yacan8 / blog Goto Github PK
View Code? Open in Web Editor NEW杨溜溜的个人博客,个人学习知识总结
Home Page: https://github.com/yacan8/blog
杨溜溜的个人博客,个人学习知识总结
Home Page: https://github.com/yacan8/blog
















































































































自动生成html,基本用法:
new HtmlWebpackPlugin({
filename: 'index.html', // 生成文件名
template: path.join(process.cwd(), './index.html') // 模班文件
})拷贝资源插件
基本用法:
new CopyWebpackPlugin([
{
from: path.join(process.cwd(), './vendor/'),
to: path.join(process.cwd(), './dist/'),
ignore: ['*.json']
}
])俩个插件效果一致,都是生成编译结果的资源单,只是资源单的数据结构不一致而已。
webpack-manifest-plugin 基本用法:
module.exports = {
plugins: [
new ManifestPlugin()
]
}assets-webpack-plugin 基本用法:
module.exports = {
plugins: [
new AssetsPlugin()
]
}在编译之前清理指定目录指定内容。
基本用法:
// 清理目录
const pathsToClean = [
'dist',
'build'
]
// 清理参数
const cleanOptions = {
exclude: ['shared.js'], // 跳过文件
}
module.exports = {
// ...
plugins: [
new CleanWebpackPlugin(pathsToClean, cleanOptions)
]
}提供带 Content-Encoding 编码的压缩版的资源。
基本用法:
module.exports = {
plugins: [
new CompressionPlugin()
]
}编译进度条插件
基本用法:
module.exports = {
//...
plugins: [
new ProgressBarPlugin()
]
}自动加载模块,如 $ 出现,就会自动加载模块;$ 默认为'jquery'的exports
用法:
new webpack.ProvidePlugin({
$: 'jquery',
})定义全局常量
用法:
new webpack.DefinePlugin({
'process.env': {
NODE_ENV: JSON.stringify(process.env.NODE_ENV)
}
})提取css样式,对比:
基本用法 extract-text-webpack-plugin:
const ExtractTextPlugin = require("extract-text-webpack-plugin");
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: "style-loader",
use: "css-loader"
})
}
]
},
plugins: [
new ExtractTextPlugin("styles.css"),
]
}基本用法 mini-css-extract-plugin:
const MiniCssExtractPlugin = require("mini-css-extract-plugin");
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: [
{
loader: MiniCssExtractPlugin.loader,
options: {
publicPath: '/' // chunk publicPath
}
},
"css-loader"
]
}
]
},
plugins: [
new MiniCssExtractPlugin({
filename: "[name].css", // 主文件名
chunkFilename: "[id].css" // chunk文件名
})
]
}忽略regExp匹配的模块
用法:
new webpack.IgnorePlugin(/^\.\/locale$/, /moment$/)代码丑化,用于js压缩
用法:
module.exports = {
//...
optimization: {
minimizer: [new UglifyJsPlugin({
cache: true, // 开启缓存
parallel: true, // 开启多线程编译
sourceMap: true, // 是否sourceMap
uglifyOptions: { // 丑化参数
comments: false,
warnings: false,
compress: {
unused: true,
dead_code: true,
collapse_vars: true,
reduce_vars: true
},
output: {
comments: false
}
}
}]
}
};css压缩,主要使用 cssnano 压缩器
用法:
module.exports = {
//...
optimization: {
minimizer: [new OptimizeCssAssetsPlugin({
cssProcessor: require('cssnano'), // css 压缩优化器
cssProcessorOptions: { discardComments: { removeAll: true } } // 去除所有注释
})]
}
};使你的chunk根据内容生成md5,用这个md5取代 webpack chunkhash。
var WebpackMd5Hash = require('webpack-md5-hash');
module.exports = {
// ...
output: {
//...
chunkFilename: "[chunkhash].[id].chunk.js"
},
plugins: [
new WebpackMd5Hash()
]
};CommonChunkPlugin 的后世,用于chunk切割。
webpack 把 chunk 分为两种类型,一种是初始加载initial chunk,另外一种是异步加载 async chunk,如果不配置SplitChunksPlugin,webpack会在production的模式下自动开启,默认情况下,webpack会将 node_modules 下的所有模块定义为异步加载模块,并分析你的 entry、动态加载(import()、require.ensure)模块,找出这些模块之间共用的node_modules下的模块,并将这些模块提取到单独的chunk中,在需要的时候异步加载到页面当中,其中默认配置如下:
module.exports = {
//...
optimization: {
splitChunks: {
chunks: 'async', // 异步加载chunk
minSize: 30000,
maxSize: 0,
minChunks: 1,
maxAsyncRequests: 5,
maxInitialRequests: 3,
automaticNameDelimiter: '~', // 文件名中chunk分隔符
name: true,
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/, //
priority: -10
},
default: {
minChunks: 2, // 最小的共享chunk数
priority: -20,
reuseExistingChunk: true
}
}
}
}
};dllPlugin 将模块预先编译,DllReferencePlugin 将预先编译好的模块关联到当前编译中,当 webpack 解析到这些模块时,会直接使用预先编译好的模块。
autodll-webpack-plugin 相当于 dllPlugin 和 DllReferencePlugin 的简化版,其实本质也是使用 dllPlugin && DllReferencePlugin,它会在第一次编译的时候将配置好的需要预先编译的模块编译在缓存中,第二次编译的时候,解析到这些模块就直接使用缓存,而不是去编译这些模块。
dllPlugin 基本用法:
const output = {
filename: '[name].js',
library: '[name]_library',
path: './vendor/'
}
module.exports = {
entry: {
vendor: ['react', 'react-dom'] // 我们需要事先编译的模块,用entry表示
},
output: output,
plugins: [
new webpack.DllPlugin({ // 使用dllPlugin
path: path.join(output.path, `${output.filename}.json`),
name: output.library // 全局变量名, 也就是 window 下 的 [output.library]
})
]
}DllReferencePlugin 基本用法:
const manifest = path.resolve(process.cwd(), 'vendor', 'vendor.js.json')
module.exports = {
plugins: [
new webpack.DllReferencePlugin({
manifest: require(manifest), // 引进dllPlugin编译的json文件
name: 'vendor_library' // 全局变量名,与dllPlugin声明的一致
}
]
}autodll-webpack-plugin 基本用法:
module.exports = {
plugins: [
new AutoDllPlugin({
inject: true, // 与 html-webpack-plugin 结合使用,注入html中
filename: '[name].js',
entry: {
vendor: [
'react',
'react-dom'
]
}
})
]
}多线程编译,加快编译速度,thread-loader不可以和 mini-css-extract-plugin 结合使用。
happypack 基本用法:
const HappyPack = require('happypack');
const os = require('os');
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length });
const happyLoaderId = 'happypack-for-react-babel-loader';
module.exports = {
module: {
rules: [{
test: /\.jsx?$/,
loader: 'happypack/loader',
query: {
id: happyLoaderId
},
include: [path.resolve(process.cwd(), 'src')]
}]
},
plugins: [new HappyPack({
id: happyLoaderId,
threadPool: happyThreadPool,
loaders: ['babel-loader']
})]
}thread-loader 基本用法:
module.exports = {
module: {
rules: [
{
test: /\.js$/,
include: path.resolve("src"),
use: [
"thread-loader",
// your expensive loader (e.g babel-loader)
"babel-loader"
]
}
]
}
}使用模块编译缓存,加快编译速度。
hard-source-webpack-plugin 基本用法:
module.exports = {
plugins: [
new HardSourceWebpackPlugin()
]
}cache-loader 基本用法:
module.exports = {
module: {
rules: [
{
test: /\.ext$/,
use: [
'cache-loader',
...loaders
],
include: path.resolve('src')
}
]
}
}编译模块分析插件
基本用法:
new BundleAnalyzerPlugin({
analyzerMode: 'server',
analyzerHost: '127.0.0.1',
analyzerPort: 8889,
reportFilename: 'report.html',
defaultSizes: 'parsed',
generateStatsFile: false,
statsFilename: 'stats.json',
statsOptions: null,
logLevel: 'info'
}),stats-webpack-plugin 将构建的统计信息写入文件,该文件可在 http://webpack.github.io/analyse中上传进行编译分析,并根据分析结果,可使用 PrefetchPlugin 对部分模块进行预解析编译(本人也不理解这个plugin,据说优化效果不明显,有兴趣的同学请见 how-to-optimize-webpacks-build-time-using-prefetchplugin-analyse-tool)。
stats-webpack-plugin 基本用法:
module.exports = {
plugins: [
new StatsPlugin('stats.json', {
chunkModules: true,
exclude: [/node_modules[\\\/]react/]
})
]
};PrefetchPlugin 基本用法:
module.exports = {
plugins: [
new webpack.PrefetchPlugin('/web/', 'app/modules/HeaderNav.jsx'),
new webpack.PrefetchPlugin('/web/', 'app/pages/FrontPage.jsx')
];
}统计编译过程中,各loader和plugin使用的时间。
const SpeedMeasurePlugin = require("speed-measure-webpack-plugin");
const smp = new SpeedMeasurePlugin();
const webpackConfig = {
plugins: [
new MyPlugin(),
new MyOtherPlugin()
]
}
module.exports = smp.wrap(webpackConfig);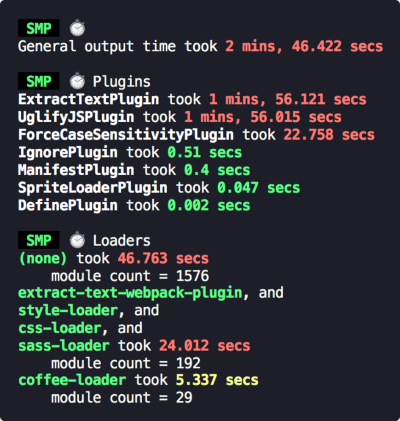
看过antd源码的都知道,antd其实是在一组react-componment组件的基础上进行了一层ui封装,本文主要解读antd组件Form的基础组件react-componment/form,另外会略过development模式下的warning代码。
解读源码首先要从自己最常用的或者感兴趣的入手,首先form组件最主要的还是在Form.create({options})这个装饰器入手。找到项目下的文件createForm.js,这个文件还是主要主要对createBaseForm.js文件进行了一层封装,提供了一些默认配置参数,下看查看createBaseForm.js里的createBaseForm方法,改方法主要是一个装饰器作用,包装一个高阶React组件,在props里注入一个值为formPropName(默认为form)变量,所有功能在这个变量里完成,主要内容如下
render() {
const { wrappedComponentRef, ...restProps } = this.props;
const formProps = {
[formPropName]: this.getForm(), // 来在 formPropName默认为form,getForm方法来自`createForm.js`
};
if (withRef) {
formProps.ref = 'wrappedComponent';
} else if (wrappedComponentRef) {
formProps.ref = wrappedComponentRef;
}
const props = mapProps.call(this, {
...formProps,
...restProps,
});
return <WrappedComponent {...props} />;
}在装饰器初始化的时候,Form初始化了一个只属于该组件实例的store,用来存放当前Form组件的一些输入的数据,主要代码如下:
const fields = mapPropsToFields && mapPropsToFields(this.props); // mapPropsToFields来自于Form.create的配置参数,用来转化来自mobx或者redux等真正的store来源的value,以初始化该Form实例的fieldsStore
this.fieldsStore = createFieldsStore(fields || {}); // createFieldsStore来自于文件`createFieldsStore.js`文件柯里化函数,通过id与参数声明的输入,返回一个函数以输入组件为入参的函数,通过该函数声明的输入组件与表单Form双向数据绑定。
...
getFieldDecorator(name, fieldOption) {
const props = this.getFieldProps(name, fieldOption); // 初始化一个field
return (fieldElem) => {
const fieldMeta = this.fieldsStore.getFieldMeta(name); // 获取变化(Form的onChange)后的field数据
const originalProps = fieldElem.props;
fieldMeta.originalProps = originalProps; // 输入组件初始化时保存的Prop
fieldMeta.ref = fieldElem.ref;
return React.cloneElement(fieldElem, {
...props,
...this.fieldsStore.getFieldValuePropValue(fieldMeta), // 获取prop属性 value
});
};
}
...查看函数 getFieldProps,主要用来初始化输入组件的props,将特定的函数缓存在内部,如onChange事件,另外初次保存field到store中
...
getFieldProps(name, usersFieldOption = {}) {
if (!name) {
throw new Error('Must call `getFieldProps` with valid name string!');
}
delete this.clearedFieldMetaCache[name];
const fieldOption = {
name,
trigger: DEFAULT_TRIGGER,
valuePropName: 'value',
validate: [],
...usersFieldOption, // 用户输入,如rules,initialValue
};
const {
rules,
trigger,
validateTrigger = trigger,
validate,
} = fieldOption;
const fieldMeta = this.fieldsStore.getFieldMeta(name);
if ('initialValue' in fieldOption) {
fieldMeta.initialValue = fieldOption.initialValue;
}
const inputProps = {
...this.fieldsStore.getFieldValuePropValue(fieldOption), // 获取输入组件的value,如果没有,返回initialValue
ref: this.getCacheBind(name, `${name}__ref`, this.saveRef),
};
if (fieldNameProp) { // 及value
inputProps[fieldNameProp] = name;
}
const validateRules = normalizeValidateRules(validate, rules, validateTrigger); // 校验规则标准化
const validateTriggers = getValidateTriggers(validateRules);
validateTriggers.forEach((action) => {
if (inputProps[action]) return;
inputProps[action] = this.getCacheBind(name, action, this.onCollectValidate); // 如果设置了输入校验rules,绑定onChange事件`this.onCollectValidate`
});
// make sure that the value will be collect
if (trigger && validateTriggers.indexOf(trigger) === -1) {
inputProps[trigger] = this.getCacheBind(name, trigger, this.onCollect); // 如果没有绑定rules校验,绑定默认的onChange事件
}
const meta = {
...fieldMeta,
...fieldOption,
validate: validateRules,
};
this.fieldsStore.setFieldMeta(name, meta); // 保存field到store中
if (fieldMetaProp) {
inputProps[fieldMetaProp] = meta;
}
if (fieldDataProp) {
inputProps[fieldDataProp] = this.fieldsStore.getField(name);
}
return inputProps;
},
...getCacheBind方法,缓存函数,使用bind方法绑定上下文并缓存部分参数,返回一个新的函数,用做onChange及数据校验。
...
getCacheBind(name, action, fn) {
if (!this.cachedBind[name]) {
this.cachedBind[name] = {};
}
const cache = this.cachedBind[name];
if (!cache[action]) {
cache[action] = fn.bind(this, name, action); // 绑定参数并返回
}
return cache[action];
},
...在getFieldProps方法中看到利用getCacheBind方法当无rules的时候绑定了一个onCollect方法,onCollect方法主要调用onCollectCommon方法,并将得到的结果保存到store。
onCollectCommon(name, action, args) {
const fieldMeta = this.fieldsStore.getFieldMeta(name);
if (fieldMeta[action]) { // 如果getFieldDecorator方法中的参数定义了onChange,则触发改onChange
fieldMeta[action](...args);
} else if (fieldMeta.originalProps && fieldMeta.originalProps[action]) { // 如果输入组件绑定了onChange,则触发该onChange
fieldMeta.originalProps[action](...args);
}
const value = fieldMeta.getValueFromEvent ? // 获取更新后的value,兼容原生组件e.target.value
fieldMeta.getValueFromEvent(...args) :
getValueFromEvent(...args);
if (onValuesChange && value !== this.fieldsStore.getFieldValue(name)) { // 如果Form.create时用户定义有onValuesChange,则触发
const valuesAll = this.fieldsStore.getAllValues();
const valuesAllSet = {};
valuesAll[name] = value;
Object.keys(valuesAll).forEach(key => set(valuesAllSet, key, valuesAll[key]));
onValuesChange(this.props, set({}, name, value), valuesAllSet);
}
const field = this.fieldsStore.getField(name); // 获取合并field,并返回
return ({ name, field: { ...field, value, touched: true }, fieldMeta });
},在有输入rules的时候getCacheBind方法绑定onCollectValidate作为onChange事件,该方法做了除了调用了onCollectCommon事件以外,还调用了校验方法validateFieldsInternal。
该方法主要是从store中获取rules校验规则并标准化后,使用async-validator模块进行校验,并把结果保存到store中,本文不做讲解。
该方法主要是设置store中的field,因为store的数据是不可观测的数据,不会引起页面的重渲染,该方法也负责调用forceUpdate()强制更新页面。
setFields(maybeNestedFields, callback) {
const fields = this.fieldsStore.flattenRegisteredFields(maybeNestedFields); // 处理field嵌套问题
this.fieldsStore.setFields(fields);
if (onFieldsChange) { // 如果设置有FieldsChange事件监听事件变化,则触发事件
const changedFields = Object.keys(fields)
.reduce((acc, name) => set(acc, name, this.fieldsStore.getField(name)), {});
onFieldsChange(this.props, changedFields, this.fieldsStore.getNestedAllFields());
}
this.forceUpdate(callback); // 强制更新视图
},主要方法大概就上面这些,其中流程差不多在每次setFields之前,会在store中存一个field的变化字段fieldMeta,在最后强制更新页面的时候,将该变量取出来做处理后覆盖到field,所有数据保存在field中,并提供了一些hock方法如setFieldsValue、validateFields等方法设置和获取store中的field字段和值。
前段时间由于性能要求,需把项目d3的版本从v3升级到v4,据了解d3由于在v4版本之前是没有进行模块化的,所以v3代码的扩展性是比较差的,考虑到长远之计,d3在v4版本算是对代码进行了模块化的重构吧,给开发者提供了一些可定制化的东西,所有api变化较大,这个坑还需各种研究文档才能填完,好了,下面开始我的表演了。
初始化函数从v3的d3.layout.force()变成v4的d3.forceSimulation(),部分参数设置方式如下:
this.force = d3.forceSimulation().alphaDecay(0.1) // 设置alpha衰减系数
.force("link", d3.forceLink().distance(100)) // distance为连线的距离设置
.force('collide', d3.forceCollide().radius(() => 30)) // collide 为节点指定一个radius区域来防止节点重叠。
.force("charge", d3.forceManyBody().strength(-400)) // 节点间的作用力为布局添加点和线
this.force.nodes(nodes) // 节点数据
.force('link', d3.forceLink(links).distance(150)); // 连线数据 distance为连线的距离设置
.alpha(1); // 设置alpha值,让里导向图有初始动力
.restart(); // 启动仿真计时器由于在v4版本中nodes的x、y坐标和加速度vx、vy只在nodes中计算一次,所有在变成有节点或连线增加的时候,必须重新执行一次force.nodes(nodes)和force('link', d3.forceLink(links)),初始化节点的数据结构。如果在v3版本中,只需在布局初始化时执行即可,在d3会在每次force.start()方法执行时重新初始化一次节点和连线的数据结构,这是一个特别需要注意的地方,另外在v4版本中start方法被遗弃,需使用restart方法。
将节点的dom结构交给react来控制,方便在节点上添加事件。以下为svg渲染部分代码。
render() {
const { width, height, nodes, links, scale, translate, selecting, grabbing } = this.props.store;
return (
<svg id="svg" ref="svg" width={width} height={height}
className={cn({
grab: !selecting && !grabbing,
grabbing: !selecting && grabbing
})}
>
<g id="outg" ref="outg" transform={`translate(${translate})scale(${scale})`}>
<g ref="lines" className="lines">
links.map(link => (
<line
key={`${link.source.uid}_${link.target.uid}`}
ref={child => this.links[`${link.source.uid}_${link.target.uid}`] = child}
x1={link.source.x}
y1={link.source.y}
x2={link.target.x}
y2={link.target.y}/>
))
</g>
<g ref="nodes" className="nodes">
{
nodes.map(node => (
<Node key={node.uid}
node={node}
store={this.props.store}
addRef={child => this.nodes[node.uid] = child}/>
))
}
</g>
</g>
</svg>
);
}Node.js 节点
以下为Node Component部分代码
class Node extends Component {
render() {
const { node, addRef, store } = this.props;
const { force } = store;
return (
<g className="node"
ref={child => {
this._node = child;
addRef(child);
}}
transform={`translate(${node.x || width / 2},${node.y || height / 2})`}
>
<g id={node.nodeIndex}>
// 节点图片dom
</g>
{
node.locked && (
<Lock
x={10}
y={10}
release={() => { // 解锁节点
node.fixed = false;
node.locked = false;
node.fx = null; // 当节点的fx、fy都为null时,节点处于活动状态
node.fy = null;
force.alpha(0.3).restart(); // 释放锁定节点时需设置alpha值并重启计时器,使得布局可以运动。
}}
/>
)
}
</g>
);
}
componentDidMount() {
this._node.__data__ = this.props.node; // 将node节点在d3内部存一份引用,让每次计时器更新的时候自动更改nodes列表中的数据
d3.select(this._node) // 各种事件
.on('click', d => {
// code
})
}
}Lock.js 节点解除固定按钮。
class Lock extends Component {
render() {
const { x, y, fixed } = this.props;
return (
<use
ref="lock"
xlinkHref="#lock"
x={x}
y={y}
/>
);
}
componentDidMount() {
const { release } = this.props;
d3.select(this.refs.lock)
.on('click', () => {
d3.event.stopPropagation();
release();
});
}
}tick计时器函数,在仿真启动的过程中,计时器的每一帧都会改变一次之前我们在内部存的引用(this._node.__data__ = this.props.node)的node的数据的x值和y值,这时我们需要更新dom结构中的节点和线偏移量。
force.on('tick', () => {
nodes.forEach(node => {
if (!node.lock) {
d3.select(self.nodes[node.uid]).attr('transform', () => `translate(${node.x},${node.y})`);
}
});
links.forEach(link => {
d3.select(self.links[`${link.source.uid}_${link.target.uid}`])
.attr('x1', () => link.source.x)
.attr('y1', () => link.source.y)
.attr('x2', () => link.target.x)
.attr('y2', () => link.target.y);
});
});在计时器的每一帧中,仿真的alpha系数会不断削减,可通过force.alpha()来获取和设置alpha系数,削减速度由alphaDecay来决定,默认值为0.0228…,衰减系数可通过force.alphaDecay()来获取和设置,当alpha到达一个系数时,仿真将会停止,也就是alpha的目标系数alphaTarget,该值区间为[0,1]. 默认为0,可通过force.alphaTarget()来获取和设置,另外还有一个速度衰减系统velocityDecay ,相当于摩擦力。区间为[0,1], 默认为0.4。在每次tick之后,节点的速度都会等于当前速度乘以1-velocityDecay,和alpha衰减类似,速度衰减越慢最终的效果越好,但是如果速度衰减过慢,可能会导致震荡。以上为tick过程的发生。需要注意的是,在v4版本中,tick事件的callback中不带任何参数,在v3版本的'tick'事件中,我们可通过callback(e)中的e.alpha来获取alpha值,而在v4版本中,alpha值只能通过force.alpha()来获取。
创建拖拽操作
let startTime = 0;
this.drag = d3.drag()
.on('start', (d) => {
startTime = (new Date()).getTime();
d3.event.sourceEvent.stopPropagation();
if (!d3.event.active) {
this.force.alphaTarget(0.3).restart(); // 当前alpha值为0,需设置alphaTarget让节点动起来
}
d.fx = d.x;
d.fy = d.y;
})
.on('drag', d => {
this.grabbing = true;
d.fx = d3.event.x;
d.fy = d3.event.y;
})
.on('end', d => {
const nowTime = (new Date()).getTime();
if (!d3.event.active) {
this.force.alphaTarget(0); // 让alpha目标值值恢复为默认值0
}
if (nowTime - startTime >= 150) { // 操作150毫秒的拖拽固定节点
d.fixed = true;
d.locked = true;
}
this.grabbing = false;
});将拖拽操作应用到指定的选择集。
d3.select('#outg').selectAll('.node').call(this.drag);在内部,拖拽操作通过selection.on来为元素添加监听事件. 事件监听器使用 .drag 来标识这是一个拖拽事件。拖拽drag的v4版本与v3不同的是,v3通过force.drag()创建拖拽操作,拖拽过程事件使用dragstart、drag、dragend,在拖拽过程中d3内部自动设置alpha相关系数让节点运动起来,而在v4中版本中需要手动设置。
在v4版本中,缩放操作通过transform对象进行,可以通过d3.zoomTransform(selection.node())获取指定节点的缩放状态,也可以通过d3.event.transform来获取当前正在缩放的节点的缩放状态。
与拖拽类似,需要先创建缩放操作。
const self = this;
const outg = d3.select('#outg');
this.zoomObj = d3.zoom()
.scaleExtent([0.2, 4]) // 缩放范围
.on('zoom',() => {
const transform = d3.event.transform;
self.scale = transform.k; // 保存当前缩放大小
self.translate = [transform.x, transform.y]; // 保存当前便宜量
outg.attr('transform', transform); // 设置缩放和偏移量 transform对象自带toString()方法
})
.on('end', () => {
// code
})将缩放操作应用于选择集,并取消双击操作
const svg = d3.select('#svg');
svg.call(this.zoomObj).on('dblclick.zoom', null);如果要禁止滚轮滚动缩放,可以在讲zoom事件应用于选择集之后移除zoom事件中的滚轮事件:
svg.call(this.zoomObj).on("wheel.zoom", null);当缩放事件被调用,d3.event会被设置为当前的zoom事件,zoom event对象由以下几部分组成:
target - 当前的缩放zoom behavior。type - 事件类型:“start”, “zoom” 或者 “end”,参考 zoom.on。transform - 当前的zoom transform(缩放变换)。sourceEvent - 原始事件, 比如 mousemove 或 touchmove。this.zoomObj.transform(d3.select('#svg'), d3.zoomIdentity.translate(newX,newY).scale(newScale))在v3版本中,可以通过zoom.scale(s)和zoom.translate(x, y)设置缩放和偏移量后通过使用'zoom.event(selection)'方法应用到指定选择节点,而在v4中版本需要通过d3.zoomIdentity创建新transform对象,并通过translate(x, y)和scale(s)方法设置偏移量和缩放级别,然后将该transform应用到选择集中。另外也可以通过zoom.translateBy(selection, x, y)、zoom.translateTo(selection, x, y)、zoom.scaleBy(selection, k)、zoom.scaleTo(selection, k)方法进行变换。
由于api变动较大,v3升级v4需要耐心看api,查看各个部分的变化,所以,升级需谨慎。最后附上d3.js v4.0中文api。
antd的Tooltip组件在react-componment/trigger的基础上进行封装,而组件Popover和Popconfirm是使用Tooltip组件的进行pop,在react-componment中,使用到组件tc-trigger的还有menu、select、dropdown、time-picker、calendar等,本文主要对tc-trigger源码进行解读。
项目结构如下:
从render方法入手,需要渲染控制pop显示的节点和pop内容节点两个节点,而pop内容节点一般渲染到body里面,不属于控制pop显示的节点内,render方法代码如下:
const trigger = React.cloneElement(child, newChildProps);
if (!IS_REACT_16) {
return (
<ContainerRender
parent={this}
visible={popupVisible}
autoMount={false}
forceRender={props.forceRender}
getComponent={this.getComponent}
getContainer={this.getContainer}
>
{({ renderComponent }) => {
this.renderComponent = renderComponent;
return trigger;
}}
</ContainerRender>
);
}
let portal;
// prevent unmounting after it's rendered
if (popupVisible || this._component || props.forceRender) {
portal = (
<Portal
key="portal"
getContainer={this.getContainer}
didUpdate={this.handlePortalUpdate}
>
{this.getComponent()}
</Portal>
);
}
return [
trigger,
portal,
];可以看到,index.js渲染了两个节点,trigger和portal,trigger即为通过事件控制portal显示状态的节点,如果react的版本不是16以上,返回ContainerRender组件,ContainerRender组件来自rc-util,该组件主要做的事情就是使用ReactDOM.unstable_renderSubtreeIntoContainer函数,将pop内容渲染到trigger节点之外,与react16提供的APIcreatePortal作用一致,如果是React16,返回了Portal组件,该组件正是利用了createPortal,将组件渲染到特定的dom节点内,但是不管是不是react16,都进行了pop渲染的判断,即popupVisible || this._component || props.forceRender,如果portal不显示且不强制第一次渲染forceRender,portal将不会被渲染到dom中,直到判断为真。
trigger节点通过props决定事件绑定情况,即通过props.trigger属性绑定事件情况,事件控制Popup组件的visible属性,这里就不详细说了。
该组件是pop的warp,渲染在trigger节点之外,通过ReactDOM.unstable_renderSubtreeIntoContainer或createPortal指定渲染的目标节点,也是render方法入手:
render() {
return (
<div>
{this.getMaskElement()}
{this.getPopupElement()}
</div>
);
}返回两个内容,getMaskElement获取遮罩,getPopupElement返回Pop节点,getMaskElement这里就不说了,渲染的视觉效果,绑定了控制pop节点的事件。
getPopupElement返回pop节点,render返回代码如下:
<Animate
component=""
exclusive
transitionAppear
transitionName={this.getTransitionName()}
showProp="xVisible"
>
<Align
target={this.getTarget}
key="popup"
ref={this.saveAlignRef}
monitorWindowResize
xVisible={visible}
childrenProps={{ visible: 'xVisible' }}
disabled={!visible}
align={align}
onAlign={this.onAlign}
>
<PopupInner
hiddenClassName={hiddenClassName}
{...popupInnerProps}
>
{children}
</PopupInner>
</Align>
</Animate>Animate来自组件rc-animate,主要负责显示状态切换时候的动态效果,其中原理是监听控制状态变化的prop属性,即代码中的showProp="xVisible",当状态变化的时候,延时改变dom的class,一般会有三个状态,分别表示进入中enter-active,消失中leave-active,隐藏hidden三个状态,进入中状态会添加transitionName-enter transitionName-enter-active两个class,消失中会添加transitionName-leave transitionName-leave-active两个class,隐藏状态不添加class,transitionName通过外部传入。
Align来自组件rc-align,主要控制节点的相对于trigger的显示位置,根据传入的target与align决定最后PopupInner显示的位置,此处target是来自于index.js的trigger节点,align也是来自于index.js,主要由index.js的prop.popupPlacement、prop.popupAlign两个属性决定,即方向与偏移量。
最后是PopupInner组件,该组件是也就pop内容组件,内容通过LazyRenderBox包裹。。。
另外,Popup.js还有两个state,targetWidth与targetHeight,即pop的宽高,该属性如果设置有prop.stretch,则计算trigger真是dom节点的宽高,然后对齐。
为隐藏状态下的pop添加hidden的class,并包裹懒加载组件LazyRenderBox。
只做一件事情,就是将popupInner的chidren进行包裹,当子节点数大于1时,包一层div以方便隐藏状态时候class控制,不用每个节点都添加hidden的class,关键如下:
render() {
const { hiddenClassName, visible, ...props } = this.props;
if (hiddenClassName || React.Children.count(props.children) > 1) {
if (!visible && hiddenClassName) {
props.className += ` ${hiddenClassName}`;
}
return <div {...props}/>;
}
return React.Children.only(props.children);
}该组件主要的实现难点在于rc-animate与rc-align,其他的主要在做事件绑定与class处理。
最近有考虑换工作么?地点:杭州,Ali
学过react的都知道,react用state和props控制组件的渲染情况,而对于JavaScript单页面日趋复杂的今天,JavaScript需要管理越来越多的state,而这些state包括着各种乱七八糟途径来的数据。甚至有的应用的state会关系到另一个组件的状态。所以为了方便对这些state的管理以及对state变化的可控性。这个时候Redux这个东西就出来了,它可以让state的变化变得可预测。
什么是redux?这里非权威的解释:就是一个应用的state管理库,甚至可以说是前端数据库。更包括的是管理数据。
state是整个应用的数据,本质上是一个普通对象。
state决定了整个应用的组件如何渲染,渲染的结果是什么。可以说,State是应用的灵魂,组件是应用的肉体。
所以,在项目开发初期,设计一份健壮灵活的State尤其重要,对后续的开发有很大的帮助。
但是,并不是所有的数据都需要保存到state中,有些属于组件的数据是完全可以留给组件自身去维护的。
数据state已经有了,那么我们是如何实现管理这些state中的数据的呢?那就是action,什么是action?按字面意思解释就是动作,也可以理解成,一个可能!改变state的动作包装。就这么简单。。。。
只有当某一个动作发生的时候才能够触发这个state去改变,那么,触发state变化的原因那么多,比如这里的我们的点击事件,还有网络请求,页面进入,鼠标移入。。。所以action的出现,就是为了把这些操作所产生或者改变的数据从应用传到store中的有效载荷。 需要说明的是,action是state的唯一来源。它本质上就是一个JavaScript对象,但是约定的包含type属性,可以理解成每个人都要有名字一般。除了type属性,别的属性,都可以.
那么这么多action一个个手动创建必然不现实,一般我们会写好actionCreator,即action的创建函数。调用actionCreator,给你返回一个action。这里我们可以使用 redux-actions,嗯呢,我们下文有介绍。
比如有一个counter数量加减应用,我们就有两个action,一个decrement,一个increment。 所以这里的action creator写成如下:
export function decrement() {
return{
type:DECREMENT_COUNTER
}
}
export function increment(){
return{
type:INCREMENT_COUNTER
}
}那么,当action创建完成了之后呢,我们怎么触发这些action呢,这时我们是要利用dispatch,比如我们执行count增减减少动作。
export function incrementIfOdd(){
return(dispatch,getState)=>{
const {counter} = getState();
if(counter%2==0) {
return;
}
dispatch(increment());
}
}
export function incrementAsync() {
return dispatch => {
setTimeout(() => {
dispatch(increment());
}, 1000);
};
}为了减少样板代码,我们使用单独的模块或文件来定义 action type 常量
export const INCREMENT_COUNTER = 'INCREMENT_COUNTER';
export const DECREMENT_COUNTER = 'DECREMENT_COUNTER';这么做不是必须的,在大型应用中把它们显式地定义成常量还是利大于弊的。
既然这个可能改变state的动作已经包装好了,那么我们怎么去判断并且对state做相应的改变呢?对,这就是reducer干的事情了。
reducer是state最终格式的确定。它是一个纯函数,也就是说,只要传入参数相同,返回计算得到的下一个 state 就一定相同。没有特殊情况、没有副作用,没有 API 请求、没有变量修改,单纯执行计算。
reducer对传入的action进行判断,然后返回一个通过判断后的state,这就是reducer的全部职责。如我们的counter应用:
import {INCREMENT_COUNTER,DECREMENT_COUNTER} from '../actions';
export default function counter(state = 0, action) {
switch (action.type){
case INCREMENT_COUNTER:
return state+1;
case DECREMENT_COUNTER:
return state-1;
default:
return state;
}
}这里我们就是对增和减两个之前在action定义好的常量做了处理。
对于一个比较大一点的应用来说,我们是需要将reducer拆分的,最后通过redux提供的combineReducers方法组合到一起。 如此项目上的:
const rootReducer = combineReducers({
counter
});
export default rootReducer;每个reducer只负责管理全局state中它负责的一部分。每个reducer的state参数都不同,分别对应它管理的那部分state数据。combineReducers()所做的只是生成一个函数,这个函数来调用你的一系列reducer,每个reducer根据它们的key来筛选出state中的一部分数据并处理, 然后这个生成的函数再将所有reducer的结果合并成一个大的对象。
store是对之前说到一个联系和管理。具有如下职责
state;getState()方法获取 statedispatch(action)方法更新 state;subscribe(listener)注册监听器;subscribe(listener)返回的函数注销监听器。store。当需要拆分数据处理逻辑时,你应该使用reducer组合,而不是创建多个store。store的创建通过redux的createStore方法创建,这个方法还需要传入reducer,很容易理解:毕竟我需要dispatch一个action来改变state嘛。 应用一般会有一个初始化的state,所以可选为第二个参数,这个参数通常是有服务端提供的,传说中的Universal渲染。后面会说。。。 第三个参数一般是需要使用的中间件,通过applyMiddleware传入。action,store,actionCreator,reducer关系就是这么如下的简单明了: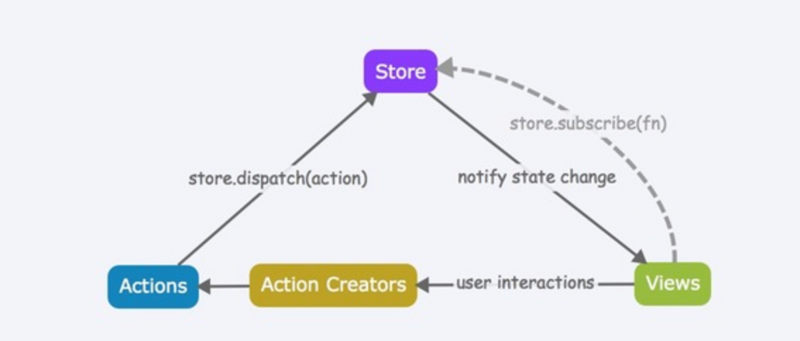
react-redux,redux和react的桥梁工具。
react-redux将组建分成了两大类,UI组建component和容器组建container。 简单的说,UI组建负责美的呈现,容器组件负责来帮你盛着,给你"力量"。
UI 组件有以下几个特征:
export default class Counter extends Component{
render(){
const { counter, increment, decrement, incrementIfOdd, incrementAsync } = this.props;
return(
<p>
Clicked:{counter} times
<button onClick={increment}>+</button>
<button onClick={decrement}>-</button>
<button onClick={incrementIfOdd}>increment if Odd</button>
<button onClick={incrementAsync}>increment async</button>
</p>
)
}
}容器组件特性则恰恰相反:
class App extends Component{
render(){
const { counter, increment, decrement, incrementIfOdd, incrementAsync } = this.props;
return(
<Counter
counter={counter}
increment={increment}
decrement={decrement}
incrementIfOdd={incrementIfOdd}
incrementAsync={incrementAsync}/>
)
}
}
export default connect(
state=>({ counter: state.counter }),
ActionCreators
)(App);connect方法接受两个参数:mapStateToProps和mapDispatchToProps。它们定义了UI组件的业务逻辑。前者负责输入逻辑,即将state映射到 UI 组件的参数(props), 后者负责输出逻辑,即将用户对 UI 组件的操作映射成Action。因为作为组件,我们只要能拿到值,能发出改变值得action就可以了,所以mapStateToProps和mapDispatchToProps正是满足这个需求的。
一个比较流行的redux的action中间件,它可以让actionCreator暂时不返回action对象,而是返回一个函数,函数传递两个参数(dispatch, getState),在函数体内进行业务逻辑的封装,比如异步操作,我们至少需要触发两个action,这时候我们可以通过redux-thunk将这两个action封装在一起,如下:
const fetchDataAction = (querys) => (dispatch, getState) => {
const setLoading = createAction('SET_LOADING');
dispatch(setLoading(true)); // 设置加载中。。。
return fetch(`${url}?${querys}`).then(r => r.json()).then(res => {
dispatch(setLoading(false)); // 设置取消加载中。。。
dispatch(createAction('DATA_DO_SOMETHIN')(res))
})
}这里我们的createCreator返回的是一个fetch对象,我们下文会介绍,我们通过dispatch触发改action
dispatch(fetchDataAction(querys))在请求数据之前,通过redux-thunk我们可以先触发加载中的action,等请求数据结束之后我们可以在次触发action,使得加载中状态取消,并处理请求结果。
既然说到了异步action,我们可以使用redux-promise,它可以让actionCreator返回一个Promise对象。
第一种做法,我们可以参考redux-thunk的部分。
第二种做法,action对象的payload属性(相当于我们的diy参数,action里面携带的其他参数)是一个Promise对象。这需要从redux-actions模块引入createAction方法,并且写法也要变成下面这样。
import { createAction } from 'redux-actions';
class AsyncApp extends Component {
componentDidMount() {
const { dispatch, selectedPost } = this.props
// 发出异步 Action
dispatch(createAction(
'FETCH_DATA',
fetch(`url`).then(res => res.json())
));
}其实redux-actions的createAction的源码是拿到fetch对象的payload结果之后又触发了一次action。
当我们的在开发大型应用的时候,对于大量的action,我们的reducer需要些大量的swich来对action.type进行判断。redux-actions可以简化这一烦琐的过程,它可以是actionCreator,也可以用来生成reducer,其作用都是用来简化action、reducer。
主要函数有createAction、createActions、handleAction、handleActions、combineActions。
创建action,参数如下
import { createAction } from 'redux-actions';
createAction(
type, // action类型
payloadCreator = Identity, // payload数据 具体参考Flux教程
?metaCreator // 具体我也没深究是啥
)例子如下:
export const increment = createAction('INCREMENT')
export const decrement = createAction('DECREMENT')
increment() // { type: 'INCREMENT' }
decrement() // { type: 'DECREMENT' }
increment(10) // { type: 'INCREMENT', payload: 10 }
decrement([1, 42]) // { type: 'DECREMENT', payload: [1, 42] }创建多个action。
import { createActions } from 'redux-actions';
createActions(
actionMap,
?...identityActions,
)第一个参数actionMap为一个对象,以action type为键值,值value有三种形式,
action创建的时候传入的参数,返回结果会作为到生成的action的payload的value。payload的值,第二个值也为一个函数,返回meta的值,不知道有什么用。actionMap对象,递归作用吧。createActions({
ADD_TODO: todo => ({ todo })
REMOVE_TODO: [
todo => ({ todo }), // payloa
(todo, warn) => ({ todo, warn }) // meta
]
});const actionCreators = createActions({
APP: {
COUNTER: {
INCREMENT: [
amount => ({ amount }),
amount => ({ key: 'value', amount })
],
DECREMENT: amount => ({ amount: -amount }),
SET: undefined // given undefined, the identity function will be used
},
NOTIFY: [
(username, message) => ({ message: `${username}: ${message}` }),
(username, message) => ({ username, message })
]
}
});
expect(actionCreators.app.counter.increment(1)).to.deep.equal({
type: 'APP/COUNTER/INCREMENT',
payload: { amount: 1 },
meta: { key: 'value', amount: 1 }
});
expect(actionCreators.app.counter.decrement(1)).to.deep.equal({
type: 'APP/COUNTER/DECREMENT',
payload: { amount: -1 }
});
expect(actionCreators.app.counter.set(100)).to.deep.equal({
type: 'APP/COUNTER/SET',
payload: 100
});
expect(actionCreators.app.notify('yangmillstheory', 'Hello World')).to.deep.equal({
type: 'APP/NOTIFY',
payload: { message: 'yangmillstheory: Hello World' },
meta: { username: 'yangmillstheory', message: 'Hello World' }
});第二个参数identityActions,可选参数,也是一个action type吧,官方例子没看懂,如下:
const { actionOne, actionTwo, actionThree } = createActions({
// function form; payload creator defined inline
ACTION_ONE: (key, value) => ({ [key]: value }),
// array form
ACTION_TWO: [
(first) => [first], // payload
(first, second) => ({ second }) // meta
],
// trailing action type string form; payload creator is the identity
}, 'ACTION_THREE');
expect(actionOne('key', 1)).to.deep.equal({
type: 'ACTION_ONE',
payload: { key: 1 }
});
expect(actionTwo('first', 'second')).to.deep.equal({
type: 'ACTION_TWO',
payload: ['first'],
meta: { second: 'second' }
});
expect(actionThree(3)).to.deep.equal({
type: 'ACTION_THREE',
payload: 3,
});字面意思理解,处理action,那就是一个reducer,包裹返回一个reducer,处理一种类型的action type。
import { handleAction } from 'redux-actions';
handleAction(
type, // action类型
reducer | reducerMap = Identity
defaultState // 默认state
)当第二个参数为一个reducer处理函数时,形式如下,处理传入的state并返回新的state:
handleAction('APP/COUNTER/INCREMENT', (state, action) => ({
counter: state.counter + action.payload.amount,
}), defaultState);当第二个参数为reducerMap时,也为处理state并返回新的state,只是必须传入key值为next和throw的两个函数,分别用来处理state和异常如下:
handleAction('FETCH_DATA', {
next(state, action) {...},
throw(state, action) {...},
}, defaultState);官方推荐使用reducerMap形式,因为与ES6的generator类似。
与handleAction不同,handleActions可以处理多个action,也返回一个reducer。
import { handleActions } from 'redux-actions';
handleActions(
reducerMap,
defaultState
)reducerMap以action type为key,value与handleAction的第二个参数一致,传入一个reducer处理函数或者一个只有next和throw两个键值的对象。
另外,键值key也可以使用createAction创建:
import { createActions, handleActions } from 'redux-actions';
const { increment, decrement } = createActions({
'INCREMENT': amount => ({ amount: 1 }),
'DECREMENT': amount => ({ amount: -1 })
});
const reducer = handleActions({
[increment](state, { payload: { amount } }) {
return { counter: state.counter + amount }
},
[decrement](state, { payload: { amount } }) {
return { counter: state.counter + amount }
}
}, defaultState);将多个action或者actionCreator结合起来,看起来很少用,具体例子如下:
const { increment, decrement } = createActions({
INCREMENT: amount => ({ amount }),
DECREMENT: amount => ({ amount: -amount })
});
const reducer = handleActions({
[combineActions(increment, decrement)](state, { payload: { amount } }) {
return { ...state, counter: state.counter + amount };
}
}, { counter: 10 });
expect(reducer({ counter: 5 }, increment(5))).to.deep.equal({ counter: 10 });
expect(reducer({ counter: 5 }, decrement(5))).to.deep.equal({ counter: 0 });
expect(reducer({ counter: 5 }, { type: 'NOT_TYPE', payload: 1000 })).to.equal({ counter: 5 });
expect(reducer(undefined, increment(5))).to.deep.equal({ counter: 15 });redux-actions说到这里,大概是这样,有什么不了解看看官方文档吧。
Reselect用来记忆selectors的库,我们定义的selectors是作为函数获取state的某一部分。使用记忆能力,我们可以组织不必要的衍生数据的重渲染和计算过程,由此加速了我们的应用。具体细节大概是在mapStateToProps的时候,讲state的某一部分交给reselect的selectors来管理,�使用selectors的记忆功能让组件的props尽量不变化,引起不必要的渲染。
下面我们以一个todolist为例子。
当我们没有reselect的时候,我们是直接通过mapStateToProps把数据传入组件内,如下。
const getVisibleTodos = (todos, filter) => {
switch (filter) {
case 'SHOW_ALL':
return todos
case 'SHOW_COMPLETED':
return todos.filter(t => t.completed)
case 'SHOW_ACTIVE':
return todos.filter(t => !t.completed)
}
}
const mapStateToProps = (state, props) => {
return {
todolist: getVisibleTodos(state, props)
}
}这个代码有一个潜在的问题。每当state tree改变时,selector都要重新运行。当state tree特别大,或者selector计算特别耗时,那么这将带来严重的运行效率问题。为了解决这个问题,reselect为selector设置了缓存,只有当selector的输入改变时,程序才重新调用selector函数。
这时我们把state转化为props的数据交给reselect来处理,我们重写mapStateToProps。
const getVisibilityFilter = state => state.todo.showStatus
const getTodos = state => state.todo.todolist
const getVisibleTodos = createSelector([getVisibilityFilter, getTodos], (visibilityFilter, todos) => {
switch (visibilityFilter) {
case 'SHOW_COMPLETED':
return todos.filter(todo => todo.completed)
case 'SHOW_ACTIVE':
return todos.filter(todo => !todo.completed)
default:
return todos
}
})
const mapStateToProps = (state, props) => {
const todolist = getVisibleTodos(state, props);
return {
todolist
}
}我们使用createSelector包裹起来,将组件内需要的两个props包裹起来,然后在返回一个获取数据的函数getVisibleTodos,这样返回的todolist就不会受到一些不必要的state的变化而变化引起冲渲染。
总结了那么多的用法,其实也是redux的基本用法,然后自己写了半天的todolist,把上面说到的技术都用了,这是 github地址,上面的内容如有错误,勿喷,毕竟入门级别。。。
笔者本科是在成都的一所双非大学念的,四年前大四的找工作时候,由于没什么好公司愿意到我们学校招人,于是我每天到隔壁985电子科技大学蹲点混宣讲会,经过了一个多月的不要脸的摸爬滚打,终于收到杭州的一家独角兽公司的offer,月薪8K,贼开心,不久之后,我就到了这家公司上班。
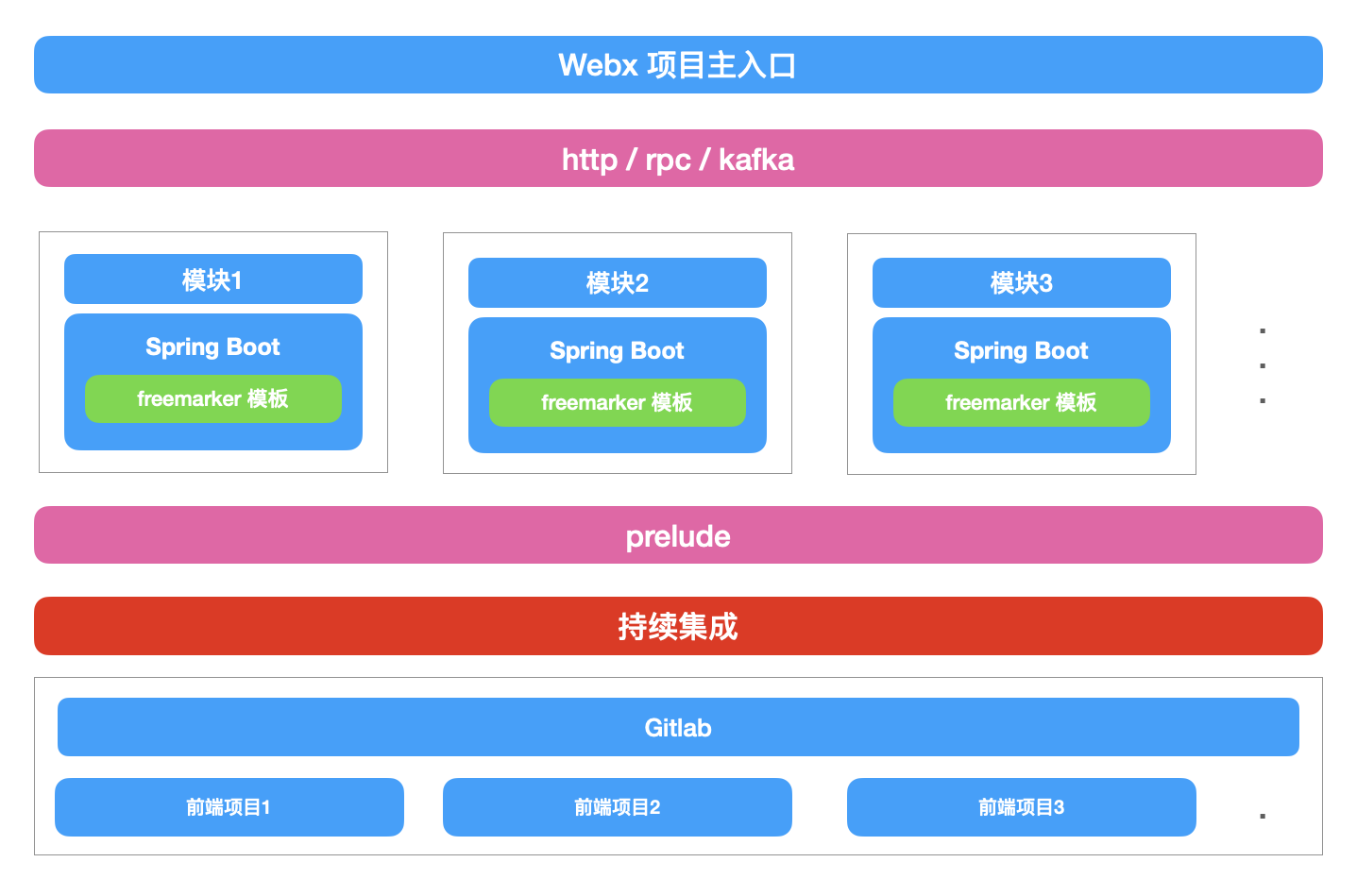
这家独角兽公司主要是toB的业务,对于前端的需求来说,项目是一个非常大的管理平台,当时前端架构也非常非常古老,前后端并没有分离,整体架构大体是这样的。
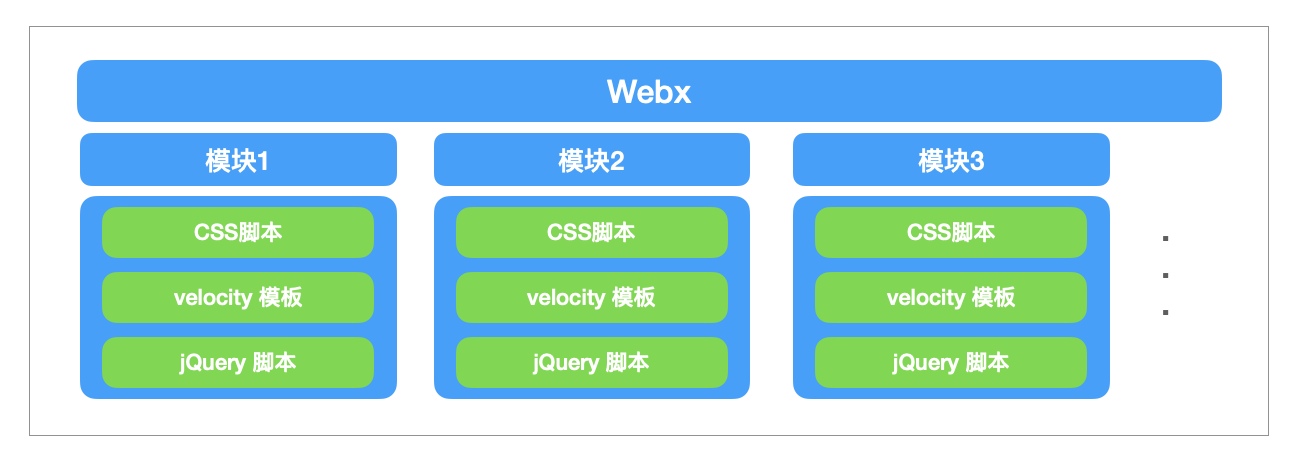
一个非常大的Java项目,用的阿里开源的JavaWeb框架Webx,然后用了类似JSP之类的东西,也就是velocity模板来渲染页面,而前端需要编写jQuery脚本和CSS脚本来完成功能,这些脚本放在Webx的静态资源目录,在velocity模板中引入对应的脚本。
可以看到,这种模式对于现在的我们来说,非常有年代感,经典的MVC模式,缺点很明显。
由于项目相对来说已经比较成熟了,所有内容推倒重做是不可能的,而且当时前端在公司的地位非常的低,没有影响力,老板是不会允许前端乱搞的,所以,只能一步一步的想办法,改变现状。
对当时的我们来说,最大的痛点是前端在开发过程中,必须启动一个后端项目,而随着后端项目的越来越庞大,每次启动都至少需要四五分钟,开发体验极差。为什么必须要启动后端项目?一个是项目开发依赖于velocity渲染的html结构,第二是因为项目请求的数据接口依赖于后端项目。
为了解决开发体验的问题,我们想到了个两全其美的办法,既可以更新技术栈,又可以提升开发体验。那就是对于老的、已完成的模块页面,先放着不管,后续有时间在重构,而对于新的需求页面,使用React进行工程化编写。
对于velocity渲染的html依赖问题,我们只需要约定好在velocity中渲染对应ID的DOM节点和初始化数据,然后在React项目中ReactDOM.render对应ID的节点并将初始化数据传递进去,这样就可以解决渲染后端项目的html渲染依赖问题。
而接口依赖问题很容易解决,可以通过mock接口解决,也可以在webpack中配置代理,将请求代理到后端的测试机器,这样就可以解决后端项目启动的问题。
而在项目发布时,将React项目的webpack的output目录指定到Webx的静态资源目录,然后在velocity中引入对应的编译结果就可以。比如现在有一个新的模块A,那么velocity中的模板是这样的:
<link rel="stylesheet" href="/static/xxx_module/moduleA/main.css?v=hash" />
<script src="/static/xxx_module/moduleA/main.js?v=hash"></script>
<script>
var _velocity_init_data_ = {
// 渲染velocity数据
};
</script>
<div id="pageA"></div>而React的项目是这样的
import React from 'react';
import React from 'react-dom';
import App from './App';
// 在开发时,声明一个带ID为pageA的空页面就可以
const container = document.getElementById('pageA');
const initData = window._velocity_init_data_;
ReactDom.render(<App initData={initData}/>, container);webpack项目配置:
const path = require('path');
module.exports = {
entry: './src/main.js',
output: {
path: path.resolve('后端项目路径', 'static', 'moduleA') // 对应的模块目录
},
// ...其他配置
}此时,项目的架构如下:
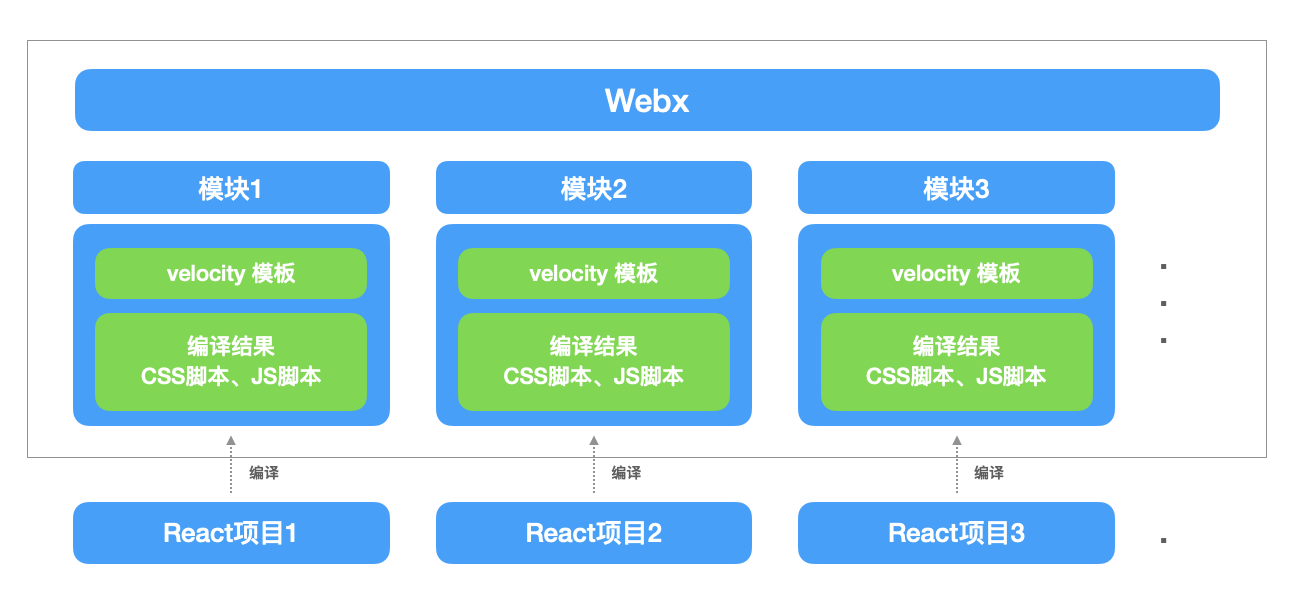
可以看到,将页面使用React工程化编写以后,前端代码与后端代码的耦合性大大降低了,后端只需要为前端提供初始化数据,前端可使用初始化数据完成相应的页面渲染。
随着公司业务的发展,整个后端项目越来越庞大,项目的单次更新部署至少都需要二三十分钟,而且由于业务场景要求,后端项目必须提升其高可用性和稳定性,这使得后端不得不将项目拆分,将各个模块各自单独开发,并且根据其访问情况,单独部署不同的机器、容器数量。这样的模块拆分,可以理解为后端项目在想微服务架构演进,各个模块有各自的路由,它们之间内部会通过http、rpc或者kafka进行通信。而当时前端在公司的影响力也并不大,以至于当时错过在后端项目拆分过程中的可以接过路由让前端管理的机会。
在后端向微服务架构演进的过程中,前端也迫不得已变成了一个微前端架构,因为公司当时没有专门做前端架构的人,所以由当时开发这部分的前端拍脑袋定了一个iframe的方案。
页面情况大体是这样,平台有一个主入口路由,这个路由由原本的Webx项目控制,这个路由渲染页面左侧的菜单栏和右侧的内容区域,所有的页面的权限控制、路由分发由原本的Webx项目完成,右侧内容区域渲染一个iframe节点,iframe根据左侧的菜单栏的选中项来加载不同模块的页面。
后端模块拆分后,大部分项目框架用的Spring Boot,而模板引擎,也从velocity切换到了freemarker,完成后架构如下:
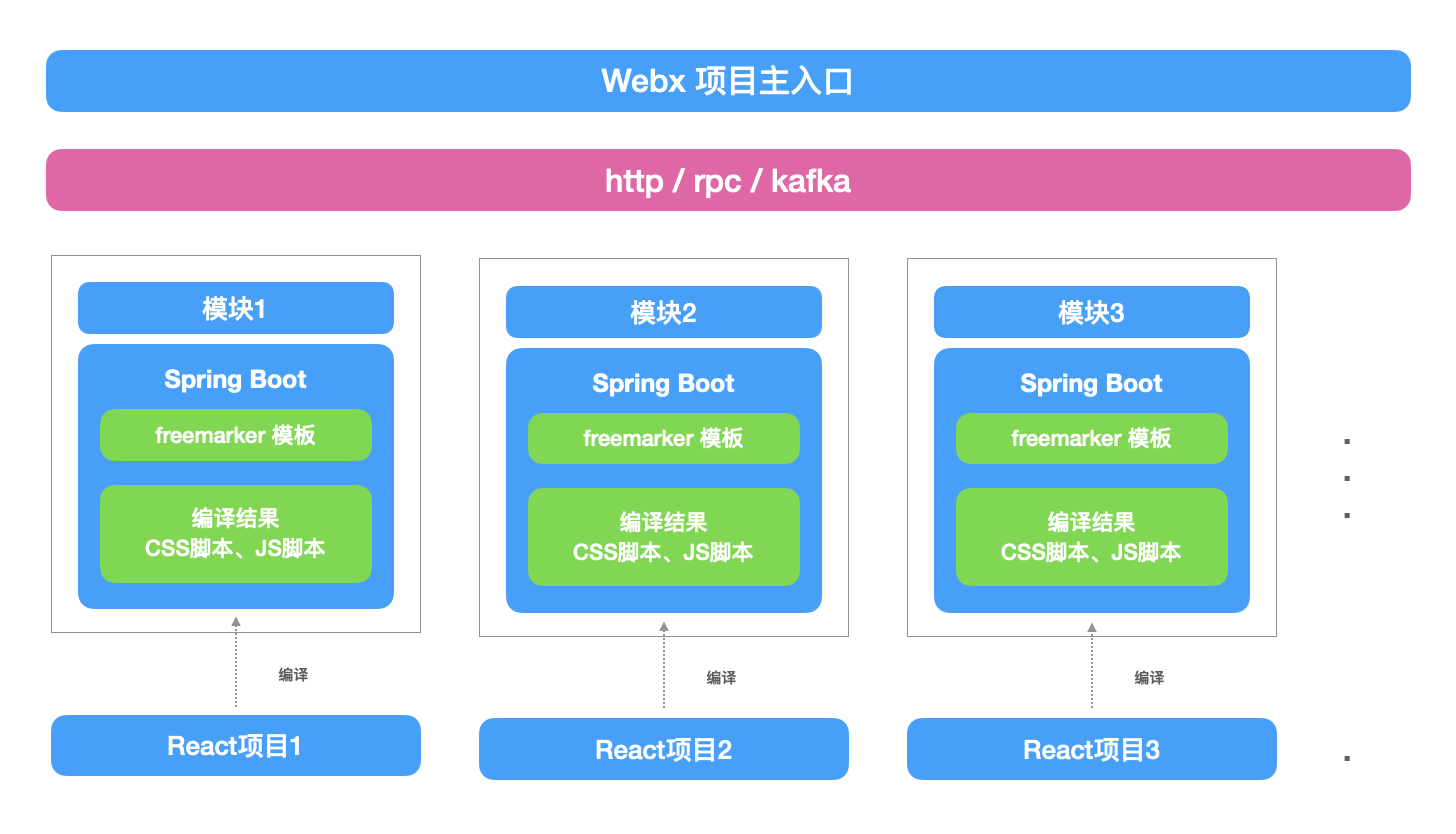
由于刚开始没有经过详细的考虑,iframe式的微前端架构缺点也慢慢暴露出来,和社区里讲的一样:
由于项目为toB项目,更注重项目的可用性,而不是性能,所以我们当时忽略了页面加载性能问题。对于用户体验问题,我们通过在iframe内实时计算高度,并用postMessage发送到主页面,主页面动态设置iframe的高度,从而解决了高度塌陷问题。而iframe内的fixed节点样式受限问题,只能见招拆招,比如前面提到的Antd的message组件和Modal组件,在设置了主页面和子页面的域解决了跨域问题后,通过设置组件的getContainer方法,将fixed节点渲染到主页面去,然后在主页面中添加对应的css样式。
iframe式微前端完成后,为了提高前端影响力,我的导师当时率先提出了前端独立发布的想法,将需要发布的前端的静态资源从后端服务中抽离出来你,部署到公司的CDN中(印象里我的导师好像是华为云的前员工,据说这个前端独立发布的想法是他在华为云提出并实践过)。
针对当时前端的情况,我们的难点很明显,路由是由后端项目来分发的,HTML的渲染也是由后端控制的,假如前端资源抽离单独发布,那么在只发布前端的时,必须保证在HTML不变的情况下(HTML决定了加载哪些CSS、JS),更新需要加载的前端资源,也就是更新需要加载的JS和CSS。
为了解决这个难点,我们实现了一个前端资源独立发布系统,项目代号prelude。每个项目的模块需要prelude在定义应用app,模块bundle,在资源发布时,应用以模块为粒度,将对应版本(版本号必须遵循Semantic Versioning规范)的静态资源发布到对应的CDN文件夹。比如,应用appA的模块bundleA,发布的V1.1.0版本,那么资源请求的路径应该是:
https://static.xxx.com/appA/bundleA/1.1.0/
在prelude控制台中,需要配置该模块bundleA初始化需要加载的资源,也可以配置的前置依赖模块,比如初始化配置了需要加载vender-chunk.js、main.js、vender-chunk.css和main.css,那么如果需要使用这个模块,则需要加载以下资源:
<link rel="stylesheet" href="https://static.xxx.com/appA/bundleA/1.1.0/vender-chunk.css" />
<link rel="stylesheet" href="https://static.xxx.com/appA/bundleA/1.1.0/main.css" />
<script src="https://static.xxx.com/appA/bundleA/1.1.0/vender-chunk.js"></script>
<script src="https://static.xxx.com/appA/bundleA/1.1.0/main.js"></script>知道了模块需要加载的资源后,prelude向外暴露了一个loader接口,这个接口接收app、bundle、version三个参数,然后渲染一段js脚本,用来向页面中注入对应app/bundle/version配置好的需要加载的所有资源,例如前面的例子,只需要在velocity或者freemarker中引入一下脚本:
<script src="https://prelude.xxx.com/prelude-loader?app=appA&bundle=bundleA&version=V1.1.0"></script>loader接口渲染的脚本大体如下:
var assets = {
css: [
'https://static.xxx.com/appA/bundleA/1.1.0/vender-chunk.css',
'https://static.xxx.com/appA/bundleA/1.1.0/main.css'
],
js: [
'https://static.xxx.com/appA/bundleA/1.1.0/vender-chunk.js',
'https://static.xxx.com/appA/bundleA/1.1.0/main.js'
]
};
// 加载CSS
assets.css.forEach(href => {
var link = document.createElement('link');
// 其他逻辑
link.rel = 'stylesheet';
link.href = hrefs;
document.head.appendChild(link);
});
// 加载JS
assets.css.forEach(src => {
var script = document.createElement('script');
// 其他逻辑
script.async = false; // 顺序执行
script.src = src;
document.body.appendChild(script);
});对此还不够,因为接口的version参数是写死的V1.1.0,如果前端发布更新了版本,那么还需要后端应用去发布更新velocity或者freemarker中的script标签的version参数,这不符合需求。于是我们将version参数进行了升级,可以使用规范的通配符,比如传入version=*,代表永远取该模块的最新版本,那么velocity或者freemarker引入的脚本就变成了下面这样:
<script src="https://prelude.xxx.com/preluer-loader?app=appA&bundle=bundleA&version=*"></script>于是,流程差不多通了,在技术方案评审过程中,收到了来自经理的疑问:假如前后端同时发布的情况下,如何保证前后端发布的同步?
