前有一段时间,我一直觉得Angular的all in one是一种挺好的策略,但最近考虑了很多事情之后,觉得将来这种方案的优势会逐渐削弱,所以,现在我也觉得纯粹做上层视图框架的Vue之类有不少好处。在未来,约束越强的框架很可能越不受欢迎,基于ES自身的语言特性做业务代码约束才是王道。
这篇主要是比较笼统地谈一些想法,后面会写两篇具体细节策略的考虑。
在Angular中,存在作用域的继承。所谓作用域的继承,是指:如果两个视图有包含关系,内层视图对应的作用域可以共享外层视图作用域的数据。比如说:
<body ng-app="test">
<div ng-controller="OuterCtrl">
<span ng-bind="a"></span>
<div ng-controller="InnerCtrl">
<span ng-bind="a"></span>
<span ng-bind="b"></span>
</div>
</div>
</body>var app = angular.module("test", []);
app.controller("OuterCtrl", function ($scope) {
$scope.a = 1;
});
app.controller("InnerCtrl", function ($scope) {
$scope.b = 100;
});内层的这个div上,一样也可以绑定变量a,因为在Angular内部,InnerCtrl的实例的原型会被设置为OuterCtrl的实例。
我们改变一下这个示例,如果在内层作用域上,对a进行赋值会怎样?
<body ng-app="test">
<div ng-controller="OuterCtrl">
<span ng-bind="a"></span>
<div ng-controller="InnerCtrl">
<span ng-bind="a"></span>
<span ng-bind="b"></span>
<button ng-click="increasea()">increase a</button>
</div>
</div>
</body>var app = angular.module("test", []);
app.controller("OuterCtrl", function ($scope) {
$scope.a = 1;
});
app.controller("InnerCtrl", function ($scope) {
$scope.b = 100;
$scope.increasea = function() {
$scope.a++;
};
});点击这个按钮的时候,发现了一个问题,内层有了a,而且值在增加,外层的不变了。这是为什么呢?
因为它其实是通过原型集成来做到这样的。像上面这样的包含关系,内层scope的prototype被自动设置为外层的scope了,所以,才可以在内层使用这个a。这时候在内层给a赋值,当然就赋到它自己上了,不会赋值到原型的那个对象上。
同理,如果内外两层作用域上存在同名变量,在内层界面赋值的时候只会赋到内层作用域上的那个变量,不会影响到外层的。
那么,除了显式的ng-controller,Angular还会在什么地方引入视图模型的继承呢,主要是这些:
在Angular里面,有ng-repeat指令,可以用于遍历数组元素、对象属性。
<ul>
<li ng-repeat="member in members">{{member.name}}</li>
</ul>单从这个片段看,看不出视图继承的意义。我们把这个例子再拓展一下:
<ul>
<li ng-repeat="member in members">{{member.name}} in {{teamname}}</li>
</ul>它对应的视图模型是这么个结构:
function TeamCtrl($scope) {
$scope.teamname = "Disney";
$scope.members = [
{name: "Tom Cat"},
{name: "Jerry Mouse"},
{name: "Donald Duck"},
{name: "Micky Mouse"}
];
}好了,注意到这里,teamname跟members里面的成员其实不在一层作用域,因为它给循环的每个元素都建立了单独的作用域,如果不允许视图模型的继承,在li里面是没法访问到teamname的。为了让这段话更容易理解,我作个转换:
var teamname = "Disney";
var members = [
{name: "Tom Cat"},
{name: "Jerry Mouse"},
{name: "Donald Duck"},
{name: "Micky Mouse"}
];
for (var i=0; i<members.length; i++) {
var member = members[i];
console.log(member.name + " in " + teamname);
}ng-repeat内部给每个循环造了个作用域,如果不这么做,各个member就无法区分开了。在这种情况下,如果没有作用域的继承关系,在循环内,就访问不到这个teamname。
在这里,我觉得不一定非要造子作用域,它搞子作用域的原因无非是为了区分每个循环变量,但其实可以换一种写法,比如,avalon框架里的repeat写法就很好,在属性上指定循环元素变量名,然后给每个元素生成ObjectProxy,包装每个元素的数据,附带$index等有可能在循环过程中访问的东西。
因此,这里其实不必出现Scope的新实例,而是用一个ObjectProxy返回元素数据即可。
很可能我们的场景还有些简单,再来个复杂的:
<div ng-controller="TestCtrl">
<div ng-repeat="boy in boys">
<span style="color:red" ng-bind="boy.name"></span>
<span style="color:green" ng-bind="boy.age"></span>
<button ng-click="boy.growUP()">grow up</button>
</div>
</div>function TestCtrl($scope){
$scope.boys = [{
name: "Tom",
age: 5,
growUP: function() {
this.age ++;
}
}, {
name: "Jerry",
age: 2,
growUP: function() {
this.age ++;
}
}];
}这里,每个boy都能自增自己的年龄,原理与上面相同,这里面growUp方法的调用,用ObjectProxy应当也能处理。
另外一个造成视图继承的原因是动态引入界面模板,比如说ng-include和ng-view等。
inner.html
<div>
<span ng-bind="name"></span>
</div>outer.html
<div ng-controller="OuterCtrl">
<span ng-bind="name"></span>
<div ng-include="'inner.html'"></div>
</div>function OuterCtrl($scope) {
$scope.name = "outer name";
}对上面这个例子来说,ng-include会创建一层作用域,如果不允许作用域继承,那么内层的HTML中就拿不到name属性。那么,为什么ng-include一定要创建子作用域呢?在这个例子里,创建子作用域并不一定必要,直接让两层HTML模板对应同一个视图模型的实例,不就可以了?
我感觉他可能是为了省事,否则要判断动态include进来的这个HTML片段中,是否还指定了别的控制器,如果不管三七二十一就创建子作用域,这事就省了。ng-view跟ng-include的情况还不一样,因为ng-view可能会在路由里面指定新的控制器,所以判断起来就更复杂了,基本上只能创建新作用域。
视图模型的继承在很多情况下是很方便,但造成问题的可能性也会非常多。真的需要这样的共享机制吗?
大家都知道,组件化是解决开发效率不高的银弹,但具体如何做组件化,人们的看法是五花八门的。Angular提供的控制器,服务,指令等概念,把不同的东西隔离到各自的地方,这是一种很好的组件化思路,但与此同时,界面模板层非常乱。
我们可以理解它的用意:只把界面模板层当作配置文件来使用,压根就不考虑它的可复用性。是啊,反正只用一次,就算我写得乱,又怎样呢?可是在Angular中,界面模板是跟控制器密切相关的。我很怀疑控制器的可重用性,注意,它虽然叫控制器,但其实更应该算视图模型。
从可重用性角度来看,如果满分5分的话,整个应用的这些部分的得分应当是这样:
从这里我们可以看到,以可重用度来排序,最有价值的是服务和控件,服务代表着业务逻辑的基本单元,控件代表了UI层的最小单元,所以它们是最值得重用的。
现在来看看中间层:视图模型值得重用吗?还是值得的。比如说,同一视图模型以不同的界面模板来展现,这就是一种很好的方式。如果说,同一个视图模型要支持多个界面模板,这些界面模板使用的模型字段或者方法有差异,也可以考虑在视图模型中取并集。例如:
function TestCtrl($scope) {
$scope.counter = 0;
$scope.increase = function() {
$scope.counter++;
};
$scope.decrease = function() {
$scope.counter--;
};
}1.html
<div ng-controller="TestCtrl">
<span ng-bind="counter"></span>
<button ng-click="increase()">increase</button>
</div>2.html
<div ng-controller="TestCtrl">
<span ng-bind="counter"></span>
<button ng-click="decrease()">decrease</button>
</div>3.html
<div ng-controller="TestCtrl">
<span ng-bind="counter"></span>
<button ng-click="increase()">increase</button>
<button ng-click="decrease()">decrease</button>
</div>三个视图的内容是有差异的,但它们仍然共用了同一个视图模型,这个视图模型的内容包含三个视图所能用到的所有属性和方法,每个视图各取所需,互不影响。
这时候,我们再来看视图模型的继承会造成什么影响。如果是我们有了视图模型的继承关系,就意味着界面模板的包含关系必须跟视图模型的继承关系完全一致,这个很大程度上是增加了管理成本的,也造成了视图模型的非通用性。
刚开始提到的例子,如果内外层有同名变量,要在内层作用域中显式变更外层的变量,需要从scope.$parent里面去赋值。而一旦在代码中写了$parent这样的东西,就意味着视图模型只能以这样的方式包含了,甚至说,如果不想变更它们的包含关系,只想变更包含层级,也是不可能的,那说不定就要变成$parent.$parent了。
我们看个场景:
<body ng-app="test">
<div ng-controller="OuterCtrl">
<span ng-bind="a"></span>
<div ng-controller="InnerCtrl">
<span ng-bind="a"></span>
<button ng-click="increaseOuterA()">increase outer a</button>
</div>
</div>
</body>var app = angular.module("test", []);
app.controller("OuterCtrl", function ($scope) {
$scope.a = 1;
});
app.controller("InnerCtrl", function ($scope) {
$scope.a = 100;
$scope.increaseOuterA = function() {
$scope.$parent.a++;
};
});这里,因为在InnerCtrl中显式调用了$parent,所以它跟OuterCtrl的视图关系就只能非常固定了。如果说,我们这时候把里面这个div提取出来,放在单独的HTML文件中,然后使用ng-view或者ng-include引入它,因为它们本来就要创建一级作用域,所以会导致这个中间又隔了一级,$parent变成了$parent.$parent,非常不好。
代码如下:
<body ng-app="test">
<div ng-controller="OuterCtrl">
<span ng-bind="a"></span>
<div ng-include="'inner.html'"></div>
</div>
</body>inner.html
<div ng-controller="InnerCtrl">
<span ng-bind="a"></span>
<button ng-click="increaseOuterA()">increase outer a</button>
</div>个人认为,在AngularJS中,视图模型的继承虽然使得很多时候代码写起来比较方便,但有些时候会造成很多麻烦。当编写视图模型代码的时候,应当尽量避免父子作用域存在同名变量的情况,以防止造成隐含的问题。不了解AngularJS实现原理的朋友很可能在这里踩很多坑。
所谓Web应用,指的是那些虽然用Web技术构建,但是展现形式却跟桌面程序或者移动端原生应用类似的产品。这类产品的特点是逻辑较重,交互复杂,通常也是单页式的。
主要包括:
大部分可以等同于所谓的“单页面应用”,可以参见之前写的这篇:构建单页Web应用
组件化的最重要作用就是提升开发和维护的效率。
最原始的组件,其功能可以单独开发测试,然后逐级拼装成更复杂的组件,直到整个应用。每一级都是易装配,可追踪,可管控的。
在开发Web应用的时候,无论技术选型,工程方案,还是对人员的技能需求都是有一些特点的,最重要的特点莫过于组件化。
组件化这个词,在UI这一层通常指“标签化”,也就是把大块的业务界面,拆分成若干小块,然后进行组装。
狭义的组件化一般是指标签化,也就是以自定义标签(自定义属性)为核心的机制。
广义的组件化包括对数据逻辑层业务梳理,形成不同层级的能力封装。
很多人会把复用作为组件化的第一需求,但实际上,在UI层,复用的价值远远比不上分治。
分治带来的是可管理性,相比一大团HTML和JavaScript的混杂,组件化之后,整个应用成为了一个很清晰的树,一眼就能看清包含关系,也能够很容易理清数据的传递方向。而且,整个应用可以从叶子节点,逐步向上测试,哪一级出了问题,可以很容易发现。
但是复用就很麻烦了,因为组件的内部实现与外部接口都很难取舍。很可能我们在设计之初,都是把组件设想成一个单一的东西,然后在实际项目中,发现最后都面目全非了。
所以,复用的工程成本很高,在使用的时候需要权衡,除了最常用了基础控件,其他的不要刻意追求。
对待资产,我们一般会比较重视,会有长远的规划,优雅的实现,持续的维护,细致的测试,详尽的文档等等,但是对于耗材,基本上会视为一次性的东西,不会有这么严谨的过程。
按照上面的分类,组件明显属于资产,而模板一般属于耗材。
在有些框架中,模板的使用度较低,但是常见的包含双向绑定的框架中,都有很大比重的模板。有些模板是嵌入到组件内部的,有些则是独立存在的,比如Angular中,可以使用ng-include动态包含一个模板,这个模板就是独立的了。
大部分Web系统的前端部分,其实都是耗材比资产多,人们选用Web相关技术的一个典型心理就是容易写,而且相对随意一些。
这个问题要从几个方面回答:
在展示内容偏多的网站中,模板是一个很常见的东西,它通过某种占位的HTML,包含简单的文本格式化,简单的条件判断,做一些很基础的动态内容生成操作。
但是在Web应用中,因为强调组件化,所以很多人对模板的重要性有些忽视了。这里的“模板”指的是双向绑定的动态模板,不是传统的静态模板,这个基本概念之前有过回答:
Handlebars 和angularjs有什么区别?分别在什么情况下使用?
在Web应用中,应当如何看待模板的地位呢?我们先来看另外一个问题:
HTML,CSS,JS,这三者里面,谁是整个Web工程的入口?
展示型的Web项目中,毫无疑问HTML是入口,也是根基,不管是JS还是CSS都是作为它的辅助。但到了Web应用中,还是这样吗?我们很多Web应用实际上是以JS为入口的,HTML不再被视为骨架,而是视为一种动态的东西,由JS创建并管理。
在这个前提下,人们对动态的HTML又有两种不同方式的认知:它是模板,还是组件?
从典型的MVVM三层中,我们可以看到,View Model是Model的外围,View是View Model的外围,一层一层出去,外层实际上可以视为内层的配置文件。而如果从组件化的角度出发,View跟View Model共同构成了组件层。
因此,动态的HTML究竟算是什么,取决于我们从什么角度去看待它,也取决于我们在使用什么框架。
我们现在开发Web应用,一般也不会从0开始,通常是选取一个核心框架(库),然后在此基础上确定一些规则,逐步构建外围体系,现在比较火的有React,Angular,Vue,Polymer等。
“MV*”:Angular,Vue等
“反应式”:React,Reactive等
标准增强:Polymer
MV*: 分层,绑定
React: 组件化,单向数据流
以上提到的几个东西,在组件化这块,可能争议最大的是Angular,因为Angular 1.x的官方指引中,并未在组件化这个方向上作一些指导,也没有提倡,甚至连建议都没有,而React和Polymer是天然组件化的,Vue提供的文档里以很大篇幅详细说明了组件化的机制和实践方式。
但是,这并不是说,Angular 1.x就是与组件化冲突的,它仍然可以通过directive等相关机制,实现自己特色的组件化方案。
Directive可以实现自定义标签和自定义属性,这两者可以理所当然地归类到组件中,但是,在Angular中,模板本身也可以视为一种组件,一种轻量级的组件,它不一定就是静态的,仍然可以有一些简单的操作和行为。
Directive和模板相当于MVVM中的View层,它们的运行,一般是离不开ViewModel的支撑的,在Angular中,这就是controller。所以,如果以Angular框架来说,directive和模板、controller,共同形成了视图层组件体系。推广到其他MVVM框架来说,也就是View和ViewModel,而React整体就处于视图层,所以这两者算是一个对等关系。
无论是哪种框架,在开发Web应用的时候都要面临一个问题:业务数据层如何设计?
这一层东西,其实目前各路框架都未提出有力的解决方案,大家的重点都还是在做上层UI。
但是从长远来看,业务数据层会是一个基本没有框架差异的东西,同一个方案,大家都可以用,比如说之前有人把flux之类的东西放到React之外的框架用,也一样可以。
而上层UI,其实现过程现在也很明确地是要往Web Components靠拢,实现逻辑都是使用ES新标准,数据绑定机制都是getter setter或者observe,加载方式都在考虑HTTP2之类,一旦某个领域出现了理念突破,很快就会被其他框架吸收融合。
所以总的来说,各框架是趋同的。
当我们把一个应用使用组件化的理念进行构建的时候,整个应用就形成了一个倒置的树,树根就是应用本身,其余节点是层层嵌套的组件们,叶子节点是最基础的组件。
如果我们有两个不同团队,同样基于组件化的理念,使用同一个框架,做同样功能的产品,最终形成的组件树可能差别很大,这个差别主要在于:
把什么视为组件,组件的粒度是怎样的。
在组件化的应用中,组件树的层级不宜过深,从根节点算起,应当尽可能控制在3到5层内,如果层级太多的话,会造成组件通讯和数据传递的负担。
在一个组件化的应用中,会存在组件之间的数据传递。
以React为例,如果存在两级嵌套的组件:
<TodoList>
<TodoItem></TodoItem>
<TodoItem></TodoItem>
<TodoItem></TodoItem>
</TodoList>这里面可能存在:
这里面,前三种都可以通过该组件的props传递进去,属于对组件的常规用法,第四种,则属于对数据层的利用。
那么,我们如何权衡两种数据通讯方式呢?
一个比较粗糙的办法是,从数据模型的角度去考虑。如果一个组件所要获取的数据模型是比较独立的,不依赖其他业务数据,可以直接去获取,如果跟其他这个数据模型跟其他数据之间存在耦合,比如主从联动关系,由父组件进行分发会比较好。
另外一个着眼点是权衡上下两级组件之间的关系密切程度,如果它们之间的关系很强,对外界来说是一个紧密结合的整体,可以直接在它们之间传递数据,如果关系不强,或者在组件树上距离较远,适合通过第三方转发通信。
从这里我们得出的结论是:
并不是选择了框架,就可以顺利把一个Web应用做出来了,还需要一件很重要的事,那就是:业务架构。组件之间的关系都是需要统筹规划的,这里面有很多技巧,可以参见一些大型桌面程序的架构,从中获取不少经验。
全组件化还带来另外一个课题,那就是数据层的设计。比如说,我们可能有一个选择城市的列表组件,它的数据来源于服务端的一个查询,为了方便起见,很可能你会选择把查询的调用封装在组件内部,然后这个组件如果被同一个可见区域的多个部分使用,或者是这个查询及其数据结果被同一可见区域的其他组件也调用了,就出现了两个问题:
另外,对于关联数据的更新,也不太便于控制,RESTful之类的服务端接口规范在复杂场景下会显得力不从心。
在数据通信这层,Meteor这样的框架提出了自己的解决思路,跳出传统HTTP的局限,把眼光转向WebSocket这样的东西,并且在前端实现类似数据库的访问接口。
Facebook对此问题提出了更暴力的解决方式,Relay和GraphQL,这两个东西我认为意义是很大的,它解决的不光是自己的痛点,而且是可以用于其他任意的前端组件化体系,对前端组件化这个领域的完善度作出了极其重大的贡献。
在不少组件化框架,包括桌面端的,Web端的,都有“可视化继承”这个概念,比如说,我们有一个List组件用于展现列表数据,然后,又有另外一个需求,在这个列表上显示checkbox,用于多选。在很多组件化框架里,都会存在这样的继承关系:
class CheckList extends List {
}我觉得有必要探讨一下这里这个extends,是不是一定要用这样的方式来实现一个形态类似原组件的新组件?
在全组件式体系中,继承是不如组合优雅的,以上面这个情况来说,它会在render方法里,重新实现自己的东西,所以,它继承了什么呢,很少很少的东西。
我们可以换种思路,保持组件不变,通过不同的配置项使其相应不同的功能。
在实现一个很基础的UI组件的时候,我们一般都会想要把它搞得既简洁,又强大,但这件事情本身是很难权衡的,针对不同的组件,可能会有不同的策略。
我们在开始实现组件的时候,通常会尽可能考虑需求,然后将其作为默认实现,并且对外提供一些配置项,用于开关这些功能。
还是用列表举例,比如我们有一个列表,可以用于选中,内部结构可能会搞成这样:
<ul class="list">
<li></li>
<li class="selected"></li>
<li></li>
<li></li>
</ul>然后对外的形式这样:
<List data="arr"></List>
或者这样:
<List>
<ListItem data="aaa"></ListItem>
<ListItem data="bbb" selected></ListItem>
<ListItem data="ccc"></ListItem>
<ListItem data="ddd"></ListItem>
</List>
然后,加需求了,列表有多种形态,一种横着排的,一种竖着排的,一种片状的,每行N个,排满换行,然后这里面还再分,元素是否定宽,还是流式。
那我们就面临着几个选择:
<List type="Tile"></List>
加配置属性,或者增加不同的元素,如TileList,HorizontalList等等。
接着,我们来了对列表项的自定义需求:
所以,这个组件变得非常复杂,对外的接口很复杂,内部实现也很复杂,代码更是臃肿不堪。摆在我们面前的有这么一个矛盾:
怎样让我们的组件既强大,又便于使用?
面对此类场景,我想给出一个解决方案,那就是:
为了说明这个理念,我花了大约一个小时,写了这样一个demo,看其中datagrid那段。
其主体实现逻辑是这段:datagrid.js
看看这个代码,再对比所展示出来的这些功能,会不会觉得差异有点大?
奥秘在哪里呢,在于我们给每种场景传入了不同的模板,如下:
<sn-datagrid grid-cols="cols" grid-data="students"></sn-datagrid>
<sn-datagrid grid-cols="cols" grid-data="students" header-cell-tpl="sortHeaderTpl"></sn-datagrid>
<sn-datagrid grid-cols="checkboxCols" grid-data="students" cell-tpl="checkboxTpl" header-cell-tpl="checkboxHeaderTpl"></sn-datagrid>
<sn-datagrid grid-cols="buttonCols" grid-data="students" cell-tpl="buttonCellTpl" header-cell-tpl="checkboxHeaderTpl"></sn-datagrid>这个理念其实并不新鲜,在Adobe Flex的组件框架中,List系列的组件就通过开放自定义itemRenderer的方式,极大提升了可扩展性,并且保持原组件实现的优雅。同理,使用类似的方式,用React也可以这样实现。
但我们这个地方会更加简洁,其原因在于两点:
对于Angular的这个作用域机制,很多人都反感,但我认为,它并不一定就比全部在传递时候赋值的immutable机制差,在业务开发中,组件化固然是有用,但频繁的上下级数据传递可能会让整个系统更加零碎化,数据层的零碎化是非常不利的。
今年大家有了React,黑Angular就格外狠了,我举这个例子也是为了说明,Angular 1.x的设计,除了module是完全的败笔,变更检测机制值得商榷,其他的并无大问题,甚至还存在一些优势。使用某框架的时候,如果熟悉原理并加以合理利用,能够巧妙解决业务上遇到的很多问题。
除了上面提到的,模板还有另外的意义。
我们会发现,在React的体系里,HTML和DOM本身还重要吗?重要性其实是大幅降低了,所以我们会看到ReactNative,ReactCanvas之类的实现,而且,最新版本的React中,把React DOM单独抽取出来了,这意味着,React未来只把DOM作为它的可选视图渲染层之一。
但是我们必须认识到,在Web体系中,HTML和DOM有不可替代的优势,它们是当前Web技术的根基,尽管有缺点,并不代表应当被抛弃,至少是在现在这个时代。
所以,在Web应用这样的体系中,组件的实现技术还是应当尽可能基于DOM来考虑。也正是在这种场景下,模板和绑定技术仍然存在很重要的作用,比如可访问性等等特性,都是别的非DOM体系所缺乏积累的。
此外,模板某种程度上可以视为“组件的字面量形式”,也就是组件的一种序列化形式,如果我们要动态加载组件,使用模板会非常方便,这也就是我上面那个数据表格例子的意义所在。
HTML本身的标签,其实做组件化是有些别扭的,这个原因在哪里呢,两点:
在其他一些体系里并不存在这样的问题,比如WPF,比如Adobe Flex,因为他们没有这样的“历史负担”。
另外一个方面,所谓的组件嵌套,从声明式代码的编写方式来看,就是标签的嵌套。标签嵌套的含义在UI层被赋予了更多潜规则,比如这个代码:
<Panel>
<Service/>
</Panel>如果Service并非有UI展现的东西,而是像polymer里面的core-ajax那样,或者Adobe Flash体系里的WebService,你可以把它当做Panel实例里面的一个成员变量,然后设置它的属性或者调用方法。但是,对于更普通的情形:
<Panel>
<Button></Button>
</Panel>同样的写法,这个含义一样吗?很明显不一样,因为Button也是一个可展示的组件,这时候你默认它是被放置在Panel的展现内部,作为它的可视化子元素的。也就是说,这时候,你不但在逻辑上把两者建立了关联,还要在布局上考虑它们的约束。
如果你的外层元素是一个布局为主的容器,那好说,比如这里的Panel,我们默认它有一块展示区,所有子节点都放在里面以某种方式排版,或者flow,或者float,或者flex,甚至border-layout,东西南北中。
如果外层元素不是一个布局为主的容器,允许它嵌套别的东西,逻辑上就很难理解。它必须约束自己所能允许放置的子元素的类型。比如:
List下面就只能放ListItem类型的东西。
我觉得,在有了类似angular那种自定义元素、属性的方式(具体实现可以改进),或者React那种自定义标签之后,Web Components的使用场景变得很尴尬了。
我们现在看Web Components的作用,主要还是隔离,包括对逻辑和内部展现的隔离。JavaScript逻辑的隔离其实作用不是很大,因为我们用其他办法也能达到相同的效果,但是Shadow DOM和Scoped CSS这两个东西就很耐人寻味了。
比如说,我们现在用Shadow DOM实现了一个东西,然后,在浏览器里面打开查看开关,还是可以看到里面的东西,那如果不纠结它的实现机制的话,跟使用某种组件化框架创建的自定义元素相比,差异是不是就没有那么大了?因为写的时候都只是写一个自定义的元素,运行的时候在内部放了具体实现细节。
至于Scoped CSS,更有意思,因为它实际上带来了对已有的工程方案的挑战。我们思考Web Components普及之后的组件化思路,在样式这块几乎都必然走到一条路上,那就是:样式的inline化,把组件的样式全部内置,否则,组件的独立性无从保证。但我们不要忘了,/deep/和::shadow选择器是用来干什么的?这是允许外部的样式对组件内部的东西作调整,这是一个很无奈的选择,因为确实有这种场景,比如你需要对所有组件设置全局风格之类。另外上次听谁说到父选择器,允许元素控制其上级的样式……真是被震惊了,我理解这种需求,比如某种图片放到一个容器里,不管它放在哪,都希望其父容器背景如何如何,但是,这是对组件化技术的一种挑战……
在实际工程中,样式inline化是有很多缺陷的,比如刚才提到的:theme怎么办?从我近期的一些文章可以看到观点,就是不赞同全组件化,尤其是在上层更倾向于直接使用HTML模板而不是封装过的组件,因为我认为:Web,或者说泛HTML体系,它跟其他任何的客户端展现技术,比如Java Swing,WPF,QT,Adobe Flex之类相比,最本质的不同在于极其强大的CSS,正是因为有它,我们才有可能极尽所能地、简单而优雅地打造不同的用户体验,而不是用各种画布去绘制像素。如果你决定在底层去各种绘制,那确实可以把UI层全组件化,但这个事情也只能在有限范围干,比如移动端,比如游戏,否则代价不堪设想。
面对theme的需求,我们只能通过往动态构建的路上去走,这里面也会有很多要考虑的点。
看到这里,有什么感觉?想要在有一定复杂度的Web应用中全面推行组件化,需要考虑的东西非常多,相当于从农业社会到工业社会的飞跃,我们不能期望一蹴而就,需要通盘考虑。
各类客户端开发技术中有很多值得借鉴的地方,结合Web技术自身的一些特点,可以触类旁通。
在Web前端技术飞速发展的今天,Angular 1.x可以说是一个比较旧的东西,而ES6是新生事物。我们想要把这两个东西结合起来,感觉就好像“十八新娘八十郎,苍苍白发对红妆。”但这件事的难度也并不大,因为我们最终是要把ES6构建成ES5代码,而ES5代码是可以很容易和Angular 1.x协作的。
不过,为什么我们要干这件事呢?
在这篇文章中,我提到过:
尽管在整个前端开发圈中,大家并不是很欢迎Angular,而且很多人认为它的1.x版本已经衰落,但我跟 @小猪有个观点是一致的,那就是:“在企业开发领域,ng1的应用才方兴未艾”,也就是说,它在这个领域其实还是上升阶段。
所以,在不少场合下,它还是要承载一些开发工作,部分老系统的逐步平滑迁移也是比较重要的。
做这件事的另外一个意图是:虽然未来的框架选型会有不少争议,但有一点毋庸置疑,那就是业务JS代码的全面ES6或者TS化,这一点我们现在就可以着手去做,并且可以尽量把数据和业务逻辑层实现成框架无关的形式。
在这篇里大致讲了点对这方面的考虑。
Angular 1.x的module机制是比较别扭的,也是一种框架私有的模块机制,所以,我们需要淡化这层东西,具体的措施是:
举例来说,我们有一个moduleA,里面有serviceA,serviceB,那么,就有这样一些文件:
serviceA的实现,service/a.js
export default class ServiceA {}serviceB的实现,service/b.js
export default class ServiceB {}moduleA的壳子定义,moduleA.js
import ServiceA from "./services/a";
import ServiceB from "./services/b";
export default angular.module("moduleA", [])
.service("ServiceA", ServiceA)
.service("ServiceB", ServiceB)
.name;存在一个moduleB要使用moduleA:
import moduleA from "./moduleA";
export default angular.module("moduleB", [moduleA]).name;注意,这里为什么我们要export module的name呢?这是为了这个module的引用者方便,如果某个module改名了,所有依赖它的module可以不修改代码。
在这里我们可以看到,a.js,b.js,moduleA.js这三个文件,只有moduleA是作为一次性的配置项,而a和b可以尽量实现成框架无关的代码,这样将来的迁移代价会比较小。
在Angular 1.x里面,有factory和service两个概念,其实这两者可以替换,service传入的是构造函数,通过new创建出实例,而factory传入的是工厂函数,通过对这个工厂函数的调用而创建实例。
所以,如果要使用ES6代码来编写这个部分,也就很自然了:
serviceA的实现,service/a.js
export default class ServiceA {}serviceA的模块包装器moduleA的实现
import ServiceA from "./service/a";
export angular.module("moduleA", [])
.service("ServiceA", ServiceA)
.name;factoryA的实现,factory/a.js
import EntityA from "./model/a";
export default function FactoryA {
return new EntityA();
}factoryA的模块包装器moduleA的实现
import FactoryA from "./factory/a";
export angular.module("moduleA", [])
.factory("FactoryA", FactoryA)
.name;注意看这个例子中,FactoryA函数的返回结果是new EntityA,在实际项目中,这里不一定是通过某个实体类创建的,也可能是直接一个对象字面量:
export default function FactoryA {
return {
a: 1
};
}在ES6下,factory的定义其实可以有一些优化,比如说,我们可以不需要factory/a.js这个文件,也不需要这层factory封装,而是在module定义的地方,这样写:
import EntityA from "./model/a";
export angular.module("moduleA", [])
.factory("FactoryA", () => new EntityA())
.name;使用ES6定义controller的方式大致与service相同,
有一点值得注意,刚才我们提到的模块定义方式里,并没有考虑依赖注入,但实际业务中一般都要注入点东西,那怎么办呢?
有两种办法:
controllers/a.js
export default class ControllerA {
constructor(ServiceA) {
this.serviceA = ServiceA;
}
}
ControllerA.$inject = ["ServiceA"];import ControllerA from "./controllers/a";
export angular.module("moduleA", [])
.controller("ControllerA", ControllerA);或者:
controllers/a.js
export default class ControllerA {
constructor(ServiceA) {
this.serviceA = ServiceA;
}
}import ControllerA from "./controllers/a";
export angular.module("moduleA", [])
.controller("ControllerA", ["ServiceA", ControllerA]);个人推荐前一种,理由是,一个模块的依赖项声明,最好跟其实现放在一起,这样对可维护性更有利。
在考虑依赖注入的时候,还存在另外一个问题,我们现在这样做,实质上已经弱化了Angular自身的DI,但这时候,为什么我们还需要DI?如果我们在一个Controller里面依赖某个Service,大可以直接import它啊,为什么还非要去从DI走一圈?
这里面有个麻烦,如果你所依赖的东西没有对Angular DI依赖,那还好,不然的话,没法实例化,比如说:
export default class ServiceA {
constructor($http) {}
}
ServiceA.$inject = ["$http"];如果我要在一个别的东西里实例化这个ServiceA,就没法给它传入$http,这些东西要从ng里获取,考虑是不是搞个专门的实例化函数,类似provider,专门去做这个实例化,这样可以消除DI,直接import。
这个是终极纠结点了,因为一个directive,可能包含有compile,link等多个成员函数,各种配置项,一个可选controller之类,这里面我们要考虑这么一些东西:
我们看一下directive主要包含些什么东西,它其实是一个ddo(Directive Definition Object),所以本质上这是一个对象,我们可以给它构建一个类。
export default class DirectiveA {
}DDO上面的东西大致可以分两类,属性和方法,所以就在构造函数里这样定义:
constructor () {
this.template = template;
this.restrict = "E";
}像这些都是基础的配置字符串,没什么特别的。剩下的就是controller和link,compile等函数了,这些东西其实也简单,比如controller,可以先实现一个普通controller类,然后赋值到controller属性上来:
this.controller = ControllerA;注意现在写directive,尽量使用controllerAs这样的语法,这样controller可以清晰些,不必注入$scope,而且还可以使用bindToController属性,把在attr上定义的属性或者方法直接传递到controller实例上来。
比如我们要做一个日期控件,最后合起来就是这样:
import template from "../templates/calendar.html";
import CalendarCtrl from "../controllers/calendar";
import "../css/calendar.css";
export default class CalendarDirective {
constructor() {
this.template = template;
this.restrict = "E";
this.controller = CalendarCtrl;
this.controllerAs = "calendarCtrl";
this.bindToController = true;
this.scope = {
minDate: "=",
maxDate: "=",
selectedDate: "=",
dateClick: "&"
};
}
link (scope) {
// 这段代码太别扭了,但问题是如果搬到controller里面去写成setter,会在constructor之前执行,真头疼,先这样吧
scope.$watch("calendarCtrl.selectedDate", newDate => {
if (newDate) {
scope.calendarCtrl.calendar.year = newDate.getFullYear();
scope.calendarCtrl.calendar.month = newDate.getMonth();
scope.calendarCtrl.calendar.date = newDate.getDate();
}
});
}
}然后,在module定义的地方:
import CalendarDirective from "./directives/calendar";
export default angular.module("components.form.calendar", [])
.directive("snCalendar", () => new CalendarDirective())
.name;上面这个例子里,还有些比较头疼的地方。本来我们剥离了清晰的controller,就是为了里面不要有$scope这些奇奇怪怪的东西,但我们需要$watch这个selectedDate的赋值,就折腾了,$watch是定义在$scope上面的,而如果在controller上给selectedDate定义一个setter,可能由于babel跟angular共同的作用,时序有点问题……后面再想办法优化吧。
一个directive除了有这些,还可以有template的定义,所以在这个例子里我们也是用import把一个html加进来了,Webpack的html loader会自动把它变成一个字符串。
还有,组件化的**指导下,单个组件也应当管理自己的样式,所以我们在这里也import了一个css,这个后面会被Webpack的css loader处理。
我们前面提到,做这套方案有一个很重要的意图,那就是在数据和业务逻辑层尽量清除Angular的影子,使得除了最上层的部分,其他都可以被其他框架方案使用,比如React和Vue,这里面有一些关键。
在Angular 1.x中,一个核心的东西是$scope,它是一切东西运行的基石,然而,把这些东西暴露给一线开发者,其实并不优雅,所以,Angular 1.2之后,逐步提供了一些选项,用于减少开发过程中对$scope的显式依赖。
那么,我们可能会在什么场景下用到$scope,主要用到它的什么能力呢?
我们一个一个来看,这些东西怎么消除。
以前我们一般要在controller中注入$scope,但是从1.2版本之后,有了controllerAs语法,所以这个就不再必要了,之前是这样:
<div ng-controller="TestCtrl">
<input ng-model="aaa">
</div>xxx.controller("TestCtrl", ["$scope", function($scope) {
$scope.aaa = 1;
}]);现在成了:
<div ng-controller="TestCtrl as testCtrl">
<input ng-model="testCtrl.aaa">
</div>xxx.controller("TestCtrl", [function() {
this.aaa = 1;
}]);这里的关键点就在于,controller变成了一个纯净的视图模型,实际上框架会做一件事:
$scope.testCtrl = new TestCtrl();所以,对于这一块,其实我们是不必担忧的,把那个function换成一个普通的ES6 Class就好了。
我们知道,在$scope上,除了有$watch,$watchGroup,$watchCollection,还有$eval(作用域上的表达式求值)这类东西,我们必须想到对它们的替代办法。
先来看看$watch,一个典型的例子是:
$scope.$watch("a", function(val) {
$scope.b = val + 1;
});这个我们的办法很简单,在ES5+,对象上是有setter和getter的,那我们只要在ES6代码里这么定义就行了:
class A {
set a(val) {
this.b = val + 1;
}
}如果有多个变量的观测,比如:
$scope.$watchGroup(["firstName", "lastName"], function(val) {
$scope.fullName = val.join(",");
});我们可以写多个setter来做,也可以写一个getter:
class A {
get fullName() {
return this.firstName + "," + this.lastName;
}
}下一个,$watchCollection,这个有些复杂,因为它可以观测数组内部元素的变化,但其实JavaScript语法层面是缺少一些东西的,对比其他语言,早在十多年前,C# 1.0中就支持了indexer,也就是可以自定义下标操作。
不过这个也难不倒我们,在Adobe Flex里面,有一个ArrayCollection,实际上是封装了对于数组的操作,所以,我们需要的只是把数组的变更操作封装起来,不直接在原始数组上进行操作就好了。
所以我们的结构就类似如下:
class A {
constructor() {
this.arr = [];
}
add(item) {
this.arr.push[item];
//这里干点别的
}
}对于这个封装好的东西,我们的原则是:读取操作可以直接取引用,但是写入操作必须通过封装的这些方法去调用。
这里还有技巧,我们其实是可以把这类数组操作全部封装,也搞成类似ArrayCollection那样,但很多时候,ArrayCollection太通用了,我们其实要的是强化的领域模型,而不是通用模型。所以,针对每个业务模型单独封装,有其自身的优势。
注意,我们这里仅仅是封装了数组元素的操作,并未对元素自身属性的变更,或者高维数组,这些需要多层封装。
在$scope上,另外一套常用的东西是$emit,$broadcast,$on,这些API其实是有争议的,因为如果说做组件的事件传递,应当以组件为单位进行通信,而不是在另外一套体系中。所以我们也可以不用它,比较直接的东西通过directive的attr来传递,更普遍的东西用全局的类似Flux的派发机制去通信。
根作用域的问题也是一样,尽量不要去使用它,对于一个应用中全局存在的东西,我们有各种策略去处理,不必纠结于$rootScope。
哎,其实理论上是可以把业务代码中每个地方都搞得完全没有$scope的,而且也能比较优雅通用,但是。。。总有一些例外。
先看看正常的吧。
我们知道,在定义directive的时候,ddo中有个属性是scope,这个里面定义了要在directive内外进行传递的属性或者方法,并且有不同的传递类型。我们又知道,directive有个controllerAs选项,可以类似前面提到的,controller中不注入$scope:
class TestCtrl {
constructor() {
this.a = 1;
}
}
export default class CalendarDirective {
constructor() {
//...
this.controller = TestCtrl;
this.controllerAs = "testCtrl";
this.scope = {
a: "="
};
}
}这时候就有个问题了,我们知道,最终结构会变成:
$scope.testCtrl.a == 1;但这句:
this.scope = {
a: "="
};又会导致$scope.a == 1,而且,在testCtrl这个实例中,如果你不显式传入$scope,还访问不到外面那个a,这跟我们的预期是不相符的。所以,这时候我们要配合用bindToController,可以写个属性true,也可以把scope对象搬上去(1.4以上版本支持)。
所以代码就成了这样:
class TestCtrl {
constructor() {
this.a = 1;
}
}
export default class CalendarDirective {
constructor() {
//...
this.controller = TestCtrl;
this.controllerAs = "testCtrl";
this.bindToController = true;
this.scope = {
a: "="
};
}
}这样都对了吗,并不会……
我们再综合一下:
class TestCtrl {
constructor() {
this.a = 1;
}
set a(val) {
this.b = val + 1;
}
}
export default class CalendarDirective {
constructor() {
//...
this.controller = TestCtrl;
this.controllerAs = "testCtrl";
this.bindToController = true;
this.scope = {
a: "="
};
}
}这里,只是在TestCtrl中给a加了一个setter,然而这个代码是不运行的,貌似绑定过程有问题,所以我才会在上面那个地方加了个很别扭的$watch,也就是:
class TestCtrl {
constructor() {
this.a = 1;
}
}
export default class CalendarDirective {
constructor() {
//...
this.controller = TestCtrl;
this.controllerAs = "testCtrl";
this.bindToController = true;
this.scope = {
a: "="
};
}
link(scope) {
scope.$watch("testCtrl.a", val => scope.testCtrl.b = val + 1);
}
}而且,这里再$watch的话,需要把controller实例的别名也作为路径放进去,testCtrl.a,而不是a。总之还是有些别扭,但我觉得这里应该还有办法解决。
// 上面这段等我有空详细再想想
有的时候,直接把setter或者getter绑定到界面,会不太适合,虽然Angular的ng-model中支持getterSetter这种辅助,但毕竟还有所不同,所以很多时候我们很多时候可能需要把带getter和setter的业务对象下沉一级,外面再包装一层给angular绑定用。
在任何一个严谨的项目中,应当有比较确定的业务模型,即使脱离界面本身,这些模型也应当是可以运作的,而ES6之类语法的便利性,使得我们可以更好地组织下层业务代码。即使目的不是为了使用Angular 1.x,这一层的精心构造也是有价值的。当做完这层之后,上层迁移到各种框架都基本只剩体力活了。
原文在此
是不是对Angular的战略有疑问?来这里就对了。在接下来的这篇文章里,我会解释Angular 2.0的主要特性区域,以及每个变化背后的动机。每个部分之后,我将提供自己在设计过程中的意见和见解,包括我认为仍然需要改进设计的重要部分。
注意:本文所反映是2014年11月6日的状态记录。如果你在较长时间之后读到此文,请检查一下我设计上是否有所变更。
在开始讨论Angular的未来之前,我们先花点时间看看当前的版本。AngularJS 1.3是迄今为止最优的Angular版本,它是几周之前发布的。它提供了大量的bug修复,功能增强和性能提升。如果你正在使用Angular,会有升级的愿望。如果将要开始用Angular做新的项目,这也会是你想要使用的版本。这是一个强大而成熟的框架,已经摆在我们面前了。
可能你现在会对AngularJS的未来有很多疑问。什么时候2.0会出来?1.x怎么办?会有从1.x到2.0的升级路径吗?AngularJS团队在回答这些问题上,可以做得更好一些,你应当鼓励他们这么做。我可以告诉你们的是,在Google内部,有1600个应用是基于Angular 1.2或者1.3构建的。所以,看起来Google对当前版本是会有很大兴趣的,也会需要支持它们一段时间。在ngEurope的Q&A环节中,Brad Green说在Angular 2.0的RTM版本发布之后,对Angular 1.3的支持会持续至少1.5-2年。我们也刚针对Angular 1.3的支持作了一些团队结构和领导的变更,即使是正在为Angular 2.0而努力,我们仍然保持了一个专有团队全职处理Angular 1.3。这个团队是由Pete Bacon Darwin领导的,我敢肯定你一定知道他在AngularJS上的丰富经验。我想要鼓励你们向Angular的引领者询问这些变化,并且一起设法完善官方的支持。
当2.0可用时,如果有人想要把Angular1.x的应用迁移到2.0,目前也没有什么可行的计划。我认为我们可以在这一块做些事。如果这对你来说也很重要,请大声说出来,当然要友善一点,但要让Angular团队知道这对你而言很重要,他们应当对此有所考虑,并且也有所规划。
那么,你可能会想知道,为什么要做Angular 2.0呢?为什么一步跨到2.0,并且作了这么多不兼容变更?这一切都是很随意的吗?我能够处理少量变更,但我所听到的消息,在2.0中有很多较大的变更,它们真的合理吗?值得吗?
在深入特性细节之前,我很乐意花点时间来探讨一些较高层次的动机,关于2.0所带来的变化。我希望这能够对后续细节建立一个基本的认识,在此基础上可以作一些有意义的批评(其中有些我打算自己提供)。
差不多五年前,当AngularJS刚创建出来的时候,它并不是给开发人员用的。它是一个工具,更倾向于给需要快速创建持久化HTML表单的设计人员用。随着时间推移,它作了改变以适应各种场景,开发人员也用它建造更多、更复杂的应用程序。Angular 1.x团队多年来一直努力增量化地改进设计,允许它适应现代Web应用程序需求的变更。然而,在所能做到的改进上,是有很大局限的,根源在于原始设计中的一些潜规则。很多这种限制,导致了当前的绑定与模板基础架构的性能问题。为了解决这些问题,需要新的策略。
从最初设想Angular所开始的五年中,Web有了明显的改变。比如说,5年前没有jQuery之类框架的帮助,是基本不可能建立一个合适的跨浏览器网站的。但是,当今的浏览器DOM实现不仅更加一致,而且这些实现更快了,也提供了与应用程序框架相关的新特性。
而且web还在继续变化……
虽然在过去几年中,发生了巨大的变化,但与未来1-3年相比,这些变化还是显得微不足道。在几个月内,ES6规范将定稿。如果我们觉得在2015年就能看到完全实现此规范的浏览器,并非不可能。今天的浏览器已经支持其中一些特性了,并且正在实现其他剩余部分。这意味着浏览器支持像module、class、lambda、generator之类东西。这些特性从根本上改变JavaScript的编程体验。但是,大的变化并不是只体现在JavaScript上,Web Components也喷薄欲出。术语Web Components通常是指四个相关的W3C规范:
通过组合这四种能力,web开发人员可以创建声明式的组件(自定义元素),并且是完全封装的(Shadow DOM)。这些组件可以描述它们自己的视图(模板元素),并且能很容易打包发布给其他开发人员(HTML Imports)。当这些规范在所有主流浏览器都可用的时候,我们就可能会看到开发人员的创造力爆发,作很多努力来创建可复用的组件,以解决常见问题,或者是弥补标准的HTML工具集所存在的不足(摘自Web Components与数据绑定)。今天,这已经变得可能,在Chrome和其他浏览器里,这些标准中有些已经实现,有些正在实现。未来显得很美好,对不对?只剩下一个问题了:当今的多数数据绑定框架尚未准备好应对这些。多数框架,包括Angular 1.x,包含一个数据绑定系统,它构建在一小部分已知的HTML元素和常用事件、行为的基础上。为了能让Angular开发人员享有Web Components,很需要有一个全新的数据绑定实现。
想想5年前……噢,计算的情景已经有了多么大的改变!现在到处都是手机和平板了!虽然Angular可以被用于创建移动应用,但它的理念并非为它们设计的。这包括了所有的东西,从我刚提到过的基本的性能问题,到它的路由的能力缺失,以及不能缓存预编译视图,甚至是过于普通的触摸支持。其中有些东西可以借助Angular 1.3来实现(比如说路由),但其余的需要根本的变更来修复。
老实说……AngularJS不是太容易学。是的,你选择了它,内心想着“这太美好,很简单,很魔幻!!!”然后开始建立自己的应用,发觉变成“TMD这什么啊!!??我不懂!!!”这种事我听得多了,甚至还有个直观的图用来描述它。如此种种,还是回头看看这个库最初的设计意图吧。比如,最开始是没有自定义指令的,它们都是硬编码的,然后,就有了一个用于添加指令的API。最开始是没有控制器的,然后……你懂的。这种绑死的特性,很多成为了现在的核心理念,导致了API的不优雅。如果Angular真想变的易学易用,那么,从一开始,它就必须对自己的核心特性有清晰的认识。对一个框架而言,如果把指令和控制器当作初始设计的一部分,肯定要比后面逐步拼凑起来要好几个数量级。
了解了Angular的设计起源,以及Web和通用计算情景的逐步变化,很明显需要作一些变更了。事实上,如果不开始解决这些问题,Angular很可能在一年内就有被淘汰的风险。一个框架,如果没法跟Web Components协作,在移动端上一塌糊涂,还继续推进自己的非标准的module和class API,离死也不远了。Angular团队对这些问题的回答是一个新版本:Angular 2.0。它本质上是为了现代Web而对AngularJS的重新想象,并且融合过去五年所得到的各种认识。
尽管我尚未涉及详细的部分,你已经可以发现AngularJS 2.0是与1.x大为不同的了。可能有人会问,这还是不是同一个框架了?我觉得这是个好问题。我之前提到,我认为Angular团队需要提供对1.x支持的具体时间表,到2.0的迁移路径,以及给企业一些指引,供当前决策或者是想要升级为2.0的计划用。对于充满技术思维的Angular团队来说,这可能是很无趣的任务,但我认为它们对社区而言,是有必要的,有帮助的,也是一种尊重。
现在,你已经对创建Angular 2.0的动机有了一点相关背景了,我们来看看一些关键的特性区域。
AtScript是一门语言,它是ES6的超集,被用来编写Angular 2.0。它使用TypeScript的类型语法来表达可选类型,这可以用来做运行时的类型推断,而不是编译时的检测。它也使用了元数据注解来扩展语言。这里有一个示例,有些AtScript代码就长这样:
import {Component} from 'angular';
import {Server} from './server';
@Component({selector: 'foo'})
export class MyComponent {
constructor(server:Server) {
this.server = server;
}
}在这里,我们在基线ES6代码上添加了一些AtScript附属物。示例顶部的import语句和class语法是直接从ES6里来的,没什么特别的,但是,看一下构造函数,注意server参数指定了一个类型。在AtScript中,这个类型是用于生成运行时类型推断的,引用也会存在于已知的位置,这样,一个框架,比如说依赖注入框架,可以定位到类型信息,并且使用它。也注意一下class定义上面的@component语法,这是一个元数据注解。组件是一个普通的类,跟其他的一样。当你使用注解来装饰一个东西的时候,编译器会生成代码,初始化注解,并且储存在一个具体的位置,这样它可以被像Angular这样的框架访问到。考虑到这一点,这就是上面的代码转译成ES6语法之后的结果:
import * as rtts from 'rtts';
import {Component} from 'angular';
import {Server} from './server';
export class MyComponent {
constructor(server) {
rtts.types(server, Server);
this.server = server;
}
}
MyComponent.parameters = [{is:Server}];
MyComponent.annotate = [
new Component({selector: 'foo'})
];RTTS的意思是运行时类型系统(RunTime Type System),这是一个小型的关于运行时类型检测的推断库。在此,编译器插入一些代码,以便把server变量推断为类型Server。你也可以编写自定义的类型推断以使用结构化类型,或者使用临时的类型规则。当部署到生产的时候,编译器可以省略这些推断以提高性能。
一个好的事情是,与类型推断相独立,类型注解和元数据注解是能够被跟踪到的。所有这些注解会被翻译成非常简单的ES5兼容数据结构,存储在MyComponent函数自身上。这使得任意框架或者库都能很容易发现这些元数据并且使用它们。多年来,这已经在像.NET和Java这样的平台上被证明是很方便的工具。它也和Ruby的元编程功能有一些相似之处。实际上,当跟一个库组合的时候,注解可以被用于做元编程,Angular 2.0就是借此简化指令的创建的。稍后将进行更详细的讨论。
我个人是喜欢AtScript的,但我已经是一个TypeScript的爱好者了,所以你可能会说我是有前提条件的。我知道有些开发人员抵制在JavaScript中加入类型,我没法责怪他们。我自己已经在类型系统上有过相当广泛的经验了,有些是好的,有些不好。AtScript有个有意思的地方,你可以只把类型语法当成向其他库提供元数据的某种简单方式,而完全不用它来作类型检测。我觉得AtScript最强大的特性之一是,在运行时拥有类型和元数据信息,可供框架利用,或者是在自己的元编程中使用。如果其他的解释型语言也加上这种特性的话,我是不会感到惊讶的。
也就是说,我持有保留意见。
我很乐于看到AtScript变得更正式些,我意思是说,我认为它应当从Angular团队自身中释放出来,它应当有自己的发言权,Angular作为它的一个重要客户。应当至少有几个开发人员全职围绕AtScript工作,实现功能,修复bug,提升代码生成,构建工具等等,同时也应当有一个长期支持计划。当一个开发人员或者团队选择一种语言来编写他们应用的时候,他们所作出的是一种重大投资。我乐于看到Google能够为了未来,在AtScript上作出相当的投资。
关于AtScript,还有另外个问题,是跟Dart相关的。Dart是Google开发的另一种语言。它跟某种简单的解释性语言有所不同,是因为它有自己的运行时和基础类库。结果就是,Dart拥有自己的API,用于DOM处理,集合,事件,正则表达式等等。这些API在它们自己的领域中都很优秀,但跟已有的JavaScript代码不兼容。由于这种阻抗不匹配,Dart和外界的任何通讯都必须通过一个特殊的编组API来完成。所以,虽然从技术上可以调用现有的JavaScript库,一般来说不太实用。对AngularJS来说,性能上的损耗将是不可接受的。所以,Google创建了Angular Dart,一种用Dart重新思考过的AngularJS版本。
问题解决了……好吧,可能没有。
现在,就有了两个Angular的版本,要在里面修改bug,实现新特性,发布,等等,使用不同的语言编写,由不同的团队维护。所以,解决了一个问题,却带来了更多问题。
现在你可能有疑问了:这跟AtScript有什么关系呢?
Angular 2.0的想法是把Angular和Angular Dart统一起来。一个团队在一个代码库上工作,要比两个团队在两个代码库上工作好多了。AtScript能在这个事情上起作用,因为它是在Traceur上面实现的,这个东西可扩展性很好。所以,Angular团队能够用AtScript编译出JavaScript和Dart两个版本。
太棒了!那么,问题在哪里呢?
记得我提到过Dart在DOM之类的东西上有不同的对象模型,这些东西就不是简单转译代码所能解决的了。因此,Angular 2.0的构建过程实际上就会复杂一些了。当开发Angular的时候,必须创建不同的门面(facade)以屏蔽JavaScript和Dart之间的API差异。然后编译器使用对应的门面来编译成每种指定的语言。这个事情在技术上肯定是令人印象深刻了,但是,却大大提高了想要转向Angular 2.0的准入门槛。值得注意的是,这方面的发展还处于试验阶段,这个问题可能会有其他的解决方案。我知道你们中的很多人已经转向了Angular,并且很珍惜这种经验。Angular团队也很珍惜它们,我们正在深度思考如何去改进这些,不过,到目前为止,还不是很理想。
注意:Angular 2.0是使用AtScript编写的,但这并不意味着你就需要用AtScript编写你的应用,或者为了使用Angular 2.0,要学AtScript的什么东西。你可以很轻松地使用TypeScript,ES6,ES5,CoffeeScript……随便什么喜欢的东西来写。目前来说,如果利用AtScript的话,能够获得最佳的Angular体验,因为它能够从语言原语自动生成元数据,不过,最终它还是会翻译成简单的ES5。最终的ES5在概念上某种程度类似于Angular 1.x里面的DDO对象,但在此情况下,它是被生成给任意JavaScript函数使用的,而不是某种指令相关的技术,需要用特殊的注册API来编写。
Angular 1.x的核心特性之一是依赖注入(DI,Dependency Injection)。通过DI,你可以很容易地在软件开发过程中遵循“分而治之”的实践。复杂的问题可以根据其角色和职责进行概念化,然后表示成对象,共同协作以完成最终目标。使用这种方式解构的大型(或者小型)系统可以通过使用DI框架在运行时进行组装。这种系统通常是容易测试的,因为结果的设计更加模块化,也允许了更容易的组件隔离。当然,这一切在Angular 1.x中都是可以的,不过有一些问题。
困扰1.x DI实现的第一个问题是由压缩(minification)引起的。鉴于DI依赖于从函数解析参数名,本质上是把它们当作字符串令牌,而在压缩过程中,这些名称会被改变,就不再匹配于注册的服务、控制器和其他组件了。结果就是应用挂了。为了使得DI对压缩友好,添加了一个API,但它缺乏原始的优雅。在.NET和Java的世界中,先进的服务端DI框架里存在更多特性,1.x的实现主要就缺乏这些东西。欠缺的特性导致开发人员受到约束,两个大的例子是:生命周期/作用域的控制,以及子注射器。
通过AtScript,我们引入了一种广义的将元数据附加到任意函数的机制。同时,AtScript元数据格式是不怕压缩的,也容易使用ES5手工编写。这使得它能够出色地支撑一个DI库,提供其所需要用于构造对象实例的信息。不必见怪,这就是新DI的运作方式。
当DI需要实例化一个类(或者调用一个函数)的时候,会检测一下,看看它上面有没有带附属的元数据。回顾一下上面从AtScript转译出来的代码:
MyComponent.parameters = [{is:Server}];如果新DI发现了parameters值,会用它来判断将要尝试调用的函数的依赖项。在本例中,它可以得知仅有一个类型为Server的参数。所以它会获取一个Server的实例,并且在调用这个函数之前传进去。你也可以显式提供一个特定的Inject注解给DI用,这会覆盖parameter数据。如果你在使用一种不能自动生成parameter元数据的语言,也很容易支持,下面就是用原生ES5代码写的样子:
MyComponent.annotate = [new Inject(Server)];这个的运行时效果跟parameter数据是一样的。值得注意的是,你可以使用任意东西当作注入令牌,所以可以这样:
MyComponent.annotate = [new Inject('my-string-token')];只要你在DI上配置过能映射到'my-string-token'的东西,它就能运行。也就是说,推荐的使用方式是通过构造函数的实例,正如我之前所有的例子所示。
在Angular 1.x中,DI容器中的所有实例都是单例。在Angular 2.0中,默认也是这样。为了获得不同的行为,你需要使用Service,Provider,Constant等等。那都挺容易让人迷惑的。幸运的是,新DI拥有一个新的,更通用,更强大的特性。它现在有实例作用域控制了。所以,如果你希望每次请求的时候,DI都创建一个类的新实例,可以这么做:
@TransientScope
export class MyClass { ... }当你组合子注射器来创建自己的作用域标识符的时候,这会更加强大……
子注射器是一个主要的新特性。子注射器从其父项那里继承到所有父项的服务,但能够在子级别上覆盖它们。当它与作用域标识符组合使用的时候,你可以很轻松地在系统中调用到特定类型的对象,这些对象应当在不同作用域中被覆盖,这非常强大。新的路由有一个“子路由”的功能,就是使用它的一个例子。在内部,每个子路由创建自己的子注射器,这使得路由的每个部分能够从父路由继承服务,或者在不同的导航场景中覆盖这些服务。
注意:自定义作用域和子注射器会被认为是对注射器的中高级用法。我不希望太多的应用代码用到它。但是,既然它在Angular的内部被使用到了,如果你需要类似功能,也可以用。
在新DI中,还有一些其他特性,比如provider(自定义函数,用于提供一个注入值),懒注入(指定你所期望注入的东西,但又不立即需要,稍后才要),还有基于promise的异步注入(注入一个promise,可以从中获取异步的依赖项)。
从个人角度,我非常喜欢新DI。我又有偏见了,因为我用DI好多年了,在我创建的其他UI框架中,它也是核心组件。新DI在Angular 2.0中扮演了很重要的角色,像子注射器等功能带来了巨大的变更。现在这个功能有了,它能够被模板引擎和路由利用,这两者都有创建作用域和隔离不同服务的需求。
然后我们就来到了一个从Angular中移除的重要特性:$scope。不过,虽然$scope自身被移除了,它的有些特性还在。这些特性被作为此设计的一个部分,重新换了个位置,也有所提升。你可能会被$scope的缺失搞得措手不及,但新的设计既简化了Angular内部的东西,也简化了提供给你,开发人员的东西。我提到这些,是因为DI的有些新功能,比如说子注射器,与$scope中之前的一些功能重叠了。在这个情况下,我认为新DI系统拿出来的是一个更好的解决方案。它更加通用,所以不但能解决Angular的内部需求,还给你们开放了很多种可能性。
不幸的是,玫瑰带着刺。我们来讨论下一些其他问题。在Angular 1.x中,还有个相关功能我没有提到:module,你可能想知道它的位置在哪。Angular 2.0的方案是吸收ES6中关于module的标准。在Angular的之前版本中,处理模块的方式是Angular特有的方式。五年前,当Angular刚开始构思时,并没有用于完成此事的标准方式。今天,事情不同了,已经有了一个明确路径。这当然是一种不兼容升级,如果有人要作迁移的话,需要对代码重新作点调整。要作这么一种不兼容变更,是很恶心,但这就是Web的变化影响框架的一个实例,如果这事现在不解决,2.0将面临被边缘化的风险。
关于DI,还有另外一个坑,特别是如果你在用ES5写代码的话。Angular 2.0依托作为元数据的注解,支持了基于类的设计。类和注解的语法在ES5中并不太好,事实上,ES5压根就没这些语法。你可以使用原型之类来表示一切,但就没有AtScript甚至ES6或者TypeScript那么清晰了,它们可是有类和静态的类成员的。我想知道能不能为不准备迁移到ES6的开发人员做点什么,也许是一个简单的可选降级库,给出一种简单的方式来创建带元数据的类?可能会类似于Angular 1.x中的DDO对象,但是更通用,这样能创建任意的类和元数据。我很想听听你对这个想法的意见,或者其他可能会解决ES5开发问题或对迁移能有所提升的主意。
如果你已经看了这么多,一定属于对Angular 2.0非常好奇的,感谢花了这么多时间。我们还有一条路要走,现在我们要进入真正有意思的地方了:模板和绑定。我打算把它们放在一起讨论,虽然从技术上看,数据绑定系统是与模板系统分离的,你在编写应用的时候却会感觉它们是一个整体。所以,我觉得把它们拿到一起来说会比较好。
我们先从理解视图到屏幕的显示过程,然后一点一点地看。本质上,你是从一段HTML片段开始的,这会存在于一个<template>元素中。这个HTML片段被传递给模板编译器,编译器遍历模板,辨识任意的指令,绑定表达式,事件处理函数等等。所有这些数据从DOM自身中提取,放到最终用于初始化模板的数据结构里。作为这个阶段的一部分,在数据上作了一些处理工作,比如说解析绑定表达式。每个包含上面这种特殊指令节点会被打上一个特殊的class。这一过程的结果会被缓存,这样才不至于需要重复这些工作。我们把这种结果称为一个ProtoView。一旦我们有了ProtoView,就可以用它来创建View。当一个ProtoView生成了View,所有刚才辨识出的指令就会初始化,并且附加到它们的DOM节点上,绑定表达式上建立了监控,事件处理器也配置好了。明白了吧。在编译阶段,之前处理过的数据结构能够让我们很快地做这些事。一旦你得到一个View了,就可以把它添加到一个ViewPort中,并且显示出来。一个ViewPort表达了屏幕的一个区域,可以在其中显示View。作为一名开发人员,大部分东西你是看不到的,你写模板就好了,它会运行的。可我还是希望在深入细节之前,在一个较高层次上把这些过程罗列出来。
Angular 1.x所缺乏的重大功能之一是代码的动态加载。如果你想在运行中添加新的指令或者控制器,非常困难,或者就做不到。它没有被支持。在2.0中,我们从开始设计东西的时候,就把异步放在心里。所以,当你开始编译一个模板的时候,实际上它是个异步过程。
现在我需要详细讨论上面一笔带过的模板编译了。当你编译一个模板的时候,你并不仅仅为编译器提供了一个模板,也同时提供了一个Component的定义。我们稍微深入一点。在模板中使用的时候,Component的定义就包含了什么指令啊,过滤器啊之类的元数据。这确保了在模板被编译器处理之前,所有必要的依赖项都已加载。由于我们的代码架设在ES6 module规范的基础上,只需简单地在Component定义中引用依赖项,如果他们尚未加载,module加载器就会加载它们。因此,通过这种结合ES6 module的方式,我们不费事就得到了各种东西的动态加载。
在我们深入模板的语法之前,需要先看一看指令——Angular用于扩展HTML自身的方式。在Angular 1.x中,使用指令定义对象(DDO,Directive Definition Object)来创建指令。这好像是很多Angular开发人员巨大痛苦的来源之一。
如果我们能把指令弄简单点,会怎样呢?