那既然是经理的疑问,该解决还是要解决,不然方案评审不给过怎么办?针对在这个问题,我们可以前后端做好约定,约定version参数只允许有第三位版本号的使用通配符,例如只能使用V1.1.*,这种情况,loader只会加载V1.1.*的最新版本,然后在做好发布的版本更新约定。
例如,当前后端同时发布时,前端先发布更新版本到V1.2.0,后端没发布时,一直用的是V1.1.*的版本,当后端发布后,更新version参数为V1.2.*,上线后就自动加载为V1.2.0的版本了。
整个项目由有三个人完成,我主要负责平台的所有配置和配置Mysql入库,我的导师负责loader接口的开发和对应redis的读写、项目基建等,另外一个同事负责CDN的对接操作,历时大概一个月左右就完成了。
项目完成并实施后,架构已经将前端慢慢的解耦出来了。
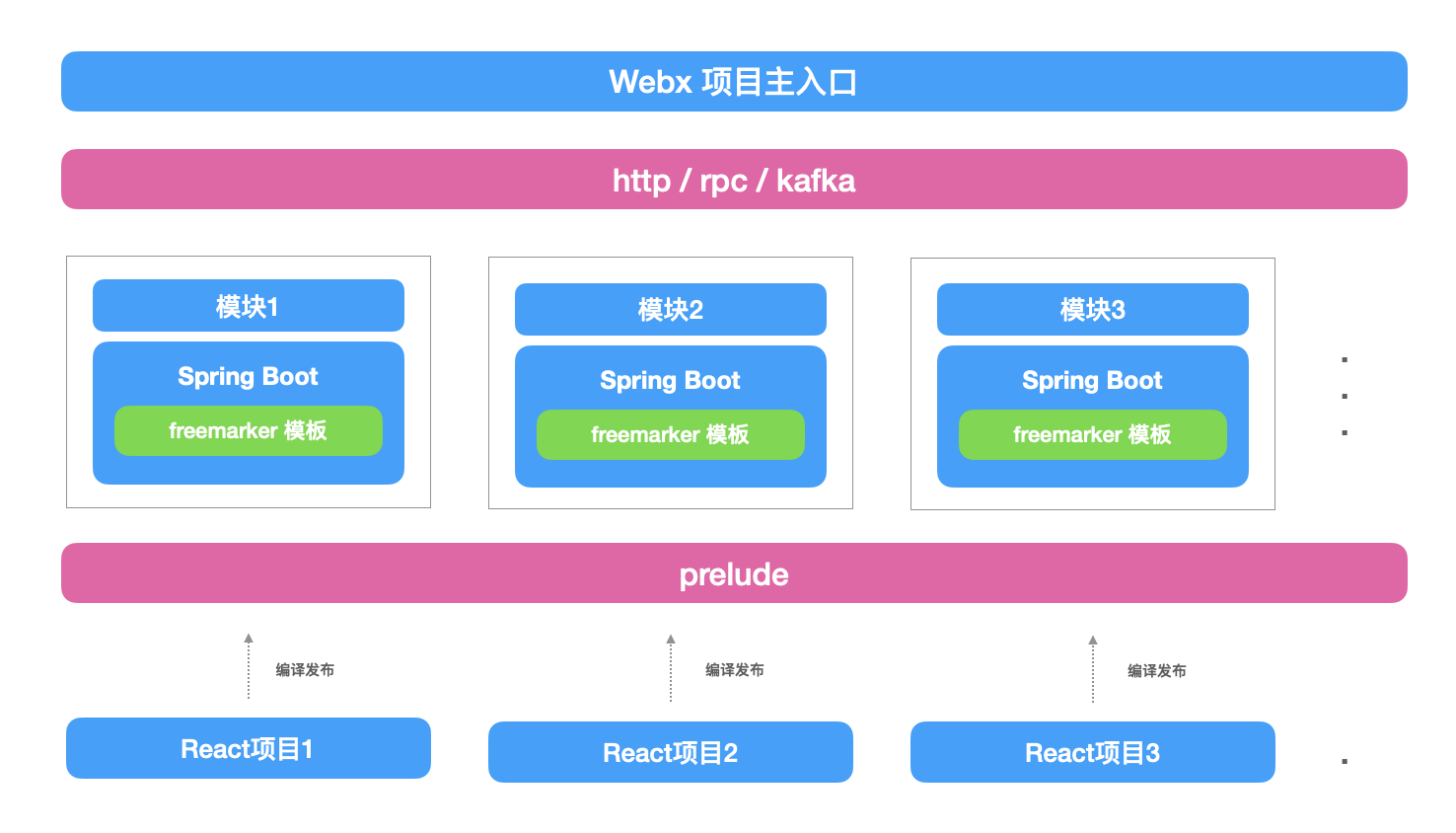
当prelude项目完成后,我们利用prelude的优势,通过新的方式弥补将iframe式的微前端架构的缺点,比如在Webx项目路由分发时,用渲染prelude-loader标签的形式代替iframe标签,制造一个伪iframe微前端的架构。
项目完成后,由于我的导师功劳巨大(期间还不断组件公司组件库的建设之类的),他直接被掉到了公司的基础架构组做前端架构。2019年12月,我从这家独角兽离职,后续偶尔有和我的导师聊两句,他说prelude的发展挺好的,得到了公司的认可,目前也和持续集成平台打通了,虽然我没有问细节,但是大体我可以想象到现在prelude的样子。
我离职的时候,prelude的状态是,模块production编译发布是在个人电脑上进行的,编译后通过手动或者webpack插件的形式上传到prelude平台,由prelude代发到CDN中,操作极其繁琐。
如今打通了持续集成后,可以做非常多的事情,例如静态类型检查、编码风格检测等,当然这都不是重点,重点是怎么利用持续集成,将前端代码的交付规范起来,而不是原本的在个人电脑上完成。
首先,前端项目方在gitlab中,我们需要规定每个项目有一个编译产出的出口目录,然后流水线按照约定好的出口目录获取产出,并发布到prelude。
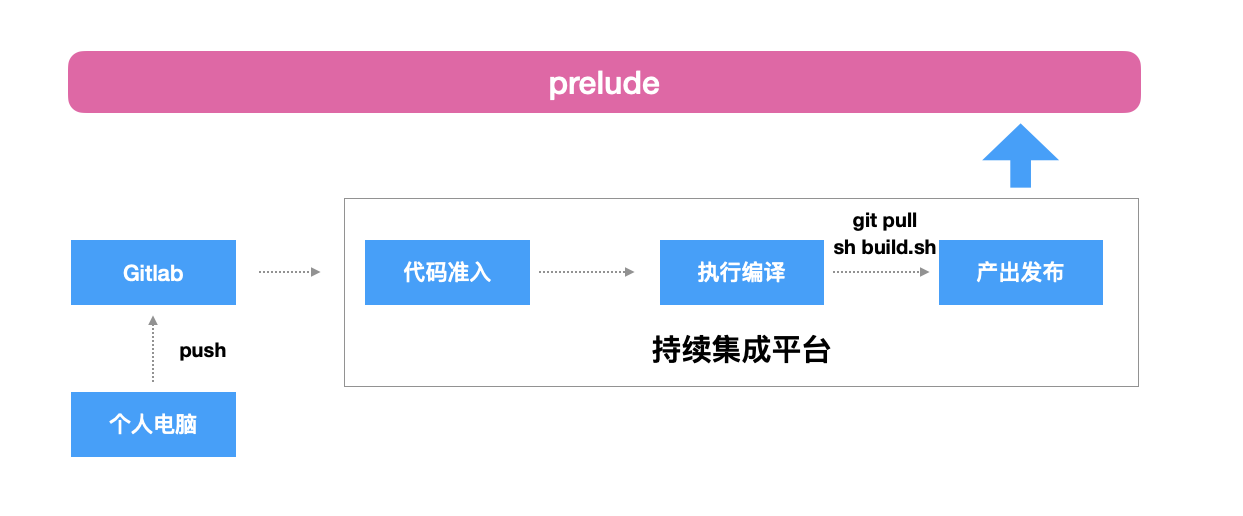
有了持续集成之后,所有production环境的代码我们不需要在自己的电脑进行build,只需要在项目根目录新建build.sh脚本,这个脚本内包含了所有编译构建的命令,让持续集成平台去执行,编译后在根目录产出output.tar.gz,然后将产出包包含app/bundle/version参数描述文件或者在产出发布时候直接传参给prelude,让prelude代发到CDN,这样就可以完成版本发布。
到了这一步,整个前端架构基本已经完全解耦出来。
整个架构的发展大概经历了两到三年的时间,中间也遇到了很多坎坎坷坷的问题,虽然我们没有全局最优的方案,但是基本都用了局部最优的方案来解决问题,这两三年时间,我也从一个前端菜鸟变成了一个还可以的前端精神小伙,还是非常感谢当时的导师。
原型与原型链一直是JavaScript中的重点与难点,虽然老生常谈了,但是还是需要对其进行深入与巩固。。。。
首先是原型,要理解原型,需要知道三个东西;
prototype:每个函数都会有的属性,它指向函数的原型对象。(注意:函数对象才有,普通对象没有。)
__proto__:每一个对象都会有个属性,当然,函数也属于对象,所以函数也有这个属性,它指向构造函数的原型对象;
constructor:原型对象上的一个属性,指向对象的构造函数;
下面用示例来验证一下其关系;
function Pig(name) {
this.name = name;
}
var peppa = new Pig('peppa');用new关键字实例化一个Pig对象,返回一个普通对象pie示例,在实例化的时候,Pig的prototype上的属性会作为原型对象赋值给实例。也就是说peppa的原型,是从Pig的prototype引用来的,即peppa.__proto__ === Pig.prototype;
peppa.__proto__ === Pig.prototype;
// true;Pig是一个函数对象,它是Function的一个实例,所以Pig.__proto__ === Function.prototype一定为true;
Pig.__proto__ === Function.prototype;
// true上面说到的constructor,它指向原型对象构造函数属性,也就是peppa.__proto__.constructor == Pig;
pie.__proto__.constructor == Pig;
// true当然我们有peppa.__proto__ === Pig.prototype,所以Pig.prototype.constructor == Pig也为true;
Pig.prototype.constructor == Pig下面我们来说一下Pig、Function、Object之间的关系;
首先,Pig为Function的实例,所以有Pig.__proto__ === Function.prototype为true;
Pig.__proto__ === Function.prototype;
// true然后由于构造函数创建的时候会给其函数加上prototype属性,方面后面实例的引用,prototype属于普通对象,为Object的实例,有:
Pig.prototype.__proto__ === Object.prototype;
// true由上可以知道,所有构造函数的原型对象的__proto__都指向Object.prototype:
Function.prototype.__proto__ === Object.prototype
// true另外,Object为一个对象,可以认为为某一个Function的实例返回,所以有:
Object.__proto__ === Function.prototype
// true至此,得到链条pie.__proto__ === Pig.prototype => Pig.__proto__ === Function.prototype => Function.prototype.__proto__ === Object.prototype;
那么Object.prototype.__proto__又指向谁,JS世界里万物皆对象,Object似乎已经到了原型链的顶端,果然不出我所料,它确实是null;
Object.prototype.__proto__ === null;
// true接着说一下原型链。正如你在上面图中所看到的,JS在创建对象的时候,会在新对象上产生一个__proto__的属性,这个属性指向了它构造函数的原型的prototype。由此一级一级向上直到到达Object.prototype.proto === null的这个链条我们称之为原型链。
关于原型与原型链大概理解如上,大部分继承都是基于原型与原型链完成的。。。
是否有很多人跟我一样有这样的一个烦恼,每天有写不完的需求、改不完的BUG,每天撸着重复、繁琐的业务代码,担心着自己的技术成长。
其实换个角度,我们所学的所有前端技术都是服务于业务的,那我们为什么不想办法使用前端技术为业务做点东西?这样既能解决业务的困扰,也能让自己摆脱每天只能写重复繁琐代码的困扰。
本文主要为笔者针对当前团队内的一些业务问题,实现的一个自动化部署平台的技术方案。
去年年初,由于团队里没有前端,刚好我是被招过来的第一个,也是唯一一个FE,于是我接手了一个一直由后端维护的JSSDK项目,其实也说不上项目,接手的时候它只是一个2000多行代码的胖脚本,没有任何工程化痕迹。
这个JSSDK,主要作用是在后端了为业务方分配appKey之后,前端将appKey写死在JSSDK中,上传到CDN后,为业务方提供数据采集服务的脚本。
有的同学可能有疑问,为什么不像一些正常的SDK一样,appKey是以参数的形式传入到JSSDK中,这样就可以统一所有业务方使用同一个JSSDK,而不需要为每个业务业务方都提供一个JSSDK。其实我刚开始也是这么想的,于是我向我的leader提出了我的这个想法,被拒绝了,拒绝原因如下:
由于我的leader现在主要是负责产品推广,经常和业务方打交道,可能他更能站在业务方的角度来考虑问题。所以,我的leader选择牺牲项目的维护成本来降低SDK的接入成本和规避风险,可以理解。
那既然我们改变不了现状,那就只能适应现状。
那么针对原来没有任何工程化情况的胖脚本,每次新增一个业务方,我需要做的事情如下:
整个过程都需要手动进行,相对来说非常繁琐,并且一不小心就会填错,每次都需要对脚本和接入文档进行检查。
针对以上情况,得到我们需要解决的问题:
介绍方案之前,先上一张平台截图,以便先有一个直观的认识:
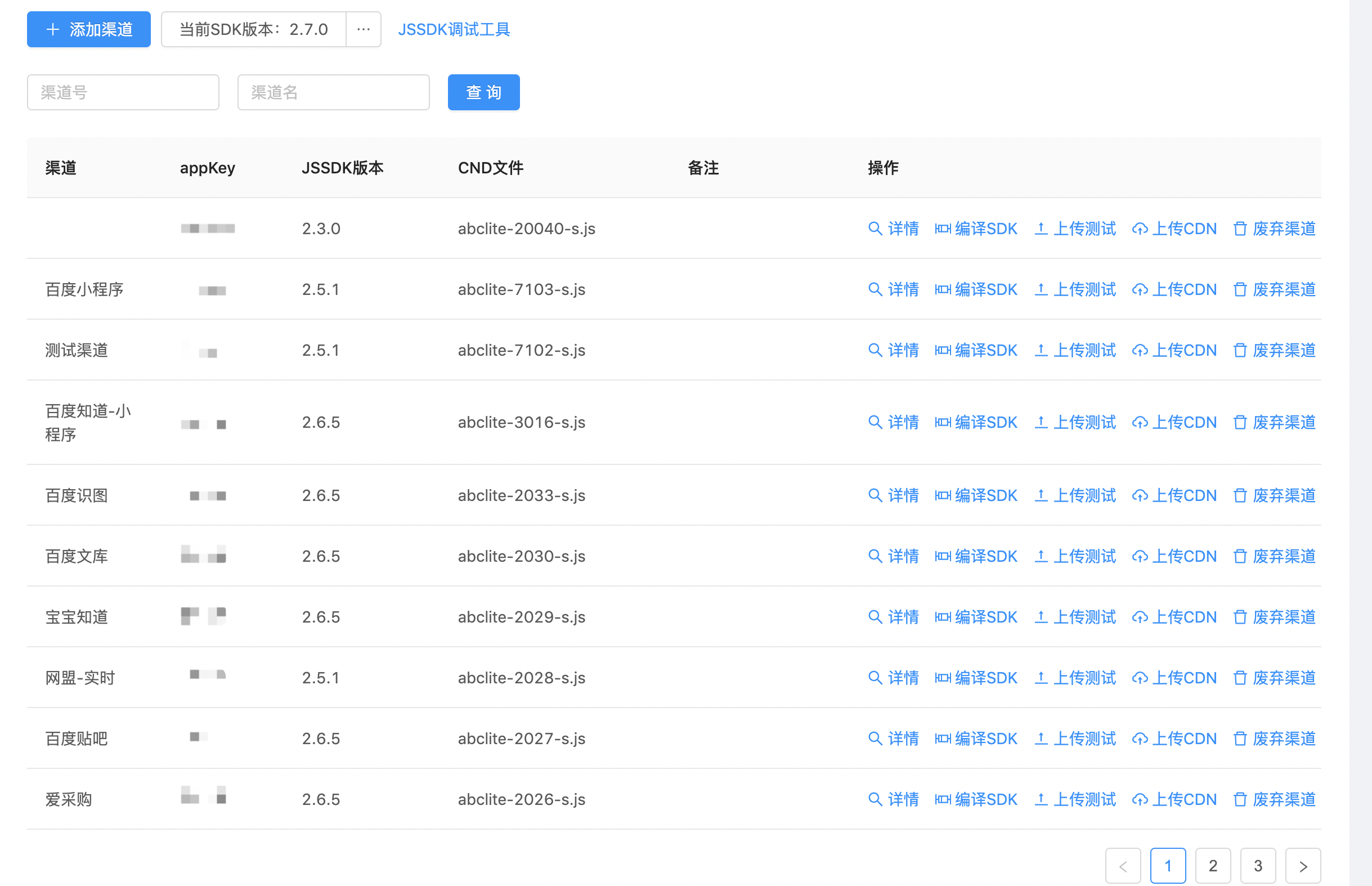
SDK自动化部署平台主要实现了JSSDK的编译,发布测试(在线预览),上传CDN功能。
服务端技术栈包括:
客户端技术栈就不介绍了,Vue全家桶 + vue-property-decorator + vuex-class。
项目搭建参考:Vue+Express+Mysql 全栈初体验
自动化部署平台主要依赖于 GIT + 本地环境 + 私有NPM源 + MYSQL,各环节之间进行通信交互,完成自动化部署。
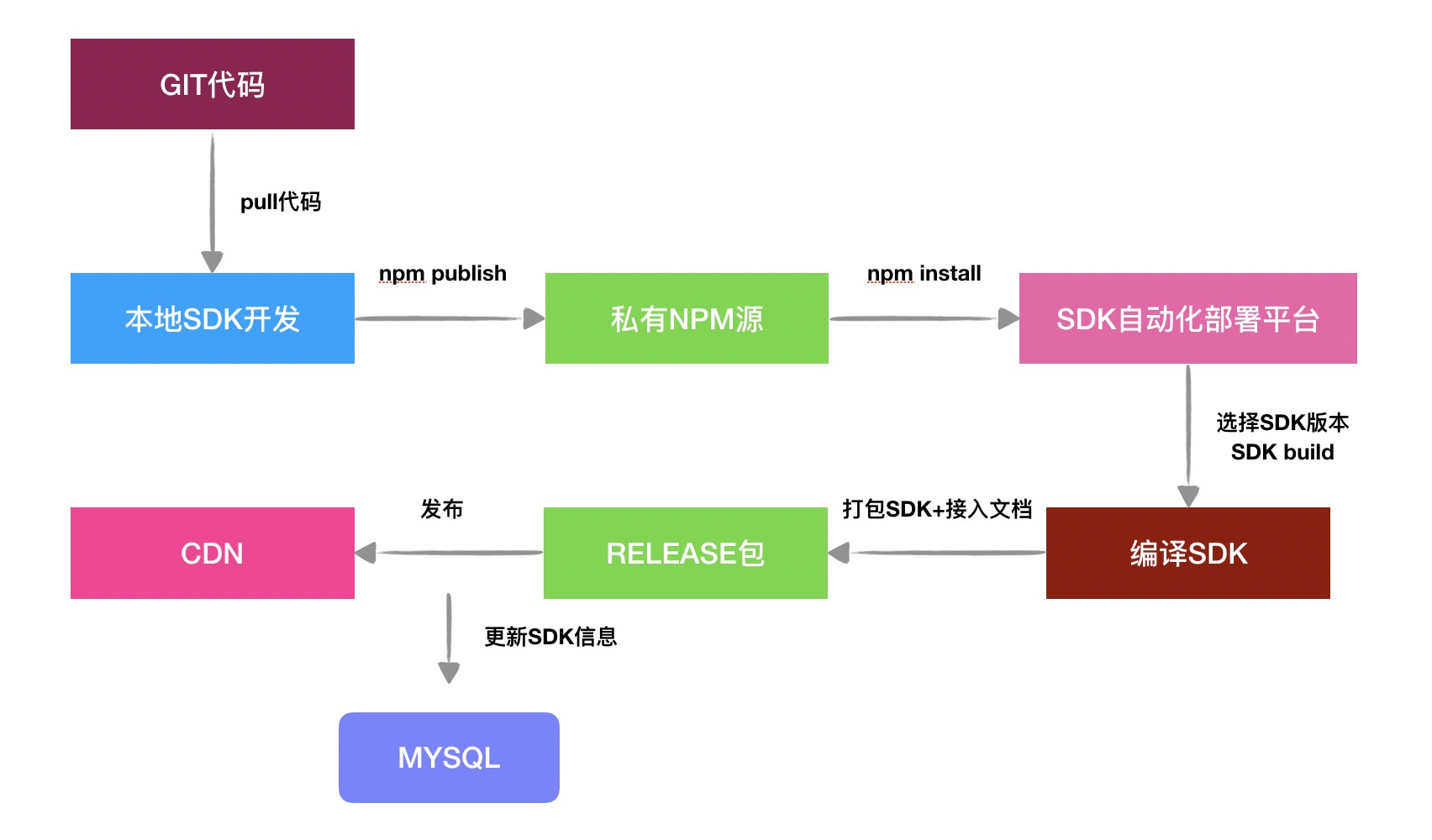
主要达到的效果:本地环境拉取git仓库代码后,进行需求开发,完成后发布一个带Rollup的SDK编译器包到私有NPM仓库,自动化部署平台在工程目录安装指定版本的SDK,并且备份到本地,在SDK编译时,选择特定版本的Rollup的SDK编译器,并传参(如appKey,appId等)到编译器中进行编译,同时自动生成JSSDK接入文档等后打包成带描述文件的Release包,在上传到CDN时,将描述文件的对应的信息写入MYSQL中进行保存。
由于JSSDK原本只是一个脚本,我们必须实现项目的工程化,从而完成版本管理,方便快速版本切换进行发布,回滚,进而快速止损。
首先,我们需要将项目工程化,使用Rollup进行模块管理,并且在发包NPM包的时候,输入为各种参数(如appKey)输出为一个Rollup Complier的函数,然后使用rollup-plugin-replace在编译时候替换代码中具体的参数。
lib/build.js,JSSDK中发包的入口文件,提供给SDK编译时使用
import * as rollup from 'rollup';
const replace = require('rollup-plugin-replace');
const path = require('path');
const pkgPath = path.join(__dirname, '..', 'package.json');
const pkg = require(pkgPath);
const proConfig = require('./proConfig');
function getRollupConfig(replaceParams) {
const config = proConfig;
// 注入系统变量
const replacePlugin = replace({
'__JS_SDK_VERSION__': JSON.stringify(pkg.version),
'__SUPPLY_ID__': JSON.stringify(replaceParams.supplyId || '7102'),
'__APP_KEY__': JSON.stringify(replaceParams.appKey)
});
return {
input: config.input,
output: config.output,
plugins: [
...config.plugins,
replacePlugin
]
};
};
module.exports = async function (params) {
const config = getRollupConfig({
supplyId: params.supplyId || '7102',
appKey: params.appKey
});
const {
input,
plugins
} = config;
const bundle = await rollup.rollup({
input,
plugins
});
const compiler = {
async write(file) {
await bundle.write({
file,
format: 'iife',
sourcemap: false,
strict: false
});
}
};
return compiler;
};在自动化部署平台中,使用shelljs安装JSSDK包:
import {route, POST} from 'awilix-express';
import {Api} from '../framework/Api';
import * as shell from 'shell';
import * as path from 'path';
@route('/supply')
export default class SupplyAPI extends Api {
// some code
@route('/installSdkVersion')
@POST()
async installSdkVersion(req, res) {
const {version} = req.body;
const pkg = `@baidu/xxx-js-sdk@${version}`;
const registry = 'http://registry.npm.baidu-int.com';
shell.exec(`npm i ${pkg} --registry=${registry}`, (code, stdout, stderr) => {
if (code !== 0) {
console.error(stderr);
res.failPrint('npm install fail');
return;
}
// sdk包备份路径
const sdkBackupPath = this.sdkBackupPath;
const sdkPath = path.resolve(sdkBackupPath, version);
shell.mkdir('-p', sdkPath).then((code, stdout, stderr) => {
if (code !== 0) {
console.error(stderr);
res.failPrint(`mkdir \`${sdkPath}\` error.`);
return;
}
const modulePath = path.resolve(process.cwd(), 'node_modules', '@baidu', 'xxx-js-sdk');
// 拷贝安装后的文件,方便后续使用
shell.cp('-rf', modulePath + '/.', sdkPath).then((code, stdout, stderr) => {
if (code !== 0) {
console.error(stderr);
res.failPrint(`backup sdk error.`);
return;
}
res.successPrint(`${pkg} install success.`);
});
})
});
}
}Release包就是我们在上传到CDN之前需要准备的压缩包。因此,打包JSSDK之后,我们需要生成的文件有,接入文档、JSSDK DEMO预览页面、JSSDK编译结果、描述文件。
首先,打包函数如下:
import {Service} from '../framework';
import * as fs from 'fs';
import path from 'path';
import _ from 'lodash';
export default class SupplyService extends Service {
async generateFile(supplyId, sdkVersion) {
// 数据库查询对应的业务方的CDN文件名
const [sdkInfoErr, sdkInfo] = await this.supplyDao.getSupplyInfo(supplyId);
if (sdkInfoErr) {
return this.fail('服务器错误', null, sdkInfoErr);
}
const {appKey, cdnFilename, name} = sdkInfo;
// 需要替换的数据
const data = {
name,
supplyId,
appKey,
'sdk_url': `https://***.com/sdk/${cdnFilename}`
};
try {
// 编译JSSDK
const sdkResult = await this.buildSdk(supplyId, appKey, sdkVersion);
// 生成接入文档
const docResult = await this.generateDocs(data);
// 生成预览DEMO html文件
const demoHtmlResult = await this.generateDemoHtml(data, 'sdk-demo.html', `JSSDK-接入页面-${data.name}.html`);
// 生成release包描述文件
const sdkInfoFileResult = await this.writeSdkVersionFile(supplyId, appKey, sdkVersion);
const success = docResult && demoHtmlResult && sdkInfoFileResult && sdkResult;
if (success) {
// release目标目录
const dir = path.join(this.releasePath, supplyId + '');
const fileName = `${supplyId}-${sdkVersion}.zip`;
const zipFileName = path.join(dir, fileName);
// 压缩所有结果文件
const zipResult = await this.zipDirFile(dir, zipFileName);
if (!zipResult) {
return this.fail('打包失败');
}
// 返回压缩包提供下载
return this.success('打包成功', {
url: `/${supplyId}/${fileName}`
});
} else {
return this.fail('打包失败');
}
} catch (e) {
return this.fail('打包失败', null, e);
}
}
}JSSDK的编译很简单,只需要加载对应版本的JSSDK的编译函数,然后将对应的参数传入编译函数得到一个Rollup Compiler,然后将 Compiler 结果写入Release路径即可。
export default class SupplyService extends Service {
async buildSdk(supplyId, appKey, sdkVersion) {
try {
const sdkBackupPath = this.sdkBackupPath;
// 加载对应版本的备份的JSSDK包的Rollup编译函数
const compileSdk = require(path.resolve(sdkBackupPath, sdkVersion, 'lib', 'build.js'));
const bundle = await compileSdk({
supplyId,
appKey: Number(sdkInfo.appKey)
});
const releasePath = path.resolve(this.releasePath, supplyId, `${supplyId}-sdk.js`);
// Rollup Compiler 编译结果至release目录
await bundle.write(releasePath);
return true;
} catch (e) {
console.error(e);
return false;
}
}
}原理很简单,使用JSZip,打开接入文档模板,然后使用Docxtemplater替换模板里的特殊字符,然后重新生成DOC文件:
import Docxtemplater from 'docxtemplater';
import JSZip from 'JSZip';
export default class SupplyService extends Service {
async generateDocs(data) {
return new Promise(async (resolve, reject) => {
if (data) {
// 读取接入文档,替换appKey,cdn路径
const supplyId = data.supplyId;
const docsFileName = 'sdk-doc.docx';
const supplyFilesPath = path.resolve(process.cwd(), 'src/server/files');
const content = fs.readFileSync(path.resolve(supplyFilesPath, docsFileName), 'binary');
const zip = new JSZip(content);
const doc = new Docxtemplater();
// 替换`[[`前缀和`]]`后缀的内容
doc.loadZip(zip).setOptions({delimiters: {start: '[[', end: ']]'}});
doc.setData(data);
try {
doc.render();
} catch (error) {
console.error(error);
reject(error);
}
// 生成DOC的buffer
const buf = doc.getZip().generate({type: 'nodebuffer'});
const releasePath = path.resolve(this.releasePath, supplyId);
// 创建目标目录
shell.mkdir(releasePath).then((code, stdout, stderr) => {
if (code !== 0 ) {
resolve(false);
return;
}
// 将替换后的结果写入release路径
fs.writeFileSync(path.resolve(releasePath, `JSSDK-文档-${data.name}.docx`), buf);
resolve(true);
}).catch(e => {
console.error(e);
resolve(false);
});
}
});
}
}与接入文档生成原理类似,打开一个DEMO模板HTML文件,替换内部字符,重新生成文件:
export default class SupplyService extends Service {
generateDemoHtml(data, file, toFile) {
return new Promise((resolve, reject) => {
const supplyId = data.supplyId;
// 需要替换的数据
const replaceData = data;
// 打开文件
const content = fs.readFileSync(path.resolve(supplyFilesPath, file), 'utf-8');
// 字符串替换`{{`前缀和`}}`后缀的内容
const replaceContent = content.replace(/{{(.*)}}/g, (match, key) => {
return replaceData[key] || match;
});
const releasePath = path.resolve(this.releasePath, supplyId);
// 写入文件
fs.writeFile(path.resolve(releasePath, toFile), replaceContent, err => {
if (err) {
console.error(err);
resolve(false);
} else {
resolve(true);
}
});
});
}
}将当前打包的一些参数存在一个文件中的,一并打包到Release包中,作用很简单,用来描述当前打包的一些参数,方便上线CDN的时候记录当前上线的是哪个SDK版本等
export default class SupplyService extends Service {
async writeSdkVersionFile(supplyId, appKey, sdkVersion) {
return new Promise(resolve => {
const writePath = path.resolve(this.releasePath, supplyId, 'version.json');
// Release描述数据
const data = {version: sdkVersion, appKey, supplyId};
try {
// 写入release目录
fs.writeFileSync(writePath, JSON.stringify(data));
resolve(true);
} catch (e) {
console.error(e);
resolve(false);
}
});
}
}将之前生成的JSSDK编译结果、接入文档、预览DEMO页面文件,描述文件使用archive打包起来:
export default class SupplyService extends Service {
zipDirFile(dir, to) {
return new Promise(async (resolve, reject) => {
const output = fs.createWriteStream(to);
const archive = archiver('zip');
archive.on('error', err => reject(err));
archive.pipe(output);
const files = fs.readdirSync(dir);
files.forEach(file => {
const filePath = path.resolve(dir, file);
const info = fs.statSync(filePath);
if (!info.isDirectory()) {
archive.append(fs.createReadStream(filePath), {
'name': file
});
}
});
archive.finalize();
resolve(true);
});
}
}大部分上传到CDN都为像CDN源站push文件,而正好我们运维在我的自动化部署平台的机器上挂载了NFS,即我只需要本地将JSSDK文件拷贝到共享目录,就实现了CDN文件上传。
export default class SupplyService extends Service {
async cp2CDN(supplyId, fileName) {
// 读取描述文件
const sdkInfoPath = path.resolve(this.releasePath, '' + supplyId, 'version.json');
if (!fs.existsSync(sdkInfoPath)) {
return this.fail('Release描述文件丢失,请重新打包');
}
const sdkInfo = JSON.parse(fs.readFileSync(sdkInfoPath, 'utf-8'));
sdkInfo.cdnFilename = fileName;
// 将文件拷贝至文件共享目录
const result = await this.cpFile(supplyId, fileName, false);
// 上传成功
if (result) {
// 将Release包描述文件的数据同步到MYSQL
const [sdkInfoErr] = await this.supplyDao.update(sdkInfo, {where: {supplyId}});
if (sdkInfoErr) {
return this.fail('JSSDK信息记录失败,请重试', null, jssdkInfoResult);
}
return this.success('上传成功', {url})
}
return this.fail('上传失败');
}
}项目效益还是很明显,从本质上解决了我们需要解决的问题:
节省了人工上传粘贴代码的时间,大大地提高了工作效率。
这个项目还是19年前半年个人花业余时间完成的工具项目,后来得到了Leader的重视,将工具正式升级为平台,集成了很多业务相关的配置在平台,我19年的前半年KPI就这么来的,哈~~~
或者这一套思路对每个业务都比较适用
其实每个项目中的痛点都一般都是XX的性能低下、XX非常低效,还是比较容易发现的,这个时候只需要主动的寻找方案并推进实现就OK了。
前端技术离不开业务,技术永远服务于业务,离开了业务的技术,那是完全没有落脚点的技术,完全没有意义的技术。所以,除了写写页面,利用前端页面实现工具化、自动化,从而推进到平台化也是一个不错的落脚点选择。
你好,已star,一次关于Vue的自我模拟面试和前端赋能业务 - Node实现自动化部署平台可以转载到公众号高级前端进阶上吗?会标明作者与来源,感谢
最近,项目进入维护期,基本没有什么需求,比较闲,这让我莫名的有了危机感,每天像是在混日子,感觉这像是在温水煮青蛙,已经毕业3年了,很怕自己到了5年经验的时候,能力却和3年经验的时候一样,没什么长进。于是开始整理自己的技术点,刚好查漏补缺,在收藏夹在翻出了一篇文章一名【合格】前端工程师的自检清单,看到了里面的两个问题:
JavaScript中的变量在内存中的具体存储形式是什么?然后各种查资料,就整理了这篇文章。
阅读本文之后,你可以了解到:
不管什么程序语言,内存生命周期基本是一致的:
与其他需要手动管理内存的语言不通,在JavaScript中,当我们创建变量(对象,字符串等)的时候,系统会自动给对象分配对应的内存。
var n = 123; // 给数值变量分配内存
var s = "azerty"; // 给字符串分配内存
var o = {
a: 1,
b: null
}; // 给对象及其包含的值分配内存
// 给数组及其包含的值分配内存(就像对象一样)
var a = [1, null, "abra"];
function f(a){
return a + 2;
} // 给函数(可调用的对象)分配内存
// 函数表达式也能分配一个对象
someElement.addEventListener('click', function(){
someElement.style.backgroundColor = 'blue';
}, false);当系统发现这些变量不再被使用的时候,会自动释放(垃圾回收)这些变量的内存,开发者不用过多的关心内存问题。
虽然这样,我们开发过程中也需要了解JavaScript的内存管理机制,这样才能避免一些不必要的问题,比如下面代码:
{}=={} // false
[]==[] // false
''=='' // true在JavaScript中,数据类型分为两类,简单类型和引用类型,对于简单类型,内存是保存在栈(stack)空间中,复杂数据类型,内存是保存在堆(heap)空间中。
而对于栈的内存空间,只保存简单数据类型的内存,由操作系统自动分配和自动释放。而堆空间中的内存,由于大小不固定,系统无法无法进行自动释放,这个时候就需要JS引擎来手动的释放这些内存。
在Chrome中,v8被限制了内存的使用(64位约1.4G/1464MB , 32位约0.7G/732MB),为什么要限制呢?
前面说到栈内的内存,操作系统会自动进行内存分配和内存释放,而堆中的内存,由JS引擎(如Chrome的V8)手动进行释放,当我们的代码没有按照正确的写法时,会使得JS引擎的垃圾回收机制无法正确的对内存进行释放(内存泄露),从而使得浏览器占用的内存不断增加,进而导致JavaScript和应用、操作系统性能下降。
在JavaScript中,其实绝大多数的对象存活周期都很短,大部分在经过一次的垃圾回收之后,内存就会被释放掉,而少部分的对象存活周期将会很长,一直是活跃的对象,不需要被回收。为了提高回收效率,V8 将堆分为两类新生代和老生代,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象。
新生区通常只支持 1~8M 的容量,而老生区支持的容量就大很多了。对于这两块区域,V8 分别使用两个不同的垃圾回收器,以便更高效地实施垃圾回收。
在JavaScript中,任何对象的声明分配到的内存,将会先被放置在新生代中,而因为大部分对象在内存中存活的周期很短,所以需要一个效率非常高的算法。在新生代中,主要使用Scavenge算法进行垃圾回收,Scavenge算法是一个典型的牺牲空间换取时间的复制算法,在占用空间不大的场景上非常适用。
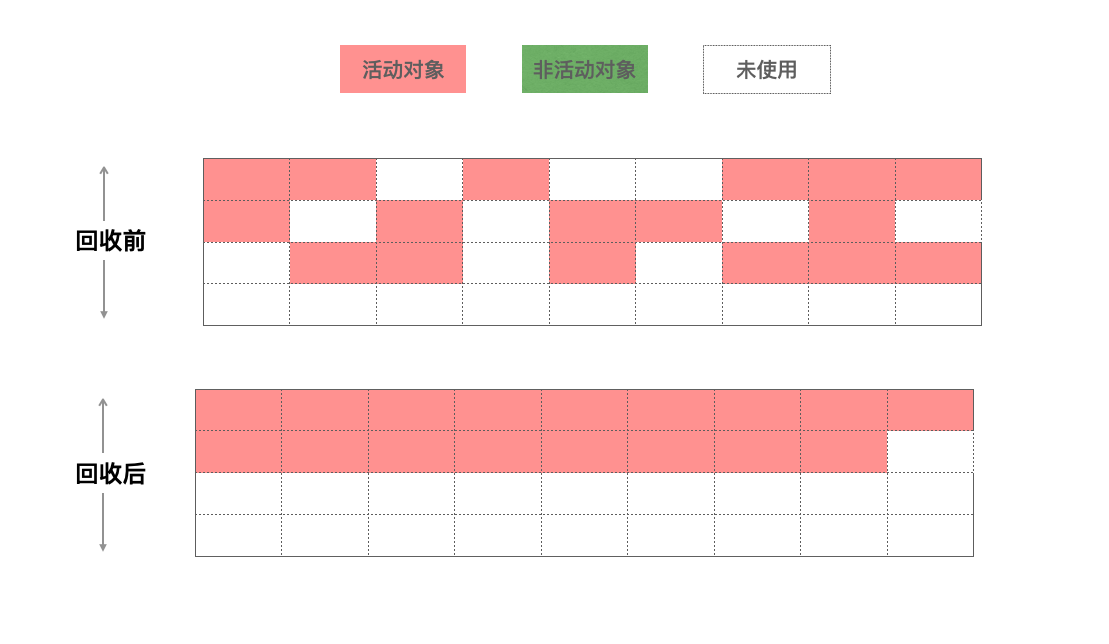
Scavange算法将新生代堆分为两部分,分别叫from-space和to-space,工作方式也很简单,就是将from-space中存活的活动对象复制到to-space中,并将这些对象的内存有序的排列起来,然后将from-space中的非活动对象的内存进行释放,完成之后,将from space 和to space进行互换,这样可以使得新生代中的这两块区域可以重复利用。

简单的描述就是:
那么,垃圾回收器是怎么知道哪些对象是活动对象和非活动对象的呢?
有一个概念叫对象的可达性,表示从初始的根对象(window,global)的指针开始,这个根指针对象被称为根集(root set),从这个根集向下搜索其子节点,被搜索到的子节点说明该节点的引用对象可达,并为其留下标记,然后递归这个搜索的过程,直到所有子节点都被遍历结束,那么没有被标记的对象节点,说明该对象没有被任何地方引用,可以证明这是一个需要被释放内存的对象,可以被垃圾回收器回收。
新生代中的对象什么时候变成老生代的对象呢?