我们已经讨论过模块、类和注解了,如果我们能用这些核心建筑来构建指令会怎样呢?好吧,我们当然就是这么干的。
在Angular 2.0中,有三种指令类型。
你可能听说过在Angular 2.0里面,Controller没了。好吧,不完全正确。其实,Controller成为了我们称之为Component的一部分。Component拥有一个View和一个Controller。View就是你的HTML模板,Controller就是你的JavaScript行为。不像在1.x中那样,要用显式的或者非标准的API来注册控制器,在2.0中,只需创建一个普通的带一些注解的类。这里是选项卡容器组件的控制器的一个部分(稍后会看到它的视图):
@ComponentDirective({
selector:'tab-container',
directives:[NgRepeat]
})
export class TabContainer {
constructor(panes:Query<Pane>) {
this.panes = panes;
}
select(selectedPane:Pane) { ... }
}这里有几个特性值得注意。
首先,组件的控制器只是一个类。它的构造函数会被自动注入其依赖项。因为使用了子注射器,它可以获得沿DOM树向上所有服务的访问,还包括从属于自己元素的本地服务。比如说,这里它就被注入了一个Query,这是一个特殊的集合,会自动跟子Pane元素保持同步,让你获知何时出现新增或者移除。同时,你也被注入了Element自身,这能让你处理与Angular 1.x中$link回调相同的逻辑,但却是通过类构造函数,用一种更一致的方式来处理的。
现在,看一看@ComponentDirective注解吧。它把类标识为一个Component,并且提供了编译器所需用于挂接的元数据。比如说,selector:'tab-container'是一个CSS选择器,会被用于匹配HTML。任何匹配这个选择器的元素都会被转换成一个TabContainer。同时,directives:[NgRepeat]表明了这个组件的模板的依赖项。到现在还没给你们看过,马上讲语法的时候就会看到了。
一个重要的需要注意的细节是,模板将会直接绑定到这个类上,意味着类的任何属性和方法都能直接在模板上访问。这根Angular 1.2中的“controller as”语法很相似。在类和模板之间,不再有$scope了。结果就是Angular内部得到了简化,开发人员也得到了更简单的语法,那种在$scope对象上搞来搞去的事情变少了。
接下来,我们来看看Decorator Directive。一个简单的NgShow是怎样的呢?
@DecoratorDirective({
selector:'[ng-show]',
bind: { 'ngShow': 'ngShow' },
observe: {'ngShow': 'ngShowChanged'}
})
export class NgShow {
constructor(element:Element) {
this.element = element;
}
ngShowChanged(newValue){
if(newValue){
this.element.style.display = 'block';
}else{
this.element.style.display = 'none';
}
}
}这里,我们可以看到指令的更多方面。我们又写了个带注解的类,构造函数注入了装饰器要附加到的HTML元素。因为有DecoratorDirective,编译器知道这是一个装饰器,也知道把它添加到任意匹配于selector:'[ng-show]' CSS选择器的元素上。
在这个注解上,还有其他一些奇怪的属性。
bind: { 'ngShow': 'ngShow' }用于把类属性映射到HTML attribute。不是所有的类属性都直接暴露成HTML的attribute的,如果你想要让属性在HTML中可绑定,需要在bind元数据中指定它。observe: {'ngShow': 'ngShowChanged'}告诉绑定系统,你想要在每次ngShow属性变更的时候得到通知,并且使用ngShowChanged方法作为回调。注意ngShowChanged回调响应变更的方式是,改变附加到的HTML元素的display。(注意,这只是个非常幼稚的实现,仅作演示之用)。
好了,那Template Directive长什么样呢?为什么不看看NgIf呢?
@TemplateDirective({
selector: '[ng-if]',
bind: {'ngIf': 'ngIf'},
observe: {'ngIf': 'ngIfChanged'}
})
export class NgIf {
constructor(viewFactory:BoundViewFactory, viewPort:ViewPort) {
this.viewFactory = viewFactory;
this.viewPort = viewPort;
this.view = null;
}
ngIfChanged(value) {
if (!value && this.view) {
this.view.remove();
this.view = null;
}
if (value) {
this.view = this.viewFactory.createView();
this.view.appendTo(this.viewPort);
}
}
}希望你能理解TemplateDirective注解。它注册了这个指令,并且提供了一些必要的元数据用于设置属性和观测,就像NgShow示例那样。这就是一个TemplateDirective,它能够访问一些特殊的服务,这些服务可以被注入它的构造函数。第一个是ViewFactory,之前我提到,Template Directive把它附加到的HTML转换为模板,模板被自动编译,然后你就能在模板指令中访问视图工厂了。调用工厂的createView API会初始化模板自身。你也可以访问ViewPort,这代表了模板从DOM中提取的位置,你可以用它在DOM上添加或者移除模板的实例。注意ngIfChanged回调是怎样响应变更,初始化模板,添加到viewport,或者从viewport上移除的。如果你在实现类似于NgRepeat的东西,可以把模板实例化很多次,甚至给createView API提供一个指定的数据项,然后可以把多个实例添加到viewport上。基本就是这样。
现在,你已经看到三种类型指令的一些典型例子了。我希望这能够大致说明了如何使用新的行为来扩展HTML编译器。
不过,还有一个重要的东西我尚未充分解释:Controllers。
怎样为应用创建一个控制器呢?设想你要建立一个路由,导航到一个控制器,然后显示它的视图。怎么做到这个呢?简单的回答就是使用一个Component Directive来做。
在Angular 1.x中,Directive和Controller是两种不同的东西,API不同,功能也不同。在Angular 2.0中,既然我们已经去掉了DDO,把Directive变成了基于类的,我们可以把Directive和Controller统一成Component模型。所以,现在可以一箭双雕,当建立路由的时候,只要把路由映射到一个ComponentDirective(本质上由一个视图和控制器构成,就像之前一样)。
所以呢,如果你创建一个假想的客户编辑控制器,可能会是这样:
@ComponentDirective
export class CustomerEditController {
constructor(server:Server) {
this.server = server;
this.customer = null;
}
activate(customerId) {
return this.server.loadCustomer(customerId)
.then(response => this.customer = response.customer);
}
}真没什么新东西,我们就是在注入假想的服务端服务,当被路由激活的时候,使用它加载客户。有意思的是,你不需要使用选择器或者是其他任何元数据,因为这个组件不是被当作自定义元素来使用的。它是被路由动态创建,然后动态渲染到DOM中的。总之,不要太在意细节了。
那么,如果你明白了怎样创建ComponentDirective,你就明白了怎样创建等同于Angular 1.x中使用路由创建的控制器。在Angular 1.x中,很难把这些统一起来,但鉴于我们在Angular 2.0中有了这么帅的类和元数据驱动系统,指令就可以很显著地简化了,用这种方式创建你的“控制器”也变得很容易了。
注意:我想指出,上面的指令代码示例基于早期的原型代码和较新的设计文档规范,它们应当被解读为一种解释的工具,而不是指令的准确语法,那东西还在不断变化。模板编译器和绑定语言现在是Angular 2.0中最不稳定的部分,设计的变更非常频繁。
至此,你已经对编译过程有了一个概要的认识了:知道它可以异步加载代码,如何编写指令,它们是怎样装配的,控制器怎么适应这些东西的。但我们尚未看一下真正的模板。我们现在来看看刚才假想的TabContainer的模板吧。为了方便起见,把指令代码再贴一遍:
@ComponentDirective({
selector:'tab-container',
directives:[NgRepeat]
})
export class TabContainer {
constructor(panes:Query<Pane>) {
this.panes = panes;
}
select(selectedPane:Pane) { ... }
}<template>
<div class="border">
<div class="tabs">
<div [ng-repeat|pane]="panes" class="tab" (^click)="select(pane)">
<img [src]="pane.icon"><span>${pane.name}</span>
</div>
</div>
<content></content>
</div>
</template>当你看到这个语法的时候,不要害怕。是啊,这是符合规范的HTML,但不是我们最后的绑定语法。不过,还是用它作例子吧,这样我们能有个比较丰富的讨论的起点。
理解数据绑定语法的关键是属性定义的左侧,考虑到这点,我们先来看一下image标签。
<img [src]="pane.icon"><span>${pane.name}</span>当你看到一个属性名称被[]包围的时候,它意思是右侧的属性值有一个绑定表达式。
当你看到一个表达式被${}包围的时候,它意思是这是一个表达式,应当被当作字符串插入到内容中(这跟ES6用来做字符串插值的语法相同)。
从模型/控制器到视图的绑定都是单向的。
现在让我们看看这可怕的div:
<div [ng-repeat|pane]="panes" class="tab" (^click)="select(pane)">ng-repeat是一个TemplateDirective,你可以看出我们正在使用一个表达式来绑定它,因为它外面有[]。不过,它里面还有个 | ,还有一个单词“pane”,这表明在模板中使用的局部变量名称为“pane”。
现在看看(^click),使用括号表明我们把这个表达式作为一个事件处理函数。如果在括号里还有个 ^ ,就意味着不把处理函数直接附加到DOM节点上,而是让它冒泡,在文档的级别处理它。
在这个和模板部分的其他东西上,我暂不表达自己的意见,到下面的评注章节再说。现在先不管你我第一次看到这个的想法,先讨论为什么会选择这样的语法。
Web Components改变了所有东西。这是另外一个Web的变化影响框架的例子。多数基于数据绑定的框架假定了HTML元素的一个固定集合,并且已经预知了一些特定元素的行为,比如说input等等。可是,在Web Components的世界里,没有什么可以假设。一个开发人员,不针对Angular,可以编写一个自定义的元素,带有任意数量的属性,高兴加什么事件就加什么事件。不幸的是,没有办法检测Web Component来收集有关这些元数据,驱动绑定系统需要这些数据。比如说,没有办法知道实际触发了什么事件。看这个例子:
<x-foo bar="..." baz="..."></x-foo>看看bar和baz,你能知道哪个是事件,哪个是属性?不……不幸的是,Angular也不知道,因为Web Components规范没有包含自描述组件的概念。这很不幸,因为它意味着一个数据绑定系统没法知道:它是不是需要连接一个绑定表达式,或者是不是需要添加一个事件处理函数来调用表达式。为了解决这个问题,我们需要一个通用的数据绑定系统,语法能够让开发人员区分哪个是事件,哪个是属性绑定。
这还不是唯一的困难。此外,所提供的信息还必须以这么一种不打破Web Component自身的方式。我这话的意思是,不能让Web Component看到这些表达式,那会破坏这个组件,它只应当看到表达式执行后的结果。实际上这不仅仅影响到Web Components,也会影响原生元素。考虑一下这个:
<img src="{{some.expression}}">这个代码会产生一个错误的http请求,企图寻找“some.expression”这个图。这压根就不是我们想要的,我们根本不想img看到这个表达式,只希望它看到值。AngularJS 1.x解决这问题的方式是使用ng-src,一个自定义指令。现在,我们回到Web Components……如果你要给任意Web Compoents的每个属性都创建一个自定义指令,会是一场灾难,是不是?我觉得不能这样,所以需要在绑定系统中更普遍地解决这个问题。
要完成这事,你有两个选择。第一个是在模板编译期间,从DOM上移除属性。这能够阻止Web Component碰到这个表达式的文本。可是,这么做就意味着检测DOM的话,跟踪不到属性上绑定表达式的执行。这会让调试更加困难。另外一个选择是把属性名编码,这样Web Component就“认不出”它。这样可以让Angular看到这些表达式,但是Web Components却看不到。我们也可以在编译后把属性留在元素上,这样检测DOM的时候可以看得到。在调试的时候,当然就好得多了。
从以上可以看到,Angular团队目前支持的是编码属性的方法,这种编码也需要区分属性和事件。上面所示的语法是完成此事的多种可选项之一。
Angular团队已经在这一块严重争论了几个月。上述语法并未获得一致同意,但被多数人认同。当制订绑定语法的时候,也有过大量的考虑。如果你对这些感兴趣,我建议你读一下关于此主题的相当广泛【丰富】的文档。
好吧,现在我们终于介绍完了模板、绑定和指令是怎么混到一起的……
关于刚才这些,我有太多话要说了……真不知道从何说起……
先从编译器自身说起吧。
我们是从一个较高层次看待模板的编译过程的。虽然在这一块,还有大量的实现要做,我对编译器的设计非常满意了。在这里面有一些挺好的东西,保持小的内存占用,减少了垃圾,并且使得模板的实例化超快。这些都很伟大,当然还需要改进,但已经很稳定了。虽然我们尚未谈及脏检测(数据绑定表达式更新的机制),它的实现也有一些新的不错的想法,可能会让模板实例化和脏检测自身的性能都有所提升。当然,能够动态加载任意东西太可怕了,这是Angular 1.x非常缺乏的一个特性,对大型应用却很关键。所以,它能作为核心需求来设计,我很高兴。
现在我们来讨论指令吧。
使用类、更好的依赖注入和注解来创建指令的新机制非常棒,它比Angular 1.x所需要的要简单多了。不幸的是,对于1.x开发人员而言,这是一个相当大的不兼容变更,如果你限于使用ES5,而不能或者不想使用ES6,TypeScript或者AtScript的话,写起来也会有些困难。本文的前面部分,我提到过提供小型库用于在ES5中更方便地创建注解类,这样的API可能会搞得像DDO对象那样,也许这能让从1.x到2.0的移植过程简单点。或许我们现在就应当开始构建它了,这样你可以在1.3里面使用,然后为2.0提供一个不同的实现……一种迁移抽象层。我也不确定,我想听听你们关于这块的想法,我知道很多人很关心这个。
关于指令,还有另外一件让我很困扰的事:注解有些冗长。回顾一下NgShow指令,你看到文本‘ngShow’或者它的某种变体重复了多少次?这对我来说显得有些傻。再看看CustomerEditController,我们要ComponentDirective干什么啊?既然路由都知道它是什么了,我们只写个普通类不行吗?
在内部我说了很多约定优于配置的想法,这也是Rails流行并影响很多现代框架的原因,我认为这是一种积极的方式。我想看到一些用于创建指令的约定能把样板消除。没有它们的话,我会认为新的指令系统并未把指令简化到应有的程度,感觉就像是把DDO的一些复杂性放到另外一个地方,也就是注解中去了。你会怎么想呢?喜欢约定吗?觉得这能让指令简单吗(假设你一直选择明确 这个地方怎么翻译啊)?
(assuming you always had the option to be explicit and override the conventions with annotations)?
不幸的是,这些都还不是真正的大问题。在Component Directive中有一个严重的问题,希望你已经看到了。注意到它们破坏了展现分离(Separated Presentation)原则吗?再看看我的TabContainer示例:
@ComponentDirective({
selector:'tab-container',
directives:[NgRepeat]
})
export class TabContainer {
constructor(panes:Query<Pane>) {
this.panes = panes;
}
select(selectedPane:Pane) { ... }
}有没有看到TabContainer必须在其元数据中,列出其模板使用到的所有指令?这是TabContainer(控制器)到其视图实现细节的直接耦合。之前我提到过,对编译器而言,这是有必要的,因为它在编译模板之前,需要知道要加载什么,但是,这抵消了使用MVC,MVVM或者其他展现分离模式所带来的主要优势。为了避免你觉得我在纸上谈兵,我来指出一些后果吧:
幸好,设计还是会有不少变化的,我提了个建议来解决这个问题,非常简单:通过让模板指定自己的imports,使得它能够完全自包含。把元数据移出指令,放到HTML模板中。可以这样使用一个自定义元素:
<ng-import src="ngRepeat"></ng-import>编译器可以很容易找到他们,并且确保编译模板内容的时候,所有东西都加载完成了。就这样,刚才我提到的所有问题都解决了。
好了,现在我们说完编译器和指令了……
我感觉接下来是不是该说模板语法了?
老实说,很多人看到这个模板语法的时候可能会吐了,不是所有人,但有不少。我个人是不太喜欢这种语法的,但这是多数人投票的结果(为了理解为什么它还是个草案,你需要看看这篇文档)。别怕!已经有一些技术性的问题让这种语法变不成事实,更不用说社区的反对之声了。Angular团队已经回头继续讨论最佳语法了,很多社区成员也加入了,并且提出了自己的见解,很棒。我会把我自己的推荐放在这里,这样每个人都可以评论。
这是我提议的基本语法:
property="{{expression}}" - 从模型到元素属性的单向绑定,使用{{}}标识
on-event="{{expression}}" - 给事件添加处理函数,执行表达式,使用on-前缀标识
${expression} - HTML内容和属性中的字符串插值(基于ES6语法)
就这样。然后,在实现的时候,我们需要把表达式从DOM移除,以避免各种Web Component的问题之类。仅在调试模式,我们可以通过一个前缀,比如bind-,把它们加回来,这样可以在不影响Web Components的情况下,通过检测DOM的方式看到它们。这使得你所写的和在DOM检测器中看到的东西不太对称,但我觉得为了清晰、更加标准的绑定语法起见,这是一种合理的权衡。不是所有人都同意我,你觉得呢?
这个提议解决了绑定的技术问题,也对向后的兼容性有所帮助。可能我们能够对向后兼容性做很多的事情。我们能够允许在HTML内容中使用{{expression}}来做字符串插值,但是你可能会对此有选择余地。它可能会计划在20xx年被淘汰。推荐的方式可能会是${expression},但这可以对模板提供一个更平缓的升级路径。也有可能创建一套可选的指令用于支持ng-click之类,同样将于20xx年废弃。此外,我们可以提供文档,对照显示新旧的差异,帮助人们在“截断日期”之前,逐步地转换模板。
这就是我提案的基本内容,也有其他的提案,当然我是有倾向的,我也想知道你们的看法。向后兼容对你来说重要吗?你是更倾向于使用{{}}这样的语法,还是用某种方式把属性名进行编码?有太多选择了。
嗯,现在我们的问题都解决了。没,还有个超大的。
看看双向绑定!
我不知道你注意到没有,整篇文章连一个双向绑定的例子都没有。其实,我上面解释过的所有语法都不能用于指定各种绑定选项,如:方向性,触发器,防反跳等等。那,怎样绑定一个input元素,把数据推送到模型中呢?怎样绑定一个需要更新模型的自定义Web Component呢?
在Angular 2.0是否需要双向的数据绑定,Angular团队中产生了激烈的辩论。如果你读过公开的设计文档(包括这篇文档),或者看过ngEurope关于Angular 2.0核心的演讲或Q&A,你可能会发现这一点。我强烈支持保留双向数据绑定,在我看来,这是Angular灵魂的一部分。我尚未看到哪个建议能提供一个优雅的替代,在我能提出之前,还是会认同支持保留双向绑定。
你可能想知道这到底为了什么。
我听到过一些有关为数据流执行DAG的解释。这个思路是最近被ReactJS搞得火起来的。但是坦率地说,你不能完全执行它。我只要用一个事件聚合器就足以把它搞挂,这是一个在复合应用中非常常见的模式。我觉得你应当教给人们有关DAG的事情,帮助他们在合适的情况下使用,但不能强求。这会使他们的工作变得困难。
我听说过另外一个论点,主要围绕校验能力的不足,但这不是一个移除双向绑定的理由。你可以很容易在底层放双向绑定功能,把校验系统放在它的上层。
我认为最大问题来自Angular用于实现绑定的脏检测。因为脏检测,你每做一次检测,其实是做了两次。原因在于,如果第一次检测导致了变化,作为一种副作用,它可能导致其他变化。所以,为了确认,你一定还要再检测一次。然后,如果第二次检测之后,又变化了,还得检测第三次……等等。这个事情就称为模型的稳定化。是啊,这是脏检测系统的痛苦,但是移除双向绑定并不能解决这个问题。你还需要移除所有的监控器,这样一个表达式的变化不会导致它们中的任意一个产生变更。很明显,这也就是也需要考虑移除监控器的原因。可是这样也还是不能解决问题,因为一个事件聚合器就能绕过它……坦白地说,有时候你是需要这样的。数据绑定是一个很强大的工具,人也是会犯错的,但我认为我们能解决它。我知道你们中的很多人都可以的。
可能你不同意我的观点,你觉得“good riddance to two-way binding.”,持这种观点的人肯定很多。不过,我怀疑多数Angular,Durandal,Knockout,Ember等框架的用户会认同我。所幸的是,Angular团队在此事上尚未下定决心,他们在尝试考虑所有的可能性。所以,没必要担心。不过,如果你爱双向绑定的话,要来帮我,我觉得,如果Angular团队的其他成员能听到你们有多爱双向绑定的话,就太好了。
另一方面,如果你认为双向绑定是个坏主意,请你帮我们调查替代品。到目前为止,我尚未见到一个差不多好的替代方式,但也许你有比较好的想法呢。如果是这样的话,我请你来跟我们分享一下。如果我们能一起想出一些更好的东西……那就太棒了。
啊!你对Angular 2.0真够感兴趣的。我真不相信你一直看到这里了。多谢!现在我们来讨论路由……
注意:如果你看累了,想要看一段有关路由的视频的话,可以找到我在ngEurope上关于这个主题的25分钟演讲。
为了让Angular 2.0成为一个能干的框架,它需要有一个强大的路由解决方案。今年早些时候,Brian Ford开始围绕Angular社区内外已有的路由解决方案,进行了大量信息的整合。我们看了已有方案的很大一部分,并且把这些案例的研究与我们从社区收到的请求整合起来。把这些放在一起之后,社区就此文档提供了反馈
,然后我尝试实现一些东西。几个短的迭代之后,我们觉得我们做了个挺酷的东西。
自然,所有你期望路由处理的基本场景,新的路由处理了……
你可能习惯了有一个路由,并且不得不提前为整个应用配置所有的路由。但是,基于我们的新路由,你拥有更多的灵活性。事实上,每个你导航到的组件都可以有一个路由。我们称之为子路由,它允许你把应用的整个功能区域进行封装。如果你有一个拥有多个团队的大型项目,或者你是个“个体户”,这能够把你的代码库良好地分割,你会喜欢这个特性的。现在你可以把应用的每个部分当做一个小型应用来构建,它们有自己的路由。然后,你只要把他们挂接到主应用上,给组件映射一个相对路径,它就能运行了。如果你想看点有意思的,看看我演讲里面的递归子路由示例。
有时候,在导航中你需要对过程有所控制。也许你是从一个带有未保存数据的数据入口屏幕离开,然后需要跟用户确认一下这样行不行。也许你在实现一个向导,在显示到第三步之前,需要确保数据存在于前两步,然后做相应的重定向。为了处理这类场景,我们实现了一个显式的导航生命周期,你的控制器可以选择对导航过程作控制。这里是一个生命周期的钩子列表:
can*回调通过返回布尔值的方式,让你控制导航。你也可以为这个值返回一个Promise,这可以让你进行异步的操作,作为过程的一部分。此外,你可以返回一个特定的NavigationCommand(比如Redirect),它能让你对过程作底层控制。
如你所愿,所有这些都可以无缝与子路由协作。
我们努力让设计尽可能可插拔。所有处理导航请求的逻辑都基于管道架构来建立,这意味着你可以向管道中加入自己的步骤,甚至移除一些我们默认的步骤。例如,如果你不喜欢屏幕激活行为,你可以把它干掉。在管道中,建模了四个步骤,每个代表一个生命周期阶段。管道的另外一个重要特性是,每一步都是异步的。所以,如果你需要发起一个服务端请求来对一个用户进行身份验证,或者为一个控制器加载数据,你可以在管道中做这个,并且把这个代码从控制器中移除。
我很难对路由表示中立,因为是我做的实现。我认为这对于一个新路由而言,是良好的起步。肯定还有缺失的功能,但我认为高层次的设计是非常强大的。
作为奖励,我们也将把它移植回Angular 1.3上。
感谢花这么多时间阅读本文。在本文发表的时间(2014年11月6日),这是有关Angular 2.0最广泛在、最新的知识来源了。所以,你赶上啦!
我试图列举主要的功能和设计的考虑,也包含了一定程度我自己的观点。设计仍然在发展,我们还处于开发的早期。所以,我希望在最终定稿之前,还能有些变化。也有一些“未知”,比如双向绑定,团队还不确定将来要如何处理。我们在尝试考虑所有的选择,也许我们会想出一些新的,令人惊讶的东西!?请耐心等待,记住,作为网络社区的成员,你们被邀请来评判这些问题。当做这些事情的时候,我恳请你们友好、礼貌,但请跟我们分享你的主意,**和观点。
谢谢!
2014年4月底在北京参加QCon,27号抽空回清华看了一遍,10多年没回来,很感慨,没想到正好还碰上校庆了。学校里面的路居然还记得,打车从东门进,到主楼附近下车了往里走,那些年的回忆涌上心头。
这是四教,入学时候英语分级考试就在这。第一节正式的课程:王致勇老师的《无机化学》也是在这里上。
这是四教和五教中间的过道。有次下雪,同学提醒我小心点,我说,你见过龙王被水呛的吗?话音未落立刻摔在地上,被群嘲了。
这是刚才的路口。有一次骑车路过,右前方的一个人急速左拐,我没刹得住车,撞在他后座,从他车上面飞了过去,手心都是血。
这是9号楼,计算机系的,后面是10号楼。
入学的时候在这个地方,有志愿者迎接新生。
体育课一般在这上。
到东面来了,左边是9号楼,右边是10号楼,在这个楼下丢过好几辆自行车。
10号楼的门口,变成办公楼了。
10号楼427,从98年住到99年,进门左手边靠窗的上铺,现在是办公室了,没进去。
宿舍斜对面的洗手间,亮亮在这里一边洗衣服一边欢快唱歌,现在他是海归副教授了,当年也有唱ws歌的一面,哈哈。
那时候宿舍没电话,家里打电话过来的时候,宿管喊427徐飞电话,然后一边答应说来了来了,一边飞奔下来。
这个地方以前是8食堂,在这吃饭次数很多。
那时候这里是个小店,有卖汽水的,我这种乡下孩子从来没喝过芬达和苹果汁,西瓜汁,不知道那个叫什么,只见过可乐和雪碧,后来听到站在我前面的来自深圳的赵铌同学说,才学着说要苹果汁。
在这学排球的,学不会,被老师训,标语很震撼人心,每个人入学的时候都默默算了一下吧?
那时候这里是平地,在这军训,很大一片操场。
10食堂,做化学实验回来一般会在这吃饭,河对面的树林里当时有练某某功的,好奇围观了一次。
28号楼,机械系在里面,某师兄的宿舍在这。
我们材料系在这,23号楼,住306,现在要刷卡进去,没能进。
23号楼背后,99年短学期有一次整个宿舍回来晚了,没喊宿管,武涛从这爬上去,然后挨个拉我们上去,那时候没有栏杆.
这是14还是15食堂?经常跟材81的吴光麟一起在这吃。那会旁边有一个店卖饼干,3块一斤,很划算。
二校门
一教,在这里上CAD课程,学autocad14
日晷和大礼堂
学堂,制图课程好像在这,也有在水利馆的
同方部
大礼堂西面的池塘
自清亭
朱自清雕像
水木清华
荷塘月色
其实这一片我很少来,太文艺了。。。
下午还去亮亮的办公室坐了会,大家都跟以前有些不一样了,他送我们下楼的时候,在电梯碰到个女生,叫他李老师好,我就在犹豫要不要把李老师当年的糗事说出来,哈哈哈哈。
前一段时间,我写了两篇文章,一篇是对目前前端主流视图框架的思考:#37,一篇是深入使用RxJS控制复杂业务逻辑的:#38,在这两篇中,我分别提到:
最近,VueJS社区升级了vue-rx这个库,实现了比较方便地把VueJS和RxJS结合的能力。
我们来详细了解一下。
VueJS本身不是基于RxJS这一套理念构建的,如果不借助任何辅助的东西,可能我们会需要干这么一些事情:
在业务开发中,我们最常用的是绑定简单的Observable,在vue-rx中,这个需求被很轻松地满足了。
与早期版本不同,vue-rx 2.0在Vue实例上添加了一个subscriptions属性,里面放置各种待绑定的Observable,用的时候类似data。
比如,我们可以这么用它:
rx-simple.vue
<template>
<div>
<h4>Single Value</h4>
<div>{{single$}}</div>
<h4>Array</h4>
<ul>
<li v-for="item of arr0$">{{item}}</li>
</ul>
<ul>
<li v-for="item of arr1$">{{item}}</li>
</ul>
<h4>Interval</h4>
<div>{{interval$}}</div>
<h4>High-order</h4>
<div>{{high$}}</div>
</div>
</template>
<script>
import { Observable } from 'rxjs/Observable'
import 'rxjs/add/observable/of'
import 'rxjs/add/observable/from'
import 'rxjs/add/operator/toArray'
import 'rxjs/add/observable/interval'
import 'rxjs/add/observable/range'
import 'rxjs/add/operator/map'
import 'rxjs/add/operator/mergeAll'
const single$ = Observable.of(Math.PI)
const arr0$ = Observable.of([1, 1, 2, 3, 5, 8, 13])
const arr1$ = Observable.from([1, 1, 2, 3, 5, 8, 13]).toArray()
const interval$ = Observable.interval(1000)
const high$ = Observable.range(1, 5)
.map(item => Observable.interval(item * 1000))
.mergeAll()
export default {
name: 'rx-simple',
subscriptions: {
single$,
arr0$,
arr1$,
interval$,
high$
}
}
</script>
这个demo里面,演示了四种不同的Rx数据形态。其中,single$和interval$虽然创建方式不同,但实际上用的时候是一样的,因为,对它们的订阅,都是取其最后一个值,这两者的区别只是,一个不变了,一个持续变,但界面展示的始终是最后那个值。
关于数组,初学者需要稍微注意一下,从同样的数组,分别通过Observable.of和Observable.from出来的形态是大为不同的:
那么,这个high$代表什么呢?
如果说不mergeAll,直接订阅map出来的那个二阶流,结果是不对的,vue-rx只支持一阶订阅绑定,不支持把高阶流直接绑定,如果有业务需要,应当自行降阶,通过各种flat、concat、merge操作,变成一阶流再进行绑定。
上面我们述及的,都是从Observable的数据到Vue的ReactiveSetter和Getter中,这条路径的操作已经很简便了,我们只需把Observable放在vue实例的subscriptions里面,就能直接绑定到视图。
但是,反过来还有一条线,我们可能会需要根据某个数据的变化,让这个数据进入一个数据流,然后进行后续运算。
例如:有一个num属性,挂在data上,还有一个数据num1,表达:始终比num大1这么一件事。
当然,我们是可以直接利用computed property去做这件事的,为了使得我们这个例子更有说服力,给它这个加一计算添加一个延时3秒,强行变成异步:始终在num属性确定之后,等3秒,把自己变成比num大1的数字。
这样,computed property就写不出来了,我们可能就要手动去$watch这个num,然后在回调方法中,去延时加一,然后回来赋值给num1。
在vur-rx中,提供了一个从$watch创建Observable的方法,叫做$watchAsObservable,我们来看看怎么用:
rx-watcher.vue
<template>
<div>
<h4>Watch</h4>
<div>
<button v-on:click="num++">add</button>
source: {{num}} -> result: {{num$}}
</div>
</div>
</template>
<script>
import 'rxjs/add/operator/pluck'
import 'rxjs/add/operator/startWith'
import 'rxjs/add/operator/delay'
export default {
name: 'rx-watch',
data() {
return {
num: 1
}
},
subscriptions() {
return {
num$: this.$watchAsObservable('num')
.pluck('newValue')
.startWith(this.num)
.map(a => a + 1)
.delay(3000)
}
}
}
</script>
这个例子里面的num$经过这么几步:
this.$watchAsObservable('num'),把num属性的变动,映射到一个数据流上$watch不到的,所以,用startWith,把当前值放进去那么,这件事的原理是什么呢?
我们知道,Vue实例中,data上的属性都会存在ReactiveSetter,所以它被赋值的时候,就会触发这个setter,所以,$watchAsObservable的内部只需根据数据变动,生成一个Observable就可以了。
$watchAsObservable的方法签名如下:
$watchAsObservable(expOrFn, [options])
这个options,跟vue的$watch方法的options一样。
有时候,我们会有这样的情况:在组件实例化的时候,数据流由于缺少某些条件,可能还没法创建。
比如说,某个组件,依赖于路由上面的某个参数,这时候,可能你不知道怎么去初始化绑定。
其实,产生这样的想法,本身就错了,因为没有用Rx的理念去思考问题。想一下下面这句话:
数据流的定义,与初始条件是否具备无关。
初始条件其实也只是整个数据流管道中的一节,如果初始不确定的话,我们只要给它留一个数据入口就好了,后续的流转定义可以全部写得出来。
const taskId$ = new Subject()
const task$ = taskId$
.distinctUntilChanged()
.switchMap(id => this.getInitialData(id))
然后,在路由变更等事件里,往这个taskId$里面next当前的id就可以了。通过这种方式,我们就可以把task$直接绑定到界面上。
或者,taskId$也可以通过在路由上面的watch转化而成,只是不能直接用$watchAsObservable,可以考虑改进一下这种情况。
这样可以实现组件canReuse的情况下,改动路由参数,触发当前页面的数据刷新,实现视图的更轻量级的刷新。
使用RxJS可以直接把DOM事件转化为Observable,vue-rx也提供了一个类似的方法来做这个事,不过我没理解这两个东西有什么差异?具体参见官方示例吧。
关注vue-rx的readme,可以发现,目前推荐使用绑定的方式是这样:
import Vue from 'vue'
import Rx from 'rxjs/Rx'
import VueRx from 'vue-rx'
// tada!
Vue.use(VueRx, Rx)
但这样会有一个问题,import的是rxjs/Rx,我们看到,这个文件里把所有可以被挂接到Rx对象上的东西都import进来了,这会导致构建的时候没法tree-shaking,用不到的那些操作符也被构建进来了,一个简单的demo,可能构建结果也有200多k,这还是太大了。
我们查看一下vue-rx的源码,发现传入的这个Rx是怎么使用的呢?
var obs$ = Rx.Observable.create(function (observer) {
...
// Returns function which disconnects the $watch expression
var disposable
if (Rx.Subscription) { // Rx5
disposable = new Rx.Subscription(unwatch)
} else { // Rx4
disposable = Rx.Disposable.create(unwatch)
}
这里,其实只是要使用Observable和Subscription这两个东西,所以我们可以改成这样:
import Vue from 'vue'
import { Observable } from 'rxjs/Observable'
import { Subscription } from 'rxjs/Subscription'
import VueRx from 'vue-rx'
// tada!
Vue.use(VueRx, { Observable, Subscription })
再试试,构建大小只有不到100k了,而且是可以正常运行的。如果用的是Rx 4,需要传入的就是Disposable而不是Subscription。
另外,如果我们使用了$watchAsObservable,还会需要引入另外一个东西:
import 'rxjs/add/operator/publish'
这是因为在$watchAsObservable里面,为了共享Observable,把它pubish之后refCount了,所以要引入,用不到这个方法的话,可以不引。
如果使用了$fromDOMEvent,还需要引入这个:
import 'rxjs/add/observable/empty'
因为$fromDOMEvent里面的这段:
if (typeof window === 'undefined') {
return Rx.Observable.empty()
}
有了这个库之后,我们就可以比较优雅地结合VueJS和RxJS了。之前,两者之间结合的麻烦点主要在于:
在RxJS体系中,数据的进、出这两头是有些繁琐的。
所以,CycleJS采用了比较极端的做法,把DOM体系也包括进去了,这样,编写代码的时候,数据就没有进出的成本,但这么做,其实是牺牲了一些视图层的编写效率。
而Angular2中,用的是async这个pipe来解决这问题,这也是一种比较方便的办法,在绑定Observable这一点上,跟有了vue-rx之后的Vue是差不多简便的。
React体系里面也有对RxJS的适配,而且还有跟Redux,Mobx对接的适配,感兴趣的可以自行关注。
从个人角度出发,vue-rx这次的升级很好地满足了我对复杂应用开发的需求了。
本文示例代码参见:这里
学习Angular,首先要理解其作用域机制。
Angular应用是分层的,主要有三个层面:视图,模型,视图模型。其中,视图很好理解,就是直接可见的界面,模型就是数据,那么视图模型是什么呢?是一种把数据包装给视图调用的东西。
所谓作用域,也就是视图模型中的一个概念。
在第一章中,有这么一个很简单的数据绑定例子:
<input ng-model="rootA"/>
<div>{{rootA}}</div>当时我们解释过,这个例子能够运行的的原因是,它的rootA变量被创建在根作用域上。每个Angular应用默认有一个根作用域,也就是说,如果用户未指定自己的控制器,变量就是直接挂在这个层级上的。
作用域在一个Angular应用中是以树的形状体现的,根作用域位于最顶层,从它往下挂着各级作用域。每一级作用域上面挂着变量和方法,供所属的视图调用。
如果想要在代码中显式使用根作用域,可以注入$rootScope。
怎么证实刚才的例子中,$rootScope确实存在,而且变量真的在它上面呢?我们来写个代码:
function RootService($rootScope) {
$rootScope.$watch("rootA", function(newVal) {
alert(newVal);
});
}这时候我们可以看到,这段代码并未跟界面产生任何关系,但里面的监控表达式确实生效了,也就是说,观测到了根作用域上rootA的变更,说明有人给它赋值了。
在开发过程中,我们可能会出现控制器的嵌套,看下面这段代码:
<div ng-controller="OuterCtrl">
<span>{{a}}</span>
<div ng-controller="InnerCtrl">
<span>{{a}}</span>
</div>
</div>function OuterCtrl($scope) {
$scope.a = 1;
}
function InnerCtrl($scope) {
}注意结果,我们可以看到界面显示了两个1,而我们只在OuterCtrl的作用域里定义了a变量,但界面给我们的结果是,两个a都有值。这里内层的a值显然来自外层,因为当我们对界面作出这样的调整之后,就只有一个了:
<div ng-controller="OuterCtrl">
<span>{{a}}</span>
</div>
<div ng-controller="InnerCtrl">
<span>{{a}}</span>
</div>这是为什么呢?在Angular中,如果两个控制器所对应的视图存在上下级关系,它们的作用域就自动产生继承关系。什么意思呢?
先考虑在纯JavaScript代码中,两个构造函数各自有一个实例:
function Outer() {
this.a = 1;
}
function Inner() {
}
var outer = new Outer();
var inner = new Inner();在这里面添加什么代码,能够让inner.a == 1呢?
熟悉JavaScript原型的我们,当然毫不犹豫就加了一句:Inner.prototype = outer;
function Outer() {
this.a = 1;
}
function Inner() {
}
var outer = new Outer();
Inner.prototype = outer;
var inner = new Inner();于是就得到想要的结果了。
再回到我们的例子里,Angular的实现机制其实也就是把这两个控制器中的$scope作了关联,外层的作用域实例成为了内层作用域的原型。
以此类推,整个Angular应用的作用域,都存在自顶向下的继承关系,最顶层的是$rootScope,然后一级一级,沿着不同的控制器往下,形成了一棵作用域的树,这也就像封建社会:天子高高在上,分茅裂土,公侯伯子男,一级一级往下,层层从属。
既然作用域是通过原型来继承的,自然也就可以推论出一些特征来。比如说这段代码,点击按钮的结果是什么?
<div ng-controller="OuterCtrl">
<span>{{a}}</span>
<div ng-controller="InnerCtrl">
<span>{{a}}</span>
<button ng-click="a=a+1">a++</button>
</div>
</div>function OuterCtrl($scope) {
$scope.a = 1;
}
function InnerCtrl($scope) {
}点了按钮之后,两个a不一致了,里面的变了,外面的没变,这是为什么?原先两层不是共用一个a吗,怎么会出现两个不同的值?看这句就能明白了,相当于我们之前那个例子里,这样赋值了:
function Outer() {
this.a = 1;
}
function Inner() {
}
var outer = new Outer();
Inner.prototype = outer;
var inner = new Inner();
inner.a = inner.a + 1;最后这句,很有意思,它有两个过程,取值的时候,因为inner自身上面没有,所以沿着原型往上取到了1,然后自增了之后,赋值给自己,这个赋值的时候就不同了,敬爱的林副主席教导我们:有a就赋值,没有a,创造一个a也要赋值。
所以这么一来,inner上面就被赋值了一个新的a,outer里面的仍然保持原样,这也就导致了刚才看到的结果。
初学者在这个问题上很容易犯错,如果不能随时很明确地认识到这些变量的差异,很容易写出有问题的程序。既然这样,我们可以用一些别的方式来减少变量的歧义。
比如说,我们就是想上下级共享变量,不创建新的,该怎么办呢?
考虑下面这个例子:
function Outer() {
this.data = {
a: 1
};
}
function Inner() {
}
var outer = new Outer();
Inner.prototype = outer;
var inner = new Inner();
console.log(outer.data.a);
console.log(inner.data.a);
// 注意,这个时候会怎样?
inner.data.a += 1;
console.log(outer.data.a);
console.log(inner.data.a);这次的结果就跟上次不同了,原因是什么呢?因为两者的data是同一个引用,对这个对象上面的属性修改,是可以反映到两级对象上的。我们通过引入一个data对象的方式,继续使用了原先的变量。把这个代码移植到AngularJS里,就变成了下面这样:
<div ng-controller="OuterCtrl">
<span>{{data.a}}</span>
<div ng-controller="InnerCtrl">
<span>{{data.a}}</span>
<button ng-click="data.a=data.a+1">increase a</button>
</div>
</div>function OuterCtrl($scope) {
$scope.data = {
a: 1
};
}
function InnerCtrl($scope) {
}从这个例子我们就发现了,如果想要避免变量歧义,显式指定所要使用的变量会是比较好的方式,那么如果我们确实就是要在上下级分别存在相同的变量该怎么办呢,比如说下级的点击,想要给上级的a增加1,我们可以使用$parent来指定上级作用域。
<div ng-controller="OuterCtrl">
<span>{{a}}</span>
<div ng-controller="InnerCtrl">
<span>{{a}}</span>
<button ng-click="$parent.a=a+1">increase a</button>
</div>
</div>function OuterCtrl($scope) {
$scope.a = 1;
}
function InnerCtrl($scope) {
}从Angular 1.2开始,引入了控制器实例的别名机制。在之前,可能都需要向控制器注入$scope,然后,控制器里面定义可绑定属性和方法都是这样:
function CtrlA($scope) {
$scope.a = 1;
$scope.foo = function() {
};
}<div ng-controller="CtrlA">
<div>{{a}}</div>
<button ng-click="foo()">click me</button>
</div>其实$scope的注入是一个比较冗余的概念,没有必要把这种概念过分暴露给用户。在应用中出现的作用域,有的是充当视图模型,而有些则是处于隔离数据的需要,前者如ng-controller,后者如ng-repeat。在最近版本的AngularJS中,已经可以不显式注入$scope了,语法是这样:
function CtrlB() {
this.a = 1;
this.foo = function() {
};
}这里面,就完全没有$scope的身影了,那这个控制器怎么使用呢?
<div ng-controller="CtrlB as instanceB">
<div>{{instanceB.a}}</div>
<button ng-click="instanceB.foo()">click me</button>
</div>注意我们在引入控制器的时候,加了一个as语法,给CtrlB的实例取了一个别名叫做instanceB,这样,它下属的各级视图都可以显式使用这个名称来调用其属性和方法,不易引起歧义。
在开发过程中,为了避免模板中的变量歧义,应当尽可能使用命名限定,比如a.b,出现歧义的可能性就比单独的b要少得多。
在一个应用中,最常见的会创建作用域的指令是ng-controller,这个很好理解,因为它会实例化一个新的控制器,往里面注入一个$scope,也就是一个新的作用域,所以一般人都会很自然地理解这里面的作用域隔离关系。但是对于另外一些情况,就有些困惑了,比如说,ng-repeat,怎么理解这个东西也会创建新作用域呢?
还是看之前的例子:
$scope.arr = [1, 2, 3];<ul>
<li ng-repeat="item in arr track by $index">{{item}}</li>
</ul>在ng-repeat的表达式里,有一个item,我们来思考一下,这个item是个什么情况。在这里,数组中有三个元素,在循环的时候,这三个元素都叫做item,这时候就有个问题,如何区分每个不同的item,可能我们这个例子还不够直接,那改一下:
<div>outer: {{sum1}}</div>
<ul>
<li ng-repeat="item in arr track by $index">
{{item}}
<button ng-click="sum1=sum1+item">increase</button>
<div>inner: {{sum1}}</div>
</li>
</ul>这个例子运行一下,我们会发现每个item都会独立改变,说明它们确实是区分开了的。事实上,Angular在这里为ng-repeat的每个子项都创建了单独的作用域,所以,每个item都存在于自己的作用域里,互不影响。有时候,我们是需要在循环内部访问外层变量的,回忆一下,在本章的前面部分中,我们举例说,如果两个控制器,它们的视图有包含关系,内层控制器的作用域可以通过$parent来访问外层控制器作用域上的变量,那么,在这种循环里,是不是也可以如此呢?
看这个例子:
<div>outer: {{sum2}}</div>
<ul>
<li ng-repeat="item in arr track by $index">
{{item}}
<button ng-click="$parent.sum2=sum2+item">increase</button>
<div>inner: {{sum2}}</div>
</li>
</ul>果然是可以的。很多时候,人们会把$parent误认为是上下两级控制器之间的访问通道,但从这个例子我们可以看到,并非如此,只是两级作用域而已,作用域跟控制器还是不同的,刚才的循环可以说是有两级作用域,但都处于同一个控制器之中。
刚才我们已经提到了ng-controller和ng-repeat这两个常用的内置指令,两者都会创建新的作用域,除此之外,还有一些其他指令也会创建新的作用域,很多初学者在使用过程中很容易产生困扰。
第一章我们提到用ng-show和ng-hide来控制某个界面块的整体展示和隐藏,但同样的功能其实也可以用ng-if来实现。那么这两者的差异是什么呢,所谓show和hide,大家很好理解,就是某个东西原先有,只是控制是否显式,而if的含义是,如果满足条件,就创建这块DOM,否则不创建。所以,ng-if所控制的界面块,只有条件为真的时候才会存在于DOM树中。
除此之外,两者还有个差异,ng-show和ng-hide是不自带作用域的,而ng-if则自己创建了一级作用域。在用的时候,两者就是有差别的,比如说内部元素访问外层定义的变量,就需要使用类似ng-repeat那样的$parent语法了。
相似的类型还有ng-switch,ng-include等等,规律可以总结,也就是那些会动态创建一块界面的东西,都是自带一级作用域。
一般而言,在Angular工程中,基本是不需要手动创建作用域的,但真想创建的话,也是可以做到的。在任意一个已有的作用域上调用$new(),就能创建一个新的作用域:
var newScope = scope.$new();刚创建出来的作用域是一个“悬空”的作用域,也就是说,它跟任何界面模板都不存在绑定关系,创建它的作用域会成为它的$parent。这种作用域可以经过$compile阶段,与某视图模板进行融合。
为了帮助理解,我们可以用DocumentFragment作类比,当作用域被创建的时候,就好比是创建了一个DocumentFragment,它是不在DOM树上的,只有当它被append到DOM树上,才能够被当做普通的DOM来使用。
那么,悬空的作用域是不是什么用处都没有呢?也不是,尽管它未与视图关联,但是它的一些方法仍然可以用。
我们在第一章里提到了$watch,这就是定义在作用域原型上的。如果我们想要监控一个数据的变化,但这个数据并非绑定到界面上的,比如下面这样,怎么办?
function IsolateCtrl($scope) {
var child = {
a: 1
};
child.a++;
}注意这个child,它并未绑定到$scope上,如果我们想要在a变化的时候做某些事情,是没有办法做的,因为直到最近的某些浏览器中,才实现了Object.observe这样的对象变更观测方法,之前某些浏览器中要做这些,会比较麻烦。
但是我们的$watch和$eval之类的方法,其实都是实现在作用域对象上的,也就是说,任何一个作用域,即使没有与界面产生关联,也是能够使用这些方法的。
function IsolateCtrl($scope) {
var child = $scope.$new();
child.a = 1;
child.$watch("a", function(newValue) {
alert(newValue);
});
$scope.change = function() {
child.a++;
};
}这时候child里面a的变更就可以被观测到,并且,这个child只有本作用域可以访问到,相当于是一个增强版的数据模型。如果我们要做一个小型流程引擎之类的东西,作用域对象上提供的这些方法会很有用。
我们刚才提到使用$parent来处理上下级的通讯,但其实这不是一种好的方式,尤其是在不同控制器之间,这会增加它们的耦合,对组件复用很不利。那怎样才能更好地解耦呢?我们可以使用事件。
提到事件,可能很多人想到的都是DOM事件,其实DOM事件只存在于上层,而且没有业务含义,如果我们想要传递一个明确的业务消息,就需要使用业务事件。这种所谓的业务事件,其实就是一种消息的传递。
假设有如图所示的应用:
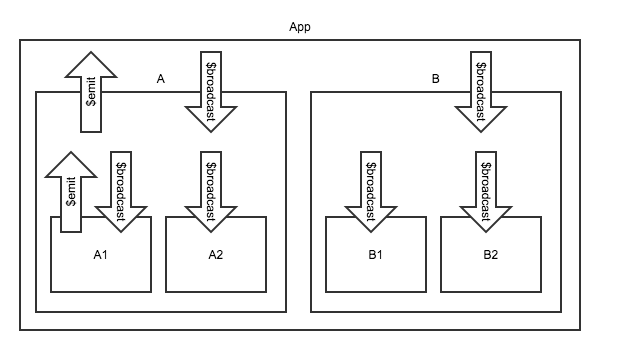
这张图中有一个应用,下面存在两个视图块A和B,它们分别又有两个子视图。这时候,如果子视图A1想要发出一个业务事件,使得B1和B2能够得到通知,过程就会是:
刚才的图形体现了界面的包含关系,如果把这个图再立体化,就会是下面这样:
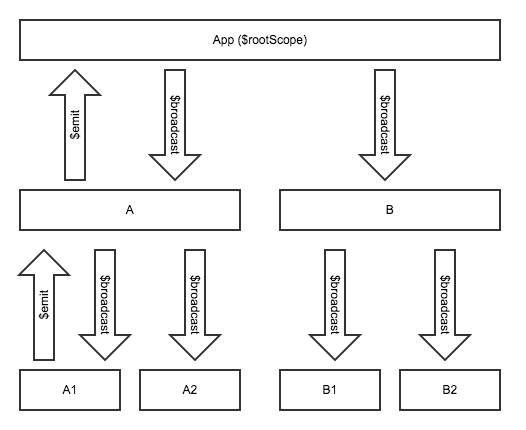
对于这种事件的传播方式,可以有个类似的比喻:
比如说,某军队中,1营1连1排长想要给1营2连下属的三个排发个警戒通知,他的通知方向是一级一级向上汇报,直到双方共同的上级,也就是1营指挥人员这里,然后再沿着二连这个路线向下去通知。
$scope.$emit("someEvent", {});$scope.$broadcast("someEvent", {});这两个方法的第二个参数是要随事件带出的数据。
注意,这两种方式传播事件,事件的发送方自己也会收到一份。
使用事件的主要作用是消除模块间的耦合,发送方是不需要知道接收方的状况的,接收方也不需要知道发送方的状况,双方只需要传送必要的业务数据即可。
无论是$emit还是$broadcast发送的事件,都可以被接收,接收这两种事件的方式是一样的:
$scope.$on("someEvent", function(e) {
// 这里从e上可以取到发送过来的数据
});注意,事件被接收了,并不代表它就中止了,它仍然会沿着原来的方向继续传播,也就是:
有时候,我们希望某一级收到事件之后,就让它停下来,不再传播,可以把事件中止。这时候,两种事件的区别就体现出来了,只有$emit发出的事件是可以被中止的,$broadcast发出的不可以。
如果想要阻止$emit事件的继续传播,可以调用事件对象的stopPropagation()方法。
$scope.$on("someEvent", function(e) {
e.stopPropagation();
});但是,想要阻止$broadcast事件的传播,就麻烦了,我们只能通过变通的方式:
首先,调用事件对象的preventDefault()方法,然后,在收取这个事件对象的时候,判断它的defaultPrevented属性,如果为true,就忽略此事件。这个过程比较麻烦,其实我们一般是不需要管的,只要不监听对应的事件就可以了。在实际使用过程中,也应当尽量少使用事件的广播,尤其是从较高的层级进行广播。
上级作用域
$scope.$on("someEvent", function(e) {
e.preventDefault();
});下级作用域
$scope.$on("someEvent", function(e) {
if (e.defaultPrevented) {
return;
}
});在Angular中,不同层级作用域之间的数据通信有多种方式,可以通过原型继承的一些特征,也可以收发事件,还可以使用服务来构造单例对象进行通信。
前面提到的这个军队的例子,有些时候沟通效率比较低,特别是层级多的时候。想象一下,刚才这个只有三层,如果更复杂,一个排长的消息都一定要报告到军长那边再下发到其他基层主官,必定贻误军情,更何况有很多下级根本不需要知道这个消息。
那怎么办呢,难道是直接打电话沟通吗?这个效率高是高,就是容易乱,这也就相当于界面块之间的直接通过id调用。
Angular的作用域树类似于传统的组织架构树,一个大型企业,一般都会有若干层级,近年来有很多管理的方法论,比如说组织架构的扁平化。
我们能不能这样:搞一个专门负责通讯的机构,大家的消息都发给它,然后由它发给相关人员,其他人员在理念上都是平级关系。
这就是一个很典型的订阅发布模式,接收方在这里订阅消息,发布方在这里发布消息。这个过程可以用这样的图形来表示:
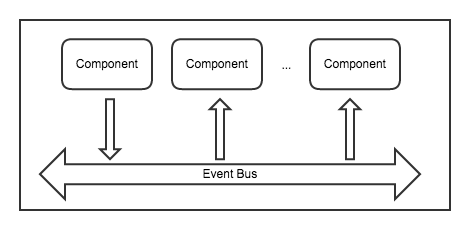
代码写起来也很简单,把它做成一个公共模块,就可以被各种业务方调用了:
app.factory("EventBus", function() {
var eventMap = {};
var EventBus = {
on : function(eventType, handler) {
//multiple event listener
if (!eventMap[eventType]) {
eventMap[eventType] = [];
}
eventMap[eventType].push(handler);
},
off : function(eventType, handler) {
for (var i = 0; i < eventMap[eventType].length; i++) {
if (eventMap[eventType][i] === handler) {
eventMap[eventType].splice(i, 1);
break;
}
}
},
fire : function(event) {
var eventType = event.type;
if (eventMap && eventMap[eventType]) {
for (var i = 0; i < eventMap[eventType].length; i++) {
eventMap[eventType][i](event);
}
}
}
};
return EventBus;
});事件订阅代码:
EventBus.on("someEvent", function(event) {
// 这里处理事件
var c = event.data.a + event.data.b;
});事件发布代码:
EventBus.fire({
type: "someEvent",
data: {
aaa: 1,
bbb: 2
}
});注意,如果在复杂的应用中使用事件总线,需要慎重规划事件名,推荐使用业务路径,比如:"portal.menu.selectedMenuChange",以避免事件冲突。
在本章,我们学习了作用域相关的知识,以及它们之间传递数据的方式。作用域在整个Angular应用中形成了一棵树,以$rootScope为根部,开枝散叶。这棵树独立于DOM而存在,又与DOM相关联。事件在整个树上传播,如蜂飞蝶舞。
总体来说,使用AngularJS对JavaScript的基本功是有一定要求的,因为这里面大部分实现都依赖于纯JavaScript语法,比如原型继承的使用。如果对这一块有充分的认识,理解Angular的作用域就会比较容易。
一个大型单页应用,需要对部件的整合方式和通信机制作良好的规划,为它们建立良好的秩序,这对于确保整个应用的稳定性是非常必要的。
首要问题不是自由,而是建立合法的公共秩序。人类可以无自由而有秩序,但不能无秩序而有自由。——缪尔·亨廷顿
本章所涉及的所有Demo,参见在线演示地址
演讲幻灯片下载:点这里
这是一篇我想写了很久的文章。一直以来,企业软件前端工程体系处于一个很尴尬的局面,无数前端对它有过各种吐槽:技术栈老旧、封闭,体验差,而项目和交付经理又会觉得开发效率太低。据我所见,大部分吐槽的人并没有理解造成这些状况的深层原因,或者说,当自己去构建这么一套体系的时候,并不理解在选型和技术集成过程中,存有哪些可能的决策点。
本文尝试从一些角度去给出自己的见解,为了说明构建这个领域前端技术体系的种种考虑,同时也会述及对应的业务特性。
目前存在的企业软件,一般是以两种形态运作的:
通常来说,前者更侧重于通用性,价格较低,复杂度一般不会特别高;后者一般提供了各种可能的定制,但价格较高,可能会有非常复杂的形态。
价格是企业选择软件的一个很重要因素,所以我们能看到,很多客户在选择软件的时候,对功能点的选择非常精细,有时候不得不舍弃一些相对次要的功能,而且,他们常常会抱怨软件实在太贵了,也并没有那么好用。
另外一头,从软件开发商的角度看,需要尽可能避免一次性的定制需求,需要努力把它们复用到其他客户那里,以此来摊薄开发成本,所以,会需要从各种角度去提高需求的复用率,降低一次性开发成本。
从刚才提及的两种部署形态来看,都有一些问题需要解决。
云端 SaaS 模式的软件,一般会从工具属性或者行业角度入手,较好地满足通用功能,一般面临的问题是可定制性。用户往往借助垂直能力,或者是通用行业模板,解决了自己的第一步问题,但随之而来,就会有更多的诉求:
中小企业在成长过程中,不可避免会需要这些诉求,SaaS 系统应当有随之成长的能力,这才是不掉队的本质。因此,当侧重于工具领域,比如:IM、协同、知识库等体系的 SaaS,其后必定需要开放很大程度的开放与定制能力,要不然,多系统集成一定会成为一个巨大的瓶颈。
我们可以参照电子行业的发展来看待问题:
几十年前,市面上存在很多各类专用设备,比如说,导航设备,那时候会有不少厂家,定制一个小的机器,然后在其上跑专用的软件。用户为这个功能所支付的价格,实际上是软件加上这个硬件的总和。再比如,数码相机,它仍然会需要有一个机器,尽管用户所需要的只是其拍摄、预览与存储能力。
现在来看,这类设备的销量大幅下降,因为手机这样的通用设备的能力得到了增强,硬件部分被合并同类项了。
那么,我们可以问自己一个问题,软件也会这样吗?
软件的同类项是什么?
是 IaaS 吗?
是 PaaS 吗?
还是?
我们是否应当为业务之外的附属基础设施,支付重复的费用呢?
回头再看企业私有部署系统,通常面临的问题就更多一些,但大部分问题都是在下面几个方面:
私有部署软件价格高的原因有两个方面:需求复杂,开发代价高。需求的复杂是不可避免的,这是业务方的原生复杂度,而需求的沟通反复,则往往成为此类交付的核心痛点,与之相比,连耗费巨大的定制化开发过程都不可避免地成为其附属环节了。
几乎所有这个领域的软件交付厂商都很早就采用了大中台,小前台的作战方式,然而在实践过程中,仍然会因为前台部分过重,中台部分难以很实际地对前台产生帮助,形成一种非常尴尬的局面,最终导致双方的互相不信任。
我个人认为,这个问题的症结在于中台支撑能力的偏弱。传统意义上的中台支撑,其技术化程度较高,往往是提供各类中间件、组件库、约定研发模式、构建发布、持续集成等等底层能力,但是在另外一件事情上做得不够远,那就是业务描述能力。
什么是业务?如何描述业务?
谁有业务抽象能力,谁就会赢得下一轮竞争。这个竞争的关键,一定不是因为你提供了多少种中间件,多少种组件,那些只是底层可扩展的能力。
所谓中台能力,不仅是指在一家软件公司里,其中台团队对业务研发团队的支撑能力。整个一个软件公司,对客户来说,也应当相当于一种中台能力,那么,到底提供怎样的能力才能有助于各行业的发展呢?
很可能一线互联网公司的研发人员还是很难理解其他一些公司的痛点:
这其实是个很难的问题,先不说多数公司是很难养得起一支高质量研发团队的,即使愿意出钱,也未必养得出。一家传统行业公司的平均薪资是取决于它所在行业的,大部分行业都达不到 IT 和金融的收入水平,他不愿意付出媲美一线互联网公司的薪资就会招不到人,他愿意付出这个薪资,就会导致自身企业中的一些意见,人性大抵如此。
因此,很多公司的软件都面临一个问题:
这个过程是非常痛苦的。如果把软件公司自身作为中台,其核心价值应该在两个方面:
当这两个能力比较好的时候,需求变更所造成的反复成本就可以缩小,业务方,无论是自身业务,还是客户那边,都更加有机会去把 IT 系统尽快调整到适合自己公司的业务发展需要上。
技术细节的屏蔽、可扩展性的支持,对这两者的权衡,将成为技术中台成败的关键因素。
作为软件形态的一种,企业软件除了共性的问题,比如需求的正确实现,一般还需要重点考虑以下几点:
这几点,几乎是影响大部分企业软件生死存亡的要素。所以,通常会需要在自身的研发过程中,去产生各种各样的快速研发、需求分支管控方案。
前面我们提到,对业务的描述是一个核心竞争力。为什么呢?
因为几乎所有软件企业,都不会希望自己做的东西是一次性的,都希望能沉淀,并且尽可能作为一种平台能力,交付给其他客户使用,以达到同等成本下,盈利的最大化。
在面向行业的交付领域,我们一定能听到这样的描述:给客户甲提供的某某功能,客户乙也想要。他想要,怎么给呢?
传统的研发管理,其分支是基于代码的,代码实际上是一种很底层的抽象,尤其因为跨越了多个不同技术栈(服务端、Web、客户端),导致很难去描述:这个需求改了哪些地方,也就因此,很难去描述业务的增量与合并。
所以,在不同项目、不同分支之间迁移需求,对研发人员来说,是一个非常苦闷而麻烦的事情,这也就是“描述业务、解释业务”的意义所在。我们需要把业务描述成一种线性的东西,去除抽象细节,可以升级,可以 diff。
对业务的抽象,除了有助于研发过程,还可能让懂得业务的人员参与,甚至拉动客户侧的一线人员,共同参与改造升级自己的业务过程。从一个大的角度去看,中台定制能力的低技术门槛化,必定是一个长期趋势。
当前,一个有意思的问题是:在你心目中,按照角色划分,企业软件前后端开发人员的比例应当大致是怎样的?
最近几年被谈得很多的一个名词是“前后端分离”,处于不同场景的人对它做出了不同解释。虽然在分界、实践路线上各有差异,有一个共识是:这意味着前后端工作职责的分离,前端去处理偏展示的部分,后端侧重于存储和服务相关的逻辑,两者通过某种基于接口描述的约定来协作。
在企业软件领域,有很大一部分应用至少十多年来都一直就是这么协作的,大部分把分界点定在 HTTP 请求这个位置,这是一个比较天然的分界,两侧的代码执行过程分别位于浏览器(或者广义的各种端上)、服务器。
前后端的职责分离,有时候又会带来协作上的麻烦。大部分的业务,无论前端还是后端,复杂度都没有到很高的程度,如果职责分离所带来的协作成本大于同一个人,往往就不如“全栈”。
全栈是一个筐,什么都可以往里装。通常这么一个全栈业务开发人员,需要同时有两种不同的开发和构建环境,有各自的包管理机制,编程语言和范式。虽然他的职责专注于业务实现,可是常常要在不同的工作上下文中切换,包括编写不同模块(前端,后端)所导致的思维方式的转换,而工具复杂度往往也造成了一定程度的困扰。从协作关系来说,我们应当想办法降低至少一端的工程复杂度。
全栈并不是只有全部使用 JavaScript 开发这么一个选项,这只是一种可能的方式:我们选择了把后端轻量化。但与之相对,也有一种把前端轻量化的方式。
多年来,人们尝试以不同的方式编写视图,有一种东西叫做 GWT,业务开发人员使用 Java 来编写视图代码,然后构建之后,生成 JavaScript 在浏览器中执行,这也是一种实际能够运作的机制,在某个时间段可能是异端,可是:为什么我们能够接受用 TypeScript、CoffeeScript、Reason、Elm 去编写 Web 视图,偏偏就觉得使用 Java 很奇怪呢?
语言并不是我们需要重点关注的东西,我们还是把目光投向视图本身。
即使是今天,我们仍然可以看到一些很奇特的东西流行着,比如 layui,在很多前端眼中,这是一个很过时的东西,然而,这并不影响很多开发人员选择它,而且,用它来开发业务,似乎效率也没有低很多。
这可以说明一个问题:在存在大量封装组件的前提下,具体在使用哪套技术栈开发,其实对研发效率并没有实质性影响,提高研发效率的东西是组件库,而不是某种具体框架,因为在存在约束的前提下,业务开发人员实际上只使用了这种框架一个非常小的子集。平台侧的技术人员所需要掌握的各种细节能力,业务开发团队并不一定需要全部掌握。仅仅写个 CRUD,就需要懂得各种编程语言底层理念甚至范畴论,这很明显是有问题的,这类方式也因此不利于周边生态的发展,对于阿里这类尝试连接天下的各种行业大中小企业的生态核心企业,其严重程度很可能远超想象。
为什么 VueJS、微信小程序这类东西,大家都认为技术细节上存在许多可改进的地方,然而其用户群体却一再增大到难以想象的程度,一线互联网公司的精英派开发人员跟这个社会的大环境到底存在多大的隔阂,为什么**共产党从农村起家,最终击败了精英派的国民党反动派,其原因值得深思。能让多少人参与进这个事情,很可能才是决定走到多远的关键因素,我们没有理由放弃社会中的每个人,仅仅因为他不能很快学会你熟悉的技术栈。
所以,长远而言,如果我们拥有了描述业务的能力,则研发过程的细节都是可被抽象,可被在底层升级的,这不是每个人都需要去关心的事情。我们现在用手机,并没有几个人去关注它的 CPU 集成了多少个元件,屏幕上一个像素点到底由什么东西组成,它们都被抽象掉了。
另外一个方面,开发方式也需要考虑成本。交付型项目的盈利很大程度上取决于成本控制,一线互联网公司的开发人员普遍是意识不到这个问题的,因为本质上他参与的研发项目是不计成本的,他不需要去关注人员的薪资,上下游环节配合等相关的成本因素,但在交付领域,这些全都是问题。
推而广之,业务软件的研发流程也是一个很可怕的事情。当我们面对一个业务的时候,按照一线互联网公司的通常做法,会发现流程是非常长的:
在此过程中,一旦产生变更,则基本上要涉及全流程的每个人,其沟通代价是阻碍高效交付的核心问题,所以,在业务侧的全栈化必定是一个非常重要的事情,否则成本无从控制。这些角色中,最好只存在产品 + 研发两个大角色,甚至在轻量业务中,借助平台能力,让二者进一步合并。
收拢角色的前提就是,每个环节需要砍掉过于灵活的可定制性,这个过程非常痛苦,并且非常考验抽象能力,但在大的生产过程中,则是非做不可的事情。
我们能给业务侧提供什么样的能力,这是平台侧研发人员需要时刻思考的东西,不要强求他变成你这样的人,才能用你的东西,要时刻从全流程的角度去看问题,找到阻碍生产力提升的地方,并且去改造它。
我们谈企业软件领域的前端,就绕不开设计体系。一直以来,企业软件领域的设计风格都以丑陋、风格过时等缺点广为诟病,谈及这个问题的时候,就需要阐述这么一个答案:企业软件领域好的设计风格到底应该是怎样的?
近年来,我们可以看到以蚂蚁 Ant Design,阿里 Fusion 为代表的,包含设计理念和组件库的一体化方案,各自的主打也都是企业级产品、中后台领域,那么,它们会是这个答案吗?
前不久有一篇文章,对比了 Ant Design 与 SAP Fiori,这篇文章的结论我很不认同,并不存在两者相比谁更优秀的问题,而是两者目前并不处于同一个维度上。
企业软件领域的设计体系,在我看来应该包含以下部分:
我们能够看到,互联网企业推出的常见的设计体系,往往都在场景上比较固化,很侧重并依赖于单个:搜索+列表+表单 的场景,对于更复杂的组合,或者是高度集成的单一视图,则缺乏指导性。
从逻辑上讲,因为一切视图背后隐含的逻辑都是数据库表操作,都可视为单表 CRUD 的聚合,或者是包含了事务的这些 CRUD 的组合,那么,如果不介意思维上的关联,我们大可以用单表管理的方式描述一切业务,或者稍复杂一些,使用主从结构的视图来管理一对多的关联表。
这个逻辑,是目前市面上存在的一些产品的理论依据,比如说 airtable,它就围绕对单表操作的各种形态,以类似 Excel 的操作体验去完成各类业务系统的定制。
我们目前所能看到的各类管理系统,出于降低开发者心智成本的考虑,很普遍地使用了这样的设计,所以大家的界面千篇一律,一切业务都是一个管理控制台,每个页面所呈现的东西都比较有限,除了聚合的 Dashboard,一般界面上放三到四块东西就结束了。
需要注意的是,尽管这样开发出来的系统,从整体感上已经不错了,但整体体验应该也就是在及格线上。为什么呢?因为前面我提到,这降低的是开发者的心智负担,而不是使用者的。
从业务使用者角度看,他们可能存在很多诉求:
业务系统设计上的难点在于:
我们再回头来看之前提到的 Ant Design 和 SAP Fiori 的对比,会发现前者在一些细节上面有明显优势,但体系化方面则跟后者存在较大差距。
所以,如果从一个大型企业角度,整体看待设计体系,会要求更多的一致性,并且,在业务上提取更多的通用准则,这些准则可能是严格的,而不是倾向于宽松。
比如说:
某个数据表格中,行内有“修改”、“删除”这类的按钮,这个按钮的大小,什么行为的按钮应该是什么颜色,都需要去做约束,而不是任由开发人员发挥。
一个用于承载业务的中台体系,如果不收敛其设计规范和前端组件,则必然导致研发流程的反复性增加。
总的来讲,从设计形态上看,倾向于“约束”而非“发挥”。而在清晰定义并描述了这些约束的前提下,很多能力应当成为默认拥有的。防止出现不符合设计规范的东西出现,提供无需额外配置就默认达到 60-80 分体验的能力,这才是业务设计体系的实质。唯其如此,才有可能精简从产品到研发中间的环节。
不适应业务的架构是失败的,作为工程与架构管控者,需要时刻思考在自己所处的环境下,存在什么痛点,什么环节,人员结构如何,主次矛盾分别是什么。
前端这个角色,受开源技术体系的影响太大了,很少人意识到:很多工程体系、库,都是需要被整合了再使用的。其整合方式取决于整个研发体系的业务形态与人员结构。
作为前端,可以尝试问问自己这些问题:
具体到企业软件前端领域,总的来说,可定制性会是一个很重要的方面,有一些可以关注的方面:
企业软件视图层面的几个基本特点:
一般来说,组件库是大家都会注意到的技术依赖项,它在构建一个大型软件的过程中,几乎是必不可少的,不同的团队拥有对组件库的不同控制力度:
在这里,组件库的实现技术并不算特别重要,更重要的是对业务场景的覆盖程度。
前端团队很容易对“业务组件”这个东西产生盲目而不切实际的追求,实际上,在企业领域,绝大部分“业务组件”是没有价值的。鲁迅先生教导我们:
其实地上本没有路,走的人多了,也便成了路。
这就好比是我们企图抽象一个大粒度的业务组件,给外界开了一些配置项。
但久而久之,配置项越来越复杂,比组件自身的内部实现还复杂了。
走的人太多了,处处都是路,又没有路了。
视图其实是:Model - ViewModel - View 的最外延,每一层的灵活程度逐次增加,自身其实就可以视为一种配置文件了,在配置文件里抽组件,很可能是性价比最低的事情。
前端需要把视野往全局去放,才能在这个事情上找到更合适的权衡。
时至今日,前端已经有了相对“正式”的开发环境,我们可以基于更先进的语言特性、更强大的工具去构建组件库或者业务视图,这些都是工程设施的重要组成部分。
然而,现在主流的前端构建体系,不一定非常适用于企业软件研发这么一个受限的领域。大如阿里的某个大部门,其 Web 系统数量可能上千,而公共的直接依赖项则未必过百,每次构建都要带着这些东西一起处理,对容器集群来说是不是一种巨大浪费,值得深思。
随着现代工程设施的引入,前端有了更明显的依赖管控机制,这个事情是一个双刃剑,一方面能得到更强大精确的依赖控制机制,另外一方面,引入了一些管理复杂度。
与构建相关的事情综合考虑,究竟是不是存在一个“公共基座”的东西,让业务方无需关注这么细节的组件版本升级、关联构建等机制,都是可以去探索的。
此类事情可能很多,其大的原则就是一个:开源技术栈应该经过怎样的定制和管控,给什么样的业务开发人员提供怎样的抽象程度?
在我看来,一家理想的软件企业,其研发管控能力的分水岭应当是:能否升级自己 3-5 年前给客户交付的系统。这个事情非常难,但如果不难的话,又怎么会有机会呢?工程师的实质就是在给定的资源条件下,寻找目标的最优解。
天生我辈,自当无惧其深,不惮其远,上下而求索。阿里有句老话:路走对了,就不怕远。
在业务开发过程中,我们总是会期望某些功能一定程度的复用。很基础的那些元素,比如按钮,输入框,它们的使用方式都已经被大部分人熟知,但是一旦某块功能复杂起来,成为一种“业务组件”的时候,就会陷入一些很奇怪的境况,最初是期望抽出来的这块组件能有比较好的复用性,但是,可能当另外一个业务想要复用它的时候,往往遇到很多问题:
诸如此类,时常使人怀疑,在一个业务体系中,组件化到底应该如何去做?
本文试图围绕这个主题,给出一些可能的解决思路。
通常,我们会有一些简单而通用的场景,需要处理状态的存放:
一般来说,我们有两种策略来实现,分别是状态外置和内置。
有状态组件:
const StatefulInput = () => {
const [value, setValue] = useState('')
return <input value={value} onChange={setValue} />
}无状态组件:
type StatelessInputProps = {
value: string
setValue: (v: string) => void
}
const StatelessInput = (props: StatelessInputProps) => {
const { value, setValue } = props
return <input value={value} onChange={setValue} />
}通常有状态组件可以位于更顶层,不受其他约束,而无状态组件则依赖于外部传入的状态与控制。有状态组件也可以在内部分成两层,一层专门处理状态,一层专门处理渲染,后者也是一个无状态组件。
一般来说,对于纯交互类组件,将最核心的状态外置通常是更好的策略,因为它的可组合性需求更强。
我们在实现一个相对复杂组件的时候,有可能面临一些外部依赖项。
比如说:
一般来说,我们给组件提供外置配置项的方式有这么几种:
这三种里面,我们需要尽可能避免直接引入全局依赖,举例来说,如果不刻意控制外部依赖,就会存在许多在组件中直接引用 request 的情况,比如说:
import request from 'xxx'
const Component = () => {
useEffect(() => {
request(xxx)
}, [])
}注意这里,我们一般意识不到直接 import 这个 request 有什么不对,但实际上,按照这个实现方式,我们可能在一个应用系统中,存在很多个直接依赖 request 的组件,它的典型后果有:
这个问题,可能有的研发团队中会选择先封装一下 request,然后再引入,这是可以消除这种问题的。
因此,要尽量避免直接引入全局性的依赖,哪怕它当前真的是某种全局,也要假定未来是可能变动的,包括但不限于:
需要尽可能把这些东西控制住,封装在某种上下文里,并且提供便利的使用方式:
// 统一封装控制
const ServiceContext = () => {
const request = useCallback(() => {
return // 这里是统一引入控制的 request
}, [])
const context: ServiceContextValue = {
request
}
return <ServiceContext.Provider value={context}>{children}</ServiceContext.Provider>
}
// 包装一个 hook
const useService = () => {
return useContext(ServiceContext)
}
// 在组件中使用
const Component = () => {
const { request } = useService()
// 这里使用 request
}这样,我们在整个大组件树上的视角就是:某一个子树往下,可以统一使用某种控制策略,这种策略在模块集成的时候会比较有用。
使用 Context,我们可以更好地表达整组的状态与操作,并且,当下层组件结构产生调整的时候,需要调整的数据连接关系较少(通常我们倾向于使用一些全局状态管理方案的原因也是这样)。
在实现组件的时候,我们往往发现它们之间存在很多共性,比如:
从更深的层次出发,我们可以意识到,几乎任意一个组件,它所使用的状态与控制能力都是由若干原子化的能力组合而出,这些原子能力可能是相关的,也可能是不相关的。
举例来说:
const Editable = (props: PropsWithChildren<{}>) => {
const { children } = props
const [editable, setEditable] = useState<boolean>(false)
const context: EditableContextValue = {
editable,
setEditable
}
return <EditableContext.Provider value={context}>{children}</EditableContext.Provider>
}这样的一个组件,表达的就是对只读状态的读写操作。如果某个组件内部需要这么一些功能,可以选择直接将它组合进去。
更复杂的情况下,比如当我们想要表达这样一种特殊的表单卡片组,其主要功能包括:
分析其特征,发现来自几种互相不相关的原子交互:
它的实现就可能是这样:
const CardList = () => {
const { list, setList, addItem } = useContext(ListContext)
const { editable, setEditable } = useContext(EditContext)
const { commit } = useContext(DraftContext)
const { selectedItems, setSelectedItems } = useContext(ListSelectionContext)
// 然后内部组合使用
}由此,我们有可能在每个组件开发的时候,将其内部结构分解为若干独立原子交互的组合,在组件实现中,只是组合并且使用它们。
注意,有可能部分状态组之间存在组合顺序依赖关系,比如:“可选择”依赖于“列表”,必须被组合在它下层,这部分可以在另外的体系中进行约束。
在业务中,组件的复用方式并不总是一样的。我们有可能需要:
每当我们需要设计一个“业务组件”的时候,就需要慎重考虑了。可以尝试询问自己一些问题:
比如说,一个内置了选择省市县的多级地址选择器,它就是这么一种“业务组件”。我们以此为例,尝试重新解构它的可复用性。
对于地址的查询,就是外部依赖。注意,尽管大部分情况下这个是不会改的,但是仍然存在这个可能性,需要提前考虑这类事情,通常,遇到有数据请求之类的东西,尽量去抽象一下。
如果需要建立另外一种选地址的组件,交互形态不同,但逻辑可以是一样的。
有可能被用来选择其他东西。
所以,回答了这些问题之后,我们就可以设计组件结构了:
业务上下文
const Business = () => {
const [state, setState] = useState()
return (
<BusinessContext.Provider value={context}>
{children}
</BusinessContext.Provider>
)
}交互上下文
const Interaction = () => {
const [state, setState] = useState()
return (
<InteractionContext.Provider value={context}>
{children}
</InteractionContext.Provider>
)
}在组件的实现中:
const ComponentA = () => {
const {} = useContext(BusinessContext)
const {} = useContext(InteractionContext)
// 在这里连接业务与交互
}使用的时候:
const App = () => {
// 下面每层传入各自需要的配置信息
return (
<Business>
<Interaction>
<ComponentA />
</Interaction>
</Business>
)
}在这个部分,总的原则是:
在细分实现中,再考虑两个部分分别由什么东西组合而成。
在一些比较复杂的场景下,状态结构也很复杂,需要管理来自不同信息源的数据。在某些实践中,选择将一切状态聚合到一个超大结构中,然后分别订阅,这当然是可行的,但是对维护就提高了一些难度。
通常,我们有机会把状态去做一些分组,最容易理解的分组方式就是将业务和交互隔离。这种思考方式可以让我们的关注点更聚焦:
在很多时候,一整块复杂的业务交互包含的内容过多,涉及多个交互块的流转,或者存在比较复杂的数据共享关系,如果非要集中管理,维护起来会很难。
当前社区的技术方案,对这块是比较欠缺考虑的,绝大部分人采用的是两种比较极端的策略:
但是考虑到在一个业务体系中,有可能有的模块的组件树深度过大,交互过于复杂。又或者,项目之间的集成关系不是一成不变的,经常有单个项目整体下沉为被集成方。诸如此类的需求,会对状态逻辑、组件结构提出更多需求。
我们可以这样的策略:
整体结构形如:
这个体系下:
这样,实现的只关注于实现,集成的只关注于集成,两者的视角相对是分离的,主要的适配逻辑都集中在各自的适配器上。
在 hooks 推出之前,React 中管理状态之间依赖关系的机制是有所欠缺的。以其他技术栈为例,往往提供了一种称为 computed 的机制,使得可以定义出一些无副作用的依赖计算链路,例如:
const firstName = ref('')
const lastName = ref('')
const fullName = computed({
get: () => `${firstName.value},${lastName.value}`,
set: val => {
const [first, last] = val.split(',')
firstName.value = first
lastName.value = last
}
})早期,React 体系只能额外借助类似 RxJS 这样的工具库来实现类似功能,在 hooks 和 Recoils 推出之后,有了更多选择。
当我们认为“组合若干个独立状态分组来实现组件,其灵活性更高”的同时,就需要面临一些将组合结果再次暴露出去的场景。在这样的场景下,有可能需要对状态依赖关系的隐式或者显式表达。
组合状态提供了一种视角:从使用者的角度看待状态数据的来源和变换关系。这对于复杂场景下,追踪状态的变化链路来说,非常有用。我们可以对于视图上每一个状态,都追溯到它是由什么业务状态所关联计算的交互状态,从而在跟踪问题的时候,能以最快的方式定位到问题。
它的视角是:
此外,以这种视角出发,还有机会把一些动态的业务计算规则通过注入的方式加进来,类似 Excel 里面的一些公式,从而更容易支持业务上的一些配置化需求。
在开发过程中,也要注意尽量以状态驱动的视角去解决问题,尽可能少用 ref 去获取“组件引用”。
除了常规的组件化生产链路,还可以关注另外一些工程方面的视角。
前端组件的发布方式也是值得考虑的,与早期静态的前端工程链路不同,组件的依赖存在两种不同的方式:
以包形态依赖的组件,其构建与发布链路是跟随主应用的,主应用与它们是比较强的耦合关系,会需要在代码结构、交互呈现方面,都结合得更紧密一些。
以服务方式依赖的组件,有单独的构建与发布链路,主引用与它们是松散耦合关系,一般来说,会采用某种微前端方案来集成它们。
这两者在业务上都是可能出现的,需要从业务集成关系的角度来判断。
在一个相对可控的体系中,建设组件依赖体系的时候,需要多考虑一些其他环节,比如依赖的反向管控。所谓依赖关系的反向管控,是指,从一个组件出发,知道依赖它的有哪些组件或者产品。通常,在以服务方式集成的组件上,这一点非常重要,否则,被多个业务依赖的组件服务要单独发版了,可能影响的范围都难以精确定位。
这个部分的方法论可以参照其他体系,比如后端的服务依赖监控策略去建设。
当前,前端技术栈的分化比较严重,对于行业软件公司,这样的情况尤其严重,因为产品周期都更长。实时翻新所有组件是不现实的,因此,我们需要寻求更通用、更长远的集成方案。
当前主流的前端框架都是数据驱动,而技术栈集成的组合是可以穷举的,比如说,我们可以有:
类似这样,就可以不必过于强求组件自身的实现方式。
业务组件的使用方式变成:
整体来看,一个应用可能是一个比较复合的组合:
整个这块,就是“前端微服务”,但是在不同场景下,存在不一样的实现策略。一般来说,如果对所有被集成方的生产过程能够有一定约束,整体实现就可以比较好一些。
需要注意的是,当前一些“微前端方案”侧重于解决的一部分场景是历史遗留问题,或者是对生产者缺乏有力约束的场景,如果是整个应用都处于可控范围,异构框架的集成就相对比较友好一些,有机会做得更好。
如果我们能够把状态管理与交互实现隔离得比较好,甚至很容易做出技术栈中立的状态管理方案,并且能够更好地隔离 UI 框架可能带来的影响。
总的来说,从交互和产品角度看,优先期望能有完整的交互集,但具体组件实现允许有异构方案。
一般的业务团队中,前端自动化测试都是一个基本无法推进的事情,主要原因是逻辑和状态过于分散,覆盖所有情况的自动化测试用例,数量可能庞大到超过想象,并且,每次需求变更,需要变动的测试也非常多。
但是,在合适的方法论下,这个事情也不是完全无解的。我们需要尽量去做到交互与业务逻辑的隔离,当组合关系比较清晰的时候,业务和交互是可以分别测试的。
在测试业务的时候,交互细节可以忽略,例如,我们在测试一个使用表格承载的业务的时候,可以检验它的数据结果始终满足某种形态的对象数组就可以了,无需关注是否正确显示为表格(这是另外一个问题)。
甚至,我们有机会造出一组专门用于测试的渲染器,专门用来配合业务测试。
此外,需要注意到,我们之前的整个探讨,都在强调一个理念:业务与交互隔离。在隔离到比较好的情况下,把交互全部视为黑盒,就可以得到很纯净的业务形态,据此,有机会去做到基于状态组合的语义化业务埋点。
总的来说,组件开发的方法论可能是相对中立和普适的,但组件库的整体建设方案,与所在的行业有不小的关系。如果是从事行业软件领域,对交互集的掌控就是非常重要的事情。
考虑方案的时候,如果优先从产品的集成关系角度出发看待问题,有可能是比较好的,它至少保证业务的可用性尽可能不被技术方案限制。
本文述及的一些策略,从另外一些视角看,可能有另外一些认知。比如说,在提到管控依赖项的策略中,如果把“基础组件”也视为是一种可注入的能力,那整个业务部分就可以变成另外一种奇特的形态:类似某种“小程序”体系。
篇幅所限,本文所提及的都是很初步的内容,更多细节需要单独展开。
07年底,我所在的团队需要重构一个产品,在此之前,我们的前端框架是这样的:
这个时期的版本不用说,肯定都是只支持IE的,我们当时需要兼容的浏览器包括IE 5.0,5.5,6,后来7出来之后还需要支持7。
这个产品重构的目的是,对近几年积累的业务需求进行整合,并且把服务端完全迁移到Java。对于前端来说,其实不做迁移也可以,但当时我们发现一个问题,FireFox这个东西突然崛起了,所以,我们从原先面临的只支持IE,变成了可能要支持跨浏览器。
所以我们觉得需要把这个事情做一下,因为当时判断,IE的份额可能会下降到70%左右,FireFox可能会占有25-30%的份额,这个兼容是有可能需要的,虽然以我们的场景,几乎全部面向行业用户,可以把浏览器限制得很死,但也有部分用户自服务的产品,将来还有扩大的趋势。
这时候我们问题就很大了,因为前端的基础功能面临大改,一些校验之类的库好办,通信封装也好办,基于htc的控件就是个大问题了,必须全部重写。
当时几个成员产生了热烈的讨论,jQuery那时候还没有一家独大,也没有产生这种趋势,可选项包含:
在这两个选择里,我们排除了第一个,因为虽然看上去它很符合我们的业务场景,但我们的定制化需求比较多,不确定有能力在这个基础上做定制,可控性不好。
所以我们就决定选一个核心js库,然后自己开发外围控件。那么,选谁呢?最终选的是prototype,因为大家判断,我们不需要类似class的机制,这样就把后面两个排除了,而我们不需要太多DOM方面的封装,因为最后业务上需要直接操作DOM的东西不会很多,都会被我们封装掉,所以又把jQuery排除了。
所以我们的需求其实也很明确,就是有一定基础功能的js核心库。然后就是在这个基础上开发控件了,时间也很仓促,大约只有2-3个人,2-3个月,最后几个东西:
最后,因为赶时间,这个版本的框架最终并未跨浏览器,部分控件的功能还是使用了IE only的特性……更致命的是,我们因为没时间,所以在业务开发指引上花的时间很少,这导致业务开发人员赶工的时候,整个就不可控了,因为我们后面还参与了业务开发,十多个写HTML和JS的人,被业务压着走,压根没人有时间看FireFox的状况……
后面几年中,这个大版本被作为基础版本,拉了无数分支出来,期间,面临了IE8之类的兼容性修改,除此之外,已经没有机会再修改基础库的部分了。
09年底,我主导这个产品下一代版本的前端框架选型。我们现在回头看这个时间点,会发现很尴尬,当时流行的,或者即将流行的所有前端方案,其实也都是第一代的理念,在现在这个时候,都已经被时代大潮冲刷得死伤殆尽了。
所以我当时非常纠结,我是预见到前端这几年的乱象的,当时大家炒得最火的概念是什么,是HTML5,然而我看了这方面的一些资料,发现广义上,更多提供的是一些功能方面的东西,或者能提升布局方式,等等,这与我们想要的东西相去甚远,好比说,我们想要蒸汽机之类的东西,发现手里将要有的还只是各种铁块。
我当时想要什么呢?想想我当时有过什么,经历过什么,早在05年初,我就有了一种设想,那就是前端的全组件化开发,当时的老大问我对现有项目有什么看法,我提出了一个方案:
这个想法在当时确实比较激进,所以当然没人支持。但我在05-09这几年的开发过程中,目睹各种业务代码的混乱,觉得可能还是应该推进组件化的开发理念。理念是有了,细节怎么处理呢,因为HTML Components这一规范被废弃之后,我发现现有的任何方案都不再能够像原先那样简便地封装组件了,如果对于业务开发人员来说,开发业务组件的代价过高,那工程成本更加不可控。
回想我们使用HTML Components的时候,开发一个组件易如反掌,就像开发普通页面一样简单,只需在头部声明对外的属性、方法、事件即可,样式也是隔离的,JS作用域也是隔离的,使用起来也是非常简单,就是一个自定义标签,而且是客户端的(区别于taglib之类的服务端标签封装)。
以05年时候那个产品的场景而言,绝大部分界面都是普通的配置和管理,每个界面的独立性都较高,并不存在强集成的场景,所以是否使用组件化方式开发,并不是很重要,这跟我前几天在微博上说:“轻量级管理控制台有至少100种做法”是一个意思。
但是后来的做的,有包括CRM和呼叫中心之类的强集成产品,不再是原先那种单菜单配置页面了,整个产品几乎就是一个菜单,然后通过各种交互去触发一系列功能,在这种场景下,组件化就变成了一个重要的实施手段。
所以我万般无奈,就把目光投到04年开始持续关注的一项技术:Adobe Flex,在这个东西刚出来的时候,我曾经预言微软会推出一个精简的CLR,作为浏览器插件运行,与Flash平台抗衡,后来大家看到了SilverLight,不过这个东西当时的普及度并不好,第一代极其简陋,第二代稍微好一点,所以我没有考虑它。
在2009年,Adobe Flex算是比较成熟了,带有完善的组件化机制,生命周期管理,强大而易于扩展的基础控件,优雅而强大的开发语言,但我当时有判断,这东西是一个走下坡路的平台,而且Adobe自身有很大不足,也没有能力把它支撑和运营好。最终,我反复权衡,仍然选择了使用它来构建这个版本。
所以当时我面临的压力非常大,公司内部的辩论达到白热化,正反双方都有相当多的人参与,而且反对者还略多些,年轻开发者居多。在有资格参与这项决策的各基层管理者和技术专家组的投票来看,双方也是基本对等的。这个争论现在回头看,很有意思,双方考虑的事情其实不在一个层面上,从基层开发者的角度,他会从流行趋势方面进行一个判断,觉得Flash必死,HTML永生,你让我1948年加入国民党,是何居心?
但从我们有些老员工的角度,看到的问题是由于公司开发人员水平参差不齐,导致很多代码写得非常糟糕,很难调试,也很难重构,更没有一些全局视图,让我们能看到代码的结构是怎样,数据的流动又是怎样,产品的质量如何,我们觉得对于大部分低层次开发者来说,JavaScript的约束还是太弱了,这样松散的语言在他们手里会造成开发效率极低,bug率很高。
当时我有个比喻,我们相当于在2000年选择了使用Delphi。这个比喻是为了向公司高层说明,我们到底是在干什么,大家在这么激烈地吵什么。因为他们虽然不一定熟悉当时的技术方案,但都是从2000年那个时代过来的,对Delphi的盛衰还是很熟悉的。
最终我们的判断是:5年之内,泛HTML体系的组件化方案不会有一个相对稳定的选择,我们是做企业软件产品的,并不害怕使用的技术相对过时,怕的是时常有剧烈变动,而且不能掌控。所以,打算用Adobe Flex这样的东西,来做一个5-8年的支撑,在这段时期内,见机行事,在泛HTML体系里作一些探索,跟进可能会流行的技术,并且加以积累。另外,选择一种轻量级的解决方案,用于构建面向个人用户的门户,这条线选择的是jQuery和BootStrap。
当时在轻量级这条线的解决方案上,我也有一些意见,因为在我们当时的开发团队中,大家对“控件”这个东西的依赖程度太高了,绝大部分人压根不具备我们现在所说的前端工程师的基本能力,只有调用控件的能力。而我认为,轻量级的场景中,应当严格控制“控件”的使用,绝大部分场景都是用基本样式加一些DOM操作就可以做到,当时我们的轻量场景是面向运营商的用户们,他们登录上去,查询话费,办理业务,兑换积分,购买一些服务或者礼品之类。
所以,当我后来发现这样的场景也引入了上M的js库的时候,我的心情是非常崩溃的,后来有的团队考虑在这种业务场景下封装一些服务端标签,这个事情我并不赞同。很多时候,我们需要去使用服务端模板之类的方式生成界面,为的是页面性能优化之类,但我们所在的场景,并不需要这么苛刻的优化,页面DOM结构是比较简单的,反倒是JS这块需要严格控制。这么轻量级的场景,做服务端组件化的必要性也不是很大,只需引入js的模板库就可以了。
回头再看Flex这头的状况,我们用这个东西针对重量级的管理系统进行开发,但令人痛苦的是,绝大部分开发人员很难理解“组件化”这么一件事情,比如说,仍然保留“页面”这个称呼,越是老开发人员越是难改变思维,我有一次很激动地说:我们这种模式下,哪里来的页面?我们做的是一个软件系统,你可以把它理解为运行在浏览器中的桌面软件,只存在组件,不存在页面,页面是HTML体系中特有的称呼。
所以,做一个全业务组件化的实践,需要一次又一次从理念上去向业务团队灌输,什么是组件,组件树是怎样的,组件跟数据层如何通信,组件之间如何通信等等,如何提取合适的组件,不把这些理念灌输下去,整个产品也很难成功。
举例来说,之前系统规划人员增加了新模块的时候,一般是把数据库表结构截图发出来,然后最多画个草图表示界面,但在组件化的开发方式中,这中间至少还有一步组件规划、整合的过程,这一步应当需要严谨的考虑。
我所在的基础技术团队中,也有不少人对我们要面临的问题看得不太清楚,把责任想得太轻。之前那种简单的管理页面,只需要基础技术团队提供基础组件和公共库,公共样式的开发,但在全组件化的实践中,做完这些事情也才完成了整个事情的30%。
除了这些,还需要对业务团队培训组件化的相关理念,需要跟踪他们的开发过程,评审、观察、纠偏,还需要构建组件的管控、测试平台,否则,仍然是一种山寨的开发流程,而享受不到组件化所应当拥有的流水化生产体验。这一步其实没有做下去,投入还是太少了。
这个大产品版本以及附属项目一共有好几十名开发人员参与,历时2年多,虽然离我心目中的目标还有不少差距,但在某些方面的提升是能够感受得出来的,比如说开发效率的提升。除此之外,这个版本的美观程度比之前所有版本都好,终于有现代气息了,谁说企业用户就都是土鳖的,甚至有一次还收到过外籍市场人员专门的邮件夸赞,这让我们感到很振奋。
开发效率的提升另一方面还源自Flex自身的特点,独立于浏览器的插件,可以说,大部分前端开发人员都会面临跨浏览器的折腾,尤其是那几年,乱得可怕,兼容问题会把人折磨死,我们面对的客户,从欧美到亚非拉,各种低端高端浏览器并存,所以我们是绕开了这个问题,而这么复杂的组件界面,如果使用传统Web技术,在IE6、7等浏览器下的性能会惨不忍睹,基于插件体系的另外一个优点是,性能不受低端浏览器的制约,下限比较高。
在这个阶段,我们实际上是做了比较取巧的选择,但从长期角度看,还是必须回到泛HTML体系的。所以,从12年开始,我就开始考虑未来的产品技术选型。
在12年这个点上,我们能看到的东西还是比较多的,至少比几年前有了很明显的发展,比如说,jQuery终于一家独大了,比如说,AMD和CMD之类js模块封装机制的出现,比如说,Backbone,Knockout,Angular分别出现了不少使用者,比如说,ES6和Web Components规范的落地快看到曙光了。
但实事求是地说,这些所有东西加起来,开发体验还是比不过Adobe Flex,在重量级场景下,泛HTML体系的整合力度还是比较弱,对开发人员的技能要求也会高一些。我也关注Dart,关注TypeScript,(为什么不关注CoffeeScript,因为所在公司几乎全是只懂Java的开发人员,跟Coffee的理念差别太大,推广成本极高)。
感慨归感慨,选型还是一直要做,只是这个选型在实际有项目应用前,一直还会处于动态调整中。
在这段时间中,我们考察了Backbone,Knockout和Angular,也持续关注了司徒正美的Avalon,最终还是比较倾向于Angular的。
倾向于Angular的主要原因是,开发团队经过磨合,已经逐步习惯了组件化的开发方式和数据绑定所带来的开发理念的改变,Angular在这方面与Flex比较接近,学习成本很低,而且那些稍微繁琐的配置,对于这些习惯了Java的人员来说,并非负担。
所以,当时我们的基础技术团队也花了不少时间来学习Angular,看源码,踩坑,期间,团队的大漠穷秋翻译出版了国内第一本Angular中文书籍。
我们研究Angular,还有另外一个原因。在基于Flex的这代产品逐步稳定之后,又实现了一个二次开发平台,从数据模型的动态定义(类似ORM),到规则、流程、服务的动态定义,再到界面的可视化配置,动态的数据绑定。这个平台的有些方面考虑是不够成熟的,尤其是动态界面这块,细节不展开了。
所谓的动态数据绑定,指什么呢,其实核心机制类似于Angular的这种绑定关系。在Flex体系中,数据绑定是通过Proxy机制实现的,对POJO有一定程度的封装,比如Object就封装为ObjectProxy,而Array封装为ArrayCollection。我们当时需要创建的是:基于单个用户(或者会话)的数据联动体系。
这个是什么意思呢,对于某个登录用户来说,他所可能拥有的全部数据结构是可预测的,绝大部分是平级关系,没有关联,部分存在联动关系,我们要做的就是把这些关系描述出来,用可视化的形式配置,挂接在ORM机制上作为外壳,并且提供给业务流程、业务规则和动态界面作为绑定数据源。
这个数据的定义和描述机制,用现有技术类比,就好像是Meteor或者Relay,但当时我们对有些东西没有考虑清楚。因为对于某个用户而言,他的所有数据结构与界面上的组件结构是无关的,这意味着,如果不把数据做拆解传递,一旦遇到组件树上的不同层级指向数据源同一位置之类的情况,就不好办。因为我们组件之间也是不共享数据的,类似现在的React。所以我们当时的问题就是数据中间层设计得不好。
以我们当时的设计,其实是适合Angular这种机制的,Angular里面,不同层级的组件之间,数据可以有穿透,比如说你在最顶层绑定了一个dataStore,在隔了很多级的叶子节点上仍然可以绑定到dataStore.a.b这样的数据,这个a.b数据路径可以与叶子节点在组件树上的路径毫无关系。
在这个过程中,我还是一直在尝试考虑基础框架与组件化业务开发的结合,包括整个组件和数据的规划流程,管控机制等,也写了几篇文章,现在回头看,有一些不成熟的地方,另外有些东西当时觉得有坑,但正好被近期出现的新技术填平了。
举例来说,当时我觉得,不管是AMD还是CMD,都是在JS模块自身代码中声明依赖项,如果是出现代码路径调整之类的情况,这些依赖项的变更就是个问题,所以我设想了一种类似npm的方式,用数据库集中存放依赖关系,模块自身的内容不维护这个关系,然后构建阶段生成出来。
今年看到Webpack,里面提到module,bundle,entry chunk之间的关系,感到已经差不多把我当时考虑的那些东西全部做到了,社区的力量真是强大啊。
在之前争论Flex方案的时候,反对方的有些观点很典型,比如:Flex代码编写之后还需要编译,JS的不用。但其实最近几年我们看到,Web应用的开发过程逐渐离不开构建环节,不可能再像十年前那样,写完代码之后,最多只做下压缩就上线了,那是一种很原始的生产方式,所以,从这个方面看,组件化、构建过程,这些都是现代富Web应用开发方案中必不可少的部分,已经逐渐被广泛接受了。最近两三年,业界对前端工程化的关注度也已经比以前高很多了,令人欣慰。
前面这些年,我们还有一个大的缺陷,那就是一直对异步编程模型关注太少了,在早期我们一直使用同步的XMLHTTP,后来到了用Flex的时候,改用异步的HTTP通信,使用AMF协议传输数据,我们的经验仍然停留在使用回调函数这种初级的方案上,间或使用事件,并不知道任何跟promise之类理念相关的东西,所以代码有不少很不优雅,这个跟眼界有关,还是缺少学习所致。
现在距离09年底已经整整6年过去了,回头看来,6年前可能接触到的任何前端领域的框架或者库,到今天都已经全部是过时的。这6年时间,我们可能积累出一些经验,但大部分东西都不可避免地失效了,这就是野蛮生长期的痛。
这6年里,我们看到AMD,CMD这些模块机制逐步流行,然后又突然衰落,Angular为代表的前端MV*框架横空出世,带给前端社区巨大的冲击,React挟组件化和Virtual DOM之力快速崛起,你方唱罢我登台,乱花渐欲迷人眼。
两年前我从之前公司离职,心中充满迷茫,未来的Web技术会怎样发展,重型Web应用应当采用怎样的整体方案去建造,自己并不能说出一个精确答案。今天我们再要考虑未来的Web应用技术选型,已经没有两年前那么迷茫了,这两年仍然在持续学习,持续思考,每次面临选型,还是如履薄冰,一再审视项目类型,人员状况。
未来的前端Web应用技术选型还有不小的变数,身为大龄前端技术人员,一方面感慨有些自己熟知的技术逐步落幕消亡,另外一方面又看到新事物不断出现,以种种方式改进和冲击着我们的开发方式。生在这个时代是一种不幸,也是幸运。毛主席教导我们:三天不学习,不如刘少奇。说到底,保持学习和思考,是现在这个阶段最该做的。旧技术虽然消亡了,但它们留下的思维启发永在。
后记:最近一直有种冲动,想把过去十年(2005-2015)时间所经历的一些事情总结一下,昨晚开始写,今天中午完善了一下,大致写完,意犹未尽,与大家共勉。
注:这是本系列的第二篇文章。第一篇是:交互的本源 —— 对渐进式交互优化路径的初步探索
近几年,随着 TypeScript 的逐步流行,类型系统逐渐被前端这个群体重视起来,也逐渐在一些组件库中被深度采用。但是,我们可以发现,如果从使用类型系统的几个层级去划分:
几乎所有组件库都处于前两个层级,并未达到类型优先的程度。那么,什么是类型优先,它有什么好处,本文尝试结合一些具体案例,给出说明。
我们在之前的文章中提到,可以构建一套语义化的交互体系。交互的语义化有巨大的价值,它至少能够带来以下几个好处:
那么,如何让交互体系更语义化呢?一般来说,包括但不限于以下方面:
这些目标都是很诱人的,但做起来并不简单,尤其是大部分“组件库”,其设计体系过于零散,也没有去追求在工程链路中的更良好结构,因此常常在某些方面有所欠缺。
对于一个原子交互而言,它很明显可以表达为对某种、或者某些数据类型的操作。例如:
如果一个交互,可以被用来表达对某种数据类型及其派生类型的操作,我们就可以以此为依据,将其表达为一个泛型交互,因此它的实现代码,也就是一个泛型组件。在某些语言和框架中,我们是可以写出这种组件的,例如:
type InputProps<T extends number | string = unknown> = {
value?: T
onChange?: (v: T) => void
}
const Input = <T extends number | string = unknown>(props: InputProps<T>) => {
// implementations
}这样,这个组件就被声明为兼容 number 和 string 的泛型输入组件了,而使用这个组件的时候,我们也可以写出类型更友好的用法:
<Input<number> value={111} />
<Input<string> value={'hello'} />借助这样的实现,我们可以在某种程度上,既明确标识了本交互兼容的类型,又对参数能够施加简单的约束。
另外一个需要简单提及的东西是布局组件。如果按照之前我们的从数据类型入手的划分,会发现布局组件并不需要接受这类参数,因此,它只需要考虑自身的配置属性,以及基于特定上下文的参数。
所谓交互类型的兼容链,指的是:在交互所表达数据类型的兼容链路上,如果存在能够更精确对应指定业务模型的交互,则默认使用这个交互;如果不存在,则使用与其兼容的交互。
例如,在业务上,基于 Object 扩展的领域模型 Person:
当我们碰到一条 Person 数据的时候,首选交互可以设置为 Profile 组件,而当碰到一条订单数据的时候,因为没有指定订单这个业务模型的精确交互,可以退而使用 Object 的默认交互表单来表达,那就是表单。
这种扩展链路,能够让交互设计与技术实现的路径更一致。当新业务中暂时没有更精确组件的时候,通过类型的降级系统,先找到最接近的那个,以此作为占位。与此同时,设计师与技术人员共同创建新的组件,再替换上去。
通过这种方式表达的泛型组件,其形态大致如下:
Form 组件:
type FormProps<T extends Object = unknown> = {
value?: T
onChange?: (v: T) => void
}
const Form = <T extends Object = unknown>(props: FormProps<T>) => {
// implementations
}Profile 组件:
type ProfileProps<T extends Person = unknown> = {
value?: T
onChange?: (v: T) => void
}
const Profile = <T extends Person = unknown>(props: ProfileProps<T>) => {
// implementations
}使用的时候:
const Demo = () => {
return (
<>
// 使用精确的交互来表达 Person 实体
<Profile<Person> value={tom} />
// 使用泛化的交互来表达 Person 实体
<Form<Person> value={tom} />
// 使用泛化的交互来表达定单实体
<Form<Order> value={myOrder} />
</>
)
}沿着上面的例子继续,在 Person 类型已经指定了呈现方式为 Profile 的情况下,某个具体业务场景中,存在一种对 Person 的扩展类型:PetKeeper。在没有给 PetKeeper 指定更精确交互的情况下,它沿着类型的扩展链一路上溯:
PetKeeper -> Person -> Object
在 Person 这个位置找到了预置的默认交互,于是自动采用了这种交互。此后,设计师给 PetKeeper 单独设计了交互组件,把用户及其宠物的头像聚合在一起,然后注册到交互系统中,于是,业务中的 PetKeeper 实体就可以使用这个新交互了。
因此,我们拥有了一套渐进式优化交互的路径,它的可替代路径,是与类型的兼容链同步的,这也就是类型优先的含义之一。
需要注意的是,在前面部分,我们提到的类型都是可能会被构建过程擦除的类型,它通常能在类似 TypeScript 这类体系中,对编写代码起一些约束作用,但是在运行时就不起作用了。
如果想要保留运行时约束,就需要为组件增加元数据。在 JavaScript 社区中,存在 prop-types 这类补充组件元类型的库,React 官方示例中给出了使用说明:https://reactjs.org/docs/typechecking-with-proptypes.html
import PropTypes from 'prop-types'
class MyComponent extends React.Component {
render() {
// This must be exactly one element or it will warn.
const children = this.props.children
return <div>{children}</div>
}
}
MyComponent.propTypes = {
children: PropTypes.element.isRequired,
}例如,这个简单的例子中,就使用 PropTypes 的 element 类型,约束了 MyComponent 组件 children 的非空行为。除此之外,我们也可以看到各类简单类型、函数、数组等等组合约束方式。
但是,在通常写代码的时候,一般并没有人写这些东西,并不会影响组件的使用,这是为什么呢?因为现在很大一部分人,放弃了运行时的这种校验,而是使用开发态的类型约束来规范自己的代码。
同样是上面的例子,可能在 TypeScript 中,会使用下面的方式来表达:
const MyComponent = ({ children }: React.PropsWithChildren<{}>) => {
return <div>{children}</div>
}这就是假定开发态的类型能够覆盖一些低级错误,一般对于业务来说是足够的,但在不少时候,还是不够精确,比如这里,在使用 MyComponent 的时候,就检测不出没有写 children。
因此,为最基础的组件提供元类型,是更完善稳妥的做法,它不再受限于某种编程语言的表达能力,而是可以借助更完善的类型描述,甚至是注入的上下文校验规则,来提供更完备的运行时检测能力。
比如说,要描述这类规则,就必须借助额外的元类型与校验函数:
另外一个角度,当我们致力于打造从设计到开发的一体化工具的时候,需要赋予工具更多能力,否则它仍然过于依赖使用者自己对细枝末节的理解与记忆,而工具的能力是完全来自组件体系提供的元信息的,因此,需要从源头,在交互的设计阶段,就把整套体系建立起来。
建立元数据类型的方式不止 PropTypes 这一种,如果想要建立贯穿前后端工程链路、跨部署架构、跨编程语言和框架的元数据推导系统,也可以借助更中立的表达方式,比如 JSON Schema 之类。
篇幅所限,本文不展开探讨元类型的定义方式,以及元类型与编程语言类型的动态转换,相关内容会在其他文章中详细叙述。
需要注意的是,原子交互本身是不包含对数据源的定义的,它只能通过某些方式,消费数据源。又比如,对数据的迭代、拆解过程,都是广泛存在的。在一个致力于让交互与程序实现拥有相等可组合性的体系中,这类不可见、只表达数据操作的组件,也是必须要考虑的。
如果要重现从原子交互到业务组合的全过程,我们就需要把状态与控制的“逻辑组件”抽象起来。实际上,在之前表达原子交互的时候,就已经有这个过程的最简形式了:
const PrimitiveDemo = () => {
return (
<Primitive<Boolean>>
<Switch />
<CheckBox />
</Primitive>
)
}我们把 value 和 onChange 包装在 Primitive 组件内部,Primitive 就持有了这部分状态,并且提供了对状态的操作,以此将原子交互纯化。
同理,我们可以对拥有相同状态与控制结构的交互们作类似的提炼:
const SelectorDemo = <T extends Object = unknown>() => {
return (
<Selector<T> type="single">
<Tabs />
<Collapse />
</Selector>
)
}这里,我们就把可单选的选项卡组件与可折叠面板组件的控制过程抽象到同一个东西上了,这样,拥有相同语义的组件的表达方式就会更简单。
进一步去思考,我们还可以把一些常见数据结构的展开过程也抽象掉,比如:
据此,其他的原子交互可以因而组装出更复杂的交互。比如我们尝试来写一个 Form 的迭代形态:
const Form = <T extends Object = unknown>() => {
return (
<Object<T>>
<ObjectIterator<T>>
<Field />
</ObjectIterator>
</Object>
)
}以上这几个层级都是不渲染视图,只处理数据的,在这几个层级之间,可以任意插入一些布局相关的东西,叶子节点 Field 下面,可以使用更精确的 Field 交互。
从这个角度出发,能够更干净地切割应用中的状态管理与渲染,使得渲染始终轻量化。再结合元数据类型,整个应用就成为了一个:基于元数据类型表达的数据驱动的渲染框架,在这个框架中可以集成各类交互,并且不局限其实现方式,也就是说,我们实质上获得了更好地让交互层成为一种服务的能力。
前面,我们已经提到,可以把承载交互和承载状态的组件分别抽象,它已经让业务的可组合性大为提高了,但在业务系统的建设过程中,仍然远远不够。思考一下这个问题:限制业务架构师(或者产品经理)的输出直接流向研发过程,在技术上的困难主要是什么?
最主要的困难,是这类产物离最终运行的形态有不小的差距,并且这个差距不是线性地补一些东西进去就可以的。比如说,设计产物是很难加逻辑和校验的,为了完成这些事情,在主流产品研发的方法论中,业务建模与交互设计总是有太强的耦合了,不正交的东西想要做拆解,是很难的。
但是我们回头来看,是什么导致这样呢?是语言、框架、还是方法论的不足,导致了这些耦合成为了必然?
还是从简单的业务例子来看一下。通常我们会有这样的场景:当表达一个用户的时候,会根据它的注册状态,选择不同的交互来填写数据。
从交互的角度看,这两者就是两套表现形式的可切换形态。那么,是什么表达了这个“切换”呢?通常我们会选择把这个“切换”理解为一个“动作”,因为主动触发了这个动作,然后再详细描述了切换到其中一个状态之后所包含的业务语义,这件事究竟因为必须这样,还是因为这只是因为我们缺乏某种基础设施所致?
不少人写过 TypeScript,下面给出了一个类似的示例:
type A = {
foo: true
a: string
}
type B = {
foo: false
b: string
}
type C = A | B
const demo: C = {
foo: true, // 当我们改变 foo 的值,下面这行的合法性会产生变化
b: 'aaa',
}思考一下这个表达,与我们之前的这个“切换”,含义是不是相同的?为什么这里不需要显式的“切换”动作呢?简单来说,是类型系统根据当前的“输入”,结合在类型 C 上的描述,使得类型更精确推导到了 A 或者 B,去除了其中的“可选”语义,引发了业务模型描述的变更。
从这里引申开去,可以挖掘出元数据类型的更多、更深刻的表达方式,细节内容不在本文中阐述。
需要注意的是,类型的扩展是存在多种方式的。通常我们看到的扩展方式,一般是符合“继承”方法论的,但是这种方法论不够灵活。如果我们能从更深的层次去思考,就有机会从更多的类型运算上思考整个交互系统的可组合性。
本文的内容,是沿着设计产物与技术人员的协作路径深入下去的。最近这些年,不少团队在谈“设计中台”这个问题,但是,很大程度上都停留在表面,对于如何深入推进,缺乏完整的工程方法论,比如:
以上种种,都会导向一个问题:在我们对真实世界建模的时候,最重要的概念到底有哪些?
类型系统毫无疑问是其中之一,在整个工程链路中保持类型系统的运算过程,会有不可估量的价值,而如果我们选择从类型优先的角度构建组件库,并为它们附加必要的元数据,则会从另外一个角度大大提升工具的配合程度。再进一步,将它与业务建模过程打通,有机会让整个工程链路都获得较大提升。
RxJS是一个强大的Reactive编程库,提供了强大的数据流组合与控制能力,但是其学习门槛一直很高,本次分享期望从一些特别的角度解读它在业务中的使用,而不是从API角度去讲解。
通常,对RxJS的解释会是这么一些东西,我们来分别看看它们的含义是什么。
什么是Reactive呢,一个比较直观的对比是这样的:
比如说,abc三个变量之间存在加法关系:
a = b + c
在传统方式下,这是一种一次性的赋值过程,调用一次就结束了,后面b和c再改变,a也不会变了。
而在Reactive的理念中,我们定义的不是一次性赋值过程,而是可重复的赋值过程,或者说是变量之间的关系:
a: = b + c
定义出这种关系之后,每次b或者c产生改变,这个表达式都会被重新计算。不同的库或者语言的实现机制可能不同,写法也不完全一样,但理念是相通的,都是描述出数据之间的联动关系。
在前端,我们通常有这么一些方式来处理异步的东西:
其中,存在两种处理问题的方式,因为需求也是两种:
在处理分发的需求的时候,回调、事件或者类似订阅发布这种模式是比较合适的;而在处理流程性质的需求时,Promise和Generator比较合适。
在前端,尤其交互很复杂的系统中,RxJS其实是要比Generator有优势的,因为常见的每种客户端开发都是基于事件编程的,对于事件的处理会非常多,而一旦系统中大量出现一个事件要修改视图的多个部分(状态树的多个位置),分发关系就更多了。
RxJS的优势在于结合了两种模式,它的每个Observable上都能够订阅,而Observable之间的关系,则能够体现流程(注意,RxJS里面的流程的控制和处理,其直观性略强于Promise,但弱于Generator)。
我们可以把一切输入都当做数据流来处理,比如说:
RxJS提供了各种API来创建数据流:
创建出来的数据流是一种可观察的序列,可以被订阅,也可以被用来做一些转换操作,比如:
也可以对若干个数据流进行组合:
这时候回头看,其实RxJS在事件处理的路上已经走得太远了,从事件到流,它被称为lodash for events,倒不如说是lodash for stream更贴切,它提供的这些操作符也确实可以跟lodash媲美。
数据流这个词,很多时候,是从data-flow翻译过来的,但flow跟stream是不一样的,我的理解是:flow只关注一个大致方向,而stream是受到更严格约束的,它更像是在无形的管道里面流动。
那么,数据的管道是什么形状的?
在RxJS中,存在这么几种东西:
前三种东西,根据它们数据进出的可能性,可以通俗地理解他们的连接方式,这也就是所谓管道的“形状”,一端密闭一端开头,还是两端开口,都可以用来辅助记忆。
上面提到的Subscription,则是订阅之后形成的一个订阅关系,可以用于取消订阅。
下面,我们通过一些示例来大致了解一下RxJS所提供的能力,以及用它进行开发所需要的思路转换。
很多时候,我们会有一些显示时间的场景,比如在页面下添加评论,评论列表中显示了它们分别是什么时间创建的,为了含义更清晰,可能我们会引入moment这样的库,把这个时间转换为与当前时间的距离:
const diff = moment(createAt).fromNow()这样,显示的时间就是:一分钟内,昨天,上个月这样的字样。
但我们注意到,引入这个转换是为了增强体验,而如果某个用户停留在当前视图时间太长,它的这些信息会变得不准确,比如说,用户停留了一个小时,而它看到的信息还显示:5分钟之前发表了评论,实际时间是一个小时零5分钟以前的事了。
从这个角度看,我们做这个体验增强的事情只做了一半,不准确的信息是不能算作增强体验的。
在没有RxJS的情况下,我们可能会通过一个定时器来做这件事,比如在组件内部:
tick() {
this.diff = moment(createAt).fromNow()
setTimeout(tick.bind(this), 1000)
}但组件并不一定只有一份实例,这样,整个界面上可能就有很多定时器在同时跑,这是一种浪费。如果要做优化,可以把定时器做成一种服务,把业务上需要周期执行的东西放进去,当作定时任务来跑。
如果使用RxJS,可以很容易做到这件事:
Observable.interval(1000).subscribe(() => {
this.diff = moment(createAt).fromNow()
})RxJS一个很强大的特点是,它以流的方式来对待数据,因此,可以用一些操作符对整个流上所有的数据进行延时、取样、调整密集度等等。
const timeA$ = Observable.interval(1000)
const timeB$ = timeA$.filter(num => {
return (num % 2 != 0)
&& (num % 3 != 0)
&& (num % 5 != 0)
&& (num % 7 != 0)
})
const timeC$ = timeB$.debounceTime(3000)
const timeD$ = timeC$.delay(2000)示例代码中,我们创建了四个流:
所以结果大致如下:
A: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
B: 1 11 13 17 19
C: 1 13 19
D: 1 13
RxJS还提供了BehaviourSubject和ReplaySubject这样的东西,用于记录数据流上一些比较重要的信息,让那些“我们来晚了”的订阅者们回放之前错过的一切。
ReplaySubject可以指定保留的值的个数,超过的部分会被丢弃。
最近新版《射雕英雄传》比较火,我们来用代码描述其中一个场景。
郭靖和黄蓉一起背书,黄蓉记忆力很好,看了什么,就全部记得;而郭靖属鱼的,记忆只有七秒,始终只记得背诵的最后三个字,两人一起背诵《九阴真经》。
代码实现如下:
const 九阴真经 = '天之道,损有余而补不足'
const 黄蓉$ = new ReplaySubject(Number.MAX_VALUE)
const 郭靖$ = new ReplaySubject(3)
const 读书$ = Observable.from(九阴真经.split(''))
读书$.subscribe(黄蓉$)
读书$.subscribe(郭靖$)执行之后,我们就可以看到,黄蓉背出了所有字,郭靖只记得“补不足”三个字。
熟悉Redux的人应该会对这样一套理念不陌生:
当前视图状态 := 之前的状态 + 本次修改的部分
从一个应用启动之后,整个全局状态的变化,就等于初始的状态叠加了之后所有action导致的状态修改结果。
所以这就是一个典型的reduce操作。在RxJS里面,有一个scan操作符可以用来表达这个含义,比如说,我们可以表达这样一个东西:
const action$ = new Subject()
const reducer = (state, payload) => {
// 把payload叠加到state上返回
}
const state$ = action$.scan(reducer)
.startWith({})只需往这个action$里面推action,就能够在state$上获取出当前状态。
在Redux里面,会有一个东西叫combineReducer,在state比较大的时候,用不同的reducer修改state的不同的分支,然后合并。如果使用RxJS,也可以很容易表达出来:
const meAction$ = new Subject()
const meReducer = (state, payload) => {}
const articleAction$ = new Subject()
const articleReducer = (state, payload) => {}
const me$ = meAction$.scan(meReducer).startWith({})
const article$ = articleAction$.scan(articleReducer).startWith({})
const state$ = Observable
.zip(
me$,
article$,
(me, article) => {me, article}
)借助这样的机制,我们实现了Redux类似的功能,社区里面也有基于RxJS实现的Redux-Observable这样的Redux中间件。
注意,我们这里的代码中,并未使用dispatch action这样的方式去严格模拟Redux。
再深入考虑,在比较复杂的场景下,reducer其实很复杂。比如说,视图上发起一个操作,会需要修改视图的好多地方,因此也就是要修改全局状态树的不同位置。
在这样的场景中,从视图发起的某个action,要么调用一个很复杂的reducer去到处改数据,要么再次发起多个action,让很多个reducer各自改自己的数据。
前者的问题是,代码耦合太严重;后者的问题是,整个流程太难追踪,比如说,某一块状态,想要追踪到自己是被从哪里发起的修改所改变的,是非常困难的事情。
如果我们能够把Observable上面的同步修改过程视为reducer,就可以从另外一些角度大幅简化代码,并且让联动逻辑清晰化。例如,如果我们想描述一篇文章的编辑权限:
const editable$ = Observable.combineLatest(article$, me$)
.map(arr => {
let [article, me] = arr
return me.isAdmin || article.author === me.id
})这段代码的实质是什么?其实本质上还是reducer,表达的是数据的合并与转换过程,而且是同步的。我们可以把article和me的变更reduce到article$和me$里,由它们派发隐式的action去推动editable计算新值。
更详细探索的可以参见之前的这篇文章:复杂单页应用的数据层设计
人生是什么样子的呢?
著名央视主持人白岩松曾经说过:
赚钱是为了买房,买房是为了赚钱。
这两句话听上去很悲哀,却很符合社会现实。(不要在意是不是白岩松说的啦,不是他就是鲁迅,要么就是莎士比亚)
作为程序员,我们可以尝试想想如何用代码把它表达出来。
如果用命令式编程的理念来描述这段逻辑,是不太好下手的,因为它看起来像个死循环,可是人生不就是一天一天的死循环吗,这个复杂的世界,谁是自变量,谁是因变量?
死循环之所以很难用代码表达,是因为你不知道先定义哪个变量,如果变量的依赖关系形成了闭环,就总有一段定义不起来。
但是,在RxJS这么一套东西中,我们可以很容易把这套关系描述出来。前面说过,基于RxJS编程,就好像是在组装管道,依赖关系其实是定义在管道上,而不是在数据上。所以,不存在命令式的那些问题,只要管道能够接起来,再放进去数据就可以了。所以,我们可以先定义管道之间的依赖关系,
首先,从这段话中寻找一些变量,得到如下结果:
然后,我们来探索它们各自的来源。
钱从哪里来?
出租房子。
房子从哪里来?
钱挣够了就买。
听上去还是死循环啊?
我们接着分析:
钱是只有一个来源吗?
不是,原始积累肯定不是房租,我们假定那是工资。所以,收入是有工资和房租两个部分组成。
房子是只有一个来源吗?