在新生代中,还进一步进行了细分,分为nursery子代和intermediate子代两个区域,一个对象第一次分配内存时会被分配到新生代中的nursery子代,如果进过下一次垃圾回收这个对象还存在新生代中,这时候我们移动到 intermediate 子代,再经过下一次垃圾回收,如果这个对象还在新生代中,副垃圾回收器会将该对象移动到老生代中,这个移动的过程被称为晋升。
新生代空间中的对象满足一定条件后,晋升到老生代空间中,在老生代空间中的对象都已经至少经历过一次或者多次的回收所以它们的存活概率会更大,如果这个时候再使用scavenge算法的话,会出现两个问题:
所以在老生代空间中采用了 Mark-Sweep(标记清除) 和 Mark-Compact(标记整理) 算法。
Mark-Sweep处理时分为两阶段,标记阶段和清理阶段,看起来与Scavenge类似,不同的是,Scavenge算法是复制活动对象,而由于在老生代中活动对象占大多数,所以Mark-Sweep在标记了活动对象和非活动对象之后,直接把非活动对象清除。

看似一切 perfect,但是还遗留一个问题,被清除的对象遍布于各内存地址,产生很多内存碎片。
由于Mark-Sweep完成之后,老生代的内存中产生了很多内存碎片,若不清理这些内存碎片,如果出现需要分配一个大对象的时候,这时所有的碎片空间都完全无法完成分配,就会提前触发垃圾回收,而这次回收其实不是必要的。
为了解决内存碎片问题,Mark-Compact被提出,它是在 Mark-Sweep的基础上演进而来的,相比Mark-Sweep,Mark-Compact添加了活动对象整理阶段,将所有的活动对象往一端移动,移动完成后,直接清理掉边界外的内存。
由于垃圾回收是在JS引擎中进行的,而Mark-Compact算法在执行过程中需要移动对象,而当活动对象较多的时候,它的执行速度不可能很快,为了避免JavaScript应用逻辑和垃圾回收器的内存资源竞争导致的不一致性问题,垃圾回收器会将JavaScript应用暂停,这个过程,被称为全停顿(stop-the-world)。
在新生代中,由于空间小、存活对象较少、Scavenge算法执行效率较快,所以全停顿的影响并不大。而老生代中就不一样,如果老生代中的活动对象较多,垃圾回收器就会暂停主线程较长的时间,使得页面变得卡顿。
orinoco为V8的垃圾回收器的项目代号,为了提升用户体验,解决全停顿问题,它利用了增量标记、懒性清理、并发、并行来降低主线程挂起的时间。
为了降低全堆垃圾回收的停顿时间,增量标记将原本的标记全堆对象拆分为一个一个任务,让其穿插在JavaScript应用逻辑之间执行,它允许堆的标记时的5~10ms的停顿。增量标记在堆的大小达到一定的阈值时启用,启用之后每当一定量的内存分配后,脚本的执行就会停顿并进行一次增量标记。

增量标记只是对活动对象和非活动对象进行标记,惰性清理用来真正的清理释放内存。当增量标记完成后,假如当前的可用内存足以让我们快速的执行代码,其实我们是没必要立即清理内存的,可以将清理的过程延迟一下,让JavaScript逻辑代码先执行,也无需一次性清理完所有非活动对象内存,垃圾回收器会按需逐一进行清理,直到所有的页都清理完毕。
增量标记与惰性清理的出现,使得主线程的最大停顿时间减少了80%,让用户与浏览器交互过程变得流畅了许多,从实现机制上,由于每个小的增量标价之间执行了JavaScript代码,堆中的对象指针可能发生了变化,需要使用写屏障技术来记录这些引用关系的变化,所以也暴露出来增量标记的缺点:
并发式GC允许在在垃圾回收的同时不需要将主线程挂起,两者可以同时进行,只有在个别时候需要短暂停下来让垃圾回收器做一些特殊的操作。但是这种方式也要面对增量回收的问题,就是在垃圾回收过程中,由于JavaScript代码在执行,堆中的对象的引用关系随时可能会变化,所以也要进行写屏障操作。
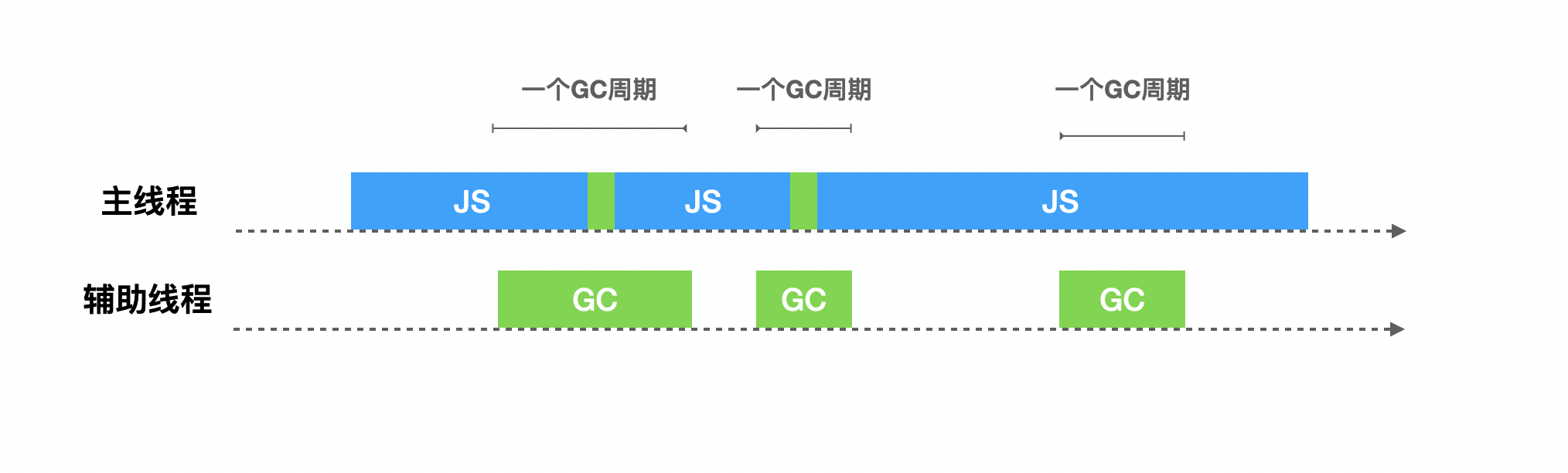
并行式GC允许主线程和辅助线程同时执行同样的GC工作,这样可以让辅助线程来分担主线程的GC工作,使得垃圾回收所耗费的时间等于总时间除以参与的线程数量(加上一些同步开销)。
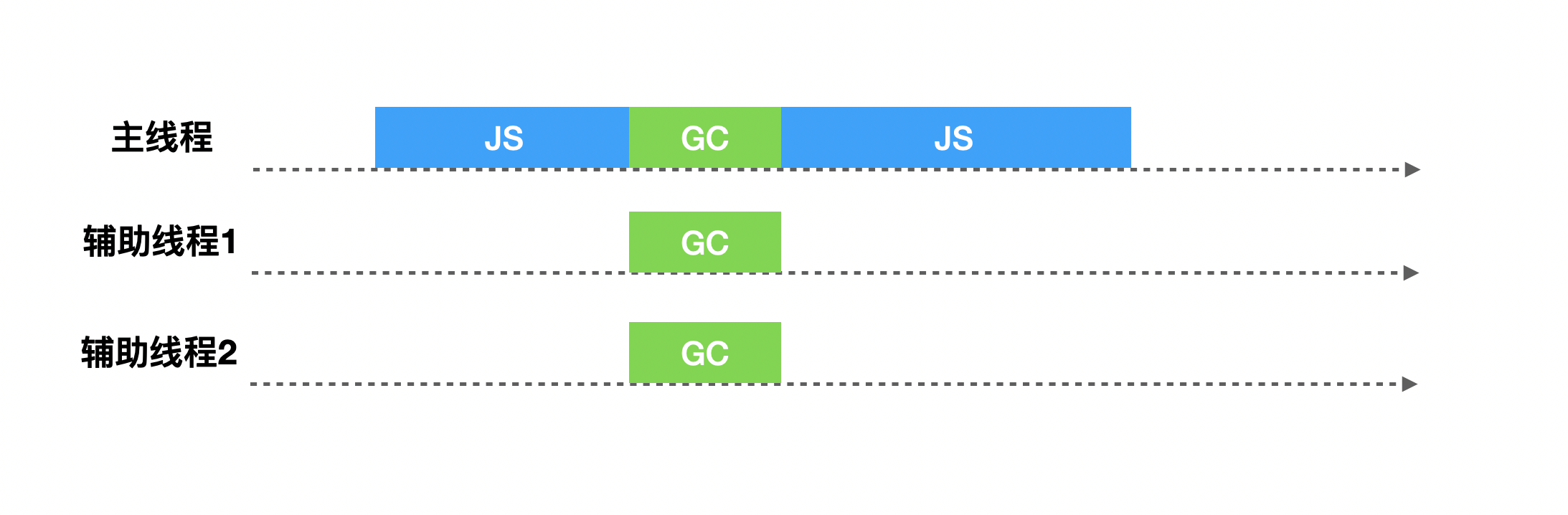
2011年,V8应用了增量标记机制。直至2018年,Chrome64和Node.js V10启动并发标记(Concurrent),同时在并发的基础上添加并行(Parallel)技术,使得垃圾回收时间大幅度缩短。
V8在新生代垃圾回收中,使用并行(parallel)机制,在整理排序阶段,也就是将活动对象从from-to复制到space-to的时候,启用多个辅助线程,并行的进行整理。由于多个线程竞争一个新生代的堆的内存资源,可能出现有某个活动对象被多个线程进行复制操作的问题,为了解决这个问题,V8在第一个线程对活动对象进行复制并且复制完成后,都必须去维护复制这个活动对象后的指针转发地址,以便于其他协助线程可以找到该活动对象后可以判断该活动对象是否已被复制。

V8在老生代垃圾回收中,如果堆中的内存大小超过某个阈值之后,会启用并发(Concurrent)标记任务。每个辅助线程都会去追踪每个标记到的对象的指针以及对这个对象的引用,而在JavaScript代码执行时候,并发标记也在后台的辅助进程中进行,当堆中的某个对象指针被JavaScript代码修改的时候,写入屏障(write barriers)技术会在辅助线程在进行并发标记的时候进行追踪。
当并发标记完成或者动态分配的内存到达极限的时候,主线程会执行最终的快速标记步骤,这个时候主线程会挂起,主线程会再一次的扫描根集以确保所有的对象都完成了标记,由于辅助线程已经标记过活动对象,主线程的本次扫描只是进行check操作,确认完成之后,某些辅助线程会进行清理内存操作,某些辅助进程会进行内存整理操作,由于都是并发的,并不会影响主线程JavaScript代码的执行。
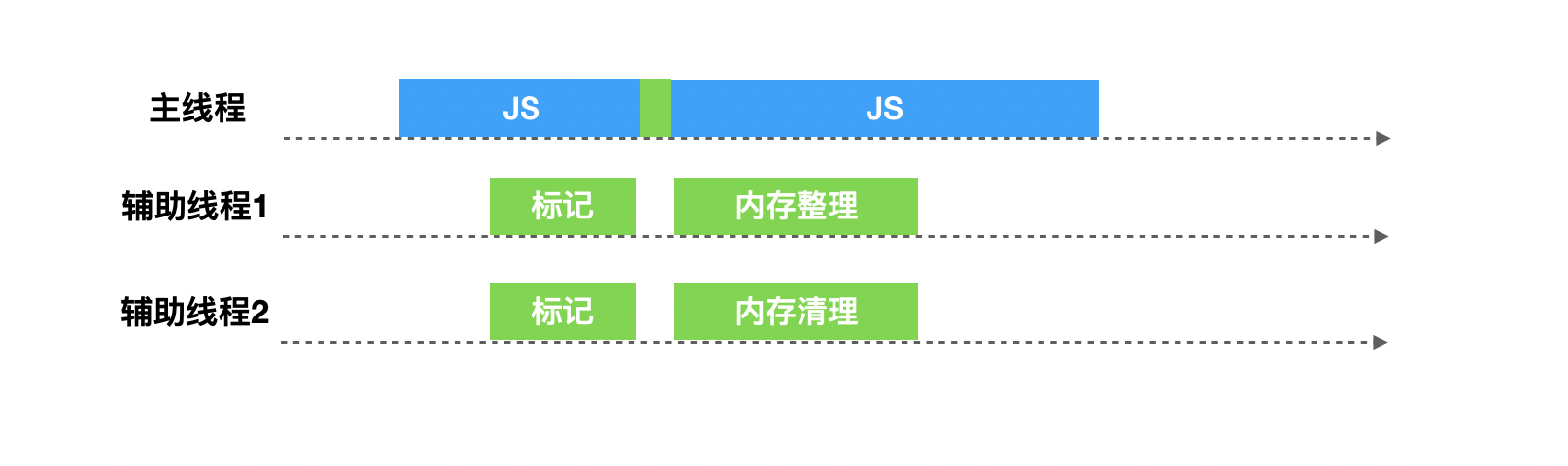
其实,大部分JavaScript开发人员并不需要考虑垃圾回收,但是了解一些垃圾回收的内部原理,可以帮助你了解内存的使用情况,根据内存使用观察是否存在内存泄露,而防止内存泄露,是提升应用性能的一个重要举措。
在安全攻防战场中,前端代码都是公开的,那么对前端进行加密有意义吗?可能大部分人的回答是,毫无意义,不要自创加密算法,直接用HTTPS吧。但事实上,即使不了解密码学,也应知道是有意义的,因为加密前和解密后的环节,是不受保护的。HTTPS只能保护传输层,此外别无用处。
而加密环节又分:
本文主要列举一些我见到的,我想到的一些加密方式,其实确切的说,应该叫混淆,不应该叫加密。
那么,代码混淆的具体原理是什么?其实很简单,就是去除代码中尽可能多的有意义的信息,比如注释、换行、空格、代码负号、变量重命名、属性重命名(允许的情况下)、无用代码的移除等等。因为代码是公开的,我们必须承认没有任何一种算法可以完全不被破解,所以,我们只能尽可能增加攻击者阅读代码的成本。
在保证代码原本的功能性的情况下,我们可以对代码的AST按需进行变更,然后将变更后的AST在生成一份代码进行输出,达到混淆的目的,我们最常用的uglify-js就是这样对代码进行混淆的,当然uglify-js的混淆只是主要进行代码压缩,即我们下面讲到的变量名混淆。
将变量名混淆成阅读比较难阅读的字符,增加代码阅读难度,上面说的uglify-js进行的混淆,就是把变量混淆成了短名(主要是为了进行代码压缩),而现在大部分安全方向的混淆,都会将其混淆成类16进制变量名,效果如下:
var test = 'hello';混淆后:
var _0x7deb = 'hello';注意事项:
eval语法,eval函数中可能使用了原来的变量名,如果不对其进行处理,可能会运行报错,如下:
var test = 'hello';
eval('console.log(test)');如果不对eval中的console.log(test)进行关联的混淆,则会报错。不过,如果eval语法超出了静态分析的范畴,比如:
var test = 'hello';
var variableName = 'test';
eval('console.log(' + variableName + ')');这种咋办呢,可能要进行遍历AST找到其运行结果,然后在进行混淆,不过貌似成本比较高。
全局变量的编码,如果代码是作为SDK进行输出的,我们需要保存全局变量名的不变,比如:
<script>
var $ = function(id) {
return document.getElementById(id);
};
</script>$变量是放在全局下的,混淆过后如下:
<script>
var _0x6482fa = function(id) {
return document.getElementById(id);
};
</script>那么如果依赖这一段代码的模块,使用$('id')调用自然会报错,因为这个全局变量已经被混淆了。
将JS中的常量提取到数组中,调用的时候用数组下标的方式调用,这样的话直接读懂基本不可能了,要么反AST处理下,要么一步一步调试,工作量大增。
以上面的代码为例:
var test = 'hello';混淆过后:
var _0x9d2b = ['hello'];
var _0xb7de = function (_0x4c7513) {
var _0x96ade5 = _0x9d2b[_0x4c7513];
return _0x96ade5;
};
var test = _0xb7de(0);当然,我们可以根据需求,将数组转化为二位数组、三维数组等,只需要在需要用到的地方获取就可以。
将常量进行加密处理,上面的代码中,虽然已经是混淆过后的代码了,但是hello字符串还是以明文的形式出现在代码中,可以利用JS中16进制编码会直接解码的特性将关键字的Unicode进行了16进制编码。如下:
var test = 'hello';结合常量提取得到混淆结果:
var _0x9d2b = ['\x68\x65\x6c\x6c\x6f'];
var _0xb7de = function (_0x4c7513) {
_0x4c7513 = _0x4c7513 - 0x0;
var _0x96ade5 = _0x9d2b[_0x4c7513];
return _0x96ade5;
};
var test = _0xb7de('0x0');当然,除了JS特性自带的Unicode自动解析以外,也可以自定义一些加解密算法,比如对常量进行base64编码,或者其他的什么rc4等等,只需要使用的时候解密就OK,比如上面的代码用base64编码后:
var _0x9d2b = ['aGVsbG8=']; // base64编码后的字符串
var _0xaf421 = function (_0xab132) {
// base64解码函数
var _0x75aed = function(_0x2cf82) {
// TODO: 解码
};
return _0x75aed(_0xab132);
}
var _0xb7de = function (_0x4c7513) {
_0x4c7513 = _0x4c7513 - 0x0;
var _0x96ade5 = _0xaf421(_0x9d2b[_0x4c7513]);
return _0x96ade5;
};
var test = _0xb7de('0x0');将所有的逻辑运算符、二元运算符都变成函数,目的也是增加代码阅读难度,让其无法直接通过静态分析得到结果。如下:
var i = 1 + 2;
var j = i * 2;
var k = j || i;混淆后:
var _0x62fae = {
_0xeca4f: function(_0x3c412, _0xae362) {
return _0x3c412 + _0xae362;
},
_0xe82ae: function(_0x63aec, _0x678ec) {
return _0x63aec * _0x678ec;
},
_0x2374a: function(_0x32487, _0x3a461) {
return _0x32487 || _0x3a461;
}
};
var i = _0x62fae._0e8ca4f(1, 2);
var j = _0x62fae._0xe82ae(p1, 2);
var k = _0x62fae._0x2374a(i, j);当然除了逻辑运算符和二元运算符以外,还可以将函数调用、静态字符串进行类似的混淆,如下:
var fun1 = function(name) {
console.log('hello, ' + name);
};
var fun2 = function(name, age) {
console.log(name + ' is ' + age + ' years old');
}
var name = 'xiao.ming';
fun1(name);
fun2(name, 8);var _0x62fae = {
_0xe82ae: function(_0x63aec, _0x678ec) {
return _0x63aec(_0x678ec);
},
_0xeca4f: function(_0x92352, _0x3c412, _0xae362) {
return _0x92352(_0x3c412, _0xae362)
},
_0x2374a: 'xiao.ming',
_0x5482a: 'hello, ',
_0x837ce: ' is ',
_0x3226e: ' years old'
};
var fun1 = function(name) {
console.log(_0x62fae._0x5482a + name);
};
var fun2 = function(name, age) {
console.log(name + _0x62fae._0x837ce + age + _0x62fae._0x3226e);
}
var name = _0x62fae._0x2374a;
_0x62fae._0xe82ae(name);
_0x62fae._0x2374a(name, 0x8);上面的例子中,fun1和fun2内的字符串相加也会被混淆走,静态字符串也会被前面提到的字符串提取抽取到数组中(我就是懒,这部分代码就不写了)。
需要注意的是,我们每次遇到相同的运算符,需不需要重新生成函数进行替换,这就按个人需求了。
将我们常用的语法混淆成我们不常用的语法,前提是不改变代码的功能。例如for换成do/while,如下:
for (i = 0; i < n; i++) {
// TODO: do something
}
var i = 0;
do {
if (i >= n) break;
// TODO: do something
i++;
} while (true)将静态执行代码添加动态判断,运行时动态决定运算符,干扰静态分析。
如下:
var c = 1 + 2;混淆过后:
function _0x513fa(_0x534f6, _0x85766) { return _0x534f6 + _0x85766; }
function _0x3f632(_0x534f6, _0x534f6) { return _0x534f6 - _0x534f6; }
// 动态判定函数
function _0x3fa24() {
return true;
}
var c = _0x3fa24() ? : _0x513fa(1, 2) : _0x3f632(1, 2);对执行流程进行混淆,又称控制流扁平化,为什么要做混淆执行流程呢?因为在代码开发的过程中,为了使代码逻辑清晰,便于维护和扩展,会把代码编写的逻辑非常清晰。一段代码从输入,经过各种if/else分支,顺序执行之后得到不同的结果,而我们需要将这些执行流程和判定流程进行混淆,让攻击者没那么容易摸清楚我们的执行逻辑。
控制流扁平化又分顺序扁平化、条件扁平化,
顾名思义,将按顺序、自上而下执行的代码,分解成数个分支进行执行,如下代码:
(function () {
console.log(1);
console.log(2);
console.log(3);
console.log(4);
console.log(5);
})();流程图如下:
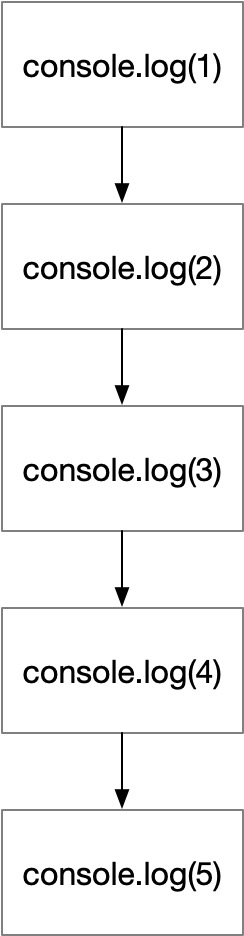
混淆过后代码如下:
(function () {
var flow = '3|4|0|1|2'.split('|'), index = 0;
while (!![]) {
switch (flow[index++]) {
case '0':
console.log(3);
continue;
case '1':
console.log(4);
continue;
case '2':
console.log(5);
continue;
case '3':
console.log(1);
continue;
case '4':
console.log(2);
continue;
}
break;
}
}());混淆过后的流程图如下:
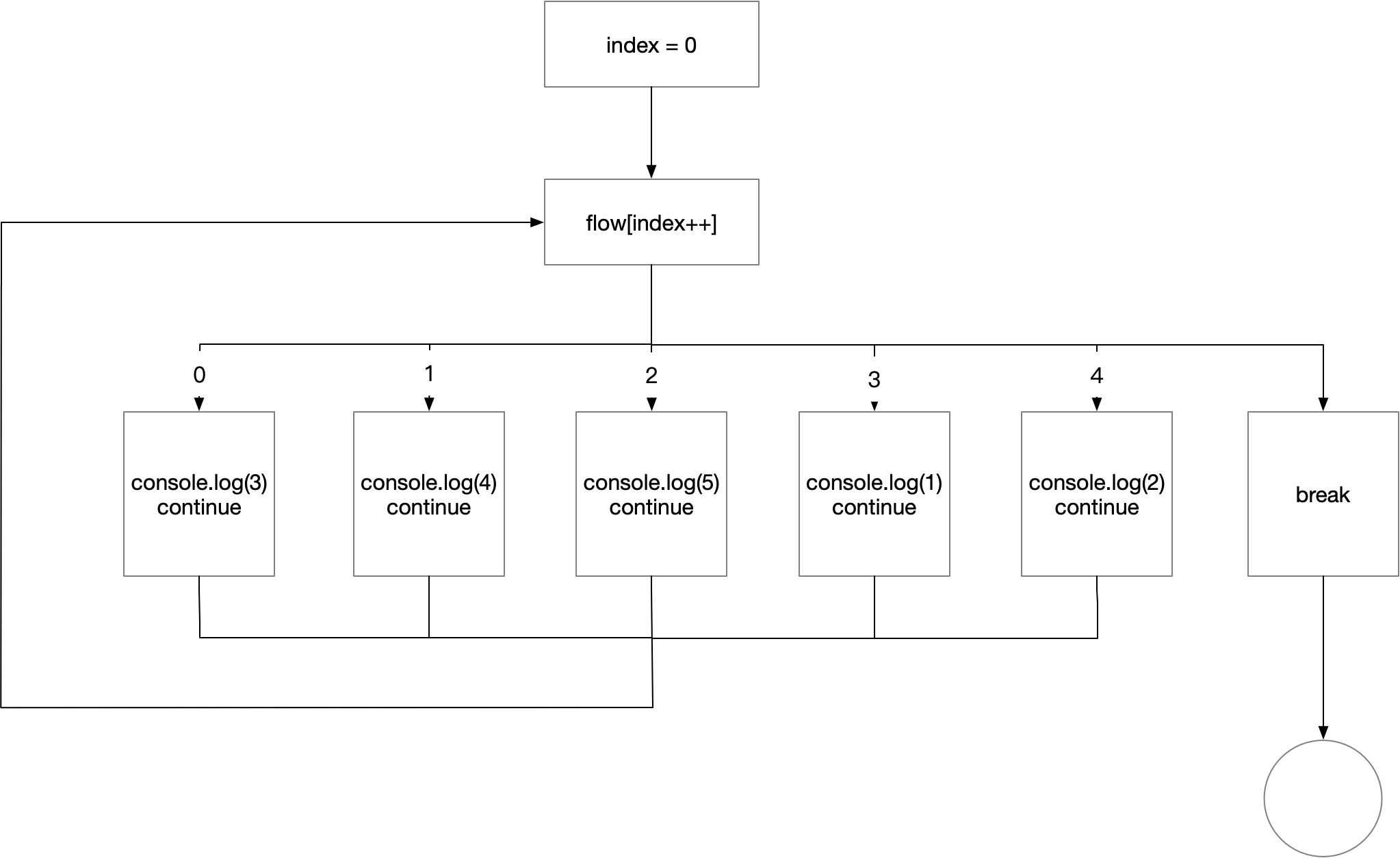
流程看起来扁了。
条件扁平化的作用是把所有if/else分支的流程,全部扁平到一个流程中,在流程图中拥有相同的入口和出口。
如下面的代码:
function modexp(y, x, w, n) {
var R, L;
var k = 0;
var s = 1;
while(k < w) {
if (x[k] == 1) {
R = (s * y) % n;
}
else {
R = s;
}
s = R * R % n;
L = R;
k++;
}
return L;
}如上代码,流程图是这样的
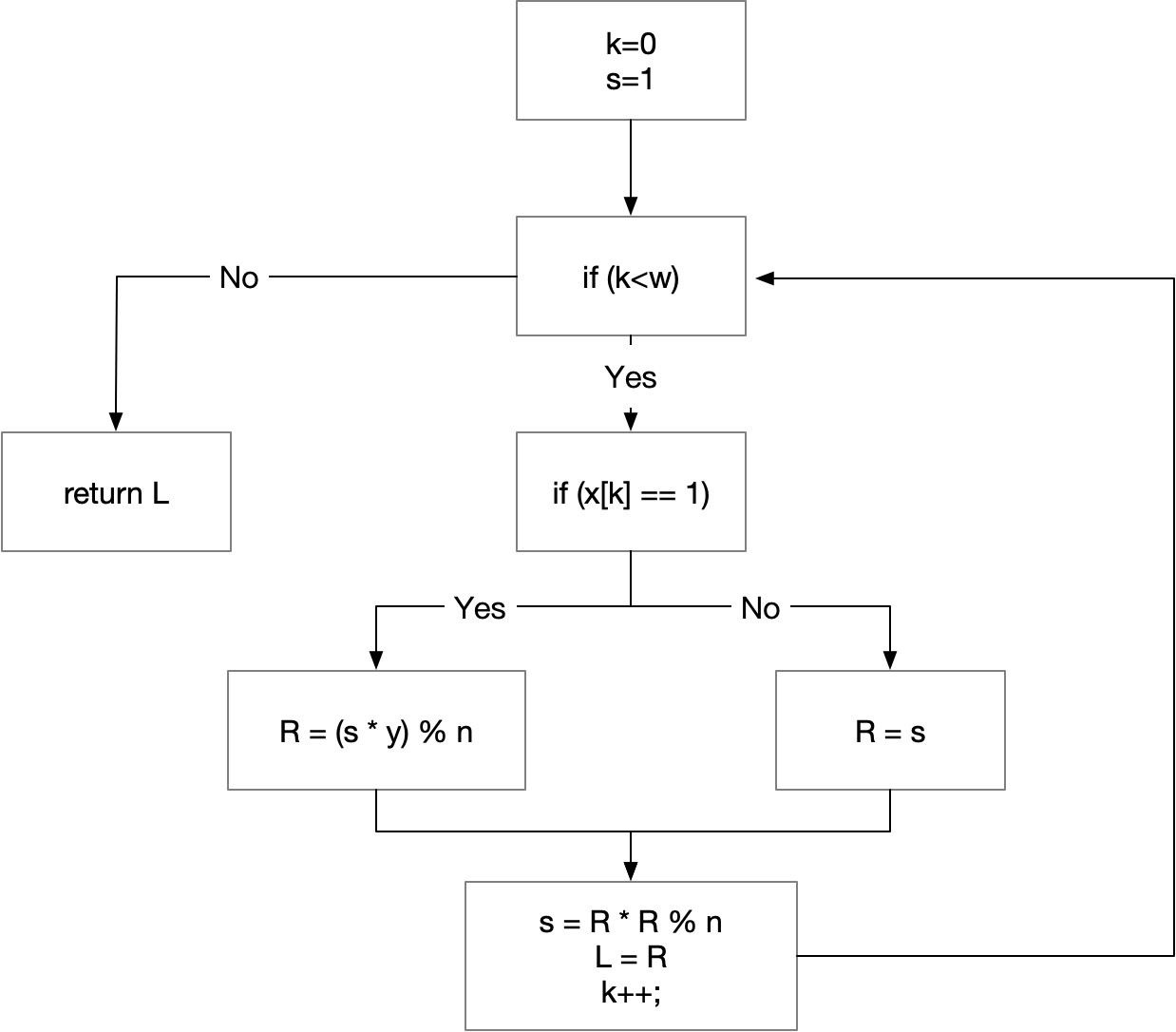
控制流扁平化后代码如下:
function modexp(y, x, w, n) {
var R, L, s, k;
var next = 0;
for(;;) {
switch(next) {
case 0: k = 0; s = 1; next = 1; break;
case 1: if (k < w) next = 2; else next = 6; break;
case 2: if (x[k] == 1) next = 3; else next = 4; break;
case 3: R = (s * y) % n; next = 5; break;
case 4: R = s; next = 5; break;
case 5: s = R * R % n; L = R; k++; next = 1; break;
case 6: return L;
}
}
}混淆后的流程图如下:
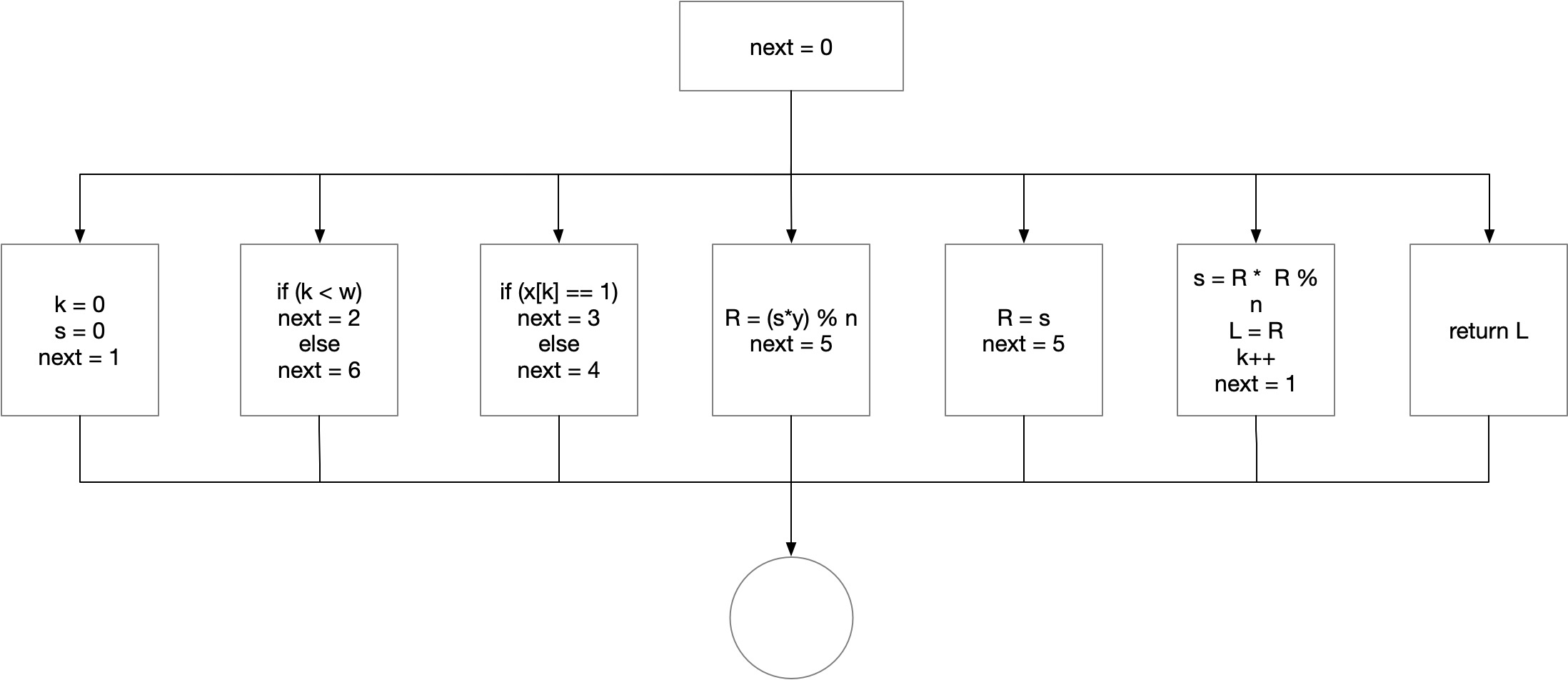
直观的感觉就是代码变扁了,所有的代码都挤到了一层当中,这样做的好处在于在让攻击者无法直观,或通过静态分析的方法判断哪些代码先执行哪些后执行,必须要通过动态运行才能记录执行顺序,从而加重了分析的负担。
需要注意的是,在我们的流程中,无论是顺序流程还是条件流程,如果出现了块作用域的变量声明(const/let),那么上面的流程扁平化将会出现错误,因为switch/case内部为块作用域,表达式被分到case内部之后,其他case无法取到const/let的变量声明,自然会报错。
上面的switch/case的判断是通过数字(也就是谓词)的形式判断的,而且是透明的,可以看到的,为了更加的混淆视听,可以将case判断设定为表达式,让其无法直接判断,比如利用上面代码,改为不透明谓词:
function modexp(y, x, w, n) {
var a = 0, b = 1, c = 2 * b + a;
var R, L, s, k;
var next = 0;
for(;;) {
switch(next) {
case (a * b): k = 0; s = 1; next = 1; break;
case (2 * a + b): if (k < w) next = 2; else next = 6; break;
case (2 * b - a): if (x[k] == 1) next = 3; else next = 4; break;
case (3 * a + b + c): R = (s * y) % n; next = 5; break;
case (2 * b + c): R = s; next = 5; break;
case (2 * c + b): s = R * R % n; L = R; k++; next = 1; break;
case (4 * c - 2 * b): return L;
}
}
}谓词用a、b、c三个变量组成,甚至可以把这三个变量隐藏到全局中定义,或者隐藏在某个数组中,让攻击者不能那么轻易找到。
将脚本进行编码,运行时 解码 再 eval 执行如:
eval (…………………………..……………. ……………. !@#$%^&* ……………. .…………………………..……………. )
但是实际上这样意义并不大,因为攻击者只需要把alert或者console.log就原形毕露了
改进方案:利用Function / (function(){}).constructor将代码当做字符串传入,然后执行,如下:
var code = 'console.log("hellow")';
(new Function(code))();如上代码,可以对code进行加密混淆,例如aaencode,原理也是如此,我们举个例子
alert("Hello, JavaScript");利用aaencode混淆过后,代码如下:
゚ω゚ノ= /`m´)ノ ~┻━┻ //*´∇`*/ ['_']; o=(゚ー゚) =_=3; c=(゚Θ゚) =(゚ー゚)-(゚ー゚); (゚Д゚) =(゚Θ゚)= (o^_^o)/ (o^_^o);(゚Д゚)={゚Θ゚: '_' ,゚ω゚ノ : ((゚ω゚ノ==3) +'_') [゚Θ゚] ,゚ー゚ノ :(゚ω゚ノ+ '_')[o^_^o -(゚Θ゚)] ,゚Д゚ノ:((゚ー゚==3) +'_')[゚ー゚] }; (゚Д゚) [゚Θ゚] =((゚ω゚ノ==3) +'_') [c^_^o];(゚Д゚) ['c'] = ((゚Д゚)+'_') [ (゚ー゚)+(゚ー゚)-(゚Θ゚) ];(゚Д゚) ['o'] = ((゚Д゚)+'_') [゚Θ゚];(゚o゚)=(゚Д゚) ['c']+(゚Д゚) ['o']+(゚ω゚ノ +'_')[゚Θ゚]+ ((゚ω゚ノ==3) +'_') [゚ー゚] + ((゚Д゚) +'_') [(゚ー゚)+(゚ー゚)]+ ((゚ー゚==3) +'_') [゚Θ゚]+((゚ー゚==3) +'_') [(゚ー゚) - (゚Θ゚)]+(゚Д゚) ['c']+((゚Д゚)+'_') [(゚ー゚)+(゚ー゚)]+ (゚Д゚) ['o']+((゚ー゚==3) +'_') [゚Θ゚];(゚Д゚) ['_'] =(o^_^o) [゚o゚] [゚o゚];(゚ε゚)=((゚ー゚==3) +'_') [゚Θ゚]+ (゚Д゚) .゚Д゚ノ+((゚Д゚)+'_') [(゚ー゚) + (゚ー゚)]+((゚ー゚==3) +'_') [o^_^o -゚Θ゚]+((゚ー゚==3) +'_') [゚Θ゚]+ (゚ω゚ノ +'_') [゚Θ゚]; (゚ー゚)+=(゚Θ゚); (゚Д゚)[゚ε゚]='\\'; (゚Д゚).゚Θ゚ノ=(゚Д゚+ ゚ー゚)[o^_^o -(゚Θ゚)];(o゚ー゚o)=(゚ω゚ノ +'_')[c^_^o];(゚Д゚) [゚o゚]='\"';(゚Д゚) ['_'] ( (゚Д゚) ['_'] (゚ε゚+(゚Д゚)[゚o゚]+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚Θ゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (o^_^o))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚o゚]) (゚Θ゚)) ('_');
这段代码看起来很奇怪,不像是JavaScript代码,但是实际上这段代码是用一些看似表情的符号,声明了一个16位的数组(用来表示16进制位置),然后将code当做字符串遍历,把每个代码符号通过string.charCodeAt取这个16位的数组下标,拼接成代码。大概的意思就是把代码当做字符串,然后使用这些符号的拼接代替这一段代码(可以看到代码里有很多加号),最后,通过(new Function(code))('_')执行。
仔细观察上面这一段代码,把代码最后的('_')去掉,在运行,你会直接看到源代码,然后Function.constructor存在(゚Д゚)变量中,感兴趣的同学可以自行查看。
除了aaencode,jjencode原理也是差不多,就不做解释了,其他更霸气的jsfuck,这些都是对代码进行加密的,这里就不详细介绍了。
由于JavaScript自带debugger语法,我们可以利用死循环性的debugger,当页面打开调试面板的时候,无限进入调试状态。
在代码开始执行的时候,使用setInterval定时触发我们的反调试函数。
在代码生成阶段,随机在部分函数体中注入我们的反调试函数,当代码执行到特定逻辑的时候,如果调试面板在打开状态,则无限进入调试状态。
由于我们的代码可能已经反调试了,攻击者可以会将代码拷贝到自己本地,然后修改,调试,执行,这个时候就需要添加一些检测进行判定,如果不是正常的环境执行,那让代码自行失败。
在代码生成的时候,为函数生成一份Hash,在代码执行之前,通过函数 toString 方法,检测代码是否被篡改
function module() {
// 篡改校验
if (Hash(module.toString()) != 'JkYxnHlxHbqKowiuy') {
// 代码被篡改!
}
}检查当前脚本的执行环境,例如当前的URL是否在允许的白名单内、当前环境是否正常的浏览器。
如果为Nodejs环境,如果出现异常环境,甚至我们可以启动木马,长期跟踪。
插入一些永远不会发生的代码,让攻击者在分析代码的时候被这些无用的废代码混淆视听,增加阅读难度。
与废代码相对立的就是有用的代码,这些有用的代码代表着被执行代码的逻辑,这个时候我们可以收集这些逻辑,增加一段判定来决定执行真逻辑还是假逻辑,如下:
(function(){
if (true) {
var foo = function () {
console.log('abc');
};
var bar = function () {
console.log('def');
};
var baz = function () {
console.log('ghi');
};
var bark = function () {
console.log('jkl');
};
var hawk = function () {
console.log('mno');
};
foo();
bar();
baz();
bark();
hawk();
}
})();可以看到,所有的console.log都是我们的执行逻辑,这个时候可以收集所有的console.log,然后制造假判定来执行真逻辑代码,收集逻辑注入后如下:
(function(){
if (true) {
var foo = function () {
if ('aDas' === 'aDas') {
console.log('abc');
} else {
console.log('def');
}
};
var bar = function () {
if ('Mfoi' !== 'daGs') {
console.log('ghi');
} else {
console.log('def');
}
};
var baz = function () {
if ('yuHo' === 'yuHo') {
console.log('ghi');
} else {
console.log('abc');
}
};
var bark = function () {
if ('qu2o' === 'qu2o') {
console.log('jkl');
} else {
console.log('mno');
}
};
var hawk = function () {
if ('qCuo' !== 'qcuo') {
console.log('jkl');
} else {
console.log('mno');
}
};
foo();
bar();
baz();
bark();
hawk();
}
})();判定逻辑中生成了一些字符串,在没有使用字符串提取的情况下,这是可以通过代码静态分析来得到真实的执行逻辑的,或者我们可以使用上文讲到的动态执行来决定执行真逻辑,可以看一下使用字符串提取和变量名编码后的效果,如下:
var _0x6f5a = [
'abc',
'def',
'caela',
'hmexe',
'ghi',
'aaeem',
'maxex',
'mno',
'jkl',
'ladel',
'xchem',
'axdci',
'acaeh',
'log'
];
(function (_0x22c909, _0x4b3429) {
var _0x1d4bab = function (_0x2e4228) {
while (--_0x2e4228) {
_0x22c909['push'](_0x22c909['shift']());
}
};
_0x1d4bab(++_0x4b3429);
}(_0x6f5a, 0x13f));
var _0x2386 = function (_0x5db522, _0x143eaa) {
_0x5db522 = _0x5db522 - 0x0;
var _0x50b579 = _0x6f5a[_0x5db522];
return _0x50b579;
};
(function () {
if (!![]) {
var _0x38d12d = function () {
if (_0x2386('0x0') !== _0x2386('0x1')) {
console[_0x2386('0x2')](_0x2386('0x3'));
} else {
console[_0x2386('0x2')](_0x2386('0x4'));
}
};
var _0x128337 = function () {
if (_0x2386('0x5') !== _0x2386('0x6')) {
console[_0x2386('0x2')](_0x2386('0x4'));
} else {
console[_0x2386('0x2')](_0x2386('0x7'));
}
};
var _0x55d92e = function () {
if (_0x2386('0x8') !== _0x2386('0x8')) {
console[_0x2386('0x2')](_0x2386('0x3'));
} else {
console[_0x2386('0x2')](_0x2386('0x7'));
}
};
var _0x3402dc = function () {
if (_0x2386('0x9') !== _0x2386('0x9')) {
console[_0x2386('0x2')](_0x2386('0xa'));
} else {
console[_0x2386('0x2')](_0x2386('0xb'));
}
};
var _0x28cfaa = function () {
if (_0x2386('0xc') === _0x2386('0xd')) {
console[_0x2386('0x2')](_0x2386('0xb'));
} else {
console[_0x2386('0x2')](_0x2386('0xa'));
}
};
_0x38d12d();
_0x128337();
_0x55d92e();
_0x3402dc();
_0x28cfaa();
}
}());除了注入执行逻辑以外,还可以埋入一个隐蔽的陷阱,在一个永不到达且无法静态分析的分支里,引用该函数,正常用户不会执行,而 AST 遍历求值时,则会触发陷阱!陷阱能干啥呢?
在代码用eval包裹,然后对eval参数进行加密,并埋下陷阱,在解码时插入无用代码,干扰显示,大量换行、注释、字符串等大量特殊字符,导致显示卡顿。
大概我想到的混淆就包括这些,单个特性使用的话,混淆效果一般,各个特性组合起来用的话,最终效果很明显,当然这个看个人需求,毕竟混淆是个双刃剑,在增加了阅读难度的同时,也增大了脚本的体积,降低了代码的运行效率。
前几天非常非常粗的读了一本书Head First 设计模式(中文版),一本 Java 语言层面的设计模式,看这本书的目的只是为了提升自己代码设计上的能力,并且可以和前端代码有所结合,一直以来,,总感觉自己的代码设计得非常非常烂。
先给个定义:设计模式,即解决某个特定场景下对某种问题的解决方案。因此,当我们遇到合适的场景时,我们可能会条件反射一样自然而然想到符合这种场景的设计模式。
概念:
定义一系列的算法,把它们一个个封装起来,并且使它们可以相互替换。
意义:
应用场景:表单校验
示例:
var strategies = {
isNonEmpty: function(value, errorMsg){
if (value === '') {
return errorMsg;
}
},
minLength: function(value, length, errorMsg){
if (value.length < length) {
return errorMsg;
}
},
isMobile: function(value, errorMsg){ // 手机号码格式
if (!/(^1[3|5|8][0-9]{9}$)/.test(value)){
return errorMsg;
}
}
};
var Validator = function(){
this.cache = []; // 保存校验规则
};
Validator.prototype.add = function(dom, rule, errorMsg) {
var ary = rule.split(':'); // 把 strategy 和参数分开
this.cache.push(function (){ // 把校验的步骤用空函数包装起来,并且放入 cache
var strategy = ary.shift(); // 用户挑选的 strategy
ary.unshift(dom.value); // 把 input 的 value 添加进参数列表
ary.push(errorMsg); // 把 errorMsg 添加进参数列表
return strategies[strategy].apply(dom, ary);
})
}
Validator.prototype.start = function(){
for (var i = 0, validatorFunc; validatorFunc = this.cache[i++];){
var msg = validatorFunc(); // 开始校验,并取得校验后的返回信息
if (msg){ // 如果有确切的返回值,说明校验没有通过
return msg;
}
}
};
var validataFunc = function(){
var validator = new Validator(); // 创建一个 validator 对象
/***************添加一些校验规则****************/
validator.add(registerForm.userName, 'isNonEmpty', '用户名不能为空');
validator.add(registerForm.password, 'minLength:6', '密码长度不能少于 6 位');
validator.add(registerForm.phoneNumber, 'isMobile', '手机号码格式不正确');
var errorMsg = validator.start(); // 获得校验结果
return errorMsg; // 返回校验结果
}
var registerForm = document.getElementById('registerForm');
registerForm.onsubmit = function(){
var errorMsg = validataFunc(); // 如果 errorMsg 有确切的返回值,说明未通过校验 if ( errorMsg ){
console.log(errorMsg);
return false; // 阻止表单提交
}
};概念:
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知。
意义:
应用场景:双向数据绑定
class EventEmitter {
constructor() {
this._events = {}
}
emit(type) {
var funL = this._events[type]
var args = Array.from(arguments).slice(1)
funL.forEach(function(e) {
e(...args)
})
}
addListener(type, func) {
this._events = this._events || {}
if (!this._events[type]) {
this._events[type] = []
}
this._events[type].push(func)
}
removeListener(type, func) {
this._events[type].splice(this._events[type].indexOf(func), 1)
}
on(type, func) {
this.addListener(type, func)
}
}
// 首先实例化 EventEmitter 然后添加监听事件以及触发事件。
var emitter = new EventEmitter()
emitter.addListener('test', function(a1, a2) {
console.log(a1 + a2)
})
emitter.on('test', function(a1, a2) {
console.log(a2)
})
emitter.emit('test', 'augument1', 'argument2')
emitter.emit('test', 'augument3', 'argument4')
//console
// augument1argument2
// argument2
// augument3argument4
// argument4概念:
保证一个类仅有一个实例,并提供一个访问它的全局访问点。实现的方法为先判断实例存在与否,如果存在则直接返回,如果不存在就创建了再返回,这就确保了一个类只有一个实例对象。
意义:
应用场景:redux 下的 store、浏览器写某个特定的浮框...
示例:
const Singleton = name => {
this.name = name
}
Singleton.prototype.getName = () => {
console.log(this.name)
}
Singleton.getInstance = (() => {
const instance = null
return name => {
if (!instance) {
instance = new Singleton(name)
}
return instance
}
})()
const a = Singleton.getInstance('sven1')
const b = Singleton.getInstance('sven2')
console.log(a === b) // true概念:
为对象提供一个代用品或者占位符,以便控制对它的访问。
意义:
应用场景:图片预加载、mobx 的变量拦截。
示例:
var myImage = (function() {
var imgNode = document.createElement('img')
document.body.appendChild(imgNode)
return {
setSrc: function(src) {
imgNode.src = src
}
}
})()
var proxyImage = (function() {
var img = new Image()
img.onload = function() {
myImage.setSrc(this.src)
}
return {
setSrc: function(src) {
myImage.setSrc('loading.gif')
img.src = src
}
}
})()
proxyImage.setSrc('http://imgcache.qq.com/music/photo/k/000GGDys0yA0Nk.jpg')概念:在不改变对象自身的基础上,在程序运行期间给对象动态地添加方法。
意义:
应用场景:动态表单验证...
示例:
function Sale(price) {
this.price = price
this.decorateList = []
}
Sale.decorators = {}
Sale.decorators.fedtax = {
getPrice: function(price) {
var price = this.uber.getPrice()
return price * 0.8 //对price进行处理
}
}
Sale.decorators.quebec = {
getPrice: function(price) {
var price = this.uber.getPrice()
return price * 0.7 //对price进行处理
}
}
Sale.decorators.money = {
getPrice: function(price) {
var price = this.uber.getPrice()
return '$' + price * 0.9 //对price进行处理
}
}
Sale.prototype.decorate = function(decorator) {
this.decorateList.push(decorator)
}
Sale.prototype.getPrice = function() {
var price = this.price
this.decorateList.forEach(function(name) {
price = Sale.decorators[name].getPrice(price)
})
return price
}
var sale = new Sale(100)
sale = sale.decorate('fedtax') //联邦税
sale = sale.decorate('quebec') //魁北克省税
sale = sale.decorate('money') //转为美元格式
console.log(sale.getPrice()) //$50.4昨晚做了一个梦,梦见自己到了一家大厂面试,面试官走近房间,坐了下来:是杨溜溜吧?国际惯例,先来个自我介绍吧。
于是我巴拉巴拉开始了长达两分钟的自我介绍,与此同时,面试官边听边看我的简历,边看边皱眉,结束后问:看你之前的项目经常用到Vue,对Vue熟悉吗?
我嘴角一笑,心里暗喜:幸好有专门看Vue的面试题,看来这次稳了。于是谦虚又装逼的回答:还行吧,您随便问。
于是面试官看我口气那么大,心想:哟嚯,来了一个装逼的,劳资今天就只问Vue。
Vue为MVVM框架,当数据模型data变化时,页面视图会得到响应更新,其原理对data的getter/setter方法进行拦截(Object.defineProperty或者Proxy),利用发布订阅的设计模式,在getter方法中进行订阅,在setter方法中发布通知,让所有订阅者完成响应。
在响应式系统中,Vue会为数据模型data的每一个属性新建一个订阅中心作为发布者,而监听器watch、计算属性computed、视图渲染template/render三个角色同时作为订阅者,对于监听器watch,会直接订阅观察监听的属性,对于计算属性computed和视图渲染template/render,如果内部执行获取了data的某个属性,就会执行该属性的getter方法,然后自动完成对该属性的订阅,当属性被修改时,就会执行该属性的setter方法,从而完成该属性的发布通知,通知所有订阅者进行更新。
计算属性computed和监听器watch都可以观察属性的变化从而做出响应,不同的是:
计算属性computed更多是作为缓存功能的观察者,它可以将一个或者多个data的属性进行复杂的计算生成一个新的值,提供给渲染函数使用,当依赖的属性变化时,computed不会立即重新计算生成新的值,而是先标记为脏数据,当下次computed被获取时候,才会进行重新计算并返回。
而监听器watch并不具备缓存性,监听器watch提供一个监听函数,当监听的属性发生变化时,会立即执行该函数。
beforeCreate:是new Vue()之后触发的第一个钩子,在当前阶段data、methods、computed以及watch上的数据和方法都不能被访问。
created:在实例创建完成后发生,当前阶段已经完成了数据观测,也就是可以使用数据,更改数据,在这里更改数据不会触发updated函数。可以做一些初始数据的获取,在当前阶段无法与Dom进行交互,如果非要想,可以通过vm.$nextTick来访问Dom。
beforeMount:发生在挂载之前,在这之前template模板已导入渲染函数编译。而当前阶段虚拟Dom已经创建完成,即将开始渲染。在此时也可以对数据进行更改,不会触发updated。
mounted:在挂载完成后发生,在当前阶段,真实的Dom挂载完毕,数据完成双向绑定,可以访问到Dom节点,使用$refs属性对Dom进行操作。
beforeUpdate:发生在更新之前,也就是响应式数据发生更新,虚拟dom重新渲染之前被触发,你可以在当前阶段进行更改数据,不会造成重渲染。
updated:发生在更新完成之后,当前阶段组件Dom已完成更新。要注意的是避免在此期间更改数据,因为这可能会导致无限循环的更新。
beforeDestroy:发生在实例销毁之前,在当前阶段实例完全可以被使用,我们可以在这时进行善后收尾工作,比如清除计时器。
destroyed:发生在实例销毁之后,这个时候只剩下了dom空壳。组件已被拆解,数据绑定被卸除,监听被移出,子实例也统统被销毁。
一个组件可能在很多地方使用,也就是会创建很多个实例,如果data是一个对象的话,对象是引用类型,一个实例修改了data会影响到其他实例,所以data必须使用函数,为每一个实例创建一个属于自己的data,使其同一个组件的不同实例互不影响。
父组件 -> 子组件:prop
子组件 -> 父组件:$on/$emit
获取组件实例:使用$parent/$children,$refs.xxx,获取到实例后直接获取属性数据或调用组件方法
Event Bus:每一个Vue实例都是一个Event Bus,都支持$on/$emit,可以为兄弟组件的实例之间new一个Vue实例,作为Event Bus进行通信。
Vuex:将状态和方法提取到Vuex,完成共享
使用provide/inject
Event Bus:同兄弟组件Event Bus通信
Vuex:将状态和方法提取到Vuex,完成共享
每一个Vue实例都是一个Event Bus,当子组件被创建的时候,父组件将事件传递给子组件,子组件初始化的时候是有$on方法将事件注册到内部,在需要的时候使用$emit触发函数,而对于原生native事件,使用addEventListener绑定到真实的DOM元素上。
slot又名插槽,是Vue的内容分发机制,组件内部的模板引擎使用slot元素作为承载分发内容的出口。插槽slot是子组件的一个模板标签元素,而这一个标签元素是否显示,以及怎么显示是由父组件决定的。
slot又分三类,默认插槽,具名插槽和作用域插槽。
实现原理:当子组件vm实例化时,获取到父组件传入的slot标签的内容,存放在vm.$slot中,默认插槽为vm.$slot.default,具名插槽为vm.$slot.xxx,xxx 为插槽名,当组件执行渲染函数时候,遇到slot标签,使用$slot中的内容进行替换,此时可以为插槽传递数据,若存在数据,则可称该插槽为作用域插槽。
vue中的模板template无法被浏览器解析并渲染,因为这不属于浏览器的标准,不是正确的HTML语法,所有需要将template转化成一个JavaScript函数,这样浏览器就可以执行这一个函数并渲染出对应的HTML元素,就可以让视图跑起来了,这一个转化的过程,就成为模板编译。
模板编译又分三个阶段,解析parse,优化optimize,生成generate,最终生成可执行函数render。
对于 Vue 组件来说,模板编译只会在组件实例化的时候编译一次,生成渲染函数之后在也不会进行编译。因此,编译对组件的 runtime 是一种性能损耗。
而模板编译的目的仅仅是将template转化为render function,这个过程,正好可以在项目构建的过程中完成,这样可以让实际组件在 runtime 时直接跳过模板渲染,进而提升性能,这个在项目构建的编译template的过程,就是预编译。
对于 runtime 来说,只需要保证组件存在 render 函数即可,而我们有了预编译之后,我们只需要保证构建过程中生成 render 函数就可以。
在 webpack 中,我们使用vue-loader编译.vue文件,内部依赖的vue-template-compiler模块,在 webpack 构建过程中,将template预编译成 render 函数。
与 react 类似,在添加了jsx的语法糖解析器babel-plugin-transform-vue-jsx之后,就可以直接手写render函数。
所以,template和jsx的都是render的一种表现形式,不同的是:
JSX相对于template而言,具有更高的灵活性,在复杂的组件中,更具有优势,而 template 虽然显得有些呆滞。但是 template 在代码结构上更符合视图与逻辑分离的习惯,更简单、更直观、更好维护。
Virtual DOM 是 DOM 节点在 JavaScript 中的一种抽象数据结构,之所以需要虚拟DOM,是因为浏览器中操作DOM的代价比较昂贵,频繁操作DOM会产生性能问题。虚拟DOM的作用是在每一次响应式数据发生变化引起页面重渲染时,Vue对比更新前后的虚拟DOM,匹配找出尽可能少的需要更新的真实DOM,从而达到提升性能的目的。
在新老虚拟DOM对比时
在diff中,只对同层的子节点进行比较,放弃跨级的节点比较,使得时间复杂从O(n^3)降低值O(n),也就是说,只有当新旧children都为多个子节点时才需要用核心的Diff算法进行同层级比较。
在对节点进行diff的过程中,判断是否为相同节点的一个很重要的条件是key是否相等,如果是相同节点,则会尽可能的复用原有的DOM节点。所以key属性是提供给框架在diff的时候使用的,而非开发者。
Vue2.0中,随着功能的增加,组件变得越来越复杂,越来越难维护,而难以维护的根本原因是Vue的API设计迫使开发者使用watch,computed,methods选项组织代码,而不是实际的业务逻辑。
另外Vue2.0缺少一种较为简洁的低成本的机制来完成逻辑复用,虽然可以minxis完成逻辑复用,但是当mixin变多的时候,会使得难以找到对应的data、computed或者method来源于哪个mixin,使得类型推断难以进行。
所以Composition API的出现,主要是也是为了解决Option API带来的问题,第一个是代码组织问题,Compostion API可以让开发者根据业务逻辑组织自己的代码,让代码具备更好的可读性和可扩展性,也就是说当下一个开发者接触这一段不是他自己写的代码时,他可以更好的利用代码的组织反推出实际的业务逻辑,或者根据业务逻辑更好的理解代码。
第二个是实现代码的逻辑提取与复用,当然mixin也可以实现逻辑提取与复用,但是像前面所说的,多个mixin作用在同一个组件时,很难看出property是来源于哪个mixin,来源不清楚,另外,多个mixin的property存在变量命名冲突的风险。而Composition API刚好解决了这两个问题。
从React Hook的实现角度看,React Hook是根据useState调用的顺序来确定下一次重渲染时的state是来源于哪个useState,所以出现了以下限制
而Composition API是基于Vue的响应式系统实现的,与React Hook的相比
虽然Compositon API看起来比React Hook好用,但是其设计**也是借鉴React Hook的。
在客户端请求服务器的时候,服务器到数据库中获取到相关的数据,并且在服务器内部将Vue组件渲染成HTML,并且将数据、HTML一并返回给客户端,这个在服务器将数据和组件转化为HTML的过程,叫做服务端渲染SSR。
而当客户端拿到服务器渲染的HTML和数据之后,由于数据已经有了,客户端不需要再一次请求数据,而只需要将数据同步到组件或者Vuex内部即可。除了数据意外,HTML也结构已经有了,客户端在渲染组件的时候,也只需要将HTML的DOM节点映射到Virtual DOM即可,不需要重新创建DOM节点,这个将数据和HTML同步的过程,又叫做客户端激活。
使用SSR的好处:
有利于SEO:其实就是有利于爬虫来爬你的页面,因为部分页面爬虫是不支持执行JavaScript的,这种不支持执行JavaScript的爬虫抓取到的非SSR的页面会是一个空的HTML页面,而有了SSR以后,这些爬虫就可以获取到完整的HTML结构的数据,进而收录到搜索引擎中。
白屏时间更短:相对于客户端渲染,服务端渲染在浏览器请求URL之后已经得到了一个带有数据的HTML文本,浏览器只需要解析HTML,直接构建DOM树就可以。而客户端渲染,需要先得到一个空的HTML页面,这个时候页面已经进入白屏,之后还需要经过加载并执行 JavaScript、请求后端服务器获取数据、JavaScript 渲染页面几个过程才可以看到最后的页面。特别是在复杂应用中,由于需要加载 JavaScript 脚本,越是复杂的应用,需要加载的 JavaScript 脚本就越多、越大,这会导致应用的首屏加载时间非常长,进而降低了体验感。
更多详情查看彻底理解服务端渲染 - SSR原理
面试官点了点头,嗯呢,这小伙还可以,懂得还挺多,可以弄进来写业务。
我也暗自窃喜,幸亏没问到我不会的,然后我坐那傻笑,笑着笑着,突然听到我的闹铃响了,然后,我梦醒了。
然后,新的搬砖的一天又开始了。
曾几何时,你有没有想过一个前端工程师的未来是什么样的?这个时候你是不是会想到了一个词”前端架构师“,那么一个合格的前端架构只会前端OK吗?那当然不行,你必须具备全栈的能力,这样才能扩大个人的形象力,才能升职加薪,才能迎娶白富美,才能走向人生巅峰...
最近我在写一些后端的项目,发现重复工作太多,尤其是框架部分,然后这就抽空整理了前后端的架子,主要是用的Vue,Express,数据存储用的Mysql,当然如果有其他需要,也可以直接切换到sqlite、postgres或者mssql。
先献上项目github
项目以todolist为🌰,简单的实现了前后端的CURD。
先看项目架构,client为前端结构,server为后端结构
|-- express-vue-web-slush
|-- client
| |-- http.js // axios 请求封装
| |-- router.js // vue-router
| |-- assets // 静态资源
| |-- components // 公用组件
| |-- store // store
| |-- styles // 样式
| |-- views // 视图
|-- server
|-- api // controller api文件
|-- container // ioc 容器
|-- daos // dao层
|-- initialize // 项目初始化文件
|-- middleware // 中间件
|-- models // model层
|-- services // service层
前端代码就不多说,一眼就能看出是vue-cli生成的结构,不一样的地方就是前端编写的代码是以Vue Class的形式编写的,具体细节请见从react转职到vue开发的项目准备
然后这里主要描述一下后端代码。
开发环境必需品,我们使用的是nodemon,在项目根目录添加nodemon.json:
{
"ignore": [
".git",
"node_modules/**/node_modules",
"src/client"
]
}ignore忽略 node_modules 和 前端代码文件夹src/client 的js文件变更,ignore以外的js文件变更nodemon.json会重启node项目。
这里为了方便,我写了一个脚本,同时启动前后端项目,如下:
import * as childProcess from 'child_process';
function run() {
const client = childProcess.spawn('vue-cli-service', ['serve']);
client.stdout.on('data', x => process.stdout.write(x));
client.stderr.on('data', x => process.stderr.write(x));
const server = childProcess.spawn('nodemon', ['--exec', 'npm run babel-server'], {
env: Object.assign({
NODE_ENV: 'development'
}, process.env),
silent: false
});
server.stdout.on('data', x => process.stdout.write(x));
server.stderr.on('data', x => process.stderr.write(x));
process.on('exit', () => {
server.kill('SIGTERM');
client.kill('SIGTERM');
});
}
run();前端用vue-cli的vue-cli-service命令启动。
后端用nodemon执行babel-node命令启动。
然后这前后端项目由node子进程启动,然后我们在package.json里添加script。
{
"scripts": {
"dev-env": "cross-env NODE_ENV=development",
"babel-server": "npm run dev-env && babel-node --config-file ./server.babel.config.js -- ./src/server/main.js",
"dev": "babel-node --config-file ./server.babel.config.js -- ./src/dev.js",
}
}server.babel.config.js为后端的bable编译配置。
所谓的项目配置呢,说的就是与业务没有关系的系统配置,比如你的日志监控配置、数据库信息配置等等
首先,在项目里面新建配置文件,config.properties,比如我这里使用的是Mysql,内容如下:
[mysql]
host=127.0.0.1
port=3306
user=root
password=root
database=test
在项目启动之前,我们使用properties对其进行解析,在我们的server/initialize新建properties.js,对配置文件进行解析:
import properties from 'properties';
import path from 'path';
const propertiesPath = path.resolve(process.cwd(), 'config.properties');
export default function load() {
return new Promise((resolve, reject) => {
properties.parse(propertiesPath, { path: true, sections: true }, (err, obj) => {
if (err) {
reject(err);
return;
}
resolve(obj);
});
}).catch(e => {
console.error(e);
return {};
});
}然后在项目启动之前,初始化mysql,在server/initialize文件夹新建文件index.js
import loadProperties from './properties';
import { initSequelize } from './sequelize';
import container from '../container';
import * as awilix from 'awilix';
import { installModel } from '../models';
export default async function initialize() {
const config = await loadProperties();
const { mysql } = config;
const sequelize = initSequelize(mysql);
installModel(sequelize);
container.register({
globalConfig: awilix.asValue(config),
sequelize: awilix.asValue(sequelize)
});
}这里我们数据持久化用的sequelize,依赖注入用的awilix,我们下文描述。
初始化所有配置后,我们在项目启动之前执行initialize,如下:
import express from 'express';
import initialize from './initialize';
import fs from 'fs';
const app = express();
export default async function run() {
await initialize(app);
app.get('*', (req, res) => {
const html = fs.readFileSync(path.resolve(__dirname, '../client', 'index.html'), 'utf-8');
res.send(html);
});
app.listen(9001, err => {
if (err) {
console.error(err);
return;
}
console.log('Listening at http://localhost:9001');
});
}
run();作为前端,对数据持久化这个词没什么概念,这里简单介绍一下,首先数据分为两种状态,一种是瞬时状态,一种是持久状态,而瞬时状态的数据一般是存在内存中,还没有永久保存的数据,一旦我们服务器挂了,那么这些数据将会丢失,而持久状态的数据呢,就是已经落到硬盘上面的数据,比如mysql、mongodb的数据,是保存在硬盘里的,就算服务器挂了,我们重启服务,还是可以获取到数据的,所以数据持久化的作用就是将我们的内存中的数据,保存在mysql或者其他数据库中。
我们数据持久化是用的sequelize,它可以帮我们对接mysql,让我们快速的对数据进行CURD。
下面我们在server/initialize文件夹新建sequelize.js,方便我们在项目初始化的时候连接:
import Sequelize from 'sequelize';
let sequelize;
const defaultPreset = {
host: 'localhost',
dialect: 'mysql',
operatorsAliases: false,
port: 3306,
pool: {
max: 10,
min: 0,
acquire: 30000,
idle: 10000
}
};
export function initSequelize(config) {
const { host, database, password, port, user } = config;
sequelize = new Sequelize(database, user, password, Object.assign({}, defaultPreset, {
host,
port
}));
return sequelize;
};
export default sequelize;initSequelize的入参config,来源于我们的config.properties,在项目启动之前执行连接。
然后,我们需要对应数据库的每个表建立我们的Model,以todolist为例,在service/models,新建文件ItemModel.js:
export default function(sequelize, DataTypes) {
const Item = sequelize.define('Item', {
recordId: {
type: DataTypes.INTEGER,
field: 'record_id',
primaryKey: true
},
name: {
type: DataTypes.STRING,
field: 'name'
},
state: {
type: DataTypes.INTEGER,
field: 'state'
}
}, {
tableName: 'item',
timestamps: false
});
return Item;
}然后在service/models,新建index.js,用来导入models文件夹下的所有model:
import fs from 'fs';
import path from 'path';
import Sequelize from 'sequelize';
const db = {};
export function installModel(sequelize) {
fs.readdirSync(__dirname)
.filter(file => (file.indexOf('.') !== 0 && file.slice(-3) === '.js' && file !== 'index.js'))
.forEach((file) => {
const model = sequelize.import(path.join(__dirname, file));
db[model.name] = model;
});
Object.keys(db).forEach((modelName) => {
if (db[modelName].associate) {
db[modelName].associate(db);
}
});
db.sequelize = sequelize;
db.Sequelize = Sequelize;
}
export default db;这个installModel也是在我们项目初始化的时候执行的。
model初始化完了之后,我们就可以定义我们的Dao层,使用model了。
依赖注入(DI)是反转控制(IOC)的最常用的方式。最早听说这个概念的相信大多数都是来源于Spring,反转控制最大的作用的帮我们创建我们所需要是实例,而不需要我们手动创建,而且实例的创建的依赖我们也不需要关心,全都由IOC帮我们管理,大大的降低了我们代码之间的耦合性。
这里用的依赖注入是awilix,首先我们创建容器,在server/container,下新建index.js:
import * as awilix from 'awilix';
const container = awilix.createContainer({
injectionMode: awilix.InjectionMode.PROXY
});
export default container;然后在我们项目初始化的时候,用awilix-express初始化我们后端的router,如下:
import { loadControllers, scopePerRequest } from 'awilix-express';
import { Lifetime } from 'awilix';
const app = express();
app.use(scopePerRequest(container));
app.use('/api', loadControllers('api/*.js', {
cwd: __dirname,
lifetime: Lifetime.SINGLETON
}));然后,我们可以在server/api下新建我们的controller,这里新建一个TodoApi.js:
import { route, GET, POST } from 'awilix-express';
@route('/todo')
export default class TodoAPI {
constructor({ todoService }) {
this.todoService = todoService;
}
@route('/getTodolist')
@GET()
async getTodolist(req, res) {
const [err, todolist] = await this.todoService.getList();
if (err) {
res.failPrint('服务端异常');
return;
}
res.successPrint('查询成功', todolist);
}
// ...
}这里可以看到构造函数的入参注入了Service层的todoService实例,然后可以直接使用。
然后,我们要搞定我们的Service层和Dao层,这也是在项目初始化的时候,告诉IOC我们所有Service和Dao文件:
import container from './container';
import { asClass } from 'awilix';
// 依赖注入配置service层和dao层
container.loadModules(['services/*.js', 'daos/*.js'], {
formatName: 'camelCase',
register: asClass,
cwd: path.resolve(__dirname)
});然后我们可以在services和daos文件夹下肆无忌惮的新建service文件和dao文件了,这里我们新建一个TodoService.js:
export default class TodoService {
constructor({ itemDao }) {
this.itemDao = itemDao;
}
async getList() {
try {
const list = await this.itemDao.getList();
return [null, list];
} catch (e) {
console.error(e);
return [new Error('服务端异常'), null];
}
}
// ...
}然后,新建一个Dao,ItemDao.js,用来对接ItemModel,也就是mysql的Item表:
import BaseDao from './base';
export default class ItemDao extends BaseDao {
modelName = 'Item';
constructor(modules) {
super(modules);
}
async getList() {
return await this.findAll();
}
}然后搞一个BaseDao,封装一些数据库的常用操作,代码太长,就不贴了,详情见代码库。
所谓事务呢,简单的比较好理解,比如我们执行了两条SQL,用来新增两条数据,当第一条执行成功了,第二条没执行成功,这个时候我们执行事务的回滚,那么第一条成功的记录也将会被取消。
然后呢,我们这里为了也满足事务,我们可以按需使用中间件,为请求注入事务,然后所以在这个请求下执行的增删改的SQL,都使用这个事务,如下中间件:
import { asValue } from 'awilix';
export default function () {
return function (req, res, next) {
const sequelize = container.resolve('sequelize');
sequelize.transaction({ // 开启事务
autocommit: false
}).then(t => {
req.container = req.container.createScope(); // 为当前请求新建一个IOC容器作用域
req.transaction = t;
req.container.register({ // 为IOC注入一个事务transaction
transaction: asValue(t)
});
next();
});
}
}然后当我们需要提交事务的时候,我们可以使用IOC注入transaction,例如,我们在TodoService.js中使用事务
export default class TodoService {
constructor({ itemDao, transaction }) {
this.itemDao = itemDao;
this.transaction = transaction;
}
async addItem(item) {
// TODO: 添加item数据
const success = await this.itemDao.addItem(item);
if (success) {
this.transaction.commit(); // 执行事务提交
} else {
this.transaction.rollback(); // 执行事务回滚
}
}
// ...
}当我们需要在Service层或者Dao层使用到当前的请求对象怎么办呢,这个时候我们需要在IOC中为每一条请求注入request和response,如下中间件:
import { asValue } from 'awilix';
export function baseMiddleware(app) {
return (req, res, next) => {
res.successPrint = (message, data) => res.json({ success: true, message, data });
res.failPrint = (message, data) => res.json({ success: false, message, data });
req.app = app;
// 注入request、response
req.container = req.container.createScope();
req.container.register({
request: asValue(req),
response: asValue(res)
});
next();
}
}然后在项目初始化的时候,使用该中间件:
import express from 'express';
const app = express();
app.use(baseMiddleware(app));使用pm2,简单实现部署,在项目根目录新建pm2.json
{
"apps": [
{
"name": "vue-express", // 实例名
"script": "./dist/server/main.js", // 启动文件
"log_date_format": "YYYY-MM-DD HH:mm Z", // 日志日期文件夹格式
"output": "./log/out.log", // 其他日志
"error": "./log/error.log", // error日志
"instances": "max", // 启动Node实例数
"watch": false, // 关闭文件监听重启
"merge_logs": true,
"env": {
"NODE_ENV": "production"
}
}
]
}这个时候,我们需要把客户端和服务端编译到dist目录,然后将服务端的静态资源目录指向客户端目录,如下:
app.use(express.static(path.resolve(__dirname, '../client')));添加vue-cli的配置文件vue.config.js:
const path = require('path');
const clientPath = path.resolve(process.cwd(), './src/client');
module.exports = {
configureWebpack: {
entry: [
path.resolve(clientPath, 'main.js')
],
resolve: {
alias: {
'@': clientPath
}
},
devServer: {
proxy: {
'/api': { // 开发环境将API前缀配置到后端端口
target: 'http://localhost:9001'
}
}
}
},
outputDir: './dist/client/'
};在package.json中添加如下script:
{
"script": {
"clean": "rimraf dist",
"pro-env": "cross-env NODE_ENV=production",
"build:client": "vue-cli-service build",
"build:server": "babel --config-file ./server.babel.config.js src/server --out-dir dist/server/",
"build": "npm run clean && npm run build:client && npm run build:server",
"start": "pm2 start pm2.json",
"stop": "pm2 delete pm2.json"
}
}执行build命令,清理dist目录,同时编译前后端代码到dist目录下,然后npm run start,pm2启动dist/server/main.js;
到此为止,部署完成。
发现自己挂羊头卖狗肉,竟然全在写后端。。。好吧,我承认我本来就是想写后端的,但是我还是觉得作为一个前端工程师,Nodejs应该是在这条路上走下去的必备技能,加油~。
学前端应该都是从 HTML 开始的吧,1991年的时候出现了世界上第一个网页,感受下当年的源代码:
<HEADER>
<TITLE>The World Wide Web project</TITLE>
<NEXTID N="55">
</HEADER>
<BODY>
<H1>World Wide Web</H1>
The WorldWideWeb (W3) is a wide-area
<A NAME=0 HREF="WhatIs.html">hypermedia ...</A>一开始全都是标签,而且没有规范,于是一帮人组成了复仇者万维网联盟专门来搞网络标准化,也就是今天常说的 W3C。
当时的网页只能做简单信息展示还很 LOW,后来一家叫 SUN 的公司搞了个 Java 小程序(Applet),可以跑在网页中制造很酷炫的效果。另外一家叫网景的公司觉得很牛逼,于是赶紧招人准备出复刻版,由于项目紧,程序员花了两周时间搞出了JavaScript,结果项目上线后效果出乎意外的好!于是 JS 大火。
有了 JS 用户就可以和网页更好的交互了,但是页面还是很 LOW,于是又过了一年,CSS 出现了,专门用来美化页面。至此,前端三巨头诞生了,网页看起来终于有模有样了,于是 WEB 发展进入繁荣时代,出现了一大波新技术比如 Spring/JSP/ASP/AJAX 等等,也出现了一大波浏览器比如 IE、Firefox、Safari、Chrome、Opera...