对,我们不是贪官,房子都是用钱买的。
好,现在我们有四个变量了:
我们尝试定义这些变量之间的关系:
调整这些变量的定义顺序,凡是不依赖别人的,一律提到最前面实现。尴尬地发现,这四个变量里,只有工资是一直不变的,先提前。
const salary$ = Observable.interval(100).mapTo(2)剩下的,都是依赖别人的,而且,没有哪个东西是只依赖已定义的变量,在存在业务上的循环依赖的时候,就会发生这样的情况。在这种情况下,我们可以从中找出被依赖最少的变量,声明一个Subject用于占位,比如这里的房子。
const house$ = new Subject()接下来再看,以上几个变量中,有哪个可以跟着确定?是房租,所以,我们可以得到房租与房子数量的关系表达式,注意,以上的salary$、house$,表达的都是单次增加的值,不代表总的值,但是,算房租是要用总的房子数量来算的,所以,我们还需要先表达出总的房子数量:
const houseCount$ = house$.scan((acc, num) => acc + num, 0).startWith(0)然后,可以得到房租的表达式:
const rent$ = Observable.interval(3000)
.withLatestFrom(houseCount$)
.map(arr => arr[1] * 5)解释一下上面这段代码:
房租定义出来了之后,钱就可以被定义了:
const income$ = Observable.merge(salary$, rent$)注意,income$所代表的含义是,所有的单次收入,包含工资和房租。
到目前为止,我们还有一个东西没有被定义,那就是房子。如何从收入转化为房子呢?为了示例简单,我们把它们的关系定义为:
一旦现金流够买房,就去买。
所以,我们需要定义现金流与房子数量的关系:
const cash$ = income$
.scan((acc, num) => {
const newSum = acc + num
const newHouse = Math.floor(newSum / 100)
if (newHouse > 0) {
house$.next(newHouse)
}
return newSum % 100
}, 0)这段逻辑的含义是:
总结一下,这么一段代码,就表达清楚了我们所有的业务需求:
// 挣钱是为了买房,买房是为了赚钱
const house$ = new Subject()
const houseCount$ = house$.scan((acc, num) => acc + num, 0).startWith(0)
// 工资始终不涨
const salary$ = Observable.interval(100).mapTo(2)
const rent$ = Observable.interval(3000)
.withLatestFrom(houseCount$)
.map(arr => arr[1] * 5)
// 一买了房,就没现金了……
const income$ = Observable.merge(salary$, rent$)
const cash$ = income$
.scan((acc, num) => {
const newSum = acc + num
const newHouse = Math.floor(newSum / 100)
if (newHouse > 0) {
house$.next(newHouse)
}
return newSum % 100
}, 0)
// houseCount$.subscribe(num => console.log(`houseCount: ${num}`))
// cash$.subscribe(num => console.log(`cash: ${num}`))这段代码所表达出来的业务关系如图:
工资周期 ———> 工资
↓
房租周期 ———> 租金 ———> 收入 ———> 现金
↑ ↓
房子数量 <——— 新购房
注意:在这个例子中,house$的处理方式与众不同,因为我们的业务逻辑是环形依赖,至少要有一个东西先从里面拿出来占位,后续再处理,否则没有办法定义整条链路。
本篇通过一些简单例子介绍了RxJS的使用场景,可以用这么一句话来描述它:
其文简,其意博,其理奥,其趣深
RxJS提供大量的操作符,用于处理不同的业务需求。对于同一个场景来说,可能实现方式会有很多种,需要在写代码之前仔细斟酌。由于RxJS的抽象程度很高,所以,可以用很简短代码表达很复杂的含义,这对开发人员的要求也会比较高,需要有比较强的归纳能力。
本文是入职蚂蚁金服之后,第一次内部分享,科普为主,后面可能会逐步作一些深入的探讨。
蚂蚁的大部分业务系统前端不太适合用RxJS,大部分是中后台CRUD系统,因为两个原因:整体性、实时性的要求不高。
什么是整体性?这是一种系统设计的理念,系统中的很多业务模块不是孤立的,比如说,从展示上,GUI与命令行的差异在于什么?在于数据的冗余展示。我们可以把同一份业务数据以不同形态展示在不同视图上,甚至在PC端,由于屏幕大,可以允许同一份数据以不同形态同时展现,这时候,为了整体协调,对此数据的更新就会要产生很多分发和联动关系。
什么是实时性?这个其实有多个含义,一个比较重要的因素是服务端是否会主动向推送一些业务更新信息,如果用得比较多,也会产生不少的分发关系。
在分发和联动关系多的时候,RxJS才能更加体现出它比Generator、Promise的优势。
大家好,现在是2017年4月。过去的3年里,前端开发领域可谓风起云涌,革故鼎新。除了开发语言的语法增强和工具体系的提升之外,大部分人开始习惯几件事:
所谓组件化,很容易理解,把视图按照功能,切分为若干基本单元,所得的东西就可以称为组件,而组件又可以一级一级组合而成复合组件,从而在整个应用的规模上,形成一棵倒置的组件树。这种方法论历史久远,其实现方式或有瑜亮,理念则大同小异。
而MDV,则是对很多低级DOM操作的简化,把对DOM的手动修改屏蔽了,通过从数据到视图的一个映射关系,达到了只要操作数据,就能改变视图的效果。
给定一个数据模型,可以得到对应的的视图,这一过程可以表达为:
V = f(M)
其中的f就是从Model到View的映射关系,在不同的框架中,实现方式有差异,整体理念则是类似的。
当数据模型产生变化的时候,其对应的视图也会随之变化:
V + ΔV = f(M + ΔM)
另外一个方面,如果从变更的角度去解读Model,数据模型不是无缘无故变化的,它是由某个操作引起的,我们也可以得出另外一个表达式:
ΔM = perform(action)
把每次的变更综合起来,可以得到对整个应用状态的表达:
state := actions.reduce(reducer, initState)
这个表达式的含义是:在初始状态上,依次叠加后续的变更,所得的就是当前状态。这就是当前最流行的数据流方案Redux的核心理念。
从整体来说,使用Redux,相当于把整个应用都实现为命令模式,一切变动都由命令驱动。
在传统的编程实践中,我们可以:
但是,很难做到:提供一种会持续变化的数据让其他模块复用。
而一些基于Reactive Programming的库可以提供一种能力,把数据包装成可持续变更、可观测的类型,供后续使用,这种库包括:RxJS,xstream,most.js等等。
对数据的包装过程类似如下:
const a$ = xs.of(1)
const arr$ = xs.from([1, 2, 3])
const interval$ = xs.periodic(1000)这段代码中的a$、arr$、interval$都是一种可观测的数据包装,如果对它们进行订阅,就可以收到所有产生的变更。
interval$.subscribe(console.log)我们可以把这种封装结构视为数据管道,在这种管道上,可以添加统一的处理规则,这种规则会作用在管道中的每个数据上,并且形成新的管道:
const interval$ = xs.periodic(1000)
const result$ = interval$
.filter(num => num % 3)
.map(num => num * 2)管道可被连续拼接,并形成新的管道。
需要注意的是:
b$和c$两个管道,都从a$变形得出,它们就共享了a$之前的所有执行过程。也可以把多个管道组合在一起形成新的管道:
const priv$ = xs.combine(user$, article$)
.map(arr => {
const [user, article] = arr
return user.isAdmin || article.creator === user.id
})从这个关系中可以看出,当user$或task$中的数据发生变更的时候,priv$都会自动计算出最新结果。
在业务开发的过程中,可以使用数据流的理念,把很多东西提高一个抽象等级:
const data$ = xs.fromPromise(service(params))
.map(data => ({ loading: false, data }))
.replaceError(error => xs.of({ loading: false, error }))
.startWith({
loading: true,
error: null,
})比如上面这个例子,统一处理了一个普通请求过程中的三种状态:请求前、成功、异常,并且把它们的数据:loading、正常数据、异常数据都统一成一种,视图直接订阅处理就行了。
很多时候,我们进行业务开发,都是在一种比较低层次的抽象维度上,在低层抽象上,存在着太多的冗余过程。如果能够对数据的来源和去向做一些归纳会怎样呢?
比如说,从实体的角度,很可能一份数据初始状态有多个来源:
也很可能有多个事件都是在修改同一个东西:
如果不做归纳,可能会写出包含以上各种东西的逻辑组合。若干个类似的操作,在过滤掉额外信息之后,可能都是一样的。从应用状态的角度,我们不会需要关心一个数据究竟是从哪里来的,也不会需要关心是通过什么东西发起的修改。
用传统的Redux写法,可能会提取出一些公共方法:
const changeTodo = todo => {
dispatch({type: 'updateTodo', payload: todo})
}
const changefromDOMEvent = () => {
const todo = formState
changeTodo(todo)
}
const changefromWebSocket = () => {
const todo = fromWS
changeTodo(todo)
}基于方法调用的逻辑不能很好地展示一份数据的生命周期,它可能有哪些来源?可能被什么修改?它是经过几千年怎样的辛苦修炼之后才能够化成人形,跟你坐在一张桌子上喝咖啡?
我们可以借助RxJS或者xstream这样的库,以数据管道的理念,把这些东西更加直观地组织在一起:
初始状态来源
const fromInitState$ = xs.of(todo)
const fromLocalStorage$ = xs.of(getTodoFromLS())
// initState
const init$ = xs
.merge(
fromInitState$,
fromLocalStorage$
)
.filter(todo => !todo)
.startWith({})数据变更过程的统一
const changeFromHTTP$ = xs.fromPromise(getTodo())
.map(result => result.data)
const changeFromDOMEvent$ = xs
.fromEvent($('.btn', 'click'))
.map(evt => evt.data)
const changeFromWebSocket$ = xs
.fromEvent(ws, 'message')
.map(evt => evt.data)
// 合并所有变更来源
const changes$ = xs
.merge(
changeFromHTTP$,
changeFromDOMEvent$,
changeFromWebSocket$
)在这样的机制里,我们可以很清楚地看到一块数据的来龙去脉,它最初是哪里来的,后来可能会被谁修改过。所有这样的数据都放置在管道中,除了指定的入口,不会有其他东西能够修改这些数据,视图可以很安全地订阅他们。
基于Reactive理念的这些数据流库,一般是没有针对业务开发的强约束的,也以直接订阅并设置组件状态,也可以拿它按照Redux的理念来使用,丰俭由人。
简单的使用
changes$.subscribe(({ payload }) => {
xxx.setState({ todo: payload })
})类似Redux的使用方式
const updateActions$ = changes$
.map(todo => ({type: 'updateTodo', payload: todo}))
const todo$ = changeActions$
.fold((state, action) => {
const { payload } = action
return {...state, ...payload}
}, initState)我们前面提到,组件树是一个树形结构。理想中的组件化,是所有视图状态全部内置在组件中,一级一级传递。只有这样,才能达到组件的最佳可复用状态,并且,组件可以放心把自己该做的事情都做了。
但事实上,组件树的层级可能很多,这会导致传递层级很多,很繁琐,而且,存在一个经典问题,那就是兄弟组件,或者是位于组件树的不同树枝上的组件之间的通信很麻烦,必须通过共同的最近的祖先节点去转发。
像Redux这样的机制,把状态的持有和更新外置,然后通过connect这样的方法,去把特定组件所需的外部状态从props设置进去,但它不仅仅是一个转发器。
我们可以看到如下事实:
所以:
这样看来,可以通过中转器修改应用中的一切状态。那么,如果所有状态都可以通过中转器修改,是否意味着都应当通过它修改?
这个问题很大程度上等价于:
组件是否应当拥有自己的内部状态?
我们可能会有如下的选择:
这两种方式,在传统软件开发领域分别称为贫血组件、充血组件,它们的差别是:组件究竟是纯展示,还是带一些逻辑。
也可以拿蚁群和人群来形容这两种组件实践。单个蚂蚁的智能程度很低,但它可以接受蚁王的指令去做某些事情,所有的麻烦事情都集中在上层,决策层的事务非常繁琐。而人类则不同,每个人都有自己的思考和执行能力,一个管理有序的体系中,管理者只需决定他和自己直接下属所需要做的事情就可以了。
在React体系中,纯展示组件可被简化为这样的形式:
const ComponentA = (props) => {
return (<div>{props.data}</div>)
}显而易见,这种组件的优势在于它的展示结果只跟输入数据有关,所有状态外置,因此,在热替换等方面,可以做到极致。
然而,一旦这个组件复杂起来,自带交互,可能就需要在事件、生命周期上做文章,免不了会需要一些中间状态来表达组件自身的形态。
我们当然可以把这种状态也外置,但这么做有几个问题:
如果是一种单独提供的组件库,比如像Ant Design这样的,却要依赖一个外部的状态管理器,这是很不合适的,它会导致组件库带有倾向性,从而对使用者造成困扰。
总的来说,状态全外置,组件退化为贫血组件这种实践,可以得到不少好处,但代价是比较大的。
在You might not need Redux这篇文章中,Redux的作者Dan Abramov提到:
Local State is Fine.
因此,我们就可能会面临一个尴尬的状况,在大部分实践中:
一个组件的状态,可能一半在组件内管理,一半在全局的Store里
以React为例,大致是这样一个状况:
constructor(props) {
super(props)
this.state = { b: 1 }
}
render(props) {
const a = this.state.b + props.c;
return (<div>{a}</div>)
}我们看到,在render里面,需要合并state和props的数据,但是在这里做这个事情,是破坏了render函数的纯洁性的。可是,除了这里,别的地方也不太适合做这种合并,怎么办呢?
所以,我们需要一种机制,能够把本地状态和props在render之外统一起来,这可能就是很多实践者倾向于把本地状态也外置的最重要原因。
在React + Redux的实践中,通常会使用connect对视图组件包装一层,变成一种叫做容器组件的东西,这个connect所做的事情就是把全局状态映射到组件的props中。
那么,考虑如下代码:
const mapStateToProps = (state: { a }) => {
return { a }
}
// const localState = { b: 1 }
// const mapLocalStateToProps = localState => localState
const ComponentA = (props) => {
const { a, b } = props
const c = a + b
return (<div>{ c }</div>)
}
return connect(mapStateToProps/*, mapLocalStateToProps*/)(ComponentA)我们是否可以把一个组件的内部状态外置到被注释掉的这个位置,然后也connect进来呢?这段代码其实是不起作用的,因为对localState的改变不会被检测到,所以组件不会刷新。
我们先探索这种模式是否可行,然后再来考虑实现的问题。
在Plug and Play All Your Observable Streams With Cycle.js这篇文章中,我们可以看到一组理念:
基于这套理念,编写代码的方式可以变得很简洁流畅:
在CycleJS的理念中,这种模式叫做MVI(Model View Intent)。在这套理念中,我们的应用可以分为三个部分:
整体结构可以这样描述:
App := View(Model(Intent({ DOM, Http, WebSocket })))
对比Redux这样的机制,它的差异在于:
此外,在CycleJS中,View是纯展示,连事件监听也不做,这部分监听的工作放在Intent中去做。
const model = (a$, b$) => {
return xs.combine(a$, b$)
}
const view = (state$) => {
return state$.map(({ a, b }) => {
const c = a + b;
return h2('c is ' + c)
})
}我们可以从中发掘这么一些东西:
对我们来说,这里面最大关键在于:所有东西的输入输出都是数据流,甚至连视图接受的参数、还有它的渲染结果也是一个流!奥秘就在这里。
因此,我们只需在把待传入视图的props与视图的state以流的方式合并,直接把合并之后的流的结果传入视图组件,就能达到我们在上一节中提出的需求。
我们之前提到过一点,在一个应用中,组件是形成倒置的树形结构的。当组件树上的某一块越来越复杂,我们就把它再拆开,延伸出新的树枝和叶子,这个过程,与分形有异曲同工之妙。
然而,因为全局状态和本地状态的分离,导致每一次分形,我们都要兼顾本组件、下级组件、全局状态、本地状态,在它们之间作一些权衡,这是一个很麻烦的过程。在React的主流实践中,一般可以利用connect这样的高阶函数,把全局状态映射进组件的props,转化为本地状态。
上一节提及的MVI结构,不仅仅能够描述一个应用的执行过程,还可以单独描述一个组件的执行过程。
Component := View(Model(Intent({ DOM, Http, WebSocket })))
所以,从整体来理解我们的应用,就是这样一个关系:
APP [ View <-- Model <-- Intent ]
|
------------------------------------------------
| |
ComponentA [ ViewA <-- ModelA <-- IntentA ] ComponentB
这样一直分形下去,每一级组件都可以拥有自己的View、Model、Intent。
在模型驱动视图这个理念下,视图始终会是调用链的最后一段,它的职责就是消费已经计算好的数据,渲染出来。所以,从这个角度看,我们的重点工作在于怎么管理状态,包括结构的定义和变更的流转过程。
Redux提供了对状态定义和变更过程的管理思路,但有不少值得探讨的地方。
基于标准Flux/Redux的实践有一个共同点:繁琐。产生这种繁琐的最主要原因是,它们都是以自定义事件为核心的,自定义事件本身就是繁琐的。由于收发事件通常位于两个以上不相同的模块中,不得不以封装的事件对象为通信载体,并且必须显式定义事件的key,否则接收方无法指定自己的响应。
一旦整个应用都是以此为基石,其中的繁琐程度可想而知,所以社区会存在一些简化action创建,或者通过约定来减少action收发中间环节的Redux周边。
如果不从根本上对事件这种机制进行抽象,就不可能彻底解决繁琐的问题,基于Reactive理念的这几个库天然就是为了处理对事件机制的抽象而出现的,所以用在这种场景下有奇效,能把action的派发与处理过程描述得优雅精妙。
const updateActions$ = changes$
.map(todo => ({type: 'updateTodo', payload: todo}))
const todo$ = updateActions$
.fold((state, action) => {
const { payload } = action
return {...state, ...payload}
}, initState)注意一个问题,既然我们之前得到一种思路,把全局状态和本地状态分开,然后合并注入组件,就需要考虑这样的问题:如何管理本地状态和全局状态,使用相同的方式去管理吗?
在Redux体系中,我们在修改全局状态的时候,使用指定的action去修改状态,原因是要区分那个哪个action修改state的什么部分,怎样修改。但是考虑本地状态的情况,它反映的只是组件内部的数据变化,一般而言,其结构复杂程度远远低于全局状态,继续采用这种方式的话并不划算。
Redux这类东西出现的初衷只是为了提供一种单向数据流的思路,防止状态修改的混乱。但是在基于数据管道的这些库中,数据天然就是单向流动的。在刚才那段代码里,其实action的type是没有意义的,一直就没有用到。
实际上,这个代码中的updateActions$自身就表达了updateTodo的含义,而它后续的fold操作,实际上就是直接在reduce。理解了这一点之后,我们就可以写出反映若干种数据变更的合集了,这个时候,可以根据不同的action去选择不同的reducer操作:
// 我们可以先把这些action全部merge之后再fold,跟Redux的理念类似
const actions = xs.merge(
addActions$,
updateActions$,
deleteActions$
)
const localState$ = actions.fold((state, action) => {
switch(action.type) {
case 'addTodo':
return addTodo(state, action)
case 'updateTodo':
return updateTodo(state, action)
case 'deleteTodo':
return deleteTodo(state, action)
}
}, initState)我们注意到,这里是把所有action全部merge了之后再fold的,这是符合Redux方式的做法。有没有可能各自fold之后再merge呢?
其实是有可能的,我们只要能够确保action导致的reducer粒度足够小,比如只修改state的同一个部分,是可以按照这种维度去组织action的。
const a$ = actionsA$.fold(reducerA, initA)
const b$ = actionsB$.fold(reducerB, initB)
const c$ = actionsC$.fold(reducerC, initC)
const state$ = xs.combine(a$, b$, c$)
.map(([a, b, c]) => ({a, b, c}))如果我们一个组件的内部状态足够简单,甚至连action的类型都可以不需要,直接从操作映射到状态结果。
const state$ = xs.fromEvent($('.btn'), click)
.map(e => e.data)这样,我们可以在组件内运行这种简化版的Redux机制,而在全局状态上运行比较完善的。这两种都是基于数据管道的,然后在容器组件中可以把它们合并,传入视图组件。
整个流程如图所示:
---------------------
↑ ↓
|-- LocalState
View <-- |
|-- GlobalState
↓ ↑
Action --> Reducer
基于redux-saga的封装库dva提供了一种分类机制,可以把一类业务的东西进行分组:
export const project = {
namespace: 'project',
state: {},
reducers: {},
effects: {},
subscriptions: {}
}从这个结构可以看出,这个在dva中被称为model的东西,定义了:
面向同一种业务实体的数据结构、业务逻辑可以组织到一起,这样,对业务代码的维护是比较有利的。对一个大型应用来说,可以根据业务来划分model。Vue技术栈的Vuex也是用类似的结构来进行业务归类的,它们都是受elm的启发而创建,因此会有类似结构。
回想到上一节,我们提到,如果若干个reducer修改的是state的不同位置,可以分别收敛之后,再进行合并。如果我们把状态结构按照上面这种业务模型的方式进行管理,就可以采用这种机制来分别收敛。这样,单个model内部就形成了一个闭环,能够比较清晰的描述自身所代表的业务含义,也便于做测试等等。
MobX的Store就是类似这样的一个组织形式:
class TodoStore {
authorStore
@observable todos = []
@observable isLoading = true
constructor(authorStore) {
this.authorStore = authorStore
this.loadTodos()
}
loadTodos() {}
updateTodoFromServer(json) {}
createTodo() {}
removeTodo(todo) {}
}依照之前的思路,我们所谓的model其实就是一个合并之后生成state结构的数据管道,因为我们的管道是可以组合的,所以没有特别的必要去按照上面那种结构定义。
那么,在整个应用的最上层,是否还有必要去做combineReducer这种操作呢?
我们之前提到一个表达式:
View = f(Model)
整个React-Redux体系,都是倾向于让使用者尽可能去从整体的角度关注变化,比如说,Redux的输入输出结果是整个应用变更前后的完整状态,React接受的是整个组件的完整状态,然后,内部再去做diff。
我们需要注意到,为什么不是直接把Redux接在React上,而是通过一个叫做react-redux的库呢?因为它需要借助这个库,去从整体的state结构上检出变化的部分,拿给对应的组件去重绘。
所以,我们发现如下事实:
整个过程,是经历了变更信息的拥有——丢失——重新拥有过程的。如果我们的数据流是按照业务模型去分别建立的,我们可以不需要去做这个全合并的操作,而是根据需要,选择合并其中一部分去进行运算。
这样的话,整个变更过程都是精确的,减少了不必要的diff和缓存。
如果为了使用redux-tool的话,可以全部合并起来,往redux-tool里面写入每次的全局状态变更信息,供调试使用,而因为数据管道是懒执行的,我们可以做到开发阶段订阅整个state,而运行时不订阅,以减少不必要的合并开销。
我们从宏观上对业务模型作了分类的组织,接下来就需要关注每种业务模型的数据管道上,数据格式应当如何管理了。
在Redux,Vuex这样的实践中,很多人都会有这样的纠结:
在store中,应当以什么样的形式存放数据?
通常,会有两种选择:
前者有利于查询和更新,而后者能够直接给视图使用。我们需要思考一个问题:
将处理过后的视图状态存放在store中是否合理?
我认为不应当存太偏向视图结构的数据,理由如下:
某一种业务数据,很可能被不同的视图使用,它们的结构未必一致,如果按照视图的格式存储,就要在store中存放不同形式的多份,它们之间的同步是个大问题,也会导致store严重膨胀,随着应用规模的扩大,这个问题更加严重。
既然这样,那就要解决从这种数据到视图所需数据的关联关系,这个处理过程放在哪里合适呢?
在Redux和Vuex中,为了数据的变更受控,应当在reducer或者mutation中去做状态变更,但这两者修改的又是store,这又绕回去了:为了视图渲染方便而计算出来的数据,如果在reducer或者mutation中做,还是得放在store里。
所以,就有了一个结论:从原始数据到视图数据的处理过程不应当放在reducer或mutation中,那很显然就应当放在视图组件的内部去做。
我们理一下这个关系:
[ View <-- VM ] <-- State
↓ ↑
Action --> Reducer
这个图中,方括号的部分是视图组件,它内部包含了从原始state到view所需数据的变动,以React为例,用代码表示:
render(props) {
const { flatternData } = props
const viewData = formatData(flatternData)
// ...render viewData
}
经过这样的拆分之后,store中的结构更加简单清晰,reducer的职责也更少了,视图有更大的自主权,去从原始数据组装成自己要的样子。
在大型业务开发的过程中,store的结构应当尽早稳定无争议,避免因为视图的变化而不停调整,因此,存放相对原始一些的数据是更合理的,这样也会避免视图组件在理解数据上的歧义。多个视图很可能以不同的业务含义去看待状态树上的同一个分支,这会造成很多麻烦。
我们期望在store中存储更偏向于更扁平化的原始数据。即使是对于从后端返回的层级数据,也可以借助normalizr这样的辅助库去展开。
展开前:
[{
id: 1,
title: 'Some Article',
author: {
id: 1,
name: 'Dan'
}
}, {
id: 2,
title: 'Other Article',
author: {
id: 1,
name: 'Dan'
}
}]展开后:
{
result: [1, 2],
entities: {
articles: {
1: {
id: 1,
title: 'Some Article',
author: 1
},
2: {
id: 2,
title: 'Other Article',
author: 1
}
},
users: {
1: {
id: 1,
name: 'Dan'
}
}
}
}很明显,这样的结构对我们的后续操作是比较便利的。因为我们手里有数据管道这样的利器,所以不担心数据是比较原始的、离散的,因为对它们作聚合处理是比较容易的,所以可以放心地把这些数据打成比较原始的形态。
之前我们提到过store里面存放的是扁平化的原始数据,但是需要注意到,同样是扁平化,可能有像map那样基于id作索引的,也可能有基于数组形式存放的,很多时候,我们是两种都要的。
在更复杂的情况下,还会需要有对象关系的关联,一对一,一对多,多对多,这就导致视图在需要使用store中的数据进行组合的时候,不管是store的结构定义还是组合操作都比较麻烦。
如果前端是单一业务模型,那我们按照前一节的方案,已经可以做到当数据变更的时候,把当前状态推送给订阅它的组件,但实际情况下,都会比这个复杂,业务模型之间会存在关联关系,在一个模型变更的时候,可能需要自动触发所关联到的模型的更新。
如果复杂度较低,我们可以手动处理这种关联,如果联动关系非常复杂,可以考虑对数据按照实体、关系进行建模,甚至加入一个迷你版的类似ORM的库来定义这种关系。
举例来说:
如果一个数据流订阅了某个组织的基本信息,它可能只反映这个组织自身实体上的变更,而另外一个数据流订阅了该组织的全部信息,用于形成一个实时更新的组织全视图,则需要聚合该组织和可能的下级组织、人员的变动汇总。
上层视图可以根据自己的需要,选择从不同的数据流订阅不同复杂度的信息。在这种情况下,可以把整个ORM模块整体视为一个外部的数据源。
整个流程如下:
[ View <-- VM ] <-- [State <-- ORM]
↓ ↑
Action --> Reducer
这里面有几个需要注意的地方:
在这么一种体系下,实际上前端存在着一个类似数据库的机制,我们可以把每种数据的变动原子化,一次提交只更新单一类型的实体。这样,我们相当于在前端部分做了一个读写分离,读取的部分是被实时更新的,可以包含一种类似游标的机制,供视图组件订阅。
下面是Redux-ORM的简单示例,是不是很像在操作数据库?
class Todo extends Model {}
Todo.modelName = 'Todo';
Todo.fields = {
user: fk('User', 'todos'),
tags: many('Tag', 'todos'),
};
class Tag extends Model {}
Tag.modelName = 'Tag';
Tag.backend = {
idAttribute: 'name';
};
class User extends Model {}
User.modelName = 'User';文章最开始,我们提到最理想的组件化开发方式是依托组件树的结构,每个组件完成自己内部事务的处理。当组件之间出现通信需求的时候,不得不借助于Redux之类的库来做转发。
但是Redux的理念,又不仅仅是只定位于做转发,它更是期望能管理整个应用的状态,这反过来对组件的实现,甚至应用的整体架构造成了较大的影响。
我们仍然会期望有一种机制,能够像分形那样进行开发,但又希望能够避免状态管理的混乱,因此,MVI这样的模式某种程度上能够满足这种需求,并且达到逻辑上的自洽。
如果以MVI的理念来进行开发,它的一个组件其实是:数据模型、动作、视图三者的集合,这么一个MVI组件相当于React-Redux体系中,connect了store之后的高阶组件。
因此,我们只需把传统的组件作一些处理:
这样,组件就是自洽的一个东西,它不关注外面是不是Redux,有没有全局的store,每个组件自己内部运行着一个类似Redux的东西,这样的一个组件可以更加容易与其他组件进行配合。
与Redux相比,这套机制的特点是:
回顾整个操作过程:
借助RxJS或者xstream这样的数据管道的理念,我们可以直观地表达出数据的整个变更过程,也可以把多个数据流进行便捷的组合。如果使用Redux,正常情况下,需要引入至少一种异步中间件,而RxJS因为自身就是为处理异步操作而设计的,所以,只需用它控制好从异步操作到同步的收敛,就可以达到Redux一样的数据单向流动。如果想要在数据管道中接入一段承担中间件职责的东西,也是非常容易的。
而RxJS、xstream所提供的数据流组合功能非常强大,天然提供了一切异步操作的统一抽象,这一点是其他异步方案很难相比的。
所以,这些库,因为拥有下面这些特性,很适合做数据流控制:
我们经常见到这么一些场景:
这类场景的一个共同特点是:
这么一个界面,我们考虑它的完全展示,可能会有这么两种方案:
微博使用的前一种,并且引入了bigpipe机制来生成界面,而Teambition则使用后一种,主要差别还是由于产品形态。
在前端渲染的情况下,这么一种界面形态,所带来的挑战有哪些呢?
所以,这就要求我们的数据查询是离散化的,任务信息和额外的关联信息分开查询,然后前端来组装,这样,一是可以减少传输数据量,二是可以分析出数据之间的关系,更新的时候容易追踪。
除此之外,Teambition的操作会在全业务维度使用WebSocket来做更新推送,比如说,当前任务看板中,有某个东西变化了(其他人创建了任务、修改了字段),都会由服务端推送消息,来促使前端更新界面。
离散的数据会让我们需要使用缓存。比如说,界面建立起来之后,如果有人在其他端创建了任务,那么,本地的看板只需收到这条任务信息并创建视图,并不需要再去查询人员、标签等关联信息,因为之前已经获取过。所以,大致会是这个样子:
某视图组件的展示,需要聚合ABC三个实体,其中,如果哪个实体在缓存中存在,就不去服务端拉取,只拉取无缓存的实体。
这个过程带给我们第一个挑战:
查询同一种数据,可能是同步的(缓存中获取),可能是异步的(AJAX获取),业务代码编写需要考虑两种情况。
WebSocket推送则用来保证我们前端缓存的正确性。但是,我们需要注意到,WebSocket的编程方式跟AJAX是不一样的,WebSocket是一种订阅,跟主流程很难整合起来,而AJAX相对来说,可以组织得包含在主流程中。
例如,对同一种更新的不同发起方(自己修改一个东西,别人修改这个东西),这两种的后续其实是一样,但代码并不相同,需要写两份业务代码。
这样就带给我们第二个挑战:
获取数据和数据的更新通知,写法是不同的,会加大业务代码编写的复杂度。
我们的数据这么离散,从视图角度看,每块视图所需要的数据,都可能是经过比较长而复杂的组合,才能满足展示的需要。
所以,第三个挑战:
每个渲染数据,都是通过若干个查询过程(刚才提到的组合同步异步)组合而成,如何清晰地定义这种组合关系?
此外,我们可能面临这样的场景:
一组数据经过多种规则(过滤,排序)之后,又需要插入新的数据(主动新增了一条,WebSocket推送了别人新建的一条),这些新增数据都不能直接加进来,而是也必须走一遍这些规则,再合并到结果中。
这就是第四个挑战:
对于已有数据和未来数据,如何简化它们应用同样规则的代码复杂度。
带着这些问题,我们来开始今天的思考过程。
在前端,经常会碰到同步、异步代码的统一。假设我们要实现一个方法:当有某个值的时候,就返回这个值,否则去服务端获取这个值。
通常的做法是使用Promise:
function getDataP() {
if (a) {
return Promise.resolve(a)
} else {
return AJAX.get('a')
}
}所以,我们处理这个事情的办法就是,如果不确定是同步还是异步,那就取异步,因为它可以兼容同步,刚才代码里面的resolve就是强制把同步的东西也转换为兼容异步的Promise。
我们只用Promise当然也可以解决问题,但RxJS中的Observable在这一点上可以一样做到:
function getDataO() {
if (a) {
return Observable.of(a)
} else {
return Observable.fromPromise(AJAX.get('a'))
}
}有人要说了,你这段代码还不如Promise,因为还是要从它转啊,优势在哪里呢?
我们来看看刚才封装出来的方法,分别是怎么使用的呢?
getDataP().then(data => {
// Promise 只有一个返回值,响应一次
console.log(data)
})
getDataO().subscribe(data => {
// Observable 可以有多个返回值,响应多次
console.log(data)
})在这一节里,我们不对比两者优势,只看解决问题可以通过怎样的办法:
结论就是,无论Promise还是Observable,都可以实现同步和异步的封装。
通常,我们在前端会使用观察者或者订阅发布模式来实现自定义事件这样的东西,这实际上就是一种订阅。
从视图的角度看,其实它所面临的是:
得到了一个新的任务数据,我要展示它
至于说,这个东西是怎么得到的,是主动查询来的,还是别人推送过来的,并不重要,这不是它的职责,它只管显示。
所以,我们要给它封装的是两个东西:
然后,就变成类似这么一个东西:
service.on('task', data => {
// render
})
这么一来,视图这里就可以用相同的方式应对两种不同来源的数据了,service内部可以去把两者统一,在各自的回调里面触发这个自定义事件task。
但我们似乎忽略了什么事,视图除了响应这种事件之外,还需要去主动触发一下初始化的查询请求:
service.on('task', data => {
// render
})
service.getData() // 加了这么一句来主动触发请求
这样看起来还是挺别扭的,回到上一节里面我们的那个Observable示例:
getDataO().subscribe(data => {
// render
})这么一句好像就搞定了我们要求的所有事情。我们可以这么去理解这件事:
这样,我们就可以把获取和订阅这两件事合并到一起,视图层的关注点就简单很多了。
依据上一节的思路,我们可以把查询过程和WebSocket响应过程抽象,融为一体。
说起来很容易,但关注其实现的话,就会发现这个过程是需要好多步骤的,比如说:
data1 data2 data3
| | |
------------ |
| |
-----------------
|
state
一个视图所需要的数据可能是这样的:
我们怎么去抽象这个过程呢?
注意,这里面data1,data2,data3,可能都是之前提到过的,包含了同步和异步封装的一个过程,具体来说,就是一个RxJS Observable。
可以把每个Observable视为一节数据流的管道,我们所要做的,是根据它们之间的关系,把这些管道组装起来,这样,从管道的某个入口传入数据,在末端就可以得到最终的结果。
RxJS给我们提供了一堆操作符用于处理这些Observable之间的关系,比如说,我们可以这样:
const A$ = Observable.interval(1000)
const B$ = Observable.of(3)
const C$ = Observable.from([5, 6, 7])
const D$ = C$.toArray()
.map(arr => arr.reduce((a, b) => a + b), 0)
const E$ = Observable.combineLatest(A$, B$, D$)
.map(arr => arr.reduce((a, b) => a + b), 0)上述的D就是通过C进行一次转换所得到的数据管道,而E是把A,B,D进行拼装之后得到的数据管道,
A ------> |
B ------> | -> E
C -> D -> |
从以上的示意图就可以看出它们之间的组合关系,通过这种方式,我们可以描述出业务逻辑的组合关系,把每个小粒度的业务封装到数据管道中,然后对它们进行组装,拼装出整体逻辑来。
在业务开发中,我们时常遇到这么一种场景:
已过滤排序的列表中加入一条新数据,要重新按照这条规则走一遍。
我用一个简单的类比来描述这件事:
每个进教室的同学都可以得到一颗糖
这句话表达了两个含义:
这里面,第一句表达的是现在,第二句表达的是未来。我们编写业务程序的时候,往往会把现在和未来分开考虑,而忽略了他们之间存在的深层次的一致性。
我们想通了这个事情之后,再反过来考虑刚才这个问题,能得到的结论是:
进入本列表的数据都应当经过某种过滤规则和某种排序规则
这才是一个合适的业务抽象,然后再编写代码就是:
const final$ = source$.map(filterA).map(sorterA)其中,source代表来源,而final代表结果。来源经过filterA变换、sorterA变换之后,得到结果。
然后,我们再去考虑来源的定义:
const source$ = start$.merge(patch$)来源等于初始数据与新增数据的合并。
然后,实现出filterA和sorterA,就完成了整个这段业务逻辑的抽象定义。给start和patch分别进行定义,比如说,start是一个查询,而patch是一个推送,它就是可运行的了。最后,我们在final上添加一个订阅,整个过程就完美地映射到了界面上。
很多时候,我们编写代码都会考虑进行合适的抽象,但这两个字代表的含义在很多场景下并不相同。
很多人会懂得把代码划分为若干方法,若干类型,若干组件,以为这样就能够把整套业务的运转过程抽象出来,其实不然。
业务逻辑的抽象是与业务单元不同的方式,前者是血脉和神经,后者是肢体和器官,两者需要结合在一起,才能够成为鲜活的整体。
一般场景下,业务单元的抽象难度相对较低,很容易理解,也容易获得关注,所以通常都能做得还不错,比如最近两年,对于组件化之类的话题,都能够谈得起来了,但对于业务逻辑的抽象,大部分项目是做得很不够的,值得深思。
以上,我们谈及的都是在业务逻辑的角度,如何使用RxJS来组织数据的获取和变更封装,最终,这些东西是需要反映到视图上去的,这里面有些什么有意思的东西呢?
我们知道,现在主流的MV*框架都基于一个共同的理念:MDV(模型驱动视图),在这个理念下,一切对于视图的变更,首先都应当是模型的变更,然后通过模型和视图的映射关系,自动同步过去。
在这个过程中,我们可能会需要通过一些方式定义这种关系,比如Angular和Vue中的模板,React中的JSX等等。
在这些体系中,如果要使用RxJS的Observable,都非常简单:
data$.subscribe(data => {
// 这里根据所使用的视图库,用不同的方式响应数据
// 如果是 React 或者 Vue,手动把这个往 state 或者 data 设置
// 如果是 Angular 2,可以不用这步,直接把 Observable 用 async pipe 绑定到视图
// 如果是 CycleJS ……
})这里面有几个点要说一下:
Angular2对RxJS的使用是非常方便的,形如:let todo of todos$ | async这种代码,可以直接绑定一个Observable到视图上,会自动订阅和销毁,比较简便优雅地解决了“等待数据”,“数据结果不为空”,“数据结果为空”这三种状态的差异。Vue也可以用插件达到类似的效果。
CycleJS比较特别,它整个运行过程就是基于类似RxJS的机制,甚至包括视图,看官方的这个Demo:
import {run} from '@cycle/xstream-run';
import {div, label, input, hr, h1, makeDOMDriver} from '@cycle/dom';
function main(sources) {
const sinks = {
DOM: sources.DOM.select('.field').events('input')
.map(ev => ev.target.value)
.startWith('')
.map(name =>
div([
label('Name:'),
input('.field', {attrs: {type: 'text'}}),
hr(),
h1('Hello ' + name),
])
)
};
return sinks;
}
run(main, { DOM: makeDOMDriver('#app-container') });这里面,注意DOM.select这段。这里,明显是在界面还不存在的情况下就开始select,开始添加事件监听了,这就是我刚才提到的预先定义规则,统一现在与未来:如果界面有.field,就立刻添加监听,如果没有,等有了就添加。
那么,我们从视图的角度,还可以对RxJS得出什么思考呢?
在上次这篇数据的关联计算里简单提了一下,其实整篇是在给这篇做伏笔。
一个分析过程可以是这样:
使用RxJS,我们可以达到以下目的:
还有:
Teambition 新版数据层使用RxJS构建,不依赖任何展现框架,可以被任何展现框架使用,甚至可以在NodeJS中使用,对外提供了一整套Reactive的API,可以查阅文档和代码来了解详细的实现机制。
基于这套机制,可以很轻松实现一套基于Teambition平台的独立视图,欢迎第三方开发者发挥自己的想象,用它构建出各种各样有趣的东西。我们也会逐步添加一些示例。
怎么理解这么一套机制呢,可以想象一下这张图:
把Teambition SDK看作一个CPU,API就是他对外提供的引脚,视图组件接在这些引脚上,每次调用API,就如同从一个引脚输入数据,但可能触发多个引脚对外发送数据。细节可以参见SDK的设计文档。
另外,对于RxJS数据流的组合,也可以参见这篇文章,你点开链接之后可能心想:这两者有什么关系!
翻到最后那个图,从侧面看到多个波叠加,你想象一下,如果把视图的状态理解为一个时间轴上的流,它可以被视为若干个其他流的叠加,这么多流叠加起来,在当前时刻的值,就是能够表达我们所见视图的全部状态数据。
这么想一遍是不是就容易理解多了?
我第一次看到RxJS相关理念大概是5年前,当时老赵他们在讨论这个,我看了几天之后的感觉就是对智商形成了巨大考验,直到最近一两年才算是入门了,不过仅限与业务应用,背后的深层数学理论仍然是不通的。现在的程度,大概相当于一个勉强能应用四则运算解应用题的小学生吧。
还有一个问题是,虽然刚才又是贴图又是贴链接,显得好厉害,但我大学时候的数字电路和信号系统都是挂了的,但最近回头想这些东西,发现突然好像能理解了,果然很多东西背后的**是一致的。
今年年初,我在知乎回答了一个问题:前端如何更好的实现接口的缓存和更新?
正是这篇文章引起的思考使得我加入Teambition,因为这正是一个完美的场景,入职之后跟团队的太狼同学详细描述了思路,经过他半年的持续努力,实现了这样的一个东西,挺不容易的。
目前我们的Mobile Web版本使用了这个SDK,Web还没有深度接入,因为需要解决新老数据的同步问题,正在努力中。
广告:招一个人参与Teambition SDK的维护,70%以上时间是维护这个东西,偶尔参与业务上的一些改进,要求熟悉RxJS。
另外,如果有对于这种情况下的视图改进有兴趣的,也可以联系我,也要一个。
这篇文章,我讲了两次,第一次是半个月之前开源**在重庆举办的分享,另一次是昨天下午在饿了么的分享。
今天总结写出来,给大家分享一下。
#1. 为什么组件化这么难做
Web应用的组件化是一个很复杂的话题。
在大型软件中,组件化是一种共识,它一方面提高了开发效率,另一方面降低了维护成本。但是在Web前端这个领域,并没有很通用的组件模式,因为缺少一个大家都能认同的实现方式,所以很多框架/库都实现了自己的组件化方式。
前端圈最热衷于造轮子了,没有哪个别的领域能出现这么混乱而欣欣向荣的景象。这一方面说明前端领域的创造力很旺盛,另一方面却说明了基础设施是不完善的。
我曾经有过这么一个类比,说明某种编程技术及其生态发展的几个阶段:
那么,对比这三个阶段,看看关注这三种东西的人数,觉得Web发展到哪一步了?
细节来说,大概是模块化和组件化标准即将大规模落地(好坏先不论),各类API也大致齐备了,终于看到起飞的希望了,各种框架几年内会有非常强力的洗牌,如果不考虑老旧浏览器的拖累,这个洗牌过程将大大加速,然后才能释放Web前端的产能。
但是我们必须注意到,现在这些即将普及的标准,很多都会给之前的工作带来改变。用工业体系的发展史来对比,前端领域目前正处于蒸汽机发明之前,早期机械(比如《木兰辞》里面的机杼,主要是动力与材料比较原始)已经普及的这么一个阶段。
所以,从这个角度看,很多框架/库是会消亡的(专门做模块化的AMD和CMD相关库,专注于标准化DOM选择器铺垫的某些库),一些则必须进行革新,还有一些受的影响会比较小(数据可视化等相关方向),可以有机会沿着自己的方向继续演进。
#2. 标准的变革
对于这类东西来说,能获得广泛群众基础的关键在于:对将来的标准有怎样的迎合程度。对前端编程方式可能造成重大影响的标准有这些:
module的问题很好理解,JavaScript第一次有了语言上的模块机制,而Web Components则是约定了基于泛HTML体系构建组件库的方式,class增强了编程体验,observe提供了数据和展现分离的一种优秀方式,promise则是目前前端最流行的异步编程方式。
这里面只有两个东西是绕不过去的,一是module,一是Web Components。前者是模块化基础,后者是组件化的基础。
module的标准化,主要影响的是一些AMD/CMD的加载和相关管理系统,从这个角度来看,正如seajs团队的@afc163 所说,不管是AMD还是CMD,都过时了。
模块化相对来说,迁移还比较容易,基本只是纯逻辑的包装,跟AMD或者CMD相比,包装形式有所变化,但组件化就是个比较棘手的问题了。
Web Components提供了一种组件化的推荐方式,具体来说,就是:
这几种东西,会对现有的各种前端框架/库产生很巨大的影响:
在2015年初这个时间点看,前端领域有三个框架/库引领时尚,那就是Angular,Polymer,React(排名按照首字母),在知乎的这篇2014 年末有哪些比较火的 Web 开发技术?里,我大致回答过一些点,其他几位朋友的答案也很值得看。关于这三者的细节分析,侯振宇的这篇讲得很好:2015前端框架何去何从
我们可以看到,Polymer这个东西在这方面是有先天优势的,因为它的核心理念就是基于Web Components的,也就是说,它基本没有考虑如何解决当前的问题,直接以未来为发展方向了。
React的编程模式其实不必特别考虑Web标准,它的迁移成本并不算高,甚至由于其实现机制,屏蔽了UI层实现方式,所以大家能看到在native上的使用,canvas上的使用,这都是与基于DOM的编程方式大为不同的,所以对它来说,处理Web Components的兼容问题要在封装标签的时候解决,反正之前也是要封装。
Angular 1.x的版本,可以说是跟同时代的多数框架/库一样,对未来标准的兼容基本没有考虑,但是重新规划之后的2.0版本对此有了很多权衡,变成了激进变更,突然就变成一个未来的东西了。
这三个东西各有千秋,在可以预见的几年内将会鼎足三分,也许还会有新的框架出现,能不能比这几个流行就难说了。
此外,原Angular 2.0的成员Rob Eisenberg创建了自己的新一代框架aurelia,该框架将成为Angular 2.0强有力的竞争者。
#4. 前端组件的复用性
看过了已有的一些东西之后,我们可以大致来讨论一下前端组件化的一些理念。假设我们有了某种底层的组件机制,先不管它是浏览器原生的,或者是某种框架/库实现的约定,现在打算用它来做一个大型的Web应用,应该怎么做呢?
所谓组件化,核心意义莫过于提取真正有复用价值的东西。那怎样的东西有复用价值呢?
对于控件的可复用性,基本上是没有争议的,因为这是实实在在的通用功能,并且比较独立。
基础逻辑功能主要指的是一些与界面无关的东西,比如underscore这样的辅助库,或者一些校验等等纯逻辑功能。
公共样式的复用性也是比较容易认可的,因此也会有bootstrap,foundation,semantic这些东西的流行,不过它们也不是纯粹的样式库了,也带有一些小的逻辑封装。
最后一块,也就是业务逻辑。这一块的复用是存在很多争议的,一方面是,很多人不认同业务逻辑也需要组件化,另一方面,这块东西究竟怎样去组件化,也很需要思考。
除了上面列出的这些之外,还有大量的业务界面,这块东西很显然复用价值很低,基本不存在复用性,但仍然有很多方案中把它们“组件化”了,使得它们成为了“不具有复用性的组件”。为什么会出现这种情况呢?
组件化的本质目的并不一定是要为了可复用,而是提升可维护性。这一点正如面向对象语言,Java要比C++纯粹,因为它不允许例外情况的出现,连main函数都必须写到某个类里,所以Java是纯面向对象语言,而C++不是。
在我们这种情况下,也可以把组件化分为:全组件化,局部组件化。怎么理解这两个东西的区别呢,有人问过js框架和库的区别是什么,一般来说,有某种较强约定的东西,称为框架,而约定比较松散的,称为库。框架很多都是有全组件化理念的,比如说,很多年前就出现的ExtJS,它是全组件化框架,而jQuery和它的插件体系,则是局部组件化。所以用ExtJS写东西,不管写什么都是差不多一样的写法,而用jQuery的时候,大部分地方是原始HTML,哪里需要有些不一样的东西,就只在那个地方调用插件做一下特殊化。
对于一个有一定规模的Web应用来说,把所有东西都“组件化”,在管理上会有较大的便利性。我举个例子,同样是编写代码,短代码明显比长代码的可读性更高,所以很多语言里会建议“一个方法一般不要超过多少行,一个类最好不要超过多少行”之类。在Web前端这个体系里,JavaScript这块是做得相对较好的,现在入门水平的人,也已经很少会有把一堆js都写在一起的了。CSS这块,最近在SASS,LESS等框架的引领下,也逐步往模块化方面发展,否则直接编写bootstrap那种css,会非常痛苦。
这个时候我们再看HTML的部分,如果不考虑模板等技术的使用,某些界面光布局代码写起来就非常多了,像一些表单,都需要一层套一层,很多简单的表单元素都需要套个三层左右,更不必说一些有复杂布局的东西了。尤其是整个系统单页化之后,界面的header,footer,各种nav或者aside,很可能都有一定复杂性。如果这些东西的代码不作切分,那么主界面的HTML一定比较难看。
我们先不管用什么方式切分了,比如用某种模板,用类似Angular中的include,或者Polymer,React中的标签,或者直接使用原生Web Components,总之是把一块一块都拆开了,然后包含进来。从这个角度看,这些拆出去的东西都像组件,但如果从复用性的角度看,很可能多数东西,每一块都只有一个地方用,压根没有复用度。这个拆出去,纯粹是为了使得整个工程易于管理,易于维护。
这时候我们再来关注不同框架/库对UI层组件化的处理方式,发现有两个类型,模板和函数。
模板是一种很常见的东西,它用HTML字符串的方式表达界面的原始结构,然后通过代入数据的方式生成真正的界面,有的是生成目标HTML,有的还生成各种事件的自动绑定。前者是静态模板,后者是动态模板。
另外有一些框架/库偏爱用函数逻辑来生成界面,早期的ExtJS,现在的React(它内部还是可能使用模板,而且对外提供的是组件创建接口的进一步封装——jsx)等,这种实现技术的优势是不同平台上编程体验一致,甚至可以给每种平台封装相同的组件,调用方轻松写一份代码,在Web和不同Native平台上可用。但这种方式也有比较麻烦的地方,那就是界面调整比较繁琐。
本文前面部分引用侯振宇的那篇文章里,他提出这些问题:
如何能把组件变得更易重用? 具体一点:
- 我在用某个组件时需要重新调整一下组件里面元素的顺序怎么办?
- 我想要去掉组件里面某一个元素怎么办?
如何把组件变得更易扩展? 具体一点:- 业务方不断要求给组件加功能怎么办?
为此,还提出了“模板复写”方案,在这一点上我有不同意见。
我们来看看如何把一个业务界面切割成组件。
有这么一个简单场景:一个雇员列表界面包括两个部分,雇员表格和用于填写雇员信息的表单。在这个场景下,存在哪些组件?
对于这个问题,主要存在两种倾向,一种是仅仅把“控件”和比较有通用性的东西封装成组件,另外一种是整个应用都组件化。
对前一种方式来说,这里面只存在数据表格这么一个组件。
对后一种方式来说,这里面有可能存在:数据表格,雇员表单,甚至还包括雇员列表界面这么一个更大的组件。
这两种方式,就是我们之前所说的“局部组件化”,“全组件化”。
我们前面提到,全组件化在管理上是存在优势的,它可以把不同层面的东西都搞成类似结构,比如刚才的这个业务场景,很可能最后写起来是这个样子:
<Employee-Panel>
<Employee-List></Employee-List>
<Employee-Form></Employee-Form>
</Employee-Panel>对于UI层,最好的组件化方式是标签化,比如上面代码中就是三个标签表达了整个界面。但我个人坚决反对滥用标签,并不是把各种东西都尽量封装就一定好。
全标签化的问题主要有这些:
第一,语义化代价太大。只要用了标签,就一定需要给它合适的语义,也就是命名。但实际用的时候,很可能只是为了把一堆html简化一下而已,到底简化出来的那东西应当叫什么名字,光是起名也费不知多少脑细胞。比如你说雇员管理的表单,这个表单有heading吗,有footer吗,能折叠吗,等等,很难起一个让别人一看就知道的名字,要么就是特别长。这还算简单的,因为我们是全组件化,所以很可能会有组合了多种东西的一个较复杂的界面,你想来想去也没法给它起个名字,于是写了个:
<Panel-With-Department-Panel-On-The-Left-And-Employee-Panel-On-The-Right>
</Panel-With-Department-Panel-On-The-Left-And-Employee-Panel-On-The-Right>这尼玛……可能我夸张了点,但很多时候项目规模够大,你不起这么复杂的名字,最后很可能没法跟功能类似的一个组件区分开,因为这些该死的组件都存在于同一个命名空间中。如果仅仅是当作一个界面片段来include,就不存在这种心理负担了。
比如Angular里面的这种:
<div ng-include="'aaa/bbb/ccc.html'"></div>就不给它什么名字,直接include进来,用文件路径来区分。这个片段的作用可以用其目录结构描述,也就是通过物理名而非逻辑名来标识,目录层次充当了一个很好的命名空间。
现在的一些主流MVVM框架,比如knockout,angular,avalon,vue等等,都有一种“界面模板”,但这种模板并不仅仅是模板,而是可以视为一种配置文件。某一块界面模板描述了自身与数据模型的关系,当它被解析之后,按照其中的各种设置,与数据建立关联,并且反过来再更新自身所对应的视图。
不含业务逻辑的UI(或者是业务逻辑已分离的UI)基本不适合作为组件来看待,因为即使在逻辑不变的情况下,界面改版的可能性也太多了。比如即使是换了新的CSS实现方式,从float布局改成flex布局,都有可能把DOM结构少套几层div,因此,在使用模板的方案中,只能把界面层视为配置文件,不能看成组件,如果这么做,就会轻松很多。
部队行军的时候讲究“逢山开路,遇水搭桥”,这句话的重点在于只有到某些地形才开路搭桥,使用MVVM这类模式解决的业务场景,多数时候是一马平川,横着走都可以,不必硬要造路。所以从整个方案看的话,UI层实现应该是模板与控件并存,大部分地方是模板,少数地方是需要单独花时间搞的路和桥。
第二,配置过于复杂。有很多东西其实不太适合封装,不但封装的代价大,使用的代价也会很大。有时候会发现,调用代码的绝大部分都是在写各种配置。
就像刚才的雇员表单,既然你不从标签的命名上去区分,那一定会在组件上加配置。比如你原来想这样:
<EmployeeForm heading="雇员表单"></EmployeeForm>然后在组件内部,判断有没有设置heading,如果没有就不显示,如果有,就显示。过了两天,产品问能不能把heading里面的某几个字加粗或者换色,然后码农开始允许这个heading属性传入html。没多久之后,你会惊奇地发现有人用你的组件,没跟你说,就在heading里面传入了折叠按钮的html,并且用选择器给折叠按钮加了事件,点一下之后还能折叠这个表单了……
然后你一想,这个不行,我得给他再加个配置,让他能很简单地控制折叠按钮的显示,但是现在这么写太不直观,于是采用对象结构的配置:
<EmployeeForm>
<Option collapsible="true">
<Heading>
<h4><strong>雇员</strong>表单</h4>
</Heading>
</Option>
</EmployeeForm>然后又有一天,发现有很多面板都可以折叠,然后特意创建了一个可折叠面板组件,又创建了一种继承机制,其他普通业务面板从它继承,从此一发不可收拾。
我举这例子的意思是为了说明什么呢,我想说,在规模较大的项目中,企图用全标签化加配置的方式来描述所有的普通业务界面,是一定事倍功半的,并且这个规模越大就越坑,这也正是ExtJS这类对UI层封装过度的体系存在的最大问题。
这个问题讨论完了,我们来看看另外一个问题:如果UI组件有业务逻辑,应该如何处理。
比如说,性别选择的下拉框,它是一个非常通用化的功能,照理说是很适合被当做组件来提供的。但是究竟如何封装它,我们就有些犯难了。这个组件里除了界面,还有数据,这些数据应当内置在组件里吗?理论上从组件的封装性来说,是都应当在里面的,于是就这么造了一个组件:
<GenderSelect></GenderSelect>这个组件非常美好,只需直接放在任意的界面中,就能显示带有性别数据的下拉框了。性别的数据很自然地是放在组件的实现内部,一个写死的数组中。这个太简单了,我们改一下,改成商品销售的国家下拉框。
表面上看,这个没什么区别,但我们有个要求,本公司商品销售的国家的信息是统一配置的,也就是说,这个数据来源于服务端。这时候,你是不是想把一个http请求封装到这组件里?
这样做也不是不可以,但存在至少两个问题:
第一个问题只是资源的浪费,第二个就是数据的不一致了。曾经在很多系统中,大家都是手动刷新当前页面来解决这问题的,但到了这个时代,人们都是追求体验的,在一个全组件化的解决方案中,不应再出现此类问题。
如何解决这样的问题呢?那就是引入一层Store的概念,每个组件不直接去到服务端请求数据,而是到对应的前端数据缓存中去获取数据,让这个缓存自己去跟服务端保持同步。
所以,在实际做方案的过程中,不管是基于Angular,React,Polymer,最后肯定都做出一层Store了,不然会有很多问题。
#5. 为什么MVVM是一种很好的选择
我们回顾一下刚才那个下拉框的组件,发现存在几个问题:
所以,从这些角度,会尽量期望在HTML界面层与JavaScript业务逻辑之间,存在一种分离。
这时候,再看看绝大多数界面组件存在什么问题:
有时候我们考虑一下DOM操作的类型,会发现其实是很容易枚举的:
多数界面组件封装的绝大部分内容不过是这些东西的重复。这些东西,其实是可以通过某些配置描述出来的,比如说,某个数组以什么形式渲染成一个select或者无序列表之类,当数组变动,这些东西也跟着变动,这些都应当被自动处理,如果某个方案在现在这个时代还手动操作这些,那真的是一种落伍。
所以我们可以看到,以Angular,Knockout,Vue,Avalon为代表的框架们在这方面做了很多事,尽管理念有所差异,但大方向都非常一致,也就是把大多数命令式的DOM操作过程简化为一些配置。
有了这种方式之后,我们可以追求不同层级的复用:
所以这么一来,我们的复用粒度就非常灵活了。正因为这样,我一直认为Angular这样的框架战略方向是很正确的,虽然有很多战术失误。我们在很多场景下,都是需要这样的高效生产手段的。
#6. 组件的长期积累
我们做组件化这件事,一定是一种长期打算,为了使得当前的很多东西可以作为一种积累,在将来还能继续使用,或者仅仅作较小的修改就能使用,所以必须考虑对未来标准的兼容。主要需要考虑的方面有这几点:
之前有很多人对Angular 2.0的激进变更很不认同,但它的变更很大程度上是对标准的全面迎合。这不仅仅是它的问题,其实是所有前端框架的问题。不面对这些问题,不管现在多么好,将来都是死路一条。这个问题的根源是,这几个已有的规范约束了模块化和元素化的推荐方式,并且,如果要对当前和未来两边做适配的话,基本就没法干了,导致以前的都不得不做一定的迁移。
模块化的迁移成本还比较小,无论是之前AMD还是CMD的,都可以根据一些规则转换过来,但组件化的迁移成本太大了,几乎每种框架都会提出自己的理念,然后有不同的组件化理念。
还是从三个典型的东西来说:Polymer,React,Angular。
Polymer中的组件化,其实就是标签化。这里的标签,并不只是界面元素,甚至逻辑组件也可以这样,比如这个代码:
<my-panel>
<core-ajax id="ajax" url="http://url" params="{{formdata}}" method="post"></core-ajax>
</my-panel>注意到这里的core-ajax标签,很明显这已经是纯逻辑的了,在大多数前端框架或者库中,调用ajax肯定不是这样的,但在浏览器端这么干也不是它独创,比如flash里面的WebService,比如早期IE中基于htc实现的webservice.htc等等,都是这么干的。在Polymer中,这类东西称为非可见元素(non-visual-element)。
React的组件化,跟Polymer略有不同,它的界面部分是标签化,但如果有单纯的逻辑,还是纯JavaScript模块。
既然大家的实现方式都那么不一致,那我们怎么搞出尽量可复用的组件呢?问题到最后还是要绕到Web Components上。
在Web Components与前端组件化框架的关系上,我觉得是这么个样子:
各种前端组件化框架应当尽可能以Web Components为基石,它致力于组织这些Components与数据模型之间的关系,而不去关注某个具体Component的内部实现,比如说,一个列表组件,它究竟内部使用什么实现,组件化框架其实是不必关心的,它只应当关注这个组件的数据存取接口。
然后,这些组件化框架再去根据自己的理念,进一步对这些标准Web Components进行封装。换句话说,业务开发人员使用某个组件的时候,他是应当感知不到这个组件内部究竟使用了Web Components,还是直接使用传统方式。(这一点有些理想化,可能并不是那么容易做到,因为我们还要管理像import之类的事情)。
#7. 我们需要关注什么
目前来看,前端框架/库仍然处于混战期,可比**历史上的春秋战国,百家齐放,作为跟随者来说,这是很痛苦的,因为无所适从,很可能你作为一个企业的前端架构师或者技术经理,需要做一些选型工作,但选哪个能保证几年后不被淘汰呢?基本没有。
虽然我们不知道将来什么框架会流行,但我们可以从一些细节方面去关注,某个具体的方面,将来会有什么,也可以了解一下在某个具体领域存在什么样的方案。一个完整的框架方案,无非是以下多个方面的综合。
这块还是不讲了,支付宝seajs还有百度ecomfe这两个团队的人应该都能比我讲得好得多。
本文前面讨论过一些,也不深入了。
我们知道,现代框架的一个特点是自动化,也就是把原有的一些手动操作提取。在前端编程中,最常见的代码是在干什么呢?读写数据和操作DOM。不少现代的框架/库都对这方面作了处理,比如说通过某种配置的方式,由框架自动添加一些关联,当数据变更的时候,把DOM进行相应修改,又比如,当DOM发生变动的时候,也更新对应的数据。
这个关联过程可能会用到几种技术。首先我们看怎么知道数据在变化,这里面有三种途径:
一、存取器的封装。这个的意思也就是对数据进行一层包装,比如:
var data = {
name: "aaa",
getName: function() {
return this.name;
},
setName: function(value) {
this.name = value;
}
}这样,不允许用户直接调用data.name,而是调用对应的两个函数。Backbone就是通过这样的机制实现数据变动观测的,这种方式适用于几乎所有浏览器,缺点就是比较麻烦,要对每个数据进行包装。
这个机制在稍微新一点的浏览器中,也有另外一种实现方式,那就是defineProperty相关的一些方法,使用更优雅的存取器,这样外界可以不用调用函数,而是直接用data.name这样进行属性的读写。
国产框架avalon使用了这个机制,低版本IE中没有defineProperty,但在低版本IE中不止有JavaScript,还存在VBScript,那里面有存取器,所以他巧妙地使用了VBS做了这么一个兼容封装。
基于存取器的机制还有个麻烦,就是每次动态添加属性,都必须再添加对应的存取器,否则这个属性的变更就无法获取。
二、脏检测。
以Angular 1.x为代表的框架使用了脏检测来获知数据变更,这个机制的大致原理是:
保存数据的新旧值,每当有一些DOM或者网络、定时器之类的事件产生,用这个事件之后的数据去跟之前保存的数据进行比对,如果相同,就不触发界面刷新,否则就刷新。
这个方式的理念是,控制所有可能导致数据变更的来源(也就是各种事件),在他们可能对数据进行操作之后,判断新旧数据是否有变化,忽略所有中间变更,也就是说,如果你在同一个事件中,把某个数据任意修改了很多次,但最后改回来了,框架会认为你什么都没干,也就不会通知界面去刷新了。
不可否认的是,脏检测的效率是比较低的,主要是不能精确获知数据变更的影响,所以当数据量更大的情况下,浪费更严重,需要手动作一些优化。比如说一个很大的数组,生成了一个界面上的列表,当某个项选中的时候,改变颜色。在这种机制下,每次改变这个项的数据状态,就需要把所有的项都跟原来比较一遍,然后,还要再全部比较一次发现没有关联引起的变化了,才能对应刷新界面。
三、观察机制。
在ES7里面,引入了Object的observe方法,可以用于监控对象或数组的变动。
这是目前为止最合理的观测方案。这个机制很精确高效,比如说,连长跟士兵说,你去观察对面那个碉堡里面的动静。这个含义很复杂,包括什么呢?
所谓观察机制,也就是观测对象属性的变更,数组元素的新增,移除,位置变更等等。我们先思考一下界面和数据的绑定,这本来就应当是一个外部的观察,你是数据,我是界面,你点头我微笑,你伸手我打人。这种绑定本来就应当是个松散关系,不应当因为要绑定,需要破坏原有的一些东西,所以很明显更合理。
除了数据的变动可以被观察,DOM也是可以的。但是目前绝大多数双向同步框架都是通过事件的方式把DOM变更同步到数据上。比如说,某个文本框绑定了一个对象的属性,那很可能,框架内部是监控了这个文本框的键盘输入、粘贴等相关事件,然后取值去往对象里写。
这么做可以解决大部分问题,但是如果你直接myInput.value="111",这个变更就没法获取了。这个不算大问题,因为在一个双向绑定框架中,一个既被监控,又手工赋值的东西,本身也比较怪,不过也有一些框架会尝试从HTMLInputELement的原型上去覆盖value赋值,尝试把这种东西也纳入框架管辖范围。
另外一个问题,那就是我们只考虑了特定元素的特定属性,可以通过事件获取变更,如何获得更广泛意义上的DOM变更?比如说,一般属性的变更,或者甚至子节点的增删?