于是前端出现了一个非常棘手的问题:浏览器兼容问题。同一个DOM操作需要写很多适配代码来兼容不同浏览器,这是一个很枯燥低效的事情。于是jQuery 诞生了:一套代码,多端运行。众前端大喜,纷纷使用至今。
由于技术发展飞快,人们对网页的要求越来越高,这时一家叫 Google 的公司认为浏览器需要更好的体验和性能,JS 需要一款更快速的引擎来迎接现代化 Web 应用。而当时微软的 IE6 占据了大部分市场份额,微软认为 IE6 已经很完美了,于是解散了IE6开发团队。
后来的事大家都知道了,IE 成了前端开发的阴影,而谷歌的 Chrome 搭上 V8 引擎上了天,美滋滋,也就由于浏览器性能的提升,W3C也为此提供了 HTML 的新特性,也就是我们现在说的 HTML5、CSS3,让我们能在网页是很快的完成一些酷炫的特效。。。
模块化开发的主要目的是实现代码的结构化,提高代码复用性、可维护性、可扩展性。JavaScript 天生没有模块化的概念(直到ES6),而不像后端语言源生自带模块功能, 比如 Java 的 import、C++ 的 include,所以需要通过其他的方式来实现模块化。
JavaScript 的最初,为了达到模块化的目的,我们往往会把一些重复使用的代码封装成一个 function,需要用到的时候时候去调用它,那么这可以看做是一种模块化,如下一段代码:
function show(element) { // 展示一个元素 }
function hide(element) { // 隐藏一个元素 }代码很直观,就是要显示、隐藏一个 dom 元素,往往这种方法需要大范围多次调用,一般我们可能会放到 util.js 这样的文件里,这是第一步。接下来我们可以在业务代码 page1.js、page2.js 中使用这两个方法,我们把两个js引入到html中:
<body>
<script src="lib/utils.js"></script>
<script src="lib/page1.js"></script>
<script src="lib/page2.js"></script>
</body>以现在的经验来看,上面的写法会带来非常明显的问题,当然也是在这个模块化引入阶段逐步暴露的。
针对问题1,全局变量冲突的风险,我们可以参考其他后端语言的特性,将变量声明到特定的命名空间里面,只要按照特定的规范来声明变量及命名空间,那么基本可以避免变量冲突的问题,如,可以按照实际情况具体到部门、team、类库来声明命名空间:
var com.company.departure.team.utils = {
show: function(ele) {}, // 显示元素
hide: function(ele) {} // 隐藏元素
}�但是还存在另外一个问题,就是 show、hide 函数里面可能依赖一些外部的变量,那么这些变量我们定义在哪的,这个时候我们可以封装一个立即执行函数,把这些变量都存放在里面,避免这些变量污染到全局变量,如下:
var mudule = {}; // 全局存放的模块
(function() {
var Company = Company || {};
Company.Base = Company.Base || {};
var name = 'username'
function show () {} // 内部引用 name 变量
function hide () {}
mudule['Company.Base.Util'] = Company.Base.Util = {
show: show,
hide: hide
}
})();这个立即执行函数,通过闭包把需要导出的模块丢到我们全局配置 mudule 中,从而达到了模块化的目的,同时也解决了全局变量冲突的风险。
那针对第二个问题人工维护依赖关系,在客户端层面,一直没有一个比较比较好的解决方案,当然,我们能想到最好的方式,那就是只有一个js,被依赖的库在这个js的前面先被声明,这样技能减少http请求,也能把依赖问题解决。那么,为了达到这样的效果,我们需要在代码运行之前,事先知道模块之间的依赖关系,这个时候我们需要对js进行预处理,然后把所有js代码进行合并。
后来,一个来自雅虎,叫 YUI compressor 的工具横空出世,它可以完成代码的合并与压缩,因为这个,那个时候业界内的网站优化以雅虎为标准,然而,适合模块化的通用工具并未出现,我们还是得手动确定依赖进行混淆合并压缩,而且 YUI compressor 是基于 Java 的,对前端同学来说,并不是很友好。
2009年,一个基于 JavaScript 的服务端语言 NodeJS 发布了,这给前端同学带来了无限的可能,也就是说,以往需要通过其他语言工具执行的编译过程也可以由前端一手接管。同时,node 也带来了 commonJS,给前端的模块化提供了新的思路。当然,commonJS 并不是 NodeJs 的产物,他只是按照该规范做了一套实现。
简单概括下 commonJS 的几个概念
我们利用 commonJs 对上面的例子进行改进:
util.js
function show() {}
function hide() {}
module.exports.show = show;
module.exports.hide = hide;page-1.js
const util = require('./util.js');
util.show();然而,这样的代码无法在客户端执行,因为浏览器识别不到 commonJS,我们需要解析 commonJS,让他变成浏览器可以识别的代码。
对于前端同学来说 node 有着天然的亲和力,让我们多了一个全新施展本领的领域,因此,为了解析 commonJS 以及提高开发效率,社区里各种构建工程不断涌出, 具有代表性的有 grunt、gulp、browserify,webpack,前端模块化可以更进一步。
说到这里,也就出现了我们目前最流行的编译构建工具 webpack,本质上,webpack 是一个现代 JavaScript 应用程序的静态模块打包器,在它打包静态资源时候,会根据模块规范,递归地构建一个依赖关系数,其中包含应用程序需要的每个模块,然后将所有这些模块打包成一个或多个浏览器可运行的文件。它不仅支持 commonJS 模块, AMD 模块、 ES6 模块、CSS、图片、 JSON、Coffeescript、 LESS 等。
后来,万维网联盟也认识到了前端开发的痛点,实现了一套模块化的方案纳入了 W3C 的标准,也就是我们现在的 ES6(ECMAScript 6) 模块化方案,这种方案是使用 import 关键字导入模块,使用 export 关键字导出模块,当然在实际开发过程中我们通常会使用 babel 来将其转化为 ES5,import 转为了 require,export 转为了 module.exports,即 commonJS。
react 的出现可以说是前端发展的一个里程碑,其双向数据绑定和 MVVM 模式将前端从 DOM 操作中解放出来,可以把重点放在数据和业务上,那么,什么是 MVVM 模式呢?
回到当初,当我们的 MVVM 没有出现的时候,最早我们是使用原生 JavaScript API 对 DOM 进行操作,手动的把视图与数据模型进行同步,因为原生 API 又臭又长,也需要手动完成浏览器兼容问题,后来,jQuery 出现了,它谈不上是框架,只是一个用来简化 DOM 操作的 JavaScript 库,当然它也提供了很多 DOM 以外的工具函数,刚好满足了那个时候的大部分前端开发的需求。但是,随着时代的发展,业务也越是复杂。。。那么手动同步视图与数据模型将是一个噩梦,大量的 DOM 操作代码使得代码臃肿,难以扩展、维护,这个时候 MVVM 的出现无疑是一套完美的解决方案。
说到 MVVM,我们得先从 MVC 说起,众所周知,MVC 是开发客户端最经典的设计模式,但是 MVC 有让人无法忽视的严重问题。
在通常的开发中,除了简单的 Model、View 以外的所有部分都被放在了 Controller 里面。Controller 负责显示界面、响应用户的操作、网络请求以及与 Model 交互。这就导致了 Controller:
于是微软的大牛提出了 MVVM,竟然 view 与 controller 紧密相连,那干脆把它们连接在一起,放到一个新的对象里,即 ViewModel,它把 view 与 model 完全隔离开来,通过 ViewModel 层交互,达到双向数据绑定的效果。
其实,所有 MVVM 模式的框架,如 VueJS、AngularJS、ReactJS,最终都是为了解决一个问题,那就是视图 view 与数据模型 model 的同步,当我们视图中的数据被用户或者其他因素改变时,数据模型会自动得到同步,反过来,数据模型的数据发生变化时,视图也自动得到了更新,这就是双向数据绑定的最终效果。
react 其实只是被定义为一个 view 层,通过组件化的形式,只关注数据呈现,也就是当外部传入的属性发生变化时候,组件会自动进行冲渲染,完成我们数据与视图同步的工作,当然 react 也提供了 state 来充当 ViewModel 这一角色,但是这种方式不被推荐,因为对于大型的前端应用当中,我们需要对数据进行统一的管理,react 组件内的 state 在组件通信上会显得非常吃力,因此出现了 redux、mobx 这类数据模型状态管理中心库,也就是我们的 ViewModel,下面我们针对 mobx 进行讲解。
���我们先定义一个 ViewModel:
import { observable, action } from 'mobx'
class ViewModel {
@observable
name = 'ming.xiao'; // 观测name的变化
@action
setName(name) {
this.name = name;
}
}
export default ViewModel;上面代码我们可以把 name 当前 model 数据,下面我们在定义我们的 view:
import React from 'react'
import { inject, observer } from 'mobx-react'
@inject('viewModel')
@observer
class View extends React.Component {
onChange(e) {
this.props.viewModel.setName(e.target.value);
}
onClick(e) {
this.props.viewModel.setName('hong.xiao');
}
render() {
var name = this.props.viewModel.name;
return <div>
<input onChange={this.onChange.bind(this)} value={name}/>
<button onClick={this.onClick.bind(this)}>改变名字</button>
</div>
}
}
export default View;mobx 作为一个统一管理数据的中心,提供了 mobx-react 让我们可以把数据 inject 注入到组件里,在渲染方法render里获取并使用,当我们在输入框输入内容时候,viewModel 执行 action 将输入框的值设置到模型数据中,这样我们就达到了视图同步模型数据的目的,当我们点击按钮的时候,viewModel 执行 action 将名字设置为hong.xiao,这个时候组件发现依赖到模型数据name发生了变化,重新执行render方法,这样,我们就实现了数据同步视图的目的,那么我们现在就完成了前面我们所说的双向数据绑定。
那么,这是如何实现的呢?其实,mobx主要做的一件事情就是收集视图数据的依赖,当组件被 observer 的时候,mobx开启了它的依赖收集,然后让组件使用到 ViewModel 里的被 observable 的属性(setter和getter方法被重写)的时候,把组件存入到 mobx 内部,当这个被 observable 的属性被改变的时候,mobx 会通过 observer 改变 inject 到 react 组件的数据,也就是传入到组件内的属性发生了变化,然后组件自动完成重渲染工作,用设计模式来解释就是,使用了发布/订阅模式,mobx 收集依赖的时候属于订阅过程,observable 数据被改变属于发布通知过程,把所有依赖该 observable 的组件进行了一次通知,让其进行重渲染。
前端技术领域的发展总是趋向于业务,所以,前端基于业务,无法脱离业务,业务飞速发展,前端技术也得快速的更新迭代。。。
一直对浏览器的进程、线程的运行一无所知,经过一次的刷刷刷相关的博客之后,对其有了初步的了解,是时候该总结一波了。
一个进程有一个或多个线程,线程之间共同完成进程分配下来的任务。打个比方:
再完善完善概念:
进程是cpu资源分配的最小单位(是能拥有资源和独立运行的最小单位),线程是cpu调度的最小单位(线程是建立在进程的基础上的一次程序运行单位)。
知道了进程与线程之间的关系之后,下面是浏览器与进程的关系了。首先,浏览器是多进程的,之所以浏览器能够运行,是因为系统给浏览器分配了资源,如cpu、内存,简单的说就是,浏览器每打开一个标签页,就相当于创建了一个独立的浏览器进程。例如我们查看chrome里面的任务管理器。
** 注意:** 在这里浏览器应该也有自己的优化机制,有时候打开多个tab页后,可以在Chrome任务管理器中看到,有些进程被合并了(譬如打开多个空白标签页后,会发现多个空白标签页被合并成了一个进程),所以每一个Tab标签对应一个进程并不一定是绝对的。
除了浏览器的标签页进程之外,浏览器还有一些其他进程来辅助支撑标签页的进程,如下:
① Browser进程:浏览器的主进程(负责协调、主控),只有一个。作用有
② 第三方插件进程:每种类型的插件对应一个进程,仅当使用该插件时才创建
③ GPU进程:最多一个,用于3D绘制等
④ 浏览器渲染进程(浏览器内核),Renderer进程,内部是多线程的,也就是我们每个标签页所拥有的进程,互不影响,负责页面渲染,脚本执行,事件处理等
如下图:
浏览器内核,即我们的渲染进程,有名Renderer进程,我们页面的渲染,js的执行,事件的循环都在这一进程内进行,也就是说,该进程下面拥有着多个线程,靠着这些现成共同完成渲染任务。那么这些线程是什么呢,如下:
① 图形用户界面GUI渲染线程
② JS引擎线程
③ 事件触发线程
④ 定时触发器线程
setInterval与setTimeout所在线程4ms的时间间隔算为4ms⑤ 异步HTTP请求线程
浏览器内核,放图加强记忆:
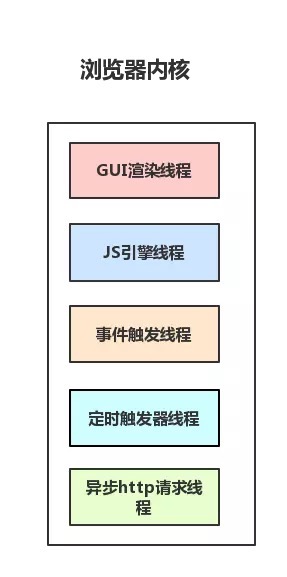
JavaScript作为一门客户端的脚本语言,主要的任务是处理用户的交互,而用户的交互无非就是响应DOM的增删改,使用事件队列的形式,一次事件循环只处理一个事件响应,使得脚本执行相对连续。如果JS引擎被设计为多线程的,那么DOM之间必然会存在资源竞争,那么语言的实现会变得非常臃肿,在客户端跑起来,资源的消耗和性能将会是不太乐观的,故设计为单线程的形式,并附加一些其他的线程来实现异步的形式,这样运行成本相对于使用JS多线程来说降低了很多。
因为JS引擎可以修改DOM树,那么如果JS引擎在执行修改了DOM结构的同事,GUI线程也在渲染页面,那么这样就会导致渲染线程获取的DOM的元素信息可能与JS引擎操作DOM后的结果不一致。为了防止这种现象,GUI线程与JS线程需要设计为互斥关系,当JS引擎执行的时候,GUI线程需要被冻结,但是GUI的渲染会被保存在一个队列当中,等待JS引擎空闲的时候执行渲染。
由此也可以推出,如果JS引擎正在进行CPU密集型计算,那么JS引擎将会阻塞,长时间不空闲,导致渲染进程一直不能执行渲染,页面就会看起来卡顿卡顿的,渲染不连贯,所以,要尽量避免JS执行时间过长。
事件触发线程、定时触发器线程、异步HTTP请求线程三个线程有一个共同点,那就是使用回调函数的形式,当满足了特定的条件,这些回调函数会被执行。这些回调函数被浏览器内核理解成事件,在浏览器内核中拥有一个事件队列,这三个线程当满足了内部特定的条件,会将这些回调函数添加到事件队列中,等待JS引擎空闲执行。例如异步HTTP请求线程,线程如果检测到请求的状态变更,如果设置有回调函数,回调函数会被添加事件队列中,等待JS引擎空闲了执行。
但是,JS引擎对事件队列(宏任务)与JS引擎内的任务(微任务)执行存在着先后循序,当每执行完一个事件队列的时间,JS引擎会检测内部是否有未执行的任务,如果有,将会优先执行(微任务)。
因为JS引擎是单线程的,当JS执行时间过长会页面阻塞,那么JS就真的对CPU密集型计算无能为力么?
所以,后来HTML5中支持了 Web Worker。
来自MDN的官方解释
Web Workers 使得一个Web应用程序可以在与主执行线程分离的后台线程中运行一个脚本操作。这样做的好处是可以在一个单独的线程中执行费时的处理任务,从而允许主(通常是UI)线程运行而不被阻塞/放慢。
注意点:
所以,如果需要进行一些高耗时的计算时,可以单独开启一个WebWorker线程,这样不管这个WebWorker子线程怎么密集计算、怎么阻塞,都不会影响JS引擎主线程,只需要等计算结束,将结果通过postMessage传输给主线程就可以了。
另外,还有个东西叫 SharedWorker,与WebWorker在概念上所不同。
SharedWorker由进程管理,WebWorker是某一个Renderer进程下的线程。
每个浏览器内核的渲染流程不一样,下面我们主要以webkit为主。
首先是渲染的前奏:
在说渲染之前,需要理解一些概念:
reflow。reflow 会从 这个 root frame 开始递归往下,依次计算所有的结点几何尺寸和位置。reflow 几乎是无法避免的。现在界面上流行的一些效果,比如树状目录的折叠、展开(实质上是元素的显 示与隐藏)等,都将引起浏览器的 reflow。鼠标滑过、点击……只要这些行为引起了页面上某些元素的占位面积、定位方式、边距等属性的变化,都会引起它内部、周围甚至整个页面的重新渲 染。通常我们都无法预估浏览器到底会 reflow 哪一部分的代码,它们都彼此相互影响着。display:none的节点不会被加入Render Tree,而visibility: hidden则会,所以display:none会触发reflow,visibility: hidden会触发repaint。浏览器内核拿到响应报文之后,渲染大概分为以下步骤
load事件,绘制流程见下图。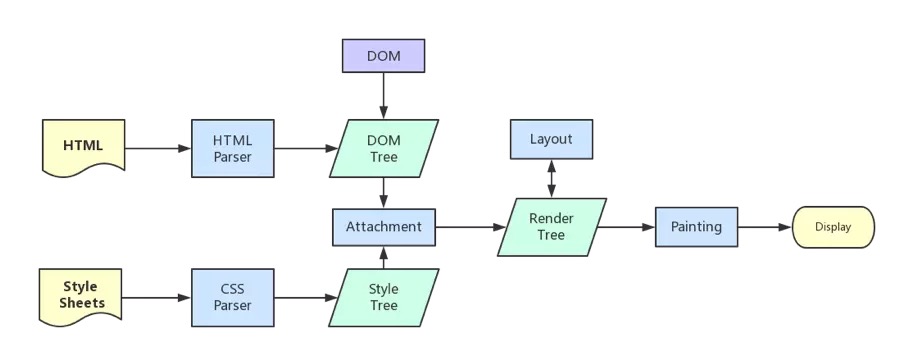
由图中可以看出,css在加载过程中不会影响到DOM树的生成,但是会影响到Render树的生成,进而影响到layout,所以一般来说,style的link标签需要尽量放在head里面,因为在解析DOM树的时候是自上而下的,而css样式又是通过异步加载的,这样的话,解析DOM树下的body节点和加载css样式能尽可能的并行,加快Render树的生成的速度,当然,如果css是通过js动态添加进来的,会引起页面的重绘或重新布局。
从有html标准以来到目前为止(2017年5月),标准一直是规定style元素不应出现在body元素中。
前面提到了load事件,那么与DOMContentLoaded事件有什么分别。
DOMContentLoaded -> load写到这里,总结了也有不少的内容,也对浏览器多线程、JS引擎有所了解,后面打算在看看JS的运行机制。前端知识也是无穷无尽,数不清的概念与无数个易忘的知识、各种框架原理,学来学去,还是发现自己知道得太少了。
当你调用fill()函数时,所有没有闭合的形状都会自动闭合,所以你不需要调用closePath()函数。但是调用stroke()时不会自动闭合。
arc()函数中表示角的单位是弧度,不是角度。角度与弧度的js表达式: 弧度=(Math.PI/180)*角度。
支持使用 rgba 形式。
fillStyle DEMO
strokeStyle DEMO
globalAlpha 属性在需要绘制大量拥有相同透明度的图形时候相当高效。相反,如果对单个元素添加透明度,推荐使用 rgba 形式。
当canvas初始化或者beginPath()调用后,你通常会使用moveTo()函数设置起点。我们也能够使用moveTo()绘制一些不连续的路径。
开始点也可以通过moveTo()函数改变。
lineWidth DEMO
lineCap DEMO
lineJoin DEMO
createLinearGradient()方法创建一个沿参数坐标指定的直线的渐变。这个方法返回 CanvasGradient。
createRadialGradient() 是 Canvas 2D API 根据参数确定两个圆的坐标,绘制放射性渐变的方法。这个方法返回 CanvasGradient。
gradient.addColorStop(position, color) addColorStop 方法接受 2 个参数,position 参数必须是一个 0.0 与 1.0 之间的数值,表示渐变中颜色所在的相对位置。例如,0.5 表示颜色会出现在正中间。color 参数必须是一个有效的 CSS 颜色值(如 #FFF, rgba(0,0,0,1),等等)。
createLinearGradient DEMO
createRadialGradient DEMO
如:
var img = new Image();
img.src = 'someimage.png';
var ptrn = ctx.createPattern(img,'repeat');与 drawImage 有点不同,你需要确认 image 对象已经装载完毕,否则图案可能效果不对的。
canvas的API可以使用下面这些类型中的一种作为图片的源:
这些源统一由 CanvasImageSource 类型来引用。
例:
var img = new Image(); // 创建img元素
img.onload = function(){
// 执行drawImage语句
}
img.src = 'myImage.png'; // 设置图片源地址save 和 restore 方法是用来保存和恢复 canvas 状态的,都没有参数。Canvas 的状态就是当前画面应用的所有样式和变形的一个快照。
Canvas状态存储在栈中,每当save()方法被调用后,当前的状态就被推送到栈中保存。一个绘画状态包括:
每一次调用 restore 方法,上一个保存的状态就从栈中弹出,所有设定都恢复。
裁切路径和普通的 canvas 图形差不多,不同的是它的作用是遮罩,用来隐藏不需要的部分。
如果和 globalCompositeOperation 属性作一比较,它可以实现与 source-in 和 source-atop差不多的效果。
你可以通过以下的步骤来画出一帧:
清空 canvas。除非接下来要画的内容会完全充满 canvas (例如背景图),否则你需要清空所有。最简单的做法就是用 clearRect 方法。
保存 canvas 状态
如果你要改变一些会改变 canvas 状态的设置(样式,变形之类的),又要在每画一帧之时都是原始状态的话,你需要先保存一下。
绘制动画图形(animated shapes)。这一步才是重绘动画帧。
恢复 canvas 状态。如果已经保存了 canvas 的状态,可以先恢复它,然后重绘下一帧。
太阳系的动画 DEMO
动画时钟 DEMO
循环全局 DEMO
ImageData 对象中存储着canvas对象真实的像素数据,它包含以下几个只读属性:
data属性返回一个 Uint8ClampedArray,它可以被使用作为查看初始像素数据。每个像素用4个1bytes值(按照红,绿,蓝和透明值的顺序; 这就是"RGBA"格式) 来代表。每个颜色值部份用0至255来代表。每个部份被分配到一个在数组内连续的索引,左上角像素的红色部份在数组的索引0位置。像素从左到右被处理,然后往下,遍历整个数组。
去创建一个新的,空白的ImageData对象,你应该会使用createImageData() 方法。有2个版本的createImageData()方法。
var myImageData = ctx.createImageData(width, height);得到场景像素数据,为了获得一个包含画布场景像素数据的ImageData对像,你可以用getImageData()方法:
var myImageData = ctx.getImageData(left, top, width, height);这个方法会返回一个ImageData对象,它代表了画布区域的对象数据,此画布的四个角落分别表示为(left, top), (left + width, top), (left, top + height), 以及(left + width, top + height)四个点。这些坐标点被设定为画布坐标空间元素。
在场景中写入像素数据,可以用putImageData()方法去对场景进行像素数据的写入。
ctx.putImageData(myImageData, dx, dy);dx和dy参数表示你希望在场景内左上角绘制的像素数据所得到的设备坐标。
canvas.toDataURL(type, quality) 创建一个base64的type类型图片,你可以有选择地提供从0到1的 quality 品质量,1表示最好品质,0基本不被辨析但有比较小的文件大小。
canvas.toBlob(callback, type, quality) 这个创建了一个在画布中的代表图片的Blob对像,callback:回调函数,可获得一个单独的Blob对象参数。type 可选 DOMString类型,指定图片格式,默认格式为image/png,quality:图片质量。
Babel为当前最流行的代码JavaScript编译器了,其使用的JavaScript解析器为babel-parser,最初是从Acorn 项目fork出来的。Acorn 非常快,易于使用,并且针对非标准特性(以及那些未来的标准特性) 设计了一个基于插件的架构。本文主要介绍esprima解析生成的抽象语法树节点,esprima的实现也是基于Acorn的。
JavaScript Parser 是把js源码转化为抽象语法树(AST)的解析器。这个步骤分为两个阶段:词法分析(Lexical Analysis) 和 语法分析(Syntactic Analysis)。
常用的JavaScript Parser:
词法分析阶段把字符串形式的代码转换为 令牌(tokens)流。你可以把令牌看作是一个扁平的语法片段数组。
n * n;例如上面n*n的词法分析得到结果如下:
[
{ type: { ... }, value: "n", start: 0, end: 1, loc: { ... } },
{ type: { ... }, value: "*", start: 2, end: 3, loc: { ... } },
{ type: { ... }, value: "n", start: 4, end: 5, loc: { ... } },
]每一个 type 有一组属性来描述该令牌:
{
type: {
label: 'name',
keyword: undefined,
beforeExpr: false,
startsExpr: true,
rightAssociative: false,
isLoop: false,
isAssign: false,
prefix: false,
postfix: false,
binop: null,
updateContext: null
},
...
}和 AST 节点一样它们也有 start,end,loc 属性。
语法分析就是根据词法分析的结果,也就是令牌tokens,将其转换成AST。
function square(n) {
return n * n;
}如上面代码,生成的AST结构如下:
{
type: "FunctionDeclaration",
id: {
type: "Identifier",
name: "square"
},
params: [{
type: "Identifier",
name: "n"
}],
body: {
type: "BlockStatement",
body: [{
type: "ReturnStatement",
argument: {
type: "BinaryExpression",
operator: "*",
left: {
type: "Identifier",
name: "n"
},
right: {
type: "Identifier",
name: "n"
}
}
}]
}
}下文将对AST各个类型节点做解释。更多AST生成,入口如下:
结合可视化工具,举个例子
如下代码:
var a = 42;
var b = 5;
function addA(d) {
return a + d;
}
var c = addA(2) + b;第一步词法分析之后长成如下图所示:

语法分析,生产抽象语法树,生成的抽象语法树如下图所示

所有节点类型都实现以下接口:
interface Node {
type: string;
range?: [number, number];
loc?: SourceLocation;
}该type字段是表示AST变体类型的字符串。该loc字段表示节点的源位置信息。如果解析器没有生成有关节点源位置的信息,则该字段为null;否则它是一个对象,包括一个起始位置(被解析的源区域的第一个字符的位置)和一个结束位置.
interface SourceLocation {
start: Position;
end: Position;
source?: string | null;
}每个Position对象由一个line数字(1索引)和一个column数字(0索引)组成:
interface Position {
line: uint32 >= 1;
column: uint32 >= 0;
}interface Program <: Node {
type: "Program";
sourceType: 'script' | 'module';
body: StatementListItem[] | ModuleItem[];
}表示一个完整的源代码树。
源代码数的来源包括两种,一种是script脚本,一种是modules模块
当为script时,body为StatementListItem。
当为modules时,body为ModuleItem。
类型StatementListItem和ModuleItem类型如下。
type StatementListItem = Declaration | Statement;
type ModuleItem = ImportDeclaration | ExportDeclaration | StatementListItem;import语法,导入模块
type ImportDeclaration {
type: 'ImportDeclaration';
specifiers: ImportSpecifier[];
source: Literal;
}ImportSpecifier类型如下:
interface ImportSpecifier {
type: 'ImportSpecifier' | 'ImportDefaultSpecifier' | 'ImportNamespaceSpecifier';
local: Identifier;
imported?: Identifier;
}ImportSpecifier语法如下:
import { foo } from './foo';ImportDefaultSpecifier语法如下:
import foo from './foo';ImportNamespaceSpecifier语法如下
import * as foo from './foo';export类型如下
type ExportDeclaration = ExportAllDeclaration | ExportDefaultDeclaration | ExportNamedDeclaration;ExportAllDeclaration从指定模块中导出
interface ExportAllDeclaration {
type: 'ExportAllDeclaration';
source: Literal;
}语法如下:
export * from './foo';ExportDefaultDeclaration导出默认模块
interface ExportDefaultDeclaration {
type: 'ExportDefaultDeclaration';
declaration: Identifier | BindingPattern | ClassDeclaration | Expression | FunctionDeclaration;
}语法如下:
export default 'foo';ExportNamedDeclaration导出部分模块
interface ExportNamedDeclaration {
type: 'ExportNamedDeclaration';
declaration: ClassDeclaration | FunctionDeclaration | VariableDeclaration;
specifiers: ExportSpecifier[];
source: Literal;
}语法如下:
export const foo = 'foo';declaration,即声明,类型如下:
type Declaration = VariableDeclaration | FunctionDeclaration | ClassDeclaration;statements,即语句,类型如下:
type Statement = BlockStatement | BreakStatement | ContinueStatement |
DebuggerStatement | DoWhileStatement | EmptyStatement |
ExpressionStatement | ForStatement | ForInStatement |
ForOfStatement | FunctionDeclaration | IfStatement |
LabeledStatement | ReturnStatement | SwitchStatement |
ThrowStatement | TryStatement | VariableDeclaration |
WhileStatement | WithStatement;变量声明,kind 属性表示是什么类型的声明,因为 ES6 引入了 const/let。
interface VariableDeclaration <: Declaration {
type: "VariableDeclaration";
declarations: [ VariableDeclarator ];
kind: "var" | "let" | "const";
}函数声明(非函数表达式)
interface FunctionDeclaration {
type: 'FunctionDeclaration';
id: Identifier | null;
params: FunctionParameter[];
body: BlockStatement;
generator: boolean;
async: boolean;
expression: false;
}例如:
function foo() {}
function *bar() { yield "44"; }
async function noop() { await new Promise(function(resolve, reject) { resolve('55'); }) }类声明(非类表达式)
interface ClassDeclaration {
type: 'ClassDeclaration';
id: Identifier | null;
superClass: Identifier | null;
body: ClassBody;
}ClassBody声明如下:
interface ClassBody {
type: 'ClassBody';
body: MethodDefinition[];
}MethodDefinition表示方法声明;
interface MethodDefinition {
type: 'MethodDefinition';
key: Expression | null;
computed: boolean;
value: FunctionExpression | null;
kind: 'method' | 'constructor';
static: boolean;
}class foo {
constructor() {}
method() {}
};continue语句
interface ContinueStatement {
type: 'ContinueStatement';
label: Identifier | null;
}例如:
for (var i = 0; i < 10; i++) {
if (i === 0) {
continue;
}
}debugger语句
interface DebuggerStatement {
type: 'DebuggerStatement';
}例如
while(true) {
debugger;
}do-while语句
interface DoWhileStatement {
type: 'DoWhileStatement';
body: Statement;
test: Expression;
}test表示while条件
例如:
var i = 0;
do {
i++;
} while(i = 2)空语句
interface EmptyStatement {
type: 'EmptyStatement';
}例如:
if(true);
var a = [];
for(i = 0; i < a.length; a[i++] = 0);表达式语句,即,由单个表达式组成的语句。
interface ExpressionStatement {
type: 'ExpressionStatement';
expression: Expression;
directive?: string;
}当表达式语句表示一个指令(例如“use strict”)时,directive属性将包含该指令字符串。
例如:
(function(){});for语句
interface ForStatement {
type: 'ForStatement';
init: Expression | VariableDeclaration | null;
test: Expression | null;
update: Expression | null;
body: Statement;
}for...in语句
interface ForInStatement {
type: 'ForInStatement';
left: Expression;
right: Expression;
body: Statement;
each: false;
}for...of语句
interface ForOfStatement {
type: 'ForOfStatement';
left: Expression;
right: Expression;
body: Statement;
}if 语句
interface IfStatement {
type: 'IfStatement';
test: Expression;
consequent: Statement;
alternate?: Statement;
}consequent表示if命中后内容,alternate表示else或者else if的内容。
label语句,多用于精确的使用嵌套循环中的continue和break。
interface LabeledStatement {
type: 'LabeledStatement';
label: Identifier;
body: Statement;
}如:
var num = 0;
outPoint:
for (var i = 0 ; i < 10 ; i++){
for (var j = 0 ; j < 10 ; j++){
if( i == 5 && j == 5 ){
break outPoint;
}
num++;
}
}return 语句
interface ReturnStatement {
type: 'ReturnStatement';
argument: Expression | null;
}Switch语句
interface SwitchStatement {
type: 'SwitchStatement';
discriminant: Expression;
cases: SwitchCase[];
}discriminant表示switch的变量。
SwitchCase类型如下
interface SwitchCase {
type: 'SwitchCase';
test: Expression | null;
consequent: Statement[];
}throw语句
interface ThrowStatement {
type: 'ThrowStatement';
argument: Expression;
}try...catch语句
interface TryStatement {
type: 'TryStatement';
block: BlockStatement;
handler: CatchClause | null;
finalizer: BlockStatement | null;
}handler为catch处理声明内容,finalizer为finally内容。
CatchClaus 类型如下
interface CatchClause {
type: 'CatchClause';
param: Identifier | BindingPattern;
body: BlockStatement;
}例如:
try {
foo();
} catch (e) {
console.erroe(e);
} finally {
bar();
}while语句
interface WhileStatement {
type: 'WhileStatement';
test: Expression;
body: Statement;
}test为判定表达式
with语句(指定块语句的作用域)
interface WithStatement {
type: 'WithStatement';
object: Expression;
body: Statement;
}如:
var a = {};
with(a) {
name = 'xiao.ming';
}
console.log(a); // {name: 'xiao.ming'}Expressions可用类型如下:
type Expression = ThisExpression | Identifier | Literal |
ArrayExpression | ObjectExpression | FunctionExpression | ArrowFunctionExpression | ClassExpression |
TaggedTemplateExpression | MemberExpression | Super | MetaProperty |
NewExpression | CallExpression | UpdateExpression | AwaitExpression | UnaryExpression |
BinaryExpression | LogicalExpression | ConditionalExpression |
YieldExpression | AssignmentExpression | SequenceExpression;Patterns可用有两种类型,函数模式和对象模式如下:
type BindingPattern = ArrayPattern | ObjectPattern;this 表达式
interface ThisExpression {
type: 'ThisExpression';
}标识符,就是我们写 JS 时自定义的名称,如变量名,函数名,属性名,都归为标识符。相应的接口是这样的:
interface Identifier {
type: 'Identifier';
name: string;
}字面量,这里不是指 [] 或者 {} 这些,而是本身语义就代表了一个值的字面量,如 1,“hello”, true 这些,还有正则表达式(有一个扩展的 Node 来表示正则表达式),如 /\d?/。
interface Literal {
type: 'Literal';
value: boolean | number | string | RegExp | null;
raw: string;
regex?: { pattern: string, flags: string };
}例如:
var a = 1;
var b = 'b';
var c = false;
var d = /\d/;数组表达式
interface ArrayExpression {
type: 'ArrayExpression';
elements: ArrayExpressionElement[];
}例:
[1, 2, 3, 4];数组表达式的节点,类型如下
type ArrayExpressionElement = Expression | SpreadElement;Expression包含所有表达式,SpreadElement为扩展运算符语法。
扩展运算符
interface SpreadElement {
type: 'SpreadElement';
argument: Expression;
}如:
var a = [3, 4];
var b = [1, 2, ...a];
var c = {foo: 1};
var b = {bar: 2, ...c};对象表达式
interface ObjectExpression {
type: 'ObjectExpression';
properties: Property[];
}Property代表为对象的属性描述
类型如下
interface Property {
type: 'Property';
key: Expression;
computed: boolean;
value: Expression | null;
kind: 'get' | 'set' | 'init';
method: false;
shorthand: boolean;
}kind用来表示是普通的初始化,或者是 get/set。
例如:
var obj = {
foo: 'foo',
bar: function() {},
noop() {}, // method 为 true
['computed']: 'computed' // computed 为 true
}函数表达式
interface FunctionExpression {
type: 'FunctionExpression';
id: Identifier | null;
params: FunctionParameter[];
body: BlockStatement;
generator: boolean;
async: boolean;
expression: boolean;
}例如:
var foo = function () {}箭头函数表达式
interface ArrowFunctionExpression {
type: 'ArrowFunctionExpression';
id: Identifier | null;
params: FunctionParameter[];
body: BlockStatement | Expression;
generator: boolean;
async: boolean;
expression: false;
}generator表示是否为generator函数,async表示是否为async/await函数,params为参数定义。
FunctionParameter类型如下
type FunctionParameter = AssignmentPattern | Identifier | BindingPattern;例:
var foo = () => {};类表达式
interface ClassExpression {
type: 'ClassExpression';
id: Identifier | null;
superClass: Identifier | null;
body: ClassBody;
}例如:
var foo = class {
constructor() {}
method() {}
};标记模板文字函数
interface TaggedTemplateExpression {
type: 'TaggedTemplateExpression';
readonly tag: Expression;
readonly quasi: TemplateLiteral;
}TemplateLiteral类型如下
interface TemplateLiteral {
type: 'TemplateLiteral';
quasis: TemplateElement[];
expressions: Expression[];
}TemplateElement类型如下
interface TemplateElement {
type: 'TemplateElement';
value: { cooked: string; raw: string };
tail: boolean;
}例如
var foo = function(a){ console.log(a); }
foo`test`;属性成员表达式
interface MemberExpression {
type: 'MemberExpression';
computed: boolean;
object: Expression;
property: Expression;
}例如:
const foo = {bar: 'bar'};
foo.bar;
foo['bar']; // computed 为 true父类关键字
interface Super {
type: 'Super';
}例如:
class foo {};
class bar extends foo {
constructor() {
super();
}
}(这个不知道干嘛用的)
interface MetaProperty {
type: 'MetaProperty';
meta: Identifier;
property: Identifier;
}例如:
new.target // 通过new 声明的对象,new.target会存在
import.meta函数执行表达式
interface CallExpression {
type: 'CallExpression';
callee: Expression | Import;
arguments: ArgumentListElement[];
}Import类型,没搞懂。
interface Import {
type: 'Import'
}ArgumentListElement类型
type ArgumentListElement = Expression | SpreadElement;如:
var foo = function (){};
foo();new 表达式
interface NewExpression {
type: 'NewExpression';
callee: Expression;
arguments: ArgumentListElement[];
}更新操作符表达式,如++、--;
interface UpdateExpression {
type: "UpdateExpression";
operator: '++' | '--';
argument: Expression;
prefix: boolean;
}如:
var i = 0;
i++;
++i; // prefix为trueawait表达式,会与async连用。
interface AwaitExpression {
type: 'AwaitExpression';
argument: Expression;
}如
async function foo() {
var bar = function() {
new Primise(function(resolve, reject) {
setTimeout(function() {
resove('foo')
}, 1000);
});
}
return await bar();
}
foo() // foo一元操作符表达式
interface UnaryExpression {
type: "UnaryExpression";
operator: UnaryOperator;
prefix: boolean;
argument: Expression;
}枚举UnaryOperator
enum UnaryOperator {
"-" | "+" | "!" | "~" | "typeof" | "void" | "delete" | "throw"
}二元操作符表达式
interface BinaryExpression {
type: 'BinaryExpression';
operator: BinaryOperator;
left: Expression;
right: Expression;
}枚举BinaryOperator
enum BinaryOperator {
"==" | "!=" | "===" | "!=="
| "<" | "<=" | ">" | ">="
| "<<" | ">>" | ">>>"
| "+" | "-" | "*" | "/" | "%"
| "**" | "|" | "^" | "&" | "in"
| "instanceof"
| "|>"
}逻辑运算符表达式
interface LogicalExpression {
type: 'LogicalExpression';
operator: '||' | '&&';
left: Expression;
right: Expression;
}如:
var a = '-';
var b = a || '-';
if (a && b) {}条件运算符
interface ConditionalExpression {
type: 'ConditionalExpression';
test: Expression;
consequent: Expression;
alternate: Expression;
}例如:
var a = true;
var b = a ? 'consequent' : 'alternate';yield表达式
interface YieldExpression {
type: 'YieldExpression';
argument: Expression | null;
delegate: boolean;
}例如:
function* gen(x) {
var y = yield x + 2;
return y;
}赋值表达式。
interface AssignmentExpression {
type: 'AssignmentExpression';
operator: '=' | '*=' | '**=' | '/=' | '%=' | '+=' | '-=' |
'<<=' | '>>=' | '>>>=' | '&=' | '^=' | '|=';
left: Expression;
right: Expression;
}operator属性表示一个赋值运算符,left和right是赋值运算符左右的表达式。
序列表达式(使用逗号)。
interface SequenceExpression {
type: 'SequenceExpression';
expressions: Expression[];
}var a, b;
a = 1, b = 2数组解析模式
interface ArrayPattern {
type: 'ArrayPattern';
elements: ArrayPatternElement[];
}例:
const [a, b] = [1,3];elements代表数组节点
ArrayPatternElement如下
type ArrayPatternElement = AssignmentPattern | Identifier | BindingPattern | RestElement | null;默认赋值模式,数组解析、对象解析、函数参数默认值使用。
interface AssignmentPattern {
type: 'AssignmentPattern';
left: Identifier | BindingPattern;
right: Expression;
}例:
const [a, b = 4] = [1,3];剩余参数模式,语法与扩展运算符相近。
interface RestElement {
type: 'RestElement';
argument: Identifier | BindingPattern;
}例:
const [a, b, ...c] = [1, 2, 3, 4];对象解析模式
interface ObjectPattern {
type: 'ObjectPattern';
properties: Property[];
}例:
const object = {a: 1, b: 2};
const { a, b } = object;AST的作用大致分为几类
IDE使用,如代码风格检测(eslint等)、代码的格式化,代码高亮,代码错误等等
代码的混淆压缩
转换代码的工具。如webpack,rollup,各种代码规范之间的转换,ts,jsx等转换为原生js
了解AST,最终还是为了让我们了解我们使用的工具,当然也让我们更了解JavaScript,更靠近JavaScript。
闲来无事,研究一下SSR,主要原因在于上周一位后端同学在一次组内技术分享的时候说,对前后端分离、服务端渲染特别感兴趣,在他分享了后端微服务之后,专门点名邀请我下周分享服务端渲染,然后我还没同意,领导就内定让我下周分享了(其实就是下周愿意下周分享,我是那个替死鬼)。
本人主要从个人角度介绍了对服务端渲染的理解,读完本文后,你将了解到:
在讲服务度渲染之前,我们先回顾一下页面的渲染流程:
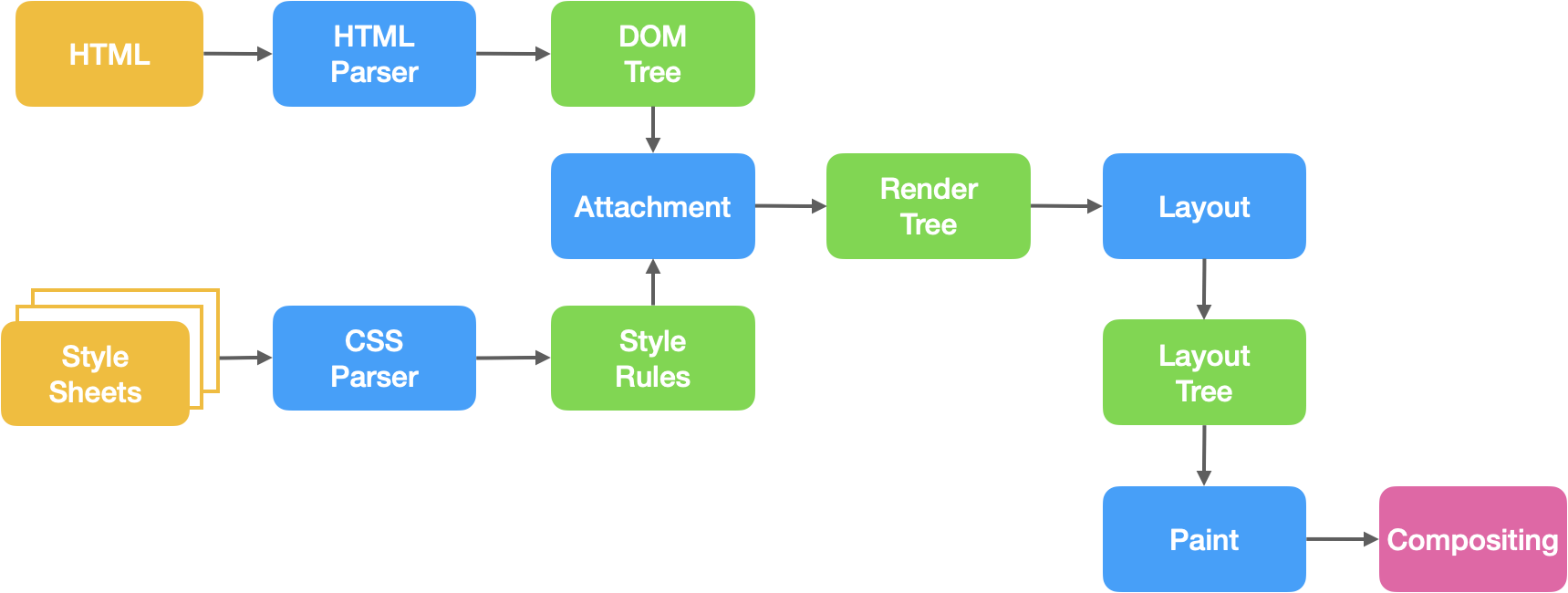
可以看到,页面的渲染其实就是浏览器将HTML文本转化为页面帧的过程。而如今我们大部分WEB应用都是使用 JavaScript 框架(Vue、React、Angular)进行页面渲染的,也就是说,在执行 JavaScript 脚本的时候,HTML页面已经开始解析并且构建DOM树了,JavaScript 脚本只是动态的改变 DOM 树的结构,使得页面成为希望成为的样子,这种渲染方式叫动态渲染,也可以叫客户端渲染(client side rende)。
那么什么是服务端渲染(server side render)?顾名思义,服务端渲染就是在浏览器请求页面URL的时候,服务端将我们需要的HTML文本组装好,并返回给浏览器,这个HTML文本被浏览器解析之后,不需要经过 JavaScript 脚本的执行,即可直接构建出希望的 DOM 树并展示到页面中。这个服务端组装HTML的过程,叫做服务端渲染。
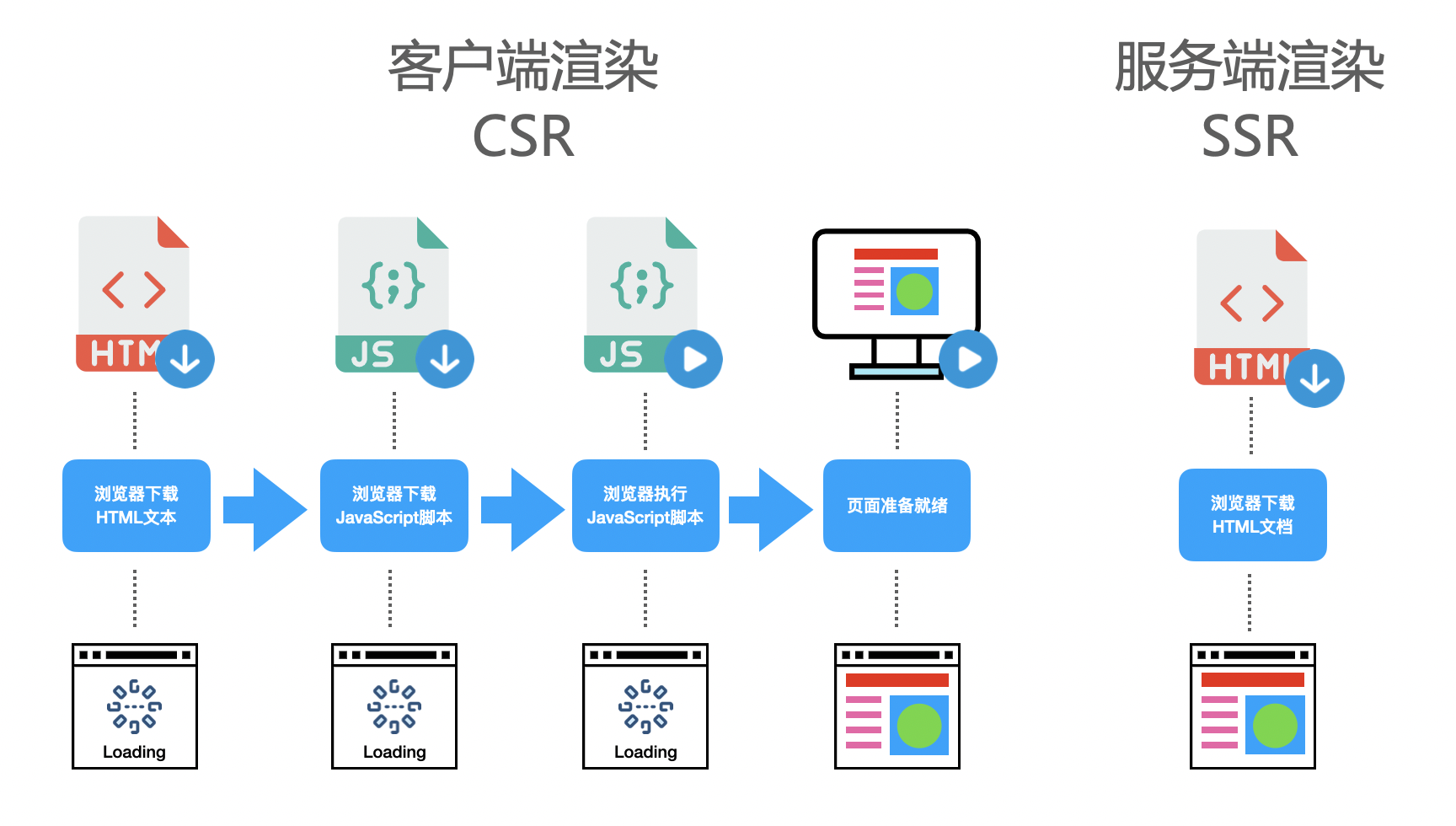
在没有AJAX的时候,也就是web1.0时代,几乎所有应用都是服务端渲染(此时服务器渲染非现在的服务器渲染),那个时候的页面渲染大概是这样的,浏览器请求页面URL,然后服务器接收到请求之后,到数据库查询数据,将数据丢到后端的组件模板(php、asp、jsp等)中,并渲染成HTML片段,接着服务器在组装这些HTML片段,组成一个完整的HTML,最后返回给浏览器,这个时候,浏览器已经拿到了一个完整的被服务器动态组装出来的HTML文本,然后将HTML渲染到页面中,过程没有任何JavaScript代码的参与。
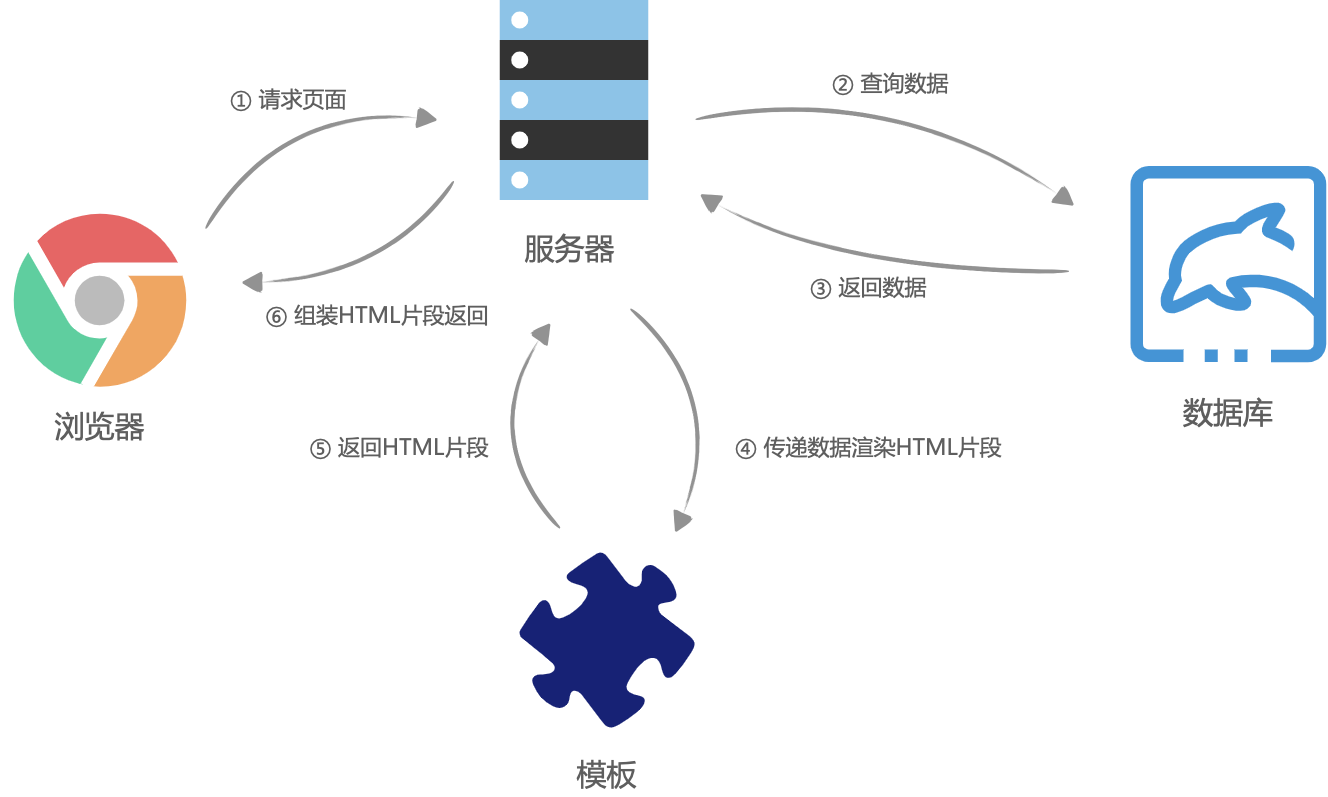
在WEB1.0时代,服务端渲染看起来是一个当时的最好的渲染方式,但是随着业务的日益复杂和后续AJAX的出现,也渐渐开始暴露出了WEB1.0服务器渲染的缺点。
而且那个时候,根本就没有前端工程师这一职位,前端js的活一般都由后端同学 jQuery 一把梭。但是随着前端页面渐渐地复杂了之后,后端开始发现js好麻烦,虽然很简单,但是坑太多了,于是让公司招聘了一些专门写js的人,也就是前端,这个时候,前后端的鄙视链就出现了,后端鄙视前端,因为后端觉得js太简单,无非就是写写页面的特效(JS),切切图(CSS),根本算不上是真正的程序员。
随之 nodejs 的出现,前端看到了翻身的契机,为了摆脱后端的指指点点,前端开启了一场前后端分离的运动,希望可以脱离后端独立发展。前后端分离,表面上看上去是代码分离,实际上是为了前后端人员分离,也就是前后端分家,前端不再归属于后端团队。
前后端分离之后,网页开始被当成了独立的应用程序(SPA,Single Page Application),前端团队接管了所有页面渲染的事,后端团队只负责提供所有数据查询与处理的API,大体流程是这样的:首先浏览器请求URL,前端服务器直接返回一个空的静态HTML文件(不需要任何查数据库和模板组装),这个HTML文件中加载了很多渲染页面需要的 JavaScript 脚本和 CSS 样式表,浏览器拿到 HTML 文件后开始加载脚本和样式表,并且执行脚本,这个时候脚本请求后端服务提供的API,获取数据,获取完成后将数据通过JavaScript脚本动态的将数据渲染到页面中,完成页面显示。
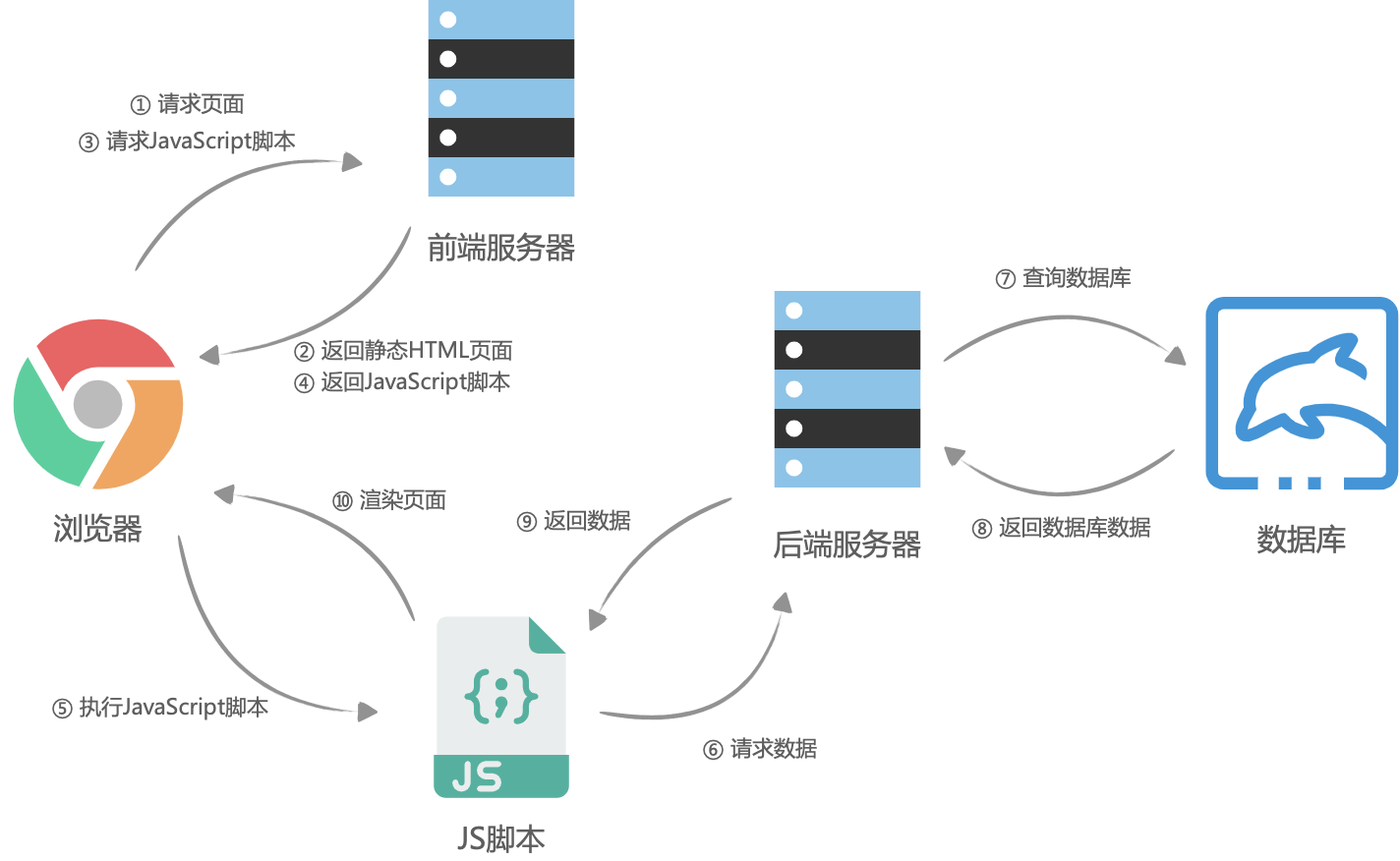
这一个前后端分离的渲染模式,也就是客户端渲染(CSR)。
随着单页应用(SPA)的发展,程序员们渐渐发现 SEO(Search Engine Optimazition,即搜索引擎优化)出了问题,而且随着应用的复杂化,JavaScript 脚本也不断的臃肿起来,使得首屏渲染相比于 Web1.0时候的服务端渲染,也慢了不少。
自己选的路,跪着也要走下去。于是前端团队选择了使用 nodejs 在服务器进行页面的渲染,进而再次出现了服务端渲染。大体流程与客户端渲染有些相似,首先是浏览器请求URL,前端服务器接收到URL请求之后,根据不同的URL,前端服务器向后端服务器请求数据,请求完成后,前端服务器会组装一个携带了具体数据的HTML文本,并且返回给浏览器,浏览器得到HTML之后开始渲染页面,同时,浏览器加载并执行 JavaScript 脚本,给页面上的元素绑定事件,让页面变得可交互,当用户与浏览器页面进行交互,如跳转到下一个页面时,浏览器会执行 JavaScript 脚本,向后端服务器请求数据,获取完数据之后再次执行 JavaScript 代码动态渲染页面。
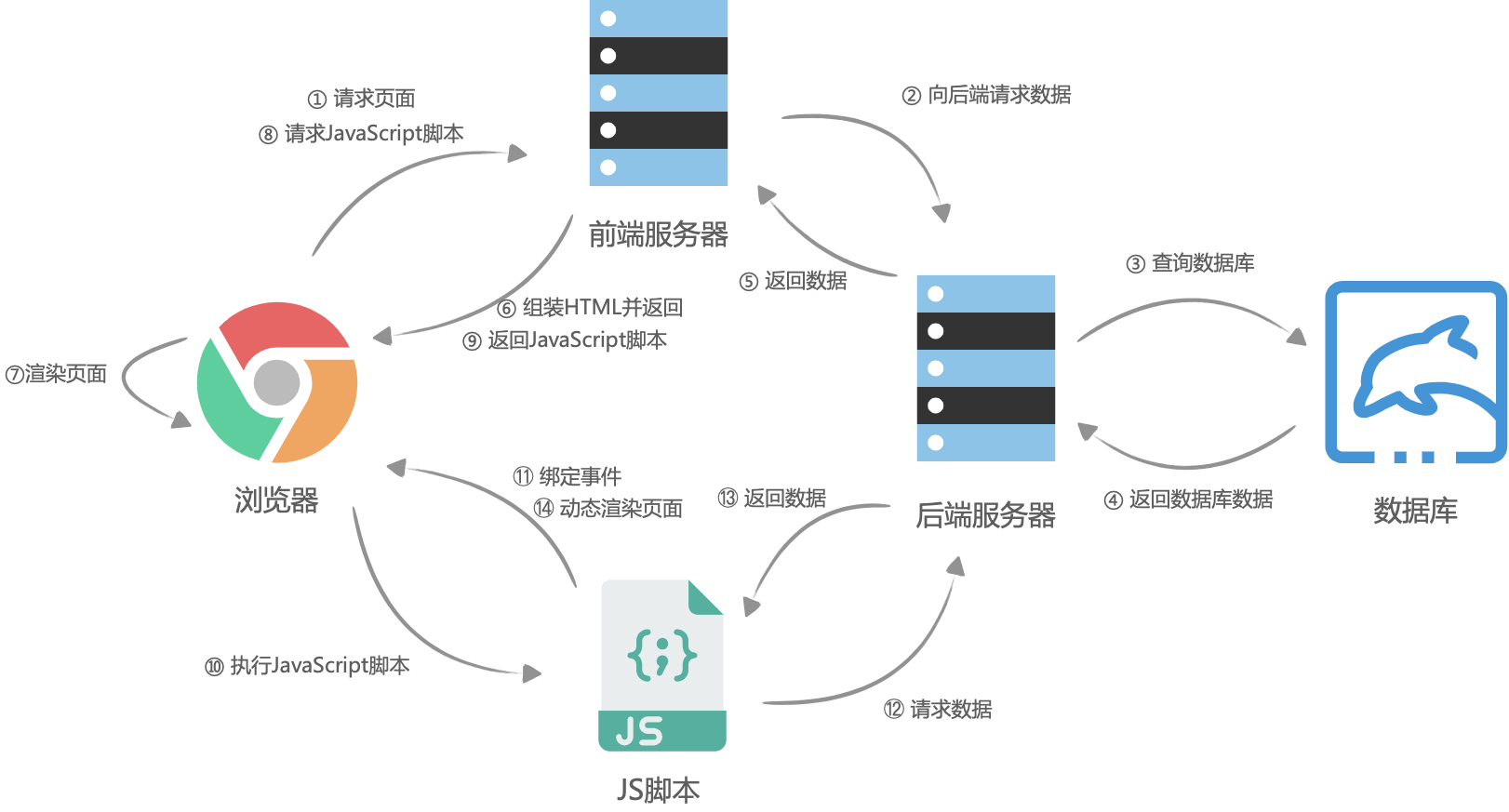
相比于客户端渲染,服务端渲染有什么优势?