DOM4引入了MutationObserver,用于实现这种变更的观测。在DOM和数据之间,是否需要这么复杂的观测与同步机制,目前尚无定论,但在整个前端开发逐步自动化的大趋势下,这也是一种值得尝试的东西。
复杂的关联监控容易导致预期之外的结果:
总之这么下来,最后影响到哪里了都不知道,谁让丘处机路过牛家村呢?
所以,变更的关联监控是很复杂的一个体系,尤其是其中产生了闭环的时候。搭建整个这么一套东西,需要极其精密的设计,否则熟悉整套机制的人只要用特定场景轻轻一推就倒了。灵智上人虽然武功过人,接连碰到欧阳锋,周伯通,黄药师,全部都是上来就直接被抓了后颈要害,大致就是这意思。
polymer实现了一个observe-js,用于观测数组、对象和路径的变更,有兴趣的可以关注。
在有些框架,比如aurelia中,是混合使用了存取器和观察模式,把存取器作为观察模式的降级方案,在浏览器不支持observe的情况下使用。值得一提的是,在脏检测方式中,变更是合并后批量提交的,这一点常常被另外两种方案的使用者忽视。其实,即使用另外两种方式,也还是需要一个合并与批量提交过程。
怎么理解这个事情呢?数据的绑定,最终都是要体现到界面上的,对于界面来说,其实只关注你每一次操作所带来的数据变更的始终,并不需要关心中间过程。比如说,你写了这么一个循环,放在某个按钮的点击中:
for (var i=0; i<10000; i++) {
obj.a += 1;
}界面有一个东西绑定到这个a,对框架来说,绝对不应当把中间过程直接应用到界面上,以刚才这个例子来说,合理的情况只应当存在一次对界面DOM的赋值,这个值就是对obj.a进行了10000次赋值之后的值。尽管用存取器或者观察模式,发现了对obj上a属性的这10000次赋值过程,这些赋值还是都必须被舍弃,否则就是很可怕的浪费。
React使用虚拟DOM来减少中间的DOM操作浪费,本质跟这个是一样的,界面只应当响应逻辑变更的结束状态,不应当响应中间状态。这样,如果有一个ul,其中的li绑定到一个1000元素的数组,当首次把这个数组绑定到这个ul上的时候,框架内部也是可以优化成一次DOM写入的,类似之前常用的那种DocumentFragment,或者是innerHTML一次写入整个字符串。在这个方面,所有优化良好的框架,内部实现机制都应当类似,在这种方案下,是否使用虚拟DOM,对性能的影响都是很小的。
Immutable Data是函数式编程中的一个概念,在前端组件化框架中能起到一些很独特的作用。
它的大致理念是,任何一种赋值,都应当被转化成复制,不存在指向同一个地方的引用。比如说:
var a = 1;
var b = a;
b = 2;
console.log(a==b);这个我们都知道,b跟a的内存地址是不一致的,简单类型的赋值会进行复制,所以a跟b不相等。但是:
var a = {
counter : 1
};
var b = a;
b.counter++;
console.log(a.counter==b.counter);这时候因为a和b指向相同的内存地址,所以只要修改了b的counter,a里面的counter也会跟着变。
Immutable Data的理念是,我能不能在这种赋值情况下,直接把原来的a完全复制一份给b,然后以后大家各自变各自的,互相不影响。光凭这么一句话,看不出它的用处,看例子:
对于全组件化的体系,不可避免会出现很多嵌套的组件。嵌套组件是一个很棘手的问题,在很多时候,是不太好处理的。嵌套组件所存在的问题主要在于生命周期的管理和数据的共享,很多已有方案的上下级组件之间都是存在数据共享的,但如果内外层存在共享数据,那么就会破坏组件的独立性,比如下面的一个列表控件:
<my-list list-data="{arr}">
<my-listitem></my-listitem>
<my-listitem></my-listitem>
<my-listitem></my-listitem>
</my-list>我们在赋值的时候,一般是在外层整体赋值一个类似数组的数据,而不是自己挨个在每个列表项上赋值,不然就很麻烦。但是如果内外层持有相同的引用,对组件的封装性很不利。
比如在刚才这个例子里,假设数据源如下:
var arr = [
{name: "Item1"},
{name: "Item2"},
{name: "Item3"}
];通过类似这样的方式赋值给界面组件,并且由它在内部给每个子组件分别进行数据项的赋值:
list.data = arr;赋值之后会有怎样的结果呢?
console.log(list.data == arr);
console.log(listitem0.data == arr[0]);
console.log(listitem1.data == arr[1]);
console.log(listitem2.data == arr[2]);这种方案里面,后面那几个log输出的结果都会是true,意思就是内层组件与外层共享数据,一旦内层组件对数据进行改变,外层中的也就改变了,这明显是违背组件的封装性的。
所以,有一些方案会引入Immutable Data的概念。在这些方案里,内外层组件的数据是不共享的,它们的引用不同,每个组件实际上是持有了自己的数据,然后引入了自动的赋值机制。
这时候再看看刚才那个例子,就会发现两层的职责很清晰:
所以我们再看这个过程,真是非常清晰明了,而且内外层各司其职,互不干涉。这是非常有利于我们打造一个全组件化的大型Web应用的。各级组件之间存在比较松散的联系,而每个组件的内部则是封闭的,这正是我们所需要的结果。
说到这里,需要再提一个容易混淆的东西,比如下面这个例子:
<outer-component>
<inner-component></inner-component>
</outer-component>如果我们为了给inner-component做一些样式定位之类的事情,很可能在内外层组件之间再加一些额外的布局元素,比如变成这样:
<outer-component>
<div>
<inner-component></inner-component>
</div>
</outer-component>这里中间多了一级div,也可能是若干级元素。如果有用过Angular 1.x的,可能会知道,假如这里面硬造一级作用域,搞个ng-if之类,就可能存在多级作用域的赋值问题。在上面这个例子里,如果在最外层赋值,数据就会是outer -> div -> inner这样,那么,从框架设计的角度,这两次赋值都应当是immutable的吗?
不是,第一次赋值是非immutable,第二次才需要是,immutable赋值应当仅存在于组件边界上,在组件内部不是特别有必要使用。刚才的例子里,依附于div的那层变量应当还是跟outer组件在同一层面,都属于outer组件的人民内部矛盾。
这里是facebook实现的immutable-js库
前端一般都习惯于用事件的方式处理异步,但很多时候纯逻辑的“串行化”场景下,这种方式会让逻辑很难阅读。在新的ES规范里,也有yield为代表的各种原生异步处理方案,但是这些方案仍然有很大的理解障碍,流行度有限,很大程度上会一直停留在基础较好的开发人员手中。尤其是在浏览器端,它的受众应该会比node里面还要狭窄。
前端里面,处理连续异步消息的最能被广泛接受的方案是promise,我这里并不讨论它的原理,也不讨论它在业务中的使用,而是要提一下它在组件化框架内部所能起到的作用。
现在已经没有哪个前端组件化框架可以不考虑异步加载问题了,因为,在前端这个领域,加载就是一个绕不过去的坎,必须有了加载,才能有执行过程。每个组件化框架都不能阻止自己的使用者规模膨胀,因此也应当在框架层面提出解决方案。
我们可能会动态配置路由,也可能在动态加载的路由中又引入新的组件,如何控制这些东西的生命周期,值得仔细斟酌,如果在框架层面全异步化,对于编程体验的一致性是有好处的。将各类接口都promise化,能够在可维护性和可扩展性上提供较多便利。
我们之前可能熟知XMLHTTP这样的通信接口,这个东西虽然被广为使用,但是在优雅性等方面,存在一些问题,所以最近出来了替代方案,那就是fetch。
细节可以参见月影翻译的这篇【翻译】这个API很“迷人”——(新的Fetch API)
在不支持的浏览器上,也有github实现的一个polyfill,虽然不全,但可以凑合用window.fetch polyfill
大家可以看到,fetch的接口就是基于promise的,这应当是前端开发人员最容易接受的方案了。
#7.7 Isomorphic JavaScript
这个东西的意思是前后端同构的JavaScript,也就是说,比如一块界面,可以选择在前端渲染,也可以选择在后端渲染,值得关注,可以解决像seo之类的问题,但现在还不能处理很复杂的状况,持续关注吧。
#8. 小结
很感谢能看到这里,以上这些是我近一年的一些思考总结。从技术选型的角度看,做大型Web应用的人会很痛苦,因为这是一个青黄不接的年代,目前已有的所有框架/库都存在不同程度的缺陷。当你向未来看去,发现它们都是需要被抛弃,或者被改造的,人最痛苦的是在知道很多东西不好,却又要从中选取一个来用。@严清 跟@寸志 @题叶讨论过这个问题,认为现在这个阶段的技术选型难做,不如等一阵,我完全赞同他们的观点。
选型是难,但是从学习的角度,可真的是挺好的时代,能学的东西太多了,我每天路上都在努力看有可能值得看的东西,可还是看不完,只能努力去跟上时代的步伐。
以下一段,与诸位共勉:
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way--in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only.
给一位打算从事前端,但是又有疑惑的在校大学生的回信
抱歉这么晚才回复这个邮件,主要是觉得你的问题有典型性,想要详细一点给出答复。
所谓的前端,在不同的公司,定义是不同的,工作内容也会有差异,有的还很大。比如有很多公司,没有专门的前端分类,所有的都属于开发人员,一些比较传统的公司,还有一些人数较少的小公司会是这样。又比如有些公司,前端人员的职责仅限于静态页面和交互效果,然后把这些东西交给业务开发人员去编写业务的JS代码。还有一些公司,前端除了PC和移动端的Web,还包括各种移动终端的开发。
这些种种不同,都是各公司自身的业务特点决定的,大体上比较适合各自的业务场景,越大的公司,内部的分工可能越明确,所以也就有了你看到的,有比较偏向JS的,有比较偏向CSS的。
个人选择什么方向,我觉得需要问自己两个问题:
这个的意思是,你觉得自己学js和css的时候,哪种觉得更轻松愉快,容易领悟。一个人选择自己最容易领悟的方面去学习,会事半功倍。
人的一生,实际上很大程度是职业细分的过程,每个人在他工作的前10年,都可能会逐步深入到某些领域,他的知识广度可能会逐步增加,但能够深入的,往往在一两个分支上。
从大的方面看,最初的软件体系基本都是以服务端为主,客户端通过字符界面去进行操作,后来桌面程序迅速发展,再后来Web兴起,最近各种终端的流行,更加促使广义的“前端”这个领域有更多的发挥空间。整体来说,后端的发展趋势是服务化,前端的发展趋势是多样化。因为消费者的促进,前端的需求和发展会是非常乐观的,无论在其中选择哪个细分方向,只要努力下去,成为这个领域的专家,肯定都会有所成就。
目前,在很多公司,搞CSS一般还没有独立职位,或者即使有,暂时比搞JS的还是稍微弱势一些,正如前端部门一般比后端部门弱势,但这种状况会好转的,每个领域都会得到适合自己的发挥。
关于原生JS和某些库的学习,我的观点是这样,除了一些很特别很怪异的点,对于语言本身的常规用法是需要都掌握的,其实也不多,常用到的就那么些。一般说的原生JS,是包括JS语言本身,还有它对DOM和BOM的操作,比如元素的创建移除,事件的添加等等,这些应该都需要懂。至于说对于某个库的学习,更重要的是学习它的思维方式,每看一个例子,就先想一想如果自己写,会把代码写成怎样,再与真实的例子进行对照,举一反三,这样的学习会是很快的过程。
现在这个时代,各种浏览器还在混战,但低版本IE的淘汰已经成为了必然,如果是现在开始学习,一定要着眼于将来,多看看CSS3各子集的规范,了解ES新版本的特性,因为世界迟早是它们的。对于低版本浏览器的兼容,一般都会有成熟的解决方案,当遇到具体问题的时候再去看也可以。
很多人看待前端,是把它当作一个很浅的层面来看的,其实前端的人多了解一些别的领域也是有好处的,从中能得到很多领悟,比如软件工程,设计模式,它们对不管什么方面的开发人员而言,都是很好的指导。
一个成熟的前端开发人员,他应当有比较宽的知识面,同时至少在某一两个细分领域有专注的研究和见解。平时在日常生活中,也可以多注意观察一些产品,对自己正在做的整个产品有深刻认识,对生活常识有充分了解,有时候也会有助于减少开发过程中走的弯路。
能够对自己的未来有所预期,并且主动寻找学习的途径,这说明你有很好的开始,在前端这条道路上认真走下去,相信会有美好的未来。
MVVM框架的性能,其实就取决于几个因素:
我们要优化Angular项目的性能,也需要从这几个方面入手。
监控值的个数怎么减少呢?
考虑极端情况,在不引入Angular的时候,监控的个数是为0的,每当我们有需要绑定的数据项,就产生了监控值。
我们注意到,Angular里面使用了一种HTML模板语法来做绑定,开发业务项目非常方便,但考虑一下,这种所谓的“模板”,其实与我们常见的那种模板是不同的。
传统的模板,是静态模板,将数据代入模板之后生成界面,之后数据再有变化,界面也不会变。但Angular的这种“模板”是动态的,当界面生成完毕,数据产生变更的时候,界面还是会更新。
这是Angular的优势,但我们有时候也会因为使用不当,反而增加困扰。因为Angular采用了变动检测的方式来跟踪数据的变化,这些事情都是有负担的,很多时候,有些数据在初始化之后就不再会变化,但因为我们没有把它们区分出来,Angular还是要生成一个监听器来跟踪这部分数据的变化,性能也就受到牵累。
在这种情况下,可以采用单次绑定,仅在初始化的时候把这些数据绑定,语法如下:
<div>{{::item}}</div><ul>
<li ng-repeat="item in ::items">{{item}}</li>
</ul>这样的数据就不会被持续观测,也就有效减少了监控值的数目,提高了性能。
这一个环节是从数据变更检测与绑定的方式入手。细节不说太多了,之前都说过。从数据到界面的更新,一般就两种方式:推、拉。
所谓推,就是在set的时候,主动把与之相关的数据更新,大部分框架是这种方式,低版本浏览器用defineSetter之类。
function Employee() {
this._firstName = "";
this._lastName = "";
this.fullName = "";
}
Employee.prototype = {
get firstName(){
return this._firstName;
},
set firstName(val){
this._firstName = val;
this.fullName = val + " " + this.lastName;
},
get lastName(){
return this._lastName;
},
set lastName(val){
this._lastName = val;
this.fullName = this.lastName + " " + val;
}
};所谓拉,就是set的时候只改变自己,关联数据等到用的时候自己去取。比如:
function Employee() {
this.firstName = "";
this.lastName = "";
}
Employee.prototype = {
get fullName() {
return this.firstName + " " + this.lastName;
}
};有些框架中,两种方式都可以用。这时候可以自己考虑下适合用哪种方式,比如说,可能有些框架是合并变更,批量更新的,可能就用拉的方式效率高;有些框架是实时变动,差异更新的,那可能就是用推的效率高些。
上面的代码能看出来,从代码编写的简洁性来说,拉模式要比推模式简单很多,如果能预知数据量较小,可以这样用。
在实际开发过程中,这两种方式是需要权衡的。我们举的这个例子比较简单,如果说某个属性依赖于很多东西,例如,一个很大的购物列表,有个总价,它是由每个商品的单价乘以购买个数,再累加起来的。
在这种情况下,如果使用拉模式,也就是在总价的get上做这个变动,它需要遍历整个数组,重新作计算。但是如果使用推模式,每次有商品价格或者商品购买个数发生变更的时候,都只要在原先的总价上,减去两次变动的差价即可。
此外,不同的框架用不同方式来检测数据的变动,比如Angular,如果有一个数组中的元素发生变化了,它是怎样知道这个数组变了呢?
它需要保持变动之前的数据,然后作比对:
所以,会有人考虑在Angular中结合immutable这样的东西,加速变更的判定过程,因为immutable的数据只要发生任何变化,其引用都一定会变,所以只要第一步判定引用就足以知道数据是否改变了。
有人说,你这个判定降低的开销并不大啊,因为引入immutable要增加复制的开销,跟这里的新旧数据比对开销相比,也低不到哪里去。但这个地方要注意,Angular在有事件产生的时候,会把所有监控数据都重新比对,也就是说,如果你在界面上有个大数组,你从未对它重新赋值,而是经常在另外一个很小的表单项绑定的数据上进行更新,这个数组也是要被比对的,这就比较坑了,所以如果引入immutable,可以大幅降低平时这种不受影响时候的比对成本。
但是引入immutable也会对整个应用造成影响,需要在每个赋值取值的地方都使用immutable的封装方式,而且还要在绑定的时候,对数据作解包,因为Angular绑定的数据是pojo。
所以,用这种方式还是要慎重,除非框架自身就构建在immutable的基础上。或许,我们可以期望有一套与ng-model平行的机制,ng-immutable之类,实现的难度也还是挺大的。
在使用ES5的场景下,可以利用一些方法加速判断,比如数组的:
它们能够返回一个全新的数组,与原先的引用不等,所以在第一步判断就可以得出结果,不必继续后面几步的比较。
不过,这个环节的优化其实很不明显,最关键的优化在于与之配套的索引优化,参见下一节。
在Angular中,可以通过ng-repeat来实现对数组或者对象的遍历,但这个遍历的机制,其实有很多技巧。
在使用简单类型数组的时候,我们很可能会碰到这么一个问题:数组中存在相同的值,比如:
this.arr = [1, 3, 5, 3];<ul>
<li ng-repeat="num in arr">{{num}}</li>
</ul这时候会报错,然后如果去搜索一下,会发现一个解决方式:
<ul>
<li ng-repeat="num in arr track by $index">{{num}}</li>
</ul为什么这就能解决呢?
我们先思考一下,如果自己实现类似Angular这样的功能,因为要在DOM和数据之间建立关联,这样,当改变数据的时候,才能刷新到对应的界面,所以,必然有个映射关系。
映射关系需要唯一的索引,在刚才那个例子中,Angular默认对简单类型使用自身当索引,当出现重复的时候,就会出错了。如果指定$index,也就是元素在数组中的下标为索引,就可以避免这个问题。
那么,对于对象数组,又是怎样呢?
比如说这么一个数组,我们用不同的两个方式来绑定:
function ListCtrl() {
this.arr = [];
for (var i=0; i<10000; i++) {
this.arr.push({
id: i,
label: "Item " + i
});
}
var time = new Date();
$timeout(function() {
alert(new Date() - time);
console.log(this.arr[0]);
}.bind(this), 0);
}<ul ng-controller="ListCtrl as listCtrl">
<li ng-repeat="item in listCtrl.arr">{{item}}</li>
</ul><ul ng-controller="ListCtrl as listCtrl">
<li ng-repeat="item in listCtrl.arr track by item.id">{{item}}</li>
</ul>看示例地址,多点击几下:
我们惊奇地发现,这两个时间有不小差别。
关注一下在绑定之后,arr里面的数据,发现在没有加track by $index的时候,原始数据被改变了,添加了一些索引信息,这些索引是当数据产生变更时,Angular能够找到关联界面的重要线索。
Object {id: 0, label: "Item 0", $$hashKey: "object:4"}如果我们知道数据的唯一性由什么保证,并且手动指定其为索引,可以减少不必要的添加索引的过程。
看到这个标题,可能有人会感到奇怪。业务数据的大小并不是由程序员控制的,怎么降低呢?这里的降低,指的是降低那些被用于绑定到界面的数据大小。
数据的大小也会影响绑定效率,我们考虑一个屏幕能展示的数据有限,并不需要把所有东西都立即展示出来,可以从数据中截取一段进行展示,比如大家都熟悉的数据分页就是这么一种方式。
很传统的那种数据分页,是会有一个分页条,上面写着总共多少数据,然后上一页,下一页,这样切换。后来出现了一些变种,比如滚动加载,当滚动条滚到底部的时候,再去加载或生成新的界面。
如果说,我们有上万条数据形成的一个列表,但是又不打算用那么老圡的方式放个分页条在下面,如何在性能与体验中取得一个平衡呢?
接触过Adobe Flex的人,可能会对其中的列表控件印象深刻,因为就算你给它上百万数据,它也不会因此而慢下来,为什么呢?因为它的滚动条是假的。
同理,我们也可能在浏览器中使用DOM来模拟一个滚动条,然后利用这个滚动条的位置,从全量数据中获取对应的那一段数据,并且绑定渲染到界面上。
这种技术一般称为Virtual List,在很多框架中都有第三方实现,可以参见这篇文章:AngularJS virtual list directive tutorial
上面这篇文章做到的,只是初步的优化,并不精细,因为它假定列表中所有项的大小是一致的,而且要在创建阶段即已预知,这样就很不灵活了。如果需要做更精细的优化,需要做实时的度量,对每个已创建并渲染的子项作度量,然后以此来更新滚动区的位置。
参见demo:http://codepen.io/xufei/pen/avRjqV
那么,数据的结构又是怎样影响到执行效率的呢?我举一个常见的例子就是树形结构,这个结构一般人会使用ul和li之类的结构做,然后不可避免地要用递归的方式来使用MVVM框架。
我们考虑一下,为什么非要使用这种方式呢?其原因有二:
这个树形数据对我们来说,是什么?是数据模型。但是我们知道,比对两个树形结构是很麻烦的,它的层级使得监控变得复杂,无论是数据的逐一比对,还是存取器、或者刚被取消的observe提案,都会比单层数据麻烦很多。
如果我们想要用一种更加扁平的DOM结构来展示它,而不是层级结构,怎么办呢?所谓的树形DOM结构,能展现给我们的无非是位置的偏移,比如所有下级节点比上级更靠右,这些东西其实可以很轻易使用定位来模拟,这么一来,就有可能适用平级DOM结构来表达树的形状了。
回忆一下,MVVM,这几个字母什么意思?
Model View ViewModel
我们看了前两者了,但从未关注过视图模型。在很多人眼里,视图模型只是模型的一个简单封装,其实那只是特例,Angular官方的demo形成了这种误导。视图模型的真正作用应当包括:把模型转化为适合视图展示的格式。
如果说我们需要在视图层有比较扁平的数据结构,就必须在这一层把原始数据拍扁,举个栗子,我们要做一个动态的组织架构图,这个展开会像一个树,内部肯定也会有树形的数据结构,但我们可以同时维护树形和扁平的两种结构,并且随时保持同步:
原始数据如下:
var source = [
{id: "0", name: "a"},
{id: "1", name: "b"},
{id: "013", name: "abd", parent: "01"},
{id: "2", name: "c"},
{id: "3", name: "d"},
{id: "00", name: "aa", parent: "0"},
{id: "01", name: "ab", parent: "0"},
{id: "02", name: "ac", parent: "0"},
{id: "010", name: "aba", parent: "01"},
{id: "011", name: "abb", parent: "01"},
{id: "012", name: "abc", parent: "01"}
];转换代码如下:
var map = {};
var dest = [];
source.forEach(function(it) {
map[it.id] = it;
});
source.forEach(function(it) {
if (!it.parent) {
//根节点
dest.push(it);
}
else {
//叶子节点
map[it.parent].children = map[it.parent].children || [];
map[it.parent].children.push(it);
}
});转换之后的dest变成了这样:
[
{
"id": "0",
"name": "a",
"children": [
{
"id": "00",
"name": "aa",
"parent": "0"
},
{
"id": "01",
"name": "ab",
"parent": "0",
"children": [
{
"id": "013",
"name": "abd",
"parent": "01"
},
{
"id": "010",
"name": "aba",
"parent": "01"
},
{
"id": "011",
"name": "abb",
"parent": "01"
},
{
"id": "012",
"name": "abc",
"parent": "01"
}
]
},
{
"id": "02",
"name": "ac",
"parent": "0"
}
]
},
{
"id": "1",
"name": "b"
},
{
"id": "2",
"name": "c"
},
{
"id": "3",
"name": "d"
}
]我们在界面绑定的时候仍然使用source,而在操作的时候使用dest。因为,绑定的时候,不必去经过深层检测,而操作的时候,需要有父子关系来使得操作便利。
比如说,我们要做一个树状拓扑图,或者是MindMap这类产品,如果不作这样的考虑,很可能会直接把界面结构绑定到树状数据上,这时候效率相对会比较低些。
但我们也可以作这种优化:
MVVM存在的意义就是尽可能提高开发效率,只有很极端情况下值得去优化性能。如果你的场景中出现非常多的性能问题,很可能是不适合用这类框架的业务形态。
总结一下我们的几种优化方式,他们的机制分别是:
可以看到,我们所有的优化都是在数据层面,不必刻意去优化界面。如果你用了一个MVVM框架,却为它作了各种各样相当多的优化,那还不如不要用它,全手工写。
针对其他MVVM框架,也大致可以用类似的几种方式,只是部分细节有差异,可以触类旁通。
这个话题其实我早就想写了,刚好最近在跟一些学生接触,而且很快有个应届生徒弟要入职了,想到了当初的自己,所以觉得打算谈谈这些年的一些感悟,希望能有所帮助。
我刚工作的时候,对公司非常热爱,热爱到偏激的程度,比如说觉得竞争对手公司毫无优点,比如每次看到公司的负面评价,都忍不住想出来反驳,甚至能为了这些事情跟多年的老同学争得面红耳赤。
多年之后回头看这一切,会为自己当时的单纯感动,也觉得挺傻的,反思之后,会用它跟另外一件事情作比较,那就是恋爱。
工作跟恋爱,真的是两件非常相似的事情,当我们开始跟一个人好,总会忽视对方的一切缺点,把优点无限放大,然后相处着相处着,好像忽然就发现对方怎么冒出这么多缺点,有时候忍不住说出来,会惹对方很不高兴,为什么呢,因为从他的角度,从未改变过,一直是这样的,为什么之前你不说,过了一阵反而不能容忍了呢?
这个是一种心理反应,体现的是预期与现实的偏差。我们一开始的时候,总是倾向于有一个完美的预期,然后逐渐发现不相符,当这些累积到超过容忍度的时候,就会爆发。
我看到很多人毕业的时候都会对第一家公司充满期待,但这个期待真的有些满,一方面源自对美好未来的期望,另一方面很可能源自企业的误导。这个事情其实不能怪企业,因为就算谈恋爱,你基本上也不可能上来就跟人家说:我先跟你说下我缺点,12345,等你说完人早跑了。企业招聘的时候显然也挑好的说,比如工资没人家高,就说但是我们加班少啊,比如加班也多,就说但是能学到东西啊,总之肯定是充满优点的,涉世未深的大学生们很可能就全信了。
但不巧这个新员工干了一阵,怎么感觉钱少事多离家远,每天干的还重复劳动,好像哪里不对啊?这时候问题就来了,真正的伤害,这种伤害很可怕,第一份工作跟初恋在心理上的重要度是同样的。受这一次伤,可能永远都痛。
这事,我觉得负责招聘的同事有必要深思,有些缺点,如实说出来会比较好,从长远来看,隐瞒一些事实的后果很严重,不如刚开始就诚恳一些。
现在我看到一些新员工跟自己之前的同学争吵,说自己公司好,对方公司是垃圾,就仿佛看到当年的我。我是过来人了,觉得这事真没必要。
每个公司有自己的企业文化,所谓企业文化,是因为一些做事方式而导致的微小差异,并不是真有那么大,就好比你是射手座,书上说射手座很热爱自由,你觉得说得很对,就信了这个,好像别人就不热爱自由似的。然后你因为有这个心理暗示,就更加显得热爱自由,然后又反过来觉得星座这东西真有道理啊。
对待企业文化,我觉得应这么看:
如果你冷静下来看看一些公司的企业文化,会发现基本都只是细节差异,因为没有谁会说自己是邪恶的。那既然都是好话,整体来说,你都可以信,如果懒得去花时间理解它们,可以直接以真善美,还有自己内心的喜好为准。
所以现在我看企业文化之类的培训,有时候会摇头笑笑,一方面是因为老油条了,你说的那些我也会,而且说不定比你说得还好,另一方面,既然我接受你,说明我要么认同你的优点,要么不介意你的缺点。
我现在倾向于这么对待企业文化:
如果能接受一家公司的氛围,那就加入。如果不能接受,就离开。
如果觉得值得改进,也有两个选择:等别人来推动,自己来推动。
我见过很多人,不停抱怨公司的各种缺点,但是一不离职,二不想办法改进,我觉得这挺奇怪的。很多时候改进没有那么难,我打个比方,你觉得公司的某个地砖不平,不好走,不找人反馈,然后每天都要吐槽一下,其实说不定就是别人没发现,你跟他一说,他去看了发现果然这样,两分钟就给摆平了。
有时候,还会有人把这样的问题上升成对这个企业的恨,好像企业是故意造出这些小问题,特意为了让员工没有好心情干活,我倾向于认为老板们不会这么蠢,有些问题他不知道而已。
人生在世,想找完全合乎自己心意的伴侣或者环境基本不可能,只有两条路可以选,一是降低预期,二是帮助对方改进。这两者都是改善自己生存状况的好方式。
再说说如何选择环境吧。我承认不同企业的环境确实存在差异,但这不是根本问题。企业对人的影响,远不如所在团队对人的影响大,最直接相处的人才会对自己造成最深刻的影响。就好比上学,一个人的成长过程,至少有大半取决于父母和自身,然后才轮到学校的同学和老师。所以选择工作的时候,也不一定太看重企业的大环境,如果有机会挑选到出色的上级和同事,那才是事业中最大的助力。
我有时候反思自己,觉得过于爱谈正能量,俗称鸡汤。这东西也没什么不对,总比散布负能量要好些,是不是?但我现在很害怕这些话被太单纯的人看见,会让他们觉得世界特别美好,这样,碰到挫折的时候伤得格外重。
这事情也有一个道理,叫做:已所欲,勿施于人。这世上当然是有一些人,或者因为理想,或者因为利益,会期望别人跟自己有相似的行为准则,但这一不小心就能变成道德绑架,我之前干过不少,很惭愧。
所以我把这些都说出来,也是期望将来的新员工能独立思考,尽量不被别人的观点影响,追随自己的内心,在不伤害团队利益的情况下,完成对自己性格的完善,达成一生事业的良好起步。
在我看来,人的成熟意味着两件事:
也就是说,对于所见所闻,如果不是大是大非的原则问题,只需客观冷静地关注能否从中学到什么,对自己的知识或者性格有所帮助,其他的完全可以不予置评。
本文尝试从数据和逻辑的角度,对业务系统中的各种交互作一个归类,简单探索其中一些共性,并以此作为渐进式交互优化的一种依据。
交互的本质是锦上添花,其中包含“锦”和“花”两种要素,二者之中,“锦”是必不可少的部分,而“花”则是为了使得交互更加友好。
那么,“锦”和“花”具体指代什么,应该如何区分呢?
一切业务系统,本质上是对数据的读写,所以,可以从是否影响业务数据的角度,来区分某种是什么类型。
如果一种交互,它所产生的数据变更,直接影响到当前的提交或汇总结果,则可认为是一种必要交互。
比如:
如果一种交互,它不会引发当前业务数据的变更,它就是一种增强交互。
比如:
需要注意的是,仅从当前交互是否提交或汇总数据来看,是不精确的,需要一直上溯。比如说:
在下拉选择中,可以快速新增的按钮及其后续操作
这个快捷新增操作是包含数据提交的,但是因为它的上层,其结果改变的是下拉框的可选项,这个地方是一个增强交互,因此,沿着交互树的树枝向根部追溯,发现经过了增强交互,所以,它就是从属于一个整体的增强交互的局部。
因此,经过完善的定义为:
在一套交互体系中,如果去除了一切友好优化,则可以得到满足业务需求的最小交互。一个业务的最小交互,是仅满足基本输入输出的最简形态,在不同的交互体系中,可以通过定义不同数据类型的原子操作形态,从而改变最小交互的默认形态。
例如:
这样,业务的最小交互就是它们的叠加,并去除了非必要的关联。
基于以上的定义,如果两个交互所处理的数据类型一致,则可认为有一定的互相替代性。
比如说,表达一组实体数据的时候,我们可以约定,最简单的情况下,使用一个表格来表达。
所以它的数据形态就是类似:
interface IListViewProps {
dataSource: Array<Entity>
}我们把这个表格称为列表数据的默认交互。
同样是这个数据源,在必要的时候,可以被呈现为数据列表,或者各种图表,比如柱状图,饼状图之类。视图只是数据形态的一种表现方式,所以,数据的查询、筛选、增删,都是独立于其呈现形态的,我们只需给这类视图提供一套协议,就足以使得它们能够无缝接入,可被任意切换,也就实现了交互的可替代性。
这些同样适配列表数据源的的交互,就可以被称为列表数据的可选交互。
推而广之,一切数据形态都可以找到它的默认交互,也可以在特定业务域中定义出一些可选交互来。这些交互集,可以辅助业务设计师/架构师,轻松快速完成业务设计。
可以大致用这样的分类方式来整理原子业务交互:
基于以上原则划分的交互形态,基本上都是可以同类互换的,将一种形态切换为另外一种,并不会影响业务实质。
比如说,业务上想要表达布尔类型,可以在 Switch、Checkbox、RadioGroup、Select 中任意选取。
另一方面,在某种交互内部,添加一些不影响提交数据的辅助交互,并不会影响其实质,比如,Select 中添加一个用于快速定位的搜索框,它最终提交的仍然是选中的那条记录。
这也符合我们上一节的论述:锦上添花,只是增加了交互的友好性,但是在其业务的实质上,存在最小集。
需要注意到的是,在很多交互中,会存在对全量元数据适度的裁剪。
比如说,一个实体,有20个字段,在表格视图下,我们查看其中10个,然后在详情视图下查询全部。这时候,表格视图就产生了对于业务实体全量交互的裁剪。
因为侧重性的问题,本文不尝试对交互裁剪作深入探讨,在此探讨一些相关问题。
关联数据的选取和变更操作,都会体现这么一个特质:两类关联关系的典型交互,其操作是孤立的,比如:
这样的交互虽然逻辑正确,但总是这样的话,可能过于死板,考虑如下业务诉求:
在宠物详情表单中,除了编辑宠物自身信息,选择主人,还能快捷编辑其主人的信息。
换句话说,多对一关系中,在“多”进行编辑的时候,以什么样的交互编辑“一”,是有可能随着业务的不同,有所不同的。
除了拓展之前我们提到的下拉选择,把每个项改成可编辑,还有可能存在其他形态的交互,比如把主人信息展开为一个子表单之类,与主表单一同编辑。
在业务中,每种关联关系都可以去考虑:是否开启以关联关系的两端为主体的交互,还是只开启其中一端。有的时候,不同场景下是可能存在不同的主体语义的。
举例来说:
主人和宠物是一对多关系。
业务设计的时候,可能有如下两组视图:
第一组:
第二组:
这两种设计视图中,前一组出现了两种不同的以人员为主体的交互,只是一种侧重于当前实体,一种侧重于关联关系的表达,而后一组把这两种交互合并在一起了。在实际设计过程中,可能需要根据场景和业务诉求来选择采用哪种方式。
在业务设计的时候,关联关系的两头可以都作为默认交互来生成,然后由业务设计师来裁剪其中一部分,以此达到最佳的业务使用合理性。
一般来说,仅靠原子交互自身,只能满足业务特性的最低限度表达,想要实现最低限度的可用性,可能还需要添加一些辅助交互。
最典型的一种交互是日期选择器,它算不算日期形态的最简交互呢?当然不算,因为用一个文本输入框去输入日期,也同样能把这个业务完成,只是体验低一些而已。
通常我们不会把系统可用性的基准定在这么低的位置,所以,我们会:
所以,这就是辅助交互的第一个层次:以选代填。
当我们使用选择来代替填空的时候,就会面临一个问题,在很多场景下,可选项过多。为了收缩可选项的数量,需要增加过滤器。过滤器的形态可以是多样化的,但实质都一样,影响的是可选项的数量.
在不同类型的选择器上,是有机会去定义出一些默认的过滤器的,可以是折叠式,可以是可展开的,搜索结构可以根据使用这些选择器的元数据来生成。
所以,这也就成为了辅助交互的第二个层次:快速选择。
前面我们提到,业务上会存在一些对等关联关系,如果能够在编辑自身数据的时候,快捷编辑所关联的数据,那往往会大幅缩短填写时间。
比如:
为一个人选择宠物的时候,可以允许他在选择过程中,快速新建一个宠物,或者修改已有的宠物。
与之对应:
当选择宠物的时候,发现该宠物尚未创建,先切换到宠物管理界面,新建了宠物之后,再切回来选。
很明显,上面那种交互的效率更高。
我们完全可以为每种关联关系创建一些可选交互,其中包含关联数据的快捷编辑功能。需要注意的是,关联数据的编辑,可能会受到关联关系的一些约束,比如是否可空等等。
这就是辅助交互的第三个层次:关联关系的快捷编辑。
以上,我们描述了一套可替换的组件化体系,基于这套体系,可以很容易实现交互的渐进式优化。
所谓的渐进式优化,我给它一个形象描述:
也就是说,最开始,仅拥有对业务实体的元数据描述,就已经得到了一个可使用的业务系统了,就好比盖房子,主框架改好的时候,内墙直接贴好了简单实用的墙砖,如果不讲究的话,都是可以用的。
然后,头痛医头,脚痛医脚,哪里不行改哪里:
通过这样的步骤,逐步把整个系统变为更专业、准确的形态。
所以,在某个设计体系下,可以逐一约定:
然后,初始化的时候,给出的都是默认交互,从默认交互的基础上逐步优化到最佳交互。
所以,我们得出了渐进式优化的三个重要路径:
本文初步着眼于业务数据变迁的过程,产生了交互的最小集、可替换性和渐进式优化方面的一些思考,基于这样的思考,是相对比较容易对基础交互进行归类,进而形成一套业务体系的标准交互的。
而整个这套体系,一旦形成,就是它发挥价值的时候。它是业务应用灵活搭建的必经之路,做好了这一步,才能突破下一级阶梯:快速装配。
从大的方面说,我是一个很坚定的分层党,而不是组件化党。
在之前这篇中,我详细阐述过这方面的看法,到现在回头看,里面有些细节待修补。大致总结一下观点如下:
这两者的区别在于复用方式。
对于组件来说,我们期望的复用方式是传递不同的参数,以达到不同形态和行为。我们需要在编写它的时候,审慎地考虑参数的设定,并且,在使用的时候,需要考虑版本变更所带来的影响。比如说,修改了一个组件,这个修改会传导到所有使用了它的链路上,因此,你的修改会需要作“是否兼容”的判断。
对于模板来说,它并不存在”复用“这个事情,我们只把它视为一次性的,如果说这个上面想要存在什么复用,我们用 snippets 去承载它。一旦一个模板被创建,它的变更仅影响自身,没有依赖链路。
仅从上面的内容来看,这些观点显得可能很非主流,甚至看上去跟我自己早先的一篇回答都是不兼容的,而且,我们通常都认为,组件化是批量制造的基础。那么,为什么我会有这样的观点呢?
这取决于我们对“模板”这个东西的认知。
从使用代价的角度看,一旦你在比较大的组件上追求可复用性,那必然会面临这样的问题:
越是大粒度的东西,要满足不同情况,必定会有越多的可配置项。一旦你的配置项多了,单个组件搞出 10 个以上的属性,或者有些配置项很复杂了,比如要搞得像 React 的 renderProps 那样,这种挖了很多洞的组件,跟不组件化到底有什么区别?
const A = (props) => {
const { foo } = props
return (
<AAA>
{ foo() }
</AAA>
)
}
const B = () => {
const renderFoo = (
<BBB />
)
return (
<A foo={renderFoo} />
)
}
const C = () => {
const renderFoo = (
<CCC />
)
return (
<A foo={renderFoo} />
)
}仔细想想,大部分场景下,它们真的一定要组织成这样吗?你为了把 A 弄成一个可复用的东西,所以要这么绕一圈,但如果你从来不把 A 视为一个可复用的东西,而是把其内容拿出来作为 snippets,用的时候在 B 和 C 里各写一份,到底会影响什么呢?
所以,很大程度上,如果你过于追求在大粒度组件上的可复用性,一定会导致抽象上的高复杂度,在这个层级的抽象,其实意义很小,还因此引入了一个依赖树的管理复杂度,性价比不高。在业务上做抽象的时候,需要慎重地权衡组件抽象所引入的代价。
从更大的角度看,如果一个组件存在非常多的可配置项,那就等同于把所有配置项及其变更逻辑抽离到一个承载容器中,剩下的部分只负责渲染。
所以,从这个角度看,真正的视图仍然是分层的,分出来的那个展示部分都可以泛指为模板。至于分层到什么形态,是函数式、流、OOP,那都是各框架自身所倾向的方法论,并不影响把视图隔离出去这么一个明显“分层”的动作。
此时,视图不过是逻辑容器的附属物,可以视为是一种配置而已。
在本文前面所提到的“模板”,都是泛指,不限于静态的类似 XML 写法表达的东西,或者是包含 JavaScript 逻辑的 JSX 写法。
下面,我们顺带探讨一下“模板式写法”,从这里开始,提到的“模板”都是这个含义了。
很多人感觉,模板这个东西,在组件化体系里显得很违和。这取决于你从什么角度理解了。
注意下面这个论断:
模板是组件化的配置式便捷写法。
如果从这个角度去看,那“模板”这个东西在组件化体系里就是自洽的了。我们整体上仍然是以组件化的方式来生产软件,只是在写视图的时候,采用了一些声明式的配置来简化其描述过程而已,并不会因为这么做了,就导致组件化的大方向出现偏差。
不仅如此,我们还发现了,如果以这种方法论来进行业务软件的前端开发:
之后,我们可以很便利地做可视化的页面搭建系统:
整个过程,彻底绕开了复杂的技术难点(你想自己解析 JSX 吗?),而且,在产品实现上也能够很平衡。在一个相对稳定的体系中,将视图和逻辑分开进行管控和复用,可以营造出门槛很低的可视化开发系统。
从整个体系来看,需要编写代码的那种组件在平台上被视为黑盒(或者是一个无限小的质点),大粒度的业务视图看作大块的平面,逻辑与数据成为骨架。整个业务系统的开发过程就是:
在骨架上铺设表皮,表皮上嵌入适当的瓷砖或者马赛克(组件)
[ 组件1 组件2 ] <模板1> [ 组件3 ]<模板2>
-----------------------------------------------
前端的逻辑容器
如上所示:分层与组件化同时存在,组件化不是一个直接切到底的东西。
在AngularJS中,有module的概念,但是它这个module,跟我们通常在AMD里面看到的module是完全不同的两种东西,大致可以相当于是一个namespace,或者package,表示的是一堆功能单元的集合。
一个比较正式的Angular应用,需要声明一个module,供初始化之用。比如说:
angular.module("test", [])
.controller("TestCtrl", ["$scope", function($scope) {
$scope.a = 1;
}]);随后,可以在HTML中指定这个module:
<div ng-app="test" ng-controller="TestCtrl">
{{a}}
</div>这样,就是以这个div为基准容器,实例化了刚才定义的module。
或者,也可以等价地这样,在这里,我们很清楚地看到,module的意义是用于标识在一个页面中可能包含的多个Angular应用。
angular.element(document).ready(function() {
angular.bootstrap(document.getElementById("app1"), ["test"]);
angular.bootstrap(document.getElementById("app2"), ["test"]);
});<div id="app1" ng-controller="TestCtrl">
{{a}}
</div>
<div id="app2" ng-controller="TestCtrl">
{{a}}
</div>这样可以在同一个页面中创建同一module的不同实例。两个应用互不干涉,在各自的容器中运行。
除此之外,我们可以看到,在module声明的时候,后面带一个数组,这个数组里面可以指定它所依赖的module。比如说:
angular.module("moduleB", [])
.service("GreetService", function() {
return {
greet: function() {
return "Hello, world";
}
};
});
angular.module("moduleA", ["moduleB"])
.controller("TestCtrl", ["$scope", "GreetService", function($scope, GreetService) {
$scope.words = "";
$scope.greet = function() {
$scope.words = GreetService.greet();
};
}]);然后对应的HTML是:
<div ng-app="moduleA">
<div ng-controller="TestCtrl">
<span ng-bind="words"></span>
<button ng-click="greet()">Greet</button>
</div>
</div>好了,注意到这个例子里面,创建了两个module,在页面上只直接初始化了moduleA,但是从moduleA的依赖关系中,引用到了moduleB,所以,moduleA下面的TestCtrl,可以像引用同一个module下其他service那样,引用moduleB中定义的service。
到这里,我们是不是就可以把module当作一种namespace那样的组织方式呢,很可惜,它远远没有想的那么好。
看下面这个例子:
angular.module("moduleA", [])
.factory("A", function() {
return "a";
})
.factory("B", function() {
return "b";
});
angular.module("moduleB", [])
.factory("A", function() {
return "A";
})
.factory("B", function() {
return "B";
});
angular.module("moduleC", ["moduleA", "moduleB"])
.factory("C", ["A", "B", function(A, B) {
return A + B;
}])
.controller("TestCtrl", ["$scope", "C", function($scope, C) {
$scope.c = C;
}]);
angular.module("moduleD", ["moduleB", "moduleA"])
.factory("C", ["A", "B", function(A, B) {
return A + B;
}])
.controller("TestCtrl", ["$scope", "C", function($scope, C) {
$scope.c = C;
}]);
angular.module("moduleE", ["moduleA"])
.factory("A", function() {
return "AAAAA";
})
.factory("C", ["A", "B", function(A, B) {
return A + B;
}])
.controller("TestCtrl", ["$scope", "C", function($scope, C) {
$scope.c = C;
}]);<div id="app1" ng-controller="TestCtrl">
<span ng-bind="c"></span>
</div>
<div id="app2" ng-controller="TestCtrl">
<span ng-bind="c"></span>
</div>
<div id="app3" ng-controller="TestCtrl">
<span ng-bind="c"></span>
</div>angular.element(document).ready(function() {
angular.bootstrap(document.getElementById("app1"), ["moduleC"]);
angular.bootstrap(document.getElementById("app2"), ["moduleD"]);
angular.bootstrap(document.getElementById("app3"), ["moduleE"]);
});我们在moduleA和moduleB中,分别定义了两个A跟B,然后,在moduleC和moduleD的时候中,分别依赖这两个module,但是依赖的顺序不同,其他所有代码完全一致,再看看结果,会发现两边的结果居然是不一致的。
再看看moduleE,它自己里面有一个A,然后结果跟前两个例子也是不同的。
照理说,我们对module会有一种预期,也就是把它当作命名空间来使用,但实际上它并未起到这种作用,只是一个简单的复制,把依赖的module中定义的东西全部复制到自己里面了,后面进来的会覆盖前面的,比如:
整个覆盖过程没有任何提示。
我们可以把module设计的初衷理解为:供不同的开发团队,或者不同的业务模块做归类约束用,但实际上完全没有起到这种作用。结果,不得不在下级组织单元的命名上继续做文章,不然在多项目集成的时候,就要面临冲突的风险。
不仅如此,这种module机制还为大型应用造成了不必要的麻烦。比如说,module不支持运行时添加依赖,看下面的例子:
angular.module("some.components", [])
//这里定义了一些组件
;假设上面是一个组件库,集中存放于components.js中,我们要在自己的应用中使用,必须:
angular.module("our.app", ["some.components"]);现在假设这个components.js较大,我们不打算在首页引入,想在某个时候动态加载,就会出现这样的尴尬局面:
关键问题就在于它不存在一个在our.app启动之后向其中添加some.components依赖的方式。我们预期的代码方式是类似这样:
angular.module("our.app", []);
require("components.js", function() {
// angular.module("our.app").addDependency("some.components");
// ready to use
});也就是这段代码中注释掉的那句。但从现在看来,它基本没法做这个,因为他用的是复制的方式,而且对同名的业务单元不做提示,也就是可能出现覆盖了已经在使用的模块,导致同一个应用中的同名业务单元出现行为不一致的情况,对排错很不利。
在一些angular最佳实践中,建议各业务模块使用module来组织业务单元,基于以上原因,我个人是不认同的,我推荐在下一级的controller,service,factory等东西上,使用标准AMD的那种方式定义名称,而彻底放弃module的声明,比如所有业务代码都适用同一个module。详细的介绍,我会在另外一篇文章中给出。
此外,考虑到在前端体系中,JavaScript是需要加载到浏览器才能使用的,module的机制自身也至少应当包括异步加载机制,很可惜,没有。没有模块加载机制,意味着什么呢?意味着做大型应用有麻烦。这个可以用一些变通的方式去处理,在这里先不提了。
可以看到,Angular中的module并未起到预期作用,相反,还造成了一些麻烦。因此,我认为这是Angular当前版本中唯一一块弊大于利的东西,在2.0中,这部分已经做了重新规划,会把这些问题解决,也加入动态加载的考虑。
在上一篇中我们提到了组件化的大致思路,这一篇主要讲述在这么做之后,我们需要哪些外围手段去管控整个开发过程。从各种角度看,面对较大规模前端开发团队,都有必要建立这么一个开发阶段的协作平台。
在这个平台上,我们要做哪些事情呢?
#1. HTML片段
我们为什么要管理HTML片段?因为有界面要用它们,当这些片段多了之后,需要有个地方来管理起来,可以检索、预览它们,还能看到大致描述。
这应该是整个环节中一个相对很简单的东西,照理说,有目录结构,然后剩下的就是单个的HTML片段文件了,这就可以解决存储和检索的问题了,但我们还要考虑更多。
已有的HTML片段,如何被使用呢?这肯定是一种类似include的方式,通过某种特殊标签(不管是前端还是后端的方式)把这些片段引用进来,这时候就有了第一个问题:
假设有界面A和界面B同时引用了片段C,在某个开发人员修改片段C内容的时候,他如何得知将会影响到界面A和B呢?一个比较勉强的方式是全项目查找,但这在很多情况下是不够的。
如果我们的HTML片段是作为独立的公共库存在的,它已经不能通过项目内查找去解决这一问题了,因为不管A还是B,只要他不处于片段C的项目空间,就无从追寻。
这时候很多人会问两个问题:
跨项目的界面片段重用,意义在哪里?
如果我们的产品是针对一个小领域,它的复杂度根本不需要划分多个项目部分来协作完成。设想场景是面对很大的行业,各项目都是子产品,将来可能是其中若干个联合部署,这时候,保持其中的一致性是非常重要的。比如我们有个基本配置界面,在多个子产品中都要用,如果各自开发一个,其操作风格很可能就是不一致的,给人的印象就是不专业。所以会需要把常见的界面片段都归集起来,供业务方挑选使用。
修改C,只提供说明,但是不通知A和B,不实时更新他们的版本,然后自行决定怎样升级,如何?
这会有一个问题,每次有小功能升级的时候,代码是最容易同步合并的,所以才会有“持续集成”这个概念,如果是一直伴随升级,总要比隔一个大阶段才升级好,升级成本应尽量分摊到平时,就像农妇养小猪,小猪每天长一点,每天都抱来抱去,不觉得吃力,即使长大了也还能抱得动。
现在问题就很明确了,一定要有一种方式来把这个依赖关系管理起来,很显然,已有的版本库是肯定管不了这些的,所以只能在外围做一些处理。
我们建立一个管理平台,除了管理实体文件的版本,还管它们之间的关系。具体这个关系如何收集整理,有两种方式:手动配置,代码分析。
手动配置是比较土的方式,开发人员每提交一个文件,就去这系统上手动配置它的依赖关系。代码分析的话,要在每次提交文件的时候解析文件的包含规则,找出确切的文件。这两者各有利弊,前者比较笨,但容易做,后者对代码格式的要求比较高,要考虑的情况较多。
我们的界面往往不是那么简单,HTML片段也可能有层次的,举例来说:
界面A里面包含了片段B,但是片段B自身又包含了片段C,所以这个依赖关系也是有层级的,需要在设计的时候一并考虑。
#2. JavaScript模块
JavaScript代码的管理,比HTML片段的状况好一些,因为业界很多这方面的解决方案。但它们还是没有解决当依赖项产生变更的时候反向通知的问题。
所以我们还是得像HTML片段一样,把它们的依赖关系都管理到平台里。于是,每个JavaScript模块都显式配置了自己所依赖的其他模块,通过这种单向关系,形成了一套完整的视图。
在JavaScript模块的代码实现中,我们是不提倡直接写依赖关系的。很多通用规范,比如AMD,往往建议我们这样写模块:
define(['dep1', 'dep2'], function (dep1, dep2) {
var moduleA = function () {};
return moduleA;
});但我们的系统是面向行业的,比这种通用解决方案要苛刻一些。比如说,如果有一天重构代码,JavaScript模块们调整了目录或者名字,这么写的就痛苦了,他必须把所有影响到的都去调整一遍,这是要搜索替换的。况且,就像上面HTML模板的部分提到的,影响了处于其他项目中依赖它的代码,缺少合适的方式去通知他们修改。
所以我们期望的是,在每个编写的JavaScript模块中只存放具体实现,而把依赖关系放在我们的平台上管理,这样,即使当前模块作了改名之类的重构处理,处于外部项目中依赖它的那些代码也不必修改,下一次版本发布的生成过程会自动把这些事情干掉。
对应到上面的这段代码,我们需要开发人员做的只是其中的实现,也就是moduleA的那个部分,外面这些依赖的壳子,是会在发布阶段根据已配置的依赖关系自动生成的。
如果需要,JavaScript模块还可以细分,比如类似Angular里面那样,把factory,controller和directive分离出来,这会对后续有些处理提供方便。
现在我们有必要讨论一下模块的粒度了,我们这里提到的都是基本的粒度,每个JavaScript模块中存放的应该只有一个很具体东西的实现。那么,有个问题,在我们发布的时候,是不是就按照这个粒度发布出去呢?
很显然不行,如果这么做,很可能会出现复杂界面一次要用10多个HTTP请求才能加载完它所需要的所有JavaScript代码的情况,所以需要做一些合并。
那么,合并的策略是什么?在我们这个平台上,开发人员又是要怎样定义这个合并关系的呢?我们需要在模块之上定义一个更大粒度的组织方式,这个方式与模块的关系,就好比Java里面,jar文件与class的关系。如果开发人员不显式配置,也可以通过全局策略,比如按最下层目录来合并。
这个时候,在实际使用这些代码的时候,需要带两个配置信息过去,一个是要动态载入的JavaScript文件(合并之后的),二是每个JavaScript文件中包含的原始模块。
#3. 单元测试
如果JavaScript模块都已经被良好有序管理起来,就可以为它们考虑单元测试的事情了。单元测试对于提高基础单元的可靠度,是有非常重要意义的。
在我们这个平台里,可以把单元测试跟JavaScript模块关联起来,每个JavaScript模块可以挂一组单元测试代码,这些代码可以在线编写,在线运行。
单元测试的本质就是编写模拟代码来调用已有模块,考虑到我们的模块是JavaScript,所以很多思路都倾向于在浏览器端执行它们,对于单个模块的单元测试,这不是个问题。
如果要批量执行整个系统的单元测试,那就不一样了。把JavaScript代码先加载到浏览器中,然后再执行,很多时候并不需要这么复杂。我们完全可以在服务端把它们做了。
借助Node.js的能力,我们可以在服务端执行JavaScript代码,也就意味着能够把绝大多数JavaScript模块的单元测试在服务端就执行掉。当然,我们为此可能要多做不少事情,比如说,有些库需要移植一份node版的,常见的有AJAX调用等等。
注意了,能够在服务端做JavaScript单元测试是有先决条件的,代码的分层必须很良好,除了视图层,其他任何层面都不能操作DOM。所以我们这里主要测试的也正是除了视图层之外的所有JavaScript业务逻辑。至于视图层怎么办?这个真的很难解决,这世界上不是所有东西都能自动做的,只能先把可做的做了,以后再来考虑这些。
#4. 文档和示例管理
现在我们有HTML片段和JavaScript模块了,需要给它们多一些描述信息。简单描述显然是不够的,我们还要详细文档。
这种详细文档可以通过某种方式生成,也可以由开发人员手动编写。与传统的离线文档不同,在线的文档更实时,并且,每当一个开发人员变更了他的文档之后,不需要经过全量构建,访问者可以实时访问到他的最新版本。
熟悉GitHub的朋友们可能早已习惯这种方式,在项目库里面存在一些以md格式结尾的文本文件,使用markdown语法来编写一些说明文档。
毫无疑问,这类格式很适合在线协作,所以我们也会在平台上集成这么一种编写文档的方式,无论是针对HTML模板还是JavaScript模块,或者是其他什么类型,甚至还可以用来当博客,就像月影同学的gitpress平台,能直接从GitHub上拉取文本或者HTML文件形成博客。
文档除了以集成的形式浏览之外,应当也可以以单独链接的方式发出去,这时候用户就可以像看一个新闻网页一样去浏览。如果再进一步做下去,还可以做电子书的生成,提供打包的离线文档。
在编写代码文档的过程中,可能免不了要插入示例,示例有两种形态,一种是纯文本,类似gist这样,一种是可在线运行,类似jsfiddle和jsbin这样。
这两种都有各自的优点,所以可以都做,示例的存放可以与文档类似,也应当能通过一个链接独立运行。
有时候我们看到一些在线的幻灯片,觉得效果很帅,比如reveal.js,我们的开发人员有时候作代码分析或者走查的时候也不免要写一些演示,如果能把这些东西也随项目管理起来,能在线查看,会是很不错的一件事。所以我们也可以考虑给它们加个存储界面,甚至做个简易的在线编写器。
#5. 项目与目录管理
说到现在,我们似乎还遗漏了一点什么。那就是以上提到的这些东西,以什么为组织单位来存储?
考虑到我们的这个平台是要管理一整个大产品的全部前端内容的,它里面应该分了很多项目,对应到子产品上,这么一来,很自然地,项目就成了第一级组织单位。项目之下,没有悬念地,只有目录了。
对于一个项目而言,它有哪些要做的事情呢?首先要能配置其实体存储位置。前面提到的这么多代码、文档之类,最终都是要实体存储的,怎么存?我们当然可以自己搞一套,在文件系统上做起来,但是还要考虑它们的版本管理,非常麻烦,所以不如直接对接某个版本库,调用它的接口去存取文件,这里配置的就是版本库的路径。
其次,要考虑从已有项目复制,类似GitHub里面的fork功能,不过内部处理机制可以略有不同,fork的项目默认未必要有实体文件,只有当产生了修改或者新增操作的时候才创建,剩下的还引用原来的就可以了。我们这里的项目复制功能是为项目化版本而考虑的,经常出现一个产品版本支持多个客户项目的情况,所以可能会用得着这个特性。
然后,也要考虑项目的依赖关系。依赖一个项目,意思是需要用到它里面的组件,所以实质是组件的依赖。提供项目依赖这个视图,只是为了未来变更的一些考虑。
#6. 评论管理
之前提到,我们整个平台的目的是为了提高大型前端团队的协作能力,协作是离不开交流的。上述的任何功能,都应当带有交流沟通的能力。
比如说,如果开发人员A使用了其他人写的一个代码组件a,对其中一些细节有疑问,他应当可以对它进行评论。在他评论的时候,任何参与维护过这个组件的人员都能收到一个提醒,这时候他可以选择过来看看,回复这个疑问。同理,在文档、示例下也可以如此操作。
在互联网上有这类产品,用于在任意URL下挂接评论交流系统,比较有名的就是Disqus,我们可以看到很多网站下面挂着它,用于做交流评论,这样用户可以用一个账号在多个网站之间交流。国内也有同类的,比如多说,能够用微博、QQ等账号登录进行交流。
从我们这个平台本身看,如果是部署在企业内部作流程提升,引入外部评论系统的可能性就比较小了。因为在企业内部用,一定是希望这个员工的账号信息跟工号挂钩,也能够跟版本服务器账号等模块作集成,权限也便于控制。
从另外一个角度讲,某个人员登录这个系统的时候,他可能收到很多消息,来自不同的代码或文档位置,挨个点过去回复也有些麻烦,我们应当给他提供一个全局视图,让他能在一个统一的界面把这些问题都答复掉,如果他需要的话,也是可以点进去到实际的位置。
#7. 用户和权限控制
从以上部分我们已经看到,这个系统是一个比较复杂的开发过程管控平台。这样的话,每个使用的人就应当可以登录,然后分配不同的权限等级。
未登录用户应当有一些东西的查看权限,但是不能发表评论。已登录的用户根据权限级别,可以控制能否创建、修改项目,创建、修改目录,代码,单元测试,文档等。
#8. 国际化字符串管理
一个跨语言区域的Web应用不可避免要跟国际化打交道,这个事情通常是在服务端做,比如通过在界面代码中嵌入类似<% =getRes(key, lan) %>这样的代码,去获取相应的字符串,替换到界面里来。
这个事情是要占用应用服务器资源的,而且国际化本身其实是一个在运行之前就已经确定的事,完全可以把这个过程放在发布阶段就做掉。比如说,我们给每种语言预先就把代码生成多份,只是部署在一起,根据需要的情况来动态加载特定的那一份。
有不少客户端的国际化方案,是把资源文件拆细,以页面为单位存储,但这其实是不太合理的。第一个原因就是在Web2.0时代,“页面”这个概念本身就已经弱化了,到了单页应用里,整个应用都只是一个页面,这个时候,资源文件以什么粒度来组织呢?
我们提到过,采用MV*框架去做Web应用的架构,有一个目标是做组件化。组件化的意图就是某个组件可以尽可能随心所欲地放在需要的地方用。如果把资源文件的粒度弄小到对应HTML片段和JavaScript模块这一级,灵活性倒是有了,带来的问题就是管理成本增大。
做一个行业应用,最重要的就是业务一致性,这包括逻辑的一致性,也包括了术语的一致性。某一个词,可能在多个资源文件中都出现,这就增加了不一致的可能性。
所以,应当有一个统一的术语管理平台,一切界面上出现的文字或者提示,都必须来自这个平台。
#9. 静态资源的管理
在发布系统的时候,除了需要发布代码,还需要发布图片等静态资源,这些东西也应当被管理起来。
静态资源在两种情况下可用:随产品发布,在本平台被引用。比如说有一个图片,在这个平台上作了管理,它可以被配置到某个项目上,在发布的时候导出。这个图片还可以被用链接的方式查看或者下载,如果本平台内部的一个文档或者示例要引用它,也是可以的。
#10. 样式与主题管理
在Web系统里,样式和主题是很重要的一环。样式的管理和发布一直是一个比较复杂的话题,早几年一般都是分块写,然后组合合并,最近这些年有LESS,SASS和Stylus这类技术,解决了编写和发布的分离问题。
我们看看发布的最大问题是什么?是不同部分的合并。为了追求灵活性,不得不把东西拆得很细,之前HTML片段和JavaScript模块的处理方式都是这样。这么做,我们就需要另外一件事:这些细小的东西,尽可能要覆盖全面。
对应到CSS里面,我们要做的是把每种在系统中可能出现的元素、类别都作为单独的规则维护起来,生成一个全局的规则列表。不同项目间,实现可以不同,但规则的名字是固定的,定制只允许修改实现,不允许修改规则。如果要新增之前没有的规则,也必须在全局规则列表里先添加,再作实现。
样式规则被管理之后,可以在界面组件上对它作关联,也可以不做。做的好处是发布的时候能只把用到的那些样式规则生成发布出去,如果能接受每次发布全量CSS,那也无所谓。
除了规则,也需要考虑一些变量的管理,在CSS中合理使用变量,会大为减轻定制化所导致的工作量。
#11. 一键发布
我们引入了这么一堆东西,其实是增加了发布的复杂度。为什么呢?
之前不管HTML、JavaScript还是CSS,都是手写出来,最多经过一个minify的工作,就发布了,整个过程很简单,两句脚本搞定。
现在可复杂了,先要分析依赖关系,然后提取文件,然后国际化字符串替换,然后合并,然后代码压缩,整个过程很折腾,不给配置管理员一个解释的话,他一定过来砍人。
我们有个原则:解决问题的过程中,如果引入了新的问题,要求负责解决原问题的人也一起解决掉。现在为了一些意图,增加了版本发布的复杂度,那也要有个办法再把这事摆平,至少不能比原来复杂。
所以我们就要把这些过程都集成到管控平台里,做一个一键发布的过程,把所有的这些操作都集成起来,配置管理员发布版本的时候只要点一下就可以把所有这些事情做掉。甚至说,这些流程还可以配置,能够加减环节。
这时候我们做到了跟之前发版本一样方便,能不能多做点什么呢?
可以把JavaScript单元测试集成到版本发布阶段。因为我们已经把JavaScript按照职责做了分层,并且把UI部分做了隔离,就可以在浏览器之外把这个单元测试做掉,平时提交代码的时候也可以做,最终在版本发布阶段再全量做一下,也是很有意义的。
代码依赖关系管理的另一个目的是什么呢?是最小化发布,既然我们都管理了文件之间的关系,那么,从根出发,显然是能够得出哪些代码文件在本项目中使用的,就可以每次从我们的全量代码库中取得确切需要的一部分来发布。这也是我们整个管控平台带来的优势。
#12. 小结
我们这一篇比较复杂,提出了一整套解决大规模前端协作的管控机制。这套理论的本质是在开发和版本发布之间加了一个环节,把Web体系中除了服务之外的一切静态资源都纳入其中,强化了现有主流的一些基于命令行的前端工程化组织模式。
相比于传统行业,比如汽车制造,我们这个环节相当于生产流水线的设计,其中一些组件的存储就类似仓储机制,发布就类似出厂过程。
这个平台本身还有不少其他的可做的东西,比如甚至可以在上面做界面的可视化定制等,这些是长远的终极目标,在后面的文章里会谈谈一些考虑。
后续文章中,我们会展望有了这个平台之后,整个前端的协作流程是怎样的。
#1. 为什么要做组件化?
无论前端也好,后端也好,都是整个软件体系的一部分。软件产品也是产品,它的研发过程也必然是有其目的。绝大多数软件产品是追逐利润的,在产品目标确定的情况下,成本有两个途径来优化:减少部署成本,提高开发效率。
减少部署成本的方面,业界研究得非常多,比如近几年很流行的“去IOE”,就是很典型的,从一些费用较高的高性能产品迁移到开源的易替换的产品集群,又比如使用Linux + Mono来部署.net应用,避开Windows Server的费用。
提高开发效率这方面,业界研究得更多,主要途径有两点:加快开发速度,减少变更代价。怎样才能加快开发速度呢?如果我们的开发不是重新造轮子,而是每一次做新产品都可以利用已有的东西,那就会好很多。怎样才能减少变更代价呢?如果我们能够理清模块之间的关系,合理分层,每次变更只需要修改其中某个部分,甚至不需要修改代码,仅仅是改变配置就可以,那就更好了。
我们先不看软件行业,来看一下制造行业,比如汽车制造业,他们是怎么造汽车的呢?造汽车之前,先设计,把整个汽车分解为不同部件,比如轮子,引擎,车门,座椅等等,分别生产,最后再组装,所以它的制造过程可以较快。如果一辆汽车轮胎被扎破了,需要送去维修,维修的人也没有在每个地方都修一下,而是只把轮胎拆下来修修就好了,这个轮胎要是实在坏得厉害,就干脆换上个新的,整个过程不需要很多时间。
席德梅尔出过一款很不错的游戏,叫做《文明》(Civilization),在第三代里面,有一项科技研究成功之后,会让工人工作效率加倍,这项科技的名字就叫做:可替换部件(Replacement Parts)。所以,软件行业也应当引入可替换的部件,一般称为组件。
#2. 早期的前端怎么做组件化的?
在服务端,我们有很多组件化的途径,像J2EE的Beans就是一种。组件建造完成之后,需要引入一些机制来让它们可配置,比如说,工作流引擎,规则引擎,这些引擎用配置的方式组织最基础的组件,把它们串联为业务流程。不管使用什么技术、什么语言,服务端的组件化思路基本没有本质差别,大家是有共识的,具体会有服务、流程、规则、模型等几个层次。
早期展示层基本以静态为主,服务端把界面生成好,浏览器去拿来展示,所以这个时期,有代码控制的东西几乎全在服务端,有分层的,也有不分的。如果做了分层,大致结构就是下图这样:
这个图里,JSP(或者其他什么P,为了举例方便,本文中相关的服务端技术都用Java系的来表示)响应浏览器端的请求,把HTML生成出来,跟相关的JavaScript和CSS一起拿出去展示。注意这里的关键,浏览器端对界面的形态和相关业务逻辑基本都没有控制权,属于别人给什么就展示什么,想要什么要先提申请的尴尬局面。
这个时期的Web开发,前端的逻辑是基本可忽略的,所以前端组件化方式大同小异,无论是ASP还是JSP还是其他什么P,都可以自定义标签,把HTML代码和行间逻辑打包成一个标签,然后使用者直接放置在想要的地方,就可以了。
在这一时代,所谓的组件化,基本都是taglib这样的思路,把某一块界面包括它的业务逻辑一起打成一个端到端的组件,整个非常独立,直接一大块从界面到逻辑都有,而且逻辑基本上都是在服务端控制,大致结构如下图所示。
#3. SPA时代,出现了新问题
自从Web2.0逐渐流行,Web前端已经不再是纯展示了,它逐渐把以前在C/S里面做的一些东西做到B/S里面来,比如说Google和微软的在线Office,这种复杂度的Web应用如果还用传统那种方式做组件化,很显然是行不通的。
我们看看之前这种组件化的方式,本质是什么?是展现层跟业务逻辑层的隔离,后端在处理业务逻辑,前端纯展现。如果现在还这么划分,就变成了前端有界面和逻辑,后端也有逻辑,这就比较乱了。我们知道,纯逻辑的分层组件化还是比较容易的,任何逻辑如果跟展现混起来,就比较麻烦了,所以我们要把分层的点往前推,推到也能把单独的展现层剥离出来。
如下图所示,因为实际上HTML、CSS、JavaScript这些都逐渐静态化,所以不再需要把它们放在应用服务器上了,我们可以把它们放在专门的高性能静态服务器上,再进一步发展,就可以是CDN(Content Delivery Network,内容分发网络)。前端跟后端的通信,基本都是通过AJAX来,也会有一些其他的比如WebSocket之类,总之尽量少刷新了。
在这张图里面可以看到,真正的前端已经形成了,它跟应用服务器之间形成了天然的隔离,所以也能够很独立地进行一些发展演进。
现在很多Web程序在往SPA(单页面程序,Single Page Application)的方向发展,这类系统通常比较类似传统的C/S程序,交互过程比较复杂,因此它的开发过程也会遇到一些困难。
那为什么大家要做SPA呢?它有很多明显的好处,最核心的优势就是高效。这个高效体现在两个方面:一是对于用户来说,这种方式做出来的东西体验较好,类似传统桌面程序,对于那些需要频繁操作的行业用户,有很大优势。二是运行的效率较高,之前集成一些菜单功能,可能要用iframe的方式引入,但每个iframe要独立引入一些公共文件,服务器文件传输的压力较大,还要初始化自己的一套内存环境,比较浪费,互相之间也不太方便通信,一般要通过postMessage之类的方式去交互。
有了SPA之后,比如一块界面,就可以是一个HTML片段,用AJAX去加载过来处理之后放到界面上。如果有逻辑的JavaScript代码,也可以用require之类的异步加载机制去运行时加载,整体的思路是比较好的。
很多人说,就以这样的需求,用jQuery再加一个异步js加载框架,不是很足够了吗?这两个东西用得好的话,也是能够解决一些问题的,但它们处理的并不是最关键的事情。在Web体系中,展现层是很天然的,因为就是HTML和CSS,如果只从文件隔离的角度,也可以做出一种划分的方式,逻辑放在单独的js文件里,html内部尽量不写js,这就是之前比较主流的前端代码划分方式。
刚才我们提到,SPA开发的过程中会遇到一些困难,这些困难是因为复杂度大为提升,导致了一些问题,有人把这些困难归结为纯界面的复杂度,比如说,控件更复杂了之类,没有这么简单。问题在于什么呢?我打个比方:我们在电脑上开两个资源管理器窗口,浏览到同一个目录,在一个目录里把某个文件删了,你猜猜另外一个里面会不会刷新?
毫无疑问,也会刷新,但是你看看你用的Web页面,如果把整个复杂系统整合成单页的,能保证对一个数据的更新就实时反馈到所有用它的地方吗?怎么做,是不是很头疼?代码组织的复杂度大为提高,所以需要做一些架构方面的提升。
#4. 架构的变更
提到架构,我们通常会往设计模式上想。在著名的《设计模式》一书中,刚开始就讲了一种典型的处理客户端开发的场景,那就是MVC。
传统的MVC理念我们并不陌生,因为有Struts,所以在Web领域也有比较经典的MVC架构,这里面的V,就负责了整个前端的渲染,而且是服务端的渲染,也就是输出HTML。如下图所示:
在SPA时代,这已经不合适了,所以浏览器端形成了自己的MVC等层次,这里的V已经变成客户端渲染了,通常会使用一些客户端的HTML模版去实现,而模型和控制器,也相应地在浏览器端形成了。
我们有很多这个层面的框架,比如Backbone,Knockout,Avalon,Angular等,采用了不同的设计**,有的是MVC,有的是MVP,有的是MVVM,各有其特点。
以Angular为例,它推荐使用双向绑定去实现视图和模型的关联,这么一来,如果不同视图绑定在同一模型上,就解决了刚才所说的问题。而模型本身也通过某种机制,跟其他的逻辑模块进行协作。
这种方式就是依赖注入。依赖注入的核心理念就是通过配置来实例化所依赖的组件。使用这种模式来设计软件架构,会牺牲一些性能,在跟踪调试的便利性等方面也会有所损失,但换来的是无与伦比的松耦合和可替代性。
比如说,这些组件就可以单独测试,然后在用的时候随手引入,毫无压力。对于从事某一领域的企业来说,光这一条就足以吸引他在上面大量投入,把所有不常变动领域模型的业务代码都用此类办法维护起来,这是一种财富。
#5. MV*框架的基本原理
如果我们来设计Angular这么一个前端框架,应当如何入手呢?很显然,逻辑的控制必须使用JavaScript,一个框架,最本质的事情在于它的逻辑处理方式。
我们的界面为什么可以多姿多彩?因为有HTML和CSS,注意到这两种东西都是配置式的写法,参照后端的依赖注入,如果把这两者视为跟Spring框架中一些XML等同的配置文件,思路就豁然开朗了。
与后端不同的是,充当前端逻辑工具的JavaScript不能做入口,必须挂在HTML里才能运行,所以出现了一个怪异的状况:逻辑要先挂在配置文件(HTML)上,先由另外的容器(浏览器或者Hybird的壳)把配置文件加载起来,然后才能从某个入口开始执行逻辑。好消息是,过了这一步,逻辑层就开始大放异彩了。
从这个时候开始,框架就启动了,它要做哪些事情呢?
这些是主线流程,还有一些支线,比如:
SPA的一个典型特征就是部分加载,界面的部件化也是其中比较重要的一环。界面片段在动态请求得到之后,借助模版引擎之类的技术,经过某种转换,放置到主界面相应的地方。所以,从这个角度来看,HTML的组件化非常容易理解,那就是界面的片段化和模板化。
JavaScript这个部分有好几个发展阶段。
JavaScript组件化的目标是什么呢,是清晰的职责,松耦合,便于单元测试和重复利用。这里的松耦合不仅体现在js代码之间,也体现在js跟DOM之间的关系,所以像Angular这样的框架会有directive的概念,把DOM操作限制到这类代码中,其他任何js代码不操作DOM。
如上图所示,总的原则是先分层次,层内再作切分。这么做的话,不再存在之前那种端到端组件了,使用起来没有原先那么方便,但在另外很多方面比较好。
这方面,业界也有很多探索,比如LESS,SASS,Stylus等。为什么CSS也要做组件化呢?传统的CSS是一种扁平的文本结构,变更成本较高,比如说想要把结构从松散改紧凑,需要改动很多。如果把实际使用的CSS只当作输出结果,而另外有一种适合变更的方式当作中间过程,这就好多了。比如说,我们把一些东西定义成变量,每个细节元素使用这些变量,当需要整体变更的时候,只需修改这些变量然后重新生成一下就可以了。
以上,我们讨论了大致的Web前端开发的组件化思路,后续将阐述组件化之后的协作过程和管控机制。
Angular团队近期公布了他们对2.0版本的一些考虑,很详尽,很诚恳,我读了好几遍,觉得有必要写点东西。
对于一个运行在浏览器中的JavaScript框架而言,最喜欢什么,最害怕什么?是标准的变动。那么,放眼最新的这些标准,有哪些因素会对框架产生影响呢?
这几点,我是按照影响程度从大到小排列的。下面逐条来说:
早期的JavaScript在模块定义方面基本没有约束,但作为框架来说,不按照某种约定的方式去写代码,就会导致一盘散沙,所以各家都自己搞一套,大部分还是各不兼容的,这是历史原因造成的,不能怪罪这些框架。最近几年,为了解决这些问题,人们又发明了AMD,CMD,以及各种配套库和工程库。好不容易有些框架向它们靠拢了,可是module又来了。
这真是没完。我知道很多人是对module有意见的,我自己也觉得有些别扭,但我坚信一个道理:有一个可用但是稍微别扭的标准,比没有标准要好得多。所以,不管怎样,既然他来了,就得想办法往上靠。不靠拢标准的后果是什么?非常严重,因为现在的Web是加速发展的,浏览器只要过了一个升级瓶颈,后面的发展快得出奇。不要看现在还有这么多老旧浏览器,很可能你睡一觉起来突然发现已经基本没人用了,到那时候,不紧跟标准的框架就很惨了,瞬间就边缘化了。
我们来看看Angular原先的module设计,如果是在五年前,它刚起步的时候看,可能觉得还可以,现在再看,问题就比较多了。Angular现有版本的module,其实跟我们在ES中看到的module不是一个概念,更像C#里面的namespace,它的各种controller,service,factory才是真的模块。
我认为现有版本的这块,有几个不好的地方:
所以,Angular 2.0中,把这一块彻底改变了,使用ES6的module来定义模块,也考虑了动态加载的需求。变动很大,很多人有意见,但我是支持他们的。这件事不得不做,即使现在不做,将来也还是要做。毛主席教导我们:革命不彻底,劳动人民就要吃两茬苦,受两茬罪。在现在这个时代,如果还继续用非标准的模块API,基本等于找死,所以它需要改变。
为什么Web Components也能带来这么大的影响呢,因为它同样会造成断代升级,也就是说,你非完全跟着它的路不可,没有选择。
Web Components标准本身同样是个见仁见智的话题,在本文中我不评价,它作为标准,既然来了,大家当然要往上靠。一个致力于大规模Web前端开发的现代框架,不考虑Web Components是完全不可想象的。那么,怎么去靠拢它呢?
Web Components提供了一种封装组件的方式,对外体现为自定义标签,对内体现为Shadow DOM,可以定义自己的属性、事件等,这样问题就来了。
我们看当前版本的Angular,能看到ng-click之类的扩展元素属性,那么,他为什么要写成ng-click?是因为这是对原生click的一层封装和转换,同理,如果我的原始事件不是click,是另外一个名字,你当然也得跟着加一个,不然针对这种东西的操作就玩不下去。所以说,其实它是给每个有价值的原生事件都写了扩展。
这就有问题了,你能这么做的原因是,你预先知道有这么一些元素,这么一些事件,也知道这些元素上的这些事件是什么行为,如果全是自定义的,他不告诉你,你急死也不知道,怎么办?所以这一块必须重新设计。
同理,属性也是这样,之前像img的src,就有一个ng-src,如果没这个,你设置在上面的表达式就会被当成真的url,先去加载一次,显然是不对的。所以,设置在ng-src上,它等表达式解析出结果了,再把结果设置到src去。如果是用Web Components扩展的自定义组件,它不知道你有哪些属性,就搞不下去了。
所以,Angular 2.0团队在这一块还很纠结,需要很多探索,很多权衡才能找到一种能接受的方式。
后来在这一块,我跟@RubyLouvre 探讨了一下,他的观点是不要让数据绑定接触到Web Components,也就是说,不让扫描进入“暗世界”,我想了想,觉得也有道理,只是这样Web Components跟原生元素就要区别对待了。
或者对所有Web Components使用同一个壳子再次封装?感觉还是很怪。
当前版本的Angular使用脏检测的方式来实现数据的关联更新,这种机制有一定优点,但缺点也非常明显。
在其他语言中要监控数据的变更,很多在语言层面上有get和set,一般都是从这个角度入手,有不少JavaScript框架也是从这个方面做下去的,Angular不是。
Angular的脏检测很有特色,它采用的是新旧值比对的方式,也就是说,对每个可变动的模型,保存上一次的值,然后通过手动,或者是封装事件调用检测,一遍又一遍地刷新模型,直到稳定,或者超出容忍限度。
为什么这里面会有不稳定现象呢?我举个简单的例子,这是伪代码,仅供演示:
function Entity() {
//初始化
this.a = 1;
this.b = 1;
this.c = 1;
//监控语句,伪代码
this.b = this.a + 1;
this.c = this.b + 1;
}这里面几条语句不是真的赋值,是用来表示:每当a变化了,b就跟着变,然后c也跟着变,那我们在这里就要创建两个监控,一个是对a的监控,在里面给b赋值,一个是对b的监控,在里面给c赋值。
好了,比如有人给a赋了个新值,我们一个脏检测循环下来,b增加了1,c也跟着增加了,好像没什么问题。那我们怎么知道整个模型稳定了呢?很简单也很无奈,再运行脏检测一次,这次a没变,所以另外两个也不变了,跟上一次检测之后的结果一样,所以就认为它稳定了。
这里我们看到,不管你怎样,只要变过数据,至少要跑两次脏检测。为什么说至少呢,因为我们这种情况刚好把坑给绕过了,来改下代码:
function Entity() {
//初始化
this.a = 1;
this.b = 1;
this.c = 1;
//监控语句,伪代码
this.c = this.b + 1;
this.b = this.a + 1;
}没改什么,只是把两条监控语句互换了,这个结果就不对了。为什么呢,比如a赋值为1之后,第一遍结果是这样的:
这里讨厌的是c的监控语句先执行了,但b还没有变,可是我们当时是不知道的。然后,我们想看看模型稳定了没有,就再检测一次。所谓的检测,其实是两个步骤:把所有监控语句跑一遍,对比本次结果与上次的差异。
那么,这次变成了:
第二轮结束。模型稳定了吗?其实已经稳定了,但是代码是不知道的,它判断稳定的依据是,本次结果与上次相同,可事实是不同的,所以它还得继续跑。
第三次跑完,终于跟第二次结果一样了,于是他认为模型稳定了,开始把真正的值拿出去用了。
所以这个过程的效率在很多种情况下偏低,但好在他这个变更不是实时的,而是通过某些东西批量触发,所以也还凑合。另外有些框架,是每次对数据赋值了就去立刻更新关联值,这当数据结构比较复杂的时候,这样比较高效。
Object.observe与之相比,在定义监控的时候比较直观一些,而且,基于set get的绑定框架,有些会在原始数据的原型上定义一些“私有”方法,相比来说,observe这种方式从数据的外部视角来处理变更,更合理一些。
Angular 2.0的数据绑定机制应该会使用observe重写,可以期待这个方面有较大的提升。
但不管什么绑定方式,都是有坑的。我知道读者中有不少坏人,你们看到这里肯定想到很多坏主意了,比如刚才的脏检测,有没有办法把这个过程搞死?很容易,我帮你写个简单的:
function Entity() {
//初始化
this.a = 1;
this.b = 1;
//监控语句,伪代码
this.a = this.b + 1;
this.b = this.a + 1;
}这个代码死循环了,形成了监控闭环。所以,在Angular里面发现循环到一定量的时候,就会觉得它停不下来,终止这个循环。在其他技术实现的绑定框架中,同样要解决此类问题,所以监控到变更的时候,也不是直接拿去应用。
很奇怪啊,我一直喜欢promise这种编写异步代码的方式。可能我对它的喜好来自一些背景,比如说,做可视化组件编程。这个可视化的意思是指通过拖拽配置,配置逻辑流程(注意,不是拖UI)。
比如说,流程细到方法的粒度,每个步骤映射到一个方法,然后拖拽这些步骤,配置出执行流程。这里面有个麻烦就是异步,比如说,某个方法异步了,那就麻烦了,因为在一个纯拖动的配置系统中,如果你还要让他手工调整什么东西甚至改代码的话,这个事情基本就白做了。
所以你看,promise在这里优势很大。每一个有异步倾向的方法,我都让它返回promise,甚至为了一致性,不异步的方法也这么干,每个方法的入参出参都是map,让promise带着,是不是就很好了?
以上是我个人见解,可忽略,谢谢。
那么,在Angular 2.0中promise有什么影响呢?
回顾Angular 1.x版本,在其中已经可以看到很多promise的身影,只是那时候用了$q,一个小型的promise实现。在2.0中,promise的使用将更加广泛,因为更多的东西是异步的了,比如新的路由系统。
promise本身是很容易被降级的,在原生不支持它的浏览器中也很容易搞出一个polyfill来。
这个事情在我个人看来是很喜闻乐见的。
Angular 2.0除了作出符合标准的改进,还有一些提升的方面:
Angular大量使用了依赖注入。在JavaScript里面怎样做依赖注入呢?比如这段代码:
function foo(moduleA, moduleB) {
moduleA.aaa(moduleB);
}a跟b这两个模块都要注入进来。对于依赖注入系统而言,首先要知道注入什么,比如这里,至少要先知道a和b是什么,怎么知道呢?很多框架都用一种方式,就是先把foo这个待注入函数toString,这就取得了函数定义的文本,然后使用正则表达式提取参数名。
这个办法可行,但不可靠,它害怕压缩。随便什么压缩工具,肯定认为形参名是没用的,随手就改成a或者b了,这样你连正确的模块名都找不到了。那怎么办呢,只能老土一些:
foo.$inject = ["moduleA", "moduleB"];这样总可以了吧?
这样写起来还是有些折腾,而且运行时的数据也不够完全,所以Angular 2.0很激进地引入了一种类似TypeScript的语言叫AtScript,支持类型和注解,比如它的这个例子:
import {Component} from 'angular';
import {Server} from './server';
@Component({selector: 'foo'})
export class MyComponent {
constructor(server:Server) {
this.server = server;
}
}一些配置信息就可以搞在注解里,类型信息也就丰富了,然后这代码编译成ES6或者5,多么美好。更美好的是,2.0借助这种语言,可能把原来的指令、控制器之类的东西统一成组件,使用普通ES6 class加注解的方式来编写它们的代码,消除原来那么多复杂冗余的概念。
其实还有很多改进点,比如路由等等,没法一一列出了,感兴趣的可以查阅Angular 2.0已经流出的文档,或者查阅它的github库。
Angular 2.0这次的规划真是脱胎换骨,看了介绍文档,简直太喜欢了,之前我考虑过的所有问题都得到了解决。这一次版本跟之前有太大变化,从旧版本迁移可能是个难题,不过相对它所带来的改进,这代价还是值得的。勇于革自己的命,总比被别人革命好,期待Angular的浴火重生!
在业务开发的过程中,我们可能会大量使用DOM操作,这个过程很繁琐,但是有了AngularJS,基本上就可以解脱了,做到这一点的关键是数据绑定。那什么是数据绑定,怎样绑定呢?本节将从多种角度,选取业务开发过程中的各种场景来举例说明。
有时候,我们会有这样的需求,界面上有个输入框,然后有另外一个地方,要把这个文本原样显示出来,如果没有数据绑定,这个代码可能很麻烦了,比如说,我们要监听输入框的各种事件,键盘按键、复制粘贴等等,然后再把取得的值写入对应位置。但是如果有数据绑定,这个事情就非常简单。
<input type="text" ng-model="a"/>
<div>{{a}}</div>这么小小一段代码,就实现了我们想要的功能,是不是很可爱?这中间的关键是什么呢,就是变量a,在这里,变量a充当了数据模型的角色,输入框的数据变更会同步到模型上,然后再分发给绑定到这个模型的其他UI元素。
注意,任意绑定到数据模型的输入元素,它的数据变更都会导致模型变更,比如说,我们有另外一个需求,两个输入框,我们想要在任意一个中输入的时候,另外一个的值始终跟它保持同步。如果用传统的方式,需要在两个输入框上都添加事件,但是有了数据绑定之后,这一切都很简单:
<input type="text" ng-model="b"/>
<input type="text" ng-model="b"/>这样的代码就可以了,核心要素还是这个数据模型b。
到目前为止的两个例子都很简单,但可能有人有问题要问,因为我们什么js都没有写,这个a跟b是哪里来的,为什么就能起作用呢?对于这个问题,我来作个类比。
比如大家写js,都知道变量可以不声明就使用:
a = 1;这时候a被赋值到哪里了呢,到了全局的window对象上,也就是说其实相当于:
window.a = 1;在AngularJS里,变量和表达式都附着在一种叫做作用域(scope)的东西上,可以自己声明新的作用域,也可以不声明。每个Angular应用默认会有一个根作用域($rootScope),凡是没有预先声明的东西,都会被创建到它上面去。
作用域的相关概念,我们会在下一章里面讲述。在这里,我们只需要知道,如果在界面中绑定了未定义的某变量,当它被赋值的时候,就会自动创建到对应的作用域上去。
前面我们在例子中提到的{{}}这种符号,称为插值表达式,这里面的内容将会被动态解析,也可以不使用这种方式来进行绑定,Angular另有一个ng-bind指令用于做这种事情:
<input ng-model="a"/>
<div>{{a}}</div>
<div ng-bind="a"></div>嗯,有时候,实际情况没有这么简单,比如说,我们可能会需要对数据作一点处理,比如,在每个表示价格的数字后面添加一个单位:
<input type="number" ng-model="price"/>
<span>{{price + "(元)"}}</span>当然我们这个例子并不好,因为,其实你可以把无关的数据都放在绑定表达式的外面,就像这样:
<input type="number" ng-model="price"/>
<span>{{price}}(元)</span>那么,考虑个稍微复杂一些的。我们经常会遇到,在界面上展示性别,但是数据库里面存的是0或者1,那么,总要对它作个转换。有些比较老土的做法是这样,在模型上添加额外的字段给显示用:
这是原始数据:
var tom = {
name: "Tom",
gender: 1
};被他转换之后,成了这样:
var tom = {
name: "Tom",
gender: 1,
genderText: "男"
};转换函数内容如下:
if (person.gender == 0)
person.genderText = "女";
if (person.gender == 1)
person.genderText = "男";这样的做法虽然能够达到效果,但破坏了模型的结构,我们可以做些改变:
<div>{{formatGender(tom.gender)}}</div>$scope.formatGender = function(gender) {
if (gender == 0)
return "女";
if (gender == 1)
return "男";
}
};这样我们就达到了目的。这个例子让我们发现,原来,在绑定表达式里面,是可以使用函数的。像我们这里的格式化函数,其实作用只存在于视图层,所以不会影响到真实数据模型。
注意:这里有两个注意点。
第一,在绑定表达式里面,只能使用自定义函数,不能使用原生函数。举个例子:
<div>{{Math.abs(-1)}}</div>这句就是有问题的,因为Angular的插值表达式机制决定了它不能使用这样的函数,它是直接用自己的解释器去解析这个字符串的,如果确实需要调用原生函数,可以用一个自定义函数作包装,在自定义函数里面可以随意使用各种原生对象,就像这样:
<div>{{abs(-1)}}</div>$scope.abs = function(number) {
return Math.abs(number);
};第二,刚才我们这个例子只是为了说明可以这么用,但不表示这是最佳方案。Angular为这类需求提供了一种叫做filter的方案,可以在插值表达式中使用管道操作符来格式化数据,这个我们后面再细看。
有时候,我们的数据并不总是这么简单,比如说,有可能会需要把一个数组的数据展示出来,这种情况下可以使用Angular的ng-repeat指令来处理,这个东西相当于一个循环,比如我们来看这段例子:
$scope.arr1 = [1, 2, 3];
$scope.add = function() {
$scope.arr1.push($scope.arr1.length + 1);
};<button ng-click="add()">Add Item</button>
<ul>
<li ng-repeat="item in arr1">{{item}}</li>
</ul>这样就可以把数组的内容展示到界面上了。数组中的数据产生变化时,也能够实时更新到界面上来。
有时候,我们会遇到数组里有重复元素的情况,这时候,ng-repeat代码不能起作用,原因是Angular默认需要在数组中使用唯一索引,那假如我们的数据确实如此,怎么办呢?可以指定它使用序号作索引,就像这样:
$scope.arr2 = [1, 1, 3];<ul>
<li ng-repeat="item in arr2 track by $index">{{item}}</li>
</ul>也可以把多维数组用多层循环的方式迭代出来:
$scope.arr3 = [
[11, 12, 13],
[21, 22, 23],
[31, 32, 33]
];<ul>
<li ng-repeat="childArr in arr3 track by $index">
{{$index}}
<ul>
<li ng-repeat="item in childArr track by $index">{{item}}</li>
</ul>
</li>
</ul>如果是数组中的元素是对象结构,也不难,我们用个表格来展示这个数组:
$scope.arr4 = [{
name: "Tom",
age: 5
}, {
name: "Jerry",
age: 2
}];<table class="table table-bordered">
<thead>
<tr>
<th>Name</th>
<th>Age</th>
</tr>
</thead>
<tbody>
<tr ng-repeat="child in arr4">
<td>{{child.name}}</td>
<td>{{child.age}}</td>
</tr>
</tbody>
</table>有时候我们想遍历对象的属性,也可以使用ng-repeat指令:
$scope.obj = {
a: 1,
b: 2,
c: 3
};<ul>
<li ng-repeat="(key, value) in obj">{{key}}: {{value}}</li>
</ul>注意,在ng-repeat表达式里,我们使用了一个(key, value)来描述键值关系,如果只想要值,也可以不用这么写,直接按照数组的写法即可。对象值有重复的话,不用像数组那么麻烦需要指定$index做索引,因为它是对象的key做索引,这是不会重复的。
有时候,我们不是直接把数据绑定到界面上,而是先要赋值到其他变量上,或者针对数据的变更,作出一些逻辑的处理,这个时候就需要使用监控。
最基本的监控很简单:
$scope.a = 1;
$scope.$watch("a", function(newValue, oldValue) {
alert(oldValue + " -> " + newValue);
});
$scope.changeA = function() {
$scope.a++;
};对作用域上的变量添加监控之后,就可以在变更时得到通知了。如果说新赋值的变量跟原先的相同,这个监控就不会被执行。比如说刚才例子中,继续对a赋值为1,不会进入监控函数。
以上这种方式可以监控到最直接的赋值,包括各种基本类型,以及复杂类型的引用赋值,比如说下面这个数组被重新赋值了,就可以被监控到:
$scope.arr = [0];
$scope.$watch("arr", function(newValue) {
alert("change:" + newValue.join(","));
});
$scope.changeArr = function() {
$scope.arr = [7, 8];
};但这种监控方式只能处理引用相等的判断,对于一些更复杂的监控,需要更细致的处理。比如说,我们有可能需要监控一个数组,但并非监控它的整体赋值,而是监控其元素的变更:
$scope.$watch("arr", function(newValue) {
alert("deep:" + newValue.join(","));
}, true);
$scope.addItem = function() {
$scope.arr.push($scope.arr.length);
};注意,这里我们在$watch函数中,添加了第三个参数,这个参数用于指示对数据的深层监控,包括数组的子元素和对象的属性等等。
刚才我们提到的例子,都是跟数据同步、数据展示相关,但数据绑定的功能是很强大的,其应用场景取决于我们的想象力。
不知道大家有没有遇到过这样的场景,有一个数据列表,点中其中某条,这条就改变样式变成加亮,如果用传统的方式,可能要添加一些事件,然后在其中作一些处理,但使用数据绑定,能够大幅简化代码:
function ListCtrl($scope) {
$scope.items = [];
for (var i=0; i<10; i++) {
$scope.items.push({
title:i
});
}
$scope.selectedItem = $scope.items[0];
$scope.select = function(item) {
$scope.selectedItem = item;
};
}<ul class="list-group" ng-controller="ListCtrl">
<li ng-repeat="item in items" ng-class="{true:'list-group-item active', false: 'list-group-item'}[item==selectedItem]" ng-click="select(item)">
{{item.title}}
</li>
</ul>在本例中,我们使用了一个循环来迭代数组中的元素,并且使用一个变量selectedItem用于标识选中项,然后关键点在于这个ng-class的表达式,它能够根据当前项是否为选中项,作出一个判断,生成对应的样式名。这是绑定的一个典型应用了,基于它,能把一些之前需要依赖于某些控件的功能用特别简单的方式做出来。
除了使用ng-class,还可以使用ng-style来对样式作更细致的控制,比如:
<input type="number" ng-model="x" ng-init="x=12"/>
<div ng-style="{'font-size': x+'pt'}">
测试字体大小
</div>有时候,我们除了控制普通的样式,还有可能要控制某个界面元素的显示隐藏。我们用ng-class或者ng-style当然都是可以控制元素的显示隐藏的,但Angular给我们提供了一种快捷方式,那就是ng-show和ng-hide,它们是相反的,其实只要一个就可以了,提供两个是为了写表达式的方便。
利用数据绑定,我们可以很容易实现原有的一些显示隐藏功能。比如说,当列表项有选中的时候,某些按钮出现,当什么都没选的时候,不出现这些按钮。
主要的代码部分还是借用上面那个列表,只添加一些相关的东西:
<button ng-show="selectedItem">有选中项的时候可以点我</button>
<button ng-hide="selectedItem">没有选中项的时候可以点我</button>把这个代码放在刚才的列表旁边,位于同一个controller下,点击列表元素,就能看到绑定状态了。
有时候,我们也想控制按钮的可点击状态,比如刚才的例子,那两个按钮直接显示隐藏,太突兀了,我们来把它们改成启用和禁用。
<button ng-disabled="!selectedItem">有选中项的时候可以点我</button>
<button ng-disabled="selectedItem">没有选中项的时候可以点我</button>同理,如果是输入框,可以用同样的方式,使用ng-readonly来控制其只读状态。
除了使用ng-show和ng-hide来控制元素的显示隐藏,还可以使用ng-if,但这个的含义与实现机制都大为不同。所谓的show和hide,意味着DOM元素已经存在,只是控制了是否显示,而if则起到了流程控制的作用,只有符合条件的DOM元素才会被创建,否则不创建。
比如下面的例子:
function IfCtrl($scope) {
$scope.condition = 1;
$scope.change = function() {
$scope.condition = 2;
};
}<div ng-controller="IfCtrl">
<ul>
<li ng-if="condition==1">if 1</li>
<li ng-if="condition==2">if 2</li>
<li ng-show="condition==1">show 1</li>
<li ng-show="condition==2">show 2</li>
</ul>
<button ng-click="change()">change</button>
</div>这个例子初始的时候,创建了三个li,其中一个被隐藏(show 2),当点击按钮,condition变成2,仍然是三个li,其中,if 1没有了,if 2创建出来了,show 1隐藏了,show 2显示了。
所以,我们现在看到的是,if的节点是动态创建的。与此类似,我们还可以使用ng-switch指令:
function SwitchCtrl($scope) {
$scope.condition = "";
$scope.a = function() {
$scope.condition = "A";
};
$scope.b = function() {
$scope.condition = "B";
};
$scope.c = function() {
$scope.condition = "C";
};
}<div ng-controller="SwitchCtrl">
<div ng-switch="condition">
<div ng-switch-when="A">A</div>
<div ng-switch-when="B">B</div>
<div ng-switch-default>default</div>
</div>
<button ng-click="a()">A</button>
<button ng-click="b()">B</button>
<button ng-click="c()">C</button>
</div>这个例子跟if基本上是一个意思,只是语法更自然些。
在做实际业务的过程中,很容易就碰到数据联动的场景,最典型的例子是省市县的三级联动。很多前端教程或者基础面试题以此为例,综合考察其中所运用到的知识点。
如果是用Angular做开发,很可能这个就不成其为一个考点了,因为实现起来非常容易。
我们刚才已经实现了一个单级列表,可以借用这段代码,做两个列表,第一个的数据变动,对第二个的数据产生过滤。
function RegionCtrl($scope) {
$scope.provinceArr = ["江苏", "云南"];
$scope.cityArr = [];
$scope.$watch("selectedProvince", function(province) {
// 真正有用的代码在这里,实际场景中这里可以是调用后端服务查询的关联数据
switch (province) {
case "江苏": {
$scope.cityArr = ["南京", "苏州"];
break;
}
case "云南": {
$scope.cityArr = ["昆明", "丽江"];
break;
}
}
});
$scope.selectProvince = function(province) {
$scope.selectedProvince = province;
};
$scope.selectCity = function(city) {
$scope.selectedCity = city;
};
}<div ng-controller="RegionCtrl">
<ul class="list-group">
<li ng-repeat="province in provinceArr" ng-class="{true:'list-group-item active', false: 'list-group-item'}[province==selectedProvince]" ng-click="selectProvince(province)">
{{province}}
</li>
</ul>
<ul class="list-group">
<li ng-repeat="city in cityArr" ng-class="{true:'list-group-item active', false: 'list-group-item'}[city==selectedCity]" ng-click="selectCity(city)">
{{city}}
</li>
</ul>
</div>这段代码看起来比刚才复杂一些,其实有价值的代码就那个$watch里面的东西。这是什么意思呢?意思是,监控selectedProvince这个变量,只要它改变了,就去查询它可能造成的更新数据,然后剩下的事情就不用我们管了。
如果是绑定到下拉框上,代码更简单,因为AngularJS专门作了这种考虑,ng-options就是这样的设置:
<select class="form-control col-md-6" ng-model="selectedProvince" ng-options="province for province in provinceArr"></select>
<select class="form-control col-md-6" ng-model="selectedCity" ng-options="city for city in cityArr"></select>从这个例子我们看到,相比于传统前端开发方式那种手动监听事件,手动更新DOM的方式,使用数据绑定做数据联动简直太容易了。如果要把这个例子改造成三级联动,只需对selectedCity也做一个监控就行了。
了解了这些细节之后,我们可以把它们结合起来做一个比较实际的综合例子。假设我们在为一家小店创建雇员的管理界面,其中包含一个雇员表格,以及一个可用于添加或编辑雇员的表单。
雇员包含如下字段:姓名,年龄,性别,出生地,民族。其中,姓名通过输入框输入字符串,年龄通过输入框输入整数,性别通过点选单选按钮来选择,出生地用两个下拉框选择省份和城市,民族可以选择汉族和少数民族,如果选择了少数民族,可以手动输入民族名称。
这个例子恰好能把我们刚才讲的绑定全部用到。我们先来看看有哪些绑定关系:
如果想做得精细,还有更多可以使用绑定的地方,不过上面这些已经足够我们把所有知识用一遍了。
这个例子的代码就不贴了,可以自行查看。
现在我们学会了数据绑定,可以借助这种特性,完成一些很别致的功能。比如说,如果想在页面上用div模拟一个正弦波,只需要把波形数据生成出来,然后一个绑定就可以完成了。
$scope.staticItems = [];
for (var i=0; i<720; i++) {
$scope.staticItems.push(Math.ceil(100 * (1 + Math.sin(i * Math.PI / 180))));
}如果我们想让这个波形动起来,也很容易,只需要结合一个定时器,动态生成这个波形数据就可以了。为了形成滚动效果,当波形采点数目超过某个值的时候,可以把最初的点逐个拿掉,保持总的数组长度。
$scope.dynamicItems = [];
var counter = 0;
function addItem() {
var newItem = Math.ceil(100 * (1 + Math.sin((counter++) * Math.PI / 180)));
if ($scope.dynamicItems.length > 500) {
$scope.dynamicItems.splice(0, 1);
}
$scope.dynamicItems.push(newItem);
$timeout(function () {
addItem();
}, 10);
}
addItem();这个例子对应的HTML代码如下:
<div ng-controller="WaveCtrl">
<style>
.wave-item {
float: left;
width: 1px;
background-color: #ffab51;
}
</style>
<div>
<div ng-repeat="item in staticItems track by $index" class="wave-item" ng-style="{'height': item+'px'}"></div>
</div>
<div style="clear: left">
<div ng-repeat="item in dynamicItems track by $index" class="wave-item" ng-style="{'height': item+'px'}"></div>
</div>
</div>有时候我们经常看到一些算法可视化的项目,比如把排序算法用可视化的方式展现出来,如果使用AngularJS的数据绑定,实现这种效果可谓易如反掌:
<div ng-controller="SortCtrl">
<style>
.data-item {
float: left;
width: 20px;
background-color: #c0c0c0;
border: 1px solid #080808;
}
</style>
<button ng-click="sort()">Sort</button>
<div>
<div ng-repeat="item in arr track by $index" class="data-item" ng-style="{'height': item*5+'px'}"></div>
</div>
</div>$scope.arr = [2, 4, 5, 63, 4, 5, 55, 2, 4, 43];
$scope.sort = function () {
if (!sort($scope.arr)) {
$timeout(function() {
$scope.sort();
}, 500);
}
};
function sort(array) {
// 喵的,写到这个才发现yield是多么好啊
for (var i = 0; i < array.length; i++) {
for (var j = array.length; j > 0; j--) {
if (array[j] < array[j - 1]) {
var temp = array[j - 1];
array[j - 1] = array[j];
array[j] = temp;
return false;
}
}
}
return true;
}看,就这么简单,一个冒泡排序算法的可视化过程就写好啦。
甚至,AngularJS还允许我们在SVG中使用数据绑定,使用它,做一些小游戏也是很容易的,比如我写了个双人对战的象棋,这里有演示地址,可以查看源码,是不是很简单?
刚才我们已经看到数据绑定的各种使用场景了,这个东西带给我们的最大好处是什么呢?我们回顾一下之前写Web界面,有一部分时间在写HTML和CSS,一部分时间在写纯逻辑的JavaScript,还有很多时间在把这两者结合起来,比如各种创建或选取DOM,设置属性,添加等等,这些事情都是很机械而繁琐的,数据绑定把这个过程简化了,代码也跟着清晰了。
数据绑定是一种思维方式,一切的核心就是数据。数据的变更导致界面的更新,如果我们想要更新界面,只需改变数据即可。
佛曰:命由己造,相由心生,世间万物皆是化相,心不动,万物皆不动,心不变,万物皆不变。
佛曰:种如是因,收如是果,一切唯心造。
本章所涉及的所有Demo,参见在线演示地址
演讲幻灯片下载:点这里
让我们先来看几个网站:
注意这几个网站的相同点,那就是在浏览器中,做了原先“应当”在客户端做的事情。它们的界面切换非常流畅,响应很迅速,跟传统的网页明显不一样,它们是什么呢?这就是单页Web应用。
所谓单页应用,指的是在一个页面上集成多种功能,甚至整个系统就只有一个页面,所有的业务功能都是它的子模块,通过特定的方式挂接到主界面上。它是AJAX技术的进一步升华,把AJAX的无刷新机制发挥到极致,因此能造就与桌面程序媲美的流畅用户体验。
其实单页应用我们并不陌生,很多人写过ExtJS的项目,用它实现的系统,很天然的就已经是单页的了,也有人用jQuery或者其他框架实现过类似的东西。用各种JS框架,甚至不用框架,都是可以实现单页应用的,它只是一种理念。有些框架适用于开发这种系统,如果使用它们,可以得到很多便利。
ExtJS可以称为第一代单页应用框架的典型,它封装了各种UI组件,用户主要使用JavaScript来完成整个前端部分,甚至包括布局。随着功能逐渐增加,ExtJS的体积也逐渐增大,即使用于内部系统的开发,有时候也显得笨重了,更不用说开发以上这类运行在互联网上的系统。
jQuery由于偏重DOM操作,它的插件体系又比较松散,所以比ExtJS这个体系更适合开发在公网运行的单页系统,整个解决方案会相对比较轻量、灵活。
但由于jQuery主要面向上层操作,它对代码的组织是缺乏约束的。如何在代码急剧膨胀的情况下控制每个模块的内聚性,并且适当在模块之间产生数据传递与共享,就成为了一种有挑战的事情。
为了解决单页应用规模增大时候的代码逻辑问题,出现了不少MV*框架,他们的基本思路都是在JS层创建模块分层和通信机制。有的是MVC,有的是MVP,有的是MVVM,而且,它们几乎都在这些模式上产生了变异,以适应前端开发的特点。
这类框架包括Backbone,Knockout,AngularJS,Avalon等。
这些在前端做分层的框架推动了代码的组件化,所谓组件化,在传统的Web产品中,更多的指UI组件,但其实组件是一个广泛概念,传统Web产品中UI组件占比高的原因是它的厚度不足,随着客户端代码比例的增加,相当一部分的业务逻辑也前端化,由此催生了很多非界面型组件的出现。
分层带来的一个优势是,每层的职责更专一了,由此,可以对其作单元测试的覆盖,以保证其质量。传统UI层测试最头疼的问题是UI层和逻辑混杂在一起,比如往往会在远程请求的回调中更改DOM,当引入分层之后,这些东西都可以分别被测试,然后再通过场景测试来保证整体流程。
与开发传统页面型网站相比,实现单页应用的过程中,有一些比较值得特别关注的点。
从单页应用的特点来看,它比页面型网站更加依赖于JavaScript,而由于页面的单页化,各种子功能的JavaScript代码聚集到了同一个作用域,所以代码的隔离、模块化变得很重要。
在单页应用中,页面模板的使用是很普遍的。很多框架内置了特定的模板,也有的框架需要引入第三方的模板。这种模板是界面片段,我们可以把它们类比成JavaScript模块,它们是另一种类型的组件。
模板也一样有隔离的需要。不隔离模板,会造成什么问题呢?模板间的冲突主要存在于id属性上,如果一个模板中包含固定的id,当它被批量渲染的时候,会造成同一个页面的作用域中出现多个相同id的元素,产生不可预测的后果。因此,我们需要在模板中避免使用id,如果有对DOM的访问需求,应当通过其他选择器来完成。如果一个单页应用的组件化程度非常高,很可能整个应用中都没有元素id的使用。
人们对于单页系统的加载时间容忍度与Web页面不同,如果说他们愿意为购物页面的加载等待3秒,有可能会愿意为单页应用的首次加载等待5-10秒,但在此之后,各种功能的使用应当都比较流畅,所有子功能页面尽量要在1-2秒时间内切换成功,否则他们就会感觉这个系统很慢。
从这些特点来看,我们可以把更多的公共功能放到首次加载,以减小每次加载的载入量,有一些站点甚至把所有的界面和逻辑全部放到首页加载,每次业务界面切换的时候,只产生数据请求,因此它的响应是非常迅速的,比如青云的控制台就是这么做的。
通常在单页应用中,无需像网站型产品一样,为了防止文件加载阻塞渲染,把js放到html后面加载,因为它的界面基本都是动态生成的。
当切换功能的时候,除了产生数据请求,还需要渲染界面,这个新渲染的界面部件一般是界面模板,它从哪里来呢?来源无非是两种,一种是即时请求,像请求数据那样通过AJAX获取过来,另一种是内置于主界面的某些位置,比如script标签或者不可见的textarea中,后者在切换功能的时候速度有优势,但是加重了主页面的负担。
在传统的页面型网站中,页面之间是互相隔离的,因此,如果在页面间存在可复用的代码,一般是提取成单独的文件,并且可能会需要按照每个页面的需求去进行合并。单页应用中,如果总的代码量不大,可以整体打包一次在首页载入,如果大到一定规模,再作运行时加载,加载的粒度可以搞得比较大,不同的块之间没有重复部分。
我们最开始看到的几个在线应用,有的是对路由作了管理的,有的没有。
管理路由的目的是什么呢?是为了能减少用户的导航成本。比如说我们有一个功能,经历过多次导航菜单的点击,才呈现出来。如果用户想要把这个功能地址分享给别人,他怎么才能做到呢?
传统的页面型产品是不存在这个问题的,因为它就是以页面为单位的,也有的时候,服务端路由处理了这一切。但是在单页应用中,这成为了问题,因为我们只有一个页面,界面上的各种功能区块是动态生成的。所以我们要通过对路由的管理,来实现这样的功能。
具体的做法就是把产品功能划分为若干状态,每个状态映射到相应的路由,然后通过pushState这样的机制,动态解析路由,使之与功能界面匹配。
有了路由之后,我们的单页面产品就可以前进后退,就像是在不同页面之间一样。
其实在Web产品之外,早就有了管理路由的技术方案,Adobe Flex中,就会把比如TabNavigator,甚至下拉框的选中状态对应到url上,因为它也是单“页面”的产品模式,需要面对同样的问题。
当产品状态复杂到一定程度的时候,路由又变得很难应用了,因为状态的管理极其麻烦,比如开始的时候我们演示的c9.io在线IDE,它就没法把状态对应到url上。
在单页应用的运作机制中,缓存是一个很重要的环节。
由于这类系统的前端部分几乎全是静态文件,所以它能够有机会利用浏览器的缓存机制,而比如动态加载的界面模板,也完全可以做一些自定义的缓存机制,在非首次的请求中直接取缓存的版本,以加快加载速度。
甚至,也出现了一些方案,在动态加载JavaScript代码的同时,把它们也缓存起来。比如Addy Osmani的这个basket.js,就利用了HTML5 localStorage作了js和css文件的缓存。
在单页产品中,业务代码也常常会需要跟本地存储打交道,存储一些临时数据,可以使用localStorage或者localStorageDB来简化自己的业务代码。
传统的Web产品通常使用JSONP或者AJAX这样的方式与服务端通信,但在单页Web应用中,有很大一部分采用WebSocket这样的实时通讯方式。
WebSocket与传统基于HTTP的通信机制相比,有很大的优势。它可以让服务端很便利地使用反向推送,前端只响应确实产生业务数据的事件,减少一遍又一遍无意义的AJAX轮询。
由于WebSocket只在比较先进的浏览器上被支持,有一些库提供了在不同浏览器中的兼容方案,比如socket.io,它在不支持WebSocket的浏览器上会降级成使用AJAX或JSONP等方式,对业务代码完全透明、兼容。
传统的Web页面一般是不需要考虑内存的管理的,因为用户的停留时间相对少,即使出现内存泄漏,可能很快就被刷新页面之类的操作冲掉了,但单页应用是不同的,它的用户很可能会把它开一整天,因此,我们需要对其中的DOM操作、网络连接等部分格外小心。
在单页应用中,因为页面的集成度高,所有页面聚集到同一作用域,样式的规划也变得重要了。
样式规划主要是几个方面:
这里面主要包括浏览器样式的重设、全局字体的设置、布局的基本约定和响应式支持。
这里面是两个层面的规划,首先是各种界面组件及其子元素的样式,其次是一些修饰样式。组件样式应当尽量减少互相依赖,各组件的样式允许冗余。
传统Web页面的特点是元素多,但是层次少,单页应用会有些不同。
在单页应用中,需要提前为各种UI组件规划堆叠次序,也就是z-index,比如说,我们可能会有各种弹出对话框,浮动层,它们可能组合成各种堆叠状态。新的对话框的z-index需要比旧的高,才能确保盖在它上面。诸如此类,都需要我们对这些可能的遮盖作规划,那么,怎样去规划呢?
了解通信知识的人,应当会知道,不同的频率段被划分给不同的通信方式使用,在一些国家,领空的使用也是有划分的,我们也可以用同样的方式来预先分段,不同类型的组件的z-index落到各自的区间,以避免它们的冲突。
我们在开始的时候提到,存在着很多新型Web产品,使用单页应用的方式构建,但实际上,这类产品不仅仅存在于Web上。点开Chrome商店,我们会发现很多离线应用,这些产品都可以算是单页应用的体现。
除了各种浏览器插件,借助node-webkit这样的外壳平台,我们可以使用Web技术来构建本地应用,产品的主要部分仍然是我们熟悉的单页应用。
单页应用的流行程度正在逐渐增加,大家如果关注了一些初创型互联网企业,会发现其中很大一部分的产品模式是单页化的。这种模式能带给用户流畅的体验,在开发阶段,对JavaScript技能水平要求较高。
单页应用开发过程中,前后端是天然分离的,双方以API为分界。前端作为服务的消费者,后端作为服务的提供者。在此模式下,前端将会推动后端的服务化。当后端不再承担模板渲染、输出页面这样工作的情况下,它可以更专注于所提供的API的实现,而在这样的情况下,Web前端与各种移动终端的地位对等,也逐渐使得后端API不必再为每个端作差异化设计了。
在现在这个时代,我们已经可以看到一种产品的出现了,那就是“无后端”的Web应用。这是一种什么东西呢?基于这种理念,你的产品很可能只需要自己编写静态Web页面,在某种BaaS(Backend as a Service)云平台上定制服务端API和云存储,集成这个平台提供的SDK,通过AJAX等方式与之打交道,实现注册认证、社交、消息推送、实时通信、云存储等功能。
我们观察一下这种模式,会发现前后端的部署已经完全分离了,前端代码完全静态化,这意味着可以把它们放置到CDN上,访问将大大地加速,而服务端托管在BaaS云上,开发者也不必去关注一些部署方面的繁琐细节。
假设你是一名创业者,正在做的是一种实时协同的单页产品,可以在云平台上,快速定制后端服务,把绝大部分宝贵的时间花在开发产品本身上。
单页应用最根本的缺陷就是不利于SEO,因为界面的绝大部分都是动态生成的,所以搜索引擎很不容易索引它。
一个产品想要单页化,首先是它必须适合单页的形态。其次,在这个过程中,对开发模式会产生一些变更,对开发技能也会有一些要求。
开发者的JavaScript技能必须过关,同时需要对组件化、设计模式有所认识,他所面对的不再是一个简单的页面,而是一个运行在浏览器环境中的桌面软件。
从业以来,一直是在企业软件领域摸爬滚打,最开始接触的就是流程、表单引擎这些东西。行业应用领域对应用架构的诉求通常就是要充分支持扩展和可定制性,因为通常会把一个业务平台交付给几十甚至上百家需求各异的客户,基于成本考虑,必须在同一个基础版本上迭代出各客户的需求,如果做不到这块,交付给每家客户的版本毫无共性,或者共性过少,那就可能出很多问题。架构的不合理性会影响业务团队的组成方式,进而影响盈利水准。
后来,大概在 2012 年那段时间,参与尝试做了一次元数据驱动的定制抽象引擎,回头看,这次尝试有很多不如意的地方,主要还是经验不足,对很多事情的理解不够深刻。也正是这段经历促使我去探索一些事情的解决方案。可以说,目前在网络上看到的我的全部输出,都是在那之后产生的,都是为了解决其中可能的问题而进行的有目的的探索,而不是纯粹为了学习技术本身。
再后来,我又经历过小型 SaaS 团队,对于小企业付费订阅这个事情,也有了不少认识,这种一个小团队每年付费几千块的模式,对我是一种很好的知识补充,因为之前积累的都是面向单笔数百万到上亿合同额交付型软件的认知。
近年来,aPaaS 这样的概念逐渐火热,借此机会,正好把自己领悟的产品观简单总结一下。
小型工具 SaaS 的生存难度很高。我们可以看下这几年最火的两个小型 SaaS,从它火爆的结果里面寻找原因。
之所以这两家火,并不是仅仅它们的产品体验只是满足了表象上的“好”,其最大价值是,有希望成为小微企业的“业务中台”。
这两个产品,看上去跟什么中台一点关系都没有,为什么要说他们能成为一种业务中台?
本文将从某些角度阐述以 aPaaS 形态作为业务中台的价值,并尝试用上述两个产品为例,解答这个问题。
从企业数字化的角度看,数据治理是一件从开始就要干的事情。每当有新业务产生,需要新的数据或者业务系统接入的时候,需要及时做好数据的集成和归并工作。
假设初期你采购了某个任务管理系统的 SaaS,后期由于业务扩展,需要购入某种 CRM 或者 ERP 系统,那么,就会面临很多集成相关的问题:
此外,企业的数字化、精细化运作,必然需要引入某种 BI 或者数据分析体系,它的先决条件就是数据是语义化的、可被理解的,这对数据的形态也提出了比较高的要求。
所以说,不管多小的公司,都存在数据中台所面临的问题,而有能力对此进行规划的人员很稀缺,并且其成本也不是小微企业能够承受的。
随着这类企业的成长,这些问题累积到一定程度,将会对企业的运作带来很大负担。当一个企业的信息系统年久失修,其管理效率也必然是大受影响。
如果存在致力于解决这些问题的数据中台,让数据的采集、分析、组合过程变得更智能化,再对企业的 IT 部门进行相关的培训,可以使得前面提到的这些问题中的大部分得到及时解决。
另外一个角度,数据治理的根源是业务治理。如果想要使得企业运作过程中产生的数据成为宝藏,而不是垃圾堆,需要控制这些数据的产生过程,也就是对业务进行治理。
业务治理是一个难度很高的工作,因为业务的集成过程往往是比较复杂的,如果不存在很先进的管理手段,只是流于文档,则其维护代价也会非常之大。
举例来说,我们可以画一些架构图,来描述当前的业务系统集成关系,然后,细化进去,每个业务系统模块内部,又可以呈现出模块与结构等更细节的组成元素。
遗憾的是,传统意义上的这类架构,都是纸面架构,它与真实系统之间的对应关系是需要人工花费巨大精力去维持的,因为业务架构的存储形态就是静态化的,业务系统的技术实现与业务架构描述之间,是不存在任何自动同步环节的。
当业务专家调整了业务模型或规则,他需要标记出更改的部分,然后交由开发团队去实现出来。这种研发方式一直是业务软件开发的主流,最主要的原因是上手成本低,并且容易被流程化,灵活性也足够。
历史上曾经出现过一些潮流,比如让业务专家学习一些领域建模知识,借助 UML 这样的表达形式,去描述软件的各种结构:实体、关系、流程、交互。很遗憾,这种方式并没有那么普及,其原因是什么?
在这些表达方式流行的时段,IT 系统是一种很昂贵的东西,只有利润非常丰厚,或者面临很高管理成本的行业,才会去大力建设,比如我国早期信息化最好的行业就是银行和电信体系。只有较高的利润,才足以支撑技能很高的业务专家团队,而大部分行业是很难承担这样的代价的。业务的表达成本必须再次大幅降低,才能满足社会对数字化的需求。
所以,如果致力于提供在线化的业务 SaaS,需要采取很多手段,把业务的表达成本尽可能降低,并且能够用多种方式把业务尽可能准确地呈现给业务专家,使其有机会介入,及时调整不合理或者不适应业务发展状况的部分。
回顾业务软件研发领域,技术栈的变迁可谓非常频繁,各种终端设备蓬勃发展,操作系统、编程框架、编程语言层出不穷,然而从业务实现的角度,今天我们每编写一行代码,就立刻为明天增加了一份历史负担。
如同城市管理,老旧小区的维护是一种非常复杂的问题。在快速发展的趋势下,大拆大建式的手段是很普遍的,所以,在大型互联网企业中,信息系统的生命周期大部分只有一两年甚至更短,使命完成之后就被拆除了。
这种方式实际上是一种不计成本的策略,因为有很大的利润来支撑,但是这种情况无法适用于大部分行业。时至今日,IT 系统的建设费用仍然是比较高的,绝大部分公司都会在这块的投入上斤斤计较。
所以,每次采购新软件的时候,大家都期望它能尽可能支撑得久一些,像大型 ERP,企业都会倾向于用到十几年之后,尽可能让自己去迁就软件系统,直到实在无法跟上业务发展。同时,不是每个行业都有足够的高技能开发人员,一旦软件的初始技术栈确定,后续很可能因为人员技能或者迁移代价,就再也不会升级了。
这就形成了一种局面,一方面,时常重构和更新迭代的代价是很多行业无法承受的,另一方面,当一套软件再也跟不上这家公司的业务发展,如何迁移到一套新版系统,也会成为非常棘手的事情。当前,有无数企业面临这样的问题,数据和业务逻辑的迁移困扰着几乎每家企业。
立足于此,凡是致力于打造业务中台的的产品,都必须能够说清自己将要如何避免之前见到过的这些问题。因为这些问题如果不解决,只是历史的周期性循环而已,并且,当客户企业的业务复杂度达到某个数量级之后,就好比老旧小区的面积大到了一定程度,拆除重建成本已经高到无法接受,只能另起炉灶造新城了,这对一家企业的运作是非常致命的问题。
随着企业管理越来越建立在数字化的基础上,这类问题也许会成为阻碍企业成为百年老店的最重要因素之一。
因此,我们需要描述数据、描述业务,并且寻求某种能把业务实质和技术栈不要绑得这么紧密的实践方式,不妨畅想,在某种理想情况下,技术栈的升级并不十分影响业务的正常运作。这种抽象过程一定是很困难的,但是我们可以寻找在“完全重建”和“部分复用”之间的平衡,寻找“抽象成本”和“迁移代价”之间的平衡。
长期以来,基于 Web 的系统以易开发、易部署等特性,逐步成为了应用系统的主流技术栈。
然而,人们从不满足于现有研发流程的效率,总是尝试各种提升方式。
如何提高业务系统的开发效率?怎样的工具或者工程体系才能提效?我们先从效率的损失过程看起。
从整体性来说,一个 Web 系统,或者泛化为一般 GUI 系统,其典型架构都是这样:
M -> X -> V
这个 X,在不同架构模式下有不同含义,也有省略它的,但总的来说,M 表达与实际存储相关的模型层,V 表示展示层,模型驱动视图,是大家的共识。
通常,这个实践链路会跨越不同的部署结构,兼有多种开发语言,并且,在某个规模以上,不可避免地涉及一系列人员的协作。
人类的协作是效率降低的本源,因为人跟人的传输协议是不标准、不稳定、语义不清的,两个人沟通一天,也许就传递了不到 1K 的有效信息,所以,重构生产关系才是提高生产力的核心手段。
另外一个很重要的问题则是需求与实现的统一管理。我们之前提到,传统的研发体系中,需求的描述是偏纸面的,它跟代码天然就有断层。每当业务进化,会需要两种截然不同的版本管理方式。如果能够找到一种方式,让需求的描述与业务实现变得更加紧密,比如说,能够以某种可视化手段描述出某次需求迭代所产生的业务变更点,并且与需求的描述一一对应,有可能让这个环节的负担变轻。
以一般的 Web 系统需求变更为例,它涉及的协作环节可能有:
一般的团队中,这些角色往往都有一定程度的合并,比如说,DBA、运维的职能,合并给后端;在不太需要高体验的场景,去掉设计师,由前端来发挥;开发人员自测,等等。
再继续合并,就对个人能力要求很高了。前后端的合并,不仅仅是开发语言的统一就可以的,还需要从思维模式上去融合,现代软件开发技术的技术栈已经门槛稍高,不太适宜于这种全栈化了。
人员的全栈化是一种很难的方式,虽然大家总是说学习某种技术很容易,但是要成为熟练工,需要很多时间,而且人的精力有限,很难在多个领域同时跟进技术的发展过程,所以,需要尽量再屏蔽掉很多不相关的因素,把技术细节隔离出去给较小的专业团队去维护,形成一种协作机制,以期能够让更多的人参与进来。
这个角度,也就是现在被称为:“低代码”、“无代码”的 aPaaS 平台所试图解决的问题。
回顾人类历史,工业化的一个重要因素是物料的标准化。在制造业,广泛存在通过编号描述的元器件,并且会在装配过程中,使用物料清单(BOM)来明确描述制造一个成品所需的物料种类和数量。
但是我们注意到,在软件行业,研发人员创造业务软件的工作方式更像是裁缝,而不是电子设备的装配工,这说明大家都是以比较自由灵活的方式去开发软件的。这种方式当然有其优势,因为程序员是比较讨厌约束的,但是也带来了一些弊端:
通常,在研发过程中,团队内部总是会尝试做一些约束,比如规定代码的典型形态,或者引入某些模式,进行一定程度的封装,在遇到某类问题的时候,能够尽可能使用比较一致的方式去表达,但是这个过程仍然是比较宽泛的,我们很难用一种通用的检查工具去提取关键的业务信息,业务专家不得不细致地进行测试,也没有一些视角能够更详细了解这些系统生产过程中的状况,目前的管控设施都过于技术化了,缺少更业务视角的解读。
所以,如果期望能够在某些业务领域有所改进,就需要从一些很基本的方面做起,比如物料的标准化。
最容易被认识到的标准物料是基础的 UI 组件库,这个环节,只要不是做得特别差,一定能够提升效率,也比较容易认识到大致的实践路线,但是从基础组件库再往前走一步,大家对于路的看法就不同了。
必须意识到,如果以装配一体化为最终的实践道路的话,从最基础的业务无关的组件库再次封装出的组件库,基本都是非标准物料,物料的业务属性需要被抽象掉。
组件物料本质上是交互物料,某个领域的组件物料,需要从交互层面的可组合性去看待,否则就会让业务设计师的成果停留在纸面上。
除此之外,也存在很多逻辑层面的元件,比如针对某种数据源的封装、针对某种数据类型的通用校验规则、常见动作的配置化描述等等。
此类细节,不在本文中详细叙述。
从整体来看,整个应用系统其实可以用一个公式简单表达:
V = f(M)
这个公式是 MDV(模型驱动视图)的核心理念,那么,这里面的 f 是什么?