有利于SEO,其实就是有利于爬虫来爬你的页面,然后在别人使用搜索引擎搜索相关的内容时,你的网页排行能靠得更前,这样你的流量就有越高。那为什么服务端渲染更利于爬虫爬你的页面呢?其实,爬虫也分低级爬虫和高级爬虫。
也就是说,低级爬虫对客户端渲染的页面来说,简直无能为力,因为返回的HTML是一个空壳,它需要执行 JavaScript 脚本之后才会渲染真正的页面。而目前像百度、谷歌、微软等公司,有一部分年代老旧的爬虫还属于低级爬虫,使用服务端渲染,对这些低级爬虫更加友好一些。
相对于客户端渲染,服务端渲染在浏览器请求URL之后已经得到了一个带有数据的HTML文本,浏览器只需要解析HTML,直接构建DOM树就可以。而客户端渲染,需要先得到一个空的HTML页面,这个时候页面已经进入白屏,之后还需要经过加载并执行 JavaScript、请求后端服务器获取数据、JavaScript 渲染页面几个过程才可以看到最后的页面。特别是在复杂应用中,由于需要加载 JavaScript 脚本,越是复杂的应用,需要加载的 JavaScript 脚本就越多、越大,这会导致应用的首屏加载时间非常长,进而降低了体验感。
并不是所有的WEB应用都必须使用SSR,这需要开发者自己来权衡,因为服务端渲染会带来以下问题:
所以在使用服务端渲染SSR之前,需要开发者考虑投入产出比,比如大部分应用系统都不需要SEO,而且首屏时间并没有非常的慢,如果使用SSR反而小题大做了。
知道了服务器渲染的利弊后,假如我们需要在项目中使用服务端渲染,我们需要做什么呢?那就是同构我们的项目。
在服务端渲染中,有两种页面渲染的方式:
这两种渲染方式有一个不同点就是,一个是在服务端中组装html的,一个是在客户端中组装html的,运行环境是不一样的。所谓同构,就是让一份代码,既可以在服务端中执行,也可以在客户端中执行,并且执行的效果都是一样的,都是完成这个html的组装,正确的显示页面。也就是说,一份代码,既可以客户端渲染,也可以服务端渲染。
为了实现同构,我们需要满足什么条件呢?首先,我们思考一个应用中一个页面的组成,假如我们使用的是Vue.js,当我们打开一个页面时,首先是打开这个页面的URL,这个URL,可以通过应用的路由匹配,找到具体的页面,不同的页面有不同的视图,那么,视图是什么?从应用的角度来看,视图 = 模板 + 数据,那么在 Vue.js 中, 模板可以理解成组件,数据可以理解为数据模型,即响应式数据。所以,对于同构应用来说,我们必须实现客户端与服务端的路由、模型组件、数据模型的共享。
知道了服务端渲染、同构的原理之后,下面从头开始,一步一步完成一次同构,通过实践来了解SSR。
首先,模拟一个最简单的服务器渲染,只需要向页面返回我们需要的html文件。
const express = require('express');
const app = express();
app.get('/', function(req, res) {
res.send(`
<html>
<head>
<title>SSR</title>
</head>
<body>
<p>hello world</p>
</body>
</html>
`);
});
app.listen(3001, function() {
console.log('listen:3001');
});启动之后打开localhost:3001可以看到页面显示了hello world。而且打开网页源代码:
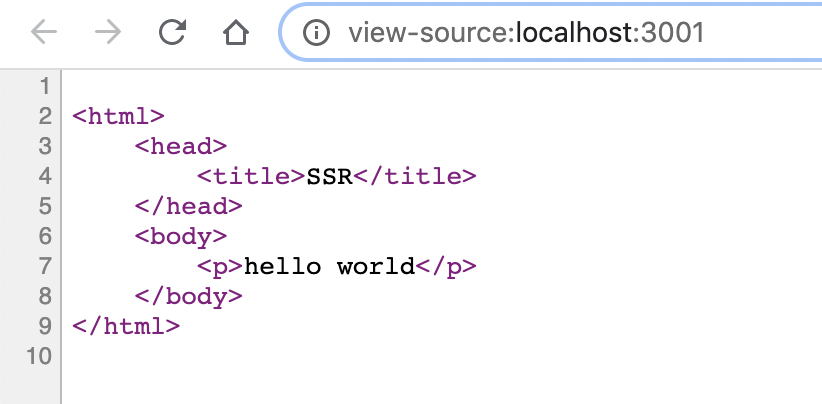
也就是说,当浏览器拿到服务器返回的这一段HTML源代码的时候,不需要加载任何JavaScript脚本,就可以直接将hello world显示出来。
我们用 vue-cli新建一个vue项目,修改一个App.vue组件:
<template>
<div>
<p>hello world</p>
<button @click="sayHello">say hello</button>
</div>
</template>
<script>
export default {
methods: {
sayHello() {
alert('hello ssr');
}
}
}
</script>然后运行npm run serve启动项目,打开浏览器,一样可以看到页面显示了 hello world,但是打开我们开网页源代码:
除了简单的兼容性处理 noscript 标签以外,只有一个简单的id为app的div标签,没有关于hello world的任何字眼,可以说这是一个空的页面(白屏),而当加载了下面的 script 标签的 JavaScript 脚本之后,页面开始这行这些脚本,执行结束,hello world 正常显示。也就是说真正渲染 hello world 的是 JavaScript 脚本。
模板组件的共享,其实就是使用同一套组件代码,为了实现 Vue 组件可以在服务端中运行,首先我们需要解决代码编译问题。一般情况,vue项目使用的是webpack进行代码构建,同样,服务端代码的构建,也可以使用webpack,借用官方的一张。
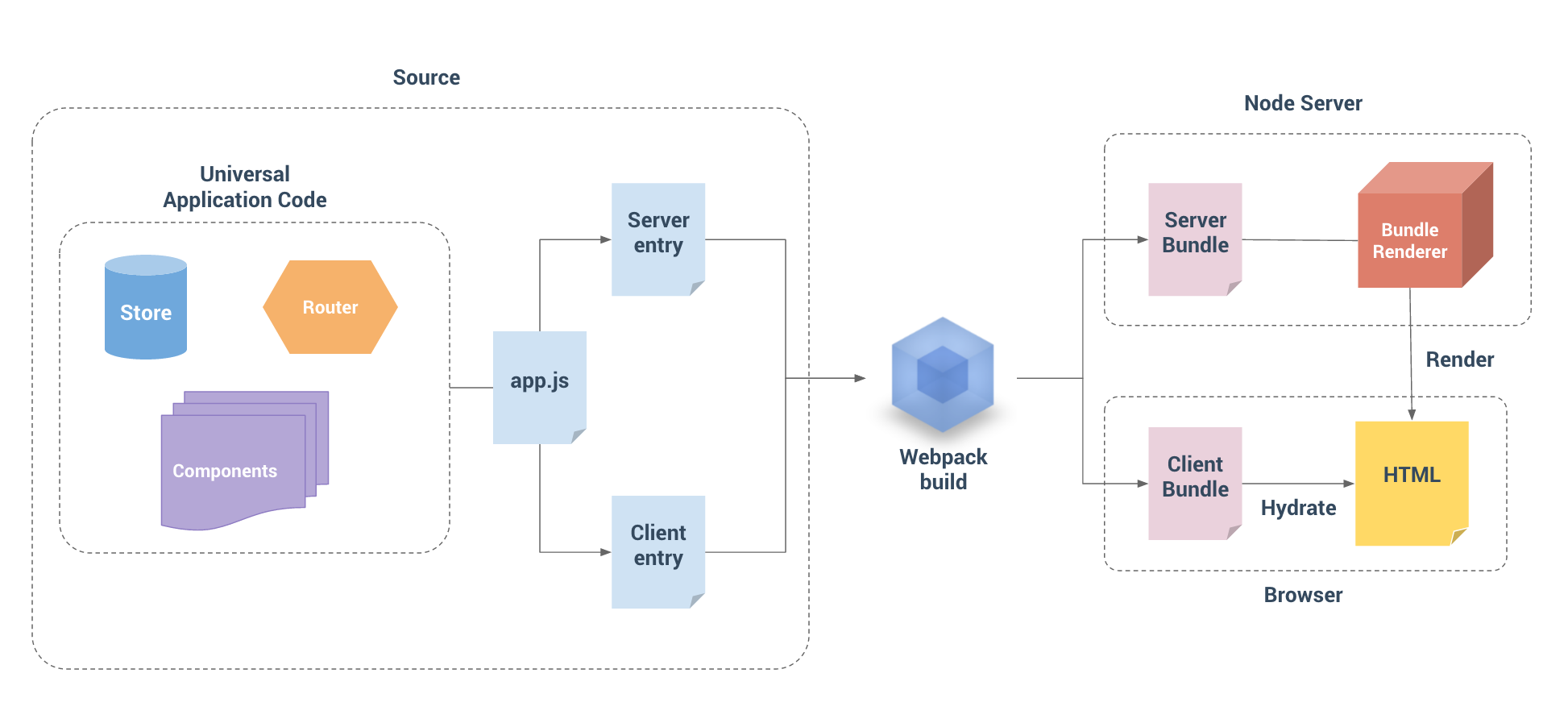
由前面的图可以看到,在服务端代码构建结束后,需要将构建结果运行在nodejs服务器上,但是,对于服务端代码的构建,有一下内容需要注意:
于是,我们得到一个服务端的 webpack 构建配置文件 vue.server.config.js
const nodeExternals = require("webpack-node-externals");
const VueSSRServerPlugin = require('vue-server-renderer/server-plugin')
module.exports = {
css: {
extract: false // 不提取 CSS
},
configureWebpack: () => ({
entry: `./src/server-entry.js`, // 服务器入口文件
devtool: 'source-map',
target: 'node', // 构建目标为nodejs环境
output: {
libraryTarget: 'commonjs2' // 构建目标加载模式 commonjs
},
// 跳过 node_mdoules,运行时会自动加载,不需要编译
externals: nodeExternals({
allowlist: [/\.css$/] // 允许css文件,方便css module
}),
optimization: {
splitChunks: false // 关闭代码切割
},
plugins: [
new VueSSRServerPlugin()
]
})
};使用 vue-server-renderer提供的server-plugin,这个插件主要配合下面讲到的client-plugin使用,作用主要是用来实现nodejs在开发过程中的热加载、source-map、生成html文件。
在构建客户端代码时,使用的是客户端的执行入口文件,构建结束后,将构建结果在浏览器运行即可,但是在服务端渲染中,HTML是由服务端渲染的,也就是说,我们要加载那些JavaScript脚本,是服务端决定的,因为HTML中的script标签是由服务端拼接的,所以在客户端代码构建的时候,我们需要使用插件,生成一个构建结果清单,这个清单是用来告诉服务端,当前页面需要加载哪些JS脚本和CSS样式表。
于是我们得到了客户端的构建配置,vue.client.config.js
const VueSSRClientPlugin = require('vue-server-renderer/client-plugin')
module.exports = {
configureWebpack: () => ({
entry: `./src/client-entry.js`,
devtool: 'source-map',
target: 'web',
plugins: [
new VueSSRClientPlugin()
]
}),
chainWebpack: config => {
// 去除所有关于客户端生成的html配置,因为已经交给后端生成
config.plugins.delete('html');
config.plugins.delete('preload');
config.plugins.delete('prefetch');
}
};使用vue-server-renderer提供的client-server,主要作用是生成构建加过清单vue-ssr-client-manifest.json,服务端在渲染页面时,根据这个清单来渲染HTML中的script标签(JavaScript)和link标签(CSS)。
接下来,我们需要将vue.client.config.js和vue.server.config.js都交给vue-cli内置的构建配置文件vue.config.js,根据环境变量使用不同的配置
// vue.config.js
const TARGET_NODE = process.env.WEBPACK_TARGET === 'node';
const serverConfig = require('./vue.server.config');
const clientConfig = require('./vue.client.config');
if (TARGET_NODE) {
module.exports = serverConfig;
} else {
module.exports = clientConfig;
}使用cross-env区分环境
{
"scripts": {
"server": "babel-node src/server.js",
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"build:server": "cross-env WEBPACK_TARGET=node vue-cli-service build --mode server"
}
}为了实现模板组件共享,我们需要将获取 Vue 渲染实例写成通用代码,如下 createApp:
import Vue from 'vue';
import App from './App';
export default function createApp (context) {
const app = new Vue({
render: h => h(App)
});
return {
app
};
};新建客户端项目的入口文件,client-entry.js
import Vue from 'vue'
import createApp from './createApp';
const {app} = createApp();
app.$mount('#app');client-entry.js是浏览器渲染的入口文件,在浏览器加载了客户端编译后的代码后,组件会被渲染到id为app的元素节点上。
新建服务端代码的入口文件,server-entry.js
import createApp from './createApp'
export default context => {
const { app } = createApp(context);
return app;
}server-entry.js是提供给服务器渲染vue组件的入口文件,在浏览器通过URL访问到服务器后,服务器需要使用server-entry.js提供的函数,将组件渲染成html。
所有东西的准备好之后,我们需要修改nodejs的HTTP服务器的启动文件。首先,加载服务端代码server-entry.js的webpack构建结果
const path = require('path');
const serverBundle = path.resolve(process.cwd(), 'serverDist', 'vue-ssr-server-bundle.json');
const {createBundleRenderer} = require('vue-server-renderer');
const serverBundle = path.resolve(process.cwd(), 'serverDist', 'vue-ssr-server-bundle.json');加载客户端代码client-entry.js的webpack构建结果
const clientManifestPath = path.resolve(process.cwd(), 'dist', 'vue-ssr-client-manifest.json');
const clientManifest = require(clientManifestPath);使用 vue-server-renderer 的createBundleRenderer创建一个html渲染器:
const template = fs.readFileSync(path.resolve(__dirname, 'index.html'), 'utf-8');
const renderer = createBundleRenderer(serverBundle, {
template, // 使用HTML模板
clientManifest // 将客户端的构建结果清单传入
});创建HTML模板,index.html
<html>
<head>
<title>SSR</title>
</head>
<body>
<!--vue-ssr-outlet-->
</body>
</html>在HTML模板中,通过传入的客户端渲染结果clientManifest,将自动注入所有link样式表标签,而占位符将会被替换成模板组件被渲染后的具体的HTML片段和script脚本标签。
HTML准备完成后,我们在server中挂起所有路由请求
const express = require('express');
const app = express();
/* code todo 实例化渲染器renderer */
app.get('*', function(req, res) {
renderer.renderToString({}, (err, html) => {
if (err) {
res.send('500 server error');
return;
}
res.send(html);
})
});接下来,我们构建客户端、服务端项目,然后执行 node server.js,打开页面源代码,

看起来是符合预期的,但是发现控制台有报错,加载不到客户端构建css和js,报404,原因很明确,我们没有把客户端的构建结果文件挂载到服务器的静态资源目录,在挂载路由前加入下面代码:
app.use(express.static(path.resolve(process.cwd(), 'dist')));看起来大功告成,点击say hello也弹出了消息,细心的同学会发现根节点有一个data-server-rendered属性,这个属性有什么作用呢?
由于服务器已经渲染好了 HTML,我们显然无需将其丢弃再重新创建所有的 DOM 元素。相反,我们需要"激活"这些静态的 HTML,然后使他们成为动态的(能够响应后续的数据变化)。
如果检查服务器渲染的输出结果,应用程序的根元素上添加了一个特殊的属性:
<div id="app" data-server-rendered="true">data-server-rendered是特殊属性,让客户端 Vue 知道这部分 HTML 是由 Vue 在服务端渲染的,并且应该以激活模式进行挂载。
完成了模板组件的共享之后,下面完成路由的共享,我们前面服务器使用的路由是*,接受任意URL,这允许所有URL请求交给Vue路由处理,进而完成客户端路由与服务端路由的复用。
为了实现复用,与createApp一样,我们创建一个createRouter.js
import Vue from 'vue';
import Router from 'vue-router';
import Home from './views/Home';
import About from './views/About';
Vue.use(Router)
const routes = [{
path: '/',
name: 'Home',
component: Home
}, {
path: '/about',
name: 'About',
component: About
}];
export default function createRouter() {
return new Router({
mode: 'history',
routes
})
}在createApp.js中创建router
import Vue from 'vue';
import App from './App';
import createRouter from './createRouter';
export default function createApp(context) {
const router = createRouter(); // 创建 router 实例
const app = new Vue({
router, // 注入 router 到根 Vue 实例
render: h => h(App)
});
return { router, app };
};router准备好了之后,修改server-entry.js,将请求的URL传递给router,使得在创建app的时候可以根据URL匹配到对应的路由,进而可知道需要渲染哪些组件
import createApp from './createApp';
export default context => {
// 因为有可能会是异步路由钩子函数或组件,所以我们将返回一个 Promise,
// 以便服务器能够等待所有的内容在渲染前就已经准备就绪。
return new Promise((resolve, reject) => {
const { app, router } = createApp();
// 设置服务器端 router 的位置
router.push(context.url)
// onReady 等到 router 将可能的异步组件和钩子函数解析完
router.onReady(() => {
const matchedComponents = router.getMatchedComponents();
// 匹配不到的路由,执行 reject 函数,并返回 404
if (!matchedComponents.length) {
return reject({
code: 404
});
}
// Promise 应该 resolve 应用程序实例,以便它可以渲染
resolve(app)
}, reject)
})
}修改server.js的路由,把url传递给renderer
app.get('*', function(req, res) {
const context = {
url: req.url
};
renderer.renderToString(context, (err, html) => {
if (err) {
console.log(err);
res.send('500 server error');
return;
}
res.send(html);
})
});为了测试,我们将App.vue修改为router-view
<template>
<div id="app">
<router-link to="/">Home</router-link>
<router-link to="/about">About</router-link>
<router-view />
</div>
</template>Home.vue
<template>
<div>Home Page</div>
</template>About.vue
<template>
<div>About Page</div>
</template>编译,运行,查看源代码

点击路由并没有刷新页面,而是客户端路由跳转的,一切符合预期。
前面我们简单的实现了服务端渲染,但是实际情况下,我们在访问页面的时候,还需要获取需要渲染的数据,并且渲染成HTML,也就是说,在渲染HTML之前,我们需要将所有数据都准备好,然后传递给renderer。
一般情况下,在Vue中,我们将状态数据交给Vuex进行管理,当然,状态也可以保存在组件内部,只不过需要组件实例化的时候自己去同步数据。
首先第一步,与createApp类似,创建一个createStore.js,用来实例化store,同时提供给客户端和服务端使用
import Vue from 'vue';
import Vuex from 'vuex';
import {fetchItem} from './api';
Vue.use(Vuex);
export default function createStore() {
return new Vuex.Store({
state: {
item: {}
},
actions: {
fetchItem({ commit }, id) {
return fetchItem(id).then(item => {
commit('setItem', item);
})
}
},
mutations: {
setItem(state, item) {
Vue.set(state.item, item);
}
}
})
}actions封装了请求数据的函数,mutations用来设置状态。
将createStore加入到createApp中,并将store注入到vue实例中,让所有Vue组件可以获取到store实例
export default function createApp(context) {
const router = createRouter();
const store = createStore();
const app = new Vue({
router,
store, // 注入 store 到根 Vue 实例
render: h => h(App)
});
return { router, store, app };
};为了方便测试,我们mock一个远程服务函数fetchItem,用于查询对应item
export function fetchItem(id) {
const items = [
{ name: 'item1', id: 1 },
{ name: 'item2', id: 2 },
{ name: 'item3', id: 3 }
];
const item = items.find(i => i.id == id);
return Promise.resolve(item);
}一般情况下,我们需要通过访问路由,来决定获取哪部分数据,这也决定了哪些组件需要渲染。事实上,给定路由所需的数据,也是在该路由上渲染组件时所需的数据。所以,我们需要在路由的组件中放置数据预取逻辑函数。
在Home组件中自定义一个静态函数asyncData,需要注意的是,由于此函数会在组件实例化之前调用,所以它无法访问 this。需要将 store 和路由信息作为参数传递进去
<template>
<div>
<div>id: {{item.id}}</div>
<div>name: {{item.name}}</div>
</div>
</template>
<script>
export default {
asyncData({ store, route }) {
// 触发 action 后,会返回 Promise
return store.dispatch('fetchItems', route.params.id)
},
computed: {
// 从 store 的 state 对象中的获取 item。
item() {
return this.$store.state.item;
}
}
}
</script>在服务器的入口文件server-entry.js中,我们通过URL路由匹配 router.getMatchedComponents()得到了需要渲染的组件,这个时候我们可以调用组件内部的asyncData方法,将所需要的所有数据都获取完后,传递给渲染器renderer上下文。
修改createApp,在路由组件匹配到了之后,调用asyncData方法,获取数据后传递给renderer
import createApp from './createApp';
export default context => {
// 因为有可能会是异步路由钩子函数或组件,所以我们将返回一个 Promise,
// 以便服务器能够等待所有的内容在渲染前就已经准备就绪。
return new Promise((resolve, reject) => {
const { app, router, store } = createApp();
// 设置服务器端 router 的位置
router.push(context.url)
// onReady 等到 router 将可能的异步组件和钩子函数解析完
router.onReady(() => {
const matchedComponents = router.getMatchedComponents();
// 匹配不到的路由,执行 reject 函数,并返回 404
if (!matchedComponents.length) {
return reject({ code: 404 })
}
// 对所有匹配的路由组件调用 `asyncData()`
Promise.all(matchedComponents.map(Component => {
if (Component.asyncData) {
return Component.asyncData({
store,
route: router.currentRoute
});
}
})).then(() => {
// 状态传递给renderer的上下文,方便后面客户端激活数据
context.state = store.state
resolve(app)
}).catch(reject);
}, reject);
})
}将state存入context后,在服务端渲染HTML时候,也就是渲染template的时候,context.state会被序列化到window.__INITIAL_STATE__中,方便客户端激活数据。
服务端预请求数据之后,通过将数据注入到组件中,渲染组件并转化成HTML,然后吐给客户端,那么客户端为了激活后端返回的HTML被解析后的DOM节点,需要将后端渲染组件时用的store的state也同步到浏览器的store中,保证在页面渲染的时候保持与服务器渲染时的数据是一致的,才能完成DOM的激活,也就是我们前面说到的data-server-rendered标记。
在服务端的渲染中,state已经被序列化到了window.__INITIAL_STATE__,比如我们访问http://localhost:3001?id=1,查看页面源代码

可以看到,状态已经被序列化到window.__INITIAL_STATE__中,我们需要做的就是将这个window.__INITIAL_STATE__在客户端渲染之前,同步到客户端的store中,下面修改client-entry.js
const { app, router, store } = createApp();
if (window.__INITIAL_STATE__) {
// 激活状态数据
store.replaceState(window.__INITIAL_STATE__);
}
router.onReady(() => {
app.$mount('#app', true);
});通过使用store的replaceState函数,将window.__INITIAL_STATE__同步到store内部,完成数据模型的状态同步。
当浏览器访问服务端渲染项目时,服务端将URL传给到预选构建好的VUE应用渲染器,渲染器匹配到对应的路由的组件之后,执行我们预先在组件内定义的asyncData方法获取数据,并将获取完的数据传递给渲染器的上下文,利用template组装成HTML,并将HTML和状态state一并吐给前端浏览器,浏览器加载了构建好的客户端VUE应用后,将state数据同步到前端的store中,并根据数据激活后端返回的被浏览器解析为DOM元素的HTML文本,完成了数据状态、路由、组件的同步,同时使得页面得到直出,较少了白屏时间,有了更好的加载体验,同时更有利于SEO。
个人觉得了解服务端渲染,有助于提升前端工程师的综合能力,因为它的内容除了前端框架,还有前端构建和后端内容,是一个性价比还挺高的知识,不学白不学,加油!
你好,你是从哪里得到的启发写出本文章的?
今年OKR定了一条KR是每一个季度进行一次前端相关技术的分享,还有十几天就到2020年了,一直忙于业务开发,没有时间准备和学习高端话题,迫于无奈,那就讲讲平时使用频率较高,却没有真正认真的了解其内部原理的 Vue.js 吧。
由于本文为一次前端技术分享的演讲稿,所以尽力不贴 Vue.js 的源码,因为贴代码在实际分享中,比较枯燥,效果不佳,而更多的是以图片和文字的形式进行表达。
分享目标:
Vue 是一套用于构建用户界面的渐进式MVVM框架。那怎么理解渐进式呢?渐进式含义:强制主张最少。
Vue.js包含了声明式渲染、组件化系统、客户端路由、大规模状态管理、构建工具、数据持久化、跨平台支持等,但在实际开发中,并没有强制要求开发者之后某一特定功能,而是根据需求逐渐扩展。
Vue.js的核心库只关心视图渲染,且由于渐进式的特性,Vue.js便于与第三方库或既有项目整合。
定义:组件就是对一个功能和样式进行独立的封装,让HTML元素得到扩展,从而使得代码得到复用,使得开发灵活,更加高效。
与HTML元素一样,Vue.js的组件拥有外部传入的属性(prop)和事件,除此之外,组件还拥有自己的状态(data)和通过数据和状态计算出来的计算属性(computed),各个维度组合起来决定组件最终呈现的样子与交互的逻辑。
每一个组件之间的作用域是孤立的,这个意味着组件之间的数据不应该出现引用关系,即使出现了引用关系,也不允许组件操作组件内部以外的其他数据。Vue中,允许向组件内部传递prop数据,组件内部需要显性地声明该prop字段,如下声明一个child组件:
<!-- child.vue -->
<template>
<div>{{msg}}</div>
</template>
<script>
export default {
props: {
msg: {
type: String,
default: 'hello world' // 当default为引用类型时,需要使用 function 形式返回
}
}
}
</script>父组件向该组件传递数据:
<!-- parent.vue -->
<template>
<child :msg="parentMsg"></child>
</template>
<script>
import child from './child';
export default {
components: {
child
},
data () {
return {
parentMsg: 'some words'
}
}
}
</script>Vue内部实现了一个事件总线系统,即EventBus。在Vue中可以使用 EventBus 来作为沟通桥梁的概念,每一个Vue的组件实例都继承了 EventBus,都可以接受事件$on和发送事件$emit。
如上面一个例子,child.vue 组件想修改 parent.vue 组件的 parentMsg 数据,怎么办呢?为了保证数据流的可追溯性,直接修改组件内 prop 的 msg 字段是不提倡的,且例子中为非引用类型 String,直接修改也修改不了,这个时候需要将修改 parentMsg 的事件传递给 child.vue,让 child.vue 来触发修改 parentMsg 的事件。如:
<!-- child.vue -->
<template>
<div>{{msg}}</div>
</template>
<script>
export default {
props: {
msg: {
type: String,
default: 'hello world'
}
},
methods: {
changeMsg(newMsg) {
this.$emit('updateMsg', newMsg);
}
}
}
</script>父组件:
<!-- parent.vue -->
<template>
<child :msg="parentMsg" @updateMsg="changeParentMsg"></child>
</template>
<script>
import child from './child';
export default {
components: {
child
},
data () {
return {
parentMsg: 'some words'
}
},
methods: {
changeParentMsg: function (newMsg) {
this.parentMsg = newMsg
}
}
}
</script>父组件 parent.vue 向子组件 child.vue 传递了 updateMsg 事件,在子组件实例化的时候,子组件将 updateMsg 事件使用$on函数注册到组件内部,需要触发事件的时候,调用函数this.$emit来触发事件。
除了父子组件之间的事件传递,还可以使用一个 Vue 实例为多层级的父子组件建立数据通信的桥梁,如:
const eventBus = new Vue();
// 父组件中使用$on监听事件
eventBus.$on('eventName', val => {
// ...do something
})
// 子组件使用$emit触发事件
eventBus.$emit('eventName', 'this is a message.');除了$on和$emit以外,事件总线系统还提供了另外两个方法,$once和$off,所有事件如下:
Vue实现了一套遵循 Web Components 规范草案 的内容分发系统,即将<slot>元素作为承载分发内容的出口。
插槽slot,也是组件的一块HTML模板,这一块模板显示不显示、以及怎样显示由父组件来决定。实际上,一个slot最核心的两个问题在这里就点出来了,是显示不显示和怎样显示。
插槽又分默认插槽、具名插槽。
又名单个插槽、匿名插槽,与具名插槽相对,这类插槽没有具体名字,一个组件只能有一个该类插槽。
如:
<template>
<!-- 父组件 parent.vue -->
<div class="parent">
<h1>父容器</h1>
<child>
<div class="tmpl">
<span>菜单1</span>
</div>
</child>
</div>
</template><template>
<!-- 子组件 child.vue -->
<div class="child">
<h1>子组件</h1>
<slot></slot>
</div>
</template>如上,渲染时子组件的slot标签会被父组件传入的div.tmpl替换。
匿名插槽没有name属性,所以叫匿名插槽。那么,插槽加了name属性,就变成了具名插槽。具名插槽可以在一个组件中出现N次,出现在不同的位置,只需要使用不同的name属性区分即可。
如:
<template>
<!-- 父组件 parent.vue -->
<div class="parent">
<h1>父容器</h1>
<child>
<div class="tmpl" slot="up">
<span>菜单up-1</span>
</div>
<div class="tmpl" slot="down">
<span>菜单down-1</span>
</div>
<div class="tmpl">
<span>菜单->1</span>
</div>
</child>
</div>
</template><template>
<div class="child">
<!-- 具名插槽 -->
<slot name="up"></slot>
<h3>这里是子组件</h3>
<!-- 具名插槽 -->
<slot name="down"></slot>
<!-- 匿名插槽 -->
<slot></slot>
</div>
</template>如上,slot 标签会根据父容器给 child 标签内传入的内容的 slot 属性值,替换对应的内容。
其实,默认插槽也有 name 属性值,为default,同样指定 slot 的 name 值为 default,一样可以显示父组件中传入的没有指定slot的内容。
作用域插槽可以是默认插槽,也可以是具名插槽,不一样的地方是,作用域插槽可以为 slot 标签绑定数据,让其父组件可以获取到子组件的数据。
如:
<template>
<!-- parent.vue -->
<div class="parent">
<h1>这是父组件</h1>
<current-user>
<template slot="default" slot-scope="slotProps">
{{ slotProps.user.name }}
</template>
</current-user>
</div>
</template><template>
<!-- child.vue -->
<div class="child">
<h1>这是子组件</h1>
<slot :user="user"></slot>
</div>
</template>
<script>
export default {
data() {
return {
user: {
name: '小赵'
}
}
}
}
</script>如上例子,子组件 child 在渲染默认插槽 slot 的时候,将数据 user 传递给了 slot 标签,在渲染过程中,父组件可以通过slot-scope属性获取到 user 数据并渲染视图。
slot 实现原理:当子组件vm实例化时,获取到父组件传入的 slot 标签的内容,存放在vm.$slot中,默认插槽为vm.$slot.default,具名插槽为vm.$slot.xxx,xxx 为 插槽名,当组件执行渲染函数时候,遇到<slot>标签,使用$slot中的内容进行替换,此时可以为插槽传递数据,若存在数据,则可曾该插槽为作用域插槽。
至此,父子组件的关系如下图:
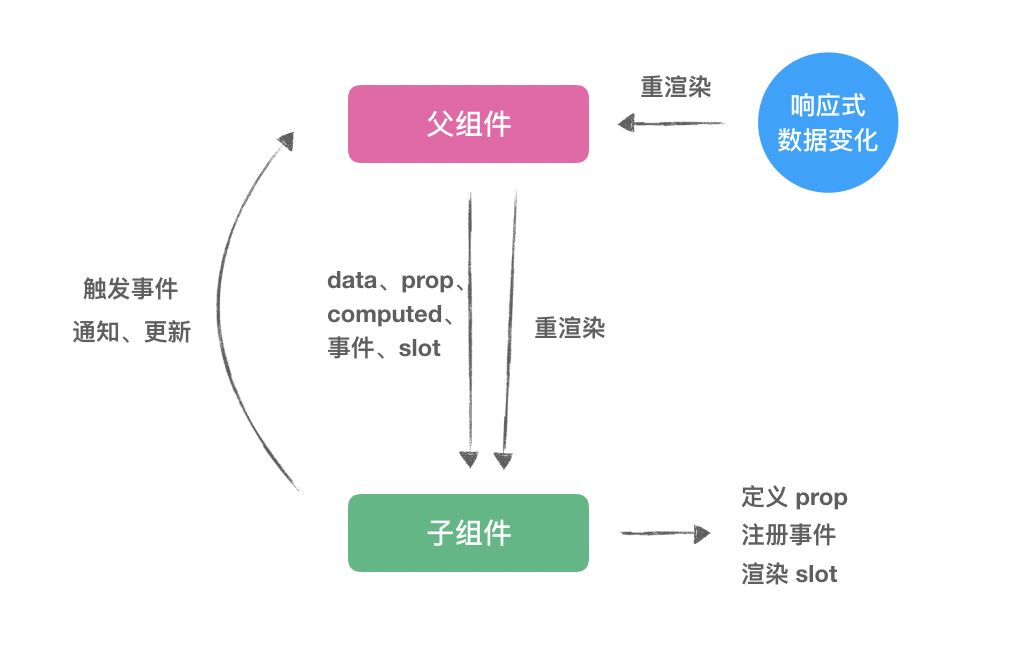
Vue.js 的核心是声明式渲染,与命令式渲染不同,声明式渲染只需要告诉程序,我们想要的什么效果,其他的事情让程序自己去做。而命令式渲染,需要命令程序一步一步根据命令执行渲染。如下例子区分:
var arr = [1, 2, 3, 4, 5];
// 命令式渲染,关心每一步、关心流程。用命令去实现
var newArr = [];
for (var i = 0; i < arr.length; i++) {
newArr.push(arr[i] * 2);
}
// 声明式渲染,不用关心中间流程,只需要关心结果和实现的条件
var newArr1 = arr.map(function (item) {
return item * 2;
});Vue.js 实现了if、for、事件、数据绑定等指令,允许采用简洁的模板语法来声明式地将数据渲染出视图。
为什么要进行模板编译?实际上,我们组件中的 template 语法是无法被浏览器解析的,因为它不是正确的 HTML 语法,而模板编译,就是将组件的 template 编译成可执行的 JavaScript 代码,即将 template 转化为真正的渲染函数。
模板编译分三个阶段,parse、optimize、generate,最终生成render函数。
parse阶段:使用正在表达式将template进行字符串解析,得到指令、class、style等数据,生成抽象语法树 AST。
optimize阶段:寻找 AST 中的静态节点进行标记,为后面 VNode 的 patch 过程中对比做优化。被标记为 static 的节点在后面的 diff 算法中会被直接忽略,不做详细的比较。
generate阶段:根据 AST 结构拼接生成 render 函数的字符串。
对于 Vue 组件来说,模板编译只会在组件实例化的时候编译一次,生成渲染函数之后在也不会进行编译。因此,编译对组件的 runtime 是一种性能损耗。而模板编译的目的仅仅是将template转化为render function,而这个过程,正好可以在项目构建的过程中完成。
比如webpack的vue-loader依赖了vue-template-compiler模块,在 webpack 构建过程中,将template预编译成 render 函数,在 runtime 可直接跳过模板编译过程。
回过头看,runtime 需要是仅仅是 render 函数,而我们有了预编译之后,我们只需要保证构建过程中生成 render 函数就可以。与 React 类似,在添加JSX的语法糖编译器babel-plugin-transform-vue-jsx之后,我们可以在 Vue 组件中使用JSX语法直接书写 render 函数。
<script>
export default {
data() {
return {
msg: 'Hello JSX.'
}
},
render() {
const msg = this.msg;
return <div>
{msg}
</div>;
}
}
</script>如上面组件,使用 JSX 之后,可以在 JS 代码中直接使用 html 标签,而且声明了 render 函数以后,我们不再需要声明 template。当然,假如我们同时声明了 template 标签和 render 函数,构建过程中,template 编译的结果将覆盖原有的 render 函数,即 template 的优先级高于直接书写的 render 函数。
相对于 template 而言,JSX 具有更高的灵活性,面对与一些复杂的组件来说,JSX 有着天然的优势,而 template 虽然显得有些呆滞,但是代码结构上更符合视图与逻辑分离的习惯,更简单、更直观、更好维护。
需要注意的是,最后生成的 render 函数是被包裹在with语法中运行的。
Vue 组件通过 prop 进行数据传递,并实现了数据总线系统EventBus,组件集成了EventBus进行事件注册监听、事件触发,使用slot进行内容分发。
除此以外,实现了一套声明式模板系统,在runtime或者预编译是对模板进行编译,生成渲染函数,供组件渲染视图使用。
Vue.js 是一款 MVVM 的JS框架,当对数据模型data进行修改时,视图会自动得到更新,即框架帮我们完成了更新DOM的操作,而不需要我们手动的操作DOM。可以这么理解,当我们对数据进行赋值的时候,Vue 告诉了所有依赖该数据模型的组件,你依赖的数据有更新,你需要进行重渲染了,这个时候,组件就会重渲染,完成了视图的更新。
在组件中,可以为每个组件定义数据模型data、计算属性computed、监听器watch。
数据模型:Vue 实例在创建过程中,对数据模型data的每一个属性加入到响应式系统中,当数据被更改时,视图将得到响应,同步更新。data必须采用函数的方式 return,不使用 return 包裹的数据会在项目的全局可见,会造成变量污染;使用return包裹后数据中变量只在当前组件中生效,不会影响其他组件。
计算属性:computed基于组件响应式依赖进行计算得到结果并缓存起来。只在相关响应式依赖发生改变时它们才会重新求值,也就是说,只有它依赖的响应式数据(data、prop、computed本身)发生变化了才会重新计算。那什么时候应该使用计算属性呢?模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的。在模板中放入太多的逻辑会让模板过重且难以维护。对于任何复杂逻辑,你都应当使用计算属性。
监听器:监听器watch作用如其名,它可以监听响应式数据的变化,响应式数据包括 data、prop、computed,当响应式数据发生变化时,可以做出相应的处理。当需要在数据变化时执行异步或开销较大的操作时,这个方式是最有用的。
在 Vue 中,数据模型下的所有属性,会被 Vue 使用Object.defineProperty(Vue3.0 使用 Proxy)进行数据劫持代理。响应式的核心机制是观察者模式,数据是被观察的一方,一旦发生变化,通知所有观察者,这样观察者可以做出响应,比如当观察者为视图时,视图可以做出视图的更新。
Vue.js 的响应式系统以来三个重要的概念,Observer、Dep、Watcher。
Observe 扮演的角色是发布者,他的主要作用是在组件vm初始化的时,调用defineReactive函数,使用Object.defineProperty方法对对象的每一个子属性进行数据劫持/监听,即为每个属性添加getter和setter,将对应的属性值变成响应式。
在组件初始化时,调用initState函数,内部执行initState、initProps、initComputed方法,分别对data、prop、computed进行初始化,让其变成响应式。
初始化props时,对所有props进行遍历,调用defineReactive函数,将每个 prop 属性值变成响应式,然后将其挂载到_props中,然后通过代理,把vm.xxx代理到vm._props.xxx中。
同理,初始化data时,与prop相同,对所有data进行遍历,调用defineReactive函数,将每个 data 属性值变成响应式,然后将其挂载到_data中,然后通过代理,把vm.xxx代理到vm._data.xxx中。
初始化computed,首先创建一个观察者对象computed-watcher,然后遍历computed的每一个属性,对每一个属性值调用defineComputed方法,使用Object.defineProperty将其变成响应式的同时,将其代理到组件实例上,即可通过vm.xxx访问到xxx计算属性。
Dep 扮演的角色是调度中心/订阅器,在调用defineReactive将属性值变成响应式的过程中,也为每个属性值实例化了一个Dep,主要作用是对观察者(Watcher)进行管理,收集观察者和通知观察者目标更新,即当属性值数据发生改变时,会遍历观察者列表(dep.subs),通知所有的 watcher,让订阅者执行自己的update逻辑。
其dep的任务是,在属性的getter方法中,调用dep.depend()方法,将观察者(即 Watcher,可能是组件的render function,可能是 computed,也可能是属性监听 watch)保存在内部,完成其依赖收集。在属性的setter方法中,调用dep.notify()方法,通知所有观察者执行更新,完成派发更新。
Watcher 扮演的角色是订阅者/观察者,他的主要作用是为观察属性提供回调函数以及收集依赖,当被观察的值发生变化时,会接收到来自调度中心Dep的通知,从而触发回调函数。
而Watcher又分为三类,normal-watcher、 computed-watcher、 render-watcher。
normal-watcher:在组件钩子函数watch中定义,即监听的属性改变了,都会触发定义好的回调函数。
computed-watcher:在组件钩子函数computed中定义的,每一个computed属性,最后都会生成一个对应的Watcher对象,但是这类Watcher有个特点:当计算属性依赖于其他数据时,属性并不会立即重新计算,只有之后其他地方需要读取属性的时候,它才会真正计算,即具备lazy(懒计算)特性。
render-watcher:每一个组件都会有一个render-watcher, 当data/computed中的属性改变的时候,会调用该Watcher来更新组件的视图。
这三种Watcher也有固定的执行顺序,分别是:computed-render -> normal-watcher -> render-watcher。这样就能尽可能的保证,在更新组件视图的时候,computed 属性已经是最新值了,如果 render-watcher 排在 computed-render 前面,就会导致页面更新的时候 computed 值为旧数据。
Observer 负责将数据进行拦截,Watcher 负责订阅,观察数据变化, Dep 负责接收订阅并通知 Observer 和接收发布并通知所有 Watcher。
在 Vue 中,template被编译成浏览器可执行的render function,然后配合响应式系统,将render function挂载在render-watcher中,当有数据更改的时候,调度中心Dep通知该render-watcher执行render function,完成视图的渲染与更新。
整个流程看似通顺,但是当执行render function时,如果每次都全量删除并重建 DOM,这对执行性能来说,无疑是一种巨大的损耗,因为我们知道,浏览器的DOM很“昂贵”的,当我们频繁的更新 DOM,会产生一定的性能问题。
为了解决这个问题,Vue 使用 JS 对象将浏览器的 DOM 进行的抽象,这个抽象被称为 Virtual DOM。Virtual DOM 的每个节点被定义为VNode,当每次执行render function时,Vue 对更新前后的VNode进行Diff对比,找出尽可能少的我们需要更新的真实 DOM 节点,然后只更新需要更新的节点,从而解决频繁更新 DOM 产生的性能问题。
VNode,全称virtual node,即虚拟节点,对真实 DOM 节点的虚拟描述,在 Vue 的每一个组件实例中,会挂载一个$createElement函数,所有的VNode都是由这个函数创建的。
比如创建一个 div:
// 声明 render function
render: function (createElement) {
// 也可以使用 this.$createElement 创建 VNode
return createElement('div', 'hellow world');
}
// 以上 render 方法返回html片段 <div>hellow world</div>render 函数执行后,会根据VNode Tree将 VNode 映射生成真实 DOM,从而完成视图的渲染。
Diff 将新老 VNode 节点进行比对,然后将根据两者的比较结果进行最小单位地修改视图,而不是将整个视图根据新的 VNode 重绘,进而达到提升性能的目的。
Vue.js 内部的 diff 被称为patch。其 diff 算法的是通过同层的树节点进行比较,而非对树进行逐层搜索遍历的方式,所以时间复杂度只有O(n),是一种相当高效的算法。
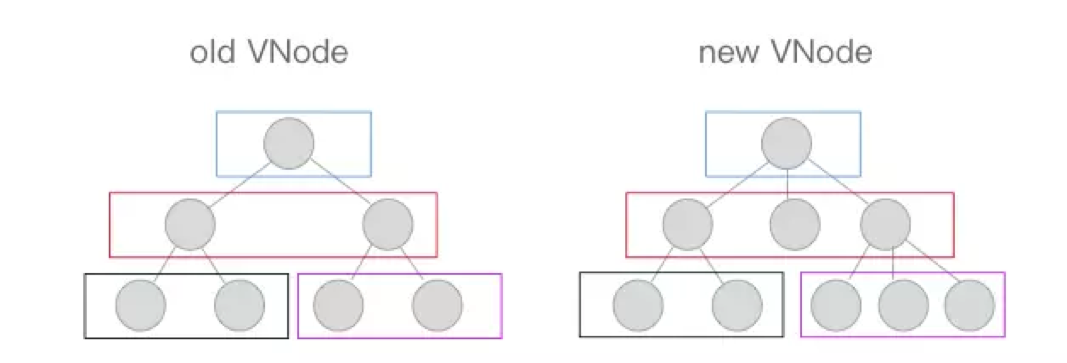
首先定义新老节点是否相同判定函数sameVnode:满足键值key和标签名tag必须一致等条件,返回true,否则false。
在进行patch之前,新老 VNode 是否满足条件sameVnode(oldVnode, newVnode),满足条件之后,进入流程patchVnode,否则被判定为不相同节点,此时会移除老节点,创建新节点。
patchVnode 的主要作用是判定如何对子节点进行更新,
如果新旧VNode都是静态的,同时它们的key相同(代表同一节点),并且新的 VNode 是 clone 或者是标记了 once(标记v-once属性,只渲染一次),那么只需要替换 DOM 以及 VNode 即可。
新老节点均有子节点,则对子节点进行 diff 操作,进行updateChildren,这个 updateChildren 也是 diff 的核心。
如果老节点没有子节点而新节点存在子节点,先清空老节点 DOM 的文本内容,然后为当前 DOM 节点加入子节点。
当新节点没有子节点而老节点有子节点的时候,则移除该 DOM 节点的所有子节点。
当新老节点都无子节点的时候,只是文本的替换。
Diff 的核心,对比新老子节点数据,判定如何对子节点进行操作,在对比过程中,由于老的子节点存在对当前真实 DOM 的引用,新的子节点只是一个 VNode 数组,所以在进行遍历的过程中,若发现需要更新真实 DOM 的地方,则会直接在老的子节点上进行真实 DOM 的操作,等到遍历结束,新老子节点则已同步结束。
updateChildren内部定义了4个变量,分别是oldStartIdx、oldEndIdx、newStartIdx、newEndIdx,分别表示正在 Diff 对比的新老子节点的左右边界点索引,在老子节点数组中,索引在oldStartIdx与oldEndIdx中间的节点,表示老子节点中为被遍历处理的节点,所以小于oldStartIdx或大于oldEndIdx的表示未被遍历处理的节点。同理,在新的子节点数组中,索引在newStartIdx与newEndIdx中间的节点,表示老子节点中为被遍历处理的节点,所以小于newStartIdx或大于newEndIdx的表示未被遍历处理的节点。
每一次遍历,oldStartIdx和oldEndIdx与newStartIdx和newEndIdx之间的距离会向中间靠拢。当 oldStartIdx > oldEndIdx 或者 newStartIdx > newEndIdx 时结束循环。
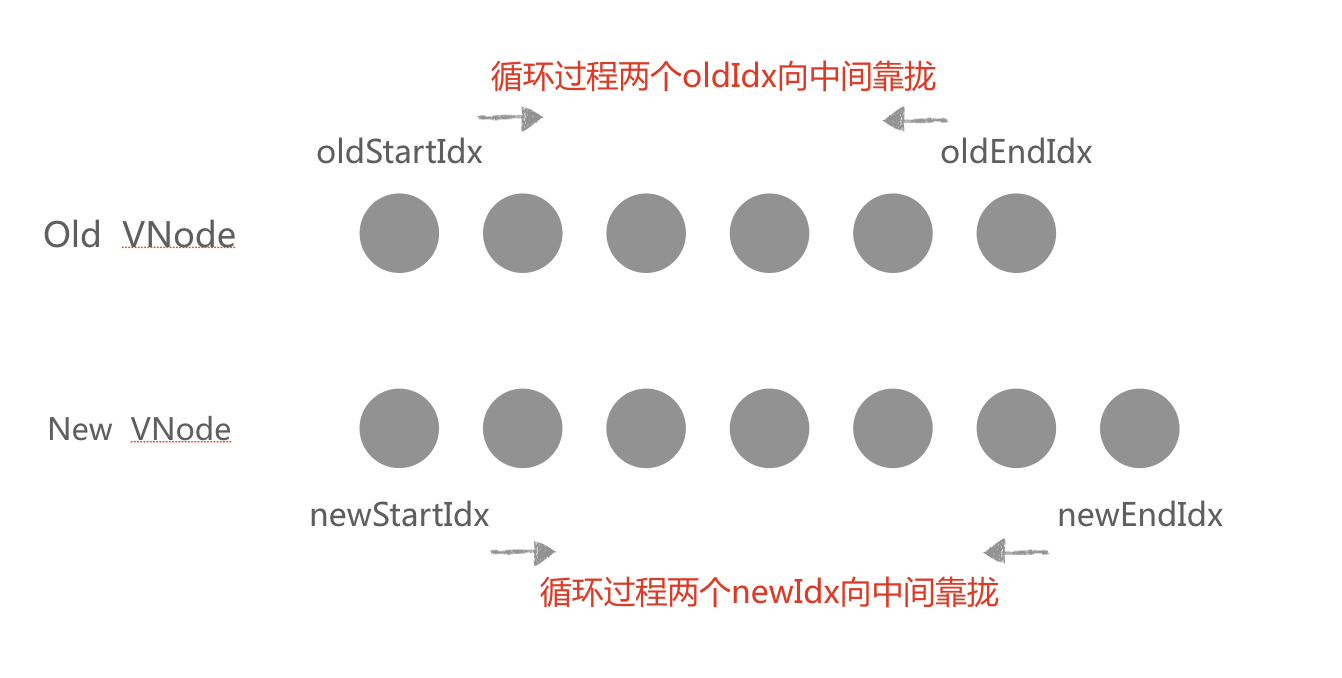
在遍历中,取出4索引对应的 Vnode节点:
diff 过程中,如果存在key,并且满足sameVnode,会将该 DOM 节点进行复用,否则则会创建一个新的 DOM 节点。
首先,oldStartVnode、oldEndVnode与newStartVnode、newEndVnode两两比较,一共有 2*2=4 种比较方法。
情况一:当oldStartVnode与newStartVnode满足 sameVnode,则oldStartVnode与newStartVnode进行 patchVnode,并且oldStartIdx与newStartIdx右移动。
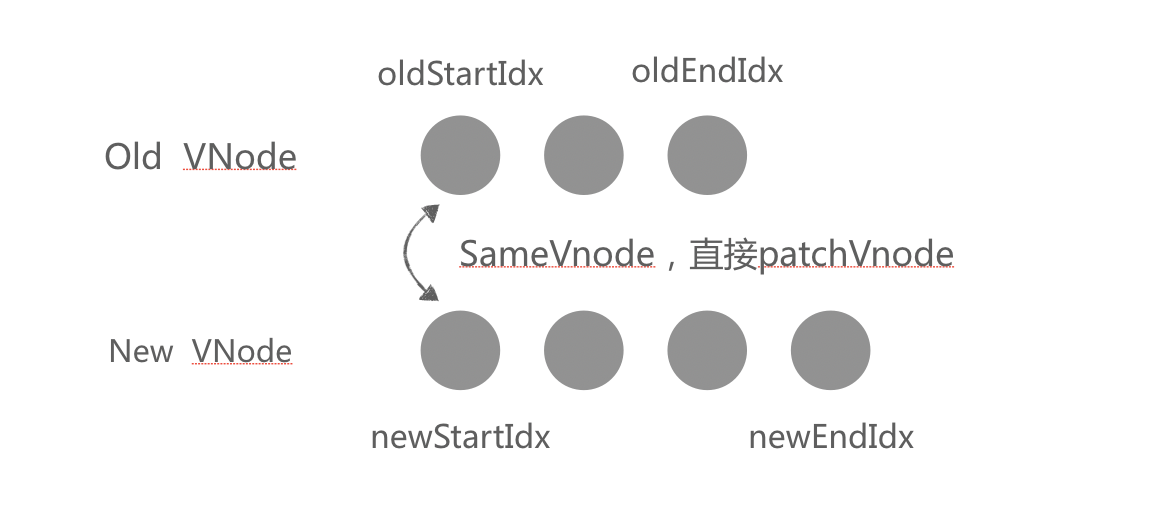
情况二:与情况一类似,当oldEndVnode与newEndVnode满足 sameVnode,则oldEndVnode与newEndVnode进行 patchVnode,并且oldEndIdx与newEndIdx左移动。
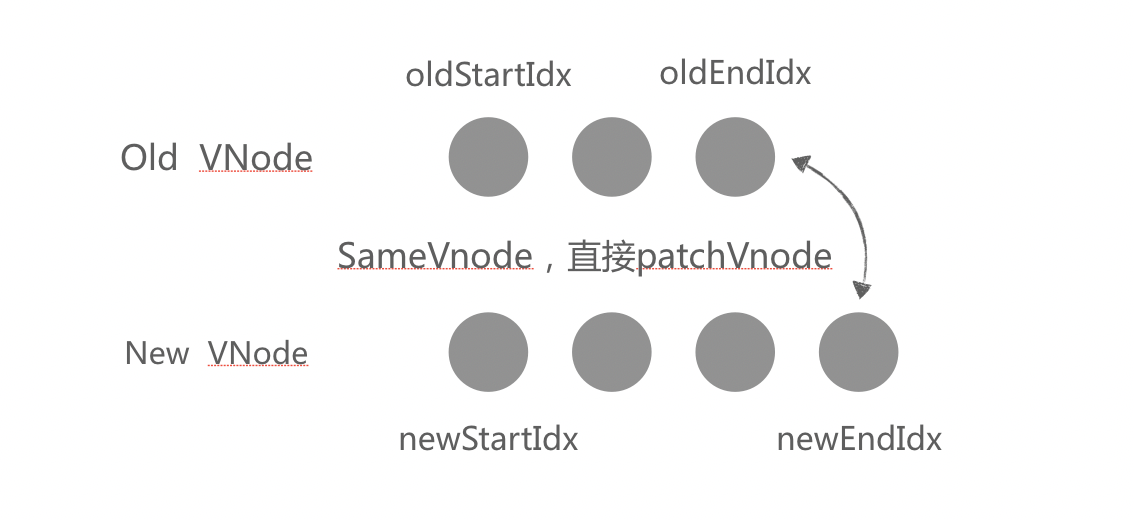
情况三:当oldStartVnode与newEndVnode满足 sameVnode,则说明oldStartVnode已经跑到了oldEndVnode后面去了,此时oldStartVnode与newEndVnode进行 patchVnode 的同时,还需要将oldStartVnode的真实 DOM 节点移动到oldEndVnode的后面,并且oldStartIdx右移,newEndIdx左移。
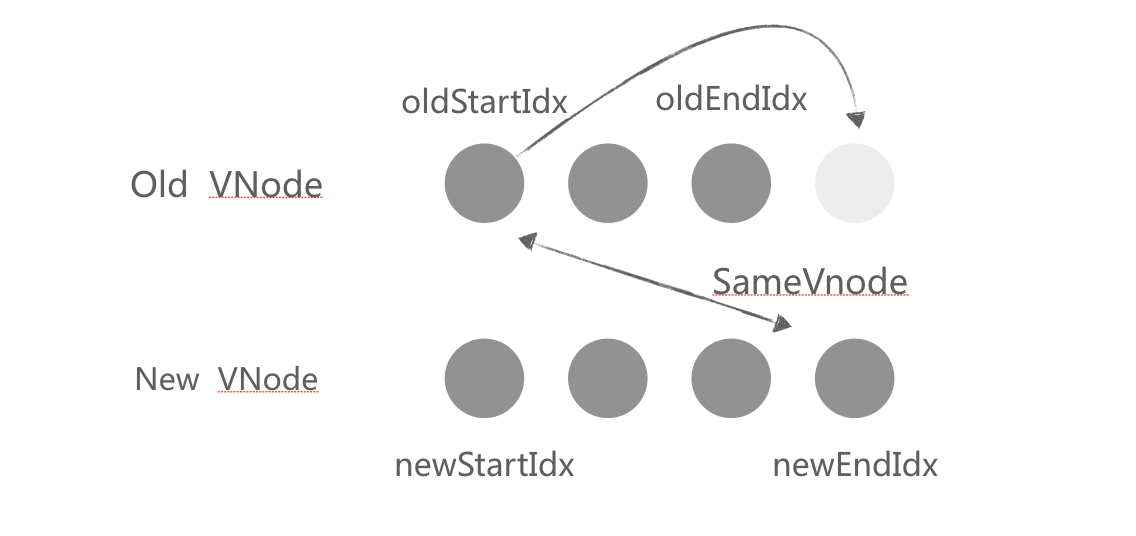
情况四:与情况三类似,当oldEndVnode与newStartVnode满足 sameVnode,则说明oldEndVnode已经跑到了oldStartVnode前面去了,此时oldEndVnode与newStartVnode进行 patchVnode 的同时,还需要将oldEndVnode的真实 DOM 节点移动到oldStartVnode的前面,并且oldStartIdx右移,newEndIdx左移。
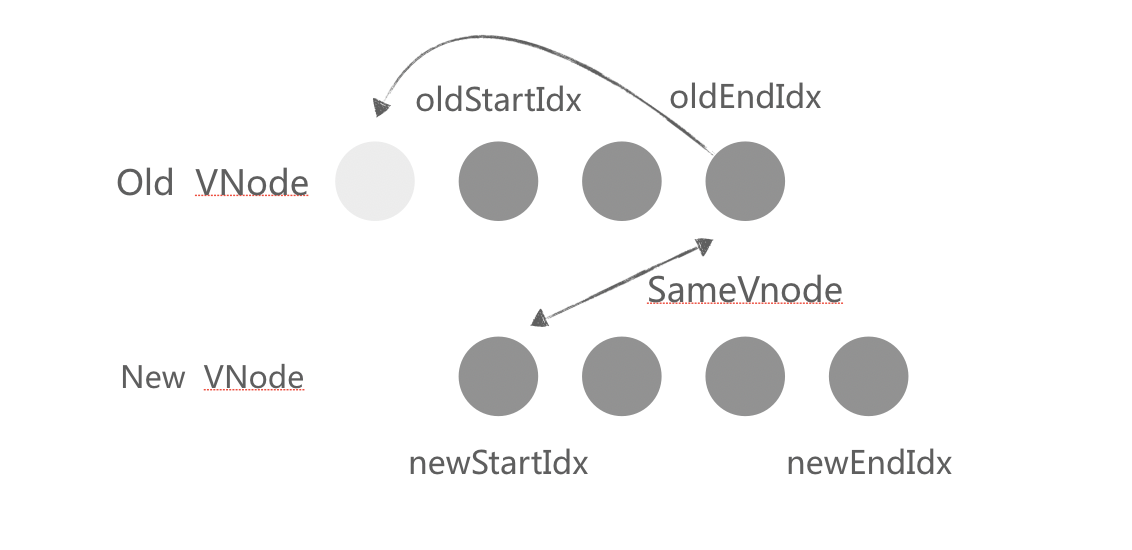
当这四种情况都不满足,则在oldStartIdx与oldEndIdx之间查找与newStartVnode满足sameVnode的节点,若存在,则将匹配的节点真实 DOM 移动到oldStartVnode的前面。
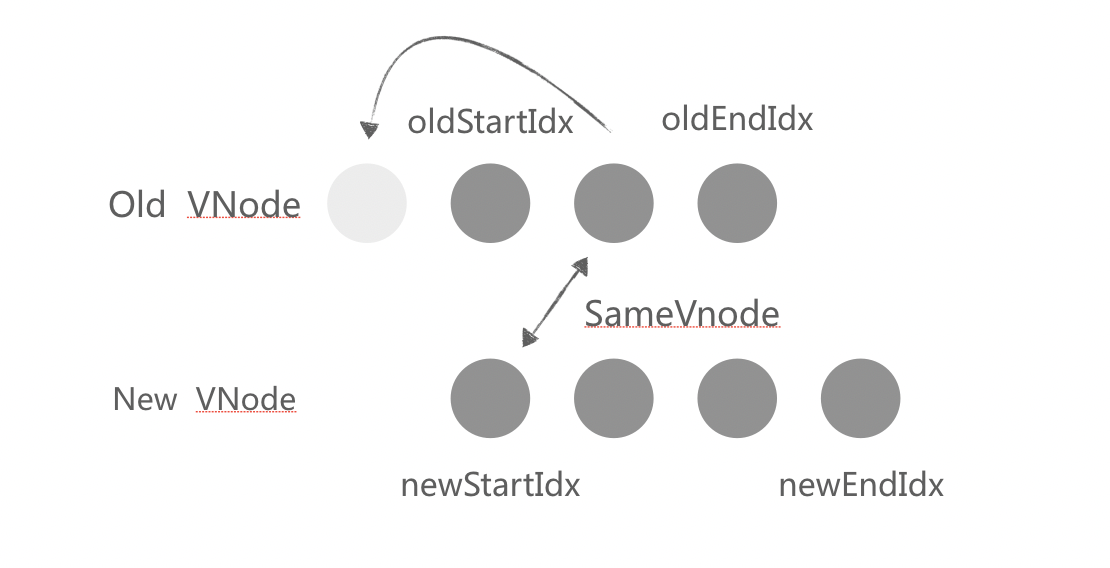
若不存在,说明newStartVnode为新节点,创建新节点放在oldStartVnode前面即可。
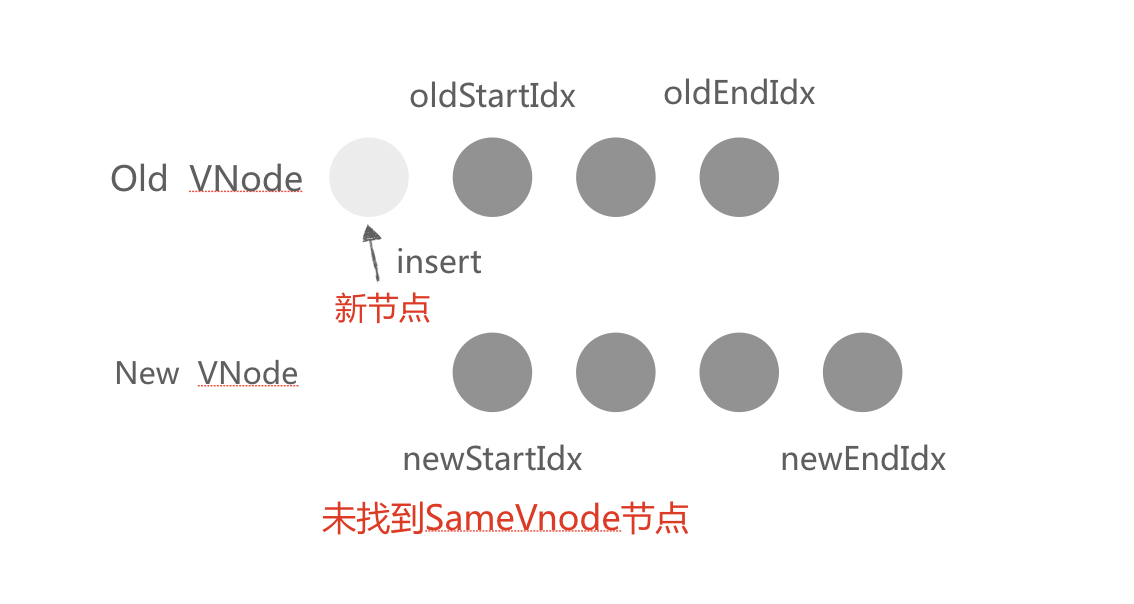
当 oldStartIdx > oldEndIdx 或者 newStartIdx > newEndIdx,循环结束,这个时候我们需要处理那些未被遍历到的 VNode。
当 oldStartIdx > oldEndIdx 时,说明老的节点已经遍历完,而新的节点没遍历完,这个时候需要将新的节点创建之后放在oldEndVnode后面。
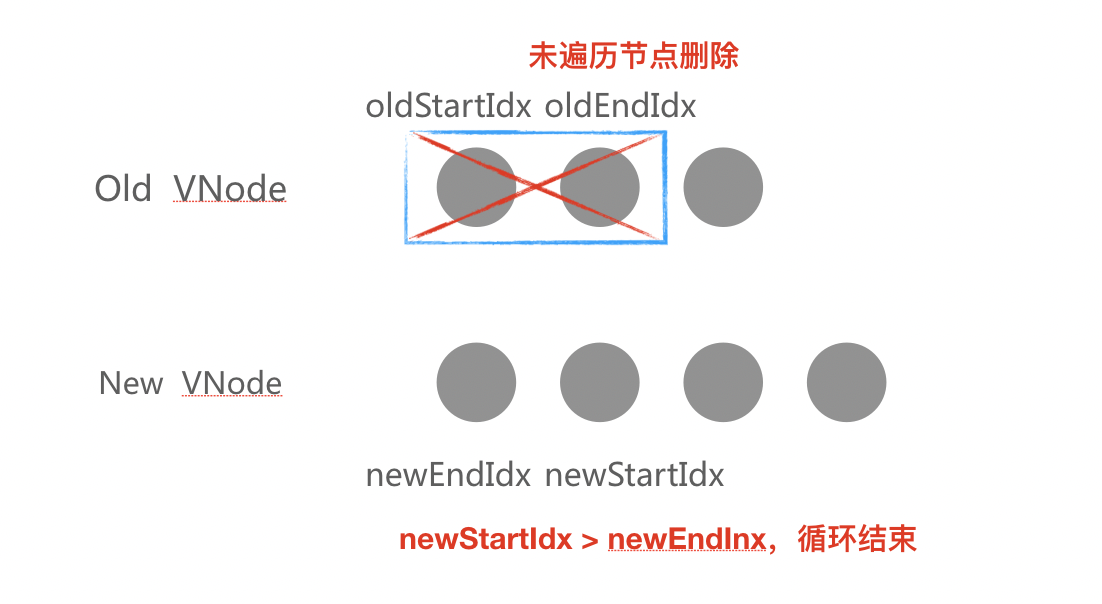
当 newStartIdx > newEndIdx 时,说明新的节点已经遍历完,而老的节点没遍历完,这个时候要将没遍历的老的节点全都删除。
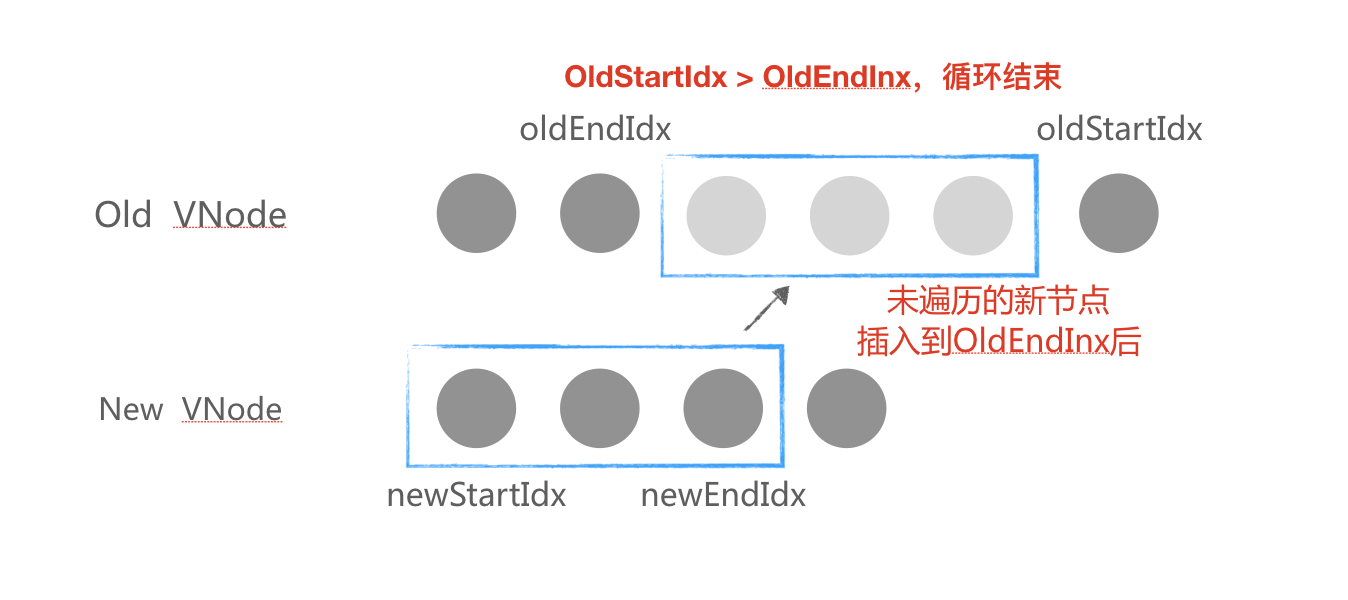
此时已经完成了子节点的匹配。下面是一个例子 patch 过程图:

借用官方的一幅图:
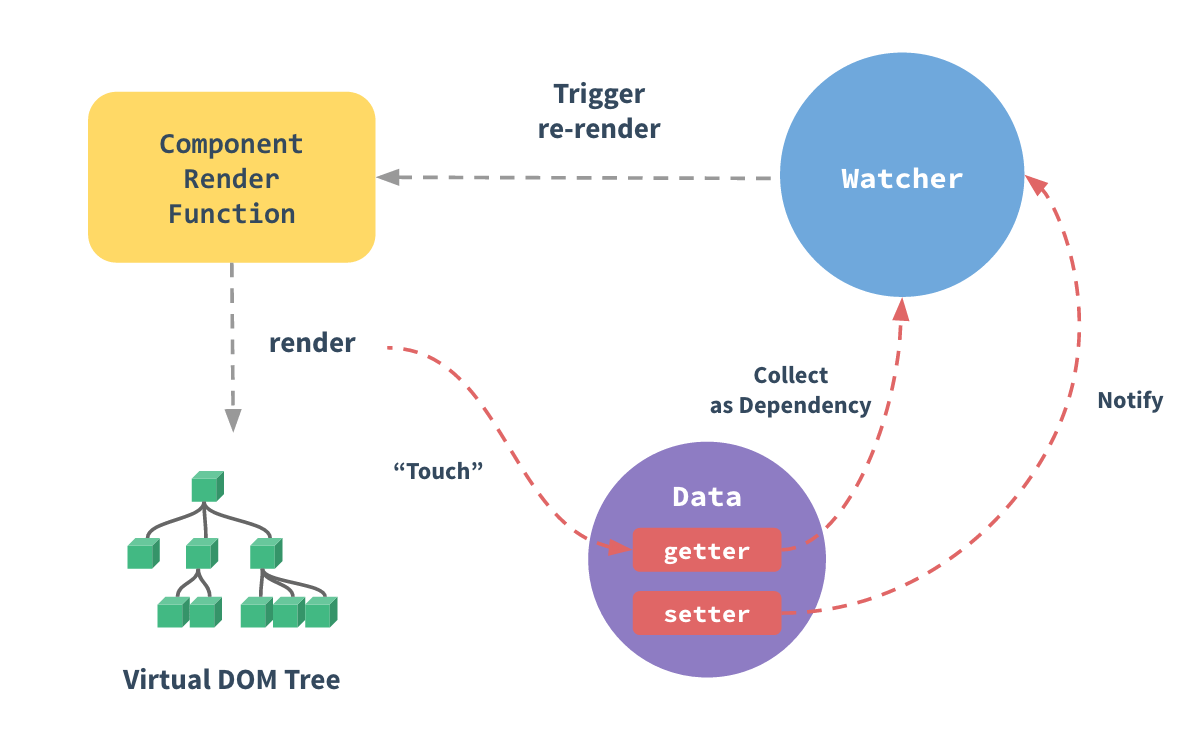
Vue.js 实现了一套声明式渲染引擎,并在runtime或者预编译时将声明式的模板编译成渲染函数,挂载在观察者 Watcher 中,在渲染函数中(touch),响应式系统使用响应式数据的getter方法对观察者进行依赖收集(Collect as Dependency),使用响应式数据的setter方法通知(notify)所有观察者进行更新,此时观察者 Watcher 会触发组件的渲染函数(Trigger re-render),组件执行的 render 函数,生成一个新的 Virtual DOM Tree,此时 Vue 会对新老 Virtual DOM Tree 进行 Diff,查找出需要操作的真实 DOM 并对其进行更新。
杭州下雪了,冷到不行,在家躺在床上玩手机,打开微信进入前端交流群里日常吹水,看到大佬在群里发了一篇文章你应该要知道的重绘与重排,文章里有一段*操作,就是为了减少重绘与重排,合并样式操作,这个*操作成功的引起了我的注意,然后开启了我的探索。
前言中描述的合并样式的*操作是如下:
var el = document.querySelector('div');
el.style.borderLeft = '1px';
el.style.borderRight = '2px';
el.style.padding = '5px';原文描述的大概意思是这段代码多次对 DOM 的修改和对样式的修改,页面会进行多次回流或者重绘,应该进行如下优化:
var el = document.querySelector('div');
el.style.cssText = 'border-left: 1px; border-right: 1px; padding: 5px;'这样的优化在以前我刚开始学习前端的时候,经常也在一些相关的性能优化的文章里看到,因为一直没有探究过,概念里一直觉得自己应该把多次 DOM 的样式的修改合并在一起,这样效率会更高,直到后来,自己对浏览器的进程与线程慢慢有了了解,曾经也写过一篇博客,浅谈浏览器多进程与JS线程,其中有一个概念是,JS线程与GUI渲染线程是互斥关系,大概的意思就是当js引擎在执行js代码的时候,浏览器的渲染引擎是被冻结了的,无法渲染页面的,必须等待js引擎空闲了才能渲染页面。
这个概念,JS线程与GUI渲染线程是互斥关系与上面描述的*操作似乎有点冲突,也就是当我们对el.style进行一些列赋值的时候,渲染引擎是被冻结的状态,怎么会进行多次重绘或者回流?带着这样的疑问,写了一个小demo,代码如下。
<!DOCTYPE html>
<html>
<head>
<title>测试页</title>
<style>
#box {
width: 109px;
height: 100px;
background-color: lightsteelblue;
border-style: solid;
}
</style>
</head>
<body>
<div id="box"></div>
</body>
<script>
var box = document.getElementById('box');
var toggle = 0;
var time = 500;
function toggleFun() {
var borderWidth = toggle ? 20 : 0;
var borderColor = toggle ? 'coral' : 'transparent';
if (toggle) {
box.style.borderWidth = '50px';
box.style.borderWidth = borderWidth + 'px';
box.style.borderColor = borderColor;
} else {
box.style.cssText = 'border: ' + borderWidth + 'px solid' + borderColor;
}
toggle = toggle ? 0 : 1;
}
setInterval(toggleFun, time)
</script>
</html>代码大概的意思就是定时以两种操作设置样式,收集浏览器的回流或者重绘次数。
打开chrome的开发者工具,切换到Performance选项卡,点击左上角的圆 ○,开始record,等几秒后stop,点击Frames查看Event log选项卡,内容如下:
大概可以看到,Recalculate Style -> Layout -> Update Layer Tree -> Paint -> Composite Layers 这个过程在循环进行,触发的目标代码是第25行代码合29行代码,也就是box.style.borderWidth = '50px';和box.style.cssText = 'border: ' + borderWidth + 'px solid' + borderColor;。
首先回顾一下浏览器渲染页面的流程:
然后在看看上面的过程,可以容易看出,
Recalculate Style,重新计算css规则树。Layout,这里的Layout可以理解成回流,重新计算每个元素的位置。Update Layer Tree,字面意思理解,更新层级树。Paint,绘制页面,在这里可以理解成重绘。Composite Layers,字面意思理解,合并层级。由上面过程得到结果,当在同一执行任务里面对DOM的样式进行多次操作的时候,只会进行一次回流或者重绘,也就是说,只要我们的js引擎时候忙碌的,渲染引擎是冻结的时候,无论对DOM样式进行多少次操作,都只会进行一次回流或者重绘,也就是说前面说的合并样式优化是无效的。
这个时候,我对上面过程又产生了新的疑问,为什么要Paint之后在Composite Layers呢?为什么不把所有层合并完了在绘制页面呢?
.........................(看搜索相关资料去了)
翻看资料结束后,我得到以下理解。
首先理解layer概念,可以理解成PS里面的图层,我们知道PS文件最后保存层PSD文件,当图层越多的时候,PSD文件就越大,在我们的浏览器里面也是一样的,我们的layer越多,所占的内存就越大。
然后理解Paint真正做的事情,paint的任务大概就是把所有的layer绘制到页面中,这个绘制与canvas的绘制不一样,canvas的绘制相当于在画布里把像素直接绘制成指定颜色,然后我们直接看到的东西就直接是像素颜色,而我们这里说的Paint只是把图层丢到页面中,最后的绘制,需要交给Composite线程处理。
最后是Composite Layers,由composite线程进行,这个线程在浏览器的Renderer进程中,任务是把Paint时候丢上页面的图层转化成位图,最终生成我们肉眼可以看到的图像,所以,真正的绘制,应该是Composite Layers过程进行的。
由于paint与composite解耦,浏览器对每一个layer都有一个标识,这个标识用来标识该layer是否需要重绘,在有CSS规则树变化的时候,浏览器只会对这些被标识的layer进行重绘,用这样的方式提高浏览器的渲染性能。
前端大法博大精深,越往下学越觉得自己不适合前端!!!仿佛看到自己在从入门到跑路这条路上快走到了终点。。。
在我们面试过程中,面试官经常会问到这么一个问题,那就是从在浏览器地址栏中输入URL到页面显示,浏览器到底发生了什么?这个问题看起来是老生常谈,但是这个问题回答的好坏,确实可以很好的反映出面试者知识的广度和深度。
本文从浏览器角度来告诉你,URL后输入后按回车,浏览器内部究竟发生了什么,读完本文后,你将了解到:
在讲浏览器架构之前,先理解两个概念,进程和线程。
进程(process)是程序的一次执行过程,是一个动态概念,是程序在执行过程中分配和管理资源的基本单位,线程(thread)是CPU调度和分派的基本单位,它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
简单的说呢,进程可以理解成正在执行的应用程序,而线程呢,可以理解成我们应用程序中的代码的执行器。而他们的关系可想而知,线程是跑在进程里面的,一个进程里面可能有一个或者多个线程,而一个线程,只能隶属于一个进程。
大家都知道,浏览器属于一个应用程序,而应用程序的一次执行,可以理解为计算机启动了一个进程,进程启动后,CPU会给该进程分配相应的内存空间,当我们的进程得到了内存之后,就可以使用线程进行资源调度,进而完成我们应用程序的功能。
而在应用程序中,为了满足功能的需要,启动的进程会创建另外的新的进程来处理其他任务,这些创建出来的新的进程拥有全新的独立的内存空间,不能与原来的进程内向内存,如果这些进程之间需要通信,可以通过IPC机制(Inter Process Communication)来进行。
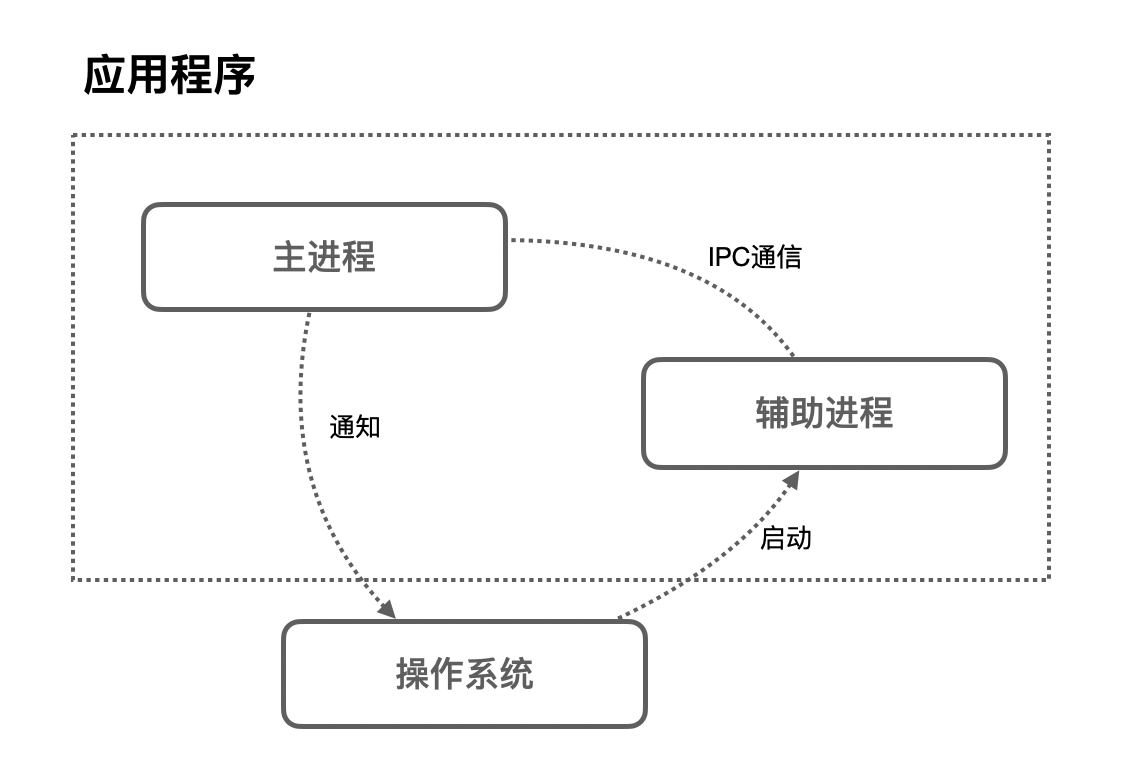
很多应用程序都会采取这种多进程的方式来工作,因为进程和进程之间是互相独立的它们互不影响,也就是说,当其中一个进程挂掉了之后,不会影响到其他进程的执行,只需要重启挂掉的进程就可以恢复运行。
假如我们去开发一个浏览器,它的架构可以是一个单进程多线程的应用程序,也可以是一个使用IPC通信的多进程应用程序。
不同的浏览器使用不同的架构,下面主要以Chrome为例,介绍浏览器的多进程架构。
在Chrome中,主要的进程有4个:
这4个进程之间的关系是什么呢?
首先,当我们是要浏览一个网页,我们会在浏览器的地址栏里输入URL,这个时候Browser Process会向这个URL发送请求,获取这个URL的HTML内容,然后将HTML交给Renderer Process,Renderer Process解析HTML内容,解析遇到需要请求网络的资源又返回来交给Browser Process进行加载,同时通知Browser Process,需要Plugin Process加载插件资源,执行插件代码。解析完成后,Renderer Process计算得到图像帧,并将这些图像帧交给GPU Process,GPU Process将其转化为图像显示屏幕。
Chrome为什么要使用多进程架构呢?
第一,更高的容错性。当今WEB应用中,HTML,JavaScript和CSS日益复杂,这些跑在渲染引擎的代码,频繁的出现BUG,而有些BUG会直接导致渲染引擎崩溃,多进程架构使得每一个渲染引擎运行在各自的进程中,相互之间不受影响,也就是说,当其中一个页面崩溃挂掉之后,其他页面还可以正常的运行不收影响。
第二,更高的安全性和沙盒性(sanboxing)。渲染引擎会经常性的在网络上遇到不可信、甚至是恶意的代码,它们会利用这些漏洞在你的电脑上安装恶意的软件,针对这一问题,浏览器对不同进程限制了不同的权限,并为其提供沙盒运行环境,使其更安全更可靠
第三,更高的响应速度。在单进程的架构中,各个任务相互竞争抢夺CPU资源,使得浏览器响应速度变慢,而多进程架构正好规避了这一缺点。
之前的我们说到,Renderer Process的作用是负责一个Tab内的显示相关的工作,这就意味着,一个Tab,就会有一个Renderer Process,这些进程之间的内存无法进行共享,而不同进程的内存常常需要包含相同的内容。
为了节省内存,Chrome提供了四种进程模式(Process Models),不同的进程模式会对 tab 进程做不同的处理。
这里需要给出 site 和 site-instance 的定义
<a target="_blank">这种方式点击打开的新页面window.open)理解了概念之后,下面解释四个进程模式
首先是Single process,顾名思义,单进程模式,所有tab都会使用同一个进程。接下来是Process-per-tab ,也是顾名思义,每打开一个tab,会新建一个进程。而对于Process-per-site,当你打开 a.baidu.com 页面,在打开 b.baidu.com 的页面,这两个页面的tab使用的是共一个进程,因为这两个页面的site相同,而如此一来,如果其中一个tab崩溃了,而另一个tab也会崩溃。
Process-per-site-instance 是最重要的,因为这个是 Chrome 默认使用的模式,也就是几乎所有的用户都在用的模式。当你打开一个 tab 访问 a.baidu.com ,然后再打开一个 tab 访问 b.baidu.com,这两个 tab 会使用两个进程。而如果你在 a.baidu.com 中,通过JS代码打开了 b.baidu.com 页面,这两个 tab 会使用同一个进程。
那么为什么浏览器使用Process-per-site-instance作为默认的进程模式呢?
Process-per-site-instance兼容了性能与易用性,是一个比较中庸通用的模式。
前面我们讲了浏览器的多进程架构,讲了多进程架构的各种好处,和Chrome是怎么优化多进程架构的,下面从用户浏览网页这一简单的场景,来深入了解进程和线程是如何呈现我们的网站页面的。
之前我们我们提到,tab以外的大部分工作由浏览器进程Browser Process负责,针对工作的不同,Browser Process 划分出不同的工作线程:
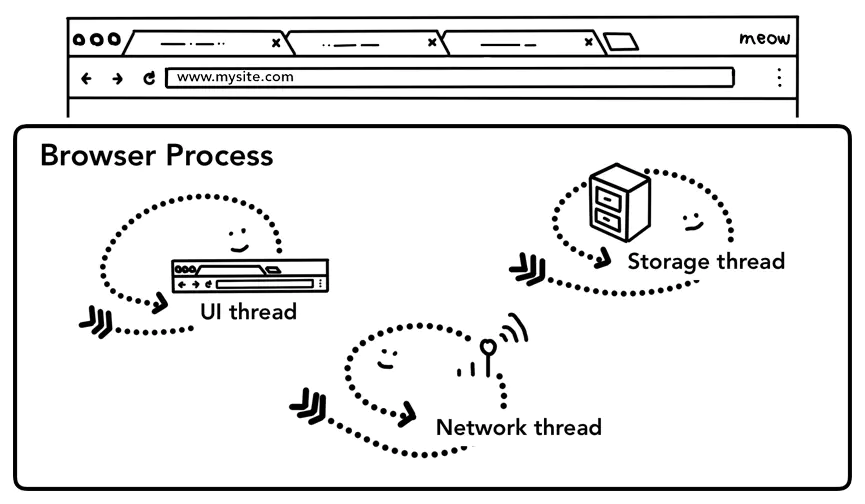
当我们在浏览器的地址栏输入内容按下回车时,UI thread会判断输入的内容是搜索关键词(search query)还是URL,如果是搜索关键词,跳转至默认搜索引擎对应都搜索URL,如果输入的内容是URL,则开始请求URL。
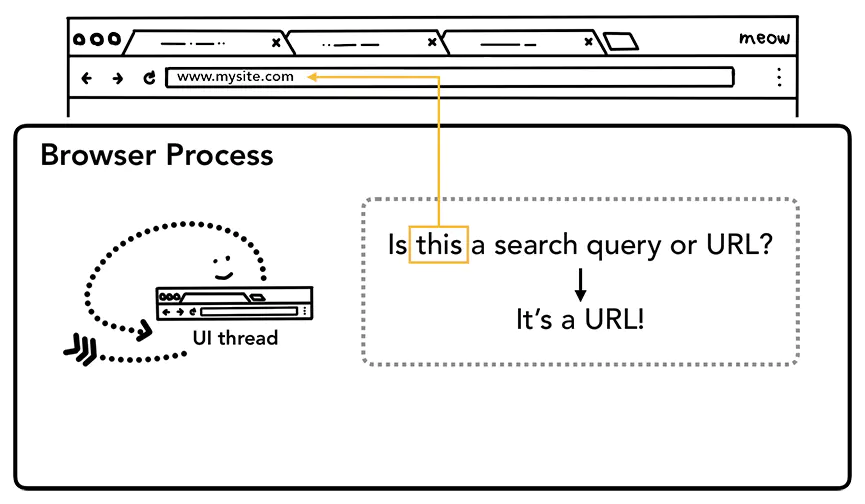
回车按下后,UI thread将关键词搜索对应的URL或输入的URL交给网络线程Network thread,此时UI线程使Tab前的图标展示为加载中状态,然后网络进程进行一系列诸如DNS寻址,建立TLS连接等操作进行资源请求,如果收到服务器的301重定向响应,它就会告知UI线程进行重定向然后它会再次发起一个新的网络请求。
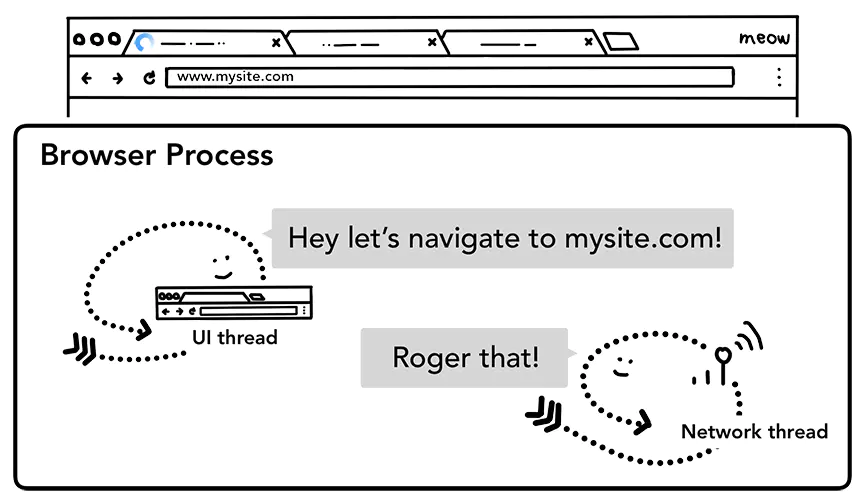
network thread接收到服务器的响应后,开始解析HTTP响应报文,然后根据响应头中的Content-Type字段来确定响应主体的媒体类型(MIME Type),如果媒体类型是一个HTML文件,则将响应数据交给渲染进程(renderer process)来进行下一步的工作,如果是 zip 文件或者其它文件,会把相关数据传输给下载管理器。
与此同时,浏览器会进行 Safe Browsing 安全检查,如果域名或者请求内容匹配到已知的恶意站点,network thread 会展示一个警告页。除此之外,网络线程还会做 CORB(Cross Origin Read Blocking)检查来确定那些敏感的跨站数据不会被发送至渲染进程。
各种检查完毕以后,network thread 确信浏览器可以导航到请求网页,network thread 会通知 UI thread 数据已经准备好,UI thread 会查找到一个 renderer process 进行网页的渲染。
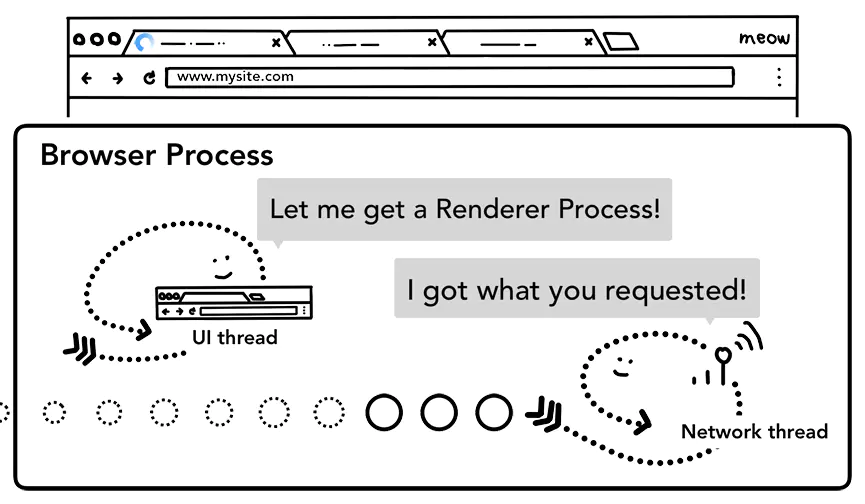
浏览器为了对查找渲染进程这一步骤进行优化,考虑到网络请求获取响应需要时间,所以在第二步开始,浏览器已经预先查找和启动了一个渲染进程,如果中间步骤一切顺利,当 network thread 接收到数据时,渲染进程已经准备好了,但是如果遇到重定向,这个准备好的渲染进程也许就不可用了,这个时候会重新启动一个渲染进程。
到了这一步,数据和渲染进程都准备好了,Browser Process 会向 Renderer Process 发送IPC消息来确认导航,此时,浏览器进程将准备好的数据发送给渲染进程,渲染进程接收到数据之后,又发送IPC消息给浏览器进程,告诉浏览器进程导航已经提交了,页面开始加载。
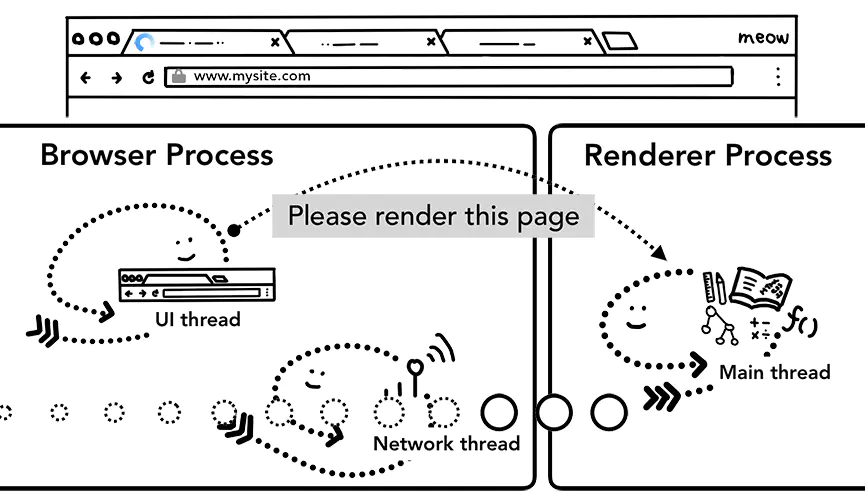
这个时候导航栏会更新,安全指示符更新(地址前面的小锁),访问历史列表(history tab)更新,即可以通过前进后退来切换该页面。
当导航提交完成后,渲染进程开始加载资源及渲染页面(详细内容下文介绍),当页面渲染完成后(页面及内部的iframe都触发了onload事件),会向浏览器进程发送IPC消息,告知浏览器进程,这个时候UI thread会停止展示tab中的加载中图标。
导航过程完成之后,浏览器进程把数据交给了渲染进程,渲染进程负责tab内的所有事情,核心目的就是将HTML/CSS/JS代码,转化为用户可进行交互的web页面。那么渲染进程是如何工作的呢?
渲染进程中,包含线程分别是:
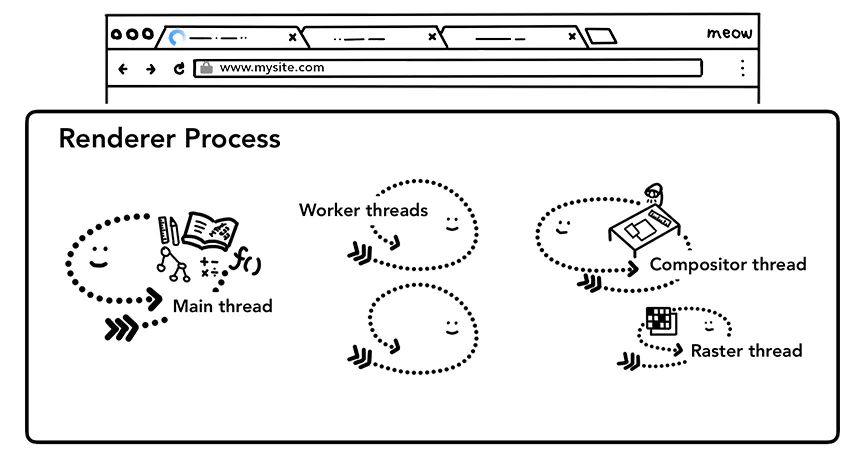
不同的线程,有着不同的工作职责。
当渲染进程接受到导航的确认信息后,开始接受来自浏览器进程的数据,这个时候,主线程会解析数据转化为DOM(Document Object Model)对象。
DOM为WEB开发人员通过JavaScript与网页进行交互的数据结构及API。
在构建DOM的过程中,会解析到图片、CSS、JavaScript脚本等资源,这些资源是需要从网络或者缓存中获取的,主线程在构建DOM过程中如果遇到了这些资源,逐一发起请求去获取,而为了提升效率,浏览器也会运行预加载扫描(preload scanner)程序,如果HTML中存在img、link等标签,预加载扫描程序会把这些请求传递给Browser Process的network thread进行资源下载。
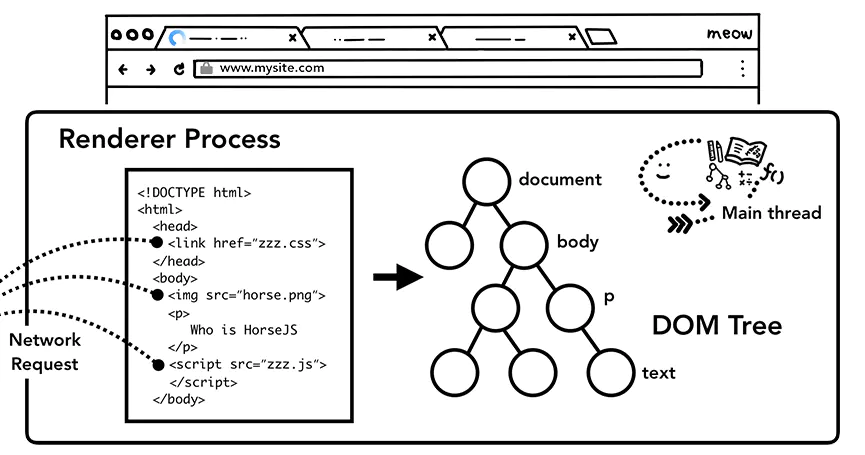
构建DOM过程中,如果遇到<script>标签,渲染引擎会停止对HTML的解析,而去加载执行JS代码,原因在于JS代码可能会改变DOM的结构(比如执行document.write()等API)
不过开发者其实也有多种方式来告知浏览器应对如何应对某个资源,比如说如果在<script> 标签上添加了 async 或 defer 等属性,浏览器会异步的加载和执行JS代码,而不会阻塞渲染。
DOM树只是我们页面的结构,我们要知道页面长什么样子,我们还需要知道DOM的每一个节点的样式。主线程在解析页面时,遇到<style>标签或者<link>标签的CSS资源,会加载CSS代码,根据CSS代码确定每个DOM节点的计算样式(computed style)。
计算样式是主线程根据CSS样式选择器(CSS selectors)计算出的每个DOM元素应该具备的具体样式,即使你的页面没有设置任何自定义的样式,浏览器也会提供其默认的样式。
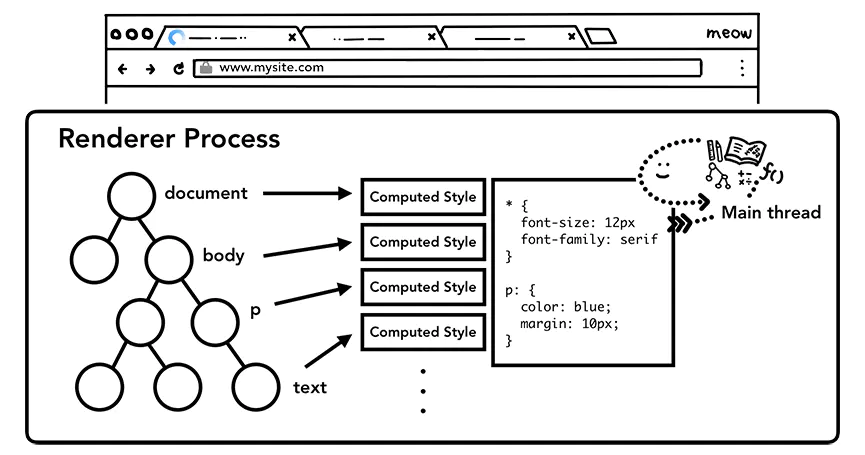
DOM树和计算样式完成后,我们还需要知道每一个节点在页面上的位置,布局(Layout)其实就是找到所有元素的几何关系的过程。
主线程会遍历DOM 及相关元素的计算样式,构建出包含每个元素的页面坐标信息及盒子模型大小的布局树(Render Tree),遍历过程中,会跳过隐藏的元素(display: none),另外,伪元素虽然在DOM上不可见,但是在布局树上是可见的。
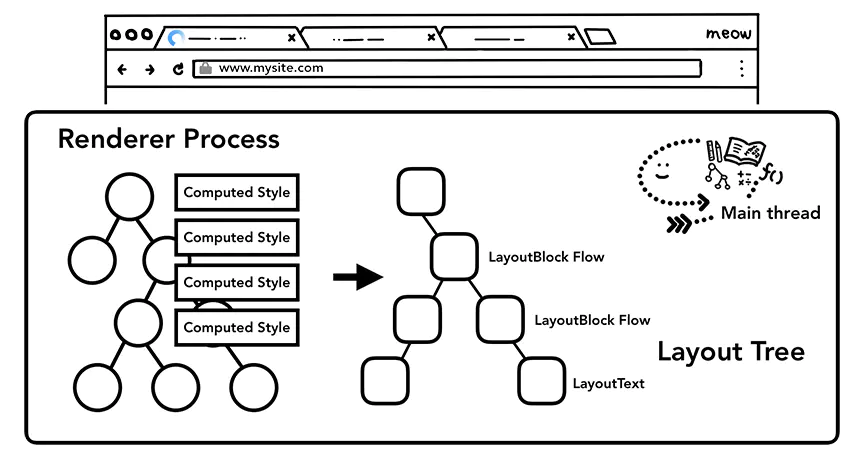
布局 layout 之后,我们知道了不同元素的结构,样式,几何关系,我们要绘制出一个页面,我们要需要知道每个元素的绘制先后顺序,在绘制阶段,主线程会遍历布局树(layout tree),生成一系列的绘画记录(paint records)。绘画记录可以看做是记录各元素绘制先后顺序的笔记。
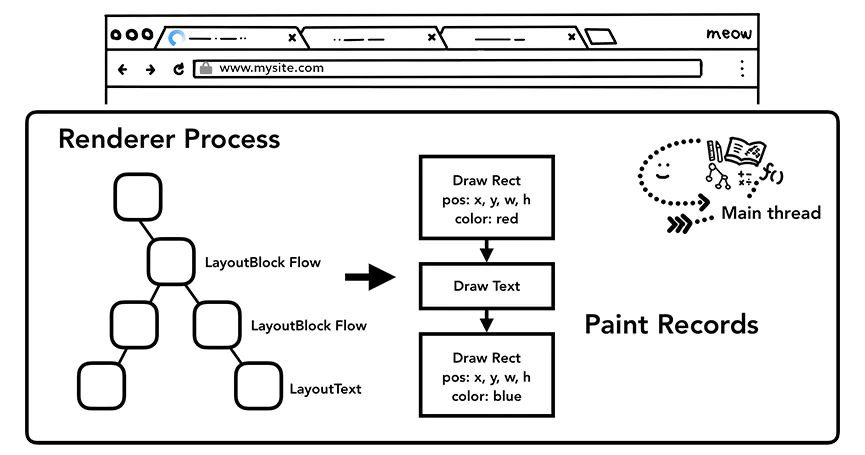
文档结构、元素的样式、元素的几何关系、绘画顺序,这些信息我们都有了,这个时候如果要绘制一个页面,我们需要做的是把这些信息转化为显示器中的像素,这个转化的过程,叫做光栅化(rasterizing)。
那我们要绘制一个页面,最简单的做法是只光栅化视口内(viewport)的网页内容,如果用户进行了页面滚动,就移动光栅帧(rastered frame)并且光栅化更多的内容以补上页面缺失的部分,如下:
Chrome第一个版本就是采用这种简单的绘制方式,这一方式唯一的缺点就是每当页面滚动,光栅线程都需要对新移进视图的内容进行光栅化,这是一定的性能损耗,为了优化这种情况,Chrome采取一种更加复杂的叫做合成(compositing)的做法。
那么,什么是合成?合成是一种将页面分成若干层,然后分别对它们进行光栅化,最后在一个单独的线程 - 合成线程(compositor thread)里面合并成一个页面的技术。当用户滚动页面时,由于页面各个层都已经被光栅化了,浏览器需要做的只是合成一个新的帧来展示滚动后的效果罢了。页面的动画效果实现也是类似,将页面上的层进行移动并构建出一个新的帧即可。
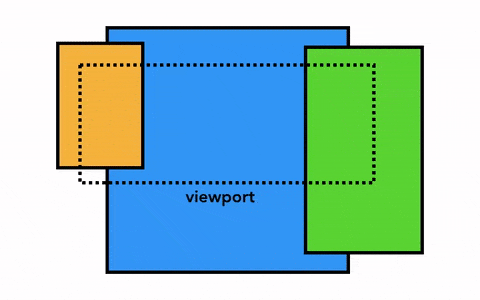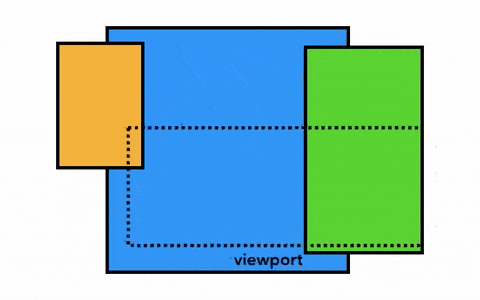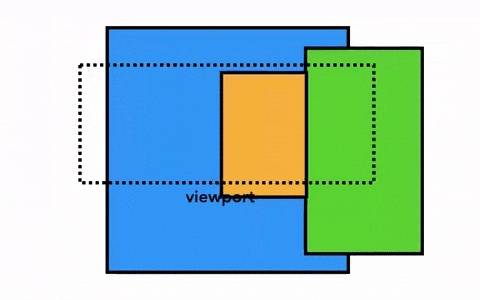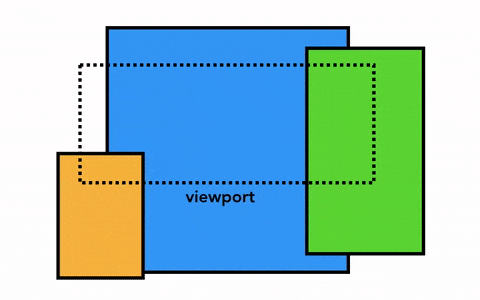
为了实现合成技术,我们需要对元素进行分层,确定哪些元素需要放置在哪一层,主线程需要遍历渲染树来创建一棵层次树(Layer Tree),对于添加了 will-change CSS 属性的元素,会被看做单独的一层,没有 will-change CSS属性的元素,浏览器会根据情况决定是否要把该元素放在单独的层。
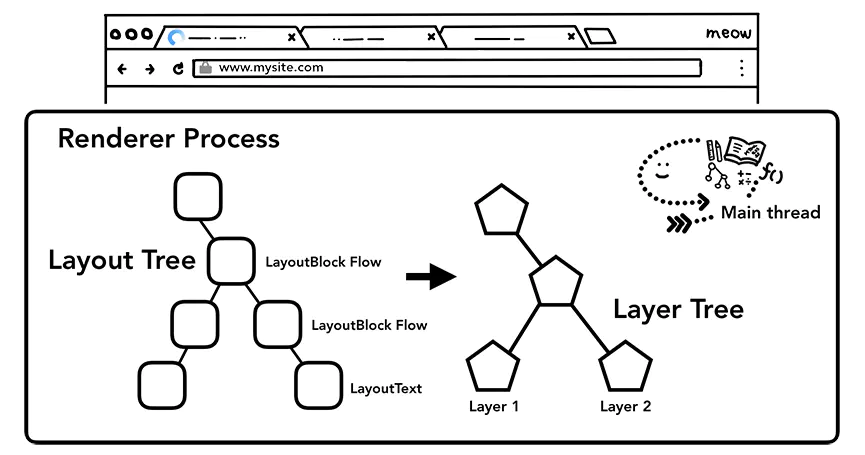
你可能会想要给页面上所有的元素一个单独的层,然而当页面的层超过一定的数量后,层的合成操作要比在每个帧中光栅化页面的一小部分还要慢,因此衡量你应用的渲染性能是十分重要的一件事情。
一旦Layer Tree被创建,渲染顺序被确定,主线程会把这些信息通知给合成器线程,合成器线程开始对层次数的每一层进行光栅化。有的层的可以达到整个页面的大小,所以合成线程需要将它们切分为一块又一块的小图块(tiles),之后将这些小图块分别进行发送给一系列光栅线程(raster threads)进行光栅化,结束后光栅线程会将每个图块的光栅结果存在GPU Process的内存中。
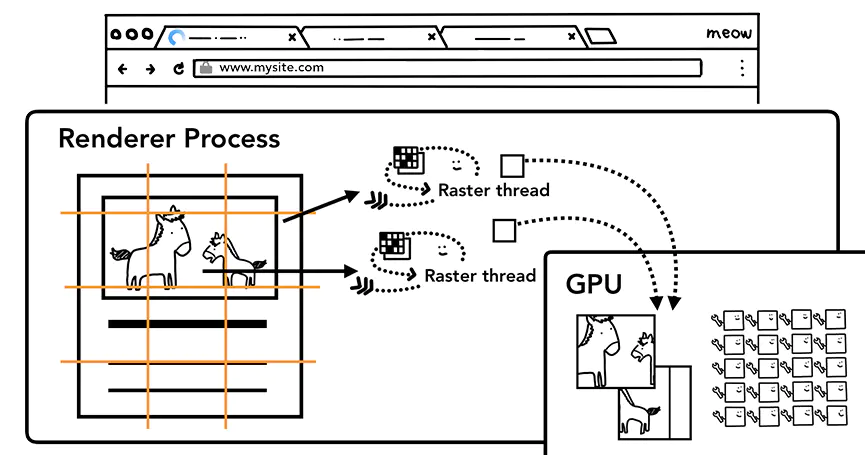
为了优化显示体验,合成线程可以给不同的光栅线程赋予不同的优先级,将那些在视口中的或者视口附近的层先被光栅化。
当图层上面的图块都被栅格化后,合成线程会收集图块上面叫做绘画四边形(draw quads)的信息来构建一个合成帧(compositor frame)。
以上所有步骤完成后,合成线程就会通过IPC向浏览器进程(browser process)提交(commit)一个渲染帧。这个时候可能有另外一个合成帧被浏览器进程的UI线程(UI thread)提交以改变浏览器的UI。这些合成帧都会被发送给GPU从而展示在屏幕上。如果合成线程收到页面滚动的事件,合成线程会构建另外一个合成帧发送给GPU来更新页面。
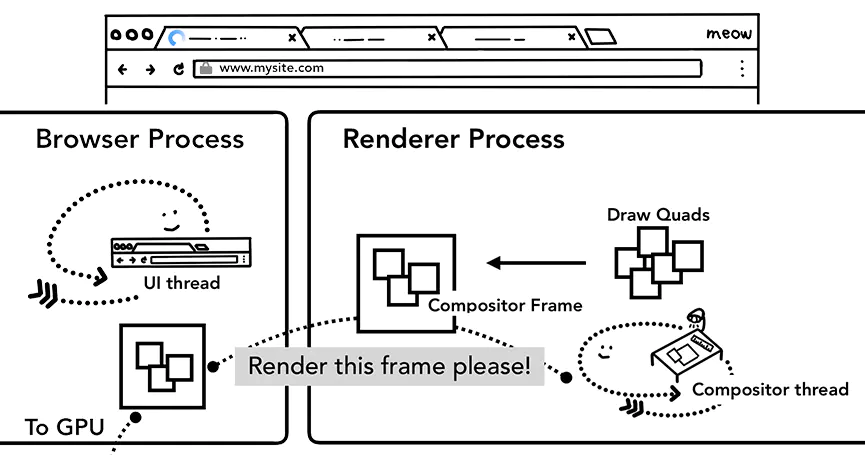
合成的好处在于这个过程没有涉及到主线程,所以合成线程不需要等待样式的计算以及JavaScript完成执行。这就是为什么合成器相关的动画最流畅,如果某个动画涉及到布局或者绘制的调整,就会涉及到主线程的重新计算,自然会慢很多。
当页面渲染完毕以后,TAB内已经显示出了可交互的WEB页面,用户可以进行移动鼠标、点击页面等操作了,而当这些事件发生时候,浏览器是如何处理这些事件的呢?
以点击事件(click event)为例,让鼠标点击页面时候,首先接受到事件信息的是Browser Process,但是Browser Process只知道事件发生的类型和发生的位置,具体怎么对这个点击事件进行处理,还是由Tab内的Renderer Process进行的。Browser Process接受到事件后,随后便把事件的信息传递给了渲染进程,渲染进程会找到根据事件发生的坐标,找到目标对象(target),并且运行这个目标对象的点击事件绑定的监听函数(listener)。
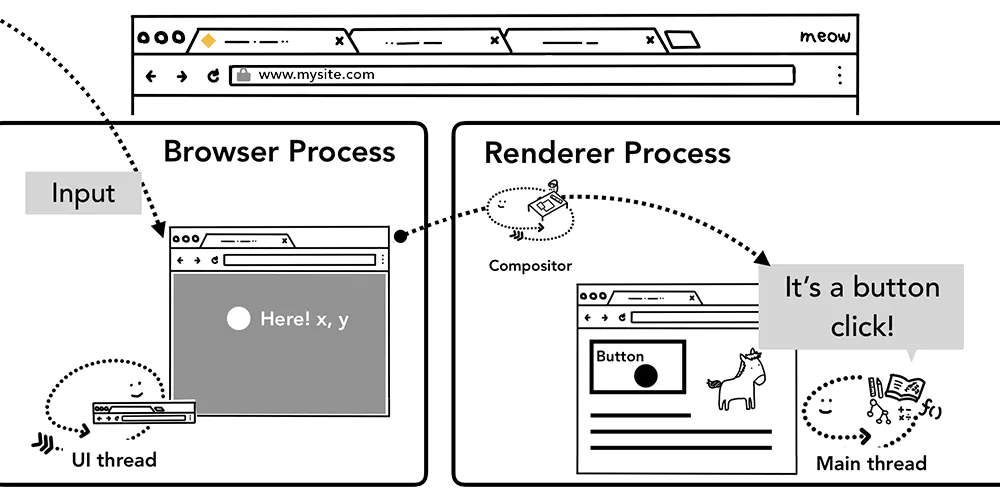
前面我们说到,合成器线程可以独立于主线程之外通过已光栅化的层创建组合帧,例如页面滚动,如果没有对页面滚动绑定相关的事件,组合器线程可以独立于主线程创建组合帧,如果页面绑定了页面滚动事件,合成器线程会等待主线程进行事件处理后才会创建组合帧。那么,合成器线程是如何判断出这个事件是否需要路由给主线程处理的呢?