这个 f,在实践中,实质上是若干引擎的叠加:交互场景、流程、规则等等。
前面环节提到的物料标准化,是有助于隔离业务属性的,比如说,视图层级物料很大程度上跟业务的关联较小,并不属于业务的核心部分。
一个比较粗陋的业务隔离形态,可以化解为:
这样的一套东西,理想状态下,是技术栈无关的。
从比较容易理解的交互层面来举例:
他们的业务实质并无不同,只是引擎所启用的解释插件集有所差异而已,只要多种插件集的表达能力一致就可以了。甚至说,在面临多系统的集成的时候,被集成方的交互风格可以自动适配到集成方的。
同理,对存储、规则、流程等等方面,都是有机会去做这样的事情的。
需要注意的是,整个这套体系的抽象代价是非常高的,需要去从整体角度,结合业务场景作很多权衡。比如说,从极其简单轻量的场景切入,或者是侧重于某种具体业务领域去设计引擎插件的某种子集。
据此,可以把业务的表达形态从硬编码中抽象出来,并且对此作更定制化的管控。
传统软件研发过程中,版本管理是基于文本的,因为输出物是代码。但是,基于这类描述式的业务表达机制,不应该继续使用这样的版本管理方式。
因为现在的业务结构是可理解的,完全可以有一种更立体化的表达。
比如,因为某需求的变更,导致:
每一块东西,都拥有了语义性,可以被更加细致地呈现出差异。本质上,业务交付的版本还是一种基于树形结构的差异描述,只是其细节更加丰富了而已。
这样的版本管理方式,对于业务迭代是一种非常有价值的提升,可以让业务专家能够更容易验证需求,也便于大规模全量自动化测试的覆盖,业务的可验证性大大增强。
理想和现实之间,总是存在权衡的。我们有理由相信,当今的时代,一个面向企业领域的 SaaS,其底层一定需要某种定制化能力才足以支撑差异化需求,然而其定制化能力的边界在哪里,则需要结合自己的业务领域去作判断。
如果面向的是很轻量的需求,完全可以在 aPaaS 的基础上,以业务模板的形式提供各种预制产品能力,用户可以在此基础上根据自己的需求进行更个性化的定制。
这个时候回头看 Airtable 和 Notion,就可以发现很多有趣的地方。我之前曾经提过,这两个东西很可能是殊途同归,一体两面。
从产品角度,两者都可以有很好的延伸。如果 Airtable 能够把自己的视图结构描述化,它就天然拥有了 Notion 的编排能力。Notion 因为要支持基于记录的模块集成,必然也需要实现关系数据的结构化表达能力。
之后的文章中,会附带一个系列的技术文,侧重从实现的角度讲述一个比较简单的这类原型系统的构建过程。
很多人看到这个标题的时候,会产生一些怀疑:
什么是“数据层”?前端需要数据层吗?
可以说,绝大部分场景下,前端是不需要数据层的,如果业务场景出现了一些特殊的需求,尤其是为了无刷新,很可能会催生这方面的需要。
我们来看几个场景,再结合场景所产生的一些诉求,探讨可行的实现方式。
所谓共享,指的是:
同一份数据被多处视图使用,并且要保持一定程度的同步。
如果一个业务场景中,不存在视图之间的数据复用,可以考虑使用端到端组件。
什么是端到端组件呢?
我们看一个示例,在很多地方都会碰到选择城市、地区的组件。这个组件对外的接口其实很简单,就是选中的项。但这时候我们会有一个问题:
这个组件需要的省市区域数据,是由这个组件自己去查询,还是使用这个组件的业务去查好了传给这个组件?
两者当然是各有利弊的,前一种,它把查询逻辑封装在自己内部,对使用者更加有利,调用方只需这么写:
<RegionSelector selected=“callback(region)”></RegionSelector>
外部只需实现一个响应取值事件的东西就可以了,用起来非常简便。这样的一个组件,就被称为端到端组件,因为它独自打通了从视图到后端的整个通道。
这么看来,端到端组件非常美好,因为它对使用者太便利了,我们简直应当拥抱它,放弃其他所有。
端到端组件示意图:
A | B | C
---------
Server
可惜并非如此,选择哪种组件实现方式,是要看业务场景的。如果在一个高度集成的视图中,刚才这个组件同时出现了多次,就有些尴尬了。
尴尬的地方在哪里呢?首先是同样的查询请求被触发了多次,造成了冗余请求,因为这些组件互相不知道对方的存在,当然有几个就会查几份数据。这其实是个小事,但如果同时还存在修改这些数据的组件,就麻烦了。
比如说:在选择某个实体的时候,发现之前漏了配置,于是点击“立刻配置”,新增了一条,然后回来继续原流程。
例如,买东西填地址的时候,发现想要的地址不在列表中,于是点击弹出新增,在不打断原流程的情况下,插入了新数据,并且可以选择。
这个地方的麻烦之处在于:
组件A的多个实例都是纯查询的,查询的是ModelA这样的数据,而组件B对ModelA作修改,它当然可以把自己的那块界面更新到最新数据,但是这么多A的实例怎么办,它们里面都是老数据,谁来更新它们,怎么更新?
这个问题为什么很值得说呢,因为如果没有一个良好的数据层抽象,你要做这个事情,一个业务上的选择和会有两个技术上的选择:
这三者都有缺点:
所以,从这个角度看,我们需要一层东西,垫在整个组件层下方,这一层需要能够把查询和更新做好抽象,并且让视图组件使用起来尽可能简单。
另外,如果多个视图组件之间的数据存在时序关系,不提取出来整体作控制的话,也很难去维护这样的代码。
添加了数据层之后的整体关系如图:
A | B | C
------------
前端的数据层
------------
Server
那么,视图访问数据层的接口会是什么样?
我们考虑耦合的问题。如果要减少耦合,很必然的就是这么一种形式:
因此,数据层应当尽可能对外提供类似订阅方式的接口。
如果要引入服务端推送,怎么调整?
考虑一个典型场景,WebIM,如果要在浏览器中实现这么一个东西,通常会引入WebSocket作更新的推送。
对于一个聊天窗口而言,它的数据有几个来源:
视图展示的数据 := 初始查询的数据 + 本机发起的更新 + 推送的更新
这里,至少有两种编程方式。
查询数据的时候,我们使用类似Promise的方式:
getListData().then(data => {
// 处理数据
})
而响应WebSocket的时候,用类似事件响应的方式:
ws.on(‘data’, data => {
// 处理数据
})
这意味着,如果没有比较好的统一,视图组件里至少需要通过这两种方式来处理数据,添加到列表中。
如果这个场景再跟上一节提到的多视图共享结合起来,就更复杂了,可能很多视图里都要同时写这两种处理。
所以,从这个角度看,我们需要有一层东西,能够把拉取和推送统一封装起来,屏蔽它们的差异。
如果说我们的业务里,有一些数据是通过WebSocket把更新都同步过来,这些数据在前端就始终是可信的,在后续使用的时候,可以作一些复用。
比如说:
在一个项目中,项目所有成员都已经查询过,数据全在本地,而且变更有WebSocket推送来保证。这时候如果要新建一条任务,想要从项目成员中指派任务的执行人员,可以不必再发起查询,而是直接用之前的数据,这样选择界面就可以更流畅地出现。
这时候,从视图角度看,它需要解决一个问题:
如果我们有一个数据层,我们至少期望它能够把同步和异步的差异屏蔽掉,否则要使用两种代码来调用。通常,我们是使用Promise来做这种差异封装的:
function getDataP() : Promise<T> {
if (data) {
return Promise.resolve(data)
} else {
return fetch(url)
}
}
这样,使用者可以用相同的编程方式去获取数据,无需关心内部的差异。
很多时候,视图上需要的数据与数据库存储的形态并不完全相同,在数据库中,我们总是倾向于储存更原子化的数据,并且建立一些关联,这样,从这种数据想要变成视图需要的格式,免不了需要一些聚合过程。
通常我们指的聚合有这么几种:
大部分传统应用在服务端聚合数据,通过数据库的关联,直接查询出聚合数据,或者在Web服务接口的地方,聚合多个底层服务接口。
我们需要考虑自己应用的特点来决定前端数据层的设计方案。有的情况下,后端返回细粒度的接口会比聚合更合适,因为有的场景下,我们需要细粒度的数据更新,前端需要知道数据之间的变更联动关系。
所以,很多场景下,我们可以考虑在后端用GraphQL之类的方式来聚合数据,或者在前端用类似Linq的方式聚合数据。但是,注意到如果这种聚合关系要跟WebSocket推送产生关联,就会比较复杂。
我们拿一个场景来看,假设有一个界面,长得像新浪微博的Feed流。对于一条Feed而言,它可能来自几个实体:
Feed消息本身
class Feed {
content: string
creator: UserId
tags: TagId[]
}
Feed被打的标签
class Tag {
id: TagId
content: string
}
人员
class User {
id: UserId
name: string
avatar: string
}
如果我们的需求跟微博一样,肯定还是会选择第一种聚合方式,也就是服务端渲染。但是,如果我们的业务场景中,存在大量的细粒度更新,就比较有意思了。
比如说,如果我们修改一个标签的名称,就要把关联的Feed上的标签也刷新,如果之前我们把数据聚合成了这样:
class ComposedFeed {
content: string
creator: User
tags: Tag[]
}
就会导致无法反向查找聚合后的结果,从中筛选出需要更新的东西。如果我们能够保存这个变更路径,就比较方便了。所以,在存在大量细粒度更新的情况下,服务端API零散化,前端负责聚合数据就比较合适了。
当然这样会带来一个问题,那就是请求数量增加很多。对此,我们可以变通一下:
做物理聚合,不做逻辑聚合。
这段话怎么理解呢?
我们仍然可以在一个接口中一次获取所需的各种数据,只是这种数据格式可能是:
{
feed: Feed
tags: Tags[]
user: User
}
不做深度聚合,只是简单地包装一下。
在这个场景中,我们对数据层的诉求是:建立数据之间的关联关系。
以上,我们述及四种典型的对前端数据层有诉求的场景,如果存在更复杂的情况,兼有这些情况,又当如何?
Teambition的场景正是这么一种情况,它的产品特点如下:
比如说:
当一条任务变更的时候,无论你处于视图的什么状态,需要把这20种可能的地方去做同步。
当任务的标签变更的时候,需要把标签信息也查找出来,进行实时变更。
甚至:
当然这些问题都是可以从产品角度权衡的,但是本文主要考虑的还是如果产品角度不放弃对某些极致体验的追求,从技术角度如何更容易地去做。
我们来分析一下整个业务场景:
这就是我们得到的一个大致认识。
以上,我们介绍了业务场景,分析了技术特点。假设我们要为这么一种复杂场景设计数据层,它要提供怎样的接口,才能让视图使用起来简便呢?
从视图角度出发,我们有这样的诉求:
根据这些,我们可用的技术选型是什么呢?
一直以来,前端框架的侧重点都是视图部分,因为这块是普适性很强的,但在数据层方面,一般都没有很深入的探索。
综合以上,我们可以发现,几乎所有现存方案都是不完整的,要么只做实体和关系的抽象,要么只做数据变化的封装,而我们需要的是实体的关系定义和数据变更链路的封装,所以需要自行作一些定制。
那么,我们有怎样的技术选型呢?
遍观流行的辅助库,我们会发现,基于数据流的一些方案会对我们有较大帮助,比如RxJS,xstream等,它们的特点刚好满足了我们的需求。
以下是这类库的特点,刚好是迎合我们之前的诉求。
这些基于数据流理念的库,提供了较高层次的抽象,比如下面这段代码:
function getDataO(): Observable<T> {
if (cache) {
return Observable.of(cache)
}
else {
return Observable.fromPromise(fetch(url))
}
}
getDataO().subscribe(data => {
// 处理数据
})
这段代码实际上抽象程度很高,它至少包含了这么一些含义:
我们再看另外一段代码:
const permission$: Observable<boolean> = Observable
.combineLatest(task$, user$)
.map(data => {
let [task, user] = data
return user.isAdmin || task.creatorId === user.id
})
这段代码的意思是,根据当前的任务和用户,计算是否拥有这条任务的操作权限,这段代码其实也包含了很多含义:
首先,它把两个数据流task$和user$合并,并且计算得出了另外一个表示当前权限状态的数据流permission$。像RxJS这类数据流库,提供了非常多的操作符,可用于非常简便地按照需求把不同的数据流合并起来。
我们这里展示的是把两个对等的数据流合并,实际上,还可以进一步细化,比如说,这里的user$,我们如果再追踪它的来源,可以这么看待:
某用户的数据流user$ := 对该用户的查询 + 后续对该用户的变更(包括从本机发起的,还有其他地方更改的推送)
如果说,这其中每个因子都是一个数据流,它们的叠加关系就不是对等的,而是这么一种东西:
user$流,恢复一次初始状态user$等于初始状态叠加后续变更,注意这是一个reduce操作,也就是把后续的变更往初始状态上合并,然后得到下一个状态这样,这个user$数据流才是“始终反映某用户当前状态”的数据流,我们也就因此可以用它与其它流组合,参与后续运算。
这么一段代码,其实就足以覆盖如下需求:
这两者导致后续操作权限的变化,都能实时根据需要计算出来。
其次,这是一个形拉实推的关系。这是什么意思呢,通俗地说,如果存在如下关系:
c = a + b // 不管a还是b发生更新,c都不动,等到c被使用的时候,才去重新根据a和b的当前值计算
如果我们站在对c消费的角度,写出这么一个表达式,这就是一个拉取关系,每次获取c的时候,我们重新根据a和b当前的值来计算结果。
而如果站在a和b的角度,我们会写出这两个表达式:
c = a1 + b // a1是当a变更之后的新值
c = a + b1 // b1是当b变更之后的新值
这是一个推送关系,每当有a或者b的变更时,主动重算并设置c的新值。
如果我们是c的消费者,显然拉取的表达式写起来更简洁,尤其是当表达式更复杂时,比如:
e = (a + b ) * c - d
如果用推的方式写,要写4个表达式。
所以,我们写订阅表达式的时候,显然是从使用者的角度去编写,采用拉取的方式更直观,但通常这种方式的执行效率都较低,每次拉取,无论结果是否变更,都要重算整个表达式,而推送的方式是比较高效精确的。
但是刚才RxJS的这种表达式,让我们写出了形似拉取,实际以推送执行的表达式,达到了编写直观、执行高效的结果。
看刚才这个表达式,大致可以看出:
permission$ := task$ + user$
这么一个关系,而其中每个东西的变更,都是通过订阅机制精确发送的。
有些视图库中,也会在这方面作一些优化,比如说,一个计算属性(computed property),是用拉的思路写代码,但可能会被框架分析依赖关系,在内部反转为推的模式,从而优化执行效率。
此外,这种数据流还有其它魔力,那就是懒执行。
什么是懒执行呢?考虑如下代码:
const a$: Subject<number> = new Subject<number>()
const b$: Subject<number> = new Subject<number>()
const c$: Observable<number> = Observable.combineLatest(a$, b$)
.map(arr => {
let [a, b] = arr
return a + b
})
const d$: Observable<number> = c$.map(num => {
console.log('here')
return num + 1
})
c$.subscribe(data => console.log(`c: ${data}`))
a$.next(2)
b$.next(3)
setTimeout(() => {
a$.next(4)
}, 1000)
注意这里的d$,如果a$或者b$中产生变更,它里面那个here会被打印出来吗?大家可以运行一下这段代码,并没有。为什么呢?
因为在RxJS中,只有被订阅的数据流才会执行。
主题所限,本文不深究内部细节,只想探讨一下这个特点对我们业务场景的意义。
想象一下最初我们想要解决的问题,是同一份数据被若干个视图使用,而视图侧的变化是我们不可预期的,可能在某个时刻,只有这些订阅者的一个子集存在,其它推送分支如果也执行,就是一种浪费,RxJS的这个特性刚好能让我们只精确执行向确实存在的视图的数据流推送。
不少视图层方案,比如Angular和Vue中,存在watch这么一种机制。在很多场景下,watch是一种很便捷的操作,比如说,想要在某个对象属性变更的时候,执行某些操作,就可以使用它,大致代码如下:
watch(‘a.b’, newVal => {
// 处理新数据
})
这类监控机制,其内部实现无非几种,比如自定义了setter,拦截数据的赋值,或者通过对比新旧数据的脏检查方式,或者通过类似Proxy的机制代理了数据的变化过程。
从这些机制,我们可以得到一些推论,比如说,它在对大数组或者复杂对象作监控的时候,监控效率都会降低。
有时候,我们也会有监控多个数据,以合成另外一个的需求,比如:
一条用于展示的任务数据 := 这条任务的原始数据 + 任务上的标签信息 + 任务的执行者信息
如果不以数据流的方式编写,这地方就需要为每个变量单独编写表达式或者批量监控多个变量,前者面临的问题是代码冗余,跟前面我们提到的推数据的方式类似;后者面临的问题就比较有意思了。
监控的方式会比计算属性强一些,原因在于计算属性处理不了异步的数据变更,而监控可以。但如果监控条件进一步复杂化,比如说,要监控的数据之间存在竞争关系等等,都不是容易表达出来的。
另外一个问题是,watch不适合做长链路的变更,比如:
c := a + b
d := c + 1
e := a * c
f := d * e
这种类型,如果要用监控表达式写,会非常啰嗦。
Rx和Redux其实没有什么关系。在表达数据变更的时候,从逻辑上讲,这两种技术是等价的,一种方式能表达出的东西,另外一种也都能够。
比如说,同样是表达数据a到b这么一个转换,两者所关注的点可能是不一样的:
由于Redux更多地是一种理念,它的库功能并不复杂,而Rx是一种强大的库,所以两者直接对比并不合适,比如说,可以用Rx依照Redux的理念作实现,但反之不行。
在数据变更的链路较长时,Rx是具有很大优势的,它可以很简便地做多级状态变更的连接,也可以做数据变更链路的复用(比如存在a -> b -> c,又存在a -> b -> d,可以把a -> b这个过程拿出来复用),还天生能处理好包括竞态在内的各种异步的情况,Redux可能要借助saga等理念才能更好地组织代码。
我们之前有些demo代码也提到了,比如说:
用户信息数据流 := 用户信息的查询 + 用户信息的更新
这段东西就是按照reducer的理念去写的,跟Redux类似,我们把变更操作放到一个数据流中,然后用它去累积在初始状态上,就能得到始终反映某个实体当前状态的数据流。
在Redux方案中,中间件是一种比较好的东西,能够对业务产生一定的约束,如果我们用RxJS实现,可以把变更过程中间接入一个统一的数据流来完成同样的事情。
以上我们谈了以RxJS为代表的数据流库的这么多好处,彷佛有了它,就像有了**,人民就自动吃饱穿暖,物质文化生活就自动丰富了,其实不然。任何一个框架和库,它都不是来直接解决我们的业务问题的,而是来增强某方面的能力的,它刚好可以为我们所用,作为整套解决方案的一部分。
至此,我们的数据层方案还缺失什么东西吗?
考虑如下场景:
某个任务的一条子任务产生了变更,我们会让哪条数据流产生变更推送?
分析子任务的数据流,可以大致得出它的来源:
subtask$ = subtaskQuery$ + subtaskUpdate$
看这句伪代码,加上我们之前的解释(这是一个reduce操作),我们得到的结论是,这条任务对应的subtask$数据流会产生变更推送,让视图作后续更新。
仅仅这样就可以了吗?并没有这么简单。
从视图角度看,我们还存在这样的对子任务的使用:那就是任务的详情界面。但这个界面订阅的是这条子任务的所属任务数据流,在其中任务数据包含的子任务列表中,含有这条子任务。所以,它订阅的并不是subtask$,而是task$。这么一来,我们必须使task$也产生更新,以此推动任务详情界面的刷新。
那么,怎么做到在subtask的数据流变更的时候,也推动所属task的数据流变更呢?这个事情并非RxJS本身能做的,也不是它应该做的。我们之前用RxJS来封装的部分,都只是数据的变更链条,记得之前我们是怎么描述数据层解决方案的吗?
实体的关系定义和数据变更链路的封装
我们前面关注的都是后面一半,前面这一半,还完全没做呢!
实体的变更关系如何做呢,办法其实很多,可以用类似Backbone的Model和Collection那样做,也可以用更加专业的方案,引入一个ORM机制来做。这里面的实现就不细说了,那是个相对成熟的领域,而且说起来篇幅太大,有疑问的可以自行了解。
需要注意的是,我们在这个里面需要考虑好与缓存的结合,前端的缓存很简单,基本就是一种精简的k-v数据库,在做它的存储的时候,需要做到两件事:
总结以上,我们的思路是:
如果说我们针对这样的复杂场景,实现了这么一套复杂的数据层方案,还可以有什么有意思的事情做呢?
这里我开几个脑洞:
我们一个一个看,好玩的地方在哪里。
第一个,之前提到,整个方案的核心是一种类似ORM的机制,外加各种数据流,这里面必然涉及数据的组合、计算之类,那么我们能否把它们隔离到渲染线程之外,让整个视图变得更流畅?
第二个,很可能我们会碰到同时开多个浏览器选项卡的客户,但是每个选项卡展现的界面状态可能不同。正常情况下,我们的整个数据层会在每个选项卡中各存在一份,并且独立运行,但其实这是没有必要的,因为我们有订阅机制来保证可以扩散到每个视图。那么,是否可以用过ServiceWorker之类的东西,实现跨选项卡的数据层共享?这样就可以减少很多计算的负担。
对这两条来说,让数据流跨越线程,可能会存在一些障碍待解决。
第三个,我们之前提到的缓存,全部是在内存中,属于易失性缓存,只要用户关掉浏览器,就全部丢了,可能有的情况下,我们需要做持久缓存,比如把不太变动的东西,比如企业通讯录的人员名单存起来,这时候可以考虑在数据层中加一些异步的与本地存储通信的机制,不但可以存localStorage之类的key-value存储,还可以考虑存本地的关系型数据库。
第四个,在业务和交互体验复杂到一定程度的时候,服务端未必还是无状态的,想要在两者之间做好状态共享,有一定的挑战。基于这么一套机制,可以考虑在前后端之间打通一个类似meteor的通道,实现状态共享。
第五个,这个话题其实跟本文的业务场景无关,只是从第四个话题引发。很多时候我们期望能做到可视化配置业务系统,但一般最多也就做到配置视图,所以,要么做到的是一个配置运营页面的东西,要么是能生成一个脚手架,供后续开发使用,但是一旦开始写代码,就没法合并回来。究其原因,是因为配不出组件的数据源和业务逻辑,找不到合理的抽象机制。如果有第四条那么一种铺垫,也许是可以做得比较好的,用数据流作数据源,还是挺合适的,更何况,数据流的组合关系能够可视化描述啊。
回顾我们整个数据层方案,它的特点是很独立,从头到尾,做掉了很长的数据变更链路,也因此带来几个优势:
我们可以看到,如果视图所消费的数据都是来源于从核心模型延伸并组合而成的各种数据流,那视图层的职责就非常单一,无非就是根据订阅的数据渲染界面,所以这就使得整个视图层非常薄。而且,视图之间是不太需要打交道的,组件之间的通信很少,大家都会去跟数据层交互,这意味着几件事:
我们采用了一种相对中立的底层方案,以抵抗整个应用架构在前端领域日新月异的情况下的变更趋势。
因为数据层的占比较高,并且相对集中,所以可以更容易对数据层做测试。此外,由于视图非常薄,甚至可以脱离视图打造这个应用的命令行版本,并且把这个版本与e2e测试合为一体,进行覆盖全业务的自动化测试。
以前我们经常会考虑做响应式布局,目的是能够减少开发的工作量,尽量让一份代码在PC端和移动端复用。但是现在,越来越少的人这么做,原因是这样并不一定降低开发的难度,而且对交互体验的设计是一个巨大考验。那么,我们能不能退而求其次,复用尽量多的数据和业务逻辑,而开发两套视图层?
在这里,可能我们需要做一些取舍。
回忆一下MVVM这个词,很多人对它的理解流于形式,最关键的点在于,M和VM的差异是什么?即使是多数MVVM库比如Vue的用户,也未必能说得出。
在很多场景下,这两者并无明显分界,服务端返回的数据直接就适于在视图上用,很少需要加工。但是在我们这个方案中,还是比较明显的:
> ------ Fetch ------------->
| |
View <-- VM <-- M <-- RESTful
^
| <-- WebSocket
这个简图大致描述了数据的流转关系。其中,M指代的是对原始数据的封装,而VM则侧重于面向视图的数据组合,把来自M的数据流进行组合。
我们需要根据业务场景考虑:是要连VM一起跨端复用呢,还是只复用M?考虑清楚了这个问题之后,我们才能确定数据层的边界所在。
除了在PC和移动版之间复用代码,我们还可以考虑拿这块代码去做服务端渲染,甚至构建到一些Native方案中,毕竟这块主要的代码也是纯逻辑。
这个标题需要结合上面那个图来理解。我们怎么理解WebSocket在整个方案中的意义呢?其实可以整体视为整个通用数据层的补丁包,因此,我们就可以用这个理念来实现它,把所有对WebSocket的处理部分,都独立出去,如果需要,就异步加载到主应用来,如果在某些场景下,想把这块拿掉,只需不引用它就行了,一行配置解决它的有无问题。
但是在具体实现的时候,需要注意:拆掉WebSocket之后的数据层,对应的缓存是不可信的,需要做相应考虑。
到目前为止,各种视图方案是逐渐趋同的,它们最核心的两个能力都是:
缺少这两个特性的方案都很容易出局。
我们会看到,不管哪种方案,都出现了针对视图之外部分的一些补充,整体称为某种“全家桶”。
全家桶方案的出现是必然的,因为为了解决业务需要,必然会出现一些默认搭配,省去技术选型的烦恼。
但是我们必须认识到,各种全家桶方案都是面向通用问题的,它能解决的都是很常见的问题,如果你的业务场景很与众不同,还坚持用默认的全家桶,就比较危险了。
通常,这些全家桶方案的数据层部分都还比较薄弱,而有些特殊场景,其数据层复杂度远非这些方案所能解决,必须作一定程度的自主设计和修正,我工作十余年来,长期从事的都是复杂的toB场景,见过很多厚重的、集成度很高的产品,在这些产品中,前端数据和业务逻辑的占比较高,有的非常复杂,但视图部分也无非是组件化,一层套一层。
所以,真正会产生大的差异的地方,往往不是在视图层,而是在水的下面。
愿读者在处理这类复杂场景的时候,慎重考虑。有个简单的判断标准是:视图复用数据是否较多,整个产品是否很重视无刷新的交互体验。如果这两点都回答否,那放心用各种全家桶,基本不会有问题,否则就要三思了。
必须注意到,本文所提及的技术方案,是针对特定业务场景的,所以未必具有普适性。有时候,很多问题也可以通过产品角度的权衡去避免,不过本文主要探讨的还是技术问题,期望能够在产品需求不让步的情况下,也能找到比较优雅、和谐的解决方案,在业务场景面前能攻能守,不至于进退失据。
即使我们面对的业务场景没有这么复杂,使用类似RxJS的库,依照数据流的理念对业务模型做适度抽象,也是会有一些意义的,因为它可以用一条规则统一很多东西,比如同步和异步、过去和未来,并且提供了很多方便的时序操作。
不久前,我写过一篇总结,内容跟本文有不少重合之处,但为什么还要写这篇呢?
上一篇,讲问题的视角是从解决方案本身出发,阐述解决了哪些问题,但是对这些问题的来龙去脉讲得并不清晰。很多读者看完之后,仍然没有得到深刻认识。
这一篇,我希望从场景出发,逐步展示整个方案的推导过程,每一步是怎样的,要如何去解决,整体又该怎么做,什么方案能解决什么问题,不能解决什么问题。
上次我那篇讲述在Teambition工作经历的回答中,也有不少人产生了一些误解,并且有反复推荐某些全家桶方案,认为能够包打天下的。平心而论,我对方案和技术选型的认识还是比较慎重的,这类事情,事关技术方案的严谨性,关系到自身综合水准的鉴定,不得不一辩到底。当时关注八卦,看热闹的人太多,对于探讨技术本身倒没有展现足够的热情,个人认为比较可惜,还是希望大家能够多关注这样一种有特色的技术场景。因此,此文非写不可。
如果有关注我比较久的,可能会发现之前写过不少关于视图层方案技术细节,或者组件化相关的主题,但从15年年中开始,个人的关注点逐步过渡到了数据层,主要是因为上层的东西,现在研究的人已经多起来了,不劳我多说,而各种复杂方案的数据层场景,还需要作更艰难的探索。可预见的几年内,我可能还会在这个领域作更多探索,前路漫漫,其修远兮。
(整个这篇写起来还是比较顺利的,因为之前思路都是完整的。上周在北京闲逛一周,本来是比较随意交流的,鉴于有些公司的朋友发了比较正式的分享邮件,花了些时间写了幻灯片,在百度、去哪儿网、58到家等公司作了比较正式的分享,回来之后,花了一整天时间整理出了本文,与大家分享一下,欢迎探讨。)
所谓单页应用,指的是在一个页面上集成多种功能,甚至整个系统就只有一个页面,所有的业务功能都是它的子模块,通过特定的方式挂接到主界面上。它是AJAX技术的进一步升华,把AJAX的无刷新机制发挥到极致,因此能造就与桌面程序媲美的流畅用户体验。
操作体验流畅,媲美本地应用的感觉,切换过程中不会频繁有被“打断”的感觉。
因为界面框架都在本地,与服务端的通讯基本只有数据,所以便于迁移,可以用比较小的代价,迁移成桌面产品,或者各种移动端Hybrid产品。
如何尽可能增强单页应用的操作体验?
- 路由的规划
- 推送的使用
- 断线重连机制
- 操作补偿机制
- 本地缓存
- 热更新
- 良好的内存管理
- 服务端预渲染
路由可以理解为url与界面状态的对应关系。
我们需要注意到,在理想状态下,url和界面状态应当是精确对应的。比如说,对同一个用户来说,两次使用同一个url所打开的界面,其状态应当是完全一致的。对于同一个界面,进行相同的操作之后,url应当能够精确反馈当前状态。
但是我们需要注意到,细碎操作如果都需要跟路由保持同步,会是一个非常繁琐的事情,所以在设计过程中应当加以取舍,舍弃那些过于细碎的状态与路由的同步。
推送的意思是,某些情况下,即使页面开着不动,服务端也主动发送消息过来,让界面能够有所体现。通常我们会使用WebSocket之类的技术来实现这种体验。
有时候,我们可能会看到一些在页面上使用推送的场景,最常见的是即时消息。
比如说,我们在应用里加一个聊天窗口,其他人发一条消息,自己这边能够实时展现出来。
如果是为了极致的用户体验,我们可以把整个应用的业务变更都使用推送,比如:
我在查看某条任务的时候,有人修改了这条任务,我这里应该不需要做什么操作,就能自动体现出他的修改。
如果对全业务的变更都做推送管理,使用体验会大为加强,但是,实现难度和代码复杂度会急剧上升。
我们如何判断一个单页面产品的技术水准呢?可以通过这样一种方式:
连续开几天不关,不需要通过“刷新”这个操作来解决一些常见问题。
为什么这个事情能够体现技术水准呢?因为要把这个事情做到极致,需要把这几件事情做好:
因为移动办公普及之类的情况,导致我们可能需要面对一些情况,比如,切换了网络,电脑休眠再打开之类,当再次联网的时候,就需要去重新链接,并且,对这个过程中发生的业务变更进行“补课”,然后逐一应用到界面上来,把界面调整到最新状态。
什么是操作补偿呢?
从逻辑上来讲,当我们在界面上操作,创建一条任务的时候,新的这条任务不应当立刻显示出来,而是应当等到服务端确认成功了,才加到界面上。但很可能我们的网络不好,这一步用户要等很久。从用户体验的角度,这样是不好的,所以我们可以先把界面放上去,然后等创建成功的消息回来之后,再把一些唯一标识之类的东西回填到内存数据中。
单步的操作补偿还算是不太难,如果有多步的话,就非常麻烦了,举个极端情况的例子来说,用户新增了一条任务,服务端还没返回的时候,他就立刻在这条任务下创建子任务,但子任务这时候没有父任务的id,如果想给这步也做操作补偿,就比较麻烦了。甚至说,连续进行了几步操作之后,发现之前的操作失败了,后续处理会非常复杂。
上面提到,如果多步连续操作中间出现了失败,局面会比较尴尬,比如你填了好多东西,提交的时候才发现网络坏了,那就非常头疼,这时候,用户会非常期望这些数据能够保存下来,等网络好了再重新尝试。
我们可以使用本地缓存来临时存储这些数据。如果这个层面做到极致,能够结合良好设计的操作补偿机制,甚至可以让用户脱机使用我们的应用,把所有产生的这些变更都缓存,等到联网的时候再批量同步合并回去。
前面提到,用户有可能长期开着我们的应用,然后中间一直没有刷新。正常情况下,业务变更都应当会被全部推送过来,界面所反馈的状况始终是最新的,符合现状的。但我们需要考虑到另外一个问题,系统升级怎么办?
我们当然可以推送一个通知:本系统已经升级了,请点击刷新。但能不能做得更好?这是有可能的,要达到这种目的,就要使用热更新这种手段,把代码的模块化和变更管理都做到极致,每次更新的代码模块也推送过来,并且作为补丁应用到当前系统上。这种机制对开发团队的水准要求很高。
要想让用户能够长期开着应用,还需要管理好内存。
数据的变动、路由的切换、组件的创建与销毁,都会带来内存的变化。完美的内存控制是几乎做不到的,如果要追求这方面的极致,对开发过程的影响会非常大,很多情况下是不划算的,所以,可以做一些针对优化,把比较常规的问题解决掉,不用的东西及时销毁。
作为一个单页应用,很经典的模式就是前后端完全分离,前端加载界面和逻辑,后端响应数据,前端根据这些数据,“生成”相应的变化。
注意到,我们这里有一个“生成”的过程,通常我们也会把这个过程称为“渲染”。它的机制就是根据数据生成对应的界面,如果是在浏览器侧生成这个界面,首先,加载界面模板或者逻辑,需要一次请求,然后,等这块准备好了,还需要去请求数据,这时候又多了一次网络请求。网络请求通常是比“生成界面”慢的,并且很可能这个时间不稳定,这时候就可能延误了用户第一次看到界面的时间。
虽然单页应用跟服务端渲染是存在矛盾的,但我们仍然可以部分优化这个事情,比如把某些页面由服务端直接代入数据生成。现在有一些开发框架也在尝试从另外一个层面解决这个问题,那就是对客户端和服务端渲染提取共性,使用合适的抽象方式来同时描述这两种机制,从而仅仅依靠配置的变更就可以切换渲染机制。
我们提到了这些能够提升单页应用体验的方式,如果实现出来,肯定是可以让使用者非常愉悦的,但需要冷静权衡理想与现实之间的差距:
本文中提到的这些体验增强方式,都是需要去权衡实现的,做得越多,所需要的技术掌控能力越强,出错概率也越高。
有一句著名的表达式:
E = MC^2
我们可以对此有不一样的解读:
Errors = (More Code) ^ 2
小时候,老师问我,你的理想是什么?我不假思索说是工程师,于是长大之后果然成了工程师。
工作这么多年,一直在思考工程师这三个字的意义,终于有一天恍然大悟,原来就是:用技术手段改进世界。
那么,在软件方面,目前的世界有哪些问题需要解决呢?有这么一些问题可以思考:
我想说说自己对这几个问题的理解。
虽然现在我们的生活与十年前相比,已经发生了巨大变化,比如智能手持设备已经非常普及,可穿戴设备也在蓬勃发展。十年前我们用手机收发短信或者邮件,浏览非常简单而老土的wap页面,但现在,绝大部分人的手机已经取代了电脑,成为日常生活中不可缺少的工具。
我们用手机交流,购物,欣赏影视,阅读书籍,玩各类游戏,尤其是飞速发展的移动购物和支付体系,使得我们能在任意场合购买心仪的物品,订购旅游服务和宾馆,叫快餐,打车等等,生活非常美好,那么,整个世界的信息化程度处于什么级别呢?
我觉得,才刚刚相当于小学二年级,整个世界的信息化程度仍然严重偏低。从现在算起,往前10年,往后10年,这20年时间中,面向个人的信息化服务处于高速发展期,这个领域非常吸引眼球,因为它与每个人的生活息息相关。可是,另外有一些领域,却非常需要发展,那就是传统行业的信息化。
之前有不少传统行业,进行了一定程度的信息化,但这个信息化仅仅能满足自身运作的基本要求,当它与整个社会的潮流相对接的时候,就显得非常落后,迟缓。比如说在网购这个大体系中,普通用户所能看到的是商品展示,比价,下单的过程,但背后的核心环节却是配货与物流。
我还在上学的时候,有老师这么说过,现在计算机行业非常火热,很可能要饱和了,你们不一定非要从事这方面的工作。现在回头看这句话,觉得很有趣,人真的很难有眼光看到未来。去年我入职苏宁培训的时候,孙为民副总讲了当年一个决策失误的例子。90年代末,公司统计发现全国空调的年销售量达到数百万台,觉得很可怕,这个行业可能要饱和,估计要再想办法拓展别的商品经营了,但现在,全国空调的保有量为七亿台,即使完全没有新增,十年换一轮,每年也卖得出去七千万台,当年凭什么说这就饱和了?
所以我现在看程序员的状况,仍然是供不应求,尤其是高端程序员,十分抢手。这个问题的背景就是全社会的信息化进程在加速,之前的程序员人数远远跟不上需求量。
那么,如何解决这个问题呢?一方面是继续培训,促使更多新人来到这个行业,并且认真做下去,另外还有一些别的手段需要考虑。
我想追问一个问题:世界上懂业务的人多,还是懂技术的人多?很明显,懂业务的人要多很多,什么叫业务?其实就是行业常识,生活经验。
比如说,一个有经验的仓库保管员,可能文化程度不高,理解不了软件的运行原理之类,但一定对产品出库入库的流程非常熟悉,包括各种审批过程和异常状况,但这些,程序员是不懂的。那如果要促进这个领域的信息化,必然要在两者之间寻找一个结合点,程序员可以学业务,业务人员也可以尝试参与软件研发过程,目前来说,都是前者比较多,因为程序员相对来说还是比较年轻,学东西快些。但从整体社会效益来说,这其实是不利的,因为程序员是更稀缺资源,而传统业务人员非常多。
之前见过一个问题:如何让业务人员更好地参与软件研发过程。这个问题的根本解决方法是DSL(Domain Specific Language),核心解决方案是二次开发平台。
什么是DSL和二次开发平台呢,这两个词听上去很高端,但其实大家有很常用的东西就属于这个范畴,比如Excel,它提供了各种各样的公式,还有VBA,使用这些东西的人绝大部分不是软件行业的,Excel就是一种很成功的二次开发平台,公式和VBA就可以算DSL了。
很多时候这些东西还不够直观,我们可以看到一些图形化的编程语言,比如Scratch,现在很多小学生的兴趣班就会学,这些东西相对学起来就比较容易了,我们也可以做一些类似的抽象,以图形化的方式让业务人员能够参与,比如流程配置等等。图形化的东西,是最适合非技术人员理解的。
所以,要促进社会的信息化程度,最好是能够想办法把各行业的业务人员都拖进来一起搞。具体的分工大致是:技术人员和业务人员一起定义DSL,技术人员负责DSL的底层平台实现,业务人员负责使用它来构建业务模型和业务流程,甚至业务界面。
那么,软件行业的生产力是偏高还是偏低呢?我认为严重偏低。什么叫严重偏低?如果以机械力量的变革来对比,软件行业目前的生产力水平处于蒸汽机发明之前。也就是说,生产力远远没有被解放,大家做的大部分东西将来是会被机械化的,不再需要这么多人来做这么重复的劳动。可能很多人会对这段话不满,怎么就重复劳动了,你说说我做的什么是可以被机器替代的?
换个角度看,为什么几乎所有外行都觉得软件贵呢?因为人力成本太高了,他们觉得,做出这么多东西,应该是不需要这么多时间。为什么双方的反差这么大呢?
我觉得其中的关键点在于绝大部分工作的抽象程度严重不足,另外有很大一部分效率损失在编程平台或编程语言的不完善,比如Web前端。
从第一代到第四代编程语言,每一代都是损失一定运行效率,而大幅提升编写效率。随着硬件技术的发展,软件编程必然越来越粗放,大的趋势是不特别重视细节效率,只要没有数量级的性能损耗。
所以我们可以预期,会有越来越多的人使用一些运行效率相对不怎么高的语言或框架,只是为了提高单位时间的生产力。从老板们角度想,也会明白,提升运行机器的性能,要比多雇几个程序员便宜多了。因此,从整体趋势看,追求细节性能的程序员们恐怕会离自己的理想越来越远了,除非是在某些特定领域。
那么,绝大部分软件系统都可靠吗?我换一句话来问:各位程序员朋友,如果你们住的房子质量跟你们正在做的软件一样,你敢住吗?感觉大家都在笑,笑是什么意思,我们都懂的。
那为什么软件系统的质量不容易高呢?我觉得主要原因是流程不完善。那为什么不完善?需求容易变。为什么容易变?是因为不论程序员自己,还是需求方,其实潜意识都认为自己做的东西是变更成本较低的。
试想一下,为什么没人在盖高楼盖一半变更需求?为什么没人修大桥修一半变更需求?甚至做衣服做一半的时候变更需求,理发到一半变更需求,都会被人认为是不讲理。但是在软件领域,好像这倒成了普遍现象。
因为整个软件系统的实现,都是虚拟的,看不见摸不着,并不消耗什么物料,所以从这个角度想,变起来当然是容易的。但软件系统的架构,其实也跟实体的没本质区别,变更时候要考虑很多关联因素,并不是就那么孤立的看一小块地方,当然,也会有一些不影响全局的变更。打个比方说,如果你在盖房子盖到一半,那变更外墙颜色肯定是要比变更窗户大小容易的。要是想变得太多,估计只好拆了重来。
我见过不少公司是通过加强测试的方式来试图控制质量,但个人觉得这种方式不划算,而且收效不高。要想很好地应对需求变更,很重要的一点就是不要有这个软件一定不会改的想法,然后,从架构上做拆分,隔离,组件化等等,力争做到即使要改,也只改某一块的内部,不影响别的地方。
很多软件公司,一方面不注重架构的设计与宣贯,导致变更的时候问题多多,程序员也不能很好领会架构意图,一方面忽视整个过程中对架构的管控,认为架构只是最初那张静态图。
任何一种架构方案,都需要一个良好的管控机制。没有哪个盖大楼的只认真管设计图纸,不控制施工过程。架构其实是跟施工过程严格相关的,架构并不是一张扁平的图,而是一个立体的东西,作为整个系统工程的骨架。如果能在开发的时候看到这个骨架逐渐建立,血肉充盈的过程,对整个系统的成功把握一定会大得多,这也就是开发过程中架构管控的理念,具体实现要依赖于不同场景。
所以,将来的软件开发方案,一定是会朝着几个方向发展:
有时候看现在的小孩子,会觉得他们很幸福,因为等他们这代长大,就不需要像我们现在这样编写程序了,那时候,编程已经成了一种令人习以为常的通用技能,就像现在的人用Office软件一样,所谓的编程,很可能已经不需要敲代码了,而是图形化,设置几个参数就完事了。
后记:昨晚翻以前写的东西,翻到06年写的一篇,挺有意思的,看自己年轻时候写的东西,总是挺多感慨。当年的自己充满对未来的向往,激情澎湃,十足的微软粉啊。那时候的工作基本是在用Java,不过个人还是一直关注着微软技术的发展。写完今天这篇,再对比当年的最后一段,虽然那时候有些幼稚,认识问题不深刻,所幸的是初心未改!
贴后面给大家看看:
2006年10月7日
昨天,微软发布了Windows Vista RC2,可能这个是Vista的最后一个测试版了,下面值得我们期待的就是正式版本。
说实话我对这个东西还是很期待的,虽然我的电脑不一定能流畅地跑起来,而且我未必就喜欢那么花哨的界面,但是这个系统里面拥有了太多令人兴奋的新特性。
据说Vista的界面非常漂亮,整个是透明的玻璃风格,窗口是3D的,甚至还可以切换视角,斜过来看,是不是微软的系统终于可以能跟MAC比一下美观了?
我最关心的不是这个,是这个系统带来的一些新的技术上的便利。据说在这个系统里面会支持传说中的XAML,这个是什么呢?是一种用写HTML网页的方式来写应用程序的开发方式,有了这个,做界面就是一件非常轻松,而且没有技术难度的事情了。
另外,据说Vista会支持传说中的.net framework 3.0,这个其实核心是2.0的版本,只是多了几个foundation,比如presentation foundation,communication foundation,甚至还有workflow foundation。
在操作系统里面集成工作流,我不知道这个创意是谁想出来的,总之,是一件非常酷的事情,这个意味着什么?以后我们用操作系统就可以玩工作流了。微软为什么要在操作系统里面集成工作流?他们的想法是将操作系统变成一个真正意义上的平台,然后使用工作流引擎调动Office的各大部件,形成协同工作。这个对于一个办公室的人来说,可能会有很多非常方便的作用。
大约在Vista系统发布的同时,Office2007也要发布了。这个东西并非完全是界面搞得很花哨,内在功能实在是提高不少。文件格式有了根本的改变,这次是基于XML的,并且文件格式是对外开放的,就是说第三方软件公司也可以更方便地读取这些文件。此外,Office2007直接支持生成pdf文件,这个直接就把Acrobat干掉了,呵呵。
有消息说微软正在开发Office的在线版本,就是说本机上都不用装Office了,能上网就直接可以用,我觉得这个想法很超前,因为网络条件并没有达到这个水准,虽然说基于Web、基于Service的软件会是未来的一种趋势,但是现在可能还为期过早。不过对于微软来说,做这个已经不早了,因为Google就在做这种东西,很明显不能让自己的竞争对手占先,不然以后亏大了。
微软的另外两个巨型产品是今年推出的Visual Studio 2005和SQL Server 2005,这两个东西也不是一般的强悍。Visual Studio一直是微软的开发工具旗舰,这个东西的特点就是高大全。虽然说令人不满的地方也不少,但是要说比它好用的开发工具还真不怎么找得到。Visual Studio 2005的特点是第一次加入了完整的团队协同方案,并且将微软开发方法论MSF融入其中,整个软件开发过程环环相扣,用这样的东西开发真是一种享受。
VS2005是基于.net framework 2.0的,它改进了C#和VB,增加了很多语言特性,比如说C#里面的Generic,不过有消息说,在C#3.0的版本里面,加入了更酷的特性,比如可以直接使用SQL语句对于集合进行查询,这个真是没得说,跟Power Builder学的?
另外Visual C++ 2005也有很大的改变,C++语言在这里演化成了C++/CLI,虽然说我总感觉这个东西有些古怪,但是比VS2003里面的C++已经要好不少了,在那个里面居然有两个下划线这种“ugly”的语法,看起来就令人十分不爽。
VS2005另外一个很特别的地方就是新搞了一个Visual Web Developer,这个东西是专门为开发ASP.Net使用的,效果相当不错。跟VS2005里面的其他部件一样,VWD一样跟SQL Server 2005进行了很好的集成,可以直接把一个表拖动到界面上去,自动形成数据绑定,然后只要进行简单的操作就可以完成分页之类的功能。
SQL Server 2005是微软花了5年时间推出的产品,说实话,我觉得SQL Server 2000的可用性已经是非常的好了,这次改进貌似还有相当大的改善,虽然说还是不如Oracle强悍,但是它的易用性实在不是一般的好。SQL Server 2005提供了很好的Reporting Service,Bussiness Intelligence,Full-Context Search之类的功能,对于企业开发应当能有相当大的帮助。
VS2005和SQL Server 2005对移动设备的开发能力也有了很大的增强,比如.net compact framework 2.0,这个就是一个非常可爱的东西,我在我的PDA上就装了一个,还写了一个小程序去上面跑,挺好玩的。还有SQL Mobile版,我也装了一个,有一个非常可爱的查询分析器界面,还有一个NorthWind例子数据库,呵呵,很习惯地写了一个“Select * from Employee”,于是出来一排熟悉的名字,这真是太美妙了。
微软这次还有一个战略,就是提供了VS2005所有语言的Express版本,这些版本都是免费下载使用的,里面集成了MSDN的Express版本和SQL Server 2005的Express版本,开发功能一点都不弱,除了没有集成VSS和缺少团队协作、移动开发功能之外,其他功能都在,对于初学者和业余开发人员来说,这实在是太好了,还有它们都有对应的中文版,甚至连MSDN都翻译成中文的了,真是非常体贴。微软的另外一个重点产品就是MSN了,它已经改名成Live,于是包括Live Messenger,Live Space在内的一系列东西,都是微软庞大Live计划的一部分,这个战略应当才开始起步,但是前景实在是很令人期待。
在Web 2.0时代,AJAX技术的盛行使得在Web界面上展现各种复杂效果都成为可能,对这一点我深有体会。微软并没有放过这个大好机会,Atlas是微软将要推出的一个基于AJAX的开发框架,现在社区预览版本早已推出了,直接可以作为VS2005的插件使用。
关于这个VS2005的插件,不得不再提一下。微软有一个Enterprise Library,它将企业开发中所遇到的典型案例整理成类似模板的东西,并且写了详细的文档来解释这些。这对于架构人员来说实在是莫大的帮助。而这个Library是可以直接跟VS2005集成的,使用起来非常方便。另外几个东西就是我上次提到过的几种Factory,包括Service Factory,Smart Client Factory和Mobile Factory,这些作为VS2005的插件,使得基于.net平台的开发如虎添翼,效率出奇地高。
后记:本来我只是随便写点对于微软的感想,没想到下笔了就没法停住,心底里对于微软的那种崇拜,那种向往使得我控制不住自己的激动。微软对于我来说,是一个永恒的动力,我所学的东西基本上都是基于微软平台的,我也曾经接触过Linux,也写过Java,可是一直不能适应它们那种理念,那种是纯粹技术的乐趣。我无法理解为什么Linux阵营的人坚持要用makefile文件来编译程序,不理解为什么有那么多人要坚持写着那么原始的代码。在我看来,那是一种信仰,一种对于技术的执着,可惜我不是。
我所憧憬的梦是让这个世界里能说话的人就可以写程序,能写字的人就可以开发软件。当技术不再成为高高在上,遥不可及的东西,留给我们技术人员的会是什么?我不知道,也许很幸福吧,就像一个职业军人遇到了永久的和平。
今年我发起了三件事:
很高兴在年底的时候,能看到这三个方向都有所进展,这三个事情都是我一个长期规划的具体实现,那就是:促进南京地区的前端生态圈。
目前,全国前端技术精英最集中的是三个地区:北京周围,长三角,珠三角。其中,南京位居长三角的一端,但是前端氛围要远远差于上海和杭州,甚至可能连武汉、成都都不如,原因在哪里呢?
我经常拿杭州跟南京比较,两个城市,规模相似,地位相当,教育程度也差不多,甚至可能南京的高校还略强些,但为什么不光前端,整个互联网的氛围都是杭州秒杀南京呢?
我看过一些文章分析两个城市,甚至两个省份人民性格的差异,说不出有没有道理,但问题总要想办法解决,我一直坚信事在人为,有些事情去推动一下,可能比想象的结果要好很多。
所以我搞了一个长期的规划,意图促进南京地区前端圈子的建立。对于生态来讲,首先要有规模,规模就是人,人从哪里来?南京有这么丰富的高校资源,如果能加以引导,应该会对整个城市的技术生态有很大的正向影响,所以从我的长久目标来看,一定要面对大学生。
所以上半年我发起了前端读书活动,这个事情我是以比较粗放的方式来搞的,因为个人精力有限,花钱是小事,没法拿出太多时间来,所以就这样,断断续续也有不少学生参与,整体感觉还可以。
然后就开始考虑以企业的名义跟学校技术社团合作,但面临的问题是我们公司内部都没有技术团体,很松散,这事情就很难办,所以又花了半年时间,整合公司内部的同行员工,成立了前端技术协会,自己作了几次大分享,然后每周形成了固定的交流,虽然说协会内部还有不稳定因素,但总算有组织了,到近期,条件终于比较成熟了,正好有两个学校的学生社团联系我,这事情也就搞起来了。
事情发展到现在,终于真正起步了,整个这个过程的效率不算高,很有改进余地,但实在没有更多精力投入了,这些都不在本职工作内,很花时间,只能保持这种状态。
这时候再回头看做的这三件事,都是有人觉得效果不一定好的,比如说,如果有兴趣的人,根本不用去推进,自己会很主动。但我更大的意图并不是聚集这些本来就有兴趣的人,因为这些人真的太少了,我想要推动的是那些观望的人。
我一直认为,人分为三种。第一种积极主动,有理想或者激情,大约占10%,另一种就是自暴自弃,负能量爆棚,也算10%,那剩下80%是什么呢,是普通人。
普通人有一个特点,他没有很强的愿望去做某件事,但如果因为某些原因他开始做了,也能习惯。我今年思考了很多,觉得对于普通的人,他有两种心理,一种是服从强权,一种是从众,而且很容易就能形成习惯。
强权很好理解,怎么理解从众呢?我打个比方,在大学宿舍里,很多人可以打牌也可以不打牌,很多时候他没想打,这时候来了个人说,打牌打牌,至少一半的人就会想,反正也没坏处,那就打吧。如果那人再坚持一下,原先不太想打的也可能参与了。
所以我想利用的就是这种心理,把这个中间的人吸引一些过来。我并不期望每个参与赠书活动的大学生都会看书,更不期望每个参加社团交流的人都能学下去,只是希望他们中的一部分,比如说之前从来没想过学前端,自己根本不会主动去看,但我送了一本书到桌上,有时候无聊,翻开看看到底讲点什么,说不定就觉得挺好玩,然后就搞下去了呢?或者原先不知道这是干什么的,随便跟人来社团听听,觉得讲得还挺有意思的,也就自己开始跟着瞎折腾了呢?
我所期待的,也就是通过这类方式,能增加愿意参与前端方向的人数,任何一项技术能够发展,都离不开一个群体,靠几个人是没法提高的,必须有很多人都参与,每人有点想法,从交流的过程中,大家才都能受益。
明年,我们将有更多这方面的规划,也期望业内同仁能多多指教,更希望有越来越多的南京地区的高校和企业参与这些活动中来,把南京地区的互联网氛围搞活。至于说这些学生,将来是不是来了苏宁,或者是去了别的地方,我觉得都不是坏事,楚人失之,楚人得之,为什么一定要那么狭隘?
也感谢这一年里家人对我的容忍,因为花了很多晚上和周末的时间搞这些事,而且差不多送出去了一万多的书。但我相信,这一切是会有回报的,就像下棋,能把一盘棋先下活,后面的机会就会更多。理想当然要有,说不定就实现了呢?
前段时间,我写过一篇文章,侧重从产品角度去谈低代码平台的一些能做和适合做的事情,以及做这些事情的方式。
在本篇中,会尝试从几个大方向出发,简单谈谈如何从技术视角看待模型驱动的低代码平台的整体架构,以及相关的部分选型。
如果说,低代码平台与通常的技术开发框架有什么差异,那就是它们对于代码和配置的侧重不同。
很显然,如果表达能力不损失,那么,低代码平台是配置优先的,并且其中的配置表达能力还需要比较强大才行。
所以,我们在技术选型的时候,要时刻牢记,这与我们通常写代码用的技术框架不同,整体不是为了写代码写得舒服,而是为了打造一套能让不同技术能力的人合理协作的机制。
还是用 Excel 来类比:有的人倾向于组合现有的公式;有的人则无视这些东西,从无到有自己写一些代码实现所需功能。前者,是我们要服务的主要对象。
类型体系是一种非常有趣的东西,它可以用来表达结构的组合与变换,从而初步验证变换的安全性。
在低代码平台中,我们可以借助类型体系,来实现业务实体的结构与关联表达,并且为规则的扩展提供一定程度的便利性,这是一种很有用的工具,也可能是整个模型驱动的低代码平台的底层方法论的核心部分。
通常,我们会在某种编程语言中,借助这种语言提供的能力来表达原子与复合类型。Web 前端最常用的类型描述体系是 TypeScript,但是需要注意到,TypeScript 能够帮助我们验证的东西,是在编译期确定的,而在低代码平台中,有很多东西是编译期不确定,要在运行时检验。
比如说:用户创造了“学校”模型,并且为其动态添加了一些字段。
整个这个过程,是完全在运行期完成的,如果我们想要为它添加类型验证,就需要从另外一些角度来解决问题。
领域模型驱动的低代码平台,天然拥有实体的元数据,并且可以依托它,传递到运行期的每个角落,相当于建立了一套基于 Schema 的类型机制。如果能把这套类型机制显式表达出来,会同时对平台和低代码的开发者有好处。
低代码平台的运行期,实际上相当于是常规软件开发流程的开发期,所以,我们要在这个层面提供类型支持,又因为整个这样的实现跨越了多端,贯穿从服务端到多个客户端的完整流程,其中至少有一个环节经历过序列化和反序列化过程,所以,这个验证过程需要能够同时确保数据的合法性。
这样一来,这套类型系统的职责就是贯穿数据的生命周期了。
在已经具备的类型结构上,可以扩展出一套校验机制来。比如,我们知道类型的 Schema 是怎样的描述,就可以生成对应的校验函数来验证对应数据的合法性。
甚至因为存在类型的组合与变换关系,可以动态生成复合类型的详细信息,并且以此作为更复杂数据结构的校验依据。
需要注意的是,这里的组合与变换,已经不是 TypeScript 里面的那种了,这是平台需要实现的能力,即使平台本身不使用 TypeScript 开发,也无损于这种变换与验证能力。
同理,基于已有的类型结构,可以在扩展的动作与方法上,提供一些额外的编程便利。不同语言之间的类型结构,是存在一定程度的转化性的,我们基于描述构建的这套类型结构,可以很方便映射到主流编程语言中。
存储是整个系统可用性的一个关键组成部分。
从编程框架的角度,针对结构化数据存储,出现过几种不同维度的抽象:
前者主要侧重于屏蔽不同数据库之间的差异,一般还要辅以特定的编程语言或者框架所约定的编程方式,比如 Java 体系中的基类、抽象类、实现类等等一套机制。
这种方式暴露的方式比较底层,控制能力强大,没有用这种方式实现不出的需求,但是在低代码平台中,大部分情况下抽象层次过低了。
而广义的 ORM 则是一个比较适中的抽象层,它首先提供了实体视角,可以面向领域模型中的物理层模型去组织数据的存取。
其次,底层的存储未必就一定要是本系统内部的结构化存储,完全可以基于外系统提供的读写 API,映射出一个虚拟的实体,此后,可以把这个虚拟实体当作真实实体一样进行关联或者组合操作。
所以从这个角度,我们可以设计一套分布式 ORM,来抽象整个广义的存储层。ORM 中的实体定义作为贯穿整个系统的元数据描述,可以与类型系统结合,贯穿整个系统的始终。
低代码平台最难以“无代码化”,或者可以说,唯一无法全部配置化的就是业务逻辑了,而且很多时候不是无法,而是不适合。
比如说,我们通常会把比较大粒度的逻辑设计为流程,然后用序列或者状态机流程图的方式去编排,但是很难把更细粒度的逻辑也用这种方式编排,因为性价比太低了,徒增理解成本。
但是需要认识到,逻辑也是可以分类的,比如,从触发方式上,可以分为:
主动的逻辑,通常可以组织为某种服务,供某些主动调用方使用,或者由定时器、生命周期触发。被动的逻辑,通常承担的是拦截、验证等职能,一般可以归类为规则。
在一般的应用系统中,视图层是抽象程度最低,而在研发流程中耗时又最多的。
从最基础的视角出发,有没有视图层,提供精致或者简陋的视图层,都不会十分影响一般业务的实质。
视图层的基础组成部分包括如下:
除了原子化交互,是一种可以隔离在外的东西,其他部分都具有一个共同特征:需要使用到实体结构,而这种实体结构,正是在后端存储部分的元数据描述之一,如果我们能让这三块内容尽量复用元数据,则有可能最大可能地降低所需额外编写的代码量。
从这个角度,我们可以从元数据结构为中心,重新组织我们的前端组件体系,以及典型的状态结构场景,并且围绕它们,去解释元数据,生成不同形态的交互系统。
从这个角度出发,再反过来看待之前的几个问题:
最没有争议的是数据请求,它可以表达为基于元数据描述的请求,在下一节详细叙述。
这里通常会存在几个流派:
需要注意的是,在低代码平台中,通常会附带额外的视图可视化搭建工具,因此:
所以在这里,很主流的选择是某种模板语法,至于这种模板是基于标签的,还是基于形如 Markdown 这样的结构表达,这是次要的,并不是很重要,两者基本可以视为等价。
状态管理的需求可以由内置的典型状态结构,外加可扩展的控制逻辑去支撑。在这个地方,我们可以来看一下近两年来争议很大的 Redux,它的实质是什么呢?
Redux 的实质是:将自身作为一种数据的持有者,并且提供了迭代器模式,让外层可以提供映射器,来处理每次的数据变更。通常在我们手写代码进行编程的时候,这种模式是比较复杂的,约束很多,格式代码也多,但从另外一个角度,它是一种很好的用来承载代码操作配置化的表达方式。
约束多,对编程不利,一般对于配置化都会比较有利。可以以这样的状态结构为蓝本,提供一些内置的动作,然后再提供额外的动作扩展能力,这样就可以很容易实现状态与逻辑的扩展了。
视图需要解决的另外一个问题是跨端。如果意识到,在我们这个体系下,并不需要为每种组件都寻求相同的跨端表达,而是只要语义等价就可以,那完全可以为各端单独设计原子交互,然后用相同的编排层去解决问题。
唯一需要考虑的是,引擎层在各端与视图层的通信或集成方式。可以尝试在 PC Web 端把逻辑引擎迁移到 Worker 中,交互层使用类似本地 RPC 的通信协议与引擎传输数据,在其他端使用类似的方式,这样,各端的交互都是本地化的,但是逻辑引擎共用一套。
注意到我们把接口放在这么靠后的位置来讨论,因为如果不在跨系统集成语义下,接口其实是个不值得过于关注的部分,因为它是一种系统内部行为。
从视图角度看,由于平台提供的能力,导致它调用的是一种封装过的 RPC 服务,至于其内部是如何传输的,并不十分重要。
但是需要考虑到一点,因为我们之前的考量,把视图整体配置化了,在视图层中,复用了“编排”,并且使其贯穿到“状态结构”与“读写”,因此,接口层必须能够灵活相应视图层的各种灵活结构调用,例如:
以及更复杂的它们的组合。在当前,最成熟的可以响应这类请求结构的方案就是 GraphQL,它提供的两个能力恰好符合我们的需求:
因此,在这里选用 GraphQL 是非常合适的,并且它还便于实现更加复杂而强大的能力,因为下层实体关系的图状结构被凸显了,可以在这一层去做一些权限之类的编排定义。
从这个角度看,我们又可以发现,在整个体系中,前端才是真正的 ORM 的消费者,数据的生命周期一直贯穿到客户端,因此这其中会涉及很有意思的思考,在我之前的某些文章有过比较详细的阐述。
另外一个角度,也可以给接口层提供多套 API 出口,以适配不同的跨系统集成方式。
作为一篇概要性的论述,本文只是简单提及了低代码平台开发过程中的一些主要方面的技术选型,细节内容是非常庞杂的,足够写几十篇来详细阐述,此处空间太小,不一一展开。
总的原则,还是要以可组合性、配置化为最高出发点,在此基础上首先构建出可运行的技术框架,然后再做上层的产品包装。
后记:上次被兔子同学说,我的技术观点和选型方式一贯比较奇怪,比如说:
主要原因是我的视角站在低代码平台这种产品形态上,考虑的一种前提是要让元数据表达的类型成为整个应用的主题,侧重于各种编排能力,因此写这么一篇简单提一下一些粗略的思考点。
在复杂的单页应用中,可能存在大量的关联计算。
什么是关联计算呢?比如说:
这样,变量b就带来了一个需要重复的计算,我们需要借助不同的机制,当a变化的时候,去重新计算b的值。
对于这类东西,通常两种途径:
通常,第一种方式会比较普遍使用。
在很多可编译到JS的语言中,都有setter和getter机制,ES的新版本也是有的,所以我们可以把这两种途径分别使用setter和getter去实现。
class A {
private _a: number
set a(val) {
this._a = val
this.b = val + 1
}
}class A {
a: number
get b() {
return this.a + 1
}
}在一些视图层框架中,存在computed property的概念,本质上就是这么一个类似getter的定义,但是实现上可能会是用的getter,也可能会在内部被转换成setter来处理了。
因为如果你直接用setter,仍然存在一个问题:什么时候触发取值。我在一个click操作里,把a的值加一了,界面上的b怎么知道就要重算呢?
在一些基于脏检查的框架里,这个事情会自动去做,因为它是在任意可导致数据变化的事件之后,获取当前数据,跟历史数据来做个对比,这时候他就会调用到b的取值,所以getter是生效的。
我们必须认识到,如果不能精确追踪到依赖关系,getter就是低效的。比如说,如果你不知道当a变了之后,才需要更新b,就可能要频繁地去看b的当前值,其中绝大部分时候都是不需要重新算的。但另外一方面,如果你已经知道了只有当a变更的时候,才需要更新b,倒不如在a的setter里做这个事了。
手动在setter中更新关联数据,效率是可以保证的,但麻烦就在于写的时候麻烦,我给自己赋个值而已,还得去管你们后续要干什么,这个代码很不可读,也难维护。所以,有些框架允许你用getter的形式定义数据依赖,自动分析出变量依赖关系之后,再在内部转换成setter,这样就比较好了。
我们上面举的例子比较简单,单级的一对一依赖,如果复杂一些,可能会有几个方向:
什么是一对多依赖呢?
get a() {
return this.b + this.c
}这里面,a依赖于多个值。
什么是多级依赖呢?
get a() {
return this.b + 1
}
get b() {
return this.c + 1
}这里,a的变化要一直追踪到c,如果控制得不好,还能写出依赖闭环,造成死循环。多级依赖的编写虽然不难,但比较罗嗦。
什么是异步依赖呢?
get a() {
return this.b + 1
}如果这里b的来源是异步的,就比较尴尬了,这样写肯定是不对的,所以,难道我们要写成这样吗?
set b(val) {
this.a = val + 1
}
foo() {
changeB().then(b => this.b = b)
}这样本质上还是利用setter。
从刚才的描述中,我们得出的认识大致是这样:
所以,在异步的情况下,我们真的就要承受setter的痛苦吗?
当然不,我们要找一种写起来类似getter,不会有无效执行,还能简洁处理异步依赖和多级依赖的情况的办法,问题是,这种办法真的存在吗?
我们考虑这么一个场景:
问:站在d的角度,这代码怎么写?
实际的业务逻辑其实很简单,就这么一句:
d = (a + b) * c最大的麻烦是,这些异步过程把业务逻辑打散了,导致这个代码特别难写,也不清晰。
如果使用RxJS,我们可以把每个数据的变更定义成流,然后定义出这些流的组合关系:
最终代码如下:
http://codepen.io/xufei/pen/PGPYLK
const A = new Rx.Subject()
const B = new Rx.Subject()
const C = new Rx.Subject()
const D = Rx.Observable
.combineLatest(A, B, C)
.map(data => {
let [a, b, c] = data
return (a + b) * c
})
D.subscribe(result => console.log(result))
setTimeout(() => A.next(2), 3000)
setTimeout(() => B.next(3), 5000)
setTimeout(() => C.next(5), 2000)
setTimeout(() => C.next(11), 10000)为了简单,我们用定时器来模拟异步消息。实际业务中,对每个Subject的赋值是可以跟AJAX或者WebSocket结合起来,而且对D的那段实现毫无影响。
我们可以看到,在整个这个过程中,最大的便利性在于,一旦定义完整个规则,变动整个表达式树上任意一个点,整个过程都会重跑一遍,以确保最终得到正确结果。无论中间环节上哪个东西变了,它只要更新自己就可以了,别人怎么用它的,不必关心。
而且,我们从D的角度看,他只关心自己的数据来源是如何组织的,这些来源最终形成了一棵树,从各叶子汇聚到树根,也就是我们的订阅者这里,树上每个节点变更,都会自动触发从它往下到树根的所有数据变动,这个过程是最精确的,不会触发无效的数据更新。
所以,借助RxJS,我们实现了:
这是对知乎上一个问题的回答:https://www.zhihu.com/question/39943474/answer/83905933
我们学一个东西,通常两个目的:
所以,在学这些东西之前,先必须了解,它们是用来解决什么问题的。
Angular,React,Vue,这三者其实面对的是同一个领域,那就是Web应用,什么是Web应用呢,我之前有一篇大致讲了:构建单页Web应用 · Issue #5 · xufei/blog · GitHub
这三者中,Angular的适用领域相对窄一些,React可以拓展到服务端,移动端Native部分,而Vue因为比较轻量,还能用于业务场景非常轻的页面中。
在Web应用中,我们需要解决的问题可以归纳为三类:
什么是状态?
在一个业务界面中,我们可能会根据某些数据去生成一块界面,然后通过界面上的某些操作,改变一些数据,从而影响界面的另外一些部分。
这里面就存在两种关系,一种是从数据到界面,一种是从界面到数据。能够描述界面当前状况的数据,就可以被称为状态。
如果不对状态作抽象,很可能会导致逻辑的混乱,比如说,一个地方点了,要改多个地方,这种代码直接写,很容易写乱的,所以,不同的框架采用不同的方式进行了处理。
比如说MVVM流的Angular和Vue,还有Avalon,Regular,Knockout,都是走的这一流派,通过类似模板的语法,描述界面状态与数据的绑定关系,然后通过内部转换,把这个结构建立起来,当界面发生变化的时候,按照配置规则去更新相应的数据,然后,再根据配置好的规则去,从数据更新界面状态。
React走的是另外一个流派,就是所谓的函数式,在这个里面,推崇的是单向数据流:给定原始界面(或数据),施加一个变化,就能推导出另外一个状态(界面或者数据的更新)。
在这里需要额外提一下ReactiveJS,它的理念又有所不同,是基于Reactive的。
刚才这些,都可以看作是满足最基本的需求,那就是业务的正确性。在这之后,就有另外的诉求了,首当其冲的就是整个业务代码的组织。
所谓组织,指的是两个方面,一方面是模块关系,另一方面是业务模型。
我们是怎样解决模块关系的呢?共识就是组件化。整个应用形成倒置的组件树,每个组件提供对外接口,然后内部只关注自己的实现。这些东西说起来简单,但实际做的时候还是有非常多需要考虑的东西,包括组件的定义,约束,管理,测试等等,而在Web这个体系中,组件化也有一些不太适合的场景,需要做一些权衡,这方面详细说就比较复杂了,需要好多篇幅才能说清楚,可以看看我这篇:Web应用组件化的权衡 · Issue #22 · xufei/blog · GitHub
那么,业务模型又是指什么呢?我们提到React的时候,就会听到Flux,Redux之类的东西,为什么又要有它们呢?我们必须认识到,脱离了这类东西,纯上层的组件化是不牢固的,如果你感受不到,只有一个原因:你的项目的业务层太薄。
业务模型指的是所处领域中的业务数据、规则、流程的集合。即使抛开所有展示层,这一层也是应当要能够运作起来的。
那么,这跟Redux之类又有什么关系呢?
我们刚才提到组件化,整个应用形成了一个组件树,组件之间可能会需要通讯,它们通讯的内容可能是简单的界面事件,也可能是业务含义较深,能够牵一发而动全身的。界面是怎么来的?是由初始界面加上状态形成的,为了能够反映界面的变化,我们必须使得对业务模型的每一个扰动都收敛到确切的状态,所以,这也就是Redux这类东西的意义所在。
所以,没有Redux之类辅助方案的React,是不完整的。而Redux本身,也不是局限到只能作为React辅助方案的,它的理念,对于Angular,Vue,照样是非常重要的补充。在同一业务场景下,对于每个框架来说,数据模型层面临的问题都是一样的,在这一层并没有任何分别。
另外,Angular 2中引入了RxJS,这个东西处理这方面也是有很大优势的。
在这里我要插一句自己的想法,很多学习能力较强的朋友,当他发现FP,FRP之类编程模型的时候,会非常喜欢,但对于大型项目,需要很多人协作的状况来说,不一定是好事。
用面向过程,面向对象的那些方式,虽然笨重,但好处是门槛低,符合大多数人的理解和思维方式,并且可以复用几十年积累的各种设计模式和经验。所以,如果不是小而精悍的团队,我对引入FP和FRP都是比较保守的。
在这些东西下层,还有Relay,GraphQL等等致力于业务模型同步的方案,但这个引入代价同样是非常大。
再插另外一句:很多人吐槽Angular大而全笨重,吐槽React全家桶,但其实世界上大部分人是没有框架整合能力的,小而美的库最后整合了,在面临各种业务需求之后不断引入新模块,也还是一个大而全的方案。在绝大部分场景下,还是有一整套标配模块比较好。你看ExtJS他也单独提供ExtCore模块,但不但竞争不过jQuery,连mootools和prototype都竞争不过,用它的人几乎都是用全方案的。
效率也分两种,一种是开发效率,一种是运行效率。
我们前面提到,组件化,这是提升开发效率的一种手段,在组件化这个点上,各路框架的组织方式大同小异,反正最终都是组件树。
具体到单个组件的实现上,我个人是倾向于MVVM流的,之前 @题叶 做过对比,MVVM系的代码量会少一些,开发效率稍高一点。
其中,Angular因为实现的特殊性,有作用域继承之类的双刃剑黑魔法,开发效率的不稳定因素要高不少,深刻理解的人用起来效率很高,不理解的用了到处是坑。
再看运行效率,这里面,Angular是较低的那个,主要在于数据变更检测方式,但这也不是绝对的,在部分场景下,脏检测未必就没有优势,这个记得 @郑海波论述过。
运行效率的另外一面主要是创建和修改DOM,在创建上,大家是没有太大差异的,而在修改DOM的时候,React首创的虚拟DOM有很大优势,所以其他框架内部实现也在逐渐借鉴。
(我之前有个对虚拟DOM的回答是有偏差的,稍后去更新)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
如果看到这里,很可能你会疑惑,题目问的明明是学哪个好,我说这些是什么意思?
我用这些篇幅说明了Web应用的业务开发中存在哪些麻烦,每种技术又是来解决什么痛点的,这样,你可以按照自己的需求去,结合业务场景进行分析,然后选择需要的挨个学下去。
其实学API之类的很快,还是要把自己业务中的难点想清楚,带着问题去学,带着需求去学,学**重于学使用,一定能事半功倍。
在过去半年里,我跟一些潜在客户进行了交谈,他们在寻找前端顾问来帮助开发团队控制Angular项目的时候,遇到了麻烦。
尽管有一些对Angular很热情的前端人员,我有种感觉,对于一个主流框架来说,他们的数量还是太少了。我期望Angular能比之前受到更多关注。
Angular更多地是面向企业的IT部门,而不是前端人员。它独特的编码风格,它那种更倾向服务端而不是浏览器侧的对HTML模板系统的封装形式,以及严重而基础的性能问题吓跑了不少人。
我曾经说过,Angular更多的用户是有Java背景的人员,因为它的编码风格是面向他们的。不幸的是,他们没有被培训以认识到Angular的性能问题。
对于Angular 1.x是否适合现代web开发,我表示怀疑。如果有人持有不太客气的倾向,他会把它描述成一个:非前端人员做给非前端人员用的前端框架。
Angular 2.0被提出了激进的改写,意图使它更符合前端人员的口味,但我怀疑他们所感兴趣的是另外一个MVC框架了。此外,重写有可能会疏远Angular的当前目标受众。
如果你想要知道为什么我有这些想法,恐怕要把这篇长文章看完了。
我感觉到Angular的基本理念在前后端之间模糊不清。看一看这个示例代码吧,这是我拉过来的真实的东西:
<body>
<h2>Todo</h2>
<div ng-controller="TodoController">
<span>{{remaining()}} of {{todos.length}} remaining</span>
[ <a href="" ng-click="archive()">archive</a> ]
<ul class="unstyled">
<li ng-repeat="todo in todos">
<input type="checkbox" ng-model="todo.done">
<span class="done-{{todo.done}}">{{todo.text}}</span>
</li>
</ul>
<form ng-submit="addTodo()">
<input type="text" ng-model="todoText" size="30"
placeholder="add new todo here">
<input class="btn-primary" type="submit" value="add">
</form>
</div>
</body>这代码让我想起了一个简单的服务端脚本语言,比如JSP或者ASP,它们使用数据库的内容来填充HTML模板。这些语言在web开发栈中有一席之地——但是在服务端,而不是浏览器端。
上个月,我在一个大型的荷兰公司参与了项目,它们庞大的网站使用了各种小部件和设计模式,做相同的事情,但不是来源于通用的代码库,整个网站间充斥复制/粘贴。这显然是个不受欢迎的状况。
他们转向Angular以解决这个问题,包括把所需的部件集中化。虽然模板是正确的解决方案,在浏览器中这么做却是根本错误的。应用程序维护的成本不应转移到所有用户的浏览器(在这里,我们所讨论的是每个月数以百万计的点击)中——尤其它们不是移动浏览器。这个事情是属于服务端的。
严格来说,这不是Angular的问题,而是这个公司使用Angular进行的实现所致。然而,从逻辑上讲,是Angular,在所有JavaScript 框架中,把这个问题更深化了。它的类似JSP的品质,允许了,甚至鼓励了这种行为。
Angular是面向大型企业的IT后端和经理们的,他们被JavaScipt疯狂扩散的工具们搞迷糊了。在一篇优秀的文章中,Andrew Austin描述了在企业IT中Angular的状况:
对整个团队都属于Google的AngularJS团队,有很多积极的看法。首先,有商业实体控制的框架通常是比较积极的,因为它完全避免了政治派系之间的斗争。在开源世界,这种内讧是公开的,严重的,影响到团队构建伟大软件的目标。
企业IT经理们想要背后有一个大公司良好维护的代码,这样他们不用担心突然就得不到支持了。此外,Google在web技术方面名声较好,所以,如果他们推出一个JavaScript库,那必须是非常好啊……是不是?
企业IT经理也喜欢这么一个事实:Angular对后端开发人员友好。我用Twitter跟weather.com的Joe Pearson进行了讨论,他告诉我,最近转向Angular,主要是为了Java开发人员。Angular所使用的代码构建方式很适合他们,但对他们的前端人员却并非如此。从我客户那里得到的消息,是他们的Java开发人员决定使用Angular。
换句话说,Angular出了吸引经理们,还打动了Java开发人员。框架与恰当的应用程序结构概念相结合,一切都不是意外。Google的目标是征服企业市场,Angular是它的工具之一。
另一方面,很多前端人员,在JavaScript和浏览器上面花了很多年,已经拥有了自己的编码风格,倾向于对Angular表示怀疑。
这本身不是个问题:人们应当使用适合自己编码风格的框架。不幸的是,Angular的问题太深了。
再看一眼Angular的示例代码吧:
<body>
<h2>Todo</h2>
<div ng-controller="TodoController">
<span>{{remaining()}} of {{todos.length}} remaining</span>
[ <a href="" ng-click="archive()">archive</a> ]
<ul class="unstyled">
<li ng-repeat="todo in todos">
<input type="checkbox" ng-model="todo.done">
<span class="done-{{todo.done}}">{{todo.text}}</span>
</li>
</ul>
<form ng-submit="addTodo()">
<input type="text" ng-model="todoText" size="30"
placeholder="add new todo here">
<input class="btn-primary" type="submit" value="add">
</form>
</div>
</body>在{{}}中的所有代码段都是Angular语句。问题在于,Angular无法发现这些语句,除非解析整个DOM,包括文本阶段和属性值——这过程的开销太大了,特别在移动端。
虽然对于整体性能而言,这不一定是致命的问题,解析整个DOM所花费的时间是需要作为一个问题被指出的。不幸的是,这种性能似乎被Angular所代表的整体所忽略了。
Filament Group的测试报告对Angular来说,不太乐观。尽管作者非常小心地提到,对一个大型、复杂的应用做测试,结果可能更积极些,他们的简单测试应用的Angular版本表现并不好。Ember的也不好,只有Backbone脱颖而出。
Steven Czerwinksi提供了有趣的细节:
每次更新都花费了一段较长时间来创建和销毁DOM元素。如果新视图有不同的行数,或者任何一行的单词数量不同,Angular的ng-repeat指令都会整体创建或销毁DOM元素。这个开销很大。
尽管这篇文章展示了如何简单地解决这个问题,我担心的是,Angular默认的就是这种性能低下的模式。前端框架默认应当使用前端建立的最佳实践。但Angular没有。
即使是Google,似乎也同意它有问题了。在对Angular的批评中,最能让我感到共鸣的文章是来自Daniel Steigerwald 写的Angular.js有什么问题的:
Google不把Angular用在自己的标志产品比如Gmail或Gplus上。
哎,你要吃你自己的狗粮哎。
对于一个普通水平的,只拥有少量前端知识的后端人员来说,这些问题是看不到的。这个框架如它宣传的那样运作,它来自一个在前端技术领域拥有声望的公司,所以,普通水平的后端人员就会默认:这就是前端世界的做事方式。
对很多前端人员而言,最大的问题是,Angular强迫自己用一种指定的方式去干活。Software Improvement Group发布了一份报告指出(我的强调):
使用AngularJS给开发人员提供了一堆好处。……这些好处为AngularJS的流行作出了贡献,当遵守AngularJS的约定时,生产力会更高。
这份报告把这个问题当作了优点,而不是缺点。在一份自认为带个人倾向的JS框架纲要中,Henrik Joreteg的观念就比较负面了:
选择Angular意味着你学习的是如何用Angular这个框架,而不是用JavaScript来解决问题。……我有些开发人员,他们的主要技能是Angular,而不是JavaScript。
因为有必要学习使用Angular的方式去处理事情,这个框架的学习曲线很陡峭。Ben Nadel,一个Angular爱好者,而不是一个反对者,把这个事情可视化了:
换句话说,Angular需要你花很多时间来学习如何使用Angular的方式来做事,有些人会喜欢这样,但另外一些会视之为一种额外负担,对其敬而远之。
这些为什么是问题呢?Angular哪里不对呢?Rob Eisenberg 给出了一个解释:
差不多五年前,当AngularJS刚创建出来的时候,它并不是给开发人员用的。它是一个工具,更倾向于给需要快速创建持久化HTML表单的设计人员用。随着时间推移,它作了改变以适应各种场景,开发人员也用它建造更多、更复杂的应用程序。
关于Angular历史的更多东西,参见Hacker News这个帖子。
我不认为,一个快速原型工具应当被用于复杂的,企业级的生产代码上。
这还没完。同一篇文章中给了另一个担忧的原因:
虽然Angular可以被用于创建移动应用,但它的理念并非为它们设计的。这包括了所有的东西,从我刚提到过的基本的性能问题,到它的路由的能力缺失,以及不能缓存预编译视图,甚至是过于普通的触摸支持。
这个只有5岁大的框架没有为移动端做有效优化,很不可理喻。回到2010年,移动也不是个问题。
不过,我们应该看的不是2010,而是2012年。我记得最早,Google开始推广Angular是2012年中。(这个日期有2012年6月的这篇文章为证,我觉得这可能是最早提到Angular的一篇了)。
在那个时候,Android对Google的未来至关重要,这事已经很明朗了,所以你在推的这个工具要支持你未来的平台,这很重要……是不是?
我想知道,当推出这么一个框架,初衷不是帮助开发人员,包含严重DOM性能问题,未对自家移动平台作优化,这个时候,Google到底在想什么。
Right hand, meet left hand.
别误会:有些前端人员是热衷于的,也存在模块仓库和最佳实践的站点。
我的观点是,我期望有更多前端人员拥抱Angular。我有种感觉,它们的数量少得吓人——看看我的客户们的那些问题,他们找个好的Angular前端顾问有多么难。怎么会这样的呢?
部分的答案是:可能因为Angular设计得更迎合Java开发人员的口味,而不是JavaScript开发人员。这使得前端人员不易接受。不过,编码风格并不是绑死语言的,所以这不是完整的答案。
更重要的原因可能是JavaScript社区的拖后腿。Angular引发了一些严重指责。Alexey Migutsky总结得最好:
Angular.js对大多数项目来说“够好”了,但对于专业Web应用开发(长期维护,在所有现代浏览器上性能可靠,有平滑的UX,对移动设备友好)来说,还是不够好。
我认为他是有发言权的。我在本文中所总结的长篇控诉,特别是性能问题,让我怀疑Angular 1.x能不能适合现代前端工程。Angular要么是一个非前端人员创建的,给非前端人员用的框架,要么是把自己的前端特征藏得太好了。
这也就是为什么我认为在本文的开始引用过的Andrew Austin,当他这么陈述的时候错了:
对一个组织来说,相比雇用jQuery开发人员,雇用AngularJS开发人员可能更难。……但是不要担心,日子一天一天过,越来越多的JavaScript开发人员会发现AngularJS的,他们会用它来创建真正的应用。……相比于雇用有AngularJS经验的开发人员,培训已有的团队,或者雇用那些对学习AngularJS有兴趣的JavaScript多面手会更加容易些。
对于一个前端人员,习惯于用特定方式来做事,迁移到Angular的方式可能比较痛苦。此外,他们反对Angular所导致的性能问题。Angular对前端的敏感点迎合得不够,所以很多前端倾向于无视它。
后端们就没这么麻烦了。他们没有先入为主的前端代码应当如何写的概念,不经过培训的话,也认识不到Angular的性能问题。
我的荷兰客户提到一个事情,加剧了这个问题:一般来说,前端开发者不喜欢企业级应用(企业IT流程,无尽的会议,为了解决简单的问题花很多周,这些的简称),因为它被视为无聊。这导致了前端Angular开发者和顾问更少了。
这也就是为什么多数Angular开发人员来自后端,特别是Java。据我所知,一个前端框架主要由非前端开发者来支撑的情况是独此一家的。
对于提到的这些抱怨和问题的总结,Angular团队并未装聋作哑。在10月的时候,他们宣布了Angular 2.0,这是对1.x的完全背离。为了能上新版本,Angular用户将不得不重新编写网站代码。
为什么需要这么激进的变更呢,很容易理解。为了给Angular一个重大性能提升,需要抛弃启动时候解析{{}}DOM的开销。为了这么做,语法必须改变,这会对开发过程造成严重后果。我想说,Angular 2.0需要开发人员在HTML模板中嵌入更少的应用逻辑,更多地放在脚本中。
我认为,这种激进的重写基本是瞄准前端人员的,他们将获得更好的性能,更符合自己对JavaScript框架预期的语法。
然而,这带来最大的代价就是会疏远最大的用户群体。企业IT选择Angular,期望能幸免于这样突然,关键的变化。采用Angular2.0会需要他们重新分配预算来重写已经在运行的代码。此外,我想知道有Java背景的人怎样看待新代码风格。
基于这些原因,我认为很多企业用户会坚守1.x,无视2.0。当然,Google最终会停止支持1.x的。因此,我认为Google想要使用Angular打破企业级前端的堡垒,在最近两三年内还是不会成功的。
虽然企业IT的背叛可以被前端人员的青睐所抵消,但Angular从此在他们心中印象就不好了。此外,前端界现在也不需要另外一个MVC框架。
尽管有严重的技术问题,Angular 1.x还是一个较大的成功,尤其是在拥有Java背景的企业开发人员中。2.0的重写是瞄准前端开发人员的,但不会对他们有太多好处,反而会失去一些当前的拥趸。我不认为Angular的新版能生存下去。
接触AngularJS已经两年多了,时常问自己一些问题,如果是我实现它,会在哪些方面选择跟它相同的道路,哪些方面不同。为此,记录了一些思考,给自己回顾,也供他人参考。
初步大致有以下几个方面:
Angular实现了双向绑定机制。所谓的双向绑定,无非是从界面的操作能实时反映到数据,数据的变更能实时展现到界面。
一个最简单的示例就是这样:
<div ng-controller="CounterCtrl">
<span ng-bind="counter"></span>
<button ng-click="counter=counter+1">increase</button>
</div>function CounterCtrl($scope) {
$scope.counter = 1;
}这个例子很简单,毫无特别之处,每当点击一次按钮,界面上的数字就增加一。
初学AngularJS的人可能会踩到这样的坑,假设有一个指令:
var app = angular.module("test", []);
app.directive("myclick", function() {
return function (scope, element, attr) {
element.on("click", function() {
scope.counter++;
});
};
});
app.controller("CounterCtrl", function($scope) {
$scope.counter = 0;
});<body ng-app="test">
<div ng-controller="CounterCtrl">
<button myclick>increase</button>
<span ng-bind="counter"></span>
</div>
</body>这个时候,点击按钮,界面上的数字并不会增加。很多人会感到迷惑,因为他查看调试器,发现数据确实已经增加了,Angular不是双向绑定吗,为什么数据变化了,界面没有跟着刷新?
试试在scope.counter++;这句之后加一句scope.digest();再看看是不是好了?
为什么要这么做呢,什么情况下要这么做呢?我们发现第一个例子中并没有digest,而且,如果你写了digest,它还会抛出异常,说正在做其他的digest,这是怎么回事?
我们先想想,假如没有AngularJS,我们想要自己实现这么个功能,应该怎样?
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>two-way binding</title>
</head>
<body onload="init()">
<button ng-click="inc">
increase 1
</button>
<button ng-click="inc2">
increase 2
</button>
<span style="color:red" ng-bind="counter"></span>
<span style="color:blue" ng-bind="counter"></span>
<span style="color:green" ng-bind="counter"></span>
<script type="text/javascript">
/* 数据模型区开始 */
var counter = 0;
function inc() {
counter++;
}
function inc2() {
counter+=2;
}
/* 数据模型区结束 */
/* 绑定关系区开始 */
function init() {
bind();
}
function bind() {
var list = document.querySelectorAll("[ng-click]");
for (var i=0; i<list.length; i++) {
list[i].onclick = (function(index) {
return function() {
window[list[index].getAttribute("ng-click")]();
apply();
};
})(i);
}
}
function apply() {
var list = document.querySelectorAll("[ng-bind='counter']");
for (var i=0; i<list.length; i++) {
list[i].innerHTML = counter;
}
}
/* 绑定关系区结束 */
</script>
</body>
</html>可以看到,在这么一个简单的例子中,我们做了一些双向绑定的事情。从两个按钮的点击到数据的变更,这个很好理解,但我们没有直接使用DOM的onclick方法,而是搞了一个ng-click,然后在bind里面把这个ng-click对应的函数拿出来,绑定到onclick的事件处理函数中。为什么要这样呢?因为数据虽然变更了,但是还没有往界面上填充,我们需要在此做一些附加操作。
从另外一个方面看,当数据变更的时候,需要把这个变更应用到界面上,也就是那三个span里。但由于Angular使用的是脏检测,意味着当改变数据之后,你自己要做一些事情来触发脏检测,然后再应用到这个数据对应的DOM元素上。问题就在于,怎样触发脏检测?什么时候触发?
我们知道,一些基于setter的框架,它可以在给数据设值的时候,对DOM元素上的绑定变量作重新赋值。脏检测的机制没有这个阶段,它没有任何途径在数据变更之后立即得到通知,所以只能在每个事件入口中手动调用apply(),把数据的变更应用到界面上。在真正的Angular实现中,这里先进行脏检测,确定数据有变化了,然后才对界面设值。
所以,我们在ng-click里面封装真正的click,最重要的作用是为了在之后追加一次apply(),把数据的变更应用到界面上去。
那么,为什么在ng-click里面调用$digest的话,会报错呢?因为Angular的设计,同一时间只允许一个$digest运行,而ng-click这种内置指令已经触发了$digest,当前的还没有走完,所以就出错了。
在Angular中,有$apply和$digest两个函数,我们刚才是通过$digest来让这个数据应用到界面上。但这个时候,也可以不用$digest,而是使用$apply,效果是一样的,那么,它们的差异是什么呢?
最直接的差异是,$apply可以带参数,它可以接受一个函数,然后在应用数据之后,调用这个函数。所以,一般在集成非Angular框架的代码时,可以把代码写在这个里面调用。
var app = angular.module("test", []);
app.directive("myclick", function() {
return function (scope, element, attr) {
element.on("click", function() {
scope.counter++;
scope.$apply(function() {
scope.counter++;
});
});
};
});
app.controller("CounterCtrl", function($scope) {
$scope.counter = 0;
});除此之外,还有别的区别吗?
在简单的数据模型中,这两者没有本质差别,但是当有层次结构的时候,就不一样了。考虑到有两层作用域,我们可以在父作用域上调用这两个函数,也可以在子作用域上调用,这个时候就能看到差别了。
对于$digest来说,在父作用域和子作用域上调用是有差别的,但是,对于$apply来说,这两者一样。我们来构造一个特殊的示例:
var app = angular.module("test", []);
app.directive("increasea", function() {
return function (scope, element, attr) {
element.on("click", function() {
scope.a++;
scope.$digest();
});
};
});
app.directive("increaseb", function() {
return function (scope, element, attr) {
element.on("click", function() {
scope.b++;
scope.$digest(); //这个换成$apply即可
});
};
});
app.controller("OuterCtrl", ["$scope", function($scope) {
$scope.a = 1;
$scope.$watch("a", function(newVal) {
console.log("a:" + newVal);
});
$scope.$on("test", function(evt) {
$scope.a++;
});
}]);
app.controller("InnerCtrl", ["$scope", function($scope) {
$scope.b = 2;
$scope.$watch("b", function(newVal) {
console.log("b:" + newVal);
$scope.$emit("test", newVal);
});
}]);<div ng-app="test">
<div ng-controller="OuterCtrl">
<div ng-controller="InnerCtrl">
<button increaseb>increase b</button>
<span ng-bind="b"></span>
</div>
<button increasea>increase a</button>
<span ng-bind="a"></span>
</div>
</div> 这时候,我们就能看出差别了,在increase b按钮上点击,这时候,a跟b的值其实都已经变化了,但是界面上的a没有更新,直到点击一次increase a,这时候刚才对a的累加才会一次更新上来。怎么解决这个问题呢?只需在increaseb这个指令的实现中,把$digest换成$apply即可。
当调用$digest的时候,只触发当前作用域和它的子作用域上的监控,但是当调用$apply的时候,会触发作用域树上的所有监控。
因此,从性能上讲,如果能确定自己作的这个数据变更所造成的影响范围,应当尽量调用$digest,只有当无法精确知道数据变更造成的影响范围时,才去用$apply,很暴力地遍历整个作用域树,调用其中所有的监控。
从另外一个角度,我们也可以看到,为什么调用外部框架的时候,是推荐放在$apply中,因为只有这个地方才是对所有数据变更都应用的地方,如果用$digest,有可能临时丢失数据变更。
很多人对Angular的脏检测机制感到不屑,推崇基于setter,getter的观测机制,在我看来,这只是同一个事情的不同实现方式,并没有谁完全胜过谁,两者是各有优劣的。
大家都知道,在循环中批量添加DOM元素的时候,会推荐使用DocumentFragment,为什么呢,因为如果每次都对DOM产生变更,它都要修改DOM树的结构,性能影响大,如果我们能先在文档碎片中把DOM结构创建好,然后整体添加到主文档中,这个DOM树的变更就会一次完成,性能会提高很多。
同理,在Angular框架里,考虑到这样的场景:
function TestCtrl($scope) {
$scope.numOfCheckedItems = 0;
var list = [];
for (var i=0; i<10000; i++) {
list.push({
index: i,
checked: false
});
}
$scope.list = list;
$scope.toggleChecked = function(flag) {
for (var i=0; i<list.length; i++) {
list[i].checked = flag;
$scope.numOfCheckedItems++;
}
};
}如果界面上某个文本绑定这个numOfCheckedItems,会怎样?在脏检测的机制下,这个过程毫无压力,一次做完所有数据变更,然后整体应用到界面上。这时候,基于setter的机制就惨了,除非它也是像Angular这样把批量操作延时到一次更新,否则性能会更低。
所以说,两种不同的监控方式,各有其优缺点,最好的办法是了解各自使用方式的差异,考虑出它们性能的差异所在,在不同的业务场景中,避开最容易造成性能瓶颈的用法。
作为Web前端,你幸福吗?
每隔18个月,前端都要难一倍。
每一年,前端都会冒出更多的概念,更多的框架/库,更多的实践。
2015年,前端有哪些东西转入流行?
但是,在这关键的一年里,Angular社区相对来说,有些沉寂了,主要原因是Angular自身处于一个剧烈变革期,1.x已经趋向成熟,难有本质提升,而2.0尚未有正式发布的消息。
2015年被黑得最多的主流前端组件化框架是什么?Angular。
黑得最漂亮的一句:
其实是 java 程序员把他们习惯的那一套『仪式感』带入了前端框架导致的。
——尤雨溪
Angular最近在搞的2.0版本,变更可谓剧烈,几乎完全是个新框架。但如果我们关注过1.x版本的演进,就会发现,它也曾经历过不少变革。我们所能看到的变化,其实都是有伏笔的,而Angular官方也在努力做一些事情,让这两代之间能尽量衔接起来。
每个框架在发展过程中,都经历过一次一次的自我革新,那么,Angular经历了什么?
这些变更,分别都有怎样的含义呢?
在1.2版本之前,我们这样写一个控制器:
angular.module("app").controller("DemoCtrl", ["$scope", function($scope) {
$scope.arr = [0, 1, 2, 3];
$scope.addItem = function() {
$scope.arr.push($scope.arr.length);
};
}]);然后这样使用它:
<div ng-controller="DemoCtrl">
<button ng-click="addItem()">add item</button>
<ul>
<li ng-repeat="item in arr">{{item}}</li>
</ul>
</div>在1.2版本之后,我们有了controllerAs,可以不必注入$scope了:
angular.module("app").controller("DemoCtrl", [function() {
this.arr = [0, 1, 2, 3];
this.addItem = function() {
this.arr.push(this.arr.length);
};
}])然后这样使用它:
<div ng-controller="DemoCtrl as demo">
<button ng-click="demo.addItem()">add item</button>
<ul>
<li ng-repeat="item in demo.arr">{{item}}</li>
</ul>
</div>更进一步,还可以把上面的逻辑代码改造成这样:
angular.module("app").controller("DemoCtrl", [Demo]);
function Demo() {
this.arr = [0, 1, 2, 3];
}
Demo.prototype.addItem = function() {
this.arr.push(this.arr.length);
};经过这样的转变,我们可以发现,原先的“controller”很清晰了,变成了很纯净的视图模型。这给我们带来的好处是,这一层的东西更容易测试和迁移。
使用controllerAs语法还有一个好处,可以做到逻辑代码的跨版本通用性,甚至是跨框架通用性。
在Angular 1.x的整个发展过程中,一直有人在质疑它的性能,为此,开发组也进行了大量的优化。
因为1.x采用的是脏检查的方式来判断数据变更,所以,如何提升变动项的查找会是一件比较重要的事。从1.0到1.4,几乎每个版本都在这个方面作了一些提升,尽可能压榨出更高的性能来。
Angular也添加了诸如单次绑定之类的特性,以减少对初次加载,但不再变更的变量的追踪。
业界有不少类似的框架使用的是存取器做数据变更观测,Angular2使用zone.js来观测数据变更。
脏检查的原理是:我们所有的对数据的赋值,都是在某些特性场景下触发的,比如:
如果在每次操作之后,对数据保留一份复制,然后下一次再有事件发生的时候,把新老数据进行比对,就可以判定哪些数据产生了变更,从而可以更新关联的界面。
而zone.js更像是一种“多线程”的技术。它把数据的变更过程利用worker切换出去,等执行完了再更新回来,这样就不会阻塞主线程,这是一个非常有创意的做法,因此,Angular2的渲染性能是比较好的。
这种理念在Web开发中前所未有,但是其实在其他一些客户端领域早有实践。
在Angular 1.4之前版本中,并未刻意强调组件化的理念,业务开发人员拥有较高的自由度,比如说,可以选择使用directive,用自定义元素、自定义属性的方式来实现一定程度的组件化,也可以直接使用ng-include和路由,以比较松散的方式完成业务功能。
但是在1.5版本中,新的组件注册语法诞生了,这就是components。
angular.module("app", []).component('counter', {
bindings: {
count: '='
},
controller: function () {
function increment() {
this.count++;
}
function decrement() {
this.count--;
}
this.increment = increment;
this.decrement = decrement;
},
template: [
'<div class="todo">',
'<input type="text" ng-model="counter.count">',
'<button type="button" ng-click="counter.decrement();">-</button>',
'<button type="button" ng-click="counter.increment();">+</button>',
'</div>'
].join('')
});这样使用:
<div ng-controller="CountCtrl as vm">
<counter count="vm.count"></counter>
</div>在Angular 2中,组件化更是变成了一种强制的理念。一个组件包含以下部分:
注意到在这里,我们不再有controller,service,directive这些概念,因为都已经转化为纯粹的ES模块。其中,组件可大致对等于以前的directive,只是配置方式更加友好了。
@Component({
selector: 'basic-routing',
directives: [ ROUTER_DIRECTIVES],
template: `<a [router-link]="['/Home']">Home</a>
<a [router-link]="['/ProductDetail']">Product Details</a>
<router-outlet></router-outlet>`
})
@RouteConfig([
{path: '/', component: HomeComponent, as: 'Home'},
{path: '/product/', component: ProductDetailComponent, as: 'ProductDetail' }
])
class RootComponent{}尽管粗略看上去,这段代码会比较奇特,但你可以这么想:主体逻辑都是放在普通的class里,剩下的组件相关的配置放在注解中。这样一想,就没有那么别扭了。
Angular 1.x早期自带的路由ngRoute比较简单,可以满足最基本的业务开发需求。
但是,在很多较复杂业务中,子路由成为了比较迫切的需求,我们可能会需要路由的嵌套,或者平级存在多个路由,因此,很多开发者选用了第三方的路由库uiRouter。
这两种路由配置方式都是典型的集中式配置,集中式路由在跟踪、定位等方面有优势,但绝大部分情形下,不灵活。
路由的实质是什么?是组件关系的一种映射,既然是这样,集中化的配置会导致,每当组件包含关系有变化,就可能需要修改全局配置,这是不太好的。
如果构建一个全组件化的系统,我们每个组件实际上只关注自身和所包含的子组件的url映射,基于这个理念,就有了Angular2的路由系统。
Angular2的路由是组件式路由,分散定义在每个组件上,并且,管理了所在组件的一些生命周期。
比如上一节的例子中,我们可以看到:
@RouteConfig([
{path: '/', component: HomeComponent, as: 'Home'},
{path: '/product/', component: ProductDetailComponent, as: 'ProductDetail' }
])这段代码是个路由配置,指明了本组件下属两个组件,分别有不同的url,它们会被加在到模板中的router-outlet部分中:
template: `<a [router-link]="['/Home']">Home</a>
<a [router-link]="['/ProductDetail']">Product Details</a>
<router-outlet></router-outlet>` 在1.4版本中,Angular引入了ngNewRouter,实际上这个就是Angular2的兼容版本,理念完全一致。
基于这套路由机制,我们可以通过canDeactivate,deactivate,canActivate,activate等方法来更好地控制组件的生命周期。
在使用Angular 1.x的时候,我们可以使用ES3进行开发,也可以使用ES5,尤其是后者,目前绝大部分主流浏览器都支持,所以可以直接使用,使用ES5编写纯逻辑代码会是一件比较舒服的事情。
但我们也可以用ES6,CoffeeScript,TypeScript之类的语言去编写Angular 1.x应用,只是需要进行一些转化,因为它们不是Angular 1.x的默认开发语言。
到2.0的时代,官方推荐用来开发Angular应用的语言就变成了TypeScript和ES6了,严格的语法检查和各种增强特性,使得开发过程变得更加准确高效。
到现在这个时间点,因为Babel之类转译工具的极大发展,前端又普遍对构建过程逐渐习惯,使用ES6和TypeScript的好处已经远远大于坏处了,所以可以从现在开始就立刻切换到这些语言,无论是在用Angular 1.x还是将来要使用2.0。
如果用过Angular2的HTTP模块,会发现跟1.x版本的已经很大不同了。
假如我们要实现一个mapData,从远程请求到一个数值数组,把里面每个元素乘以2之后,再传递给下一个方法。
在1.x里,我们是这样写的:
function mapData() {
return $http.get(url)
.then(result => result.data)
.then(data => data.map(item => item * 2));
//下面的写法不必要,因为内部非异步,感谢@imcotton提醒
/*
var defer = $q.defer();
$http.get(url).then(function(result) {
var newData = result.map(function(item) {
return item * 2;
});
defer.resolve(newData);
});
return defer.promise;
*/
}但是在2里面,是这样写:
function mapData() {
return Http.get(url).map(item =>item * 2);
}可以看到,这两者有不少差别。1.x的$http.get方法,返回结果是个Promise,所以,如果要持续传递下去,我们也要新建一个Promise并且返回。但是在2里面,Http.get的返回类型是RX Observable,它对很多东西的处理方式会不太一样,所以业务代码的写法也会有所不同,从代码上看,会有很明显的简化。
粗略一看,可能觉得这个RX Observable的例子没什么奇特的,即使你返回一个普通的数组,它也可以map啊,可以reduce,可以filter之类,仍然能传递下去,但RX的这个还可以subscribe之类,像这样:
Http.get(url).map(item => item * 2)
.subscribe(result => {
this.todoList.push(result);
});这类特性能很大程度上减少我们实现业务功能所需的代码量。
参阅:RxJS
综合以上,我们发现Angular从1.x到2.0的发展过程中,出现了这样一些变革:
这些变革体现了Angular在往一个强大而灵活,复杂而高效的前端组件化框架方向努力。
对自我的彻底革新,并不代表过去“错了”,而是代表过去曾经辉煌过的一些东西,随着时代的发展,渐渐走向过时。如果一个东西不随着时代的发展而修正自己,很快就会被历史的车轮无情碾过。(上面一句请勿联想,不主动不拒绝不承认不负责)
JavaScript框架/库一直就是百花齐放,最近几年更是层出不穷。回顾这几年,有两个最引人注目的东西,一个是Angular,一个是React。其中,Angular最火的时间是2013年中到2014年末,React从2014年中开始升温,然后又由于ReactNative等周边项目,导致关注度很高。
2014年末,Angular官方宣布了一个大新闻,要完全重写Angular 2.0。这个事情让很多想要使用Angular的人止步不前,也给很多人带来了困惑。
随后,Angular 2.0的开发者之一创建了新的框架Aurelia,整体思路上与Angular相似,有一些细节的差异。那么,我们应当如何看待这些框架呢?
如果不是有重大原因,没有哪个开发者会做出彻底重写,产生很多不兼容变更的决定。对于Angular来说,它面临这么一些原因:
也正是Angular 2.0那篇大新闻,使大家知道了AtScript这样的语言,它在TypeScript的基础上添加了注解等功能。
有很多语言可以转译成JavaScript,比如CoffeeScript,Dart,TypeScript等,从最近的一些事件来看,TypeScript可以算是JavaScript转译领域的最大赢家。
很多人可能会有这样的疑问:为什么我们要用这些东西,而不是直接编写原生的JavaScript?开发语言的选择,很大程度上反映了我们对JavaScript组件化方案抽象度的需求。
比如说,Angular中,可以使用TypeScript来写业务代码,React中,通过JSX来使用组件,这都是具有较高抽象度的方案,能够让业务代码变得更直观。
先不看这些转译语言,来看看ES6,它给我们带来了很多编程的便利,每一次这种语言细节的升级,都引入了一些好用的东西,所以我们当然是期望尽早使用它。但问题是,浏览器的支持程度总是落后的,如果用它写了,在很多浏览器上不支持,比如箭头函数:
this.removeTodo = function(todo) {
this.todos = this.todos.filter(item => todo!=item);
};所幸,我们有Babel这样的转换器,可以把这样的代码翻译成ES5代码,它的生成结果就是
this.removeTodo = function(todo) {
this.todos = this.todos.filter(function(item) {
return todo != item;
});
};这个例子并不明显,如果你使用class之类的东西,就能体会到更大的改变。虽然说class这些只是语法糖,但用起来还是很爽的,可以复用一些传统的设计模式之类。
对于那些只需支持ES5+的项目而言,现在开始选用ES6语法编写代码是非常合适的,因为我们有Babel这样的东西,我们可以享受ES6新语法带来的愉悦编程体验,而无需承担兼容风险。
ES6新语法有很多,想要在生产过程中更好地使用,可以参见百度ecomfe的这篇使用ES6进行开发的思考
Angular和Aurelia都支持TypeScript,可以直接使用TypeScript编写业务代码。如果选用这样的框架,个人建议直接使用TypeScript。
为什么在类似Angular这样的体系里,我要建议使用TypeScript呢,因为这么几个原因:
很可能在现在这个阶段,你的项目还需要面对一些不支持ES6的浏览器,所以不能直接写ES6代码,但有可能有一天,浏览器支持了,但你的代码还是老的,它基本上还在使用ES5编写,想要迁移到ES6比较麻烦,以后每次迁移都是痛苦的过程。TypeScript就是以生成JavaScript为目标的,所以如果你用它写,只需选择生成参数,比如生成es5,es6就可以了,就算以后es继续升级,也只要改个参数就完事。
TypeScript为代码提示作了很多特殊优化,比如:
ele.on("click", function(e) {
// 这里我们是不知道e上面有什么,在编写的时候得不到提示
});但是如果使用TypeScript编写,因为这个e的类型确定,所以就能有提示。
使用这样的语言也能够更快让非前端方向的人参与项目。
Angular的整体方案,由于分层很清晰,在JavaScript代码中基本就是纯逻辑,这样的代码如果使用TypeScript编写,会更加精炼,更加清晰。
这几年,大家逐渐接受了一个现实,那就是:前端也是需要构建的,所以我们有grunt,gulp这样的构建工具。之前我们不愿意写转译语言,是因为其他环节不需要构建,为了一些语法糖而引入整个构建环节代价太大。现在,既然发布之前的构建环节不可缺少,使用转译语言也不过就是加一段配置而已,这个使用代价已经小很多了。
Angular这样的解决方案,所面向的多数都是重量级产品,这些产品本身就会有构建环节,也基本上会使用IDE,所以,使用TypeScript的代价不大。
当项目变大的时候,我们会面临很大的管理成本,比如对代码的分析,结构调整,模块依赖关系梳理等,在TypeScript上面做,会比在JavaScript上面做更有优势。
最近几年前端领域“工程化”这个词被说得太多,但其实绝大部分说的都只是“工具化”。早在Visual Studio 2005中,就存在很多Factory插件,举例来说,一个普通项目的工作流程可能是这样:
比如说我们做到一半,需要变更模型,也只是需要在ER图那边修改,然后依次一键变更过来。很多时候我们也会有代码的目录调整,批量更名,如果使用约束较强的语言,这部分可靠性会更高。
如果用过angular 1.x,会对它的路由机制印象深刻。有复杂业务需求的人一般都不会使用内置的ng-route,而是会使用第三方的ui-router,这两者的核心差别是子路由的定义。
比如:
A界面有两个选项卡,分别B,C,如果我们想要:
app.html#a/b
app.html#a/c
这样的多级路由,在ng-route中想要定义,就比较麻烦,而在ui-router中,允许使用嵌套的ui-view指令,可以比较方便地支持这一功能。
在这两种方式下,路由都是全局配置的,但我们考虑在全组件化的场景下,组件的嵌套会受到这种路由配置的制约。比如,本来我们只是期望把某个组件嵌入到另外一个组件中,就能完成功能,但为了路由,不得不额外在全局路由配置的地方,加一个配置,而且每当组件层级发生变更的时候,这个配置都需要改,这就大幅拖累了我们组件体系的灵活度。
为此,我们可能会期望把路由配置放在每个组件中,比如说,组件A定义自己的路由为a,组件B的路由为b,组件C的路由为c,无需额外的配置,当B和C放在A中作为选项卡的时候,上面那两条路由会自动生效。
在Angular的新路由机制中,就是这样处理的,这也是Angular 2.0和Aurelia的共同路由机制。在这种机制下,如果有一天我们在另外一个更高层的组件D中,引入了组件A,那路由就会自己变成类似:
app.html#d/a/b
app.html#d/a/c
这个是非常灵活的,这对于我们构建一个全组件化的系统很有利,另外,这实际上实现了路由的动态配置。
当然,对这个问题,也是有争议的,因为路由不再集中配置,很难有一个地方能查看所有的路由状况了。
此外,由于在Angular 2和Aurelia中都凸显了组件的概念,组件的生命周期被引入了,比如说,组件的四个状态:
这些跟路由进行配合,可以把我们的加载过程,前置、后置条件过程都整理得很清楚。
最近,越来越多的人开始关注Web相关标准的推进,在HTML这个方面,最重要的标准就是Web Components,它主要是提供扩展HTML元素的能力(Custom Elements)。
HTML is great for declaring static documents, but it falters when we try to use it for declaring dynamic views in web-applications. AngularJS lets you extend HTML vocabulary for your application. The resulting environment is extraordinarily expressive, readable, and quick to develop.
这一段来自Angular的官方介绍。扩展HTML的词汇,是Angular的一种愿景,在这个里面,除了包含对元素的扩展,还有属性(Attribute)。
很多时候,仅仅有元素的扩展,是不足以满足需求的。举例说,让某个按钮闪烁,我们有两种方式实现:
其中,前者是特定的解决方案,创建一个自定义元素<blink-button></blink-button>可以达到目的,但闪烁这个动作可以是一种通用行为,我们可能需要让图片闪烁,让链接闪烁,让各种元素都能闪烁,把这种行为扩展到不同的元素上。
如果用jQuery,我们可能会写:
$.fn.blink = function(options) {
// 这里对DOM进行处理,添加闪烁功能
};然后在使用的时候:
$('.some-element').blink();如果说有自定义属性,可能我们就只要写:
<span blink>aaa</span>
<a blink>aaa</a>
<button blink>aaa</button>借助数据绑定,还可以把blink绑定到一个变量上,由这个变量动态控制是否闪烁。
<div blink="hasNewMessage">aaa</div>在Angular 1.x中,使用指令(directive)来实现自定义元素和自定义属性,这个东西设计得很复杂,所以不太容易上手,在2.0中,这一块改了。
在Angular 2和Aurelia中,使用很简单的标记来表明某个东西是自定义元素还是属性。
@customAttribute('blink')
@inject(Element)
export class Blink {
element:any;
constructor(element) {
this.element = element;
}
}@customElement('my-calendar')
export class Calendar {
}自定义属性的理念,在早期IE中实现的HTML Components中有很好的体现,它允许使用JavaScript编写DOM元素相关的代码,然后在css中作为行为附加到选择器上。
对于大型Web应用来说,组件化是必须的,但是如何实现组件化,每个人都有自己的看法,所以组件化这个词就像**,法制一样,容易谈,难做。
我们所期望的组件化往往是这样:

但实际上,很可能是这样:

实际在用组件,尤其UI组件的时候,会出现很多尴尬的地方,比如说同一个组件在不同场景下形态不一致,所以我们需要多个层次的组件复用级别。
在Angular 1.x中,组件化并不是一个很明确的概念,它的整体思路还是:逻辑层+模板层这样的概念,此外,有一些指令(directive),用于表达对HTML标签、属性的增强。
在2.0版本中,组件成为了一个很清晰的东西。一个常见的组件,包含界面模板片段和逻辑类两个部分。
如果我们经历过Angular 1.2之前的版本,可能会感受到controller的一些变化。比如说,之前我们写一个controller,可能是:
function TestCtrl($scope) {
$scope.counter = 0;
$scope.inc = function() {
$scope.counter++;
};
}然后这样用:
<div ng-controller="TestCtrl">
{{counter}}
<button ng-click="inc()">+1</button>
</div>在1.2之后,我们会这样写:
function TestCtrl() {
this.counter = 0;
this.inc = function() {
this.counter++;
};
}然后这样用:
<div ng-controller="TestCtrl as test">
{{test.counter}}
<button ng-click="test.inc()">+1</button>
</div>注意TestCtrl的实现,里面没有$scope了,这意味着什么呢?意味着这个“controller”已经不再是controller了,而是view model,这个部分的代码变得更加纯净,每有一个对应的界面片,就实例化一个出来与之对应绑定。
在Angular 2和Aurelia里面,HTML模板与视图模型被视为一体,当做一个组件,而Aurelia的灵活度更高,因为它尽可能地把额外的配置放在HTML模板中,所以视图模型变得更单纯,也存在复用价值了。
Aurelia跟Angular 2有不少细节差异,写法上大致的对比可以从这里看出:Porting an Angular 2.0 App to Aurelia
Angular支持使用pojo作为数据模型,这可以算是它的优点之一,这样,它对模型层的定义就比BackBone和Knockout简洁很多。
但是在2.0时代,我个人是倾向于预定义模型类型的,因为在MVVM这三层中,不宜过于淡化VM和M的分界,分清哪些东西是从属于模型的,哪些东西是从属于视图模型,在很多情况下都会很重要。这会影响我们另外一些工程策略,比如测试环节的处理方式。
在大型应用中,model应当与store视为一体,在比如数据的共享,缓存,防冲突,防脏等方面综合考虑,而view model可以不要考虑得这么复杂。
基于MVVM,我们可以在不同层级复用组件,可以把模板和视图模型当做一个整体复用,也可以只复用视图模型,使用不同的模板。在这一点上,Angular 2显然比Aurelia欠考虑。
Angular的这次升级,最令人不满的是它的不兼容变更。这些变更很多方面来说,是无奈之举,因为前后的差距确实有那么大,想要短期平滑,就得在未来背负更重的历史负担。
但事实上,我们在很多场景下,比如企业应用领域,并没有比它更好的解决方案,所以这时候需要来看看如果想要作一个版本迁移,需要做哪些事情。
如果我们要做从Angular 1.x到2.0的代码迁移,相对最容易,也最值得做迁移的部分是数据模型,但这个问题说难也难,说简单也简单。
很多对分层理解不深的人,很可能把这个代码迁移想得过于复杂。但其实,一个规划良好的Angular 1.x工程,它的代码结构应该是非常有序的,什么东西放在模板里,什么东西放在controller,service,都是非常清楚的,而且,绝大多数controller和service中,是不应有DOM相关的代码的。
比如,service中是什么?主要是数据模型的存取,与服务端的交互,本地缓存,公共方法等,这些东西要迁移到2.0中,是很容易的,只是写法会稍有差别。
接下来往上看看,看这个所谓的controller。在2.0中,不再有controller,service这些东西的区分,一切都是普通的ES类,但是理念还是有的。比如一个含有视图的组件,它的逻辑部分就会是一个ES类,这个也就是视图模型,基本上也就对等于1.x中的controller。
比如最简单的todo:
function TodosCtrl() {
this.todos = [];
this.newTodo = {};
this.addTodo = function() {
this.todos.push(this.newTodo);
this.newTodo = {};
};
this.removeTodo = function(todo) {
this.todos = this.todos.filter(function(item) {
return item != todo;
});
};
this.remainingCount = function() {
return this.todos.filter(function(item) {
return item.finished;
}).length;
};
}这代码很简单,就是给一个列表添加移除东西,假设我们要把这个代码移植到2.0,可以说基本没有代价,因为在2.0里你要实现这样的功能,也得这么写。
(注意,下面这段是Aurelia代码,并且不是使用ES6,而是使用TypeScript编写)
export class Todos {
public todos: Array<Object> = [];
public newTodo: Object = {};
addTodo(): void {
this.todos.push(this.newTodo);
this.newTodo = { content: "" };
}
removeTodo(todo): void {
this.todos = this.todos.filter(item => todo != item);
}
get remainingCount() {
return this.todos.filter(item => item["finished"]).length;
}
}这么一看,好像也很容易迁移过去,多数情况下是这样,但这里面有坑。坑在什么地方呢?主要是手动添加变更检测的部分。变更检测是个复杂的话题,在本文中先不讲,后面专门写一篇来讲。
现在我们把逻辑层摆平了,来看界面层,这里主要有三个东西,一个是原先的指令,一个是普通的模板,还有一个是过滤器。
指令的问题好办,我们刚才提到的自定义元素,自定义属性,其实对使用者是没什么差别的,也就是实现的人要把代码迁移一下。
我个人并不赞同在一个业务型的项目中封装太多自定义元素,仅仅那种被称为“控件”的东西才有这个必要,其他东西可以直接采用模板加视图模型的方式,具体理由在前一篇的组件化之路中提到过。如果是按照这种理念去实现的业务项目,指令这块迁移成本也不算高。
过滤器也很好办,2.0 有同样类似的机制实现。
普通模板这边,绝大部分都是固定的工作量,比如ng-repeat,ng-click换个写法而已,里面有一些影响,但基本上是可以用批量转换去搞定的。
所以我们发现,迁移的成本并没有想象的那么大,为了更好地拥抱Web标准和更好的性能,这样的事情是比较值得去做的。
这两种东西代表着现代Web前端的两种方法论,前者是以分层和绑定为核心的大一统框架,后者提供了渲染模型多样化,带生命周期的多层组件机制。由于实现理念的不同,用它们分别开发同样的Web应用也会有很大差异。好比我们造一个仿生机器人,用Angular是先造完骨架,把基本运动功能调试完,然后加装肌肉等部件,最后贴皮肤,眉毛,头发,指甲;用React是先造出各种器官,肢体,然后再拼装。
方法论的事情那个很难说对错,只有看场景。比如亚洲农民跟美洲农民种地,理念肯定是不同的,因为他们面临的场景不同,比如亚洲种地普遍很精细化,美国种地很粗放。这也有些像React和Angular的差别。
我个人不赞同在框架的问题上有太多争论,因为天下武功,到底什么厉害,完全是看人的,一阳指在段正淳手里,只能算二流,到了南帝段智兴手里,可与降龙十八掌齐名。聚贤庄一战,乔帮主用最普通的太祖长拳,打得天下英雄落花流水。如果深刻理解了一个技术的优点和缺点所在,扬长避短,则无往而不利。
近年来,各框架是在互相学习的过程,但是每个东西到底有什么不同,最好还是列出需求,分别用代码体现。现在已经有todomvc这么一个库,用各种框架实现todo,但在我看来,这个需求还太小,不足以表达各自的优势。
我倡议,每个框架的熟练使用者能够选出一些典型场景,然后写一些demo,供更多的人学习对比之用。
到目前为止,我们在浏览器中看到系统从规模来说都是中小型的,与传统桌面的大型软件们相比,还很幼小。比如Office的开发团队,千人以上的规模,无论是代码的架构,还是人员的分工协作,都可以算是伟大的工程。
在大型系统中,组件化可以说是立足的基础,但怎样去实践组件化的**,是一个见仁见智的话题。
还是以Office为例,它除了提供图形化的操作界面,还提供了一套API,可以被VBA这样的嵌入语言调用。
比如说,我们可以在界面上选中一个工作表,然后在某行某列填入数据,也可以在VBA中使用这样的语句去达到同样的目的
这就意味着,对于同一种操作,存在多样化的外围接口。继续分析下去,我们会发现,存在一种叫做Office Object Model的东西,这也就是一个核心数据模型,我们所有的操作其实都是体现在这个模型上的,GUI和VBA分别是这个模型的两个外围表现。
所以可以想象,如果Office的测试团队想要测试功能是否正确,他是有两条路要走:
从这里可以大致感受到,当系统越复杂的时候,独立的模型层越重要,因为必须保持这一层的绝对清晰,才能确保整个系统是正确而稳定的。层层叠加,单向依赖,这使得软件正确性的验证过程变得更加可控。
在业务系统中,又存在另外一些问题。以我曾经从事过的电信行业软件系统为例,整个运营与业务支撑系统由若干个子系统构成,比如:
这些系统基本都已经Web化,如果我们要探讨它们的组件化方式,必须作相当深远的考虑,因为,还可能出现终极杀手——比如呼叫中心系统。
大家打客服电话的时候,有没有注意到,客服人员可以操作的东西,是超过了前台营业员的,这也就说明他实际上能够操作以上某几个系统。可是我们也没有发现他在切换多种功能的时候,花太多时间,说明其实他有一个高度集成的界面入口。
这就来了问题了,如果这里的多数功能是集成其他系统的组件所致,那都该是一些什么样的组件啊?
篇幅所限,不在本文中讨论这些问题。抛出这样的问题来,是为了让大家察觉,在很多不为人知的地方,存在很值得思考的东西。一些新的Web标准是为了解决Web系统的大型化,应用化,但仅仅以这些标准本身而言,还是存在一定的不足,需要更深刻的改变。
我们期望Angular2和Aurelia为代表的新型框架能够给这些领域带来一些灵感,互相碰撞,解放更多人的生产力。
总而言之:
“I think we agree, the past is over.” – George W. Bush
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.