由于执行 JS 是主线程的工作,当页面合成时,合成器线程会标记页面中绑定有事件处理器的区域为非快速滚动区域(non-fast scrollable region),如果事件发生在这些存在标注的区域,合成器线程会把事件信息发送给主线程,等待主线程进行事件处理,如果事件不是发生在这些区域,合成器线程则会直接合成新的帧而不用等到主线程的响应。
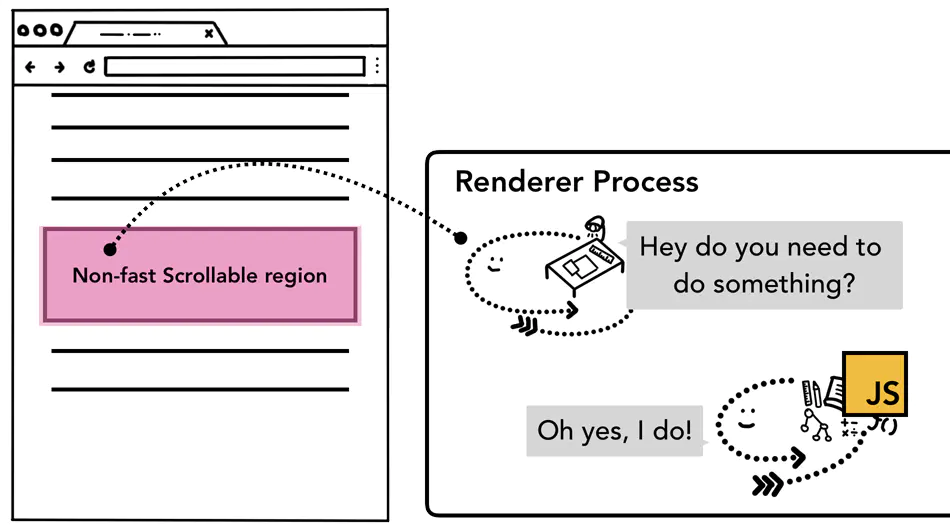
而对于非快速滚动区域的标记,开发者需要注意全局事件的绑定,比如我们使用事件委托,将目标元素的事件交给根元素body进行处理,代码如下:
document.body.addEventListener('touchstart', event => {
if (event.target === area) {
event.preventDefault()
}
})在开发者角度看,这一段代码没什么问题,但是从浏览器角度看,这一段代码给body元素绑定了事件监听器,也就意味着整个页面都被编辑为一个非快速滚动区域,这会使得即使你的页面的某些区域没有绑定任何事件,每次用户触发事件时,合成器线程也需要和主线程通信并等待反馈,流畅的合成器独立处理合成帧的模式就失效了。
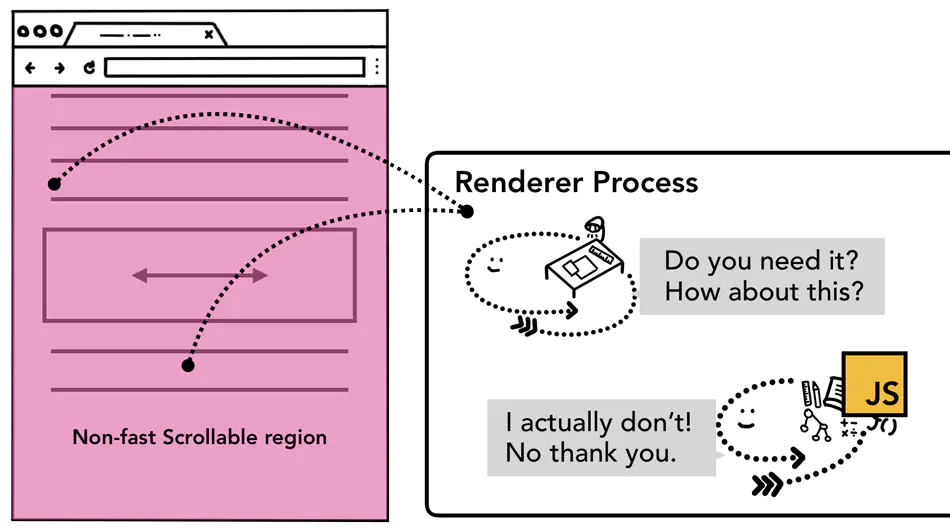
其实这种情况也很好处理,只需要在事件监听时传递passtive参数为 true,passtive会告诉浏览器你既要绑定事件,又要让组合器线程直接跳过主线程的事件处理直接合成创建组合帧。
document.body.addEventListener('touchstart',
event => {
if (event.target === area) {
event.preventDefault()
}
}, {passive: true});当合成器线程接收到事件信息,判定到事件发生不在非快速滚动区域后,合成器线程会向主线程发送这个时间信息,主线程获取到事件信息的第一件事就是通过命中测试(hit test)去找到事件的目标对象。具体的命中测试流程是遍历在绘制阶段生成的绘画记录(paint records)来找到包含了事件发生坐标上的元素对象。
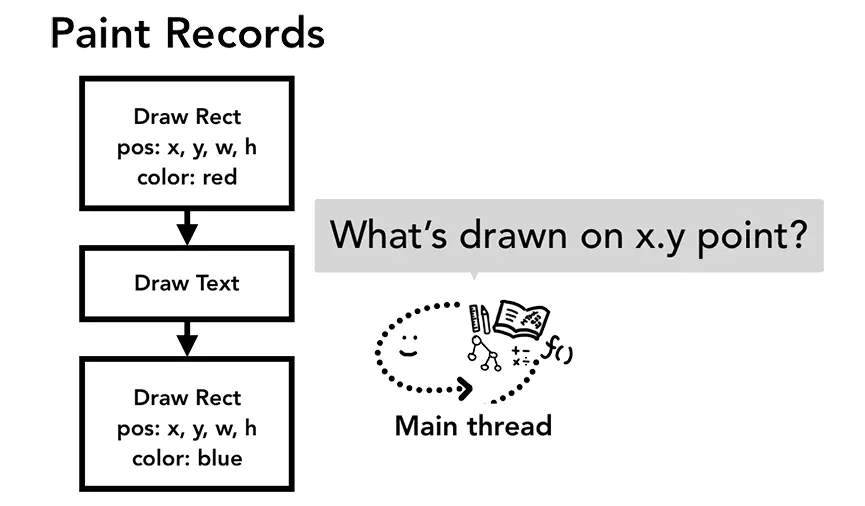
一般我们屏幕的帧率是每秒60帧,也就是60fps,但是某些事件触发的频率超过了这个数值,比如wheel,mousewheel,mousemove,pointermove,touchmove,这些连续性的事件一般每秒会触发60~120次,假如每一次触发事件都将事件发送到主线程处理,由于屏幕的刷新速率相对来说较低,这样使得主线程会触发过量的命中测试以及JS代码,使得性能有了没必要是损耗。
出于优化的目的,浏览器会合并这些连续的事件,延迟到下一帧渲染是执行,也就是requestAnimationFrame之前。
而对于非连续性的事件,如keydown,keyup,mousedown,mouseup,touchstart,touchend等,会直接派发给主线程去执行。
浏览器的多进程架构,根据不同的功能划分了不同的进程,进程内不同的使命划分了不同的线程,当用户开始浏览网页时候,浏览器进程进行处理输入、开始导航请求数据、请求响应数据,查找新建渲染进程,提交导航,之后渲染又进行了解析HTML构建DOM、构建过程加载子资源、下载并执行JS代码、样式计算、布局、绘制、合成,一步一步的构建出一个可交互的WEB页面,之后浏览器进程又接受页面的交互事件信息,并将其交给渲染进程,渲染进程内主进程进行命中测试,查找目标元素并执行绑定的事件,完成页面的交互。
本文大部分内容也是对inside look at modern web browser系列文章的整理、解读和翻译吧,整理过程还是收获非常大的,希望读者读了本文只有有所启发吧。
随着业务复杂度的不断的增加,工程模块的体积也会不断增加,构建后的模块通常要以M为单位计算。在构建过程中,基于nodejs的webpack在单进程的情况下loader表现变得越来越慢,在不做任何特殊处理的情况下,构建完后的多项目之间公用基础资源存在重复打包,基础库代码复用率也不高,这都慢慢暴露出webpack的问题。
针对存在的问题,社区涌出了各种解决方案,包括webpack自身也在不断优化。
下面利用相关的方案对实际项目一步一步进行构建优化,提升我们的编译速度,本次优化相关属性如下:
机器: Macbook Air 四核 8G内存
Webpack: v4.10.2
项目:922个模块
构建优化方案如下:
减少编译体积大小
将大型库外链
将库预先编译
使用缓存
并行编译
初始构建时间如下:
| 增量构建 | Development 构建 | Production 构建 | 备注 |
|---|---|---|---|
| 3088ms | 43702ms | 89371ms |
初始构建时候,我们利用webpack-bundle-analyzer对编译结果进行分析,结果如下:
可以看到,td-ui(类似于antd的ui组件库)、moment库的locale、BizCharts占了项目的大部分体积,而在没有全部使用这些库的全部内容的情况下,我们可以对齐进行按需加载。
针对td-ui和BizCharts,我们对齐添加按需加载babel-plugin-import,这个包可以在使用ES6模块导入的时候,对其进行分析,解析成引入相应文件夹下面的模块,如下:

首先,我们先添加babel的配置,在plugins中加入babel-plugin-import:
{
"plugins": [
["import", [
{ "libraryName": "td-ui", "style": true },
{ "libraryName": "bizcharts", "libraryDirectory": "lib/components" }
]]
]
}可以看到,我们给bizcharts也添加了按需加载,配置中添加了按需加载的指定文件夹,针对bizcharts,编译前后代码对比如下:
编译前:

编译后:
注意:bizcharts按需加载需要引入其核心代码bizcharts/lib/core;
到此为止,td-ui和bizcharts的按需加载已经处理完毕,接下来是针对moment的处理。moment的主要体积来源于locale国际化文件夹,由于项目中有中英文国际化的需求,我们这里使用webpack.ContextReplacementPugin对该文件夹的上下文进行匹配,只匹配中文和英文的语言包,plugin配置如下:
new webpack.ContextReplacementPugin(
/moment[\/\\]locale$/, //匹配文件夹
/zh-cn|en-us/ // 中英文语言包
)如果没有国际化的需求,可以使用webpack.IgnorePlugin对整个locale文件夹进行忽略,配置如下:
new webpack.IgnorePlugin(/^\.\/locale$/, /moment$/)减少编译体积大小完成之后得到如下构建对比结果:
| 增量构建 | Development 构建 | Production 构建 | 备注 |
|---|---|---|---|
| 3088ms | 43702ms | 89371ms | |
| 2561ms | 27864ms | 67441ms | 减少编译体积大小 |
为了避免一些已经编译好的大型库重新编译,我们需要将这些库放在编译意外的地方,或者预先编译这些库。
webpack也为我们提供了将模块外链的配置externals,比如我们把lodash外链,配置如下
module.exports = {
//...
externals : {
lodash: 'window._'
},
// 或者
externals : {
lodash : {
commonjs: 'lodash',
amd: 'lodash',
root: '_' // 指向全局变量
}
}
};针对库预先编译,webpack也提供了相应的插件,那就是webpack.Dllplugin,这个插件可以预先编译制定好的库,最后在实际项目中使用webpack.DllReferencePlugin将预先编译好的库关联到当前的编译结果中,无需重新编译。
Dllplugin配置文件webpack.dll.config.js如下:
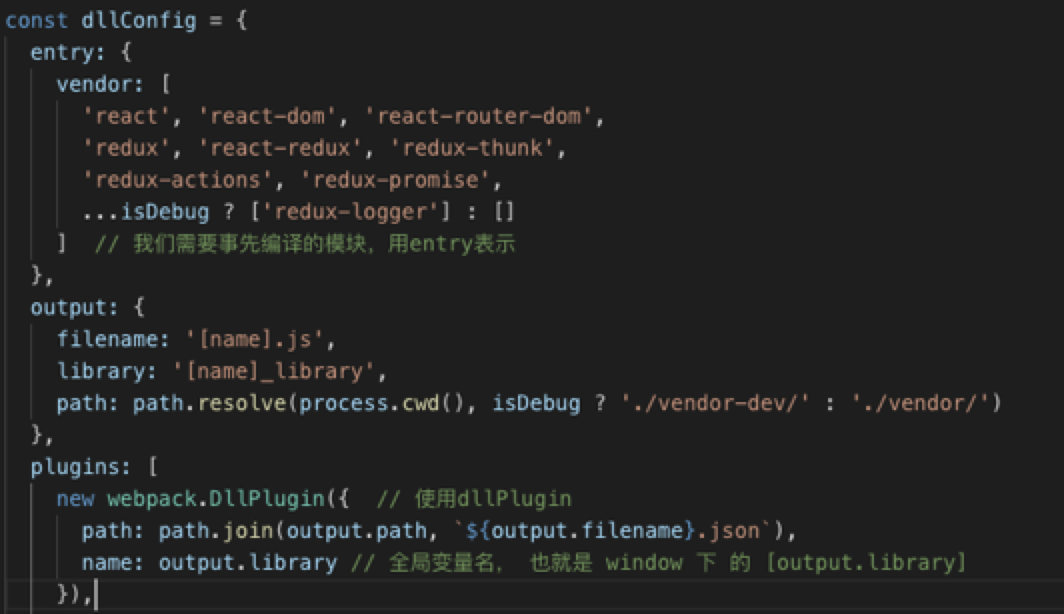
dllReference配置文件webpack.dll.reference.config.js如下:
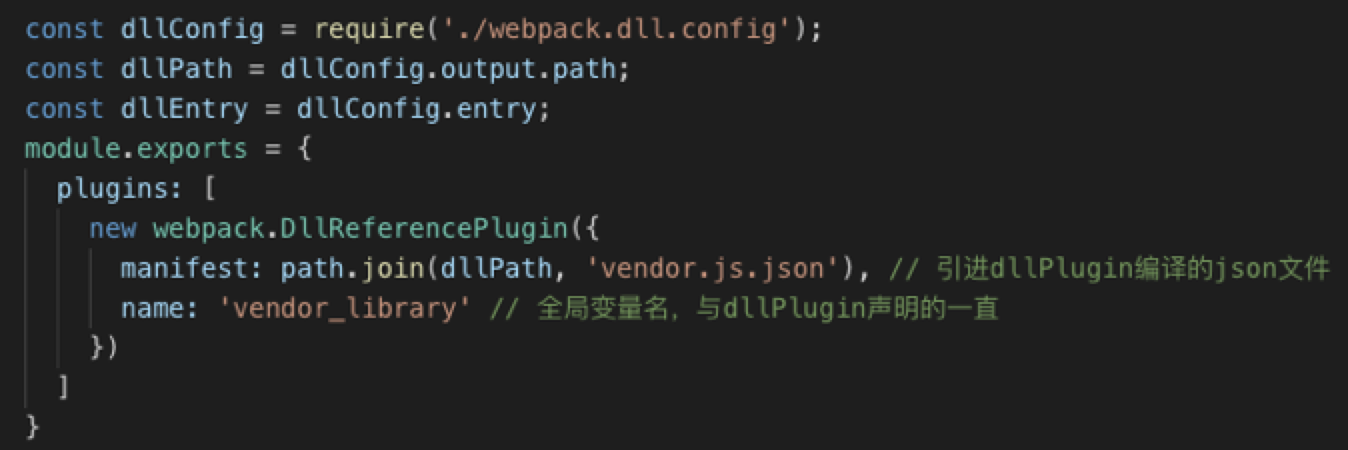
最后使用webpack-merge将webpack.dll.reference.config.js合并到到webpack配置中。
注意:预先编译好的库文件需要在html中手动引入并且必须放在webpack的entry引入之前,否则会报错。
其实,将大型库外链和将库预先编译也属于减少编译体积的一种,最后得到编译时间结果如下:
| 增量构建 | Development 构建 | Production 构建 | 备注 |
|---|---|---|---|
| 3088ms | 43702ms | 89371ms | |
| 2561ms | 27864ms | 67441ms | 减少编译体积大小 |
| 2246ms | 22870ms | 50601ms | Dll优化后 |
首先,我们开启babel-loader自带的缓存功能(默认其实就是打开的)。
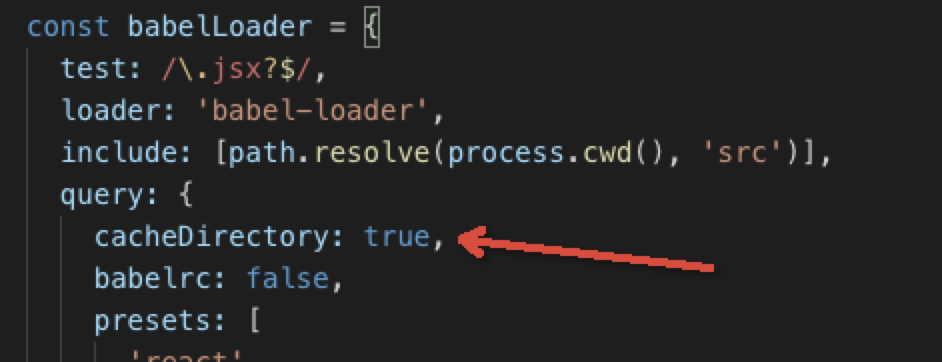
另外,开启uglifyjs-webpack-plugin的缓存功能。
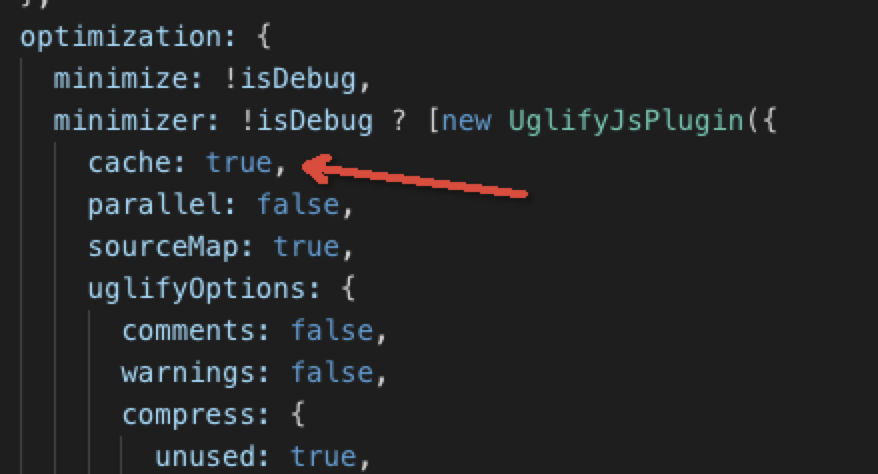
添加缓存插件hard-source-webpack-plugin(当然也可以添加cache-loader)
const hardSourcePlugin = require('hard-source-webpack-plugin');
moudle.exports = {
// ...
plugins: [
new hardSourcePlugin()
],
// ...
}添加缓存后编译结果如下:
| 增量构建 | Development 构建 | Production 构建 | 备注 |
|---|---|---|---|
| 3088ms | 43702ms | 89371ms | |
| 2561ms | 27864ms | 67441ms | 减少编译体积大小 |
| 2246ms | 22870ms | 50601ms | Dll优化后 |
| 1918ms | 10056ms | 17298ms | 使用缓存后 |
可以看到,编译效果极好。
由于nodejs为单线程,为了更好利用好电脑多核的特性,我们可以将编译并行开始,这里我们使用happypack,当然也可以使用thread-loader,我们将babel-loader和样式的loader交给happypack接管。
babel-loader配置如下:
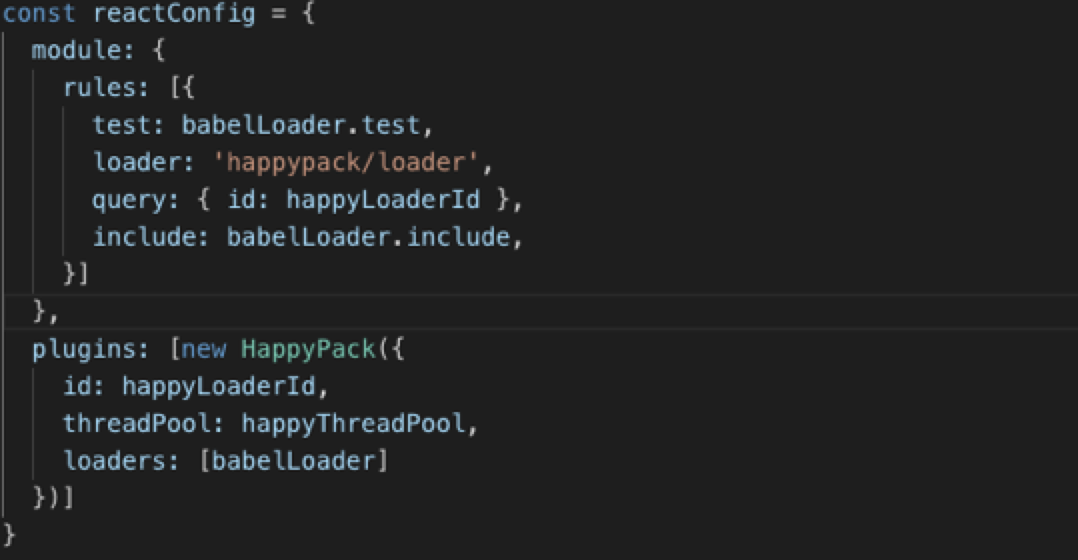
less-loader配置如下:
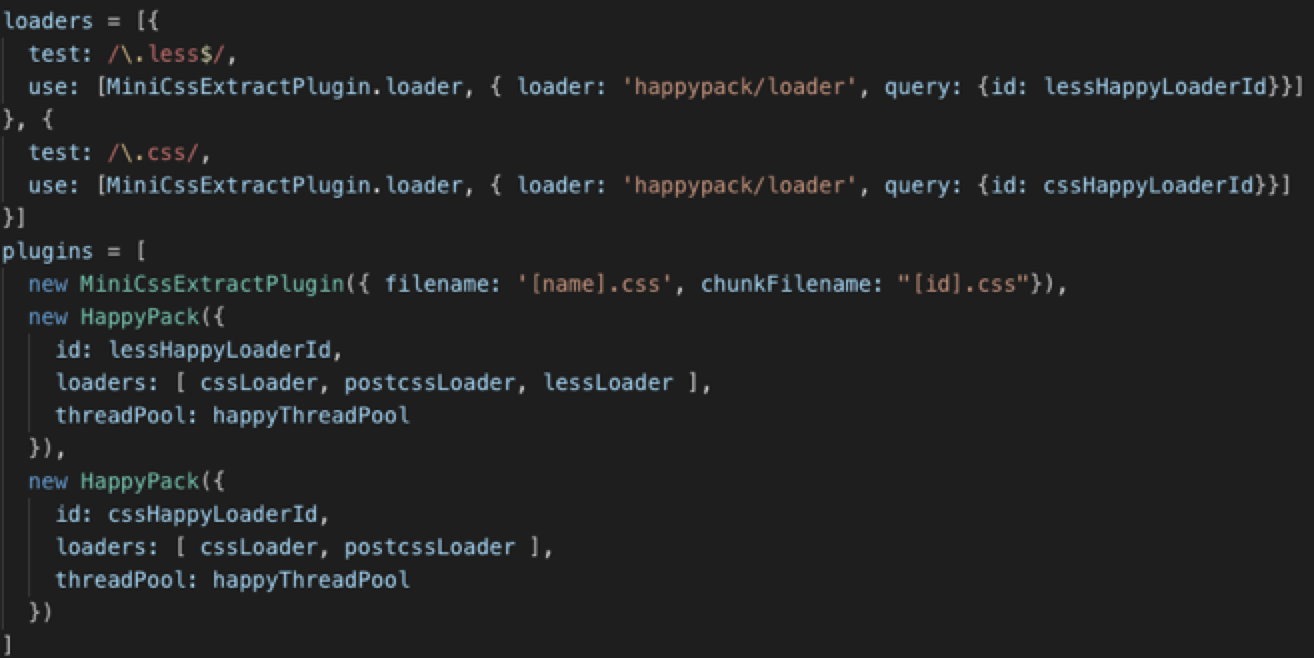
构建结果如下:
| 增量构建 | Development 构建 | Production 构建 | 备注 |
|---|---|---|---|
| 3088ms | 43702ms | 89371ms | |
| 2561ms | 27864ms | 67441ms | 减少编译体积大小 |
| 2246ms | 22870ms | 50601ms | Dll优化后 |
| 1918ms | 10056ms | 17298ms | 使用缓存后 |
| 2252ms | 11846ms | 18727ms | 开启happypack后 |
可以看到,添加happypack之后,编译时间有所增加,针对这个结果,我对webpack版本和项目大小进行了对比测试,如下:
Webpack:v2.7.0
项目:1013个模块
全量production构建:105395ms
添加happypack之后,全量production构建时间降低到58414ms。
针对webpack版本:
Webpack:v4.23.0
项目:1013个模块
全量development构建 : 12352ms
添加happypack之后,全量development构建降低到11351ms。
得到结论:Webpack v4 之后,happypack已经力不从心,效果并不明显,而且在小型中并不适用。
所以针对并行加载方案要不要加,要具体项目具体分析。
对于webpack编译出来的结果,也有相应的性能优化的措施。方案如下:
减少模块数量及大小
合理缓存
合理拆包
针对减少模块数量及大小,我们在构建优化的章节中有提到很多,具体点如下:
前面两点我们就不具体描述,在构建优化章节中有说。
树摇功能,将树上没用的叶子摇下来,寓意将没有必要的代码删除。该功能在webapck V2中已被webpack默认开启,但是使用前提是,模块必须是ES6模块,因为ES6模块为静态分析,动态引入的特性,可以让webpack在构建模块的时候知道,哪些模块内容在引入中被使用,哪些模块没有被使用,然后将没有被引用的的模块在转为为AST后删除。
由于必须使用ES6模块,我们需要将babel的自动模块转化功能关闭,否则你的es6模块将自动转化为commonjs模块,配置如下:
{
"presets": [
"react",
"stage-2",
[
"env",
{
"modlues": false // 关闭babel的自动转化模块功能,保留ES6模块语法
}
]
]
}Tree-shaking编译时候可以在命令后使用--display-used-exports可以在shell打印出关于代码剔除的提示。
作用域提升,尽可能的把打散的模块合并到一个函数中,前提是不能造成代码冗余。因此只有那些被引用了一次的模块才能被合并。
可能不好理解,下面demo对比一下有无Scope-Hoisting的编译结果。
首先定义一个util.js文件
export default 'Hello,Webpack';然后定义入口文件main.js
import str from './util.js'
console.log(str);下面是无Scope-Hoisting结果:
然后是Scope-Hoisting后的结果:
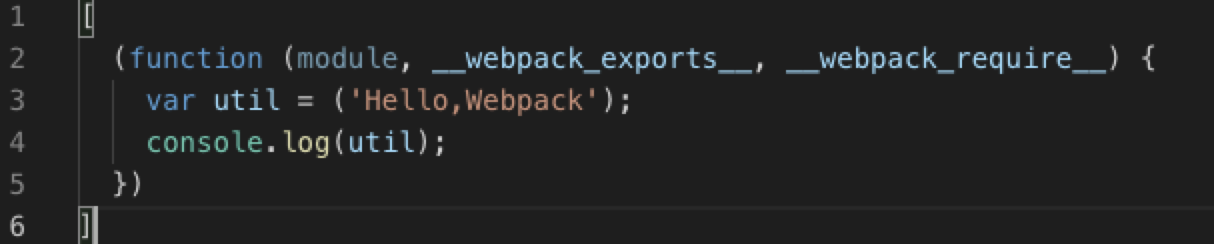
与Tree-Shaking类似,使用Scope-Hoisting的前提也是必须是ES6模块,除此之外,还需要加入webpack内置插件,位于webpack文件夹,webpack/lib/optimize/ModuleConcatenationPlugin,配置如下:
const ModuleConcatenationPlugin = require('webpack/lib/optimize/ModuleConcatenationPlugin');
module.exports = {
//...
plugins: [
new ModuleConcatenationPlugin()
]
//...
}另外,为了跟好的利用Scope-Hoisting,针对Npm的第三方模块,它们也可能提供了ES6模块,我们可以指定优先使用它们的ES6模块,而不是使用它们编译后的代码,webpack的配置如下:
module.exports = {
//...
resolve: {
// 优先采用jsnext:main中指定的ES6模块文件
mainFields: ['jsnext:main', 'module', 'browser', 'main']
}
//...
}jsnext:main为业内大家约定好的存放ES6模块的文件夹,后续为了规范,更改为module文件夹。
在我们实际的项目中,为了兼容一些老式的浏览器,我们需要在项目加入babel-polyfill这个包。由于babel-polyfill太大,导致我们编译后的包体积增大,降低我们的加载性能,但是实际上,我们只需要加入我们使用到的不兼容的内容的polyfill就可以,这个时候babel-plugin-transform-runtime就可以帮我们去除那些我们没有使用到的polyfill,当然,你需要在babal-preset-env中配置你需要兼容的浏览器,否则会使用默认兼容浏览器。
添加babel-plugin-transform-runtime的.babelrc配置如下:
{
"presets": [["env", {
"targets": {
"browsers": ["last 2 versions", "safari >= 7", "ie >= 9", "chrome >= 52"] // 配置兼容浏览器版本
},
"modules": false
}], "stage-2"],
"plugins": [
"transform-class-properties",
"transform-runtime", // 添加babel-plugin-transform-runtime
"transform-decorators-legacy"
]
}webpack对应的缓存方案为添加hash,那我们为什么要给静态资源添加hash呢?
然后,webpack对应的hash有两种,hash和chunkhash。
细想我们期望的最理想的hash就是当我们的编译后的文件,不管是初始化文件,还是chunk文件或者样式文件,只要文件内容一修改,我们的hash就应该更改,然后刷新缓存。可惜,hash和chunkhash的最终效果都没有达到我们的预期。
另外,还有来自于的 extract-text-webpack-plugin的 contenthash,contenthash针对编译后的每个文件内容生成hash。只是extract-text-webpack-plugin在wbepack4中已经被弃用,而且这个插件只对css文件生效。
为了达到我们的预期效果,我们可以为webpack添加webpack-md5-hash插件,这个插件可以让webpack的chunkhash根据文件内容生成hash,相对稳定,这样就可以达到我们预期的效果了,配置如下:
var WebpackMd5Hash = require('webpack-md5-hash');
module.exports = {
// ...
output: {
//...
chunkFilename: "[chunkhash].[id].chunk.js"
},
plugins: [
new WebpackMd5Hash()
]
};为了减少首屏加载的时候,我们需要将包拆分成多个包,然后需要的时候在加载,拆包方案有:
针对第一点第三方包,我们也在第一章节构建优化中有介绍,这里就不详细说了。
首先是import(),这是webpack提供的语法,webpack在解析到这样的语法时,会将指定的目录文件打包成一个chunk,当成异步加载文件输出到编译结果中,语法如下:
import(/* webpackChunkName: chunkName */ './chunkFile.js').then(_module => {
// do something
});import()遵循promise规范,可以在then的回调函数中处理模块。
注意:import()的参数不能完全是动态的,如果是动态的字符串,需要预先指定前缀文件夹,然后webpack会把整个文件夹编译到结果中,按需加载。
然后是require.ensure(),与import()类似,为webpack提供函数,也是用来生成异步加载模块,只是是使用callback的形式处理模块,语法如下:
// require.ensure(dependencies: String[], callback: function(require), chunkName: String)
require.ensure([], function(require){
const _module = require('chunkFile.js');
}, 'chunkName');webpack4中,将commonChunksPlugin废弃,引入splitChunksPlugin,两个plugin的作用都是用来切割chunk。
webpack 把 chunk 分为两种类型,initial和async。在webpack4的默认情况下,production构建会分析你的 entry、动态加载(import()、require.ensure)模块,找出这些模块之间共用的node_modules下的模块,并将这些模块提取到单独的chunk中,在需要的时候异步加载到页面当中。
默认配置如下:
module.exports = {
//...
optimization: {
splitChunks: {
chunks: 'async', // 标记为异步加载的chunk
minSize: 30000,
minChunks: 1,
maxAsyncRequests: 5,
maxInitialRequests: 3,
automaticNameDelimiter: '~', // 文件名中chunk的分隔符
name: true,
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10
},
default: {
minChunks: 2, // 最小共享的chunk数
priority: -20,
reuseExistingChunk: true
}
}
}
}
};splitChunksPlugin提供了灵活的配置,开发者可以根据自己的需求分割chunk,比如下面官方的例子1代码:
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
commons: {
name: 'commons',
chunks: 'initial',
minChunks: 2
}
}
}
}
};
意思是在所有的初始化模块中抽取公共部分,生成一个chunk,chunk名字为comons。
在如官方例子2代码:
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
commons: {
test: /[\\/]node_modules[\\/]/,
name: 'vendors',
chunks: 'all'
}
}
}
}
};意思是从所有模块中抽离来自于node_modules下的所有模块,生成一个chunk。当然这只是一个例子,实际生产环境中并不推荐,因为会使我们首屏加载的包增大。
针对官方例子2,我们可以在开发环境中使用,因为在开发环境中,我们的node_modules下的所有文件是基本不会变动的,我们将其生产一个chunk之后,每次增量编译,webpack都不会去编译这个来自于node_modules的已经生产好的chunk,这样如果项目很大,来源于node_modules的模块非常多,这个时候可以大大降低我们的构建时间。
现在大部分前端项目都是基于webpack进行构建的,面对这些项目,或多或少都有一些需要优化的地方,或许做优化不为完成KPI,仅为自己有更好的开发体验,也应该行动起来。
首先,为什么我需要做这个项目准备工作呢?因为常年习惯React开发的我,最近突然接手了一个Vue项目,而之前基本没有过Vue的实践,这么突兀让还在沉溺于React开发的我进行Vue开发,甚是不习惯,那自然我需要想办法让Vue开发尽量与React相似,这样大概让自己在开发过程中更得心应手吧。
众所周知,Vue和React都有那么一个特性,那就是可以让我们进行组件化开发,这样可以让代码得到更好的重用以及解耦,在架构定位中这个应该叫纵向分层吧。但是,两个框架开发组件的写法都有所不同(这个不同是基于我的开发习惯),下面先看一下不同的地方。
首先是React,个人习惯于es6的写法(从来没用过es5的createClass的写法):
import React, { Component } from 'react';
import propTypes from 'prop-types';
export default class Demo extends Component {
state = {
text: 'hello world'
};
static propTypes = {
title: PropTypes.String
}
static defaultProps = {
title: 'React Demo'
}
setText = e => {
this.setState({
text: '点击了按钮'
})
}
componentWillReveiveProps(nextProps) {
console.log(`标题从 ${this.props.title} 变为了 ${nextProps.title}`)
}
render() {
const { title } = this.props;
const { text } = this.state;
return <div>
<h1>{title}</h1>
<span>{text}<span>
<button onClick={this.setText}>按钮<button>
</div>
}
}下面是常见vue的写法:
<template>
<div>
<h1>{{title}}</h1>
<span>{{text}}<span>
<button @click="setText">按钮</button>
</div>
</template>
<script>
export default {
props: {
title: {
type: String,
default: 'Vue Demo'
}
},
watch: {
title(newTitle, oldTitle) {
console.log(`标题从 ${oldTile} 变为了 ${newTitle}`)
}
},
data() {
return {
text: 'hello world'
}
},
methods: {
setText(e) {
this.text = '点击了按钮';
}
}
}
</script>这里的视图渲染我们先忽略,下一节在详细对比。
prop对比:
prop-types对其声明约束。组件状态对比,Vue为data,React为state:
setState,否则视图不会更新。然后是组件方法对比:
methods字段下声明。React的方法用方法的方式声明在组件下即可。计算属性computed对比:
computed字段中声明。React中无计算属性特性,需要其他库如mobx辅助完成。监听数据对比:
watch字段中对prop、data、computed进行对比,然后做相应的操作。在React所有变化需要在声明周期componentWillReveiveProps中手动将state和prop进行对比。对比完后发现,其实Vue给我的个人感觉就是自己在写配置,只不过配置是以函数的形式在写,然后Vue帮你把这些配置好的东西挂载到组件下面。而且prop、data、computed、方法所有都是挂载组件下,其实单单从js语法上很难以理解,比如说我在computed中,想获取data的text数据,使用的是this.text来获取,如果抛开vue,单单用js语法来看,其实this大多情况是指向computed对象的,所以个人觉得这样的语法是反面向对象的。
这个时候在反过来看React的class写法,本来就是属于面向对象的写法,状态state归状态,属性prop归属性,方法归方法,想获取什么内容,通过this直接获取,更接近于JavaScript编程,相对来说比较好理解。
针对Vue的反面向对象,我们可以更改其写法,通过语法糖的形式,将其我们自己的写法编译成Vue需要的写法。
vue-class-component 是Vue英文官网推荐的一个包,可以以class的模式写vue组件,它带来了很多便利:
vue-property-decorator 这个包完全依赖于vue-class-component,提供了多个装饰器,辅助完成prop、watch、model等属性的声明。
由于使用的是装饰器语法糖,我们需要在我们webpack的babel编译器中对齐进行支持。
首先是class语法支持,针对babel6及更低的版本,需要配置babel的plugin中添加class语法支持插件babel-plugin-transform-class-properties,针对babel7,需要使用插件@babel/plugin-proposal-class-properties对class进行语法转换。
然后是装饰器语法支持,针对babel6及更低的版本,需要配置babel的plugin中添加装饰器语法支持插件babel-plugin-transform-decorators-legacy,针对babel7,需要使用插件@babel/plugin-proposal-decorators对装饰器进行语法转换。
针对bable6,配置.babelrc如下
{
"presets": ["env", "stage-1"],
"plugins": [
"transform-runtime",
"syntax-dynamic-import",
"transform-class-properties", // 新增class语法支持
"transform-decorators-legacy" // 新增装饰器语法支持
]
}对于bable7,官方推荐直接使用@vue/apppreset,该预设包含了@babel/plugin-proposal-class-properties和@babel/plugin-proposal-decorators两个插件,另外还包含了动态分割加载chunks支持@babel/plugin-syntax-dynamic-import,同时也包含了@babel/envpreset,.babelrc配置如下:
{
"presets": [
["@vue/app", {
"loose": true,
"decoratorsLegacy": true
}]
]
}编译插件准备好之后,我们对上面的Vue组件进行改写,代码如下
<template>
<div>
<h1>{{title}}</h1>
<span>{{text}}<span>
<button @click="setText">按钮</button>
</div>
</template>
<script>
import { Vue, Component, Watch, Prop } from 'vue-property-decorator';
@Component
export default class Demo extends Vue {
text = 'hello world';
@Prop({type: String, default: 'Vue Demo'}) title;
@Watch('title')
titleChange(newTitle, oldTitle) {
console.log(`标题从 ${oldTile} 变为了 ${newTitle}`)
}
setText(e) {
this.text = '点击了按钮';
}
}
</script>到此为止,我们的组件改写完毕,相对先前的“写配置”的写法,看起来相对来说要好理解一些吧。
注意:Vue的class的写法的methods还是没办法使用箭头函数进行的,详细原因这里就不展开,大概就是因为Vue内部挂载函数的方式的原因。
针对视图的开发,Vue推崇html、js、css分离的写法,React推崇all-in-js,所有都在js中进行写法。
当然各有各的好处,如Vue将其进行分离,代码易读性较好,但是在html中无法完美的展示JavaScript的编程能力,而对于React的jsx写法,因为有JavaScript的编程语法支持,让我们更灵活的完成视图开发。
对于这类不灵活的情况,Vue也对jsx进行了支持,只需要在babel中添加插件babel-plugin-transform-vue-jsx、babel-plugin-syntax-jsx、babel-helper-vue-jsx-merge-props(babel6,对于babel7,官方推荐的@vue/app预设中已包含了jsx的转化插件),我们就可以像React一样,在组件中声明render函数并返回jsx对象,如下我们对上一节的组件进行改造:
<script>
import { Vue, Component, Watch, Prop } from 'vue-property-decorator';
@Component
export default class Demo extends Vue {
title = 'hello world';
@Prop({type: String, default: 'Vue Demo'}) title;
@Watch('title')
titleChange(newTitle, oldTitle) {
console.log(`标题从 ${oldTile} 变为了 ${newTitle}`)
}
setText(e) {
this.text = '点击了按钮';
}
render() {
const { title, text } = this;
return <div>
<h1>{title}</h1>
<span>{text}<span>
<button onClick={this.setText}>按钮<button>
</div>
}
}
</script>写到这里,也基本上发现其写法已经与React的class写法雷同了。那么Vue的jsx和React的jsx有什么不同呢。
在React的jsx语法需要React支持,也就是说,在你使用jsx的模块中,必须引进React。
而Vue的jsx语法需要Vue的createElement支持,也就是说在你的jsx语法的作用域当中,必须存在变量h,变量h为createElement的别名,这是Vue生态系统中的一个通用惯例,在render中h变量由编译器自动注入到作用域中,自动注入详情见plugin-transform-vue-jsx,如果没有变量h,需要从组件中获取并声明,代码如下:
const h = this.$createElement;这里借助官方的一个例子,基本包含了所有Vue的jsx常用语法,如下:
// ...
render (h) {
return (
<div
// normal attributes or component props.
id="foo"
// DOM properties are prefixed with `domProps`
domPropsInnerHTML="bar"
// event listeners are prefixed with `on` or `nativeOn`
onClick={this.clickHandler}
nativeOnClick={this.nativeClickHandler}
// other special top-level properties
class={{ foo: true, bar: false }}
style={{ color: 'red', fontSize: '14px' }}
key="key"
ref="ref"
// assign the `ref` is used on elements/components with v-for
refInFor
slot="slot">
</div>
)
}但是,Vue的jsx语法无法支持Vue的内建指令,唯一的例外是v-show,该指令可以使用v-show={value}的语法。大多数指令都可以用编程方式实现,比如v-if就是一个三元表达式,v-for就是一个array.map()等。
如果是自定义指令,可以使用v-name={value}语法,但是该语法不支持指令的参数arguments和修饰器modifier。有以下两个解决方法:
v-name={{ value, modifier: true }}const directives = [
{ name: 'my-dir', value: 123, modifiers: { abc: true } }
]
return <div {...{ directives }}/>那么,我们什么时候使用jsx,什么时候template呢?很明显,面对那么复杂多变的视图渲染,我们使用jsx语法更能得心应手,面对简单的视图,我们使用template能开发得更快。
针对状态管理,Vue的Vuex和React的Redux很雷同,都是Flow数据流。
对于React来说,state需要通过mapStateToProps将state传入到组件的props中,action需要通过mapDispatchToProps将action注入到组件的props中,然后在组件的props中获取并执行。
而在Vue中,store在组件的$store中,可以直接this.$store.dispatch(actionType)来分发action,属性也可以通过mapState,或者mapGetter把state或者getter挂载到组件的computed下,更粗暴的可以直接this.$store.state或者this.$store.getter获取,非常方便。
我们为了更贴切于es6的class写法,更好的配合vue-class-component,我们需要通过其他的方式将store的数据注入到组件中。
vuex-class,这个包的出现,就是为了更好的讲Vuex与class方式的Vue组件连接起来。
如下,我们声明一个store
import Vuex from 'vuex';
const store = new Vuex.Store({
modules: {
foo: {
namespaced: true,
state: {
text: 'hello world',
},
actions: {
setTextAction: ({commit}, newText) => {
commit('setText', newText);
}
},
mutations: {
setText: (state, newText) => {
state.text = newText;
}
}
}
}
})针对这个store,我们改写我们上一章节的组件
<template>
<div>
<h1>{{title}}</h1>
<span>{{text}}<span>
<button @click="setText">按钮</button>
</div>
</template>
<script>
import { Vue, Component, Watch, Prop } from 'vue-property-decorator';
import { namespace } from 'vuex-class';
const fooModule = namespace('foo');
@Component
export default class Demo extends Vue {
@fooModule.State('text') text;
@fooModule.Action('setTextAction') setTextAction;
@Prop({type: String, default: 'Vue Demo'}) title;
@Watch('title')
titleChange(newTitle, oldTitle) {
console.log(`标题从 ${oldTile} 变为了 ${newTitle}`)
}
setText(e) {
this.setTextAction('点击了按钮');
}
}
</script>这里可以发现,store声明了一个foo模块,然后在使用的时候从store中取出了foo模块,然后使用装饰器的形式将state和action注入到组件中,我们就可以省去dispatch的代码,让语法糖帮我们dispatch。这样的代码,看起来更贴切与面向对象。。。好吧,我承认这个代码越写越像Java了。
然而,之前的我并不是使用Redux开发React的,而是Mobx,所以这种 dispatch -> action -> matation -> state 的形式对我来说也不是很爽,我还是更喜欢把状态管理也以class的形式去编写,这个时候我又找了另外一个包(vuex-module-decorators)[https://www.npmjs.com/package/vuex-module-decorators]来改写我的store.module。
下面我们改写上面的store:
import Vuex from 'vuex';
import { Module, VuexModule, Mutation, Action } from 'vuex-module-decorators';
@Module
class foo extends VuexModule {
text = 'hello world'
@Mutation
setText(text) {
this.text = text;
}
@Action({ commit: 'setText' })
setTextAction(text) {
return text;
}
}
const store = new Vuex.Store({
modules: {
foo: foo
})
export default store;这样,我们的项目准备基本上完毕了,把Vue组件和Vuex状态管理以class的形式来编写。大概是我觉得es5的写法显得不太优雅吧,没有es6的写法那么高端。
class语法和装饰器decorators语法都是ES6的提案,都带给了前端不一样的编程体验,大概也是前端的一个比较大的革命吧,我们应该拥抱这样的革命变化。
C/S协议,请求与响应构成,短连接协议,请求响应完成后马上断开连接。
GET请求包含一个URL,然后是请求头,POST除了URL和请求头外,还拥有请求体,请求之前要组装请求体,所以速度上没有GET请求快。
HTTP响应包含请求码、响应头和响应体。
如果浏览器支持和服务器支持的话,使用压缩来减少响应大小。浏览器使用Accept-Encoding:gzip,deflate来声明它支持压缩。服务器使用Content-Encoding:gzip来确认响应内容已被压缩。
对缓存的内容进行确认的请求(通过判断Last-Modified),如果服务端确认有效,则进行下一步确认是否使用缓存。
在次确认是否使用缓存,客户端和服务端的再一次往返确认,以执行有效性检验。
使浏览器和客户端可以在一次连接下进行多次请求,使用Connecttion头来支出对Keep-Alive的支持,使用Connecttion: close来关闭连接。
80%~90%时间花在HTML文档所应用的组件上(图片、脚本、样式等)进行的HTTP请求上,因为是短连接,每次都需要进行重连,所以耗时长。
合并图片,把css的背景图片合并在一张图片中,通过background-position来控制显示。
通过是使用data:URL模式,如使用base64流图片,这样的图片无需进行HTTP请求。
每个脚本与样式表都要建立一次HTTP请求,与合并图片类似,把脚本和样式表合并在一起,减少HTTP请求次数。
一组分布在多个不同地理位置的WEB服务器,用于更加有效的向用户发布内容。CDN可以选择地理位置最近的或者响应时间最短的服务器对其内容进行响应。
通过使用长久的Expires头,可以使一些资源被缓存,这会会在后续的页面浏览中避免不必要的HTTP请求。
Web服务器用Expires头来告诉客户端,可以使用一个组件的当前副本,知道指定时间为止。
如Expires: Thu 15 Apr 2010 20:00:00 GMT
这是一个长久有效的Expires头,告诉浏览器该响应有效性持续到2010年4约14日为止,如果为一个页面中的一张图片返回了这个头,浏览器在后续的页面浏览中会使用缓存的图片,这将减少一个HTTP请求的数量。
Expires用的是一个特定的时间,它要求服务器和客户端的时钟严格同步,Cache-Control:Max-Age可以克服这种限制,Cache-Control使用max-age指令指定组件被缓存多久,它以秒为单位定义了一个更新窗。
如果HTTP请求产生的响应包很小,传输时间就会减少,因为只需要将很小的包从服务器传输到客户端,这样对速度较慢的带宽效果尤其明显。
从http1.1开始,Web客户端可以通过HTTP请求头中的Accept-Encoding来表示对压缩的支持。gzip是目前最流行和最有效的方法,deflate效果略逊且不太流行。
可以压缩HTML、JSON、XML、脚本和样式(很多网站没有做)。
图片和PDF不应该压缩,因为它们本来就被压缩了。
压缩成本:服务器CPU资源、客户端要对压缩的文件进行解压。
对代理服务器来说,可以缓存来自web服务器的资源,但是不同的浏览器对gzip的支持不一样,那么假如代理服务器缓存了一份gzip过的组件,但是一个不支持gzip的浏览器请求了这个代理服务器,那么将无法正常解压这个组件,所以需要在空缓存,也就是第一次请求是把给请求头加上Vary:Accept-Encoding,告诉代理服务器,为Accept-Encoding请求头的每个值多缓存一份,这样有无Accept-Encoding:gzip都可以进行处理了。
样式表与脚本的放置顺序决定了下载的优先级,由于CSS会阻塞DOM的渲染,所以CSS放在顶部,可以使页面第一次渲染的时候把样式呈现完整,如果CSS放在底部,页面会先呈现没有样式的页面,等CSS样式加载完成,在进行一次回流重绘,降低了用户体验。
浏览器为了保证脚本的执行顺序,在解析html的时候,遇到JavaScript脚本标签,会阻止浏览器的并行加载。假如脚本放在页面顶部的话,会阻塞对其他内容的下载和呈现,直至脚本加载完毕,所以需要把脚本放在页面底部,这样不会阻止页面内容的呈现,而且页面中的可视组件可以今早下载。
CSS表达式,即在CSS中是用JavaScript表达式,如下
background-color: expression((new Date()).getHours() % 2 ? "#b8d4ff" : "#f08a00")表达式的问题在于对其进行求值的频率比人们期望的要高,它不只在页面呈现的大小改变时求值,当页面滚动、甚至用户鼠标在页面上移动时都要求值。也正因为更新频率太高,所以会验证影响页面的性能。
使用代码处理,让更新频率只执行一次,如下
background-color: expression(altBgcolor(this))function altBgcolor(elem) {
Elem.style.backgroundColor = (new Date()).getHours() % 2 ? "#b8d4ff" : "#f08a00"
}内联的优点:
缺点:
外部JavaScript与CSS的优点:
缺点:
纯粹而言(空缓存),内联的效率要比外部文件要快得多,因为减少了很多http请求,但是当用户多次访问的时候(完整缓存),内联的效率会明显低于外部文件。
DNS:Domain Name System,将域名映射到IP地址,URL和实际宿主它们的服务器之间的间接层。通常,浏览器查找一个给定的主机名的IP地址要话费20~120毫秒,故DNS查询次数越多,页面效率越慢。
DNS查找可以被缓存起来以提高性能,浏览器、操作系统都可以对DNS进行缓存,当我们浏览器缓存DNS后,就不会麻烦操作系统来解析这个域名。
TTL(Time-to-live),影响DNS缓存的因素,该值告诉客户端可以对该记录缓存多久,浏览器通常会忽略该值,操作系统才会考虑TTL。HTTP协议中的keep-alive可以同时覆盖TTL和浏览器的时间限制,也就是说只要浏览器与服务器保持这TCP连接的打开状态,就不会进行DNS查询。
当客户端的DNS缓存为空时候,DNS的查找数量与web页面中唯一主机名的数量相同,包括URL、图片、脚本、样式表等主机名。减少唯一主机名的数量就可以减少DNS查找数量(每个主机名并行下载的组件有限)。
通过工具构造静态资源文件,减少JavaScript与CSS文件大小来加快加载速度。
重定向会增加http请求的次数,会影响到整个网站的性能,但是必要的重定向又可以提高用户体验,所以我们需要在性能和用户体验之间去权衡,达到最好的目的。
以百度为例:用户在浏览器中输入网址 http://www.baidu.com/ 或者 http://www.baidu.com/index.php ,实际上访问的都是本站的首页;用户在浏览器中输入网址 http://www.baidu.com/ 或者 http://baidu.com/ ,访问的依然都是本站的首页。
实体标签(Entity Tag)是Web服务器和浏览器用于确认缓存组件的有效性的一种机制。ETag是唯一表示了一个组件的一个特定版本的字符串。唯一的格式约束是该字符串必须用引号引起来。ETag的假如为验证实体提供了比最新更新时间更灵活的机制,即如果ETag不一致,则使用不使用缓存。
在Promise没有出现之前,异步编程需要通过回调的方式进行完成,当回调函数嵌套过多时,会使代码丑化,也降低了代码的可理解性,后期维护起来会相对困难,Promise是异步编程的一种解决方案,比传统的解决方案——回调函数和事件——更合理和更强大。它由社区最早提出和实现,ES6将其写进了语言标准,统一了用法,原生提供了Promise对象,本文主要针对Promise/A+规范,实现一个小型的Promise对象。
Promise规范有很多,如Promise/A,Promise/B,Promise/D 以及 Promise/A 的升级版Promise/A+,因为ES6主要用的是Promise/A+规范,该规范内容也比较多,我们挑几个简单的说明下:
pending、fulfilled、reject,状态之间的转化只能是pending->fulfilled、pending->reject,状态变化不可逆。then方法,该方法可以被调用多次,并且返回一个Promise对象(返回新的Promise还是老的Promise对象,规范没有提)。具体规范可参考:
由于Promise为状态机,我们需先定义状态
var PENDING = 0; // 进行中
var FULFILLED = 1; // 成功
var REJECTED = 2; // 失败function Promise(fn) {
var state = PENDING; // 存储PENDING, FULFILLED或者REJECTED的状态
var value = null; // 存储成功或失败的结果值
var handlers = []; // 存储成功或失败的处理程序,通过调用`.then`或者`.done`方法
// 成功状态变化
function fulfill(result) {
state = FULFILLED;
value = result;
handlers.forEach(handle); // 处理函数,下文会提到
handlers = null;
}
// 失败状态变化
function reject(error) {
state = REJECTED;
value = error;
handlers.forEach(handle); // 处理函数,下文会提到
handlers = null;
}
}resolve方法可以接受两种参数,一种为普通的值/对象,另外一种为一个Promise对象,如果是普通的值/对象,则直接把结果传递到下一个对象;
如果是一个 Promise 对象,则必须先等待这个子任务序列完成。
function Promise(fn) {
...
function resolve(result) {
try {
var then = getThen(result);
if (then) {
doResolve(then.bind(result), resolve, reject)
return;
}
fulfill(result);
} catch (e) {
reject(e);
}
}
...
}resolve需要两个辅助方法getThen、和doResolve。
// getThen 检查如果value是一个Promise对象,则返回then方法等待执行完成。
function getThen(value) {
var t = typeof value;
if (value && (t === 'object' || t === 'function')) {
var then = value.then;
if (typeof then === 'function') {
return then;
}
}
return null;
}
// 异常参数检查函数,确保onFulfilled和onRejected两个函数中只执行一个且只执行一次,但是不保证异步。
function doResolve(fn, onFulfilled, onRejected) {
var done = false;
try {
fn(
function(value) {
if (done) return;
done = true;
onFulfilled(value);
},
function(reason) {
if (done) return;
done = true;
onRejected(reason);
}
);
} catch(ex) {
if (done) return;
done = true;
onRejected(ex);
}
}上面已经完成了一个完整的内部状态机,但我们并没有暴露一个方法去解析或则观察 Promise 。现在让我们开始解析 Promise :
function Promise(fn) {
...
doResolve(fn, resolve, reject);
}如你所见,我们复用了doResolve,因为对于初始化的fn也要对其进行控制。fn允许调用resolve或则reject多次,甚至抛出异常。这完全取决于我们去保证promise对象仅被resolved或则rejected一次,且状态不能随意改变。
在实现then方法之前,我们这里实现了一个执行方法done,该方法用来处理执行then方法的回调函数,一下为promise.done(onFullfilled, onRejected)方法的几个点。
function Promise(fn) {
...
// 不同状态,进行不同的处理
function handle(handler) {
if (state === PENDING) {
handlers.push(handler);
} else {
if (state === FULFILLED && typeof handler.onFulfilled === 'function') {
handler.onFulfilled(value);
}
if (state === REJECTED && typeof handler.onRejected === 'function') {
handler.onRejected(value);
}
}
}
this.done = function (onFulfilled, onRejected) {
// 保证异步
setTimeout(function () {
handle({onFulfilled: onFulfilled, onRejected: onRejected});
}, 0);
}
}当 Promise 被 resolved 或者 rejected 时,我们保证 handlers 将被通知。
then方法
function Promise(fn) {
...
this.then = function(onFulfilled, onRejected) {
var self = this;
return new Promise(function (resolve, reject) {
self.done(function (result) {
if (typeof onFulfilled === 'function') {
try {
// onFulfilled方法要有返回值!
return resolve(onFulfilled(result));
} catch (ex) {
return reject(ex);
}
} else {
return resolve(result);
}
}, function (error) {
if (typeof onRejected === 'function') {
try {
return resolve(onRejected(error));
} catch (ex) {
return reject(ex);
}
} else {
return reject(error);
}
});
});
}
}catch方法,我们直接调用then处理异常
this.catch = function(errorHandle) {
return this.then(null, errorHandle);
}以上为promise实现原理~
在Promise没有出现之前,异步编程需要通过回调的方式进行完成,当回调函数嵌套过多时,会使代码丑化,也降低了代码的可理解性,后期维护起来会相对困难,Promise是异步编程的一种解决方案,比传统的解决方案——回调函数和事件——更合理和更强大。它由社区最早提出和实现,ES6将其写进了语言标准,统一了用法,原生提供了Promise对象,本文主要针对Promise/A+规范,实现一个小型的Promise对象。
Promise规范有很多,如Promise/A,Promise/B,Promise/D 以及 Promise/A 的升级版Promise/A+,因为ES6主要用的是Promise/A+规范,该规范内容也比较多,我们挑几个简单的说明下:
pending、fulfilled、reject,状态之间的转化只能是pending->fulfilled、pending->reject,状态变化不可逆。then方法,该方法可以被调用多次,并且返回一个Promise对象(返回新的Promise还是老的Promise对象,规范没有提)。具体规范可参考:
由于Promise为状态机,我们需先定义状态
var PENDING = 0; // 进行中
var FULFILLED = 1; // 成功
var REJECTED = 2; // 失败function Promise(fn) {
var state = PENDING; // 存储PENDING, FULFILLED或者REJECTED的状态
var value = null; // 存储成功或失败的结果值
var handlers = []; // 存储成功或失败的处理程序,通过调用`.then`或者`.done`方法
// 成功状态变化
function fulfill(result) {
state = FULFILLED;
value = result;
handlers.forEach(handle); // 处理函数,下文会提到
handlers = null;
}
// 失败状态变化
function reject(error) {
state = REJECTED;
value = error;
handlers.forEach(handle); // 处理函数,下文会提到
handlers = null;
}
}resolve方法可以接受两种参数,一种为普通的值/对象,另外一种为一个Promise对象,如果是普通的值/对象,则直接把结果传递到下一个对象;
如果是一个 Promise 对象,则必须先等待这个子任务序列完成。
function Promise(fn) {
...
function resolve(result) {
try {
var then = getThen(result);
if (then) {
doResolve(then.bind(result), resolve, reject)
return;
}
fulfill(result);
} catch (e) {
reject(e);
}
}
...
}resolve需要两个辅助方法getThen、和doResolve。
// getThen 检查如果value是一个Promise对象,则返回then方法等待执行完成。
function getThen(value) {
var t = typeof value;
if (value && (t === 'object' || t === 'function')) {
var then = value.then;
if (typeof then === 'function') {
return then;
}
}
return null;
}
// 异常参数检查函数,确保onFulfilled和onRejected两个函数中只执行一个且只执行一次,但是不保证异步。
function doResolve(fn, onFulfilled, onRejected) {
var done = false;
try {
fn(
function(value) {
if (done) return;
done = true;
onFulfilled(value);
},
function(reason) {
if (done) return;
done = true;
onRejected(reason);
}
);
} catch(ex) {
if (done) return;
done = true;
onRejected(ex);
}
}上面已经完成了一个完整的内部状态机,但我们并没有暴露一个方法去解析或则观察 Promise 。现在让我们开始解析 Promise :
function Promise(fn) {
...
doResolve(fn, resolve, reject);
}如你所见,我们复用了doResolve,因为对于初始化的fn也要对其进行控制。fn允许调用resolve或则reject多次,甚至抛出异常。这完全取决于我们去保证promise对象仅被resolved或则rejected一次,且状态不能随意改变。
在实现then方法之前,我们这里实现了一个执行方法done,该方法用来处理执行then方法的回调函数,一下为promise.done(onFullfilled, onRejected)方法的几个点。
function Promise(fn) {
...
// 不同状态,进行不同的处理
function handle(handler) {
if (state === PENDING) {
handlers.push(handler);
} else {
if (state === FULFILLED && typeof handler.onFulfilled === 'function') {
handler.onFulfilled(value);
}
if (state === REJECTED && typeof handler.onRejected === 'function') {
handler.onRejected(value);
}
}
}
this.done = function (onFulfilled, onRejected) {
// 保证异步
setTimeout(function () {
handle({onFulfilled: onFulfilled, onRejected: onRejected});
}, 0);
}
}当 Promise 被 resolved 或者 rejected 时,我们保证 handlers 将被通知。
then方法
function Promise(fn) {
...
this.then = function(onFulfilled, onRejected) {
var self = this;
return new Promise(function (resolve, reject) {
self.done(function (result) {
if (typeof onFulfilled === 'function') {
try {
// onFulfilled方法要有返回值!
return resolve(onFulfilled(result));
} catch (ex) {
return reject(ex);
}
} else {
return resolve(result);
}
}, function (error) {
if (typeof onRejected === 'function') {
try {
return resolve(onRejected(error));
} catch (ex) {
return reject(ex);
}
} else {
return reject(error);
}
});
});
}
}catch方法,我们直接调用then处理异常
this.catch = function(errorHandle) {
return this.then(null, errorHandle);
}以上为promise实现原理~
人家都说,前端需要每年定期出来面面试,衡量一下自己当前的技术水平以及价值,本人17年7月份,毕业到现在都没出来试过,也没很想换工作,就出来试试,看看自己水平咋样。
以下为我现场面试时候的一些回答,部分因人而异的问题我就不回答了,回答的都为参考答案,也有部分错误的地方或者不好的地方,有更好的答案的可以在评论区评论。
先完成笔试题
function run(input) {
if (typeof input !== 'string') return false;
return input.split('').reverse().join('') === input;
}// 1
.wrapper {
position: relative;
.box {
position: absolute;
top: 50%;
left: 50%;
width: 100px;
height: 100px;
margin: -50px 0 0 -50px;
}
}
// 2
.wrapper {
position: relative;
.box {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
}
// 3
.wrapper {
.box {
display: flex;
justify-content:center;
align-items: center;
height: 100px;
}
}
// 4
.wrapper {
display: table;
.box {
display: table-cell;
vertical-align: middle;
}
}
const box = document.getElementById('box');
function isIcon(target) {
return target.className.includes('icon');
}
box.onclick = function(e) {
e.stopPropagation();
const target = e.target;
if (isIcon(target)) {
target.style.border = '1px solid red';
}
}
const doc = document;
doc.onclick = function(e) {
const children = box.children;
for(let i = 0; i < children.length; i++) {
if (isIcon(children[i])) {
children[i].style.border = 'none';
}
}
}<input id="input"/>const data = {};
const input = document.getElementById('input');
Object.defineProperty(data, 'text', {
set(value) {
input.value = value;
this.value = value;
}
});
input.onchange = function(e) {
data.text = e.target.value;
}var instance = null;
class Storage {
static getInstance() {
if (!instance) {
instance = new Storage();
}
return this.instance;
}
setItem = (key, value) => localStorage.setItem(key, value),
getItem = key => localStorage.getItem(key)
}Q1 你的技术栈主要是react,那你说说你用react有什么坑点?
1、JSX做表达式判断时候,需要强转为boolean类型,如:
render() {
const b = 0;
return <div>
{
!!b && <div>这是一段文本</div>
}
</div>
}如果不使用 !!b 进行强转数据类型,会在页面里面输出 0。
2、尽量不要在 componentWillReviceProps 里使用 setState,如果一定要使用,那么需要判断结束条件,不然会出现无限重渲染,导致页面崩溃。(实际不是componentWillReviceProps会无限重渲染,而是componentDidUpdate)
3、给组件添加ref时候,尽量不要使用匿名函数,因为当组件更新的时候,匿名函数会被当做新的prop处理,让ref属性接受到新函数的时候,react内部会先清空ref,也就是会以null为回调参数先执行一次ref这个props,然后在以该组件的实例执行一次ref,所以用匿名函数做ref的时候,有的时候去ref赋值后的属性会取到null。
详情见
4、遍历子节点的时候,不要用 index 作为组件的 key 进行传入。
Q2 我现在有一个button,要用react在上面绑定点击事件,要怎么做?
class Demo {
render() {
return <button onClick={(e) => {
alert('我点击了按钮')
}}>
按钮
</button>
}
}Q3 接上一个问题,你觉得你这样设置点击事件会有什么问题吗?
由于onClick使用的是匿名函数,所有每次重渲染的时候,会把该onClick当做一个新的prop来处理,会将内部缓存的onClick事件进行重新赋值,所以相对直接使用函数来说,可能有一点的性能下降(个人认为)。
修改
class Demo {
onClick = (e) => {
alert('我点击了按钮')
}
render() {
return <button onClick={this.onClick}>
按钮
</button>
}
}当然你在内部声明的不是箭头函数,然后你可能需要在设置onClick的时候使用bind绑定上下文,这样的效果和先前的使用匿名函数差不多,因为bind会返回新的函数,也会被react认为是一个新的prop。
Q4 你说说event loop吧
首先,js是单线程的,主要的任务是处理用户的交互,而用户的交互无非就是响应DOM的增删改,使用事件队列的形式,一次事件循环只处理一个事件响应,使得脚本执行相对连续,所以有了事件队列,用来储存待执行的事件,那么事件队列的事件从哪里被push进来的呢。那就是另外一个线程叫事件触发线程做的事情了,他的作用主要是在定时触发器线程、异步HTTP请求线程满足特定条件下的回调函数push到事件队列中,等待js引擎空闲的时候去执行,当然js引擎执行过程中有优先级之分,首先js引擎在一次事件循环中,会先执行js线程的主任务,然后会去查找是否有微任务microtask(promise),如果有那就优先执行微任务,如果没有,在去查找宏任务macrotask(setTimeout、setInterval)进行执行。
Q5 说说事件流吧
事件流分为两种,捕获事件流和冒泡事件流。
捕获事件流从根节点开始执行,一直往子节点查找执行,直到查找执行到目标节点。
冒泡事件流从目标节点开始执行,一直往父节点冒泡查找执行,直到查到到根节点。
DOM�事件流分为三个阶段,一个是捕获节点,一个是处于目标节点阶段,一个是冒泡阶段。
Q6 我现在有一个进度条,进度条中间有一串文字,当我的进度条覆盖了文字之后,文字要与进度条反色,怎么实现?
。。。当时我给的是js的方案,在进度条宽度变化的时候,计算盖过每一个文字的50%,如果超过,设置文字相反颜色。
当然css也有对应的方案,也就是 mix-blend-mode,我并没有接触过。
对应html也有对应方案,也就设置两个相同位置但是颜色相反的dom结构在重叠在一起,顶层覆盖底层,最顶层的进度条取overflow为hidden,其宽度就为进度。
Q1 你为什么要离开上一家公司?
-
Q2 你觉得理想的前端地位是什么?
-
Q3 那你意识到问题所在,你又尝试过解决问题吗?
-
Q1 说一下你上一家公司的一个整体开发流程吧
-
Q2 react 的虚拟dom是怎么实现的
首先说说为什么要使用Virturl DOM,因为操作真实DOM的耗费的性能代价太高,所以react内部使用js实现了一套dom结构,在每次操作在和真实dom之前,使用实现好的diff算法,对虚拟dom进行比较,递归找出有变化的dom节点,然后对其进行更新操作。为了实现虚拟DOM,我们需要把每一种节点类型抽象成对象,每一种节点类型有自己的属性,也就是prop,每次进行diff的时候,react会先比较该节点类型,假如节点类型不一样,那么react会直接删除该节点,然后直接创建新的节点插入到其中,假如节点类型一样,那么会比较prop是否有更新,假如有prop不一样,那么react会判定该节点有更新,那么重渲染该节点,然后在对其子节点进行比较,一层一层往下,直到没有子节点。
Q3 react 的渲染过程中,兄弟节点之间是怎么处理的?也就是key值不一样的时候。
通常我们输出节点的时候都是map一个数组然后返回一个ReactNode,为了方便react内部进行优化,我们必须给每一个reactNode添加key,这个key prop在设计值处不是给开发者用的,而是给react用的,大概的作用就是给每一个reactNode添加一个身份标识,方便react进行识别,在重渲染过程中,如果key一样,若组件属性有所变化,则react只更新组件对应的属性;没有变化则不更新,如果key不一样,则react先销毁该组件,然后重新创建该组件。
Q4 我现在有一个数组[1,2,3,4],请实现算法,得到这个数组的全排列的数组,如[2,1,3,4],[2,1,4,3]。。。。你这个算法的时间复杂度是多少
这个我没写出来,大概给了个思路,将每一个数组拆除俩个小数组进行求它的全排列,然后得到的结果互相之间又进行全排列,然后把最后的结果连接起来。。。
感兴趣的同学见数组全排列
Q5 我现在有一个背包,容量为m,然后有n个货物,重量分别为w1,w2,w3...wn,每个货物的价值是v1,v2,v3...vn,w和v没有任何关系,请求背包能装下的最大价值。
这个我也没写出来,也给了个思路,首先使用Q4的方法得到货物重量数组的全组合(包括拆分成小数组的全组合),然后计算每一个组合的价值,并进行排序,然后遍历数组,找到价值较高切刚好能装进背包m的组合。
本题动态规划面试题,感兴趣的同学请自行百度或者谷歌。
Q1 请说一下你的上一家公司的研发发布流程。
-
Q2 你说一下webpack的一些plugin,怎么使用webpack对项目进行优化。
正好最近在做webpack构建优化和性能优化的事儿,当时吹了大概15~20分钟吧,插件请见webpack插件归纳总结。
构建优化
1、减少编译体积 ContextReplacementPugin、IgnorePlugin、babel-plugin-import、babel-plugin-transform-runtime。
2、并行编译 happypack、thread-loader、uglifyjsWebpackPlugin开启并行
3、缓存 cache-loader、hard-source-webpack-plugin、uglifyjsWebpackPlugin开启缓存、babel-loader开启缓存
4、预编译 dllWebpackPlugin && DllReferencePlugin、auto-dll-webapck-plugin
性能优化
1、减少编译体积 Tree-shaking、Scope Hositing。
2、hash缓存 webpack-md5-plugin
3、拆包 splitChunksPlugin、import()、require.ensure
Q3 es6 class 的new实例和es5的new实例有什么区别
这个我觉得是一样的(当时因为很少看babel编译之后的结果),面试官说不一样。。。后来我看了一下babel的编译结果,发现只是类的方法声明的过程不一样而已,最后new的结果是一样的。。。具体答案现在我也不知道。。。
Q4 看你简历上写了canvas,你说一下为什么canvas的图片为什么过有跨域问题。
canvas图片为什么跨域我不知道,至今没查出来,也差不多,大概跨域原因和浏览器跨域的原因是一样的吧。
Q5 我现在有一个canvas,上面随机布着一些黑块,请实现方法,计算canvas上有多少个黑块。
使用getImageData获取像素数组,然后遍历数组,把在遍历节点的过程中,查看节点上下左右的像素颜色是否相同,如果相同,然后设置标识,最后groupBy一下所有像素。(这是我当时的方案)
其他更好的答案见地址
Q6 请手写实现一个promise
这个就不写了,详情见promise实现原理
注:四面是一个超级可爱的小姐姐,电脑给我让我写完之后,我说我写得差不多了,然后电脑给她,然后她竟然默默的在看我的代码,尝试寻找我的思路,也没有问我实现思路是啥,然后我就问她,你不应该是让我给你解释我的代码思路吗。。。你竟然在尝试寻找我的思路,我自己都不知道我自己是思路是啥。。。然后我两都笑了,哈哈哈。最后结束的时候我说我午饭还没吃,她还叫了另外一个小哥哥先带了下去吃饭,真是一个善良的小姐姐,非常感谢。
Q1 你说一下你的技术有什么特点
-
Q2 说一下你觉得你最得意的一个项目?你这个项目有什么缺陷,弊端吗?
-
Q3 现在有那么一个团队,假如让你来做技术架构,你会怎么做?
考虑到团队每一个前端的技术栈可能不一致,这个时候我可能选择微前端架构,让每个人负责的模块可以单独开发,单独部署,单独回滚,不依赖于其他项目模块,在尽可能的情况下节约团队成员之间的学习成本,当然这肯定也有缺点,那就是每个模块都需要一个前端项目,单独部署,单独回滚无疑也加大了运维成本。
Q4 说一下你上一家公司的主要业务流程,你参与到其中了吗?
-
Q1 自我介绍
-
Q2 说说从输入URL到看到页面发生的全过程,越详细越好。
Q3 你刚刚说了三次握手,四次挥手,那你描述一下?
本人对计算机网络的这些概念一直不是很熟悉,所以这个问题回答不会,这里mark下文章,感兴趣的同学查看地址
Q4 刚刚Q2中说的CSS和JS的位置会影响页面效率,为什么?
css在加载过程中不会影响到DOM树的生成,但是会影响到Render树的生成,进而影响到layout,所以一般来说,style的link标签需要尽量放在head里面,因为在解析DOM树的时候是自上而下的,而css样式又是通过异步加载的,这样的话,解析DOM树下的body节点和加载css样式能尽可能的并行,加快Render树的生成的速度。
js脚本应该放在底部,原因在于js线程与GUI渲染线程是互斥的关系,如果js放在首部,当下载执行js的时候,会影响渲染行程绘制页面,js的作用主要是处理交互,而交互必须得先让页面呈现才能进行,所以为了保证用户体验,尽量让页面先绘制出来。
Q5 现在有一个函数A和函数B,请你实现B继承A
// 方式1
function B(){}
function A(){}
B.prototype = new A();
// 方式2
function A(){}
function B(){
A.call(this);
}
// 方式3
function B(){}
function A(){}
B.prototype = new A();
function B(){
A.call(this);
}Q6 刚刚你在Q5中说的几种继承的方式,分别说说他们的优缺点
方式1:简单易懂,但是无法实现多继承,父类新增原型方法/原型属性,子类都能访问到
方式2:可以实现多继承,但是只能继承父类的实例属性和方法,不能继承原型属性/方法
方式3:可以继承实例属性/方法,也可以继承原型属性/方法,但是示例了两个A的构造函数
Q7 说说CSS中几种垂直水平居中的方式
参考前面百度一面笔试题Q2
Q8 Q7中说的flex布局,垂直水平居中必须知道宽度吗?
是的,必须知道高度(�脑子进水了回答了必须知道,其实答案是不需要知道高度的)
Q9 描述一下this
this,函数执行的上下文,可以通过apply,call,bind改变this的指向。对于匿名函数或者直接调用的函数来说,this指向全局上下文(浏览器为window,nodejs为global),剩下的函数调用,那就是谁调用它,this就指向谁。当然还有es6的箭头函数,箭头函数的指向取决于该箭头函数声明的位置,在哪里声明,this就指向哪里。
Q10 说一下浏览器的缓存机制
浏览器缓存机制有两种,一种为强缓存,一种为协商缓存。
对于强缓存,浏览器在第一次请求的时候,会直接下载资源,然后缓存在本地,第二次请求的时候,直接使用缓存。
对于协商缓存,第一次请求缓存且保存缓存标识与时间,重复请求向服务器发送缓存标识和最后缓存时间,服务端进行校验,如果失效则使用缓存。
强缓存方案
Exprires:服务端的响应头,第一次请求的时候,告诉客户端,该资源什么时候会过期。Exprires的缺陷是必须保证服务端时间和客户端时间严格同步。
Cache-control:max-age,表示该资源多少时间后过期,解决了客户端和服务端时间必须同步的问题,
协商缓存方案
If-None-Match/ETag:缓存标识,对比缓存时使用它来标识一个缓存,第一次请求的时候,服务端会返回该标识给客户端,客户端在第二次请求的时候会带上该标识与服务端进行对比并返回If-None-Match标识是否表示匹配。
Last-modified/If-Modified-Since:第一次请求的时候服务端返回Last-modified表明请求的资源上次的修改时间,第二次请求的时候客户端带上请求头If-Modified-Since,表示资源上次的修改时间,服务端拿到这两个字段进行对比。
Q11 ETag是这个字符串是怎么生成的?
没答出来,我当时猜是根据文件内容或者最后修改时间进行的加密算法。其实官方没有明确指定生成ETag值的方法。 通常,使用内容的散列,最后修改时间戳的哈希值,或简单地使用版本号。
Q12 现在要你完成一个Dialog组件,说说你设计的思路?它应该有什么功能?
Q13 你觉得你做过的你觉得最值得炫耀的项目?
Q1 描述一下你最近做的可视化的项目
Q2 刚刚说的java调用js离线生成数据报告?java调用js的promise异步返回结果怎么实现的?
使用java的js引擎Nashorn,Nashorn不支持事件队列,是要引进polyfill,然后java调用js方法获得java的promise对象,然后在调用该对象的then方法,回调函数为java中的某各类的某个方法,然后while一个表示是否已执行回调的变量,如果未执行,则让java主线程sleep,如果已经执行,则跳出循环,表示是否已执行回调的变量在传入promise的回调函数中设置更改。详情代码见地址
Q3 说说svg和canvas各自的优缺点?
共同点:都是有效的图形工具,对于数据较小的情况下,都很又高的性能,它们都使用 JavaScript 和 HTML;它们都遵守万维网联合会 (W3C) 标准。
svg优点:
矢量图,不依赖于像素,无限放大后不会失真。
以dom的形式表示,事件绑定由浏览器直接分发到节点上。
svg缺点:
dom形式,涉及到动画时候需要更新dom,性能较低。
canvas优点:
定制型更强,可以绘制绘制自己想要的东西。
非dom结构形式,用JavaScript进行绘制,涉及到动画性能较高。
canvas缺点:
事件分发由canvas处理,绘制的内容的事件需要自己做处理。
依赖于像素,无法高效保真,画布较大时候性能较低。
Q4 你刚刚说的canvas渲染较大画布的时候性能会较低?为什么?
因为canvas依赖于像素,在绘制过程中是一个一个像素去绘制的,当画布足够大,像素点也就会足够多,那么想能就会足够低。
Q6 假设我现在有5000个圆,完全绘制出来,点击某一个圆,该圆高亮,另外4999个圆设为半透明,分别说说用svg和canvas怎么实现?
首先,从数据出发,我们的每个圆是一个数据,这个数据有圆的x、y、radius�、isHighlight如果是svg,直接渲染节点即可,然后往节点上边绑定点击事件,点击改变所有数据的高亮属性(必须同步执行完成),然后让浏览器进行绘制。如果是canvas,我们需要自己绑定事件到canvans标签上,然后点击的时候判断点击的位置是否在圆内,如果在某个圆内,则更新所有数据的高亮属性,之后在进行一次性绘制。
Q7 刚刚说的canvas的点击事件,怎么样实现?假如不是圆,这些图形是正方形、长方形、规则图形、不规则图形呢。
针对于每一个形状,将其抽象成shape类,每一个类有自己的方法isPointInSide来判断节点是否在图形内,对于不规则图形,当做矩形处理,点击的时候执行该方法判断点击位置是否在图形内。
Q8 那假如我的图形可能有变形、放大、偏移、旋转的需求呢?你的这个isPointInSide怎么处理?
这个我答不出来,据面试官提示,好像有相应的API处理变形、旋转、放大等等之后的位置映射关系。
Q9 那个这个canvas的点击事件,点击的时候怎么样快速的从这5000个圆中找到你点击的那个圆(不完全遍历5000个节点)?
可以通过预查找的形式,当鼠标划过的时候预先查找到鼠标附近的一些节点,当点击的时候在从这些预先筛选好的节点里查找点击下来的节点,当然这个方法的前提是不能影响js主线程的执行,必须是异步的形式。
Q10 那你用过@antv/g6,里面有一个tree,说说你大学时候接触到的tree的数据结构是怎么实现的?
毕业一年多,tree的结构大概忘记了,我当时是这么回答的:
大学使用的是C++学的数据结构,是用指针的形式,首先有一个根节点,根节点里有一个指针数组指向它的所有子节点,然后每一个子节点也是,拥有着子节点的指针数组,一层一层往下,直到为叶子节点,指针数组指向为空。
Q11 还记得二叉树吗?描述二叉树的几种遍历方式?
先序遍历:若二叉树非空,访问根结点,遍历左子树,遍历右子树。
中序遍历:若二叉树非空,遍历左子树;访问根结点;遍历右子树。
后序遍历:若二叉树非空,遍历左子树;遍历右子树;访问根结点。
所有遍历是以递归的形似,直到没有子节点。
Q12 说说你记得的所有的排序,他们的原理是什么?
冒泡排序:双层遍历,对比前后两个节点,如果满足条件,位置互换,直到遍历结束。
快速排序:去数组中间的那一个数,然后遍历所有数,小于该数的push到一个数组,大于该数的push到另外一个数组,然后递归去排序这两个数组,最后将所有结果连接起来。
选择排序:声明一个数组,每次去输入数组里面找数组中的最大值或者最小值,取出来后push到声明的数组中,直到输入数组为空。
Q13 说一下你觉得你做过的最复杂的项目?中间遇到的困难,以及你是怎么解决的?
面试官:我这边问题差不多问完了,你还有什么问题?
我:很惊讶今天全都是问可视化相关的,没怎么问js,css,html。
面试官:那我们继续吧
我:。。。
Q14 那给我介绍一下react吧(面试官是做可视化开发的,根本不懂react)
以前我们没有jquery的时候,我们大概的流程是从后端通过ajax获取到数据然后使用jquery生成dom结果然后更新到页面当中,但是随着业务发展,我们的项目可能会越来越复杂,我们每次请求到数据,或则数据有更改的时候,我们又需要重新组装一次dom结构,然后更新页面,这样我们手动同步dom和数据的成本就越来越高,而且频繁的操作dom,也使我我们页面的性能慢慢的降低。
这个时候mvvm出现了,mvvm的双向数据绑定可以让我们在数据修改的同时同步dom的更新,dom的更新也可以直接同步我们数据的更改,这个特定可以大大降低我们手动去维护dom更新的成本,mvvm为react的特性之一,虽然react属于单项数据流,需要我们手动实现双向数据绑定。
有了mvvm还不够,因为如果每次有数据做了更改,然后我们都全量更新dom结构的话,也没办法解决我们频繁操作dom结构(降低了页面性能)的问题,为了解决这个问题,react内部实现了一套虚拟dom结构,也就是用js实现的一套dom结构,他的作用是讲真实dom在js中做一套缓存,每次有数据更改的时候,react内部先使用算法,也就是鼎鼎有名的diff算法对dom结构进行对比,找到那些我们需要新增、更新、删除的dom节点,然后一次性对真实DOM进行更新,这样就大大降低了操作dom的次数。
那么diff算法是怎么运作的呢,首先,diff针对类型不同的节点,会直接判定原来节点需要卸载并且用新的节点来装载卸载的节点的位置;针对于节点类型相同的节点,会对比这个节点的所有属性,如果节点的所有属性相同,那么判定这个节点不需要更新,如果节点属性不相同,那么会判定这个节点需要更新,react会更新并重渲染这个节点。
react设计之初是主要负责UI层的渲染,虽然每个组件有自己的state,state表示组件的状态,当状态需要变化的时候,需要使用setState更新我们的组件,但是,我们想通过一个组件重渲染它的兄弟组件,我们就需要将组件的状态提升到父组件当中,让父组件的状态来控制这两个组件的重渲染,当我们组件的层次越来越深的时候,状态需要一直往下传,无疑加大了我们代码的复杂度,我们需要一个状态管理中心,来帮我们管理我们状态state。
这个时候,redux出现了,我们可以将所有的state交给redux去管理,当我们的某一个state有变化的时候,依赖到这个state的组件就会进行一次重渲染,这样就解决了我们的我们需要一直把state往下传的问题。redux有action、reducer的概念,action为唯一修改state的来源,reducer为唯一确定state如何变化的入口,这使得redux的数据流非常规范,同时也暴露出了redux代码的复杂,本来那么简单的功能,却需要完成那么多的代码。
后来,社区就出现了另外一套解决方案,也就是mobx,它推崇代码简约易懂,只需要定义一个可观测的对象,然后哪个组价使用到这个可观测的对象,并且这个对象的数据有更改,那么这个组件就会重渲染,而且mobx内部也做好了是否重渲染组件的生命周期shouldUpdateComponent,不建议开发者进行更改,这使得我们使用mobx开发项目的时候可以简单快速的完成很多功能,连redux的作者也推荐使用mobx进行项目开发。但是,随着项目的不断变大,mobx也不断暴露出了它的缺点,就是数据流太随意,出了bug之后不好追溯数据的流向,这个缺点正好体现出了redux的优点所在,所以针对于小项目来说,社区推荐使用mobx,对大项目推荐使用redux。
Q15 假如我一个组件有一个状态count为1,然后我在componentDidMount()里面执行执行了两次this.setState({count: ++this.state.count}),然后又执行了两次setTimeout(() => { this.setState({count: ++this.state.count}) }, 0),最后count为多少?为什么?
count为4,因为第二次执行setState的时候,取不到第一次++this.state.count的结果,react在一轮生命周期结束后才会更新内部的state,如果在一轮生命周期内多次使用了setState,react内部会有一个字段isBatchUpdate标识本次更新为批量更新,然后在最后render的时候将所有setState的结果提交到state中,一次性进行更新,并且把isBatchUpdate这个字段设置为false。
备注:这个count的答案似乎有疑问,写了个demo,答案并不是4,Demo地址 https://jsfiddle.net/yacan8/5gspLrda/13/
针对于两次setTimeout,js引擎会把这两个setState丢到事件队列中,等待js空闲了去执行,而我们的渲染函数render是同步执行的(react16版本默认没有开启异步渲染),所以等我们render执行完全,也就是我们的state被同步完后,在取事件队列里面的setState进行执行,setTimeout的第二个setState也是一样的,所以最后结果是4。
Q16 说一下你觉得你做过的最值得你说的吧
-
这几轮面试的面试官都非常和蔼好交流,百度的五轮面试不知道过了没有,只记得五面的面试官说,你稍等一下,我去问一下其他人对你还有什么其他要求,然后过了一会儿HR就喊我先回去了,叫我等HR面的消息,如果没通过,也不会在联系我了,已经过了四天了,但愿后面有消息吧。然后有赞、蚂蚁金服的两个一面都过了,因为每次面完试面试官问我还有什么问题吗?我都会询问一下本次面试面试官对我的评论是啥。
接上一篇面试总结一年半经验,百度、有赞、阿里面试总结,把这段时间的面试结束一下吧。
本文主要记录一下当天面试的全过程(可能有遗漏,事隔三四天了,我已经尽量回忆了),答案亦为参考答案,仅供借鉴。
有赞一面结束后过了两天就收到了二面的邀请,我回复面试邀请的短信,说最近可能请假太多,能不能约到晚上面试,对方很很爽快的答应了,就约在了晚上七点半,我回复可以的,然后第二天,收到了确切的面试的时间和地点,时间定在了晚上7点15分。
到了面试当天,我提前了五分钟下班,照着百度地图的提示路线(约1小时9分钟),到了公交站等车。。。然后等呀等,等了十五分钟公交还没来,怕自己迟到,就打了个滴滴过去,到了面试地点之后上到了公司的前台,前台没有人,可能是因为到饭点了,前台去吃饭了吧。然后看到前台那层楼好多人在打乒乓球,大家也玩得挺开心,看起来环境也很不错,当时想,诶呀,原来有赞的环境这么好。等了一会儿之后,看了一下短信,发现面试邀请里留有面试官的联系电话,果断打了过去,过了一会儿面试官到前台接我,然后找了一个会议室,开始了当天的面试。
面试官:先自我介绍吧
我:巴拉巴拉...
面试官:先说一下你上一家公司的研发部署流程
我:巴拉巴拉...(其实这个是我绝活,每次都可以吹很久)
面试官:既然你们是文件覆盖式发布,那你们的缓存是怎么刷新的
我:从公司的业务出发,巴拉巴拉...(还没说完)
面试官:那我现在就不谈业务,你说一下浏览器的缓存方案吧
我:哦,脱离业务呀,首先,浏览器有两种缓存方案,一种是强缓存一种是协商缓存。
面试官:嗯,那怎么使用强缓存?
我:浏览器在第一次请求资源的时候,服务端响应头里可以设置expires字段,该字段表示该资源的缓存过期时间,第二次请求的时候,如果时间还在该缓存时间之内,则会直接使用缓存,否则重新加载资源,这个expires字段有个缺陷,就是它必须服务端和客户端的时间严格同步才能生效,所以现在很多人不会使用改方案。另外一种方案是第一次请求资源的时候,服务端设置响应头cache-control: max-age,这样设置的意思是告诉浏览器,这个资源什么时候过期,等第二次请求资源的时候,判断是否超出了过期时间,如果没超出,直接使用缓存。
面试官:cache-control这个头是服务端设置的还是客户端设置的?
我:cache-control服务端设置的
面试官:cache-control的其他值,你也说一下吧
我:首先是public,客户端和服务端都可以缓存;然后是private,只能客户端缓存;no-store,不使用缓存;no-cache,使用协商缓存。
面试官:那你往下说,说一下协商缓存
我:协商缓存有两种,一种是Last-Modified,就是第一次请求资源的时候,服务端会在响应头里面设置该字段,表示该资源的最后修改时间,浏览器第二次请求该资源的时候,会在请求头里面加上一个字段If-Modified-Since,值为第一次请求的时候服务端返回的Last-Modified的值,服务端会判断资源当时的最后更改时间与请求头里面的If-Modified-Since字段是否相同,如果相同,则告诉客户端使用缓存,否则重新下载资源。然后另外一种协商缓存时使用ETag,原理与Last-Modified类似,就是第一次请求的时候,服务端会根据资源的内容或者最后修改时间生成一个标识,然后在响应头里面设置为ETag返回给客户端,客户端第二次请求的时候会在请求头里面带上这个ETag,也就是在请求头里面加上If-None-Match字段,服务端接收到了ETag之后判断是否与原来第一次的标识相同,如果相同,则告诉客户端使用缓存。
说一下Last-modified/If-Modified-Since和If-None-Match/ETag两种方案的优缺点
我:嗯呢,这个我想一想(我并不知道,假装思考一下)......我觉得其实ETag其实也是有的时候是根据资源的最后修改时间生成的,原理和Last-modified好像有点类似,而ETag需要耗费服务端的资源去生成,所以性能较低。。。(虽然不会,也尽量说说,万一面试官也不知道呢。哈哈哈哈)
面试官:那说一下性能优化的方案吧
我:首先,减少HTTP请求次数,比如说合并CSS和JS文件,但是也不要完全的合并在同一个文件里面,一个域名分散三四个资源,这样方便浏览器去并行下载,当然浏览器对每个域名的并行下载个数有限制,一个域名分配三四个资源虽然增加了HTTP请求数量,但是对比并行下载来说,性价比更高。
面试官:为什么浏览器要限制同一域名并行下载资源的个数。
我:嗯呢,这个我也想一下(其实我也不知道)......这个我没有深究过,难道是因为浏览器启动了太多下载线程的原因?
面试官:下载资源和线程有什么关系?
我:除了了每个标签页是一个进程以外,浏览器有一个进程是专门用来管理下载,我觉得大概是每下载一个资源启动一个线程吧(反正我也不知道,也猜猜结果是不是这样)
面试官:(沉默了一会儿),进程和线程区别是什么
我:进程是分配内存的最小单位,线程是CPU调度的最小单位,进程可以包含多个线程。
面试官:nodejs用得多吗?说一下nodejs线程之间是怎么通信的
我:nodejs用的比较少,nodejs可以启动子线程,然后用主线程来监听订阅子线程的消息,子线程之间的通信,由主线程来控制。
面试官:好吧,性能优化继续往下说
我:减少HTTP请求数量还可以把图标合并在同一张图片里面,使用的时候用background-position去控制。然后首屏的时候图片使用懒加载的形式,尽量在需要显示的时候在加载它,当然占位符和图片尽量指定宽度和高度,避免图片加载完之后替换图片浏览器会进行回流。
面试官:图片懒加载怎么实现
我:监听浏览器的滚动事件,结合clientHeight、offsetHeight、scrollTop、scrollHeight等等变量计算当前图片是否在可视区域,如果在,则替换src加载图片,当然这个滚动事件要主要节流。
面试官:怎么判断图片是否加载完成
我:使用onload事件。
面试官:好吧,你继续往下说。
我:性能优化的话,还可以合理的利用缓存,尽量把CSS和JS文件使用外链的形式,虽然使用内联的CSS和JS在空缓存的时候更快,因为内联的样式和脚本不需要发送HTTP请求,但是为了尽量发挥浏览器的缓存功能,尽量使用外链形式。
我:然后尽量把CSS放在头部,JS放在底部。
面试官:假如现在页面里放在head的css文件下载速度很慢,页面会出现什么情况?
我:大概页面会等待这个CSS的下载,这个时候页面是白屏状态,然后这个CSS资源会有一个超时时间,假如超过了这个超时时间,这个资源相当于会下载失败,浏览器会直接跳过这个CSS资源,根据已有的CSS资源生成CSS规则树,进而生成Render树,然后渲染页面。
面试官:假如我现在在页面动态添加了一个CSS文件,页面一定会回流吗?
我:只要加入的CSS影响到了页面的结构,那么浏览器就会回流。
面试官:例如页面这个CSS文件中有translate3d呢?
我:其实我感觉它不会回流,因为translate3d只是变换了自己的位置,不会影响其他元素的位置,但是实际上是会造成回流的。
面试官:那假如我在页面里面加了一个<div style="position:absolute;width:0;hegiht:0"></div>呢,会回流吗
我:不会,因为没有影响页面结构的变化。
面试官:好吧,那你继续往下说
我:性能优化,尽量使用CDN。
面试官:CDN的原理是啥?
我:首先,浏览器会先请求CDN域名,CDN域名服务器会给浏览器返回指定域名的CNAME,浏览器在对这些CNAME进行解析,得到CDN缓存服务器的IP地址,浏览器在去请求缓存服务器,CDN缓存服务器根据内部专用的DNS解析得到实际IP,然后缓存服务器会向实际IP地址请求资源,缓存服务器得到资源后进行本地保存和返回给浏览器客户端。
面试官:你来实现以下刚刚说的节流函数吧
。。。当时有点不记得什么是防抖,什么节流,把函数写成了防抖。(这个时候有一个人走进了会议室,好像是一面小哥)
var debounce = function(fn, delay, context) {
let timer = null;
return function() {
if (timer) {
clearTimeout(timer);
}
timer = setTimeout(() => {
const arg = Array.prototype.slice.call(arguments);
fn.apply(context, arg);
}, delay)
}
}
// 测试部分
var run = function(text) {
console.log(text);
}
run = debounce(run, 200);
run('run1');
run('run2');
setTimeout(() => {
run('run3');
}, 201)面试官:我这边没有什么问题了,你还有什么要补充的吗?
我:那我把性能优化这个问题说完?
面试官:可以。
然后我开始描述使用webpack使用进行减少js文件的体积,可以使用babel-plugin-import、babel-plugin-component、webpack.ContextReplacementPlugin、webpack.IgnorePlugin...
面试官:这个我知道。你还有什么问题吗?(大概是想结束面试了吧,不想让我往下说了)
我:巴拉巴拉。。。问了很多关于有赞公司的问题,比如公司有多少层楼啊、公司主要技术栈啊、公司主要做2B还是2C的啊,公司有多少前端的啊(本人可能还是太啰嗦)
最后问了一个问题,问了一下面试官本次便是的评价是啥,面试官只回了一句,还好吧。然后面试到此结束了,全称大概一个多小时。
面试结束后,面试官送我到电梯口。。。可以说楼层是真的高,上楼和下楼都需要等很久的电梯。。。到了外面之后,下着大雨,落汤鸡似的又打了个滴滴回家,结束了当天的面试之旅。
直到昨天,收到了有赞的面试结果回复邮件,告知没有合适的职位(有赞还是挺不错的,没通过面试还通知一下),心里虽然有点不甘,但是想想确实可能是自己不够优秀,或者是自己面得不是很好,或者是自己的能力跟公司的职位不太匹配。
在上一篇面试总结中一年半经验,百度、有赞、阿里面试总结,部分同学关心最后面试结果情况,情况是已经有幸的收到了百度的offer,蚂蚁金服的一面面试已经过一周了,不知道是因为流程太长还是一面被挂了。
这个时候一想,其实面试还是有很大的运气成分在里面,正好公司需要,正好你又合适,这个时候就很幸运。
Nashorn JavaScript引擎是Java SE 8 的一部分,并且和其它独立的引擎例如 Google V8(用于Google Chrome和Node.js的引擎)互相竞争。Nashorn通过在JVM上,以原生方式运行动态的JavaScript代码来扩展Java的功能。
Java代码中简单的HelloWorld如下所示:
ScriptEngine engine = new ScriptEngineManager().getEngineByName("nashorn");
engine.eval("print('Hello World!');");为了在Java中执行JavaScript,你首先要通过javax.script包创建脚本引擎。
JavaScript代码既可以通过传递JavaScript代码字符串,也可以传递指向你的JS脚本文件的FileReader来执行:
ScriptEngine engine = new ScriptEngineManager().getEngineByName("nashorn");
engine.eval(new FileReader("script.js"));Nashorn JavaScript基于 ECMAScript 5.1,但是它的后续版本会对ES6提供支持:
Nashorn的当前策略遵循ECMAScript规范。当我们在JDK8中发布它时,它将基于ECMAScript 5.1。Nashorn未来的主要发布基于ECMAScript 6。
Nashorn 支持从Java代码中直接调用定义在脚本文件中的JavaScript函数。你可以将Java对象传递为函数参数,并且从函数返回数据来调用Java方法。
var fun1 = function(name) {
print('Hi there from Javascript, ' + name);
return "greetings from javascript";
};
var fun2 = function (object) {
print("JS Class Definition: " + Object.prototype.toString.call(object));
};ScriptEngine内置了invokeFunction方法,提调用javascript函数并返回结果。
ScriptEngine engine = new ScriptEngineManager().getEngineByName("nashorn");
engine.eval(new FileReader("script.js"));
Object result = invocable.invokeFunction("fun1", "Peter Parker");
System.out.println(result);
System.out.println(result.getClass());
// Hi there from Javascript, Peter Parker
// greetings from javascript
// class java.lang.String##在JavaScript中调用Java方法
在JavaScript中调用Java方法十分容易。我们首先需要定义一个Java静态方法。
static String fun1(String name) {
System.out.format("Hi there from Java, %s", name);
return "greetings from java";
}Java类可以通过Java.typeAPI扩展在JavaScript中引用。它就和Java代码中的import类似。只要定义了Java类型,我们就可以自然地调用静态方法fun1(),然后像sout打印信息。由于方法是静态的,我们不需要首先创建实例。
var MyJavaClass = Java.type('my.package.MyJavaClass');
var result = MyJavaClass.fun1('John Doe');
print(result);
// Hi there from Java, John Doe
// greetings from java在使用JavaScript原生类型调用Java方法时,Nashorn 如何处理类型转换?让我们通过简单的例子来弄清楚。
下面的Java方法简单打印了方法参数的实际类型:
static void fun2(Object object) {
System.out.println(object.getClass());
}为了理解背后如何处理类型转换,我们使用不同的JavaScript类型来调用这个方法:
MyJavaClass.fun2(123);
// class java.lang.Integer
MyJavaClass.fun2(49.99);
// class java.lang.Double
MyJavaClass.fun2(true);
// class java.lang.Boolean
MyJavaClass.fun2("hi there")
// class java.lang.String
MyJavaClass.fun2(new Number(23));
// class jdk.nashorn.internal.objects.NativeNumber
MyJavaClass.fun2(new Date());
// class jdk.nashorn.internal.objects.NativeDate
MyJavaClass.fun2(new RegExp());
// class jdk.nashorn.internal.objects.NativeRegExp
MyJavaClass.fun2({foo: 'bar'});
// class jdk.nashorn.internal.scripts.JO4JavaScript原始类型转换为合适的Java包装类,而JavaScript原生对象会使用内部的适配器类来表示。要记住jdk.nashorn.internal中的类可能会有所变化,所以不应该在客户端面向这些类来编程。
##ScriptObjectMirror
在向Java传递原生JavaScript对象时,你可以使用ScriptObjectMirror类,它实际上是底层JavaScript对象的Java表示。ScriptObjectMirror实现了Map接口,位于jdk.nashorn.api中。这个包中的类可以用于客户端代码。
下面的例子将参数类型从Object改为ScriptObjectMirror,所以我们可以从传入的JavaScript对象中获得一些信息。
static void fun3(ScriptObjectMirror mirror) {
System.out.println(mirror.getClassName() + ": " +
Arrays.toString(mirror.getOwnKeys(true)));
}当向这个方法传递对象(哈希表)时,在Java端可以访问其属性:
MyJavaClass.fun3({
foo: 'bar',
bar: 'foo'
});
// Object: [foo, bar]我们也可以在Java中调用JavaScript的成员函数。让我们首先定义JavaScript Person类型,带有属性firstName 和 lastName,以及方法getFullName。
function Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
this.getFullName = function() {
return this.firstName + " " + this.lastName;
}
}JavaScript方法getFullName可以通过callMember()在ScriptObjectMirror上调用。
static void fun4(ScriptObjectMirror person) {
System.out.println("Full Name is: " + person.callMember("getFullName"));
}当向Java方法传递新的Person时,我们会在控制台看到预期的结果:
var person1 = new Person("Peter", "Parker");
MyJavaClass.fun4(person1);
// Full Name is: Peter Parker通过使用promise实现服务端渲染。
由于当前Nashorn基于es5,不支持部分es6对象,我们需要引入polyfill文件,nashorn-polyfill。
该polyfill通过java与JavaScript的结合使用,使Nashorn支持console, process, Blob, Promise等对象和setTimeout, clearTimeout, setInterval, clearInterval等函数。
实例化工具类,通过该类操作Javascript对象。
public class NashornHelper {
/**
* 用于本类的日志
*/
private static final Logger logger = LoggerFactory.getLogger(NashornHelper.class);
private static final String JAVASCRIPT_DIR = "static"; // js文件目录
private static final String LIB_DIR = JAVASCRIPT_DIR + File.separator + "lib";
private static final String[] VENDOR_FILE_NAME = {"vendor.js"}; // webpack打包的三方库,如react,lodash
private static final String SRC_DIR = JAVASCRIPT_DIR + File.separator + "src"; // 文件目录
private static final String POLYFILL_FILE_NAME = "nashorn-polyfill.js";
private final NashornScriptEngine engine;
private static NashornHelper nashornHelper;
private static ScriptContext sc = new SimpleScriptContext();
private static ScheduledExecutorService globalScheduledThreadPool = Executors.newScheduledThreadPool(20);
// 单例模式
public static synchronized NashornHelper getInstance() {
if (nashornHelper == null) {
long start = System.currentTimeMillis();
nashornHelper = new NashornHelper();
long end = System.currentTimeMillis();
logger.error("init nashornHelper cost time {}ms", (end - start));
}
return nashornHelper;
}
private NashornHelper(){
long start = System.currentTimeMillis();
engine = (NashornScriptEngine) new ScriptEngineManager().getEngineByName("nashorn");
Bindings bindings = new SimpleBindings();
bindings.put("logger", logger); // 向nashorn引擎注入logger对象
sc.setBindings(engine.createBindings(), ScriptContext.ENGINE_SCOPE);
sc.getBindings(ScriptContext.ENGINE_SCOPE).putAll(bindings);
sc.setAttribute("__IS_SSR__", true, ScriptContext.ENGINE_SCOPE);
sc.setAttribute("__NASHORN_POLYFILL_TIMER__", globalScheduledThreadPool, ScriptContext.ENGINE_SCOPE);
engine.setBindings(sc.getBindings(ScriptContext.ENGINE_SCOPE), ScriptContext.ENGINE_SCOPE);
long end = System.currentTimeMillis();
logger.info("init nashornHelper cost time {}ms", (end - start));
try { // 执行js文件
engine.eval(read(LIB_DIR + File.separator + POLYFILL_FILE_NAME));
for (String fileName : NashornHelper.VENDOR_FILE_NAME) {
engine.eval(read(SRC_DIR + File.separator + fileName));
}
engine.eval(read(SRC_DIR + File.separator + "app.js"));
} catch (ScriptException e) {
logger.error("load javascript failed.", e);
}
}
// 获取Nashorn作用域下的对象
public ScriptObjectMirror getGlobalGlobalMirrorObject(String objectName) {
return (ScriptObjectMirror) engine.getBindings(ScriptContext.ENGINE_SCOPE).get(objectName);
}
// 调用全局方法
public Object callRender(String methodName, Object... input) {
try {
return engine.invokeFunction(methodName, input);
} catch (ScriptException e) {
logger.error("run javascript failed.", e);
return null;
} catch (NoSuchMethodException e) {
logger.error("no such method.", e);
return null;
}
}
// 读取文件
private Reader read(String path) {
InputStream in = getClass().getClassLoader().getResourceAsStream(path);
return new InputStreamReader(in);
}实例化工具类
NashornHelper engine = NashornHelper.getInstance();执行调用javasript,java中获取promise对象
ScriptObjectMirror promise = (ScriptObjectMirror) engine.callRender("ssr_render");执行promise的then方法,等待执行完成并回调
promise.callMember("then", fnResolve);
ScriptObjectMirror nashornEventLoop = engine.getGlobalGlobalMirrorObject("nashornEventLoop");
nashornEventLoop.callMember("process"); // 执行nashornEventLoops.process()使主线程执行回调函数
int i = 0;
int jsWaitTimeout = 1000 * 60;
int interval = 200; // 等待时间间隔
int totalWaitTime = 0; // 实际等待时间
while (!promiseResolved && totalWaitTime < jsWaitTimeout) {
nashornEventLoop.callMember("process");
try {
Thread.sleep(interval);
} catch (InterruptedException e) {
}
totalWaitTime = totalWaitTime + interval;
if (interval < 500) interval = interval * 2;
i = i + 1;
}回调函数
private Consumer<Object> fnResolve = object -> {
synchronized (promiseLock) {
html = (String) object;
promiseResolved = true;
}
};最后结果已字符串形式存在html中,可将其渲染到页面中.
Jest 是 Facebook 开发的一个测试框架,它集成了测试执行器、断言库、spy、mock、snapshot和测试覆盖率报告等功能。React项目本身也是使用Jest进行单测的,因此它们俩的契合度相当高。
Enzyme 是由 airbnb 开发的React单测工具。它扩展了React的TestUtils并通过支持类似jQuery的find语法可以很方便的对render出来的结果做各种断言。
Jest+Enzyme是目前比较流行的React项目单测组合。
npm install --save-dev jest jest-cli enzyme
在package.json中添加jest命令,并指定配置文件.jest.js
scripts: {
"test": "jest --config .jest.js"
}
在项目根目录新建配置文件.jest.js,如下
module.exports = {
setupFiles: [
'./tests/setup.js', // 测试启动文件
],
testURL: 'http://localhost', // 测试环境URL
testEnvironment: 'jsdom', // 测试环境
moduleFileExtensions: ['js', 'jsx'], // 单元测试文件检测后缀名
testPathIgnorePatterns: ['/node_modules/'],
moduleNameMapper: { // mock模块
"\\.(jpg|jpeg|png|gif|eot|otf|webp|svg|ttf|woff|woff2|mp4|webm|wav|mp3|m4a|aac|oga)$": "<rootDir>/tests/__mocks__/fileMock.js",
"\\.(css|less)$": "<rootDir>/tests/__mocks__/cssMock.js"
},
transformIgnorePatterns: [ // 不转化es6的文件夹匹配
'node_modules\/[^/]+?\/(?!(es|node_modules)\/)', // Ignore modules without es dir
]
};由配置文件的testEnvironment可以看到,测试环境使用的是jsdom,jsdom 为许多 WEB标准的 JavaScript 实现,它主要是为了在服务器端模拟足够的Web浏览器子集,以便进行自动化测试。
由于jest默认不支持es6和jsx语法,我们需要通过babel对其进行转化,在项目根目录新建.babelrc文件:
{
"env": {
"test": {
"presets": ["es2015", "react", "stage-2"]
}
}
}对于测试环境来说,一些模块我们不需要进行处理,比如图片模块、样式模块,我们需要把这些模块mock掉,通过moduleNameMapper配置,把指定文件后缀的模块使用自定义文件mock掉,如图片模块,我们新建/tests/__mock__/fileMock.js文件�:
module.exports = {}
导出一个空对象来mock图片文件。
对于一些css、less等文件,可能涉及到一些css-module的内容,可能引入的模块里包含了css中:export导出的内容,如classPrefix,这个时候如果导出空对象可能会影响测试的结果,我们这里针对项目导出写死的内容,/tests/__mock__/cssMock.js如下:
module.exports = {
prefix: "test",
switchPrefix: "test-switch",
btnPrefix: "test-btn",
inputPrefix: "test-input"
}这个时候当我们导入css模块时候,我们可以模拟到css-module的功能,使用s.prefix取到test字符串。
接下来新建启动文件/tests/setup.js
import { JSDOM } from 'jsdom';
// fixed jsdom miss
if (typeof window !== 'undefined') {
const documentHTML = '<!doctype html><html><body</body></html>';
global.document = new JSDOM(documentHTML); // 模拟 document 对象
global.window = document.parentWindow; // 模拟 window 对象
}
global.requestAnimationFrame = global.requestAnimationFrame || function (cb) { // 处理兼容 添加 requestAnimationFrame 动画函数
return setTimeout(cb, 0);
};
const Enzyme = require('enzyme');
const Adapter = require('enzyme-adapter-react-16');
Enzyme.configure({ adapter: new Adapter() }); // 为 enzyme 添加适配器,针对不同的react版本使用不同的适配器默认情况下,jest会检测__tests__文件下的所有.js和.jsx后缀以及项目中.test.js和.spec.js后缀(包括jsx)的文件,以标记这些文件为单元测试文件。
以antd为例,新建一个button.test.js文件:
import React, { Component } from 'react';
import { render, mount } from 'enzyme';
import { Button } from 'antd';
describe('Button', () => {
it('按钮测试', () => {
const wrapper = render(
<Button>测试</Button>
);
expect(wrapper).toMatchSnapshot();
});
it('测试加载中', () => {
class DefaultButton extends Component {
state = {
loading: false,
};
enterLoading = () => {
this.setState({ loading: true });
}
render() {
return <Button loading={this.state.loading} onClick={this.enterLoading}>Button</Button>;
}
}
const wrapper = mount(
<DefaultButton />
);
wrapper.simulate('click');
expect(wrapper.find('.ant-btn-loading').length).toBe(1);
});
})toMatchSnapshot方法会测试两次单测渲染的结果是否一致。
执行命令 npm run test,结果如下:
enzyme提供了三种渲染方式,render、mount、shallow,分别存在以下区别:
render采用的是第三方库Cheerio的渲染,渲染结果是普通的html结构,对于snapshot使用render比较合适。shallow和mount对组件的渲染结果不是html的dom树,而是react树,如果你chrome装了react devtool插件,他的渲染结果就是react devtool tab下查看的组件结构,而render函数的结果是element tab下查看的结果。shallow和mount的结果是个被封装的ReactWrapper,可以进行多种操作,譬如find()、parents()、children()等选择器进行元素查找;state()、props()进行数据查找,setState()、setprops()操作数据;simulate()模拟事件触发。shallow只渲染当前组件,只能能对当前组件做断言;mount会渲染当前组件以及所有子组件,对所有子组件也可以做上述操作。一般交互测试都会关心到子组件,我使用的都是mount。但是mount耗时更长,内存啥的也都占用的更多,如果没必要操作和断言子组件,可以使用shallow。enzyme还提供了simulate()接口模拟事件,实际上simulate是通过触发事件绑定函数,来模拟事件的触发。触发事件后,去判断props上特定函数是否被调用,传参是否正确;组件状态是否发生预料之中的修改;某个dom节点是否存在是否符合期望。
自 WebStorm 2017.3之后的版本(之前几个版本也有,但是不知道怎么试都不行),WebStorm也提供了jest的单元测试环境,下面结合我们前面的项目进行配置:
打开debug配置窗口,在defaults里面找到jest,修改jest的全局配置,选择jest配置文件,如下:
选择完后点击确定,然后找到对应的单元测试文件,点击左边的运行键,如下:
选择 Debug 即可在对应的位置打断点进行调试。
单元测试的目的是为了检测一段代码在特定条件下某个特定的函数行为,对程序员来说,单元测试还是很必要的存在,因为测试人员不会完全把bug测出来,这个时候为了更好的发现bug,我们就需要单元测试来保证测试的全面性。
上面项目 github传送门。
最近新项目过多,在新项目中每次使用 webpack 都是拷贝之前的项目的配置文件过来,改改直接使用,很多配置还是一知半解,一直想用心的从头配置一次 webpack,加深对 webpack 的理解,所以,有了本文,先献上以下内容github地址。
首先,配置entry
const base = {
entry: ['./src/index']
}自 webpack4 起,webpack 提供了默认 entry,也就是我们上面使用的 './src/index',这里我们用数组包裹一下,方便动态增删,往下
配置 output:
const base = {
entry: ['./src/index'],
output: {
publicPath: '/', // 项目根目录
path: path.resolve(__dirname, './dist'),
chunkFilename: '[name].[chunkhash].chunk.js'
}
}配置 resolve.extensions, require的时候省略文件后缀
const base = {
resolve: {
extensions: [".js", ".json"],
}
}配置 devServer,开发环境 webpack-dev-server 配置使用
const host = 'localhost';
const port = 8080;
const base = {
devServer: {
contentBase: [path.join(process.cwd(), './vendor-dev/'), path.join(process.cwd(), './vendor/')], // dllPlugin使用,下文有讲
hot: true, // 热加载
compress: false,
open: true, //
host: host,
port: port,
disableHostCheck: true, // 跳过host检测
stats: { colors: true },
filename: '[name].chunk.js',
headers: { 'Access-Control-Allow-Origin': '*' }
}
}根据不同的环境,我们需要对默认的 entry 进行处理,如下
const CleanWebpackPlugin = require('clean-webpack-plugin');
const isDebug = process.env.NODE_ENV !== 'production';
if (isDebug) {
base.entry.unshift(`webpack-dev-server/client?http://${host}:${port}`, 'webpack/hot/dev-server'); // 添加devServer入口
base.plugins.unshift(new webpack.HotModuleReplacementPlugin()); // 添加热加载
base.devtool = 'source-map';
} else {
base.entry.unshift('babel-polyfill'); // 加入 polyfill
base.plugins.push(new CleanWebpackPlugin( // 清理目标目录文件
"*",
{
root: base.output.path, //根目录
verbose: true, //开启在控制台输出信息
dry: false //启用删除文件
}
))
}添加图片、字体文件处理:
const base = {
module: {
rules: [{
test: /\.(woff|woff2|ttf|eot|png|jpg|jpeg|gif|svg)(\?v=\d+\.\d+\.\d+)?$/i, // 图片加载
loader: 'url-loader',
query: {
limit: 10000
}
}]
}
}production 生成环境对编译进行 optimization
const UglifyJsPlugin = require('uglifyjs-webpack-plugin');
const base = {
optimization: {
minimize: !isDebug, // 是否压缩
minimizer: !isDebug ? [new UglifyJsPlugin({
cache: true, // 使用缓存
parallel: true, // 多线程并行处理
sourceMap: true, // 使用sourceMap
uglifyOptions: {
comments: false,
warnings: false,
compress: {
unused: true,
dead_code: true,
collapse_vars: true,
reduce_vars: true
},
output: {
comments: false
}
}
})] : [],
splitChunks: { // 自行切割所有chunk
chunks: 'all'
}
},
}splitChunks 配置的 chunks: 'all' 会改变html的引进的脚本,加了chunksHash后每次编译的结果会不一致,需要结合html-webpack-plugin 使用。
下面添加 plugins
const ProgressBarPlugin = require('progress-bar-webpack-plugin');
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
const HtmlWebpackPlugin = require('html-webpack-plugin');
const base = {
plugins: [
new ProgressBarPlugin(), // 为编译添加进度条
new webpack.DefinePlugin({ // 为项目注入环境变量
'process.env.NODE_ENV': JSON.stringify(process.env.NODE_ENV),
'__DEV__': isDebug
}),
new BundleAnalyzerPlugin({ // 生成编译结果分析报告
analyzerMode: 'server',
analyzerHost: '127.0.0.1',
analyzerPort: 8889,
reportFilename: 'report.html',
defaultSizes: 'parsed',
generateStatsFile: false,
statsFilename: 'stats.json',
statsOptions: null,
logLevel: 'info'
}),
new HtmlWebpackPlugin({ // 使用html模板,编译结束后会根据 entry 注入 script脚本 和 css样式表
filename: 'index.html',
template: path.resolve(__dirname, './index.html')
})
]
}导出配置
module.exports = base;webpack 的 react 配置,只要是针对 babel-loader 进行配置,首先声明一个 bable-loader:
const path = require('path');
const babelLoader = {
test: /\.jsx?$/,
loader: 'babel-loader',
include: [path.resolve(process.cwd(), 'src')],
query: {
babelrc: false, // 禁止使用.babelrc文件
presets: [ // 配置 presets
'react',
'stage-0',
[
'env',
{
targets: {
browsers: ["last 2 versions", "safari >= 7", "ie >= 9", 'chrome >= 52']
},
useBuiltIns: true,
debug: false
}
]
],
plugins: [
'transform-decorators-legacy',
'transform-class-properties'
]
}
}首先对preset进行理解,就是bable的一个套餐,里面包含了各种plugin
另外,添加另外的 plugins
另外,我们针对开发环境,为react组件添加热替换 preset,babel-preset-react-hmre
if (isDebug) {
babelLoader.query.presets = ['react-hmre'].concat(babelLoader.query.presets)
}另外,为了加快编译速度,我们使用happypack进行多线程编译
const HappyPack = require('happypack');
const os = require('os');
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length }); // cpus核数
const happyLoaderId = 'happypack-for-react-babel-loader';
const reactConfig = {
module: {
rules: [{
test: babelLoader.test,
loader: 'happypack/loader',
query: {
id: happyLoaderId
},
include: babelLoader.include
}]
},
plugins: [new HappyPack({
id: happyLoaderId,
threadPool: happyThreadPool,
loaders: [babelLoader]
})]
}
delete babelLoader.test;
delete babelLoader.include;
module.exports = reactConfig;首先,配置 css-loader
const isDebug = process.env.NODE_ENV !== 'production';
const cssLoader = {
loader: `css-loader`,
options: {
sourceMap: isDebug, // 是否添加source-map
modules: true, // 是否使用css-module
localIdentName: '[local]', // 使用class本身名字,不添加任何hash
}
}配置 postcss-loader
const postcssLoader = {
loader: 'postcss-loader',
options: {
config: {
path: __dirname
}
}
}这里我们使用配置文件 postcss.config.js 路径指向当前文件夹,然后新建配置文件 postcss.config.js,如下
module.exports = {
plugins: () => {
return [
require('postcss-nested')(), // 用于解开 @media, @supports, @font-face 和 @document 等css规则
require('pixrem')(), // 为 rem 单位添加像素转化
require('autoprefixer')({ // 添加内核前缀
browsers: ['last 2 versions', 'Firefox ESR', '> 1%', 'ie >= 8']
}),
require('postcss-flexibility')(), // 添加 flex 布局 polyfill
require('postcss-discard-duplicates')() // 去除css中的重复规则
]
}
}配置 less-loader
const lessLoader = {
loader: 'less-loader',
options: {
sourceMap: isDebug,
javascriptEnabled: true // 支持内联JavaScript
}
}接下来,我们针对不同的环境,为webpack添加不同的 module.rules 和 plugins,首先是开发环境,我们使用 style-loader 将css进行内联(个人认为内联css对热部署比较友好),另外,同react配置,为了加快编译,我们使用 happypack 对 loader 进行包裹
const HappyPack = require('happypack');
const os = require('os');
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length });
const lessHappyLoaderId = 'happypack-for-less-loader';
const cssHappyLoaderId = 'happypack-for-css-loader';
let loaders = [];
let plugins = [];
if (isDebug) {
loaders = [{
test: /\.less$/,
loader: 'happypack/loader',
query: {id: lessHappyLoaderId}
}, {
test: /\.css$/,
loader: 'happypack/loader',
query: {id: cssHappyLoaderId}
}]
plugins = [new HappyPack({
id: lessHappyLoaderId,
threadPool: happyThreadPool,
loaders: ['style-loader', cssLoader, postcssLoader, lessLoader ]
}), new HappyPack({
id: cssHappyLoaderId,
threadPool: happyThreadPool,
loaders: ['style-loader', cssLoader, postcssLoader ]
})]
}然后,对于生产环境,我们使用 mini-css-extract-plugin 将 css 文件分离出来,并打包成 chunks,以便减少线上的首屏加载时间。
if (!isDebug) {
loaders = [{
test: /\.less$/,
use: [MiniCssExtractPlugin.loader, {
loader: 'happypack/loader',
query: {id: lessHappyLoaderId}
}]
}, {
test: /\.css/,
use: [MiniCssExtractPlugin.loader, {
loader: 'happypack/loader',
query: {id: cssHappyLoaderId}
}]
}]
plugins = [new MiniCssExtractPlugin({
filename: '[name].css',
// chunkFilename: "[id].css"
}), new HappyPack({
id: lessHappyLoaderId,
loaders: [
cssLoader,
postcssLoader,
lessLoader
],
threadPool: happyThreadPool
}), new HappyPack({
id: cssHappyLoaderId,
loaders: [
cssLoader,
postcssLoader
],
threadPool: happyThreadPool
})]
}最后,导出配置
const OptimizeCssAssetsPlugin = require('optimize-css-assets-webpack-plugin');
const lessConfig = {
module: {
rules: loaders
},
plugins,
optimization: {
minimizer: [new OptimizeCssAssetsPlugin({ // 使用 OptimizeCssAssetsPlugin 对css进行压缩
cssProcessor: require('cssnano'), // css 压缩优化器
cssProcessorOptions: { discardComments: { removeAll: true } } // 去除所有注释
})]
}
};
module.exports = lessConfig;最后,我们将所有配置 merge 在一起
const merge = require('webpack-merge');
const baseConfig = require('./webpack.base.config');
const reactConfig = require('./webpack.react.config');
const lessConfig = require('./webpack.less.config');
const config = merge(baseConfig, reactConfig, lessConfig);
module.exports = config;然后我们配置 package.json 的 sctipts,这里我们使用better-npm-run导出环境变量
{
"scripts": {
"start": "better-npm-run start",
"build": "better-npm-run build"
},
"betterScripts": {
"start": {
"command": "webpack-dev-server --config ./build/webpack.config.js",
"env": {
"NODE_ENV": "development"
}
},
"build": {
"command": "webpack --config ./build/webpack.config.js",
"env": {
"NODE_ENV": "production"
}
}
},
}好的,配置到这里已经完成,我们可以肆无忌惮的执行 npm run start了。
针对 React 项目,对于开发过程,我们只关心业务代码的增量编译,对于一些第三方 module 我们不需要对齐进行更改,对于生产环境,这些第三方包也可以利用缓存将其缓存起来,优化线上用户体验,所以我们可以使用DllPlugin或者SplitChunksPlugin对这些第三方包进行分离。
DllPlugin 可以将指定的module提前编译好,然后在每次解析到这些指定的module时,webpack可直接使用这些module,而不用重新编译,这样可以大大的增加我们的编译速度。
SplitChunksPlugin,可以使用test对module进行正则匹配,对指定的模块打包成chunk,然后每次编译的时候直接使用这些chunk的缓存,而不用每次解析组装这些module。当然,使用SplitChunksPlugin生成的chunk在生成环境可能因为我们指定了chunkHash每次文件名不一样,导致我们不能好好利用浏览器缓存这些第三方库,也会因此影响到我们html中每次引入的script,必须结合html-webpack-plugin进行使用,但对于一些没有完全前后端分离的业务项目来说(如路由由后端来控制,html渲染是后端控制),这很明显是一个麻烦。
dllPlugin的原理就是预先编译模块,然后在html中最先引进这些打包完的包,这样 webpack 就可以从全局变量里面去找这些预先编译好的模块。
下面我们使用配置使用 dllPlugin,新建配置文件 webpack.dll.config.js,这个文件为 webpack 需要事先编译的配置文件
首先声明输出 output
const path = require('path');
const isDebug = process.env.NODE_ENV !== 'production';
const output = {
filename: '[name].js',
library: '[name]_library',
path: path.resolve(process.cwd(), isDebug ? './vendor-dev/' : './vendor/') // 编译打包后的目录
}然后声明总体配置
const dllConfig = {
entry: {
vendor: ['react', 'react-dom'] // 我们需要事先编译的模块,用entry表示
},
output: output,
plugins: [
new webpack.DllPlugin({ // 使用dllPlugin
path: path.join(output.path, `${output.filename}.json`),
name: output.library // 全局变量名, 也就是 window 下 的 [output.library]
}),
new ProgressBarPlugin(),
new webpack.DefinePlugin({
'process.env.NODE_ENV': JSON.stringify(process.env.NODE_ENV),
__DEV__: isDebug
})
],
optimization: {}
}然后,我们根据不同的环境,添加配置
if (!isDebug) {
dllConfig.mode = 'production';
dllConfig.optimization.minimize = true;
dllConfig.optimization.minimizer = [new UglifyJsPlugin({
cache: true,
parallel: true,
sourceMap: true,
uglifyOptions: {
comments: false,
warnings: false,
compress: {
unused: true,
dead_code: true,
collapse_vars: true,
reduce_vars: true
},
output: {
comments: false
}
}
})];
} else {
dllConfig.mode = 'development';
}
module.exports = dllConfig;需要注意的是,当我们使用dllPlugin对react进行编译时,我们需要使用isDebug对react进行生产环境和开发环境的区分,因为当我们在生成环境使用开发环境的react的时候,react会报错,所以,我们这里需要对不同环境的库进行打包。
编译打包,最后生成了一个 vendor.js 和 vendor.js.json,然后,我们可以在我们编译的配置中使用 dllReferencePlugin 引进这个json
下面我们新建配置文件 webpack.dll.reference.config.js
const path = require('path');
const dllConfig = require('./webpack.dll.config');
const baseConfig = require('./webpack.base.config');
const webpack = require('webpack');
const isDebug = process.env.NODE_ENV !== 'production';
const CopyWebpackPlugin = require('copy-webpack-plugin');
const dllPath = dllConfig.output.path;
const dllEntry = dllConfig.entry;
const plugins = [
new CopyWebpackPlugin([{ from: path.join(process.cwd(), isDebug ? './vendor-dev/' : './vendor/'), to: baseConfig.output.path, ignore: ['*.json']}]) // 将dll文件拷贝到编译目录
];
Object.keys(dllEntry).forEach((key) => {
const manifest = path.join(dllPath, `${key}.js.json`);
plugins.push(new webpack.DllReferencePlugin({
manifest: require(manifest), // 引进dllPlugin编译的json文件
name: `${key}_library` // 全局变量名,与dllPlugin声明的一直
}))
})
module.exports = {
plugins
}最后,我们把这个配置在 webpack.config.js 里 merge 进来
const merge = require('webpack-merge');
const baseConfig = require('./webpack.base.config');
const reactConfig = require('./webpack.react.config');
const lessConfig = require('./webpack.less.config');
const dllReferenceConfig = require('./webpack.dll.reference.config');
const config = merge(baseConfig, reactConfig, lessConfig, dllReferenceConfig);
module.exports = config;然后在package.json添加预编译脚本
{
"scripts": {
"start:dll": "better-npm-run start:dll",
"build:dll": "better-npm-run build:dll"
},
"betterScripts": {
"start:dll": {
"command": "webpack --config ./build/webpack.dll.config.js",
"env": {
"NODE_ENV": "development"
}
},
"build:dll": {
"command": "webpack --config ./build/webpack.dll.config.js",
"env": {
"NODE_ENV": "production"
}
}
}
}打完收工,最后,在npm run start之前,我们得先执行npm run start:dll,并在html中引进这个vendor.js,不然会报错,找不到library,html如下
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title>app</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<script src="/vendor.js"></script> <!-- 根据根目录设置 -->
</head>
<body>
</body>
</html>针对 SplitChunksPlugin,其实就是打包 chunks,如我们把node_modules下的所有模块打到一个chunk中
const splitChunkConfig = {
optimization: {
splitChunks: {
cacheGroups: {
vendor: {
name: 'vendor',
chunks: 'initial',
priority: -10,
reuseExistingChunk: false,
test: /node_modules\/(.*)\.js/
}
}
}
}
}使用 test 匹配 node_modules,最后会生成一个 vendor.chunk.js,如果设置有 chunkHash,文件名会带hash,然后在html中引进即可。
以上,基本搞了一套 webpack 相对编译较快的配置,嗯呢~,该沉淀一下,献上以上github地址,以上配置,已整理成cli,项目根目录一键生成,详情见 README
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.